Opracowanie w modelu PGAS wybranych, równoległych algorytmów grafowych
|
|
|
- Lech Zawadzki
- 6 lat temu
- Przeglądów:
Transkrypt

1 Opracowanie w modelu PGAS wybranych, równoległych algorytmów grafowych i ich implementacja przy użyciu języka Java Wydział Matematyki i Informatyki Uniwersytet Mikołaja Kopernika Chopina 12/18, Toruń gdama@mat.umk.pl Opiekun naukowy: prof. dr hab. Piotr Bała Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski bala@icm.edu.pl
2 Cel oraz wkład pracy Cel oraz wkład pracy: opracowanie nowych, równoległych algorytmów grafowych dostosowanych do modelu PGAS zastosowane optymalizacje np. nakładanie komunikacji i obliczeń wydajna implementacja w języku Java dla środowiska równoległego i rozproszonego (dostosowanie do specyfiki języka Java) weryfikacja skalowalności i wydajności opracowanych algorytmów na różnych architekturach sprzętowych porównanie z dostępnymi rozwiazaniami w języku C bazujacymi na MPI
3 Cel oraz wkład pracy Cel oraz wkład pracy: opracowanie nowych, równoległych algorytmów grafowych dostosowanych do modelu PGAS zastosowane optymalizacje np. nakładanie komunikacji i obliczeń wydajna implementacja w języku Java dla środowiska równoległego i rozproszonego (dostosowanie do specyfiki języka Java) weryfikacja skalowalności i wydajności opracowanych algorytmów na różnych architekturach sprzętowych porównanie z dostępnymi rozwiazaniami w języku C bazujacymi na MPI
4 Cel oraz wkład pracy Cel oraz wkład pracy: opracowanie nowych, równoległych algorytmów grafowych dostosowanych do modelu PGAS zastosowane optymalizacje np. nakładanie komunikacji i obliczeń wydajna implementacja w języku Java dla środowiska równoległego i rozproszonego (dostosowanie do specyfiki języka Java) weryfikacja skalowalności i wydajności opracowanych algorytmów na różnych architekturach sprzętowych porównanie z dostępnymi rozwiazaniami w języku C bazujacymi na MPI
5 Cel oraz wkład pracy Cel oraz wkład pracy: opracowanie nowych, równoległych algorytmów grafowych dostosowanych do modelu PGAS zastosowane optymalizacje np. nakładanie komunikacji i obliczeń wydajna implementacja w języku Java dla środowiska równoległego i rozproszonego (dostosowanie do specyfiki języka Java) weryfikacja skalowalności i wydajności opracowanych algorytmów na różnych architekturach sprzętowych porównanie z dostępnymi rozwiazaniami w języku C bazujacymi na MPI
6 Cel oraz wkład pracy Cel oraz wkład pracy: opracowanie nowych, równoległych algorytmów grafowych dostosowanych do modelu PGAS zastosowane optymalizacje np. nakładanie komunikacji i obliczeń wydajna implementacja w języku Java dla środowiska równoległego i rozproszonego (dostosowanie do specyfiki języka Java) weryfikacja skalowalności i wydajności opracowanych algorytmów na różnych architekturach sprzętowych porównanie z dostępnymi rozwiazaniami w języku C bazujacymi na MPI
7 Cel oraz wkład pracy Cel oraz wkład pracy: opracowanie nowych, równoległych algorytmów grafowych dostosowanych do modelu PGAS zastosowane optymalizacje np. nakładanie komunikacji i obliczeń wydajna implementacja w języku Java dla środowiska równoległego i rozproszonego (dostosowanie do specyfiki języka Java) weryfikacja skalowalności i wydajności opracowanych algorytmów na różnych architekturach sprzętowych porównanie z dostępnymi rozwiazaniami w języku C bazujacymi na MPI
8 Plan prezentacji 1 Wprowadzenie 2 Model PGAS Główne założenia Biblioteka PCJ 3 Graph500 Specyfikacja 4 Graph500 w PGAS i PCJ Kernel 1 Kernel 2 Wyniki 5 Dalsze prace
9 Plan prezentacji 1 Wprowadzenie 2 Model PGAS Główne założenia Biblioteka PCJ 3 Graph500 Specyfikacja 4 Graph500 w PGAS i PCJ Kernel 1 Kernel 2 Wyniki 5 Dalsze prace
10 Plan prezentacji 1 Wprowadzenie 2 Model PGAS Główne założenia Biblioteka PCJ 3 Graph500 Specyfikacja 4 Graph500 w PGAS i PCJ Kernel 1 Kernel 2 Wyniki 5 Dalsze prace
11 Plan prezentacji 1 Wprowadzenie 2 Model PGAS Główne założenia Biblioteka PCJ 3 Graph500 Specyfikacja 4 Graph500 w PGAS i PCJ Kernel 1 Kernel 2 Wyniki 5 Dalsze prace
12 Plan prezentacji 1 Wprowadzenie 2 Model PGAS Główne założenia Biblioteka PCJ 3 Graph500 Specyfikacja 4 Graph500 w PGAS i PCJ Kernel 1 Kernel 2 Wyniki 5 Dalsze prace
13 Pierwsza praca z teorii grafów Pierwsze rozważania na temat grafów sięgaja XVIII wieku i dotycza tzw. problemu mostów królewieckich. Sformułowanie zagadnienia przez Eulera i opublikowanie pod tytułem: Solutio problematis ad geometriam situs pertinenti uznawane jest za pierwsza pracę z teorii grafów.
14 Pierwsza praca z teorii grafów Pierwsze rozważania na temat grafów sięgaja XVIII wieku i dotycza tzw. problemu mostów królewieckich. Sformułowanie zagadnienia przez Eulera i opublikowanie pod tytułem: Solutio problematis ad geometriam situs pertinenti uznawane jest za pierwsza pracę z teorii grafów.
15 Rozwój tematyki zwiazanej z grafami Od tego czasu obserwujemy znaczny rozwój tematyki zwiazanej z grafami. Wiele problemów obliczeniowych może być łatwo przedstawionych w języku grafów, które w naturalny sposób obrazuja wszelkiego rodzaju relacje. Grafy wykorzystywane sa w wielu różnych dziedzinach np. w socjologii, biologii...
16 Rozwój tematyki zwiazanej z grafami Od tego czasu obserwujemy znaczny rozwój tematyki zwiazanej z grafami. Wiele problemów obliczeniowych może być łatwo przedstawionych w języku grafów, które w naturalny sposób obrazuja wszelkiego rodzaju relacje. Grafy wykorzystywane sa w wielu różnych dziedzinach np. w socjologii, biologii...
17 Rozwój tematyki zwiazanej z grafami Od tego czasu obserwujemy znaczny rozwój tematyki zwiazanej z grafami. Wiele problemów obliczeniowych może być łatwo przedstawionych w języku grafów, które w naturalny sposób obrazuja wszelkiego rodzaju relacje. Grafy wykorzystywane sa w wielu różnych dziedzinach np. w socjologii, biologii...
18 Rozwój tematyki zwiazanej z grafami Od tego czasu obserwujemy znaczny rozwój tematyki zwiazanej z grafami. Wiele problemów obliczeniowych może być łatwo przedstawionych w języku grafów, które w naturalny sposób obrazuja wszelkiego rodzaju relacje. Grafy wykorzystywane sa w wielu różnych dziedzinach np. w socjologii, biologii... sieć społecznościowa
19 Rozwój tematyki zwiazanej z grafami Od tego czasu obserwujemy znaczny rozwój tematyki zwiazanej z grafami. Wiele problemów obliczeniowych może być łatwo przedstawionych w języku grafów, które w naturalny sposób obrazuja wszelkiego rodzaju relacje. Grafy wykorzystywane sa w wielu różnych dziedzinach np. w socjologii, biologii... sieć społecznościowa interakcje białek
20 Rozwój tematyki zwiazanej z grafami Od tego czasu obserwujemy znaczny rozwój tematyki zwiazanej z grafami. Wiele problemów obliczeniowych może być łatwo przedstawionych w języku grafów, które w naturalny sposób obrazuja wszelkiego rodzaju relacje. Grafy wykorzystywane sa w wielu różnych dziedzinach np. w socjologii, biologii... sieć społecznościowa interakcje białek mapa Internetu




21 Rozwój tematyki zwiazanej z grafami Od tego czasu obserwujemy znaczny rozwój tematyki zwiazanej z grafami. Wiele problemów obliczeniowych może być łatwo przedstawionych w języku grafów, które w naturalny sposób obrazuja wszelkiego rodzaju relacje. Grafy wykorzystywane sa w wielu różnych dziedzinach np. w socjologii, biologii... sieć społecznościowa interakcje białek mapa Internetu IBM Watson
22 Wykorzystanie komputera dla obliczeń grafowych Badanie właściwości grafów często wymaga dużych mocy obliczeniowych. Przykładem wykorzystania komputerów w teorii grafów jest eksperyment przeprowadzony przez matematyków Kenneth a Appel a oraz Wolfgang a Haken a. W 1976 roku udowodnili oni twierdzenie o czterech barwach dla grafów planarnych wykorzystujac program napisany w języku Fortran.
23 Wykorzystanie komputera dla obliczeń grafowych Badanie właściwości grafów często wymaga dużych mocy obliczeniowych. Przykładem wykorzystania komputerów w teorii grafów jest eksperyment przeprowadzony przez matematyków Kenneth a Appel a oraz Wolfgang a Haken a. W 1976 roku udowodnili oni twierdzenie o czterech barwach dla grafów planarnych wykorzystujac program napisany w języku Fortran.
24 Wykorzystanie komputera dla obliczeń grafowych Badanie właściwości grafów często wymaga dużych mocy obliczeniowych. Przykładem wykorzystania komputerów w teorii grafów jest eksperyment przeprowadzony przez matematyków Kenneth a Appel a oraz Wolfgang a Haken a. W 1976 roku udowodnili oni twierdzenie o czterech barwach dla grafów planarnych wykorzystujac program napisany w języku Fortran.

25 Wykorzystanie komputera dla obliczeń grafowych Badanie właściwości grafów często wymaga dużych mocy obliczeniowych. Przykładem wykorzystania komputerów w teorii grafów jest eksperyment przeprowadzony przez matematyków Kenneth a Appel a oraz Wolfgang a Haken a. W 1976 roku udowodnili oni twierdzenie o czterech barwach dla grafów planarnych wykorzystujac program napisany w języku Fortran.
26 Trudności w obliczeniach na grafach Wśród problemów jakie można wyróżnić przy obliczeniach na grafach sa: znaczne rozmiary grafów, zapewnienie wystarczajacej ilości pamięci potrzebnej do przechowywania i przetwarzania grafów (miliardy wierzchołków) np. graf Internetu, Facebook różnorodność w strukturze grafu np. grafy regularne, losowe czy sieci typu Scale Free
27 Trudności w obliczeniach na grafach Wśród problemów jakie można wyróżnić przy obliczeniach na grafach sa: znaczne rozmiary grafów, zapewnienie wystarczajacej ilości pamięci potrzebnej do przechowywania i przetwarzania grafów (miliardy wierzchołków) np. graf Internetu, Facebook różnorodność w strukturze grafu np. grafy regularne, losowe czy sieci typu Scale Free
28 Trudności w obliczeniach na grafach Wśród problemów jakie można wyróżnić przy obliczeniach na grafach sa: znaczne rozmiary grafów, zapewnienie wystarczajacej ilości pamięci potrzebnej do przechowywania i przetwarzania grafów (miliardy wierzchołków) np. graf Internetu, Facebook różnorodność w strukturze grafu np. grafy regularne, losowe czy sieci typu Scale Free
29 Trudności w obliczeniach na grafach Obliczenia na grafach przekraczaja możliwości pojedynczego komputera. Wielkość analizowanych grafów coraz częściej wymaga zastosowania algorytmów i komputerów równoległych.
30 Trudności w obliczeniach na grafach Obliczenia na grafach przekraczaja możliwości pojedynczego komputera. Wielkość analizowanych grafów coraz częściej wymaga zastosowania algorytmów i komputerów równoległych.
31 Trudności w obliczeniach na grafach Przy równoległych obliczeniach ważnym problemem jest również: znaczna ilość komunikacji oraz synchronizacji co znaczaco utrudnia efektywne zrównoleglenie skomplikowany schemat równoległości
32 Trudności w obliczeniach na grafach Przy równoległych obliczeniach ważnym problemem jest również: znaczna ilość komunikacji oraz synchronizacji co znaczaco utrudnia efektywne zrównoleglenie skomplikowany schemat równoległości
33 Trudności w obliczeniach na grafach Przy równoległych obliczeniach ważnym problemem jest również: znaczna ilość komunikacji oraz synchronizacji co znaczaco utrudnia efektywne zrównoleglenie skomplikowany schemat równoległości
34 Trudności w obliczeniach na grafach Z punktu widzenia komputera obliczenia na grafach sa: różne od tradycyjnych intensywnych obliczeń na liczbach zmiennoprzecinkowych mierzonych na przykład za pomoca benchmarku LINPACK systemy oparte o MapReduce nie zawsze sa odpowiednie do przetwarzania danych w postaci ogromnych grafów
35 Trudności w obliczeniach na grafach Z punktu widzenia komputera obliczenia na grafach sa: różne od tradycyjnych intensywnych obliczeń na liczbach zmiennoprzecinkowych mierzonych na przykład za pomoca benchmarku LINPACK systemy oparte o MapReduce nie zawsze sa odpowiednie do przetwarzania danych w postaci ogromnych grafów
36 Trudności w obliczeniach na grafach Z punktu widzenia komputera obliczenia na grafach sa: różne od tradycyjnych intensywnych obliczeń na liczbach zmiennoprzecinkowych mierzonych na przykład za pomoca benchmarku LINPACK systemy oparte o MapReduce nie zawsze sa odpowiednie do przetwarzania danych w postaci ogromnych grafów
37 Motywacja badań Stworzono wiele narzędzi dedykowanych obliczeniom na grafach. Większość narzędzi do przetwarzania grafów bazuje na tradycyjnym języku programowania jakim jest C/C++. Coraz więcej aplikacji tworzonych jest w Javie, dlatego wzrasta również zainteresowanie na przetwarzanie dużych grafów w języku Java. Obecnie nie ma aplikacji w Javie do analizy dużych grafów.
38 Motywacja badań Stworzono wiele narzędzi dedykowanych obliczeniom na grafach. Większość narzędzi do przetwarzania grafów bazuje na tradycyjnym języku programowania jakim jest C/C++. Coraz więcej aplikacji tworzonych jest w Javie, dlatego wzrasta również zainteresowanie na przetwarzanie dużych grafów w języku Java. Obecnie nie ma aplikacji w Javie do analizy dużych grafów.
39 Motywacja badań Stworzono wiele narzędzi dedykowanych obliczeniom na grafach. Większość narzędzi do przetwarzania grafów bazuje na tradycyjnym języku programowania jakim jest C/C++. Coraz więcej aplikacji tworzonych jest w Javie, dlatego wzrasta również zainteresowanie na przetwarzanie dużych grafów w języku Java. Obecnie nie ma aplikacji w Javie do analizy dużych grafów.
