Klasyfikacja i dyskryminacja
|
|
|
- Dominika Stasiak
- 5 lat temu
- Przeglądów:
Transkrypt
1 i dyskryminacja Nina Stulich Kazimierz Najmajer Statystyka II i dyskryminacja
2 Definicja Cel Definicja i dyskryminacja - pod tymi pojęciami rozumie się wielowymiarowe metody zajmujące się rozdzielaniem odrębnych zbiorów obserwacji, które następnie przydziela się do wcześniej zdefiniowanych zbiorów (grup). W celu zbadania obserwowanych różnic wykorzystuje się analizę dyskryminacyjną, jako procedurę rozdzielającą. Z kolei procedury klasyfikacji wykorzystywane są do przydzielania nowych obserwacji do danych zbiorów. i dyskryminacja
3 Definicja Cel Cele wykorzystywania klasyfikacji i dyskryminacji Możemy wyszczególnić dwa najważniejsze cele: 1 - wykorzystujemy ją do posortowania obserwacji na co najmniej dwie klasy (może być ich więcej). W szczególności ustalamy reguły pozwalające na przypisanie nowych obiektów do poszczególnych klas. 2 Dyskryminacja - wykorzystujemy ją do opisu graficznego jak i algebraicznego różniących cech obserwacji z kilku znanych zbiorów (populacji). Z jej pomocą znajdujemy wyróżniki i odpowiadające im wartości liczbowe, które pozwalają nam odpowiednio rozdzielić zbiory. i dyskryminacja
4 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Przykład Przejdziemy za chwilę do pierwszego przykładu. Oznaczmy zatem nasze dwie klasy jako π 1 oraz π 2. Obserwacje są zazwyczaj rozdzielone na podstawie pommiarów, przykładowo p powiązanych między sobą zmiennych losowych X = [X 1, X 2,..., X p ], przy czym obserwowane wartości X różnią się pomiędzy klasami. Wartości pochodzące z pierwszej klasy możemy traktować jako populację π 1 o wartościach x, natomiast wartości pochodzące z drugiej klasy traktujemy jako populację π 2 o wartościach x. Obie populacje mogą być opisane przez funkcje gęstości prawdopodobieństwa f 1 (x) oraz f 2 (x). Zatem możemy mówić o przypisywaniu obserwacji do populacji. i dyskryminacja
5 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Przykład i dyskryminacja
6 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Przykład Przeanalizujmy teraz przykład 2. Widzimy, że badana jest tu grupa przyszłych studentów, która zostanie rozdzielona na dwie klasy: osoby, które dostaną się na studia oraz osoby, które nie dostaną się na studia. Podział ten nastąpi na podstawie zaobserwowanych wartości z drugiej kolumny tabeli, a mianowicie wyniki egzaminu wstępnego, średnia ocen z liceum oraz liczba zajęć w liceum. Na podstawie tych danych można zidentyfikować obserwacje postaci x = [x 1 (wyniki egzaminu wstępnego), x 2 (średnia ocen z liceum), x 3 (liczba zajęć w liceum)] jako populację π 1 ( osoby, które dostaną się na studia ) oraz populację π 2 ( osoby, które nie dostaną się na studia ). i dyskryminacja
7 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Problemy w metodzie klasyfikacji nie zawsze może zapewnić bezbłędne metody przydziału, ponieważ nie może być wyraźnych różnic między mierzonymi cechami populacji, a zatem grupy mogą się pokrywać. Zdarza się to w przypadku gdy błędnie zaklasyfikujemy obiekt z π 2 do π 1 albo odwrotnie. Przykładowe problemy klasyfikacji: Niepełna wiedza o przyszłych wynikach. Perfekcyjne informacje wymagają zniszczenia obiektu. Niedostępne lub drogie informacje. i dyskryminacja
8 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Optymalna reguła klasyfikacji Optymalna reguła klasyfikacji przedstawia się następująco: bierze pod uwagę prawdopodobieństwa a priori uwzględnia koszty związane z błędną klasyfikacją i dyskryminacja
9 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Prawdopodobieństwo P(2 1) - oznacza klasyfikację obiektu należącego do π 1 jako należący do π 2 i wyraża się wzorem: P(2 1) = P(X R 2 π 1 ) = R 2 =Ω R 1 f 1 (x)dx P(1 2) - oznacza klasyfikację obiektu należącego do π 2 jako należący do π 1 i wyraża się wzorem: P(1 2) = P(X R 1 π 2 ) = R 1 f 2 (x)dx gdzie: f 1 (x), f 2 (x) - funkcje gęstości prawdopodobieństwa dla π 1, π 2 Ω - zbiór wszystkich możliwych obserwacji R 1 - zbiór wartości x, dla których klasyfikujemy obiekty jako populacje π 1 R 2 = Ω R 1 - analogicznie i dyskryminacja
10 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Prawdopodobieństwo i dyskryminacja
11 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Prawdopodobieństwo Niech: p 1 - prawdopodobieństwo a priori dla π 1 p 2 - prawdopodobieństwo a priori dla π 2 Wtedy: P(obserwacja poprawnie sklasyfikowana jako π 1 ) = P(X R 1 π 1 )P(π 1 ) = P(1 1)p 1 P(obserwacja poprawnie sklasyfikowana jako π 2 ) = P(X R 2 π 2 )P(π 2 ) = P(2 2)p 2 P(obserwacja błędnie sklasyfikowana jako π 1 ) = P(X R 1 π 2 )P(π 2 ) = P(1 2)p 2 P(obserwacja błędnie sklasyfikowana jako π 2 ) = P(X R 2 π 1 )P(π 1 ) = P(2 1)p 1 i dyskryminacja
12 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Koszty błędnej klasyfikacji MACIERZ KOSZTÓW i dyskryminacja
13 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Oczekiwany koszt błędnej klasyfikacji - ECM Oczekiwany koszt błędnej klasyfikacji (ECM) wyznaczamy poprzez pomnożenie anty-diagonalnych wyrazów z macierzy kosztów przez ich prawdopodobieństwa. Otrzymujemy wtedy: ECM = c(2 1)P(2 1)p 1 + c(1 2)P(1 2)p 2 Regiony R 1 i R 2, które minimallizują ECM są zdefiniowane przez następujące nierówności: R 1 : f 1(x) c(1 2) f 2 (x) ( c(2 1) )( p 2 p 1 ) R 1 : f 1(x) f 2 (x) < ( c(1 2) c(2 1) )( p 2 p 1 ) i dyskryminacja
14 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Przykład Klasyfikowanie nowej obserwacji do jednej z dwóch populacji Mamy wystarczającą ilość danych aby oszacować funkcje gęstości. Załóżmy, że c(2 1) = 5 i c(1 2) = 10. Ponadto dane są znane od 20% obiektów z całej populacji należącej do π 2. Stąd prawdopodobieństwa apriori wynoszą odpowiednio π 1 = 0.8 oraz π 2 = 0.2. Wyznaczyć regiony klasyfikacji. R 1 : f 1(x) f 2 (x) ( )( R 2 : f 1(x) f 2 (x) < ( ) = )( 0.8 ) = 0.5 i dyskryminacja
