Przetwarzanie instrukcji w mikroprocesorach
|
|
|
- Zofia Ostrowska
- 7 lat temu
- Przeglądów:
Transkrypt
1 Przetwarzanie instrukcji w mikroprocesorach
2 Przetwarzanie sekwencyjne Przetwarzanie sekwencyjne ang. Sequential tradycyjna technika przetwarzania instrukcji w mikroprocesorach; polega na ściśle określonym scenariuszu wykonywania instrukcji; poszczególne etapy wykonania operacji następują po sobie sekwencyjnie; rozpoczęcie wykonywania kolejnej instrukcji może nastąpić dopiero po całkowitym wykonaniu poprzedniej instrukcji. Computer Organization and Design T H E H A R D W A R E / S O F T W A R E I N T E R F A C E, p. 331 fig.4.25 David A. Patterson, University of California, Berkeley John L. Hennessy, Stanford University
3 Pipeline Przetwarzanie potokowe ang. Pipelining technika przetwarzania rozkazów w mikroprocesorach, która polega na podziale logiki procesora wykonującej instrukcje, na specjalizowane grupy, w taki sposób aby każda z nich wykonywała część pracy związanej z wykonaniem instrukcji; praca ta może być wykonywana równocześnie, czyli z punktu widzenia otoczenia równolegle. Computer Organization and Design T H E H A R D W A R E / S O F T W A R E I N T E R F A C E, p. 331 fig.4.25 David A. Patterson, University of California, Berkeley John L. Hennessy, Stanford University
 Throughput U(n) Efficiency")
4 Pipeline Pipeline korzyści Speed-up S(n) Throughput U(n) Efficiency E(n)
5 Pipeline - wydajność Rozważmy m instrukcji wykonanych przy użyciu n etapowego potoku. Całkowity czas potrzebny na wykonanie powyższych operacji zajmuje mxn 1 jednostek czasu (np. cykli zegarowych). Wówczas przyspieszenie przetwarzania możemy wyrazić wzorem: Time using sequential processing S n = Time using pipeline processing m n t = m + n 1 t = m n m + n 1 lim S n = m n
6 Pipeline - wydajność Przepustowość możemy wyrazić następującą zależnością: U n = no of tasks executed per unit time m = m + n 1 t lim U n = 1, m zakładając t = 1 jednostce czasu.
7 Pipeline - wydajność Efektywność możemy wyrazić następującą zależnością: E n = Ratio of the actual to the maximum speed up Speed up m = = n m + n 1 lim E n = 1 m
8 Pipeline - wydajność Pipeline CPI Ideal pipeline CPI Structural stalls Data hazard stalls Control stalls CPI Cycles Per Instruction
9 Pipeline zależności i hazardy Określenie wzajemnych zależności pomiędzy instrukcjami jest krytyczne dla określenia jaka część kodu programu możliwa będzie do wykonania z wykorzystaniem przetwarzania równoległego. W ogólności aby korzystać z równoległości na poziomie instrukcji musimy określić, które instrukcje mogą być wykonane równolegle. Dwie instrukcje są równoległe tylko wówczas gdy mogą być wykonane równocześnie na dowolnym etapie pipeline u, bez powodowania zaburzenia potoku instrukcji. Jeżeli dwie instrukcje są wzajemnie zależne muszą być wykonane w określonej sekwencji.
10 Pipeline Data Dependences Data Dependences możemy wyróżnić trzy typy zależności: True data dependences; Name dependences; Control dependences.
11 Pipeline - niebezpieczeństwa Pipeline hazard zjawisko ma miejsce gdy potok instrukcji lub jego część zostaje wstrzymany z powodu warunków, które nie zezwalają na jego wykonywanie. Możemy wyróżnić trzy rodzaje hazardów: Resources hazards; Data hazards; Control hazards.
12 Pipeline True Data Dependences Instrukcja A INSTR A jest zależna od instrukcji B INSTR B jeżeli spełniony jest jeden z poniższych warunków: INSTR B generuje wynik, który może być wykorzystany przez INSTR A, lub INSTR A zależy od INSTR C, a INSTR C zależy od INSTR B
13 Pipeline True Data Dependences Zależności danych określają nam trzy zagadnienia: Możliwość wystąpienia hazardu; Porządek wykonywania programu; Górną granicę wykorzystania przetwarzania równoległego.
14 Pipeline Name Dependences Name Dependence ma miejsce w sytuacji gdy dwie instrukcje używają tego samego rejestru lub tego samego obszaru pamięci, zwanych nazwą, w sytuacji gdy nie ma przepływu danych pomiędzy instrukcjami powiązanymi z tą nazwą. Wyróżniamy dwa typy zależności nazwy pomiędzy instrukcją INSTR A, która poprzedza instrukcję INSTR B w programie.
15 Pipeline Name Dependences Antidependence pomiędzy INSTR A a INSTR B, ma miejsce gdy INSTR B wpisuje do rejestru lub obszaru pamięci, z których INSTR A czyta. Pierwotna kolejność musi być zachowana dla pewności iż INSTR A czyta właściwą wartość. Output dependence zachodzi w sytuacji gdy INSTR A i INSTR B zapisują do tego samego rejestru lub obszaru pamięci. Kolejność musi być zachowana dla pewności iż końcowa zapisana wartość odpowiada INSTR B.
16 Pipeline - niebezpieczeństwa Data hazard ma miejsce w sytuacji gdy dochodzi do konfliktu w czasie dostępu do lokalizacji operandu. Dwie instrukcje zostaną wykonane kolejno po sobie i obie odwołują się do konkretnej lokalizacji w pamięci lub rejestru operandu. Niebezpieczeństwa danych mogą być klasyfikowane w zależności od kolejności wykonywania operacji odczytu i zapisu w instrukcjach. Dla dwóch instrukcji INSTR A i INSTR B, gdzie INSTR A poprzedza INSTR B w programie otrzymujemy następujące zależności:
17 Pipeline - niebezpieczeństwa RAW (read after write) INSTR B próbuje czytać źródło przed jego zapisem przez INSTR A. INSTR B błędnie pobiera starą wartość. Najczęściej występujący przykład True Data Dependence. WAW (write after write) INSTR B próbuje zapisać operand zanim zostanie zapisany przez INSTR A. Zapisy wykonane są w niewłaściwej kolejności, pozostawiają wartość zapisaną przez INSTR A zamiast wartości zapisanej przez INSTR B. Przykład output dependence.
18 Pipeline - niebezpieczeństwa WAR (write after read) INSTR B próbuje zapisu do lokalizacji docelowej zanim INSTR A odczyta z tej lokalizacji, INSTR A niepoprawnie odczytuje nową wartość. Hazard ten jest wynikiem antidependence. Hazard tego typu pojawia się rzadko gdyż wszystkie odczyty wykonywane są wcześniej (w ID) natomiast zapisy późno (w WB). WAR może mieć miejsce w czasie reorganizacji potoku instrukcji. RAR (read after read) nie jest hazardem.
19 Pipeline Control Dependences Control Dependence określa kolejność instrukcji, INSTR A, w odniesieniu do instrukcji warunkowych, tak więc instrukcja INSTR A jest wykonywana zgodnie z programem i tylko wtedy gdy powinna być wykonana. if P1 { S1; }; if P2 { S2; } S1 jest zależny od P1, S2 jest zależny od P2 ale nie od P1.
20 Pipeline Control Dependences W ogólności możemy wyróżnić dwa typy zależności kontrolnych : Instrukcja, która zależna jest od warunku i nie może zostać przesunięta przed warunek, tak więc jej wykonanie nie jest dłużej kontrolowane przez ten warunek. Przykład nie możemy przenieść fragmentu wyrażenia if przed wyrażeniem if. Instrukcja, która nie zależy od warunku ale nie może być przesunięta za warunek, tak więc jej wykonanie jest kontrolowane przez warunek. Przykład nie możemy przenieść wyrażenia występującego przed wyrażeniem if do fragmentu wyrażenia if.


21 Pipeline - niebezpieczństwa Resource hazard ma miejsce w sytuacji gdy dwie lub więcej instrukcji z potoku potrzebują tego samego zasobu. W rezultacie instrukcje muszą być wykonywane szeregowo, a nie równolegle. Resource hazard często nazywany jest hazardem strukturalnym ang. structural hazard.
22 Pipeline Data Path and Control Instruction Fetch pobranie instrukcji z pamięci z pod aktualnego adresu PC i umieszczenie jej w rejestrze IF/ID. Wartość PC jest zmodyfikowana i zapisana do PC aby mogła być odczytana w następnym cyklu zegarowym. Zmodyfikowana wartość PC jest zapisana również do IF/ID dla późniejszych instrukcji warunkowych. Procesor nie wie jaka instrukcja jest pobierana i musi przygotować dla każdej instrukcji ścieżkę w dół potoku do przesyłania wymaganych informacji.
23 Pipeline Data Path and Control Instruction decode and register file read rejestr IF/ID dostarcza 16- bitową część bezpośrednią instrukcji, która jest rozszerzona do 32 bitów oraz numery rejestrów do odczytu dwóch rejestrów. Wszystkie trzy wartości zapisane są w rejestrze ID/EX łącznie ze zmodyfikowaną wartością PC.
24 Pipeline Data Path and Control Execute or address calculation instrukcja ładowania czyta zawartość rejestru 1 i rozszerzoną wartość bezpośrednią z ID/EX a następnie dodaje je do siebie w ALU. Suma umieszczona zostaje w rejestrze EX/MEM.
25 Pipeline Data Path and Control Memory access instrukcja ładowania czyta zawartość pamięci spod adresu zamieszczonego w rejestrze EX/MEM, a następnie umieszcza odczytaną wartość w rejestrze MEM/WB.
26 Pipeline Data Path and Control Write-back w końcowym etapie następuje odczyt danej z rejestru MEM/WB i zapis do zbioru rejestrów.
27 Pipeline Forwarding Forwarding przesyłanie danej, jak tylko jest ona dostępna, do innych jednostek, które jej potrzebują, zanim będzie możliwe odczytanie jej ze zbioru rejestrów.
28 Pipelining Przetwarzanie potokowe jednoetapowe ang. single-level pipelining możliwe do realizacji dzięki architekturze harwardzkiej i zbiorowi szybkich rejestrów; przetwarzanie rozkazów podzielone jest na następujące etapy: fetch; execute. XMEGA D [MANUAL] XMEGA CPU
29 Pipelining Pojedynczy cykl operacji ALU składa się z kilku faz: Pobranie operandów fetch; Operacja ALU execute; Zapis wyniku writeback. XMEGA D [MANUAL]
30 Pipelining Przetwarzanie potokowe trójetapowe przetwarzanie rozkazów podzielone jest na następujące etapy: fetch; decode; execute.
31 Pipelining Przetwarzanie potokowe pięcioetapowy przetwarzanie rozkazów podzielone jest na następujące etapy: fetch; decode; execute; memory access; write back.
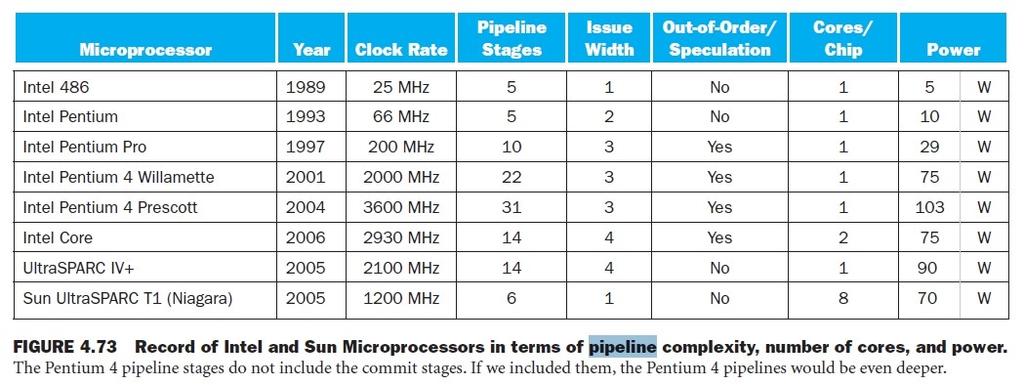
32 Pipelining
33 Pipelining UltraSPARC IV

34 Pipelining UltraSPARC IV
35 Pipelining Pentium 4 Willamette
36 Pipelining Pentium 4 Willamette TC Nxt IP: Trace cache next instruction pointer. This stage looks at branch target buffer (BTB) for the next microinstruction to be executed. This step takes two stages. TC Fetch: Trace cache fetch. Loads, from the trace cache, this microinstruction. This step takes two stages. Drive: Sends the microinstruction to be processed to the resource allocator and register renaming circuit. Alloc: Allocate. Checks which CPU resources will be needed by the microinstruction for example, the memory load and store buffers. Rename: If the program uses one of the eight standard x86 registers it will be renamed into one of the 128 internal registers present on Pentium 4. This step takes two stages. Que: Queue. The microinstructions are put in queues according to their types (for example, integer or floating point). They are held in the queue until there is an open slot of the same type in the scheduler. Sch: Schedule. Microinstructions are scheduled to be executed according to its type (integer, floating point, etc). Before arriving to this stage, all instructions are in order, i.e., on the same order they appear on the program. At this stage, the scheduler re-orders the instructions in order to keep all execution units full. For example, if there is one floating point unit going to be available, the scheduler will look for a floating point instruction to send it to this unit, even if the next instruction on the program is an integer one. The scheduler is the heart of the out-of-order engine of Intel 7th generation processors. This step takes three stages. Disp: Dispatch. Sends the microinstructions to their corresponding execution engines. This step takes two stages. RF: Register file. The internal registers, stored in the instructions pool, are read. This step takes two stages. Ex: Execute. Microinstructions are executed. Flgs: Flags. The microprocessor flags are updated. Br Ck: Branch check. Checks if the branch taken by the program is the same predicted by the branch prediction circuit. Drive: Sends the results of this check to the branch target buffer (BTB) present on the processor s entrance.
