Analiza wypowiedzi w celu rozpoznawania własności mówcy na przykładzie przemówień sejmowych
|
|
|
- Kajetan Piątkowski
- 8 lat temu
- Przeglądów:
Transkrypt
1 Analiza wypowiedzi w celu rozpoznawania własności mówcy na przykładzie przemówień sejmowych Piotr Przybyła, Paweł Teisseyre IPI PAN 28 kwietnia of 44

2 Plan prezentacji Wstęp Dane Korpus Mówcy Klasyfikacja Cechy Selekcja zmiennych Predykcja Wyniki Wydajność klasyfikacji Istotne zmienne Podsumowanie 2 of 44 Project co-financed by European Union within the framework of European Social Fund

3 Wprowadzenie Cel: Identyfikacja własności posłów, takich jak: płeć, wykształcenie, przynależność partyjna, roku urodzenia na podstawie ich wypowiedzi w polskim Sejmie. 3 of 44

4 Wprowadzenie Problemy związane z klasyfikacją tekstów: duża liczba cech p w porównaniu z liczbą rekordów n (u nas: p = , n = 8780) wymaga: redukcji wymiaru danych i/lub selekcji cech, zastosowania metod przystosowanych do sytuacji danych wysokowymiarowych. ekstrakcja cech wymaga użycia wiedzy i narzędzi lingwistycznych 4 of 44

5 Wprowadzenie Podobne problemy: Bardzo popularne zagadnienie: klasyfikacja płci/wieku na podstawie nieformalnych wypowiedzi (blogi, Twitter, posty na forum, czaty, itp.), np. praca Argamon et. al. (2007). Identyfikacja płci na podstawie bardziej formalnych tekstów (np. dokumenty z korpusu BNC), praca Koppel (2002). Przewidywanie przynależności partyjnej w oparciu o wypowiedzi polityków, praca Dahllöf, M. (2012). Przewidywanie opini na temat polityków w oparciu o nieformalne wypowiedzi, np. praca Conover et. al (2011). 5 of 44
.")
6 Wprowadzenie Cechy używane do predykcji płci/wieku: n-gramy słów (np. słowa mom, cried, freaked, gosh ) n-gramy części mowy klasy słów (np. słowa zakończone na -less) grupy słów (np. związane z rodziną: family, mother, children, father, kids, parents lub polityką: Bush, president, Iraq, Kerry, war, american, political) stylistyczne (np. procent słów mających więcej niż 6 liter) strukturalne (liczba paragrafów, liczba linków, liczba obrazków) słownikowe (liczba skrótów, liczba przekleństw, liczba spójników) liczba błędów językowych 6 of 44
 stylistyczne (np.")
7 Wprowadzenie Pytania: Czy jest możliwa efektywna klasyfikacja posłów (ze względu na płeć, wykształcenie, przynależność partyjną) na podstawie ich bardzo formalnych wypowiedzi? Czy możliwe jest oszacowanie roku urodzenia posła na podstawie wypowiedzi? Jakie cechy są najbardziej istotne? Jak ilość cech wpływa na jakość klasyfikacji? Które metody klasyfikacji/regresji działają efektywnie? W jakim stopniu odmiana czasownika w języku polskim ułatwia zadanie klasyfikacji płci? 7 of 44

8 Korpus sejmowy Korpus wypowiedzi sejmowych, opisany w Ogrodniczuk (2012) i dostępny via CLIP 6 kadencji (lata ), podzielonych na posiedzenia, podzielonych na wypowiedzi z przypisanym autorem. Oznaczony automatycznie (format NKJP): analiza morfosyntaktyczna (Morfeusz SGJP), ujednoznacznianie (PANTERA), grupy składniowe (Spejd), byty nazwane (NERF + Quant (z RAFAELa)), 300 milionów segmentów, pominęliśmy interpelacje i pytania (jedynie posiedzenia). 8 of 44
, byty nazwane (NERF + Quant (z RAFAELa)), 300 milionów segmentów, pominęliśmy interpelacje i pytania")

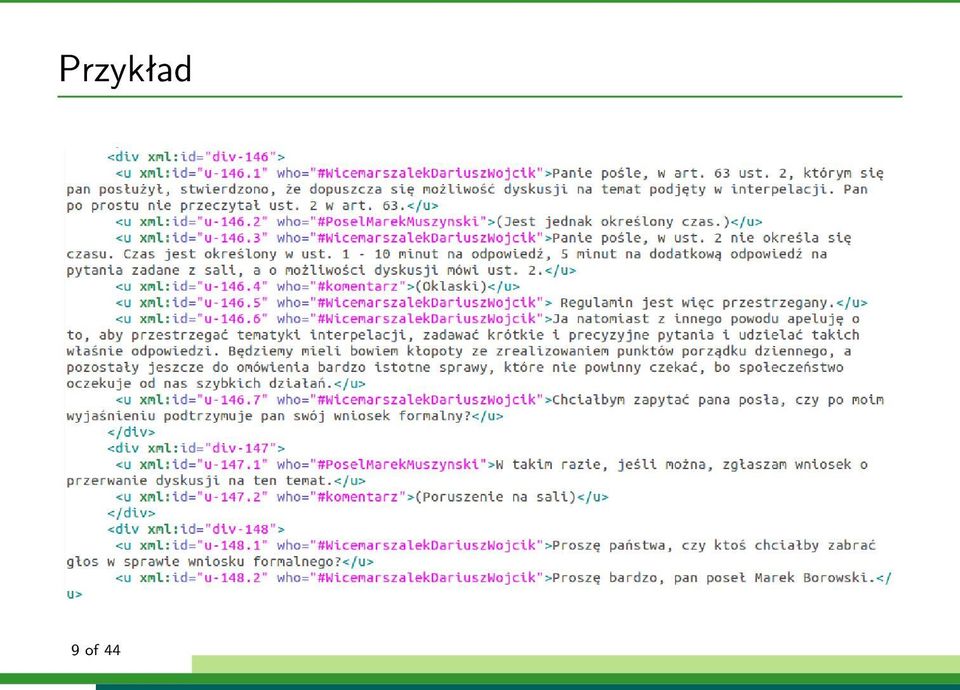
9 Przykład 9 of 44
, 1920-1985, µ=1953, σ=9,4 płeć (na podstawie imienia), kobiety: 17% partia (komitet wyborczy), 4-6 na kadencję")
10 Mówcy Automatyczne pozyskiwanie ze strony sejmu skryptem w Pythonie. 10 of 44 Wydobywane własności: rok urodzenia (ciągły, uwzględniając dzień i miesiąc), , µ=1953, σ=9,4 płeć (na podstawie imienia), kobiety: 17% partia (komitet wyborczy), 4-6 na kadencję wykształcenie, uproszczone do: podstawowe (1,5%), średnie zawodowe (14%), średnie ogólne (1,7%), policealne (2,5%), wyższe (71%), doktorat (9%).
, średnie zawodowe (14%), średnie ogólne (1,7%),")
11 Budowa zadania klasyfikacji 1. Grupowanie wypowiedzi według posła (kadencje osobno), 2. Podział grupy na podgrupy po 100 wypowiedzi, 3. Każda podgrupa pojedynczym przypadkiem uczącym, traktowanym jak ciągły tekst, = spośród posłów tylko miało min. 100 wypowiedzi, = powstało przypadków uczących, słów, średnio Ekstrakcja wektora cech dla każdego tekstu; przypisanie własności autora do tekstu, 5. Klasyfikacja.! Nie korzystamy ze związku między wypowiedziami o wspólnym autorze. 11 of 44

