WYBRANE TECHNIKI PRZYGOTOWYWANIA REKOMENDACJI DLA UŻYTKOWNIKÓW SERWISU INTERNETOWEGO
|
|
|
- Włodzimierz Malinowski
- 9 lat temu
- Przeglądów:
Transkrypt
1 Politechnika Łódzka Instytut Informatyki PRACA MAGISTERSKA WYBRANE TECHNIKI PRZYGOTOWYWANIA REKOMENDACJI DLA UŻYTKOWNIKÓW SERWISU INTERNETOWEGO Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Promotor: dr hab. inż. Maria Pietruszka, mgr inż. Magdalena Stobińska Dyplomant: Artur Ziółkowski Nr albumu: Kierunek: Informatyka Specjalność: Sztuczna Inteligencja i Inżynieria Oprogramowania Łódź 2010 Instytut Informatyki Łódź, ul. Wólczańska 215, budynek B9 tel , , fax office@ics.p.lodz.pl

2 Spis treści 1 Wstęp Problematyka Cele pracy i zakres pracy Analiza zagadnienia Wprowadzenie Eksploracja danych Problemy związane ze źródłem danych Pozyskiwanie informacji o użytkownikach stron Log serwera Podsłuchiwanie połączenia użytkownika z serwerem Dedykowany serwis internetowy Strategie przygotowywania rekomendacji Techniki analizy danych 14 4 Grupowanie Metody hierarchiczne K-średnich Samoorganizująca się mapa Sieć neuronowa Sieć Kohonena Klasyfikacja Sieci neuronowe na przykładzie wielowarstwowego perceptronu Klasyfikator Bayesa Twierdzenie Bayesa Naiwny klasyfikator Bayesa Przykład zastosowania NBC Metoda k-najbliższych sąsiadów Znajdowanie reguł asocjacji Reprezentacje struktur danych Kryteria oceny reguł Algorytm A priori Przykład

3 Spis treści 2 7 Przeglad istniejacych rozwiazań Narzędzia analizy danych CLUTO SPSS Clementine Google Analytics Microsoft SQL Server Analysis Service WEKA Portal internetowy wykorzystujący rekomendacje Problem praktyczny Opis problemu Wymagania funkcjonalne Pozyskanie danych testowych Projekt Moduł dostępu do danych Szczegóły implementacji Projekt testowej bazy danych Moduł analizy danych Szczegóły implementacji wybranych elementów Moduł statystyczny Graficzny interfejs użytkownika Przykładowe uruchomienie Podsumowanie 93 Bibliografia 94

4 Streszczenie W pracy zostaną omówione zagadnienia związane z przygotowywaniem rekomendacji dla użytkowników serwisu internetowego. Jest to bardzo ciekawe zagadnienie, tym bardziej, że staje się coraz popularniejsze w serwisach internetowych. W pierwszej części pracy został przedstawiony ogólny zarys problemu oraz zakres pracy. Starałem się wprowadzić w zagadnienia związane z przygotowywaniem rekomendacji, aby nakreślić istotę zadania. W dalszej części pracy przedstawiłem techniki, które mogą zostać wykorzystane przy tworzeniu rekomendacji. Są one ściśle związane z tematyką eksploracji danych. W tej części pracy zostały również opisane istniejące na rynku rozwiązania, które wykorzystują opisane metody eksploracji danych. Przedstawiłem również przykład prawdziwego serwisu internetowego, który z powodzeniem wdrożył różne mechanizmy przygotowywania rekomendacji. Wskazałem na konkretne przykłady i sposób jego działania. Na potrzeby pracy powstała aplikacja, która realizuje grupowanie danych jako technikę przygotowywania rekomendacji. Aplikacja współpracuje z serwerem baz danych i pozwala analizować dane związane z dowolną tematyką. Pozostając w obrębie użytkowników serwisu internetowego przetestowałem aplikację na testowym zbiorze danych, który zawiera informacje o aktywności użytkowników na stronach internetowych popularnego serwisu internetowego Merlin.pl. Jako ciekawostkę opisałem sposób pozyskania tych danych. Pracę zakończyłem podsumowaniem opisującym wnioski i przemyślenia powstałe w czasie pisania pracy oraz testowania projektu.

5 Rozdział 1 Wstęp 1.1 Problematyka W obecnych czasach można zaobserwować nasycenie się rynku dostawców wielu produktów i usług. Bardzo trudne stało się pozyskanie nowych klientów oraz utrzymanie ich w stanie lojalności wobec przedsiębiorstwa. Dotyczy to każdej branży, zarówno tej zajmującej się świadczeniem usług, jak i tej zajmującej się handlem. Każdy z klientów oczekuje wysokiej jakości produktów (lub usług), ale dodatkowo chce być obsłużonym na wysokim poziomie. Jeśli firma nie będzie dbała o swojego klienta, ten bardzo szybko może zrezygnować z oferty firmy na rzecz innej, konkurencyjnej. Wykorzystanie Internetu jako medium dla handlu elektronicznego uprościło klientom dostęp do różnych dostawców dóbr. Zazwyczaj ludzie są bardzo leniwi. Nie lubią przeszkód i szybko się zniechęcają, co może zaowocować rezygnacją z usług. Z tego powodu bardzo ważne jest aby relacja firmy z klientem była trwała, a co za tym idzie musi być stale pielęgnowana. Analiza poszczególnych klientów, a co za tym idzie ich potrzeb, jest pewnym rozwiązaniem tego problemu. Może ono przynieść firmie wymierne korzyści. Jednak jest to rozwiązanie bardzo skomplikowane, a często wręcz niewykonalne. Ocena klienta pod kątem atrakcyjności jest bardzo trudna. Pod uwagę można brać różne kryteria oceny. Ważne stało się to, czy klient jest w stanie polecić firmę swoim znajomym, którzy mogą zostać potencjalnymi klientami. Taki sposób oceny często uważany jest za o wiele istotniejszy, niż sam zysk. Klient, który w pewnej firmie kupi bardzo mało, ale będzie zadowolony z wysokiej jakości obsługi, może polecić ją stu innym osobom. Aby taka pozytywna opinia mogła zostać wystawiona klient musi być zadowolony, a to już jest kolejne wyzwanie dla firmy. Klient będzie zadowolony tylko wtedy, gdy oferta kierowana do niego będzie rzeczowa i zostanie przygotowana pod jego kątem. Nie mogą się w niej znaleźć produkty i usługi, którymi klient nie będzie zainteresowany. Niedbale przygotowana oferta może jedynie zniechęcić klienta do zakupów i go spłoszyć. Rekomendacji jako pojęcia można używać w różnych kontekstach. Zazwyczaj posługujemy się nim w znaczeniu opiniowania, czy polecania komuś czegoś. W swojej pracy rekomendację będę utożsamiał właśnie z ofertą kierowaną do klienta (lub do grupy klientów o podobnych charakterach), a w szczególności do użytkowników serwisu internetowego. Taka rekomendacja może zawierać w sobie jeden bądź wiele produktów, nie jest to tak istotne. Najlepiej taki cel można osiągnąć podchodząc indywidualnie do każdego klienta. Niestety jest to nierealne. Wyobraźmy sobie sytuację, w której firma obsługuje dziennie tysiąc klientów. Ludzie obsługujący klientów będą mieć wiedzę o kliencie, który w jakiś sposób się wyróżnia (np. duże zakupy), a jak wcześniej napisałem do wszystkich powinniśmy podejść tak samo profesjonalnie. Do tego dochodzi realizacja komunikacji z klientem za pomocą Internetu. To sam użytkownik serwisu internetowego składa zamówienia na produkty bądź usługi, a w procesie tym nie biorą udziału osoby fizyczne. Pojawia się wiec pytanie, jak w takim razie przygotować ofertę indywidualną dla wielu klientów nie mając z nimi kontaktu fizycznego? W sytuacji, kiedy mamy przygotować ofertę dla wielu klientów można posłużyć się zaawansowanymi technikami, które nas wspomogą. Kilka wybranych technik, które są najczęściej wykorzystywane, opisa-
, ale dodatkowo chce być obsłużonym na wysokim poziomie.")
6 1.2 Cele pracy i zakres pracy 5 łem w swojej pracy. Charakteryzują się one różnym podejściem do postawionego problemu, a co za tym idzie potrzebują trochę innego przygotowania danych do przeprowadzenia procesu wydobywania wiedzy z tych danych. Bardzo ciekawe w opisywanych przez mnie technikach jest to, że wykorzystują one dane zebrane w całkiem innym celu niż analizowanie potrzeb klientów. Zazwyczaj firmy prowadząc swoją działalność gromadzą różne dane. W przypadku użytkowników serwisu internetowego mogą to być informacje np. o zakupionych produktach, bądź odwiedzonych stronach internetowych. Można więc z powodzeniem je wykorzystać i za pomocą zastosowania pewnych technik usprawnić działanie serwisu internetowego tak, aby stał się bardziej przyjazny użytkownikowi, a sam użytkownik miał wrażenie, jakby serwis był ukierunkowany wyłącznie na niego. 1.2 Cele pracy i zakres pracy W swojej pracy postawiłem dwa cele, które chciałem osiągnąć. Pierwszy cel dotyczy części teoretycznej pracy i zakłada dokonanie przeglądu zagadnień oraz rozwiązań związanych z przygotowaniem rekomendacji dla użytkowników serwisu internetowego. Konieczne było przedstawienie analizy zagadnienia oraz problemów jakie można napotkać podczas tworzenia rozwiązań umożliwiających przygotowywanie rekomendacji. Chciałem się także dowiedzieć jakie możliwości daje stosowanie wybranych technik wydobywania wiedzy z danych oraz jakie rozwiązania już na rynku istnieją. Czy faktycznie ich wprowadzenie ułatwia użytkownikom korzystanie z systemu, a nie jest tylko wymyślnym mechanizmem, który nie znajduje praktycznego zastosowania. Będę chciał podać kilka przykładów. Mam tu na myśli narzędzia, które wspierają analityków w codziennej pracy podczas pracy ze zbiorami danych, ale oprócz tego chciałem sprawdzić jak na przykładzie istniejącego serwisu internetowego jak wygląda wspomaganie użytkownika w podejmowaniu decyzji dotyczących zakupów. W tej części pracy opiszę również wybrane techniki eksploracji danych, które mogą być wykorzystane do przygotowywania rekomendacji dla użytkowników serwisu internetowego. Zamierzam pokazać ich ogólny charakter, a także wskazać zalety i wady ich stosowania. Postaram się wytłumaczyć wszystko w jasny sposób podpierając się przy tym odpowiednimi schematami oraz rysunkami. W ramach drugiego celu chciałem stworzyć aplikację, która pozwala przeprowadzić grupowanie wybranych danych pochodzących ze wskazanej bazy danych. Aplikacja posiada graficzny interfejs użytkownika, który w szybki i intuicyjny sposób udostępnia wszystkie niezbędne funkcje. Program ma budowę modułową, a każdy z nich charakteryzuje się inną odpowiedzialnością. Poszczególne moduły nie komunikują się ze sobą bezpośrednio. Sterowaniem oraz przepływem danych zarządza okno aplikacji, które jest powiadamiane za pomocą zdarzeń o realizacji kolejnych zadań przez moduły. Przewidziałem w aplikacji trzy następujące moduły: moduł dostępu do danych moduł analizy danych moduł statystyczny W ramach modułu dostępu do danych zaprojektuję i zaimplementuję dedykowanych mechanizm komunikacji z serwerem baz danych. Dzięki takiemu rozwiązaniu aplikacja będzie współpracowała z dowolną bazą danych obsługiwała przez wyznaczony serwer baz danych. Projekt zostanie zrealizowany tak, aby umożliwić użytkownikowi definiowanie wejściowego zbioru danych poprzez tworzenie skryptów w języku zapytań. W tym celu w aplikację zostanie wbudowany edytor ze wspomaganiem przy budowie skryptów i kolorowaniem składni. Do celów testowych pozyskałem bazę danych zawierającą informacje o aktywności użytkowników na stronach internetowych popularnego serwisu Merlin.pl. Moduł analizy danych będzie przeprowadzał grupowanie obiektów z przygotowanego zbioru danych. Będzie w tym celu wykorzystywał mechanizm samoorganizującej się sieci neuronowej, która uczy się bez nadzoru. Zostanie ona zrealizowana zgodnie z ideą sieci Kohonena, ale dodatkowo zostanie wzbogacona o dwa dodatkowe mechanizmy usprawniające proces nauki: mechanizm zmęczenia neuronów oraz malejący

7 1.2 Cele pracy i zakres pracy 6 krok nauki. Program będzie umożliwiał konfigurowanie procesu sieci nauki za pomocą odpowiednich parametrów. Uzyskane wyniki będą prezentowane w przejrzysty sposób, tak aby umożliwiały szybką weryfikację. Dodatkowo będą rysowane dwa wykresy umożliwiające przeprowadzenie interpretacji uzyskanych wyników. Poszczególne moduły aplikacji zostaną szczegółowo opisane z uwzględnieniem szczegółów projektowych oraz implementacyjnych. Na koniec zaprezentuję przykładowe działanie programu. Wszystkie swoje przemyślenia i uwagi zapiszę w postaci podsumowania.

8 Rozdział 2 Analiza zagadnienia 2.1 Wprowadzenie W związku z dynamicznym rozwojem technologicznym pojawiło się wiele nowych możliwości. Wydajny sprzęt komputerowy pozwolił na składowanie coraz większych ilości informacji. Szybkość przetwarzania danych wzrosła wielokrotnie w porównaniu do jeszcze nie tak odległych lat. Obecna technika powoli dochodzi do fizycznych granic minimalizacji komponentów wykorzystywanych przy budowie komputerów. Duże korporacje oraz mniejsze firmy mając na celu zwiększenie swoich dochodów poszukiwały pewnych źródeł informacji, które mogłyby im pomóc w osiągnięciu sukcesu biznesowego. Zaczęły składować najróżniejsze dane. Powstały ogromne bazy danych, które magazynują fakty ze wszystkich możliwych obszarów działalności ludzi. Oczywista stała się chęć pozyskania cennych informacji z tak zebranych danych. W taki sposób powstała dziedzina zajmująca się tym zagadnieniem zwana eksploracja danych. 2.2 Eksploracja danych Każda dziedzina naukowa posiada wiele definicji. Związane jest to z tym, że wiele osób ma różny pogląd dotyczący zakresu obszaru zainteresowania wybranej dziedziny. Nie inaczej jest w przypadku eksploracji danych. W literaturze można spotkać wiele odmian definicji tego zagadnienia. Eksploracja danych wykorzystuje metody oraz narzędzia pochodzące z różnych innych dziedzin, takich jak bazy danych, statystyka i uczenie maszynowe. Hand w swojej książce definiuje eksplorację danych skupiając się na jej istocie, a nie wykorzystywanych przez nią technikach: Eksploracja danych jest analizą (często ogromnych) zbiorów danych obserwacyjnych w celu znalezienia nieoczekiwanych związków i podsumowania danych w oryginalny sposób tak, aby były zarówno zrozumiałe, jak i przydatne dla ich właściciela. Chciałem odnieść się do powyższej definicji i zwrócić uwagę na to, że eksploracja danych w swojej idei ma analizować dane obserwacyjne. Jest to bardzo istotne określenie danych. Oznacza to, że eksploracja danych zwykle jest przeprowadzana na zbiorze danych, który został zebrany z innych przyczyn niż przetwarzanie mające na celu wydobywanie wiedzy. Przykładem takich danych mogą być bilingi telefoniczne. Same w sobie są zbierane do dokumentowania rozmów wychodzących, za które abonent musi zapłacić. Z drugiej jednak strony mogą posłużyć za źródło danych dla eksploracji. Dzięki temu można poznać informację na różne pytania. Przykładem może być zbadanie gdzie dzwonią mieszkańcy poszczególnych województw oraz jak długo rozmawiają. To pozwoli np. ocenić czy promocja dotycząca obniżenia kosztów pierwszej minuty rozmowy będzie opłacalna dla firmy telekomunikacyjnej. Definicja zwraca uwagę na fakt, że eksploracja danych zajmuje się przetwarzaniem ogromnych zbiorów danych. Wspomniane przeze mnie bilingi rozmów są przykładem właśnie takiego wolumenu. Praktycznie każda osoba posiada telefon komórkowy, a czasem kilka. Nie jesteśmy w stanie wyobrazić sobie ile rozmów

9 2.3 Problemy zwiazane ze źródłem danych 8 telefonicznych odbywa się w ciągu jednej minuty. W swoje książce [8] Daniel Larose również zwrócił uwagę na ciekawą sytuację. Postawił czytelnika przy kasie supermarketu i kazał zamknąć na chwilę oczy. Zwrócił uwagę na to, że poza błaganiem dzieci o słodycze słychać dźwięki skanera kodów kreskowych i terminali potwierdzających poprawne wykonanie operacji kartą płatniczą. Gdyby wsłuchać się dokładnie w te dźwięki, to nie bylibyśmy w stanie policzyć ich wszystkich, tak znaczna jest to liczba. Biorąc pod uwagę skalę kraju albo państwa, duża sieć supermarketów ma o nas wszystkich bardzo dużo informacji, którymi może się posłużyć. To, że tych danych jest tak dużo daje ogromne możliwości, ale również stawia analityków przed różnymi wyzwaniami ściśle związanymi z ilością danych oraz ich spójnością. Techniki wykorzystywane do analizowania dużych zbiorów informacji muszą być sprawne. Mam tu na przykład na myśli zoptymalizowany sposób poszukiwania zależności. Gdybyśmy mieli szukać zależności sprawdzając wszystkie możliwe kombinacje, to moglibyśmy nie doczekać się wyników. Poniekąd ma to też swoją wadę. Metody te działają z pewną dokładnością, zazwyczaj można na nią wpływać, ale nie da się ocenić jakiejś sytuacji ze stu procentową pewnością. Może zdarzyć się również sytuacja, że analityk chciałby dowiedzieć się czegoś ciekawego z danych, które były zebrane jakiś czas temu. Nie może być pewien ich spójności w sensie cech obiektów, ani też tego, że nie ma tam informacji błędnych, które mogłyby przekłamać wynik. Na rynku oprogramowania znajduje się wiele ofert programów zajmujących się eksploracją danych. Przed dokonaniem wyboru trzeba się zastanowić, czy wybrany program będzie odpowiadał realnym potrzebom firmy. Jeżeli firma ma nietypowe potrzeby dotyczące sposobu wydobywania wiedzy, to może się okazać, że uniwersalne oprogramowanie nie będzie się do tego nadawało. Jeśli posiadamy nietypową reprezentację danych, to albo możemy bardzo się napracować przygotowując dane do przetwarzania albo uzyskać błędne wyniki nie otrzymując do tego żadnego powiadomienia. Często nazywa się taki model czarną skrzynką. Nie wiemy jak dane są przetwarzane, dlatego możemy nie zrozumieć końcowego rezultatu. Wiedza informatyczna jest niezbędna do stworzenia narzędzia, jednak analityk, który zajmuje się interpretacją uzyskanych wyników musi rozumieć ich istotę. Jeśli znamy wewnętrzne mechanizmy systemu przetwarzającego dane i wiemy jak się cały proces odbywa, to możemy powiedzieć, że mamy do czynienia z modelem białej skrzynki. Wiele osób, które jeszcze nie miały możliwości poznać bliżej eksploracji danych sądzą, że polega to na zastosowaniu pewnych technik statystycznych czy pochodzących z dziedziny sztucznej inteligencji w celu uzyskania odpowiedzi na konkretne pytania. Przekonanie o eksploracji danych jako o samodzielnym narzędziu, które mogłoby zostać wykorzystane do przeprowadzania analiz, przez grupę specjalistów jest błędne. Eksploracja danych powinna być postrzegana jako proces złożony z kilku etapów. Powinna być utożsamiana z metodologią, która określa ściśle tok działania. Istnieje kilka podejść do odkrywania wiedzy, jednak wszystkie powinny uwzględnić następujące etapy: przygotowanie danych wybór technik analizy ocena wykorzystanie Przykładem metodologii przedstawiającej odkrywanie wiedzy jako proces jest Cross-Industry Standard Process (CRISP-DM) [[7, 8]]. Metodologia powstała w 1996 roku z inicjatywy takich firm jak Daimler- Chrysler, SPSS i NCR. Określa standardowy proces dopasowania eksploracji danych w celu rozwiązywania problemów biznesowych i badawczych. Poza wyżej przedstawionymi podstawowymi etapami eksploracji danych CRISP-DM zawiera dodatkowe dwa, które poprzedzają przygotowanie danych. Jest interaktywny i adaptacyjny, co oznacza, że można przechodzić z jednego etapu do drugiego w zależności od ustalonych założeń i ograniczeń. Rysunek numer 2.1 przedstawia go za pomocą prostego diagramu. 2.3 Problemy zwiazane ze źródłem danych Poprzednia część rozdziału była wprowadzeniem do zagadnień związanych z eksploracją danych. Wskazałem przykładowe bazy danych, które mogłyby posłużyć jako źródło do przeprowadzania analizy i wydo-

10 Rysunek 2.1: Schemat metodologii CRISP-DM
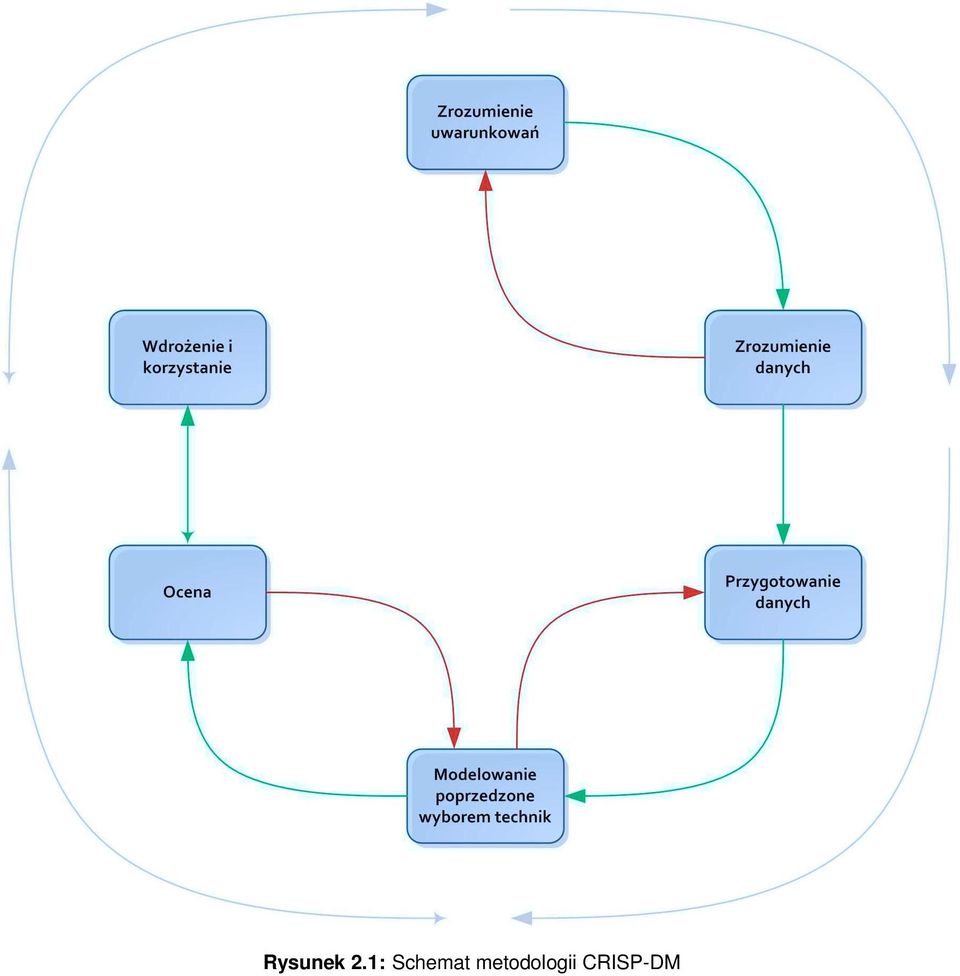
11 2.3 Problemy zwiazane ze źródłem danych 10 bywania wiedzy. W tej części poruszę problemy, z którymi borykają się osoby zajmujące się odkrywaniem wiedzy. Problemy te związane są z reprezentacją oraz charakterem danych wejściowych. Eksploracja danych może korzystać z baz danych, które nie były stworzone wyłącznie w celu odkrywania wiedzy, dlatego mogą one posiadać niepożądane cechy. Do takich cech można zaliczyć: kolumny, które są przestarzałe i nie są już dłużej wypełniane wiersze z brakującymi wartościami format bazy danych może być nie odpowiedni niektóre wartości są niezgodne z logiką i pewnym podejściem (sprzeczne założenia) Rolą analityka, czy też innej osoby odpowiedzialnej za eksplorację danych jest przygotowanie danych tak, aby nadawały się do przetwarzania. Aby taka baza danych mogła być użyta musi zostać poddana wstępnej obróbce. Jest to jeden z etapów przedstawionej wcześniej metodologi CRISP-DM. Często takie zadanie jest trudne i wymaga podjęcia pewnych decyzji, które mogą zaważyć na rezultatach odkrywania wiedzy z danych. Źle przeprowadzona wstępna obróbka może sprawić, że wynik końcowy nie będzie miał żadnego sensu. W przypadku kolumn, które już wcale nie są wypełniane sytuacja jest dość prosta. Wystarczy wykonać projekcję dla tabeli pomijającą niepoprawne kolumny. Trudniej wybrnąć z problemu brakujących wartości w rekordach. Jest to problem, który przejawia się na okrągło. Metody analizy, które są bardzo zaawansowane i mogą dawać dobre rezultaty w satysfakcjonującym czasie mogą zawieźć jeśli natrafią na brakujące wartości. Wiadomym jest, że im więcej mamy informacji na temat jakiegoś obiektu, tym lepiej możemy go scharakteryzować. Brak informacji na jakiś temat jest zawsze niemile widziany. Na przykład kiedy poszukujemy przestępcy, chcemy wiedzieć o nim jak najwięcej, aby go szybko znaleźć. Może zdarzyć się, że nie mamy wszystkich danych niezbędnych do analizy. Komplikuje to dodatkowo zadanie. Najprostszym sposobem poradzenia sobie z brakującymi danymi jest po prostu pominięcie takiego rekordu. Wydaje się, że problem rozwiązany. Nie ma danych, które mogłyby zachwiać wynik. A co jeśli celem odkrywania wiedzy było rozpoznanie sekwencji występowania pewnych zdarzeń? Jeśli usuniemy taki rekord dostaniemy całkiem inną sekwencję, która nie będzie zgodna ze stanem rzeczywistym. Z tego powodu analitycy posługują się metodami, które odtwarzają brakujące wartości. Jest kilka takich metod. Najpopularniejsze są: Zastąpienie brakującej wartości stałą określaną przez analityka Zastąpienie brakującej wartości wartością średnią policzoną na podstawie innych rekordów Zastąpienie brakującej wartości wartością losową wygenerowaną na podstawie obserwowanego rozkładu zmiennej W literaturze wiele miejsca poświęca się rozwiązywaniu tego typu problemów. Larose wskazuje wady i zalety powyższych rozwiązań [8]. Pierwsze podejście jest najprostsze, ale obarczone dużym błędem. Nie dość, że wartość może nie pasować do danych, to jeszcze analityk mając przed oczami zbiór milionów albo miliardów rekordów nie jest w stanie ocenić jaki zakres posiada dane pole. Z kolei zastąpienie wartością średnią zapewnia, że zakres będzie poprawny, ale jeśli zbyt dużo wartości będzie brakowało i zostaną zastąpione, to wszystkie obiekty pod tym kątem staną się podobne, a to może spowodować, że wynik będzie zbyt optymistyczny. Autor najbardziej chwali trzeci sposób. Metoda zapewnia odpowiedni rozrzut wartości w danym zakresie. Na podstawie przeprowadzonych eksperymentów stwierdził, że prawdopodobieństwo wygenerowania zbliżonych do oryginalnych wartości jest dość duże. Przestrzega jednak, że nie zawsze mogą mieć sens w aspekcie całości obiektu (razem z innymi atrybutami). Jeśli chodzi o format bazy danych, to nie ma wiele pola do popisu. Format musi być odpowiedni, więc baza musi zostać przekonwertowana. Problemem może być wydajność przetwarzania ogromnej ilości wierszy. Może to trwać bardzo długo. Ostatni problem dotyczył wartości niezgodnych z logiką. Głównie dotyczy to wartości jakościowych, czyli etykiet, które nie powinny być porównywane z liczbami. Należy przyjąć jakąś miarę podobieństwa dla poszczególnych pól, tak aby porównanie miało sens logiczny, czyli np. pojęcie duży > mały. W przypadku wartości liczbowych często dane się normalizuje czyli przelicza na odpowiednią wartość z przedziału od 0,0 do 1,0.

12 2.4 Pozyskiwanie informacji o użytkownikach stron WWW Pozyskiwanie informacji o użytkownikach stron WWW W pracy zajmuję się analizą informacji o użytkownikach stron internetowych, dlatego nie mogę pominąć kwestii pozyskiwania danych ze stron WWW. Zazwyczaj można spotkać się z trzema podejściami Log serwera WWW Jednym ze sposobów jest analizowanie logów serwera stron internetowych. Log, jest to plik tekstowy, w którym zapisywane informacje o odwiedzinach danej strony internetowej. Szybki przegląd stron internetowych dotyczących eksploracji danych o użytkownikach serwisu internetowego pokazuje, że jest to najczęściej wykorzystywana metoda zbierania danych. Całą pracę wykonuje oprogramowanie serwera WWW, które zapisuje wszelkiego rodzaju informacje dotyczące każdego wejścia na stronę internetową. Mogą się tam znaleźć nazwy użytkowników, daty, numery IP oraz adresy odwiedzonych stron. Przykładowy plik loga zamieszczony jest na listingu 2.1. Fragment loga pochodzi ze strony internetowej Listing 2.1 Listing przedstawiający log serwera NASA [01/Jul/1995:00:00: ] "GET /history/apollo/ HTTP/1.0" unicomp6.unicomp.net - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/ HTTP/1.0" [01/Jul/1995:00:00: ] "GET /shuttle/missions/sts-73/mission-sts-73.html HTTP/1.0" burger.letters.com - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/liftoff.html HTTP/1.0" [01/Jul/1995:00:00: ] "GET /shuttle/missions/sts-73/sts-73-patch-small.gif HTTP/1.0" burger.letters.com - - [01/Jul/1995:00:00: ] "GET /images/nasa-logosmall.gif HTTP/1.0" burger.letters.com - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/video/livevideo.gif HTTP/1.0" [01/Jul/1995:00:00: ] "GET /shuttle/countdown/countdown.html HTTP/1.0" d104.aa.net - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/ HTTP/1.0" [01/Jul/1995:00:00: ] "GET / HTTP/1.0" unicomp6.unicomp.net - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/count.gif HTTP/1.0" unicomp6.unicomp.net - - [01/Jul/1995:00:00: ] "GET /images/nasa-logosmall.gif HTTP/1.0" unicomp6.unicomp.net - - [01/Jul/1995:00:00: ] "GET /images/ksc-logosmall.gif HTTP/1.0" d104.aa.net - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/count.gif HTTP/1.0" d104.aa.net - - [01/Jul/1995:00:00: ] "GET /images/nasa-logosmall.gif HTTP/1.0" d104.aa.net - - [01/Jul/1995:00:00: ] "GET /images/ksc-logosmall.gif HTTP/1.0" [01/Jul/1995:00:00: ] "GET /images/ksclogo-medium.gif HTTP/1.0" [01/Jul/1995:00:00: ] "GET /images/launch-logo.gif HTTP/1.0" Na pierwszy rzut oka wydaje się, że posiadamy wszelkie potrzebne informacje i możemy przestąpić do przetwarzania. Niestety nie jest tak dobrze, jak mogłoby się wydawać. Plik loga serwera może zawierać zarazem informacje nadmiarowe, jak i niekompletne. Nadmiarowość wynika z tego, że podczas łączenia się użytkownika ze stroną internetową serwisu przesyłane są oprócz treści stron internetowych także obrazki, czy reklamy podłączone do innych serwerów. Trzeba zatem przefiltrować zawartość pliku pozostawiając tylko informacje dotyczące wyłącznie aktualnego serwera i strony WWW. Wszystkie reklamy oraz obrazki i pliki dodatkowe muszą zostać odrzucone. Dodatkowo okazuje się, że część danych znajdujących się w pliku loga danych jest sztuczna i nie została zapisana w wyniku interakcji użytkownika z serwisem internetowym. Te sztuczne dane zostały wygenerowane przez roboty internetowe, które są programami komputerowymi przeszukującymi strony WWW. Robot odwiedza każdą stronę internetową serwisu którą może (poza dostępem wymagającym zalogowania). Dla naszej sprawy jest to kłopotliwe, ponieważ zaciemnia akcje użytkowników. Pytanie jakie się od razu nasuwa, to czy da się odróżnić działanie robota, od zwykłego użytkownika? Zdecydowanie tak. W pojedynczej linii loga, jak można było zobaczyć na listingu 2.1, znajdują się informacje dotyczące przeglądarki internetowej, z której korzystał użytkownik. Roboty internetowe wpisują tam swoje nazwy lub adresy stron internetowych wskazujących na konkretny program komputerowy. Istnieje nawet baza danych opisująca popularne roboty internetowe. Nie powinno być zatem problemu z pozbyciem się niechcianych wpisów.

