Metody Eksploracji Danych. Klasyfikacja
|
|
|
- Amelia Henryka Kozak
- 6 lat temu
- Przeglądów:
Transkrypt
1 Metody Eksploracji Danych Klasyfikacja w wykładzie wykorzystano: 1. materiały dydaktyczne przygotowane w ramach projektu Opracowanie programów nauczania na odległość na kierunku studiów wyższych Informatyka 2. Internetowy Podręcznik Statystyki Krzysztof Regulski, WIMiIP, KISiM, regulski@agh.edu.pl B5, pok. 408
2 Klasyfikacja Klasyfikacja jest metodą analizy danych, której celem jest predykcja wartości określonego atrybutu w oparciu o pewien zbiór danych treningowych. Obejmuje metody odkrywania modeli (tak zwanych klasyfikatorów) lub funkcji opisujących zależności pomiędzy charakterystyką obiektów a ich zadaną klasyfikacją. Odkryte modele klasyfikacji są wykorzystywane do klasyfikacji nowych obiektów o nieznanej klasyfikacji. Wiele technik: statystyka, drzewa decyzyjne, sieci neuronowe, etc. 2
3 Klasyfikacja algorytm Atrybut Ryzyko związany z informacją, że dany kierowca spowodował wcześniej wypadki czy nie powodował wcześniej wypadku. Jeżeli jest autorem kilku wypadków wartość atrybutu Ryzyko przyjmuje wartość High, w przypadku gdy nie spowodował żadnego wypadku atrybut Ryzyko przyjmuje wartość Low. Atrybut Ryzyko jest atrybutem decyzyjnym. W naszym przykładzie wynikiem działania algorytmu klasyfikacji jest klasyfikator w postaci pojedynczej reguły decyzyjnej: Jeżeli wiek kierowcy jest mniejszy niż 31 lub typ samochodu sportowy to Ryzyko jest wysokie". 3
4 Wynik klasyfikacji: Klasyfikacja wynik» Reguły klasyfikacyjne postaci IF - THEN» Formuły logiczne» Drzewa decyzyjne Istotną sprawą z punktu widzenia poprawności i efektywności modelu jest tzw. dokładność modelu. dla przykładów testowych, dla których znane są wartości atrybutu decyzyjnego, wartości te są porównywane z wartościami atrybutu decyzyjnego generowanymi dla tych przykładów przez klasyfikator. Miarą, która weryfikuje poprawność modelu jest współczynnik dokładności. 4
5 Klasyfikacja wynik Jeżeli dokładność klasyfikatora jest akceptowalna, wówczas możemy wykorzystać klasyfikator do klasyfikacji nowych danych. Celem klasyfikacji, jak pamiętamy jest przyporządkowanie nowych danych dla których wartość atrybutu decyzyjnego nie jest znana do odpowiedniej klasy. 5
6 Rodzaje modeli klasyfikacyjnych:» k-nn - k-najbliższe sąsiedztwo» Klasyfikatory Bayes'owskie» Klasyfikacja poprzez indukcję drzew decyzyjnych» Sieci Neuronowe» Analiza statystyczna» Metaheurystyki (np. algorytmy genetyczne)» SVM Support Vector Machine Metoda wektorów nośnych» Zbiory przybliżone 6
7 Klasyfikatory knn 1. Klasyfikator knn - klasyfikator k-najbliższych sąsiadów (k-nearest neighbor classifier) 2. Klasyfikacja nowych przypadków jest realizowana na bieżąco", tj. wtedy, gdy pojawia się potrzeba. 3. Należy do grupy algorytmów opartych o analizę przypadku. Algorytmy te prezentują swoją wiedzę o świecie w postaci zbioru przypadków lub doświadczeń. 4. Idea klasyfikacji polega na metodach wyszukiwania tych zgromadzonych przypadków, które mogą być zastosowane do klasyfikacji nowych sytuacji. 7
8 knn - przykład Mamy przypadki dodatnie i ujemne oraz nowy punkt, oznaczony na czerwono. Zadanie polega na zaklasyfikowaniu nowego obiektu do plusów lub minusów, na bazie tego, z kim sąsiaduje. 1. Zacznijmy od rozpatrzenia przypadku jednego, najbliższego sąsiada. Widać, że najbliżej czerwonego punktu jest plus, tak więc nowy przypadek zostanie zaklasyfikowany do plusów. 2. Zwiększmy teraz liczbę najbliższych sąsiadów do dwóch. Niestety, jest kłopot, drugi sąsiad to minus, więc plusy i minusy występują w tej samej ilości, nikt nie ma przewagi. 3. Zwiększmy dalej liczbę najbliższych sąsiadów, do pięciu. Są to przypadki znajdujące się wewnątrz kółka na rysunku. Jest tam przewaga minusów, więc nowy przypadek oceniamy jako minus. 8
 odpowiadająca x 4, czyli y 4.")
9 Regresja i knn Mamy danych kilka "przykładowych" punktów, a podać musimy wartość y dla dowolnego x. dla pojedynczego najbliższego sąsiada: Najbliżej nowego X znajduje się punkt o odciętej x 4. Tak więc, jako wartość dla nowego X przyjęta będzie wartość (rzędna) odpowiadająca x 4, czyli y 4. Oznacza to, że dla jednego najbliższego sąsiada wynikiem jest Y = y 4 dwóch najbliższych sąsiadów: szukamy dwóch punktów mających najbliżej do X. Są to punkty o wartościach rzędnych y 3 i y 4. Biorąc średnią z dwóch wartości, otrzymujemy: W podobny sposób postępujemy przy dowolnej liczbie K najbliższych sąsiadów. Wartość Y zmiennej zależnej otrzymujemy jako średnią z wartości zmiennej zależnej dla K punktów o wartościach zmiennych niezależnych X najbliższych nowemu X-owi. 9
10 Klasyfikacja w oparciu o Naiwny klasyfikator Bayesa Zadaniem klasyfikatora Bayes'a jest przyporządkowanie nowego przypadku do jednej z klas decyzyjnych, przy czym zbiór klas decyzyjnych musi być skończony i zdefiniowany a priori. Naiwny klasyfikator Bayes'a jest statystycznym klasyfikatorem, opartym na twierdzeniu Bayesa. P(C X) prawdopodobieństwo a posteriori, że przykład X należy do klasy C Naiwny klasyfikator Bayes'a różni się od zwykłego klasyfikatora tym, że konstruując go zakładamy wzajemną niezależność atrybutów opisujących każdy przykład. 10