12 Zakres danych Sejm środowisko silnie dynamiczne, w każdej kadencji powstaje na nowo, brak ciągłości przynależności partyjnej i wykształcenia. = Konieczne wskazanie zakresu klasyfikacji: płeć i rok urodzenia na całych danych, przynależność partyjna według komitetu wyborczego, w każdej kadencji osobno, pomijamy pierwszą kadencję (34 partie) i małe partie (<5 przypadków) wykształcenie tylko w IV kadencji ( : SLD, PO, Samoobrona, PiS, LPR, PSL) w pozostałych ponad 80% to wykształcenie wyższe 12 of 44
 i małe partie (<5 przypadków) wykształcenie tylko")
13 Cechy statystyczne średnia długość słowa w średnia długość zdania w udział słów dłuższych niż 6 udział słów dłuższych niż 8 udział słów dłuższych niż 10 średnia liczba grup składniowych na średnia długość grup średnia liczba bytów nazwanych na zdanie według typów: 13 of 44

14 Cechy leksykalne Częstości (liczność/długość tekstu) tokenów: form powierzchniowych, lematów (pref. $), interpretacji (pref. :), bigramy: form powierzchniowych (pref. #), lematów (pref. #$), interpretacji (pref. #:), części mowy (pref. #;). czarne koty czarne koty $czarny $kot :adj:pl:nom:m2:pos :subst:pl:nom:m2 #czarne koty #$czarny kot #:adj:pl:nom:m2:pos subst:pl:nom:m2 #;adj subst = różnych tokenów, w co najmniej 10 przypadkach 14 of 44

15 Przekształcony tekst To $to :qub #BEG To #$BEG to #:BEG qub #;BEG qub dlatego $dlatego :adv #To dlatego #$to dlatego #:qub adv #;qub adv, $, :interp #dlatego, #$dlatego, #:adv interp #;adv interp Wysoki $wysoki :adj:sg:voc:m3:pos #, Wysoki #$, wysoki #:interp adj:sg:voc:m3:pos #;interp adj Sejmie $sejm :subst:sg:voc:m3 #Wysoki Sejmie #$wysoki sejm #:adj:sg:voc:m3:pos subst:sg:voc:m3 #;adj subst, $, :interp #Sejmie, #$sejm, #:subst:sg:voc:m3 interp #;subst interp na $na :prep:loc #, na #$, na #:interp prep:loc #;interp prep początku $początek :subst:sg:loc:m3 #na początku #$na początek #:prep:loc subst:sg:loc:m3 #;prep subst zacytował $zacytować :praet:sg:m1:perf #początku zacytował #$początek zacytować #:subst:sg:loc:m3 praet:sg:m1:perf #;subst praet em $być :aglt:sg:pri:imperf:wok #zacytował em #$zacytować być #:praet:sg:m1:perf aglt:sg:pri:imperf:wok #;praet aglt Pliki wczytywane i przeliczane do DocumentTermMatrix przez pakiet tm w R. 15 of 44

16 Koniugacja a płeć chciał em $chcieć $być chciałem :praet:sg:m1:imperf :aglt:sg:pri:imperf:wok #chciał em #$chcieć być #:praet:sg:m1:imperf aglt:sg:pri:imperf:wok #;praet aglt 16 of 44

17 Selekcja cech Miary wykorzystane do selekcji zmiennych (pakiet FSelector w R): Przyrost informacji: IG(y, x) := H(y) H(y x), H(x) gdzie H oznacza entropię. 1 IG(y, x) 0, IG(y, x) = 0 jeżeli x i y są niezależne. Współczynnik korelacji liniowej: i COR(y, x) := (x i x)(y i ȳ) i (x i x) 2 i (x i x) 2 17 of 44
 := (x i x)(y i ȳ) i (x i x) 2 i")
18 Selekcja cech Cechy: 14, 259, 202 (cechy leksykalne) 7 (cechy statystyczne) Selekcja zmiennych: 1. Odrzucenie tokenów występujących w mniej niż 10 przypadkach uczących (co daje 37, 916 cech). 2. Wybór cech z najwyższą wartością informacji wzajemnej (dla klasyfikacji) i największą korelacją (dla regresji). 3. Budowa modelu przy użyciu: 500, 5000, najbardziej istotnych cech (+wszystkie). 4. Cechy statystyczne są zawsze włączone do modelu. 18 of 44
. 4.")
19 Selekcja cech Miara oceny istotności cech: Miara oparta na lasach losowych (pakiet RandomForest w R): VI (x) := (drzewa) (węzły zawierające x) IG(y, x > t) gdzie: x > t jest testem użytym w danym węźle do podziału danych. IG(y, x > t) jest przerostem informacji y związanym z podziałem danych. Miara przyjmuje duże wartości, jeżeli: zmienna x była często wykorzystywana do podziałów. użycie zmiennej x do podziału zmniejszyło entropię y. 19 of 44