13 2.4 Pozyskiwanie informacji o użytkownikach stron WWW 12 Aby wyjaśnić niekompletność danych w logach muszę najpierw zaznaczyć, że istniej kilka standardów takich plików. Standard określa jakie dane i w jakim formacie mają zostać zapisane do pliku. Większość serwerów nie zapisuje informacji o nazwie użytkownika mającej sens w ramach serwisu internetowego. Zapisywane są informacje o domenie z jakiej pochodzi komputer albo wyłącznie numer IP interfejsu sieciowego. Pozyskanie nazw użytkowników musi być przeprowadzone na podstawie dodatkowych plików, jak np. pliki cookies, które przechowują informacje o sesji użytkownika i jego logowaniu. Dopiero wtedy jednoznacznie można zidentyfikować użytkownika. Kolejnym problemem powodującym niekompletność danych jest używanie przez użytkowników przycisku wstecz w przeglądarkach. Powoduje to wczytanie ostatnio oglądanej strony z bufora programu. Nie jest wtedy wysyłane żądanie do serwera strony WWW, a co za tym idzie nie jest to odnotowane w logu. Gdybyśmy analizowali taki plik pod kątem sekwencji działań użytkownikami to mogłoby się okazać, że sekwencja nie ma sensu. Najprościej pokazać taką sytuację na przykładzie. Załóżmy, że możliwe jest przejście ze strony A do B oraz ze strony A do C. Przejście ze strony B do C nie jest możliwe. Przeanalizujmy pewien scenariusz: 1. Użytkownik odwiedza stronę A 2. Użytkownik odwiedza stronę B 3. Użytkownik wciska przycisk wstecz w swojej przeglądarce internetowej, co skutkuje wczytaniem strony A z bufora programu 4. Użytkownik przechodzi na stronę C W dzienniku odwiedzin zarejestrowane zostanie następujące przejście: A => B => C, co nie jest możliwe. Sposobem na taki absurd jest odtworzenie ścieżek serwisu internetowego na podstawie możliwych przejść. Aby jednak tego dokonać potrzebujemy dodatkowej wiedzy o strukturze serwisu internetowego. Używanie loga jako źródła danych dla eksploracji danych przestaje być zatem bez wad i nie nadaje się do wszystkich zastosowań bez wcześniejszego zweryfikowania danych Podsłuchiwanie połaczenia użytkownika z serwerem WWW Inną metodą na zebranie informacji o użytkowniku internetowym jest podsłuchanie komunikacji pomiędzy przeglądarką internetową klienta a serwerem WWW. Można to zrealizować na kilka sposobów. Jednym z nich jest podsłuchiwanie pakietów protokołów sieciowych przesyłanych po sieci. Kolejnym jest zastosowanie specjalnej wtyczki do przeglądarki internetowej, która będzie zapisywała informację o stronach internetowych w pliku tekstowym. Można spotkać kilka wtyczek tego typu do różnych przeglądarek internetowych. W przypadku pierwszej techniki wymagana są umiejętności programistyczne, ponieważ trzeba zadbać o odpowiednie skojarzenie ze sobą przesyłanych pakietów tak, aby przesyłane dane były spójne. Niespójności mogą się pojawić, ponieważ w ramach protokołu TCP jedna ramka informacji może być przesłana ponownie w przypadku błędów. W porównaniu do tej metody zastosowanie wtyczki w przeglądarce nie wymaga dodatkowej, żmudnej pracy. W obydwu przypadkach pozostaje problem identyfikacji użytkowników. Dla pierwszego sposobu można dowiedzieć się tego analizując np. adres odnośnika do strony, albo dodatkowe argumenty dla niego. Dla drugiego sposobu musimy przeprowadzić jawny zapis informacji personalnych dla każdego użytkownika korzystającego z przeglądarki na terminalu. Nie jesteśmy w stanie inaczej odróżnić, czy z serwisu internetowego korzysta Ania, czy Marek Dedykowany serwis internetowy Ostatnim sposobem pozyskiwania danych jest przygotowanie odpowiedniego serwisu internetowego, który sam będzie potrafił zapisywać niezbędne dla nas informacje. Zaletą tego rozwiązania jest to, że mamy te dane, o które nam się rozchodzi. Nie musimy przeprowadzać dodatkowej obróbki danych polegającej na filtrowaniu, uzupełnianiu ścieżek, czy też identyfikacji użytkowników. Niestety takie podejście ma jedną, ale za to dużą wadę. Wymaga stworzenia dedykowanego serwisu, a to oznacza, że jest to podejście jednorazowe. Oczywiście można stworzyć taki szkielet, który można by wykorzystać w wielu miejscach,

14 2.5 Strategie przygotowywania rekomendacji 13 jednak czy uda się go rozpowszechnić? Większa część serwisów internetowych chce zaskakiwać, zachęcać i wyróżniać się dlatego nie zdecyduje się na zakup takiego szkieletu. Sprawia to, że rozwiązanie jest kosztowne czasowo, a nie wiadomo, czy taki serwis będzie chętnie odwiedzany i przyniesie odpowiednio rekompensujący pracę dochód. 2.5 Strategie przygotowywania rekomendacji Kończąc analizę zagadnienia chciałem poruszyć zagadnienie strategii przygotowywania rekomendacji. Osoby, które na co dzień nie zajmują się handlem i usługami, mogą nie zdawać sobie sprawy z tego, że stosuje się pewne strategie sprzedaży, które mają na celu spowodowanie tego, aby klient myślał, że firma go rozumie i wychodzi naprzeciw jego potrzebom i zainteresowaniom. Istnieje wiele takich strategii. Każda zakłada realizację pewnych celów. Poniżej opisuję dwie szczególnie interesujące, bo najczęściej stosowane: sprzedaż krzyżowa (ang. cross-selling) sprzedaż rozszerzona (ang. up-selling) Sprzedaż krzyżowa polega na tym, że proponuje się klientowi produkty, które są często kupowane przez innych klientów. Przewidywanie takiego zainteresowania przeprowadza się na podstawie wcześniej zakupionych produktów. Strategia ta jest bardzo często spotykana w sklepach internetowych. Objawia się to tym, że na stronie internetowej sklepu występuje sekcja o tytule Ci którzy kupili produkt X kupili również.... Właśnie pod tym kątem opisałem techniki przygotowywania rekomendacji w swojej pracy. Analizowanie danych niezbędnych do przygotowania rekomendacji w ramach tej strategii może odbywać się w inny sposób. Można analizować dane o zakupach, jak wcześniej wspomniałem, ale można także analizować sekwencje zakupów konkretnych produktów. Aby lepiej zobrazować sytuację przytoczę pewien przykład. Załóżmy, że użytkownik sklepu internetowego zakupił aparat fotograficzny, a dokładnie lustrzankę cyfrową. W ofercie firmy znajduje się także szkolenie dotyczące obsługi aparatu i wykonywania profesjonalnych zdjęć. Na podstawie sekwencji zakupów innych użytkowników można dowiedzieć się, że osoby kupujące aparat typu lustrzanka niedługo po jego zakupie zdecydowały się na zakup profesjonalnego szkolenia. W przypadku sprzedaży rozszerzonej chodzi o to, aby klientowi proponować lepsze wersje produktów niż już posiada. Najlepszym przykładem pokazującym zastosowanie będzie sprzedaż produktów, na które nałożony jest abonament. Weźmy pod uwagę telewizję cyfrową. Klient zakupił dekoder i zdecydował się na odpowiedni pakiet kanałów telewizyjnych. Po jakimś czasie można zaproponować mu zmianę pakietu kanałów, które może oglądać lub przedstawić ofertę dodatkowych kanałów, które można wykupić bez przechodzenia na wyższy abonament. Opisane wyżej strategie są praktycznie wszędzie wykorzystywane. Dają obopólną korzyść. Klient jest zadowolony, bo oferta, która jest do niego kierowana jest rzeczowa i celuje w jego zainteresowania, natomiast firma zwiększa swoje dochody, a jednocześnie utrwala więź z klientem.

15 Rozdział 3 Techniki analizy danych Eksploracja danych wykorzystuje zdobycze wielu dziedzin nauki takich jak statystyka, matematyka czy uczenie maszynowe. Ma w związku z tym charakter interdyscyplinarny. Udostępnia szeroki wachlarz technik analizy danych. W kolejnych trzech rozdziałach swojej pracy przyjrzę się bliżej wybranym technikom analizy danych. Jest ich wiele, dlatego wybrałem kilka najbardziej ciekawych i popularnych. Dla każdej postaram się przedstawić ideę oraz zasadę działania. Wskażę również wady i zalety ich stosowania. Poruszę trzy rodziny technik analizy danych. Będą to: grupowanie klasyfikacja reguły asocjacji Każda z tych technik zajmuje się innym zadaniem. Grupowanie zajmuje tak zwanym uczeniem nienadzorowanym, w którym nie posiadamy informacji o etykietach obiektów znajdujących się w zbiorze. Z kolei klasyfikacja jest uczeniem z nadzorem, ponieważ przyporządkowanie etykiet do obiektów ze zbioru wykonywane jest przez zewnętrznego agenta (może być wykorzystane grupowanie), a klasyfikacja przyporządkowuje jeden obiekt do wybranej kategorii. Wymienione typy zadań można zaklasyfikować do zadań kombinatorycznych. Mają przeszukać jakąś przestrzeń rozwiązań w poszukiwaniu pewnych zależności. Największą pewność daje przeszukiwanie wszystkich możliwych, jednak jest to bardzo czasochłonne. Zakładając, że w grupowaniu mamy do rozmieszczenia w dwóch klasach tylko sto obiektów daje nam to możliwych rozmieszczeń. Żeby lepiej ocenić jak wielka jest to liczba napiszę tylko, że Sprawdzenie każdej możliwości, pamiętając, że mamy do czynienia z ogromnymi zbiorami informacji jest po prostu niemożliwe. Należy zatem skorzystać z bardziej wyrafinowanych metod, które w jakiś zoptymalizowany i konsekwentny sposób będą poszukiwały oczekiwanych rozmieszczeń, klasyfikacji czy asocjacji. W różnych metodach analizy pojawiają się często te pytania dotyczące tych samych problemów. Zanim rozpocznie się analizę trzeba sobie na nie odpowiedzieć. Takimi przykładowymi pytaniami mogą być: Jak mierzyć podobieństwo? Jak zakodować zmienne? Jak standaryzować lub normalizować wartości? Metody klasyfikacji czy grupowania badają podobieństwo między obiektami. Trzeba w jakiś sposób określić dlaczego obiekt A jest bardziej podobny do obiektu B niż do C. Aby zrozumieć zasady działania algorytmów trzeba najpierw poznać zasadę reprezentacji obiektów w systemie. W wielu omawianych przeze mnie metodach obiekty poddawane analizie są reprezentowane w postaci par cecha-wartość. Przykładowo obiekt osoba można przedstawić jako zestaw par: płeć-kobieta, wiek-28, wzrost-169 itd. Ilość cech dla obiektów tego samego typu jest identyczna. Różnią się one między sobą wyłącznie wartościami poszczególnych cech. Można to podejście uogólnić w momencie, jeśli kolejność występowania kolejnych cech

16 3 Techniki analizy danych 15 jest ustalona. Sprowadzi się to wtedy do reprezentacji w postaci wektora wartości cech danego obiektu. Taki sposób reprezentacji znajduje szerokie zastosowanie w metodach uczenia maszynowego. Wykorzystanie reprezentacji wektorowej pozwala na proste badanie podobieństwa pomiędzy obiektami. Można w tym celu posłużyć się miarami odległości wektorów. Ich działanie opiera się zazwyczaj na porównywaniu wartości kolejnych atrybutów dwóch obiektów. Chyba najbardziej popularną miarą jest miara euklidesowa wyrażona za pomocą wzoru 3.1. d Euklidesa (x, y)= (x i y i ) 2, (3.1) i Bardzo często spotykać można również miarę miejska zwaną też Manhattan, która wyrażona jest za pomocą wzoru: d Manhattan (x, y)= x i y i, (3.2) i Inne miary, które są chętnie używane, ale nie są opisywane tak często jak wcześniejsze, to miara Czybyszewa (wzór XXX) oraz miara Canberra (wzór XXX). d Czybyszewa (x, y)=max( x i y i ), (3.3) d Cranberra (x, y)= i x i y i x i + y i, (3.4) W przypadku, kiedy mamy do czynienia ze zmiennymi jakościowymi możemy posłużyć się prostą zasadą, która zakłada, ze jeżeli wartości wybranej cechy dwóch obiektów są równe, to wtedy miara odległości jest równa 0. W innym wypadku jest równa 1 (wzór 3.5). 0, gdy x i = y i d Jakościowa (x i, y i )= (3.5) 1, w przeciwnym wypadku Można również wyróżnić sytuację, w której dla pewnego atrybutu jakościowego wartości jest kilka. Jeżeli wartości będą zachowywały gradację to można będzie przyporządkować im liczby porządkowe. Przykładowo, jeżeli mamy atrybut wzrost o możliwych wartościach, duży, średni, mały, to przyporządkowujemy im wartości następująco: 0 - mały, 1 - średni, 2 - duży. Pozwoli to porównywać bez większych problemów wartości stawiając pomiędzy nimi znak nierówności. Algorytmy klasyfikacji oraz grupowania wymagają przeprowadzenia normalizacji danych, po to aby wartość jednego atrybutu ani ich podzbiór nie przekłamały porównania obiektów. W tym celu można zastosować jedną z dwóch metod: normalizację min-max lub standaryzację. Normalizację min-max przeprowadza się zgodnie ze wzorem 3.6. Jest to transformacja, która nadaje wektorowi długość 1 bez zmiany jego kierunku. normalizacja X = X min(x) max(x) min(x) Standaryzacja wykorzystuje do przekształcenia wartość średniej i odchylenia standardowego. Formalny zapis przedstawia wzór 3.7 standaryzacja X = X X (3.7) σ(x) Obydwie operacje przeprowadza się po kolei dla każdej składowej wektora cech wybranego obiektu. (3.6)
= (x i y i ) 2, (3.")
17 Rozdział 4 Grupowanie W literaturze można spotkać się z różnymi określeniami tych technik eksploracji danych. Najbardziej popularnymi określeniami są: analiza skupień i klastrowanie. Będę posługiwał się nimi zamiennie. Grupowanie jest rodziną metod, które można zaklasyfikować do uczenia bez nadzoru. Obiekty, które mają być poddane przetwarzaniu nie są w żaden sposób oznaczone. Przetwarzaniu podlega surowy zbiór nie posiadający dodatkowych informacji. Celem grupowania jest znalezienie pewnych wzorców, które niekoniecznie muszą być oczywiste i proste do odgadnięcia. Grupowanie może w ten sposób, jak sama nazwa wskazuje, pogrupować podobne obiekty lub rozmieścić je w uporządkowanej strukturze (najczęściej jest to struktura drzewiasta). Analizowane dane wpadają do różnych grup. W jednej grupie powinny być obiekty najbardziej do siebie podobne, natomiast dwa obiekty z dwóch różnych grup powinny być od siebie jak najbardziej odległe w sensie wybranej miary odległości. Rysunek 4.1 ilustruje ideę grupowania obiektów do trzech grup. Każdy obiekt opisany jest za pomocą wartości dla pewnych atrybutów, co pozwala umiejscowić go w jakimś układzie współrzędnych wielowymiarowych. Analiza skupień znajduje szerokie pole zastosowań w różnych dziedzinach. Na przykład na rynku usług informatycznych można kategoryzować użytkowników serwisów internetowych pod kątem ich potrzeb. W ten sposób można określić ich krąg zainteresowania produktami. Algorytmy wykorzystywane do przetwarzania danych zgodnie z ideą analizy skupień posiadają swoje charakterystyki. W związku z tym można przedstawić pewną klasyfikację metod grupowania: 1. Metody grupowania, które za kryterium przyporządkowania uznają podobieństwo obiektów oraz metody działające w oparciu o aparat statystyczny. 2. Metody grupowania, które deterministycznie określają przynależność do grupy (albo obiekt do niej trafia albo nie) oraz probabilistyczne. w którym dla każdego obiektu wyznaczane jest prawdopodobieństwo przyporządkowania do wszystkich dostępnych grup. Mamy wtedy wiedzę nie tylko o najlepszym dopasowaniu, ale także o kolejnych. 3. Metody grupowania, które pozwalają na utworzenie hierarchii obiektów lub takie które wszystkie grupy umieszczają w płaskiej przestrzeni. Pierwsze podejście pozwala rozróżnić pewne podgrupy wśród grup. Może się to przydać chociażby w identyfikowaniu kategorii stron internetowych. Drugie podejście traktuje wszystkie grupy jednocześnie i nie ustala wśród nich hierarchii. 4. Metody grupowania, które potrzebują całego zbioru, aby przeprowadzić proces grupowania oraz metody, które działają przyrostowo i są w stanie w danej chwili zająć się obiektami bez przyporządkowania i uaktualnić wynik grupowania bez analizy całego zbioru danych. Niewątpliwie utrudnieniem, które wynika z charakteru metody jest określenie poprawności rezultatów przetwarzania. Ciężko, o ile to w ogóle możliwe jest sformułować pewien warunek określający, czy grupowanie przebiegło zgodnie z oczekiwaniami analityka. Poprawność jest uzależniona od podejścia analityka. Jeśli wyda mu się interesujące, może on ocenić rezultat jako przydatny. Z kolei dla innej osoby taki wynik nie będzie miał sensu, ponieważ określenie tego, czy grupowanie jest interesujące zależy od zastosowania i
.")
18 4.1 Metody hierarchiczne 17 Rysunek 4.1: Idea grupowania danych jest w pewnym stopniu subiektywne. Istnieje kilka metod, które próbują szacować na ile grupowanie się powiodło. Ich działanie oparte jest na badaniu odległości pomiędzy obiektami w grupach. Im mniejsza suma odległości w każdej z grup, tym grupowanie było w pewnym sensie dokładniejsze. W ramach podrozdziału dotyczącego grupowania omówię trzy metody grupowania. Będą to: Metoda hierarchiczna z przedstawicielem w postaci grupowania aglomeracyjnego Metoda k-średnich Metoda wykorzystująca samo organizujące się mapy omówiona w oparciu o sieć Kohonena Postaram się przybliżyć zasadę ich działania, zastosowania oraz opiszę wady i zalety poszczególnych reprezentantów. 4.1 Metody hierarchiczne Metoda reprezentuje podejście hierarchiczne, które zalicza się do metod opartych na podziale. Wynikiem tej metody grupowania jest drzewo podziałów grup na podgrupy. Nazywa się je dendrogramem. Przykładowe drzewo podziałów prezentuje rysunek 4.2. Przedstawione drzewo prezentuje podział liczb na podstawie pewnego kryterium (nie jest ono w tej chwili ważne). Pionowa oś diagramu wyznacza podobieństwo poszczególnych grup na tym samym poziomie. Jak widać na rysunku, na samym dole każdy obiekt reprezentowany przez liczbę znajduje się w osobnej grupie. Na samej górze natomiast widać już tylko jedną grupę. Od razu nasuwa się wniosek, że grupowanie hierarchiczne za pomocą podziału mogłoby się wykonywać w obydwu kierunkach. Tak właśnie jest. Wyróżnia się dwa podejścia do klastrowania hierarchicznego. Pierwsze z nich jest nazywane aglomeracyjnym i zakłada ścieżkę przejścia od dołu do góry dendrogramu. Początkowo algorytm pracuje na pojedynczych obiektach (w całości jest zapisany za pomocą diagramu blokowego na rysunku XXX). Umieszcza każdy z nich w osobnej grupie, a następnie porównuje takie grupy ze sobą i stara się je łączyć w coraz większe grupy, aż pozostanie wyłącznie jedna. Z kolei drugie podejście, nazywane rozdzielającym, zakłada, że

19 4.1 Metody hierarchiczne 18 Rysunek 4.2: Przykładowy dendrogram powstały w wyniku przeprowadzenia grupowania hierarchicznego cały zbiór obiektów tworzy jedną grupę, a zadaniem algorytmu jest tak podzielić tą wejściową grupę, aby każdy z obiektu znajdował się w osobnej grupie. Jest to trudniejsze podejście, ponieważ należy określić jak daną grupę będziemy dzielić. Największą uwagę należy w tej metodzie przyłożyć do kryterium podziału. Analiza skupień w oparciu o algorytm aglomeracyjny jest prostsza i o wiele bardziej popularna. Wynika to z tego, że wystarczające jest posługiwanie się miarą odległości (bądź podobieństwa, które jest przeciwnością odległości) pomiędzy obiektami jako kryterium. Należy jednak zauważyć, że miara odległości pomiędzy obiektami jest wykorzystywana tylko w pierwszym kroku, gdy każdy obiekt znajduje się w osobnym skupieniu. W takiej sytuacji miara odległości (podobieństwa) pomiędzy skupieniami jest równa mierze odległości pomiędzy obiektami. Co w przypadku, gdy mamy porównać grupy na wyższym poziomie, które składać się mogą z innych podgrup? Można uogólnić miary tak, by można było je stosować dla grup. Daniel Larose wyróżnia cztery metody uogólniania miary podobieństwa. Zakładając, że S 1 oraz S 2 są dwoma skupieniami zawierającymi wektory cech d. Podobieństwosim(S 1,S 2 ) można zdefiniować jako: odległość pomiędzy centroidami grup - za podobieństwo dwóch skupień uznawane jest podobieństwo centroidów tych skupień, gdzie centroid skupienia jest zdefiniowany jako c= 1 d, S sεs maksymalne podobieństwo - algorytm używający tej miary nazywany jest grupowaniem najbliższych sąsiadów. Za podobieństwo uznaje maksymalne podobieństwo wektorów w tych grupach. minimalne podobieństwo - liczone jest analogicznie jak maksymalne podobieństwo, z tym, że zamiast funkcji maksimum wykorzystywana jest funkcja minimum. średnie podobieństwo - jako podobieństwo dwóch skupień przyjmowane jest średnie podobieństwo wektorów tych skupień Algorytm aglomeracyjny pnie się w górę drzewa podziału, aż do scalenia wszystkich grup. Można jednak wprowadzić dodatkowe kryteria i zatrzymać algorytm wcześniej. Wszystko zależy od tego, czy zależy nam na określonej ilości grup, czy współczynniku podobieństwa pomiędzy grupami. Wady i zalety Na pewno do zalet można zaliczyć prostą kontrolę nad wykonywaniem się algorytmu. W zależności od zapotrzebowania można przerwać wykonywanie otrzymując wymagany podział obiektów. Nieocenioną zaletą jest tworzenie się hierarchii obiektów. Niektóre zadania, takie jak choćby katalogowanie produktów czy stron internetowych wymaga podziału na podkategorie. W przypadku algorytmu aglomeracyjnego ogromnym plusem jest prostota uogólnienia miar odległości i podobieństwa na grupy obiektów, co praktycznie zwalnia z dobierania nietrywialnego kryterium podziału.

