Architektury systemów równoległych
|
|
|
- Klaudia Walczak
- 7 lat temu
- Przeglądów:
Transkrypt
1 Architektury systemów równoległych 1
2 Architektury systemów z pamięcią wspólną Architektury procesorów Procesory wielordzeniowe Procesory graficzne Akceleratory Procesory hybrydowe Architektury systemów z pamięcią wspólną UMA SMP NUMA DSM cache coherence 2
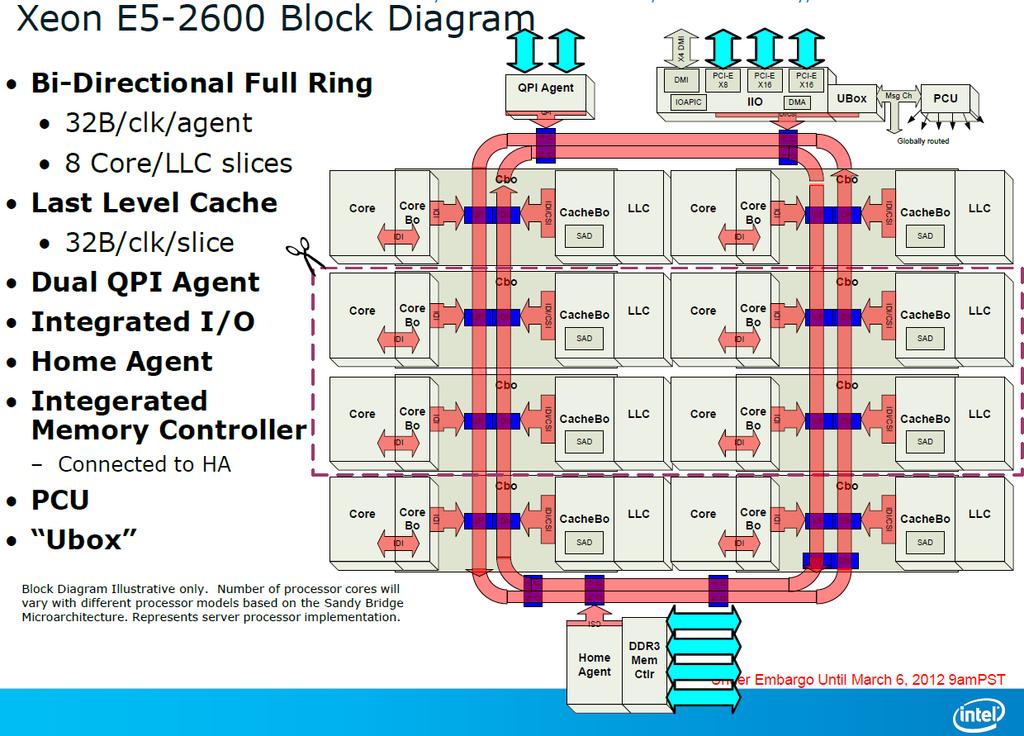
3 3
4 Architektura procesora G80 4


5 Akceleratory 48 rdzeniowy procesor ogólnego przeznaczenia firmy Intel Single chip Cloud Computer SCC procesor hybrydowy IBM PowerXCell 5


6 SMP, UMA, NUMA, etc. UMA SMP NUMA DSM 6
7 Sieci połączeń w systemach równoległych Rodzaje sieci połączeń: podział ze względu na łączone elementy: połączenia procesory pamięć (moduły pamięci) połączenia międzyprocesorowe (międzywęzłowe) podział ze względu na charakterystyki łączenia: sieci statyczne zbiór połączeń dwupunktowych sieci dynamiczne przełączniki o wielu dostępach 7

8 Sieci połączeń Sieci (połączenia) dynamiczne magistrala (bus) krata przełączników (crossbar switch przełącznica krzyżowa) sieć wielostopniowa (multistage network) Sieć wielostopniowa p wejść i p wyjść, stopnie pośrednie (ile?) każdy stopień pośredni złożony z p/2 przełączników 2x2 poszczególne stopnie połączone w sposób realizujący idealne przetasowanie (perfect shuffle) (j=2i lub j=2i+1 p) przy dwójkowym zapisie pozycji wejść i wyjść idealne przetasowanie odpowiada rotacji bitów, przełączniki umożliwiają zmianę wartości ostatniego bitu 8
9 Sieci połączeń Porównanie sieci dynamicznych: wydajność szerokość pasma transferu (przepustowość) możliwość blokowania połączeń koszt liczba przełączników skalowalność zależność wydajności i kosztu od liczby procesorów 9
10 Sieci połączeń Sieci statyczne Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D Kraty z zawinięciem, torusy Drzewa: zwykłe lub tłuste Hiperkostki: 1D, 2D, 3D itd.. Wymiar d, liczba procesorów 2^d Bitowy zapis położenia węzła Najkrótsza droga między 2 procesorami = ilość bitów, którymi różnią się kody położenia procesorów 10

11 Topologia torusa 11

12 Topologie hiperkostki i drzewa 12

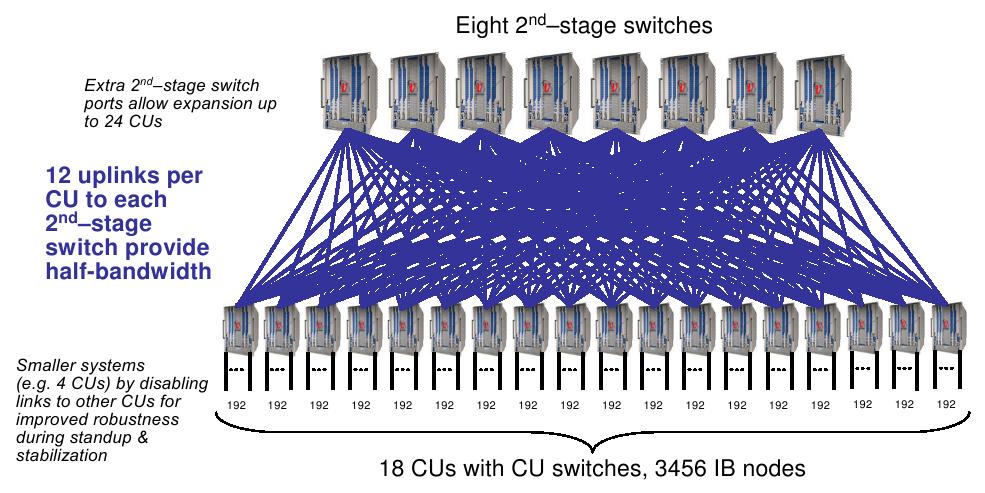
13 Sieci połączeń 13
14 Wątki pthreads Specyfikacja POSIX (IEEE , 1995, 2001) Operacje na wątkach: określanie atrybutów ( odłączalność, adres i rozmiar stosu, itp.) tworzenie i uruchamianie (pthread_create) porównywanie identyfikatorów (pthread_equal, pthread_self) zabijanie i przesyłanie sygnałów (pthread_cancel, pthread_kill) odłączanie (pthread_detach) oczekiwanie na zakończenie (pthread_join) int pthread_create(pthread_t *thread, pthread_attr_t *attr, void * (*start_routine)(void *), void * arg) int pthread_join(pthread_t th, void **thread_return) 14
15 Komunikacja między wątkami Komunikacja między wątkami odbywa się głównie za pomocą pamięci wspólnej W celu realizacji modelu SPMD można do wielu wątków wykonujących ten sam kod przesłać różne dane jako argumenty pierwotnie wywoływanej procedury częstym przypadkiem jest przesłanie identyfikatora wątku każdy wątek posiada indywidualny identyfikator i na jego podstawie może: zlokalizować dane, na których dokonuje przetwarzania dane[ f(my_id) ] wybrać ścieżkę wykonania programu if(my_id ==...){...} określić iteracje pętli, które ma wykonać for( i=f1(my_id); i< f2(my_id); i += f3(my_id) ){... } 15
16 Wzajemne wykluczanie wątków Specyfikacja POSIX: muteks mutual exclusion tworzenie muteksa int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutex attr_t *mutexattr) zamykanie muteksa int pthread_mutex_lock(pthread_mutex_t *mutex) próba zamknięcia muteksa (jeśli muteks wolny działa jak pthread_mutex_lock, jeśli zajęty procedura wraca natychmiastowo, zwraca 0 jeśli muteks typu reentrant został zamknięty przez ten sam wątek, zwraca EBUSY w pozostałych przypadkach) int pthread_mutex_trylock(pthread_mutex_t *mutex) otwieranie muteksa int pthread_mutex_unlock(pthread_mutex_t *mutex) odpowiedzialność za poprawne użycie muteksów (gwarantujące bezpieczeństwo i żywotność) spoczywa na programiście 16
17 Zmienne warunku Pthreads Zmienne warunku condition variables: zmienne warunku są zmiennymi wspólnymi dla wątków, które służą do identyfikacji grupy uśpionych wątków tworzenie zmiennej warunku: int pthread_cond_init( pthread_cond_t *cond, pthread_condattr_t *cond_attr) uśpienie wątku w miejscu identyfikowanym przez zmienną warunku cond, wątek śpi (czeka) do momentu, gdy jakiś inny wątek wyśle odpowiedni sygnał budzenia dla zmiennej cond int pthread_cond_wait( pthread_cond_t *cond, pthread_mutex_t *mutex) sygnalizowanie (budzenie pierwszego w kolejności wątku oczekującego na zmiennej *cond) int pthread_cond_signal( pthread_cond_t *cond) rozgłaszanie sygnału (budzenie wszystkich wątków oczekujących na zmiennej *cond) int pthread_cond_broadcast( pthread_cond_t *cond) 17
18 OpenMP składnia dyrektyw format ( dla powiązania z językami C i C++ ): #pragma omp nazwa_dyrektywy lista_klauzul znak_nowej_linii najważniejszymi z dyrektyw są dyrektywy podziału pracu (work sharing constructs), występujące w obszarze równoległym i stosowane do rozdzielenia poleceń realizowanych przez poszczególne procesory najważniejsze klauzule określają sposób traktowania zmiennych przez wątki w obszarze równoległym każda dyrektywa posiada swój własny zestaw dopuszczalnych klauzul 18
19 OpenMP składnia dyrektyw parallel #pragma omp parallel lista_klauzul { /* obszar równoległy */ } lista_klauzul (pusta lub dowolna kombinacja poniższych): if( warunek ) num_threads ( liczba ) klauzule_zmiennych ( private, firstprivate, shared, reduction ) za chwilę inne 19
20 OpenMP traktowanie zmiennych zmienna jest wspólna (dostępna wszystkim wątkom) jeśli: istnieje przed wejściem do obszaru równoległego i nie występuje w dyrektywach i klauzulach czyniących ją prywatną została zdefiniowana wewnątrz obszaru równoległego jako zmienna statyczna zmienna jest prywatna (lokalna dla wątku) jeśli została zadeklarowana dyrektywą threadprivate została umieszczona w klauzuli private lub podobnej (firstprivate, lastprivate, reduction ) została zdefiniowana wewnątrz obszaru równoległego jako zmienna automatyczna jest zmienną sterującą równoległej pętli for 20
