Wprowadzenie do programu RapidMiner, częśd 1 Michał Bereta Program RapidMiner (RM) ma trzy główne widoki (perspektywy):
|
|
|
- Nina Wawrzyniak
- 9 lat temu
- Przeglądów:
Transkrypt
1 Wprowadzenie do programu RapidMiner, częśd 1 Michał Bereta Program Rapid Miner jest dostępny na stronie: Korzystamy z bezpłatnej wersji RapidMiner Community Edition. Zalecane jest obejrzenie video tutorialów: 1. Wstęp wczytywanie i wizualizacja danych Program RapidMiner (RM) ma trzy główne widoki (perspektywy): 1


2 W widoku projektu zakładamy nowe repozytorium. Będą tam zapisywane nasze dane, projekty oraz wyniki. 2


3 Następnie tworzymy nowy proces (crtl +N, File->New Process lub z widoku powitalnego) Importujemy dane. Przeciągnij jeden z dostępnych operatorów dla formatu ARFF: Wybierz plik dla bazy danych irysów iris.arff. Jeśli plik nie może byd odnaleziony w miejscu instalacji RM, pobierz dane ze strony przedmiotu. 3


4 Żółta ikona sygnalizuje, że proces nie został jeszcze wykonany. Uruchom proces: Zachowaj projekt w repozytorium. Mimo informacji, że żadne wyniki nie zostały wygenerowane, przejdź do widoku wyników. 4


5 Zakładka Meta Data View przedstawia streszczenie wszystkich danych i podstawowe statystyki. Można tu odczytad, że każdy obiekt opisany jest pięcioma atrybutami. Są to: sepallength, sepalwidth, petallength, petalwidth oraz class. Atrybut class wskazuje, do której klasy należy dany przykład. Widad, że są trzy klasy: Iris-setosa, Iris-versicolor, Iris-virginica. Z każdej klasy mamy po 50 przykładów. Upewnij się, że rozumiesz co przedstawia każda kolumna. Role = regular oznacza, że atrybut nie został wyszczególniony jako np. etykieta klasy lub id obiektu. Czasami informacja o tym, który atrybut pełni rolę etykiety klasy jest zapisana pliku z danymi (w przypadku niektórych formatów zapisu danych). W innych przypadkach należy samodzielnie wskazad, który atrybut wskazuje na etykietę klasy. W zakładce Data View można dokładnie obejrzed wartości atrybutów opisujących każdy z przykładów. Numer wiersza (Row No.) nie jest atrybutem. 5
.")

6 Dzięki zakładce Plot View możemy poddad dane wnikliwej wizualnej analizie za pomocą różnego typu wykresów. Każda oś może wskazad na wybrany atrybut. Kolor dobrze jest ustawid na atrybut opisujący etykietę klasy. Wtedy każda klasa ma swój kolor, jak na rysunku powyżej. Widad, że jedynie dwa wybrane atrybuty, przy całkowitym pominięciu pozostałych, nie pozwalają na łatwe oddzielenie wszystkich trzech klas od siebie. Stosunkowo łatwo jest oddzielid klasę Iris-setosa (kolor niebieski), lecz nie pozostałe dwie od siebie. Jak sprawdzid czy inne dwa wybrane atrybuty pozwalają lepiej lub gorzej oddzielid od siebie klasy? Można po kolei sprawdzad wszystkie pary atrybutów, lecz lepiej skorzystad z wykresu Scatter Matrix, przedstawiającego wszystkie pary jednocześnie. 6
, lecz nie pozostałe dwie od siebie.")

7 Jak widad, żadne dwie pary atrybutów nie gwarantują rozdzielenia wszystkich klas. Dostępne są również analogiczne wykresy w 3D: 7


8 Przykładowym innym rodzajem wykresu jest Bubble. Wartośd trzeciego wybranego atrybutu jest przedstawiona jako wielkośd koła reprezentującego dany przykład. Z wykresu poniżej widad, że przykłady z klasy Iris-setosa mają stosunkowo małe wartości atrybutu petallength, gdyż niebieskie koła są niewielkich rozmiarów. Inny przykład to typowy Pie. Poniżej przykład prezentujący średnie wartości atrybutu petallength w każdej klasie. 8


9 Bardzo przydatny w analizie jest histogram, prezentujący częstości występowanie wartości z danego zakresu. Lub też z wykorzystaniem podziału na klasy Histogram color : 9

.")
10 Ciągłym odpowiednikiem histogramu jest wykres rozkładu gęstości prawdopodobieostwa. Może on również sugerowad, które atrybuty lepiej nadają się do rozróżniania klas (porównaj dwa poniższe wykresy). Inny przykład to wykres Quartile color tzw. wykres pudełkowy (box plot). 10
.")

11 Bardzo dobrym rodzajem wykresu jest Parallel, który jest w stanie zaprezentowad wysoko wymiarowe dane każdy atrybut ma przydzieloną jedną pionową oś. Z poniższego widad, że atrybutem, który jest najbardziej obiecujący jeśli chodzi o odzielenie klas jest petallength w zupełności wystarczy on do oddzielenia klasy Iris-setosa. Najmniej przydatny wydaje się byd atrybut sepalwidth. Nie znaczy to jednak, że nie jest on przydatny, gdyż w tej chwili mówimy jedynie o każdym atrybucie z osobna. W czterech wymiarach może to jednak wyglądad inaczej (ciężko to sobie jednak wyobrazid). 11


12 Bardziej przejrzysty może byd czasami wykres Deviation. Poniżej widad średnie wartości każdego z atrybutów wraz z odchyleniem standardowym przedstawionym jako zacieniony obszar. Może on sugerowad, że dwa najlepsze atrybuty do przedstawienia danych to petalwidth i petallength, co widad na poniższym scatter plot. 12

 niż to co widad poniżej:")
13 Powyższy wykres jest dużo lepszy (w sensie oddzielenia klas) niż to co widad poniżej: 13


14 Zadanie: Wczytaj plik z danymi sonar.aml. Zawiera ona dane z pomiarów mających za zadanie wykryd, czy dany obiekt należy do klasy rock czy też mine. Przeanalizuj meta-dane ile jest atrybutów, klas, itd. Poniższy wykres pokazuje, że żadne dwa atrybuty nie oddzielają dobrze klas. Ciężko nawet wskazad, które nadają się chod trochę lepiej niż inne. Inny rodzaj wykresu może byd bardziej pomocny. Widad jednak, że problem jest trudniejszy niż w przypadku zbioru iris. 14

, że niektóre atrybuty przynajmniej sugerują większą użytecznośd w oddzielaniu klas.")
15 Na tym przykładzie widad, że wykres Deviation jest zdecydowanie bardziej przejrzysty niż Parallel. Widad na nim (poniżej), że niektóre atrybuty przynajmniej sugerują większą użytecznośd w oddzielaniu klas. Z poniższego wykresu wynika, że atrybut 26-ty zdaje się nie wnosid praktycznie nic do procesu dyskryminacji. 15

