Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska
|
|
|
- Julian Kulesza
- 5 lat temu
- Przeglądów:
Transkrypt


1 Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska bartosz.krawczyk@pwr.wroc.pl
2 Czym jest klasyfikacja jednoklasowa? Celem klasyfikacji wieloklasowej jest rozróżnienie między obiektami pochodzącymi z dwóch lub więcej klas, zachowując jak najmniejszy błąd.
3 Czym jest klasyfikacja jednoklasowa? Celem klasyfikacji wieloklasowej jest rozróżnienie między obiektami pochodzącymi z dwóch lub więcej klas, zachowując jak najmniejszy błąd.
4 Czym jest klasyfikacja jednoklasowa? W przypadku klasyfikacji jednoklasowej na etapie uczenia mamy do dyspozycji wyłącznie obiekty pochodzące z jednej klasy. Nazywa się to nauką przy braku kontrprzykładów.
5 Czym jest klasyfikacja jednoklasowa? Jednym z najbardziej popularnych podejść jest estymacja zamkniętej granicy decyzyjnej, zawierającej w sobie wszystkie istotne obiekty z klasy celu.
6 Czym jest klasyfikacja jednoklasowa? Zakłada się, że w trakcie eksploatacji klasyfikatora jednoklasowego mogą pojawić się nowe, nieznane obserwacje. Nazywa się je obserwacjami odstającymi.
7 Komitety klasyfikatorów jednoklasowych W klasyfikacji jednoklasowej niezbędne są metody poprawiające jakość i stabilność modelu komitety klasyfikatorów są więc obiecujacym kierunkiem badań. Do tej pory większość prac w tej dziedzinie skupiała się na aplikacjach istnieje potrzeba rozbudowania teoretycznych podstaw tej dziedziny.

8 Klasyfikatory w puli Aby komitet klasyfikatorów osiągał dobrą skuteczność rozpoznawania, musi być on zbudowany z puli klasyfikatorów które jednocześnie mają niski błąd klasyfikacji oraz są zróżnicowane względem siebie.
9 Klasyfikatory w puli Jeżeli klasyfikatory niezależnie uzyskują niski błąd klasyfikacji, ale nie są zróżnicowane to nie wnoszą nic do komitetu. Jeśli klasyfikatory są zróżnicowane względem siebie, ale nie przejawiają dobrej jakości rozpoznawania to pogorszymy jakość komitetu.
10 Trudności w budowie komitetów jednoklasowych W literaturze istnieje bogaty wachlarz sposobów w jaki budować i dobierać komitety klasyfikatorów dedykowany problemom wieloklasowym. Niestety te metody nie mogą zostać zastosowane w problemie klasyfikacji jednoklasowej. Głownym problemem jest brak kontrzpykładów na etapie nauki: metody budowy komitetów, takie jak boosting opierają się na minimalizacji błędu rozpoznawania miary różnorodności bazują na wskazaniach dwóch i więcej klasyfikatorów dla danego obiektu i jego klasy metody selekcji / przycinania komitetów potrzebują miary kryterialnej, którą najczęściej jest błąd komitetu
11 Dwa główne zagadnienia w budowie komitetów komitety klasyfikatorów jednoklasowych metody budowy puli klasyfikatorów metody selekcji klasyfikatorów podział przestrzeni cech podział przestrzeni obiektów wykorzystujące kryterium nieparametryczne Krawczyk B., Woźniak M., Cyganek B., Clustering-based ensembles for one-class classification. Information Sciences, 2013
12 Budowa komitetu przez podział przestrzeni cech Budowa komitetów klasyfikatorów jednoklasowych za pomocą podziału przestrzeni cech polega na uczeniu klasyfikatorów na zredukowanej przestrzeni cech, co zapewni wstępną różnorodność modeli. Jest to metoda bardzo obiecująca dla klasyfikacji jednoklasowej, gdyż redukuje złożoność obliczeniową każdego klasyfikatora. Niestety istnieje ryzyko utworzenia wielu zbliżonych do siebie podprzestrzeni, lub podprzestrzeni wykorzystujących cechy o niskiej wartości informacyjnej. Z tego powodu zaproponowano podejście Overproduce and Select, które opiera się na zbudowaniu dużej liczby podprzestrzeni a następnie przycinaniu komitetu. Krawczyk B., Woźniak M., Diversity measures for one-class classifier ensembles. Neurocomputing, 2013
13 Metody selekcji klasyfikatorów jednoklasowych W wielu przypadkach (np. zastosowania metody Random Subspace) nie należy wykorzystać wszystkich klasyfikatorów dostępnych w puli. Istnieją dwie główne motywacje dokonania selekcji klasyfikatorów / przycinania komitetu: eliminacja słabych klasyfikatorów, które mogą wpłynąć negatywnie na wynik decyzji komitetu redukcja ilości klasyfikatorów w puli, co prowadzi do redukcji złożoności komitetu Zaproponowano dwa typy podejść: wymagające miary kryterialnej oraz nieparametryczne. Typ pierwszy jest modyfikacją istniejących metod selekcji, z reguły opierający się na metodach optymalizacji. Wymagana jednak jest dedykowana miara dla klasyfikacji jednoklasowej. Typ drugi jest alternatywnym podejściem, nie wymagającym dedykowanej miary. Krawczyk B., Filipczuk P., Cytological Image Analysis with Firefly Nuclei Detection and Hybrid One- Class Classification Decomposition. Engineering Applications of Artificial Intelligence, 2013

14 Miary w klasyfikacji jednoklasowej Zaproponowano szereg nowych miar różnorodności, wyspecjalizowanych pod kątem klasyfikacji jednoklasowej. Jedną z najskuteczniejszych miar jest miara nakładania się sfer. Jako miarę jakości zamiast tradycyjnego błedu klasyfikacji proponuje się zastosowanie miary spójności przestrzeni.
