Mail: Pokój 214, II piętro
|
|
|
- Julian Kowalewski
- 8 lat temu
- Przeglądów:
Transkrypt



1 Wykład 2
2 Mail: Pokój 214, II piętro
3 Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych, wcześniej niesklasyfikowanych. Opis danych - zdolność do identyfikacji interesujących faktów, wzorców, zależności, relacji lub nieprawidłowości w danych, wiedza taka ma być potem wykorzystana w odpowiednim celu, np. wykrywanie fałszywych roszczeń ubezpieczeniowych.
4 Asocjacje wykrywanie pewnych zależności między danymi, które wielokrotnie występują wspólnie np. produktów kupowanych razem przez klientów. Grupowanie wykrywanie profili klientów, dla ukierunkowanych kampanii marketingowych. Wykrywanie odchyleń (outliers) defraudacje.
5 Klasyfikacja - model może przewidzieć, czy klient kupi, czy nie dany produkt (metody takie jak regresja logistyczna, analiza dyskryminacyjna, naiwny klasyfikator Bayesa) Przewidywanie związane z estymacją, prognozowaniem i odnoszące się do generowania oceny lub prognozy na zmiennej ciągłej. Np. Model, który przewiduje sprzedaż za dany kwartał (najczęściej za pomocą regresji).
6 Oprogramowanie Traceis pozwala na: Przygotowanie danych do analizy, Generowanie statystyk, Wizualizacja zmiennych, grupowanie obserwacji, predykcję.
7 Typ zadania specyfika rola metody opis asocjacje Znajdowanie powiązań między częstymi danymi, Reguły asocjacyjne, drzewa decyzyjne, grupowanie Podział danych na grupy o podobnych cechach Analiza skupień, drzewa decyzyjne outliery Wykrywanie odchyleń w danych Grupowanie, wykresy predykcja klasyfikacja Przewidywanie wartości zmiennych jakościowych Analiza dyskryminacyjna, naiwny klasyfikator Bayesa regresja Oszacowanie wartości zmiennych ilościowych Regresja wielokrotna
8
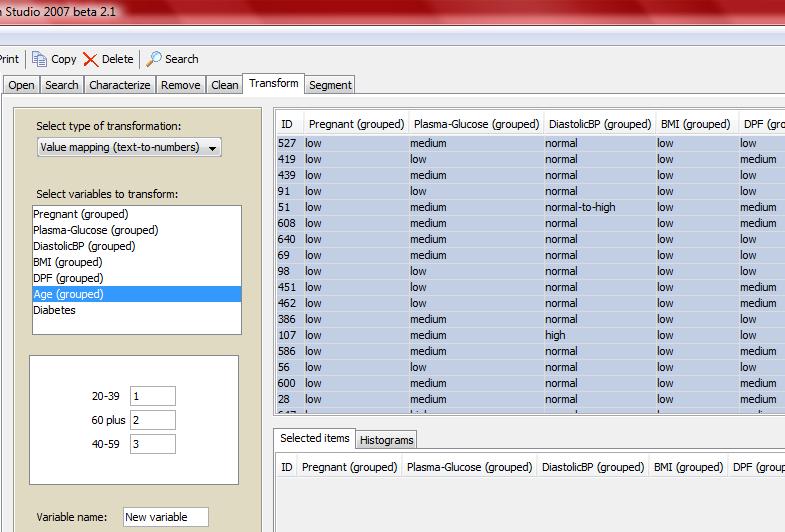
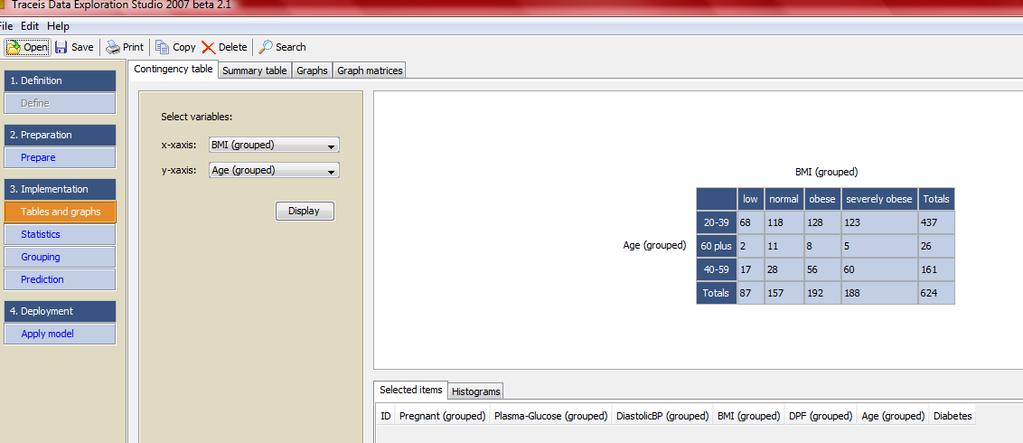
9 Ładowanie danych: zbiory danych mogą zawierać nawet 20 tyś. Wierszy i 30 tyś. kolumn Przygotowanie danych Tabele i wykresy: tablice kontyngencji, wykresy częstości, histogram, wykresy pudełkowe Statystyki: statystyka opisowa, przedziały ufności, rozkład chi-kwadrat, testowanie hipotez statystycznych, analiza wariancji Grupowanie:analiza skupień, reguły asocjacyjne, drzewa klasyfikacyjne Predykcja: k-nn, naiwny klasyfikator Bayesa, sieci neuronowe
10