37 ARM11 Pipelining ARM11 MPCore potok 8 etapowy: 2 stages of instruction fetch Fe1, Fe2; Decode stage De; Issue stage Iss; 4 stages of execution.
38 ARM11 Pipelining Etapy przetwarzania potokowego: Fe1 etap pierwszy pobierania instrukcji i predykcji skoku; Fe2 etap drugi pobierania instrukcji i predykcji skoku; De dekodowanie instrukcji; Iss odczyt rejestru i wydanie instrukcji; Sh etap przesuwnika; ALU obliczenia arytmetyczne; Sat ; Wbex zapis danej z mnożenia lub głównego potoku wykonania; MAC1 pierwszy etap pipeline u mnożenia; MAC2 drugi etap pipeline u mnożenia; MAC3 trzeci etap pipeline u mnożenia;
39 ARM11 Pipelining Etapy przetwarzania potokowego: ADD etap generowania adresu; DC1 etap pierwszy dostępu do pamięci podręcznej danych; DC2 etap drugi dostępu do pamięci podręcznej danych; WBIs zapis danych z LSU Load Store Unit.
40 ARM11 Pipelining Etapy pobierania mogą obejmować maksymalnie 4 instrukcji, predykcja skoku wykonywana jest przed instrukcjami na podstawie wcześniej wykonanych instrukcji. Etapy wydania i dekodowania mogą zawierać dowolne instrukcje równolegle z przewidywanym skokiem. Etapy wykonania, pamięci i zapisu, przewidywany skok, operacje ALU lub mnożenia, operacje wielokrotnego ładowania / zapisu oraz instrukcje koprocesora wykonywane są równolegle.
Przetwarzanie potokowe pipelining
 Przetwarzanie potokowe pipelining (część A) Przypomnienie - implementacja jednocyklowa 4 Add Add PC Address memory ister # isters Address ister # ister # memory Wstęp W implementacjach prezentowanych tydzień
Przetwarzanie potokowe pipelining (część A) Przypomnienie - implementacja jednocyklowa 4 Add Add PC Address memory ister # isters Address ister # ister # memory Wstęp W implementacjach prezentowanych tydzień
UTK ARCHITEKTURA PROCESORÓW 80386/ Budowa procesora Struktura wewnętrzna logiczna procesora 80386
 Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Architektura komputerów, Informatyka, sem.iii. Rozwiązywanie konfliktów danych i sterowania w architekturze potokowej
 Rozwiązywanie konfliktów danych i sterowania w architekturze potokowej Konflikty w przetwarzaniu potokowym Konflikt danych Data Hazard Wstrzymywanie kolejki Pipeline Stall Optymalizacja kodu (metody programowe)
Rozwiązywanie konfliktów danych i sterowania w architekturze potokowej Konflikty w przetwarzaniu potokowym Konflikt danych Data Hazard Wstrzymywanie kolejki Pipeline Stall Optymalizacja kodu (metody programowe)
Architektura potokowa RISC
 Architektura potokowa RISC Podział zadania na odrębne części i niezależny sprzęt szeregowe Brak nawrotów" podczas pracy potokowe Przetwarzanie szeregowe i potokowe Podział instrukcji na fazy wykonania
Architektura potokowa RISC Podział zadania na odrębne części i niezależny sprzęt szeregowe Brak nawrotów" podczas pracy potokowe Przetwarzanie szeregowe i potokowe Podział instrukcji na fazy wykonania
Architektura typu Single-Cycle
 Architektura typu Single-Cycle...czyli budujemy pierwszą maszynę parową Przepływ danych W układach sekwencyjnych przepływ danych synchronizowany jest sygnałem zegara Elementy procesora - założenia Pamięć
Architektura typu Single-Cycle...czyli budujemy pierwszą maszynę parową Przepływ danych W układach sekwencyjnych przepływ danych synchronizowany jest sygnałem zegara Elementy procesora - założenia Pamięć
Architektura mikroprocesorów z rdzeniem ColdFire
 Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
Witold Komorowski: RISC. Witold Komorowski, dr inż.
 Witold Komorowski, dr inż. Koncepcja RISC i przetwarzanie potokowe RISC koncepcja architektury i organizacji komputera Aspekty opisu komputera Architektura Jak się zachowuje? Organizacja Jak działa? Realizacja
Witold Komorowski, dr inż. Koncepcja RISC i przetwarzanie potokowe RISC koncepcja architektury i organizacji komputera Aspekty opisu komputera Architektura Jak się zachowuje? Organizacja Jak działa? Realizacja
4 Literatura. c Dr inż. Ignacy Pardyka (Inf.UJK) ASK SP.01 Rok akad. 2011/2012 2 / 27
 ASK SP.01 Rok akad. 2011/2012 2 / 27") ARCHITEKTURA SYSTEÓW KOPUTEROWYCH strktry procesorów ASK SP. c Dr inż. Ignacy Pardyka UNIWERSYTET JANA KOCHANOWSKIEGO w Kielcach Rok akad. 2/22 Założenia konstrkcyjne Układ pobierania instrkcji Układ przygotowania
ARCHITEKTURA SYSTEÓW KOPUTEROWYCH strktry procesorów ASK SP. c Dr inż. Ignacy Pardyka UNIWERSYTET JANA KOCHANOWSKIEGO w Kielcach Rok akad. 2/22 Założenia konstrkcyjne Układ pobierania instrkcji Układ przygotowania
architektura komputerów w. 4 Realizacja sterowania
 architektura komputerów w. 4 Realizacja sterowania Model komputera CPU Jednostka sterująca Program umieszczony wraz z danymi w pamięci jest wykonywany przez CPU program wykonywany jest sekwencyjnie, zmiana
architektura komputerów w. 4 Realizacja sterowania Model komputera CPU Jednostka sterująca Program umieszczony wraz z danymi w pamięci jest wykonywany przez CPU program wykonywany jest sekwencyjnie, zmiana
4 Literatura. c Dr inż. Ignacy Pardyka (Inf.UJK) ASK SP.02 Rok akad. 2011/ / 35
 ASK SP.02 Rok akad. 2011/ / 35") ARCHITEKTURA SYSTEÓW KOPUTEROWYCH strktry procesorów ASK SP.2 c Dr inż. Ignacy Pardyka UNIWERSYTET JANA KOCHANOWSKIEGO w Kielcach Rok akad. 2/22 Procesor IPS R3 Potokowe wykonywanie instrkcji Konflikty
ARCHITEKTURA SYSTEÓW KOPUTEROWYCH strktry procesorów ASK SP.2 c Dr inż. Ignacy Pardyka UNIWERSYTET JANA KOCHANOWSKIEGO w Kielcach Rok akad. 2/22 Procesor IPS R3 Potokowe wykonywanie instrkcji Konflikty
Architektura komputerów
 Architektura komputerów Wykład 5 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) c.d. 2 Architektura CPU Jednostka arytmetyczno-logiczna (ALU) Rejestry Układ sterujący przebiegiem programu
Architektura komputerów Wykład 5 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) c.d. 2 Architektura CPU Jednostka arytmetyczno-logiczna (ALU) Rejestry Układ sterujący przebiegiem programu
Page 1. Pięcio-krokowy pipeline
 1 Pięcio-krokowy pipeline Każdy cykl zegara staje się jednym krokiem pipeline Kroki mogą być wykonywane równolegle Mimo, że wykonanie instrukcji zabiera 5 cykli zegara, liczba CPI zmienia się z 5 na 1
1 Pięcio-krokowy pipeline Każdy cykl zegara staje się jednym krokiem pipeline Kroki mogą być wykonywane równolegle Mimo, że wykonanie instrukcji zabiera 5 cykli zegara, liczba CPI zmienia się z 5 na 1
LEKCJA TEMAT: Współczesne procesory.
 LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
Adam Korzeniewski p Katedra Systemów Multimedialnych
 Adam Korzeniewski adamkorz@sound.eti.pg.gda.pl p. 732 - Katedra Systemów Multimedialnych Operacja na dwóch funkcjach dająca w wyniku modyfikację oryginalnych funkcji (wynikiem jest iloczyn splotowy). Jest
Adam Korzeniewski adamkorz@sound.eti.pg.gda.pl p. 732 - Katedra Systemów Multimedialnych Operacja na dwóch funkcjach dająca w wyniku modyfikację oryginalnych funkcji (wynikiem jest iloczyn splotowy). Jest
Technika mikroprocesorowa. Linia rozwojowa procesorów firmy Intel w latach
 mikrokontrolery mikroprocesory Technika mikroprocesorowa Linia rozwojowa procesorów firmy Intel w latach 1970-2000 W krótkim pionierskim okresie firma Intel produkowała tylko mikroprocesory. W okresie
mikrokontrolery mikroprocesory Technika mikroprocesorowa Linia rozwojowa procesorów firmy Intel w latach 1970-2000 W krótkim pionierskim okresie firma Intel produkowała tylko mikroprocesory. W okresie
Programowanie Niskopoziomowe
 Programowanie Niskopoziomowe Wykład 3: Architektura procesorów x86 Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Pojęcia ogólne Budowa mikrokomputera Cykl
Programowanie Niskopoziomowe Wykład 3: Architektura procesorów x86 Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Pojęcia ogólne Budowa mikrokomputera Cykl
Architektura Systemów Komputerowych
 Architektura Systemów Komputerowych Wykład 7: Potokowe jednostki wykonawcze Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Budowa potoku Problemy synchronizacji
Architektura Systemów Komputerowych Wykład 7: Potokowe jednostki wykonawcze Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Budowa potoku Problemy synchronizacji
Architektura systemów komputerowych. dr Artur Bartoszewski
 Architektura systemów komputerowych dr Artur Bartoszewski Procesor część II Rejestry procesora dostępne programowo AX Akumulator Zawiera jeden z operandów działania i do niego przekazywany jest wynik BX,CX,DX,EX,HX,LX
Architektura systemów komputerowych dr Artur Bartoszewski Procesor część II Rejestry procesora dostępne programowo AX Akumulator Zawiera jeden z operandów działania i do niego przekazywany jest wynik BX,CX,DX,EX,HX,LX
Wstęp do informatyki. Architektura co to jest? Architektura Model komputera. Od układów logicznych do CPU. Automat skończony. Maszyny Turinga (1936)
") Wstęp doinformatyki Architektura co to jest? Architektura Model komputera Dr inż Ignacy Pardyka Slajd 1 Slajd 2 Od układów logicznych do CPU Automat skończony Slajd 3 Slajd 4 Ile jest automatów skończonych?
Wstęp doinformatyki Architektura co to jest? Architektura Model komputera Dr inż Ignacy Pardyka Slajd 1 Slajd 2 Od układów logicznych do CPU Automat skończony Slajd 3 Slajd 4 Ile jest automatów skończonych?
Organizacja typowego mikroprocesora
 Organizacja typowego mikroprocesora 1 Architektura procesora 8086 2 Architektura współczesnego procesora 3 Schemat blokowy procesora AVR Mega o architekturze harwardzkiej Wszystkie mikroprocesory zawierają
Organizacja typowego mikroprocesora 1 Architektura procesora 8086 2 Architektura współczesnego procesora 3 Schemat blokowy procesora AVR Mega o architekturze harwardzkiej Wszystkie mikroprocesory zawierają
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
Architektura typu multi cycle
 PC ux ress Write data emdata [3-26] [25-2] [2-6] [5-] register [5-] Cond IorD em emwrite emtoreg IRWrite [25-] [5-] Outputs Control Op [5-] ux ux PCSource Op SrcB Src RegWrite RegDst register register
PC ux ress Write data emdata [3-26] [25-2] [2-6] [5-] register [5-] Cond IorD em emwrite emtoreg IRWrite [25-] [5-] Outputs Control Op [5-] ux ux PCSource Op SrcB Src RegWrite RegDst register register
Przetwarzanie potokowe (cd.) oraz zaawansowane organizacje procesorów
 oraz zaawansowane organizacje procesorów") Przetwarzanie potokowe (cd.) oraz zaawansowane organizacje procesorów Wynik porównania dla branch znany dopiero w fazie MEM (pod koniec EX) 4.8 Control Hazards Hazardy sterowania unieszkodliwić te rozkazy
Przetwarzanie potokowe (cd.) oraz zaawansowane organizacje procesorów Wynik porównania dla branch znany dopiero w fazie MEM (pod koniec EX) 4.8 Control Hazards Hazardy sterowania unieszkodliwić te rozkazy
Architektura komputera. Dane i rozkazy przechowywane są w tej samej pamięci umożliwiającej zapis i odczyt
 Architektura komputera Architektura von Neumanna: Dane i rozkazy przechowywane są w tej samej pamięci umożliwiającej zapis i odczyt Zawartośd tej pamięci jest adresowana przez wskazanie miejsca, bez względu
Architektura komputera Architektura von Neumanna: Dane i rozkazy przechowywane są w tej samej pamięci umożliwiającej zapis i odczyt Zawartośd tej pamięci jest adresowana przez wskazanie miejsca, bez względu
Programowalne układy logiczne
 Programowalne układy logiczne Mikroprocesor Szymon Acedański Marcin Peczarski Instytut Informatyki Uniwersytetu Warszawskiego 6 grudnia 2014 Zbudujmy własny mikroprocesor Bardzo prosty: 16-bitowy, 16 rejestrów
Programowalne układy logiczne Mikroprocesor Szymon Acedański Marcin Peczarski Instytut Informatyki Uniwersytetu Warszawskiego 6 grudnia 2014 Zbudujmy własny mikroprocesor Bardzo prosty: 16-bitowy, 16 rejestrów
Architektura Systemów Komputerowych
 Architektura Systemów Komputerowych Wykład 8: Procesory wielopotokowe, czyli superskalarne Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Struktury i rodzaje
Architektura Systemów Komputerowych Wykład 8: Procesory wielopotokowe, czyli superskalarne Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Struktury i rodzaje
organizacja procesora 8086
 Systemy komputerowe Procesor 8086 - tendencji w organizacji procesora organizacja procesora 8086 " # $ " % strali " & ' ' ' ( )" % *"towego + ", -" danych. Magistrala adresowa jest 20.bitowa, co pozwala
Systemy komputerowe Procesor 8086 - tendencji w organizacji procesora organizacja procesora 8086 " # $ " % strali " & ' ' ' ( )" % *"towego + ", -" danych. Magistrala adresowa jest 20.bitowa, co pozwala
Logiczny model komputera i działanie procesora. Część 1.
