Seminarium DSP AGH. Przegląd technik zwiększających wydajność obliczeniową algorytmów weryfikacji mówcy opartych o modelowanie GMM-UBM oraz HMM
|
|
|
- Edyta Lewandowska
- 5 lat temu
- Przeglądów:
Transkrypt

1 Seminarium DSP AGH Przegląd technik zwiększających wydajność obliczeniową algorytmów weryfikacji mówcy opartych o modelowanie GMM-UBM oraz HMM Michał Salasa , Kraków
2 Przedstawienie problemu Systemy weryfikacji mówcy oparte o modelowanie GMM-UBM lub HMM do skutecznego działania wymagają stosunkowo dużej mocy obliczeniowej procesora. Duża ilość danych związana z ilością użytecznych parametrów wektora cech, długością weryfikowanej wypowiedzi i strukturą samego modelu GMM/HMM powoduje bardzo szybki przyrost obliczeń (przekleństwo wymiarowości). Komputery stacjonarne mniejszy problem Systemy wbudowane znaczący problem (SafeLock)
3 Kategorie technik optymalizacyjnych 1) Techniki ingerujące w przebieg procesu weryfikacji mówcy: modyfikacja sposobu obliczania logarytmu prawdopodobieństwa (PDE, BMP, DGS), wykorzystywanie odpowiednio przekształconych modeli mówców (Sorted GMM). 2) Techniki skutkujące zmniejszeniem ilości danych wykorzystywanych do weryfikacji: decymacja wektorów cech z pojedynczej wypowiedzi (FRD, VFR, ARD). 3) Akceleracja sprzętowa i programowa: koprocesor zmiennoprzecinkowy - Cortex-M4F, wykorzystywanie tablicowania (lookup table).
4 GMM-UBM, krótki opis metody Model mówcy składa się z M mikstur (komponentów) i jest wytrenowany metodą MAP z modelu UBM Każdy komponent opisywany jest przez: wagę, wektor wartości średnich (N-elementowy), wektor wartości pochodzących z diagonalnej macierzy kowariancji (N-elementowy). Weryfikacja polega na porównaniu wypowiedzi z modelem mówcy poprzez obliczenie logarytmu prawdopodobieństwa dla każdego wektora cech:

5 GMM-UBM, opis metody Proces weryfikacji: t = 1 t = 2 t = 3 t = T
6 GMM-UBM, opis metody
7 GMM-UBM, złożoność obliczeniowa Czynniki, które w znaczący sposób wpływają na złożoność obliczeniową metody GMM-UBM to: wymiarowość wektora cech, ilość wektorów cech (długość wypowiedzi), struktura modelu mówcy (ilość komponentów), ilość modeli wybranych do t-normalizacji, potrzeba obliczania dużej ilości logarytmów. Złożoność obliczeniowa GMM-UBM: O(M + M)
8 GMM-UBM, wstępna optymalizacja
9 GMM-UBM, wstępna optymalizacja Dodanie do modelu mówcy dodatkowego wektora zawierającego stały czynnik normalizacyjny każdego komponentu, pozwala zaoszczędzić wiele mocy obliczeniowej (brak dużej ilości logarytmów) i przyspieszyć proces weryfikacji.
10 GMM-UBM, Top-C mixtures Najpopularniejszą techniką zwiększającą wydajność obliczeniową metody GMM-UBM jest technika zwana top-c mixtures : Modele mówców muszą być wytrenowane metodą MAP Wykorzystanie faktu, że jeden wektor cech jest modelowany niewielką ilością komponentów oraz, że komponenty UBM modelujące ten wektor w dużym stopniu pokrywają się z komponentami wytrenowanego modelu mówcy. Ilość komponentów wykorzystywanych do obliczania końcowego wyniku jest redukowana do małej ilości (zazwyczaj C = 5) Znaczne zmniejszenie ilości obliczeń kosztem niewielkiego spadku (a w niektórych przypadkach nawet wzrostu!) skuteczności weryfikacji
11 GMM-UBM, Top-C mixtures Zmodyfikowany proces weryfikacji: Dla aktualnie badanego wektora cech należy obliczyć logarytm prawdopodobieństwa każdego komponentu modelu UBM. Wybrać C komponentów cechujących się najlepszym wynikiem. Obliczenia dla modelu weryfikowanego mówcy oraz modeli wybranych do t-normalizacji przeprowadzić już tylko dla tych C wybranych komponentów. Uzyskana złożoność obliczeniowa: O(M + C)
12 GMM-UBM, Sorted GMM Kolejna technika Sorted GMM jest rozszerzeniem poprzedniej. Skupiono w niej uwagę na proces poszukiwania C-najlepszych komponentów modelu UBM. Aby zwiększyć efektywność poszukiwań komponenty modelu UBM są porządkowane według określonego klucza tworząc nową strukturę nazywaną: Sorted GMM Porządkowanie (sortowanie) odbywa się względem zmiennej s(.), która jest funkcją parametrów komponentów. Umiejętne wykorzystanie posortowanej struktury pozwala na szybsze znalezienie C-najlepszych komponentów
13 GMM-UBM, Sorted GMM Przykładowe założenia procesu weryfikacji (H. Mohhamadi, R. Saeidi): Zmienna s(.) = suma wszystkich składników wektora wejściowego Sorted GMM mikstury posortowane względem sumy elementów wektora wartości średnich M s ilość badanych komponentów (zawsze mniejsza do ilości komponentów w modelu)
14 GMM-UBM, Sorted GMM Weryfikacja oparta o te założenia: Sortujemy odpowiednio komponenty modelu UBM otrzymując wektor S = [s 1 + s s M ] Dla badanego wektora cech obliczamy sumę jego elementów składowych: S x Dokonujemy kwantyzacji skalarnej sumy S x względem wektora S otrzymując element s i Obliczamy logarytm prawdopodobieństwa tylko dla komponentów odległych o M s / 2 od komponentu o indeksie i Wybieramy C najlepszych komponentów
15 GMM-UBM, Sorted GMM Złożoność obliczeniowa Sorted GMM: O(M s + C)
16 GMM-UBM, decymacja wektorów cech 1) Fixed-Rate Decimation Dla każdej wypowiedzi, do obliczania logarytmu prawdopodobieństwa brany jest co N-ty wektor cech Redukcja ilości wektorów cech na poziomie: 1/N 2) Variable Frame Rate Porównuje kolejne wektory cech i jeśli są do siebie dostatecznie podobne to logarytm prawdopodobieństwa obliczany jest tylko dla jednego z nich, a wynik dla pozostałych wektorów jest powielany Miara podobieństwa: najczęściej metryka euklidesowa 3) Adaptive-Rate Decimation Współczynnik decymacji jest adaptowany do bieżącej wypowiedzi tak aby zawsze otrzymać taką samą ilość wektorów cech
17 GMM-UBM, decymacja wektorów cech Fixed-Rate Decimation vs EER (%)
18 GMM-UBM, decymacja wektorów cech Variable Frame Rate vs EER (%)
19 GMM-UBM, decymacja wektorów cech Adaptive-Rate Decimation vs EER (%)
20 GMM-UBM, uwagi Brak eksperymentów, które zbadałyby skuteczność zastosowania dwóch metod naraz (top-c + decymacja) Dotychczasowe testy przeprowadzono dla stosunkowo dużych modeli GMM (od 64 do 2048 mikstur) i długich wypowiedzi (od 3s do 15s) aktualny system biometryczny wykorzystuje modele GMM zbudowane z 16 mikstur i długością hasła do 3s.