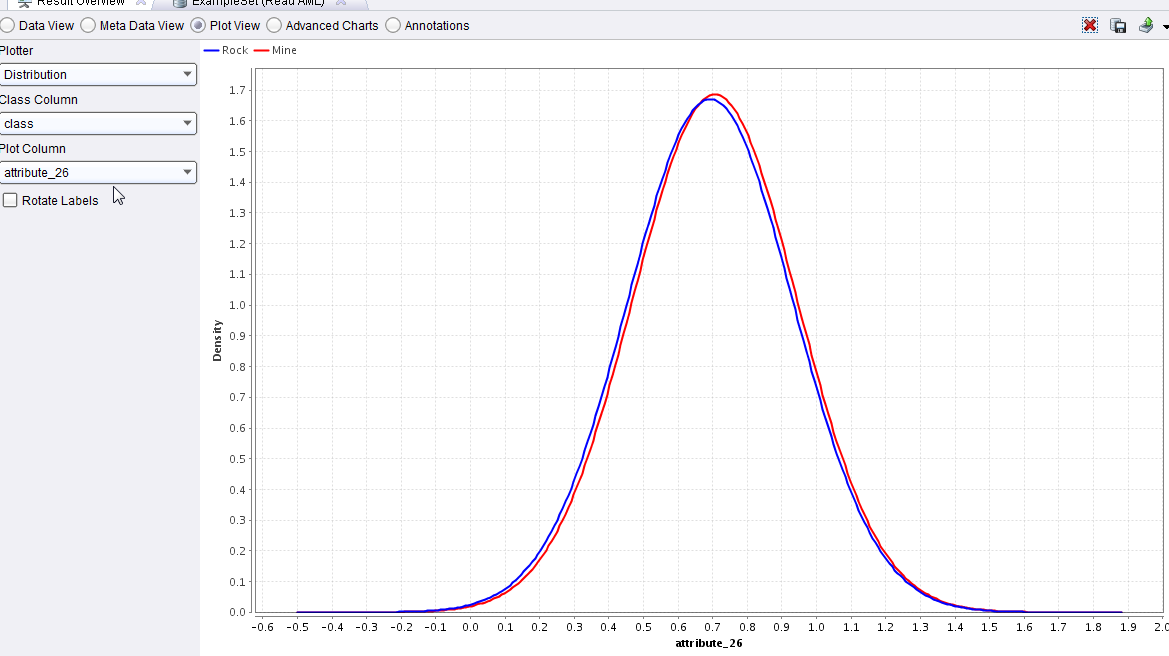
16 16
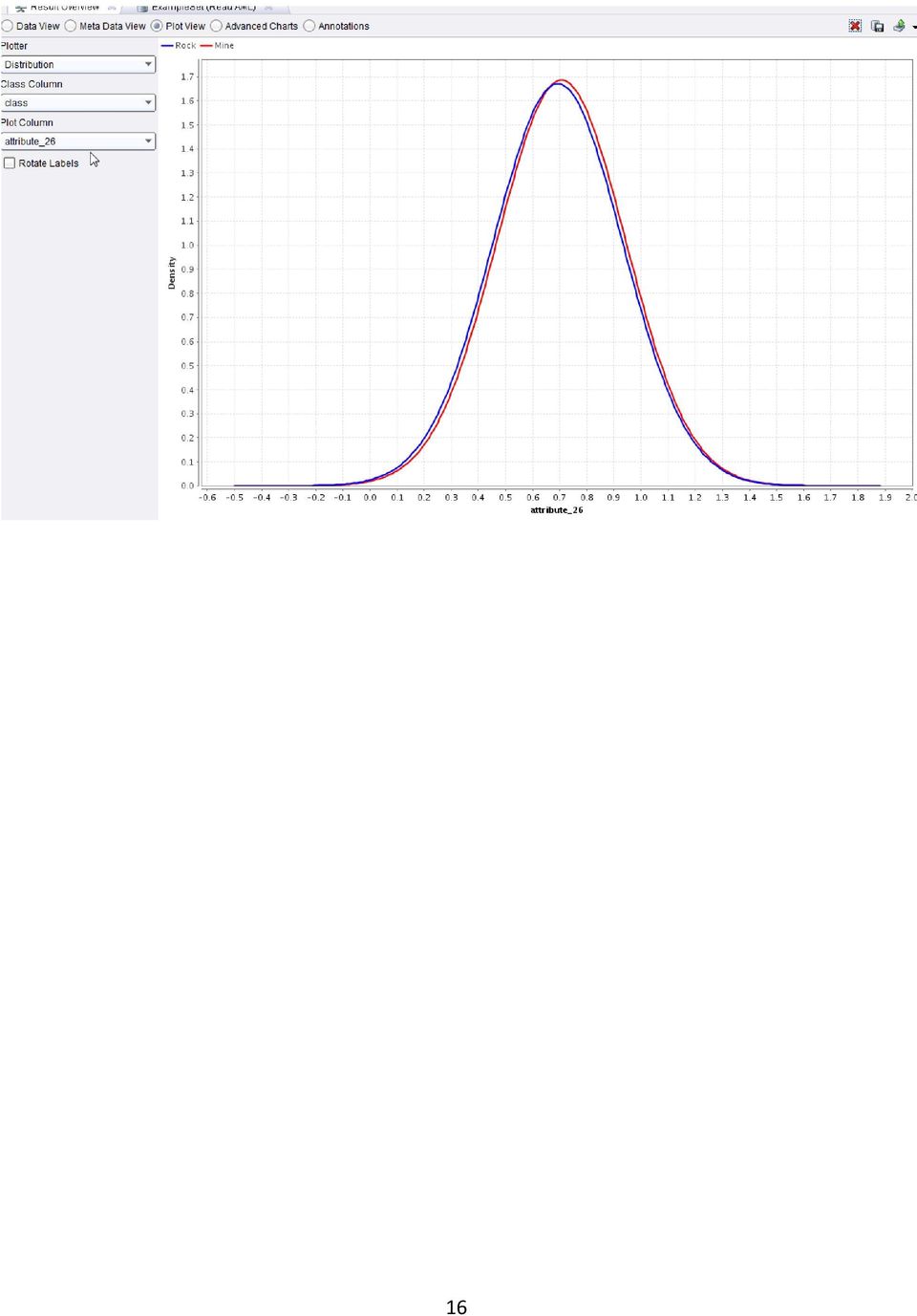
.")
17 2. Tworzenie prostego klasyfikatora Stwórz nowy proces i wczytaj dane iris. Wyszukaj operator Decision Tree (pomocny jest przy tym filtr, jak widad poniżej). Przeciągnij i upuśd go na istniejącym linku. 17
.")
. Jeśli chcesz obejrzed wczytane dane zanim zacznie się indukcja drzewa, ustaw breakpoint z menu kontekstowego na ikonie wczytywania danych. 18")
18 Jak widad powyżej drzewo decyzyjne będzie utworzone na podstawie przekazanych mu na wejście danych, a utworzony model (wyjście mod) zostanie przekazane jako rezultat (res na prawej brzegu). Jeśli chcesz obejrzed wczytane dane zanim zacznie się indukcja drzewa, ustaw breakpoint z menu kontekstowego na ikonie wczytywania danych. 18


19 Uruchom proces: Jako pierwszy wynik zobaczyd można wczytane dane. Jeśli był ustawiony break point, należy kontynuowad proces (niebieski trójkąt jeszcze raz jak powyżej). Jako wynik dostaniemy model drzewa decyzyjnego. Powyższe drzewo zależy od ustawieo pewnych parametrów. Wród do widoku projektu, zaznacz ikonę drzewa i po prawej przeanalizuj dostępne parametry: 19


20 Niektóre operatory mają również tzw. expert mode, gdzie dostępnych jest więcej parametrów: Aby przetestowad nasze drzewo decyzyjne (sprawdzid jak klasyfikuje dane) potrzebny jest operator Apply Model : 20
")
21 Umieśd go w projekcie jak poniżej: Czerwona dioda sygnalizuje problem. Tutaj: brak danych, które mają byd klasyfikowane przez model. Jeśli połączymy jak poniżej, nasze drzewo spróbuje klasyfikowad te same dane, na podstawie których było utworzone. Jednocześnie chcemy przekazad lab z Apply Model (od label, czyli wyniki klasyfikacji) do res. Uruchom ponownie proces. W wynikach można odnaleźd kolumnę prediction. Porównaj z kolumną labe l, czyli poprawnymi odpowiedziami. Widad, że w niektórych przypadkach odpowiedź nie jest poprawna (dlaczego?) 21

22 Aby uzyskad podsumowanie jakości tej klasyfikacji możemy użyd operatora Performance i podłączyd go jak poniżej. Uruchom ponownie proces. W widoku wyniki otrzymaliśmy zakładkę Performance vector. Ogólna jakośd klasyfikacji wyrażona jest przez accuracy. Co oznaczają class recall oraz class precision? W wynikach powyższego procesu nie ma już szczegółów odnośnie nadanych etykiet jak poprzednio. Jest tak dlatego, że lab ( labelled data ) z Apply Model jest teraz połączony z lab operatora 22
23 Performance. Nie możemy bezpośrednio połączyd lab z Apply Model do obu jednocześnie. Jeśli chcemy uzyskad szczegółowe informacje o klasyfikacji, możemy użyd operatora Multiply, który duplikuje przekazane mu na wejściu dane. W powyższym doświadczeniu testowaliśmy nasze drzewo decyzyjne na tych samych danych, na podstawie których było ono utworzone. To nie daje dobrego wyobrażenia o powstałym modelu, taka ocena zawsze będzie optymistyczna. Należy użyd danych testowych oddzielnych od zbioru treningowego. 23
.")
24 3. Tworzenie i testowanie klasyfikatora na podstawie odrębnych zbiorów danych. W najprostszy sposób można wykorzystad operator Split Data Należy ustalid jaki podział danych ma byd wygenerowany. Dwukrotnie kliknij Add Entry i wpisz poniższe wartości. Oznaczają one, że planujemy przeznaczyd losowe 60% przykładów na trening a pozostałe 40% na testowanie (wartości muszą sumowad się do 1). 24

25 Na poniższym schemacie widad, że do trenowania używamy pierwszej części danych wygenerowanej przez operator Split Data a do operatora Apply Model (czyli do testowania) przekazujemy drugą częśd. Uruchom powyższy proces i przeanalizuj wyniki. Poniżej widad, że do testowania nie została użyta cała baza iris. Zadanie: Jak przedstawid wyniki predykcji zarówno dla danych testowych jak i trenujących? Czy poniższy schemat jest poprawny? Zwród uwagę na koniecznośd duplikowania zbioru trenującego oraz drzewa. 25

26 Jak widad sprawa się trochę komplikuje. Aby wstępnie przetestowad dany model na zbiorze danych, można użyd operatora Split Validation, który samodzielnie podzieli dane na zbiór trenujący i testowy. 26

27 Operator ten jest tzw. Building block. Nazwijmy go podprocesem. Kliknij dwukrotnie: W ustawieniach podprocesu należy ustalid szczegóły dwóch jego faz: treningu i testowania. W fazie trenowania chcemy użyd drzewa decyzyjnego: 27

28 W fazie testowania musimy użyd operatora Apply Model oraz sprawdzid jakośd klasyfikacji operatorem Performance. Należy jeszcze ustalid szczegóły losowego podziału na zbiór trenujacy i testowy: Co oznacza split ratio możemy sprawdzid w pomocy poniżej: Aby powrócid do projektu głównego procesu, naciśnij : 28
29 Aby po uruchomieniu procesu zobaczyd streszczenie jakości klasyfikacji dla danych testowych należy jeszcze połączyd ave z res. Jeśli chcesz zobaczyd również powstałe drzewo, musisz połaczyd również mod do res : Uruchom proces i przeanalizuj wyniki. 29
30 30
31 4. Ocena jakości klasyfikatora za pomocą kroswalidacji Aby ocenid jakośd działania klasyfikatora, często lepszym rozwiązaniem jest stosowanie kroswalidacji zamiast jednego podziału na zbiór trenujący i testowy. Domyślnie używana jest jest 10-ciokrotna kroswalidacja, tzn. dane są dzielone na 10 części i proces uczenia powtarzany jest 10-cio krotnie dla każdej części wykorzystanej jako dane testowe (nie biorące udział w procesie tworzenia modelu). Wyniki z dziesięciu prób są uśredniane i wykorzystane jako ocena jakości modelu. Otrzymamy: Widoczny powyżej operator walidacji jest podprocesem. Na poniższym rysunku widad, że domyślnie użyte jest drzewo decyzyjne. Można go jednak usunąd i zastąpid innym klasyfikatorem. 31

32 Domyślnie (poniżej) kros walidacja jest 10-krotna. Skrajnym przypadkiem jest leave one out gdzie każdy przykład jest kolejno użyty jako jednoelementowy zbiór testowy a pozostałe jako zbiór trenujący. Wymaga to dużego nakładu obliczeo (proces tworzenia klasyfikatora należy powtórzyd tyle razy ile mamy przykładów). Po uruchomieniu: 32

33 Zadanie: Jak porównad za pomocą kroswalidacji, który model lepiej nadaje się jako klasyfikator w konkretnym przypadku? Przykładowo, porównaj drzewo decyzyjne z naiwnym klasyfikatorem Bayesa. Zaprojektuj poniższy proces (zwród uwagę, że z poziomu menu kontekstowego można zmienid nazwy instancji operatorów na np. Validation drzewo oraz Validation Bayes ). 33

34 Po uruchomieniu, dla drzewa otrzymujamy: a dla naiwnego Bayesa: Wynika z tego, że lepszy tutaj mógłby byd klasyfikator naiwnego Bayesa. Zagadnienie, czy różnica między nimi jest istotna, zostawimy na inną okazję. Zadanie: Wykonaj powyższe porównanie dla zbioru sonar (Uwaga: jako że dane sonar są dużo większe niż iris, obliczenia będą trwad dłużej). Przykładowe wyniki: Dla Decision Tree : Dla Naive Bayes : 34
 ma drzewo (68.67% w porównaniu do 61.")
35 Zwród uwagę, że mimo iż accuracy jest w obu przypadkach zbliżone, to jednak class recall oraz class precision bardzo się różnią. Może to mied znaczenie jeśli zależy nam np. na minimalizacji błędów danego typu. Np. w wykrywaniu klasy Rock większą precyzję (tzn. jest mało fałszywych wykryd Mine jako Rock ) ma drzewo (68.67% w porównaniu do 61.54% dla naiwnego Bayesa), ale jeśli chodzi o to ile obiektów Rock ze wszystkich takich obiektów jest wykrytych to lepszy jest naiwny Bayes (82.47% w porównaniu do 58.76% dla drzewa). Zadanie: Wybrany zbiór danych podziel na dwie części w zadanej proporcji za pomocą operatora Split Data. Następnie zapisz każdą cześd do osobnego pliku.csv za pomocą operatora Write CSV. Używaj przecinka jako separatora w plikach csv. Zadanie: Poprzednie zadanie wykonaj z dodatkowym krokiem: z drugiego zbioru usuo kolumnę (atrybut) zawierający informację o klasie obiektu. Podpowiedź 1: Użyj operatora Select Attributes. Podpowiedź 2: Aby usunąd kolumnę z oznaczoną rolą jako label najpierw trzeba zmienid jej rolę. Użyj do tego operatora Set Role. 35
36 Podpowiedź: 36

37 Zadanie: Importowanie danych z plików csv. Mając dane w niektórych formatach, np. plikach csv, nie od razu wiadomo, jakie role mają poszczególne kolumny. Przeanalizujmy teraz następujący scenariusz. Dostajemy dwa pliki: train.csv oraz test.csv Jak widad są to pliki wygenerowane przez nas w poprzednim zadaniu, ale udawajmy, że ktoś dał nam zbiór danych trenujących ze znanymi etykietami klas dla przykładów oraz drugi plik bez informacji, do jakiej klasy należą przykłady w każdym wierszu. Naszym zadaniem jest dostarczyd takie odpowiedzi za pomocą drzewa decyzyjnego lub naiwnego Bayesa w zależności od tego, który z nich uznamy za lepszy. Jako odpowiedź mamy przekazad jedynie plik z odpowiedziami. 37

38 Zwród uwagę, że atrybut z kolumny id nie powinien byd wykorzystany do klasyfikacji ani podczas treningu ani podczas generowania odpowiedzi dla danych testowych. W tym zadaniu nie dowiemy się jak dobrze wypadły odpowiedzi dla danych testowych, gdyż ich nie mamy. Możemy jednak ocenid za pomocą kroswalidacji, który klasyfikator działa lepiej na danych trenujących. Kroswalidacja jest konieczna, gdyż nie możemy oceniad jakości klasyfikatora przez podstawienie tych samych danych (byłoby to zbyt optymistyczne). Krok 1 dodanie danych do repozytorium Przeciągnij i upuśd plik train.cvs na obszar localnego repozytorium w RM. Pojawi się okno dialogowe importu danych. Zmieo Column separation na przecinek (lub inny odpowiedni). Next 38
.")
39 Możesz zmienid rolę atrybutu label z attribute na label by rzeczywiści pełniło rolę etykiety klasy. Podobnie można zmienid rolę kolumny id na id. (Proszę nie mylid nazwy kolumny z nazwą roli jaką ma odgrywad ta kolumna). Załóżmy jednak, że w tym przypadku tego nie zrobimy, by zilustrowad pewne zachowania RM w kolejnych krokach. 39

40 Zachowaj pod wybraną nazwą w repozytorium: 40

41 Można od razu obejrzed dane. W podobny sposób zaimportuj dane testowe z pliku test.csv. Krok 2. Wybór modelu - oszacowanie jakości klasyfikatorów na podstawie zbioru trenującego. Tworzymy nowy projekt, w którym porównamy jakośd działania drzewa decyzyjnego oraz naiwnego klasyfikatora Bayesa w tym konkretnym problemie. Z repozytorium przeciągamy train_data na obszar widoku projektu. Dodajemy operator kros walidacji. Jak pamiętamy jest to w RM tzw. building block. Dodaj Edit->NewBuildingBlock: Pozostaw domyślny klasyfikator drzewo decyzyjne. Zmieo nazwę operatora Performance na Performance drzewo. Poniżej widad, że jest pewien problem (czerwona dioda na operatorze Validation ): 41

42 RM podpowiada: Musimy zatem wskazad, który atrybut ma byd traktowany jako etykieta klasy (jako, że nie zrobiliśmy tego wcześniej). Skorzystaj z Quick bugfixes : Wybierz kolumnę o nazwie label. RM automatycznie doda operator SetRole. Nie chcemy używad atrybutu id jako nie wnoszącego nic do procesu dyskryminacji. Dodaj operator Select Attributes : 42

43 W ustawieniach tego operatora wybierz: Invert selection pozwala w prosty sposób użyd wszystkich atrybutów z wyjątkiem tego jednego. Dodaj jeszcze jeden operator kroswalidacji, jednak tym razem zmieo domyślne drzewo na operator naiwnego Bayesa. Zmieo nazwę operatora Performance na Performance Bayes. 43

44 Aby dane mogły byd przekazane do dwóch operatorów kroswalidacji, użyj operatora Multiply : Uruchom proces: Dla drzewa otrzymujemy: A dla naiwnego Bayesa: 44

45 Jak widad wartośd accuracy sugeruje, że lepiej w tym zadaniu sprawdza się naiwny Bayes. Należy jednak pamiętad, że nie musi tak byd dla innych danych. Inny zbiór trenujący mógłby dad inne wyniki. Jednak musimy podjąd decyzję na podstawie tego czym dysponujemy i dlatego decydujemy się na klasyfikator Bayesa. Warto jeszcze przypomnied, że niekiedy ważniejsze są inne parametry jak class recall czy class precision. Wspomniane to było przy okazji jednego z poprzednich przykładów. Krok 3: Po zdecydowaniu się na klasyfikator naiwnego Bayesa przystępujemy do kolejnego etapu. Tym razem przygotowujemy ostateczny klasyfikator wybranego typu na podstawie całego zbioru trenującego i sprawdzamy jego odpowiedzi dla danych ze zbioru testowego. Wygodnie jest stworzyd nowy projekt. Tym razem nie wykorzystujemy operatora kroswalidacji lecz od razu trenujemy klasyfikator Bayesa wykorzystując do tego cały zbiór trenujący. Poniższy schemat powinien byd już dośd oczywisty: wczytujemy dane trenujące z repozytorium, dokonujemy wyboru atrybutów (odrzucamy id ) i wskazujemy który atrybut powinien byd traktowany jako etykieta klasy (operator SetRole ). Następnie operator ApplyModel pozwala sprawdzid odpowiedź wytrenowanego klasyfikatora dla danych testowych. Zwród uwagę, że RM inteligentnie sam wybierze te atrybuty, które będą mus potrzebne podczas używania przykładów ze zbioru testowego (tzn. nie ma potrzeby stosowad operatora SelectAttribute dla danych testowych). W danych wynikowych widad, że dodane zostały kolumny prediction(label) oraz confidence dla każdej klasy. 45

46 Aby wyeksportowad dane do pliku csv najpierw wybieramy operatorem SelectAttribute jedynie kolumnę prediction i przekazujemy ją do WriteCSV. Zawartośd wygenerowanego pliku answers.csv: 46

47 Jak widad, RM traktuje kolumnę prediction jako powiązaną z kolumnami confindence. Niemniej jednak otrzymaliśmy jako ostateczny wynik naszego zadania klasyfikację dla każdego przykładu ze zbioru testowego. Zadanie: Wykonaj podobną analizę wyboru najlepszego modelu dla bazy sonar. 47
Data Mining z wykorzystaniem programu Rapid Miner
 Data Mining z wykorzystaniem programu Rapid Miner Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community
Data Mining z wykorzystaniem programu Rapid Miner Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community
Testowanie modeli predykcyjnych
 Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta
 Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Porównanie systemów automatycznej generacji reguł działających w oparciu o algorytm sekwencyjnego pokrywania oraz drzewa decyzji
 Porównanie systemów automatycznej generacji reguł działających w oparciu o algorytm sekwencyjnego pokrywania oraz drzewa decyzji Wstęp Systemy automatycznego wyodrębniania reguł pełnią bardzo ważną rolę
Porównanie systemów automatycznej generacji reguł działających w oparciu o algorytm sekwencyjnego pokrywania oraz drzewa decyzji Wstęp Systemy automatycznego wyodrębniania reguł pełnią bardzo ważną rolę
Konfiguracja programu
 Spis treści Konfiguracja programu... 1 Import wyciągu bankowego... 5 Kilka syntetyk kontrahenta... 13 Rozliczanie i uzgadnianie kontrahenta... 14 Reguły księgowania... 16 Konfiguracja programu Po uruchomieniu
Spis treści Konfiguracja programu... 1 Import wyciągu bankowego... 5 Kilka syntetyk kontrahenta... 13 Rozliczanie i uzgadnianie kontrahenta... 14 Reguły księgowania... 16 Konfiguracja programu Po uruchomieniu
Wybór / ocena atrybutów na podstawie oceny jakości działania wybranego klasyfikatora.
 Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
Wprowadzenie do programu RapidMiner, część 4 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 4 Michał Bereta www.michalbereta.pl 1. Wybór atrybutów (ang. attribute selection, feature selection). Jedną z podstawowych metod analizy współoddziaływania /
Wprowadzenie do programu RapidMiner, część 4 Michał Bereta www.michalbereta.pl 1. Wybór atrybutów (ang. attribute selection, feature selection). Jedną z podstawowych metod analizy współoddziaływania /
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów
 Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
INSTRUKCJA OTWIERANIA PLIKU DPT (data point table)
") INSTRUKCJA OTWIERANIA PLIKU DPT (data point table) Plik DPT jest tekstowym zapisem widma. Otwarty w notatniku wygląda następująco: Aby móc stworzyć wykres, należy tak zaimportować plik do arkusza kalkulacyjnego,
INSTRUKCJA OTWIERANIA PLIKU DPT (data point table) Plik DPT jest tekstowym zapisem widma. Otwarty w notatniku wygląda następująco: Aby móc stworzyć wykres, należy tak zaimportować plik do arkusza kalkulacyjnego,
1. Cele eksploracyjnej analizy danych Rapid Miner zasady pracy i wizualizacja danych Oracle Data Miner -zasady pracy.
 Spis treści: 1. Cele eksploracyjnej analizy danych...1 2. Rapid Miner zasady pracy i wizualizacja danych...3 3. Oracle Data Miner -zasady pracy.12 3.1 ODM PL/SQL.......12 3.2 ODM JAVA API......12 3.2.1
Spis treści: 1. Cele eksploracyjnej analizy danych...1 2. Rapid Miner zasady pracy i wizualizacja danych...3 3. Oracle Data Miner -zasady pracy.12 3.1 ODM PL/SQL.......12 3.2 ODM JAVA API......12 3.2.1
Zadanie 1. Tworzenie nowej "strony sieci WEB". Będziemy korzystad ze stron w technologii ASP.NET.
 Zadanie 1. Tworzenie nowej "strony sieci WEB". Będziemy korzystad ze stron w technologii ASP.NET. Ważne! Przy pierwszym uruchomieniu Visual Studio zostaniemy zapytani, jaki ma byd podstawowy język programowania
Zadanie 1. Tworzenie nowej "strony sieci WEB". Będziemy korzystad ze stron w technologii ASP.NET. Ważne! Przy pierwszym uruchomieniu Visual Studio zostaniemy zapytani, jaki ma byd podstawowy język programowania
Program Qmak Podręcznik użytkownika
 Program Qmak Podręcznik użytkownika Krzysztof Mroczek Leszek Tur Damian Wójcik 2 lipca 2007 Maciej Zuchniak 1 Spis treści 1 Wprowadzenie do Qmaka 3 1.1 Informacje techniczne................................
Program Qmak Podręcznik użytkownika Krzysztof Mroczek Leszek Tur Damian Wójcik 2 lipca 2007 Maciej Zuchniak 1 Spis treści 1 Wprowadzenie do Qmaka 3 1.1 Informacje techniczne................................
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Moduł Handlowo-Magazynowy Przeprowadzanie inwentaryzacji z użyciem kolektorów danych
 Moduł Handlowo-Magazynowy Przeprowadzanie inwentaryzacji z użyciem kolektorów danych Wersja 3.77.320 29.10.2014 r. Poniższa instrukcja ma zastosowanie, w przypadku gdy w menu System Konfiguracja Ustawienia
Moduł Handlowo-Magazynowy Przeprowadzanie inwentaryzacji z użyciem kolektorów danych Wersja 3.77.320 29.10.2014 r. Poniższa instrukcja ma zastosowanie, w przypadku gdy w menu System Konfiguracja Ustawienia
System imed24 Instrukcja Moduł Analizy i raporty
 System imed24 Instrukcja Moduł Analizy i raporty Instrukcja obowiązująca do wersji 1.8.0 Spis treści 1. Moduł Analizy i Raporty... 3 1.1. Okno główne modułu Analizy i raporty... 3 1.1.1. Lista szablonów
System imed24 Instrukcja Moduł Analizy i raporty Instrukcja obowiązująca do wersji 1.8.0 Spis treści 1. Moduł Analizy i Raporty... 3 1.1. Okno główne modułu Analizy i raporty... 3 1.1.1. Lista szablonów
Eksploracja danych w środowisku R
 Eksploracja danych w środowisku R Moi drodzy, niniejszy konspekt nie omawia eksploracji danych samej w sobie. Nie dowiecie się tutaj o co chodzi w generowaniu drzew decyzyjnych czy grupowaniu danych. Te
Eksploracja danych w środowisku R Moi drodzy, niniejszy konspekt nie omawia eksploracji danych samej w sobie. Nie dowiecie się tutaj o co chodzi w generowaniu drzew decyzyjnych czy grupowaniu danych. Te
Instrukcja do zdjęć. Instrukcja krok po kroku umieszczania zdjęd na aukcji bez ograniczeo. MD-future. md-future@o2.pl
 Instrukcja do zdjęć 2011 Instrukcja krok po kroku umieszczania zdjęd na aukcji bez ograniczeo. md-future@o2.pl Spis treści Krok 1. Dopasowanie rozmiaru zdjęcia do standardów.... 3 Krok 2. Wstawianie zdjęcia
Instrukcja do zdjęć 2011 Instrukcja krok po kroku umieszczania zdjęd na aukcji bez ograniczeo. md-future@o2.pl Spis treści Krok 1. Dopasowanie rozmiaru zdjęcia do standardów.... 3 Krok 2. Wstawianie zdjęcia
PODRĘCZNIK UŻYTKOWNIKA PEŁNA KSIĘGOWOŚĆ. Płatności
 Płatności Odnotowuj płatności bankowe oraz gotówkowe, rozliczenia netto pomiędzy dostawcami oraz odbiorcami, dodawaj nowe rachunki bankowe oraz kasy w menu Płatności. Spis treści Transakcje... 2 Nowa płatność...
Płatności Odnotowuj płatności bankowe oraz gotówkowe, rozliczenia netto pomiędzy dostawcami oraz odbiorcami, dodawaj nowe rachunki bankowe oraz kasy w menu Płatności. Spis treści Transakcje... 2 Nowa płatność...
Klasyfikacja i regresja Wstęp do środowiska Weka
 Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
etrader Pekao Podręcznik użytkownika Strumieniowanie Excel
 etrader Pekao Podręcznik użytkownika Strumieniowanie Excel Spis treści 1. Opis okna... 3 2. Otwieranie okna... 3 3. Zawartość okna... 4 3.1. Definiowanie listy instrumentów... 4 3.2. Modyfikacja lub usunięcie
etrader Pekao Podręcznik użytkownika Strumieniowanie Excel Spis treści 1. Opis okna... 3 2. Otwieranie okna... 3 3. Zawartość okna... 4 3.1. Definiowanie listy instrumentów... 4 3.2. Modyfikacja lub usunięcie
Zawartość. Wstęp. Moduł Rozbiórki. Wstęp Instalacja Konfiguracja Uruchomienie i praca z raportem... 6
 Zawartość Wstęp... 1 Instalacja... 2 Konfiguracja... 2 Uruchomienie i praca z raportem... 6 Wstęp Rozwiązanie przygotowane z myślą o użytkownikach którzy potrzebują narzędzie do podziału, rozkładu, rozbiórki
Zawartość Wstęp... 1 Instalacja... 2 Konfiguracja... 2 Uruchomienie i praca z raportem... 6 Wstęp Rozwiązanie przygotowane z myślą o użytkownikach którzy potrzebują narzędzie do podziału, rozkładu, rozbiórki
Laboratorium 4. Naiwny klasyfikator Bayesa.
 Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Dopasowywanie czasu dla poszczególnych zasobów
 Dopasowywanie czasu dla poszczególnych zasobów Narzędzia Zmień czas pracy W polu dla kalendarza wybieramy zasób dla którego chcemy zmienić czas pracy, np. wpisać urlop albo zmienić godziny pracy itp. Dalej
Dopasowywanie czasu dla poszczególnych zasobów Narzędzia Zmień czas pracy W polu dla kalendarza wybieramy zasób dla którego chcemy zmienić czas pracy, np. wpisać urlop albo zmienić godziny pracy itp. Dalej
1. Wprowadzenie do oprogramowania gretl. Wprowadzanie danych.
 Laboratorium z ekonometrii (GRETL) 1. Wprowadzenie do oprogramowania gretl. Wprowadzanie danych. Okno startowe: Póki nie wczytamy jakiejś bazy danych (lub nie stworzymy własnej), mamy dostęp tylko do dwóch
Laboratorium z ekonometrii (GRETL) 1. Wprowadzenie do oprogramowania gretl. Wprowadzanie danych. Okno startowe: Póki nie wczytamy jakiejś bazy danych (lub nie stworzymy własnej), mamy dostęp tylko do dwóch
POZIOM DOŚWIADCZONY CZĘŚĆ III
 POZIOM DOŚWIADCZONY CZĘŚĆ III Tworzenie własnych strategii W tej części poradnika chciałbym pokazad w jaki sposób powstają strategie do opcji binarnych i gdzie są zapisywane. Każdy kto posiada MetaTrader4
POZIOM DOŚWIADCZONY CZĘŚĆ III Tworzenie własnych strategii W tej części poradnika chciałbym pokazad w jaki sposób powstają strategie do opcji binarnych i gdzie są zapisywane. Każdy kto posiada MetaTrader4
Tytuł: Jak stworzyd krzywe do symulacji NIBP ( O Curve ) dla Rigel BP-SIM i UNI-SIM.
 dla Rigel BP-SIM i UNI-SIM.") Nota aplikacyjna: 0022 Tytuł: Jak stworzyd krzywe do symulacji NIBP ( O Curve ) dla Rigel BP-SIM i UNI-SIM. Wstęp Producenci kardiomonitorów korzystają z nieznacznie innych algorytmów pomiaru ciśnienia
Nota aplikacyjna: 0022 Tytuł: Jak stworzyd krzywe do symulacji NIBP ( O Curve ) dla Rigel BP-SIM i UNI-SIM. Wstęp Producenci kardiomonitorów korzystają z nieznacznie innych algorytmów pomiaru ciśnienia
Tworzenie i modyfikowanie wykresów
 Tworzenie i modyfikowanie wykresów Aby utworzyć wykres: Zaznacz dane, które mają być zilustrowane na wykresie: I sposób szybkie tworzenie wykresu Naciśnij na klawiaturze klawisz funkcyjny F11 (na osobnym
Tworzenie i modyfikowanie wykresów Aby utworzyć wykres: Zaznacz dane, które mają być zilustrowane na wykresie: I sposób szybkie tworzenie wykresu Naciśnij na klawiaturze klawisz funkcyjny F11 (na osobnym
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl
 Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Przed rozpoczęciem pracy otwórz nowy plik (Ctrl +N) wykorzystując szablon acadiso.dwt
 wykorzystując szablon acadiso.dwt") Przed rozpoczęciem pracy otwórz nowy plik (Ctrl +N) wykorzystując szablon acadiso.dwt Zadanie: Utwórz szablon rysunkowy składający się z: - warstw - tabelki rysunkowej w postaci bloku (według wzoru poniżej)
Przed rozpoczęciem pracy otwórz nowy plik (Ctrl +N) wykorzystując szablon acadiso.dwt Zadanie: Utwórz szablon rysunkowy składający się z: - warstw - tabelki rysunkowej w postaci bloku (według wzoru poniżej)
Opis konfiguracji Sz@rk ST do współpracy z kolektorem DENSO BHT 8000
 Opis konfiguracji Sz@rk ST do współpracy z kolektorem DENSO BHT 8000 1. Wstęp Program Sz@rk ST od wersji 10.10.20 został rozbudowany o możliwośd współpracy z kolektorami typu DENSO BHT 80xx z zainstalowanym
Opis konfiguracji Sz@rk ST do współpracy z kolektorem DENSO BHT 8000 1. Wstęp Program Sz@rk ST od wersji 10.10.20 został rozbudowany o możliwośd współpracy z kolektorami typu DENSO BHT 80xx z zainstalowanym
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych
 WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
Bazy danych raporty. 1. Przekopiuj na dysk F:\ bazę M5BIB.mdb z dysku wskazanego przez prowadzącego.
 Bazy danych raporty 1. Przekopiuj na dysk F:\ bazę M5BIB.mdb z dysku wskazanego przez prowadzącego. 2. Otwórz bazę (F:\M5BIB). 3. Utwórz raport wyświetlający wszystkie pola z tabeli KSIAZKI. Pozostaw ustawienia
Bazy danych raporty 1. Przekopiuj na dysk F:\ bazę M5BIB.mdb z dysku wskazanego przez prowadzącego. 2. Otwórz bazę (F:\M5BIB). 3. Utwórz raport wyświetlający wszystkie pola z tabeli KSIAZKI. Pozostaw ustawienia
EXCEL. Diagramy i wykresy w arkuszu lekcja numer 6. Instrukcja. dla Gimnazjum 36 - Ryszard Rogacz Strona 20
 Diagramy i wykresy w arkuszu lekcja numer 6 Tworzenie diagramów w arkuszu Excel nie jest sprawą skomplikowaną. Najbardziej czasochłonne jest przygotowanie danych. Utworzymy następujący diagram (wszystko
Diagramy i wykresy w arkuszu lekcja numer 6 Tworzenie diagramów w arkuszu Excel nie jest sprawą skomplikowaną. Najbardziej czasochłonne jest przygotowanie danych. Utworzymy następujący diagram (wszystko
Aby zastosowad tabelę przestawną należy wybrad dowolną komórkę w arkuszu i z menu Wstawianie wybierz opcję Tabela Przestawna.
 Zajęcia nr 3: Tabele i wykresy przestawne Przypuśdmy, że mamy zbiór do analizy: Aby zastosowad tabelę przestawną należy wybrad dowolną komórkę w arkuszu i z menu Wstawianie wybierz opcję Tabela Przestawna.
Zajęcia nr 3: Tabele i wykresy przestawne Przypuśdmy, że mamy zbiór do analizy: Aby zastosowad tabelę przestawną należy wybrad dowolną komórkę w arkuszu i z menu Wstawianie wybierz opcję Tabela Przestawna.
WIZUALIZER 3D APLIKACJA DOBORU KOSTKI BRUKOWEJ. Instrukcja obsługi aplikacji
 /30 WIZUALIZER 3D APLIKACJA DOBORU KOSTKI BRUKOWEJ Instrukcja obsługi aplikacji Aby rozpocząć pracę z aplikacją, należy zarejestrować się w celu założenia konta. Wystarczy wpisać imię, nazwisko, adres
/30 WIZUALIZER 3D APLIKACJA DOBORU KOSTKI BRUKOWEJ Instrukcja obsługi aplikacji Aby rozpocząć pracę z aplikacją, należy zarejestrować się w celu założenia konta. Wystarczy wpisać imię, nazwisko, adres
INSTRUKCJA IMPORTU PRODUKTÓW DO SKLEPU
 INSTRUKCJA IMPORTU PRODUKTÓW DO SKLEPU 1. W panelu administracyjnym w zakładce produkty uzupełnij drzewo kategorii (rys. nr 1.) oraz dodaj przykładowy produkt (lub kilka produktów jeżeli posiadasz w ofercie
INSTRUKCJA IMPORTU PRODUKTÓW DO SKLEPU 1. W panelu administracyjnym w zakładce produkty uzupełnij drzewo kategorii (rys. nr 1.) oraz dodaj przykładowy produkt (lub kilka produktów jeżeli posiadasz w ofercie
Zajęcia nr VII poznajemy Rattle i pakiet R.
 Okno główne Rattle wygląda następująco: Zajęcia nr VII poznajemy Rattle i pakiet R. Widzimy główne zakładki: Data pozwala odczytad dane z różnych źródeł danych (pliki TXT, CSV) i inne bazy danych. Jak
Okno główne Rattle wygląda następująco: Zajęcia nr VII poznajemy Rattle i pakiet R. Widzimy główne zakładki: Data pozwala odczytad dane z różnych źródeł danych (pliki TXT, CSV) i inne bazy danych. Jak
Zadanie Wstaw wykres i dokonaj jego edycji dla poniższych danych. 8a 3,54 8b 5,25 8c 4,21 8d 4,85
 Zadanie Wstaw wykres i dokonaj jego edycji dla poniższych danych Klasa Średnia 8a 3,54 8b 5,25 8c 4,21 8d 4,85 Do wstawienia wykresu w edytorze tekstu nie potrzebujemy mieć wykonanej tabeli jest ona tylko
Zadanie Wstaw wykres i dokonaj jego edycji dla poniższych danych Klasa Średnia 8a 3,54 8b 5,25 8c 4,21 8d 4,85 Do wstawienia wykresu w edytorze tekstu nie potrzebujemy mieć wykonanej tabeli jest ona tylko
Rys.1. Technika zestawiania części za pomocą polecenia WSTAWIAJĄCE (insert)
") Procesy i techniki produkcyjne Wydział Mechaniczny Ćwiczenie 3 (2) CAD/CAM Zasady budowy bibliotek parametrycznych Cel ćwiczenia: Celem tego zestawu ćwiczeń 3.1, 3.2 jest opanowanie techniki budowy i wykorzystania
Procesy i techniki produkcyjne Wydział Mechaniczny Ćwiczenie 3 (2) CAD/CAM Zasady budowy bibliotek parametrycznych Cel ćwiczenia: Celem tego zestawu ćwiczeń 3.1, 3.2 jest opanowanie techniki budowy i wykorzystania
Laboratorium 6. Indukcja drzew decyzyjnych.
 Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Nagrywamy podcasty program Audacity
 Pobieranie i instalacja Program Audacity jest darmowym zaawansowanym i wielościeżkowym edytorem plików dźwiękowych rozpowszechnianym na licencji GNU GPL. Jest w wersjach dla systemów typu Unix/Linux, Microsoft
Pobieranie i instalacja Program Audacity jest darmowym zaawansowanym i wielościeżkowym edytorem plików dźwiękowych rozpowszechnianym na licencji GNU GPL. Jest w wersjach dla systemów typu Unix/Linux, Microsoft
Uruchom polecenie z menu Wstaw Wykres lub ikonę Kreator wykresów na Standardowym pasku narzędzi.
 Tworzenie wykresów w Excelu. Część pierwsza. Kreator wykresów Wpisz do arkusza poniższą tabelę. Podczas tworzenia wykresów nie ma znaczenia czy tabela posiada obramowanie lub inne elementy formatowania
Tworzenie wykresów w Excelu. Część pierwsza. Kreator wykresów Wpisz do arkusza poniższą tabelę. Podczas tworzenia wykresów nie ma znaczenia czy tabela posiada obramowanie lub inne elementy formatowania
Nowa płatność Dodaj nową płatność. Wybierz: Płatności > Transakcje > Nowa płatność
 Podręcznik Użytkownika 360 Księgowość Płatności Wprowadzaj płatności bankowe oraz gotówkowe, rozliczenia netto pomiędzy dostawcami oraz odbiorcami, dodawaj nowe rachunki bankowe oraz kasy w menu Płatności.
Podręcznik Użytkownika 360 Księgowość Płatności Wprowadzaj płatności bankowe oraz gotówkowe, rozliczenia netto pomiędzy dostawcami oraz odbiorcami, dodawaj nowe rachunki bankowe oraz kasy w menu Płatności.
Kadry Optivum, Płace Optivum
 Kadry Optivum, Płace Optivum Jak seryjnie przygotować wykazy absencji pracowników? W celu przygotowania pism zawierających wykazy nieobecności pracowników skorzystamy z mechanizmu Nowe wydruki seryjne.
Kadry Optivum, Płace Optivum Jak seryjnie przygotować wykazy absencji pracowników? W celu przygotowania pism zawierających wykazy nieobecności pracowników skorzystamy z mechanizmu Nowe wydruki seryjne.
Import danych z plików CSV
 Import danych z plików CSV Program Moje kolekcje umożliwia importowanie danych zgromadzonych w innych aplikacjach, w tym z plików formatu *.csv Opis procedury importu danych Przed przystąpieniem do importu
Import danych z plików CSV Program Moje kolekcje umożliwia importowanie danych zgromadzonych w innych aplikacjach, w tym z plików formatu *.csv Opis procedury importu danych Przed przystąpieniem do importu
WIZUALIZER 3D APLIKACJA DOBORU KOSTKI BRUKOWEJ. Instrukcja obsługi aplikacji
 /30 WIZUALIZER 3D APLIKACJA DOBORU KOSTKI BRUKOWEJ Instrukcja obsługi aplikacji Aby rozpocząć pracę z aplikacją, należy zarejestrować się w celu założenia konta. Wystarczy wpisać imię, nazwisko, adres
/30 WIZUALIZER 3D APLIKACJA DOBORU KOSTKI BRUKOWEJ Instrukcja obsługi aplikacji Aby rozpocząć pracę z aplikacją, należy zarejestrować się w celu założenia konta. Wystarczy wpisać imię, nazwisko, adres
Baza danych. Program: Access 2007
 Baza danych Program: Access 2007 Bazę danych składa się z czterech typów obiektów: tabela, formularz, kwerenda i raport (do czego, który służy, poszukaj w podręczniku i nie bądź za bardzo leniw) Pracę
Baza danych Program: Access 2007 Bazę danych składa się z czterech typów obiektów: tabela, formularz, kwerenda i raport (do czego, który służy, poszukaj w podręczniku i nie bądź za bardzo leniw) Pracę
Tworzenie tabeli przestawnej krok po kroku
 Tabele przestawne Arkusz kalkulacyjny jest narzędziem przeznaczonym do zapisu, przechowywania i analizy danych. Jeśli w arkuszu zamierzamy gromadzić dane o osobach i cechach je opisujących (np. skąd pochodzą,
Tabele przestawne Arkusz kalkulacyjny jest narzędziem przeznaczonym do zapisu, przechowywania i analizy danych. Jeśli w arkuszu zamierzamy gromadzić dane o osobach i cechach je opisujących (np. skąd pochodzą,
Usługi Informatyczne "SZANSA" - Gabriela Ciszyńska-Matuszek ul. Świerkowa 25, Bielsko-Biała
 Usługi Informatyczne "SZANSA" - Gabriela Ciszyńska-Matuszek ul. Świerkowa 25, 43-305 Bielsko-Biała NIP 937-22-97-52 tel. +48 33 488 89 39 zwcad@zwcad.pl www.zwcad.pl Aplikacja do rysowania wykresów i oznaczania
Usługi Informatyczne "SZANSA" - Gabriela Ciszyńska-Matuszek ul. Świerkowa 25, 43-305 Bielsko-Biała NIP 937-22-97-52 tel. +48 33 488 89 39 zwcad@zwcad.pl www.zwcad.pl Aplikacja do rysowania wykresów i oznaczania
Podstawy grupowania danych w programie RapidMiner Michał Bereta
 Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Podręcznik Użytkownika 360 Księgowość Projekty i centra kosztów
 Podręcznik Użytkownika Projekty i centra kosztów Projekty i centra kosztów mogą być wykorzystane do szczegółowych analiz dochodów i wydatków. Aby móc wprowadzić transakcje do projektów i centrów kosztów
Podręcznik Użytkownika Projekty i centra kosztów Projekty i centra kosztów mogą być wykorzystane do szczegółowych analiz dochodów i wydatków. Aby móc wprowadzić transakcje do projektów i centrów kosztów
Bioinformatyka. Program UGENE
 Bioinformatyka Program UGENE www.michalbereta.pl UGENE jest darmowym programem do zadań bioinformatycznych. Można go pobrać ze strony http://ugene.net/. 1 1. Wczytanie rekordu z bazy ENA do programu UGENE
Bioinformatyka Program UGENE www.michalbereta.pl UGENE jest darmowym programem do zadań bioinformatycznych. Można go pobrać ze strony http://ugene.net/. 1 1. Wczytanie rekordu z bazy ENA do programu UGENE
Ćwiczenia nr 4. Arkusz kalkulacyjny i programy do obliczeń statystycznych
 Ćwiczenia nr 4 Arkusz kalkulacyjny i programy do obliczeń statystycznych Arkusz kalkulacyjny składa się z komórek powstałych z przecięcia wierszy, oznaczających zwykle przypadki, z kolumnami, oznaczającymi
Ćwiczenia nr 4 Arkusz kalkulacyjny i programy do obliczeń statystycznych Arkusz kalkulacyjny składa się z komórek powstałych z przecięcia wierszy, oznaczających zwykle przypadki, z kolumnami, oznaczającymi
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT. Część I: analiza regresji
 Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
Twoja ulotka instrukcja obsługi programu
 Twoja ulotka instrukcja obsługi programu Spis treści: Wprowadzenie... 2 Instalacja... 3 Uruchomienie... 7 Wybór układu ulotki... 8 Ekran główny... 11 Tworzenie ulotki... 12 Dodawanie własnego produktu...
Twoja ulotka instrukcja obsługi programu Spis treści: Wprowadzenie... 2 Instalacja... 3 Uruchomienie... 7 Wybór układu ulotki... 8 Ekran główny... 11 Tworzenie ulotki... 12 Dodawanie własnego produktu...
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
1 Wstęp. 2 Uruchomienie programu
 1 Wstęp Weka jest zestawem narzędzi związanych z uczeniem maszynowego. System został stowrzony i jest rozwijany przez Uniwersystet Waikato w Nowej Zelandii. Nazwa WEKA jest akronimem dla Waikato Environment
1 Wstęp Weka jest zestawem narzędzi związanych z uczeniem maszynowego. System został stowrzony i jest rozwijany przez Uniwersystet Waikato w Nowej Zelandii. Nazwa WEKA jest akronimem dla Waikato Environment
Sky-Shop.pl. Poradnik. Pierwsze kroki: Importowanie własnego pliku XML Integracje z hurtowniami
 Sky-Shop.pl Poradnik Pierwsze kroki: Importowanie własnego pliku XML Integracje z hurtowniami Wstęp Sky-Shop.pl jest w pełni autorskim, opracowanym od podstaw programem do prowadzenia nowoczesnych sklepów
Sky-Shop.pl Poradnik Pierwsze kroki: Importowanie własnego pliku XML Integracje z hurtowniami Wstęp Sky-Shop.pl jest w pełni autorskim, opracowanym od podstaw programem do prowadzenia nowoczesnych sklepów
Tworzenie menu i authoring w programie DVDStyler
 Tworzenie menu i authoring w programie DVDStyler DVDStyler jest to wieloplatformowy program do authoringu płyt DVD (tworzenia płyt DVD z indywidualnym menu, grafiką i materiałem filmowym). Dzięki niemu
Tworzenie menu i authoring w programie DVDStyler DVDStyler jest to wieloplatformowy program do authoringu płyt DVD (tworzenia płyt DVD z indywidualnym menu, grafiką i materiałem filmowym). Dzięki niemu
Moduł Handlowo-Magazynowy Zaawansowane analizy sprzedaży i zakupu
 Moduł Handlowo-Magazynowy Zaawansowane analizy sprzedaży i zakupu Wersja 3.59.305 4.04.2013 r. W systemie Streamsoft Prestiż użytkownik ma możliwość samodzielnego tworzenia rozszerzonych analiz w zakresie
Moduł Handlowo-Magazynowy Zaawansowane analizy sprzedaży i zakupu Wersja 3.59.305 4.04.2013 r. W systemie Streamsoft Prestiż użytkownik ma możliwość samodzielnego tworzenia rozszerzonych analiz w zakresie
Instrukcja użytkowania
 Instrukcja użytkowania Aby skutecznie pracować z programem Agrinavia Map należy zrozumieć zasadę interfejsu aplikacji. Poniżej można odszukać zasady działania Agrinavia Map. Szczegółowe informacje na temat
Instrukcja użytkowania Aby skutecznie pracować z programem Agrinavia Map należy zrozumieć zasadę interfejsu aplikacji. Poniżej można odszukać zasady działania Agrinavia Map. Szczegółowe informacje na temat
Księgowość Optivum. Jak wykonać eksport danych z programu Księgowość Optivum do SIO?
 Księgowość Optivum Jak wykonać eksport danych z programu Księgowość Optivum do SIO? Program Księgowość Optivum eksportuje do systemu informacji oświatowej dane, którymi wypełniana jest tabela KO1 koszty.