20 Predykcja 3 problemy: klasyfikacja binarna (płeć) klasyfikacja wieloklasowa (wykształcenie, partie) regresja (rok urodzenia) 20 of 44
 regresja")
21 Predykcja Model klasyfikacyjne: regresja logistyczna z regularyzacją (LOGISTIC) drzewa decyzyjne (CART) lasy losowe (RF) maszyny wektorów podpierających (SVM) naiwny klasyfikator Bayesa (NB) metoda najbliższych sąsiadów (KNN) 21 of 44
22 Predykcja Model regresyjne: drzewa regresyjne (CART) lasy losowe (RF) maszyny wektorów podpierających (SVM) regresja liniowa z regularyzacją (LASSO) metoda najbliższych sąsiadów (KNN) regresja składowych głównych (PCR) regresja częściowych najmniejszych kwadratów (PLSR) 22 of 44
23 Predykcja Ocena modeli: Kroswalidacja 5-krotna. Oznaczenia: y i : prawdziwa wartość odpowiedzi dla przypadku i ŷ i : przewidywana wartość odpowiedzi dla przypadku i n: liczba przypadków w zbiorze testowym +: klasa wyróżniona 23 of 44
24 Predykcja Wskaźniki oceny: Dokładność klasyfikacji: Czułość (recall): Precyzja (precision): Accuracy := #{y i = ŷ i } n Recall := #{y i = +, ŷ i = +} #{y i = +} Precision := #{y i = +, ŷ i = +} #{ŷ i = +} Spierwiastkowany błąd średniokwadratowy (RMSE): RMSE := 1 n (y i ŷ i ) n 2 24 of 44 i=1
25 Płeć Classification Accuracy CART KNN SVM RF NB LOGISTIC MAJOR CLASS of 44 number of features
26 Płeć. Recall (a) oraz Precision (b). Recall CART KNN SVM RF NB LOGISTIC Precision CART KNN SVM RF NB LOGISTIC number of features (a) number of features (b) 26 of 44
27 Wykształcenie (4 kadencja) Classification Accuracy CART KNN SVM RF NB MAJOR CLASS of 44 number of features
28 Partie (2, 3 kadencja) Term 2 Term 3 Classification Accuracy CART KNN SVM RF NB MAJOR CLASS Classification Accuracy CART KNN SVM RF NB MAJOR CLASS all number of features all number of features 28 of 44
29 Partie (4, 5 kadencja) Term 4 Term 5 Classification Accuracy CART KNN SVM RF NB all number of features MAJOR CLASS Classification Accuracy CART KNN SVM RF NB number of features MAJOR CLASS 29 of 44
30 Partie Partia 2 kad. 3 kad. 4 kad. 5 kad. 6 kad. PSL P: 91% 88% 98% 100% 100% R: 58% 84% 67% 83% 82% SLD P: 64% 79% 81% 82% 92% R: 92% 86% 98% 82% 64% PIS P: 99% 69% 74% R: 87% 93% 92% Samoobrona P: 93% 100% R: 89% 76% PO P: 98% 75% 82% R: 74% 65% 77% Największa partia SLD AWS SLD PIS PO 30 of 44
31 Rok urodzenia RMSE CART LASSO SVR RF PCR PLSR KNN NAIVE RMSE of 44 number of features
32 Podsumowanie Zadanie Metoda Liczba cech Dokładność Poziom odniesienia Płeć LOGISTIC wszystkie 96,72% 82,85% Wykształcenie (4 kad.) KNN wszystkie 95,40% 70,76% Partia (2 kad.) RF ,74% 34,77% Partia (3 kad.) KNN wszystkie 86,02% 40,66% Partia (4 kad.) RF ,31% 32,57% Partia (5 kad.) RF ,91% 29,19% Partia (6 kad.) RF wszystkie 81,83% 39,41% Rok urodzenia KNN wszystkie 6,48 8,55 32 of 44
33 Istotne zmienne płeć najsilniejsze 5 cech to interpretacje (i ich bigramy), przesądzające o rodzaju: :praet:sg:m1:imperf :praet:sg:f:imperf, #:praet:sg:f:imperf qub, :aglt:sg:pri:imperf:nwok, #:praet:sg:m1:imperf qub dalej także formy powierzchniowe powstałe z chciałam, chciałabym, słowa typowe dla kobiet (oraz ich lematy): dzieci, państwo, kobieta, dziecko i rodzina, kobiety używają dłuższych słów, @longlongwords mężczyźni częściej stosują byty 33 of 44

34 Istotne zmienne płeć 34 of 44
35 Istotne zmienne partia (3. kadencja) najmocniejsza cecha: $? posłowie partii opozycyjnych zadawali pytania dwukrotnie częściej (AWS vs SLD), niektóre partie są rzadko wspominane przez pozostałe (PSL, UW), opozycja częściej odnosiła się do rządu, ministrów, a także używała słowa pan i wołacza (:subst:sg:voc:m1). 35 of 44
 36 of 44")
36 Istotne zmienne partia (3. kadencja) 36 of 44
37 Istotne zmienne wykształcenie pierwsze 10 pozycji to cechy pochodne od wyrażenia klub parlamentarny Samoobrona Rzecz(y)pospolitej Polskiej, żaden doktor nie użył ani razu słowa samoobrona, następnie cechy związane z długością słów, choć niemonotonicznie z długością edukacji (doktorzy nie zawsze lepiej od magistrów, absolwenci szkół zawodowych gorzej od podstawowych), z czasem edukacji rośnie również złożoność 37 of 44

38 Istotne zmienne wykształcenie 38 of 44
39 Istotne zmienne rok urodzenia Dużo cech trudnych do interpretacji. Poza tym: u starszych częstsze odwołania do emerytury i emerytów, u młodszych cechy pochodne od nazw partii PO i PiS, posiadających średnio nieco młodszych członków, inne słowa: naprawdę, wniosek (młodsi); sprawa, zagadnienie (starsi). 39 of 44