21 HMM, krótki opis System weryfikacji mówcy oparty o modelowanie HMM wymaga o wiele większej mocy obliczeniowej.
22 HMM, krótki opis Pojedynczy model HMM mówcy składa się z kilku/kilkunastu stanów emitujących, z których każdy posiada własną funkcję gęstości prawdopodobieństwa GMM Do pełnego opisu modelu HMM mówcy wymagana jest macierz przejść i funkcje gęstości prawdopodobieństwa (GMM) Weryfikacja mówcy algorytmem Viterbiego lub algorytmem Forward
23 HMM, opis metody Proces weryfikacji: t = 1 t = 2 t = 3 t = T
24 HMM, złożoność obliczeniowa Główne czynniki wpływające na długość obliczeń: Ilość stanów emitujących Ilość komponentów GMM dla każdego stanu Wymiarowość wektora cech Długość wypowiedzi
25 HMM, VQ-Based Gaussian Selection Podobnie jak w przypadku GMM-UMB tak i w HMM techniki zwiększające wydajność obliczeniową systemu weryfikacji mówcy oparte są na zmniejszeniu ilości wykorzystywanych komponentów pochodzących z GMM Zazwyczaj dla jednego wektora cech tylko kilka, lub nawet jeden komponent dominuje rozkład prawdopodobieństwa GMM. Z tego wynika, że obliczenia mogą być ograniczone do jednego lub kilku komponentów i aproksymowane na pozostałe komponenty. Głównym celem metod optymalizacyjnych w przypadku HMM jest więc efektywne znalezienie tej grupy komponentów.
26 HMM, VQ-Based Gaussian Selection Metoda optymalizacji HMM oparta o kwantyzację wektorową (VQ) polega na podzieleniu wektorów cech na kilka podprzestrzeni (klasterów) i określeniu dla każdego klastra grupy komponentów maksymalizujących prawdopodobieństwo. Proces weryfikacji: Przydzielenie bieżącego wektora cech do jednego z wcześniej zdefiniowanych klastrów (metryka euklidesowa, itp.) Wykorzystanie wcześniej przygotowanej grupy komponentów do obliczenia logarytmu prawdopodobieństwa Poważny minus: potrzebne duże zasoby pamięci
27 HMM, Partial Distance Elimination Zamiast obliczać prawdopodobieństwo dla wszystkich komponentów, można w uproszczeniu przyjąć, że prawdopodobieństwo emisji danego stanu jest równe prawdopodobieństwu najlepiej rokującej mikstury. Z tej zasady korzysta metoda PDE. Proces weryfikacji: Należy obliczyć pełne prawdopodobieństwo dla pierwszej mikstury Rozpocząć obliczenia dla kolejnej i przerwać je w momencie gdy wynik zacznie być gorszy od poprzedniego Kontynuować obliczenia do momentu znalezienia najlepszego komponentu
28 HMM, Partial Distance Elimination Zamiast obliczać prawdopodobieństwo dla wszystkich komponentów, można w uproszczeniu przyjąć, że prawdopodobieństwo emisji danego stanu jest równe prawdopodobieństwu najlepiej rokującej mikstury. Z tej zasady korzysta metoda PDE. Proces weryfikacji: Należy obliczyć pełne prawdopodobieństwo dla pierwszej mikstury Rozpocząć obliczenia dla kolejnej i przerwać je w momencie gdy wynik zacznie być gorszy od poprzedniego Kontynuować obliczenia do momentu znalezienia najlepszego komponentu
29 HMM, PDE + BMP + FER Istnieją dwie techniki wspierające algorytm PDE: 1) Best Mixture Prediction polega na zapamiętaniu najlepszej mikstury z poprzedniego wektora cech i rozpoczęciu od niej obliczeń na nowych wektorze 2) Feature Element Reordering zamiana kolejności elementów wektorów cech w ten sposób, by te, które silniej wpływają na rezultat obliczeń były wykorzystywane jako pierwsze
30 HMM, Dynamic Gaussian Selection Łączy w sobie plusy VQ-BGS i PDE: Nie potrzebuje dodatkowej pamięci Tworzy na bieżąco grupę najlepszych komponentów Uproszczony schemat działania: Na początku oblicza wynik dla BMP Następnie każdy komponent jest analizowany za pomocą algorytmu PDE Po przekroczeniu określonej ilości iteracji algorytm przechodzi do następnego komponentu Po uzyskaniu określonej ilości komponentów (zazwyczaj 5) algorytm kończy działanie
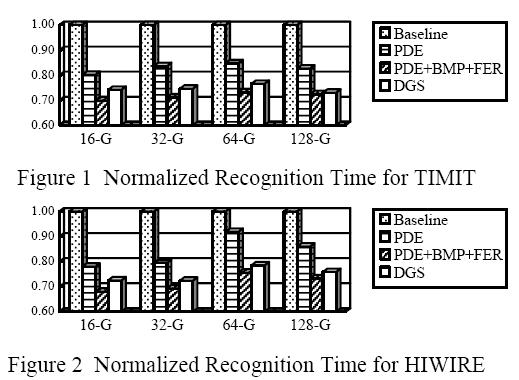
31 HMM
32 HMM
33 Akceleracja sprzętowa i programowa Rozwiązania zależne od platformy: NVIDIA CUDA obliczenia równoległe Cortex M4F koprocesor zmiennoprzecinkowy Itp.. Optymalizacja algorytmów podstawowych funkcji matematycznych: W szczególności exp, log Z wykorzystaniem tablicowania (look-up table)
34 Dziękuję za uwagę!
35 Źródła: [1] McLaughlin - A Study of Computation Speed-ups of the GMM-UBM Speaker Recognition System [2] Kinnunen - Real-Time Speaker Identificatin and Verification [3] Mohammadi - Efficient Implementation of GMM Based Speaker Verification Using Sorted GMM [4] Cai - Dynamic Gaussian Selection Technique for Speeding Up HMM-Based Continuous Speech Recognition [5] Bocchieri - Vector Quantization for the Efficient Computation of Continuous Density Likelihoods [6] HTK BOOK
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Sortowanie Shella Shell Sort
 Sortowanie Shella Shell Sort W latach 50-tych ubiegłego wieku informatyk Donald Shell zauważył, iż algorytm sortowania przez wstawianie pracuje bardzo efektywnie w przypadku gdy zbiór jest w dużym stopniu
Sortowanie Shella Shell Sort W latach 50-tych ubiegłego wieku informatyk Donald Shell zauważył, iż algorytm sortowania przez wstawianie pracuje bardzo efektywnie w przypadku gdy zbiór jest w dużym stopniu
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, Spis treści
 Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Transformata Fouriera. Sylwia Kołoda Magdalena Pacek Krzysztof Kolago
 Transformata Fouriera Sylwia Kołoda Magdalena Pacek Krzysztof Kolago Transformacja Fouriera rozkłada funkcję okresową na szereg funkcji okresowych tak, że uzyskana transformata podaje w jaki sposób poszczególne
Transformata Fouriera Sylwia Kołoda Magdalena Pacek Krzysztof Kolago Transformacja Fouriera rozkłada funkcję okresową na szereg funkcji okresowych tak, że uzyskana transformata podaje w jaki sposób poszczególne
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Sortowanie przez wstawianie Insertion Sort
 Sortowanie przez wstawianie Insertion Sort Algorytm sortowania przez wstawianie można porównać do sposobu układania kart pobieranych z talii. Najpierw bierzemy pierwszą kartę. Następnie pobieramy kolejne,
Sortowanie przez wstawianie Insertion Sort Algorytm sortowania przez wstawianie można porównać do sposobu układania kart pobieranych z talii. Najpierw bierzemy pierwszą kartę. Następnie pobieramy kolejne,
TEORETYCZNE PODSTAWY INFORMATYKI
 1 TEORETYCZNE PODSTAWY INFORMATYKI 16/01/2017 WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Repetytorium złożoność obliczeniowa 2 Złożoność obliczeniowa Notacja wielkie 0 Notacja Ω i Θ Rozwiązywanie
1 TEORETYCZNE PODSTAWY INFORMATYKI 16/01/2017 WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Repetytorium złożoność obliczeniowa 2 Złożoność obliczeniowa Notacja wielkie 0 Notacja Ω i Θ Rozwiązywanie
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytmy i struktury danych
 Algorytmy i struktury danych Proste algorytmy sortowania Witold Marańda maranda@dmcs.p.lodz.pl 1 Pojęcie sortowania Sortowaniem nazywa się proces ustawiania zbioru obiektów w określonym porządku Sortowanie
Algorytmy i struktury danych Proste algorytmy sortowania Witold Marańda maranda@dmcs.p.lodz.pl 1 Pojęcie sortowania Sortowaniem nazywa się proces ustawiania zbioru obiektów w określonym porządku Sortowanie
AKUSTYKA MOWY. Podstawy rozpoznawania mowy część I
 AKUSTYKA MOWY Podstawy rozpoznawania mowy część I PLAN WYKŁADU Część I Podstawowe pojęcia z dziedziny rozpoznawania mowy Algorytmy, parametry i podejścia do rozpoznawania mowy Przykłady istniejących bibliotek
AKUSTYKA MOWY Podstawy rozpoznawania mowy część I PLAN WYKŁADU Część I Podstawowe pojęcia z dziedziny rozpoznawania mowy Algorytmy, parametry i podejścia do rozpoznawania mowy Przykłady istniejących bibliotek
CMAES. Zapis algorytmu. Generacja populacji oraz selekcja Populacja q i (t) w kroku t generowana jest w następujący sposób:
 w kroku t generowana jest w następujący sposób:") CMAES Covariance Matrix Adaptation Evolution Strategy Opracowanie: Lidia Wojciechowska W algorytmie CMAES, podobnie jak w algorytmie EDA, adaptowany jest rozkład prawdopodobieństwa generacji punktów, opisany
CMAES Covariance Matrix Adaptation Evolution Strategy Opracowanie: Lidia Wojciechowska W algorytmie CMAES, podobnie jak w algorytmie EDA, adaptowany jest rozkład prawdopodobieństwa generacji punktów, opisany
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I
 Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II
 Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Sztuczne sieci neuronowe. Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335
 Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Eksploracja danych. Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Algorytmy sortujące. Sortowanie bąbelkowe
 Algorytmy sortujące Sortowanie bąbelkowe Sortowanie bąbelkowe - wstęp Algorytm sortowania bąbelkowego jest jednym z najstarszych algorytmów sortujących. Zasada działania opiera się na cyklicznym porównywaniu
Algorytmy sortujące Sortowanie bąbelkowe Sortowanie bąbelkowe - wstęp Algorytm sortowania bąbelkowego jest jednym z najstarszych algorytmów sortujących. Zasada działania opiera się na cyklicznym porównywaniu
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Podejście memetyczne do problemu DCVRP - wstępne wyniki. Adam Żychowski
 Podejście memetyczne do problemu DCVRP - wstępne wyniki Adam Żychowski Na podstawie prac X. S. Chen, L. Feng, Y. S. Ong A Self-Adaptive Memeplexes Robust Search Scheme for solving Stochastic Demands Vehicle
Podejście memetyczne do problemu DCVRP - wstępne wyniki Adam Żychowski Na podstawie prac X. S. Chen, L. Feng, Y. S. Ong A Self-Adaptive Memeplexes Robust Search Scheme for solving Stochastic Demands Vehicle