20 Rysunek 4.3: Diagram blokowy dla algorytmu grupowania aglomeracyjnego (maksymalizujacy podobieństwo)

21 4.2 K-średnich 20 Jedną z poważniejszych wad algorytmu jest jego wydajność. Wymaga dość wielu obliczeń. Aby porównywać ze sobą obiekty musimy już na początku programu znać wszystkie podobieństwa każdej możliwej pary. Daje to złożoność czasową rzęduo(n 2 ). Jeśli chcielibyśmy możliwie wydajnie zaimplementować algorytm powinniśmy na samym początku policzyć miary podobieństwa i przechować je w pamięci, aby od razu były dostępne. Wiąże się to ze złożonością pamięciową rzędu O(n 2 ). Wniosek z tego płynie taki, że nie da się wykorzystać tego algorytmu dla dużych zbiorów danych. Związany jest z tym faktem inny problem. Interpretowanie drzewa podziału przy dużych ilościach danych byłoby niemożliwe dla analityka, co przeczyłoby z ideą pomocy tego narzędzia w jego pracy. 4.2 K-średnich Algorytm K-średnich jest bardzo dobrym przykładem algorytmu, który w prosty i obrazowy sposób prezentuje zasadę optymalnego przeszukiwania przestrzeni rozwiązań. Nadaje się do przeprowadzania analizy skupień dla dużych zbiorów danych. Jego zasady działania są proste i zrozumiałe. Wiadomo czego można spodziewać się po tej metodzie, dlatego jest chętnie wykorzystywana przez statystyków. Występuje kilka różnych odmian tego algorytmu, które do podstawowej wersji wprowadzają dodatkowe mechanizmy optymalizacji. Nazwa metody wzięła się stąd, że działa w oparciu o pewną stałą ilość średnich wartości podobieństw w grupach. Liczbę pożądanych grup określa parametr k. Aby rozpocząć przetwarzanie tą metodą na wejściu musimy mieć zdefiniowane dwa elementy: Przygotowany zbiór obiektów (np. w reprezentacji wektorowej - znormalizowanej) Parametr k Jak wspomniałem zasada działania metody jest bardzo prosta. Opiera się na migrowaniu obiektów pomiędzy grupami do momentu, aż żaden z obiektów nie zmieni już grupy. Cały algorytm można zapisać w kilku następujących krokach: 1. Wybieramy k obiektów ze zbioru wejściowego, które mają reprezentować centroidy skupień. Zazwyczaj są one wybierane losowo, ale spotyka się implementację, gdzie wybierane są one w jakiś ustalony sposób, np. tak aby pokryć odpowiednio przestrzeń rozwiązań. 2. Dla każdego obiektu ze zbioru obiektów wyznaczamy skupienie, do którego ma należeć. Przeprowadzane jest to z użyciem miary podobieństwa (lub odległości) do każdego z wybranych k-centroidów. Jeśli odległość jest najmniejsza, lub podobieństwo największe, to wybrany obiekt wpisujemy do grupy reprezentującej przez odpowiedni centroid. 3. Po zakończeniu dowiązywania obiektów do grup wyliczamy ponownie centroidy grup używając zebranych informacji o obiektach z danej grupy. 4. Jeżeli żaden obiekt nie zmienił swojej grupy, to kończymy działanie algorytmu. W innym przypadku wykonujemy kroki od punktu 2 włącznie. Najważniejszym punktem w wypisanych wyżej krokach jest punkt numer 2. Decyduje on o tym jaki obiekt do jakiej grupy trafi. Odbywa się to za pomocą funkcji kryterialnej grupowania, której zadaniem jest maksymalizowanie podobieństwa wewnątrz grupy. Sama funkcja kryterialna, jak wynika z algorytmu, jest oparta o centroid grupy, natomiast samo grupowanie oparte jest o uśrednione podobieństwo. Wady i zalety W podstawowej odmianie algorytmu początkowe centroidy wyznaczające skupienia są wybierane losowo. Każda losowość w algorytmach nie jest mile widziana. Tak jest też w tym wypadku. Powoduje ona to, że w kolejnych uruchomieniach algorytmu mogą się wylosować inne środki grup. W rezultacie może to całkowicie zmienić wynik przetwarzania. Aby uznać wyniki za wiarygodne należałoby uruchomić kilkakrotnie grupowanie aby potwierdzić ich prawdziwość. Najlepszym rozwiązaniem będzie to rozwiązanie,
22 Rysunek 4.4: Diagram blokowy dla algorytmu grupowania metoda k-średnich
23 4.3 Samoorganizujaca się mapa 22 które będzie maksymalizowało podobieństwo w grupach. Da się to ocenić metodą podobną do sumy kwadratów. Dla każdej ustalonej grupy należy sumować podobieństwo obiektu i centroidu tej grupy. Formalny zapis przedstawia wzór 4.1 (oznaczmy za pomocą symbolu x obiekt ze zbioru danych D, natomiast c jako centroid k-tej grupy): k i=1 j x j εd i sim(c i,x j ), gdzie jε 1, D i (4.1) Może się okazać, że podczas przeszukiwania przestrzeni rozwiązań zostanie pominięte dobre rozwiązanie skupieniowe, ponieważ samo przeszukiwanie jest ograniczone do małej przestrzeni możliwych podziałów. Maksymalizacja funkcji kryterialnej odbywa się lokalnie. Rozwiązaniem tego problemu również jest wielokrotne przeprowadzenie grupowania z różnymi początkowymi środkami skupień (to akurat zapewnia nam losowy wybór). Metoda k-średnich jest niewątpliwie jedną z najbardziej popularnych i lubianych przez analityków. Nadaje się do wykorzystania dla dużych zbiorów danych. Jest prosty i stosunkowo wydajny. Na wydajność ma wpływ zbiór danych. Jeśli zawiera obiekty dobrze od siebie oddzielone będzie szybciej zbieżny. Złożoność tego algorytmu wynosi O(kni) gdzie: i - liczba iteracji głównej pętli algorytmu k - ilość skupień n - ilość obiektów Dodatkową zaletą jest stosunkowo proste przetransformowanie go do algorytmu hierarchicznego. Wymagałoby to rekurencyjnego wywoływania dla każdej z ustalonych grup. Metoda doczekała się wielu modyfikacji. Wprowadzono różne ciekawe mechanizmy, które mają usprawnić przeszukiwanie przestrzeni dostępnych rozwiązań skupieniowych. Jednym z nich jest dzielenie i łączenie skupień. Podobnie jak to się odbywa w grupowaniu hierarchicznym. Odbywać miałoby się to za pomocą przenoszenia pomiędzy skupieniami tylko jednego obiektu w danej chwili, po czym następowałaby ocena rozwiązania. Na podobnych zasadach działa algorytm optymalizacji obliczeniowej nazywany symulowanym wyżarzaniem, który wybiera początkowe rozwiązanie, a następnie je modyfikuje w ustalony sposób i sprawdza, czy jest ono lepsze od poprzedniego. 4.3 Samoorganizujaca się mapa Grupowanie za pomocą samoorganizujących się map wykorzystuje w swoim działaniu sieci neuronowe. Sieci neuronowe są mechanizmem bardzo popularnym i chętnie wykorzystywanym na różnych polach informatyki. Zastosowania można wymieniać bez końca. O wiele krócej, niż wymienianie zastosowań, trwało by wymienianie zadań, w których sieci neuronowych nie można użyć. Jako przykład można wymienić aproksymację funkcji, kompresję obrazów, rozpoznawanie pisma odręcznego, czyli de facto klasyfikację, która polega na przyporządkowaniu pewnemu obrazkowi odpowiadającej mu litery z alfabetu oraz właśnie grupowanie. Zanim jednak rozpocznę omawianie grupowania za pomocą samoorganizujących się map wyjaśnię czym właściwie jest sieć neuronowa Sieć neuronowa Informatyka, tak jak wiele innych nauk próbuje czerpać z natury ile się tylko da. Nie ma na świecie bardziej zmyślnych mechanizmów, niż te, które pozwalają przetrwać organizmom żywym. Sieć neuronowa wzorowana jest na mózgu. Idea i zasada działania sieci neuronowych w informatyce jest bardzo zbliżona do działania jej biologicznego odpowiednika. Jak zapewne łatwo się domyślić niemożliwym byłoby dokładne odwzorowanie zachodzących w mózgu procesów dlatego wprowadzono pewne uproszczenia. Sieci neuronowe zbudowane są z połączonych ze sobą neuronów - odpowiedników biologicznych komórek nerwowych. Mogą mieć budowę warstwową, co oznacza, że wybrany neuron z warstwy jest połą-
24 4.3 Samoorganizujaca się mapa 23 czony ze wszystkimi neuronami z warstwy kolejnej. Sieci neuronowe mogą charakteryzować się różnymi właściwościami. Na właściwości największy wpływ ma budowa pojedynczego neuronu. Model matematyczny jest bardzo prosty. Podstawowy neuron jest elementem liniowym i składa się z ustalonej liczby wejść, elementu sumującego oraz wyjścia. Rysunek 4.5 przedstawia jego schemat budowy. Zasada działania pojedynczego neuronu również jest bardzo prosta. Na wszystkie wejścia neuronu podawany jest sygnał. Każde z wejść posiada swój współczynnik wagowy. Nazwa się wzięła stąd, że owy współczynnik może być interpretowany jako znaczenie wybranego wejścia. Wartość wyjściowa y neuronu, będąca odpowiedzią na zadany sygnał jest sumarycznym pobudzeniem neuronu, często oznaczanym jako -net. Zakładając, że neuron posiada n wejść, z których każde i-te wejście posiada swoją wagę w i, to wartość będącą odpowiedzią neuronu można opisać za pomocą wzoru 4.2: y=net = k i=1 w j x j (4.2) Analizując wzór 4.2 można zauważyć, że całkowite pobudzenie neuronu zależy od stopnia podobieństwa poszczególnych elementów x j sygnału x z odpowiadającymi im współczynnikami wagowymi w j wektora wag w. Im większe jest to podobieństwo tym większa będzie wartość pobudzenia neuronu. Rysunek 4.5: Schemat przedstawiajacy budowę neuronu Celem postawionym przed siecią neuronową jest przystosowanie się do pewnego sygnału, aby móc odpowiadać zgodnie z jakimś założeniem. Proces adaptacji do sygnałów nazywany jest uczenie albo trenowaniem sieci neuronowej. Uczenie odbywa się za pomocą przykładów. Pojedynczy przykład składa się z dwóch elementów < x,z>, gdzie x, to wektor wartości wejściowych, a z - wartość oczekiwana. Uczenie odbywa się poprzez prezentowanie przykładów i sprawdzanie jak bardzo różni się odpowiedź sieci neuronowej od wartości oczekiwanej. Podczas nauki trzeba potrafić oceniać, czy sieć neuronowa, a w tym przypadku pojedynczy neuron już został nauczony. Najwygodniejszym i zarówno najczęściej spotykanym kryterium oceny jakości nauki jest błąd średnio kwadratowy wyrażony wzorem 4.3(gdzie p - ilość przykładów) : E(W)= 1 2 p p=1 (z p y p ) 2 (4.3) Korzystając z powyższego kryterium możemy stwierdzić, czy sieć neuronowa powinna być dalej poddawana procesowi nauki. Trzeba jeszcze wyjaśnić jak przebiega sama nauka, bo przecież podawanie w nieskończoność przykładów nic nowego nie wprowadzi. Najbardziej podstawową metodą nauki sieci neuronowej (również dotyczy pojedynczego neuronu) jest reguła delta. Została wprowadzona przez panów Widrowa oraz Hoffa w roku 1960 i jest do tej pory z sukcesami wykorzystywana. Modyfikacjom podlega wektor wagowy każdego neuronu. Liniowy neuron podlegający nauce nosi nazwę ADALINE, czyli ADAptive LInear NEuron. Załóżmy, że ilość iteracji nauki jest skończona. W każdej i-tej iteracji wagi będą zmodyfikowane zgodnie z zależnością 4.4:
25 4.3 Samoorganizujaca się mapa 24 w i+1 = w i + w i (4.4) Jest to ogólne podejście poszukiwania optymalnego zestawu wag. W każdej iteracji wektor wagowy jest odpowiednio korygowany, aby był jak najbardziej podobny do wektora sygnałów wejściowych. Jeśli odpowiedź sieci na zadany wektor wejściowy jest większa niż wartość oczekiwana y>z, to wtedy z definicji iloczynu skalarnego dla dwóch wektorów kąt pomiędzy tymi wektorami będzie za mały i należy go zwiększyć. Sprowadza się to do zmiany kierunku wektora wagowego w kolejnej iteracji, czyli de facto odpowiedniej zmiany poszczególnych jego wartości. Ostateczną formułę reguły delta przedstawia wzór 4.5. w i+1 = w i + α(z i y i ) x i (4.5) Współczynnik α określa jak duża zmiana powinna być zastosowana dla wybranej iteracji. Nazywany jest często krokiem nauki, natomiast różnica wartości oczekiwanej oraz odpowiedzi sieci (z y) jest oznaczana jako δ. W zrozumieniu całego mechanizmu może pomóc rysunek 4.6. Przedstawia on schematyczną ścieżkę sygnałów w liniowym neuronie inne sieci. Rysunek 4.6: Schemat procesu nauki pojedynczego neuronu realizowanego przez adaptację wektora wagowego Jak wspomniałem wcześniej duże znaczenie w zachowywaniu się sieci neuronowych mają same neurony. Występuje wiele wariacji dotyczących samej budowy. Najczęściej mówi się o neuronach z pojedynczym wyjściem tzw. zdegradowanych, ale można spotkać także takie, które mają tych wyjść kilka. Takie rozwiązania stosuje się zazwyczaj przy szybkich przekształceniach liniowych Sieć Kohonena Sieć Kohonena jest siecią samoorganizującą wymyśloną w latach 80 przez norweskiego uczonego Teuvo Kohonena. Do tej pory jest z powodzeniem znajduje swoje zastosowania. Na jej podstawie powstało wiele
26 4.3 Samoorganizujaca się mapa 25 innych zmodyfikowanych samoorganizujących się sieci neuronowych. Omówienie sieci Kohonena należy zacząć od wyjaśnienia czym tak właściwie jest sieć samoorganizująca się. Sieć neuronowa może być uczona z nauczycielem lub może uczyć się sama. W nauczaniu z nauczycielem potrzebny jest arbiter, który stwierdzi, czy proces musi być kontynuowany oraz nadzoruje każdy etap nauki. W przypadku nienadzorowanej sieci neuronowej taki arbiter nie jest konieczny. Sieć potrafi sama stwierdzić jak ma się uczyć. Siłą samoorganizujących się sieci neuronowych jest to, że potrafią one nie tylko samodzielnie się uczyć, ale także potrafią uzgadniać i rozdzielać odpowiedzialność pomiędzy wszystkie neurony. Daje to możliwość znajdowania ciekawych i często bardzo złożonych odwzorowań, które zazwyczaj nie mogą zostać deterministycznie określone lub przewidziane. Sieć Kohonena nosi nazwę warstwy topologicznej. Jest tak, ponieważ w podstawowej wersji, jest to pojedyncza warstwa neuronów, z których każdy ma n-elementowy wektor wag i jedno wyjście, gdzie wystawiana jest odpowiedź na zadany sygnał. Jednowarstwową sieć Kohonena przedstawia rysunek 4.7. Na rysunku kółkami oznaczone są neurony, natomiast prostokąty oznaczają wejścia sieci. W praktycznych Rysunek 4.7: Architektura jednowarstwowej sieci Kohonena rozwiązaniach sieci Kohonena oraz inne sieci samoorganizujące obsługują nie jedno (jak na rysunku schematycznym), ale nawet do kilkudziesięciu wejść. Stąd stwierdzenie faktu, że nadają się dla znajdowania bardzo złożonych odwzorowań (wiele zmiennych). Ilość wyjść może być jeszcze większa, ponieważ rozmiary sieci mogą osiągnąć niebagatelne rozmiary. W warstwie topologicznej może znaleźć się nawet tysiące neuronów. Do działania sieci neuronowej niezbędny jest n-elementowy wektor wartości wejściowych, który jest wysyłany do każdego j-tego neuronu ( j = 1,..,m oraz mε N). Wektor wagowy każdego neuronu musi posiadać taki sam rozmiar jak wektor wartości wejściowych, aby można sprawdzić podobieństwo dwóch wektorów. Podobieństwo jest utożsamiane z miarą odległości, czyli im wartość miary odległości jest większa, tym podobieństwo wektorów mniejsze. Jeśli wartość miary odległości jest równa 1, to wektory są identyczne. Do wyliczania miary odległości można wykorzystać dowolną metodę opisaną przeze mnie na stronie na stronie 15. Ważne jest, aby obydwa wektory brane do porównywania były znormalizowane. Zapewnia to, że wpływ na wynik porównania będą miały jedynie kierunki wektorów w przestrzeni wielowymiarowej. Ich długość będzie taka sama i równa jedności. W swojej książce [1]prof. Osowski zwraca uwagę na fakt, ze wystarczy, aby wektor wartości wejściowych będzie znormalizowany, a wektor wagowy, który będzie poddawany adaptacji będzie dążył do upodobnienia się do wektora wartości. W efekcie zostanie znormalizowany. Do przeprowadzenia normalizacji można skorzystać z metody Minimum-Maksimum, opisywanej wcześniej we wprowadzeniu (rozdział 3 na stronie 15 - wzór 3.6). Istnieje też inna metoda (wzór 4.6) normalizacji, którą można zastosować [2, 1].
27 4.3 Samoorganizujaca się mapa 26 x i = x i (4.6) n (x j ) 2 j=1 Mechanizm samoorganizacji oparty jest o istnienie sąsiedztwa pomiędzy neuronami. nie znaczy to, że są ze sobą połączone i wymieniają się wartościami, ale leżą względem siebie blisko. Określenie bliskości może być interpretowane dwojako. Pierwsze podejście opiera się na położeniu neuronów, które tworzą mapę. Dokładne określenie zależy od organizacji mapy neuronów. Może to być zwykła lista, płaszczyzna lub jakaś bryła w przypadku trzech wymiarów. Drugie podejście określa bliskość na podstawie odpowiedzi na zadany sygnał wejściowy. W zależności od odpowiedzi neurony są szeregowane od najlepszego do najgorszego. Będą wtedy wiedziały jaki neuron o podobnym przystosowaniu do sygnału leży obok, albo dwa pola dalej. Rysunek 4.8: Sasiedztwo neuronów w sieci Kohonena Rysunek 4.9: Szczególny przypadek sasiedztwa - sasiedztwo jednowymiarowe Przykładowe podejścia do realizacji sąsiedztwa pokazane są na rysunkach 4.8 i 4.9 (im dalej od wybranego neuronu, tym słabsze nasycenie koloru). Najczęściej stosowane jest to z rysunku 4.8 ponieważ utożsamiane jest z mapą działania neuronów, która może dać ciekawy efekt wizualizacyjny. Na wspomnianym rysunku przerywanymi liniami zostały oznaczone dodatkowe połączenia, które nie zawsze są uwzględniane. Można to potraktować jako rozszerzoną wersję sąsiedztwa. Sąsiedztwo odgrywa ważną rolę w adaptacji wektora wagowego każdego neuronu. Określa, czy wybrany neuron powinien być poddawany nauce czy też nie. Są także takie metody wyznaczania współczynnika sąsiedztwa, które poza odpowiedzią TAK/NIE pozwalają uczyć neuron w mniejszym stopniu. W samoorganizujących się mapach odwzorowań działających w oparciu o algorytm Kohonena najpierw określa się zwycięzcę rywalizacji stosując wybraną miarę odległości wektora wag w neuronu oraz wektora wartości wejściowych x, a następnie wylicza się wartość współczynnika adaptacji neuronów należących do sąsiedztwa neuronu wygranego. Wartość tego współczynnika decyduje o szybkości zmian wag neuronów sąsiadujących z wygranym w pewnym promieniu λ. Adaptacja wag i-tego neuronu odbywa się zgodnie z zależnością 4.7 (w z - wektor wag neuronu wygrywającego rywalizację): w i = w i + η G(w i,w z ) [x w i ] (4.7) Współczynnik η określa jak szybko ma przebiegać uczenie. Prof. Ryszard Tadeusiewicz wyjaśnił działanie współczynnika nauki za pomocą prostej anegdoty [3]. Naukę neuronu można przyrównać do
28 4.3 Samoorganizujaca się mapa 27 skaczącego kangura pomiędzy dwoma pagórkami, któremu zasłonięto oczy. On wie, w którym kierunku ma skoczyć, ale nie wie jak duży ma być to skok, aby trafił w odpowiednie miejsce. Będzie próbował dopóki mu się uda. Wracając do adaptacji wag. Do wyliczania współczynnika sąsiedztwa można wykorzystać jedną z kilku wariantów funkcji sąsiedztwa G(i,i z ): Klasyczna - podstawowa funkcja sąsiedztwa dla algorytmu Kohonena. Uczy neurony w takim samym stopniu jeśli znajdują się w odpowiedniej odległości od neuronu wygrywającego { 1 dla w=w G(w,w z )= z (4.8) 0 dla w w z WTA (zwycięzca bierze wszystko) - adaptacji podlega tylko neuron zwycięzcy { 1 dla d(w,w G(w,w z )= z ) λ 0 dla pozostalych (4.9) Gauss a - bardziej złożona funkcja sąsiedztwa. Im dalej od neuronu wygrywającego tym współczynnik sąsiedztwa mniejszy G(w,w z )=e d2 (w,wz) 2 λ 2 (4.10) Początkowe wartości wektorów wagowych dla wszystkich neuronów są ustalane losowo z zadanego przedziału. Może zdarzyć się taka sytuacja, że część neuronów będzie na tyle daleko od pozostałych, że nie będzie miała szans zaklasyfikować się do grupy podlegającej nauce. Trzeba o to zadbać, bo w przeciwnym razie wyniki uzyskane mogą być niedokładne. Sytuacja ta może też mieć miejsce gdy jeden z neuronów, lub grupa jest o wiele lepiej przystosowany niż inne. W rezultacie tylko on będzie adaptowany, a reszta nie. Rozwiązaniem tego problemu jest wprowadzenie drobnej modyfikacji nazywanej mechanizmem zmęczenia neuronów. Kiedy jest wykorzystywany pozwala na zapewnienie udziału wszystkich neuronów w samoorganizacji. Uwzględnia liczbę zwycięstw poszczególnych neuronów i organizuje proces uczenia w taki sposób, aby dać szansę zwycięstwa neuronom mniej aktywnym. Działanie tego mechanizmu jest oparte o zachowanie się neuronów biologicznych. Jeśli neuron wygra rywalizację, to zaraz po zwycięstwie będzie odpoczywał określony czas przed następnym współzawodnictwem. Jedno z podejść do tego mechanizmu zakłada zastosowanie wartości potencjału p (gdzie p ε[0 : 1] ) dla każdego neuronu, który jest modyfikowany, podczas każdej k-tej prezentacji wzorca wejściowego x n-neuronom: p i (k+ 1)={ pi (k)+ 1 n p i (k) p min (4.11) Wartość potencjału minimalnego p min decyduje o tym, kiedy przestawić stan neuronu na odpoczywa.jeśli aktualna wartość potencjału spadnie poniżej p min, to i-ty neuron będzie miał zmieniony stan i nie będzie brał udziału w rywalizacji do czasu, aż jego potencjał nie wzrośnie, czyli da szansę na zwycięstwo innym neuronom. W literaturze nie ma podanego jednoznacznego sposobu na określanie błędu sieci Kohonena. Wynika to w pewnym stopniu z faktu, że sieć uczy się bez nadzoru, a więc z definicji nie ma złych i dobrych odpowiedzi. Jedną z możliwości jest badanie wektorów błędu jako odległości między wektorami ze zbioru uczącego a najbliższymi względem nich wektorami wag neuronów, czyli wektorów wag zwycięzcy. Odległość tych wektorów może w pewnym stopniu informować o zdolności sieci do grupowania danych. Można jednak z powodzeniem przyjąć następującą metodę pomiaru błędu sieci Kohonena: gdzie: E = 1 p p i=1 x i w i (4.12) p ilość wzorców prezentowanych sieci,
29 4.3 Samoorganizujaca się mapa 28 x i wektor wartości sygnału wejściowego dla wybranego wzorca, w i wektor wag neuronu wygrywającego dla wybranego wzorca Cały algorytm można zapisać w następujących krokach (zakładam, że dane wejściowe są już odpowiednio przygotowane): i jest licznikiem epok j jest licznikiem wektorów wejściowych p min minimalna wartość potencjału, która dopuszcza neuron do rywalizacji Wszystkie neurony na początku nauki posiadają stan aktywny oraz potencjał pozwalający im brać udział w rywalizacji. 1. i=0; j=0 ; ZMECZENIE=TRUE ; ZMNIEJSZAJWSPNAUKI= FALSE ; 2. Wylosuj wagi dla wszystkich neuronów warstwy odwzorowującej 3. Jeśli wartość licznika i osiągnęła wartość równą liczbie epok, po której ma nastąpić wyłączenie zmęczenia, to ZMECZENIE= FALSE oraz ZMNIEJSZAJWSPNAUKI=TRUE 4. Przetasuj zbiór wzorców 5. Jeśli ZMNIEJSZAJWSPNAUKI=TRUE, to zmniejsz wartość współczynnika nauki η 6. Jako wartości neuronów warstwy wejściowej ustaw wartości j-tego wzorca 7. Policz miary odległości wektorów wagowych każdego neuronu oraz wektora wzorcowego 8. Znajdź neuron wygrywający (tylko wśród neuronów aktywnych), czyli ten o najmniejszej odległości wektora wagowego od wektora wzorca 9. Dla każdego neuronu warstwy odwzorowującej policz współczynnik adaptacji jako wartość funkcji sąsiedztwa względem neuronu zwycięskiego 10. Jeśli mechanizm zmęczenia neuronów jest włączony, to policz nowa wartość potencjału i w oparciu o wartość p min uaktualnij stan neuronu 11. Uaktualnij wartości wag wszystkich neuronów wykorzystując policzone wartości współczynnika adaptacji 12. Zwiększ licznik wzorców j 13. Jeśli pozostały jeszcze jakieś wzorce do podania w tej epoce, to idź do punktu 6, w innym wypadku kontynuuj 14. Policz błąd dla i-tej epoki 15. Zwiększ licznik epok i 16. Jeśli wartość licznika i jest mniejsza od maksymalnej ilości epok oraz błąd sieci nie osiągnął jeszcze pożądanej wartości, to idź do punktu 3, w innym wypadku KONIEC
30 4.3 Samoorganizujaca się mapa 29 Rysunek 4.10: Diagram blokowy dla algorytmu grupowania za pomoca sieci Kohonena Wady i zalety Sieć Kohonena jako reprezentant grupy samoorganizujących się sieci neuronowych jest uogólnieniem metody K-średnich. Zasada działania jest podobna. Różnice widać w etapie zmiany środków centroidów grup. W algorytmie K-średnich są one wybierane na nowo, natomiast w algorytmie Kohonena są one odpowied-
31 4.3 Samoorganizujaca się mapa 30 nio adaptowane w kolejnych etapach uczenia. Bardzo ciekawym urozmaiceniem w stosunku do metody K-średnich jest reprezentacja graficzna, która jest również poszukiwanym rozwiązaniem. Jest to mapa, która każdej próbce przyporządkowuje informację o neuronie, który do niej najlepiej pasuje. Neuron ten jest środkiem grupy. Metoda grupowania za pomocą sieci Kohonena może być stosowana w różnych problemach grupowania. Jest w stanie znaleźć odpowiednie powiązania dla problemów o wielu zmiennych i wielu grupach. Grupowanie jest metodą odkrywania wiedzy, która ma sens w pewnym wąskim zagadnieniu. To osoba zlecająca badania musi wiedzieć jakich wyników oczekuje. Algorytm Kohonena wymaga podania odpowiedniej reprezentacji danych wejściowych. Muszą one być odpowiednio przygotowane tak jak dla innych metod grupowania. Przykładowo, gdy analizujemy dane księgarni internetowej i chcemy poznać jakimi gatunkami książek są zainteresowani wybrani klienci, musimy przygotować odpowiednio wektory wejściowe reprezentujące ilość kupionych przez klienta książek z każdej kategorii, a następnie tak przygotowane dane przekazać sieci neuronowej. Wyniki działania algorytmu zależą od ustalonych warunków początkowych. Wagi neuronów są ustalane w sposób losowy, dlatego aby potwierdzić uzyskany rezultat przetwarzanie powinno być przeprowadzone kilkukrotnie.
32 Rozdział 5 Klasyfikacja Klasyfikacja należy do metod uczenia z nadzorem. Zadanie klasyfikacji polega na podaniu pewnej reguły decyzyjnej dla rozpatrywanej próbki obserwacyjnej. Często mówi się też o regule dyskryminacyjnej lub klasyfikacyjnej. Aby taka reguła decyzyjna mogła zostać utworzona dane podlegające przetwarzaniu muszą posiadać pewną ilość niezbędnych informacji. Zbiór danych zazwyczaj nazywa się populacją, a elementy tego zbioru próbkami obserwacyjnymi lub obiektami. Zakłada się również istnienie zbioru klas, czy też etykiet, które w odpowiedni sposób podsumowują każdy obiekt. Przykładem takiego zbioru klas może być {dobry samochód miejski, zły samochód miejski}. Każdy obiekt ma swoją charakterystykę opisywaną przez pary atrybut - wartość. Są to cechy obiektu, na podstawie których podejmowana jest decyzja dotycząca przyporządkowania etykiety ze zbioru etykiet dla tego obiektu. Większość metod klasyfikacji działa zgodnie z pewną metodologią. Tak jak wspomniałem wcześniej do działania niezbędny jest zbiór uczący, czyli zawierający obiekty z przypisanymi już etykietami. Jest to niezbędne aby mechanizm (czy to sieć neuronów, czy jakiś inny kombinatoryczny) mógł nauczyć się odwzorowań. Ważne jest, aby obiekty z tego zbioru uczącego posiadały jak najwięcej pełnych informacji. Pełnych, czyli ustalonych. Przykładowo jeśli rozpatrujemy spalanie paliwa samochodu na 100 kilometrów, to idealnym scenariuszem byłoby, gdyby dla wszystkich aut to spalanie było znane. Niepełne informacje na temat obiektu mogą doprowadzić do stworzenia niepoprawnej reguły decyzyjnej. Mechanizm podlega nauce w oparciu o zbiór uczący, ale aby mógł być używany dla innych przypadków należy sprawdzić, jak to wytrenowane narzędzie radzi sobie z danymi pochodzącymi ze zbioru uczącego, ale z ukrytymi informacjami o docelowej etykiecie. Jest to konieczne, aby zminimalizować ryzyko błędu. Jeśli test przebiegł pomyślnie można walidować model na danych innych niż te ze zbioru uczącego. Jeśli wyniki nie są prawidłowe i błąd klasyfikacji jest zbyt duży, to należy sprawdzić czemu tak się stało. Najczęściej popełnianym błędem jest niepoprawne przygotowanie zbioru uczącego. Z kolei na etapie walidacji na zbiorze wyjściowym zawierającym dane nie pochodzące ze zbioru uczącego może dojść do sytuacji, w której klasyfikacja również będzie niepoprawna. Możliwe jest wtedy, że zbiór uczący posiadał błędne założenia lub zbyt indywidualnie i szczegółowo traktował obiekty. Klasyfikator nauczył się odwzorowań na pamięć i nie był w stanie znaleźć odwzorowania dla nowych obiektów. Jest to odwieczny kompromis pomiędzy złożonością, a zdolnością uogólniania. Bardzo trudne jest zbalansowanie tych dwóch racji. Jeśli model będzie zbyt złożony stanie się zbyt dopasowany do danych. Jeśli będzie zbyt ogólny może nie wykazywać popranych nawyków zgodnych z intuicją, a dane zostaną niepoprawnie zaklasyfikowane. W tym rozdziale zaprezentuję trzy podejścia do klasyfikacji. W każdym z nich zwrócę uwagę na kluczowe aspekty ich działania. Pierwsze będzie prezentowało zastosowanie sieci neuronowej jako klasyfikatora. Następnie przedstawię podejście kombinatoryczne za pomocą algorytmu k-najbliższych Sąsiadów, a na samym końcu podejście statystyczne wykorzystując Naiwny Klasyfikator Bayesa.
33 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu Sieci neuronowe na przykładzie wielowarstwowego perceptronu W ostatnim rozdziale przedstawiłem przydatność sieci neuronowych w grupowaniu danych. Okazuje się, że mogą one mieć znacznie więcej zastosowań. Nadają się również jako klasyfikatory. Zanim opisze strukturę bardziej złożonej sieci neuronowej oraz jej zachowanie chciałbym jeszcze nawiązać do tego jak pojedynczy neuron oraz ich grupa klasyfikuje obiekty. Załóżmy, że mamy zbiór obiektów oraz dwie klasy liniowo separowalne {1 - kółka, 2 - trójkąty}, widoczne na rysunku 5.1. Pojęcie liniowo separowalne oznacza tyle, że da się poprowadzić hiperpłaszczyznę rozdzielającą obiekty dwóch klas tak, że po jednej stronie są obiekty tylko klasy 1, a po drugiej tylko obiekty klasy 2. W przypadku, gdy rozpatrujemy dwa wymiary, hiperpłaszczyzną będzie prosta, dla trzech wymiarów będzie to już płaszczyzna itd. Rysunek 5.1: Podział zbioru obiektów na dwie klasy liniowo separowalne Jest to sytuacja idealna. Może się jednak zdarzyć sytuacja, że obiekty będą tak rozłożone (na podstawie wartości wektora cech), że taki podział będzie niemożliwy. Takich prostych rozdzielających może być nieskończenie wiele i wszystkie będą poprawnym rozwiązaniem. Rozłożenie obiektów w przestrzeni wielowymiarowej ma ogromny wpływ na równanie opisujące hiperpłaszczyznę rozdzielającą. W zależności od złożoności sieci neuronowej może ona radzić sobie lepiej lub gorzej z klasyfikacją obiektów do odpowiednich grup. Wcześniej o tym nie wspomniałem, ale model neuronu, który przedstawiłem we wprowadzeniu do sieci neuronowych ( na stronie 22) może posiadać jeszcze jeden element. Dla przypomnienia rysunek 5.2 przedstawia ponownie model ADALINE opisany wcześniej we wprowadzeniu (4.3.1). Dodatkowym elementem, który się może pojawić jest blok aktywacji. Najprościej rzecz ujmując jest to funkcja realizująca jakieś przekształcenie na wartości pobudzenia. Taki model neuronu nazywa się perceptronem. Różni
34 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu 33 Rysunek 5.2: Schemat budowy neuronu liniowego Rysunek 5.3: Schemat budowy perceptronu - neuron nieliniowy się tym od ADALINE, że w procesie uczenia neuronu ADALINE, blok aktywacji jest pomijany (nie istnieje). Pod uwagę brana jest tylko wartość pobudzenia sieci. W przypadku perceptronu blok aktywacji ma wpływ na wartość wyjściową sieci i jest uwzględniany w procesie uczenia. Schemat budowy perceptronu jest widoczny na rysunku XX. Najczęsciej stosowaną funkcją aktywacji jest funkcja sigmoidalna. Wyrażona jest wzorem 5.1: y= 1 1+e x (5.1) Jest to funkcja najpopularniejsza ze względu na swój charakter. Przebieg tej funkcji przedstawia rysunek 5.4. Rysunek przedstawia wykres funkcji sigmoidalnej na przedziale 5 < x < 5. Dziedziną funkcji jest zbiór liczb rzeczywistych. Funkcja przyjmuje wartości z przedziału od 0 do 1. W punkcie 0 następuje przegięcie. W pewnej odległości na lewo i prawo od środka dziedziny można powiedzieć, że funkcja sigmoidalna ma charakter liniowy. W miarę jak oddalamy się od tego miejsca funkcja zyskuje charakter liniowy. Poza pewnym przedziałem jest prawie stała. Siła naszych umiejętności postrzegania i kojarzenia bierze się stąd, że neurony w mózgu choć same są prostej budowy to w połączeniu mogą wykonywać bardzo złożone obliczenia. Tak samo jest ze sztucznymi sieciami neuronowymi. Neurony mogą tworzyć warstwy, mogą tworzyć sieć połączeń, mogą nawet tworzyć sprzężenia zwrotne.zaprezentuję sieć nazywaną wielowarstwowym perceptronem. Przykład prostej sieci przedstawia rysunek 5.5. Jest to sieć warstwowa i wyróżnia się w niej trzy warstwy. Warstwę wejściową, która nie bierze udziału w procesie nauki. Pełni rolę medium propagującego sygnał. Każdy neuron posiada jedno wejście o wadze równej 1 i jednostkowej funkcji aktywacji. Kolejna warstwa nosi nazwę ukrytej. Każdy neuron ma zestaw wag o odpowiednim rozmiarze, równym ilości sygnałów pochodzących z warstwy wejściowej. Warstwa ukryta wykonuje większą część pracy przygotowując sygnały do interpretacji dla warstwy wyjściowej, która zwraca wyniki. Ilość neuronów w warstwie ukrytej jest bardzo istotna dla przetwarzania. Zbyt mała ich ilość powoduje duże błędy. Sieć nie jest w stanie odnaleźć odpowiedniego odwzorowania dla danych. Z kolei zbyt duża ilość neuronów w warstwie ukrytej sprawia, że sieć uczy się odwzorowania na pamięć i traci swoje zdolności uogólniające. Wielowarstwowy perceptron jest siecią
35 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu 34 Rysunek 5.4: Przebieg funkcji sigmoidalnej na przedziale [ 5;5] jednokierunkową, bez sprzężeń. Jest też siecią pełną. Oznacza to, że każdy neuron z warstwy jest połączony tylko ze wszystkimi neuronami z warstwy następnej i nie jest połączony z żadnym neuronem ze swojej warstwy. Należy wspomnieć, że w perceptronie stosuje się dodatkowo jedno wejście więcej. Nazywa się je wejściem obciążającym (bias). Posiada ono na stałe sygnał jednostkowy, natomiast waga tego wejścia jest poddawana adaptacji, tak samo jak inne. Istnienie wejścia obciążającego dodaje neuronowi pewnej elastyczności. Jest on w stanie przesuwać dziedzinę dla funkcji aktywacji, co może sprawić, że nawet dla sygnału zerowego wartość będzie niezerowa. Doświadczenie pokazuje, że neurony z wejściem obciążającym uczą się znacznie szybciej. Wielowarstwowy perceptron wykorzystuje metodę uczenia z nadzorem, która wymaga dużego zbioru przykładów. Pojedynczy przykład zawiera wartość wejściową oraz wartość oczekiwaną. Mogą to być wektory. Wszystko zależy od zadania, jakie sieć rozwiązuje. Istniej wiele metod nauki wielowarstwowego perceptronu. Najbardziej popularną jest metoda wstecznej propagacji. W metodzie wstecznej propagacji każdy przykład jest prezentowany sieci. Obliczana jest dla niego wartość wyjściowa sieci i porównywana z wartością oczekiwaną zawartą w przykładzie. Na tej podstawie obliczany jest błąd sieci. Błąd jest sumą kwadratów błędów dla każdego prezentowanego przykładu (wzór pojawi się w szczegółowym opisie algorytmu).błąd ten jest następnie propagowany do wszystkich neuronów w niższych warstwach i w oparciu o jego wartość przeprowadzana jest adaptacja wag. Cały problem sprowadza się zatem do znalezienia zbioru wag, który będzie minimalizował wspomniany błąd sieci. Zbieżność algorytmu można przyspieszyć poprzez zwiększenie kroku iteracji, oznaczmy go jako ν, jednak zbyt duża jego wartość może spowodować rozbieżność algorytmu. Nawiązując do anegdoty z kangurem. Będzie on wykonywał zbyt duże skoki, i zawsze przeskoczy docelowe miejsce. Innym sposobem na poprawienie zbieżności algorytmu jest wprowadzenie współczynnika momentum µ, który nadaje procesowi uczenia pewną bezwładność - uzależnia zmianę wag od poprzednich przyrostów wag. Poniżej zamieszczony został szczegółowy algorytm wstecznej propagacji błędów. ZAŁOŻENIA WSTEPNE: przez L oznaczmy ilość warstw naszej sieci przez N ( j) oznaczmy ilość neuronów w j-tej warstwie, j= 1,2,..,L
36 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu 35 Rysunek 5.5: Wielowarstwowy perceptron - przykładowa sieć przez y k oznaczmy wyjście k-tego neuronu aktualnej warstwy przez w i,k oznaczmy wagę i-tego wejścia k-tego neuronu N( j 1) przez S i oznaczmy sumę ważoną wejść neuronu, czyli i=1 y i w i (gdzie y i oznacza wartość wyjścia i-tego neuronu poprzedniej warstwy, a N ( j 1) oznacza ilość wejść neurony, czyli ilość neuronów poprzedniej warstwy (jeśli neuron posiada wejście obciążające, to ilość jego wejść równa się N ( j 1) + 1) wzorzec trenujący to para wektorów, z których pierwszy (E) podawany jest na wejście sieci, a drugi (C) przedstawia poprawne wartości wyjściowe, jakich oczekujemy od sieci - uzyskiwanych tych wartości będziemy uczyć sieć zbiór trenujący to zbiór wszystkich wzorców, które przedstawiamy sieci w procesie uczenia za kryterium stopu przyjmujemy uzyskanie przez sieć błędu mniejszego niż zadana wartość (np. 0,0001). Na ogół podaje się dodatkowe kryterium stopu w postaci ograniczenia liczby iteracji. błąd sieci obliczany jest następująco: Q = 1 2 G g=1 N(k) k=1( yk,g C k,g ) 2,gdzie Ck,g -oznacza oczekiwaną wartość k-tego wyjścia neuronu, G - oznacza ilość prezentowanych przykładów uczących, a g- oznacza prezentację danego wzorca trenującego KROKI ALGORYTMU: 1. Należy wybrać wartość ν > 0 (najlepiej, aby ν < 1) zwaną krokiem iteracji (nauki) 2. Należy wybrać wartość µ > 0 (najlepiej, aby µ < 1) zwaną momentum 3. Sprawdź kryterium stopu. Jeśli spełnione, zakończ naukę 4. Podaj kolejny wzorzec trenujący (para: wektor wejściowy i wektor oczekiwanych wartości wyjściowych) 5. Propagacja wprzód: dla każdego neurony sieci należy wyznaczyć sumę ważoną jego wejść S i oraz wyznaczyć wartość jego funkcji aktywacji y= f(s i ) ( wartość wyjściową tego neuronu). Oczywiście faza ta przebiega od pierwszej warstwy ( często jest to warstwa wejściowa), poprzez kolejne warstwy
37 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu 36 ukryte, aż do warstwy ostatniej - wyjściowej. 6. Propagacja wstecz: tę fazę wykonujemy w odwrotnej kolejności, czyli zaczynami od warstwy ostatniej (wyjściowej) i poruszamy się ku pierwszej warstwie ( jeśli sieć posada warstwę wejściową, to ta warstwa nie podlega uczeniu). Faza przebiega następująco: (a) Dla każdego neuronu warstwy wyjściowej należy obliczyć współczynnik δ k =(C k y k ) f (S i ), który związany jest z błędem, z jakim dane wyjście odpowiedziało na dane wejściowe (b) Dla każdego neuronu każdej warstwy niższej niż ostatnia (oprócz warstwy wejściowej, która nie N( j+1) ( podlega uczeniu) należy obliczyć współczynnik δ k = r=1 δr w k,r ) f (S i ), gdzie r iteruje po neuronach warstwy o jeden wyższej, a w k,r to waga k-tego wejścia r-tego neurony wyższej warstwy (k-te wejście jest połączone w wyjście k-tego neuronu aktualnej warstwy. (c) Każdemu neuronowi każdej warstwy (oprócz warstwy wejściowej) należy uaktualni wagi jego wejśc. Wykonuje się to za pomocą formuły: w i,k = w i,k+ ν δ k y i + µ i,k, gdzie w i,k - nowa waga i-tego wejścia k-tego neurony aktualnej warstwy, y i - to wyjście i-tego neuronu warstwy o jeden niższej i,k - to wartość poprzedniego przyrostu wagi i-tego wejścia k-tego neurony. Wartość ta równa jest różnicy wartości w i,k i wartości tej wagi z poprzedniej iteracji (czyli zanim nadaliśmy tej wadze wartość w i,k ) 7. Jeśli zaprezentowano wszystkie wzorce (zakończono daną iterację), to przetasuj wzorce, aby kolejność prezentowania w kolejnej epoce była inna i idź do punktu 3. Jeśli nie wszystkie wzorce zostały jeszcze zaprezentowane, idź do punktu 4. Na podstawie własnego doświadczenia z sieciami neuronowymi mogę powiedzieć, że bez istnienia wejścia obciążającego sieć neuronowa uczy się bardzo opornie. Potrzebuje bardzo dużo epok lub nie jest w stanie się nauczyć. Wejście obciążające dba o to, aby wartość funkcji aktywacji nie była zerowa w momencie, kiedy na wszystkie inne wejścia neuronu podana jest wartość 0. Można to rozumieć także jako przesunięcie układu współrzędnych charakterystyki funkcji aktywacji w lewą lub w prawą stronę w zależności od wagi wejścia obciążającego. Powoduje to przesunięcie progu pobudzenia w stronę mniejszych lub większych wartości. Daje to sieci większe możliwości adaptacji, ponieważ np. dla mniejszych wartości wag może otrzymać taką samą wartość na wyjściu. Mogę również z powodzeniem stwierdzić, że wartości ν oraz µ mają decydujący wpływ na szybkość adaptacji sieci. Proces nauki sieci polega na dostosowywaniu wag do odpowiednich sygnałów na wejściach. Osiągane jest to poprzez odpowiednie zmiany wag uzależnione od błędu. Metoda określania błędu dla danego neuronu przypomina metodę najszybszego spadku. W tej metodzie musimy wiedzieć, w którym kierunku poruszać się, aby znaleźć optimum (tak dobrać wagi, aby błąd był jak najmniejszy), ale oprócz tego tak dobrać długość skoku w wybranym kierunku, aby zmiany nie były zbyt silne (wartość błędu się zmniejszała a nie zwiększała żeby nie przeskoczyć optimum). Wybranie współczynnika za małego prowadzi do bardzo powolnego procesu uczenia się (wagi są poprawiane w każdym kroku o bardzo niewielką wartość, więc trzeba wykonać dużo takich kroków). Z kolei zbyt duży współczynnik powoduje zbyt gwałtowne zmiany wag, co może prowadzić zaburzenia stabilności procesu uczenia (sieć miota się wkoło optimum, nie mogąc znaleźć odpowiednich wag). Proces nauki można zoptymalizować dodając człon momentum, który powoduje, że zmiany wag nie zależą tylko od wartości skoku w danym momencie, ale także od błędów popełnianych przez sieć w poprzednich iteracjach (epokach). Pozytywnym skutkiem tej sytuacji jest to, że szybciej dążymy do optimum, rzadziej zmieniając wagi, a proces uczenia jest spokojniejszy (wagi nie zmieniają się zbyt gwałtownie). Wady i zalety Niewątpliwą zaletą wielowarstwowego perceptronu jako klasyfikatora jest prostota. Jest on zbudowany z pojedynczych neuronów wykonujących proste obliczenia, które dopiero w skali makro nabierają sensu. Bardzo ciekawe jest to, że neuron nie wie czemu dokładnie służy obliczona przez niego wartość. Pozwala
38 Rysunek 5.6: Diagram blokowy dla algorytmu wstecznej propagacji błędu jako metody nauki wielowarstwowego perceptrony
39 5.2 Klasyfikator Bayesa 38 to na rozdzielenie odpowiedzialności i przeniesienie jej do wyższych warstw abstrakcji tworząc koordynatorów zarządzających procesem uczenia. Umożliwia to bardzo łatwe zrównoleglenie, choćby przez rozproszenie neuronów po wielu procesorach w klastrach obliczeniowych. Daje to olbrzymi zysk wydajnościowy, którego nie da się przecenić, a w dodatku coraz bardziej przypomina działanie biologicznego mózgu. Cały proces nauki sprowadza się do znalezienia takiego zbioru wag dla neuronów, które minimalizują błąd. Można więc zapamiętać cały zestaw wag neuronów, co pozwoli na wykorzystanie sieci w przyszłości bez konieczności jej ponownego trenowania. Niestety sieci neuronowe mają także swoje wady. Jedną z nich jest trudność w budowaniu struktury połączeń oraz znajdowaniu odpowiedniej ilości neuronów tworzących sieć. Do każdego zadania trzeba podejść indywidualnie i metodą prób i błędów spróbować znaleźć strukturę, która daje najlepsze wyniki. Można w tym celu skorzystać z zaawansowanych metod poszukiwania rozwiązań takich jak algorytmy genetyczne i im zlecić odnalezienie optymalnej struktury sieci. Jest to jednak dodatkowa trudność. Aby sieć zdobyła dobrą zdolność uogólniania należy przedstawić jej duży zbiór przykładów. Może być on na tyle duży, że czas nauki będzie bardzo długi. Bardzo ważne jest również określenie poprawnego zbioru przykładów, takiego, który będzie rozważał najróżniejsze przypadki z całej przestrzeni możliwych rozwiązań. Nie tylko sytuacje najbardziej popularne, ale również te skrajne. Proces nauki opera się na losowej inicjalizacji wektorów wagowych wszystkich neuronów. Skutkiem tego jest różne zachowanie się sieci neuronowej w kolejnych uruchomieniach. Aby stwierdzić, że wyniki są poprawne należy przeprowadzić kilkakrotnie proces nauki. 5.2 Klasyfikator Bayesa W książce Pawła Cichosza[4] można przeczytać, że matematyczna teoria prawdopodobieństwa miała swoje początki już w XVI wieku, co stawia metody statystyczna na szczycie drzewa genealogicznego metod uczenia się. Pomimo tego, że ten dział nauki nie był w pełni sformalizowany, jednak metody i narzędzia jakie wprowadzał były stosowane w praktyce z dużym powodzeniem. Prawdopodobieństwo bardzo przydaje się w systemach uczących. Pozwala bowiem na interpretowanie pewnych regularności w zaobserwowanych sytuacjach, które zdarzają się codziennie, od rzucania kostkami do gry, po zjawiska zmiany pogody. Jest aparatem, który służy w pewien sposób do oceny naszej wiedzy na temat pewnych zjawisk Twierdzenie Bayesa W większości mechanizmów wnioskowania systemów uczących się w oparciu o metody probabilistyczne u podstaw leży twierdzenie wielebnego Thomasa Bayesa. Zostało on opublikowane dopiero po jego śmierci w 1763 roku. Traktuje ono o idei żonglowania prawdopodobieństwami warunkowymi, czyli prawdopodobieństwami zajścia pewnych zdarzeń pod warunkiem spełnienia pewnych założeń (źródłem definicji jest [5]). Definicja 1. Niech A i B będa dowolnymi zdarzeniami, A zawiera się w S i B zawiera się w S (S - zbiór zdarzeń elementarnych), przy czym prawdopodobieństwo zdarzenia A jest dodatnie, P(A)>0. Prawdopodobieństwo warunkowe zdarzenia B pod warunkiem zajścia zdarzenia A jest dane wzorem P(B A)= P(A B) P(A). Dodatkowo prawdopodobieństwo P(B A) spełnia dwa następujace postulaty: P(A A)=1 P(B A)=P(A B A) Stosowanie prawdopodobieństwa warunkowego pozwala na obliczenia interesujących prawdopodobieństw, co jest chwytem nie do przecenienia.
40 5.2 Klasyfikator Bayesa Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa (NBC 1 ) pozwala na stosowanie w większości przypadków. Nie posiada praktycznie ograniczeń. Algorytm ten klasyfikuje przykłady do odpowiednich kategorii za pomocą oszacowań pewnych prawdopodobieństw wyznaczanych w oparciu o zbiór uczący T. Skoro algorytm do działania wymaga tylko oszacowań, to bardzo dobrze byłoby wiedzieć jak te oszacowania otrzymać. Niezbędna tutaj jest definicja przykładu uczącego, który składa się z wektora wejściowego i wyjściowego. Wektor wejściowy jest reprezentowany przez zestaw pewnych atrybutów, a wektor wyjściowy przez przypisaną do wektora wejściowego etykietę pojęciową wskazującą na daną kategorię. Niestety większość metod liczenia czegokolwiek wymaga formalnego zapisu, który niekiedy jest niezrozumiały dla normalnego człowieka, nie inaczej jest w tym przypadku. Istnieje jednak proste wytłumaczenie sposobu otrzymania oszacowań, które są potrzebne do zastosowania omawianej metody, które będę chciał właśnie zaprezentować. Pomijając formalności, całe zadanie można określić następująco: dla wszystkich kategorii liczymy ile jest w zbiorze uczącym przykładów poszczególnych kategorii, a następnie uzyskane wyniki dzielimy przez liczbę wszystkich przykładów zbioru uczącego. Na potrzeby przykładu, który będę chciał później zaprezentować, zapiszę postać matematyczną, jaką przedstawił w swojej książce [4] Paweł Cichosz: P(c(x)=d)= T d T (5.2) dla wszystkich kategorii i wartości wszystkich atrybutów liczymy ile jest przykładów każdej kategorii o pewnych wartościach atrybutów, a następnie dzielimy uzyskane wyniki przez liczbę wszystkich przykładów zbioru uczącego. Jak wyżej matematyczna reprezentacja: P(a i (x)=v c(x)=d)= T d a i =v T d, gdzie a i (x) jest i-tym atrybutem przykładu x (5.3) Stosując takie podejście napotykamy jednak na problem w momencie gdy, w którejś z grup (kategorii) nie ma żadnego przykładu. Każdy zauważy, że wtedy licznik ułamków jest równy 0 i automatycznie prawdopodobieństwo jest równe 0. Taki obrót spraw pozwala wysnuć jeden niepodważalny wniosek. Mianowicie fakt, że nie występuje w danej kategorii przykład z pewnymi atrybutami pozwala przypuszczać, że nie istnieje on w całej dziedzinie przykładów. Takie radykalne posunięcie może niekiedy powodować pewne komplikacje, dlatego trzeba dokonać pewnych modyfikacji oszacowań. Najprostszym i skutecznym rozwiązaniem w przypadku pojawienia się omawianego zera jest przyjęcie za wynik pewnej małej liczby. Oznaczmy ją symbolem ε. Pytanie jakie trzeba sobie w tym momencie zadać brzmi: Jak mała ma być ta liczba. Nie jest to trywialne pytanie. Jest to wartość oszacowania, która ma wpływ na obliczenia i klasyfikację. Najrozsądniej byłoby przyjąć wartość ε < 1, ponieważ gdyby wartość była większa od T d rozpatrywanej, to znaczyłoby, że oszacowanie ma wartość taką, jakby w zbiorze trenującym znajdował się jeden przykład spełniający wymienione we wzorach 5.2 lub 5.3 wymagania. Najbezpieczniejszym i najmniej kosztownym posunięciem będzie zastosowanie pewnej heurystyki, np. przyjąć, że wartość ε = 1 2 T d lub ε = 1. Mamy wtedy zapewnienie, że przekłamanie nam się nie wkradnie. W ogólnym rozumieniu 3 T d algorytm jest również przedstawiony za pomocą diagramu blokowego na rysunku Przykład zastosowania NBC Chciałbym zademonstrować przykład, w którym pokażę, jak zastosować naiwny klasyfikator bayesowski do zbioru trenującego z dziedziny samochodów. Elementami tej dziedziny są dostępne na rynku modele samochodów. Niech każdy z samochodów będzie opisany przez następujące atrybuty: klasa: o wartościach miejski, duży, mały, kompakt 1 Skrót angielskiego terminu Naive Bayes Classifier
41 Rysunek 5.7: Diagram blokowy dla algorytmu Naiwnej Klasyfikatora Bayesa
42 5.2 Klasyfikator Bayesa 41 cena: o wartościach niska, umiarkowana, wysoka osiągi: o wartościach słabe, przeciętne, dobre niezawodność: o wartościach mała, przeciętna, duża Dane tego przykładu przedstawia tablica 5.1. x klasa cena osiagi niezawodność c(x) 1 miejski niska słabe mała 1 2 duży niska słabe mała 1 3 kompakt niska dobre przeciętna 1 4 mały niska przeciętne mała 1 5 mały umiarkowana przeciętne przeciętna 1 6 kompakt umiarkowana przeciętne przeciętna 1 7 miejski umiarkowana przeciętne przeciętna 0 8 mały umiarkowana dobre duża 0 9 kompakt wysoka dobre duża 0 10 duży wysoka przeciętne przeciętna 0 11 duży wysoka dobre duża 0 Tablica 5.1: Przedstawia zbiór trenujacy dla pojęcia docelowego c, które może być interpretowane jako popularny model samochodu. Dane znajdujace się w tabeli pochodza ze zbioru tabel przykładowych do ćwiczeń, z ksiażki Pawła Cichosza[4]. Oszacowania prawdopodobieństw będę wykonywał za pomocą wzorów 5.2 oraz 5.3, a w sytuacji, gdy w którejś z kategorii, dla danego atrybutu nie będzie przykładu, zastosuję wspomnianą wcześniej heurystykę i przybliżę brakujące prawdopodobieństwo wartością ε = 1 2 T = P x (c(x)=1)= 6 11 P x (klasa(x)=mie jski c(x)=1)= 1 6 P x (klasa(x)=mie jski c(x)=0)= 1 5 P x (klasa(x)=duzy c(x)=1)= 1 6 P x (klasa(x)=duzy c(x)=0)= 2 5 P x (klasa(x)=kompakt c(x)=1)= 2 6 P x (klasa(x)=kompakt c(x)=0)= 1 5 P x (klasa(x)=maly c(x)=1)= 2 6 P x (klasa(x)=maly c(x)=0)= 1 5 P x (cena(x)=niska c(x)=1)= 4 6 P x (cena(x)=niska c(x)=0)= 1 22 P x (cena(x)=umiarkowana c(x)=1)= 2 6 P x (cena(x)=umiarkowana c(x)=0)= 2 5 P x (cena(x)=wysoka c(x)=1)= 1 22 P x (cena(x)=wysoka c(x)=0)= 3 5 P x (osiagi(x)=slabe c(x)=1)= 2 6 P x (osiagi(x)=slabe c(x)=0)= 1 22 P x (osiagi(x)= przecietne c(x)=1)= 3 6 P x (osiagi(x)= przecietne c(x)=0)= 1 5 P x (osiagi(x)=dobre c(x)=1)= 1 6 P x (osiagi(x)=dobre c(x)=0)= 3 5 P x (niezawodnosc(x)=mala c(x)=1)= 2 6 P x (niezawodnosc(x)=mala c(x)=0)= 1 22
43 5.3 Metoda k-najbliższych sasiadów 42 P x (niezawodnosc(x)= przecietna c(x)=1)= 6 2 P x (niezawodnosc(x)= przecietna c(x)=0)= 5 1 P x (niezawodnosc(x)=duza c(x)=1)= 22 1 P x (niezawodnosc(x)=duza c(x)=0)= 3 5 Otrzymany zestaw wartości poszczególnych prawdopodobieństw reprezentuje hipotezę h, jakiej nauczył się naiwny klasyfikator bayesowski na podstawie zbioru trenującego. Można ją wykorzystać do klasyfikowania przykładów trenujących ze zbioru T. Dla przykładu pierwszego, tzn. x = 1 mamy następujące wartości atrybutów: klasa(1) = miejski cena(1) = niska osiągi(1) = słabe niezawodność(1)=mała Na podstawie powyższych wartości dla poszczególnych atrybutów oraz dla kategorii c(x)=1 oraz c(x)=0 obliczamy iloczyny prawdopodobieństw, których porównanie będzie podstawą klasyfikacji przykładu 1: P x (c(x)=1) P x (klasa(x)=mie jski c(x)=1) P x (cena(x)=niska c(x)=1) P x (osiagi(x)=slabe c(x)=1) P x (niezawodnosc(1)=mala c(x)=1)= = = 1089 = P x (c(x)=0) P x (klasa(x)=mie jski c(x)=0) P x (cena(x)=niska c(x)=0) P x (osiagi(x)=slabe c(x)=0) P x (niezawodnosc(1)=mala c(x)=0)= = = = oznacza to, że h(1) = c(1) = 1 Wady i zalety Podsumowując klasyfikacja w oparciu o twierdzenie Bayesa daje duże możliwości. Klasyfikator charakteryzuje się niedużym błędem klasyfikacji, pozwala na zastosowanie w większości problemów. Uwolniony jest od liczenia prawdopodobieństw warunkowych co pozwala osiągnąć wysoką wydajność. Do działania wykorzystywane są tylko proste operacje arytmetyczne. Jak pokazałem w przykładzie zastosowanie NBC jest bardzo proste i nie sprawia większych problemów. 5.3 Metoda k-najbliższych sasiadów Metody eksploracji danych potrafią być bardzo złożone, a ich mechanizmy trudne do zrozumienia. Podstawowe odmiany metody k-najbliższych sąsiadów wcale takie nie są. Przeciwnie, dzięki nim można osiągać bardzo dobre rezultaty klasyfikacji nie angażując dużo siły w rozumienie mechanizmu. Jest to metoda nadzorowana, która wymaga wcześniejszego przygotowania danych uczących, podobnie jak to miało miejsce przy sieci neuronowej. Klasyfikacja odbywa się w oparciu o podobieństwo analizowanego, nieznanego obiektu z elementami zbioru uczącego. Na tej podstawie podejmowana jest decyzja. Podobieństwo obiektów oceniane jest na podstawie miar odległości dwóch wektorów reprezentujących atrybuty oraz ich wartości dla obu obiektów. Algorytm do podjęcia decyzji wykorzystuję małą część całego zbioru uczącego.
44 5.3 Metoda k-najbliższych sasiadów 43 Rysunek 5.8: Diagram blokowy dla algorytmu klasyfikacji K-Najbliższych Sasiadów Jak duża jest to część określa współczynnik k. Jest to tak zwane sąsiedztwo, spośród którego wybiera się najczęstszą etykietę dla obiektu i właśnie ją przypisuje się analizowanemu obiektowi. Algorytm nazywa się leniwym. Jest tak dlatego, że nie zakłada tworzenia modelu, który w jakiś sposób przetwarza dane. Działanie algorytmu bazuje na tym, że cały zbiór uczący jest dostępny podczas klasyfikacji i na jego podstawie dokonywana jest ocena przynależności do klas. Takie rozwiązanie stawia pewne wymagania na pamięć operacyjną. Dostęp do danych uczących musi być pewny i szybki. Dla dużych zbiorów uczących jest to przeszkoda przed stosowaniem tego algorytmu. W takich sytuacjach nie mógłby on być wykorzystywany w czasie rzeczywistym. Czas przeglądania i porównywania wszystkich obiektów ze zbioru uczącego z jednym jedynym, który ma zostać zaklasyfikowany może trwać dość długo. Warto przyjrzeć się bliżej temu tajemniczemu współczynnikowi k. Najpierw jednak dokładnie przybliżę etap wybierania klasy dla analizowanego obiektu. (algorytm został również zapisany za pomocą diagrau blokowego na rysunku 5.8). Otóż obiekt porównywany jest ze wszystkimi elementami ze zbioru uczącego. Wyliczana jest wartość miary odległości. Następnie zbiera się k-elementów ze zbioru uczącego, które są najbardziej podobne do wzorca, który chcemy zaklasyfikować. Kolejnym etapem jest przeprowadzenie głosowania, które ma rozstrzygnąć jaką klasą oznaczyć wejściowy obiekt. W najprostszym wariancie głosowania obiekt zostanie przypisany do klasy, która jest reprezentowana przez największą ilość obiektów ze zbioru uczącego. Co jednak w sytuacji, gdy mamy remis. Można zdać się na los, ale można także badać położenie elementów i jako rozwiązanie wybrać ten leżący najbliżej. Współczynnik k określa jak duże sąsiedztwo będziemy brali pod uwagę podczas głosowania. Minimalną wartościąk jest 1, natomiast maksymalną jest liczność zbioru uczącego. Tak skrajne wartości nie znajdą na pewno praktycznego zastosowania. Dla wartości 1 klasyfikator będzie posiadał bardzo dużą wariancję. Może zostać przeuczony i nie będzie w stanie dobrze generalizować. Z kolei zwiększanie współczynnika k może doprowadzić do zbytniego uogólniania. W sąsiedztwie będą się mogły znaleźć obiekty, które tak naprawdę nie znajdują się wystarczająco blisko, abyśmy musieli je brać pod uwagę. Dobór odpowiedniej wartości zawsze przysparza analitykom problemów. Zależy od rozpatrywanego problemu, ilości zmiennych decyzyjnych i wielu innych czynników. Kontynuując wątek zmiennych decyzyjnych. Algorytm ma to do siebie, że nie jest w stanie brać pod uwagę tylko niektórych najbardziej istotnych danych. W sytuacjach, gdy rekordy zawierają pełną informację, poza zwiększeniem czasu obliczeń nie powinno mieć to negatywnych skutków. W sytuacji, gdy pojawiają się
45 5.3 Metoda k-najbliższych sasiadów 44 dane rzadkie. Może okazać się, że wybór klasy jest trudny, a to, żeby był zgodny z intuicją jeszcze bardziej jest nieosiągalne. Bardzo przydatną praktyką jest stosowanie wag dla poszczególnych składowych wektora cech. Pozwala to na ustalenie ważności. Jeśli dla niektórych cech przypiszemy wagę 0, to nie będą one wcale brane pod uwagę. Wady i zalety Podsumowując algorytm k-najbliższych sąsiadów jest bardzo prostym klasyfikatorem. Posiada on jednak kilka ciekawych właściwości. Bardzo łatwo jest go zaprogramować (mówię oczywiście o podstawowej wersji bez zbędnych optymalizacji). Dla wielu zastosowań jego zdolności klasyfikacyjne można ocenić jako dobre i wystarczające. Może się okazać, że nakład pracy na zaimplementowanie klasyfikatora w stosunku do wyników będzie niewspółmiernie mniejszy niż choćby na to w sieciach neuronowych. Algorytm po prostych modyfikacjach może odrzucać wybrane kolumny w rekordach, aby pomijać brakujące wartości, które jak wiadomo nigdy nie będą dobrze wpływały na wynik. Algorytm posiada jednak znaczne wady, o których trzeba wspomnieć. Najważniejszą jest jego leniwość ona powoduje wynikanie pozostałych wad. Metoda wymaga przechowywania całego zbioru uczącego i wykonywania porównania dla każdego analizowanego obiektu od nowa. Można oczywiście zastosować jakieś modyfikacje, które skracają czas i zmniejszają zapotrzebowanie na pamięć. Choćby odrzucić część informacji, albo próbkować co którąś. W książce [7] przeczytałem o zabiegu, który najpierw zakładał przeprowadzenie grupowania na danych zbioru uczącego, a następnie operowanie centroidami tych grup. Koniec końców leniwość algorytmu stawia analityków pod ścianą, bo nie mogą zastosować tego narzędzia dla wszystkich typów problemów. Sporym problemem jest też rozwiązanie kompromisu wariacyjno-obciążeniowego, czyli odpowiednika przeuczenia i niedouczenia. Jak wybrać stosowną wartość parametru k określającego wielkość sąsiedztwa. Nie pozostaje nic innego jak metoda prób i błędów.
46 Rozdział 6 Znajdowanie reguł asocjacji Trzecim typem technik przydatnych przydatnych podczas zbierania informacji o klientach jest znajdowanie reguł asocjacji. Reguły asocjacji zajmują się badaniem i wyszukiwaniem popularnych powiązań, które na pierwszy rzut oka nie miałyby szansy zostać zauważone. Powiązania mogą być ustanowione pomiędzy wieloma obiektami, które często są identyfikowane za pomocą cech, czy atrybutów. Pojedyncza reguła wiążąca ze sobą dwa obiekty składa się z dwóch elementów: poprzednika i następnika. Ma ona następującą formę: Jeżeli poprzednik, to następnik. Jest to standardowa i zarazem najprostsza reprezentacja pewnego zdarzenia warunkowego. Jeśli pierwszy element nie wystąpi, to nie ma możliwości, aby wystąpił drugi. Znajdowanie reguł asocjacji znajduje szerokie zastosowanie w wielu dziedzinach. Próbuje się wywnioskować jak zachowuje się rynek klientów telefonii komórkowych, którzy przy określonym abonamencie kupują określone aparaty telefoniczne. Innym przykładem może być analiza koszyka sklepowego w hipermarketach. Często tak określa się wykorzystanie metod zajmujących się znajdowaniem reguł asocjacji. Duże sieci sklepów chcąc mieć jak największy dochód próbują zainteresować klienta produktami układając je w odpowiednim miejscu na trasie przejazdu wózka sklepowego. Istnieje duża szansa, że klientowi się przypomni, że miał coś kupić, lub przeciwnie, sama dostępność towaru skusi go do zakupów. Reguły asocjacji można zastosować także w medycynie oceniając prawidłowość działania nowo wynajdywanych leków. Każdy człowiek może prowadzić inny styl życia, więc będzie inaczej reagował na podawany lek. Odnajdując te powiązania można się dowiedzieć o najczęstszych przypadkach. Firmy farmaceutyczne prowadzą takie badania, ponieważ nie mogą sobie pozwolić na nieuświadomienie klienta przed zażyciem leku. Ma to dla firmy zbyt duże konsekwencje prawne i finansowe. Jako, że piszę pod kątem przygotowywania rekomendacji dla użytkowników internetowych nie wypada zapomnieć o zastosowaniach internetowych. Otóż tak samo jak ludzie podróżują między regałami w supermarkecie, tak samo odwiedzają strony internetowe. Znajomość zależności pomiędzy stronami pozwoli ocenić które strony są najczęściej są odwiedzane i tak zmodyfikować hierarchię stron, aby użytkownik łatwo mógł znaleźć to co go interesuje. Idąc dalej można mu zarekomendować pewne odnośniki, które może kliknąć. Ma to się analogicznie do podstawienia towaru pod nos klientowi hipermarketu. Wyszukiwanie reguł asocjacji, choć jest bardzo interesującą techniką z technicznego punktu widzenia może nieść za sobą pewne problemy. Dotyczą one ilości wymiarowości problemy, czyli ilości atrybutów występujących w regule. Im więcej trybutów chcemy rozpatrywać, tym więcej możliwości jest do przetestowania. Wyłowienie interesujących związków jest zadaniem nietrywialnym. Aby nie być gołosłownym, jeżeli jest m-atrybutów binarnych (klient kupuje coś, lub nie), to liczba możliwych reguł wynosi m 2 m 1. Zakładając jako zastosowanie analizę koszyka sklepowego, gdzie klienci kupują bardzo dożo różnych produktów złożoność obliczeniowa rośnie dramatycznie, a sytuacja staje się beznadziejna. Oczekiwanie na wynik trwało by bardzo długo. Nawet posiadanie 10 artykułów, co pozwala skorzystać z szybkiej kasy daje w efekcie możliwych reguł, jeśli zwiększymy liczbę produktów do 100, to jest to już ogromna ilość możliwych do przetworzenia reguł, bo wynosi , czyli ponad Algorytmów przeszukujących zbiory reguł jest kilka. Według mnie najbardziej zasługujący na uwagę jest algorytm A priori. Uważam, tak, ponieważ zrozumienie jego działania otwiera drzwi do stosowania
47 6.1 Reprezentacje struktur danych 46 bardziej wyrafinowanych i złożonych algorytmów. Większa część z nich korzysta jednak, lub przynajmniej wspiera się w swoim działaniu na algorytmie A priori. Co jest w nim takiego interesującego, co powoduje, że często się go wykorzystuje? Otóż stosuje on pewne kryteria dla reguł, które przy zastosowaniu pewnych struktur reguł pozwalają na ograniczenie zbioru do przetwarzania poprzez odrzucenie reguł, które na pewno nie będą miały prawa zaistnieć. Zanim przejdę do sedna algorytmu, w kolejnych rozdziałach przybliżę sposób realizacji struktur danych, o których wspomniałem i przedstawię dwa kryteria, które służą do oceny przydatności rozpatrywanej reguły. 6.1 Reprezentacje struktur danych Skoro wcześniej wspomniałem już o koszyku sklepowym, to pozostanę już przy tej tematyce. Opowiadanie o strukturach danych warto wzbogacić o przykłady, dlatego na z pomocą kilku produktów ze sklepu spożywczego postaram się wprowadzić w reprezentacje danych. Rozważmy sytuację, w której jakiś nasz ulubiony sklep spożywczy sprzedaje następujące produkty: chleb, masło, mleko, ser, wędlina, pomidory, herbata. Dla ułatwienia zbiór wymienionych produktów będę oznaczał symbolem I. W ciągu całego dnia klienci odwiedzali sklep i kupowali potrzebne im rzeczy. Każdy produkt przechodząc przez kasę był rejestrowany przez system, a informacja o jego zakupie została zapisana do bazy danych. Na tym etapie nie jest istotna ilość zakupionych produktów, ale ich rodzaj i powiązania. Klientów w sklepie było wielu, ale załóżmy, że pierwszych czternastu zakupiło następujące produkty : 1. mleko, wędlina, ser 2. chleb, pomidory, ser 3. ser, herbata, masło, pomidory 4. wędlina, ser, herbata, masło 5. masło, chleb, mleko 6. pomidory, chleb, masło, herbata 7. herbata, ser 8. mleko, herbata, wędlina 9. pomidory, chleb, masło 10. masło, ser 11. wędlina, mleko, masło, pomidory 12. chleb, masło, pomidory 13. pomidory, ser, chleb, masło 14. ser, wędlina, herbata, masło, mleko Każdy z klientów zakupił pewną ilość różnych produktów. W eksploracji danych polegającej na odnajdywaniu powiązań pomiędzy atrybutami za pomocą reguł asocjacji stosuje się dwie reprezentacje danych: transakcyjną macierzową Różnią się one między sobą ilością kolumn kolekcji przechowującej informacje o zakupach dla jednego klienta. Transakcyjny sposób przechowywania danych wymaga istnienia dwóch pól. Identyfikatora transakcji (ID), który identyfikuje klienta oraz produktu, który został zakupiony w ramach tej transakcji. Dla podanych wcześniej przykładowych danych będzie to wyglądało jak w tabeli 6.1. Kolejność zarejestrowania poszczególnych transakcji nie musi być taka ja w tabeli powyżej. Mogą one się przeplatać. Wiadomym jest, że w sklepie klienci mogą być obsługiwani przez wiele kas. Zaprezentowałem dane w tabeli w ten sposób tylko dlatego, aby pokazać, jak ze zbioru produktów klienta można ułożyć pewną sekwencję transakcji.
48 6.2 Kryteria oceny reguł 47 ID PRODUKT 1 mleko 1 wędlina 1 ser 2 chleb 2 pomidory 2 ser 3 ser 3 herbata 3 masło 3 pomidory 4 wędlina 4 ser 4 herbata 4 masło Tablica 6.1: Transakcyjna reprezentacja danych dotyczacych koszyka sklepowego W macierzowej reprezentacji rekordów jest tyle ile kupujących (identyfikowanych za pomocą kolumny ID) natomiast kolumn tyle ile dostępnych towarów w sklepie. W poszczególnych komórkach dla danego klienta zaznaczane jest czy klient kupił taki produkt czy nie. Przykład zakupów z wykorzystaniem macierzowej reprezentacji danych prezentuje tabela Kryteria oceny reguł Aby znaleźć odpowiednie reguły asocjacji trzeba kierować się pewnymi kryteriami wyboru. W jakiś sposób trzeba ocenić, czy znaleziona asocjacja jest wartościowa dla analityka. W tym celu wykorzystuje się kilka wskaźników i właściwości, które w tej sekcji opiszę. Aby wyjaśnienia były przejrzyste zbiór wszystkich transakcji T oznaczę jako D. Każda transakcja reprezentuje zbiór produktów z wcześniej ustalonego I. Niech będą dane dwa zbiory artykułów: A i B, które reprezentują kolejno poprzednika i następnika. Reguła asocjacyjna ma zatem postać A B, co słownie można zapisać jako: JEŻELI A, TO B. Zbiory A i B są podzbiorami zbioru oznaczonego jako I. Są również rozłączne, co zapobiega prostym regułom typu: {chleb} {chleb, masło}. Pierwszym wskaźnikiem pozwalającym oceniać reguły asocjacyjne jest wsparcie. Jest obliczane jako procent transakcji pochodzących ze zbioru transakcji D, które zawierają zarówno poprzednik A, jak i następnik B. Wzór 6.1 przedstawia formalny zapis tej procedury. wsparcie= liczba transakcji zawierających A i B liczba wszystkich transakcji Drugim wskaźnikiem jest ufność reguły. Jest to miara dokładności określona jako procent transakcji zawierających A, które zawierają także B. Wzór 6.2 przedstawia formalny zapis procedury. ufnosc= liczba transakcji zawierających A i B liczba transakcji zawierających A W ocenie analityka reguła jest akceptowalna i powinna być brana pod uwagę w dalszym przetwarzaniu jeśli jej wsparcie i ufność są większe bądź równe ustalonym progom. Każdy zbiór zbudowany z elementów pochodzących ze zbioru I będziemy nazywali zbiorem zdarzeń. Takimi zbiorami są zatem poprzednik A oraz następnik B. Nie ma ograniczeń co do liczności elementów tego zbioru. Przykładowym zdarzeniem może być następujący 3-elementowy zbiór {masło, wędlina, (6.1) (6.2)
49 6.3 Algorytm A priori 48 ID CHLEB MASŁO MLEKO SER WEDLINA POMIDORY HERBATA 1 X X X 2 X X X 3 X X X X 4 X X X X 5 X X X 6 X X X X 7 X X 8 X X X 9 X X X 10 X X 11 X X X X 12 X X X 13 X X X X 14 X X X X X Tablica 6.2: Macierzowa reprezentacja danych dotyczacych koszyka sklepowego chleb}. Bardzo ważnym określeniem jest częstość zbioru zdarzeń. Jest definiowane jako liczba transakcji, które zawierają w sobie dany zbiór zdarzeń. Natomiast taki zbiór zdarzeń, który występuje w liczbie równej lub większej od ustalonego progu, nazwijmy go φ nazywa się zbiorem częstym. Będę go oznaczał F k (gdzie k oznacza liczność zbioru częstego, czyli z ilu elementów się składa). Pojęcie zbiorów częstych ma ogromne znaczenie dla algorytmu A priori. W oparciu o to stwierdzenie podejmowana jest decyzja o pozostawieniu, bądź odrzuceniu reguły. 6.3 Algorytm A priori Jak wspomniałem wcześniej określenie, czy w regule znajduje się zbiór częsty ma niebagatelny wpływ na działanie algorytmu. Zachowanie algorytmu definiuje właściwość a priori, która mówi, że jeżeli zbiór zdarzeń nie jest częsty, to dodanie dowolnego elementu do zespołu nie spowoduje, że nowo powstały zbiór będzie zbiorem częstym. Czyli żaden zbiór zawierający w sobie ten nieczęsty zbiór również nie będzie częsty. Ta właściwość pozwala na znaczne zredukowanie ilości reguł, które muszą być sprawdzone. Algorytm składa się z dwóch podstawowych kroków: 1. Znalezienie wszystkich zbiorów częstych (czyli tych, dla których częstości są φ 2. Na podstawie znalezionych zbiorów częstych utworzyć reguły, które posiadają wsparcie i ufność równe lub większe od ustalonego progu Przykład Postaram się pokazać na przykładzie jak działa algorytm A priori. W tym celu skorzystam ze zbioru zakupów wprowadzonego w 6.1 na stronie 46. Jako wartość φ decydującą o tym, czy zbiór jest częsty czy też nie przyjmę 4. Pozwoli to na rozpatrzenie dłuższej ścieżki działania algorytmu. Pierwszym krokiem jest odnalezienie wszystkich zbiorów częstych. Zaczynamy od zbiorów częstych złożonych z jednego elementu, czyli F 1. Trzeba w tym celu zsumować występowanie każdego produktu i stwierdzić czy jest ono większe od progu φ. Do zbioru F 1 wchodzą wszystkie produkty, czyli zbiór F 1 będzie postaci 6.3. F 1 ={chleb, masło, mleko, ser, wędlina, pomidory, herbata} (6.3) Korzystając ze zbioru F 1 wyznaczamy F 2. Aby znaleźć zbiór F k najpierw konstruuje się kandydatów poprzez łączenie ze sobą zbiorów F k 1. Łączenie może mieć miejsce jeśli pomiędzy dwoma zbiorami jest
50 6.3 Algorytm A priori 49 k 1 pierwszych wspólnych elementów. Korzystając z własności A priori wyrzuca się te zbiory, które nie są częste. Zbiory, które pozostały po czystce tworzą zbiór F k. Zbiór kandydatów C 2 zawiera w sobie wszystkie kombinacje produktów. One następnie są łączone zgodnie z wyżej opisaną zasadą, a następnie docinane (w tej sytuacji żaden zbiór nie zostanie usunięty, ponieważ każdy zbiór 1-elementowy jest częsty). Zbiór F 2 będzie wyglądał jak we wzorze 6.4 (zbiory mają liczność φ). F 2 = { } {chleb,masło}, {chleb,pomidory}, {masło,ser}, {masło,pomidory}, {masło,herbata}, {mleko,wędlina}, {ser,herbata} Na podstawie F_2 tworzony jest zbiór kandydatów 3-elementowych. Łączenie przebiega analogicznie. Dla przykładu łącząc {chleb, masło} oraz {chleb, pomidory} widać, że mają 2 1 = 1 elementów wspólnych. W wyniku łączenia powstanie następujący kandydując zbiór zdarzeń {chleb, masło, pomidory}. Podobnie tworzeni są inni kandydaci. Zbiór C 3 będzie jak w 6.5. { } {chleb, masło, pomidory}, {masło, ser, pomidory} C 3 = {masło, ser, herbata}, {masło, pomidory, herbata} Każdy zbiór zdarzeń zostanie rozłożony na k 1 elementowe podzbiory, a następnie zostanie sprawdzone, czy wszystkie są częste. Jeśli którykolwiek z nich nie jest częsty, czyli liczba wystąpień< φ, to cały zbiór zdarzeń jest usuwany. I tak dla zbioru zdarzeń {chleb, masło pomidory} tworzone są trzy podzbiory 2-elementowe {chleb, masło}, {chleb, pomidory} oraz {masło, pomidory}. Okazuje się, że występują odpowiednią ilość razy (łatwo to sprawdzić w tabeli 6.2 na poprzedniej stronie), zatem zbiór zdarzeń nie zostanie usunięty. Rozważmy jednak zbiór {masło, ser, pomidory}. Po rozłożeniu na podzbiory otrzymujemy {masło, ser}, {masło, pomidory} i {ser, pomidory}. Trzeci podzbiór {ser, pomidory} występuje w tej samej tabeli 6.2 tylko 3 razy, a więc nie osiąga progu minimalnego, który jest równy 4. Zatem cały zbiór zdarzeń {masło, ser, pomidory} zostanie odrzucony. Z tego samego powodu usunięty zostanie również zbiór zdarzeń {masło, pomidory, herbata}. Trzeba jeszcze sprawdzić liczność dla tych kandydatów, którzy pozostali. Zbiór {chleb, masło pomidory} występuje cztery razy, ale {masło, ser, herbata} już tylko trzy razy. Dlatego zostanie usunięty. W efekcie zbiór F 3 będzie składał się z pojedynczego zbioru zdarzeń opisanego za pomocą 6.6. (6.4) (6.5) F 3 ={{chleb,masło,pomidory}} (6.6) To kończy etap poszukiwania częstych zbiorów zdarzeń. Kolejnym etapem jest tworzenie reguł asocjacji z otrzymanych wcześniej zbiorów zdarzeń częstych. Aby utworzyć reguły najpierw dla pewnego zbioru zdarzeń tworzy się jego wszystkie podzbiory, a następnie ustala się reguły dla wszystkich podzbiorów takie, że (podzbiór (zbiór zdarzeń\ podzbiór)). Dla prostoty zazwyczaj jako następnik podawany jest jednoelementowy zbiór zdarzeń. Przeanalizujmy możliwe reguły dla F_3 z 6.6. Możliwe podzbiory zdarzeń, to : {chleb}, {masło}, {pomidory}, {chleb, masło}, {chleb, pomidory} oraz {masło, pomidory}. Rozważmy regułę dla podzbioru {chleb, masło}. Zostanie on poprzednikiem. Następnikiem będzie zbiór zdarzeń {pomidory}. Końcową regułę można zatem zapisać. Jeżeli klient kupuje chleb i masło, to kupuje też pomidory. Może wydaje się to w jakiś sposób oczywiste dla czytelnika, ale może być to tylko spowodowane wykorzystanymi nazwami produktów. Jeśli byłyby to książki, mogłoby już to nie być takie oczywiste. Sprawdźmy jeszcze jakie wskaźniki posiada ta reguła. Policzymy wsparcie zgodnie ze wzorem 6.1 na stronie 47. Poprzednik i następnik wystąpiły 4 razy w 6.2 na poprzedniej stronie. Wszystkich transakcji jest 14, czyli wsparcie wynosi 4/14 100% = 28%. Z kolei ufność liczona w oparciu o wzór 6.2 na stronie 47wynosi 4/5 100%=80%, bo liczba wystąpień poprzednika i następnika wynosiła 4, a liczba wystąpień samego poprzednika wynosiła 5. Analogicznie postępuje się wyznaczając kolejne reguły.
51 6.3 Algorytm A priori 50 Wady i zalety Algorytm A priori jest bardzo często podstawą dla innych algorytmów. Przykładami mogą być choćby algorytmy znajdowania wzorców sekwencji. Zasada działania jest bardzo prosta i sprowadza się do kombinatorycznego tworzenia nowych zbiorów, ale z pewnym mechanizmem odrzucającym te zbiory, które nie będą miały szans pojawić się w rozwiązaniu. Zawęża to krąg poszukiwań. Jest to skutkiem tego, że w kolejnych iteracjach do generowania nowych zbiorów zdarzeń wykorzystywane są te, które zostały znalezione w poprzedniej iteracji. Algorytm posiada dwie poważne wady. Pierwsza dotyczy warunku stopu. Wynika z charakteru algorytmu. Zadanie uznawane jest za zakończone, jeśli nie ma więcej kandydatów lub żaden z kandydatów nie jest częsty i kropka. Nic nie da się tutaj zrobić. Drugą wadą jest wielokrotne przeglądanie bazy. Kiedy zastanowimy się nad praktycznym wykorzystaniem algorytmu w praktyce ma to spore konsekwencje. Przeglądanie bazy danych o duży rozmiarach i wyliczanie na bieżąco ilości występowania dla każdego zbioru zdarzeń, nie wspominając o wartościach wskaźników jest bardzo kosztowne i zajmuje dużo czasu.
52 Rozdział 7 Przeglad istniejacych rozwiazań W tym rozdziale, tak jak wspomniałem we wstępie chciałbym przedstawić kilka narzędzi, które pozwalają na przeprowadzenie analizy zgromadzonych danych. Zaprezentuje także na przykładzie serwisu internetowego zastosowanie metod eksploracji danych w praktyce. Pokażę jakie korzystne skutki dla użytkownika i serwisu internetowego może mieć wdrożenie w portalu internetowym zaawansowanych mechanizmów analizy danych. 7.1 Narzędzia analizy danych Obecny rynek oprogramowania jest bogaty w najróżniejsze narzędzia. Konkurencyjność jest bardzo duża. Firmy prześcigają się w produkowaniu nowoczesnych rozwiązań, które zdeklasują konkurencję. Nie inaczej jest w przypadku narzędzi do przeprowadzania analizy danych najróżniejszego typu. Nowopowstające narzędzia muszą być coraz to bardziej przyjazne użytkownikowi i wykorzystywać najnowsze osiągnięcia technologiczne. Poza sektorem komercyjnym oprogramowanie z dziedziny eksploracji danych rozwija się także w sektorze oprogramowania rozprowadzonego w ramach bezpłatnych licencji. Zaprezentuje kilka przykładów aplikacji, które pozwalają na wydobywanie wiedzy z danych CLUTO CLUTO jest rodziną bibliotek i programów, które służą do przeprowadzania wydajnych obliczeń w ramach klastrowania danych. Zostało stworzone przez firmę Karypis Lab i jest dostępne do użytku nieodpłatnie. Oprogramowanie może być stosowane zarówno dla prostych zbiorów danych oraz dla złożonych skarbnic wiedzy. Pakiet narzędzi CLUTO składa się z trzech części: 1. CLUTO - Software for Clustering High-Dimensional Datasets: pakiet oprogramowania służący jako narzędzie do analizy danych w wielu obszarach zastosowań takich jak zakupy, serwisy transakcyjne, portale internetowe, nauka i biologia. 2. gcluto - Graphical Clustering Toolkit: jest to wieloplatformowe narzędzie z interfejsem graficznym użytkownika, które pozwala na pełne wykorzystanie bibliotek i narzędzi oferowanych przez rodzinę CLUTO. 3. wcluto - Web-based Clustering of Microarray Data: jest narzędziem, które zostało zaprojektowane do klastrowania i analizy danych za pomocą serwerów webowych. Zostało zbudowane w oparciu o biblioteki CLUTO. Użytkownicy mogą wysłać własnych zbiór danych, wybrać jedną z wielu możliwych metod klastrowania i przeprowadzić analizę na serwerze. Wyniki mogą być prezentowane za pomocą różnych wizualizacji. Na uwagę zasługuje szeroki wybór algorytmów klastrowania. Zarówno tych, które polegają na dzieleniu przestrzeni rozwiązań, jak i algorytmów hierarchicznych (aglomeracyjne). Program pozwala na wybór
53 7.1 Narzędzia analizy danych 52 Rysunek 7.1: Przykładowy ekran aplikacji gcluto wielu miar odległości dla obiektów. Można skorzystać ze standardowej miary euklidesowej, ale także kosinusowej, współczynnika korelacji, miary Jaccarda. Niektórych z nich nie opisywałem. Świadczy to o fakcie, że miar odległości, które mogą być zastosowane jest bardzo wiele. W przypadku stosowania aglomeracyjnego grupowania można wskazać jeden z kilku sposobów łączenia grup. Zostały one opisane przy okazji grupowania aglomeracyjnego. Wyniki działania programu mogą zostać zapisane w wielu formatach graficznych. Mowa tutaj o najróżniejszych wizualizacjach. W tym celu można posłużyć się mapami, trójwymiarowymi wykresami lub prostymi diagramami, np. dendrogramem, które jest chyba najbardziej charakterystyczną cechą grupowania hierarchicznego. Poniżej zamieściłem przykładowy ekran programu (rysunek 7.1) przedstawiający przykładową wizualizację danych dla programu gcluto. Na rysunku zostały zaznaczone literkami od a do d - cztery obszary warte uwagi. Literką a jest oznaczone drzewo nawigacji po zbiorach danych i otwartych projektach. Literką b oznaczone jest okno ze szczegółami dotyczącymi projektu. Wybraną metodą i jej parametrami. W kolejnym obszarze widać fragment dendrogramu dla grupowania hierarchicznego, a w ostatnim obszarze można zaobserwować wizualizację wykonaną za pomocą silnika OpenGL, który przedstawia trójwymiarowy rozkład poszczególnych klas obiektów SPSS Clementine Kolejnym systemem wartym uwagi jest SPSS Clementine. Jest to oprogramowanie do statystycznej analizy danych. Powstało w 1968 roku pod nazwą Statistical Package for the Social Sciences. Obecnie nazwa ta nie jest już używana, ale z poprzednich lat z pewnością zachowane zostało profesjonalne podejście do problemu. Program, który od wielu lat jest z sukcesami wdrażany w najróżniejszych instytucjach i firmach na pewno jest cenionym rozwiązaniem na rynku światowym. Wykorzystuje się go w badaniach naukowych, ale także z dala od świata nauki. Z powodzeniem sprawdza się w badaniu rynku oraz opinii publicznej. Wielkim osiągnięciem twórców jest stworzenie systemu, który używany jest przez 25 największych banków świata. W Polsce wykorzystywany jest m.in. przez Bre Bank S.A., Bank Zachodni WBK S.A., Ministerstwo
54 7.1 Narzędzia analizy danych 53 Rysunek 7.2: Ekran systemu SPSS prezentujacy edytor danych i zarazem główne okno programu. Na rysunku widać wczytane dane z przykładowej bazy danych zawierajacej informacje o samochodach. Finansów, PKO Bank Polski S.A. Urz ad Kontroli Skarbowej i wiele innych. System ma budowę modułową. Składa się z wielu pojedynczych bloczków, z których każdy oferuje dodatkową funkcjonalność. Część modułów jest darmowa dla użytkowników aplikacji podstawowej. Za niektóre trzeba jednak zapłacić. W podstawowej wersji programu można korzystać z niektórych analiz statystycznych jak np. analiza skupień oraz zarządzać danymi i wyświetlać podsumowania w postaci wykresów i diagramów. W codziennej pracy z programem wykorzystuje się okna dialogowe i kreatory graficzne, które ułatwiają odnalezienie oczekiwanych funkcji. Aplikacja została jednak zaprojektowana w taki sposób, aby nie ograniczać się wyłącznie do interfejsu graficznego. Bardziej zaawansowani użytkownicy mogą posługiwać się językiem komend i wykonywać tę samą pracę. Interfejs graficzny wywołuje poszczególne funkcje właśnie za pomocą odpowiednich poleceń konsolowych. Takie rozwiązanie jest bardzo popularne. Oprócz dodatkowego sposobu korzystania z programu ułatwia programistom utrzymanie ustanowionego porządku architektury aplikacji. System może być uruchomiony w postaci samodzielnej aplikacji, ale istnieją również dystrybucje budowane w oparciu o architekturę klient-serwer. Sam serwer jest dostępny na kilka systemów operacyjnych: Linux, UniX i inne, ale sama aplikacja kliencka dostępna jest wyłącznie dla systemów z rodziny Windows. Możliwości programu można sprawdzić korzystając z aplikacji, która jest ograniczona czasowo. Można ją pobrać z różnych serwisów internetowych. Do wprowadzania danych można skorzystać z wbudowanego edytora (rysunek 7.2), w którym możemy zdefiniować atrybuty dla obiektów. Po zainstalowaniu aplikacji dostępne są jednak przykładowe bazy danych, z których można skorzystać. W ramach zapoznania z programem przeprowadziłem kilka eksperymentów polegających na grupowaniu samochodów z przykładowej bazy danych (jej fragment zaprezentowany jest na rysunku 7.2). Wypróbowałem algorytm grupowania hierarchicznego oraz K-środków. Muszę przyznać, że kreatory dla metod grupowania były przejrzyste i można było łatwo zdecydować, które atrybuty mają być brane pod uwagę podczas grupowania (rysunek 7.3).
.")
55 7.1 Narzędzia analizy danych 54 Rysunek 7.3: Ekran przedstawiajacy kreator dla grupowania hierarchicznego Wyniki działania programu wyświetlane są w formie raportu w oddzielnym oknie (widoczne an rysunku 7.4). Można przeglądać poszczególne sekcje. To co znajdzie się w raporcie określane jest przed uruchomieniem przetwarzania, np. czy ma być rysowany dendrogram dla grupowania hierarchicznego. Moja przygoda z tym systemem była niedługa, więc nie byłem w stanie poznać jego prawdziwych możliwości, ale po zapoznaniu się mogę stwierdzić, że ma duży potencjał i zapewne zasłużenie jest wychwalany przez środowisko analityków. Rysunek 7.4: Ekran przedstawiajacy wyniki przetwarzania programu. Wyniki sa prezentowane w postaci raportu z podziałem na sekcje Google Analytics Firma Google stała się potentatem rynku informatycznego wprowadzając do użycia wiele przydatnych narzędzi. W ofercie firmy można znaleźć przeglądarki internetowe, wyszukiwarki internetowe, ale także pakiety biurowe i wiele innych. Wszystkie oferowane przez firmę narzędzia są bezpłatne i dostępne dla wszystkich. Może być jedynie wymagana wcześniejsza rejestracja. Nic więc dziwnego, że liczący się twórca oprogramowania zainteresował się pozyskiwaniem wiedzy z danych.
56 7.1 Narzędzia analizy danych 55 Listing 7.1 Przykładowy kod Java Script dla usługi Google Analytics pozwalający na śledzenie stron internetowych portalu użytkownika <script type="text/javascript"> var _gaq = _gaq []; _gaq.push([ _setaccount, UA-1745XXXX-X ]); _gaq.push([ _trackpageview ]); (function() { var ga = document.createelement( script ); ga.type = text/javascript ; ga.async = true; ga.src = ( https: == document.location.protocol? : ) +.google-analytics.com/ga.js ; var s = document.getelementsbytagname( script )[0]; s.parentnode.insertbefore(ga, s); })(); </script> Rysunek 7.5: Strona panelu informacyjnego usługi Google a. Raporty pojawiaja się dopiero po kilku godzinach pracy skryptu śledzacego Google stworzyło pakiet analityczny który nazywa się Google Analytics. Służy do analizy statystyk serwisów WWW. Dzięki wykorzystaniu tego narzędzia właściciele serwisów mogą dowiedzieć się wielu cennych informacji na temat wykorzystania ich portalu. Dotyczy to głównie kampanii reklamowych, sklepów internetowych, bannerów. Zebrane dane prezentowane są w postaci wielorakich raportów na różny temat. Same dane zbierane są poprzez nasłuchiwanie zachowań strony internetowej polegające na śledzeniu za pomocą skryptu napisanego w języku programowania Java Script. Aby móc korzystać z pakietu analitycznego wystarczy mieć konto Google, np. pocztowe i zarejestrować się w usłudze Analytics. Rejestracja jest bardzo prosta i zajmuje dosłownie chwilę. Ostatnim etapem rejestracji jest przekazanie użytkownikowi skryptu śledzącego. Musi on zostać zainstalowany na każdej stronie internetowej portalu użytkownika. Jeśli tak nie będzie raport może być niekompletny, a przez to przekłamany. Każdy użytkownik otrzymuje unikalny kod. Różnią się one specjalnym identyfikatorem przypisanym do konta użytkownika. Przykładowy kod zamieściłem na listingu 7.1. Pierwsze wejście na stronę internetową narzędzia odsłania ogrom informacji prezentowanych na temat śledzonej witryny internetowej. Na rysunku 7.5 widać panel główny usługi Analytics. Dane dla użytkownika końcowego są prezentowane w postaci różnych raportów. Mogą one przedstawiać informacje za pomocą map, wykresów, tabel itd. Istnieje możliwość eksportowania raportów do popularnych formatów plików, które mogą być wykorzystane w przyszłości. Google Analytics zapewnia możliwość tworzeni segmentów użytkowników, którzy odwiedzali serwis internetowy. Można utworzyć segment w oparciu o jedno z wielu dostępnych kryteriów. Na rysunku 7.6 widać ile informacji powiązanych jest właśnie z użytkownikiem końcowym.
57 7.1 Narzędzia analizy danych 56 Rysunek 7.6: Lista dostępnych raportów na temat użytkowników korzystajacych z analizowanego serwisu internetowego Niewątpliwą zaletą Google Analytics jest możliwość integracji z aplikacjami e-commerce, a więc pozwala na zbieranie i przetwarzanie realnych danych dotyczących transakcji finansowych. Dodatkowo Google udostępnia interfejs programistyczny, który pozwala na tworzenie aplikacji działających w oparciu o kod Google Analytics. Dzięki temu dostęp do usługi jest jeszcze bardziej ułatwiony i możliwy nawet z dala od komputera, ponieważ powstało już wiele aplikacji dostępowych na urządzenia mobilne. Podsumowując tę krótką charakterystykę chciałbym wskazać pięć powodów, dla których Google Analytics jest wart uwagi: Koszty - jest w pełni darmowy (do 5 milionów odsłon miesięcznie) Możliwość tworzenia różnych widoków dla danych i analiz Integracja z różnymi systemami, jak AdWords (serwis reklamowy Google a) reklamy, bannery Analiza lojalności klientów oraz wskazanie miejsca i czasu opuszczenia portalu internetowego, co pozwala na usunięcie wadliwych linków, czy poprawienie przejrzystości interfejsu Możliwość przeprowadzenia analizy dla e-commerce, czyli uzyskanie informacji na temat prawdziwych zysków Microsoft SQL Server Analysis Service Microsoft również zainteresował się zagadnieniem eksploracji danych i stworzył moduł, który w działając w oparciu o SQL Server pozwala na przeprowadzanie analizy danych. Jest to dodatkowa płatna usługa, którą się doinstalowuje. Najnowszą odsłoną jest wersja z roku 2008 i działa w powiązaniu z tą samą wersją serwera bazodanowego. Powstała na podstawie wersji z Względem niej wprowadzono istotne ulepszenia w zakresie skalowalności oraz zaawansowanych funkcji analitycznych. Została również dodana możliwość współpracy z pakietem Microsoft Office chętnie używanego przez większość osób korzystających z pakietów biurowych. Usługa pozwala na budowanie hurtowni danych na skalę korporacyjną. Microsoft w swoich reklamach podkreśla, że ich produkt charakteryzuje się bardzo dużą wydajnością i skalowalnością. Biorąc pod uwagę wyższość serwera baz danych SQL firmy Microsoft nad innymi serwerami bazodanowymi tak właśnie może być. Nie miałem możliwości sprawdzić jak zachowuje się usługa
58 7.1 Narzędzia analizy danych 57 Microsoft SQL Server Analysis Service w praktyce, jednak mogę zapewnić, że SQL Server na którym pracuje zasługuje na miano jednego z najlepszych. Można zatem wnioskować, że narzędzie może pozytywnie zaskoczyć szybkością pracy. Oprogramowanie pozwala na przeprowadzanie różnych analiz danych. Między innymi można wykorzystać algorytmy segmentacji (tak nazywa je Microsoft), czyli grupowania, np. K-Środków lub nie opisany przeze mnie EM, działający w oparciu o aparat statystyczny. Dostępne są również funkcje: analizy koszyka sklepowego, analizy rynkowej, przewidywania giełdowe, uczenie maszynowe bez nadzorcy, analiza tekstów. Zapewne jedną z zalet poza reklamowaną wydajnością jest wprowadzenie integracji z pakietem Microsoft Office. Za pomocą arkusza kalkulacyjnego można skorzystać z funkcji oferowanych przez SQL Server Analysis Service. Raporty mogą być tworzone w oparciu o program Word, a Visio może wspomóc w stworzeniu bogatych widoków graficznych WEKA Ostatnim rozwiązaniem na rynku, które chciałem przedstawić jest WEKA, czyli Waikato Environment for Knowledge Analysis. Jest to środowisko, które udostępnia wiele algorytmów uczenia maszynowego w celu pozyskiwania wiedzy z baz danych. WEKA jest oprogramowaniem darmowym, dostępnym na różne systemy operacyjne dzięki temu, że zostało napisane w języku Java. Najczęściej jest używane w środowisku badaczy i naukowców, ale może posłużyć również do nauki i obserwacji działania poszczególnych mechanizmów uczenia maszynowego. Program podzielony jest na kilka modułów dostępnych w zakładkach przez interfejs graficzny użytkownika. Są to: filtry, klasyfikatory, klastrowanie, selekcja atrybutów oraz wizualizacja. Program pozwala skorzystać podczas przetwarzania z najróżniejszych algorytmów, nawet tych starszych, które zostały od nowa przepisane na język Java z zachowaniem obiektowego podejścia. Po uruchomieniu WEKA sprawia wrażenie trudnej w obsłudze. Jest tak prawdopodobnie z tego powodu, że oferuje bardzo dużo funkcji i opcji. Poza interfejsem graficznym udostępniony jest także interfejs linii poleceń. Chciałbym zaprezentować podstawy zbiorów danych definiowanych właśnie za pomocą interfejsu komend. Podstawowym pojęciem, które często pojawia się w przypadku uczenia maszynowego jest baza danych, czyli zbiór obiektów reprezentowanych przez zestaw par atrybut-wartość. Często baza danych nosi także nazwę zbioru uczącego, a jej elementy nazywa się przykładami. WEKA korzysta z plików ARFF, do przechowywania danych. zawiera ona nagłówki określające typ atrybutu, a dane dla poszczególnych atrybutów są rozdzielane przecinkami. Przykładowy zbiór danych zapisałem w listingu 7.2. Listing 7.2 Przykładowy zbiór danych, które mogą być wykorzystane przez program outlook {sunny, overcast windy {TRUE, temperature humidity play {yes, sunny,false,85,85,no sunny,true,80,90,no overcast,false,83,86,yes rainy,false,70,96,yes rainy,false,68,80,yes... Pierwsza linia definiuje wewnętrzną nazwę dla zbioru danych. Powinna być jak najbardziej rzeczowa i samoopisująca się. Następnie definiowane są dwa atrybuty outlook oraz windy. Pierwszy może przyjmować trzy wartości, a drugi tylko dwie (jest binarny): TRUE lub FALSE. Można także zdefiniować atrybut
59 7.1 Narzędzia analizy danych 58 numeryczny, który zaprezentowany jest na przykładzie temperature. Ostatni atrybut o nazwie play może określać cel klasyfikacji dla przewidywania. W przytoczonym przeze mnie przypadku przyjmuje dwie wartości, TRUE i FALSE, czyli jest to problem klasyfikacji binarnej. Następnie po zapisane są dane. Każda linia odpowiada pojedynczemu przykładowi. W listingu nie pojawił się atrybut ciągu tekstowego i daty, ale one również są wspierane przez system. Tak przygotowane dane można poddać analizie. Interfejs graficzny pozwala na zarządzanie wieloma opcjami i uruchamianie rożnych funkcji. Jedną z ważniejszych zakładek jest panel o nazwie Preprocess. Na tym panelu można wczytać bazę z różnych źródeł, przeglądać charakterystyki atrybutów oraz wskazać filtry dla danych. Panel Preproces jest widoczny na rysunku 7.7. Rysunek 7.7: Panel Preproces oprogramowania WEKA (została wczytana przykładowa baza danych dostarczana z programem, dotyczaca warunków pogodowych) Rysunek 7.8: Panel klasyfikacji oprogramowania WEKA. Jak przykład wykorzystania programu WEKA zaprezentuję klasyfikowanie obiektów. Odbywa się to na panelu Classify. Pozwala on na konfigurację i uruchomienie wybranego klasyfikatora dl wczytanych danych. Błędy klasyfikacji mogą być przedstawione w dodatkowym oknie. Jeśli klasyfikator generuje drzewo decyzyjne ono również może być narysowane. Wyniki dla przeprowadzonej klasyfikacji Naiwnym Klasyfikatorem Bayesa przedstawiam na rysunku 7.8. Klasyfikacja została przeprowadzona na zbiorze danych pogodowych.
60 7.2 Portal internetowy wykorzystujacy rekomendacje Portal internetowy wykorzystujacy rekomendacje W tej części chciałem zaprezentować ciekawe podejście do użytkowników serwisu internetowego na przykładzie portalu Amazon.com. Swoje początki serwis Amazon.com miał w roku 1995, kiedy to w garażu Jeff a Bezos a w Seattle została sprzedana pierwsza książka. Jedenaście lat po tym fakcie, w 2006 roku Amazon.com sprzedawał już o ogromne ilości egzemplarzy i posiadał strony obsługujące siedem krajów z 21 centrami obsługi na całym świecie. Same magazyny zajmowany ponad 3 miliony metrów kwadratowych powierzchni. Takie liczby robią wrażenie. Amazon.com sprzedaje wiele różnych produktów. Bezpośrednio podejście do sprzedaży nie różni się od tego, które obowiązuje w innych dużych sieciach sprzedaży. Jedyną różnicą jest różnorodność oferowanych produktów. Na stronie portalu można znaleźć biżuterię, ubrania, jedzenie, artykuły sportowe i zoologiczne, książki, płyty, komputery, a nawet meble - ogrodowe. To sprawia, że Amazon.com ma bardzo wysoką pozycję wśród sprzedawców detalicznych. Na rysunku 7.9 przedstawiłem stronę zawierającą spis działów i kategorii produktów jakie ma w ofercie portal. Poza niesamowitym obszarem zainteresowania produktami Amazon sprawdza i realizuje każdą możliwą próbę spersonalizowania podejścia do klienta. Rysunek 7.9: Spis działów i kategorii produktów na portalu Amazon.com Kiedy odwiedza się stronę serwis internetowy sprawia wrażenie normalnego i niczym niewyróżniającego się, jeśli jednak odbędzie się krótką wycieczkę, po kategoriach i produktach, to można zauważyć, że bez wcześniejszej rejestracji system śledzi nasze gusta i rejestruje sobie wszystkie zachowania użytkownika. Do identyfikacji wystarczające jest zezwolenie na zapisywanie przez przeglądarkę tzw. ciasteczek, czyli plików z informacjami o sesji połączenia ze stroną internetową. To wystarcza, aby wprawić użytkownika w osłupienie pokazując mu przygotowaną dla niego ofertę, podpowiedzi produktów, które mogą go zainteresować. Przed zalogowaniem przejrzałem kilka książek z kategorii fantasy, którymi osobiście się interesuję. Po przejściu na stronę startową system zaprezentował mi planszę jak na rysunku 7.10, na której już mogłem zapoznać się z pierwszymi propozycjami.
 Jeśli użytkownik jest zarejestrowany i zaloguje się portal powita go grzecznie i zachęci do skorzystania systemu rekomendacji (rysunek 7.")
61 7.2 Portal internetowy wykorzystujacy rekomendacje 60 Rysunek 7.10: Pierwsze propozycje ofertowe (bez rejestracji) Jeśli użytkownik jest zarejestrowany i zaloguje się portal powita go grzecznie i zachęci do skorzystania systemu rekomendacji (rysunek 7.11), w trakcie wędrówki po gałęziach ofertowych użytkownik będzie również zachęcany do rozwijania swoich zainteresowań i umacniania opinii na temat pewnych produktów, przez co serwis internetowy Amazon.com będzie mógł lepiej dopasować się do gustów poszczególnych użytkowników. Rysunek 7.11: Powitanie personalne Amazon.com i zachęta do korzystania z systemu rekomendacji Wbudowane techniki marketingowe, które Amazon.com wdrożył w swoje działania w celu przygotowywania rekomendacji są najlepszym przykładem poprawnego podejścia firmy do sprzedaży, które można w skrócie podsumować jednym zdaniem poznaj swojego klienta jak najlepiej. Tak jak wspomniałem, jeśli tylko pozwoli się przeglądarce internetowej zapisać ciasteczko z informacją na dysku twardym Amazon zaskoczy odwiedzającego różnego rodzaju przydatnymi cechami, które sprawiają, że kupowanie staje się przyjemniejsze i szybsze. Można np. korzystać z rekomendacji powstałych w oparciu o odwiedzone strony internetowe. Innym przykładem mogą być recenzje, przewodniki napisane przez innych użytkowników, które w ramach pewnej dziedziny proponują zakup tej lub innej rzeczy. Rysunek 7.12 przedstawia listę funkcjonalności wchodzących w skład modułu personalizacji portalu. Rysunek 7.12: Funkcjonalność systemu rekomendacji portalu Amazon.com Powracając do śledzenia poczynań użytkowników. Wykonywane jest ono zawsze, kiedy użytkownik odwiedza serwis logując się do niego. Amazon zarekomenduje użytkownikowi produkty które są: podobne do tych, które były obecnie poszukiwane (tzw. on-the-fly recomendations, czyli rekomendacje przygotowywane w locie, które wymagają niewyobrażalnych mocy obliczeniowych - bo przecież każdy użytkownik może z tego korzystać) powiązanych, do tych, które były kiedyś wyszukiwane lub kliknięte

62 7.2 Portal internetowy wykorzystujacy rekomendacje 61 zakupione przez innych ludzi, którzy poszukiwali to co poszukiwał użytkownik lub tych, którzy kupili to samo, co kupił użytkownik Na dowód, że tak faktycznie jest na rysunkach 7.13, 7.14, 7.15 prezentuję plansze dotyczące rekomendacji przygotowanych w ramach odwiedzin jednej książki. Podając więcej informacji o sobie i swoich zainteresowaniach można dodatkowo sprecyzować swoje preferencje i pomóc portalowi w określeniu odpowiednich rekomendacji. Można także ocenić (rysunek 7.16) na ile podobała nam się wyświetlona pozycja, co zasugeruje systemowi analizowanie podpowiedzi znajdujących się w pewnej odległości w sensie podobieństwa od ocenionego produktu. Oczywiście pod warunkiem, że ocenimy go pozytywnie. W przypadku negatywnej oceny system będzie unikał proponowania nam podobnych artykułów. Po prostu skarb, nie sprzedawca. Rysunek 7.13: Rekomendacja portalu Amazon.com - produkty kupowane razem Rysunek 7.14: Rekomendacja portalu Amazon.com - ci co kupili produkt X kupili też Y Rysunek 7.15: Rekomendacja portalu Amazon.com - co zrobili użytkownicy po obejrzeniu tego produktu Rysunek 7.16: Ocena prezentowanego artykułu w celu wyrażenia osobistej opinii, która może pomóc przy ocenie przydatności innych podobnych artykułów dla klienta Do systemu zostały wprowadzone również dodatkowe usprawnienia. Aktualnie śledzenie użytkowników może zbierać dane na temat użytkowników, którzy nigdy nie odwiedzili portalu Amazon.com. Ta funkcjonalność nazywana jest rekomendacjami dotyczącymi prezentów. Zbierane są informacje dotyczące
63 7.2 Portal internetowy wykorzystujacy rekomendacje 62 produktów zakupionych dla pewnej osoby. Można także wskazać pewne obszary zainteresowania bliskich, aby uzyskać przykładowe propozycje. Jak to działa? Przykładowo Jeśli kupisz we wrześniu swojemu małemu siostrzeńcowi ciuchcię, to Amazon.com dowie się z tego faktu, że chłopiec w wieku od 4 do 10 lat może lubić pociągi. System w przyszłym roku może zaproponować jakiś dodatek do serii pociągów, może stację kolejową? Baza danych, do której trafiają informacje o prezentach i charakterystyki osób, dla których są one przeznaczone, jest prawdopodobnie uwspólniona. Pozwala to wyciągnięcie wiedzy z większej ilości przykładów. Taki sposób pozyskiwania wiedzy wzbudza pewne kontrowersje. Niektórzy mówią, że Amazon.com przechowuje zbyt dużo informacji, o czym powiadomiło Centrum Prywatności Informacji Elektronicznych już w 2000 roku. Uwaga na ten fakt została zwrócona ponieważ Amazon zaczął dzielić się zdobytymi informacjami ze swoimi partnerami handlowymi. Należy do tego jeszcze dodać, że po wprowadzeniu tzw. list życzeń sprawa została na nowo poruszona. Stało się to dlatego, że każdy użytkownik może przeglądać listy życzeń innych użytkowników. Na pierwszy rzut oka nie wydaje się to niebezpieczne, bo przecież znajdują się tam tylko informacje na temat preferencji dotyczących produktów. Spotkałem się jednak w Internecie z artykułem, który był istnym instruktarzem wydobywania informacji o ludziach na podstawie list życzeń znalezionych w bazach Amazon.com Pomimo obaw o zapędy portalu Amazon.com na stanowisko Wielkiego Brata, masa ludzi uwielbia spersonalizowane podejście portalu Amazon.com. Sklep internetowy, który początkowo powstał w garażu przeistoczył się w społeczeństwo bazujące na wspólnej wiedzy i gustach. Ludzie piszą swoje własne recenzje, przewodniki po produktach i najróżniejsze listy. Był kiedyś taki przypadek, że pewien użytkownik sporządził listę 25 najbardziej dziwnych rzeczy jakie można kupić na Amazon.com. Tak więc poza przyspieszeniem wyszukiwania np. ciekawej książki na piątkowy wieczór po wejściu na Amazon.com można sobie poprawić humor do końca dnia.
64 Rozdział 8 Problem praktyczny W zależności od potrzeb i sytuacji wykorzystuje się różne metody przygotowywania rekomendacji. Wszystko zależy od ustalonego wcześniej scenariusza postępowania z informacjami o użytkownikach. W części praktycznej swojej pracy zająłem się problemem grupowania użytkowników, ponieważ uważam tą metodę pozyskiwania wiedzy za podstawową, wyznaczającą pewne kierunki dalszego procesu pozyskiwania wiedzy dla innych metod. 8.1 Opis problemu W ramach zadania praktycznego stworzyłem aplikację, która pozwala na wczytanie danych z bazy danych, a następnie poddaje je analizie. Efektem działania aplikacji jest przyporządkowanie obiektów reprezentowanych przez rekordy danych do odpowiednich klas. Informacje dotyczące osiągniętego rozwiązania prezentowane są w przystępny i czytelny sposób dzięki graficznemu interfejsowi użytkownika. Program może komunikować się i współpracować z bazami danych przechowującymi informacje na dowolny temat. To użytkownik za pomocą języka zapytań baz danych decyduje o tym co będą reprezentowały dane wejściowe. Ważne jest aby dane spełniały odpowiednie założenia. W ramach problemu praktycznego chciałem zbadać jak zachowywałaby się metoda grupowania opierająca się o sieć neuronową. Chodzi dokładnie o sieć Kohonena, opisywaną w rozdziale 4.3 na stronie 22. Jako dane wejściowe do analizy posłużyły mi informacje na temat odwiedzin stron internetowych z książkami na popularnym portalu internetowym Merlin.pl. W celu zdobycia tych danych posłużyłem się jedną z opisanych przeze mnie wcześniej technik. W kolejnym rozdziale przybliżę proces pozyskania tych danych. 8.2 Wymagania funkcjonalne Aplikacja, którą stworzyłem realizuje pewien zbiór ustanowionych na etapie projektowania wymagań. Jest to niezbędne do osiągnięcia założonych celów. Wymagania dotyczą zarówno sposobu reprezentacji danych wejściowych, sposobu przetwarzania tych danych oraz prezentowania wyników. Program powstał w oparciu o platformę programistyczną Microsoft.Net 3.5. w języku programowania C#. Wykorzystałem środowisko programistyczne Microsoft Visual Studio 2008, które oferuje bardzo dobre wsparcie programistyczne. Między innymi pozwala w bardzo wygodny sposób analizować kod w trakcie jego działania, co bardzo skraca czas potrzebny na znalezienie i poprawienie błędu. Aplikacja jest przeznaczona na systemy z rodziny Microsoft Windows i wymaga, aby w systemie operacyjnym było zainstalowane środowisko uruchomieniowe platformy programistycznej Microsoft.Net 3.5. Jest ono dostępne bezpłatnie dla większości systemów Microsoft Windows. Głównym założeniem było, aby program był prosty i przyjazny w obsłudze. Funkcje miały być dostępne w wygodny i przejrzysty sposób. Program miał działać w oparciu o dane przechowywane w bazie danych nadzorowanej przez serwer Microsoft SQL. Dostęp do tych danych miał być dynamiczny. W moich założeniach program miał dawać
65 8.2 Wymagania funkcjonalne 64 dużą swobodę użytkownikowi w kształtowaniu analizowanych danych. Do dyspozycji użytkownika zostało przewidziane proste narzędzie wbudowane w aplikację, które pozwala na pobieranie danych definiowanych za pomocą języka skryptowego T-SQL 1. Dodatkowym zamierzeniem było, aby aplikacja wspomagała użytkownika w czasie definiowania skryptu. W tym celu została wyposażona w prosty edytor tekstowy, który oferuje kolorowanie słów kluczowych języka T-SQL, a także po wciśnięciu odpowiedniej kombinacji klawiszy podpowiada słowa kluczowe. Program pozwala podłączyć się do różnych instancji serwera SQL znajdujących się na dowolnej maszynie z odpowiednio skonfigurowanym dostępem. Wskazanie serwera bazy danych oraz samej bazy danych obsługiwane jest przez dedykowany formularz, który zapewnia mechanizm testowania połączenia z serwerem bazodanowym. Bardzo ważną funkcją jest możliwość zapisania skryptu znajdującego się w edytorze tekstowym do wybranego pliku. Pozwoli to na kontynuowanie pracy nad danymi w przyszłości bez konieczności ponownego definiowania skryptu wybierającego dane. W czasie projektowania programu przewidziałem również sytuację, w której użytkownik końcowy nie będzie miał dostępu do bazy danych. W takim przypadku osoba korzystająca z programu może użyć wcześniej przygotowanych plików z danymi. Taki plik z danymi jest wynikiem wykonania zapytania do bazy danych oraz wywołania funkcji zapisującej pobrane dane do pliku. Pozwala to prezentować działanie programu niezależnie od dostępu do bazy danych czy sieci komputerowej. Przed uruchomieniem przetwarzania użytkownik musi dostarczyć dane do mechanizmu grupowania. Można to zrobić wykonując wprowadzony skrypt lub wczytując wspomniany plik z danymi. Taka kolejność kroków pozwala upewnić się, że dane które chcemy analizować mają poprawny format i przedstawiają to, co powinny. W przypadku wystąpienia błędu podczas wykonywania skryptu użytkownik zostanie o tym powiadomiony stosownym komunikatem. Komunikat będzie zawierał wskazówkę dotyczącą miejsca, w którym może znajdować się błąd. Użytkownik ma możliwość skonfigurować wszystkie niezbędne parametry sieci neuronowej. Zaprojektowana sieć Kohonena została wyposażona w dwa dodatkowe mechanizmy usprawniające proces nauki neuronów. Pierwszym z nich jest mechanizm zmęczenia neuronów opisywany przeze mnie w, natomiast drugii to malejący współczynnik nauki. Użytkownik może w obydwu przypadkach zdecydować jak mają się zachowywać obydwa mechanizmy. Postęp procesu grupowania jest widoczny na pasku postępu, jak również na wyznaczonym polu tekstowym, w którym prezentowane są komunikaty tekstowe. Po zakończeniu grupowania wyświetlane jest podsumowanie opisujące otrzymane wyniki. W tym podsumowaniu znalazły się takie informacje jak ilość znalezionych grup, powiązania obiektów z grupami, centroidy grup oraz wartości wejściowe dla wszystkich obiektów. Wszystkie te informacje są prezentowane w formacie tekstowym. Program posiada także moduł statystyczny udostępniający dwa wykresy. Pierwszy z nich prezentuje rozkład udziału grup. Jest to wykres kołowy, na którym widać ile udziału w całości ma każda z grup. Drugim wykresem jest wykres słupkowy. Charakteryzuje on przekrojowo wszystkie obiekty względem każdego z atrybutów przedstawiając wartości średnie. Oprócz wykresów można wyświetlić centroid wybranej grupy, co pozwala ją scharakteryzować. 1 T-SQL (ang. Transact-SQL), oznacza transakcyjny SQL, czyli rozszerzenie języka SQL umożliwiające tworzenie konstrukcji takich jak pętle, instrukcje warunkowe oraz zmienne. Jest używany do tworzenia wyzwalaczy, procedur i funkcji składowanych w bazie. Został stworzony przez Sybase i wbudowany do serwerów SQL tej firmy, później prawa kupiła firma Microsoft i wykorzystuje ten język w kolejnych wersjach MS SQL Server.
66 Rozdział 9 Pozyskanie danych testowych Dane testowe, które zostały wykorzystane do testowania programu dotyczą odwiedzin stron internetowych z książkami przez różnych użytkowników. Każdy z użytkowników korzystając z przeglądarki internetowej odwiedzał stronę internetową. Użytkownicy posługiwali się przeglądarką internetową Mozilla Firefox, która posiadała zainstalowaną specjalna wtyczkę o nazwie Wiwex poszerzająca jej funkcjonalność o moduł zapisu informacji o odwiedzinach na stronach internetowych. Informacja o identyfikatorze, czasie odwiedzin oraz linku do odwiedzanej strony były zapisywane do pliku tekstowego na odpowiednim serwerze internetowym. Plik ten był dostępny pod odpowiednim adresem internetowym. Można go przeglądać i pobierać bezpośrednio z serwera internetowego. Dla każdego użytkownika tworzony jest osobny plik z linkami do odwiedzonych stron internetowych. Aby dane o odwiedzinach użytkownika zostały zarejestrowane przez moduł śledzący użytkownik musi się najpierw zalogować. Wystarczy w tym celu otworzyć okno ustawień dla wtyczki dostępne poprzez menu narzędzia na głównym pasku menu przeglądarki. Pojawi się nieduże okno widoczne na rysunku 9.1, w którym należy wpisać login i hasło użytkownika i zalogować się. Od tego momentu informacje dotyczące przeglądania stron internetowych będą zapisywane. Loginy i hasła można uzyskać na stronie autorów wtyczki, po wcześniejszej rejestracji. Cały proces pozyskania niezbędnych informacji na temat odwiedzonych książek można sformułować w kilku punktach: 1. Pobranie pliku z linkami do odwiedzonych stron 2. Pobranie każdej strony internetowej 3. Wydobycie informacji o książce 4. Zapisanie informacji do bazy danych Zadanie zbierania danych na temat odwiedzin stron internetowych przez użytkowników realizuje stworzona przeze mnie na te potrzeby aplikacja. Aplikacja została wyposażona w graficzny interfejs użytkownika, który pozwala skonfigurować połaczenie do bazy danych, w której składowane będą dane, a także określić adresy plików przechowujących informacje o aktywności użytkowników. Rysunek numer 9.2 przedstawia opisywaną aplikację podczas pracy. Okno główne programu ma wydzielone trzy częsci. W górnej częsci zostało umieszczone pole tekstowe, które pozwala na zdefiniowanie ciągu połączeniowego do bazy danych obsługiwanej przez serwer Microsoft SQL. Projekt bazy danych zostanie opisany przy okazji omawiania dostępu do bazy danych głównej aplikacji realizowanej w ramach projektu praktycznego. Obok pola tekstowego znajdują się dwa przyciski, pierwszy oznaczony napisem Test pozwala na zweryfikowanie poprawności ciągu połączeniowego. Przycisk z podpisem Usuń dane służy do czyszczenia wszystkich tabel bazy danych. W środkowej części formularza znajduje się wydzielona przestrzeń dla listy adresów prowadzących do plików przechowujących dane o aktywności poszczególnych użytkowników. Program pozwala dodawać do listy i usuwać z niej kolejne wpisy. Wpisy te mogą zostać zapamiętane w pliku konfiguracyjnym programu. Zapis wyzwalany jest
67 Rysunek 9.1: Okno logowania użytkownika do wtyczki programu Mozilla Firefox śledzacej wędrówkę użytkownika po stronach internetowych Rysunek 9.2: Okno programu zajmujacego się pozyskiwaniem danych o odwiedzonych przez użytkowników portalu internetowego ksiażkach
68 9 Pozyskanie danych testowych 67 Listing 9.1 Przykładowy wpis dotyczący aktywności użytkownika na portalu Merlin.pl user :03:21 user :03:23 user :03:45 user :04:06 user :04:09 user :24:46 user :24:55 user :25:30 user :27:57 user :28:19 user :28:29 user :29:21 poprzez naciśnięcie przycisku zapisu na formularzu. Jest to udogodnienie, dzięki któremu nie trzeba będzie wpisywać od nowa wszystkich adresów przy kolejnym uruchomieniu programu. Ostatnia część znajdująca się na dole formularza służy do monitorowania pracy aplikacji. Każda operacja wykonywana przez aplikację jest zapisywana do dziennika zdarzeń. Każde zdarzenie posiada odpowiednie formatowanie (kolor, czcionka) aby ułatwić rozróżnienie błędu od komunikatu poprawnego wykonania operacji. Dziennik jest czyszczony cyklicznie po wyczerpaniu bufora tekstowego. Uruchamianie i zatrzymywanie pobierania danych wykonywane jest za pomocą tego samego przycisku, który zmienia swój stan (dla ułatwienia zmieniana jest nazwa i kolor napisu). Po uruchomieniu pobierania danych na stosownej etykiecie wyświetlany jest całkowity czas operacji. Pasek postępu informuje o tym jaka część zadania została już wykonana. Pierwszą czynnością po uruchomieniu programu jest pobranie z serwera wszystkich plików przechowujących aktywności użytkowników. Program pobiera i zapisuje zawartość każdego pliku do osobnego pliku na dysku lokalnym w katalogu tymczasowym programu. Nazwa dla niego jest ustalana losowo na podstawie znacznika czasu. W kolejnym kroku analizowane są te pliki, aby określić ilość aktywności, które muszą zostać przeanalizowane. Następnie dla każdego takiego pliku pobierana jest informacja o każdej aktywności. Pojedyncza aktywność jest reprezentowana przez trójkę danych. Przykładowy wpis przedstawia listing 9.1. Poszczególne wpisy są przetwarzane równolegle aby przyspieszyć przetwarzanie i lepiej wykorzystać łącze sieciowe. W przypadku pobierania małych plików narzut na komunikację z serwerem WWW jest większy niż czas potrzebny na pobranie zawartości strony internetowej. Przetwarzanie równoległe znacznie przyspiesza ten proces. Zostało ono zrealizowane za pomocą mechanizmu puli wątków. Polega to na tym, że aplikacja utrzymuje pewną stałą liczbę wątków. Każde zadanie uruchamiane jest w osobnym wątku. Po zakończeniu zadania wątek jest zwalniany i może zostać wykorzystany przez inne zadanie, które oczekuje w kolejce na wykonanie. Zastosowanie tego mechanizmu pozwala na wykonywanie się poszczególnych zadań na różnych rdzeniach procesorów jeśli takie są dostępne na maszynie uruchomieniowej. Przetwarzanie każdej aktywności składa się z kilku etapów. Pierwszy etap polega na sprawdzeniu poprawności linka pod kątem zawartości. Docelowo poszukiwane są linki, które reprezentują strony z produktami, a wiec leżące najniżej w drzewiastej strukturze portalu internetowego. Zawierają one stosowne znaczniki w adresie, po których można je rozpoznać. Aktywności, które nie spełniają warunków są odrzucane, natomiast te, które zostały zweryfikowne podlegają dalszej analizie. Program został przygotowany w taki sposób, aby zapewnić poprawność danych oraz zabezpieczyć przed dublowaniem wpisów dlatego w kolejnym kroku sprawdzane jest, czy aby aktualny wpis nie został już wcześniej przetworzony. Jeśli tak się już stało, to analiza dobiega końca. W inny przypadku pobierana jest zawartość strony internetowej zlokalizowanej pod wskazanym adresem internetowym. Po pobraniu następuje dogłębna analiza kodu html, która ma na celu sprawdzenie, czy np. kategoria produktu nie istnieje już w bazie danych. Jeśli nie istnieje, to program ją dodaje do bazy danych Jeśli natomiast istnieje, to pobiera jej identyfikator, który będzie potrzebny podczas wstawiania danych do bazy danych. Postępuje się analogicznie dla różnych atrybutów produktu: autora, kategorii, podkategorii itp. Ostatnią operacją jest wstawienie rekordów do odpowiednich tabel w bazie danych, co kończy przetwarzanie pojedynczej aktywności.
69 Rozdział 10 Projekt Na etapie projektowania trzeba podjąć wiele trudnych decyzji dotyczących tego, jak program będzie funkcjonował w etapie końcowym. Jest to bardzo ważne z tego względu, że błędy projektowe jest ciężko poprawić, gdy większa część pracy została już wykonana. Musiałem zadecydować w jaki sposób program będzie działał. Podczas projektowania trzeba wziąć pod uwagę zarówno elementy logiki jak i przepływu danych. Zaprojektowanie aplikacji, która w intuicyjny i sprawny sposób zarządza zasobami poprzez graficzny interfejs użytkownika nie jest zadaniem trywialnym. Można to zrobić szybko, ale taki sposób realizacji uniemożliwia później szybkie odnajdywanie błędów i utrudnia rozwój aplikacji. Z tego też powodu starałem się wyodrębnić poszczególne części programu w postaci osobnych modułów, które różnią się między sobą odpowiedzialnością, a każdy z nich nie wie o istnieniu innych. Komunikacja odbywa się poprzez interfejs użytkownika, który za pomocą obsługi zdarzeń dowiaduje się o przekazaniu sterowania do innego modułu. W tym rozdziale przybliżę swoje pomysły dotyczące realizacji poszczególnych części programu, a także przedstawię przykładowe uruchomienie programu i przetestuję jego działanie Moduł dostępu do danych W założeniu program miał korzystać z bazy danych. Należało się zastanowić nad dostawcą serwera bazodanowego, który obsługiwałby bazę danych. Wybrałem serwer Microsoft SQL wykorzystujący do zarządzania bazami danych język T-SQL. Program nie obsługuje innych serwerów baz danych. Moduł pobierania danych jest dedykowany dla serwera Microsoft SQL i nie wykorzystuje żadnych dodatkowych bibliotek oferujących mapowanie obiektowo-relacyjne. Niektórzy programiści mogą uznać to za wadę, a niektórzy za zaletę. Osobiście uważam takie podejście za bardzo dobre. Po pierwsze zastosowanie dedykowanego mechanizmu komunikacji z serwerem pozwala na osiągnięcie większej wydajności, ponieważ serwer SQL wykonuje dokładnie takie zadania jakie mu zlecimy. Warunkiem jest oczywiście poprawne napisanie skryptu pobierającego dane. Może to być trudność dla osób, które na co dzień nie posługują się językiem T-SQL lub nie miały z nim do czynienia. Niepodważalną zaletą w stosunku do rozwiązań typu ORM 1 jest elastyczność modułu pobierającego dane. Nie jest on ograniczony do określonego typu danych (tabeli), który ma ustalone atrybuty i innych mieć nie może. Dzięki zastosowaniu mojego rozwiązania program może współpracować z różnymi bazami danych i różnymi tabelami. Wadą mojego rozwiązania jest niewątpliwie większy nakład pracy nad modułem pobierania danych, gdyż trzeba od podstaw napisać mechanizm komunikowania się z serwerem SQL i interpretowania jego wyników oraz zadbać o poprawną obsługę błędów. Zanim przejdę do omówienia szczegółów projektowych oraz wyjaśnienia sposobu działania poszczególnych elementów składowych modułu dostępu do danych pokażę jak od strony programisty, który wykorzystuje mechanizm komunikacji z serwerem bazy danych, wygląda gotowy komponent połączeniowy. 1 ORM (ang. Object-Relational Mapping), czyli mapowanie obiektowo-relacyjne, rozumiane jako sposób odwzorowania obiektowej architektury systemu informatycznego na bazę danych (lub inny element systemu) o relacyjnym charakterze.

70 10.1 Moduł dostępu do danych 69 Rysunek 10.1: Diagram klasy reprezentujacej wzorzec wyjatku, którym posługuje się mechanizm obsługi serwera baz danych Liczba klas, które składają się na cały mechanizm nie jest duża. Są to trzy klasy, które oferują wystarczającą funkcjonalność dla zapewnienia elastycznego zarządzania zasobami bazy danych. Pierwszą klasą, którą opiszę jest klasa o nazwie SerwerSqlException. Jest ona wykorzystywana dla zapewnienia poprawnej obsługi błędów. Widoczna jest na rysunku numer10.1. Klasa reprezentuje obiekty wyjątków, czyli obiektów, którymi posługuje się program napotykając na sytuacje odbiegające od normy, czy też poprawnego działania. Budowany jest wtedy taki obiekt, a następnie wypełniany dodatkowymi informacjami i przekazywany do obsługi. Informuje on odpowiednie komponenty o występującym problemie i zmusza do podjęcia działań naprawczych oraz powiadomienia użytkownika końcowego o zaistniałej sytuacji. Jak widać na rysunku 10.1, ponad klasą SerwerSqlException znajduje się dodatkowy element o nazwie Exception. Jest to klasa, z której wywodzi się klasa wyjątku serwera. Została ona stworzona przez autorów maszyny uruchomieniowej programu i jest zaszyta w bibliotekach platformy programistycznej. Można z niej korzystać podczas obsługi błędów, ale nie jest to zalecane. Jest to najbardziej ogólny wzorzec reprezentujący sytuację wyjątkową, więc otrzymując taki obiekt komponent może nie wiedzieć jaką obsługę błędu uruchomić. W standardzie programistycznym przyjęło się stosowanie ściśle określonych wzorców wyjątków. Wtedy jednoznacznie można zareagować na jego wystąpienie. Kolejnym elementem mechanizmu dostępu do danych jest klasa reprezentująca parametry (rysunek 10.2), które mogą być definiowane w skrypcie języka T-SQL. Są one wykorzystywane przy poleceniach i pełnią rolę zmiennych. Serwer SQL zapewnia poprawność typów przekazywanych parametrów dla określonego polecenia. Nie dopuści do sytuacji, w której zamiast identyfikatora typu BIGINT o wartości 1 przekażemy wartość logiczną typu BIT również o wartości 1. Jak widać na rysunku Klasa parametrów posiada słownik przechowujący listę par obiektów. Pierwszy element tej pary określa nazwę pojedynczego parametru, natomiast drugi określa wartość wybranego typu. W języku C# typ OBJECT jest najbardziej ogólny i można w nich przechowywać wartości wszystkich typów. Klasa posiada kilka metod. Na pierwszym miejscu warto wyróżnić dwa konstruktory (metody, które nazywają się tak samo jak klasa). Konstruktory mają za zadanie zainicjalizować obiekt klasy. Powołują słownik parametrów i rezerwują dla niego fragment pamięci operacyjnej. Pierwszy jest konstruktorem domyślnym i przygotowuje on podstawowy obiekt parametrów, natomiast drugi pozwala zdefiniować podczas konstrukcji pojedynczy parametr. Taka metoda przydaje się w sytuacjach, kiedy potrzebujemy tylko jednego parametru, np. identyfikatora klucza głównego jakiejś wybranej tabeli. Metodą wywoływaną przez programistę korzystającego z obiektów tej klasy jest metoda o nazwie definiuj(). Służy ona do definiowania nowych parametrów. Wywołanie tej metody powoduje dodanie parametru do już istniejących. Pozostałe dwie metody są pomocnicze i wykorzystywane przez inne komponenty. Metoda ToString() jako

71 10.1 Moduł dostępu do danych 70 Rysunek 10.2: Diagram klasy reprezentujacej listę parametrów definiowanych dla polecenia wykonywanego przez serwer baz danych Rysunek 10.3: Diagram klasy reprezentujacej serwer bazy danych. Oferuje funkcjonalności pozwalajace na komunikację i zarzadzanie zasobami serwera rezultat zwraca pewien ustalony przez autora klasy ciąg tekstowy, może to być np. opis parametrów. Ostatnią nieopisaną do tej pory metodą jest metoda GetEnumerator(). Jest ona ściśle związana z elementem oznaczonym okręgiem znajdującym się nad bloczkiem reprezentującym klasę. Ten okrągły element oznacza, że klasa ParametrySql implementuje pewną funkcjonalność interfejsu IEnumerable związaną właśnie z metodą GetEnumerator(). Funkcjonalność ta pozwala przeglądać kolejne parametry znajdujące się w opisywanym wcześniej słowniku. Opisane komponenty wykorzystywane są przez klasę o nazwie SerwerSql. Jest to klasa statyczna, co oznacza, że nie trzeba konstruować jej obiektów, aby móc korzystać z oferowanych przez nią funkcjonalności. Klasy statyczne zazwyczaj wykorzystywane są w roli narzędzi, które pozwalają wykonać pewne pojedyncze operacje. Klasa SerwerSql została przedstawiona na rysunku Klasa posiada dwa pola przechowujące wartość tekstową i liczbową. Pole o nazwie ciagpolaczeniowy wskazuje na serwer i bazę danych, do której będą odnosiły się polecenia i zapytania, natomiast pole Timeout określa ile czasu przeznaczone jest na oczekiwanie na odpowiedź serwera. Klasa posiada metodę testującą połączenie, która pozwala zweryfikować, czy połączenie z serwerem bazy danych i samą bazą danych jest poprawne. Pozostałe metody różniące się częściami nazw służą do wykonywania pewnych zadań na serwerze bazy danych. Można wykonać listę poleceń, wstawiać rekordy uzyskując identyfikator dla wstawianego rekordu, wykonać polecenie, np. usunięcie (lub zmianę wartości). Można także zapytać serwer o dane. Otrzymamy wtedy w rezultacie obiekt utożsamiany z tablicą danych.
72 10.1 Moduł dostępu do danych Szczegóły implementacji Platforma programistyczna, z której korzystałem do pisania aplikacji pozwala obsługiwać wielu dostawców internetowych. Definicje sposobu komunikowania się i korzystania z nich zawarte są w przestrzeniach, które wydzielają pewien obszar pod względem funkcjonalności. Język C# pozwala korzystać z warstwy połączeniowej dla wielu dostawców baz danych nazywanej ADO.NET. Powstało ono z myślą o komunikacji bezpołączeniowej wykorzystującej zbiory danych przechowywane w pamięci (dowolne liczby kopii tabel bazy danych), które mogły być modyfikowane bez połączenia z bazą danych. Na życzenie wszystkie modyfikacje mogły zostać naniesione na bazę danych za pomocą specjalnego adaptera danych. Z punktu widzenia programisty wykorzystującego dostawców baz danych najważniejszym pakietem bibliotek jest System.Data.dll, który dostarcza wielu przestrzeni dla ADO.NET, jedną z nich jest System.Data.SqlClient, z której korzystałem. Tak jak wspomniałem ADO.NET powstało z myślą o bezpołączeniowym świecie obiektów, w którym wszystko jest przechowywane w pamięci. ADO.NET ma jednak także drugą twarz. Pozwala korzystać z warstwy połączeniowej, w której używa się kodu, który łączy się z bazą danych wykonuje pewne operacje i rozłącza się. Już na tym etapie osoba, która kiedyś miała do czynienia z programowaniem może stwierdzić, że wczytanie i przechowywanie dużych zbiorów danych w pamięci jest bardzo kosztowne tym bardziej, że nie zawsze wszystkich się używa. Dodatkową wadą rozwiązania jest to, że do pamięci wczytywane są wszystkie dane ze wskazanej adapterowi tabeli, a filtrowane są dopiero w pamięci. Co z tego, że ilość połączeń wykonywanych do bazy danych jest mała, jak odpowiedz i reakcja programu na akcje użytkownika będzie bardzo opóźniona ze względu na przesłanie dużej ilości danych. Pomimo tego, że pamięć operacyjna jest coraz tańsza i komputery osobiste posiadają jej coraz więcej nie jest to dobry sposób do zarządzania bazą danych. Może on się sprawdzić dla prostych programów, które nie korzystają z dużych baz danych. W moim przypadku oczywistym wyborem jest wybranie techniki połączeniowej. Wykorzystuje ona w tym celu następujące interfejsy: IDbConnection - definiuje zbiór składowych służących do konfiguracji połączenia z określonym magazynem danych. Dodatkowo pozwala uzyskać dostęp do obiektu Transaction IDbTransaction - dzięki temu obiektowi można komunikować się programistycznie z sesją transakcji i wykorzystywanym magazynem danych IDbCommand - pozwala programiście manipulować instrukcjami SQL, składowanymi procedurami i sparametryzowanymi zapytaniami. Poza tym dzięki specjalnej metodzie o nazwie ExecuteReader() zapewnia dostęp do typu czytnika danych dostawcy danych. IDbParameter - pozwala zapisywać i korzystać z parametrów w poleceniach SQL IDataReader - czytnik danych. Można korzystać z niego przeglądając dane w trybie do odczytu i tylko od początku do końca. Wymienione interfejsy są implementowane dla różnych dostawców baz danych. Zapewnia to istnienie polimorfizmu, czyli oferowanie tej samej funkcjonalności w inny sposób. Na listingu 10.1 został zaprezentowany fragment kodu odpowiedzialnego za pobranie danych z bazy danych. Realizuje on powyżej opisane kroki.
73 10.1 Moduł dostępu do danych 72 Listing 10.1 Fragment kodu programu odpowiedzialnego za pobranie danych z bazy danych public static DataTable wykonajzapytanie(string zapytanie, ParametrySql parametrysql){ SqlConnection sqlconnection = new SqlConnection(ciagPolaczeniowy); SqlCommand sqlcommand = new SqlCommand(zapytanie, sqlconnection); sqlcommand.commandtimeout = Timeout; foreach (KeyValuePair<string, object> param in parametrysql){ SqlParameter parameter = new SqlParameter(param.Key, param.value); parameter.direction = ParameterDirection.Input; sqlcommand.parameters.add(parameter); } SqlDataReader sqlreader; DataTable dtresult = new DataTable(); try { sqlconnection.open(); sqlreader = sqlcommand.executereader(); int liczbakolumn = sqlreader.fieldcount; for (int i = 0; i < liczbakolumn; i++) { Type typ = sqlreader.getfieldtype(i); string nazwakolumny = sqlreader.getname(i); dtresult.columns.add(nazwakolumny, typ); } object[] datarow = new object[sqlreader.fieldcount]; while (sqlreader.read()){ sqlreader.getvalues(datarow); dtresult.rows.add(datarow); } sqlreader.close(); return dtresult; }catch (SqlException blad){ throw new SerwerSqlException("Błąd w trakcie wykonywania zapytania" + blad.message, blad); }catch (Exception blad){ throw new SerwerSqlException("Błąd", blad); }finally{ sqlconnection.dispose(); sqlcommand.dispose(); dtresult.dispose(); } } Kiedy chcemy się połączyć z bazą danych i wykonać odczyt rekordów za pomocą warstwy połączeniowej musimy wykonać następujące czynności: 1. Utworzyć, skonfigurować i otworzyć obiekt Connection 2. Utworzyć, skonfigurować obiekt Command, określając dla niego obiekt połączenia - Connection 3. Wywołać metodę odczytu - ExecuteReader() na utworzonym obiekcie komendy 4. Przetworzyć każdy rekord z czytnika danych 5. Zamknąć połączenie i zwolnić zasoby Listing 10.2 Ciąg połączeniowy do bazy testowej Data Source=localhost,12001; Initial Catalog=merlin; User Id=tester; Password=tester; Ważnym elementem komunikacji z bazą danych, o którym jeszcze nie pisałem jest konstrukcja ciągu połączeniowego. Jest on niezbędny do utworzenia obiektu połączenia - Connection. Jest to sformatowany łańcuch tekstowy, który zbudowany jest z pewnej ilości par NAZWA=WARTOŚĆ, oddzielonych średnikami.
74 10.1 Moduł dostępu do danych 73 Informacje w nim zawarte służą do identyfikowania nazwy komputera z którym chcemy się połączyć, określenia zabezpieczeń, nazwy bazy danych na wskazanym komputerze oraz innych dodatkowych informacji związanych z wybranym dostawcą bazy danych. Ciąg połączeniowy do bazy testowej zaprezentowany jest na listingu Jak łatwo można się domyśleć atrybut Data Source wskazuje na komputer. W tym przykładzie jest to komputer lokalny. Po przecinku podany jest numer port dla gniazda sieciowego, ponieważ połączenie wykorzystuje do komunikacji protokół TCP/IP. Initial Catalog wskazuje na bazę danych. Pozostałe parametry to uprawnienia, czyli nazwa użytkownika i hasło. Są niezbędne nie tylko do zalogowania do serwera, ale także określają prawa wykonania poleceń i dostępu do tabel, widoków, funkcji Projekt testowej bazy danych Testowa baza danych została wypełniona danymi za pomocą specjalnego programu. Aby to było możliwe baza danych musiała być wcześniej zaprojektowana i utworzona. Została ona zaprojektowana zgodnie ze standardem tworzenia relacyjnych baz danych. Powiązania pomiędzy krotkami (czyli obiektami reprezentowanymi przez rekordy w tabelach) są oparte o klucze główne i klucze obce. Zapewnia to wiązanie, weryfikujące poprawność relacji. W bazie danych występują relacje jeden do wielu. Nie było potrzebne stworzenie relacji wiele do wielu. Baza danych składa się z kilku tabel. Jej zadaniem jest przechowywanie informacji na temat książek (kategorie, autorzy, tytuły, oceny itp.) oraz użytkowników i czasu odwiedzenia przez nich strony internetowej z wybraną książką. Przy projektowaniu bazy danych zostały wykorzystane następujące typy danych (BIGINT - liczba całkowita o dużym zakresie, DATETIME - data i czas, VARCHAR - łańcuch tekstowy, INT - liczba całkowita, FLOAT - liczba zmiennopozycyjna o podwójnej precyzji). Poniżej wymienione zostały poszczególne tabele, a na rysunkach zaprezentowane schematy budowy. Dla każdego pola został określony typ przechowywanych danych oraz informacja o tym, czy pole zezwala na przechowywanie wartości pustych - NULL. Tabela AUTORZY (rysunek 10.4) przechowuje dane o autorach. Składa się z dwóch pól: identyfikatora będącego kluczem głównym i nazwy. Identyfikator jest typu bigint, aby zapewnić odpowiedni zakres dla danych. Jest polem, któremu wartość jest nadawana przyrostowo podczas dodawania rekordu. Zdecydowałem, że pole nazwa określające autora jest wystarczające i nie ma potrzeby go dzielić na imię i nazwisko. Z punktu widzenia aplikacji nie będzie miało to większego znaczenia. Rysunek 10.4: Schemat tabeli AUTORZY Tabela UZYTKOWNICY (rysunek 10.5) jest zbudowana podobnie do tabeli autorów. Każdy rekord jest jednoznacznie identyfikowany za pomocą pola identyfikatora będącego kluczem głównym, które w dodatku jest auto-numerowane. Polem opisującym jest nazwa. Analogicznie jak to jest w tabeli autorów nie ma wyszczególnionego imienia i nazwiska. Rysunek 10.5: Schemat tabeli UZYTKOWNICY
 zawiera więcej pól.")
75 10.1 Moduł dostępu do danych 74 Tabela WYDAWNICTWA (rysunek 10.6) jest analogiczna do dwóch poprzednich. Każde wydawnictwo opisywane jest przez nazwę, a identyfikowane przez wartość klucza głównego. Rysunek 10.6: Schemat tabeli WYDAWNICTWA Tabela KSIAZKI (rysunek 10.7) zawiera więcej pól. Poza polami opisowymi takimi jak liczba stron średnia ocen, czy ilość recenzji, które przechowują konkretne wartości znajdują się pola przechowuje też identyfikatory dla kluczy obcych, które wiążą książkę z wydawnictwem, autorem, i podkategorią. Rysunek 10.7: Schemat tabeli KSIAZKI Tabela PODKATEGORIE (rysunek 10.8) powiązana jest z książką i kategorią. Może istnieć wiele podkategorii w ramach jednej kategorii. Poza występowaniem dodatkowego klucza obcego wiążącego podkategorię z kategorią budowa tabeli jest analogiczna do budowy tabel autorów użytkowników i wydawnictw. Rysunek 10.8: Schemat tabeli PODKATEGORIE Tabela KATEGORIE (rysunek 10.9) ma analogiczną konstrukcję jak pozostałe tabele słownikowe opisywane wyżej.
76 10.1 Moduł dostępu do danych 75 Rysunek 10.9: Schemat tabeli KATEGORIE Tabela AKTYWNOSCI (rysunek 10.10) przechowuje informacje o powiązaniach użytkownika i książki oraz czasie, w którym dany użytkownik odwiedził stronę z książką. Krotki są identyfikowane za pomocą wartości klucza głównego, który jest automatycznie zwiększany. Dodatkowo występuje pole przechowujące adres url. Jest to pole pomocnicze, które jest wykorzystywane podczas parsowania informacji o odwiedzinach przez program pobierający dane i uzupełniający bazę danych. Pozwala na stwierdzenie, czy aktualnie przetwarzany przez program link był już analizowany, czy też nie. Rysunek 10.10: Schemat tabeli AKTYWNOSCI Schemat przedstawiający wszystkie tabele z naniesionymi relacjami widać na rysunku Rysunek 10.11: Ogólny schemat testowej bazy danych Przygotowałem odpowiedni skrypt w języku T-SQL i wykonałem zapytanie do bazy danych. Wyniki
77 10.1 Moduł dostępu do danych 76 Listing 10.3 Skrypt wybierający dane z testowej bazy danych (ze względu na czytelność w wyniku zapytania zostały pominięte niektóre kolumny) SELECT nazwa AS uzytkownik, data, tytul, wydawnictwo, autor, kategoria, podkategoria, isbn FROM aktywnosci AS aktyw JOIN uzytkownicy AS u ON aktyw.id_uzytkownicy = u.id_uzytkownicy JOIN ( SELECT id_ksiazki, tytul, w.nazwa AS wydawnictwo, a.nazwa AS autor, k2.nazwa AS kategoria, p.nazwa AS podkategoria, liczba_stron, srednia_ocena, ilosc_recenzji, isbn FROM ksiazki AS k JOIN wydawnictwa AS w ON k.id_wydawnictwa = w.id_wydawnictwa JOIN autorzy AS a ON a.id_autorzy = k.id_autorzy JOIN podkategorie AS p ON k.id_podkategorie = p.id_podkategorie JOIN kategorie AS k2 ON k2.id_kategorie = p.id_kategorie ) AS ksi ON aktyw.id_ksiazki = ksi.id_ksiazki ORDER BY ksi.id_ksiazki ASC tego zapytania przedstawiają przykładowe dane z pozyskanej bazy danych. Skrypt jest widoczny na listingu 10.3, natomiast wynik zapytania z danymi można zaobserwować na rysunku Rysunek 10.12: Przykładowe dane pobrane z testowej bazy danych zawierajacej aktywności użytkowników na stronach internetowych z ksiażkami

78 10.2 Moduł analizy danych Moduł analizy danych Moduł zajmuje się przetwarzaniem informacji zgromadzonych i przekazanych przez moduł dostępu do danych. Przekazane dane mogą pochodzić bezpośrednio z bazy danych lub z odpowiedniego pliku. Z perspektywy opisywanego modułu nie ma to znaczenia i nie wpływa to na jego działanie. Analiza danych nie odbywa się na obiektach baz danych pochodzących z warstwy ADO.NET. W tym celu wykorzystywane są specjalne wzorce przechowujących niezbędne informacje o każdym z obiektów. Pierwszym etapem grupowania, bo tym się właściwie zajmuje moduł analizy danych, jest przekształcenie informacji przechowywanej w obiektach bazy danych DataTable do wzorców (diagram klasy na rysunku 10.16). Analiza danych wymaga, aby przekazywane dane spełniały założenia dotyczące formatu i struktury pojedynczego rekordu danych. Jeśli te warunki nie będą spełnione zostanie zgłoszony błąd, a działanie przerwane. Pojedynczy rekord musi liczbowo charakteryzować dane. Nie dopuszczane są w kolumnach atrybutów inne wartości jak liczbowe. Mogą to być jednak wartości całkowite lub zmiennopozycyjne, pojedynczej lub podwójnej precyzji. Wyjątkiem jest pierwsza kolumna, która pełni rolę opisującą. Może tam znajdować się wartość dowolnego typu. Zazwyczaj jednak będzie to wartość tekstowa opisująca obiekt, np. model samochodu, imię i nazwisko, jakiś identyfikator. Konwersja obiektów z danymi przeprowadzana jest przez logikę interfejsu użytkownika, który jako jedyny posiada informację dotyczącą przepływu danych pomiędzy modułami. Po tej czynności wykonywana jest ostatnia czynność inicjalizacyjna, którą jest przygotowanie konfiguracji sieci neuronowej. Pobierane są wartości poszczególnych parametrów odpowiednich kontrolek na formularzu graficznego interfejsu użytkownika i wpisywane do specjalnie przygotowanego obiektu klasy KonfiguracjaSieciNeuronowej (diagram na rysunku 10.13). Przechowuje ona wszelkie parametry konfiguracyjne określające dokładnie sposób działania sieci neuronowej. Rysunek 10.13: Diagram klasy odpowiedzialnej za przechowywanie konfiguracji sieci neuronowej Przed przystąpieniem do wykonywania analizy dane znajdujące się we wzorach uczących muszą zostać znormalizowane względem atrybutów, aby odległość rekordu danych nie była zdominowana przez wartość któregoś z atrybutów. Zbudowałem klasę o nazwie NormalizacjaAtrybutow (diagram na rysunku 10.14). Obiekt tej klasy wykonuje niezbędne czynności mającej na celu odpowiednio przeskalować wszystkie war-

79 10.2 Moduł analizy danych 78 Rysunek 10.14: Diagram klasy normalizujacej wartości w ramach jednego atrybutu Rysunek 10.15: Diagram klasy kreatora sieci neuronowej tości. Najpierw wykonywane jest skanowanie wszystkich wartości. Celem tego skanowania jest znalezienie wartości minimalnych i maksymalnych dla wszystkich atrybutów. Są one zapamiętane. W kolejnym przebiegu wykonywane jest skalowanie w oparciu o znalezione wartości graniczne. Nowa wartość jest przeliczana zgodnie ze wzorem 3.6 na stronie 15. Wartości graniczne nie są usuwane. Zostaną wykorzystane ponownie po wykonaniu analizy, aby przywrócić wartości atrybutów do oryginalnej skali. Jeśli wszystko przebiegło bez błędów, to w oparciu o przygotowaną wcześniej konfigurację tworzona jest struktura sieci neuronowej. Struktura sieci jest zgodna z ideą sieci Kohonena. Zawiera jedną warstwę neuronów wejściowych, które będą propagowały wzorce oraz jedną warstwę neuronów pełniących rolę jednostek obliczeniowych. Tworzeniem sieci neuronowej zajmuje się komponent startera widoczny na rysunku Efektem jego działań jest gotowa do uruchomienia sieć Kohonena. Sieć Kohonena zbudowana jest z neuronów pogrupowanych logicznie dzięki warstwom. Neuron jest najmniejszą jednostką sieci, która wykonuje obliczenia i ma wpływ na wynik. Przygotowałem diagram klas (rysunek 10.16), który przedstawia wszystkie składowe elementy sieci neuronowej. Widać na nim klasę wzorca, którym posługują się neurony. Jest ona wykorzystywana w momencie przekazania wartości wejść neuronów wejściowych na poszczególne wejścia neuronów warstwy obliczeniowej. Klasa warstwy posiada podstawową funkcjonalność, która jest niezbędna do utworzenia struktury sieci. Udostępnia metodę dodaj(), która do aktualnej warstwy dodaje jeden neuron. Pozwala także poznać rozmiar sieci, czyli liczbę neuronów oraz uzyskać dostęp do wybranego neuronu. Klasa warstwy implementuje interfejs IEnumerable, aby umożliwić przeglądanie listy neuronów jeden po drugim. Związana z warstwą jest klasa wyjątku WarstwaNieIstniejeException, która informuje o sytuacji, w której chcemy dostać się do warstwy w sieci neuronowej, która nie istnieje. Pojedynczy neuron posiada określoną z góry liczbę wejść neuronu. Na pojedyncze wejście składają się trzy wartości OstatniPrzyrost, Waga oraz Wartość. Są to podstawowe wartości, którymi operuje neuron (ich opis znajduje się w rozdziale 4.3.1). W neuronie poza metodami i polami związanymi z jego podstawowym działaniem (obliczenie nowego wektora wagowego, ustawiania wejść itp.) pojawiły się dodatkowe pola. Są one wynikiem wprowadzenia mechanizmu zmęczenia neuronu. Wartość logiczna Odpoczywajacy służy do określenia, czy neuron może brać udział w rywalizacji neuronów o reprezentację pewnego przedstawianego wzorca. Jeśli neuron odpoczywa, to nie bierze udziału w rywalizacji, co skutkuje tym, że nie może być w tym czasie uczony. Wartość potencjału określa jego stan związany

80 10.2 Moduł analizy danych 79 Rysunek 10.16: Diagram klas ze składowymi elementami sieci neuronowej z nauką. Przy każdym zwycięstwie w rywalizacji wartość potencjału jest zmniejszana o pewną stałą wartość. Jeśli osiągnie wystarczający próg, neuron jest usypiany - przechodzi w stan odpoczynku. Przy każdej kolejnej prezentacji wzorca uczącego jego potencjał rośnie o wartość wynikającą z ilości wszystkich neuronów. Jeśli będzie większa niż stan graniczny, to neuron zostanie obudzony i będzie mógł brać czynny udział w nauce sieci. Mechanizm ten może być wyłączony po pewnym czasie. Formalny zapis przedstawionego zjawiska został opisany przy okazji omawiania sieci Kohonena ( na stronie 24). Sieć została zaprojektowana i zaimplementowana zgodnie z opisanym przeze mnie wcześniej algorytmem działania. Mogę nawet stwierdzić, że efekt mojej programistycznej pracy jest lustrzanym odbiciem zaprojektowanego przeze mnie algorytmu (jest to pewne rozszerzenie algorytmu Kohonena). Dlatego też nie będę opisywał ponownie wykonywanych kroków. Dokładny opis zasady działania znajduje się na stronie 28, a schemat blokowy został przedstawiony na rysunku 4.10 na stronie 29. Warto opowiedzieć o sposobie reprezentacji rozwiązań sieci neuronowej dla prezentowanych wzorców. Kiedy wzorzec jest pokazywany sieci neuronowej ona musi podjąć decyzję na drodze rywalizacji neuronów, aby określić, który z neuronów jest najbardziej podobny do zadanego wzorca. Informacja o tym, który neuron może być utożsamiany (oczywiście z pewnym przybliżeniem) ze wzorcem zapisywana jest w tak zwanej książce kodowej. Taka książka kodowa przechowuje pary IDENTYFIKATOR WZORCA == IDENTYFIKATOR NEURONU. Dzięki temu podczas analizowania rozwiązań można odwołać się do neuronu, aby pobrać jego wagi. Wagi te określają centroid grupy, ponieważ jeden neuron może reprezentować wiele wzorców. Może także zostać przyporządkowany tylko jednemu wzorcowi, lub może mieć wektor wagowy na tyle odległy od wektora wartości wzorca, że nie będzie mógł się dopasować do żadnego wzorca. Będziemy mieli do czynienia wtedy z pustą grupą. Niestety nie da się przewidzieć wyniku nauki. Jest ona nienadzorowana. Można jedynie starać się tak dobrać parametry sieci, aby spowodować przesunięcie wszystkich neuronów w przestrzeń zagęszczonych rozwiązań tak, aby nie było neuronów odosobnionych. Właśnie do tego służy mechanizm zmęczenia neuronów. Zaimplementowany wariant książki

81 10.2 Moduł analizy danych 80 Rysunek 10.17: Diagram klasy przechowujacej rozwiazania (powiazania obiekt-grupa) kodowej można zobaczyć na rysunku Została ona rozszerzona o kilka dodatkowych słowników i metod wybierających wartości. Wszystko po to, aby mieć ułatwiony dostęp do oznaczeń i centroidów. Sieć Kohonena nie działałaby, gdyby nie dwa podstawowe pojęcia: odległość oraz sąsiedztwo. Te dwa pojęcia wyznaczają kierunek nauki. Odległość ma wpływ na to, który neuron będzie reprezentował w rozwiązaniach zadany wzorzec, a sąsiedztwo określa pewien współczynnik adaptacji, który znacznie wpływa na proces nauki. Obie funkcje odległości i sąsiedztwa zostały oparte o interfejsy, aby w razie potrzeby umożliwić poszerzenie wachlarza funkcji. Zdecydowałem się zaimplementować trzy funkcje odległości: Euklidesową Manhattan (znaną również pod nazwą Miejska) Czybyszewa Dostęp do nich został zrealizowany poprzez realizację wzorca fabryki obiektów (na rysunku znajduje się diagram klas obrazujący działanie wzorca fabryki). Obiekt fabryki posiada statyczną metodę, która w zależności od wskazanej nazwy utworzy i zwróci żądany obiekt. Jest to bardzo eleganckie i wygodne rozwiązanie. Pozwala także na bardzo proste rozszerzanie funkcjonalności o nowe typy metryk. W przypadku funkcji sąsiedztwa również zostały zaimplementowane trzy typy (diagram na rysunku 10.19), opisane w części teoretycznej mojej pracy, jednak zadecydowałem, że program będzie używał tylko funkcji Gaussowskiej funkcji sąsiedztwa. Pozwala ona na otrzymywanie najciekawszych rezultatów. Nie dość, że neurony znajdujące się w pewnym sąsiedztwie są uczone, to im dalej od neuronu zwycięskiego, tym stopień modyfikacji będzie mniejszy. Współczynnik sąsiedztwa jest obliczany przez dedykowany komponent, który podczas tworzenia otrzymuje w parametrze promień sąsiedztwa niezbędny do określenia obszaru w jakim neurony są uznawane za sąsiadujące oraz funkcję sąsiedztwa, która definiuje jednoznacznie sposób wyznaczania tego współczynnika.
82 Rysunek 10.18: Diagram klas. Realizacja wzorca fabryki. Metryki Rysunek 10.19: Diagram klas funkcji sasiedztwa oraz klasy liczacej wartość współczynnika sasiedztwa
83 10.2 Moduł analizy danych Szczegóły implementacji wybranych elementów W tej części chciałbym przedstawić kilka szczegółów implementacyjnych dotyczących analizy danych. Bardzo ciężko jest wybrać fragmenty kodu, które będą w całości zrozumiałe, ponieważ niektóre metody stanowią jakąś część zadania lub wykorzystują inne metody do realizacji pewnego zadania. Wybrałem kilka przykładowych listingów (10.4, 10.5, 10.6, 10.7), które opisują prostsze i bardziej ogólne zadania. Listing 10.4 Normalizacja wzorców uczących przed rozpoczęciem grupowania public class NormalizacjaAtrybutow { public double[] wartosciminimalne { get; private set;} public double[] wartoscimaksymalne { get; private set;} public void przeprowadznormalizacje(list<wzorzec> listawzorcow){ if(listawzorcow == null listawzorcow.count == 0){ throw new ArgumentException("Nie można przeprowadzić normalizacji"); } //inicjalizacja tablic normalizacji wartosciminimalne = new double[listawzorcow[0].wartosci.length]; wartoscimaksymalne = new double[listawzorcow[0].wartosci.length]; for (int i = 0; i < wartoscimaksymalne.length; i++) { wartoscimaksymalne[i] = double.minvalue; } for (int i = 0; i < wartosciminimalne.length; i++) { wartosciminimalne[i] = double.maxvalue; } //znajdywanie min i max foreach (Wzorzec wzorzec in listawzorcow) { double[] tablica = wzorzec.wartosci; for (int i = 0; i < tablica.length; i++) { double wartosc = tablica[i]; if(wartosc > wartoscimaksymalne[i]) { wartoscimaksymalne[i] = wartosc; } if(wartosc < wartosciminimalne[i]){ wartosciminimalne[i] = wartosc; } } } } //normalizacja poszczegolnych wartosci foreach (Wzorzec wzorzec in listawzorcow){ double[] tablica = wzorzec.wartosci; for (int i = 0; i < tablica.length; i++){ tablica[i] = normalizujwartosc(tablica[i], wartosciminimalne[i], wartoscimaksymalne[i]); } } public void odwrocnormalizacje(double[] tablica) { for (int i = 0; i < tablica.length; i++){ tablica[i] = przywrocwartosc(tablica[i], wartosciminimalne[i], wartoscimaksymalne[i]); } } private double normalizujwartosc(double x, double min, double max){ return (x - min)/(max - min); } private double przywrocwartosc(double x2, double min, double max){ return x2 * (max - min) + min; } }
84 10.3 Moduł statystyczny 83 Listing 10.5 Przeprowadzenie pojedynczej epoki nauki sieci neuronowej private double epokanauki(list<wzorzec> listawzorcow){ RozwiazaniaSieciNeuronowej.pobierz().wyczysc(); double blad = 0.0; foreach (Wzorzec wzorzec in listawzorcow){ ustawwejsciasieci(wzorzec); policzodleglosci(); try { Neuron neuronzwyciezcy = pobierzostatniawarstwe()[indekszwyciezcy]; blad += neuronzwyciezcy.odleglosc; rozwiazania.dodajrozwiazanie(wzorzec.obiekt, IndeksZwyciezcy, neuronzwyciezcy.pobierzwagi()); adaptujsiec(); }catch (Exception ex){ throw new ArgumentOutOfRangeException("Nie można przypisać wzorca do grupy.",ex); } } return blad / listawzorcow.count; } Listing 10.6 Implementacja metryki Czybyszewa private class MetrykaCzybyszewa : IMetryka { private const int ID = FabrykaMetryk.CZYBYSZEWA; public int identyfikator() { return ID; } public double oblicz(double[] x, double[] w) { double max = 0.0; for (int i = 0; i < w.length; i++){ double newmax = Math.Abs(x[i] - w[i]); if (max < newmax){ max = newmax; } return max; } } } Listing 10.7 Implementacja Gaussowskiej funkcji sąsiedztwa public class GaussowskaFunkcjaSasiedztwa : IFunkcjaSasiedztwa{ IMetryka metryka; public GaussowskaFunkcjaSasiedztwa(IMetryka funkcjametryki) { metryka = funkcjametryki; } public double oblicz(double[] wektor, double[] zwyciezca, double promien){ return Math.Exp(-0.5 * Math.Pow(metryka.oblicz(wektor, zwyciezca), 2) / Math.Pow(promien, 2)); } } 10.3 Moduł statystyczny Jest to najmniejsza część logiki programu. Wynika to z kilku powodów. Po pierwsze w wynikach grupowania można zaobserwować pewne podsumowanie wyników analizy, a po drugie wymaga najmniej kodu. Zdecydowałem się jednak napisać parę słów o tej części, aby zaznaczyć jej istnienie. Moduł statystyczny
85 10.4 Graficzny interfejs użytkownika 84 jest głównie odpowiedzialny za wyświetlanie dwóch wykresów oraz przedstawienie kilku wartości statystycznych. Udostępnia również informacje na temat centroidów poszczególnych grup, co jest pomocne przy interpretacji wykresu kołowego. W rysowaniu wykresów posłużyłem się zewnętrzną biblioteką o nazwie ZedGraph. Jest ona przeznaczona na platformę programistyczną.net i oferuje bardzo dużą funkcjonalność. Jest przy tym bardzo prosta w użyciu, a jej budowa jest intuicyjna, co pozwala szybko odnaleźć się w gąszczu możliwości. Przygotowywanie statystyk odbywa się w trzech następujących krokach: 1. Przygotowanie danych statystycznych - na tym etapie liczone są potrzebne wartości, które zostaną później wykorzystane przy rysowaniu wykresu i wyświetlone na odpowiedniej etykiecie 2. Wypełnianie informacji ogólnych - polega na wypisaniu danych z poprzedniego kroku. Wypełnianie informacjami dotyczy głównie przygotowywania kontrolek do wyświetlania centroidów znalezionych grup. 3. Rysowanie wykresów - należy odpowiednio skonfigurować obiekty wykresów pochodzące z zewnętrznej biblioteki, a następnie przekazać im przygotowane dane statystyczne Graficzny interfejs użytkownika Budowa modułowa programu wymusza odpowiednie zaprojektowanie graficznego interfejsu użytkownika. Musi on być tak skonstruowany, aby mógł koordynować działania poszczególnych modułów i zlecać wykonanie wybranych zadań. Musi kontrolować przepływ danych, zarówno wejściowych jak i wyjściowych, które są wynikiem działania wybranego modułu. Bardzo ważne jest, aby poszczególne zadania wykonywały się w innych wątkach niż wątek interfejsu użytkownika. Zapobiega to zamrażaniu interfejsu, co objawia się tym, że nie można z niego korzystać. Jeśli zadanie wykonywałoby się w wątku GUI, to nie byłoby możliwie anulowanie tego zadania, czy też zlecenie innego do czasu jego zakończenia. Dzięki rozdzieleniu wątku zadań i wątku interfejsu użytkownika program staje się bardziej czytelny dla użytkownika końcowego. Użytkownik może śledzić postęp wykonania zadania za pomocą pojawiających się komunikatów lub innych dodatkowych kontrolek, jak np. popularne paski postępu. Poprawne rozwiązanie tego problemu spoczywa na programiście. Musi on zadbać, aby wątki się nie krzyżowały (nie korzystały na wzajem ze swoich zasobów), ponieważ może to doprowadzić do błędów programu i nieprawidłowej pracy. Wymusza to odpowiednie zarządzanie wymianą obiektów pomiędzy używanymi wątkami oraz umiejętne przekazywanie parametrów w obydwu kierunkach. W swoim projekcie wykorzystałem bardzo ciekawy mechanizm polegający na zlecaniu pewnym obiektom wykonania pewnych zadań. Mechanizm ten nosi nazwę delegatów. Jego bardziej rozszerzoną obsługą są zdarzenia. Zdarzenia pozwalają na wyzwolenie działania pewnego komponentu z innego komponentu, kiedy zachodzi taka potrzeba. Najciekawsze jest to, że komponent, który podnosi zdarzenie nie musi wiedzieć, kto je wykona oraz jak się ono wykona. Jego zadaniem jest tylko je wyzwolić, a reszta zostanie wykonana przez osobny komponent, stąd nazwa delegatów. Odpowiedzialność zostaje oddelegowana do innego fragmentu programu. Projektowanie interfejsu od strony wizualnej jest również trudną sztuką. Najważniejsze jest, aby użytkownik końcowy łatwo mógł odnaleźć poszukiwane przez siebie funkcje. Interfejs użytkownika musi być intuicyjny, co oznacza, że każdy używany element powinien być w łatwo dostępnym miejscu. Kontrolki, które są ze sobą skorelowane powinny znajdować się w niedalekiej odległości, aby użytkownik miał pogląd na całość ustawień. Podczas projektowania interfejsu wzorowałem się na ogólnie przyjętych standardach tworzenia graficznego interfejsu użytkownika. Jeśli użytkownik zobaczy coś podobnego do tego co już kiedyś widział, będzie mu łatwiej się zaznajomić z funkcjonalnością. Wszystkie ustawienia aplikacji są zapamiętywane w pliku konfiguracyjnym. Jeśli użytkownik ustawi wszystkie parametry i zamknie program, to przy ponownym otwarciu wszystkie ustawienia zostaną wczytane. Funkcjonalność ta została jeszcze rozszerzona o możliwość zapisywania plików konfiguracyjnych w wybranych lokalizacjach. Można w ten sposób stworzyć scenariusze uruchomieniowe i wczytywać je na życzenie. Pliki konfiguracyjne są zapisy-
86 10.4 Graficzny interfejs użytkownika 85 Rysunek 10.20: Pasek narzędziowy aplikacji wane w języku znaczników XML, więc są łatwe w edycji nawet po zapisaniu na dysku. Można w łatwy sposób zmodyfikować wybrany parametr bez otwierania programu. Użytkownik ma możliwość korzystać z trzech następujących zakładek: 1. Przygotowanie zbioru danych 2. Grupowanie danych 3. Podsumowanie wyników W aplikacji każdy moduł znajduje się na oddzielnej zakładce. Jest to wygodne rozwiązanie, ponieważ można łatwo przełączać się pomiędzy zakładkami. W dalszej części rozdziału zostaną omówione dokładnie wszystkie trzy zakładki. Zanim jednak to uczynię chciałbym opisać funkcjonalność paska narzędziowego, który udostępnia najważniejsze funkcje ze wszystkich trzech zakładek. Pasek narzędziowy jest umieszczony w górnej części okna aplikacji. Został przedstawiony na rysunku Kolejno ponumerowane przyciski mają następujące znaczenie: 1. Wczytywanie ustawień - pozwala wczytać ustawienia programu z zewnętrznego pliku. Wskazanie pliku odbywa się poprzez okno dialogowe. Obsługiwane są pliki o rozszerzeniu *.xml 2. Zapisanie ustawień - pozwala zapisać ustawienia programu do zewnętrznego pliku. Wskazanie pliku odbywa się poprzez okno dialogowe. Obsługiwane są pliki o rozszerzeniu *.xml 3. Wczytanie skryptu - pozwala wczytać skrypt języka T-SQL z zewnętrznego pliku. Zostanie on załadowany do edytora skryptów. Jeśli w edytorze znajduje się jakiś skrypt, to użytkownik zostanie zapytany, czy skrypt ma być nadpisany. Wskazanie pliku odbywa się poprzez okno dialogowe. Obsługiwane są pliki o rozszerzeniu *.sql oraz *.txt 4. Zapisanie skryptu - pozwala zapisać skrypt języka T-SQL znajdujący się w edytorze skryptu do zewnętrznego pliku. Wskazanie pliku odbywa się poprzez okno dialogowe. Jeśli zostanie wskazany plik, który już istnieje na dysku, to użytkownik zostanie zapytany o nadpisanie zawartości. Obsługiwany jest zapis do formatu *.sql oraz *.txt 5. Wyczyść skrypt - czyści okno edytora. Skrypt, który się tam aktualnie znajduje zostanie skasowany 6. Konfiguracja połaczenia z baza danych - wyświetla specjalne okno dialogowe, w którym definiowany jest ciąg połączeniowy do serwera baz danych. 7. Pobierz dane - pobiera dane ze skonfigurowanej bazy danych na podstawie zdefiniowanego skryptu T-SQL. Jeśli aktywna jest inna zakładka niż pobieranie danych, to zostanie ona przełączona na zakładkę pobierania danych 8. Uruchom grupowanie - uruchamia grupowanie dla przygotowanego zbioru danych. Jeśli danych jeszcze nie ma, powiadomi o tym komunikatem. Wykonuje grupowanie zgodnie z ustalonymi parametrami na kontrolce grupowania. Jeśli przy wyzwoleniu aktywna jest inna zakładka, to zostanie ona przełączona na zakładkę grupowania danych 9. Pokaż podsumowanie - przełącza na zakładkę podsumowań Zakładka przygotowywania zbioru danych (rysunek 10.21) zawiera edytor kodu zapytania w języku T-SQL, które definiuje sposób wybierania danych. Edytor koloruje składnie skryptu z zachowaniem formatowania dla wszystkich słów kluczowych. Dodatkowo po wciśnięciu kombinacji klawiszy (CTRL+SPACJA) pojawi się małe menu pomocnicze, które podpowie jakie słowa kluczowe można wykorzystać. Edytor ma podpięte
87 10.4 Graficzny interfejs użytkownika 86 Rysunek 10.21: Kontrolka przygotowywania zbioru danych menu podręczne, które pojawia się po kliknięciu na obszar edycyjny prawym klawiszem myszy. W tym menu znaleźć można wszystkie funkcje niezbędne przy pracy ze skryptem. Edytor obsługuje również skróty klawiaturowe kopiowania (CTRL+C), wycinania (CTRL+X) oraz wklejania (CTRL+V) tekstu. Poniżej edytora znajduje się kilka przycisków. Przycisk Połaczenie wyzwala pojawienie się okna dialogowego (rysunek 10.22), w którym można zdefiniować ciąg połączeniowy do bazy danych. Okno oferuje także możliwość przetestowania połączenia z bazą danych. Przycisk Wykonaj powoduje wysłanie do serwera przygotowanego skryptu T-SQL znajdującego się w edytorze tekstowym. Jeśli skrypt był poprawny w odpowiedzi serwera otrzymamy zestaw danych, który zostanie załadowany do podglądu, jak to jest widoczne na rysunku Jeśli skrypt był niepoprawny program zgłosi błąd, w którym znajdzie się informacja przekazana przez serwer o prawdopodobnym miejscu, w którym nastąpiła pomyłka. Przyciski Zapisz dane oraz Wczytaj dane pozwalają zapisać dane z podglądu do pliku binarnego i wczytać je w późniejszym czasie. Umożliwia to osobom, które nie mają połączenia z serwerem bazy danych korzystać z Rysunek 10.22: Okno dialogowe konfiguracji połaczenia z baza danych
88 10.4 Graficzny interfejs użytkownika 87 programu. Warunkiem koniecznym jest wcześniejsze przygotowanie plików. Kontrolka grupowania danych przedstawiona na rysunku w górnej części pozwala ustawić wszystkie parametry sieci neuronowej. Jeśli którykolwiek będzie niepoprawny zostanie zgłoszony błąd. Pod panelem parametrów znajduje się dziennik zdarzeń, w którym wypisywane są informacje dotyczące działania sieci neuronowej. Na samym dole znajduje się pole tekstowe, w którym pojawiają się wyniki grupowania. Można tam odczytać ile grup udało się znaleźć, a także jak przedstawiają się powiązania obiektów z grupami. Można również przyjrzeć się centroidom znalezionych grup i oryginalnym obiektom przekazanym do grupowania. Rysunek 10.23: Kontrolka grupowania danych Kontrolka podsumowań służy do prezentowania wykresów. Miejsce przeznaczone do wyświetlenia wykresu znajduje się w dolnej części obszaru formularza. W zależności od typu wykres posiada stosowną legendę. Nad wykresem znajduje się pole wyboru grupy umożliwiające wczytanie wartości środka grupy ułatwiającego interpretację wykresu. Dodatkowo można odczytać ile grup nie zostało powiązanych z obiektami oraz które grupy miały największy i najmniejszy wkład w podziale obiektów.
89 10.5 Przykładowe uruchomienie 88 Rysunek 10.24: Kontrolka podsumowań 10.5 Przykładowe uruchomienie Zaprezentuję dwa przykładowe uruchomienia programu. Pierwsze będzie miało na celu pokazanie na prostych spreparowanych danych zasadę działania programu. Drugi przykład pokaże zachowanie programu na bardziej złożonych danych pochodzących z testowej bazy danych. Te dwa przykłady będą dowodem na to, że program przy zachowaniu założeń dotyczących formatowania danych może zostać wykorzystany dla różnych zagadnień. W testowej bazie danych znajdują się informacje na temat odwiedzin przez użytkowników pewnych stron internetowych z książkami. Baza danych nie dysponuje żadnymi innymi danymi. Można jednak wykorzystać sytuację, że serwer SQL potrafi poza wyciąganiem danych również wykonywać obliczenia. Można odpowiednim zapytaniem zmusić serwer, aby przygotował dla nas dane w odpowiednim formacie. Na potrzeby testu przygotowałem takie zapytanie. Można je przeanalizować na listingu Czynności związane z pobraniem danych są identyczne jak w standardowym scenariuszu pobierania danych z serwera. Całą niezbędną pracę związaną z przygotowaniem danych wykona za nas serwer bazy danych. Analizując skrypt można wywnioskować, że wynikiem zapytania będzie tabela z trzema kolumnami. Pierwsza kolumna będzie zawierała imiona osób. Będzie przechowywała dane tekstowe. Kolejne dwie kolumny będą reprezentowały dane liczbowe. Wartości w obydwu kolumnach definiują płeć osoby. Grupowanie zostało przeprowadzone przy użyciu dwóch neuronów, ponieważ większa ilość nie miała sensu. Chcemy podzielić osoby na dwie grupy: kobiet i mężczyzn. Wynik grupowania jakie otrzymałem widoczne są na listingu Analizując wyniki stwierdzić można, że ilość grup jest poprawna, a centroidy mają przewidywany układ. Wszystkie obiekty zostały poprawnie zaklasyfikowane do grup. Dane do drugiego przykładu zostały pobrane z bazy danych odpowiednim zapytaniem. Zapytanie to
90 Listing 10.8 Zapytanie języka T-SQL, które wymusi spreparowanie danych przez serwer bazy danych SELECT Asia AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Ania AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Staszek AS Imie, 0 AS Kobieta, 1 AS Mezczyzna UNION SELECT Marek AS Imie, 0 AS Kobieta, 1 AS Mezczyzna UNION SELECT Kasia AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Jurek AS Imie, 0 AS Kobieta, 1 AS Mezczyzna UNION SELECT Magda AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Krzys AS Imie, 0 AS Kobieta, 1 AS Mezczyzna UNION SELECT Monika AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Agnieszka AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Ola AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Ela AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Artur AS Imie, 0 AS Kobieta, 1 AS Mezczyzna UNION SELECT Mariusz AS Imie, 0 AS Kobieta, 1 AS Mezczyzna UNION SELECT Przemek AS Imie, 0 AS Kobieta, 1 AS Mezczyzna UNION SELECT Gosia AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Zosia AS Imie, 1 AS Kobieta, 0 AS Mezczyzna UNION SELECT Marcin AS Imie, 0 AS Kobieta, 1 AS Mezczyzna UNION SELECT Grzegorz AS Imie, 0 AS Kobieta, 1 AS Mezczyzna UNION SELECT Jacek AS Imie, 0 AS Kobieta, 1 AS Mezczyzna Listing 10.9 Wyniki działania grupowania na spreparowanych danych testowych Liczba znalezionych grup = 2 Powiązania: Agnieszka Ania Artur Asia Ela Grupa 1 Grupa 1 Grupa 2 Grupa 1 Grupa 1 Gosia Grzegorz Jacek Jurek Kasia Grupa 1 Grupa 2 Grupa 2 Grupa 2 Grupa 1 Krzys Magda Marcin Marek Mariusz Grupa 2 Grupa 1 Grupa 2 Grupa 2 Grupa 2 Monika Ola Przemek Staszek Zosia Grupa 1 Grupa 1 Grupa 2 Grupa 2 Grupa 1 Szczegóły grup: Grupa Grupa 2 1
91 10.5 Przykładowe uruchomienie 90 Listing Zapytanie wybierające dane z testowej bazy danych SELECT DISTINCT odwiedziny.uzytkownik, SUM(CASE WHEN odwiedziny.kategoria = albumy THEN 1 ELSE 0 END ) AS albumy, SUM(CASE WHEN odwiedziny.kategoria = dla dzieci THEN 1 ELSE 0 END ) AS dzieci, SUM(CASE WHEN odwiedziny.kategoria = encyklopedie, słowniki THEN 1 ELSE 0 END ) AS encyklopedie_słowniki, SUM(CASE WHEN odwiedziny.kategoria = fantastyka THEN 1 ELSE 0 END ) AS fantastyka, SUM(CASE WHEN odwiedziny.kategoria = kryminał i sensacja THEN 1 ELSE 0 END ) AS kryminal_sensacja, SUM(CASE WHEN odwiedziny.kategoria = literatura faktu THEN 1 ELSE 0 END ) AS literatura_faktu, SUM(CASE WHEN odwiedziny.kategoria = nauka THEN 1 ELSE 0 END ) AS nauka, SUM(CASE WHEN odwiedziny.kategoria = poradniki THEN 1 ELSE 0 END ) AS poradniki FROM ( SELECT nazwa AS uzytkownik, data, ksi.id_ksiazki, tytul, wydawnictwo, autor, kategoria, podkategoria, liczba_stron, srednia_ocena, ilosc_recenzji, isbn FROM aktywnosci AS aktyw JOIN uzytkownicy AS u ON aktyw.id_uzytkownicy = u.id_uzytkownicy JOIN ( SELECT id_ksiazki, tytul, w.nazwa AS wydawnictwo, a.nazwa AS autor, k2.nazwa AS kategoria, p.nazwa AS podkategoria, liczba_stron, srednia_ocena, ilosc_recenzji, isbn FROM ksiazki AS k JOIN wydawnictwa AS w ON k.id_wydawnictwa = w.id_wydawnictwa JOIN autorzy AS a ON a.id_autorzy = k.id_autorzy JOIN podkategorie AS p ON k.id_podkategorie = p.id_podkategorie JOIN kategorie AS k2 ON k2.id_kategorie = p.id_kategorie ) AS ksi ON aktyw.id_ksiazki = ksi.id_ksiazki) AS odwiedziny GROUP BY odwiedziny.uzytkownik Listing Przykładowy rekord, dla losowo wybranego użytkownika pobrany za pomocą skryptu z listingu albumy dzieci encykl fantas krymin lit. fakt nauka porad user znalazło się w listingu Postanowiłem pogrupować użytkowników pod kątem kategorii książek, które odwiedzają. Liczba kategorii w bazie danych jest bardzo duża, dlatego na potrzeby tego przykładu ograniczyłem ich ilość do ośmiu. Pozwoli to na czytelniejsze przedstawienie wyników. Zapytanie widoczne na listingu zostało napisane w taki sposób, aby dla każdego obiektu reprezentowanego przez użytkownika odwiedzającego strony internetowe znalazło się 8 wartości w kolejnych kolumnach. W każdej kolumnie znajduje się wartość liczbowa będąca sumą odwiedzin użytkownika na stronach książek z odpowiedniej kategorii. Dokładną strukturę pojedynczego rekordu przedstawiłem na listingu Dotyczy ona losowo wybranego użytkownika. Można zaobserwować, że w niektórych kolumnach są wartości równe zeru. Oznacza to, że użytkownik nigdy nie odwiedził żadnej strony internetowej z książką tej kategorii. Przykładowy użytkownik interesuje się akurat książkami dla książkami dla dzieci, kryminałami oraz przeglądał albumy. Wartości poszczególnych parametrów grupowania zostały ustawione jak na rysunku Na rysunku widać, że parametr określający ilość neuronów został ustawiony na wartość 5. Oznacza to, że docelowo może zostać wyłonionych 5 grup. To ile uda się wykorzystać zależy od ustawień początkowych i charakterystyki danych. Chciałbym w tym momencie przypomnieć, że wszystkie neurony są inicjalizowane losowym wektorem wag, dlatego każde uruchomienie grupowania dla tych samych danych i tych samych ustawień może dać w efekcie inne rezultaty. Z wyników grupowania można odczytać, że udało się rozdzielić dane do 5 grup, czyli żaden neuron nie był odosobniony i wszystkie neurony brały czynny udział w procesie grupowania. Oznacza to, że dla analizowanych danych ustawienia były poprawnie dobrane.
92 10.5 Przykładowe uruchomienie 91 Rysunek 10.25: Przebieg grupowania dla danych testowych Listing Rezultat analizy danych (fragment) Grupa 2: user9 user42 Grupa 3: user2 user15 user37 user39 Grupa 4: user1 user8 user10 user21 Grupa 5: user24 user31 albumy dzieci encykl fantas krymin lit.fakt nauka porad Grupa 1 2,546 17,111 15,697 40,612 3,245,51,293 8,779 Grupa 2 6,277 10,087 1,118 1,985 6,519 1,061 9,515 19,812 Grupa 3 19,955 25,852 15,405 51,454 2,624 Grupa 4,196 44,981 1,572 7,059 2,249,396 5,201 Grupa 5 41,104 8,174 1,943 8,461 8,713 7,351 3,096 3,96 albumy dzieci encykl fantas krymin lit.fakt nauka porad user user user user user user user user user user user user Z tabelki powiązań można odczytać, który użytkownik został zaklasyfikowany do której grupy. Wybrałem kilka rekordów danych wejściowych, aby pokazać, jak program je pogrupował. Wyniki grupowania są widoczne na listingu Listing zawiera powiązania dla wybranych obiektów, centroidy grup oraz dane wejściowe dla wybranych obiektów. Wyniki udostępniane przez moduł grupowania pozwalają prześledzić i zweryfikować poprawność analizy danych. Grupa 1 nie występuje w wynikach, ale nie oznacza, że żaden obiekt do niej nie trafił. Prezentuję wyłącznie część rezultatu, ponieważ całość miała zbyt duże rozmiary. Uważam, że rezultaty analizy są w bardzo przystępny sposób prezentowane użytkownikowi, który musi dokonać ich interpretacji. Bardzo łatwo można dowiedzieć się, czy dwa lub więcej obiektów, które trafiły do jednej grupy są faktycznie podobne. Weźmy pod uwagę grupę numer 4. Jest ona najbardziej liczna w tym wybiórczym podsumowaniu. Do tej grupy zostały przyporządkowane następujące obiekty: user1, user8, user10, user21. Przypatrując się wektorom tych obiektów można stwierdzić, że faktycznie są one podobne i powinny znaleźć się w jednej grupie. Na podstawie centroidu grupy można również stwierdzić, że głównym zainteresowaniem osób, które znalazły się w tej grupie, były książki dla dzieci. Analogicznie

