Technologie Mowy Bartosz Ziółko
|
|
|
- Seweryna Czyż
- 8 lat temu
- Przeglądów:
Transkrypt
1 Technologie Mowy Bartosz Ziółko 1

2 Technologie Mowy 2
3 Technologie Mowy 3

4 Technologie Mowy 4
5 Dane kontaktowe Dr inż. Jakub Gałka C2/419 Telefon Dr inż. Bartosz Ziółko C2/418 Telefon
6 Wykłady Wprowadzenie i historia Fizjologia mowy i elementy fonetyki języka polskiego. Dialekty języka polskiego. Właściwości sygnału mowy Zbiory nagrań mowy i tekstów. Słowniki komputerowe Redukcja zakłóceń i przetwarzanie wstępne sygnału Metody parametryzacji i segmentacji sygnału Kodowanie, kompresja i transmisja mowy. Synteza mowy Metody rozpoznawania wzorców 6
7 Wykłady Ukryte modele Markowa. Rozpoznawanie słów izolowanych HTK, ANN, SVM, DBN, K-NN Weryfikacja i identyfikacja mówcy. Emocje w głosie Metryka edycyjna. Rozpoznawanie mowy ciągłej. Syntaktyczne modelowanie języka Semantyczne modelowanie. Ontologie Interfejs głosowy i systemy dialogowe Istniejące systemy i przyszłość TM 7
8 Laboratoria Zaprojektowanie własnego systemu rozpoznawania mowy o ograniczonym słownictwie w oparciu o HTK Wykonanie korpusu własnej mowy Zaimplementowanie konkatencyjnego syntezatora mowy Rozszerzenie korpusu mowy i usprawnienie syntezatora Implementacja prostego kodera i kompresora mowy Rozpoznawanie słów izolowanych (MFCC+DTW) Implementacja prostego HMM Przygotowanie modelu HMM z wykorzystaniem własnego korpusu Przetestowanie opracowanego systemu rozpoznawania mowy Poprawki i usprawnienia własnego systemu rozpoznawania mowy opartego o HTK 8
9 Ćwiczenia Elementy statystyki matematycznej (Bayes, rozkłady, Gaussiany, itd.) Zapis fonetyczny, dialekty Dyskusje o technologiach mowy na podstawie artykułów Analizy grafów 3 Kolokwia (także z wykładów) Obliczanie HMM bez komputera Prezentacje studentów na wybrany temat Analiza spektogramów 9
10 Prezentacje Elementy lingwistyki języka polskiego Wybrane komercyjne lub eksperymentalne systemy technologii mowy Zreferowanie wybranego artykułu na temat technologii mowy Pomysł na własny biznes wykorzystujący technologie mowy Można zgłaszać własne propozycje tematów prezentacji Śpiew traktujemy jako mowę 10
11 Oceny Laboratorium Wykonanie zadań laboratoryjnych, ich staranność i jakość Obecność na zajęciach Ćwiczenia 3 kolokwia z ćwiczeń i wykładów (60%) Prezentacja (10%) Wykonanie ćwiczeń w trakcie zajęć (w tym aktywność) (30%) 11


12 Podręcznik 12
13 Bibliografia D. Jurafsky and J.H. Martin Speech and Language Processing, 2nd edition W. Kwiatkowski, Metody automatycznego rozpoznawania wzorców, BEL Studio, Warszawa 2007 (28 zł) J. Koronacki, J. Ćwik, Statystyczne systemy uczące się, Wyd 2., EXIT, Warszawa 2008 (45 zł) M. Krzyśko, W. Wołyński, T. Górecki, M. Skorzybut, Systemy uczące się, WNT, Warszawa 2008 (47 zł) W. Kasprzak, Rozpoznawanie obrazów i sygnałów mowy, WPW, 2009 (28 zł) S. Theodoridis, K. Koutroumbas, Pattern Recognition, Academic Press, 2009 R. O. Duda, P. E. Hart, D. G. Stork, Pattern Classification, 2nd Edition, Wiley & Sons 2000 J. P. Marques de Sa, Pattern Recognition, Springer %20systemach%20detekcji.pdf




14 Człowiek vs. komputer

15 Pierwsze syntezatory mowy Christian Kratzenstein - urządzenie umożliwiające generowanie dźwięków przypominających 5 różnych głosek Równolegle, nad swoją akustycznomechaniczną maszyną imitującą mowę pracował Wolfgang von Kempelen 15

16 Alexander Graham Bell Profesor fizjologii dźwięku na Uniwersytecie w Bostonie oraz nauczyciel głuchoniemych. Badania Bella finansowane przez jego teścia doprowadziły do zbudowania telefonu w latach osiemdziesiątych XIX wieku, a więc także mikrofonu i słuchawki. 16
17 Lampa próżniowa W 1914 roku Harold D. Arnold opracował lampę próżniową, będącą wzmacniaczem sygnału akustycznego generowanego przez prąd elektryczny. Umożliwiło to firmie AT&T (American Telephone and Telegraph) pierwszą transkontynentalną rozmowę w 1915 roku. 17

18 Ferdynand de Saussure Określił język jako system norm społecznych umożliwiający przekazywanie informacji. Dokonał rozróżnienia między językiem (fr. langue) a mówieniem (fr. parole). Zdefiniował język jako systemem symboli i reguł ich tworzenia, który nie może być wytworem pojedynczego człowieka. Określił go więc jako abstrakcję, urzeczywistniającą się w mówieniu realizowanym przez indywidualnych ludzi. 18
19 Cztery 19
20 Sygnał mowy 20
![REX - 1920 Przymocowany do płytki reagującej obrotem na drgania o częstotliwości 500 [Hz] odpowiadającej między innymi głosce e.](/docs-images/63/50517012/images/21-1.jpg "Przy tej częstotliwości pojawiał się rezonans, który odcinał prąd, wypychając psa z budy. W ten sposób zabawka reagowała na imię Rex.")
21 REX Przymocowany do płytki reagującej obrotem na drgania o częstotliwości 500 [Hz] odpowiadającej między innymi głosce e. Przy tej częstotliwości pojawiał się rezonans, który odcinał prąd, wypychając psa z budy. W ten sposób zabawka reagowała na imię Rex. 21
22 VOCODER Bell Labs Posiadał klawiaturę i mógł między innymi syntezować mowę. Służył także do kodowania mowy na potrzeby transmisji. Działało w oparciu o bank filtrów. Z urządzenia najprawdopodobniej korzystali Churchill i Roosevelt do przeprowadzania transkontynentalnych konferencji. Po wojnie zaczęto wykorzystywać ulepszone urządzenia oparte na VOCODERZE w muzyce. 22

23 Bell Labs digit recogniser Analiza spektrum podzielonego na 2 pasma częstotliwości (powyżej i poniżej 900 Hz). Rozpoznawał cyfry wypowiadane po angielsku z błędem mniejszym niż 2%, zakładając, że użytkownik nie zmienił położenia ust względem mikrofonu pomiędzy fazą ustalania parametrów głosu a testowaniem. 23
24 24

25 Japoński system rozpoznawania samogłosek (J. Suzuki, K. Nakata, Radio Research Labs, Japonia, 1961) 25
26 Zimna wojna Szybka transformata Fouriera (FFT) Hidden Markov Model (HMM) ARPA Speech Understanding Project ($15M) Rozpoznawanie mowy ciągłej Słownik około 1000 słów => system CMU Harpy (5% błędów) Algorytm Viterbiego do ćwiczenia modeli
27 LPC Linear predictive coding F. Itakura Bell/NTT Labs 27
28 Podstawowe technologie mowy Automatyczne rozpoznawanie mowy Synteza mowy Rozpoznawanie mówcy Rozpoznawanie emocji Generowanie emocji Synteza z ruchem ust Tłumaczenie mowa-mowa Aplikacje w nauce języków obcych 28
29 Zalety technologii mowy Naturalność (nie wymagają przeszkolenia) Pozostawiają swobodę rąk i oczu Szybkie (3 razy szybciej mówimy niż piszemy na klawiaturze) Ekonomiczność (tekst zajmuje dużo mniej bajtów niż sygnał akustyczny) Szczególnie istotne dla osób nieprzyzwyczajonych do komputerów, niepełnosprawnych oraz w zastosowaniach telefonicznych 29
30 Zastosowanie w telekomunikacji 30

31 Systemy dialogowe 31

32 32

33 Różne poziomy modelowania 33
34 Komunikacja z komputerem 34
35 Komunikacja z komputerem 35
36 Ogólny schemat rozpoznawania mowy 36

37 Komunikacja z komputerem 37
38 Możliwe zastosowania ASR Głównie jako wejście Proste komendy i sterowanie Krótkie wprowadzanie danych (np. przez telefon) Dyktowanie Interaktywne (z rozumieniem) Punkty informacyjne Przetwarzanie transakcji Wirtualni doradcy 38
39 Zakres mowy i słuchu człowieka (Tadeusiewicz, 1988) 39
40 Cechy systemów mowy Mowa izolowana lub ciągła Czytana lub spontaniczna Zależny lub niezależny od mówcy Mały (20 słów) lub duży (>50 000) słownik Model językowy stały lub zależny od kontekstu Perpleksja (entropia) wypowiedzi SNR (<10 db niski, >30 db wysoki) Sposób rejestracji (telefon, komputer, mikrofon z niwelowaniem szumu) Miara nieokreśloności H k i 1 p i log 2 p i 2^H 40

41 41
42 Fonetyka Dialekty języka polskiego Zbiory nagrań i tekstów Słowniki Bartosz Ziółko 42
43 Alfabety fonetyczne Dialekty języka polskiego Korpusy mowy polskiej Korpusy tekstów - przykłady Słowniki przykłady Słowniki - formaty Wordnet 43
44 44
45 45

46 IPA 46

47 IPA 47
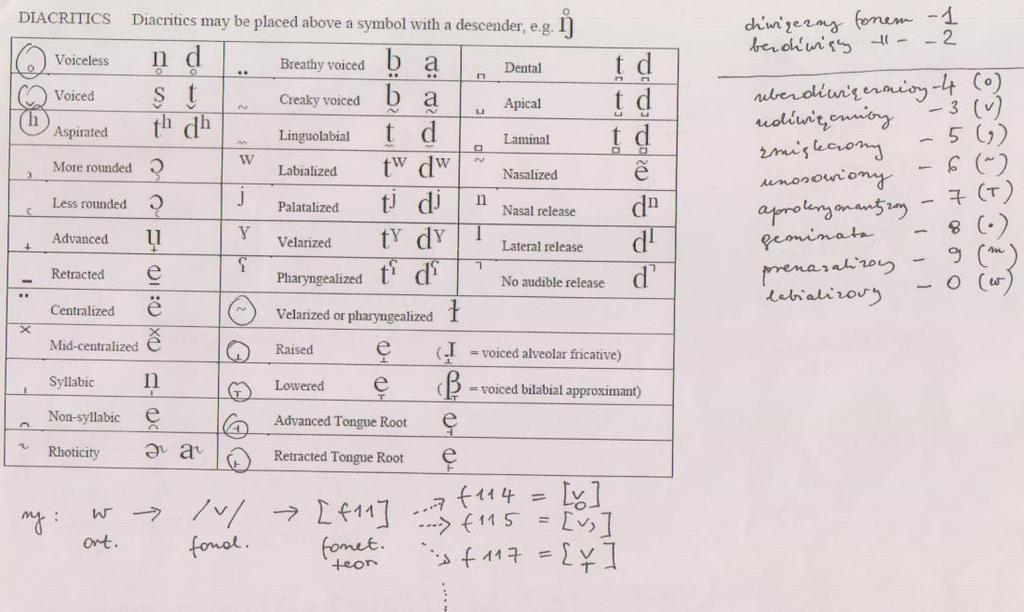
48 IPA 48


49 Baldi features accurate, visible articulators (CSLU Toolkit) 49
50 Fonem i trifon Pojęcie fonemu, jako pierwszy wprowadził Jan Niecisław Ignacy Baudouin de Courtenay. Obecnie fonem najczęściej definiuje się jako najmniejszą rozróżnialną jednostkę mowy. Szerzej znane pojęcie głoski, opisuje realizację konkretnego fonemu w jakiejś wypowiedzi. Zbiór fonemów, opisujących dany język całościowo jest więc alfabetem fonetycznym. Trifon to fonem w lewym i prawym kontekście, a NIE trzy fonemy 50

51 System AGH - Dostawca transkrypcji Tomasz Jadczyk 51

52 OrtFon transkryptor ortofonetyczny 52

53 Tabele OrtFona 53

54 Tabele OrtFona 54


55 Dialekty języka polskiego Wykorzystano materiały Pauliny Macury i Darii Korzec oraz
56 Dialekt a gwara Dialekt charakteryzują swoiste cechy fonetyczne, leksykalne, semantyczne i fleksyjne odróżniające go od ogólnonarodowego języka, używanego przez ogół społeczności Mówiony wariant terytorialny (lokalny) języka narodowego używany na stosunkowo niewielkim terenie Zespół gwar ludowych używanych na większym obszarze, termin nadrzędny w stosunku do gwary ludowej Dialekt jest pojęciem szerszym
57 Język ogólny Dialekt Gwara
58 Cechy dialektów Mazurzenie wymowa spółgłosek dziąsłowych sz, ż, cz, dż jako przedniojęzykowo-zębowe s, z, c, dz np. lepsze = lepse, czas = cas, żeby = żeby, rz nie podlega mazurzeniu!!! np. rzeka (a nie zeka), przypali (nie psypali) Fonetyka międzywyrazowa - dwa wyrazy, gdy pierwszy kończy się na spółgłoskę, a drugi rozpoczyna się od głosek m, n, r, l, j, ł, lub od samogłoski -nieudźwięczniająca - pomósz mje = pomóż mi, tak_ jakby -udźwięczniająca pomóż_mje = pomóż mi, tag_jakby
59 Cechy dialektów Samogłoski pochylone a o, e y występowanie samogłosek pochylonych, czyli gwarowych kontynuantów staropolskich samogłosek długich: ā, ō, ē. Ich realizacja przedstawia się następująco: -a pochylone á - jako dźwięk pośredni między a i o, kontynuant staropolskiego ā, np. górole, downo, krzoki; -o pochylone ó jako dźwięk pośredni między o i u, kontynuant staropolskiego ō, np. wóz, dziadów, kónia; -e pochylone jako dźwięk równy samogłosce y, kontynuant staropolskiego ē, występuje po spółgłoskach twardych i miękkich, np. mlyko, tyz, śpiywo, biyda; 59
60 Cechy dialektów Sziakanie (jabłonkowanie) taka sama wymowa spółgłosek dziąsłowych sz, ż, cz, dż i spółgłosek środkowojęzykowych ś, ź, ć,dź jako zmiękczone dziąsłowe sz, ż, cz, dż np. cziarni czielak = czarny cielak Szadzenie - zjawisko polegające na zastąpieniu szeregu spółgłosek zębowych: c, s, z, dz szeregiem spółgłosek dziąsłowych cz, sz, ż, dż; wynika z przesadnego unikania mazurzenia, występuje na Suwalszczyźnie
61 Cechy dialektów Prejotacja - poprzedzenie samogłosek w nagłosie j niezgłoskotwórczym np. j ile, J ewa, j anioł = ile, Ewa, anioł J igła, j indycka, j innych Labializacja - to zjawisko poprzedzania samogłosek tylnych o niezgłoskotwórczym u, zwykle osłabionym (zapisywanym jako ł), Okno = łokno, golec łorkiestra


62 MAPA DIALEKTÓW
 Brak mazurzenia Sziakanie (jabłonkowanie) Samogłoski pochylone 1-os. lp. cz. przeszłego np.")
63 Dialekt śląski Wymowa udźwięczniająca ostatnią głoskę pierwszego wyrazu w połączeniach wyrazowych, np: tag_robili, mógbyź_mi (pomóc) Brak mazurzenia Sziakanie (jabłonkowanie) Samogłoski pochylone 1-os. lp. cz. przeszłego np. byłech, robiłech
64 Powiedzioł mi wczora chlapiec 1.Powiedzioł mi wczora chłapiec, że nie umiem chleba napiyc. Cieszyn, Opawa, Frydek, Morawa, chleba napiyc. 2. Jo się na to rozgniewała, móki, soli napojczała. Cieszyn, Opawa, Frydek, Morawa, napojczała. 3. Taki się mi chlyb wydarził, spoza skury kot wyłaził. Cieszyn, Opawa, Frydek, Morawa, kocur łaził. 4. Z jednej stróny woda ciekła, z drugi stróny mysz uciekła. Cieszyn, Opawa, Frydek, Morawa, mysz uciykła.

65 Dialekt śląski 65
 Podhale - 1-os. lp. cz. przeszłego np.")
66 Dialekt małopolski Mazurzenie Fonetyka międzywyrazowa udźwięczniająca Samogłoski pochylone Przejście wygłosowego -ch jako -k, np. tych = tyk, na polach = na polak (Spisz ch na f) Podhale - 1-os. lp. cz. przeszłego np. byłek, robiłek
67 Siwy dym Kiebyś miała rozum i do ludzi zdanie Hej! To byś mnie kochała za samo śpiywanie Siwy dym, siwy dym Biołe sadze niesie Hej! Pockoj mnie dziywcynko przy zielonym lesie.
68 Dialekt małopolski (Spisz, Jurgów) To w ogóle nie było wody. Wiycie jako była biyda o wode. Ludzie to takie mieli beckid rewniane i wozili tum wode w tyk becka(ch). No to nos było duzo dziewco u nt bo było nos pieńć siostrók, a u sąsiadów zaś było duzo chłopców no to tam wiyncyj tum wode prziwozili te chłopc i, bo no bo z aprzągli kónia i jechali. Tak to cza bylo, jak choć kiedy to my tak sły...p ł ozycciez nom do wiadra wody. No bo cza było d aleko po nium jechać. Tam ze dwa tam jak do p otoka to d aleko. Tako becka byla d rewniano. Taki korek był w epchany. Nej sie go w ycią u gło i ta woda tak z tej becki l eciała. No to a p rasuwanie. No to pranie, no pranie, bo pralków n ie było. To była tako mied..., tako była bajla, tako tako zela... Tako jak no so u m jesce teroz takie. Takie ani... alimunowane c i takie jak to sie nazywajom. No to i tako była r ajbacka, tak sie rynkum tako tyz zelazno. My nie mieli pralki, to jo potym ho ho juz nie wiym c i do siódmej klasy nie chodziła, kiej mama takom Franie p amiyntom p rziwiezłaz miasta. Byli z p rosientami. A tak to w ryncach prali. Nej płukać to tak d aleko my miały d o wody, to c i ch ł odniki c i co, no to cza było straśnie ł oscyndzać, zeby zeby z tym praniym. To jag my juz wyprały takie cosi b ielizne c i z p ł ościele c i cosi, co była c yściyjso woda, to juz my potym to tum wodom podłoge musiały myć, zeby jom nie w ylywać, zeby jom na cosi zuzyć. No a p rasuwać to takie było z elazko lampy... jak sie p oliło w piecu no to ono mia.. 68
69 Dialekt małopolski (Lubelszczyzna Wsch, Moniatycze) ur. w 1934 r. w Jankach koło Hrubieszowa kilka kilometrów na zachód od Moniatycz). Ukończyła 4 klasy szkoły podstawowej. Wyjeżdżała jedynie do Hrubieszowa. K j edyś? Kiedyś taniec to był naprawde: polka o u berek to to już było zakładanie, to sie kiedyś zakładało. Dajmy na to, jak ja bym poszła na na óberek, tańczyć, to chłopcy sie zakładali, ilie ona wytrwa. Ódbijali. Pięć, sześć, siedem chłopców, a jedna dziwczynka, ilie ona wytrwa tego oberka. Więc ta dziwczynka zarab j ała. Czy na cze y ko u lade, czy na cukierki, czy na jak jak latem było, czy na do u brego loda. No bo to kiedyś co to, to ludzie róbili w domu. A jak sie coś dzieś trafiło, to to było jak ja w j em? Ziarko w morzu. No i i takim to to była taka właśnie moja młodość, o. A ja byłam taka sprytna, ży ja wszyskichprzytańczyłam, bo ja tańczyłam przyz noge. Nie tak jak to sie po u dbijali oboma no u gami, ty l ko ja przyz noge tańczyłam, tak że ja wszyskim mogłam przytańczyć, ja sie ni ma nie męczyłam. To już jak szed ten zakład z chło u pakami to już ja już widziałam, że oni sie zakładajo, że idzie chtoś do mnie. A szed najpierw taki, co ni umiał tańczyć. Żeby ja gouczyła, żeby ja sie zmynczyła. A ja nie tak nie Bo jak przyz noge sie tańczy, to tak sie i chłópaka ni męczy i sam sie nie i męczy. Ja mówi: czekaj, do u tego chło u paka. 69

70 Dialekt wielkopolski Brak mazurzenia fonetyka międzywyrazowa udźwięczniająca- np. szeź_arów, laz_uruojs = sześć arów, las urósł Samogłoski pochylone -ow jako -ew np. majowy = majewy Labializacja
71 Dialekt wielkopolski (Baranówko, koło Poznania) Kiedyź no to, kiedyś to wykopki odbywały sie dziabkom, nawet wprawdzie nie u nas, w naszym gospodarstwie nie, ale w gospodarstwach w takich tych pegeerowskich, w tych majontkach, to dziabkami, dziabkami wykopywali, to tam cały szereg tych pań szło. Mówili na to: na szefle chodzóm i to miały płacone od wykopków, od tych szefli, nie wiem, ile na taki szefel tam wchodziło, w każdym bądź razie że one szły z koszykami, wsypały do jakigoś tam pojemnika, to był, który nazywał sie tym szeflym i ten, ten, ten, ten który tam pilnował, nadzorował, to on to zapisywał i od tego miały obliczane. U naz natomias była maszyna tak zwana figaka, to ona tak wyrzucała na boki i każdom jednom radlone, radlin... radline brała, a dwóch musiało zbierać, bo to tam rorzuciła na jakieś tszy metry. I to ludzie byli paramirozstawini, co kawołek inna para, takie tam cztery pi ń ć par czasym zbierało te zimniaki, jak zależności od tego, jakie było długie pole, nie. A w kóńcu przyszły te el... elewatorowe tak zwane ciągnikowe maszyny, które wyrzucały do tyłu i zabierały dwie radliny, a zbierał jeden człowiek i wtynczas znowuż zbierali raz przy razie mogli sobie zbierać wszyscy i z boku sie jechało czy tam końmi, czy ciągnikiem i jeden wysypywał te ziemniaki na... na... do skrzyni, do tej, do tej przyczepy, tak. No a obecnie to som już tam te kombajny, które... które wybierajom, no som jeszcze że jeszcze tam, jeszcze sie spotyka, że jeszcze wybierajom takimi też zimniakami, te zimniaki, tymi ewelator... elewatorowymi, 71
 ja- w je-, np. jak = jek, jagoda = jegoda, oraz ra- w re-, np.")
72 Dialekt mazowiecki Mazurzenie Fonetyka ubezdźwięczniająca międzywyrazowa np. tak_jakby Stwardnienie grupy li w ly np. lypa, malyna Przejście nagłosowego (na początku) ja- w je-, np. jak = jek, jagoda = jegoda, oraz ra- w re-, np. rano = reno Po spółgłoskach wargowych miękkich pojawiają się dodatkowe spółgłoski, np. mniasto
73 Dialekt mazowiecki (Janówek, koło Warszawy) Drzewa to se teras nie obdziabuje. Obdziabuje sie, śnuruje, panie, sie. Mas pan sznur i zaznacas ołówkem tu, tu, zeby było prosto, panie, i mozna obdziabywać albo oberżno u nć na pile, panie, tak, takie drzewo i zeby było cy do kantu, ji na jakie chces pan, cy na łaty, cy na te krokwy. No bo jak na łaty chces pan, pod blache bić, to cienkie, a na krokwi to musombyć, panie, dobre drzewo, grubse i mocne. To pan dajes później trempel, to trempel, zebysie nie zawaliło, ten, ten dach, jak to, no to musi być zmocowany, jak to sie mówi, panie. I to wszystko jest, to robota była, panie, taka, i panie ji. Robiło sie na Ursynowje, budynkistawjało sie, wjeżowce, panie, Ł okeńcie sie budowało, na Ł okeńcie byłem, było tepowjenkszenie tego Okeńcia, tyż robiłem, panie, zakłady Nowotki, polskie nagranie, na strzelnicy sie robiło tu, na Bjelanach, tu na Młocinach, wszystko robiło tamoj, panie, strzelnicy, to poszli duzo piniendzy a to nic z tego nie wysło, bo to w kepskim mjejscuzaplanowali. Bo to ta Wisłostrada leci, tutej rozjazdy, wje pan, panie. Wszystko to, widzis pan, wszystko to robiłem sam, panie, ł o. 73
74 Dialekt mazowiecki (Czerwonka, Podlasie) Kiedyś co tutaj było? Kowal. Kawal był, wszystko było swoje, nie, tedy wszystko, nichto ni kupował, wszystko swoje, dawali, warzywo, nie warzywo, wszystko, tylko tera to tam o robio, no. Ale też tak kawala nie ma, już koso i nie ko szo, cepami nie młóco, maszynami, niestety, już wszystko, zmieniło a s ie, no bardzo zmieniło sie... Jak ja jeszcze byłam nawet młodo a m, to w szkole a organizo a wali komedyjki takie różne, przedstawienia różne, brałam dużo udziału w tym. To jeszcze było w Pokośnem, do szkoły chodząc i ze szkoły różne tance, rozmaite, różne te stro u je te. Są takie spódnicy, baby nosili kiedyś, naszywane a, długie a z takimi ko a ronkami różne, jeszcze gdzieś tam może na górze jest. Z tych tradycyjów, było ale już tera nie ma, zanikło. Bo nie ma młodych, my już stare, to co tam, nie dasz rady, no to co tam, nie robisz nic i tak, o. Są jeszcze tradycje różne. Alejusz nie już tylko tak, we a s iele jeszcze tradycyjne jest, pogrzeb tradycyjny jest, no i chrzciny tradycyjne spotykajo, że podajo dz ieciaka do chrztu. No to jest jeszcze tradycja. Nie ma te y go, jusz jakie może dziesięć lat jusz nie ma tego, co było kiedyś. Byli zabawy to jak liatem u stodołach, dz iś jusz nie ma tych zabawów. A jeszcze kiedys to po a mieszkaniach, to było a byli, no i grali tutaj, o tam u kogoś gdz ie młodych dużo było, to poproszo i grali i tańczyli, było a więcej rozrywki było, różne takie przyśpiewki śpiewali. 74

75 Nowe dialekty mieszane Termin stosowany na określenie odmian języka polskiego używanych na ziemiach zachodnich i północnych Polski, tzw. ziemiach odzyskanych. Powstały ze zmieszania się kilku różnych gwar. Stały się polszczyzną ogólną z elementami gwarowymi.
76 Język kaszubski Od 2005 roku język regionalny z możliwością wprowadzenia do urzędów jako język pomocniczy W województwie pomorskim Można zdawać maturę z języka kaszubskiego Inne znaki fonetyczne niż w języku polskim Spółgłoski które w wielu gwarach polskich ulegają mazurzeniu w kaszubszczyźnie upodabniają się do ś, ź, ć, dź - kaszubienie
77 Kaszubski 77
78 Mazurzenie

79 Lwowski 79

80 Fonetyka międzywyrazowa TAK_JAKB Y TAG_JAKB Y
81 Ziemniaki Grule Podhale Rzepy Orawa Pyry Wielkopolska Kobzale, knule, jabłka Śląsk Kartofle Mazowsze i Śląsk Bulwy Pomorze Pantówki - Kujawy
82 Dialekty angielskiego 82

83 83

84 84
85 Znaczenie korpusów Większość metod w przetwarzaniu mowy opiera się na statystykach => Jakość i wielkość korpusów jest kluczowa dla jakości systemów 85
86 Korpus a zbiór danych Przetwarzalny przez maszyny Autentyczne dane językowe Reprezentatywny Zwykle anotowany (transkrypcje do mowy, funkcje gramatyczne do tekstów, osoby wypowiadające się itd.) 86


87 Jakość sygnału mowy 87
88 Anotacje Wykonanie wszelkiego rodzaju anotacji jest procesem bardzo czasochłonnym i uciążliwym (1 min mowy -> 20 min pracy) => Korpusy są dużo kosztowniejsze niż ich nie przetworzona zawartość Stosuje się coraz częściej także podejścia automatyczne, bez anotacji przez ludzi (Google) 88

89 Anotator AGH 89

90 Segmentacja na fonemy 90
91 Aspekt prawny Teksty i nagrania są wytworem myśli i jako takie są chronione prawem autorskim Prawo w Polsce dopuszcza pobieranie tekstów z internetu, zabrania ich udostępniania bez zgody autorów Nie ma przepisów prawnych odnośnie praw do modeli językowych wytworzonych na podstawie tekstów objętych ochroną prawem autorskim Można założyć, że statystyki nie są już chronione prawem, ale trzeba liczyć się z wątpliwościami 91
92 Polskie korpusy mowy Grocholewski CORPORA Jurisdic GlobalPhone Luna SpeechDat(E) EPPS European Parliament corpus Szklanny corpus (PJWSTK) AGH corpus 92
93 CORPORA - anotacja "*/ak1c1kzm.lab 0 0 sil k a zi i m j e r a sil. MLF, CHR, FON Programy LABEL98 i BASAK98 93
94 GlobalPhone - anotacja ;SprecherID 001 ; 1: Niemiecka gazeta "Franfurter Rundschau" wczorajsza~ korespondencje~ z Krakowa zatytul1owal1a "Wieczna postac1" ; 2: Dziennik nawia~zal1 do wypowiedzi jednej z ml1odych mieszkanek Krakowa kto1ra mial1a cztery lata gdy kardynal1 Wojtyl1a wyjechal1 do Rzymu w tysia~c dziewie~c1set siedemdziesia~tym o1smym roku ; 3: Cal1e moje z0ycie przebiega pod znakiem Jana Pawl1a drugiego ;timestamp: 1999 ;BEGIN ;LANGUAGE:Polish ;SUPERVISOR:Patrycja H ;TAPELABEL:notape ;RECORD DATE: ;ARTICLE READORDER: ;TOPIC ARTICLE: ;SPEAKERDATA ;NAME OF SPEAKER:Patrycja ;SPEAKER ID:001 ;NATIVE LANGUAGE:Polish ;RAISED IN:Poland ;DIALECT: ;SEX:female ;AGE:22 ;OCCUPATION:student ;COLD OR ALLERGY:ok ;SMOKER:nonsmoking ;RECORDING SETUP ;RECORD PLACE: ;ENVIRONMENT NOISE: ;RECORD CONDITIONS: ;COMMENTS: ;END 94
95 Luna anotacja (2 sek) 95
96 Luna anotacja (2 sek) c.d. 96
97 Luna anotacja (2 sek) c.d. 97
98 Luna anotacja c.d. 98
99 Europarlament - anotacja <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE Trans SYSTEM "trans-14.dtd"> <Trans audio_filename="1655_1730_pl_sat" version="2" version_date="110106"> <Speakers> <Speaker id="spk1" name="unknown" type="unknown" dialect="native" accent="" scope="global"/> <Speaker id="spk2" name="geremek" check="no" dialect="native" accent="" scope="local"/> </Speakers> <Episode> <Section type="report" starttime="0" endtime=" "> <Turn starttime="0" endtime="32.526"><sync time="0"/> 99
100 Europarlament anotacja c.d. </Turn> <Turn speaker="spk1" starttime="32.526" endtime=" "> <Sync time="32.526"/> [noise] <Sync time=" "/> [pause] <Sync time=" "/> [noise] </Turn> <Turn speaker="spk2" starttime=" " endtime="246.34"> <Sync time=" "/> dziękuję panie przewodniczący. <Sync time=" "/> muszę wyznać, że przemówienia pana premiera [xxx] mają siłę uwodzicielską. <Sync time="174.29"/> i po przemówieniu czerwcowym w parlamencie słuchając końcowego dzisiejszego, 100
101 Europarlament anotacja c.d. Sync time="181.06"/> chciałem rozpocząć moje wystąpienie od tego, że uważam premiera [xxx] [xxx] za jednego z nielicznych europejskich mężów stanu. <Sync time=" "/> ale czar prysł, gdy pan premier wyszedł. <Sync time=" "/> i dlatego moje słowa będą nieco odmienny charakter nosiły. <Sync time=" "/> wiele wskazuje na to, że prezydencja brytyjska będzie miała bilans, który będzie smutny dla unii europejskiej. <Sync time=" "/> [applause] </Turn> <Turn speaker="spk1" starttime="246.34" endtime=" "> <Sync time="246.34"/>[noise]</turn> <Turn starttime=" " endtime=" "> <Sync time=" "/> </Turn> </Section></Episode></Trans> 101
102 Szklanny - anotacja File type = "ootextfile" Object class = "TextGrid" xmin = 0 xmax = 5.54 tiers? <exists> size = 1 item []: item [1]: class = "IntervalTier" name = "Alignment" xmin = 0 xmax = 5.54 intervals: size = 57 intervals [1]: xmin = 0 xmax = text = "_sil_" intervals [2]: xmin = xmax = text = "n'" intervals [3]: xmin = xmax = text = "e" intervals [4]: xmin = xmax = text = "z" intervals [5]: xmin = xmax = text = "a" intervals [6]: xmin = xmax = text = "m" intervals [7]: xmin = xmax = text = "j" intervals [8]: xmin = xmax = text = "e" intervals [9]: xmin = xmax = text = "Z" intervals [10]: xmin = xmax = text = "a" intervals [11]: xmin = xmax = text = "m" intervals [12]: xmin = xmax = text = "m" 102
103 AGH - anotacja 103
 Notatki PAP Wikipedia Inne strony (crawling) http://clip.ipipan.waw.")
104 Polskie korpusy tekstów IPI PAN (z POS tagami) NKJP (National Corpus of Polish) Rzeczpospolita Literatura Transkrypcje Sejmu i zjazdów Solidarności Nazwiska (Lista Wildsteina, PESEL, ANWIL SA) Notatki PAP Wikipedia Inne strony (crawling) 104
105 Korpus IPI PAN <tok> <orth>porządek</orth> <lex><base>porządek</base><ctag>subst:sg:acc:m3</ctag></lex> <lex disamb="1"> <base>porządek</base><ctag>subst:sg:nom:m3</ctag> </lex> </tok> <tok> <orth>dzienny</orth> <lex><base>dzienny</base><ctag>adj:sg:acc:m3:pos</ctag></lex> <lex><base>dzienny</base><ctag>adj:sg:nom:m1:pos</ctag></lex> <lex><base>dzienny</base><ctag>adj:sg:nom:m2:pos</ctag></lex> <lex disamb="1"> <base>dzienny</base><ctag>adj:sg:nom:m3:pos</ctag> </lex> </tok> 105

106 Polskie korpusy tekstów 106
107 Problemy z formatem polskich liter Standardy polskich liter: -UTF-8 -Windows ISO Mazovia -IBM CP 852 -? Czasami w jednym pliku może być użytych kilka
108 Litery języka polskiego w UTF-8 108

109 Litery języka polskiego w UTF-8 109
110 Korpusy tekstów angielskich - American National Corpus (ANC) 22 mln (2009) - CollinsWordbank, mixed mainly British 56 mln (2009) - British National Corpus (BNC) 100 mln (spoken and written) - Corpus of Contemporary American English (COCA) 385 mln (spoken, literature, journals, academic papers) - Brown Corpus (1967) 1 mln but with POS tags - International Corpus of English (ICE) 1 mln (British, Hong Kong, Western Africa, India, New Zeland, Philipines & Singapur) - Oxford English Corpus mln (but including Internet websites) - Scottish Corpus of Texts and Speech 4 mln of Scottish 110
111 Inne typy korpusów Wielojęzyczne (do uczenia tłumaczeń) Wielomodalne (np. audiovideo) Emocjonalne (z pracy mgr inż. Magdaleny Igras) medyczne 111

112 Korpus audiovideo AGH 112


113 Korpusy Ultrasonograficzne Thomas Hueber 1, Elie-Laurent Benaroya2, Bruce Denby 3,2, Gérard Chollet 1GIPSA-lab, 2Sigma Laboratory, ESPCI Paristech, 3Université Pierre et Marie Curie, Paris, France 4LTCI/CNRS, Telecom ParisTech 113
")
114 Korpusy z obrazowaniem metodą rezonansu magnetycznego (MRI) 114
115 Korpusy z obrazowaniem metodą rezonansu magnetycznego (MRI) 115