 Logiczny model komputera i działanie procesora. Część 1. Klasyczny komputer o architekturze podanej przez von Neumana składa się z trzech podstawowych bloków: procesora pamięci operacyjnej urządzeń wejścia/wyjścia.
Logiczny model komputera i działanie procesora. Część 1. Klasyczny komputer o architekturze podanej przez von Neumana składa się z trzech podstawowych bloków: procesora pamięci operacyjnej urządzeń wejścia/wyjścia.
Budowa i zasada działania komputera. dr Artur Bartoszewski
 Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Zrównoleglenie i przetwarzanie potokowe
 Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Projekt prostego procesora
 Projekt prostego procesora Opracowany przez Rafała Walkowiaka dla zajęć z PTC 2012/2013 w oparciu o Laboratory Exercise 9 Altera Corporation Rysunek 1 przedstawia schemat układu cyfrowego stanowiącego
Projekt prostego procesora Opracowany przez Rafała Walkowiaka dla zajęć z PTC 2012/2013 w oparciu o Laboratory Exercise 9 Altera Corporation Rysunek 1 przedstawia schemat układu cyfrowego stanowiącego
Przetwarzanie potokowe
 p. 1/3 Przetwarzanie potokowe (pipelining) p. 2/3 Przypomnienie - implementacja jednocyklowa 4 Add Add PC Address Instrction Instrction ister # isters Address ister # ister # p. 3/3 Wstęp W implementacjach
p. 1/3 Przetwarzanie potokowe (pipelining) p. 2/3 Przypomnienie - implementacja jednocyklowa 4 Add Add PC Address Instrction Instrction ister # isters Address ister # ister # p. 3/3 Wstęp W implementacjach
Architektura komputerów
 Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
ARCHITEKTURA SYSTEMÓW KOMPUTEROWYCH. Klasyczny cykl pracy procesora sekwencyjnego. współczesne architektury. c Dr inż.
 ARCHITETURA SYSTEMÓW OMPUTEROWYCH współczesne architektury c Dr inż. Ignacy Pardyka UNIWERSYTET JANA OCHANOWSIEGO w ielcach 1 Rok akad. 2014/2015 1 lasyczne procesory sekwencyjne i potokowe 1 Instytut
ARCHITETURA SYSTEMÓW OMPUTEROWYCH współczesne architektury c Dr inż. Ignacy Pardyka UNIWERSYTET JANA OCHANOWSIEGO w ielcach 1 Rok akad. 2014/2015 1 lasyczne procesory sekwencyjne i potokowe 1 Instytut
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Wstęp do informatyki. System komputerowy. Magistrala systemowa. Architektura komputera. Cezary Bolek
 Wstęp do informatyki Architektura komputera Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki System komputerowy systemowa (System Bus) Pamięć operacyjna ROM,
Wstęp do informatyki Architektura komputera Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki System komputerowy systemowa (System Bus) Pamięć operacyjna ROM,
Architektura Systemów Komputerowych
 Architektura Systemów Komputerowych Wykład 6: Budowa jednostki centralnej - CPU Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Procesor jednocyklowy Procesor
Architektura Systemów Komputerowych Wykład 6: Budowa jednostki centralnej - CPU Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Procesor jednocyklowy Procesor
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Architektura komputera. Cezary Bolek. Uniwersytet Łódzki. Wydział Zarządzania. Katedra Informatyki. System komputerowy
 Wstęp do informatyki Architektura komputera Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki System komputerowy systemowa (System Bus) Pamięć operacyjna ROM,
Wstęp do informatyki Architektura komputera Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki System komputerowy systemowa (System Bus) Pamięć operacyjna ROM,
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Procesory. Schemat budowy procesora
 Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Adam Korzeniewski p Katedra Systemów Multimedialnych
 Adam Korzeniewski adamkorz@sound.eti.pg.gda.pl p. 732 - Katedra Systemów Multimedialnych Komputer (elektroniczna maszyna cyfrowa) jest to maszyna programowalna. Maszyna programowalna ma dwie cechy: Reaguje
Adam Korzeniewski adamkorz@sound.eti.pg.gda.pl p. 732 - Katedra Systemów Multimedialnych Komputer (elektroniczna maszyna cyfrowa) jest to maszyna programowalna. Maszyna programowalna ma dwie cechy: Reaguje
Magistrala systemowa (System Bus)
") Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki systemowa (System Bus) Pamięć operacyjna ROM, RAM Jednostka centralna Układy we/wy In/Out Wstęp do Informatyki
Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki systemowa (System Bus) Pamięć operacyjna ROM, RAM Jednostka centralna Układy we/wy In/Out Wstęp do Informatyki
Struktura i działanie jednostki centralnej
 Struktura i działanie jednostki centralnej ALU Jednostka sterująca Rejestry Zadania procesora: Pobieranie rozkazów; Interpretowanie rozkazów; Pobieranie danych Przetwarzanie danych Zapisywanie danych magistrala
Struktura i działanie jednostki centralnej ALU Jednostka sterująca Rejestry Zadania procesora: Pobieranie rozkazów; Interpretowanie rozkazów; Pobieranie danych Przetwarzanie danych Zapisywanie danych magistrala
Architektura von Neumanna. Jak zbudowany jest współczesny komputer? Schemat architektury typowego PC-ta. Architektura PC wersja techniczna
 Architektura von Neumanna CPU pamięć wejście wyjście Jak zbudowany jest współczesny komputer? magistrala systemowa CPU jednostka centralna (procesor) pamięć obszar przechowywania programu i danych wejście
Architektura von Neumanna CPU pamięć wejście wyjście Jak zbudowany jest współczesny komputer? magistrala systemowa CPU jednostka centralna (procesor) pamięć obszar przechowywania programu i danych wejście
MOŻLIWOŚCI PROGRAMOWE MIKROPROCESORÓW
 MOŻLIWOŚCI PROGRAMOWE MIKROPROCESORÓW Projektowanie urządzeń cyfrowych przy użyciu układów TTL polegało na opracowaniu algorytmu i odpowiednim doborze i zestawieniu układów realizujących różnorodne funkcje
MOŻLIWOŚCI PROGRAMOWE MIKROPROCESORÓW Projektowanie urządzeń cyfrowych przy użyciu układów TTL polegało na opracowaniu algorytmu i odpowiednim doborze i zestawieniu układów realizujących różnorodne funkcje
. III atyka, sem, Inform Symulator puterów Escape rchitektura kom A
 Symulator Escape Konfiguracja ogólna Enable MUL and DIV Complete Set of Comp.Oper Sign Extension of B/H/W Memory Oper on B/H/W Program Program Dane Dane Załaduj konfigurację symulatora (File -> OpenFile)
Symulator Escape Konfiguracja ogólna Enable MUL and DIV Complete Set of Comp.Oper Sign Extension of B/H/W Memory Oper on B/H/W Program Program Dane Dane Załaduj konfigurację symulatora (File -> OpenFile)
Podstawy Techniki Mikroprocesorowej
 Podstawy Techniki Mikroprocesorowej Architektury mikroprocesorów Wydział Elektroniki Mikrosystemów i Fotoniki dr inż. Piotr Markowski Na prawach rękopisu. Na podstawie dokumentacji ATmega8535, www.atmel.com.
