Architektury komputerów systemy komputerowe i ich klasyfikacja. Tomasz Dziubich
|
|
|
- Jacek Stachowiak
- 9 lat temu
- Przeglądów:
Transkrypt
1 Architektury komputerów systemy komputerowe i ich klasyfikacja Tomasz Dziubich

2 Klasyfikacja Flynna Pojedynczy strumień danych Wiele strumieni danych Pojedynczy strumień instrukcji SISD SIMD Wielokrotny strumień instrukcji MISD MIMD

3 Systemy SIMD Ściśle powiązane Luźno powiązane Jednostka sterująca (CU) LM LM LM EU EU EU LM LM LM EU EU EU LM LM LM EU EU EU

4 MMX grupa instrukcji MMX (multimedia extension) przeznaczona jest do wykonywania w sposób równoległy operacji na liczbach 8 i 16 bitowych Pentium 57 instrukcji wprowadzono osiem 64-bitowych rejestrów oznaczonych MM0, MM1,..., MM7, które częściowo pokrywają się z rejestrami koprocesora arytmetycznego w takim przypadku używa się instrukcji EMMS, która przygotowuje do użycia rejestry stosu koprocesora, jeśli wcześniej używane były instrukcje MMX dane MMX przechowywane są wg konwencji mniejsze niżej, tj. mniej znaczący bajt umieszczony jest w lokacji pamięci o niższym adresie (little endian)

5 MMX upakowany bajt (ang. packed byte) upakowane słowo (ang. packed word) upakowane podwójne słowo (ang. packed double word) 63 0 poczwórne słowo (ang. quadword)
 63 32 31 0 upakowane podwójne słowo (ang.")
6 MMX na poziomie asemblera instrukcje MMX kodowane są w konwencjonalny sposób prawie wszystkie mnemoniki instrukcji MMX zaczynają się od litery P (packed) instrukcje MMX nie zmieniają rejestru znaczników kody instrukcji MMX są dwubajtowe i zaczynają się od bajtu 0FH; przed kodem może wystąpić przedrostek rozmiaru adresu lub przedrostek chwilowej zmiany segmentu; instrukcje MMX mogą powodować wyjątki

7 MMX w mnemonikach instrukcji, obok zwykłego skrótu operacji (np. ADD), stosowane są dodatkowe litery: S arytmetyka nasycenia (saturation), U liczby bez znaku (unsigned), L młodsza część (low), H starsza część (high), B bajt (8 bitów) W słowo (16 bitów), D podwójne słowo (32 bity), Q poczwórne słowo (64 bity); 1. arytmetyka przewinięcia PADDB mm, mm/m64 ; dodawanie bajtami PADDW mm, mm/m64 ; dodawanie słowami PADDD mm, mm/m64 ; dodawanie podw. słowami 2. arytmetyka nasycenia dla liczb ze znakiem PADDSB mm, mm/m64 ; dodawanie bajtami PADDSW mm, mm/m64 ; dodawanie słowami 3. arytmetyka nasycenia dla liczb bez znaku PADDUSB mm, mm/m64 ;dodawanie bajtami PADDUSW mm, mm/m64 ; dodawanie słowami

8 Przykład.686.MMX.data p1 dq 0F7F8F9FAFBFCFDFEH p2 dq H wynik dq?.code zacznij: movq mm1, p1 ; wpisanie zmiennej p1 ; do rejestru mm1 paddusb mm1, p2 ; dodawanie bajtowe ; (liczb bez znaku) do mm2 movq wynik, mm1 ; przesłanie wyniku ; do zmiennej wynik
 do mm2")
9 MMX Arytmetyka przewinięcia Arytmetyka nasycenia liczby ze znakiem i bez znaku liczby bez znaku liczby ze znak. dodawanie: 9000H + A010H = 3010H dodawanie: 9000H + A010H = FFFFH (nasycenie do górnej granicy) dodawanie: 9000H +A010H = 8000H (nasycenie do dolnej granicy) odejmowanie: 9000H A010H = EFF0H odejmowanie: 9000H - A010H = 0H (nasycenie do dolnej granicy) odejmowanie: 9000H - A010H = EFF0H (nie ma nasycenia)
 odejmowanie: 9000H A010H = EFF0H")
10 Przykład Przykład działania instrukcji PADDUSW mm6, mm MM6 A000H A000H A000H 4000H MM1 1000H B000H 9000H 6000H MM6 B000H FFFFH FFFFH A000H

11 SSE instrukcje SSE (Streaming SIMD Extensions) - Pentium III (1999) - zestaw instrukcji wykonujących działania na liczbach zmiennoprzecinkowych wykonują równoległe operacje na czterech 32-bitowych liczbach zmiennoprzecinkowych zastosowanie w grafice komputerowej (3D), gdzie występują operacje przetwarzania dużych zbiorów liczb zmiennoprzecinkowych dla potrzeb SSE zdefiniowano 8 nowych 128 bitowych rejestrów (xmm0 - xmm7) każdy rejestr zawiera 4 liczby zmiennoprzecinkowe; rejestry oznaczone są symbolami; zestaw instrukcji SSE obejmuje 70 instrukcji 50 instrukcji operacji zmiennoprzecinkowych 12 instrukcji operacji stałoprzecinkowych 8 instrukcji pomocniczych

12 SSE Działania na liczbach upakowanych (psxxx) a3 a2 a1 a0 op op op op b3 b2 b1 b a3 op b3 a2 op b2 a1 op b1 a0 op b0 0

13 SSE Działania na liczbach skalarnych (xxxs) a3 a2 a1 a0 op b3 b2 b1 b a3 a2 a1 a0 op b0 0

14 Propozycja klasyfikacji architektur Instruction Level Parallelizm - ILP Thread Level Parallelizm TLP Data Level Parallelizm - DLP

15 Vector Memory-Memory vs Maszyna z rejestrami wektorowymi Instrukcje wektorowe pamięć-pamięć utrzymują wszystkie operandy w pamięci operacyjnej Cray-1 (1976) był pierwszą maszyną z rejestrami wektorowymi Kod Vector Memory-Memory Przykład kodu źródłowego ADDV C, A, B SUBV D, A, B for (i=0; i<n; i++) { C[i] = A[i] + B[i]; D[i] = A[i] - B[i]; } Kod dla maszyny z rejestrami wektorowymi LV V1, A LV V2, B ADDV V3, V1, V2 SV V3, C SUBV V4, V1, V2 SV V4, D
![Memory-Memory Przykład kodu źródłowego ADDV C, A, B SUBV D, A, B for (i=0; i<n; i++) { C[i] = A[i] + B[i]; D[i]](/docs-images/43/3671499/images/page_15.jpg "= A[i] - B[i]; } Kod dla maszyny z rejestrami wektorowymi LV V1, A LV V2, B ADDV V3, V1, V2 SV V3, C SUBV V4,")

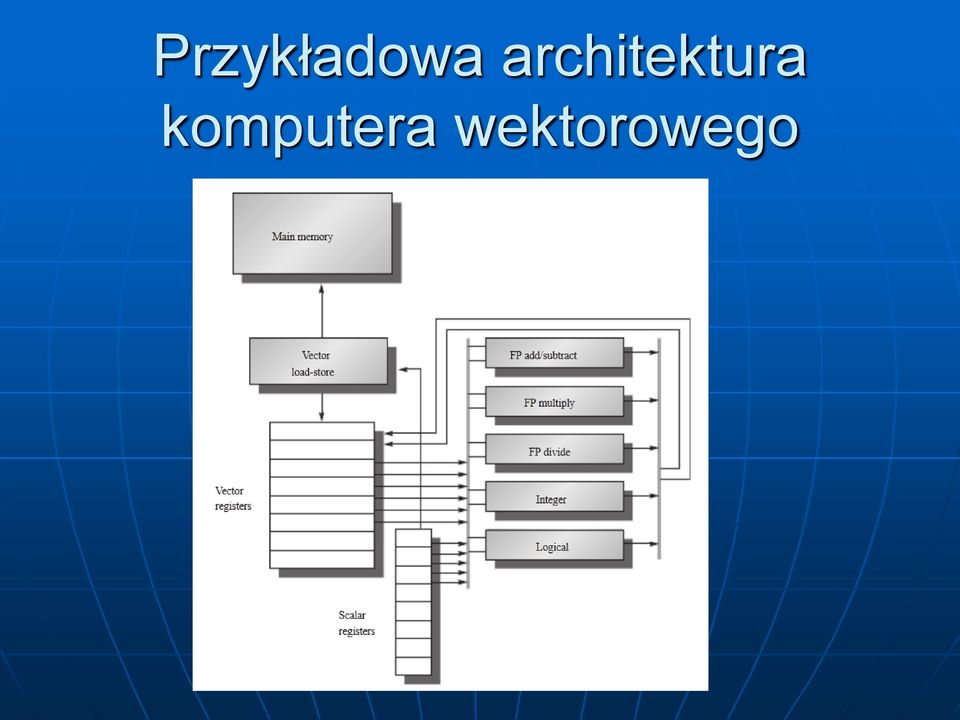
16 Przykładowa architektura komputera wektorowego
17 Wykonanie instrukcji wektorowych ADDV C,A,B Pojedyncza jednostka wektorowa Wykonanie z czterema jednostkami A[6] B[6] A[24] B[24] A[25] B[25] A[26] B[26] A[27] B[27] A[5] B[5] A[20] B[20] A[21] B[21] A[22] B[22] A[23] B[23] A[4] B[4] A[16] B[16] A[17] B[17] A[18] B[18] A[19] B[19] A[3] B[3] A[12] B[12] A[13] B[13] A[14] B[14] A[15] B[15] C[2] C[8] C[9] C[10] C[11] C[1] C[4] C[5] C[6] C[7] C[0] C[0] C[1] C[2] C[3]
![A[22] B[22] A[23] B[23] A[4] B[4] A[16] B[16] A[17] B[17] A[18] B[18] A[19] B[19] A[3] B[3] A[12] B[12]](/docs-images/43/3671499/images/page_17.jpg "A[13] B[13] A[14] B[14] A[15] B[15] C[2] C[8] C[9] C[10] C[11] C[1] C[4] C[5] C[6] C[7] C[0] C[0] C[1]")
18 Budowa jednostki wektorowej Jednostka funkcyjna Rejestry wektorowe Elementy 0, 4, 8, Elementy 1, 5, 9, Elementy 2, 6, 10, Elementy 3, 7, 11, Tor (lane) Podsystem pamięci
 Podsystem")
19 Zrównoleglenie instrukcji wektorowych Przykład maszyny, która ma 32 elementy na rejestr wektorowy i 8 torów czas load load Load Unit Multiply Unit Add Unit mul mul add add Instruction issue Ukończenie 24 operacji/cykl podczas wykonania 1 instrukcji/cykl

20 Intel Advanced Vector Extensions (AVX) AVX rozszerza 16 rejestrów XMM do 256 bitów YMM0 XMM0 256 bits (2010) 128 bits (1999) AVX może pracować na Całych 256 bitach Młodszych 128 bitach (instrukcje SSE) Zachowuje wszystkie instrukcje SSE Starsza część jest zerowana Nie jest generowany błąd wyrównania

21 AVX AVX (Advanced Vector Extensions) bitowych rejestrów (YMM) 8x32 bity, 4 x 64 bity Format rozkazu VxxxxPS/PD/SS/SD Np. VMOVUPD ymm1, mem256 VMOVUPS ymm0. mem256 VMOVPAD z wyrównanego adresu (do 32) VADDPD ymm3,ymm2,ymm1 W planach AVX-512 (32 rejestry, ZMM, Xeon Phi)
![AVX Prawie wszystkie instrukcje SSE FP zostały wypromowane do 256 bitów VADDPS YMM1, YMM2, [m256] ; dodanie dwóch liczb wektorów i zapis w rejestrze Prawie wszystkie instrukcje mają](/docs-images/24/3671499/images/22-0.png "możliwość kodowania w nowym formacie (za wyjątkiem tych które odwołują się do rejestrów MMX) VADDPS XMM1, XMM2, [m128] VMULSS XMM1, XMM2, [m32] ; mnożenie skalarne dwóch najmłodszych")
22 AVX Prawie wszystkie instrukcje SSE FP zostały wypromowane do 256 bitów VADDPS YMM1, YMM2, [m256] ; dodanie dwóch liczb wektorów i zapis w rejestrze Prawie wszystkie instrukcje mają możliwość kodowania w nowym formacie (za wyjątkiem tych które odwołują się do rejestrów MMX) VADDPS XMM1, XMM2, [m128] VMULSS XMM1, XMM2, [m32] ; mnożenie skalarne dwóch najmłodszych liczb
23 AVX addps xmm1,xmm2 ; (xmm1 = xmm1 + xmm2) instrukcja SSE dodawanie czterech par liczb pojedynczej precyzji vaddps ymm1, ymm2, ymm3 ; (ymm1 = ymm2 + ymm3) instrukcja AVX dodawanie ośmiu par liczb pojedynczej precyzji Typ asemblerowy YMMWORD Język C VADDPS m256 _mm256_add_ps ( m256 a, m256 b); ADDPS m128 _mm_add_ps ( m128 a, m128 b);

24 Intel Xeon Phi
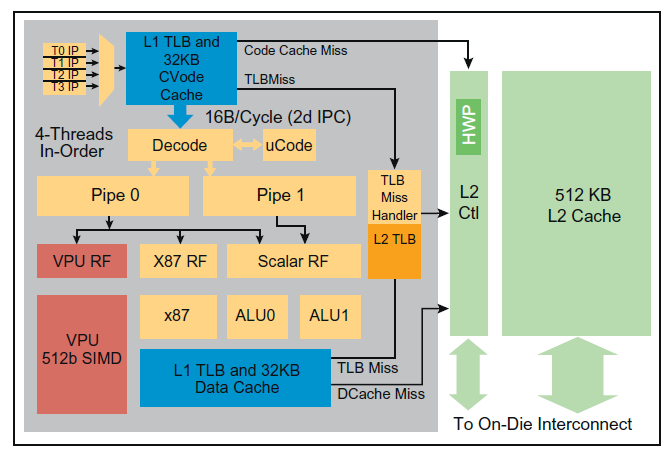

25 Archiektura rdzenia

26 Intel Xeon Phi - pamięć
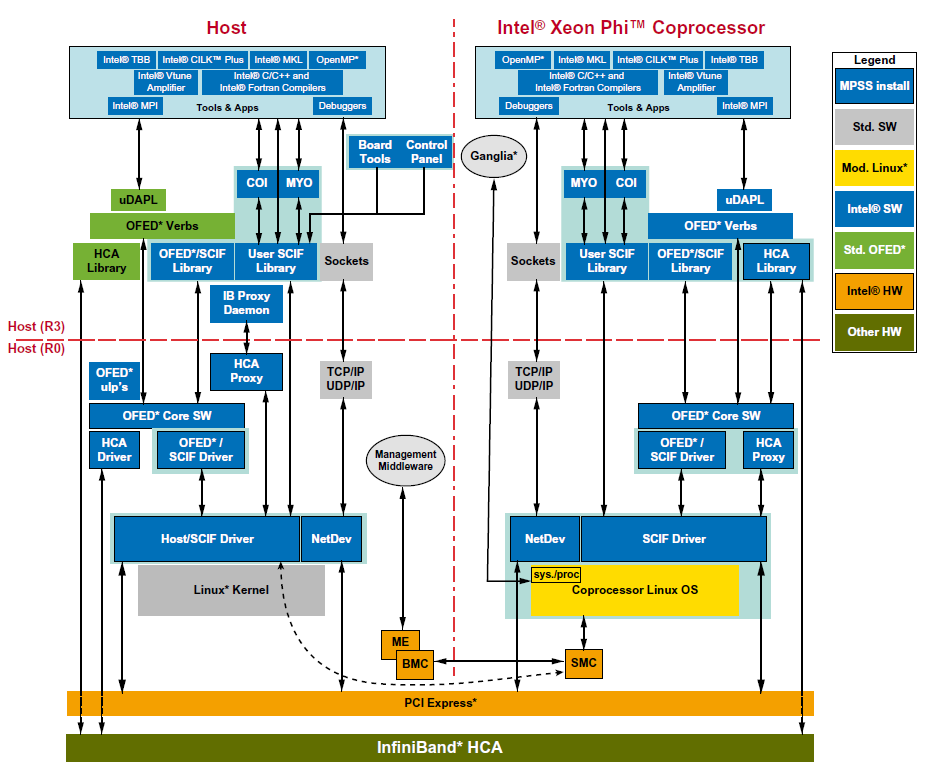
27 Architektura oprogramowania
28 Wydajność
29 Systemy MIMD Ze wspólną pamięcią Z pamięcią rozproszoną Z rozproszoną pamięcią wspólną
30 MIMD z pamięcią wspólną Procesory P1, P2,..., Pn P1 P2 Pn Sieć połączeń Pamięć
31 MIMD z pamięcią rozproszoną Węzeł 1 Węzeł 2 Węzeł 3 Pamięć lokalna Pamięć lokalna Pamięć lokalna Procesor Procesor Procesor Układy we/wy Układy we/wy Układy we/wy System przesyłania komunikatów
32 MIMD z rozproszoną pamięcią wspólną
33 Architektura klastra Klaster Połączenie niezależnych komputerów przy użyciu sieci komputerowej w celu dostarczenia wspólnej usługi Serwery high-end Bazy danych, serwery plików, web serwery, symulacje, itp. Potrzeba wysokiej dostępności, łatwej lokalizacji uszkodzeń i żądanej niezawodności Potrzeba skalowalności
34 Zalety klastrów Izolacja błędów Oddzielna przestrzeń adresowa ogranicza rozprzestrzenianie się błędów Naprawa Łatwość wymiany uszkodzonego węzła bez konieczności zatrzymywania systemu Łatwa skalowalność Niski koszt Amazon, AOL, Google, Hotmail, and Yahoo
35 Wady klastrów Koszty administracji (n maszyn a 1) Połączenia za pomocą I/O (a nie szyny pamięci) Klaster potrzebuje N niezależnych pamięci i n kopii OS