15 Metody selekcji z kryterium Aby uniknąć problemu doboru tylko dokładnych albo tylko zróżnicowanych klasyfikatorów jednoklasowych, zaproponowano wykorzystanie metod optymalizacji wielokryterialnej. Funkcją celu jest liniową kombinacją jednej z miar różnorodności (np. miary nakładania się sfer) oraz miary spójności przestrzeni. Wcześniejsze badania przeprowadzono z użyciem algorytmów genetycznych. Dobre wyniki zachęciły do dalszych badan nad metodą przeszukiwania. Obecnie proponuje się stosowanie algorytmu memetycznego, łączącego algorytm genetyczny z lokalnym przeszukiwaniem za pomocą metody tabu search. Szczurek A., Krawczyk B. & Maciejewska M., VOCs classification based on committee of classifiers coupled with single sensor signals. Chemometrics and Intelligent Laboratory Systems vol. 125: 1-10.

16 Metody selekcji z kryterium Metody oparte na podejściu optymalizacyjnym mogą być złożone obliczeniowo dla rozbudowanych komitetów. Alternatywą może być wykorzystanie algorytmów klasteryzacji. Proponuje się, aby działały one na macierzy złożonej z wartości parowych miar różnorodności. W ten sposób miara różnorodności jest tożsama z odległością między obiektami w klasycznej analizie skupień. Następnie dla każdego z klastrów wybiera się reprezentanta za pomocą jednej z kilku badanych metod (najbliższy centroidowi, najdalszy od innych centroidów, uczenie nowego klasyfikatora itd). Krawczyk B., Pruning and Weighted Fusion of One-Class Classifier Ensemble with Firefly Algorithm. Machine Learning in review

17 Metody nieparametryczne Alternatywnym podejściem do wprowadzania nowych miar jest szukanie metod nieparametrycznych do przycinania komitetów klasyfikatorów jednoklasowych. Nasuwającym się tu rozwiązaniem jest zastosowanie metod klasteryzacji. Analizy skupień dokonuje się w nowej przestrzeni, gdzie obiektem jest klasyfikator, zaś cechami wartości funkcji wsparć dla poszczególnych obiektów. Wyszukuje się najbardziej podobne klastry klasyfikatorów, tworzące pewne profile decyzyjne. Krawczyk B., Woźniak M., Influence of Distance Measures on the Effectiveness of One-Class Classification Ensembles. Applied Artificial Intelligence, 2013
18 Badania eksperymentalne Wykonane na 20 bazach z UCI machine learning repository. Klasyfikator bazowy Support Vector Domain Description z jądrem RBF. Pula 30 klasyfikatorów, budowana na Random Subspace złożonej z 40% oryginalnych przestrzeni cech. Wykorzystano test rankingowy Friedmana.
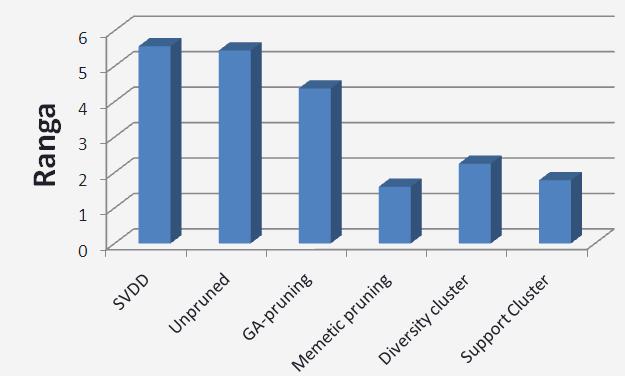
19 Badania eksperymentalne
20 Dziękuję za uwagę
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej. Adam Żychowski
 Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Meta-uczenie co to jest?