15 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Przykład Gdzie sklasyfikowałbyś nową obserwację? Załóżmy, że dla nowej obserwacji x 0 funkcje gęstości wynoszą odpowiednio f 1 (x 0 ) = 0.3 oraz f 2 (x 0 ) = 0.4. Otrzymujemy zatem f 1(x) f 2 (x) = = 0.75 Stąd mamy f 1(x) f 2 (x) Wynik = 0.75 > ( c(1 2) c(2 1) )( p 2 p 1 ) = 0.5 Na podstawie otrzymanej nierówności wnioskujemy, że x 0 R 1 i klasyfikujemy nową obserwację x 0 jako należącą do populacji π 1. i dyskryminacja
16 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Σ 1 = Σ 2 = Σ Rozważamy przypadek, gdy macierze kowariancji dla obu populacji są równe. Zakładamy, że gęstości f i (x) są wielowymiarowymi funkcjami gęstości rozkładu normalnego i wyrażają się wzorem: f i (x) = 1 (2π) p/2 Σ 1/2 exp[ 1 2 (x µ i) Σ 1 (x µ i )], i = 1, 2 Możemy zatem wyznaczyć regiony R 1 oraz R 2 oraz skonstruować zasadę przydziału, która minimalizuje ECM: i dyskryminacja
17 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Σ 1 = Σ 2 = Σ W większości przypadków niestety parametry µ 1, µ 2, Σ są nieznane, więc zasadę trzeba było zmodyfikować. Zastąpiono parametry populacji przez odpowiedniki próbkowe. Załóżmy, że mamy n 1 obserwacji z π 1 oraz n 2 obserwacji z π 2. Otrzymujemy następujące macierze: i dyskryminacja
18 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Σ 1 = Σ 2 = Σ Z uzyskanych macierzy tworzymy próbkowe wektory średnich i macierzy kowariancji: Próbkowe macierze kowariancji S 1 i S 2 łączy się w celu uzyskania pojedyńczego estymatora Σ: i dyskryminacja
19 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Estymacyjna zasada minimalizacji ECM dla dwóch normalnych populacji (Σ 1 = Σ 2 = Σ) Podstawiając x 1, x 2, S pooled odpowiednio za µ 1, µ 2, Σ otrzymujemy nową (próbkową) zasadę klasyfikacji. Przypisujemy x 0 do π 1 gdy oraz postępujemy analogicznie, gdy przypisujemy x 0 do π 2. i dyskryminacja
20 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Σ 1 Σ 2 W przypadku, gdy macierze kowariancji nie są sobie równe, reguły klasyfikacji są bardziej skomplikowane. Zastępując gęstości wielowymiarowego rozkładu normalnego innymi macierzami kowariancji otrzymujemy (po uproszczeniu) regiony klasyfikacji: gdzie i dyskryminacja
21 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami W celu oceny wyników dowolnej metody klasyfikacyjnej obliczamy jej wskaźnik błędów lub prawdopodobieństwo błędnej klasyfikacji. Ze względu na to iż wyjściowe populacje rzadko są znane, skupimy się na wskaźnikach błędów powiązanych z próbkową funkcją klasyfikacyjną. i dyskryminacja
22 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Miary oceny skuteczności funkcji klasyfikacyjnych Całkowite prawdopodobieństwo błędnej klasyfikacji (TPM) TPM = p 1 R 2 f 1 (x)dx + p 2 R 1 f 2 (x)dx Najmniejszą wartość TPM nazywamy najlepszym wskaźnikiem błędów (OER). Najlepszy wskaźnik błędów (OER) gdzie: OER = p 1 R 2 f 1 (x)dx + p 2 R 1 f 2 (x)dx R 1 : f 1(x) f 2 (x) p 2 p 1 R 2 : f 1(x) f 2 (x) < p 2 p 1 i dyskryminacja
23 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Miary oceny skuteczności funkcji klasyfikacyjnych OER oznacza jaki procent składników będzie niepoprawnie przydzielony po zastosowaniu najlepszej reguły klasyfikacji, np. OER = 13% oznacza, że reguła klasyfikacji niepoprawnie przydzieli około 13% składników do pierwszej lub drugiej populacji. Najlepszy wskaźnik błędów (OER) najłatwiej obliczyć, gdy funkcje gęstości populacji są znane. i dyskryminacja
24 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Miary oceny skuteczności próbkowch funkcji klasyfikacyjnych Rzeczywisty wskaźnik błędów (AER) AER = p 1 ˆR 2 f 1 (x)dx + p 2 ˆR 1 f 2 (x)dx gdzie ˆR 1 i ˆR2 - obszary klasyfikacyjne. AER ukazuje jak próbkowa funkcja klasyfikacyjna będzie zachowywała się dla przyszłych próbek. i dyskryminacja
25 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Miary oceny skuteczności próbkowch funkcji klasyfikacyjnych Wskaźnik błędów pozornych (APER) APER jest zdefiniowany jako ułamek obserwacji, który został błędnie sklasyfikowany przez próbkową funkcje klasyfikacyjną. Może być on łatwo obliczony z macierzy pomyłek, która przedstawia rzeczywistą i przewidywaną przynależność do grup. Jest to miara skuteczności, która nie zależy od postaci populacji macierzystej. i dyskryminacja
26 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Miary oceny skuteczności próbkowch funkcji klasyfikacyjnych Mamy n 1 obserwacji z π 1 oraz n 2 obserwacji z π 2. Macierz pomyłek wygląda następująco: gdzie n 1C - liczba pozycji z π 1 poprawnie sklasyfikowanych jako π 1 n 1M - liczba pozycji z π 1 błędnie sklasyfikowanych jako π 2 n 2C - liczba pozycji z π 2 poprawnie sklasyfikowanych jako π 2 n 2M - liczba pozycji z π 2 błędnie sklasyfikowanych jako π 1 i dyskryminacja
27 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Miary oceny skuteczności próbkowch funkcji klasyfikacyjnych Obliczenie wskaźnika APER: APER = n 1M+n 2M n 1 +n 2 Wskaźnik ten rozumiemy jako udział pozycji ze zbioru uczącego, które są błędnie sklasyfikowane. i dyskryminacja
28 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Przykład Dla podanej poniżej macierzy pomyłek obliczono wskaźnik APER: Wynik ten oznacza, że 16, 7% pozycji ze zbioru uczącego jest błędnie sklasyfikowane. i dyskryminacja
29 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami z kilkoma populacjami Uogólnijmy procedury klasyfikacyjne dla g 2 grup. Metoda Minimum Oczekiwanego Kosztu Błędnej Klasyfikacji Niech f i (x) będzie gęstością powiązaną z populacją π 1. Niech: p i - prawdopodobieństwa a priori populacji π i c(k i) - koszty przydziału pozycji do π k, jeśli naprawdę należy ona do π i dla k, i = 1, 2,..., g Dla k = i, c(i i) = 0. R k - zbiór x-ów sklasyfikowanych jako π k P(k i) = R k f i (x)dx dla k, i = 1, 2,..., g, gdzie P(i i) = 1 g k=1,k i P(k i) i dyskryminacja
30 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Warunkowy oczekiwany koszt błędnej klasyfikacji W podobny sposów można uzyskać warunkowe oczekiwane koszty błędnej klasyfikacji ECM(2),...,ECM(g). Po wymnożeniu każdego warunkowego ECM przez jego prawdopodobieństwo a priori i zsumowanie daje całkowity ECM. Wzór przedstawiono na kolejnym slajdzie prezentacji. i dyskryminacja
31 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Oczekiwany koszt błędnej klasyfikacji i dyskryminacja
32 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Analogicznie do klasyfikacji dla dwóch populacji wybranie najlepszej reguły klasyfikacyjnej sprowadza się do wyboru wzajemnie rozłącznych obszarów klasyfikacji R 1, R 2,..., R g tak aby ECM było minimum. Obszary klasyfikujące, które minimalizują ECM są zdefiniowane przez przydzielenie x do tej populacji π k, k = 1, 2,..., g, dla której g i=1,1 k p if i (x)c(k i) jest najmniejsze. i dyskryminacja
33 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Reguła Minimum Oczekiwanego Kosztu Błędnej Klasyfikacji (ECM) przy równych kosztach błędnej klasyfikacji: Przydzielamy x 0 do π 1 jeżeli p k f k (x) > p i f i (x) dla wszystkich i k lub lnp k f k (x) > lnp i f i (x) dla wszystkich i k Należy pamiętać, że do realizacji powyższych reguł konieczne jest wcześniejsze oszacowanie prawdopodobieństw a priori, kosztów błędnej klasyfikacji oraz funkcji gęstości. i dyskryminacja
34 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Przykład nowej obserwacji do jednej z trzech znanych populacji: Przyporządkujemy obserwację x 0 do π 1, π 2 lub π 3 znając prawdopodobieństwa a priori, koszta błędnej klasyfikacji oraz wartości gęstości prawdopodobieństwa. i dyskryminacja
35 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Przykład Wartościami dla 3 i=1,i k p i f i (x 0 )c(k i) są Najmniejszą wartość otrzymujemy dla k = 2, a zatem przyporządkowujemy x 0 do π 2. i dyskryminacja
36 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Przykład W przypadku gdy koszta błędnej klasyfikacji są takie same, to posługujemy się zasadą minimum ECM przy równych kosztach. Zatem potrzebujemy tylko następujących iloczynów: p 1 f 1 (x 0 ) = (0.05)(0.01) = p 2 f 2 (x 0 ) = (0.60)(0.85) = p 3 f 3 (x 0 ) = (0.35)(2) = Widzimy, że p 3 f 3 (x 0 ) osiąga największą wartość i stąd przyporządkowujemy x 0 do π 3. i dyskryminacja
37 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami kilku populacji normalnych W przypadku, gdy f i (x) są wielowymiarowymi gęstościami rozkładu normalnego z wektorami średnich µ i i macierzami kowariancji i oraz c(i i) = 0, c(k i) = 1, k i (lub równoważnie koszty błędnych klasyfikacji są równe) następuje reguła: Przydziel x do π k jeżeli i dyskryminacja
38 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Ponieważ stała ( p 2 )ln(2π) jest taka sama dla wszystkich populacji, to może zostać pominięta. Otrzymujemy w ten sposób kwadratowy wynik dyskryminacji dla i-tej populacji jako Kwadratowy wynik dyskryminacji i dyskryminacja
39 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami W przypadku korzystania z kwadratowych wyników dyskryminacji zasada klasyfikacji przedstawia się następująco: Zasada minimalnego całkowitego prawdopodobieństwa błędnej klasyfikacji (TPM) dla populacji normalnych - nierówne i Przydziel x do π k jeżeli d Q k (x) = największy z d Q 1 (x), d Q 2 (x),..., d Q g (x). i dyskryminacja
40 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami W rzeczywistości µ i oraz i są nieznane. Wtedy korzystamy z zasady klasyfikacji opartej na próbie. Oszacowany kwadratowy wynik dyskryminacji wygląda następująco: gdzie x i - próbka wektora średniej S i - próbka macierzy kowariancji n i - rozmiar próbki i dyskryminacja
41 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Zasada szacowania minimum (TPM) dla kilku populacji normalnych - nierówne i Przydziel x do π k jeżeli ˆ d Q ˆ k (x) = największy z d1 Q (x),..., ˆ d Q 2 (x) i dyskryminacja
42 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami W przypadku, gdy macierze kowariancji populacji są równe, wynik dyskryminacji obliczamy za pomocą poniższego wzoru: Pierwsze dwa składniki są takie same dla d Q i (x), a zatem możemy je pominąć. i dyskryminacja
43 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Oszacowanie liniowego dyskryminantu d ˆQ i (x) oparte jest na oszacowaniu : i wyraża się wzorem: i dyskryminacja
44 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Zasada szacowania minimum (TPM) dla równych kowariancji populacji normalnych Przydziel x do π k jeżeli ˆ d Q ˆ k (x) = największy z d1 Q (x),..., ˆ d Q g (x). i dyskryminacja
45 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Absolwenci szkoły biznesowej - KLASYFIKACJA Za pomocą danych zawierających GPA (średnia uzyskanych ocen) oraz GMAT (wyniki testu końcowego) zadecydujemy, którzy studenci mogą zostać dopuszczeni do studiów podyplomowych. Dane zawierają wyniki potencjalnych kandydatów, którzy zostali podzieleni na trzy grupy: admit - dopuszczeni, border - graniczący, notadmit - niedopuszczeni. i dyskryminacja
46 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Próbka testowa Procedura SURVEYSELECT zapewnia różne metody wybierania losowych próbek opartych na prawdopodobieństwie. Procedura może wybrać prostą losową próbkę lub próbkę zgodnie ze złożonym wieloetapowym projektem próbki, który obejmuje stratyfikację, grupowanie i nierówne prawdopodobieństwo selekcji. i dyskryminacja

47 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami i dyskryminacja
48 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami i dyskryminacja
49 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami i dyskryminacja
50 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami PROC DISCRIM i dyskryminacja

51 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami PROC DISCRIM i dyskryminacja
 Opcja WCOV wyświetla kowariancję wewnątrz każdej klasy.")
52 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami PROC DISCRIM (opcja WCOV) Opcja WCOV wyświetla kowariancję wewnątrz każdej klasy. i dyskryminacja
 Opcja PCOV wyświetla połączoną międzyklasową macierz kowariancji.")
53 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami PROC DISCRIM (opcja PCOV) Opcja PCOV wyświetla połączoną międzyklasową macierz kowariancji. i dyskryminacja

54 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami PROC DISCRIM (opcja MANOVA) Opcja MANOVA wyświetla wielowymiarowe statystyki do testowania hipotezy, że średnie w klasie są równe w populacji. i dyskryminacja
55 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami PROC DISCRIM (liniowa funkacja rozpoznawcza) Liniowe funkcje rozpoznawcze odpowiednio dla każdej klasy: d admit ˆ (x) = GPA GMAT d borde ˆ (x) = GPA GMAT d notadmit ˆ (x) = GPA GMAT i dyskryminacja

56 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami PROC DISCRIM (opcja LISTERR) Opcja LISTERR wyświetla wyniki klasyfikacji resubstytucyjnej tylko dla błędnie sklasyfikowanych obserwacji. i dyskryminacja

57 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami i dyskryminacja

58 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Podsumowanie klasyfikacji dla danych testowych i dyskryminacja

59 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Analiza dyskryminacyjna - sposób II i dyskryminacja

60 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Analiza dyskryminacyjna - sposób II i dyskryminacja

61 dla dwóch wielowymiarowych normalnych populacji z kilkoma populacjami Analiza dyskryminacyjna - sposób II i dyskryminacja
62 Fishera dla dwóch populacji Fisher doszedł do statystki liniowej klasyfikacji, używając zupełnie innego argumentu. Jego pomysłem byłoa transformacja wielowymiarowych obserwacji do jednowymiarowych obserwacji y, takich, że y pochodzące z obserwacji π 1 i π 2 były oddzielone od siebie tak bardzo jak to możliwe. Fisher zasugerował wzięcie liniowych kombinacji x aby stworzyć y ponieważ są one wystarczająco proste aby można było się nimi łatwo posługiwać i dyskryminacja
63 Fishera, dwie populacje-ciąg dalszy Kombinacja liniowa xów przybiera wartości y 11, y 12,..., y 1π1 dla obserwacji z pierwszej populacji i wartości y 21, y 22,..., y 2π2 dla obserwacji z drugiej populacji. Rozdział tych dwóch zbiorów jednowymiarowych ygreków jest oceniana różnicą między ȳ 1 i ȳ 2 wyrażonych w jednostkach odchylenia standardowego i dyskryminacja
64 Fishera, dwie populacje, ciąg dalszy II Separacja ta wyraża się następującym wzorem,gdzie s 2 y = separacja = ȳ1 ȳ 2 s y (1) n1 j=1 (y 1j ȳ 1 ) 2 + n 2 j=1 (y 2j ȳ 2 ) 2 n 1 + n 2 2 jest estymacją wariancji, natomiast celem jest wybranie kombinacji liniowej xów, aby osiągnąć maksymalny rozdział próbkowych średnich ȳ 1 i ȳ 2 (2) i dyskryminacja
65 Rozwiązanie Kombinacja liniowa ŷ = â x = ( x 1 x 2 )S 1 pooled x maksymalizuję rozdział. i dyskryminacja
66 Zasada klasyfikacji Fishera Alokuj x 0 do π 1 jeśli ŷ 0 = ( x 1 x 2 ) S 1 pooled x 0 ˆm = 1 2 ( x 1 x 2 ) S 1 pooled ( x 1 + x 2 ) (3) Alokuj x 0 do pi 2 jeśli ŷ 0 < ˆm (4) i dyskryminacja
67 Dyskryminacja Fishera-obrazek i dyskryminacja
68 Metoda Fishera dla dyskryminacji pomiędzy wieloma populacjami Fisher zaproponował także rozszerzenie swojej metody, do kilku populacji. Motywacją idącą za analizą dyskryminacyjną Fishera jest potrzeba uzyskania rozsądnej reprezentacji populacji za pomocą jedynie kilku liniowych kombinacji obserwacji takich jaka 1,a 2,a 3 i dyskryminacja
69 Zalety dyskryminacji Fishera 1 Wygodna reprezentacja g populacji, która redukuje wymiar, z wielkiej liczby charakterystyk to relatywnie niewielu kombinacji liniowych. Oczywiście część informacji może zostać stracona 2 Pozwala na wykreślenie średnich pierwszych dwóch lub trzech kombinacji liniowych, co pozwala na zobaczenie relacji i możliwych podziałów populacji i dyskryminacja
70 Założenia W dyskryminacji Fishera nie musimy koniecznie zakładać, że g populacji mają wielowymiarowy rozkład normalny. Musimy jednak założyć, że macierze kowariancji populacji są sobie równe, czyli Σ 1 = Σ 2 =... = Σ g = Σ (5) i dyskryminacja
71 Dyskryminacja Fishera Przyjmujemy następujące oznaczenia B µ = g i=1 (µ i µ)(µ i µ) oraz ˆµ = 1 g g i=1 µ i Rozważamy kombinację liniową Y = a X o wartości oczekiwanej dla populacji π i : i wariancji dla wszystkich populacji E(Y ) = a E(X π i ) = a µ i (6) Var(Y ) = a Cov(X )a = a Σa (7) i dyskryminacja
72 Dyskryminacja Fishera wartość oczekiwana µ iy = a µ i zmienia się wraz ze zmianą populacji z której jest wybrany X. Definiujemy ogólną średnia jako ū Y = 1 g g a µ i = a ( 1 g i=1 g µ i ) = a ˆµ (8) i=1 i tworzymy stosunek sumy dystansów podniesionych do kwadratu od populacji od ogólnej średniej Y do wariancji i dyskryminacja
73 Dyskryminacja Fishera Stosunek ten wyraża się wzorem g i=1 (µ iy µ Y ) 2 ) σ 2 Y = a B µ a a σa (9) Szukamy a który zmaksymalizuje ten stosunek i dyskryminacja
74 Dyskryminacja Fishera Ponieważ zwykle Σ i µ są niedostępne, korzystamy zazwyczaj ze zbioru treningowego poprawnie zaklasyfikowanych obserwacji. Zakładamy, że zbiór treningowy składa się z prób losowych rozmiaru n i z populacji π i, i=1,2...g. i dyskryminacja
75 Dyskryminacja Fishera Tworzymy wektor średnich z próby n j x i = 1 x ij (10) n i j=1 i macierzy kowariancji S i Definiujemy wektor ogólnej średniej x = 1 g x i (11) g i=1 Następnie analogicznie do B µ, definiujemy macierz B g B = ( x i x)( x i x) (12) i=1 i dyskryminacja
76 Dyskryminacja Fishera Następnie estymacja Σ opiera się na W g n i W = ( x i x)( x i x) (13) i=1 j=1 Estymacja Σ,wyraża sie wzorem S pooled = W n 1 + n n g g (14) i dyskryminacja
