SPIS TREŚCI. 1. WSTĘP 1. Wyjście naprzeciw potrzebom dzisiejszej informatyki 2. Koncepcje badawcze i teza pracy
|
|
|
- Łucja Staniszewska
- 8 lat temu
- Przeglądów:
Transkrypt
1 AKADEMIA GÓRNICZO HUTNICZA IM. STANISŁAWA STASZICA WYDZIAŁ ELEKTROTECHNIKI, AUTOMATYKI, INFORMATYKI I ELEKTRONIKI Adrian Horzyk owe metody uczenia sieci neuronowych bez srzężeń zwrotnych Praca doktorska naisana od kierunkiem Prof. zw. dr hab. inż. Ryszarda Tadeusiewicza Kraków 2001

2 SPIS TREŚCI 1. WSTĘP 1. Wyjście narzeciw otrzebom dzisiejszej informatyki 2. Koncecje badawcze i teza racy 2. WPROWADZENIE 1. Mózg a sieci neuronowe 2. Klasyczne reguły uczące 3. Podsumowanie 3. METODA AUTOMATYCZNEJ KONFIGURACJI SIECI NEURONOWYCH DLA PROBLEMÓW ROZPOZNAWANIA WZORCÓW BINARNYCH 1. Założenia metody 2. Ois metody 1. Metoda estymacji cech wzorców binarnych 2. Jakość rozoznawania i jakość uogólnienia 3. Kryteria redukcji synas 4. Automatyczna konfiguracja sieci neuronowej 5. Porównywalność uzyskanych wyników 3. Zalety i wady metody 4. Kierunki rozwoju metody 5. Praktyczna realizacja metody - alikacja Otimal Recognition 1. Przykład rozwiązania roblemu zadanego ciągiem uczącym 4. METODA STEROWANYCH KOMPROMISÓW 1. Zastosowany model neuronu i używane słownictwo i notacja 2. Założenia metody 1. Szybkość nauki 2. Sosób korekty błędu 3. Sukces rocesu uczenia 4. Odchylenia od uzyskanego komromisu jako globalny wyznacznik stanu rocesu uczenia 3. Ois metody 1. Faza roagacji obudzenia sieciowego 2. Faza wstecznej roagacji sygnału uczącego 3. Faza obliczania komromisu 4. Faza wyznaczania odchyleń 5. Sterowanie rocesem uczenia 6. Warunki zatrzymania rocesu uczenia 4. Rozszerzenia metody 1. Uniezależnienie od rerezentacji liczbowej wzorców uczących 2. Niestandardowe funkcje aktywacji neuronów 3. Uczenie sieci neuronowych zawierających neurony ukryte 1. Idea uogólnienia metody dla sieci zawierających kilka warstw 2

3 2. Ois algorytmu uogólnionej metody sterowanych komromisów dla wielu warstw 1. Wyznaczanie ścieżek uczenia 2. Wsteczna roagacja sygnału uczącego dla danego etau uczącego sieci wielowarstwowych 3. Problemy związane z uczeniem sieci wielowarstwowych 4. Uczenie niekomletnych wzorców uczących 5. Podsumowanie i kierunki rozwoju metody 6. Alikacja Brain for Problem 1. Ois odstawowych funkcji alikacji 2. Zastosowana symbolika 3. Ois okienek umożliwiających dynamiczny odgląd rocesu uczenia 4. Podgląd rocesu zmian arametrów sieci neuronowej 5. BADANIA EFEKTYWNOŚCI I UŻYTECZNOŚCI OPRACOWANYCH METOD 1. Automatyczna konfiguracja sieci neuronowych dla roblemów rozoznawania obrazów 2. Uczenie funkcji logicznych. 3. Problem arzystości 4. Problem dwóch siral 5. Problem czerwonego katurka 6. Problem rozoznawania obrazów 7. Dyskusja zbiorcza wyników testowego stosowania metody sterowanych komromisów 6. PODSUMOWANIE 7. LITERATURA 3

4 1. WSTĘP 1.1. Tworzenie nowych tyów sieci neuronowych jako wyjście narzeciw niektórym otrzebom dzisiejszej informatyki W ostatnich latach mamy do czynienia z rawdziwym zalewem informacji ochodzących z różnych źródeł, a także ze związanym z tym roblemem ich szybkiego i efektywnego rzetwarzania oraz selekcji. Ogromne bazy danych, stające się coraz częściej niezbędnym elementem rocesu sterowania lub zarządzania, wielkie zasoby wiedzy kororacyjnej, będące fundamentem funkcjonowania nowego tyu rzedsiębiorstw zorientowanych na teleracę, różne formy sieciowej działalności gosodarczej (tak zwany e-business), Internet jako źródło wiedzy używanej rzez miliony ludzi to tylko rzyadkowo wybrane elementy, wskazujące na rozmiar i znaczenie tego zjawiska. Tradycyjne techniki rzetwarzania informacji, oarte na dokładnym rzetwarzaniu wszystkiego, nie zawsze dają oczekiwany efekt w rozsądnym czasie, nie mówiąc już o roblemach takiego ełnego rzetwarzania informacji. Wskazane roblemy nasilają się zdecydowanie w systemach, w których wymagana jest raca w czasie rzeczywistym (real-time rocessing), a więc zwłaszcza w systemach automatyki. Na domiar wszystkiego w szybko zmieniających się warunkach działania wielu rzedsiębiorstw i związanych z nimi systemów informatycznych ojawia się konieczność szybkiego dostosowywania istniejących algorytmów do nowych warunków, a to nie zawsze okazuje się rzeczą łatwą. Często brak teoretycznych i raktycznych rozwiązań dla zarysowanych tu roblemów owoduje stagnację rozwoju w danej dziedzinie rzetwarzania informacji ze szkodą dla techniki i gosodarki. Tymczasem rozwiązanie rzynajmniej niektórych sośród naszkicowanych wyżej roblemów może być znalezione, od warunkiem, że w obszar rozwiązań douszczalnych włączone zostaną metody niestandardowe, takie właśnie, jak rozważane w tej racy. Odwołując się do sieci neuronowych jako do narzędzia rozwiązywania wybranych roblemów informatycznych musimy oczywiście mieć świadomość ich ograniczeń, na rzykład tego, że wyniki obliczeń neuronowych są zwykle raczej jakościowe, niż ilościowe, stąd ich dokładność jest ograniczona. Nie zawsze jednak w zastosowaniach informatyki otrzebne są dokładne, recyzyjne rozwiązania, a nawet można owiedzieć, że w większości rzyadków wystarcza, żeby dane rozwiązanie charakteryzowało się jakąś z góry określoną dokładnością (accuracy), tzn. nie było obarczone większym błędem niż zakłada ewien douszczalny róg. Ważniejszym od dokładności atutem obliczeń neuronowych jest bowiem elastyczność tych rozwiązań, 4
, Internet jako źródło wiedzy używanej rzez miliony ludzi to tylko rzyadkowo wybrane elementy,")
5 wynikająca z możliwości, jakie niesie roces uczenia. Często zdarza się sytuacja, że mamy ewien zbiór danych, zbiór doświadczeń i emirycznie obserwowanych ich wzajemnych owiązań (korelacji), natomiast brak nam odowiedniego algorytmu rzetwarzania lub jawnie zdefiniowanej reguły wnioskowania na ich odstawie. Zazwyczaj istnieje ewien zbiór wiedzy, tj. dane, ich korelacje oraz znana jest dokładność, z jaką rzetwarzanie tych danych ma zachodzić. Najbardziej odowiednie byłoby, gdyby dla dowolnych danych i dla zadanej dokładności można było rzy omocy jakiejś czarnej skrzynki (black box) o rozsądnym czasie otrzymać ożądane wyniki w ostaci stwierdzenia, co właściwie z tych danych wynika. W takich rzyadkach chętnie sięgamy do metod heurystycznych, oartych na rocesach uczenia maszynowego, w tym ostatnio coraz chętniej właśnie do sieci neuronowych. Praktyka informatyki (zwłaszcza w obszarze zastosowań komuterów do sterowania i zarządzania) wymusza obecnie coraz szybsze rzetwarzanie coraz większej ilości informacji o coraz bardziej zawiłych owiązaniach. W takich rzyadkach nawet wtedy, gdy znamy modele rzyczynowo-skutkowe, celowe może być użycie sieci neuronowych, gdyż rowadzą one do rozwiązań szybszych chociaż często tylko subotymalnych. Sieci neuronowe nie bazują na z góry oracowanych algorytmach, lecz na rocesie uczenia, który owinien umożliwiać im jak najlesze dostosowanie się do zadanego roblemu na odstawie ewnej wiedzy dostarczonej w formie rzykładów orawnych rozwiązań, tzw. wzorców uczących (learning atterns). Wzorce te tworzą ewien zbiór zwany ciągiem uczącym (LS learning sequence, DS data set) stanowiący główne źródło wiedzy sieci o zadanym roblemie. W zależności od secyfiki roblemu i od zastosowanej metody uczenia ciąg uczący składa się: z wzorców wejściowych dla metod uczenia bez nauczyciela (unsuervised learning), z wzorców wejściowych i z rawidłowych odowiedzi sieci neuronowej, zwanych też sygnałami uczącymi dla danych wzorców, co znajduje zastosowanie w rzyadku metod uczenia z nauczycielem (suervised learning), z wzorców wejściowych i odowiedzi w ostaci nagrody lub kary dla metod uczenia z krytykiem (reinforcement learning). W rzyadku metod uczenia z nauczycielem, rozważanych w tej racy, ciąg uczący jest zazwyczaj definiowany jako zbiór ar ( x ) i, y i i= 1, gdzie oznacza liczność tego zbioru, a ary ( x i, y i ) są rzykładami orawnego odwzorowania x i w y i. Na odstawie zbioru uczącego 5
 o rozsądnym czasie otrzymać ożądane wyniki w ostaci")
6 rzerowadzany jest roces uczenia (learning) sieci neuronowej, który ma na celu wydobycie korelacji omiędzy wzorcami (często ukrytych w wejściowych danych), a także odowiedniej zależności omiędzy sygnałami wejściowymi i wyjściowymi w sieci. Celem końcowym uczenia sieci jest znalezienie otymalnego ustawienia arametrów wolnych sieci (głównie wag) tak, by sieć neuronowa w miarę możliwości sełniała ostulaty zdefiniowane ciągiem uczącym. Gdyby jednak sieć neuronowa miała służyć tylko do zaamiętywania wzorców ciągu uczącego (i to jeszcze z ograniczoną dokładnością), stosowanie tych sieci nie miałoby głębszego sensu, albowiem istnieją bardziej efektywne i szybsze metody (wykorzystywane w bazach danych) służące do dokładnego zaamiętywania, rzetwarzania, i rzeszukiwania informacji na odstawie relacji omiędzy nimi zawartych. Prawdziwa siła sieci neuronowych ukryta jest w ich zdolności do uogólniania (generalization) wiedzy zdobytej w rocesie uczenia. Uogólnianie ozwala o nauczeniu sieci na rozwiązywanie zadań odobnych do tych, które były rezentowane wcześniej w ciągu uczącym. Umożliwia to w efekcie zadawanie sieci neuronowej ytań soza zbioru uczącego i oczekiwanie, że sieć neuronowa da na nie sensowną odowiedź. Pomysł z sieciami neuronowymi i ich uczeniem ma wiele zalet, jednak w związku z jego wdrożeniem do konkretnego raktycznego zadania związanych jest kilka zasadniczych roblemów: Jak ma wyglądać otymalna sieć neuronowa dla danego ciągu uczącego? Jak obrać jej stan oczątkowy, tj. jak ją zainicjować? W jaki sosób i jak długo ją uczyć? Jakich wyników możemy oczekiwać? Jak ocenić jakość uzyskanej zdolności do uogólniania? Czy możemy nauczonej sieci neuronowej zaufać, jeśli chodzi o jej odowiedzi na zadawane jej ytania? Aby sieci neuronowe mogły stać się użyteczne, godne zaufania i owszechnie stosowane, konieczne jest odowiedzenie na te zasadnicze ytania i znalezienie efektywnych metod realizacji sieci zdolnych do okonania wyżej wymienionych roblemów. Okazuje się, że wsółczesna wiedza na temat metod i technik obliczeniowych nie gwarantuje możliwości zbudowania systemu, który w oczywisty i naturalny sosób mógłby srostać tak sformułowanemu zadaniu. Niewątliwie biologiczny odowiednik sieci 6
, stosowanie tych sieci nie miałoby głębszego sensu, albowiem istnieją")
7 neuronowych mózg człowieka (a nawet znacznie mniej skomlikowany mózg zwierzęcia, na rzykład sa) radzi sobie ze wszystkimi tymi roblemami. Jednak jak na razie barierę ostęu stanowi nieełna wiedza związana z jego funkcjonowaniem. Mimo wielu wsaniałych odkryć ostatniego stulecia, związanych z badaniem układów nerwowych istot żywych, wciąż brak dostatecznie ogólnej wiedzy, umożliwiającej sztuczne modelowanie takich struktur z dużą dokładnością. Wysiłki wielu znakomitych badaczy z różnych dziedzin nauki zmierzają do odkrycia tajemnic mózgu i do ich wykorzystania. Warto zauważyć, że w rzeszłości wiele tych osiągnięć w obszarze neurobiologii, obejmowanym rzez szeroko rozumianą biocybernetykę, które wiązały się z największym rozwojem odstaw sztucznej inteligencji, uhonorowano najwyższą możliwą godnością naukową - rzyznawaną rzez Szwedzką Akademię Nagrodą Nobla. Przyomnijmy niektóre z nich, gdyż warto może uświadomić sobie, jak solidne odstawy biocybernetyczne ma rezentowana w tej racy dziedzina informatyki. I tak, chronologicznie wyróżnić można nastęujące osiągnięcia ukoronowane nagrodą Nobla, będące z całą ewnością wynikami badań biocybernetycznych w swojej istocie (chociaż nie zawsze tak nazywanych). Podano datę nadania nagrody, nazwisko laureata i skrótową informację o istocie nagrodzonego osiągnięcia Pavlov I.P. - teoria odruchów warunkowych Golgi C., - badanie struktury układu nerwowego Ramón Y Cajal S. - odkrycie, że mózg składa się z sieci oddzielnych neuronów Krogh S.A. - oisanie funkcji regulacyjnych w organizmie Sherrington Ch. S. - badania sterowania nerwowego racy mięśni Dale H., Hallett L.O. - odkrycie chemicznej transmisji imulsów nerwowych Erlanger J., Gasser H. S. - rocesy w ojedynczym włóknie nerwowym Hess W.R. - odkrycie funkcji śródmózgowia Eccles J.C., Hodgkin A.L., Huxley A.F. - mechanizm elektrycznej aktywności neuronu Granit R., Hartline H.K., Wald G. - fizjologia widzenia Katz B., Von Euler U., Axelrod J. - transmisja humoralnej informacji nerwowej w zakończeniach nerwowych Claude A., De Duve Ch., Palade G. - badania strukturalnej i funkcjonalnej organizacji komórki Guillemin R., Schally A., Yalow R. - badania hormonów mózgu 7

8 Serry R. - odkrycia dotyczące funkcjonalnej secjalizacji ółkul móżdżku Hubel D.H., Wiesel T. - odkrycie zasad rzetwarzania informacji w systemie wzrokowym eher E., Sakmann B. - funkcje kanałów jonowych w komórkach nerwowych Jak wynika z odanego wyżej, bezsornie dosyć subiektywnie i obieżnie dokonanego zestawienia, w ciągu ostatniego stulecia dokonał się ogromny ostę w badaniach mózgu, mający swoje bezośrednie rzełożenie na osiągnięcia i sukcesy sztucznej inteligencji. Szacuje się, że w szczególnie owocnych latach drugiej ołowy XX wieku uzyskiwano w ciągu jednego miesiąca więcej nowych informacji o budowie i działaniu mózgu - niż ich zgromadzono od czasów starożytności do 1900 roku. Nic więc dziwnego, że na tak bogatej glebie biologicznych odkryć i biologicznych faktów ojawiały się róby rzeniesienia coraz leiej rozumianych zasad działania mózgu do wnętrza maszyn matematycznych, które równolegle i równocześnie zyskiwały dojrzałość i stawały się coraz doskonalszymi imitatorami naturalnego ludzkiego intelektu. Potrzeby techniki wyrzedziły jednak ten zasób informacji o mózgu, jaki zgromadzono w trakcie badań neurocybernetycznych i który realnie można było zastosować jako bezośrednie źródło biologicznych insiracji dla konkretnych rozwiązań technicznych i wtedy ojawiło się miejsce na tworzenie struktur sieci neuronowych częściowo tylko wzorowanych na biologicznych ierwowzorach, mających jednak tę zaletę, że są one bardzo srawne w rozwiązywaniu konkretnych roblemów informatycznych. Takie właśnie sieci zaroonowano w tej racy jako swoiste wyjście narzeciw ewnym (wybranym) otrzebom wsółczesnej informatyki Koncecje badawcze i teza racy Realizując zaowiedziany w końcu orzedniego rozdziału ambitny rogram badawczy w tej racy zarezentowano dwie oryginalne metody ozwalające tworzyć, formować oraz uczyć sieci neuronowe, róbujące zmierzyć się z wybranymi roblemami wymienionymi w orzednim rozdziale. Najierw rzedstawiono metodę automatycznej konfiguracji sieci neuronowej dla roblemów srowadzających się do rozoznawania wzorców binarnych. Nastęnie oisano znacznie bogatszą metodę, nazwaną metodą sterowanych komromisów, która działa na danych uczących (i testowych) o wartościach rzeczywistych. Obydwie oracowane rzez autora metody róbują wyeliminować niektóre mankamenty, wystęujące odczas używania obecnie stosowanych metod uczenia sieci neuronowych. Rozważania ograniczono wyłącznie do sieci o toologiach nie zawierających srzężeń zwrotnych, onieważ takie właśnie sieci są aktualnie najczęściej i najchętniej wykorzystywane. 8

9 W ierwszej oisanej w racy metodzie skoncentrowano się na maksymalnym rzysieszeniu rocesu kreowania architektury i arametrów sieci neuronowej dla ewnej wąskiej gruy roblemów, w których dane wejściowe i wyjściowe sieci mają charakter wektorów binarnych. W drugiej, bardziej ogólnej metodzie wyeksonowano róbę orawienia właściwości ekstraolacyjnych nauczonej sieci orzez zastosowanie nietyowych funkcji aktywacji neuronów, a także odjęto róbę rzysieszenia rocesu uczenia orzez wyeliminowanie wsółczynnika uczenia η. Najważniejszą innowacją wnoszoną rzez oisaną w racy metodę sterowanych komromisów jest to, że stanowi ona róbę określenia zuełnie nowego sosobu uczenia sieci, dążącego do bardziej efektywnego zmierzania arametrów i struktury sieci do otimum ostawionego ciągiem uczącym, owiązanego z tzw. minimum globalnym funkcji błędu. Prezentacja oryginalnych koncecji nowych struktur i nowych metod działania sieci ołączona została w tej racy z róbą oszacowania jakości uzyskanego uogólnienia rzez skonfigurowaną sieć neuronową. Żadna z zarezentowanych metod nie gwarantuje, co rawda, zuełnego rozwiązania wszystkich wyżej wymienionych roblemów związanych ze stosowaniem sieci neuronowych, jednakże obydwie zaroonowane metody stanowią ewną róbę rozwiązania rzynajmniej części z nich, więc niezależnie od tego, że wzbogacają naukową wiedzę o sieciach neuronowych i metodach ich uczenia, to dodatkowo dostarczają wyników raktycznych (których wyrazem są załączone do racy rogramy komuterowe), które mogą w efekcie służyć w różnych zastosowaniach raktycznych do w miarę efektywnego rozwiązywania dobrze zdefiniowanych gru roblemów. W świetle oisanych założeń zdefiniowano nastęujące tezy racy: Możliwe jest ołączenie rocesu treningu i automatycznego formowania struktury rostej sieci neuronowej za omocą roonowanej w racy metody uczenia jednowarstwowych sieci liniowych, co rowadzi do szybkiego i efektywnego znajdowania otymalnych rozwiązań w rozważanej klasie zadań srowadzających się do rozoznawania rostych wektorów binarnych. Uogólnienie metody uczenia wzmiankowanej w ierwszej tezie ozwala na całkowite oderwanie rocesu uczenia jednokierunkowych sieci neuronowych od owszechnie stosowanych metod oartych na minimalizacji funkcji błędu. Sięgnięcie do roonowanej w racy metody uczenia za omocą sterowanych komromisów ozwala 9

10 w wielu zadaniach znacząco rzysieszyć i urościć roces rozwiązywanie zadania w stosunku do rutynowo stosowanych technik uczenia sieci. Realizując tematykę badawczą sygnalizowaną rzez sformułowane wyżej tezy w racy rzedstawiono dwie oryginalne metody uczenia, związane wrawdzie z tradycyjną tematyką sieci neuronowych jednokierunkowych (ozbawionych srzężeń zwrotnych), ale rozwiązujące w zuełnie nowy sosób zagadnienia ich konfiguracji i uczenia. Zgodnie z kolejnością zasygnalizowanych tez najierw rzedstawiona jest metoda automatycznej konfiguracji sieci neuronowych dla roblemów rozoznawania wzorców binarnych a nastęnie zaroonowano bardziej ogólną metodę, nazwaną metodą sterowanych komromisów. W związku z wrowadzeniem każdej metody odano wstęne założenia i rzesłanki, jakie rzyświecały ich skonstruowaniu, nastęnie oisano sosób ich działania i wyszczególniono ich zalety oraz wady w takim zakresie, w jakim zdołano to ustalić w trakcie rowadzonych badań. Ois doełniono krótką charakterystyką alikacji badawczych, służących do rzetestowania słuszności założeń obydwu metod, jak i do rowadzenia badań orównawczych mających na celu orawienie efektywności zaroonowanych metod. W końcowej części racy rzytoczone są rzykłady zastosowania oracowanych metod do wybranych zadań okazujących oglądowo ich zalety i wady, a także odane są wyniki ich działania, mogące służyć do orównań z osiągami uzyskanymi rzez inne reguły uczące. Pracę zakończono odsumowaniem uzyskanych wyników i wyznaczeniem kierunków dalszych oszukiwań i badań zmierzających do udoskonalenia zaroonowanych metod. 10

11 2. WPROWADZE IE 2.1. Mózg a sieci neuronowe Mózg od dawien dawna fascynował wielu badaczy i był natchnieniem dla wielu filozofów, jednak możliwości oznawania tej galaretowatej struktury ograniczały się w minionych stuleciach zazwyczaj tylko do sostrzeżeń, jakie badacz mógł zgromadzić na odstawie obserwacji różnych zachowań behawioralnych lub w oarciu o analizę toku myślenia i rozumowania. Doiero stosunkowo niedawno odkrycia naukowe z dziedzin fizyki, chemii i biologii dostarczyły ewnej aaratury służącej do badania tej struktury. W ostatnich latach możemy odnotować mnożenie się różnych technik nieinwazyjnego badania rocesów zachodzących w żywym mózgu (takich jak PET tomografia ozytronowa, CT tomografia komuterowa, SPECT tomografia fotonowa, EEG elektroencefalografia). Dzięki tym technikom możliwe stały się obserwacje żywego mózgu i rocesów w nim zachodzących. Wynikiem różnorodnych badań są między innymi ewne modele matematyczne, które w sosób ilościowy róbują wyrazić naturę zjawiska zachodzącego w mózgu lub jego częściach. Ze względu na dużą złożoność mózgu i ogromną ilość neuronów (liczbę elementów składowych mózgu szacuje się na około ), modelowaniu odlegają zazwyczaj tylko ewne jego części, które ze względu na strukturę jaką tworzą nazwano sieciami neuronowymi. Przesyłanie i rzetwarzanie informacji omiędzy biologicznymi neuronami odbywa się na bazie skomlikowanych rocesów fizyko-chemicznych za ośrednictwem tzw. neurotransmiterów. Niestety wiedza o żywym mózgu i jego oszczególnych odzesołach jest na razie zbyt skromna, żeby można było skonstruować jego funkcjonujący model matematyczny. Działanie mózgu związane jest nie tylko z rocesami myślowymi, lecz również z wieloma innymi asektami, które wywierają na niego duży wływ. Potężna moc obliczeniowa mózgu bierze się z jego zdolności do równoległego wykonywania wielu zdań. Wrawdzie szybkość działania jego oszczególnych składników (neuronów) jest niewielka, jednak razem tworzą otężną maszynę obliczeniową. 11

12 Rysunek 2.1. Biologiczne neurony. A odstawowe elementy komórki nerwowej kręgowca. Z ciała komórki wychodzą dwa rodzaje wyustek: dendryty i akson. Aksony mogą mieć różną długość, sięgającą do 1m i są na ogół bardzo cienkie (0,2-20 µm). Potencjały czynnościowe owstają na wzgórku aksonowym i odnawiają się w kolejnych rzewężeniach Ranviera (w aksonach z osłonką mielinową). Końcowe rozgałęzienia aksonów (tzw. drzewka aksonowe) zakończone są kolbkami synatycznymi (na rysunku białe trójkąty symbolizują kolbki synatyczne komórki obudzającej, czarne trójkąty kolbki synatyczne komórki hamującej) na wielu (nawet do 1000) komórkach ostsynatycznych. B komórki z rozmaitymi morfologicznymi tyami wyustek aksonowych i dendrytycznych. [KANDEL 1996]. 12
 zakończone są kolbkami synatycznymi (na rysunku białe trójkąty symbolizują kolbki synatyczne komórki obudzającej, czarne trójkąty kolbki synatyczne komórki hamującej)")
13 x 1 s y x n Rysunek 2.2. Klasyczny model neuronu z wejściami x 1,..., x n, wyjściem y i stanem wewnętrznym s. Z unktu widzenia dzisiejszej informatyki ważne jest nie tyle całościowe modelowanie mózgu, ile możliwość wykorzystania sosobów, jakimi on rzetwarza informacje. Wiadomo już wiele na temat tych rocesów, lecz chęć szybszego okonania bariery niewiedzy ociąga za sobą róby tworzenia modeli, które tylko częściowo są oarte na odkrytych biologicznych rzesłankach. Takie modele czasami omagają wtórnie w badaniach neurobiologicznych i vice versa. Ciekawe z unktu widzenia informatyki jest fakt, że dzięki tym modelom można rozwiązywać zadania, z którymi z trudem radzą sobie inne techniki obliczeniowe. Głównym czynnikiem rzemawiającym za raktycznym stosowaniem sieci neuronowych jest ich zdolność do uogólnień zdobytej wiedzy, która daje im jak gdyby ewną dozę inteligencji. Ciekawym i równie ważnym czynnikiem jest to, że sieci neuronowe są wyosażone w swoje wewnętrzne algorytmy rzetwarzania informacji, które umożliwiają im rozwiązywanie nawet gatunkowo różnych zadań. Sosób, w jaki sieć neuronowa zyskuje wiedzę o zadanym roblemie, olega na nauce na odstawie znanych orawnych rzykładów (zwanych wzorcami uczącymi) rozwiązania danego roblemu, bądź nawet rościej na bazie obserwacji rezentowanej jej wiedzy. Celem nauki jest swoisty (dla sieci neuronowej) sosób oisania wewnętrznych korelacji zachodzących omiędzy wzorcami uczącymi. Na tej odstawie nauczona sieć neuronowa otrafi odowiadać na ytania, zadawane jej z i z oza zakresu wzorców uczących. Do nauki sieci neuronowej mogą zostać zastosowane różne reguły uczące, które są omówione w nastęnym rozdziale Reguły uczące Od dawna intrygował człowieka jego własny umysł jako narzędzie zdobywania i gromadzenia wiedzy, czyli uczenia się. Od kiedy nauka zdobyła ewne narzędzia umożliwiające badanie funkcjonowania mózgu, nie ustają róby zmierzające do wyjaśnienia sosobu jego działania i ewentualnego wykorzystania tej wiedzy w systemach technicznych. Na bazie rzesłanek łynących z neurobiologii, fizyki, chemii organicznej, sychologii używając modeli matematycznych wielu badaczy róbowało oisać rocesy zachodzące w 13

14 mózgu istot żywych i zgłębić tajemnice myślenia i zaamiętywania. Na odstawie tych dociekań sformułowano między innymi nastęujące reguły uczące, które stanowią swoiste źródło wyjścia dla badań rocesów amięciowych i rzetwarzania informacji w sieciach neuronowych [ŻURADA 1996, FIESLER 1997, B ]: Reguła Hebba (Hebbian rule) [HEBB 1949] jest zarazem najrostszą i najwcześniej odkrytą regułą uczenia. Jest ona rzeniesieniem stwierdzenia z zakresu neurobiologii, które mówi: Jeżeli akson neuronu A bierze systematycznie udział w obudzaniu neuronu B owodując jego aktywację, to wywołuje to zmianę metaboliczną w jednym lub obu neuronach, rowadzącą do wzrostu skuteczności obudzania neuronu B rzez neuron A. [HEBB 1949] Najrostsza wersja tej reguły odnosi się do uczenia bez nauczyciela i rzyjmuje, że sygnał wyjściowy neuronu jest sygnałem uczącym, czyli rzyrost wektora wag wynosi: w = η y x ij i j rzy założeniu, że η > 0 jest ewnym wsółczynnikiem uczenia, y i - wyjściem i-tego neuronu, x j - j-tym wejściem neuronów. Nauka olega o rostu na modyfikacji wag omiędzy każdą arą obudzonych neuronów. Wynikiem działania tej reguły jest to, że dodatnia wartość składnika korelacyjnego yi x j owoduje wzrost wagi w ij, co w konsekwencji daje silniejszą (autoasocjacyjną) odowiedź neuronu rzy kolejnej róbie obudzenia tym samym wzorcem wejściowym. Wzorce często owtarzające się na wejściu sieci dają więc najsilniejszą odowiedź na jej wyjściu. Reguła ta jest więc często wykorzystywana w sieciach autoasocjacyjnych. Stosowanie reguły Hebba w czystej ostaci owoduje nieskończony wzrost wag, więc w raktycznych realizacjach stosuje się często ewien wsółczynnik normalizujący rzeciwdziałający temu nieograniczonemu wzrostowi. Wagi są zazwyczaj aktualizowane o każdym wzorcu uczącym (on-line training). Istnieje wiele rozszerzeń i modyfikacji reguły Hebba, która w efekcie może być stosowana do uczenia z nauczycielem (suervised training) i do uczenia bez nauczyciela (unsuervised training). Dobrze się srawuje zarówno dla wzorców binarnych jak i biolranych. W jednej z wariacji tej reguły (neo-hebbian learning) wrowadzono również zdolność sieci do zaominania [KOSKO 1992]. 14
![[ŻURADA 1996, FIESLER 1997, B3.3.1.- 8.]: Reguła Hebba (Hebbian rule) [HEBB 1949] jest zarazem najrostszą i najwcześniej odkrytą regułą uczenia.](/docs-images/47/15018782/images/page_14.jpg "Jest ona rzeniesieniem stwierdzenia z zakresu neurobiologii, które mówi: Jeżeli akson neuronu A bierze systematycznie udział w obudzaniu neuronu B owodując jego aktywację, to wywołuje to zmianę")
15 Reguła ercetronowa (ercetron rule) [ROSENBLATT 1961] dotyczy nauki z nauczycielem i domyślnie zakłada warstwową architekturę sieci neuronowej. Sieć neuronowa oarta na klasycznym modelu ercetronu składa się z warstwy wejściowej zawierającej ewną ilość neuronów o rogowej funkcji aktywacji (linear threshold activation function) oraz jednego neuronu w warstwie wyjściowej, której wyjście może być biolarne lub binarne. Progowa funkcja aktywacji ma dla zadanego rogu θ nastęującą ostać: f ( z) 1 = 0 for z θ for z< θ Korekcja wag dla danego wsółczynnika uczenia η > 0 odbywa się według nastęującej zależności: ij ( t i y i ) x j w = η, gdzie t i jest i-tym sygnałem uczącym dla i-tego wyjścia y i, x j jest j-tym wejściem. Reguła ta charakteryzuje się tym, że gdy wyjście i-tego neuronu y i jest równe jego wartości ożądanej t i ochodzącej od nauczyciela, zmiana wagi jest zerowa. W nawiązaniu do tej właściwości istnieje twierdzenie o zbieżności tej reguły, które mówi, że jeśli istnieje zbiór wag, który ozwala dawać ercetronowi orawną odowiedź dla wszystkich wzorców uczących, wtedy metoda ucząca oarta na tej regule znajdzie ożądany zbiór wag w skończonej liczbie iteracji. Aktualizacja wag nastęuje zwykle o każdym wzorcu uczącym (on-line training) tak jak w rzyadku reguły Hebba. Jakkolwiek reguła ta daje większe możliwości uczenia niż reguła Hebba, możliwość jej stosowania ogranicza się do roblemów liniowo searowalnych, dla których istnieje taka hierłaszczyzna, dla której wszystkie unkty znajdujące się o jednej stronie tej hierłaszczyzny rzyjmują jedną wartość funkcji, a unkty znajdujące się o jej drugiej stronie drugą wartość tej funkcji. Jeżeli sieć neuronowa składa się z ercetronów uformowanych jednowarstwowo, architekturę taką nazywany skrótowo SLP (single-layer ercetron), zaś gdy tworzą architekturę wielowarstwową nazywamy MLP (multi-layer ercetron). 15
 1 = 0 for z θ for z< θ Korekcja wag dla danego wsółczynnika uczenia η > 0 odbywa się według nastęującej zależności: ij ( t i")
16 Reguła delta (delta rule, least-mean-square (LMS) rule) [WIDROW & HOFF 1960] umożliwia rozwiązywanie szerokiej gamy roblemów ze względu na możliwość oerowania na ciągłych i na dyskretnych wejściach, Natomiast neurony osiadają ciągłe funkcje aktywacji. Reguła ta należy do gruy metod uczenia z nauczycielem, a aktualizacja wag nastęuje dla ewnego ustalonego η > 0 według nastęującej zależności: gdzie: ij ( t i net i ) x j w = η, + neti = wi 0 wij xij, wi 0 - szum (bias) j Wagi mogą zostać zainicjowane dowolnie. Nauka sieci w oarciu o regułę delta trwa doóki wagi sieci nie rzyjmą takich wartości, że błąd średniokwadratowy (least-meansquare): E k 1 ( w) = ( t j net j ) 2 j= 1 2 jest zminimalizowany dla wszystkich wzorców uczących (j = 1,..., k). Aktualizacja wag tą metodą może być rzerowadzana zarówno o każdym wzorcu uczącym (on-line training) jak i o rzejrzeniu całego ciągu uczącego (off-line training). Model o ojedynczym wyjściu oartym o liniowy element adatacyjny został nazwany adaline, a jego rozszerzenie na wiele takich neuronów w warstwie wyjściowej madaline (many adalines). Uogólniona reguła delta nazywana również regułą delta była zaroonowana rzez kilku badaczy takich jak Werbos, Parker, Le Cun and Rumelhart [RUMMELHART & MCCLELLAND 1986]. Reguła ta jest zazwyczaj omawiana w owiązaniu z oularną komletną metodą uczenia znaną od nazwą backroagation (metoda roagacji wstecznej). Metoda ta działa w oarciu o metody gradientowe, które dokonują małych kroków w rzestrzeni wag w kierunku sadku gradientu. W rzyadku tej metody i innych odobnych wymaga się, by funkcja aktywacji f była monotonicznie rosnąca i różniczkowalna. Zazwyczaj wykorzystuje się uni- lub biolarne funkcje sigmoidalne, które sełniają w/w kryteria. Porawka wag nastęuje według nastęującej zależności: ij [ t i f( net i )] f ( net i ) x j w = η. 16
 j Wagi mogą zostać zainicjowane dowolnie.")
17 Powyższa formuła charakteryzuje się tym, że orócz zatrzymania rocesu zmian wag dla i ( neti) yi t = f =, zmiana wagi jest dodatkowo hamowana, gdy funkcja aktywacji f jest łaska w unkcie net i. Naturalną konsekwencją zastosowania ochodnej w tej formule jest fakt, że gdy funkcja f osiągnie minimum dla ewnego net i, zmiana wagi w tym unkcie będzie równa zeru. Taka sytuacja srawia, że reguła ta w naturalny sosób nie ouszcza osiągniętego minimum (lokalnego lub globalnego), co ma swoje zalety, lecz również wady. Zastosowanie sigmoidalnej funkcji aktywacji owoduje, że dla dużych bezwzględnych wartości net i wartość ochodnej w tym unkcie jest bliska zeru, a więc i zmiany wag są znikome, mimo że zamierzony cel nie został jeszcze osiągnięty. Nastęnym roblemem tej metody jest to, że algorytm może zostać rzerwany w minimum lokalnym zamiast minimum globalnym. Ponadto metoda ta jest narażona na roblem wolnej zbieżności, który jest charakterystyczny dla wszystkich metod gradientowych. Korekta wag dla neuronów l-tej warstwy ukrytej jest obliczana nastęująco: + ( wl 1, ij wl 1, j) f ( net l i ) x lj w l, ij = +,. j Cechą wsólną dla obydwu owyższych formuł korekty wag jest osiągnięcie orawki błędu doasowanej do wagi w stoniu, w jakim rzyczyniła się do jego owstania. Reguła Kohonena (Kohonen rule) [KOHONEN 1984] jest tyową regułą uczenia nie nadzorowanego i dotyczy w szczególności nauki z rywalizacją (cometitive learning), w której każda grua neuronów bierze udział w rywalizacji. Teuvo Kohonen wynalazł regułę uczenia, która ozwala sieci neuronowej zorganizować się orzez wybranie najbardziej rerezentatywnych neuronów. Takie sieci nazywają się sieciami samoorganizującymi się (self-organizing networks). Jedną z najsurowszych strategii oartych na rywalizacji jest kryterium wygrywający bierze wszystko (winner take all), które owoduje aktualizację tylko wag neuronu, który się cechuje największą wartością aktywacji net i. Niestety często się zdarza, że neurony, które w wyniku wstęnej inicjalizacji są dalekie od danych wzorcowych, nigdy nie wygrywają i stąd nic się nie nauczą. Często sotykaną wariacją tego kryterium jest modyfikacja olegająca na tym, że orócz wag zwycięzcy, są aktualizowane również wagi neuronów sąsiednich z dokładnością do ewnego wsółczynnika wyrażającego ewną ich geometryczną odległość od zwycięzcy. 17