40 Motywacja badań Stworzono wiele narzędzi dedykowanych obliczeniom na grafach. Większość narzędzi do przetwarzania grafów bazuje na tradycyjnym języku programowania jakim jest C/C++. Coraz więcej aplikacji tworzonych jest w Javie, dlatego wzrasta również zainteresowanie na przetwarzanie dużych grafów w języku Java. Obecnie nie ma aplikacji w Javie do analizy dużych grafów.
41 Tradycyjne modele HPC Wsród tradycyjnych modeli programowania HPC możemy wyróżnić: model pamięci współdzielonej (wspólnej) np. OpenMP (Open Multi-Processing) model przesyłania komunikatów MPI (Message-Passing Interface) (procesy, każdy z oddzielna pamięcia wymieniaja wiadomości)
42 Tradycyjne modele HPC Wsród tradycyjnych modeli programowania HPC możemy wyróżnić: model pamięci współdzielonej (wspólnej) np. OpenMP (Open Multi-Processing) model przesyłania komunikatów MPI (Message-Passing Interface) (procesy, każdy z oddzielna pamięcia wymieniaja wiadomości)
43 Tradycyjne modele HPC Wsród tradycyjnych modeli programowania HPC możemy wyróżnić: model pamięci współdzielonej (wspólnej) np. OpenMP (Open Multi-Processing) model przesyłania komunikatów MPI (Message-Passing Interface) (procesy, każdy z oddzielna pamięcia wymieniaja wiadomości)
44 Tradycyjne modele HPC - model pamięci współdzielonej Model pamięci współdzielonej np. OpenMP pamięć wspólna komunikacja odbywa się poprzez zapisywanie i odczyt z pamięci (wiele procesów może pisać i czytać z pamięci współdzielonej) łatwość programowania
45 Tradycyjne modele HPC - model pamięci współdzielonej Model pamięci współdzielonej np. OpenMP pamięć wspólna komunikacja odbywa się poprzez zapisywanie i odczyt z pamięci (wiele procesów może pisać i czytać z pamięci współdzielonej) łatwość programowania
46 Tradycyjne modele HPC - model pamięci współdzielonej Model pamięci współdzielonej np. OpenMP pamięć wspólna komunikacja odbywa się poprzez zapisywanie i odczyt z pamięci (wiele procesów może pisać i czytać z pamięci współdzielonej) łatwość programowania
47 Tradycyjne modele HPC - model pamięci współdzielonej Model pamięci współdzielonej np. OpenMP pamięć wspólna komunikacja odbywa się poprzez zapisywanie i odczyt z pamięci (wiele procesów może pisać i czytać z pamięci współdzielonej) łatwość programowania
48 Tradycyjne modele HPC - model przesyłania komunikatów Model przesyłania komunikatów MPI (procesy, każdy z oddzielna pamięcia wymieniaja wiadomości) jawna komunikacja osobne (fizycznie) obszary pamięci dla procesów bardziej skalowalne i wydajniejsze
49 Tradycyjne modele HPC - model przesyłania komunikatów Model przesyłania komunikatów MPI (procesy, każdy z oddzielna pamięcia wymieniaja wiadomości) jawna komunikacja osobne (fizycznie) obszary pamięci dla procesów bardziej skalowalne i wydajniejsze
50 Tradycyjne modele HPC - model przesyłania komunikatów Model przesyłania komunikatów MPI (procesy, każdy z oddzielna pamięcia wymieniaja wiadomości) jawna komunikacja osobne (fizycznie) obszary pamięci dla procesów bardziej skalowalne i wydajniejsze
51 Tradycyjne modele HPC - model przesyłania komunikatów Model przesyłania komunikatów MPI (procesy, każdy z oddzielna pamięcia wymieniaja wiadomości) jawna komunikacja osobne (fizycznie) obszary pamięci dla procesów bardziej skalowalne i wydajniejsze
52 Model PGAS - dlaczego został stworzony? Rozwój architektur sprzętowych wiaże się z problemami takimi jak: NUMA (Non-Uniform Memory Access), NUCC (Non-Uniform Cluster Computing). Rozpoczęto prace nad nowymi metodami programowania równoległego i rozproszonego. Model PGAS (Partitioned Global Address Space)
53 Model PGAS Główne założenia: pojedyncza przestrzeń adresowa dostarczane sa dodatkowe mechanizmy, aby rozróżnić lokalny i zdalny dostęp do danych szczegóły komunikacji ukryte przed użytkownikiem komunikacja jednostronna
54 Model PGAS Główne założenia: pojedyncza przestrzeń adresowa dostarczane sa dodatkowe mechanizmy, aby rozróżnić lokalny i zdalny dostęp do danych szczegóły komunikacji ukryte przed użytkownikiem komunikacja jednostronna
55 Model PGAS Główne założenia: pojedyncza przestrzeń adresowa dostarczane sa dodatkowe mechanizmy, aby rozróżnić lokalny i zdalny dostęp do danych szczegóły komunikacji ukryte przed użytkownikiem komunikacja jednostronna
56 Model PGAS Główne założenia: pojedyncza przestrzeń adresowa dostarczane sa dodatkowe mechanizmy, aby rozróżnić lokalny i zdalny dostęp do danych szczegóły komunikacji ukryte przed użytkownikiem komunikacja jednostronna
57 Model PGAS Główne założenia: pojedyncza przestrzeń adresowa dostarczane sa dodatkowe mechanizmy, aby rozróżnić lokalny i zdalny dostęp do danych szczegóły komunikacji ukryte przed użytkownikiem komunikacja jednostronna
58 Model PGAS Model PGAS można sklasyfikować jako model pośredni między MPI, a modelem pamięci współdzielonej z modelu pamięci wspólnej zakłada, że procesy działaja na pojedynczej pamięci która jest współdzielona pomiędzy procesami z modelu przesyłania komunikatów czerpie ideę kosztu zwiazanego z komunikacja miedzy procesami
59 Model PGAS Model PGAS można sklasyfikować jako model pośredni między MPI, a modelem pamięci współdzielonej z modelu pamięci wspólnej zakłada, że procesy działaja na pojedynczej pamięci która jest współdzielona pomiędzy procesami z modelu przesyłania komunikatów czerpie ideę kosztu zwiazanego z komunikacja miedzy procesami
60 Model PGAS Model PGAS można sklasyfikować jako model pośredni między MPI, a modelem pamięci współdzielonej z modelu pamięci wspólnej zakłada, że procesy działaja na pojedynczej pamięci która jest współdzielona pomiędzy procesami z modelu przesyłania komunikatów czerpie ideę kosztu zwiazanego z komunikacja miedzy procesami
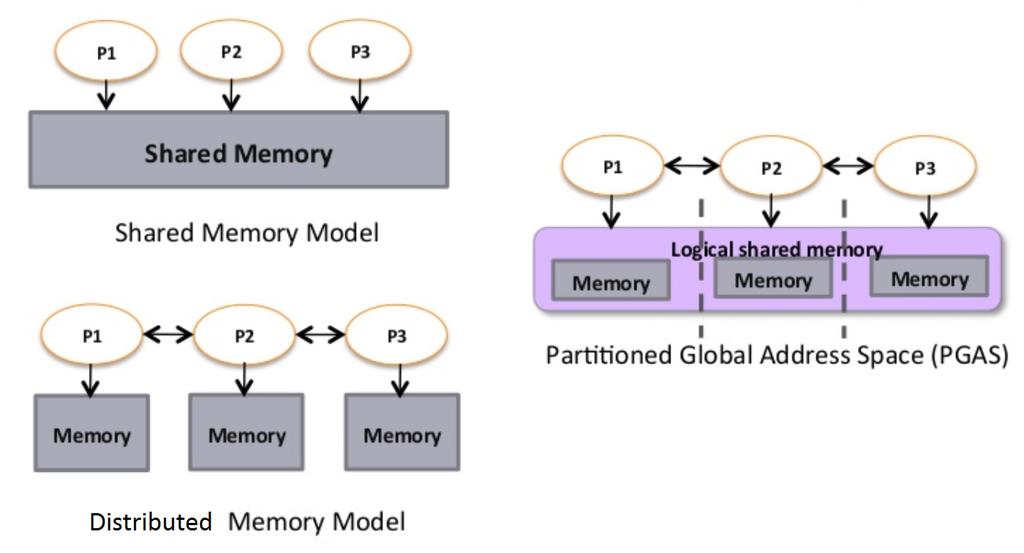
61 Schematy modeli
62 Języki PGAS Zgodnie z praca Partitioned Global Address Space Languages języki PGAS podzielone zostały na cztery grupy: oryginalne języki PGAS (późne lata 1990) np. CoArray Fortran (1998) (D), Titanium (D), UPC (D) języki PGAS HPCS (High Productivity Computing System) (2004) np. Chapel (L), X10 (L), Fortress (L) retrospektywne języki PGAS (wczesne lata 1990) np. HPF (D), ZPL (L), Global Arrays (MW) współczesne (po 2005) np. XCalableMP (E) L: new language D: language dialect E: pragma extension MW: middleware
63 Języki PGAS Zgodnie z praca Partitioned Global Address Space Languages języki PGAS podzielone zostały na cztery grupy: oryginalne języki PGAS (późne lata 1990) np. CoArray Fortran (1998) (D), Titanium (D), UPC (D) języki PGAS HPCS (High Productivity Computing System) (2004) np. Chapel (L), X10 (L), Fortress (L) retrospektywne języki PGAS (wczesne lata 1990) np. HPF (D), ZPL (L), Global Arrays (MW) współczesne (po 2005) np. XCalableMP (E) L: new language D: language dialect E: pragma extension MW: middleware
64 Języki PGAS Zgodnie z praca Partitioned Global Address Space Languages języki PGAS podzielone zostały na cztery grupy: oryginalne języki PGAS (późne lata 1990) np. CoArray Fortran (1998) (D), Titanium (D), UPC (D) języki PGAS HPCS (High Productivity Computing System) (2004) np. Chapel (L), X10 (L), Fortress (L) retrospektywne języki PGAS (wczesne lata 1990) np. HPF (D), ZPL (L), Global Arrays (MW) współczesne (po 2005) np. XCalableMP (E) L: new language D: language dialect E: pragma extension MW: middleware
65 Języki PGAS Zgodnie z praca Partitioned Global Address Space Languages języki PGAS podzielone zostały na cztery grupy: oryginalne języki PGAS (późne lata 1990) np. CoArray Fortran (1998) (D), Titanium (D), UPC (D) języki PGAS HPCS (High Productivity Computing System) (2004) np. Chapel (L), X10 (L), Fortress (L) retrospektywne języki PGAS (wczesne lata 1990) np. HPF (D), ZPL (L), Global Arrays (MW) współczesne (po 2005) np. XCalableMP (E) L: new language D: language dialect E: pragma extension MW: middleware
66 Języki PGAS Zgodnie z praca Partitioned Global Address Space Languages języki PGAS podzielone zostały na cztery grupy: oryginalne języki PGAS (późne lata 1990) np. CoArray Fortran (1998) (D), Titanium (D), UPC (D) języki PGAS HPCS (High Productivity Computing System) (2004) np. Chapel (L), X10 (L), Fortress (L) retrospektywne języki PGAS (wczesne lata 1990) np. HPF (D), ZPL (L), Global Arrays (MW) współczesne (po 2005) np. XCalableMP (E) L: new language D: language dialect E: pragma extension MW: middleware
67 PCJ Jako narzędzie do implementacji została użyta biblioteka PCJ (Parallel Computations in Java) PCJ to biblioteka do obliczeń równoległych i rozproszonych w języku Java bazujaca na modelu PGAS.
68 PCJ Jako narzędzie do implementacji została użyta biblioteka PCJ (Parallel Computations in Java) PCJ to biblioteka do obliczeń równoległych i rozproszonych w języku Java bazujaca na modelu PGAS.
69 PCJ - dlaczego PCJ? Dlaczego PCJ? biblioteka oparta o język Java samodzielna biblioteka w postaci jar niezależna od dodatkowych bibliotek (nie używa zewnętrznych bibliotek ani technologii JNI) jest oparta na natywnych mechanizmach Javy nie wymaga specjalnego kompilatora czy innych rozszerzeń używana beż żadnych modyfikacji języka Java
70 PCJ - dlaczego PCJ? Dlaczego PCJ? biblioteka oparta o język Java samodzielna biblioteka w postaci jar niezależna od dodatkowych bibliotek (nie używa zewnętrznych bibliotek ani technologii JNI) jest oparta na natywnych mechanizmach Javy nie wymaga specjalnego kompilatora czy innych rozszerzeń używana beż żadnych modyfikacji języka Java
71 PCJ - dlaczego PCJ? Dlaczego PCJ? biblioteka oparta o język Java samodzielna biblioteka w postaci jar niezależna od dodatkowych bibliotek (nie używa zewnętrznych bibliotek ani technologii JNI) jest oparta na natywnych mechanizmach Javy nie wymaga specjalnego kompilatora czy innych rozszerzeń używana beż żadnych modyfikacji języka Java
72 PCJ - dlaczego PCJ? Dlaczego PCJ? biblioteka oparta o język Java samodzielna biblioteka w postaci jar niezależna od dodatkowych bibliotek (nie używa zewnętrznych bibliotek ani technologii JNI) jest oparta na natywnych mechanizmach Javy nie wymaga specjalnego kompilatora czy innych rozszerzeń używana beż żadnych modyfikacji języka Java
73 PCJ - dlaczego PCJ? Dlaczego PCJ? biblioteka oparta o język Java samodzielna biblioteka w postaci jar niezależna od dodatkowych bibliotek (nie używa zewnętrznych bibliotek ani technologii JNI) jest oparta na natywnych mechanizmach Javy nie wymaga specjalnego kompilatora czy innych rozszerzeń używana beż żadnych modyfikacji języka Java
74 PCJ - dlaczego PCJ? Dlaczego PCJ? PCJ jest odpowiedzialny za odpowiednie ustawienia i pozwala użytkownikowi na rozpoczęcie obliczeń na wielu węzłach przy wielu watkach na węźle otwarte oprogramowanie (open source) o licencji BSD (kod źródłowy dostępny na GitHubie) poczatkowo napisana przy użyciu Java SE7, a obecnie bazuje na Java SE8
75 PCJ - dlaczego PCJ? Dlaczego PCJ? PCJ jest odpowiedzialny za odpowiednie ustawienia i pozwala użytkownikowi na rozpoczęcie obliczeń na wielu węzłach przy wielu watkach na węźle otwarte oprogramowanie (open source) o licencji BSD (kod źródłowy dostępny na GitHubie) poczatkowo napisana przy użyciu Java SE7, a obecnie bazuje na Java SE8
76 PCJ - dlaczego PCJ? Dlaczego PCJ? PCJ jest odpowiedzialny za odpowiednie ustawienia i pozwala użytkownikowi na rozpoczęcie obliczeń na wielu węzłach przy wielu watkach na węźle otwarte oprogramowanie (open source) o licencji BSD (kod źródłowy dostępny na GitHubie) poczatkowo napisana przy użyciu Java SE7, a obecnie bazuje na Java SE8
77 PCJ - dlaczego PCJ? Dlaczego PCJ? PCJ jest odpowiedzialny za odpowiednie ustawienia i pozwala użytkownikowi na rozpoczęcie obliczeń na wielu węzłach przy wielu watkach na węźle otwarte oprogramowanie (open source) o licencji BSD (kod źródłowy dostępny na GitHubie) poczatkowo napisana przy użyciu Java SE7, a obecnie bazuje na Java SE8
78 PCJ - komunikacja Typowa aplikacja PCJ nie ogranicza się do pojedynczej JVM. Komunikacja jest realizowana przez: Java Concurrency komunikacja sieciowa poprzez gniazda
79 PCJ - główne cechy Główne cechy biblioteki PCJ: program składa się z jednakowych watków, które prowadza obliczenia na heterogenicznych danych (SPMD)
80 PCJ - główne cechy Główne cechy biblioteki PCJ: rozproszony system pamięci jest widziany jako globalna przestrzeń adresowa
81 PCJ - główne cechy Główne cechy biblioteki PCJ: ukrycie szczegółów komunikacyjnych np. obsługa watków, programowanie sieciowe
82 PCJ - główne cechy Główne cechy biblioteki PCJ: każdy watek wykonuje swoje własne obliczenia i ma dostęp do swojej lokalnej pamięci
83 PCJ - główne cechy Główne cechy biblioteki PCJ: domyślnie zmienne przechowywane sa w pamięci lokalnej dla watków wykonania programu
84 PCJ - główne cechy Główne cechy biblioteki PCJ: zmienne oznaczone staja się dostępne dla innych watków, moga być współdzielone między watkami

85 PCJ - główne cechy Główne cechy biblioteki PCJ: bazuje na komunikacji jednostronnej
86 PCJ - API PCJ dostarcza metod potrzebnych do tworzenia równoległych i rozproszonych aplikacji: jednostronna komunikacja za pomoca put oraz get
87 PCJ - API PCJ.broadcast( String variable, Object newvalue ) PCJ.barrier() int PCJ.waitFor( String variable ) tworzenie grup watków
88 Graph500 Benchamrk Graph500 został stworzony w celu przeprowadzenia oceny skalownalności klastrów komputerów w kontekście intensywnej wymiany danych. Benchmark wymusza znaczna ilośc komunikacji i synchronizacji oraz znaczne zapotrzebowanie i ociażenie pamięci do przechowywania oraz procesowania grafu. Graph500 jest konkurencyjnym do Top500 sposobem badania mocy obliczeniowej komputerow. Zamiast mierzyć moc potrzebna do obliczeń zmiennoprzecinkowych bada wydajność maszyny przy przetwarzaniu grafów.