21 OpenMP dyrektywy podziału pracy for #pragma omp for lista_klauzul for(...){...} // pętla w postaci kanonicznej lista_klauzul: klauzule_zmiennych ( private, firstprivate, lastprivate ) schedule( rodzaj, rozmiar_porcji ) ; rodzaje: static, dynamic, guided, runtime inne: reduction, nowait obszar równoległy składający się z pojedynczej równoległej pętli for: #pragma omp parallel for lista_klauzul znak_nowej_linii for(...) {...} 21
22 OpenMP równoległość zadań task #pragma omp task lista_klauzul znak_nowej_linii {... } generowanie zadań do wykonania przez wątki, realizacja odbywa się w sposób asynchroniczny zadanie może zostać wykonane od razu, może też zostać zrealizowane w późniejszym czasie przez dowolny wątek z danego obszaru równoległego lista_klauzul: klauzule_zmiennych ( default, private, firstprivate, shared ) if jeśli warunek nie jest spełniony, zadanie nie jest zlecane do wykonania asynchronicznego, jest realizowane od razu untied w przypadku wstrzymania wykonywania może być kontynuowana przez inny wątek niż dotychczasowy final jeśli warunek prawdziwy kolejne napotkane zadania są wykonywane od razu mergeable dla zadań zagnieżdżonych, 22
23 Środowisko przesyłania komunikatów MPI Podstawowe pojęcia: komunikator (predefiniowany komunikator MPI_COMM_WORLD) ranga procesu Podstawowe procedury: int MPI_Init( int *pargc, char ***pargv) int MPI_Comm_size(MPI_Comm comm, int *psize) int MPI_Comm_rank(MPI_Comm comm, int *prank) ( 0 <= *prank < *psize ) int MPI_Finalize(void) 23
24 Środowisko przesyłania komunikatów MPI Procedury dwupunktowego przesyłania komunikatów: Przesyłanie blokujące procedura nie przekazuje sterowania dalej dopóki operacje komunikacji nie zostaną ukończone i nie będzie można bezpiecznie korzystać z buforów (zmiennych) będących argumentami operacji int MPI_Send(void* buf, int count, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm) int MPI_Recv(void *buf, int count, MPI_Datatype dtype, int src, int tag, MPI_Comm comm, MPI_Status *stat) Wykorzystanie zmiennej *stat do uzyskania parametrów odebranego komunikatu (m.in. MPI_Get_count) 24
25 Środowisko przesyłania komunikatów MPI #include mpi.h int main( int argc, char** argv ){ int rank, ranksent, size, source, dest, tag, i; MPI_Status status; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); if( rank!= 0 ){ dest=0; tag=0; MPI_Send( &rank, 1, MPI_INT, dest, tag, MPI_COMM_WORLD ); } else { for( i=1; i<size; i++ ) { MPI_Recv( &ranksent, 1, MPI_INT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status ); printf( Dane od procesu o randze: %d (%d)\n, ranksent, status.mpi_source );} } MPI_Finalize(); return(0); } 25
26 Procedury komunikacji grupowej MPI bariera int MPI_Barrier( MPI_Comm comm ) rozgłaszanie jeden do wszystkich int MPI_Bcast( void *buff, int count, MPI_Datatype datatype, int root, MPI_Comm comm ) zbieranie wszyscy do jednego int MPI_Gather(void *sbuf, int scount, MPI_Datatype sdtype, void *rbuf, int rcount, MPI_Datatype rdtype, int root, MPI_Comm comm) zbieranie wszyscy do wszystkich równoważne rozgłaszaniu wszyscy do wszystkich (brak wyróżnionego procesu root) int MPI_Allgather( void *sbuf, int scount, MPI_Datatype sdtype, void *rbuf, int rcount, MPI_Datatype rdtype, MPI_Comm comm ) 26
27 Procedury komunikacji grupowej MPI rozpraszanie jeden do wszystkich int MPI_Scatter(void *sbuf, int scount, MPI_Datatype sdtype, void *rbuf, int rcount, MPI_Datatype rdtype, int root, MPI_Comm comm) rozpraszanie wszyscy do wszystkich równoważne wymianie wszyscy do wszystkich (brak wyróżnionego procesu root) int MPI_Alltoall( void *sbuf, int scount, MPI_Datatype sdtype, void *rbuf, int rcount, MPI_Datatype rdtype, MPI_Comm comm ) redukcja wszyscy do jednego int MPI_Reduce(void *sbuf, void *rbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm) redukcja połączona z rozgłaszaniem MPI_Allreduce 27
28 Procedury komunikacji grupowej MPI Operacje stosowane przy realizacji redukcji: predefiniowane operacje uchwyty do obiektów typu MPI_Op (każda z operacji ma swoje dozwolone typy argumentów): MPI_MAX maksimum MPI_MIN minimum MPI_SUM suma MPI_PROD iloczyn operacje maksimum i minimum ze zwróceniem indeksów operacje logiczne i bitowe operacje definiowane przez użytkownika za pomocą procedury: int MPI_Op_create(MPI_User_function *func, int commute, MPI_Op *pop); 28
Operacje grupowego przesyłania komunikatów
 Operacje grupowego przesyłania komunikatów 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany jest pomiędzy więcej niż dwoma procesami
Operacje grupowego przesyłania komunikatów 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany jest pomiędzy więcej niż dwoma procesami
Operacje grupowego przesyłania komunikatów. Krzysztof Banaś Obliczenia równoległe 1
 Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
Message Passing Interface
 Message Passing Interface Interfejs programowania definiujący powiązania z językami C, C++, Fortran Standaryzacja (de facto) i rozszerzenie wcześniejszych rozwiązań dla programowania z przesyłaniem komunikatów
Message Passing Interface Interfejs programowania definiujący powiązania z językami C, C++, Fortran Standaryzacja (de facto) i rozszerzenie wcześniejszych rozwiązań dla programowania z przesyłaniem komunikatów
Programowanie w modelu przesyłania komunikatów specyfikacja MPI. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Model przesyłania komunikatów Paradygmat send receive wysyłanie komunikatu: send( cel, identyfikator_komunikatu,
Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Model przesyłania komunikatów Paradygmat send receive wysyłanie komunikatu: send( cel, identyfikator_komunikatu,
