Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego
|
|
|
- Magdalena Kruk
- 10 lat temu
- Przeglądów:
Transkrypt
1 POLITECHNIKA ŁÓDZKA Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Praca dyplomowa Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego Artur Ziółkowski Nr albumu: Opiekun pracy: prof. dr hab. inż. Maria Pietruszka Dodatkowy opiekun: mgr inż. Magdalena Stobińska Łódź, wrzesień 2010

2 Oświadczenie autora Ja, niżej podpisany Artur Ziółkowski oświadczam, że praca ta została napisana samodzielnie i wykorzystywała (poza zdobyta na studiach wiedza) jedynie wyniki prac zamieszczonych w spisie literatury (Podpis autora) Oświadczenie promotora Oświadczam, że praca spełnia wymogi stawiane pracom magisterskim (Podpis promotora)
 Oświadczenie promotora Oświadczam, że praca")
3 Spis treści 1 Wstęp Problematyka Cele pracy Przegląd literatury w dziedzinie Analiza zagadnienia Wprowadzenie do dziedziny problemu Eksploracja danych Problemy związane ze źródłem danych Pozyskiwanie informacji o użytkownikach stron Log serwera Podsłuchiwanie połączenia użytkownika z serwerem Dedykowany serwis internetowy Strategie przygotowywania rekomendacji Techniki analizy danych 14 4 Grupowanie Metody hierarchiczne K-średnich Samoorganizująca się mapa Sieć neuronowa Sieć Kohonena Klasyfikacja Sieci neuronowe na przykładzie wielowarstwowego perceptronu Klasyfikator Bayesa Twierdzenie Bayesa Klasyfikacja bayesowska Optymalny klasyfikator Bayesa Naiwny klasyfikator Bayesa Klasyfikowanie przykładów Przykład zastosowania NBC Metoda k-najbliższych sąsiadów Znajdowanie reguł asocjacji Reprezentacje struktur danych Kryteria oceny reguł

4 Spis treści Algorytm A priori Przykład Przeglad istniejacych rozwiazań Narzędzia analizy danych Systemy wykorzystujące rekomendacje Problem praktyczny Opis problemu Analiza wymagań Studium możliwości Wymagania funkcjonalne Ograniczenia projektu Projekt Projekt warstwy danych Projekt warstwy logiki Projekt warstwy interfejsu użytkownika Implementacja: punkty kluczowe Testy Podsumowanie Dyskusja wyników Ocena możliwości wdrożenia Fakty i mity Bibliografia 58

5 Streszczenie Streszczenie pracy zostanie napisane w późniejszym czasie. Będzie tutaj opis układu pracy, dotyczący tego jakie zagadnienia zostały poruszone w poszczególnych częściach.

6 Rozdział 1 Wstęp 1.1 Problematyka W obecnych czasach można zaobserwować nasycenie się rynku dostawców wielu produktów i usług. Bardzo trudne stało się pozyskanie nowych klientów oraz utrzymanie ich w stanie lojalności wobec przedsiębiorstwa. Dotyczy to każdej branży, zarówno tej zajmującej się świadczeniem usług, jak i tej zajmującej się handlem. Każdy z klientów oczekuje wysokiej jakości produktów (lub usług), ale dodatkowo chce być obsłużonym na wysokim poziomie. Jeśli firma nie będzie dbała o swojego klienta, ten bardzo szybko może zrezygnować z oferty firmy na rzecz innej, konkurencyjnej. Wykorzystanie Internetu jako medium dla handlu elektronicznego uprościło klientom dostęp do różnych dostawców dóbr. Zazwyczaj ludzie są bardzo leniwi. Nie lubią przeszkód i szybko się zniechęcają, co może zaowocować rezygnacją z usług. Z tego powodu bardzo ważne jest aby relacja firmy z klientem była trwała, a co za tym idzie musi być stale pielęgnowana. W Polsce nie tak dawno temu przedsiębiorstwa charakteryzowało podejście polegające na minimalizacji poniesionych kosztów i maksymalizacji zysków. Często się zdarza, że rynek jest zalewany bardzo dużą ilością produktów, która nigdy nie zostanie sprzedana. Wytwarza się bardzo dużo dóbr nie zastanawiając się wcale, czy uda się to sprzedać. Trudno jest znaleźć taką liczbę klientów, która będzie chciała skorzystać z oferty. Bardzo ważne jest też, aby poszukując nowych klientów zwracać większą uwagę na tych, którzy są z naszej perspektywy atrakcyjniejsi od innych. Analiza poszczególnych klientów, a co za tym idzie ich potrzeb, jest pewnym rozwiązaniem tego problemu. Może ono przynieść firmie wymierne korzyści, jednak jest bardzo skomplikowane, a często również niewykonalne. Ocena klienta pod kątem atrakcyjności jest bardzo trudna. Można brać pod uwagę różne kryteria oceny. Dla niektórych najważniejszym kryterium jest zysk, a dla innych całkiem coś innego. Dziś często pod uwagę bierze się kryterium, które wcześniej nie miało odpowiedniej wagi. Ważne stało się to, czy klient jest w stanie polecić firmę swoim znajomym, którzy mogą zostać potencjalnymi klientami. Taki sposób oceny często uważany jest za o wiele istotniejszy, niż sam zysk. Klient, który w pewnej firmie kupi bardzo mało, ale będzie zadowolony z wysokiej jakości obsługi, może polecić ją stu innym osobom. Aby taka pozytywna opinia mogła zostać wystawiona klient musi być zadowolony, a to już jest kolejne wyzwanie dla firmy. Klient będzie zadowolony tylko wtedy, gdy oferta kierowana do niego będzie rzeczowa i zostanie przygotowana pod jego kątem. Nie mogą się w niej znaleźć produkty i usługi, którymi klient nie będzie zainteresowany. Niedbale przygotowana oferta może jedynie zniechęcić klienta do zakupów i go spłoszyć. Rekomendacji jako pojęcia można używać w różnych kontekstach. Zazwyczaj posługujemy się nim w znaczeniu opiniowania, czy polecania komuś czegoś. W swojej pracy rekomendację będę utożsamiał właśnie z ofertą kierowaną do klienta (lub do grupy klientów o podobnych charakterach), a w szczególności do użytkowników serwisu internetowego. Taka rekomendacja może zawierać w sobie jeden bądź wiele produktów, nie jest to tak istotne. Najważniejsze jest to, aby sama w sobie nie szkodziła. Taki cel można osiągnąć podchodząc indywidualnie do każdego klienta. Niestety jest to nierealne. Wyobraźmy sobie sytuację, w której
, ale dodatkowo chce być obsłużonym na wysokim poziomie.")
7 1.2 Cele pracy 5 firma obsługuje dziennie tysiąc klientów. Oczywiście większa część z nich jest stała, więc można by powiedzieć, że obsługa zna ich gusta. W rzeczywistości tak raczej nie będzie. Ludzie obsługujący klientów będą mieć wiedzę o kliencie, który w jakiś sposób się wyróżnia (np. duże zakupy), a jak wcześniej napisałem do wszystkich powinniśmy podejść tak samo profesjonalnie. Do tego dochodzi realizacja komunikacji z klientem za pomocą Internetu. To sam użytkownik serwisu internetowego składa zamówienia na produkty bądź usługi, a w procesie tym nie biorą udziału osoby fizyczne. Pojawia się wiec pytanie pytanie, jak w takim razie przygotować ofertę indywidualną dla wielu klientów nie mając z nimi kontaktu fizycznego? W sytuacji, kiedy mamy przygotować ofertę dla wielu klientów można posłużyć się zaawansowanymi technikami, które nas wspomogą. Kilka wybranych technik, które są najczęściej wykorzystywane, opisałem w swojej pracy. Charakteryzują się one różnym podejściem do postawionego problemu, a co za tym idzie potrzebują trochę innego przygotowania danych do przeprowadzenia procesu wydobywania wiedzy z tych danych. Bardzo ciekawe w technikach, którymi się zajmowałem jest to, że wykorzystują one dane zebrane w całkiem innym celu niż analizowanie potrzeb klientów. Zazwyczaj firmy prowadząc swoją działalność gromadzą różne dane. W przypadku użytkowników serwisu internetowego mogą to być informacje np. o zakupionych produktach, bądź odwiedzonych stronach internetowych. Można więc z powodzeniem je wykorzystać i za pomocą zastosowania pewnych technik usprawnić działanie serwisu internetowego tak, aby stał się bardziej przyjazny użytkownikowi, a sam użytkownik miał wrażenie, jakby serwis był ukierunkowany wyłącznie na niego. 1.2 Cele pracy W swojej pracy postawiłem dwa cele, które chciałem osiągnąć. Pierwszy cel dotyczy części teoretycznej pracy i zakłada dokonanie przeglądu zagadnień oraz rozwiązań związanych z przygotowaniem rekomendacji dla użytkowników serwisu internetowego. Konieczne było przedstawienie analizy zagadnienia oraz problemów jakie można napotkać podczas tworzenia rozwiązań umożliwiających przygotowywanie rekomendacji. Chciałem się także dowiedzieć jakie możliwości daje stosowanie wybranych technik wydobywania wiedzy z danych oraz jakie rozwiązania już na rynku istnieją. Czy faktycznie ich wprowadzenie ułatwia użytkownikom korzystanie z systemu, a nie jest tylko wymyślnym mechanizmem, który nie znajduje praktycznego zastosowania. Będę chciał podać kilka przykładów. Mam tu na myśli serwisy internetowe, które wprowadziły rekomendacje na swoich stronach internetowych, ale oprócz tego chciałem sprawdzić, jakie systemy umożliwiają dokonywania analizy za pomocą metod eksploracji danych. W tej części pracy opiszę również wybrane techniki eksploracji danych, które mogą być wykorzystane do przygotowywania rekomendacji dla użytkowników serwisu internetowego. Zamierzam pokazać ich ogólny charakter, a także wskazać zalety i wady ich stosowania. Postaram się wytłumaczyć wszystko w jasny sposób podpierając się przy tym odpowiednimi schematami oraz rysunkami. W ramach drugiego celu chciałem stworzyć aplikację, która pozwala przeprowadzić analizę użytkowników w celu przygotowania rekomendacji. Jest to szerokie zagadnienie, które będzie dogłębnie opisane w rozdziale 9, dlatego nie będę go opisywał szczegółowo w tym rozdziale. Na wstępie mogę powiedzieć, że aplikacja, która ma umożliwiać analizę danych musi realizować pewne trzy podstawowe zadania: 1. dostęp do bazy danych 2. analizę danych 3. wizualizację wyników Przedstawię projekt swojej aplikacji oraz zaproponuję rozwiązania wybranych problemów, które napotkałem podczas realizacji swojego pomysłu. Nie będę opisywał wszystkich, ponieważ jest to temat zbyt obszerny do opisania w całości. Elementarne znaczenie w tej części pracy będzie miała analiza i interpretacja otrzymanych wyników. Za pomocą pewnych, wybranych metod oceny postaram się stwierdzić, czy dokładność tych technik jest satysfakcjonująca i nadają się one do praktycznego zastosowania. Wszystkie swoje przemyślenia i uwagi zapiszę w postaci wniosków.

8 1.3 Przeglad literatury w dziedzinie Przeglad literatury w dziedzinie TODO Opisać szczegółowo poszczególne typy literatury (książki polskie i zagraniczne, artykuły oraz źródła elektroniczne)

9 Rozdział 2 Analiza zagadnienia 2.1 Wprowadzenie do dziedziny problemu W związku z dynamicznym rozwojem technologicznym pojawiło się wiele nowych możliwości. Wydajny sprzęt komputerowy pozwolił na składowanie coraz większych ilości informacji. Szybkość przetwarzania danych wzrosła wielokrotnie w porównaniu do jeszcze nie tak odległych lat. Obecna technika powoli dochodzi do fizycznych granic minimalizacji komponentów wykorzystywanych przy budowie komputerów. Duże korporacje oraz mniejsze firmy mając na celu zwiększenie swoich dochodów poszukiwały pewnych źródeł informacji, które mogłyby im pomóc w osiągnięciu sukcesu biznesowego. Zaczęły składować najróżniejsze dane. Powstały ogromne bazy danych, które magazynują fakty ze wszystkich możliwych obszarów działalności ludzi. Oczywista stała się chęć pozyskania cennych informacji z tak zebranych danych. W taki sposób powstała dziedzina zajmująca się tym zagadnieniem zwana eksploracja danych. 2.2 Eksploracja danych Każda dziedzina naukowa posiada wiele definicji. Związane jest to z tym, że wiele osób ma różny pogląd dotyczący zakresu obszaru zainteresowania wybranej dziedziny. Nie inaczej jest w przypadku eksploracji danych. W literaturze można spotkać wiele odmian definicji tego zagadnienia. Eksploracja danych wykorzystuje metody oraz narzędzia pochodzące z różnych innych dziedzin, takich jak bazy danych, statystyka i uczenie maszynowe. Nie można zatem jednoznacznie stwierdzić, jakie granice powinna posiadać jako pojęcie. W książce [7] przeczytałem bardzo ciekawą definicję, która wskazuje na istotę eksploracji danych, a nie skupia się na wykorzystywanych przez nią technikach. Pozwolę sobie ją zacytować: Eksploracja danych jest analizą (często ogromnych) zbiorów danych obserwacyjnych w celu znalezienia nieoczekiwanych związków i podsumowania danych w oryginalny sposób tak, aby były zarówno zrozumiałe, jak i przydatne dla ich właściciela. Chciałem odnieść się do powyższej definicji i zwrócić uwagę na to, że eksploracja danych w swojej idei ma analizować dane obserwacyjne. Jest to bardzo istotne określenie danych. Oznacza to, że eksploracja danych zwykle jest przeprowadzana na zbiorze danych, który został zebrany z innych przyczyn niż przetwarzanie mające na celu wydobywanie wiedzy. Przykładem takich danych mogą być bilingi telefoniczne. Same w sobie są zbierane do dokumentowania rozmów wychodzących, za które abonent musi zapłacić. Z drugiej jednak strony mogą posłużyć za źródło danych dla eksploracji. Dzięki temu można poznać informację na różne pytania. Przykładem może być zbadanie gdzie dzwonią mieszkańcy poszczególnych województw oraz jak długo rozmawiają. To pozwoli np. ocenić czy promocja dotycząca obniżenia kosztów pierwszej minuty rozmowy będzie opłacalna dla firmy telekomunikacyjnej. Definicja zwraca uwagę na fakt, że eksploracja danych zajmuje się przetwarzaniem ogromnych zbiorów danych. Wspomniane przeze mnie bilingi rozmów są przykładem właśnie takiego wolumenu. Praktycznie

10 2.2 Eksploracja danych 8 każda osoba posiada telefon komórkowy, a czasem kilka. Nie jesteśmy w stanie wyobrazić sobie ile rozmów telefonicznych odbywa się w ciągu jednej minuty. W swoje książce [8] Daniel Larose również zwrócił uwagę na ciekawą sytuację. Postawił czytelnika przy kasie supermarketu i kazał zamknąć na chwilę oczy. Zwrócił uwagę na to, że poza błaganiem dzieci o słodycze słychać dźwięki skanera kodów kreskowych i terminali potwierdzających poprawne wykonanie operacji kartą płatniczą. Gdyby wsłuchać się dokładnie w te dźwięki, to nie bylibyśmy w stanie policzyć ich wszystkich, tak znaczna jest to liczba. Biorąc pod uwagę skalę kraju albo państwa, duża sieć supermarketów ma o nas wszystkich bardzo dużo informacji, którymi może się posłużyć. To, że tych danych jest tak dużo daje ogromne możliwości, ale również stawia analityków przed różnymi wyzwaniami ściśle związanymi z ilością danych oraz ich spójnością. Techniki wykorzystywane do analizowania dużych zbiorów informacji muszą być sprawne. Mam tu na przykład na myśli zoptymalizowany sposób poszukiwania zależności. Gdybyśmy mieli szukać zależności sprawdzając wszystkie możliwe kombinacje, to moglibyśmy nie doczekać się wyników. Poniekąd ma to też swoją wadę. Metody te działają z pewną dokładnością (zazwyczaj można na nią wpływać), ale nie da się ocenić jakiejś sytuacji ze stu procentową pewnością. Gdybyśmy mięli powiedzieć, że jakiś przedmiot nam się podoba, to też ciężko nam jest wydać pewną opinię. Może zdarzyć się również sytuacja, że analityk chciałby dowiedzieć się czegoś ciekawego z danych, które były zebrane jakiś czas temu. Nie może być pewien ich spójności w sensie cech obiektów, ani też tego, że nie ma tam informacji błędnych, które mogłyby przekłamać wynik. Na rynku oprogramowania znajduje się wiele pozycji, które zasługują na uwagę i udowodniły wielokrotnie swoją wyższość nad innymi. Można spotkać też mniej znane produkty, które zachęcają bardzo przyjaznym interfejsem użytkownika. Może to być bardzo mylące i należy zastanowić się, czy dane, które posiadamy mogą być przetwarzane przez zewnętrzne. Takie oprogramowanie zazwyczaj posiada uniwersalny charakter, a to nie zawsze jest zaletą. Jeśli posiadamy nietypową reprezentację danych, to albo możemy bardzo się napracować przygotowując dane do przetwarzania albo uzyskać błędne wyniki nie otrzymując do tego żadnego powiadomienia. Często w zwyczaju nazywa się taki model czarną skrzynką. Nie wiemy jak dane są przetwarzane, dlatego możemy nie zrozumieć końcowego rezultatu. Wiedza informatyczna jest niezbędna do stworzenia narzędzia, jednak analityk, który zajmuje się interpretacją uzyskanych wyników musi rozumieć ich istotę. Jeśli znamy wewnętrzne mechanizmy systemu przetwarzającego dane i wiemy jak się cały proces odbywa, to możemy powiedzieć, że mamy do czynienia z modelem białej skrzynki. Wiele osób, które jeszcze nie miały możliwości poznać bliżej eksploracji danych sądzą, że polega to na zastosowaniu pewnych technik statystycznych czy pochodzących z dziedziny sztucznej inteligencji w celu uzyskania odpowiedzi na konkretne pytania. Przekonanie o eksploracji danych jako o samodzielnym narzędziu, które mogłoby zostać wykorzystane do przeprowadzania analiz, przez grupę specjalistów jest błędne. Jak właśnie pokazałem rzeczywistość jest mniej kolorowa, niż może się wydawać. Eksploracja danych powinna być postrzegana jako proces złożony z kilku etapów. Powinna być utożsamiana z metodologią, która określa ściśle tok działania. Istnieje kilka podejść do odkrywania wiedzy, jednak wszystkie powinny uwzględnić następujące etapy: przygotowanie danych wybór technik analizy ocena wykorzystanie Przykładem metodologii przedstawiającej odkrywanie wiedzy jako proces jest Cross-Industry Standard Process (CRISP-DM) opisany w [[7, 8]]. Metodologia powstała w 1996 roku z inicjatywy takich firm jak DaimlerChrysler, SPSS i NCR. Określa standardowy proces dopasowania eksploracji danych w celu rozwiązywania problemów biznesowych i badawczych. Poza wyżej przedstawionymi podstawowymi etapami eksploracji danych CRISP-DM zawiera dodatkowe dwa, które poprzedzają przygotowanie danych. Jest interaktywny i adaptacyjny, co oznacza, że można przechodzić z jednego etapu do drugiego w zależności od ustalonych założeń i ograniczeń. Rysunek 2.1 przedstawia go za pomocą prostego diagramu.

11 Rysunek 2.1: Schemat metodologii CRISP-DM
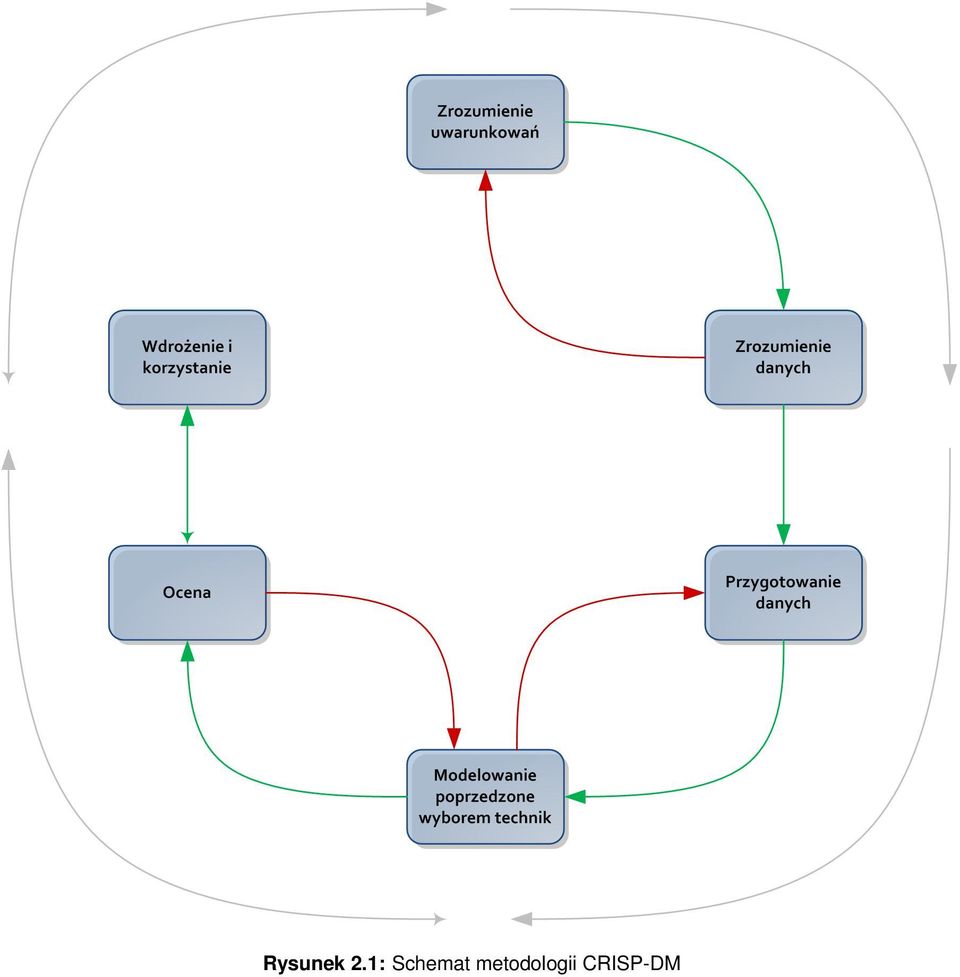
12 2.3 Problemy zwiazane ze źródłem danych Problemy zwiazane ze źródłem danych Poprzednia część rozdziału była wprowadzeniem do zagadnień związanych z eksploracją danych. Wskazałem przykładowe bazy danych, które mogłyby posłużyć jako źródło do przeprowadzania analizy i wydobywania wiedzy. W tej części poruszę problemy, z którymi borykają się osoby zajmujące się odkrywaniem wiedzy. Problemy te związane są z reprezentacją oraz charakterem danych wejściowych. Eksploracja danych może korzystać z baz danych, które nie były stworzone wyłącznie w celu odkrywania wiedzy, dlatego mogą one posiadać niepożądane cechy. Do takich cech można zaliczyć: kolumny, które są przestarzałe i nie są już dłużej wypełniane wiersze z brakującymi wartościami format bazy danych może być nie odpowiedni niektóre wartości są niezgodne z logiką i pewnym podejściem (sprzeczne założenia) Rolą analityka, czy też innej osoby odpowiedzialnej za eksplorację danych jest przygotowanie danych tak, aby nadawały się do przetwarzania. Aby taka baza danych mogła być użyta musi zostać poddana wstępnej obróbce. Jest to jeden z etapów przedstawionej wcześniej metodologi CRISP-DM. Często takie zadanie jest trudne i wymaga podjęcia pewnych decyzji, które mogą zaważyć na rezultatach odkrywania wiedzy z danych. Źle przeprowadzona wstępna obróbka może sprawić, że wynik końcowy nie będzie miał żadnego sensu. W przypadku kolumn, które już wcale nie są wypełniane sytuacja jest dość prosta. Wystarczy wykonać projekcję dla tabeli pomijającą niepoprawne kolumny. Trudniej wybrnąć z problemu brakujących wartości w rekordach. Jest to problem, który przejawia się na okrągło. Metody analizy, które są bardzo zaawansowane i mogą dawać dobre rezultaty w satysfakcjonującym czasie mogą zawieźć jeśli natrafią na brakujące wartości. Wiadomym jest, że im więcej mamy informacji na temat jakiegoś obiektu, tym lepiej możemy go scharakteryzować. Brak informacji na jakiś temat jest zawsze niemile widziany. Na przykład kiedy poszukujemy przestępcy, chcemy wiedzieć o nim jak najwięcej, aby go szybko znaleźć. Pomimo tego, że niektórych danych może brakować przed analitykiem ciągle stoi zadanie, z które musi zostać wykonane. Najprostszym sposobem poradzenia sobie z brakującymi danymi jest po prostu pominięcie takiego rekordu. Wydaje się, że problem rozwiązany. Nie ma danych, które mogłyby zachwiać wynik. A co jeśli celem odkrywania wiedzy było rozpoznanie sekwencji występowania pewnych zdarzeń? Jeśli usuniemy taki rekord dostaniemy całkiem inną sekwencję, która nie będzie zgodna ze stanem rzeczywistym. Z tego powodu analitycy posługują się metodami, które odtwarzają brakujące wartości. Jest kilka takich metod. Najpopularniejsze są: Zastąpienie brakującej wartości stałą określaną przez analityka Zastąpienie brakującej wartości wartością średnią policzoną na podstawie innych rekordów Zastąpienie brakującej wartości wartością losową wygenerowaną na podstawie obserwowanego rozkładu zmiennej W literaturze wiele miejsca poświęca się rozwiązywaniu tego typu problemów. Choćby w [8] pan Larose wskazuje wady i zalety powyższych rozwiązań. Pierwsze podejście jest najprostsze, ale obarczone dużym błędem. Nie dość, że wartość może nie pasować do danych, to jeszcze analityk mając przed oczami zbiór milionów albo miliardów rekordów nie jest w stanie ocenić jaki zakres posiada dane pole. Z kolei zastąpienie wartością średnią zapewnia, że zakres będzie poprawny, ale jeśli zbyt dużo wartości będzie brakowało i zostaną zastąpione, to wszystkie obiekty pod tym kątem staną się podobne, a to może spowodować, że wynik będzie zbyt optymistyczny. Autor najbardziej chwali trzeci sposób. Metoda zapewnia odpowiedni rozrzut wartości w danym zakresie. Na podstawie przeprowadzonych eksperymentów stwierdził, że prawdopodobieństwo wygenerowania zbliżonych do oryginalnych wartości jest dość duże. Przestrzega jednak, że nie zawsze mogą mieć sens w aspekcie całości obiektu (razem z innymi atrybutami). Jeśli chodzi o format bazy danych, to nie ma wiele pola do popisu. Format musi być odpowiedni, więc baza musi zostać przekonwertowana. Problemem może być wydajność przetwarzania ogromnej ilości wierszy. Może

13 2.4 Pozyskiwanie informacji o użytkownikach stron WWW 11 to trwać bardzo długo. Ostatni problem dotyczył wartości niezgodnych z logiką. Głównie dotyczy to wartości jakościowych, czyli etykiet, które nie powinny być porównywane z liczbami. Należy przyjąć jakąś miarę podobieństwa dla poszczególnych pól, tak aby porównanie miało sens logiczny, czyli np. pojęcie duży > mały. W przypadku wartości liczbowych często dane się normalizuje czyli przelicza na odpowiednią wartość z przedziału od 0,0 do 1, Pozyskiwanie informacji o użytkownikach stron WWW W pracy zajmuję się analizą informacji o użytkownikach stron internetowych, dlatego nie mogę pominąć kwestii pozyskiwania danych ze stron WWW. Zazwyczaj można spotkać się z trzema podejściami Log serwera WWW Jednym ze sposobów jest analizowanie logów serwera stron internetowych. Log, jest to plik tekstowy, w którym zapisywane informacje o odwiedzinach danej strony internetowej. Szybki przegląd stron internetowych dotyczących eksploracji danych o użytkownikach serwisu internetowego pokazuje, że jest to najczęściej wykorzystywana metoda zbierania danych. Całą pracę wykonuje oprogramowanie serwera WWW, które zapisuje wszelkiego rodzaju informacje dotyczące każdego wejścia na stronę internetową. Mogą się tam znaleźć nazwy użytkowników, daty, numery IP oraz adresy odwiedzonych stron. Przykładowy plik loga zamieszczony jest na listingu 2.1. Fragment loga pochodzi ze strony internetowej Listing 2.1 Listing przedstawiający log serwera NASA [01/Jul/1995:00:00: ] "GET /history/apollo/ HTTP/1.0" unicomp6.unicomp.net - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/ HTTP/1.0" [01/Jul/1995:00:00: ] "GET /shuttle/missions/sts-73/mission-sts-73.html HTTP/1.0" burger.letters.com - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/liftoff.html HTTP/1.0" [01/Jul/1995:00:00: ] "GET /shuttle/missions/sts-73/sts-73-patch-small.gif HTTP/1.0" burger.letters.com - - [01/Jul/1995:00:00: ] "GET /images/nasa-logosmall.gif HTTP/1.0" burger.letters.com - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/video/livevideo.gif HTTP/1.0" [01/Jul/1995:00:00: ] "GET /shuttle/countdown/countdown.html HTTP/1.0" d104.aa.net - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/ HTTP/1.0" [01/Jul/1995:00:00: ] "GET / HTTP/1.0" unicomp6.unicomp.net - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/count.gif HTTP/1.0" unicomp6.unicomp.net - - [01/Jul/1995:00:00: ] "GET /images/nasa-logosmall.gif HTTP/1.0" unicomp6.unicomp.net - - [01/Jul/1995:00:00: ] "GET /images/ksc-logosmall.gif HTTP/1.0" d104.aa.net - - [01/Jul/1995:00:00: ] "GET /shuttle/countdown/count.gif HTTP/1.0" d104.aa.net - - [01/Jul/1995:00:00: ] "GET /images/nasa-logosmall.gif HTTP/1.0" d104.aa.net - - [01/Jul/1995:00:00: ] "GET /images/ksc-logosmall.gif HTTP/1.0" [01/Jul/1995:00:00: ] "GET /images/ksclogo-medium.gif HTTP/1.0" [01/Jul/1995:00:00: ] "GET /images/launch-logo.gif HTTP/1.0" Na pierwszy rzut oka wydaje się, że posiadamy wszelkie potrzebne informacje i możemy przestąpić do przetwarzania. Niestety nie jest tak dobrze, jak mogłoby się wydawać. Plik loga serwera może zawierać zarazem informacje nadmiarowe, jak i niekompletne. Nadmiarowość wynika z tego, że podczas łączenia się użytkownika ze stroną internetową serwisu przesyłane są oprócz treści stron internetowych także obrazki, czy reklamy podłączone do innych serwerów. Trzeba zatem przefiltrować zawartość pliku pozostawiając tylko informacje dotyczące wyłącznie aktualnego serwera i strony WWW. Wszystkie reklamy oraz obrazki i pliki dodatkowe muszą zostać odrzucone. Dodatkowo okazuje się, że część danych znajdujących się w pliku loga danych jest sztuczna i nie została zapisana w wyniku interakcji użytkownika z serwisem internetowym. Te sztuczne dane zostały wygenerowane przez roboty internetowe, które są programami komputerowymi przeszukującymi strony WWW.

14 2.4 Pozyskiwanie informacji o użytkownikach stron WWW 12 Robią to, abyśmy mogli sprawnie wykorzystywać wyszukiwarki internetowe i otrzymywać wyniki w zadowalającym czasie. Nikt przecież nie lubi czekać na odpowiedź. Robot odwiedza każdą stronę internetową serwisu którą może (poza dostępem wymagającym zalogowania). Dla naszej sprawy jest to kłopotliwe, ponieważ zaciemnia akcje użytkowników. Nie interesują nas przecież informacje nieprawdziwe. Pytanie jakie się od razu nasuwa, to czy da się odróżnić działanie robota, od zwykłego użytkownika? Zdecydowanie tak. W pojedynczej linii loga, jak można było zobaczyć na listingu 2.1, znajdują się informacje dotyczące przeglądarki internetowej, z której korzystał użytkownik. Roboty internetowe wpisują tam swoje nazwy lub adresy stron internetowych wskazujących na konkretny program komputerowy. Istnieje nawet baza danych opisująca popularne roboty internetowe. Nie powinno być zatem problemu z pozbyciem się niechcianych wpisów. Aby wyjaśnić niekompletność danych w logach muszę najpierw zaznaczyć, że istniej kilka standardów takich plików. Standard określa jakie dane i w jakim formacie mają zostać zapisane do pliku. Większość serwerów nie zapisuje informacji o nazwie użytkownika mającej sens w ramach serwisu internetowego. Zapisywane są informacje o domenie z jakiej pochodzi komputer albo wyłącznie numer IP interfejsu sieciowego. Pozyskanie nazw użytkowników musi być przeprowadzone na podstawie dodatkowych plików, jak np. pliki cookies, które przechowują informacje o sesji użytkownika i jego logowaniu. Dopiero wtedy jednoznacznie można zidentyfikować użytkownika. Kolejnym problemem powodującym niekompletność danych jest używanie przez użytkowników przycisku wstecz w przeglądarkach. Powoduje to wczytanie ostatnio oglądanej strony z bufora programu. Nie jest wtedy wysyłane żądanie do serwera strony WWW, a co za tym idzie nie jest to odnotowane w logu. Gdybyśmy analizowali taki plik pod kątem sekwencji działań użytkownikami to mogłoby się okazać, że sekwencja nie ma sensu. Najprościej pokazać taką sytuację na przykładzie. Załóżmy, że możliwe jest przejście ze strony A do B oraz ze strony A do C. Przejście ze strony B do C nie jest możliwe. Przeanalizujmy pewien scenariusz: 1. Użytkownik odwiedza stronę A 2. Użytkownik odwiedza stronę B 3. Użytkownik wciska przycisk wstecz w swojej przeglądarce internetowej, co skutkuje wczytaniem strony A z bufora programu 4. Użytkownik przechodzi na stronę C W dzienniku odwiedzin zarejestrowane zostanie następujące przejście: A => B => C, co nie jest możliwe. Sposobem na taki absurd jest odtworzenie ścieżek serwisu internetowego na podstawie możliwych przejść. Aby jednak tego dokonać potrzebujemy dodatkowej wiedzy o strukturze serwisu internetowego. Używanie loga jako źródła danych dla eksploracji danych przestaje być zatem bez wad i nie nadaje się do wszystkich zastosowań bez wcześniejszego zweryfikowania danych Podsłuchiwanie połaczenia użytkownika z serwerem WWW Inną metodą na zebranie informacji o użytkowniku internetowym jest podsłuchanie komunikacji pomiędzy przeglądarką internetową klienta a serwerem WWW. Można to zrealizować na kilka sposobów. Jednym z nich jest podsłuchiwanie pakietów protokołów sieciowych przesyłanych po sieci. Kolejnym jest zastosowanie specjalnej wtyczki do przeglądarki internetowej, która będzie zapisywała informację o stronach internetowych w pliku tekstowym. Można spotkać kilka wtyczek tego typu do różnych przeglądarek internetowych. W przypadku pierwszej techniki wymagana są umiejętności programistyczne, ponieważ trzeba zadbać o odpowiednie skojarzenie ze sobą przesyłanych pakietów tak, aby przesyłane dane były spójne. Niespójności mogą się pojawić, ponieważ w ramach protokołu TCP jedna ramka informacji może być przesłana ponownie w przypadku błędów. W porównaniu do tej metody zastosowanie wtyczki w przeglądarce nie wymaga dodatkowej, żmudnej pracy. W obydwu przypadkach pozostaje problem identyfikacji użytkowników. Dla pierwszego sposobu można dowiedzieć się tego analizując np. adres odnośnika do strony, albo dodatkowe argumenty dla niego. Dla drugiego sposobu musimy przeprowadzić jawny zapis informacji personalnych dla każdego użytkownika korzystającego z przeglądarki na terminalu. Nie jesteśmy w stanie inaczej odróżnić, czy z serwisu internetowego korzysta Ania, czy Marek.

15 2.5 Strategie przygotowywania rekomendacji Dedykowany serwis internetowy Ostatnim sposobem pozyskiwania danych jest przygotowanie odpowiedniego serwisu internetowego, który sam będzie potrafił zapisywać niezbędne dla nas informacje. Zaletą tego rozwiązania jest to, że mamy te dane, o które nam się rozchodzi. Nie musimy przeprowadzać dodatkowej obróbki danych polegającej na filtrowaniu, uzupełnianiu ścieżek, czy też identyfikacji użytkowników. Niestety takie podejście ma jedną, ale za to dużą wadę. Wymaga stworzenia dedykowanego serwisu, a to oznacza, że jest to podejście jednorazowe. Oczywiście można stworzyć taki szkielet, który można by wykorzystać w wielu miejscach, jednak czy uda się go rozpowszechnić? Większa część serwisów internetowych chce zaskakiwać, zachęcać i wyróżniać się dlatego nie zdecyduje się na zakup takiego szkieletu. Sprawia to, że rozwiązanie jest kosztowne czasowo, a nie wiadomo, czy taki serwis będzie chętnie odwiedzany i przyniesie odpowiednio rekompensujący pracę dochód. 2.5 Strategie przygotowywania rekomendacji Kończąc analizę zagadnienia chciałem przedstawić dwa typy strategii przygotowywania rekomendacji. Osoby, które na co dzień nie zajmują się handlem i usługami, mogą nie zdawać sobie sprawy z tego, że stosuje się pewne strategie sprzedaży, które mają na celu spowodowanie tego, aby klient myślał, że firma go rozumie i wychodzi naprzeciw jego potrzebom i zainteresowaniom. Studiując literaturę napotkałem w książce [?] na dwie strategie, które moim zdaniem są najczęściej spotykane w codzienności. Były to: sprzedaż krzyżowa (ang. cross-selling) sprzedaż rozszerzona (ang. up-selling) Sprzedaż krzyżowa polega na tym, że proponuje się klientowi produkty, które są często kupowane przez innych klientów. Przewidywanie takiego zainteresowania przeprowadza się na podstawie wcześniej zakupionych produktów. Strategia ta jest bardzo często spotykana w sklepach internetowych. Objawia się to tym, że na stronie internetowej internetowej sklepu występuje sekcja o tytule Ci którzy kupili produkt X kupili również.... Właśnie pod tym kątem opisałem techniki przygotowywania rekomendacji w swojej pracy. Analizowanie danych niezbędnych do przygotowania rekomendacji w ramach tej strategii może odbywać się w inny sposób. Można analizować dane o zakupach, jak wcześniej wspomniałem, ale można także analizować sekwencje zakupów konkretnych produktów. Aby lepiej zobrazować sytuację przytoczę pewien przykład. Załóżmy, że użytkownik sklepu internetowego zakupił aparat fotograficzny, a dokładnie lustrzankę cyfrową. W ofercie firmy znajduje się także szkolenie dotyczące obsługi aparatu i wykonywania profesjonalnych zdjęć. Na podstawie sekwencji zakupów innych użytkowników można dowiedzieć się, że osoby kupujące aparat typu lustrzanka niedługo po jego zakupie zdecydowały się na zakup profesjonalnego szkolenia. W przypadku sprzedaży rozszerzonej chodzi o to, aby klientowi proponować lepsze wersje produktów niż już posiada. Najlepszym przykładem pokazującym zastosowanie będzie sprzedaż produktów, na które nałożony jest abonament. Weźmy pod uwagę telewizję cyfrową. Klient zakupił dekoder i zdecydował się na odpowiedni pakiet kanałów telewizyjnych. Po jakimś czasie można zaproponować mu zmianę pakietu kanałów, które może oglądać lub przedstawić ofertę dodatkowych kanałów, które można wykupić bez przechodzenia na wyższy abonament. Opisane wyżej strategie są praktycznie wszędzie wykorzystywane. Dają obopólną korzyść. Klient jest zadowolony, bo oferta, która jest do niego kierowana jest rzeczowa i celuje w jego zainteresowania, natomiast firma zwiększa swoje dochody, a jednocześnie utrwala więź z klientem.

16 Rozdział 3 Techniki analizy danych Eksploracja danych wykorzystuje zdobycze wielu dziedzin nauki takich jak statystyka, matematyka czy uczenie maszynowe. Ma w związku z tym charakter interdyscyplinarny. Udostępnia szeroki wachlarz technik analizy danych. W kolejnych trzech rozdziałach swojej pracy przyjrzę się bliżej wybranym technikom analizy danych. Jest ich wiele, dlatego wybrałem kilka najbardziej ciekawych i popularnych. Skupię się na nich dokładnie. Dla każdej postaram się przedstawić ideę oraz zasadę działania. Podsumuję je także wskazując wady i zalety ich stosowania. Poruszę trzy dziedziny technik analizy danych. Będą to: grupowanie klasyfikacja reguły asocjacji Każda z tych technik zajmuje się innym zadaniem. Grupowanie zajmuje tak zwanym uczeniem nienadzorowanym, w którym nie posiadamy informacji o etykietach obiektów znajdujących się w zbiorze. Z kolei na przykład klasyfikacja jest uczeniem z nadzorem, ponieważ przyporządkowanie etykiet do do obiektów ze zbioru wykonywane jest przez zewnętrznego agenta (może być wykorzystane grupowanie), a klasyfikacja przyporządkowuje jeden obiekt do wybranej kategorii. Wymienione typy zadań można zaklasyfikować do zadań kombinatorycznych. Mają przeszukać jakąś przestrzeń rozwiązań w poszukiwaniu pewnych zależności. Największą pewność daje przeszukiwanie wszystkich możliwych, jednak jest to bardzo czasochłonne. Zakładając, że w grupowaniu mamy do rozmieszczenia w dwóch klasach tylko sto obiektów daje nam to możliwych rozmieszczeń. Żeby lepiej ocenić jak wielka jest to liczba napiszę tylko, że Sprawdzenie każdej możliwości, pamiętając, że mamy do czynienia z ogromnymi zbiorami informacji jest po prostu niemożliwe. Należy zatem skorzystać z yfikowanych metod, które w jakiś zoptymalizowany i konsekwentny sposób będą poszukiwały oczekiwanych rozmieszczeń, klasyfikacji czy asocjacji. W różnych metodach analizy pojawiają się często te pytania dotyczące tych samych problemów. Zanim rozpocznie się analizę trzeba sobie na nie odpowiedzieć. Takimi przykładowymi pytaniami mogą być: Jak mierzyć podobieństwo? Jak zakodować zmienne? Jak standaryzować lub normalizować wartości? Takich pytań jest wiele. Na większość trzeba odpowiedzieć indywidualnie dla danej metody, jednak z punktu widzenia wszystkich wspomniane wyżej pojawiają się wszędzie. Metody klasyfikacji czy grupowania badają podobieństwo między obiektami. Trzeba w jakiś sposób określić dlaczego obiekt A jest bardziej podobny do obiektu B niż do C. Aby zrozumieć zasady działania algorytmów trzeba najpierw poznać zasadę reprezentacji obiektów w systemie. W wielu omawianych przeze mnie metodach obiekty poddawane analizie są reprezentowane w postaci par cecha-wartość. Przykładowo obiekt osoba można przedstawić jako zestaw par: płeć-kobieta, wiek-28, wzrost-169 itd. Ilość cech dla

17 3 Techniki analizy danych 15 obiektów tego samego typu jest identyczna. Różnią się one między sobą wyłącznie wartościami poszczególnych cech. Można to podejście uogólnić w momencie, jeśli kolejność występowania kolejnych cech jest ustalona. Sprowadzi się to wtedy do reprezentacji w postaci wektora wartości cech danego obiektu. Taki sposób reprezentacji znajduje szerokie zastosowanie w metodach uczenia maszynowego. Wykorzystanie reprezentacji wektorowej pozwala na proste badanie podobieństwa pomiędzy obiektami. Można w tym celu posłużyć się miarami odległości wektorów. Ich działanie opiera się zazwyczaj na porównywaniu wartości kolejnych atrybutów dwóch obiektów. Chyba najbardziej popularną miarą jest miara euklidesowa wyrażona za pomocą wzoru 3.1. d Euklidesa (x, y) = (x i y i ) 2, (3.1) i Bardzo często spotykać można również miarę miejska zwaną też Manhattan, która wyrażona jest za pomocą wzoru: d Manhattan (x, y) = x i y i, (3.2) i Inne miary, które są chętnie używane, ale nie są opisywane tak często jak wcześniejsze, to miara Czybyszewa (wzór XXX) oraz miara Canberra (wzór XXX). d Czybyszewa (x, y) = max( x i y i ), (3.3) d Cranberra (x, y) = i x i y i x i + y i, (3.4) W przypadku, kiedy mamy do czynienia ze zmiennymi jakościowymi możemy posłużyć się prostą zasadą, która zakłada, ze jeżeli wartości wybranej cechy dwóch obiektów są równe, to wtedy miara odległości jest równa 0. W innym wypadku jest równa 1 (wzór 3.5). 0, gdy x i = y i d Jakościowa (x i, y i ) = (3.5) 1, w przeciwnym wypadku Można również wyróżnić sytuację, w której dla pewnego atrybutu jakościowego wartości jest kilka. Jeżeli będą one zachowywały pewną gradację, czyli jedna będzie bardziej od drugiej, to wtedy można przyporządkować im liczby porządkowe. Przykładowo, jeżeli mamy atrybut wzrost o możliwych wartościach, duży, średni, mały, to przyporządkowujemy im wartości następująco: 0 - mały, 1 - średni, 2 - duży. Pozwoli to porównywać bez większych problemów wartości stawiając pomiędzy nimi znak nierówności. Algorytmy klasyfikacji oraz grupowania wymagają przeprowadzenia normalizacji danych, po to aby wartość jednego atrybutu ani ich podzbiór nie przekłamały porównania obiektów. W tym celu można zastosować jedną z dwóch metod: normalizację min-max lub standaryzację. Normalizację min-max przeprowadza się zgodnie ze wzorem 3.6. Jest to transformacja, która nadaje wektorowi długość 1 bez zmiany jego kierunku. normalizacja X = X min(x) max(x) min(x) Standaryzacja wykorzystuje do przekształcenia wartość średniej i odchylenia standardowego. Formalny zapis przedstawia wzór 3.7 standaryzacja X = X X (3.7) σ(x) Obydwie operacje przeprowadza się po kolei dla każdej składowej wektora cech wybranego obiektu. (3.6)

18 Rozdział 4 Grupowanie W literaturze można spotkać się z różnymi określeniami tych technik eksploracji danych. Najbardziej popularnymi określeniami są: analiza skupień i klastrowanie. Będę posługiwał się nimi zamiennie. Grupowanie jest rodziną metod, które można zaklasyfikować do uczenia bez nadzoru. Obiekty, które mają być poddane przetwarzaniu nie są w żaden sposób oznaczone. Przetwarzaniu podlega surowy zbiór nie posiadający dodatkowych informacji. Celem grupowania jest znalezienie pewnych wzorców, które niekoniecznie muszą być oczywiste i proste do odgadnięcia. Grupowanie może w ten sposób, jak sama nazwa wskazuje, pogrupować podobne obiekty lub rozmieścić je w uporządkowanej strukturze (najczęściej jest to struktura drzewiasta). Analizowane dane wpadają do różnych grup. W jednej grupie powinny być obiekty najbardziej do siebie podobne, natomiast dwa obiekty z dwóch różnych grup powinny być od siebie jak najbardziej odległe w sensie wybranej miary odległości. Rysunek 4.1 ilustruje ideę grupowania obiektów do trzech grup. Każdy obiekt opisany jest za pomocą wartości dla pewnych atrybutów, co pozwala umiejscowić go w jakimś układzie współrzędnych wielowymiarowych. Analiza skupień znajduje szerokie pole zastosowań w różnych dziedzinach. Przykłady można wymieniać bez końca, ale o kilku ciekawych warto wspomnieć. W medycynie może być wykorzystana, do kreślenia, czy dany przypadek choroby nie jest jakimś szczególnym przypadkiem innej już znanej, np. nową mutacją wirusa grypy. W biologii może pomóc w określeniu, czy na pozór podobnie wyglądające organizmy naprawdę są jednego gatunku, np. koń i osioł. Z kolei na rynku usług informatycznych można kategoryzować użytkowników serwisów internetowych pod kątem ich potrzeb. W ten sposób można określić ich krąg zainteresowania produktami. Algorytmy wykorzystywane do przetwarzania danych zgodnie z idea analizy skupień posiadają swoje charakterystyki. W związku z tym można przedstawić pewną klasyfikację metod grupowania: 1. Metody grupowania, które za kryterium przyporządkowania uznają podobieństwo obiektów oraz metody działające w oparciu o aparat statystyczny. 2. Metody grupowania, które deterministycznie określają przynależność do grupy (albo obiekt do niej trafia albo nie) oraz probabilistyczne. w którym dla każdego obiektu wyznaczane jest prawdopodobieństwo przyporządkowania do wszystkich dostępnych grup. Mamy wtedy wiedzę nie tylko o najlepszym dopasowaniu, ale także o kolejnych. 3. Metody grupowania, które pozwalają na utworzenie hierarchii obiektów lub takie które wszystkie grupy umieszczają w płaskiej przestrzeni. Pierwsze podejście pozwala rozróżnić pewne podgrupy wśród grup. Może się to przydać chociażby w identyfikowaniu kategorii stron internetowych. Drugie podejście traktuje wszystkie grupy jednocześnie i nie ustala wśród nich hierarchii. 4. Metody grupowania, które potrzebują całego zbioru, aby przeprowadzić proces grupowania oraz metody, które działają przyrostowo i są w stanie w danej chwili zająć się obiektami bez przyporządkowania i uaktualnić wynik grupowania bez analizy całego zbioru danych. Niewątpliwie utrudnieniem, które wynika z charakteru metody jest określenie poprawności rezultatów prze-
.")
19 4.1 Metody hierarchiczne 17 Rysunek 4.1: Idea grupowania danych twarzania. Ciężko, o ile to w ogóle możliwe jest sformułować pewien warunek określający, czy grupowanie przebiegło zgodnie z oczekiwaniami analityka. Poprawność jest uzależniona od podejścia analityka. Jeśli wyda mu się interesujące, może on ocenić rezultat jako przydatny. Z kolei dla innej osoby taki wynik nie będzie miał sensu, ponieważ określenie tego, czy grupowanie jest interesujące zależy od zastosowania i jest w pewnym stopniu subiektywne. Istnieje kilka metod, które próbują szacować na ile grupowanie się powiodło. Ich działanie oparte jest na badaniu odległości pomiędzy obiektami w grupach. Im mniejsza suma odległości w każdej z grup, tym grupowanie było w pewnym sensie dokładniejsze. W ramach podrozdziału dotyczącego grupowania omówię trzy metody grupowania. Będą to: Metoda hierarchiczna z przedstawicielem w postaci grupowania aglomeracyjnego Metoda k-średnich Metoda wykorzystująca samo organizujące się mapy omówiona w oparciu o sieć Kohonena Postaram się przybliżyć zasadę ich działania, zastosowania oraz opiszę wady i zalety poszczególnych reprezentantów. 4.1 Metody hierarchiczne Metoda reprezentuje podejście hierarchiczne, które zalicza się do metod opartych na podziale. Wynikiem tej metody grupowania jest drzewo podziałów grup na podgrupy. Nazywa się je dendrogramem. Przykładowe drzewo podziałów prezentuje rysunek 4.2. Przedstawione drzewo prezentuje podział liczb na podstawie pewnego kryterium (nie jest ono w tej chwili ważne). Pionowa oś diagramu wyznacza podobieństwo poszczególnych grup na tym samym poziomie. Jak widać na rysunku, na samym dole każdy obiekt reprezentowany przez liczbę znajduje się w osobnej grupie. Na samej górze natomiast widać już tylko jedną grupę. Od razu nasuwa się wniosek, że grupowanie hierarchiczne za pomocą podziału mogłoby się wykonywać w obydwu kierunkach. Tak właśnie jest. Wyróżnia się dwa podejścia do klastrowania hierarchicznego. Pierwsze z nich jest nazywane aglomeracyjnym i zakłada ścieżkę przejścia od dołu do góry dendrogramu. Początkowo algorytm pracuje na poje-

20 4.1 Metody hierarchiczne 18 Rysunek 4.2: Przykładowy dendrogram powstały w wyniku przeprowadzenia grupowania hierarchicznego dynczych obiektach (w całości jest zapisany za pomocą diagramu blokowego na rysunku XXX). Umieszcza każdy z nich w osobnej grupie, a następnie porównuje takie grupy ze sobą i stara się je łączyć w coraz większe grupy, aż pozostanie wyłącznie jedna. Z kolei drugie podejście, nazywane rozdzielającym, zakłada, że cały zbiór obiektów tworzy jedną grupę, a zadaniem algorytmu jest tak podzielić tą wejściową grupę, aby każdy z obiektu znajdował się w osobnej grupie. Jest to trudniejsze podejście, ponieważ należy określić jak daną grupę będziemy dzielić. Największą uwagę należy w tej metodzie przyłożyć do kryterium podziału. Analiza skupień w oparciu o algorytm aglomeracyjny jest prostsza i o wiele bardziej popularna. Wynika to z tego, że wystarczające jest posługiwanie się miarą odległości (bądź podobieństwa, które jest przeciwnością odległości) pomiędzy obiektami jako kryterium. Należy jednak zauważyć, że miara odległości pomiędzy obiektami jest wykorzystywana tylko w pierwszym kroku, gdy każdy obiekt znajduje się w osobnym skupieniu. W takiej sytuacji miara odległości (podobieństwa) pomiędzy skupieniami jest równa mierze odległości pomiędzy obiektami. Co w przypadku, gdy mamy porównać grupy na wyższym poziomie, które składać się mogą z innych podgrup? Można uogólnić miary tak, by można było je stosować dla grup. Zarówno w [7]jak i w [8] opisane są przykładowe uogólnienia. Daniel Larose wyróżnia cztery metody uogólniania miary podobieństwa. Zakładając, że S 1 oraz S 2 są dwoma skupieniami zawierającymi wektory cech d. Podobieństwosim(S 1,S 2 ) można zdefiniować jako: odległość pomiędzy centroidami grup - za podobieństwo dwóch skupień uznawane jest podobieństwo centroidów tych skupień, gdzie centroid skupienia jest zdefiniowany jako c = 1 d, S sεs maksymalne podobieństwo - algorytm używający tej miary nazywany jest grupowaniem najbliższych sąsiadów. Za podobieństwo uznaje maksymalne podobieństwo wektorów w tych grupach. minimalne podobieństwo - liczone jest analogicznie jak maksymalne podobieństwo, z tym, że zamiast funkcji maksimum wykorzystywana jest funkcja minimum. średnie podobieństwo - jako podobieństwo dwóch skupień przyjmowane jest średnie podobieństwo wektorów tych skupień Algorytm aglomeracyjny pnie się w górę drzewa podziału, aż do scalenia wszystkich grup. Można jednak wprowadzić dodatkowe kryteria i zatrzymać algorytm wcześniej. Wszystko zależy od tego, czy zależy nam na określonej ilości grup, czy współczynniku podobieństwa pomiędzy grupami. Wady i zalety Na pewno do zalet można zaliczyć prostą kontrolę nad wykonywaniem się algorytmu. W zależności od zapotrzebowania można przerwać wykonywanie otrzymując wymagany podział obiektów. Nieocenioną


21 Rysunek 4.3: Diagram blokowy dla algorytmu grupowania aglomeracyjnego (maksymalizujacy podobieństwo)
22 4.2 K-średnich 20 zaletą jest tworzenie się hierarchii obiektów. Niektóre zadania, takie jak choćby katalogowanie produktów czy stron internetowych wymaga podziału na podkategorie. W przypadku algorytmu aglomeracyjnego ogromnym plusem jest prostota uogólnienia miar odległości i podobieństwa na grupy obiektów, co praktycznie zwalnia z dobierania nietrywialnego kryterium podziału. Jedną z poważniejszych wad algorytmu jest jego wydajność. Wymaga dość wielu obliczeń. Aby porównywać ze sobą obiekty musimy już na początku programu znać wszystkie podobieństwa każdej możliwej pary. Daje to złożoność czasową rzęduo(n 2 ). Jeśli chcielibyśmy możliwie wydajnie zaimplementować algorytm powinniśmy na samym początku policzyć miary podobieństwa i przechować je w pamięci, aby od razu były dostępne. Wiąże się to ze złożonością pamięciową rzędu O(n 2 ). Wniosek z tego płynie taki, że nie da się wykorzystać tego algorytmu dla dużych zbiorów danych. Związany jest z tym faktem inny problem. Interpretowanie drzewa podziału przy dużych ilościach danych byłoby niemożliwe dla analityka, co przeczyłoby z ideą pomocy tego narzędzia w jego pracy. 4.2 K-średnich Algorytm K-średnich jest bardzo dobrym przykładem algorytmu, który w prosty i obrazowy sposób prezentuje zasadę optymalnego przeszukiwania przestrzeni rozwiązań. Nadaje się do przeprowadzania analizy skupień dla dużych zbiorów danych. Jego zasady działania są proste i zrozumiałe. Wiadomo czego można spodziewać się po tej metodzie, dlatego jest chętnie wykorzystywana przez statystyków. Występuje kilka różnych odmian tego algorytmu, które do podstawowej wersji wprowadzają dodatkowe mechanizmy optymalizacji. Wspomnę słowem jakie mogą to być optymalizacje, ale omówię podstawową odmianę, od której inne się wywodzą. Nazwa metody wzięła się stąd, że działa w oparciu o pewną stałą ilość średnich wartości podobieństw w grupach. Liczbę pożądanych grup określa parametr k. Aby rozpocząć przetwarzanie tą metodą na wejściu musimy mieć zdefiniowane dwie elementy: Przygotowany zbiór obiektów (np. w reprezentacji wektorowej - znormalizowanej) Parametr k Jak wspomniałem zasada działania metody jest bardzo prosta. Opiera się na migrowaniu obiektów pomiędzy grupami do momentu, aż żaden z obiektów nie zmieni już grupy. Cały algorytm można zapisać w kilku następujących krokach: 1. Wybieramy k obiektów ze zbioru wejściowego, które mają reprezentować centroidy skupień. Zazwyczaj są one wybierane losowo, ale spotyka się implementację, gdzie wybierane są one w jakiś ustalony sposób, np. tak aby pokryć odpowiednio przestrzeń rozwiązań. 2. Dla każdego obiektu ze zbioru obiektów wyznaczamy skupienie, do którego ma należeć. Przeprowadzane jest to z użyciem miary podobieństwa (lub odległości) do każdego z wybranych k-centroidów. Jeśli odległość jest najmniejsza, lub podobieństwo największe, to wybrany obiekt wpisujemy do grupy reprezentującej przez odpowiedni centroid. 3. Po zakończeniu dowiązywania obiektów do grup wyliczamy ponownie centroidy grup używając zebranych informacji o obiektach z danej grupy. 4. Jeżeli żaden obiekt nie zmienił swojej grupy, to kończymy działanie algorytmu. W innym przypadku wykonujemy kroki od punktu 2 włącznie. Najważniejszym punktem w wypisanych wyżej krokach jest punkt numer 2. Decyduje on o tym jaki obiekt do jakiej grupy trafi. Odbywa się to za pomocą funkcji kryterialnej grupowania, której zadaniem jest maksymalizowanie podobieństwa wewnątrz grupy. Sama funkcja kryterialna, jak wynika z algorytmu, jest oparta o centroid grupy, natomiast samo grupowanie oparte jest o uśrednione podobieństwo.

23 Rysunek 4.4: Diagram blokowy dla algorytmu grupowania metoda k-średnich
24 4.3 Samoorganizujaca się mapa 22 Wady i zalety W podstawowej odmianie algorytmu początkowe centroidy wyznaczające skupienia są wybierane losowo. Każda losowość w algorytmach nie jest mile widziana. Tak jest też w tym wypadku. Powoduje ona to, że w kolejnych uruchomieniach algorytmu mogą się wylosować inne środki grup. W rezultacie może to całkowicie zmienić wynik przetwarzania. Aby uznać wyniki za wiarygodne należałoby uruchomić kilkakrotnie grupowanie aby potwierdzić ich prawdziwość. Najlepszym rozwiązaniem będzie to rozwiązanie, które będzie maksymalizowało podobieństwo w grupach. Da się to ocenić metodą podobną do sumy kwadratów. Dla każdej ustalonej grupy należy sumować podobieństwo obiektu i centroidu tej grupy. Formalny zapis przedstawia wzór 4.1 (oznaczmy za pomocą symbolu x obiekt ze zbioru danych D, natomiast c jako centroid k-tej grupy): k i=1 j x j εd i sim(c i,x j ), gdzie jε 1, D i (4.1) Może się okazać, że podczas przeszukiwania przestrzeni rozwiązań zostanie pominięte dobre rozwiązanie skupieniowe, ponieważ samo przeszukiwanie jest ograniczone do małej przestrzeni możliwych podziałów. Maksymalizacja funkcji kryterialnej odbywa się lokalnie. Rozwiązaniem tego problemu również jest wielokrotne przeprowadzenie grupowania z różnymi początkowymi środkami skupień (to akurat zapewnia nam losowy wybór). Metoda k-średnich jest niewątpliwie jedną z najbardziej popularnych i lubianych przez analityków. Nadaje się do wykorzystania dla dużych zbiorów danych. Jest prosty i stosunkowo wydajny. Na wydajność ma wpływ zbiór danych. Jeśli zawiera obiekty dobrze od siebie oddzielone będzie szybciej zbieżny. Złożoność tego algorytmu wynosi O(kni) gdzie: i - liczba iteracji głównej pętli algorytmu k - ilość skupień n - ilość obiektów Dodatkową zaletą jest stosunkowo proste przetransformowanie go do algorytmu hierarchicznego. Wymagałoby to rekurencyjnego wywoływania dla każdej z ustalonych grup. Metoda doczekała się wielu modyfikacji. Wprowadzono różne ciekawe mechanizmy, które mają usprawnić przeszukiwanie przestrzeni dostępnych rozwiązań skupieniowych. Jednym z nich jest dzielenie i łączenie skupień. Podobnie jak to się odbywa w grupowaniu hierarchicznym. Odbywać miałoby się to za pomocą przenoszenia pomiędzy skupieniami tylko jednego obiektu w danej chwili, po czym następowałaby ocena rozwiązania. Na podobnych zasadach działa algorytm optymalizacji obliczeniowej nazywany symulowanym wyżarzaniem, który wybiera początkowe rozwiązanie, a następnie je modyfikuje w ustalony sposób i sprawdza, czy jest ono lepsze od poprzedniego. 4.3 Samoorganizujaca się mapa Grupowanie za pomocą samoorganizujących się map wykorzystuje w swoim działaniu sieci neuronowe. Sieci neuronowe są mechanizmem bardzo popularnym i chętnie wykorzystywanym na różnych polach informatyki. Zastosowania można wymieniać bez końca. O wiele krócej, niż wymienianie zastosowań, trwało by wymienianie zadań, w których sieci neuronowych nie można użyć. Jako przykład można wymienić aproksymację funkcji, kompresję obrazów, rozpoznawanie pisma odręcznego, czyli de facto klasyfikację, która polega na przyporządkowaniu pewnemu obrazkowi odpowiadającej mu litery z alfabetu oraz właśnie grupowanie. Zanim jednak rozpocznę omawianie grupowania za pomocą samoorganizujących się map wyjaśnię czym właściwie jest sieć neuronowa. Co kryje się pod tym tajemniczym pojęciem i czy jest tak skomplikowane, jak można przypuszczać.
25 4.3 Samoorganizujaca się mapa Sieć neuronowa Informatyka, tak jak wiele innych nauk próbuje czerpać z natury ile się tylko da. Nie ma na świecie bardziej zmyślnych mechanizmów, niż te, które pozwalają przetrwać organizmom żywym. Sieć neuronowa wzorowana jest na mózgu. Idea i zasada działania sieci neuronowych w informatyce jest bardzo zbliżona do działania jej biologicznego odpowiednika. Jak zapewne łatwo się domyślić niemożliwym byłoby dokładne odwzorowanie zachodzących w mózgu procesów dlatego wprowadzono pewne uproszczenia. Nie przeszkodziło to jednak stworzyć bardzo elastycznego narzędzia, które może posłużyć do rozwiązywania wszelakich problemów. Sieci neuronowe zbudowane są z połączonych ze sobą neuronów - odpowiedników biologicznych komórek nerwowych. Mogą mieć budowę warstwową, co oznacza, że wybrany neuron z warstwy jest połączony ze wszystkimi neuronami z warstwy kolejnej. Sieci neuronowe mogą charakteryzować się różnymi właściwościami. Na właściwości największy wpływ ma budowa pojedynczego neuronu. Model matematyczny jest bardzo prosty. Podstawowy neuron jest elementem liniowym i składa się z ustalonej liczby wejść, elementu sumującego oraz wyjścia. Rysunek 4.5 przedstawia jego schemat budowy. Zasada działania pojedynczego neuronu również jest bardzo prosta. Na wszystkie wejścia neuronu podawany jest sygnał. Każde z wejść posiada swój współczynnik wagowy. Nazwa się wzięła stąd, że owy współczynnik może być interpretowany jako znaczenie wybranego wejścia. Wartość wyjściowa y neuronu, będąca odpowiedzią na zadany sygnał jest sumarycznym pobudzeniem neuronu, często oznaczanym jako -net. Zakładając, że neuron posiada n wejść, z których każde i-te wejście posiada swoją wagę w i, to wartość będącą odpowiedzią neuronu można opisać za pomocą wzoru 4.2: y = net = k i=1 w j x j (4.2) Analizując wzór 4.2 można zauważyć, że całkowite pobudzenie neuronu zależy od stopnia podobieństwa poszczególnych elementów x j sygnału x z odpowiadającymi im współczynnikami wagowymi w j wektora wag w. Im większe jest to podobieństwo tym większa będzie wartość pobudzenia neuronu. Rysunek 4.5: Schemat przedstawiajacy budowę neuronu Celem postawionym przed siecią neuronową jest przystosowanie się do pewnego sygnału, aby móc odpowiadać zgodnie z jakimś założeniem. Proces adaptacji do sygnałów nazywany jest uczenie albo trenowaniem sieci neuronowej. Uczenie odbywa się za pomocą przykładów. Pojedynczy przykład składa się z dwóch elementów < x,z >, gdzie x, to wektor wartości wejściowych, a z - wartość oczekiwana. Uczenie odbywa się poprzez prezentowanie przykładów i sprawdzanie jak bardzo różni się odpowiedź sieci neuronowej od wartości oczekiwanej. Podczas nauki trzeba potrafić oceniać, czy sieć neuronowa, a w tym przypadku pojedynczy neuron już został nauczony. Najwygodniejszym i zarówno najczęściej spotykanym kryterium oceny jakości nauki jest błąd średnio kwadratowy wyrażony wzorem 4.3(gdzie p - ilość przykładów) : E(W) = 1 2 p p=1 (z p y p ) 2 (4.3)

26 4.3 Samoorganizujaca się mapa 24 Korzystając z powyższego kryterium możemy stwierdzić, czy sieć neuronowa powinna być dalej poddawana procesowi nauki. Trzeba jeszcze wyjaśnić jak przebiega sama nauka, bo przecież podawanie w nieskończoność przykładów nic nowego nie wprowadzi. Najbardziej podstawową metodą nauki sieci neuronowej (również dotyczy pojedynczego neuronu) jest reguła delta. Została wprowadzona przez panów Widrowa oraz Hoffa w roku 1960 i jest do tej pory z sukcesami wykorzystywana. Modyfikacjom podlega wektor wagowy każdego neuronu. Liniowy neuron podlegający nauce nosi nazwę ADALINE, czyli ADAptive LInear NEuron. Załóżmy, że ilość iteracji nauki jest skończona. W każdej i-tej iteracji wagi będą zmodyfikowane zgodnie z zależnością 4.4: w i+1 = w i + w i (4.4) Jest to ogólne podejście poszukiwania optymalnego zestawu wag. W każdej iteracji wektor wagowy jest odpowiednio korygowany, aby był jak najbardziej podobny do wektora sygnałów wejściowych. Jeśli odpowiedź sieci na zadany wektor wejściowy jest większa niż wartość oczekiwana y>z, to wtedy z definicji iloczynu skalarnego dla dwóch wektorów kąt pomiędzy tymi wektorami będzie za mały i należy go zwiększyć. Sprowadza się to do zmiany kierunku wektora wagowego w kolejnej iteracji, czyli de facto odpowiedniej zmiany poszczególnych jego wartości. Ostateczną formułę reguły delta przedstawia wzór 4.5. w i+1 = w i + α(z i y i ) x i (4.5) Współczynnik α określa jak duża zmiana powinna być zastosowana dla wybranej iteracji. Nazywany jest często krokiem nauki, natomiast różnica wartości oczekiwanej oraz odpowiedzi sieci (z y) jest oznaczana jako δ. W zrozumieniu całego mechanizmu może pomóc rysunek 4.6. Przedstawia on schematyczną ścieżkę sygnałów w liniowym neuronie inne sieci. Rysunek 4.6: Schemat procesu nauki pojedynczego neuronu realizowanego przez adaptację wektora wagowego Jak wspomniałem wcześniej duże znaczenie w zachowywaniu się sieci neuronowych mają same neu-
27 4.3 Samoorganizujaca się mapa 25 rony. Występuje wiele wariacji dotyczących samej budowy. Najczęściej mówi się o neuronach z pojedynczym wyjściem tzw. zdegradowanych, ale można spotkać także takie, które mają tych wyjść kilka. Takie rozwiązania stosuje się zazwyczaj przy szybkich przekształceniach liniowych Sieć Kohonena Sieć Kohonena jest siecią samoorganizującą wymyśloną w latach 80 przez norweskiego uczonego Teuvo Kohonena. Do tej pory jest z powodzeniem znajduje swoje zastosowania. Na jej podstawie powstało wiele innych zmodyfikowanych samoorganizujących się sieci neuronowych. Omówienie sieci Kohonena należy zacząć od wyjaśnienia czym tak właściwie jest sieć samoorganizująca się. W poprzedniej sekcji wyjaśniłem czym jest sieć neuronowa. Wprowadziłem do podstawowych pojęci wykorzystywanych w tej dziedzinie informatyki i wyjaśniłem podstawowe aspekty działania sieci neuronowej i pojedynczego neuronu. Było to konieczne, abym mógł w tech chwili swobodnie posługiwać się tą terminologią. Wcześniej o tym nie napisałem, ale sieć neuronowa może być uczona z nauczycielem lub może uczyć się sama. W nauczaniu z nauczycielem potrzebny jest arbiter, który stwierdzi, czy proces musi być kontynuowany oraz nadzoruje każdy etap nauki. W przypadku nienadzorowanej sieci neuronowej taki arbiter ni jest konieczny. Sieć potrafi sama stwierdzić jak ma się uczyć. Siłą samoorganizujących się sieci neuronowych jest to, że potrafią one nie tylko samodzielnie się uczyć, ale także potrafią uzgadniać i rozdzielać odpowiedzialność pomiędzy wszystkie neurony. Daje to możliwość znajdowania ciekawych i często bardzo złożonych odwzorowań, które zazwyczaj nie mogą zostać deterministycznie określone lub wogóle przewidziane. Sieć Kohonena nosi nazwę warstwy topologicznej. Jest tak, ponieważ w podstawowej wersji, jest to pojedyncza warstwa neuronów, z których każdy ma n-elementowy wektor wag i jedno wyjście, gdzie wystawiana jest odpowiedź na zadany sygnał. Jednowarstwową sieć Kohonena przedstawia rysunek 4.7. Na rysunku kółkami oznaczone są neurony, natomiast prostokąty oznaczają wejścia sieci. W praktycznych, Rysunek 4.7: Architektura jednowarstwowej sieci Kohonena rzeczywistych rozwiązaniach sieci Kohonena oraz inne sieci samoorganizujące obsługują nie jedno (jak na rysunku schematycznym), ale nawet do kilkudziesięciu wejść. Stąd stwierdzenie faktu, że nadają się dla znajdowania bardzo złożonych odwzorowań (wiele zmiennych). Ilość wyjść może być jeszcze większa, ponieważ rozmiary sieci mogą osiągnąć niebagatelne rozmiary. W warstwie topologicznej może znaleźć się nawet tysiące neuronów. Do działania sieci neuronowej niezbędny jest n-elementowy wektor wartości wejściowych, który jest wysyłany do każdego j-tego neuronu ( j = 1,..,m oraz mε N). Wektor wagowy każdego neuronu musi posiadać taki sam rozmiar jak wektor wartości wejściowych, aby można sprawdzić podobieństwo dwóch wektorów. Podobieństwo jest utożsamiane z miarą odległości, czyli im wartość miary odległości jest więk-
28 4.3 Samoorganizujaca się mapa 26 sza, tym podobieństwo wektorów mniejsze. Jeśli wartość miary odległości jest równa 1, to wektory są identyczne. Do wyliczania miary odległości można wykorzystać dowolną metodę opisaną przeze mnie na stronie na stronie 15. Ważne jest, aby obydwa wektory brane do porównywania były znormalizowane. Zapewnia to, że wpływ na wynik porównania będą miały jedynie kierunki wektorów w przestrzeni wielowymiarowej. Ich długość będzie taka sama i równa jedności. W swojej książce [1]prof. Osowski zwraca uwagę na fakt, ze wystarczy, aby wektor wartości wejściowych będzie znormalizowany, a wektor wagowy, który będzie poddawany adaptacji będzie dążył do upodobnienia się do wektora wartości. W efekcie zostanie znormalizowany. Do przeprowadzenia normalizacji można skorzystać z metody Minimum-Maksimum, opisywanej wcześniej we wprowadzeniu (rozdział 3 na stronie 15 - wzór 3.6). Istnieje też inna metoda (wzór 4.6) normalizacji, którą można zastosować. Przeczytałem o niej w [2, 1]. x i = x i (4.6) n (x j ) 2 j=1 Mechanizm samoorganizacji oparty jest o istnienie sąsiedztwa pomiędzy neuronami. nie znaczy to, że są ze sobą połączone i wymieniają się wartościami, ale leżą względem siebie blisko. Określenie bliskości może być interpretowane dwojako. Pierwsze podejście opiera się na położeniu neuronów, które tworzą mapę. Dokładne określenie zależy od organizacji mapy neuronów. Może to być zwykła lista, płaszczyzna lub jakaś bryła w przypadku trzech wymiarów. Drugie podejście określa bliskość na podstawie odpowiedzi na zadany sygnał wejściowy. W zależności od odpowiedzi neurony są szeregowane od najlepszego do najgorszego. Będą wtedy wiedziały jaki neuron o podobnym przystosowaniu do sygnału leży obok, albo dwa pola dalej. Rysunek 4.8: Sasiedztwo neuronów w sieci Kohonena Rysunek 4.9: Szczególny przypadek sasiedztwa - sasiedztwo jednowymiarowe Przykładowe podejścia do realizacji sąsiedztwa pokazane są na rysunkach 4.8 i 4.9 (im dalej od wybranego neuronu, tym słabsze nasycenie koloru). Najczęściej stosowane jest to z rysunku 4.8 ponieważ utożsamiane jest z mapą działania neuronów, która może dać ciekawy efekt wizualizacyjny. Na wspomnianym rysunku przerywanymi liniami zostały oznaczone dodatkowe połączenia, które nie zawsze są uwzględniane. Można to potraktować jako rozszerzoną wersję sąsiedztwa. Sąsiedztwo odgrywa ważną rolę w adaptacji wektora wagowego każdego neuronu. Określa, czy wybrany neuron powinien być poddawany nauce czy też nie. Są także takie metody wyznaczania współczynnika sąsiedztwa, które poza odpowiedzią TAK/NIE pozwalają uczyć neuron w mniejszym stopniu.
29 4.3 Samoorganizujaca się mapa 27 W samoorganizujących się mapach odwzorowań działających w oparciu o algorytm Kohonena najpierw określa się zwycięzcę rywalizacji stosując wybraną miarę odległości wektora wag w neuronu oraz wektora wartości wejściowych x, a następnie wylicza się wartość współczynnika adaptacji neuronów należących do sąsiedztwa neuronu wygranego. Wartość tego współczynnika decyduje o szybkości zmian wag neuronów sąsiadujących z wygranym w pewnym promieniu λ. Adaptacja wag i-tego neuronu odbywa się zgodnie z zależnością 4.7 (w z - wektor wag neuronu wygrywającego rywalizację): w i = w i + η G(w i,w z ) [x w i ] (4.7) Współczynnik η określa jak szybko ma przebiegać uczenie. W książce [3] Ryszard Tadeusiewicz wyjaśnił działanie współczynnika nauki za pomocą prostej anegdoty. Naukę neuronu można przyrównać do skaczącego kangura pomiędzy dwoma pagórkami, któremu zasłonięto oczy. On wie, w którym kierunku ma skoczyć, ale nie wie jak duży ma być to skok, aby trafił w odpowiednie miejsce. Będzie próbował dopóki mu się uda. Wracając do adaptacji wag. Do wyliczania współczynnika sąsiedztwa można wykorzystać jedną z kilku wariantów funkcji sąsiedztwa G(i,i z ): Klasyczna - podstawowa funkcja sąsiedztwa dla algorytmu Kohonena. Uczy neurony w takim samym stopniu jeśli znajdują się w odpowiedniej odległości od neuronu wygrywającego { 1 dla w = w G(w,w z ) = z (4.8) 0 dla w w z WTA (zwycięzca bierze wszystko) - adaptacji podlega tylko neuron zwycięzcy { 1 dla d(w,w G(w,w z ) = z ) λ 0 dla pozostalych (4.9) Gauss a - bardziej złożona funkcja sąsiedztwa. Im dalej od neuronu wygrywającego tym współczynnik sąsiedztwa mniejszy G(w,w z ) = e d2 (w,wz) 2 λ 2 (4.10) Początkowe wartości wektorów wagowych dla wszystkich neuronów są ustalane losowo z zadanego przedziału. Może zdarzyć się taka sytuacja, że część neuronów będzie na tyle daleko od pozostałych, że nie będzie miała szans zaklasyfikować się do grupy podlegającej nauce. Trzeba o to zadbać, bo w przeciwnym razie wyniki uzyskane mogą być niedokładne. Sytuacja ta może też mieć miejsce gdy jeden z neuronów, lub grupa jest o wiele lepiej przystosowany niż inne. W rezultacie tylko on będzie adaptowany, a reszta nie. Rozwiązaniem tego problemu jest wprowadzenie drobnej modyfikacji nazywanej mechanizmem zmęczenia neuronów. Kiedy jest wykorzystywany pozwala na zapewnienie udziału wszystkich neuronów w samoorganizacji. Uwzględnia liczbę zwycięstw poszczególnych neuronów i organizuje proces uczenia w taki sposób, aby dać szansę zwycięstwa neuronom mniej aktywnym. Działanie tego mechanizmu jest oparte o zachowanie się neuronów biologicznych. Jeśli neuron wygra rywalizację, to zaraz po zwycięstwie będzie odpoczywał określony czas przed następnym współzawodnictwem. Jedno z podejść do tego mechanizmu zakłada zastosowanie wartości potencjału p (gdzie p ε [0 : 1] ) dla każdego neuronu, który jest modyfikowany, podczas każdej k-tej prezentacji wzorca wejściowego x n-neuronom: p i (k + 1) = { pi (k) + 1 n p i (k) p min (4.11) Wartość potencjału minimalnego p min decyduje o tym, kiedy przestawić stan neuronu na odpoczywa.jeśli aktualna wartość potencjału spadnie poniżej p min, to i-ty neuron będzie miał zmieniony stan i nie będzie brał udziału w rywalizacji do czasu, aż jego potencjał nie wzrośnie, czyli da szansę na zwycięstwo innym neuronom. W literaturze traktującej o sieciach samoorganizujących nie ma podanego jednoznacznego sposobu na określanie błędu sieci Kohonena. Wynika to w pewnym stopniu z faktu, że sieć uczy się bez nadzoru, a
30 4.3 Samoorganizujaca się mapa 28 więc z definicji nie ma złych i dobrych odpowiedzi. Jedną z możliwości jest badanie wektorów błędu jako odległości między wektorami ze zbioru uczącego a najbliższymi względem nich wektorami wag neuronów, czyli wektorów wag zwycięzcy. Odległość tych wektorów może w pewnym stopniu informować o zdolności sieci do grupowania danych. Można jednak z powodzeniem przyjąć następującą metodę pomiaru błędu sieci Kohonena: gdzie: E = 1 p p i=1 x i w i (4.12) p ilość wzorców prezentowanych sieci, x i wektor wartości sygnału wejściowego dla wybranego wzorca, w i wektor wag neuronu wygrywającego dla wybranego wzorca Cały algorytm można zapisać w następujących krokach (zakładam, że dane wejściowe są już odpowiednio przygotowane): i jest licznikiem epok j jest licznikiem wektorów wejściowych p min minimalna wartość potencjału, która dopuszcza neuron do rywalizacji Wszystkie neurony na początku nauki posiadają stan aktywny oraz potencjał pozwalający im brać udział w rywalizacji. 1. i=0; j=0 ; ZMECZENIE=TRUE ; ZMNIEJSZAJWSPNAUKI= FALSE ; 2. Wylosuj wagi dla wszystkich neuronów warstwy odwzorowującej 3. Jeśli wartość licznika i osiągnęła wartość równą liczbie epok, po której ma nastąpić wyłączenie zmęczenia, to ZMECZENIE= FALSE oraz ZMNIEJSZAJWSPNAUKI=TRUE 4. Przetasuj zbiór wzorców 5. Jeśli ZMNIEJSZAJWSPNAUKI=TRUE, to zmniejsz wartość współczynnika nauki η 6. Jako wartości neuronów warstwy wejściowej ustaw wartości j-tego wzorca 7. Policz miary odległości wektorów wagowych każdego neuronu oraz wektora wzorcowego 8. Znajdź neuron wygrywający (tylko wśród neuronów aktywnych), czyli ten o najmniejszej odległości wektora wagowego od wektora wzorca 9. Dla każdego neuronu warstwy odwzorowującej policz współczynnik adaptacji jako wartość funkcji sąsiedztwa względem neuronu zwycięskiego 10. Jeśli mechanizm zmęczenia neuronów jest włączony, to policz nowa wartość potencjału i w oparciu o wartość p min uaktualnij stan neuronu 11. Uaktualnij wartości wag wszystkich neuronów wykorzystując policzone wartości współczynnika adaptacji 12. Zwiększ licznik wzorców j 13. Jeśli pozostały jeszcze jakieś wzorce do podania w tej epoce, to idź do punktu 6, w innym wypadku kontynuuj 14. Policz błąd dla i-tej epoki 15. Zwiększ licznik epok i

31 4.3 Samoorganizujaca się mapa Jeśli wartość licznika i jest mniejsza od maksymalnej ilości epok oraz błąd sieci nie osiągnął jeszcze pożądanej wartości, to idź do punktu 3, w innym wypadku KONIEC Rysunek 4.10: Diagram blokowy dla algorytmu grupowania za pomoca sieci Kohonena
32 4.3 Samoorganizujaca się mapa 30 Wady i zalety Sieć Kohonena jako reprezentant grupy samoorganizujących się sieci neuronowych jest uogólnieniem metody K-średnich. Zasada działania jest podobna. Różnice widać w etapie zmiany środków centroidów grup. W algorytmie K-średnich są one wybierane na nowo, natomiast w algorytmie Kohonena są one odpowiednio adaptowane w kolejnych etapach uczenia. Bardzo ciekawym urozmaiceniem w stosunku do metody K-średnich jest reprezentacja graficzna, która jest również poszukiwanym rozwiązaniem. Jest to mapa, która każdej próbce przyporządkowuje informację o neuronie, który do niej najlepiej pasuje. Neuron ten jest środkiem grupy. Metoda grupowania za pomocą sieci Kohonena może być stosowana w różnych problemach grupowania. Jest w stanie znaleźć odpowiednie powiązania dla problemów o wielu zmiennych i wielu grupach. Grupowanie jest metodą odkrywania wiedzy, która ma sens w pewnym wąskim zagadnieniu. To osoba zlecająca badania musi wiedzieć jakich wyników oczekuje. Algorytm Kohonena wymaga podania odpowiedniej reprezentacji danych wejściowych. Muszą one być odpowiednio przygotowane tak jak dla innych metod grupowania. Przykładowo, gdy analizujemy dane księgarni internetowej i chcemy poznać jakimi gatunkami książek są zainteresowani wybrani klienci, musimy przygotować odpowiednio wektory wejściowe reprezentujące ilość kupionych przez klienta książek z każdej kategorii, a następnie tak przygotowane dane przekazać sieci neuronowej. Wyniki działania algorytmu zależą od ustalonych warunków początkowych. Wagi neuronów są ustalane w sposób losowy, dlatego aby potwierdzić uzyskany rezultat przetwarzanie powinno być przeprowadzone kilkukrotnie.
33 Rozdział 5 Klasyfikacja Klasyfikacja należy do metod uczenia z nadzorem. Zadanie klasyfikacji polega na podaniu pewnej reguły decyzyjnej dla rozpatrywanej próbki obserwacyjnej. Często mówi się też o regule dyskryminacyjnej lub klasyfikacyjnej. Aby taka reguła decyzyjna mogła zostać utworzona dane podlegające przetwarzaniu muszą posiadać pewną ilość niezbędnych informacji. Zbiór danych zazwyczaj nazywa się populacją, a elementy tego zbioru próbkami obserwacyjnymi lub obiektami. Zakłada się również istnienie zbioru klas, czy też etykiet, które w odpowiedni sposób podsumowują każdy obiekt. Przykładem takiego zbioru klas może być {dobry samochód miejski, zły samochód miejski}. Każdy obiekt ma swoją charakterystykę opisywaną przez pary atrybut - wartość. Są to cechy obiektu, na podstawie których podejmowana jest decyzja dotycząca przyporządkowania etykiety ze zbioru etykiet dla tego obiektu. Większość metod klasyfikacji działa zgodnie z pewną metodologią. Tak jak wspomniałem wcześniej do działania niezbędny jest zbiór uczący, czyli zawierający obiekty z przypisanymi już etykietami. Jest to niezbędne aby mechanizm (czy to sieć neuronów, czy jakiś inny kombinatoryczny) mógł nauczyć się odwzorowań. Ważne jest, aby obiekty z tego zbioru uczącego posiadały jak najwięcej pełnych informacji. Pełnych, czyli ustalonych. Przykładowo jeśli rozpatrujemy spalanie paliwa samochodu na 100 kilometrów, to idealnym scenariuszem byłoby, gdyby dla wszystkich aut to spalanie było znane. Niepełne informacje na temat obiektu mogą doprowadzić do stworzenia niepoprawnej reguły decyzyjnej. Mechanizm podlega nauce w oparciu o zbiór uczący, ale aby mógł być używany dla innych przypadków należy sprawdzić, jak to wytrenowane narzędzie radzi sobie z danymi pochodzącymi ze zbioru uczącego, ale z ukrytymi informacjami o docelowej etykiecie. Jest to konieczne, aby zminimalizować ryzyko błędu. Jeśli test przebiegł pomyślnie można walidować model na danych innych niż te ze zbioru uczącego. Jeśli wyniki nie są prawidłowe i błąd klasyfikacji jest zbyt duży, to należy sprawdzić czemu tak się stało. Najczęściej popełnianym błędem jest niepoprawne przygotowanie zbioru uczącego. Z kolei na etapie walidacji na zbiorze wyjściowym zawierającym dane nie pochodzące ze zbioru uczącego może dojść do sytuacji, w której klasyfikacja również będzie niepoprawna. Możliwe jest wtedy, że zbiór uczący posiadał błędne założenia lub zbyt indywidualnie i szczegółowo traktował obiekty. Klasyfikator nauczył się odwzorowań na pamięć i nie był w stanie znaleźć odwzorowania dla nowych obiektów. Jest to odwieczny kompromis pomiędzy złożonością, a zdolnością uogólniania. Bardzo trudne jest zbalansowanie tych dwóch racji. Jeśli model będzie zbyt złożony stanie się zbyt dopasowany do danych. Jeśli będzie zbyt ogólny może nie wykazywać popranych nawyków zgodnych z intuicją, a dane zostaną niepoprawnie zaklasyfikowane. W tym rozdziale zaprezentuję trzy podejścia do klasyfikacji. W każdym z nich zwrócę uwagę na kluczowe aspekty ich działania. Pierwsze będzie prezentowało zastosowanie sieci neuronowej jako klasyfikatora. Następnie przedstawię podejście kombinatoryczne za pomocą algorytmu k-najbliższych Sąsiadów, a na samym końcu podejście statystyczne wykorzystując Naiwny Klasyfikator Bayesa.
34 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu Sieci neuronowe na przykładzie wielowarstwowego perceptronu W ostatnim rozdziale przedstawiłem przydatność sieci neuronowych w grupowaniu danych. Okazuje się, że mogą one mieć znacznie więcej zastosowań. Nadają się również jako klasyfikatory. Mogą np. rozpoznawać cyfry pisane ręcznie, a jest to nic innego jak zadanie klasyfikacji obrazów dla 10 klas (od 0 do 9). Skoro jest to narzędzie tak popularne w obecnych czasach dobrze jest wiedzieć jak ono funkcjonuje, aby zrozumieć jego działanie. Sieci neuronowe same w sobie są tematem bardzo rozległy. Poświęcone jest im wiele publikacji i książek. Nie sposób w krótkim opracowaniu skondensować całej wiedzy na ten temat. Chciałbym jednak przybliżyć najważniejsze elementy i zasady rządzące funkcjonowaniem sieci neuronowych. Zanim opisze strukturę bardziej złożonej sieci neuronowej oraz jej zachowanie chciałbym jeszcze nawiązać do tego jak pojedynczy neuron oraz ich grupa klasyfikuje obiekty. Załóżmy, że mamy zbiór obiektów oraz dwie klasy liniowo separowalne {1 - kółka, 2 - trójkąty}, widoczne na rysunku XXX. Pojęcie liniowo separowalne oznacza tyle, że da się poprowadzić hiperpłaszczyznę rozdzielającą obiekty dwóch klas tak, że po jednej stronie są obiekty tylko klasy 1, a po drugiej tylko obiekty klasy 2. W przypadku, gdy rozpatrujemy dwa wymiary, hiperpłaszczyzną będzie prosta, dla trzech wymiarów będzie to już płaszczyzna itd. Rysunek 5.1: Podział zbioru obiektów na dwie klasy liniowo separowalne Jest to sytuacja idealna. Może się jednak zdarzyć sytuacja, ze obiekty będą tak rozłożone (na podstawie wartości wektora cech), że taki podział będzie niemożliwy. Takich prostych rozdzielających, jak ta widoczna na poprzednim rysunku może być nieskończenie wiele i wszystkie będą poprawnym rozwiązaniem. Rozłożenie obiektów w przestrzeni wielowymiarowej ma ogromny wpływ na równanie opisujące hiperpłaszczyznę rozdzielającą. W zależności od złożoności sieci neuronowej może ona radzić sobie lepiej lub gorzej z klasyfikacją obiektów do odpowiednich grup.
35 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu 33 Rysunek 5.2: Schemat budowy neuronu liniowego Rysunek 5.3: Schemat budowy perceptronu - neuron nieliniowy Wcześniej o tym nie wspomniałem, ale model neuronu, który przedstawiłem we wprowadzeniu do sieci neuronowych ( na stronie 23) może posiadać jeszcze jeden element. Dla przypomnienia rysunek 5.2 przedstawia ponownie model ADALINE opisany wcześniej we wprowadzeniu (4.3.1). Dodatkowym elementem, który się może pojawić jest to blok aktywacji. Najprościej rzecz ujmując jest to funkcja realizująca jakieś przekształcenie na wartości pobudzenia. Taki model neuronu nazywa się perceptronem. Różni się tym od ADALINE, że w procesie uczenia neuronu ADALINE, blok aktywacji jest pomijany (nie istnieje). Pod uwagę brana jest tylko wartość pobudzenia sieci. W przypadku perceptronu blok aktywacji ma wpływ na wartość wyjściową sieci i jest uwzględniany w procesie uczenia. Schemat budowy perceptronu jest widoczny na rysunku XX. Najczęsciej stosowaną funkcją aktywacji jest funkcja sigmoidalna. Wyrażona jest wzorem 5.1: y = e x (5.1) Jest to funkcja najpopularniejsza ze względu na swój charakter. Przebieg tej funkcji przedstawia rysunek 5.4. Rysunek przedstawia wykres funkcji sigmoidalnej na przedziale 5 < x < 5. Dziedziną funkcji jest zbiór liczb rzeczywistych. Funkcja przyjmuje wartości z przedziału od 0 do 1. W punkcie 0 następuje powiedzmy kolokwialnie przegięcie. W pewnej odległości na lewo i prawo od środka dziedziny można powiedzieć, że funkcja sigmoidalna ma charakter liniowy. W miarę jak oddalamy się od tego miejsca funkcja zyskuje charakter liniowy. Poza pewnym przedziałem jest prawie stała. Siła naszych umiejętności postrzegania i kojarzenia bierze się stąd, ze neurony w mózgu choć same są prostej budowy to w połączeniu mogą wykonywać bardzo złożone obliczenia. Tak samo jest ze sztucznymi sieciami neuronowymi. Neurony mogą tworzyć warstwy, mogą tworzyć sieć połączeń, mogą nawet tworzyć sprzężenia zwrotne. Sieci ze sprzężeniami są rzadziej wykorzystywane, dlatego nimi zajmował się nie będę. Zaprezentuję natomiast sieć nazywaną wielowarstwowym perceptronem. Przykład prostej sieci przedstawia rysunek 5.5. Jest to sieć warstwowa, jak sama nazwa mówi. Wyróżnia się w niej trzy warstwy. Warstwę wejściową, która nie bierze udziału w procesie nauki. Pełni rolę medium propagującego sygnał. Każdy neuron posiada jedno wejście o wadze równej 1 i jednostkowej funkcji aktywacji. Kolejna warstwa
36 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu 34 Rysunek 5.4: Przebieg funkcji sigmoidalnej na przedziale [ 5; 5] nosi nazwę ukrytej. Każdy neuron ma zestaw wag o odpowiednim rozmiarze, równym ilości sygnałów pochodzących z warstwy wejściowej. To tutaj dzieje się cała magia. Warstwa ukryta wykonuje większą część pracy przygotowując sygnały do interpretacji dla warstwy wyjściowej, która zwraca wyniki. Ilość neuronów w warstwie ukrytej jest bardzo istotna dla przetwarzania. Zbyt mała ich ilość powoduje duże błędy. Sieć nie jest w stanie odnaleźć odpowiedniego odwzorowania dla danych. Z kolei zbyt duża ilość neuronów w warstwie ukrytej sprawia, że sieć uczy się odwzorowania na pamięć i traci swoje zdolności uogólniające. Wielowarstwowy perceptron jest siecią jednokierunkową, bez sprzężeń. Jest też siecią pełną. Oznacza to, że każdy neuron z warstwy jest połączony tylko ze wszystkimi neuronami z warstwy następnej i nie jest połączony z żadnym neuronem ze swojej warstwy. Należy wspomnieć, że w perceptronie stosuje się dodatkowo jedno wejście więcej. Nazywa się je wejściem obciążającym (bias). Posiada ono na stałe sygnał jednostkowy, natomiast waga tego wejścia jest poddawana adaptacji, tak samo jak inne. Istnienie wejścia obciążającego dodaje neuronowi pewnej elastyczności. Jest on w stanie przesuwać dziedzinę dla funkcji aktywacji, co może sprawić, że nawet dla sygnału zerowego wartość będzie niezerowa. Doświadczenie pokazuje, że neurony z wejściem obciążającym uczą się znacznie szybciej. Wielowarstwowy perceptron wykorzystuje metodę uczenia z nadzorem, która wymaga dużego zbioru przykładów. Pojedynczy przykład zawiera wartość wejściową oraz wartość oczekiwaną. Mogą to być wektory. Wszystko zależy od zadania, jakie sieć rozwiązuje. Istniej wiele metod nauki wielowarstwowego perceptronu. Najbardziej popularną jest metoda wstecznej propagacji. W metodzie wstecznej propagacji każdy przykład jest prezentowany sieci. Obliczana jest dla niego wartość wyjściowa sieci i porównywana z wartością oczekiwaną zawartą w przykładzie. Na tej podstawie obliczany jest błąd sieci. Błąd jest sumą kwadratów błędów dla każdego prezentowanego przykładu (wzór pojawi się w szczegółowym opisie algorytmu).błąd ten jest następnie propagowany do wszystkich neuronów w niższych warstwach i w oparciu o jego wartość przeprowadzana jest adaptacja wag. Cały problem sprowadza się zatem do znalezienia zbioru wag, który będzie minimalizował wspomniany błąd sieci. Zbieżność algorytmu można przyspieszyć poprzez zwiększenie kroku iteracji, oznaczmy go jako ν, jednak zbyt duża jego wartość może spowodować rozbieżność algorytmu. Nawiązując do anegdoty z kangurem. Będzie on wykonywał zbyt duże skoki, i zawsze przeskoczy docelowe miejsce. Innym sposobem na poprawienie zbieżności algorytmu jest wprowadzenie współczynnika momentum µ, który nadaje procesowi uczenia pewną bezwładność - uzależnia
37 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu 35 Rysunek 5.5: Wielowarstwowy perceptron - przykładowa sieć zmianę wag od poprzednich przyrostów wag. Poniżej zamieszczony został szczegółowy algorytm wstecznej propagacji błędów. ZAŁOŻENIA WSTEPNE: przez L oznaczmy ilość warstw naszej sieci przez N ( j) oznaczmy ilość neuronów w j-tej warstwie, j = 1,2,..,L przez y k oznaczmy wyjście k-tego neuronu aktualnej warstwy przez w i,k oznaczmy wagę i-tego wejścia k-tego neuronu N( j 1) przez S i oznaczmy sumę ważoną wejść neuronu, czyli i=1 y i w i (gdzie y i oznacza wartość wyjścia i-tego neuronu poprzedniej warstwy, a N ( j 1) oznacza ilość wejść neurony, czyli ilość neuronów poprzedniej warstwy (jeśli neuron posiada wejście obciążające, to ilość jego wejść równa się N ( j 1) + 1) wzorzec trenujący to para wektorów, z których pierwszy (E) podawany jest na wejście sieci, a drugi (C) przedstawia poprawne wartości wyjściowe, jakich oczekujemy od sieci - uzyskiwanych tych wartości będziemy uczyć sieć zbiór trenujący to zbiór wszystkich wzorców, które przedstawiamy sieci w procesie uczenia za kryterium stopu przyjmujemy uzyskanie przez sieć błędu mniejszego niż zadana wartość (np. 0,0001). Na ogół podaje się dodatkowe kryterium stopu w postaci ograniczenia liczby iteracji. błąd sieci obliczany jest następująco: Q = 1 2 G g=1 N(k) k=1 ( yk,g C k,g ) 2,gdzie Ck,g -oznacza oczekiwaną wartość k-tego wyjścia neuronu, G - oznacza ilość prezentowanych przykładów uczących, a g- oznacza prezentację danego wzorca trenującego KROKI ALGORYTMU: 1. Należy wybrać wartość ν > 0 (najlepiej, aby ν < 1) zwaną krokiem iteracji (nauki) 2. Należy wybrać wartość µ > 0 (najlepiej, aby µ < 1) zwaną momentum 3. Sprawdź kryterium stopu. Jeśli spełnione, zakończ naukę
38 5.1 Sieci neuronowe na przykładzie wielowarstwowego perceptronu Podaj kolejny wzorzec trenujący (para: wektor wejściowy i wektor oczekiwanych wartości wyjściowych) 5. Propagacja wprzód: dla każdego neurony sieci należy wyznaczyć sumę ważoną jego wejść S i oraz wyznaczyć wartość jego funkcji aktywacji y = f (S i ) ( wartość wyjściową tego neuronu). Oczywiście faza ta przebiega od pierwszej warstwy ( często jest to warstwa wejściowa), poprzez kolejne warstwy ukryte, aż do warstwy ostatniej - wyjściowej. 6. Propagacja wstecz: tę fazę wykonujemy w odwrotnej kolejności, czyli zaczynami od warstwy ostatniej (wyjściowej) i poruszamy się ku pierwszej warstwie ( jeśli sieć posada warstwę wejściową, to ta warstwa nie podlega uczeniu). Faza przebiega następująco: (a) Dla każdego neuronu warstwy wyjściowej należy obliczyć współczynnik δ k = (C k y k ) f (S i ), który związany jest z błędem, z jakim dane wyjście odpowiedziało na dane wejściowe (b) Dla każdego neuronu każdej warstwy niższej niż ostatnia (oprócz warstwy wejściowej, która nie N( j+1) ( ) podlega uczeniu) należy obliczyć współczynnik δ k = r=1 δr w k,r f (S i ), gdzie r iteruje po neuronach warstwy o jeden wyższej, a w k,r to waga k-tego wejścia r-tego neurony wyższej warstwy (k-te wejście jest połączone w wyjście k-tego neuronu aktualnej warstwy. (c) Każdemu neuronowi każdej warstwy (oprócz warstwy wejściowej) należy uaktualni wagi jego wejśc. Wykonuje się to za pomocą formuły: w i,k = w i,k + ν δ k y i + µ i,k, gdzie w i,k - nowa waga i-tego wejścia k-tego neurony aktualnej warstwy, y i - to wyjście i-tego neuronu warstwy o jeden niższej i,k - to wartość poprzedniego przyrostu wagi i-tego wejścia k-tego neurony. Wartość ta równa jest różnicy wartości w i,k i wartości tej wagi z poprzedniej iteracji (czyli zanim nadaliśmy tej wadze wartość w i,k ) 7. Jeśli zaprezentowano wszystkie wzorce (zakończono daną iterację), to przetasuj wzorce, aby kolejność prezentowania w kolejnej epoce była inna i idź do punktu 3. Jeśli nie wszystkie wzorce zostały jeszcze zaprezentowane, idź do punktu 4. Na podstawie własnego doświadczenia z sieciami neuronowymi mogę powiedzieć, że bez istnienia wejścia obciążającego sieć neuronowa uczy się bardzo opornie. Potrzebuje bardzo dużo epok lub nie jest w stanie się nauczyć. Wejście obciążające dba o to, aby wartość funkcji aktywacji nie była zerowa w momencie, kiedy na wszystkie inne wejścia neuronu podana jest wartość 0. Można to rozumieć także jako przesunięcie układu współrzędnych charakterystyki funkcji aktywacji w lewą lub w prawą stronę w zależności od wagi wejścia obciążającego. Powoduje to przesunięcie progu pobudzenia w stronę mniejszych lub większych wartości. Daje to sieci większe możliwości adaptacji, ponieważ np. dla mniejszych wartości wag może otrzymać taką samą wartość na wyjściu. Mogę również z powodzeniem stwierdzić, że wartości ν oraz µ mają decydujący wpływ na szybkość adaptacji sieci. Proces nauki sieci polega na dostosowywaniu wag do odpowiednich sygnałów na wejściach. Osiągane jest to poprzez odpowiednie zmiany wag uzależnione od błędu. Metoda określania błędu dla danego neuronu przypomina metodę najszybszego spadku. W tej metodzie musimy wiedzieć, w którym kierunku poruszać się, aby znaleźć optimum (tak dobrać wagi, aby błąd był jak najmniejszy), ale oprócz tego tak dobrać długość skoku w wybranym kierunku, aby zmiany nie były zbyt silne (wartość błędu się zmniejszała a nie zwiększała żeby nie przeskoczyć optimum). Wybranie współczynnika za małego prowadzi do bardzo powolnego procesu uczenia się (wagi są poprawiane w każdym kroku o bardzo niewielką wartość, więc trzeba wykonać dużo takich kroków). Z kolei zbyt duży współczynnik powoduje zbyt gwałtowne zmiany wag, co może prowadzić zaburzenia stabilności procesu uczenia (sieć miota się wkoło optimum, nie mogąc znaleźć odpowiednich wag). Proces nauki można zoptymalizować dodając człon momentum, który powoduje, że zmiany wag nie zależą tylko od wartości skoku w danym momencie, ale także od błędów popełnianych przez sieć w poprzednich iteracjach (epokach). Pozytywnym skutkiem tej sytuacji jest to, że szybciej dążymy do optimum, rzadziej zmieniając wagi, a proces uczenia jest spokojniejszy (wagi nie zmieniają się zbyt gwałtownie).

39 Rysunek 5.6: Diagram blokowy dla algorytmu wstecznej propagacji błędu jako metody nauki wielowarstwowego perceptrony
40 5.2 Klasyfikator Bayesa 38 Wady i zalety Niewątpliwą zaletą wielowarstwowego perceptronu jako klasyfikatora jest prostota. Jest on zbudowany z pojedynczych neuronów wykonujących proste obliczenia, które dopiero w skali makro nabierają sensu. Bardzo ciekawe jest to, że neuron nie wie czemu dokładnie służy obliczona przez niego wartość. Pozwala to na rozdzielenie odpowiedzialności i przeniesienie jej do wyższych warstw abstrakcji tworząc koordynatorów zarządzających procesem uczenia.umożliwia to bardzo łatwe zrównoleglenie, choćby przez rozproszenie neuronów po wielu procesorach w klastrach obliczeniowych. Daje to olbrzymi zysk wydajnościowy, którego nie da się przecenić, a w dodatku coraz bardziej przypomina działanie biologicznego mózgu. Cały proces nauki sprowadza się do znalezienia takiego zbioru wag dla neuronów, które minimalizują błąd. Można więc zapamiętać cały zestaw wag neuronów, co pozwoli na wykorzystanie sieci w przyszłości bez konieczności jej ponownego trenowania. Niestety sieci neuronowe mają także swoje wady. Jedną z nich jest trudność w budowaniu struktury połączeń oraz znajdowaniu odpowiedniej ilości neuronów tworzących sieć. Do każdego zadania trzeba podejść indywidualnie i metodą prób i błędów spróbować znaleźć strukturę, która daje najlepsze wyniki. Można w tym celu skorzystać z zaawansowanych metod poszukiwania rozwiązań takich jak algorytmy genetyczne i im zlecić odnalezienie optymalnej struktury sieci. Jest to jednak dodatkowa trudność. Aby sieć zdobyła dobrą zdolność uogólniania należy przedstawić jej duży zbiór przykładów. Może być on na tyle duży, że czas nauki będzie bardzo długi. Bardzo ważne jest również określenie poprawnego zbioru przykładów, takiego, który będzie rozważał najróżniejsze przypadki z całej przestrzeni możliwych rozwiązań. Nie tylko sytuacje najbardziej popularne, ale również te skrajne. Proces nauki opera się na losowej inicjalizacji wektorów wagowych wszystkich neuronów. Skutkiem tego jest różne zachowanie się sieci neuronowej w kolejnych uruchomieniach. Aby stwierdzić, że wyniki są poprawne należy przeprowadzić kilkakrotnie proces nauki. 5.2 Klasyfikator Bayesa W książce Pawła Cichosza[4] można przeczytać, że matematyczna teoria prawdopodobieństwa miała swoje początki już w XVI wieku, co stawia metody statystyczna na szczycie drzewa genealogicznego metod uczenia się. Pomimo tego, że ten dział nauki nie był w pełni sformalizowany, jednak metody i narzędzia jakie wprowadzał były stosowane w praktyce z dużym powodzeniem. Prawdopodobieństwo bardzo przydaje się w systemach uczących. Pozwala bowiem na interpretowanie pewnych regularności w zaobserwowanych sytuacjach, które zdarzają się codziennie, od rzucania kostkami do gry, po zjawiska zmiany pogody. Jest aparatem, który służy w pewien sposób do oceny naszej wiedzy na temat pewnych zjawisk. Paweł Cichosz w swojej książce [4] opisuje to zagadnienie bardzo dokładnie, ale zarazem tak aby czytelnik nie musiał brać głębokiego wdechu przed kolejnym rozdziałem. Powoli odkrywa przed czytelnikiem nowe możliwości jakie oferują metody probabilistyczne i nie wymaga dogłębnej znajomości statystyki, dlatego na tej książce będę opierał swoje przemyślenia Twierdzenie Bayesa W większości mechanizmów wnioskowania systemów uczących się w oparciu o metody probabilistyczne u podstaw leży twierdzenie wielebnego Thomasa Bayesa. Zostało on opublikowane dopiero po jego śmierci w 1763 roku. Traktuje ono o idei żonglowania prawdopodobieństwami warunkowymi, czyli prawdopodobieństwami zajścia pewnych zdarzeń pod warunkiem spełnienia pewnych założeń (źródłem definicji jest [5]). Definicja 1. Niech A i B będa dowolnymi zdarzeniami, A zawiera się w S i B zawiera się w S (S - zbiór zdarzeń elementarnych), przy czym prawdopodobieństwo zdarzenia A jest dodatnie, P(A) > 0. Prawdopodobieństwo warunkowe zdarzenia B pod warunkiem zajścia zdarzenia A jest dane wzorem P(B A) = P(A B) P(A). Dodatkowo prawdopodobieństwo P(B A) spełnia dwa następujace postulaty:
41 5.2 Klasyfikator Bayesa 39 P(A A) = 1 P(B A) = P(A B A) Stosowanie prawdopodobieństwa warunkowego pozwala na obliczenia interesujących prawdopodobieństw, co jest chwytem nie do przecenienia. Aby dobrze zrozumieć ideę reguły Bayesa, bo tak często nazywa się to twierdzenie, chciałbym opisać na początku pewne wielkości, które w matematycznym zapisie występują. Podstawowymi założeniami są istnienie zbioru danych oznaczonego symbolem D oraz istnienie prawdopodobieństwa zaobserwowania tych danych P(D). Dodatkowa wiedza na temat tych założeń jest na tym etapie zbędna. Oprócz zbioru danych zakładamy także istnienie pewnej hipotezy h (funkcji, przypisującej przykłady do pojęcia lub klasy, zgodnie z [6] najlepsza hipoteza jest rozumiana jako najbardziej prawdopodobna po zaobserwowaniu danych D), która należy do zbioru (przestrzeni) hipotez H. Przede wszystkim należy przyjąć, że dla każdej hipotezy h Histnieje pewne prawdopodobieństwo P(h), które nie zależało od innych wartości, obserwacji, mogących mieć wpływ na jego wartość. Gdyby prawdopodobieństwo P(h) byłoby zależne od jakichś danych ze zbioru D, to mielibyśmy do czynienia z prawdopodobieństwem warunkowym P(h D). Zgodnie z obranymi przez mnie oznaczeniami twierdzenie Bayesa będzie miało następującą postać. Twierdzenie 1. BAYESA Dla dowolnej hipotezy oraz zbioru danych D zachodzi równość: P(h D) = P(h) P(D h). (5.2) P(D) Wzór określa zależność, pomiędzy prawdopodobieństwami a priori 1 i a posteriori 2.W podanym wzorze występuje prawdopodobieństwo, o którym wcześniej nie wspomniałem, a które wymagają omówienia. Prawdopodobieństwo warunkowe P(D h) jest prawdopodobieństwem zaobserwowania danych D przy założeniu istnienia poprawnej hipotezy h. Przyjmę, że dla dowolnej, istniejącej i poprawnej hipotezy h możliwe jest policzenie prawdopodobieństwa P(D h). W klasyfikacji Bayesa wystarczające jest wyznaczenie względnego prawdopodobieństwa warunkowego P(h D), ponieważ porównywane będą hipotezy względem siebie, a wszystkie będą zależały od tych samych danych. Oznacza to, że zależność od prawdopodobieństwa P(D) nie jest wcale brana pod uwagę, a w obliczeniach liczy się tylko licznik ułamka wzoru 5.2. Z tego powodu pominę wyjaśnianie wyznaczania mianownika, porównywanie hipotez, będzie się opierało na porównywaniu iloczynów P(h) P(D h) Klasyfikacja bayesowska W poprzednim podpunkcie zakładałem istnienie pewnej hipotezy h, jednak teraz muszę trochę uściślić jej postać. Hipotezy h będą funkcjami, które odwzorowują przykłady w oparciu o atrybuty na pewne kategorie, zwane także grupami. Jak wspomniałem przy okazji wprowadzenia do klasyfikatorów z nadzorem, niezbędny do uczenia się jest zbiór danych trenujących, który może występować w różnych postaciach. W przypadku właśnie omawianej klasyfikacji niech to będzie zbiór T, składający się z etykietowanych przykładów, czyli takich pojęć c, które odwzorowują przykłady z dziedziny X w zbiór pojęć(kategorii) C. W formalnym zapisie zbiór T będzie się składał z c : X C oraz zestawu atrybutów opisujących cechy przykładów(np. biorąc pod uwagę samochody, atrybutami będą: cena, pojemność silnika, prędkość maksymalna itd.). Klasyfikacja bayesowska w swojej idei zakłada wybór jednej, najlepszej hipotezy ze zbioru hipotez H. Jak od razu można się domyślić, będzie to najlepsza hipoteza dla zbioru danych trenujących T (potwierdza 1 Termin pochodzący z języka łacińskiego. Znaczy tyle co: "z góry", "uprzedzając fakty". Służy jako określenie tego, co pierwotne, uprzednie lub wcześniejsze i nie wymagające dowodzenia. Określenie prawdopodobieństwa a priori w stosunku do prawdopodobieństwa, rozumie się jako prawdopodobieństwo, przy wyznaczaniu którego nie były uwzględniane żadne dodatkowe warunki. 2 Termin pochodzący z języka łacińskiego. Jest określeniem przeciwnym dla a priori i oznaczający tyle, co: "po fakcie" tudzież "w następstwie faktu". Określenie prawdopodobieństwa a posteriori rozumie się jako prawdopodobieństwo warunkowe, wymagające uwzględnienia pewnych warunków.
42 5.2 Klasyfikator Bayesa 40 to również [6]). Cichosz w [4] podaje dwa standardowe sposoby precyzowania 3, warunków, które muszą spełniać hipotezy, aby były uznane za najlepsze: zasada maksymalnej zgodności, nazywana krótko ML 4. Wybieramy hipotezę h ML H, która maksymalizuje warunkowe prawdopodobieństwo danych trenujących, czyli: h ML = arg max h H P(T h), (5.3) zasada maksymalnego prawdopodobieństwa a posteriori, nazywana krótko MAP 5. Wybieramy hipotezę h MAP H o maksymalnym prawdopodobieństwie a posteriori, czyli: h MAP = arg max h H P(h T ). (5.4) Analizując obydwa podane przeze mnie wyżej wzory można zauważyć, że tylko wzór 5.4 jest warunkiem bayesowskim dla określania hipotezy, ponieważ wymaga wyznaczenia prawdopodobieństw a posteriori dla wszystkich hipotez i wyboru tej, dla której jest ono największe. Pierwsze podejście nie wykorzystuje wcale twierdzenia 1. Podejście drugie uznawane jest jako bardziej naturalne, jednak wymaga podania prawdopodobieństw a priori dla wszystkich hipotez h, co przy założeniu, że zbiór wszystkich hipotez ma skończoną, ale bardzo dużą liczność, może być sporym problemem. Wtedy podejście pierwsze jest dobrą alternatywą. Zgodnie z tym co napisałem przy okazji wyjaśniania twierdzenia 1 stosując metodę MAP nie ma konieczności liczenia prawdopodobieństwa P(h T ) i tym samym określenia P(T ) (mianownika wzoru 5.2). Wystarczy porównać tylko iloczyny P(h) P(T h) dla każdego h. Algorytm który wykorzystuje metodę MAP do określania najlepszej hipotezy dla zbioru trenującego nazywa się bezpośrednim algorytmem MAP. Pozbywając się kłopotów z określaniem prawdopodobieństwa P(T ) pozostaje tylko jedna niejasność. W jaki sposób wyznacza się prawdopodobieństwo P(T h). Słownie można by powiedzieć, że to prawdopodobieństwo określa jak bardzo prawdopodobne jest, aby przykłady pochodzące ze zbioru T miały takie etykiety kategorii (do których zostały przyporządkowane), jakie występują w podanym do nauki zbiorze T. Jeśli systemowi uczącemu się został podany poprawny zbiór trenujący T (występujące w nim etykiety przykładów, są etykietami kategorii, jakie przyporządkowuje pojęcie c, zdefiniowane na początku tego rozdziału), to jeśli hipoteza h przyporządkowuje przykładom ze zbioru T takie same etykiety, jakie występują w definicji zbioru trenującego 6 T, to jego prawdopodobieństwo warunkowe wynosi 1. Jeśli hipoteza h przypisuje chociaż jednemu przykładowi ze zbioru T etykietę nie występującą w zbiorze T, to takie prawdopodobieństwo równe jest 0. W opisywanym podrozdziale znalazło się wiele wzorów i oznaczeń, które ciężko zapamiętać, a które póki co nie dają wiele wymiernych zysków. Są jednak wymagane do opisu ciekawszych zagadnień. W kolejnych dwóch częściach podrozdziału, w końcu będę mógł zostawić za sobą czysto teoretyczne zagadnienia i opisać to co najciekawsze i najistotniejsze w klasyfikacji Bayesa, czyli dwa znane algorytmy klasyfikacji Optymalny klasyfikator Bayesa Optymalny klasyfikator Bayesa (BOC 7 ) określa najbardziej prawdopodobną kategorię dla przykładu x X jako kategorię, do której zaliczają ten przykład wszystkie hipotezy. Oczywiście taki scenariusz raczej nie jest możliwy, a jeśli jest, to zdarza się rzadko, dlatego kategorią najbardziej prawdopodobną jest ta, dla której suma prawdopodobieństw jest największa (innymi słowy, ta która najbardziej pasuje). Formalny zapis, tego co właśnie opisałem w języku zrozumiałym dla 90% ludzkiej populacji, wygląda następująco (opis formalny zaczerpnięty z książki [4]): 3 W książce [?] panów Krawca i Stefanowskiego można przeczytać tylko na temat zasady maksymalnego prawdopodobieństwa a posteriori. Wskazują oni na tą zasadę jako zalecaną do większości problemów. 4 Skrót pochodzi od angielskiego terminu Maximum Likelihood 5 Skrót pochodzi od angielskiego terminu Maximum a Posteriori 6 Ze względu na jasność oznaczeń określam w tekście zbiór przykładów symbolem T, jednak pełna definicja zbioru T obejmuje towarzyszące przykładom etykiety c, oraz zestaw atrybutów A opisujących cechy danego przykładu. 7 Skrót od angielskiego terminu Bayes Optimal Classifier
43 5.2 Klasyfikator Bayesa 41 Prawdopodobieństwo tego, że pewien dowolny przykład x X należy do kategorii d C pojęcia docelowego c : X C, szacowane na podstawie zbioru T etykietowanych przykładów tego pojęcia, możemy wyrazić w następujący sposób: P(c(x) = d T ) = P(c(x) = d h) P(h T ) (5.5) h H przy czym dla każdej hipotezy h H 1 jeśli h(x) = d P(c(x) = d h) = 0 w przeciwnym przypadku Algorytm zalicza przykład x X do kategorii arg max d C P(c(x) = d T ). Optymalny klasyfikator Bayesa zawdzięcza swoją nazwę temu, że maksymalizuje prawdopodobieństwo poprawnej klasyfikacji, co w domyśle oznacza, że minimalizuje prawdopodobieństwo popełnienia błędu. Nie ma takiego drugiego algorytmu klasyfikacji, który na tym samym zbiorze hipotez i tych samych danych trenujących dokonałby przypisania lepszej hipotezy. Niestety algorytm ma swoje wady, co sprawia, że tak samo jak bezpośredni algorytm MAP nie jest algorytmem charakteryzującym się częstym stosowaniem w klasyfikacji obiektów. Podstawowymi dwiema zaporami, które powstrzymują przed stosowaniem tych algorytmów są: konieczność określenia prawdopodobieństw a priori, czyli P(h) trzeba brać pod uwagę wszystkie hipotezy, przynajmniej na etapie uczenia się Te dwa ograniczenia nakładane na metody sprawiają, że nie można ich stosować w problemach, gdzie liczba hipotez jest bardzo duża, ponieważ koszty obliczeniowe wynikające z liczenia prawdopodobieństwa warunkowego dla wszystkich hipotez byłyby ogromne i nieopłacalne. Nie oznacza to, że algorytmy nie znajdują żadnego zastosowania. Bardzo dobrze sprawdzają się w problemach, które wymagają bardzo dokładnej klasyfikacji, a które dzięki zastosowaniu innych metod uczących zyskały znacznie zredukowaną ilość hipotez Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa(NBC 8 ) pozwala na stosowanie w większości przypadków. Nie posiada takich ograniczeń, jak opisywany przeze mnie algorytm BOC. Brak jakichkolwiek ograniczeń dotyczący zbioru hipotez bierze się z tego, że w tym algorytmie taki zbiór hipotez nie jest wcale rozważany. Algorytm ten klasyfikuje przykłady do odpowiednich kategorii za pomocą oszacowań pewnych prawdopodobieństw wyznaczanych w oparciu o zbiór uczący T. Skoro algorytm nie wykorzystuje przestrzeni hipotez, do działania, tylko oszacowań, to bardzo dobrze byłoby wiedzieć jak te oszacowania otrzymać. Czasami aby zrobić krok w przód, trzeba najpierw wrócić do miejsca, z którego się wystartowało. Nie inaczej jest w tym przypadku. Aby zrozumieć zasadę wyznaczania oszacowań, o których jest teraz mowa trzeba sobie przypomnieć budowę pojedynczego przykładu uczącego (próby uczącej). Wektor wejściowy jest reprezentowany przez zestaw pewnych atrybutów, a wektor wyjściowy przez przypisaną do wektora wejściowego etykietę pojęciową wskazującą na daną kategorię. Niestety większość metod liczenia czegokolwiek wymaga formalnego zapisu, który niekiedy jest niezrozumiały dla normalnego człowieka, nie inaczej jest w tym przypadku. Istnieje jednak proste wytłumaczenie sposobu otrzymania oszacowań, które są potrzebne do zastosowania omawianej metody, które będę chciał właśnie zaprezentować. Pomijając formalności, całe zadanie można określić następująco: 8 Skrót angielskiego terminu Naive Bayes Classifier
44 5.2 Klasyfikator Bayesa 42 dla wszystkich kategorii liczymy ile jest w zbiorze uczącym przykładów poszczególnych kategorii, a następnie uzyskane wyniki dzielimy przez liczbę wszystkich przykładów zbioru uczącego. Na potrzeby przykładu, który będę chciał później zaprezentować, zapiszę postać matematyczną, jaką przedstawił w swojej książce [4] Paweł Cichosz: P(c(x) = d) = T d T (5.6) dla wszystkich kategorii i wartości wszystkich atrybutów liczymy ile jest przykładów każdej kategorii o pewnych wartościach atrybutów, a następnie dzielimy uzyskane wyniki przez liczbę wszystkich przykładów zbioru uczącego. Jak wyżej matematyczna reprezentacja: P(a i (x) = v c(x) = d) = T d a i =v T d, gdzie a i (x) jest i-tym atrybutem przykładu x (5.7) Stosując takie podejście napotykamy jednak na problem w momencie gdy, w którejś z grup (kategorii) nie ma żadnego przykładu. Każdy zauważy, że wtedy licznik ułamków jest równy 0 i automatycznie prawdopodobieństwo jest równe 0. Taki obrót spraw pozwala wysnuć jeden niepodważalny wniosek. Mianowicie fakt, że nie występuje w danej kategorii przykład z pewnymi atrybutami pozwala przypuszczać, że nie istnieje on w całej dziedzinie przykładów. Takie radykalne posunięcie może niekiedy powodować pewne komplikacje, dlatego trzeba dokonać pewnych modyfikacji oszacowań. Najprostszym i skutecznym rozwiązaniem w przypadku pojawienia się omawianego zera jest przyjęcie za wynik pewnej małej liczby. Oznaczmy ją symbolem ε. Pytanie jakie trzeba sobie w tym momencie zadać brzmi: Jak mała ma być ta liczba. Nie jest to trywialne pytanie. Jest to wartość oszacowania, która ma wpływ na obliczenia i klasyfikację. Najrozsądniej byłoby przyjąć wartość ε < 1, ponieważ gdyby wartość była większa od T d rozpatrywanej, to znaczyłoby, że oszacowanie ma wartość taką, jakby w zbiorze trenującym znajdował się jeden przykład spełniający wymienione we wzorach 5.6 lub 5.7 wymagania. Najbezpieczniejszym i najmniej kosztownym posunięciem będzie zastosowanie pewnej heurystyki, np. przyjąć, że wartość ε = 1 2 T d lub ε = 1. Mamy wtedy zapewnienie, że przekłamanie nam się nie wkradnie. W ogólnym rozumieniu 3 T d algorytm jest również przedstawiony za pomocą diagramu blokowego na rysunku Klasyfikowanie przykładów Wiemy już jak dokonać oszacowań reprezentujących pewną hipotezę. Pora wprowadzić wiedzę w życie. Wspomniałem, ze klasyfikator NBC wybiera kategorię najbardziej prawdopodobną, ale najbardziej prawdopodobną dla pewnego przykładu o zadanych wartościach atrybutów. Chciałbym dla dobrego zrozumienia przytoczyć definicje hipotezy h podaną przez Pawła Cichosza w [4]: h(x ) = arg max d C P x (c(x) = d a 1 (x) = a 1 (x ) a 2 (x) = a 2 (x )... a n (x) = a n (x )), oznacza wybór przykładu x kategorii najbardziej prawdopodobnej dla dowolnego przykładu x z dziedziny X, który jest opisany przez wektor wartości atrybutów : < a 1 (x ),a 2 (x ),...,a n (x ) >. Otrzymane prawdopodobieństwo można korzystając z reguły Bayesa, przekształcić (pamiętając, ze do porównywania hipotez wystarczy znajomość licznika wzoru 5.2) oraz zakładając, że wartości poszczególnych atrybutów są względem kategorii niezależne, otrzymać końcowy wzór na hipotezę reprezentowaną przez

45 Rysunek 5.7: Diagram blokowy dla algorytmu Naiwnej Klasyfikatora Bayesa
46 5.2 Klasyfikator Bayesa 44 rozkłady prawdopodobieństw: h(x ) = arg max d C P x (c(x) = d) n i=1 P x (a i (x) = a i (x ) c(x) = d) (5.8) Jeśli podczas klasyfikacji przykładu natrafimy na brakującą wartość atrybuty, to spokojnie możemy przyjąć, że P x (a i (x) = a i (x ) c(x) = d) = 1, co w przypadku mnożenia będzie neutralnym posunięciem, ponieważ nie wpłynie na wynik. W tym momencie przyda nam się założenie które poczyniliśmy w stosunku do oszacowań w poprzednim punkcie. W sytuacji, gdy dla pewnej kategorii d i pewnej wartości v k atrybuty a k przyjmiemy wartość P x (a i (x) = a i (x ) c(x) = d) = 0, to automatycznie uzyskamy 0 dla prawdopodobieństw biorących pod uwagę inne wartości atrybutów. Wniosek jest taki, że jeśli w zbiorze trenującym T nie pojawi się przykład x z kategorii d, to każdy inny przykład x będzie miał prawdopodobieństwo zaliczenia go do kategorii d równą 0, co nie powinno się stać Przykład zastosowania NBC Chciałbym na koniec omawiania klasyfikatorów Bayesa zademonstrować przykład, w którym pokażę, jak zastosować naiwny klasyfikator bayesowski do zbioru trenującego z dziedziny samochodów. Elementami tej dziedziny są dostępne na rynku modele samochodów. Niech każdy z samochodów będzie opisany przez następujące atrybuty: klasa: o wartościach miejski, duży, mały, kompakt cena: o wartościach niska, umiarkowana, wysoka osiągi: o wartościach słabe, przeciętne, dobre niezawodność: o wartościach mała, przeciętna, duża Dane tego przykładu przedstawia tablica 5.1. x klasa cena osiagi niezawodność c(x) 1 miejski niska słabe mała 1 2 duży niska słabe mała 1 3 kompakt niska dobre przeciętna 1 4 mały niska przeciętne mała 1 5 mały umiarkowana przeciętne przeciętna 1 6 kompakt umiarkowana przeciętne przeciętna 1 7 miejski umiarkowana przeciętne przeciętna 0 8 mały umiarkowana dobre duża 0 9 kompakt wysoka dobre duża 0 10 duży wysoka przeciętne przeciętna 0 11 duży wysoka dobre duża 0 Tablica 5.1: Przedstawia zbiór trenujacy dla pojęcia docelowego c, które może być interpretowane jako popularny model samochodu. Dane znajdujace się w tabeli pochodza ze zbioru tabel przykładowych do ćwiczeń, z ksiażki Pawła Cichosza[4]. Oszacowania prawdopodobieństw będę wykonywał za pomocą wzorów 5.6 oraz 5.7, a w sytuacji, gdy w którejś z kategorii, dla danego atrybutu nie będzie przykładu, zastosuję wspomnianą wcześniej heurystykę i przybliżę brakujące prawdopodobieństwo wartością ε = 1 2 T = P x (c(x) = 1) = 6 11 P x (klasa(x) = mie jski c(x) = 1) = 1 6 P x (klasa(x) = mie jski c(x) = 0) = 1 5
47 5.2 Klasyfikator Bayesa 45 P x (klasa(x) = duzy c(x) = 1) = 1 6 P x (klasa(x) = duzy c(x) = 0) = 2 5 P x (klasa(x) = kompakt c(x) = 1) = 2 6 P x (klasa(x) = kompakt c(x) = 0) = 1 5 P x (klasa(x) = maly c(x) = 1) = 2 6 P x (klasa(x) = maly c(x) = 0) = 1 5 P x (cena(x) = niska c(x) = 1) = 4 6 P x (cena(x) = niska c(x) = 0) = 1 22 P x (cena(x) = umiarkowana c(x) = 1) = 2 6 P x (cena(x) = umiarkowana c(x) = 0) = 2 5 P x (cena(x) = wysoka c(x) = 1) = 1 22 P x (cena(x) = wysoka c(x) = 0) = 3 5 P x (osiagi(x) = slabe c(x) = 1) = 2 6 P x (osiagi(x) = slabe c(x) = 0) = 1 22 P x (osiagi(x) = przecietne c(x) = 1) = 3 6 P x (osiagi(x) = przecietne c(x) = 0) = 1 5 P x (osiagi(x) = dobre c(x) = 1) = 1 6 P x (osiagi(x) = dobre c(x) = 0) = 3 5 P x (niezawodnosc(x) = mala c(x) = 1) = 2 6 P x (niezawodnosc(x) = mala c(x) = 0) = 1 22 P x (niezawodnosc(x) = przecietna c(x) = 1) = 2 6 P x (niezawodnosc(x) = przecietna c(x) = 0) = 1 5 P x (niezawodnosc(x) = duza c(x) = 1) = 1 22 P x (niezawodnosc(x) = duza c(x) = 0) = 3 5 Otrzymany zestaw wartości poszczególnych prawdopodobieństw reprezentuje hipotezę h, jakiej nauczył się naiwny klasyfikator bayesowski na podstawie zbioru trenującego. Można ją wykorzystać do klasyfikowania przykładów trenujących ze zbioru T. Dla przykładu pierwszego, tzn. x = 1 mamy następujące wartości atrybutów: klasa(1) = miejski cena(1) = niska osiągi(1) = słabe niezawodność(1)=mała Na podstawie powyższych wartości dla poszczególnych atrybutów oraz dla kategorii c(x)=1 oraz c(x)=0 obliczamy iloczyny prawdopodobieństw, których porównanie zgodnie z równaniem 5.8 będzie podstawą klasyfikacji przykładu 1: P x (c(x) = 1) P x (klasa(x) = mie jski c(x) = 1) P x (cena(x) = niska c(x) = 1) P x (osiagi(x) = slabe c(x) = 1) P x (niezawodnosc(1) = mala c(x) = 1) = = = 1089 = P x (c(x) = 0) P x (klasa(x) = mie jski c(x) = 0) P x (cena(x) = niska c(x) = 0) P x (osiagi(x) = slabe c(x) = 0) P x (niezawodnosc(1) = mala c(x) = 0) = = = =
48 5.3 Metoda k-najbliższych sasiadów 46 oznacza to, że h(1) = c(1) = 1 Wady i zalety Podsumowując klasyfikacja w oparciu o twierdzenie Bayesa daje duże możliwości. Zastosowanie optymalnego klasyfikatora pozwala na zminimalizowanie błędu kosztem wydajności, co w niektórych przypadkach jest ważne i przeważa na niekorzyść tego klasyfikatora. Z drugiej strony można posługiwać się naiwnym klasyfikatorem, który nie charakteryzuje się dużym błędem klasyfikacji, a pozwala na zastosowanie w większości problemów. Uwolniony jest od liczenia prawdopodobieństw warunkowych co pozwala osiągnąć wyższą wydajność i uwalnia klasyfikator od wad poprzednika. Do działania wykorzystywane są tylko proste operacje arytmetyczne. Jak pokazałem w przykładzie zastosowanie NBC jest bardzo proste i nie sprawia większych problemów. 5.3 Metoda k-najbliższych sasiadów Metody eksploracji danych potrafią być bardzo złożone, a ich mechanizmy trudne do zrozumienia. Podstawowe odmiany metody k-najbliższych sąsiadów wcale takie nie są. Przeciwnie, dzięki nim można osiągać bardzo dobre rezultaty klasyfikacji nie angażując dużo siły w rozumienie mechanizmu. Jest to metoda nadzorowana, która wymaga wcześniejszego przygotowania danych uczących, podobnie jak to miało miejsce przy sieci neuronowej. Klasyfikacja odbywa się w oparciu o podobieństwo analizowanego, nieznanego obiektu z elementami zbioru uczącego. Na tej podstawie podejmowana jest decyzja. Podobieństwo obiektów oceniane jest na podstawie miar odległości dwóch wektorów reprezentujących atrybuty oraz ich wartości dla obu obiektów. Algorytm do podjęcia decyzji wykorzystuję małą część całego zbioru uczącego. Jak duża jest to część określa współczynnik k. Jest to tak zwane sąsiedztwo, spośród którego wybiera się najczęstszą etykietę dla obiektu i właśnie ją przypisuje się analizowanemu obiektowi. Algorytm nazywa się leniwym. Jest tak dlatego, że nie zakłada tworzenia modelu, który w jakiś sposób przetwarza dane. Działanie algorytmu bazuje na tym, że cały zbiór uczący jest dostępny podczas klasyfikacji i na jego podstawie dokonywana jest ocena przynależności do klas. Takie rozwiązanie stawia pewne wymagania na pamięć operacyjną. Dostęp do danych uczących musi być pewny i szybki. Dla dużych zbiorów uczących jest to przeszkoda przed stosowaniem tego algorytmu. W takich sytuacjach nie mógłby on być wykorzystywany w czasie rzeczywistym. Czas przeglądania i porównywania wszystkich obiektów ze zbioru uczącego z jednym jedynym, który ma zostać zaklasyfikowany może trwać dość długo. Warto przyjrzeć się bliżej temu tajemniczemu współczynnikowi k. Najpierw jednak dokładnie przybliżę etap wybierania klasy dla analizowanego obiektu. (algorytm został również zapisany za pomocą diagrau blokowego na rysunku 5.8). Otóż obiekt porównywany jest ze wszystkimi elementami ze zbioru uczącego. Wyliczana jest wartość miary odległości. Następnie zbiera się k-elementów ze zbioru uczącego, które są najbardziej podobne do wzorca, który chcemy zaklasyfikować. Kolejnym etapem jest przeprowadzenie głosowania, które ma rozstrzygnąć jaką klasą oznaczyć wejściowy obiekt. W najprostszym wariancie głosowania obiekt zostanie przypisany do klasy, która jest reprezentowana przez największą ilość obiektów ze zbioru uczącego. Co jednak w sytuacji, gdy mamy remis. Można zdać się na los, ale można także badać położenie elementów i jako rozwiązanie wybrać ten leżący najbliżej. Współczynnik k określa jak duże sąsiedztwo będziemy brali pod uwagę podczas głosowania. Minimalną wartościąk jest 1, natomiast maksymalną jest liczność zbioru uczącego. Tak skrajne wartości nie znajdą na pewno praktycznego zastosowania. Dla wartości 1 klasyfikator będzie posiadał bardzo dużą wariancję. Może zostać przeuczony i nie będzie w stanie dobrze generalizować. Z kolei zwiększanie współczynnika k może doprowadzić do zbytniego uogólniania. W sąsiedztwie będą się mogły znaleźć obiekty, które tak naprawdę nie znajdują się wystarczająco blisko, abyśmy musieli je brać pod uwagę. Dobór odpowiedniej wartości zawsze przysparza analitykom problemów. Zależy od rozpatrywanego problemu, ilości zmiennych decyzyjnych i wielu innych czynników. Kontynuując wątek zmiennych decyzyjnych. Algorytm ma to do siebie, że nie jest w stanie brać pod uwagę tylko niektórych najbardziej istotnych danych. W sytuacjach, gdy rekordy zawierają pełną informację, poza zwiększeniem czasu obliczeń nie powinno mieć to negatywnych skutków. W sytuacji, gdy pojawiają się

49 5.3 Metoda k-najbliższych sasiadów 47 Rysunek 5.8: Diagram blokowy dla algorytmu klasyfikacji K-Najbliższych Sasiadów dane rzadkie. Może okazać się, że wybór klasy jest trudny, a to, żeby był zgodny z intuicją jeszcze bardziej jest nieosiągalne. Bardzo przydatną praktyką jest stosowanie wag dla poszczególnych składowych wektora cech. Pozwala to na ustalenie ważności. Jeśli dla niektórych cech przypiszemy wagę 0, to nie będą one wcale brane pod uwagę. Wady i zalety Podsumowując algorytm k-najbliższych sąsiadów jest bardzo prostym klasyfikatorem. Posiada on jednak kilka ciekawych właściwości. Bardzo łatwo jest go zaprogramować (mówię oczywiście o podstawowej wersji bez zbędnych optymalizacji). Dla wielu zastosowań jego zdolności klasyfikacyjne można ocenić jako dobre i wystarczające. Może się okazać, że nakład pracy na zaimplementowanie klasyfikatora w stosunku do wyników będzie niewspółmiernie mniejszy niż choćby na to w sieciach neuronowych. Algorytm po prostych modyfikacjach może odrzucać wybrane kolumny w rekordach, aby pomijać brakujące wartości, które jak wiadomo nigdy nie będą dobrze wpływały na wynik. Algorytm posiada jednak znaczne wady, o których trzeba wspomnieć. Najważniejszą jest jego leniwość ona powoduje wynikanie pozostałych wad. Metoda wymaga przechowywania całego zbioru uczącego i wykonywania porównania dla każdego analizowanego obiektu od nowa. Można oczywiście zastosować jakieś modyfikacje, które skracają czas i zmniejszają zapotrzebowanie na pamięć. Choćby odrzucić część informacji, albo próbkować co którąś. W książce [7] przeczytałem o zabiegu, który najpierw zakładał przeprowadzenie grupowania na danych zbioru uczącego, a następnie operowanie centroidami tych grup. Koniec końców leniwość algorytmu stawia analityków pod ścianą, bo nie mogą zastosować tego narzędzia dla wszystkich typów problemów. Sporym problemem jest też rozwiązanie kompromisu wariacyjno-obciążeniowego, czyli odpowiednika przeuczenia i niedouczenia. Jak wybrać stosowną wartość parametru k określającego wielkość sąsiedztwa. Nie pozostaje nic innego jak metoda prób i błędów.
Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego
 POLITECHNIKA ŁÓDZKA Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Praca dyplomowa Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego Artur Ziółkowski
POLITECHNIKA ŁÓDZKA Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Praca dyplomowa Wybrane techniki przygotowywania rekomendacji dla użytkowników serwisu internetowego Artur Ziółkowski
Spis treści. 1.1 Problematyka... 4 1.2 Cele pracy i zakres pracy... 5
 Spis treści 1 Wstęp 4 1.1 Problematyka.......................... 4 1.2 Cele pracy i zakres pracy...................... 5 2 Analiza zagadnienia 7 2.1 Wprowadzenie.......................... 7 2.2 Eksploracja
Spis treści 1 Wstęp 4 1.1 Problematyka.......................... 4 1.2 Cele pracy i zakres pracy...................... 5 2 Analiza zagadnienia 7 2.1 Wprowadzenie.......................... 7 2.2 Eksploracja
WYBRANE TECHNIKI PRZYGOTOWYWANIA REKOMENDACJI DLA UŻYTKOWNIKÓW SERWISU INTERNETOWEGO
 Politechnika Łódzka Instytut Informatyki PRACA MAGISTERSKA WYBRANE TECHNIKI PRZYGOTOWYWANIA REKOMENDACJI DLA UŻYTKOWNIKÓW SERWISU INTERNETOWEGO Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej
Politechnika Łódzka Instytut Informatyki PRACA MAGISTERSKA WYBRANE TECHNIKI PRZYGOTOWYWANIA REKOMENDACJI DLA UŻYTKOWNIKÓW SERWISU INTERNETOWEGO Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Priorytetyzacja przypadków testowych za pomocą macierzy
 Priorytetyzacja przypadków testowych za pomocą macierzy W niniejszym artykule przedstawiony został problem przyporządkowania priorytetów do przypadków testowych przed rozpoczęciem testów oprogramowania.
Priorytetyzacja przypadków testowych za pomocą macierzy W niniejszym artykule przedstawiony został problem przyporządkowania priorytetów do przypadków testowych przed rozpoczęciem testów oprogramowania.
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Wyszukiwanie binarne
 Wyszukiwanie binarne Wyszukiwanie binarne to technika pozwalająca na przeszukanie jakiegoś posortowanego zbioru danych w czasie logarytmicznie zależnym od jego wielkości (co to dokładnie znaczy dowiecie
Wyszukiwanie binarne Wyszukiwanie binarne to technika pozwalająca na przeszukanie jakiegoś posortowanego zbioru danych w czasie logarytmicznie zależnym od jego wielkości (co to dokładnie znaczy dowiecie
Zapisywanie algorytmów w języku programowania
 Temat C5 Zapisywanie algorytmów w języku programowania Cele edukacyjne Zrozumienie, na czym polega programowanie. Poznanie sposobu zapisu algorytmu w postaci programu komputerowego. Zrozumienie, na czym
Temat C5 Zapisywanie algorytmów w języku programowania Cele edukacyjne Zrozumienie, na czym polega programowanie. Poznanie sposobu zapisu algorytmu w postaci programu komputerowego. Zrozumienie, na czym
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Maciej Piotr Jankowski
 Reduced Adder Graph Implementacja algorytmu RAG Maciej Piotr Jankowski 2005.12.22 Maciej Piotr Jankowski 1 Plan prezentacji 1. Wstęp 2. Implementacja 3. Usprawnienia optymalizacyjne 3.1. Tablica ekspansji
Reduced Adder Graph Implementacja algorytmu RAG Maciej Piotr Jankowski 2005.12.22 Maciej Piotr Jankowski 1 Plan prezentacji 1. Wstęp 2. Implementacja 3. Usprawnienia optymalizacyjne 3.1. Tablica ekspansji
Analiza i projektowanie oprogramowania. Analiza i projektowanie oprogramowania 1/32
 Analiza i projektowanie oprogramowania Analiza i projektowanie oprogramowania 1/32 Analiza i projektowanie oprogramowania 2/32 Cel analizy Celem fazy określania wymagań jest udzielenie odpowiedzi na pytanie:
Analiza i projektowanie oprogramowania Analiza i projektowanie oprogramowania 1/32 Analiza i projektowanie oprogramowania 2/32 Cel analizy Celem fazy określania wymagań jest udzielenie odpowiedzi na pytanie:
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Sposoby prezentacji problemów w statystyce
 S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
Badania operacyjne: Wykład Zastosowanie kolorowania grafów w planowaniu produkcji typu no-idle
 Badania operacyjne: Wykład Zastosowanie kolorowania grafów w planowaniu produkcji typu no-idle Paweł Szołtysek 12 czerwca 2008 Streszczenie Planowanie produkcji jest jednym z problemów optymalizacji dyskretnej,
Badania operacyjne: Wykład Zastosowanie kolorowania grafów w planowaniu produkcji typu no-idle Paweł Szołtysek 12 czerwca 2008 Streszczenie Planowanie produkcji jest jednym z problemów optymalizacji dyskretnej,
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
8. Neuron z ciągłą funkcją aktywacji.
 8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Programowanie i techniki algorytmiczne
 Temat 2. Programowanie i techniki algorytmiczne Realizacja podstawy programowej 1) wyjaśnia pojęcie algorytmu, podaje odpowiednie przykłady algorytmów rozwiązywania różnych 2) formułuje ścisły opis prostej
Temat 2. Programowanie i techniki algorytmiczne Realizacja podstawy programowej 1) wyjaśnia pojęcie algorytmu, podaje odpowiednie przykłady algorytmów rozwiązywania różnych 2) formułuje ścisły opis prostej
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
znalezienia elementu w zbiorze, gdy w nim jest; dołączenia nowego elementu w odpowiednie miejsce, aby zbiór pozostał nadal uporządkowany.
 Przedstawiamy algorytmy porządkowania dowolnej liczby elementów, którymi mogą być liczby, jak również elementy o bardziej złożonej postaci (takie jak słowa i daty). Porządkowanie, nazywane również często
Przedstawiamy algorytmy porządkowania dowolnej liczby elementów, którymi mogą być liczby, jak również elementy o bardziej złożonej postaci (takie jak słowa i daty). Porządkowanie, nazywane również często
Algorytmy sztucznej inteligencji
 www.math.uni.lodz.pl/ radmat Przeszukiwanie z ograniczeniami Zagadnienie przeszukiwania z ograniczeniami stanowi grupę problemów przeszukiwania w przestrzeni stanów, które składa się ze: 1 skończonego
www.math.uni.lodz.pl/ radmat Przeszukiwanie z ograniczeniami Zagadnienie przeszukiwania z ograniczeniami stanowi grupę problemów przeszukiwania w przestrzeni stanów, które składa się ze: 1 skończonego
Efekt kształcenia. Ma uporządkowaną, podbudowaną teoretycznie wiedzę ogólną w zakresie algorytmów i ich złożoności obliczeniowej.
 Efekty dla studiów pierwszego stopnia profil ogólnoakademicki na kierunku Informatyka w języku polskim i w języku angielskim (Computer Science) na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie-
Efekty dla studiów pierwszego stopnia profil ogólnoakademicki na kierunku Informatyka w języku polskim i w języku angielskim (Computer Science) na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie-
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Łączenie liczb i tekstu.
 Łączenie liczb i tekstu. 1 (Pobrane z slow7.pl) Rozpoczynamy od sposobu pierwszego. Mamy arkusz przedstawiony na rysunku poniżej w którym zostały zawarte wypłaty pracowników z wykonanym podsumowaniem.
Łączenie liczb i tekstu. 1 (Pobrane z slow7.pl) Rozpoczynamy od sposobu pierwszego. Mamy arkusz przedstawiony na rysunku poniżej w którym zostały zawarte wypłaty pracowników z wykonanym podsumowaniem.
Ćwiczenie numer 4 JESS PRZYKŁADOWY SYSTEM EKSPERTOWY.
 Ćwiczenie numer 4 JESS PRZYKŁADOWY SYSTEM EKSPERTOWY. 1. Cel ćwiczenia Celem ćwiczenia jest zapoznanie się z przykładowym systemem ekspertowym napisanym w JESS. Studenci poznają strukturę systemu ekspertowego,
Ćwiczenie numer 4 JESS PRZYKŁADOWY SYSTEM EKSPERTOWY. 1. Cel ćwiczenia Celem ćwiczenia jest zapoznanie się z przykładowym systemem ekspertowym napisanym w JESS. Studenci poznają strukturę systemu ekspertowego,
SCENARIUSZ LEKCJI. TEMAT LEKCJI: Zastosowanie średnich w statystyce i matematyce. Podstawowe pojęcia statystyczne. Streszczenie.
 SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Porównywanie populacji
 3 Porównywanie populacji 2 Porównywanie populacji Tendencja centralna Jednostki (w grupie) według pewnej zmiennej porównuje się w ten sposób, że dokonuje się komparacji ich wartości, osiągniętych w tej
3 Porównywanie populacji 2 Porównywanie populacji Tendencja centralna Jednostki (w grupie) według pewnej zmiennej porównuje się w ten sposób, że dokonuje się komparacji ich wartości, osiągniętych w tej
Automatyczna klasyfikacja zespołów QRS
 Przetwarzanie sygnałów w systemach diagnostycznych Informatyka Stosowana V Automatyczna klasyfikacja zespołów QRS Anna Mleko Tomasz Kotliński AGH EAIiE 9 . Opis zadania Tematem projektu było zaprojektowanie
Przetwarzanie sygnałów w systemach diagnostycznych Informatyka Stosowana V Automatyczna klasyfikacja zespołów QRS Anna Mleko Tomasz Kotliński AGH EAIiE 9 . Opis zadania Tematem projektu było zaprojektowanie
Programowanie celowe #1
 Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Automatyczne tworzenie trójwymiarowego planu pomieszczenia z zastosowaniem metod stereowizyjnych
 Automatyczne tworzenie trójwymiarowego planu pomieszczenia z zastosowaniem metod stereowizyjnych autor: Robert Drab opiekun naukowy: dr inż. Paweł Rotter 1. Wstęp Zagadnienie generowania trójwymiarowego
Automatyczne tworzenie trójwymiarowego planu pomieszczenia z zastosowaniem metod stereowizyjnych autor: Robert Drab opiekun naukowy: dr inż. Paweł Rotter 1. Wstęp Zagadnienie generowania trójwymiarowego
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Szukanie rozwiązań funkcji uwikłanych (równań nieliniowych)
") Szukanie rozwiązań funkcji uwikłanych (równań nieliniowych) Funkcja uwikłana (równanie nieliniowe) jest to funkcja, która nie jest przedstawiona jawnym przepisem, wzorem wyrażającym zależność wartości
Szukanie rozwiązań funkcji uwikłanych (równań nieliniowych) Funkcja uwikłana (równanie nieliniowe) jest to funkcja, która nie jest przedstawiona jawnym przepisem, wzorem wyrażającym zależność wartości
Odwrotna analiza wartości brzegowych przy zaokrąglaniu wartości
 Odwrotna analiza wartości brzegowych przy zaokrąglaniu wartości W systemach informatycznych istnieje duże prawdopodobieństwo, że oprogramowanie będzie się błędnie zachowywać dla wartości na krawędziach
Odwrotna analiza wartości brzegowych przy zaokrąglaniu wartości W systemach informatycznych istnieje duże prawdopodobieństwo, że oprogramowanie będzie się błędnie zachowywać dla wartości na krawędziach
biegle i poprawnie posługuje się terminologią informatyczną,
 INFORMATYKA KLASA 1 1. Wymagania na poszczególne oceny: 1) ocenę celującą otrzymuje uczeń, który: samodzielnie wykonuje na komputerze wszystkie zadania z lekcji, wykazuje inicjatywę rozwiązywania konkretnych
INFORMATYKA KLASA 1 1. Wymagania na poszczególne oceny: 1) ocenę celującą otrzymuje uczeń, który: samodzielnie wykonuje na komputerze wszystkie zadania z lekcji, wykazuje inicjatywę rozwiązywania konkretnych
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
S O M SELF-ORGANIZING MAPS. Przemysław Szczepańczyk Łukasz Myszor
 S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
operacje porównania, a jeśli jest to konieczne ze względu na złe uporządkowanie porównywanych liczb zmieniamy ich kolejność, czyli przestawiamy je.
 Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Budowa argumentacji bezpieczeństwa z użyciem NOR-STA Instrukcja krok po kroku
 Budowa argumentacji bezpieczeństwa z użyciem NOR-STA Instrukcja krok po kroku NOR-STA jest narzędziem wspierającym budowę, ocenę oraz zarządzanie strukturą argumentacji wiarygodności (assurance case),
Budowa argumentacji bezpieczeństwa z użyciem NOR-STA Instrukcja krok po kroku NOR-STA jest narzędziem wspierającym budowę, ocenę oraz zarządzanie strukturą argumentacji wiarygodności (assurance case),
Ćwiczenie 1 Planowanie trasy robota mobilnego w siatce kwadratów pól - Algorytm A
 Ćwiczenie 1 Planowanie trasy robota mobilnego w siatce kwadratów pól - Algorytm A Zadanie do wykonania 1) Utwórz na pulpicie katalog w formacie Imię nazwisko, w którym umieść wszystkie pliki związane z
Ćwiczenie 1 Planowanie trasy robota mobilnego w siatce kwadratów pól - Algorytm A Zadanie do wykonania 1) Utwórz na pulpicie katalog w formacie Imię nazwisko, w którym umieść wszystkie pliki związane z
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
FILM - SALON SPRZEDAŻY TELEFONÓW KOMÓRKOWYCH (A2 / B1 )
") FILM - SALON SPRZEDAŻY TELEFONÓW KOMÓRKOWYCH (A2 / B1 ) Klient: Dzień dobry panu! Pracownik: Dzień dobry! W czym mogę pomóc? Klient: Pierwsza sprawa: jestem Włochem i nie zawsze jestem pewny, czy wszystko
FILM - SALON SPRZEDAŻY TELEFONÓW KOMÓRKOWYCH (A2 / B1 ) Klient: Dzień dobry panu! Pracownik: Dzień dobry! W czym mogę pomóc? Klient: Pierwsza sprawa: jestem Włochem i nie zawsze jestem pewny, czy wszystko
Kurs programowania. Wykład 12. Wojciech Macyna. 7 czerwca 2017
 Wykład 12 7 czerwca 2017 Czym jest UML? UML składa się z dwóch podstawowych elementów: notacja: elementy graficzne, składnia języka modelowania, metamodel: definicje pojęć języka i powiazania pomiędzy
Wykład 12 7 czerwca 2017 Czym jest UML? UML składa się z dwóch podstawowych elementów: notacja: elementy graficzne, składnia języka modelowania, metamodel: definicje pojęć języka i powiazania pomiędzy
2
 1 2 3 4 5 Dużo pisze się i słyszy o projektach wdrożeń systemów zarządzania wiedzą, które nie przyniosły oczekiwanych rezultatów, bo mało kto korzystał z tych systemów. Technologia nie jest bowiem lekarstwem
1 2 3 4 5 Dużo pisze się i słyszy o projektach wdrożeń systemów zarządzania wiedzą, które nie przyniosły oczekiwanych rezultatów, bo mało kto korzystał z tych systemów. Technologia nie jest bowiem lekarstwem
Pomorski Czarodziej 2016 Zadania. Kategoria C
 Pomorski Czarodziej 2016 Zadania. Kategoria C Poniżej znajduje się 5 zadań. Za poprawne rozwiązanie każdego z nich możesz otrzymać 10 punktów. Jeżeli otrzymasz za zadanie maksymalną liczbę punktów, możesz
Pomorski Czarodziej 2016 Zadania. Kategoria C Poniżej znajduje się 5 zadań. Za poprawne rozwiązanie każdego z nich możesz otrzymać 10 punktów. Jeżeli otrzymasz za zadanie maksymalną liczbę punktów, możesz
XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery
 http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych
 Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
TEORETYCZNE PODSTAWY INFORMATYKI
 1 TEORETYCZNE PODSTAWY INFORMATYKI 16/01/2017 WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Repetytorium złożoność obliczeniowa 2 Złożoność obliczeniowa Notacja wielkie 0 Notacja Ω i Θ Rozwiązywanie
1 TEORETYCZNE PODSTAWY INFORMATYKI 16/01/2017 WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Repetytorium złożoność obliczeniowa 2 Złożoność obliczeniowa Notacja wielkie 0 Notacja Ω i Θ Rozwiązywanie
Za pierwszy niebanalny algorytm uważa się algorytm Euklidesa wyszukiwanie NWD dwóch liczb (400 a 300 rok przed narodzeniem Chrystusa).
.") Algorytmy definicja, cechy, złożoność. Algorytmy napotykamy wszędzie, gdziekolwiek się zwrócimy. Rządzą one wieloma codziennymi czynnościami, jak np. wymiana przedziurawionej dętki, montowanie szafy z
Algorytmy definicja, cechy, złożoność. Algorytmy napotykamy wszędzie, gdziekolwiek się zwrócimy. Rządzą one wieloma codziennymi czynnościami, jak np. wymiana przedziurawionej dętki, montowanie szafy z
Wstęp do Informatyki zadania ze złożoności obliczeniowej z rozwiązaniami
 Wstęp do Informatyki zadania ze złożoności obliczeniowej z rozwiązaniami Przykład 1. Napisz program, który dla podanej liczby n wypisze jej rozkład na czynniki pierwsze. Oblicz asymptotyczną złożoność
Wstęp do Informatyki zadania ze złożoności obliczeniowej z rozwiązaniami Przykład 1. Napisz program, który dla podanej liczby n wypisze jej rozkład na czynniki pierwsze. Oblicz asymptotyczną złożoność
Wymagania edukacyjne z matematyki w klasie III gimnazjum
 Wymagania edukacyjne z matematyki w klasie III gimnazjum - nie potrafi konstrukcyjnie podzielić odcinka - nie potrafi konstruować figur jednokładnych - nie zna pojęcia skali - nie rozpoznaje figur jednokładnych
Wymagania edukacyjne z matematyki w klasie III gimnazjum - nie potrafi konstrukcyjnie podzielić odcinka - nie potrafi konstruować figur jednokładnych - nie zna pojęcia skali - nie rozpoznaje figur jednokładnych
SCENARIUSZ LEKCJI. Streszczenie. Czas realizacji. Podstawa programowa
 Autorzy scenariusza: SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH
Autorzy scenariusza: SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH
Wymagania na poszczególne oceny szkolne dla klasy VI. (na podstawie Grażyny Koba, Teraz bajty. Informatyka dla szkoły podstawowej.
 1 Wymagania na poszczególne oceny szkolne dla klasy VI (na podstawie Grażyny Koba, Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI ) 2 1. Obliczenia w arkuszu kalkulacyjnym słucha poleceń nauczyciela
1 Wymagania na poszczególne oceny szkolne dla klasy VI (na podstawie Grażyny Koba, Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI ) 2 1. Obliczenia w arkuszu kalkulacyjnym słucha poleceń nauczyciela
Diagramy ERD. Model struktury danych jest najczęściej tworzony z wykorzystaniem diagramów pojęciowych (konceptualnych). Najpopularniejszym
. Najpopularniejszym") Diagramy ERD. Model struktury danych jest najczęściej tworzony z wykorzystaniem diagramów pojęciowych (konceptualnych). Najpopularniejszym konceptualnym modelem danych jest tzw. model związków encji (ERM
Diagramy ERD. Model struktury danych jest najczęściej tworzony z wykorzystaniem diagramów pojęciowych (konceptualnych). Najpopularniejszym konceptualnym modelem danych jest tzw. model związków encji (ERM
Faza Określania Wymagań
 Faza Określania Wymagań Celem tej fazy jest dokładne określenie wymagań klienta wobec tworzonego systemu. W tej fazie dokonywana jest zamiana celów klienta na konkretne wymagania zapewniające osiągnięcie
Faza Określania Wymagań Celem tej fazy jest dokładne określenie wymagań klienta wobec tworzonego systemu. W tej fazie dokonywana jest zamiana celów klienta na konkretne wymagania zapewniające osiągnięcie
Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI
 1 Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI 1. Obliczenia w arkuszu kalkulacyjnym Rozwiązywanie problemów z wykorzystaniem aplikacji komputerowych obliczenia w arkuszu kalkulacyjnym wykonuje
1 Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI 1. Obliczenia w arkuszu kalkulacyjnym Rozwiązywanie problemów z wykorzystaniem aplikacji komputerowych obliczenia w arkuszu kalkulacyjnym wykonuje
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
Materiały dla finalistów
 Materiały dla finalistów Malachoviacus Informaticus 2016 11 kwietnia 2016 Wprowadzenie Poniższy dokument zawiera opisy zagadnień, które będą niezbędne do rozwiązania zadań w drugim etapie konkursu. Polecamy
Materiały dla finalistów Malachoviacus Informaticus 2016 11 kwietnia 2016 Wprowadzenie Poniższy dokument zawiera opisy zagadnień, które będą niezbędne do rozwiązania zadań w drugim etapie konkursu. Polecamy
Zajęcia nr. 3 notatki
 Zajęcia nr. 3 notatki 22 kwietnia 2005 1 Funkcje liczbowe wprowadzenie Istnieje nieskończenie wiele funkcji w matematyce. W dodaktu nie wszystkie są liczbowe. Rozpatruje się funkcje które pobierają argumenty
Zajęcia nr. 3 notatki 22 kwietnia 2005 1 Funkcje liczbowe wprowadzenie Istnieje nieskończenie wiele funkcji w matematyce. W dodaktu nie wszystkie są liczbowe. Rozpatruje się funkcje które pobierają argumenty
Diagramu Związków Encji - CELE. Diagram Związków Encji - CHARAKTERYSTYKA. Diagram Związków Encji - Podstawowe bloki składowe i reguły konstrukcji
 Diagramy związków encji (ERD) 1 Projektowanie bazy danych za pomocą narzędzi CASE Materiał pochodzi ze strony : http://jjakiela.prz.edu.pl/labs.htm Diagramu Związków Encji - CELE Zrozumienie struktury
Diagramy związków encji (ERD) 1 Projektowanie bazy danych za pomocą narzędzi CASE Materiał pochodzi ze strony : http://jjakiela.prz.edu.pl/labs.htm Diagramu Związków Encji - CELE Zrozumienie struktury
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Efekty kształcenia dla kierunku studiów INFORMATYKA, Absolwent studiów I stopnia kierunku Informatyka WIEDZA
 Symbol Efekty kształcenia dla kierunku studiów INFORMATYKA, specjalność: 1) Sieciowe systemy informatyczne. 2) Bazy danych Absolwent studiów I stopnia kierunku Informatyka WIEDZA Ma wiedzę z matematyki
Symbol Efekty kształcenia dla kierunku studiów INFORMATYKA, specjalność: 1) Sieciowe systemy informatyczne. 2) Bazy danych Absolwent studiów I stopnia kierunku Informatyka WIEDZA Ma wiedzę z matematyki
Obliczenia inspirowane Naturą
 Obliczenia inspirowane Naturą Wykład 01 Modele obliczeń Jarosław Miszczak IITiS PAN Gliwice 05/10/2016 1 / 33 1 2 3 4 5 6 2 / 33 Co to znaczy obliczać? Co to znaczy obliczać? Deterministyczna maszyna Turinga
Obliczenia inspirowane Naturą Wykład 01 Modele obliczeń Jarosław Miszczak IITiS PAN Gliwice 05/10/2016 1 / 33 1 2 3 4 5 6 2 / 33 Co to znaczy obliczać? Co to znaczy obliczać? Deterministyczna maszyna Turinga
Bioinformatyka. Ocena wiarygodności dopasowania sekwencji.
 Bioinformatyka Ocena wiarygodności dopasowania sekwencji www.michalbereta.pl Załóżmy, że mamy dwie sekwencje, które chcemy dopasować i dodatkowo ocenić wiarygodność tego dopasowania. Interesujące nas pytanie
Bioinformatyka Ocena wiarygodności dopasowania sekwencji www.michalbereta.pl Załóżmy, że mamy dwie sekwencje, które chcemy dopasować i dodatkowo ocenić wiarygodność tego dopasowania. Interesujące nas pytanie
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Klasa 2 INFORMATYKA. dla szkół ponadgimnazjalnych zakres rozszerzony. Założone osiągnięcia ucznia wymagania edukacyjne na. poszczególne oceny
 Klasa 2 INFORMATYKA dla szkół ponadgimnazjalnych zakres rozszerzony Założone osiągnięcia ucznia wymagania edukacyjne na poszczególne oceny Algorytmy 2 3 4 5 6 Wie, co to jest algorytm. Wymienia przykłady
Klasa 2 INFORMATYKA dla szkół ponadgimnazjalnych zakres rozszerzony Założone osiągnięcia ucznia wymagania edukacyjne na poszczególne oceny Algorytmy 2 3 4 5 6 Wie, co to jest algorytm. Wymienia przykłady
Zasady Wykorzystywania Plików Cookies
 Zasady Wykorzystywania Plików Cookies Definicje i objaśnienia używanych pojęć Ilekroć w niniejszym zbiorze Zasad wykorzystywania plików Cookies pojawia się któreś z poniższych określeń, należy rozumieć
Zasady Wykorzystywania Plików Cookies Definicje i objaśnienia używanych pojęć Ilekroć w niniejszym zbiorze Zasad wykorzystywania plików Cookies pojawia się któreś z poniższych określeń, należy rozumieć
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Algorytmika i pseudoprogramowanie
 Przedmiotowy system oceniania Zawód: Technik Informatyk Nr programu: 312[ 01] /T,SP/MENiS/ 2004.06.14 Przedmiot: Programowanie Strukturalne i Obiektowe Klasa: druga Dział Dopuszczający Dostateczny Dobry
Przedmiotowy system oceniania Zawód: Technik Informatyk Nr programu: 312[ 01] /T,SP/MENiS/ 2004.06.14 Przedmiot: Programowanie Strukturalne i Obiektowe Klasa: druga Dział Dopuszczający Dostateczny Dobry
Programowanie w Baltie klasa VII
 Programowanie w Baltie klasa VII Zadania z podręcznika strona 127 i 128 Zadanie 1/127 Zadanie 2/127 Zadanie 3/127 Zadanie 4/127 Zadanie 5/127 Zadanie 6/127 Ten sposób pisania programu nie ma sensu!!!.
Programowanie w Baltie klasa VII Zadania z podręcznika strona 127 i 128 Zadanie 1/127 Zadanie 2/127 Zadanie 3/127 Zadanie 4/127 Zadanie 5/127 Zadanie 6/127 Ten sposób pisania programu nie ma sensu!!!.
Metody probabilistyczne klasyfikatory bayesowskie
 Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Wymagania edukacyjne z informatyki w klasie IIIa gimnazjum
 Lp. Wymagania edukacyjne z informatyki w klasie IIIa gimnazjum 1. Internet i sieci [17 godz.] 1 Sieci komputerowe. Rodzaje sieci, topologie, protokoły transmisji danych w sieciach. Internet jako sie rozległa
Lp. Wymagania edukacyjne z informatyki w klasie IIIa gimnazjum 1. Internet i sieci [17 godz.] 1 Sieci komputerowe. Rodzaje sieci, topologie, protokoły transmisji danych w sieciach. Internet jako sie rozległa
Autostopem przez galaiktykę: Intuicyjne omówienie zagadnień. Tom I: Optymalizacja. Nie panikuj!
 Autostopem przez galaiktykę: Intuicyjne omówienie zagadnień Tom I: Optymalizacja Nie panikuj! Autorzy: Iwo Błądek Konrad Miazga Oświadczamy, że w trakcie produkcji tego tutoriala nie zginęły żadne zwierzęta,
Autostopem przez galaiktykę: Intuicyjne omówienie zagadnień Tom I: Optymalizacja Nie panikuj! Autorzy: Iwo Błądek Konrad Miazga Oświadczamy, że w trakcie produkcji tego tutoriala nie zginęły żadne zwierzęta,
Komputerowe Systemy Przemysłowe: Modelowanie - UML. Arkadiusz Banasik arkadiusz.banasik@polsl.pl
 Komputerowe Systemy Przemysłowe: Modelowanie - UML Arkadiusz Banasik arkadiusz.banasik@polsl.pl Plan prezentacji Wprowadzenie UML Diagram przypadków użycia Diagram klas Podsumowanie Wprowadzenie Języki
Komputerowe Systemy Przemysłowe: Modelowanie - UML Arkadiusz Banasik arkadiusz.banasik@polsl.pl Plan prezentacji Wprowadzenie UML Diagram przypadków użycia Diagram klas Podsumowanie Wprowadzenie Języki
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1.
 Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI
 1 Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI Opis założonych osiągnięć ucznia przykłady wymagań na poszczególne oceny szkolne dla klasy VI Grażyna Koba Spis treści 1. Obliczenia w arkuszu
1 Teraz bajty. Informatyka dla szkoły podstawowej. Klasa VI Opis założonych osiągnięć ucznia przykłady wymagań na poszczególne oceny szkolne dla klasy VI Grażyna Koba Spis treści 1. Obliczenia w arkuszu
Zad. 3: Układ równań liniowych
 1 Cel ćwiczenia Zad. 3: Układ równań liniowych Wykształcenie umiejętności modelowania kluczowych dla danego problemu pojęć. Definiowanie właściwego interfejsu klasy. Zwrócenie uwagi na dobór odpowiednich
1 Cel ćwiczenia Zad. 3: Układ równań liniowych Wykształcenie umiejętności modelowania kluczowych dla danego problemu pojęć. Definiowanie właściwego interfejsu klasy. Zwrócenie uwagi na dobór odpowiednich
Jazda autonomiczna Delphi zgodna z zasadami sztucznej inteligencji
 Jazda autonomiczna Delphi zgodna z zasadami sztucznej inteligencji data aktualizacji: 2017.10.11 Delphi Kraków Rozwój jazdy autonomicznej zmienia krajobraz technologii transportu w sposób tak dynamiczny,
Jazda autonomiczna Delphi zgodna z zasadami sztucznej inteligencji data aktualizacji: 2017.10.11 Delphi Kraków Rozwój jazdy autonomicznej zmienia krajobraz technologii transportu w sposób tak dynamiczny,
Transformacja wiedzy w budowie i eksploatacji maszyn
 Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Temat 20. Techniki algorytmiczne
 Realizacja podstawy programowej 5. 1) wyjaśnia pojęcie algorytmu, podaje odpowiednie przykłady algorytmów rozwiązywania różnych problemów; 2) formułuje ścisły opis prostej sytuacji problemowej, analizuje
Realizacja podstawy programowej 5. 1) wyjaśnia pojęcie algorytmu, podaje odpowiednie przykłady algorytmów rozwiązywania różnych problemów; 2) formułuje ścisły opis prostej sytuacji problemowej, analizuje
OPTYMALIZACJA HARMONOGRAMOWANIA MONTAŻU SAMOCHODÓW Z ZASTOSOWANIEM PROGRAMOWANIA W LOGICE Z OGRANICZENIAMI
 Autoreferat do rozprawy doktorskiej OPTYMALIZACJA HARMONOGRAMOWANIA MONTAŻU SAMOCHODÓW Z ZASTOSOWANIEM PROGRAMOWANIA W LOGICE Z OGRANICZENIAMI Michał Mazur Gliwice 2016 1 2 Montaż samochodów na linii w
Autoreferat do rozprawy doktorskiej OPTYMALIZACJA HARMONOGRAMOWANIA MONTAŻU SAMOCHODÓW Z ZASTOSOWANIEM PROGRAMOWANIA W LOGICE Z OGRANICZENIAMI Michał Mazur Gliwice 2016 1 2 Montaż samochodów na linii w
PRZEDMIOTOWY SYSTEM OCENIANIA - MATEMATYKA
 PRZEDMIOTOWY SYSTEM OCENIANIA - MATEMATYKA WYMAGANIA KONIECZNE - OCENA DOPUSZCZAJĄCA uczeń posiada niepełną wiedzę określoną programem nauczania, intuicyjnie rozumie pojęcia, zna ich nazwy i potrafi podać
PRZEDMIOTOWY SYSTEM OCENIANIA - MATEMATYKA WYMAGANIA KONIECZNE - OCENA DOPUSZCZAJĄCA uczeń posiada niepełną wiedzę określoną programem nauczania, intuicyjnie rozumie pojęcia, zna ich nazwy i potrafi podać
Wymagania edukacyjne na poszczególne oceny z informatyki w gimnazjum klasa III Rok szkolny 2015/16
 Wymagania edukacyjne na poszczególne oceny z informatyki w gimnazjum klasa III Rok szkolny 2015/16 Internet i sieci Temat lekcji Wymagania programowe 6 5 4 3 2 1 Sieci komputerowe. Rodzaje sieci, topologie,
Wymagania edukacyjne na poszczególne oceny z informatyki w gimnazjum klasa III Rok szkolny 2015/16 Internet i sieci Temat lekcji Wymagania programowe 6 5 4 3 2 1 Sieci komputerowe. Rodzaje sieci, topologie,
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
komputery? Andrzej Skowron, Hung Son Nguyen Instytut Matematyki, Wydział MIM, UW
 Czego moga się nauczyć komputery? Andrzej Skowron, Hung Son Nguyen son@mimuw.edu.pl; skowron@mimuw.edu.pl Instytut Matematyki, Wydział MIM, UW colt.tex Czego mogą się nauczyć komputery? Andrzej Skowron,
Czego moga się nauczyć komputery? Andrzej Skowron, Hung Son Nguyen son@mimuw.edu.pl; skowron@mimuw.edu.pl Instytut Matematyki, Wydział MIM, UW colt.tex Czego mogą się nauczyć komputery? Andrzej Skowron,
Wymagania edukacyjne z informatyki dla klasy szóstej szkoły podstawowej.
 Wymagania edukacyjne z informatyki dla klasy szóstej szkoły podstawowej. Dział Zagadnienia Wymagania podstawowe Wymagania ponadpodstawowe Arkusz kalkulacyjny (Microsoft Excel i OpenOffice) Uruchomienie
Wymagania edukacyjne z informatyki dla klasy szóstej szkoły podstawowej. Dział Zagadnienia Wymagania podstawowe Wymagania ponadpodstawowe Arkusz kalkulacyjny (Microsoft Excel i OpenOffice) Uruchomienie
Deduplikacja danych. Zarządzanie jakością danych podstawowych
 Deduplikacja danych Zarządzanie jakością danych podstawowych normalizacja i standaryzacja adresów standaryzacja i walidacja identyfikatorów podstawowa standaryzacja nazw firm deduplikacja danych Deduplication
Deduplikacja danych Zarządzanie jakością danych podstawowych normalizacja i standaryzacja adresów standaryzacja i walidacja identyfikatorów podstawowa standaryzacja nazw firm deduplikacja danych Deduplication
ALGORYTMY SZTUCZNEJ INTELIGENCJI
 ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Proces informacyjny. Janusz Górczyński
 Proces informacyjny Janusz Górczyński 1 Proces informacyjny, definicja (1) Pod pojęciem procesu informacyjnego rozumiemy taki proces semiotyczny, ekonomiczny i technologiczny, który realizuje co najmniej
Proces informacyjny Janusz Górczyński 1 Proces informacyjny, definicja (1) Pod pojęciem procesu informacyjnego rozumiemy taki proces semiotyczny, ekonomiczny i technologiczny, który realizuje co najmniej
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
Podstawowe zagadnienia z zakresu baz danych
 Podstawowe zagadnienia z zakresu baz danych Jednym z najważniejszych współczesnych zastosowań komputerów we wszelkich dziedzinach życia jest gromadzenie, wyszukiwanie i udostępnianie informacji. Specjalizowane
Podstawowe zagadnienia z zakresu baz danych Jednym z najważniejszych współczesnych zastosowań komputerów we wszelkich dziedzinach życia jest gromadzenie, wyszukiwanie i udostępnianie informacji. Specjalizowane