89 Graph500 Benchamrk Graph500 został stworzony w celu przeprowadzenia oceny skalownalności klastrów komputerów w kontekście intensywnej wymiany danych. Benchmark wymusza znaczna ilośc komunikacji i synchronizacji oraz znaczne zapotrzebowanie i ociażenie pamięci do przechowywania oraz procesowania grafu. Graph500 jest konkurencyjnym do Top500 sposobem badania mocy obliczeniowej komputerow. Zamiast mierzyć moc potrzebna do obliczeń zmiennoprzecinkowych bada wydajność maszyny przy przetwarzaniu grafów.

90 Graph500 Benchamrk Graph500 został stworzony w celu przeprowadzenia oceny skalownalności klastrów komputerów w kontekście intensywnej wymiany danych. Benchmark wymusza znaczna ilośc komunikacji i synchronizacji oraz znaczne zapotrzebowanie i ociażenie pamięci do przechowywania oraz procesowania grafu. Graph500 jest konkurencyjnym do Top500 sposobem badania mocy obliczeniowej komputerow. Zamiast mierzyć moc potrzebna do obliczeń zmiennoprzecinkowych bada wydajność maszyny przy przetwarzaniu grafów.
91 Graph500 - schemat W ocenie wydajności pod uwagę brane sa kernele 1 oraz 2. Gdy obydwa kernele kończa pracę następuje faza walidacji w celu sprawdzenia czy wynik BFS jest poprawny. Jest 64 iteracji kernala 2 razem z testem walidacji. Żadne dalsze modyfikacje pomiędzy obliczeniami kernelów nie sa dozwolone.
92 Graph500 - schemat W ocenie wydajności pod uwagę brane sa kernele 1 oraz 2. Gdy obydwa kernele kończa pracę następuje faza walidacji w celu sprawdzenia czy wynik BFS jest poprawny. Jest 64 iteracji kernala 2 razem z testem walidacji. Żadne dalsze modyfikacje pomiędzy obliczeniami kernelów nie sa dozwolone.
93 Graph500 - schemat W ocenie wydajności pod uwagę brane sa kernele 1 oraz 2. Gdy obydwa kernele kończa pracę następuje faza walidacji w celu sprawdzenia czy wynik BFS jest poprawny. Jest 64 iteracji kernala 2 razem z testem walidacji. Żadne dalsze modyfikacje pomiędzy obliczeniami kernelów nie sa dozwolone.
94 Graph500 - schemat W ocenie wydajności pod uwagę brane sa kernele 1 oraz 2. Gdy obydwa kernele kończa pracę następuje faza walidacji w celu sprawdzenia czy wynik BFS jest poprawny. Jest 64 iteracji kernala 2 razem z testem walidacji. Żadne dalsze modyfikacje pomiędzy obliczeniami kernelów nie sa dozwolone.
95 Graph500 - schemat W ocenie wydajności pod uwagę brane sa kernele 1 oraz 2. Gdy obydwa kernele kończa pracę następuje faza walidacji w celu sprawdzenia czy wynik BFS jest poprawny. Jest 64 iteracji kernala 2 razem z testem walidacji. Żadne dalsze modyfikacje pomiędzy obliczeniami kernelów nie sa dozwolone.
96 Graph500 - Generator Benchmark Graph500 zawiera generator grafów, który konstuuje graf w postaci listy krawędzi. Każda krawędź jest nieskierowana z punktami końcowymi krawędzi określonymi jako <wierzchołek startowy, wierzchołek końcowy>. Wierzchołki maja identyfikatory liczone od 0. Generator pozwala zapisać wygenerowany graf do pliku binarnego - każda krawędź zajmuje 16 bajtów danych (8 bajtów na wierzchołek - bez znaku)
97 Graph500 - Generator Benchmark Graph500 zawiera generator grafów, który konstuuje graf w postaci listy krawędzi. Każda krawędź jest nieskierowana z punktami końcowymi krawędzi określonymi jako <wierzchołek startowy, wierzchołek końcowy>. Wierzchołki maja identyfikatory liczone od 0. Generator pozwala zapisać wygenerowany graf do pliku binarnego - każda krawędź zajmuje 16 bajtów danych (8 bajtów na wierzchołek - bez znaku)
98 Graph500 - Generator Benchmark Graph500 zawiera generator grafów, który konstuuje graf w postaci listy krawędzi. Każda krawędź jest nieskierowana z punktami końcowymi krawędzi określonymi jako <wierzchołek startowy, wierzchołek końcowy>. Wierzchołki maja identyfikatory liczone od 0. Generator pozwala zapisać wygenerowany graf do pliku binarnego - każda krawędź zajmuje 16 bajtów danych (8 bajtów na wierzchołek - bez znaku)
99 Graph500 - Generator Benchmark Graph500 zawiera generator grafów, który konstuuje graf w postaci listy krawędzi. Każda krawędź jest nieskierowana z punktami końcowymi krawędzi określonymi jako <wierzchołek startowy, wierzchołek końcowy>. Wierzchołki maja identyfikatory liczone od 0. Generator pozwala zapisać wygenerowany graf do pliku binarnego - każda krawędź zajmuje 16 bajtów danych (8 bajtów na wierzchołek - bez znaku)
100 Graph500 - Generator Generator wykorzystuje model grafów Kroneckera - rzadkie sieci z mała średnica, typu Scale Free. Sa to sieci które dobrze symuluja grafy świata rzeczywistego. Prawdopodobieństwo wystapienia połaczenia pomiędzy nowym węzłem a każdym węzłem należacym do sieci bardzo silnie zależy od posiadanej przez te węzły liczby krawędzi k i wynosi P(k) k c. Wykładnik potęgi zależy od rodzaju rozpatrywanej sieci np. dla WWW około 2.2. Najwięcej nowych węzłów łaczy się z węzłami, które już posiadaja najwięcej sasiadów.
101 Graph500 - Generator Generator wykorzystuje model grafów Kroneckera - rzadkie sieci z mała średnica, typu Scale Free. Sa to sieci które dobrze symuluja grafy świata rzeczywistego. Prawdopodobieństwo wystapienia połaczenia pomiędzy nowym węzłem a każdym węzłem należacym do sieci bardzo silnie zależy od posiadanej przez te węzły liczby krawędzi k i wynosi P(k) k c. Wykładnik potęgi zależy od rodzaju rozpatrywanej sieci np. dla WWW około 2.2. Najwięcej nowych węzłów łaczy się z węzłami, które już posiadaja najwięcej sasiadów.
102 Graph500 - Generator Generator wykorzystuje model grafów Kroneckera - rzadkie sieci z mała średnica, typu Scale Free. Sa to sieci które dobrze symuluja grafy świata rzeczywistego. Prawdopodobieństwo wystapienia połaczenia pomiędzy nowym węzłem a każdym węzłem należacym do sieci bardzo silnie zależy od posiadanej przez te węzły liczby krawędzi k i wynosi P(k) k c. Wykładnik potęgi zależy od rodzaju rozpatrywanej sieci np. dla WWW około 2.2. Najwięcej nowych węzłów łaczy się z węzłami, które już posiadaja najwięcej sasiadów.
 k c.")
103 Graph500 - Generator Generator wykorzystuje model grafów Kroneckera - rzadkie sieci z mała średnica, typu Scale Free. Sa to sieci które dobrze symuluja grafy świata rzeczywistego. Prawdopodobieństwo wystapienia połaczenia pomiędzy nowym węzłem a każdym węzłem należacym do sieci bardzo silnie zależy od posiadanej przez te węzły liczby krawędzi k i wynosi P(k) k c. Wykładnik potęgi zależy od rodzaju rozpatrywanej sieci np. dla WWW około 2.2. Najwięcej nowych węzłów łaczy się z węzłami, które już posiadaja najwięcej sasiadów.
104 Graph500 - Kernel 1 Pierwszy kernel: odpowiada za konstrukcję z listy krawędzi, nieskierowanego grafu w dowolnym formacie używanym przez kolejny kernel. W obliczeniach dane sa jedynie lista krawędzi oraz wielkość tej listy. Pozostałe informacje takie jak liczba wierzchołków musza być obliczone w trakcie działania programu. Pierwszy kernel polega na budowie z listy krawędzi dowolnej reprezentacji grafu nieskierowanego, która lepiej nadaje się do przechowywania grafów rzadkich. Specyfikacja benchmarku Graph500 nie narzuca konkretnego formatu.
105 Graph500 - Kernel 1 Pierwszy kernel: odpowiada za konstrukcję z listy krawędzi, nieskierowanego grafu w dowolnym formacie używanym przez kolejny kernel. W obliczeniach dane sa jedynie lista krawędzi oraz wielkość tej listy. Pozostałe informacje takie jak liczba wierzchołków musza być obliczone w trakcie działania programu. Pierwszy kernel polega na budowie z listy krawędzi dowolnej reprezentacji grafu nieskierowanego, która lepiej nadaje się do przechowywania grafów rzadkich. Specyfikacja benchmarku Graph500 nie narzuca konkretnego formatu.
106 Graph500 - Kernel 1 Pierwszy kernel: odpowiada za konstrukcję z listy krawędzi, nieskierowanego grafu w dowolnym formacie używanym przez kolejny kernel. W obliczeniach dane sa jedynie lista krawędzi oraz wielkość tej listy. Pozostałe informacje takie jak liczba wierzchołków musza być obliczone w trakcie działania programu. Pierwszy kernel polega na budowie z listy krawędzi dowolnej reprezentacji grafu nieskierowanego, która lepiej nadaje się do przechowywania grafów rzadkich. Specyfikacja benchmarku Graph500 nie narzuca konkretnego formatu.
107 Graph500 - Kernel 2 Drugi kernel: odpowiada za przeszukiwanie grafu wszerz. Obliczenia wykonywane sa 64 razy, jedno po drugim. Każdy przebieg rozpoczyna się od innego, wybranego losowo werzchołka startowego (źródła). Źródłowy wierzchołek jest losowo wybrany z wierzchołków grafu. Aby uniknać trywialnych przeszukiwań, tylko wierzchołki ze stopniem co najmniej 1 brane sa pod uwagę (nie liczac pętli).
108 Graph500 - Kernel 2 Drugi kernel: odpowiada za przeszukiwanie grafu wszerz. Obliczenia wykonywane sa 64 razy, jedno po drugim. Każdy przebieg rozpoczyna się od innego, wybranego losowo werzchołka startowego (źródła). Źródłowy wierzchołek jest losowo wybrany z wierzchołków grafu. Aby uniknać trywialnych przeszukiwań, tylko wierzchołki ze stopniem co najmniej 1 brane sa pod uwagę (nie liczac pętli).
109 Graph500 - Kernel 2 Drugi kernel: odpowiada za przeszukiwanie grafu wszerz. Obliczenia wykonywane sa 64 razy, jedno po drugim. Każdy przebieg rozpoczyna się od innego, wybranego losowo werzchołka startowego (źródła). Źródłowy wierzchołek jest losowo wybrany z wierzchołków grafu. Aby uniknać trywialnych przeszukiwań, tylko wierzchołki ze stopniem co najmniej 1 brane sa pod uwagę (nie liczac pętli).
110 Graph500 - Kernel 2 Drugi kernel: odpowiada za przeszukiwanie grafu wszerz. Obliczenia wykonywane sa 64 razy, jedno po drugim. Każdy przebieg rozpoczyna się od innego, wybranego losowo werzchołka startowego (źródła). Źródłowy wierzchołek jest losowo wybrany z wierzchołków grafu. Aby uniknać trywialnych przeszukiwań, tylko wierzchołki ze stopniem co najmniej 1 brane sa pod uwagę (nie liczac pętli).
111 Graph500 - Kernel 2 Drugi kernel: odpowiada za przeszukiwanie grafu wszerz. Obliczenia wykonywane sa 64 razy, jedno po drugim. Każdy przebieg rozpoczyna się od innego, wybranego losowo werzchołka startowego (źródła). Źródłowy wierzchołek jest losowo wybrany z wierzchołków grafu. Aby uniknać trywialnych przeszukiwań, tylko wierzchołki ze stopniem co najmniej 1 brane sa pod uwagę (nie liczac pętli).
