Od rozpoznawania do tłumaczenia mowy polskiej
|
|
|
- Kornelia Łuczak
- 10 lat temu
- Przeglądów:
Transkrypt
1 Od rozpoznawania do tłumaczenia mowy polskiej Krzysztof Marasek PJWSTK

2 Plan prezentacji Wprowadzenie Komponenty systemu tłumaczącego Aktualne działania

3 Dlaczego automatyczne tłumaczenie mowy? Czynniki techniczne Choć nadal dalekie od perfekcji, metody maszynowego tłumaczenia dokonały w ostatnich latach wyraźnego postępu NIST MT workshops (od 2002) IWSLT workshops (od 2002) TC-STAR workshop ( ) ACL/NAACL Shared Tasks ( ) Czynniki sukcesu to: Coraz silniejsze komputery (trening na klastrach PC, dużo RAM) Rozwój metod statystycznych i bazujących na danych (data driven) Odpowiednie zasoby lingwistyczne (korpusy bilingualne) Rozwój metod oceny jakości tłumaczenia (miary błędów) Stopniowe komplikowanie zadań Zaangażowanie wielkich firm: Google, Microsoft, IBM, itd.. Rozwój interfejsów głosowych Rozpoznawanie mowy działa coraz lepiej Mowę syntetyczną coraz trudniej odróżnić od naturalnej Czynniki ludzkie Lazzari, 06 Potrzeby komunikacyjne w kurczącym się geograficznie świecie, komercyjne zastosowania SST He, Deng, 11
 Odpowiednie zasoby lingwistyczne (korpusy bilingualne) Rozwój metod oceny jakości tłumaczenia (miary błędów) Stopniowe komplikowanie zadań Zaangażowanie wielkich firm: Google, Microsoft, IBM,")
4 Komponenty systemu tłumaczącego Rozpoznawanie mowy Tłumaczenie wykorzystujące modele statystyczne Intelligent Software Lab, 06 Synteza mowy

5 Jakość rozpoznawania mowy ASR da się używać! ASR działa najlepiej dla ściśle określonego mówcy, im mniejszy słownik tym lepiej, angielski lepiej niż inne języki Stopa błędów rozpoznawania mowy spontanicznej jest co najmniej dwukrotnie większa niż dla czytania, stopa błędów jest wysoka dla konwersacji wielu mówców w trudnym akustycznie środowisku

6 Nasze aktualne wyniki ASR Projekt badawczy NCN N System automatycznej transliteracji nagrań mowy polskiej nagrania posiedzeń i komisji Senatu RP Dekoder ACC CORR PP Julius + IRSTLM 44k Słownik w weryfikacji SYNAT: Interdyscyplinarny system interaktywnej informacji naukowej i naukowo technicznej: transliteracja rzeczywistych nagrań wiadomości radiowych Dekoder ACC CORR PP Autorski System LSTM Julius + SRILM mix 40k Julius + IRSTLM 30K Julius + IRSTLM 60K

7 Czym dysponujemy 1 Moduł wyszukiwania mowy w sygnale (VAD) MFCC, sieć LSTM, wyjście w formacie TextGrid (Praat) Wysoka skuteczność, także w szumie, obecności muzyki 0,1 czasu rzeczywistego Normalizator tekstu Rozwijanie liczebników i skrótów Uzgadnianie form gramatycznych liczebników i skrótów Kombinacja LM dla słów, form podstawowych i POS, synchroniczny dekoder Viterbiego (ISMIS 2012) Koneksjonistyczny model języka Sieć neuronowa modeluje zależności pomiędzy słowami W eksperymentach perplexity mniejsze o ok. 20% niż najlepszy model n-gramowy (ISMIS 2011)

8 Czym dysponujemy 2 Własny dekoder LSTM autorska implementacja sieci LSTM w modelowaniu akustycznym, koneksjonistyczny model języka Zoptymalizowany, bardzo szybki - < czas rzeczywisty na laptopie Konwersja tekst ortograficzny zapis fonetyczny System regułowy Warianty wymowy Spikes rzadka reprezentacja sygnału Kodowanie mowy w sposób zbliżony do działania słuchu Zasoby językowe Nagrania i stenogramy senackie część ręcznie poprawiona, ok. 300 h nagrań mowy, 5 mln słów (domenowy korpus transliteracji) Teksty prawnicze z Wolters-Kluwer (ok. 1 mld słów) Korpus nagrań radiowych 77 h nagrań mowy, transliteracja nagrań (727 tys. słów) Zbieranie korpusów równoległych (Euronews)
 Teksty prawnicze z Wolters-Kluwer (ok.")
9 Tłumaczenie mowy PL-EN EU-Bridge ( FP 7, tłumaczenie mowy: napisy, parlament, aplikacje mobilne, wykłady IWSLT 2012, pierwszy benchmark PL->EN, wykłady TED, crowd sourcing (tłumaczone przez wolontariuszy), truecase dekoder Moses, training Giza++ BLEU jako miara jakości (porównanie tekstu MT z ręcznym tłumaczeniem) Zbiór treningowy: ok. 130 tys. zdań, development: 767, test: 1564 (2 dodatkowe zbiory do oceny przez organizatorów) Narzędzia: Politechnika Wrocławska, Stanford, własny tagger BLEU Słowosłowo Forma podstawowa PL Faktor1: word:stem:tag Faktor2: word:stem:tag test 15,37 14,41 11,06 8,02 devel 20,36 18,74 13,22 9,47
 Narzędzia: Politechnika Wrocławska, Stanford, własny tagger BLEU Słowosłowo")
10 U-STAR PL<->EN U-STAR consortium (NICT): 23 języki, rozproszona struktura serwerowa, standardy przyjęte przez ITU aplikacja VoiceTra4U na IPhone, IPad Równoczesna rozmowa do 5 osób równocześnie domena: rozmówki turystyczne PJWSTK: PL<->EN, na podstawie BTEC (110 tys. zdań, własne tłumaczenie, 2009), BLEU=71*** ASR Julius, CentOS, Tomcat

11 Inne CLARIN Synteza mowy polskiej własny system syntezy korpusowej (Festival) Systemy dialogowe (Primespeech) Patologia mowy, jakość fonacji Zasoby mowy ELRA
 Patologia mowy,")
12 Dziękuje za uwagę!

13 Synteza mowy regułowa formantowa artykulacyjna konkatenacyjna difonowa korpusowa

14 Automatyczne tłumaczenie statystyczne Input : SMT system otrzymuje zdanie do przetłumaczenia Output : SMT system generuje zdanie które jest tłumaczeniem zdania wejściowego Language Model (model języka) jest modelem określającym prawdopodobieństwo dowolnej sekwencji słów w danym języku Translation Model (model tłumaczenia) określa prawdopodobieństwa par tłumaczeń Decoding Algorithm (dekodowanie) to algorytm przeszukiwania grafu wyznaczający optymalne przejście przez graf słów
 to algorytm przeszukiwania grafu wyznaczający")

15 Jak to działa? coraz popularniejsze, coraz bardziej akceptowalne wyniki Coraz rzadziej systemy regułowe, interlingua, modelowanie Phrase based translation zamiast analizy składni, pasowania zdań Każda fraza jest tłumaczona na frazę i wynik może mieć zmienioną kolejność Model matematyczny argmax e p(e f) = argmax e p(f e) p(e) model języka e i model tłumaczenia p(f e) Podczas dekodowania sekwencja słów F jest dzielona na sekwencje I fraz f 1 I o jednakowym prawdopodobieństwie, każda z fraz f i z f 1 I jest tłumaczona na frazę e i i mogą one zostać poprzestawiane. Tłumaczenie jest modelowane jako rozkład φ(f i e i ), przestawianie fraz jako d(start i,end i-1 ) = α start i -end i-1-1 z odpowiednią wartością α, wprowadza się też czynnik ω>1 aby chętniej generować krótsze zdania Zatem najlepsze tłumaczenie to e best = argmax e p(e f) = argmax e p(f e) p_lm(e) ω length(e) gdzie p(f e) jest przedstawianie jako: p(f 1I e 1I ) = Φ i=1 I φ(f i e i ) d(start i,end i-1 ) 06

 www.statmt.")
16 Tłumaczenie fraz, czyli phrase alignment Dopasowanie na podstawie bilingualnego korpusu modelowanie Dwukierunkowe dopasowanie słów pozwala wyznaczyć te najbardziej odpowiednie słowa Na tej podstawie próbuje się tłumaczyć frazy, np. szukamy takich fraz które są dopasowane do siebie z wykorzystaniem tylko słów z ich wnętrza (Och, 2003) 06

17 Proces dekodowania


18 Dekodowanie czyli tłumaczenie System wyszukuje możliwe tłumaczenia fraz Uwzględnia koszt związany z tłumaczeniem, przestawianiem fraz i modelem języka minimalizuje koszt, czyli maksymalizuje prawdopodobieństwo Metoda wyszukiwania jest zbliżona do używanej w rozpoznawaniu mowy Można generować listę najlepszych tłumaczeń 06

19 Sprzężenie rozpoznawania i tłumaczenia Wykorzystanie krat słów jako wejścia do tłumaczania z użyciem FST Noisy Channel Model I e ˆ ˆ argmax Pr(A)Pr( f J,e I A) Pr(x e I ) f J,I,e I e e ˆ ˆ I ˆ argmax Pr(e f I J I )Pr(x,e x) I )Pr(x e I ) e I ) f J I,e,I,e II I eˆ Iˆ arg max max ~ e J, a A f J J p( f j, e ~ j f j 1 j m, e ~ j 1 j m, a) t t p( x j j 1 f j ) Best English sentence Length of source length Translation Target Aligned model LM target French word audio Lexical context Acoustic context Using an alignment model, A Instead of modeling the alignment, search for the best alignment Wykorzystanie interlingua i modeli sematycznych Wykorzystanie prozodii do wspomagania parsingu zdań Matusov, 05

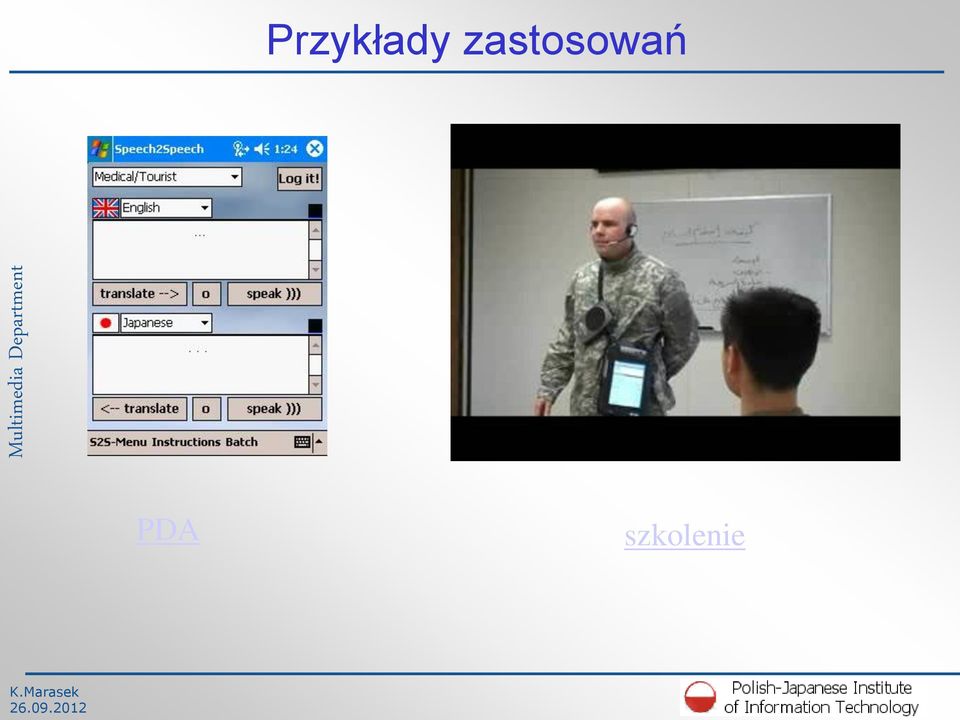
20 Przykłady zastosowań PDA szkolenie
21 Przygotowanie korpusu BTEC dla języka polskiego Współpraca z ATR Spoken Language Translation Research Laboratories, Kyoto, dr Eiichiro Sumita Ok zdań z rozmów japońskich turystów mówiących po angielsku ( angielskie rozmówki ) Cel: Przygotowanie systemu automatycznego tłumaczenia z mowy na mowę pomiędzy polskim i angielskim dla ograniczonej domeny (rozmówki turystyczne) Przygotowanie równoległego korpusu polsko-angielskiego (dopasowanie na poziomie zdań i fraz) Nasza praca: Przetłumaczenie zdań z angielskiego na polski Sformatowanie plików zgodnie z formatem BTEC Anotacja morfo-syntaktyczna polskiego korpusu Aktualny stan zaawansowana: Przetłumaczono ok. 80% tekstów
Statystyczne tłumaczenie mowy polskiej
 Statystyczne tłumaczenie mowy polskiej Krzysztof Marasek Krzysztof Wołk Łukasz Brocki Danijel Korzinek PJATK Plan prezentacji Wprowadzenie Komponenty systemu tłumaczącego Aktualne działania Nowe metody
Statystyczne tłumaczenie mowy polskiej Krzysztof Marasek Krzysztof Wołk Łukasz Brocki Danijel Korzinek PJATK Plan prezentacji Wprowadzenie Komponenty systemu tłumaczącego Aktualne działania Nowe metody
Korpusy i Narzędzia do Analizy Mowy w Clarin-PL
 1 / 21 Korpusy i w Clarin-PL Danijel Koržinek i Łukasz Brocki Polsko-Japońska Akademia Technik Komputerowych 3 lutego 2017 r., Łódź 2 / 21 3 / 21 Motywacja Brak darmowych ogólnodostępnych korpusów komercyjne:
1 / 21 Korpusy i w Clarin-PL Danijel Koržinek i Łukasz Brocki Polsko-Japońska Akademia Technik Komputerowych 3 lutego 2017 r., Łódź 2 / 21 3 / 21 Motywacja Brak darmowych ogólnodostępnych korpusów komercyjne:
Korpusy i Narzędzia do Analizy Mowy w Clarin-PL
 1 / 20 Korpusy i w Clarin-PL Krzysztof Marasek, Danijel Koržinek, Łukasz Brocki, Krzysztof Wołk Polsko-Japońska Akademia Technik Komputerowych 2 / 20 Plan prezentacji 1 2 3 / 20 4 / 20 Motywacja Brak darmowych
1 / 20 Korpusy i w Clarin-PL Krzysztof Marasek, Danijel Koržinek, Łukasz Brocki, Krzysztof Wołk Polsko-Japońska Akademia Technik Komputerowych 2 / 20 Plan prezentacji 1 2 3 / 20 4 / 20 Motywacja Brak darmowych
Program warsztatów CLARIN-PL
 W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
dr inż. Ewa Kuśmierek, Kierownik Projektu Warszawa, 25 czerwca 2014 r.
 Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst, dedykowany dla służb odpowiedzialnych za bezpieczeństwo państwa dr inż. Ewa Kuśmierek, Kierownik Projektu Warszawa,
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst, dedykowany dla służb odpowiedzialnych za bezpieczeństwo państwa dr inż. Ewa Kuśmierek, Kierownik Projektu Warszawa,
4 Zasoby językowe Korpusy obcojęzyczne Korpusy języka polskiego Słowniki Sposoby gromadzenia danych...
 Spis treści 1 Wstęp 11 1.1 Do kogo adresowana jest ta książka... 12 1.2 Historia badań nad mową i językiem... 12 1.3 Obecne główne trendy badań... 16 1.4 Opis zawartości rozdziałów... 18 2 Wyzwania i możliwe
Spis treści 1 Wstęp 11 1.1 Do kogo adresowana jest ta książka... 12 1.2 Historia badań nad mową i językiem... 12 1.3 Obecne główne trendy badań... 16 1.4 Opis zawartości rozdziałów... 18 2 Wyzwania i możliwe
Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego
 Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego Witold Kieraś Łukasz Kobyliński Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN III Konferencja DARIAH-PL Poznań 9.11.2016
Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego Witold Kieraś Łukasz Kobyliński Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN III Konferencja DARIAH-PL Poznań 9.11.2016
Korpusy mowy i narzędzia do ich przetwarzania
 Korpusy mowy i narzędzia do ich przetwarzania Danijel Korzinek, Krzysztof Marasek Polsko-Japońska Akademia Technik Komputerowych Katedra Multimediów kmarasek@pjwstk.edu.pl danijel@pjwstk.edu.pl 2015-05-18
Korpusy mowy i narzędzia do ich przetwarzania Danijel Korzinek, Krzysztof Marasek Polsko-Japońska Akademia Technik Komputerowych Katedra Multimediów kmarasek@pjwstk.edu.pl danijel@pjwstk.edu.pl 2015-05-18
Polszczyzna i inżynieria lingwistyczna. Autor: Marcin Miłkowski (IFiS PAN)
") Polszczyzna i inżynieria lingwistyczna Autor: Marcin Miłkowski (IFiS PAN) 1 Polszczyzna i jej cechy szczególne Polszczyzną posługuje się od 40 do 48 milionów osób: najczęściej używany język zachodniosłowiański
Polszczyzna i inżynieria lingwistyczna Autor: Marcin Miłkowski (IFiS PAN) 1 Polszczyzna i jej cechy szczególne Polszczyzną posługuje się od 40 do 48 milionów osób: najczęściej używany język zachodniosłowiański
NeuroVoice. Synteza i analiza mowy. Paweł Mrówka
 NeuroVoice Synteza i analiza mowy Paweł Mrówka pawel.mrowka@neurosoft.pl Plan prezentacji Synteza mowy - SynTalk Wprowadzenie do syntezy konkatenacyjnej Zastosowanie analizy językowej tekstu MoŜliwości
NeuroVoice Synteza i analiza mowy Paweł Mrówka pawel.mrowka@neurosoft.pl Plan prezentacji Synteza mowy - SynTalk Wprowadzenie do syntezy konkatenacyjnej Zastosowanie analizy językowej tekstu MoŜliwości
Synteza mowy (TTS) Rozpoznawanie mowy (ARM) Optyczne rozpoznawanie znaków (OCR) Jolanta Bachan
 Rozpoznawanie mowy (ARM) Optyczne rozpoznawanie znaków (OCR) Jolanta Bachan") Synteza mowy (TTS) Rozpoznawanie mowy (ARM) Optyczne rozpoznawanie znaków (OCR) Jolanta Bachan Synteza mowy System przetwarzania tekstu pisanego na mowę Text-to-Speech (TTS) TTS powinien być w stanie przeczytać
Synteza mowy (TTS) Rozpoznawanie mowy (ARM) Optyczne rozpoznawanie znaków (OCR) Jolanta Bachan Synteza mowy System przetwarzania tekstu pisanego na mowę Text-to-Speech (TTS) TTS powinien być w stanie przeczytać
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, Spis treści
 Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Tłumaczenie maszynowe. Zasady działania. Autorzy: Josef van Genabith (DFKI), Krzysztof Łoboda (Uniwersytet Jagielloński)
, Krzysztof Łoboda (Uniwersytet Jagielloński)") Tłumaczenie maszynowe. Zasady działania Autorzy: Josef van Genabith (DFKI), Krzysztof Łoboda (Uniwersytet Jagielloński) 1 Tłumaczenie maszynowe Zarys prezentacji: Uzasadnienie dla technologii MT: liczba
Tłumaczenie maszynowe. Zasady działania Autorzy: Josef van Genabith (DFKI), Krzysztof Łoboda (Uniwersytet Jagielloński) 1 Tłumaczenie maszynowe Zarys prezentacji: Uzasadnienie dla technologii MT: liczba
Lokalizacja Oprogramowania
 mgr inż. Anton Smoliński anton.smolinski@zut.edu.pl Lokalizacja Oprogramowania 16/12/2016 Wykład 6 Internacjonalizacja, Testowanie, Tłumaczenie Maszynowe Agenda Internacjonalizacja Testowanie lokalizacji
mgr inż. Anton Smoliński anton.smolinski@zut.edu.pl Lokalizacja Oprogramowania 16/12/2016 Wykład 6 Internacjonalizacja, Testowanie, Tłumaczenie Maszynowe Agenda Internacjonalizacja Testowanie lokalizacji
Opisy efektów kształcenia dla modułu
 Karta modułu - Technologia mowy 1 / 5 Nazwa modułu: Technologia mowy Rocznik: 2012/2013 Kod: RIA-1-504-s Punkty ECTS: 7 Wydział: Inżynierii Mechanicznej i Robotyki Poziom studiów: Studia I stopnia Specjalność:
Karta modułu - Technologia mowy 1 / 5 Nazwa modułu: Technologia mowy Rocznik: 2012/2013 Kod: RIA-1-504-s Punkty ECTS: 7 Wydział: Inżynierii Mechanicznej i Robotyki Poziom studiów: Studia I stopnia Specjalność:
CLARIN rozproszony system technologii językowych dla różnych języków europejskich
 CLARIN rozproszony system technologii językowych dla różnych języków europejskich Maciej Piasecki Politechnika Wrocławska Instytut Informatyki G4.19 Research Group maciej.piasecki@pwr.wroc.pl Projekt CLARIN
CLARIN rozproszony system technologii językowych dla różnych języków europejskich Maciej Piasecki Politechnika Wrocławska Instytut Informatyki G4.19 Research Group maciej.piasecki@pwr.wroc.pl Projekt CLARIN
Portal e-learningowy zaprojektowany dla Studentów i Nauczycieli
 Portal e-learningowy zaprojektowany dla Studentów i Nauczycieli Campus universities 2013 Międzynarodowe uznanie dla TELL ME MORE Dopasowanie do wymagań Common European Framework Popierany przez Ministerstwa
Portal e-learningowy zaprojektowany dla Studentów i Nauczycieli Campus universities 2013 Międzynarodowe uznanie dla TELL ME MORE Dopasowanie do wymagań Common European Framework Popierany przez Ministerstwa
AKUSTYKA MOWY. Podstawy rozpoznawania mowy część I
 AKUSTYKA MOWY Podstawy rozpoznawania mowy część I PLAN WYKŁADU Część I Podstawowe pojęcia z dziedziny rozpoznawania mowy Algorytmy, parametry i podejścia do rozpoznawania mowy Przykłady istniejących bibliotek
AKUSTYKA MOWY Podstawy rozpoznawania mowy część I PLAN WYKŁADU Część I Podstawowe pojęcia z dziedziny rozpoznawania mowy Algorytmy, parametry i podejścia do rozpoznawania mowy Przykłady istniejących bibliotek
Oprogramowanie typu CAT
 Oprogramowanie typu CAT (Computer Aided Translation) Informacje ogólne Copyright Jacek Scholz 2009 Wprowadzenie: narzędzia do wspomagania translacji Bazy pamięci tłumaczet umaczeń (Translation Memory)
Oprogramowanie typu CAT (Computer Aided Translation) Informacje ogólne Copyright Jacek Scholz 2009 Wprowadzenie: narzędzia do wspomagania translacji Bazy pamięci tłumaczet umaczeń (Translation Memory)
Transkrypcja fonetyczna i synteza mowy. Jolanta Bachan
 Transkrypcja fonetyczna i synteza mowy Jolanta Bachan IPA Międzynarodowy alfabet fonetyczny, MAF (ang. International Phonetic Alphabet, IPA) alfabet fonetyczny, system transkrypcji fonetycznej przyjęty
Transkrypcja fonetyczna i synteza mowy Jolanta Bachan IPA Międzynarodowy alfabet fonetyczny, MAF (ang. International Phonetic Alphabet, IPA) alfabet fonetyczny, system transkrypcji fonetycznej przyjęty
TTIC 31190: Natural Language Processing
 TTIC 31190: Natural Language Processing Kevin Gimpel Spring 2018 Lecture 17: Machine TranslaDon; SemanDcs Roadmap words, morphology, lexical semandcs text classificadon simple neural methods for NLP language
TTIC 31190: Natural Language Processing Kevin Gimpel Spring 2018 Lecture 17: Machine TranslaDon; SemanDcs Roadmap words, morphology, lexical semandcs text classificadon simple neural methods for NLP language
13. Statistical Alignment and Machine Translation
 13. Statistical Alignment and Machine Translation MT najważniejsze zastosowanie NLP. Obecnie nie m dobrych systemów MT poza bardzo specyficznymi, np. tłumaczącymi prognozy pogody. Różne podejścia do MT:
13. Statistical Alignment and Machine Translation MT najważniejsze zastosowanie NLP. Obecnie nie m dobrych systemów MT poza bardzo specyficznymi, np. tłumaczącymi prognozy pogody. Różne podejścia do MT:
Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2
 Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2 ws.clarin-pl.eu/websty.shtml Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej
Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2 ws.clarin-pl.eu/websty.shtml Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej
Open Access w technologii językowej dla języka polskiego
 Open Access w technologii językowej dla języka polskiego Marek Maziarz, Maciej Piasecki Grupa Naukowa Technologii Językowych G4.19 Zakład Sztucznej Inteligencji, Instytut Informatyki, W-8, Politechnika
Open Access w technologii językowej dla języka polskiego Marek Maziarz, Maciej Piasecki Grupa Naukowa Technologii Językowych G4.19 Zakład Sztucznej Inteligencji, Instytut Informatyki, W-8, Politechnika
Automatyczne rozpoznawanie mowy. Autor: mgr inż. Piotr Bratoszewski
 Automatyczne rozpoznawanie mowy Autor: mgr inż. Piotr Bratoszewski Rys historyczny 1930-1950 pierwsze systemy Automatycznego rozpoznawania mowy (ang. Automatic Speech Recognition ASR), metody holistyczne;
Automatyczne rozpoznawanie mowy Autor: mgr inż. Piotr Bratoszewski Rys historyczny 1930-1950 pierwsze systemy Automatycznego rozpoznawania mowy (ang. Automatic Speech Recognition ASR), metody holistyczne;
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst
 Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst Mariusz Owsianny, PCSS Dr inż. Ewa Kuśmierek, Kierownik Projektu, PCSS Partnerzy konsorcjum Zaawansowany system automatycznego
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst Mariusz Owsianny, PCSS Dr inż. Ewa Kuśmierek, Kierownik Projektu, PCSS Partnerzy konsorcjum Zaawansowany system automatycznego
System wspomagania harmonogramowania przedsięwzięć budowlanych
 System wspomagania harmonogramowania przedsięwzięć budowlanych Wojciech Bożejko 1 Zdzisław Hejducki 2 Mariusz Uchroński 1 Mieczysław Wodecki 3 1 Instytut Informatyki, Automatyki i Robotyki Politechnika
System wspomagania harmonogramowania przedsięwzięć budowlanych Wojciech Bożejko 1 Zdzisław Hejducki 2 Mariusz Uchroński 1 Mieczysław Wodecki 3 1 Instytut Informatyki, Automatyki i Robotyki Politechnika
"Tell Me More Campus" w Politechnice Rzeszowskiej
 "Tell Me More Campus" w Politechnice Rzeszowskiej Od 1 października br. w Politechnice Rzeszowskiej rusza nowoczesna forma nauki języków obcych - portal e-learningowy TELL ME MORE Campus. Za pomocą portalu
"Tell Me More Campus" w Politechnice Rzeszowskiej Od 1 października br. w Politechnice Rzeszowskiej rusza nowoczesna forma nauki języków obcych - portal e-learningowy TELL ME MORE Campus. Za pomocą portalu
Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury. Paweł Kobojek, prof. dr hab. inż. Khalid Saeed
 Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury Paweł Kobojek, prof. dr hab. inż. Khalid Saeed Zakres pracy Przegląd stanu wiedzy w dziedzinie biometrii, ze szczególnym naciskiem
Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury Paweł Kobojek, prof. dr hab. inż. Khalid Saeed Zakres pracy Przegląd stanu wiedzy w dziedzinie biometrii, ze szczególnym naciskiem
Inforex - zarządzanie korpusami i ich anotacja
 Inforex - zarządzanie korpusami i ich anotacja Marcin Oleksy marcin.oleksy@pwr.edu.pl Michał Marcińczuk michal.marcinczuk@pwr.edu.pl Politechnika Wrocławska Katedra Inteligencji Obliczeniowej Grupa Technologii
Inforex - zarządzanie korpusami i ich anotacja Marcin Oleksy marcin.oleksy@pwr.edu.pl Michał Marcińczuk michal.marcinczuk@pwr.edu.pl Politechnika Wrocławska Katedra Inteligencji Obliczeniowej Grupa Technologii
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN
 Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN") KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN Podstawowe informacje o projekcie Projekt realizowany przez IJP
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN Podstawowe informacje o projekcie Projekt realizowany przez IJP
Rozpoznawanie mowy dla języków semickich. HMM - HTK, CMU SPHINX-4, Simon
 Rozpoznawanie mowy dla języków semickich HMM - HTK, CMU SPHINX-4, Simon Charakterystyka języków semickich Przykłady: arabski, hebrajski, amharski, tigrinia, maltański (280 mln użytkowników). Budowa spółgłoskowo
Rozpoznawanie mowy dla języków semickich HMM - HTK, CMU SPHINX-4, Simon Charakterystyka języków semickich Przykłady: arabski, hebrajski, amharski, tigrinia, maltański (280 mln użytkowników). Budowa spółgłoskowo
Analiza metod wykrywania przekazów steganograficznych. Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl
 Analiza metod wykrywania przekazów steganograficznych Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl Plan prezentacji Wprowadzenie Cel pracy Tezy pracy Koncepcja systemu Typy i wyniki testów Optymalizacja
Analiza metod wykrywania przekazów steganograficznych Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl Plan prezentacji Wprowadzenie Cel pracy Tezy pracy Koncepcja systemu Typy i wyniki testów Optymalizacja
11 Probabilistic Context Free Grammars
 11 Probabilistic Context Free Grammars Ludzie piszą i mówią wiele rzeczy, a ich wypowiedzi mają zawsze jakąś określoną strukture i regularność. Celem jest znalezienie i wyizolowanie tego typu struktur.
11 Probabilistic Context Free Grammars Ludzie piszą i mówią wiele rzeczy, a ich wypowiedzi mają zawsze jakąś określoną strukture i regularność. Celem jest znalezienie i wyizolowanie tego typu struktur.
TEST DIAGNOSTYCZNY. w ramach projektu TIK? tak! - na kompetencje cyfrowe najwyższy czas!
 TEST DIAGNOSTYCZNY w ramach projektu TIK? tak! - na kompetencje cyfrowe najwyższy czas! ZASADY OCENY TESTU 1. Test diagnostyczny składa się z 20 pytań. 2. Każde pytanie zawiera cztery propozycje odpowiedzi.
TEST DIAGNOSTYCZNY w ramach projektu TIK? tak! - na kompetencje cyfrowe najwyższy czas! ZASADY OCENY TESTU 1. Test diagnostyczny składa się z 20 pytań. 2. Każde pytanie zawiera cztery propozycje odpowiedzi.
Compact Open Remote Nao
 Damian Kluba Katarzyna Lasak Amadeusz Starzykiewicz Techniki obiektowe i komponentowe Compact Open Remote Nao CORN Podsumowanie projektu 1. Powstałe komponenty 1.1. Video Component 1.1.1. Elementy komponentu
Damian Kluba Katarzyna Lasak Amadeusz Starzykiewicz Techniki obiektowe i komponentowe Compact Open Remote Nao CORN Podsumowanie projektu 1. Powstałe komponenty 1.1. Video Component 1.1.1. Elementy komponentu
Model zaszumionego kanału
 W X kanal Y W^ koder dekoder p(y x) Oryginalna praca Shannona polegała na poszukiwaniu takiego kodowania, które umożliwiało ustalenie nadmiarowości informacji w taki sposób, żeby na wyjściu można było
W X kanal Y W^ koder dekoder p(y x) Oryginalna praca Shannona polegała na poszukiwaniu takiego kodowania, które umożliwiało ustalenie nadmiarowości informacji w taki sposób, żeby na wyjściu można było
Systemy eksperckie. Plan wykładu Wprowadzenie do sztucznej inteligencji. Wnioski z prób automatycznego wnioskowania w rachunku predykatów
 Plan wykładu Systemy eksperckie Dr hab. inż. Joanna Józefowska, prof. pp 1/1 Wnioski z badań nad systemami mi w rachunku predykatów Reguły produkcji jako system reprezentacji Algorytm rozpoznaj-wykonaj
Plan wykładu Systemy eksperckie Dr hab. inż. Joanna Józefowska, prof. pp 1/1 Wnioski z badań nad systemami mi w rachunku predykatów Reguły produkcji jako system reprezentacji Algorytm rozpoznaj-wykonaj
Forma. Główny cel kursu. Umiejętności nabywane przez studentów. Wymagania wstępne:
 WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
HCI Human Computer Interaction
 HCI Human Computer Interaction Bartosz Dzirba Gabriel Kujawski praca dyplomowa magisterska opiekun: prof. dr hab. Zbigniew Kotulski 1 Plan prezentacji HCI Co to jest? W jakim celu? Jak projektować? Etapy
HCI Human Computer Interaction Bartosz Dzirba Gabriel Kujawski praca dyplomowa magisterska opiekun: prof. dr hab. Zbigniew Kotulski 1 Plan prezentacji HCI Co to jest? W jakim celu? Jak projektować? Etapy
PRZEWODNIK PO PRZEDMIOCIE. Wprowadzenie do przekładu tekstów ogólnych Angielski Język Biznesu
 Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu Wprowadzenie do tekstów ogólnych Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom kwalifikacji
Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu Wprowadzenie do tekstów ogólnych Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom kwalifikacji
Tell Me More v.10: nowe oblicze nauczania języków obcych. Kwiecień 2012 r.
 Tell Me More v.10: nowe oblicze nauczania języków obcych Kwiecień 2012 r. TELL ME MORE ogólnie Języ ki o bce d Na świecie w Europie, Azji, Północnej i Środkowej Ameryce Dystrybucja w 70 krajach. la K o
Tell Me More v.10: nowe oblicze nauczania języków obcych Kwiecień 2012 r. TELL ME MORE ogólnie Języ ki o bce d Na świecie w Europie, Azji, Północnej i Środkowej Ameryce Dystrybucja w 70 krajach. la K o
KorBa. Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk
 Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk") KorBa Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk ALLPPT.com _ Free PowerPoint Templates, Diagrams and Charts PODSTAWOWE
KorBa Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk ALLPPT.com _ Free PowerPoint Templates, Diagrams and Charts PODSTAWOWE
Sposoby wyszukiwania multimedialnych zasobów w Internecie
 Sposoby wyszukiwania multimedialnych zasobów w Internecie Lidia Derfert-Wolf Biblioteka Główna Uniwersytetu Technologiczno-Przyrodniczego w Bydgoszczy e-mail: lidka@utp.edu.pl III seminarium z cyklu INFOBROKER:
Sposoby wyszukiwania multimedialnych zasobów w Internecie Lidia Derfert-Wolf Biblioteka Główna Uniwersytetu Technologiczno-Przyrodniczego w Bydgoszczy e-mail: lidka@utp.edu.pl III seminarium z cyklu INFOBROKER:
Wyszukiwarka i usługi Google
 Wyszukiwarka i usługi Google Funkcjonalność: Łączenie wiadomości w wątki, Ochrona przed spamem, Filtry i zaawansowana kategoryzacja poczty, Pojemność 15 GB (współdzielona z Google Drive i Zdjęcia Google+),
Wyszukiwarka i usługi Google Funkcjonalność: Łączenie wiadomości w wątki, Ochrona przed spamem, Filtry i zaawansowana kategoryzacja poczty, Pojemność 15 GB (współdzielona z Google Drive i Zdjęcia Google+),
Praktyczna nauka drugiego języka obcego II
 OPIS PRZEDMIOTÓW DO PLANU STUDIÓWNA ROK AKADEMICKI 2016/2017 PLAN STUDIÓW kierunek studiów: Filologia germańska profil studiów: ogólnoakademicki stopień: II ( ) forma studiów: stacjonarne specjalność:
OPIS PRZEDMIOTÓW DO PLANU STUDIÓWNA ROK AKADEMICKI 2016/2017 PLAN STUDIÓW kierunek studiów: Filologia germańska profil studiów: ogólnoakademicki stopień: II ( ) forma studiów: stacjonarne specjalność:
Analiza danych tekstowych i języka naturalnego
 Kod szkolenia: Tytuł szkolenia: ANA/TXT Analiza danych tekstowych i języka naturalnego Dni: 3 Opis: Adresaci szkolenia Dane tekstowe stanowią co najmniej 70% wszystkich danych generowanych w systemach
Kod szkolenia: Tytuł szkolenia: ANA/TXT Analiza danych tekstowych i języka naturalnego Dni: 3 Opis: Adresaci szkolenia Dane tekstowe stanowią co najmniej 70% wszystkich danych generowanych w systemach
Zarządzanie i anotowanie korpusów tekstowych w systemie Inforex
 Zarządzanie i anotowanie korpusów tekstowych w systemie Inforex Michał Marcińczuk michal.marcinczuk@pwr.edu.pl Marcin Oleksy marcin.oleksy@pwr.edu.pl Politechnika Wrocławska Katedra Inteligencji Obliczeniowej
Zarządzanie i anotowanie korpusów tekstowych w systemie Inforex Michał Marcińczuk michal.marcinczuk@pwr.edu.pl Marcin Oleksy marcin.oleksy@pwr.edu.pl Politechnika Wrocławska Katedra Inteligencji Obliczeniowej
PRZEWODNIK PO PRZEDMIOCIE RODZAJ ZAJĘĆ LICZBA GODZIN W SEMESTRZE WYKŁAD ĆWICZENIA LABORATORIUM PROJEKT SEMINARIUM 30
 Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu Wprowadzenie do tekstów użytkowych Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom kwalifikacji
Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu Wprowadzenie do tekstów użytkowych Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom kwalifikacji
Imagination Is More Important Than Knowledge
 Imagination Is More Important Than Knowledge 1 -Albert Einstein https://www.flickr.com/photos/9555503@n07/5095475676/ Odblokuj potencjał tkwiący w danych - poznaj usługi kognitywne Grażyna Dadej Executive
Imagination Is More Important Than Knowledge 1 -Albert Einstein https://www.flickr.com/photos/9555503@n07/5095475676/ Odblokuj potencjał tkwiący w danych - poznaj usługi kognitywne Grażyna Dadej Executive
Algorytm SiRF dekoder i jego wykorzystanie w systemie ASG-EUPOS
 Katedra Geodezji Satelitarnej i Nawigacji Bartłomiej Oszczak, Krzysztof Serżysko Uniwersytet Warmińsko-Mazurski w Olsztynie Algorytm SiRF dekoder i jego wykorzystanie w systemie ASG-EUPOS SiRF Technology
Katedra Geodezji Satelitarnej i Nawigacji Bartłomiej Oszczak, Krzysztof Serżysko Uniwersytet Warmińsko-Mazurski w Olsztynie Algorytm SiRF dekoder i jego wykorzystanie w systemie ASG-EUPOS SiRF Technology
System Korekty Tekstu Polskiego
 Wnioski Grzegorz Szuba System Korekty Tekstu Polskiego Plan prezentacji Geneza problemu i cele pracy Opis algorytmu bezkontekstowego Opis algorytmów kontekstowych Wyniki testów Rozszerzenie pracy - uproszczona
Wnioski Grzegorz Szuba System Korekty Tekstu Polskiego Plan prezentacji Geneza problemu i cele pracy Opis algorytmu bezkontekstowego Opis algorytmów kontekstowych Wyniki testów Rozszerzenie pracy - uproszczona
Praca Magisterska. Automatyczna kontekstowa korekta tekstów na podstawie Grafu Przyzwyczajeń. internetowego dla języka polskiego
 Praca Magisterska Automatyczna kontekstowa korekta tekstów na podstawie Grafu Przyzwyczajeń Lingwistycznych zbudowanego przez robota internetowego dla języka polskiego Marcin A. Gadamer Promotor: dr Adrian
Praca Magisterska Automatyczna kontekstowa korekta tekstów na podstawie Grafu Przyzwyczajeń Lingwistycznych zbudowanego przez robota internetowego dla języka polskiego Marcin A. Gadamer Promotor: dr Adrian
Aldona Sopata Uniwersytet im. Adama Mickiewicza w Poznaniu NOWE TECHNOLOGIE W KSZTAŁCENIU TŁUMACZY NA WYDZIALE NEOFILOLOGII UAM W POZNANIU
 Aldona Sopata Uniwersytet im. Adama Mickiewicza w Poznaniu NOWE TECHNOLOGIE W KSZTAŁCENIU TŁUMACZY NA WYDZIALE NEOFILOLOGII UAM W POZNANIU 2 Studia wydziałowe na Wydziale Neofilologii UAM 3 Wydziałowe
Aldona Sopata Uniwersytet im. Adama Mickiewicza w Poznaniu NOWE TECHNOLOGIE W KSZTAŁCENIU TŁUMACZY NA WYDZIALE NEOFILOLOGII UAM W POZNANIU 2 Studia wydziałowe na Wydziale Neofilologii UAM 3 Wydziałowe
Wstęp do Językoznawstwa
 Wstęp do Językoznawstwa Prof. Nicole Nau UAM, IJ, Językoznawstwo Komputerowe Dziesiąte zajęcie 08.12.2015 Składnia: Co bada? Jak bada? Konstrukcja składniowa a) ciąg (zespół) form wyrazowych związanych
Wstęp do Językoznawstwa Prof. Nicole Nau UAM, IJ, Językoznawstwo Komputerowe Dziesiąte zajęcie 08.12.2015 Składnia: Co bada? Jak bada? Konstrukcja składniowa a) ciąg (zespół) form wyrazowych związanych
PRZEWODNIK PO PRZEDMIOCIE. Wprowadzenie do przekładu tekstów użytkowych Angielski Język Biznesu
 Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu Wprowadzenie do przekładu tekstów użytkowych Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom
Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu Wprowadzenie do przekładu tekstów użytkowych Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom
Możliwości kierowania reklam na urządzenia mobilne w AdWords i AdMob. Wprowadzenie
 Wprowadzenie Reklama mobilna Reklama mobilna Reklama mobilna Źródło fotografii www.askcaptainobvious.com Dane statystyczne liczba urządzeń/użytkowników developerzy, więcej aplikacji czas spędzany web/aplikacje
Wprowadzenie Reklama mobilna Reklama mobilna Reklama mobilna Źródło fotografii www.askcaptainobvious.com Dane statystyczne liczba urządzeń/użytkowników developerzy, więcej aplikacji czas spędzany web/aplikacje
HLT_12 Warszawa. Lingwistyka matematyczna w Katedrze Elektroniki AGH
 HLT_12 Warszawa Lingwistyka matematyczna w Katedrze Elektroniki AGH 1 Lingwistyka jaka jest każdy widzi Lingwistyka matematyczna: - identyfikacja rozmówcy - przetwarzanie języka naturalnego - przetwarzanie
HLT_12 Warszawa Lingwistyka matematyczna w Katedrze Elektroniki AGH 1 Lingwistyka jaka jest każdy widzi Lingwistyka matematyczna: - identyfikacja rozmówcy - przetwarzanie języka naturalnego - przetwarzanie
Wstęp do programowania
 wykład 6 Agata Półrola Wydział Matematyki i Informatyki UŁ sem. zimowy 2017/2018 Losowanie liczb całkowitych Dostępne biblioteki Najprostsze losowanie liczb całkowitych można wykonać za pomocą funkcji
wykład 6 Agata Półrola Wydział Matematyki i Informatyki UŁ sem. zimowy 2017/2018 Losowanie liczb całkowitych Dostępne biblioteki Najprostsze losowanie liczb całkowitych można wykonać za pomocą funkcji
Synteza mowy. opracowanie: mgr inż. Kuba Łopatka
 Synteza mowy opracowanie: mgr inż. Kuba Łopatka Synteza mowy (ang. TTS - Text-To-Speech ) zamiana tekstu w formie pisanej na sygnał akustyczny, którego brzmienie naśladuje brzmienie ludzkiej mowy. Podstawowe
Synteza mowy opracowanie: mgr inż. Kuba Łopatka Synteza mowy (ang. TTS - Text-To-Speech ) zamiana tekstu w formie pisanej na sygnał akustyczny, którego brzmienie naśladuje brzmienie ludzkiej mowy. Podstawowe
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
CLARIN infrastruktura naukowa technologii językowych i jej potencjał jako narzędzia badawczego
 CLARIN infrastruktura naukowa technologii językowych i jej potencjał jako narzędzia badawczego Maciej Piasecki Politechnika Wrocławska Instytut Informatyki Grupa Naukowa G4.19 maciej.piasecki@pwr.wroc.pl
CLARIN infrastruktura naukowa technologii językowych i jej potencjał jako narzędzia badawczego Maciej Piasecki Politechnika Wrocławska Instytut Informatyki Grupa Naukowa G4.19 maciej.piasecki@pwr.wroc.pl
Skalowalna Platforma dla eksperymentów dużej skali typu Data Farming z wykorzystaniem środowisk organizacyjnie rozproszonych
 1 Skalowalna Platforma dla eksperymentów dużej skali typu Data Farming z wykorzystaniem środowisk organizacyjnie rozproszonych D. Król, Ł. Dutka, J. Kitowski ACC Cyfronet AGH Plan prezentacji 2 O nas Wprowadzenie
1 Skalowalna Platforma dla eksperymentów dużej skali typu Data Farming z wykorzystaniem środowisk organizacyjnie rozproszonych D. Król, Ł. Dutka, J. Kitowski ACC Cyfronet AGH Plan prezentacji 2 O nas Wprowadzenie
Praca magisterska Jakub Reczycki. Opiekun : dr inż. Jacek Rumiński. Katedra Inżynierii Biomedycznej Wydział ETI Politechnika Gdańska
 System gromadzenia, indeksowania i opisu słownikowego norm i rekomendacji Praca magisterska Jakub Reczycki Opiekun : dr inż. Jacek Rumiński Katedra Inżynierii Biomedycznej Wydział ETI Politechnika Gdańska
System gromadzenia, indeksowania i opisu słownikowego norm i rekomendacji Praca magisterska Jakub Reczycki Opiekun : dr inż. Jacek Rumiński Katedra Inżynierii Biomedycznej Wydział ETI Politechnika Gdańska
SYNTEZA MOWY W E-LEARNINGU DLA OSÓB NIEPEŁNOSPRAWNYCH
 SYNTEZA MOWY W E-LEARNINGU DLA OSÓB NIEPEŁNOSPRAWNYCH Krzysztof Szklanny kszklanny@pjwstk.edu.pl Polsko-Japońska Wyższa Szkoła Technik Komputerowych Słowa kluczowe:
SYNTEZA MOWY W E-LEARNINGU DLA OSÓB NIEPEŁNOSPRAWNYCH Krzysztof Szklanny kszklanny@pjwstk.edu.pl Polsko-Japońska Wyższa Szkoła Technik Komputerowych Słowa kluczowe:
OMNITRACKER Wersja testowa. Szybki przewodnik instalacji
 OMNITRACKER Wersja testowa Szybki przewodnik instalacji 1 Krok 1:Rejestracja pobrania (jeżeli nie wykonana dotychczas) Proszę dokonać rejestracji na stronieomninet (www.omnitracker.com) pod Contact. Po
OMNITRACKER Wersja testowa Szybki przewodnik instalacji 1 Krok 1:Rejestracja pobrania (jeżeli nie wykonana dotychczas) Proszę dokonać rejestracji na stronieomninet (www.omnitracker.com) pod Contact. Po
Multimedialne Systemy Interaktywne
 Multimedialne Systemy Interaktywne Sem. 1 studiów magisterskich dziennych Wymiar wykład 30 h projekt 15 h seminarium 15 h Prowadzący wykład dr inż. Mariusz Szwoch szwoch@pg.gda.pl dr inż. Jan Daciuk jandac@eti.pg.gda.pl
Multimedialne Systemy Interaktywne Sem. 1 studiów magisterskich dziennych Wymiar wykład 30 h projekt 15 h seminarium 15 h Prowadzący wykład dr inż. Mariusz Szwoch szwoch@pg.gda.pl dr inż. Jan Daciuk jandac@eti.pg.gda.pl
Wykaz tematów prac magisterskich w roku akademickim 2018/2019 kierunek: informatyka
 Wykaz tematów prac magisterskich w roku akademickim 2018/2019 kierunek: informatyka L.p. Nazwisko i imię studenta Promotor Temat pracy magisterskiej 1. Wojciech Kłopocki dr Bartosz Ziemkiewicz Automatyczne
Wykaz tematów prac magisterskich w roku akademickim 2018/2019 kierunek: informatyka L.p. Nazwisko i imię studenta Promotor Temat pracy magisterskiej 1. Wojciech Kłopocki dr Bartosz Ziemkiewicz Automatyczne
PRZEWODNIK PO PRZEDMIOCIE. Wprowadzenie do przekładu tekstów ogólnych Angielski Język Biznesu
 Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu Wprowadzenie do przekładu tekstów ogólnych Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom kwalifikacji
Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu Wprowadzenie do przekładu tekstów ogólnych Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom kwalifikacji
System Korekty Tekstu Polskiego
 System Korekty Tekstu Polskiego Plan prezentacji Geneza problemu i cele pracy Opis algorytmu bezkontekstowego Opis algorytmów kontekstowych Wyniki testów Wersja algorytmu dla języka hiszpańskiego Wnioski
System Korekty Tekstu Polskiego Plan prezentacji Geneza problemu i cele pracy Opis algorytmu bezkontekstowego Opis algorytmów kontekstowych Wyniki testów Wersja algorytmu dla języka hiszpańskiego Wnioski
PRZEDMIOTOWE ZASADY OCENIANIA Z JĘZYKA ANGIELSKIEGO I ETAP EDUKACYJNY KLASY I-III
 PRZEDMIOTOWE ZASADY OCENIANIA Z JĘZYKA ANGIELSKIEGO I ETAP EDUKACYJNY KLASY I-III ROK SZKOLNY 2018/2019 Podczas nauki języka angielskiego na I etapie edukacyjnym nauczyciel stopniowo rozwija u uczniów
PRZEDMIOTOWE ZASADY OCENIANIA Z JĘZYKA ANGIELSKIEGO I ETAP EDUKACYJNY KLASY I-III ROK SZKOLNY 2018/2019 Podczas nauki języka angielskiego na I etapie edukacyjnym nauczyciel stopniowo rozwija u uczniów
Sprawozdanie z laboratoriów HTK!
 Inżynieria akustyczna - Technologia mowy 2013 Błażej Chwiećko Sprawozdanie z laboratoriów HTK! 1. Przeznaczenie tworzonego systemu! Celem było stworzenie systemu służącego do sterowania samochodem. Zaimplementowane
Inżynieria akustyczna - Technologia mowy 2013 Błażej Chwiećko Sprawozdanie z laboratoriów HTK! 1. Przeznaczenie tworzonego systemu! Celem było stworzenie systemu służącego do sterowania samochodem. Zaimplementowane
Od e-materiałów do e-tutorów
 Od e-materiałów do e-tutorów Lech Banachowski, Elżbieta Mrówka-Matejewska, Agnieszka Chądzyńska-Krasowska, Jerzy Paweł Nowacki, Wydział Informatyki, Polsko-Japońska Akademia Technik Komputerowych Plan
Od e-materiałów do e-tutorów Lech Banachowski, Elżbieta Mrówka-Matejewska, Agnieszka Chądzyńska-Krasowska, Jerzy Paweł Nowacki, Wydział Informatyki, Polsko-Japońska Akademia Technik Komputerowych Plan
Propozycje tematów prac magisterskich 2013/14 Automatyka i Robotyka - studia stacjonarne Pracowania Układów Elektronicznych i Przetwarzania Sygnałów
 Propozycje tematów prac magisterskich 2013/14 Automatyka i Robotyka - studia stacjonarne Pracowania Układów Elektronicznych i Przetwarzania Sygnałów Stanowisko do lokalizacji źródła dźwięku Zaprojektowanie
Propozycje tematów prac magisterskich 2013/14 Automatyka i Robotyka - studia stacjonarne Pracowania Układów Elektronicznych i Przetwarzania Sygnałów Stanowisko do lokalizacji źródła dźwięku Zaprojektowanie
Włodzimierz Wyraz Radcomp Integral Sp. z o.o.
 . Jak usprawnić funkcjonowanie Urzędu Administracji Publicznej poprzez zastosowanie głosowej edycji dokumentów? Włodzimierz Wyraz Radcomp Integral Sp. z o.o. Wprowadzenie Nowoczesna technologia rozpoznawania
. Jak usprawnić funkcjonowanie Urzędu Administracji Publicznej poprzez zastosowanie głosowej edycji dokumentów? Włodzimierz Wyraz Radcomp Integral Sp. z o.o. Wprowadzenie Nowoczesna technologia rozpoznawania
Maciej Oleksy Zenon Matuszyk
 Maciej Oleksy Zenon Matuszyk Jest to proces związany z wytwarzaniem oprogramowania. Jest on jednym z procesów kontroli jakości oprogramowania. Weryfikacja oprogramowania - testowanie zgodności systemu
Maciej Oleksy Zenon Matuszyk Jest to proces związany z wytwarzaniem oprogramowania. Jest on jednym z procesów kontroli jakości oprogramowania. Weryfikacja oprogramowania - testowanie zgodności systemu
Regulamin Przedmiotowy XIV Konkursu Języka Rosyjskiego dla uczniów gimnazjów województwa świętokrzyskiego w roku szkolnym 2015/2016
 Regulamin Przedmiotowy XIV Konkursu Języka Rosyjskiego dla uczniów gimnazjów województwa świętokrzyskiego w roku szkolnym 2015/2016 I. Informacje ogólne 1. Niniejszy Regulamin określa szczegółowe wymagania
Regulamin Przedmiotowy XIV Konkursu Języka Rosyjskiego dla uczniów gimnazjów województwa świętokrzyskiego w roku szkolnym 2015/2016 I. Informacje ogólne 1. Niniejszy Regulamin określa szczegółowe wymagania
Kryteria wymagań na poszczególne oceny dla uczniów z upośledzeniem w stopniu lekkim z języka angielskiego. Gramatyka i słownictwo Osiągnięcia ucznia:
 Kryteria wymagań na poszczególne y dla uczniów z upośledzeniem w stopniu lekkim z języka angielskiego. Gramatyka i słownictwo potrafi budować proste zdania, poprawne pod względem gramatycznym i logicznym
Kryteria wymagań na poszczególne y dla uczniów z upośledzeniem w stopniu lekkim z języka angielskiego. Gramatyka i słownictwo potrafi budować proste zdania, poprawne pod względem gramatycznym i logicznym
Analiza dialogu na potrzeby tworzenia systemów dialogowych. Jolanta Bachan
 Analiza dialogu na potrzeby tworzenia systemów dialogowych Jolanta Bachan 1 Dlaczego analiza dialogu? badania są potrzebne? Obecne systemy opierają się głównie na intuicji inżynierów mowy, nie na systematycznej
Analiza dialogu na potrzeby tworzenia systemów dialogowych Jolanta Bachan 1 Dlaczego analiza dialogu? badania są potrzebne? Obecne systemy opierają się głównie na intuicji inżynierów mowy, nie na systematycznej
Kurs MATURA Z INFORMATYKI
 Kurs MATURA Z INFORMATYKI Cena szkolenia Cena szkolenia wynosi 90 zł za 60 min. Ilość godzin szkolenia jest zależna od postępów w nauce uczestnika kursu oraz ilości czasu, którą będzie potrzebował do realizacji
Kurs MATURA Z INFORMATYKI Cena szkolenia Cena szkolenia wynosi 90 zł za 60 min. Ilość godzin szkolenia jest zależna od postępów w nauce uczestnika kursu oraz ilości czasu, którą będzie potrzebował do realizacji
Modelowanie interakcji helis transmembranowych
 Modelowanie interakcji helis transmembranowych Witold Dyrka, Jean-Christophe Nebel, Małgorzata Kotulska Instytut Inżynierii Biomedycznej i Pomiarowej, Politechnika Wrocławska Faculty of Computing, Information
Modelowanie interakcji helis transmembranowych Witold Dyrka, Jean-Christophe Nebel, Małgorzata Kotulska Instytut Inżynierii Biomedycznej i Pomiarowej, Politechnika Wrocławska Faculty of Computing, Information
PL B1. AKADEMIA GÓRNICZO-HUTNICZA IM. STANISŁAWA STASZICA, Kraków, PL BUP 01/11. WIESŁAW WAJS, Kraków, PL
 PL 215208 B1 RZECZPOSPOLITA POLSKA (12) OPIS PATENTOWY (19) PL (11) 215208 (13) B1 Urząd Patentowy Rzeczypospolitej Polskiej (21) Numer zgłoszenia: 388382 (22) Data zgłoszenia: 25.06.2009 (51) Int.Cl.
PL 215208 B1 RZECZPOSPOLITA POLSKA (12) OPIS PATENTOWY (19) PL (11) 215208 (13) B1 Urząd Patentowy Rzeczypospolitej Polskiej (21) Numer zgłoszenia: 388382 (22) Data zgłoszenia: 25.06.2009 (51) Int.Cl.
PRZEDMIOTOWE ZASADY OCENIANIA Z JĘZYKA ANGIELSKIEGO I ETAP EDUKACYJNY- KLASY I-III
 PRZEDMIOTOWE ZASADY OCENIANIA Z JĘZYKA ANGIELSKIEGO I ETAP EDUKACYJNY- KLASY I-III WYMAGANIA DLA UCZNIA KOŃCZĄCEGO KLASĘ PIERWSZĄ SZKOŁY PODSTAWOWEJ ( ZGODNIE Z NOWĄ PODSTAWĄPROGRAMOWĄ) Uczeń kończący
PRZEDMIOTOWE ZASADY OCENIANIA Z JĘZYKA ANGIELSKIEGO I ETAP EDUKACYJNY- KLASY I-III WYMAGANIA DLA UCZNIA KOŃCZĄCEGO KLASĘ PIERWSZĄ SZKOŁY PODSTAWOWEJ ( ZGODNIE Z NOWĄ PODSTAWĄPROGRAMOWĄ) Uczeń kończący
PRZEDMIOTOWY SYSTEM OCENIANIA Z JĘZYKA ANGIELSKIEGO kl. I-III ROK SZKOLNY 2016/2017
 PRZEDMIOTOWY SYSTEM OCENIANIA Z JĘZYKA ANGIELSKIEGO kl. I-III ROK SZKOLNY 2016/2017 1) Ocenianie osiągnięć edukacyjnych ucznia polega na rozpoznawaniu przez nauczycieli poziomu i postępów w opanowaniu
PRZEDMIOTOWY SYSTEM OCENIANIA Z JĘZYKA ANGIELSKIEGO kl. I-III ROK SZKOLNY 2016/2017 1) Ocenianie osiągnięć edukacyjnych ucznia polega na rozpoznawaniu przez nauczycieli poziomu i postępów w opanowaniu
Czy komputery potrafią mówić? Innowacyjne aplikacje wykorzystujące przetwarzanie dźwięku i mowy. Plan prezentacji.
 Czy komputery potrafią mówić? Innowacyjne aplikacje wykorzystujące przetwarzanie dźwięku i mowy Wydział Informatyki PB, Katedra Mediów Cyfrowych i Grafiki Komputerowej dr inż. Paweł Tadejko, p.tadejko@pb.edu.pl
Czy komputery potrafią mówić? Innowacyjne aplikacje wykorzystujące przetwarzanie dźwięku i mowy Wydział Informatyki PB, Katedra Mediów Cyfrowych i Grafiki Komputerowej dr inż. Paweł Tadejko, p.tadejko@pb.edu.pl
Szybkie prototypowanie w projektowaniu mechatronicznym
 Szybkie prototypowanie w projektowaniu mechatronicznym Systemy wbudowane (Embedded Systems) Systemy wbudowane (ang. Embedded Systems) są to dedykowane architektury komputerowe, które są integralną częścią
Szybkie prototypowanie w projektowaniu mechatronicznym Systemy wbudowane (Embedded Systems) Systemy wbudowane (ang. Embedded Systems) są to dedykowane architektury komputerowe, które są integralną częścią
1 Narzędzia przetwarzania 2 tekſtów hiſtorycznych
 1 Narzędzia przetwarzania 2 tekſtów hiſtorycznych Marcin Wolińſki, Witold Kieraś, Dorota Komo ńska, Emanuel Modrzejewſki Zespół Inżynieriey Lingw tyczney In ytut Pod aw Informatyki Polſkiey Akademii Nauk
1 Narzędzia przetwarzania 2 tekſtów hiſtorycznych Marcin Wolińſki, Witold Kieraś, Dorota Komo ńska, Emanuel Modrzejewſki Zespół Inżynieriey Lingw tyczney In ytut Pod aw Informatyki Polſkiey Akademii Nauk
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.)
") KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN, Instytut Podstaw Informatyki PAN Podstawowe informacje o projekcie
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN, Instytut Podstaw Informatyki PAN Podstawowe informacje o projekcie
Podstawy automatycznego rozpoznawania mowy. Autor: mgr inż. Piotr Bratoszewski
 Podstawy automatycznego rozpoznawania mowy Autor: mgr inż. Piotr Bratoszewski Rys historyczny 1930-1950 pierwsze systemy Automatycznego rozpoznawania mowy (ang. Automatic Speech Recognition ASR), metody
Podstawy automatycznego rozpoznawania mowy Autor: mgr inż. Piotr Bratoszewski Rys historyczny 1930-1950 pierwsze systemy Automatycznego rozpoznawania mowy (ang. Automatic Speech Recognition ASR), metody
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe.
 Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
UNIWERSYTET ŚLĄSKI W KATOWICACH
 UNIWERSYTET ŚLĄSKI W KATOWICACH STUDIUM PRAKTYCZNEJ NAUKI JĘZYKÓW OBCYCH FORMAT EGZAMINU: EGZAMIN CERTYFIKUJĄCY Z JĘZYKA OBCEGO, POZIOM B2 Egzamin sprawdza znajomość języka obcego ogólnego na poziomie
UNIWERSYTET ŚLĄSKI W KATOWICACH STUDIUM PRAKTYCZNEJ NAUKI JĘZYKÓW OBCYCH FORMAT EGZAMINU: EGZAMIN CERTYFIKUJĄCY Z JĘZYKA OBCEGO, POZIOM B2 Egzamin sprawdza znajomość języka obcego ogólnego na poziomie
Procesy ETL. 10maja2009. Paweł Szołtysek
 Procesy 10maja2009 Paweł Szołtysek 1/12 w praktyce w praktyce 2/12 Zagadnienie Business Inteligence w praktyce 3/12 Czym jest proces? w praktyce Dane: dowolny zbiór danych ze źródeł zewnętrznych. Szukane:
Procesy 10maja2009 Paweł Szołtysek 1/12 w praktyce w praktyce 2/12 Zagadnienie Business Inteligence w praktyce 3/12 Czym jest proces? w praktyce Dane: dowolny zbiór danych ze źródeł zewnętrznych. Szukane:
Jestem turystą, znam język angielski i nie zawaham się go użyć
 Autorski program nauczania opracowany w ramach projektu Urzędu Marszałkowskiego Województwa Kujawsko Pomorskiego pt. Coaching i tutoring w stronę nowoczesnej pracy dydaktycznej. TYTUŁ PROGRAMU: Jestem
Autorski program nauczania opracowany w ramach projektu Urzędu Marszałkowskiego Województwa Kujawsko Pomorskiego pt. Coaching i tutoring w stronę nowoczesnej pracy dydaktycznej. TYTUŁ PROGRAMU: Jestem
Architektura systemu e-schola
 ą ą ą Architektura systemu e-schola System e-schola zbudowany jest w postaci interaktywnej witryny intranetowej, działającej jako aplikacja serwerowa typu WEB(oparta o serwer WWW) Architektura systemu
ą ą ą Architektura systemu e-schola System e-schola zbudowany jest w postaci interaktywnej witryny intranetowej, działającej jako aplikacja serwerowa typu WEB(oparta o serwer WWW) Architektura systemu
Sterowniki Programowalne (SP)
") Sterowniki Programowalne (SP) Wybrane aspekty procesu tworzenia oprogramowania dla sterownika PLC Podstawy języka funkcjonalnych schematów blokowych (FBD) Politechnika Gdańska Wydział Elektrotechniki i
Sterowniki Programowalne (SP) Wybrane aspekty procesu tworzenia oprogramowania dla sterownika PLC Podstawy języka funkcjonalnych schematów blokowych (FBD) Politechnika Gdańska Wydział Elektrotechniki i
Przedmiotowy system oceniania z języka angielskiego Klasy IV-VI Szkoła Podstawowa w Młodzawach
 Przedmiotowy system oceniania z języka angielskiego Klasy IV-VI Szkoła Podstawowa w Młodzawach I. Zasady ogólne Przedmiotowy system nauczania ma na celu: 1) Bieżące i systematyczne obserwowanie postępów
Przedmiotowy system oceniania z języka angielskiego Klasy IV-VI Szkoła Podstawowa w Młodzawach I. Zasady ogólne Przedmiotowy system nauczania ma na celu: 1) Bieżące i systematyczne obserwowanie postępów
Wprowadzenie do teorii systemów ekspertowych
 Myślące komputery przyszłość czy utopia? Wprowadzenie do teorii systemów ekspertowych Roman Simiński siminski@us.edu.pl Wizja inteligentnych maszyn jest od wielu lat obecna w literaturze oraz filmach z
Myślące komputery przyszłość czy utopia? Wprowadzenie do teorii systemów ekspertowych Roman Simiński siminski@us.edu.pl Wizja inteligentnych maszyn jest od wielu lat obecna w literaturze oraz filmach z
Zastosowanie sztucznych sieci neuronowych w prognozowaniu szeregów czasowych (prezentacja 2)
") Zastosowanie sztucznych sieci neuronowych w prognozowaniu szeregów czasowych (prezentacja 2) Ewa Wołoszko Praca pisana pod kierunkiem Pani dr hab. Małgorzaty Doman Plan tego wystąpienia Teoria Narzędzia
Zastosowanie sztucznych sieci neuronowych w prognozowaniu szeregów czasowych (prezentacja 2) Ewa Wołoszko Praca pisana pod kierunkiem Pani dr hab. Małgorzaty Doman Plan tego wystąpienia Teoria Narzędzia
JĘZYK ANGIELSKI NA CO ZWRACAMY UWAGĘ OCENIAJĄC : 1.UMIEJĘTNOŚĆ WYPOWIEDZI USTNEJ:
 JĘZYK ANGIELSKI NA CO ZWRACAMY UWAGĘ OCENIAJĄC : 1.UMIEJĘTNOŚĆ WYPOWIEDZI USTNEJ: zgodność z tematem wkład pracy, przygotowanie poprawność gramatyczna wymowa - poprawność fonetyczna zasób słownictwa i
JĘZYK ANGIELSKI NA CO ZWRACAMY UWAGĘ OCENIAJĄC : 1.UMIEJĘTNOŚĆ WYPOWIEDZI USTNEJ: zgodność z tematem wkład pracy, przygotowanie poprawność gramatyczna wymowa - poprawność fonetyczna zasób słownictwa i