Akceleracja obliczeń metodami sprzętowymi w ACK CYFRONET AGH. Prof. Kazimierz Wiatr
|
|
|
- Martyna Cichoń
- 7 lat temu
- Przeglądów:
Transkrypt
1 Akceleracja obliczeń metodami sprzętowymi w ACK CYFRONET AGH Prof. Kazimierz Wiatr Dyrektor ACK Cyfronet AGH 27 marzec 2009 r.
2 Dzisiejsze wymagania systemów obliczeniowych szybkość!!!! cena wielkość niezawodność
3 Szybkość komputerów wczoraj dziś jutro
4 Metody zwiększania szybkości pracy komputerów szybszy zegar optymalizacja kodu wiele procesorów architektura wewnętrzna sprawne otoczenie procesora
5 Rodzaje komputerów komputery osobiste superkomuptery architektury specjalizowane
6 Akceleracja obliczeń g zbyt długie czasy obliczeń w procesorach GPP i DSP oraz komputerów HPC g poszukiwanie przyspieszenia-akceleracji obliczeń g ograniczenie rodzaju obliczeń i ich aplikacji g poszukiwanie nowych jakościowo metod szybkiej realizacji algorytmów S = t sys_klasycznego / t sys_specjalizowanego
7 Akceleracja obliczeń w systemach wieloprocesorowych Dla systemów wieloprocesorowych (Prawo Amdahl a) S = (s + p) / (s + p/n) gdzie: s - czas algorytmu w części szeregowej programu p - czas algorytmu w części równoległej
8 Akceleracja obliczeń w systemie wieloprocesorowym S (n) s = 0% s = 5% s = 10% s = 15% 0 liczba procesorów (n)
9 Potrzeby obliczeniowe systemy on-line systemy off-line np. obliczenia symulacyjne DNA (ok.100 procesorów Itanium2): 20 atomów - 3 godziny 200 atomów - 34 lata np. medycyna z interakcją itp.
10 Sprzętowe metody akceleracji obliczeń Systemy obliczeniowe Wpływ architektury systemu na szybkość obliczeń Specjalizowane procesory sprzętowe Implementacja w układach FPGA Parametryzacja implementacji Rekonfigurowalne systemy obliczeniowe Dedykowane użytkownikowi platformy CCM Hardware/Software CoDesign Elementy IP Szybkość pracy systemów obliczeniowych
11 Kierunki badawcze poszukiwanie przyspieszenia obliczeń ograniczenie rodzaju obliczeń i ich aplikacji poszukiwanie nowych jakościowo metod szybkiej realizacji algorytmów poszukiwania w 2 kierunkach: specjalizowane elementy obliczeniowe - procesory dedykowane połączenia tych elementów - architektura prace badawcze oprzeć na realnych możliwościach implementacji w dostępnych technologiach
12 Sprzętowa akceleracja obliczeń wielkie ilości przetwarzanych danych bardzo szybkie systemy obliczeniowe algorytmy zdominowane przez dane algorytmy zdominowane przez instrukcje
13 Liczba przesłań operandów w operacjach przetwarzania obrazów OPERACJA 1 PIKSEL 1 OBRAZ 1 SEKUNDA LUT MEDIANA KONWOLUCJA 3x
14 Liczba operacji w przetwarzaniu obrazów (w czasie 1 s) OPERACJA MNOŻENIA DODAWANIA PRZESŁANIA PORÓWNANIA LUT MEDIANA MEDIANA KONWOLUCJA 3x
15 Architektura MISD specjalizowanych procesorów sprzętowych FPGA FPGA FPGA JS JS... JS SR SR SR A/C SD SD SD JP JP JP SD PAMIĘĆ VIDEO SD BUS
16 Schemat blokowy architektury potokowej DePiAr L Sygnały Przerwan Procesor Dane Video WEJŚCIE P P P WYJŚCIE Sygnały Sterujące Magistrala Danych [8 bitów] Magistrala Adresowa [13 bitów] Magistrala VME

17 Moduł z architekturą potokową DePiAr
18 Architektura potokowa DePiAr Zalety: minimalizacja czasu transmisji minimalizacja czasu obliczeń przez dedykowane procesory sprzętowe procesory są autonomiczne: elastyczna zmiana kolejności operacji niezależne projektowanie procesorów implementacja w dowolnym otoczeniu sprzętowym dostęp do procesorów z zewnętrznej magistrali: dynamiczna zmiana parametrów przetwarzania dynamiczna rekonfiguracja kolejności operacji Wymagania: kolejnoliniowy sygnał wizyjny szybka transmisja na wyjściu potoku konieczność zachowania wymogów czasowych: jednakowe opóźnienia dla danych i sygnałów sterujących opóźnienie wielokrotnością czasu trwania piksela
19 Czasy realizacji operacji wizyjnych: DePiAr, DSP i GPP System Histogram Odejmowanie Konwolucja 3 3 Mediana LUT DePiAr 15 MHz 66,0 ns 132,0 ns 102,0 µs 68,0 µs 66,0 ns 198,0 ns 198,0 ns TMS320C80 4,3 ms 5,4 ms 19,4 ms 10,7 ms Dedykowany moduł Pentium II 466 MHz 4,0 ms 2,7 ms 6,8 ms 3,0 ms Akceleracja
20 Implementacja w układach FPGA
21 Parametryzacja implementacji w układach FPGA parametryzacja szybkości pracy parametryzacja użytych zasobów układu FPGA automatyczna generacja kodu VHDL optymalizacja implementacji struktur obliczeniowych DA
22 Dobór struktury elementów obliczeniowych układy mnożące bezmnożne MM układy mnożące LM z pamięcią LUT układy ze stałym współczynnikiem KCM układy ze zmiennym współczynnikiem VCM układy z dynamiczną rekonfiguracją DKCM
23 System z wielokrotnym wykorzystaniem do obliczeń jednego układu FPGA FPGA Linia transmisyjna FPGA A C C A Kamera Przyjęcie danych Kompresja Wstępne przetworzenie Modulacja Pamięć konfiguracyjna
24 Parametry rekonfiguracji układów FPGA Seria układu Komórki CLB Bramki [ 1000] Czas rekonfig. Rekonfig. częściowa Flex [ms] Flex [ms] Flex [ms] XC ,5 10 [ms] XC [ms] XC4000EX/XL [ms] XC ,2 [ms] Y Spartan [ms] Virtex ,1 [ms] Virtex II [ms] Y AT [ms] Y AT40K [ms] Y QL [ms] DY [ms]
25 Systemy CTR i RTR systemy rekonfigurowane przed wykonaniem całości obliczeń CTR (ang. Compile Time Reconfigurable), systemy rekonfigurowane w trakcie obliczeń w celu wielokrotnego wykorzystania tego samego sprzętu dla realizacji różnych fragmentów realizowanego algorytmu RTR (ang. Run Time Reconfigurable).
26 Efektywność stosowania systemów CTR i RTR f = T T R O E E RTR CTR max 1 f
27 Dedykowane użytkownikowi platformy obliczeniowe CCM Custom Computing Machines Elasty czność CISC RISC DSP CCM FPGA/CPLD Specjalizowane moduły ASIC Wydajność Wydajność a elastyczność układów obliczeniowych
28 Architektura karty procesorowej w systemie Splash2 SBus Poprzednia karta 36 M0 M1 M2 M3 M4 M5 M6 M7 M8 X1 X2 X3 X4 X5 X6 X7 X8 SIMD 36 X0 Matryca krzyżowa (crossbar switch) RBus 36 X16 X15 X14 X13 X12 X11 X10 X9 Następna karta 36 M16 M15 M14 M13 M12 M11 M10 M9
29 Implementacja detekcji obiektów i etykietowania Buforowanie danych Oznaczanie Scalanie Scalanie PE-0 PE-1 PE-2 PE-3 PE-4 PE-5 PE-6 PE-7 PE-8 Wejście wideo Wyjście wideo PE-16 Układy niewykorzystywane PE-15 PE-14 PE-13 PE-12 PE-11 PE-10 PE-9 Formatowanie danych wyjściowych
30 Implementacja transformacji Hough a Wejście wideo LUT i szeregowanie Hough P1 Hough P2 Hough P3 Hough P4 Hough P5 Hough P6 PE-0 PE-1 PE-2 PE-3 PE-4 PE-5 PE-6 PE-7 PE-8 Bufor wejścia Wyjście wideo PE-16 PE-15 PE-14 PE-13 PE-12 PE-11 PE-10 PE-9 Hough P14 Hough P13 Hough P12 Hough P11 Hough P10 Hough P9 Hough P8 Hough P7
31 Implementacja szybkiej transformaty Fouriera FFT Podwójne buforowanie Bank 1 lewy renumeracja Algorytm Butterfly PE-0 PE-1 PE-2 PE-3 PE-4 PE-5 PE-6 PE-7 PE-8 Wejście wideo Wyjście wideo PE-16 PE-15 PE-14 PE-13 PE-12 PE-11 PE-10 PE-9 Filtracja w dziedzinie częstotliwości Bank 2 prawy renumeracja
32 Projektowanie metodą Hardware/Software CoDesign Wczesne i późne rozdzielanie hardware u i software u w projektowaniu systemów a) b) Design Design Hardware Software Hardware Software
33 Hardware/Software CoDesign Kod źródłowy ( C ) Podział hardware/software Hardware (PLD, FPGA) Software (up, uc, DSP) Język opisu sprzętu (VHDL, Verilog) Język programowania (C, Asembler)
34 Wzrost pojemności układów programowalnych PLD RODZAJ FIRMA BRAMKI CLB I/O REJESTRY KONFIG. Classic Altera EEPROM Max5000 Altera EPROM Flex8000 Altera SRAM APEX 20k Altera SRAM APEX II Altera SRAM ACT2 Actel OTP A500k Actel AX2000 Actel ATV5100 Atmel EPROM ATK40k Atmel SRAM XC4000 Xilinx SRAM XC9500 Xilinx ISP(EEPROM) SPARTAN Xilinx SRAM VIRTEX Xilinx SRAM (2,5V) VIRTEX II Xilinx SRAM (2,5V) VIRTEX Pro Xilinx SRAM (1,5V)