 Meta-uczenie co to jest? Uczenie się tego jak się uczyć Uwolnienie się od uciażliwego doboru MODELU i PAREMETRÓW modelu. Bachotek05/1 Cele meta-uczenia Pełna ale kryterialna automatyzacja modelowania danych
Meta-uczenie co to jest? Uczenie się tego jak się uczyć Uwolnienie się od uciażliwego doboru MODELU i PAREMETRÓW modelu. Bachotek05/1 Cele meta-uczenia Pełna ale kryterialna automatyzacja modelowania danych
mgr inż. Magdalena Deckert Poznań, r. Uczenie się klasyfikatorów przy zmieniającej się definicji klas.
 mgr inż. Magdalena Deckert Poznań, 01.06.2010r. Uczenie się klasyfikatorów przy zmieniającej się definicji klas. Plan prezentacji Wstęp Concept drift Typy zmian Podział algorytmów stosowanych w uczeniu
mgr inż. Magdalena Deckert Poznań, 01.06.2010r. Uczenie się klasyfikatorów przy zmieniającej się definicji klas. Plan prezentacji Wstęp Concept drift Typy zmian Podział algorytmów stosowanych w uczeniu
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji
 Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Ontogeniczne sieci neuronowe. O sieciach zmieniających swoją strukturę
 Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner
 Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
7. Maszyny wektorów podpierajacych SVMs
 Algorytmy rozpoznawania obrazów 7. Maszyny wektorów podpierajacych SVMs dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Maszyny wektorów podpierajacych - SVMs Maszyny wektorów podpierających (ang.
Algorytmy rozpoznawania obrazów 7. Maszyny wektorów podpierajacych SVMs dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Maszyny wektorów podpierajacych - SVMs Maszyny wektorów podpierających (ang.
SPOTKANIE 2: Wprowadzenie cz. I
 Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych Mateusz Kobos, 07.04.2010 Seminarium Metody Inteligencji Obliczeniowej Spis treści Opis algorytmu i zbioru
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych Mateusz Kobos, 07.04.2010 Seminarium Metody Inteligencji Obliczeniowej Spis treści Opis algorytmu i zbioru
KARTA MODUŁU KSZTAŁCENIA
 KARTA MODUŁU KSZTAŁCENIA I. Informacje ogólne 1 Nazwa modułu kształcenia Sztuczna inteligencja 2 Nazwa jednostki prowadzącej moduł Instytut Informatyki, Zakład Informatyki Stosowanej 3 Kod modułu (wypełnia
KARTA MODUŁU KSZTAŁCENIA I. Informacje ogólne 1 Nazwa modułu kształcenia Sztuczna inteligencja 2 Nazwa jednostki prowadzącej moduł Instytut Informatyki, Zakład Informatyki Stosowanej 3 Kod modułu (wypełnia
Metody zbiorów przybliżonych w uczeniu się podobieństwa z wielowymiarowych zbiorów danych
 Metody zbiorów przybliżonych w uczeniu się podobieństwa z wielowymiarowych zbiorów danych WMIM, Uniwersytet Warszawski ul. Banacha 2, 02-097 Warszawa, Polska andrzejanusz@gmail.com 13.06.2013 Dlaczego
Metody zbiorów przybliżonych w uczeniu się podobieństwa z wielowymiarowych zbiorów danych WMIM, Uniwersytet Warszawski ul. Banacha 2, 02-097 Warszawa, Polska andrzejanusz@gmail.com 13.06.2013 Dlaczego
CLUSTERING. Metody grupowania danych
 CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
2. Empiryczna wersja klasyfikatora bayesowskiego
 Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
MATLAB Neural Network Toolbox przegląd
 MATLAB Neural Network Toolbox przegląd WYKŁAD Piotr Ciskowski Neural Network Toolbox: Neural Network Toolbox - zastosowania: przykłady zastosowań sieci neuronowych: The 1988 DARPA Neural Network Study
MATLAB Neural Network Toolbox przegląd WYKŁAD Piotr Ciskowski Neural Network Toolbox: Neural Network Toolbox - zastosowania: przykłady zastosowań sieci neuronowych: The 1988 DARPA Neural Network Study
Metody selekcji cech
 Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Pattern Classification
 Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
8. Drzewa decyzyjne, bagging, boosting i lasy losowe
 Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Algorytm genetyczny (genetic algorithm)-
-") Optymalizacja W praktyce inżynierskiej często zachodzi potrzeba znalezienia parametrów, dla których system/urządzenie będzie działać w sposób optymalny. Klasyczne podejście do optymalizacji: sformułowanie
Optymalizacja W praktyce inżynierskiej często zachodzi potrzeba znalezienia parametrów, dla których system/urządzenie będzie działać w sposób optymalny. Klasyczne podejście do optymalizacji: sformułowanie
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy oólny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK
Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy oólny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK
Algorytmy rozpoznawania obrazów. 11. Analiza skupień. dr inż. Urszula Libal. Politechnika Wrocławska
 Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
Metody komputerowe statystyki Computer Methods in Statistics. Matematyka. Poziom kwalifikacji: II stopnia. Liczba godzin/tydzień: 2W, 3L
 Nazwa przedmiotu: Kierunek: Metody komputerowe statystyki Computer Methods in Statistics Matematyka Rodzaj przedmiotu: przedmiot obowiązkowy dla specjalności matematyka przemysłowa Rodzaj zajęć: wykład,
Nazwa przedmiotu: Kierunek: Metody komputerowe statystyki Computer Methods in Statistics Matematyka Rodzaj przedmiotu: przedmiot obowiązkowy dla specjalności matematyka przemysłowa Rodzaj zajęć: wykład,
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych
 Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGNOZOWANIE Z WYKORZYSTANIEM SYSTEMÓW INFORMATYCZNYCH Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU
Nazwa przedmiotu: PROGNOZOWANIE Z WYKORZYSTANIEM SYSTEMÓW INFORMATYCZNYCH Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU
UCZENIE MASZYNOWE III - SVM. mgr inż. Adam Kupryjanow
 UCZENIE MASZYNOWE III - SVM mgr inż. Adam Kupryjanow Plan wykładu Wprowadzenie LSVM dane separowalne liniowo SVM dane nieseparowalne liniowo Nieliniowy SVM Kernel trick Przykłady zastosowań Historia 1992
UCZENIE MASZYNOWE III - SVM mgr inż. Adam Kupryjanow Plan wykładu Wprowadzenie LSVM dane separowalne liniowo SVM dane nieseparowalne liniowo Nieliniowy SVM Kernel trick Przykłady zastosowań Historia 1992
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE
 UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
Multiklasyfikatory z funkcją kompetencji
 3 stycznia 2011 Problem klasyfikacji Polega na przewidzeniu dyskretnej klasy na podstawie cech obiektu. Obiekt jest reprezentowany przez wektor cech Zbiór etykiet jest skończony x X Ω = {ω 1, ω 2,...,
3 stycznia 2011 Problem klasyfikacji Polega na przewidzeniu dyskretnej klasy na podstawie cech obiektu. Obiekt jest reprezentowany przez wektor cech Zbiór etykiet jest skończony x X Ω = {ω 1, ω 2,...,
Drzewa decyzyjne i lasy losowe
 Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
POŁĄCZENIE ALGORYTMÓW SYMULACYJNYCH ORAZ DZIEDZINOWYCH METOD HEURYSTYCZNYCH W ZAGADNIENIACH DYNAMICZNEGO PODEJMOWANIA DECYZJI
 POŁĄCZENIE ALGORYTMÓW SYMULACYJNYCH ORAZ DZIEDZINOWYCH METOD HEURYSTYCZNYCH W ZAGADNIENIACH DYNAMICZNEGO PODEJMOWANIA DECYZJI mgr inż. Karol Walędzik k.waledzik@mini.pw.edu.pl prof. dr hab. inż. Jacek
POŁĄCZENIE ALGORYTMÓW SYMULACYJNYCH ORAZ DZIEDZINOWYCH METOD HEURYSTYCZNYCH W ZAGADNIENIACH DYNAMICZNEGO PODEJMOWANIA DECYZJI mgr inż. Karol Walędzik k.waledzik@mini.pw.edu.pl prof. dr hab. inż. Jacek
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Kognitywne hierarchiczne aktywne podziały. Arkadiusz Tomczyk.
 Arkadiusz Tomczyk arkadiusz.tomczyk@p.lodz.pl projekt finansowany przez: Narodowe Centrum Nauki numer projektu: 2012/05/D/ST6/03091 Przykładowy problem Diagnostyka zatorowości płucnej Obrazowanie CT sprzężone
Arkadiusz Tomczyk arkadiusz.tomczyk@p.lodz.pl projekt finansowany przez: Narodowe Centrum Nauki numer projektu: 2012/05/D/ST6/03091 Przykładowy problem Diagnostyka zatorowości płucnej Obrazowanie CT sprzężone
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
przetworzonego sygnału
 Synteza falek ortogonalnych na podstawie oceny przetworzonego sygnału Instytut Informatyki Politechnika Łódzka 28 lutego 2012 Plan prezentacji 1 Sformułowanie problemu 2 3 4 Historia przekształcenia falkowego
Synteza falek ortogonalnych na podstawie oceny przetworzonego sygnału Instytut Informatyki Politechnika Łódzka 28 lutego 2012 Plan prezentacji 1 Sformułowanie problemu 2 3 4 Historia przekształcenia falkowego
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU
 WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Rozpoznawanie obiektów na podstawie zredukowanego zbioru cech. Piotr Porwik Uniwersytet Śląski w Katowicach
 Rozpoznawanie obiektów na podstawie zredukowanego zbioru cech Piotr Porwik Uniwersytet Śląski w Katowicach ?? It is obvious that more does not mean better, especially in the case of classifiers!! *) *)
Rozpoznawanie obiektów na podstawie zredukowanego zbioru cech Piotr Porwik Uniwersytet Śląski w Katowicach ?? It is obvious that more does not mean better, especially in the case of classifiers!! *) *)
w analizie wyników badań eksperymentalnych, w problemach modelowania zjawisk fizycznych, w analizie obserwacji statystycznych.
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
mgr inż. Magdalena Deckert Poznań, r. Metody przyrostowego uczenia się ze strumieni danych.
 mgr inż. Magdalena Deckert Poznań, 30.11.2010r. Metody przyrostowego uczenia się ze strumieni danych. Plan prezentacji Wstęp Concept drift i typy zmian Algorytmy przyrostowego uczenia się ze strumieni
mgr inż. Magdalena Deckert Poznań, 30.11.2010r. Metody przyrostowego uczenia się ze strumieni danych. Plan prezentacji Wstęp Concept drift i typy zmian Algorytmy przyrostowego uczenia się ze strumieni
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Zastosowanie sztucznej inteligencji w testowaniu oprogramowania
 Zastosowanie sztucznej inteligencji w testowaniu oprogramowania Problem NP Problem NP (niedeterministycznie wielomianowy, ang. nondeterministic polynomial) to problem decyzyjny, dla którego rozwiązanie
Zastosowanie sztucznej inteligencji w testowaniu oprogramowania Problem NP Problem NP (niedeterministycznie wielomianowy, ang. nondeterministic polynomial) to problem decyzyjny, dla którego rozwiązanie
Recenzja rozprawy doktorskiej mgr Mirona Bartosza Kursy p/t. Robust and Efficient Approach to Feature Selection and Machine Learning
 Warszawa, 30.01.2017 Prof. Dr hab. Henryk Rybinski Instytut Informatyki Politechniki Warszawskiej hrb@ii.pw.edu.pl Recenzja rozprawy doktorskiej mgr Mirona Bartosza Kursy p/t. Robust and Efficient Approach
Warszawa, 30.01.2017 Prof. Dr hab. Henryk Rybinski Instytut Informatyki Politechniki Warszawskiej hrb@ii.pw.edu.pl Recenzja rozprawy doktorskiej mgr Mirona Bartosza Kursy p/t. Robust and Efficient Approach
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Maszyny wektorów podpierajacych w regresji rangowej
 Maszyny wektorów podpierajacych w regresji rangowej Uniwersytet Mikołaja Kopernika Z = (X, Y ), Z = (X, Y ) - niezależne wektory losowe o tym samym rozkładzie X X R d, Y R Z = (X, Y ), Z = (X, Y ) - niezależne
Maszyny wektorów podpierajacych w regresji rangowej Uniwersytet Mikołaja Kopernika Z = (X, Y ), Z = (X, Y ) - niezależne wektory losowe o tym samym rozkładzie X X R d, Y R Z = (X, Y ), Z = (X, Y ) - niezależne
Jazda autonomiczna Delphi zgodna z zasadami sztucznej inteligencji
 Jazda autonomiczna Delphi zgodna z zasadami sztucznej inteligencji data aktualizacji: 2017.10.11 Delphi Kraków Rozwój jazdy autonomicznej zmienia krajobraz technologii transportu w sposób tak dynamiczny,
Jazda autonomiczna Delphi zgodna z zasadami sztucznej inteligencji data aktualizacji: 2017.10.11 Delphi Kraków Rozwój jazdy autonomicznej zmienia krajobraz technologii transportu w sposób tak dynamiczny,
9. Praktyczna ocena jakości klasyfikacji
 Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Uczenie sieci radialnych (RBF)
") Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
Modelowanie interakcji helis transmembranowych
 Modelowanie interakcji helis transmembranowych Witold Dyrka, Jean-Christophe Nebel, Małgorzata Kotulska Instytut Inżynierii Biomedycznej i Pomiarowej, Politechnika Wrocławska Faculty of Computing, Information
Modelowanie interakcji helis transmembranowych Witold Dyrka, Jean-Christophe Nebel, Małgorzata Kotulska Instytut Inżynierii Biomedycznej i Pomiarowej, Politechnika Wrocławska Faculty of Computing, Information
Transformacja wiedzy w budowie i eksploatacji maszyn
 Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Sztuczne sieci neuronowe. Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 311
 Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 311 PLAN: Wykład 5 - Metody doboru współczynnika uczenia - Problem inicjalizacji wag - Problem doboru architektury
Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 311 PLAN: Wykład 5 - Metody doboru współczynnika uczenia - Problem inicjalizacji wag - Problem doboru architektury
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Techniki uczenia maszynowego nazwa przedmiotu SYLABUS