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury. Paweł Kobojek, prof. dr hab. inż. Khalid Saeed
 Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury Paweł Kobojek, prof. dr hab. inż. Khalid Saeed Zakres pracy Przegląd stanu wiedzy w dziedzinie biometrii, ze szczególnym naciskiem
Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury Paweł Kobojek, prof. dr hab. inż. Khalid Saeed Zakres pracy Przegląd stanu wiedzy w dziedzinie biometrii, ze szczególnym naciskiem
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Numeryczna algebra liniowa. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak
Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak
Algorytmy zrandomizowane
 Algorytmy zrandomizowane http://zajecia.jakubw.pl/nai ALGORYTMY ZRANDOMIZOWANE Algorytmy, których działanie uzależnione jest od czynników losowych. Algorytmy typu Monte Carlo: dają (po pewnym czasie) wynik
Algorytmy zrandomizowane http://zajecia.jakubw.pl/nai ALGORYTMY ZRANDOMIZOWANE Algorytmy, których działanie uzależnione jest od czynników losowych. Algorytmy typu Monte Carlo: dają (po pewnym czasie) wynik
INFORMATYKA SORTOWANIE DANYCH.
 INFORMATYKA SORTOWANIE DANYCH http://www.infoceram.agh.edu.pl SORTOWANIE Jest to proces ustawiania zbioru obiektów w określonym porządku. Sortowanie stosowane jest w celu ułatwienia późniejszego wyszukania
INFORMATYKA SORTOWANIE DANYCH http://www.infoceram.agh.edu.pl SORTOWANIE Jest to proces ustawiania zbioru obiektów w określonym porządku. Sortowanie stosowane jest w celu ułatwienia późniejszego wyszukania
Ewolucja Różnicowa Differential Evolution
 Ewolucja Różnicowa Differential Evolution Obliczenia z wykorzystaniem metod sztucznej inteligencji Arkadiusz Kalinowski Szczecin, 2016 Zachodniopomorski Uniwersytet Technologiczny w Szczecinie 1 / 22 Plan
Ewolucja Różnicowa Differential Evolution Obliczenia z wykorzystaniem metod sztucznej inteligencji Arkadiusz Kalinowski Szczecin, 2016 Zachodniopomorski Uniwersytet Technologiczny w Szczecinie 1 / 22 Plan
Zadania do wykonania. Rozwiązując poniższe zadania użyj pętlę for.
 Zadania do wykonania Rozwiązując poniższe zadania użyj pętlę for. 1. apisz program, który przesuwa w prawo o dwie pozycje zawartość tablicy 10-cio elementowej liczb całkowitych tzn. element t[i] dla i=2,..,9
Zadania do wykonania Rozwiązując poniższe zadania użyj pętlę for. 1. apisz program, który przesuwa w prawo o dwie pozycje zawartość tablicy 10-cio elementowej liczb całkowitych tzn. element t[i] dla i=2,..,9
Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska
 Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska e-mail: bartosz.krawczyk@pwr.wroc.pl Czym jest klasyfikacja
Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska e-mail: bartosz.krawczyk@pwr.wroc.pl Czym jest klasyfikacja
Metody iteracyjne rozwiązywania układów równań liniowych (5.3) Normy wektorów i macierzy (5.3.1) Niech. x i. i =1
 Normy wektorów i macierzy (5.3.1) Niech. x i. i =1") Normy wektorów i macierzy (5.3.1) Niech 1 X =[x x Y y =[y1 x n], oznaczają wektory przestrzeni R n, a yn] niech oznacza liczbę rzeczywistą. Wyrażenie x i p 5.3.1.a X p = p n i =1 nosi nazwę p-tej normy
Normy wektorów i macierzy (5.3.1) Niech 1 X =[x x Y y =[y1 x n], oznaczają wektory przestrzeni R n, a yn] niech oznacza liczbę rzeczywistą. Wyrażenie x i p 5.3.1.a X p = p n i =1 nosi nazwę p-tej normy
Zastosowanie modelu regresji logistycznej w ocenie ryzyka ubezpieczeniowego. Łukasz Kończyk WMS AGH
 Zastosowanie modelu regresji logistycznej w ocenie ryzyka ubezpieczeniowego Łukasz Kończyk WMS AGH Plan prezentacji Model regresji liniowej Uogólniony model liniowy (GLM) Ryzyko ubezpieczeniowe Przykład
Zastosowanie modelu regresji logistycznej w ocenie ryzyka ubezpieczeniowego Łukasz Kończyk WMS AGH Plan prezentacji Model regresji liniowej Uogólniony model liniowy (GLM) Ryzyko ubezpieczeniowe Przykład
Definicja. Ciąg wejściowy: Funkcja uporządkowująca: Sortowanie polega na: a 1, a 2,, a n-1, a n. f(a 1 ) f(a 2 ) f(a n )
 f(a 2 ) f(a n )") SORTOWANIE 1 SORTOWANIE Proces ustawiania zbioru elementów w określonym porządku. Stosuje się w celu ułatwienia późniejszego wyszukiwania elementów sortowanego zbioru. 2 Definicja Ciąg wejściowy: a 1,
SORTOWANIE 1 SORTOWANIE Proces ustawiania zbioru elementów w określonym porządku. Stosuje się w celu ułatwienia późniejszego wyszukiwania elementów sortowanego zbioru. 2 Definicja Ciąg wejściowy: a 1,
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Rozpoznawanie mówców metodą i-wektorów/plda na urządzeniach mobilnych
 Rozpoznawanie mówców metodą i-wektorów/plda na urządzeniach mobilnych Autor: Radosław Białobrzeski Opiekun: prof. Andrzej Pacut Seminarium Zespołu Biometrii i Uczenia Maszynowego, 24.10.2017 1/27 1. Cel
Rozpoznawanie mówców metodą i-wektorów/plda na urządzeniach mobilnych Autor: Radosław Białobrzeski Opiekun: prof. Andrzej Pacut Seminarium Zespołu Biometrii i Uczenia Maszynowego, 24.10.2017 1/27 1. Cel
Dynamiczny przydział pamięci w języku C. Dynamiczne struktury danych. dr inż. Jarosław Forenc. Metoda 1 (wektor N M-elementowy)
") Rok akademicki 2012/2013, Wykład nr 2 2/25 Plan wykładu nr 2 Informatyka 2 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr III, studia niestacjonarne I stopnia Rok akademicki 2012/2013
Rok akademicki 2012/2013, Wykład nr 2 2/25 Plan wykładu nr 2 Informatyka 2 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr III, studia niestacjonarne I stopnia Rok akademicki 2012/2013
Wybór / ocena atrybutów na podstawie oceny jakości działania wybranego klasyfikatora.
 Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
Teoretyczne podstawy informatyki
 Teoretyczne podstawy informatyki Wykład 4a: Rozwiązywanie rekurencji http://kiwi.if.uj.edu.pl/~erichter/dydaktyka2010/tpi-2010 Prof. dr hab. Elżbieta Richter-Wąs 1 Czas działania programu Dla konkretnych
Teoretyczne podstawy informatyki Wykład 4a: Rozwiązywanie rekurencji http://kiwi.if.uj.edu.pl/~erichter/dydaktyka2010/tpi-2010 Prof. dr hab. Elżbieta Richter-Wąs 1 Czas działania programu Dla konkretnych
WYRAŻENIA ALGEBRAICZNE
 WYRAŻENIA ALGEBRAICZNE Wyrażeniem algebraicznym nazywamy wyrażenie zbudowane z liczb, liter, nawiasów oraz znaków działań, na przykład: Symbole literowe występujące w wyrażeniu algebraicznym nazywamy zmiennymi.
WYRAŻENIA ALGEBRAICZNE Wyrażeniem algebraicznym nazywamy wyrażenie zbudowane z liczb, liter, nawiasów oraz znaków działań, na przykład: Symbole literowe występujące w wyrażeniu algebraicznym nazywamy zmiennymi.
Sortowanie bąbelkowe - wersja nr 1 Bubble Sort
 Sortowanie bąbelkowe - wersja nr 1 Bubble Sort Algorytm Algorytm sortowania bąbelkowego jest jednym z najstarszych algorytmów sortujących. Można go potraktować jako ulepszenie opisanego w poprzednim rozdziale
Sortowanie bąbelkowe - wersja nr 1 Bubble Sort Algorytm Algorytm sortowania bąbelkowego jest jednym z najstarszych algorytmów sortujących. Można go potraktować jako ulepszenie opisanego w poprzednim rozdziale
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
Analiza efektywności przetwarzania współbieżnego. Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Podstawy Informatyki. Inżynieria Ciepła, I rok. Iteracja warunkowadopóki(while) Blok instrukcji. Pascal: begin instrukcja1; C: { end;
 Blok instrukcji. Pascal: begin instrukcja1; C: { end;") Podstawy Informatyki Inżyria Ciepła, I rok Wykład 8 Algorytmy, cd Instrukcja decyzyjna wybierz Zda wybierz służy do wyboru jednej z kilku możliwości Ma ono postać: wybierz przełącznik z wartość_1: zda_1
Podstawy Informatyki Inżyria Ciepła, I rok Wykład 8 Algorytmy, cd Instrukcja decyzyjna wybierz Zda wybierz służy do wyboru jednej z kilku możliwości Ma ono postać: wybierz przełącznik z wartość_1: zda_1
Maciej Piotr Jankowski
 Reduced Adder Graph Implementacja algorytmu RAG Maciej Piotr Jankowski 2005.12.22 Maciej Piotr Jankowski 1 Plan prezentacji 1. Wstęp 2. Implementacja 3. Usprawnienia optymalizacyjne 3.1. Tablica ekspansji
Reduced Adder Graph Implementacja algorytmu RAG Maciej Piotr Jankowski 2005.12.22 Maciej Piotr Jankowski 1 Plan prezentacji 1. Wstęp 2. Implementacja 3. Usprawnienia optymalizacyjne 3.1. Tablica ekspansji
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
16 Jednowymiarowy model Isinga
 16 Jednowymiarowy model Isinga Jest to liniowy łańcuch N spinów mogących przyjmować wartości ± 1. Mikrostanem układu jest zbiór zmiennych σ i = ±1, gdzie i = 1,,..., N (16.1) Określają one czy i-ty spin
16 Jednowymiarowy model Isinga Jest to liniowy łańcuch N spinów mogących przyjmować wartości ± 1. Mikrostanem układu jest zbiór zmiennych σ i = ±1, gdzie i = 1,,..., N (16.1) Określają one czy i-ty spin
Programowanie liniowe. Tadeusz Trzaskalik
 Programowanie liniowe Tadeusz Trzaskalik .. Wprowadzenie Słowa kluczowe Model matematyczny Cel, środki, ograniczenia Funkcja celu funkcja kryterium Zmienne decyzyjne Model optymalizacyjny Układ warunków
Programowanie liniowe Tadeusz Trzaskalik .. Wprowadzenie Słowa kluczowe Model matematyczny Cel, środki, ograniczenia Funkcja celu funkcja kryterium Zmienne decyzyjne Model optymalizacyjny Układ warunków
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Rozdział 1 PROGRAMOWANIE LINIOWE
 Wprowadzenie do badań operacyjnych z komputerem Opisy programów, ćwiczenia komputerowe i zadania. T. Trzaskalik (red.) Rozdział 1 PROGRAMOWANIE LINIOWE 1.2 Ćwiczenia komputerowe Ćwiczenie 1.1 Wykorzystując
Wprowadzenie do badań operacyjnych z komputerem Opisy programów, ćwiczenia komputerowe i zadania. T. Trzaskalik (red.) Rozdział 1 PROGRAMOWANIE LINIOWE 1.2 Ćwiczenia komputerowe Ćwiczenie 1.1 Wykorzystując
Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11,
 1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
S O M SELF-ORGANIZING MAPS. Przemysław Szczepańczyk Łukasz Myszor
 S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Metoda określania pozycji wodnicy statków na podstawie pomiarów odległości statku od głowic laserowych
 inż. Marek Duczkowski Metoda określania pozycji wodnicy statków na podstawie pomiarów odległości statku od głowic laserowych słowa kluczowe: algorytm gradientowy, optymalizacja, określanie wodnicy W artykule
inż. Marek Duczkowski Metoda określania pozycji wodnicy statków na podstawie pomiarów odległości statku od głowic laserowych słowa kluczowe: algorytm gradientowy, optymalizacja, określanie wodnicy W artykule
System kontroli dostępu oparty na biometrycznej weryfikacji głosu
 Jakub GAŁKA, Mariusz MĄSIOR, Michał SALASA AGH Akademia Górniczo-Hutnicza, Wydział Informatyki, Elektroniki i Telekomunikacji, Katedra Elektroniki System kontroli dostępu oparty na biometrycznej weryfikacji
Jakub GAŁKA, Mariusz MĄSIOR, Michał SALASA AGH Akademia Górniczo-Hutnicza, Wydział Informatyki, Elektroniki i Telekomunikacji, Katedra Elektroniki System kontroli dostępu oparty na biometrycznej weryfikacji
Opisy efektów kształcenia dla modułu
 Karta modułu - Technologia mowy 1 / 5 Nazwa modułu: Technologia mowy Rocznik: 2012/2013 Kod: RIA-1-504-s Punkty ECTS: 7 Wydział: Inżynierii Mechanicznej i Robotyki Poziom studiów: Studia I stopnia Specjalność:
Karta modułu - Technologia mowy 1 / 5 Nazwa modułu: Technologia mowy Rocznik: 2012/2013 Kod: RIA-1-504-s Punkty ECTS: 7 Wydział: Inżynierii Mechanicznej i Robotyki Poziom studiów: Studia I stopnia Specjalność:
Teoretyczne podstawy informatyki
 Teoretyczne podstawy informatyki Wykład 10a: O złożoności obliczeniowej raz jeszcze. Złożoność zamortyzowana Model danych zewnętrznych i algorytmy obróbki danych 1 Złożoność zamortyzowana W wielu sytuacjach
Teoretyczne podstawy informatyki Wykład 10a: O złożoności obliczeniowej raz jeszcze. Złożoność zamortyzowana Model danych zewnętrznych i algorytmy obróbki danych 1 Złożoność zamortyzowana W wielu sytuacjach
Wydajność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń równoległych Podobnie jak w obliczeniach sekwencyjnych, gdzie celem optymalizacji wydajności było maksymalne
Wydajność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń równoległych Podobnie jak w obliczeniach sekwencyjnych, gdzie celem optymalizacji wydajności było maksymalne
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych
 Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2014/15 Znajdowanie maksimum w zbiorze
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2014/15 Znajdowanie maksimum w zbiorze
WHILE (wyrażenie) instrukcja;
 instrukcja;") INSTRUKCJE ITERACYJNE WHILE, DO WHILE, FOR Instrukcje iteracyjne pozwalają powtarzać daną instrukcję programu określoną liczbę razy lub do momentu osiągnięcia określonego skutku. Pętla iteracyjna while
INSTRUKCJE ITERACYJNE WHILE, DO WHILE, FOR Instrukcje iteracyjne pozwalają powtarzać daną instrukcję programu określoną liczbę razy lub do momentu osiągnięcia określonego skutku. Pętla iteracyjna while
Modelowanie rynków finansowych z wykorzystaniem pakietu R
 Modelowanie rynków finansowych z wykorzystaniem pakietu R Metody numeryczne i symulacje stochastyczne Mateusz Topolewski woland@mat.umk.pl Wydział Matematyki i Informatyki UMK Plan działania 1 Całkowanie
Modelowanie rynków finansowych z wykorzystaniem pakietu R Metody numeryczne i symulacje stochastyczne Mateusz Topolewski woland@mat.umk.pl Wydział Matematyki i Informatyki UMK Plan działania 1 Całkowanie
wagi cyfry 7 5 8 2 pozycje 3 2 1 0
 Wartość liczby pozycyjnej System dziesiętny W rozdziale opiszemy pozycyjne systemy liczbowe. Wiedza ta znakomicie ułatwi nam zrozumienie sposobu przechowywania liczb w pamięci komputerów. Na pierwszy ogień
Wartość liczby pozycyjnej System dziesiętny W rozdziale opiszemy pozycyjne systemy liczbowe. Wiedza ta znakomicie ułatwi nam zrozumienie sposobu przechowywania liczb w pamięci komputerów. Na pierwszy ogień
SYSTEM BIOMETRYCZNY IDENTYFIKUJĄCY OSOBY NA PODSTAWIE CECH OSOBNICZYCH TWARZY. Autorzy: M. Lewicka, K. Stańczyk
 SYSTEM BIOMETRYCZNY IDENTYFIKUJĄCY OSOBY NA PODSTAWIE CECH OSOBNICZYCH TWARZY Autorzy: M. Lewicka, K. Stańczyk Kraków 2008 Cel pracy projekt i implementacja systemu rozpoznawania twarzy, który na podstawie
SYSTEM BIOMETRYCZNY IDENTYFIKUJĄCY OSOBY NA PODSTAWIE CECH OSOBNICZYCH TWARZY Autorzy: M. Lewicka, K. Stańczyk Kraków 2008 Cel pracy projekt i implementacja systemu rozpoznawania twarzy, który na podstawie
Modelowanie glikemii w procesie insulinoterapii
 Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
WHILE (wyrażenie) instrukcja;
 instrukcja;") INSTRUKCJE ITERACYJNE WHILE, DO WHILE, FOR Instrukcje iteracyjne pozwalają powtarzać daną instrukcję programu określoną liczbę razy lub do momentu osiągnięcia określonego skutku. Pętla iteracyjna while
INSTRUKCJE ITERACYJNE WHILE, DO WHILE, FOR Instrukcje iteracyjne pozwalają powtarzać daną instrukcję programu określoną liczbę razy lub do momentu osiągnięcia określonego skutku. Pętla iteracyjna while
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Zad. 3: Układ równań liniowych
 1 Cel ćwiczenia Zad. 3: Układ równań liniowych Wykształcenie umiejętności modelowania kluczowych dla danego problemu pojęć. Definiowanie właściwego interfejsu klasy. Zwrócenie uwagi na dobór odpowiednich
