Metoda dokładnej rekonstrukcji drzew filogenetycznych genów. współczynników substytucji dla genów i gatunków
|
|
|
- Katarzyna Bednarek
- 7 lat temu
- Przeglądów:
Transkrypt
1 Metoda dokładnej rekonstrukcji drzew filogenetycznych genów z zastosowaniem współczynników substytucji dla genów i gatunków Na podstawie artykułu Accurate gene-tree reconstruction by learning gene- and species-specific substitution rates across multiple complete genomes autorstwa Matthew D. Rasmussen i Manolis Kellis 21 października 2009
2 Streszczenie problemu Przedstawienie zagadnienia Niedokładności drzew genów Problem: dokładna rekonstrukcja drzew genów dla danego zbioru gatunków na podstawie kompletnych genomów Sytuacja: istniejace metody traktuja każde drzewo genów osobno duże niedokładności - zbyt mało danych w pojedynczych genach Pomysł autorów: drzewa genów danego zbioru gatunków maja wspólne własności współczynniki ewolucyjne moga być rozłożone na: gene-specific rate - współczynnik genowy species-specific rate - współczynnik gatunkowy informacja o współczynnikach specyficznych zawarta w genomie
3 Streszczenie problemu c.d. Przedstawienie zagadnienia Niedokładności drzew genów Przedstawione rozwiazanie: metodologia rekonstrukcji drzew genów wykorzystujaca przedstawione własności znaczaco większa dokładność rekonstrukcji umożliwienie studiów nad ewolucja genów w kontekście ewolucji gatunków
4 Genomika porównawcza Przedstawienie zagadnienia Niedokładności drzew genów badanie relacji między genomami różnych gatunków lub szczepów w szczególności: ewolucyjnie konserwowane elementy funkcjonalne udział zduplikowanych genów w pojawianiu się nowych funkcji analizy zależa od dokładnego mapowania drzew paralogów i ortologów na drzewo genów
5 Drzewa filogenetyczne Przedstawienie zagadnienia Niedokładności drzew genów narzędzie do porównywania genów drzewa genów ortologicznych badanie ewolucji gatunków węzły - specjacja drzewa genów paralogicznych badanie ekspansji rodziny genów węzły - duplikacja

6 Filogenomika Przedstawienie zagadnienia Niedokładności drzew genów genomika w kontekście całych genomów jedno ogólne drzewo genów historia ewolucyjna rodziny genów w porównywanych gatunkach uzgadnianie mapowanie drzewa genów na drzewo gatunków połaczenie informacji o relacjach ortologów i paralogów założenia: znane drzewo gatunków i poprawne drzewo genów
7 Materiał badań autorów Przedstawienie zagadnienia Niedokładności drzew genów 12 zsekwencjonowanych genomów Drosophilia 9 publicznie znanych genomów grzybów
8 Materiał badań autorów c.d. Przedstawienie zagadnienia Niedokładności drzew genów
9 Wkład badań Przedstawienie zagadnienia Niedokładności drzew genów wniosek: przyczyna niezgodności drzew genów - niedokładność rekonstrukcji niezgodności głównie dla krótkich i wolno ewoluuj acych genów niezgodności bardziej metodologiczne niż biologiczne odkrycie: współczynnik substytucji jako produkt: gene-specific rate - współczynnika genowego species-specific rate - współczynnika gatunkowego znane rozkłady obydwu współczynników dekompozycja współczynnika pasujaca do obserwacji
10 Wkład badań c.d. Przedstawienie zagadnienia Niedokładności drzew genów przedstawienie: framework probabilistyczny do rekonstrukcji drzew genów dla kompletnych genomów oparty na rozkładach współczynników pobranych z uliniowienia jednoznacznych ortologów zaimplementowany w wnioskowanie drzew genów prowadzi do dokładniejszych rekonstrukcji rozwiazanie problemów z długościami krawędzi w drzewach
11 Przedstawienie zagadnienia Niedokładności drzew genów Badania nad dokładnościa metod rekonstrukcji filogenetycznych metody rekonstrukcji opieraja się na: uliniowieniach mikroewolucji obserwowanej eksperymentalnie
12 Przedstawienie zagadnienia Niedokładności drzew genów Test dokładności metod filogenetycznych rekonstrukcja drzew na podstawie regionów z zachowanym porzadkiem genów w wielu kompletnych genomach wszystkie takie geny pochodza z jednego genu wspólnego przodka gatunków drzewo takich genów powinno być zgodne z drzewem gatunków możliwe przeszkody: horyzontalny transfer genów konwersja genów incomplete lineage sorting jednak drzewa dla takich genów często nie zgadzaja się z drzewem gatunków

13 Przedstawienie zagadnienia Niedokładności drzew genów Dokładność metod - wyniki autorów
14 Przedstawienie zagadnienia Niedokładności drzew genów Dokładność metod - wyniki autorów materiał: 5154 ortologi z 12 genomów Drosophilia uznane drzewo gatunków T1 istniejace metody rekonstrukcji zgadzały się z nim dla 24 wyniki niezależne od użytych metod: PHYML, DNAML, MrBayes, BIONJ, Parsimony uliniowienia białkowe i nukleotydowe jednak żadna inna topologia nie okazała się lepsza
15 Przedstawienie zagadnienia Niedokładności drzew genów Domniemane przyczyny niezgodności mechanizmy biologiczne: incomplete lineage sorting i inne nieprawdopodobne, żeby były odpowiedzialne za wszystkie przypadki wiele poszlaków, że niezgodności w dużej części przypadków wynikaja z niedokładności algorytmów
16 Obserwacje autorów Przedstawienie zagadnienia Niedokładności drzew genów 1 Dokładność a długość genów 2 Dokładność a tempo ewolucji 3 Dokładność symulowanej rekonstrukcji 4 Dokładność a wymaganie identycznych wyników
17 Dokładność a długość genów Przedstawienie zagadnienia Niedokładności drzew genów oczywista monotoniczna zależność średnia dokładność metod: 40% dokładność dla krótkich genów (<800 bp): 25% dokładność dla długich genów (>2300 bp): 60% rekomendowane długości sa nieosiagalne dla pojedynczych genów, a konkatenacja nie jest sposobem
18 Dokładność a tempo ewolucji Przedstawienie zagadnienia Niedokładności drzew genów 48% dokładności dla genów identycznych w 40%-50% 25% dokładności dla genów identycznych w 70% 35% dokładności dla genów identycznych w 25% wolno ewoluujace geny - za mało wydarzeń, za mało informacji szybko ewoluujace geny - nie różnia się od siebie w różnych topologiach

19 Dokładność a tempo ewolucji c.d. Przedstawienie zagadnienia Niedokładności drzew genów
20 Dokładność a tempo ewolucji c.d. Przedstawienie zagadnienia Niedokładności drzew genów
21 Przedstawienie zagadnienia Niedokładności drzew genów Dokładność w symulowanej rekonstrukcji symulowana rekonstrukcja drzew prowadzi do tych samych topologii drzew T1-T5 symulowana filogeneza drzew genów znana topologia gatunków podobne długości krawędzi najwet najczęstsze niezgodne topologie moga wynikać z błędów rekonstrukcji poprawna filogeneza uzyskana dla 72 różnica ok. 30% - potencjalnie z powodu incomplete lineage sorting wyjaśnienie 30% przypadków nie pokrywa wszystkich rozbieżności
22 Przedstawienie zagadnienia Niedokładności drzew genów Dokładność a wymaganie identycznych wyników konsekwencje domniemanych biologicznych przyczyn niezgodności: te same wyniki dla wielu metod duży bootstrap support znaczaco większe prawdopodobieństwo drzew fakty nieobserwowane wymaganie zgodności metod (odnośnie topologii drzewa) topologie T2-T5 - mniejsza częstość (4%-11% do 1%-5%) drzewa niezgodne z topologia drzewa gatunków - mniejszy bootstrap support wiele alternatywnych topologii nie ma dostatecznego wsparcia
23 Wniosek Przedstawienie zagadnienia Niedokładności drzew genów wiele niezgodności spowodowanych niedokładnościa metod potrzebna dodatkowa informacja do polepszenia zgodności rozważanie drzew genów osobno - brak takiej informacji rozważanie wielu drzew genów z wielu gatunków - poznanie własności wspólnych dla drzew genów wykorzystanie własności drzew genów w ich rekonstrukcji
24 Idea wykorzystanie zbioru filogenomicznego wiele genów ewoluuje w tym samym drzewie gatunków na tej podstawie wymodelowanie ich wspólnych cech
25 Definicja współczynników b i - współczynnik substytucji genu w gałęzi drzewa g - współczynnik genowy s i - współczynnik gatunkowy - modeluje dynamikę ewolucji gatunku i: wielkość populacji zachowania rozrodcze ogólny współczynnik mutacji produktem g oraz s i jest b i zaobserwowana niezależność między g a s i
26 Uzyskiwanie rozkładów współczynników 5154 ortologi muszek wymaganie, aby każde drzewo genów było zgodne z drzewem gatunków długości krawędzi obliczone parami za pomoca maximum likelihood z modelu oczekiwanie, że g dla każdego drzewa będzie proporcjonalne do całkowitej długości drzewa dla każdego drzewa genów g jako suma długości bezwzględnych wszystkich krawędzi b i - ogólny współczynnik substytucji dla drzewa s i jako b i /g - względna długość krawędzi po normalizacji przez g
 - bardziej zwarty rozkład")
27 Rozkłady współczynników g - rozkład gamma G = Γ(α, β) s i - rozkład normalny S i = N(µ i, σ 2 i ) - bardziej zwarty rozkład niż b i
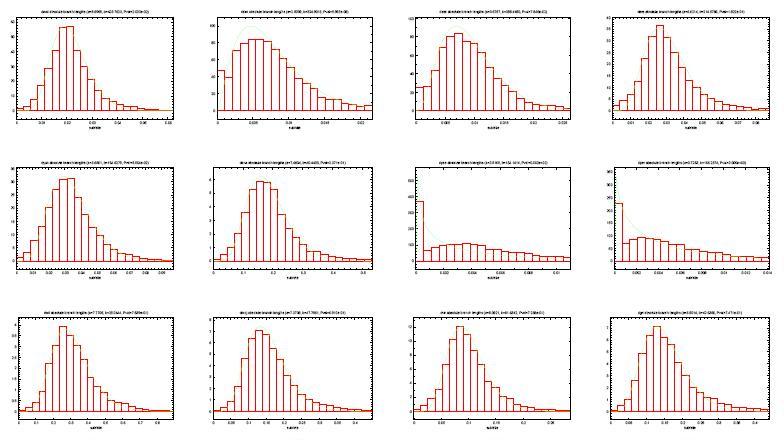
28 Rozkłady współczynników c.d.
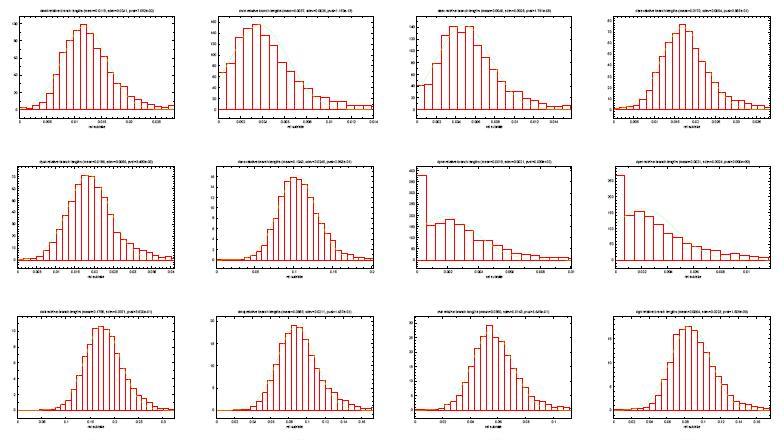
29 Rozkłady współczynników c.d.
30 Zgodność własności współczynników z obserwacjami założenie niezależności g i s i implikuje zaobserwowane własności: korelacja między długościami drzew genów - wyskalowana wersja średniego drzewa genów faktyczna korelacja drzew ze soba faktyczna korelacja większości drzew z drzewem gatunków korelacja b i pomiędzy każda para gatunków niezależność s i - względnych długości krawędzi

31 Zgodność własności współczynników z obserwacjami c.d.
32 Model współczynnik substytucji rozłożony na współczynnik genowy i gatunkowy współczynniki aproksymowane rozkładami model ewolucji drzew genów w wielu kompletnych genomach: drzewo genów tworzone jako produkt g z rozkładu gamma i s i z rozkładu normalnego każdy rozkład niezależny model - Species-Informed Distance-Based Reconstruction sprawdzanie i ewaluacja prawdopodobieństwa różnych topologii drzewa genów
33 Model - uzgodnienie uzgodnienie drzewa genów z drzewem gatunków mapowanie węzłów genów b l na węzły gatunków i gałaź b l - gałaż biegnaca od węzła b l w kierunku korzenia węzeł R(b l ) w drzewie gatunków odpowiada węzłowi b i w drzewie genów definicja parsymoniczna: R(b l ) = LCA( c children(b l ) R(c)) gdy brak duplikacji i strat węzły mapuja się jeden do jednego: R(b i ) = i
34 Model - uzgodnienie uogólnione mapowanie R z węzła genu b l na węzeł gatunku i oraz punkt duplikacyjny k l R(b l ) = (i, k l ) jeśli węzeł b l oznacza duplikację, k l oznacza ułamek gałęzi gatunku i, na której pojawiła się duplikacja
35 Model - uzgodnienie uogólnione krawędzi mapowanie R b z gałęzi genów na gałęzie gatunków gałaź genu może mapować się na wiele gałęzi gatunków, a także na ich części definicja: R b (b l ) = ((s 1, s 2,..., s m ), (p 1, p 2,..., p m )) s 1,..., s m - ścieżka gałęzi w drzewie gatunków p 1,..., p m - część każdej użytej gałęzi gatunków k l implikuje p j
36 Model ewolucji drzew genów - przypadek prosty dla rodzin bez duplikacji i strat genów współczynnik genowy z rozkładem gamma (G = Γ(α, β)) i współczynnik gatunkowy z rozkładem normalnym S i = N(µ i, σ 2 i ) µ i : średni współczynnik gatunku w porównaniu z innymi σi 2 : wariancja - do jakiego stopnia gen ewoluujacy w gatunku odchyla się od współczynnika genowego b i - bezwzględna długość gałęzi s i = b i /g - względna długość gałęzi L - całkowita długość gałęzi drzewa - oszacowanie współczynnika genowego E[L] = E[Σ i b i ] = e[σ i s i g] = (Σ i mu i )E[g] = 1 E[g]
37 Przypadek prosty - liczenie prawdopodobieństwa drzewa majac dany współczynnik g możemy policzyć prawdopodobieństwo P(T G = g) = Π i P(B i = b i G = g) = Π i N(S i = b i g µ i, σ 2 i ) = Π i N(S i = s i µ i, σ 2 i ) z rozkładu współczynnika genowego wybiera się takie g, które maksymalizuje to prawdopodobieństwo
38 Model ewolucji drzew genów - przypadek ogólny dopuszczamy duplikacje i straty uzyskujemy możliwość liczenia prawdopodobieństwa drzewa genów o dowolnej topologii
39 Przypadek ogólny - generowanie długości krawędzi b l - bezwzględna długość krawędzi x l - względna długość krawędzi (teraz różna od s i ) ogólne uzgodnienie - mapowanie gałęzi x i na ścieżkę gałęzi w drzewie gatunków: R b (b l ) = ((s 1, s 2,..., s m ), (p 1, p 2,..., p m )) y j - segment gałęzi b l, y j uzgadnia się z jedna gałęzia s j z ułamkiem p j x l - suma zmiennych y 1, y 2,..., y m jeśli p j = 1, rozkład y j normalny: y j N(µ i, σ 2 i ) jeśli p j < 1, nowy rozkład y j : y j N(p j µ i, p j σ 2 i ) wówczas: y j + y j+1 N(p j µ i, p j σ 2 i ) + N(p j+1 µ i, p j+1 σ 2 i ) = N(µ i, σ 2 i )
40 Przypadek ogólny - generowanie długości krawędzi c.d. całkowita długość krawędzi x l : x l cały czas ma rozkład normalny