40 Istotne zmienne rok urodzenia 40 of 44
41 Wnioski 1. Dla każdego zadania wyniki klasyfikacji są lepsze niż poziom odniesienia. 2. Wszystkie rodzaje zmiennych (leksykalne oraz statystyczne) są przydatne do predykcji. 3. Zwykle duża liczba cech jest potrzebna aby osiągnąć lepsze wyniki predykcji. 4. Zazwyczaj najlepszą metodą klasyfikacji są lasy losowe. 41 of 44
42 Kierunki dalszych prac 1. Użycie bardziej wyrafinowanych metod do selekcji zmiennych, np. zastosowanie miar pozwalających zidentyfikować skomplikowane nieliniowe zależności między odpowiedzią a atrybutami. 2. Wykorzystanie metod klasyfikacji wieloetykietowej do jednoczesnego przewidywania kilku zmiennych (np. przynależności partyjnej i wykształcenia). 3. Modyfikacja zadania przewidywania roku urodzenia (rozluźnienie do klasyfikacji, zastąpienie wiekiem). 4. Inne własności mówców? 5. Inne cechy, np. klasy słów? 42 of 44
43 Literatura Ogrodniczuk M., (2012). The Polish Sejm Corpus. In Proceedings of the Eighth International Conference on Language Resources and Evaluation, LREC Argamon, S., Koppel, M., Pennebaker, J. W., Schler, J. (2007). Mining the Blogosphere: Age, gender and the varieties of self-expression. First Monday. Dahllöf, M. (2012). Automatic prediction of gender, political affiliation, and age in Swedish politicians from the wording of their speeches A comparative study of classifiability. Literary and Linguistic Computing, 27(2), doi: /llc/fqs010 Koppel, M. (2002). Automatically Categorizing Written Texts by Author Gender. Literary and Linguistic Computing, 17(4), doi: /llc/ Conover, M. D., Goncalves, B., Ratkiewicz, J., Flammini, A., Menczer, F. (2011). Predicting the Political Alignment of Twitter Users. In 2011 IEEE Third Int l Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third Int l Conference on Social Computing (pp ). IEEE of 44
44 Pytania? Przybyła, P, Teisseyre, P. (2014) Analysing Utterances in Polish Parliament to Predict Speaker s Background. Journal of Quantitative Linguistics. 44 of 44
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Analiza statystyczna trudności tekstu
 Analiza statystyczna trudności tekstu Łukasz Dębowski ldebowsk@ipipan.waw.pl Problem badawczy Chcielibyśmy mieć wzór matematyczny,...... który dla dowolnego tekstu...... na podstawie pewnych statystyk......
Analiza statystyczna trudności tekstu Łukasz Dębowski ldebowsk@ipipan.waw.pl Problem badawczy Chcielibyśmy mieć wzór matematyczny,...... który dla dowolnego tekstu...... na podstawie pewnych statystyk......
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Korpus Dyskursu Parlamentarnego
 Korpus Dyskursu Parlamentarnego Maciej Ogrodniczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki PAN Warsztaty CLARIN-PL Lublin, 25 września 2019 r. Korpus Dyskursu Parlamentarnego W pigułce:
Korpus Dyskursu Parlamentarnego Maciej Ogrodniczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki PAN Warsztaty CLARIN-PL Lublin, 25 września 2019 r. Korpus Dyskursu Parlamentarnego W pigułce:
Testowanie modeli predykcyjnych
 Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2
 Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2 ws.clarin-pl.eu/websty.shtml Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej
Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2 ws.clarin-pl.eu/websty.shtml Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej
Analiza listów pożegnalnych w oparciu o metody lingwistyki informatycznej i klasyfikacji semantycznej tekstów
 Analiza listów pożegnalnych w oparciu o metody lingwistyki informatycznej i klasyfikacji semantycznej tekstów Maciej Piasecki, Jan Kocoń Politechnika Wrocławska Katedra InteligencjiObliczeniowej Grupa
Analiza listów pożegnalnych w oparciu o metody lingwistyki informatycznej i klasyfikacji semantycznej tekstów Maciej Piasecki, Jan Kocoń Politechnika Wrocławska Katedra InteligencjiObliczeniowej Grupa
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Co wylicza Jasnopis? Bartosz Broda
 Co wylicza Jasnopis? Bartosz Broda Analiza języka polskiego Ekstrakcja tekstu Dokument narzędzie do mierzenia zrozumiałości Analiza morfologiczna Analiza morfosyntaktyczna Indeksy Klasa trudności:
Co wylicza Jasnopis? Bartosz Broda Analiza języka polskiego Ekstrakcja tekstu Dokument narzędzie do mierzenia zrozumiałości Analiza morfologiczna Analiza morfosyntaktyczna Indeksy Klasa trudności:
Metody eksploracji danych Laboratorium 4. Klasyfikacja dokumentów tekstowych Naiwny model Bayesa Drzewa decyzyjne
 Metody eksploracji danych Laboratorium 4 Klasyfikacja dokumentów tekstowych Naiwny model Bayesa Drzewa decyzyjne Zbiory danych Podczas ćwiczeń będziemy przetwarzali dane tekstowe pochodzące z 5 książek
Metody eksploracji danych Laboratorium 4 Klasyfikacja dokumentów tekstowych Naiwny model Bayesa Drzewa decyzyjne Zbiory danych Podczas ćwiczeń będziemy przetwarzali dane tekstowe pochodzące z 5 książek
Program warsztatów CLARIN-PL
 W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
W ramach Letniej Szkoły Humanistyki Cyfrowej odbędzie się III cykl wykładów i warsztatów CLARIN-PL w praktyce badawczej. Narzędzia cyfrowe do analizy języka w naukach humanistycznych i społecznych 17-19
PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE
 UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
DRZEWA REGRESYJNE I LASY LOSOWE JAKO
 DRZEWA REGRESYJNE I LASY LOSOWE JAKO NARZĘDZIA PREDYKCJI SZEREGÓW CZASOWYCH Z WAHANIAMI SEZONOWYMI Grzegorz Dudek Instytut Informatyki Wydział Elektryczny Politechnika Częstochowska www.gdudek.el.pcz.pl
DRZEWA REGRESYJNE I LASY LOSOWE JAKO NARZĘDZIA PREDYKCJI SZEREGÓW CZASOWYCH Z WAHANIAMI SEZONOWYMI Grzegorz Dudek Instytut Informatyki Wydział Elektryczny Politechnika Częstochowska www.gdudek.el.pcz.pl
Pattern Classification
 Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Data Mining podstawy analizy danych Część druga
 Data Mining podstawy analizy danych Część druga W części pierwszej dokonaliśmy procesu analizy danych treningowych w oparciu o algorytm drzewa decyzyjnego. Proces analizy danych treningowych może być realizowany
Data Mining podstawy analizy danych Część druga W części pierwszej dokonaliśmy procesu analizy danych treningowych w oparciu o algorytm drzewa decyzyjnego. Proces analizy danych treningowych może być realizowany
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
PODSTAWY STATYSTYCZNEGO MODELOWANIA DANYCH. Wykład 6 Drzewa klasyfikacyjne - wprowadzenie. Reguły podziału i reguły przycinania drzew.
 PODSTAWY STATYSTYCZNEGO MODELOWANIA DANYCH Wykład 6 Drzewa klasyfikacyjne - wprowadzenie. Reguły podziału i reguły przycinania drzew. Wprowadzenie Drzewo klasyfikacyjne Wprowadzenie Formalnie : drzewo
PODSTAWY STATYSTYCZNEGO MODELOWANIA DANYCH Wykład 6 Drzewa klasyfikacyjne - wprowadzenie. Reguły podziału i reguły przycinania drzew. Wprowadzenie Drzewo klasyfikacyjne Wprowadzenie Formalnie : drzewo
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Stan dotychczasowy. OCENA KLASYFIKACJI w diagnostyce. Metody 6/10/2013. Weryfikacja. Testowanie skuteczności metody uczenia Weryfikacja prosta
 Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Analiza metod wykrywania przekazów steganograficznych. Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl
 Analiza metod wykrywania przekazów steganograficznych Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl Plan prezentacji Wprowadzenie Cel pracy Tezy pracy Koncepcja systemu Typy i wyniki testów Optymalizacja
Analiza metod wykrywania przekazów steganograficznych Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl Plan prezentacji Wprowadzenie Cel pracy Tezy pracy Koncepcja systemu Typy i wyniki testów Optymalizacja
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Konstrukcja biortogonalnych baz dyskryminacyjnych dla problemu klasyfikacji sygnałów. Wit Jakuczun
 Konstrukcja biortogonalnych baz dyskryminacyjnych dla problemu klasyfikacji sygnałów Politechnika Warszawska Strona 1 Podstawowe definicje Politechnika Warszawska Strona 2 Podstawowe definicje Zbiór treningowy
Konstrukcja biortogonalnych baz dyskryminacyjnych dla problemu klasyfikacji sygnałów Politechnika Warszawska Strona 1 Podstawowe definicje Politechnika Warszawska Strona 2 Podstawowe definicje Zbiór treningowy
Metody zbiorów przybliżonych w uczeniu się podobieństwa z wielowymiarowych zbiorów danych
 Metody zbiorów przybliżonych w uczeniu się podobieństwa z wielowymiarowych zbiorów danych WMIM, Uniwersytet Warszawski ul. Banacha 2, 02-097 Warszawa, Polska andrzejanusz@gmail.com 13.06.2013 Dlaczego
Metody zbiorów przybliżonych w uczeniu się podobieństwa z wielowymiarowych zbiorów danych WMIM, Uniwersytet Warszawski ul. Banacha 2, 02-097 Warszawa, Polska andrzejanusz@gmail.com 13.06.2013 Dlaczego
Jakość uczenia i generalizacja
 Jakość uczenia i generalizacja Dokładność uczenia Jest koncepcją miary w jakim stopniu nasza sieć nauczyła się rozwiązywać określone zadanie Dokładność mówi na ile nauczyliśmy się rozwiązywać zadania które
Jakość uczenia i generalizacja Dokładność uczenia Jest koncepcją miary w jakim stopniu nasza sieć nauczyła się rozwiązywać określone zadanie Dokładność mówi na ile nauczyliśmy się rozwiązywać zadania które
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Morfeusz 2 analizator i generator fleksyjny dla języka polskiego
 Morfeusz 2 analizator i generator fleksyjny dla języka polskiego Marcin Woliński i Anna Andrzejczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Warsztaty CLARIN-PL,
Morfeusz 2 analizator i generator fleksyjny dla języka polskiego Marcin Woliński i Anna Andrzejczuk Zespół Inżynierii Lingwistycznej Instytut Podstaw Informatyki Polskiej Akademii Nauk Warsztaty CLARIN-PL,
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej. Adam Żychowski
 Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
INFORMATYKA W SELEKCJI
 INFORMATYKA W SELEKCJI INFORMATYKA W SELEKCJI - zagadnienia 1. Dane w pracy hodowlanej praca z dużym zbiorem danych (Excel) 2. Podstawy pracy z relacyjną bazą danych w programie MS Access 3. Systemy statystyczne
INFORMATYKA W SELEKCJI INFORMATYKA W SELEKCJI - zagadnienia 1. Dane w pracy hodowlanej praca z dużym zbiorem danych (Excel) 2. Podstawy pracy z relacyjną bazą danych w programie MS Access 3. Systemy statystyczne
Rozmyte drzewa decyzyjne. Łukasz Ryniewicz Metody inteligencji obliczeniowej
 µ(x) x µ(x) µ(x) x x µ(x) µ(x) x x µ(x) x µ(x) x Rozmyte drzewa decyzyjne Łukasz Ryniewicz Metody inteligencji obliczeniowej 21.05.2007 AGENDA 1 Drzewa decyzyjne kontra rozmyte drzewa decyzyjne, problemy