1 Cel ćwiczenia Zad. 3: Układ równań liniowych Wykształcenie umiejętności modelowania kluczowych dla danego problemu pojęć. Definiowanie właściwego interfejsu klasy. Zwrócenie uwagi na dobór odpowiednich
Modelowanie niezawodności prostych struktur sprzętowych
 Modelowanie niezawodności prostych struktur sprzętowych W ćwiczeniu tym przedstawione zostaną proste struktury sprzętowe oraz sposób obliczania ich niezawodności przy założeniu, że funkcja niezawodności
Modelowanie niezawodności prostych struktur sprzętowych W ćwiczeniu tym przedstawione zostaną proste struktury sprzętowe oraz sposób obliczania ich niezawodności przy założeniu, że funkcja niezawodności
Matematyczne Podstawy Informatyki
 Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 2013/2014 Algorytm 1. Termin algorytm jest używany w informatyce
Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 2013/2014 Algorytm 1. Termin algorytm jest używany w informatyce
LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI. Wprowadzenie do środowiska Matlab
 LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI Wprowadzenie do środowiska Matlab 1. Podstawowe informacje Przedstawione poniżej informacje maja wprowadzić i zapoznać ze środowiskiem
LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI Wprowadzenie do środowiska Matlab 1. Podstawowe informacje Przedstawione poniżej informacje maja wprowadzić i zapoznać ze środowiskiem
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Analiza efektywności przetwarzania współbieżnego
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Temat: Sieci neuronowe oraz technologia CUDA
 Elbląg, 27.03.2010 Temat: Sieci neuronowe oraz technologia CUDA Przygotował: Mateusz Górny VIII semestr ASiSK Wstęp Sieci neuronowe są to specyficzne struktury danych odzwierciedlające sieć neuronów w
Elbląg, 27.03.2010 Temat: Sieci neuronowe oraz technologia CUDA Przygotował: Mateusz Górny VIII semestr ASiSK Wstęp Sieci neuronowe są to specyficzne struktury danych odzwierciedlające sieć neuronów w
SCHEMAT ROZWIĄZANIA ZADANIA OPTYMALIZACJI PRZY POMOCY ALGORYTMU GENETYCZNEGO
 SCHEMAT ROZWIĄZANIA ZADANIA OPTYMALIZACJI PRZY POMOCY ALGORYTMU GENETYCZNEGO. Rzeczywistość (istniejąca lub projektowana).. Model fizyczny. 3. Model matematyczny (optymalizacyjny): a. Zmienne projektowania
SCHEMAT ROZWIĄZANIA ZADANIA OPTYMALIZACJI PRZY POMOCY ALGORYTMU GENETYCZNEGO. Rzeczywistość (istniejąca lub projektowana).. Model fizyczny. 3. Model matematyczny (optymalizacyjny): a. Zmienne projektowania
Grupowanie Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633
 Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Algorytm Grovera. Kwantowe przeszukiwanie zbiorów. Robert Nowotniak
 Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Politechnika Łódzka 13 listopada 2007 Plan wystapienia 1 Informatyka Kwantowa podstawy 2 Opis problemu (przeszukiwanie zbioru) 3 Intuicyjna
Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Politechnika Łódzka 13 listopada 2007 Plan wystapienia 1 Informatyka Kwantowa podstawy 2 Opis problemu (przeszukiwanie zbioru) 3 Intuicyjna
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
WYKŁAD 9 METODY ZMIENNEJ METRYKI
 WYKŁAD 9 METODY ZMIENNEJ METRYKI Kierunki sprzężone. Metoda Newtona Raphsona daje dobre przybliżenie najlepszego kierunku poszukiwań, lecz jest to okupione znacznym kosztem obliczeniowym zwykle postać
WYKŁAD 9 METODY ZMIENNEJ METRYKI Kierunki sprzężone. Metoda Newtona Raphsona daje dobre przybliżenie najlepszego kierunku poszukiwań, lecz jest to okupione znacznym kosztem obliczeniowym zwykle postać
PRACA DYPLOMOWA INŻYNIERSKA
 AKADEMIA GÓRNICZO-HUTNICZA IM. STANISŁAWA STASZICA W KRAKOWIE Wydział Informatyki, Elektroniki i Telekomunikacji Katedra Elektroniki PRACA DYPLOMOWA INŻYNIERSKA Temat: Adaptacyjny system redukcji szumu
AKADEMIA GÓRNICZO-HUTNICZA IM. STANISŁAWA STASZICA W KRAKOWIE Wydział Informatyki, Elektroniki i Telekomunikacji Katedra Elektroniki PRACA DYPLOMOWA INŻYNIERSKA Temat: Adaptacyjny system redukcji szumu
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Stochastic modelling of phase transformations using HPC infrastructure
 Stochastic modelling of phase transformations using HPC infrastructure (Stochastyczne modelowanie przemian fazowych z wykorzystaniem komputerów wysokiej wydajności) Daniel Bachniak, Łukasz Rauch, Danuta
Stochastic modelling of phase transformations using HPC infrastructure (Stochastyczne modelowanie przemian fazowych z wykorzystaniem komputerów wysokiej wydajności) Daniel Bachniak, Łukasz Rauch, Danuta
Kompresja danych DKDA (7)