35 Struktura układu FPGA serii Virtex-II Pro Pamięć blokowa BSRAM PowerPC Pamięć blokowa BSRAM Logika stała Logika rekonfigurowalna
36 Zasoby układów FPGA serii Virtex-II Pro Układ Rocket Power LC Slice Distr. RAM Mnożarki BSR DCM I/O I/O PC kb 18x18 kb XC2VP XC2VP XC2VP XC2VP XC2VP XC2VP XC2VP XC2VP XC2VP XC2VP

37 Lokalizacja zasobów w układzie Virtex-II Pro

38 Przyłączenie wbudowanego procesora PowerPC do zasobów układu Virtex-II Pro
39 Blok łącz szeregowych Rocket I/O o przepustowości 3,125 Gb/s
40 Połączenie elementów IP poprzez interfejs IPIF z magistralą peryferyjną OPB i magistralą lokalną procesora PLB
41 Przyłączenie jednego z procesorów PowerPC 405 do magistrali lokalnej procesora PLB oraz układów peryferyjnych
42 Elementy IP - operacje przetwarzania obrazów Funkcja Biblioteka Firma Układ Użyte zasoby f [MHz] FFT/IFFT 1024 p-kty LogiCORE Xilinx XC2V % 100 FFT/IFFT 64 p-kty LogiCORE Xilinx XC2V % 100 FFT/IFFT 32 p-kty LogiCORE Xilinx XC2V % 110 FFT/IFFT 16 p-któw LogiCORE Xilinx XC2V % 130 2D DCT/IDCT AllianceCORE Barco-Silex XC2V % 133 2D FDCT AllianceCORE CAST XC2V % 83 2D DWT AllianceCORE CAST XC2V % 52 FIDCT AllianceCORE Telecom XCV % 78 MAC FIR LogiCORE Xilinx XCV % Dekoder Huffmana AllianceCORE CAST XC2V % 25 Dekoder Reed Solomon AllianceCORE Telecom XC2V % 61 TMS32025 DSP core AllianceCORE CAST XC2V % 63
43 Wzrost liczby tranzystorów w układach różnego typu FPGA Intel PowerPC AMD Lata
44 Mikroprocesor z rekonfigurowalnym koprocesorem Główny procesor Cache instrukcji Cache danych Globalna jednostka kontrolna Rejestry danych Matryca rekonfigurowalna Koprocesor rekonfigurowalny Interfejs jednostki


45
 standardowo 14,75 MHz (67,8")
46 Potrzeby obliczeniowe systemów nieustannie rosną szybkość akwizycji 1000 do 5000 obrazów na sekundę rozdzielczość 128x128 i 256x256 napływ pikseli do 327,68 MHz (3,1 ns) standardowo 14,75 MHz (67,8 ns)

 10")
47 1280 x 1024 x 628 = 823 MHz ( Hz) 10 bitów/piksel
48 Logika rekonfigurowana za pomocą internetu wykorzystywana do akceleracji obliczeń Host PAVE SIF WindRiver PAVE Payload Upgrade Portal Target PAVE API WindRiver TCP / IP Network PAVE C++ Application PAVE API VxWorks RTOS VxWorks Board Support Package (BSP) Microprocessor FPGA


49 Infrastruktura informatyczna Klaster HP Blade System C TFLOPS Klaster IBM BladeCenter HS21XM 3,7 TFLOPS Klaster IBM BladeCenter HS21-2,4 TFLOPS Klaster komputerów PC RackSaver 2,1 TFLOPS SGI Altix ,5 TFLOPS 2x10 Gbps Klaster serwerów HP Integrity rx GFLOPS SGI Altix GFLPOS SunFire ,2 GFLOPS SunFire V GFLOPS ~ 30 TFLOPS
50 Komputery Dużej Mocy Obliczeniowej KDMO

51 Komputery Dużej Mocy Obliczeniowej KDMO
52 HP Blade System 7000 System operacyjny Linux 512 procesorów 4-rdzeniowych Intel 4 TB pamięci operacyjnej 30 TB Pamięci dyskowej Teoretyczna moc obliczeniowa ~ 20 TFLOPS TOP500!


53 system operacyjny: Linux konfiguracja: 256 procesory Intel Itanium 2 z zegarem 1.5 GHz pamięć operacyjna 512 GB pamięć dyskowa 4,75 TB Moc obliczeniowa 1,5 Tflops SGI Altix 3700

54 SGI Altix 4700 system operacyjny: Linux konfiguracja: 32 procesory Intel Itanium 2 z zegarem 1.66 GHz pamięć operacyjna 64 GB pamięć dyskowa 1,8 TB Moc obliczeniowa 212 Gflops Dodatkowo zawiera węzeł z procesorami programowalnymi FPGA - Virtex do akceleracji obliczeń
55 IBM BladeCenter HS21 system operacyjny: Linux konfiguracja: 112 procesorów Intel z zegarem 2,66 GHz (2-rdzeniowe) pamięć operacyjna 448 GB pamięć dyskowa 5 TB Moc obliczeniowa 2,4 Tflops
 pamięć operacyjna 448 GB pamięć dyskowa 5 TB Moc obliczeniowa 3,65")
56 IBM BladeCenter HS21XM system operacyjny: Linux konfiguracja: 98 procesorów Intel z zegarem 2,33 GHz (4-rdzeniowe) pamięć operacyjna 448 GB pamięć dyskowa 5 TB Moc obliczeniowa 3,65 Tflops




57 Klaster komputerów PC 384 procesorów Xeon 440 GB pamięci operacyjnej 17.4 TB pamięci dyskowej Moc obliczeniowa 2071 Gflops Klaster serwerów HP Integrity rx procesorów Intel Itanium2 56 GB pamięci operacyjnej 2 TB pamięci dyskowej Moc obliczeniowa 291 Gflops

58 Sun Fire 6800 system operacyjny: Solaris konfiguracja: 24 procesorów UltraSparc III z zegarem 900 MHz pamięć operacyjna 24 GB pamięć dyskowa 3 TB Moc obliczeniowa 43,2 Gflops





59 HP Integrity SuperDome system operacyjny: HP-UX 11i konfiguracja: 8 procesorów Intel Itanium2 z zegarem 1.5 Ghz pamięć operacyjna - 8 GB pamięć dyskowa - 2 TB Moc obliczeniowa 48 Gflops SuperDome może pracować pod systemami operacyjnymi: HP-UX, Windows Serwer 2003 i Linux.


60 SGI Onyx 300 system operacyjny: IRIX 6.5 konfiguracja: 8 procesorów R14000 z zegarem 600Mhz pamięć operacyjna - 8 GB pamięć dyskowa GB Moc obliczeniowa 9,6 Gflops Serwer graficzny Onyx 300 wyposażony w grafikę Infinite Reality przeznaczony jest głownie do wizualizacji i obliczeń dużej skali. InfiniteReality4 to nowa generacja grafiki, łącząca narzędzia 2D, 3D i przetwarzanie danych video w jednolite środowisko graficzne. Wizualizacja systemów dużej skali i wirtualnej rzeczywistości w połączeniu z aplikacjami VizServer daje obrazy o wysokiej profesjonalnej jakości.
61 Hierarchiczny system składowania danych


62 Hierarchiczny system składowania danych W ACK CYFRONET AGH serwery obliczeniowe i sieciowe przyłączone są do centralnego zasobu pamięci dyskowej o pojemności 130 TB Macierze dyskowe: HP XP TB HP EVA TB Biblioteki taśmowe: ATL pojemność 10 TB ATL pojemność 7 TB HP ESL712e - pojemność 280 TB
63 Hierarchiczny system składowania danych Centralne zasoby pamięci dyskowej o pojemności 541 TB, w tym: 6 TB na dyskach FC 211 TB na dyskach FATA 324 TB na dyskach SATA Zasoby Systemu Składowania Danych: Macierz dyskowa HP XP12000: przestrzeń dyskowa 7 TB (dyski FC) Macierz dyskowa HP EVA 8000; przestrzeń dyskowa 120 TB (dyski FATA) Macierz dyskowa HP EVA 8100 przestrzeń dyskowa 96 TB (dyski FATA) zasoby
64 Hierarchiczny system składowania danych zasoby (c.d) Zasoby Systemu Składowania Danych c.d. Serwery storage owe SUN: 324 TB Serwer dyskowy SUN X4500: 2 dwurdzeniowe procesory AMD Opteron; 16 GB pamięci RAM; przestrzeń dyskowa serwera 36TB; jeden port 10 Gigabit Ethernet. Sześć serwerów dyskowych Sun X4540: 2 czterordzeniowe procesory AMD Opteron; 32 GB pamięci RAM; przestrzeń dyskowa pojedynczego serwera 48TB; dwa porty 10 Gigabit Ethernet. Biblioteka taśmowa HP ESL712e 6 napędów HP LTO-3 Ultrium; 4 napędy HP LTO-4 Ultrium; 636 slotów na taśmy LTO.
65 Niezawodnie zasilanie, zasilanie awaryjne i klimatyzacja technologiczna
66 Trafo








67 Trafo 1MW







68 Trafo
69 Agregat prądotwórczy 1MW
70 Agregaty -1 MW - 50 kw






71 Hala maszyn
72 Klimatyzacja
73 Klimatyzacja

74 Current diagram of CPU commitments ROC - ACK Polska Węgry Austria Słowacja Słowenia Czechy Chorwacja

75 Current diagram of storage commitments ROC - ACK Polska Węgry Austria Słowacja Słowenia Czechy Chorwacja
76 Konsorcjum PL-GRID W listopadzie 2006 roku w Warszawie, z inicjatywy ACK CYFRONET AGH, zostało zawarte porozumienie pomiędzy przedstawicielami: ACK CYFRONET AGH koordynator Programu PL-Grid, ICM UW, PCSS, CI TASK, WCSS - uczestnicy, będącymi członkami- założycielami Programu PL-Grid. Sygnatariusze niniejszego porozumienia powołali Radę Programu PL_Grid, która będzie czuwać nad tworzeniem i rozwojem polskiego gridu, wykorzystującego dotychczasowy dorobek polskich zespołów w tej dziedzinie i w pełni zintegrowanego z gridem europejskim.




77 Zestawienie oprogramowania aplikacyjnego Program SGI 2800 SGI Altix 3700 SUN Fire 6800 HP Super Dome SGI Onyx 300, SGI Octane/SE ABAQUS x x x x Accelrys/Insight II x Accelrys/Cerius2 x Accelrys/Catalyst x Accelrys/Quanta x ANSYS x x x ARC/INFO x ERDAS/IMAGINE x FIDAP x x FLUENT x x x x GAMESS x GAUSSIAN 03 x x MAPLE x x MATHEMATICA x MATLAB x x MSC/FATIGUE x x MSC/NASTRAN x x MSC/PATRAN x x OPERA-2d x x ORACLE x SAS x SYBYL x


78 Aplikacje chemiczne ACCELRYS InsightII - do modelowania dużych molekuł biologicznych Cerius2 - do modelowania małych molekuł i ciała stałego Quanta - do modelowania molekularnego przeznaczony z zakresu krystalografii Catalyst - pakiet do projektowania leków SYBYL - pakiet programów do modelowania i analizy struktur molekularnych. Celem oprogramowania jest budowanie, analiza i manipulacja molekułami. GAUSSIAN - system przeznaczony do obliczeń orbitali molekularnych przy użyciu metod półempirycznych i ab initio. GAMESS - wszechstronny pakiet do obliczeń chemii kwantowej.
79 SGI Altix 4700 i projekt Gaussian Pakiet Gaussian (82% obliczeń) Przyśpieszenie obliczeń kwantowo-chemicznych Operacje algebraiczne na macierzach
80 Problemy do rozwiązania Funktory FP Implementacja bibliotek BLAS i LAPACK Równoległe algorytmy operacji na macierzach Biblioteki softwer owe

81 SGI RASC Blade

82 SGI RASC Blade Pojedynczy moduł rekonfigurowany

83 SGI RASC Blade
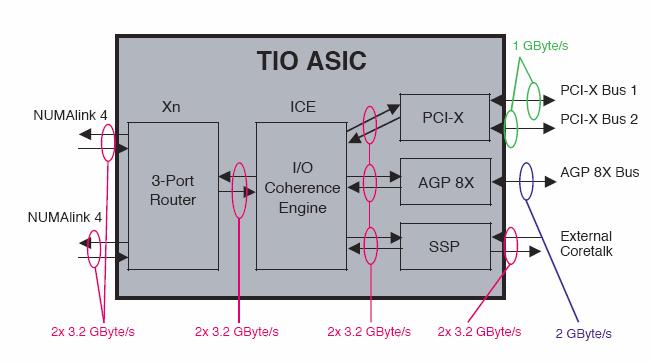
84 RASC Technology

85 RASC Technology - NUMAlink

86 RASC Technology Różne konfiguracje pracy
87 Zagadnienia realizowane w ramach projektu Profiling Implementacja wytypowanych w profilingu funkcji Stworzenie własnego środowiska automatyzującego projektowanie oraz testowanie aplikacji HPTC
88 Prace badawczo-rozwojowe prowadzone obecnie przez Zespół Akceleracji Obliczeń Współpraca z wydziałem Chemii Teoretycznej UJ Rozwiązywanie równania Schroedingera metodą Hartree-Focka Potrzeba zrównoleglenia obliczeń funkcji najbardziej czasochłonnych oraz najczęściej pojawiających się, takich jak: Pierwiastek kwadratowy Eksponenta Logarytm Funkcja power Argumenty funkcji oraz uzyskane wyniki są zgodne ze standardem IEEE 754 double
89 Oprogramowanie Mitrion C Podstawowa składania jest taka sama jak dla języka C {},=,if, for, while.. Nie występują wskaźniki Brak możliwości dynamicznego przydzielania pamięci Zmienne mogą mieć nadaną wartość tylko raz (wynika z równoległości interpretacji zapisu kodu) Występują listy interpretowane jako implementacja potokowości Wszystkie funkcje są wywoływane przez wartość oraz są typu inline ZAPRASZAMY Dziękuję za uwagę
90
Tarnów. nowoczesne technologie. Tarnów - 27 marca 2007 r.
 Tarnów i nowoczesne technologie Tarnów - 27 marca 2007 r. Akceleracja obliczeń w ultraszybkich zastosowaniach Prof. Kazimierz Wiatr Senator RP Przewodniczący Komisji Nauki, Edukacji i Sportu Dyrektor ACK
Tarnów i nowoczesne technologie Tarnów - 27 marca 2007 r. Akceleracja obliczeń w ultraszybkich zastosowaniach Prof. Kazimierz Wiatr Senator RP Przewodniczący Komisji Nauki, Edukacji i Sportu Dyrektor ACK
Akceleracja obliczeń metodami sprzętowymi
 Akceleracja obliczeń metodami sprzętowymi Kazimierz Wiatr Akademickie Centrum Komputerowe CYFRONET AGH email: k.wiatr@cyfronet.krakow.pl Dzisiejsze wymagania wobec komputerów szybkość!!!! cena wielkość
Akceleracja obliczeń metodami sprzętowymi Kazimierz Wiatr Akademickie Centrum Komputerowe CYFRONET AGH email: k.wiatr@cyfronet.krakow.pl Dzisiejsze wymagania wobec komputerów szybkość!!!! cena wielkość
High Performance Computers in Cyfronet. Andrzej Oziębło Zakopane, marzec 2009
 High Performance Computers in Cyfronet Andrzej Oziębło Zakopane, marzec 2009 Plan Podział komputerów dużej mocy Podstawowe informacje użytkowe Opis poszczególnych komputerów Systemy składowania danych
High Performance Computers in Cyfronet Andrzej Oziębło Zakopane, marzec 2009 Plan Podział komputerów dużej mocy Podstawowe informacje użytkowe Opis poszczególnych komputerów Systemy składowania danych
Nauka i społeczeństwo informacyjne a nauczanie Jana Pawła II
 Nauka i społeczeństwo informacyjne a nauczanie Jana Pawła II Tarnowskie Towarzystwo Naukowe 27 października 2009 r. (31 lat i 11 dni po Habemus Papam) Kazimierz Wiatr Akademickie Centrum Komputerowe CYFRONET
Nauka i społeczeństwo informacyjne a nauczanie Jana Pawła II Tarnowskie Towarzystwo Naukowe 27 października 2009 r. (31 lat i 11 dni po Habemus Papam) Kazimierz Wiatr Akademickie Centrum Komputerowe CYFRONET
Wykorzystanie układów FPGA w implementacji systemów bezpieczeństwa sieciowego typu Firewall
 Grzegorz Sułkowski, Maciej Twardy, Kazimierz Wiatr Wykorzystanie układów FPGA w implementacji systemów bezpieczeństwa sieciowego typu Firewall Plan prezentacji 1. Architektura Firewall a załoŝenia 2. Punktu
Grzegorz Sułkowski, Maciej Twardy, Kazimierz Wiatr Wykorzystanie układów FPGA w implementacji systemów bezpieczeństwa sieciowego typu Firewall Plan prezentacji 1. Architektura Firewall a załoŝenia 2. Punktu
Kazimierz Wiatr. Akademickie Centrum Komputerowe CYFRONET AGH. Konferencja Użytkowników KDM 12-13 marca 2009 r. Zakopane
 Kazimierz Wiatr Akademickie Centrum Komputerowe CYFRONET AGH Konferencja Użytkowników KDM 12-13 marca 2009 r. Zakopane Zadania i misja udostępnianie mocy obliczeniowej oraz innych usług informatycznych
Kazimierz Wiatr Akademickie Centrum Komputerowe CYFRONET AGH Konferencja Użytkowników KDM 12-13 marca 2009 r. Zakopane Zadania i misja udostępnianie mocy obliczeniowej oraz innych usług informatycznych
Programowalne Układy Logiczne Konfiguracja/Rekonfiguracja
 Programowalne Układy Logiczne Konfiguracja/Rekonfiguracja dr inż. Paweł Russek Program wykładu Metody konfigurowania PLD Zaawansowane metody konfigurowania FPGA Rekonfigurowalne systemy obliczeniowe Pamięć
Programowalne Układy Logiczne Konfiguracja/Rekonfiguracja dr inż. Paweł Russek Program wykładu Metody konfigurowania PLD Zaawansowane metody konfigurowania FPGA Rekonfigurowalne systemy obliczeniowe Pamięć
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Cyfronet w CTA. Andrzej Oziębło DKDM
 Cyfronet w CTA Andrzej Oziębło DKDM ACK CYFRONET AGH Akademickie Centrum Komputerowe CYFRONET Akademii Górniczo-Hutniczej im. Stanisława Staszica w Krakowie ul. Nawojki 11 30-950 Kraków 61 tel. centrali:
Cyfronet w CTA Andrzej Oziębło DKDM ACK CYFRONET AGH Akademickie Centrum Komputerowe CYFRONET Akademii Górniczo-Hutniczej im. Stanisława Staszica w Krakowie ul. Nawojki 11 30-950 Kraków 61 tel. centrali:
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Infrastruktura PLGrid Nowa jakość usług informatycznych w służbie nauki
 Infrastruktura PLGrid Nowa jakość usług informatycznych w służbie nauki Maciej Czuchry, Mariola Czuchry ACK Cyfronet AGH Katedra Robotyki i Mechatroniki, Kraków 2015 Agenda ACK Cyfronet AGH główne kompetencje
Infrastruktura PLGrid Nowa jakość usług informatycznych w służbie nauki Maciej Czuchry, Mariola Czuchry ACK Cyfronet AGH Katedra Robotyki i Mechatroniki, Kraków 2015 Agenda ACK Cyfronet AGH główne kompetencje
Program Obliczeń Wielkich Wyzwań Nauki i Techniki (POWIEW)
") Program Obliczeń Wielkich Wyzwań Nauki i Techniki (POWIEW) Maciej Cytowski, Maciej Filocha, Maciej E. Marchwiany, Maciej Szpindler Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego
Program Obliczeń Wielkich Wyzwań Nauki i Techniki (POWIEW) Maciej Cytowski, Maciej Filocha, Maciej E. Marchwiany, Maciej Szpindler Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego
Konsolidacja wysokowydajnych systemów IT. Macierze IBM DS8870 Serwery IBM Power Przykładowe wdrożenia
 Konsolidacja wysokowydajnych systemów IT Macierze IBM DS8870 Serwery IBM Power Przykładowe wdrożenia Mirosław Pura Sławomir Rysak Senior IT Specialist Client Technical Architect Agenda Współczesne wyzwania:
Konsolidacja wysokowydajnych systemów IT Macierze IBM DS8870 Serwery IBM Power Przykładowe wdrożenia Mirosław Pura Sławomir Rysak Senior IT Specialist Client Technical Architect Agenda Współczesne wyzwania:
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Komputer IBM PC niezależnie od modelu składa się z: Jednostki centralnej czyli właściwego komputera Monitora Klawiatury
 1976 r. Apple PC Personal Computer 1981 r. pierwszy IBM PC Komputer jest wart tyle, ile wart jest człowiek, który go wykorzystuje... Hardware sprzęt Software oprogramowanie Komputer IBM PC niezależnie
1976 r. Apple PC Personal Computer 1981 r. pierwszy IBM PC Komputer jest wart tyle, ile wart jest człowiek, który go wykorzystuje... Hardware sprzęt Software oprogramowanie Komputer IBM PC niezależnie
Wykład 2. Temat: (Nie)zawodność sprzętu komputerowego. Politechnika Gdańska, Inżynieria Biomedyczna. Przedmiot:
zawodność sprzętu komputerowego. Politechnika Gdańska, Inżynieria Biomedyczna. Przedmiot:") Wykład 2 Przedmiot: Zabezpieczenie systemów i usług sieciowych Temat: (Nie)zawodność sprzętu komputerowego 1 Niezawodność w świecie komputerów Przedmiot: Zabezpieczenie systemów i usług sieciowych W przypadku
Wykład 2 Przedmiot: Zabezpieczenie systemów i usług sieciowych Temat: (Nie)zawodność sprzętu komputerowego 1 Niezawodność w świecie komputerów Przedmiot: Zabezpieczenie systemów i usług sieciowych W przypadku
NOWY OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA
 NOWY OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA Załącznik nr 4 do SIWZ/ załącznik do umowy Przedmiotem zamówienia jest dostawa 2 serwerów, licencji oprogramowania wirtualizacyjnego wraz z konsolą zarządzającą
NOWY OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA Załącznik nr 4 do SIWZ/ załącznik do umowy Przedmiotem zamówienia jest dostawa 2 serwerów, licencji oprogramowania wirtualizacyjnego wraz z konsolą zarządzającą
Infrastruktura PLGrid dla młodych naukowców
 Infrastruktura PLGrid dla młodych naukowców Mariola Czuchry ACK Cyfronet AGH Koło Naukowe Geodetów Dahlta, AGH, Kraków 2015 Agenda ACK Cyfronet AGH główne kompetencje Infrastruktura PLGrid PLGrid to Struktura
Infrastruktura PLGrid dla młodych naukowców Mariola Czuchry ACK Cyfronet AGH Koło Naukowe Geodetów Dahlta, AGH, Kraków 2015 Agenda ACK Cyfronet AGH główne kompetencje Infrastruktura PLGrid PLGrid to Struktura
Tarnów i nowoczesne technologie. Tarnów - 13 czerwca 2006 r.
 Tarnów i nowoczesne technologie Tarnów - 13 czerwca 2006 r. Sieć Pionier i szybki Internet w Tarnowie Prof. Kazimierz Wiatr Senator RP Przewodniczący Komisji Nauki, Edukacji i Sportu Dyrektor ACK Cyfronet
Tarnów i nowoczesne technologie Tarnów - 13 czerwca 2006 r. Sieć Pionier i szybki Internet w Tarnowie Prof. Kazimierz Wiatr Senator RP Przewodniczący Komisji Nauki, Edukacji i Sportu Dyrektor ACK Cyfronet
ZASTOSOWANIA UKŁADÓW FPGA W ALGORYTMACH WYLICZENIOWYCH APPLICATIONS OF FPGAS IN ENUMERATION ALGORITHMS
 inż. Michał HALEŃSKI Wojskowy Instytut Techniczny Uzbrojenia ZASTOSOWANIA UKŁADÓW FPGA W ALGORYTMACH WYLICZENIOWYCH Streszczenie: W artykule przedstawiono budowę oraz zasadę działania układów FPGA oraz
inż. Michał HALEŃSKI Wojskowy Instytut Techniczny Uzbrojenia ZASTOSOWANIA UKŁADÓW FPGA W ALGORYTMACH WYLICZENIOWYCH Streszczenie: W artykule przedstawiono budowę oraz zasadę działania układów FPGA oraz
Technika mikroprocesorowa. Linia rozwojowa procesorów firmy Intel w latach
 mikrokontrolery mikroprocesory Technika mikroprocesorowa Linia rozwojowa procesorów firmy Intel w latach 1970-2000 W krótkim pionierskim okresie firma Intel produkowała tylko mikroprocesory. W okresie
mikrokontrolery mikroprocesory Technika mikroprocesorowa Linia rozwojowa procesorów firmy Intel w latach 1970-2000 W krótkim pionierskim okresie firma Intel produkowała tylko mikroprocesory. W okresie
System mikroprocesorowy i peryferia. Dariusz Chaberski
 System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA
 OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA Załącznik nr 4 do SIWZ/ załącznik do umowy Przedmiotem zamówienia jest dostawa 2 serwerów, licencji oprogramowania wirtualizacyjnego wraz z konsolą zarządzającą oraz
OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA Załącznik nr 4 do SIWZ/ załącznik do umowy Przedmiotem zamówienia jest dostawa 2 serwerów, licencji oprogramowania wirtualizacyjnego wraz z konsolą zarządzającą oraz
Tarnów i nowoczesne technologie. Tarnów - 13 czerwca 2006 r.
 Tarnów i nowoczesne technologie Tarnów - 13 czerwca 2006 r. Sieć Pionier i szybki Internet w Tarnowie Prof. Kazimierz Wiatr Senator RP Przewodniczący Komisji Nauki, Edukacji i Sportu Dyrektor ACK Cyfronet
Tarnów i nowoczesne technologie Tarnów - 13 czerwca 2006 r. Sieć Pionier i szybki Internet w Tarnowie Prof. Kazimierz Wiatr Senator RP Przewodniczący Komisji Nauki, Edukacji i Sportu Dyrektor ACK Cyfronet
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
SYSTEMY OPERACYJNE WYKŁAD 1 INTEGRACJA ZE SPRZĘTEM
 SYSTEMY OPERACYJNE WYKŁAD 1 INTEGRACJA ZE SPRZĘTEM Marcin Tomana marcin@tomana.net SKRÓT WYKŁADU Zastosowania systemów operacyjnych Architektury sprzętowe i mikroprocesory Integracja systemu operacyjnego
SYSTEMY OPERACYJNE WYKŁAD 1 INTEGRACJA ZE SPRZĘTEM Marcin Tomana marcin@tomana.net SKRÓT WYKŁADU Zastosowania systemów operacyjnych Architektury sprzętowe i mikroprocesory Integracja systemu operacyjnego
1. Serwer. 2. Komputer desktop 9szt. Załącznik nr 1 do SIWZ
 1. Serwer Załącznik nr 1 do SIWZ Lp. Nazwa elementu, Opis wymagań parametru lub cechy 1 Obudowa RACK o wysokości max. 2U z szynami i elementami niezbędnymi do zabudowy w szafie 19" 2 Procesor Czterordzeniowy
1. Serwer Załącznik nr 1 do SIWZ Lp. Nazwa elementu, Opis wymagań parametru lub cechy 1 Obudowa RACK o wysokości max. 2U z szynami i elementami niezbędnymi do zabudowy w szafie 19" 2 Procesor Czterordzeniowy
Klaster obliczeniowy
 Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
Składowanie, archiwizacja i obliczenia modelowe dla monitorowania środowiska Morza Bałtyckiego
 Składowanie, archiwizacja i obliczenia modelowe dla monitorowania środowiska Morza Bałtyckiego Rafał Tylman 1, Bogusław Śmiech 1, Marcin Wichorowski 2, Jacek Wyrwiński 2 1 CI TASK Politechnika Gdańska,
Składowanie, archiwizacja i obliczenia modelowe dla monitorowania środowiska Morza Bałtyckiego Rafał Tylman 1, Bogusław Śmiech 1, Marcin Wichorowski 2, Jacek Wyrwiński 2 1 CI TASK Politechnika Gdańska,
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
Wybrane bloki i magistrale komputerów osobistych (PC) Opracował: Grzegorz Cygan 2010 r. CEZ Stalowa Wola
 Opracował: Grzegorz Cygan 2010 r. CEZ Stalowa Wola") Wybrane bloki i magistrale komputerów osobistych (PC) Opracował: Grzegorz Cygan 2010 r. CEZ Stalowa Wola Ogólny schemat komputera Jak widać wszystkie bloki (CPU, RAM oraz I/O) dołączone są do wspólnych
Wybrane bloki i magistrale komputerów osobistych (PC) Opracował: Grzegorz Cygan 2010 r. CEZ Stalowa Wola Ogólny schemat komputera Jak widać wszystkie bloki (CPU, RAM oraz I/O) dołączone są do wspólnych
2014 LENOVO INTERNAL. ALL RIGHTS RESERVED
 2014 LENOVO INTERNAL. ALL RIGHTS RESERVED 3 SUSE OpenStack - Architektura SUSE OpenStack - Funkcje Oprogramowanie Open Source na bazie OpenStack Scentralizowane monitorowanie zasobów Portal samoobsługowy
2014 LENOVO INTERNAL. ALL RIGHTS RESERVED 3 SUSE OpenStack - Architektura SUSE OpenStack - Funkcje Oprogramowanie Open Source na bazie OpenStack Scentralizowane monitorowanie zasobów Portal samoobsługowy
Architektura komputerów
 Architektura komputerów Tydzień 11 Wejście - wyjście Urządzenia zewnętrzne Wyjściowe monitor drukarka Wejściowe klawiatura, mysz dyski, skanery Komunikacyjne karta sieciowa, modem Urządzenie zewnętrzne
Architektura komputerów Tydzień 11 Wejście - wyjście Urządzenia zewnętrzne Wyjściowe monitor drukarka Wejściowe klawiatura, mysz dyski, skanery Komunikacyjne karta sieciowa, modem Urządzenie zewnętrzne
Programowalne Układy Logiczne. Wykład I dr inż. Paweł Russek
 Programowalne Układy Logiczne Wykład I dr inż. Paweł Russek Literatura www.actel.com www.altera.com www.xilinx.com www.latticesemi.com Field Programmable Gate Arrays J.V. Oldfield, R.C. Dorf Field Programable
Programowalne Układy Logiczne Wykład I dr inż. Paweł Russek Literatura www.actel.com www.altera.com www.xilinx.com www.latticesemi.com Field Programmable Gate Arrays J.V. Oldfield, R.C. Dorf Field Programable
Systemy na Chipie. Robert Czerwiński
 Systemy na Chipie Robert Czerwiński Cel kursu Celem kursu jest zapoznanie słuchaczy ze współczesnymi metodami projektowania cyfrowych układów specjalizowanych, ze szczególnym uwzględnieniem układów logiki
Systemy na Chipie Robert Czerwiński Cel kursu Celem kursu jest zapoznanie słuchaczy ze współczesnymi metodami projektowania cyfrowych układów specjalizowanych, ze szczególnym uwzględnieniem układów logiki
Infrastruktura PLGrid: narzędzia wsparcia w nauce i dydaktyce. Mariola Czuchry, Klemens Noga, Katarzyna Zaczek. ACK Cyfronet AGH
 Infrastruktura PLGrid: narzędzia wsparcia w nauce i dydaktyce Mariola Czuchry, Klemens Noga, Katarzyna Zaczek ACK Cyfronet AGH Seminarium Katedry Metalurgii Stopów Żelaza, Kraków 2015 Plan prezentacji
Infrastruktura PLGrid: narzędzia wsparcia w nauce i dydaktyce Mariola Czuchry, Klemens Noga, Katarzyna Zaczek ACK Cyfronet AGH Seminarium Katedry Metalurgii Stopów Żelaza, Kraków 2015 Plan prezentacji
Spis treúci. Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1. Przedmowa... 9. Wstęp... 11
 Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1 Spis treúci Przedmowa... 9 Wstęp... 11 1. Komputer PC od zewnątrz... 13 1.1. Elementy zestawu komputerowego... 13 1.2.
Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1 Spis treúci Przedmowa... 9 Wstęp... 11 1. Komputer PC od zewnątrz... 13 1.1. Elementy zestawu komputerowego... 13 1.2.
Zasoby i usługi Wrocławskiego Centrum Sieciowo-Superkomputerowego
 Zasoby i usługi Wrocławskiego Centrum Sieciowo-Superkomputerowego Mateusz Tykierko WCSS 20 stycznia 2012 Mateusz Tykierko (WCSS) 20 stycznia 2012 1 / 16 Supernova moc obliczeniowa: 67,54 TFLOPS liczba
Zasoby i usługi Wrocławskiego Centrum Sieciowo-Superkomputerowego Mateusz Tykierko WCSS 20 stycznia 2012 Mateusz Tykierko (WCSS) 20 stycznia 2012 1 / 16 Supernova moc obliczeniowa: 67,54 TFLOPS liczba
Infrastruktura PLGrid Nowa jakość usług informatycznych dla Polskiej Nauki
 Infrastruktura PLGrid Nowa jakość usług informatycznych dla Polskiej Nauki Klemens Noga, Katarzyna Zaczek, Mariusz Sterzel ACK Cyfronet AGH Katedra Katedra Fizykochemii i Modelowania Procesów WIMiC, AGH,
Infrastruktura PLGrid Nowa jakość usług informatycznych dla Polskiej Nauki Klemens Noga, Katarzyna Zaczek, Mariusz Sterzel ACK Cyfronet AGH Katedra Katedra Fizykochemii i Modelowania Procesów WIMiC, AGH,
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Opis przedmiotu zamówienia / Formularz Oferty Technicznej (dokument należy złożyć wraz z ofertą)
") ... Nazwa (firma) wykonawcy albo wykonawców ubiegających się wspólnie o udzielenie zamówienia Załącznik nr 4 do SIWZ przedmiotu zamówienia / Formularz Oferty Technicznej (dokument należy złożyć wraz z
... Nazwa (firma) wykonawcy albo wykonawców ubiegających się wspólnie o udzielenie zamówienia Załącznik nr 4 do SIWZ przedmiotu zamówienia / Formularz Oferty Technicznej (dokument należy złożyć wraz z
OPIS PRZEDMIOTU ZAMÓWIENIA - PARAMETRY TECHNICZNE I OKRES GWARANCJI (formularz) - po modyfikacji
 - po modyfikacji") Załącznik nr 2 do SIWZ... miejscowość, data OPIS PRZEDMIOTU ZAMÓWIENIA - PARAMETRY TECHNICZNE I OKRES GWARANCJI (formularz) - po modyfikacji Tabela nr 1. ELEMENTY I URZĄDZENIA DO ROZBUDOWY MACIERZY: ELEMENTY
Załącznik nr 2 do SIWZ... miejscowość, data OPIS PRZEDMIOTU ZAMÓWIENIA - PARAMETRY TECHNICZNE I OKRES GWARANCJI (formularz) - po modyfikacji Tabela nr 1. ELEMENTY I URZĄDZENIA DO ROZBUDOWY MACIERZY: ELEMENTY
Laboratorium Chmur obliczeniowych. Paweł Świątek, Łukasz Falas, Patryk Schauer, Radosław Adamkiewicz
 Laboratorium Chmur obliczeniowych Paweł Świątek, Łukasz Falas, Patryk Schauer, Radosław Adamkiewicz Agenda SANTOS Lab laboratorium badawcze Zagadnienia badawcze Infrastruktura SANTOS Lab Zasoby laboratorium
Laboratorium Chmur obliczeniowych Paweł Świątek, Łukasz Falas, Patryk Schauer, Radosław Adamkiewicz Agenda SANTOS Lab laboratorium badawcze Zagadnienia badawcze Infrastruktura SANTOS Lab Zasoby laboratorium
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Część V - Serwery. UWAGA! Część V stanowi nierozerwalną całość. Ocena będzie łączna dla 4 zadań. Zadanie nr 1. SERWER BAZODANOWY KWESTURA
 Załącznik nr 3E do SIWZ DZP-0431-1257/2009 Część V - Serwery UWAGA! Część V stanowi nierozerwalną całość. Ocena będzie łączna dla 4 zadań Zadanie nr 1. SERWER BAZODANOWY OBUDOWA Parametr KWESTURA Wymagane
Załącznik nr 3E do SIWZ DZP-0431-1257/2009 Część V - Serwery UWAGA! Część V stanowi nierozerwalną całość. Ocena będzie łączna dla 4 zadań Zadanie nr 1. SERWER BAZODANOWY OBUDOWA Parametr KWESTURA Wymagane
Architektura komputerów
 Architektura komputerów Tydzień 8 Magistrale systemowe Magistrala Układy składające się na komputer (procesor, pamięć, układy we/wy) muszą się ze sobą komunikować, czyli być połączone. Układy łączymy ze
Architektura komputerów Tydzień 8 Magistrale systemowe Magistrala Układy składające się na komputer (procesor, pamięć, układy we/wy) muszą się ze sobą komunikować, czyli być połączone. Układy łączymy ze
Komputery Dużej Mocy w Cyfronecie. Andrzej Oziębło Patryk Lasoń, Łukasz Flis, Marek Magryś
 Komputery Dużej Mocy w Cyfronecie Andrzej Oziębło Patryk Lasoń, Łukasz Flis, Marek Magryś Administratorzy KDM Baribal, Mars, Panda, Platon U3: Stefan Świąć Piotr Wyrostek Zeus: Łukasz Flis Patryk Lasoń
Komputery Dużej Mocy w Cyfronecie Andrzej Oziębło Patryk Lasoń, Łukasz Flis, Marek Magryś Administratorzy KDM Baribal, Mars, Panda, Platon U3: Stefan Świąć Piotr Wyrostek Zeus: Łukasz Flis Patryk Lasoń
IBM BladeCenter Niezwykle wydajny, elastyczny i kompaktowy system nowej koncepcji
 IBM BladeCenter Niezwykle wydajny, elastyczny i kompaktowy system nowej koncepcji Technologia serwerów kasetowych Blade nowy trend w informatyce. Obudowy IBM BladeCenter IBM BladeCenter E IBM BladeCenter
IBM BladeCenter Niezwykle wydajny, elastyczny i kompaktowy system nowej koncepcji Technologia serwerów kasetowych Blade nowy trend w informatyce. Obudowy IBM BladeCenter IBM BladeCenter E IBM BladeCenter
Tom II: SZCZEGÓŁOWY OPIS PRZEDMIOTU ZAMÓWIENIA (SOPZ): Przedmiotem zamówienia jest dostawa sprzętu infrastruktury serwerowej i sieciowej.
: Przedmiotem zamówienia jest dostawa sprzętu infrastruktury serwerowej i sieciowej.") Tom II: SZCZEGÓŁOWY OPIS PRZEDMIOTU ZAMÓWIENIA (SOPZ): 1. Wstęp 1.1 Wymagania projektu Przedmiotem zamówienia jest dostawa sprzętu infrastruktury serwerowej i sieciowej. Lp Nazwa urządzenia Liczba sztuk
Tom II: SZCZEGÓŁOWY OPIS PRZEDMIOTU ZAMÓWIENIA (SOPZ): 1. Wstęp 1.1 Wymagania projektu Przedmiotem zamówienia jest dostawa sprzętu infrastruktury serwerowej i sieciowej. Lp Nazwa urządzenia Liczba sztuk
Akademickie Centrum Komputerowe CYFRONET AGH
 Akademickie Centrum Komputerowe CYFRONET AGH Kazimierz Wiatr Dyrektor ACK Cyfronet AGH Kolegium Rektorów Szkół Wyższych Krakowa Kraków, 30 stycznia 2013 Zadania i misja Akademickie Centrum Komputerowe
Akademickie Centrum Komputerowe CYFRONET AGH Kazimierz Wiatr Dyrektor ACK Cyfronet AGH Kolegium Rektorów Szkół Wyższych Krakowa Kraków, 30 stycznia 2013 Zadania i misja Akademickie Centrum Komputerowe
Alternatywa dla technologii BladeCenter. Kamil Pecio Inżynier Technicznego Wsparcia Sprzedaży
 Alternatywa dla technologii BladeCenter Kamil Pecio Inżynier Technicznego Wsparcia Sprzedaży Agenda Pozycjonowanie BladeCenter Pozycjonowanie PureSystems Budowa Chassis Serwery 2S i 4S Zasilanie oraz Chłodzenie
Alternatywa dla technologii BladeCenter Kamil Pecio Inżynier Technicznego Wsparcia Sprzedaży Agenda Pozycjonowanie BladeCenter Pozycjonowanie PureSystems Budowa Chassis Serwery 2S i 4S Zasilanie oraz Chłodzenie
Wrocławskie Centrum Sieciowo-Superkomputerowe
 Wrocławskie Centrum Sieciowo-Superkomputerowe Mateusz Tykierko WCSS 26 czerwca 2012 Mateusz Tykierko (WCSS) 26 czerwca 2012 1 / 23 Wstęp Wrocławskie Centrum Sieciowo-Superkomputerowe Jednostka działająca
Wrocławskie Centrum Sieciowo-Superkomputerowe Mateusz Tykierko WCSS 26 czerwca 2012 Mateusz Tykierko (WCSS) 26 czerwca 2012 1 / 23 Wstęp Wrocławskie Centrum Sieciowo-Superkomputerowe Jednostka działająca
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Załącznik nr 3 do SIWZ DZP /2009-II
 Załącznik nr 3 do SIWZ DZP-0431-1490/2009-II Zadanie nr 1. SERWER BAZODANOWY Parametr Wymagane parametry Parametry oferowane (Wymienić: nazwę, typ, model ilość sztuk oferowanych podzespołów) OBUDOWA Maksymalnie
Załącznik nr 3 do SIWZ DZP-0431-1490/2009-II Zadanie nr 1. SERWER BAZODANOWY Parametr Wymagane parametry Parametry oferowane (Wymienić: nazwę, typ, model ilość sztuk oferowanych podzespołów) OBUDOWA Maksymalnie
Infrastruktura PLGrid Nowa jakość usług informatycznych dla Polskiej Nauki
 Infrastruktura PLGrid Nowa jakość usług informatycznych dla Polskiej Nauki Klemens Noga, Katarzyna Zaczek ACK Cyfronet AGH Wydział Fizyki, Astronomii i Informatyki Stosowanej, Kraków 2015 Agenda ACK Cyfronet
Infrastruktura PLGrid Nowa jakość usług informatycznych dla Polskiej Nauki Klemens Noga, Katarzyna Zaczek ACK Cyfronet AGH Wydział Fizyki, Astronomii i Informatyki Stosowanej, Kraków 2015 Agenda ACK Cyfronet
Z parametrów procesora zamieszczonego na zdjęciu powyżej wynika, że jest on taktowany z częstotliwością a) 1,86 GHz b) 540 MHz c) 533 MHz d) 1 GHz
 1,86 GHz b) 540 MHz c) 533 MHz d) 1 GHz") Test z przedmiotu Urządzenia techniki komputerowej semestr 1 Zadanie 1 Liczba 200 zastosowana w symbolu opisującym pamięć DDR-200 oznacza a) Efektywną częstotliwość, z jaka pamięć może pracować b) Przepustowość
Test z przedmiotu Urządzenia techniki komputerowej semestr 1 Zadanie 1 Liczba 200 zastosowana w symbolu opisującym pamięć DDR-200 oznacza a) Efektywną częstotliwość, z jaka pamięć może pracować b) Przepustowość
Opis przedmiotu zamówienia
 Opis przedmiotu zamówienia Stanowiska do badań algorytmów sterowania interfejsów energoelektronicznych zasobników energii bazujących na układach programowalnych FPGA. Stanowiska laboratoryjne mają służyć
Opis przedmiotu zamówienia Stanowiska do badań algorytmów sterowania interfejsów energoelektronicznych zasobników energii bazujących na układach programowalnych FPGA. Stanowiska laboratoryjne mają służyć
Prof. Kazimierz Wiatr - Dyrektor ACK Cyfronet AGH. ACK Cyfronet AGH w roku 2005
 Prof. Kazimierz Wiatr - Dyrektor ACK Cyfronet AGH ACK Cyfronet AGH w roku 2005 Zadania i misja udostępnianie mocy obliczeniowej oraz innych usług informatycznych podmiotom realizującym badania naukowe
Prof. Kazimierz Wiatr - Dyrektor ACK Cyfronet AGH ACK Cyfronet AGH w roku 2005 Zadania i misja udostępnianie mocy obliczeniowej oraz innych usług informatycznych podmiotom realizującym badania naukowe
Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki
 Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki Cel Konfiguracja i testowanie serwera WWW Apache w celu optymalizacji wydajności. 2/25 Zakres Konfigurowanie serwera Apache jako wydajnego
Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki Cel Konfiguracja i testowanie serwera WWW Apache w celu optymalizacji wydajności. 2/25 Zakres Konfigurowanie serwera Apache jako wydajnego
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Infrastruktura PLGrid Nowa jakość usług informatycznych w służbie nauki
 Infrastruktura PLGrid Nowa jakość usług informatycznych w służbie nauki Maciej Czuchry, Mariola Czuchry ACK Cyfronet AGH Katedra Biochemii i Neurobiologii, Kraków 2015 Agenda ACK Cyfronet AGH główne kompetencje
Infrastruktura PLGrid Nowa jakość usług informatycznych w służbie nauki Maciej Czuchry, Mariola Czuchry ACK Cyfronet AGH Katedra Biochemii i Neurobiologii, Kraków 2015 Agenda ACK Cyfronet AGH główne kompetencje
Serwer biznesowy o podwójnym zastosowaniu moc obliczeniowa i pamięć masowa w jednej obudowie
 QNAP TDS-16489U-SB3 66 636,11 PLN brutto 54 175,70 PLN netto Producent: QNAP Firma QNAP rozwija innowacyjność w segmencie serwerów biznesowych i wprowadza do oferty TDS-16489U wydajny podwójny serwer łączący
QNAP TDS-16489U-SB3 66 636,11 PLN brutto 54 175,70 PLN netto Producent: QNAP Firma QNAP rozwija innowacyjność w segmencie serwerów biznesowych i wprowadza do oferty TDS-16489U wydajny podwójny serwer łączący
Zaawansowane technologie w nowoczesnych układach sterowania
 Zaawansowane technologie w nowoczesnych układach sterowania Leszek A. Szałek Cito Systems, Inc. 3940 Freedom Circle, Santa Clara, CA 95054, USA leszeks@citosys.com 1. Wstęp Postępujący rozwój technologii
Zaawansowane technologie w nowoczesnych układach sterowania Leszek A. Szałek Cito Systems, Inc. 3940 Freedom Circle, Santa Clara, CA 95054, USA leszeks@citosys.com 1. Wstęp Postępujący rozwój technologii
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Badanie właściwości wysokorozdzielczych przetworników analogowo-cyfrowych w systemie programowalnym FPGA. Autor: Daniel Słowik
 Badanie właściwości wysokorozdzielczych przetworników analogowo-cyfrowych w systemie programowalnym FPGA Autor: Daniel Słowik Promotor: Dr inż. Daniel Kopiec Wrocław 016 Plan prezentacji Założenia i cel
Badanie właściwości wysokorozdzielczych przetworników analogowo-cyfrowych w systemie programowalnym FPGA Autor: Daniel Słowik Promotor: Dr inż. Daniel Kopiec Wrocław 016 Plan prezentacji Założenia i cel
Dyski, VAT 22%, gwarancja producenta. Opis:
 Załącznik nr 1 do SIWZ Znak sprawy: KA-2/059/2009 SZCZEGÓŁOWY OPIS PRZEDMIOTU ZAMÓWIENIA Zadanie nr Nazwa zadania 1 Dostawa dla M-0: drukarki -1 szt., przełącznika-1 szt. Opis zadania Dukarka HP - LaserJet
Załącznik nr 1 do SIWZ Znak sprawy: KA-2/059/2009 SZCZEGÓŁOWY OPIS PRZEDMIOTU ZAMÓWIENIA Zadanie nr Nazwa zadania 1 Dostawa dla M-0: drukarki -1 szt., przełącznika-1 szt. Opis zadania Dukarka HP - LaserJet
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Infrastruktura informatyczna dla nauki w Polsce
 Infrastruktura informatyczna dla nauki w Polsce Kazimierz Wiatr KRASP, 16 listopada 2018 Struktura infrastruktury informatycznej dla nauki w Polsce Infrastruktura ogólnopolska Sieć komputerowa PIONIER
Infrastruktura informatyczna dla nauki w Polsce Kazimierz Wiatr KRASP, 16 listopada 2018 Struktura infrastruktury informatycznej dla nauki w Polsce Infrastruktura ogólnopolska Sieć komputerowa PIONIER
Architektura systemu komputerowego
 Zakres przedmiotu 1. Wstęp do systemów mikroprocesorowych. 2. Współpraca procesora z pamięcią. Pamięci półprzewodnikowe. 3. Architektura systemów mikroprocesorowych. 4. Współpraca procesora z urządzeniami
Zakres przedmiotu 1. Wstęp do systemów mikroprocesorowych. 2. Współpraca procesora z pamięcią. Pamięci półprzewodnikowe. 3. Architektura systemów mikroprocesorowych. 4. Współpraca procesora z urządzeniami
Stacja robocza TYP1A Zał. 8.1, pkt. 1.1) 2. Monitor LCD 21.3 Zał. 8.1, pkt. 1.1) 2. Zasilacz awaryjny UPS Zał. 8.1, pkt. 1.1) 2
 2. Monitor LCD 21.3 Zał. 8.1, pkt. 1.1) 2. Zasilacz awaryjny UPS Zał. 8.1, pkt. 1.1) 2") Załącznik nr 7 do SIWZ nr TA/ZP-4/2007 Formularz cenowy oferowanego sprzętu GRUPA 1 (Szczegółowa specyfikacja w Załączniku nr 8.1) Stacje robocze przetwarzania graficznego wysokiej wydajności z monitorem
Załącznik nr 7 do SIWZ nr TA/ZP-4/2007 Formularz cenowy oferowanego sprzętu GRUPA 1 (Szczegółowa specyfikacja w Załączniku nr 8.1) Stacje robocze przetwarzania graficznego wysokiej wydajności z monitorem
Polityka wspierania prac naukowych i wdrożeniowych w obszarze informatyki jako element budowy społeczeństwa informacyjnego w Polsce
 i wdrożeniowych w obszarze informatyki jako element budowy społeczeństwa informacyjnego w Polsce Kazimierz Wiatr Światowy Zjazd Inżynierów Polskich Warszawa Politechnika Warszawska 8 września 2010 r. Kazimierz
i wdrożeniowych w obszarze informatyki jako element budowy społeczeństwa informacyjnego w Polsce Kazimierz Wiatr Światowy Zjazd Inżynierów Polskich Warszawa Politechnika Warszawska 8 września 2010 r. Kazimierz
Działanie 2.3: Inwestycje związane z rozwojem infrastruktury informatycznej nauki
 Program Obliczeń Wielkich Wyzwań Nauki i Techniki POWIEW Marek Niezgódka, Maciej Filocha ICM, Uniwersytet Warszawski Konferencja Nauka idzie w biznes, Warszawa, 7.11.2012 1 Informacje ogólne Działanie
Program Obliczeń Wielkich Wyzwań Nauki i Techniki POWIEW Marek Niezgódka, Maciej Filocha ICM, Uniwersytet Warszawski Konferencja Nauka idzie w biznes, Warszawa, 7.11.2012 1 Informacje ogólne Działanie
SZCZEGÓŁOWE INFORMACJE DOTYCZĄCE KONFIGURACJI OFEROWANEGO SPRZĘTU. Przetarg nieograniczony Dostawa sprzętu komputerowego
 OR.272.10.2017 www.powiat.turek.pl P O W I A T T U R E C K I Powiat Innowacji i Nowoczesnych Technologii Załącznik nr 3b do SIWZ SZCZEGÓŁOWE INFORMACJE DOTYCZĄCE KONFIGURACJI OFEROWANEGO SPRZĘTU Przetarg
OR.272.10.2017 www.powiat.turek.pl P O W I A T T U R E C K I Powiat Innowacji i Nowoczesnych Technologii Załącznik nr 3b do SIWZ SZCZEGÓŁOWE INFORMACJE DOTYCZĄCE KONFIGURACJI OFEROWANEGO SPRZĘTU Przetarg
Infrastruktura PLGrid Nowa jakość usług informatycznych dla Polskiej Nauki
 Infrastruktura PLGrid Nowa jakość usług informatycznych dla Polskiej Nauki Maciej Czuchry, Klemens Noga ACK Cyfronet AGH Seminarium Katedry Informatyki Stosowanej, AGH, Kraków 2015 Agenda ACK Cyfronet
Infrastruktura PLGrid Nowa jakość usług informatycznych dla Polskiej Nauki Maciej Czuchry, Klemens Noga ACK Cyfronet AGH Seminarium Katedry Informatyki Stosowanej, AGH, Kraków 2015 Agenda ACK Cyfronet
Infrastruktura PLGrid (nie tylko) dla młodych naukowców
 dla młodych naukowców") Infrastruktura PLGrid (nie tylko) dla młodych naukowców Mariola Czuchry, Mariusz Sterzel ACK Cyfronet AGH Wydział Mechaniczny, PK, Kraków 16 XI 2015 Agenda ACK Cyfronet AGH Infrastruktura PLGrid Charakterystyka
Infrastruktura PLGrid (nie tylko) dla młodych naukowców Mariola Czuchry, Mariusz Sterzel ACK Cyfronet AGH Wydział Mechaniczny, PK, Kraków 16 XI 2015 Agenda ACK Cyfronet AGH Infrastruktura PLGrid Charakterystyka
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM. Juliusz Pukacki,PCSS
 DLA FIRM. Juliusz Pukacki,PCSS") USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
LPAR - logiczne partycjonowanie systemów
 Mateusz Błażewicz Piotr Butryn Jan Sikora MIMUW 20 grudnia 2007 1 2 Budowa i możliwości Instalacja 3 Budowa Co to jest? LPAR - logiczne partycjonowanie sprzętu Dzielenie zasobów fizycznego serwera na niezależne,
Mateusz Błażewicz Piotr Butryn Jan Sikora MIMUW 20 grudnia 2007 1 2 Budowa i możliwości Instalacja 3 Budowa Co to jest? LPAR - logiczne partycjonowanie sprzętu Dzielenie zasobów fizycznego serwera na niezależne,
OFERTA NA SYSTEM LIVE STREAMING
 JNS Sp. z o.o. ul. Wróblewskiego 18 93-578 Łódź NIP: 725-189-13-94 tel. +48 42 209 27 01, fax. +48 42 209 27 02 e-mail: biuro@jns.pl Łódź, 2015 r. OFERTA NA SYSTEM LIVE STREAMING JNS Sp. z o.o. z siedzibą
JNS Sp. z o.o. ul. Wróblewskiego 18 93-578 Łódź NIP: 725-189-13-94 tel. +48 42 209 27 01, fax. +48 42 209 27 02 e-mail: biuro@jns.pl Łódź, 2015 r. OFERTA NA SYSTEM LIVE STREAMING JNS Sp. z o.o. z siedzibą
DZIERŻAWA I KOLOKACJA SERWERÓW DEDYKOWANYCH
 DZIERŻAWA I KOLOKACJA SERWERÓW DEDYKOWANYCH ZASTOSOWANIA wysoko wydajne serwery aplikacyjne serwery hostingowe serwery bazodanowe serwery gier, platformy wirtualizacyjne, platformy e-commerce systemy wieloserwerowe
DZIERŻAWA I KOLOKACJA SERWERÓW DEDYKOWANYCH ZASTOSOWANIA wysoko wydajne serwery aplikacyjne serwery hostingowe serwery bazodanowe serwery gier, platformy wirtualizacyjne, platformy e-commerce systemy wieloserwerowe
Układ sterowania, magistrale i organizacja pamięci. Dariusz Chaberski
 Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
Szczegółowy Opis Przedmiotu Zamówienia: Zestaw do badania cyfrowych układów logicznych
 ZP/UR/46/203 Zał. nr a do siwz Szczegółowy Opis Przedmiotu Zamówienia: Zestaw do badania cyfrowych układów logicznych Przedmiot zamówienia obejmuje następujące elementy: L.p. Nazwa Ilość. Zestawienie komputera
ZP/UR/46/203 Zał. nr a do siwz Szczegółowy Opis Przedmiotu Zamówienia: Zestaw do badania cyfrowych układów logicznych Przedmiot zamówienia obejmuje następujące elementy: L.p. Nazwa Ilość. Zestawienie komputera
SPECYFIKACJA ISTOTNYCH WARUNKÓW ZAMÓWIENIA
 A. Komputer stacjonarny typu all in one 13 sztuk 1. Procesor Procesor dwurdzeniowy zgodny z x86, o wydajności ocenionej, na co najmniej 212 punktów zdobytych w teście SYSmark 2007 Preview Rating według
A. Komputer stacjonarny typu all in one 13 sztuk 1. Procesor Procesor dwurdzeniowy zgodny z x86, o wydajności ocenionej, na co najmniej 212 punktów zdobytych w teście SYSmark 2007 Preview Rating według
Rozwiązania HPE Storage jak zapewnić pełne bezpieczeństwo Twoich danych?
 Rozwiązania HPE Storage jak zapewnić pełne bezpieczeństwo Twoich danych? Marek Kozicki, Storage Solutions Architect, HPE 19 maja 2016 r. Przed czym powinniśmy zabezpieczyć nasze dane? Architektura sprzętowo-programowa
Rozwiązania HPE Storage jak zapewnić pełne bezpieczeństwo Twoich danych? Marek Kozicki, Storage Solutions Architect, HPE 19 maja 2016 r. Przed czym powinniśmy zabezpieczyć nasze dane? Architektura sprzętowo-programowa
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Bajt (Byte) - najmniejsza adresowalna jednostka informacji pamięci komputerowej, z bitów. Oznaczana jest literą B.
 - najmniejsza adresowalna jednostka informacji pamięci komputerowej, z bitów. Oznaczana jest literą B.") Jednostki informacji Bajt (Byte) - najmniejsza adresowalna jednostka informacji pamięci komputerowej, składająca się z bitów. Oznaczana jest literą B. 1 kb = 1024 B (kb - kilobajt) 1 MB = 1024 kb (MB -
Jednostki informacji Bajt (Byte) - najmniejsza adresowalna jednostka informacji pamięci komputerowej, składająca się z bitów. Oznaczana jest literą B. 1 kb = 1024 B (kb - kilobajt) 1 MB = 1024 kb (MB -
Szczegółowy Opis Przedmiotu Zamówienia
 Szczegółowy Opis Przedmiotu Zamówienia Załącznik nr 3 do SIWZ znak sprawy: 20/DI/PN/2015 1. Zamówienie jest realizowane w ramach projektu System ulg i bonifikat skierowanych do rodzin wielodzietnych certyfikowany
Szczegółowy Opis Przedmiotu Zamówienia Załącznik nr 3 do SIWZ znak sprawy: 20/DI/PN/2015 1. Zamówienie jest realizowane w ramach projektu System ulg i bonifikat skierowanych do rodzin wielodzietnych certyfikowany
 ODPOWIEDZI I. Pytania formalne: 1. Zamawiający dopuszcza złożenie oferty tylko na część przedmiotu Zamówienia. 2. Zamawiający dopuszcza wniesienie zabezpieczenia w postaci gwarancji bankowej. II. Serwery:
ODPOWIEDZI I. Pytania formalne: 1. Zamawiający dopuszcza złożenie oferty tylko na część przedmiotu Zamówienia. 2. Zamawiający dopuszcza wniesienie zabezpieczenia w postaci gwarancji bankowej. II. Serwery:
Opis przedmiotu zamówienia CZĘŚĆ 1
 Opis przedmiotu zamówienia CZĘŚĆ 1 Stanowiska do badań algorytmów sterowania interfejsów energoelektronicznych zasobników energii bazujących na układach programowalnych FPGA. Stanowiska laboratoryjne mają
Opis przedmiotu zamówienia CZĘŚĆ 1 Stanowiska do badań algorytmów sterowania interfejsów energoelektronicznych zasobników energii bazujących na układach programowalnych FPGA. Stanowiska laboratoryjne mają
Kinowa Biblioteka Filmowa KINOSERWER. KinoSerwer
 Kinowa Biblioteka Filmowa KINOSERWER KinoSerwer Zewnętrzna biblioteka filmowa KINOSERWER do przechowywania plików filmowych DCP, o pojemności minimalnej 12TB z możliwością rozbudowy do 42TB. Oferujemy
Kinowa Biblioteka Filmowa KINOSERWER KinoSerwer Zewnętrzna biblioteka filmowa KINOSERWER do przechowywania plików filmowych DCP, o pojemności minimalnej 12TB z możliwością rozbudowy do 42TB. Oferujemy
Wykład I. Podstawowe pojęcia. Studia Podyplomowe INFORMATYKA Architektura komputerów
 Studia Podyplomowe INFORMATYKA Architektura komputerów Wykład I Podstawowe pojęcia 1, Cyfrowe dane 2 Wewnątrz komputera informacja ma postać fizycznych sygnałów dwuwartościowych (np. dwa poziomy napięcia,
Studia Podyplomowe INFORMATYKA Architektura komputerów Wykład I Podstawowe pojęcia 1, Cyfrowe dane 2 Wewnątrz komputera informacja ma postać fizycznych sygnałów dwuwartościowych (np. dwa poziomy napięcia,
OFERTA. Załącznik nr 1 do zapytania ofertowego: Wzór oferty. Dane oferenta. Pełna nazwa oferenta: Adres:. REGON:.. Tel./fax.: .
 Załącznik nr 1 do zapytania ofertowego: Wzór oferty (miejscowość, data) OFERTA Dane oferenta Pełna nazwa oferenta:. Adres:. NIP: REGON:.. Tel./fax.: e-mail:. W odpowiedzi na upublicznione przez Info-Projekt
Załącznik nr 1 do zapytania ofertowego: Wzór oferty (miejscowość, data) OFERTA Dane oferenta Pełna nazwa oferenta:. Adres:. NIP: REGON:.. Tel./fax.: e-mail:. W odpowiedzi na upublicznione przez Info-Projekt