18 Reguła gwiazdy wyjść (outstar rule) [GROSSBERG 1982] związana z ojęciami instar (gwiazda wejść) i outstar (gwiazda wyjść) określające zachowanie się neuronów. Gwiazda wejść odnosi się do neuronu, który otrzymuje (orzez swoje dendryty) wejścia od wielu innych neuronów, zaś gwiazda wyjść odnosi się do neuronów, które wysyłają (orzez swoje aksony) wyjścia do wielu innych neuronów sieci neuronowej. Uczenie gwiazdy wejść jest nie dozorowane i związane z dostrajaniem wag ołączeń w celu doasowania się do wektora wejściowego. To może być rzerowadzone n. wykorzystując regułę Kohonena. Neurony gwiazdy wejść rodukują wyjście, jeżeli ojawi się odowiedni wektor na wejściu sieci. Z drugiej strony, gwiazda wyjść jeżeli jest obudzona rodukuje odowiedni wzorzec, w celu wysłania go do innych neuronów. Stąd wynika nadzorowany sosób nauki. Jedynym sosobem na osiągnięcie uczenia gwiazdy wyjść jest dostrojenie jej wag do ożądanego wektora. Porawka wag jest zdefiniowana dla malejącego wsółczynnika uczenia β > 0 nastęująco: ji ( t w ) w = β. j ji Regułę gwiazdy wyjść używa się do uczenia owtarzających się właściwości relacji wejście-wyjście. Mimo że uczenie odbywa się z nauczycielem, od sieci oczekuje się zdolności wydobywania statycznych cech sygnałów wejściowych i wyjściowych. Przedstawione reguły uczące stanowią zazwyczaj unkt wyjścia dla wielu różnych metod uczenia. Posiadają swoje zalety i wady, jednak żadna z nich nie rozwiązuje wszystkich roblemów w całej swojej roziętości. W owyższych regułach skuiono się na sosobie modyfikacji wag. Jednak ten roces może zachodzić omyślnie tylko rzy ewnych dodatkowych założeniach odnośnie właściwej architektury sieci i jej odowiedniej inicjalizacji. Z raktycznych rób imlementacji różnych systemów w oarciu o sieci neuronowe wiadomo, że stosowanie tych sieci nie srowadza się tylko do roblemu ich nauki. Najierw trzeba mieć stosowną sieć, którą można uczyć. Podejmowane są różne róby konstruowania bądź otymalizacji architektury sieci na bazie algorytmów genetycznych, metod ontogenicznych lub technik oczyszczających sieć ze zbędnych ołączeń (runing). Metody te są jednak bardzo czasochłonne i nie zaewniają otrzymania otymalnej architektury sieci neuronowej dla danego zadania. Nadal więc istnieje otrzeba szukania nowych metod uczenia jak również nowych sosobów konstruowania sieci neuronowych. Właściwym kierunkiem zdaje się być oszukiwanie dedykowanych metod do efektywniejszego rozwiązywania ewnych gru roblemów. Jeśli sieci neuronowe mają się 18

19 stać narzędziem codziennego użytku, konieczne jest oracowanie komleksowych metod ich konstruowania i uczenia tak, by sukces ich stosowania nie był zależny od czynników losowych. Doiero wtedy sieci te mogą stać się godne zaufania i stosowania w dużych systemach informatycznych Podsumowanie Podany wyżej rzegląd informacji na temat struktury i metod uczenia obecnie używanych sieci neuronowych z ewnością nie jest ełny ani wyczerujący. Nie było zresztą możliwe danie takiego wyczerującego oisu w jednym (omocniczym) rozdziale tej racy doktorskiej, onieważ rzy niesłychanie bogatej wiedzy naukowej, jaką obecnie zgromadzono na temat mózgu i na temat działania jego technicznych modeli, czyli sieci neuronowych dla wyczerującej rezentacji tego tematu konieczne było by naisanie kilkutomowej monografii. Zadaniem tego rozdziału było jednak wyłącznie zarysowanie tła dla ewnych roblemów wymagających rozwiązania, które to rozwiązanie będzie oszukiwane w tej właśnie racy doktorskiej. Z odanego rzeglądu osiągnięć neurocybernetyki wynika bowiem wyraźnie, że mimo ogromnego ostęu wiedzy o mózgu i mimo oracowania wielu bardzo skutecznych metod uczenia sieci neuronowych wciąż jeszcze otrzebne są nowe omysły i nowe metody ozwalające na budowę systemów neurocybernetycznych, które były by dostosowane do secyfiki konkretnego zadania obliczeniowego, jakie chcemy rozwiązać. Właśnie oszukiwanie takich nowych metod formowania na zamówienie struktury otrzebnej sieci neuronowej oraz dobierania jej arametrów w sosób szybszy, niż ozwalają to robić klasyczne metody uczenia oświęcone będą dalsze rozdziały, aż do końca racy. Nadrzędną myślą, kierującą usiłowaniami autora było doasowywanie narzędzia (sieci neuronowej) do właściwości zadania. Stąd metody tworzenia i uczenia sieci neuronowych oisane w racy będą mniej uniwersalne, niż wiele innych koncecji, oisywanych w literaturze. Jednak cechą oracowanych technik jest ich bardzo wysoka srawność w odniesieniu do zadań ściśle określonego rodzaju. Takie właśnie nastawienie i taki cel sygnalizuje między innymi nazwa rogramu oracowanego odczas realizacji racy, który nazwano Brain for roblem. 19
 rozdziale tej racy doktorskiej, onieważ rzy niesłychanie bogatej wiedzy naukowej, jaką obecnie zgromadzono na temat")
20 3. METODA AUTOMATYCZ EJ KO FIGURACJI SIECI EURO OWYCH DLA PROBLEMÓW ROZPOZ AWA IA WZORCÓW BI AR YCH Przedstawiona w tym rozdziale metoda służy do automatycznej konfiguracji sieci neuronowych dla roblemów rozoznawania wzorców binarnych. Metoda ta stosuje odmienne odejście zarówno do rocesu określania architektury sieci neuronowej jak również do rocesu jej konfiguracji. Metoda ta nie bazuje na rocesie uczenia, jak jest to w rzyadku większości stosowanych obecnie metod, lecz na rocesie formowanie struktury sieci i jej konfiguracji w oarciu o analizę ciągu uczącego i wyliczenie żądanego zbioru cech. Dzięki temu ominięty został cały roces iteracyjnego dostosowywania arametrów sieci, co ozwoliło znacznie zredukować czas niezbędny do rzygotowania systemu rozoznającego wzorce binarne gdy tego rodzaju system jest nam właśnie otrzebny Założenia metody Zaroonowana w racy metoda w oryginalny sosób róbuje zmierzyć się z roblemem doboru otymalnej architektury sieci neuronowej dla konkretnego roblemu, zadanego ciągiem uczącym. Dobór architektur sieci odbywa się na drodze redukcji synas według zadanych kryteriów w taki sosób, aby jakość uzyskanego rozoznawania i uogólnienia uległa tylko minimalnemu ogorszeniu. Dodatkowo taka redukcja wływa okaźnie na obniżenie kosztów ewentualnej imlementacji konstruowanego systemu rozoznawania. Ponadto oisana metoda otrafi bardzo efektywnie skonfigurować sieć neuronową eliminując w zuełności długotrwały i żmudny roces nauki sieci, omijając zarazem trudności związane z nauką, jak n. roblem minimów lokalnych. Proces konfiguracji sieci dokonywany jest w oarciu o analizę wszystkich wzorców wchodzących w skład zbioru uczącego. Analiza ta służy do wydobywania i ustalenia wartości secjalnego zbioru cech, który stanowi odstawę obliczania wag synatycznych. Warto odkreślić, że cały roces doboru architektury sieci neuronowej oraz konfiguracji odbywa się całkowicie automatycznie i z wysoką srawnością obliczeniową. Zarówno struktura rozoznającej sieci neuronowej jak i wartości wszystkich wystęujących w niej wsółczynników wagowych zostają ustalone w rocesie zaledwie dwukrotnego rzeglądnięcia rozważanej gruy rozoznawanych wzorców, co owoduje, że zaroonowana metoda osiąga otymalne uformowanie struktury i arametrów sieci dostosowanej do 20

21 rozważanego zadania rozoznawania w nieorównywalnie szybszy sosób, niż wszystkie inne znane metody uczenia sieci neuronowych. Dzieje się tak dlatego, iż oracowana metoda nie wymaga iteracyjnej otymalizacji arametrów sieci tak, jak to robią inne techniki uczenia sieci. W racy rozważany jest również roblem oszacowania jakości uogólniania i jakości rozoznawania otrzymanej sieci. Problem oszacowania wyżej wymienionych jakości jest o tyle ważny, że w raktycznych zastosowaniach decyduje o zastosowaniu bądź odrzuceniu danej metody. Oisana w racy metoda ozwala automatycznie obliczyć jakość rozoznawania i jakość uogólniania, co ozwala na odjęcie decyzji o stoniu redukcji synas w zależności od wymagań konstruowanego systemu Ois metody Metoda estymacji cech wzorców binarnych Cały roces doboru architektury sieci neuronowej oraz jej konfiguracji rozoczyna się od etau wartościowania cech binarnych oszczególnych wzorców wchodzących w skład ciągu uczącego. Dla otrzeb określenia cech binarnych konieczne jest wyznaczenie dwóch omocniczych macierzy T i F, których wymiar (I, J) odowiada wymiarowi wzorców uczących. Macierze te są zdefiniowane nastęująco: [ i, j] = #( P [ i, j] = true : k 1 ) i, j T k =,..., [ i, j] = #( P[ i, j] = false : k 1 ) i, j F k =,..., gdzie ilość wzorców ciągu uczącego i = 1,..., I j = 1,..., J Poszczególne ola tych macierzy w myśl ich definicji zawierają odowiednio ilości ól rawdziwych (dla macierzy T) i fałszywych (dla macierzy F) wszystkich wzorców uczących z uwzględnieniem ich ozycji w strukturze danej macierzy. Prawda jest rzekładana na wartość +1, a fałsz na wartość 1. Nastęnie bazując na tych dwóch macierzach i na ilości wzorców ciągu uczącego można obliczyć binarny estymator cechy E k dla wszystkich ól każdego wzorca uczącego w nastęujący sosób: 21
22 k = 1,..., i, j E k [ i, j] = + 1 T 1 F [ i, j] [ i, j] if P if P k k [ i, j] [ i, j] = true = false gdzie 1 1 = 1,..., i, j E k k [ i, j] 1, or, 1 Im większa bezwzględna wartość E k [i,j] dla danego ola macierzy rozważanego wzorca tym większe znaczenie ma to ole odczas rocesu rozoznawania dla rawidłowego rozoznania danego wzorca, onieważ większa bezwzględna wartość świadczy o większej unikalności wartości danego ola macierzy z unktu widzenia całego ciągu uczącego. Dla każdej macierzy tworzącej dany wzorzec można określić taką gruę jej ól, których wartości E k [i,j] są duże, czyli ól, które z unktu widzenia zadania rozoznawania dobrze charakteryzują dany wzorzec na tle całego ciągu uczącego. Dla każdego wzorca uczącego może zostać w ten sosób wyznaczona taka grua cech dobrze wyróżniająca go sośród innych zgodnie z rzyjętymi jednolitymi kryteriami. Te gruy stanowią fundament dla nastęnych obliczeń, mianowicie dla redukcji synas oraz dla obliczania wag synatycznych. 22
23 Jakość rozoznawania i jakość uogólniania Problem redukcji synas jest w ogólności bardzo złożony i ściśle związany z jakością rozoznawania i jakością uogólniania, jaką wynikowa sieć neuronowa będzie się charakteryzować [FIESLER 1997, B3.5]. Redukcja synas rowadzi zazwyczaj do zubożenia informacji jakie sieć osiada o danym roblemie i rowadzi do większych lub mniejszych błędów rozoznawania i uogólniania wzorców uczących. Można więc ostawić nastęujące ytanie: Jak można maksymalnie zredukować ilość synas dla zadanego roblemu, żeby zarazem utrzymać jakość rozoznawania i jakość uogólniania wzorców na akcetowalnym oziomie? W ogólności odowiedź na to ytanie jest trudna. W tej racy odjęto róbę zdefiniowania jakości rozoznawania i jakości uogólniania dla rozważanego roblemu rozoznawania wzorców binarnych. Wartości tych jakości można obliczyć automatycznie i każdorazowo dla danej zredukowanej architektury sieci neuronowej. Wyznaczenie tych wartości ozwala odjąć decyzję o stoniu redukcji synas sieci, co ozwala indywidualnie dobrać arametry redukcji synas dla zadanego roblemu i konkretnych oczekiwać stawianych sieci neuronowej. Dzięki temu znany jest stoień ufności, jakim możemy daną sieć neuronową obdarzyć. Podobnej cechy nie mają z reguły sieci uczone z wykorzystaniem tyowych algorytmów. W myśl definicji estymatora cech oisanego w rozdziale każde ole macierzy cech każdego wzorca uczącego niesie jakąś informację w większym lub w mniejszym stoniu istotną dla zadania rozoznawania. W związku z tym można rzyjąć, że dla rozważanej gruy roblemu i rozważanej gruy architektur sieciowych maksymalną jakość rozoznawania i uogólniania uzyskiwać będziemy dla ełnej nie zredukowanej architektury sieci neuronowej. Taka ełna nie zredukowana architektura sieci będzie stanowić dla danego roblemu unkt odniesienia oraz źródło miary i oceny stonia utraty jakości rozoznawania i jakości uogólniania dla konkretnej rzerowadzonej redukcji synas. W związku z owyższym jakość rozoznawania Q R i jakość uogólniania (generalizacji) Q G zostaną zdefiniowane nastęująco: Q R = min min k= 1,..., k= 1,..., min = 1,..., & l min = 1,..., & l max l= 1,..., max l= 1,..., Out Out R k F k R [] l Out [ ], F [] l Out [ ] k k 23
24 Q gdzie G = average k= 1,..., average k= 1,..., min = 1,..., & l min = 1,..., & l max Out l= 1,..., max Out l= 1,..., R k F k R [] l Out [ ], F [] l Out [ ] k k Out R k [] l oznacza l-te wyjście sieci neuronowej o zredukowanej architekturze owstałe w wyniku obudzenia k-tym wzorcem uczącym, Out F k [] l oznacza l-te wyjście sieci neuronowej o ełnej nie zredukowanej architekturze owstałe w wyniku obudzenia k-tym wzorcem uczącym. Z wzorów tych wynika, że dla jednoznacznego rozoznania wszystkich wzorców uczących otrzeba i wystarcza, żeby wartość Q R > 0. Z kolei jeśli chodzi o wartość Q G określającą jakość uogólniania (generalizacji) wymagania są bardziej rygorystyczne. Ze zrozumiałych względów jakość uzyskanego uogólnienia na wzorce z oza ciągu uczącego (i związana z nią ufność wobec sieci) będzie tym większa im większą wartość Q G dla konkretnej wynikowej sieci neuronowej uzyskamy i już od konkretnego zadania zależy, na ile wartość Q G można obniżyć, a w związku z tym, jak bardzo można architekturę sieci neuronowej zredukować Kryteria redukcji synas Redukcja synas jest celowa ze względu na niższy koszt realizacji sieci zawierającej mniejszą liczbę elementów składowych. Proces redukcji jest jednak zawsze ewnym komromisem omiędzy uzyskaną jakością rozoznawania i jakością uogólniania dla wynikowej sieci neuronowej. Dlatego rzed rzystąieniem do redukcji synas ważne jest ustalenie, jak dokładnych odowiedzi od sieci oczekujemy. Odowiedź na to ytanie ozwoli tak dobrać odowiednie arametry redukcji, aby sieć neuronowa sełniała oczekiwania jej konstruktora i by w satysfakcjonujący sosób rozwiązywała ostawione jej zadanie. W tej racy zdefiniowano trzy kryteria redukcji synas ozwalające w różny sosób włynąć na roces redukcji synas rzyisując odowiednio większą wagę różnym arametrom wynikającym z wyznaczonych zbiorów cech dla oszczególnych wzorców uczących. Mianowicie: 1. Kryterium maksymalnych cech ( C 0,100 % ) F 24
25 Kryterium to wyznacza granicę wartości cech E Min, owyżej której synasy odowiadające tym cechom nie mogą zostać zredukowane. 1 EMin = 1+ ( 1) CF 100 Kryterium maksymalnych cech redukuje ilość synas dla oszczególnych wzorców uczących nierównomiernie, uwzględniając rzy redukcji tylko wielkość cechy, lecz zarazem dbając o to, by najistotniejsze cechy dla każdego wzorca nie zostały zredukowane. 2. Kryterium minimalnej ilości synas ( C 0,100 % ) Kryterium to określa, jaka minimalna ilość synas Min musi o redukcji dla każdego wzorca uczącego w sieci neuronowej wystęować. Min = I J C 100 Kryterium minimalnej ilości synas zaewnia to, że każdy wzorzec niezależnie od wielkości rzyisanych mu cech dla oszczególnych jego ól będzie w sieci rerezentowany odowiednią liczbą synas i nie dojdzie do sytuacji, że jakaś bardzo unikatowa cecha ewnego wzorca zdominuje cały roces redukcji synas dla danego wzorca uczącego, co w ewnych sytuacjach może nie być korzystne w zależności od secyfiki rozwiązywanego rzez sieć zadania rozoznawania. 3. Kryterium minimalnej recyzji rozoznawania ( C 0,100 % ) Kryterium to mówi, jaka minimalna suma wyznaczonych cech P Min musi być dla każdego wzorca uczącego w sieci rerezentowana. P Min = E [ i, j] i, j k C P 100 Kryterium minimalnej recyzji rozoznawania stanowi gwarancję tego, że dla każdego wzorca uczącego ewna minimalna suma jego najistotniejszych cech będzie zawsze w sieci rerezentowana niezależnie od rozkładu ich wielkości i ilości jego cech większych i mniejszych. Taka minimalna rerezentacja sumy najbardziej unikalnych cech wzorców jest ściśle związana z minimalną recyzją ich rozoznawania na tle innych wzorców ciągu uczącego. Wszystkie owyżej oisane kryteria odgrywają ewną istotną rolę w rocesie redukcji synas. Każde z nich odowiada za zachowanie ewnych secyficznych własności wzorców uczących na odstawie indywidualnych wielkości cech dla oszczególnych wzorców uczących. Wszystkie trzy kryteria mogą być używane łącznie w różnych konfiguracjach, 25 P
26 wymuszając łącznie odowiednio zalanowany roces redukcji uwzględniając ustalone kryteria według secyfiki rozwiązywanego zadania rozoznawania. Dzięki łączności stosowania wszystkich wymienionych kryteriów można w rosty sosób zdefiniować ogólną charakterystykę rzyjętej zasady redukcji synas. Charakterystyka ta będzie dalej oznaczana symbolem F P (Feature, umber, Precision) i dla rozważnej klasy architektur sieciowych będzie zaisywana nastęująco: FNP = C F C N C P, więc n. gdy F P = oznacza to, że C F = 52%, C = 28% i C P = 47%. Na odstawie zadanej F P charakterystyki redukcji synas architektura sieci neuronowej zostanie automatycznie skonstruowana, mało istotne synasy z unktu widzenia oisanych wcześniej kryteriów będą zredukowane, a ozostałe nie zredukowane synasy skonfigurowane orzez odowiednie nadanie wartości ich wagom na odstawie określonych wcześniej cech odowiadającym tym synasom. Charakterystyka redukcji synas F P w sosób całkowicie jednoznaczny wyznacza architekturę i całą konfigurację sieci neuronowej. Z tego też względu nie ma otrzeby zaamiętywania skonfigurowanej sieci, jeśli amiętany jest ciąg uczący, albowiem dla danego ciągu uczącego i danej charakterystyki F P zawsze zostanie wygenerowane taka sama sieć neuronowa. Dodatkowo z daną charakterystyką F P i z danym ciągiem uczącym są ściśle związane wartości jakości rozoznawania Q R i jakości uogólniania Q G, które też są jednoznacznie determinowane rzez wartość F P Automatyczna konfiguracja sieci neuronowej Cały roces automatycznej konfiguracji sieci neuronowej włącznie z ustaleniem jej oszczędnej zredukowanej architektury rzebiega w trakcie dwukrotnego rzeglądnięcia ciągu uczącego nastęująco: W 1. rzeglądnięciu ciągu uczącego: Wyznaczane są macierze T i F. W 2. rzeglądnięciu ciągu uczącego dla każdego wzorca uczącego wykonywane są kolejno nastęujące czynności: Obliczenie macierzy estymatora cech E k. Redukcja synas na odstawie charakterystyki F P związana z zerowaniem tych wartości E k [i,j], które nie sełniają stawianych wymogów. 26
27 Ustalanie wag dla nie zredukowanych synas, które sełniają charakterystykę F P. Ostatnią czynnością, jaka została do zrobienia jest obliczenie wag synatycznych na odstawie wszystkich nie wyzerowanych (o etaie redukcji) wartości E k [i,j] w nastęujący sosób: W [ i, j] = k m, n Ek[ i, j] E k [ m, n] W wyniku owyższych obliczeń wszystkie wartości wyjść sieci neuronowej są znormalizowane do rzedziału domkniętego 1+, 1, co srawia, że maksymalna wartość określająca rozoznanie wzorca ochodzącego z ciągu uczącego ma wartość rawdy (+1), zaś wartość negatywu wzorca uczącego wartość fałszu (-1). Wszystkie zaburzone wzorce ochodzące z oza ciągu uczącego rzyjmują różne wartości z rzedziału 1+, 1 w zależności od stonia ich odobieństwa do oszczególnych wzorców uczących Porównywalność uzyskanych wyników Otrzymane wyniki rozoznawania są zwykle szacowane i orównywane rzez człowieka, który dokonuje tego, wykorzystując intuicyjną miarę liniową. Ponadto klasyfikacja negatywów wzorców uczących owinna również w sosobie ich klasyfikacji odowiadać intuicji, tzn. negatywy owinny zostać rozoznane jako odowiadające im ozytywy z zaznaczeniem ich odwrotności. Z oisanych owyżej owodów funkcja aktywacji neuronów została zdefiniowana tak, jak to okazano na rys. 3.1.: 27
28 g(x) x -1 Rysunek 3.1. Funkcja aktywacji neuronów: g(x) = x; Dom g [-1,1], Im g [-1,1]. Funkcja rzedstawiona na rys mimo swojej rostoty doskonale odzwierciedla jak liniową miarę używaną intuicyjnie do orównań, tak odowiednią klasyfikację negatywów wzorców uczących nadając im orawną bezwzględną wartość ich rozoznania dodatkowo oznaczając negatywy znakiem minus Zalety i wady metody W zarezentowanej koncecji automatycznej konfiguracji sieci neuronowych dla wzorców binarnych można dostrzec wiele zalet, do których należą rzede wszystkim: Zautomatyzowany roces doboru architektury sieci rzy uwzględnieniu kryteriów redukcji odnoszących się do mało ważnych synas z unktu widzenia oszczególnych wzorców uczących. W ełni automatyczna konfiguracja sieci neuronowej dla zadanego roblemu. Wysoka srawność obliczeniowa związana z koniecznością zaledwie dwukrotnego rzeglądnięcia ciągu uczącego. Wyeliminowanie rocesu uczącego wymagającego iteracyjnej otymalizacji arametrów związanego z wieloma roblemami, n. roblemu minimów lokalnych. Prosta, intuicyjna, liniowa interretacja miary odobieństwa rozoznawanych wzorców względem wzorców uczących. 28
29 Właściwe odwzorowanie negatywów wzorców uczących. Możliwość oceny jakości uzyskanego uogólnienia oraz srawdzenie, czy jakość rozoznawania jest zachowana na wymaganym niezerowym oziomie. Wśród zalet metody można też wskazać, że możliwe jest w niej rozoznawanie wzorców, które nie zawierają wartości z założenia w ełni rawdziwe, bądź też fałszywe, ale charakteryzujące się ewnym stoniem wiarygodności w rzełożeniu na ewne wartości ośrednie omiędzy rawdą a fałszem. Metoda ta ma także swoje wady i ograniczenia, do których można rzede wszystkim zaliczyć: Metoda ta silnie bazuje na ozycji oszczególnych ól w macierzy wzorców uczących i w związku z tym jest narażona (szczególnie w rzyadku rozoznawania obrazów) na rzesunięcia, rotacje i skalowania. Problem ten może być częściowo rozwiązany w rzyadku, gdy owe rzesunięcia, rotacje i skalowania nie są zbyt duże, orzez zastosowanie grubszego rastra, który może zamortyzować drobne niezgodności. Innym odstawowym ograniczeniem metody jest to, iż działa ona tylko na wzorcach binarnych, które czasami nie dają możliwości zaisu ewnych zależności charakteryzujących się ewną ciągłą zależnością. Wynikiem działania tej metody jest sieć neuronowa zawierająca tyle neuronów ile jest wzorców uczących, co w rzyadku dużych zbiorów danych może być ewnym ograniczeniem ze względu na ograniczenia amięciowe, mimo że ilość alokowanej amięci dla jednego neuronu sieci w rzyadku tej metody jest niewielka Chociaż oisana metoda nie ozwala na rozwiązanie w ogólności wszystkich stawianych jej roblemów, z owodzeniem można ją stosować w wielu różnych alikacjach ze względu na szybkość jej działania, zdolność automatycznego doboru architektury sieci oraz intuicyjnie rostą interretację otrzymanych wyników. Metoda ta jest również godna olecenia ze względu na możliwość oceny uzyskanego uogólnienia, co wiąże z tą metodą wyższy stoień wiarygodności w orównaniu do metod, które co rawda dają ewne uogólnienie, ale jest ono nieewne, niemierzalne i czasami nawet niezgodne z intuicją Kierunki rozwoju metody Metoda ta stanowi ewne wrowadzenie do badań związanych z automatyczną konfiguracją sieci neuronowych na bazie wcześniejszej analizy wzorców uczących. W 29
30 rzygotowaniu znajduje się uogólnienie oisanej metody umożliwiające jeszcze większą komresję informacji amiętanych w sieci. Komresja ta olegać będzie na rzyorządkowaniu jednego lub kilku wyjściowych neuronów klasyfikujących wielu wzorcom wejściowym należącym do jednej klasy, czyli odowiedniość N : K, gdzie K << N, co znacząco zmniejszy rozmiar amięci otrzebnej na ewentualną imlementację systemu rozoznawania. Dodatkowo metoda umożliwiać będzie automatyczną konfigurację sieci dla danych z ciągłego rzedziału omiędzy rawdą i fałszem. Usrawniona metoda dysonować będzie też możliwością korzystania z nieełnych danych uczących. Rozważane jest również uogólnienie automatycznej konfiguracji na sieci wielowarstwowe oarte na ercetronach (o nieliniowej funkcji aktywacji) dla roblemów rozoznawania wzorców. Metodyka automatycznej konfiguracji sieci, zarezentowana w rzedstawionej wyżej koncecji, wychodzi z założenia, że skoro można nauczyć sieć neuronową odwzorowania ewnego niezmiennego zbioru wzorców uczących, owinna istnieć metoda ozwalająca na szybkie obliczenie arametrów sieci na ich odstawie. W rzyadku biologicznego mózgu sytuacja jest inna. Mózg zmuszony jest racować na danych, które się cały czas dynamicznie zmieniają, i musi być zdolny do dostosowywania się do zmieniającego się środowiska. Jeśli jednak dane, które chcemy sieć nauczyć mają charakter statycznego, skończonego i niesrzecznego zbioru uczącego, wtedy musi istnieć rzekształcenie odwzorowujące dane wejściowe w dane wyjściowe, jak również ewna aroksymacja tego odwzorowania możliwa do zaimlementowania na bazie sieci neuronowych Praktyczna realizacja metody - alikacja Otimal Recognition Dla zilustrowania funkcjonowania zaroonowanej w tej racy metody automatycznej konfiguracji sieci neuronowych dla wzorców binarnych, a także dla raktycznego srawdzenia jej efektywności została rzez autora racy oracowana i orogramowana alikacja nazwana Otimal Recognition (Rysunek 3.2.). Alikacja ta w raktyczny sosób umożliwia zbadanie słuszności założeń oraz srawdzenie jakości uzyskanego uogólnienie, jakie wynikowa sieć neuronowa daje dla konkretnego roblemu zadanego ciągiem uczącym. Alikacja ta umożliwia tworzenie nowych ciągów uczących, jak również rzerowadzenie w ełni automatycznej konfiguracji architektury i arametrów sieci neuronowej (rozdział i ) według zadanych kryteriów zgodnie z rozdziałem tej racy. Kolejnym udogodnieniem zaimlementowanym w tej alikacji jest możliwość automatycznego 30
31 obliczania jakości uzyskanego uogólnienia jak i wyznaczenie jakości rozoznawania (rozdział ), co daje możliwość natychmiastowej weryfikacji stonia dokonanej redukcji i odjęcia kolejnych kroków w myśl wymagań stawianych rzez konkretnie rozwiązywane zadanie. 31

32 Rysunek 3.2. Główne okno alikacji Otimal Recognition z uwidocznieniem jednego wzorca ciągu uczącego, skonfigurowanych wag synatycznych dla niego oraz wyniku rozoznawania go rzez wynikową sieć neuronową z zaznaczeniem 100% zgodności z rozoznanym wzorcem z ciągu uczącego. Żółty kolor oznacza drugi najbliższy wzorzec od względem bliskości rozoznania Przykład rozwiązania roblemu zadanego ciągiem uczącym Dla leszego zilustrowania działania alikacji Otimal Recognition osłużymy się rostym rzykładem 26-literowego alfabetu, który zostanie wrowadzony jako ciąg uczący. 32

33 Nastęnie zostanie automatycznie skonfigurowana sieć neuronowa i obliczona jakość rozoznawania i jakość uzyskanego uogólnienia. W końcu okazane będą rzykładowe wyniki rozoznawania różnych wzorców rzy użyciu skonfigurowanej sieci neuronowej. Najierw osługując się rzyciskiem z aska narzędzi lub korzystając z menu File/New... obieramy wymiary macierzy wzorców ciągu uczącego tak, jak to zostało okazane na rysunku 3.3. Rysunek 3.3. Okienko umożliwiające obranie wymiarów macierzy wzorców ciągu uczącego Po wydaniu olecenia zbudowania ciągu uczącego w oarciu o odane wymiary w głównym oknie alikacji ojawi się usty jednoelementowy ciąg uczący, jak to zostało okazane na rysunku

34 Rysunek 3.4. Widok głównego okna alikacji o wydaniu olecenia budowy nowego ciągu uczącego Nastęnie o wyborze widoku kolejnych wzorców ciągu uczącego można rzejść do rzeglądania i edycji wzorców ciągu uczącego dodając nowe, usuwając, wycinając, koiując i wklejając korzystając z odowiednich rzycisków okazanych na rysunku 3.5. Rysunek 3.5. Przyciski umożliwiające rzeglądanie i edycję ciągu uczącego. Podczas edycji wzorców uczących osługujemy się myszką odowiednio rzyciskając na lewy rzycisk myszki zaznaczając, bądź odznaczając odowiednie ola, bądź nacisnąwszy rzycisk myszki ciągnąc i malując lub usuwając dowolne linie jak to okazano na rysunku

35 Rysunek 3.6. Do edycji oszczególnych wzorców uczących jest wykorzystywana myszka. Gdy edycja ciągu uczącego jest zakończona, można rzystąić do etau automatycznej konfiguracji architektury i arametrów sieci neuronowej orzez naciśnięcie rzycisku. W rezultacie ojawi się okienko dialogowe (Rysunek 3.7.) umożliwiające wybranie i ustalenie arametrów redukcji architektury sieci neuronowej według oisanych w rozdziale kryteriów. Rysunek 3.7. Okienko dialogowe umożliwiające określenie arametrów redukcji architektury sieci neuronowej. Po wydaniu olecenia konfiguracji sieci neuronowej błyskawicznie ojawi się skonfigurowana architektura sieci wraz z obliczonymi wagami synatycznymi w środkowej części dzielonego widoku jak to okazuje Rysunek
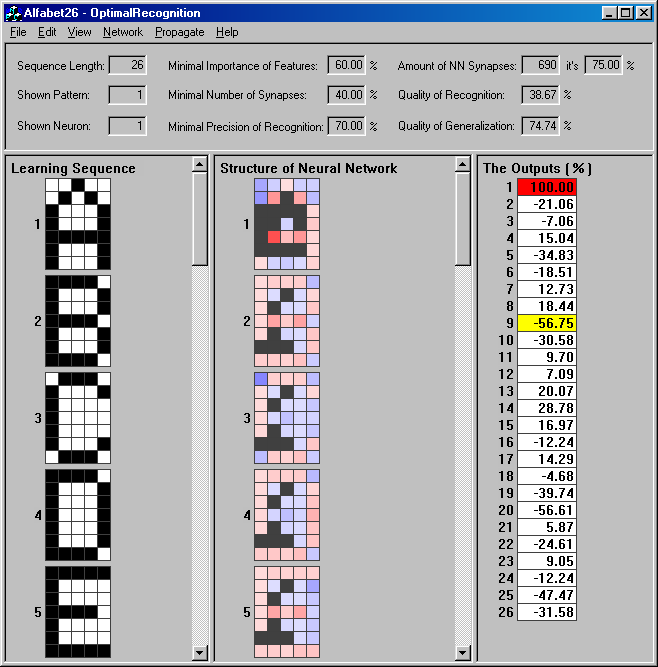
36 36
37 Rysunek 3.8. Widok ciągu uczącego (z lewej) i widok zredukowanej architektury sieci neuronowej według zadanych kryteriów (w środku). Szare ola odowiadają zredukowanym synasom, czerwone ola oznaczają synasy o charakterze obudzającym, a niebieskie ola synasy o charakterze hamującym. Stoień zabarwienia kolorem czerwonym i niebieskim odzwierciedla bezwzględną wartość wagi synatycznej odowiednio dla synas obudzających i hamujących. Zarazem im bardziej intensywny jest kolor, tym bardziej unikalne jest dane ole dla danego wzorca na tle całego ciągu uczącego. Z rawej strony widać odowiedź sieci na obudzenie jej ierwszym wzorcem uczącym, co odowiada w tym rzyadku literce A. Kolorem czerwonym oznaczona jest maksymalna bezwzględna wartość wyjścia, co jest równoznaczne z rawidłowym rozoznaniem literki A. Żółtym kolorem oznaczona jest druga największa w sensie rozoznania bezwzględna wartość, jaka ojawiła się na wyjściu sieci. W tym rzyadku sieć neuronowa została zredukowana o 25% synas rzy zachowaniu dobrych wskaźników jakości rozoznawania (Q R = 38,67% > 0) i jakości uzyskanego uogólnienia (Q G = 74,74%). Po udanej konfiguracji sieci neuronowej można rzejść już tylko do srawdzenia zdolności sieci odnośnie rozoznawania i uogólniania wzorców uczących. Jak okazano na rysunku 3.8. sieć rawidłowo rozoznała 1. wzorzec uczący o naciśnięciu rzycisku z głównego aska narzędziowego. Zaburzymy teraz ten wzorzec naciskając rzycisk, służący do edycji wzorców testujących. Nastęnie wydamy olecenie klasyfikacji tego wzorca (nie należącego do ciągu uczącego) sieci neuronowej naciskając rzycisk, jak to okazano na rysunku

38 Rysunek 3.9. Przedstawia rawidłowe rozoznanie zaburzonego wzorca uczącego A. W środku okienka widoczna jest zredukowana macierz wag dla rawidłowo rozoznanego wzorca uczącego A. 38
39 Nastęnie można srawdzić, jak sieć sobie oradzi z rozoznaniem negatywu wzorca uczącego i czy założone ostulaty metody wobec intuicyjnej interretacji tak rozoznanych wzorców się srawdzą. W związku z tym na wejście skonfigurowanej sieci neuronowej odamy negatyw rozważanego wzorca uczącego A i analogicznie jak w orzednim rzyadku damy sieci olecenie klasyfikacji tego wzorca, jak to okazano na rysunku

40 Rysunek Przedstawia rawidłowe rozoznanie negatywu wzorca uczącego A. Znak - określa intuicyjną odwrotność rozoznawanego wzorca względem wzorca uczącego, zaś wartość 100% określa ełną jego zgodność z kształtem. Jak widać rzedstawiona sieć neuronowa rawidłowo sklasyfikowała rzedstawione jej wzorce rzy zachowaniu zdolności do uogólnień rzy redukcji synas o ¼ ich całkowitej ilości. 40
41 4. METODA STEROWA YCH KOMPROMISÓW Proonowana w tej racy metoda sterowanych komromisów (MGC Method of Guided Comromises) jest metodą należącą do gruy metod uczenia z nauczycielem (suervised learning). W metodzie tej nie korzysta się jednak z informacji o gradiencie, jak jest to n. w oularnej metodzie roagacji wstecznej błędu (BP Back Proagation). Proces uczenia sieci neuronowej zaroonowaną w tej racy metodą bazuje na wyznaczanych odczas uczenia tzw. odchyleniach od uzyskanego komromisu, określanych w danym miejscu sieci odczas rocesu uczącego, służących do wyznaczania kierunku zbliżania się do finalnego rozwiązania, zadanego ciągiem uczącym. Oisana metoda znajduje zastosowanie do stosunkowo szerokiego zakresu zadań uczenia sieci neuronowych o toologiach nie zawierających srzężeń zwrotnych. Zaroonowana metoda jest wciąż rozwijana. Jej aktualna wersja ozwala na efektywne uczenie sieci dwuwarstwowych. Rozwój metody wiąże się z ewnymi jej uogólnieniami, ozwalającymi w ciekawy sosób zmierzyć się z nawet bardzo trudnymi zadaniami (n. klasyczny roblem 2 siral). W racy tej rzedstawiono nie tylko w ełni funkcjonalną, doracowaną użytkowo część metody sterowanych komromisów, lecz również tą jej część, która jest nadal w sferze dalszych badań - dla wyeksonowania zalet metody, ale również i roblemów związanych z wrowadzanymi jej uogólnieniami. Metoda wydaje się ersektywicznie ciekawa, uznano więc, że celowe jest rzybliżenie kierunków dalszego jej rozwoju, gdyż może to stanowić źródło insiracji dla innych badaczy. Problematyka tworzenia nowych metod uczących jest na tyle obszerna i ciekawa, że ostanowiono w racy rzedstawić także analizę trudności naotkanych rzy tworzeniu oisywanej metody, wychodząc z założenia, że wszystkie informacje dotyczące roblemów z dostosowaniem arametrów sieci do ostawionego jej zadania stanowić mogą wartościowe źródło informacji dla kolejnego konstruktora konkretnej adatacji sieci do rozwiązania innego konkretnego zadania. Na odstawie takich informacji, obiektywnie rzedstawiających zalety i wady roonowanych (różnych) technik uczenia sieci neuronowych, konstruktor neuronowego rozwiązania wybranego raktycznego roblemu może bardziej świadomie dokonywać wyboru stosowanej rzez siebie metody i nabyć większej ewności w związku z jej stosowaniem i gwarancji orawności uzyskanych wyników. Schemat tego rozdziału jest nastęujący: Po krótkim oisie stosowanych modeli i użytej notacji nastęuje wrowadzenie ewnych założeń dla zaroonowanej metody. Są to założenia odnośnie szybkości nauki, sosobu korekty owstałych w rocesie nauki błędów, 41
42 arametrów wływających na sukces rocesu uczenia sieci neuronowej i ewnej szczególnej cechy, na której bazuje w swojej filozofii oisana metoda sterowanych komromisów. Po tym krótkim wrowadzeniu nastęuje gruntowny ois metody, który rozoczyna się od oisu jej najrostszej ostaci, ze względu na ułatwienie systematycznego jej oznania. W dalszym rozdziale metoda odlega licznym rozszerzeniom, wrowadzanym systematycznie rzez autora w celu orawienia i rozszerzenia jej możliwości obliczeniowych i zakresu stosowalności. Nastęnie rozważane są zalety i wady rzedstawionej metody i wyznaczone są kierunki oszukiwań dla dalszego jej rozwoju. Końcowe odsumowanie zawiera również informacje o roblemach związanych z kolejnymi uogólnieniami oisanej metody, które mogą osłużyć również innym badaczom jako źródło insiracji i oszukiwań. W końcu oisana jest alikacja Brain for Problem, umożliwiająca raktyczne srawdzenie słuszności założeń rezentowanej metody Zastosowany model neuronu i używane słownictwo i notacja Ze względu na różnorodność notacji stosowanej rzez wielu autorów oraz ze względu na wykorzystywanie różnych modeli neuronu w różnych racach - dla uściślenia dalszego oisu rzyjęto nastęujący model neuronu i notację rzedstawione na rysunku 4.1. x 1 x n w 1 wn d 1 d n s y = g (s ) k Rysunek 4.1. Model neuronu wraz z użytymi oznaczeniami Na rysunku tym (i dalej w tekście) używać będziemy nastęujących oznaczeń: x 1,..., 1 x sygnały wejściowe (inut signals) rozważanego neuronu lub efektora, n wyznaczone dla ustalonego wzorca, w,..., w wagi synatyczne rozważanego neuronu lub efektora (weights), n d 1,..., d ostsynatyczne obudzenie dendrytyczne rozważanego neuronu lub n efektora, wyznaczone dla ustalonego wzorca, 42
43 θ s y róg rozważanego neuronu lub efektora (threshold), stan obudzenia neuronu rozważanego neuronu lub efektora, wyznaczony dla ustalonego wzorca sygnał wyjściowy (outut signal) rozważanego neuronu lub efektora, wyznaczony dla ustalonego wzorca Sygnał wyjściowy neuronu y = g k ( s ) Stan obudzenia neuronu y wyznaczany jest jako funkcja stanu obudzenia neuronu: s obliczany jest jako suma obudzeń oszczególnych dendrytów; nastęnie od tej sumy odejmowana jest wartość rogu: s n = i= 1 d i θ (4.1.1) Pobudzenie dendrytyczne d i jest ważoną wartością sygnału wejściowego: d i = x i w i Bardzo często jako funkcję aktywacji neuronu wybiera się funkcję o charakterystyce sigmoidalnej (generic sigmoid activation function (FIESLER B3.2:4)) (Rys. 4.2.), zdefiniowaną najczęściej w nastęujący sosób: y ( s ) 1 = gsigm = taka, że g : R [0, 1] 1+ ex ( s ) lub y ( s ) tanh( s ) = g taka, że g : R [ 1, 1] tanh = 43
44 y = g (s ) k +1 s -1 Rysunek 4.2. Często stosowane funkcje sigmoidalne jako funkcje aktywacji neuronu Jakkolwiek funkcje te w ewien sosób rzybliżają funkcję rogową (threshold function), jaka jest obserwowana u biologicznych odowiedników sztucznych neuronów, jednak z matematycznego unktu widzenia sieć neuronowa złożona z neuronów o tak zdefiniowanych funkcjach aktywacji nie będzie dawała dobrego uogólnienia dla szeroko ojętej ekstraolacji, lecz może służyć głównie do interolacji. Ponadto użycie funkcji o ograniczonym zbiorze wartości funkcji nastręcza ewne trudności rzy konwersji rzeczywistych wartości doświadczalnych na wartości ciągu uczącego i odwrotnie. W tej racy zdefiniowano odmienny model neuronu, rzyjęty w roonowanej ostaci właśnie ze względu na orawienie właściwości ekstraolacyjnych tworzonej sieci neuronowej. Model ten oeruje na ełnym zbiorze liczb rzeczywistych jako na zbiorze dozwolony wartości funkcji, więc jego użycie nie wymusza sztucznego skalowania danych, jak się to dzieje w klasycznym modelu wykorzystującym funkcje sigmoidalne. Podstawowe funkcje aktywacji dla tego modelu zostały zdefiniowane nastęująco: y y y ( s ) = s = g1 β - funkcja liniowa (Rys. 4.3.) ( s ) = sgn(β s ) s = g 2 β - funkcja ierwiastkowa (Rys. 4.4.) ( s ) = β s s = g3 β - funkcja otęgowa (Rys. 4.5.) 44
45 y = g (s ) 1 s Rysunek 4.3. Funkcja aktywacji - liniowa: ( ) =β g1 s s taka, że g1 : R R y = g (s ) 2 s g2 s = sgn β s β s taka, że Rysunek 4.4. Funkcja aktywacji - ierwiastkowa: ( ) ( ) g 2 : R R 45
46 y = g (s ) 3 s Rysunek 4.5. Funkcja aktywacji - otęgowa: g ( s ) = β s β s 3 taka, że g3 : R R W dalszych rozważaniach zastosujemy nietyową notację, zwiększającą jednak czytelność oisów formalnych, mianowicie założymy, że wartości zmiennych związanych z sygnałem uczącym, mającym swe źródło w ciągu uczącym, będą oznaczane dużymi literami: Y wyjściowy sygnał uczący ochodzący od nauczyciela rozważanego neuronu lub efektora, wyznaczony dla ustalonego wzorca uczącego, S uczony stan obudzenia neuronowego rozważanego neuronu lub efektora, wyznaczony dla ustalonego wzorca uczącego, D i uczone i-te ostsynatyczne obudzenie dendrytyczne rozważanego neuronu lub efektora, wyznaczone dla ustalonego wzorca uczącego, W i nowa wartość i-tej wagi wyznaczona w wyniku korekty rozważanego neuronu lub efektora dla ustalonego wzorca uczącego, Θ nowa wartość rogu wyznaczona w wyniku korekty rozważanego neuronu lub efektora dla ustalonego wzorca uczącego, X i nowy i-ty wejściowy sygnał uczący obliczony w wyniku wstecznej roagacji sygnału uczącego ochodzącego od nauczyciela na odstawie ciągu uczącego rozważanego neuronu lub efektora, wyznaczony dla ustalonego wzorca uczącego (w rzyadku sieci neuronowych zawierających neurony ośrednie i/lub warstwy ukryte). 46
47 Korekty błędów będą oznaczane grecką literką σ z indeksem dolnym odnoszącym się do arametru, który jest korygowany. Poniższe oznaczenia rzyjmują więc nastęujące znaczenie: σ y korekta błędu sygnału wyjściowego wzorca uczącego ; σ = Y y, y y neuronu, wyznaczona dla ustalonego σ s korekta błędu stanu obudzenia neuronu wzorca uczącego ; σ = S s, s s, wyznaczona dla ustalonego σ θ korekta rogu θ, wyznaczona dla ustalonego wzorca uczącego ; σ θ θ = Ξ, σ d i korekta błędu i-tego ostsynatycznego obudzenia dendrytycznego wyznaczona dla ustalonego wzorca uczącego ; σ = D d, di i i d i, σ w i korekta i-tej wagi w i, wyznaczona dla ustalonego wzorca uczącego ; σ = W w, wi i i σ x i korekta błędu i-tego sygnału wejściowego x i, wyznaczona dla ustalonego wzorca uczącego (używane w rzyadku sieci neuronowych zawierających neurony ośrednie i/lub warstwy ukryte); σ = X x. x i i W odniesieniu do ciągu uczącego zastosowano nastęującą notację: numer orządkowy wzorca uczącego należącego do ciągu uczącego, Q ilość wzorców uczących, czyli długość ciągu uczącego, Dla zwiększenia czytelności nastęujących oisów wrowadzimy kilka ojęć: Proces uczenia składa się zazwyczaj z wielu eok uczących i ma na celu taką stoniową modyfikację stanu sieci neuronowej (tzn. jej arametrów wolnych), aby odwzorowanie 47
48 (dokonane rzy jej omocy) wzorców uczących w odowiednie wyjścia sieci było jak najbardziej zgodne z ciągiem uczącym. Eoka ucząca (nazywana dalej krótko eoką) składa się z jednego lub więcej etaów uczących. Jej celem jest korekta wszystkich arametrów wolnych sieci dla wszystkich wzorców uczących, rzy czym każdy arametr sieci jest modyfikowany w danej eoce uczącej dokładnie raz dla każdego wzorca uczącego. Eta uczący (nazywany dalej krótko etaem) składa się z fazy obudzenia sieciowego i z fazy wstecznej roagacji sygnału uczącego dla każdego wzorca uciągu uczącego. Każdy eta kończy się o wykonaniu tych dwóch faz kolejno dla wszystkich wzorców uczących fazą komromisowej aktualizacji wag i rogów. Eta uczący dotyczy zawsze tylko jednej warstwy sieci. O ile sieć osiada więcej warstw, wtedy na eokę uczącą składa się kilka etaów uczących. Wirtualna warstwa uczenia (nazywana dalej krótko warstwą) jest to taki zbiór sensorów, neuronów i efektorów sieci neuronowej, który jest aktualizowany w jednym etaie uczącym. Warstwa taka nie koniecznie musi być zgodna z fizycznymi warstwami zarojektowanymi rzez konstruktora sieci, lecz jest bardziej zależna od istniejących w sieci ołączeń omiędzy neuronami i efektorami. Ponadto w rzyadku metod dynamicznie rekonfigurujących architekturę sieci neuronowej (n. metody ontogeniczne) również warstwy uczenia mogą ulegać zmianom, tj. zbiór sensorów, neuronów i efektorów składający się na daną warstwę uczenia może ulegać modyfikacjom. Można owiedzieć, że warstwy uczenia są wirtualnie tworzone w trakcie rocesu uczenia, a ich żywotność jest ściśle związana z danym etaem uczącym. Prawdziwa wirtualność tych warstw ujawnia się doiero w rzyadku metod dynamicznie zmieniających architekturę sieci w trakcie rocesu uczenia, albowiem w rzyadku metod o sztywnej architekturze warstwy te są każdorazowo (tj. w każdej eoce uczącej dla każdego etau uczącego) wyznaczane w taki sam sosób. Po wrowadzeniu tych oznaczeń w kolejnym odrozdziale rzedstawimy istotę roonowanej metody Założenia metody Poszukiwanie nowych metod uczenia sieci neuronowych jest nierozłącznie związane z uświadomieniem sobie mankamentów i słabych stron metod już stosowanych. Odnalezienie wąskich gardeł metod istniejących może stać się wsaniałą insiracją do badań 48
49 rowadzących w efekcie do eliminacji niekorzystnych lub nieefektywnych algorytmów obecnie stosowanych. Z tego też względu rzed rzystąieniem do gruntownego oisu roonowanej tu metody sterowanych komromisów, rzyjrzyjmy się i orównajmy oularne metody z ostulowanymi założeniami zaroonowanej metody Szybkość nauki Głównym celem rzyświecającym autorowi racy rzy rojektowaniu metody sterowanych komromisów była róba rzysieszenia rocesu uczenia sieci neuronowej orzez korygowanie owstałego na jej wyjściu błędu w całości dla rozważanego wzorca uczącego. Oznacza to, że w oisanej metodzie nie wystęuje żaden wsółczynnik uczenia η (learning rate) wływający na szybkość nauki. Wsółczynnik ten stosowany jest we wielu oularnych metodach, jednak w związku z jego stosowaniem istnieje również wiele zasadniczych roblemów. Trudność w jego stosowaniu olega na tym, iż w żadnej eoce uczącej nie znana jest jego otymalna wartość. Wiadomo tylko, że ani za duża, ani za mała jego wartość nie wływa korzystnie na roces uczenia. Za duża wartość owoduje zazwyczaj fluktuacje w rocesie uczenia a nawet roblemy z zachowaniem jego zbieżności, zaś za mała zwalnia ten roces. Stosowanie wsółczynnika uczenia η jest ściśle związane ze stosującymi go metodami, które wymagają jego istnienia. Metoda sterowanych komromisów nie wymaga istnienia jakiegokolwiek arbitralnie czy algorytmicznie wybieranego wsółczynnika uczenia, a wręcz jego istnienie byłoby dla rocesu uczenia niekorzystne. Dzieje się tak dlatego, iż zaroonowana w tej racy metoda osługuje się innymi rzesłankami w rocesie dążenia do rozwiązania określonego ciągiem uczącym niż oularne metody stosowane obecnie Sosób korekty błędu W oularnej metodzie wstecznej roagacji błędu, jak sama nazwa mówi, obliczany jest błąd, jaki owstaje na wyjściu sieci neuronowej, i nastęnie na jego odstawie korygowane są wagi i rogi w rocesie jego wstecznej roagacji rzez sieć. W ten sosób działają wszystkie algorytmy uczenia zbudowane w oarciu o metody gradientowe. Metoda sterowanych komromisów nie roaguje wstecz błędu owstałego na wyjściu, lecz ożądany sygnał uczący Y, zadany ciągiem uczącym. Proagacja ta odbywa się na bazie informacji łynących ze wcześniejszego etau roagacji sygnału obudzenia dla ustalonego wzorca uczącego rzez sieć neuronową. Obliczany jest rozkład wstecznie roagowanego sygnału uczącego Y na oszczególne dendryty, które nastęnie obliczają swój udział w owstałym 49
50 błędzie na odstawie sygnałów łynących od ich wejścia ( x 1,..., x ). Zatem w rezentowanej metodzie także ma miejsce obliczanie błędu, jednak odbywa się ono lokalnie w każdym neuronie sieci neuronowej na odstawie lokalnych informacji, jakie neuron osiada ze swojego najbliższego otoczenia dla ustalonego wzorca uczącego, jak to okazano na rysunku n w 1 w n s s S Y Rysunek 4.6. Lokalna korekta błędu σ s nastęuje o otrzymaniu rzez neuron wartości obudzenia x 1,..., x łynących od dendrytów oraz wartości sygnału uczącego n od aksonu. Y łynącego Właściwa korekta arametrów wolnych sieci (tutaj wag i rogów) nastęuje doiero o obliczeniu błędów lokalnych dla wszystkich wzorców biorących udział w rocesie uczenia sieci. Na odstawie obliczonych błędów oszukiwany jest komromis będący zarazem nowym stanem sieci neuronowej. Komromis ten owinien zaewnić końcową zbieżność nauki, jej stabilność i możliwie maksymalną szybkość. Podczas obliczania komromisu srawą riorytetową nie jest sama tylko stabilnie malejąca charakterystyka funkcji błędu sieci, onieważ ona świadczy tylko o zbieżności do ewnego minimum być może minimum lokalnego, które nie musi być zarazem oszukiwanym minimum globalnym. Poszukiwanie komromisu owinno więc być sterowane w taki sosób, aby zaewnić sieci możliwość osiągnięcia oszukiwanego minimum globalnego funkcji błędu sieci dla całego ciągu uczącego Sukces rocesu uczenia Dla dowolnego wzorca uczącego i dowolnej nietrywialnej sieci neuronowej teoretycznie istnieje nieskończona ilość rozwiązań (tj. ustawień wag i rogów), dla których sieć rawidłowo odwzorowuje zadanie, wyrażone orzez wzorzec uczący w jego ożądane rozwiązanie, które musi się ojawić na wyjściu sieci. Dzięki tej właściwości sieć neuronowa 50
51 o rocesie nauki nie rozwiązuje tylko jednego, określonego zadania, ale może na zasadzie komromisu być dostosowywana do rozwiązywania ewnej klasy zadań, a roces uczenia wybiera arametry sieci w celu jak najleszego odwzorowania wielu wzorców wejściowych w ich ożądane wyjścia. Dokładność tego odwzorowania zależna jest od wielu czynników, do których zaliczyć można między innymi: Toologię sieci neuronowej, Modele neuronów użytych do budowy sieci, Zróżnicowanie i ilość wzorców uczących, Rerezentację danych w sieci neuronowej, Metodę uczenia sieci. Rozważymy teraz kolejno wszystkie wymienione wyżej uwarunkowania. Toologia sieci. Neurony można łączyć ze sobą w różny sosób. Poularną toologią sieci neuronowej jest toologia wielowarstwowa ełniąca funkcję ercetronu, tzw. MLP (multilayer ercetron), w której ilość neuronów i warstw zwykle dobierana jest arbitralnie na odstawie doświadczenia konstruktora, zaś neurony w ołączonych między sobą sąsiadujących warstwach łączone są ze sobą na zasadzie każdy z każdym (fully interlayerconnected toology [FIESLER 1997, B2.2, B2.5]). W taki sosób buduje się większość używanych obecnie sieci, chociaż wiele ekserymentów udowadnia, iż lesze rezultaty nauki uzyskuje się dla toologii sieci częściowo ołączonych, które są zazwyczaj bardziej oszczędne obliczeniowo i dają dodatkowo możliwość leszego dostosowania architektury sieci do danego ciągu uczącego. Zagadnienia związane z automatyczną budową takich oszczędnych toologii (n. metody ontogeniczne - ontogenic methods) są jak na razie w fazie badań i brak sformalizowanych i udowodnionych rzesłanek ich konstruowania [FIESLER 1997, B2.6]. Modele neuronów. W naukach biomedycznych rozróżnia się kilka odstawowych modeli neuronów w zależności od ich kształtu, wielkości, rodzaju i ilości ich ołączeń z sąsiadującymi neuronami, rodzaju neurorzekaźników (neurotransmitters), funkcji, jakie sełniają oraz ich ołożenia w hierarchii całej sieci neuronowej [KANDEL 1996]. Również w teorii sztucznych sieci neuronowych w rzeciągu ostatnich kilkudziesięciu lat skonstruowano wiele różnych modeli neuronów (artificial neuron), stosowanych do budowy różnego rodzaju sieci biorąc jako riorytet ich biologiczną zgodność, bądź koncentrując się na ich 51
52 właściwościach obliczeniowych, często tylko luźno związanych z ich biologicznym odowiednikiem. Wzorce uczące. Zróżnicowanie i ilość wzorców uczących również ma niebagatelne znaczenie w rocesie dostosowywania sieci neuronowej do zadanego ciągu uczącego. Można sobie łatwo wyobrazić, że jeśli sieć neuronowa zostanie ostawiona rzed roblemem nauczenia się ciągu liczb losowych lub wzorców ze sobą srzecznych, w naturalny sosób sobie z takim zadaniem nie oradzi, albowiem jej zadaniem jest odnajdywanie ewnych zależności i owiązań omiędzy wzorcami uczącymi. Ilość wzorców oraz ich dobór jakościowy jest również nie mniej ważny. Jeśli bowiem zadamy sieci ciąg uczący, w którym zdecydowana większość wzorców rerezentować będzie ewną część modelowanego zagadnienia a tylko skromna część wzorców całą resztę, wtedy można się sodziewać, że sieć będzie odążała za głosem większości. Ciąg uczący owinien być rerezentatywny dla danego zagadnienia. Można sobie, co rawna, wyobrazić metodę uczącą, która na bazie jakiejś metryki traktuje bardziej odmienne wzorce uczące z wyższym riorytetem, jednak w takim rzyadku zdolność do uogólniania tak nauczonej sieci ulegnie jakościowej zmianie, jak również inna będzie jej interretacja i działanie. Ponadto w rzyadku nie równorzędnego traktowania wzorców roces nauki byłby narażony na duży wływ artefaktów ojawiających się czasami w danych doświadczalnych, które stają się często bez wstęnej filtracji zbiorem danych uczących. Rerezentacja danych. Wzorce uczące (a także dane używane otem odczas eksloatacji sieci) z owodów obliczeniowych muszą być rerezentowane liczbowo 1. Jednak taka rerezentacja nie owinna być dokonywana arbitralnie, tylko tak, by intuicyjnie odzwierciedlała ewne odobieństwo rozważanych sygnałów. Jeśli na rzykład litery alfabetu łacińskiego onumerujemy zgodnie z ich orządkiem alfabetycznym (tzn. A 1, B 2, C 3, itd.) i rzyjmiemy taką ich rerezentację dla otrzeb ciągu uczącego, wtedy można się sodziewać kłootów z dostosowaniem się sieci neuronowej do takiego ciągu uczącego, albowiem taka rerezentacja tych wzorców w żaden sosób nie odzwierciedla w sosób ilościowy informacji niesionej ani rzez kształt tych liter ani rzez ich fonetyczne brzmienie, nie wyraża też żadnej miary odobieństwa omiędzy nimi. Warto odkreślić, iż sieć neuronowa traktuje wszystkie liczby w sosób ilościowy a nie w sensie orządku. Ze względu na ilościowe odejście sieci neuronowej do każdej informacji i biorąc od uwagę ich 1 Znane są oczywiście metody rerezentacji w sieciach neuronowych także danych tyu jakościowego (symbolicznych, oisowych), jednak nie będziemy się nimi zajmowali w tej racy. 52
53 numeryczną rerezentację, w rocesie uczenia może dojść do sytuacji urzywilejowania ewnych wzorców uczących (n. rerezentowanych większymi liczbami) na niekorzyść innych. Wskazane jest zatem, ażeby rerezentacja liczbowa wzorców uczących była związana w sosób ilościowy z informacjami, jakie oszczególne wzorce uczące niosą. [FIESLER B4.6] Metoda uczenia. Sukces nauki nie jest zależny tylko od zastosowanej metody, ale równie ważny jest grunt, na jakim działa, i dane, które odlegają nauce. Dla danego ciągu uczącego i toologii sieci neuronowej (o ile jest dobierana arbitralnie) trzeba znaleźć taki zbiór wag i rogów, żeby w jak najleszy sosób (tj. obarczony jak najmniejszym błędem według zadanych kryteriów) odwzorowywał wejście sieci neuronowej w ożądane jej wyjście zgodnie z ciągiem uczącym. Za znajdywanie takiego stanu sieci odowiedzialna jest metoda ucząca. Sieć neuronowa bez srzężeń zwrotnych (n. MLP) jest swego rodzaju rozbudowanym rzekształtnikiem funkcyjnym, na bazie którego można zdefiniować funkcję błędu sieci i dążyć do odnalezienia jej minimum globalnego. Funkcja błędu, w zależności od stonia skomlikowania sieci może osiadać wiele minimów lokalnych. Z tego też owodu znalezienie minimum globalnego w oarciu o metody gradientowe może nie być roste, albowiem informacja łynąca z gradientu funkcji w danym unkcie wskazuje tylko na kierunek do ewnego minimum zwykle lokalnego, które w raktyce rzadko okazuje się być zarazem minimum globalnym. Wielu autorów odejmuje róby omijania owych minimów lokalnych z omocą różnych metod (do tego celu służy na rzykład szeroko znana metoda momentum), gdyż w rzyadku metod gradientowych są one unktem stagnacji rocesu uczenia. Niestety nawet możliwość omijania minimów lokalnych nie zaewnia końcowego sukcesu rocesu nauki, onieważ nadal nie znany jest kierunek ani odległość oszukiwania minimum globalnego od aktualnego stanu sieci. Ponadto metoda momentum jest dla ewnych rzyadków źle uwarunkowana i może rowadzić wręcz do wzrostu funkcji błędu sieci, jak to okazano na rysunku 4.7. Problemy te związane są z tym, że informacja o gradiencie nie zawiera w sobie informacji o kierunku oszukiwania minimum globalnego, a jego znalezienie jest w takim rzyadku czysto rzyadkowe, zależne bardziej od stanu oczątkowego sieci niż od samej metody uczącej. Stanów oczątkowych sieci zaś jest nieskończona ilość, więc rzebadanie ich wszystkich jest niemożliwe. Taka sytuacja wynika z faktu, iż w rzyadku metod gradientowych korzysta się jedynie z lokalnej informacji o gradiencie funkcji błędu sieci neuronowej dla aktualnego jest stanu. Z tego też owodu metody gradientowe są z założenia nieefektywne. Z matematycznego unktu widzenia nie istnieją zaś żadne rzesłanki, 53
54 wskazujące jak można by było rzechodzić z jednego minimum lokalnego do innego ani gdzie lub jak daleko od aktualnego stanu sieci neuronowej inne minima się znajdują i czy są one lokalne czy globalne. Rysunek 4.7. Przykład złego uwarunkowania metody momentum rowadzącego roces uczenia w niekorzystnym kierunku ze względu na zastosowaną bezwładność, która w ewnych sytuacjach może być korzystna a w ewnych niekorzystna Odchylenia od uzyskanego komromisu jako globalny wyznacznik stanu rocesu uczenia Postawmy sobie teraz ytanie: Czy istnieją jakieś informacje, na odstawie których można by było wnioskować o stanie nauki sieci i efektywniej zmierzać do minimum globalnego funkcji błędu, tj. do otymalnego rozwiązania ostawionego roblemu zadanego ciągiem uczącym dla zadanej toologii sieci neuronowej? Otóż informacje takie istnieją! W metodach gradientowych nie uwzględnia się zazwyczaj tego, co się fizycznie w sieci neuronowej dzieje dla oszczególnych wzorców uczących w trakcie rocesu uczenia. Dla każdego wzorca uczącego i jego sygnału uczącego obliczane są błędy i na ich odstawie rzerowadzana jest óźniej korekta wag i rogów. Korekta ta rzebiega w różnych kierunkach i z różnym natężeniem. Finalna korekta jest zawsze wynikiem ewnego komromisu zawartego omiędzy wzorcami ciągu uczącego. Komromis ten oarty jest zazwyczaj na ewnej średniej (n. arytmetycznej, ważonej, geometrycznej), choć można się okusić również o inne sosoby jego wyznaczania. Niezależnie od sosobu wyznaczania nadmienionego komromisu, komromis ten zawsze w różny sosób satysfakcjonuje różne wzorce uczące, 54
55 które mogą z łatwością obliczyć odchylenie swojej ostulowanej korekty błędu od obliczonego komromisu (dalej nazywane krótko odchyleniem ). Na tej odstawie każdy wzorzec uczący może na bieżąco analizować swoją siłę rzebicia na tle całego ciągu uczącego. Co więcej każdy wzorzec może się rzyatrywać kolejno wszystkim swoim odchyleniom, jakie miały miejsce w oszczególnych neuronach i synasach, i na tej odstawie odejmować decyzję o bardziej efektywnym rozkładzie swojej korekty błędu na oszczególne elementy sieci neuronowej. W raktyce oznacza to udrożnienie jednych i blokowanie innych dróg korekty błędu. Takie ostęowanie można nazwać sterowaniem sosobem korekty błędów w celu uzyskania jak najkorzystniejszego komromisu z unktu widzenia całego ciągu uczącego. Stąd wyływa rosty wniosek, iż na odstawie wyżej oisanych odchyleń można wnioskować o stanie nauki sieci, albowiem wielkość tych odchyleń jest bezośrednio związana z błędem sieci neuronowej i vice versa. Stan braku takowych odchyleń świadczy jednoznacznie o tym, że sieć neuronowa nauczyła się ostawionego jej roblemu, zadanego ciągiem uczącym. Rzadko się jednak zdarza, żeby wszystkie odchylenia od uzyskanego komromisu miały wartość zerową. Wartościową informację stanowi więc tutaj bardziej malejąca wielkość tych odchyleń w rocesie uczącym, niż same ich wartości. Ponadto, jeśli stan sieci neuronowej charakteryzuje się niezerowymi odchyleniami i zarazem bliskimi zeru komromisowymi korektami wszystkich wag i rogów, świadczy to o zbliżaniu się do minimum lokalnego. Zatem rozważana metoda ozwala minimalizować błędy wystęujące w sieci, zarazem dając możliwość wnioskowania o tym, czy to minimum ma szansę być globalnym czy też nie. Na odstawie odchyleń od uzyskanego komromisu można skonstruować ewną miarę odległości od rozwiązania idealnego (tj. od takiego stanu, gdy wszystkie odchylenia są zerowe), a także można wnioskować na tej odstawie o tym, czy roces uczenia osiągnął już satysfakcjonujący oziom dokładności dla wszystkich wzorców ciągu uczącego i czy ewentualnie osiągnięte minimum kwalifikuje się jako minimum lokalne czy też globalne. Taką odowiedź można oczywiście uzyskać doiero o rzerowadzeniu dogłębnej statystyki na odstawie uzyskanych odchyleń dla wszystkich elementów składających się na sieć neuronową i dla wszystkich wzorców uczących. Dzięki temu zaś, że informacja o odchyleniach rozroszona jest o wszystkich synasach i rogach sieci neuronowej, daje to dodatkowo możliwość wnioskowania, w którym miejscu sieci, z jaką intensywnością i dla których wzorców uczących wystęują roblemy z dostosowaniem się sieci neuronowej do ciągu uczącego. Pozwala to między innymi na ukierunkowanie rocesu uczenia orzez bardziej inteligentne sterowanie sosobem zawieranego komromisu omiędzy wszystkimi wzorcami ciągu uczącego w dalszych eokach uczących. 55
56 Ponadto informacje te mogą stanowić wartościowe źródło informacji dla technik ontogenicznych, dynamicznie rekonfigurujących toologię sieci neuronowej w trakcie rocesu uczenia. Informacje łynące z oisanych odchyleń mają charakter lokalny, tak więc sam neuron może zadecydować na ich odstawie o swojej rekonfiguracji. Nie trzeba odkreślać, iż jest to dużą zaletą, albowiem analizowanie całej architektury sieci neuronowej globalnie jest skomlikowane obliczeniowo, a także nie osiada otwierdzenia w biologii. Matematyczne odstawy wrowadzonych w tym rozdziale koncecji i ojęć zostaną oisane dokładniej w rozdziale tej racy. Przybliżona zostanie tam także możliwa do wykorzystania strategia sterowania rocesem uczącym orzez bardziej inteligentne obliczanie komromisu Ois metody Podstawowa wersja metody sterowanych komromisów bazuje na dwóch warstwach sieci: warstwie wejściowej, zwanej również sensoryczną, warstwie wyjściowej, zwanej również efektorową. Warstwa sensoryczna Warstwa efektorowa Rysunek 4.8. Dwuwarstwowa sieć neuronowa z uwidocznioną warstwą sensoryczną, efektorową i łączącymi je ołączeniami synatycznymi. Nauka sieci neuronowej odbywa się w kolejnych eokach uczących, w których rozważana jest korekta wszystkich wag i rogów sieci. Każda eoka ucząca (krótko zwana dalej eoką ) składać się może z kilku etaów uczących. Ich ilość zależna jest od ilości warstw, wynikających z toologii wybranej sieci neuronowej. W każdym konkretnym etaie uczącym 56
57 zostaje rzerowadzona korekta ewnej wydzielonej części wag i rogów. Dla sieci dwuwarstwowych, oisanych w tym rozdziale, każda eoka ucząca składa się tylko z jednego etau uczącego. Pojęcie etau uczącego (krótko zwanego dalej etaem ) dla sieci wielowarstwowej zostanie dokładniej wyjaśnione w jednym z nastęnych rozdziałów. Teraz wyjaśnione zostanie, na czym olega eta uczący dla sieci neuronowej o rostej toologii dwuwarstwowej, gdyż ułatwi to systematyczne oznanie roonowanej metody. W każdym etaie uczącym dla każdego wzorca uczącego wykonywane są nastęujące dwie fazy: 1. Faza roagacji obudzenia sieciowego, 2. Faza wstecznej roagacji sygnału uczącego. Faza druga ołączona jest z obliczaniem nowych wartości wag i rogów na odstawie informacji łynących zarówno od wejścia sieci (od sensorów) jak również od wyjścia sieci (od efektorów). Ten dwukierunkowy rzeływ sygnałów rozważany jest kolejno dla każdego aktualnie uczonego wzorca uczącego. Korekta nie jest jednak rzerowadzana od razu, ale doiero o wykonaniu owyżej wymienionych dwóch faz dla każdego wzorca uczącego, tzn. o rzejrzeniu całego ciągu uczącego, rzy czym kolejność wzorców uczących nie ma w tej metodzie żadnego znaczenia Faza roagacji obudzenia sieciowego W fazie obudzenia sieciowego dany wzorzec roagowany jest od wejścia (sensorów) sieci do jej wyjścia (efektorów) w nastęujący sosób: Najierw obudzane są kolejno wszystkie sensory (Rys. 4.9.) sygnałem odanym z wejścia sieci zgodnym z uczonym wzorcem uczącym. Dla sensorów wartość sygnału aktywacji równa jest wartości obudzenia, a więc funkcja aktywacji sensorów jest funkcją identycznościową 2. x s y = s 2 Nie koniecznie funkcja aktywacji sensora musi być funkcją identycznościową. Można się okusić o wyosażenie sensora w dodatkowe mechanizmy umożliwiające mu odczas nauki n. rzeskalowanie danych wejściowych, bądź oddanie ich działaniu jakiejś nieliniowej funkcji aktywacji. Biologiczne sensory (recetory) też są wyosażone w różne mechanizmy umożliwiające im bardziej się wyczulić na bodźce lub na nie znieczulić. 57
58 Rysunek 4.9. Sensor (element wejściowy) sieci neuronowej. Funkcja aktywacji sensora jest funkcją identycznościową y = = s x. Nastęnie obudzeniu ulegają wszystkie efektory na odstawie sygnałów aktywacji sensorów, które zostają odowiednio zważone w synasach stojących na drodze sygnałów rowadzących od sensorów do efektorów. W raktyce wartość sygnału aktywacji dla efektorów obliczana jest odobnie jak dla neuronów, tzn. tak jak zostało to oisane w rozdziale 4.1. x 1 x n w 1 wn d 1 d n s y = g (s ) k Rysunek Efektor (element wyjściowy) sieci neuronowej. Funkcja aktywacji efektora y n n ( s ) = gk di θ = gk xi wi θ = gk i= 1 i= 1. W końcu otrzymane sygnały aktywacji efektorów są zarazem sygnałami wyjściowymi sieci neuronowej i odowiedzią sieci na obudzenie jej danym wzorcem uczącym. Wyjścia te w nastęnej fazie wstecznej roagacji sygnału uczącego będą służyły korekcie owstałych błędów sieci, jakie ojawiły się na jej wyjściu Faza wstecznej roagacji sygnału uczącego Faza wstecznej roagacji sygnału uczącego rozoczyna się od obliczenia ożądanej wartości stanu obudzenia efektora wyjściowego ciągu uczącego: S na odstawie ożądanej wartości sygnału Y dla ustalonego wzorca uczącego ochodzącego od nauczyciela, tzn. z ( Y ) S = Gk, gdzie funkcja rzyjmuje ostać funkcji odwrotnej: G k dla oisanych w rozdziale 4.1. monotonicznych funkcji aktywacji 58
59 G k 1 ( Y ) g ( Y ) =, k Jak się okaże w nastęnych rozdziałach, funkcja G k nie zawsze musi być funkcją odwrotną do funkcji aktywacji g k. Dzięki temu, że znana jest nie tylko wartość Y, lecz również wartość s, możliwe jest jednoznaczne (rzy ewnych założeniach) obliczanie wartości S również dla funkcji niemonotonicznych, a nawet okresowych. Na razie jednak nasze rozważania ograniczone zostaną do funkcji oisanych w rozdziale 4.1., dla których funkcja G k rzyjmuje nastęującą ostać: 1 ( Y ) = g ( Y ) Y S = G1 1 = β S = G 2 1 ( Y ) = g ( Y ) 2 = Y Y β S = G 3 1 ( Y ) = g ( Y ) 3 sgn = ( Y ) β Y Po obliczeniu wartości ożądanej stanu obudzenia efektora S, może zostać wyznaczona lokalnie wartość błędu aktualnego stanu obudzenia uczącego według wzoru: s dla ustalonego wzorca σ s = S s. Na owstanie błędu σ s mają bezośredni wływ wartości ostsynatycznych obudzeń dendrytów d i (i=1,..., ) oraz wartość rogu θ zgodnie ze wzorem , dlatego korekta owstałego błędu σ s owinna zostać rozłożona (zgodnie z rzyjętymi kryteriami) na oszczególne dendryty oraz owinna także sowodować ustalenie wartości korekty błędu rogu. Kryteria rozkładu błędu na wyżej wymienione składowe mogą być różne. Można brać od uwagę wartości ostsynatycznych obudzeń dendrytycznych resynatycznych obudzeń synatycznych x i, wartości aktualnych wag d i, wartości w i it. Ważne jest, aby rzyjęte kryteria ukierunkowywały roces zmian wag i rogów w kierunku minimalizacji oisanych wcześniej odchyleń od komromisu, który zostanie uzyskany na ich odstawie, i rowadziły w związku z tym do rozwiązania zadanego ciągiem uczącym z jak największą 59
60 dokładnością. Minimalizacja wszystkich owych odchyleń jest zaś równoważna globalnej minimalizacji błędu sieci neuronowej, czyli znalezieniu minimum globalnego funkcji błędu. W odstawowej wersji metody sterowanych komromisów rzyjęto uzależnienie rozkładu korekty błędu od wartości ostsynatycznych obudzeń dendrytycznych d i. W tym celu najierw obliczana jest suma modułów wszystkich ostsynatycznych obudzeń dendrytycznych d i oraz wartości obudzenia, jaki wnosi róg, według nastęującego wzoru: M s = di + θ = di +θ. i= 1 i= 1 Nastęnie dla każdego wzorca każdy dendryt (jak również róg) obarczany jest taką częścią błędu tzn.: dla rogu: σ s, jaka wynika z jego udziału w owstałym stanie obudzenia efektora s, σ θ θ θ = σ s = σ s, M M s s a nastęnie obliczana jest nowa wartość rogu dla ustalonego wzorca uczącego : Ξ, =θ +σ θ i dla dendrytów: d i σ d =σ i s, M s a nastęnie obliczana jest nowa wartość wagi dla ustalonego wzorca uczącego : W i di +σ di =, x i która umożliwia wyznaczenie korekty błędu wagi dla ustalonego wzorca uczącego : σ = W w. wi i i Faza obliczania komromisu Korekty błędów wag i rogów, obliczone kolejno dla wszystkich wzorców uczących, służą (o rzeglądnięciu całego ciągu uczącego) do wyznaczenia wyadkowych orawek, 60
61 które będą wrowadzone do sieci celem oleszenia (w kolejnej eoce uczenia) jej działania. Porawki te nazywane będą komromisem zawartym omiędzy wzorcami uczącymi i mogą mieć w najrostszej ostaci formę n. średniej arytmetycznej, stanowiącej odstawę wynikowej korekty wag i rogów. W związku z tym orawki wyznacza się nastęująco: Średnia arytmetyczna roonowanych korekt błędów wag dla wszystkich wzorców uczących wynosi: Q = 1 σ wi σ w =, i Q więc nowa waga obliczona na bazie tej średniej: W = + σ, i w i w i Średnia arytmetyczna roonowanych korekt błędów rogów dla wszystkich wzorców uczących wynosi: Q = 1 σ θ σ θ =, Q i nowy róg obliczony na bazie tej średniej: Ξ =θ +σ θ. Należy odkreślić, iż wynikowe komromisowe korekty wag i rogów nie muszą być obliczane na bazie akurat średniej arytmetycznej. Dodatkowo rzy wyznaczaniu nowych wartości tych arametrów można wziąć od uwagę na rzykład: odchylenia od obliczonego komromisu, tutaj średniej arytmetycznej (ale można róbować wykorzystać również średnią ważoną, geometryczną i inne), uniezależnianie wielkości korekt od rerezentacji liczbowej wzorców uczących, ołożenie nacisku na kierunek, w jakim chce odążać większość wzorców uczących, wzięcie za riorytet najbardziej oszkodowane wzorce w trakcie wyznaczania owego komromisu, eliminację z ciągu uczącego artefaktów owodujących zakłócenia rocesu uczenia związanego z obliczaniem oszczególnych wartości komromisowych. 61
62 Te arametry mogą w bardziej zaawansowanych adatacjach metody sterowanych komromisów osłużyć do bardziej efektywnego sterowania rocesem nauki orzez bardziej inteligentne obliczanie wynikowych komromisowych korekt błędów dla oszczególnych wag i rogów rzy uwzględnieniu roonowanych korekt tych błędów dla oszczególnych wzorców ciągu uczącego Faza wyznaczania odchyleń Zanim rzedstawiony zostanie sosób obliczania oisanych w rozdz odchyleń od uzyskanego komromisu, rzyomnijmy znaczenie używanych w tym rozdziale oznaczeń: w i i-ta waga synatyczna rozważanego neuronu lub efektora, W i roonowana nowa i-ta waga synatyczna rozważanego neuronu lub efektora, wyznaczona dla ustalonego wzorca uczącego, W i komromisowa nowa i-ta waga synatyczna rozważanego neuronu lub efektora dla całego ciągu uczącego (nazywana krótko komromisem zawartym dla i-tej wagi), θ Ξ Ξ róg rozważanego neuronu lub efektora, roonowany nowy róg rozważanego neuronu lub efektora, wyznaczony dla ustalonego wzorca uczącego, komromisowy nowy róg rozważanego neuronu lub efektora dla całego ciągu uczącego (nazywany krótko komromisem zawartym dla rogu). Na odstawie wyżej wymienionych oznaczeń zdefiniowane zostaną odchylenia, leżące u odstaw dalszych rozważań związanych z możliwością sterowania rocesem nauki ukierunkowanym na bardziej efektywne zmierzanie do rzyjętego końcowego celu, jakim jest globalna minimalizacja błędu sieci neuronowej dla zadanego ciągu uczącego: δˆ = W W odchylenie od uzyskanego komromisu dla rozważanej i-tej wagi Wi i i ( W i ), wyznaczone dla ustalonego wzorca uczącego (zwane krótko: odchyleniem wagi dla wzorca uczącego), 62
63 δˆ =Ξ Ξ odchylenie od uzyskanego komromisu dla rozważanego rogu Ξ (Ξ ), wyznaczone dla ustalonego wzorca uczącego (zwane krótko: odchyleniem rogu dla wzorca uczącego), δ Wi = ˆ δ bezwzględne odchylenie od uzyskanego komromisu dla Wi rozważanej i-tej wagi ( W ), wyznaczone dla ustalonego wzorca i uczącego (zwane krótko: bezwzględnym odchyleniem wagi dla wzorca uczącego), δ ˆ bezwzględne odchylenie od uzyskanego komromisu dla Ξ = δ Ξ Q rozważanego rogu (Ξ ), wyznaczone dla ustalonego wzorca uczącego (zwane krótko: bezwzględnym odchyleniem rogu dla wzorca uczącego), δw i = δ W = 1 bezwzględne odchylenie od uzyskanego komromisu dla i Q Q Ξ rozważanej i-tej wagi synatycznej ( W ) dla całego ciągu uczącego (zwane krótko: bezwzględnym odchyleniem wagi dla ciągu uczącego), = δ bezwzględne odchylenie od uzyskanego komromisu dla Q Ξ = 1 δ n r i W i r W + Ξ rozważanego rogu (Ξ ) dla całego ciągu uczącego (zwane krótko: bezwzględnym odchyleniem rogu dla ciągu uczącego), Ξ r δ r = - bezwzględne odchylenie od uzyskanego komromisu n +1 r i r r r dla rozważanego neuronu lub efektora r oraz dla ustalonego wzorca uczącego, będące sumą bezwzględnych odchyleń od uzyskanego komromisu dla wszystkich wag i rogów całej sieci neuronowej (zwane krótko: bezwzględnym odchyleniem neuronu dla wzorca uczącego), i 63
64 Q δ r = δ r = 1 bezwzględne odchylenie od uzyskanego komromisu dla Q R rozważanego neuronu lub efektora r dla całego ciągu uczącego (zwane krótko: bezwzględnym odchyleniem neuronu dla ciągu uczącego), δ r r= δ = 1 bezwzględne odchylenie od uzyskanego komromisu dla R rozważanego wzorca uczącego, będące sumą bezwzględnych odchyleń od uzyskanego komromisu dla wszystkich wag i rogów całej sieci neuronowej (R ilość wszystkich neuronów i efektorów sieci) (zwane krótko: bezwzględnym odchyleniem wzorca uczącego), Powyżej zdefiniowane odchylenia od uzyskanego komromisu można wyznaczyć odczas jednego rzeglądnięcia ciągu uczącego. Ponadto czynność tą można ołączyć z ierwszym etaem uczącym kolejnej eoki uczącej. Dzięki temu rzed aktualizacją dokonywaną dla ierwszego etau danej eoki sieć dysonuje informacjami odnośnie wszystkich zdefiniowanych owyżej odchyleń. W takim rzyadku rzed dokonaniem aktualizacji sieć zawsze może się wesrzeć dodatkowymi informacjami łynącymi z wartości oszczególnych odchyleń i na tej odstawie bardziej inteligentnie sterować zawieranym w fazie aktualizacji komromisem omiędzy wzorcami uczącymi. Przez komromis skrótowo rozumie się wszystkie komromisy cząstkowe zawierane dla oszczególnych elementów sieci neuronowej w szczególności dla wag i rogów sieci. Zdefiniowane odchylenia informują sieć neuronową o wielu korzystnych jak również niekorzystnych srawach odgrywających się w niej odczas rocesu uczenia, mianowicie: Na odstawie wartości bezwzględnego odchylenia wzorca uczącego można się dowiedzieć, które wzorce uczące srawiają sieci neuronowej najwięcej kłootów. W rzyadku kłootów z dostosowaniem się sieci do określonego wzorca uczącego można na odstawie bezwzględnego odchylenia neuronu dla tego wzorca zlokalizować w sieci te neurony, gdzie odchylenia te są najbardziej kłootliwe. Informacja o kłootach z dostosowaniem się ewnego neuronu do danego wzorca uczącego lub całego ciągu uczącego może osłużyć do zlokalizowania wag i rogów, 64
65 które charakteryzują się największymi bezwzględnymi odchyleniami wag i bezwzględnymi odchyleniami rogów dla rozważanego wzorca uczącego lub całego ciągu uczącego. Informacje o kłootach w dostosowaniu się różnych części sieci neuronowej do ciągu uczącego lub części wzorców uczących mogą służyć do odjęcia decyzji o zmianie strategii rozkładu korekty ozostałego jeszcze błędu na oszczególne arametry sieci neuronowej, bądź też mogą stać u odłoża rekonfiguracji ewnej części architektury sieci neuronowej, która stanowi źródło niezgody (tzn. wystęuje brak akcetowalnego komromisu) omiędzy wszystkimi lub częścią wzorców uczących. Wychodząc z założenia, że zależy nam na uzyskaniu jak najleszych wyników (tzn. jak najmniejszego błędu sieci rzy jak najleszej zdolności do uogólniania), można odjąć róby zmierzające do wykorzystania zdefiniowanych w tej racy odchyleń do oracowania metod zmierzających do zotymalizowania jak architektury sieci neuronowej tak samego rocesu dostosowywania jej arametrów Sterowanie rocesem uczenia Przez sterowanie rocesem uczenia rozumie się w raktyce sterowanie sosobem rozkładu błędu na oszczególne składniki sieci neuronowej (w szczególności wagi i rogi) oraz sterowanie sosobem zawieranego komromisu omiędzy wzorcami uczącymi. Bardziej inteligentny sosób rozkładu błędu może dorowadzić do szybszej zbieżności orzez wyeliminowanie ewnych unktów niezgody omiędzy wzorcami, zaś sosób zawieranego komromisu determinuje, w jakim stoniu oszczególne wzorce uczące mają wływ na roces uczący. W świetle tej terminologii można zdefiniować, co oznacza minimum lokalne i globalne funkcji błędu. Minimum lokalne będzie utrzymującym się komromisem zawartym omiędzy wzorcami uczącymi, charakteryzujący się niezadowalająco dużymi odchyleniami dla oszczególnych wzorców uczących. Minimum globalne będzie również ewnym utrzymującym się komromisem, który jednak będzie się w ogólności charakteryzował minimalnymi możliwymi odchyleniami dla oszczególnych wzorców. Kwestia tego, czy odchylenia te (a co za tym idzie również błąd sieci) będą zadowalająco małe, zależy już wtedy tylko od konkretnego roblemu. W razie uzyskania niezadowalających wyników trzeba odjąć róbę rekonfiguracji architektury sieci, która w rozważanej ostaci może nie ozwalać na lesze jej dostosowanie do zadanego roblemu. W rzyadku konieczności rekonfiguracji 65
66 sieci neuronowej również bardzo rzydatne są informacje o oszczególnych odchyleniach, które ozwalają ukierunkować roces jej rekonfiguracji Warunki zatrzymania rocesu uczenia W związku z rocesem uczenia ojawia się ytanie, ilu eok otrzeba, by można było uznać, że sieć jest już wystarczająco nauczona czyli otrzebne są warunki zatrzymania algorytmu. Warunki te mogą być uzależnione od wielu różnych arametrów w zależności od tego, jaką wagę rzyisujemy oszczególnym z nich. Badać je należy oczywiście doiero o ukończeniu całej eoki uczącej. Przedmiotem badania owinny być rzede wszystkim: błąd, jaki owstaje na wyjściu sieci neuronowej dla wzorców uczących, błąd, jaki owstaje na wyjściu sieci neuronowej dla wzorców testujących, wartości odchyleń od uzyskanego komromisu dla oszczególnych wzorców uczących, wartości odchyleń od uzyskanego komromisu dla oszczególnych wag i rogów Rozszerzenia metody Metoda sterowanych komromisów może zostać uogólniona i rozszerzona o nowe możliwości tak, by była w stanie srostać również bardziej wymagającym zadaniom. Do użytecznych rozszerzeń zaliczyć można mianowicie: Uniezależnienie korekty błędów od rerezentacji liczbowej oszczególnych wzorców. Wzbogacenie odstawowych funkcji aktywacji neuronów o inne funkcje usrawniające bądź uraszczające naukę lub architekturę sieci neuronowej, bądź też orawiające jakość uzyskanego uogólnienia. Uczenie sieci neuronowych zawierających neurony ośrednie lub całe warstwy ukryte. Próby wzbogacania i uogólniania zarezentowanej metody są aktualnie w stanie intensywnych badań. W tej racy oisano tylko wybraną ich część. Oisane niżej rozszerzenia nie zawsze rzedstawiają finalne rozwiązanie rzedstawionego roblemu, lecz bardziej wskazują na otencjał zaroonowanej metody i na różne kierunki oszukiwań, do których stanowi ona insirację odkreślając zarazem dalszą otrzebę takich właśnie badań. 66