Księgowość Optivum Jak wykonać eksport danych z programu Księgowość Optivum do SIO? Program Księgowość Optivum eksportuje do systemu informacji oświatowej dane, którymi wypełniana jest tabela KO1 koszty.
Finanse. Jak wykonać import listy płac z programu Płace Optivum do aplikacji Finanse?
 Finanse Jak wykonać import listy płac z programu Płace Optivum do aplikacji Finanse? Operacja importu list płac z programu Płace Optivum do aplikacji Finanse przebiega w następujących krokach: 1. wybór
Finanse Jak wykonać import listy płac z programu Płace Optivum do aplikacji Finanse? Operacja importu list płac z programu Płace Optivum do aplikacji Finanse przebiega w następujących krokach: 1. wybór
Ćwiczenie 12. Metody eksploracji danych
 Ćwiczenie 12. Metody eksploracji danych Modelowanie regresji (Regression modeling) 1. Zadanie regresji Modelowanie regresji jest metodą szacowania wartości ciągłej zmiennej celu. Do najczęściej stosowanych
Ćwiczenie 12. Metody eksploracji danych Modelowanie regresji (Regression modeling) 1. Zadanie regresji Modelowanie regresji jest metodą szacowania wartości ciągłej zmiennej celu. Do najczęściej stosowanych
Spis treści Szybki start... 4 Podstawowe informacje opis okien... 6 Tworzenie, zapisywanie oraz otwieranie pliku... 23
 Spis treści Szybki start... 4 Podstawowe informacje opis okien... 6 Plik... 7 Okna... 8 Aktywny scenariusz... 9 Oblicz scenariusz... 10 Lista zmiennych... 11 Wartości zmiennych... 12 Lista scenariuszy/lista
Spis treści Szybki start... 4 Podstawowe informacje opis okien... 6 Plik... 7 Okna... 8 Aktywny scenariusz... 9 Oblicz scenariusz... 10 Lista zmiennych... 11 Wartości zmiennych... 12 Lista scenariuszy/lista
Przewodnik... Tworzenie ankiet
 Przewodnik... Tworzenie ankiet W tym przewodniku dowiesz się jak Dowiesz się, w jaki sposób zadawać pytania tak często, jak potrzebujesz i uzyskiwać informacje pomocne w ulepszeniu Twoich produktów i kampanii
Przewodnik... Tworzenie ankiet W tym przewodniku dowiesz się jak Dowiesz się, w jaki sposób zadawać pytania tak często, jak potrzebujesz i uzyskiwać informacje pomocne w ulepszeniu Twoich produktów i kampanii
Jak pobrad mapę z PK? Na stronie Pucharu Warszawy i Mazowsza w RJnO 2019 należy odszukad interesujący nas etap:
 Do nanoszenia śladu na mapę przydatny może byd programu QuickRoute, do pobrania ze strony http://www.matstroeng.se/quickroute/en/download.php Zanim zacznie się pracę z programem należy przygotowad sobie
Do nanoszenia śladu na mapę przydatny może byd programu QuickRoute, do pobrania ze strony http://www.matstroeng.se/quickroute/en/download.php Zanim zacznie się pracę z programem należy przygotowad sobie
MobiReg nowoczesny dziennik internetowy. Ocena opisowa
 MobiReg nowoczesny dziennik internetowy. Ocena opisowa Podręcznik użytkownika, czyli jak dobrze wdrożyd e-dziennik. Ocena opisowa Moduł oceny opisowej umożliwia utworzenie własnych, lokalnych obszarów
MobiReg nowoczesny dziennik internetowy. Ocena opisowa Podręcznik użytkownika, czyli jak dobrze wdrożyd e-dziennik. Ocena opisowa Moduł oceny opisowej umożliwia utworzenie własnych, lokalnych obszarów
Jeśli wcześniej było wybierane połączenie z bazą danych w oknie Połączenia pokaże się jego nazwa, jeśli nie należy dodad Nowe połączenie.
 Wstawianie punktów adresowych Dodawanie warstwy wektorowej punktów adresowych... 1 Dodawanie warstwy Google Satellite (WMS z plugina OpenLayers)... 2 Dodawanie warstwy ortofotomapa (WMS z GUGiK)... 3 Dodawanie
Wstawianie punktów adresowych Dodawanie warstwy wektorowej punktów adresowych... 1 Dodawanie warstwy Google Satellite (WMS z plugina OpenLayers)... 2 Dodawanie warstwy ortofotomapa (WMS z GUGiK)... 3 Dodawanie
Lekcja 1: Origin GUI GUI to Graficzny interfejs użytkownika (ang. GraphicalUserInterface) często nazywany też środowiskiem graficznym
 często nazywany też środowiskiem graficznym") Lekcja 1: Origin GUI GUI to Graficzny interfejs użytkownika (ang. GraphicalUserInterface) często nazywany też środowiskiem graficznym jest to ogólne określenie sposobu prezentacji informacji przez komputer
Lekcja 1: Origin GUI GUI to Graficzny interfejs użytkownika (ang. GraphicalUserInterface) często nazywany też środowiskiem graficznym jest to ogólne określenie sposobu prezentacji informacji przez komputer
Po naciśnięciu przycisku Dalej pojawi się okienko jak poniżej,
 Tworzenie wykresu do danych z tabeli zawierającej analizę rozwoju wyników sportowych w pływaniu stylem dowolnym na dystansie 100 m, zarejestrowanych podczas Igrzysk Olimpijskich na przestrzeni lat 1896-2012.
Tworzenie wykresu do danych z tabeli zawierającej analizę rozwoju wyników sportowych w pływaniu stylem dowolnym na dystansie 100 m, zarejestrowanych podczas Igrzysk Olimpijskich na przestrzeni lat 1896-2012.
Podstawowe informacje potrzebne do szybkiego uruchomienia e-sklepu
 Podstawowe informacje potrzebne do szybkiego uruchomienia e-sklepu Niniejszy mini poradnik ma na celu pomóc Państwu jak najszybciej uruchomić Wasz nowy sklep internetowy i uchronić od popełniania najczęstszych
Podstawowe informacje potrzebne do szybkiego uruchomienia e-sklepu Niniejszy mini poradnik ma na celu pomóc Państwu jak najszybciej uruchomić Wasz nowy sklep internetowy i uchronić od popełniania najczęstszych
Podręcznik użytkownika. Instrukcje
 Podręcznik użytkownika W podręczniku użytkownika opisane są najważniejsze, podstawowe zasady pracy w programie. W celu zapoznania się z bardziej szczegółowym opisem, należy zapoznać się z dalszymi instrukcjami.
Podręcznik użytkownika W podręczniku użytkownika opisane są najważniejsze, podstawowe zasady pracy w programie. W celu zapoznania się z bardziej szczegółowym opisem, należy zapoznać się z dalszymi instrukcjami.
Rys. 1 Okno startowe programu RapidMiner
 RapidMiner podstawy Zagadnienia analizy i eksploracji danych wiążą się z doborem odpowiedniego oprogramowania. Wśród światowych liderów w tym obszarze są SAS, IBM SPSS, Knime, Weka, R oraz RapidMiner.
RapidMiner podstawy Zagadnienia analizy i eksploracji danych wiążą się z doborem odpowiedniego oprogramowania. Wśród światowych liderów w tym obszarze są SAS, IBM SPSS, Knime, Weka, R oraz RapidMiner.
Instrukcja użytkownika. Aplikacja dla Comarch ERP XL
 Instrukcja użytkownika Aplikacja dla Comarch ERP XL Instrukcja użytkownika Aplikacja dla Comarch ERP XL Wersja 1.0 Warszawa, Listopad 2015 Strona 2 z 12 Instrukcja użytkownika Aplikacja dla Comarch ERP
Instrukcja użytkownika Aplikacja dla Comarch ERP XL Instrukcja użytkownika Aplikacja dla Comarch ERP XL Wersja 1.0 Warszawa, Listopad 2015 Strona 2 z 12 Instrukcja użytkownika Aplikacja dla Comarch ERP
Palety by CTI. Instrukcja
 Palety by CTI Instrukcja Spis treści 1. Logowanie... 3 2. Okno główne programu... 4 3. Konfiguracja... 5 4. Zmiana Lokalizacji... 6 5. Nowa Paleta z dokumentu MMP... 8 6. Realizacja Zlecenia ZW... 10 7.
Palety by CTI Instrukcja Spis treści 1. Logowanie... 3 2. Okno główne programu... 4 3. Konfiguracja... 5 4. Zmiana Lokalizacji... 6 5. Nowa Paleta z dokumentu MMP... 8 6. Realizacja Zlecenia ZW... 10 7.
Numeracja dla rejestrów zewnętrznych
 Numeracja dla rejestrów zewnętrznych System ZPKSoft Doradca udostępnia możliwość ręcznego nadawania numerów dla procedur i dokumentów zgodnie z numeracją obowiązującą w rejestrach zewnętrznych, niezwiązanych
Numeracja dla rejestrów zewnętrznych System ZPKSoft Doradca udostępnia możliwość ręcznego nadawania numerów dla procedur i dokumentów zgodnie z numeracją obowiązującą w rejestrach zewnętrznych, niezwiązanych
Instalacja programu:
 Instrukcja programu Konwerter Lido Aktualizacja instrukcji : 2012/03/25 INSTALACJA PROGRAMU:... 1 OKNO PROGRAMU OPIS... 3 DODANIE MODUŁÓW KONWERSJI... 3 DODANIE LICENCJI... 5 DODANIE FIRMY... 7 DODAWANIE
Instrukcja programu Konwerter Lido Aktualizacja instrukcji : 2012/03/25 INSTALACJA PROGRAMU:... 1 OKNO PROGRAMU OPIS... 3 DODANIE MODUŁÓW KONWERSJI... 3 DODANIE LICENCJI... 5 DODANIE FIRMY... 7 DODAWANIE
INSTRUKCJA INSTALACJI APLIKACJI PROF- EAN 2
 INSTRUKCJA INSTALACJI APLIKACJI PROF- EAN 2 1. Instalacja programu PROF-EAN 2 Instalacje uruchamiamy poprzez plik:, wówczas kreator automatycznie poprowadzi nas przez proces instalacji. 2. Deklaracja instalacji
INSTRUKCJA INSTALACJI APLIKACJI PROF- EAN 2 1. Instalacja programu PROF-EAN 2 Instalacje uruchamiamy poprzez plik:, wówczas kreator automatycznie poprowadzi nas przez proces instalacji. 2. Deklaracja instalacji
Dane w poniższej tabeli przedstawiają sprzedaż w dolarach i sztukach oraz marżę wyrażoną w dolarach dla:
 Przykład 1. Dane w poniższej tabeli przedstawiają sprzedaż w dolarach i sztukach oraz marżę wyrażoną w dolarach dla: 24 miesięcy, 8 krajów, 5 kategorii produktów, 19 segmentów i 30 brandów. Tabela ta ma
Przykład 1. Dane w poniższej tabeli przedstawiają sprzedaż w dolarach i sztukach oraz marżę wyrażoną w dolarach dla: 24 miesięcy, 8 krajów, 5 kategorii produktów, 19 segmentów i 30 brandów. Tabela ta ma
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Instrukcja instalacji systemu
 Instrukcja obsługi System do obsługi pizzerii Instrukcja instalacji systemu (rev 2.0) ANT.COM Andrzej Tomaszewski www.antcom.pl System do obsługi pizzerii instrukcja instalacji systemu 2 Niniejszy dokument
Instrukcja obsługi System do obsługi pizzerii Instrukcja instalacji systemu (rev 2.0) ANT.COM Andrzej Tomaszewski www.antcom.pl System do obsługi pizzerii instrukcja instalacji systemu 2 Niniejszy dokument
To narzędzie służy do umieszczania w postach filmów z takich portali jak: YouTube, Vimeo, Google Video, Metacafe, DailyMotion i wiele innych.
 Video Quicktags To narzędzie służy do umieszczania w postach filmów z takich portali jak: YouTube, Vimeo, Google Video, Metacafe, DailyMotion i wiele innych. Najlepiej zacząd od ustawieo Video Quicktags
Video Quicktags To narzędzie służy do umieszczania w postach filmów z takich portali jak: YouTube, Vimeo, Google Video, Metacafe, DailyMotion i wiele innych. Najlepiej zacząd od ustawieo Video Quicktags
Podstawowa konfiguracja modułu Szkolenia
 Podstawowa konfiguracja modułu Szkolenia Soneta Sp z o.o. ul. Wadowicka 8a, wejście B 31-415 Kraków tel./fax +48 (12) 261 36 41 http://www.enova.pl e-mail: crm@enova.pl Spis treści Konfiguracja... 3 Definicja
Podstawowa konfiguracja modułu Szkolenia Soneta Sp z o.o. ul. Wadowicka 8a, wejście B 31-415 Kraków tel./fax +48 (12) 261 36 41 http://www.enova.pl e-mail: crm@enova.pl Spis treści Konfiguracja... 3 Definicja
Jak utworzyć plik SIO dla aktualnego spisu?
 System Informacji Oświatowej Jak utworzyć plik SIO dla aktualnego spisu? Programy Arkusz Optivum, Kadry Optivum, Płace Optivum, Sekretariat Optivum oraz Księgowość Optivum dostarczają znaczną część danych
System Informacji Oświatowej Jak utworzyć plik SIO dla aktualnego spisu? Programy Arkusz Optivum, Kadry Optivum, Płace Optivum, Sekretariat Optivum oraz Księgowość Optivum dostarczają znaczną część danych
Edytor materiału nauczania
 Edytor materiału nauczania I. Uruchomienie modułu zarządzania rozkładami planów nauczania... 2 II. Opuszczanie elektronicznej biblioteki rozkładów... 5 III. Wyszukiwanie rozkładu materiałów... 6 IV. Modyfikowanie
Edytor materiału nauczania I. Uruchomienie modułu zarządzania rozkładami planów nauczania... 2 II. Opuszczanie elektronicznej biblioteki rozkładów... 5 III. Wyszukiwanie rozkładu materiałów... 6 IV. Modyfikowanie
System obsługi wag suwnicowych
 System obsługi wag suwnicowych Wersja 2.0-2008- Schenck Process Polska Sp. z o.o. 01-378 Warszawa, ul. Połczyńska 10 Tel. (022) 6654011, fax: (022) 6654027 schenck@schenckprocess.pl http://www.schenckprocess.pl
System obsługi wag suwnicowych Wersja 2.0-2008- Schenck Process Polska Sp. z o.o. 01-378 Warszawa, ul. Połczyńska 10 Tel. (022) 6654011, fax: (022) 6654027 schenck@schenckprocess.pl http://www.schenckprocess.pl
Instrukcja konfigurowania sieci WiFi w Akademii Leona Koźmioskiego dla telefonów komórkowych z systemem Bada
 Instrukcja konfigurowania sieci WiFi w Akademii Leona Koźmioskiego dla telefonów komórkowych z systemem Bada Niniejsza instrukcja została przygotowana na telefonie z systemem operacyjnym Bada 1.1!!! UWAGA!!!
Instrukcja konfigurowania sieci WiFi w Akademii Leona Koźmioskiego dla telefonów komórkowych z systemem Bada Niniejsza instrukcja została przygotowana na telefonie z systemem operacyjnym Bada 1.1!!! UWAGA!!!
Qtiplot. dr Magdalena Posiadała-Zezula
 Qtiplot dr Magdalena Posiadała-Zezula Magdalena.Posiadala@fuw.edu.pl www.fuw.edu.pl/~mposiada Start! qtiplot poza rysowaniem wykresów pozwala też na zaawansowaną obróbkę danych.! qtiplot jest silnie wzorowany
Qtiplot dr Magdalena Posiadała-Zezula Magdalena.Posiadala@fuw.edu.pl www.fuw.edu.pl/~mposiada Start! qtiplot poza rysowaniem wykresów pozwala też na zaawansowaną obróbkę danych.! qtiplot jest silnie wzorowany
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych
 WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
Edytor tekstu OpenOffice Writer Podstawy
 Edytor tekstu OpenOffice Writer Podstawy OpenOffice to darmowy zaawansowany pakiet biurowy, w skład którego wchodzą następujące programy: edytor tekstu Writer, arkusz kalkulacyjny Calc, program do tworzenia
Edytor tekstu OpenOffice Writer Podstawy OpenOffice to darmowy zaawansowany pakiet biurowy, w skład którego wchodzą następujące programy: edytor tekstu Writer, arkusz kalkulacyjny Calc, program do tworzenia
MobiReg nowoczesny dziennik internetowy.
 MobiReg nowoczesny dziennik internetowy. Podręcznik użytkownika, czyli jak dobrze wdrożyd e-dziennik. Rozpoczęcie nowego roku szkolnego. Spis treści 1. Nowy rok szkolny... 3 1.1. Rozpoczęcie roku szkolnego
MobiReg nowoczesny dziennik internetowy. Podręcznik użytkownika, czyli jak dobrze wdrożyd e-dziennik. Rozpoczęcie nowego roku szkolnego. Spis treści 1. Nowy rok szkolny... 3 1.1. Rozpoczęcie roku szkolnego
Instrukcja obsługi programu Do-Exp
 Instrukcja obsługi programu Do-Exp Autor: Wojciech Stark. Program został utworzony w ramach pracy dyplomowej na Wydziale Chemicznym Politechniki Warszawskiej. Instrukcja dotyczy programu Do-Exp w wersji
Instrukcja obsługi programu Do-Exp Autor: Wojciech Stark. Program został utworzony w ramach pracy dyplomowej na Wydziale Chemicznym Politechniki Warszawskiej. Instrukcja dotyczy programu Do-Exp w wersji
Obiektowy PHP. Czym jest obiekt? Definicja klasy. Składowe klasy pola i metody
 Obiektowy PHP Czym jest obiekt? W programowaniu obiektem można nazwać każdy abstrakcyjny byt, który programista utworzy w pamięci komputera. Jeszcze bardziej upraszczając to zagadnienie, można powiedzieć,
Obiektowy PHP Czym jest obiekt? W programowaniu obiektem można nazwać każdy abstrakcyjny byt, który programista utworzy w pamięci komputera. Jeszcze bardziej upraszczając to zagadnienie, można powiedzieć,
Tworzenie pliku źródłowego w aplikacji POLTAX2B.
 Tworzenie pliku źródłowego w aplikacji POLTAX2B. Po utworzeniu spis przekazów pocztowych klikamy na ikonę na dole okna, przypominającą teczkę. Następnie w oknie Export wybieramy format dokumentu o nazwie
Tworzenie pliku źródłowego w aplikacji POLTAX2B. Po utworzeniu spis przekazów pocztowych klikamy na ikonę na dole okna, przypominającą teczkę. Następnie w oknie Export wybieramy format dokumentu o nazwie
PROTEKTOR Instrukcja Obsługi
 PROTEKTOR Instrukcja Obsługi Uniwersalna Aplikacja Do Składania i Weryfikacji Podpis Elektronicznego W formacie XADES Wszystkich Dostawców Certyfikatów Wersja 1.0.0.1 Instrukcja użytkownika: 3 grudnia
PROTEKTOR Instrukcja Obsługi Uniwersalna Aplikacja Do Składania i Weryfikacji Podpis Elektronicznego W formacie XADES Wszystkich Dostawców Certyfikatów Wersja 1.0.0.1 Instrukcja użytkownika: 3 grudnia
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
SIMULINK 2. Lekcja tworzenia czytelnych modeli
 SIMULINK 2 Lekcja tworzenia czytelnych modeli W tej krótkiej części kursu zaproponuję metodę tworzenia modeli, które będą bardziej czytelne. Jest to bardzo ważne, ponieważ osoba oglądająca nasz model może
SIMULINK 2 Lekcja tworzenia czytelnych modeli W tej krótkiej części kursu zaproponuję metodę tworzenia modeli, które będą bardziej czytelne. Jest to bardzo ważne, ponieważ osoba oglądająca nasz model może
Integracja programów LeftHand z systemem Skanuj.to
 Integracja programów LeftHand z systemem Skanuj.to Niniejsza instrukcja zawiera praktyczny opis działań, które należy wykonać aby zintegrować usługę automatycznego skanowania i rozpoznawania dokumentów
Integracja programów LeftHand z systemem Skanuj.to Niniejsza instrukcja zawiera praktyczny opis działań, które należy wykonać aby zintegrować usługę automatycznego skanowania i rozpoznawania dokumentów