11 Naiwny klasyfikator Bayesa 11
 Maksymalizujemy wartość P(X/C i )*P(C i ), dla i=1,2")
12 Przykład Chcemy dokonać predykcji klasy, do której należy nowy przypadek C 1 (kupi_komputer ='tak') C 2 (kupi_komputer ='nie') Nowy przypadek: X = (wiek='<=30', dochód='średni', student = 'tak', status='kawaler') Maksymalizujemy wartość P(X/C i )*P(C i ), dla i=1,2 12
13 Indukcja drzew decyzyjnych Drzewo decyzyjne jest grafem o strukturze drzewiastej, gdzie» każdy wierzchołek wewnętrzny reprezentuje test na atrybucie (atrybutach),» każdy łuk reprezentuje wynik testu,» każdy liść reprezentuje pojedynczą klasę lub rozkład wartości klas Drzewo decyzyjne dzieli zbiór treningowy na partycje do momentu, w którym każda partycja zawiera dane należące do jednej klasy, lub, gdy w ramach partycji dominują dane należące do jednej klasy Każdy wierzchołek wewnętrzny drzewa zawiera tzw. punkt podziału (ang. split point), którym jest test na atrybucie (atrybutach), który dzieli zbiór danych na partycje 13
14 Ekstrakcja reguł klasyfikacyjnych z drzew decyzyjnych Drzewo decyzyjne można przedstawić w postaci zbioru tzw. reguł klasyfikacyjnych postaci IF-THEN Dla każdej ścieżki drzewa decyzyjnego, łączącej korzeń drzewa z liściem drzewa tworzymy regułę klasyfikacyjną 14

15 Klasyfikacja / Regresja Zmienne niezależne (objaśniające, predykatory) zm. wejściowe Zmienna zależna - objaśniana KLASYFIKACYJNE REGRESYJNE 15


16 CART (C&RT) i CHAID Classification & Regression Trees C&RT Chi-square Automatic Interaction Detection 16

17 Drzewa klasyfikacyjne Krok 1: Szukamy zmiennej, która najsilniej wpływa na ostateczną klasyfikację krajowy zagraniczny KRAJ POCHODZENIA żółty fioletowy KOLOR 17
18 Przykład: segmentacja pod kątem dochodów Cel: segmentacja ze względu na dochód, charakterystyka segmentów Dane zawierają przypadków Każdy przypadek reprezentuje jedną osobę Każda osoba opisana jest przez 14 cech oraz zmienną dochód 18

19 Dochód skategoryzowany do 2 klas: <=50K poniżej >50K powyżej




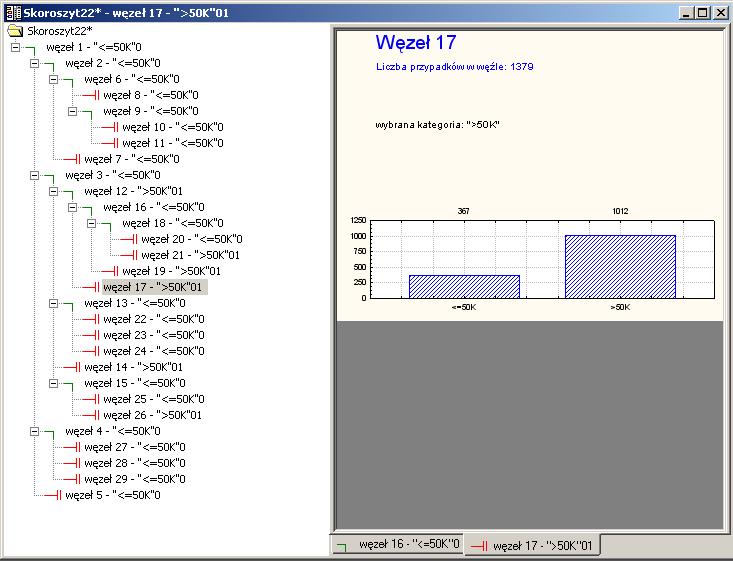
20 STATISTICA - przykład drzewa C&RT
21 4 5 21
22 22
23 23
24 24
25 25
 (z")
26 Reguły Jeżeli osoba pozostaje w związku małżeńskim i jej liczba lat edukacji przekracza 12,5 roku, wtedy jej dochód prawdopodobnie przekracza $ (węzeł ID5) (z prawdopodobieństwem 72%) Jeżeli osoba pozostaje w związku małżeńskim, jej liczba lat edukacji nie przekracza 12,5 roku, wykonuje zawód oraz ma ponad 33,5 lat wtedy jej dochód prawdopodobnie przekracza $ (węzeł ID9) (z prawdopodobieństwem 53%) Jeżeli osoba ma ponad 33,5 lat, pozostaje w związku małżeńskim, liczba lat jej edukacji mieści się w przedziale 9,5 do 12,5 lat, wykonuje zawód wtedy jej dochód prawdopodobnie przekracza $ (węzeł ID11) (z prawdopodobieństwem 60%) 26
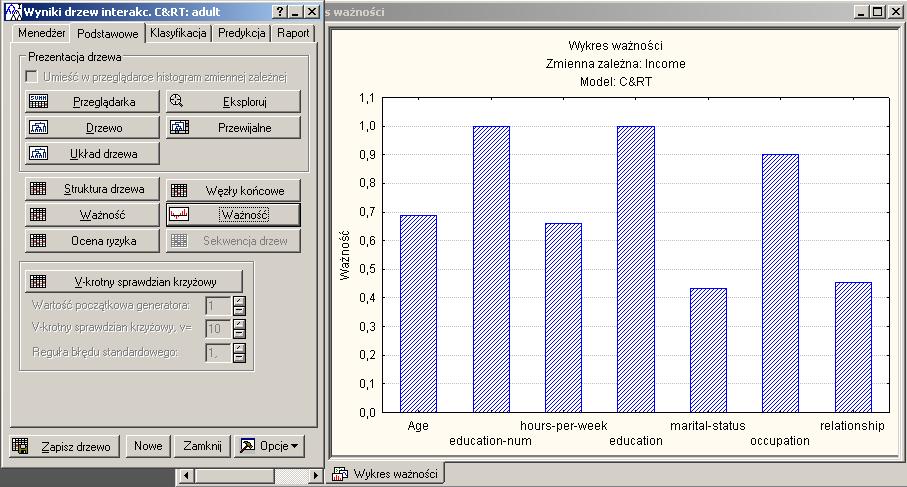
27 Pewność reguł (ufność reguły, dokładność) wsparcie reguły stopień magistra daje mężczyznom 70,38% szans na zarobki pow.50tys ufność reguły studia podyplomowe i doktorat podnosi szansę na zarobki pow.50tys o ponad 8 punktów procentowych 27
28 Wsparcie i Ufność Wsparcie = 217/9950 = 2,2% jest bardzo mało kobiet wysoko wykształconych większość kobiet, nawet bardzo dobrze wykształconych, nie zarabia pow. 50 tys. Ufność = 41,01% kobiety ze stopniem magistra (i wyżej) mają jedynie 41% szans na zarobki >50K 28
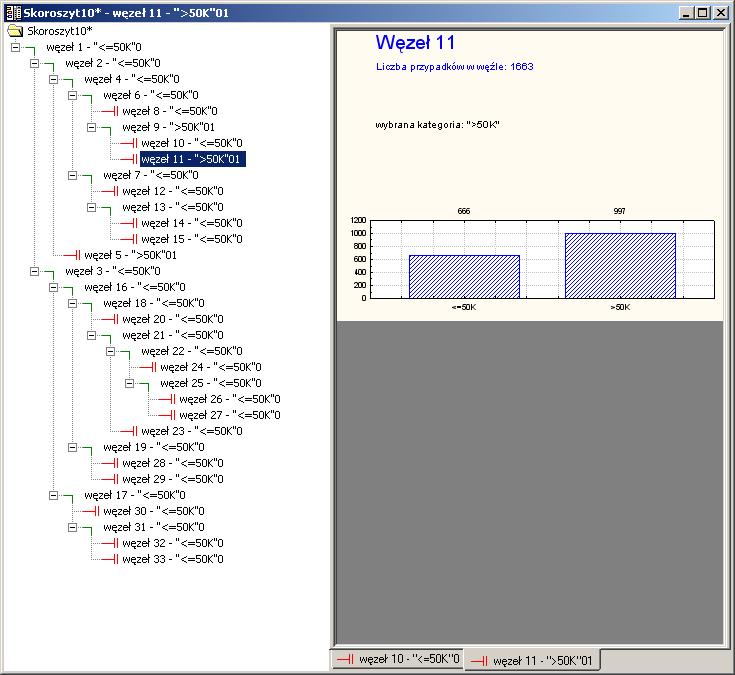
 ID11: 997/1633 = 0,5995")