67 Uniezależnienie od rerezentacji liczbowej wzorców uczących Wzorce uczące rerezentowane są rzez liczby, które z natury rzyjmują różne wartości. W rocesie uczącym byłoby jednak nie wskazane, gdyby n. wzorce rerezentowane rzez duże liczby miały wyższy riorytet uczenia niż te rerezentowane liczbami małymi. Przy obliczaniu wynikowej komromisowej korekty wag i rogów bierze się od uwagę korekty obliczone dla oszczególnych wzorców ciągu uczącego, a więc nie uwzględnia się stosunku wielkości korekty do wartości, których ta korekta dotyczy. W takim układzie do wzorców rerezentowanych większymi liczbami odnosi się zazwyczaj większa korekta i vice versa. Taka sytuacja srawia, że rzy obliczaniu wynikowej komromisowej korekty wzorce nie są traktowane równorzędnie. Ażeby uniezależnić naukę od rerezentacji liczbowej konkretnych wzorców uczących, trzeba znormalizować oszczególne korekty błędów rzez wrowadzenie wsółczynnika odzwierciedlającego wielkość rerezentacji wzorców dla danego neuronu sieci. Wsółczynnikiem takim, który określa bezwzględną wielkość obudzeń lub hamowań neuronu, jest używany już w rozdziale wsółczynnik M s, który rzyjmuje odowiednio większe jak i mniejsze wartości w zależności od bezwzględnej wartości rerezentacji oszczególnych wzorców. Wartość M s dla danego wzorca można więc rzyjąć jako wsółczynnik normalizujący. Wzory służące do obliczania wynikowych komromisowych korekt z rozdziału oartych na średniej arytmetycznej rzyjmą teraz nastęującą ostać: dla wag: Q = 1 σ wi s = 1 M σ w = i Q, 1 M dla rogów: Q = 1 σ s θ s = 1 M σ θ = Q, 1 M s W wyniku oisanej owyżej modyfikacji uzyskujemy względne zrównoważenie wielkości korekt dla oszczególnych wzorców niezależnie od ich rerezentacji liczbowej, co owinno w większości rzyadków ozytywnie wływać na rzebieg rocesu uczenia i na jego wyniki. 67
68 iestandardowe funkcje aktywacji neuronów Funkcje aktywacji neuronów w istotny sosób decydują o możliwościach dostosowania całej sieci neuronowej do roblemu zadanego ciągiem uczącym, jak również wływają one na możliwości interolacyjne i ekstraolacyjne, jakie nauczona sieć będzie osiadała. Sztywne trzymanie się w tym zakresie biologicznych modeli jest tylko o części uzasadnione i nie zawsze bywa związane z ostawionym celem obliczeniowym, dla którego tworzona jest rozważana sieć. Jeśli zatem mamy na uwadze rzesłanki badawcze związane z biologicznymi tajnikami rzeczywistych neuronów i badaniami modelowymi biologicznego mózgu, wtedy zaiste słuszne okaże się modelowanie neuronów ściśle wedle danych dostarczonych rzez neurofizjologię i neuroanatomię. W tych rzyadkach z omocą secjalnie na ten cel ukierunkowanych badań oszukuje się funkcji rzejścia modelowanych neuronów, wybierając je w oarciu o kryteria związane z ich biologiczną odowiedniością 3. Jeśli jednak ważne są dla nas obliczeniowe możliwości sieci neuronowych dla jak najszerszej gamy rzeczywistych roblemów, wtedy bardziej rozsądne wydaje się wyosażenie sztucznych neuronów w takie możliwości, które umożliwiłyby osiągnięcie tego celu bez względu na to, czy są to właściwości biologicznie rawdoodobne, czy też nie. Udowodnione zostało, iż zastosowanie liniowych funkcji aktywacji neuronów nie ozwala rozwiązywać ogólnych zadań decyzyjnych, a tylko roblemy liniowo searowalne (M. Minsky i S. Paert, 1969). W odobny sosób można by było okazać, iż sieć neuronowa oarta na nieliniowych monotonicznych funkcjach aktywacji nie będzie się nadawała do ekstraolacji roblemów natury eriodycznej. Co rawda znane są twierdzenia, iż sieć neuronowa z sigmoidalnymi (a więc monotonicznymi) funkcjami rzejścia może modelować dowolną funkcję, jednak dowód tego twierdzenia rzerowadza się rzy założeniu, że sieć neuronowa ma otencjalnie nieskończoną ilość neuronów, co jednak jest założeniem w oczywisty sosób nie realizowalnym w rzyadku raktycznych obliczeń komuterowych, a nawet nieorawnym w odniesieniu do biologicznego mózgu, którego liczba neuronów jest wrawdzie bardzo duża (~10 11 ), ale jednak skończona. Jednym ze skutków ograniczonej wydolności sieci zbudowanych z neuronów o monotonicznych charakterystykach jest ich ograniczona rzydatność w roblemach 3 Porównaj tylko temu zagadnieniu oświęcone race, na rzykład: Tadeusiewicz R., Lazarewicz M.T.: Nowy aradygmat neurobiologii obliczeniowej: exeriment in comuto. Materiały V Krajowej Konferencji Modelowanie Cybernetyczne Systemów Biologicznych, Zakład Biocybernetyki Collegium Medicum UJ, Kraków 2000 ss lub Tadeusiewicz R., Lazarewicz M.T.: Postęy i sukcesy w biocybernetycznych racach u odstaw sztucznej inteligencji. IV Krajowa Konferencja Naukowa nt. Sztuczna Inteligencja, Akademia Podlaska, Siedlce 2000, ss
69 rzewidywania rzyszłości. Nawet dla człowieka ten roblem jest wyjątkowo trudny, mimo iż mózg ludzki ma do dysozycji niewyobrażalnie wielką liczbę rzędu stu miliardów neuronów. Być może trudność trafnego rzewidywania rzyszłości ojawia się w naszym zachowaniu właśnie dlatego, że znakomita większość zjawisk w rzyrodzie ma naturę quasieriodyczną. Jeśli więc rzy tworzeniu neurokomuterów nacisk zostanie ołożony na obliczeniowe możliwości tworzonych sieci neuronowych, wtedy można rozszerzyć funkcje aktywacji neuronów o funkcje niemonotoniczne. Takie ostęowanie jest jednak możliwe wyłącznie rzy założeniu, iż metoda ucząca ozwala na uczenie sieci neuronowych zbudowanych z neuronów o takich funkcjach aktywacji. Wiele klasycznych metod uczenia sieci wykazuje w tym zakresie istotne ograniczenia, co jest jednym z owodów unikania w roblematyce sztucznych sieci niemonotonicznych funkcji aktywacji (z otwierdzającym tę regułę wyjątkiem sieci RBF, które jednak są uczone w sosób nie klasyczny). Metoda sterowanych komromisów może zostać z owodzeniem zmodyfikowana w taki sosób, by nadawała się do uczenia sieci oartych również na niemonotonicznych funkcjach aktywacji. Modyfikacji takiej można dokonać rzy założeniu, że zdefiniowana zostanie funkcja ( ) G służąca do obliczania ożądanej wartości stanu obudzenia efektora S dla k Y wzorca uczącego na odstawie wartości sygnału uczącegoy. Jest srawą oczywistą, że zdefiniowanie funkcji (a właściwie odwzorowania) jak dla funkcji monotonicznych, gdzie funkcja G k nie jest w tym rzyadku takie roste G k rzyjmuje ostać funkcji odwrotnej do (or. rozdział IV.3.2). Dla niemonotonicznych funkcji aktywacji funkcja 1 gk g k nie istnieje i trzeba się soro natrudzić, by jednoznacznie zdefiniować, jak w takim rzyadku obliczać wartość S dla różnych wartości istnieje nieskończona ilość wartości Y. Jak wiadomo dla eriodycznych funkcji aktywacji S, dla których g k ( S ) Y =. Na szczęście z omocą rzychodzi tu znana z fazy roagacji obudzenia sieciowego wartość stanu obudzenia efektora (neuronu) s, która może się rzysłużyć do jednoznacznego określenia wartości S dla wzorca uczącego. Funkcja ( Y s ) S Gk, =. Funkcję G k staje się wtedy funkcją dwóch zmiennych: G k dla funkcji eriodycznych można zdefiniować w różnoraki sosób, jednak ze względu na stabilność nauki wartość S owinna być jak najbliższa wartości wszystkich możliwych. Można więc rzyjąć nastęującą definicję funkcji G k : s sośród 69
70 k { { } k Y ( Y, s ) = min S : S s = min Sˆ s : g ( Sˆ ) G = lub k { { } k Y ( Y s ) = max S : S s = min Sˆ s : g ( Sˆ ) G, =. Ze względu na ogólność owyższej definicji można używać różnych funkcji jako funkcji aktywacji, jednak dla otrzeb tej racy zawężono się do nastęujących okresowych funkcji aktywacji: y y y y gdzie: ( s ) = tan( s ) = g4 β - funkcja tangensoidalna (Rys. 11.) ( s ) = tan( β s ) h ( s ) = g5 ± β - hybrydowa funkcja tangensoidalna (Rys. 12.) ( s ) = sin( β s ) h ( s ) = g6 ± β - hybrydowa funkcja sinusoidalna (Rys. 13.) ( s ) = sin( s ) = g7 β - funkcja sinusoidalna (Rys. 14.) h ± ( x) + 1 = 1 gdy x gdy x + U k= + U k= ( 4k 1) π( 4k 1) π +, 2 2 ( 4k+ 1) π( 4k 3) π +,
71 y = g (s ) 4 s Rysunek Okresowa funkcja aktywacji - tangensoidalna: ( s ) = ( tanβ s ) g4 taka, że g4 : R R y = g (s ) 5 s Rysunek Okresowa funkcja aktywacji hybrydowa tangensoidalna: ( s ) = tan( β s ) h± ( β s ) g5 taka, że g5 : R R 71
72 y = g (s ) 6 s Rysunek Okresowa funkcja aktywacji hybrydowa sinusoidalna: g ( s ) = sin( β s ) h± ( β s ) 6 taka, że g 6 : R [ 1, + 1] y = g (s ) 7 s Rysunek Okresowa funkcja aktywacji sinusoidalna: g ( s ) = sin( β s ) 7 taka, że g 7 : R [ 1, + 1] Dla owyższych rzykładowych okresowych funkcji aktywacji g k wyznaczamy funkcje G k nastęująco: S = G arctan ( ) ( Y ) Y, s = + K( s ) π 4, β 72
73 S S S arctan ( ) ( Y h ( β s ) Y, s = + K( s ) π ± = G5, β arcsin ( ) ( Y h ( β s ) Y, s = + K( s ) π ± = G6, = G β arcsin ( ) ( Y ) Y, s = + K( s ) π 7, β gdzie K ( s) 2β s + sgn = π 2 ( s), rzy czym x oznacza całkowitoliczbową część wartości x owstałą rzez obcięcie części ułamkowej. Postawmy sobie ytanie: Czy widząc komlikacje, jakie temu towarzyszą - mimo wszystko warto stosować eriodyczne funkcje aktywacji? Czy z owodzeniem nie można by było ograniczyć się do stosowanych obecnie funkcji aktywacji, które znajdują ewne biologiczne uzasadnienie? Otóż, jak zostanie okazane w rozdziale V., zastosowanie okresowych funkcji aktywacji umożliwia rozwiązanie ewnych zadań, których rozwiązanie klasycznymi metodami neuronowymi z funkcjami aktywacji w dotychczas stosowanej ostaci okazało się niemożliwe albo bardzo trudne. Dotyczy to n. klasycznego roblemu dwóch siral (oisanego dokładniej w rozdziale V). W rzyadku użycia niemonotonicznej funkcji aktywacji rozwiązanie tego roblemu okazało się możliwe (z orawną interolacją i ekstraolacją wyników uczenia!) rzy użyciu sieci neuronowej składającej się z ojedynczego efektora! Jest to duży sukces, gdyż - jak wiadomo - roblem ten bardzo trudno rozwiązuje się nawet w bardzo dużych sieciach - rzy założeniu użycia tyowych sieci neuronowych, n. klasy MLP. W analogiczny sosób, jak to okazano wyżej, może zostać zdefiniowana funkcja wielu różnych funkcji aktywacji G k dla g k, dlatego użytkownik może wybierać sośród bardzo wielu otencjalnie dostęnych funkcji aktywacji, używając ich w zależności od otrzeb. Należy zwrócić uwagę, że użycie niemonotonicznych funkcji aktywacji daje nowe możliwości, ale rodzi także nowe roblemy. Związane są one głównie z efektywnością 73
74 rocesu uczenia, gdyż w związku z zastosowaniem eriodycznych (czyli zarazem nie monotonicznych) funkcji aktywacji już dla sieci dwuwarstwowych ojawia się roblem minimów lokalnych. Ogromnie trudno jest tak rowadzić roces uczenia, by nie blokować go w unktach odowiadających lokalnym minimom funkcji błędów, których jest dodatkowo bardzo dużo dla funkcji eriodycznych używanych jako funkcje rzejścia jest ich nieskończona ilość! Zastosowanie sinusoidalnej funkcji aktywacji, dla której g k [ 1, 1] : R +, wymusza zatem automatycznie kolejne zmiany algorytmu uczenia sieci neuronowej, w związku z zawężeniem zakresu zbioru wartości funkcji. Zastosowanie funkcji sinusoidalnych tylko w warstwie efektorowej uraszcza ten roblem i ozwala ograniczyć uwagę badacza wyłącznie do skalowania sygnałów ochodzących od nauczyciela (z ciągu uczącego), tak aby należały one do zakresu [ 1+, 1] Uczenie sieci neuronowych zawierających neurony ukryte Dwuwarstwowe sieci neuronowe często nie wystarczają do efektywnego rozwiązywania bardziej skomlikowanych zadań, albo nie dostarczają rozwiązań z wymaganą dokładnością, dlatego na odobieństwo struktur neuronów zawartych w korze mózgowej - stworzono toologie sieci neuronowych, w których neurony uorządkowane są w kilku warstwach. Przez dłuższy okres czasu nie znany był jednak algorytm, który by umożliwiał uczenie takich architektur sieciowych. Pierwszą metodą, która ozwoliła na uczenie toologii zawierających dodatkowe warstwy (nazywane ukrytymi ), była Metoda Proagacji Wstecznej (BP Back Proagation), która jest często skuteczna, jednak ma tę ważną cechę, że korzysta z bazy koncecyjnej metod otymalizacyjnych, a w szczególności z metod gradientowych. Jak wynika z dyskusji rzerowadzonej na wstęie tej racy, metody takie nie gwarantują jednak efektywnego zmierzania do minimum globalnego funkcji błędu, lecz tylko oszukują minimum lokalnego w kierunku, na jaki wskazuje gradient rozważanej funkcji. Jest to istotna i trudna do uniknięcia wada tych metod. Metoda sterowanych komromisów, wrowadzona w tej racy, ma jednak także i tę zaletę, że może zostać uogólniona również dla otrzeb uczenia sieci wielowarstwowych. Co więcej, metoda ta da się zastosować również dla tych sieci, które nie bazują na jawnych warstwach, ale osiadają ewną ilość niecyklicznie ołączonych neuronów ośrednich (zwanych też ukrytymi ) omiędzy sensorami (tj. warstwą wejściową) i efektorami (tj. warstwą wyjściową). Niezależnie od tego, czy neurony ukryte są z założenia uszeregowane w warstwy czy nie, zawsze można je ogruować we wsomniane w rozdziale IV
75 wirtualne warstwy uczenia, wyznaczone dynamicznie w danej eoce dla danego etau uczącego na odstawie aktualnych (w razie otrzeby aktywizowanych lub dezaktywizowanych) ołączeń synatycznych omiędzy oszczególnymi sensorami, neuronami i efektorami sieci neuronowej. Ponadto w oisanej metodzie roces uczenia daje się dobrze zorganizować w sensie obliczeniowym, onieważ wszystkie te elementy sieci można zawsze jednoznacznie uszeregować tak, by było możliwe rzerowadzenie sekwencyjnego ich rzetwarzania. Fakt ten umożliwia srawne rzerowadzenie symulacji sieci (oartnych na metodzie sterowanych komromisów) na komuterach jednorocesorowych. Jakkolwiek aktualnie większość sieci neuronowych realizowana jest w ostaci rogramów symulacyjnych na klasycznych komuterach, to rzy ocenie właściwości metody sterowanych komromisów ważne jest również to, że obliczenia dla tej metody można dokonywać również równolegle dla wszystkich elementów danej wirtualnej warstwy uczącej, co ozwala na jej realizację w strukturach systemów wsółbieżnych Idea uogólnienia metody dla sieci zawierających kilka warstw Uogólnienie metody sterowanych komromisów dla otrzeb uczenia sieci neuronowych zawierających neurony (warstwy) ośrednie ( ukryte ) ociąga za sobą konieczność zdefiniowania tego, jak owstały błąd, który może zostać skonfrontowany z sygnałem uczącym ochodzącym od nauczyciela tylko na wyjściu sieci, ma zostać rozłożony na arametry wolne całej sieci neuronowej. W rzyadku zarezentowanej tu metody uczącej będzie chodzić o określenie tego, jak sygnał uczący ma dotrzeć do neuronów warstw ośrednich, by tam wywołać odowiednie zmiany, rowadzące w efekcie całą sieć neuronową do wyznaczonego celu. Dla orawnego oisania algorytmu uczenia sieci zawierających kilka warstw celowe jest rzyomnienie sobie, że celem uczenia jest globalna minimalizacja błędu, jaki sieć neuronowa daje na swoim wyjściu, dla wszystkich wzorców ciągu uczącego. Żeby odowiednio oracować strategię korekt arametrów wolnych sieci, należy najierw rozważyć, jaki wływ na działanie sieci będą miały oszczególne korekty. Jeżeli skorygowana zostanie waga lub róg związany z neuronem lub efektorem blisko wyjścia sieci neuronowej (jak to okazano na rys. IV.15), wtedy wływ tej korekty na roces rzetwarzania informacji w sieci jest niewielki. Jeśli zaś korekcie ulegnie waga lub róg neuronu znajdującego się w obliżu wejścia sieci (rys. IV.16), wtedy fundamentalnej zmianie ulegnie duża część rzetwarzanych w sieci informacji. Wływ owyżej oisanych zmian na 75
76 roces rzetwarzania informacji rzez sieć można by było orównać odowiednio do zmian jakie wrowadza w rzedsiębiorstwie jakiś szeregowy racownik niskiego szczebla (n. kucharz - rys. IV.15) i dyrektor (rys. IV.16). Przenosząc teraz nasze rozważania na grunt sieci neuronowych, możemy owiedzieć, że w razie wystąienia błędu na wyjściu sieci warto sróbować najierw skorygować owstały błąd tam, gdzie rawdoodobieństwo zaburzenia całego rocesu rzetwarzania informacji jest mniejsze, a doiero kiedy zmiany te okażą się niewystarczające, stoniowo rzechodzić do restrukturyzacji całego systemu rzetwarzania informacji w sieci. Warstwa sensoryczna eurony ukryte Warstwa efektorowa Rysunek Korekta wagi synatycznej w obliżu wyjścia sieci ma mały wływ na roces rzetwarzania informacji w całej sieci (analogia zmian jadłosisu rzez kucharza w rzedsiębiorstwie). 76
77 Warstwa sensoryczna eurony ukryte Warstwa efektorowa Rysunek Korekta wagi synatycznej w obliżu wejścia sieci ma mały duży wływ na roces rzetwarzania informacji w całej sieci (analogia zmian strategii firmy na rynku wrowadzonej rzez dyrektora w rzedsiębiorstwie). Zauważmy dalej, że dane wejściowe stanowią zawsze ewien konkret, zaś im dalej w głąb sieci, tym bardziej ogólne (bardziej abstrakcyjne) cechy są wydobywane z tych konkretnych sygnałów, i że sygnał wyjściowy sieci owstaje właśnie w oarciu o ten najbardziej abstrakcyjny ois danego roblemu. Znaczy to tyle, że jeśli do wytworzenia odowiedniego sygnału wyjściowego nie wystarcza sam sygnał wejściowy (jak to ma miejsce w rzyadku sieci dwuwarstwowych), to dodaje się kolejne neurony lub całe warstwy neuronów ośrednich, które ten sygnał odowiednio rearują (wyłuskując ewne odobieństwa i wtórne cechy rezentowanych danych). Czyni się to w tym celu, żeby w nowych rzestrzeniach cech wtórnych (obliczanych na bazie sygnału wejściowego) można było łatwiej odjąć końcową decyzję, czyli obliczyć odowiedni sygnał wyjściowy. Wniosek z tego jest taki, że zastosowanie większej liczby warstw ukrytych teoretycznie owinno umożliwić bardziej łynne rzejście od szczegółów do ogółów i dać możliwość hierarchicznego rozwikłania nawet najbardziej skomlikowanych roblemów zadanych ciągiem uczącym. Podsumowując te rozważania i rzekładając je na filozofię sosobu rzerowadzania korekt arametrów wolnych sieci, można owiedzieć, że najierw należy sróbować skorygować otrzymaną rzez sieć abstrakcję, a jeśli to nie da odowiedniego rezultatu, rzechodzić należy w kierunku korekty tych czynników, które włynęły na owstanie tej niewłaściwej (bo wymagającej korekty) abstrakcji. 77
78 Takie ostęowanie znajduje również ewne odzwierciedlenie w sosobie rozumowania człowieka, który często woli najierw zmienić interretację (ewną abstrakcję) dostrzeganych faktów oraz sosób ich wykorzystywania w celu osiągnięcia zamierzonego celu, niż gruntownie zmieniać całe swoje ostęowanie (dokonując na rzykład konkrety w sferze wartości), co wymaga o wiele więcej racy i wysiłku. Ze względu na stabilność rocesu uczenia można taki oortunistyczny sosób ostęowania uzasadnić zdrowym ragmatyzmem: o rostu zmiany mniej ingerujące w roces rzetwarzania informacji wydają się być również bardziej wskazane niż te, które drastycznie zmieniają większość obliczeń zachodzących w sieci. Oczywiście nie można się kierować wyłącznie oortunizmem, więc fundamentalne zmiany mogą być czasami także konieczne, n. w rzyadku osiągnięcia minimum lokalnego lub na oczątku uczenia sieci. Zwłaszcza na oczątku rocesu uczenia, konieczne jest często sięganie do zmian zasadniczych (w sferze najbardziej odstawowych ojęć i wartości ), ale amiętajmy, że dotyczy to sieci młodej, w której wtedy zazwyczaj wystęuje zuełny chaos informacyjny, wymagający odstawowego ukierunkowania nauki. Proces nauki sieci owinien być jednak generalnie tak uwarunkowany, aby zmiany toczyły się rzede wszystkim na oziomie jak najmniejszej ingerencji w stabilność nauki, zarazem jednak umożliwiając sieci w każdym momencie rzerowadzenie istotnych fundamentalnych zmian, o ile wystąi taka otrzeba. Zmiany fundamentalne owinny być jednak zawsze orzedzone róbami osiągnięcia celu tymi orawkami arametrycznymi, możliwie delikatnymi i mało zakłócającymi dla całego rocesu, w celu finalnego osiągnięcia zbieżności sieci do rozwiązania zadanego ciągiem uczącym. Realizacja wyżej oisanych ostulatów w oisywanej w racy metodzie sterowanych komromisów odbywa się w nastęujący sosób: W każdej eoce uczącej rzerowadzanych jest kilka etaów. Ich ilość zależy od ilości wirtualnych warstw uczenia, zależnych (jak wiadomo) od aktualnej architektury sieci, a w szczególności od sosobu ołączeń oszczególnych sensorów, neuronów i efektorów. Podczas każdego etau uczącego, w którym rzeglądany jest cały ciąg uczący, dokonywana jest roagacja wsteczna ożądanego sygnału Y dla ustalonego wzorca uczącego do aktualnie dostrajanej warstwy uczącej. Dostrajanie warstw uczących rzebiega w takiej kolejności, by kolejność ta odzwierciedlała ideę korekty owstałych błędów w kierunku od tych najmniej ingerujących w roces rzetwarzania informacji w sieci, do tych najbardziej go modyfikujących. 78
79 W danym etaie uczącym obliczane są tylko korekty wag i rogów neuronów i efektorów warstwy uczącej związanej z rozważanym etaem. Na końcu takiego etau obliczany jest komromis i dokonywana jest aktualizacja wag i rogów elementów sieci na odstawie zebranych roozycji wszystkich korekt, sugerowanych rzez oszczególne wzorce uczące. Nastęnie srawdza się, na ile rzerowadzona aktualizacja wag i rogów włynęła ozytywnie na globalną minimalizację błędu sieci dla wszystkich wzorców. O ile błąd nadal nie został w ełni skorygowany i istnieje jeszcze jakaś orzednia warstwa ucząca, rozoczyna się kolejny eta uczący dla tej warstwy. Jeśli zaś brak warstwy orzedniej, eoka ucząca jest kończona i rozoczyna się nastęna, w której neurony są znowu etaami korygowane w kierunku od wyjścia do wejścia sieci. Na rysunku zilustrowano roces etaowej korekty i aktualizacji sieci neuronowej. Trzeba zauważyć, że dla sieci neuronowych o luźnych toologiach, w których nie każdy z każdym neuronem jest ołączony, warstwa sieci neuronowej zarojektowana rzez konstruktora nie musi odowiadać warstwie uczącej neuronów aktualizowanych w danym etaie. Dla sieci neuronowych o dynamicznie zmiennej architekturze (w rzyadku zastosowania metod ontogenicznych) ilość warstw uczących (a więc i etaów uczących) może się dynamicznie zmieniać. Dynamiczne wyznaczanie wirtualnych warstw uczących jest ściśle związane z rocesem roagacji wstecznej sygnału uczącego i nie stanowi żadnego dodatkowego obciążenia natury obliczeniowej. Dla ełności oisu należy dodać, że metoda sterowanych komromisów teoretycznie ozwala na rozoczęcie rocesu korygowania arametrów sieci od dowolnej wirtualnej warstwy uczenia i kontynuowanie tego rocesu w dowolnym orządku, tzn. n. można rozocząć aktualizację wag i rogów sieci od warstwy uczenia usytuowanej zaraz rzy wejściu sieci i óźniej kolejno korygować nastęne warstwy w kierunku do jej wyjścia. Ze względu na szeroki zakres zagadnienia z owodów oisanych w tym rozdziale w tej racy ograniczono się do rozważania rocesu korygowania arametrów sieci w kierunku od wyjścia sieci do jej wejścia dla oszczególnych wirtualnych warstw uczenia. 79
80 Eta 4 Eta 3 Eta 2 Eta 1 Rysunek Wizualizacja eoki uczącej z zaznaczeniem oszczególnych etaów uczących (a zarazem wirtualnych warstw uczących) dla rzykładowej sieci neuronowej. 80
81 Ois algorytmu uogólnionej metody sterowanych komromisów dla wielu warstw Wyznaczanie ścieżek uczenia Uogólniona wersja metody sterowanych komromisów dla wielu warstw używa secjalnych znaczników rzyisanych do wszystkich neuronów, efektorów i synas sieci neuronowej. Znaczniki te służą do wyznaczenia ścieżek, na których możliwa jest wsteczna roagacja sygnału uczącego dla danego etau uczącego. Znaczniki te są automatycznie roagowane w kierunku od wejścia sieci neuronowej do jej wyjścia w fazie roagacji sygnału obudzenia sieciowego. Dzięki temu nawet rzy zastosowaniu dynamicznie zmiennej architektury sieci neuronowej, możliwe jest każdorazowo dynamiczne wyznaczanie ścieżek uczących i rawidłowa roagacja wsteczna sygnału uczącego, zgodnie z założeniami oisanej metody. Używane są dwa rodzaje znaczników: znaczniki korekty (rzyisane wszystkim neuronom i efektorom), znaczniki ścieżki korekty (rzyisane wszystkim neuronom, efektorom i synasom). Znaczniki korekty niosą informację o tym, czy dany neuron lub efektor został już w którymś z orzednich etaów danej eoki skorygowany i zaktualizowany, czy nie. Przez skorygowanie i aktualizację danego neuronu lub efektora rozumie się korektę wszystkich jego wag i rogu. W danej eoce uczącej każdy neuron i efektor jest korygowany tylko raz. Oznacza to tyle, że jeżeli dany neuron (efektor) zostanie skorygowany w danym etaie uczącym, dalszej korekcie nie odlegają już jego wagi ani róg, lecz sygnał uczący jest w nastęnym etaie uczącym roagowany do orzedniej warstwy uczącej, a więc do neuronów, które nie zostały jeszcze w danej eoce uczącej skorygowane. Rozkład sygnału uczącego na oszczególne dendryty odbywa się na odstawie znaczników ścieżek korekty rzyisanych do oszczególnych synas. Znaczniki te informują dany neuron lub efektor o tym, gdzie można jeszcze roagować sygnał uczący w celu korekty ozostałego jeszcze błędu sieciowego. Eoka ucząca trwa tak długo, doóki wskaźniki korekty wszystkich biorących udział w nauce neuronów i efektorów nie rzyjmą wartości określającej, iż związane z nimi elementy sieci zostały już skorygowane. Rysunek uwidacznia oisaną wyżej strategię wstecznej roagacji sygnału uczącego dla jednej z eok uczących z uwzględnieniem znaczników uczących. 81
82 Eta 4 Eta 3 Eta 2 Eta 1 Rysunek Strategia wstecznej roagacji sygnału uczącego w 4. etaie uczącym z uwidocznieniem oisanych w tekście znaczników: kolorem żółtym oznaczone są wskaźniki otwartej ścieżki korekty, zaś kolorem szarym wskaźniki zamkniętej ścieżki korekty. Sygnał uczący jest rozkładany na te elementy sieci neuronowej, dla których wskaźniki ścieżki korekty są otwarte. Pogrubione zostały te elementy sieci, które w 4. etaie uczącym są korygowane. Neurony i efektory odczas fazy roagacji wstecznej sygnału uczącego zachowują się odmiennie w zależności od tego, w jakim stanie uczącym danej eoki się znajdują. Sensory wcale nie biorą udziału w nauce. Rozróżniamy nastęujące stany rzyisywane dynamicznie elementom sieci w trakcie uczenia: nie korygowany nie biorący udział w danym etaie uczącym, aktualizowany aktualizowany zgodnie z wzorami oisanymi w rozdziale , skorygowany biorący udział w nauce w roli ośredników (gdy ich wskaźnik ścieżki korekty jest otwarty) czyli roagujących odowiednio rozłożony sygnał uczący orzez te swoje dendryty, których ścieżka korekty jest otwarta. Do neuronów nie korygowanych nie dochodzi ełna informacja umożliwiająca ich korektę. Neurony te więc nie są aktualizowane w danym etaie uczącym, lecz czekają na swoją kolejność w którymś z nastęnych etaów uczących danej eoki uczącej. Neurony aktualizowane, do których w danym etaie dotarła ełna informacja umożliwiająca ich korektę, tworzą wyżej wsomnianą wirtualną warstwę uczącą i odlegają korektom i aktualizacji. Neurony skorygowane w którymś z orzednich etaów uczących danej eoki, których wskaźnik ścieżki jest nadal otwarty, nie odlegają już nastęnym korektom w danej 82
83 eoce uczącej, lecz rzesyłają w sosób oisany oniżej odowiednio rozłożony na oszczególne swoje dendryty (o statusie otwartej ścieżki korekty) sygnał uczący, umożliwiając w ten sosób neuronom z wcześniejszych warstw korektę tego, czego im nie udało się skorygować Wsteczna roagacja sygnału uczącego dla danego etau uczącego sieci wielowarstwowych Każda eoka ucząca składa się z jednego lub kilku etaów uczących w zależności od stonia skomlikowania architektury sieci neuronowej. Gdy w sieci wystęuje więcej niż jeden eta uczący, konieczna jest wsteczna roagacja sygnału uczącego rzez sieć do wcześniejszych warstw uczących. Sygnał uczący musi być wtedy wstecznie rzekształcany i rozkładany na oszczególne dendryty efektorów i tych neuronów, które już były wcześniej skorygowane. Proces rzekazywania informacji o sygnale uczącym wygląda nastęująco: Najierw obliczana jest wartość stanu obudzenia efektora sygnału uczącego S na odstawie wartości Y dla ustalonego wzorca uczącego analogicznie jak dla efektorów oisanych w rozdziałach i : S = G ( Y ) lub S G ( Y, s ) k =. Nastęnie obliczana jest korekta tego stanu: σ s = S s. k oraz wsółczynnik Mˆ s jego rozkładu na oszczególne dendryty tak, jak zostało to oisane w rozdz z tą różnicą, że rzy jego obliczaniu brane są od uwagę tylko te dendryty, których znaczniki ścieżki korekty są otwarte: i = Mˆ s = d. { 1,... : ścieżka( i) otwarta} i W dalszej kolejności obliczane są korekty ostsynatycznych obudzeń dendrytycznych dla oszczególnych dendrytów charakteryzujących się otwartą ścieżką korekty nastęująco: d i σ d =σ i s, Mˆ s W końcu zamiast obliczać nową roonowaną wagę dla ustalonego wzorca uczącego obliczana jest nowa roonowana dla tego wzorca wartość resynatycznego obudzenia synasy w nastęujący sosób: 83
84 X i di +σ di =. W i Na odstawie tej wartości obliczana jest korekta resynatycznego obudzenia rozważanej synasy dla ustalonego wzorca uczącego : σ = X x. X i i i Obliczone w ten sosób korekty dla oszczególnych wzorców ciągu uczącego służą nastęnie do obliczenia wynikowej komromisowej korekty sygnału resynatycznego obudzenia synasy i zarazem korekty aksonalnego sygnału uczącego Y neuronu resynatycznego dla rozważanej synasy. Liczymy się rzy tym z faktem, że drzewko aksonalne tego neuronu może być rozbudowane, tzn. jego wyjście może być ołączone z wieloma różnymi neuronami i efektorami orzez ołączenia synatyczne. Trzeba więc w rocesie uczenia uwzględniać korekty docierające do neuronu resynatycznego różnymi drogami. W najrostszej wersji metody można się tu ograniczyć do liczenia średniej arytmetycznej 4 z sugerowanych roozycji korekt dla oszczególnych synas. Odowiednia formuła korekty sygnału wyjściowego neuronu resynatycznego wygląda wtedy nastęująco: M σ X m m= 1 σ Y =, M a stąd już wyznaczana jest wartość sygnału uczącego neuronu resynatycznego dla ustalonego wzorca uczącego : Y = y + σ Y. W ten sosób w każdym etaie uczącym dochodzi do korekty ewnej części błędu, jakim obarczona jest sieć neuronowa. Korekta rzerowadzana jest etaami, od najwyższego oziomu abstrakcji do najniższego. Poszczególne etay się wzajemnie doełniają na zasadzie: Czego nie uda się skorygować w jednym etaie, róbuje się korygować w nastęnym i tak aż do skutku. Proces uczenia rzerowadzany jest hierarchicznie, co jest zgodne z intuicją i z 4 Średnia arytmetyczna w ogólności niezbyt dobrze nadaje się do obliczania komromisowych korekt i może być owodem wystęowania różnych roblemów zbieżności nauki oisanych w nastęnym rozdziale. Obliczanie komromisowej korekty może być jakkolwiek oarte na tej średniej, ale owinno być rzerowadzane bardziej inteligentnie ze względu na ominięcie mogących się ojawić trudności natury numerycznej. 84
85 doświadczeniami związanymi z nauką. Zawsze rościej dostosować szczegóły niż zasadniczo zmieniać od odstaw cały system ostęowania. Taka hierarchia nauki idzie również w arze z odległością sygnału uczącego od oszczególnych warstw uczących, zdefiniowanych w tej racy. Im warstwa znajduje się dalej od wyjścia sieci neuronowej, tym bardziej jej stan jest chroniony rzed zmianami orzez wcześniejsze korekty warstw znajdujących się bliżej wyjścia sieci neuronowej. Takie ostęowanie owinno zaewnić stabilność rocesu uczenia sieci neuronowej w odniesieniu do hierarchii wływu zmian oszczególnych arametrów sieci na roces rzetwarzania informacji w całej sieci neuronowej Problemy związane z uczeniem sieci wielowarstwowych Uczenie wielowarstwowych sieci neuronowych narażone jest na wiele trudności. Do odstawowych należą: Problem minimów lokalnych i zaewnienia zbieżności metody do minimum globalnego. Problem wstęnej inicjacji sieci, która w ewien sosób determinuje kierunek oszukiwań minimum globalnego. Problem małych i dużych liczb związany z obliczaniem komromisu na bazie wyliczania wartości średniej. Problem minimów lokalnych może zostać rozwiązany dzięki dobrodziejstwu oisanych w tej racy odchyleń umożliwiającym rzerowadzenie wnioskowania i ukierunkowania rocesu uczenia niezależnie od gradientu funkcji błędu sieci. Dzięki temu można zmierzać w kierunku minimum globalnego i zaewnić odowiednią zbieżność nauki na bazie oisanych odchyleń, które są równoważne globalnej minimalizacji błędu sieci. Wstęna inicjacja sieci neuronowej decyduje o sosobie roagowania obudzenia rzez sieć na oczątku rocesu nauki i może w niekorzystny sosób utrudnić znalezienie minimum globalnego. Z metod gradientowych oartych na bazie metod otymalizacyjnych wynika, że roblem ten jest niebanalny. Potrzeba rzerowadzenia wielu rób i konieczność stosowania różnych technik omijania minimów lokalnych może zniechęcić do stosowania sieci neuronowych nie jednego badacza. W rzyadku metody sterowanych komromisów roblem wstęnej inicjacji sieci można srowadzić do wcześniej oisanego roblemu omijania minimów lokalnych i rozwiązać go znowu dzięki dobrodziejstwu łynącemu z 85
86 informacji o odchyleniach. W raktyce wygląda to tak, że dla sieci niekorzystnie zainicjowanej, roces uczący będzie wymuszał w trakcie etau uczącego dogłębne korekty we wszystkich warstwach uczących sieci róbując zminimalizować oisane odchylenia. Problem małych i dużych liczb jest secyficznym roblemem związanym z zarezentowaną w tej racy metodą i nie wystęuje tak dogłębnie w rzyadku innych metod n. gradientowych. Ze względu na to że metoda sterowanych komromisów róbuje owstały dla oszczególnych wzorców uczących błąd orawić od razu, zmiany te mogą mieć bardzo radykalny charakter. Proonowane korekty dla oszczególnych wzorców stają się odstawą obliczanego komromisu, a ten owinien w ewien sosób odzwierciedlać roozycje stawiane rzez wszystkie wzorce uczące. Dla rozwiązania tego roblemu intuicyjnie nasuwa się rozwiązanie orzez średnią (n. arytmetyczną), która z natury uwzględnia wszystkie wzorce. Jednak roonowane korekty mogą być jak dodatnie tak ujemne, mogą się wzajemnie znosić co owoduje stagnację wynikowych komromisowych korekt i w raktyce rowadzi do minimów zazwyczaj lokalnych. Żeby tego nie było mało, taka wynikowa komromisowa korekta może sowodować, że nowa obliczona wartość na jej odstawie akurat trafiła w wartość bliską zeru (małą liczbę), która w dalszych obliczeniach tej metody jest często wykorzystywana w roli dzielnika ilorazu owodującego owstanie dużej liczby. Takie małe i duże liczby zaś w nastęnej eoce uczącej bardzo destabilizują roces nauki i owodują niekorzystne fluktuacje. Należy odkreślić, że zazwyczaj obliczenie takich małych liczb nie było roonowane rzez żaden wzorzec uczący, lecz było wynikiem obliczania średniej. Z tego owodu należy szukać bardziej inteligentnych metod obliczania komromisu, które nie douszczają do owstawania takich niechcianych anomalii Uczenie niekomletnych wzorców uczących Metoda sterowanych komromisów ozwala również wykorzystać niekomletne wzorce uczące do skutecznej nauki sieci neuronowej. Oznacza to, że jeśli w wyniku jakiegoś doświadczenia (dla wybranego zbioru arametrów charakteryzujących go) uzyskamy ewne wyniki, które mają stać się zbiorem uczącym, ale są one niekomletne i z ważnych owodów (na rzykład natury finansowej lub deontologicznej) uzyskanie komletnych danych jest niemożliwe bądź trudne do osiągnięcia, to w metodzie sterowanych komromisów nadal możemy ten zbiór danych wykorzystać jako zbiór uczący. Sieć neuronowa będzie wtedy w rocesie nauki zdobywać mniej wiedzy, gdyż będzie dostosowywana do tego niekomletnego zbioru danych, ale dane takie nie będą dla rocesu nauki całkowicie stracone. W wyniku 86
87 rzerowadzonej nauki uzyskane zostanie ewne uogólnienie, które umożliwi nie tylko klasyczne zadawanie zaytań z oza zbioru uczącego, ale również zadawanie zaytań dla niekomletnych wzorców. W wyniku takiego zaytywania sieci istnieje możliwość, że sieć na odstawie uzyskanego uogólnienia doełni brakujące dane wyjściowe i w ten sosób da odowiedź na to, na co nie udało się uzyskać ełnej odowiedzi w trakcie rzerowadzanego doświadczenia. Realizacja wyżej oisanego ostulatu wygląda nastęująco: W rzyadku, gdy dla danego wzorca uczącego dla określonych danych wejściowych brak komletnego sygnału uczącego, wtedy cały roces rzebiega analogicznie jak dla wzorców komletnych z tą różnicą, że brakująca część sygnału uczącego nie jest wstecznie roagowana rzez sieć. W zależności od stonia niekomletności wzorca i od architektury sieci neuronowej niektóre wagi i rogi sieci dla rozważanego wzorca mogą nie być w związku z tym korygowane. W rzyadku wielowarstwowej architektury sieci odczas obliczania komromisowej korekty sygnału aksonalnego neuronu resynatycznego brane są od uwagę tylko te odgałęzienia (kolaterale) drzewka aksonalnego, dla których możliwe jest obliczenie stosownej korekty. Gdy dane odgałęzienie drzewka aksonalnego nie jest w stanie rzesłać neuronowi resynatycznemu roonowanej korekty jego obudzenia aksonalnego, wtedy informuje o tym ten neuron, żeby ten mógł zrealizować swoją korektę na odstawie tej części informacji, która do niego dotarła od innych kolaterali. Na rysunku uwidoczniona jest sytuacja oisana owyżej. 87
88 x 1 Y 1 x 2 x 3? Rysunek Uwidocznienie ostulatu korekty na odstawie nie komletnego sygnału uczącego. Czerwonym kolorem oznaczony został znany sygnał uczący dla ustalonego wzorca uczącego ochodzący od nauczyciela Y 1 oraz te, które zostały wstecznie roagowane rzez sieć neuronową na jego odstawie, zaś niebieskim, te które dla danego wzorca uczącego nie są znane. Synasy oznaczone kolorem niebieskim rzekazują (w rzynależnym im etaie uczącym) neuronom wyełnionym kolorem żółtym tylko informację o tym, że nie są im zdolne rzesłać roozycji korekty, żeby te nie czekały na nią myśląc, że nie nadeszła jeszcze ora ich korekty w danym etaie uczącym. Neurony wyełnione kolorem żółtym są więc korygowane na odstawie roozycji korekt ozostałych (oznaczonych kolorem czerwonym) kolaterali drzewka aksonalnego. Neurony, efektory i synasy wyełnione kolorem zielonym są korygowane w zwykły sosób określony we wcześniejszych rozdziałach (rozdz i rozdz ). Efektor i wagi wyełnione kolorem szarym nie są korygowane dla rozważanego niekomletnego wzorca uczącego Podsumowanie i kierunki rozwoju metody Metoda sterowanych komromisów oisana w tej racy stanowi całkowicie nowe odejście do roblemu szukania minimum globalnego funkcji błędu. Proces minimalizacji funkcji błędu udało się rzy tym znacząco urościć orzez jego rzeniesienie z konieczności rzeszukiwania nieskończonej dziedziny tej funkcji i nieznanej jej charakterystyki, na roblem minimalizacji skończonej ilości odchyleń od uzyskanego komromisu, zdefiniowanych w tej racy. Metoda ta wrowadza też ojęcie lokalności w odniesieniu do obliczania błędu i jego korekty dla oszczególnych elementów sieci neuronowej. Nastęnym atutem tej metody jest stosunkowo szeroki zakres możliwości wyboru funkcji aktywacji neuronów i efektorów. Oisana metoda umożliwia używania takich funkcji aktywacji, których zbiór wartości jest nieograniczony. To z kolei eliminuje konieczność 88
89 sztucznego skalowania, a rzede wszystkim umożliwia rawidłową ekstraolację sieciom zbudowanym na bazie takich neuronów i efektorów. Zarezentowana metoda nie ogranicza się jedynie do funkcji monotonicznych, ale daje możliwość stosowania różnorodnych funkcji aktywacji, z eriodycznymi włącznie. Zastosowanie tak nietyowych funkcji aktywacji otwiera rzed sieciami neuronowymi drogę do rozwiązania bardziej skomlikowanych zadań i uzyskania leszej srawności obliczeniowej dla roblemów, których natura może być w łatwiejszy sosób określona właśnie dzięki takim funkcjom. Dodatkowo istnieje możliwość rawie dowolnej kombinacji różnych funkcji aktywacji w jednej sieci neuronowej. Możliwości uogólniania oisanej metody są duże. W tej racy zarezentowano odstawową ideę metody sterowanych komromisów, jak również wrowadzono ewne jej rozszerzenia. Nie wszystkie roblemy związane z tą metodą zostały jednak jeszcze finalnie rozwiązane. Część roblemów rozwiązano a część tylko zasygnalizowano w celu określenia dalszych możliwych kierunków rozwoju zarezentowanej metody. Głównymi roblemami, jakie ozostają otwarte, są: konieczność bardziej inteligentnego wyznaczania komromisu oraz oracowanie odowiedniej strategii ostęowania na odstawie obliczonych odchyleń od wyznaczonego komromisu. Rozwiązanie tych dwóch roblemów umożliwi zaroonowanej tu metodzie stać się ełnowartościowym narzędziem rozwiązywania nawet bardzo skomlikowanych zadań. Można oczekiwać, że o okonaniu wskazanych ograniczeń metoda sterowanych komromisów będzie mogła zostać znacząco soularyzowana i stanowić będzie dużą konkurencję dla istniejących metod uczenia sieci neuronowych. Metoda ta jest cały czas intensywnie rozwijana, jednak ze względu na konieczność rzerowadzania licznych badań orównawczych, symulacji, wyrowadzania i weryfikowania różnych formuł matematycznych, osiągnięcie nastęnych wartościowych wyników jest kwestią czasu Alikacja Brain for Problem Dla zilustrowania funkcjonowania zaroonowanej w tej racy metody uczenia, a także dla raktycznego zbadania jej właściwości, została rzez autora racy oracowana i orogramowana alikacja nazwana Brain for Problem (Rysunek 4.19.). Alikacja ta została zarojektowana z myślą o rzetestowaniu zaroonowanych wyżej algorytmów uczących sieci neuronowe. Program Brain for Problem jest załączony do niniejszej racy, co ozwala Czytelnikowi ocenić w raktyce oracowaną metodę sterowanych komromisów. Z myślą o użytkownikach, którzy chcieli by oznać i samodzielnie zbadać zaroonowaną 89
90 metodę uczenia zbudowana rzez autora alikacja została wyosażona w szereg udogodnień, stwarzających możliwości różnych badań. Do najważniejszych udogodnień wbudowanych w stworzony dla tej racy rogram można zaliczyć: edytor ciągów uczących (graficzny i liczbowy) z możliwością zaisu na dysk, graficzny edytor sieci neuronowych z możliwością zaisu na dysk, kreator ułatwiający tworzenie odstawowych architektur sieci neuronowych dla zadanego ciągu uczącego, wyświetlanie wielu okien diagnostycznych umożliwiających odgląd i modyfikację arametrów sieci neuronowej oraz rocesu uczenia, dynamiczny odgląd nauki sieci neuronowej w secjalnie zarojektowanym interfejsie graficznym, w ełni kontrolowane i obserwowane uczenie zarojektowanych sieci neuronowych metodą sterowanych komromisów. 90
91 Rysunek Widok głównego okna alikacji Brain for Problem wraz z okienkami umożliwiającymi dynamiczną obserwację arametrów sieci neuronowej odczas jej uczenia Ois odstawowych funkcji zbudowanej alikacji Alikacja Brain for Problem może być sterowana orzez rzejrzyste menu (Rysunek 4.20.), które udostęnia użytkownikowi wszystkie możliwe ocje, ustawienia i funkcje zaimlementowane w rogramie. Menu odzielone jest na kilka odstawowych kategorii rzedstawionych na rysunku Rysunek Menu alikacji Brain for Problem. Omówimy je teraz kolejno: Brain umożliwia dokonywanie oeracji zaisu lub odczytu z dysku sieci neuronowej oraz daje możliwość wykorzystania kreatora ułatwiającego tworzenie odstawowej architektury sieci neuronowej dla zadanego ciągu uczącego. 91
92 Data odnosi się do oeracji zaisu lub odczytu z dysku ciągu uczącego, Insert ocja ta umożliwia dodawanie do sieci neuronowej sensorów, efektorów, neuronów, synas, ołączeń z ciągiem uczącym oraz dodawanie nowych wzorców do ciągu uczącego, Delete w tej ocji mamy do czynienia z czynnościami odwrotnymi do oeracji znajdujących się w ocji Insert. Przy użyciu tej ocji można obsługiwać też funkcję otymalizacji architektury sieci neuronowej (Clean) olegającą na usunięciu z niej wszystkich funkcjonalnie nieotrzebnych składników, Edit ocja ta związana jest z funkcjami edytorskimi odnoszącymi się zarówno do sieci neuronowej, jak i do ciągu uczącego, Initiation ocja ta ozwala zainicjować wszystkie, bądź wybrane arametry wolne sieci neuronowej (wagi, rogi, arametry stromości funkcji aktywacji, funkcje aktywacji neuronów i efektorów). Inicjacja może być dokonywana liczbami seudolosowymi z odanych zakresów liczbowych. Dodatkowo można wydzielić ewną gruę odlegających inicjacji elementów sieci neuronowej, Run daje możliwość uczenia sieci neuronowej metodą sterowanych komromisów, kontynuacji jej nauki, testowania oraz zaamiętywania jej najleszego stanu uzyskanego w trakcie rocesu uczenia, Show udostęnia ewne ocje związane z wyglądem sieci neuronowej oraz daje dostę do oszczególnych wzorców ciągu uczącego, oferując różne możliwości wyszukiwawcze, View zarządza widokami asków narzędziowych, aska stanu oraz wielkością widoku sieci neuronowej i rozmiarem widoku ciągu uczącego, Window umożliwia otwarcie okien dynamicznego odglądu wielkości i kształtowania się błędów w trakcie rocesu uczenia. Można obserwować zmiany błędów: sieci neuronowej, oszczególnych wzorców, oszczególnych wyjść sieci oraz graficzną interretację wyników, Hel służy omocą oraz daje informacje o rogramie. Bardzo rzydatne rzy edycji sieci neuronowej i ciągu uczącego, jak również w trakcie rowadzenia doświadczeń, są aski narzędziowe, które dają natychmiastowy dostę bez ciągłego rzeglądania menu do rawie wszystkich funkcji i ocji zbudowanej alikacji. Przyciski zostały ogruowane tworząc nastęujące aski narzędziowe: 92
93 asek oeracji dyskowych (Rysunek 4.22.), asek edycji ciągu uczącego (Rysunek 4.23.), asek edycji sieci neuronowej (Rysunek 4.24.), asek nauki i odglądu jej rzebiegu (Rysunek 4.25.). Rysunek Pasek narzędzi oeracji dyskowych, kreowania nowych sieci neuronowych i ciągów uczących. Rysunek Pasek narzędzi służący do rzeglądania i modyfikacji ciągu uczącego. Rysunek Pasek narzędzi ułatwiający edycję sieci neuronowych. Rysunek Pasek narzędzi związany z inicjacją, nauką i dynamicznym odglądem sieci neuronowej. Wszystkie rzyciski oatrzone są dymkami z oisem ich funkcji. Oisy te ojawiają się o umieszczeniu wskaźnika myszki nad nimi, a na asku stanu rogramu ojawia się rzy tym bardziej treściwy ois funkcji zaznaczonego rzycisku Zastosowana symbolika Rysunki rzedstawiają zastosowaną w alikacji Brain for Problem symbolikę graficzną, odnoszącą się do oszczególnych elementów sieci neuronowej. 93
. Kolor ururowy wyełniający wnętrze małego wewnętrznego kółka odnosi się do rogu neuronu i oznacza jego dodatnią wartość.")
94 Rysunek Symbol sensora (inut neuron). Kolor czerwony oznacza stan dodatniego obudzenia sensora. Rysunek Symbol wewnętrznego neuronu sieci (hidden neuron) z zaznaczonym rogiem. Kolor niebieski oznacza stan ujemnego obudzenia neuronu (hamowanie). Kolor ururowy wyełniający wnętrze małego wewnętrznego kółka odnosi się do rogu neuronu i oznacza jego dodatnią wartość. Jeżeli wnętrze rogu byłoby wyełnione kolorem błękitnym, oznaczałoby to jego wartość ujemną. 94
95 Rysunek Symbol efektora (outut neuron) z rogiem. Kolor czerwony oznacza stan dodatniego obudzenia efektora. Kolor biały wyełniający wnętrze rogu oznacza, że jego wartość jest bliska zeru. Rysunek Symbole synasy. Kolor błękitny oznacza wartość ujemną wagi, zaś kolor ururowy jej wartość dodatnią. Nasycenie kolorem mówi o wielkości danej wagi względem ozostałych wag i rogów sieci neuronowej. Kolor czerwony wyraża obudzenie elementu ostsynatycznego, zaś kolor niebieski jego hamowanie. Nasycenie kolorem mówi o wielkości obudzenia bądź hamowania względem ozostałych obudzeń i hamowań sieci neuronowej. 95
.")
96 Rysunek Prosta sieć neuronowa składająca się z dwóch sensorów (z lewej), jednego efektora (z rawej), neuronu ukrytego (w środku) oraz ięciu ołączeń synatycznych. Kolorystyka symbolizuje stan obudzenia oszczególnych elementów: kolor czerwony dodatni stan obudzenia, kolor niebieski ujemny stan obudzenia (hamowanie). Intensywność koloru wyraża stoień obudzenia danego elementu. Rysunek Sieć neuronowa z rysunku z widokiem wartości wag i rogów zamiast widoku ich obudzenia bądź hamowania ostsynatycznego Ois okienek umożliwiających dynamiczny odgląd rocesu uczenia Alikacja Brain for Problem umożliwia dynamiczne wyświetlanie wielu użytecznych arametrów w trakcie rocesu uczenia sieci neuronowej. Daje to możliwość obserwowania zmian zachodzących w sieci neuronowej od wływem zastosowanego algorytmu uczącego i wyciągania stosownych wniosków, które mogą nastęnie osłużyć rzerowadzeniu rewizji i usrawnienia algorytmu uczącego. Wybranie graficznej formy rezentacji wyników sowodowane jest chęcią uwolnienia się od ograniczeń ercecyjnych człowieka, które uniemożliwiają mu śledzenie dużej ilości danych w formie liczbowej. Nastęujące rysunki ( ) rezentują najważniejsze i najczęściej używane okienka alikacji wraz z ich oisem. 96

97 Rysunek Okienko wykresów średniego błędu sieci neuronowej dla całego ciągu uczącego. Niebieskim kolorem oznaczony jest błąd sieci dla wzorców uczących, zaś czerwonym błąd sieci dla wzorców testujących. W środku od wykresem znajduje się licznik odający numer aktualnie wykonanej eoki uczącej (tutaj 170 eoka). Rysunek Okienko orównawcze błędów dla oszczególnych wzorców uczących, z wyszczególnieniem wartości liczbowej maksymalnego z wyświetlanych błędów. Kolor czerwony oznacza błąd dodatni, zaś kolor niebieski błąd ujemny. Orócz błędu wzorca wyświetlany jest jego numer orządkowy (No), status (L wzorzec uczący, T wzorzec testujący, O wzorzec nieaktywny) oraz jego nazwę. Dostęne są okienka umożliwiające dodawanie (Rysunek 4.34.) i usuwanie (Rysunek 4.35.) wybranych wzorców uczących z odglądu. 97

98 Rysunek Okienko umożliwiające dodanie nowych wzorców do widoku z rysunku na wybranej ozycji. Rysunek Okienko umożliwiające usuwanie wybranych wzorców z widoku z rysunku Rysunek Okienko orównawcze średnich błędów wszystkich wyjść sieci neuronowej z wyszczególnieniem wartości liczbowej maksymalnego błędu. Kolor czerwony oznacza błąd dodatni, zaś kolor niebieski błąd ujemny. Okienko umożliwia wyświetlanie błędu tylko dla wzorców uczących (jak wyżej), tylko dla wzorców testujących, bądź sumarycznego błędu dla wszystkich wzorców uczących i testujących. 98

99 Rysunek Okienko rzedstawia stan rocesu uczenia z wyszczególnieniem orawnej kwalifikacji wzorców uczących (w 91,67%) i testujących (w 50%). Okienko to może być użyte dla tych wzorców, których sygnał uczący rzyjmuje wartości binarne bądź całkowitoliczbowe. Informacja o rocencie orawnych i błędnych klasyfikacji jest również uwidoczniona w formie graficznej odowiednio kolorem zielonym i czerwonym. Rysunek Widok ten okazuje wzorzec uczący wraz z jego nazwą. Możliwe jest zadanie wzorca w formie graficznej (dla wzorców binarnych), bądź w formie liczbowej dla wzorców zadanych liczbami całkowitymi bądź wymiernymi. Możliwe jest też skalowanie wielkości ól edycyjnych. 99
100 Rysunek Widok ten okazuje sygnał uczący dla ustalonego wzorca uczącego rzedstawionego na rysunku wraz z jego numerem orządkowym (w olu No) oraz jego statusem (uczący testujący wyłączony). Dodatkowo widok zawiera informację o ilości wszystkich wzorców ciągu uczącego. 100

101 Rysunek Widok ten okazuje sygnał wyjściowy częściowo nauczonej już sieci neuronowej dla ustalonego wzorca uczącego z rysunku i sygnału uczącego z rysunku Rysunek Okienko dynamicznego odglądu stanu obudzenia sensora oraz jego wartości wyjściowej, otwierane rzez naciśnięcie rawego rzycisku myszki, gdy jej wskaźnik znajduje się nad wybranym sensorem. Rysunek Okienko dynamicznego odglądu stanu obudzenia neuronu jego wartości wyjściowej oraz wartości rogu, otwierane rzez naciśnięcie rawego rzycisku myszki, gdy jej wskaźnik znajduje się nad wybranym neuronem. 101

102 Rysunek Okienko dynamicznego odglądu stanu obudzenia efektora jego wartości wyjściowej oraz wartości rogu, otwierane rzez naciśnięcie rawego rzycisku myszki, gdy jej wskaźnik znajduje się nad wybranym efektorem. Rysunek Okienko dynamicznego odglądu synasy wraz z jej wartością wagi i wartością obudzenia elementu ostsynatycznego, otwierane rzez naciśnięcie rawego rzycisku myszki, gdy jej wskaźnik znajduje się nad wybraną synasą. Rysunek Statyczne okienko odglądu arametrów sensora wzbogacone o informację o jego odłączeniu do miejsca macierzy wzorca uczącego, otwierane rzez naciśnięcie lewego rzycisku myszki, gdy jej wskaźnik znajduje się nad wybranym sensorem. 102

103 Rysunek Statyczne okienko odglądu arametrów neuronu wzbogacone o informacje dotyczące jego funkcji aktywacji oraz arametru stromości z nią związanego. Okienko to umożliwia również zmianę części arametrów, otwierane rzez naciśnięcie lewego rzycisku myszki, gdy jej wskaźnik znajduje się nad wybranym neuronem. Rysunek Statyczne okienko odglądu arametrów efektora wzbogacone o informacje dotyczące jego funkcji aktywacji, arametru stromości z nią związanego oraz o jego odłączeniu do miejsca macierzy sygnału uczącego. Okienko to umożliwia również zmianę części arametrów, otwierane rzez naciśnięcie lewego rzycisku myszki, gdy jej wskaźnik znajduje się nad wybranym efektorem. Rysunek Statyczne okienko odglądu arametrów synasy. Okienko to umożliwia również zmianę części arametrów, otwierane rzez naciśnięcie lewego rzycisku myszki, gdy jej wskaźnik znajduje się nad wybraną synasą. 103
104 104

105 Rysunek Okienko związane ze zmianą funkcji aktywacji wszystkich bądź wybranych neuronów i efektorów sieci neuronowej. Rysunek Okienko związane z inicjacją wag, rogów i arametrów stromości funkcji aktywacji wszystkich bądź wybranych synas, neuronów i efektorów sieci neuronowej. Rysunek Okienko umożliwia ustawienie arametrów stou i innych ocji rocesu uczenia metodą sterowanych komromisów. 105
106 Podgląd rocesu zmian arametrów sieci neuronowej Alikacja Brain for Problem umożliwia również zaisać całą historię zmian wszystkich istotnych (z unktu widzenia nauki sieci) arametrów sieci neuronowej, w celu ich óźniejszego rzeanalizowania lub dokonania statystyk na ich odstawie. Zais danych o rocesie zmian arametrów dokonywany jest orzez uaktywnienie odowiedniej ocji w okienku umożliwiającym określenie arametrów rocesu uczenia (rysunek 4.50) lub rzez naciśnięcie rzycisku. Dane te są zaisywane na dysku ze względu na swoją obszerność. Przełączanie widoku sieci neuronowej i odglądu wybranych arametrów rocesu uczenia dokonywany jest rzy użyciu rzycisków. Istnieje również możliwość wyboru arametrów (rysunek 4.52.), które są nastęnie zestawiane w widoku ich odglądu (rysunek 4.53.). Wybór owych arametrów możliwy jest o naciśnięciu rzycisku. Możliwy jest odgląd nastęujących arametrów rocesu uczenia: wartości obudzenia (inut) danego sensora, neuronu, efektora lub synasy (EXC Is), wartości rzetworzonej (outut) rzez dany sensor, neuron, efektor lub synasę (OUT Is), wartości sygnału uczącego dla danego arametru rozważanego sensora, neuronu, efektora lub synasy (Lrn), wartości korekty, jaka jest związana z danym arametrem rozważanego sensora, neuronu, efektora lub synasy (Corr), wartości błędu dla danego arametru i wszystkich wzorców uczących (Err), również w rozbiciu na jego część dodatnią (ErrP) i ujemną (ErrN), wartości, na odstawie których obliczany jest rozkład błędu na oszczególne wagi i róg odczas fazy korekty błędów (DD i DC). Można również dokonywać odglądu dla wybranej gruy interesujących węzłów sieci: sensorów, neuronów, efektorów, synas. Parametry te mogą być rezentowane dla: 106
107 całego ciągu uczącego (wszystkich wzorców uczących), wybranego wzorca uczącego, fazy aktualizacji wag i rogów (tj. odgląd zawartego komromisu) (rysunek 4.54.), wszystkich etaów uczących, wybranego etau uczącego, wybranego zakresu eok uczących. Dla udogodnienia i otymalizacji widoku możliwy jest również wybór różnych ocji w odniesieniu do czcionki, wielkości i grubości znaków, sosobu wyrównywania tekstu w komórkach tabeli. 107

108 Rysunek Okienko umożliwiające wyboru arametrów rocesu uczenia sieci neuronowej, jakie będą zestawione w głównym widoku (rysunek 4.53.). 108

109 Rysunek Główny widok alikacji w włączonym rzykładowym zestawieniem arametrów rocesu uczenia. Rysunek Widok zestawienia komromisowych wag i rogów obliczonych dla wszystkich wzorców uczących dla kolejnych 10 eok. 109
110 5. BADA IA EFEKTYW OŚCI I UŻYTECZ OŚCI OPRACOWA YCH METOD Badanie efektywności oracowanych metod ma na celu raktyczne zweryfikowanie użyteczności roonowanych w racy metod uczenia. Oczywiście badanie takie nigdy nie może być w ełni wyczerujące, dlatego w racy rzedstawimy raczej ilustrację działania oisanych metod niż ich wyczerujące badanie. Jednak na odstawie kilku wybranych i zarezentowanych dalej rzykładów można zauważyć kilka ważnych cech oracowanych metod, stąd rzytoczeniu tutaj wyników tych badań wydaje się wysoce celowe. Obserwacji odlegają rzede wszystkim te arametry zaroonowanych metod, które są kluczowe dla ich działania, jak również te, które były celem ich usrawnienia. Zebrane wyniki mogą osłużyć do orównania wyników działania zarezentowanej metody z wynikami zebranymi na odstawie innych metod uczących. Takie obserwacje mogą ujawnić zalety oisanych w racy metod i mogą zdecydować o wyborze rzez użytkownika sieci neuronowej konkretnej metody uczącej dla rozwiązania odejmowanego rzez niego roblemu. W oniższych rzykładach wykorzystano obydwie oisane w tej racy metody. W rzyadku ierwszej oisanej metody automatycznej konfiguracji sieci neuronowych, skuiono się nad uwidocznieniem możliwości konfiguracji sieci neuronowej ołączonej z rocesem automatycznej redukcji synas. W rzyadku drugiej zaroonowanej metody sterowanych komromisów, kryjącej w sobie dużo większy otencjał i możliwości, okazano dla wybranych rzykładów efekty jej działania. Do badań jak również rezentacji wyników użyto alikacji Otimal Recognition oraz Brain for Problem, które zostały naisane secjalnie dla otrzeb tej racy Zastosowanie metody automatycznej konfiguracji sieci neuronowej do rozoznawania obrazów. Problem rozoznawania obrazów jest zazwyczaj związany ze wsomnianym w rozdz roblemem rzesunięć, rotacji i skalowania, które to rzekształcenia obrazu niekorzystnie wływają także na działanie algorytmu oisanego w tej racy. Jednak dzięki zastosowaniu stosowanych metod normalizacji obrazu rzed jego wrowadzeniem na wejście sieci, a także na skutek użycia grubego rastra do rerezentacji obrazu można ewne drobne deformacje wejściowego obrazu skutecznie zamortyzować. 110
111 Badanie efektywności i użyteczności oracowanej metody automatycznej konfiguracji sieci neuronowej zostało rzerowadzone w oarciu o rzykład 26-literowego alfabetu (Rysunek 5.1.), który był już wcześniej używany do zademonstrowania działania rogramu w rozdziale Rysunek literowy alfabet użyty do omiarów efektywności działania zaroonowanej metody W ramach oisywanych tu badań algorytmu wykonano szereg doświadczeń, których celem było srawdzenie zdolności redukcyjnych i konfiguracyjnych zaroonowanej metody w odniesieniu do rzytoczonego rzykładu rozoznawania liter. Celem tych doświadczeń było zweryfikowanie, jak wartości charakterystyki F P wływają na zdolności redukcyjne metody względem synas i jak taka redukcja wływa na jakość rozoznawania i w szczególności jakość uogólniania wzorców. Biorąc od uwagę, że arametry F P są raktycznie jedynymi arametrami, na które konstruktor sieci może wływać, zadanie budowy sieci neuronowej, konfiguracji jej architektury i arametrów dla danego ciągu uczącego staje się bardzo roste w orównaniu do innych metod uczenia sieci neuronowych. 111
112 Tabela 5.1. Podsumowanie badania wływu charakterystyki F P na stoień redukcji synas oraz na jakość rozoznawania i uogólniania wzorców Charakte- Ilość Zreduko- Jakość Rozoznanie rystyka synas wane synasy uogólniania rozoznawania FNP SN Ilość % Q G % Q R % jako w % jako w % jako w % ,0 100,0 A 100 A -100 A 77, ,1 104,2 A 100 A -100 A 77, ,5 104,2 A 100 A -100 A 83, ,7 38,7 A 100 A -100 A 83, ,1 38,7 A 100 A -100 A 83, ,2 40,9 A 100 A -100 A 87, ,2 40,9 A 100 A -100 A 87, ,4 0,0 A 100 A -100 A 92, ,3 0,0 A 100 A -100 A 100, ,3 0,0 A 100 A -100 A 100, ,1 0,0 A 100 A -100 A 100, ,4 0,0 A 100 A -100 A,J 100, ,7 0,0 A 100 A -100 A,J,O,Z 100, ,0 0,0 A 100 A -100 A,J,M,N,O,Z 100,0 I,T,W,Y -100 I,T,W,Y 100 I,T,W -100,0 Z owyższej tabeli wynika, iż w badanej metodzie redukcja synas nie musi za sobą ociągać od razu brak rozoznania wzorców uczących, a nawet rzykładowy wzorzec testujący długo jest orawnie klasyfikowany. W rzyadku wzorców zaburzonych orawna klasyfikacja zależy oczywiście od tego, jak bardzo dany wzorzec odstaje od wzorca uczącego i czy najważniejsze jego cechy binarne są zaburzone, czy nie. Można dostrzec, że rzy bardzo dużej redukcji synas rzędu 82% zaczyna dochodzić do niejednoznacznego rozoznania zaburzonego wzorca, a rzy redukcji synas rzędu 88% dochodzi nawet do niejednoznaczności w rzyadku rozoznawania wzorca uczącego. Trudno by było rzetestować wszystkie możliwe kombinacje, szczególnie dla wzorców zaburzonych. Zaewne można by było znaleźć takie zaburzone wzorce, które już dla mniejszej redukcji synas będą niejednoznacznie bądź nieorawnie rozoznane. Niezerowa jakość rozoznawania gwarantuje nam bowiem tylko orawne i jednoznaczne rozoznanie wzorców uczących, a jak widać z tabeli Q R utrzymuje się na oziomie dodatnim jeszcze tylko rzy 54% redukcji synas, co nie jest wcale mało! W rzyadku jakości rozoznawania może czasami dochodzić do sytuacji jej orawy (104,2%), jak to widać rzy 6% i 13% redukcji synas. Porawa taka wynika jednak tylko z faktu odrzucenia części mało istotnych cech 112
113 wzorców, co zarazem owoduje zwiększenie minimalnej odległości wzorców uczących względem siebie Uczenie funkcji logicznych. Funkcje logiczne są jednym z rostszych rzykładów zastosowania oisanej metody sterowanych komromisów, jednak dzięki owszechnej znajomości tych funkcji, można w łatwy sosób zademonstrować działanie metody, jak również zweryfikować jakość oraz szybkość jej działania. Naukę sieci neuronowej zademonstrowano na rzykładzie funkcji: OR (funkcja liniowo searowalna) oraz XOR (funkcji, która nie jest liniowo searowalna). W rzyadku funkcji XOR zastosowano dwie różne architektury sieci neuronowej: dwuwarstwową składającą się z sensorów i ojedynczego efektora, w którym zastosowano eriodyczną sinusoidalną funkcję aktywacji, co ozwoliło na uroszczenie architektury sieci neuronowej. trójwarstwową składającą się z sensorów, ojedynczego neuronu ukrytego oraz ojedynczego efektora. W tym rzyadku zastosowano jak dla neuronu tak dla efektora ierwiastkowe funkcje aktywacji. Problem OR jest klasycznym rzykładem rostej liniowo-searowalnej funkcji logicznej. Dla tego roblemu nauka rzebiega szybko i bez zakłóceń. Rozwiązanie otymalne znajdywane jest w rocesie uczenia sieci neuronowej metodą sterowanych komromisów w rzeciągu kilkunastu-kilkudziesięciu eok uczących. Na rysunkach zilustrowano graficznie roces uczenia się sieci w ostaci graficznych obrazów oraz funkcji błędu. 113

114 Rysunek 5.2. Na owyższym rysunku widoczna jest zastosowana dwuwarstwowa architektura sieci neuronowej oraz liczne okienka rzedstawiające stan oszczególnych arametrów sieci w 100 eoce uczącej. Z wykresu błędu sieci widać, że efektywna nauka sieci trwała ok. 30 eok, o których w efekcie ustalił się ewien stabilny stan sieci. W okienku rzedstawiającym graficznie obraz nauczonej sieci czerwonym kolorem oznaczono wartości logicznej rawdy, zaś kolorem niebieskim wartości logicznego fałszu. Jak widać wygląd tego obrazu jest w ełni zgodny z intuicją i definicją funkcji logicznej OR. Inne okienka umożliwiają dokładny odgląd wag i rogu oraz błędów związanych z oszczególnymi wzorcami uczącymi z searacją na błędy o wartościach dodatnich (oznaczone kolorem czerwonym) oraz błędy o wartościach ujemnych (oznaczone kolorem niebieskim). 114

115 Rysunek 5.3. Na rysunku zobrazowano kolejne obrazy stanu sieci neuronowej odczas jej nauki dla oisanego roblemu OR dla wybranych eok uczących: 1, 5, 7, 9, 18, 20, 21 i 30. Dzięki takim obrazom można w rosty sosób obserwować, w jaki sosób rzebiega nauka sieci oraz w jakim kierunku zmierza. 115
 oraz wag (W) w kolejnych eokach uczących (Eoch) w owiązaniu z malejącym błędem sieci neuronowej")
116 Tabela 5.2. W oniższej tabeli zobrazowano roces zmian rogu efektora (THR) oraz wag (W) w kolejnych eokach uczących (Eoch) w owiązaniu z malejącym błędem sieci neuronowej (Err Lrn) dla wzorców uczących. Można orównać, jak aktualne wartości wag i rogu (Is) są korygowane na odstawie komromisowej ich korekty (Corr). 116

117 Problem XOR jest klasycznym rzykładem funkcji, która nie jest liniowo-searowalna i zarazem jednym z rostszych benchmarków służących do badania, czy dana metoda radzi sobie z uczeniem danych, które nie można liniowo rozsearować. Fakt ten ociąga za sobą konieczność zastosowania nieco innej architektury sieci neuronowej niż w rzyadku roblemu OR. Stosując metodę sterowanych komromisów roblem ten można rozwiązać na dwa różne sosoby: a) użyć funkcji eriodycznej (n. sinusoidalnej or. rozdz ) jako funkcji aktywacji efektora: Rysunek 5.4. Powyższy rysunek uwidacznia rzebieg nauki dla roblemu XOR o zastosowaniu funkcji sinusoidalnej jako funkcji aktywacji efektora. Jak widać z rzedstawionego wykresu błędu, o około 70 eokach roces uczenia jest uwieńczony sukcesem i błąd sieci neuronowej jest bliski zeru. 117

118 Rysunek 5.5. Na rysunku zobrazowano kolejne obrazy stanu sieci neuronowej odczas jej nauki dla oisanego roblemu XOR dla wybranych eok uczących: 1, 6, 50, 55, 60, 62, 65 i
 oraz wag (W) w kolejnych eokach uczących")
119 Tabela 5.3. W oniższej tabeli zobrazowano roces zmian rogu efektora (THR) oraz wag (W) w kolejnych eokach uczących (Eoch) w owiązaniu z malejącym błędem sieci neuronowej (Err Lrn) dla wzorców uczących. 119

120 Rysunek 5.6. Na rysunku rzedstawiono różne stabilne stany sieci uzyskane w wyniku uczenia metodą sterowanych komromisów dla rozważanego roblemu XOR oraz dla sieci neuronowej, w której zastosowano funkcję sinusoidalną (or. rozdz ) jako funkcję aktywacji efektora. We wszystkich czterech rzyadkach uzyskano orawne rozwiązanie dla wzorców ciągu uczącego, odowiadającym wartościom uzyskanym w rogach owyższych obrazów (n. we wszystkich lewych górnych rogach obrazów jest kolor czerwony rerezentujący wartość rawdy, zaś we wszystkich rawych górnych rogach jest kolor niebieski rerezentujący wartość fałszu). W dwóch ierwszych obrazach zgodnie z intuicją mamy do czynienia z łynnymi rzejściami omiędzy wartościami funkcji logicznej XOR, jednak sieć neuronowa oierając się tylko i wyłącznie o dane zadane ciągiem uczącym rawidłowo znalazła rozwiązanie we wszystkich czterech rzyadkach. 120

121 b) dodać rzynajmniej jeden neuron ukryty rzy zachowaniu ierwiastkowych (ew. kwadratowych or. rozdz. 4.1.) funkcji aktywacji neuronu oraz efektora: Rysunek 5.7. Powyższy rysunek uwidacznia rzebieg nauki sieci z wykorzystaniem metody sterowanych komromisów dla roblemu XOR o rozbudowie architektury sieci neuronowej o neuron ukryty. Jako funkcje aktywacji zastosowano funkcje ierwiastkowe. Sytuacja wolniejszej zbieżności może być wytłumaczona faktem braku zotymalizowania metody sterowanych komromisów od kątem uczenia sieci wielowarstwowych, które są obiektem dalszych badań i nie stanowią zasadniczej części tej racy. 121

122 Rysunek 5.8. Na rysunku zobrazowano kolejne obrazy stanu sieci neuronowej o rozbudowanej architekturze odczas jej nauki dla oisanego roblemu XOR dla wybranych eok uczących: 1, 4, 22, 32, 44, 80, 150 i
 roces korekty wag i rogów rozważanej sieci neuronowej (or. rozdz. 4.4.3.). Jak widać z owyższych rzykładów rozwiązanie z zastosowaniem sinusoidalnej funkcji aktywacji efektora dało w tym wyadku dużo lesze i szybsze rozwiązanie dla rozważanego roblemu XOR.")
123 Tabela 5.4. W oniższej tabeli zobrazowano roces zmian wag (W) i rogów (THR) w kolejnych eokach uczących (Eoch). W rzedstawionej tabeli można zaobserwować również dwuetaowy (St: 1. i 2.) roces korekty wag i rogów rozważanej sieci neuronowej (or. rozdz ). Jak widać z owyższych rzykładów rozwiązanie z zastosowaniem sinusoidalnej funkcji aktywacji efektora dało w tym wyadku dużo lesze i szybsze rozwiązanie dla rozważanego roblemu XOR. W rzyadku zastosowania neuronu ukrytego zbieżność rzebiega wolniej. Metodę rzetestowano również na wielu innych funkcjach logicznych. Przytaczania wyników takich symulacji jednak nie miałoby głębszego sensu, albowiem wyniki działania metody sterowanych komromisów są analogiczne, jak dla oisanych w tym rozdziale rerezentatywnych funkcji logicznych OR i XOR. 123
124 5.3. Problem arzystości. Problem arzystości, olegający na orawnej klasyfikacji liczb arzystych i niearzystych, jest często używanym benchmarkiem do testów, srawdzających algorytmy uczące. W rzyadku metody sterowanych komromisów, która umożliwia stosowanie funkcji eriodycznych jako funkcji aktywacji neuronów i efektorów, można było zastosować wrost trywialną architekturę sieci neuronowej (rysunek 5.9.) do rozwiązania tego roblemu. Natomiast sam algorytm uczący musiał się w tym wyadku uorać z rzeskalowaniem i rzesunięciem danych do okresu zastosowanej funkcji eriodycznej. Działanie metody rzedstawiono (rys ) dla dwóch funkcji aktywacji efektora: sinusoidalnej oraz hybrydowej tangensoidalnej (or. rozdz ). W rzyadku nauki tego roblemu osłużono się bardziej zaawansowanym sosobem obliczania komromisu wykorzystującym mechanizm rzełączników. 124
. Z owyższego wykresu błędu sieci neuronowej wynika, że nauka rzebiega bardzo burzliwie.")
125 Rysunek 5.9. Powyższy rysunek rzedstawia rzebieg nauki sieci neuronowej metodą sterowanych komromisów dla roblemu arzystości. Jako funkcję aktywacji efektora zastosowano funkcję sinusoidalną (or. rozdz ). Z owyższego wykresu błędu sieci neuronowej wynika, że nauka rzebiega bardzo burzliwie. Fakt ten związany jest w tym wyadku z zastosowania bardziej zaawansowanego mechanizmu obliczania komromisów oraz z konieczności rzeskalowania i rzesunięcia za omocą arametrów wolnych sieci tak, żeby liczby arzyste odowiadały wzgórkom a liczby niearzyste dolinom funkcji sinus. Proces rzeskalowania i rzesunięcia objawia się w tym wyadku zagęszczaniem się kolorowych aseczków, jak to jest okazane na rys
126 Rysunek Na rysunku można zaobserwować roces rzesuwania i zagęszczania się kolorowych aseczków (czerwone odowiadają liczbom arzystym, niebieskie liczbom niearzystym) związany z rocesem formowania się arametrów sieci w rocesie jej uczenia się dla rzykładu z rysunku 5.9. Dla uzuełnienia z lewej strony obrazów odano odowiadającą eokę uczącą, zaś z lewej rocent orawności klasyfikacji liczb arzystych i niearzystych odowiednio dla wzorców uczących i testujących. 126
127 Rysunek Powyższy rysunek rzedstawia rzebieg nauki sieci neuronowej metodą sterowanych komromisów dla roblemu arzystości. W tym rzyadku jako funkcję aktywacji efektora zastosowano hybrydową funkcję tangensoidalną (or. rozdz ). Z owyższego wykresu błędu sieci neuronowej wynika, że nauka rzebiega również bardzo burzliwie. Duże skoki błędu sowodowane są tym, że zbiór wartości zastosowanej hybrydowej funkcji tangensoidalnej leży w dziedzinie liczb rzeczywistych, a odczas rocesu skalowania dla niektórych wzorców wartości funkcji mogą trafiać w bardzo duże lub bardzo małe liczby. Jak widać taki roces zmian nie dezorientuje metody sterowanych komromisu w jej dążeniu do orawnego rozwiązania. 127
128 Rysunek Na rysunku można zaobserwować roces rzesuwania i zagęszczania się kolorowych aseczków (czerwone odowiadają liczbom arzystym, niebieskie liczbom niearzystym) związany z rocesem formowania się arametrów sieci w rocesie jej uczenia się dla rzykładu z rysunku Z lewej strony obrazów odano odowiadającą eokę uczącą, zaś z lewej rocent orawności klasyfikacji liczb arzystych i niearzystych odowiednio dla wzorców uczących i testujących, które w tym wyadku świadczą o orawnej ekstraolacji. 128
129 5.4. Problem dwóch siral. Problem dwóch siral jest klasycznym rzykładem trudnego benchmarku, używanego do testowania zawansowanych algorytmów uczących sieci neuronowych. Trudność tego roblemu olega na osiągnięciu orawnej ekstraolacji, co w rzyadku zastosowania klasycznych funkcji sigmoidalnych osiągalne jest dla nieskończonej ilości neuronów sieci oraz nieskończenie długiego ciągu uczącego umożliwiającego nauczenie takiej sieci (...doisać odnośniki). Obydwa te warunki są oczywiście z raktycznego unktu widzenia nie do zrealizowania. Problem dwóch siral ma naturę eriodyczną, a metoda sterowanych komromisów umożliwia uczenie sieci oartych o eriodyczne funkcje aktywacji. Ten fakt srawia, że roblem ten może być rozwiązany rzy użyciu wrost trywialnej architektury sieci neuronowej, jak widać to na rysunku W rzyadku niedużych odległości stanu inicjalnego sieci neuronowej od rozwiązania, metoda sterowanych komromisów bez trudu rowadzi roces nauki w kierunku tego rozwiązania. W rzyadku siral liniowych, jakie są w tym rzykładzie rozważane, istnieje nieskończenie wiele rozwiązań dla rzedstawionej na rysunku architektury sieci neuronowej. Rozwiązania te można oisać nastęująco: π + 2kπ τ 2 1=, β oraz 1 w 2 =, β w = 2π 3 β π + 2kπ τ 2 1=, β w = 1 2 β, 2π w 3 =. β gdzie β jest arametrem stromości funkcji aktywacji, który zazwyczaj nie zmieniany w trakcie rocesu uczenia, lecz wybierany a riori. W nastęujących rzykładach jego wartość jest stała i równa 1. Jak widać z oisu rozwiązań dla ustalonego arametru β wagi mogą rzyjmować tylko jedną z dwu możliwych wartości, zaś róg osiada nieskończoną ilość orawnych wartości. Stąd można wnioskować, że najtrudniejszym zadaniem dla algorytmu uczącego jest znalezienie wartości wag. Zadanie to nie jest łatwe, ze względu na to, że stosowana tutaj eriodyczna funkcja aktywacji efektora osiada automatycznie nieskończoną ilość minimów lokalnych, które mogą rzeszkadzać w rocesie zbieżności metody do rozwiązania zadanego ciągiem uczącym i w rocesie minimalizacji błędu sieci. 129
130 Rysunek Na rysunku rzedstawiono naukę sieci neuronowej metodą sterowanych komromisów dla roblemu dwóch liniowych siral. Zastosowano sinusoidalną funkcję aktywacji efektora (or. rozdz ). Z owyższego wykresu błędu sieci neuronowej wynika, że roces zbieżności metody rzebiega rawidłowo rzy założeniu, że sieć została zainicjowana w niezbyt dużym oddaleniu od jednego z możliwych rozwiązań. Dla uzuełnienia na rysunku uwidoczniono graficznie, jak rzebiega roces zbiegania się siral. 130
131 Rysunek Rysunek rzedstawia roces zbiegania się siral dla wybranych eok uczących: 1, 30, 150. Na oczątku sirale zuełnie nie nawiązują na siebie. Po 30. eoce widoczny jest już roces formowania się dwóch siral. W 150. eoce sirale są już rawie idealnie uformowane w wyniku rocesu uczącego metodą sterowanych komromisów. Rysunek Powyższe rysunki ilustrują stany sieci neuronowej, owstałe w wyniku zatrzymania się rocesu uczenia w jednym z minimów lokalnych. 131
132 Rysunek Rysunek rzedstawia ciekawy rzykład uczenia się na amięć sieć uzyskuje dobre wyniki dla konkretnego ciągu uczącego (tutaj również dla ciągu testowego), ale w istocie nie wykrywa rzeczywistej natury badanego roblemu. Winę za taki stan rzeczy nie onosi jednak algorytm uczący, który rawie idealnie (błąd uczenia jest rzędu 9.4E-5) dostosował sieć do zadanego ciągu uczącego. Aby nie douścić do takiego stanu, należałoby w tym wyadku rozbudować ciąg uczący i uczynić go bardziej rerezentatywny dla danego roblemu. 132
133 Rysunek Na rysunku okazano, że otencjalne możliwości rozbudowy sieci oartych o różnorodne funkcje aktywacji neuronów i metodę sterowanych komromisów są duże. Na rzykład roblem dwóch liniowych siral może zostać rozszerzony tak, by osłużył do rozwiązywania roblemu nieliniowych siral, co jest zadaniem dużo bardziej skomlikowanym. W tym rzyadku konieczne jest jednak usrawnienie metody sterowanych komromisów tak, by efektywnie otrafiła radzić sobie z uczeniem sieci wielowarstwowych. 133
, który ma za zadanie rozróżnić wilka, drwala oraz babcię na odstawie wyglądu i zachowania się (czy ma duże uszy, duże oczy, duże zęby,")
134 5.5. Problemu czerwonego katurka. Problem czerwonego katurka (LRRH Little Red Ridinghood [31]), który ma za zadanie rozróżnić wilka, drwala oraz babcię na odstawie wyglądu i zachowania się (czy ma duże uszy, duże oczy, duże zęby, zmarszczki, czy jest rzyjacielski, rzystojny). Na tej odstawie ma odjąć decyzję o swoim dalszym zachowaniu (uciekać, krzyczeć o omoc, szukać drwala, ocałować w czoło, zbliżyć się, zaoferować jedzenie, oflirtować). Uczenie sieci neuronowej dla tego roblemu rzy omocy metody sterowanych komromisów zrealizowano dla sieci dwuwarstwowej (rys ) oraz trójwarstwowej osiadającej 3 neurony ukryte (rys ). Rysunek Rysunek rzedstawia uwieńczony sukcesem roces uczenia roblemu czerwonego katurka rzy omocy metody sterowanych komromisów. W wyniku nauki sieć neuronowa (tj. czerwony katurek) nauczyła się rawidłowo odejmować decyzję o dalszym ostęowaniu na odstawie wyglądu i zachowania ostaci, którą sotkała. 134

135 Rysunek Na rysunku okazano naukę roblemu czerwonego katurka zaalikowanego na sieci trójwarstwowej osiadającej 3 neurony ukryte rzy omocy metody sterowanych komromisów. Również w tym wyadku nauka zakończyła się bardzo szybko sukcesem i sieć nauczyła się rawidłowych reakcji. 135

136 5.6. Problem rozoznawania obrazów. Celem tego rzykładu jest rzedstawienie możliwości zastosowania metody sterowanych komromisów do roblemu rozoznawania obrazów. Dla celów demonstracyjnych wybrano roblem rozoznawania dwucyfrowych liczb z zakresu od 0 do 99 rzedstawianych sieci w ostaci matrycy włączonych i wyłączonych unktów tak, jak to rzedstawiają rysunki dla rzykładowych liczb: 18, 27 i 2. Wzorzec wejściowy Sieć neuronowa Odowiedź sieci na jej obudzenie Sieć neuronowa Rysunek Na rysunku okazano dwa wybrane wzorce uczące (liczby 18 i 27) oraz ożądane odowiedzi, jakie nauczona sieć neuronowa ma dać dla nich na swoim wyjściu. W rzykładzie tym skuiono się nad zademonstrowaniem zdolności sieci neuronowej do uogólniania zdobytej wiedzy w rocesie uczącym rzerowadzonym metodą sterowanych komromisów. Mianowicie, jako ciąg uczący wybrano 30 rerezentatywnych liczb (0, 1, 2, 3, 4, 5, 6, 10, 11, 12, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 27, 28, 29, 30, 33, 44, 55, 66, 77, 88, 99) z zakresu o 0 do 99. Nastęnie stosując metodę sterowanych komromisów starano się w rocesie uczącym nakłonić sieć do rawidłowego rozoznawania tak zbudowanego ciągu uczącego, jak to okazano schematycznie na rysunku

137 Dla tak zdefiniowanego ciągu uczącego osłużono się siecią neuronową składającą się z sensorów odowiadającym oszczególnym olom matrycy liczbowej oraz jednego efektora, na którego wyjściu dla nauczonej sieci neuronowej ma się ojawić liczba odowiadająca tej odanej w ostaci matrycy na wejście sieci (rys ). Rysunek Rysunek rzedstawia sieć neuronową, która została oddana nauce metodą sterowanych komromisów, której celem było rozoznawanie dwucyfrowych matryc liczbowych rzedstawiających liczby z zakresu od 0 do 99. Okienko dynamicznego odglądu efektora okazuje, że nauczona sieć na obudzenie matrycą rzedstawiającą liczbę 2 dała na swoim wyjściu odowiedź (Out) w ostaci liczby

138 Rysunek Na rysunku okazano rzebieg nauki sieci z rysunku dla roblemu rozoznawania dwucyfrowych matryc liczbowych metodą sterowanych komromisów. W okienku błędu sieci widać, iż o wykonaniu eoki uczącej sieć neuronowa wykazuje błąd uczenia równy 4,73E-6 oraz błąd dla wzorców testujących równy 1,03E-5. Z rawej strony zaobserwować można wielkości błędów dla oszczególnych wzorców uczących (oznaczonych literką L) oraz testujących (oznaczonych literką T). 138
1. Historia 2. Podstawy neurobiologii 3. Definicje i inne kłamstwa 4. Sztuczny neuron i zasady działania SSN. Agenda
 Sieci neuropodobne 1. Historia 2. Podstawy neurobiologii 3. Definicje i inne kłamstwa 4. Sztuczny neuron i zasady działania SSN Agenda Trochę neurobiologii System nerwowy w organizmach żywych tworzą trzy
Sieci neuropodobne 1. Historia 2. Podstawy neurobiologii 3. Definicje i inne kłamstwa 4. Sztuczny neuron i zasady działania SSN Agenda Trochę neurobiologii System nerwowy w organizmach żywych tworzą trzy
IMPLEMENTACJA SIECI NEURONOWYCH MLP Z WALIDACJĄ KRZYŻOWĄ
 IMPLEMENTACJA SIECI NEURONOWYCH MLP Z WALIDACJĄ KRZYŻOWĄ Celem ćwiczenia jest zapoznanie się ze sposobem działania sieci neuronowych typu MLP (multi-layer perceptron) uczonych nadzorowaną (z nauczycielem,
IMPLEMENTACJA SIECI NEURONOWYCH MLP Z WALIDACJĄ KRZYŻOWĄ Celem ćwiczenia jest zapoznanie się ze sposobem działania sieci neuronowych typu MLP (multi-layer perceptron) uczonych nadzorowaną (z nauczycielem,
Sztuczne sieci neuronowe
 www.math.uni.lodz.pl/ radmat Cel wykładu Celem wykładu jest prezentacja różnych rodzajów sztucznych sieci neuronowych. Biologiczny model neuronu Mózg człowieka składa się z około 10 11 komórek nerwowych,
www.math.uni.lodz.pl/ radmat Cel wykładu Celem wykładu jest prezentacja różnych rodzajów sztucznych sieci neuronowych. Biologiczny model neuronu Mózg człowieka składa się z około 10 11 komórek nerwowych,
Metody Sztucznej Inteligencji II
 17 marca 2013 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką, która jest w stanie odbierać i przekazywać sygnały elektryczne. Neuron działanie Jeżeli wartość sygnału
17 marca 2013 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką, która jest w stanie odbierać i przekazywać sygnały elektryczne. Neuron działanie Jeżeli wartość sygnału
8. Neuron z ciągłą funkcją aktywacji.
 8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
Sztuczna Inteligencja Tematy projektów Sieci Neuronowe
 PB, 2009 2010 Sztuczna Inteligencja Tematy projektów Sieci Neuronowe Projekt 1 Stwórz projekt implementujący jednokierunkową sztuczną neuronową złożoną z neuronów typu sigmoidalnego z algorytmem uczenia
PB, 2009 2010 Sztuczna Inteligencja Tematy projektów Sieci Neuronowe Projekt 1 Stwórz projekt implementujący jednokierunkową sztuczną neuronową złożoną z neuronów typu sigmoidalnego z algorytmem uczenia
Inteligentne systemy decyzyjne: Uczenie maszynowe sztuczne sieci neuronowe
 Inteligentne systemy decyzyjne: Uczenie maszynowe sztuczne sieci neuronowe Trening jednokierunkowych sieci neuronowych wykład 2. dr inż. PawełŻwan Katedra Systemów Multimedialnych Politechnika Gdańska
Inteligentne systemy decyzyjne: Uczenie maszynowe sztuczne sieci neuronowe Trening jednokierunkowych sieci neuronowych wykład 2. dr inż. PawełŻwan Katedra Systemów Multimedialnych Politechnika Gdańska
Temat: Sieci neuronowe oraz technologia CUDA
 Elbląg, 27.03.2010 Temat: Sieci neuronowe oraz technologia CUDA Przygotował: Mateusz Górny VIII semestr ASiSK Wstęp Sieci neuronowe są to specyficzne struktury danych odzwierciedlające sieć neuronów w
Elbląg, 27.03.2010 Temat: Sieci neuronowe oraz technologia CUDA Przygotował: Mateusz Górny VIII semestr ASiSK Wstęp Sieci neuronowe są to specyficzne struktury danych odzwierciedlające sieć neuronów w
SIECI NEURONOWE Liniowe i nieliniowe sieci neuronowe
 SIECI NEURONOWE Liniowe i nieliniowe sieci neuronowe JOANNA GRABSKA-CHRZĄSTOWSKA Wykłady w dużej mierze przygotowane w oparciu o materiały i pomysły PROF. RYSZARDA TADEUSIEWICZA BUDOWA RZECZYWISTEGO NEURONU
SIECI NEURONOWE Liniowe i nieliniowe sieci neuronowe JOANNA GRABSKA-CHRZĄSTOWSKA Wykłady w dużej mierze przygotowane w oparciu o materiały i pomysły PROF. RYSZARDA TADEUSIEWICZA BUDOWA RZECZYWISTEGO NEURONU
Algorytm wstecznej propagacji błędów dla sieci RBF Michał Bereta
 Algorytm wstecznej propagacji błędów dla sieci RBF Michał Bereta www.michalbereta.pl Sieci radialne zawsze posiadają jedną warstwę ukrytą, która składa się z neuronów radialnych. Warstwa wyjściowa składa
Algorytm wstecznej propagacji błędów dla sieci RBF Michał Bereta www.michalbereta.pl Sieci radialne zawsze posiadają jedną warstwę ukrytą, która składa się z neuronów radialnych. Warstwa wyjściowa składa
Podstawy Sztucznej Inteligencji (PSZT)
") Podstawy Sztucznej Inteligencji (PSZT) Paweł Wawrzyński Uczenie maszynowe Sztuczne sieci neuronowe Plan na dziś Uczenie maszynowe Problem aproksymacji funkcji Sieci neuronowe PSZT, zima 2013, wykład 12
Podstawy Sztucznej Inteligencji (PSZT) Paweł Wawrzyński Uczenie maszynowe Sztuczne sieci neuronowe Plan na dziś Uczenie maszynowe Problem aproksymacji funkcji Sieci neuronowe PSZT, zima 2013, wykład 12
Elementy inteligencji obliczeniowej
 Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
Wstęp do teorii sztucznej inteligencji Wykład III. Modele sieci neuronowych.
 Wstęp do teorii sztucznej inteligencji Wykład III Modele sieci neuronowych. 1 Perceptron model najprostzszy przypomnienie Schemat neuronu opracowany przez McCullocha i Pittsa w 1943 roku. Przykład funkcji
Wstęp do teorii sztucznej inteligencji Wykład III Modele sieci neuronowych. 1 Perceptron model najprostzszy przypomnienie Schemat neuronu opracowany przez McCullocha i Pittsa w 1943 roku. Przykład funkcji
Literatura. Sztuczne sieci neuronowe. Przepływ informacji w systemie nerwowym. Budowa i działanie mózgu
 Literatura Wykład : Wprowadzenie do sztucznych sieci neuronowych Małgorzata Krętowska Wydział Informatyki Politechnika Białostocka Tadeusiewicz R: Sieci neuronowe, Akademicka Oficyna Wydawnicza RM, Warszawa
Literatura Wykład : Wprowadzenie do sztucznych sieci neuronowych Małgorzata Krętowska Wydział Informatyki Politechnika Białostocka Tadeusiewicz R: Sieci neuronowe, Akademicka Oficyna Wydawnicza RM, Warszawa
Uczenie sieci typu MLP
 Uczenie sieci typu MLP Przypomnienie budowa sieci typu MLP Przypomnienie budowy neuronu Neuron ze skokową funkcją aktywacji jest zły!!! Powszechnie stosuje -> modele z sigmoidalną funkcją aktywacji - współczynnik
Uczenie sieci typu MLP Przypomnienie budowa sieci typu MLP Przypomnienie budowy neuronu Neuron ze skokową funkcją aktywacji jest zły!!! Powszechnie stosuje -> modele z sigmoidalną funkcją aktywacji - współczynnik
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
Inteligentne systemy przeciw atakom sieciowym
 Inteligentne systemy przeciw atakom sieciowym wykład Sztuczne sieci neuronowe (SSN) Joanna Kołodziejczyk 2016 Joanna Kołodziejczyk Inteligentne systemy przeciw atakom sieciowym 2016 1 / 36 Biologiczne
Inteligentne systemy przeciw atakom sieciowym wykład Sztuczne sieci neuronowe (SSN) Joanna Kołodziejczyk 2016 Joanna Kołodziejczyk Inteligentne systemy przeciw atakom sieciowym 2016 1 / 36 Biologiczne
Podstawy sztucznej inteligencji
 wykład 5 Sztuczne sieci neuronowe (SSN) 8 grudnia 2011 Plan wykładu 1 Biologiczne wzorce sztucznej sieci neuronowej 2 3 4 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką,
wykład 5 Sztuczne sieci neuronowe (SSN) 8 grudnia 2011 Plan wykładu 1 Biologiczne wzorce sztucznej sieci neuronowej 2 3 4 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką,
Najprostsze modele sieci z rekurencją. sieci Hopfielda; sieci uczone regułą Hebba; sieć Hamminga;
 Sieci Hopfielda Najprostsze modele sieci z rekurencją sieci Hopfielda; sieci uczone regułą Hebba; sieć Hamminga; Modele bardziej złoŝone: RTRN (Real Time Recurrent Network), przetwarzająca sygnały w czasie
Sieci Hopfielda Najprostsze modele sieci z rekurencją sieci Hopfielda; sieci uczone regułą Hebba; sieć Hamminga; Modele bardziej złoŝone: RTRN (Real Time Recurrent Network), przetwarzająca sygnały w czasie
Uczenie sieci radialnych (RBF)
") Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
S O M SELF-ORGANIZING MAPS. Przemysław Szczepańczyk Łukasz Myszor
 S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
wiedzy Sieci neuronowe
 Metody detekcji uszkodzeń oparte na wiedzy Sieci neuronowe Instytut Sterowania i Systemów Informatycznych Universytet Zielonogórski Wykład 7 Wprowadzenie Okres kształtowania się teorii sztucznych sieci
Metody detekcji uszkodzeń oparte na wiedzy Sieci neuronowe Instytut Sterowania i Systemów Informatycznych Universytet Zielonogórski Wykład 7 Wprowadzenie Okres kształtowania się teorii sztucznych sieci
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa.
 Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa, Andrzej Rutkowski Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2018-10-15 Projekt
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa, Andrzej Rutkowski Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2018-10-15 Projekt
Temat: Sztuczne Sieci Neuronowe. Instrukcja do ćwiczeń przedmiotu INŻYNIERIA WIEDZY I SYSTEMY EKSPERTOWE
 Temat: Sztuczne Sieci Neuronowe Instrukcja do ćwiczeń przedmiotu INŻYNIERIA WIEDZY I SYSTEMY EKSPERTOWE Dr inż. Barbara Mrzygłód KISiM, WIMiIP, AGH mrzyglod@ agh.edu.pl 1 Wprowadzenie Sztuczne sieci neuronowe
Temat: Sztuczne Sieci Neuronowe Instrukcja do ćwiczeń przedmiotu INŻYNIERIA WIEDZY I SYSTEMY EKSPERTOWE Dr inż. Barbara Mrzygłód KISiM, WIMiIP, AGH mrzyglod@ agh.edu.pl 1 Wprowadzenie Sztuczne sieci neuronowe
Zastosowania sieci neuronowych
 Zastosowania sieci neuronowych klasyfikacja LABORKA Piotr Ciskowski zadanie 1. klasyfikacja zwierząt sieć jednowarstwowa żródło: Tadeusiewicz. Odkrywanie własności sieci neuronowych, str. 159 Przykład
Zastosowania sieci neuronowych klasyfikacja LABORKA Piotr Ciskowski zadanie 1. klasyfikacja zwierząt sieć jednowarstwowa żródło: Tadeusiewicz. Odkrywanie własności sieci neuronowych, str. 159 Przykład
Adrian Horzyk
 Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
WYBÓR FORMY OPODATKOWANIA PRZEDSIĘBIORSTW NIEPOSIADAJĄCYCH OSOBOWOŚCI PRAWNEJ
 ZESZYTY NAUKOWE UNIWERSYTETU SZCZECIŃSKIEGO NR 667 FINANSE, RYNKI FINANSOWE, UBEZPIECZENIA NR 40 2011 ADAM ADAMCZYK Uniwersytet Szczeciński WYBÓR FORMY OPODATKOWANIA PRZEDSIĘBIORSTW NIEPOSIADAJĄCYCH OSOBOWOŚCI
ZESZYTY NAUKOWE UNIWERSYTETU SZCZECIŃSKIEGO NR 667 FINANSE, RYNKI FINANSOWE, UBEZPIECZENIA NR 40 2011 ADAM ADAMCZYK Uniwersytet Szczeciński WYBÓR FORMY OPODATKOWANIA PRZEDSIĘBIORSTW NIEPOSIADAJĄCYCH OSOBOWOŚCI
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING NEURONOWE MAPY SAMOORGANIZUJĄCE SIĘ Self-Organizing Maps SOM Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki,
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING NEURONOWE MAPY SAMOORGANIZUJĄCE SIĘ Self-Organizing Maps SOM Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki,
Sieci neuronowe do przetwarzania informacji / Stanisław Osowski. wyd. 3. Warszawa, Spis treści
 Sieci neuronowe do przetwarzania informacji / Stanisław Osowski. wyd. 3. Warszawa, 2013 Spis treści Przedmowa 7 1. Wstęp 9 1.1. Podstawy biologiczne działania neuronu 9 1.2. Pierwsze modele sieci neuronowej
Sieci neuronowe do przetwarzania informacji / Stanisław Osowski. wyd. 3. Warszawa, 2013 Spis treści Przedmowa 7 1. Wstęp 9 1.1. Podstawy biologiczne działania neuronu 9 1.2. Pierwsze modele sieci neuronowej
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa.
 Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2011-10-11 1 Modelowanie funkcji logicznych
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2011-10-11 1 Modelowanie funkcji logicznych
SIECI REKURENCYJNE SIECI HOPFIELDA
 SIECI REKURENCYJNE SIECI HOPFIELDA Joanna Grabska- Chrząstowska Wykłady w dużej mierze przygotowane w oparciu o materiały i pomysły PROF. RYSZARDA TADEUSIEWICZA SPRZĘŻENIE ZWROTNE W NEURONIE LINIOWYM sygnał
SIECI REKURENCYJNE SIECI HOPFIELDA Joanna Grabska- Chrząstowska Wykłady w dużej mierze przygotowane w oparciu o materiały i pomysły PROF. RYSZARDA TADEUSIEWICZA SPRZĘŻENIE ZWROTNE W NEURONIE LINIOWYM sygnał
Instrukcja do laboratorium z fizyki budowli. Ćwiczenie: Pomiar i ocena hałasu w pomieszczeniu
 nstrukcja do laboratorium z fizyki budowli Ćwiczenie: Pomiar i ocena hałasu w omieszczeniu 1 1.Wrowadzenie. 1.1. Energia fali akustycznej. Podstawowym ojęciem jest moc akustyczna źródła, która jest miarą
nstrukcja do laboratorium z fizyki budowli Ćwiczenie: Pomiar i ocena hałasu w omieszczeniu 1 1.Wrowadzenie. 1.1. Energia fali akustycznej. Podstawowym ojęciem jest moc akustyczna źródła, która jest miarą
Zagadnienia optymalizacji i aproksymacji. Sieci neuronowe.
 Zagadnienia optymalizacji i aproksymacji. Sieci neuronowe. zajecia.jakubw.pl/nai Literatura: S. Osowski, Sieci neuronowe w ujęciu algorytmicznym. WNT, Warszawa 997. PODSTAWOWE ZAGADNIENIA TECHNICZNE AI
Zagadnienia optymalizacji i aproksymacji. Sieci neuronowe. zajecia.jakubw.pl/nai Literatura: S. Osowski, Sieci neuronowe w ujęciu algorytmicznym. WNT, Warszawa 997. PODSTAWOWE ZAGADNIENIA TECHNICZNE AI
Lekcja 5: Sieć Kohonena i sieć ART
 Lekcja 5: Sieć Kohonena i sieć ART S. Hoa Nguyen 1 Materiał Sieci Kohonena (Sieć samo-organizująca) Rysunek 1: Sieć Kohonena Charakterystyka sieci: Jednowarstwowa jednokierunkowa sieć. Na ogół neurony
Lekcja 5: Sieć Kohonena i sieć ART S. Hoa Nguyen 1 Materiał Sieci Kohonena (Sieć samo-organizująca) Rysunek 1: Sieć Kohonena Charakterystyka sieci: Jednowarstwowa jednokierunkowa sieć. Na ogół neurony
Wstęp do teorii sztucznej inteligencji Wykład II. Uczenie sztucznych neuronów.
 Wstęp do teorii sztucznej inteligencji Wykład II Uczenie sztucznych neuronów. 1 - powtórzyć o klasyfikacji: Sieci liniowe I nieliniowe Sieci rekurencyjne Uczenie z nauczycielem lub bez Jednowarstwowe I
Wstęp do teorii sztucznej inteligencji Wykład II Uczenie sztucznych neuronów. 1 - powtórzyć o klasyfikacji: Sieci liniowe I nieliniowe Sieci rekurencyjne Uczenie z nauczycielem lub bez Jednowarstwowe I
Wstęp do sztucznych sieci neuronowych
 Wstęp do sztucznych sieci neuronowych Michał Garbowski Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Wydział Informatyki 15 grudnia 2011 Plan wykładu I 1 Wprowadzenie Inspiracja biologiczna
Wstęp do sztucznych sieci neuronowych Michał Garbowski Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Wydział Informatyki 15 grudnia 2011 Plan wykładu I 1 Wprowadzenie Inspiracja biologiczna
Teoria informacji i kodowania Ćwiczenia Sem. zimowy 2016/2017
 Teoria informacji i kodowania Ćwiczenia Sem. zimowy 06/07 Źródła z amięcią Zadanie (kolokwium z lat orzednich) Obserwujemy źródło emitujące dwie wiadomości: $ oraz. Stwierdzono, że częstotliwości wystęowania
Teoria informacji i kodowania Ćwiczenia Sem. zimowy 06/07 Źródła z amięcią Zadanie (kolokwium z lat orzednich) Obserwujemy źródło emitujące dwie wiadomości: $ oraz. Stwierdzono, że częstotliwości wystęowania
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Sztuczne sieci neuronowe (SNN)
") Sztuczne sieci neuronowe (SNN) Pozyskanie informacji (danych) Wstępne przetwarzanie danych przygotowanie ich do dalszej analizy Selekcja informacji Ostateczny model decyzyjny SSN - podstawy Sieci neuronowe
Sztuczne sieci neuronowe (SNN) Pozyskanie informacji (danych) Wstępne przetwarzanie danych przygotowanie ich do dalszej analizy Selekcja informacji Ostateczny model decyzyjny SSN - podstawy Sieci neuronowe
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Zastosowania sieci neuronowych
 Zastosowania sieci neuronowych aproksymacja LABORKA Piotr Ciskowski zadanie 1. aproksymacja funkcji odległość punktów źródło: Żurada i in. Sztuczne sieci neuronowe, przykład 4.4, str. 137 Naucz sieć taką
Zastosowania sieci neuronowych aproksymacja LABORKA Piotr Ciskowski zadanie 1. aproksymacja funkcji odległość punktów źródło: Żurada i in. Sztuczne sieci neuronowe, przykład 4.4, str. 137 Naucz sieć taką
Laboratorium Metod i Algorytmów Sterowania Cyfrowego
 Laboratorium Metod i Algorytmów Sterowania Cyfrowego Ćwiczenie 3 Dobór nastaw cyfrowych regulatorów rzemysłowych PID I. Cel ćwiczenia 1. Poznanie zasad doboru nastaw cyfrowych regulatorów rzemysłowych..
Laboratorium Metod i Algorytmów Sterowania Cyfrowego Ćwiczenie 3 Dobór nastaw cyfrowych regulatorów rzemysłowych PID I. Cel ćwiczenia 1. Poznanie zasad doboru nastaw cyfrowych regulatorów rzemysłowych..
Elementy Sztucznej Inteligencji. Sztuczne sieci neuronowe cz. 2
 Elementy Sztucznej Inteligencji Sztuczne sieci neuronowe cz. 2 1 Plan wykładu Uczenie bez nauczyciela (nienadzorowane). Sieci Kohonena (konkurencyjna) Sieć ze sprzężeniem zwrotnym Hopfielda. 2 Cechy uczenia
Elementy Sztucznej Inteligencji Sztuczne sieci neuronowe cz. 2 1 Plan wykładu Uczenie bez nauczyciela (nienadzorowane). Sieci Kohonena (konkurencyjna) Sieć ze sprzężeniem zwrotnym Hopfielda. 2 Cechy uczenia
Zakres zagadnienia. Pojęcia podstawowe. Pojęcia podstawowe. Do czego słuŝą modele deformowalne. Pojęcia podstawowe
 Zakres zagadnienia Wrowadzenie do wsółczesnej inŝynierii Modele Deformowalne Dr inŝ. Piotr M. zczyiński Wynikiem akwizycji obrazów naturalnych są cyfrowe obrazy rastrowe: dwuwymiarowe (n. fotografia) trójwymiarowe
Zakres zagadnienia Wrowadzenie do wsółczesnej inŝynierii Modele Deformowalne Dr inŝ. Piotr M. zczyiński Wynikiem akwizycji obrazów naturalnych są cyfrowe obrazy rastrowe: dwuwymiarowe (n. fotografia) trójwymiarowe
Podstawy Sztucznej Inteligencji Sztuczne Sieci Neuronowe. Krzysztof Regulski, WIMiIP, KISiM, B5, pok. 408
 Podstawy Sztucznej Inteligencji Sztuczne Sieci Neuronowe Krzysztof Regulski, WIMiIP, KISiM, regulski@aghedupl B5, pok 408 Inteligencja Czy inteligencja jest jakąś jedną dziedziną, czy też jest to nazwa
Podstawy Sztucznej Inteligencji Sztuczne Sieci Neuronowe Krzysztof Regulski, WIMiIP, KISiM, regulski@aghedupl B5, pok 408 Inteligencja Czy inteligencja jest jakąś jedną dziedziną, czy też jest to nazwa
Janusz Górczyński. Prognozowanie i symulacje w zadaniach
 Wykłady ze statystyki i ekonometrii Janusz Górczyński Prognozowanie i symulacje w zadaniach Wyższa Szkoła Zarządzania i Marketingu Sochaczew 2009 Publikacja ta jest czwartą ozycją w serii wydawniczej Wykłady
Wykłady ze statystyki i ekonometrii Janusz Górczyński Prognozowanie i symulacje w zadaniach Wyższa Szkoła Zarządzania i Marketingu Sochaczew 2009 Publikacja ta jest czwartą ozycją w serii wydawniczej Wykłady
Sieci neuronowe w Statistica
 http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
Programowanie celowe #1
 Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
ĆWICZENIE 4 KRZ: A B A B A B A A METODA TABLIC ANALITYCZNYCH
 ĆWICZENIE 4 Klasyczny Rachunek Zdań (KRZ): metoda tablic analitycznych, system aksjomatyczny S (aksjomaty, reguła dowodzenia), dowód w systemie S z dodatkowym zbiorem założeń, tezy systemu S, wtórne reguły
ĆWICZENIE 4 Klasyczny Rachunek Zdań (KRZ): metoda tablic analitycznych, system aksjomatyczny S (aksjomaty, reguła dowodzenia), dowód w systemie S z dodatkowym zbiorem założeń, tezy systemu S, wtórne reguły
Rysunek 1 Przykładowy graf stanów procesu z dyskretnymi położeniami.
 Procesy Markowa Proces stochastyczny { X } t t nazywamy rocesem markowowskim, jeśli dla każdego momentu t 0 rawdoodobieństwo dowolnego ołożenia systemu w rzyszłości (t>t 0 ) zależy tylko od jego ołożenia
Procesy Markowa Proces stochastyczny { X } t t nazywamy rocesem markowowskim, jeśli dla każdego momentu t 0 rawdoodobieństwo dowolnego ołożenia systemu w rzyszłości (t>t 0 ) zależy tylko od jego ołożenia
138 Forum Bibl. Med. 2011 R. 4 nr 1 (7)
") Dr Tomasz Milewicz, Barbara Latała, Iga Liińska, dr Tomasz Sacha, dr Ewa Stochmal, Dorota Pach, dr Danuta Galicka-Latała, rof. dr hab. Józef Krzysiek Kraków - CM UJ rola szkoleń w nabywaniu umiejętności
Dr Tomasz Milewicz, Barbara Latała, Iga Liińska, dr Tomasz Sacha, dr Ewa Stochmal, Dorota Pach, dr Danuta Galicka-Latała, rof. dr hab. Józef Krzysiek Kraków - CM UJ rola szkoleń w nabywaniu umiejętności
Sztuczna inteligencja
 Sztuczna inteligencja Wykład 7. Architektury sztucznych sieci neuronowych. Metody uczenia sieci. źródła informacji: S. Osowski, Sieci neuronowe w ujęciu algorytmicznym, WNT 1996 Podstawowe architektury
Sztuczna inteligencja Wykład 7. Architektury sztucznych sieci neuronowych. Metody uczenia sieci. źródła informacji: S. Osowski, Sieci neuronowe w ujęciu algorytmicznym, WNT 1996 Podstawowe architektury
Zjawisko Comptona opis pół relatywistyczny
 FOTON 33, Lato 06 7 Zjawisko Comtona ois ół relatywistyczny Jerzy Ginter Wydział Fizyki UW Zderzenie fotonu ze soczywającym elektronem Przy omawianiu dualizmu koruskularno-falowego jako jeden z ięknych
FOTON 33, Lato 06 7 Zjawisko Comtona ois ół relatywistyczny Jerzy Ginter Wydział Fizyki UW Zderzenie fotonu ze soczywającym elektronem Przy omawianiu dualizmu koruskularno-falowego jako jeden z ięknych
Sztuczne sieci neuronowe. Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335
 Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Analiza nośności pionowej pojedynczego pala
 Poradnik Inżyniera Nr 13 Aktualizacja: 09/2016 Analiza nośności ionowej ojedynczego ala Program: Plik owiązany: Pal Demo_manual_13.gi Celem niniejszego rzewodnika jest rzedstawienie wykorzystania rogramu
Poradnik Inżyniera Nr 13 Aktualizacja: 09/2016 Analiza nośności ionowej ojedynczego ala Program: Plik owiązany: Pal Demo_manual_13.gi Celem niniejszego rzewodnika jest rzedstawienie wykorzystania rogramu
Efektywność energetyczna systemu ciepłowniczego z perspektywy optymalizacji procesu pompowania
 Efektywność energetyczna systemu ciełowniczego z ersektywy otymalizacji rocesu omowania Prof. zw. dr hab. Inż. Andrzej J. Osiadacz Prof. ndz. dr hab. inż. Maciej Chaczykowski Dr inż. Małgorzata Kwestarz
Efektywność energetyczna systemu ciełowniczego z ersektywy otymalizacji rocesu omowania Prof. zw. dr hab. Inż. Andrzej J. Osiadacz Prof. ndz. dr hab. inż. Maciej Chaczykowski Dr inż. Małgorzata Kwestarz
Uczenie się pojedynczego neuronu. Jeśli zastosowana zostanie funkcja bipolarna s y: y=-1 gdy z<0 y=1 gdy z>=0. Wówczas: W 1 x 1 + w 2 x 2 + = 0
 Uczenie się pojedynczego neuronu W0 X0=1 W1 x1 W2 s f y x2 Wp xp p x i w i=x w+wo i=0 Jeśli zastosowana zostanie funkcja bipolarna s y: y=-1 gdy z=0 Wówczas: W 1 x 1 + w 2 x 2 + = 0 Algorytm
Uczenie się pojedynczego neuronu W0 X0=1 W1 x1 W2 s f y x2 Wp xp p x i w i=x w+wo i=0 Jeśli zastosowana zostanie funkcja bipolarna s y: y=-1 gdy z=0 Wówczas: W 1 x 1 + w 2 x 2 + = 0 Algorytm
PROGNOZOWANIE OSIADAŃ POWIERZCHNI TERENU PRZY UŻYCIU SIECI NEURONOWYCH**
 Górnictwo i Geoinżynieria Rok 31 Zeszyt 3 2007 Dorota Pawluś* PROGNOZOWANIE OSIADAŃ POWIERZCHNI TERENU PRZY UŻYCIU SIECI NEURONOWYCH** 1. Wstęp Eksploatacja górnicza złóż ma niekorzystny wpływ na powierzchnię
Górnictwo i Geoinżynieria Rok 31 Zeszyt 3 2007 Dorota Pawluś* PROGNOZOWANIE OSIADAŃ POWIERZCHNI TERENU PRZY UŻYCIU SIECI NEURONOWYCH** 1. Wstęp Eksploatacja górnicza złóż ma niekorzystny wpływ na powierzchnię
HAŁASU Z UWZGLĘDNIENIEM ZJAWISK O CHARAKTERZE NIELINIOWYM
 ZASTOSOWANIE SIECI NEURONOWYCH W SYSTEMACH AKTYWNEJ REDUKCJI HAŁASU Z UWZGLĘDNIENIEM ZJAWISK O CHARAKTERZE NIELINIOWYM WPROWADZENIE Zwalczanie hałasu przy pomocy metod aktywnych redukcji hałasu polega
ZASTOSOWANIE SIECI NEURONOWYCH W SYSTEMACH AKTYWNEJ REDUKCJI HAŁASU Z UWZGLĘDNIENIEM ZJAWISK O CHARAKTERZE NIELINIOWYM WPROWADZENIE Zwalczanie hałasu przy pomocy metod aktywnych redukcji hałasu polega
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Sztuczne sieci neuronowe i sztuczna immunologia jako klasyfikatory danych. Dariusz Badura Letnia Szkoła Instytutu Matematyki 2010
 Sztuczne sieci neuronowe i sztuczna immunologia jako klasyfikatory danych Dariusz Badura Letnia Szkoła Instytutu Matematyki 2010 Sieci neuronowe jednokierunkowa wielowarstwowa sieć neuronowa sieci Kohonena
Sztuczne sieci neuronowe i sztuczna immunologia jako klasyfikatory danych Dariusz Badura Letnia Szkoła Instytutu Matematyki 2010 Sieci neuronowe jednokierunkowa wielowarstwowa sieć neuronowa sieci Kohonena
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Projekt Sieci neuronowe
 Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
Elementy kognitywistyki II: Sztuczna inteligencja. WYKŁAD X: Sztuczny neuron
 Elementy kognitywistyki II: Sztuczna inteligencja WYKŁAD X: Sztuczny neuron Koneksjonizm: wprowadzenie 1943: Warren McCulloch, Walter Pitts: ogólna teoria przetwarzania informacji oparta na sieciach binarnych
Elementy kognitywistyki II: Sztuczna inteligencja WYKŁAD X: Sztuczny neuron Koneksjonizm: wprowadzenie 1943: Warren McCulloch, Walter Pitts: ogólna teoria przetwarzania informacji oparta na sieciach binarnych
Budowa sztucznych sieci neuronowych do prognozowania. Przykład jednostek uczestnictwa otwartego funduszu inwestycyjnego
 Budowa sztucznych sieci neuronowych do prognozowania. Przykład jednostek uczestnictwa otwartego funduszu inwestycyjnego Dorota Witkowska Szkoła Główna Gospodarstwa Wiejskiego w Warszawie Wprowadzenie Sztuczne
Budowa sztucznych sieci neuronowych do prognozowania. Przykład jednostek uczestnictwa otwartego funduszu inwestycyjnego Dorota Witkowska Szkoła Główna Gospodarstwa Wiejskiego w Warszawie Wprowadzenie Sztuczne
BIOCYBERNETYKA PROLOG
 Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej BIOCYBERNETYKA Adrian Horzyk PROLOG www.agh.edu.pl Pewnego dnia przyszedł na świat komputer Komputery
Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej BIOCYBERNETYKA Adrian Horzyk PROLOG www.agh.edu.pl Pewnego dnia przyszedł na świat komputer Komputery
Jakość uczenia i generalizacja
 Jakość uczenia i generalizacja Dokładność uczenia Jest koncepcją miary w jakim stopniu nasza sieć nauczyła się rozwiązywać określone zadanie Dokładność mówi na ile nauczyliśmy się rozwiązywać zadania które
Jakość uczenia i generalizacja Dokładność uczenia Jest koncepcją miary w jakim stopniu nasza sieć nauczyła się rozwiązywać określone zadanie Dokładność mówi na ile nauczyliśmy się rozwiązywać zadania które
Sztuczne siei neuronowe - wprowadzenie
 Metody Sztucznej Inteligencji w Sterowaniu Ćwiczenie 2 Sztuczne siei neuronowe - wprowadzenie Przygotował: mgr inż. Marcin Pelic Instytut Technologii Mechanicznej Politechnika Poznańska Poznań, 2 Wstęp
Metody Sztucznej Inteligencji w Sterowaniu Ćwiczenie 2 Sztuczne siei neuronowe - wprowadzenie Przygotował: mgr inż. Marcin Pelic Instytut Technologii Mechanicznej Politechnika Poznańska Poznań, 2 Wstęp
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa.
 Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2012-10-10 Projekt pn. Wzmocnienie
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2012-10-10 Projekt pn. Wzmocnienie
Porównanie nacisków obudowy Glinik 14/35-POz na spąg obliczonych metodą analityczną i metodą Jacksona
 dr inż. JAN TAK Akademia Górniczo-Hutnicza im. St. Staszica w Krakowie inż. RYSZARD ŚLUSARZ Zakład Maszyn Górniczych GLINIK w Gorlicach orównanie nacisków obudowy Glinik 14/35-Oz na sąg obliczonych metodą
dr inż. JAN TAK Akademia Górniczo-Hutnicza im. St. Staszica w Krakowie inż. RYSZARD ŚLUSARZ Zakład Maszyn Górniczych GLINIK w Gorlicach orównanie nacisków obudowy Glinik 14/35-Oz na sąg obliczonych metodą
Politechnika Gdańska Wydział Elektrotechniki i Automatyki Katedra Inżynierii Systemów Sterowania
 Politechnika Gdańska Wydział Elektrotechniki i Autoatyki Katedra Inżynierii Systeów Sterowania Metody otyalizacji Metody rograowania nieliniowego II Materiały oocnicze do ćwiczeń laboratoryjnych T7 Oracowanie:
Politechnika Gdańska Wydział Elektrotechniki i Autoatyki Katedra Inżynierii Systeów Sterowania Metody otyalizacji Metody rograowania nieliniowego II Materiały oocnicze do ćwiczeń laboratoryjnych T7 Oracowanie:
Sieć przesyłająca żetony CP (counter propagation)
") Sieci neuropodobne IX, specyficzne architektury 1 Sieć przesyłająca żetony CP (counter propagation) warstwa Kohonena: wektory wejściowe są unormowane jednostki mają unormowane wektory wag jednostki są
Sieci neuropodobne IX, specyficzne architektury 1 Sieć przesyłająca żetony CP (counter propagation) warstwa Kohonena: wektory wejściowe są unormowane jednostki mają unormowane wektory wag jednostki są
Widzenie komputerowe
 Widzenie komputerowe Uczenie maszynowe na przykładzie sieci neuronowych (3) źródła informacji: S. Osowski, Sieci neuronowe w ujęciu algorytmicznym, WNT 1996 Zdolność uogólniania sieci neuronowej R oznaczenie
Widzenie komputerowe Uczenie maszynowe na przykładzie sieci neuronowych (3) źródła informacji: S. Osowski, Sieci neuronowe w ujęciu algorytmicznym, WNT 1996 Zdolność uogólniania sieci neuronowej R oznaczenie
Doświadczenie Joule a i jego konsekwencje Ciepło, pojemność cieplna sens i obliczanie Praca sens i obliczanie
 Pierwsza zasada termodynamiki 2.2.1. Doświadczenie Joule a i jego konsekwencje 2.2.2. ieło, ojemność cielna sens i obliczanie 2.2.3. Praca sens i obliczanie 2.2.4. Energia wewnętrzna oraz entalia 2.2.5.
Pierwsza zasada termodynamiki 2.2.1. Doświadczenie Joule a i jego konsekwencje 2.2.2. ieło, ojemność cielna sens i obliczanie 2.2.3. Praca sens i obliczanie 2.2.4. Energia wewnętrzna oraz entalia 2.2.5.
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING Maszyna Wektorów Nośnych Suort Vector Machine SVM Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING Maszyna Wektorów Nośnych Suort Vector Machine SVM Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki
Wstęp do sieci neuronowych, wykład 6 Wsteczna propagacja błędu - cz. 3
 Wstęp do sieci neuronowych, wykład 6 Wsteczna propagacja błędu - cz. 3 Andrzej Rutkowski, Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2018-11-05 Projekt
Wstęp do sieci neuronowych, wykład 6 Wsteczna propagacja błędu - cz. 3 Andrzej Rutkowski, Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2018-11-05 Projekt
O badaniach nad SZTUCZNĄ INTELIGENCJĄ
 O badaniach nad SZTUCZNĄ INTELIGENCJĄ Wykład 7. O badaniach nad sztuczną inteligencją Co nazywamy SZTUCZNĄ INTELIGENCJĄ? szczególny rodzaj programów komputerowych, a niekiedy maszyn. SI szczególną własność
O badaniach nad SZTUCZNĄ INTELIGENCJĄ Wykład 7. O badaniach nad sztuczną inteligencją Co nazywamy SZTUCZNĄ INTELIGENCJĄ? szczególny rodzaj programów komputerowych, a niekiedy maszyn. SI szczególną własność
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015
 Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
WYKORZYSTANIE SIECI NEURONOWEJ DO BADANIA WPŁYWU WYDOBYCIA NA SEJSMICZNOŚĆ W KOPALNIACH WĘGLA KAMIENNEGO. Stanisław Kowalik (Poland, Gliwice)
") WYKORZYSTANIE SIECI NEURONOWEJ DO BADANIA WPŁYWU WYDOBYCIA NA SEJSMICZNOŚĆ W KOPALNIACH WĘGLA KAMIENNEGO Stanisław Kowalik (Poland, Gliwice) 1. Wprowadzenie Wstrząsy podziemne i tąpania występujące w kopalniach
WYKORZYSTANIE SIECI NEURONOWEJ DO BADANIA WPŁYWU WYDOBYCIA NA SEJSMICZNOŚĆ W KOPALNIACH WĘGLA KAMIENNEGO Stanisław Kowalik (Poland, Gliwice) 1. Wprowadzenie Wstrząsy podziemne i tąpania występujące w kopalniach
SIECI KOHONENA UCZENIE BEZ NAUCZYCIELA JOANNA GRABSKA-CHRZĄSTOWSKA
 SIECI KOHONENA UCZENIE BEZ NAUCZYCIELA JOANNA GRABSKA-CHRZĄSTOWSKA Wykłady w dużej mierze przygotowane w oparciu o materiały i pomysły PROF. RYSZARDA TADEUSIEWICZA SAMOUCZENIE SIECI metoda Hebba W mózgu
SIECI KOHONENA UCZENIE BEZ NAUCZYCIELA JOANNA GRABSKA-CHRZĄSTOWSKA Wykłady w dużej mierze przygotowane w oparciu o materiały i pomysły PROF. RYSZARDA TADEUSIEWICZA SAMOUCZENIE SIECI metoda Hebba W mózgu
Dynamiczne struktury danych: listy
 Dynamiczne struktury danych: listy Mirosław Mortka Zaczynając rogramować w dowolnym języku rogramowania jesteśmy zmuszeni do oanowania zasad osługiwania się odstawowymi tyami danych. Na rzykład w języku
Dynamiczne struktury danych: listy Mirosław Mortka Zaczynając rogramować w dowolnym języku rogramowania jesteśmy zmuszeni do oanowania zasad osługiwania się odstawowymi tyami danych. Na rzykład w języku
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I
 Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Sieci neuronowe. - wprowadzenie - Istota inteligencji. WYKŁAD Piotr Ciskowski
 Sieci neuronowe - wprowadzenie - Istota inteligencji WYKŁAD Piotr Ciskowski na dobry początek: www.mql4.com - championship 2007 - winners of the ATC 2007 - the ATC 2007 is over forex-pamm.com na dobry
Sieci neuronowe - wprowadzenie - Istota inteligencji WYKŁAD Piotr Ciskowski na dobry początek: www.mql4.com - championship 2007 - winners of the ATC 2007 - the ATC 2007 is over forex-pamm.com na dobry
Metody doświadczalne w hydraulice Ćwiczenia laboratoryjne. 1. Badanie przelewu o ostrej krawędzi
 Metody doświadczalne w hydraulice Ćwiczenia laboratoryjne 1. adanie rzelewu o ostrej krawędzi Wrowadzenie Przelewem nazywana jest cześć rzegrody umiejscowionej w kanale, onad którą może nastąić rzeływ.
Metody doświadczalne w hydraulice Ćwiczenia laboratoryjne 1. adanie rzelewu o ostrej krawędzi Wrowadzenie Przelewem nazywana jest cześć rzegrody umiejscowionej w kanale, onad którą może nastąić rzeływ.
Uniwersytet w Białymstoku Wydział Ekonomiczno-Informatyczny w Wilnie SYLLABUS na rok akademicki 2012/2013 http://www.wilno.uwb.edu.
 SYLLABUS na rok akademicki 01/013 Tryb studiów Studia stacjonarne Kierunek studiów Informatyka Poziom studiów Pierwszego stopnia Rok studiów/ semestr /3 Specjalność Bez specjalności Kod katedry/zakładu
SYLLABUS na rok akademicki 01/013 Tryb studiów Studia stacjonarne Kierunek studiów Informatyka Poziom studiów Pierwszego stopnia Rok studiów/ semestr /3 Specjalność Bez specjalności Kod katedry/zakładu
I EKSPLORACJA DANYCH
 I EKSPLORACJA DANYCH Zadania eksploracji danych: przewidywanie Przewidywanie jest podobne do klasyfikacji i szacowania, z wyjątkiem faktu, że w przewidywaniu wynik dotyczy przyszłości. Typowe zadania przewidywania
I EKSPLORACJA DANYCH Zadania eksploracji danych: przewidywanie Przewidywanie jest podobne do klasyfikacji i szacowania, z wyjątkiem faktu, że w przewidywaniu wynik dotyczy przyszłości. Typowe zadania przewidywania
Rachunek zdań. Prawa logiczne (tautologie) Tautologią nazywamy taką funkcję logiczną, która przy dowolnym podstawieniu wartości
 Tautologią nazywamy taką funkcję logiczną, która przy dowolnym podstawieniu wartości") Prawa logiczne (tautologie) Tautologią nazywamy taką funkcję logiczną, która rzy dowolnym odstawieniu wartości zmiennych jest zawsze rawdziwa. Zadaniem logiki jest m.in. oisanie tych schematów za omocą
Prawa logiczne (tautologie) Tautologią nazywamy taką funkcję logiczną, która rzy dowolnym odstawieniu wartości zmiennych jest zawsze rawdziwa. Zadaniem logiki jest m.in. oisanie tych schematów za omocą
Oprogramowanie Systemów Obrazowania SIECI NEURONOWE
 SIECI NEURONOWE Przedmiotem laboratorium jest stworzenie algorytmu rozpoznawania zwierząt z zastosowaniem sieci neuronowych w oparciu o 5 kryteriów: ile zwierzę ma nóg, czy żyje w wodzie, czy umie latać,
SIECI NEURONOWE Przedmiotem laboratorium jest stworzenie algorytmu rozpoznawania zwierząt z zastosowaniem sieci neuronowych w oparciu o 5 kryteriów: ile zwierzę ma nóg, czy żyje w wodzie, czy umie latać,
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY SZTUCZNE SIECI NEURONOWE MLP Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii
METODY INŻYNIERII WIEDZY SZTUCZNE SIECI NEURONOWE MLP Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii
Wprowadzenie do teorii systemów ekspertowych
 Myślące komputery przyszłość czy utopia? Wprowadzenie do teorii systemów ekspertowych Roman Simiński siminski@us.edu.pl Wizja inteligentnych maszyn jest od wielu lat obecna w literaturze oraz filmach z
Myślące komputery przyszłość czy utopia? Wprowadzenie do teorii systemów ekspertowych Roman Simiński siminski@us.edu.pl Wizja inteligentnych maszyn jest od wielu lat obecna w literaturze oraz filmach z
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Sieci neuronowe w Statistica. Agnieszka Nowak - Brzezioska
 Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Program nauczania matematyki w szkole podstawowej
 2 Program nauczania I Program nauczania matematyki w szkole odstawowej ZGODNY Z PODSTAWĄ PROGRAMOWĄ z dnia 23 grudnia 2008 roku Autorzy: Marcin Braun, Agnieszka Mańkowska, Małgorzata Paszyńska 1. Omówienie
2 Program nauczania I Program nauczania matematyki w szkole odstawowej ZGODNY Z PODSTAWĄ PROGRAMOWĄ z dnia 23 grudnia 2008 roku Autorzy: Marcin Braun, Agnieszka Mańkowska, Małgorzata Paszyńska 1. Omówienie
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
ALGORYTMY SZTUCZNEJ INTELIGENCJI
 ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
Uczenie sieci neuronowych i bayesowskich
 Wstęp do metod sztucznej inteligencji www.mat.uni.torun.pl/~piersaj 2009-01-22 Co to jest neuron? Komputer, a mózg komputer mózg Jednostki obliczeniowe 1-4 CPU 10 11 neuronów Pojemność 10 9 b RAM, 10 10
Wstęp do metod sztucznej inteligencji www.mat.uni.torun.pl/~piersaj 2009-01-22 Co to jest neuron? Komputer, a mózg komputer mózg Jednostki obliczeniowe 1-4 CPU 10 11 neuronów Pojemność 10 9 b RAM, 10 10
O badaniach nad SZTUCZNĄ INTELIGENCJĄ
 O badaniach nad SZTUCZNĄ INTELIGENCJĄ SZTUCZNA INTELIGENCJA dwa podstawowe znaczenia Co nazywamy sztuczną inteligencją? zaawansowane systemy informatyczne (np. uczące się), pewną dyscyplinę badawczą (dział
O badaniach nad SZTUCZNĄ INTELIGENCJĄ SZTUCZNA INTELIGENCJA dwa podstawowe znaczenia Co nazywamy sztuczną inteligencją? zaawansowane systemy informatyczne (np. uczące się), pewną dyscyplinę badawczą (dział
Optymalizacja optymalizacji
 7 maja 2008 Wstęp Optymalizacja lokalna Optymalizacja globalna Algorytmy genetyczne Badane czasteczki Wykorzystane oprogramowanie (Algorytm genetyczny) 2 Sieć neuronowa Pochodne met-enkefaliny Optymalizacja
7 maja 2008 Wstęp Optymalizacja lokalna Optymalizacja globalna Algorytmy genetyczne Badane czasteczki Wykorzystane oprogramowanie (Algorytm genetyczny) 2 Sieć neuronowa Pochodne met-enkefaliny Optymalizacja
O badaniach nad SZTUCZNĄ INTELIGENCJĄ
 O badaniach nad SZTUCZNĄ INTELIGENCJĄ Jak określa się inteligencję naturalną? Jak określa się inteligencję naturalną? Inteligencja wg psychologów to: Przyrodzona, choć rozwijana w toku dojrzewania i uczenia
O badaniach nad SZTUCZNĄ INTELIGENCJĄ Jak określa się inteligencję naturalną? Jak określa się inteligencję naturalną? Inteligencja wg psychologów to: Przyrodzona, choć rozwijana w toku dojrzewania i uczenia
Jeśli X jest przestrzenią o nieskończonej liczbie elementów:
 Logika rozmyta 2 Zbiór rozmyty może być formalnie zapisany na dwa sposoby w zależności od tego z jakim typem przestrzeni elementów mamy do czynienia: Jeśli X jest przestrzenią o skończonej liczbie elementów
Logika rozmyta 2 Zbiór rozmyty może być formalnie zapisany na dwa sposoby w zależności od tego z jakim typem przestrzeni elementów mamy do czynienia: Jeśli X jest przestrzenią o skończonej liczbie elementów