KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.)
|
|
|
- Iwona Marcinkowska
- 5 lat temu
- Przeglądów:
Transkrypt
1 KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN, Instytut Podstaw Informatyki PAN
2 Podstawowe informacje o projekcie Projekt realizowany przez IJP PAN we współpracy z IPI PAN, finansowany w ramach Narodowego Programu Rozwoju Humanistyki na lata: Kierownik projektu: prof. dr hab. Włodzimierz Gruszczyński Planowana objętość korpusu to 12 mln segmentów Korpus historyczny rozszerzający Narodowy Korpus Języka Polskiego Kryptonim: KORBA (KORpus BArokowy) (obecnie dostępny dla członków zespołu pracującego nad korpusem oraz w Pracowni Historii Języka Polskiego XVII i XVIII w. IJP PAN w Warszawie)
3 Zakres znakowania Znakowanie socjolingwistyczne (informacje o autorze, wydawcy, tłumaczu) umieszczone w metryczce każdego tekstu. Znakowanie stylistyczno-genologiczne umieszczone w metryczce każdego tekstu. Znakowanie strukturalne i tekstowe, umożliwiające dokładną lokalizację cytatu w tekście (paginacja; rozdziały, części, księgi itp.; notki marginesowe, przypisy itp.; podpisy pod ilustracjami; także oznaczenie wszystkich wtrętów obcych, z podziałem na języki). Znakowanie morfosyntaktyczne 0,5 mln segmentów ręczne reszta automatyczne


4 Znakowanie socjolingwistyczne
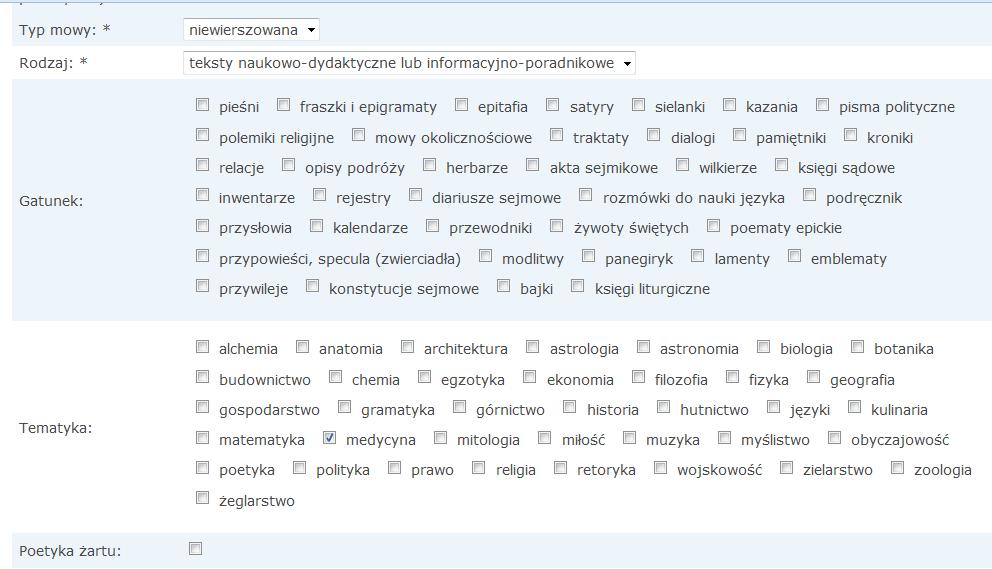
5 Znakowanie stylistyczno-genologiczne
6 Znakowanie strukturalne i tekstowe Oznaczenie istotnych elementów struktury tekstu, np. elementów strony tytułowej, fragmentów obcojęzycznych itp. Znakowanie Korby odbywa się w szablonie dokumentu Word umożliwiającym wprowadzanie znaczników za pomocą skrótów klawiaturowych Na potrzeby projektu został stworzony program do konwersji plików Worda na format XML zgodny ze standardem TEI
7 Znaczniki strukturalne

8 Znaczniki tekstowe
9 Oznaczenia języków obcych
10 Komentarze i poprawki skryptorów Informacja o liczbie nieczytelnych znaków COMED<..> Informacja o możliwości błędnego odczytania słowa gospodarz <?> Informacja o zaskakującym zapisie gorzski <!> Rozwinięcie skrótów oznaczonych tyldą atrame t <atrament> Poprawka oczywistej literówki wsziędze <wszędzie> 10
11 Próbka tekstu Word
12 Próbka tekstu XML 12
13 Znakowanie morfosyntaktyczne Przypisanie każdemu segmentowi informacji gramatycznej: o jego przynależności do określonej klasy gramatycznej o wartościach kategorii gramatycznych Umożliwia zaawansowane przeszukiwanie korpusu, np. wyszukanie wszystkich form fleksyjnych leksemu Znakowanie Korby będzie się odbywać na wzór znakowania NKJP Tagset (zbiór znaczników) będzie oparty na tagsecie NKJP, który zostanie dostosowany do potrzeb opisu polszczyzny barokowej Znakowanie będzie się odbywać na tekstach transkrybowanych, a nie transliterowanych
14 Konwersja do wersji transkrybowanej transliteracja B. Nie záda mi żaden tey rzeczy, ktoraby bárziey owemu niżeli mnie należeć nie miáłá. A ták śmierć y Kupidyn pozárszy się iáko bestie, posnęli w Kośćiele Bacchusowym, gdźie niewyszumiawszy z przepićia śmierć Cupidinow, á Cupido śmierći należący przypasawszy sáydak do boku szły, swych należących odpráwowáć powinnośći. transkrypcja B. Nie zada mi żaden tej rzeczy, któraby barzyej owemu niżeli mnie należeć nie miała. A tak śmierć i Kupidyn pozarszy się jako beztie, posnęli w Kościele Bacchusowym, gdzie niewyszumiawszy z przepicia śmierć Cupidynów, a Cupido śmierci należący przypasawszy sajdak do boku szły, swych należących odprawować powinności.
15 Narzędzia wspomagające znakowanie morfosyntaktyczne Analizator morfologiczny przypisuje formie gramatycznej wszystkie możliwe interpretacje Tager ujednoznacznia interpretację gramatyczną Słownik gramatyczny zawiera paradygmaty leksemów danego języka, stanowi podstawę działania analizatora morfologicznego Podstawą Morfeusza analizatora morfologicznego przeznaczonego do analizy tekstów współczesnych (używanego przy znakowaniu NKJP) jest Słownik gramatyczny języka polskiego (SGJP Podstawą Morfeusza XVII-wiecznego będzie postarzony SGJP
16 Postarzanie SGJP Uzupełnienie SGJP o paradygmaty leksemów wyciągniętych z e-sxvii (niepełne paradygmaty zostaną automatycznie uzupełnione) Modyfikacja paradygmatów SGJP Dodanie form historycznych do paradygmatów współczesnych, np. imiesłów przysłówkowy uprzedni zostanie dodany do paradygmatów czasowników niedokonanych (widziawszy) Dodanie dodatkowych wartości do niektórych kategorii gramatycznych, np. liczby podwójnej (żabie) Dodanie nowych, regularnie tworzonych derywatów, np. imiesłowów przymiotnikowych w stopniu wyższym (bolątszy) Modyfikacja kategorii rodzaju
17 Hierarchia rodzaju zneutralizowany męski żeński nijaki męskożywotny męskonieżywotny męskożywotny 1 męskożywotny 2 forma wartości lemat gramatyczne abrysom Dat. pl ABRYS (?) ABRYSA (?) ABRYSO (?) rodzaj abrysu Gen. sg ABRYS męski zneutralizowany abrys Acc. sg ABRYS męskonieżywotny abrysę Acc. sg ABRYSA żeński
18 Tworzenie Morfeusza XVII SGJP e-sxvii Morfeus z XVII postarzony SGJP uzupełnione paradygmaty wstępna wersja Morfeusza XVII rozszerzona wersja e-sxvii tekst automatyczna anotacja ręczne ujednoznacznienie i weryfikacja tekst anotowan y tekst ujednoznaczniony
19 Dziękujemy za uwagę
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN
 Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN") KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN Podstawowe informacje o projekcie Projekt realizowany przez IJP
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN Podstawowe informacje o projekcie Projekt realizowany przez IJP
Doświadczenia z prac nad Korpusem tekstów polskich z XVII i XVIII wieku
 Doświadczenia z prac nad Korpusem tekstów polskich z XVII i XVIII wieku zasady doboru tekstów, zakres znakowania, sposób udostępniania Włodzimierz Gruszczyński IJP PAN e-mail: wlodekiewa@poczta.onet.pl
Doświadczenia z prac nad Korpusem tekstów polskich z XVII i XVIII wieku zasady doboru tekstów, zakres znakowania, sposób udostępniania Włodzimierz Gruszczyński IJP PAN e-mail: wlodekiewa@poczta.onet.pl
KorBa. Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk
 Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk") KorBa Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk ALLPPT.com _ Free PowerPoint Templates, Diagrams and Charts PODSTAWOWE
KorBa Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk ALLPPT.com _ Free PowerPoint Templates, Diagrams and Charts PODSTAWOWE
Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) prezentacja znakowania morfosyntaktycznego i możliwości wyszukiwarki
 prezentacja znakowania morfosyntaktycznego i możliwości wyszukiwarki") Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) prezentacja znakowania morfosyntaktycznego i możliwości wyszukiwarki Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk
Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) prezentacja znakowania morfosyntaktycznego i możliwości wyszukiwarki Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk
Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.)
") Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Dorota Adamiec IJP PAN Włodzimierz Gruszczyński IJP PAN Maciej Ogrodniczuk IPI PAN Stan przekrojowych badań nad słownictwem polskim
Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Dorota Adamiec IJP PAN Włodzimierz Gruszczyński IJP PAN Maciej Ogrodniczuk IPI PAN Stan przekrojowych badań nad słownictwem polskim
Włodzimierz Gruszczyński * Maciej Ogrodniczuk ** Marcin Woliński ** *IJP PAN **IPI PAN
 Włodzimierz Gruszczyński * Maciej Ogrodniczuk ** Marcin Woliński ** *IJP PAN **IPI PAN Wystąpienie przygotowane w ramach projektu Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do roku 1772)
Włodzimierz Gruszczyński * Maciej Ogrodniczuk ** Marcin Woliński ** *IJP PAN **IPI PAN Wystąpienie przygotowane w ramach projektu Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do roku 1772)
Dobór tekstów do Elektronicznego korpusu tekstów polskich z XVII i XVIII w. (do 1772 r.) możliwości i ograniczenia budowanego warsztatu badawczego
 możliwości i ograniczenia budowanego warsztatu badawczego") Dobór tekstów do Elektronicznego korpusu tekstów polskich z XVII i XVIII w. (do 1772 r.) możliwości i ograniczenia budowanego warsztatu badawczego Dorota Adamiec Instytut Języka Polskiego PAN Elektroniczny
Dobór tekstów do Elektronicznego korpusu tekstów polskich z XVII i XVIII w. (do 1772 r.) możliwości i ograniczenia budowanego warsztatu badawczego Dorota Adamiec Instytut Języka Polskiego PAN Elektroniczny
1 Narzędzia przetwarzania 2 tekſtów hiſtorycznych
 1 Narzędzia przetwarzania 2 tekſtów hiſtorycznych Marcin Wolińſki, Witold Kieraś, Dorota Komo ńska, Emanuel Modrzejewſki Zespół Inżynieriey Lingw tyczney In ytut Pod aw Informatyki Polſkiey Akademii Nauk
1 Narzędzia przetwarzania 2 tekſtów hiſtorycznych Marcin Wolińſki, Witold Kieraś, Dorota Komo ńska, Emanuel Modrzejewſki Zespół Inżynieriey Lingw tyczney In ytut Pod aw Informatyki Polſkiey Akademii Nauk
Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego
 Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego Witold Kieraś Łukasz Kobyliński Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN III Konferencja DARIAH-PL Poznań 9.11.2016
Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego Witold Kieraś Łukasz Kobyliński Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN III Konferencja DARIAH-PL Poznań 9.11.2016
WŁODZIMIERZ GRUSZCZYŃSKI, DOROTA ADAMIEC, MACIEJ OGRODNICZUK
 POLONICA XXXIII PL ISSN 0137-9712 WŁODZIMIERZ GRUSZCZYŃSKI, DOROTA ADAMIEC, MACIEJ OGRODNICZUK Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego
POLONICA XXXIII PL ISSN 0137-9712 WŁODZIMIERZ GRUSZCZYŃSKI, DOROTA ADAMIEC, MACIEJ OGRODNICZUK Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego
Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego
 prezentacja projektu badawczego") WŁODZIMIERZ GRUSZCZYŃSKI DOROTA ADAMIEC MACIEJ OGRODNICZUK Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego Projekt Elektroniczny korpus tekstów
WŁODZIMIERZ GRUSZCZYŃSKI DOROTA ADAMIEC MACIEJ OGRODNICZUK Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego Projekt Elektroniczny korpus tekstów
Tworzenie korpusu tekstów dawnych a korpusu tekstów współczesnych: różnice teoretyczne i warsztatowe
 Tworzenie korpusu tekstów dawnych a korpusu tekstów współczesnych: różnice teoretyczne i warsztatowe (na przykładzie Korpusu tekstów polskich XVII-XVIII wieku) W. Gruszczyński R. Bronikowska IJP PAN Porównywane
Tworzenie korpusu tekstów dawnych a korpusu tekstów współczesnych: różnice teoretyczne i warsztatowe (na przykładzie Korpusu tekstów polskich XVII-XVIII wieku) W. Gruszczyński R. Bronikowska IJP PAN Porównywane
Morfeusz 2 analizator i generator fleksyjny dla języka polskiego
 Morfeusz 2 analizator i generator fleksyjny dla języka polskiego Marcin Woliński i Anna Andrzejczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Warsztaty CLARIN-PL,
Morfeusz 2 analizator i generator fleksyjny dla języka polskiego Marcin Woliński i Anna Andrzejczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Warsztaty CLARIN-PL,
Włodzimierz Gruszczyński. Instytut Języka Polskiego PAN Korpusy Diachroniczne Polszczyzny Katowice, kwietnia 2017 r.
 Tagset barokowy problemy opracowania zestawu kategorii morfologicznych i ich wartości na potrzeby Elektronicznego Korpusu Tekstów Polskich XVII i XVIII w. (do 1772 r.) Włodzimierz Gruszczyński Instytut
Tagset barokowy problemy opracowania zestawu kategorii morfologicznych i ich wartości na potrzeby Elektronicznego Korpusu Tekstów Polskich XVII i XVIII w. (do 1772 r.) Włodzimierz Gruszczyński Instytut
KORBEUSZ. Włodzimierza Grußczyńſkiego, Dorotę Adamiec, Renatę Bronikowſką Inſtytut Języka Polſkiego PAN
 Korpus hiſtoryczny, czyli problemata tranſliteracyi, tranſkrypcyi i annotacyi na przykładzie Elektronicznego Korpusu Textów Polſkich z XVII i XVIII w. (do 1772 r.) metodą wokalną wyłożone i rycinami zexemplifikowane
Korpus hiſtoryczny, czyli problemata tranſliteracyi, tranſkrypcyi i annotacyi na przykładzie Elektronicznego Korpusu Textów Polſkich z XVII i XVIII w. (do 1772 r.) metodą wokalną wyłożone i rycinami zexemplifikowane
WK, FN-1, semestr letni 2010 Tworzenie list frekwencyjnych za pomocą korpusów i programu Poliqarp
 WK, FN-1, semestr letni 2010 Tworzenie list frekwencyjnych za pomocą korpusów i programu Poliqarp Natalia Kotsyba, IBI AL UW 24 marca 2010 Plan zajęć Praca domowa na zapytania do Korpusu IPI PAN za pomocą
WK, FN-1, semestr letni 2010 Tworzenie list frekwencyjnych za pomocą korpusów i programu Poliqarp Natalia Kotsyba, IBI AL UW 24 marca 2010 Plan zajęć Praca domowa na zapytania do Korpusu IPI PAN za pomocą
Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI, XVII i XVIII w.
 Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI, XVII i XVIII w. Prezentacja projektu i jego zastosowania w pracy naukowej oraz dydaktyce Włodzimierz Gruszczyński 1 Maciej Ogrodniczuk
Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI, XVII i XVIII w. Prezentacja projektu i jego zastosowania w pracy naukowej oraz dydaktyce Włodzimierz Gruszczyński 1 Maciej Ogrodniczuk
Elektroniczny Korpus Textow Polſkich z XVII i XVIII w. (do 1772 r.)
") to iest Elektroniczny Korpus Textow Polſkich z XVII i XVIII w. (do 1772 r.) KORBEUSZ W Wárßáwie, dniá 18. Iunii A.D. MMXVIII Podstawowe dane projektu KORBEUSZ Tytuł: Elektroniczny korpus tekstów polskich
to iest Elektroniczny Korpus Textow Polſkich z XVII i XVIII w. (do 1772 r.) KORBEUSZ W Wárßáwie, dniá 18. Iunii A.D. MMXVIII Podstawowe dane projektu KORBEUSZ Tytuł: Elektroniczny korpus tekstów polskich
The Use of Electronic Historical Dictionary Data in Corpus Design
 Studies in Polish Linguistics vol. 11, 2016, issue 2, pp. 47 56 doi:10.4467/23005920spl.16.003.4818 www.ejournals.eu/spl Renata Bronikowska, Włodzimierz Gruszczyński, Maciej Ogrodniczuk, Marcin Woliński
Studies in Polish Linguistics vol. 11, 2016, issue 2, pp. 47 56 doi:10.4467/23005920spl.16.003.4818 www.ejournals.eu/spl Renata Bronikowska, Włodzimierz Gruszczyński, Maciej Ogrodniczuk, Marcin Woliński
Tworzenie przeszukiwalnych korpusów j zyka polskiego za pomoc Korpusomatu
 Tworzenie przeszukiwalnych korpusów j zyka polskiego za pomoc Korpusomatu Witold Kiera± Šukasz Kobyli«ski Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN IV cykl wykªadów i warsztatów CLARIN-PL Šód¹
Tworzenie przeszukiwalnych korpusów j zyka polskiego za pomoc Korpusomatu Witold Kiera± Šukasz Kobyli«ski Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN IV cykl wykªadów i warsztatów CLARIN-PL Šód¹
SPIS TREŚCI. Spis treści Wstęp Wykaz skrótów, symboli i terminów gramatycznych MIANOWNIK
 5 SPIS TREŚCI Spis treści... 5-12 Wstęp... 13-14 Wykaz skrótów, symboli i terminów gramatycznych... 15-16 MIANOWNIK... 17-65 TABELA prezentująca końcówki fleksyjne rzeczowników... 17 RZECZOWNIK, PRZYMIOTNIK...
5 SPIS TREŚCI Spis treści... 5-12 Wstęp... 13-14 Wykaz skrótów, symboli i terminów gramatycznych... 15-16 MIANOWNIK... 17-65 TABELA prezentująca końcówki fleksyjne rzeczowników... 17 RZECZOWNIK, PRZYMIOTNIK...
Analizator fleksyjny Morfeusz 2
 Analizator fleksyjny Morfeusz 2 Katarzyna Krasnowska-Kieraś Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Lublin, 25 września 2019 Katarzyna Krasnowska-Kieraś Morfeusz
Analizator fleksyjny Morfeusz 2 Katarzyna Krasnowska-Kieraś Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Lublin, 25 września 2019 Katarzyna Krasnowska-Kieraś Morfeusz
MARCIN WOLIŃSKI MORFEUSZ REAKTYWACJA IPI PAN, 7 KWIETNIA /28 ...
 MARCIN WOLIŃSKI MORFEUSZ REAKTYWACJA IPI PAN, 7 KWIETNIA 2014 1/28 Zespół Małgorzata Marciniak nadzór ogólny Marcin Woliński specyfikacja Michał Lenart implementacja Jan Daciuk konsultacja automatologiczna
MARCIN WOLIŃSKI MORFEUSZ REAKTYWACJA IPI PAN, 7 KWIETNIA 2014 1/28 Zespół Małgorzata Marciniak nadzór ogólny Marcin Woliński specyfikacja Michał Lenart implementacja Jan Daciuk konsultacja automatologiczna
Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI XVIII Wieku jako uzupełniona bibliografia Zawadzkiego
 Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI XVIII Wieku jako uzupełniona bibliografia Zawadzkiego Włodzimierz Gruszczyński Maciej Ogrodniczuk Instytut Języka Polskiego Polskiej
Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI XVIII Wieku jako uzupełniona bibliografia Zawadzkiego Włodzimierz Gruszczyński Maciej Ogrodniczuk Instytut Języka Polskiego Polskiej
ĆWICZENIE 1 SKŁAD TEKSTU DO DRUKU
 ĆWICZENIE 1 SKŁAD TEKSTU DO DRUKU 1. Skopiowanie przykładowego surowego tekstu (format.txt) wybranego rozdziału pracy magisterskiej wraz z tekstem przypisów do niego (w osobnym pliku) na komputery studentów.
ĆWICZENIE 1 SKŁAD TEKSTU DO DRUKU 1. Skopiowanie przykładowego surowego tekstu (format.txt) wybranego rozdziału pracy magisterskiej wraz z tekstem przypisów do niego (w osobnym pliku) na komputery studentów.
Adam Przepiórkowski. Korpus IPI PAN. wersja wstępna INSTYTUT PODSTAW INFORMATYKI PAN
 Adam Przepiórkowski Korpus IPI PAN wersja wstępna INSTYTUT PODSTAW INFORMATYKI PAN WARSZAWA 2004 Instytut Podstaw Informatyki Polska Akademia Nauk ul. Ordona 21 01-237 Warszawa Copyright 2004 by Adam Przepiórkowski
Adam Przepiórkowski Korpus IPI PAN wersja wstępna INSTYTUT PODSTAW INFORMATYKI PAN WARSZAWA 2004 Instytut Podstaw Informatyki Polska Akademia Nauk ul. Ordona 21 01-237 Warszawa Copyright 2004 by Adam Przepiórkowski
NAKŁADKA KORPUSOWA (NKJP, KORBA) OPARTA O TRADYCYJNĄ KLASYFIKACJĘ CZĘŚCI MOWY. Emanuel Modrzejewski.
 OPARTA O TRADYCYJNĄ KLASYFIKACJĘ CZĘŚCI MOWY. Emanuel Modrzejewski.") NAKŁADKA KORPUSOWA OPARTA O TRADYCYJNĄ KLASYFIKACJĘ CZĘŚCI MOWY (NKJP, KORBA) Emanuel Modrzejewski modrzejewski.emanuel@gmail.com DOTYCHCZASOWE NAKŁADKI KORPUSOWE: Polsko-rosyjski i rosyjsko-polski korpus
NAKŁADKA KORPUSOWA OPARTA O TRADYCYJNĄ KLASYFIKACJĘ CZĘŚCI MOWY (NKJP, KORBA) Emanuel Modrzejewski modrzejewski.emanuel@gmail.com DOTYCHCZASOWE NAKŁADKI KORPUSOWE: Polsko-rosyjski i rosyjsko-polski korpus
Spis treści 0. Szkoła Tokarskiego Marcin Woliński Adam Przepiórkowski Korpus IPI PAN Inne pojęcia LXIII Zjazd PTJ, Warszawa
 Spis treści -1 LXIII Zjazd PTJ, Warszawa 16-17.09.2003 Pomor, Humor Morfeusz SIAT Poliqarp Holmes Kryteria wyboru Robert Wołosz Marcin Woliński Adam Przepiórkowski Michał Rudolf Niebieska gramatyka Saloni,
Spis treści -1 LXIII Zjazd PTJ, Warszawa 16-17.09.2003 Pomor, Humor Morfeusz SIAT Poliqarp Holmes Kryteria wyboru Robert Wołosz Marcin Woliński Adam Przepiórkowski Michał Rudolf Niebieska gramatyka Saloni,
CLARIN rozproszony system technologii językowych dla różnych języków europejskich
 CLARIN rozproszony system technologii językowych dla różnych języków europejskich Maciej Piasecki Politechnika Wrocławska Instytut Informatyki G4.19 Research Group maciej.piasecki@pwr.wroc.pl Projekt CLARIN
CLARIN rozproszony system technologii językowych dla różnych języków europejskich Maciej Piasecki Politechnika Wrocławska Instytut Informatyki G4.19 Research Group maciej.piasecki@pwr.wroc.pl Projekt CLARIN
Korpusomat narz dzie do tworzenia przeszukiwalnych korpusów j zyka polskiego
 Korpusomat narz dzie do tworzenia przeszukiwalnych korpusów j zyka polskiego Witold Kiera± Šukasz Kobyli«ski Maciej Ogrodniczuk Michaª Wasiluk Zbigniew Gawªowicz Instytut Podstaw Informatyki PAN IX cykl
Korpusomat narz dzie do tworzenia przeszukiwalnych korpusów j zyka polskiego Witold Kiera± Šukasz Kobyli«ski Maciej Ogrodniczuk Michaª Wasiluk Zbigniew Gawªowicz Instytut Podstaw Informatyki PAN IX cykl
SGJP Model odmiany Przymiotniki Rzeczowniki Czasowniki Podsumowanie
 Warszawa, Wiedza Powszechna 2007 Publikacja przygotowana w latach 2003 2006 w ramach projektu Słownik gramatyczny języka polskiego, sponsorowanego przez Komitet Badań Naukowych (nr rejestracyjny 2 H01D
Warszawa, Wiedza Powszechna 2007 Publikacja przygotowana w latach 2003 2006 w ramach projektu Słownik gramatyczny języka polskiego, sponsorowanego przez Komitet Badań Naukowych (nr rejestracyjny 2 H01D
j INSTYTUT PODSTAW INFORMATYKI
 Format dokumentów w projekcie elektronicznego korpusu tekstów polskich z XVII i XVIII w. Maciej Ogrodniczuk Michał Lenart Institute of Computer Science Polish Academy of Sciences j INSTYTUT PODSTAW INFORMATYKI
Format dokumentów w projekcie elektronicznego korpusu tekstów polskich z XVII i XVIII w. Maciej Ogrodniczuk Michał Lenart Institute of Computer Science Polish Academy of Sciences j INSTYTUT PODSTAW INFORMATYKI
Instrukcja. opracował Marcin Oleksy
 Instrukcja opracował Marcin Oleksy Wstęp Zarządzanie korpusem Flagi Flagowanie korpusu Usuwanie i edytowanie flag Użytkownicy Przypisywanie użytkowników Role użytkowników Cofnięcie dostępu Podkorpusy Tworzenie
Instrukcja opracował Marcin Oleksy Wstęp Zarządzanie korpusem Flagi Flagowanie korpusu Usuwanie i edytowanie flag Użytkownicy Przypisywanie użytkowników Role użytkowników Cofnięcie dostępu Podkorpusy Tworzenie
Korpusy językowe podstawowa terminologia i metody tworzenia. Natalia Kotsyba IBI AL Uniwersytet Warszawski 12 i 26 stycznia 2011 r.
 Korpusy językowe podstawowa terminologia i metody tworzenia Natalia Kotsyba IBI AL Uniwersytet Warszawski 12 i 26 stycznia 2011 r. Czym jest korpus? Zbiór tekstów albo zapisanych wypowiedzi, wykorzystywany
Korpusy językowe podstawowa terminologia i metody tworzenia Natalia Kotsyba IBI AL Uniwersytet Warszawski 12 i 26 stycznia 2011 r. Czym jest korpus? Zbiór tekstów albo zapisanych wypowiedzi, wykorzystywany
Zasób leksykalny polszczyzny II poł. XIX wieku a możliwość automatycznej analizy morfologicznej tekstów z tego okresu
 Zasób leksykalny polszczyzny II poł. XIX wieku a możliwość automatycznej analizy morfologicznej tekstów z tego okresu DEC-2012/07/B/HS2/00570 Magdalena Derwojedowa Witold Kieraś Danuta Skowrońska Robert
Zasób leksykalny polszczyzny II poł. XIX wieku a możliwość automatycznej analizy morfologicznej tekstów z tego okresu DEC-2012/07/B/HS2/00570 Magdalena Derwojedowa Witold Kieraś Danuta Skowrońska Robert
Porównywanie tagerów dopuszczajacych niejednoznaczności
 Porównywanie tagerów dopuszczajacych niejednoznaczności (na przykładzie tagerów wykorzystanych w Korpusie IPI PAN) 3 listopad 2008 Plan prezentacji 1 Wprowadzenie Problem niejednoznaczności Poprawna interpretacja
Porównywanie tagerów dopuszczajacych niejednoznaczności (na przykładzie tagerów wykorzystanych w Korpusie IPI PAN) 3 listopad 2008 Plan prezentacji 1 Wprowadzenie Problem niejednoznaczności Poprawna interpretacja
Odkrywanie CAQDAS : wybrane bezpłatne programy komputerowe wspomagające analizę danych jakościowych / Jakub Niedbalski. Łódź, 2013.
 Odkrywanie CAQDAS : wybrane bezpłatne programy komputerowe wspomagające analizę danych jakościowych / Jakub Niedbalski. Łódź, 2013 Spis treści Wprowadzenie 11 1. Audacity - program do edycji i obróbki
Odkrywanie CAQDAS : wybrane bezpłatne programy komputerowe wspomagające analizę danych jakościowych / Jakub Niedbalski. Łódź, 2013 Spis treści Wprowadzenie 11 1. Audacity - program do edycji i obróbki
Zautomatyzowane tworzenie korpusów błędów dla języka polskiego
 Zautomatyzowane tworzenie korpusów błędów dla języka polskiego Marcin Miłkowski Instytut Filozofii i Socjologii PAN Zakład Logiki i Kognitywistyki Adres projektu: morfologik.blogspot.com Korpusy błędów
Zautomatyzowane tworzenie korpusów błędów dla języka polskiego Marcin Miłkowski Instytut Filozofii i Socjologii PAN Zakład Logiki i Kognitywistyki Adres projektu: morfologik.blogspot.com Korpusy błędów
extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl
 extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl Plan wykładu Wprowadzenie: historia rozwoju technik znakowania tekstu Motywacje dla prac nad XML-em Podstawowe koncepcje XML-a XML jako metajęzyk
extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl Plan wykładu Wprowadzenie: historia rozwoju technik znakowania tekstu Motywacje dla prac nad XML-em Podstawowe koncepcje XML-a XML jako metajęzyk
Lokalizacja Oprogramowania
 mgr inż. Anton Smoliński anton.smolinski@zut.edu.pl Lokalizacja Oprogramowania 16/12/2016 Wykład 6 Internacjonalizacja, Testowanie, Tłumaczenie Maszynowe Agenda Internacjonalizacja Testowanie lokalizacji
mgr inż. Anton Smoliński anton.smolinski@zut.edu.pl Lokalizacja Oprogramowania 16/12/2016 Wykład 6 Internacjonalizacja, Testowanie, Tłumaczenie Maszynowe Agenda Internacjonalizacja Testowanie lokalizacji
Problem normy językowej w leksykografii historycznej
 Problem normy językowej w leksykografii historycznej Włodzimierz Gruszczyński Instytut Języka Polskiego PAN wlodekiewa@poczta.onet.pl Cechy słownika historycznego Słownik historyczny jest zazwyczaj: w
Problem normy językowej w leksykografii historycznej Włodzimierz Gruszczyński Instytut Języka Polskiego PAN wlodekiewa@poczta.onet.pl Cechy słownika historycznego Słownik historyczny jest zazwyczaj: w
Forma. Główny cel kursu. Umiejętności nabywane przez studentów. Wymagania wstępne:
 WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
PoliMorf otwarty słownik morfologiczny
 PoliMorf otwarty słownik morfologiczny Marcin Woliński Marcin Miłkowski Maciej Ogrodniczuk Adam Przepiórkowski Łukasz Szałkiewicz Jan Szejko j IPI PAN, 5 grudnia 2011 Plan prezentacji 1 Projekt CESAR 2
PoliMorf otwarty słownik morfologiczny Marcin Woliński Marcin Miłkowski Maciej Ogrodniczuk Adam Przepiórkowski Łukasz Szałkiewicz Jan Szejko j IPI PAN, 5 grudnia 2011 Plan prezentacji 1 Projekt CESAR 2
Wydobywanie reguł na potrzeby ujednoznaczniania morfo-syntaktycznego oraz płytkiej analizy składniowej tekstów polskich
 Wydobywanie reguł na potrzeby ujednoznaczniania morfo-syntaktycznego oraz płytkiej analizy składniowej tekstów polskich Adam Radziszewski Instytut Informatyki Stosowanej PWr SIIS 23, 12 czerwca 2008 O
Wydobywanie reguł na potrzeby ujednoznaczniania morfo-syntaktycznego oraz płytkiej analizy składniowej tekstów polskich Adam Radziszewski Instytut Informatyki Stosowanej PWr SIIS 23, 12 czerwca 2008 O
Skorzystaj z Worda i stwórz profesjonalnie wyglądające dokumenty.
 ABC Word 2007 PL. Autor: Aleksandra Tomaszewska-Adamarek Czasy maszyn do pisania odchodzą w niepamięć. Dziś narzędziami do edycji tekstów są aplikacje komputerowe, wśród których niekwestionowaną palmę
ABC Word 2007 PL. Autor: Aleksandra Tomaszewska-Adamarek Czasy maszyn do pisania odchodzą w niepamięć. Dziś narzędziami do edycji tekstów są aplikacje komputerowe, wśród których niekwestionowaną palmę
Od ZX Spectrum do Jasnopisu
 Od ZX Spectrum do Jasnopisu Włodzimierz Gruszczyński IJP PAN Kraków, 14 października 2016 Jak to się zaczęło? Miałem być inżynierem lub matematykiem Dostałem się na polonistykę Na I roku przeczytałem jeden
Od ZX Spectrum do Jasnopisu Włodzimierz Gruszczyński IJP PAN Kraków, 14 października 2016 Jak to się zaczęło? Miałem być inżynierem lub matematykiem Dostałem się na polonistykę Na I roku przeczytałem jeden
II cykl wykładów i warsztatów. CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w naukach humanistycznych i społecznych
 II cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w naukach humanistycznych i społecznych 18-20 maja 2015 roku Politechnika Wrocławska, Centrum Kongresowe,
II cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w naukach humanistycznych i społecznych 18-20 maja 2015 roku Politechnika Wrocławska, Centrum Kongresowe,
Raport rozliczeniowy
 1 Raport rozliczeniowy Liliana Błaszak Wydział Ekonomiczno-Finansowy Zachodniopomorski Oddział Wojewódzki NFZ Szczecin, 6 luty 2006 r. 2 Raport rozliczeniowy - II-Faza wymiany danych (1) Zalety rozwiązania:
1 Raport rozliczeniowy Liliana Błaszak Wydział Ekonomiczno-Finansowy Zachodniopomorski Oddział Wojewódzki NFZ Szczecin, 6 luty 2006 r. 2 Raport rozliczeniowy - II-Faza wymiany danych (1) Zalety rozwiązania:
Narzędzia do pisania. Korektor pisowni i korektor gramatyczny
 Narzędzia do pisania Word oferuje wiele narzędzi ułatwiających pracę. Jedne służą do łatwego znalezienia i poprawienia błędów, inne pomagają nadać właściwą formę dokumentom przygotowanym do publikacji.
Narzędzia do pisania Word oferuje wiele narzędzi ułatwiających pracę. Jedne służą do łatwego znalezienia i poprawienia błędów, inne pomagają nadać właściwą formę dokumentom przygotowanym do publikacji.
1. Skopiować naswój komputer: (tymczasowy adres)
") Instrukcja instalacji Programu Ewangelie i pracy z nim 1. Skopiować naswój komputer: http://grant.rudolf.waw.pl/ (tymczasowy adres) a/ katalog ze skanami przekładu Nowego Testamentu b/pliki z edycjami
Instrukcja instalacji Programu Ewangelie i pracy z nim 1. Skopiować naswój komputer: http://grant.rudolf.waw.pl/ (tymczasowy adres) a/ katalog ze skanami przekładu Nowego Testamentu b/pliki z edycjami
Oprogramowanie typu CAT
 Oprogramowanie typu CAT (Computer Aided Translation) Informacje ogólne Copyright Jacek Scholz 2009 Wprowadzenie: narzędzia do wspomagania translacji Bazy pamięci tłumaczet umaczeń (Translation Memory)
Oprogramowanie typu CAT (Computer Aided Translation) Informacje ogólne Copyright Jacek Scholz 2009 Wprowadzenie: narzędzia do wspomagania translacji Bazy pamięci tłumaczet umaczeń (Translation Memory)
Gramatyka opisowa języka polskiego Kod przedmiotu
 Gramatyka opisowa języka polskiego - opis przedmiotu Informacje ogólne Nazwa przedmiotu Gramatyka opisowa języka polskiego Kod przedmiotu 09.3-WH-FiP-GOP-1-K-S14_pNadGen0FA8C Wydział Kierunek Wydział Humanistyczny
Gramatyka opisowa języka polskiego - opis przedmiotu Informacje ogólne Nazwa przedmiotu Gramatyka opisowa języka polskiego Kod przedmiotu 09.3-WH-FiP-GOP-1-K-S14_pNadGen0FA8C Wydział Kierunek Wydział Humanistyczny
MINISTERSTWO SPRAW WEWNĘTRZNYCH I ADMINISTRACJI DEPARTAMENT INFORMATYZACJI
 MINISTERSTWO SPRAW WEWNĘTRZNYCH I ADMINISTRACJI DEPARTAMENT INFORMATYZACJI ul. Wspólna 1/3 00-529 Warszawa ZASADY NAZEWNICTWA DOKUMENTÓW XML Projekt współfinansowany Przez Unię Europejską Europejski Fundusz
MINISTERSTWO SPRAW WEWNĘTRZNYCH I ADMINISTRACJI DEPARTAMENT INFORMATYZACJI ul. Wspólna 1/3 00-529 Warszawa ZASADY NAZEWNICTWA DOKUMENTÓW XML Projekt współfinansowany Przez Unię Europejską Europejski Fundusz
SYLLABUS. Uniwersytet Przyrodniczo-Humanistyczny w Siedlcach Wydział Humanistyczny
 Uniwersytet Przyrodniczo-Humanistyczny w Siedlcach Wydział Humanistyczny SYLLABUS Instytut Filologii Polskiej i Lingwistyki Stosowanej Zakład Językoznawstwa Kierunek Podyplomowe Studium Filologii Polskiej
Uniwersytet Przyrodniczo-Humanistyczny w Siedlcach Wydział Humanistyczny SYLLABUS Instytut Filologii Polskiej i Lingwistyki Stosowanej Zakład Językoznawstwa Kierunek Podyplomowe Studium Filologii Polskiej
Korekta OCR problemy i rozwiązania
 Korekta OCR problemy i rozwiązania Edyta Kotyńska eteka.com.pl Kraków, 24-25.01.2013 r. Tekst, który nie jest cyfrowy - nie istnieje w sieci OCR umożliwia korzystanie z materiałów historycznych w formie
Korekta OCR problemy i rozwiązania Edyta Kotyńska eteka.com.pl Kraków, 24-25.01.2013 r. Tekst, który nie jest cyfrowy - nie istnieje w sieci OCR umożliwia korzystanie z materiałów historycznych w formie
METODY REPREZENTACJI INFORMACJI
 Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Magisterskie Studia Uzupełniające METODY REPREZENTACJI INFORMACJI Ćwiczenie 1: Budowa i rozbiór gramatyczny dokumentów XML Instrukcja
Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Magisterskie Studia Uzupełniające METODY REPREZENTACJI INFORMACJI Ćwiczenie 1: Budowa i rozbiór gramatyczny dokumentów XML Instrukcja
Korpus Dyskursu Parlamentarnego
 Korpus Dyskursu Parlamentarnego Maciej Ogrodniczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki PAN Warsztaty CLARIN-PL Lublin, 25 września 2019 r. Korpus Dyskursu Parlamentarnego W pigułce:
Korpus Dyskursu Parlamentarnego Maciej Ogrodniczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki PAN Warsztaty CLARIN-PL Lublin, 25 września 2019 r. Korpus Dyskursu Parlamentarnego W pigułce:
KATEGORIA OBSZAR WIEDZY
 Moduł 3 - Przetwarzanie tekstów - od kandydata wymaga się zaprezentowania umiejętności wykorzystywania programu do edycji tekstu. Kandydat powinien wykonać zadania o charakterze podstawowym związane z
Moduł 3 - Przetwarzanie tekstów - od kandydata wymaga się zaprezentowania umiejętności wykorzystywania programu do edycji tekstu. Kandydat powinien wykonać zadania o charakterze podstawowym związane z
Nr Tytuł Przykład Str.
 Spis treści Nr Tytuł Przykład Str. 1. Bezokolicznik Ӏ Pytania bezokolicznika:?? Zakończenia bezokolicznika -, -, - 10 2. Czasowniki niedokonane i dokonane Użycie postaci czasowników Nieregularne formy
Spis treści Nr Tytuł Przykład Str. 1. Bezokolicznik Ӏ Pytania bezokolicznika:?? Zakończenia bezokolicznika -, -, - 10 2. Czasowniki niedokonane i dokonane Użycie postaci czasowników Nieregularne formy
Gramatyka. języka rosyjskiego z ćwiczeniami
 Gramatyka języka rosyjskiego z ćwiczeniami Autor Dorota Dziewanowska Projekt graficzny okładki i strony tytułowej Krzysztof Kiełbasiński Ilustracje Maja Chmura (majachmura@wp.pl) Krzysztof Kiełbasiński
Gramatyka języka rosyjskiego z ćwiczeniami Autor Dorota Dziewanowska Projekt graficzny okładki i strony tytułowej Krzysztof Kiełbasiński Ilustracje Maja Chmura (majachmura@wp.pl) Krzysztof Kiełbasiński
NaCoBeZu na co będę zwracać uwagę. Nauka o języku
 NaCoBeZu na co będę zwracać uwagę Komunikacja językowa: Nauka o języku znam pojęcia z zakresu komunikacji językowej: schemat komunikacyjny; nadawca; odbiorca; komunikat; kod; kontekst ; znaki niewerbalne
NaCoBeZu na co będę zwracać uwagę Komunikacja językowa: Nauka o języku znam pojęcia z zakresu komunikacji językowej: schemat komunikacyjny; nadawca; odbiorca; komunikat; kod; kontekst ; znaki niewerbalne
Plan szkoleń z zakresu pakietu Microsoft Office 2007
 Plan szkoleń z zakresu pakietu Microsoft Office 2007 I. Microsoft Office Word 2007 Zakres podstawowy poziom I Tworzenie prostych dokumentów 1. Tworzenie, otwieranie i zapisywanie dokumentów Uruchamianie
Plan szkoleń z zakresu pakietu Microsoft Office 2007 I. Microsoft Office Word 2007 Zakres podstawowy poziom I Tworzenie prostych dokumentów 1. Tworzenie, otwieranie i zapisywanie dokumentów Uruchamianie
Zasady Nazewnictwa. Dokumentów XML 2007-11-08. Strona 1 z 9
 Zasady Nazewnictwa Dokumentów 2007-11-08 Strona 1 z 9 Spis treści I. Wstęp... 3 II. Znaczenie spójnych zasady nazewnictwa... 3 III. Zasady nazewnictwa wybrane zagadnienia... 3 1. Język oraz forma nazewnictwa...
Zasady Nazewnictwa Dokumentów 2007-11-08 Strona 1 z 9 Spis treści I. Wstęp... 3 II. Znaczenie spójnych zasady nazewnictwa... 3 III. Zasady nazewnictwa wybrane zagadnienia... 3 1. Język oraz forma nazewnictwa...
Korpusomat narz dzie do tworzenia przeszukiwalnych korpusów j zyka polskiego
 Korpusomat narz dzie do tworzenia przeszukiwalnych korpusów j zyka polskiego Witold Kiera± Šukasz Kobyli«ski Maciej Ogrodniczuk Michaª Wasiluk Instytut Podstaw Informatyki PAN V cykl wykªadów i warsztatów
Korpusomat narz dzie do tworzenia przeszukiwalnych korpusów j zyka polskiego Witold Kiera± Šukasz Kobyli«ski Maciej Ogrodniczuk Michaª Wasiluk Instytut Podstaw Informatyki PAN V cykl wykªadów i warsztatów
Dygitalizacja i komputeryzacja słowników na przykładzie Słownika polszczyzny XVI wieku
 Dygitalizacja i komputeryzacja słowników na przykładzie Słownika polszczyzny XVI wieku Janusz S. Bień Katedra Lingwistyki Formalnej UW Język polski wczoraj, dziś, jutro W 100. rocznicę urodzin prof. S.
Dygitalizacja i komputeryzacja słowników na przykładzie Słownika polszczyzny XVI wieku Janusz S. Bień Katedra Lingwistyki Formalnej UW Język polski wczoraj, dziś, jutro W 100. rocznicę urodzin prof. S.
Narzędzia do automatycznej analizy semantycznej tekstu na poziomach: leksykalnym i struktur
 Narzędzia do automatycznej analizy semantycznej tekstu na poziomach: leksykalnym i struktur Maciej Piasecki, Paweł Kędzia Politechnika ska Katedra Inteligencji Obliczeniowej Grupa Naukowa G4.19 Plan prezentacji
Narzędzia do automatycznej analizy semantycznej tekstu na poziomach: leksykalnym i struktur Maciej Piasecki, Paweł Kędzia Politechnika ska Katedra Inteligencji Obliczeniowej Grupa Naukowa G4.19 Plan prezentacji
P.2.1 WSTĘPNA METODA OPISU I
 1 S t r o n a P.2.1 WSTĘPNA METODA OPISU I ZNAKOWANIA DOKUMENTACJI MEDYCZNEJ W POSTACI ELEKTRONICZNEJ P.2. REKOMENDACJA OPISU I OZNAKOWANIA DOKUMENTACJI MEDYCZNEJ W POSTACI ELEKTRONICZNEJ 2 S t r o n a
1 S t r o n a P.2.1 WSTĘPNA METODA OPISU I ZNAKOWANIA DOKUMENTACJI MEDYCZNEJ W POSTACI ELEKTRONICZNEJ P.2. REKOMENDACJA OPISU I OZNAKOWANIA DOKUMENTACJI MEDYCZNEJ W POSTACI ELEKTRONICZNEJ 2 S t r o n a
MONIKA CZEREPOWICKA IWONA KOSEK SEBASTIAN PRZYBYSZEWSKI
 POLONICA XXXIV PL ISSN 0137-9712 MONIKA CZEREPOWICKA IWONA KOSEK SEBASTIAN PRZYBYSZEWSKI O projekcie elektronicznego słownika odmiany frazeologizmów czasownikowych 1. Charakter i cel badań W artykule zamierzamy
POLONICA XXXIV PL ISSN 0137-9712 MONIKA CZEREPOWICKA IWONA KOSEK SEBASTIAN PRZYBYSZEWSKI O projekcie elektronicznego słownika odmiany frazeologizmów czasownikowych 1. Charakter i cel badań W artykule zamierzamy
Lab.1. Praca z tekstem: stosowanie arkuszy stylów w dokumentach OO oraz HTML/CSS
 Lab.1. Praca z tekstem: stosowanie arkuszy stylów w dokumentach OO oraz HTML/CSS Cel ćwiczenia: zapoznanie się z pojęciem stylów w dokumentach. Umiejętność stosowania stylów do automatycznego przygotowania
Lab.1. Praca z tekstem: stosowanie arkuszy stylów w dokumentach OO oraz HTML/CSS Cel ćwiczenia: zapoznanie się z pojęciem stylów w dokumentach. Umiejętność stosowania stylów do automatycznego przygotowania
INFORMATYKA KLASA IV
 1 INFORMATYKA KLASA IV WYMAGANIA NA POSZCZEGÓLNE OCENY SZKOLNE 1. Komputer i programy komputerowe Posługiwanie się komputerem i praca z programem komputerowym wymienia przynajmniej trzy podstawowe zasady
1 INFORMATYKA KLASA IV WYMAGANIA NA POSZCZEGÓLNE OCENY SZKOLNE 1. Komputer i programy komputerowe Posługiwanie się komputerem i praca z programem komputerowym wymienia przynajmniej trzy podstawowe zasady
MS Word 2010. Długi dokument. Praca z długim dokumentem. Kinga Sorkowska 2011-12-30
 MS Word 2010 Długi dokument Praca z długim dokumentem Kinga Sorkowska 2011-12-30 Dodawanie strony tytułowej 1 W programie Microsoft Word udostępniono wygodną galerię wstępnie zdefiniowanych stron tytułowych.
MS Word 2010 Długi dokument Praca z długim dokumentem Kinga Sorkowska 2011-12-30 Dodawanie strony tytułowej 1 W programie Microsoft Word udostępniono wygodną galerię wstępnie zdefiniowanych stron tytułowych.
EXCEL ANALIZA DANYCH. Konspekt szczegółowy
 Przeznaczenie szkolenia Dla osób zaawansowanych, które potrzebują narzędzi do wszechstronnej analizy danych i prezentacji w różnych formach Wersje aplikacji MS EXCEL 2000, 2003, 2007, 2010 Wersje językowe
Przeznaczenie szkolenia Dla osób zaawansowanych, które potrzebują narzędzi do wszechstronnej analizy danych i prezentacji w różnych formach Wersje aplikacji MS EXCEL 2000, 2003, 2007, 2010 Wersje językowe
CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w pracy humanistów i tłumaczy
 Cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w pracy humanistów i tłumaczy 13 15 kwietnia 2015 roku Warszawa, Pałac Staszica, ul. Nowy Świat 72, sala 144
Cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w pracy humanistów i tłumaczy 13 15 kwietnia 2015 roku Warszawa, Pałac Staszica, ul. Nowy Świat 72, sala 144
Teraz bajty. Informatyka dla szkoły podstawowej. Klasa 4 Wymagania edukacyjne na poszczególne oceny szkolne dla klasy 4
 1 Teraz bajty. Informatyka dla szkoły podstawowej. Klasa 4 Wymagania edukacyjne na poszczególne oceny szkolne dla klasy 4 1. Komputer i programy komputerowe Posługiwanie się komputerem i praca z programem
1 Teraz bajty. Informatyka dla szkoły podstawowej. Klasa 4 Wymagania edukacyjne na poszczególne oceny szkolne dla klasy 4 1. Komputer i programy komputerowe Posługiwanie się komputerem i praca z programem
Projekt "Collective Intelligence metodą podniesienia poziomu innowacyjności polskich przedsiębiorstw" UMOWA O POWIERZENIE GRANTU NR 22/GRSin/ZGD/2017
 1 R A P O R T Z M O D Y F I K A C J I Fundacja Instytut Aurea Libertas ul. Stefana Batorego 2 lok. 30 31-135 Kraków Projekt "Collective Intelligence metodą podniesienia poziomu innowacyjności polskich
1 R A P O R T Z M O D Y F I K A C J I Fundacja Instytut Aurea Libertas ul. Stefana Batorego 2 lok. 30 31-135 Kraków Projekt "Collective Intelligence metodą podniesienia poziomu innowacyjności polskich
KPWr (otwarty korpus języka polskiego o wielowarstwowej anotacji) Inforex (system do budowania, anotowania i przeszukiwania korpusów)
 Inforex (system do budowania, anotowania i przeszukiwania korpusów)") KPWr (otwarty korpus języka polskiego o wielowarstwowej anotacji) Inforex (system do budowania, anotowania i przeszukiwania korpusów) Marcin Oleksy Michał Marcińczuk Politechnika ska Instytut Informatyki
KPWr (otwarty korpus języka polskiego o wielowarstwowej anotacji) Inforex (system do budowania, anotowania i przeszukiwania korpusów) Marcin Oleksy Michał Marcińczuk Politechnika ska Instytut Informatyki
ROZPORZĄDZENIE MINISTRA SPRAW WEWNĘTRZNYCH I ADMINISTRACJI [1]) z dnia... 2006 r.
![ROZPORZĄDZENIE MINISTRA SPRAW WEWNĘTRZNYCH I ADMINISTRACJI [1]) z dnia... 2006 r.](/thumbs/27/11146513.jpg "ROZPORZĄDZENIE MINISTRA SPRAW WEWNĘTRZNYCH I ADMINISTRACJI [1]) z dnia... 2006 r.") Źródło: http://bip.mswia.gov.pl/bip/projekty-aktow-prawnyc/2006/584,projekt-rozporzadzenia-ministra-swia-z-dnia-2006-r-w-s prawie-wymagan-technicznyc.html Wygenerowano: Poniedziałek, 4 stycznia 2016, 08:37
Źródło: http://bip.mswia.gov.pl/bip/projekty-aktow-prawnyc/2006/584,projekt-rozporzadzenia-ministra-swia-z-dnia-2006-r-w-s prawie-wymagan-technicznyc.html Wygenerowano: Poniedziałek, 4 stycznia 2016, 08:37
Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2
 Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2 ws.clarin-pl.eu/websty.shtml Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej
Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2 ws.clarin-pl.eu/websty.shtml Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej
Wikisłownik. (więcej niż słownik) Piotr Derbeth Kubowicz. Wikiwarsztaty Wrocław, 7 marca 2009. Stowarzyszenie Wikimedia Polska
 Piotr Derbeth Kubowicz. Wikiwarsztaty Wrocław, 7 marca 2009. Stowarzyszenie Wikimedia Polska") Wikisłownik (więcej niż słownik) Piotr Derbeth Kubowicz Stowarzyszenie Wikimedia Polska Wikiwarsztaty Wrocław, 7 marca 2009 Piotr Kubowicz (WMPL) Wikisłownik 7 marca 2009 1 / 35 Część I Wstęp Piotr Kubowicz
Wikisłownik (więcej niż słownik) Piotr Derbeth Kubowicz Stowarzyszenie Wikimedia Polska Wikiwarsztaty Wrocław, 7 marca 2009 Piotr Kubowicz (WMPL) Wikisłownik 7 marca 2009 1 / 35 Część I Wstęp Piotr Kubowicz
Open Access w technologii językowej dla języka polskiego
 Open Access w technologii językowej dla języka polskiego Marek Maziarz, Maciej Piasecki Grupa Naukowa Technologii Językowych G4.19 Zakład Sztucznej Inteligencji, Instytut Informatyki, W-8, Politechnika
Open Access w technologii językowej dla języka polskiego Marek Maziarz, Maciej Piasecki Grupa Naukowa Technologii Językowych G4.19 Zakład Sztucznej Inteligencji, Instytut Informatyki, W-8, Politechnika
ZMIANY WPROWADZONE W AKTUALIZACJI SYSTEMU POMOST STD
 ZMIANY WPROWADZONE W AKTUALIZACJI 3-18.2 SYSTEMU POMOST STD Aktualizacji 3-18.2 można dokonać z wersji 3-18.0 lub 3-18.1. Dane osobowe na wszystkich ilustracjach są fikcyjne. 1. Umożliwienie zaplanowania
ZMIANY WPROWADZONE W AKTUALIZACJI 3-18.2 SYSTEMU POMOST STD Aktualizacji 3-18.2 można dokonać z wersji 3-18.0 lub 3-18.1. Dane osobowe na wszystkich ilustracjach są fikcyjne. 1. Umożliwienie zaplanowania
Przyrostowa metoda dygitalizacji słowników
 Janusz S. Bień, Joanna Bilińska, Mateusz Sarnecki Wydział Neofilologii Uniwersytet Warszawski Leksykografia polska, ukraińska, bułgarska: słowniki tradycyjne i elektroniczne Warszawa, 13.11.2014 r. Słowniki
Janusz S. Bień, Joanna Bilińska, Mateusz Sarnecki Wydział Neofilologii Uniwersytet Warszawski Leksykografia polska, ukraińska, bułgarska: słowniki tradycyjne i elektroniczne Warszawa, 13.11.2014 r. Słowniki
XML i nowoczesne metody zarządzania treścią
 XML i nowoczesne metody zarządzania treścią Wykład 14: Studium przypadku: System SET Władysław Baksza, Maciej Ogrodniczuk MIMUW, 14 stycznia 2010 Wykład 14: Studium przypadku: System SET XML i nowoczesne
XML i nowoczesne metody zarządzania treścią Wykład 14: Studium przypadku: System SET Władysław Baksza, Maciej Ogrodniczuk MIMUW, 14 stycznia 2010 Wykład 14: Studium przypadku: System SET XML i nowoczesne
Barokowa polszczyzna w Internecie,
 Barokowa polszczyzna w Internecie, czyli jak powstają Elektroniczny słownik języka polskiego XVII i XVIII w. oraz Elektroniczny korpus tekstów polskich z XVII i XVIII w. Włodzimierz Gruszczyński Instytut
Barokowa polszczyzna w Internecie, czyli jak powstają Elektroniczny słownik języka polskiego XVII i XVIII w. oraz Elektroniczny korpus tekstów polskich z XVII i XVIII w. Włodzimierz Gruszczyński Instytut
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst
 Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst Mariusz Owsianny, PCSS Dr inż. Ewa Kuśmierek, Kierownik Projektu, PCSS Partnerzy konsorcjum Zaawansowany system automatycznego
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst Mariusz Owsianny, PCSS Dr inż. Ewa Kuśmierek, Kierownik Projektu, PCSS Partnerzy konsorcjum Zaawansowany system automatycznego
Przedmiotem zamówienia jest zakup oprogramowania biurowego dla Urzędu Miasta Lublin, w liczbie 50 licencji.
 Zał. nr 1 do SIWZ (zał. nr 1 do wzoru umowy) Przedmiotem zamówienia jest zakup oprogramowania biurowego dla Urzędu Miasta Lublin, w liczbie 50 licencji. Zamawiający oświadcza, iż w związku z potrzebą zapewnienia
Zał. nr 1 do SIWZ (zał. nr 1 do wzoru umowy) Przedmiotem zamówienia jest zakup oprogramowania biurowego dla Urzędu Miasta Lublin, w liczbie 50 licencji. Zamawiający oświadcza, iż w związku z potrzebą zapewnienia
Polsko ukraiński korpus równoległy (PolUKR) 1
 1") MAGDALENA TURSKA (bez afiliacji) NATALIA KOTSYBA Instytut Slawistyki PAN Polsko ukraiński korpus równoległy (PolUKR) 1 1. Korpusy i korpusy równoległe. Obecnie można zaobserwować stale i szybko rosnące
MAGDALENA TURSKA (bez afiliacji) NATALIA KOTSYBA Instytut Slawistyki PAN Polsko ukraiński korpus równoległy (PolUKR) 1 1. Korpusy i korpusy równoległe. Obecnie można zaobserwować stale i szybko rosnące
Program warsztatów CLARIN-PL
 W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
1. Zaczynamy! (9) 2. Edycja dokumentów (33)
 2. Edycja dokumentów (33)") 1. Zaczynamy! (9) Uruchamiamy program Word i co z tego wynika... (10) o Obszar roboczy, czyli miejsce do pracy (12) Otwieranie dokumentów w programie Word (14) o Tworzenie nowego dokumentu (14) o Otwieranie
1. Zaczynamy! (9) Uruchamiamy program Word i co z tego wynika... (10) o Obszar roboczy, czyli miejsce do pracy (12) Otwieranie dokumentów w programie Word (14) o Tworzenie nowego dokumentu (14) o Otwieranie
EXCEL ZAAWANSOWANY. Konspekt szczegółowy
 Przeznaczenie szkolenia Dla osób dużo pracujących w Excelu, tworzących raporty i zestawienia Wersje aplikacji MS EXCEL 2000, 2003, 2007, 2010 Wersje językowe Czas trwania Kurs poprzedzający Kurs następujący
Przeznaczenie szkolenia Dla osób dużo pracujących w Excelu, tworzących raporty i zestawienia Wersje aplikacji MS EXCEL 2000, 2003, 2007, 2010 Wersje językowe Czas trwania Kurs poprzedzający Kurs następujący
PRÓBNY EGZAMIN GIMNAZJALNY Z NOWĄ ERĄ 2015/2016 JĘZYK POLSKI
 PRÓBNY EGZAMIN GIMNAZJALNY Z NOWĄ ERĄ 2015/2016 JĘZYK POLSKI ZASADY OCENIANIA ROZWIĄZAŃ ZADAŃ Copyright by Nowa Era Sp. z o.o. Zadanie 1. (0 1) Wymagania szczegółowe 2) wyszukuje w wypowiedzi potrzebne
PRÓBNY EGZAMIN GIMNAZJALNY Z NOWĄ ERĄ 2015/2016 JĘZYK POLSKI ZASADY OCENIANIA ROZWIĄZAŃ ZADAŃ Copyright by Nowa Era Sp. z o.o. Zadanie 1. (0 1) Wymagania szczegółowe 2) wyszukuje w wypowiedzi potrzebne
Instrukcja korzystania z wyszukiwarki do Elektronicznego Korpusu Tekstów Polskich z XVII i XVIII wieku (do 1772 r.)
") Instrukcja korzystania z wyszukiwarki do Elektronicznego Korpusu Tekstów Polskich z XVII i XVIII wieku (do 1772 r.) Spis treści Wprowadzenie.......................................... 1 1. Teksty w korpusie
Instrukcja korzystania z wyszukiwarki do Elektronicznego Korpusu Tekstów Polskich z XVII i XVIII wieku (do 1772 r.) Spis treści Wprowadzenie.......................................... 1 1. Teksty w korpusie
EXCEL POZIOM EXPERT. Konspekt szczegółowy
 Przeznaczenie szkolenia Dla osób, których większość pracy to Excel, potrzebujących zróżnicowanej wiedzy i makr do automatyzacji pracy. Osoby przygotowujące pliki dla innych Wersje aplikacji MS EXCEL 2000,
Przeznaczenie szkolenia Dla osób, których większość pracy to Excel, potrzebujących zróżnicowanej wiedzy i makr do automatyzacji pracy. Osoby przygotowujące pliki dla innych Wersje aplikacji MS EXCEL 2000,
METODA SŁÓW KLUCZY W BADANIU POLSZCZYZNY DAWNEJ
 METODA SŁÓW KLUCZY W BADANIU POLSZCZYZNY DAWNEJ NA PRZYKŁADZIE TEKSTÓW Z ZAKRESU POLITYKI PRÓBY MAGDALENA MAJDAK, INSTYTUT JĘZYKA POLSKIEGO PAN Sens? Metoda słów kluczy zastosowana do polszczyzny historycznej
METODA SŁÓW KLUCZY W BADANIU POLSZCZYZNY DAWNEJ NA PRZYKŁADZIE TEKSTÓW Z ZAKRESU POLITYKI PRÓBY MAGDALENA MAJDAK, INSTYTUT JĘZYKA POLSKIEGO PAN Sens? Metoda słów kluczy zastosowana do polszczyzny historycznej
MODUŁ AM3: PRZETWARZANIE TEKSTU
 ECDL ADVANCED ECDL-A EUROPEJSKI CERTYFIKAT UMIEJĘTNOŚCI KOMPUTEROWYCH POZIOM ZAAWANSOWANY MODUŁ AM3: PRZETWARZANIE TEKSTU Syllabus v. 1.0 Oficjalna wersja jest dostępna w serwisie WWW Polskiego Biura ECDL
ECDL ADVANCED ECDL-A EUROPEJSKI CERTYFIKAT UMIEJĘTNOŚCI KOMPUTEROWYCH POZIOM ZAAWANSOWANY MODUŁ AM3: PRZETWARZANIE TEKSTU Syllabus v. 1.0 Oficjalna wersja jest dostępna w serwisie WWW Polskiego Biura ECDL
NARZĘDZIA Narzędzia Narzędzia
 - 1 - NARZĘDZIA Aby uruchomić menu programu należy Wskazać myszką podmenu Narzędzia a następnie nacisnąć lewy przycisk myszki lub Wcisnąć klawisz (wejście do menu), następnie klawiszami kursorowymi
- 1 - NARZĘDZIA Aby uruchomić menu programu należy Wskazać myszką podmenu Narzędzia a następnie nacisnąć lewy przycisk myszki lub Wcisnąć klawisz (wejście do menu), następnie klawiszami kursorowymi
Część 1. Wydobywanie informacji z tekstu i stylometria CLARIN-PL. Tomasz Walkowiak, Maciej Piasecki
 Wydobywanie informacji z tekstu i stylometria Część 1 Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej Wydział Informatyki i Zarządzania
Wydobywanie informacji z tekstu i stylometria Część 1 Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej Wydział Informatyki i Zarządzania
Siostrzane projekty Wikipedii: Wikisłownik
 Siostrzane projekty Wikipedii: Wikisłownik Helena Polak (Rovdyr) Piotr Kubowicz (Derbeth) Dariusz Jażdżyk (joystick) Wsparcie moralne i techniczne Piotr PMG Gackowski Czym jest Wikisłownik? Kalendarium
Siostrzane projekty Wikipedii: Wikisłownik Helena Polak (Rovdyr) Piotr Kubowicz (Derbeth) Dariusz Jażdżyk (joystick) Wsparcie moralne i techniczne Piotr PMG Gackowski Czym jest Wikisłownik? Kalendarium