29 Wsparcie (pokrycie) reguły / ufność (dokładność) ID11: 997/1633 = 0,5995 ufność reguły N konkluzji /N węzła wsparcie reguły: N węzła / N zbioru ID11: 1633/32561=5% 29


30 Macierz klasyfikacji Ile razy model się pomylił? Pojęcie kosztu FN FP 30
31 CHAID Algorytm drzew klasyfikacyjnych Zmienne ilościowe dzielone są na 10 kategorii, zmienne jakościowe obsługiwane w sposób naturalny Wyszukiwanie par kategorii podobnych do siebie ze względu na zmienną zależną Test Chi^2 31
32 STATISTICA - przykład drzewa CHAID
33 Przykład: badanie intencji zakupowych studentów Co wpływa na skłonność zakupu samochodu nowego bądź używanego? Wybór jednego z 12 profili aut o porównywalnej cenie (połowa z nich używane, połowa nowe) 1200 ankietowanych, dane demograficzne + wybór 33



34 34



35 Zmienną decyzyjną najsilniej różnicuje płeć 35


36 STATISTICA - inny przykład drzewa CHAID
37 1,1 Wykres ważności Zmienna zależna: Income Model: CHAID 1,0 0,9 0,8 0,7 Ważność 0,6 0,5 0,4 0,3 0,2 0,1 0,0 Age hours-per-week education-num education marital-status occupation relationship 37


38 FN 1 FP 2 38
39 39
 Jeżeli osoba pozostaje w związku małżeńskim i skończyła studia magisterskie, wtedy jej dochód prawdopodobnie przekracza 50 000 $ (węzeł ID14) (z")
40 Jeżeli osoba pozostaje w związku małżeńskim skończyła szkołę z grupy, ale jest profesjonalistą w swoim zawodzie, wtedy jej dochód prawdopodobnie przekracza $ (węzeł ID17) (z prawdopodobieństwem 73%) Jeżeli osoba pozostaje w związku małżeńskim i skończyła studia magisterskie, wtedy jej dochód prawdopodobnie przekracza $ (węzeł ID14) (z prawdopodobieństwem 77%) 40
41 Drzewa regresyjne Dla drzew klasyfikacyjnych stosuje się różne miary niejednorodności: Indeks Giniego, Chi-kwadrat lub G-kwadrat. Podział węzłów w drzewach regresyjnych, następuje na podstawie odchylenia najmniejszych kwadratów (LSD - Least Significant Difference). gdzie N w (t) - ważona liczba przypadków w węźle t, w i - wartość zmiennej ważącej dla przypadku i, f i - wartość zmiennej częstotliwości, y i - wartość zmiennej odpowiedzi, y(t) jest średnią ważoną w węźle t. Źródło: dla wzorów wykorzystywanych przez model C&RT zaimplementowany w STATISTICA wykorzystano fragmenty z Internetowego Podręcznika Statystyki, StatSoft, Inc., , jest to oficjalny podręcznik wydany przez dystrybutora oprogramowania. 41
42 Drzewo dla parametru: umowna granica plastyczności R 0,2 ID=2 N=16 ID=1 N=46 Śr=246, Var=2171, przesycanie = H3... = Inne ID=3 N=30 Śr=203, Var=839, temperatura starzenia = 700 o C = inna ID=4 N=8 ID=5 N=8 Śr=269, Var=1389, temperatura starzenia = 500 o C = inna ID=10 N=14 ID=11 N=16 Śr=180, Var=128, Śr=227, Var=426, Śr=291, Var=903, Śr=250, Var=1049, prędkość starzenia prędkość starzenia = na powietrzu = inna ID=12 N=7 ID=13 N=7 = na powietrzu = inna ID=18 N=8 ID=19 N=8 Śr=272, Var=1002, Śr=309, Var=137, Śr=229, Var=895, Śr=271, Var=326, Klasy dla poszczególnych parametrów R m, R 0,2, A zostały wyznaczone za pomocą modeli drzew regresyjnych w oparciu o zmienne predykcyjne jakimi były:» Rodzaj modyfikatora» Przesycanie prędkość chłodzenia» Temperatura starzenia» Starzenie prędkość studzenia rodszaj modyfikatora = F = inny ID=20 N=2 ID=21 N=6 Śr=272, Var=1024, Śr=215, Var=40,
43 1,1 1,0 0,9 0,8 0,7 Ważność 0,6 0,5 0,4 0,3 0,2 0,1 0,0 rodzaj modyfikatora temperatura starzenia przesycanie - prędkość chłodzenia starzenie - prędkosc studzenia 43
44 Ocena drzewa Dla potrzeb oceny modeli wprowadzono pojecie kosztu. Koszt określony jest poprzez wariancję. Konieczność minimalizacji kosztów wynika z tego, że niektóre błędy mogą mieć bardziej katastrofalne skutki niż inne. Jakość modelu regresyjnego oceniamy również poprzez współczynnik determinacji. 44
45 Współczynnik determinacji r 2 (R 2 ) współczynnik determinacji (wielkość ta oznacza kwadrat współczynnika korelacji) przyjmuje wartości z przedziału [0,1] jest miarą stopnia w jakim model wyjaśnia kształtowanie się zmiennej Y. Jeśli wartość R 2 jest duża, to oznacza to, że błędy dla tego modelu są stosunkowo małe i w związku z tym model jest dobrze dopasowany do rzeczywistych danych. Im jego wartość jest bliższa 1, tym lepsze dopasowanie modelu do danych empirycznych 45

46 Dobroć dopasowania (1) 46
 współczynnik")

47 Dobroć dopasowania (2) współczynnik determinacji to kwadrat współczynnika korelacji 47

48 Koszt Korzystamy z dwóch rodzajów kosztów: kosztu sprawdzianu krzyżowego (SK) oraz kosztu resubstytucji. Wybiera się drzewo o minimalnym koszcie SK, lub drzewo najmniej złożone, którego koszty SK nie różnią się znacznie od minimalnych 48
49 Koszt resubstytucji Narzędziem pomocniczym jest koszt resubstytucji. Oblicza się tu oczekiwany błąd kwadratowy dla próby uczącej. gdzie próba ucząca Z składa się z punktów (x i,y i ), i = 1,2,...,N. Miara ta obliczana jest dla tego samego zbioru danych, na bazie którego zbudowano model (partycję) d. niski koszt resubstytucji = wartości zmiennej zależnej bliskie średniej w danym liściu 49
 się przecinają. 3500 3000 2500 2000 Koszt 1500 1000 500 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Drzew o numer Koszt resubst.")
50 Wybór drzewa przycinanie drzewa (1) Jedną z metod doboru drzewa jest wybranie takiego, dla którego koszty resubstytucji i koszt sprawdzianu krzyżowego (SK) się przecinają Koszt Drzew o numer Koszt resubst. Koszt SK 50
51 Wybór drzewa przycinanie drzewa (2) 51
52 Efekt? na podstawie drzewa nr 9 dla R m można określić reguły: Jeśli próbka poddana została przesycaniu H3 i starzeniu w 500 C, wtedy wytrzymałość będzie miała rozkład o średniej E(X)=476[Mpa] i wariancji D 2 (X)=793 Jeśli próbka poddana została przesycaniu H3 i starzeniu w 700 C lub bez starzenia, wtedy wytrzymałość będzie miała rozkład o średniej E(X)=530[Mpa] i wariancji D 2 (X)=33 Jeśli próbka modyfikowana borem (K) poddana została przesycaniu (H2) wtedy wytrzymałość będzie miała rozkład o średniej E(X)=577[Mpa] i wariancji D 2 (X)=43 Jeśli próbka modyfikowana borem (K) poddana została przesycaniu (H1) wtedy wytrzymałość będzie miała rozkład o średniej E(X)=546[Mpa] i wariancji D 2 (X)=2187 Jeśli próbka pochodząca z innego wytopu niż K poddana została przesycaniu (H2 lub H1) wtedy wytrzymałość będzie miała rozkład o średniej E(X)=600 [Mpa] i wariancji D 2 (X)=325 52
53 Własności drzew Naturalna obsługa zmiennych mierzonych na różnych skalach pomiarowych Związki pomiędzy zmiennymi nie muszą być liniowe Rozkłady zmiennych nie muszą być normalne Jeśli spełnione są wymogi regresji wielorakiej to lepszy model daje regresja Drzewa nazywane białą skrzynką dobrze rozpoznany model i interpretacja 53
54 Własności drzew Niewrażliwość na zmienne bez znaczenia mają niską ocenę ważności predyktorów Niewrażliwość na nadmierną korelację jeśli dwie zmienne ze sobą skorelowane, jeden z predykatów nie wchodzi do drzewa Niewrażliwość na wartości odstające podział w punkcie, nawet jeśli jakieś zmienne osiągają bardzo wysokie/niskie wartości Radzenie sobie z brakami danych podziały zastępcze Naturalna interpretacja w postaci reguł Zastosowania: predykcja, budowa reguł, segmentacja rynku 54
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Klasyfikacja. Sformułowanie problemu Metody klasyfikacji Kryteria oceny metod klasyfikacji. Eksploracja danych. Klasyfikacja wykład 1
 Klasyfikacja Sformułowanie problemu Metody klasyfikacji Kryteria oceny metod klasyfikacji Klasyfikacja wykład 1 Niniejszy wykład poświęcimy kolejnej metodzie eksploracji danych klasyfikacji. Na początek
Klasyfikacja Sformułowanie problemu Metody klasyfikacji Kryteria oceny metod klasyfikacji Klasyfikacja wykład 1 Niniejszy wykład poświęcimy kolejnej metodzie eksploracji danych klasyfikacji. Na początek
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Data Mining Wykład 4. Plan wykładu
 Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ
 REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
Klasyfikacja metodą Bayesa
 Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Drzewa decyzyjne i lasy losowe
 Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y).
 na zmienną zależną (Y).") Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE
 UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, Spis treści
 Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
STATYSTYKA MATEMATYCZNA
 Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność (jeśli
Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność (jeśli
Zadanie 1. a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1
 Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1") Zadanie 1 a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1 b) W naszym przypadku populacja są inżynierowie w Tajlandii. Czy można jednak przypuszczać, że na zarobki kobiet-inżynierów
Zadanie 1 a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1 b) W naszym przypadku populacja są inżynierowie w Tajlandii. Czy można jednak przypuszczać, że na zarobki kobiet-inżynierów
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
WSTĘP DO REGRESJI LOGISTYCZNEJ. Dr Wioleta Drobik-Czwarno
 WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
Klasyfikacja. Indeks Gini Zysk informacyjny. Eksploracja danych. Klasyfikacja wykład 2
 Klasyfikacja Indeks Gini Zysk informacyjny Klasyfikacja wykład 2 Kontynuujemy prezentacje metod klasyfikacji. Na wykładzie zostaną przedstawione dwa podstawowe algorytmy klasyfikacji oparte o indukcję
Klasyfikacja Indeks Gini Zysk informacyjny Klasyfikacja wykład 2 Kontynuujemy prezentacje metod klasyfikacji. Na wykładzie zostaną przedstawione dwa podstawowe algorytmy klasyfikacji oparte o indukcję
Inżynieria Środowiska. II stopień ogólnoakademicki. przedmiot podstawowy obowiązkowy polski drugi. semestr zimowy
 Załącznik nr 7 do Zarządzenia Rektora nr../12 z dnia.... 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2017/2018 STATYSTYKA
Załącznik nr 7 do Zarządzenia Rektora nr../12 z dnia.... 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2017/2018 STATYSTYKA
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład I dr inż. 2015/2016
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Własności statystyczne regresji liniowej. Wykład 4
 Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
8. Drzewa decyzyjne, bagging, boosting i lasy losowe
 Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
data mining machine learning data science
 data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować?
 Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO
 Zał. nr 4 do ZW WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA STOSOWANA Nazwa w języku angielskim APPLIED STATISTICS Kierunek studiów (jeśli dotyczy): Specjalność
Zał. nr 4 do ZW WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA STOSOWANA Nazwa w języku angielskim APPLIED STATISTICS Kierunek studiów (jeśli dotyczy): Specjalność
Indukowane Reguły Decyzyjne I. Wykład 8
 Indukowane Reguły Decyzyjne I Wykład 8 IRD Wykład 8 Plan Powtórka Krzywa ROC = Receiver Operating Characteristic Wybór modelu Statystyka AUC ROC = pole pod krzywą ROC Wybór punktu odcięcia Reguły decyzyjne
Indukowane Reguły Decyzyjne I Wykład 8 IRD Wykład 8 Plan Powtórka Krzywa ROC = Receiver Operating Characteristic Wybór modelu Statystyka AUC ROC = pole pod krzywą ROC Wybór punktu odcięcia Reguły decyzyjne
W2. Zmienne losowe i ich rozkłady. Wnioskowanie statystyczne.
 W2. Zmienne losowe i ich rozkłady. Wnioskowanie statystyczne. dr hab. Jerzy Nakielski Katedra Biofizyki i Morfogenezy Roślin Plan wykładu: 1. Etapy wnioskowania statystycznego 2. Hipotezy statystyczne,
W2. Zmienne losowe i ich rozkłady. Wnioskowanie statystyczne. dr hab. Jerzy Nakielski Katedra Biofizyki i Morfogenezy Roślin Plan wykładu: 1. Etapy wnioskowania statystycznego 2. Hipotezy statystyczne,
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Przykład eksploracji danych o naturze statystycznej Próba 1 wartości zmiennej losowej odległość
 Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Data Mining Wykład 6. Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa.
 Naiwny klasyfikator Bayesa.") GLM (Generalized Linear Models) Data Mining Wykład 6 Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa jest klasyfikatorem statystycznym -
GLM (Generalized Linear Models) Data Mining Wykład 6 Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa jest klasyfikatorem statystycznym -
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
Sztuczna inteligencja : Algorytm KNN
 Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska. Anna Stankiewicz Izabela Słomska
 Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
DRZEWA KLASYFIKACYJNE W BADANIACH SATYSFAKCJI
 StatSoft Polska, tel. (1) 48400, (601) 414151, info@statsoft.pl, www.statsoft.pl DRZEWA KLASYFIKACYJNE W BADANIACH SATYSFAKCJI I LOJALNOŚCI KLIENTÓW Mariusz Łapczyński Akademia Ekonomiczna w Krakowie,
StatSoft Polska, tel. (1) 48400, (601) 414151, info@statsoft.pl, www.statsoft.pl DRZEWA KLASYFIKACYJNE W BADANIACH SATYSFAKCJI I LOJALNOŚCI KLIENTÓW Mariusz Łapczyński Akademia Ekonomiczna w Krakowie,
Statystyczne Metody Opracowania Wyników Pomiarów
 Statystyczne Metody Opracowania Wyników Pomiarów dla studentów Ochrony Środowiska Teresa Jaworska-Gołąb 2017/18 Co czytać [1] H. Szydłowski, Pracownia fizyczna, PWN, Warszawa 1999. [2] A. Zięba, Analiza
Statystyczne Metody Opracowania Wyników Pomiarów dla studentów Ochrony Środowiska Teresa Jaworska-Gołąb 2017/18 Co czytać [1] H. Szydłowski, Pracownia fizyczna, PWN, Warszawa 1999. [2] A. Zięba, Analiza
E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne
 E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne Przypominajka: 152 drzewo filogenetyczne to drzewo, którego liśćmi są istniejące gatunki, a węzły wewnętrzne mają stopień większy niż jeden i reprezentują
E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne Przypominajka: 152 drzewo filogenetyczne to drzewo, którego liśćmi są istniejące gatunki, a węzły wewnętrzne mają stopień większy niż jeden i reprezentują
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład II 2017/2018
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Metody analizy skupień Wprowadzenie Charakterystyka obiektów Metody grupowania Ocena poprawności grupowania
 Wielowymiarowe metody segmentacji CHAID Metoda Automatycznej Detekcji Interakcji CHAID Cele CHAID Dane CHAID Przebieg analizy CHAID Parametry CHAID Wyniki Metody analizy skupień Wprowadzenie Charakterystyka
Wielowymiarowe metody segmentacji CHAID Metoda Automatycznej Detekcji Interakcji CHAID Cele CHAID Dane CHAID Przebieg analizy CHAID Parametry CHAID Wyniki Metody analizy skupień Wprowadzenie Charakterystyka
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Klasyfikacja LDA + walidacja
 Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Co to są drzewa decyzji
 Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Kontekstowe wskaźniki efektywności nauczania - warsztaty
 Kontekstowe wskaźniki efektywności nauczania - warsztaty Przygotowała: Aleksandra Jasińska (a.jasinska@ibe.edu.pl) wykorzystując materiały Zespołu EWD Czy dobrze uczymy? Metody oceny efektywności nauczania
Kontekstowe wskaźniki efektywności nauczania - warsztaty Przygotowała: Aleksandra Jasińska (a.jasinska@ibe.edu.pl) wykorzystując materiały Zespołu EWD Czy dobrze uczymy? Metody oceny efektywności nauczania
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
ZJAZD 4. gdzie E(x) jest wartością oczekiwaną x
 jest wartością oczekiwaną x") ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych.
 Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych. Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Hipotezy i Testy statystyczne Każde
Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych. Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Hipotezy i Testy statystyczne Każde
WYMAGANIA WSTĘPNE W ZAKRESIE WIEDZY, UMIEJĘTNOŚCI I INNYCH KOMPETENCJI
 WYDZIAŁ GEOINŻYNIERII, GÓRNICTWA I GEOLOGII KARTA PRZEDMIOTU Nazwa w języku polskim: Statystyka matematyczna Nazwa w języku angielskim: Mathematical Statistics Kierunek studiów (jeśli dotyczy): Górnictwo
WYDZIAŁ GEOINŻYNIERII, GÓRNICTWA I GEOLOGII KARTA PRZEDMIOTU Nazwa w języku polskim: Statystyka matematyczna Nazwa w języku angielskim: Mathematical Statistics Kierunek studiów (jeśli dotyczy): Górnictwo
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap
 Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
STATYSTYKA MATEMATYCZNA WYKŁAD 4. WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X.
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 11-12
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez statystycznych
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez statystycznych
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Liczba godzin Punkty ECTS Sposób zaliczenia. ćwiczenia 16 zaliczenie z oceną
 Wydział: Zarządzanie i Finanse Nazwa kierunku kształcenia: Finanse i Rachunkowość Rodzaj przedmiotu: podstawowy Opiekun: prof. nadzw. dr hab. Tomasz Kuszewski Poziom studiów (I lub II stopnia): II stopnia
Wydział: Zarządzanie i Finanse Nazwa kierunku kształcenia: Finanse i Rachunkowość Rodzaj przedmiotu: podstawowy Opiekun: prof. nadzw. dr hab. Tomasz Kuszewski Poziom studiów (I lub II stopnia): II stopnia
Naszym zadaniem jest rozpatrzenie związków między wierszami macierzy reprezentującej poziomy ekspresji poszczególnych genów.
 ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 8
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Metody probabilistyczne klasyfikatory bayesowskie
 Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Drzewa klasyfikacyjne Lasy losowe. Wprowadzenie
 Wprowadzenie Konstrukcja binarnych drzew klasyfikacyjnych polega na sekwencyjnym dzieleniu podzbiorów przestrzeni próby X na dwa rozłączne i dopełniające się podzbiory, rozpoczynając od całego zbioru X.
Wprowadzenie Konstrukcja binarnych drzew klasyfikacyjnych polega na sekwencyjnym dzieleniu podzbiorów przestrzeni próby X na dwa rozłączne i dopełniające się podzbiory, rozpoczynając od całego zbioru X.
Metoda Automatycznej Detekcji Interakcji CHAID
 Metoda Automatycznej Detekcji Interakcji CHAID Metoda ta pozwala wybrać z konkretnego, dużego zbioru zmiennych te z nich, które najsilniej wpływają na wskazaną zmienną (objaśnianą) zmienne porządkowane
Metoda Automatycznej Detekcji Interakcji CHAID Metoda ta pozwala wybrać z konkretnego, dużego zbioru zmiennych te z nich, które najsilniej wpływają na wskazaną zmienną (objaśnianą) zmienne porządkowane
Ekonometria. Modele regresji wielorakiej - dobór zmiennych, szacowanie. Paweł Cibis pawel@cibis.pl. 1 kwietnia 2007
 Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład III 2016/2017
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład III bogumil.konopka@pwr.edu.pl 2016/2017 Wykład III - plan Regresja logistyczna Ocena skuteczności klasyfikacji Macierze pomyłek Krzywe
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład III bogumil.konopka@pwr.edu.pl 2016/2017 Wykład III - plan Regresja logistyczna Ocena skuteczności klasyfikacji Macierze pomyłek Krzywe
Laboratorium 11. Regresja SVM.
 Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Metody scoringowe w regresji logistycznej
 Metody scoringowe w regresji logistycznej Andrzej Surma Wydział Matematyki, Informatyki i Mechaniki Uniwersytetu Warszawskiego 19 listopada 2009 AS (MIMUW) Metody scoringowe w regresji logistycznej 19
Metody scoringowe w regresji logistycznej Andrzej Surma Wydział Matematyki, Informatyki i Mechaniki Uniwersytetu Warszawskiego 19 listopada 2009 AS (MIMUW) Metody scoringowe w regresji logistycznej 19