Analiza Skupień Cluster analysis
|
|
|
- Kazimierz Szymański
- 6 lat temu
- Przeglądów:
Transkrypt
1 Metody Eksploracji Danych w wykładzie wykorzystano: 1. materiały dydaktyczne przygotowane w ramach projektu Opracowanie programów nauczania na odległość na kierunku studiów wyższych Informatyka 2. Internetowy Podręcznik Statystyki Analiza Skupień Cluster analysis Krzysztof Regulski, WIMiIP, KISiM, regulski@agh.edu.pl B5, pok. 408
2 Rodzaje modeli:» metoda k-średnich (iteracyjno-optymalizacyjne),» metody hierarchiczne,» sieci Kohonena,» grupowanie probabilistyczne - algorytm EM» algorytm BIRCH,» grupowanie oparte na gęstości 2
3 Grupowanie Znajdź naturalne" pogrupowanie obiektów w oparciu o ich wartości zastosowania grupowania:» grupowanie dokumentów» grupowanie klientów» segmentacja rynku» Kompresja obrazów» Odkrywanie oszustw 3
4 Grupowanie Grupowanie (klastrowanie) - obejmuje metody znajdowania skończonych zbiorów klastrów obiektów posiadających podobne cechy. W przeciwieństwie do metod klasyfikacji i predykcji, podział na klastry nie jest znany a-priori, lecz jest celem metod grupowania. Metody te grupują obiekty w klasy w taki sposób, aby maksymalizować podobieństwo wewnątrzklasowe obiektów i minimalizować podobieństwo pomiędzy klasami obiektów. W przeciwieństwie do klasyfikacji wzorcowej (analizy z nauczycielem), polegającej na przyporządkowywaniu przypadków do jednej z określonych klas, tu klasy nie są znane ani w żaden sposób scharakteryzowane przed przystąpieniem do analizy. 4
5 Sformułowanie problemu Grupowanie może dotyczyć zarówno obiektów rzeczywistych (np. pacjentów, sekwencji DNA, dokumenty tekstowe), jak również obiektów abstrakcyjnych (sekwencja dostępów do stron WWW, grafy reprezentujące dokumenty XML, itp.). Grupowanie jest jedną z najstarszych i najbardziej popularnych metod eksploracji danych (1939). 5
6 Czym jest klaster? Zbiór obiektów, które są podobne. Zbiór obiektów, takich, że odległość pomiędzy dwoma dowolnymi obiektami należącymi do klastra jest mniejsza aniżeli odległość pomiędzy dowolnym obiektem należącym do klastra i dowolnym obiektem nie należącym do tego klastra. Spójny obszar przestrzeni wielowymiarowej, charakteryzujący się dużą gęstością występowania obiektów. 6
 obiektów.")
7 Klasyfikacja metod hierarchiczna próba odkrycia struktury skupień znalezienia optymalnego podziału zbioru przykładów na określoną liczbę skupień Pierwsza grupa algorytmów konstruuje klastry sekwencyjnie wykorzystując cechy obiektów, druga konstruuje klastry wykorzystując jednocześnie wszystkie cechy (atrybuty) obiektów. Metody hierarchiczne generują zagnieżdżoną sekwencję podziałów zbiorów obiektów w procesie grupowania Metody z iteracyjno-optymalizacyjne generują tylko jeden podział (partycję) zbioru obiektów w dowolnym momencie procesu grupowania Algorytmy oparte na gęstościach (ang. density-based algorithms), które dzielą zbiory przykładów korzystając z modelu probabilistycznego dla bazowych skupień. 7
8 Metody grupowania hierarchicznego 8
9 Metody grupowania hierarchicznego C1 C3 C2 Metoda grupowania hierarchicznego polega na sekwencyjnym grupowaniu obiektów - drzewo klastrów (tzw. dendrogram) Początkowo, wszystkie obiekty A, B,... G należą do osobnych klastrów. Następnie, w kolejnych krokach, klastry są łączone w większe klastry (łączymy B i C, D i E, oraz F i G, następnie, A łączymy z klastrem zawierającym obiekty B i C, itd.). C1 C2 C3 Proces łączenia klastrów jest kontynuowany tak długo, aż liczba uzyskanych klastrów nie osiągnie zadanej liczby klastrów. Graficznie, na dendrogramie, warunek stopu (tj. zadana liczba klastrów) przedstawia linia pozioma przecinająca dendrogram. C1={A, B, C}, C2={D, E} oraz C3={F, G}. 9
10 Odległość klastrów odległość średnich minimalna odległość maksymalna odległość d max d min d mean d ave średnia odległość 10
11 Hierarchiczny aglomeracyjny algorytm grupowania 1. Umieść każdy obiekt w osobnym klastrze. Skonstruuj macierz przyległości zawierającą odległości pomiędzy każdą parą klastrów 2. Korzystając z macierzy przyległości znajdź najbliższą parę klastrów. Połącz znalezione klastry tworząc nowy klaster. Uaktualnij macierz przyległości po operacji połączenia 3. Jeżeli wszystkie obiekty należą do jednego klastra, zakończ procedurę grupowania, w przeciwnym razie przejdź do kroku 2 11
12 Algorytm aglomeracyjnej analizy skupień macierz przyległości dendrogram 12