11

12
13
14

15
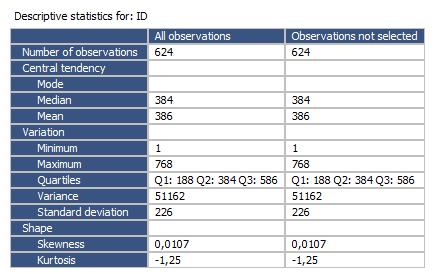
16


17

18

19
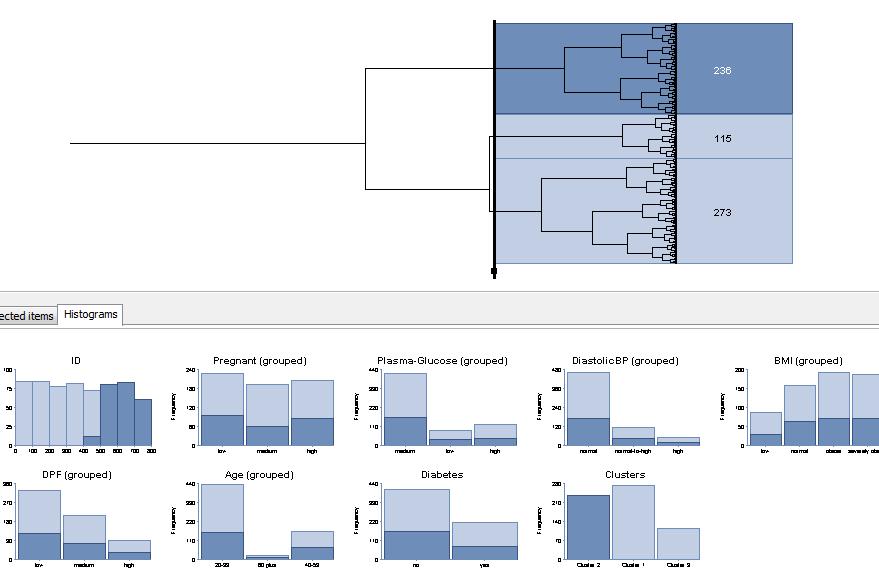
20
21
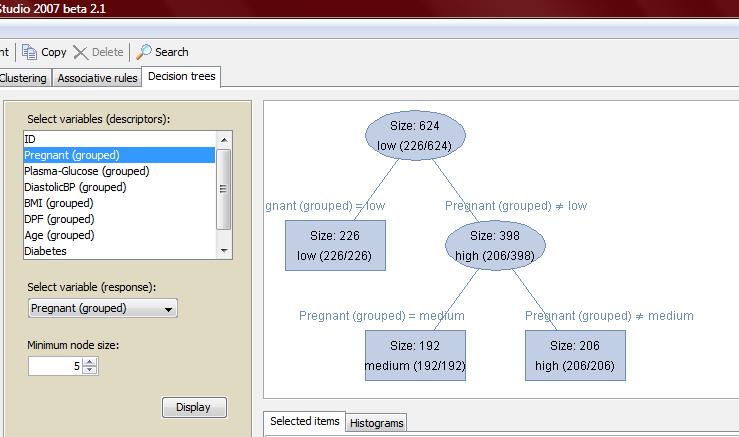
22
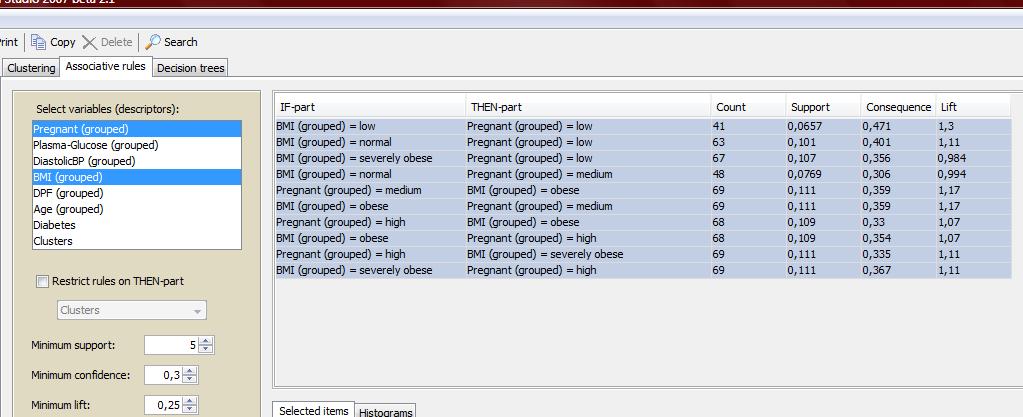
23
![Abalone Database [ftp://ftp.ics.uci.edu/pub/machine-learning-databases/abalone/] Adult Database[ftp://ftp.ics.uci.edu/pub/machine-learning-databases/adult/] Auto-Mpg [ftp://ftp.ics.uci.edu/pub/machine-learning-databases/auto-mpg/] Pima Indians Diabetes Database [ftp://ftp.](/docs-images/62/47436871/images/24-2.jpg "ics.uci.edu/pub/machine-learningdatabases/pima-indians-diabetes/] Dodatkowe źródła danych dostępne: Kdnuggets [http://www.kdnuggets.com/datasets/index.")
24 Abalone Database [ftp://ftp.ics.uci.edu/pub/machine-learning-databases/abalone/] Adult Database[ftp://ftp.ics.uci.edu/pub/machine-learning-databases/adult/] Auto-Mpg [ftp://ftp.ics.uci.edu/pub/machine-learning-databases/auto-mpg/] Pima Indians Diabetes Database [ftp://ftp.ics.uci.edu/pub/machine-learningdatabases/pima-indians-diabetes/] Dodatkowe źródła danych dostępne: Kdnuggets [ IEEE Neural Networks Council Standards Committee [ Frequent Itemset Mining Dataset Repository [ National Cancer Institute Data Sets [ KDDCUP [ StatLib [



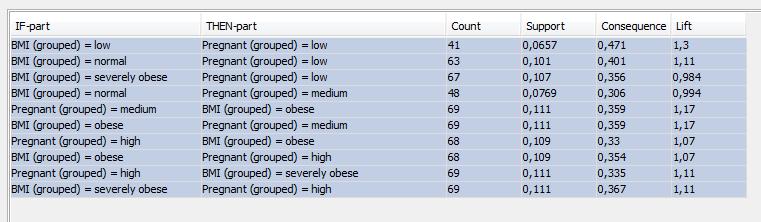
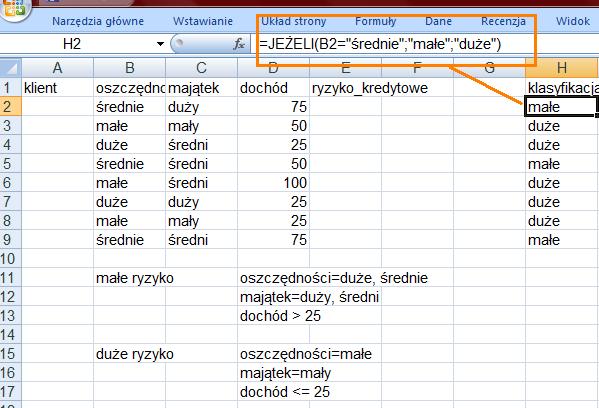
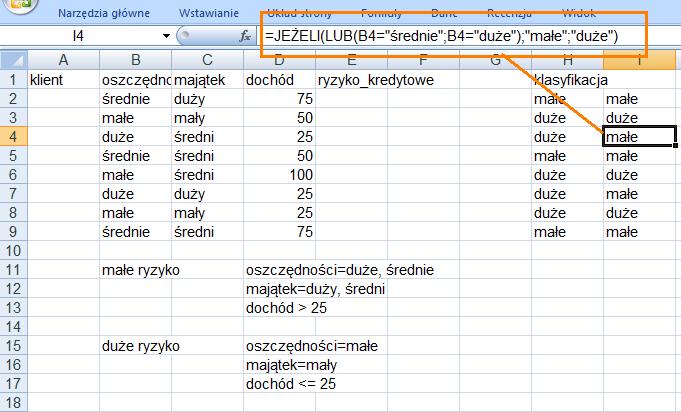
25 Reguły klasyfikacji:

26 Wersja I

27 Wersja II


28 Wersja III
29 metoda typ Zmienna niezależna Regresja liniowa Regresja Wszystkie ilościowe Zakłada liniową zależność, prosta w implementacji Analiza dyskryminacyjna klasyfikacja Wszystkie ilościowe Zakłada istnienie podobnych grup Regresja logistyczna Klasyfikacja Wszystkie ilościowe Oblicza prawdopodobieństwo Naiwny klasyfikator Bayesa klasyfikacja Tylko nominalne (jakościowe) Wymaga dużego zbioru danych K-NN Regresja lub klasyfikacja Wszystkie ilościowe Dobre dla nieliniowych zależności, dla odchyleń w danych, i dobrze wyjaśnia dane Sieci neuronowe Regresja lub klasyfikacja Wszystkie ilościowe Model czarnej skrzynki CART Regresja lub klasyfikacja Każde Dobrze wyjaśnia rozumowanie za pomocą drzew klasyfikacji
30 mały Duże ryzyko majątek Średni, duży oszczędności Małe, średnie duże majątek Małe ryzyko duży Średni Małe ryzyko Duże ryzyko
31 Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe może być określenie- model cech niezależnych. Model prawdopodobieństwa można wyprowadzić korzystając z twierdzenia Bayesa. W zależności od rodzaju dokładności modelu prawdopodobieństwa, naiwne klasyfikatory bayesowskie można uczyć bardzo skutecznie w trybie uczenia z nadzorem.
32 Jeśli wiemy, że kulek czerwonych jest 2 razy mniej niż zielonych (bo czerwonych jest 20 a zielonych 40) to prawdopodobieństwo tego, że kolejna (nowa) kulka będzie koloru zielonego jest dwa razy większe niż tego, że kulka będzie czerwona. Dlatego możemy napisać, że znane z góry prawdopodobieństwa:

33 Jeśli więc czerwonych jest 20 a zielonych 40, to razem wszystkich jest 60. Więc Więc teraz gdy mamy do czynienia z nową kulką ( na rysunku biała):
34 To spróbujmy ustalić jaka ona będzie. Dokonujemy po prostu klasyfikacji kulki do jednej z dwóch klas: zielonych bądź czerwonych. Jeśli weźmiemy pod uwagę sąsiedztwo białej kulki takie jak zaznaczono, a więc do 4 najbliższych sąsiadów, to widzimy, że wśród nich są 3 kulka czerwone i 1 zielona. Obliczamy liczbę kulek w sąsiedztwie należących do danej klasy : zielonych bądź czerwonych z wzorów: W naszym przypadku, jest dziwnie, bo akurat w sąsiedztwie kulki X jest więcej kulek czerwonych niż zielonych, mimo, iż kulek zielonych jest ogólnie 2 razy więcej niż czerwonych. Dlatego zapiszemy, że
35 Dlatego ostatecznie powiemy, że Prawdopodobieństwo że kulka X jest zielona = prawdopodobieństwo kulki zielonej * prawdopodobieństwo, że kulka X jest zielona w swoim sąsiedztwie = Prawdopodobieństwo że kulka X jest czerwona = prawdopodobieństwo kulki czerwonej * prawdopodobieństwo, że kulka X jest czerwona w swoim sąsiedztwie = Ostatecznie klasyfikujemy nową kulkę X do klasy kulek czerwonych, ponieważ ta klasa dostarcza nam większego prawdopodobieostwa posteriori.
36 jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. -

37 Dany jest zbiór uczący zawierający obserwacje z których każda ma przypisany wektor zmiennych objaśniających oraz wartośd zmiennej objaśnianej Y. Dana jest obserwacja C z przypisanym wektorem zmiennych objaśniających dla której chcemy prognozowad wartośd zmiennej objaśnianej Y.
38 1. porównanie wartości zmiennych objaśniających dla obserwacji C z wartościami tych zmiennych dla każdej obserwacji w zbiorze uczącym. 2. wybór k (ustalona z góry liczba) najbliższych do C obserwacji ze zbioru uczącego. 3. Uśrednienie wartości zmiennej objaśnianej dla wybranych obserwacji, w wyniku czego uzyskujemy prognozę. Przez "najbliższą obserwację" mamy na myśli, taką obserwację, której odległośd do analizowanej przez nas obserwacji jest możliwie najmniejsza.

39
40

41 Najbliższy dla naszego obiektu buźka jest obiekt Więc przypiszemy nowemu obiektowi klasę:

42 Mimo, że najbliższy dla naszego obiektu buźka jest obiekt Metodą głosowania ustalimy, że skoro mamy wziąć pod uwagę 5 najbliższych sąsiadów tego obiektu, a widać, że 1 z nich ma klasę: Zaś 4 pozostałe klasę: To przypiszemy nowemu obiektowi klasę:
43 Schemat algorytmu: Poszukaj obiektu najbliższego w stosunku do obiektu klasyfikowanego. Określenie klasy decyzyjnej na podstawie obiektu najbliższego. Cechy algorytmu: Bardziej odporny na szumy - w poprzednim algorytmie obiekt najbliższy klasyfikowanemu może być zniekształcony - tak samo zostanie zaklasyfikowany nowy obiekt. Konieczność ustalenia liczby najbliższych sąsiadów. Wyznaczenie miary podobieństwa wśród obiektów (wiele miar podobieństwa). Dobór parametru k - liczby sąsiadów: Jeśli k jest małe, algorytm nie jest odporny na szumy jakość klasyfikacji jest niska. Jeśli k jest duże, czas działania algorytmu rośnie - większa złożoność obliczeniowa. Należy wybrać k, które daje najwyższą wartość klasyfikacji.
44 Wyznaczanie odległości obiektów: odległość euklidesowa
45 Obiekty są analizowane w ten sposób, że oblicza się odległości bądź podobieństwa między nimi. Istnieją różne miary podobieństwa czy odległości. Powinny być one wybierane konkretnie dla typu danych analizowanych: inne są bowiem miary typowo dla danych binarnych, inne dla danych nominalnych a inne dla danych numerycznych. Nazwa Wzór gdzie: x,y - to wektory wartości cech porównywanych obiektów w przestrzeni p- wymiarowej, gdzie odpowiednio wektory wartości to: oraz. odległośd euklidesowa odległośd kątowa współczynnik korelacji liniowej Pearsona Miara Gowera
46 Oblicz odległość punktu A o współrzędnych (2,3) do punktu B o współrzędnych (7,8) A B D (A,B) = pierwiastek ((7-2) 2 + (8-3) 2 ) = pierwiastek ( ) = pierwiastek (50) = 7.07
47 9 8 B A A B C 2 1 C Mając dane punkty: A(2,3), B(7,8) oraz C(5,1) oblicz odległości między punktami: D (A,B) = pierwiastek ((7-2) 2 + (8-3) 2 ) = pierwiastek ( ) = pierwiastek (50) = 7.07 D (A,C) = pierwiastek ((5-2) 2 + (3-1) 2 ) = pierwiastek (9 + 4) = pierwiastek (13) = 3.60 D (B,C) = pierwiastek ((7-5) 2 + (3-8) 2 ) = pierwiastek (4 + 25) = pierwiastek (29) = 5.38

48 Obiekt klasyfikowany podany jako ostatni : a = 3, b = 6 Teraz obliczmy odległości poszczególnych obiektów od wskazanego. Dla uproszczenia obliczeń posłużymy sie wzorem:
49

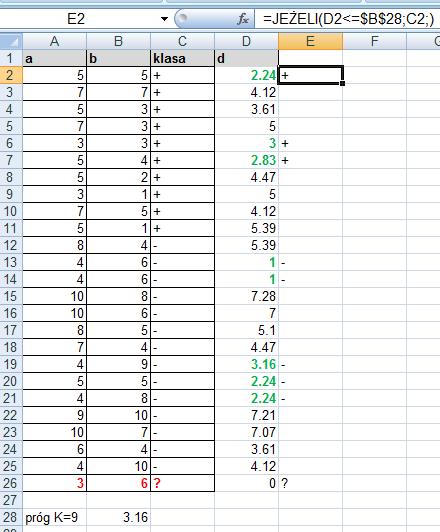
50 Znajdujemy więc k najbliższych sąsiadów. Załóżmy, że szukamy 9 najbliższych sąsiadów. Wyróżnimy ich kolorem zielonym. Sprawdzamy, które z tych 9 najbliższych sąsiadów są z klasy + a które z klasy -? By to zrobić musimy znaleźć k najbliższych sąsiadów (funkcja Excela o nazwie MIN.K)
51
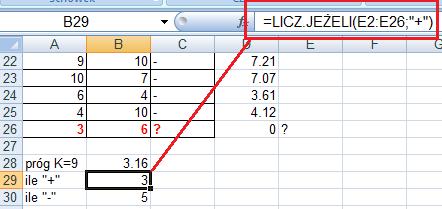
52

53 eraz w komórce (kolumna C, wiersz 26) wreszcie możemy napisad formułę, która wstawi odpowiednią wartośd. W ten sposób stwierdzimy, że obiekt a=3 i b=6 zaliczymy do klasy -
54 Wyobraźmy sobie, że nie mamy 2 zmiennych opisujących każdy obiekt, ale tych zmiennych jest np. 5: {v1,v2,v3,v4,v5} i że obiekty opisane tymi zmiennymi to 3 punkty: A, B i C: V1 V2 V3 V4 V5 A B C Policzmy teraz odległość między punktami: D (A,B) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.03) = 0.17 D (A,C) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.69) = 0.83 D (B,C) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.74) = 0.86 Szukamy najmniejszej odległości, bo jeśli te dwa punkty są najbliżej siebie, dla których mamy najmniejszą odległości! A więc najmniejsza odległość jest między punktami A i B!
55

56 Czym różni się predykcja od klasyfikacji? Na czym polega algorytm K-NN? Na czym bazuje alg. Naiwnego klasyfikatora Bayesa? Co wiemy dzięki badaniu korelacji?
57
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Sztuczna inteligencja : Algorytm KNN
 Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Regresja liniowa, klasyfikacja metodą k-nn. Agnieszka Nowak Brzezińska
 Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, Spis treści
 Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE
 UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować?
 Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład I dr inż. 2015/2016
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Własności statystyczne regresji liniowej. Wykład 4
 Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Regresja i Korelacja
 Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Klasyfikacja LDA + walidacja
 Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Analiza współzależności zjawisk
 Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Algorytmy, które estymują wprost rozkłady czy też mapowania z nazywamy algorytmami dyskryminacyjnymi.
 Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
STATYSTYKA MATEMATYCZNA
 Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność (jeśli
Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność (jeśli
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
WSTĘP DO REGRESJI LOGISTYCZNEJ. Dr Wioleta Drobik-Czwarno
 WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Sposoby prezentacji problemów w statystyce
 S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
Przedmowa Wykaz symboli Litery alfabetu greckiego wykorzystywane w podręczniku Symbole wykorzystywane w zagadnieniach teorii
 SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Co to jest klasyfikacja? Klasyfikacja a grupowanie Naiwny klasyfikator Bayesa
 Co to jest klasyfikacja? Klasyfikacja a grupowanie Naiwny klasyfikator Bayesa Odkrywanie asocjacji Wzorce sekwencji Analiza koszykowa Podobieństwo szeregów temporalnych Klasyfikacja Wykrywanie odchyleń
Co to jest klasyfikacja? Klasyfikacja a grupowanie Naiwny klasyfikator Bayesa Odkrywanie asocjacji Wzorce sekwencji Analiza koszykowa Podobieństwo szeregów temporalnych Klasyfikacja Wykrywanie odchyleń
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Wykład Centralne twierdzenie graniczne. Statystyka matematyczna: Estymacja parametrów rozkładu
 Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska. Anna Stankiewicz Izabela Słomska
 Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Statystyka w zarządzaniu : pełny wykład / Amir D. Aczel. wyd. 1, dodr. 5. Warszawa; Spis treści
 Statystyka w zarządzaniu : pełny wykład / Amir D. Aczel. wyd. 1, dodr. 5. Warszawa; 2011 Spis treści Od autora 11 1. Wprowadzenie i statystyka opisowa 15 1.1. Wprowadzenie 15 1.2. Percentyle i kwartyle
Statystyka w zarządzaniu : pełny wykład / Amir D. Aczel. wyd. 1, dodr. 5. Warszawa; 2011 Spis treści Od autora 11 1. Wprowadzenie i statystyka opisowa 15 1.1. Wprowadzenie 15 1.2. Percentyle i kwartyle
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: przedmiot obowiązkowy w ramach treści kierunkowych, moduł kierunkowy ogólny Rodzaj zajęć: wykład, ćwiczenia I KARTA PRZEDMIOTU CEL PRZEDMIOTU
Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: przedmiot obowiązkowy w ramach treści kierunkowych, moduł kierunkowy ogólny Rodzaj zajęć: wykład, ćwiczenia I KARTA PRZEDMIOTU CEL PRZEDMIOTU
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
WYMAGANIA WSTĘPNE W ZAKRESIE WIEDZY, UMIEJĘTNOŚCI I INNYCH KOMPETENCJI
 WYDZIAŁ GEOINŻYNIERII, GÓRNICTWA I GEOLOGII KARTA PRZEDMIOTU Nazwa w języku polskim: Statystyka matematyczna Nazwa w języku angielskim: Mathematical Statistics Kierunek studiów (jeśli dotyczy): Górnictwo
WYDZIAŁ GEOINŻYNIERII, GÓRNICTWA I GEOLOGII KARTA PRZEDMIOTU Nazwa w języku polskim: Statystyka matematyczna Nazwa w języku angielskim: Mathematical Statistics Kierunek studiów (jeśli dotyczy): Górnictwo
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Zmienne losowe i teoria prawdopodobieństwa 3. Populacje i próby danych 4. Testowanie hipotez i estymacja parametrów 5. Najczęściej wykorzystywane testy statystyczne
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Zmienne losowe i teoria prawdopodobieństwa 3. Populacje i próby danych 4. Testowanie hipotez i estymacja parametrów 5. Najczęściej wykorzystywane testy statystyczne
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
Podstawy statystyki matematycznej w programie R
 Podstawy statystyki matematycznej w programie R Piotr Ćwiakowski Wydział Fizyki Uniwersytetu Warszawskiego Zajęcia 1. Wprowadzenie 1 marca 2017 r. Program R Wprowadzenie do R i badań statystycznych podstawowe
Podstawy statystyki matematycznej w programie R Piotr Ćwiakowski Wydział Fizyki Uniwersytetu Warszawskiego Zajęcia 1. Wprowadzenie 1 marca 2017 r. Program R Wprowadzenie do R i badań statystycznych podstawowe
Ekonometria. Modele regresji wielorakiej - dobór zmiennych, szacowanie. Paweł Cibis pawel@cibis.pl. 1 kwietnia 2007
 Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
P: Czy studiujący i niestudiujący preferują inne sklepy internetowe?
 2 Test niezależności chi-kwadrat stosuje się (między innymi) w celu sprawdzenia czy pomiędzy zmiennymi istnieje związek/zależność. Stosujemy go w sytuacji, kiedy zmienna zależna mierzona jest na skali
2 Test niezależności chi-kwadrat stosuje się (między innymi) w celu sprawdzenia czy pomiędzy zmiennymi istnieje związek/zależność. Stosujemy go w sytuacji, kiedy zmienna zależna mierzona jest na skali
X Y 4,0 3,3 8,0 6,8 12,0 11,0 16,0 15,2 20,0 18,9
 Zadanie W celu sprawdzenia, czy pipeta jest obarczona błędem systematycznym stałym lub zmiennym wykonano szereg pomiarów przy różnych ustawieniach pipety. Wyznacz równanie regresji liniowej, które pozwoli
Zadanie W celu sprawdzenia, czy pipeta jest obarczona błędem systematycznym stałym lub zmiennym wykonano szereg pomiarów przy różnych ustawieniach pipety. Wyznacz równanie regresji liniowej, które pozwoli
Spis treści 3 SPIS TREŚCI
 Spis treści 3 SPIS TREŚCI PRZEDMOWA... 1. WNIOSKOWANIE STATYSTYCZNE JAKO DYSCYPLINA MATEMATYCZNA... Metody statystyczne w analizie i prognozowaniu zjawisk ekonomicznych... Badania statystyczne podstawowe
Spis treści 3 SPIS TREŚCI PRZEDMOWA... 1. WNIOSKOWANIE STATYSTYCZNE JAKO DYSCYPLINA MATEMATYCZNA... Metody statystyczne w analizie i prognozowaniu zjawisk ekonomicznych... Badania statystyczne podstawowe
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Badanie zależności skala nominalna
 Badanie zależności skala nominalna I. Jak kształtuje się zależność miedzy płcią a wykształceniem? II. Jak kształtuje się zależność między płcią a otyłością (opis BMI)? III. Jak kształtuje się zależność
Badanie zależności skala nominalna I. Jak kształtuje się zależność miedzy płcią a wykształceniem? II. Jak kształtuje się zależność między płcią a otyłością (opis BMI)? III. Jak kształtuje się zależność
2. Empiryczna wersja klasyfikatora bayesowskiego
 Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Teoria prawdopodobieństwa i elementy kombinatoryki 3. Zmienne losowe 4. Populacje i próby danych 5. Testowanie hipotez i estymacja parametrów 6. Test t 7. Test
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Teoria prawdopodobieństwa i elementy kombinatoryki 3. Zmienne losowe 4. Populacje i próby danych 5. Testowanie hipotez i estymacja parametrów 6. Test t 7. Test
Inżynieria Środowiska. II stopień ogólnoakademicki. przedmiot podstawowy obowiązkowy polski drugi. semestr zimowy
 Załącznik nr 7 do Zarządzenia Rektora nr../12 z dnia.... 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2017/2018 STATYSTYKA
Załącznik nr 7 do Zarządzenia Rektora nr../12 z dnia.... 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2017/2018 STATYSTYKA
data mining machine learning data science
 data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Statystyka. Wykład 7. Magdalena Alama-Bućko. 16 kwietnia Magdalena Alama-Bućko Statystyka 16 kwietnia / 35
 Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO
 Zał. nr 4 do ZW WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA STOSOWANA Nazwa w języku angielskim APPLIED STATISTICS Kierunek studiów (jeśli dotyczy): Specjalność
Zał. nr 4 do ZW WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA STOSOWANA Nazwa w języku angielskim APPLIED STATISTICS Kierunek studiów (jeśli dotyczy): Specjalność
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
dr Jerzy Pusz, st. wykładowca, Wydział Matematyki i Nauk Informacyjnych Politechniki Warszawskiej B. Ogólna charakterystyka przedmiotu
 Kod przedmiotu TR.SIK303 Nazwa przedmiotu Probabilistyka I Wersja przedmiotu 2015/16 A. Usytuowanie przedmiotu w systemie studiów Poziom kształcenia Studia I stopnia Forma i tryb prowadzenia studiów Stacjonarne
Kod przedmiotu TR.SIK303 Nazwa przedmiotu Probabilistyka I Wersja przedmiotu 2015/16 A. Usytuowanie przedmiotu w systemie studiów Poziom kształcenia Studia I stopnia Forma i tryb prowadzenia studiów Stacjonarne
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Z poprzedniego wykładu
 PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne
PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne
Importowanie danych do SPSS Eksportowanie rezultatów do formatu MS Word... 22
 Spis treści Przedmowa do wydania pierwszego.... 11 Przedmowa do wydania drugiego.... 15 Wykaz symboli.... 17 Litery alfabetu greckiego wykorzystywane w podręczniku.... 17 Symbole wykorzystywane w zagadnieniach
Spis treści Przedmowa do wydania pierwszego.... 11 Przedmowa do wydania drugiego.... 15 Wykaz symboli.... 17 Litery alfabetu greckiego wykorzystywane w podręczniku.... 17 Symbole wykorzystywane w zagadnieniach
MATEMATYKA3 Mathematics3. Elektrotechnika. I stopień ogólnoakademicki. studia stacjonarne. Katedra Matematyki dr Zdzisław Piasta
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/13 MATEMATYKA3 Mathematics3 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW Kierunek
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/13 MATEMATYKA3 Mathematics3 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW Kierunek
STATYSTYKA OPISOWA. Dr Alina Gleska. 12 listopada Instytut Matematyki WE PP
 STATYSTYKA OPISOWA Dr Alina Gleska Instytut Matematyki WE PP 12 listopada 2017 1 Analiza współzależności dwóch cech 2 Jednostka zbiorowości - para (X,Y ). Przy badaniu korelacji nie ma znaczenia, która
STATYSTYKA OPISOWA Dr Alina Gleska Instytut Matematyki WE PP 12 listopada 2017 1 Analiza współzależności dwóch cech 2 Jednostka zbiorowości - para (X,Y ). Przy badaniu korelacji nie ma znaczenia, która
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
ZJAZD 4. gdzie E(x) jest wartością oczekiwaną x
 jest wartością oczekiwaną x") ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