Podstawy Techniki Mikroprocesorowej Architektury mikroprocesorów Wydział Elektroniki Mikrosystemów i Fotoniki dr inż. Piotr Markowski Na prawach rękopisu. Na podstawie dokumentacji ATmega8535, www.atmel.com.
Architektury Komputerów. Tomasz Dziubich p.530, konsultacje czwartek. 9-10 i 11-12, dziubich@eti.pg.gda.pl
 Architektury Komputerów Tomasz Dziubich p.530, konsultacje czwartek. 9-10 i 11-12, dziubich@eti.pg.gda.pl Urządzenia przetwarzające zwane komputerami - kiedyś EDSAC, University of Cambridge, UK, 1949 i
Architektury Komputerów Tomasz Dziubich p.530, konsultacje czwartek. 9-10 i 11-12, dziubich@eti.pg.gda.pl Urządzenia przetwarzające zwane komputerami - kiedyś EDSAC, University of Cambridge, UK, 1949 i
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
Architektura systemów komputerowych. Przetwarzanie potokowe I
 Architektura systemów komputerowych Plan wykładu. Praca potokowa. 2. Projekt P koncepcja potoku: 2.. model ścieżki danych 2.2. rejestry w potoku, 2.3. wykonanie instrukcji, 2.3. program w potoku. Cele
Architektura systemów komputerowych Plan wykładu. Praca potokowa. 2. Projekt P koncepcja potoku: 2.. model ścieżki danych 2.2. rejestry w potoku, 2.3. wykonanie instrukcji, 2.3. program w potoku. Cele
UTK Można stwierdzić, że wszystkie działania i operacje zachodzące w systemie są sterowane bądź inicjowane przez mikroprocesor.
 Zadaniem centralnej jednostki przetwarzającej CPU (ang. Central Processing Unit), oprócz przetwarzania informacji jest sterowanie pracą pozostałych układów systemu. W skład CPU wchodzą mikroprocesor oraz
Zadaniem centralnej jednostki przetwarzającej CPU (ang. Central Processing Unit), oprócz przetwarzania informacji jest sterowanie pracą pozostałych układów systemu. W skład CPU wchodzą mikroprocesor oraz
Architektura systemów komputerowych. dr Artur Bartoszewski
 Architektura systemów komputerowych dr Artur Bartoszewski Procesor część II Rejestry procesora dostępne programowo A B D H PC SP F C E L A Akumulator Zawiera jeden z operandów działania i do niego przekazywany
Architektura systemów komputerowych dr Artur Bartoszewski Procesor część II Rejestry procesora dostępne programowo A B D H PC SP F C E L A Akumulator Zawiera jeden z operandów działania i do niego przekazywany
Architektura systemów komputerowych
 Studia stacjonarne inżynierskie, kierunek INFORMATYKA Architektura systemów komputerowych Architektura systemów komputerowych dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat
Studia stacjonarne inżynierskie, kierunek INFORMATYKA Architektura systemów komputerowych Architektura systemów komputerowych dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat
dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia i ich zastosowań w przemyśle" POKL
 Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Procesory rodziny x86. Dariusz Chaberski
 Procesory rodziny x86 Dariusz Chaberski 8086 produkowany od 1978 magistrala adresowa - 20 bitów (1 MB) magistrala danych - 16 bitów wielkość instrukcji - od 1 do 6 bajtów częstotliwośc pracy od 5 MHz (IBM
Procesory rodziny x86 Dariusz Chaberski 8086 produkowany od 1978 magistrala adresowa - 20 bitów (1 MB) magistrala danych - 16 bitów wielkość instrukcji - od 1 do 6 bajtów częstotliwośc pracy od 5 MHz (IBM
Prosty procesor dla framgentu listy rozkazów MIPSa
 p. /33 Prosty procesor dla framgent listy rozkazów IPSa (rysnki pochodza z ksiażki Hennessy ego i Pattersona) p. 2/33 Wstęp Naszym celem będzie zaprojektowanie prostego procesora realizjacego fragment
p. /33 Prosty procesor dla framgent listy rozkazów IPSa (rysnki pochodza z ksiażki Hennessy ego i Pattersona) p. 2/33 Wstęp Naszym celem będzie zaprojektowanie prostego procesora realizjacego fragment
Architektura komputerów
 Wykład jest przygotowany dla IV semestru kierunku Elektronika i Telekomunikacja. Studia I stopnia Dr inż. Małgorzata Langer Architektura komputerów Prezentacja multimedialna współfinansowana przez Unię
Wykład jest przygotowany dla IV semestru kierunku Elektronika i Telekomunikacja. Studia I stopnia Dr inż. Małgorzata Langer Architektura komputerów Prezentacja multimedialna współfinansowana przez Unię
Zygmunt Kubiak Instytut Informatyki Politechnika Poznańska
 Zygmunt Kubiak Instytut Informatyki Politechnika Poznańska Zygmunt Kubiak 2 Centralny falownik (ang. central inverter system) Zygmunt Kubiak 3 Micro-Inverter Mikro-przetwornice działają podobnie do systemów
Zygmunt Kubiak Instytut Informatyki Politechnika Poznańska Zygmunt Kubiak 2 Centralny falownik (ang. central inverter system) Zygmunt Kubiak 3 Micro-Inverter Mikro-przetwornice działają podobnie do systemów
Systemy wbudowane. Poziomy abstrakcji projektowania systemów HW/SW. Wykład 9: SystemC modelowanie na różnych poziomach abstrakcji
 Systemy wbudowane Wykład 9: SystemC modelowanie na różnych poziomach abstrakcji Poziomy abstrakcji projektowania systemów HW/SW 12/17/2011 S.Deniziak:Systemy wbudowane 2 1 Model czasu 12/17/2011 S.Deniziak:Systemy
Systemy wbudowane Wykład 9: SystemC modelowanie na różnych poziomach abstrakcji Poziomy abstrakcji projektowania systemów HW/SW 12/17/2011 S.Deniziak:Systemy wbudowane 2 1 Model czasu 12/17/2011 S.Deniziak:Systemy
Układ sterowania, magistrale i organizacja pamięci. Dariusz Chaberski
 Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
Architektura Systemów Komputerowych. Architektura potokowa Klasyfikacja architektur równoległych
 Archiekura Sysemów Kompuerowych Archiekura pookowa Klasyfikacja archiekur równoległych 1 Archiekura pookowa Sekwencyjne wykonanie programu w mikroprocesorze o archiekurze von Neumanna Insr.1 Φ1 Insr.1
Archiekura Sysemów Kompuerowych Archiekura pookowa Klasyfikacja archiekur równoległych 1 Archiekura pookowa Sekwencyjne wykonanie programu w mikroprocesorze o archiekurze von Neumanna Insr.1 Φ1 Insr.1
Architektura systemów komputerowych. dr Artur Bartoszewski
 Architektura systemów komputerowych 1 dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat blokowy CPU 4. Architektura CISC i RISC 2 Jednostka arytmetyczno-logiczna 3 Schemat blokowy
Architektura systemów komputerowych 1 dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat blokowy CPU 4. Architektura CISC i RISC 2 Jednostka arytmetyczno-logiczna 3 Schemat blokowy
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Architektura systemów komputerowych Laboratorium 14 Symulator SMS32 Implementacja algorytmów
 Marcin Stępniak Architektura systemów komputerowych Laboratorium 14 Symulator SMS32 Implementacja algorytmów 1. Informacje Poniższe laboratoria zawierają podsumowanie najważniejszych informacji na temat
Marcin Stępniak Architektura systemów komputerowych Laboratorium 14 Symulator SMS32 Implementacja algorytmów 1. Informacje Poniższe laboratoria zawierają podsumowanie najważniejszych informacji na temat
Jednostka centralna. dr hab. inż. Krzysztof Patan, prof. PWSZ
 Jednostka centralna dr hab. inż. Krzysztof Patan, prof. PWSZ Instytut Politechniczny Państwowa Wyższa Szkoła Zawodowa w Głogowie k.patan@issi.uz.zgora.pl Architektura i organizacja komputerów Architektura
Jednostka centralna dr hab. inż. Krzysztof Patan, prof. PWSZ Instytut Politechniczny Państwowa Wyższa Szkoła Zawodowa w Głogowie k.patan@issi.uz.zgora.pl Architektura i organizacja komputerów Architektura
ARCHITEKTURA PROCESORA,
 ARCHITEKTURA PROCESORA, poza blokami funkcjonalnymi, to przede wszystkim: a. formaty rozkazów, b. lista rozkazów, c. rejestry dostępne programowo, d. sposoby adresowania pamięci, e. sposoby współpracy
ARCHITEKTURA PROCESORA, poza blokami funkcjonalnymi, to przede wszystkim: a. formaty rozkazów, b. lista rozkazów, c. rejestry dostępne programowo, d. sposoby adresowania pamięci, e. sposoby współpracy
Mikroprocesory rodziny INTEL 80x86
 Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Metody optymalizacji soft-procesorów NIOS
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
Komputer. Komputer (computer) jest to urządzenie elektroniczne służące do zbierania, przechowywania, przetwarzania i wizualizacji informacji
 jest to urządzenie elektroniczne służące do zbierania, przechowywania, przetwarzania i wizualizacji informacji") Komputer Komputer (computer) jest to urządzenie elektroniczne służące do zbierania, przechowywania, przetwarzania i wizualizacji informacji Budowa komputera Drukarka (printer) Monitor ekranowy skaner Jednostka
Komputer Komputer (computer) jest to urządzenie elektroniczne służące do zbierania, przechowywania, przetwarzania i wizualizacji informacji Budowa komputera Drukarka (printer) Monitor ekranowy skaner Jednostka
architektura komputerów w 1 1
 8051 Port P2 Port P3 Serial PORT Timers T0, T1 Interrupt Controler DPTR Register Program Counter Program Memory Port P0 Port P1 PSW ALU B Register SFR accumulator STRUCTURE OF 8051 architektura komputerów
8051 Port P2 Port P3 Serial PORT Timers T0, T1 Interrupt Controler DPTR Register Program Counter Program Memory Port P0 Port P1 PSW ALU B Register SFR accumulator STRUCTURE OF 8051 architektura komputerów
Architektura komputerów
 Architektura komputerów Tydzień 5 Jednostka Centralna Zadania realizowane przez procesor Pobieranie rozkazów Interpretowanie rozkazów Pobieranie danych Przetwarzanie danych Zapisanie danych Główne zespoły
Architektura komputerów Tydzień 5 Jednostka Centralna Zadania realizowane przez procesor Pobieranie rozkazów Interpretowanie rozkazów Pobieranie danych Przetwarzanie danych Zapisanie danych Główne zespoły
Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f)
 i częstotliwości (f)") Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
Projektowanie. Projektowanie mikroprocesorów
 WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Laboratorium - Używanie programu Wireshark do obserwacji mechanizmu uzgodnienia trójetapowego TCP
 Laboratorium - Używanie programu Wireshark do obserwacji mechanizmu uzgodnienia trójetapowego Topologia Cele Część 1: Przygotowanie Wireshark do przechwytywania pakietów Wybór odpowiedniego interfejsu
Laboratorium - Używanie programu Wireshark do obserwacji mechanizmu uzgodnienia trójetapowego Topologia Cele Część 1: Przygotowanie Wireshark do przechwytywania pakietów Wybór odpowiedniego interfejsu
Wydajność obliczeń a architektura procesorów
 Wydajność obliczeń a architektura procesorów 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych zadań, np.: liczba rozkazów na sekundę
Wydajność obliczeń a architektura procesorów 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych zadań, np.: liczba rozkazów na sekundę
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Mikroprocesor RISC Power PC 603. Literatura: MPC603e & EC603e RISC Microprocessors User's Manual
 Mikroprocesor RISC Power PC 603 Literatura: MPC603e & EC603e RISC Microprocessors User's Manual Schemat blokowy INSTRUCTION UNIT SEQUENTIAL FETCHER- zatrzaskuje kolejne instrukcje z pamięci podręcznej
Mikroprocesor RISC Power PC 603 Literatura: MPC603e & EC603e RISC Microprocessors User's Manual Schemat blokowy INSTRUCTION UNIT SEQUENTIAL FETCHER- zatrzaskuje kolejne instrukcje z pamięci podręcznej
Rejestry procesora. Nazwa ilość bitów. AX 16 (accumulator) rejestr akumulatora. BX 16 (base) rejestr bazowy. CX 16 (count) rejestr licznika
 rejestr akumulatora. BX 16 (base) rejestr bazowy. CX 16 (count) rejestr licznika") Rejestry procesora Procesor podczas wykonywania instrukcji posługuje się w dużej części pamięcią RAM. Pobiera z niej kolejne instrukcje do wykonania i dane, jeżeli instrukcja operuje na jakiś zmiennych.