112 Graph500 - Walidacja Kernela 2 Aby zweryfikować poprawność wyniku przeprowadzone sa następujace testy: drzewo BFS nie zawiera cykli każda krawędź łaczy wierzchołki, których odległość od źródła różni się o 1 każda krawędź w wejściowej liście ma wierzchołki o odległościach które różnia się o najwyżej 1 albo oba nie sa w drzewie BFS drzewo BFS rozpina cała spójna składowa wierzchołek i jego rodzic sa połaczone krawędzia w poczatkowym grafie
113 Graph500 - Walidacja Kernela 2 Aby zweryfikować poprawność wyniku przeprowadzone sa następujace testy: drzewo BFS nie zawiera cykli każda krawędź łaczy wierzchołki, których odległość od źródła różni się o 1 każda krawędź w wejściowej liście ma wierzchołki o odległościach które różnia się o najwyżej 1 albo oba nie sa w drzewie BFS drzewo BFS rozpina cała spójna składowa wierzchołek i jego rodzic sa połaczone krawędzia w poczatkowym grafie
114 Graph500 - Walidacja Kernela 2 Aby zweryfikować poprawność wyniku przeprowadzone sa następujace testy: drzewo BFS nie zawiera cykli każda krawędź łaczy wierzchołki, których odległość od źródła różni się o 1 każda krawędź w wejściowej liście ma wierzchołki o odległościach które różnia się o najwyżej 1 albo oba nie sa w drzewie BFS drzewo BFS rozpina cała spójna składowa wierzchołek i jego rodzic sa połaczone krawędzia w poczatkowym grafie
115 Graph500 - Walidacja Kernela 2 Aby zweryfikować poprawność wyniku przeprowadzone sa następujace testy: drzewo BFS nie zawiera cykli każda krawędź łaczy wierzchołki, których odległość od źródła różni się o 1 każda krawędź w wejściowej liście ma wierzchołki o odległościach które różnia się o najwyżej 1 albo oba nie sa w drzewie BFS drzewo BFS rozpina cała spójna składowa wierzchołek i jego rodzic sa połaczone krawędzia w poczatkowym grafie
116 Graph500 - Walidacja Kernela 2 Aby zweryfikować poprawność wyniku przeprowadzone sa następujace testy: drzewo BFS nie zawiera cykli każda krawędź łaczy wierzchołki, których odległość od źródła różni się o 1 każda krawędź w wejściowej liście ma wierzchołki o odległościach które różnia się o najwyżej 1 albo oba nie sa w drzewie BFS drzewo BFS rozpina cała spójna składowa wierzchołek i jego rodzic sa połaczone krawędzia w poczatkowym grafie
117 Graph500 - Walidacja Kernela 2 Aby zweryfikować poprawność wyniku przeprowadzone sa następujace testy: drzewo BFS nie zawiera cykli każda krawędź łaczy wierzchołki, których odległość od źródła różni się o 1 każda krawędź w wejściowej liście ma wierzchołki o odległościach które różnia się o najwyżej 1 albo oba nie sa w drzewie BFS drzewo BFS rozpina cała spójna składowa wierzchołek i jego rodzic sa połaczone krawędzia w poczatkowym grafie
118 Graph500 - implementacje Benchmark Graph500 dostarcza kilka implementacji: GNU Octave sekwencyjne OpenMP Cray XMT kilka implementacji wykorzystujacych MPI
119 Graph500 - wielkość grafu Wielkość grafu opisana jest za pomoca następujacych zmiennych: SCALE - logarytm o podstawie 2 z ilości wierzchołków edgefactor - stosunek liczby krawędzi grafu do liczby wierzchołków Zmienne SCALE oraz edgefactor determinuja wielkość grafu: liczba wierzchołków N = 2 SCALE liczba krawędzi M = edgefactor N
120 Graph500 - wielkość grafu Wielkość grafu opisana jest za pomoca następujacych zmiennych: SCALE - logarytm o podstawie 2 z ilości wierzchołków edgefactor - stosunek liczby krawędzi grafu do liczby wierzchołków Zmienne SCALE oraz edgefactor determinuja wielkość grafu: liczba wierzchołków N = 2 SCALE liczba krawędzi M = edgefactor N
121 Graph500 - Generator - wielkości plików Wielkości wygenerowanych plików:
122 Graph500 w PGAS i PCJ - Kernel 1 Kernel 1: Dane: graf G w postaci listy krawędzi (graf nieskierowany) Wynik: graf G w postaci CSR (Compressed Sparse Row)
123 Graph500 w PGAS i PCJ - Kernel 1 - CSR CSR (Compressed Sparse Row) jest efektywna reprezentacja grafów rzadkich, gdzie graf jest przechowywany w trzech jednowymiarowych tablicach: pierwsza tablica przechowuje przesunięcie (offset) które wskazuje na wierzchołek poczatkowy krawędzi (tablica wierzchołków) druga tablica przechowuje numery kolumn wszystkich niezerowych elementów dla macierzy sasiedztwa czytajac wiersze w kolejności od góry do dołu - punkty końcowe krawędzi (tablica krawędzi) trzecia tablica przechowuje wartości numeryczne
124 Graph500 w PGAS i PCJ - Kernel 1 - CSR CSR (Compressed Sparse Row) jest efektywna reprezentacja grafów rzadkich, gdzie graf jest przechowywany w trzech jednowymiarowych tablicach: pierwsza tablica przechowuje przesunięcie (offset) które wskazuje na wierzchołek poczatkowy krawędzi (tablica wierzchołków) druga tablica przechowuje numery kolumn wszystkich niezerowych elementów dla macierzy sasiedztwa czytajac wiersze w kolejności od góry do dołu - punkty końcowe krawędzi (tablica krawędzi) trzecia tablica przechowuje wartości numeryczne
125 Graph500 w PGAS i PCJ - Kernel 1 - CSR CSR (Compressed Sparse Row) jest efektywna reprezentacja grafów rzadkich, gdzie graf jest przechowywany w trzech jednowymiarowych tablicach: pierwsza tablica przechowuje przesunięcie (offset) które wskazuje na wierzchołek poczatkowy krawędzi (tablica wierzchołków) druga tablica przechowuje numery kolumn wszystkich niezerowych elementów dla macierzy sasiedztwa czytajac wiersze w kolejności od góry do dołu - punkty końcowe krawędzi (tablica krawędzi) trzecia tablica przechowuje wartości numeryczne
126 Graph500 w PGAS i PCJ - Kernel 1 - CSR CSR (Compressed Sparse Row) jest efektywna reprezentacja grafów rzadkich, gdzie graf jest przechowywany w trzech jednowymiarowych tablicach: pierwsza tablica przechowuje przesunięcie (offset) które wskazuje na wierzchołek poczatkowy krawędzi (tablica wierzchołków) druga tablica przechowuje numery kolumn wszystkich niezerowych elementów dla macierzy sasiedztwa czytajac wiersze w kolejności od góry do dołu - punkty końcowe krawędzi (tablica krawędzi) trzecia tablica przechowuje wartości numeryczne
127 Graph500 w PGAS i PCJ - Kernel 1 - CSR Przykład zaczerpnięty z ksiażki Graph Algorithms in the Language of Linear Algebra
128 Graph500 w PGAS i PCJ - Kernel 1 - CSR CSR jest prawie identyczna z reprezentacja w postaci listy krawędzi. W praktyce CSR: ma mniej narzutu pamięciowego Strzałki w reprezentacji listy sasiedztwa sa wskaźnikami na miejsca w pamięci (w CSR już nie). dużo lepsza efektywność buforowania Zamiast przechowywać tablicę list, składa się z tablic które przechowuja całe wiersze w ciagłej porcji pamięci. Wierzchołki sasiednie do v i sa zaraz obok wierzchołków sasiednich wierzchołka v i + 1. Tablica wierzchołków przechowuje poczatkowy punkt każdego ciagłego sasiedniego bloku wierzchołka.
129 Graph500 w PGAS i PCJ - Kernel 1 - CSR CSR jest prawie identyczna z reprezentacja w postaci listy krawędzi. W praktyce CSR: ma mniej narzutu pamięciowego Strzałki w reprezentacji listy sasiedztwa sa wskaźnikami na miejsca w pamięci (w CSR już nie). dużo lepsza efektywność buforowania Zamiast przechowywać tablicę list, składa się z tablic które przechowuja całe wiersze w ciagłej porcji pamięci. Wierzchołki sasiednie do v i sa zaraz obok wierzchołków sasiednich wierzchołka v i + 1. Tablica wierzchołków przechowuje poczatkowy punkt każdego ciagłego sasiedniego bloku wierzchołka.
130 Graph500 w PGAS i PCJ - Kernel 1 - CSR CSR jest prawie identyczna z reprezentacja w postaci listy krawędzi. W praktyce CSR: ma mniej narzutu pamięciowego Strzałki w reprezentacji listy sasiedztwa sa wskaźnikami na miejsca w pamięci (w CSR już nie). dużo lepsza efektywność buforowania Zamiast przechowywać tablicę list, składa się z tablic które przechowuja całe wiersze w ciagłej porcji pamięci. Wierzchołki sasiednie do v i sa zaraz obok wierzchołków sasiednich wierzchołka v i + 1. Tablica wierzchołków przechowuje poczatkowy punkt każdego ciagłego sasiedniego bloku wierzchołka.
131 Graph500 w PGAS i PCJ - Kernel 1 - CSR CSR jest prawie identyczna z reprezentacja w postaci listy krawędzi. W praktyce CSR: ma mniej narzutu pamięciowego Strzałki w reprezentacji listy sasiedztwa sa wskaźnikami na miejsca w pamięci (w CSR już nie). dużo lepsza efektywność buforowania Zamiast przechowywać tablicę list, składa się z tablic które przechowuja całe wiersze w ciagłej porcji pamięci. Wierzchołki sasiednie do v i sa zaraz obok wierzchołków sasiednich wierzchołka v i + 1. Tablica wierzchołków przechowuje poczatkowy punkt każdego ciagłego sasiedniego bloku wierzchołka.
132 Graph500 w PGAS i PCJ - Kernel 1 - CSR CSR jest prawie identyczna z reprezentacja w postaci listy krawędzi. W praktyce CSR: ma mniej narzutu pamięciowego Strzałki w reprezentacji listy sasiedztwa sa wskaźnikami na miejsca w pamięci (w CSR już nie). dużo lepsza efektywność buforowania Zamiast przechowywać tablicę list, składa się z tablic które przechowuja całe wiersze w ciagłej porcji pamięci. Wierzchołki sasiednie do v i sa zaraz obok wierzchołków sasiednich wierzchołka v i + 1. Tablica wierzchołków przechowuje poczatkowy punkt każdego ciagłego sasiedniego bloku wierzchołka.
133 Graph500 w PGAS i PCJ - Kernel 1 - CSR W eksperymencie przeprowadzonym w 1998 roku reprezentacja oparta o tablice okazała się 10 razy szybsza do przeszukania niż reprezentacja listy sasiedztwa (spowodowane wysokim kosztem śledzenia wskaźników w połaczonych strukturach danych). CSR ma też wady, które polegaja na nieefektywnych operacjach dodawania lub usuwania krawędzi. CSR nadaje się do przechowywania grafów statycznych. J.R. Black, C.U. Martel and H. Qi. Graph and hashing algorithms for modern architectures: Design and performance. In Algorithm Engineering, 37-48, 1998.
134 Graph500 w PGAS i PCJ - Kernel 1 - CSR W eksperymencie przeprowadzonym w 1998 roku reprezentacja oparta o tablice okazała się 10 razy szybsza do przeszukania niż reprezentacja listy sasiedztwa (spowodowane wysokim kosztem śledzenia wskaźników w połaczonych strukturach danych). CSR ma też wady, które polegaja na nieefektywnych operacjach dodawania lub usuwania krawędzi. CSR nadaje się do przechowywania grafów statycznych. J.R. Black, C.U. Martel and H. Qi. Graph and hashing algorithms for modern architectures: Design and performance. In Algorithm Engineering, 37-48, 1998.
135 Graph500 w PGAS i PCJ - Kernel 1 - CSR W eksperymencie przeprowadzonym w 1998 roku reprezentacja oparta o tablice okazała się 10 razy szybsza do przeszukania niż reprezentacja listy sasiedztwa (spowodowane wysokim kosztem śledzenia wskaźników w połaczonych strukturach danych). CSR ma też wady, które polegaja na nieefektywnych operacjach dodawania lub usuwania krawędzi. CSR nadaje się do przechowywania grafów statycznych. J.R. Black, C.U. Martel and H. Qi. Graph and hashing algorithms for modern architectures: Design and performance. In Algorithm Engineering, 37-48, 1998.
136 Graph500 w PGAS i PCJ - Kernel 1 - CSR W eksperymencie przeprowadzonym w 1998 roku reprezentacja oparta o tablice okazała się 10 razy szybsza do przeszukania niż reprezentacja listy sasiedztwa (spowodowane wysokim kosztem śledzenia wskaźników w połaczonych strukturach danych). CSR ma też wady, które polegaja na nieefektywnych operacjach dodawania lub usuwania krawędzi. CSR nadaje się do przechowywania grafów statycznych. J.R. Black, C.U. Martel and H. Qi. Graph and hashing algorithms for modern architectures: Design and performance. In Algorithm Engineering, 37-48, 1998.
137 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: graf w postaci CSR (przechowywany w dwóch wektorach) Ponieważ graf jest statyczny i nie zmienia się podczas obliczeń, bedziemy tworzyć graf w postaci CSR. rozmieszczenie wierzchołków i krawędzi grafu w systemie rozproszonym jest realizowane przez 1-wymiarowy podział danych (1D partitioning) 1-wymiarowy podział danych można łatwo zwizualizować przez 1-wymiarowy podział macierzy sasiedztwa grafu.
138 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: graf w postaci CSR (przechowywany w dwóch wektorach) Ponieważ graf jest statyczny i nie zmienia się podczas obliczeń, bedziemy tworzyć graf w postaci CSR. rozmieszczenie wierzchołków i krawędzi grafu w systemie rozproszonym jest realizowane przez 1-wymiarowy podział danych (1D partitioning) 1-wymiarowy podział danych można łatwo zwizualizować przez 1-wymiarowy podział macierzy sasiedztwa grafu.
139 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: graf w postaci CSR (przechowywany w dwóch wektorach) Ponieważ graf jest statyczny i nie zmienia się podczas obliczeń, bedziemy tworzyć graf w postaci CSR. rozmieszczenie wierzchołków i krawędzi grafu w systemie rozproszonym jest realizowane przez 1-wymiarowy podział danych (1D partitioning) 1-wymiarowy podział danych można łatwo zwizualizować przez 1-wymiarowy podział macierzy sasiedztwa grafu.
140 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: graf w postaci CSR (przechowywany w dwóch wektorach) Ponieważ graf jest statyczny i nie zmienia się podczas obliczeń, bedziemy tworzyć graf w postaci CSR. rozmieszczenie wierzchołków i krawędzi grafu w systemie rozproszonym jest realizowane przez 1-wymiarowy podział danych (1D partitioning) 1-wymiarowy podział danych można łatwo zwizualizować przez 1-wymiarowy podział macierzy sasiedztwa grafu.
141 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: graf w postaci CSR (przechowywany w dwóch wektorach) Ponieważ graf jest statyczny i nie zmienia się podczas obliczeń, bedziemy tworzyć graf w postaci CSR. rozmieszczenie wierzchołków i krawędzi grafu w systemie rozproszonym jest realizowane przez 1-wymiarowy podział danych (1D partitioning) 1-wymiarowy podział danych można łatwo zwizualizować przez 1-wymiarowy podział macierzy sasiedztwa grafu.