Liczba godzin Punkty ECTS Sposób zaliczenia. ćwiczenia 30 zaliczenie z oceną
 Wydział: Zarządzanie i Finanse Nazwa kierunku kształcenia: Finanse i Rachunkowość Rodzaj przedmiotu: podstawowy Opiekun: prof. nadzw. dr hab. Tomasz Kuszewski Poziom studiów (I lub II stopnia): I stopnia
Wydział: Zarządzanie i Finanse Nazwa kierunku kształcenia: Finanse i Rachunkowość Rodzaj przedmiotu: podstawowy Opiekun: prof. nadzw. dr hab. Tomasz Kuszewski Poziom studiów (I lub II stopnia): I stopnia
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
GRUPY NIEZALEŻNE Chi kwadrat Pearsona GRUPY ZALEŻNE (zmienne dwuwartościowe) McNemara Q Cochrana
 McNemara Q Cochrana") GRUPY NIEZALEŻNE Chi kwadrat Pearsona Testy stosujemy w sytuacji, kiedy zmienna zależna mierzona jest na skali nominalnej Liczba porównywanych grup (czyli liczba kategorii zmiennej niezależnej) nie ma
GRUPY NIEZALEŻNE Chi kwadrat Pearsona Testy stosujemy w sytuacji, kiedy zmienna zależna mierzona jest na skali nominalnej Liczba porównywanych grup (czyli liczba kategorii zmiennej niezależnej) nie ma
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY)
") STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
Z-LOG-033I Statystyka Statistics
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Z-LOG-033I Statystyka Statistics Obowiązuje od roku akademickiego 2012/2013 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Z-LOG-033I Statystyka Statistics Obowiązuje od roku akademickiego 2012/2013 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
Z-0033z Statystyka. Zarządzanie i Inżynieria Produkcji I stopień Ogólnoakademicki. Stacjonarne Wszystkie Katedra Matematyki dr Zdzisław Piasta
 KARTA MODUŁU / KARTA PRZEDMIOTU Z-0033z Statystyka Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Statistics Obowiązuje od roku akademickiego 2012/2013 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
KARTA MODUŁU / KARTA PRZEDMIOTU Z-0033z Statystyka Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Statistics Obowiązuje od roku akademickiego 2012/2013 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
Liczba godzin Punkty ECTS Sposób zaliczenia. ćwiczenia 16 zaliczenie z oceną
 Wydział: Zarządzanie i Finanse Nazwa kierunku kształcenia: Finanse i Rachunkowość Rodzaj przedmiotu: podstawowy Opiekun: prof. nadzw. dr hab. Tomasz Kuszewski Poziom studiów (I lub II stopnia): II stopnia
Wydział: Zarządzanie i Finanse Nazwa kierunku kształcenia: Finanse i Rachunkowość Rodzaj przedmiotu: podstawowy Opiekun: prof. nadzw. dr hab. Tomasz Kuszewski Poziom studiów (I lub II stopnia): II stopnia
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
W1. Wprowadzenie. Statystyka opisowa
 W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
Z-LOGN1-006 Statystyka Statistics
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Z-LOGN-006 Statystyka Statistics Obowiązuje od roku akademickiego 0/0 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW Kierunek
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Z-LOGN-006 Statystyka Statistics Obowiązuje od roku akademickiego 0/0 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW Kierunek
Z-ZIPN1-004 Statystyka. Zarządzanie i Inżynieria Produkcji I stopień Ogólnoakademicki Niestacjonarne Wszystkie Katedra Matematyki dr Zdzisław Piasta
 KARTA MODUŁU / KARTA PRZEDMIOTU Z-ZIPN-004 Statystyka Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Statistics Obowiązuje od roku akademickiego 0/04 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
KARTA MODUŁU / KARTA PRZEDMIOTU Z-ZIPN-004 Statystyka Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Statistics Obowiązuje od roku akademickiego 0/04 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
Rozpoznawanie wzorców. Dr inż. Michał Bereta p. 144 / 10, Instytut Informatyki
 Rozpoznawanie wzorców Dr inż. Michał Bereta p. 144 / 10, Instytut Informatyki mbereta@pk.edu.pl beretam@torus.uck.pk.edu.pl www.michalbereta.pl Twierzdzenie: Prawdopodobieostwo, że n obserwacji wybranych
Rozpoznawanie wzorców Dr inż. Michał Bereta p. 144 / 10, Instytut Informatyki mbereta@pk.edu.pl beretam@torus.uck.pk.edu.pl www.michalbereta.pl Twierzdzenie: Prawdopodobieostwo, że n obserwacji wybranych
Liczba godzin Punkty ECTS Sposób zaliczenia. ćwiczenia 30 zaliczenie z oceną. laboratoria 30 zaliczenie z oceną
 Wydział: Psychologia Nazwa kierunku kształcenia: Psychologia Rodzaj przedmiotu: podstawowy Opiekun: dr Andrzej Tarłowski Poziom studiów (I lub II stopnia): Jednolite magisterskie Tryb studiów: Stacjonarne
Wydział: Psychologia Nazwa kierunku kształcenia: Psychologia Rodzaj przedmiotu: podstawowy Opiekun: dr Andrzej Tarłowski Poziom studiów (I lub II stopnia): Jednolite magisterskie Tryb studiów: Stacjonarne
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
WYMAGANIA WSTĘPNE W ZAKRESIE WIEDZY, UMIEJĘTNOŚCI I INNYCH KOMPETENCJI
 Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA (EiT stopień) Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność
Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA (EiT stopień) Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność
Eksploracja danych - wykład IV
 - wykład 1/41 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 27 października 2016 - wykład 2/41 wykład 1 2 3 4 5 - wykład 3/41 CRISP-DM - standaryzacja wykład
- wykład 1/41 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 27 października 2016 - wykład 2/41 wykład 1 2 3 4 5 - wykład 3/41 CRISP-DM - standaryzacja wykład