36 Przykład Czas życia klastra ok. 3 lat Twórcy: Larry Page i Sergey Brin (09.98) W swoich bazach Google przechowuje informacje (01/2007) o 8 miliardach obiektów, w tym 4,3 miliarda stron WWW, 880 milionów obrazków oraz 850 milionów wiadomości z grup dyskusyjnych. Większość systemu została napisana w C lub C++ i działa na komputerach wyposażonych w system Linux
37 Architektura klastra Engine wyszukiwarki wymaga wysokiej liczby obliczeń na pojedyncze żądanie Pojedyncze żądanie w Google (średnio) odczyt rzędu setek MB danych pochłania ok. 10 bilionów cyklów CPU Szczytowe wymagania (peak request) Tysiące żądań w ciągu sekundy Wymagana jest dekompozycja i porównywalny rozmiar z superkomputerami
38 Systemy Obliczeniowe Wysokiej Wydajności High Performance Computing Techniques Supercomputers Clusters Grid Systems Custom build Shared memory processing (SMP) Not-parallelizable problems Optimized processors Use parallelism Consists of more than one computers Distributed memory processing Internet is the computer No geographical limitations
39 Architektura klastra Google Połączone ~15,000 zwykłych PC ów Zamiast mniejszej liczby serwerów (high-end) Najważniejsze czynniki brane pod uwagę przy projektowaniu Pobór energii Współczynnik cena/wydajność Aplikacja Google pozwala na łatwe zrównoleglenie Różne zapytania mogą być wykonane na różnych procesorach Pojedyncze pytanie może używać wielu procesorów ponieważ cały index jest podzielony
40 Wymagania Projektowany pod kątem uzyskania najlepszej średniej przepustowości a nie najkrótszego czasu odpowiedzi Niezawodność Bazuje na poziomie oprogramowania a nie na poziomie sprzętu Możliwe więc wykorzystanie zwykłych PC (niska cena) Budowanie niezawodnego przetwarzania na bazie klastra zawodnych (niewiarygodnych) PC
41 Wykonanie zapytania Załóżmy zapytanie (żądanie) Przeglądarka Generuje zapytanie do Systemu Rozwiązywania Nazw - Domain Name System (DNS) aby dokonać mapowania nazwy na konkretny adres IP
42 Wykonanie zapytania Nadrzędny DNS jest rozproszony pod względem geograficznym i również wykonany w postaci klastrów Zabezpiecza przed wystąpieniem awarii katastroficznej Systemy DNS są to systemy równoważące obciążenie (load-balancing) i wybierają klaster zgodnie z Aproksymacją geograficzną użytkownika Dostępną pojemnością przetwarzania żądań na różnych klastrach Przeglądarka Wysyła zapytanie HTTP do jednego z klastrów google Żądanie trafia do tzw. front-end computer kierującego ruchem zapytań
43 Ścieżka wykonania zapytania Front-end jest wyposażony w sprzętowy load-balancer Monitoruje dostępne Google Web Servers (GWSs) Dokonuje przekierowanie zapytania do jednego z GWS Maszyna GWS Koordynuje wykonanie zapytania Generuje rezultat w postaci kodu HTML