") Kompresja danych DKDA (7) Marcin Gogolewski marcing@wmi.amu.edu.pl Uniwersytet im. Adama Mickiewicza w Poznaniu Poznań, 22 listopada 2016 1 Kwantyzacja skalarna Wprowadzenie Analiza jakości Typy kwantyzatorów
Kompresja danych DKDA (7) Marcin Gogolewski marcing@wmi.amu.edu.pl Uniwersytet im. Adama Mickiewicza w Poznaniu Poznań, 22 listopada 2016 1 Kwantyzacja skalarna Wprowadzenie Analiza jakości Typy kwantyzatorów
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Pętle i tablice. Spotkanie 3. Pętle: for, while, do while. Tablice. Przykłady
 Pętle i tablice. Spotkanie 3 Dr inż. Dariusz JĘDRZEJCZYK Pętle: for, while, do while Tablice Przykłady 11/26/2016 AGH, Katedra Informatyki Stosowanej i Modelowania 2 Pętla w największym uproszczeniu służy
Pętle i tablice. Spotkanie 3 Dr inż. Dariusz JĘDRZEJCZYK Pętle: for, while, do while Tablice Przykłady 11/26/2016 AGH, Katedra Informatyki Stosowanej i Modelowania 2 Pętla w największym uproszczeniu służy
Fuzja sygnałów i filtry bayesowskie
 Fuzja sygnałów i filtry bayesowskie Roboty Manipulacyjne i Mobilne dr inż. Janusz Jakubiak Katedra Cybernetyki i Robotyki Wydział Elektroniki, Politechnika Wrocławska Wrocław, 10.03.2015 Dlaczego potrzebna
Fuzja sygnałów i filtry bayesowskie Roboty Manipulacyjne i Mobilne dr inż. Janusz Jakubiak Katedra Cybernetyki i Robotyki Wydział Elektroniki, Politechnika Wrocławska Wrocław, 10.03.2015 Dlaczego potrzebna
KATEDRA SYSTEMÓW MULTIMEDIALNYCH. Inteligentne systemy decyzyjne. Ćwiczenie nr 12:
 KATEDRA SYSTEMÓW MULTIMEDIALNYCH Inteligentne systemy decyzyjne Ćwiczenie nr 12: Rozpoznawanie mowy z wykorzystaniem ukrytych modeli Markowa i pakietu HTK Opracowanie: mgr inż. Kuba Łopatka 1. Wprowadzenie
KATEDRA SYSTEMÓW MULTIMEDIALNYCH Inteligentne systemy decyzyjne Ćwiczenie nr 12: Rozpoznawanie mowy z wykorzystaniem ukrytych modeli Markowa i pakietu HTK Opracowanie: mgr inż. Kuba Łopatka 1. Wprowadzenie
Programowanie celowe #1
 Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych
 Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
Ataki na RSA. Andrzej Chmielowiec. Centrum Modelowania Matematycznego Sigma. Ataki na RSA p. 1
 Ataki na RSA Andrzej Chmielowiec andrzej.chmielowiec@cmmsigma.eu Centrum Modelowania Matematycznego Sigma Ataki na RSA p. 1 Plan prezentacji Wprowadzenie Ataki algebraiczne Ataki z kanałem pobocznym Podsumowanie
Ataki na RSA Andrzej Chmielowiec andrzej.chmielowiec@cmmsigma.eu Centrum Modelowania Matematycznego Sigma Ataki na RSA p. 1 Plan prezentacji Wprowadzenie Ataki algebraiczne Ataki z kanałem pobocznym Podsumowanie
Podstawy metodologiczne symulacji
 Sławomir Kulesza kulesza@matman.uwm.edu.pl Symulacje komputerowe (05) Podstawy metodologiczne symulacji Wykład dla studentów Informatyki Ostatnia zmiana: 26 marca 2015 (ver. 4.1) Spirala symulacji optymistycznie
Sławomir Kulesza kulesza@matman.uwm.edu.pl Symulacje komputerowe (05) Podstawy metodologiczne symulacji Wykład dla studentów Informatyki Ostatnia zmiana: 26 marca 2015 (ver. 4.1) Spirala symulacji optymistycznie
Analiza ilościowa w przetwarzaniu równoległym
 Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Pojęcie szeregu nieskończonego:zastosowania do rachunku prawdopodobieństwa wykład 1
 Pojęcie szeregu nieskończonego:zastosowania do rachunku prawdopodobieństwa wykład dr Mariusz Grządziel 5 lutego 04 Paradoks Zenona z Elei wersja uwspółcześniona Zenek goni Andrzeja; prędkość Andrzeja:
Pojęcie szeregu nieskończonego:zastosowania do rachunku prawdopodobieństwa wykład dr Mariusz Grządziel 5 lutego 04 Paradoks Zenona z Elei wersja uwspółcześniona Zenek goni Andrzeja; prędkość Andrzeja:
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
FIZYKA klasa 1 Liceum Ogólnokształcącego (4 letniego)
") 2019-09-01 FIZYKA klasa 1 Liceum Ogólnokształcącego (4 letniego) Treści z podstawy programowej przedmiotu POZIOM ROZSZERZONY (PR) SZKOŁY BENEDYKTA Podstawa programowa FIZYKA KLASA 1 LO (4-letnie po szkole
2019-09-01 FIZYKA klasa 1 Liceum Ogólnokształcącego (4 letniego) Treści z podstawy programowej przedmiotu POZIOM ROZSZERZONY (PR) SZKOŁY BENEDYKTA Podstawa programowa FIZYKA KLASA 1 LO (4-letnie po szkole
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
znalezienia elementu w zbiorze, gdy w nim jest; dołączenia nowego elementu w odpowiednie miejsce, aby zbiór pozostał nadal uporządkowany.
 Przedstawiamy algorytmy porządkowania dowolnej liczby elementów, którymi mogą być liczby, jak również elementy o bardziej złożonej postaci (takie jak słowa i daty). Porządkowanie, nazywane również często
Przedstawiamy algorytmy porządkowania dowolnej liczby elementów, którymi mogą być liczby, jak również elementy o bardziej złożonej postaci (takie jak słowa i daty). Porządkowanie, nazywane również często