116 Korpusy elektromiograficzne (EMG) Michael Wand, Matthias Janke, Tanja Schultz (KIT) 116


117 Korpusy z elektromagnetycznym artykulografem (EMA) P. West, Oxford University Phonetics Lab 117
118 Korpusy mowy i tekstów czym się kierować przy wyborze Jakość i wielkość potrzebna optymalna decyzja Format nagrań lub tekstów Anotacje Zgodność z tekstem Szczegółowość (zdania, słowa, fonemy) Dodatkowe informacje Kim byli mówcy O czym jest korpus Czy mówcy powtarzają te same wypowiedzi Cena (od 2000 Euro do Euro) 118

119 Słowniki 3 reprezentacje Pliki tekstowe Bazy danych Finite State Automaton 119
120 Słowniki języka polskiego Synonimy Open Office Wielki Słownik Języka Polskiego Słownik wyrazów obcych i zwrotów obcojęzycznych Władysława Kopalińskiego Wikisłownik Słownik synonimów i antonimów Piotra Żmigrodzkiego Słownik Języka Polskiego N-gramowy słownik frekwencyjny języka polskiego 120
121 Słowniki do rozpoznawania mowy zawsze będą mieć transkrypcję fonetyczną. może moze Morze moze tak tak tak tag 121
122 Słownik AGH baza danych projektowane jako pliki tekstowe -> przetwarzanie do BD (SQL wolne, lepiej stosować Berkley DB i inne nierelacyjne) Mariusz Mąsior 122
123 Wybór silnika bazy danych Potrzeby: - Duża szybkość odczytu - Odpowiednia licencja - Małe zużycie zasobów - Prostota - Łatwość instalacji (brak serwera usług) - Przenośność danych Dawid Skurzok
124 SQL vs nosql SQL Structured Query Language relacyjne bazy danych (MySQL, Ms SQL, Oracle, SQLite...) NoSQL - not only SQL - wszystkie inne key-value store, document store, graph DB, object DB, tabular, (BerkeleyDB, BigTable, CouchDB, ) Dawid Skurzok
125 Wybór silnika bazy danych RDBMS (MySQL, Postgres, MS SQL) Dostępność Wybierz dwa! Tokyo Cabinet, CouchDB, Cassandra Relational Key-Value Tabular Document Spójność BerkeleyDB, BigTable (Google), MongoDB Podzielność Dawid Skurzok
126 Wybór silnika bazy danych Tylko czytanie danych Dostępność Wybierz dwa! Spójność Podzielność Dawid Skurzok
127 Wybór silnika bazy danych Tylko czytanie danych Dostępność Wybierz dwa! Spójność Zapis danych jednowątkowo Podzielność Dawid Skurzok
128 Wybór silnika bazy danych Tylko czytanie danych Dostępność Wybierz dwa! Spójność Zapis danych jednowątkowo Podzielność Dane przechowywane tylko lokalnie Dawid Skurzok

129 Wybór silnika bazy danych Tylko czytanie danych Dostępność HODB key-value store (DSP AGH) - Duża szybkość odczytu - Własna licencja - Prosta implementacja Spójność Zapis danych jednowątkowo Podzielność Dane przechowywane tylko lokalnie Dawid Skurzok
130 Testowane silniki baz danych SQLite lekki silnik relacyjnych baz danych BerkeleyDB nierelacyjna baza danych przechowuje dane w oparciu o schemat kluczwartość HODB własna implementacja bazy danych w oparciu o tablicę mieszającą (hash table) Dawid Skurzok
131 Zbieranie danych do modelu językowego Dawid Skurzok
132 Odczyt danych dane rzeczywiste Dawid Skurzok
133 Semantyczne zasoby dla języka Polskiego Słowosieć Wikipedia i DBPedia Synonimy w OpenOffice Wielki Słownik Języka Polskiego Słownik Języka Polskiego 133
134 Słowosieć Elektronika jest typem sprzętu Elektronika jest typem nauki matematycznoprzyrodniczej i nauki ścisłej 134
135 Słowosieć Automatyka Informatyka Mechanika Inżynieria 135
136 Konstruowanie Słowosieci 136
137 Podsumowanie Orientacja w zagadnieniach związanych z korpusami mowy i tekstów (jak się je robi, ocenia ich jakość, wielkość itp.) Rodzaje korpusów (tekst, mowa, wielojęzyczne, audiovideo, emocje, obrazy medyczne ) Implementacje słowników (tekst, BD, FSA) Słowosieć (sprawdzić stronę) 137
138 HTK 138
139 Czym jest HTK Zbiór programów implementujących Niejawne Łańcuchy Markowa - Hidden Markov Models (HMMs) ASR, synteza mowa, rozpoznawanie liter, badania nad sekwencjami DNA Analiza mowy, wyćwiczenie HMM, testowanie i analiza rezultatów HTK dopasowuje hipotezę każdego rozpoznania do jednego z elementów słownika przygotowanego przez użytkownika Porównanie transkrypcji fonetycznych słów 139
140 Schemat HTK 140
141 Sekwencja symboli 141
142 Rozpoznanie pojedynczego słowa 142
143 Łańcuch Markowa 143
144 Ćwiczenie 144
145 Rozpoznawanie 145
146 Reprezentowanie mikstur 146
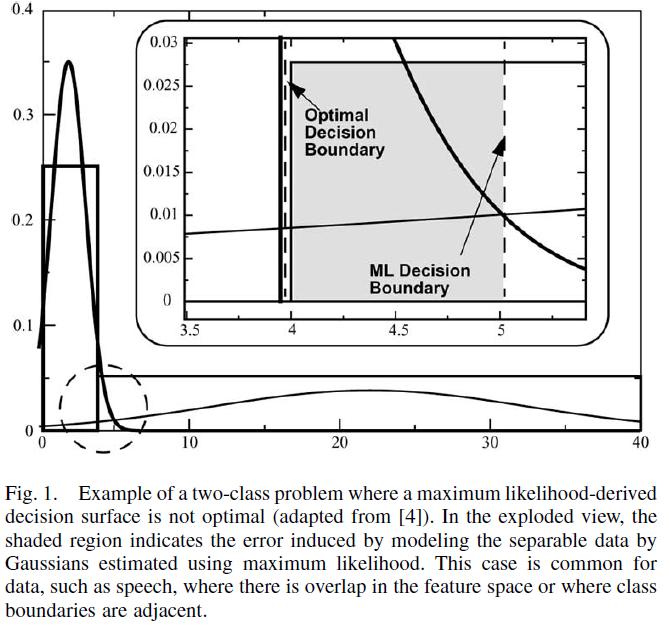
147 Reestymacja Najpierw robi się zgrubne przybliżenie wartości parametrów HMM Następnie dokładniejsze parametry można znaleźć stosując reestymację Baum-Welcha Według kryterium maksymalnego podobieństwa (maximum likelihood) 147
148 Algorytm Viterbiego dla rozpoznawania izolowanych słów 148
149 Sieć rozpoznawania dla mowy ciągłej 149
150 Tokeny wykrywające granice słów 150
151 Używanie HTK System można wykonać korzystając z tutoriala HTK Book, jednakże niektóre kroki będą inne, a niektóre można pominąć Step 7-8 Fixing the Silence Models Step 9-10 Making Triphones from Monophones Różnice i niedopatrzenia Przygotuj plik config1 i codetr.scp (config jak w tutorialu ale z SOURCEFORMAT = WAV) Utwórz katalogi hmm0, hmm1,
152 Rzeczy o których należy pamiętać Dokumentuj używane komendy i inne czynności Dbaj o porządek w swoich plikach Nagrywaj mowę w dobrej jakości (głośno, poprawnie wymowa, jak najmniej zakłóceń i szumu, bez przesterowania) Nagrania muszą idealnie pasować do transkrypcji Niczego nie kasuj Aby otrzymać ocenę wyślij sprawozdanie, nagrania, transkrypcję i cały system 152
153 Modelowanie mowy Bartosz Ziółko 153
154 HMM 154
155 155
156 156
157 157
158 Probability density function 158

159 Maximum A Posteriori (MAP) Estimation Maximising the posterior pdf 159
160 Maximum-Likelihood (ML) Estimation Maximising the likelihood function 160
161 Common problems with using statistics 161
162 162
163 Klasyfikowanie i dekodowanie w ASR poza HMM Klasyfikator k-nn Artificial Neural Networks (ANN), Sztuczne sieci neuronowe Support Vector Machine (SVM), Maszyna wektorów nośnych Dynamic Bayesian Networks (DBN), Dynamiczne sieci Bayesa Graphical Model Toolkit (GMTK) Maximum Entropy Direct Model Conditional Random Fields (CRF) 163
164 Wartość cechy 2 (x[2]) Modyfikacja AGH klasyfikatora k-nn c 1 c x -0.6 J. Gałka Wartość cechy 1 (x[1]) 164
165 Artificial Neural Networks (ANN, NN) 165
166 Modelowanie czasu i kontekstu w ANN 166
167 Hosom, Cole, Fanty, CSLU at Oregon Institute of Science and Technology 167
168 168
169 169
, 13 th -order MFCC with no delta values (MFCC13), 9 th -order MFCC with and without delta values")
170 EVALUATION AND INTEGRATION OF NEURAL- NETWORK TRAINING TECHNIQUES FOR CONTINUOUS DIGIT RECOGNITION J.-P. Hosom, R. A. Cole, and P. Cosi Features: 13 th -order MFCC with delta values (as in the baseline system, referred to as MFCC13D), 13 th -order MFCC with no delta values (MFCC13), 9 th -order MFCC with and without delta values (MFCC9D and MFCC9), 13 th -order and 9 th -order PLP with and without delta values (PLP13D, PLP13, PLP9D, PLP9), a combination of 13 th -order PLP and 13 th -order MFCC (PM13), a combination of 9 th -order PLP and 9 th -order MFCC (PM9). All PLP features were computed using RASTA pre-processing, and all MFCC features were computed using CMS pre-processing. Grammars: allowing optional silence between digits (SIL), allowing an optional garbage word as well as optional silence between digits (GAR). 170
171 Metodologia empirycznego oceniania Wyniki testów niczego nie dowodzą, mogą jedynie wskazywać itp. Konieczne jest rozdzielenie danych treningowych i testowych, aczkolwiek można crossować Prawo wielkich liczb, ale Niektóre systemy statystyczne mogą się przećwiczyć Oceniamy na raz wyłącznie jedną zmienną, reszta systemu musi być całkowicie stabilna Należy podać jak najwięcej szczegółów dotyczących danych testowych, a w miarę możliwości używać ogólnodostępnych testów Wyniki naukowe powinny być falsyfikowalne otwarcie na krytykę 171
172 Support Vector Machine (SVM) 172
173 173
174 Ganapathiraju, Hamaker, Picone: Applications of Support Vector Machines to Speech Recognition SVM nie może modelować wprost struktur czasowych Stosuje się rozwiązania hybrydowe SVM/HMM SVM zapewnia miarę i dyskryminant umożliwiający porównywanie klasyfikatorów Brak jasnych relacji między dystansem klastrów i prawdopodobieństw a posteriori Projektowanie klasyfikatora: jeden przeciwko wszystkim lub jeden na jeden Model segmentowy ze stałą liczbą regionów 174
175 Ganapathiraju, Hamaker, Picone: Applications of Support Vector Machines to Speech Recognition 175
176 Ganapathiraju, Hamaker, Picone: Applications of Support Vector Machines to Speech Recognition 176
177 Nieliniowe klasyfikacje SVM ZPrZA 177
178 Rezultaty stosowania SVM z różnymi ustawieniami w rozpoznawaniu mowy 178
179 Sieć Bayesowska Skierowany acykliczny graf reprezentujący zbiór zmiennych losowych i zależności warunkowych między nimi. 183
180 Sieć Bayesowska 184
181 185
182 Dynamiczne sieci Bayesowskie Wyrażenie s ozna cza wystąpienia stanów koncepcyjnych z dyskretnymi wartościami opisującymi fizyczny system o wartościach ciągłych ze stanami x i obserwacjami y 186

183 187
184 HMM a DBN HMM jest podklasą DBN DBN reprezentuje wprost właściwości rozkładu na czynniki Rozkład na czynniki określony przez DBN narzuca warunki które model musi spełnić DBNy przekazują informację strukturalną o ukrytym problemie 188

185 Edinburgh articulatory DBN model manner, place, voicing, rounding, front-back, static 189
186 Graphical Model Toolkit extension of DBN Dopuszcza krawędzie ukierunkowane przeciwnie do upływu czasu Płaszczyzny sieci mogą obejmować wiele ramek czasowych Łamie założenia Markowa Mechanizm do przełączania dziedziczenia Dziedziczenie zmiennej może być wielokrotne a także ulokowane w przyszłości Dopuszcza różne wieloramkowe struktury pojawiające się zarówno na początku jak i na końcu sieci Bilmes, Bartels: Graphical Model Architecture for Speech Recognition 190
187 GMTK 191
188 Maximum Entropy Markov Model Kuo, Gao: Maximum Entropy Direct Models for Speech Recognition 192
189 Conditional Random Fields DBNy modelują dystrybucję prawdopodobieństw wielu zmiennych p(y,x) CRFy modelują dystrybucję prawdopodobieństw warunkowych p(y x) 193
190 Deep Neural Networks Zwykle więcej warstw Wysokopoziomowe cechy są definiowane w oparciu o niskopoziomowe 194
191 Dynamic Time Warping 195
192 196
193 197

194 198
195 Podsumowanie W ASR stosuje się rozwiązania konkurencyjne do HMM (knn, ANN, SVM, DBN, MEDM, GMTK, CRF, DNN). We wspomnianych metodach są problemy z modelowaniem czasu i kontekstu koartykulacyjnego, dlatego często stosuje się hybrydy z HMM. Metodologia testowania i oceny ASR Przeszukiwanie grafów szerokie i dogłębne 199
196 Metryka edycyjna Rozpoznawanie mowy ciągłej (wykorzystano materiały Dawida Skurzoka i MIT) 200
197 Levenshtein Distance Wolfram Mathematica Demo: Edit Distance 201
198 Modyfikacja metryki edycyjnej o d t a p g d i e k o n t f d u a l a m k o t a A L A Lepsze dopasowanie niemożliwe przerwanie analizy kolejnych segmentów D. Skurzok
199 Modyfikacja metryki edycyjnej o d t a p g d i e k o n t f d u a l a m k o t a D O M Przerwanie analizy
200 Modyfikacja metryki edycyjnej o d t a 0.5 e k o o 0.25 a l a n 0 O K O Ilość segmentów = 3 końcowa odległość: 1 / 3 = Ilość segmentów = 4 końcowa odległość: 1 / 4 = 0.25
201 Tworzenie siatki a l a m k o t a e k o n t f d u o d t a p g d i a ala akta ola atrapa.
202 Tworzenie siatki a l a m k o t a e k o n t f d u o d t a p g d i dom lama koń kotdam
203 Tworzenie siatki a l a m k o t a e k o n t f d u o d t a p g d i a ono tak amok
204 Tworzenie siatki a l a m k o t a e k o n t f d u o d t a p g d i kot akta akt
205 Tworzenie siatki a l a m k o t a e k o n t f d u o d t a p g d i kot akta akt
206 Tworzenie siatki a l a m k o t a e k o n t f d u o d t a p g d i kot akta akt
207 Łączenie wyrazów Ala Oko dom lamo koń ono tak a auto ma nip a i u kota to kodu a
208 Usuwanie tych samych wyrazów dom lamo koń ono tak a auto ma nip a i ma kota to a dom lamo koń ono tak auto ma nip a i kota to a
209 Usuwanie tych samych wyrazów dom lamo koń ono tak auto ma nip a i kota to a dom lamo koń ono tak auto ma nip a i kota to
210 Usuwanie ślepych ścieżek ala dom Ono Auto oko lamo Tak Ma koń a nip a
211 Usuwanie ślepych ścieżek ala dom Ono Auto oko Ma koń a nip a
212 Wyszukiwanie najlepszych ścieżek Ala oko a dom lamo koń ono tak a auto ma nip a i u kota to kodu od ot oda a u i.
213 Przykład hipotezy zdania
214 Modified Weighted Levenshtein Distance MWLD( A, B) min{ K k 1 l nk r k ( w) K k 1 h k i( w) K k 1 g k d( w)} Substitution weight: l nk (ln( p 1 k ) ln( p nk )) Insertion weight: h k ln( p ) ins const Deletion weight: g k ln( p 1 k ) ln( p del ) 218
215 substitution = deletion + insertion Substitution can be replaced by insertion and deletion Sum of insertion and deletion weights have to be bigger then weight of substitution h k g k l nk 219
216 1 substitution and 1 deletion Segment 1 Segment 2 Segment 3 Segment 4 Segment 5 Phon. prob. Phon. prob. Phon. prob. Phon. Prob. Phon. Prob. j 0.35 e 0.35 ż 0.30 w 0.30 p 0.30 i 0.25 y 0.30 sz 0.25 y 0.25 t 0.25 e 0.15 j 0.20 ś 0.20 e 0.20 e 0.20 MWLD (ln( p k ) ln( pnk)) (ln( p1 ) ln( p 1 k del MWLD Substitution has low weight (0.18), because the phoneme, for which we replace, was high on the hypotheses list. Deletion weight is higher because the deleted phoneme has relativelly high probability. )) 220

217 Modified Weighted Levenshtein Distance 221

218 222
219 amplitude Dzielenie na słowa silne 450 [ms] działanie 450 [ms] uboczne 600 [ms] /s il/ /ne/ /dz'a/ /wa/ /n e/ /u/ /bo/ / tsne/ pause 110 [ms ] time [s] 223

220 Rozpoznawanie mowy ciągłej 224
221 225
222 226
223 227
224 228
225 229
226 230
227 231
228 232
229 233
230 234
231 235
232 236
233 237
234 238
235 239
236 240
237 241
238 242

239 Podsumowanie Metryka edycyjna (Levenshteina) Zjawisko braku ciszy między słowami Level builder Konstruowanie siatki słów Łączenie sekwencji HMMów 243

240 Katedra Elektroniki, Zespół Przetwarzania Sygnałów Rozpoznawanie mówcy i emocji Bartosz Ziółko Wykorzystano materiały Davida Sierry, Wojciecha Kozłowskiego i Magdaleny Igras 244
241 Wprowadzenie Mowa zawiera nie tylko informacje słowne o przekazywanej wiadomości Rozpoznawanie mowy Rozpoznawanie mówcy Rozpoznawanie emocji -> co? -> kto? -> jak? Mowa może być wykorzystana w systemach biometrycznych 245

242 Rozpoznawanie mówcy 246
243 Architektura systemów automatycznego rozpoznawania mówcy 247
244 Ogólny podział systemów automatycznego rozpoznawania mówców 248


245 Weryfikacja a identyfikacja Źródło: WERYFIKACJA IDENTYFIKACJA Źródło: PAP 249
246 Opis jakości systemu stopień rozpoznania 250



247 Zastosowania Biometryczne systemy bezpieczeństwa Zalety w porównaniu do innych systemów Nieskończona ilość materiału do analizy (więcej nagrań większa dokładność) Wymagany jedynie tani sprzęt Niewymagana obecność (zdalne rozpoznanie) Bezpieczeństwo
248 Zastosowania 252

249 Zastosowania Biometryczne systemy bezpieczeństwa Oczekiwany wzrost zainteresowania systemami rozpoznawani mówcy w porównaniu do innych systemów biometrycznych
250 Zastosowania Biometryczne systemy bezpieczeństwa Przez telefon Transakcje bankowe» Zmniejszenie strat powiązanych z defraudacjami» Zmniejszenie kosztów prewencji defraudacji» Zwiększenie przychodu w związku ze wzrostem satysfakcji klientów Poczta głosowa Zakupy przez telefon Głosowe interaktywne systemy odpowiadające

251 Zastosowania Biometryczne systemy bezpieczeństwa Defraudacje związane z podszywaniem się Jedynie w 2006 roku, 8,9 milliona dorosłych obywateli US było ofiarami podszywania się 1,3 miliarda funtów strat rocznie w Zjednoczonym Królestwie Przychód z systemów biometrycznych



252 Zastosowania systemy bezpieczeństwa Fizyczny dostęp (klucz) VADC (Voice Activated Device Control) Bankomaty bez kart


253 Zastosowania systemy bezpieczeństwa - Dostęp do komputerów i sieci 257

254 Zastosowania systemy bezpieczeństwa Odzyskiwanie hasła przez telefon 30 do 40 % telefonów do obsługi klienta to problemy z hasłem Telephony system SR USER Password Reset Authentication centre Target system
255 Zastosowanie Monitoring Kontrola zdalnej pracy i obecności pracowników Weryfikacja zwolnień warunkowych i aresztów domowych Gmina Iberville w LA (US) używa identyfikacji mówcy przez telefon dla osób objętych opieką kuratora Przed automatyzacją -> 1400 $/dziecko Po -> 193 $/dziecko Użycie telefonów więziennych


256 Zastosowania Wsparcie służb W kryminalistyce Rozpoznawanie mówców na żywo w identyfikacji osób dzwoniących Śledzenie mówcy, wykrywanie i nadzór Analiza mowy syntezowanej i modulowanej Cechy głosu są trudniejsze do ukrycia niż twarz
257 Zastosowania Rozpoznawanie mowy i mówcy Ulepszenie systemów bezpieczeństwa Transkrybowanie wielu mówców na raz w konwersacji - Rozprawy sądowe, parlamenty i inne transkrypcje spotkań

258 Zastosowania NIST Korpusy do oceny systemów rozpoznawania mówcy Departament Sprawiedliwości US The European CAller VErification Project Voicetrust PerSay Voice Biometrics ww.persay.com International Biometric Group, New York Mało ale dużych użytkowników (korporacje i instytucje rządowe) => wysokie ceny

259 Klasyfikacja Zamknięty/ otwarty-zbiór Narzucone błędne rozpoznanie Baza danych?? Baza danych nie pasuje do żadnego System z zamkniętym zbiorem Poza bazą danych Weryfikacja / Identyfikacja?? System ze zbiorem otwartym Tak Nowak? Mówca N Nie Baza danych Baza danych Zależne (stałe lub zmienne) lub niezależne od tekstu Cechy niskiego poziomu (akustyczne) lub wysokiego (lingwistyczne, dialektowe, społeczne, itd.)
260 Poziomy rozpoznawania mówcy Cechy wysokiego poziomu (nieakustyczne) Semantyka, dykcja, wymowa Status społecznofinansowy, edukacja, miejsce urodzin Trudna ekstrakcja Prozodia, rytm, tempo intonacji, modulacja głośności Typ osobowości, wpływ rodziców Cechy niskiego poziomu (fizyczne) Akustyczne aspekty mowy Anatomiczna struktura narządów mowy Łatwa ekstrakcja
261 Przygotowywanie systemu 265
262 Rozpoznawanie 266
263 System weryfikacji mówcy Microphone or Telephone Claimed identity YES Filtering & A/D Digital Speech Feature extraction Feature Vectors Pattern matching Match scores Decision NO Verified identity Enrollment Speaker models
264 System identyfikacji mówcy 268


265 Pobieranie danych Ściana Zmienność kanału pomiędzy nagraniami Zmiana głosu mówcy wraz z czasem A/D Kanał Źródło szumu Wpływ innych rozmów, przepięcia, inne zakłócenie sprzętowe Niska rozdzielcz ość, np. GSM
266 Ekstrakcja cech Celem jest wydzielenie, najważniejszych, charakterystycznych informacji z sygnału Różne metody: LPC Cepstrum MFCC DWT
 Maszyna wektorów nośnych")
267 Dopasowywanie wzorców Modele z wzorcami DTW VQ Source Modelling knn Modele stochastyczne HMM + GMM Sieci neuronowe (NN) Maszyna wektorów nośnych (SVM)
268 Klasy (dźwięczna\bezdźwięczna) 272
269 Klasy (dźwięczna\bezdźwięczna) Cztery 273
270 Klasy (dźwięczna\bezdźwięczna) 274
271 Decyzje Bez modelu tła Porównanie do średniej pozostałych hipotez 275
272 Decyzje 276

273 Przykład podejmowania decyzji system AGH Średnia prawdopodobieństw hipotez 2-5 to około >> 0.14 => Decyzja może być podjęta mówcą jest Andrzej Jajszczyk 277

274 Decyzje Uniwersalne modele tła (UBM) Model dla odrzucanych i niezidentyfikowanych rozpoznań 278
275 Testowanie Krzywa DET (detection error trade-off) Zaakceptowany właściwy mówca Odrzucony właściwy mówca Zaakceptowany błędny mówca Odrzucony błędny mówca 279
 CMN - Cepstral mean normalisation")
276 Analiza możliwych wersji systemu Przypadek projektowania systemu identyfikacji mówcy jako pracy magisterskiej (David Sierra) CMN - Cepstral mean normalisation 280
277 Typy cech akustycznych 281
278 Liczba stanów w HMM 282
279 Liczba mikstur w GMM 283
 co powinno być wykonane na innych")
280 Optymalna wersja systemu w warunkach projektowych System został wykonany i wówczas może być testowany (w tym przypadku w warunkach otwartego zbioru) co powinno być wykonane na innych danych 284
281 Eksperymenty z różnymi systemami podejmowania decyzji SNR- Signal to Noise Ratio RAPT - Robust Algorithm for Pitch Tracking 285

282 Wyniki testów systemów decyzyjnych 286
283 Eksperymenty stosowania uniwersalnych modeli tła 287

284 Rezultaty stosowania uniwersalnych modeli tła 288
285 Eksperymenty z ilością materiału przygotowawczego (Angielski TIMIT) 289
286 Eksperymenty z ilością materiału przygotowawczego (CORPORA) 290
287 Eksperymenty z ilością materiału przygotowawczego (CORPORA) 291
288 Skuteczność w zależności od szumu 292
289 Skuteczność w zależności od liczby mówców 293
290 Standardy, testy i certyfikaty Systemy rozpoznawania mówców są w dużej mierze wykorzystywane przez służby mundurowe, specjalne i sądownictwo Duży nacisk na wykazanie ich skuteczności Niezależne instytucje (firmy i uniwersytety) przeprowadzają testy i wydają certyfikaty skuteczności Nawet z certyfikatami, skazywanie na podstawie dowodów w postaci analizy systemu rozpoznawania mówcy może być kwestionowane Problemy z nienadążaniem prawa za rozwojem informatyki 294
291 Podsumowanie Architektura systemu rozpoznawania mówcy Podział systemów rozpoznawania mówcy Przykładowe zastosowania Dźwięczność i bezdźwięczność mowy (sposoby analizy) Prawdopodobieństwo a podejmowanie decyzji w systemach rozpoznawania mówcy Universal background model Metodologia projektowania, testowania i wykazywania skuteczności 295
292 296

293 Rozpoznawanie emocji 297

294 Klasyfikacja emocji 298

295 Analiza głosu 299

296 Kismet emotional robot 300

297 Geminoid 301

298 Geminoid 302
299 Geminoid 303
300 Syntaktyczne modelowanie języka Bartosz Ziółko Wykorzystano materiały Dawida Skurzoka, MIT i Wikipedii 304
301 Gramatyka/ modelowanie syntaktyczne Parsery Analizatory morfologiczne / POS tagery n-grams Wygładzanie modeli Filtry Blooma 305
302 Nadmiarowość w językach Konieczna z tego samego powodu co w kodach transmisyjnych Prawdopodobnie stopień nadmiarowości zależy od warunków geograficznych Demo z Mathematica (RedundancyInWrittenLanguage) 306
303 Powody modelowania syntaktycznego Niektóre zdania mogą brzmieć bardzo podobnie: I helped Apple wreck a nice beach. I helped Apple recognise speech. W języku polskim nawet identycznie: może / morze 307



304 Noam Chomsky Gramatyka formalna składa się z: skończonego zbioru symboli końcowych skończonego zbioru symboli niekońcowych skończonego zbioru reguł produkcji na lewo i prawo składających się z sekwencji tych symboli symbol startowy 308

305 Hierarchia Chomskiego 309
306 MIT Regina Barzilay Michael Collins N = noun, V = verb, D = determiner 310
307 311
308 312
309 313
310 Disambiguity in parsing 314

311 Analizator morfologiczny / POS tager Proces zaznaczania słów w tekście jako odpowiadających szczególnym częściom mowy, oparty zarówno na ich definicjach, jak i ich kontekstach. 315
312 Sekwencje słów są przewidywalne Mathematica demo: Nonsense sentence generator 316
313 1-gramy słów (wybrane korpusy) 1) się (2,6%) 2) i (2,4%) 3) w (2,3%) 4) nie (2,1%) 5) na (1,9%) 6) z (1,6 %) 7) do (1,2 %) 8) to (1,2 %) 9) że ) a ) o ) jak ) ale ) po ) co ) jest ) tak ) za ) od ) jego ) go ) już ) tym ) czy
314 2-gramy słów (wybrane korpusy) 1) się w (0,17%) 2) się na (0,14%) 3) się z (0,12%) 4) się do (0,12%) 5) się że (0,08%) 6) że nie (0,07%) 7) w tym (0,07%) 8) nie ma (0,06%) 9) o tym (0,06%) 10) to nie ) się i ) się nie ) i nie ) ale nie ) na to ) że to ) mi się ) nie jest ) a potem ) nigdy nie ) mu się ) po prostu ) w tej ) to co ) w końcu ) nie było ) co się
315 3-gramy słów (wybrane korpusy) 1) w ten sposób (0,015%) 2) na to że (0,012%) 3) w tej chwili (0,012%) 4) w każdym razie (0,011%) 5) po raz pierwszy (0,010%) 6) mi się że (0,009%) 7) sobie sprawę że (0,008%) 8) mam nadzieję że (0,008%) 9) w takim razie (0,008%) 10) zwrócił się do ) wydaje mi się ) od czasu do ) się z nim ) to nie jest ) czasu do czasu ) w tym momencie ) po drugiej stronie ) w ogóle nie

316 Naprawianie n-gram 320
317 Zastosowanie n-gramów N-gramy są najpopularniejszym sposobem modelowania języka w rozpoznawaniu mowy: Z powodów obliczeniowych, zależność jest ograniczana do n słów wstecz. Prawdopodobnie najpopularniejszym jest model trigramowy ponieważ zależność od dwóch poprzednich słów jest bardzo silna, podczas gdy komplikacja modelu jest dość mała a zapotrzebowanie na statystyki realizowalne. 321
318 Siatka słów prezydent wejście strefy rezydent aportuje dwieście to do o trafi szelkę prezydium aprobuje nieście stepy szogun operuje dom schengen 322
319 Siatka słów z zaznaczonym prawidłowym zdaniem prezydent wejście strefy rezydent prezydium aportuje aprobuje dwieście nieście to do o trafi stepy szelkę szogun operuje dom schengen 323
320 Podkreślmy szczególnie prawdopodobne 1- i 2-gramy prezydent wejście strefy rezydent aportuje dwieście to trafi szelkę prezydium aprobuje nieście do o stepy szogun operuje dom schengen 324
321 Ponownie nałóżmy poprawne zdanie prezydent wejście strefy rezydent aportuje dwieście to o trafi szelkę prezydium aprobuje nieście do stepy szogun operuje dom schengen 325
322 Usuńmy mało prawdopodobne 2-gramy prezydent wejście strefy rezydent prezydium aportuje aprobuje dwieście nieście do to o trafi stepy szelkę szogun schengen operuje dom 326
323 i nałóżmy zdanie prezydent wejście strefy rezydent prezydium aportuje aprobuje dwieście nieście do to o trafi stepy szelkę szogun operuje dom schengen 327
324 Zbiory tekstów języka polskiego Źródło MBajty Mil. słów Różnych słów Różnych dwójek Różnych trójek Rzeczpospolita Wikipedia Literatura Transkrypcje Literatura Literatura W Literatura 2 : Słowa występujące więcej niż 10 razy to Dwójki słów występujące więcej niż 10 razy to Trójki słów występujące więcej niż 10 razy to
325 Problemy z n-gramami - Różne pisowanie (np. u - ó), - błędne formaty, - sprawdzanie ze słownikiem, np. myspell?,

326 Histogram n-gramów 330

327 Przykład wyliczeń modelu n-gramowego 331
328 Przykład wyliczeń modelu n-gramowego \begin{equation} E(s,h)=\frac{N(s,h)}{N(h)} \;, \end{equation} 332
329 Przykład wyliczeń modelu n-gramowego 333


330 Przykład wyliczeń modelu n-gramowego 334
331 Algorytm Dijkstry 335
 lub sumujemy")
332 Przykład wyliczeń modelu n-gramowego Licząc ścieżkę nie sumujemy dystansów tak jak w telekomunikacji, a mnożymy prawdopodobieństwa (ze względu na regułę Bayesa) lub sumujemy logarytmy! 336
333 Wyszukiwanie najlepszych ścieżek z użyciem 3-gramów. Ala ale ma ładnego kota. Złamała łapie keta Ala ma ładnego kota

334 Klasyczny algorytm Dijkstry (bigramy) koszt = 0.1 koszt = 1. Ala 0.1 ale 1 Złamała 1 ma 0.2 ładnego 0.3 łapie 1.2 kota 0.4 keta
335 Zipf Law Demo Mathematica 339
336 Back-off ), ( ) ( ) ( 0 ), ( ) ( ) ( w h N if h w h w h N if h w h w p N liczba zliczeń słowa z danych statystycznych β bardziej ogólna dystrybucja niż α - czynnik normalizacyjny zapewniający spełnianie przez p(w h) aksjomatu sumowania do jedności, określony jednoznacznie przez α i β: 0 ), ( : 0 ), ( : ˆ) ( ) ( 1 ) ( w h w N w h w N h w h w h jest 3-gramem a jest 2-gramem
337 Metoda Floor ( w h) N( w, h) ( w N h) N liczba słów w danych statystycznych - parametr, często równy liczbie słów w słowniku Metoda przeszacowuje prawdopodobieństwa wydarzeń z małą liczbą zliczeń. 341
338 Przykład ciemny zielony materiał 3-gram C = 0 ciemny zielony 2-gram C > 0 zielony materiał 2-gram C > 0 => wygładzony model ciemny zielony materiał P > 0 ufortyfikowany zamek nierdzewny 3-gram C = 0 ufortyfikowany zamek 2-gram C > 0 zamek nierdzewny 2-gram C > 0 => wygładzony model ufortyfikowany zamek nierdzewny P > 0 342
339 Wygładzanie modeli statystycznych Statystyki wyliczone ze zbiorów danych, opisują ściśle, rzecz biorąc te zbiory a nie rzeczywistość, jak na przykład język jako całokształt. Z tego powodu model n-gramowy można wygładzić w celu uzyskania większej efektywności poprzez zmniejszenie zależności od specyfiki wykorzystanych zbiorów. 343
340 Przykład wygładzania modelu n- gramowego Add-one 344