41 Przypadek ogólny - generowanie długości krawędzi c.d.
42 Przypadek ogólny - liczenie prawdopodobieństwa drzewa długość gałęzi zależy od gałęzi gatunków, na które się mapuje, i punktów duplikacyjnych k l prawdopodobieństwo drzewa jako produkt prawdopodobieństw niezależnych poddrzew korzeń i liście poddrzewa: węzły specjacyjne węzły wewnętrzne poddrzewa: węzły duplikacyjne prawdopodobieństwo poddrzewa:
43 Przypadek ogólny - liczenie prawdopodobieństwa drzewa c.d.
44 Szkic działania dwa etapy pracy: 1 uczenie się modelu ewolucji genów i gatunków na podstawie jednoznacznych ortologów 2 zastosowanie nauczonego modelu do rekonstrukcji drzew genów
45 Uczenie szacowanie rozkładów g i s i na podstawie uliniowienia jednoznacznych ortologów założenia: drzewo gatunków znane lub wiarygodnie wydedukowane zbiór treningowy zawiera jednoznaczne ortologi z filogeneza zgodna z drzewem gatunków np. ortologi synteniczne w rozważanych 12 gatunkach muszek - ok. 1/3 wszystkich genów
46 Uczenie c.d. konstrukcja drzew genów zgodnych z topologia drzewa gatunków b i oszacowane metoda najmniejszych kwadratów każde drzewo genów - 1 gen ze wszystkich gatunków oszacowanie g: i b i oszacowanie pojedynczych s i : b i /g tysiace g i s i, do których dopasowujemy rozkłady gamma i normalny, wsnioskujac parametry (α, β, µ i, σ i )
47 Wnioskowanie użycie modelu do wnioskowania filogenezy pozostałych genów, zawierajacych potencjalnie duplikacje i straty genów rekonstrukcja oparta na odległościach macierz odległości na podstawie uliniowienia wielu sekwencji przeszukiwanie wielu topologii i szukanie drzewa o maksymalnym prawdopodobieństwie dla każdej topologii długości krawędzi liczone z macierzy odległości prawdopodobieństwo tych długości liczone na podstawie parametrów (α, β, µ i, σ i )
48 Wnioskowanie c.d. jeśli zaproponowana topologia drzewa zgadza się z topologia drzewa gatunków - produkt prawdopodobieństw: P(b G, S) = P(g G)Π i [P(b i /g s i )] każda gałaź drzewa genów mapuje się na jedna gałaź drzewa genów jeśli zaproponowana topologia drzewa genów nie zgadza się z topologia drzewa gatunków (zawiera duplikacje i straty genów), brakujace dane oszacowuje się na podstawie współczynnika g własności współczynników genowych i gatunkowych pozwalaja na policzenie prawdopodobieństwa drzewa genów o dowolnej topologii każde drzewo sprawdzone pod względem rozkładów wyuczonych z reszty genomu pozwala rozróżnić b i pasujace i niepasujace do rozkładów
49 Wnioskowanie c.d.
50 Przykład ortologi 4 ssaków - gen hemoglobiny-β topologia T1 3,5 razy bardziej prawdopodobna niż T2, każda gałaź bardziej pasuje do rozkładu wszystkie tradycyjne metody wskazały T2 zwn. long branch attraction, z powodu szybciej ewoluujacej gałęzi gryzoni metoda wskazała T1, bo spodziewał się dłuższej gałęzi efekt obserwowany również dla innych genów
51 Brak faworyzacji drzewa gatunków metoda działa również dla poprawnych drzew genów różnych od drzew gatunków szukanie drzewa genów dla paralogów: hemoglobiny-α psa i człowieka i hemoglobiny-β szczurów wskazanie poprawnej topologii: T2 metoda nie ma tendencji do wskazywania zawsze topologii drzewa gatunków
52 Dane badań dwie wersje : z/bez kary za duplikacje i straty materiał: 12 genomów Drosophilia i 9 genomów grzybów zbiór treningowy: 500 drzew genów Drosophilia, 200 drzew genów grzybów, wybranych losowo zbiór testowy: 4654 drzewa genów Drosophilia, 539 drzew genów grzybów testowanie działania w porównaniu z innymi metodami
53 Wyniki wyniki lepsze od tych uzyskanych przez inne metody
54 Własności dokładność koreluje z liczba miejsc informacji działanie wzrasta ze wzrostem długości genów działanie najlepsze dla genów o średniej prędkości ewolucji wyprzedza inne metody brak faworyzacji topologii drzew gatunków

55 Własności c.d.
56 Badania nad własnościami genów i gatunków pokazanie, że drzewa genów sa wynikiem dwóch sił ewolucji: specyficznej dla genów i dla gatunków pokazanie, że sa niezależne od siebie oczekiwanie, że dalsze badania ujawnia dodatkowe własności filogenezy genów i gatunków zwiększenie dokładności rekonstrukcji nowe spojrzenie na ewolucję
57 Nowe podejście do rekonstrukcji drzew współczynniki specyficzne dla genów i gatunków jako nowe podejście do rekonstrukcji drzew genów, z zastosowaniem kompletnych genomów istniejace metody traktuja każde drzewo osobno poprawia dokładność rekonstrukcji lepsze działanie pod wieloma względami niż działanie istniejacych metod użycie rekonstrukcji opartej na odległościach, można użyć rekonstrukcji character based model do specyfikacji długości krawędzi - może zastapić tradycyjny model rozwiazanie zachęcajace do dalszego rozwijania
58 Problem długich krawędzi długie krawędzie przyczyna błędów w rekonstrukcji drzew genów szybko ewoluujace gałęzie wymieszane z wolno ewoluujacymi sformułowanie problemu na poziomie gatunków szybko ewoluujace gałęzie sa tak samo porównywalnie szybsze w całym genomie model spodziewajac się długich gałęzi pozwala uniknać problemu długich krawędzi
59 Inne zastosowania współczynników specyficznych tutaj: zastosowanie współczynników specyficznych do uzyskania dokładnych drzew genów możliwe zastosowanie: niezwykłe przypadki zmian ewolucyjnych rozróżnienie, czy długość krawędzi wynika z: większego współczynnika genu szybko ewoluujacych gatunków szczególne przyspieszenie ewolucji danego genu w danym gatunku na poziomie indywidualnych genów lub zbiorów genów o pewnej kategorii funkcjonalności
60 Metodologia użyta do badania wielu gatunków przewidywane zsekwencjonowanie genomów wielu gatunków ssaków, grzybów, bakterii, wirusów wzrost liczby gatunków zdekwencjonowanych - odkrycia biologiczne, studia ewolucyjne wymaganie rygorystycznych metod porównywania genomów jednogenowe metody nie sa w stanie dobrze działać dla wielu gatunków metody powinny korzystać z dużej ilości informacji w kompletnych genomach metodologia przedstawiona jest ogólna, może być pomocna przy porównywaniu wielu kompletnych genomów