44 Schemat blokowy google
45 Przetwarzanie zapytania w klastrze Fazy wykonania zapytania Serwer indeksowy wyznacza odpowiednie dokumenty Korzysta z tzw. Odwróconego indeksu Wyzwanie w połączeniu z dużą ilością danych Surowe dokumenty -> kilka dziesiątek TB danych Inverted index -> również rzędu TB of data Szukając w sposób wysoce równoległy Podział zbioru indeksów na części - udziały (index shards) Dla każdego udziału, przepytanie dokonane przez inną maszynę Serwer dokumentów określa faktyczne adresy URL i generuje odpowiedz na udział
46 Zasady projektowania klastrów google Zapewnienie niezawodności przez oprogramowanie Bez wsparcia sprzętowego dodatkowych zasilaczy. Lepszych pamięci czy macierzy dyskowych RAID. Użycie replikacji Price/performance a nie peak performance Użycie zwykłych PC zmniejsza koszty przetwarzania
47 Pierwszy sewer google Computer History Museum (od 1999) Każdy tray zawierał 8x22GB HDD i jeden zasilacz
48 Budowa Google s racks Od 40 do 80 serwerów klasy x86 Serwery zbliżone do desktopowych PC ze średniej półki za wyjątkiem dużej przestrzeni dyskowej Zakres (2003) od 533-MHz Intel-Celeron do dual 1.4-GHz Intel Pentium III Połączenia w rack ach przez 100 Mbps Ethernet Wszystkie rack i połączone przez gigabit switch
49 Koszt Zestawienie kosztów klastra i komputera klasy mainframe Rack -> GHz Xeon CPUs Gbytes RAM + 7 Tbytes of disk space = $278,000 Server -> 8 2-GHz Xeon CPUs + 64 Gbytes RAM + 8 Tbytes of disk space = $758,000
50 Problemy energetyczne Serwery z dwoma procesorami 1.4- GHz Pentium III 90 W 55 W 2 CPUs 10 W - HDD 25 W DRAM i płyta główna Wydajność zasilacza (typowa) 75% 120 W zasilacz per server ok 10 kw per rack
51
52
53 Problemy energetyczne Szafa (rack) Zajmuje 25 ft2 (2,32 m2) Oznacza to oddaną moc rzędu 400 W/ ft2 Dla lepszych procesorów 700 W/ft2 Zalecana moc oddana dla komercyjnych składnic danych W/ft2 Konieczność dodatkowego chłodzenia i klimatyzacja Można użyć procesorów z redukcją mocy ale nie można zauważyć spadku wydajności i wzrostu kosztów
54 Charakterystyka sprzętowa Umiarkowanie wysoki CPI Pentium III ma możliwość wykonania 3 instrukcji/cykl Jednak występuje znacząca liczba trudnych do przewidzenia skoków Trawersowanie po dynamicznych strukturach danych Kontrola sterowania zależna od danych W nowszych procesor Pentium 4 To samo obciążenie, CPI jest zbliżone lub mniejsze Pomimo, że Pentium 4 Ma możliwość wykonywania większej liczby instrukcji równolegle i dysponuje lepszą logiką predykcji Google (oprogramowanie) nie wykorzystują możliwości instrukcji równoległych
55 Charakterystyka sprzętowa Zrównoleglenie uzyskuje się w sposób programowy Kolejkując procesy żądań i przypisując je do węzłów w klastrze Wykorzystując zrównoleglenie wątków i procesów na poziomie sprzętowym Procesory z Simultaneous multithreading (SMT) 30% wzrostu wydajności Architektury wielordzeniowe (multicore)
56 Pamięć podręczna Dobra wydajność dla pamięci podręcznej instrukcji i TLB instrukcji w związku z relatywnie małymi rozmiarami pętli kodu Bloki danych indeksowanych Brak lokalności czasowej ze względu na rozmiar danych i nieprzewidywalny wzorzec wyszukiwanych danych Korzyści lokalność przestrzennej możliwość użycia dłuższego wiersza w cache u
57 Pamięć RAM Przepustowość pamięci RAM nie jest tutaj wąskim gardłem Odpowiednia pamięć dla odczytu Relatywnie mały rozmiar L2 cache Krótkie CL przy dostępie do L2 cache i RAM Dłuższe (od 128 bajtów) wiersze (linie) w pamięci cache
58 Podsumowanie Infrastruktura Google Rozproszone systemy MIMD Ogromnej wielkości klaster tanich maszyn Indeksacja danych pozwala na zmniejszenie liczby komunikatów przesyłanych przez sieć łatwe zarządzanie równoważeniem obciążenia Łatwiejsze zarządzanie systemem i mniejsze koszty ewentualnej awarii Oprogramowanie zostało wyprodukowane przez studentów
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
MMX i SSE. Zbigniew Koza. Wydział Fizyki i Astronomii Uniwersytet Wrocławski. Wrocław, 10 marca 2011. Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16
 MMX i SSE 1 / 16") MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Architektura Komputerów
 1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Architektura komputerów
 Architektura komputerów Tydzień 4 Tryby adresowania i formaty Tryby adresowania Natychmiastowy Bezpośredni Pośredni Rejestrowy Rejestrowy pośredni Z przesunięciem stosowy Argument natychmiastowy Op Rozkaz
Architektura komputerów Tydzień 4 Tryby adresowania i formaty Tryby adresowania Natychmiastowy Bezpośredni Pośredni Rejestrowy Rejestrowy pośredni Z przesunięciem stosowy Argument natychmiastowy Op Rozkaz
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Rejestry procesora. Nazwa ilość bitów. AX 16 (accumulator) rejestr akumulatora. BX 16 (base) rejestr bazowy. CX 16 (count) rejestr licznika
 rejestr akumulatora. BX 16 (base) rejestr bazowy. CX 16 (count) rejestr licznika") Rejestry procesora Procesor podczas wykonywania instrukcji posługuje się w dużej części pamięcią RAM. Pobiera z niej kolejne instrukcje do wykonania i dane, jeżeli instrukcja operuje na jakiś zmiennych.
Rejestry procesora Procesor podczas wykonywania instrukcji posługuje się w dużej części pamięcią RAM. Pobiera z niej kolejne instrukcje do wykonania i dane, jeżeli instrukcja operuje na jakiś zmiennych.
Procesory rodziny x86. Dariusz Chaberski
 Procesory rodziny x86 Dariusz Chaberski 8086 produkowany od 1978 magistrala adresowa - 20 bitów (1 MB) magistrala danych - 16 bitów wielkość instrukcji - od 1 do 6 bajtów częstotliwośc pracy od 5 MHz (IBM
Procesory rodziny x86 Dariusz Chaberski 8086 produkowany od 1978 magistrala adresowa - 20 bitów (1 MB) magistrala danych - 16 bitów wielkość instrukcji - od 1 do 6 bajtów częstotliwośc pracy od 5 MHz (IBM
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Architektura komputerów
 Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki
 Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki Cel Konfiguracja i testowanie serwera WWW Apache w celu optymalizacji wydajności. 2/25 Zakres Konfigurowanie serwera Apache jako wydajnego
Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki Cel Konfiguracja i testowanie serwera WWW Apache w celu optymalizacji wydajności. 2/25 Zakres Konfigurowanie serwera Apache jako wydajnego
Organizacja typowego mikroprocesora
 Organizacja typowego mikroprocesora 1 Architektura procesora 8086 2 Architektura współczesnego procesora 3 Schemat blokowy procesora AVR Mega o architekturze harwardzkiej Wszystkie mikroprocesory zawierają
Organizacja typowego mikroprocesora 1 Architektura procesora 8086 2 Architektura współczesnego procesora 3 Schemat blokowy procesora AVR Mega o architekturze harwardzkiej Wszystkie mikroprocesory zawierają
Programowanie w asemblerze Architektury równoległe
 Programowanie w asemblerze Architektury równoległe 24 listopada 2015 1 1 Ilustracje: Song Ho Anh Klasyfikacja Flynna Duża różnorodność architektur równoległych, stad różne kryteria podziału. Najstarsza
Programowanie w asemblerze Architektury równoległe 24 listopada 2015 1 1 Ilustracje: Song Ho Anh Klasyfikacja Flynna Duża różnorodność architektur równoległych, stad różne kryteria podziału. Najstarsza
SSE (Streaming SIMD Extensions)
") SSE (Streaming SIMD Extensions) Zestaw instrukcji wprowadzony w 1999 roku po raz pierwszy w procesorach Pentium III. SSE daje przede wszystkim możliwość wykonywania działań zmiennoprzecinkowych na 4-elementowych
SSE (Streaming SIMD Extensions) Zestaw instrukcji wprowadzony w 1999 roku po raz pierwszy w procesorach Pentium III. SSE daje przede wszystkim możliwość wykonywania działań zmiennoprzecinkowych na 4-elementowych
Procesory. Schemat budowy procesora
 Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Mikroprocesory rodziny INTEL 80x86
 Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
PAMIĘCI. Część 1. Przygotował: Ryszard Kijanka
 PAMIĘCI Część 1 Przygotował: Ryszard Kijanka WSTĘP Pamięci półprzewodnikowe są jednym z kluczowych elementów systemów cyfrowych. Służą do przechowywania informacji w postaci cyfrowej. Liczba informacji,
PAMIĘCI Część 1 Przygotował: Ryszard Kijanka WSTĘP Pamięci półprzewodnikowe są jednym z kluczowych elementów systemów cyfrowych. Służą do przechowywania informacji w postaci cyfrowej. Liczba informacji,
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Architektura systemów informatycznych
 Architektura systemów informatycznych Architektura i organizacja pamięci Literatura: Hyde R. 2005, Zrozumieć komputer, Profesjonalne programowanie Część 1, Helion, Gliwice Podstawowe elementy systemu komputerowego
Architektura systemów informatycznych Architektura i organizacja pamięci Literatura: Hyde R. 2005, Zrozumieć komputer, Profesjonalne programowanie Część 1, Helion, Gliwice Podstawowe elementy systemu komputerowego
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy ogólny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK
Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy ogólny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK
Architektura komputerów egzamin końcowy
 Architektura komputerów egzamin końcowy Warszawa, dn. 25.02.11 r. I. Zaznacz prawidłową odpowiedź (tylko jedna jest prawidłowa): 1. Czteroetapowe przetwarzanie potoku architektury superskalarnej drugiego
Architektura komputerów egzamin końcowy Warszawa, dn. 25.02.11 r. I. Zaznacz prawidłową odpowiedź (tylko jedna jest prawidłowa): 1. Czteroetapowe przetwarzanie potoku architektury superskalarnej drugiego
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Wybrane bloki i magistrale komputerów osobistych (PC) Opracował: Grzegorz Cygan 2010 r. CEZ Stalowa Wola
 Opracował: Grzegorz Cygan 2010 r. CEZ Stalowa Wola") Wybrane bloki i magistrale komputerów osobistych (PC) Opracował: Grzegorz Cygan 2010 r. CEZ Stalowa Wola Ogólny schemat komputera Jak widać wszystkie bloki (CPU, RAM oraz I/O) dołączone są do wspólnych
Wybrane bloki i magistrale komputerów osobistych (PC) Opracował: Grzegorz Cygan 2010 r. CEZ Stalowa Wola Ogólny schemat komputera Jak widać wszystkie bloki (CPU, RAM oraz I/O) dołączone są do wspólnych
Komputer IBM PC niezależnie od modelu składa się z: Jednostki centralnej czyli właściwego komputera Monitora Klawiatury
 1976 r. Apple PC Personal Computer 1981 r. pierwszy IBM PC Komputer jest wart tyle, ile wart jest człowiek, który go wykorzystuje... Hardware sprzęt Software oprogramowanie Komputer IBM PC niezależnie
1976 r. Apple PC Personal Computer 1981 r. pierwszy IBM PC Komputer jest wart tyle, ile wart jest człowiek, który go wykorzystuje... Hardware sprzęt Software oprogramowanie Komputer IBM PC niezależnie
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Wprowadzenie. Klastry komputerowe. Superkomputery. informatyka +
 Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Tworzenie aplikacji bazodanowych
 Tworzenie aplikacji bazodanowych wykład Joanna Kołodziejczyk 2016 Joanna Kołodziejczyk Tworzenie aplikacji bazodanowych 2016 1 / 36 Klasyfikacja baz danych Plan wykładu 1 Klasyfikacja baz danych 2 Architektura
Tworzenie aplikacji bazodanowych wykład Joanna Kołodziejczyk 2016 Joanna Kołodziejczyk Tworzenie aplikacji bazodanowych 2016 1 / 36 Klasyfikacja baz danych Plan wykładu 1 Klasyfikacja baz danych 2 Architektura
Komputer. Komputer (computer) jest to urządzenie elektroniczne służące do zbierania, przechowywania, przetwarzania i wizualizacji informacji
 jest to urządzenie elektroniczne służące do zbierania, przechowywania, przetwarzania i wizualizacji informacji") Komputer Komputer (computer) jest to urządzenie elektroniczne służące do zbierania, przechowywania, przetwarzania i wizualizacji informacji Budowa komputera Drukarka (printer) Monitor ekranowy skaner Jednostka
Komputer Komputer (computer) jest to urządzenie elektroniczne służące do zbierania, przechowywania, przetwarzania i wizualizacji informacji Budowa komputera Drukarka (printer) Monitor ekranowy skaner Jednostka
Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
 1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
Mikroinformatyka. Koprocesory arytmetyczne 8087, 80187, 80287, i387
 Mikroinformatyka Koprocesory arytmetyczne 8087, 80187, 80287, i387 Koprocesor arytmetyczny 100 razy szybsze obliczenia numeryczne na liczbach zmiennoprzecinkowych. Obliczenia prowadzone równolegle z procesorem
Mikroinformatyka Koprocesory arytmetyczne 8087, 80187, 80287, i387 Koprocesor arytmetyczny 100 razy szybsze obliczenia numeryczne na liczbach zmiennoprzecinkowych. Obliczenia prowadzone równolegle z procesorem
Wstęp do informatyki. Architektura co to jest? Architektura Model komputera. Od układów logicznych do CPU. Automat skończony. Maszyny Turinga (1936)
") Wstęp doinformatyki Architektura co to jest? Architektura Model komputera Dr inż Ignacy Pardyka Slajd 1 Slajd 2 Od układów logicznych do CPU Automat skończony Slajd 3 Slajd 4 Ile jest automatów skończonych?
Wstęp doinformatyki Architektura co to jest? Architektura Model komputera Dr inż Ignacy Pardyka Slajd 1 Slajd 2 Od układów logicznych do CPU Automat skończony Slajd 3 Slajd 4 Ile jest automatów skończonych?
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
Systemy rozproszone. na użytkownikach systemu rozproszonego wrażenie pojedynczego i zintegrowanego systemu.
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Spis treúci. Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1. Przedmowa... 9. Wstęp... 11
 Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1 Spis treúci Przedmowa... 9 Wstęp... 11 1. Komputer PC od zewnątrz... 13 1.1. Elementy zestawu komputerowego... 13 1.2.
Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1 Spis treúci Przedmowa... 9 Wstęp... 11 1. Komputer PC od zewnątrz... 13 1.1. Elementy zestawu komputerowego... 13 1.2.
Wprowadzenie. Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra.
 N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
Wprowadzenie do informatyki i użytkowania komputerów. Kodowanie informacji System komputerowy
 1 Wprowadzenie do informatyki i użytkowania komputerów Kodowanie informacji System komputerowy Kodowanie informacji 2 Co to jest? bit, bajt, kod ASCII. Jak działa system komputerowy? Co to jest? pamięć
1 Wprowadzenie do informatyki i użytkowania komputerów Kodowanie informacji System komputerowy Kodowanie informacji 2 Co to jest? bit, bajt, kod ASCII. Jak działa system komputerowy? Co to jest? pamięć
Mikrokontroler ATmega32. Język symboliczny
 Mikrokontroler ATmega32 Język symboliczny 1 Język symboliczny (asembler) jest językiem niskiego poziomu - pozwala pisać programy złożone z instrukcji procesora. Kody instrukcji są reprezentowane nazwami
Mikrokontroler ATmega32 Język symboliczny 1 Język symboliczny (asembler) jest językiem niskiego poziomu - pozwala pisać programy złożone z instrukcji procesora. Kody instrukcji są reprezentowane nazwami
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
Systemy operacyjne. Wprowadzenie. Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak
 Wprowadzenie Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego
Wprowadzenie Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego
Parametry wydajnościowe systemów internetowych. Tomasz Rak, KIA
 Parametry wydajnościowe systemów internetowych Tomasz Rak, KIA 1 Agenda ISIROSO System internetowy (rodzaje badań, konstrukcja) Parametry wydajnościowe Testy środowiska eksperymentalnego Podsumowanie i
Parametry wydajnościowe systemów internetowych Tomasz Rak, KIA 1 Agenda ISIROSO System internetowy (rodzaje badań, konstrukcja) Parametry wydajnościowe Testy środowiska eksperymentalnego Podsumowanie i
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]
![Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]](/thumbs/57/40653782.jpg "Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]") Procesor ma architekturę akumulatorową. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset or Rx, Ry, A add Rx load A, [Rz] push Rx sub Rx, #3, A load Rx, [A] Procesor ma architekturę rejestrową
Procesor ma architekturę akumulatorową. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset or Rx, Ry, A add Rx load A, [Rz] push Rx sub Rx, #3, A load Rx, [A] Procesor ma architekturę rejestrową
Pamięci półprzewodnikowe w oparciu o książkę : Nowoczesne pamięci. Ptc 2013/2014 13.12.2013
 Pamięci półprzewodnikowe w oparciu o książkę : Nowoczesne pamięci półprzewodnikowe, Betty Prince, WNT Ptc 2013/2014 13.12.2013 Pamięci statyczne i dynamiczne Pamięci statyczne SRAM przechowywanie informacji
Pamięci półprzewodnikowe w oparciu o książkę : Nowoczesne pamięci półprzewodnikowe, Betty Prince, WNT Ptc 2013/2014 13.12.2013 Pamięci statyczne i dynamiczne Pamięci statyczne SRAM przechowywanie informacji
dr inż. Konrad Sobolewski Politechnika Warszawska Informatyka 1
 dr inż. Konrad Sobolewski Politechnika Warszawska Informatyka 1 Cel wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działanie systemu operacyjnego
dr inż. Konrad Sobolewski Politechnika Warszawska Informatyka 1 Cel wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działanie systemu operacyjnego
UTK ARCHITEKTURA PROCESORÓW 80386/ Budowa procesora Struktura wewnętrzna logiczna procesora 80386
 Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Programowanie Niskopoziomowe
 Programowanie Niskopoziomowe Wykład 4: Architektura i zarządzanie pamięcią IA-32 Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Wstęp Tryby pracy Rejestry
Programowanie Niskopoziomowe Wykład 4: Architektura i zarządzanie pamięcią IA-32 Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Wstęp Tryby pracy Rejestry
Układ wykonawczy, instrukcje i adresowanie. Dariusz Chaberski
 Układ wykonawczy, instrukcje i adresowanie Dariusz Chaberski System mikroprocesorowy mikroprocesor C A D A D pamięć programu C BIOS dekoder adresów A C 1 C 2 C 3 A D pamięć danych C pamięć operacyjna karta
Układ wykonawczy, instrukcje i adresowanie Dariusz Chaberski System mikroprocesorowy mikroprocesor C A D A D pamięć programu C BIOS dekoder adresów A C 1 C 2 C 3 A D pamięć danych C pamięć operacyjna karta
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Bajt (Byte) - najmniejsza adresowalna jednostka informacji pamięci komputerowej, z bitów. Oznaczana jest literą B.
 - najmniejsza adresowalna jednostka informacji pamięci komputerowej, z bitów. Oznaczana jest literą B.") Jednostki informacji Bajt (Byte) - najmniejsza adresowalna jednostka informacji pamięci komputerowej, składająca się z bitów. Oznaczana jest literą B. 1 kb = 1024 B (kb - kilobajt) 1 MB = 1024 kb (MB -
Jednostki informacji Bajt (Byte) - najmniejsza adresowalna jednostka informacji pamięci komputerowej, składająca się z bitów. Oznaczana jest literą B. 1 kb = 1024 B (kb - kilobajt) 1 MB = 1024 kb (MB -
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Konsolidacja wysokowydajnych systemów IT. Macierze IBM DS8870 Serwery IBM Power Przykładowe wdrożenia
 Konsolidacja wysokowydajnych systemów IT Macierze IBM DS8870 Serwery IBM Power Przykładowe wdrożenia Mirosław Pura Sławomir Rysak Senior IT Specialist Client Technical Architect Agenda Współczesne wyzwania:
Konsolidacja wysokowydajnych systemów IT Macierze IBM DS8870 Serwery IBM Power Przykładowe wdrożenia Mirosław Pura Sławomir Rysak Senior IT Specialist Client Technical Architect Agenda Współczesne wyzwania:
Budowa i zasada działania komputera. dr Artur Bartoszewski
 Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Systemy operacyjne. Systemy operacyjne. Systemy operacyjne. Zadania systemu operacyjnego. Abstrakcyjne składniki systemu. System komputerowy
 Systemy operacyjne Systemy operacyjne Dr inż. Ignacy Pardyka Literatura Siberschatz A. i inn. Podstawy systemów operacyjnych, WNT, Warszawa Skorupski A. Podstawy budowy i działania komputerów, WKiŁ, Warszawa
Systemy operacyjne Systemy operacyjne Dr inż. Ignacy Pardyka Literatura Siberschatz A. i inn. Podstawy systemów operacyjnych, WNT, Warszawa Skorupski A. Podstawy budowy i działania komputerów, WKiŁ, Warszawa
LEKCJA TEMAT: Współczesne procesory.
 LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Petabajtowe systemy przechowywania danych dla dostawców treści
 Petabajtowe systemy przechowywania danych dla dostawców treści Krzysztof Góźdź, HP 2008 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice Rafał
Petabajtowe systemy przechowywania danych dla dostawców treści Krzysztof Góźdź, HP 2008 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice Rafał
Przykładowe pytania DSP 1
 Przykładowe pytania SP Przykładowe pytania Systemy liczbowe. Przedstawić liczby; -, - w kodzie binarnym i hexadecymalnym uzupełnionym do dwóch (liczba 6 bitowa).. odać dwie liczby binarne w kodzie U +..
Przykładowe pytania SP Przykładowe pytania Systemy liczbowe. Przedstawić liczby; -, - w kodzie binarnym i hexadecymalnym uzupełnionym do dwóch (liczba 6 bitowa).. odać dwie liczby binarne w kodzie U +..
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Wykład 2. Temat: (Nie)zawodność sprzętu komputerowego. Politechnika Gdańska, Inżynieria Biomedyczna. Przedmiot:
zawodność sprzętu komputerowego. Politechnika Gdańska, Inżynieria Biomedyczna. Przedmiot:") Wykład 2 Przedmiot: Zabezpieczenie systemów i usług sieciowych Temat: (Nie)zawodność sprzętu komputerowego 1 Niezawodność w świecie komputerów Przedmiot: Zabezpieczenie systemów i usług sieciowych W przypadku
Wykład 2 Przedmiot: Zabezpieczenie systemów i usług sieciowych Temat: (Nie)zawodność sprzętu komputerowego 1 Niezawodność w świecie komputerów Przedmiot: Zabezpieczenie systemów i usług sieciowych W przypadku
Wydajność programów sekwencyjnych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Systemy rozproszone System rozproszony
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA
 OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA Załącznik nr 4 do SIWZ/ załącznik do umowy Przedmiotem zamówienia jest dostawa 2 serwerów, licencji oprogramowania wirtualizacyjnego wraz z konsolą zarządzającą oraz
OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA Załącznik nr 4 do SIWZ/ załącznik do umowy Przedmiotem zamówienia jest dostawa 2 serwerów, licencji oprogramowania wirtualizacyjnego wraz z konsolą zarządzającą oraz
współbieżność - zdolność do przetwarzania wielu zadań jednocześnie
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI
 ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
MIKROKONTROLERY I MIKROPROCESORY
 PLAN... work in progress 1. Mikrokontrolery i mikroprocesory - architektura systemów mikroprocesorów ( 8051, AVR, ARM) - pamięci - rejestry - tryby adresowania - repertuar instrukcji - urządzenia we/wy
PLAN... work in progress 1. Mikrokontrolery i mikroprocesory - architektura systemów mikroprocesorów ( 8051, AVR, ARM) - pamięci - rejestry - tryby adresowania - repertuar instrukcji - urządzenia we/wy
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Struktura i funkcjonowanie komputera pamięć komputerowa, hierarchia pamięci pamięć podręczna. System operacyjny. Zarządzanie procesami
 Rok akademicki 2015/2016, Wykład nr 6 2/21 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2015/2016
Rok akademicki 2015/2016, Wykład nr 6 2/21 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2015/2016
Programowanie Niskopoziomowe
 Programowanie Niskopoziomowe Wykład 3: Architektura procesorów x86 Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Pojęcia ogólne Budowa mikrokomputera Cykl
Programowanie Niskopoziomowe Wykład 3: Architektura procesorów x86 Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Pojęcia ogólne Budowa mikrokomputera Cykl
Architektura komputerów
 Architektura komputerów Tydzień 8 Magistrale systemowe Magistrala Układy składające się na komputer (procesor, pamięć, układy we/wy) muszą się ze sobą komunikować, czyli być połączone. Układy łączymy ze
Architektura komputerów Tydzień 8 Magistrale systemowe Magistrala Układy składające się na komputer (procesor, pamięć, układy we/wy) muszą się ze sobą komunikować, czyli być połączone. Układy łączymy ze
Architektura Systemów Komputerowych. Jednostka ALU Przestrzeń adresowa Tryby adresowania
 Architektura Systemów Komputerowych Jednostka ALU Przestrzeń adresowa Tryby adresowania 1 Jednostka arytmetyczno- logiczna ALU ALU ang: Arythmetic Logic Unit Argument A Argument B A B Ci Bit przeniesienia
Architektura Systemów Komputerowych Jednostka ALU Przestrzeń adresowa Tryby adresowania 1 Jednostka arytmetyczno- logiczna ALU ALU ang: Arythmetic Logic Unit Argument A Argument B A B Ci Bit przeniesienia
System mikroprocesorowy i peryferia. Dariusz Chaberski
 System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
Klasyfikacja systemów komputerowych. Architektura von Neumanna. dr inż. Jarosław Forenc
 Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011