142 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm
143 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: dystrybucja wierzchołków pomiędzy watki jest realizowana blokowo - watek 0 posiada wierzchołki < 0,X >, watek 1 posiada wierzchołki < X + 1,Y > itd. wszystkie wierzchołki i krawędzie poczatkowego grafu sa rozdzielone - każdy watek posiada N/p wierzchołków wraz z sasiaduj acymi krawędziami N - liczba wierzchołków w grafie p - liczba watków W przypadku grafów nieskierowanych wszystkie krawędzie sa przechowywane dwa razy.
144 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: dystrybucja wierzchołków pomiędzy watki jest realizowana blokowo - watek 0 posiada wierzchołki < 0,X >, watek 1 posiada wierzchołki < X + 1,Y > itd. wszystkie wierzchołki i krawędzie poczatkowego grafu sa rozdzielone - każdy watek posiada N/p wierzchołków wraz z sasiaduj acymi krawędziami N - liczba wierzchołków w grafie p - liczba watków W przypadku grafów nieskierowanych wszystkie krawędzie sa przechowywane dwa razy.
145 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: dystrybucja wierzchołków pomiędzy watki jest realizowana blokowo - watek 0 posiada wierzchołki < 0,X >, watek 1 posiada wierzchołki < X + 1,Y > itd. wszystkie wierzchołki i krawędzie poczatkowego grafu sa rozdzielone - każdy watek posiada N/p wierzchołków wraz z sasiaduj acymi krawędziami N - liczba wierzchołków w grafie p - liczba watków W przypadku grafów nieskierowanych wszystkie krawędzie sa przechowywane dwa razy.
146 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: dystrybucja wierzchołków pomiędzy watki jest realizowana blokowo - watek 0 posiada wierzchołki < 0,X >, watek 1 posiada wierzchołki < X + 1,Y > itd. wszystkie wierzchołki i krawędzie poczatkowego grafu sa rozdzielone - każdy watek posiada N/p wierzchołków wraz z sasiaduj acymi krawędziami N - liczba wierzchołków w grafie p - liczba watków W przypadku grafów nieskierowanych wszystkie krawędzie sa przechowywane dwa razy.
147 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Implementacja w PCJ: dystrybucja wierzchołków pomiędzy watki jest realizowana blokowo - watek 0 posiada wierzchołki < 0,X >, watek 1 posiada wierzchołki < X + 1,Y > itd. wszystkie wierzchołki i krawędzie poczatkowego grafu sa rozdzielone - każdy watek posiada N/p wierzchołków wraz z sasiaduj acymi krawędziami N - liczba wierzchołków w grafie p - liczba watków W przypadku grafów nieskierowanych wszystkie krawędzie sa przechowywane dwa razy.
148 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Proces konstrukcji grafu z listy krawędzi do postaci CSR można podzielić na dwie części: podział danych obliczenie CSR - wszystkie watki tworza reprezentacje CSR części grafu, biorac pod uwagę tylko posiadane wierzchołki i ich incydentne krawędzie
149 Graph500 w PGAS i PCJ - Kernel 1 - Algorytm Proces konstrukcji grafu z listy krawędzi do postaci CSR można podzielić na dwie części: podział danych obliczenie CSR - wszystkie watki tworza reprezentacje CSR części grafu, biorac pod uwagę tylko posiadane wierzchołki i ich incydentne krawędzie
150 Graph500 w PGAS i PCJ - Kernel 1 - Pseudokod Algorithm Creation of CSR graph representation from a list of edge tuples. Input: Undirected graph G(V, E) in the form of list of edge tuples L Output: CSR representation of the graph G 1: for all processors in parallel do 2: localmax FIND-MAX(Lp) Lp is a chunk of L processed by processor p 3: if processor 0 4: globalmax REDUCE(localMax) 5: BROADCAST(globalMax) 6: for all processors in parallel do 7: FIND-RANGE(globalMax) range of vertices the processor owns 8: COMPUTE-CSR(L) CSR computation for owned vertices
151 Graph500 w PGAS i PCJ - Kernel 1 - Pseudokod Algorithm Creation of CSR graph representation from a list of edge tuples. Input: Undirected graph G(V, E) in the form of list of edge tuples L Output: CSR representation of the graph G 1: for all processors in parallel do 2: localmax FIND-MAX(Lp) Lp is a chunk of L processed by processor p 3: if processor 0 4: globalmax REDUCE(localMax) 5: BROADCAST(globalMax) 6: for all processors in parallel do 7: FIND-RANGE(globalMax) range of vertices the processor owns 8: COMPUTE-CSR(L) CSR computation for owned vertices Pierwszym krokiem algorytmu jest znalezienie maksymalnego identyfikatora wierzchołka w grafie listy krawędzi.
152 Graph500 w PGAS i PCJ - Kernel 1 - Pseudokod Algorithm Creation of CSR graph representation from a list of edge tuples. Input: Undirected graph G(V, E) in the form of list of edge tuples L Output: CSR representation of the graph G 1: for all processors in parallel do 2: localmax FIND-MAX(Lp) Lp is a chunk of L processed by processor p 3: if processor 0 4: globalmax REDUCE(localMax) 5: BROADCAST(globalMax) 6: for all processors in parallel do 7: FIND-RANGE(globalMax) range of vertices the processor owns 8: COMPUTE-CSR(L) CSR computation for owned vertices Każdy watek przeszukuje inna część listy krawędzi i znajduje jego maksimum.
153 Graph500 w PGAS i PCJ - Kernel 1 - Pseudokod Algorithm Creation of CSR graph representation from a list of edge tuples. Input: Undirected graph G(V, E) in the form of list of edge tuples L Output: CSR representation of the graph G 1: for all processors in parallel do 2: localmax FIND-MAX(Lp) Lp is a chunk of L processed by processor p 3: if processor 0 4: globalmax REDUCE(localMax) 5: BROADCAST(globalMax) 6: for all processors in parallel do 7: FIND-RANGE(globalMax) range of vertices the processor owns 8: COMPUTE-CSR(L) CSR computation for owned vertices Następnie robiona jest redukcja i jest znajdowany globalny maksymalny wierzchołek.
154 Graph500 w PGAS i PCJ - Kernel 1 - Pseudokod Algorithm Creation of CSR graph representation from a list of edge tuples. Input: Undirected graph G(V, E) in the form of list of edge tuples L Output: CSR representation of the graph G 1: for all processors in parallel do 2: localmax FIND-MAX(Lp) Lp is a chunk of L processed by processor p 3: if processor 0 4: globalmax REDUCE(localMax) 5: BROADCAST(globalMax) 6: for all processors in parallel do 7: FIND-RANGE(globalMax) range of vertices the processor owns 8: COMPUTE-CSR(L) CSR computation for owned vertices Watek oblicza zakres posiadanych wierzchołków bazujac na 1-wymiarowym podziale danych.
155 Graph500 w PGAS i PCJ - Kernel 1 - Pseudokod Algorithm Creation of CSR graph representation from a list of edge tuples. Input: Undirected graph G(V, E) in the form of list of edge tuples L Output: CSR representation of the graph G 1: for all processors in parallel do 2: localmax FIND-MAX(Lp) Lp is a chunk of L processed by processor p 3: if processor 0 4: globalmax REDUCE(localMax) 5: BROADCAST(globalMax) 6: for all processors in parallel do 7: FIND-RANGE(globalMax) range of vertices the processor owns 8: COMPUTE-CSR(L) CSR computation for owned vertices Wierzchołki grafu sa podzielone w taki sposób, że każdy wierzchołek ma dokładnie jednego właściciela.
156 Graph500 w PGAS i PCJ - Kernel 1 - Pseudokod Algorithm Creation of CSR graph representation from a list of edge tuples. Input: Undirected graph G(V, E) in the form of list of edge tuples L Output: CSR representation of the graph G 1: for all processors in parallel do 2: localmax FIND-MAX(Lp) Lp is a chunk of L processed by processor p 3: if processor 0 4: globalmax REDUCE(localMax) 5: BROADCAST(globalMax) 6: for all processors in parallel do 7: FIND-RANGE(globalMax) range of vertices the processor owns 8: COMPUTE-CSR(L) CSR computation for owned vertices Każdy watek wybiera tylko krawędzie sasiaduj ace do posiadanych wierzchołków.
157 Graph500 w PGAS i PCJ - Kernel 1 - Przykład
158 Graph500 w PGAS i PCJ - Kernel 2 Kernel 2: Dane: graf G(V,E) w postaci CSR, podzielony pomiędzy watkami, źródło v V Wynik: tablica poprzedników - drzewo BFS
159 Graph500 w PGAS i PCJ - Kernel 2 BFS rozpoczyna od wyróżnionego wierzchołka pobranego z Genaratora benchmarku Graph500. Źródłowy wierzchołek jest losowo wybrany z wierzchołków grafu. Aby uniknać trywialnych przeszukiwań, tylko wierzchołki ze stopniem co najmniej 1 nie liczac pętli sa brane pod uwagę.
160 Graph500 w PGAS i PCJ - Kernel 2 BFS rozpoczyna od wyróżnionego wierzchołka pobranego z Genaratora benchmarku Graph500. Źródłowy wierzchołek jest losowo wybrany z wierzchołków grafu. Aby uniknać trywialnych przeszukiwań, tylko wierzchołki ze stopniem co najmniej 1 nie liczac pętli sa brane pod uwagę.
161 Graph500 w PGAS i PCJ - Kernel 2 BFS rozpoczyna od wyróżnionego wierzchołka pobranego z Genaratora benchmarku Graph500. Źródłowy wierzchołek jest losowo wybrany z wierzchołków grafu. Aby uniknać trywialnych przeszukiwań, tylko wierzchołki ze stopniem co najmniej 1 nie liczac pętli sa brane pod uwagę.
162 Graph500 w PGAS i PCJ - Kernel 2 Po obliczeniach Kernela 1, poczatkowy graf jest trzymany w rozproszonym formacie CSR. Każdy watek trzyma swój własny podzbiór wierzchołków razem z sasiednimi krawędziami. Implementacja równoległego algorytmu BFS jest oparta na idei synchronizacji watków po każdym poziomie.
163 Graph500 w PGAS i PCJ - Kernel 2 Po obliczeniach Kernela 1, poczatkowy graf jest trzymany w rozproszonym formacie CSR. Każdy watek trzyma swój własny podzbiór wierzchołków razem z sasiednimi krawędziami. Implementacja równoległego algorytmu BFS jest oparta na idei synchronizacji watków po każdym poziomie.
164 Graph500 w PGAS i PCJ - Kernel 2 Po obliczeniach Kernela 1, poczatkowy graf jest trzymany w rozproszonym formacie CSR. Każdy watek trzyma swój własny podzbiór wierzchołków razem z sasiednimi krawędziami. Implementacja równoległego algorytmu BFS jest oparta na idei synchronizacji watków po każdym poziomie.
165 Graph500 w PGAS i PCJ - Kernel 2 Każdy wierzchołek w odległości k od źródła jest odwiedzony wcześniej niż wierzchołek na poziomie k + 1. Odległość pomiędzy dwoma wierzchołkami jest najkrótsza ścieżka łacz ac a te wierzchołki. Nieskierowany graf ze źródłowym wierzchołkiem jako punktem centralnym razem z wierzchołkami na poziomie 1 oraz 2.
166 Graph500 w PGAS i PCJ - Kernel 2 Każdy wierzchołek w odległości k od źródła jest odwiedzony wcześniej niż wierzchołek na poziomie k + 1. Odległość pomiędzy dwoma wierzchołkami jest najkrótsza ścieżka łacz ac a te wierzchołki. Nieskierowany graf ze źródłowym wierzchołkiem jako punktem centralnym razem z wierzchołkami na poziomie 1 oraz 2.

167 Graph500 w PGAS i PCJ - Kernel 2 Każdy wierzchołek w odległości k od źródła jest odwiedzony wcześniej niż wierzchołek na poziomie k + 1. Odległość pomiędzy dwoma wierzchołkami jest najkrótsza ścieżka łacz ac a te wierzchołki. Nieskierowany graf ze źródłowym wierzchołkiem jako punktem centralnym razem z wierzchołkami na poziomie 1 oraz 2.
