1 Narzędzia przetwarzania 2 tekſtów hiſtorycznych
|
|
|
- Edward Kowalewski
- 6 lat temu
- Przeglądów:
Transkrypt
1 1 Narzędzia przetwarzania 2 tekſtów hiſtorycznych Marcin Wolińſki, Witold Kieraś, Dorota Komo ńska, Emanuel Modrzejewſki Zespół Inżynieriey Lingw tyczney In ytut Pod aw Informatyki Polſkiey Akademii Nauk K W Wárßáwie, 18 dnia Czerwca A.D. MMXVIII J 1/32
2 K Projekt Chronofleks J 1 Przedstawione narzędzia zostały opracowane (głównie) w ramach projektu: Model formalny diachronicznego op u fleksji polskiej i jego komputerowa implementacja grant NCN 2014/15/B/HS2/03119 czas trwania: 11 sierpnia lutego /32
3 K Narzędzia przetwarzania tekstu barokowego J 1 narzędzie do automatycznej transkrypcji tekstów, 1 Korbeusz automatyczny analizator fleksyjny na bazie Morfeusza 2, 1 Anotatornia 2 system do ręcznego znakowania korpusów, 1 automatyczne narzędzie ujednoznaczniające (tager) 3/32
4 K Schemat działania J dokument źródłowy plik tekstowy transkrypcja ujednoznacznienie analiza fleksyjna znakowany korpus 4/32
5 K Schemat działania J dokument źródłowy plik tekstowy transkrypcja ujednoznacznienie analiza fleksyjna znakowany korpus ręczne znakowanie 4/32
6 K Schemat działania J dokument źródłowy Wczytywacz Transkryber Concraft/Toygger Morfeusz 2 (Korbeusz) znakowany korpus Anotatornia 2 4/32
7 K Transkrypcja J 1 Normalizacji podlegają wyłącznie warianty ortograficzne, nie są zaś modyfikowane dawne formy fleksyjne. 1 Nie jest to decyzja oczywista w wielu korpusach historycznych dla innych języków normalizacji podlega ogół zjawisk językowych (czasem nawet leksyka!), by znormalizowany tekst można było przetwarzać dalej narzędziami dla współczesnego wariantu języka bez konieczności ich modyfikacji. 1 Nie zawsze niestety da się ściśle odgraniczyć zjawiska ortograficzne od fleksyjnych. 5/32
8 K Transkrypcja przykład J KOMISJA (między rokiem 1650 i 1918): comm siey, comm syi, kom ja, kom ją, kom ję, kom ji, kom sja, kom sya, kom syę, kom syi, kom ya, kom yą, kom ye, kom yę, kom yi, kom yj, kom yją, kom yję, komm ij, komm ja, komm jów, komm sii, komm sij, komm sją, komm sje, komm sjów, komm sya, komm syi, komm syiey, komm yi. W procesie transkrypcji: 1 zmieniono inicjalne c na k, 1 usunięto podwojenia liter spółgłoskowych s i m, 1 wprowadzono j zamiast y lub i. 1 pozostawiono dawne formy fleksyjne: kom jej, kom jów i kom ją (w B. lp.). 6/32
9 K Transkrypcja przykłady reguł J lewy kontekst znajdź prawy kontekst zmień na wyjątki 1..* ˆoˆ.* go 2. ˆ naiw.* najw naiwn.* 3. T j T y mjr 7/32
10 K Korbeusz J Słownik: 1 postarzone dane SGJP konwersja tagsetu i dotworzenie niektórych regularnych dawnych form (walidacjej, ładnę, ładnemi, zmienim, klęczta, klęczwa itp.), 1 dane fleksyjne SXVII, 1 automatycznie zrekonstruowane częściowe paradygmaty SXVII. Reguły segmentacyjne: 1 pisownia łączna z nie, 1 pisownia łączna licznych partykuł (ć, li, że, ż), 1 znacznie bardziej ruchome aglutynanty. 8/32
11 K Automatyczna rekonstrukcja J celnictwo subst:sg:nom:n celnictwem subst:sg:inst:n celnictwie subst:sg:loc:n bogactwo subst:sg:nom:n bogactwa subst:sg:gen:n bogactwem subst:sg:inst:n bogactwie subst:sg:loc:n bogactwa subst:pl:nom:n bogactw subst:pl:gen:n bogactwa subst:pl:nom:n bogactwy subst:pl:inst:n rdzeń celnictwa subst:sg:gen:n celnictwa subst:pl:nom:n celnictw subst:pl:gen:n celnictwa subst:pl:nom:n celnictwy subst:pl:inst:n zakończenia i znaczniki 9/32
12 K Tagery J 1 Concraft: conditional random fields, ujednoznacznianie niejednoznacznej segmentacji ( 94%), C słabsze wyniki dezambiguacji ( 88%), C nieco lepsze zgadywanie. 1 Toygger: sieci neuronowe (bi-lstm), wyłącznie ujednoznacznianie znaczników na zadanej segmentacji, lepsze wyniki dezambiguacji ( 91%), C nieco słabsze zgadywanie. 10/32
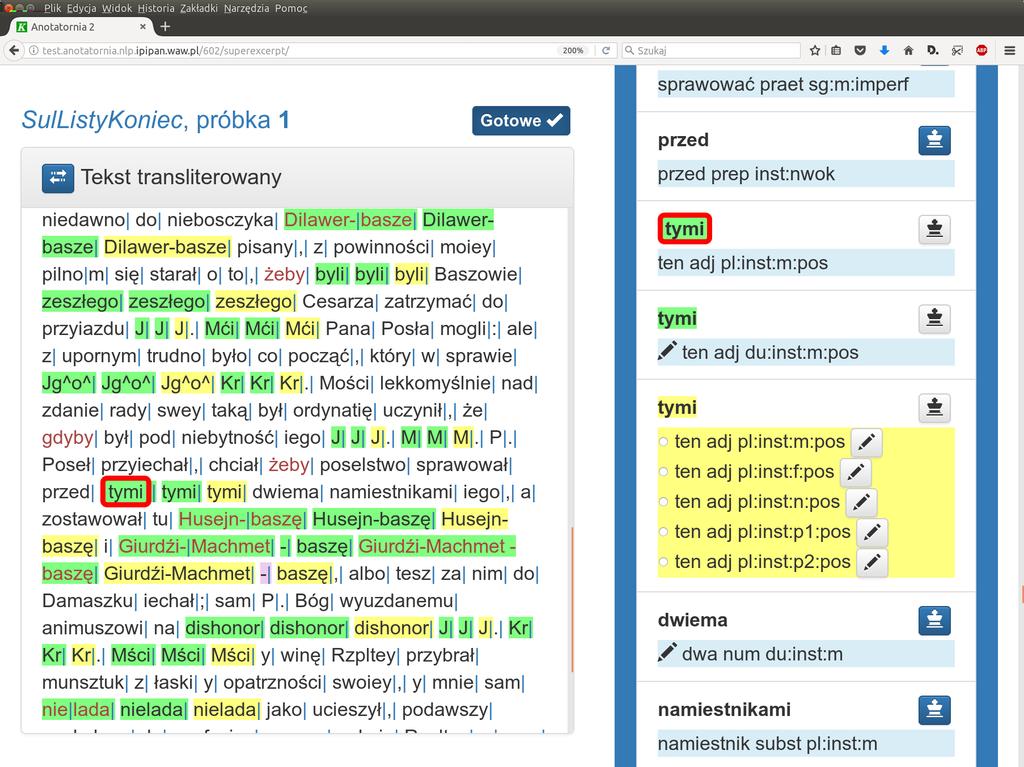
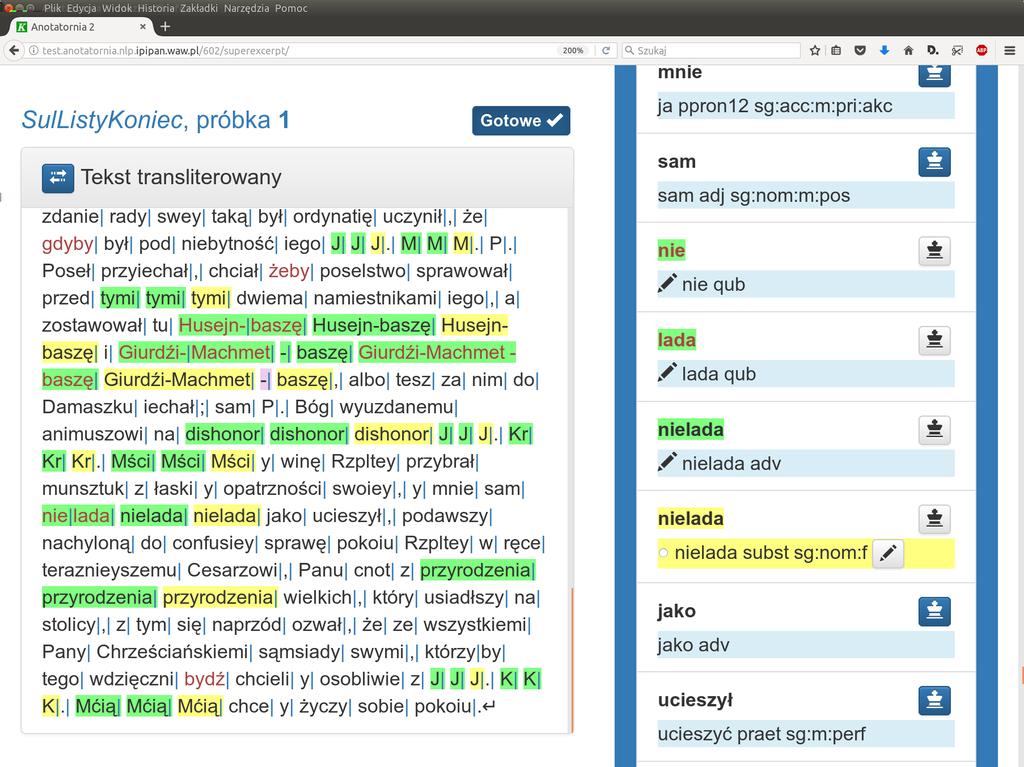
13 K Anotatornia 2 J 1 System Anotatornia 2 służy do ręcznego ujednoznaczniania i weryfikacji znakowania fleksyjnego tekstu historycznego. 1 Uwzględnia specyficzne potrzeby korpusów historycznych: C tekst istnieje w dwóch równoległych postaciach: transliterowanej i transkrybowanej, C musi być zachowywana informacja o numerach stron oryginałów, z których pochodzą poszczególne wyrazy. 11/32
14 K Anotatornia 2 J Praca w Anotatorni obejmuje: 1 korektę segmentacji wyróżnienia wykładników tekstowych form fleksyjnych, 1 korektę transkrypcji, 1 korektę podziału na zdania, 1 ujednoznacznienie i uzupełnienie opisu fleksyjnego dostarczonego przez Korbeusza. 12/32
15 K Anotatornia 2: Tryb znakowania AA+A J Powszechnie przyjęty tryb znakowania korpusów: 1 każda próbka korpusowa jest znakowana niezależnie przez dwóch annotatorów, 1 lista konfliktów jest przedstawiana annotatorom do ponownego sprawdzenia, 1 pozostałe konflikty rozstrzyga arbiter ( superannotator ). 13/32
16 K Anotatornia 2: Tryb znakowania AT+A J Pomysł usprawnienia: zastąpić jednego z annotatorów programem automatycznym (tagerem): 1 każda próbka korpusowa jest znakowana tylko przez jednego annotatora, 1 wynik jego pracy jest porównywany z wynikami tagera, 1 lista konfliktów jest przedstawiana annotatorowi do ponownego sprawdzenia, 1 pozostałe konflikty rozstrzyga arbiter. 14/32
17 15/32 A INTERFEJS ANNOTATORA D
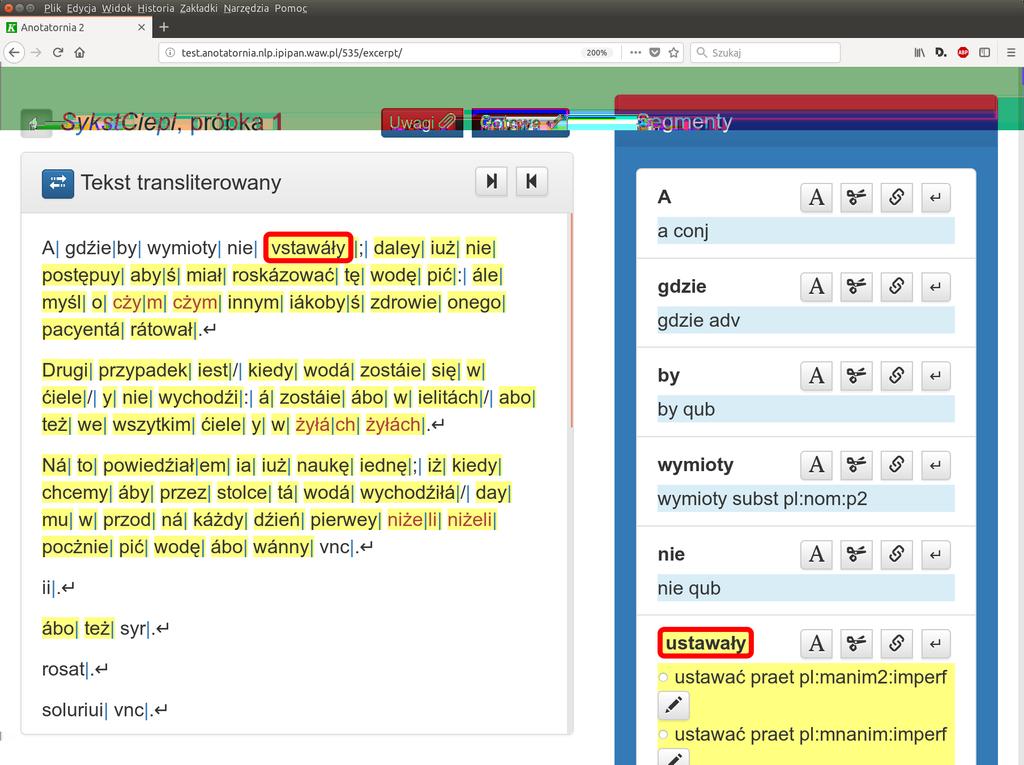

18 16/32
19 17/32
20 18/32
21 19/32
22 20/32
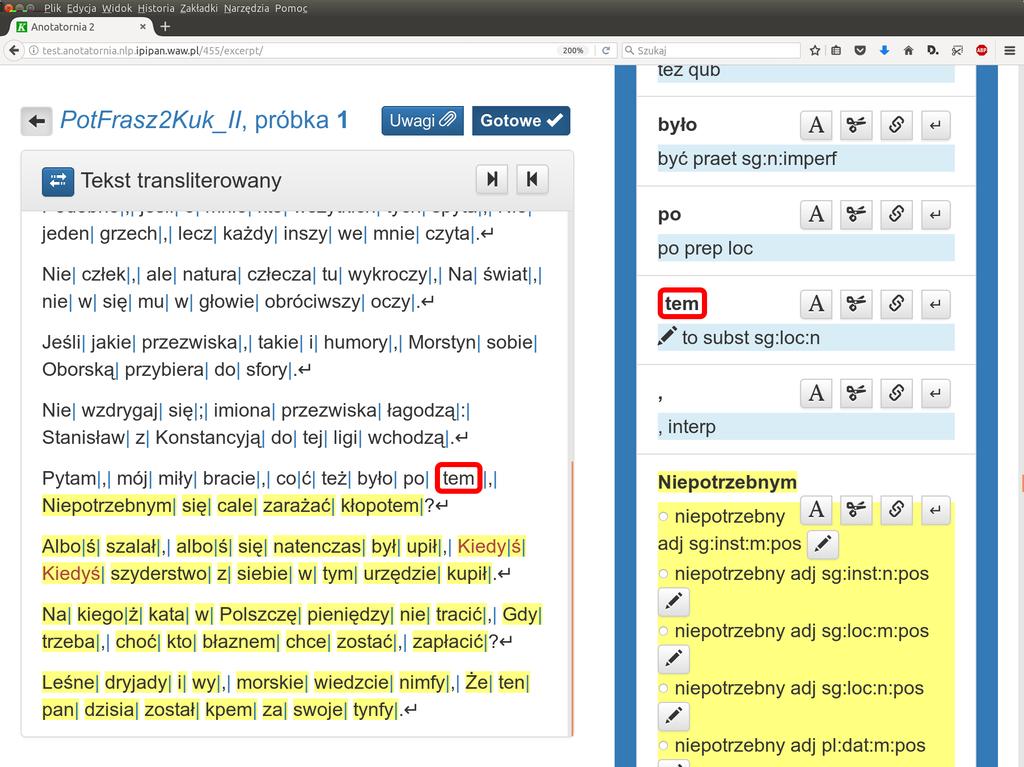
23 21/32
24 22/32
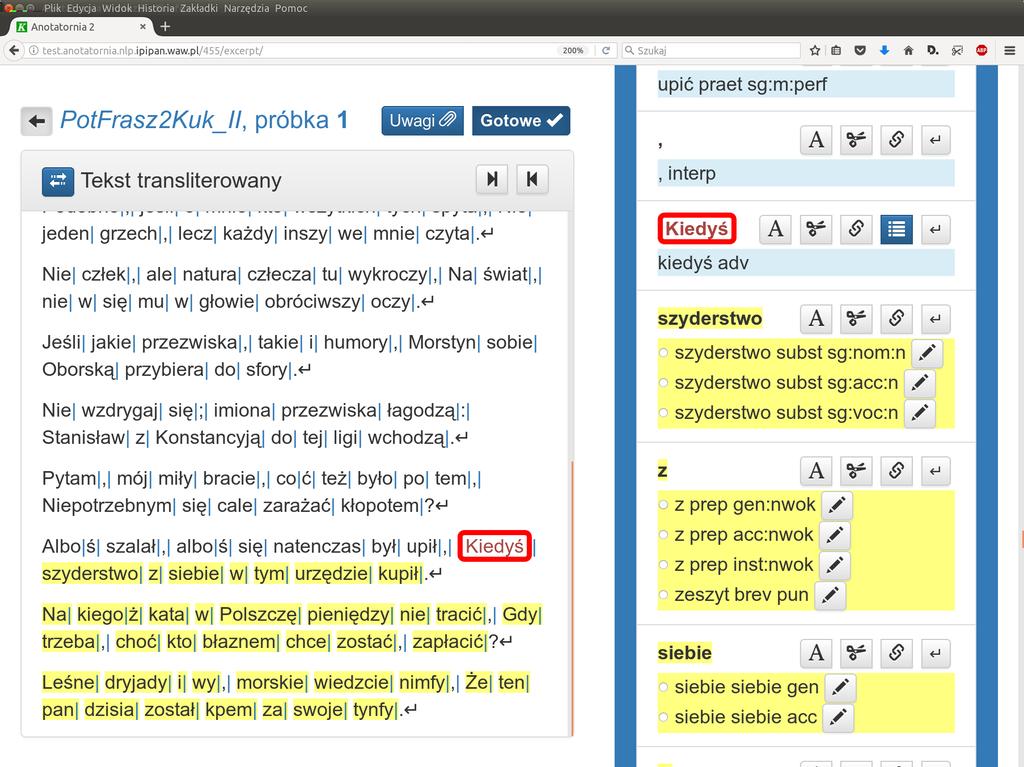
25 23/32
26 24/32
27 25/32
28 26/32 A WYKRYTO KOLIZJE D
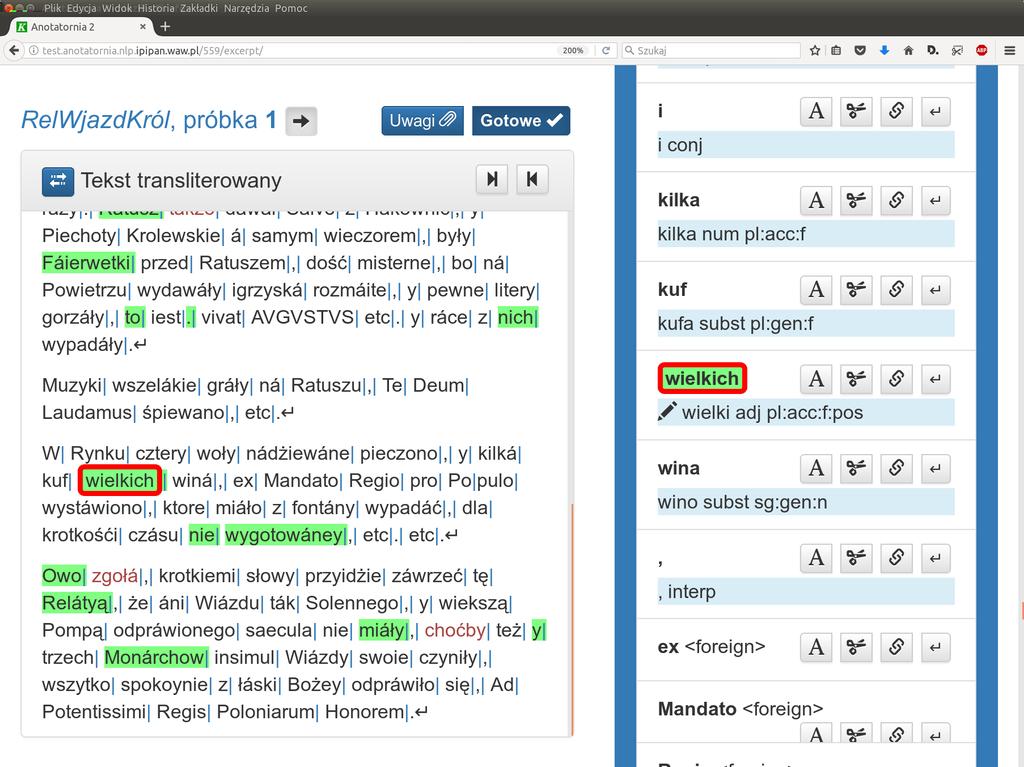
29 27/32
30 28/32 A INTERFEJS SUPERANNOTATORA D
31 29/32
32 30/32
33 K Ręcznie oznakowana część korpusu J 1 W ramach projektu KorBa oznakowano w Anotatorni 2 fragment korpusu barokowego: C w trybie AA+A zostało oznakowane segmentów, C ponadto segmentów zostało oznakowanych tylko przez jednego annotatora. C Łączna długość korpusu znakowanego ręcznie: segmenty. 31/32
34 K Podsumowanie J 1 Narzędzia opracowane w ramach projektu Chronofleks (a więc przede wszystkim odpowiednie wersje Morfeusza 2 i Anotatornia 2) zostały użyte do znakowania korpusów z trzech okresów: C barokowego, C XIX wieku, C współczesnego. 1 Pozwala to wyrazić przekonanie, że narzędzia te można zastosować również do tekstów z innych epok. Do czego serdecznie zachęcamy. 32/32
Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) prezentacja znakowania morfosyntaktycznego i możliwości wyszukiwarki
 prezentacja znakowania morfosyntaktycznego i możliwości wyszukiwarki") Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) prezentacja znakowania morfosyntaktycznego i możliwości wyszukiwarki Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk
Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) prezentacja znakowania morfosyntaktycznego i możliwości wyszukiwarki Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN
 Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN") KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN Podstawowe informacje o projekcie Projekt realizowany przez IJP
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN Podstawowe informacje o projekcie Projekt realizowany przez IJP
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.)
") KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN, Instytut Podstaw Informatyki PAN Podstawowe informacje o projekcie
KORBA Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Pracownia Historii Języka Polskiego XVII i XVIII wieku IJP PAN, Instytut Podstaw Informatyki PAN Podstawowe informacje o projekcie
KorBa. Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk
 Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk") KorBa Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk ALLPPT.com _ Free PowerPoint Templates, Diagrams and Charts PODSTAWOWE
KorBa Elektroniczny korpus tekstów polskich XVII i XVIII w. (do 1772 r.) Renata Bronikowska Instytut Języka Polskiego Polska Akademia Nauk ALLPPT.com _ Free PowerPoint Templates, Diagrams and Charts PODSTAWOWE
Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego
 Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego Witold Kieraś Łukasz Kobyliński Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN III Konferencja DARIAH-PL Poznań 9.11.2016
Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego Witold Kieraś Łukasz Kobyliński Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN III Konferencja DARIAH-PL Poznań 9.11.2016
Morfeusz 2 analizator i generator fleksyjny dla języka polskiego
 Morfeusz 2 analizator i generator fleksyjny dla języka polskiego Marcin Woliński i Anna Andrzejczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Warsztaty CLARIN-PL,
Morfeusz 2 analizator i generator fleksyjny dla języka polskiego Marcin Woliński i Anna Andrzejczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Warsztaty CLARIN-PL,
Włodzimierz Gruszczyński * Maciej Ogrodniczuk ** Marcin Woliński ** *IJP PAN **IPI PAN
 Włodzimierz Gruszczyński * Maciej Ogrodniczuk ** Marcin Woliński ** *IJP PAN **IPI PAN Wystąpienie przygotowane w ramach projektu Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do roku 1772)
Włodzimierz Gruszczyński * Maciej Ogrodniczuk ** Marcin Woliński ** *IJP PAN **IPI PAN Wystąpienie przygotowane w ramach projektu Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do roku 1772)
Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.)
") Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Dorota Adamiec IJP PAN Włodzimierz Gruszczyński IJP PAN Maciej Ogrodniczuk IPI PAN Stan przekrojowych badań nad słownictwem polskim
Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.) Dorota Adamiec IJP PAN Włodzimierz Gruszczyński IJP PAN Maciej Ogrodniczuk IPI PAN Stan przekrojowych badań nad słownictwem polskim
KORBEUSZ. Włodzimierza Grußczyńſkiego, Dorotę Adamiec, Renatę Bronikowſką Inſtytut Języka Polſkiego PAN
 Korpus hiſtoryczny, czyli problemata tranſliteracyi, tranſkrypcyi i annotacyi na przykładzie Elektronicznego Korpusu Textów Polſkich z XVII i XVIII w. (do 1772 r.) metodą wokalną wyłożone i rycinami zexemplifikowane
Korpus hiſtoryczny, czyli problemata tranſliteracyi, tranſkrypcyi i annotacyi na przykładzie Elektronicznego Korpusu Textów Polſkich z XVII i XVIII w. (do 1772 r.) metodą wokalną wyłożone i rycinami zexemplifikowane
Dobór tekstów do Elektronicznego korpusu tekstów polskich z XVII i XVIII w. (do 1772 r.) możliwości i ograniczenia budowanego warsztatu badawczego
 możliwości i ograniczenia budowanego warsztatu badawczego") Dobór tekstów do Elektronicznego korpusu tekstów polskich z XVII i XVIII w. (do 1772 r.) możliwości i ograniczenia budowanego warsztatu badawczego Dorota Adamiec Instytut Języka Polskiego PAN Elektroniczny
Dobór tekstów do Elektronicznego korpusu tekstów polskich z XVII i XVIII w. (do 1772 r.) możliwości i ograniczenia budowanego warsztatu badawczego Dorota Adamiec Instytut Języka Polskiego PAN Elektroniczny
Doświadczenia z prac nad Korpusem tekstów polskich z XVII i XVIII wieku
 Doświadczenia z prac nad Korpusem tekstów polskich z XVII i XVIII wieku zasady doboru tekstów, zakres znakowania, sposób udostępniania Włodzimierz Gruszczyński IJP PAN e-mail: wlodekiewa@poczta.onet.pl
Doświadczenia z prac nad Korpusem tekstów polskich z XVII i XVIII wieku zasady doboru tekstów, zakres znakowania, sposób udostępniania Włodzimierz Gruszczyński IJP PAN e-mail: wlodekiewa@poczta.onet.pl
Analizator fleksyjny Morfeusz 2
 Analizator fleksyjny Morfeusz 2 Katarzyna Krasnowska-Kieraś Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Lublin, 25 września 2019 Katarzyna Krasnowska-Kieraś Morfeusz
Analizator fleksyjny Morfeusz 2 Katarzyna Krasnowska-Kieraś Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Lublin, 25 września 2019 Katarzyna Krasnowska-Kieraś Morfeusz
Spis treści Wstęp 1. Językoznawstwo sądowe
 Spis treści Podziękowania... 11 Wstęp... 13 1. Językoznawstwo sądowe... 17 1.1. Język a prawo... 17 1.2. Językoznawstwo sądowe metody badań... 20 1.2.1. Metody ilościowe... 20 1.2.1.1. Stylometria i metody
Spis treści Podziękowania... 11 Wstęp... 13 1. Językoznawstwo sądowe... 17 1.1. Język a prawo... 17 1.2. Językoznawstwo sądowe metody badań... 20 1.2.1. Metody ilościowe... 20 1.2.1.1. Stylometria i metody
Wydobywanie reguł na potrzeby ujednoznaczniania morfo-syntaktycznego oraz płytkiej analizy składniowej tekstów polskich
 Wydobywanie reguł na potrzeby ujednoznaczniania morfo-syntaktycznego oraz płytkiej analizy składniowej tekstów polskich Adam Radziszewski Instytut Informatyki Stosowanej PWr SIIS 23, 12 czerwca 2008 O
Wydobywanie reguł na potrzeby ujednoznaczniania morfo-syntaktycznego oraz płytkiej analizy składniowej tekstów polskich Adam Radziszewski Instytut Informatyki Stosowanej PWr SIIS 23, 12 czerwca 2008 O
Forma. Główny cel kursu. Umiejętności nabywane przez studentów. Wymagania wstępne:
 WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
Spis treści 0. Szkoła Tokarskiego Marcin Woliński Adam Przepiórkowski Korpus IPI PAN Inne pojęcia LXIII Zjazd PTJ, Warszawa
 Spis treści -1 LXIII Zjazd PTJ, Warszawa 16-17.09.2003 Pomor, Humor Morfeusz SIAT Poliqarp Holmes Kryteria wyboru Robert Wołosz Marcin Woliński Adam Przepiórkowski Michał Rudolf Niebieska gramatyka Saloni,
Spis treści -1 LXIII Zjazd PTJ, Warszawa 16-17.09.2003 Pomor, Humor Morfeusz SIAT Poliqarp Holmes Kryteria wyboru Robert Wołosz Marcin Woliński Adam Przepiórkowski Michał Rudolf Niebieska gramatyka Saloni,
MARCIN WOLIŃSKI MORFEUSZ REAKTYWACJA IPI PAN, 7 KWIETNIA /28 ...
 MARCIN WOLIŃSKI MORFEUSZ REAKTYWACJA IPI PAN, 7 KWIETNIA 2014 1/28 Zespół Małgorzata Marciniak nadzór ogólny Marcin Woliński specyfikacja Michał Lenart implementacja Jan Daciuk konsultacja automatologiczna
MARCIN WOLIŃSKI MORFEUSZ REAKTYWACJA IPI PAN, 7 KWIETNIA 2014 1/28 Zespół Małgorzata Marciniak nadzór ogólny Marcin Woliński specyfikacja Michał Lenart implementacja Jan Daciuk konsultacja automatologiczna
Semantyczna analiza języka naturalnego
 Semantyczna analiza języka naturalnego Rozwiązanie Applica oparte o IBM SPSS Modeler Piotr Surma Applica 2 Agenda O Applica Analiza tekstu w języku polskim - wyzwania Rozwiązanie Applica Analiza Tekstu
Semantyczna analiza języka naturalnego Rozwiązanie Applica oparte o IBM SPSS Modeler Piotr Surma Applica 2 Agenda O Applica Analiza tekstu w języku polskim - wyzwania Rozwiązanie Applica Analiza Tekstu
Oprogramowanie typu CAT
 Oprogramowanie typu CAT (Computer Aided Translation) Informacje ogólne Copyright Jacek Scholz 2009 Wprowadzenie: narzędzia do wspomagania translacji Bazy pamięci tłumaczet umaczeń (Translation Memory)
Oprogramowanie typu CAT (Computer Aided Translation) Informacje ogólne Copyright Jacek Scholz 2009 Wprowadzenie: narzędzia do wspomagania translacji Bazy pamięci tłumaczet umaczeń (Translation Memory)
WŁODZIMIERZ GRUSZCZYŃSKI, DOROTA ADAMIEC, MACIEJ OGRODNICZUK
 POLONICA XXXIII PL ISSN 0137-9712 WŁODZIMIERZ GRUSZCZYŃSKI, DOROTA ADAMIEC, MACIEJ OGRODNICZUK Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego
POLONICA XXXIII PL ISSN 0137-9712 WŁODZIMIERZ GRUSZCZYŃSKI, DOROTA ADAMIEC, MACIEJ OGRODNICZUK Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego
Lokalizacja Oprogramowania
 mgr inż. Anton Smoliński anton.smolinski@zut.edu.pl Lokalizacja Oprogramowania 16/12/2016 Wykład 6 Internacjonalizacja, Testowanie, Tłumaczenie Maszynowe Agenda Internacjonalizacja Testowanie lokalizacji
mgr inż. Anton Smoliński anton.smolinski@zut.edu.pl Lokalizacja Oprogramowania 16/12/2016 Wykład 6 Internacjonalizacja, Testowanie, Tłumaczenie Maszynowe Agenda Internacjonalizacja Testowanie lokalizacji
Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego
 prezentacja projektu badawczego") WŁODZIMIERZ GRUSZCZYŃSKI DOROTA ADAMIEC MACIEJ OGRODNICZUK Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego Projekt Elektroniczny korpus tekstów
WŁODZIMIERZ GRUSZCZYŃSKI DOROTA ADAMIEC MACIEJ OGRODNICZUK Elektroniczny korpus tekstów polskich z XVII i XVIII wieku (do 1772 roku) prezentacja projektu badawczego Projekt Elektroniczny korpus tekstów
NeuroVoice. Synteza i analiza mowy. Paweł Mrówka
 NeuroVoice Synteza i analiza mowy Paweł Mrówka pawel.mrowka@neurosoft.pl Plan prezentacji Synteza mowy - SynTalk Wprowadzenie do syntezy konkatenacyjnej Zastosowanie analizy językowej tekstu MoŜliwości
NeuroVoice Synteza i analiza mowy Paweł Mrówka pawel.mrowka@neurosoft.pl Plan prezentacji Synteza mowy - SynTalk Wprowadzenie do syntezy konkatenacyjnej Zastosowanie analizy językowej tekstu MoŜliwości
Program warsztatów CLARIN-PL
 W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w pracy humanistów i tłumaczy
 Cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w pracy humanistów i tłumaczy 13 15 kwietnia 2015 roku Warszawa, Pałac Staszica, ul. Nowy Świat 72, sala 144
Cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w pracy humanistów i tłumaczy 13 15 kwietnia 2015 roku Warszawa, Pałac Staszica, ul. Nowy Świat 72, sala 144
Open Access w technologii językowej dla języka polskiego
 Open Access w technologii językowej dla języka polskiego Marek Maziarz, Maciej Piasecki Grupa Naukowa Technologii Językowych G4.19 Zakład Sztucznej Inteligencji, Instytut Informatyki, W-8, Politechnika
Open Access w technologii językowej dla języka polskiego Marek Maziarz, Maciej Piasecki Grupa Naukowa Technologii Językowych G4.19 Zakład Sztucznej Inteligencji, Instytut Informatyki, W-8, Politechnika
Skrócona instrukcja obsługi grupowego portalu głosowego
 Skrócona instrukcja obsługi grupowego portalu głosowego Konfigurowanie portalu głosowego Do konfigurowania grupowego portalu głosowego służy interfejs internetowy Rysunek 1. Grupa Usługi Portal głosowy
Skrócona instrukcja obsługi grupowego portalu głosowego Konfigurowanie portalu głosowego Do konfigurowania grupowego portalu głosowego służy interfejs internetowy Rysunek 1. Grupa Usługi Portal głosowy
NAKŁADKA KORPUSOWA (NKJP, KORBA) OPARTA O TRADYCYJNĄ KLASYFIKACJĘ CZĘŚCI MOWY. Emanuel Modrzejewski.
 OPARTA O TRADYCYJNĄ KLASYFIKACJĘ CZĘŚCI MOWY. Emanuel Modrzejewski.") NAKŁADKA KORPUSOWA OPARTA O TRADYCYJNĄ KLASYFIKACJĘ CZĘŚCI MOWY (NKJP, KORBA) Emanuel Modrzejewski modrzejewski.emanuel@gmail.com DOTYCHCZASOWE NAKŁADKI KORPUSOWE: Polsko-rosyjski i rosyjsko-polski korpus
NAKŁADKA KORPUSOWA OPARTA O TRADYCYJNĄ KLASYFIKACJĘ CZĘŚCI MOWY (NKJP, KORBA) Emanuel Modrzejewski modrzejewski.emanuel@gmail.com DOTYCHCZASOWE NAKŁADKI KORPUSOWE: Polsko-rosyjski i rosyjsko-polski korpus
Co wylicza Jasnopis? Bartosz Broda
 Co wylicza Jasnopis? Bartosz Broda Analiza języka polskiego Ekstrakcja tekstu Dokument narzędzie do mierzenia zrozumiałości Analiza morfologiczna Analiza morfosyntaktyczna Indeksy Klasa trudności:
Co wylicza Jasnopis? Bartosz Broda Analiza języka polskiego Ekstrakcja tekstu Dokument narzędzie do mierzenia zrozumiałości Analiza morfologiczna Analiza morfosyntaktyczna Indeksy Klasa trudności:
Włodzimierz Gruszczyński. Instytut Języka Polskiego PAN Korpusy Diachroniczne Polszczyzny Katowice, kwietnia 2017 r.
 Tagset barokowy problemy opracowania zestawu kategorii morfologicznych i ich wartości na potrzeby Elektronicznego Korpusu Tekstów Polskich XVII i XVIII w. (do 1772 r.) Włodzimierz Gruszczyński Instytut
Tagset barokowy problemy opracowania zestawu kategorii morfologicznych i ich wartości na potrzeby Elektronicznego Korpusu Tekstów Polskich XVII i XVIII w. (do 1772 r.) Włodzimierz Gruszczyński Instytut
CLARIN rozproszony system technologii językowych dla różnych języków europejskich
 CLARIN rozproszony system technologii językowych dla różnych języków europejskich Maciej Piasecki Politechnika Wrocławska Instytut Informatyki G4.19 Research Group maciej.piasecki@pwr.wroc.pl Projekt CLARIN
CLARIN rozproszony system technologii językowych dla różnych języków europejskich Maciej Piasecki Politechnika Wrocławska Instytut Informatyki G4.19 Research Group maciej.piasecki@pwr.wroc.pl Projekt CLARIN
SYLABUS DOTYCZY CYKLU KSZTAŁCENIA Bieżący sylabus w semestrze zimowym roku 2016/17
 Załącznik nr 4 do Uchwały Senatu nr 430/01/2015 SYLABUS DOTYCZY CYKLU KSZTAŁCENIA 2016-2018 Bieżący sylabus w semestrze zimowym roku 2016/17 1.1. PODSTAWOWE INFORMACJE O PRZEDMIOCIE/MODULE Nazwa przedmiotu/
Załącznik nr 4 do Uchwały Senatu nr 430/01/2015 SYLABUS DOTYCZY CYKLU KSZTAŁCENIA 2016-2018 Bieżący sylabus w semestrze zimowym roku 2016/17 1.1. PODSTAWOWE INFORMACJE O PRZEDMIOCIE/MODULE Nazwa przedmiotu/
AUTOMATYKA INFORMATYKA
 AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
Generated by Foxit PDF Creator Foxit Software http://www.foxitsoftware.com For evaluation only. System Szablonów
 System Szablonów System szablonów System szablonów to biblioteka, która pozwala oddzielić warstwę prezentacji od warstwy logicznej. Aplikacja WWW najpierw pobiera wszystkie dane, przetwarza je i umieszcza
System Szablonów System szablonów System szablonów to biblioteka, która pozwala oddzielić warstwę prezentacji od warstwy logicznej. Aplikacja WWW najpierw pobiera wszystkie dane, przetwarza je i umieszcza
Elektroniczny Korpus Textow Polſkich z XVII i XVIII w. (do 1772 r.)
") to iest Elektroniczny Korpus Textow Polſkich z XVII i XVIII w. (do 1772 r.) KORBEUSZ W Wárßáwie, dniá 18. Iunii A.D. MMXVIII Podstawowe dane projektu KORBEUSZ Tytuł: Elektroniczny korpus tekstów polskich
to iest Elektroniczny Korpus Textow Polſkich z XVII i XVIII w. (do 1772 r.) KORBEUSZ W Wárßáwie, dniá 18. Iunii A.D. MMXVIII Podstawowe dane projektu KORBEUSZ Tytuł: Elektroniczny korpus tekstów polskich
Odkrywanie CAQDAS : wybrane bezpłatne programy komputerowe wspomagające analizę danych jakościowych / Jakub Niedbalski. Łódź, 2013.
 Odkrywanie CAQDAS : wybrane bezpłatne programy komputerowe wspomagające analizę danych jakościowych / Jakub Niedbalski. Łódź, 2013 Spis treści Wprowadzenie 11 1. Audacity - program do edycji i obróbki
Odkrywanie CAQDAS : wybrane bezpłatne programy komputerowe wspomagające analizę danych jakościowych / Jakub Niedbalski. Łódź, 2013 Spis treści Wprowadzenie 11 1. Audacity - program do edycji i obróbki
II cykl wykładów i warsztatów. CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w naukach humanistycznych i społecznych
 II cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w naukach humanistycznych i społecznych 18-20 maja 2015 roku Politechnika Wrocławska, Centrum Kongresowe,
II cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Cyfrowe narzędzia do analizy języka w naukach humanistycznych i społecznych 18-20 maja 2015 roku Politechnika Wrocławska, Centrum Kongresowe,
Problem normy językowej w leksykografii historycznej
 Problem normy językowej w leksykografii historycznej Włodzimierz Gruszczyński Instytut Języka Polskiego PAN wlodekiewa@poczta.onet.pl Cechy słownika historycznego Słownik historyczny jest zazwyczaj: w
Problem normy językowej w leksykografii historycznej Włodzimierz Gruszczyński Instytut Języka Polskiego PAN wlodekiewa@poczta.onet.pl Cechy słownika historycznego Słownik historyczny jest zazwyczaj: w
Modelowanie Data Mining na wielką skalę z SAS Factory Miner. Paweł Plewka, SAS
 Modelowanie Data Mining na wielką skalę z SAS Factory Miner Paweł Plewka, SAS Wstęp SAS Factory Miner Nowe narzędzie do data mining - dostępne od połowy 2015 r. Aktualna wersja - 14.1 Interfejs webowy
Modelowanie Data Mining na wielką skalę z SAS Factory Miner Paweł Plewka, SAS Wstęp SAS Factory Miner Nowe narzędzie do data mining - dostępne od połowy 2015 r. Aktualna wersja - 14.1 Interfejs webowy
Korekta OCR problemy i rozwiązania
 Korekta OCR problemy i rozwiązania Edyta Kotyńska eteka.com.pl Kraków, 24-25.01.2013 r. Tekst, który nie jest cyfrowy - nie istnieje w sieci OCR umożliwia korzystanie z materiałów historycznych w formie
Korekta OCR problemy i rozwiązania Edyta Kotyńska eteka.com.pl Kraków, 24-25.01.2013 r. Tekst, który nie jest cyfrowy - nie istnieje w sieci OCR umożliwia korzystanie z materiałów historycznych w formie
Inforex - zarządzanie korpusami i ich anotacja
 Inforex - zarządzanie korpusami i ich anotacja Marcin Oleksy marcin.oleksy@pwr.edu.pl Michał Marcińczuk michal.marcinczuk@pwr.edu.pl Politechnika Wrocławska Katedra Inteligencji Obliczeniowej Grupa Technologii
Inforex - zarządzanie korpusami i ich anotacja Marcin Oleksy marcin.oleksy@pwr.edu.pl Michał Marcińczuk michal.marcinczuk@pwr.edu.pl Politechnika Wrocławska Katedra Inteligencji Obliczeniowej Grupa Technologii
Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI XVIII Wieku jako uzupełniona bibliografia Zawadzkiego
 Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI XVIII Wieku jako uzupełniona bibliografia Zawadzkiego Włodzimierz Gruszczyński Maciej Ogrodniczuk Instytut Języka Polskiego Polskiej
Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI XVIII Wieku jako uzupełniona bibliografia Zawadzkiego Włodzimierz Gruszczyński Maciej Ogrodniczuk Instytut Języka Polskiego Polskiej
ZMODYFIKOWANY Szczegółowy opis przedmiotu zamówienia
 ZP/ITS/11/2012 Załącznik nr 1a do SIWZ ZMODYFIKOWANY Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych
ZP/ITS/11/2012 Załącznik nr 1a do SIWZ ZMODYFIKOWANY Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych
ZMIANY WPROWADZONE W AKTUALIZACJI SYSTEMU POMOST STD
 ZMIANY WPROWADZONE W AKTUALIZACJI 3-18.2 SYSTEMU POMOST STD Aktualizacji 3-18.2 można dokonać z wersji 3-18.0 lub 3-18.1. Dane osobowe na wszystkich ilustracjach są fikcyjne. 1. Umożliwienie zaplanowania
ZMIANY WPROWADZONE W AKTUALIZACJI 3-18.2 SYSTEMU POMOST STD Aktualizacji 3-18.2 można dokonać z wersji 3-18.0 lub 3-18.1. Dane osobowe na wszystkich ilustracjach są fikcyjne. 1. Umożliwienie zaplanowania
Tworzenie korpusu tekstów dawnych a korpusu tekstów współczesnych: różnice teoretyczne i warsztatowe
 Tworzenie korpusu tekstów dawnych a korpusu tekstów współczesnych: różnice teoretyczne i warsztatowe (na przykładzie Korpusu tekstów polskich XVII-XVIII wieku) W. Gruszczyński R. Bronikowska IJP PAN Porównywane
Tworzenie korpusu tekstów dawnych a korpusu tekstów współczesnych: różnice teoretyczne i warsztatowe (na przykładzie Korpusu tekstów polskich XVII-XVIII wieku) W. Gruszczyński R. Bronikowska IJP PAN Porównywane
Wybrane problemy z dziedziny modelowania i wdrażania baz danych przestrzennych w aspekcie dydaktyki. Artur Krawczyk AGH Akademia Górniczo Hutnicza
 Wybrane problemy z dziedziny modelowania i wdrażania baz danych przestrzennych w aspekcie dydaktyki Artur Krawczyk AGH Akademia Górniczo Hutnicza Problem modelowania tekstowego opisu elementu geometrycznego
Wybrane problemy z dziedziny modelowania i wdrażania baz danych przestrzennych w aspekcie dydaktyki Artur Krawczyk AGH Akademia Górniczo Hutnicza Problem modelowania tekstowego opisu elementu geometrycznego
Praca licencjacka. Seminarium dyplomowe Zarządzanie przedsiębiorstwem dr Kalina Grzesiuk
 Praca licencjacka Seminarium dyplomowe Zarządzanie przedsiębiorstwem dr Kalina Grzesiuk 1.Wymagania formalne 1. struktura pracy zawiera: stronę tytułową, spis treści, Wstęp, rozdziały merytoryczne (teoretyczne
Praca licencjacka Seminarium dyplomowe Zarządzanie przedsiębiorstwem dr Kalina Grzesiuk 1.Wymagania formalne 1. struktura pracy zawiera: stronę tytułową, spis treści, Wstęp, rozdziały merytoryczne (teoretyczne
Paweł Gołębiewski. Softmaks.pl Sp. z o.o. ul. Kraszewskiego 1 85-240 Bydgoszcz www.softmaks.pl kontakt@softmaks.pl
 Paweł Gołębiewski Softmaks.pl Sp. z o.o. ul. Kraszewskiego 1 85-240 Bydgoszcz www.softmaks.pl kontakt@softmaks.pl Droga na szczyt Narzędzie Business Intelligence. Czyli kiedy podjąć decyzję o wdrożeniu?
Paweł Gołębiewski Softmaks.pl Sp. z o.o. ul. Kraszewskiego 1 85-240 Bydgoszcz www.softmaks.pl kontakt@softmaks.pl Droga na szczyt Narzędzie Business Intelligence. Czyli kiedy podjąć decyzję o wdrożeniu?
Wymagania edukacyjne - Informatyka w klasie I
 Wymagania edukacyjne - Informatyka w klasie I Poziom niski wyrażony cyfrą 2 wymagania konieczne. Uczeń ma duże trudności ze spełnieniem wymagań, potrzebuje częstej pomocy nauczyciela. Poziom dostateczny
Wymagania edukacyjne - Informatyka w klasie I Poziom niski wyrażony cyfrą 2 wymagania konieczne. Uczeń ma duże trudności ze spełnieniem wymagań, potrzebuje częstej pomocy nauczyciela. Poziom dostateczny
Instrukcja. opracował Marcin Oleksy
 Instrukcja opracował Marcin Oleksy Wstęp Zarządzanie korpusem Flagi Flagowanie korpusu Usuwanie i edytowanie flag Użytkownicy Przypisywanie użytkowników Role użytkowników Cofnięcie dostępu Podkorpusy Tworzenie
Instrukcja opracował Marcin Oleksy Wstęp Zarządzanie korpusem Flagi Flagowanie korpusu Usuwanie i edytowanie flag Użytkownicy Przypisywanie użytkowników Role użytkowników Cofnięcie dostępu Podkorpusy Tworzenie
Inforex - zarządzanie korpusami i ich anotacja. Politechnika Wrocławska Katedra Inteligencji Obliczeniowej Grupa Technologii Językowych G4.
 Inforex - zarządzanie korpusami i ich anotacja Michał Marcińczuk michal.marcinczuk@pwr.edu.pl Marcin Oleksy Jan Wieczorek Jan Kocoń marcin.oleksy@pwr.edu.pl jan.wieczorek@pwr.edu.pl jan.kocon@pwr.edu.pl
Inforex - zarządzanie korpusami i ich anotacja Michał Marcińczuk michal.marcinczuk@pwr.edu.pl Marcin Oleksy Jan Wieczorek Jan Kocoń marcin.oleksy@pwr.edu.pl jan.wieczorek@pwr.edu.pl jan.kocon@pwr.edu.pl
FORMULARZ SYSTEMU ZARZĄDZANIA JAKOŚCIĄ. Aktualizacja stawek VAT na rok 2011. Wydanie: 1 Data wydania: 17.12.2010 Strona/ stron: 1/11
 FORMULARZ SYSTEMU ZARZĄDZANIA JAKOŚCIĄ Aktualizacja stawek VAT na rok 2011 KS-FKW Wydanie: 1 Data wydania: 17.12.2010 Strona/ stron: 1/11 Zmiana stawek VAT od 2011 roku a konfiguracja systemu KS-FKW Spis
FORMULARZ SYSTEMU ZARZĄDZANIA JAKOŚCIĄ Aktualizacja stawek VAT na rok 2011 KS-FKW Wydanie: 1 Data wydania: 17.12.2010 Strona/ stron: 1/11 Zmiana stawek VAT od 2011 roku a konfiguracja systemu KS-FKW Spis
Nadzorowanie stanu serwerów i ich wykorzystania przez użytkowników
 Uniwersytet Mikołaja Kopernika w Toruniu Wydział Matematyki i Informatyki Wydział Fizyki, Astronomii i Informatyki Stosowanej Tomasz Kapelak Nr albumu: 187404 Praca magisterska na kierunku Informatyka
Uniwersytet Mikołaja Kopernika w Toruniu Wydział Matematyki i Informatyki Wydział Fizyki, Astronomii i Informatyki Stosowanej Tomasz Kapelak Nr albumu: 187404 Praca magisterska na kierunku Informatyka
Tworzenie przeszukiwalnych korpusów j zyka polskiego za pomoc Korpusomatu
 Tworzenie przeszukiwalnych korpusów j zyka polskiego za pomoc Korpusomatu Witold Kiera± Šukasz Kobyli«ski Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN IV cykl wykªadów i warsztatów CLARIN-PL Šód¹
Tworzenie przeszukiwalnych korpusów j zyka polskiego za pomoc Korpusomatu Witold Kiera± Šukasz Kobyli«ski Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN IV cykl wykªadów i warsztatów CLARIN-PL Šód¹
L E X. Generator analizatorów leksykalnych
 L E X Generator analizatorów leksykalnych GENERATOR L E X Zadaniem generatora LEX jest wygenerowanie kodu źródłowego analizatora leksykalnego (domyślnie) w języku C; Kod źródłowy generowany jest przez
L E X Generator analizatorów leksykalnych GENERATOR L E X Zadaniem generatora LEX jest wygenerowanie kodu źródłowego analizatora leksykalnego (domyślnie) w języku C; Kod źródłowy generowany jest przez
polski ENCYKLOPEDIA W TABELACH Wydawnictwo Adamantan
 polski / ENCYKLOPEDIA W TABELACH Wydawnictwo Adamantan SPIS TREŚCI FONETYKA Narządy mowy 13 Klasyfikacja głosek i fonemów 14 Samogłoski 16 Spółgłoski 17 Pisownia fonetyczna 19 Fonemy języka polskiego 20
polski / ENCYKLOPEDIA W TABELACH Wydawnictwo Adamantan SPIS TREŚCI FONETYKA Narządy mowy 13 Klasyfikacja głosek i fonemów 14 Samogłoski 16 Spółgłoski 17 Pisownia fonetyczna 19 Fonemy języka polskiego 20
extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl
 extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl Plan wykładu Wprowadzenie: historia rozwoju technik znakowania tekstu Motywacje dla prac nad XML-em Podstawowe koncepcje XML-a XML jako metajęzyk
extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl Plan wykładu Wprowadzenie: historia rozwoju technik znakowania tekstu Motywacje dla prac nad XML-em Podstawowe koncepcje XML-a XML jako metajęzyk
Sztuczna Inteligencja Tematy projektów Sieci Neuronowe
 PB, 2009 2010 Sztuczna Inteligencja Tematy projektów Sieci Neuronowe Projekt 1 Stwórz projekt implementujący jednokierunkową sztuczną neuronową złożoną z neuronów typu sigmoidalnego z algorytmem uczenia
PB, 2009 2010 Sztuczna Inteligencja Tematy projektów Sieci Neuronowe Projekt 1 Stwórz projekt implementujący jednokierunkową sztuczną neuronową złożoną z neuronów typu sigmoidalnego z algorytmem uczenia
Scalanie kilku plików JPK-VAT
 [Wpisz tutaj] Krzysztof Piasecki, FINKA.PL Programy księgowe dla firm Autor jest współtwórcą oprogramowania FINKA, przeznaczonego m.in. do generowania i weryfikacji JPK. 4600 wdrożonych licencji i ponad
[Wpisz tutaj] Krzysztof Piasecki, FINKA.PL Programy księgowe dla firm Autor jest współtwórcą oprogramowania FINKA, przeznaczonego m.in. do generowania i weryfikacji JPK. 4600 wdrożonych licencji i ponad
Zautomatyzowane tworzenie korpusów błędów dla języka polskiego
 Zautomatyzowane tworzenie korpusów błędów dla języka polskiego Marcin Miłkowski Instytut Filozofii i Socjologii PAN Zakład Logiki i Kognitywistyki Adres projektu: morfologik.blogspot.com Korpusy błędów
Zautomatyzowane tworzenie korpusów błędów dla języka polskiego Marcin Miłkowski Instytut Filozofii i Socjologii PAN Zakład Logiki i Kognitywistyki Adres projektu: morfologik.blogspot.com Korpusy błędów
REGULAMIN MIĘDZYSZKOLNEGO KONKURSU ORTOGRAFICZNEGO SZKÓŁ PODSTAWOWYCH MIASTA POZNANIA
 SZKOŁA PODSTAWOWA NR 18 W POZNANIU REGULAMIN MIĘDZYSZKOLNEGO KONKURSU ORTOGRAFICZNEGO SZKÓŁ PODSTAWOWYCH MIASTA POZNANIA Organizator : Szkoła Podstawowa nr 18 im. Zofii Nałkowskiej w Poznaniu Współorganizatorzy
SZKOŁA PODSTAWOWA NR 18 W POZNANIU REGULAMIN MIĘDZYSZKOLNEGO KONKURSU ORTOGRAFICZNEGO SZKÓŁ PODSTAWOWYCH MIASTA POZNANIA Organizator : Szkoła Podstawowa nr 18 im. Zofii Nałkowskiej w Poznaniu Współorganizatorzy
SZTUCZNA INTELIGENCJA
 Stefan Sokołowski SZTUCZNA INTELIGENCJA Inst Informatyki UG, Gdańsk, 2009/2010 Wykład1,17II2010,str1 SZTUCZNA INTELIGENCJA reguły gry Zasadnicze informacje: http://infugedupl/ stefan/dydaktyka/sztintel/
Stefan Sokołowski SZTUCZNA INTELIGENCJA Inst Informatyki UG, Gdańsk, 2009/2010 Wykład1,17II2010,str1 SZTUCZNA INTELIGENCJA reguły gry Zasadnicze informacje: http://infugedupl/ stefan/dydaktyka/sztintel/
Programowanie Strukturalne i Obiektowe Słownik podstawowych pojęć 1 z 5 Opracował Jan T. Biernat
 Programowanie Strukturalne i Obiektowe Słownik podstawowych pojęć 1 z 5 Program, to lista poleceń zapisana w jednym języku programowania zgodnie z obowiązującymi w nim zasadami. Celem programu jest przetwarzanie
Programowanie Strukturalne i Obiektowe Słownik podstawowych pojęć 1 z 5 Program, to lista poleceń zapisana w jednym języku programowania zgodnie z obowiązującymi w nim zasadami. Celem programu jest przetwarzanie
PRÓBNY EGZAMIN GIMNAZJALNY Z NOWĄ ERĄ 2016/2017 JĘZYK POLSKI
 PRÓBNY EGZAMIN GIMNAZJALNY Z NOWĄ ERĄ 2016/2017 JĘZYK POLSKI ZASADY OCENIANIA ROZWIĄZAŃ ZADAŃ Copyright by Nowa Era Sp. z o.o. Zadanie 1. (0 1) 2) wyszukuje w wypowiedzi potrzebne informacje [ ]. PP Zadanie
PRÓBNY EGZAMIN GIMNAZJALNY Z NOWĄ ERĄ 2016/2017 JĘZYK POLSKI ZASADY OCENIANIA ROZWIĄZAŃ ZADAŃ Copyright by Nowa Era Sp. z o.o. Zadanie 1. (0 1) 2) wyszukuje w wypowiedzi potrzebne informacje [ ]. PP Zadanie
OPIS MODUŁU (PRZEDMIOTU)
") Załącznik Nr 1.11 pieczątka jednostki organizacyjnej OPIS PRZEDMIOTU, PROGRAMU NAUCZANIA ORAZ SPOSOBÓW WERYFIKACJI EFEKTÓW KSZTAŁCENIA CZEŚĆ A * (opis przedmiotu i programu nauczania) OPIS MODUŁU (PRZEDMIOTU)
Załącznik Nr 1.11 pieczątka jednostki organizacyjnej OPIS PRZEDMIOTU, PROGRAMU NAUCZANIA ORAZ SPOSOBÓW WERYFIKACJI EFEKTÓW KSZTAŁCENIA CZEŚĆ A * (opis przedmiotu i programu nauczania) OPIS MODUŁU (PRZEDMIOTU)
Zasób leksykalny polszczyzny II poł. XIX wieku a możliwość automatycznej analizy morfologicznej tekstów z tego okresu
 Zasób leksykalny polszczyzny II poł. XIX wieku a możliwość automatycznej analizy morfologicznej tekstów z tego okresu DEC-2012/07/B/HS2/00570 Magdalena Derwojedowa Witold Kieraś Danuta Skowrońska Robert
Zasób leksykalny polszczyzny II poł. XIX wieku a możliwość automatycznej analizy morfologicznej tekstów z tego okresu DEC-2012/07/B/HS2/00570 Magdalena Derwojedowa Witold Kieraś Danuta Skowrońska Robert
jest dostępne na różne systemy operacyjne. Niniejsza instrukcja opisuje podstawowe operacje i opcje niezbędne do rozpoczęcia pracy w tym programie.
 OmegaT to darmowe narzędzie CAT wykonane w technologii Java, dzięki czemu jest dostępne na różne systemy operacyjne. Niniejsza instrukcja opisuje podstawowe operacje i opcje niezbędne do rozpoczęcia pracy
OmegaT to darmowe narzędzie CAT wykonane w technologii Java, dzięki czemu jest dostępne na różne systemy operacyjne. Niniejsza instrukcja opisuje podstawowe operacje i opcje niezbędne do rozpoczęcia pracy
Bielskiego Mistrza Ortografii 2014
 Bielsko-Biała, 10 lutego 2014. Sz. Państwo Dyrekcja, Nauczyciele i Uczniowie Szkoły Podstawowej nr w Bielsku-Białej Regulamin I Międzyszkolnego Dyktanda dla uczniów klas IV-VI o tytuł Bielskiego Mistrza
Bielsko-Biała, 10 lutego 2014. Sz. Państwo Dyrekcja, Nauczyciele i Uczniowie Szkoły Podstawowej nr w Bielsku-Białej Regulamin I Międzyszkolnego Dyktanda dla uczniów klas IV-VI o tytuł Bielskiego Mistrza
REGULAMIN SZKOLNEGO KONKURSU ORTOGRAFICZNEGO MISTRZ ORTOGRAFII DLA UCZNIÓW KLAS IV-VI
 REGULAMIN SZKOLNEGO KONKURSU ORTOGRAFICZNEGO MISTRZ ORTOGRAFII DLA UCZNIÓW KLAS IV-VI Cele konkursu 1. Poznawanie i zrozumienie przez wychowanków podstawowych zasad funkcjonowania języka. 2. Kształcenie
REGULAMIN SZKOLNEGO KONKURSU ORTOGRAFICZNEGO MISTRZ ORTOGRAFII DLA UCZNIÓW KLAS IV-VI Cele konkursu 1. Poznawanie i zrozumienie przez wychowanków podstawowych zasad funkcjonowania języka. 2. Kształcenie
Zasady interpretacji Raportu antyplagiatowego
 Zasady interpretacji Raportu antyplagiatowego Strona 1 z 8 Spis treści 1. Informacje ogólne... 3 2. Wskaźniki analizy antyplagiatowej... 4 3. Wskaźniki dodatkowe analizy antyplagiatowej... 5 4. Konflikty...
Zasady interpretacji Raportu antyplagiatowego Strona 1 z 8 Spis treści 1. Informacje ogólne... 3 2. Wskaźniki analizy antyplagiatowej... 4 3. Wskaźniki dodatkowe analizy antyplagiatowej... 5 4. Konflikty...
Spis treści 3. Spis treści
 3 Wstęp... 9 1. Informatyka w procesie zarządzania przedsiębiorstwem... 15 1.1. Związek informatyki z zarządzaniem przedsiębiorstwem... 17 1.2. System informacyjny a system informatyczny... 21 1.3. Historia
3 Wstęp... 9 1. Informatyka w procesie zarządzania przedsiębiorstwem... 15 1.1. Związek informatyki z zarządzaniem przedsiębiorstwem... 17 1.2. System informacyjny a system informatyczny... 21 1.3. Historia
Dygitalizacja i komputeryzacja słowników na przykładzie Słownika polszczyzny XVI wieku
 Dygitalizacja i komputeryzacja słowników na przykładzie Słownika polszczyzny XVI wieku Janusz S. Bień Katedra Lingwistyki Formalnej UW Język polski wczoraj, dziś, jutro W 100. rocznicę urodzin prof. S.
Dygitalizacja i komputeryzacja słowników na przykładzie Słownika polszczyzny XVI wieku Janusz S. Bień Katedra Lingwistyki Formalnej UW Język polski wczoraj, dziś, jutro W 100. rocznicę urodzin prof. S.
XML i nowoczesne metody zarządzania treścią
 XML i nowoczesne metody zarządzania treścią Wykład 14: Studium przypadku: System SET Władysław Baksza, Maciej Ogrodniczuk MIMUW, 14 stycznia 2010 Wykład 14: Studium przypadku: System SET XML i nowoczesne
XML i nowoczesne metody zarządzania treścią Wykład 14: Studium przypadku: System SET Władysław Baksza, Maciej Ogrodniczuk MIMUW, 14 stycznia 2010 Wykład 14: Studium przypadku: System SET XML i nowoczesne
Propozycja rozszerzenia składni zapytań programu Poliqarp o elementy statystyczne
 Propozycja rozszerzenia składni zapytań programu Poliqarp o elementy statystyczne Aleksander Buczyński 2006.06.26 Poliqarp - stan obecny Zwracane są kolejne konteksty wystąpień ciągów segmentów pasujących
Propozycja rozszerzenia składni zapytań programu Poliqarp o elementy statystyczne Aleksander Buczyński 2006.06.26 Poliqarp - stan obecny Zwracane są kolejne konteksty wystąpień ciągów segmentów pasujących
Stefan Sokołowski SZTUCZNAINTELIGENCJA. Inst. Informatyki UG, Gdańsk, 2009/2010
 Stefan Sokołowski SZTUCZNAINTELIGENCJA Inst. Informatyki UG, Gdańsk, 2009/2010 Wykład1,17II2010,str.1 SZTUCZNA INTELIGENCJA reguły gry Zasadnicze informacje: http://inf.ug.edu.pl/ stefan/dydaktyka/sztintel/
Stefan Sokołowski SZTUCZNAINTELIGENCJA Inst. Informatyki UG, Gdańsk, 2009/2010 Wykład1,17II2010,str.1 SZTUCZNA INTELIGENCJA reguły gry Zasadnicze informacje: http://inf.ug.edu.pl/ stefan/dydaktyka/sztintel/
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst
 Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst Mariusz Owsianny, PCSS Dr inż. Ewa Kuśmierek, Kierownik Projektu, PCSS Partnerzy konsorcjum Zaawansowany system automatycznego
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst Mariusz Owsianny, PCSS Dr inż. Ewa Kuśmierek, Kierownik Projektu, PCSS Partnerzy konsorcjum Zaawansowany system automatycznego
Wykład 3: Prezentacja danych statystycznych
 Wykład 3: Prezentacja danych statystycznych Dobór metody prezentacji danych Dobór metody prezentacji danych zależy od: charakteru danych statystycznych (inne metody wybierzemy dla danych przekrojowych,
Wykład 3: Prezentacja danych statystycznych Dobór metody prezentacji danych Dobór metody prezentacji danych zależy od: charakteru danych statystycznych (inne metody wybierzemy dla danych przekrojowych,
Korpus tekstów drugiej połowy doby nowopolskiej ( )
") Korpus tekstów drugiej połowy doby nowopolskiej (1830-1918) Joanna Bilińska, Danuta Skowrońska, Witold Kieraś Magdalena Derwojedowa, Robert Wołosz Uniwersytet Warszawski Uniwersytet w Pécsu Grammar & Corpora
Korpus tekstów drugiej połowy doby nowopolskiej (1830-1918) Joanna Bilińska, Danuta Skowrońska, Witold Kieraś Magdalena Derwojedowa, Robert Wołosz Uniwersytet Warszawski Uniwersytet w Pécsu Grammar & Corpora
REGULAMIN DYKTANDA GMINNEGO PN. JĘZYKOWE POTYCZKI Z HISTORIĄ W TLE. Gminne Centrum Kultury w Jerzmanowej. Wójt Gminy Jerzmanowa Lesław Golba
 REGULAMIN DYKTANDA GMINNEGO I. Organizator konkursu: Gminne Centrum Kultury w Jerzmanowej II. Patronat: Wójt Gminy Jerzmanowa Lesław Golba III. Miejsce i termin dyktanda: Dyktando odbędzie się 18 października
REGULAMIN DYKTANDA GMINNEGO I. Organizator konkursu: Gminne Centrum Kultury w Jerzmanowej II. Patronat: Wójt Gminy Jerzmanowa Lesław Golba III. Miejsce i termin dyktanda: Dyktando odbędzie się 18 października
PoliTa multitager morfosyntaktyczny dla j. ezyka polskiego
 PoliTa multitager morfosyntaktyczny dla j ezyka polskiego Lukasz Kobyliński Instytut Podstaw Informatyki Polskiej Akademii Nauk ul. Jana Kazimierza 5, 01-248 Warszawa, Poland 3.03.2014 Lukasz Kobyliński
PoliTa multitager morfosyntaktyczny dla j ezyka polskiego Lukasz Kobyliński Instytut Podstaw Informatyki Polskiej Akademii Nauk ul. Jana Kazimierza 5, 01-248 Warszawa, Poland 3.03.2014 Lukasz Kobyliński
PLAN WYNIKOWY KLASA 1
 PLAN WYNIKOWY KLASA 1 1. Pracownia komputerowa 2. Podstawowy zestaw komputerowy Zasady bezpiecznej pracy i przebywania w pracowni komputerowej i nazywamy elementy podstawowego zestawu komputerowego wie,
PLAN WYNIKOWY KLASA 1 1. Pracownia komputerowa 2. Podstawowy zestaw komputerowy Zasady bezpiecznej pracy i przebywania w pracowni komputerowej i nazywamy elementy podstawowego zestawu komputerowego wie,
5. WORD W POLSKIEJ WERSJI
 5. WORD W POLSKIEJ WERSJI 5.1. PISOWNIA I GRAMATYKA Polska wersja pakietu Microsoft Office 2000 jest dostarczana wraz z narzędziami sprawdzania pisowni dla języka polskiego, angielskiego i niemieckiego.
5. WORD W POLSKIEJ WERSJI 5.1. PISOWNIA I GRAMATYKA Polska wersja pakietu Microsoft Office 2000 jest dostarczana wraz z narzędziami sprawdzania pisowni dla języka polskiego, angielskiego i niemieckiego.
Dlaczego GML? Gdańsk r. Karol Stachura
 Dlaczego GML? Gdańsk 13.03.2017r. Karol Stachura Zanim o GML najpierw o XML Dlaczego stosuje się pliki XML: Tekstowe Samoopisujące się Elastyczne Łatwe do zmiany bez zaawansowanego oprogramowania Posiadające
Dlaczego GML? Gdańsk 13.03.2017r. Karol Stachura Zanim o GML najpierw o XML Dlaczego stosuje się pliki XML: Tekstowe Samoopisujące się Elastyczne Łatwe do zmiany bez zaawansowanego oprogramowania Posiadające
Walutowe dokumenty sprzedaży - automatyczne dostosowywanie języka do preferencji kontrahenta
 Walutowe dokumenty sprzedaży - automatyczne dostosowywanie języka do preferencji kontrahenta (ProLider ) W programie ProLider istnieje możliwość : - przypisania do kontrahenta języka, w którym mają być
Walutowe dokumenty sprzedaży - automatyczne dostosowywanie języka do preferencji kontrahenta (ProLider ) W programie ProLider istnieje możliwość : - przypisania do kontrahenta języka, w którym mają być
REGULAMIN MIĘDZYSZKOLNEGO KONKURSU ORTOGRAFICZNEGO SZKÓŁ PODSTAWOWYCH MIASTA POZNANIA
 SZKOŁA PODSTAWOWA NR 18 W POZNANIU REGULAMIN MIĘDZYSZKOLNEGO KONKURSU ORTOGRAFICZNEGO SZKÓŁ PODSTAWOWYCH MIASTA POZNANIA Organizator : Szkoła Podstawowa nr 18 im. Zofii Nałkowskiej w Poznaniu Współorganizatorzy
SZKOŁA PODSTAWOWA NR 18 W POZNANIU REGULAMIN MIĘDZYSZKOLNEGO KONKURSU ORTOGRAFICZNEGO SZKÓŁ PODSTAWOWYCH MIASTA POZNANIA Organizator : Szkoła Podstawowa nr 18 im. Zofii Nałkowskiej w Poznaniu Współorganizatorzy
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe.
 Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Walutowe dokumenty sprzedaży - automatyczne dostosowywanie języka do preferencji kontrahenta
 Walutowe dokumenty sprzedaży - automatyczne dostosowywanie języka do preferencji kontrahenta (ProLider ) W programie ProLider istnieje możliwość : - przypisania do kontrahenta języka, w którym mają być
Walutowe dokumenty sprzedaży - automatyczne dostosowywanie języka do preferencji kontrahenta (ProLider ) W programie ProLider istnieje możliwość : - przypisania do kontrahenta języka, w którym mają być
ECDL/ICDL Przetwarzanie tekstów Moduł B3 Sylabus - wersja 6.0
 ECDL/ICDL Przetwarzanie tekstów Moduł B3 Sylabus - wersja 6.0 Przeznaczenie sylabusa Dokument ten zawiera szczegółowy sylabus dla modułu ECDL/ICDL Przetwarzanie tekstów. Sylabus opisuje zakres wiedzy i
ECDL/ICDL Przetwarzanie tekstów Moduł B3 Sylabus - wersja 6.0 Przeznaczenie sylabusa Dokument ten zawiera szczegółowy sylabus dla modułu ECDL/ICDL Przetwarzanie tekstów. Sylabus opisuje zakres wiedzy i
Mapa Literacka analiza odniesień geograficznych w tekstach literackich
 CLARIN-PL Mapa Literacka analiza odniesień geograficznych w tekstach literackich Michał Marcińczuk Politechnika Wrocławska Katedra Inteligencji Obliczeniowej Grupa Naukowa G4.19 michal.marcinczuk@pwr.edu.pl
CLARIN-PL Mapa Literacka analiza odniesień geograficznych w tekstach literackich Michał Marcińczuk Politechnika Wrocławska Katedra Inteligencji Obliczeniowej Grupa Naukowa G4.19 michal.marcinczuk@pwr.edu.pl
Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI, XVII i XVIII w.
 Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI, XVII i XVIII w. Prezentacja projektu i jego zastosowania w pracy naukowej oraz dydaktyce Włodzimierz Gruszczyński 1 Maciej Ogrodniczuk
Cyfrowa Biblioteka Druków Ulotnych Polskich i Polski Dotyczących z XVI, XVII i XVIII w. Prezentacja projektu i jego zastosowania w pracy naukowej oraz dydaktyce Włodzimierz Gruszczyński 1 Maciej Ogrodniczuk
L6.1 Systemy liczenia stosowane w informatyce
 L6.1 Systemy liczenia stosowane w informatyce Projekt współfinansowany przez Unię Europejską w ramach Europejskiego Funduszu Społecznego Publikacja jest dystrybuowana bezpłatnie Program Operacyjny Kapitał
L6.1 Systemy liczenia stosowane w informatyce Projekt współfinansowany przez Unię Europejską w ramach Europejskiego Funduszu Społecznego Publikacja jest dystrybuowana bezpłatnie Program Operacyjny Kapitał
Automatyczna ekstrakcja i klasyfikacja semantyczna wielosegmentowych jednostek leksykalnych języka naturalnego
 AKADEMIA GÓRNICZO-HUTNICZA IM. STANISŁAWA STASZICA W KRAKOWIE WYDZIAŁ INFORMATYKI, ELEKTRONIKI I TELEKOMUNIKACJI KATEDRA INFORMATYKI Paweł Chrzaszcz Automatyczna ekstrakcja i klasyfikacja semantyczna wielosegmentowych
AKADEMIA GÓRNICZO-HUTNICZA IM. STANISŁAWA STASZICA W KRAKOWIE WYDZIAŁ INFORMATYKI, ELEKTRONIKI I TELEKOMUNIKACJI KATEDRA INFORMATYKI Paweł Chrzaszcz Automatyczna ekstrakcja i klasyfikacja semantyczna wielosegmentowych
KRYTERIA OCENY BIEŻĄCEJ DLA UCZNIÓW KLAS I ZE SPECYFICZNYMI TRUDNOŚCIAMI W UCZENIU SIĘ LUB DEFICYTAMI ROZWOJOWYMI
 Załącznik nr 5 KRYTERIA OCENY BIEŻĄCEJ DLA UCZNIÓW KLAS I ZE SPECYFICZNYMI TRUDNOŚCIAMI W UCZENIU SIĘ LUB DEFICYTAMI ROZWOJOWYMI SŁUCHANIE EDUKACJA POLONISTYCZNA 6 p Słucha ze zrozumieniem poleceń i wypowiedzi
Załącznik nr 5 KRYTERIA OCENY BIEŻĄCEJ DLA UCZNIÓW KLAS I ZE SPECYFICZNYMI TRUDNOŚCIAMI W UCZENIU SIĘ LUB DEFICYTAMI ROZWOJOWYMI SŁUCHANIE EDUKACJA POLONISTYCZNA 6 p Słucha ze zrozumieniem poleceń i wypowiedzi
Wydział Informatyki, Elektroniki i Telekomunikacji. Katedra Informatyki
 Wydział Informatyki, Elektroniki i Telekomunikacji Katedra Informatyki Pastebin w wersji zorientowanej na środowisko mobilne z klientem pozwalającym na oba kierunki przeklejania. Dokumentacja deweloperska
Wydział Informatyki, Elektroniki i Telekomunikacji Katedra Informatyki Pastebin w wersji zorientowanej na środowisko mobilne z klientem pozwalającym na oba kierunki przeklejania. Dokumentacja deweloperska
Praca Magisterska. Automatyczna kontekstowa korekta tekstów na podstawie Grafu Przyzwyczajeń. internetowego dla języka polskiego
 Praca Magisterska Automatyczna kontekstowa korekta tekstów na podstawie Grafu Przyzwyczajeń Lingwistycznych zbudowanego przez robota internetowego dla języka polskiego Marcin A. Gadamer Promotor: dr Adrian
Praca Magisterska Automatyczna kontekstowa korekta tekstów na podstawie Grafu Przyzwyczajeń Lingwistycznych zbudowanego przez robota internetowego dla języka polskiego Marcin A. Gadamer Promotor: dr Adrian
Uniwersytet Śląski w Katowicach str. 1 Wydział Filologiczny Katedra Międzynarodowych Studiów Polskich
 Uniwersytet Śląski w Katowicach str. 1 Kierunek i poziom studiów: międzynarodowe studia polskie, studia I stopnia Sylabus modułu: Historia, struktura i zróżnicowanie języka polskiego Kod modułu: 02-MSP1OS-14-KHSJP
Uniwersytet Śląski w Katowicach str. 1 Kierunek i poziom studiów: międzynarodowe studia polskie, studia I stopnia Sylabus modułu: Historia, struktura i zróżnicowanie języka polskiego Kod modułu: 02-MSP1OS-14-KHSJP
GH - Charakterystyka arkuszy egzaminacyjnych.
 GH - Charakterystyka arkuszy egzaminacyjnych. A. Arkusz standardowy GH-A, B, C oraz arkusze przystosowane: GH-A4, GH-A5, GH-A6. Zestaw zadań z zakresu przedmiotów humanistycznych, skonstruowany wokół tematu
GH - Charakterystyka arkuszy egzaminacyjnych. A. Arkusz standardowy GH-A, B, C oraz arkusze przystosowane: GH-A4, GH-A5, GH-A6. Zestaw zadań z zakresu przedmiotów humanistycznych, skonstruowany wokół tematu
Skrypty korpusowe instrukcja (wersja z 3 lipca 2012 ) redakcja K. Szafran
 redakcja K. Szafran") Tomasz Olejniczak Skrypty korpusowe instrukcja (wersja z 3 lipca 2012 ) redakcja K. Szafran 1. Wprowadzenie Tekst niniejszy jest nieznacznie zmodyfikowaną wersją dokumentu zatytułowanego instrukcja.txt
Tomasz Olejniczak Skrypty korpusowe instrukcja (wersja z 3 lipca 2012 ) redakcja K. Szafran 1. Wprowadzenie Tekst niniejszy jest nieznacznie zmodyfikowaną wersją dokumentu zatytułowanego instrukcja.txt