13 dane dotyczące przebiegu procesu wytopu surówki w wielkim piecu 13
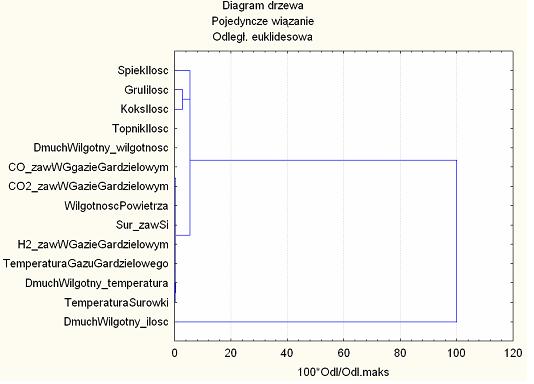

14 14

15 Macierz odległości pomiędzy łączonymi zmiennymi Najmniejsza odległość występuje pomiędzy zawartością krzemu w surówce a zawartością wodoru w gazie gardzielowym Istnieje powiązanie pomiędzy zawartością CO i CO 2 w gazie gardzielowym Następne grupy tworzą wilgotność powietrza z Si w surówce i H 2 w gazie gardzielowym. 15

16 mediany 16
17 Probabilistyczny algorytm EM 17

18 Probabilistyczny algorytm EM Expectation Maximisation Przykład: obserwujemy dużą próbę pomiarów jednej zmiennej ilościowej. Zamiast patrzyć tylko na odległość, uwzględniamy dodatkowo informację o rozkładzie przykładów. Zamiast przypisywać definitywnie przykład do grupy estymuje prawdopodobieństwo takiego przynależenia. różne rozkłady, jak np. rozkład normalny, logarytmicznonormalny czy Poissona. Możemy także wybrać różne rozkłady dla różnych zmiennych i stąd, wyznaczać grupy z mieszanin różnych typów rozkładów. 18
19 Algorytm EM Zmienne jakościowe. Implementacja algorytmu EM potrafi korzystać ze zmiennych jakościowych. Najpierw losowo przydziela prawdopodobieństwa (wagi) każdej z klas (kategorii), w każdym ze skupień. W kolejnych iteracjach prawdopodobieństwa są poprawiane tak, by zmaksymalizować wiarygodność danych przy podanej ilości skupień. Prawdopodobieństwa klasyfikacyjne zamiast klasyfikacji. Wyniki analizy skupień metodą EM są inne niż obliczone metodą k-średnich. Ta ostatnia wyznacza skupienia. Algorytm EM nie wyznacza przyporządkowania obserwacji do klas lecz prawdopodobieństwa klasyfikacyjne. 19
20 Algorytm EM Metoda składa się z dwu kroków wykonywanych na przemian tak długo, aż pomiędzy kolejnymi przebiegami nie dochodzi do zauważalnej poprawy. 1. Estymacja (expectation). Dla aktualnego, wyestymowanego układu parametrów rozkładu przykładów dokonaj przypisania przykładom prawdopodobieństwa przynależenia do grup. 2. Maksymalizuj - Zamień aktualne parametry rozkładu na takie, które prowadzą do modelu bardzie zgodnego z danymi (rozkładem przykładów). W tym celu wykorzystaj prawdopodobieństwa przynależenia do grup z kroku 1. 20
21 Gaussian mixture model
22 Gaussian mixture model

23 Jak dobrać k? Podobnie jak w przypadku metody k-średnich, problem dotyczy liczby skupień W praktyce analityk nie ma zazwyczaj pojęcia ile skupień jest w próbie. Algorytm v-krotnego sprawdzianu krzyżowego automatycznie wyznacza liczbę skupień danych. 23
24 Metody iteracyjno-optymalizacyjne 24
25 Metody iteracyjno-optymalizacyjne Iteracyjno-optymalizacyjne metody grupowania tworzą jeden podział zbioru obiektów (partycję) w miejsce hierarchicznej struktury podziałów Metody iteracyjno-optymalizacyjne realokują obiekty pomiędzy klastrami optymalizując funkcję kryterialną zdefiniowaną lokalnie (na podzbiorze obiektów) lub globalnie (na całym zbiorze obiektów) Przeszukanie całej przestrzeni wszystkich możliwych podziałów zbioru obiektów pomiędzy k klastrów jest, praktycznie, nie realizowalne W praktyce, algorytm grupowanie jest uruchamiany kilkakrotnie, dla różnych podziałów początkowych, a następnie, najlepszy z uzyskanych podziałów jest przyjmowany jako wynik procesu grupowania 25
26 Funkcje kryterialne: Suma błędów kwadratowych Suma błędów kwadratowych: Klastry powinny być zwarte Klastry powinny być maksymalnie rozłączne odchylenie wewnątrzklastrowe: dla każdego obiektu należącego do klastra obliczamy odległość tego punktu do najbliższego obiektu w tym klastrze, i bierzemy max z tych odległości 26
27 Algorytm K-means idea algorytmu K-means (k-średnich) - rozpoczyna się od losowo wybranego grupowania punktów, następnie ponownie przypisuje się punkty tak, aby otrzymać największy wzrost (spadek) w funkcji oceny, po czym przelicza się zaktualizowane skupienia, po raz kolejny przypisuje się punkty i tak dalej aż do momentu, w którym nie ma już żadnych zmian w funkcji oceny lub w składzie skupień. To zachłanne podejście ma tę zaletę, że jest proste i gwarantuje otrzymanie co najmniej lokalnego maksimum (minimum) funkcji oceny. Osiągnięcie optimum" globalnego podziału obiektów wymaga przeanalizowania wszystkich możliwych podziałów zbioru n obiektów pomiędzy k klastrów 27

28 Algorytm K-means 28
29 krok 1 Założenie: k = 3 wybierz 3 początkowe środki klastrów (losowo) 29
30 krok 2 Przydziel każdy obiekt do klastra w oparciu o najmniejszą odległość obiektu od środka klastra 30
31 krok 3 Uaktualnij środki (średnie) wszystkich klastrów 31
32 krok 4 Realokuj obiekty do najbliższych klastrów 32
33 krok 4b Oblicz nowe średnie klastrów Algorytm bardzo czuły na dane zaszumione lub dane zawierające punkty osobliwe, gdyż punkty takie w istotny sposób wpływają na średnie klastrów powodując ich zniekształcenie punkt osobliwy (outlier) i wracamy do kroku realokacji obiektów. Dla każdego obiektu następuje weryfikacja, czy obiekt ten podlega realokacji. Jeżeli żaden z obiektów nie wymaga realokacji następuje zakończenie działania algorytmu. 33
34 Algorytm k-średnich Wynik działania algorytmu (tj. ostateczny podział obiektów pomiędzy klastrami) silnie zależy od początkowego podziału obiektów Algorytm może wpaść w optimum lokalne W celu zwiększenia szansy znalezienia optimum globalnego należy kilkakrotnie uruchomić algorytm dla różnych podziałów początkowych 34
35 Algorytm k-średnich Przyjmijmy, że środkami klastrów są obiekty A,B, i D, wokół których konstruowane są klastry Lepszy (z mniejszym błędem średniokwadratowym) podział uzyskamy przyjmując początkowe środki klastrów A, D, i F (prostokąty) A C B F D E G 35
36 Algorytm k-medoidów W celu uodpornienia algorytmu k-średnich na występowanie punktów osobliwych, zamiast średnich klastrów jako środków tych klastrów, możemy przyjąć medoidy najbardziej centralnie ulokowane punkty klastrów: Średnia zbioru 1, 3, 5, 7, 9 wynosi 5 Średnia zbioru 1, 3, 5, 7, 1009 wynosi 205 Medoid zbioru 1, 3, 5, 7, 1009 wynosi 5 36
37 Inne metody grupowania Metody oparte o analizę gęstości» dany klaster jest rozszerzany o obiekty należące do jego sąsiedztwa, pod warunkiem, że gęstość obiektów w danym sąsiedztwie przekracza zadaną wartość progową (algorytmy DBSCAN, OPTICS, DENCLUE)» Ta grupa metod była rozwijana, głównie, w odniesieniu do zastosowań w dziedzinie rozpoznawania obrazów. Metody oparte o strukturę gridową» przestrzeń obiektów jest dzielona na skończona liczbę komórek, które tworzą strukturę gridu; cały proces grupowania jest wykonywany na tej strukturze (algorytmy STING, CLIQUE)» Cechą i zasadniczą zaletą tej grupy metod jest skalowalność i możliwość analizy dużych wolumenów danych wielowymiarowych. 37
38 Przykład w STATISTICA Adult.sta 38



39 1 Przykład w STATISTICA






40 Losowanie warstwowe 40




41

42 42
, skupienia 2 i 4 to starsi (45 lat), skupienie 3 (40lat)")

43 Statystyki opisowe skupień Wniosek 1: skupienie 1. to ludzie młodsi (30lat), skupienia 2 i 4 to starsi (45 lat), skupienie 3 (40lat) Wniosek 2: skupienie 2. to ludzie lepiej wykształceni niż skupienia 1., 3. i 4. Wniosek 3: najmniej pracują osoby ze skupienia 1, najciężej ze skupienia 2.; skupienia 3 i 4 pracują normalnie ok. 40h/tydzień 43
; bardzo dobrze wykształceni; pracujący dużo; Skupienie 3: w wieku ok. 40 lat; słabo wykształceni; pracujący stosunkowo dużo; Skupienie 4: w średnim wieku (ok.")
44 Co już wiemy? Skupienie 1: młodzi (30lat); średnio wykształceni; pracujący stosunkowo mało; Skupienie 2: w średnim wieku (ok. 45lat); bardzo dobrze wykształceni; pracujący dużo; Skupienie 3: w wieku ok. 40 lat; słabo wykształceni; pracujący stosunkowo dużo; Skupienie 4: w średnim wieku (ok. 45lat); raczej słabo wykształceni; pracujący ok. 41h/tyg kto jest najlepszym klientem? 44

; bardzo dobrze")
45 Najlepiej zarabia skupienie 2 kim ONI są? Skupienie 2: w średnim wieku (ok. 45lat); bardzo dobrze wykształceni; pracujący dużo; 45
; bardzo dobrze wykształceni; pracujący dużo; w małżeństwie; zawód:")
46 Co nowego o skupieniu 2? Skupienie 2 to: ludzie średnim wieku (ok. 45lat); bardzo dobrze wykształceni; pracujący dużo; w małżeństwie; zawód: specjalista/kierownik mężczyzna 46
; średnio wykształcone; pracujące stosunkowo")
47 Co z kobietami? Kobiety w naszej próbie zdominowały skupienie 1: są młode (30lat); średnio wykształcone; pracujące stosunkowo mało (dzieci?); niezamężne; pracują w usługach; prawie wszystkie zarabiają poniżej $; 47

48 Kim są pozostali? Skupienie 3: w wieku ok. 40 lat; słabo wykształceni; pracujący stosunkowo dużo; mężczyźni; żonaci; głównie sprzedawcy; zarabiają poniżej $ Skupienie 4: w średnim wieku (ok. 45lat); raczej słabo wykształceni; pracujący ok. 41h/tyg; kobiety i mężczyźni po rozwodzie, rzemieślnicy, fachowcy zarabiający poniżej $ 48

49 Kto się najbardziej różni? Najbardziej rozróżnialne są skupienia 1. i 2. czyli młodzi specjaliści i panny na wydaniu Widać to również w zarobkach. Po ślubie różnice się wyrównują 49
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Grupowanie Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633
 Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Grupowanie. Iteracyjno-optymalizacyjne metody grupowania Algorytm k-średnich Algorytm k-medoidów. Eksploracja danych. Grupowanie wykład 2
 Grupowanie Iteracyjno-optymalizacyjne metody grupowania Algorytm k-średnich Algorytm k-medoidów Grupowanie wykład 2 Tematem wykładu są iteracyjno-optymalizacyjne algorytmy grupowania. Przedstawimy i omówimy
Grupowanie Iteracyjno-optymalizacyjne metody grupowania Algorytm k-średnich Algorytm k-medoidów Grupowanie wykład 2 Tematem wykładu są iteracyjno-optymalizacyjne algorytmy grupowania. Przedstawimy i omówimy
Eksploracja danych. Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Eksploracja danych. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Tematem wykładu są zagadnienia związane z grupowaniem. Rozpoczniemy od krótkiego wprowadzenia
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Tematem wykładu są zagadnienia związane z grupowaniem. Rozpoczniemy od krótkiego wprowadzenia
CLUSTERING. Metody grupowania danych
 CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
Grupowanie danych. Wprowadzenie. Przykłady
 Grupowanie danych str. 1 Wprowadzenie Celem procesu grupowania jest podział zbioru obiektów, fizycznych lub abstrakcyjnych, na klasy obiektów o podobnych cechach, nazywane klastrami lub skupieniami Klaster
Grupowanie danych str. 1 Wprowadzenie Celem procesu grupowania jest podział zbioru obiektów, fizycznych lub abstrakcyjnych, na klasy obiektów o podobnych cechach, nazywane klastrami lub skupieniami Klaster
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Zagadnienie klasyfikacji (dyskryminacji)
") Zagadnienie klasyfikacji (dyskryminacji) Przykład Bank chce klasyfikować klientów starających się o pożyczkę do jednej z dwóch grup: niskiego ryzyka (spłacających pożyczki terminowo) lub wysokiego ryzyka
Zagadnienie klasyfikacji (dyskryminacji) Przykład Bank chce klasyfikować klientów starających się o pożyczkę do jednej z dwóch grup: niskiego ryzyka (spłacających pożyczki terminowo) lub wysokiego ryzyka
Analiza skupień. Idea
 Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Idea. Algorytm zachłanny Algorytmy hierarchiczne Metoda K-średnich Metoda hierarchiczna, a niehierarchiczna. Analiza skupień
 Idea jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień. Obiekty należące do danego skupienia
Idea jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień. Obiekty należące do danego skupienia
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Statystyka w pracy badawczej nauczyciela
 Statystyka w pracy badawczej nauczyciela Wykład 1: Terminologia badań statystycznych dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyka (1) Statystyka to nauka zajmująca się zbieraniem, badaniem
Statystyka w pracy badawczej nauczyciela Wykład 1: Terminologia badań statystycznych dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyka (1) Statystyka to nauka zajmująca się zbieraniem, badaniem
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
1. Grupowanie Algorytmy grupowania:
 1. 1.1. 2. 3. 3.1. 3.2. Grupowanie...1 Algorytmy grupowania:...1 Grupowanie metodą k-średnich...3 Grupowanie z wykorzystaniem Oracle Data Miner i Rapid Miner...3 Grupowanie z wykorzystaniem algorytmu K-Means
1. 1.1. 2. 3. 3.1. 3.2. Grupowanie...1 Algorytmy grupowania:...1 Grupowanie metodą k-średnich...3 Grupowanie z wykorzystaniem Oracle Data Miner i Rapid Miner...3 Grupowanie z wykorzystaniem algorytmu K-Means
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Naszym zadaniem jest rozpatrzenie związków między wierszami macierzy reprezentującej poziomy ekspresji poszczególnych genów.
 ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
Sieci Kohonena Grupowanie
 Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Metody analizy skupień Wprowadzenie Charakterystyka obiektów Metody grupowania Ocena poprawności grupowania
 Wielowymiarowe metody segmentacji CHAID Metoda Automatycznej Detekcji Interakcji CHAID Cele CHAID Dane CHAID Przebieg analizy CHAID Parametry CHAID Wyniki Metody analizy skupień Wprowadzenie Charakterystyka
Wielowymiarowe metody segmentacji CHAID Metoda Automatycznej Detekcji Interakcji CHAID Cele CHAID Dane CHAID Przebieg analizy CHAID Parametry CHAID Wyniki Metody analizy skupień Wprowadzenie Charakterystyka
Wykład 10: Elementy statystyki
 Wykład 10: Elementy statystyki dr Mariusz Grządziel 0 grudnia 010 Podstawowe pojęcia Biolodzy: -badają pojedyńcze rośliny lub zwierzęta; -chcemy rozszerzyć wnioski na wszystkich przedstawicieli gatunku
Wykład 10: Elementy statystyki dr Mariusz Grządziel 0 grudnia 010 Podstawowe pojęcia Biolodzy: -badają pojedyńcze rośliny lub zwierzęta; -chcemy rozszerzyć wnioski na wszystkich przedstawicieli gatunku
Uczenie sieci radialnych (RBF)
") Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Zadania laboratoryjne i projektowe - wersja β
 Zadania laboratoryjne i projektowe - wersja β 1 Laboratorium Dwa problemy do wyboru (jeden do realizacji). 1. Water Jug Problem, 2. Wieże Hanoi. Water Jug Problem Ograniczenia dla każdej z wersji: pojemniki
Zadania laboratoryjne i projektowe - wersja β 1 Laboratorium Dwa problemy do wyboru (jeden do realizacji). 1. Water Jug Problem, 2. Wieże Hanoi. Water Jug Problem Ograniczenia dla każdej z wersji: pojemniki
W1. Wprowadzenie. Statystyka opisowa
 W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych.
 Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych. Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Hipotezy i Testy statystyczne Każde
Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych. Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Hipotezy i Testy statystyczne Każde
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Metody Programowania
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Metody Programowania www.pk.edu.pl/~zk/mp_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 8: Wyszukiwanie
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Metody Programowania www.pk.edu.pl/~zk/mp_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 8: Wyszukiwanie
Techniki grupowania danych w środowisku Matlab
 Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
Optymalizacja. Przeszukiwanie lokalne
 dr hab. inż. Instytut Informatyki Politechnika Poznańska www.cs.put.poznan.pl/mkomosinski, Maciej Hapke Idea sąsiedztwa Definicja sąsiedztwa x S zbiór N(x) S rozwiązań, które leżą blisko rozwiązania x
dr hab. inż. Instytut Informatyki Politechnika Poznańska www.cs.put.poznan.pl/mkomosinski, Maciej Hapke Idea sąsiedztwa Definicja sąsiedztwa x S zbiór N(x) S rozwiązań, które leżą blisko rozwiązania x
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)
, które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)") Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez statystycznych
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez statystycznych
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Matematyka ubezpieczeń majątkowych r.
 Matematyka ubezpieczeń majątkowych 3..007 r. Zadanie. Każde z ryzyk pochodzących z pewnej populacji charakteryzuje się tym że przy danej wartości λ parametru ryzyka Λ rozkład wartości szkód z tego ryzyka
Matematyka ubezpieczeń majątkowych 3..007 r. Zadanie. Każde z ryzyk pochodzących z pewnej populacji charakteryzuje się tym że przy danej wartości λ parametru ryzyka Λ rozkład wartości szkód z tego ryzyka
Analiza skupień. Idea
 Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja)
") PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
zbieranie porządkowanie i prezentacja (tabele, wykresy) analiza interpretacja (wnioskowanie statystyczne)
 analiza interpretacja (wnioskowanie statystyczne)") STATYSTYKA zbieranie porządkowanie i prezentacja (tabele, wykresy) analiza interpretacja (wnioskowanie statystyczne) DANYCH STATYSTYKA MATEMATYCZNA analiza i interpretacja danych przy wykorzystaniu metod
STATYSTYKA zbieranie porządkowanie i prezentacja (tabele, wykresy) analiza interpretacja (wnioskowanie statystyczne) DANYCH STATYSTYKA MATEMATYCZNA analiza i interpretacja danych przy wykorzystaniu metod
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
STATYSTYKA
 Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Algorytmy rozpoznawania obrazów. 11. Analiza skupień. dr inż. Urszula Libal. Politechnika Wrocławska
 Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
Algorytmy i struktury danych. Wykład 6 Tablice rozproszone cz. 2
 Algorytmy i struktury danych Wykład 6 Tablice rozproszone cz. 2 Na poprzednim wykładzie Wiele problemów wymaga dynamicznych zbiorów danych, na których można wykonywać operacje: wstawiania (Insert) szukania
Algorytmy i struktury danych Wykład 6 Tablice rozproszone cz. 2 Na poprzednim wykładzie Wiele problemów wymaga dynamicznych zbiorów danych, na których można wykonywać operacje: wstawiania (Insert) szukania
Spacery losowe generowanie realizacji procesu losowego
 Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Analiza skupień. Idea
 Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Generowanie ciągów pseudolosowych o zadanych rozkładach przykładowy raport
 Generowanie ciągów pseudolosowych o zadanych rozkładach przykładowy raport Michał Krzemiński Streszczenie Projekt dotyczy metod generowania oraz badania własności statystycznych ciągów liczb pseudolosowych.
Generowanie ciągów pseudolosowych o zadanych rozkładach przykładowy raport Michał Krzemiński Streszczenie Projekt dotyczy metod generowania oraz badania własności statystycznych ciągów liczb pseudolosowych.
Pozyskiwanie wiedzy z danych
 Pozyskiwanie wiedzy z danych dr Agnieszka Goroncy Wydział Matematyki i Informatyki UMK PROJEKT WSPÓŁFINANSOWANY ZE ŚRODKÓW UNII EUROPEJSKIEJ W RAMACH EUROPEJSKIEGO FUNDUSZU SPOŁECZNEGO Pozyskiwanie wiedzy
Pozyskiwanie wiedzy z danych dr Agnieszka Goroncy Wydział Matematyki i Informatyki UMK PROJEKT WSPÓŁFINANSOWANY ZE ŚRODKÓW UNII EUROPEJSKIEJ W RAMACH EUROPEJSKIEGO FUNDUSZU SPOŁECZNEGO Pozyskiwanie wiedzy
Kolokwium ze statystyki matematycznej
 Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Testy nieparametryczne
 Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane cd.
 Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane cd. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 2013-11-26 Projekt pn. Wzmocnienie potencjału
Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane cd. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 2013-11-26 Projekt pn. Wzmocnienie potencjału
Analiza wariancji. dr Janusz Górczyński
 Analiza wariancji dr Janusz Górczyński Wprowadzenie Powiedzmy, że badamy pewną populację π, w której cecha Y ma rozkład N o średniej m i odchyleniu standardowym σ. Powiedzmy dalej, że istnieje pewien czynnik
Analiza wariancji dr Janusz Górczyński Wprowadzenie Powiedzmy, że badamy pewną populację π, w której cecha Y ma rozkład N o średniej m i odchyleniu standardowym σ. Powiedzmy dalej, że istnieje pewien czynnik
Zofia Kruczkiewicz, Algorytmu i struktury danych, Wykład 14, 1
 Wykład Algorytmy grafowe metoda zachłanna. Właściwości algorytmu zachłannego:. W przeciwieństwie do metody programowania dynamicznego nie występuje etap dzielenia na mniejsze realizacje z wykorzystaniem
Wykład Algorytmy grafowe metoda zachłanna. Właściwości algorytmu zachłannego:. W przeciwieństwie do metody programowania dynamicznego nie występuje etap dzielenia na mniejsze realizacje z wykorzystaniem
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11,
 1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
Środowisko R wprowadzenie c.d. Wykład R2; 21.05.07 Struktury danych w R c.d.
 Środowisko R wprowadzenie c.d. Wykład R2; 21.05.07 Struktury danych w R c.d. Oprócz zmiennych i wektorów strukturami danych w R są: macierze; ramki (ang. data frames); listy; klasy S3 1 Macierze Macierze
Środowisko R wprowadzenie c.d. Wykład R2; 21.05.07 Struktury danych w R c.d. Oprócz zmiennych i wektorów strukturami danych w R są: macierze; ramki (ang. data frames); listy; klasy S3 1 Macierze Macierze
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Strefa pokrycia radiowego wokół stacji bazowych. Zasięg stacji bazowych Zazębianie się komórek
 Problem zapożyczania kanałów z wykorzystaniem narzędzi optymalizacji Wprowadzenie Rozwiązanie problemu przydziału częstotliwości prowadzi do stanu, w którym każdej stacji bazowej przydzielono żądaną liczbę
Problem zapożyczania kanałów z wykorzystaniem narzędzi optymalizacji Wprowadzenie Rozwiązanie problemu przydziału częstotliwości prowadzi do stanu, w którym każdej stacji bazowej przydzielono żądaną liczbę
Seminarium IO. Zastosowanie algorytmu UCT w Dynamic Vehicle Routing Problem. Michał Okulewicz
 Seminarium IO Zastosowanie algorytmu UCT w Dynamic Vehicle Routing Problem Michał Okulewicz 05.11.2013 Plan prezentacji Przypomnienie Problem DVRP Algorytm UCT Zastosowanie algorytmu UCT/PSO w DVRP Zastosowanie
Seminarium IO Zastosowanie algorytmu UCT w Dynamic Vehicle Routing Problem Michał Okulewicz 05.11.2013 Plan prezentacji Przypomnienie Problem DVRP Algorytm UCT Zastosowanie algorytmu UCT/PSO w DVRP Zastosowanie
Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować?
 Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej
 Pojęcie losowej próby prostej") 7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
Metoda określania pozycji wodnicy statków na podstawie pomiarów odległości statku od głowic laserowych
 inż. Marek Duczkowski Metoda określania pozycji wodnicy statków na podstawie pomiarów odległości statku od głowic laserowych słowa kluczowe: algorytm gradientowy, optymalizacja, określanie wodnicy W artykule
inż. Marek Duczkowski Metoda określania pozycji wodnicy statków na podstawie pomiarów odległości statku od głowic laserowych słowa kluczowe: algorytm gradientowy, optymalizacja, określanie wodnicy W artykule
Schemat programowania dynamicznego (ang. dynamic programming)
") Schemat programowania dynamicznego (ang. dynamic programming) Jest jedną z metod rozwiązywania problemów optymalizacyjnych. Jej twórcą (1957) był amerykański matematyk Richard Ernest Bellman. Schemat ten
Schemat programowania dynamicznego (ang. dynamic programming) Jest jedną z metod rozwiązywania problemów optymalizacyjnych. Jej twórcą (1957) był amerykański matematyk Richard Ernest Bellman. Schemat ten
Testowanie modeli predykcyjnych
 Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Skalowanie wielowymiarowe idea
 Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Układy stochastyczne
 Instytut Informatyki Uniwersytetu Śląskiego 21 stycznia 2009 Definicja Definicja Proces stochastyczny to funkcja losowa, czyli funkcja matematyczna, której wartości leżą w przestrzeni zdarzeń losowych.
Instytut Informatyki Uniwersytetu Śląskiego 21 stycznia 2009 Definicja Definicja Proces stochastyczny to funkcja losowa, czyli funkcja matematyczna, której wartości leżą w przestrzeni zdarzeń losowych.
Podstawowe pojęcia statystyczne
 Podstawowe pojęcia statystyczne Istnieją trzy rodzaje kłamstwa: przepowiadanie pogody, statystyka i komunikat dyplomatyczny Jean Rigaux Co to jest statystyka? Nauka o metodach ilościowych badania zjawisk
Podstawowe pojęcia statystyczne Istnieją trzy rodzaje kłamstwa: przepowiadanie pogody, statystyka i komunikat dyplomatyczny Jean Rigaux Co to jest statystyka? Nauka o metodach ilościowych badania zjawisk
Rozkłady statystyk z próby
 Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Drzewa spinające MST dla grafów ważonych Maksymalne drzewo spinające Drzewo Steinera. Wykład 6. Drzewa cz. II
 Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem
Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem
Metody probabilistyczne
 Metody probabilistyczne 13. Elementy statystki matematycznej I Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 17.01.2019 1 / 30 Zagadnienia statystki Przeprowadzamy
Metody probabilistyczne 13. Elementy statystki matematycznej I Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 17.01.2019 1 / 30 Zagadnienia statystki Przeprowadzamy
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
Metody probabilistyczne klasyfikatory bayesowskie
 Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Czym jest analiza skupień?
 Statystyczna analiza danych z pakietem SAS Analiza skupień metody hierarchiczne Czym jest analiza skupień? wielowymiarowa technika pozwalająca wykrywać współzależności między obiektami; ściśle związana
Statystyczna analiza danych z pakietem SAS Analiza skupień metody hierarchiczne Czym jest analiza skupień? wielowymiarowa technika pozwalająca wykrywać współzależności między obiektami; ściśle związana
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
8. Neuron z ciągłą funkcją aktywacji.
 8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
Sztuczna Inteligencja Projekt
 Sztuczna Inteligencja Projekt Temat: Algorytm F-LEM1 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm F LEM 1. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu F LEM1
Sztuczna Inteligencja Projekt Temat: Algorytm F-LEM1 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm F LEM 1. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu F LEM1
Statystyka. #5 Testowanie hipotez statystycznych. Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik. rok akademicki 2016/ / 28
 Statystyka #5 Testowanie hipotez statystycznych Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2016/2017 1 / 28 Testowanie hipotez statystycznych 2 / 28 Testowanie hipotez statystycznych
Statystyka #5 Testowanie hipotez statystycznych Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2016/2017 1 / 28 Testowanie hipotez statystycznych 2 / 28 Testowanie hipotez statystycznych
W kolejnym kroku należy ustalić liczbę przedziałów k. W tym celu należy wykorzystać jeden ze wzorów:
 Na dzisiejszym wykładzie omówimy najważniejsze charakterystyki liczbowe występujące w statystyce opisowej. Poszczególne wzory będziemy podawać w miarę potrzeby w trzech postaciach: dla szeregu szczegółowego,
Na dzisiejszym wykładzie omówimy najważniejsze charakterystyki liczbowe występujące w statystyce opisowej. Poszczególne wzory będziemy podawać w miarę potrzeby w trzech postaciach: dla szeregu szczegółowego,