168 Graph500 w PGAS i PCJ - Kernel 2
169 Graph500 w PGAS i PCJ - Kernel 2 Aby przyspieszyć działanie zastosowano kilka optymalizacji: bitmapa, zawierajaca informacje o odwiedzonych wierzchołkach, aby zredukować ilość potrzebnej pamięci, a co najważniejsze ograniczyć komunikację pomiędzy watkami Każdy watek przechwuje wektor bitów bitmap[v] - bit ustawiony jest na 1 jeśli wierzchołek jest odwiedzony Po każdym poziomie informacje w bitmapie sa wymieniane pomiędzy watkami użycie tablicowych buforów danych (ważne ze względu na specyfikę biblioteki PCJ, która wspiera wysyłanie tablic po indeksach), co pozwala na zminimalizowanie narzutu zwiazanego z rozpoczęciem komunikacji (zamiast przesyłać pojedynczy wierzchołek, każdy watek grupuje kilka wiadomości) nakładanie komunikacji i obliczeń, poprzez wykonywanie niezależnych procedur np. VISIT-VERTICES w trakcie oczekiwania na zakończenie komunikacji - watek przetwarza dane, które już otrzymał (PCJ.waitFor("variable",0) - zwraca liczbę otrzymanych danych)
170 Graph500 w PGAS i PCJ - Kernel 2 Aby przyspieszyć działanie zastosowano kilka optymalizacji: bitmapa, zawierajaca informacje o odwiedzonych wierzchołkach, aby zredukować ilość potrzebnej pamięci, a co najważniejsze ograniczyć komunikację pomiędzy watkami Każdy watek przechwuje wektor bitów bitmap[v] - bit ustawiony jest na 1 jeśli wierzchołek jest odwiedzony Po każdym poziomie informacje w bitmapie sa wymieniane pomiędzy watkami użycie tablicowych buforów danych (ważne ze względu na specyfikę biblioteki PCJ, która wspiera wysyłanie tablic po indeksach), co pozwala na zminimalizowanie narzutu zwiazanego z rozpoczęciem komunikacji (zamiast przesyłać pojedynczy wierzchołek, każdy watek grupuje kilka wiadomości) nakładanie komunikacji i obliczeń, poprzez wykonywanie niezależnych procedur np. VISIT-VERTICES w trakcie oczekiwania na zakończenie komunikacji - watek przetwarza dane, które już otrzymał (PCJ.waitFor("variable",0) - zwraca liczbę otrzymanych danych)
171 Graph500 w PGAS i PCJ - Kernel 2 Aby przyspieszyć działanie zastosowano kilka optymalizacji: bitmapa, zawierajaca informacje o odwiedzonych wierzchołkach, aby zredukować ilość potrzebnej pamięci, a co najważniejsze ograniczyć komunikację pomiędzy watkami Każdy watek przechwuje wektor bitów bitmap[v] - bit ustawiony jest na 1 jeśli wierzchołek jest odwiedzony Po każdym poziomie informacje w bitmapie sa wymieniane pomiędzy watkami użycie tablicowych buforów danych (ważne ze względu na specyfikę biblioteki PCJ, która wspiera wysyłanie tablic po indeksach), co pozwala na zminimalizowanie narzutu zwiazanego z rozpoczęciem komunikacji (zamiast przesyłać pojedynczy wierzchołek, każdy watek grupuje kilka wiadomości) nakładanie komunikacji i obliczeń, poprzez wykonywanie niezależnych procedur np. VISIT-VERTICES w trakcie oczekiwania na zakończenie komunikacji - watek przetwarza dane, które już otrzymał (PCJ.waitFor("variable",0) - zwraca liczbę otrzymanych danych)
172 Graph500 w PGAS i PCJ - Kernel 2 Aby przyspieszyć działanie zastosowano kilka optymalizacji: bitmapa, zawierajaca informacje o odwiedzonych wierzchołkach, aby zredukować ilość potrzebnej pamięci, a co najważniejsze ograniczyć komunikację pomiędzy watkami Każdy watek przechwuje wektor bitów bitmap[v] - bit ustawiony jest na 1 jeśli wierzchołek jest odwiedzony Po każdym poziomie informacje w bitmapie sa wymieniane pomiędzy watkami użycie tablicowych buforów danych (ważne ze względu na specyfikę biblioteki PCJ, która wspiera wysyłanie tablic po indeksach), co pozwala na zminimalizowanie narzutu zwiazanego z rozpoczęciem komunikacji (zamiast przesyłać pojedynczy wierzchołek, każdy watek grupuje kilka wiadomości) nakładanie komunikacji i obliczeń, poprzez wykonywanie niezależnych procedur np. VISIT-VERTICES w trakcie oczekiwania na zakończenie komunikacji - watek przetwarza dane, które już otrzymał (PCJ.waitFor("variable",0) - zwraca liczbę otrzymanych danych)
173 Graph500 w PGAS i PCJ - Kernel 2 Aby przyspieszyć działanie zastosowano kilka optymalizacji: bitmapa, zawierajaca informacje o odwiedzonych wierzchołkach, aby zredukować ilość potrzebnej pamięci, a co najważniejsze ograniczyć komunikację pomiędzy watkami Każdy watek przechwuje wektor bitów bitmap[v] - bit ustawiony jest na 1 jeśli wierzchołek jest odwiedzony Po każdym poziomie informacje w bitmapie sa wymieniane pomiędzy watkami użycie tablicowych buforów danych (ważne ze względu na specyfikę biblioteki PCJ, która wspiera wysyłanie tablic po indeksach), co pozwala na zminimalizowanie narzutu zwiazanego z rozpoczęciem komunikacji (zamiast przesyłać pojedynczy wierzchołek, każdy watek grupuje kilka wiadomości) nakładanie komunikacji i obliczeń, poprzez wykonywanie niezależnych procedur np. VISIT-VERTICES w trakcie oczekiwania na zakończenie komunikacji - watek przetwarza dane, które już otrzymał (PCJ.waitFor("variable",0) - zwraca liczbę otrzymanych danych)
174 Graph500 w PGAS i PCJ - Kernel 2 Aby przyspieszyć działanie zastosowano kilka optymalizacji: bitmapa, zawierajaca informacje o odwiedzonych wierzchołkach, aby zredukować ilość potrzebnej pamięci, a co najważniejsze ograniczyć komunikację pomiędzy watkami Każdy watek przechwuje wektor bitów bitmap[v] - bit ustawiony jest na 1 jeśli wierzchołek jest odwiedzony Po każdym poziomie informacje w bitmapie sa wymieniane pomiędzy watkami użycie tablicowych buforów danych (ważne ze względu na specyfikę biblioteki PCJ, która wspiera wysyłanie tablic po indeksach), co pozwala na zminimalizowanie narzutu zwiazanego z rozpoczęciem komunikacji (zamiast przesyłać pojedynczy wierzchołek, każdy watek grupuje kilka wiadomości) nakładanie komunikacji i obliczeń, poprzez wykonywanie niezależnych procedur np. VISIT-VERTICES w trakcie oczekiwania na zakończenie komunikacji - watek przetwarza dane, które już otrzymał (PCJ.waitFor("variable",0) - zwraca liczbę otrzymanych danych)
175 Graph500 w PGAS i PCJ - Kernel 2 Algorithm BFS pseudocode. Input: Graph G(V, E) in the form of CSR distributed by blocks between processors, source vertex s V Output: Array of predecessors (pred) in the BFS outcome tree rooted at s

176 Graph500 w PGAS i PCJ - Kernel 2
177 Graph500 w PGAS i PCJ - Kernel 2

178 Graph500 w PGAS i PCJ - Kernel 2
179 Graph500 w PGAS i PCJ - Dane testowe Dane testowe: Generator Grafów Kroneckera benchmarku Graph 500 (grafy w postaci listy krawędzi) Testy przeprowadzono na grafach o rozmiarach: edgefactor = 16 SCALE {25,26,27,28,29,30} SCALE - logarytm o podstawie 2 z ilości wierzchołków edgefactor - stosunek liczby krawędzi grafu do liczny wierzchołków liczba wierzchołków N = 2 SCALE liczba krawędzi M = edgefactor N
180 Graph500 w PGAS i PCJ - Środowisko testowe klaster Hydra - obliczenia wykonywane były na wezłach: Istanbul - 96 wezłów z dwoma 6-rdzeniowymi procesorami AMD Opteron(tm) Processor GHz oraz z 32 GB pamięci RAM oraz łaczem Infiniband DDR + 1Gb Ethernet Interlagos - 16 wezłów z czterema 16-rdzeniowymi procesorami AMD Opteron(TM) Processor GHz oraz z 512 GB pamięci RAM oraz łaczem 10Gb Ethernet Magnycours - 30 węzłów z czterema 12-rdzeniowymi procesorami AMD Opteron(TM) Processor GHz oraz z 256 GB pamięci oraz łaczem 10Gb Ethernet
181 Graph500 w PGAS i PCJ - Środowisko testowe klaster Hydra - obliczenia wykonywane były na wezłach: Istanbul - 96 wezłów z dwoma 6-rdzeniowymi procesorami AMD Opteron(tm) Processor GHz oraz z 32 GB pamięci RAM oraz łaczem Infiniband DDR + 1Gb Ethernet Interlagos - 16 wezłów z czterema 16-rdzeniowymi procesorami AMD Opteron(TM) Processor GHz oraz z 512 GB pamięci RAM oraz łaczem 10Gb Ethernet Magnycours - 30 węzłów z czterema 12-rdzeniowymi procesorami AMD Opteron(TM) Processor GHz oraz z 256 GB pamięci oraz łaczem 10Gb Ethernet
182 Graph500 w PGAS i PCJ - Środowisko testowe klaster Hydra - obliczenia wykonywane były na wezłach: Istanbul - 96 wezłów z dwoma 6-rdzeniowymi procesorami AMD Opteron(tm) Processor GHz oraz z 32 GB pamięci RAM oraz łaczem Infiniband DDR + 1Gb Ethernet Interlagos - 16 wezłów z czterema 16-rdzeniowymi procesorami AMD Opteron(TM) Processor GHz oraz z 512 GB pamięci RAM oraz łaczem 10Gb Ethernet Magnycours - 30 węzłów z czterema 12-rdzeniowymi procesorami AMD Opteron(TM) Processor GHz oraz z 256 GB pamięci oraz łaczem 10Gb Ethernet
183 Graph500 w PGAS i PCJ - Środowisko testowe klaster Hydra - obliczenia wykonywane były na wezłach: Istanbul - 96 wezłów z dwoma 6-rdzeniowymi procesorami AMD Opteron(tm) Processor GHz oraz z 32 GB pamięci RAM oraz łaczem Infiniband DDR + 1Gb Ethernet Interlagos - 16 wezłów z czterema 16-rdzeniowymi procesorami AMD Opteron(TM) Processor GHz oraz z 512 GB pamięci RAM oraz łaczem 10Gb Ethernet Magnycours - 30 węzłów z czterema 12-rdzeniowymi procesorami AMD Opteron(TM) Processor GHz oraz z 256 GB pamięci oraz łaczem 10Gb Ethernet
184 Graph500 w PGAS i PCJ - Środowisko testowe klaster Topola: węzły haswell z dwoma 14-rdzeniowymi procesorami Intel(R) Xeon(R) CPU E v3 o taktowaniu 2.1GHz z AVX2, do 3.0GHz oraz łaczem Infiniband FDR + 1Gb Ethernet, 60 węzłów z pamięcia RAM 128GB oraz 163 węzły zpamięcia RAM 64GB klaster Okeanos 1084 wezłów obliczeniowych z dwoma 24-rdzeniowymi procesorami Intel Xeon CPU E v3 2.6 GHz oraz z 128 GB pamięci RAM. Każdy węzeł posiada dedykowane porty komunikacji Cray Aries, a wszystkie węzły połaczone sa wysokowydajna siecia o topologii Dragonfly (testowany w ramach programu Early Science)
185 Graph500 w PGAS i PCJ - Środowisko testowe klaster Topola: węzły haswell z dwoma 14-rdzeniowymi procesorami Intel(R) Xeon(R) CPU E v3 o taktowaniu 2.1GHz z AVX2, do 3.0GHz oraz łaczem Infiniband FDR + 1Gb Ethernet, 60 węzłów z pamięcia RAM 128GB oraz 163 węzły zpamięcia RAM 64GB klaster Okeanos 1084 wezłów obliczeniowych z dwoma 24-rdzeniowymi procesorami Intel Xeon CPU E v3 2.6 GHz oraz z 128 GB pamięci RAM. Każdy węzeł posiada dedykowane porty komunikacji Cray Aries, a wszystkie węzły połaczone sa wysokowydajna siecia o topologii Dragonfly (testowany w ramach programu Early Science)
186 Graph500 w PGAS i PCJ - Środowisko testowe klaster Topola: węzły haswell z dwoma 14-rdzeniowymi procesorami Intel(R) Xeon(R) CPU E v3 o taktowaniu 2.1GHz z AVX2, do 3.0GHz oraz łaczem Infiniband FDR + 1Gb Ethernet, 60 węzłów z pamięcia RAM 128GB oraz 163 węzły zpamięcia RAM 64GB klaster Okeanos 1084 wezłów obliczeniowych z dwoma 24-rdzeniowymi procesorami Intel Xeon CPU E v3 2.6 GHz oraz z 128 GB pamięci RAM. Każdy węzeł posiada dedykowane porty komunikacji Cray Aries, a wszystkie węzły połaczone sa wysokowydajna siecia o topologii Dragonfly (testowany w ramach programu Early Science)
187 Graph500 w PGAS i PCJ - Środowisko testowe klaster Topola: węzły haswell z dwoma 14-rdzeniowymi procesorami Intel(R) Xeon(R) CPU E v3 o taktowaniu 2.1GHz z AVX2, do 3.0GHz oraz łaczem Infiniband FDR + 1Gb Ethernet, 60 węzłów z pamięcia RAM 128GB oraz 163 węzły zpamięcia RAM 64GB klaster Okeanos 1084 wezłów obliczeniowych z dwoma 24-rdzeniowymi procesorami Intel Xeon CPU E v3 2.6 GHz oraz z 128 GB pamięci RAM. Każdy węzeł posiada dedykowane porty komunikacji Cray Aries, a wszystkie węzły połaczone sa wysokowydajna siecia o topologii Dragonfly (testowany w ramach programu Early Science)
188 Graph500 w PGAS i PCJ - Środowisko testowe Do testów użyto 64-bitowa Wirtualna Maszynę Javy Oracle (Java 8) oraz OpenMPI w wersji Testy przeprowadzone były przy różnych ilościach procesów na węzeł (ozn. pn - per node) ze względu na znaczne wymagania pamięciowe obliczeń. Wydajność algorytmu oprócz czasu wykonania była mierzona przy użyciu wskaźnika TEPS (Traversed Edges per Second).
189 Graph500 w PGAS i PCJ - Środowisko testowe Do testów użyto 64-bitowa Wirtualna Maszynę Javy Oracle (Java 8) oraz OpenMPI w wersji Testy przeprowadzone były przy różnych ilościach procesów na węzeł (ozn. pn - per node) ze względu na znaczne wymagania pamięciowe obliczeń. Wydajność algorytmu oprócz czasu wykonania była mierzona przy użyciu wskaźnika TEPS (Traversed Edges per Second).
190 Graph500 w PGAS i PCJ - Środowisko testowe Do testów użyto 64-bitowa Wirtualna Maszynę Javy Oracle (Java 8) oraz OpenMPI w wersji Testy przeprowadzone były przy różnych ilościach procesów na węzeł (ozn. pn - per node) ze względu na znaczne wymagania pamięciowe obliczeń. Wydajność algorytmu oprócz czasu wykonania była mierzona przy użyciu wskaźnika TEPS (Traversed Edges per Second).
191 Graph500 w PGAS i PCJ - Kernel 1 Całkowity czas wykonania Kernela 1 razem z wydajnościa TEPS dla grafów SCALE 25 oraz 26 (Topola).
192 Graph500 w PGAS i PCJ - Kernel 2
193 Graph500 w PGAS i PCJ - Kernel 2 Implementacja w Javie przy użyciu PCJ ma podobna wydajność i skalowalność co implementacja MPI w C.
194 Graph500 w PGAS i PCJ - Kernel 2 Przyspieszenie jest liniowe do 32 watków i jest niezależne od ilości watków na pojedynczym węźle.
195 Graph500 w PGAS i PCJ - Kernel 2 Wyniki dla większej liczby węzłów, pogarszaja się co wynika z przewagi czasu poświęconego na komunikację w stosunku do czasu obliczeń (najlepsze rezultaty uzyskano dla węzłów z połaczeniem Infiniband) (dużo lepsze wyniki uzyskano dla klastra Okeanos).
196 Graph500 w PGAS i PCJ - Kernel 2 Przy badaniu wydajności algorytm podzielono na cztery części: część 1 - inicjalizacja struktur danych, przetworzenie wszystkich wierzchołków w obecnym poziomie oraz wysłanie danych do innych watków część 2 - oczekiwanie na dane i przeprocesowanie odebranych danych część 3 - redukcja i rozgłoszenie oraz oczekiwanie na wiadomość dotyczac a obliczenia kolejnego poziomu część 4 - powtórna inicjalizacja danych oraz komunikacja all-to-all - wymiana bitmapy
197 Graph500 w PGAS i PCJ - Kernel 2 Przy badaniu wydajności algorytm podzielono na cztery części: część 1 - inicjalizacja struktur danych, przetworzenie wszystkich wierzchołków w obecnym poziomie oraz wysłanie danych do innych watków część 2 - oczekiwanie na dane i przeprocesowanie odebranych danych część 3 - redukcja i rozgłoszenie oraz oczekiwanie na wiadomość dotyczac a obliczenia kolejnego poziomu część 4 - powtórna inicjalizacja danych oraz komunikacja all-to-all - wymiana bitmapy
198 Graph500 w PGAS i PCJ - Kernel 2 Przy badaniu wydajności algorytm podzielono na cztery części: część 1 - inicjalizacja struktur danych, przetworzenie wszystkich wierzchołków w obecnym poziomie oraz wysłanie danych do innych watków część 2 - oczekiwanie na dane i przeprocesowanie odebranych danych część 3 - redukcja i rozgłoszenie oraz oczekiwanie na wiadomość dotyczac a obliczenia kolejnego poziomu część 4 - powtórna inicjalizacja danych oraz komunikacja all-to-all - wymiana bitmapy
199 Graph500 w PGAS i PCJ - Kernel 2 Przy badaniu wydajności algorytm podzielono na cztery części: część 1 - inicjalizacja struktur danych, przetworzenie wszystkich wierzchołków w obecnym poziomie oraz wysłanie danych do innych watków część 2 - oczekiwanie na dane i przeprocesowanie odebranych danych część 3 - redukcja i rozgłoszenie oraz oczekiwanie na wiadomość dotyczac a obliczenia kolejnego poziomu część 4 - powtórna inicjalizacja danych oraz komunikacja all-to-all - wymiana bitmapy
200 Graph500 w PGAS i PCJ - Kernel 2 Przy badaniu wydajności algorytm podzielono na cztery części: część 1 - inicjalizacja struktur danych, przetworzenie wszystkich wierzchołków w obecnym poziomie oraz wysłanie danych do innych watków część 2 - oczekiwanie na dane i przeprocesowanie odebranych danych część 3 - redukcja i rozgłoszenie oraz oczekiwanie na wiadomość dotyczac a obliczenia kolejnego poziomu część 4 - powtórna inicjalizacja danych oraz komunikacja all-to-all - wymiana bitmapy
201 Graph500 w PGAS i PCJ - Kernel 2 Procentowy czas wykonania algorytmu BFS dla grafu Scale 26 dla PCJ na węzłach istanbul i okeanos.

202 Graph500 w PGAS i PCJ - Kernel 2 Procentowy czas wykonania algorytmu BFS dla grafu Scale 26 dla PCJ na węzłach istanbul i okeanos.
Jak ujarzmić hydrę czyli programowanie równoległe w Javie. dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski
 Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery
 http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
RECENZJA ROZPRAWY DOKTORSKIEJ
 Częstochowa, dn. 5.08.2018 Prof. dr hab. inż. Roman Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska ul. Dąbrowskiego 69 42-201 Częstochowa RECENZJA ROZPRAWY DOKTORSKIEJ
Częstochowa, dn. 5.08.2018 Prof. dr hab. inż. Roman Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska ul. Dąbrowskiego 69 42-201 Częstochowa RECENZJA ROZPRAWY DOKTORSKIEJ
61 Topologie wirtualne
 61 Topologie wirtualne pozwalają opisać dystrybucję procesów w przestrzeni z uwzględnieniem struktury komunikowania się procesów aplikacji między sobą, umożliwiają łatwą odpowiedź na pytanie: kto jest
61 Topologie wirtualne pozwalają opisać dystrybucję procesów w przestrzeni z uwzględnieniem struktury komunikowania się procesów aplikacji między sobą, umożliwiają łatwą odpowiedź na pytanie: kto jest
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Grafem nazywamy strukturę G = (V, E): V zbiór węzłów lub wierzchołków, Grafy dzielimy na grafy skierowane i nieskierowane:
: V zbiór węzłów lub wierzchołków, Grafy dzielimy na grafy skierowane i nieskierowane:") Wykład 4 grafy Grafem nazywamy strukturę G = (V, E): V zbiór węzłów lub wierzchołków, E zbiór krawędzi, Grafy dzielimy na grafy skierowane i nieskierowane: Formalnie, w grafach skierowanych E jest podzbiorem
Wykład 4 grafy Grafem nazywamy strukturę G = (V, E): V zbiór węzłów lub wierzchołków, E zbiór krawędzi, Grafy dzielimy na grafy skierowane i nieskierowane: Formalnie, w grafach skierowanych E jest podzbiorem
Reprezentacje grafów nieskierowanych Reprezentacje grafów skierowanych. Wykład 2. Reprezentacja komputerowa grafów
 Wykład 2. Reprezentacja komputerowa grafów 1 / 69 Macierz incydencji Niech graf G będzie grafem nieskierowanym bez pętli o n wierzchołkach (x 1, x 2,..., x n) i m krawędziach (e 1, e 2,..., e m). 2 / 69
Wykład 2. Reprezentacja komputerowa grafów 1 / 69 Macierz incydencji Niech graf G będzie grafem nieskierowanym bez pętli o n wierzchołkach (x 1, x 2,..., x n) i m krawędziach (e 1, e 2,..., e m). 2 / 69
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
AiSD zadanie trzecie
 AiSD zadanie trzecie Gliwiński Jarosław Marek Kruczyński Konrad Marek Grupa dziekańska I5 5 czerwca 2008 1 Wstęp Celem postawionym przez zadanie trzecie było tzw. sortowanie topologiczne. Jest to typ sortowania
AiSD zadanie trzecie Gliwiński Jarosław Marek Kruczyński Konrad Marek Grupa dziekańska I5 5 czerwca 2008 1 Wstęp Celem postawionym przez zadanie trzecie było tzw. sortowanie topologiczne. Jest to typ sortowania
Zadania badawcze prowadzone przez Zakład Technik Programowania:
 Zadania badawcze prowadzone przez Zakład Technik Programowania: - Opracowanie metod zrównoleglania programów sekwencyjnych o rozszerzonym zakresie stosowalności. - Opracowanie algorytmów obliczenia tranzytywnego
Zadania badawcze prowadzone przez Zakład Technik Programowania: - Opracowanie metod zrównoleglania programów sekwencyjnych o rozszerzonym zakresie stosowalności. - Opracowanie algorytmów obliczenia tranzytywnego
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
Programowanie obiektowe zastosowanie języka Java SE
 Programowanie obiektowe zastosowanie języka Java SE Wstęp do programowania obiektowego w Javie Autor: dr inŝ. 1 Java? Java język programowania obiektowo zorientowany wysokiego poziomu platforma Javy z
Programowanie obiektowe zastosowanie języka Java SE Wstęp do programowania obiektowego w Javie Autor: dr inŝ. 1 Java? Java język programowania obiektowo zorientowany wysokiego poziomu platforma Javy z
Wprowadzenie do programowania współbieżnego
 Wprowadzenie do programowania współbieżnego Marcin Engel Instytut Informatyki Uniwersytet Warszawski Zamiast wstępu... Zamiast wstępu... Możliwość wykonywania wielu akcji jednocześnie może ułatwić tworzenie
Wprowadzenie do programowania współbieżnego Marcin Engel Instytut Informatyki Uniwersytet Warszawski Zamiast wstępu... Zamiast wstępu... Możliwość wykonywania wielu akcji jednocześnie może ułatwić tworzenie
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Częstochowa, dn
 Częstochowa, dn. 19.10.2017 Prof. dr hab. inż. Roman Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska ul. Dąbrowskiego 69 42-201 Częstochowa RECENZJA ROZPRAWY DOKTORSKIEJ
Częstochowa, dn. 19.10.2017 Prof. dr hab. inż. Roman Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska ul. Dąbrowskiego 69 42-201 Częstochowa RECENZJA ROZPRAWY DOKTORSKIEJ
Programowanie obiektowe
 Programowanie obiektowe Sieci powiązań Paweł Daniluk Wydział Fizyki Jesień 2015 P. Daniluk (Wydział Fizyki) PO w. IX Jesień 2015 1 / 21 Sieci powiązań Można (bardzo zgrubnie) wyróżnić dwa rodzaje powiązań
Programowanie obiektowe Sieci powiązań Paweł Daniluk Wydział Fizyki Jesień 2015 P. Daniluk (Wydział Fizyki) PO w. IX Jesień 2015 1 / 21 Sieci powiązań Można (bardzo zgrubnie) wyróżnić dwa rodzaje powiązań
Porównanie algorytmów wyszukiwania najkrótszych ścieżek międz. grafu. Daniel Golubiewski. 22 listopada Instytut Informatyki
 Porównanie algorytmów wyszukiwania najkrótszych ścieżek między wierzchołkami grafu. Instytut Informatyki 22 listopada 2015 Algorytm DFS w głąb Algorytm przejścia/przeszukiwania w głąb (ang. Depth First
Porównanie algorytmów wyszukiwania najkrótszych ścieżek między wierzchołkami grafu. Instytut Informatyki 22 listopada 2015 Algorytm DFS w głąb Algorytm przejścia/przeszukiwania w głąb (ang. Depth First
2 WRZEŚNIA S t r o n a WROCŁAW
 2 WRZEŚNIA 2016 1 S t r o n a WROCŁAW Materiały konferencyjne Innowacyjne Projekty Badawcze Wrocław 2 września 2016 2 S t r o n a Skład i łamanie tekstu mgr inż. Anna Okniańska Projekt okładki inż. Magdalena
2 WRZEŚNIA 2016 1 S t r o n a WROCŁAW Materiały konferencyjne Innowacyjne Projekty Badawcze Wrocław 2 września 2016 2 S t r o n a Skład i łamanie tekstu mgr inż. Anna Okniańska Projekt okładki inż. Magdalena
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami
 Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
RECENZJA ROZPRAWY DOKTORSKIEJ DLA INSTYTUTU PODSTAW INFORMATYKI POLSKIEJ AKADEMII NAUK
 dr hab. inż. Paweł Czarnul Katedra Architektury Systemów Komputerowych Wydział Elektroniki, Telekomunikacji i Informatyki Politechnika Gdańska Gdańsk, 17 lipca 2017 RECENZJA ROZPRAWY DOKTORSKIEJ DLA INSTYTUTU
dr hab. inż. Paweł Czarnul Katedra Architektury Systemów Komputerowych Wydział Elektroniki, Telekomunikacji i Informatyki Politechnika Gdańska Gdańsk, 17 lipca 2017 RECENZJA ROZPRAWY DOKTORSKIEJ DLA INSTYTUTU
Programowanie obiektowe. Literatura: Autor: dr inŝ. Zofia Kruczkiewicz
 Programowanie obiektowe Literatura: Autor: dr inŝ. Zofia Kruczkiewicz Java P. L. Lemay, Naughton R. Cadenhead Java Podręcznik 2 dla kaŝdego Języka Programowania Java Linki Krzysztof Boone oprogramowania
Programowanie obiektowe Literatura: Autor: dr inŝ. Zofia Kruczkiewicz Java P. L. Lemay, Naughton R. Cadenhead Java Podręcznik 2 dla kaŝdego Języka Programowania Java Linki Krzysztof Boone oprogramowania
Przykłady grafów. Graf prosty, to graf bez pętli i bez krawędzi wielokrotnych.
 Grafy Graf Graf (ang. graph) to zbiór wierzchołków (ang. vertices), które mogą być połączone krawędziami (ang. edges) w taki sposób, że każda krawędź kończy się i zaczyna w którymś z wierzchołków. Graf
Grafy Graf Graf (ang. graph) to zbiór wierzchołków (ang. vertices), które mogą być połączone krawędziami (ang. edges) w taki sposób, że każda krawędź kończy się i zaczyna w którymś z wierzchołków. Graf
Biblioteka PCJ w wybranych zastosowaniach matematycznych - FFT i grafy Kroneckera
 Biblioteka PCJ w wybranych zastosowaniach matematycznych - FFT i grafy Kroneckera Toruńska Studencka Konferencja Matematyki Stosowanej M. Ryczkowska, Ł. Górski, M. Nowicki, P. Bała Uniwersytet Mikołaja
Biblioteka PCJ w wybranych zastosowaniach matematycznych - FFT i grafy Kroneckera Toruńska Studencka Konferencja Matematyki Stosowanej M. Ryczkowska, Ł. Górski, M. Nowicki, P. Bała Uniwersytet Mikołaja
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Automatyzacja procesu tworzenia sprzętowego narzędzia służącego do rozwiązywania zagadnienia logarytmu dyskretnego na krzywych eliptycznych
 Automatyzacja procesu tworzenia sprzętowego narzędzia służącego do rozwiązywania zagadnienia logarytmu dyskretnego na krzywych eliptycznych Autor: Piotr Majkowski Pod opieką: prof. Zbigniew Kotulski Politechnika
Automatyzacja procesu tworzenia sprzętowego narzędzia służącego do rozwiązywania zagadnienia logarytmu dyskretnego na krzywych eliptycznych Autor: Piotr Majkowski Pod opieką: prof. Zbigniew Kotulski Politechnika
Ogólne wiadomości o grafach
 Ogólne wiadomości o grafach Algorytmy i struktury danych Wykład 5. Rok akademicki: / Pojęcie grafu Graf zbiór wierzchołków połączonych za pomocą krawędzi. Podstawowe rodzaje grafów: grafy nieskierowane,
Ogólne wiadomości o grafach Algorytmy i struktury danych Wykład 5. Rok akademicki: / Pojęcie grafu Graf zbiór wierzchołków połączonych za pomocą krawędzi. Podstawowe rodzaje grafów: grafy nieskierowane,
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Pojęcie bazy danych. Funkcje i możliwości.
 Pojęcie bazy danych. Funkcje i możliwości. Pojęcie bazy danych Baza danych to: zbiór informacji zapisanych według ściśle określonych reguł, w strukturach odpowiadających założonemu modelowi danych, zbiór
Pojęcie bazy danych. Funkcje i możliwości. Pojęcie bazy danych Baza danych to: zbiór informacji zapisanych według ściśle określonych reguł, w strukturach odpowiadających założonemu modelowi danych, zbiór
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Programowanie Rozproszone i Równoległe. Edward Görlich http://th.if.uj.edu.pl/~gorlich goerlich@th.if.uj.edu.pl
 Programowanie Rozproszone i Równoległe Edward Görlich http://th.if.uj.edu.pl/~gorlich goerlich@th.if.uj.edu.pl Motywacja wyboru Programowanie rozproszone równoległość (wymuszona) Oprogramowanie równoległe/rozproszone:
Programowanie Rozproszone i Równoległe Edward Görlich http://th.if.uj.edu.pl/~gorlich goerlich@th.if.uj.edu.pl Motywacja wyboru Programowanie rozproszone równoległość (wymuszona) Oprogramowanie równoległe/rozproszone:
Wykład Ćwiczenia Laboratorium Projekt Seminarium
 WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
Struktury danych i złożoność obliczeniowa Wykład 5. Prof. dr hab. inż. Jan Magott
 Struktury danych i złożoność obliczeniowa Wykład. Prof. dr hab. inż. Jan Magott Algorytmy grafowe: podstawowe pojęcia, reprezentacja grafów, metody przeszukiwania, minimalne drzewa rozpinające, problemy
Struktury danych i złożoność obliczeniowa Wykład. Prof. dr hab. inż. Jan Magott Algorytmy grafowe: podstawowe pojęcia, reprezentacja grafów, metody przeszukiwania, minimalne drzewa rozpinające, problemy
Zagadnienia egzaminacyjne INFORMATYKA. Stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Algorytmy równoległe. Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2010
 Algorytmy równoległe Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka Znajdowanie maksimum w zbiorze n liczb węzły - maksimum liczb głębokość = 3 praca = 4++ = 7 (operacji) n - liczność
Algorytmy równoległe Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka Znajdowanie maksimum w zbiorze n liczb węzły - maksimum liczb głębokość = 3 praca = 4++ = 7 (operacji) n - liczność
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Prof. dr hab. inż. Zbigniew J. Czech Gliwice 25 lipiec 2018 r. Politechnika Śląska Instytut Informatyki
 Prof. dr hab. inż. Zbigniew J. Czech Gliwice 25 lipiec 2018 r. Politechnika Śląska Instytut Informatyki e-mail: zczech@polsl.pl RECENZJA ROZPRAWY DOKTORSKIEJ DLA RADY NAUKOWEJ INSTYTUTU PODSTAW INFORMATYKI
Prof. dr hab. inż. Zbigniew J. Czech Gliwice 25 lipiec 2018 r. Politechnika Śląska Instytut Informatyki e-mail: zczech@polsl.pl RECENZJA ROZPRAWY DOKTORSKIEJ DLA RADY NAUKOWEJ INSTYTUTU PODSTAW INFORMATYKI
Spis treści. I. Skuteczne. Od autora... Obliczenia inżynierskie i naukowe... Ostrzeżenia...XVII
 Spis treści Od autora..................................................... Obliczenia inżynierskie i naukowe.................................. X XII Ostrzeżenia...................................................XVII
Spis treści Od autora..................................................... Obliczenia inżynierskie i naukowe.................................. X XII Ostrzeżenia...................................................XVII
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Dariusz Brzeziński. Politechnika Poznańska, Instytut Informatyki
 Dariusz Brzeziński Politechnika Poznańska, Instytut Informatyki Język programowania prosty bezpieczny zorientowany obiektowo wielowątkowy rozproszony przenaszalny interpretowany dynamiczny wydajny Platforma
Dariusz Brzeziński Politechnika Poznańska, Instytut Informatyki Język programowania prosty bezpieczny zorientowany obiektowo wielowątkowy rozproszony przenaszalny interpretowany dynamiczny wydajny Platforma
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Kryptografia na procesorach wielordzeniowych
 Kryptografia na procesorach wielordzeniowych Andrzej Chmielowiec andrzej.chmielowiec@cmmsigma.eu Centrum Modelowania Matematycznego Sigma Kryptografia na procesorach wielordzeniowych p. 1 Plan prezentacji
Kryptografia na procesorach wielordzeniowych Andrzej Chmielowiec andrzej.chmielowiec@cmmsigma.eu Centrum Modelowania Matematycznego Sigma Kryptografia na procesorach wielordzeniowych p. 1 Plan prezentacji
Efekt kształcenia. Ma uporządkowaną, podbudowaną teoretycznie wiedzę ogólną w zakresie algorytmów i ich złożoności obliczeniowej.