 Techniki uczenia maszynowego nazwa SYLABUS Obowiązuje od cyklu kształcenia: 2014/20 Część A. Informacje ogólne Elementy składowe sylabusu Nazwa jednostki prowadzącej studiów Poziom kształcenia Profil studiów
Techniki uczenia maszynowego nazwa SYLABUS Obowiązuje od cyklu kształcenia: 2014/20 Część A. Informacje ogólne Elementy składowe sylabusu Nazwa jednostki prowadzącej studiów Poziom kształcenia Profil studiów
Metody statystyczne wykorzystywane do oceny zróżnicowania kolekcji genowych roślin. Henryk Bujak
 Metody statystyczne wykorzystywane do oceny zróżnicowania kolekcji genowych roślin Henryk Bujak e-mail: h.bujak@ihar.edu.pl Ocena różnorodności fenotypowej Różnorodność fenotypowa kolekcji roślinnych zasobów
Metody statystyczne wykorzystywane do oceny zróżnicowania kolekcji genowych roślin Henryk Bujak e-mail: h.bujak@ihar.edu.pl Ocena różnorodności fenotypowej Różnorodność fenotypowa kolekcji roślinnych zasobów
AUTOMATYKA INFORMATYKA
 AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Selekcja modelu liniowego i predykcja metodami losowych podprzestrzeni
 Selekcja modelu liniowego i predykcja metodami losowych podprzestrzeni Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre Selekcja modelu liniowego i predykcja 1 / 29 Plan
Selekcja modelu liniowego i predykcja metodami losowych podprzestrzeni Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre Selekcja modelu liniowego i predykcja 1 / 29 Plan
SPOTKANIE 1: Wprowadzenie do uczenia maszynowego
 Wrocław University of Technology SPOTKANIE 1: Wprowadzenie do uczenia maszynowego Adam Gonczarek Studenckie Koło Naukowe Estymator adam.gonczarek@pwr.wroc.pl 18.10.2013 Początki uczenia maszynowego Cybernetyka
Wrocław University of Technology SPOTKANIE 1: Wprowadzenie do uczenia maszynowego Adam Gonczarek Studenckie Koło Naukowe Estymator adam.gonczarek@pwr.wroc.pl 18.10.2013 Początki uczenia maszynowego Cybernetyka
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Odkrywanie algorytmów kwantowych za pomocą programowania genetycznego
 Odkrywanie algorytmów kwantowych za pomocą programowania genetycznego Piotr Rybak Koło naukowe fizyków Migacz, Uniwersytet Wrocławski Piotr Rybak (Migacz UWr) Odkrywanie algorytmów kwantowych 1 / 17 Spis
Odkrywanie algorytmów kwantowych za pomocą programowania genetycznego Piotr Rybak Koło naukowe fizyków Migacz, Uniwersytet Wrocławski Piotr Rybak (Migacz UWr) Odkrywanie algorytmów kwantowych 1 / 17 Spis
TEORETYCZNE PODSTAWY INFORMATYKI
 1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 16 2 Data Science: Uczenie maszynowe Uczenie maszynowe: co to znaczy? Metody Regresja Klasyfikacja Klastering
1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 16 2 Data Science: Uczenie maszynowe Uczenie maszynowe: co to znaczy? Metody Regresja Klasyfikacja Klastering
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym, kontynuacja badań
 w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym, kontynuacja badań") Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym, kontynuacja badań Jan Karwowski Wydział Matematyki i Nauk Informacyjnych PW
Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym, kontynuacja badań Jan Karwowski Wydział Matematyki i Nauk Informacyjnych PW
Plan. Zakres badań teorii optymalizacji. Teoria optymalizacji. Teoria optymalizacji a badania operacyjne. Badania operacyjne i teoria optymalizacji
 Badania operacyjne i teoria optymalizacji Instytut Informatyki Poznań, 2011/2012 1 2 3 Teoria optymalizacji Teoria optymalizacji a badania operacyjne Teoria optymalizacji zajmuje się badaniem metod optymalizacji
Badania operacyjne i teoria optymalizacji Instytut Informatyki Poznań, 2011/2012 1 2 3 Teoria optymalizacji Teoria optymalizacji a badania operacyjne Teoria optymalizacji zajmuje się badaniem metod optymalizacji
Semantyczne podobieństwo stron internetowych
 Uniwersytet Mikołaja Kopernika Wydział Matematyki i Informatyki Marcin Lamparski Nr albumu: 184198 Praca magisterska na kierunku Informatyka Semantyczne podobieństwo stron internetowych Praca wykonana
Uniwersytet Mikołaja Kopernika Wydział Matematyki i Informatyki Marcin Lamparski Nr albumu: 184198 Praca magisterska na kierunku Informatyka Semantyczne podobieństwo stron internetowych Praca wykonana
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Dariusz Brzeziński. Politechnika Poznańska
 Dariusz Brzeziński Politechnika Poznańska Klasyfikacja strumieni danych Algorytm AUE Adaptacja klasyfikatorów blokowych do przetwarzania przyrostowego Algorytm OAUE Dlasze prace badawcze Blokowa i przyrostowa
Dariusz Brzeziński Politechnika Poznańska Klasyfikacja strumieni danych Algorytm AUE Adaptacja klasyfikatorów blokowych do przetwarzania przyrostowego Algorytm OAUE Dlasze prace badawcze Blokowa i przyrostowa
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Analiza metod wykrywania przekazów steganograficznych. Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl
 Analiza metod wykrywania przekazów steganograficznych Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl Plan prezentacji Wprowadzenie Cel pracy Tezy pracy Koncepcja systemu Typy i wyniki testów Optymalizacja
Analiza metod wykrywania przekazów steganograficznych Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl Plan prezentacji Wprowadzenie Cel pracy Tezy pracy Koncepcja systemu Typy i wyniki testów Optymalizacja
O badaniach nad SZTUCZNĄ INTELIGENCJĄ
 O badaniach nad SZTUCZNĄ INTELIGENCJĄ Jak określa się inteligencję naturalną? Jak określa się inteligencję naturalną? Inteligencja wg psychologów to: Przyrodzona, choć rozwijana w toku dojrzewania i uczenia
O badaniach nad SZTUCZNĄ INTELIGENCJĄ Jak określa się inteligencję naturalną? Jak określa się inteligencję naturalną? Inteligencja wg psychologów to: Przyrodzona, choć rozwijana w toku dojrzewania i uczenia
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I
 Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Praktyczne aspekty stosowania metody punktów funkcyjnych COSMIC. Jarosław Świerczek
 Praktyczne aspekty stosowania metody punktów funkcyjnych COSMIC Jarosław Świerczek Punkty funkcyjne Punkt funkcyjny to metryka złożoności oprogramowania wyznaczana w oparciu o określające to oprogramowanie
Praktyczne aspekty stosowania metody punktów funkcyjnych COSMIC Jarosław Świerczek Punkty funkcyjne Punkt funkcyjny to metryka złożoności oprogramowania wyznaczana w oparciu o określające to oprogramowanie
Odniesienie symbol II/III [1] [2] [3] [4] [5] Efekt kształcenia. Wiedza
![Odniesienie symbol II/III [1] [2] [3] [4] [5] Efekt kształcenia. Wiedza](/thumbs/93/112686729.jpg "Odniesienie symbol II/III [1] [2] [3] [4] [5] Efekt kształcenia. Wiedza") Efekty dla studiów drugiego stopnia profil ogólnoakademicki na kierunku Inżynieria i Analiza Danych prowadzonym przez Wydział Matematyki i Nauk Informacyjnych Użyte w poniższej tabeli: 1) w kolumnie 4
Efekty dla studiów drugiego stopnia profil ogólnoakademicki na kierunku Inżynieria i Analiza Danych prowadzonym przez Wydział Matematyki i Nauk Informacyjnych Użyte w poniższej tabeli: 1) w kolumnie 4
SYSTEM BIOMETRYCZNY IDENTYFIKUJĄCY OSOBY NA PODSTAWIE CECH OSOBNICZYCH TWARZY. Autorzy: M. Lewicka, K. Stańczyk
 SYSTEM BIOMETRYCZNY IDENTYFIKUJĄCY OSOBY NA PODSTAWIE CECH OSOBNICZYCH TWARZY Autorzy: M. Lewicka, K. Stańczyk Kraków 2008 Cel pracy projekt i implementacja systemu rozpoznawania twarzy, który na podstawie
SYSTEM BIOMETRYCZNY IDENTYFIKUJĄCY OSOBY NA PODSTAWIE CECH OSOBNICZYCH TWARZY Autorzy: M. Lewicka, K. Stańczyk Kraków 2008 Cel pracy projekt i implementacja systemu rozpoznawania twarzy, który na podstawie
Rozmyte drzewa decyzyjne. Łukasz Ryniewicz Metody inteligencji obliczeniowej
 µ(x) x µ(x) µ(x) x x µ(x) µ(x) x x µ(x) x µ(x) x Rozmyte drzewa decyzyjne Łukasz Ryniewicz Metody inteligencji obliczeniowej 21.05.2007 AGENDA 1 Drzewa decyzyjne kontra rozmyte drzewa decyzyjne, problemy
µ(x) x µ(x) µ(x) x x µ(x) µ(x) x x µ(x) x µ(x) x Rozmyte drzewa decyzyjne Łukasz Ryniewicz Metody inteligencji obliczeniowej 21.05.2007 AGENDA 1 Drzewa decyzyjne kontra rozmyte drzewa decyzyjne, problemy
Optymalizacja optymalizacji
 7 maja 2008 Wstęp Optymalizacja lokalna Optymalizacja globalna Algorytmy genetyczne Badane czasteczki Wykorzystane oprogramowanie (Algorytm genetyczny) 2 Sieć neuronowa Pochodne met-enkefaliny Optymalizacja
7 maja 2008 Wstęp Optymalizacja lokalna Optymalizacja globalna Algorytmy genetyczne Badane czasteczki Wykorzystane oprogramowanie (Algorytm genetyczny) 2 Sieć neuronowa Pochodne met-enkefaliny Optymalizacja
Propensity score matching (PSM)
") Propensity score matching (PSM) Jerzy Mycielski Uniwersytet Warszawski Maj 2010 Jerzy Mycielski (Uniwersytet Warszawski) Propensity score matching (PSM) Maj 2010 1 / 18 Badania ewaluacyjne Ocena wpływu
Propensity score matching (PSM) Jerzy Mycielski Uniwersytet Warszawski Maj 2010 Jerzy Mycielski (Uniwersytet Warszawski) Propensity score matching (PSM) Maj 2010 1 / 18 Badania ewaluacyjne Ocena wpływu
WYKAZ PUBLIKACJI I. Artykuły Ia. Opublikowane przed obroną doktorską
 Dr Marcin Pełka Uniwersytet Ekonomiczny we Wrocławiu Wydział Ekonomii, Zarządzania i Turystyki Katedra Ekonometrii i Informatyki WYKAZ PUBLIKACJI I. Artykuły Ia. Opublikowane przed obroną doktorską 1.
Dr Marcin Pełka Uniwersytet Ekonomiczny we Wrocławiu Wydział Ekonomii, Zarządzania i Turystyki Katedra Ekonometrii i Informatyki WYKAZ PUBLIKACJI I. Artykuły Ia. Opublikowane przed obroną doktorską 1.
Narzędzia geoprzestrzenne Business Intelligence (BI)
") Narzędzia geoprzestrzenne Business Intelligence (BI) Paweł Pręcikowski Dyrektor Administracja i Bezpieczeństwo Publiczne Kraków, 17-18 maja 2018 r. Agenda 1. Wprowadzenie do BI 2. Prezentacja rozwiązań:
Narzędzia geoprzestrzenne Business Intelligence (BI) Paweł Pręcikowski Dyrektor Administracja i Bezpieczeństwo Publiczne Kraków, 17-18 maja 2018 r. Agenda 1. Wprowadzenie do BI 2. Prezentacja rozwiązań:
Systemy baz danych w zarządzaniu przedsiębiorstwem. W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi
 Systemy baz danych w zarządzaniu przedsiębiorstwem W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi Proces zarządzania danymi Zarządzanie danymi obejmuje czynności: gromadzenie
Systemy baz danych w zarządzaniu przedsiębiorstwem W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi Proces zarządzania danymi Zarządzanie danymi obejmuje czynności: gromadzenie
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykrywanie nietypowości w danych rzeczywistych
 Wykrywanie nietypowości w danych rzeczywistych dr Agnieszka NOWAK-BRZEZIŃSKA, mgr Artur TUROS 1 Agenda 1 2 3 4 5 6 Cel badań Eksploracja odchyleń Metody wykrywania odchyleń Eksperymenty Wnioski Nowe badania
Wykrywanie nietypowości w danych rzeczywistych dr Agnieszka NOWAK-BRZEZIŃSKA, mgr Artur TUROS 1 Agenda 1 2 3 4 5 6 Cel badań Eksploracja odchyleń Metody wykrywania odchyleń Eksperymenty Wnioski Nowe badania
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - testy na sztucznych danych
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji - testy na sztucznych danych Mateusz Kobos, 25.11.2009 Seminarium Metody Inteligencji Obliczeniowej 1/25 Spis treści Dolne ograniczenie na wsp.
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - testy na sztucznych danych Mateusz Kobos, 25.11.2009 Seminarium Metody Inteligencji Obliczeniowej 1/25 Spis treści Dolne ograniczenie na wsp.
TADEUSZ KWATER 1, ROBERT PĘKALA 2, ALEKSANDRA SALAMON 3
 Wydawnictwo UR 2016 ISSN 2080-9069 ISSN 2450-9221 online Edukacja Technika Informatyka nr 4/18/2016 www.eti.rzeszow.pl DOI: 10.15584/eti.2016.4.46 TADEUSZ KWATER 1, ROBERT PĘKALA 2, ALEKSANDRA SALAMON
Wydawnictwo UR 2016 ISSN 2080-9069 ISSN 2450-9221 online Edukacja Technika Informatyka nr 4/18/2016 www.eti.rzeszow.pl DOI: 10.15584/eti.2016.4.46 TADEUSZ KWATER 1, ROBERT PĘKALA 2, ALEKSANDRA SALAMON
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu