Wyk lad 7: Drzewa decyzyjne dla dużych zbiorów danych
|
|
|
- Bogusław Król
- 8 lat temu
- Przeglądów:
Transkrypt
1 Wyk lad 7: Drzewa decyzyjne dla dużych zbiorów danych

2 Funkcja rekurencyjna buduj drzewo(u, dec, T): 1: if (kryterium stopu(u, dec) = true) then 2: T.etykieta = kategoria(u, dec); 3: return; 4: end if 5: t := wybierz test(u, TEST); 6: T.test := t; 7: for v R t do 8: U v := {x U : t(x) = v}; 9: utwórz nowe poddrzewo T ; 10: T.ga l aź(v) = T ; 11: buduj drzewo(u v, dec, T ) 12: end for
 = v}; 9: utwórz nowe")
3 Funkcje pomocnicze Kryterium stopu: Zatrzymamy konstrukcji drzewa, gdy aktualny zbiór obiektów: jest pusty lub zawiera obiekty wy l acznie jednej klasy decyzyjnej lub nie ulega podziale przez żaden test Wyznaczenie etykiety zasada wiekszościow a: kategoria(p, dec) = arg max c V dec P [dec=c] tzn., etykieta dla danego zbioru obiektów jest klasa decyzyjna najliczniej reprezentowana w tym zbiorze. Kryterium wyboru testu: heurytyczna funkcja oceniajaca testy.
![zasada wiekszościow a: kategoria(p, dec) = arg max c V dec P [dec=c] tzn.](/docs-images/44/23233294/images/page_3.jpg ", etykieta dla danego zbioru obiektów jest klasa decyzyjna najliczniej reprezentowana w tym zbiorze.")
4 Miary różnorodności zbioru Każdy zbiór obiektów X ulega podziale na klasy decyzyjne: X = C 1 C 2... C d gdzie C i = {u X : dec(u) = i}. Wektor (p 1,..., p r ), gdzie p i = C i X, nazywamy rozk ladem klas decyzyjnych w X. Conflict(X) = i<j C i C j = 1 2 ( X 2 C i 2) Entropy(X) = C i X log C i X = p i log p i Gini(X) = 1 p 2 i
 = i<j C i C j = 1 2 ( X 2 C i 2) Entropy(X) = C i X log C i X = p i")
5 Ocena funkcji testu Każdy test t jest oceniony na podstawie informacji zawartych w X, X 1,..., X nt t X1 X2... X nt X Podzia l zbioru X dokonany przez test t;

6 Ocena funkcji testu Rozróżnialność: disc(t, X) = conflict(x) conflict(x i ) Przyrostu informacji (Information gain). Gain(t, X) = Entropy(X) X i X Entropy(X i) Gini s index G(t, X) = Gini(X) X i X Gini(X i) Kara za zbyt drobny podzia l, np. gain ratio Gain ratio = Gain(t, X) r X i i=1 X log X i X
 Kara za zbyt drobny podzia l, np.")
7 Przyk lad
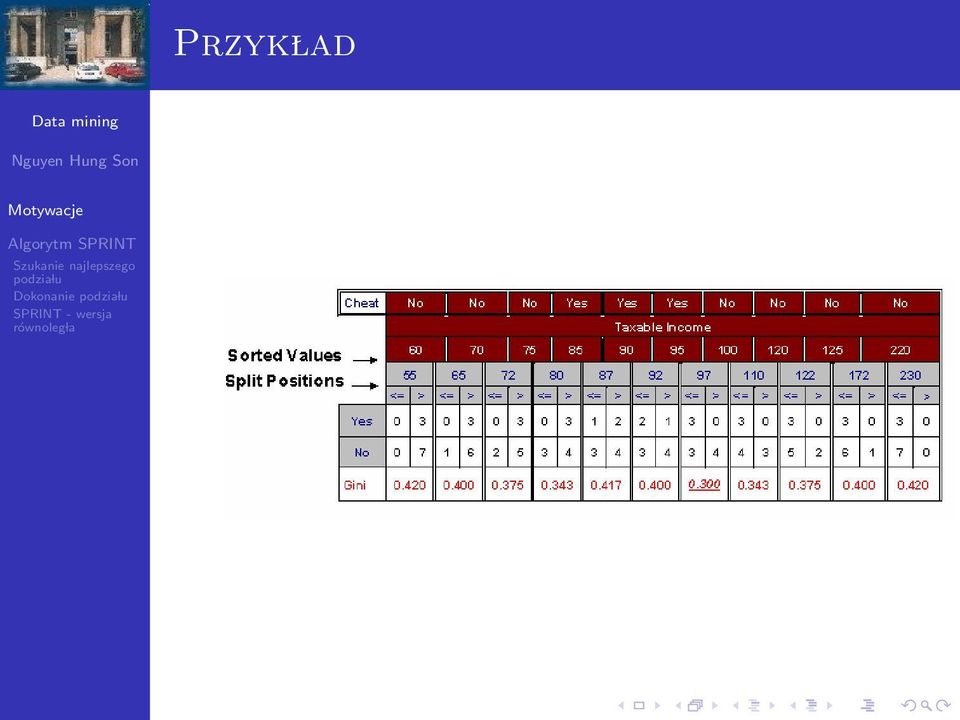
8 S labości standardowego algorytmu: Każdy weze l jest skojarzony z podzbiorem danych: ograniczenie pamieciowe Wyznaczenie najlepszego wymaga wielokrotnego sortowania danych: czasoch lonne Dany atrybut rzeczywisty a i zbiór możliwych cieć (c 1, c 2,...c N ), najlepszy test (a, c i ) można znaleźć w czasie Ω(N) Minimalna liczba prostych zapytań SQL potrzebna do szukania najlepszego testu jest O(dN), gdzie d jest liczba klas decyzyjnych Wniosek: szukanie najlepszego jest kosztowne, jeśli atrybut zawiera dużo różnych wartości.
, gdzie d jest liczba klas decyzyjnych Wniosek: szukanie najlepszego jest kosztowne, jeśli atrybut")
9 Charaterystyka algorytmu SPRINT Nadaje si e dla danych cz eściowo umieszczonych na dysku Używa si e techniki pre-sortowania w celu przyspieszenia procesu obliczenia na atrybutach rzeczywistych; Dane s a sortowane tylko raz przed obliczeniem Latwo można zrównoleglić

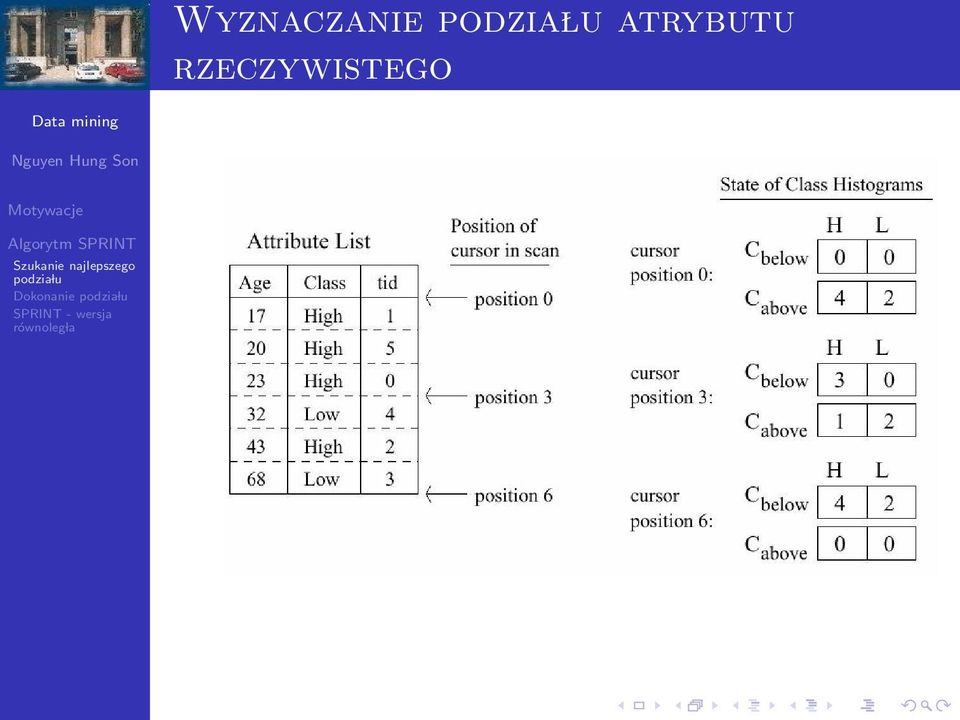
10 Struktura danych w SPRINT Każdy atrybut ma swoja liste wartości Każdy element listy ma trzy pole: - wartość atrybutu, - numer klasy i - rid (numer obiektu w zbiorze danych) Rzeczywiste atrybuty sa uporzadkowane (tylko raz przy utworzeniu) Na poczatku listy sa stowarzyszone z korzeniem drzewa Kiedy weze l podlega podziale, listy sa podzielone i sa skojarzone z odpowiednimi nastepnikami Listy sa zapisane na dysku w razie potrzeby

11 Przyk lad

12 Struktura danych w SPRINT SPRINT używa: indeksu Gini do oceny jakości testu typu (a c) dla atrybutów rzeczywistych testu typu (a V ) dla atrybutów symbolicznych Histogram: rozk lad klas decyzyjnych zbadanego zbioru danych Dla atrybutu rzeczywistego dwa histogramy: C below : histogram dla danych poniżej wartości progowej C above : histogram dla danych powyżej wartości progowej Dla atrybutu symbolicznego jeden histogram zwany count matrix

13 Przyk lad Car Type family sports sports family Class High High High Low rid Punkt podziału Age Class rid 17 High 1 20 High 5 23 High 0 32 Low 4 truck Low 4 43 High 2 family high 5 68 Low 3 Count matrix H L family 2 1 sports 2 0 truck 0 1 Histogram klas

14 Outline 1 2

15 Wyznaczanie atrybutu rzeczywistego
16 Wyznaczanie atrybutu symbolicznego Lista wartości CarType Car Type Class rid family High 0 sports High 1 sports High 2 family Low 3 truck Low 4 family high 5 Count Matrix H L family 2 1 sports 2 0 truck Wyznacz macierz rozkładu klas obiektów w danym węźle 2. Używając algorytmu aproksymacyjnego (w SLIQ) wyznacz podzbiór wartości V D a t. żeby test (a V) był optymalny
 wyznacz podzbiór wartości V D a t.")
17 Outline 1 2

18 G lówna idea Każda lista jest podzielona na dwie listy Atrybut zawierajacy test: Podziel wartości listy zgodnie z testem Atrybut niewierajacy test: Nie można korzystać z informacji w funkcji testu. Skorzystaj z rid Skorzystaj z tablicy haszujacej Przy podziale atrybutu zawierajacy test: wstaw rid rekordów do tablicy haszujacej. Tablica haszujaca: informacje o tym do którego poddrzewa rekord zosta l przeniesiony. Algorytm: Przegladaj kolejny rekord listy Dla każdego rekordu wyznacz (na podstawie tablicy haszujacej) poddrzewo, do którego rekord ma być przeniesiony

19 Problem: zbyt duża tablica haszujaca Algorytm: Krok 1: Podziel zbiór wartości atrybutu testujacego na ma le porcje tak, żeby tablica haszujaca mieści la sie w pamieci Krok 2: Dla każdej porcji Podziel rekordy atrybutu testujacego do w laściwego podrzewa Buduj tablice haszujacej Przegladaj kolejny rekord atrybutu nietestujacego i przynieś go do odpowiedniego poddrzewa jeśli rekord wystepuje w tablicy haszujacej Krok 3: Jeśli wszystkie rekordy zosta ly przydzielone do poddrzew stop, wpp. idź do krok 2

20 Outline 1 2

21 Równoleg ly SPRINT Listy wartości atrybutów sa równo podzielone Atrybut rzeczywisty: sortuj zbiór wartości i podziel go na równe przedzia ly Atrybut numeryczny: podziel wed lug rid Każdy procesor ma jedna cześć każdej listy
22 Dla atrybutu rzeczywistego: Każdy procesor ma przedzia l wartości atrybutu Każdy procesor inicjalizuje C below i C above uwzgledniaj ac rozk lad klas w innych procesorach Każdy procesor przeglada swoja liste i wyznacza najlepsza lokalna wartość progowa Procesory komunikuja sie w celu znalezienia globalnie najlepszego ciecia Dla atrybutu symbolicznego: Każdy procesor buduje lokalne count matrix i wysy la wynik do centralnego procesora Centralny procesor oblicza globalny count matrix Procesory wyznaczaja najlepszy podzia l na podstawie globalnego count matrix
23 Przyk lad Age Class rid 17 High 1 20 High 5 23 High 0 Procesor 0 Car Type Class rid family High 0 sports High 1 sports High 2 Age Class rid 32 Low 4 43 High 2 68 Low 3 Procesor 1 Car Type Class rid family Low 3 truck Low 4 family high 5
24 Podzia l atrybutu zawierajacy test: Każdy procesor wyznacza poddrzewa, do których rekordy w lokalnej liście bed a przeniesione Procesory wymieniaja ze soba informacje rids, poddrzewo Podzia l pozosta lych atrybutów: Po otrzymaniu informacji ze wszystkich procesorów każdy procesor buduje tablice haszujac a i wykonuje podzia ly dla pozosta lych atrybutów
25 Wady algorytmu SPRINT Dodatkowe struktury danych Nieefektywny jeśli atrybut ma dużo wartości Nie wykorzystuje mocnych narz edzi systemów baz danych
Wyk lad 7: Drzewa decyzyjne dla dużych zbiorów danych
 Wyk lad 7: Drzewa decyzyjne dla dużych zbiorów danych Nguyen Hung Son Nguyen Hung Son () Data mining 1 / 39 Funkcja rekurencyjna buduj drzewo(u, dec, T): 1: if (kryterium stopu(u, dec) = true) then 2:
Wyk lad 7: Drzewa decyzyjne dla dużych zbiorów danych Nguyen Hung Son Nguyen Hung Son () Data mining 1 / 39 Funkcja rekurencyjna buduj drzewo(u, dec, T): 1: if (kryterium stopu(u, dec) = true) then 2:
Drzewa decyzyjne. Nguyen Hung Son. Nguyen Hung Son () DT 1 / 34
 DT 1 / 34") Drzewa decyzyjne Nguyen Hung Son Nguyen Hung Son () DT 1 / 34 Outline 1 Wprowadzenie Definicje Funkcje testu Optymalne drzewo 2 Konstrukcja drzew decyzyjnych Ogólny schemat Kryterium wyboru testu Przycinanie
Drzewa decyzyjne Nguyen Hung Son Nguyen Hung Son () DT 1 / 34 Outline 1 Wprowadzenie Definicje Funkcje testu Optymalne drzewo 2 Konstrukcja drzew decyzyjnych Ogólny schemat Kryterium wyboru testu Przycinanie
Systemy decyzyjne Wyk lad 4: Drzewa decyzyjne
 Systemy decyzyjne Wyk lad 4: Outline Wprowadzenie 1 Wprowadzenie 2 Problem brakujacych wartości 3 Co to jest drzewo decyzyjne Jest to struktura drzewiasta, w której wez ly wewnetrzne zawieraja testy na
Systemy decyzyjne Wyk lad 4: Outline Wprowadzenie 1 Wprowadzenie 2 Problem brakujacych wartości 3 Co to jest drzewo decyzyjne Jest to struktura drzewiasta, w której wez ly wewnetrzne zawieraja testy na
Systemy decyzyjne Wykªad 5: Drzewa decyzyjne
 Nguyen Hung Son () W5: Drzewa decyzyjne 1 / 38 Systemy decyzyjne Wykªad 5: Drzewa decyzyjne Nguyen Hung Son Przykªad: klasyfikacja robotów Nguyen Hung Son () W5: Drzewa decyzyjne 2 / 38 Przykªad: drzewo
Nguyen Hung Son () W5: Drzewa decyzyjne 1 / 38 Systemy decyzyjne Wykªad 5: Drzewa decyzyjne Nguyen Hung Son Przykªad: klasyfikacja robotów Nguyen Hung Son () W5: Drzewa decyzyjne 2 / 38 Przykªad: drzewo
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
Podstawy Informatyki. Metody dostępu do danych
 Podstawy Informatyki c.d. alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Bazy danych Struktury danych Średni czas odszukania rekordu Drzewa binarne w pamięci dyskowej 2 Sformułowanie
Podstawy Informatyki c.d. alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Bazy danych Struktury danych Średni czas odszukania rekordu Drzewa binarne w pamięci dyskowej 2 Sformułowanie
Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
 : idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
: idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne
 WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
Drzewa podstawowe poj
 Drzewa podstawowe poj ecia drzewo graf reprezentujacy regularna strukture wskaźnikowa, gdzie każdy element zawiera dwa lub wiecej wskaźników (ponumerowanych) do takich samych elementów; wez ly (albo wierzcho
Drzewa podstawowe poj ecia drzewo graf reprezentujacy regularna strukture wskaźnikowa, gdzie każdy element zawiera dwa lub wiecej wskaźników (ponumerowanych) do takich samych elementów; wez ly (albo wierzcho
Drzewa AVL definicje
 Drzewa AVL definicje Uporzadkowane drzewo binarne jest drzewem AVL 1, jeśli dla każdego wez la różnica wysokości dwóch jego poddrzew wynosi co najwyżej 1. M D S C H F K Z typowe drzewo AVL minimalne drzewa
Drzewa AVL definicje Uporzadkowane drzewo binarne jest drzewem AVL 1, jeśli dla każdego wez la różnica wysokości dwóch jego poddrzew wynosi co najwyżej 1. M D S C H F K Z typowe drzewo AVL minimalne drzewa
Przykładowe B+ drzewo
 Przykładowe B+ drzewo 3 8 1 3 7 8 12 Jak obliczyć rząd indeksu p Dane: rozmiar klucza V, rozmiar wskaźnika do bloku P, rozmiar bloku B, liczba rekordów w indeksowanym pliku danych r i liczba bloków pliku
Przykładowe B+ drzewo 3 8 1 3 7 8 12 Jak obliczyć rząd indeksu p Dane: rozmiar klucza V, rozmiar wskaźnika do bloku P, rozmiar bloku B, liczba rekordów w indeksowanym pliku danych r i liczba bloków pliku
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Klasyfikacja. Indeks Gini Zysk informacyjny. Eksploracja danych. Klasyfikacja wykład 2
 Klasyfikacja Indeks Gini Zysk informacyjny Klasyfikacja wykład 2 Kontynuujemy prezentacje metod klasyfikacji. Na wykładzie zostaną przedstawione dwa podstawowe algorytmy klasyfikacji oparte o indukcję
Klasyfikacja Indeks Gini Zysk informacyjny Klasyfikacja wykład 2 Kontynuujemy prezentacje metod klasyfikacji. Na wykładzie zostaną przedstawione dwa podstawowe algorytmy klasyfikacji oparte o indukcję
< K (2) = ( Adams, John ), P (2) = adres bloku 2 > < K (1) = ( Aaron, Ed ), P (1) = adres bloku 1 >
 = ( Adams, John ), P (2) = adres bloku 2 > < K (1) = ( Aaron, Ed ), P (1) = adres bloku 1 >") Typy indeksów Indeks jest zakładany na atrybucie relacji atrybucie indeksowym (ang. indexing field). Indeks zawiera wartości atrybutu indeksowego wraz ze wskaźnikami do wszystkich bloków dyskowych zawierających
Typy indeksów Indeks jest zakładany na atrybucie relacji atrybucie indeksowym (ang. indexing field). Indeks zawiera wartości atrybutu indeksowego wraz ze wskaźnikami do wszystkich bloków dyskowych zawierających
Co to są drzewa decyzji
 Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
Bazy danych. Andrzej Łachwa, UJ, /15
 Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 15/15 PYTANIA NA EGZAMIN LICENCJACKI 84. B drzewa definicja, algorytm wyszukiwania w B drzewie. Zob. Elmasri:
Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 15/15 PYTANIA NA EGZAMIN LICENCJACKI 84. B drzewa definicja, algorytm wyszukiwania w B drzewie. Zob. Elmasri:
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II
 Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy i. Wykład 5: Drzewa. Dr inż. Paweł Kasprowski
 Algorytmy i struktury danych Wykład 5: Drzewa Dr inż. Paweł Kasprowski pawel@kasprowski.pl Drzewa Struktury przechowywania danych podobne do list ale z innymi zasadami wskazywania następników Szczególny
Algorytmy i struktury danych Wykład 5: Drzewa Dr inż. Paweł Kasprowski pawel@kasprowski.pl Drzewa Struktury przechowywania danych podobne do list ale z innymi zasadami wskazywania następników Szczególny
Wyk lad 8: Leniwe metody klasyfikacji
 Wyk lad 8: Leniwe metody Wydzia l MIM, Uniwersytet Warszawski Outline 1 2 lazy vs. eager learning lazy vs. eager learning Kiedy stosować leniwe techniki? Eager learning: Buduje globalna hipoteze Zaleta:
Wyk lad 8: Leniwe metody Wydzia l MIM, Uniwersytet Warszawski Outline 1 2 lazy vs. eager learning lazy vs. eager learning Kiedy stosować leniwe techniki? Eager learning: Buduje globalna hipoteze Zaleta:
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Równoleg le sortowanie przez scalanie
 Równoleg le sortowanie przez scalanie Bartosz Zieliński 1 Zadanie Napisanie programu sortuj acego przez scalanie tablicȩ wygenerowanych losowo liczb typu double w którym każda z procedur scalania odbywa
Równoleg le sortowanie przez scalanie Bartosz Zieliński 1 Zadanie Napisanie programu sortuj acego przez scalanie tablicȩ wygenerowanych losowo liczb typu double w którym każda z procedur scalania odbywa
Metody teorii gier. ALP520 - Wykład z Algorytmów Probabilistycznych p.2
 Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Definicja pliku kratowego
 Pliki kratowe Definicja pliku kratowego Plik kratowy (ang grid file) jest strukturą wspierająca realizację zapytań wielowymiarowych Uporządkowanie rekordów, zawierających dane wielowymiarowe w pliku kratowym,
Pliki kratowe Definicja pliku kratowego Plik kratowy (ang grid file) jest strukturą wspierająca realizację zapytań wielowymiarowych Uporządkowanie rekordów, zawierających dane wielowymiarowe w pliku kratowym,
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
2012-01-16 PLAN WYKŁADU BAZY DANYCH INDEKSY - DEFINICJE. Indeksy jednopoziomowe Indeksy wielopoziomowe Indeksy z użyciem B-drzew i B + -drzew
 0-0-6 PLAN WYKŁADU Indeksy jednopoziomowe Indeksy wielopoziomowe Indeksy z użyciem B-drzew i B + -drzew BAZY DANYCH Wykład 9 dr inż. Agnieszka Bołtuć INDEKSY - DEFINICJE Indeksy to pomocnicze struktury
0-0-6 PLAN WYKŁADU Indeksy jednopoziomowe Indeksy wielopoziomowe Indeksy z użyciem B-drzew i B + -drzew BAZY DANYCH Wykład 9 dr inż. Agnieszka Bołtuć INDEKSY - DEFINICJE Indeksy to pomocnicze struktury
Bazy danych - BD. Indeksy. Wykład przygotował: Robert Wrembel. BD wykład 7 (1)
") Indeksy Wykład przygotował: Robert Wrembel BD wykład 7 (1) 1 Plan wykładu Problematyka indeksowania Podział indeksów i ich charakterystyka indeks podstawowy, zgrupowany, wtórny indeks rzadki, gęsty Indeks
Indeksy Wykład przygotował: Robert Wrembel BD wykład 7 (1) 1 Plan wykładu Problematyka indeksowania Podział indeksów i ich charakterystyka indeks podstawowy, zgrupowany, wtórny indeks rzadki, gęsty Indeks
Indeksy. Wprowadzenie. Indeksy jednopoziomowe indeks podstawowy indeks zgrupowany indeks wtórny. Indeksy wielopoziomowe
 1 Plan rozdziału 2 Indeksy Indeksy jednopoziomowe indeks podstawowy indeks zgrupowany indeks wtórny Indeksy wielopoziomowe Indeksy typu B-drzewo B-drzewo B+ drzewo B* drzewo Wprowadzenie 3 Indeks podstawowy
1 Plan rozdziału 2 Indeksy Indeksy jednopoziomowe indeks podstawowy indeks zgrupowany indeks wtórny Indeksy wielopoziomowe Indeksy typu B-drzewo B-drzewo B+ drzewo B* drzewo Wprowadzenie 3 Indeks podstawowy
Problem 1 prec f max. Algorytm Lawlera dla problemu 1 prec f max. 1 procesor. n zadań T 1,..., T n (ich zbiór oznaczamy przez T )
") Joanna Berlińska Algorytmika w projektowaniu systemów - ćwiczenia 1 1 Problem 1 prec f max 1 procesor (ich zbiór oznaczamy przez T ) czas wykonania zadania T j wynosi p j z zadaniem T j związana jest niemalejąca
Joanna Berlińska Algorytmika w projektowaniu systemów - ćwiczenia 1 1 Problem 1 prec f max 1 procesor (ich zbiór oznaczamy przez T ) czas wykonania zadania T j wynosi p j z zadaniem T j związana jest niemalejąca
Kolejka priorytetowa. Często rozważa się kolejki priorytetowe, w których poszukuje się elementu minimalnego zamiast maksymalnego.
 Kolejki Kolejka priorytetowa Kolejka priorytetowa (ang. priority queue) to struktura danych pozwalająca efektywnie realizować następujące operacje na zbiorze dynamicznym, którego elementy pochodzą z określonego
Kolejki Kolejka priorytetowa Kolejka priorytetowa (ang. priority queue) to struktura danych pozwalająca efektywnie realizować następujące operacje na zbiorze dynamicznym, którego elementy pochodzą z określonego
PRZYSPIESZENIE KNN. Ulepszone metody indeksowania przestrzeni danych: R-drzewo, R*-drzewo, SS-drzewo, SR-drzewo.
 PRZYSPIESZENIE KNN Ulepszone metody indeksowania przestrzeni danych: R-drzewo, R*-drzewo, SS-drzewo, SR-drzewo. Plan wykładu Klasyfikacja w oparciu o przykładach Problem indeksowania przestrzeni obiektów
PRZYSPIESZENIE KNN Ulepszone metody indeksowania przestrzeni danych: R-drzewo, R*-drzewo, SS-drzewo, SR-drzewo. Plan wykładu Klasyfikacja w oparciu o przykładach Problem indeksowania przestrzeni obiektów
Wyk lad 9 Baza i wymiar przestrzeni liniowej
 Wyk lad 9 Baza i wymiar liniowej Baza liniowej Niech V bedzie nad cia lem K Powiemy, że zbiór wektorów {α,, α n } jest baza V, jeżeli wektory α,, α n sa liniowo niezależne oraz generuja V tzn V = L(α,,
Wyk lad 9 Baza i wymiar liniowej Baza liniowej Niech V bedzie nad cia lem K Powiemy, że zbiór wektorów {α,, α n } jest baza V, jeżeli wektory α,, α n sa liniowo niezależne oraz generuja V tzn V = L(α,,
Podstawy Informatyki. Wykład 6. Struktury danych
 Podstawy Informatyki Wykład 6 Struktury danych Stałe i zmienne Podstawowymi obiektami występującymi w programie są stałe i zmienne. Ich znaczenie jest takie samo jak w matematyce. Stałe i zmienne muszą
Podstawy Informatyki Wykład 6 Struktury danych Stałe i zmienne Podstawowymi obiektami występującymi w programie są stałe i zmienne. Ich znaczenie jest takie samo jak w matematyce. Stałe i zmienne muszą
Struktury danych i złożoność obliczeniowa Wykład 2. Prof. dr hab. inż. Jan Magott
 Struktury danych i złożoność obliczeniowa Wykład 2. Prof. dr hab. inż. Jan Magott Metody konstrukcji algorytmów: Siłowa (ang. brute force), Dziel i zwyciężaj (ang. divide-and-conquer), Zachłanna (ang.
Struktury danych i złożoność obliczeniowa Wykład 2. Prof. dr hab. inż. Jan Magott Metody konstrukcji algorytmów: Siłowa (ang. brute force), Dziel i zwyciężaj (ang. divide-and-conquer), Zachłanna (ang.
Indukowane Reguły Decyzyjne I. Wykład 3
 Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
Wnioskowanie Boolowskie i teoria zbiorów przybli»onych
 Wnioskowanie Boolowskie i teoria zbiorów przybli»onych 4 Zbiory przybli»one Wprowadzenie do teorii zbiorów przybli»onych Zªo»ono± problemu szukania reduktów 5 Wnioskowanie Boolowskie w obliczaniu reduktów
Wnioskowanie Boolowskie i teoria zbiorów przybli»onych 4 Zbiory przybli»one Wprowadzenie do teorii zbiorów przybli»onych Zªo»ono± problemu szukania reduktów 5 Wnioskowanie Boolowskie w obliczaniu reduktów
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Paradygmaty programowania. Paradygmaty programowania
 Paradygmaty programowania Paradygmaty programowania Dr inż. Andrzej Grosser Cz estochowa, 2013 2 Spis treści 1. Zadanie 2 5 1.1. Wprowadzenie.................................. 5 1.2. Wskazówki do zadania..............................
Paradygmaty programowania Paradygmaty programowania Dr inż. Andrzej Grosser Cz estochowa, 2013 2 Spis treści 1. Zadanie 2 5 1.1. Wprowadzenie.................................. 5 1.2. Wskazówki do zadania..............................
Algorytmy i Struktury Danych
 Algorytmy i Struktury Danych Kopce Bożena Woźna-Szcześniak bwozna@gmail.com Jan Długosz University, Poland Wykład 11 Bożena Woźna-Szcześniak (AJD) Algorytmy i Struktury Danych Wykład 11 1 / 69 Plan wykładu
Algorytmy i Struktury Danych Kopce Bożena Woźna-Szcześniak bwozna@gmail.com Jan Długosz University, Poland Wykład 11 Bożena Woźna-Szcześniak (AJD) Algorytmy i Struktury Danych Wykład 11 1 / 69 Plan wykładu
Przykład eksploracji danych o naturze statystycznej Próba 1 wartości zmiennej losowej odległość
 Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
celu przyjmijmy: min x 0 = n t Zadanie transportowe nazywamy zbilansowanym gdy podaż = popyt, czyli n
 123456789 wyk lad 9 Zagadnienie transportowe Mamy n punktów wysy lajacych towar i t punktów odbierajacych. Istnieje droga od każdego dostawcy do każdego odbiorcy i znany jest koszt transportu jednostki
123456789 wyk lad 9 Zagadnienie transportowe Mamy n punktów wysy lajacych towar i t punktów odbierajacych. Istnieje droga od każdego dostawcy do każdego odbiorcy i znany jest koszt transportu jednostki
Algorytmy i Struktury Danych, 2. ćwiczenia
 Algorytmy i Struktury Danych, 2. ćwiczenia 2015-10-09 Spis treści 1 Szybkie potęgowanie 1 2 Liczby Fibonacciego 2 3 Dowód, że n 1 porównań jest potrzebne do znajdowania minimum 2 4 Optymalny algorytm do
Algorytmy i Struktury Danych, 2. ćwiczenia 2015-10-09 Spis treści 1 Szybkie potęgowanie 1 2 Liczby Fibonacciego 2 3 Dowód, że n 1 porównań jest potrzebne do znajdowania minimum 2 4 Optymalny algorytm do
ALGORYTMY I STRUKTURY DANYCH
 ALGORYTMY I STRUKTURY DANYCH Temat : Drzewa zrównoważone, sortowanie drzewiaste Wykładowca: dr inż. Zbigniew TARAPATA e-mail: Zbigniew.Tarapata@isi.wat.edu.pl http://www.tarapata.strefa.pl/p_algorytmy_i_struktury_danych/
ALGORYTMY I STRUKTURY DANYCH Temat : Drzewa zrównoważone, sortowanie drzewiaste Wykładowca: dr inż. Zbigniew TARAPATA e-mail: Zbigniew.Tarapata@isi.wat.edu.pl http://www.tarapata.strefa.pl/p_algorytmy_i_struktury_danych/
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Podstawy programowania 2. Temat: Drzewa binarne. Przygotował: mgr inż. Tomasz Michno
 Instrukcja laboratoryjna 5 Podstawy programowania 2 Temat: Drzewa binarne Przygotował: mgr inż. Tomasz Michno 1 Wstęp teoretyczny Drzewa są jedną z częściej wykorzystywanych struktur danych. Reprezentują
Instrukcja laboratoryjna 5 Podstawy programowania 2 Temat: Drzewa binarne Przygotował: mgr inż. Tomasz Michno 1 Wstęp teoretyczny Drzewa są jedną z częściej wykorzystywanych struktur danych. Reprezentują
Struktury danych i złozoność obliczeniowa. Prof. dr hab. inż. Jan Magott
 Struktury danych i złozoność obliczeniowa Prof. dr hab. inż. Jan Magott Formy zajęć: Wykład 1 godz., Ćwiczenia 1 godz., Projekt 2 godz.. Adres strony z materiałami do wykładu: http://www.zio.iiar.pwr.wroc.pl/sdizo.html
Struktury danych i złozoność obliczeniowa Prof. dr hab. inż. Jan Magott Formy zajęć: Wykład 1 godz., Ćwiczenia 1 godz., Projekt 2 godz.. Adres strony z materiałami do wykładu: http://www.zio.iiar.pwr.wroc.pl/sdizo.html
Programowanie w VB Proste algorytmy sortowania
 Programowanie w VB Proste algorytmy sortowania Sortowanie bąbelkowe Algorytm sortowania bąbelkowego polega na porównywaniu par elementów leżących obok siebie i, jeśli jest to potrzebne, zmienianiu ich
Programowanie w VB Proste algorytmy sortowania Sortowanie bąbelkowe Algorytm sortowania bąbelkowego polega na porównywaniu par elementów leżących obok siebie i, jeśli jest to potrzebne, zmienianiu ich
Wybrane zadania przygotowujące do egzaminu z ISO- cz. 2. dr Piotr Wąsiewicz
 Wybrane zadania przygotowujące do egzaminu z ISO- cz. 2 dr Piotr Wąsiewicz. Ze zbioru treningowego podanego w tabeli poniżej wykreować metodą zstępującej konstrukcji drzewo decyzyjne(jak najmniej rozbudowane-
Wybrane zadania przygotowujące do egzaminu z ISO- cz. 2 dr Piotr Wąsiewicz. Ze zbioru treningowego podanego w tabeli poniżej wykreować metodą zstępującej konstrukcji drzewo decyzyjne(jak najmniej rozbudowane-
Algorytmy i struktury danych. Co dziś? Tytułem przypomnienia metoda dziel i zwyciężaj. Wykład VIII Elementarne techniki algorytmiczne
 Algorytmy i struktury danych Wykład VIII Elementarne techniki algorytmiczne Co dziś? Algorytmy zachłanne (greedyalgorithms) 2 Tytułem przypomnienia metoda dziel i zwyciężaj. Problem można podzielić na
Algorytmy i struktury danych Wykład VIII Elementarne techniki algorytmiczne Co dziś? Algorytmy zachłanne (greedyalgorithms) 2 Tytułem przypomnienia metoda dziel i zwyciężaj. Problem można podzielić na
Indeksowanie w bazach danych
 w bazach Katedra Informatyki Stosowanej AGH 5grudnia2013 Outline 1 2 3 4 Czym jest indeks? Indeks to struktura, która ma przyspieszyć wyszukiwanie. Indeks definiowany jest dla atrybutów, które nazywamy
w bazach Katedra Informatyki Stosowanej AGH 5grudnia2013 Outline 1 2 3 4 Czym jest indeks? Indeks to struktura, która ma przyspieszyć wyszukiwanie. Indeks definiowany jest dla atrybutów, które nazywamy
Optymalizacja zapytań. Proces przetwarzania i obliczania wyniku zapytania (wyrażenia algebry relacji) w SZBD
 w SZBD") Optymalizacja zapytań Proces przetwarzania i obliczania wyniku zapytania (wyrażenia algebry relacji) w SZBD Elementy optymalizacji Analiza zapytania i przekształcenie go do lepszej postaci. Oszacowanie
Optymalizacja zapytań Proces przetwarzania i obliczania wyniku zapytania (wyrażenia algebry relacji) w SZBD Elementy optymalizacji Analiza zapytania i przekształcenie go do lepszej postaci. Oszacowanie
Analiza zrekonstruowanych śladów w danych pp 13 TeV
 Analiza zrekonstruowanych śladów w danych pp 13 TeV Odtwarzanie rozk ladów za pomoc a danych Monte Carlo Jakub Cholewiński, pod opiek a dr hab. Krzysztofa Woźniaka 31 lipca 2015 r. Jakub Cholewiński, pod
Analiza zrekonstruowanych śladów w danych pp 13 TeV Odtwarzanie rozk ladów za pomoc a danych Monte Carlo Jakub Cholewiński, pod opiek a dr hab. Krzysztofa Woźniaka 31 lipca 2015 r. Jakub Cholewiński, pod
prowadzący dr ADRIAN HORZYK /~horzyk e-mail: horzyk@agh tel.: 012-617 Konsultacje paw. D-13/325
 PODSTAWY INFORMATYKI WYKŁAD 8. prowadzący dr ADRIAN HORZYK http://home home.agh.edu.pl/~ /~horzyk e-mail: horzyk@agh agh.edu.pl tel.: 012-617 617-4319 Konsultacje paw. D-13/325 DRZEWA Drzewa to rodzaj
PODSTAWY INFORMATYKI WYKŁAD 8. prowadzący dr ADRIAN HORZYK http://home home.agh.edu.pl/~ /~horzyk e-mail: horzyk@agh agh.edu.pl tel.: 012-617 617-4319 Konsultacje paw. D-13/325 DRZEWA Drzewa to rodzaj
Dynamiczny przydział pamięci w języku C. Dynamiczne struktury danych. dr inż. Jarosław Forenc. Metoda 1 (wektor N M-elementowy)
") Rok akademicki 2012/2013, Wykład nr 2 2/25 Plan wykładu nr 2 Informatyka 2 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr III, studia niestacjonarne I stopnia Rok akademicki 2012/2013
Rok akademicki 2012/2013, Wykład nr 2 2/25 Plan wykładu nr 2 Informatyka 2 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr III, studia niestacjonarne I stopnia Rok akademicki 2012/2013
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Algorytmy i struktury danych
 Algorytmy i struktury danych Proste algorytmy sortowania Witold Marańda maranda@dmcs.p.lodz.pl 1 Pojęcie sortowania Sortowaniem nazywa się proces ustawiania zbioru obiektów w określonym porządku Sortowanie
Algorytmy i struktury danych Proste algorytmy sortowania Witold Marańda maranda@dmcs.p.lodz.pl 1 Pojęcie sortowania Sortowaniem nazywa się proces ustawiania zbioru obiektów w określonym porządku Sortowanie
Drzewa binarne. Drzewo binarne to dowolny obiekt powstały zgodnie z regułami: jest drzewem binarnym Jeśli T 0. jest drzewem binarnym Np.
 Drzewa binarne Drzewo binarne to dowolny obiekt powstały zgodnie z regułami: jest drzewem binarnym Jeśli T 0 i T 1 są drzewami binarnymi to T 0 T 1 jest drzewem binarnym Np. ( ) ( ( )) Wielkość drzewa
Drzewa binarne Drzewo binarne to dowolny obiekt powstały zgodnie z regułami: jest drzewem binarnym Jeśli T 0 i T 1 są drzewami binarnymi to T 0 T 1 jest drzewem binarnym Np. ( ) ( ( )) Wielkość drzewa
Wyk lad 5 W lasności wyznaczników. Macierz odwrotna
 Wyk lad 5 W lasności wyznaczników Macierz odwrotna 1 Operacje elementarne na macierzach Bardzo ważne znaczenie w algebrze liniowej odgrywaja tzw operacje elementarne na wierszach lub kolumnach macierzy
Wyk lad 5 W lasności wyznaczników Macierz odwrotna 1 Operacje elementarne na macierzach Bardzo ważne znaczenie w algebrze liniowej odgrywaja tzw operacje elementarne na wierszach lub kolumnach macierzy
Programowanie dynamiczne cz. 2
 Programowanie dynamiczne cz. 2 Wykład 7 16 kwietnia 2019 (Wykład 7) Programowanie dynamiczne cz. 2 16 kwietnia 2019 1 / 19 Outline 1 Mnożenie ciągu macierzy Konstruowanie optymalnego rozwiązania 2 Podstawy
Programowanie dynamiczne cz. 2 Wykład 7 16 kwietnia 2019 (Wykład 7) Programowanie dynamiczne cz. 2 16 kwietnia 2019 1 / 19 Outline 1 Mnożenie ciągu macierzy Konstruowanie optymalnego rozwiązania 2 Podstawy
WSTĘP DO INFORMATYKI. Drzewa i struktury drzewiaste
 Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej WSTĘP DO INFORMATYKI Adrian Horzyk Drzewa i struktury drzewiaste www.agh.edu.pl DEFINICJA DRZEWA Drzewo
Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej WSTĘP DO INFORMATYKI Adrian Horzyk Drzewa i struktury drzewiaste www.agh.edu.pl DEFINICJA DRZEWA Drzewo
Wykład XII. optymalizacja w relacyjnych bazach danych
 Optymalizacja wyznaczenie spośród dopuszczalnych rozwiązań danego problemu, rozwiązania najlepszego ze względu na przyjęte kryterium jakości ( np. koszt, zysk, niezawodność ) optymalizacja w relacyjnych
Optymalizacja wyznaczenie spośród dopuszczalnych rozwiązań danego problemu, rozwiązania najlepszego ze względu na przyjęte kryterium jakości ( np. koszt, zysk, niezawodność ) optymalizacja w relacyjnych
CLUSTERING. Metody grupowania danych
 CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
Analiza algorytmów zadania podstawowe
 Analiza algorytmów zadania podstawowe Zadanie 1 Zliczanie Zliczaj(n) 1 r 0 2 for i 1 to n 1 3 do for j i + 1 to n 4 do for k 1 to j 5 do r r + 1 6 return r 0 Jaka wartość zostanie zwrócona przez powyższą
Analiza algorytmów zadania podstawowe Zadanie 1 Zliczanie Zliczaj(n) 1 r 0 2 for i 1 to n 1 3 do for j i + 1 to n 4 do for k 1 to j 5 do r r + 1 6 return r 0 Jaka wartość zostanie zwrócona przez powyższą
Wysokość drzewa Głębokość węzła
 Drzewa Drzewa Drzewo (ang. tree) zbiór węzłów powiązanych wskaźnikami, spójny i bez cykli. Drzewo posiada wyróżniony węzeł początkowy nazywany korzeniem (ang. root). Drzewo ukorzenione jest strukturą hierarchiczną.
Drzewa Drzewa Drzewo (ang. tree) zbiór węzłów powiązanych wskaźnikami, spójny i bez cykli. Drzewo posiada wyróżniony węzeł początkowy nazywany korzeniem (ang. root). Drzewo ukorzenione jest strukturą hierarchiczną.
Podstawy Informatyki Metody dostępu do danych
 Podstawy Informatyki Metody dostępu do danych alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Wprowadzenie Czym zajmuje się informatyka 2 Wprowadzenie Podstawowe problemy baz danych Struktury
Podstawy Informatyki Metody dostępu do danych alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Wprowadzenie Czym zajmuje się informatyka 2 Wprowadzenie Podstawowe problemy baz danych Struktury
Drzewa spinające MST dla grafów ważonych Maksymalne drzewo spinające Drzewo Steinera. Wykład 6. Drzewa cz. II
 Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem
Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem
Metody numeryczne I Równania nieliniowe
 Metody numeryczne I Równania nieliniowe Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/66 Równania nieliniowe 1. Równania nieliniowe z pojedynczym pierwiastkiem
Metody numeryczne I Równania nieliniowe Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/66 Równania nieliniowe 1. Równania nieliniowe z pojedynczym pierwiastkiem
Ćwiczenie 6. Hurtownie danych
 Ćwiczenie 6. Hurtownie danych Drzewa decyzyjne 1. Reprezentacja drzewa decyzyjnego Metody uczenia si e drzew decyzyjnych to najcz eściej stosowane algorytmy indukcji symbolicznej reprezentacji wiedzy z
Ćwiczenie 6. Hurtownie danych Drzewa decyzyjne 1. Reprezentacja drzewa decyzyjnego Metody uczenia si e drzew decyzyjnych to najcz eściej stosowane algorytmy indukcji symbolicznej reprezentacji wiedzy z
Wyk lad 7 Metoda eliminacji Gaussa. Wzory Cramera
 Wyk lad 7 Metoda eliminacji Gaussa Wzory Cramera Metoda eliminacji Gaussa Metoda eliminacji Gaussa polega na znalezieniu dla danego uk ladu a x + a 2 x 2 + + a n x n = b a 2 x + a 22 x 2 + + a 2n x n =
Wyk lad 7 Metoda eliminacji Gaussa Wzory Cramera Metoda eliminacji Gaussa Metoda eliminacji Gaussa polega na znalezieniu dla danego uk ladu a x + a 2 x 2 + + a n x n = b a 2 x + a 22 x 2 + + a 2n x n =
Aproksymacja kraw. Od wielu lokalnych cech (edge elements) do spójnej, jednowymiarowej. epnej aproksymacji
 do spójnej, jednowymiarowej. epnej aproksymacji") Aproksymacja kraw edzi Od wielu lokalnych cech (edge elements) do spójnej, jednowymiarowej cechy (edge). Różne podejścia: szukanie w pobliżu wst epnej aproksymacji transformacja Hough a. Wiedza o obiektach:
Aproksymacja kraw edzi Od wielu lokalnych cech (edge elements) do spójnej, jednowymiarowej cechy (edge). Różne podejścia: szukanie w pobliżu wst epnej aproksymacji transformacja Hough a. Wiedza o obiektach:
Ogólne wiadomości o grafach
 Ogólne wiadomości o grafach Algorytmy i struktury danych Wykład 5. Rok akademicki: / Pojęcie grafu Graf zbiór wierzchołków połączonych za pomocą krawędzi. Podstawowe rodzaje grafów: grafy nieskierowane,
Ogólne wiadomości o grafach Algorytmy i struktury danych Wykład 5. Rok akademicki: / Pojęcie grafu Graf zbiór wierzchołków połączonych za pomocą krawędzi. Podstawowe rodzaje grafów: grafy nieskierowane,
Klasyfikacja. Wprowadzenie. Klasyfikacja (1)
") Klasyfikacja Wprowadzenie Celem procesu klasyfikacji jest znalezienie ogólnego modelu podziału zbioru predefiniowanych klas obiektów na podstawie pewnego zbioru danych historycznych, a następnie, zastosowanie
Klasyfikacja Wprowadzenie Celem procesu klasyfikacji jest znalezienie ogólnego modelu podziału zbioru predefiniowanych klas obiektów na podstawie pewnego zbioru danych historycznych, a następnie, zastosowanie
stopie szaro ci piksela ( x, y)
") I. Wstp. Jednym z podstawowych zada analizy obrazu jest segmentacja. Jest to podział obrazu na obszary spełniajce pewne kryterium jednorodnoci. Jedn z najprostszych metod segmentacji obrazu jest progowanie.
I. Wstp. Jednym z podstawowych zada analizy obrazu jest segmentacja. Jest to podział obrazu na obszary spełniajce pewne kryterium jednorodnoci. Jedn z najprostszych metod segmentacji obrazu jest progowanie.
Wyk lad 6: Drzewa decyzyjne
 Wyk lad 6: Drzewa decyzyjne Outline 1 2 Konstrukcja drzew decyzyjnych Ogólny Kryterium wyboru testu Przycinanie drzew Problem brakujacych wartości 3 Soft cuts and soft Decision tree Co to jest drzewo decyzyjne
Wyk lad 6: Drzewa decyzyjne Outline 1 2 Konstrukcja drzew decyzyjnych Ogólny Kryterium wyboru testu Przycinanie drzew Problem brakujacych wartości 3 Soft cuts and soft Decision tree Co to jest drzewo decyzyjne
Wstęp do Programowania potok funkcyjny
 Wstęp do Programowania potok funkcyjny Marcin Kubica 2010/2011 Outline Zasada dziel i rządź i analiza złożoności 1 Zasada dziel i rządź i analiza złożoności Definition : Zbiór wartości: nieograniczonej
Wstęp do Programowania potok funkcyjny Marcin Kubica 2010/2011 Outline Zasada dziel i rządź i analiza złożoności 1 Zasada dziel i rządź i analiza złożoności Definition : Zbiór wartości: nieograniczonej
Złożoność i zagadnienia implementacyjne. Wybierz najlepszy atrybut i ustaw jako test w korzeniu. Stwórz gałąź dla każdej wartości atrybutu.
 Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Plan wykładu Generowanie
Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Plan wykładu Generowanie
METODA SYMPLEKS. Maciej Patan. Instytut Sterowania i Systemów Informatycznych Uniwersytet Zielonogórski
 METODA SYMPLEKS Maciej Patan Uniwersytet Zielonogórski WSTĘP Algorytm Sympleks najpotężniejsza metoda rozwiązywania programów liniowych Metoda generuje ciąg dopuszczalnych rozwiązań x k w taki sposób,
METODA SYMPLEKS Maciej Patan Uniwersytet Zielonogórski WSTĘP Algorytm Sympleks najpotężniejsza metoda rozwiązywania programów liniowych Metoda generuje ciąg dopuszczalnych rozwiązań x k w taki sposób,
BAZY DANYCH. Microsoft Access. Adrian Horzyk OPTYMALIZACJA BAZY DANYCH I TWORZENIE INDEKSÓW. Akademia Górniczo-Hutnicza
 BAZY DANYCH Microsoft Access OPTYMALIZACJA BAZY DANYCH I TWORZENIE INDEKSÓW Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki
BAZY DANYCH Microsoft Access OPTYMALIZACJA BAZY DANYCH I TWORZENIE INDEKSÓW Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki
Podstawy Programowania C++
 Wykład 3 - podstawowe konstrukcje Instytut Automatyki i Robotyki Warszawa, 2014 Wstęp Plan wykładu Struktura programu, instrukcja przypisania, podstawowe typy danych, zapis i odczyt danych, wyrażenia:
Wykład 3 - podstawowe konstrukcje Instytut Automatyki i Robotyki Warszawa, 2014 Wstęp Plan wykładu Struktura programu, instrukcja przypisania, podstawowe typy danych, zapis i odczyt danych, wyrażenia:
Wstęp do programowania. Listy. Piotr Chrząstowski-Wachtel
 Wstęp do programowania Listy Piotr Chrząstowski-Wachtel Do czego stosujemy listy? Listy stosuje się wszędzie tam, gdzie występuje duży rozrzut w możliwym rozmiarze danych, np. w reprezentacji grafów jeśli
Wstęp do programowania Listy Piotr Chrząstowski-Wachtel Do czego stosujemy listy? Listy stosuje się wszędzie tam, gdzie występuje duży rozrzut w możliwym rozmiarze danych, np. w reprezentacji grafów jeśli
Sortowanie przez scalanie
 Sortowanie przez scalanie Wykład 2 12 marca 2019 (Wykład 2) Sortowanie przez scalanie 12 marca 2019 1 / 17 Outline 1 Metoda dziel i zwyciężaj 2 Scalanie Niezmiennik pętli - poprawność algorytmu 3 Sortowanie
Sortowanie przez scalanie Wykład 2 12 marca 2019 (Wykład 2) Sortowanie przez scalanie 12 marca 2019 1 / 17 Outline 1 Metoda dziel i zwyciężaj 2 Scalanie Niezmiennik pętli - poprawność algorytmu 3 Sortowanie
Funkcje systemu Unix
 Funkcje systemu Unix Witold Paluszyński witold@ict.pwr.wroc.pl http://sequoia.ict.pwr.wroc.pl/ witold/ Copyright c 2002 2005 Witold Paluszyński All rights reserved. Niniejszy dokument zawiera materia ly
Funkcje systemu Unix Witold Paluszyński witold@ict.pwr.wroc.pl http://sequoia.ict.pwr.wroc.pl/ witold/ Copyright c 2002 2005 Witold Paluszyński All rights reserved. Niniejszy dokument zawiera materia ly
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Sztuczna Inteligencja Projekt
 Sztuczna Inteligencja Projekt Temat: Algorytm F-LEM1 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm F LEM 1. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu F LEM1
Sztuczna Inteligencja Projekt Temat: Algorytm F-LEM1 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm F LEM 1. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu F LEM1
System plików przykłady implementacji
 System plików przykłady implementacji Dariusz Wawrzyniak CP/M MS DOS ISO 9660 UNIX NTFS Plan wykładu System plików (2) Przykłady implementacji systemu plików (1) Przykłady implementacji systemu plików
System plików przykłady implementacji Dariusz Wawrzyniak CP/M MS DOS ISO 9660 UNIX NTFS Plan wykładu System plików (2) Przykłady implementacji systemu plików (1) Przykłady implementacji systemu plików
operacje porównania, a jeśli jest to konieczne ze względu na złe uporządkowanie porównywanych liczb zmieniamy ich kolejność, czyli przestawiamy je.
 Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Indukowane Reguły Decyzyjne I. Wykład 8
 Indukowane Reguły Decyzyjne I Wykład 8 IRD Wykład 8 Plan Powtórka Krzywa ROC = Receiver Operating Characteristic Wybór modelu Statystyka AUC ROC = pole pod krzywą ROC Wybór punktu odcięcia Reguły decyzyjne
Indukowane Reguły Decyzyjne I Wykład 8 IRD Wykład 8 Plan Powtórka Krzywa ROC = Receiver Operating Characteristic Wybór modelu Statystyka AUC ROC = pole pod krzywą ROC Wybór punktu odcięcia Reguły decyzyjne
wykład Organizacja plików Opracował: dr inż. Janusz DUDCZYK
 wykład Organizacja plików Opracował: dr inż. Janusz DUDCZYK 1 2 3 Pamięć zewnętrzna Pamięć zewnętrzna organizacja plikowa. Pamięć operacyjna organizacja blokowa. 4 Bufory bazy danych. STRUKTURA PROSTA
wykład Organizacja plików Opracował: dr inż. Janusz DUDCZYK 1 2 3 Pamięć zewnętrzna Pamięć zewnętrzna organizacja plikowa. Pamięć operacyjna organizacja blokowa. 4 Bufory bazy danych. STRUKTURA PROSTA
INDUKCJA DRZEW DECYZYJNYCH
 INDUKCJA DRZEW DECYZYJNYCH 1. Pojęcia podstawowe. 2. Idea algorytmów TDIT. 3. Kryteria oceny atrybutów entropia. 4. "Klasyczna" postać algorytmu ID3. 5. Przykład ilustracyjny. 6. Transformacja drzewa do
INDUKCJA DRZEW DECYZYJNYCH 1. Pojęcia podstawowe. 2. Idea algorytmów TDIT. 3. Kryteria oceny atrybutów entropia. 4. "Klasyczna" postać algorytmu ID3. 5. Przykład ilustracyjny. 6. Transformacja drzewa do
System plików przykłady. implementacji
 Dariusz Wawrzyniak Plan wykładu CP/M MS DOS ISO 9660 UNIX NTFS System plików (2) 1 Przykłady systemu plików (1) CP/M katalog zawiera blok kontrolny pliku (FCB), identyfikujący 16 jednostek alokacji (zawierający
Dariusz Wawrzyniak Plan wykładu CP/M MS DOS ISO 9660 UNIX NTFS System plików (2) 1 Przykłady systemu plików (1) CP/M katalog zawiera blok kontrolny pliku (FCB), identyfikujący 16 jednostek alokacji (zawierający
Obliczenia rozproszone z wykorzystaniem MPI
 Obliczenia rozproszone z wykorzystaniem Zarys wst u do podstaw :) Zak lad Metod Obliczeniowych Chemii UJ 8 sierpnia 2005 1 e konkretniej Jak szybko, i czemu tak wolno? 2 e szczegó lów 3 Dyspozytor Macierz
Obliczenia rozproszone z wykorzystaniem Zarys wst u do podstaw :) Zak lad Metod Obliczeniowych Chemii UJ 8 sierpnia 2005 1 e konkretniej Jak szybko, i czemu tak wolno? 2 e szczegó lów 3 Dyspozytor Macierz
Wstęp do Programowania potok funkcyjny
 i programowanie dynamiczne Wstęp do Programowania potok funkcyjny Marcin Kubica 2010/2011 i programowanie dynamiczne Outline 1 i programowanie dynamiczne i programowanie dynamiczne Rekurencyjny zapis rozwiązania
i programowanie dynamiczne Wstęp do Programowania potok funkcyjny Marcin Kubica 2010/2011 i programowanie dynamiczne Outline 1 i programowanie dynamiczne i programowanie dynamiczne Rekurencyjny zapis rozwiązania
Podstawowe techniki segmentacji obszarów
 Podstawowe techniki segmentacji obszarów lokalne punkty (pixels) sa w l aczane do regionu na podstawie w lasności ich najbliższego sasiedztwa; globalne punkty (pixels) sa grupowane na podstawie w lasności
Podstawowe techniki segmentacji obszarów lokalne punkty (pixels) sa w l aczane do regionu na podstawie w lasności ich najbliższego sasiedztwa; globalne punkty (pixels) sa grupowane na podstawie w lasności
Drzewo. Drzewo uporządkowane ma ponumerowanych (oznaczonych) następników. Drzewo uporządkowane składa się z węzłów, które zawierają następujące pola:
 następników. Drzewo uporządkowane składa się z węzłów, które zawierają następujące pola:") Drzewa Drzewa Drzewo (ang. tree) zbiór węzłów powiązanych wskaźnikami, spójny i bez cykli. Drzewo posiada wyróżniony węzeł początkowy nazywany korzeniem (ang. root). Drzewo ukorzenione jest strukturą hierarchiczną.
Drzewa Drzewa Drzewo (ang. tree) zbiór węzłów powiązanych wskaźnikami, spójny i bez cykli. Drzewo posiada wyróżniony węzeł początkowy nazywany korzeniem (ang. root). Drzewo ukorzenione jest strukturą hierarchiczną.
EGZAMIN - Wersja A. ALGORYTMY I STRUKTURY DANYCH Lisek89 opracowanie kartki od Pani dr E. Koszelew
 1. ( pkt) Dany jest algorytm, który dla dowolnej liczby naturalnej n, powinien wyznaczyd sumę kolejnych liczb naturalnych mniejszych od n. Wynik algorytmu jest zapisany w zmiennej suma. Algorytm i=1; suma=0;
1. ( pkt) Dany jest algorytm, który dla dowolnej liczby naturalnej n, powinien wyznaczyd sumę kolejnych liczb naturalnych mniejszych od n. Wynik algorytmu jest zapisany w zmiennej suma. Algorytm i=1; suma=0;
WYŻSZA SZKOŁA INFORMATYKI STOSOWANEJ I ZARZĄDZANIA
 Rekurencja - zdolność podprogramu (procedury) do wywoływania samego (samej) siebie Wieże Hanoi dane wejściowe - trzy kołki i N krążków o różniących się średnicach wynik - sekwencja ruchów przenosząca krążki
Rekurencja - zdolność podprogramu (procedury) do wywoływania samego (samej) siebie Wieże Hanoi dane wejściowe - trzy kołki i N krążków o różniących się średnicach wynik - sekwencja ruchów przenosząca krążki
REGU LY ASOCJACYJNE. Nguyen Hung Son. Wydzia l Matematyki, Informatyki i Mechaniki Uniwersytet Warszawski. 28.II i 6.III, 2008
 REGU LY ASOCJACYJNE Nguyen Hung Son Wydzia l Matematyki, Informatyki i Mechaniki Uniwersytet Warszawski 28.II i 6.III, 2008 Nguyen Hung Son (MIMUW) W2 28.II i 6.III, 2008 1 / 38 Outline 1 Dane transakcyjne
REGU LY ASOCJACYJNE Nguyen Hung Son Wydzia l Matematyki, Informatyki i Mechaniki Uniwersytet Warszawski 28.II i 6.III, 2008 Nguyen Hung Son (MIMUW) W2 28.II i 6.III, 2008 1 / 38 Outline 1 Dane transakcyjne
Typy danych. 2. Dane liczbowe 2.1. Liczby całkowite ze znakiem i bez znaku: 32768, -165, ; 2.2. Liczby rzeczywiste stało i zmienno pozycyjne:
 Strona 1 z 17 Typy danych 1. Dane tekstowe rozmaite słowa zapisane w różnych alfabetach: Rozwój metod badawczych pozwala na przesunięcie granicy poznawania otaczającego coraz dalej w głąb materii: 2. Dane
Strona 1 z 17 Typy danych 1. Dane tekstowe rozmaite słowa zapisane w różnych alfabetach: Rozwój metod badawczych pozwala na przesunięcie granicy poznawania otaczającego coraz dalej w głąb materii: 2. Dane
Przykłady problemów optymalizacyjnych
 Przykłady problemów optymalizacyjnych NAJKRÓTSZA ŚCIEŻKA W zadanym grafie G = (V, A) wyznacz najkrótsza ścieżkę od wierzchołka s do wierzchołka t. 2 7 5 5 3 9 5 s 8 3 1 t 2 2 5 5 1 5 4 Przykłady problemów
Przykłady problemów optymalizacyjnych NAJKRÓTSZA ŚCIEŻKA W zadanym grafie G = (V, A) wyznacz najkrótsza ścieżkę od wierzchołka s do wierzchołka t. 2 7 5 5 3 9 5 s 8 3 1 t 2 2 5 5 1 5 4 Przykłady problemów
Luty 2001 Algorytmy (4) 2000/2001
 2000/2001") Mając dany zbiór elementów, chcemy znaleźć w nim element największy (maksimum), bądź najmniejszy (minimum). We wszystkich naturalnych metodach znajdywania najmniejszego i największego elementu obecne jest
Mając dany zbiór elementów, chcemy znaleźć w nim element największy (maksimum), bądź najmniejszy (minimum). We wszystkich naturalnych metodach znajdywania najmniejszego i największego elementu obecne jest