 Efekty dla studiów pierwszego stopnia profil ogólnoakademicki na kierunku Informatyka w języku polskim i w języku angielskim (Computer Science) na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie-
Efekty dla studiów pierwszego stopnia profil ogólnoakademicki na kierunku Informatyka w języku polskim i w języku angielskim (Computer Science) na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie-
Efektywność algorytmów
 Efektywność algorytmów Algorytmika Algorytmika to dział informatyki zajmujący się poszukiwaniem, konstruowaniem i badaniem własności algorytmów, w kontekście ich przydatności do rozwiązywania problemów
Efektywność algorytmów Algorytmika Algorytmika to dział informatyki zajmujący się poszukiwaniem, konstruowaniem i badaniem własności algorytmów, w kontekście ich przydatności do rozwiązywania problemów
Programowanie Strukturalne i Obiektowe Słownik podstawowych pojęć 1 z 5 Opracował Jan T. Biernat
 Programowanie Strukturalne i Obiektowe Słownik podstawowych pojęć 1 z 5 Program, to lista poleceń zapisana w jednym języku programowania zgodnie z obowiązującymi w nim zasadami. Celem programu jest przetwarzanie
Programowanie Strukturalne i Obiektowe Słownik podstawowych pojęć 1 z 5 Program, to lista poleceń zapisana w jednym języku programowania zgodnie z obowiązującymi w nim zasadami. Celem programu jest przetwarzanie
Programowanie komputerów
 Programowanie komputerów Wykład 1-2. Podstawowe pojęcia Plan wykładu Omówienie programu wykładów, laboratoriów oraz egzaminu Etapy rozwiązywania problemów dr Helena Dudycz Katedra Technologii Informacyjnych
Programowanie komputerów Wykład 1-2. Podstawowe pojęcia Plan wykładu Omówienie programu wykładów, laboratoriów oraz egzaminu Etapy rozwiązywania problemów dr Helena Dudycz Katedra Technologii Informacyjnych
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych
 Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1.
 Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Programowanie obiektowe
 Programowanie obiektowe Sieci powiązań Paweł Daniluk Wydział Fizyki Jesień 2014 P. Daniluk (Wydział Fizyki) PO w. IX Jesień 2014 1 / 24 Sieci powiązań Można (bardzo zgrubnie) wyróżnić dwa rodzaje powiązań
Programowanie obiektowe Sieci powiązań Paweł Daniluk Wydział Fizyki Jesień 2014 P. Daniluk (Wydział Fizyki) PO w. IX Jesień 2014 1 / 24 Sieci powiązań Można (bardzo zgrubnie) wyróżnić dwa rodzaje powiązań
Klaster obliczeniowy
 Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
a) 7 b) 19 c) 21 d) 34
 7 b) 19 c) 21 d) 34") Zadanie 1. Pytania testowe dotyczące podstawowych własności grafów. Zadanie 2. Przy każdym z zadań może się pojawić polecenie krótkiej charakterystyki algorytmu. Zadanie 3. W zadanym grafie sprawdzenie
Zadanie 1. Pytania testowe dotyczące podstawowych własności grafów. Zadanie 2. Przy każdym z zadań może się pojawić polecenie krótkiej charakterystyki algorytmu. Zadanie 3. W zadanym grafie sprawdzenie
5. Model komunikujących się procesów, komunikaty
 Jędrzej Ułasiewicz str. 1 5. Model komunikujących się procesów, komunikaty Obecnie stosuje się następujące modele przetwarzania: Model procesów i komunikatów Model procesów komunikujących się poprzez pamięć
Jędrzej Ułasiewicz str. 1 5. Model komunikujących się procesów, komunikaty Obecnie stosuje się następujące modele przetwarzania: Model procesów i komunikatów Model procesów komunikujących się poprzez pamięć
Historia modeli programowania
 Języki Programowania na Platformie.NET http://kaims.eti.pg.edu.pl/ goluch/ goluch@eti.pg.edu.pl Maszyny z wbudowanym oprogramowaniem Maszyny z wbudowanym oprogramowaniem automatyczne rozwiązywanie problemu
Języki Programowania na Platformie.NET http://kaims.eti.pg.edu.pl/ goluch/ goluch@eti.pg.edu.pl Maszyny z wbudowanym oprogramowaniem Maszyny z wbudowanym oprogramowaniem automatyczne rozwiązywanie problemu
Metody optymalizacji soft-procesorów NIOS
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
Algorytmy grafowe. Wykład 1 Podstawy teorii grafów Reprezentacje grafów. Tomasz Tyksiński CDV
 Algorytmy grafowe Wykład 1 Podstawy teorii grafów Reprezentacje grafów Tomasz Tyksiński CDV Rozkład materiału 1. Podstawowe pojęcia teorii grafów, reprezentacje komputerowe grafów 2. Przeszukiwanie grafów
Algorytmy grafowe Wykład 1 Podstawy teorii grafów Reprezentacje grafów Tomasz Tyksiński CDV Rozkład materiału 1. Podstawowe pojęcia teorii grafów, reprezentacje komputerowe grafów 2. Przeszukiwanie grafów
Produktywne tworzenie aplikacji webowych z wykorzystaniem Groovy i
 Program szkolenia: Produktywne tworzenie aplikacji webowych z wykorzystaniem Groovy i Informacje: Nazwa: Kod: Kategoria: Grupa docelowa: Czas trwania: Forma: Produktywne tworzenie aplikacji webowych z
Program szkolenia: Produktywne tworzenie aplikacji webowych z wykorzystaniem Groovy i Informacje: Nazwa: Kod: Kategoria: Grupa docelowa: Czas trwania: Forma: Produktywne tworzenie aplikacji webowych z
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych. Instytut Telekomunikacji Zakład Podstaw Telekomunikacji
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Opiekun naukowy: dr
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Opiekun naukowy: dr
Algorytm. Krótka historia algorytmów
 Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Metody uporządkowania
 Metody uporządkowania W trakcie faktoryzacji macierzy rzadkiej ilość zapełnień istotnie zależy od sposobu numeracji równań. Powstaje problem odnalezienia takiej numeracji, przy której: o ilość zapełnień
Metody uporządkowania W trakcie faktoryzacji macierzy rzadkiej ilość zapełnień istotnie zależy od sposobu numeracji równań. Powstaje problem odnalezienia takiej numeracji, przy której: o ilość zapełnień
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Zarządzanie pamięcią operacyjną
 Dariusz Wawrzyniak Plan wykładu Pamięć jako zasób systemu komputerowego hierarchia pamięci przestrzeń owa Wsparcie dla zarządzania pamięcią na poziomie architektury komputera Podział i przydział pamięci
Dariusz Wawrzyniak Plan wykładu Pamięć jako zasób systemu komputerowego hierarchia pamięci przestrzeń owa Wsparcie dla zarządzania pamięcią na poziomie architektury komputera Podział i przydział pamięci
Definicje. Algorytm to:
 Algorytmy Definicje Algorytm to: skończony ciąg operacji na obiektach, ze ściśle ustalonym porządkiem wykonania, dający możliwość realizacji zadania określonej klasy pewien ciąg czynności, który prowadzi
Algorytmy Definicje Algorytm to: skończony ciąg operacji na obiektach, ze ściśle ustalonym porządkiem wykonania, dający możliwość realizacji zadania określonej klasy pewien ciąg czynności, który prowadzi
Kierunek:Informatyka- - inż., rok I specjalność: Grafika komputerowa
 :Informatyka- - inż., rok I specjalność: Grafika komputerowa Rok akademicki 018/019 Metody uczenia się i studiowania. 1 Podstawy prawne. 1 Podstawy ekonomii. 1 Matematyka dyskretna. 1 30 Wprowadzenie do
:Informatyka- - inż., rok I specjalność: Grafika komputerowa Rok akademicki 018/019 Metody uczenia się i studiowania. 1 Podstawy prawne. 1 Podstawy ekonomii. 1 Matematyka dyskretna. 1 30 Wprowadzenie do
Podstawy i języki programowania
 Podstawy i języki programowania Laboratorium 1 - wprowadzenie do przedmiotu mgr inż. Krzysztof Szwarc krzysztof@szwarc.net.pl Sosnowiec, 16 października 2017 1 / 25 mgr inż. Krzysztof Szwarc Podstawy i
Podstawy i języki programowania Laboratorium 1 - wprowadzenie do przedmiotu mgr inż. Krzysztof Szwarc krzysztof@szwarc.net.pl Sosnowiec, 16 października 2017 1 / 25 mgr inż. Krzysztof Szwarc Podstawy i
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II
 Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Strefa pokrycia radiowego wokół stacji bazowych. Zasięg stacji bazowych Zazębianie się komórek
 Problem zapożyczania kanałów z wykorzystaniem narzędzi optymalizacji Wprowadzenie Rozwiązanie problemu przydziału częstotliwości prowadzi do stanu, w którym każdej stacji bazowej przydzielono żądaną liczbę
Problem zapożyczania kanałów z wykorzystaniem narzędzi optymalizacji Wprowadzenie Rozwiązanie problemu przydziału częstotliwości prowadzi do stanu, w którym każdej stacji bazowej przydzielono żądaną liczbę
Algorytm. Krótka historia algorytmów
 Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
Skalowalna Platforma dla eksperymentów dużej skali typu Data Farming z wykorzystaniem środowisk organizacyjnie rozproszonych
 1 Skalowalna Platforma dla eksperymentów dużej skali typu Data Farming z wykorzystaniem środowisk organizacyjnie rozproszonych D. Król, Ł. Dutka, J. Kitowski ACC Cyfronet AGH Plan prezentacji 2 O nas Wprowadzenie
1 Skalowalna Platforma dla eksperymentów dużej skali typu Data Farming z wykorzystaniem środowisk organizacyjnie rozproszonych D. Król, Ł. Dutka, J. Kitowski ACC Cyfronet AGH Plan prezentacji 2 O nas Wprowadzenie
Model semistrukturalny
 Model semistrukturalny standaryzacja danych z różnych źródeł realizacja złożonej struktury zależności, wielokrotne zagnieżdżania zobrazowane przez grafy skierowane model samoopisujący się wielkości i typy
Model semistrukturalny standaryzacja danych z różnych źródeł realizacja złożonej struktury zależności, wielokrotne zagnieżdżania zobrazowane przez grafy skierowane model samoopisujący się wielkości i typy
Zagadnienia egzaminacyjne INFORMATYKA. stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Informatyka wspomaga przedmioty ścisłe w szkole
 Informatyka wspomaga przedmioty ścisłe w szkole Prezentuje : Dorota Roman - Jurdzińska W arkuszu I na obu poziomach występują dwa zadania związane z algorytmiką: Arkusz I bez komputera analiza algorytmów,
Informatyka wspomaga przedmioty ścisłe w szkole Prezentuje : Dorota Roman - Jurdzińska W arkuszu I na obu poziomach występują dwa zadania związane z algorytmiką: Arkusz I bez komputera analiza algorytmów,
Matematyczne Podstawy Informatyki
 Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 2013/2014 Informacje podstawowe 1. Konsultacje: pokój
Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 2013/2014 Informacje podstawowe 1. Konsultacje: pokój
Zdalne monitorowanie i zarządzanie urządzeniami sieciowymi
 Uniwersytet Mikołaja Kopernika w Toruniu Wydział Matematyki i Informatyki Wydział Fizyki, Astronomii i Infomatyki Stosowanej Piotr Benetkiewicz Nr albumu: 168455 Praca magisterska na kierunku Informatyka
Uniwersytet Mikołaja Kopernika w Toruniu Wydział Matematyki i Informatyki Wydział Fizyki, Astronomii i Infomatyki Stosowanej Piotr Benetkiewicz Nr albumu: 168455 Praca magisterska na kierunku Informatyka
Wprowadzenie. Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra.
 N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
Zapisywanie algorytmów w języku programowania
 Temat C5 Zapisywanie algorytmów w języku programowania Cele edukacyjne Zrozumienie, na czym polega programowanie. Poznanie sposobu zapisu algorytmu w postaci programu komputerowego. Zrozumienie, na czym
Temat C5 Zapisywanie algorytmów w języku programowania Cele edukacyjne Zrozumienie, na czym polega programowanie. Poznanie sposobu zapisu algorytmu w postaci programu komputerowego. Zrozumienie, na czym
Algorytm. Słowo algorytm pochodzi od perskiego matematyka Mohammed ibn Musa al-kowarizimi (Algorismus - łacina) z IX w. ne.
 z IX w. ne.") Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
Struktury systemów operacyjnych
 Struktury systemów operacyjnych Jan Tuziemski Część slajdów to zmodyfiowane slajdy ze strony os-booi.com copyright Silberschatz, Galvin and Gagne, 2013 Cele wykładu 1. Opis usług dostarczanych przez OS
Struktury systemów operacyjnych Jan Tuziemski Część slajdów to zmodyfiowane slajdy ze strony os-booi.com copyright Silberschatz, Galvin and Gagne, 2013 Cele wykładu 1. Opis usług dostarczanych przez OS
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
HPC na biurku. Wojciech De bski
 na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one