341 Przykład wygładzania modelu n- gramowego Add-one 345
342 Model interpretacji liniowej z parametrem interpolacyjnym Zdefiniujmy parametr N gdzie 0 1, Wówczas otrzymujemy równanie interpolacyjne Jelinka N( w, h) ( w h) (1 ) ( w hˆ) N Małe zliczenia nie są aż tak bardzo podbijane dzięki interpolacji. 346
343 Wygładzanie Katz a Katz wprowadził ogólną funkcję dyskontującą d : w d( w) i zależną od niej dyskontowaną masę prawdopodobieństwa Q[ d] 1 N W w 1 d( w) Równanie wygładzające wygląda N( w, h) d( w) ( w h) Q[ d] ( w h) N 347
344 Rozkład brzegowy n i = P(X = i). n i = P(X = i,y = j). j Rozkład brzegowy podzbioru zmiennych losowych jest rozkładem prawdopodobieństw zmiennych zawartych w tym podzbiorze. 348
345 Przykład wyliczania rozkładu brzegowego Prawdopodobieństwo bycia potrąconym pod warunkiem określonego światła p(w S), gdzie W oznacza wypadek, a S oznacza typ światła na sygnalizatorze. 349
346 Przykład wyliczania rozkładu brzegowego 350
347 Wygładzanie Kneser-Ney z rozkładem brzegowym jako ograniczeniem W metodzie Katza, całkowita zniżka powoduje, że N( w, h) d( w) ( w h) gdzie 0 d 1 N Zdefiniujmy Maximum Likelihood Estimation (MLE) dla rozkładu brzegowego N( w, hˆ) N( hˆ, g) p( w hˆ) i p( g hˆ) N N gdzie połączona liczba wystąpień N ( hˆ, g) jest równa N(g) jeśli hˆ gˆ i 0 w przeciwnym przypadku. Wówczas ( w hˆ) v N( w, hˆ) [ N( hˆ, v) g: gˆ hˆ, N ( g, w) 0 [ N( g, w) d] g: gˆ hˆ, N ( g, v) 0 [ N( g, v) d]] 351
348 Leaving-one-out (również Kneser-Ney) Przygotowujemy model korzystając z danych, tak jakby nie zawierały konkretnego zdarzenia, które wystąpiło tylko raz. W przypadku n-gramów, wyliczamy model, pomijając na przykład jeden trigram, który wystąpił w zbiorach tekstów tylko raz. Następnie wykorzystujemy model, aby estymować prawdopodobieństwo usuniętego zdarzenia. Procedurę powtarzamy wielokrotnie używając rożnych trigramów. Suma logarytmów wszystkich wyliczonych w ten sposób prawdopodobieństw daje nam logarytm podobieństwa leaving-one-out, który następnie służy jak kryterium optymalizacji F ( g, v): N ( g, v) 1 ln[ ( g) ( v gˆ)] const({ ( v gˆ)}). 352
349 Trigramy z Dijkstry Koszt dotarcia do poprzedniego węzła z punku widzenia wyróżnionego węzła Ala 0.1 ale 1 ma ładnego łapie Koszt dotarcia do danego węzła w zależności od następnego węzła następny koszt ładnego 0.2 łapie 1.1
350 Wyróżnione trigramy. Ala ma Ala ma ładnego ma ładnego kota koszt = 0.1 ładnego kota.. Ala ma ładnego kota. koszt = 0.4
351 Wyszukiwanie najlepszych ścieżek. Ala ładnego ma 3-gram koszt. Ala ma 0.1. Ala ładnego 1 następny poprzedni koszt ładnego. 1 ma. 0.1
352 Wyszukiwanie najlepszych ścieżek 3-gram koszt. ale ma. ale ma 1 następny poprzedni ma. 1 koszt
353 Wyszukiwanie najlepszych ścieżek Ala 0.1 ale 1 ma ładnego łapie 3-gram koszt Ala ma ładnego 0.1 ale ma ładnego 0.1 Ala ma łapie 1 ale ma łapie 1 następny poprzedni koszt ładnego łapie Ala = 0.2 ale = 1.1 Ala = 1.1 ale = 2

354 Wyszukiwanie najlepszych ścieżek Ala ma Złamała 1 kota ładnego keta następny poprzedni koszt Ala = 2 kota ma = 0.3 Złamała = 2 Ala = 2 keta ma = 2 Złamała = 2 3-gram koszt Ala ładnego kota 1 Ala ładnego keta 1 ma ładnego kota 0.1 ma ładnego keta 1 Złamała ładnego kota 1 Złamałą ładnego keta 1
355 Wyszukiwanie najlepszych ścieżek ładnego łapie kota. 3-gram koszt ładnego kota. 0.1 łapie kota. 1 następny poprzedni koszt ładnego = 0.4. łapie = 3 dodajemy koszt bigramów dla kropki
356 Wyszukiwanie najlepszych ścieżek. Ala ale ma ładnego kota. Złamała łapie keta 10 węzłów 17 krawędzi 26 możliwych 3-gramów
357 Rzeczywisty przypadek

358 Funkcja haszująca Funkcja haszująca jest każdą, dobrze definiowaną procedurą lub funkcją matematyczną, która zamienia dużą ilość danych, które mogą mieć niestałą długość, na małą reprezentację, często w postaci jednego integera, który może służyć na przykład za indeks. 362
359 Filtr Blooma 363
360 Podsumowanie Hierarchia Chomskyego Parser Tagger N-gram model Stosowanie n-gramów Algorytm Dijkstry Właściwości n-gramów (Zipf, histogram, konieczność wygładzania) Filtr Blooma 364
361 Technologie Mowy Modele semantyczne i ontologie Bartosz Ziółko Wykorzystano materiały MIT, Li Fei-Fei, Aleksandra Pohla, Jana Wicijowskiego, Mariusza Mąsiora i Wikipedię 365
362 Rule-to-rule Bag-of-words Latent Semantic Analysis Wordnet CYC 366
363 Rule-to-Rule Semantic interpretation [aka syntax directed translation ]: pair syntax, semantic rules. Generalised Phrase Structure Grammars (GPSG): pair each context free rule with semantic action ; as in compiler theory due to Knuth,


364 Meanings by compositionality Robert Berwick (MIT) 368


365 But there are exceptions 369


366 Exceptions - Business class Airlines Business class is luxury, not much to do with making a good business; Hotels - business class is a hotel, where you rent a room if you go in business. It is clean and has all useful things but small and nothing to do with luxury. Copyright Singapore Airlines 370

367 Human-like and computer-like analysis of expressions Kirk: Spock, are there any Romulans in Sector 6471? Spock: None, captain. Kirk: Are you certain, Spock? Spock: A 100% probability, Captain [camera rolls] Kirk: Damn your Vulcan ears, Spock, I thought you said there were no Romulans in sector 6471! Spock: But there is no sector 6471 Logic dictates 371
 Principle of Compositionality.")
368 Bag-of-words Semantics of NL sentences and phrases can be composed from the semantics of their subparts (for example words) Principle of Compositionality. 372
")
369 Bag-of-words by Li Fei-Fei (Princeton) 373
")
370 Bag-of-words by Li Fei-Fei (Princeton) 374
")
371 Bag-of-words by Li Fei-Fei (Princeton) 375
")
372 Bag-of-words by Li Fei-Fei (Princeton) 376
")
373 Bag-of-words by Li Fei-Fei (Princeton) 377
")
374 Bag-of-words by Li Fei-Fei (Princeton) 378
375 379





376 Vector space model Jan Wicijowski.xml 380

377 topics Applying Semantic Model to Recognition words word-topic matrix hypothesis vector similarities vector Jan Wicijowski Języki torricelli Język vanimo Język sahu Język wiaki Język yapunda Chesterfield F.C Andrew Latimer Parnassius hunza Tom Smith Mononukleotyd flawinowy 381
378 Latent Semantic Analysis (LSA) A row in this matrix will be a vector corresponding to a term, giving its relation to each document, a column in this matrix will be a vector corresponding to a document, giving its relation to each term. The dot product between two term vectors gives the correlation between the terms over the documents. 382
379 Latent Semantic Analysis (LSA) 383
380 Latent Semantic Analysis (LSA) 384
381 Bag-of-words with graphs Big John has a house. Big John has a black, aggressive cat. The black aggressive cat has a small mouse. The small mouse is a mammal. 385
382 TFIDF (Term Frequency - Inverse Document Frequency) TFIDF i,j = ( N i,j / N *,j ) * log( D / D i ) where N i,j = the number of times word i appears in document j (the original cell count). N *,j = the number of total words in document j (just add the counts in column j). D = the number of documents (the number of columns). D i = the number of documents in which word i appears (the number of non-zero columns in row i). 386
383 LSA tutorial ws-and-articles/articles/33.html?start=1 387




384 Semantyczne zasoby dla języka polskiego Słowosieć Wikipedia and DBPedia Synonims in OpenOffice Wielki Słownik Języka Polskiego Słownik Języka Polskiego 388

385 Słowosieć Elektronika jest typem sprzętu Elektronika jest typem nauki matematycznoprzyrodniczej i nauki ścisłej 389

386 Słowosieć Automatyka Informatyka Mechanika Inżynieria 390

387 Konstruowanie Słowosieci 391

388 Ontologie Slajdy Aleksandra Pohla Po co nam to wszystko? 392

389 393
390 Ontologie RDFS Resource Description Framework Schema 394
391 Ontologie 395
392 Ontologie 396
393 Ontologie 397
394 Ontologie 398

395 Ontologie 399
396 Definicje ontologii w filozofii i informatyce Ontologia (filozofia): Termin wywodzący się z greckiego słowa oznaczającego byt, ale ukuty w XVII w. na oznaczenie gałęzi metafizyki zajmującej się tym co istnieje. Ontologia (informatyka): Oksfordzki Słownik Filozoficzny Formalna specyfikacja konceptualizacji wybranej dziedziny wiedzy. Tom Gruber
397 Ogólna charakterystyka ontologii Elementy definicyjne: formalna specyfikacja: CycL, FLogic, KIF, LOOM, OCML,OWL, RDF......konceptualizacji: indywidua, pojęcia, własności, relacje, funkcje, procesy......wybranej dziedziny wiedzy: ontologie ogólne ontologie dziedzinowe
398 Cyc jako przykład ontologii ogólnej Cyc produkt Cycorp Rozpoczęcie prac: Największa znana ontologia: 300 tyś. pojęć 26 tyś. predykatów 3 miliony asercji 3 wersje: komercyjna, rozwojowa, otwarta Zaawansowany silnik inferencyjny Leksykon dla języka angielskiego
399 CycL język ontologii CycL: nadbudowany nad rachunkiem predykatów 2-rzędu teoria mnogości ZF asercje na meta-poziomie operatory modalne 2 poziomy języka epistemologiczny heurystyczny (SubL dialekt Lispa)
400 Struktura wiedzy 1. Pojęcia podstawowe #$Thing korzeń ontologii #$Collection kolekcja wszystkich kolekcji #$Individual kolekcja wszystkich indywiduów #$genls relacja generalizacji #$isa relacja należenia do kolekcji
401 Struktura wiedzy 2. Kolekcje i indywidua Kolekcje 1-ego rzędu: #$Intangible,#$PartiallyTangilbe, #$TemporalThing, #$SpatialThing Kolekcje 2-ego rzędu: #$TemporalStuffType, #$TemporalObjectType, #$ExistingStuffType, #$ExistingObjectType
402 Struktura wiedzy 3. Predykaty arność typ argumentów format argumentów relacja genlpreds przykład (#$coloroftype, #$conceptuallyrelated) Funkcje pozwalają unikać reifikacji przykład (#$CapitalFn COUNTRY)
403 Mikroteorie 3 miliony asercji! Trudność spełnienia wymogu globalnej niesprzeczności Podział wiedzy na mniejsze jednostki mikroteorie predykat #$genlmt #$BaseKB korzeń drzewa mikroteorii #$EverythingPSC suma wszystkich mikroteorii
404 Leksykon Mapowanie pomiędzy pojęciami (#$Dog) a słowami języków naturalnych ( dog ) Symboliczna reprezentacja słów (X-TheWord) Predykat denotacji (#$denotation WORD POS N DENOTATION) Bank(1) (#$denotation #$Bank-TheWord #$CountNoun 0 #$Bank-Topographical) Bank(2) (#$denotation #$Bank-TheWord #$CountNoun 1 #$BankOrganization)

405 Architektura Cyc Cycorp
406 Architektura Cyc Baza wiedzy Świat Wyciąg operacji, serwer operacji Partycje wiedzy Silnik inferencyjny Interfejs użytkownika API Narzędzie integracji źródeł wiedzy
407 Organizacja danych Świat - obraz pamięci działającej ontologii zapisany w formacie CFASL może być załadowany z powrotem bez sprawdzania integralności danych Wyciąg operacji zestaw operacji wykonywanych przez użytkownika w czasie pracy z systemem Serwer operacji pośredniczy w wymianie informacji pomiędzy sesjami różnych użytkowników Partycja wiedzy fragment Świata
408 Interfejs użytkownika
409 Interfejs użytkownika Interfejs webowy pozwala przeglądać ontologią, wprowadzać nowe fakty, zadawać pytania, etc. (HTML + CGI) Edytor faktów (Fact Editor) pozwala wprowadzać fakty osobom, które nie są zaznajomione ze strukturą ontologii (Java) Biblioteka zapytań (Query Library) pozwala tworzyć zapytania i je wykonywać. Wykorzystuje mechanizmy NLP (Java).
410 Komunikacja ze światem zewnętrznym API: SubL: protokoły ASCII oraz CFASL przez TCP/IP, brak wsparcia dla wywołań zwrotnych Java: nadbudowany nad SubL, zapewnia łatwą integrację z systemami napisanymi w Javie, wspiera wywołania zwrotne Wspierane języki RW: CycML, DAML, OWL SKSI: narzędzie pozwalające na integrację z bazami danych i stronami internetowymi

411 Zastosowania Cyc
412 Zastosowania Cyc - aktualne Integracja baz danych Integracja baz wiedzy Inteligentne wyszukiwanie informacji: na podstawie krótkich opisów (np. zdjęcia) na stronach WWW Rozproszona AI Przetwarzanie języka naturalnego
413 Zastosowania Cyc - potencjalne Automatyczne pośrednictwo w sprzedaży dóbr Tworzenie inteligentnych interfejsów Tłumaczenie maszynowe wysokiej jakości Rozpoznawanie mowy wspomagane wiedzą Zaawansowane modelowania zachowań użytkowników Semantyczny data-mining Wsparcie dla e-biznesu
414 Bazy danych Wymagania: zmapowanie tabel i ich atrybutów na pojęcia występujące w Cyc. Rezultat: Możliwość wykrycia anomalnych danych poprzez ich analizę z wykorzystaniem wiedzy zdroworozsądkowej. Integracja wiedzy występującej w wielu bazach danych: wykrycie danych sprzecznych generowanie zapytań obejmujących wiele baz danych

415 CYC 419

416 CYC 420
417 Przykład CYC 421







")


418 Wyszukiwanie informacji 1. Założenia: baza danych/wiedzy obejmująca tysiące lub setki tysięcy danych niepodlegających analizie tekstowej, zawierających krótkie opisy (np. zdjęcia, filmy, abstrakty) Rezultat: możliwość inteligentnego wyszukiwania informacji znacznie wykraczającego poza zwykłe mechanizmy dopasowania/zastępowania synonimami.
419 Wyszukiwanie informacji 2. Założenie: dziedzinowe bazy wiedzy dostępne przez WWW, implementujące protokół komunikacyjny Cyc Rezultat: możliwość zaawansowanego wyszukiwania wszelkich informacji dostępnych w dziedzinowych bazach wiedzy (dla użytkownika końcowego wygląda to tak, jakby cała wiedza znajdowała się w Cyc).
420 Problemy ze stosowaniem ontologii Ogromne koszty Wiedza zmienia się z czasem Ontologie zawierają ograniczoną wiedzę Mogą być błędy wynikające z automatycznej ekstrakcji faktów z tekstów Ale Watson wygrał w Va Banque z mistrzami 424
421 Watson gra z mistrzami w Va Banque 425
422 Przetwarzanie języka naturalnego Precyzyjne przetwarzanie języka naturalnego wymaga często posiadania wiedzy zdroworozsądkowej: I saw clouds flying over Zurich. Widziałem chmury lecące nad Zurychem. I saw buildings flying over Zurich. Widziałem domy lecąc nad Zurychem.

423 Linked Data 427
424 Podsumowanie Zasada kompozycyjności (fioletowa krowa) Koncepcja modelu bag-of-words Podstawy LSA Orientacja w zagadnieniach związanych z korpusami mowy i tekstów (jak się je robi, ocenia ich jakość, wielkość itp.) Implementacje słowników (tekst, SQL, FSA) Słowosieć (koniecznie sprawdzić stronę) Czym jest ontologia, czyli jak dodać Mruczka do Facebooka 428
425 Technologie Mowy Interfejs głosowy, systemy dialogowe Bartosz Ziółko Wykorzystano materiały Aleksandra Pohla, MIT, Stanusch Technologies i AIML 429
426 Interfejs głosowy 430

427 Początki komunikacji człowiek - komputer 431
428 Kilka zasad dobrego interfejsu Szybkość vs potwierdzanie komend Syndrom bankomatu Rozumienie potrzeb i możliwości użytkownika (rozpoznawanie vs przypominanie) Ilość dźwięków w interfejsie Szkocka winda Standaryzacja (dlaczego McDonalds odniosło sukces) Jasna i łatwo powtarzalna nawigacja Problem zniecierpliwienia (10 sekund) 432


429 Interfejs głosowy vs ekrany dotykowe Według Microsoftu ekrany dotykowe będą przyszłością komunikacji człowiek komputer. Na razie bez znaczących sukcesów komercyjnych, poza urządzeniami mobilnymi. 433


430 Obecne zastosowania ekranów dotykowych 434


431 Przyszłość, już teraz tylko nikt jej nie chce * * (poza Billem Gatesem) Microsoft Surface - a new $10,000 touchscreen table. 435

432 Problemy z ekranami dotykowymi Touch Table Microsoftu miał być przełomem w sprzęcie korporacyjnym. Sprzedano jednak bardzo niewielką ilość. - Za bardzo nastawiony na pracę zespołową (?), - zbyt rewolucyjny pod kątem ergonomicznym nie tylko usunięcie klawiatury, ale także patrzenie na ekran w dół (?). 436
433 Kto to? 437

434 HAL 9000 Odyseja kosmiczna 438
435 Systemy dialogowe Najbardziej naturalny sposób komunikacji dla człowieka Atrakcyjny Prosty dla nieprzeszkolonych osób Sprzyja miniaturyzacji 439


436 Wirtualni doradcy Symulacja osobowości Mowa ciała Zaskakiwanie Synteza mowy Planowane ASR 440
437 Wirtualni doradcy WD: Witaj w centrum obsługi technicznej naszej telewizji. Nazywam się Jerzy i postaram się rozwiązać Twoje problemy. Bedzie nam łatwiej jeżeli będę się do Ciebie zwracać po imieniu. Powiedz mi jak masz na imię? Użytkownik: Ewa WD: Witaj Ewo. Jaki masz problem. Użytkownik: Nie ma obrazu. WD: Czy telewizor jest włączony i czy świeci się kontrolka jego włączenia? Użytkownik: Tak WD: Czy dekoder telewizji jest włączony? Użytkownik: Tak WD: Czy telewizor jest ustawiony na kanał na którym odbierasz programy satelitarne? Użytkownik: Tak WD: Podejdź do telewizora i sprawdź czy kable łączące telewizor i odbiornik telewizji satelitarnej nie poluzowały się. Użytkownik: Zadziałało! Jest obraz. Dziękuje bardzo. WD: Bardzo proszę. Czy mogę jeszcze w czymś pomóc? 441

438 Standard dialogue in a computer game 442

439 443

440 444
441 Rozumienie języka ludzi przez komputery Masz długopis? => proszę podaj mi swój długopis, jeśli masz takowy Każdy rolnik, który ma owce, lubi je. Po zebraniu makulatury, sprzedaliśmy ją razem z panią. Kasia to moja siostra cioteczna, Jurek też. 445
442 Dialogue System Architecture MIT Regina Barzilay 446
443 447
444 Example 448
445 449
446 450
447 Surface form is a weak predictor 451
448 452
449 Hidden Markov Model for Dialogue Acts Interpretation 453
450 HMMs for dialogue acts interpretation 454
451 455
452 How to Generate This Semantics 456
453 Natural language generation 457
454 States in the dialogue system 458
455 States in the dialogue system greet=0 if user has to be greeted, 1 otherwise attr represents attribute being queried; 1/2/3 =activity/location/time, 4 = done with attributes conf represents confidence in the attribute value. 0,1,2=low/miidle/high confidence in the speech recognizer; 3=recognition system has received YES as an answer to a confirmation; 4=system has received NO val=1 if attribute value has been obtained, 0 otherwise times=number of times system has asked about the attribute gram=type of grammar used to obtain the attribute value hist=0 if system has had problems in understanding the user earlier in the conversation; 1 otherwise 459


456 AIML - Artificial Intelligence Markup Language 460


457 AIML - Artificial Intelligence Markup Language 461
458 AIML - Artificial Intelligence Markup Language AIML (Artificial Intelligence Markup Language) is an XML-compliant language that's easy to learn, and makes it possible for you to begin customising an Alicebot or creating one from scratch within minutes. The most important units of AIML are: <aiml>: the tag that begins and ends an AIML document <category>: the tag that marks a "unit of knowledge" in an Alicebot's knowledge base <pattern>: used to contain a simple pattern that matches what a user may say or type to an Alicebot <template>: contains the response to a user input 462
459 Categories The free A.L.I.C.E. AIML includes a knowledge base of approximately categories. Here's an example of one of them: <category> <pattern>what ARE YOU</pattern> <template> <think><set name="topic">me</set></think> I am the latest result in artificial intelligence, which can reproduce the capabilities of the human brain with greater speed and accuracy. </template> </category> 463
460 Recursion AIML implements recursion with the <srai> operator. No agreement exists about the meaning of the acronym. The "A.I." stands for artificial intelligence, but "S.R." may mean "stimulus-response," "syntactic rewrite," "symbolic reduction," "simple recursion," or "synonym resolution." The disagreement over the acronym reflects the variety of applications for <srai> in AIML 464
461 Symbolic reduction It refers to the process of simplifying complex grammatical forms into simpler ones. Usually, the atomic patterns in categories storing robot knowledge are stated in the simplest possible terms, for example we tend to prefer patterns like "WHO IS SOCRATES" to ones like "DO YOU KNOW WHO SOCRATES IS" when storing biographical information about Socrates. <category> <pattern>do YOU KNOW WHO * IS</pattern> <template><srai>who IS <star/></srai></template> </category> Whatever input matched this pattern, the portion bound to the wildcard * may be inserted into the reply with the markup <star/>. This category reduces any input of the form "Do you know who X is?" to "Who is X?" 465
462 Divide and conquer Many individual sentences may be reduced to two or more subsentences, and the reply formed by combining the replies to each. A sentence beginning with the word "Yes" for example, if it has more than one word, may be treated as the subsentence "Yes." plus whatever follows it. <category> <pattern>yes *</pattern> <template><srai>yes</srai> <sr/></template> </category> The markup <sr/> is simply an abbreviation for <srai><star/></srai> 466
463 Synonyms The AIML 1.01 standard does not permit more than one pattern per category. Synonyms are perhaps the most common application of <srai>. Many ways to say the same thing reduce to one category, which contains the reply: <category> <pattern>hello </pattern> <template>hi there! </template> </category> <category> <pattern>hi </pattern> <template><srai> HELLO </srai></template> </category> <category> <pattern>hi THERE </pattern> <template><srai> HELLO </srai></template> </category> 467
464 Spelling and grammar correction The single most common client spelling mistake is the use of "your" when "you are" is intended. Not every occurrence of "your" however should be turned into "you are." A small amount of grammatical context is usually necessary to catch this error: <category> <pattern>your A *</pattern> <template>i think you mean "you are" not "your." <srai>you ARE A <star/></srai> </template> </category> Here the bot both corrects the client input and acts as a language tutor. 468
465 Keywords AIML template which is activated by the appearance of a keyword anywhere in the input sentence. <category> <pattern>mother</pattern> <template> Tell me more about your family. </template> </category> <category> <pattern>_ MOTHER</pattern> <template><srai>mother</srai> </template> </category> Both, detects the keyword when it appears by itself, and provides the generic response. Detects the keyword as the suffix of a sentence. 469
466 Keywords <category> <pattern>mother _ </pattern> <template> <srai> MOTHER </srai> </template> </category> <category> <pattern>_ MOTHER * </pattern> <template> <srai> MOTHER </srai></template> </category> Detects it as the prefix of an input sentence detects the keyword as an infix. Each of the last three categories uses <srai> to link to the first, so that all four cases produce the same reply, but it needs to be written and stored only once. 470
467 Conditionals Conditional branches using only the <srai> tag. <category> <pattern>who IS HE</pattern> <template><srai> WHOISHE <get name="he"/></srai> </template> </category> <category> <pattern>whoishe * </pattern> <template>he is <get name="he"/>. </template> </category> <category> <pattern> WHOISHE UNKNOWN </pattern> <template> I don t know who he is. </template> </category> Provided that the predicate "he" is initialised to "Unknown," the categories execute a conditional branch depending on whether "he" has been set. AIML also provides the equivalent function through the <condition> tag. 471
468 Targeting User: Where do I find the webpage with Australopithecus? Alice: Where do you want to find it? User: Bad Answer Alice, time to Learn a new Line Alice: How would you answer "Where do I find the webpage with Australopithecus?" User: I would say: " Alice: Thanks, human. Try asking me again. User: Where do I find the webpage with Australopithecus? Alice: 472
469 CONTEXT The keyword "that" in AIML refers to the bot s previous utterance. Specifically, if the bot responds with a multiple sentence paragraph, the value of that is set to the last sentence in the sequence. The choice of the keyword "that" is motivated by its use in ordinary language: R: Today is yesterday. C: That makes no sense. R: The answer is approximately. C: That is cool. 473
470 That In AIML the syntax <that>...</that> encloses a pattern that matches the robot s previous utterance. A common application of <that> is found in yes-no questions: <category> <pattern>yes</pattern> <that>do YOU LIKE MOVIES</that> <template>what is your favorite movie? </template> </category> This category is activated when the client says YES. The robot must find out what is he saying "yes" to. If the robot asked, "Do you like movies?," this category matches, and the response, "What is your favorite movie?," continues the conversation along the same lines. 474
471 Topic INPUT <that> THAT <topic> TOPIC. <topic name="cars"> <category> <pattern>*</pattern> <template> <random> <li>what s your favorite car?</li> <li>what kind of car do you drive?</li> <li>do you get a lot of parking tickets?</li> <li>my favorite car is one with a driver.</li> </random> </template> 475

472 Facade Download and play 476

473 Typy wypowiedzi 477
474 Podsumowanie Czym jest ontologia, czyli jak dodać Mruczka do Facebooka Podchwytliwe pytanie Co to jest CYC? Podstawowe zasady projektowania interfejsów Zalety i wady stosowania mowy w interfejsach Czym system dialogowy różni się od zwykłego interfejsu Systemu dialogowe AIML 478
475 Istniejące systemy technologii mowy Przyszłość technologii mowy Bartosz Ziółko 479

476 480
Czym jest HTK HMMs ASR
 HTK 138 Czym jest HTK Zbiór programów implementujących Niejawne Łańcuchy Markowa - Hidden Markov Models (HMMs) ASR, synteza mowa, rozpoznawanie liter, badania nad sekwencjami DNA Analiza mowy, wyćwiczenie
HTK 138 Czym jest HTK Zbiór programów implementujących Niejawne Łańcuchy Markowa - Hidden Markov Models (HMMs) ASR, synteza mowa, rozpoznawanie liter, badania nad sekwencjami DNA Analiza mowy, wyćwiczenie
Dialekty języka polskiego. Wykonały: Paulina Macura i Daria Korzec
 Dialekty języka polskiego Wykonały: Paulina Macura i Daria Korzec Spis treści Dialekt a gwara Pojęcia związane z dialektem i gwarą Geograficzny podział dialektów Cechy dialektów: Śląski Małopolski Wielkopolski
Dialekty języka polskiego Wykonały: Paulina Macura i Daria Korzec Spis treści Dialekt a gwara Pojęcia związane z dialektem i gwarą Geograficzny podział dialektów Cechy dialektów: Śląski Małopolski Wielkopolski
Rozpoznawanie mówcy i emocji
 Katedra Elektroniki, Zespół Przetwarzania Sygnałów www.dsp.agh.edu.pl http://rozpoznawaniemowy.blogspot.com/ Rozpoznawanie mówcy i emocji Bartosz Ziółko Wykorzystano materiały Davida Sierry, Wojciecha
Katedra Elektroniki, Zespół Przetwarzania Sygnałów www.dsp.agh.edu.pl http://rozpoznawaniemowy.blogspot.com/ Rozpoznawanie mówcy i emocji Bartosz Ziółko Wykorzystano materiały Davida Sierry, Wojciecha
Technologie Mowy Bartosz Ziółko
 www.dsp.agh.edu.pl http://rozpoznawaniemowy.blogspot.com/ Technologie Mowy Bartosz Ziółko 1 Technologie Mowy 2 Technologie Mowy 3 Technologie Mowy 4 Dane kontaktowe Dr inż. Jakub Gałka C2/419 Telefon 50-68
www.dsp.agh.edu.pl http://rozpoznawaniemowy.blogspot.com/ Technologie Mowy Bartosz Ziółko 1 Technologie Mowy 2 Technologie Mowy 3 Technologie Mowy 4 Dane kontaktowe Dr inż. Jakub Gałka C2/419 Telefon 50-68
Znaczenie korpusów. Większość metod w przetwarzaniu mowy opiera się na statystykach => Jakość i wielkość korpusów jest kluczowa dla jakości systemów
 Znaczenie korpusów Większość metod w przetwarzaniu mowy opiera się na statystykach => Jakość i wielkość korpusów jest kluczowa dla jakości systemów 85 Korpus a zbiór danych Przetwarzalny przez maszyny
Znaczenie korpusów Większość metod w przetwarzaniu mowy opiera się na statystykach => Jakość i wielkość korpusów jest kluczowa dla jakości systemów 85 Korpus a zbiór danych Przetwarzalny przez maszyny
Opisy efektów kształcenia dla modułu
 Karta modułu - Technologia mowy 1 / 5 Nazwa modułu: Technologia mowy Rocznik: 2012/2013 Kod: RIA-1-504-s Punkty ECTS: 7 Wydział: Inżynierii Mechanicznej i Robotyki Poziom studiów: Studia I stopnia Specjalność:
Karta modułu - Technologia mowy 1 / 5 Nazwa modułu: Technologia mowy Rocznik: 2012/2013 Kod: RIA-1-504-s Punkty ECTS: 7 Wydział: Inżynierii Mechanicznej i Robotyki Poziom studiów: Studia I stopnia Specjalność:
AKUSTYKA MOWY. Podstawy rozpoznawania mowy część I
 AKUSTYKA MOWY Podstawy rozpoznawania mowy część I PLAN WYKŁADU Część I Podstawowe pojęcia z dziedziny rozpoznawania mowy Algorytmy, parametry i podejścia do rozpoznawania mowy Przykłady istniejących bibliotek
AKUSTYKA MOWY Podstawy rozpoznawania mowy część I PLAN WYKŁADU Część I Podstawowe pojęcia z dziedziny rozpoznawania mowy Algorytmy, parametry i podejścia do rozpoznawania mowy Przykłady istniejących bibliotek
4 Zasoby językowe Korpusy obcojęzyczne Korpusy języka polskiego Słowniki Sposoby gromadzenia danych...
 Spis treści 1 Wstęp 11 1.1 Do kogo adresowana jest ta książka... 12 1.2 Historia badań nad mową i językiem... 12 1.3 Obecne główne trendy badań... 16 1.4 Opis zawartości rozdziałów... 18 2 Wyzwania i możliwe
Spis treści 1 Wstęp 11 1.1 Do kogo adresowana jest ta książka... 12 1.2 Historia badań nad mową i językiem... 12 1.3 Obecne główne trendy badań... 16 1.4 Opis zawartości rozdziałów... 18 2 Wyzwania i możliwe
Syntaktyczne modelowanie języka
 Syntaktyczne modelowanie języka Bartosz Ziółko Wykorzystano materiały Dawida Skurzoka, MIT i Wikipedii 304 Gramatyka/ modelowanie syntaktyczne Parsery Analizatory morfologiczne / POS tagery n-grams Wygładzanie
Syntaktyczne modelowanie języka Bartosz Ziółko Wykorzystano materiały Dawida Skurzoka, MIT i Wikipedii 304 Gramatyka/ modelowanie syntaktyczne Parsery Analizatory morfologiczne / POS tagery n-grams Wygładzanie
KATEDRA SYSTEMÓW MULTIMEDIALNYCH. Inteligentne systemy decyzyjne. Ćwiczenie nr 12:
 KATEDRA SYSTEMÓW MULTIMEDIALNYCH Inteligentne systemy decyzyjne Ćwiczenie nr 12: Rozpoznawanie mowy z wykorzystaniem ukrytych modeli Markowa i pakietu HTK Opracowanie: mgr inż. Kuba Łopatka 1. Wprowadzenie
KATEDRA SYSTEMÓW MULTIMEDIALNYCH Inteligentne systemy decyzyjne Ćwiczenie nr 12: Rozpoznawanie mowy z wykorzystaniem ukrytych modeli Markowa i pakietu HTK Opracowanie: mgr inż. Kuba Łopatka 1. Wprowadzenie
Transkrypcja fonetyczna i synteza mowy. Jolanta Bachan
 Transkrypcja fonetyczna i synteza mowy Jolanta Bachan IPA Międzynarodowy alfabet fonetyczny, MAF (ang. International Phonetic Alphabet, IPA) alfabet fonetyczny, system transkrypcji fonetycznej przyjęty
Transkrypcja fonetyczna i synteza mowy Jolanta Bachan IPA Międzynarodowy alfabet fonetyczny, MAF (ang. International Phonetic Alphabet, IPA) alfabet fonetyczny, system transkrypcji fonetycznej przyjęty
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, Spis treści
 Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Rozpoznawanie mowy za pomocą HTK
 Kinga Frydrych Wydział Inżynierii Mechanicznej i Robotyki Inżynieria Akustyczna, rok III, 2013/2014 Sprawozdanie z ćwiczeń laboratoryjnych z Technologii mowy Rozpoznawanie mowy za pomocą HTK 1. Opis gramatyki
Kinga Frydrych Wydział Inżynierii Mechanicznej i Robotyki Inżynieria Akustyczna, rok III, 2013/2014 Sprawozdanie z ćwiczeń laboratoryjnych z Technologii mowy Rozpoznawanie mowy za pomocą HTK 1. Opis gramatyki
Automatyczne rozpoznawanie mowy. Autor: mgr inż. Piotr Bratoszewski
 Automatyczne rozpoznawanie mowy Autor: mgr inż. Piotr Bratoszewski Rys historyczny 1930-1950 pierwsze systemy Automatycznego rozpoznawania mowy (ang. Automatic Speech Recognition ASR), metody holistyczne;
Automatyczne rozpoznawanie mowy Autor: mgr inż. Piotr Bratoszewski Rys historyczny 1930-1950 pierwsze systemy Automatycznego rozpoznawania mowy (ang. Automatic Speech Recognition ASR), metody holistyczne;
HLT_12 Warszawa. Lingwistyka matematyczna w Katedrze Elektroniki AGH
 HLT_12 Warszawa Lingwistyka matematyczna w Katedrze Elektroniki AGH 1 Lingwistyka jaka jest każdy widzi Lingwistyka matematyczna: - identyfikacja rozmówcy - przetwarzanie języka naturalnego - przetwarzanie
HLT_12 Warszawa Lingwistyka matematyczna w Katedrze Elektroniki AGH 1 Lingwistyka jaka jest każdy widzi Lingwistyka matematyczna: - identyfikacja rozmówcy - przetwarzanie języka naturalnego - przetwarzanie
Korpusy mowy i narzędzia do ich przetwarzania
 Korpusy mowy i narzędzia do ich przetwarzania Danijel Korzinek, Krzysztof Marasek Polsko-Japońska Akademia Technik Komputerowych Katedra Multimediów kmarasek@pjwstk.edu.pl danijel@pjwstk.edu.pl 2015-05-18
Korpusy mowy i narzędzia do ich przetwarzania Danijel Korzinek, Krzysztof Marasek Polsko-Japońska Akademia Technik Komputerowych Katedra Multimediów kmarasek@pjwstk.edu.pl danijel@pjwstk.edu.pl 2015-05-18
Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego
 Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego Witold Kieraś Łukasz Kobyliński Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN III Konferencja DARIAH-PL Poznań 9.11.2016
Korpusomat narzędzie do tworzenia przeszukiwalnych korpusów języka polskiego Witold Kieraś Łukasz Kobyliński Maciej Ogrodniczuk Instytut Podstaw Informatyki PAN III Konferencja DARIAH-PL Poznań 9.11.2016
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Program warsztatów CLARIN-PL
 W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
Podstawy automatycznego rozpoznawania mowy. Autor: mgr inż. Piotr Bratoszewski
 Podstawy automatycznego rozpoznawania mowy Autor: mgr inż. Piotr Bratoszewski Rys historyczny 1930-1950 pierwsze systemy Automatycznego rozpoznawania mowy (ang. Automatic Speech Recognition ASR), metody
Podstawy automatycznego rozpoznawania mowy Autor: mgr inż. Piotr Bratoszewski Rys historyczny 1930-1950 pierwsze systemy Automatycznego rozpoznawania mowy (ang. Automatic Speech Recognition ASR), metody
Omówienie różnych metod rozpoznawania mowy
 Omówienie różnych metod rozpoznawania mowy Na podstawie artykułu: Comparative study of automatic speech recognition techniques Beniamin Sawicki Wydział Inżynierii Mechanicznej i Robotyki Inżynieria Akustyczna
Omówienie różnych metod rozpoznawania mowy Na podstawie artykułu: Comparative study of automatic speech recognition techniques Beniamin Sawicki Wydział Inżynierii Mechanicznej i Robotyki Inżynieria Akustyczna
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner
 Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Rozpoznawanie mowy dla języków semickich. HMM - HTK, CMU SPHINX-4, Simon
 Rozpoznawanie mowy dla języków semickich HMM - HTK, CMU SPHINX-4, Simon Charakterystyka języków semickich Przykłady: arabski, hebrajski, amharski, tigrinia, maltański (280 mln użytkowników). Budowa spółgłoskowo
Rozpoznawanie mowy dla języków semickich HMM - HTK, CMU SPHINX-4, Simon Charakterystyka języków semickich Przykłady: arabski, hebrajski, amharski, tigrinia, maltański (280 mln użytkowników). Budowa spółgłoskowo
Pattern Classification
 Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
SYSTEM BIOMETRYCZNY IDENTYFIKUJĄCY OSOBY NA PODSTAWIE CECH OSOBNICZYCH TWARZY. Autorzy: M. Lewicka, K. Stańczyk
 SYSTEM BIOMETRYCZNY IDENTYFIKUJĄCY OSOBY NA PODSTAWIE CECH OSOBNICZYCH TWARZY Autorzy: M. Lewicka, K. Stańczyk Kraków 2008 Cel pracy projekt i implementacja systemu rozpoznawania twarzy, który na podstawie
SYSTEM BIOMETRYCZNY IDENTYFIKUJĄCY OSOBY NA PODSTAWIE CECH OSOBNICZYCH TWARZY Autorzy: M. Lewicka, K. Stańczyk Kraków 2008 Cel pracy projekt i implementacja systemu rozpoznawania twarzy, który na podstawie
Synteza mowy (TTS) Rozpoznawanie mowy (ARM) Optyczne rozpoznawanie znaków (OCR) Jolanta Bachan
 Rozpoznawanie mowy (ARM) Optyczne rozpoznawanie znaków (OCR) Jolanta Bachan") Synteza mowy (TTS) Rozpoznawanie mowy (ARM) Optyczne rozpoznawanie znaków (OCR) Jolanta Bachan Synteza mowy System przetwarzania tekstu pisanego na mowę Text-to-Speech (TTS) TTS powinien być w stanie przeczytać
Synteza mowy (TTS) Rozpoznawanie mowy (ARM) Optyczne rozpoznawanie znaków (OCR) Jolanta Bachan Synteza mowy System przetwarzania tekstu pisanego na mowę Text-to-Speech (TTS) TTS powinien być w stanie przeczytać
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe.
 Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
AUTOMATYKA INFORMATYKA
 AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
Tyle języków, ile pragnień dialekt, dialektyzmy i dialektyzacja języka.
 Tyle języków, ile pragnień dialekt, dialektyzmy i dialektyzacja języka. Dialekt to odmiana języka narodowego, charakterystyczna dla określonego terytorium. W ramach dialektu wyróżnia się także gwary (odmiany
Tyle języków, ile pragnień dialekt, dialektyzmy i dialektyzacja języka. Dialekt to odmiana języka narodowego, charakterystyczna dla określonego terytorium. W ramach dialektu wyróżnia się także gwary (odmiany
PRZESTRZENNE BAZY DANYCH WYKŁAD 2
 PRZESTRZENNE BAZY DANYCH WYKŁAD 2 Baza danych to zbiór plików, które fizycznie przechowują dane oraz system, który nimi zarządza (DBMS, ang. Database Management System). Zadaniem DBMS jest prawidłowe przechowywanie
PRZESTRZENNE BAZY DANYCH WYKŁAD 2 Baza danych to zbiór plików, które fizycznie przechowują dane oraz system, który nimi zarządza (DBMS, ang. Database Management System). Zadaniem DBMS jest prawidłowe przechowywanie
ROZPOZNAWANIE SYGNAŁÓW FONICZNYCH
 Przetwarzanie dźwięków i obrazów ROZPOZNAWANIE SYGNAŁÓW FONICZNYCH mgr inż. Kuba Łopatka, p. 628 klopatka@sound.eti.pg.gda.pl Plan wykładu 1. Wprowadzenie 2. Zasada rozpoznawania sygnałów 3. Parametryzacja
Przetwarzanie dźwięków i obrazów ROZPOZNAWANIE SYGNAŁÓW FONICZNYCH mgr inż. Kuba Łopatka, p. 628 klopatka@sound.eti.pg.gda.pl Plan wykładu 1. Wprowadzenie 2. Zasada rozpoznawania sygnałów 3. Parametryzacja
PRZEWODNIK PO PRZEDMIOCIE. PNJA Fonetyka praktyczna (j.a. brytyjski) Angielski Język Biznesu
 Angielski Język Biznesu") Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu PNJA Fonetyka praktyczna (j.a. brytyjski) Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom kwalifikacji
Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu PNJA Fonetyka praktyczna (j.a. brytyjski) Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom kwalifikacji
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Lokalizacja Oprogramowania
 mgr inż. Anton Smoliński anton.smolinski@zut.edu.pl Lokalizacja Oprogramowania 16/12/2016 Wykład 6 Internacjonalizacja, Testowanie, Tłumaczenie Maszynowe Agenda Internacjonalizacja Testowanie lokalizacji
mgr inż. Anton Smoliński anton.smolinski@zut.edu.pl Lokalizacja Oprogramowania 16/12/2016 Wykład 6 Internacjonalizacja, Testowanie, Tłumaczenie Maszynowe Agenda Internacjonalizacja Testowanie lokalizacji
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Łańcuchy Markowa: zagadnienia graniczne. Ukryte modele Markowa. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ KLASYFIKACJA STANÓW Stan i jest osiągalny
Elementy modelowania matematycznego Łańcuchy Markowa: zagadnienia graniczne. Ukryte modele Markowa. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ KLASYFIKACJA STANÓW Stan i jest osiągalny
MATLAB Neural Network Toolbox przegląd
 MATLAB Neural Network Toolbox przegląd WYKŁAD Piotr Ciskowski Neural Network Toolbox: Neural Network Toolbox - zastosowania: przykłady zastosowań sieci neuronowych: The 1988 DARPA Neural Network Study
MATLAB Neural Network Toolbox przegląd WYKŁAD Piotr Ciskowski Neural Network Toolbox: Neural Network Toolbox - zastosowania: przykłady zastosowań sieci neuronowych: The 1988 DARPA Neural Network Study
PRZEWODNIK PO PRZEDMIOCIE. PNJA Fonetyka praktyczna (j.a. amerykański) Angielski Język Biznesu
 Angielski Język Biznesu") Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu PNJA Fonetyka praktyczna (j.a. amerykański) Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom
Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu PNJA Fonetyka praktyczna (j.a. amerykański) Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst
 Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst Mariusz Owsianny, PCSS Dr inż. Ewa Kuśmierek, Kierownik Projektu, PCSS Partnerzy konsorcjum Zaawansowany system automatycznego
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst Mariusz Owsianny, PCSS Dr inż. Ewa Kuśmierek, Kierownik Projektu, PCSS Partnerzy konsorcjum Zaawansowany system automatycznego
W tym rozdziale książka opisuje kilka podejść do poszukiwania kolokacji.
 5 Collocations Związek frazeologiczny (kolokacja), to często używane zestawienie słów. Przykłady: strong tea, weapons of mass destruction, make up. Znaczenie całości wyrażenia, nie zawsze wynika ze znaczeń
5 Collocations Związek frazeologiczny (kolokacja), to często używane zestawienie słów. Przykłady: strong tea, weapons of mass destruction, make up. Znaczenie całości wyrażenia, nie zawsze wynika ze znaczeń
PRZEWODNIK PO PRZEDMIOCIE. PNJA Fonetyka praktyczna (j.a. amerykański) Angielski Język Biznesu
 Angielski Język Biznesu") Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu PNJA Fonetyka praktyczna (j.a. amerykański) Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom
Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu PNJA Fonetyka praktyczna (j.a. amerykański) Kierunek Angielski Język Biznesu Forma studiów stacjonarne Poziom
Zastosowanie sztucznych sieci neuronowych w prognozowaniu szeregów czasowych (prezentacja 2)
") Zastosowanie sztucznych sieci neuronowych w prognozowaniu szeregów czasowych (prezentacja 2) Ewa Wołoszko Praca pisana pod kierunkiem Pani dr hab. Małgorzaty Doman Plan tego wystąpienia Teoria Narzędzia
Zastosowanie sztucznych sieci neuronowych w prognozowaniu szeregów czasowych (prezentacja 2) Ewa Wołoszko Praca pisana pod kierunkiem Pani dr hab. Małgorzaty Doman Plan tego wystąpienia Teoria Narzędzia
dr inż. Ewa Kuśmierek, Kierownik Projektu Warszawa, 25 czerwca 2014 r.
 Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst, dedykowany dla służb odpowiedzialnych za bezpieczeństwo państwa dr inż. Ewa Kuśmierek, Kierownik Projektu Warszawa,
Zaawansowany system automatycznego rozpoznawania i przetwarzania mowy polskiej na tekst, dedykowany dla służb odpowiedzialnych za bezpieczeństwo państwa dr inż. Ewa Kuśmierek, Kierownik Projektu Warszawa,
Korpusy i Narzędzia do Analizy Mowy w Clarin-PL
 1 / 21 Korpusy i w Clarin-PL Danijel Koržinek i Łukasz Brocki Polsko-Japońska Akademia Technik Komputerowych 3 lutego 2017 r., Łódź 2 / 21 3 / 21 Motywacja Brak darmowych ogólnodostępnych korpusów komercyjne:
1 / 21 Korpusy i w Clarin-PL Danijel Koržinek i Łukasz Brocki Polsko-Japońska Akademia Technik Komputerowych 3 lutego 2017 r., Łódź 2 / 21 3 / 21 Motywacja Brak darmowych ogólnodostępnych korpusów komercyjne:
Korpusy i Narzędzia do Analizy Mowy w Clarin-PL
 1 / 20 Korpusy i w Clarin-PL Krzysztof Marasek, Danijel Koržinek, Łukasz Brocki, Krzysztof Wołk Polsko-Japońska Akademia Technik Komputerowych 2 / 20 Plan prezentacji 1 2 3 / 20 4 / 20 Motywacja Brak darmowych
1 / 20 Korpusy i w Clarin-PL Krzysztof Marasek, Danijel Koržinek, Łukasz Brocki, Krzysztof Wołk Polsko-Japońska Akademia Technik Komputerowych 2 / 20 Plan prezentacji 1 2 3 / 20 4 / 20 Motywacja Brak darmowych
BIOMETRIA WYKŁAD 6 CECHY BIOMETRYCZNE: GŁOS
 BIOMETRIA WYKŁAD 6 CECHY BIOMETRYCZNE: GŁOS Wykorzystanie mowy w technologii Automatyczne rozpoznawanie mowy Synteza mowy Rozpoznawania mówcy Rozpoznawanie emocji Generowanie emocji Synteza z ruchem ust
BIOMETRIA WYKŁAD 6 CECHY BIOMETRYCZNE: GŁOS Wykorzystanie mowy w technologii Automatyczne rozpoznawanie mowy Synteza mowy Rozpoznawania mówcy Rozpoznawanie emocji Generowanie emocji Synteza z ruchem ust
Kompresja Kodowanie arytmetyczne. Dariusz Sobczuk
 Kompresja Kodowanie arytmetyczne Dariusz Sobczuk Kodowanie arytmetyczne (lata 1960-te) Pierwsze prace w tym kierunku sięgają początków lat 60-tych XX wieku Pierwszy algorytm Eliasa nie został opublikowany
Kompresja Kodowanie arytmetyczne Dariusz Sobczuk Kodowanie arytmetyczne (lata 1960-te) Pierwsze prace w tym kierunku sięgają początków lat 60-tych XX wieku Pierwszy algorytm Eliasa nie został opublikowany
Automatyzacja testowania oprogramowania. Automatyzacja testowania oprogramowania 1/36
 Automatyzacja testowania oprogramowania Automatyzacja testowania oprogramowania 1/36 Automatyzacja testowania oprogramowania 2/36 Potrzeba szybkich rozwiązań Testowanie oprogramowania powinno być: efektywne
Automatyzacja testowania oprogramowania Automatyzacja testowania oprogramowania 1/36 Automatyzacja testowania oprogramowania 2/36 Potrzeba szybkich rozwiązań Testowanie oprogramowania powinno być: efektywne
Egzamin / zaliczenie na ocenę*
 Zał. nr do ZW /01 WYDZIAŁ / STUDIUM KARTA PRZEDMIOTU Nazwa w języku polskim Identyfikacja systemów Nazwa w języku angielskim System identification Kierunek studiów (jeśli dotyczy): Inżynieria Systemów
Zał. nr do ZW /01 WYDZIAŁ / STUDIUM KARTA PRZEDMIOTU Nazwa w języku polskim Identyfikacja systemów Nazwa w języku angielskim System identification Kierunek studiów (jeśli dotyczy): Inżynieria Systemów
Model semistrukturalny
 Model semistrukturalny standaryzacja danych z różnych źródeł realizacja złożonej struktury zależności, wielokrotne zagnieżdżania zobrazowane przez grafy skierowane model samoopisujący się wielkości i typy
Model semistrukturalny standaryzacja danych z różnych źródeł realizacja złożonej struktury zależności, wielokrotne zagnieżdżania zobrazowane przez grafy skierowane model samoopisujący się wielkości i typy
Dobór tekstów do Elektronicznego korpusu tekstów polskich z XVII i XVIII w. (do 1772 r.) możliwości i ograniczenia budowanego warsztatu badawczego
 możliwości i ograniczenia budowanego warsztatu badawczego") Dobór tekstów do Elektronicznego korpusu tekstów polskich z XVII i XVIII w. (do 1772 r.) możliwości i ograniczenia budowanego warsztatu badawczego Dorota Adamiec Instytut Języka Polskiego PAN Elektroniczny
Dobór tekstów do Elektronicznego korpusu tekstów polskich z XVII i XVIII w. (do 1772 r.) możliwości i ograniczenia budowanego warsztatu badawczego Dorota Adamiec Instytut Języka Polskiego PAN Elektroniczny
Forma. Główny cel kursu. Umiejętności nabywane przez studentów. Wymagania wstępne:
 WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
Rozwój mowy dziecka OKRES ZDANIA - OD 2 DO 3 ROKU ŻYCIA.
 Rozwój mowy dziecka OKRES ZDANIA - OD 2 DO 3 ROKU ŻYCIA. Między 2 a 3 rokiem życia następuje rozkwit mowy dziecka. Dziecko zaczyna budować zdania, początkowo są to zdania proste, które są złożone z dwóch,
Rozwój mowy dziecka OKRES ZDANIA - OD 2 DO 3 ROKU ŻYCIA. Między 2 a 3 rokiem życia następuje rozkwit mowy dziecka. Dziecko zaczyna budować zdania, początkowo są to zdania proste, które są złożone z dwóch,
System Korekty Tekstu Polskiego
 Wnioski Grzegorz Szuba System Korekty Tekstu Polskiego Plan prezentacji Geneza problemu i cele pracy Opis algorytmu bezkontekstowego Opis algorytmów kontekstowych Wyniki testów Rozszerzenie pracy - uproszczona
Wnioski Grzegorz Szuba System Korekty Tekstu Polskiego Plan prezentacji Geneza problemu i cele pracy Opis algorytmu bezkontekstowego Opis algorytmów kontekstowych Wyniki testów Rozszerzenie pracy - uproszczona
Polszczyzna i inżynieria lingwistyczna. Autor: Marcin Miłkowski (IFiS PAN)
") Polszczyzna i inżynieria lingwistyczna Autor: Marcin Miłkowski (IFiS PAN) 1 Polszczyzna i jej cechy szczególne Polszczyzną posługuje się od 40 do 48 milionów osób: najczęściej używany język zachodniosłowiański
Polszczyzna i inżynieria lingwistyczna Autor: Marcin Miłkowski (IFiS PAN) 1 Polszczyzna i jej cechy szczególne Polszczyzną posługuje się od 40 do 48 milionów osób: najczęściej używany język zachodniosłowiański
Instrukcja do panelu administracyjnego. do zarządzania kontem FTP WebAs. www.poczta.greenlemon.pl
 Instrukcja do panelu administracyjnego do zarządzania kontem FTP WebAs www.poczta.greenlemon.pl Opracowanie: Agencja Mediów Interaktywnych GREEN LEMON Spis treści 1.Wstęp 2.Konfiguracja 3.Konto FTP 4.Domeny
Instrukcja do panelu administracyjnego do zarządzania kontem FTP WebAs www.poczta.greenlemon.pl Opracowanie: Agencja Mediów Interaktywnych GREEN LEMON Spis treści 1.Wstęp 2.Konfiguracja 3.Konto FTP 4.Domeny
SPOTKANIE 2: Wprowadzenie cz. I
 Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
Analiza leksykalna 1. Teoria kompilacji. Dr inż. Janusz Majewski Katedra Informatyki
 Analiza leksykalna 1 Teoria kompilacji Dr inż. Janusz Majewski Katedra Informatyki Zadanie analizy leksykalnej Kod źródłowy (ciąg znaków) Analizator leksykalny SKANER Ciąg symboli leksykalnych (tokenów)
Analiza leksykalna 1 Teoria kompilacji Dr inż. Janusz Majewski Katedra Informatyki Zadanie analizy leksykalnej Kod źródłowy (ciąg znaków) Analizator leksykalny SKANER Ciąg symboli leksykalnych (tokenów)
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych
 Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
Rozkład materiału do nauczania informatyki w liceum ogólnokształcącym Wersja II
 Zespół TI Instytut Informatyki Uniwersytet Wrocławski ti@ii.uni.wroc.pl http://www.wsip.com.pl/serwisy/ti/ Rozkład materiału do nauczania informatyki w liceum ogólnokształcącym Wersja II Rozkład wymagający
Zespół TI Instytut Informatyki Uniwersytet Wrocławski ti@ii.uni.wroc.pl http://www.wsip.com.pl/serwisy/ti/ Rozkład materiału do nauczania informatyki w liceum ogólnokształcącym Wersja II Rozkład wymagający
Projekt badawczy. Zastosowania technologii dynamicznego podpisu biometrycznego
 Projekt badawczy Zastosowania technologii dynamicznego podpisu biometrycznego Multimodalny biometryczny system weryfikacji tożsamości klienta bankowego Warszawa, 27.10.2016 r. Projekt finansowany przez
Projekt badawczy Zastosowania technologii dynamicznego podpisu biometrycznego Multimodalny biometryczny system weryfikacji tożsamości klienta bankowego Warszawa, 27.10.2016 r. Projekt finansowany przez
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Krzysztof Ślot Biometria Łódź, ul. Wólczańska 211/215, bud. B9 tel
 Krzysztof Ślot Biometria 9-924 Łódź, ul. Wólczańska 211/215, bud. B9 tel. 42 636 65 www.eletel.p.lodz.pl, ie@p.lodz.pl Wprowadzenie Biometria Analiza rejestrowanych zachowań i cech osobniczych (np. w celu
Krzysztof Ślot Biometria 9-924 Łódź, ul. Wólczańska 211/215, bud. B9 tel. 42 636 65 www.eletel.p.lodz.pl, ie@p.lodz.pl Wprowadzenie Biometria Analiza rejestrowanych zachowań i cech osobniczych (np. w celu
Wykład I. Wprowadzenie do baz danych
 Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Opisy efektów kształcenia dla modułu
 Karta modułu - Metodyki i techniki programowania 1 / 5 Nazwa modułu: Metodyki i techniki programowania Rocznik: 2012/2013 Kod: RIA-1-103-s Punkty ECTS: 7 Wydział: Inżynierii Mechanicznej i Robotyki Poziom
Karta modułu - Metodyki i techniki programowania 1 / 5 Nazwa modułu: Metodyki i techniki programowania Rocznik: 2012/2013 Kod: RIA-1-103-s Punkty ECTS: 7 Wydział: Inżynierii Mechanicznej i Robotyki Poziom
P R Z E T W A R Z A N I E S Y G N A Ł Ó W B I O M E T R Y C Z N Y C H
 W O J S K O W A A K A D E M I A T E C H N I C Z N A W Y D Z I A Ł E L E K T R O N I K I Drukować dwustronnie P R Z E T W A R Z A N I E S Y G N A Ł Ó W B I O M E T R Y C Z N Y C H Grupa... Data wykonania
W O J S K O W A A K A D E M I A T E C H N I C Z N A W Y D Z I A Ł E L E K T R O N I K I Drukować dwustronnie P R Z E T W A R Z A N I E S Y G N A Ł Ó W B I O M E T R Y C Z N Y C H Grupa... Data wykonania
ANALIZA SEMANTYCZNA OBRAZU I DŹWIĘKU
 ANALIZA SEMANTYCZNA OBRAZU I DŹWIĘKU i klasyfikacja sygnału audio dr inż. Jacek Naruniec Sygnał mowy mózg (układ sterujący) głośnia (źródło dźwięku) rezonator akustyczny (filtr) sygnał mowy 2 Sygnał mowy
ANALIZA SEMANTYCZNA OBRAZU I DŹWIĘKU i klasyfikacja sygnału audio dr inż. Jacek Naruniec Sygnał mowy mózg (układ sterujący) głośnia (źródło dźwięku) rezonator akustyczny (filtr) sygnał mowy 2 Sygnał mowy
CLARIN rozproszony system technologii językowych dla różnych języków europejskich
 CLARIN rozproszony system technologii językowych dla różnych języków europejskich Maciej Piasecki Politechnika Wrocławska Instytut Informatyki G4.19 Research Group maciej.piasecki@pwr.wroc.pl Projekt CLARIN
CLARIN rozproszony system technologii językowych dla różnych języków europejskich Maciej Piasecki Politechnika Wrocławska Instytut Informatyki G4.19 Research Group maciej.piasecki@pwr.wroc.pl Projekt CLARIN
FONETYKA. Co to jest fonetyka? Język polski Klasa III Gim
 FONETYKA Język polski Klasa III Gim Co to jest fonetyka? Fonetyka Fonetyka (z gr. phonetikos) to dział nauki o języku badający i opisujący cechy dźwięków mowy, czyli głosek. Zajmuje się ona procesami powstawania
FONETYKA Język polski Klasa III Gim Co to jest fonetyka? Fonetyka Fonetyka (z gr. phonetikos) to dział nauki o języku badający i opisujący cechy dźwięków mowy, czyli głosek. Zajmuje się ona procesami powstawania
Sprawozdanie z laboratoriów HTK!
 Inżynieria akustyczna - Technologia mowy 2013 Błażej Chwiećko Sprawozdanie z laboratoriów HTK! 1. Przeznaczenie tworzonego systemu! Celem było stworzenie systemu służącego do sterowania samochodem. Zaimplementowane
Inżynieria akustyczna - Technologia mowy 2013 Błażej Chwiećko Sprawozdanie z laboratoriów HTK! 1. Przeznaczenie tworzonego systemu! Celem było stworzenie systemu służącego do sterowania samochodem. Zaimplementowane
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Podstawy programowania. Wprowadzenie
 Podstawy programowania Wprowadzenie Proces tworzenia programu Sformułowanie problemu funkcje programu zakres i postać danych postać i dokładność wyników Wybór / opracowanie metody rozwiązania znaleźć matematyczne
Podstawy programowania Wprowadzenie Proces tworzenia programu Sformułowanie problemu funkcje programu zakres i postać danych postać i dokładność wyników Wybór / opracowanie metody rozwiązania znaleźć matematyczne
Uniwersytet w Białymstoku Wydział Ekonomiczno-Informatyczny w Wilnie SYLLABUS na rok akademicki 2012/2013 http://www.wilno.uwb.edu.
 SYLLABUS na rok akademicki 01/013 Tryb studiów Studia stacjonarne Kierunek studiów Informatyka Poziom studiów Pierwszego stopnia Rok studiów/ semestr /3 Specjalność Bez specjalności Kod katedry/zakładu
SYLLABUS na rok akademicki 01/013 Tryb studiów Studia stacjonarne Kierunek studiów Informatyka Poziom studiów Pierwszego stopnia Rok studiów/ semestr /3 Specjalność Bez specjalności Kod katedry/zakładu
Rozkład materiału do nauczania informatyki w liceum ogólnokształcącym Wersja I
 Zespół TI Instytut Informatyki Uniwersytet Wrocławski ti@ii.uni.wroc.pl http://www.wsip.com.pl/serwisy/ti/ Rozkład materiału do nauczania informatyki w liceum ogólnokształcącym Wersja I Rozkład zgodny
Zespół TI Instytut Informatyki Uniwersytet Wrocławski ti@ii.uni.wroc.pl http://www.wsip.com.pl/serwisy/ti/ Rozkład materiału do nauczania informatyki w liceum ogólnokształcącym Wersja I Rozkład zgodny
Extensible Markup Language (XML) Wrocław, Java - technologie zaawansowane
 Wrocław, Java - technologie zaawansowane") Extensible Markup Language (XML) Wrocław, 15.03.2019 - Java - technologie zaawansowane Wprowadzenie XML jest językiem znaczników (ang. markup language) używanym do definiowania zbioru zasad rozmieszczenia
Extensible Markup Language (XML) Wrocław, 15.03.2019 - Java - technologie zaawansowane Wprowadzenie XML jest językiem znaczników (ang. markup language) używanym do definiowania zbioru zasad rozmieszczenia
DATABASE SNAPSHOT GEEK DIVE. Cezary Ołtuszyk Blog: coltuszyk.wordpress.com
 DATABASE SNAPSHOT GEEK DIVE Cezary Ołtuszyk Blog: coltuszyk.wordpress.com Kilka słów o mnie Kierownik Działu Administracji Systemami w firmie BEST S.A. (warstwa bazodanowa i aplikacyjna) Konsultant z zakresu
DATABASE SNAPSHOT GEEK DIVE Cezary Ołtuszyk Blog: coltuszyk.wordpress.com Kilka słów o mnie Kierownik Działu Administracji Systemami w firmie BEST S.A. (warstwa bazodanowa i aplikacyjna) Konsultant z zakresu
Faza Określania Wymagań
 Faza Określania Wymagań Celem tej fazy jest dokładne określenie wymagań klienta wobec tworzonego systemu. W tej fazie dokonywana jest zamiana celów klienta na konkretne wymagania zapewniające osiągnięcie
Faza Określania Wymagań Celem tej fazy jest dokładne określenie wymagań klienta wobec tworzonego systemu. W tej fazie dokonywana jest zamiana celów klienta na konkretne wymagania zapewniające osiągnięcie
Systemy agentowe. Uwagi organizacyjne i wprowadzenie. Jędrzej Potoniec
 Systemy agentowe Uwagi organizacyjne i wprowadzenie Jędrzej Potoniec Kontakt mgr inż. Jędrzej Potoniec Jedrzej.Potoniec@cs.put.poznan.pl http://www.cs.put.poznan.pl/jpotoniec https://github.com/jpotoniec/sa
Systemy agentowe Uwagi organizacyjne i wprowadzenie Jędrzej Potoniec Kontakt mgr inż. Jędrzej Potoniec Jedrzej.Potoniec@cs.put.poznan.pl http://www.cs.put.poznan.pl/jpotoniec https://github.com/jpotoniec/sa
NeuroVoice. Synteza i analiza mowy. Paweł Mrówka
 NeuroVoice Synteza i analiza mowy Paweł Mrówka pawel.mrowka@neurosoft.pl Plan prezentacji Synteza mowy - SynTalk Wprowadzenie do syntezy konkatenacyjnej Zastosowanie analizy językowej tekstu MoŜliwości
NeuroVoice Synteza i analiza mowy Paweł Mrówka pawel.mrowka@neurosoft.pl Plan prezentacji Synteza mowy - SynTalk Wprowadzenie do syntezy konkatenacyjnej Zastosowanie analizy językowej tekstu MoŜliwości
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
SYLABUS MODUŁU KSZTAŁCENIA
 Lp. Element Opis SYLABUS MODUŁU KSZTAŁCENIA Nazwa modułu Typ modułu Fonetyka obowiązkowy 3 Instytut Instytut Nauk Humanistyczno-Społecznych i Turystyki 4 5 Kod modułu Kierunek, specjalność, poziom i profil
Lp. Element Opis SYLABUS MODUŁU KSZTAŁCENIA Nazwa modułu Typ modułu Fonetyka obowiązkowy 3 Instytut Instytut Nauk Humanistyczno-Społecznych i Turystyki 4 5 Kod modułu Kierunek, specjalność, poziom i profil
PRZEWODNIK PO PRZEDMIOCIE. PNJA Fonetyka praktyczna j. angielskiego brytyjskiego Angielski Język Biznesu
 Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu PNJA Fonetyka praktyczna j. brytyjskiego Kierunek Forma studiów Poziom kwalifikacji Rok Semestr Jednostka prowadząca
Politechnika Częstochowska, Wydział Zarządzania PRZEWODNIK PO PRZEDMIOCIE Nazwa przedmiotu PNJA Fonetyka praktyczna j. brytyjskiego Kierunek Forma studiów Poziom kwalifikacji Rok Semestr Jednostka prowadząca
Prof. Stanisław Jankowski
 Prof. Stanisław Jankowski Zakład Sztucznej Inteligencji Zespół Statystycznych Systemów Uczących się p. 228 sjank@ise.pw.edu.pl Zakres badań: Sztuczne sieci neuronowe Maszyny wektorów nośnych SVM Maszyny
Prof. Stanisław Jankowski Zakład Sztucznej Inteligencji Zespół Statystycznych Systemów Uczących się p. 228 sjank@ise.pw.edu.pl Zakres badań: Sztuczne sieci neuronowe Maszyny wektorów nośnych SVM Maszyny
Egzamin / zaliczenie na ocenę*
 WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI Zał. nr 4 do ZW 33/01 KARTA PRZEDMIOTU Nazwa w języku polskim CYFROWE PRZETWARZANIE SYGNAŁÓW Nazwa w języku angielskim DIGITAL SIGNAL PROCESSING Kierunek studiów
WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI Zał. nr 4 do ZW 33/01 KARTA PRZEDMIOTU Nazwa w języku polskim CYFROWE PRZETWARZANIE SYGNAŁÓW Nazwa w języku angielskim DIGITAL SIGNAL PROCESSING Kierunek studiów
System Korekty Tekstu Polskiego
 System Korekty Tekstu Polskiego Plan prezentacji Geneza problemu i cele pracy Opis algorytmu bezkontekstowego Opis algorytmów kontekstowych Wyniki testów Wersja algorytmu dla języka hiszpańskiego Wnioski
System Korekty Tekstu Polskiego Plan prezentacji Geneza problemu i cele pracy Opis algorytmu bezkontekstowego Opis algorytmów kontekstowych Wyniki testów Wersja algorytmu dla języka hiszpańskiego Wnioski
Poradnik HTK. Adrian Sekuła
 Poradnik HTK Adrian Sekuła Wstęp Poradnik wykonano do przedmiotu Technologia Mowy, prowadzonego przez dr inż. Bartosza Ziółko i dr inż. Jakuba Gałkę na studiach Inżynieria Akustyczna na AGH w Krakowie.
Poradnik HTK Adrian Sekuła Wstęp Poradnik wykonano do przedmiotu Technologia Mowy, prowadzonego przez dr inż. Bartosza Ziółko i dr inż. Jakuba Gałkę na studiach Inżynieria Akustyczna na AGH w Krakowie.
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: moduł specjalności obowiązkowy: Sieci komputerowe Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE
Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: moduł specjalności obowiązkowy: Sieci komputerowe Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Informatyka Studia II stopnia
 Wydział Elektrotechniki, Elektroniki, Informatyki i Automatyki Politechnika Łódzka Informatyka Studia II stopnia Katedra Informatyki Stosowanej Program kierunku Informatyka Specjalności Administrowanie
Wydział Elektrotechniki, Elektroniki, Informatyki i Automatyki Politechnika Łódzka Informatyka Studia II stopnia Katedra Informatyki Stosowanej Program kierunku Informatyka Specjalności Administrowanie
Spis treści. Od autorów / 9
 Od autorów / 9 Rozdział 1. Bezpieczny i legalny komputer / 11 1.1. Komputer we współczesnym świecie / 12 Typowe zastosowania komputera / 12 1.2. Bezpieczna i higieniczna praca z komputerem / 13 Wpływ komputera
Od autorów / 9 Rozdział 1. Bezpieczny i legalny komputer / 11 1.1. Komputer we współczesnym świecie / 12 Typowe zastosowania komputera / 12 1.2. Bezpieczna i higieniczna praca z komputerem / 13 Wpływ komputera
Modele sprzedaży i dystrybucji oprogramowania Teoria a praktyka SaaS vs. BOX. Bartosz Marciniak. Actuality Sp. z o.o.
 Modele sprzedaży i dystrybucji oprogramowania Teoria a praktyka SaaS vs. BOX Bartosz Marciniak Actuality Sp. z o.o. Prezes Zarządu Społeczeństwo informacyjne społeczeństwo, które znalazło zastosowanie
Modele sprzedaży i dystrybucji oprogramowania Teoria a praktyka SaaS vs. BOX Bartosz Marciniak Actuality Sp. z o.o. Prezes Zarządu Społeczeństwo informacyjne społeczeństwo, które znalazło zastosowanie
Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym
 w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym") Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym Jan Karwowski Wydział Matematyki i Nauk Informacyjnych PW 17 XII 2013 Jan Karwowski
Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym Jan Karwowski Wydział Matematyki i Nauk Informacyjnych PW 17 XII 2013 Jan Karwowski
Programowanie. programowania. Klasa 3 Lekcja 9 PASCAL & C++
 Programowanie Wstęp p do programowania Klasa 3 Lekcja 9 PASCAL & C++ Język programowania Do przedstawiania algorytmów w postaci programów służą języki programowania. Tylko algorytm zapisany w postaci programu
Programowanie Wstęp p do programowania Klasa 3 Lekcja 9 PASCAL & C++ Język programowania Do przedstawiania algorytmów w postaci programów służą języki programowania. Tylko algorytm zapisany w postaci programu
Analiza sygnałów biologicznych
 Analiza sygnałów biologicznych Paweł Strumiłło Zakład Elektroniki Medycznej Instytut Elektroniki PŁ Co to jest sygnał? Funkcja czasu x(t) przenosząca informację o stanie lub działaniu układu (systemu),
Analiza sygnałów biologicznych Paweł Strumiłło Zakład Elektroniki Medycznej Instytut Elektroniki PŁ Co to jest sygnał? Funkcja czasu x(t) przenosząca informację o stanie lub działaniu układu (systemu),
S O M SELF-ORGANIZING MAPS. Przemysław Szczepańczyk Łukasz Myszor
 S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
Efekt Lombarda. Czym jest efekt Lombarda?
 Efekt Lombarda Na podstawie raportu Priscilli Lau z roku 2008 na Uniwersytecie w Berkeley wykonanego na podstawie badań w laboratorium Fonologii. Autor prezentacji: Antoni Lis Efekt Lombarda Czym jest
Efekt Lombarda Na podstawie raportu Priscilli Lau z roku 2008 na Uniwersytecie w Berkeley wykonanego na podstawie badań w laboratorium Fonologii. Autor prezentacji: Antoni Lis Efekt Lombarda Czym jest
E-I2G-2008-s1. Informatyka II stopień (I stopień / II stopień) Ogólnoakademicki (ogólno akademicki / praktyczny)
 Ogólnoakademicki (ogólno akademicki / praktyczny)") KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu E-I2G-2008-s1 Nazwa modułu Zaawansowane przetwarzanie obrazów Nazwa modułu w języku angielskim
KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu E-I2G-2008-s1 Nazwa modułu Zaawansowane przetwarzanie obrazów Nazwa modułu w języku angielskim