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Programowanie systemów z pamięcią wspólną specyfikacja OpenMP. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie systemów z pamięcią wspólną specyfikacja OpenMP Krzysztof Banaś Obliczenia równoległe 1 OpenMP Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
Programowanie systemów z pamięcią wspólną specyfikacja OpenMP Krzysztof Banaś Obliczenia równoległe 1 OpenMP Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
Programowanie Równoległe Wykład 5. MPI - Message Passing Interface. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład 5 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Dorobiliśmy się strony WWW www.ift.uni.wroc.pl/~koma/pr/index.html MPI, wykład 2. Plan: - komunikacja
Programowanie Równoległe Wykład 5 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Dorobiliśmy się strony WWW www.ift.uni.wroc.pl/~koma/pr/index.html MPI, wykład 2. Plan: - komunikacja
Programowanie Równoległe Wykład 4. MPI - Message Passing Interface. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład 4 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Jak używać w MPI? Donald Knuth: We should forget about small efficiencies, say about 97% of
Programowanie Równoległe Wykład 4 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Jak używać w MPI? Donald Knuth: We should forget about small efficiencies, say about 97% of
Programowanie równoległe i rozproszone. Monitory i zmienne warunku. Krzysztof Banaś Programowanie równoległe i rozproszone 1
 Programowanie równoległe i rozproszone Monitory i zmienne warunku Krzysztof Banaś Programowanie równoległe i rozproszone 1 Problemy współbieżności Problem producentów i konsumentów: jedna grupa procesów
Programowanie równoległe i rozproszone Monitory i zmienne warunku Krzysztof Banaś Programowanie równoległe i rozproszone 1 Problemy współbieżności Problem producentów i konsumentów: jedna grupa procesów
Programowanie równoległe i rozproszone. W1. Wielowątkowość. Krzysztof Banaś Programowanie równoległe i rozproszone 1
 Programowanie równoległe i rozproszone W1. Wielowątkowość Krzysztof Banaś Programowanie równoległe i rozproszone 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np.
Programowanie równoległe i rozproszone W1. Wielowątkowość Krzysztof Banaś Programowanie równoległe i rozproszone 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np.
Programowanie współbieżne... (4) Andrzej Baran 2010/11
 Andrzej Baran 2010/11") Programowanie współbieżne... (4) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Przykład Zaczniemy od znanego już przykładu: Iloczyn skalarny różne modele Programowanie współbieżne...
Programowanie współbieżne... (4) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Przykład Zaczniemy od znanego już przykładu: Iloczyn skalarny różne modele Programowanie współbieżne...
Elementy składowe: Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
 dla różnych języków programowania") OpenMP Elementy składowe: o o o dyrektywy dla kompilatorów funkcje biblioteczne zmienne środowiskowe Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
OpenMP Elementy składowe: o o o dyrektywy dla kompilatorów funkcje biblioteczne zmienne środowiskowe Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 Środowisko przesyłania komunikatów MPI Rodzaje procedur: blokujące nieblokujące Tryby przesyłania
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 Środowisko przesyłania komunikatów MPI Rodzaje procedur: blokujące nieblokujące Tryby przesyłania
Temat zajęć: Tworzenie i obsługa wątków.
 Temat zajęć: Tworzenie i obsługa wątków. Czas realizacji zajęć: 180 min. Zakres materiału, jaki zostanie zrealizowany podczas zajęć: Tworzenie wątków, przekazywanie parametrów do funkcji wątków i pobieranie
Temat zajęć: Tworzenie i obsługa wątków. Czas realizacji zajęć: 180 min. Zakres materiału, jaki zostanie zrealizowany podczas zajęć: Tworzenie wątków, przekazywanie parametrów do funkcji wątków i pobieranie
w odróżnieniu od procesów współdzielą przestrzeń adresową mogą komunikować się za pomocą zmiennych globalnych
 mechanizmy posix Wątki w odróżnieniu od procesów współdzielą przestrzeń adresową należą do tego samego użytkownika są tańsze od procesów: wystarczy pamiętać tylko wartości rejestrów, nie trzeba czyścić
mechanizmy posix Wątki w odróżnieniu od procesów współdzielą przestrzeń adresową należą do tego samego użytkownika są tańsze od procesów: wystarczy pamiętać tylko wartości rejestrów, nie trzeba czyścić
Problemy współbieżności
 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe) realizowana programowo (bariera, sekcja krytyczna, operacje atomowe) wzajemne wykluczanie
Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe) realizowana programowo (bariera, sekcja krytyczna, operacje atomowe) wzajemne wykluczanie
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 2 Jan Kazimirski 1 MPI 1/2 2 Dlaczego klastry komputerowe? Wzrost mocy obliczeniowej jednego jest coraz trudniejszy do uzyskania. Koszt dodatkowej mocy obliczeniowej
Programowanie współbieżne i rozproszone WYKŁAD 2 Jan Kazimirski 1 MPI 1/2 2 Dlaczego klastry komputerowe? Wzrost mocy obliczeniowej jednego jest coraz trudniejszy do uzyskania. Koszt dodatkowej mocy obliczeniowej
Przetwarzanie wielowątkowe przetwarzanie współbieżne. Krzysztof Banaś Obliczenia równoległe 1
 Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 MPI dynamiczne zarządzanie procesami MPI 2 umożliwia dynamiczne zarządzanie procesami, choć
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 MPI dynamiczne zarządzanie procesami MPI 2 umożliwia dynamiczne zarządzanie procesami, choć
Modele programowania równoległego. Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak dla PR PP
 Modele programowania równoległego Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak dla PR PP MPP - Cechy charakterystyczne 1 Prywatna, wyłączna przestrzeń adresowa.
Modele programowania równoległego Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak dla PR PP MPP - Cechy charakterystyczne 1 Prywatna, wyłączna przestrzeń adresowa.
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Modele programowania równoległego. Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak
 Modele programowania równoległego Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak MPP - Cechy charakterystyczne 1 Prywatna - wyłączna przestrzeń adresowa. Równoległość
Modele programowania równoległego Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak MPP - Cechy charakterystyczne 1 Prywatna - wyłączna przestrzeń adresowa. Równoległość
Tryby komunikacji między procesami w standardzie Message Passing Interface. Piotr Stasiak Krzysztof Materla
 Tryby komunikacji między procesami w standardzie Message Passing Interface Piotr Stasiak 171011 Krzysztof Materla 171065 Wstęp MPI to standard przesyłania wiadomości (komunikatów) pomiędzy procesami programów
Tryby komunikacji między procesami w standardzie Message Passing Interface Piotr Stasiak 171011 Krzysztof Materla 171065 Wstęp MPI to standard przesyłania wiadomości (komunikatów) pomiędzy procesami programów
Wydajność komunikacji grupowej w obliczeniach równoległych. Krzysztof Banaś Obliczenia wysokiej wydajności 1
 Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
Wprowadzenie do OpenMP
 Wprowadzenie do OpenMP OZUKO Kamil Dworak OZUKO Wprowadzenie do OpenMP Kamil Dworak 1 / 25 OpenMP (ang. Open Multi-Processing) opracowany w 1997 przez radę Architecture Review Board, obliczenia rówoległe
Wprowadzenie do OpenMP OZUKO Kamil Dworak OZUKO Wprowadzenie do OpenMP Kamil Dworak 1 / 25 OpenMP (ang. Open Multi-Processing) opracowany w 1997 przez radę Architecture Review Board, obliczenia rówoległe
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Plan wykładu. Obliczenia równoległe w zagadnieniach inżynierskich. Wykład 1 p. Wzajemne wykluczanie. Procesy współbieżne
 Plan wykładu Obliczenia równoległe w zagadnieniach inżynierskich Wykład 1 Podstawowe pojęcia i model programowania Sposoby realizacji watków w systemach operacyjnych Tworzenie watów i zarzadzanie nimi
Plan wykładu Obliczenia równoległe w zagadnieniach inżynierskich Wykład 1 Podstawowe pojęcia i model programowania Sposoby realizacji watków w systemach operacyjnych Tworzenie watów i zarzadzanie nimi
Modele programowania równoległego. Pamięć współdzielona Rafał Walkowiak dla III roku Informatyki PP
 Modele programowania równoległego Pamięć współdzielona Rafał Walkowiak dla III roku Informatyki PP Procesy a wątki [1] Model 1: oparty o procesy - Jednostka tworzona przez system operacyjny realizująca
Modele programowania równoległego Pamięć współdzielona Rafał Walkowiak dla III roku Informatyki PP Procesy a wątki [1] Model 1: oparty o procesy - Jednostka tworzona przez system operacyjny realizująca
Operacje kolektywne MPI
 Operacje kolektywne MPI 1 Operacje kolektywne Do tej pory w operacje przesyłania komunikatu miały charakter punkt-punkt (najczęściej pomiędzy nadawcą i odbiorcą). W operacjach grupowych udział biorą wszystkie
Operacje kolektywne MPI 1 Operacje kolektywne Do tej pory w operacje przesyłania komunikatu miały charakter punkt-punkt (najczęściej pomiędzy nadawcą i odbiorcą). W operacjach grupowych udział biorą wszystkie
Open MP wer Rafał Walkowiak Instytut Informatyki Politechniki Poznańskiej Wiosna
 Open MP wer. 2.5 Rafał Walkowiak Instytut Informatyki Politechniki Poznańskiej Wiosna 2019.0 OpenMP standard specyfikacji przetwarzania współbieżnego uniwersalny i przenośny model równoległości (typu rozgałęzienie
Open MP wer. 2.5 Rafał Walkowiak Instytut Informatyki Politechniki Poznańskiej Wiosna 2019.0 OpenMP standard specyfikacji przetwarzania współbieżnego uniwersalny i przenośny model równoległości (typu rozgałęzienie
Rozszerzenia MPI-2 1
 Rozszerzenia MPI-2 1 2 Dynamiczne tworzenie procesów Aplikacja MPI 1 jest statyczna z natury Liczba procesów określana jest przy starcie aplikacji i się nie zmienia. Gwarantuje to szybką komunikację procesów.
Rozszerzenia MPI-2 1 2 Dynamiczne tworzenie procesów Aplikacja MPI 1 jest statyczna z natury Liczba procesów określana jest przy starcie aplikacji i się nie zmienia. Gwarantuje to szybką komunikację procesów.
http://www.mcs.anl.gov/research/projects/mpi/standard.html
 z przedmiotu, prowadzonych na Wydziale BMiI, Akademii Techniczno-Humanistycznej w Bielsku-Białej. MPI czyli Message Passing Interface stanowi specyfikację pewnego standardu wysokopoziomowego protokołu
z przedmiotu, prowadzonych na Wydziale BMiI, Akademii Techniczno-Humanistycznej w Bielsku-Białej. MPI czyli Message Passing Interface stanowi specyfikację pewnego standardu wysokopoziomowego protokołu
Programowanie w standardzie MPI
 Programowanie w standardzie MPI 1 2 Podstawy programowania z przesyłaniem komunikatów Model systemu równoległego w postaci p procesów, każdy z nich z własną przestrzenią adresową, nie współdzieloną z innymi
Programowanie w standardzie MPI 1 2 Podstawy programowania z przesyłaniem komunikatów Model systemu równoległego w postaci p procesów, każdy z nich z własną przestrzenią adresową, nie współdzieloną z innymi
Przetwarzanie równoległesprzęt. Rafał Walkowiak Wybór
 Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
Komputerowe Obliczenia Równoległe: Wstęp do OpenMP i MPI
 Komputerowe Obliczenia Równoległe: Wstęp do OpenMP i MPI Patryk Mach Uniwersytet Jagielloński, Instytut Fizyki im. Mariana Smoluchowskiego OpenMP (Open Multi Processing) zbiór dyrektyw kompilatora, funkcji
Komputerowe Obliczenia Równoległe: Wstęp do OpenMP i MPI Patryk Mach Uniwersytet Jagielloński, Instytut Fizyki im. Mariana Smoluchowskiego OpenMP (Open Multi Processing) zbiór dyrektyw kompilatora, funkcji
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Architektura sieci połączeń między procesorami, sterowanie komunikacjami, biblioteki komunikacyjne
 Wykład 4 Architektura sieci połączeń między procesorami, sterowanie komunikacjami, biblioteki komunikacyjne Spis treści: 1. Statyczne sieci połączeń w systemach równoległych 2. Dynamiczne sieci połączeń
Wykład 4 Architektura sieci połączeń między procesorami, sterowanie komunikacjami, biblioteki komunikacyjne Spis treści: 1. Statyczne sieci połączeń w systemach równoległych 2. Dynamiczne sieci połączeń
1. Uruchom poniższy program tworzący pojedynczy wątek:
 9 Wątki 1. Uruchom poniższy program tworzący pojedynczy wątek: #include #include #include void* worker(void* info) int i; for(i=0; i
9 Wątki 1. Uruchom poniższy program tworzący pojedynczy wątek: #include #include #include void* worker(void* info) int i; for(i=0; i
Programowanie Równoległe Wykład 5. MPI - Message Passing Interface (część 3) Maciej Matyka Instytut Fizyki Teoretycznej
 Maciej Matyka Instytut Fizyki Teoretycznej") Programowanie Równoległe Wykład 5 MPI - Message Passing Interface (część 3) Maciej Matyka Instytut Fizyki Teoretycznej MPI, wykład 3. Plan: - wirtualne topologie - badanie skalowanie czasu rozwiązania
Programowanie Równoległe Wykład 5 MPI - Message Passing Interface (część 3) Maciej Matyka Instytut Fizyki Teoretycznej MPI, wykład 3. Plan: - wirtualne topologie - badanie skalowanie czasu rozwiązania
Plan wykładu. Programowanie aplikacji równoległych i rozproszonych. Wykład 1 p. Wzajemne wykluczanie. Procesy współbieżne
 Plan wykładu Programowanie aplikacji równoległych i rozproszonych Wykład 1 Podstawowe pojęcia i model programowania Sposoby realizacji watków w systemach operacyjnych Tworzenie watów i zarzadzanie nimi
Plan wykładu Programowanie aplikacji równoległych i rozproszonych Wykład 1 Podstawowe pojęcia i model programowania Sposoby realizacji watków w systemach operacyjnych Tworzenie watów i zarzadzanie nimi
Programowanie aplikacji równoległych i rozproszonych. Wykład 1
 Wykład 1 p. 1/52 Programowanie aplikacji równoległych i rozproszonych Wykład 1 Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Plan wykładu
Wykład 1 p. 1/52 Programowanie aplikacji równoległych i rozproszonych Wykład 1 Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Plan wykładu
Programowanie Współbieżne
 Programowanie Współbieżne Pthread http://www.unix.org/version2/whatsnew/threadsref.html Oraz strony podręcznika systemowego man 1 Wątki W tradycyjnym modelu w systemie Unix, jeżeli proces wymaga, by część
Programowanie Współbieżne Pthread http://www.unix.org/version2/whatsnew/threadsref.html Oraz strony podręcznika systemowego man 1 Wątki W tradycyjnym modelu w systemie Unix, jeżeli proces wymaga, by część
Mariusz Rudnicki PROGRAMOWANIE WSPÓŁBIEŻNE I SYSTEMY CZASU RZECZYWISTEGO CZ.4
 Mariusz Rudnicki mariusz.rudnicki@eti.pg.gda.pl PROGRAMOWANIE WSPÓŁBIEŻNE I SYSTEMY CZASU RZECZYWISTEGO CZ.4 Synchronizacja wątków Omawiane zagadnienia Czym jest synchronizacja wątków? W jakim celu stosuje
Mariusz Rudnicki mariusz.rudnicki@eti.pg.gda.pl PROGRAMOWANIE WSPÓŁBIEŻNE I SYSTEMY CZASU RZECZYWISTEGO CZ.4 Synchronizacja wątków Omawiane zagadnienia Czym jest synchronizacja wątków? W jakim celu stosuje
Systemy rozproszone. Państwowa Wyższa Szkoła Zawodowa w Chełmie. ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej w Lublinie
 Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
Implementacje zgodne z tym standardem są nazywane wątkami POSIX lub Pthreads.
 pthreads (POSIX) implementacji równoległości poprzez wątki w architekturach wieloprocesorowych z pamięcią współdzieloną przenośność problem programistyczny, gdy dostawcy sprzętu wdrażali własne wersje
pthreads (POSIX) implementacji równoległości poprzez wątki w architekturach wieloprocesorowych z pamięcią współdzieloną przenośność problem programistyczny, gdy dostawcy sprzętu wdrażali własne wersje
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie maszyn z pamięcią wspólną w standardzie OpenMP.
 Programowanie maszyn z pamięcią wspólną w standardzie OpenMP. 1 OpenMP Standard rozwinięty i zdefiniowany w latach 90 przez grupę specjalistów z przemysłu. Strona www: www.openmp.org Składa się ze zbioru
Programowanie maszyn z pamięcią wspólną w standardzie OpenMP. 1 OpenMP Standard rozwinięty i zdefiniowany w latach 90 przez grupę specjalistów z przemysłu. Strona www: www.openmp.org Składa się ze zbioru
Wielowątkowy serwer TCP
 Wielowątkowy serwer TCP Wątek współbieżne działanie współdzielenie danych wykonywanie tego samego programu tańsze tworzenie w porównaniu do fork() join(), a detach() pthread - interesujące fragmenty pthread_create(),
Wielowątkowy serwer TCP Wątek współbieżne działanie współdzielenie danych wykonywanie tego samego programu tańsze tworzenie w porównaniu do fork() join(), a detach() pthread - interesujące fragmenty pthread_create(),
Open MP wer Rafał Walkowiak Instytut Informatyki Politechniki Poznańskiej Jesień 2014
 Open MP wer. 2.5 Wykład PR część 3 Rafał Walkowiak Instytut Informatyki Politechniki Poznańskiej Jesień 2014 OpenMP standard specyfikacji przetwarzania współbieżnego uniwersalny (przenośny) model równoległości
Open MP wer. 2.5 Wykład PR część 3 Rafał Walkowiak Instytut Informatyki Politechniki Poznańskiej Jesień 2014 OpenMP standard specyfikacji przetwarzania współbieżnego uniwersalny (przenośny) model równoległości
Mariusz Rudnicki PROGRAMOWANIE SYSTEMÓW CZASU RZECZYWISTEGO CZ.4
 Mariusz Rudnicki mariusz.rudnicki@eti.pg.gda.pl PROGRAMOWANIE SYSTEMÓW CZASU RZECZYWISTEGO CZ.4 Synchronizacja wątków Omawiane zagadnienia Czym jest synchronizacja wątków? W jakim celu stosuje się mechanizmy
Mariusz Rudnicki mariusz.rudnicki@eti.pg.gda.pl PROGRAMOWANIE SYSTEMÓW CZASU RZECZYWISTEGO CZ.4 Synchronizacja wątków Omawiane zagadnienia Czym jest synchronizacja wątków? W jakim celu stosuje się mechanizmy
Łagodne wprowadzenie do Message Passing Interface (MPI)
") Łagodne wprowadzenie do Message Passing Interface (MPI) Szymon Łukasik Zakład Automatyki PK szymonl@pk.edu.pl Szymon Łukasik, 8 listopada 2006 Łagodne wprowadzenie do MPI - p. 1/48 Czym jest MPI? Własności
Łagodne wprowadzenie do Message Passing Interface (MPI) Szymon Łukasik Zakład Automatyki PK szymonl@pk.edu.pl Szymon Łukasik, 8 listopada 2006 Łagodne wprowadzenie do MPI - p. 1/48 Czym jest MPI? Własności
Jak wygląda praca na klastrze
 Jak wygląda praca na klastrze Upraszczając nieco sprawę można powiedzieć, że klaster to dużo niezależnych komputerów (jednostek) połączonych mniej lub bardziej sprawną siecią. Często poszczególne jednostki
Jak wygląda praca na klastrze Upraszczając nieco sprawę można powiedzieć, że klaster to dużo niezależnych komputerów (jednostek) połączonych mniej lub bardziej sprawną siecią. Często poszczególne jednostki
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE. Wykład 02
 METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE Wykład 02 NAJPROSTSZY PROGRAM /* (Prawie) najprostszy przykład programu w C */ /*==================*/ /* Między tymi znaczkami można pisać, co się
METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE Wykład 02 NAJPROSTSZY PROGRAM /* (Prawie) najprostszy przykład programu w C */ /*==================*/ /* Między tymi znaczkami można pisać, co się
5. Model komunikujących się procesów, komunikaty
 Jędrzej Ułasiewicz str. 1 5. Model komunikujących się procesów, komunikaty Obecnie stosuje się następujące modele przetwarzania: Model procesów i komunikatów Model procesów komunikujących się poprzez pamięć
Jędrzej Ułasiewicz str. 1 5. Model komunikujących się procesów, komunikaty Obecnie stosuje się następujące modele przetwarzania: Model procesów i komunikatów Model procesów komunikujących się poprzez pamięć
Programowanie współbieżne Wstęp do OpenMP. Rafał Skinderowicz
 Programowanie współbieżne Wstęp do OpenMP Rafał Skinderowicz Czym jest OpenMP? OpenMP = Open Multi-Processing interfejs programowania aplikacji (API) dla pisania aplikacji równoległych na komputery wieloprocesorowe
Programowanie współbieżne Wstęp do OpenMP Rafał Skinderowicz Czym jest OpenMP? OpenMP = Open Multi-Processing interfejs programowania aplikacji (API) dla pisania aplikacji równoległych na komputery wieloprocesorowe
Sprzęt czyli architektury systemów równoległych
 Sprzęt czyli architektury systemów równoległych 1 Architektura von Neumanna Program i dane w pamięci komputera Pojedynczy procesor: pobiera rozkaz z pamięci rozkodowuje rozkaz i znajduje adresy argumentów
Sprzęt czyli architektury systemów równoległych 1 Architektura von Neumanna Program i dane w pamięci komputera Pojedynczy procesor: pobiera rozkaz z pamięci rozkodowuje rozkaz i znajduje adresy argumentów
Podstawy programowania współbieżnego. 1. Wprowadzenie. 2. Podstawowe pojęcia
 Podstawy programowania współbieżnego Opracowanie: Sławomir Samolej, Tomasz Krzeszowski Politechnika Rzeszowska, Katedra Informatyki i Automatyki, Rzeszów, 2010 1. Wprowadzenie Programowanie współbieżne
Podstawy programowania współbieżnego Opracowanie: Sławomir Samolej, Tomasz Krzeszowski Politechnika Rzeszowska, Katedra Informatyki i Automatyki, Rzeszów, 2010 1. Wprowadzenie Programowanie współbieżne
Jędrzej Ułasiewicz Programownie aplikacji współbieżnych str. 1. Wątki
 Jędrzej Ułasiewicz Programownie aplikacji współbieżnych str. 1 1 Informacje wstępne...2 2 Rodzaje wątków...7 poziomu jądra...7 poziomu użytkownika...8 Rozwiązania mieszane...8 3 Biblioteka pthreads...12
Jędrzej Ułasiewicz Programownie aplikacji współbieżnych str. 1 1 Informacje wstępne...2 2 Rodzaje wątków...7 poziomu jądra...7 poziomu użytkownika...8 Rozwiązania mieszane...8 3 Biblioteka pthreads...12
Katedra Elektrotechniki Teoretycznej i Informatyki. wykład 12 - sem.iii. M. Czyżak
 Katedra Elektrotechniki Teoretycznej i Informatyki wykład 12 - sem.iii M. Czyżak Język C - preprocesor Preprocesor C i C++ (cpp) jest programem, który przetwarza tekst programu przed przekazaniem go kompilatorowi.
Katedra Elektrotechniki Teoretycznej i Informatyki wykład 12 - sem.iii M. Czyżak Język C - preprocesor Preprocesor C i C++ (cpp) jest programem, który przetwarza tekst programu przed przekazaniem go kompilatorowi.
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Autor: dr inż. Zofia Kruczkiewicz, Programowanie aplikacji internetowych 1
 Wątki 1. Wątki - wprowadzenie Wątkiem nazywamy sekwencyjny przepływ sterowania w procesie, który wykonuje dany program np. odczytywanie i zapisywanie plików Program Javy jest wykonywany w obrębie jednego
Wątki 1. Wątki - wprowadzenie Wątkiem nazywamy sekwencyjny przepływ sterowania w procesie, który wykonuje dany program np. odczytywanie i zapisywanie plików Program Javy jest wykonywany w obrębie jednego
Tworzenie wątków. #include <pthread.h> pthread_t thread;
 Wątki Wątek (ang, thread) jest to niezależna sekwencja zdarzeń w obrębie procesu. Podczas wykonywania procesu równolegle i niezależnie od siebie może być wykonywanych wiele wątków. Każdy wątek jest wykonywany
Wątki Wątek (ang, thread) jest to niezależna sekwencja zdarzeń w obrębie procesu. Podczas wykonywania procesu równolegle i niezależnie od siebie może być wykonywanych wiele wątków. Każdy wątek jest wykonywany
Programowanie Współbieżne
 Programowanie Współbieżne MPI ( główne źródło http://pl.wikipedia.org/wiki/mpi) 1 Historia Początkowo (lata 80) różne środowiska przesyłania komunikatów dla potrzeb programowania równoległego. Niektóre
Programowanie Współbieżne MPI ( główne źródło http://pl.wikipedia.org/wiki/mpi) 1 Historia Początkowo (lata 80) różne środowiska przesyłania komunikatów dla potrzeb programowania równoległego. Niektóre
Wyklad 11 Języki programowania równoległego
 Wyklad 11 Języki programowania równoległego Części wykładu: 1. Środowisko programu równoległego - procesy i wątki 2. Podstawowe problemy języków programowania równoległego 3. Języki programowania w środowisku
Wyklad 11 Języki programowania równoległego Części wykładu: 1. Środowisko programu równoległego - procesy i wątki 2. Podstawowe problemy języków programowania równoległego 3. Języki programowania w środowisku
POZNA SUPERCOMPUTING AND NETWORKING. Wprowadzenie do MPI
 Wprowadzenie do MPI literatura W. Gropp, E. Lusk, An Introduction to MPI, ANL P.S. Pacheco, A User s Guide to MPI, 1998 Ian Foster, Designing and Building Parallel Programs, Addison-Wesley 1995, http://www-unix.mcs.anl.gov/dbpp/
Wprowadzenie do MPI literatura W. Gropp, E. Lusk, An Introduction to MPI, ANL P.S. Pacheco, A User s Guide to MPI, 1998 Ian Foster, Designing and Building Parallel Programs, Addison-Wesley 1995, http://www-unix.mcs.anl.gov/dbpp/
OpenMP. Programowanie aplikacji równoległych i rozproszonych. Wykład 2. Model programowania. Standard OpenMP. Dr inż. Tomasz Olas
 OpenMP Programowanie aplikacji równoległych i rozproszonych Wykład 2 Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska OpenMP (Open Multi-Processing)
OpenMP Programowanie aplikacji równoległych i rozproszonych Wykład 2 Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska OpenMP (Open Multi-Processing)
Wprowadzenie do zrównoleglania aplikacji z wykorzystaniem standardu OpenMP
 OpenMP p. 1/4 Wprowadzenie do zrównoleglania aplikacji z wykorzystaniem standardu OpenMP Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska OpenMP OpenMP
OpenMP p. 1/4 Wprowadzenie do zrównoleglania aplikacji z wykorzystaniem standardu OpenMP Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska OpenMP OpenMP
Kolejne funkcje MPI 1
 Kolejne funkcje MPI 1 Przypomnienie: sieci typu mesh (Grama i wsp.) 2 Topologie MPI Standard MPI abstrahuje od topologii systemu wieloprocesorowego. Sposób uruchamiania aplikacji (mpirun) nie jest częścią
Kolejne funkcje MPI 1 Przypomnienie: sieci typu mesh (Grama i wsp.) 2 Topologie MPI Standard MPI abstrahuje od topologii systemu wieloprocesorowego. Sposób uruchamiania aplikacji (mpirun) nie jest częścią
Wykład 5. Synchronizacja (część II) Wojciech Kwedlo, Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB
 Wojciech Kwedlo, Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB") Wykład 5 Synchronizacja (część II) Wojciech Kwedlo, Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB Wady semaforów Jeden z pierwszych mechanizmów synchronizacji Generalnie jest to mechanizm bardzo
Wykład 5 Synchronizacja (część II) Wojciech Kwedlo, Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB Wady semaforów Jeden z pierwszych mechanizmów synchronizacji Generalnie jest to mechanizm bardzo
Wątki. S. Samolej: Wątki 1
 Wątki dr inż. Sławomir Samolej Katedra Informatyki i Automatyki Politechnika Rzeszowska Program przedmiotu oparto w części na materiałach opublikowanych na: http://wazniak.mimuw.edu.pl/ oraz na materiałach
Wątki dr inż. Sławomir Samolej Katedra Informatyki i Automatyki Politechnika Rzeszowska Program przedmiotu oparto w części na materiałach opublikowanych na: http://wazniak.mimuw.edu.pl/ oraz na materiałach
Biblioteka PCJ do naukowych obliczeń równoległych
 Biblioteka PCJ do naukowych obliczeń równoległych Zakład Obliczeń Równoległych i Rozproszonych Wydział Matematyki i Informatyki Uniwersytet Mikołaja Kopernika Chopina 12/18, 87-100 Toruń faramir@mat.umk.pl
Biblioteka PCJ do naukowych obliczeń równoległych Zakład Obliczeń Równoległych i Rozproszonych Wydział Matematyki i Informatyki Uniwersytet Mikołaja Kopernika Chopina 12/18, 87-100 Toruń faramir@mat.umk.pl
synchronizacji procesów
 Dariusz Wawrzyniak Definicja semafora Klasyfikacja semaforów Implementacja semaforów Zamki Zmienne warunkowe Klasyczne problemy synchronizacji Plan wykładu (2) Semafory Rodzaje semaforów (1) Semafor jest
Dariusz Wawrzyniak Definicja semafora Klasyfikacja semaforów Implementacja semaforów Zamki Zmienne warunkowe Klasyczne problemy synchronizacji Plan wykładu (2) Semafory Rodzaje semaforów (1) Semafor jest
Wskaźniki. Informatyka
 Materiały Wskaźniki Informatyka Wskaźnik z punktu widzenia programisty jest grupą komórek pamięci (rozmiar wskaźnika zależy od architektury procesora, najczęściej są to dwa lub cztery bajty ), które mogą
Materiały Wskaźniki Informatyka Wskaźnik z punktu widzenia programisty jest grupą komórek pamięci (rozmiar wskaźnika zależy od architektury procesora, najczęściej są to dwa lub cztery bajty ), które mogą
synchronizacji procesów
 Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja semafora Klasyfikacja semaforów Implementacja semaforów Zamki Zmienne warunkowe Klasyczne problemy synchronizacji (2) Semafory
Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja semafora Klasyfikacja semaforów Implementacja semaforów Zamki Zmienne warunkowe Klasyczne problemy synchronizacji (2) Semafory
Wykład VII. Programowanie. dr inż. Janusz Słupik. Gliwice, 2014. Wydział Matematyki Stosowanej Politechniki Śląskiej. c Copyright 2014 Janusz Słupik
 Wykład VII Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Kompilacja Kompilator C program do tłumaczenia kodu źródłowego na język maszynowy. Preprocesor
Wykład VII Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Kompilacja Kompilator C program do tłumaczenia kodu źródłowego na język maszynowy. Preprocesor
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
 1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
Podstawy programowania skrót z wykładów:
 Podstawy programowania skrót z wykładów: // komentarz jednowierszowy. /* */ komentarz wielowierszowy. # include dyrektywa preprocesora, załączająca biblioteki (pliki nagłówkowe). using namespace
Podstawy programowania skrót z wykładów: // komentarz jednowierszowy. /* */ komentarz wielowierszowy. # include dyrektywa preprocesora, załączająca biblioteki (pliki nagłówkowe). using namespace
Podstawy programowania w języku C
 Podstawy programowania w języku C WYKŁAD 1 Proces tworzenia i uruchamiania programów Algorytm, program Algorytm przepis postępowania prowadzący do rozwiązania określonego zadania. Program zapis algorytmu
Podstawy programowania w języku C WYKŁAD 1 Proces tworzenia i uruchamiania programów Algorytm, program Algorytm przepis postępowania prowadzący do rozwiązania określonego zadania. Program zapis algorytmu
Wsparcie dla OpenMP w kompilatorze GNU GCC Krzysztof Lamorski Katedra Informatyki, PWSZ Chełm
 Wsparcie dla OpenMP w kompilatorze GNU GCC Krzysztof Lamorski Katedra Informatyki, PWSZ Chełm Streszczenie Tematem pracy jest standard OpenMP pozwalający na programowanie współbieŝne w systemach komputerowych
Wsparcie dla OpenMP w kompilatorze GNU GCC Krzysztof Lamorski Katedra Informatyki, PWSZ Chełm Streszczenie Tematem pracy jest standard OpenMP pozwalający na programowanie współbieŝne w systemach komputerowych
PMiK Programowanie Mikrokontrolera 8051
 PMiK Programowanie Mikrokontrolera 8051 Wykład 3 Mikrokontroler 8051 PMiK Programowanie mikrokontrolera 8051 - wykład S. Szostak (2006) Zmienna typu bit #define YES 1 // definicja stałych #define NO 0
PMiK Programowanie Mikrokontrolera 8051 Wykład 3 Mikrokontroler 8051 PMiK Programowanie mikrokontrolera 8051 - wykład S. Szostak (2006) Zmienna typu bit #define YES 1 // definicja stałych #define NO 0
PARADYGMATY I JĘZYKI PROGRAMOWANIA. Programowanie współbieżne... (w13)
") PARADYGMATY I JĘZYKI PROGRAMOWANIA Programowanie współbieżne... (w13) Treść 2 Wstęp Procesy i wątki Szybkość obliczeń prawo Amdahla Wyścig do zasobów Synchronizacja i mechanizmy synchronizacji semafory
PARADYGMATY I JĘZYKI PROGRAMOWANIA Programowanie współbieżne... (w13) Treść 2 Wstęp Procesy i wątki Szybkość obliczeń prawo Amdahla Wyścig do zasobów Synchronizacja i mechanizmy synchronizacji semafory
Open MP. Rafał Walkowiak Instytut Informatyki Politechniki Poznańskie Jesień 2011
 Open MP wersja 2.5 Rafał Walkowiak Instytut Informatyki Politechniki Poznańskie Jesień 2011 OpenMP standard specyfikacji przetwarzania współbieŝnego uniwersalny (przenośny) model równoległości typu fork-join
Open MP wersja 2.5 Rafał Walkowiak Instytut Informatyki Politechniki Poznańskie Jesień 2011 OpenMP standard specyfikacji przetwarzania współbieŝnego uniwersalny (przenośny) model równoległości typu fork-join
Wskaźniki. Programowanie Proceduralne 1
 Wskaźniki Programowanie Proceduralne 1 Adresy zmiennych Sterta 1 #include 2 3 int a = 2 ; 4 5 int main ( ) 6 { 7 int b = 3 ; 8 9 printf ( " adres zmiennej a %p\n", &a ) ; 10 printf ( " adres
Wskaźniki Programowanie Proceduralne 1 Adresy zmiennych Sterta 1 #include 2 3 int a = 2 ; 4 5 int main ( ) 6 { 7 int b = 3 ; 8 9 printf ( " adres zmiennej a %p\n", &a ) ; 10 printf ( " adres
Programowanie w modelu przesyłania komunikatów specyfikacja MPI. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Środowisko przesyłania komunikatów MPI Rodzaje procedur: blokujące nieblokujące Tryby przesyłania
Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Środowisko przesyłania komunikatów MPI Rodzaje procedur: blokujące nieblokujące Tryby przesyłania
Programowanie maszyn z pamięcią wspólną w standardzie OpenMP.
 Programowanie maszyn z pamięcią wspólną w standardzie OpenMP. 1 OpenMP Standard rozwinięty i zdefiniowany w latach 90 przez grupę specjalistów z przemysłu. Strona www: www.openmp.org Składa się ze zbioru
Programowanie maszyn z pamięcią wspólną w standardzie OpenMP. 1 OpenMP Standard rozwinięty i zdefiniowany w latach 90 przez grupę specjalistów z przemysłu. Strona www: www.openmp.org Składa się ze zbioru
Wprowadzenie do MPI. Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.
 Wprowadzenie do MPI Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.pl Maciej Cytowski m.cytowski@icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl
Wprowadzenie do MPI Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.pl Maciej Cytowski m.cytowski@icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
PROGRAMOWANIE SYSTEMÓW CZASU RZECZYWISTEGO
 PROGRAMOWANIE SYSTEMÓW CZASU RZECZYWISTEGO LABORATORIUM Temat: QNX Neutrino Interrupts Mariusz Rudnicki 2016 Wstęp W QNX Neutrino wszystkie przerwania sprzętowe przechwytywane są przez jądro systemu. Obsługę
PROGRAMOWANIE SYSTEMÓW CZASU RZECZYWISTEGO LABORATORIUM Temat: QNX Neutrino Interrupts Mariusz Rudnicki 2016 Wstęp W QNX Neutrino wszystkie przerwania sprzętowe przechwytywane są przez jądro systemu. Obsługę
Strona główna. Strona tytułowa. Programowanie. Spis treści. Sobera Jolanta 16.09.2006. Strona 1 z 26. Powrót. Full Screen. Zamknij.
 Programowanie Sobera Jolanta 16.09.2006 Strona 1 z 26 1 Wprowadzenie do programowania 4 2 Pierwsza aplikacja 5 3 Typy danych 6 4 Operatory 9 Strona 2 z 26 5 Instrukcje sterujące 12 6 Podprogramy 15 7 Tablice
Programowanie Sobera Jolanta 16.09.2006 Strona 1 z 26 1 Wprowadzenie do programowania 4 2 Pierwsza aplikacja 5 3 Typy danych 6 4 Operatory 9 Strona 2 z 26 5 Instrukcje sterujące 12 6 Podprogramy 15 7 Tablice
Spis treści. Dzień 1. I Rozpoczęcie pracy ze sterownikiem (wersja 1707) II Bloki danych (wersja 1707) ZAAWANSOWANY TIA DLA S7-300/400
 II Bloki danych (wersja 1707) ZAAWANSOWANY TIA DLA S7-300/400") ZAAWANSOWANY TIA DLA S7-300/400 Spis treści Dzień 1 I Rozpoczęcie pracy ze sterownikiem (wersja 1707) I-3 Zadanie Konfiguracja i uruchomienie sterownika I-4 Etapy realizacji układu sterowania I-5 Tworzenie
ZAAWANSOWANY TIA DLA S7-300/400 Spis treści Dzień 1 I Rozpoczęcie pracy ze sterownikiem (wersja 1707) I-3 Zadanie Konfiguracja i uruchomienie sterownika I-4 Etapy realizacji układu sterowania I-5 Tworzenie
wykład II uzupełnienie notatek: dr Jerzy Białkowski Programowanie C/C++ Język C - funkcje, tablice i wskaźniki wykład II dr Jarosław Mederski Spis
 i cz. 2 Programowanie uzupełnienie notatek: dr Jerzy Białkowski 1 i cz. 2 2 i cz. 2 3 Funkcje i cz. 2 typ nazwa ( lista-parametrów ) { deklaracje instrukcje } i cz. 2 typ nazwa ( lista-parametrów ) { deklaracje
i cz. 2 Programowanie uzupełnienie notatek: dr Jerzy Białkowski 1 i cz. 2 2 i cz. 2 3 Funkcje i cz. 2 typ nazwa ( lista-parametrów ) { deklaracje instrukcje } i cz. 2 typ nazwa ( lista-parametrów ) { deklaracje
Podstawy programowania. Wykład Pętle. Tablice. Krzysztof Banaś Podstawy programowania 1
 Podstawy programowania. Wykład Pętle. Tablice. Krzysztof Banaś Podstawy programowania 1 Pętle Pętla jest konstrukcją sterującą stosowaną w celu wielokrotnego wykonania tego samego zestawu instrukcji jednokrotne
Podstawy programowania. Wykład Pętle. Tablice. Krzysztof Banaś Podstawy programowania 1 Pętle Pętla jest konstrukcją sterującą stosowaną w celu wielokrotnego wykonania tego samego zestawu instrukcji jednokrotne