61 Dziękuję za uwagę.
Dopasowanie sekwencji (sequence alignment)
") Co to jest alignment? Dopasowanie sekwencji (sequence alignment) Alignment jest sposobem dopasowania struktur pierwszorzędowych DNA, RNA lub białek do zidentyfikowanych regionów w celu określenia podobieństwa;
Co to jest alignment? Dopasowanie sekwencji (sequence alignment) Alignment jest sposobem dopasowania struktur pierwszorzędowych DNA, RNA lub białek do zidentyfikowanych regionów w celu określenia podobieństwa;
Genomika Porównawcza. Agnieszka Rakowska Instytut Informatyki i Matematyki Komputerowej Uniwersytet Jagiellooski
 Genomika Porównawcza Agnieszka Rakowska Instytut Informatyki i Matematyki Komputerowej Uniwersytet Jagiellooski 1 Plan prezentacji 1. Rodzaje i budowa drzew filogenetycznych 2. Metody ukorzeniania drzewa
Genomika Porównawcza Agnieszka Rakowska Instytut Informatyki i Matematyki Komputerowej Uniwersytet Jagiellooski 1 Plan prezentacji 1. Rodzaje i budowa drzew filogenetycznych 2. Metody ukorzeniania drzewa
Acknowledgement. Drzewa filogenetyczne
 Wykład 8 Drzewa Filogenetyczne Lokalizacja genów Some figures from: Acknowledgement M. Zvelebil, J.O. Baum, Introduction to Bioinformatics, Garland Science 2008 Tradycyjne drzewa pokrewieństwa Drzewa oparte
Wykład 8 Drzewa Filogenetyczne Lokalizacja genów Some figures from: Acknowledgement M. Zvelebil, J.O. Baum, Introduction to Bioinformatics, Garland Science 2008 Tradycyjne drzewa pokrewieństwa Drzewa oparte
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
Bioinformatyka Laboratorium, 30h. Michał Bereta
 Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Często dopasować chcemy nie dwie sekwencje ale kilkanaście lub więcej 2 Istnieją dokładne algorytmy, lecz są one niewydajne
Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Często dopasować chcemy nie dwie sekwencje ale kilkanaście lub więcej 2 Istnieją dokładne algorytmy, lecz są one niewydajne
PODSTAWY BIOINFORMATYKI WYKŁAD 5 ANALIZA FILOGENETYCZNA
 PODSTAWY BIOINFORMATYKI WYKŁAD 5 ANALIZA FILOGENETYCZNA ANALIZA FILOGENETYCZNA 1. Wstęp - filogenetyka 2. Struktura drzewa filogenetycznego 3. Metody konstrukcji drzewa 4. Etapy konstrukcji drzewa filogenetycznego
PODSTAWY BIOINFORMATYKI WYKŁAD 5 ANALIZA FILOGENETYCZNA ANALIZA FILOGENETYCZNA 1. Wstęp - filogenetyka 2. Struktura drzewa filogenetycznego 3. Metody konstrukcji drzewa 4. Etapy konstrukcji drzewa filogenetycznego
Konstruowanie drzew filogenetycznych. Magda Mielczarek Katedra Genetyki Uniwersytet Przyrodniczy we Wrocławiu
 Konstruowanie drzew filogenetycznych Magda Mielczarek Katedra Genetyki Uniwersytet Przyrodniczy we Wrocławiu Drzewa filogenetyczne ukorzenione i nieukorzenione binarność konstrukcji topologia (sposób rozgałęziana
Konstruowanie drzew filogenetycznych Magda Mielczarek Katedra Genetyki Uniwersytet Przyrodniczy we Wrocławiu Drzewa filogenetyczne ukorzenione i nieukorzenione binarność konstrukcji topologia (sposób rozgałęziana
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
plezjomorfie: podobieństwa dziedziczone po dalszych przodkach (c. atawistyczna)
") Podobieństwa pomiędzy organizmami - cechy homologiczne: podobieństwa wynikające z dziedziczenia - apomorfie: podobieństwa dziedziczone po najbliższym przodku lub pojawiająca się de novo (c. ewolucyjnie
Podobieństwa pomiędzy organizmami - cechy homologiczne: podobieństwa wynikające z dziedziczenia - apomorfie: podobieństwa dziedziczone po najbliższym przodku lub pojawiająca się de novo (c. ewolucyjnie
Bioinformatyka Laboratorium, 30h. Michał Bereta
 Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Filogenetyka molekularna wykorzystuje informację zawartą w sekwencjach aminokwasów lub nukleotydów do kontrukcji drzew
Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Filogenetyka molekularna wykorzystuje informację zawartą w sekwencjach aminokwasów lub nukleotydów do kontrukcji drzew
Wstęp do Biologii Obliczeniowej
 Wstęp do Biologii Obliczeniowej Zagadnienia na kolokwium Bartek Wilczyński 5. czerwca 2018 Sekwencje DNA i grafy Sekwencje w biologii, DNA, RNA, białka, alfabety, transkrypcja DNA RNA, translacja RNA białko,
Wstęp do Biologii Obliczeniowej Zagadnienia na kolokwium Bartek Wilczyński 5. czerwca 2018 Sekwencje DNA i grafy Sekwencje w biologii, DNA, RNA, białka, alfabety, transkrypcja DNA RNA, translacja RNA białko,
E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne
 E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne Przypominajka: 152 drzewo filogenetyczne to drzewo, którego liśćmi są istniejące gatunki, a węzły wewnętrzne mają stopień większy niż jeden i reprezentują
E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne Przypominajka: 152 drzewo filogenetyczne to drzewo, którego liśćmi są istniejące gatunki, a węzły wewnętrzne mają stopień większy niż jeden i reprezentują
Modelowanie motywów łańcuchami Markowa wyższego rzędu
 Modelowanie motywów łańcuchami Markowa wyższego rzędu Uniwersytet Warszawski Wydział Matematyki, Informatyki i Mechaniki 23 października 2008 roku Plan prezentacji 1 Źródła 2 Motywy i ich znaczenie Łańcuchy
Modelowanie motywów łańcuchami Markowa wyższego rzędu Uniwersytet Warszawski Wydział Matematyki, Informatyki i Mechaniki 23 października 2008 roku Plan prezentacji 1 Źródła 2 Motywy i ich znaczenie Łańcuchy
VI WYKŁAD STATYSTYKA. 9/04/2014 B8 sala 0.10B Godz. 15:15
 VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
Filogenetyka molekularna I
 2 Literatura Krzysztof Spalik, Marcin Piwczyński (2009), Rekonstrukcja filogenezy i wnioskowanie filogenetyczne w badaniach ewolucyjnych, Kosmos 58(3-4): 485-498 Filogenetyka molekularna I John C. Avise
2 Literatura Krzysztof Spalik, Marcin Piwczyński (2009), Rekonstrukcja filogenezy i wnioskowanie filogenetyczne w badaniach ewolucyjnych, Kosmos 58(3-4): 485-498 Filogenetyka molekularna I John C. Avise
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Błędy przy testowaniu hipotez statystycznych. Decyzja H 0 jest prawdziwa H 0 jest faszywa
 Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Spis treści Wstęp Estymacja Testowanie. Efekty losowe. Bogumiła Koprowska, Elżbieta Kukla
 Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Matematyka ubezpieczeń majątkowych r.
 Matematyka ubezpieczeń majątkowych 3..007 r. Zadanie. Każde z ryzyk pochodzących z pewnej populacji charakteryzuje się tym że przy danej wartości λ parametru ryzyka Λ rozkład wartości szkód z tego ryzyka
Matematyka ubezpieczeń majątkowych 3..007 r. Zadanie. Każde z ryzyk pochodzących z pewnej populacji charakteryzuje się tym że przy danej wartości λ parametru ryzyka Λ rozkład wartości szkód z tego ryzyka
Statystyka matematyczna dla leśników
 Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Filogenetyka molekularna I. Krzysztof Spalik
 Filogenetyka molekularna I Krzysztof Spalik Literatura Krzysztof Spalik, Marcin Piwczyński (2009), Rekonstrukcja filogenezy i wnioskowanie filogenetyczne w badaniach ewolucyjnych, Kosmos 58(3-4): 485-498
Filogenetyka molekularna I Krzysztof Spalik Literatura Krzysztof Spalik, Marcin Piwczyński (2009), Rekonstrukcja filogenezy i wnioskowanie filogenetyczne w badaniach ewolucyjnych, Kosmos 58(3-4): 485-498
Metody Rozmyte i Algorytmy Ewolucyjne
 mgr inż. Wydział Matematyczno-Przyrodniczy Szkoła Nauk Ścisłych Uniwersytet Kardynała Stefana Wyszyńskiego Podstawowe operatory genetyczne Plan wykładu Przypomnienie 1 Przypomnienie Metody generacji liczb
mgr inż. Wydział Matematyczno-Przyrodniczy Szkoła Nauk Ścisłych Uniwersytet Kardynała Stefana Wyszyńskiego Podstawowe operatory genetyczne Plan wykładu Przypomnienie 1 Przypomnienie Metody generacji liczb
STATYSTYKA MATEMATYCZNA WYKŁAD 5. 2 listopada 2009
 STATYSTYKA MATEMATYCZNA WYKŁAD 5 2 listopada 2009 Poprzedni wykład: przedział ufności dla µ, σ nieznane Rozkład N(µ, σ). Wnioskowanie o średniej µ, gdy σ nie jest znane Testowanie H : µ = µ 0, K : µ
STATYSTYKA MATEMATYCZNA WYKŁAD 5 2 listopada 2009 Poprzedni wykład: przedział ufności dla µ, σ nieznane Rozkład N(µ, σ). Wnioskowanie o średniej µ, gdy σ nie jest znane Testowanie H : µ = µ 0, K : µ
Analizy filogenetyczne
 BIOINFORMATYKA edycja 2016 / 2017 wykład 6 Analizy filogenetyczne dr Jacek Śmietański jacek.smietanski@ii.uj.edu.pl http://jaceksmietanski.net Plan wykładu 1. Cele i zastosowania 2. Podstawy ewolucyjne
BIOINFORMATYKA edycja 2016 / 2017 wykład 6 Analizy filogenetyczne dr Jacek Śmietański jacek.smietanski@ii.uj.edu.pl http://jaceksmietanski.net Plan wykładu 1. Cele i zastosowania 2. Podstawy ewolucyjne
Testowanie hipotez statystycznych. Wprowadzenie
 Wrocław University of Technology Testowanie hipotez statystycznych. Wprowadzenie Jakub Tomczak Politechnika Wrocławska jakub.tomczak@pwr.edu.pl 10.04.2014 Pojęcia wstępne Populacja (statystyczna) zbiór,
Wrocław University of Technology Testowanie hipotez statystycznych. Wprowadzenie Jakub Tomczak Politechnika Wrocławska jakub.tomczak@pwr.edu.pl 10.04.2014 Pojęcia wstępne Populacja (statystyczna) zbiór,
Filogenetyka molekularna I. Krzysztof Spalik Zakład Filogenetyki Molekularnej i Ewolucji
 Filogenetyka molekularna I Krzysztof Spalik Zakład Filogenetyki Molekularnej i Ewolucji 3 Literatura Krzysztof Spalik, Marcin Piwczyński (2009), Rekonstrukcja filogenezy i wnioskowanie filogenetyczne w
Filogenetyka molekularna I Krzysztof Spalik Zakład Filogenetyki Molekularnej i Ewolucji 3 Literatura Krzysztof Spalik, Marcin Piwczyński (2009), Rekonstrukcja filogenezy i wnioskowanie filogenetyczne w
Wykład Bioinformatyka 2012-09-24. Bioinformatyka. Wykład 7. E. Banachowicz. Zakład Biofizyki Molekularnej IF UAM. Ewolucyjne podstawy Bioinformatyki
 Bioinformatyka Wykład 7 E. Banachowicz Zakład Biofizyki Molekularnej IF UAM http://www.amu.edu.pl/~ewas 1 Plan Bioinformatyka Ewolucyjne podstawy Bioinformatyki Filogenetyka Bioinformatyczne narzędzia
Bioinformatyka Wykład 7 E. Banachowicz Zakład Biofizyki Molekularnej IF UAM http://www.amu.edu.pl/~ewas 1 Plan Bioinformatyka Ewolucyjne podstawy Bioinformatyki Filogenetyka Bioinformatyczne narzędzia
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych
 Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
LABORATORIUM Populacja Generalna (PG) 2. Próba (P n ) 3. Kryterium 3σ 4. Błąd Średniej Arytmetycznej 5. Estymatory 6. Teoria Estymacji (cz.
 2. Próba (P n ) 3. Kryterium 3σ 4. Błąd Średniej Arytmetycznej 5. Estymatory 6. Teoria Estymacji (cz.") LABORATORIUM 4 1. Populacja Generalna (PG) 2. Próba (P n ) 3. Kryterium 3σ 4. Błąd Średniej Arytmetycznej 5. Estymatory 6. Teoria Estymacji (cz. I) WNIOSKOWANIE STATYSTYCZNE (STATISTICAL INFERENCE) Populacja
LABORATORIUM 4 1. Populacja Generalna (PG) 2. Próba (P n ) 3. Kryterium 3σ 4. Błąd Średniej Arytmetycznej 5. Estymatory 6. Teoria Estymacji (cz. I) WNIOSKOWANIE STATYSTYCZNE (STATISTICAL INFERENCE) Populacja
Elementy statystyki STA - Wykład 5
 STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
Filogeneza: problem konstrukcji grafu (drzewa) zależności pomiędzy gatunkami.
 zależności pomiędzy gatunkami.") 181 Filogeneza: problem konstrukcji grafu (drzewa) zależności pomiędzy gatunkami. 3. D T(D) poprzez algorytm łączenia sąsiadów 182 D D* : macierz łącząca sąsiadów n Niech TotDist i = k=1 D i,k Definiujemy
181 Filogeneza: problem konstrukcji grafu (drzewa) zależności pomiędzy gatunkami. 3. D T(D) poprzez algorytm łączenia sąsiadów 182 D D* : macierz łącząca sąsiadów n Niech TotDist i = k=1 D i,k Definiujemy
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Statystyka matematyczna. Wykład IV. Weryfikacja hipotez statystycznych
 Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Spis treści. Przedmowa... XI. Wprowadzenie i biologiczne bazy danych. 1 Wprowadzenie... 3. 2 Wprowadzenie do biologicznych baz danych...
 Przedmowa... XI Część pierwsza Wprowadzenie i biologiczne bazy danych 1 Wprowadzenie... 3 Czym jest bioinformatyka?... 5 Cele... 5 Zakres zainteresowań... 6 Zastosowania... 7 Ograniczenia... 8 Przyszłe
Przedmowa... XI Część pierwsza Wprowadzenie i biologiczne bazy danych 1 Wprowadzenie... 3 Czym jest bioinformatyka?... 5 Cele... 5 Zakres zainteresowań... 6 Zastosowania... 7 Ograniczenia... 8 Przyszłe
Wszystkie wyniki w postaci ułamków należy podawać z dokładnością do czterech miejsc po przecinku!
 Pracownia statystyczno-filogenetyczna Liczba punktów (wypełnia KGOB) / 30 PESEL Imię i nazwisko Grupa Nr Czas: 90 min. Łączna liczba punktów do zdobycia: 30 Czerwona Niebieska Zielona Żółta Zaznacz znakiem
Pracownia statystyczno-filogenetyczna Liczba punktów (wypełnia KGOB) / 30 PESEL Imię i nazwisko Grupa Nr Czas: 90 min. Łączna liczba punktów do zdobycia: 30 Czerwona Niebieska Zielona Żółta Zaznacz znakiem
Filogenetyka molekularna. Dr Anna Karnkowska Zakład Filogenetyki Molekularnej i Ewolucji
 Filogenetyka molekularna Dr Anna Karnkowska Zakład Filogenetyki Molekularnej i Ewolucji Co to jest filogeneza? Filogeneza=drzewo filogenetyczne=drzewo rodowe=drzewo to rozgałęziający się diagram, który
Filogenetyka molekularna Dr Anna Karnkowska Zakład Filogenetyki Molekularnej i Ewolucji Co to jest filogeneza? Filogeneza=drzewo filogenetyczne=drzewo rodowe=drzewo to rozgałęziający się diagram, który
Wykład 9 Wnioskowanie o średnich
 Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średn
 Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
PODSTAWY BIOINFORMATYKI 6 ANALIZA FILOGENETYCZNA
 PODSTAWY BIOINFORMATYKI 6 ANALIZA FILOGENETYCZNA ANALIZA FILOGENETYCZNA 1. Wstęp - filogenetyka 2. Struktura drzewa filogenetycznego 3. Metody konstrukcji drzewa - przykłady 4. Etapy konstrukcji drzewa
PODSTAWY BIOINFORMATYKI 6 ANALIZA FILOGENETYCZNA ANALIZA FILOGENETYCZNA 1. Wstęp - filogenetyka 2. Struktura drzewa filogenetycznego 3. Metody konstrukcji drzewa - przykłady 4. Etapy konstrukcji drzewa
Algorytm genetyczny (genetic algorithm)-
-") Optymalizacja W praktyce inżynierskiej często zachodzi potrzeba znalezienia parametrów, dla których system/urządzenie będzie działać w sposób optymalny. Klasyczne podejście do optymalizacji: sformułowanie
Optymalizacja W praktyce inżynierskiej często zachodzi potrzeba znalezienia parametrów, dla których system/urządzenie będzie działać w sposób optymalny. Klasyczne podejście do optymalizacji: sformułowanie
SMOP - wykład. Rozkład normalny zasady przenoszenia błędów. Ewa Pawelec
 SMOP - wykład Rozkład normalny zasady przenoszenia błędów Ewa Pawelec 1 iepewność dla rozkładu norm. Zamiast dodawania całych zakresów uwzględniamy prawdopodobieństwo trafienia dwóch wartości: P x 1, x
SMOP - wykład Rozkład normalny zasady przenoszenia błędów Ewa Pawelec 1 iepewność dla rozkładu norm. Zamiast dodawania całych zakresów uwzględniamy prawdopodobieństwo trafienia dwóch wartości: P x 1, x
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
Zmienność ewolucyjna. Ewolucja molekularna
 Zmienność ewolucyjna Ewolucja molekularna Mechanizmy ewolucji Generujące zmienność mutacje rearanżacje genomu horyzontalny transfer genów! Działające na warianty wytworzone przez zmienność dobór naturalny
Zmienność ewolucyjna Ewolucja molekularna Mechanizmy ewolucji Generujące zmienność mutacje rearanżacje genomu horyzontalny transfer genów! Działające na warianty wytworzone przez zmienność dobór naturalny
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Estymacja parametrów rozkładu cechy
 Estymacja parametrów rozkładu cechy Estymujemy parametr θ rozkładu cechy X Próba: X 1, X 2,..., X n Estymator punktowy jest funkcją próby ˆθ = ˆθX 1, X 2,..., X n przybliżającą wartość parametru θ Przedział
Estymacja parametrów rozkładu cechy Estymujemy parametr θ rozkładu cechy X Próba: X 1, X 2,..., X n Estymator punktowy jest funkcją próby ˆθ = ˆθX 1, X 2,..., X n przybliżającą wartość parametru θ Przedział
Testowanie hipotez statystycznych
 Temat Testowanie hipotez statystycznych Kody znaków: Ŝółte wyróŝnienie nowe pojęcie pomarańczowy uwaga kursywa komentarz 1 Zagadnienia omawiane na zajęciach 1. Idea i pojęcia teorii testowania hipotez
Temat Testowanie hipotez statystycznych Kody znaków: Ŝółte wyróŝnienie nowe pojęcie pomarańczowy uwaga kursywa komentarz 1 Zagadnienia omawiane na zajęciach 1. Idea i pojęcia teorii testowania hipotez
Estymacja przedziałowa - przedziały ufności dla średnich. Wrocław, 5 grudnia 2014
 Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI
 LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 3 - model statystyczny, podstawowe zadania statystyki matematycznej
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 3 - model statystyczny, podstawowe zadania statystyki matematycznej Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 3 1 / 8 ZADANIE z rachunku
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 3 - model statystyczny, podstawowe zadania statystyki matematycznej Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 3 1 / 8 ZADANIE z rachunku
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Teoria ewolucji. Podstawy wspólne pochodzenie.
 Teoria ewolucji. Podstawy wspólne pochodzenie. Ewolucja biologiczna } Znaczenie ogólne: } proces zmian informacji genetycznej (częstości i rodzaju alleli), } które to zmiany są przekazywane z pokolenia
Teoria ewolucji. Podstawy wspólne pochodzenie. Ewolucja biologiczna } Znaczenie ogólne: } proces zmian informacji genetycznej (częstości i rodzaju alleli), } które to zmiany są przekazywane z pokolenia
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Kalibracja. W obu przypadkach jeśli mamy dane, to możemy znaleźć równowagę: Konwesatorium z Ekonometrii, IV rok, WNE UW 1
 Kalibracja Kalibracja - nazwa pochodzi z nauk ścisłych - kalibrowanie instrumentu oznacza wyznaczanie jego skali (np. kalibrowanie termometru polega na wyznaczeniu 0C i 100C tak by oznaczały punkt zamarzania
Kalibracja Kalibracja - nazwa pochodzi z nauk ścisłych - kalibrowanie instrumentu oznacza wyznaczanie jego skali (np. kalibrowanie termometru polega na wyznaczeniu 0C i 100C tak by oznaczały punkt zamarzania
Testowanie hipotez statystycznych cd.
 Temat Testowanie hipotez statystycznych cd. Kody znaków: żółte wyróżnienie nowe pojęcie pomarańczowy uwaga kursywa komentarz 1 Zagadnienia omawiane na zajęciach 1. Przykłady testowania hipotez dotyczących:
Temat Testowanie hipotez statystycznych cd. Kody znaków: żółte wyróżnienie nowe pojęcie pomarańczowy uwaga kursywa komentarz 1 Zagadnienia omawiane na zajęciach 1. Przykłady testowania hipotez dotyczących:
1.1 Wstęp Literatura... 1
 Spis treści Spis treści 1 Wstęp 1 1.1 Wstęp................................ 1 1.2 Literatura.............................. 1 2 Elementy rachunku prawdopodobieństwa 2 2.1 Podstawy..............................
Spis treści Spis treści 1 Wstęp 1 1.1 Wstęp................................ 1 1.2 Literatura.............................. 1 2 Elementy rachunku prawdopodobieństwa 2 2.1 Podstawy..............................
STATYSTYKA MATEMATYCZNA WYKŁAD października 2009
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 26 października 2009 Rozkład N(µ, σ). Estymacja σ σ 2 = 1 σ 2π + = E µ,σ (X µ) 2 { (x µ) 2 exp 1 ( ) } x µ 2 dx 2 σ Rozkład N(µ, σ). Estymacja σ σ 2 = 1 σ 2π + = E µ,σ
STATYSTYKA MATEMATYCZNA WYKŁAD 4 26 października 2009 Rozkład N(µ, σ). Estymacja σ σ 2 = 1 σ 2π + = E µ,σ (X µ) 2 { (x µ) 2 exp 1 ( ) } x µ 2 dx 2 σ Rozkład N(µ, σ). Estymacja σ σ 2 = 1 σ 2π + = E µ,σ
Natalia Neherbecka. 11 czerwca 2010
 Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Porównywanie i dopasowywanie sekwencji
 Porównywanie i dopasowywanie sekwencji Związek bioinformatyki z ewolucją Wraz ze wzrostem dostępności sekwencji DNA i białek pojawiła się nowa możliwość śledzenia ewolucji na poziomie molekularnym Ewolucja
Porównywanie i dopasowywanie sekwencji Związek bioinformatyki z ewolucją Wraz ze wzrostem dostępności sekwencji DNA i białek pojawiła się nowa możliwość śledzenia ewolucji na poziomie molekularnym Ewolucja
Propensity score matching (PSM)
") Propensity score matching (PSM) Jerzy Mycielski Uniwersytet Warszawski Maj 2010 Jerzy Mycielski (Uniwersytet Warszawski) Propensity score matching (PSM) Maj 2010 1 / 18 Badania ewaluacyjne Ocena wpływu
Propensity score matching (PSM) Jerzy Mycielski Uniwersytet Warszawski Maj 2010 Jerzy Mycielski (Uniwersytet Warszawski) Propensity score matching (PSM) Maj 2010 1 / 18 Badania ewaluacyjne Ocena wpływu
TESTY NIEPARAMETRYCZNE. 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa.
 TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
Wnioskowanie statystyczne. Statystyka w 5
 Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja)
") PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
WYKŁAD 5 TEORIA ESTYMACJI II
 WYKŁAD 5 TEORIA ESTYMACJI II Teoria estymacji (wyznaczanie przedziałów ufności, błąd badania statystycznego, poziom ufności, minimalna liczba pomiarów). PRÓBA Próba powinna być reprezentacyjna tj. jak
WYKŁAD 5 TEORIA ESTYMACJI II Teoria estymacji (wyznaczanie przedziałów ufności, błąd badania statystycznego, poziom ufności, minimalna liczba pomiarów). PRÓBA Próba powinna być reprezentacyjna tj. jak
klasyfikacja fenetyczna (numeryczna)
") Teorie klasyfikacji klasyfikacja fenetyczna (numeryczna) systematyka powinna być wolna od wszelkiej teorii (a zwłaszcza od teorii ewolucji) filogeneza jako ciąg zdarzeń jest niepoznawalna opiera się na
Teorie klasyfikacji klasyfikacja fenetyczna (numeryczna) systematyka powinna być wolna od wszelkiej teorii (a zwłaszcza od teorii ewolucji) filogeneza jako ciąg zdarzeń jest niepoznawalna opiera się na
Teoria ewolucji. Podstawowe pojęcia. Wspólne pochodzenie.
 Teoria ewolucji Podstawowe pojęcia. Wspólne pochodzenie. Ewolucja Znaczenie ogólne: zmiany zachodzące stopniowo w czasie W biologii ewolucja biologiczna W astronomii i kosmologii ewolucja gwiazd i wszechświata
Teoria ewolucji Podstawowe pojęcia. Wspólne pochodzenie. Ewolucja Znaczenie ogólne: zmiany zachodzące stopniowo w czasie W biologii ewolucja biologiczna W astronomii i kosmologii ewolucja gwiazd i wszechświata
Wykład Centralne twierdzenie graniczne. Statystyka matematyczna: Estymacja parametrów rozkładu
 Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Ekonometria. Zajęcia
 Ekonometria Zajęcia 16.05.2018 Wstęp hipoteza itp. Model gęstości zaludnienia ( model gradientu gęstości ) zakłada, że gęstość zaludnienia zależy od odległości od okręgu centralnego: y t = Ae βx t (1)
Ekonometria Zajęcia 16.05.2018 Wstęp hipoteza itp. Model gęstości zaludnienia ( model gradientu gęstości ) zakłada, że gęstość zaludnienia zależy od odległości od okręgu centralnego: y t = Ae βx t (1)
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/
 Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Badanie doboru naturalnego na poziomie molekularnym
 Badanie doboru naturalnego na poziomie molekularnym Podstawy ewolucji molekulanej Jak ewoluują sekwencje Zmiany genetyczne w ewolucji Mutacje tworzą nowe allele genów Inwersje zmieniają układ genów na
Badanie doboru naturalnego na poziomie molekularnym Podstawy ewolucji molekulanej Jak ewoluują sekwencje Zmiany genetyczne w ewolucji Mutacje tworzą nowe allele genów Inwersje zmieniają układ genów na
2. Założenie niezależności zakłóceń modelu - autokorelacja składnika losowego - test Durbina - Watsona
 Sprawdzanie założeń przyjętych o modelu (etap IIIC przyjętego schematu modelowania regresyjnego) 1. Szum 2. Założenie niezależności zakłóceń modelu - autokorelacja składnika losowego - test Durbina - Watsona
Sprawdzanie założeń przyjętych o modelu (etap IIIC przyjętego schematu modelowania regresyjnego) 1. Szum 2. Założenie niezależności zakłóceń modelu - autokorelacja składnika losowego - test Durbina - Watsona
Testowanie hipotez statystycznych
 Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Testowanie hipotez. Marcin Zajenkowski. Marcin Zajenkowski () Testowanie hipotez 1 / 25
 Testowanie hipotez 1 / 25") Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Mechanizmy zmienności ewolucyjnej. Podstawy ewolucji molekularnej.
 Mechanizmy zmienności ewolucyjnej Podstawy ewolucji molekularnej. Mechanizmy ewolucji } Generujące zmienność } mutacje } rearanżacje genomu } horyzontalny transfer genów } Działające na warianty wytworzone
Mechanizmy zmienności ewolucyjnej Podstawy ewolucji molekularnej. Mechanizmy ewolucji } Generujące zmienność } mutacje } rearanżacje genomu } horyzontalny transfer genów } Działające na warianty wytworzone
ANALIZA STATYSTYCZNA WYNIKÓW BADAŃ
 ANALIZA STATYSTYCZNA WYNIKÓW BADAŃ Dopasowanie rozkładów Dopasowanie rozkładów- ogólny cel Porównanie średnich dwóch zmiennych 2 zmienne posiadają rozkład normalny -> test parametryczny (t- studenta) 2
ANALIZA STATYSTYCZNA WYNIKÓW BADAŃ Dopasowanie rozkładów Dopasowanie rozkładów- ogólny cel Porównanie średnich dwóch zmiennych 2 zmienne posiadają rozkład normalny -> test parametryczny (t- studenta) 2
Porównywanie i dopasowywanie sekwencji
 Porównywanie i dopasowywanie sekwencji Związek bioinformatyki z ewolucją Wraz ze wzrostem dostępności sekwencji DNA i białek narodziła się nowa dyscyplina nauki ewolucja molekularna Ewolucja molekularna
Porównywanie i dopasowywanie sekwencji Związek bioinformatyki z ewolucją Wraz ze wzrostem dostępności sekwencji DNA i białek narodziła się nowa dyscyplina nauki ewolucja molekularna Ewolucja molekularna
Przyrównanie sekwencji. Magda Mielczarek Katedra Genetyki Uniwersytet Przyrodniczy we Wrocławiu
 Przyrównanie sekwencji Magda Mielczarek Katedra Genetyki Uniwersytet Przyrodniczy we Wrocławiu Sequence alignment - przyrównanie sekwencji Poszukiwanie ciągów znaków (zasad nukleotydowych lub reszt aminokwasowych),
Przyrównanie sekwencji Magda Mielczarek Katedra Genetyki Uniwersytet Przyrodniczy we Wrocławiu Sequence alignment - przyrównanie sekwencji Poszukiwanie ciągów znaków (zasad nukleotydowych lub reszt aminokwasowych),
Psychometria PLAN NAJBLIŻSZYCH WYKŁADÓW. Co wyniki testu mówią nam o samym teście? A. Rzetelność pomiaru testem. TEN SLAJD JUŻ ZNAMY
 definicja rzetelności błąd pomiaru: systematyczny i losowy Psychometria Co wyniki testu mówią nam o samym teście? A. Rzetelność pomiaru testem. rozkład X + błąd losowy rozkład X rozkład X + błąd systematyczny
definicja rzetelności błąd pomiaru: systematyczny i losowy Psychometria Co wyniki testu mówią nam o samym teście? A. Rzetelność pomiaru testem. rozkład X + błąd losowy rozkład X rozkład X + błąd systematyczny
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Modelowanie sieci złożonych
 Modelowanie sieci złożonych B. Wacław Instytut Fizyki UJ Czym są sieci złożone? wiele układów ma strukturę sieci: Internet, WWW, sieć cytowań, sieci komunikacyjne, społeczne itd. sieć = graf: węzły połączone
Modelowanie sieci złożonych B. Wacław Instytut Fizyki UJ Czym są sieci złożone? wiele układów ma strukturę sieci: Internet, WWW, sieć cytowań, sieci komunikacyjne, społeczne itd. sieć = graf: węzły połączone
Co to są drzewa decyzji
 Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
Metody Statystyczne. Metody Statystyczne. #8 Błąd I i II rodzaju powtórzenie. Dwuczynnikowa analiza wariancji
 gkrol@mail.wz.uw.edu.pl #8 Błąd I i II rodzaju powtórzenie. Dwuczynnikowa analiza wariancji 1 Ryzyko błędu - powtórzenie Statystyka niczego nie dowodzi, czyni tylko wszystko mniej lub bardziej prawdopodobnym
gkrol@mail.wz.uw.edu.pl #8 Błąd I i II rodzaju powtórzenie. Dwuczynnikowa analiza wariancji 1 Ryzyko błędu - powtórzenie Statystyka niczego nie dowodzi, czyni tylko wszystko mniej lub bardziej prawdopodobnym
PODSTAWY WNIOSKOWANIA STATYSTYCZNEGO czȩść II
 PODSTAWY WNIOSKOWANIA STATYSTYCZNEGO czȩść II Szkic wykładu 1 Wprowadzenie 2 3 4 5 Weryfikacja hipotez statystycznych Obok estymacji drugim działem wnioskowania statystycznego jest weryfikacja hipotez
PODSTAWY WNIOSKOWANIA STATYSTYCZNEGO czȩść II Szkic wykładu 1 Wprowadzenie 2 3 4 5 Weryfikacja hipotez statystycznych Obok estymacji drugim działem wnioskowania statystycznego jest weryfikacja hipotez
Statystyczna analiza danych
 Statystyczna analiza danych ukryte modele Markowa, zastosowania Anna Gambin Instytut Informatyki Uniwersytet Warszawski plan na dziś Ukryte modele Markowa w praktyce modelowania rodzin białek multiuliniowienia
Statystyczna analiza danych ukryte modele Markowa, zastosowania Anna Gambin Instytut Informatyki Uniwersytet Warszawski plan na dziś Ukryte modele Markowa w praktyce modelowania rodzin białek multiuliniowienia
Matematyka ubezpieczeń majątkowych r.
 Matematyka ubezpieczeń majątkowych 0.0.005 r. Zadanie. Likwidacja szkody zaistniałej w roku t następuje: w tym samym roku z prawdopodobieństwem 0 3, w następnym roku z prawdopodobieństwem 0 3, 8 w roku
Matematyka ubezpieczeń majątkowych 0.0.005 r. Zadanie. Likwidacja szkody zaistniałej w roku t następuje: w tym samym roku z prawdopodobieństwem 0 3, w następnym roku z prawdopodobieństwem 0 3, 8 w roku
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria Wykład 5 dr inż. Anna Skowrońska-Szmer zima 2017/2018 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją
Statystyka matematyczna i ekonometria Wykład 5 dr inż. Anna Skowrońska-Szmer zima 2017/2018 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją
Prawdopodobieństwo i rozkład normalny cd.
 # # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
# # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Teoria ewolucji. Podstawowe pojęcia. Wspólne pochodzenie.
 Teoria ewolucji Podstawowe pojęcia. Wspólne pochodzenie. Informacje Kontakt: Paweł Golik Instytut Genetyki i Biotechnologii, Pawińskiego 5A pgolik@igib.uw.edu.pl Informacje, materiały: http://www.igib.uw.edu.pl/
Teoria ewolucji Podstawowe pojęcia. Wspólne pochodzenie. Informacje Kontakt: Paweł Golik Instytut Genetyki i Biotechnologii, Pawińskiego 5A pgolik@igib.uw.edu.pl Informacje, materiały: http://www.igib.uw.edu.pl/
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Zad. 4 Należy określić rodzaj testu (jedno czy dwustronny) oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:
 oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:") Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y).
 na zmienną zależną (Y).") Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Agata Boratyńska Statystyka aktuarialna... 1
 Agata Boratyńska Statystyka aktuarialna... 1 ZADANIA NA ĆWICZENIA Z TEORII WIAROGODNOŚCI Zad. 1. Niech X 1, X 2,..., X n będą niezależnymi zmiennymi losowymi z rozkładu wykładniczego o wartości oczekiwanej
Agata Boratyńska Statystyka aktuarialna... 1 ZADANIA NA ĆWICZENIA Z TEORII WIAROGODNOŚCI Zad. 1. Niech X 1, X 2,..., X n będą niezależnymi zmiennymi losowymi z rozkładu wykładniczego o wartości oczekiwanej
2.1 Przykład wstępny Określenie i konstrukcja Model dwupunktowy Model gaussowski... 7
 Spis treści Spis treści 1 Przedziały ufności 1 1.1 Przykład wstępny.......................... 1 1.2 Określenie i konstrukcja...................... 3 1.3 Model dwupunktowy........................ 5 1.4
Spis treści Spis treści 1 Przedziały ufności 1 1.1 Przykład wstępny.......................... 1 1.2 Określenie i konstrukcja...................... 3 1.3 Model dwupunktowy........................ 5 1.4