Drzewa klasyfikacyjne
|
|
|
- Bogusław Kacper Paluch
- 6 lat temu
- Przeglądów:
Transkrypt
1 Yes Refund No NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES Drzewa klasyfikacyjne Agnieszka Nowak Brzezińska
2 Zadania sztucznej inteligencji Klasyfikacja, predykcja, przewidywanie polega ona na znajdowaniu odwzorowania danych w zbiór predefiniowanych klas. Na podstawie zawartości bazy danych budowany jest model (np. drzewo decyzyjne, reguły logiczne), który służy do klasyfikowania nowych obiektów w bazie danych lub głębszego zrozumienia istniejącego podziału obiektów na predefiniowane klasy. Ogromne zastosowanie znalazła w systemach medycznych, przykładowo, w bazie danych medycznych znalezione mogą być reguły klasyfikujące poszczególne schorzenia, a następnie przy pomocy znalezionych reguł automatycznie może być przeprowadzone diagnozowanie kolejnych pacjentów. Klasyfikacja jest metodą eksploracji danych z nadzorem (z nauczycielem). Proces klasyfikacji składa się z kilku etapów budowania modelu, po czym następuje faza testowania oraz predykcji nieznanych wartości.
3 Klasyfikacja danych jest dwuetapowym procesem: Etap 1: budowa modelu (klasyfikatora) opisującego predefiniowany zbiór klas danych lub zbiór pojęć Etap : zastosowanie opracowanego modelu do klasyfikacji nowych danych
4 10 Przykład Tid Refund Marital Status Taxable Income Cheat Splitting Attributes 1 Yes Single 15K No No Married 100K No 3 No Single 70K No 4 Yes Married 10K No 5 No Divorced 95K Yes 6 No Married 60K No 7 Yes Divorced 0K No 8 No Single 85K Yes Refund Yes No NO MarSt Single, Divorced TaxInc < 80K > 80K Married NO 9 No Married 75K No 10 No Single 90K Yes NO YES Dane treningowe Model: Decision Tree
5 10 Inne drzewo decyzyjne Tid Refund Marital Status Taxable Income 1 Yes Single 15K No No Married 100K No Cheat Married NO MarSt Yes Single, Divorced Refund No 3 No Single 70K No NO TaxInc 4 Yes Married 10K No < 80K > 80K 5 No Divorced 95K Yes 6 No Married 60K No NO YES 7 Yes Divorced 0K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes Drzew różnych dla tego samego zbioru danych może być wiele!
6 10 10 Zadanie drzew klasyfikacyjnych Tid Attrib1 Attrib Attrib3 Class 1 Yes Large 15K No No Medium 100K No Tree Induction algorithm 3 No Small 70K No 4 Yes Medium 10K No 5 No Large 95K Yes Induction 6 No Medium 60K No 7 Yes Large 0K No 8 No Small 85K Yes 9 No Medium 75K No Learn Model 10 No Small 90K Yes Training Set Tid Attrib1 Attrib Attrib3 Class Apply Model Model Decision Tree 11 No Small 55K? 1 Yes Medium 80K? 13 Yes Large 110K? Deduction 14 No Small 95K? 15 No Large 67K? Test Set
7 10 Zastosowanie modelu do danych Start od korzenia Test Data Refund Marital Status Taxable Income Cheat Refund No Married 80K? Yes No NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES
8 10 Zastosowanie modelu do danych Test Data Refund Marital Status Taxable Income Cheat Yes Refund No No Married 80K? NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES
9 10 Zastosowanie modelu do danych Test Data Refund Marital Status Taxable Income Cheat Yes Refund No No Married 80K? NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES
10 10 Zastosowanie modelu do danych Test Data Refund Marital Status Taxable Income Cheat Yes Refund No No Married 80K? NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES
11 10 Zastosowanie modelu do danych Test Data Refund Marital Status Taxable Income Cheat Yes Refund No No Married 80K? NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES
12 10 Zastosowanie modelu do danych Test Data Refund Marital Status Taxable Income Cheat Yes NO Refund No MarSt Single, Divorced Married No Married 80K? No TaxInc < 80K > 80K NO NO YES
13 10 10 Zadanie klasyfikacji DD Tid Attrib1 Attrib Attrib3 Class 1 Yes Large 15K No No Medium 100K No Tree Induction algorithm 3 No Small 70K No 4 Yes Medium 10K No 5 No Large 95K Yes Induction 6 No Medium 60K No 7 Yes Large 0K No 8 No Small 85K Yes 9 No Medium 75K No Learn Model 10 No Small 90K Yes Training Set Tid Attrib1 Attrib Attrib3 Class Apply Model Model Decision Tree 11 No Small 55K? 1 Yes Medium 80K? 13 Yes Large 110K? Deduction 14 No Small 95K? 15 No Large 67K? Test Set
14 W informatyce pod pojęciem drzewa rozumiemy spójny skierowany graf acykliczny, z którym związane jest następujące nazewnictwo: krawędzie grafu nazywane są gałęziami; wierzchołki, z których wychodzi co najmniej jedna krawędź to węzły, pozostałe zaś określane są mianem liści. Przyjmuje sie, ze wierzchołek ma co najwyżej jedną krawędź wchodzącą, a liczba krawędzi wychodzących jest równa 0 albo większa od 1; węzeł lub liść do którego nie prowadza żadne krawędzie to korzeń.
15 Definicja Drzewo decyzyjne jest drzewem, w którym węzły odpowiadają testom przeprowadzanym na wartościach atrybutów reguł, gałęzie są możliwymi wynikami takich testów zaś liście reprezentują część decyzyjną. Drzewa decyzyjne jako forma reprezentacji zbioru reguł zdobyły wśród programistów SI dużą popularność przede wszystkim ze względu na swą czytelność oraz znaczne zmniejszenie wymaganych do przechowania bazy, zasobów pamięci. Fakt ten zilustrowany jest tablica poniżej zawierającą przykładowa bazę reguł, oraz rysunkiem przedstawiającym odpowiadające jej drzewo decyzyjne.
16 Drzewo decyzyjne - schemat
17 Definicje Drzewo to graf bez cykli (pętli), w którym istnieje tylko jedna ścieżka między dwoma różnymi węzłami. Czyli, to graf spójny bez cykli. To drzewo reprezentujące pewien proces podziału zbioru obiektów na jednorodne klasy. Jego wewnętrzne węzły opisują sposób dokonania tego podziału, a liście odpowiadają klasom, do których należą obiekty. Z kolei krawędzie drzewa reprezentują wartości cech, na podstawie których dokonano podziału.
18 Drzewo klasyfikacyjne Składa się z korzenia, z którego wychodzą co najmniej dwie krawędzie do węzłów leżących na niższym poziomie. Z każdym węzłem związane jest pytanie o wartości cech, jeśli np. pewien obiekt posiada te wartości, przenosi się go w dół odpowiednią krawędzią. Węzły, z których nie wychodzą już żadne krawędzie, to liście, które reprezentują klasy.
19 Drzewo to reguły decyzyjne W przypadku spadku cen akcji: "jeżeli stopa procentowa rośnie i zyski przedsiębiorstw spadają to ceny akcji spadają" w przypadku wzrostu cen akcji: "jeżeli stopa procentowa spada, lub jeśli stopa procentowa rośnie ale jednocześnie rosną zyski przedsiębiorstw rosną to ceny akcji rosną."
20 Drzewa decyzyjne Najpowszechniejsza forma reprezentowania wiedzy przez dostępne oprogramowanie. Węzły są opisywane przez atrybuty eksplorowanej relacji, krawędzie opisują możliwe wartości dla atrybutu. Klasyfikacja odbywa się poprzez przeglądanie drzewa od korzenia do liści przez krawędzie opisane wartościami atrybutów.
21 Drzewa decyzyjne Przykład: automatyczny podział kierowców na powodujących i nie powodujących wypadki drogowe Dwie klasy: TAK i NIE
22 Drzewa decyzyjne IF marka = BMW AND wiek_kier < 5 THEN wypadek = TAK
23 Drzewa decyzyjne Drzewo decyzyjne jest formą opisu wiedzy klasyfikującej Węzłom drzewa odpowiadają atrybuty eksplorowanej relacji Krawędzie opisują wartości atrybutów Liśćmi drzewa są wartości atrybutu klasyfikacyjnego
24 Drzewa decyzyjne - przykład
25 Drzewa decyzyjne dla przykładu
26 Drzewa decyzyjne indukcja drzewa Problemy: Od jakiego atrybutu zacząć? Jakie atrybuty umieszczać w węzłach? Kiedy zaprzestać rozbudowywać drzewo? Co z atrybutami o zbyt dużej liczbie wartości lub atrybutami ilościowymi? Jak uwzględniać dane sprzeczne, brakujące lub błędne? Estymacja błędu klasyfikowania
27 Trening i testowanie Zbiór dostępnych krotek(przykładów, obserwacji, próbek) dzielimy na dwa zbiory: zbiór treningowy i zbiór testowy Model klasyfikacyjny (klasyfikator)jest budowany dwu-etapowo: Uczenie (trening) klasyfikator jest budowany w oparciu o zbiór treningowy danych Testowanie dokładność (jakość) klasyfikatora jest weryfikowana w oparciu o zbiór testowy danych Zbiór danych Liczba danych = 100 /3 1/3 Zbiór treningowy(uczący) Liczba danych = 66 Zbiór testujący (walidacyjny) Liczba danych = 34
28 Podział obiektów ze względu na wartości atrybutów Każdy atrybut dzieli obiekty w systemie na grupy. Grup jest tyle ile wartości atrybutu, który analizujemy. W grupie dla danej wartości są tylko obiekty opisane tą wartością atrybutu.