µ(x) x µ(x) µ(x) x x µ(x) µ(x) x x µ(x) x µ(x) x Rozmyte drzewa decyzyjne Łukasz Ryniewicz Metody inteligencji obliczeniowej 21.05.2007 AGENDA 1 Drzewa decyzyjne kontra rozmyte drzewa decyzyjne, problemy
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład I dr inż. 2015/2016
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
CBOS CENTRUM BADANIA OPINII SPOŁECZNEJ OPINIE O ODEBRANIU ANDRZEJOWI LEPPEROWI IMMUNITETU POSELSKIEGO BS/28/2002 KOMUNIKAT Z BADAŃ WARSZAWA, LUTY 2002
 CBOS CENTRUM BADANIA OPINII SPOŁECZNEJ SEKRETARIAT OŚRODEK INFORMACJI 629-35 - 69, 628-37 - 04 693-46 - 92, 625-76 - 23 UL. ŻURAWIA 4A, SKR. PT.24 00-503 W A R S Z A W A TELEFAX 629-40 - 89 INTERNET http://www.cbos.pl
CBOS CENTRUM BADANIA OPINII SPOŁECZNEJ SEKRETARIAT OŚRODEK INFORMACJI 629-35 - 69, 628-37 - 04 693-46 - 92, 625-76 - 23 UL. ŻURAWIA 4A, SKR. PT.24 00-503 W A R S Z A W A TELEFAX 629-40 - 89 INTERNET http://www.cbos.pl
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Wydobywanie reguł na potrzeby ujednoznaczniania morfo-syntaktycznego oraz płytkiej analizy składniowej tekstów polskich
 Wydobywanie reguł na potrzeby ujednoznaczniania morfo-syntaktycznego oraz płytkiej analizy składniowej tekstów polskich Adam Radziszewski Instytut Informatyki Stosowanej PWr SIIS 23, 12 czerwca 2008 O
Wydobywanie reguł na potrzeby ujednoznaczniania morfo-syntaktycznego oraz płytkiej analizy składniowej tekstów polskich Adam Radziszewski Instytut Informatyki Stosowanej PWr SIIS 23, 12 czerwca 2008 O
SPOTKANIE 2: Wprowadzenie cz. I
 Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować?
 Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Narzędzia do automatycznego wydobywania kolokacji
 Narzędzia do automatycznego wydobywania kolokacji Jan Kocoń, Agnieszka Dziob, Marek Maziarz, Maciej Piasecki, Michał Wendelberger Politechnika Wrocławska Katedra Inteligencji Obliczeniowej marek.maziarz@pwr.edu.pl
Narzędzia do automatycznego wydobywania kolokacji Jan Kocoń, Agnieszka Dziob, Marek Maziarz, Maciej Piasecki, Michał Wendelberger Politechnika Wrocławska Katedra Inteligencji Obliczeniowej marek.maziarz@pwr.edu.pl
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
5. Model sezonowości i autoregresji zmiennej prognozowanej
 5. Model sezonowości i autoregresji zmiennej prognozowanej 1. Model Sezonowości kwartalnej i autoregresji zmiennej prognozowanej (rząd istotnej autokorelacji K = 1) Szacowana postać: y = c Q + ρ y, t =
5. Model sezonowości i autoregresji zmiennej prognozowanej 1. Model Sezonowości kwartalnej i autoregresji zmiennej prognozowanej (rząd istotnej autokorelacji K = 1) Szacowana postać: y = c Q + ρ y, t =
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
LABORATORIUM 3. Jeśli p α, to hipotezę zerową odrzucamy Jeśli p > α, to nie mamy podstaw do odrzucenia hipotezy zerowej
 LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba, J. Kaczmar Cel zadania Celem zadania jest implementacja klasyfikatorów
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba, J. Kaczmar Cel zadania Celem zadania jest implementacja klasyfikatorów
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner
 Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
UCZENIE MASZYNOWE I SZTUCZNA INTELIGENCJA Jako narzędzia wspomagania decyzji w zarządzaniu kapitałem ludzkim organizacji
 UCZENIE MASZYNOWE I SZTUCZNA INTELIGENCJA Jako narzędzia wspomagania decyzji w zarządzaniu kapitałem ludzkim organizacji Filip Wójcik Wydział Zarządzania, Informatyki i Finansów Instytut Informatyki Ekonomicznej
UCZENIE MASZYNOWE I SZTUCZNA INTELIGENCJA Jako narzędzia wspomagania decyzji w zarządzaniu kapitałem ludzkim organizacji Filip Wójcik Wydział Zarządzania, Informatyki i Finansów Instytut Informatyki Ekonomicznej
WebSty otwarty webowy system do analiz stylometrycznych
 WebSty otwarty webowy system do analiz stylometrycznych Maciej Piasecki, Tomasz Walkowiak, Maciej Eder Politechnika Wrocławska Katedra Inteligencji Obliczeniowej Grupa Naukowa G4.19 maciej.piasecki@pwr.edu.pl
WebSty otwarty webowy system do analiz stylometrycznych Maciej Piasecki, Tomasz Walkowiak, Maciej Eder Politechnika Wrocławska Katedra Inteligencji Obliczeniowej Grupa Naukowa G4.19 maciej.piasecki@pwr.edu.pl
Regresja nieparametryczna series estimator
 Regresja nieparametryczna series estimator 1 Literatura Bruce Hansen (2018) Econometrics, rozdział 18 2 Regresja nieparametryczna Dwie główne metody estymacji Estymatory jądrowe Series estimators (estymatory
Regresja nieparametryczna series estimator 1 Literatura Bruce Hansen (2018) Econometrics, rozdział 18 2 Regresja nieparametryczna Dwie główne metody estymacji Estymatory jądrowe Series estimators (estymatory
Klasyfikacja i regresja Wstęp do środowiska Weka
 Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
R dla każdego : zaawansowane analizy i grafika statystyczna / Jared P. Lander. Warszawa, Spis treści
 R dla każdego : zaawansowane analizy i grafika statystyczna / Jared P. Lander. Warszawa, 2018 Spis treści Słowo wstępne Wprowadzenie xi xii 1 Poznajemy R 1 1.1 Pobieranie R 1 1.2 Wersja R 2 1.3 Wersja
R dla każdego : zaawansowane analizy i grafika statystyczna / Jared P. Lander. Warszawa, 2018 Spis treści Słowo wstępne Wprowadzenie xi xii 1 Poznajemy R 1 1.1 Pobieranie R 1 1.2 Wersja R 2 1.3 Wersja
Python : podstawy nauki o danych / Alberto Boschetti, Luca Massaron. Gliwice, cop Spis treści
 Python : podstawy nauki o danych / Alberto Boschetti, Luca Massaron. Gliwice, cop. 2017 Spis treści O autorach 9 0 recenzencie 10 Wprowadzenie 11 Rozdział 1. Pierwsze kroki 15 Wprowadzenie do nauki o danych
Python : podstawy nauki o danych / Alberto Boschetti, Luca Massaron. Gliwice, cop. 2017 Spis treści O autorach 9 0 recenzencie 10 Wprowadzenie 11 Rozdział 1. Pierwsze kroki 15 Wprowadzenie do nauki o danych
Klasyfikacja LDA + walidacja
 Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Metody eksploracji danych Laboratorium 1. Weka + Python + regresja
 Metody eksploracji danych Laboratorium 1 Weka + Python + regresja Zasoby Cel Metody eksploracji danych Weka (gdzieś na dysku) Środowisko dla języka Python (Spyder, Jupyter, gdzieś na dysku) Zbiory danych
Metody eksploracji danych Laboratorium 1 Weka + Python + regresja Zasoby Cel Metody eksploracji danych Weka (gdzieś na dysku) Środowisko dla języka Python (Spyder, Jupyter, gdzieś na dysku) Zbiory danych
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Matlab podstawy + testowanie dokładności modeli inteligencji obliczeniowej
 Matlab podstawy + testowanie dokładności modeli inteligencji obliczeniowej Podstawy matlaba cz.ii Funkcje Dotychczas kod zapisany w matlabie stanowił skrypt który pozwalał na określenie kolejności wykonywania
Matlab podstawy + testowanie dokładności modeli inteligencji obliczeniowej Podstawy matlaba cz.ii Funkcje Dotychczas kod zapisany w matlabie stanowił skrypt który pozwalał na określenie kolejności wykonywania
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Sztuczna Inteligencja w medycynie projekt (instrukcja) Bożena Kostek
 Bożena Kostek") Sztuczna Inteligencja w medycynie projekt (instrukcja) Bożena Kostek Cel projektu Celem projektu jest przygotowanie systemu wnioskowania, wykorzystującego wybrane algorytmy sztucznej inteligencji; Nabycie
Sztuczna Inteligencja w medycynie projekt (instrukcja) Bożena Kostek Cel projektu Celem projektu jest przygotowanie systemu wnioskowania, wykorzystującego wybrane algorytmy sztucznej inteligencji; Nabycie
AUTOMATYKA INFORMATYKA
 AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład II 2017/2018
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy
Graficzna prezentacja danych statystycznych
 Szkolenie dla pracowników Urzędu Statystycznego nt. Wybrane metody statystyczne w analizach makroekonomicznych Katowice, 12 i 26 czerwca 2014 r. Dopasowanie narzędzia do typu zmiennej Dobór narzędzia do
Szkolenie dla pracowników Urzędu Statystycznego nt. Wybrane metody statystyczne w analizach makroekonomicznych Katowice, 12 i 26 czerwca 2014 r. Dopasowanie narzędzia do typu zmiennej Dobór narzędzia do
Ekonometria. Regresja liniowa, współczynnik zmienności, współczynnik korelacji liniowej, współczynnik korelacji wielorakiej
 Regresja liniowa, współczynnik zmienności, współczynnik korelacji liniowej, współczynnik korelacji wielorakiej Paweł Cibis pawel@cibis.pl 23 lutego 2007 1 Regresja liniowa 2 wzory funkcje 3 Korelacja liniowa
Regresja liniowa, współczynnik zmienności, współczynnik korelacji liniowej, współczynnik korelacji wielorakiej Paweł Cibis pawel@cibis.pl 23 lutego 2007 1 Regresja liniowa 2 wzory funkcje 3 Korelacja liniowa
Modelowanie glikemii w procesie insulinoterapii
 Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 16 listopada 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 16 listopada 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Szacowanie wartości hodowlanej. Zarządzanie populacjami
 Szacowanie wartości hodowlanej Zarządzanie populacjami wartość hodowlana = wartość cechy? Tak! Przy h 2 =1 ? wybitny ojciec = wybitne dzieci Tak, gdy cecha wysokoodziedziczalna. Wartość hodowlana genetycznie
Szacowanie wartości hodowlanej Zarządzanie populacjami wartość hodowlana = wartość cechy? Tak! Przy h 2 =1 ? wybitny ojciec = wybitne dzieci Tak, gdy cecha wysokoodziedziczalna. Wartość hodowlana genetycznie
Laboratorium 4. Naiwny klasyfikator Bayesa.
 Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Analiza współzależności zjawisk
 Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
8. Drzewa decyzyjne, bagging, boosting i lasy losowe
 Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
FIAT i inne firmy zagraniczne w Polsce
 K.076/12 FIAT i inne firmy zagraniczne w Polsce Warszawa, grudzień 2012 r. Sondaż TNS Polska przeprowadzony w dniach 6-10.12.2012 r. pokazuje aktualny stan opinii publicznej w sprawie firm zagranicznych
K.076/12 FIAT i inne firmy zagraniczne w Polsce Warszawa, grudzień 2012 r. Sondaż TNS Polska przeprowadzony w dniach 6-10.12.2012 r. pokazuje aktualny stan opinii publicznej w sprawie firm zagranicznych
Technologie Informacyjne
 Systemy Uczące się Szkoła Główna Służby Pożarniczej Zakład Informatyki i Łączności January 16, 2017 1 Wprowadzenie 2 Uczenie nadzorowane 3 Uczenie bez nadzoru 4 Uczenie ze wzmocnieniem Uczenie się - proces
Systemy Uczące się Szkoła Główna Służby Pożarniczej Zakład Informatyki i Łączności January 16, 2017 1 Wprowadzenie 2 Uczenie nadzorowane 3 Uczenie bez nadzoru 4 Uczenie ze wzmocnieniem Uczenie się - proces
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
WK, FN-1, semestr letni 2010 Tworzenie list frekwencyjnych za pomocą korpusów i programu Poliqarp
 WK, FN-1, semestr letni 2010 Tworzenie list frekwencyjnych za pomocą korpusów i programu Poliqarp Natalia Kotsyba, IBI AL UW 24 marca 2010 Plan zajęć Praca domowa na zapytania do Korpusu IPI PAN za pomocą
WK, FN-1, semestr letni 2010 Tworzenie list frekwencyjnych za pomocą korpusów i programu Poliqarp Natalia Kotsyba, IBI AL UW 24 marca 2010 Plan zajęć Praca domowa na zapytania do Korpusu IPI PAN za pomocą
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Oracle Data Mining 10g
 Oracle Data Mining 10g Zastosowanie algorytmu Support Vector Machines do problemów biznesowych Piotr Hajkowski Oracle Consulting Agenda Podstawy teoretyczne algorytmu SVM SVM w bazie danych Klasyfikacja
Oracle Data Mining 10g Zastosowanie algorytmu Support Vector Machines do problemów biznesowych Piotr Hajkowski Oracle Consulting Agenda Podstawy teoretyczne algorytmu SVM SVM w bazie danych Klasyfikacja
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Narzędzia do automatycznego wydobywania kolokacji
 Narzędzia do automatycznego wydobywania kolokacji Jan Kocoń, Agnieszka Dziob, Marek Maziarz, Maciej Piasecki, Michał Wendelberger Politechnika Wrocławska Katedra Inteligencji Obliczeniowej marek.maziarz@pwr.edu.pl
Narzędzia do automatycznego wydobywania kolokacji Jan Kocoń, Agnieszka Dziob, Marek Maziarz, Maciej Piasecki, Michał Wendelberger Politechnika Wrocławska Katedra Inteligencji Obliczeniowej marek.maziarz@pwr.edu.pl
Analiza współzależności dwóch cech I
 Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
O czym w Sejmie piszczy? Analiza tekstowa przemówień poselskich
 O czym w Sejmie piszczy? Analiza tekstowa przemówień poselskich mgr Aleksander Nosarzewski Szkoła Główna Handlowa w Warszawie pod kierunkiem naukowym dr hab. Bogumiła Kamińskiego, prof. SGH Problem Potrzeba
O czym w Sejmie piszczy? Analiza tekstowa przemówień poselskich mgr Aleksander Nosarzewski Szkoła Główna Handlowa w Warszawie pod kierunkiem naukowym dr hab. Bogumiła Kamińskiego, prof. SGH Problem Potrzeba
Algorytmy, które estymują wprost rozkłady czy też mapowania z nazywamy algorytmami dyskryminacyjnymi.
 Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
PODSTAWY STATYSTYCZNEJ ANALIZY DANYCH
 Wykład 3 Liniowe metody klasyfikacji. Wprowadzenie do klasyfikacji pod nadzorem. Fisherowska dyskryminacja liniowa. Wprowadzenie do klasyfikacji pod nadzorem. Klasyfikacja pod nadzorem Klasyfikacja jest
Wykład 3 Liniowe metody klasyfikacji. Wprowadzenie do klasyfikacji pod nadzorem. Fisherowska dyskryminacja liniowa. Wprowadzenie do klasyfikacji pod nadzorem. Klasyfikacja pod nadzorem Klasyfikacja jest
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
Kod IEEE754. IEEE754 (1985) - norma dotycząca zapisu binarnego liczb zmiennopozycyjnych (pojedynczej precyzji) Liczbę binarną o postaci
 - norma dotycząca zapisu binarnego liczb zmiennopozycyjnych (pojedynczej precyzji) Liczbę binarną o postaci") Kod IEEE754 IEEE Institute of Electrical and Electronics Engineers IEEE754 (1985) - norma dotycząca zapisu binarnego liczb zmiennopozycyjnych (pojedynczej precyzji) Liczbę binarną o postaci (-1) s 1.f
Kod IEEE754 IEEE Institute of Electrical and Electronics Engineers IEEE754 (1985) - norma dotycząca zapisu binarnego liczb zmiennopozycyjnych (pojedynczej precyzji) Liczbę binarną o postaci (-1) s 1.f
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka - adres mailowy: scichocki@o2.pl - strona internetowa: www.wne.uw.edu.pl/scichocki - dyżur: po zajęciach lub po umówieniu mailowo - 80% oceny: egzaminy - 20% oceny:
Stanisław Cichocki Natalia Nehrebecka - adres mailowy: scichocki@o2.pl - strona internetowa: www.wne.uw.edu.pl/scichocki - dyżur: po zajęciach lub po umówieniu mailowo - 80% oceny: egzaminy - 20% oceny:
SCENARIUSZ LEKCJI. TEMAT LEKCJI: Zastosowanie średnich w statystyce i matematyce. Podstawowe pojęcia statystyczne. Streszczenie.
 SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
LEM wydobywanie statystyk z korpusów
 LEM wydobywanie statystyk z korpusów Maciej Piasecki, Tomasz Walkowiak Politechnika Wroc awska Katedra Inteligencji Obliczeniowej Grupa Naukowa G4.19 Maciej Maryl Instytut Bada Literackich Polska Akademia
LEM wydobywanie statystyk z korpusów Maciej Piasecki, Tomasz Walkowiak Politechnika Wroc awska Katedra Inteligencji Obliczeniowej Grupa Naukowa G4.19 Maciej Maryl Instytut Bada Literackich Polska Akademia
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Narzędzia do automatycznego wydobywania słowników kolokacji i do oceny leksykalności połączeń wyrazowych
 Narzędzia do automatycznego wydobywania słowników kolokacji i do oceny leksykalności połączeń wyrazowych Agnieszka Dziob, Marek Maziarz, Maciej Piasecki, Michał Wendelberger Politechnika Wrocławska Katedra
Narzędzia do automatycznego wydobywania słowników kolokacji i do oceny leksykalności połączeń wyrazowych Agnieszka Dziob, Marek Maziarz, Maciej Piasecki, Michał Wendelberger Politechnika Wrocławska Katedra
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA
 ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności