Agnieszka Nowak Brzezińska
|
|
|
- Adam Nowak
- 8 lat temu
- Przeglądów:
Transkrypt
1 Agnieszka Nowak Brzezińska
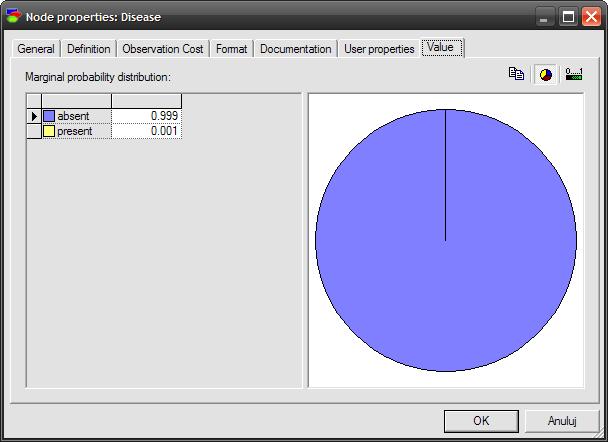
2 Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo przynależności obiektu do klasy. Opiera się na twierdzeniu Bayesa. Twierdzenia Bayesa pokazuje, w jaki sposób obliczyć prawdopodobieństwo warunkowe P(H X), jeśli znane są prawdopodobieństwa: warunkowe P(X H) oraz bezwarunkowe P(H) i P(X). Prawdopodobieństwa: P(X H), P(H) oraz P(X) mogą być bezpośrednio wyliczone z danych zgromadzonych w treningowym zbiorze danych (w bazie danych).
3 Każdy obiekt traktowany jest jako wektor X (krotka) wartości atrybutów A 1,..., A n : X = (x1, x2,..., xn). Niech C 1,..., C m będą klasami, do których może należeć X, P(C X) niech oznacza prawdopodobieństwo przynależności X (ściślej: obiektów o właściwości X) do klasy C. W klasyfikacji Bayesa przypisujemy X do tej klasy, do której prawdopodobieństwo warunkowe przynależności X jest największe. X jest więc przypisany do C i, jeśli P(C i X) P(C k X), dla każdego k, 1 k m, k i.
4 1. W klasyfikacji Bayesa maksymalizujemy: 2. Ponieważ P(X) jest stałe, więc wystarczy maksymalizować Iloczyn P(X C i )P(C i ). 3. Ponadto przyjmujemy: P(C i ) = s i / s, gdzie s oznacza liczbę obiektów w zbiorze treningowym, a s i oznacza liczbę obiektów w klasie C i. 4. Dla X = (x 1, x 2,..., x n ), wartość P(X C i ) obliczamy jako iloczyn: P(X C i ) = P(x 1 C i )*P(x 2 C i )*... *P(x n C i ), przy czym: P(x k C i ) = s ik / s i, gdzie s ik oznacza liczbę obiektów klasy C i, dla których wartość atrybutu A k jest równa x k, a s i oznacza liczbę wszystkich obiektów klasy Ci w zadanym zbiorze treningowym.
5 Klasyfikacja bayesowska, to metoda budowy systemu ekspertowego, w której wiedza przedstawiona jest á priori z warunkowymi prawdopodobieństwami, a wnioskowanie polega na liczeniu następnych prawdopodobieństw. Mechanizm wnioskowania wykorzystujący twierdzenie Bayesa polega na obliczaniu prawdopodobieństwa każdego możliwego wyniku, gdy znany jest dany konkretny przypadek.
6 Wadą tej metody jest fakt, że wymaga ona znajomości dokładnych wartości lub rozkładów prawdopodobieństw pojawienia się parametrów zjawiska, czyli problemu będącego przedmiotem rozważań. Innym problemem jest to, że należy dokonać pewnych nierealistycznych założeń na przykład w klasyfikacji bayesowskiej wymagane wyniki, np. rozpoznawania, musza się wzajemnie wykluczać. Niestety w wielu przypadkach mogą występować liczne podobne wyniki (np. w diagnostyce: pacjent może mieć wiele chorób). Innym założeniem, co prawda niewymaganym przez twierdzenie Bayesa, ale wymuszonym przez praktykę, jest statystyczna niezależność cechy problemu.
7 Koncepcja sieci Bayesa wynika wprost z koncepcji prawdopodobieństwa warunkowego. Jak się okazuje w rzeczywistym świecie jest wiele sytuacji w których wystąpienie jakiegoś zdarzenia ściśle zależy od innego zdarzenia. Zastosowanie sieci Bayesa pozwala na uniknięcie obliczeń o dużej złożoności obliczenie jednego prawdopodobieństwa a posteriori łączy się z uprzednim obliczeniem wykorzystywanych prawdopodobieństw. Sieci Bayesa służą do przedstawiania niepewności wiedzy. Niepewność wiedzy używanej zawartej w systemach ekspertowych może mieć wiele czynników: niepewność ekspertów dotycząca ich wiedzy niepewność tkwiąca w modelowanej dziedzinie niepewność inżyniera próbującego przetłumaczyć wiedzę niepewność wynikła z dokładności dostępnej wiedzy
8 Sieci Bayesa używają teorii prawdopodobieństwa do określenia niepewności przez jawne reprezentowanie warunkowych zależności pomiędzy różnymi częściami wiedzy. Pozwala to na intuicyjną graficzną wizualizację wiedzy zawierającą wzajemne oddziaływania pomiędzy różnymi źródłami niepewności. Sieci Bayesa są stosowane w diagnostyce, w rozumowaniu przebiegającym od efektów do przyczyn i odwrotnym. W systemach ekspertowych sieci Bayesa znalazły zastosowanie w medycynie (systemy doradcze, które rozpoznają chorobę na podstawie podawanych objawów).
9 Wejście: Rozważana populacja obiektów (klientów) opisana jest za pomocą czterech atrybutów: Wiek, Dochód, Studia, OcenaKred. Interesuje nas przynależność obiektów do jednej z dwóch klas: klienci kupujący komputery (o etykiecie TAK) i klienci nie kupujący komputerów (o etykiecie NIE). Z bazy danych wybrano zbiór treningowy. Obiekt X o nieznanej przynależności klasowej ma postać: X = (Wiek = <=30, Dochód = średni, Student = tak, OcenaKred = dobra ) Wyjście: Określić przynależność obiektu X do klasy C1 ( tak ) lub C2 ( nie ) za pomocą klasyfikacji Bayesa.
10
11 Klasyfikowany obiekt: X = (Wiek = <=30, Dochód = średni, Student = tak, OcenaKred = dobra ) Należy obliczyć, dla jakiej wartości i, (i =1, 2) iloczyn P(X C i )*P(C i ), osiąga maksimum. 2. P(C i ) oznacza prawdopodobieństwo bezwarunkowe przynależności obiektu do klasy (inaczej: prawdopodobieństwo klasy) C i, i = 1, 2. Ze zbioru treningowego obliczamy: P(C 1 ) = 9/14 = P(C 2 ) = 5/14 = Prawdopodobieństwa warunkowe P(X C i ) są odpowiednio równe iloczynom prawdopodobieństw warunkowych: P(X C 1 ) = P(Wiek= <=30 C 1 ) * P(Dochód= średni C 1 ) P(Studia= tak C 1 ) * P(OcenaKred= dobra C 1 ), P(X C 2 ) = P(Wiek= <=30 C 2 ) * P(Dochód= średni C 2 ) P(Studia= tak C 2 ) * P(OcenaKred= dobra C 2 ),
 = 6/9 = 0.667 P(Wiek= <=30 C 2 ) = 3/5 = 0.600 P(Dochód= średni C 2 ) = 2/5 = 0,400 P(Studia= tak C 2 ) = 1/5 = 0.")
12 Ze zbioru treningowego obliczamy: P(Wiek= <=30 C 1 ) = 2/9 = P(Dochód= średni C 1 ) = 4/9 = P(Studia= tak C 1 ) = 6/9 = P(OcenaKred= dobra C 1 ) = 6/9 = P(Wiek= <=30 C 2 ) = 3/5 = P(Dochód= średni C 2 ) = 2/5 = 0,400 P(Studia= tak C 2 ) = 1/5 = P(OcenaKred= dobra C 2 ) = 2/5 = 0.400
13 Stąd: P(X C 1 ) = 0.222*0.444*0.667*0.667 = P(X C 1 )P(C 1 ) = 0.044*0.643 = P(X C 2 ) = 0.600*0.400*0.200*0.400 = P(X C 2 )P(C 2 ) = 0.019*0.357 = X został zaklasyfikowany do C 1.
 brytyjski matematyk i duchowny prezbiteriański, znany ze sformułowania opublikowanego")
14 Thomas Bayes (ur. ok w Londynie zm. 17 kwietnia 1761) brytyjski matematyk i duchowny prezbiteriański, znany ze sformułowania opublikowanego pośmiertnie twierdzenia Bayesa, które to zapoczątkowało dział statystyki.
15 (od nazwiska Thomasa Bayesa) to twierdzenie teorii prawdopodobieństwa, wiążące prawdopodobieństwa warunkowe zdarzeń. Na przykład, jeśli jest zdarzeniem "u pacjenta występuje wysoka gorączka", i jest zdarzeniem "pacjent ma grypę", twierdzenie Bayesa pozwala przeliczyć znany odsetek gorączkujących wśród chorych na grypę i znane odsetki gorączkujących i chorych na grypę w całej populacji, na prawdopodobieństwo, że ktoś jest chory na grypę, gdy wiemy że ma wysoką gorączkę. Twierdzenie stanowi podstawę teoretyczną sieci bayesowskich, stosowanych w eksploracji danych.
16 Jeśli A i B są prostymi zdarzeniami w przestrzeni prób, to prawdopodobieństwo warunkowe P(A/B) będzie określone jako: P( A B) P( A B) P( B) liczba wyników liczba Również P(B/A) = P(AB)/P(A). zarówno wyników w w A jak B Przekształcając ten wzór, otrzymujemy wzór na przecięcie zdarzeń P(AB) = P(B/A)P(A) i po podstawieniu mamy: P( B / A) P( A) P( A B) P( B) Co jest tezą twierdzenia Bayesa dla prostych zdarzeń. i B
17
18 Sieć bayesowska to acykliczny (nie zawierający cykli) graf skierowany, w którym: węzły reprezentują zmienne losowe (np. temperaturę jakiegoś źródła, stan pacjenta, cechę obiektu itp.) łuki (skierowane) reprezentują zależność typu zmienna X ma bezpośredni wpływ na zmienna Y, każdy węzeł X ma stowarzyszona z nim tablice prawdopodobieństw warunkowych określających wpływ wywierany na X przez jego poprzedników (rodziców) w grafie, Zmienne reprezentowane przez węzły przyjmują wartości dyskretne (np.: TAK, NIE).
19 Siecią Bayesa nazywamy skierowany graf acykliczny o wierzchołkach reprezentujących zmienne losowe i łukach określających zależności. Istnienie łuku pomiędzy dwoma wierzchołkami oznacza istnienie bezpośredniej zależności przyczynowo skutkowej pomiędzy odpowiadającymi im zmiennymi. Siła tej zależności określona jest przez tablice prawdopodobieństw warunkowych.
20 a E b d c G F gdzie a, b, c, d to obserwacje, E, F, G to hipotezy Aby zdefiniować graf zwykle podaje się zbiór jego wierzchołków oraz zbiór jego krawędzi. Każdy wierzchołek reprezentuje obserwację lub hipotezę, każda krawędź jest określona w ten sposób, że podaje się dla niej informacje o wierzchołkach które dana krawędź łączy, oraz ewentualnie dla grafów skierowanych informację o kierunku krawędzi. Załóżmy, że G będzie grafem określonym zbiorem wierzchołków N i krawędzi E. Załóżmy, również że dany jest zbiór prawdopodobieństw warunkowych CP. Elementami tego zbiory są prawdopodobieństwa opisujące poszczególne krawędzie grafu
 węzły w grafie odpowiadające zbiorom obserwacji i hipotez E (ang.")
21 Pod pojęciem sieci Bayesowskiej rozumieć będziemy trójkę: B = { N, E, CP } gdzie dwójka {N,E} jest zorientowanym grafem acyklicznym zbudowanym na podstawie zadanych prawdopodobieństw warunkowych zawartych w zbiorze CP. N (ang. Nodes) węzły w grafie odpowiadające zbiorom obserwacji i hipotez E (ang. edges) krawędzie odzwierciedlające kierunek wnioskowania Każdy wierzchołek w sieci przechowuje rozkład P(X i (i) ) gdzie X (i) jest zbiorem wierzchołków odpowiadających (i) poprzednikom (rodzicom) wierzchołka (i).

22 Prawdopodobieństwo wystąpienia anginy w przypadku objawów takich jak ból gardła i gorączka jest wysokie i wynosić może 0.8. Jednak wystąpienie gorączki i bólu głowy może świadczyć o grypie, co jest hipoteza prawdopodobna na 0.6. W przypadku gdy pacjent cierpiący na grypę nie wyleczył się całkowicie może dojść do zapalenia oskrzeli z prawdopodobieństwem 0.4. Zapalenie oskrzeli może spowodować ból gardła z prawdopodobieństwem 0.3. Hipotezy: A Angina D-grypa O-Zapalenie oskrzeli b g 0.8 A 0.3 Objawy: b-ból gardła g-gorączka c-ból głowy c 0.6 D e 0.4 O e-brak całkowitego wyleczenia CP = {P(A b,g)=0.8; P(D g,c)=0.6; P(O D,e)=0.4;P(b O)=0.3}
23 Rozkład prawdopodobieństw zapisuje się jako: P( x n,..., x ) P( x X ) 1 n i ( i) i1 W grafie wierzchołki są etykietowane nazwami atrybutów. Przy każdym wierzchołku występuje tabela prawdopodobieństw warunkowych pomiędzy danym wierzchołkiem i jego rodzicami.
24 Węzeł A jest rodzicem lub poprzednikiem wierzchołka X, a wierzchołek X jest potomkiem lub następnikiem węzła A, jeżeli istnieje bezpośrednia krawędź z wierzchołka A do X. p( X m 1 x1, X 2 x2,..., X m xm) p( X i xi rodzice( X i )) i1 A więc prawdopodobieństwo pojawienia się wierzchołka potomnego zależy tylko od jego rodziców!
25 zdefiniowanie zmiennych, zdefiniowanie połączeń pomiędzy zmiennymi, określenie prawdopodobieństw warunkowych i a priori (łac. z założenia) wprowadzenie danych do sieci, uaktualnienie sieci, wyznaczenie prawdopodobieństw a posteriori ( łac. z następstwa) Sieć bayesowska koduje informacje o określonej dziedzinie za pomocą wykresu, którego wierzchołki wyrażają zmienne losowe, a krawędzie obrazują probabilistyczne zależności między nimi.
26 Sieci te mają wiele zastosowań m.in. w Sztucznej inteligencji, medycynie (w diagnozowaniu), w genetyce, statystyce, w ekonomii. O popularności SB zadecydowało to, że są dla nich wydajne metody wnioskowania. Możliwe jest proste wnioskowanie o zależności względnej i bezwzględnej badanych atrybutów. Niezależność może tak zmodularyzować naszą wiedzę, że wystarczy zbadanie tylko części informacji istotnej dla danego zapytania, zamiast potrzeby eksploracji całej wiedzy. Sieci Bayesowskie mogą być ponadto rekonstruowane, nawet jeśli tylko część właściwości warunkowej niezależności zmiennych jest znana. Inną cechą SB jest to, że taką sieć można utworzyć mając niepełne dane na temat zależności warunkowej atrybutów.
27 Przykład: jakie są szanse zdania ustnego egzaminu u prof. X, który jest kibicem Wisły i nie lubi deszczu? Z - zaliczony egzamin N - dobre przygotowanie H - dobry humor egzaminatora A - awans Wisły do Ligi Mistrzów D - deszcz Łączny rozkład prawdopodobieństwa: P(Z, N, H, A,D) wyznaczony przez 2 5 wartości (32 wartości)
28 Prawdopodobieństwo dobrego humoru, jeżeli Wisła awansowała: P(H=trueA=true): D N Z D A H N Z P A H P,, ),,,, ( ), ( D H N Z D A H N Z P A P,,, ),,,, ( ) ( 8 sumowań 16 sumowań ) ( ), ( ) ( A P A H P A H P obliczymy z łącznego rozkładu P(Z, N, H, A,D), na podstawie prawdopodobieństw brzegowych:
 = P(Z H) N H P(Z) T 0.90 T F 0.55 T 0.")
29 P(A) 0.20 P(D) 0.30 P(N) 0.20 A D P(H) T 0.95 T F 0.99 T 0.05 F F 0.15 P(Z H,D) = P(Z H) N H P(Z) T 0.90 T F 0.55 T 0.45 F F 0.05
30 Musimy pamiętać mniej wartości: w naszym przypadku 11 zamiast 31 (ogólnie n2 k, n-liczba wierzchołków, k - maksymalna liczba rodziców; zamiast 2 n -1 wszystkich wartości w rozkładzie pełnym) Naturalne modelowanie: łatwiej oszacować prawd. warunkowe bezpośrednich zależności niż koniunkcji wszystkich możliwych zdarzeń Dowolny kierunek wnioskowania Czytelna reprezentacja wiedzy Łatwa modyfikacja
31 Reguła łańcuchowa: z def. P(X 1,X 2 )=P(X 1 X 2 )P(X 2 ) P( X,..., X n) P( X i X i1,..., X 1 n i Numerując wierzchołki grafu tak aby indeks każdej zmiennej był mniejszy niż indeks przypisany jego przodkom oraz korzystając z warunkowej niezależności otrzymujemy: ) P( Xi X i1,..., X n) P( Xi Parents ( Xi)) Model zupełny P( X1,..., X n) P( X i i Parents ( X i ))
32 P(Z,N,H,A,D) = P(Z N,H) P(N) P(H A,D) P(A) P(D) Jaka jest szansa zaliczenia dla nieprzygotowanego studenta, gdy pada, Wisła odpadła i egzaminator jest w złym humorze? P(Z N H A D) = = P(A) 0.20 P(D) 0.30 P(N) 0.20 N H P(Z) T 0.90 T F 0.55 T 0.45 F F 0.05 A D P(H) T 0.95 T F 0.99 T 0.05 F F 0.15
33 Prawdopodobieństwo Zaliczenia 74%
 z 20% do 40%, przy spadku P(D) -")
34 Egzamin zaliczony, jakie były tego przyczyny? Wzrost P(A) z 20% do 40%, przy spadku P(D) - wykluczanie

35 Jeśli się przygotowaliśmy, to jaka jest szansa na zaliczenie? Spadek P(Z) z 26% do 17%
36 ... ale dodatkowo, Wisła awansowała i świeci słońce! Wzrost P(Z) z 17% do 45%. Podchodzić?
 Podej Zalicz Styp true false true true 7000 5000 false false 2500")
37 Dodajemy wierzchołki decyzyjne (Podejście) oraz użyteczności (Stypendium) i możemy mierzyć wpływ ilościowy decyzji (Podchodzić, Nie Podchodzić) Podej Zalicz Styp true false true true false false

38 Czy warto iść gdy jesteśmy nieprzygotowani, świeci słońce i Wisła awansowała?
39 A pogoda (słonecznie/pochmurno/deszczowo/wietrznie) B czas wolny (tak/nie) X humor (bardzo dobry/dobry/nietęgi) C zajęcie na zewnątrz (spacer/basen/rower) D zajęcie w domu(komputer/książka/gotowanie) A X B C D
40 If A=a1 and B=b1 then X=x1 with 30% If A=a1 and B=b1 then X=x2 with 30% If A=a1 and B=b1 then X=x2 with 40% If A=a1 and B=b2 then X=x1 with 20% If A=a1 and B=b2 then X=x2 with 40% If A=a1 and B=b2 then X=x2 with 40% If A=a2 and B=b1 then X=x1 with 10% If A=a2 and B=b1 then X=x2 with 30% If A=a2 and B=b1 then X=x2 with 60% If A=a2 and B=b2 then X=x1 with 5% If A=a2 and B=b2 then X=x2 with 35% If A=a2 and B=b2 then X=x2 with 60% If A=a3 and B=b1 then X=x1 with 40% If A=a3 and B=b1 then X=x2 with 40% If A=a3 and B=b1 then X=x2 with 20% P(X A,B) x1 x2 x3 a1b a1b a2b a2b a3b a3b a4b a4b If A=a3 and B=b2 then X=x1 with 20% If A=a3 and B=b2 then X=x2 with 50% If A=a3 and B=b2 then X=x2 with 30% If A=a4 and B=b1 then X=x1 with 60% If A=a4 and B=b1 then X=x2 with 35% If A=a4 and B=b1 then X=x2 with 5% If A=a4 and B=b2 then X=x1 with 30% If A=a4 and B=b2 then X=x2 with 40% If A=a4 and B=b2 then X=x2 with 30%
41 A a a a a P(X A,B) x1 x2 x3 a1b a1b a2b a2b a3b a3b a4b a4b B b1 0.4 b2 0.6 P(C X) c1 c2 c3 X X X P(DX) d1 d2 d3 X X X
42 A a a a a B b1 0.4 b2 0.6 P(X A,B) X1 x2 x3 a1b a1b a2b a2b a3b a3b a4b a4b P(C X) c1 c2 c3 X X X P(DX) d1 d2 d3 X X X *0.6*0.05*0.5*0.4 ) ( ) ( ) ( ) ( ) ( ),,,, ( ) ( ) ( ) ( ) ( ) ( ),,,, ( x X d D p x X c C p b B a A x X p b B p a A p x X d D c C b B a A p x X d D p x X c C p b B a A x X p b B p a A p x X d D c C b B a A p
43 A a a a a P(X A,B) X1 x2 x3 a1b a1b a2b a2b a3b a3b a4b a4b B b1 0.4 b2 0.6 p( X x1 A a1 B b1 )* p( A a1)* p( B b1 ) 0.3*(0.25*0.4) 0.3*
44 A a a a a B b1 0.4 b2 0.6 P(C X) c1 c2 c3 X X X P(DX) d1 d2 d3 X X X * * * * * * * *0.1 ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( b B a A p b B a A x X p b B a A p b B a A x X p b B a A p b B a A x X p b B a A p b B a A x X p b B a A p b B a A x X p b B a A p b B a A x X p b B a A p b B a A x X p b B a A p b B a A x X p x X p P(X A,B) X1 x2 x3 a1b a1b a2b a2b a3b a3b a4b a4b

45 Jakie są szanse zdania ustnego egzaminu u prof. X, który jest kibicem Wisły i nie lubi deszczu? Wynik egzaminu zależy od: dobrego przygotowania studenta dobrego humor egzaminatora awansu Wisły do Ligi Mistrzów Deszczu by nie padał!!!
46 Jak prawdopodobne jest zdanie egzaminu gdy humor egzaminatora i przygotowanie studenta jest pewne w skali pół na pół?

47 Jak prawdopodobne jest zdanie egzaminu gdy humor egzaminatora i przygotowanie studenta jest pewne przynajmniej w 70 %?
48 Jak prawdopodobne jest zdanie egzaminu gdy humor egzaminatora jest dobry ale przygotowanie studenta niestety fatalne!?
49
50
51
52
53
54
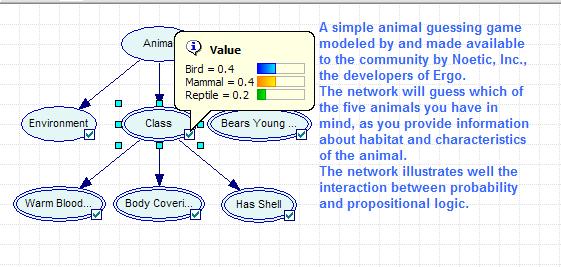
55 SMILE Zestaw klas C++ implementujących różne modele decyzyjne w oparciu o analizę probabilistyczną. Wśród nich sieci Bayesa, modele równań strukturalnych. SMILE doskonałe sprawdzi się w roli engine'u dla różnego rodzaju aplikacji, których celem jest tworzenia graficznej reprezentacji model probabilistycznego. Biblioteka została zaprojektowana w ten sposób, iż może być wykorzystana w kodzie C poprzez wywołania funkcji. Co więcej, istnieje również wersja przeznaczona dla platformy.net. Platforma: Macintosh, Linux, Solaris, Windows Licencja: Decision Systems Laboratory, University of Pittsburgh License GeNIe 2 GeNIe stanowi komplementarny element dla SMILE. Jest graficzną nakładką dla tej biblioteki. Z uwagi na to, że twórcy SMILE rozwijali również GeNIe, można być pewnym bezproblemowej współpracy. Za sprawą wbudowanego edytora modeli GeNIe pozwala na swobodną modyfikację modeli probabilistycznych. Możliwa jest także wymiana danych z innymi aplikacjami (Excel). Platforma: Windows Licencja: Decision Systems Laboratory, University of Pittsburgh License


56 Przedstawione na grafie zależności są modelowane przez przedstawione liczbowo prawdopodobieństwo wyrażające siłę, z jaką oddziałują na siebie zmienne. Prawdopodobieństwo jest kodowane w tabelach dołączanych do każdego węzła i indeksowanych przez węzły nadrzędne. Górne wiersze tabeli przedstawiają wszystkie kombinacje stanów zmiennych nadrzędnych.
57 Węzły bez poprzedników są opisane głównymi prawdopodobieństwami. Węzeł Success będzie opisany przez rozkład prawdopodobieństw tylko jego dwóch wyników możliwych: Success i Failure. Węzeł Forecast będzie natomiast opisany przez rozkład prawdopodobieństw wyjściowych wartości (Good, Moderate, Poor) uwarunkowanych dodatkowo przez ich poprzedniki (węzeł Success, i wyjściowe wartości Success i Failure).

58
59
60

61
62

63
64

65 Sieć Bayesa
66 Rozważmy osobę, która spędza sporo czasu przy komputerze, w wolnych chwilach gra na komputerze oraz przegląda Internet. Mało czasu poświęca na sport czy spotkania z przyjaciółmi. W szkole nie ma problemów z przedmiotami ścisłymi typu matematyka czy fizyka, jednak ma pewne problemy z przedmiotami humanistycznymi. Osoba lubi majsterkować ze sprzętem Węzeł Odpowiedź Komentarz zdolności techniczne tak Typowy gracz jest zainteresowany nowinkami technologicznymi, zdobywa różnego rodzaju gadżety i potrafi je obsługiwać. Dodatkowo, gry uczą logicznego myślenia. twórczość nie Brak poczucia estetyki i twórczego myślenia. zdolności werbalne nie Mogą być problemy z wysłowieniem się poza wirtualnym światem, dosyć ograniczone słownictwo. zdolności liczbowe tak Zamiłowanie do matematyki, fizyki. praca z ludźmi nie Trudności w poznawaniu nowych ludzi. Rzadkie spotkania z przyjaciółmi wskazują na zamkniętość osoby. polityka nie Brak zainteresowania bieżącymi wydarzeniami społecznymi i gospodarczymi. status społeczny wysoki Oczekiwanie wysokiego statusu społecznego. zarobki wysokie Oczekiwanie wysokich zarobków. kontakt z ludźmi brak Oczekiwanie braku częstego kontaktu z ludźmi w pracy praca indywidualna.


67 Rozważmy osobę, która spędza sporo czasu przy komputerze, w wolnych chwilach gra na komputerze oraz przegląda Internet. Mało czasu poświęca na sport czy spotkania z przyjaciółmi. W szkole nie ma problemów z przedmiotami ścisłymi typu matematyka czy fizyka, jednak ma pewne problemy z przedmiotami humanistycznymi. Osoba lubi majsterkować ze sprzętem
68 Otrzymane wyniki (kolor fioletowy na diagramie): Warstwa kierunki studiów: Kierunki techniczne: otrzymały najwyższy wynik (pole żaden uzyskało tylko 5%). Osoba nie mająca problemów z przedmiotami ścisłymi ma predyspozycje do kierunków technicznych. W ramach tego typu kierunków widać niewielką przewagę kierunku informatyka (50%) nad kierunkiem budownictwo (45%). Kierunki ekonomiczne: również przystępny wynik (pole żaden uzyskało 33%). Brak problemów z matematyką osoby, wpłynął na dosyć wysoki wynik dla kierunku finanse (48%) oraz niższy dla kierunku marketing (20%). Sumowanie się wyników do 101% jest spowodowane zapewne błędem programu GeNIe. Kierunki społeczne i artystyczne: otrzymano 100% i 96% dla pola żaden. Osoba, która rzadko spotyka się z przyjaciółmi, czy ma problemy z przedmiotami humanistycznymi powinna unikać tych kierunków.
69 Warstwa praca zawodowa, stanowisko: Praca inżynierska: Wysoki wynik dla kierunków technicznych w poprzedniej warstwie wpłynął na dosyć wysoki wynik dla zawodów, które wymagają tytułu inżyniera (85%). Branża rozrywkowa: Niski wynik spowodowany unikaniem kontaktów z ludźmi przez typowego gracza Stanowisko kierownicze: Dosyć wysoki wynik (80%) wynika z predyspozycji osoby do kierunków technicznych oraz ekonomicznych. Marketing: Tutaj również unikanie kontaktów z ludźmi zaniżyło wynik (11%), mimo dosyć dobrych wyników kierunków ekonomicznych. Finanse: Dosyć wysoki wynik (63%) spowodowany zdolnościami technicznymi oraz liczbowymi typowego gracza. Warstwa różne cechy i aspekty pracy: Kariera zawodowa: Dobre wyniki dla pracy jako inżynier oraz w finansach w poprzedniej warstwie, spowodowały wysoki wynik dla stabilności kariery zawodowej typowego gracza (87%).
70 Sieci bayesowskie - efektywne narzędzie w zagadnieniach systemów eksperckich oraz sztucznej inteligencji Szerokie zastosowania: NASA-AutoClass, Microsoft-Office Assistant, w przemyśle - medycyna, sądownictwo, itd. Sieci Bayesa stanowią naturalną reprezentację niezależności warunkowej (indukowanej przyczynowo). Topologia sieci i tablice prawdopodobieństwa warunkowego (CPT) pozwalają na zwartą reprezentację rozkładu łącznego prawdopodobieństwa. Sieci Bayesa są szczególnie przydane i łatwe do zastosowania w systemach ekspertowych.

71
72 Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe może być określenie- model cech niezależnych. Model prawdopodobieństwa można wyprowadzić korzystając z twierdzenia Bayesa. W zależności od rodzaju dokładności modelu prawdopodobieństwa, naiwne klasyfikatory bayesowskie można uczyć bardzo skutecznie w trybie uczenia z nadzorem.

73

74
75 Jeśli wiemy, że kulek czerwonych jest 2 razy mniej niż zielonych (bo czerwonych jest 20 a zielonych 40) to prawdopodobieństwo tego, że kolejna (nowa) kulka będzie koloru zielonego jest dwa razy większe niż tego, że kulka będzie czerwona. Dlatego możemy napisać, że znane z góry prawdopodobieństwa:

76 Jeśli więc czerwonych jest 20 a zielonych 40, to razem wszystkich jest 60. Więc Więc teraz gdy mamy do czynienia z nową kulką ( na rysunku biała):
77 To spróbujmy ustalić jaka ona będzie. Dokonujemy po prostu klasyfikacji kulki do jednej z dwóch klas: zielonych bądź czerwonych. Jeśli weźmiemy pod uwagę sąsiedztwo białej kulki takie jak zaznaczono, a więc do 4 najbliższych sąsiadów, to widzimy, że wśród nich są 3 kulka czerwone i 1 zielona. Obliczamy liczbę kulek w sąsiedztwie należących do danej klasy : zielonych bądź czerwonych z wzorów: W naszym przypadku, jest dziwnie, bo akurat w sąsiedztwie kulki X jest więcej kulek czerwonych niż zielonych, mimo, iż kulek zielonych jest ogólnie 2 razy więcej niż czerwonych. Dlatego zapiszemy, że
78 Dlatego ostatecznie powiemy, że Prawdopodobieństwo że kulka X jest zielona = prawdopodobieństwo kulki zielonej * prawdopodobieństwo, że kulka X jest zielona w swoim sąsiedztwie = Prawdopodobieństwo że kulka X jest czerwona = prawdopodobieństwo kulki czerwonej * prawdopodobieństwo, że kulka X jest czerwona w swoim sąsiedztwie = Ostatecznie klasyfikujemy nową kulkę X do klasy kulek czerwonych, ponieważ ta klasa dostarcza nam większego prawdopodobieństwa posteriori.
79 Tylko dla cech jakościowych Tylko dla dużych zbiorów danych
80
81
82
83 Aby obliczyć P(diabetes=1) należy zliczyć liczbę obserwacji dla których spełniony jest warunek diabetes=1. Jest ich dokładnie 9 z 20 wszystkich. Podobnie, aby obliczyć P(diabetes=0) należy zliczyć liczbę obserwacji dla których spełniony jest warunek diabetes=0. Jest ich dokładnie 11 z 20 wszystkich.

84 Zakładając, że zmienne niezależne faktycznie są niezależne, wyliczenie P(X diabetes=1) wymaga obliczenia prawdopodobieństwa warunkowego wszystkich wartości dla X: Np. obliczenie P(BP=high diabetes=1) wymaga znów obliczenia P(BP=high) i P(diabetes=1) co jest odpowiednio równe 4 i 9 zatem prawdopodobieństwo to wynosi 4/9:
 można wyznaczyć iloczyn tych")
85 Zatem: Mając już prawdopodobieństwa P(X diabetes=1) i P(diabetes=1) można wyznaczyć iloczyn tych prawdopodobieństw:


86 Teraz podobnie zrobimy w przypadku P(X diabetes=0)
87 Możemy więc wyznaczyć P(X diabetes=0): Ostatecznie iloczyn prawdopodobieństw jest wyznaczany: Jakoże P(X diabeltes=1)p(diabetes=1) jest większe niż P(X diabetes=0)p(diabetes=0) nowa obserwacja będzie zaklasyfikowana do klasy diabetes=1. Prawdopodobieństwo ostateczne że jeśli obiekt ma opis taki jak X będzie z klasy diabetes=1 jest równe:
88 Jakie będzie prawdopodobieństwo klasyfikacji do klasy diabetes=1 gdy mamy następujące przypadki: X:BP=Average ; weight=above average; FH= yes; age=50+ X:BP=low ; weight=average; FH= no; age=50+ X:BP=high ; weight=average; FH= yes; age=50+

89
90
91 jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również być używany do klasyfikacji. - Założenia Dany jest zbiór uczący zawierający obserwacje z których każda ma przypisany wektor zmiennych objaśniających oraz wartość zmiennej objaśnianej Y. Dana jest obserwacja C z przypisanym wektorem zmiennych objaśniających dla której chcemy prognozować wartość zmiennej objaśnianej Y.
92
93
94 Wyznaczanie odległości obiektów: odległość euklidesowa
95 Obiekty są analizowane w ten sposób, że oblicza się odległości bądź podobieństwa między nimi. Istnieją różne miary podobieństwa czy odległości. Powinny być one wybierane konkretnie dla typu danych analizowanych: inne są bowiem miary typowo dla danych binarnych, inne dla danych nominalnych a inne dla danych numerycznych. Nazwa Wzór gdzie: x,y - to wektory wartości cech porównywanych obiektów w przestrzeni p- wymiarowej, gdzie odpowiednio wektory wartości to: oraz. odległość euklidesowa odległość kątowa współczynnik korelacji liniowej Pearsona Miara Gowera
96 Oblicz odległość punktu A o współrzędnych (2,3) do punktu B o współrzędnych (7,8) A B D (A,B) = pierwiastek ((7-2) 2 + (8-3) 2 ) = pierwiastek ( ) = pierwiastek (50) = 7.07
97 9 8 B A A B C 2 1 C Mając dane punkty: A(2,3), B(7,8) oraz C(5,1) oblicz odległości między punktami: D (A,B) = pierwiastek ((7-2) 2 + (8-3) 2 ) = pierwiastek ( ) = pierwiastek (50) = 7.07 D (A,C) = pierwiastek ((5-2) 2 + (3-1) 2 ) = pierwiastek (9 + 4) = pierwiastek (13) = 3.60 D (B,C) = pierwiastek ((7-5) 2 + (3-8) 2 ) = pierwiastek (4 + 25) = pierwiastek (29) = 5.38
98 1. porównanie wartości zmiennych objaśniających dla obserwacji C z wartościami tych zmiennych dla każdej obserwacji w zbiorze uczącym. 2. wybór k (ustalona z góry liczba) najbliższych do C obserwacji ze zbioru uczącego. 3. Uśrednienie wartości zmiennej objaśnianej dla wybranych obserwacji, w wyniku czego uzyskujemy prognozę. Przez "najbliższą obserwację" mamy na myśli, taką obserwację, której odległość do analizowanej przez nas obserwacji jest możliwie najmniejsza.
99
100

101 Najbliższy dla naszego obiektu buźka jest obiekt Więc przypiszemy nowemu obiektowi klasę:
102 Mimo, że najbliższy dla naszego obiektu buźka jest obiekt Metodą głosowania ustalimy, że skoro mamy wziąć pod uwagę 5 najbliższych sąsiadów tego obiektu, a widać, że 1 z nich ma klasę: Zaś 4 pozostałe klasę: To przypiszemy nowemu obiektowi klasę:

103 Obiekt klasyfikowany podany jako ostatni : a = 3, b = 6 Teraz obliczmy odległości poszczególnych obiektów od wskazanego. Dla uproszczenia obliczeń posłużymy sie wzorem:
104
105

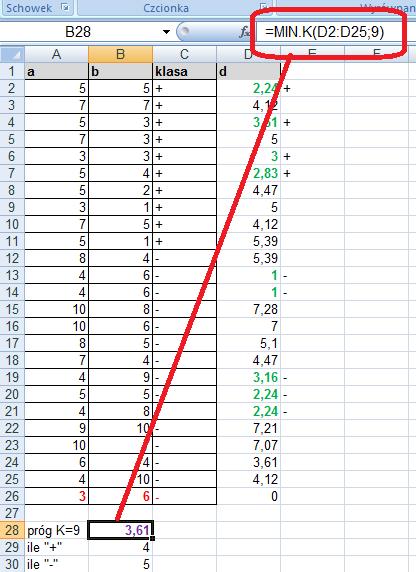
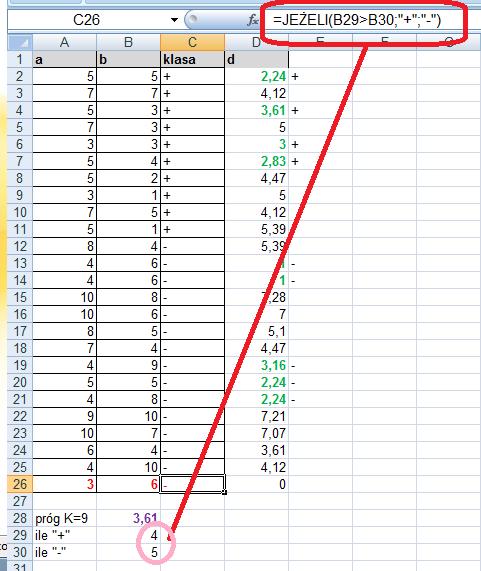
106 Znajdujemy więc k najbliższych sąsiadów. Załóżmy, że szukamy 9 najbliższych sąsiadów. Wyróżnimy ich kolorem zielonym. Sprawdzamy, które z tych 9 najbliższych sąsiadów są z klasy + a które z klasy -? By to zrobić musimy znaleźć k najbliższych sąsiadów (funkcja Excela o nazwie MIN.K)
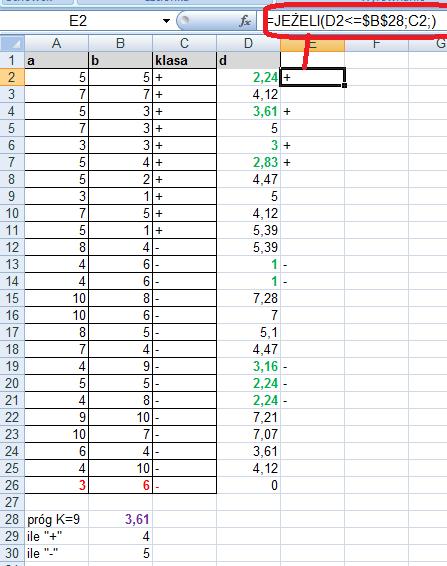
107
108
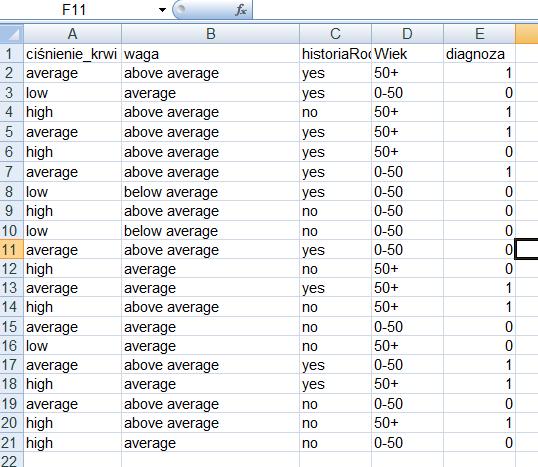
109 Wyobraźmy sobie, że nie mamy 2 zmiennych opisujących każdy obiekt, ale tych zmiennych jest np. 5: {v1,v2,v3,v4,v5} i że obiekty opisane tymi zmiennymi to 3 punkty: A, B i C: V1 V2 V3 V4 V5 A B C Policzmy teraz odległość między punktami: D (A,B) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.03) = 0.17 D (A,C) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.69) = 0.83 D (B,C) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.74) = 0.86 Szukamy najmniejszej odległości, bo jeśli te dwa punkty są najbliżej siebie, dla których mamy najmniejszą odległości! A więc najmniejsza odległość jest między punktami A i B!
110
111
112
113

114
115
116

117 Schemat algorytmu: Poszukaj obiektu najbliższego w stosunku do obiektu klasyfikowanego. Określenie klasy decyzyjnej na podstawie obiektu najbliższego. Cechy algorytmu: Bardziej odporny na szumy - w poprzednim algorytmie obiekt najbliższy klasyfikowanemu może być zniekształcony - tak samo zostanie zaklasyfikowany nowy obiekt. Konieczność ustalenia liczby najbliższych sąsiadów. Wyznaczenie miary podobieństwa wśród obiektów (wiele miar podobieństwa). Dobór parametru k - liczby sąsiadów: Jeśli k jest małe, algorytm nie jest odporny na szumy jakość klasyfikacji jest niska. Jeśli k jest duże, czas działania algorytmu rośnie - większa złożoność obliczeniowa. Należy wybrać k, które daje najwyższą wartość klasyfikacji.
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Klasyfikacja metodą Bayesa
 Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Sieci Bayesowskie. Agnieszka Nowak Brzezińska Wykład III i IV
 Sieci Bayesowskie Agnieszka Nowak Brzezińska Wykład III i IV Definicja sieci Bayesowskiej Sied bayesowska to acykliczny nie zawierający cykli graf skierowany, w którym: węzły reprezentują zmienne losowe
Sieci Bayesowskie Agnieszka Nowak Brzezińska Wykład III i IV Definicja sieci Bayesowskiej Sied bayesowska to acykliczny nie zawierający cykli graf skierowany, w którym: węzły reprezentują zmienne losowe
OSP Odkryj Swoją Przyszłość System do wybierania kierunku studiów oraz pracy zawodowej Jan Burkot Krzysztof Staroń. Wersja 1.0, 3.06.
 OSP Odkryj Swoją Przyszłość System do wybierania kierunku studiów oraz pracy zawodowej Jan Burkot Krzysztof Staroń Wersja 1.0, 3.06.2011 Spis treści: 1 Opis przeznaczenia systemu... 3 2 Wiedza systemu...
OSP Odkryj Swoją Przyszłość System do wybierania kierunku studiów oraz pracy zawodowej Jan Burkot Krzysztof Staroń Wersja 1.0, 3.06.2011 Spis treści: 1 Opis przeznaczenia systemu... 3 2 Wiedza systemu...
Systemy ekspertowe - wiedza niepewna
 Instytut Informatyki Uniwersytetu Śląskiego lab 8 Rozpatrzmy następujący przykład: Miażdżyca powoduje często zwężenie tętnic wieńcowych. Prowadzi to zazwyczaj do zmniejszenia przepływu krwi w tych naczyniach,
Instytut Informatyki Uniwersytetu Śląskiego lab 8 Rozpatrzmy następujący przykład: Miażdżyca powoduje często zwężenie tętnic wieńcowych. Prowadzi to zazwyczaj do zmniejszenia przepływu krwi w tych naczyniach,
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Sztuczna inteligencja : Algorytm KNN
 Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Sieci Bayesowskie. Agnieszka Nowak Brzezińska
 Sieci Bayesowskie Agnieszka Nowak Brzezińska Rodzaje niepewności Niepewność stochastyczna np. nieszczęśliwy wypadek, ryzyko ubezpieczenia, wygrana w lotto metody rachunku prawdopodobieństwa Niepewność
Sieci Bayesowskie Agnieszka Nowak Brzezińska Rodzaje niepewności Niepewność stochastyczna np. nieszczęśliwy wypadek, ryzyko ubezpieczenia, wygrana w lotto metody rachunku prawdopodobieństwa Niepewność
Sieci Bayesowskie. Agnieszka Nowak Brzezińska
 Sieci Bayesowskie Agnieszka Nowak Brzezińska Riodzaje niepewności Niepewność stochastyczna np. nieszczęśliwy wypadek, ryzyko ubezpieczenia, wygrana w lotto (metody rachunku prawdopodobieństwa Niepewność
Sieci Bayesowskie Agnieszka Nowak Brzezińska Riodzaje niepewności Niepewność stochastyczna np. nieszczęśliwy wypadek, ryzyko ubezpieczenia, wygrana w lotto (metody rachunku prawdopodobieństwa Niepewność
Algorytmy stochastyczne, wykład 08 Sieci bayesowskie
 Algorytmy stochastyczne, wykład 08 Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2014-04-10 Prawdopodobieństwo Prawdopodobieństwo Prawdopodobieństwo warunkowe Zmienne
Algorytmy stochastyczne, wykład 08 Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2014-04-10 Prawdopodobieństwo Prawdopodobieństwo Prawdopodobieństwo warunkowe Zmienne
Gdzie: N zbiór wierzchołków grafu, E zbiór krawędzi grafu, Cp zbiór prawdopodobieostw warunkowych.
 Laboratorium z przedmiotu Sztuczna inteligencja Temat: Sieci Bayesa, Wnioskowanie probabilistyczne, GeNIe Laboratorium nr 1 Sied Bayesowska służy do przedstawiania zależności pomiędzy zdarzeniami bazując
Laboratorium z przedmiotu Sztuczna inteligencja Temat: Sieci Bayesa, Wnioskowanie probabilistyczne, GeNIe Laboratorium nr 1 Sied Bayesowska służy do przedstawiania zależności pomiędzy zdarzeniami bazując
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Sieci Bayesa mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Sosnowiec, 2011
 Sieci Bayesa mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Sosnowiec, 2011 Sieć Bayesowska służy do przedstawiania zależności pomiędzy zdarzeniami bazując na rachunku prawdopodobieństwa.
Sieci Bayesa mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Sosnowiec, 2011 Sieć Bayesowska służy do przedstawiania zależności pomiędzy zdarzeniami bazując na rachunku prawdopodobieństwa.
System do wybierania kierunku studiów oraz pracy zawodowej. Krzysztof Staroń Jan Burkot
 System do wybierania kierunku studiów oraz pracy zawodowej Krzysztof Staroń Jan Burkot Cele systemu ekspertowego Bayex Bayes OSPA Odkryj Swoje Przeznaczenie Akademickie OSP Odkryj Swoją Przyszłość Wybór
System do wybierania kierunku studiów oraz pracy zawodowej Krzysztof Staroń Jan Burkot Cele systemu ekspertowego Bayex Bayes OSPA Odkryj Swoje Przeznaczenie Akademickie OSP Odkryj Swoją Przyszłość Wybór
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Metody probabilistyczne klasyfikatory bayesowskie
 Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Spacery losowe generowanie realizacji procesu losowego
 Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Wykład z Technologii Informacyjnych. Piotr Mika
 Wykład z Technologii Informacyjnych Piotr Mika Uniwersalna forma graficznego zapisu algorytmów Schemat blokowy zbiór bloków, powiązanych ze sobą liniami zorientowanymi. Jest to rodzaj grafu, którego węzły
Wykład z Technologii Informacyjnych Piotr Mika Uniwersalna forma graficznego zapisu algorytmów Schemat blokowy zbiór bloków, powiązanych ze sobą liniami zorientowanymi. Jest to rodzaj grafu, którego węzły
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Regresja liniowa, klasyfikacja metodą k-nn. Agnieszka Nowak Brzezińska
 Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
P(F=1) F P(C1 = 1 F = 1) P(C1 = 1 F = 0) P(C2 = 1 F = 1) P(C2 = 1 F = 0) P(R = 1 C2 = 1) P(R = 1 C2 = 0)
 F P(C1 = 1 F = 1) P(C1 = 1 F = 0) P(C2 = 1 F = 1) P(C2 = 1 F = 0) P(R = 1 C2 = 1) P(R = 1 C2 = 0)") Sieci bayesowskie P(F=) F P(C = F = ) P(C = F = 0) C C P(C = F = ) P(C = F = 0) M P(M = C =, C = ) P(M = C =, C = 0) P(M = C = 0, C = ) P(M = C = 0, C = 0) R P(R = C = ) P(R = C = 0) F pali papierosy C
Sieci bayesowskie P(F=) F P(C = F = ) P(C = F = 0) C C P(C = F = ) P(C = F = 0) M P(M = C =, C = ) P(M = C =, C = 0) P(M = C = 0, C = ) P(M = C = 0, C = 0) R P(R = C = ) P(R = C = 0) F pali papierosy C
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Sposoby prezentacji problemów w statystyce
 S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba Cel zadania Celem zadania jest implementacja klasyfikatorów
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba Cel zadania Celem zadania jest implementacja klasyfikatorów
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Indukowane Reguły Decyzyjne I. Wykład 3
 Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
SCENARIUSZ LEKCJI. TEMAT LEKCJI: Zastosowanie średnich w statystyce i matematyce. Podstawowe pojęcia statystyczne. Streszczenie.
 SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
komputery? Andrzej Skowron, Hung Son Nguyen Instytut Matematyki, Wydział MIM, UW
 Czego moga się nauczyć komputery? Andrzej Skowron, Hung Son Nguyen son@mimuw.edu.pl; skowron@mimuw.edu.pl Instytut Matematyki, Wydział MIM, UW colt.tex Czego mogą się nauczyć komputery? Andrzej Skowron,
Czego moga się nauczyć komputery? Andrzej Skowron, Hung Son Nguyen son@mimuw.edu.pl; skowron@mimuw.edu.pl Instytut Matematyki, Wydział MIM, UW colt.tex Czego mogą się nauczyć komputery? Andrzej Skowron,
Modelowanie Niepewności
 Na podstawie: AIMA, ch13 Wojciech Jaśkowski Instytut Informatyki, Politechnika Poznańska 21 marca 2014 Na podstawie: AIMA, ch13 Wojciech Jaśkowski Instytut Informatyki, Politechnika Poznańska 21 marca
Na podstawie: AIMA, ch13 Wojciech Jaśkowski Instytut Informatyki, Politechnika Poznańska 21 marca 2014 Na podstawie: AIMA, ch13 Wojciech Jaśkowski Instytut Informatyki, Politechnika Poznańska 21 marca
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/
 Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba, J. Kaczmar Cel zadania Celem zadania jest implementacja klasyfikatorów
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba, J. Kaczmar Cel zadania Celem zadania jest implementacja klasyfikatorów
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Data Mining Wykład 6. Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa.
 Naiwny klasyfikator Bayesa.") GLM (Generalized Linear Models) Data Mining Wykład 6 Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa jest klasyfikatorem statystycznym -
GLM (Generalized Linear Models) Data Mining Wykład 6 Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa jest klasyfikatorem statystycznym -
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Propozycje rozwiązań zadań otwartych z próbnej matury rozszerzonej przygotowanej przez OPERON.
 Propozycje rozwiązań zadań otwartych z próbnej matury rozszerzonej przygotowanej przez OPERON. Zadanie 6. Dane są punkty A=(5; 2); B=(1; -3); C=(-2; -8). Oblicz odległość punktu A od prostej l przechodzącej
Propozycje rozwiązań zadań otwartych z próbnej matury rozszerzonej przygotowanej przez OPERON. Zadanie 6. Dane są punkty A=(5; 2); B=(1; -3); C=(-2; -8). Oblicz odległość punktu A od prostej l przechodzącej
Wstęp. Regresja logistyczna. Spis treści. Hipoteza. powrót
 powrót Spis treści 1 Wstęp 2 Regresja logistyczna 2.1 Hipoteza 2.2 Estymacja parametrów 2.2.1 Funkcja wiarygodności 3 Uogólnione modele liniowe 3.1 Rodzina wykładnicza 3.1.1 Rozkład Bernouliego 3.1.2 Rozkład
powrót Spis treści 1 Wstęp 2 Regresja logistyczna 2.1 Hipoteza 2.2 Estymacja parametrów 2.2.1 Funkcja wiarygodności 3 Uogólnione modele liniowe 3.1 Rodzina wykładnicza 3.1.1 Rozkład Bernouliego 3.1.2 Rozkład
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
dr Jerzy Pusz, st. wykładowca, Wydział Matematyki i Nauk Informacyjnych Politechniki Warszawskiej B. Ogólna charakterystyka przedmiotu
 Kod przedmiotu TR.SIK303 Nazwa przedmiotu Probabilistyka I Wersja przedmiotu 2015/16 A. Usytuowanie przedmiotu w systemie studiów Poziom kształcenia Studia I stopnia Forma i tryb prowadzenia studiów Stacjonarne
Kod przedmiotu TR.SIK303 Nazwa przedmiotu Probabilistyka I Wersja przedmiotu 2015/16 A. Usytuowanie przedmiotu w systemie studiów Poziom kształcenia Studia I stopnia Forma i tryb prowadzenia studiów Stacjonarne
EGZAMIN MATURALNY W ROKU SZKOLNYM 2014/2015
 EGZAMIN MATURALNY W ROKU SZKOLNYM 0/0 FORMUŁA OD 0 ( NOWA MATURA ) MATEMATYKA POZIOM PODSTAWOWY ZASADY OCENIANIA ROZWIĄZAŃ ZADAŃ ARKUSZ MMA-P CZERWIEC 0 Egzamin maturalny z matematyki nowa formuła Klucz
EGZAMIN MATURALNY W ROKU SZKOLNYM 0/0 FORMUŁA OD 0 ( NOWA MATURA ) MATEMATYKA POZIOM PODSTAWOWY ZASADY OCENIANIA ROZWIĄZAŃ ZADAŃ ARKUSZ MMA-P CZERWIEC 0 Egzamin maturalny z matematyki nowa formuła Klucz
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Elementy inteligencji obliczeniowej
 Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
Rozdział 1. Wektory losowe. 1.1 Wektor losowy i jego rozkład
 Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
Opis przedmiotu: Probabilistyka I
 Opis : Probabilistyka I Kod Nazwa Wersja TR.SIK303 Probabilistyka I 2012/13 A. Usytuowanie w systemie studiów Poziom Kształcenia Stopień Rodzaj Kierunek studiów Profil studiów Specjalność Jednostka prowadząca
Opis : Probabilistyka I Kod Nazwa Wersja TR.SIK303 Probabilistyka I 2012/13 A. Usytuowanie w systemie studiów Poziom Kształcenia Stopień Rodzaj Kierunek studiów Profil studiów Specjalność Jednostka prowadząca
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Algorytmy, które estymują wprost rozkłady czy też mapowania z nazywamy algorytmami dyskryminacyjnymi.
 Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować?
 Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
INFORMATYKA W SZKOLE. Podyplomowe Studia Pedagogiczne. Dr inż. Grażyna KRUPIŃSKA. D-10 pokój 227
 INFORMATYKA W SZKOLE Dr inż. Grażyna KRUPIŃSKA grazyna@fis.agh.edu.pl D-10 pokój 227 Podyplomowe Studia Pedagogiczne 2 Algorytmy Nazwa algorytm wywodzi się od nazwiska perskiego matematyka Muhamed ibn
INFORMATYKA W SZKOLE Dr inż. Grażyna KRUPIŃSKA grazyna@fis.agh.edu.pl D-10 pokój 227 Podyplomowe Studia Pedagogiczne 2 Algorytmy Nazwa algorytm wywodzi się od nazwiska perskiego matematyka Muhamed ibn
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
0 + 0 = 0, = 1, = 1, = 0.
 5 Kody liniowe Jak już wiemy, w celu przesłania zakodowanego tekstu dzielimy go na bloki i do każdego z bloków dodajemy tak zwane bity sprawdzające. Bity te są w ścisłej zależności z bitami informacyjnymi,
5 Kody liniowe Jak już wiemy, w celu przesłania zakodowanego tekstu dzielimy go na bloki i do każdego z bloków dodajemy tak zwane bity sprawdzające. Bity te są w ścisłej zależności z bitami informacyjnymi,
LUBELSKA PRÓBA PRZED MATURĄ 09 MARCA Kartoteka testu. Maksymalna liczba punktów. Nr zad. Matematyka dla klasy 3 poziom podstawowy
 Matematyka dla klasy poziom podstawowy LUBELSKA PRÓBA PRZED MATURĄ 09 MARCA 06 Kartoteka testu Nr zad Wymaganie ogólne. II. Wykorzystanie i interpretowanie reprezentacji.. II. Wykorzystanie i interpretowanie
Matematyka dla klasy poziom podstawowy LUBELSKA PRÓBA PRZED MATURĄ 09 MARCA 06 Kartoteka testu Nr zad Wymaganie ogólne. II. Wykorzystanie i interpretowanie reprezentacji.. II. Wykorzystanie i interpretowanie
Przepustowość kanału, odczytywanie wiadomości z kanału, poprawa wydajności kanału.
 Przepustowość kanału, odczytywanie wiadomości z kanału, poprawa wydajności kanału Wiktor Miszuris 2 czerwca 2004 Przepustowość kanału Zacznijmy od wprowadzenia równości IA, B HB HB A HA HA B Można ją intuicyjnie
Przepustowość kanału, odczytywanie wiadomości z kanału, poprawa wydajności kanału Wiktor Miszuris 2 czerwca 2004 Przepustowość kanału Zacznijmy od wprowadzenia równości IA, B HB HB A HA HA B Można ją intuicyjnie
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Geometria analityczna
 Geometria analityczna Paweł Mleczko Teoria Informacja (o prostej). postać ogólna prostej: Ax + By + C = 0, A + B 0, postać kanoniczna (kierunkowa) prostej: y = ax + b. Współczynnik a nazywamy współczynnikiem
Geometria analityczna Paweł Mleczko Teoria Informacja (o prostej). postać ogólna prostej: Ax + By + C = 0, A + B 0, postać kanoniczna (kierunkowa) prostej: y = ax + b. Współczynnik a nazywamy współczynnikiem
Analiza współzależności zjawisk. dr Marta Kuc-Czarnecka
 Analiza współzależności zjawisk dr Marta Kuc-Czarnecka Wprowadzenie Prawidłowości statystyczne mają swoje przyczyny, w związku z tym dla poznania całokształtu badanego zjawiska potrzebna jest analiza z
Analiza współzależności zjawisk dr Marta Kuc-Czarnecka Wprowadzenie Prawidłowości statystyczne mają swoje przyczyny, w związku z tym dla poznania całokształtu badanego zjawiska potrzebna jest analiza z
Sztuczna inteligencja : Tworzenie sieci Bayesa
 Instytut Informatyki Uniwersytetu Śląskiego 13 kwiecień 2011 Rysunek: Sieć Bayesa Rysunek: Sieć Bayesa Matura z matematyki na 60 %. Matura z matematyki na 100 %. Rozpatrzmy następujące przypadki: Uczeń
Instytut Informatyki Uniwersytetu Śląskiego 13 kwiecień 2011 Rysunek: Sieć Bayesa Rysunek: Sieć Bayesa Matura z matematyki na 60 %. Matura z matematyki na 100 %. Rozpatrzmy następujące przypadki: Uczeń
), którą będziemy uważać za prawdziwą jeżeli okaże się, że hipoteza H 0
, którą będziemy uważać za prawdziwą jeżeli okaże się, że hipoteza H 0") Testowanie hipotez Każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy nazywamy hipotezą statystyczną. Hipoteza określająca jedynie wartości nieznanych parametrów liczbowych badanej cechy
Testowanie hipotez Każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy nazywamy hipotezą statystyczną. Hipoteza określająca jedynie wartości nieznanych parametrów liczbowych badanej cechy
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Zastosowanie Excela w matematyce
 Zastosowanie Excela w matematyce Komputer w dzisiejszych czasach zajmuje bardzo znamienne miejsce. Trudno sobie wyobrazić jakąkolwiek firmę czy instytucję działającą bez tego urządzenia. W szkołach pierwsze
Zastosowanie Excela w matematyce Komputer w dzisiejszych czasach zajmuje bardzo znamienne miejsce. Trudno sobie wyobrazić jakąkolwiek firmę czy instytucję działającą bez tego urządzenia. W szkołach pierwsze
Algorytm. Krótka historia algorytmów
 Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
Analiza współzależności zjawisk
 Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Jacek Skorupski pok. 251 tel konsultacje: poniedziałek , sobota zjazdowa
 Jacek Skorupski pok. 251 tel. 234-7339 jsk@wt.pw.edu.pl http://skorupski.waw.pl/mmt prezentacje ogłoszenia konsultacje: poniedziałek 16 15-18, sobota zjazdowa 9 40-10 25 Udział w zajęciach Kontrola wyników
Jacek Skorupski pok. 251 tel. 234-7339 jsk@wt.pw.edu.pl http://skorupski.waw.pl/mmt prezentacje ogłoszenia konsultacje: poniedziałek 16 15-18, sobota zjazdowa 9 40-10 25 Udział w zajęciach Kontrola wyników
istocie dziedzina zajmująca się poszukiwaniem zależności na podstawie prowadzenia doświadczeń jest o wiele starsza: tak na przykład matematycy
 MODEL REGRESJI LINIOWEJ. METODA NAJMNIEJSZYCH KWADRATÓW Analiza regresji zajmuje się badaniem zależności pomiędzy interesującymi nas wielkościami (zmiennymi), mające na celu konstrukcję modelu, który dobrze
MODEL REGRESJI LINIOWEJ. METODA NAJMNIEJSZYCH KWADRATÓW Analiza regresji zajmuje się badaniem zależności pomiędzy interesującymi nas wielkościami (zmiennymi), mające na celu konstrukcję modelu, który dobrze
8. Neuron z ciągłą funkcją aktywacji.
 8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
Wydział Matematyki. Testy zgodności. Wykład 03
 Wydział Matematyki Testy zgodności Wykład 03 Testy zgodności W testach zgodności badamy postać rozkładu teoretycznego zmiennej losowej skokowej lub ciągłej. Weryfikują one stawiane przez badaczy hipotezy
Wydział Matematyki Testy zgodności Wykład 03 Testy zgodności W testach zgodności badamy postać rozkładu teoretycznego zmiennej losowej skokowej lub ciągłej. Weryfikują one stawiane przez badaczy hipotezy
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
AiSD zadanie trzecie
 AiSD zadanie trzecie Gliwiński Jarosław Marek Kruczyński Konrad Marek Grupa dziekańska I5 5 czerwca 2008 1 Wstęp Celem postawionym przez zadanie trzecie było tzw. sortowanie topologiczne. Jest to typ sortowania
AiSD zadanie trzecie Gliwiński Jarosław Marek Kruczyński Konrad Marek Grupa dziekańska I5 5 czerwca 2008 1 Wstęp Celem postawionym przez zadanie trzecie było tzw. sortowanie topologiczne. Jest to typ sortowania
5. Rozwiązywanie układów równań liniowych
 5. Rozwiązywanie układów równań liniowych Wprowadzenie (5.1) Układ n równań z n niewiadomymi: a 11 +a 12 x 2 +...+a 1n x n =a 10, a 21 +a 22 x 2 +...+a 2n x n =a 20,..., a n1 +a n2 x 2 +...+a nn x n =a
5. Rozwiązywanie układów równań liniowych Wprowadzenie (5.1) Układ n równań z n niewiadomymi: a 11 +a 12 x 2 +...+a 1n x n =a 10, a 21 +a 22 x 2 +...+a 2n x n =a 20,..., a n1 +a n2 x 2 +...+a nn x n =a
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Opis przedmiotu. Karta przedmiotu - Probabilistyka I Katalog ECTS Politechniki Warszawskiej
 Kod przedmiotu TR.NIK304 Nazwa przedmiotu Probabilistyka I Wersja przedmiotu 2015/16 A. Usytuowanie przedmiotu w systemie studiów Poziom kształcenia Studia I stopnia Forma i tryb prowadzenia studiów Niestacjonarne
Kod przedmiotu TR.NIK304 Nazwa przedmiotu Probabilistyka I Wersja przedmiotu 2015/16 A. Usytuowanie przedmiotu w systemie studiów Poziom kształcenia Studia I stopnia Forma i tryb prowadzenia studiów Niestacjonarne
CZEŚĆ PIERWSZA. Wymagania na poszczególne oceny,,matematyka wokół nas Klasa III I. POTĘGI
 Wymagania na poszczególne oceny,,matematyka wokół nas Klasa III CZEŚĆ PIERWSZA I. POTĘGI Zamienia potęgi o wykładniku całkowitym ujemnym na odpowiednie potęgi o wykładniku naturalnym. Oblicza wartości
Wymagania na poszczególne oceny,,matematyka wokół nas Klasa III CZEŚĆ PIERWSZA I. POTĘGI Zamienia potęgi o wykładniku całkowitym ujemnym na odpowiednie potęgi o wykładniku naturalnym. Oblicza wartości
Kształcenie w zakresie podstawowym. Klasa 2
 Kształcenie w zakresie podstawowym. Klasa 2 Poniżej podajemy umiejętności, jakie powinien zdobyć uczeń z każdego działu, aby uzyskać poszczególne stopnie. Na ocenę dopuszczającą uczeń powinien opanować
Kształcenie w zakresie podstawowym. Klasa 2 Poniżej podajemy umiejętności, jakie powinien zdobyć uczeń z każdego działu, aby uzyskać poszczególne stopnie. Na ocenę dopuszczającą uczeń powinien opanować
Systemy ekspertowe : program PCShell
 Instytut Informatyki Uniwersytetu Śląskiego lab 1 Opis sytemu ekspertowego Metody wnioskowania System PcShell Projekt System ekspertowy - system ekspertowy to system komputerowy zawierający w sobie wyspecjalizowaną
Instytut Informatyki Uniwersytetu Śląskiego lab 1 Opis sytemu ekspertowego Metody wnioskowania System PcShell Projekt System ekspertowy - system ekspertowy to system komputerowy zawierający w sobie wyspecjalizowaną
1 Analizy zmiennych jakościowych
 1 Analizy zmiennych jakościowych Przedmiotem analizy są zmienne jakościowe. Dokładniej wyniki pomiarów jakościowych. Pomiary tego typu spotykamy w praktyce badawczej znacznie częściej niż pomiary typu
1 Analizy zmiennych jakościowych Przedmiotem analizy są zmienne jakościowe. Dokładniej wyniki pomiarów jakościowych. Pomiary tego typu spotykamy w praktyce badawczej znacznie częściej niż pomiary typu
Inżynieria wiedzy Wnioskowanie oparte na wiedzy niepewnej Opracowane na podstawie materiałów dra Michała Berety
 mgr Adam Marszałek Zakład Inteligencji Obliczeniowej Instytut Informatyki PK Inżynieria wiedzy Wnioskowanie oparte na wiedzy niepewnej Opracowane na podstawie materiałów dra Michała Berety Wstępnie na
mgr Adam Marszałek Zakład Inteligencji Obliczeniowej Instytut Informatyki PK Inżynieria wiedzy Wnioskowanie oparte na wiedzy niepewnej Opracowane na podstawie materiałów dra Michała Berety Wstępnie na
Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb
 Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Wstęp do sieci neuronowych, wykład 11 Łańcuchy Markova
 Wstęp do sieci neuronowych, wykład 11 Łańcuchy Markova M. Czoków, J. Piersa 2010-12-21 1 Definicja Własności Losowanie z rozkładu dyskretnego 2 3 Łańcuch Markova Definicja Własności Losowanie z rozkładu
Wstęp do sieci neuronowych, wykład 11 Łańcuchy Markova M. Czoków, J. Piersa 2010-12-21 1 Definicja Własności Losowanie z rozkładu dyskretnego 2 3 Łańcuch Markova Definicja Własności Losowanie z rozkładu
Analiza współzależności dwóch cech I
 Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej
 Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Metody probabilistyczne
 Metody probabilistyczne 13. Elementy statystki matematycznej I Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 17.01.2019 1 / 30 Zagadnienia statystki Przeprowadzamy
Metody probabilistyczne 13. Elementy statystki matematycznej I Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 17.01.2019 1 / 30 Zagadnienia statystki Przeprowadzamy
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Jeśli X jest przestrzenią o nieskończonej liczbie elementów:
 Logika rozmyta 2 Zbiór rozmyty może być formalnie zapisany na dwa sposoby w zależności od tego z jakim typem przestrzeni elementów mamy do czynienia: Jeśli X jest przestrzenią o skończonej liczbie elementów
Logika rozmyta 2 Zbiór rozmyty może być formalnie zapisany na dwa sposoby w zależności od tego z jakim typem przestrzeni elementów mamy do czynienia: Jeśli X jest przestrzenią o skończonej liczbie elementów