Rejestry procesora Procesor podczas wykonywania instrukcji posługuje się w dużej części pamięcią RAM. Pobiera z niej kolejne instrukcje do wykonania i dane, jeżeli instrukcja operuje na jakiś zmiennych.
Programowanie mikroprocesorów jednoukładowych
 Programowanie mikroprocesorów jednoukładowych Pamięć cache Mariusz Naumowicz Programowanie mikroprocesorów jednoukładowych 11 września 2017 1 / 22 Plan I Cache Mariusz Naumowicz Programowanie mikroprocesorów
Programowanie mikroprocesorów jednoukładowych Pamięć cache Mariusz Naumowicz Programowanie mikroprocesorów jednoukładowych 11 września 2017 1 / 22 Plan I Cache Mariusz Naumowicz Programowanie mikroprocesorów
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Moduł wspierający diagnostykę i sprzętowe debugowanie
 Moduł wspierający diagnostykę i sprzętowe debugowanie 1 Diagnostyka mikroprocesorowego systemu czasu rzeczywistego Programowe emulatory procesorów, Sprzętowe emulatory procesorów, Debugery programowe,
Moduł wspierający diagnostykę i sprzętowe debugowanie 1 Diagnostyka mikroprocesorowego systemu czasu rzeczywistego Programowe emulatory procesorów, Sprzętowe emulatory procesorów, Debugery programowe,
LEKCJA TEMAT: Zasada działania komputera.
 LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
Materiały do wykładu. 4. Mikroprocesor. Marcin Peczarski. Instytut Informatyki Uniwersytet Warszawski
 Materiały do wykładu 4. Mikroprocesor Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 19 marca 2007 Małe przypomnienie 4.1 Rejestry Układ współpracy z szynami Jednostka sterująca połączenia
Materiały do wykładu 4. Mikroprocesor Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 19 marca 2007 Małe przypomnienie 4.1 Rejestry Układ współpracy z szynami Jednostka sterująca połączenia
Elementy składowe systemu komputerowego
 SWB - Systemy wbudowane - wprowadzenie - wykład 9 asz 1 Elementy składowe systemu komputerowego Podstawowe elementy składowe: procesor z ALU pamięć komputera (zawierająca dane i program) urządzenia wejścia/wyjścia
SWB - Systemy wbudowane - wprowadzenie - wykład 9 asz 1 Elementy składowe systemu komputerowego Podstawowe elementy składowe: procesor z ALU pamięć komputera (zawierająca dane i program) urządzenia wejścia/wyjścia
Wstęp do informatyki. Maszyna RAM. Schemat logiczny komputera. Maszyna RAM. RAM: szczegóły. Realizacja algorytmu przez komputer
 Realizacja algorytmu przez komputer Wstęp do informatyki Wykład UniwersytetWrocławski 0 Tydzień temu: opis algorytmu w języku zrozumiałym dla człowieka: schemat blokowy, pseudokod. Dziś: schemat logiczny
Realizacja algorytmu przez komputer Wstęp do informatyki Wykład UniwersytetWrocławski 0 Tydzień temu: opis algorytmu w języku zrozumiałym dla człowieka: schemat blokowy, pseudokod. Dziś: schemat logiczny
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Odczyt danych z klawiatury Operatory w Javie
 Odczyt danych z klawiatury Operatory w Javie Operatory W Javie występują następujące typy operatorów: Arytmetyczne. Inkrementacji/Dekrementacji Przypisania. Porównania. Bitowe. Logiczne. Pozostałe. Operacje
Odczyt danych z klawiatury Operatory w Javie Operatory W Javie występują następujące typy operatorów: Arytmetyczne. Inkrementacji/Dekrementacji Przypisania. Porównania. Bitowe. Logiczne. Pozostałe. Operacje
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]
![Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]](/thumbs/57/40653782.jpg "Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]") Procesor ma architekturę akumulatorową. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset or Rx, Ry, A add Rx load A, [Rz] push Rx sub Rx, #3, A load Rx, [A] Procesor ma architekturę rejestrową
Procesor ma architekturę akumulatorową. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset or Rx, Ry, A add Rx load A, [Rz] push Rx sub Rx, #3, A load Rx, [A] Procesor ma architekturę rejestrową
procesów Współbieżność i synchronizacja procesów Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak
 Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Abstrakcja programowania współbieżnego Instrukcje atomowe i ich przeplot Istota synchronizacji Kryteria poprawności programów współbieżnych
Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Abstrakcja programowania współbieżnego Instrukcje atomowe i ich przeplot Istota synchronizacji Kryteria poprawności programów współbieżnych
Rys. 1. Podłączenie cache do procesora.
 Cel stosowania pamięci cache w procesorach Aby określić cel stosowania pamięci podręcznej cache, należy w skrócie omówić zasadę działania mikroprocesora. Jest on układem cyfrowym taktowanym przez sygnał
Cel stosowania pamięci cache w procesorach Aby określić cel stosowania pamięci podręcznej cache, należy w skrócie omówić zasadę działania mikroprocesora. Jest on układem cyfrowym taktowanym przez sygnał
Lista Rozkazów: Język komputera
 Lista Rozkazów: Język komputera Większość slajdów do tego wykładu to tłumaczenia i przeróbki oficjalnych sladjów do podręcznika Pattersona i Hennessy ego Lista rozkazów Zestaw rozkazów wykonywanych przez
Lista Rozkazów: Język komputera Większość slajdów do tego wykładu to tłumaczenia i przeróbki oficjalnych sladjów do podręcznika Pattersona i Hennessy ego Lista rozkazów Zestaw rozkazów wykonywanych przez
Komputer IBM PC niezależnie od modelu składa się z: Jednostki centralnej czyli właściwego komputera Monitora Klawiatury
 1976 r. Apple PC Personal Computer 1981 r. pierwszy IBM PC Komputer jest wart tyle, ile wart jest człowiek, który go wykorzystuje... Hardware sprzęt Software oprogramowanie Komputer IBM PC niezależnie
1976 r. Apple PC Personal Computer 1981 r. pierwszy IBM PC Komputer jest wart tyle, ile wart jest człowiek, który go wykorzystuje... Hardware sprzęt Software oprogramowanie Komputer IBM PC niezależnie