77 Dyskryminacja Fishera Niech ˆλ 1, ˆλ 2,...ˆλ s oznaczają s min(g 1, p) niezerowych wartości własnych W 1 B i ê 1, ê 2,...ê s będą odpowiadającym nim wartością własnym przeskalowanym aby ês pooled ê = 1 Wektor â musi zmaksymalizować stosunek â Bâ â W â = â ( g i=1 ( x i x)( x i x) â) â [ g ni i=1 j=1 ( x i x)( x i x) ]â (15) I tym wektorem jest â 1 = ê 1.Liniowa kombinacja â 1 x jest nazywana pierwsza próbkową dyskryminantą. Analogicznie â k x nazywamy k-tą liniową dyskryminantą i dyskryminacja
78 Dyskryminanty Fishera powstały w celu uzyskania niskowymiarowej reprezentacji danych, która separuje populacje tak mocno jak to możliwe. Chociaż dyskryminanty powstały w celu separacji, dają także podstawy dla zasady klasyfikacyjnej. Najpierw wyjaśnimy ten związek korzystając z dyskryminant populacji a i X i dyskryminacja
79 Ustalając Y k = a k X =k-ta dyskryminanta, k s Mamy,które posiada wektor średnich Y = [Y 1 Y 2... Y s ] µ iy = [a 1µ i... a sµ i ] i dyskryminacja
80 Ponieważ elementy Y mają jednostkowe wariancje i zerową kowariancję odpowiednia miarą kwadratu odległości pomiędzy Y = y do µ iy jest (y µ iy ) (y µ iy ) = g (y j µ iyj ) 2 (16) Rozsądną reguła klasyfikacji jest taka,która przyporządkowuje y do populacji π k jeśli kwadrat odległości między y a µ ky jest mniejszy od kwadratu odległości od y do µ iy, dla i różnych od k j=1 i dyskryminacja
81 Dla r dyskryminant zasada alokacji prezentuje się następująco. Alokuj x do π k jeśli: r (y j µ kyj ) 2 = j=1 r [a j(x µ k )] 2 j=1 jest spełnione dla wszystkich i k r [a j(x µ i )] 2 (17) j=1 i dyskryminacja
82 Kiedy używamy regresji logistycznej? Podstawowymi przypadkami w którzy można użyć regresji logistycznej są te gdy mamy zmienną objaśnianą dychotomiczną, czyli taką, która przyjmuje dwie wartości. Na przykład weźmy zmienną objaśnianą- firma zbankrutuje. Zmienna ta będzie posiadała 2 wartości- bankructwo(1) i brak bankructwa(0). Będzie ona miała rozkład zerojedynkowy, czyli Bernoulliego z parametrami B(1,p). Parametr p to szukane przez na prawdopodobieństwo bankructwa. i dyskryminacja
83 Szansa i logit Model regresji logistycznej posługuje się terminem szansy. Wyraża się ona wzorem: szansa = p (18) 1 p Z kolei funkcja logit wyraża się wzorem p logit(p) = ln(szansa) = ln( 1 p ) i dyskryminacja
84 Model W najprostszym modelu z jedną zmienną objaśniającą zakładamy, że logarytm szans jest liniowo zależny od zmiennej objaśniającej eksponencjując θ(z) = p ln( 1 p ) = β 0 + β 1 z (19) p(z) 1 p(z) = exp(β 0 + β 1 z) (20) i dyskryminacja
85 Model cz.2 Rozwiązując równanie(numer), ze względu na θ(x) otrzymujemy równanie krzywej logistycznej p(z) = exp(β 0 + β 1 z) 1 + exp(β 0 + β 1 z) (21) Krzywa logistyczna pokazuje nam jak zmienia się prawdopodobieństwo wraz ze zmianą w z. i dyskryminacja
86 Analiza regresji logistycznej Rozważamy model z wieloma zmiennymi objaśniającymi. Niech z j1, z j2,..., z jr, będą wartościami r zmiennych objaśniających dla jtej obserwacji.wektor z j = [1, z j1, z j2,..., z jr ].Przypuszczamy że obserwacja Y j jest próbą Bernoulliego z prawdopodobieństwem sukcesu p(z j ).Wtedy dla y j = 0, 1 P(Y j = y j ) = p y j (z j )(1 p(z j )) 1 y j (22) i dyskryminacja
87 Analiza regresji logistycznej-ciąg dalszy Z równania (numer), wynika, że E(Y j ) = p(z j ) (23) oraz Var(Y j ) = p(z j )(1 p(z j )) (24) i dyskryminacja
88 Model regresji logistycznej dla wielu predyktorów Równanie modelu regresji logistycznej przedstawia się następującym wzorem p(z) ln( 1 p(z) = β 0 + r β i z i (25) i=1 i dyskryminacja
89 Estymacja metodą największej wiarygodności Oszacowania bet mogą być uzyskane dzięki metodzie największej wiarygodności. Wiarygodność L jest dana wspólnym rozkładem prawdopodobieństwa ewaluowanym dla obserwowanych zliczeń y j. A więc: L(b 0, b 1...b r ) = n p y j (z j )(1 p(z j )) 1 y j = j=1 = nj=1 e y j (b 0 +b 1 z j b r z jr ) nj=1 (1 + e b 0+b 1 z j b r z jr ) (26) i dyskryminacja
90 Przedziały ufności Uzyskane estymacje będziemy reprezentowali przez ˆβ, który przy założeniu duzej próbki pochodzi z rozkładu normalnego o średniej β. Wtedy: ˆ Cov( ˆβ) [ n ˆp(z j )(1 hatp(z j )z j z j ] 1 (27) j=1 Pierwiastki kwadratowe elementów powyższej macierzy są błędami standardowymi estymatorów ˆβ 0, ˆβ 1,..., ˆβ r i dyskryminacja
91 Przedziały ufności cz.2 Dużopróbkowy 95% przedział ufności dla β k wyraża się następującym wzorem: ˆβ k ± 1, 96SE(ˆ(β k )) (28) i dyskryminacja
92 Test ilrazu wiarygodności Aby sprawdzić istotność zmiennej objaśniającej w modelu używamy testy stosunku wiarygodności.hipotezą zerową jest H 0 : β k = 0 Statystyka testowa, która nazywamy dewiancją ma formę: L( 2ln( ˆβ 0, ˆβ 1,..., ˆβ k 1, ˆβ k+1,... ˆβ r ) L( ˆβ 0, ˆβ 1,..., ˆβ k 1, ˆβ k, ˆβ k+1,... ˆβ r ) ) (29) W przypadku podanym powyżej statystyka testowa dla hipotezy zerowej ma rozkład chi kwadrat z 1 stopniem swobody. i dyskryminacja
93 Niech zmienna objaśniana Y będzie równa jeden jeśli obserwowany przypadek należy do populacji 1, natomiast równa 0, jeśli przypadek należy do populacji 2. Za zasadę klasyfikująca możemy przyjąć Zasada klasyfikacyjna Przyporządkuj z do populacji 1 jeśli szacunkowa szansa jest większa niż 1, czyli ˆp(z) 1 ˆp(z) = exp( ˆβ 0 + ˆβ 1 z ˆβ r z r ) > 1 (30) i dyskryminacja
94 Przykład z łososiem Chcemy zaklasyfikować łososie jako alaskańskie bądź kanadyjskie. Użyjemy w tym celu regresji logistycznej, korzystając z sasowej proc logistic. i dyskryminacja
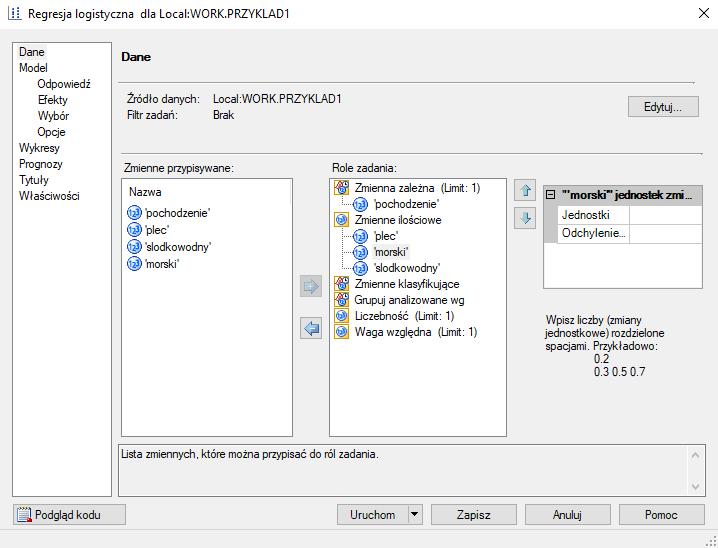
95 Przykład i dyskryminacja
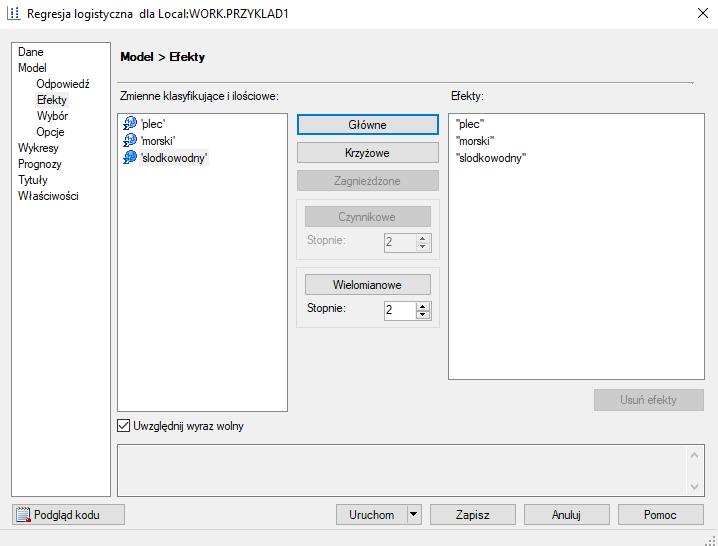
96 Przykład i dyskryminacja
97 Przykład i dyskryminacja
98 Przykład i dyskryminacja
99 Odmienna od przedstawionych wcześniej metod jest metoda drzew klasyfikacyjnych. Na początku wszystkie obiekty znajdują się w jednej grupie, następnie dzielimy je na dwie podgrupy według wartości jednej zmiennej, potem dzielimy te podgrupy według wartości kolejnej zmiennej i tak dalej, aż do osiągniecia odpowiedniego punktu zatrzymania. i dyskryminacja
100 Przykładowe drzewo klasyfikacyjne i dyskryminacja
101 Przykład drzewa klasyfikacyjnego w SAS Używając proc hpsplit SAS wykonamy drzewo klasyfikacyjne w celu zbadania prawdopodobieństwa, że kredyt hipoteczny będzie złym kredytem, zależnie od tego kto o niego występuje. i dyskryminacja
102 są alogorytmicznymi procedurami służącymi przekształceniu wejść w oczekiwane wyjścia, używając wysoko połączonych sieci relatywnie prostych jednostek przetwarzających(nazywanych neuronami). Ich trzema koniecznymi cechami są: podstawowe jednostki obliczeniowe(neurony), architektura sieci opisująca połączenia miedzy jednostkami obliczeniowymi i algorytm treningowy używany do znalezienia parametrów sieci(wag) służących wykonaniu określonego zadania. i dyskryminacja
103 Przykładowa sięć neuronowa i dyskryminacja
104 Dodatek Bibliografia I Johnson, R. A., Wichern, D. W.. Applied multivariate statistical analysis. Prentice Hall i dyskryminacja
Klasyfikacja i dyskrymiancja - Statystyka w SAS
 Klasyfikacja i dyskrymiancja - Statystyka w SAS Agnieszka Gołota, Paweł Grabowski Dariusz Bełczowski, Paweł Cejrowski Politechnika Gdańska Wydział Fizyki Technicznej i Matematyki Stosowanej Pojęcie klasyfikacji
Klasyfikacja i dyskrymiancja - Statystyka w SAS Agnieszka Gołota, Paweł Grabowski Dariusz Bełczowski, Paweł Cejrowski Politechnika Gdańska Wydział Fizyki Technicznej i Matematyki Stosowanej Pojęcie klasyfikacji
Klasyfikacja i dyskryminacja
 2018 Wstęp Dyskryminacja i klasyfikacja dla dwóch populacji Klasyfikacja dla dwóch populacji Wstęp Definicja klasyfikacji i dyskryminacji Dyskriminacja i klasyfikacja są wielowymiarowymi metodami zajmującymi
2018 Wstęp Dyskryminacja i klasyfikacja dla dwóch populacji Klasyfikacja dla dwóch populacji Wstęp Definicja klasyfikacji i dyskryminacji Dyskriminacja i klasyfikacja są wielowymiarowymi metodami zajmującymi
Wprowadzenie. { 1, jeżeli ˆr(x) > 0, pozatym. Regresja liniowa Regresja logistyczne Jądrowe estymatory gęstości. Metody regresyjne
 > 0, pozatym. Regresja liniowa Regresja logistyczne Jądrowe estymatory gęstości. Metody regresyjne") Wprowadzenie Prostym podejściem do klasyfikacji jest estymacja funkcji regresji r(x) =E(Y X =x)zpominięciemestymacjigęstościf k. Zacznijmyodprzypadkudwóchgrup,tj.gdy Y = {1,0}. Wówczasr(x) =P(Y =1 X =x)ipouzyskaniuestymatora
Wprowadzenie Prostym podejściem do klasyfikacji jest estymacja funkcji regresji r(x) =E(Y X =x)zpominięciemestymacjigęstościf k. Zacznijmyodprzypadkudwóchgrup,tj.gdy Y = {1,0}. Wówczasr(x) =P(Y =1 X =x)ipouzyskaniuestymatora
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Własności statystyczne regresji liniowej. Wykład 4
 Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Natalia Neherbecka. 11 czerwca 2010
 Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Metoda największej wiarygodności
 Rozdział Metoda największej wiarygodności Ogólnie w procesie estymacji na podstawie prób x i (każde x i może być wektorem) wyznaczamy parametr λ (w ogólnym przypadku również wektor) opisujący domniemany
Rozdział Metoda największej wiarygodności Ogólnie w procesie estymacji na podstawie prób x i (każde x i może być wektorem) wyznaczamy parametr λ (w ogólnym przypadku również wektor) opisujący domniemany
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX = 4 i EY = 6. Rozważamy zmienną losową Z =.
 Prawdopodobieństwo i statystyka 3..00 r. Zadanie Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX 4 i EY 6. Rozważamy zmienną losową Z. X + Y Wtedy (A) EZ 0,
Prawdopodobieństwo i statystyka 3..00 r. Zadanie Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX 4 i EY 6. Rozważamy zmienną losową Z. X + Y Wtedy (A) EZ 0,
WNIOSKOWANIE W MODELU REGRESJI LINIOWEJ
 WNIOSKOWANIE W MODELU REGRESJI LINIOWEJ Dana jest populacja generalna, w której dwuwymiarowa cecha (zmienna losowa) (X, Y ) ma pewien dwuwymiarowy rozk lad. Miara korelacji liniowej dla zmiennych (X, Y
WNIOSKOWANIE W MODELU REGRESJI LINIOWEJ Dana jest populacja generalna, w której dwuwymiarowa cecha (zmienna losowa) (X, Y ) ma pewien dwuwymiarowy rozk lad. Miara korelacji liniowej dla zmiennych (X, Y
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Błędy przy testowaniu hipotez statystycznych. Decyzja H 0 jest prawdziwa H 0 jest faszywa
 Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Współczynnik korelacji. Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ
 Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
WSTĘP DO REGRESJI LOGISTYCZNEJ. Dr Wioleta Drobik-Czwarno
 WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
Testowanie hipotez statystycznych
 Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
Statystyka. Rozkład prawdopodobieństwa Testowanie hipotez. Wykład III ( )
") Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Zad. 4 Należy określić rodzaj testu (jedno czy dwustronny) oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:
 oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:") Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Ważne rozkłady i twierdzenia c.d.
 Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/
 Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
... i statystyka testowa przyjmuje wartość..., zatem ODRZUCAMY /NIE MA POD- STAW DO ODRZUCENIA HIPOTEZY H 0 (właściwe podkreślić).
.") Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
WYKŁAD 6. Witold Bednorz, Paweł Wolff. Rachunek Prawdopodobieństwa, WNE, Uniwersytet Warszawski. 1 Instytut Matematyki
 WYKŁAD 6 Witold Bednorz, Paweł Wolff 1 Instytut Matematyki Uniwersytet Warszawski Rachunek Prawdopodobieństwa, WNE, 2010-2011 Własności Wariancji Przypomnijmy, że VarX = E(X EX) 2 = EX 2 (EX) 2. Własności
WYKŁAD 6 Witold Bednorz, Paweł Wolff 1 Instytut Matematyki Uniwersytet Warszawski Rachunek Prawdopodobieństwa, WNE, 2010-2011 Własności Wariancji Przypomnijmy, że VarX = E(X EX) 2 = EX 2 (EX) 2. Własności
Testowanie hipotez statystycznych
 round Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 13 grudnia 2014 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
round Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 13 grudnia 2014 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Metoda momentów i kwantyli próbkowych. Wrocław, 7 listopada 2014
 Metoda momentów i kwantyli próbkowych Wrocław, 7 listopada 2014 Metoda momentów Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa. Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa.
Metoda momentów i kwantyli próbkowych Wrocław, 7 listopada 2014 Metoda momentów Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa. Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa.
Testowanie hipotez statystycznych
 Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Definicja 1 Statystyką nazywamy (mierzalną) funkcję obserwowalnego wektora losowego
 funkcję obserwowalnego wektora losowego") Rozdział 1 Statystyki Definicja 1 Statystyką nazywamy (mierzalną) funkcję obserwowalnego wektora losowego X = (X 1,..., X n ). Uwaga 1 Statystyka jako funkcja wektora zmiennych losowych jest zmienną losową
Rozdział 1 Statystyki Definicja 1 Statystyką nazywamy (mierzalną) funkcję obserwowalnego wektora losowego X = (X 1,..., X n ). Uwaga 1 Statystyka jako funkcja wektora zmiennych losowych jest zmienną losową
Stanisław Cichocki Natalia Nehrebecka. Wykład 7
 Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
5. Analiza dyskryminacyjna: FLD, LDA, QDA
 Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
Testowanie hipotez. Hipoteza prosta zawiera jeden element, np. H 0 : θ = 2, hipoteza złożona zawiera więcej niż jeden element, np. H 0 : θ > 4.
 Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 3 Metody estymacji. Estymator największej wiarygodności Zad. 1 Pojawianie się spamu opisane jest zmienną losową y o rozkładzie zero-jedynkowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 3 Metody estymacji. Estymator największej wiarygodności Zad. 1 Pojawianie się spamu opisane jest zmienną losową y o rozkładzie zero-jedynkowym
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap
 Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
MATEMATYKA Z ELEMENTAMI STATYSTYKI LABORATORIUM KOMPUTEROWE DLA II ROKU KIERUNKU ZARZĄDZANIE I INŻYNIERIA PRODUKCJI ZESTAWY ZADAŃ
 MATEMATYKA Z ELEMENTAMI STATYSTYKI LABORATORIUM KOMPUTEROWE DLA II ROKU KIERUNKU ZARZĄDZANIE I INŻYNIERIA PRODUKCJI ZESTAWY ZADAŃ Opracowała: Milena Suliga Wszystkie pliki pomocnicze wymienione w treści
MATEMATYKA Z ELEMENTAMI STATYSTYKI LABORATORIUM KOMPUTEROWE DLA II ROKU KIERUNKU ZARZĄDZANIE I INŻYNIERIA PRODUKCJI ZESTAWY ZADAŃ Opracowała: Milena Suliga Wszystkie pliki pomocnicze wymienione w treści
Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb
 Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
SIMR 2017/18, Statystyka, Przykładowe zadania do kolokwium - Rozwiązania
 SIMR 7/8, Statystyka, Przykładowe zadania do kolokwium - Rozwiązania. Dana jest gęstość prawdopodobieństwa zmiennej losowej ciągłej X : { a( x) dla x [, ] f(x) = dla pozostałych x Znaleźć: i) Wartość parametru
SIMR 7/8, Statystyka, Przykładowe zadania do kolokwium - Rozwiązania. Dana jest gęstość prawdopodobieństwa zmiennej losowej ciągłej X : { a( x) dla x [, ] f(x) = dla pozostałych x Znaleźć: i) Wartość parametru
Klasyfikacja metodą Bayesa
 Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
1 Gaussowskie zmienne losowe
 Gaussowskie zmienne losowe W tej serii rozwiążemy zadania dotyczące zmiennych o rozkładzie normalny. Wymagana jest wiedza na temat własności rozkładu normalnego, CTG oraz warunkowych wartości oczekiwanych..
Gaussowskie zmienne losowe W tej serii rozwiążemy zadania dotyczące zmiennych o rozkładzie normalny. Wymagana jest wiedza na temat własności rozkładu normalnego, CTG oraz warunkowych wartości oczekiwanych..
REGRESJA LINIOWA Z UOGÓLNIONĄ MACIERZĄ KOWARIANCJI SKŁADNIKA LOSOWEGO. Aleksander Nosarzewski Ekonometria bayesowska, prowadzący: dr Andrzej Torój
 1 REGRESJA LINIOWA Z UOGÓLNIONĄ MACIERZĄ KOWARIANCJI SKŁADNIKA LOSOWEGO Aleksander Nosarzewski Ekonometria bayesowska, prowadzący: dr Andrzej Torój 2 DOTYCHCZASOWE MODELE Regresja liniowa o postaci: y
1 REGRESJA LINIOWA Z UOGÓLNIONĄ MACIERZĄ KOWARIANCJI SKŁADNIKA LOSOWEGO Aleksander Nosarzewski Ekonometria bayesowska, prowadzący: dr Andrzej Torój 2 DOTYCHCZASOWE MODELE Regresja liniowa o postaci: y
Kolokwium ze statystyki matematycznej
 Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
Statystyczna analiza danych
 Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średn
 Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
Estymacja przedziałowa - przedziały ufności dla średnich. Wrocław, 5 grudnia 2014
 Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
Statystyka matematyczna. Wykład III. Estymacja przedziałowa
 Statystyka matematyczna. Wykład III. e-mail:e.kozlovski@pollub.pl Spis treści Rozkłady zmiennych losowych 1 Rozkłady zmiennych losowych Rozkład χ 2 Rozkład t-studenta Rozkład Fischera 2 Przedziały ufności
Statystyka matematyczna. Wykład III. e-mail:e.kozlovski@pollub.pl Spis treści Rozkłady zmiennych losowych 1 Rozkłady zmiennych losowych Rozkład χ 2 Rozkład t-studenta Rozkład Fischera 2 Przedziały ufności
Testowanie hipotez statystycznych
 Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 28 listopada 2018 Plan zaj eć 1 Rozk lad estymatora b 2 3 dla parametrów 4 Hipotezy l aczne - test F 5 Dodatkowe za lożenie
Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 28 listopada 2018 Plan zaj eć 1 Rozk lad estymatora b 2 3 dla parametrów 4 Hipotezy l aczne - test F 5 Dodatkowe za lożenie
Metoda największej wiarogodności
 Wprowadzenie Założenia Logarytm funkcji wiarogodności Metoda Największej Wiarogodności (MNW) jest bardziej uniwersalną niż MNK metodą szacowania wartości nieznanych parametrów Wprowadzenie Założenia Logarytm
Wprowadzenie Założenia Logarytm funkcji wiarogodności Metoda Największej Wiarogodności (MNW) jest bardziej uniwersalną niż MNK metodą szacowania wartości nieznanych parametrów Wprowadzenie Założenia Logarytm
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Estymacja parametrów rozkładu cechy
 Estymacja parametrów rozkładu cechy Estymujemy parametr θ rozkładu cechy X Próba: X 1, X 2,..., X n Estymator punktowy jest funkcją próby ˆθ = ˆθX 1, X 2,..., X n przybliżającą wartość parametru θ Przedział
Estymacja parametrów rozkładu cechy Estymujemy parametr θ rozkładu cechy X Próba: X 1, X 2,..., X n Estymator punktowy jest funkcją próby ˆθ = ˆθX 1, X 2,..., X n przybliżającą wartość parametru θ Przedział
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych
 Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Wszystkie wyniki w postaci ułamków należy podawać z dokładnością do czterech miejsc po przecinku!
 Pracownia statystyczno-filogenetyczna Liczba punktów (wypełnia KGOB) / 30 PESEL Imię i nazwisko Grupa Nr Czas: 90 min. Łączna liczba punktów do zdobycia: 30 Czerwona Niebieska Zielona Żółta Zaznacz znakiem
Pracownia statystyczno-filogenetyczna Liczba punktów (wypełnia KGOB) / 30 PESEL Imię i nazwisko Grupa Nr Czas: 90 min. Łączna liczba punktów do zdobycia: 30 Czerwona Niebieska Zielona Żółta Zaznacz znakiem
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Analiza wariancji. dr Janusz Górczyński
 Analiza wariancji dr Janusz Górczyński Wprowadzenie Powiedzmy, że badamy pewną populację π, w której cecha Y ma rozkład N o średniej m i odchyleniu standardowym σ. Powiedzmy dalej, że istnieje pewien czynnik
Analiza wariancji dr Janusz Górczyński Wprowadzenie Powiedzmy, że badamy pewną populację π, w której cecha Y ma rozkład N o średniej m i odchyleniu standardowym σ. Powiedzmy dalej, że istnieje pewien czynnik
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji ML Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji ML Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Rozkłady statystyk z próby
 Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 4 - zagadnienie estymacji, metody wyznaczania estymatorów
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 4 - zagadnienie estymacji, metody wyznaczania estymatorów Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 4 1 / 23 ZAGADNIENIE ESTYMACJI Zagadnienie
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 4 - zagadnienie estymacji, metody wyznaczania estymatorów Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 4 1 / 23 ZAGADNIENIE ESTYMACJI Zagadnienie
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria Wykład 5 dr inż. Anna Skowrońska-Szmer zima 2017/2018 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją
Statystyka matematyczna i ekonometria Wykład 5 dr inż. Anna Skowrońska-Szmer zima 2017/2018 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 13 i 14 - Statystyka bayesowska
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 13 i 14 - Statystyka bayesowska Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 13 i 14 1 / 15 MODEL BAYESOWSKI, przykład wstępny Statystyka
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 13 i 14 - Statystyka bayesowska Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 13 i 14 1 / 15 MODEL BAYESOWSKI, przykład wstępny Statystyka
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 8
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Wnioskowanie statystyczne. Statystyka w 5
 Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
WYKŁAD 8 ANALIZA REGRESJI
 WYKŁAD 8 ANALIZA REGRESJI Regresja 1. Metoda najmniejszych kwadratów-regresja prostoliniowa 2. Regresja krzywoliniowa 3. Estymacja liniowej funkcji regresji 4. Testy istotności współczynnika regresji liniowej
WYKŁAD 8 ANALIZA REGRESJI Regresja 1. Metoda najmniejszych kwadratów-regresja prostoliniowa 2. Regresja krzywoliniowa 3. Estymacja liniowej funkcji regresji 4. Testy istotności współczynnika regresji liniowej
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Estymacja parametrów w modelu normalnym
 Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Rozdział 1. Wektory losowe. 1.1 Wektor losowy i jego rozkład
 Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
Rozkład normalny. Marcin Zajenkowski. Marcin Zajenkowski () Rozkład normalny 1 / 26
 Rozkład normalny 1 / 26") Rozkład normalny Marcin Zajenkowski Marcin Zajenkowski () Rozkład normalny 1 / 26 Rozkład normalny Krzywa normalna, krzywa Gaussa, rozkład normalny Rozkłady liczebności wielu pomiarów fizycznych, biologicznych
Rozkład normalny Marcin Zajenkowski Marcin Zajenkowski () Rozkład normalny 1 / 26 Rozkład normalny Krzywa normalna, krzywa Gaussa, rozkład normalny Rozkłady liczebności wielu pomiarów fizycznych, biologicznych
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Metoda największej wiarygodności
 Metoda największej wiarygodności Próbki w obecności tła Funkcja wiarygodności Iloraz wiarygodności Pomiary o różnej dokładności Obciążenie Informacja z próby i nierówność informacyjna Wariancja minimalna
Metoda największej wiarygodności Próbki w obecności tła Funkcja wiarygodności Iloraz wiarygodności Pomiary o różnej dokładności Obciążenie Informacja z próby i nierówność informacyjna Wariancja minimalna
STATYSTYKA MATEMATYCZNA WYKŁAD stycznia 2010
 STATYSTYKA MATEMATYCZNA WYKŁAD 14 18 stycznia 2010 Model statystyczny ROZKŁAD DWUMIANOWY ( ) {0, 1,, n}, {P θ, θ (0, 1)}, n ustalone P θ {K = k} = ( ) n θ k (1 θ) n k, k k = 0, 1,, n Geneza: Rozkład Bernoulliego
STATYSTYKA MATEMATYCZNA WYKŁAD 14 18 stycznia 2010 Model statystyczny ROZKŁAD DWUMIANOWY ( ) {0, 1,, n}, {P θ, θ (0, 1)}, n ustalone P θ {K = k} = ( ) n θ k (1 θ) n k, k k = 0, 1,, n Geneza: Rozkład Bernoulliego
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Wprowadzenie do teorii ekonometrii. Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe
 Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
1.1 Wstęp Literatura... 1
 Spis treści Spis treści 1 Wstęp 1 1.1 Wstęp................................ 1 1.2 Literatura.............................. 1 2 Elementy rachunku prawdopodobieństwa 2 2.1 Podstawy..............................
Spis treści Spis treści 1 Wstęp 1 1.1 Wstęp................................ 1 1.2 Literatura.............................. 1 2 Elementy rachunku prawdopodobieństwa 2 2.1 Podstawy..............................
Algorytmy, które estymują wprost rozkłady czy też mapowania z nazywamy algorytmami dyskryminacyjnymi.
 Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
VII WYKŁAD STATYSTYKA. 30/04/2014 B8 sala 0.10B Godz. 15:15
 VII WYKŁAD STATYSTYKA 30/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 7 (c.d) WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności,
VII WYKŁAD STATYSTYKA 30/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 7 (c.d) WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności,
Statystyka matematyczna. Wykład IV. Weryfikacja hipotez statystycznych
 Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
STATYSTYKA
 Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów re
 Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
STATYSTYKA. Rafał Kucharski. Uniwersytet Ekonomiczny w Katowicach 2015/16 ROND, Finanse i Rachunkowość, rok 2
 STATYSTYKA Rafał Kucharski Uniwersytet Ekonomiczny w Katowicach 2015/16 ROND, Finanse i Rachunkowość, rok 2 Zależność przyczynowo-skutkowa, symptomatyczna, pozorna (iluzoryczna), funkcyjna stochastyczna
STATYSTYKA Rafał Kucharski Uniwersytet Ekonomiczny w Katowicach 2015/16 ROND, Finanse i Rachunkowość, rok 2 Zależność przyczynowo-skutkowa, symptomatyczna, pozorna (iluzoryczna), funkcyjna stochastyczna