93 10.5 Przykładowe uruchomienie 92 Rysunek 10.27: Wykres przedstawiajacy średnie zainteresowanie produktami z wybranych kategorii można prześledzić przyporządkowania innych obiektów. Rozkład udziału poszczególnych grup przedstawił się jak na rysunku Przyjrzyjmy się jeszcze wykresowi średnich wartości z zakładki podsumowania. W przypadku analizowanych danych testowych wykres jest interpretowany jako średnie zainteresowanie książkami z wybranych kategorii. Z wykresu można odczytać, że największym zainteresowaniem cieszą się kategorie: albumy, dla dzieci, kryminały i sensacja oraz poradniki. Zdobyta wiedza jest bardzo cenna, bo wskazuje pewien problem dla sztabu osób opiekujących się serwisem internetowym. Mogą oni zwiększyć wachlarz produktów z najczęściej odwiedzanych kategorii lub spróbować dowiedzieć się co jest powodem niskich wskaźników odwiedzin dla pozostałych kategorii. Rysunek 10.26: Wykres kołowy przedstawiaj acy rozkład udziału poszczególnych grup w końcowej klasyfikacji użytkowników
Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego
 POLITECHNIKA ŁÓDZKA Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Praca dyplomowa Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego Artur Ziółkowski
POLITECHNIKA ŁÓDZKA Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Praca dyplomowa Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego Artur Ziółkowski
Spis treści. 1.1 Problematyka... 4 1.2 Cele pracy i zakres pracy... 5
 Spis treści 1 Wstęp 4 1.1 Problematyka.......................... 4 1.2 Cele pracy i zakres pracy...................... 5 2 Analiza zagadnienia 7 2.1 Wprowadzenie.......................... 7 2.2 Eksploracja
Spis treści 1 Wstęp 4 1.1 Problematyka.......................... 4 1.2 Cele pracy i zakres pracy...................... 5 2 Analiza zagadnienia 7 2.1 Wprowadzenie.......................... 7 2.2 Eksploracja
Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego
 POLITECHNIKA ŁÓDZKA Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Praca dyplomowa Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego Artur Ziółkowski
POLITECHNIKA ŁÓDZKA Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Praca dyplomowa Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego Artur Ziółkowski
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Analiza i projektowanie oprogramowania. Analiza i projektowanie oprogramowania 1/32
 Analiza i projektowanie oprogramowania Analiza i projektowanie oprogramowania 1/32 Analiza i projektowanie oprogramowania 2/32 Cel analizy Celem fazy określania wymagań jest udzielenie odpowiedzi na pytanie:
Analiza i projektowanie oprogramowania Analiza i projektowanie oprogramowania 1/32 Analiza i projektowanie oprogramowania 2/32 Cel analizy Celem fazy określania wymagań jest udzielenie odpowiedzi na pytanie:
Priorytetyzacja przypadków testowych za pomocą macierzy
 Priorytetyzacja przypadków testowych za pomocą macierzy W niniejszym artykule przedstawiony został problem przyporządkowania priorytetów do przypadków testowych przed rozpoczęciem testów oprogramowania.
Priorytetyzacja przypadków testowych za pomocą macierzy W niniejszym artykule przedstawiony został problem przyporządkowania priorytetów do przypadków testowych przed rozpoczęciem testów oprogramowania.
Ćwiczenie numer 4 JESS PRZYKŁADOWY SYSTEM EKSPERTOWY.
 Ćwiczenie numer 4 JESS PRZYKŁADOWY SYSTEM EKSPERTOWY. 1. Cel ćwiczenia Celem ćwiczenia jest zapoznanie się z przykładowym systemem ekspertowym napisanym w JESS. Studenci poznają strukturę systemu ekspertowego,
Ćwiczenie numer 4 JESS PRZYKŁADOWY SYSTEM EKSPERTOWY. 1. Cel ćwiczenia Celem ćwiczenia jest zapoznanie się z przykładowym systemem ekspertowym napisanym w JESS. Studenci poznają strukturę systemu ekspertowego,
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Maciej Piotr Jankowski
 Reduced Adder Graph Implementacja algorytmu RAG Maciej Piotr Jankowski 2005.12.22 Maciej Piotr Jankowski 1 Plan prezentacji 1. Wstęp 2. Implementacja 3. Usprawnienia optymalizacyjne 3.1. Tablica ekspansji
Reduced Adder Graph Implementacja algorytmu RAG Maciej Piotr Jankowski 2005.12.22 Maciej Piotr Jankowski 1 Plan prezentacji 1. Wstęp 2. Implementacja 3. Usprawnienia optymalizacyjne 3.1. Tablica ekspansji
Wyszukiwanie binarne
 Wyszukiwanie binarne Wyszukiwanie binarne to technika pozwalająca na przeszukanie jakiegoś posortowanego zbioru danych w czasie logarytmicznie zależnym od jego wielkości (co to dokładnie znaczy dowiecie
Wyszukiwanie binarne Wyszukiwanie binarne to technika pozwalająca na przeszukanie jakiegoś posortowanego zbioru danych w czasie logarytmicznie zależnym od jego wielkości (co to dokładnie znaczy dowiecie
Sposoby prezentacji problemów w statystyce
 S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
Budowa argumentacji bezpieczeństwa z użyciem NOR-STA Instrukcja krok po kroku
 Budowa argumentacji bezpieczeństwa z użyciem NOR-STA Instrukcja krok po kroku NOR-STA jest narzędziem wspierającym budowę, ocenę oraz zarządzanie strukturą argumentacji wiarygodności (assurance case),
Budowa argumentacji bezpieczeństwa z użyciem NOR-STA Instrukcja krok po kroku NOR-STA jest narzędziem wspierającym budowę, ocenę oraz zarządzanie strukturą argumentacji wiarygodności (assurance case),
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Zad. 3: Układ równań liniowych
 1 Cel ćwiczenia Zad. 3: Układ równań liniowych Wykształcenie umiejętności modelowania kluczowych dla danego problemu pojęć. Definiowanie właściwego interfejsu klasy. Zwrócenie uwagi na dobór odpowiednich
1 Cel ćwiczenia Zad. 3: Układ równań liniowych Wykształcenie umiejętności modelowania kluczowych dla danego problemu pojęć. Definiowanie właściwego interfejsu klasy. Zwrócenie uwagi na dobór odpowiednich
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery
 http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
Łączenie liczb i tekstu.
 Łączenie liczb i tekstu. 1 (Pobrane z slow7.pl) Rozpoczynamy od sposobu pierwszego. Mamy arkusz przedstawiony na rysunku poniżej w którym zostały zawarte wypłaty pracowników z wykonanym podsumowaniem.
Łączenie liczb i tekstu. 1 (Pobrane z slow7.pl) Rozpoczynamy od sposobu pierwszego. Mamy arkusz przedstawiony na rysunku poniżej w którym zostały zawarte wypłaty pracowników z wykonanym podsumowaniem.
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
SCENARIUSZ LEKCJI. Streszczenie. Czas realizacji. Podstawa programowa
 Autorzy scenariusza: SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH
Autorzy scenariusza: SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Programowanie celowe #1
 Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Szukanie rozwiązań funkcji uwikłanych (równań nieliniowych)
") Szukanie rozwiązań funkcji uwikłanych (równań nieliniowych) Funkcja uwikłana (równanie nieliniowe) jest to funkcja, która nie jest przedstawiona jawnym przepisem, wzorem wyrażającym zależność wartości
Szukanie rozwiązań funkcji uwikłanych (równań nieliniowych) Funkcja uwikłana (równanie nieliniowe) jest to funkcja, która nie jest przedstawiona jawnym przepisem, wzorem wyrażającym zależność wartości
REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i realizacja serwisu ogłoszeń z inteligentną wyszukiwarką
 REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i realizacja serwisu ogłoszeń z inteligentną wyszukiwarką Autor: Paweł Konieczny Promotor: dr Jadwigi Bakonyi Kategorie: aplikacja www Słowa kluczowe: Serwis
REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i realizacja serwisu ogłoszeń z inteligentną wyszukiwarką Autor: Paweł Konieczny Promotor: dr Jadwigi Bakonyi Kategorie: aplikacja www Słowa kluczowe: Serwis
Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych
 Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
8. Neuron z ciągłą funkcją aktywacji.
 8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
Deduplikacja danych. Zarządzanie jakością danych podstawowych
 Deduplikacja danych Zarządzanie jakością danych podstawowych normalizacja i standaryzacja adresów standaryzacja i walidacja identyfikatorów podstawowa standaryzacja nazw firm deduplikacja danych Deduplication
Deduplikacja danych Zarządzanie jakością danych podstawowych normalizacja i standaryzacja adresów standaryzacja i walidacja identyfikatorów podstawowa standaryzacja nazw firm deduplikacja danych Deduplication
Badania operacyjne: Wykład Zastosowanie kolorowania grafów w planowaniu produkcji typu no-idle
 Badania operacyjne: Wykład Zastosowanie kolorowania grafów w planowaniu produkcji typu no-idle Paweł Szołtysek 12 czerwca 2008 Streszczenie Planowanie produkcji jest jednym z problemów optymalizacji dyskretnej,
Badania operacyjne: Wykład Zastosowanie kolorowania grafów w planowaniu produkcji typu no-idle Paweł Szołtysek 12 czerwca 2008 Streszczenie Planowanie produkcji jest jednym z problemów optymalizacji dyskretnej,
Zapisywanie algorytmów w języku programowania
 Temat C5 Zapisywanie algorytmów w języku programowania Cele edukacyjne Zrozumienie, na czym polega programowanie. Poznanie sposobu zapisu algorytmu w postaci programu komputerowego. Zrozumienie, na czym
Temat C5 Zapisywanie algorytmów w języku programowania Cele edukacyjne Zrozumienie, na czym polega programowanie. Poznanie sposobu zapisu algorytmu w postaci programu komputerowego. Zrozumienie, na czym
Faza Określania Wymagań
 Faza Określania Wymagań Celem tej fazy jest dokładne określenie wymagań klienta wobec tworzonego systemu. W tej fazie dokonywana jest zamiana celów klienta na konkretne wymagania zapewniające osiągnięcie
Faza Określania Wymagań Celem tej fazy jest dokładne określenie wymagań klienta wobec tworzonego systemu. W tej fazie dokonywana jest zamiana celów klienta na konkretne wymagania zapewniające osiągnięcie
Kurs programowania. Wykład 12. Wojciech Macyna. 7 czerwca 2017
 Wykład 12 7 czerwca 2017 Czym jest UML? UML składa się z dwóch podstawowych elementów: notacja: elementy graficzne, składnia języka modelowania, metamodel: definicje pojęć języka i powiazania pomiędzy
Wykład 12 7 czerwca 2017 Czym jest UML? UML składa się z dwóch podstawowych elementów: notacja: elementy graficzne, składnia języka modelowania, metamodel: definicje pojęć języka i powiazania pomiędzy
REFERAT PRACY DYPLOMOWEJ
 REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i implementacja aplikacji internetowej do wyszukiwania promocji Autor: Sylwester Wiśniewski Promotor: dr Jadwiga Bakonyi Kategorie: aplikacja webowa Słowa
REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i implementacja aplikacji internetowej do wyszukiwania promocji Autor: Sylwester Wiśniewski Promotor: dr Jadwiga Bakonyi Kategorie: aplikacja webowa Słowa
Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych
 Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych dr inż. Adam Iwaniak Infrastruktura Danych Przestrzennych w Polsce i Europie Seminarium, AR Wrocław
Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych dr inż. Adam Iwaniak Infrastruktura Danych Przestrzennych w Polsce i Europie Seminarium, AR Wrocław
Efekt kształcenia. Ma uporządkowaną, podbudowaną teoretycznie wiedzę ogólną w zakresie algorytmów i ich złożoności obliczeniowej.
 Efekty dla studiów pierwszego stopnia profil ogólnoakademicki na kierunku Informatyka w języku polskim i w języku angielskim (Computer Science) na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie-
Efekty dla studiów pierwszego stopnia profil ogólnoakademicki na kierunku Informatyka w języku polskim i w języku angielskim (Computer Science) na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie-
Procesowa specyfikacja systemów IT
 Procesowa specyfikacja systemów IT BOC Group BOC Information Technologies Consulting Sp. z o.o. e-mail: boc@boc-pl.com Tel.: (+48 22) 628 00 15, 696 69 26 Fax: (+48 22) 621 66 88 BOC Management Office
Procesowa specyfikacja systemów IT BOC Group BOC Information Technologies Consulting Sp. z o.o. e-mail: boc@boc-pl.com Tel.: (+48 22) 628 00 15, 696 69 26 Fax: (+48 22) 621 66 88 BOC Management Office
Komputerowe Systemy Przemysłowe: Modelowanie - UML. Arkadiusz Banasik arkadiusz.banasik@polsl.pl
 Komputerowe Systemy Przemysłowe: Modelowanie - UML Arkadiusz Banasik arkadiusz.banasik@polsl.pl Plan prezentacji Wprowadzenie UML Diagram przypadków użycia Diagram klas Podsumowanie Wprowadzenie Języki
Komputerowe Systemy Przemysłowe: Modelowanie - UML Arkadiusz Banasik arkadiusz.banasik@polsl.pl Plan prezentacji Wprowadzenie UML Diagram przypadków użycia Diagram klas Podsumowanie Wprowadzenie Języki
Wymagania edukacyjne z informatyki dla klasy szóstej szkoły podstawowej.
 Wymagania edukacyjne z informatyki dla klasy szóstej szkoły podstawowej. Dział Zagadnienia Wymagania podstawowe Wymagania ponadpodstawowe Arkusz kalkulacyjny (Microsoft Excel i OpenOffice) Uruchomienie
Wymagania edukacyjne z informatyki dla klasy szóstej szkoły podstawowej. Dział Zagadnienia Wymagania podstawowe Wymagania ponadpodstawowe Arkusz kalkulacyjny (Microsoft Excel i OpenOffice) Uruchomienie
Efekty kształcenia dla kierunku studiów INFORMATYKA, Absolwent studiów I stopnia kierunku Informatyka WIEDZA
 Symbol Efekty kształcenia dla kierunku studiów INFORMATYKA, specjalność: 1) Sieciowe systemy informatyczne. 2) Bazy danych Absolwent studiów I stopnia kierunku Informatyka WIEDZA Ma wiedzę z matematyki
Symbol Efekty kształcenia dla kierunku studiów INFORMATYKA, specjalność: 1) Sieciowe systemy informatyczne. 2) Bazy danych Absolwent studiów I stopnia kierunku Informatyka WIEDZA Ma wiedzę z matematyki
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
biegle i poprawnie posługuje się terminologią informatyczną,
 INFORMATYKA KLASA 1 1. Wymagania na poszczególne oceny: 1) ocenę celującą otrzymuje uczeń, który: samodzielnie wykonuje na komputerze wszystkie zadania z lekcji, wykazuje inicjatywę rozwiązywania konkretnych
INFORMATYKA KLASA 1 1. Wymagania na poszczególne oceny: 1) ocenę celującą otrzymuje uczeń, który: samodzielnie wykonuje na komputerze wszystkie zadania z lekcji, wykazuje inicjatywę rozwiązywania konkretnych
Diagramy ERD. Model struktury danych jest najczęściej tworzony z wykorzystaniem diagramów pojęciowych (konceptualnych). Najpopularniejszym
. Najpopularniejszym") Diagramy ERD. Model struktury danych jest najczęściej tworzony z wykorzystaniem diagramów pojęciowych (konceptualnych). Najpopularniejszym konceptualnym modelem danych jest tzw. model związków encji (ERM
Diagramy ERD. Model struktury danych jest najczęściej tworzony z wykorzystaniem diagramów pojęciowych (konceptualnych). Najpopularniejszym konceptualnym modelem danych jest tzw. model związków encji (ERM
DLA SEKTORA INFORMATYCZNEGO W POLSCE
 DLA SEKTORA INFORMATYCZNEGO W POLSCE SRK IT obejmuje kompetencje najważniejsze i specyficzne dla samego IT są: programowanie i zarządzanie systemami informatycznymi. Z rozwiązań IT korzysta się w każdej
DLA SEKTORA INFORMATYCZNEGO W POLSCE SRK IT obejmuje kompetencje najważniejsze i specyficzne dla samego IT są: programowanie i zarządzanie systemami informatycznymi. Z rozwiązań IT korzysta się w każdej
Algorytmy sztucznej inteligencji
 www.math.uni.lodz.pl/ radmat Przeszukiwanie z ograniczeniami Zagadnienie przeszukiwania z ograniczeniami stanowi grupę problemów przeszukiwania w przestrzeni stanów, które składa się ze: 1 skończonego
www.math.uni.lodz.pl/ radmat Przeszukiwanie z ograniczeniami Zagadnienie przeszukiwania z ograniczeniami stanowi grupę problemów przeszukiwania w przestrzeni stanów, które składa się ze: 1 skończonego
Odwrotna analiza wartości brzegowych przy zaokrąglaniu wartości
 Odwrotna analiza wartości brzegowych przy zaokrąglaniu wartości W systemach informatycznych istnieje duże prawdopodobieństwo, że oprogramowanie będzie się błędnie zachowywać dla wartości na krawędziach
Odwrotna analiza wartości brzegowych przy zaokrąglaniu wartości W systemach informatycznych istnieje duże prawdopodobieństwo, że oprogramowanie będzie się błędnie zachowywać dla wartości na krawędziach
Inżynieria wymagań. Wykład 3 Zarządzanie wymaganiami w oparciu o przypadki użycia. Część 5 Definicja systemu
 Inżynieria wymagań Wykład 3 Zarządzanie wymaganiami w oparciu o przypadki użycia Część 5 Definicja systemu Opracowane w oparciu o materiały IBM (kurs REQ480: Mastering Requirements Management with Use
Inżynieria wymagań Wykład 3 Zarządzanie wymaganiami w oparciu o przypadki użycia Część 5 Definicja systemu Opracowane w oparciu o materiały IBM (kurs REQ480: Mastering Requirements Management with Use
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1.
 Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Automatyczna klasyfikacja zespołów QRS
 Przetwarzanie sygnałów w systemach diagnostycznych Informatyka Stosowana V Automatyczna klasyfikacja zespołów QRS Anna Mleko Tomasz Kotliński AGH EAIiE 9 . Opis zadania Tematem projektu było zaprojektowanie
Przetwarzanie sygnałów w systemach diagnostycznych Informatyka Stosowana V Automatyczna klasyfikacja zespołów QRS Anna Mleko Tomasz Kotliński AGH EAIiE 9 . Opis zadania Tematem projektu było zaprojektowanie
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Wymagania edukacyjne na poszczególne oceny z informatyki w gimnazjum klasa III Rok szkolny 2015/16
 Wymagania edukacyjne na poszczególne oceny z informatyki w gimnazjum klasa III Rok szkolny 2015/16 Internet i sieci Temat lekcji Wymagania programowe 6 5 4 3 2 1 Sieci komputerowe. Rodzaje sieci, topologie,
Wymagania edukacyjne na poszczególne oceny z informatyki w gimnazjum klasa III Rok szkolny 2015/16 Internet i sieci Temat lekcji Wymagania programowe 6 5 4 3 2 1 Sieci komputerowe. Rodzaje sieci, topologie,
Laboratorium - Przechwytywanie i badanie datagramów DNS w programie Wireshark
 Laboratorium - Przechwytywanie i badanie datagramów DNS w programie Wireshark Topologia Cele Część 1: Zapisanie informacji dotyczących konfiguracji IP komputerów Część 2: Użycie programu Wireshark do przechwycenia
Laboratorium - Przechwytywanie i badanie datagramów DNS w programie Wireshark Topologia Cele Część 1: Zapisanie informacji dotyczących konfiguracji IP komputerów Część 2: Użycie programu Wireshark do przechwycenia
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Podstawy inżynierii oprogramowania
 Podstawy inżynierii oprogramowania Modelowanie. Podstawy notacji UML Aleksander Lamża ZKSB Instytut Informatyki Uniwersytet Śląski w Katowicach aleksander.lamza@us.edu.pl Zawartość Czym jest UML? Wybrane
Podstawy inżynierii oprogramowania Modelowanie. Podstawy notacji UML Aleksander Lamża ZKSB Instytut Informatyki Uniwersytet Śląski w Katowicach aleksander.lamza@us.edu.pl Zawartość Czym jest UML? Wybrane
Automatyczne tworzenie trójwymiarowego planu pomieszczenia z zastosowaniem metod stereowizyjnych
 Automatyczne tworzenie trójwymiarowego planu pomieszczenia z zastosowaniem metod stereowizyjnych autor: Robert Drab opiekun naukowy: dr inż. Paweł Rotter 1. Wstęp Zagadnienie generowania trójwymiarowego
Automatyczne tworzenie trójwymiarowego planu pomieszczenia z zastosowaniem metod stereowizyjnych autor: Robert Drab opiekun naukowy: dr inż. Paweł Rotter 1. Wstęp Zagadnienie generowania trójwymiarowego
Ćwiczenie 1 Planowanie trasy robota mobilnego w siatce kwadratów pól - Algorytm A
 Ćwiczenie 1 Planowanie trasy robota mobilnego w siatce kwadratów pól - Algorytm A Zadanie do wykonania 1) Utwórz na pulpicie katalog w formacie Imię nazwisko, w którym umieść wszystkie pliki związane z
Ćwiczenie 1 Planowanie trasy robota mobilnego w siatce kwadratów pól - Algorytm A Zadanie do wykonania 1) Utwórz na pulpicie katalog w formacie Imię nazwisko, w którym umieść wszystkie pliki związane z
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA
 METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
Transformacja wiedzy w budowie i eksploatacji maszyn
 Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Webowy generator wykresów wykorzystujący program gnuplot
 Uniwersytet Mikołaja Kopernika Wydział Fizyki, Astronomii i Informatyki Stosowanej Marcin Nowak nr albumu: 254118 Praca inżynierska na kierunku informatyka stosowana Webowy generator wykresów wykorzystujący
Uniwersytet Mikołaja Kopernika Wydział Fizyki, Astronomii i Informatyki Stosowanej Marcin Nowak nr albumu: 254118 Praca inżynierska na kierunku informatyka stosowana Webowy generator wykresów wykorzystujący
zna metody matematyczne w zakresie niezbędnym do formalnego i ilościowego opisu, zrozumienia i modelowania problemów z różnych
 Grupa efektów kierunkowych: Matematyka stosowana I stopnia - profil praktyczny (od 17 października 2014) Matematyka Stosowana I stopień spec. Matematyka nowoczesnych technologii stacjonarne 2015/2016Z
Grupa efektów kierunkowych: Matematyka stosowana I stopnia - profil praktyczny (od 17 października 2014) Matematyka Stosowana I stopień spec. Matematyka nowoczesnych technologii stacjonarne 2015/2016Z
Diagramu Związków Encji - CELE. Diagram Związków Encji - CHARAKTERYSTYKA. Diagram Związków Encji - Podstawowe bloki składowe i reguły konstrukcji
 Diagramy związków encji (ERD) 1 Projektowanie bazy danych za pomocą narzędzi CASE Materiał pochodzi ze strony : http://jjakiela.prz.edu.pl/labs.htm Diagramu Związków Encji - CELE Zrozumienie struktury
Diagramy związków encji (ERD) 1 Projektowanie bazy danych za pomocą narzędzi CASE Materiał pochodzi ze strony : http://jjakiela.prz.edu.pl/labs.htm Diagramu Związków Encji - CELE Zrozumienie struktury
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Systemy baz danych w zarządzaniu przedsiębiorstwem. W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi
 Systemy baz danych w zarządzaniu przedsiębiorstwem W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi Proces zarządzania danymi Zarządzanie danymi obejmuje czynności: gromadzenie
Systemy baz danych w zarządzaniu przedsiębiorstwem W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi Proces zarządzania danymi Zarządzanie danymi obejmuje czynności: gromadzenie
Zapytania do bazy danych
 Zapytania do bazy danych Tworzenie zapytań do bazy danych MS Access może być realizowane na dwa sposoby. Standard SQL (Stucture Query Language) lub QBE (Query by Example). Warto wiedzieć, że drugi ze sposobów
Zapytania do bazy danych Tworzenie zapytań do bazy danych MS Access może być realizowane na dwa sposoby. Standard SQL (Stucture Query Language) lub QBE (Query by Example). Warto wiedzieć, że drugi ze sposobów
Programowanie i techniki algorytmiczne
 Temat 2. Programowanie i techniki algorytmiczne Realizacja podstawy programowej 1) wyjaśnia pojęcie algorytmu, podaje odpowiednie przykłady algorytmów rozwiązywania różnych 2) formułuje ścisły opis prostej
Temat 2. Programowanie i techniki algorytmiczne Realizacja podstawy programowej 1) wyjaśnia pojęcie algorytmu, podaje odpowiednie przykłady algorytmów rozwiązywania różnych 2) formułuje ścisły opis prostej
znalezienia elementu w zbiorze, gdy w nim jest; dołączenia nowego elementu w odpowiednie miejsce, aby zbiór pozostał nadal uporządkowany.
 Przedstawiamy algorytmy porządkowania dowolnej liczby elementów, którymi mogą być liczby, jak również elementy o bardziej złożonej postaci (takie jak słowa i daty). Porządkowanie, nazywane również często
Przedstawiamy algorytmy porządkowania dowolnej liczby elementów, którymi mogą być liczby, jak również elementy o bardziej złożonej postaci (takie jak słowa i daty). Porządkowanie, nazywane również często
Opis Architektury Systemu Galileo
 Opis Architektury Systemu Galileo Sławomir Pawlewicz Alan Pilawa Joanna Sobczyk Marek Sobierajski 5 czerwca 2006 1 Spis treści 1 Wprowadzenie 5 1.1 Cel.......................................... 5 1.2 Zakres........................................
Opis Architektury Systemu Galileo Sławomir Pawlewicz Alan Pilawa Joanna Sobczyk Marek Sobierajski 5 czerwca 2006 1 Spis treści 1 Wprowadzenie 5 1.1 Cel.......................................... 5 1.2 Zakres........................................
2
 1 2 3 4 5 Dużo pisze się i słyszy o projektach wdrożeń systemów zarządzania wiedzą, które nie przyniosły oczekiwanych rezultatów, bo mało kto korzystał z tych systemów. Technologia nie jest bowiem lekarstwem
1 2 3 4 5 Dużo pisze się i słyszy o projektach wdrożeń systemów zarządzania wiedzą, które nie przyniosły oczekiwanych rezultatów, bo mało kto korzystał z tych systemów. Technologia nie jest bowiem lekarstwem
APIO. W4 ZDARZENIA BIZNESOWE. ZALEŻNOŚCI MIĘDZY FUNKCJAMI. ELEMENTY DEFINICJI PROCESU. DIAGRAM ZALEŻNOŚCI FUNKCJI.
 APIO. W4 ZDARZENIA BIZNESOWE. ZALEŻNOŚCI MIĘDZY FUNKCJAMI. ELEMENTY DEFINICJI PROCESU. DIAGRAM ZALEŻNOŚCI FUNKCJI. dr inż. Grażyna Hołodnik-Janczura W8/K4 ZDARZENIA BIZNESOWE W otoczeniu badanego zakresu
APIO. W4 ZDARZENIA BIZNESOWE. ZALEŻNOŚCI MIĘDZY FUNKCJAMI. ELEMENTY DEFINICJI PROCESU. DIAGRAM ZALEŻNOŚCI FUNKCJI. dr inż. Grażyna Hołodnik-Janczura W8/K4 ZDARZENIA BIZNESOWE W otoczeniu badanego zakresu
WOJSKOWA AKADEMIA TECHNICZNA
 WOJSKOWA AKADEMIA TECHNICZNA PROJEKT MODELOWANIE SYSTEMÓW TELEINFORMATYCZNYCH Stopień, imię i nazwisko prowadzącego Stopień, imię i nazwisko słuchacza Grupa szkoleniowa dr inż. Zbigniew Zieliński inż.
WOJSKOWA AKADEMIA TECHNICZNA PROJEKT MODELOWANIE SYSTEMÓW TELEINFORMATYCZNYCH Stopień, imię i nazwisko prowadzącego Stopień, imię i nazwisko słuchacza Grupa szkoleniowa dr inż. Zbigniew Zieliński inż.
Wymagania na poszczególne oceny szkolne dla klasy VI. (na podstawie Grażyny Koba, Teraz bajty. Informatyka dla szkoły podstawowej.
 1 Wymagania na poszczególne oceny szkolne dla klasy VI (na podstawie Grażyny Koba, Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI ) 2 1. Obliczenia w arkuszu kalkulacyjnym słucha poleceń nauczyciela
1 Wymagania na poszczególne oceny szkolne dla klasy VI (na podstawie Grażyny Koba, Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI ) 2 1. Obliczenia w arkuszu kalkulacyjnym słucha poleceń nauczyciela
ANALIZA DANYCH PIERWOTNYCH mgr Małgorzata Kromka
 ANALIZA DANYCH PIERWOTNYCH mgr Małgorzata Kromka Wprowadzenie do SPSS PRACA SOCJALNA Rok 1 Czym jest SPSS? SPSS to bardzo rozbudowany program. Pozwala sprawnie pracować ze zbiorami danych, analizować własne
ANALIZA DANYCH PIERWOTNYCH mgr Małgorzata Kromka Wprowadzenie do SPSS PRACA SOCJALNA Rok 1 Czym jest SPSS? SPSS to bardzo rozbudowany program. Pozwala sprawnie pracować ze zbiorami danych, analizować własne
Algorytmika i pseudoprogramowanie
 Przedmiotowy system oceniania Zawód: Technik Informatyk Nr programu: 312[ 01] /T,SP/MENiS/ 2004.06.14 Przedmiot: Programowanie Strukturalne i Obiektowe Klasa: druga Dział Dopuszczający Dostateczny Dobry
Przedmiotowy system oceniania Zawód: Technik Informatyk Nr programu: 312[ 01] /T,SP/MENiS/ 2004.06.14 Przedmiot: Programowanie Strukturalne i Obiektowe Klasa: druga Dział Dopuszczający Dostateczny Dobry
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
INFORMATYKA Pytania ogólne na egzamin dyplomowy
 INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja
INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja
Technologia informacyjna
 Technologia informacyjna Pracownia nr 9 (studia stacjonarne) - 05.12.2008 - Rok akademicki 2008/2009 2/16 Bazy danych - Plan zajęć Podstawowe pojęcia: baza danych, system zarządzania bazą danych tabela,
Technologia informacyjna Pracownia nr 9 (studia stacjonarne) - 05.12.2008 - Rok akademicki 2008/2009 2/16 Bazy danych - Plan zajęć Podstawowe pojęcia: baza danych, system zarządzania bazą danych tabela,
World Wide Web? rkijanka
 World Wide Web? rkijanka World Wide Web? globalny, interaktywny, dynamiczny, wieloplatformowy, rozproszony, graficzny, hipertekstowy - system informacyjny, działający na bazie Internetu. 1.Sieć WWW jest
World Wide Web? rkijanka World Wide Web? globalny, interaktywny, dynamiczny, wieloplatformowy, rozproszony, graficzny, hipertekstowy - system informacyjny, działający na bazie Internetu. 1.Sieć WWW jest
Bioinformatyka. Ocena wiarygodności dopasowania sekwencji.
 Bioinformatyka Ocena wiarygodności dopasowania sekwencji www.michalbereta.pl Załóżmy, że mamy dwie sekwencje, które chcemy dopasować i dodatkowo ocenić wiarygodność tego dopasowania. Interesujące nas pytanie
Bioinformatyka Ocena wiarygodności dopasowania sekwencji www.michalbereta.pl Załóżmy, że mamy dwie sekwencje, które chcemy dopasować i dodatkowo ocenić wiarygodność tego dopasowania. Interesujące nas pytanie
Podstawowe pakiety komputerowe wykorzystywane w zarządzaniu przedsiębiorstwem. dr Jakub Boratyński. pok. A38
 Podstawowe pakiety komputerowe wykorzystywane w zarządzaniu przedsiębiorstwem zajęcia 1 dr Jakub Boratyński pok. A38 Program zajęć Bazy danych jako podstawowy element systemów informatycznych wykorzystywanych
Podstawowe pakiety komputerowe wykorzystywane w zarządzaniu przedsiębiorstwem zajęcia 1 dr Jakub Boratyński pok. A38 Program zajęć Bazy danych jako podstawowy element systemów informatycznych wykorzystywanych
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Pliki cookies. Jaki rodzaj Cookies jest używany? Podczas wizyty na tej stronie używane są następujące pliki Cookies:
 Pliki cookies Co to są Cookies? Cookies to niewielkie pliki tekstowe umieszczane na Twoim komputerze przez witryny, które odwiedzasz. Są one szeroko stosowane w celu zapewnienia możliwości funkcjonowania
Pliki cookies Co to są Cookies? Cookies to niewielkie pliki tekstowe umieszczane na Twoim komputerze przez witryny, które odwiedzasz. Są one szeroko stosowane w celu zapewnienia możliwości funkcjonowania
REFERAT O PRACY DYPLOMOWEJ
 REFERAT O PRACY DYPLOMOWEJ Temat pracy: Projekt i implementacja mobilnego systemu wspomagającego organizowanie zespołowej aktywności fizycznej Autor: Krzysztof Salamon W dzisiejszych czasach życie ludzi
REFERAT O PRACY DYPLOMOWEJ Temat pracy: Projekt i implementacja mobilnego systemu wspomagającego organizowanie zespołowej aktywności fizycznej Autor: Krzysztof Salamon W dzisiejszych czasach życie ludzi
Oferta szkoleniowa Yosi.pl 2012/2013
 Oferta szkoleniowa Yosi.pl 2012/2013 "Podróżnik nie posiadający wiedzy, jest jak ptak bez skrzydeł" Sa'Di, Gulistan (1258 rok) Szanowni Państwo, Yosi.pl to dynamicznie rozwijająca się firma z Krakowa.
Oferta szkoleniowa Yosi.pl 2012/2013 "Podróżnik nie posiadający wiedzy, jest jak ptak bez skrzydeł" Sa'Di, Gulistan (1258 rok) Szanowni Państwo, Yosi.pl to dynamicznie rozwijająca się firma z Krakowa.
ZASADY KORZYSTANIA Z PLIKÓW COOKIES ORAZ POLITYKA PRYWATNOŚCI W SERWISIE INTERNETOWYM PawłowskiSPORT.pl
 ZASADY KORZYSTANIA Z PLIKÓW COOKIES ORAZ POLITYKA PRYWATNOŚCI W SERWISIE INTERNETOWYM PawłowskiSPORT.pl Niniejsze zasady dotyczą wszystkich Użytkowników strony internetowej funkcjonującej w domenie http://www.pawlowskisport.pl,
ZASADY KORZYSTANIA Z PLIKÓW COOKIES ORAZ POLITYKA PRYWATNOŚCI W SERWISIE INTERNETOWYM PawłowskiSPORT.pl Niniejsze zasady dotyczą wszystkich Użytkowników strony internetowej funkcjonującej w domenie http://www.pawlowskisport.pl,
KUP KSIĄŻKĘ NA: PRZYKŁADOWY ROZDZIAŁ KOMUNIKATY DLA UŻYTKOWNIKA
 KUP KSIĄŻKĘ NA: WWW.PRAKTYCZNEPHP.PL PRZYKŁADOWY ROZDZIAŁ KOMUNIKATY DLA UŻYTKOWNIKA KOMUNIKATY DLA UŻYTKOWNIKA W większości aplikacji potrzebujesz mieć możliwość powiadomienia użytkownika o rezultacie
KUP KSIĄŻKĘ NA: WWW.PRAKTYCZNEPHP.PL PRZYKŁADOWY ROZDZIAŁ KOMUNIKATY DLA UŻYTKOWNIKA KOMUNIKATY DLA UŻYTKOWNIKA W większości aplikacji potrzebujesz mieć możliwość powiadomienia użytkownika o rezultacie
Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI
 1 Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI 1. Obliczenia w arkuszu kalkulacyjnym Rozwiązywanie problemów z wykorzystaniem aplikacji komputerowych obliczenia w arkuszu kalkulacyjnym wykonuje
1 Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI 1. Obliczenia w arkuszu kalkulacyjnym Rozwiązywanie problemów z wykorzystaniem aplikacji komputerowych obliczenia w arkuszu kalkulacyjnym wykonuje
Internet, jako ocean informacji. Technologia Informacyjna Lekcja 2
 Internet, jako ocean informacji Technologia Informacyjna Lekcja 2 Internet INTERNET jest rozległą siecią połączeń, między ogromną liczbą mniejszych sieci komputerowych na całym świecie. Jest wszechstronnym
Internet, jako ocean informacji Technologia Informacyjna Lekcja 2 Internet INTERNET jest rozległą siecią połączeń, między ogromną liczbą mniejszych sieci komputerowych na całym świecie. Jest wszechstronnym
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
System magazynowy małego sklepu.
 System magazynowy małego sklepu. dokumentacja użytkownika. Mariusz Grabowski e-mail: mariosh@interia.pl Jabber ID: mariosh@jabber.autocom.pl Spis treści 1 Wstęp. 2 2 Przed uruchomieniem. 3 3 Korzystanie
System magazynowy małego sklepu. dokumentacja użytkownika. Mariusz Grabowski e-mail: mariosh@interia.pl Jabber ID: mariosh@jabber.autocom.pl Spis treści 1 Wstęp. 2 2 Przed uruchomieniem. 3 3 Korzystanie
MASKI SIECIOWE W IPv4
 MASKI SIECIOWE W IPv4 Maska podsieci wykorzystuje ten sam format i sposób reprezentacji jak adresy IP. Różnica polega na tym, że maska podsieci posiada bity ustawione na 1 dla części określającej adres
MASKI SIECIOWE W IPv4 Maska podsieci wykorzystuje ten sam format i sposób reprezentacji jak adresy IP. Różnica polega na tym, że maska podsieci posiada bity ustawione na 1 dla części określającej adres
Projektowanie baz danych za pomocą narzędzi CASE
 Projektowanie baz danych za pomocą narzędzi CASE Metody tworzenia systemów informatycznych w tym, także rozbudowanych baz danych są komputerowo wspomagane przez narzędzia CASE (ang. Computer Aided Software
Projektowanie baz danych za pomocą narzędzi CASE Metody tworzenia systemów informatycznych w tym, także rozbudowanych baz danych są komputerowo wspomagane przez narzędzia CASE (ang. Computer Aided Software
Podstawowe zagadnienia z zakresu baz danych
 Podstawowe zagadnienia z zakresu baz danych Jednym z najważniejszych współczesnych zastosowań komputerów we wszelkich dziedzinach życia jest gromadzenie, wyszukiwanie i udostępnianie informacji. Specjalizowane
Podstawowe zagadnienia z zakresu baz danych Jednym z najważniejszych współczesnych zastosowań komputerów we wszelkich dziedzinach życia jest gromadzenie, wyszukiwanie i udostępnianie informacji. Specjalizowane
Wymagania edukacyjne z matematyki w klasie III gimnazjum
 Wymagania edukacyjne z matematyki w klasie III gimnazjum - nie potrafi konstrukcyjnie podzielić odcinka - nie potrafi konstruować figur jednokładnych - nie zna pojęcia skali - nie rozpoznaje figur jednokładnych
Wymagania edukacyjne z matematyki w klasie III gimnazjum - nie potrafi konstrukcyjnie podzielić odcinka - nie potrafi konstruować figur jednokładnych - nie zna pojęcia skali - nie rozpoznaje figur jednokładnych
3.1. Na dobry początek
 Klasa I 3.1. Na dobry początek Regulamin pracowni i przepisy BHP podczas pracy przy komputerze Wykorzystanie komputera we współczesnym świecie Zna regulamin pracowni i przestrzega go. Potrafi poprawnie
Klasa I 3.1. Na dobry początek Regulamin pracowni i przepisy BHP podczas pracy przy komputerze Wykorzystanie komputera we współczesnym świecie Zna regulamin pracowni i przestrzega go. Potrafi poprawnie
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski. Bazy danych ITA-101. Wersja 1
 Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski Bazy danych ITA-101 Wersja 1 Warszawa, wrzesień 2009 Wprowadzenie Informacje o kursie Opis kursu We współczesnej informatyce coraz większą
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski Bazy danych ITA-101 Wersja 1 Warszawa, wrzesień 2009 Wprowadzenie Informacje o kursie Opis kursu We współczesnej informatyce coraz większą
Efekt kształcenia. Wiedza
 Efekty dla studiów drugiego stopnia profil ogólnoakademicki na kierunku Informatyka na specjalności Przetwarzanie i analiza danych, na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie oznacza
Efekty dla studiów drugiego stopnia profil ogólnoakademicki na kierunku Informatyka na specjalności Przetwarzanie i analiza danych, na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie oznacza
Analiza głównych składowych- redukcja wymiaru, wykł. 12
 Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy