Propensity Score Matching
|
|
|
- Beata Maciejewska
- 6 lat temu
- Przeglądów:
Transkrypt
1 Zajęcia 6
2 Plan na dziś 1
3 Does matching overcome LaLonde s critique of nonexperimental estimators Jeffrey A. Smith, Petra E. Todd (2005) Journal of Econometrics, vol. 125, str
4 Brak zgody w literaturze W literaturze brak jest zgody wśród autorów czy można ilościowo oceniać programy społeczne bez przeprowadzania randomizowanych eksperymentów Randomizacja zapewnia, że jednostki w grupie poddanej oddziaływaniu eksperymentalnemu i w grupie kontrolnej mają identyczne rozkłady cech obserwowanych i nieobserwowanych Eksperymenty społeczne są kosztowne, mogą zaburzać inne programy, występuje problem odmowy udziału w eksperymencie oraz poszukiwania innego oddziaływania przez jednostki przydzielone do grupy kontrolnej Z kolei zgromadzenie danych nieeksperymentalnych jest tańsze i nie wpływa na zachowanie badanych jednostek
5 Brak zgody w literaturze LaLonde (1986) w artykule, który stanowi obecnie punkt odniesienia pokazał że wyniki oceny uzyskane na podstawie danych nieeksperymentalnych są uzależnione od techniki szacowania efektu oddziaływania Badacze szukają sposobu szacowania efektu oddziaływania eksperymentalnego, który w każdym przypadku rozwiąże problem selekcji Dehejia i Wahba (1999, 2002) zwrócili uwagę na klasę estymatorów propensity score matching pokazując, że można odtworzyć wyniki eksperymentalne. W tym celu wykorzystali te same dane co LaLonde (1986) Ich badanie spopularyzowało metodę propensity score matching
6 Brak zgody w literaturze Niewielkie obciążenie estymatora efektu oddziaływania uzyskanego metodą PSM pokazane przez Deheiję i Wahbę jest sprzeczne wynikami prac Heckman, Ichimura i Todd (1997) [HIT] oraz Heckman, Ichimura, Smith i Todd (1998) [HIST] Prace HIT oraz HIST pokazują, że analizowane dane powinny być homogeniczne, zbiór informacji bogaty i zmienna mierząca wynik powinna być w taki sam sposób mierzona w grupie poddanej oddziaływaniu i grupie kontrolnej Dane NSW analizowane przez LaLonde (1986) oraz Dehejia i Wahba (1999, 2002) żadnego z tych warunków nie spełniają
7 Cel artykułu Smith i Todd powtórnie analizują dane LaLonde wykorzystując technikę propensity score matching Pokazują, że niewielkie obciążenie oszacowań uzyskane przez Dehejia i Wahba (1999, 2002) występuje wyłącznie w specyficznej podpróbie danych analizowanej przez Dehejia i Wahba Wyniki są również w małym stopniu odporne na modyfikacje specyfikacji wektora propensity score Wykorzystanie metody różnic w różnicach (ang. difference-in-differrences (DID)) pozwala uzyskać lepsze rezultaty w stosunku do analizy danych przekrojowych
8 Wyniki w artykule Rezultaty uzyskane przez są zgodne z wynikami prac HIT (1997) oraz HIST (1998) w zakresie dotyczącym unikania geograficznego niedopasowania grupy eksperymentalnej i grupy kontrolnej oraz sposobu pomiaru zmiennej wynikowej w obu grupach More generally, our findings make it clear that propensity score matching does not represent magic bullet that solves the selection problem in every context.
9 Program szkoleń NSW Program prowadzono w dziesięciu miejscach w Stanach Zjednoczonych Ameryki Północnej (Atlanta, Chicago, Hartford, Jersey City, Newark, Nowy Jork, Oakland, Filadelfia, San Francisco, Wisconsin) Do programu mogłybyć być przyjęte: kobiety korzystające z federalnego programu pomocy Aid to Families with Dependent Children osoby, które wyszły z uzależnienia od narkotyków osoby z przeszłością kryminalną osoby które przerwały naukę przed ukończeniem szkoły
10 Wyniki LaLonde LaLonde (1986) wykorzystał kilka technik szacowania efektów programu Uzyskane wartości oszacowań efektu programu są uzależnione od wybranej grupy odniesienia i wykorzystanej techniki szacowania parametrów modelu LaLonde podsumował wyniki stwierdzając, że ponieważ nie ma mechanizmu wskazującego, które oszacowania są najlepsze, wykorzystanie danych nieeksperymentalnych nie jest efektywnym sposobem szacowania efektów programu W podobnym badaniu Fraker i Maynard (1987) skupili swą uwagę na procesie selekcji do programu i wysnuli podobne wnioski
11 Wyniki HIT i HIST (1) Autorzy zaproponowali wykorzystanie estymatorów wykorzystujących funkcje jądrowe (ang. kernel) oraz lokalną regresję liniową (ang. local linear matching) W odróżnieniu od łączenia 1 do 1 wykorzystują one większą liczbę obserwacji z grupy kontrolnej przy konstrukcji wyniku kontrfaktycznego Podstawową zaletą tych estymatorów jest znacznie mniejszy asymptotyczny błąd średniokwadratowy Dodatkowo, zaproponowali estymatory metody łączenia dla powtarzanych prób przekrojowych i danych panelowych. Eliminują one stałe w czasie różnice pomiędzy grupą eksperymentalną i kontrolną
12 Wyniki HIT i HIST (2) Wysoka jakość danych jest warunkiem niezbędnym dla uzyskania rzetelnych oszacowań nieznanych parametrów Rozpatrywane przez nich estymatory miały pożądane właściwości przy spełnionych warunkach: identyczne źródło danych dla grupy eksperymentalnej i kontrolnej jednostki obserwowane na tym samym obszarze (w identycznym otoczeniu) dane zawierają bogaty zbiór cech wpływających na selekcję do grupy oraz wynik (efekt) programu HIT oraz HIST przypuszczają, że niska jakość danych jest przyczną wyników LaLonde (1986)
13 Wyniki Dehejia i Wahba Dehejia i Wahba (1999, 2002) wykorzystali metodę propensity score matching do analizy danych LaLonde (1986) Udało im się odtworzyć wyniki eksperymentu z wykorzystaniem danych nieeksperymentalnych Wynik został uzyskany, pomimo tego, że żadne z kryteriów sformułowanych przez HIT (1997) i HIST (1998) nie było spełnione W rezultacie ich badania są często cytowane jako pokazujące, że wykorzystanie propensity score matching rozwiązuje problem nielosowej selekcji
14 Analiza Smith i Todd Wykorzystanie danych LaLonde (1986) Wykorzystanie łączenia 1 do 1 oraz innych technik wykorzystujących propensity score matching Podstawową różnicą między analizą LaLonde (1986) a Dehejia i Wahba (1999 i 2002) jest wykluczenie około 40% obserwacji w celu uwzględnienia jednej dodatkowej zmiennej w modelu Wykluczenie obserwacji spowodowało usunięcie z próby informacji o osobach, które przed programem zarabiały relatywnie więcej Powoduje to, że łatwiej jest rozwiązać problem selekcji Niemal każdy sposób estymacji zastosowany do danych Dehejia i Wahba daje lepsze rezultaty niż zastosowany do danych LaLonde (1986)
15 ATT Celem jest oszacowanie przeciętnego efektu oddziaływania wobec jednostek poddanych oddziaływaniu (ATT) Niech Y 1it oraz Y 0it oznaczają wynik oddziaływania, w grupie eksperymentalnej oraz kontrolnej i są dane jako Y 1it = φ 1 (X it ) + U 1it gdzie U 0it, U 1it IID(0, σ 2 ) Y 0it = φ 0 (X it ) + U 0it
16 Wynik oddziaływania W danych obserwowane jest Y it = D i Y 1it + (1 D i )Y 0it Wstawiając wyrażenia z poprzedniego slajdu otrzymujemy Y it = D i (φ 1 (X it ) + U 1it ) + (1 D i )(φ 0 (X it ) + U 0it ) Po mnożeniu i uporządkowaniu daje to Y it = D i φ 1 (X it ) D i φ 0 (X it ) + D i U 1it D i U 0it + φ 0 (X it ) + U 0it Wyciągając wspólny czynnik D i uzyskujemy Y it = D i [φ 1 (X it φ 0 (X it ) + U 1it U 0it ] +φ }{{} 0 (X it ) + U 0it α (X it )
17 Wynik oddziaływania Zatem wychodząc od równania (2) otrzymaliśmy równanie (3) ze strony 311 Y it = φ 0 (X it ) + D i α (X it ) + U 0it Jest to model o losowych współczynnikach Przy założeniu U 0it = U 1it, czyli część nieobserwowana jest taka sama dla grupy eksperymentalnej i kontrolnej Oraz φ 1 (X it ) φ 0 (X it ) jest stałe względem X it Uzyskiwany jest model przeciętnego efektu oddziaływania wobec jednostek poddanych oddziaływaniu
18 Estymator przed-po Wykorzystuje on charakterystyki obiektów sprzed programu do wyznaczenia kontrfaktycznego wyniku oddziaływania dla grupy eksprymentalnej Zakładając, że wpływ oddziaływania α jest stały niech t oraz t oznaczają dwa okresy czasu przed programem i po jego zakończeniu (w jego trakcie) Estymator przed-po (ang. before-after) jest rozwiązaniem MNK dla α problemu Y it Y it = φ(x it ) φ(x it ) + α + U it U it Estymator jest zgodny jeżeli E(U it U it ) = 0 oraz E((U it U it )(φ(x it ) φ(x it ))) = 0
19 Estymator przed-po Estymator nie jest zidentyfikowany jeżeli model zawiera stałe specyficzne dla okresów czasu Wartość liczbowa estymatora jest podatna na obserwowane w badaniach zjawisko, że wartość zmiennej wynikowej przed programem dla osób zakwalifikowanych do grupy eksperymentalnej maleje (tzw. Ashenfelter dip (Ashenfelter, 1978))
20 Estymator przekrojowy Wykorzystywane są dane przekrojowe z jednego momentu czasu Wykorzystuje on charakterystyki obiektów z grupy kontrolnej do wyznaczenia kontrfaktycznego wyniku oddziaływania dla grupy eksperymentalnej Estymator jest rozwiązaniem MNK dla α problemu Y it = φ(x it ) + α + U it Jeżeli E(U it D i ) 0 lub E(U it φ(x it )) 0 to estymator jest obciążony
21 Estymator różnic w różnicach (DID) Estymator różnic w różnicach (ang. difference-in-differences) szacuje wpływ programu jako różnice między zmianą wartości zmiennej wynikowej dla grupy eksperymentalnej i kontrolnej W tym celu wykorzystywane są informacje sprzed programu t oraz po programie t dla obu grup Estymator jest rozwiązaniem MNK dla α problemu Y it Y it = φ(x it ) φ(x it ) + D i α + U it U it Estymator jest zgodny jeżeli E(U it U it ) = 0, E((U it U it )D i ) = 0 oraz E((U it U it )(φ(x it ) φ(x it ))) = 0
22 Estymator różnic w różnicach (DID) Estymator wymaga spełnienie większej liczby założeń, ale w porównaniu do estymatora przed-po pozwala na umieszczenie w równaniach wyniku stałych specyficznych dla okresów czasu, które są wspólne dla grup
23 Szacowanie ATT Gdy celem jest szacowanie ATT, założenie CIA jest silne. Wystarczy, że E(Y 0 X, D = 1) = E(Y 0 X, D = 0) = E(Y 0 Z) Słabszą wersją warunku wspólnego przedziału określoności (ang. overlap) jest Wówczas Pr(D = 1 Z) < 1 ATT = E(Y 1 Y 0 D = 1) ATT = E(Y 1 D = 1) E X D=1 [E Y (Y 0 D = 1, X )] ATT = E(Y 1 D = 1) E X D=1 [E Y (Y 0 D = 0, X )] Pierwszy czynnik jest szacowany na podstawie grupy eksperymentalnej, drugi kontrolnej

24 Propensity Score Cytat ze strony 314, de-facto powtórzeniem za Rosenbaum i Rubin (1983)
25 Estymator metody łączenia Niech P = Pr(D = 1 X ) Typowy estymator metody łączenia dla efektów oddziaływania wobec jednostek poddanych oddziaływaniu przyjmuje postać ˆα M = 1 n 1 [ Y1i E(Y 0i D i = 1, P i ) ] i I 1 S p gdzie I 1 oznacza grupę eksperymentalną, I 0 zbiór obiektów nie poddanych oddziaływaniu, S P wspólny przedział określoności, n 1 oznacza liczbę jednostek w zbiorze I 1 S p E(Y 0i D i = 1, P i ) = j I 0 W (i, j)y 0j gdzie W (i, j) jest macierzą wag zależną od odległości obiektów z grupy eksperymentalnej do obiektów z grupy kontrolnej
26 Sąsiedztwo Niech C(P i ) oznacza sąsiedztwo dla każdego obiektu i z grupy eksperymentalnej Sąsiadami obiektu i z grupy eksperymentalnej są obiekty z grupy nie poddanej oddziaływaniu, dla których P j C(P i ) Obiekty dołączone do i tworzą zbiór A i = {j I 0 P j C(P i )} Techniki łączenia różnią się sposobem zdefiniowania sąsiedztwa i wag przypisywanych obserwacjom z grupy kontrolnej
27 Łączenie 1 do 1 Łączenie 1 do 1 nazywane jest również metodą najbliższego sąsiada C(P i ) = min j I 0 P i P j Dołączany jest ten obiekt z nie poddanych oddziaływaniu, który ma najbliższą wartość propensity score Zazwyczaj nie jest wymagane spełnienie założenia o wspólnym przedziale określoności (mniej ważne), a łączenie jest bez zwracania (ważne!)
28 Łączenie 1 do 1, Smith i Todd wykorzystują łączenie 1:1 oraz 1:10 W przypadku łączenia 1:10 każda obserwacja otrzymuje identyczną wagę Estymator łączenia 1:10 ma mniejszą wariancję (większa liczba obserwacji) kosztem obciążenia (są przeciętnie gorzej dopasowane) Dodatkowo wykorzystano łączenie bez zwracnia. Ono z kolei zmniejsza obciążenie (potencjalnie lepsze dopasowanie) kosztem zwiększonej wariancji (mniejsza liczba obserwacji) Dehejia i Wahba (1999) wykorzystali łączenie ze zwracaniem Dehejia i Wahba (2002) pokazali, że łącznie bez zwracania prowadzi do łączenia obiektów o znacznych różnicach w wartości propensity score
29 Łączenie 1 do 1, Ujmując problem w sposób bardziej ogólny: łączenie metodą najbliższego sąsiada bez zwracania ma dodatkową wadę, wynikającą z faktu, że wartość oszacowania uzależniona jest od kolejności łączenia obserwacji w zbiorze
30 Odcięcie Łączenie z odcięciem (ang. caliper matching) jest modyfikacją łączenia metodą najbliższego sąsiada Zaproponowane by unikać słabo dopasowanych łączeń Definiowana jest tolerancja na odległość P i od P j C(P i ) = {P j min j I 0 P i P j < ε} Obiekty z grupy eksperymentalnej dla którego nie ma bliskiego odpowiednika w grupie kontrolnej jest usuwany z analizy
31 Odcięcie Ustalenie poziomu odcięcia jest jednym ze sposobów na zapewnienie spełnienia założenia o wspólnym przedziale określoności Problemem jest fakt, trudno jest ustalić a-priori jaka wartość odcięcia jest rozsądna Dehejia i Wahba (2002) wykorzystali wariant odcięcia nazywany łączeniem wewnątrz promienia (ang. radius matching). W tym wariancie wielkość kontrfaktyczna jest średnią wartością dla jednostek nie poddanych oddziaływaniu wewnątrz promienia.
32 Warstwowanie Wspólny przedział określoności jest dzielony na warstwy W każdej warstwie obliczana jest wielkość efektu jako różnica w średniej wartości zmiennej wynikowej w grupie eksperymentalnej i kontrolnej Oszacowaniem efektu oddziaływania jest średnia ważona wyników w każdej warstwie, której wagami są liczebności w grupie eksperymentalnej Ten sposób szacowania został wykorzystany w Dehejia i Wahba (1999). Warstwy dobrano tak, by różnica w średnich wartościach propensity score dla grupy eksperymentalnej i kontrolnej nie była statystycznie istotna
33 Wykorzystanie jądra i lokalnej regresji liniowej Metoda opracowana przez HIT Wykorzystuje ważenie z wykorzystaniem jądrowego estymatora gęstości Estymator metody łączenia dla efektów oddziaływania wobec jednostek poddanych oddziaływaniu jest dany przez ˆα KM = 1 [ Y 1i Y ] 0iK( ) n 1 K( ) i I 1 gdzie K( ) jest funkcją jądrową Wzór na sąsiedztwo jest uzależniony od wyboru funkcji jądra Jeżeli K( ) ma średnią zero i całkuje się do 1 daje to zgodny estymator dla wyniku kontrfaktycznego
34 Lokalna regresja liniowa wykorzystują wariant estymatora wykorzystującego funkcję jądrową nazywany lokalną regresją liniową Można o tym estymatorze myśleć jako o ważonej regresji Y 0j na stałą, w której wagami W (i, j) są wyznaczane przez funkcję jądrową i zależą od odległości między obiektem i a obiektem j. Oszacowanie stałej jest oszacowaniem średniej wartości kontrfaktycznej Lokalna regresja liniowa zawiera stałą oraz czynnik liniowy względem P i Ma lepsze właściwości w przypadku dziur w rozkładzie propensity score oraz, gdy rozkłady propensity score są różne w grupie eksperymentalnej i kontrolnej
35 Przycinanie Wspólny przedział określoności wymaga by funkcja gęstość propensity score w grupie eksperymentalnej i kontrolnej miały wartość większą od zera Mechanizm przycinanie (ang. trimming) zapewnia spełnienie tego warunku Obserwacje z przedziałów dziedziny o mniejszej gęstości niż kwantyl q dystrybuanty rozkładu propensity score nie są uwzględniane
36 Estymator różnic w różnicach Ten estymator jest analogiczny do standardowego estymatora różnic w różnicach dla regresji liniowej W przypadku metody propensity score matching wymagane jest by E(Y 0t Y 0t P, D = 1) = E(Y 0t Y 0t P, D = 0) Dodatkowo warunek wspólnego przedziału określoności musi być spełniony w obu okresach t oraz t ˆα DDM = 1 n 1 i I 1 S p [ (Y1ti Y 0t i ) ] W (i, j)(y 0tj Y 0t j ) j I 1 S p gdzie wartości wagi W (i, j) zależą od wartości estymatora dla danych przekrojowych
37 Nadreprezentacja Przy badaniu wpływu programu dane z reguły nie są prostą próbą losową Uczestnicy eksperymentu są nadmiernie reprezentowani w próbie w porównaniu z osobami, które są potencjalnymi uczestnikami eksperymentu w populacji W takim przypadku ważne jest ważenie zbioru Heckmann i Todd (1995) pokazali, że nawet w przypadku braku wag można wykorzystać łączenie danych ponieważ ilorazy szans w takim przypadku są liniowymi wielokrotnościami prawdziwych wartości Zatem do łączenia można wykorzystać ilorazy szans, czyli PS(X ) 1 PS(X ) W przypadku łączenia 1:1 nie ma znaczenia czy obserwacje są łączone według propensity score czy ilorazów szans
38 Próby Próba LaLonde (1986) Próba Dehejia-Wahba (1999, 2002) Podpróba Deheija-Wahba, bez obserwacji po kwietniu 1976 Próba z CPS Próba z PSID
39 Charakterystyka prób
40 Próba Dehejia-Wahba (1999) Smith i Todd nie byli w stanie odtworzyć prob z badania Dehejia i Wahba pomimo iż uzyskali je od autorów Ustalili, że kryteria doboru były następujące Włączyć wszystkich zakwalifikowanych do programu między styczniem 1976 a kwietniem 1976 Z osób zakwalifikowanych po kwietniu 1976 wybrać tylko takie które miały zerowe zarobki w okresie 13 do 24 miesięcy przed programem Według ST drugi warunek nie jest prawidłowy, dodatkowo zauważają, że zarobki miesiące przed programem nie są zarobkami z 1974 roku
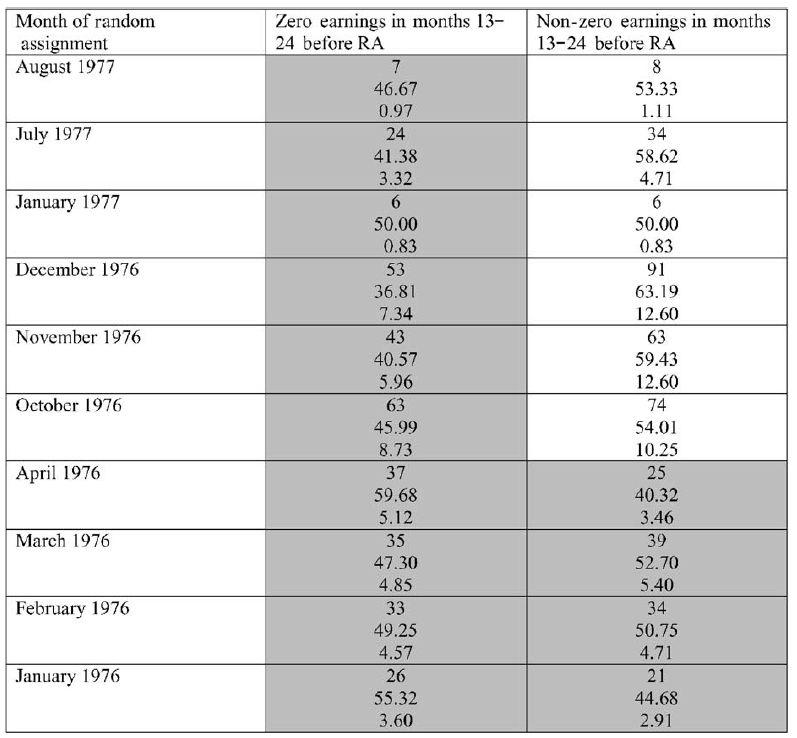
41 Próba Dehejia-Wahba (1999)
42 Podpróba Dehejia-Wahba (1999) Jest to podzbiór zbioru Dehejia i Wahba, z którego usunięto osoby przyjęte do programu po kwietniu 1976 Dzięki temu obserwacje w grupie eksperymentalnej i kontrolnej pochodzą z tego samego okresu, w przeciwieństwie do próby Dehejia i Wahba Oszacowanie wyniku eksperymentu dla tej podpróby wynosi 2748$ i jest znacznie wyższe niż w dwóch pozostałych
43 Specyfikacje propensity score Wykorzystano dwie specyfikacje formy funkcyjnej dla wektora propensity score Pierwsza, wykorzystywana przez Dehejia i Wahba (1999) Druga, zmienne które wykorzystał LaLonde (1986) w równaniu uczestnictwa szacując model z selekcją W obu przypadkach autorzy wykorzystali funkcję logistyczną
44 Oszacowania propensity score Oszacowano trzy pary modeli oddzielnie dla prób CPS oraz PSID W każdym przypadku zmienną zależną była zmienna wskazując przynależność do grupy eksperymentalnej Analogicznie do Dehejia i Wahba autorzy wykorzystali nieznacznie różniące się specyfikacje dla prób CPS oraz PSID Wyniki dla próby Dehejia i Wahba z ich specyfikacją różnią się od oryginalnych z dwóch powodów Dehejia i Wahba nie wykorzystywali obserwacji z grupy kontrolnej eksperymentu Dehejia i Wahba nie uwzględnili stałej w modelu
45 Oszacowania propensity score
46 Oszacowania propensity score Zdecydowana większość oszacowań parametrów jest zgodna z oczekiwaniami Pod względem jakościowym i ilościowym oszacowania różnych wariantów modelu są bardzo podobne Propensity score dobrze sobie radzi jako narzędzie do odseparowania grupy eksperymentalnej od grupy kontrolnej. W pięciu na 6 przypadków poprawnie klasyfikowanych jest ponad 90% obserwacji
47 Oszacowania propensity score Rysunek 1, zbyt duży by umieścić w prezentacji, przedstawia rozkłady logarytmów ilorazów szans dla trzech grup eksperymentalnych połączonych z dwiema grupami kontrolnymi Rozkład propensity score w grupach eksperymentalnych znacznie różni się od rozkładu w grupach kontrolnych Rozkład w grupach kontrolnych jest skupiony na lewo od rozkładu w grupach eksperymentalnych
48 Oszacowania propensity score W przypadku formy funkcyjnej propensity score z badania LaLonde wyniki są podobne Wartości propensity score uzyskane z różnych prób eksperymentalnych są bardzo silnie skorelowane, powyżej 0,9

49 Oszacowania propensity score
50 Dobór zmiennych i testy zbilansowania Z twierdzenia 2 Rosenbauma i Rubina (1983) wynika, że uwzględnienie dodatkowej zmiennej nie powinno nieść informacji o stanie oddziaływania Wykorzystano podejście zaproponowane przez Rosenbauma i Rubina (1985) (test równości standaryzowanych różnic) oraz Dehejia i Wahba (1999) (test równości propensity score w warstwach) Dla danych z artykułu Dehejia i Wahba wykorzystano testy w warstwach Dla zbioru LaLonde dokonano doboru zmiennych na podstawie tego czy zmienna poprawiała prognozy stanu uczestnictwa w programie
51 Oszacowania PSM W celu wyznaczenia obciążenia ST łączą grupę pozostawioną poza programem z grupą kontrolną. Dla niej oszacowanie efektu programu powinno wynosić zero Drugą różnica w porównaniu z Dehejia i Wahba (1999, 2002) jest łączenie względem ilorazów szans Trzecią jest wykorzystanie przycinania do kontrolowania wspólnego przedziału określoności Tabela 5 prezentuje obciążenie estymatorów metody PSM Wykorzystując próbę Dehejia i Wahba i ich specyfikację odtworzono niskie obciążenie oszacowań Specyfikacja DW zastosowana do próby LaLonde czy podpróby DW nie daje tak dobry rezultatów. W przypadku podpróby obciążenie jest jednym z najwyższych w tabeli
52 Oszacowania PSM Wymuszenie wspólnego przedziału określoności dla propensity score ma niewielki wpływ na wartości oszacowań w próbie LaLonde i DW, ale duże znaczenie dla wyników uzyskanych na podstawie podpróby DW Wykorzystanie metody łączenia 1:10 zmniejsza obciążenie w relatywnie małej podpróbie Dehejia i Wahba, ale ma niewielki wpływ na wyniki w bardziej liczebnych próbach Model wykorzystujące zmienne LaLonde zastosowany do danych LaLonde daje słabe wyniki, o wysokim obciążeniu Podsumowując, wyniki uzyskane przez Dehejia i Wahba (1999) są bardzo czułe na zmiany prób i specyfikację propensity score
53 Oszacowania PSM-LLR Wyniki uzyskane metodą lokalnej regresji liniowej są bardzo podobne do uzyskanych metodą łączenia 1:1 (najbliższego sąsiada) Forma funkcyjna zaproponowana przez Dehejię i Wahba prowadzi do uzyskania prawidłowych oszacowań w ich zbiorze i obciążonych w dwóch pozostałych Ponownie, wyniki uzyskane przez Dehejia i Wahba (1999) są bardzo czułe na zmiany prób i specyfikację propensity score
54 Oszacowania PSM-DID Oszacowania PSM-DID prowadzą do uzyskania nieobciążonych wyników w przypadku forma funkcyjnej zaproponowana przez Dehejię i Wahba zastosowanej do zbioru Dehejia i Wahba Obciążenie estymatorów metody PSM-DID jest takiego samego rzędu wielkości jak efekt lub niższe dla wszystkich prób i specyfikacji propensty score Wymuszenie spełnienia założenia o wspólnym przedziale określoności (ang. common support) ma niewielki wpływ na wyniki Ponownie, wyniki uzyskane przez Dehejia i Wahba (1999) są bardzo czułe na zmiany prób i specyfikację propensity score, lecz zmiany są niższe niż w przypadku PSM
55 Oszacowania wykorzystujące regresję Autorzy oszacowali kilka standardowych modeli regresji dla każdego z trzech zbiorów eksperymentalnych w połączeniu z dwiema grupami odniesienia Chcieli sprawdzić jakie własności mają estymatory w tych próbach Po drugie, czy dobre wyniki w próbie Dehejia-Wahba wynikają z własności estymatora PSM czy doboru zmiennych do wektora propensity score Różnica między regresją a łączeniem danych jest taka, że ten ostatni model nie zakłada liniowego związku między zmiennymi
56 Oszacowania wykorzystujące regresję Wyniki prezentuje tabela 7 Porównanie obciążenia estymatorów w próbach pokazuje, że za każdym razem w przypadku regresji i PSM-DID najniższe obciążenie estymatory mają w próbie Dehejia-Wahba Prowadzi to do wniosku, że próba Dehejia-Wahba jest dobrana w taki sposób, że problem selekcji jest łatwiejszy do usunięcia
57 Oszacowania wykorzystujące regresję W przypadku drugiego pytania wyniki nie są jednoznaczne W przypadku grupy kontrolnej z CPS kluczem do uzyskania wyników o niskim obciążeniu jest wybór podpróby i zmiennych do wektora propensity score W przypadku grupy kontrolnej z PSID oszacowania PSM mają dużo niższe obciążenie niż oszacowania z regresji. Zatem to nieliniowość odgrywa rolę
58 Testy specyfikacji Ostatnim elementem sprawdzonym przez Smitha i Todd była strategia wyznaczania specyfikacji modelu przyjęta przez Dehejię i Wahbę Test polegał na zachowaniu specyfikacji propensity score i wykorzystaniu jako zmiennej wynikowej zarobków z 1975 roku, czyli sprzed programu Dla obu grup porównawczych wyniki wykazały, że procedura testowa wykorzystująca zarobki sprzed programu jest efektywna W prawidłowy sposób identyfikuje ona estymatory, których użycie prowadzą do obciążonych oszacowań efektu programu
59 Po pierwsze Estymatory metody PSM nie są bardziej efektywne od tradycyjnych metod ekonometrycznych Wyniki uzyskane przez Deheija i Wahba (1999) wynikają ze specyficznej konstrukcji próby i odpowiedniego doboru zmiennych do wektora propensity score i nie powinny być uogólniane Różne estymatory mają różne założenia i fakt czy są one spełnione w konkretnym zbiorze danych decyduje czy pozwolą na uzyskanie nieobciążonych oszacowań Optymalna strategia szacowania efektów oddziaływania na podstawie danych nieeksperymentalnych zależy od statystycznych własności zbioru danych i mechanizmu selekcji do programu
60 Po drugie Estymatory wykorzystujące PSM-DID mają lepsze właściwości niż standardowe estymatory PSM Pozwalają one na usunięcie wpływu zmiennych których wartości są stałe względem czasu Metody łączenia nie radzą sobie z tym problemem, ponieważ nie jest to ich cel
61 Po trzecie Wybór technik związanych z PSM ma niewielki wpływ na wyniki Zatem wybór między łączeniem 1 do 1 czy opartym o jądro, wybór rozmiaru odcięcia, czy wybór szerokości pasma nie mają wielkiego wpływu na uzyskiwane rezultaty i obciążenie estymatorów Wyjątkiem jest wymuszenie wspólnej części przedziału określoności dla propensity score, które poprawia część oszacowań
Propensity Score Matching
 Zajęcia 5 Plan na dziś 1 Dehejia i Wahba (1999) Dehejia i Wahba (1999) Causal Effects in Nonexperimental Studies: Reevaluating the Evaluation of Training Programs Rajeev H. Dehejia, Sadek Wahba, Journal
Zajęcia 5 Plan na dziś 1 Dehejia i Wahba (1999) Dehejia i Wahba (1999) Causal Effects in Nonexperimental Studies: Reevaluating the Evaluation of Training Programs Rajeev H. Dehejia, Sadek Wahba, Journal
Propensity Score Matching
 Zajęcia 4 Plan na dziś 1 Potencjalne i obserwowane wyniki Regresja dla danych eksperymentalnych 2 Angrist i Pischke, 2009 Potencjalne i obserwowane wyniki Regresja dla danych eksperymentalnych Mostly Harmless
Zajęcia 4 Plan na dziś 1 Potencjalne i obserwowane wyniki Regresja dla danych eksperymentalnych 2 Angrist i Pischke, 2009 Potencjalne i obserwowane wyniki Regresja dla danych eksperymentalnych Mostly Harmless
Propensity score matching (PSM)
") Propensity score matching (PSM) Jerzy Mycielski Uniwersytet Warszawski Maj 2010 Jerzy Mycielski (Uniwersytet Warszawski) Propensity score matching (PSM) Maj 2010 1 / 18 Badania ewaluacyjne Ocena wpływu
Propensity score matching (PSM) Jerzy Mycielski Uniwersytet Warszawski Maj 2010 Jerzy Mycielski (Uniwersytet Warszawski) Propensity score matching (PSM) Maj 2010 1 / 18 Badania ewaluacyjne Ocena wpływu
Propensity Score Matching
 Zajęcia 7 Plan na dziś Deheija (2005) 1 Deheija (2005) Powtórzenie wyników Dehejia i Wahba Oszacowania propensity score Analiza wrażliwości wyników 2 PSM dla danych NSW Testy bilansowania Powtórzenie wyników
Zajęcia 7 Plan na dziś Deheija (2005) 1 Deheija (2005) Powtórzenie wyników Dehejia i Wahba Oszacowania propensity score Analiza wrażliwości wyników 2 PSM dla danych NSW Testy bilansowania Powtórzenie wyników
Propensity Score Matching
 Zajęcia 2 Plan dzisiejszych zajęć 1 Doświadczenia Idealne doświadczenie Nie-idealne doświadczenia 2 Idealne doświadczenie Nie-idealne doświadczenia Plan idealnego doświadczenia (eksperymentu) Plan doświadczenia
Zajęcia 2 Plan dzisiejszych zajęć 1 Doświadczenia Idealne doświadczenie Nie-idealne doświadczenia 2 Idealne doświadczenie Nie-idealne doświadczenia Plan idealnego doświadczenia (eksperymentu) Plan doświadczenia
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
 Wprowadzenie W ostatnich latach metody mikroekonometryczne zdobywają coraz większą popularność i uznanie badaczy. Jest to związane przede wszystkim z rozwojem technik gromadzenia i przetwarzania danych.
Wprowadzenie W ostatnich latach metody mikroekonometryczne zdobywają coraz większą popularność i uznanie badaczy. Jest to związane przede wszystkim z rozwojem technik gromadzenia i przetwarzania danych.
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Natalia Neherbecka. 11 czerwca 2010
 Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 8
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Zastosowanie schematu analizy difference-in-differences w badaniach politycznych. Adam Gendźwiłł Tomasz Żółtak Uniwersytet Warszawski
 Zastosowanie schematu analizy difference-in-differences w badaniach politycznych Adam Gendźwiłł Tomasz Żółtak Uniwersytet Warszawski Potential outcomes framework Indywidualny efekt przyczynowy różnica
Zastosowanie schematu analizy difference-in-differences w badaniach politycznych Adam Gendźwiłł Tomasz Żółtak Uniwersytet Warszawski Potential outcomes framework Indywidualny efekt przyczynowy różnica
Monte Carlo, bootstrap, jacknife
 Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Estymacja parametrów w modelu normalnym
 Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Zad. 4 Należy określić rodzaj testu (jedno czy dwustronny) oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:
 oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:") Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Mikroekonometria 5. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 5 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.medexp3.dta przygotuj model regresji kwantylowej 1. Przygotuj model regresji kwantylowej w którym logarytm wydatków
Mikroekonometria 5 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.medexp3.dta przygotuj model regresji kwantylowej 1. Przygotuj model regresji kwantylowej w którym logarytm wydatków
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej
 Pojęcie losowej próby prostej") 7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Własności statystyczne regresji liniowej. Wykład 4
 Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Definicja danych panelowych Typy danych panelowych Modele dla danych panelowych. Dane panelowe. Część 1. Dane panelowe
 Część 1 to dane, które jednocześnie posiadają cechy danych przekrojowych i szeregów czasowych to dane, które jednocześnie posiadają cechy danych przekrojowych i szeregów czasowych Czyli obserwujemy te
Część 1 to dane, które jednocześnie posiadają cechy danych przekrojowych i szeregów czasowych to dane, które jednocześnie posiadają cechy danych przekrojowych i szeregów czasowych Czyli obserwujemy te
Kolokwium ze statystyki matematycznej
 Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
... i statystyka testowa przyjmuje wartość..., zatem ODRZUCAMY /NIE MA POD- STAW DO ODRZUCENIA HIPOTEZY H 0 (właściwe podkreślić).
.") Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Zadania ze statystyki cz. 8 I rok socjologii. Zadanie 1.
 Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Pobieranie prób i rozkład z próby
 Pobieranie prób i rozkład z próby Marcin Zajenkowski Marcin Zajenkowski () Pobieranie prób i rozkład z próby 1 / 15 Populacja i próba Populacja dowolnie określony zespół przedmiotów, obserwacji, osób itp.
Pobieranie prób i rozkład z próby Marcin Zajenkowski Marcin Zajenkowski () Pobieranie prób i rozkład z próby 1 / 15 Populacja i próba Populacja dowolnie określony zespół przedmiotów, obserwacji, osób itp.
Wykład Centralne twierdzenie graniczne. Statystyka matematyczna: Estymacja parametrów rozkładu
 Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Ekonometria egzamin 01/02/ W trakcie egzaminu wolno używać jedynie długopisu o innym kolorze atramentu niż czerwony oraz kalkulatora.
 imię, nazwisko, nr indeksu: Ekonometria egzamin 01/02/2019 1. Egzamin trwa 90 minut. 2. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu.
imię, nazwisko, nr indeksu: Ekonometria egzamin 01/02/2019 1. Egzamin trwa 90 minut. 2. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu.
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych
 Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Metoda największej wiarogodności
 Wprowadzenie Założenia Logarytm funkcji wiarogodności Metoda Największej Wiarogodności (MNW) jest bardziej uniwersalną niż MNK metodą szacowania wartości nieznanych parametrów Wprowadzenie Założenia Logarytm
Wprowadzenie Założenia Logarytm funkcji wiarogodności Metoda Największej Wiarogodności (MNW) jest bardziej uniwersalną niż MNK metodą szacowania wartości nieznanych parametrów Wprowadzenie Założenia Logarytm
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Prawdopodobieństwo i rozkład normalny cd.
 # # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
# # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
Estymacja przedziałowa - przedziały ufności dla średnich. Wrocław, 5 grudnia 2014
 Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
Stanisław Cichocki. Natalia Nehrebecka. Wykład 9
 Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
WYKŁAD 8 ANALIZA REGRESJI
 WYKŁAD 8 ANALIZA REGRESJI Regresja 1. Metoda najmniejszych kwadratów-regresja prostoliniowa 2. Regresja krzywoliniowa 3. Estymacja liniowej funkcji regresji 4. Testy istotności współczynnika regresji liniowej
WYKŁAD 8 ANALIZA REGRESJI Regresja 1. Metoda najmniejszych kwadratów-regresja prostoliniowa 2. Regresja krzywoliniowa 3. Estymacja liniowej funkcji regresji 4. Testy istotności współczynnika regresji liniowej
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
Stanisław Cichocki Natalia Nehrebecka. Wykład 7
 Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Właściwości testu Jarque-Bera gdy w danych występuje obserwacja nietypowa.
 Właściwości testu Jarque-Bera gdy w danych występuje obserwacja nietypowa. Paweł Strawiński Uniwersytet Warszawski Wydział Nauk Ekonomicznych 16 stycznia 2006 Streszczenie W artykule analizowane są właściwości
Właściwości testu Jarque-Bera gdy w danych występuje obserwacja nietypowa. Paweł Strawiński Uniwersytet Warszawski Wydział Nauk Ekonomicznych 16 stycznia 2006 Streszczenie W artykule analizowane są właściwości
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/
 Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Testowanie hipotez. Marcin Zajenkowski. Marcin Zajenkowski () Testowanie hipotez 1 / 25
 Testowanie hipotez 1 / 25") Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średn
 Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja)
") PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap
 Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1 2 3 1. Wprowadzenie do danych panelowych a) Charakterystyka danych panelowych b) Zalety i ograniczenia 2. Modele ekonometryczne danych panelowych a) Model efektów
Stanisław Cichocki Natalia Nehrebecka 1 2 3 1. Wprowadzenie do danych panelowych a) Charakterystyka danych panelowych b) Zalety i ograniczenia 2. Modele ekonometryczne danych panelowych a) Model efektów
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
w analizie wyników badań eksperymentalnych, w problemach modelowania zjawisk fizycznych, w analizie obserwacji statystycznych.
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Metoda momentów i kwantyli próbkowych. Wrocław, 7 listopada 2014
 Metoda momentów i kwantyli próbkowych Wrocław, 7 listopada 2014 Metoda momentów Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa. Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa.
Metoda momentów i kwantyli próbkowych Wrocław, 7 listopada 2014 Metoda momentów Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa. Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa.
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 11-12
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Zadania ze statystyki cz.8. Zadanie 1.
 Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
Testowanie hipotez. Hipoteza prosta zawiera jeden element, np. H 0 : θ = 2, hipoteza złożona zawiera więcej niż jeden element, np. H 0 : θ > 4.
 Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Statystyka matematyczna dla leśników
 Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Modele quasi-eksperymentalne: Różnica w różnicy oraz inne metody
 Warsztaty szkoleniowe z zakresu oceny oddziaływania instrumentów aktywnej polityki rynku pracy Modele quasi-eksperymentalne: Różnica w różnicy oraz inne metody Celine Ferre, Gdańsk, 22 lutego 2017 r. Metody
Warsztaty szkoleniowe z zakresu oceny oddziaływania instrumentów aktywnej polityki rynku pracy Modele quasi-eksperymentalne: Różnica w różnicy oraz inne metody Celine Ferre, Gdańsk, 22 lutego 2017 r. Metody
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
STATYSTYKA MATEMATYCZNA WYKŁAD stycznia 2010
 STATYSTYKA MATEMATYCZNA WYKŁAD 14 18 stycznia 2010 Model statystyczny ROZKŁAD DWUMIANOWY ( ) {0, 1,, n}, {P θ, θ (0, 1)}, n ustalone P θ {K = k} = ( ) n θ k (1 θ) n k, k k = 0, 1,, n Geneza: Rozkład Bernoulliego
STATYSTYKA MATEMATYCZNA WYKŁAD 14 18 stycznia 2010 Model statystyczny ROZKŁAD DWUMIANOWY ( ) {0, 1,, n}, {P θ, θ (0, 1)}, n ustalone P θ {K = k} = ( ) n θ k (1 θ) n k, k k = 0, 1,, n Geneza: Rozkład Bernoulliego
STATYSTYKA MATEMATYCZNA WYKŁAD 4. Testowanie hipotez Estymacja parametrów
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
Ekonometria egzamin 02/02/ W trakcie egzaminu wolno używać jedynie długopisu o innym kolorze atramentu niż czerwony oraz kalkulatora.
 imię, nazwisko, nr indeksu: Ekonometria egzamin 0/0/0. Egzamin trwa 90 minut.. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu. Złamanie
imię, nazwisko, nr indeksu: Ekonometria egzamin 0/0/0. Egzamin trwa 90 minut.. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu. Złamanie
Stanisław Cichocki. Natalia Nehrebecka. Wykład 13
 Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Autokorelacja Konsekwencje Testowanie autokorelacji 2. Metody radzenia sobie z heteroskedastycznością i autokorelacją Uogólniona Metoda Najmniejszych
Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Autokorelacja Konsekwencje Testowanie autokorelacji 2. Metody radzenia sobie z heteroskedastycznością i autokorelacją Uogólniona Metoda Najmniejszych
K wartość kapitału zaangażowanego w proces produkcji, w tys. jp.
 Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
STATYSTYKA MATEMATYCZNA WYKŁAD 4. WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X.
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
Wykład 9 Testy rangowe w problemie dwóch prób
 Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Komputerowa Analiza Danych Doświadczalnych
 Komputerowa Analiza Danych Doświadczalnych Prowadząca: dr inż. Hanna Zbroszczyk e-mail: gos@if.pw.edu.pl tel: +48 22 234 58 51 konsultacje: poniedziałek, 10-11, środa: 11-12 www: http://www.if.pw.edu.pl/~gos/students/kadd
Komputerowa Analiza Danych Doświadczalnych Prowadząca: dr inż. Hanna Zbroszczyk e-mail: gos@if.pw.edu.pl tel: +48 22 234 58 51 konsultacje: poniedziałek, 10-11, środa: 11-12 www: http://www.if.pw.edu.pl/~gos/students/kadd
Oszacowanie i rozkład t
 Oszacowanie i rozkład t Marcin Zajenkowski Marcin Zajenkowski () Oszacowanie i rozkład t 1 / 31 Oszacowanie 1 Na podstawie danych z próby szacuje się wiele wartości w populacji, np.: jakie jest poparcie
Oszacowanie i rozkład t Marcin Zajenkowski Marcin Zajenkowski () Oszacowanie i rozkład t 1 / 31 Oszacowanie 1 Na podstawie danych z próby szacuje się wiele wartości w populacji, np.: jakie jest poparcie
Stanisław Cichocki. Natalia Neherbecka. Zajęcia 13
 Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Stosowana Analiza Regresji
 prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
Wnioskowanie statystyczne. Statystyka w 5
 Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Uogólniona Metoda Momentów
 Uogólniona Metoda Momentów Momenty z próby daż a do momentów teoretycznych (Prawo Wielkich Liczb) plim 1 n y i = E (y) n i=1 Klasyczna Metoda Momentów (M M) polega na szacowaniu momentów teoretycznych
Uogólniona Metoda Momentów Momenty z próby daż a do momentów teoretycznych (Prawo Wielkich Liczb) plim 1 n y i = E (y) n i=1 Klasyczna Metoda Momentów (M M) polega na szacowaniu momentów teoretycznych
166 Wstęp do statystyki matematycznej
 166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów 5. Testowanie
Stanisław Cichocki Natalia Nehrebecka 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów 5. Testowanie
Mikroekonometria 6. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 6 Mikołaj Czajkowski Wiktor Budziński Metody symulacyjne Monte Carlo Metoda Monte-Carlo Wykorzystanie mocy obliczeniowej komputerów, aby poznać charakterystyki zmiennych losowych poprzez
Mikroekonometria 6 Mikołaj Czajkowski Wiktor Budziński Metody symulacyjne Monte Carlo Metoda Monte-Carlo Wykorzystanie mocy obliczeniowej komputerów, aby poznać charakterystyki zmiennych losowych poprzez
Ważne rozkłady i twierdzenia c.d.
 Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Ekonometria egzamin 07/03/2018
 imię, nazwisko, nr indeksu: Ekonometria egzamin 07/03/2018 1. Egzamin trwa 90 minut. 2. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu.
imię, nazwisko, nr indeksu: Ekonometria egzamin 07/03/2018 1. Egzamin trwa 90 minut. 2. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu.
Próbkowanie. Wykład 4 Próbkowanie i rozkłady próbkowe. Populacja a próba. Błędy w póbkowaniu, cd, Przykład 1 (Ochotnicy)
") Wykład 4 Próbkowanie i rozkłady próbkowe µ = średnia w populacji, µ=ey, wartość oczekiwana zmiennej Y σ= odchylenie standardowe w populacji, σ =(Var Y) 1/2, pierwiastek kwadratowy wariancji zmiennej Y,
Wykład 4 Próbkowanie i rozkłady próbkowe µ = średnia w populacji, µ=ey, wartość oczekiwana zmiennej Y σ= odchylenie standardowe w populacji, σ =(Var Y) 1/2, pierwiastek kwadratowy wariancji zmiennej Y,
Modele DSGE. Jerzy Mycielski. Maj Jerzy Mycielski () Modele DSGE Maj / 11
 Modele DSGE Maj / 11") Modele DSGE Jerzy Mycielski Maj 2008 Jerzy Mycielski () Modele DSGE Maj 2008 1 / 11 Modele DSGE DSGE - Dynamiczne, stochastyczne modele równowagi ogólnej (Dynamic Stochastic General Equilibrium Model)
Modele DSGE Jerzy Mycielski Maj 2008 Jerzy Mycielski () Modele DSGE Maj 2008 1 / 11 Modele DSGE DSGE - Dynamiczne, stochastyczne modele równowagi ogólnej (Dynamic Stochastic General Equilibrium Model)
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski
 Kamil Krzysztof Derkowski") Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Współczynnik korelacji. Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ
 Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Estymacja punktowa i przedziałowa
 Temat: Estymacja punktowa i przedziałowa Kody znaków: żółte wyróżnienie nowe pojęcie czerwony uwaga kursywa komentarz 1 Zagadnienia 1. Statystyczny opis próby. Idea estymacji punktowej pojęcie estymatora
Temat: Estymacja punktowa i przedziałowa Kody znaków: żółte wyróżnienie nowe pojęcie czerwony uwaga kursywa komentarz 1 Zagadnienia 1. Statystyczny opis próby. Idea estymacji punktowej pojęcie estymatora
Zadania ze statystyki, cz.6
 Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
Wykład 9 Wnioskowanie o średnich
 Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Dokładne i graniczne rozkłady statystyk z próby
 Dokładne i graniczne rozkłady statystyk z próby Przypomnijmy Populacja Próba Wielkość N n Średnia Wariancja Odchylenie standardowe 4.2 Rozkład statystyki Mówimy, że rozkład statystyki (1) jest dokładny,
Dokładne i graniczne rozkłady statystyk z próby Przypomnijmy Populacja Próba Wielkość N n Średnia Wariancja Odchylenie standardowe 4.2 Rozkład statystyki Mówimy, że rozkład statystyki (1) jest dokładny,
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Wprowadzenie do teorii ekonometrii. Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe
 Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Czasowy wymiar danych
 Problem autokorelacji Model regresji dla szeregów czasowych Model regresji dla szeregów czasowych y t = X t β + ε t Zasadnicze różnice 1 Budowa prognoz 2 Problem stabilności parametrów 3 Problem autokorelacji
Problem autokorelacji Model regresji dla szeregów czasowych Model regresji dla szeregów czasowych y t = X t β + ε t Zasadnicze różnice 1 Budowa prognoz 2 Problem stabilności parametrów 3 Problem autokorelacji
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA
 ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności
Metoda Monte Carlo. Jerzy Mycielski. grudzien Jerzy Mycielski () Metoda Monte Carlo grudzien / 10
 Metoda Monte Carlo grudzien / 10") Metoda Monte Carlo Jerzy Mycielski grudzien 2012 Jerzy Mycielski () Metoda Monte Carlo grudzien 2012 1 / 10 Przybliżanie całek Powiedzmy, że mamy do policzenia następującą całkę: b f (x) dx = I a Założmy,
Metoda Monte Carlo Jerzy Mycielski grudzien 2012 Jerzy Mycielski () Metoda Monte Carlo grudzien 2012 1 / 10 Przybliżanie całek Powiedzmy, że mamy do policzenia następującą całkę: b f (x) dx = I a Założmy,
IV WYKŁAD STATYSTYKA. 26/03/2014 B8 sala 0.10B Godz. 15:15
 IV WYKŁAD STATYSTYKA 26/03/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 4 Populacja generalna, próba, losowanie próby, estymatory Statystyka (populacja generalna, populacja próbna, próbka mała, próbka duża, reprezentatywność,
IV WYKŁAD STATYSTYKA 26/03/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 4 Populacja generalna, próba, losowanie próby, estymatory Statystyka (populacja generalna, populacja próbna, próbka mała, próbka duża, reprezentatywność,