29 A B C 1 A1 B1 C1 A B1 C 3 A1 B C3 4 A B C4 5 A1 B C1 6 A B C 7 A1 B C3 8 A B C4 A B C 1 A1 B1 C1 A B1 C 3 A1 B C3 4 A B C4 5 A1 B C1 6 A B C 7 A1 B C3 8 A B C4 A1 A A 1,3,5,7,4,6,8 B1 B B 1, 3,4,5,6,7,8 A B C 1 A1 B1 C1 A B1 C 3 A1 B C3 C1 4 A B C4 5 A1 B C1 c C3 6 A B C 1,5 7 A1 B C3 8 A B C4 3,7,6 C C4 4,8
30 Podział cech (atrybutów) Ilościowe numeryczne np. liczba języków obcych, waga w kg, wzrost w cm, wiek w latach etc. Jakościowe (nominalne) to cechy nienumeryczne, nie da się z nich policzyć wartości średniej, ale da się np. powiedzieć która wartość tej cechy występuje najczęściej, np. waga w kategoriach {niska, średnia, wysoka}, kolor oczu, wykształcenie, płeć z wartościami {kobieta, mężczyzna}
31 Algorytm generowania drzewa decyzyjnego Algorytm top-down dla zbioru uczącego S 1. Wybierz najlepszy atrybut A. Rozbuduj drzewo poprzez dodanie do węzła nowych gałęzi odpowiadającym poszczególnym wartościom atrybutu A 3. Podziel zbiór S na podzbiory S1,..., Sn zgodnie z wartościami atrybutu A i przydziel do odpowiednich gałęzi 4. Jeśli wszystkie przykłady Si należą do tej samej klasy C zakończ gałąź liściem wskazującym C; w przeciwnym razie rekurencyjnie buduj drzewo Ti dla Si (tzn. powtórz kroki 1-4)
32 Wybór atrybutu do budowania drzewa
33 Drzewo decyzyjne Odległość < 0 km tak nie Pogoda słonecznie deszczowo Pojęcia: korzeń drzewa, węzeł wewnętrzny, węzeł końcowy (liść), gałąź, ścieżka.
34 Konstrukcja drzewa decyzyjnego y a y 1 y a y 1 a a 3 y < a 1 y 1 < a 3 tak nie tak nie y 1 < a y < a 1 tak nie tak nie 1 1
35 Konstrukcja drzew decyzyjnych Jeden zbiór danych wiele możliwych drzew Czym należy się kierować wybierając (konstruując) drzewo?
36 Kryteria optymalizacji Globalne Lokalne - średnie prawdopodobieństwo błędu - średnia długość ścieżki - liczba węzłów drzewa - stopień zróżnicowania danych - przyrost informacji - współczynnik przyrostu informacji i inne
37 Podział węzła - przykłady 1. Cecha porównana z wartością progową (typowe dla atrybutów ciągłych). y i > i tak nie. Uwzględnione wszystkie możliwe wartości danego atrybutu (typowe dla atrybutów nominalnych). y i y i1 y i y ik
38 Podział węzła Najczęściej reguły decyzyjne budowane są na podstawie pojedynczych cech źródłowych. Prowadzi to do dzielenia przestrzeni cech hiperłaszczyznami prostopadłymi do osi cech. Wybierając cechę można się kierować jedną ze znanych miar, np. przyrostem informacji, wskaźnikiem przyrostu informacji, wskaźnikiem zróżnicowania danych itd.
39 Podział węzła w przypadku atrybutów nominalnych 1. Dla każdego atrybutu y i oblicz wartość wybranej miary.. Wybierz atrybut optymalny w sensie powyższej miary. 3. Od danego węzła utwórz tyle gałęzi, ile różnych wartości przyjmuje atrybut y i. t y i y i1 y i y ik t 1 t t k
40 Entropia Entropia w ramach teorii informacji jest definiowana jako średnia ilość informacji, przypadająca na znak symbolizujący zajście zdarzenia z pewnego zbioru. Zdarzenia w tym zbiorze mają przypisane prawdopodobieństwa wystąpienia. gdzie p(i) - prawdopodobieństwo zajścia zdarzenia i.
41 Logarytm Logarytm przy podstawie a z liczby b, zapisywany log a b to taka liczba c, że podstawa a podniesiona do potęgi c daje logarytmowaną liczbę b. Symbolicznie: log a b = c a c =b gdzie a>0,a 1 oraz b > 0. Na przykład log 8 = 3, ponieważ 3 =8.
42 Entropia Entropię można interpretować jako niepewność wystąpienia danego zdarzenia elementarnego w następnej chwili. Jeżeli następujące zdarzenie występuje z prawdopodobieństwem równym 1, to z prostego podstawienia wynika, że entropia wynosi 0, gdyż z góry wiadomo co się stanie - nie ma niepewności. Własności entropii: jest nieujemna jest maksymalna, gdy prawdopodobieństwa zajść zdarzeń są takie same jest równa 0, gdy stany systemu przyjmują wartości 0 albo 1 własność superpozycji - gdy dwa systemy są niezależne to entropia sumy systemów równa się sumie entropii.

43 Entropia dwie decyzje
44

45 Przykład: który atrybut wybrać?
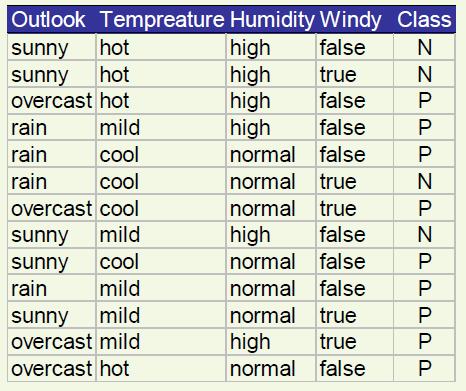
![Ile informacji zawiera dany podział? Średnia liczba bitów do zakodowania dowolnego wektora wynosi: Outlook = sunny info([,3]) = entropy(/5,3/5) = - / 5log( / 5) - 3/ 5log(3/ 5) = 0.](/docs-images/93/114040197/images/46-0.jpg "971bits Outlook = overcast info([4,0]) = entropy(1,0) = -1log(1) - 0log(0) = 0 bits Outlook = rainy info([3,]) = entropy(3/5,/5) = -3/5log(3/ 5) - /5log(/ 5) = 0.")
46 Ile informacji zawiera dany podział? Średnia liczba bitów do zakodowania dowolnego wektora wynosi: Outlook = sunny info([,3]) = entropy(/5,3/5) = - / 5log( / 5) - 3/ 5log(3/ 5) = 0.971bits Outlook = overcast info([4,0]) = entropy(1,0) = -1log(1) - 0log(0) = 0 bits Outlook = rainy info([3,]) = entropy(3/5,/5) = -3/5log(3/ 5) - /5log(/ 5) = 0.971bits Wartość dla atrybutu: info([3,],[4,0],[3,]) = (5/14) (4 /14) 0 + (5/14) 0.971= bits
47 INFORMATION GAIN = informacja przed rozdzieleniem informacja po Rozdzieleniu gain("outlook") = info([9,5]) - info([,3],[4,0],[3,]) = = 0.47 bits Przyrosty informacji dla poszczególnych atrybutów w danych testowych: gain("outlook") = 0.47 bits gain("temperature") = 0.09bits gain("humidity") = 0.15 bits gain("windy") = bits
 = 0.971bits gain(\"windy\") = 0.")
48 Przykład: Dalszy podział gain("temperature") = 0.571bits gain("humidity") = 0.971bits gain("windy") = 0.00 bits

49 Przykład: Końcowe drzewo Uwaga: Nie wszystkie liście muszą być czyste. Czasami identyczne instancje mają różne klasy. Proces budowy drzewa zatrzymuje się gdy dalszy podział nie jest możliwy (lub spełnione jest inne kryterium stopu)
50 Rodzaje drzew Drzewo binarne Drzewo niebinarne, regresyjne
51 Budowanie drzewa Mając zbiór obiektów S, sprawdź, czy należą one do tej samej klasy. Jeśli tak, to zakończ pracę.. W przeciwnym przypadku rozważ wszystkie możliwe podziały zbioru S na podzbiory S 1,S,,S n tak, aby były one jak najbardziej jednorodne. 3. Dokonaj oceny jakości każdego z tych podziałów zgodnie z przyjętym kryterium i wybierz najlepszy z nich. 4. Podziel zbiór S w wybrany sposób. 5. Wykonaj kroki1-4 rekurencyjnie dla każdego z podzbiorów. S S1 S Sn S11 S1 S1k
52 Algorytmy Id3 Quinlan 1986 C4.5 na podstawie id3 Quinlan 1993 Cart Breiman 1984 Chaid już lata 70-te Chi-squared-Automatic- Interaction-Detection (oryginalnie tylko dla danych nominalnych) Hunt s Algorithm (jeden z pierwszych) SLIQ,SPRINT
53 ID 3 (Quinlan, 1986) Bardzo prosty algorytm Opiera się na kryterium information gain Bada czy wszystkie obiekty w danym poddrzewie mają tę samą wartość analizowanej cechy ID3 nie zakłada prunningu drzew ID3 nie dopuszcza też danych numerycznych ani wartości brakujących
54 Algorytm ID 3 Quinlana Cechy algorytmu: wybór atrybutów, dla których kolejno przeprowadzane są testy, aby końcowe drzewo było jak najprostsze i jak najefektywniejsze. Wybór opiera się na liczeniu entropii, która decyduje, który z atrybutów da największy przyrost informacji. Czyli ten, który podzieli zbiór przykładów na jak najbardziej równe podzbiory. Poważną wadą jest wymóg dyskretności wszystkich cech przestrzeni klasyfikacji. Ta sama metoda ID3 może dawać bardzo różne rezultaty dla różnych metod dyskretyzacji. Kryterium oceniającym podziały jest kryterium przyrostu czystości. Miarą niejednorodności węzła jest miara entropii. Przyrost czystości jest nazywany wówczas przyrostem informacyjnym. Metoda ta polega na rekurencyjnym dzieleniu węzłów na podwęzły, aż do uzyskania maksymalnego drzewa. W każdym kroku metoda dzieli dany węzeł na tyle podwęzłów ile wartości ma najbardziej informatywna cecha (cechą oferująca maksymalną redukcję entropii). Niekorzystną konsekwencją takiej strategii jest tendencja do częstszego wykorzystywania cech, które mają dużą (w stosunku do innych) liczbę możliwych wartości.
55 Algorytm ID 3 Quinlana Zalety algorytmu: prostota algorytmu, jeżeli w zbiorze treningowym nie ma zjawiska hałasu, tzn. nie ma rekordów, które dla tych samych wartości atrybutów mają przypisaną różną kategorię, wtedy ID3 daje poprawny wynik dla wszystkich rekordów ze zbioru treningowego. Wady algorytmu: algorytm nie radzi sobie z ciągłymi dziedzinami atrybutów (zakłada, że wartości atrybutów są dyskretne), zakłada, że wszystkie rekordy w zbiorze treningowym są wypełnione. Algorytm nie zadziała, jeżeli choć jeden rekord zawiera niepełne dane. duży rozmiar drzewa, brak odporności na zjawisko overfitting - algorytm nie radzi sobie z danymi zaburzającymi ogólną ich informację może to prowadzić do wysokiego współczynnika błędów na danych testowych.
56 C4.5 (Quinlan, 1993) Rozwinięcie ID3 Stosuje kryterium gain ratio Podział drzewa kończy się gdy liczba obiektów do podziału jest już mniejsza niż pewna wartości progowa Przycinanie drzew jest możliwe już po zbudowaniu drzewa Dopuszcza się wartości numeryczne
57 Algorytm C4.5 Podział danych na podwęzły wprowadza wówczas wagi dla wektorów treningowych, które dla wektora z brakującą wartością atrybutu decyzyjnego odpowiadają rozkładowi pozostałych danych w podwęzłach. Stosownej modyfikacji podlegają wówczas współczynniki Pi ze wzoru a zamiast mocy zbiorów liczy się sumy wag elementów tych zbiorów. Współczynniki pi są uwzględniane również przy podejmowaniu decyzji na podstawie drzewa, by wyliczyć prawdopodobieństwa wpadania do poszczególnych węzłów oraz przynależenia do poszczególnych klas. System C4.5 oprócz metody indukcji drzewa decyzji oferuje klasyfikator będący zbiorem reguł logiki klasycznej. Reguły traktowane są tutaj jako różny od drzewa model klasyfikacji, ponieważ nie są one wierną reprezentacją drzewa. Reguły wiernie opisujące drzewo są poddawane procesowi oczyszczania: w każdej regule usuwane są przesłanki, których pominięcie nie powoduje spadku jakości klasyfikacji zbioru treningowego. Wykonywane jest dla każdej reguły z osobna, można w ten sposób otrzymać klasyfikator istotnie różny od drzewa (zwykle dający w testach niższe wartości poprawności).
58 CART (Classification and Regression Buduje drzewa binarne Trees) (Breiman, 1984) Kryterium podziału jest tzw. twoing criteria Drzewo można przycinać stosując kryterium kosztu i złożoności przycinania Buduje drzewa regresyjne (w liściach są wartości rzeczywiste a nie klasy) Algorytm stara się tak podzielić obiekty by minimalizować błąd predykcji (metoda najmniejszych kwadratów) Predykcja w każdym liściu drzewa opiera się na ważonej średniej dla węzła
59 CHAID oparty na metodzie Chi Przewidziany dla wartości nominalnych. Przewiduje wartości brakujące. Nie przewiduje przycinania drzewa. Nie buduje drzew binarnych w budowanym drzewie dany węzeł może mieć więcej niż potomków. Jeśli mamy dane nominalne to mamy od razu podział na kategorie. Jeśli mamy dane ilościowe musimy podzielić obserwacje na kategorie tak by mniej więcej każda kategoria miała tyle samo obserwacji. Wybiera się z wszystkich cech (pogrupowanych w kategorie) takie pary, które się od siebie najmniej różnią - oblicza się test F. Jeśli test nie wykaże istotnej różnicy taką parę cech łączy się w jedną kategorię i ponownie szuka się kolejnej pary. Potem wybiera się taką cechę, która daje najbardziej istotny podział i robi się to tak długo aż kolejne wybierane cechy dają wartość niższą niż zadana wartość p. Proces jest powtarzany tak długo, póki możliwe są kolejne podziały.
60 Cechy algorytmu Algorytm ID3 Algorytm C4.5 Wartości atrybutów Odporność na brak wartości atrybutów Odporność na nadmierne dopasowanie (ang. overfitting) tylko dyskretne dla wartości ciągłych niezbędny proces dyskretyzacji wartości atrybutów brak algorytm nie zadziała jeśli w zestawie danych wejściowych brakuje chodź jednej wartości atrybutu brak z reguły algorytm tworzy duże drzewa dyskretne jak i ciągłe dla atrybutów ciągłych algorytm rozpatruje wszystkie możliwe podziały na dwa podzbiory zdeterminowane punktem podziału, atrybuty ciągłe mogą pojawiać się na wielu poziomach tej samej gałęzi drzewa, dla każdego z możliwych podziałów ocenia się jego jakość mierząc wartość względnego zysku informacyjnego i wybiera ten, który maksymalizuje zysk. jest przyrost informacji nie bierze pod uwagę danych, dla których brakuje wartości atrybutu, przyrost informacji skaluje się mnożąc go przez częstość występowania wartości tej cechy w próbie treningowej jest zastosowanie przycinania bardzo skutecznie zapobiega nadmiernemu rozrostowi drzewa dane poddrzewo, które ma zostać przycięte zastępowane jest przez tą wartość atrybutu, która w przycinanym poddrzewie występuje najczęściej
61 Tworzenie drzewa decyzyjnego Drzewo decyzyjne powstaje na podstawie rekurencyjnego podziału zbioru uczącego na podzbiory, do momentu uzyskania ich jednorodności ze względu na przynależność obiektów do klas. Postuluje się jak najmniejszą liczbę węzłów w powstałym dendrogramie, co powinno zapewnić prostotę powstałych reguł klasyfikacji. Ogólny schemat tworzenia drzewa decyzyjnego na podstawie zbioru uczącego można przedstawić w pięciu punktach: 1. Badając zbiór obiektów S należy sprawdzić, czy należą one do tej samej klasy. Jeżeli tak, można zakończyć pracę.. Jeżeli analizowane obserwacje nie należą do jednej klasy, należy zbadać wszystkie możliwe podziały zbioru S na podzbiory jak najbardziej jednorodne. 3. Następnie należy ocenić jakość każdego podzbioru według przyjętego kryterium i wybrać najlepszy z nich. 4. W następnym kroku należy podzielić zbiór początkowy w wybrany sposób. 5. Wyżej opisane algorytm należy zastosować dla każdego z podzbiorów.
62 Uczymy się budować drzewa decyzyjne algorytmem ID 3 Rozważmy binarną klasyfikację C. Jeśli mamy zbiór przykładów S, dla którego potrafimy stwierdzić, które przykłady ze zbioru S dają wartość pozytywną dla C (p + ) a które wartość negatywną dla C (p - ) wówczas entropię (ang. Entropy) dla S obliczymy jako: Zatem mając daną klasyfikację na większą liczbę klas (C dzieli się na kategorie c 1,..., c n ) i wiedząc które przykłady ze zbioru S mają klasę c i obliczymy odpowiednią proporcję dla p i, a wtedy entropię dla S policzymy jako:
63 Interpretacja wartości: -p*log (p) jest taka, że kiedy p osiąga wartość bliską zeru (0) (tak się dzieje m.in. wtedy, gdy kategoria ma tylko kilka przykładów (jest mało liczna), wtedy wartość log(p) osiąga dużą wartość ujemną, ale po wymnożeniu przez wartość p ostatecznie cała entropia osiąga wartość bliską 0. Podobnie, jeśli p osiąga wartość bliską 1 (gdy kategoria rozważana pochłania większość przykładów ze zbioru), wtedy wartość log(p) jest bliska 0, a wtedy całościowa entropia także osiąga wartość 0. To ma na celu pokazać, że entropia osiąga wartość bliską 0 albo wtedy gdy dla danej kategorii jest bardzo mało przykładów, albo wręcz dana kategoria pochłania większość przykładów zadanych w analizowanym zbiorze.
64 Information Gain Na każdym etapie budowy drzewa trzeba wybrać atrybut który będzie tworzył dany węzeł w drzewie. Na początku powstaje problem, który atrybut powinien budować korzeń drzewa. W tym celu oblicza się zysk informacyjny jaki da dany atrybut jeśli to jego użyjemy do budowy węzła w drzewie: Jeśli więc mamy atrybut A z jego możliwymi wartościami, dla każdej możliwej wartości v, obliczymy entropię dla tej wartości danego atrybutu (S v ):
65 Information Gain przyrost informacji Wybór najlepszego atrybutu do węzła Information gain miara zmiany entropii wybieramy atrybut, dla którego ta miara jest największa
66 Drzewa decyzyjne Najpowszechniejsza forma reprezentowania wiedzy przez dostępne oprogramowanie. Węzły są opisywane przez atrybuty eksplorowanej relacji, krawędzie opisują możliwe wartości dla atrybutu. Klasyfikacja odbywa się poprzez przeglądanie drzewa od korzenia do liści przez krawędzie opisane wartościami atrybutów.

67 Drzewa decyzyjne Przykład: automatyczny podział kierowców na powodujących i nie powodujących wypadki drogowe Dwie klasy: TAK i NIE
68 Drzewa decyzyjne IF marka = BMW AND wiek_kier < 5 THEN wypadek = TAK
69 Drzewa decyzyjne Drzewo decyzyjne jest formą opisu wiedzy klasyfikującej Węzłom drzewa odpowiadają atrybuty eksplorowanej relacji Krawędzie opisują wartości atrybutów Liśćmi drzewa są wartości atrybutu klasyfikacyjnego
70 Drzewa decyzyjne - przykład
71 Drzewa decyzyjne dla przykładu
 Dana blonde tall average yes none (negative) Alex brown short average yes")

72 Name Hair Height Weight Lotion Result Sarah blonde average light no sunburned (positive) Dana blonde tall average yes none (negative) Alex brown short average yes none Annie blonde short average no sunburned Emily red average heavy no sunburned Pete brown tall heavy no none John brown average heavy no none Katie blonde short light yes none


73


74

75


76 Wyniki obliczeń.i budujemy drzewo
77 Ocena jakości drzewa Jakość drzewa ocenia się: rozmiarem: im drzewo jest mniejsze, tym lepsze małą liczbą węzłów, małą wysokością, lub małą liczbą liści; dokładnością klasyfikacji na zbiorze treningowym dokładnością klasyfikacji na zbiorze testowym
78 Przykład obiekt pogoda temperatura wilgotność wiatr grać(x) x 1 słonecznie gorąco wysoka słaby nie x słonecznie gorąco wysoka silny nie x 3 pochmurno gorąco wysoka słaby tak x 4 deszczowo łagodnie wysoka słaby tak x 5 deszczowo zimno normalna słaby tak x 6 deszczowo zimno normalna silny nie x 7 pochmurno zimno normalna silny tak x 8 słonecznie łagodnie wysoka słaby nie x 9 słonecznie zimno normalna słaby tak x 10 deszczowo łagodnie normalna słaby tak x 11 słonecznie łagodnie normalna silny tak x 1 pochmurno łagodnie wysoka silny tak x 13 pochmurno gorąco normalna słaby tak x 14 deszczowo łagodnie wysoka silny nie
79 Drzewa decyzyjne - przykład
80 W tabeli znajdują się cztery atrybuty warunkowe (pogoda, temperatura, wilgotność wiatr) oraz atrybut decyzyjny grać. Na początku należy wyznaczyć liczność każdego zbiorów trenujących: T tak = {3, 4, 5, 7, 9, 10, 11, 1, 13 } = 9, oraz T nie = {1,, 6, 8, 14} = 5. T(pogoda, słonecznie) = {1,, 8, 9, 11} = 5 T tak( pogoda, słonecznie) = {9, 11} = T nie (pogoda, słonecznie) = {1,, 8} = 3 T(pogoda, pochmurno) = {3, 7, 1, 13} = 4 T tak (pogoda, pochmurno) = {3, 7, 1, 13} = 4 T nie (pogoda, pochmurno) = {} = 0 T(pogoda, deszczowo) = {4, 5, 6, 10, 14} = 5 T tak (pogoda, deszczowo) = {4, 5, 10} = 3 T nie (pogoda, deszczowo) = {6, 14} =
81 Po obliczeniu liczności zbiorów trenujących należy obliczyć entropię. d d Korzystając ze wzoru, P P przyjmując logarytmy dwójkowe kolejno obliczamy: Ent(S) Ze wzoru E tr ( P) obliczamy informację zawartą w zbiorze etykietowanych przykładów P I(P) Ptr Następnie ze wzoru Et ( P) Etr ( P) obliczam entropię ważoną: d C tr P tr log log log 0,4097 0,5305 0, d P I( P) P d C 9 log 14 log 9 14 r R d P P t P 5 log ,4097 0,5305 0, tr P tr Ent(S Pogoda) ( log log ) ( log log ) ( log log ) *0.97 *
82 Ent (S Temperatura) 4 ( log log ) ( log log ) ( log log ) *1 *0.91 * Ent (S Wilgotność) Ent(S Wiatr) ( log log ) ( log log ) *0.98 * ( log log ) ( log log ) *0.81 * Teraz możemy policzyć przyrost informacji dla każdego atrybutu, korzystając ze wzoru na przyrost informacji ( P) I( P) E ( P) Gain Information (Pogoda) = = Gain Information (Temperatura) = = 0.09 Gain Information (Wilgotność) = = Gain Information (Wiatr) = = Z powyższych obliczeń wynika, że największy przyrost informacji da atrybut pogoda Rysujemy zatem drzewo decyzyjne g t t
83 obiekt pogoda temperatura wilgotność wiatr grać(x) x 1 słonecznie gorąco wysoka słaby nie x słonecznie gorąco wysoka silny nie obi ekt pogoda temperat ura wilgotno ść wiatr grać x 3 pochmurno gorąco wysoka słaby tak x 4 deszczowo łagodnie wysoka słaby tak x 5 deszczowo zimno normalna słaby tak x 1 x słoneczni e słoneczni e gorąco wysoka słaby nie gorąco wysoka silny nie x 6 deszczowo zimno normalna silny nie x 7 pochmurno zimno normalna silny tak x 8 słonecznie łagodnie wysoka słaby nie x 9 słonecznie zimno normalna słaby tak x 8 x 9 x 11 słoneczni e słoneczni e słoneczni e łagodnie wysoka słaby nie zimno normalna słaby tak łagodnie normalna silny tak x 10 deszczowo łagodnie normalna słaby tak x 11 słonecznie łagodnie normalna silny tak obiekt pogoda tempera tura wilgotność wiatr grać (x) x 1 pochmurno łagodnie wysoka silny tak x 13 pochmurno gorąco normalna słaby tak x 14 deszczowo łagodnie wysoka silny nie x 3 pochmurno gorąco wysoka słaby tak x 7 pochmurno zimno normalna silny tak x 1 pochmurno łagodni e wysoka silny tak x 13 pochmurno gorąco normalna słaby tak obiekt pogoda temperatura wilgotno ść wiatr grać x 4 deszczowo łagodnie wysoka słaby tak x 5 deszczowo zimno normalna słaby tak x 6 deszczowo zimno normalna silny nie x 10 deszczowo łagodnie normalna słaby tak x 14 deszczowo łagodnie wysoka silny nie
84 obie kt pogoda temperatura wilgotność wiatr grać POGODA x 1 słonecznie gorąco wysoka słaby nie SŁONECZNIE POCHMURNO DESZCZOWO??? x słonecznie gorąco wysoka silny nie x 8 słonecznie łagodnie wysoka słaby nie x 9 słonecznie zimno normalna słaby tak x 11 słonecznie łagodnie normalna silny tak Rozpoczynamy drugą iterację algorytmu: generujemy lewe poddrzewo wykonując kolejne obliczenia entropii oczywiście w ramach atrybutów z podzbioru Pogoda Słonecznie Ent(S Wilgotność) = ( log log ) 0 ( log log ) Ent(S Wiatr) = Ent(S Temperatura) ( log log ) ( log log ) 5 *0.918 * ( log log ) ( log log ) ( log log ) *1 5 Następnie po obliczeniu entropii generujemy przyrost informacji: Gain Information (PogodaSłonecznie + Wilgotność) = 0.97 Gain Information (PogodaSłonecznie + Wiatr) = ,81908 Gain Information (PogodaSłonecznie + Temperatura) = Największy przyrost informacji spośród tych atrybutów da wilgotność dorysowujemy zatem kolejny węzeł drzewa decyzyjnego
85 obiekt pogoda temperat ura wilgotność wiatr grać (x) POGODA SŁONECZNIE POCHMURNO DESZCZOWO WILGOTNOŚĆ TAK? x 3 pochmurno gorąco wysoka słaby tak x 7 pochmurno zimno normalna silny tak x 1 pochmurno łagodnie wysoka silny tak x 13 pochmurno gorąco normalna słaby tak Dla środkowego poddrzewa nie ma potrzeby tworzenia kolejnych węzłów ponieważ wszystkie atrybuty tego podzbioru należą do tej samej klasy decyzyjnej. Możemy zatem wyznaczyć węzeł dla prawego poddrzewa: Ent(S PogodaDeszczowo+Wilgotność)= Ent(S PogodaDeszczowo+Wiatr)= Ent(S PogodaDeszczowo+Temperatura)= obiekt pogoda temperatura wilgotno ść wiatr grać ( log log ) ( log log ) *1 * ( log log ) ( log log ) ( log log ) ( log log ) *0.918 * x 4 deszczowo łagodnie wysoka słaby tak x 5 deszczowo zimno normalna słaby tak x 6 deszczowo zimno normalna silny nie x 10 deszczowo łagodnie normalna słaby tak x 14 deszczowo łagodnie wysoka silny nie
86 3 GainInformation(PogodaDeszczowo+Temperatura)= 0.97 *0.918 *1 0 0, GainInformation(PogodaDeszczowo+Wilgotność)= *1 * , GainInformation(PogodaDeszczowo+Wiatr)= 0.97 Możemy zatem dorysować kolejny węzeł drzewa: POGODA SŁONECZNIE POCHMURNO DESZCZOWO WILGOTNOŚĆ TAK WIATR WYSOKA SŁABY SILNY Koniec TAK NIE TAK NIE
87 Każde drzewo decyzyjne jest reprezentacją pewnego zbioru reguł decyzyjnych, przy czym każdej ścieżce od korzenia do liścia odpowiada jedna reguła. -Jeżeli Kłopoty z kręgosłupem=tak, to Sport=Pływanie -Jeżeli Kłopoty z kręgosłupem=nie & Kontuzja kolana=tak, to Sport=Pływanie -Jeżeli Kłopoty z kręgosłupem=nie & Kontuzja kolana=tak, to Sport=Biegi Oczywiście, nie każdy zbiór reguł będzie miał swój odpowiednik w postaci drzewa. Możliwe jest także, że algorytm generujący drzewo decyzyjne będzie generował również zbiór reguł decyzyjnych nie pokrywających się z tymi, które wynikają bezpośrednio z samej struktury drzewa. Zabieg ten stosuje się, aby dostarczyć reguły w formie jak najbardziej zminimalizowanej.
88 -Jeżeli Kłopoty z kręgosłupem=tak, to Sport=Pływanie -Jeżeli Kłopoty z kręgosłupem=nie & Kontuzja kolana=tak, to Sport=Pływanie -Jeżeli Kłopoty z kręgosłupem=nie & Kontuzja kolana=tak, to Sport=Biegi
89 Przycinanie drzewa
90 Przycinanie drzewa
91 Przycinanie drzew y y 1 Cel: zlikwidować nadmierne dopasowanie klasyfikatora do niepoprawnych danych.
92 Przycinanie drzew Na podstawie oddzielnego zbioru przycinania Na podstawie zbioru uczącego Wykorzystujące zasadę minimalnej długości kodu
93 Metody przycinania drzew Metody przycinania drzew można dzielić na grupy według różnych kryteriów. Podział podstawowy to: -Przycinanie w trakcie wzrostu (ang. pre-pruning). Drzewo jest przycinane w trakcie jego tworzenia tzn. algorytm rozrostu zawiera kryterium stopu zapobiegające powstawaniu zbyt dużych drzew. Bardzo trudno jest znaleźć takie kryterium, co prowadzi do tego, że metoda ta nie daje zbyt dobrych wyników. Przykładem może być tutaj algorytm ID3 IV, gdzie jako jedno z kryteriów stopu został wprowadzony test χ. -Przycinanie rozrośniętego drzewa (ang. post-pruning). Generowane jest pełne drzewo, a przycinanie następuje potem. Proces ten jest rozpoczynany przy liściach i sukcesywnie wędruje w kierunku korzenia. Przykładem stosującym takie podejście może być algorytm C4.5. -Metody mieszane Kombinacje metod z dwóch poprzednich grup.
94 Przycinanie drzew reduced error pruning Błąd szacowany na podstawie odrębnego zbioru przycinania. Węzły przeglądane od dołu. Poddrzewo T t zastępowane liściem t gdy error(t) error(t t ). Procedura powtarzana dopóki dalsze przycinanie nie zwiększa błędu. Zalety: prostota, niski koszt obliczeniowy. Wady: konieczność poświęcenia części danych na przycinanie; czasem drzewo zostaje przycięte zbyt mocno (zwłaszcza gdy zbiór przycinania jest znacznie mniejszy niż zbiór uczący).
95 Przycinanie drzew reduced error pruning, przykład < 0 wiek 0 typ y A B tak nie Zbiór przycinania kolor wiek typ y Klasa 1 czarny 11 B tak + biały 3 B tak - 3 czarny A nie - 4 czarny 18 B nie + 5 czarny 15 B tak biały kolor czarny A biały typ kolor B czarny A typ B biały 7 B nie +
96 Przycinanie drzew reduced error pruning, przykład < 0 wiek 0 typ y A B tak nie biały kolor czarny biały kolor czarny A typ B typ A B
97 Przycinanie drzew reduced error pruning, przykład A typ < 0 B wiek tak 0 y nie biały kolor czarny A typ B typ A B
98 Przycinanie drzew reduced error pruning, przykład < 0 wiek tak y nie kolor typ biały czarny A B A typ B
99 Przycinanie drzew reduced error pruning, przykład < 0 wiek tak y nie biały typ kolor czarny A typ B A B
100 Przycinanie drzew reduced error pruning, przykład < 0 wiek tak y nie biały kolor czarny typ A B
101 Po co stosujemy przycinanie drzew? Aby uniknąć nadmiernego przystosowania się hipotez do przykładów, tzw. 'przeuczenia' w algorytmach opartych na drzewach decyzyjnych. Nadmiernie dopasowane drzewo charakteryzuje się małym błędem dla przykładów trenujących, jednak na innych przykładach ma zbyt duży błąd. Taka sytuacja może mieć miejsce na przykład w przypadku zaszumienia zbioru trenującego i zbytniego dopasowania się algorytmu do błędnych danych. Przycinanie polega na zastąpieniu poddrzewa liściem reprezentującym kategorię najczęściej występującą w przykładach z usuwanego poddrzewa. Kategoria ta zwana jest kategorią większościową. Przycięcie drzewa, oprócz zwiększenia dokładności klasyfikacji dla danych rzeczywistych prowadzi także do uproszczenia budowy drzewa.
102 Zalety drzew decyzyjnych szybka klasyfikacja zrozumiały proces decyzyjny możliwość stosowania cech różnego typu efektywne z punktu widzenia przechowywania w pamięci
103 Wady drzew decyzyjnych im więcej klas oraz im bardziej się one nakładają, tym większe drzewo decyzyjne trudno zapewnić jednocześnie wysoką jakość klasyfikacji i małe rozmiary drzewa lokalna optymalizacja metody nieadaptacyjne
104 Bibliografia J.Koronacki, J.Ćwik: Statystyczne systemy uczące się, wydanie drugie, Exit,Warsaw,008,rozdział 4. Gatnar E. : Symboliczne metody klasyfikacji danych, PWN, 1998
Drzewa klasyfikacyjne
 Drzewa klasyfikacyjne Agnieszka Nowak Brzezińska Wykład VII Drzewo klasyfikacyjne Składa się z korzenia, z którego wychodzą co najmniej dwie krawędzie do węzłów leżących na niższym poziomie. Z każdym węzłem
Drzewa klasyfikacyjne Agnieszka Nowak Brzezińska Wykład VII Drzewo klasyfikacyjne Składa się z korzenia, z którego wychodzą co najmniej dwie krawędzie do węzłów leżących na niższym poziomie. Z każdym węzłem
Moduł: algorytmy sztucznej inteligencji, wykład 3. Agnieszka Nowak Brzezińska
 Moduł: algorytmy sztucznej inteligencji, wykład 3 Agnieszka Nowak Brzezińska Klasyfikacja, predykcja, przewidywanie polega ona na znajdowaniu odwzorowania danych w zbiór predefiniowanych klas. Na podstawie
Moduł: algorytmy sztucznej inteligencji, wykład 3 Agnieszka Nowak Brzezińska Klasyfikacja, predykcja, przewidywanie polega ona na znajdowaniu odwzorowania danych w zbiór predefiniowanych klas. Na podstawie
Drzewa klasyfikacyjne
 Yes Refund No NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES Drzewa klasyfikacyjne Agnieszka Nowak Brzezińska Tydzień temu Dziś PREDYKCJA KLASYFIKACJA W czym predykcja różni się od klasyfikacji?
Yes Refund No NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES Drzewa klasyfikacyjne Agnieszka Nowak Brzezińska Tydzień temu Dziś PREDYKCJA KLASYFIKACJA W czym predykcja różni się od klasyfikacji?
Drzewa klasyfikacyjne
 Yes Refund No NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES Drzewa klasyfikacyjne Agnieszka Nowak Brzezińska Tydzień temu Dziś PREDYKCJA KLASYFIKACJA W czym predykcja różni się od klasyfikacji?
Yes Refund No NO Single, Divorced MarSt Married TaxInc < 80K > 80K NO NO YES Drzewa klasyfikacyjne Agnieszka Nowak Brzezińska Tydzień temu Dziś PREDYKCJA KLASYFIKACJA W czym predykcja różni się od klasyfikacji?
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne
 WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
Indukowane Reguły Decyzyjne I. Wykład 3
 Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
PODSTAWY STATYSTYCZNEGO MODELOWANIA DANYCH. Wykład 6 Drzewa klasyfikacyjne - wprowadzenie. Reguły podziału i reguły przycinania drzew.
 PODSTAWY STATYSTYCZNEGO MODELOWANIA DANYCH Wykład 6 Drzewa klasyfikacyjne - wprowadzenie. Reguły podziału i reguły przycinania drzew. Wprowadzenie Drzewo klasyfikacyjne Wprowadzenie Formalnie : drzewo
PODSTAWY STATYSTYCZNEGO MODELOWANIA DANYCH Wykład 6 Drzewa klasyfikacyjne - wprowadzenie. Reguły podziału i reguły przycinania drzew. Wprowadzenie Drzewo klasyfikacyjne Wprowadzenie Formalnie : drzewo
Co to są drzewa decyzji
 Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
Przykład eksploracji danych o naturze statystycznej Próba 1 wartości zmiennej losowej odległość
 Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
8. Drzewa decyzyjne, bagging, boosting i lasy losowe
 Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Drzewa decyzyjne i lasy losowe
 Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
INDUKCJA DRZEW DECYZYJNYCH
 INDUKCJA DRZEW DECYZYJNYCH 1. Pojęcia podstawowe. 2. Idea algorytmów TDIT. 3. Kryteria oceny atrybutów entropia. 4. "Klasyczna" postać algorytmu ID3. 5. Przykład ilustracyjny. 6. Transformacja drzewa do
INDUKCJA DRZEW DECYZYJNYCH 1. Pojęcia podstawowe. 2. Idea algorytmów TDIT. 3. Kryteria oceny atrybutów entropia. 4. "Klasyczna" postać algorytmu ID3. 5. Przykład ilustracyjny. 6. Transformacja drzewa do
Uczenie się maszyn. Dariusz Banasiak. Katedra Informatyki Technicznej Wydział Elektroniki
 Dariusz Banasiak Katedra Informatyki Technicznej Wydział Elektroniki Machine Learning (uczenie maszynowe, uczenie się maszyn, systemy uczące się) interdyscyplinarna nauka, której celem jest stworzenie
Dariusz Banasiak Katedra Informatyki Technicznej Wydział Elektroniki Machine Learning (uczenie maszynowe, uczenie się maszyn, systemy uczące się) interdyscyplinarna nauka, której celem jest stworzenie
Drzewa klasyfikacyjne algorytm podstawowy
 DRZEWA DECYZYJNE Drzewa klasyfikacyjne algorytm podstawowy buduj_drzewo(s przykłady treningowe, A zbiór atrybutów) { utwórz węzeł t (korzeń przy pierwszym wywołaniu); if (wszystkie przykłady w S należą
DRZEWA DECYZYJNE Drzewa klasyfikacyjne algorytm podstawowy buduj_drzewo(s przykłady treningowe, A zbiór atrybutów) { utwórz węzeł t (korzeń przy pierwszym wywołaniu); if (wszystkie przykłady w S należą
Drzewa klasyfikacyjne Lasy losowe. Wprowadzenie
 Wprowadzenie Konstrukcja binarnych drzew klasyfikacyjnych polega na sekwencyjnym dzieleniu podzbiorów przestrzeni próby X na dwa rozłączne i dopełniające się podzbiory, rozpoczynając od całego zbioru X.
Wprowadzenie Konstrukcja binarnych drzew klasyfikacyjnych polega na sekwencyjnym dzieleniu podzbiorów przestrzeni próby X na dwa rozłączne i dopełniające się podzbiory, rozpoczynając od całego zbioru X.
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Data Mining Wykład 4. Plan wykładu
 Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne
 E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne Przypominajka: 152 drzewo filogenetyczne to drzewo, którego liśćmi są istniejące gatunki, a węzły wewnętrzne mają stopień większy niż jeden i reprezentują
E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne Przypominajka: 152 drzewo filogenetyczne to drzewo, którego liśćmi są istniejące gatunki, a węzły wewnętrzne mają stopień większy niż jeden i reprezentują
TEORETYCZNE PODSTAWY INFORMATYKI
 1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 14c 2 Definicje indukcyjne Twierdzenia dowodzone przez indukcje Definicje indukcyjne Definicja drzewa
1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 14c 2 Definicje indukcyjne Twierdzenia dowodzone przez indukcje Definicje indukcyjne Definicja drzewa
Klasyfikacja. Sformułowanie problemu Metody klasyfikacji Kryteria oceny metod klasyfikacji. Eksploracja danych. Klasyfikacja wykład 1
 Klasyfikacja Sformułowanie problemu Metody klasyfikacji Kryteria oceny metod klasyfikacji Klasyfikacja wykład 1 Niniejszy wykład poświęcimy kolejnej metodzie eksploracji danych klasyfikacji. Na początek
Klasyfikacja Sformułowanie problemu Metody klasyfikacji Kryteria oceny metod klasyfikacji Klasyfikacja wykład 1 Niniejszy wykład poświęcimy kolejnej metodzie eksploracji danych klasyfikacji. Na początek
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Drzewa decyzyjne. Inteligentne Obliczenia. Wydział Mechatroniki Politechniki Warszawskiej. Anna Sztyber
 Drzewa decyzyjne Inteligentne Obliczenia Wydział Mechatroniki Politechniki Warszawskiej Anna Sztyber INO (IAiR PW) Drzewa decyzyjne Anna Sztyber / Drzewa decyzyjne w podstawowej wersji algorytm klasyfikacji
Drzewa decyzyjne Inteligentne Obliczenia Wydział Mechatroniki Politechniki Warszawskiej Anna Sztyber INO (IAiR PW) Drzewa decyzyjne Anna Sztyber / Drzewa decyzyjne w podstawowej wersji algorytm klasyfikacji
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Złożoność i zagadnienia implementacyjne. Wybierz najlepszy atrybut i ustaw jako test w korzeniu. Stwórz gałąź dla każdej wartości atrybutu.
 Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Plan wykładu Generowanie
Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Plan wykładu Generowanie
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
Klasyfikacja. Indeks Gini Zysk informacyjny. Eksploracja danych. Klasyfikacja wykład 2
 Klasyfikacja Indeks Gini Zysk informacyjny Klasyfikacja wykład 2 Kontynuujemy prezentacje metod klasyfikacji. Na wykładzie zostaną przedstawione dwa podstawowe algorytmy klasyfikacji oparte o indukcję
Klasyfikacja Indeks Gini Zysk informacyjny Klasyfikacja wykład 2 Kontynuujemy prezentacje metod klasyfikacji. Na wykładzie zostaną przedstawione dwa podstawowe algorytmy klasyfikacji oparte o indukcję
INDUKCJA DRZEW DECYZYJNYCH
 Jerzy Stefanowski Instytut Informatyki Politechniki Poznańskiej Wykład z przedmiotu Uczenie maszynowe i sieci neuronowe INDUKCJA DRZEW DECYZYJNYCH 1. Pojęcia podstawowe. 2. Idea algorytmów TDIT. 3. Kryteria
Jerzy Stefanowski Instytut Informatyki Politechniki Poznańskiej Wykład z przedmiotu Uczenie maszynowe i sieci neuronowe INDUKCJA DRZEW DECYZYJNYCH 1. Pojęcia podstawowe. 2. Idea algorytmów TDIT. 3. Kryteria
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Temat: Algorytm kompresji plików metodą Huffmana
 Temat: Algorytm kompresji plików metodą Huffmana. Wymagania dotyczące kompresji danych Przez M oznaczmy zbiór wszystkich możliwych symboli występujących w pliku (alfabet pliku). Przykład M = 2, gdy plik
Temat: Algorytm kompresji plików metodą Huffmana. Wymagania dotyczące kompresji danych Przez M oznaczmy zbiór wszystkich możliwych symboli występujących w pliku (alfabet pliku). Przykład M = 2, gdy plik
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
 : idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
: idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
Wprowadzenie do klasyfikacji
 Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
operacje porównania, a jeśli jest to konieczne ze względu na złe uporządkowanie porównywanych liczb zmieniamy ich kolejność, czyli przestawiamy je.
 Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
WYKŁAD 6. Reguły decyzyjne
 Wrocław University of Technology WYKŁAD 6 Reguły decyzyjne autor: Maciej Zięba Politechnika Wrocławska Reprezentacje wiedzy Wiedza w postaci reguł decyzyjnych Wiedza reprezentowania jest w postaci reguł
Wrocław University of Technology WYKŁAD 6 Reguły decyzyjne autor: Maciej Zięba Politechnika Wrocławska Reprezentacje wiedzy Wiedza w postaci reguł decyzyjnych Wiedza reprezentowania jest w postaci reguł
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Eksploracja danych. KLASYFIKACJA I REGRESJA cz. 2. Wojciech Waloszek. Teresa Zawadzka.
 Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Politechnika Warszawska Wydział Elektroniki i Technik Informacyjnych Warszawa, Polska k.mizinski@stud.elka.pw.edu.pl Streszczenie Niniejszy dokument opisuje jedna
Algorytmy klasyfikacji Konrad Miziński Politechnika Warszawska Wydział Elektroniki i Technik Informacyjnych Warszawa, Polska k.mizinski@stud.elka.pw.edu.pl Streszczenie Niniejszy dokument opisuje jedna
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Grafy (3): drzewa. Wykłady z matematyki dyskretnej dla informatyków i teleinformatyków. UTP Bydgoszcz
: drzewa. Wykłady z matematyki dyskretnej dla informatyków i teleinformatyków. UTP Bydgoszcz") Grafy (3): drzewa Wykłady z matematyki dyskretnej dla informatyków i teleinformatyków UTP Bydgoszcz 13 (Wykłady z matematyki dyskretnej) Grafy (3): drzewa 13 1 / 107 Drzewo Definicja. Drzewo to graf acykliczny
Grafy (3): drzewa Wykłady z matematyki dyskretnej dla informatyków i teleinformatyków UTP Bydgoszcz 13 (Wykłady z matematyki dyskretnej) Grafy (3): drzewa 13 1 / 107 Drzewo Definicja. Drzewo to graf acykliczny
ALGORYTMY I STRUKTURY DANYCH
 LGORTM I STRUKTUR DNH Temat 6: Drzewa ST, VL Wykładowca: dr inż. bigniew TRPT e-mail: bigniew.tarapata@isi.wat.edu.pl http://www.tarapata.strefa.pl/p_algorytmy_i_struktury_danych/ Współautorami wykładu
LGORTM I STRUKTUR DNH Temat 6: Drzewa ST, VL Wykładowca: dr inż. bigniew TRPT e-mail: bigniew.tarapata@isi.wat.edu.pl http://www.tarapata.strefa.pl/p_algorytmy_i_struktury_danych/ Współautorami wykładu
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
WSTĘP DO INFORMATYKI. Drzewa i struktury drzewiaste
 Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej WSTĘP DO INFORMATYKI Adrian Horzyk Drzewa i struktury drzewiaste www.agh.edu.pl DEFINICJA DRZEWA Drzewo
Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej WSTĘP DO INFORMATYKI Adrian Horzyk Drzewa i struktury drzewiaste www.agh.edu.pl DEFINICJA DRZEWA Drzewo
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Uczenie maszyn. Projekt: Porównanie algorytmów tworzenia drzew decyzyjnych. Politechnika Wrocławska. Michał Płodowski Michał Suszko
 Politechnika Wrocławska Projekt: Porównanie algorytmów tworzenia drzew decyzyjnych Uczenie maszyn Michał Płodowski 163763 Michał Suszko 171132 Kamil Markuszewski 171016 1. WSTĘP... 2 2. CEL PROJEKTU...
Politechnika Wrocławska Projekt: Porównanie algorytmów tworzenia drzew decyzyjnych Uczenie maszyn Michał Płodowski 163763 Michał Suszko 171132 Kamil Markuszewski 171016 1. WSTĘP... 2 2. CEL PROJEKTU...
Algorytmy i struktury danych. Drzewa: BST, kopce. Letnie Warsztaty Matematyczno-Informatyczne
 Algorytmy i struktury danych Drzewa: BST, kopce Letnie Warsztaty Matematyczno-Informatyczne Drzewa: BST, kopce Definicja drzewa Drzewo (ang. tree) to nieskierowany, acykliczny, spójny graf. Drzewo może
Algorytmy i struktury danych Drzewa: BST, kopce Letnie Warsztaty Matematyczno-Informatyczne Drzewa: BST, kopce Definicja drzewa Drzewo (ang. tree) to nieskierowany, acykliczny, spójny graf. Drzewo może
Metoda tabel semantycznych. Dedukcja drogi Watsonie, dedukcja... Definicja logicznej konsekwencji. Logika obliczeniowa.
 Plan Procedura decyzyjna Reguły α i β - algorytm Plan Procedura decyzyjna Reguły α i β - algorytm Logika obliczeniowa Instytut Informatyki 1 Procedura decyzyjna Logiczna konsekwencja Teoria aksjomatyzowalna
Plan Procedura decyzyjna Reguły α i β - algorytm Plan Procedura decyzyjna Reguły α i β - algorytm Logika obliczeniowa Instytut Informatyki 1 Procedura decyzyjna Logiczna konsekwencja Teoria aksjomatyzowalna
Projekt Sieci neuronowe
 Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
Testowanie modeli predykcyjnych
 Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Indukcja drzew decyzyjnych
 Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Divide et impera
Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Divide et impera
Zofia Kruczkiewicz, Algorytmu i struktury danych, Wykład 14, 1
 Wykład Algorytmy grafowe metoda zachłanna. Właściwości algorytmu zachłannego:. W przeciwieństwie do metody programowania dynamicznego nie występuje etap dzielenia na mniejsze realizacje z wykorzystaniem
Wykład Algorytmy grafowe metoda zachłanna. Właściwości algorytmu zachłannego:. W przeciwieństwie do metody programowania dynamicznego nie występuje etap dzielenia na mniejsze realizacje z wykorzystaniem
w analizie wyników badań eksperymentalnych, w problemach modelowania zjawisk fizycznych, w analizie obserwacji statystycznych.
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Metoda Tablic Semantycznych
 Procedura Plan Reguły Algorytm Logika obliczeniowa Instytut Informatyki Plan Procedura Reguły 1 Procedura decyzyjna Logiczna równoważność formuł Logiczna konsekwencja Procedura decyzyjna 2 Reguły α, β,
Procedura Plan Reguły Algorytm Logika obliczeniowa Instytut Informatyki Plan Procedura Reguły 1 Procedura decyzyjna Logiczna równoważność formuł Logiczna konsekwencja Procedura decyzyjna 2 Reguły α, β,
Programowanie celowe #1
 Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
2012-01-16 PLAN WYKŁADU BAZY DANYCH INDEKSY - DEFINICJE. Indeksy jednopoziomowe Indeksy wielopoziomowe Indeksy z użyciem B-drzew i B + -drzew
 0-0-6 PLAN WYKŁADU Indeksy jednopoziomowe Indeksy wielopoziomowe Indeksy z użyciem B-drzew i B + -drzew BAZY DANYCH Wykład 9 dr inż. Agnieszka Bołtuć INDEKSY - DEFINICJE Indeksy to pomocnicze struktury
0-0-6 PLAN WYKŁADU Indeksy jednopoziomowe Indeksy wielopoziomowe Indeksy z użyciem B-drzew i B + -drzew BAZY DANYCH Wykład 9 dr inż. Agnieszka Bołtuć INDEKSY - DEFINICJE Indeksy to pomocnicze struktury
B jest globalnym pokryciem zbioru {d} wtedy i tylko wtedy, gdy {d} zależy od B i nie istnieje B T takie, że {d} zależy od B ;
 Algorytm LEM1 Oznaczenia i definicje: U - uniwersum, tj. zbiór obiektów; A - zbiór atrybutów warunkowych; d - atrybut decyzyjny; IND(B) = {(x, y) U U : a B a(x) = a(y)} - relacja nierozróżnialności, tj.
Algorytm LEM1 Oznaczenia i definicje: U - uniwersum, tj. zbiór obiektów; A - zbiór atrybutów warunkowych; d - atrybut decyzyjny; IND(B) = {(x, y) U U : a B a(x) = a(y)} - relacja nierozróżnialności, tj.
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015
 Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
SCENARIUSZ LEKCJI. TEMAT LEKCJI: Zastosowanie średnich w statystyce i matematyce. Podstawowe pojęcia statystyczne. Streszczenie.
 SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
Sztuczna Inteligencja Projekt
 Sztuczna Inteligencja Projekt Temat: Algorytm F-LEM1 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm F LEM 1. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu F LEM1
Sztuczna Inteligencja Projekt Temat: Algorytm F-LEM1 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm F LEM 1. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu F LEM1
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II
 Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Algorytmy i struktury danych. Co dziś? Tytułem przypomnienia metoda dziel i zwyciężaj. Wykład VIII Elementarne techniki algorytmiczne
 Algorytmy i struktury danych Wykład VIII Elementarne techniki algorytmiczne Co dziś? Algorytmy zachłanne (greedyalgorithms) 2 Tytułem przypomnienia metoda dziel i zwyciężaj. Problem można podzielić na
Algorytmy i struktury danych Wykład VIII Elementarne techniki algorytmiczne Co dziś? Algorytmy zachłanne (greedyalgorithms) 2 Tytułem przypomnienia metoda dziel i zwyciężaj. Problem można podzielić na
Sztuczna Inteligencja Projekt
 Sztuczna Inteligencja Projekt Temat: Algorytm LEM2 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm LEM 2. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu LEM 2 wygenerować
Sztuczna Inteligencja Projekt Temat: Algorytm LEM2 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm LEM 2. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu LEM 2 wygenerować
Laboratorium 6. Indukcja drzew decyzyjnych.
 Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
3.2 Wykorzystanie drzew do generowania pytań
 Algorithm 3.2 Schemat prostego przycinania drzewa function przytnij_drzewo( T: drzewo do przycięcia, P: zbiór_przykładów) returns drzewo decyzyjne begin for węzły n drzewa T: T* = w drzewie T zastąp n
Algorithm 3.2 Schemat prostego przycinania drzewa function przytnij_drzewo( T: drzewo do przycięcia, P: zbiór_przykładów) returns drzewo decyzyjne begin for węzły n drzewa T: T* = w drzewie T zastąp n
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Drzewa decyzyjne. 1. Wprowadzenie.
 Drzewa decyzyjne. 1. Wprowadzenie. Drzewa decyzyjne są graficzną metodą wspomagania procesu decyzyjnego. Jest to jedna z najczęściej wykorzystywanych technik analizy danych. Drzewo składają się z korzenia
Drzewa decyzyjne. 1. Wprowadzenie. Drzewa decyzyjne są graficzną metodą wspomagania procesu decyzyjnego. Jest to jedna z najczęściej wykorzystywanych technik analizy danych. Drzewo składają się z korzenia
Algorytmy i str ruktury danych. Metody algorytmiczne. Bartman Jacek
 Algorytmy i str ruktury danych Metody algorytmiczne Bartman Jacek jbartman@univ.rzeszow.pl Metody algorytmiczne - wprowadzenia Znamy strukturę algorytmów Trudność tkwi natomiast w podaniu metod służących
Algorytmy i str ruktury danych Metody algorytmiczne Bartman Jacek jbartman@univ.rzeszow.pl Metody algorytmiczne - wprowadzenia Znamy strukturę algorytmów Trudność tkwi natomiast w podaniu metod służących
Podstawy programowania 2. Temat: Drzewa binarne. Przygotował: mgr inż. Tomasz Michno
 Instrukcja laboratoryjna 5 Podstawy programowania 2 Temat: Drzewa binarne Przygotował: mgr inż. Tomasz Michno 1 Wstęp teoretyczny Drzewa są jedną z częściej wykorzystywanych struktur danych. Reprezentują
Instrukcja laboratoryjna 5 Podstawy programowania 2 Temat: Drzewa binarne Przygotował: mgr inż. Tomasz Michno 1 Wstęp teoretyczny Drzewa są jedną z częściej wykorzystywanych struktur danych. Reprezentują
Instrukcje dla zawodników
 Instrukcje dla zawodników Nie otwieraj arkusza z zadaniami dopóki nie zostaniesz o to poproszony. Instrukcje poniżej zostaną ci odczytane i wyjaśnione. 1. Arkusz składa się z 3 zadań. 2. Każde zadanie
Instrukcje dla zawodników Nie otwieraj arkusza z zadaniami dopóki nie zostaniesz o to poproszony. Instrukcje poniżej zostaną ci odczytane i wyjaśnione. 1. Arkusz składa się z 3 zadań. 2. Każde zadanie
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
WYKŁAD: DRZEWA KLASYFIKACYJNE I REGRESYJNE. Metoda CART. MiNI PW
 WYKŁAD: DRZEWA KLASYFIKACYJNE I REGRESYJNE. Metoda CART MiNI PW Drzewa służą do konstrukcji klasyfikatorów prognozujących Y {1, 2,..., g} na podstawie p-wymiarowego wektora atrybutów (dowolne atrybuty:
WYKŁAD: DRZEWA KLASYFIKACYJNE I REGRESYJNE. Metoda CART MiNI PW Drzewa służą do konstrukcji klasyfikatorów prognozujących Y {1, 2,..., g} na podstawie p-wymiarowego wektora atrybutów (dowolne atrybuty:
Wybrane zagadnienia uczenia maszynowego. Zastosowania Informatyki w Informatyce W2 Krzysztof Krawiec
 Wybrane zagadnienia uczenia maszynowego Zastosowania Informatyki w Informatyce W2 Krzysztof Krawiec Przygotowane na podstawie T. Mitchell, Machine Learning S.J. Russel, P. Norvig, Artificial Intelligence
Wybrane zagadnienia uczenia maszynowego Zastosowania Informatyki w Informatyce W2 Krzysztof Krawiec Przygotowane na podstawie T. Mitchell, Machine Learning S.J. Russel, P. Norvig, Artificial Intelligence
Metody teorii gier. ALP520 - Wykład z Algorytmów Probabilistycznych p.2
 Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Metody numeryczne I Równania nieliniowe
 Metody numeryczne I Równania nieliniowe Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/66 Równania nieliniowe 1. Równania nieliniowe z pojedynczym pierwiastkiem
Metody numeryczne I Równania nieliniowe Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/66 Równania nieliniowe 1. Równania nieliniowe z pojedynczym pierwiastkiem
Reguły decyzyjne, algorytm AQ i CN2. Reguły asocjacyjne, algorytm Apriori.
 Analiza danych Reguły decyzyjne, algorytm AQ i CN2. Reguły asocjacyjne, algorytm Apriori. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ REGUŁY DECYZYJNE Metoda reprezentacji wiedzy (modelowania
Analiza danych Reguły decyzyjne, algorytm AQ i CN2. Reguły asocjacyjne, algorytm Apriori. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ REGUŁY DECYZYJNE Metoda reprezentacji wiedzy (modelowania
Konspekt do zajęć: Statystyczne metody analizy danych. Agnieszka Nowak-Brzezińska 14 maja 2012
 Drzewa klasyfikacyjne Konspekt do zajęć: Statystyczne metody analizy danych Agnieszka Nowak-Brzezińska 14 maja 2012 1 Wprowadzenie Drzewa klasyfikacyjne 1 jako reprezentacja wiedzy o klasyfikacji są dość
Drzewa klasyfikacyjne Konspekt do zajęć: Statystyczne metody analizy danych Agnieszka Nowak-Brzezińska 14 maja 2012 1 Wprowadzenie Drzewa klasyfikacyjne 1 jako reprezentacja wiedzy o klasyfikacji są dość
Drzewa decyzyjne. Nguyen Hung Son. Nguyen Hung Son () DT 1 / 34
 DT 1 / 34") Drzewa decyzyjne Nguyen Hung Son Nguyen Hung Son () DT 1 / 34 Outline 1 Wprowadzenie Definicje Funkcje testu Optymalne drzewo 2 Konstrukcja drzew decyzyjnych Ogólny schemat Kryterium wyboru testu Przycinanie
Drzewa decyzyjne Nguyen Hung Son Nguyen Hung Son () DT 1 / 34 Outline 1 Wprowadzenie Definicje Funkcje testu Optymalne drzewo 2 Konstrukcja drzew decyzyjnych Ogólny schemat Kryterium wyboru testu Przycinanie
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych. Regresja logistyczna i jej zastosowanie
 Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych