SYSTEMY INFORMACYJNE I WYSZUKIWANIE INFORMACJI 3 Projekt
|
|
|
- Klaudia Bielecka
- 10 lat temu
- Przeglądów:
Transkrypt
1 SYSTEMY INFORMACYJNE I WYSZUKIWANIE INFORMACJI 3 Projekt System wyszukiwania dokumentów tekstowych Katarzyna Rzerzicha, Wojciech Skórski, Paweł Szołtysek SPPI 3 6 czerwca 2008

2 Streszczenie W dobie informatyzacji społeczeństwa oraz błyskawicznego postępu technologicznego coraz większego znaczenia nabiera możliwość trafnego i sprawnego przeszukiwania zasobów elektronicznych. Niniejsza praca przedstawia projekt systemu wyszukiwania dokumentów tekstowych. Duży nacisk położono na szybkość wyszukiwania, wskutek czego zaproponowano autorski sposób indeksowania dokumentów opierający się na strukturach grafowych. Ponadto dokonano analizy i modyfikacji istniejących sposobów reprezentacji tego typu struktur, dzięki czemu zoptymalizowano zapis cyfrowy indeksu. Innowacyjność systemu polega także na zindywidualizowaniu wymagań osób korzystających z wyszukiwarki, dzięki stworzeniu profilu użytkownika. Zarówno personalizacja, jak i prowadzenie rankingu publicznego dokumentów pozwala na bardziej relewantne wyszukiwanie oraz pozycjonowanie wyników. Poza tym, spore znaczenie ma wprowadzenie nowatorskiego procesu rekomendacji - podczas korzystania z systemu proponowane jest użytkownikowi przeglądnięcie dodatkowych, potencjalnie interesujących go dokumentów. Wysoka jakość tego procesu jest osiągana dzięki wykorzystaniu struktur grafowych. Zaprezentowano także propozycje implementacji systemu, pomocne w fazie fizycznej. Zastosowanie prekursorskich rozwiązań pozwala na znaczne zwiększenie efektywności działania systemu wyszukiwania.

3 Streszczenie Facing society computerization and immediate technical developement, availability of relevant and fast searching in electronic resources means more and more. This work shows a project of text documents searching system. Thanks to the fact, that main emphasis has been putted on the speed of the searching process, the new way of the document indexation based on the graph structures was introduced. Moreover, analysis and modification of existing methods of these type of structure reprezentation has been done, what leads to optimization them for this specific example. Innovation of the system is as well about individual needs of users, thanks to profiles for each of them. Personalization, as well as public rank, allows more relevant searching and better positioning of results. Furthermore, quite big importance has original recommendation process - while using, the system itself suggests other, potentally noteworthy documents in this topic. High level of quality of this action is reached thanks to the usage of the graph structure. Part of the work shows as well proposition of implementation, which can be useful in physical stage. Usage of precursor solutions allows to increase the efficiency of searching system significantly.

4 Spis treści 1 Wstęp Uwagi ogólne Użyte oznaczenia Organizacja bazy dokumentów Dokument w pojęciu semantycznym Indeksowanie Przykłady sposobów indeksowania Własna koncepcja indeksowania Formalizacja procesu indeksowania Schemat UML indeksowania Struktura bazy Mechanizm wyszukiwania Meta-język wyszukiwania Silnik wyszukiwania Pozycjonowanie Przebieg procesu wyszukiwania System rekomendacji Profil użytkownika Struktura profilu użytkownika Rankingi Typy rekomendacji Rekomendacja typu A - nowo zaindeksowane dokumenty Rekomendacja typu B - na podstawie historii zapytań innych użytkowników Rekomendacja typu C - wykorzystanie synonimów Rekomendacja typu D - na podstawie podobieństwa dokumentów Diagram UML rekomendacji

5 5 Wskazówki do implementacji Funkcje GetWords GetTerms CreateGraph GetCatForTerm GetCatForDoc Indeks Sposoby implementacji struktur grafowych Optymalizacja reprezentacji grafu Ostateczny sposób reprezentacji Podsumowanie 40 2

6 Rozdział 1 Wstęp Zadanie wyszukiwania tekstu wydaje się być nieskomplikowanym procesem. Jednak zaprojektowanie wydajnego i sprawnego systemu okazuje się w praktyce bardziej złożonym problemem. Dzieje się tak z kilku względów. 1. Istnieją słowa, które, chociaż mają taką samą budowę składniową, różnią się semantycznie. Między innymi z tego powodu komputer nie jest w stanie zrozumieć, co jest napisane w dokumencie. 2. Ludzka wiedza oraz tworzone dokumenty oparte są na doświadczeniach i inteligencji. Dzięki temu człowiek jest w stanie zrozumieć i opisać dokumenty, które czyta. 3. Ważnym jest zauważenie pewnej paralelności (wielowątkowości) wyszukiwarki: z jednej strony, musi ona nieustannie indeksować nowe dokumenty, a z drugiej bez przerwy odpowiadać na zapytania do niej kierowane. 4. Dokumenty wcześniej zaindeksowane mogą podlegać zmianom. Z perspektywy wyszukiwarki, dokument jest przetwarzany w trzech głównych etapach. Najpierw specjalny robot przeszukuje pewien zasób dokumentów, w celu znalezienia nowych (takich, które nie istnieją w bazie danych) lub uaktualnionych (takich, które już istnieją w bazie, ale jest dostępna ich nowa wersja). Po odnalezieniu takowego, wysyła odpowiednią informację do algorytmu indeksującego, który ponownie pobiera dokument z zasobu. Następnie dokonuje operacji złączenia (merging) istniejącej bazy danych z nowo znalezionym dokumentem. Po wykonaniu tego, algorytm wyszukujący będzie uwzględniał ten dokument. Proces ten jest zobrazowany na rysunku 1.1. Widać więc, że każdy etap ma znaczny wpływ na jakość wyszukiwania. Niska jakość któregoś z modułów będzie się bezpośrednio przekładała na słabsze i mniej dokładne wyszukiwanie w indeksie. Wobec tego ważnym etapem 3

7 Rysunek 1.1: Zobrazowanie schematu wyszukiwania. przy projektowaniu systemów do tego służących jest poprawne zdefiniowanie struktury bazy danych. Ponadto należy wnikliwie zastanowić się nad sposobem ich indeksowania, umożliwiającym sprawne i trafne przeszukiwanie. W tej pracy skupiono się nad każdym kolejnym etapem tworzenia takiej wyszukiwarki. W rozdziale 2. zostanie przedstawiony temat organizacji bazy dokumentów. Kolejno będą najpierw rozbijane zdania semantycznie na obiekty URI, do których się ono odnosi, po czym takie rozbicia będą upraszczane. Zostaną też przedstawione dwa typowe, proste podejścia do indeksowania dokumentów tekstowych, na podstawie których będzie zaprezentowany autorski algorytm indeksowania. Rozdział 3. przedstawia przykładowe zapytania, jakie mogą być kierowane do silnika wyszukiwarki. W postaci sformalizowanej oraz UML przedstawione zostaną takie wyszukiwania dla zaproponowanego wcześniej indeksu. W rozdziale tym można znaleźć też diagram przypadków użycia wyszukiwarki. Procesy rekomendacji zostaną omówione w rozdziale 4. Umieszczono tam m. 4

8 in. strukturę zaprojektowanego profilu użytkownika, sposób tworzenia rankingów oraz cztery sposoby rekomendacji, w tym jeden autorski. Rozdział 5. zawiera propozycje implementacji zarówno funkcji (w formie pseudokodu) potrzebnych przy indeksowaniu i wyszukiwaniu w zaproponowanym systemie. Dodatkowo ma miejsce analiza dostępnych form reprezentacji grafu i na ich podstawie zaproponowano własny sposób takiej reprezentacji, przystosowany do przedstawionej struktury indeksu. 1.1 Uwagi ogólne W dalszych rozważaniach przyjmujemy, że: średnia wielkość dokumentu wynosi liter (tj. 50kB); średniej wielkości dokument zawiera słów, czyli ok różnych termów; średni term liczy ok 7 liter (tj. 7B). 1.2 Użyte oznaczenia System wyszukiwania informacji składa się z: zbioru dokumentów D, zbioru profilów użytkownika P, zbioru zapytań Z, zbioru termów T, słownika S, zbioru kategorii K. Definiujemy graf G = (V, E) jako: V - zbiór wierzchołków taki, że V T, E - zbiór krawędzi etykietowanych taki, że e E : e = (v i, v j, w), gdzie v i, v j V oraz w R Profil użytkownika p P jest wyznaczany przez: p k - zbiór kategorii wskazanych bezpośrednio przez użytkownika jako te, którymi się interesuje, 5
; średniej wielkości dokument zawiera 7 000 słów, czyli ok.")
9 p l - zbiór wszystkich kategorii z przypisanymi wagami definiowanymi jako stopień zainteresowania użytkownika daną kategorią. Wagę określa się za pomocą liczby pozytywnie ocenionych dokumentów w kontekście kategorii. 6

10 Rozdział 2 Organizacja bazy dokumentów 2.1 Dokument w pojęciu semantycznym Zwykle, dokument opisuje pewną część świata w którym się poruszamy. Konkretniej, składa się z pewnych prostych zdań (np. Adam świeci latarką.) opisujących związek między pewnymi podmiotami realnie istniejącymi w świecie (lub lepiej - związek między pewnymi URI). Ich ewentualne rozwinięcia (np. Adam Borowik świeci latarką na czerwone krzesło.) sprowadzają się tylko do precyzowania tego związku. Obrazowo zostało to przedstawione odpowiednio na rysunkach 2.1 oraz 2.2. Rysunek 2.1: Semantycznie rozumiane zdanie Adam świeci latarką. Rysunek 2.2: Semantycznie rozumiane zdanie Adam Borowik świeci latarką na czerwone krzesło. Rysunek 2.3 przedstawia natomiast rozkład gramatyczny zdania rozwiniętego. Widać zasadnicze różnice między obydwoma podejściami. Generalnie można je jednak sprowadzić do następującego stwierdzenia: Podczas, gdy 7

11 Rysunek 2.3: Gramatyka zdania Adam Borowik świeci latarką na czerwone krzesło. rozbicie semantyczne zdania dzieli je na podmioty i akcje, które zachodzą między podmiotami, rozbicie gramatyczne dzieli je na wyrazy odpowiednio ze sobą połączone. Generuje to nam szereg różnych wniosków. Większość z nich nie będzie rozpatrywana w tej pracy. Jednym z takich wniosków jest fakt, iż obie wersje mają strukturę zbliżoną do grafowej, w której wierzchołkami są URI lub wyrazy. Taka reprezentacja w istocie bardzo trafnie odzwierciedla powiązania między wyrazami, jednakże analiza gramatyczna języka jest trudnym i czasochłonnym zadaniem. Znacznie prostszym sposobem przedstawienia struktury zdań w formie grafowej jest wykorzystanie bliskości wyrazów. W przeważającej liczbie przypadków grafy uzyskane obiema metodami są do siebie zbliżone. 2.2 Indeksowanie Istnieje wiele czynników, które wpływają na zadanie indeksowania. Niektóre z nich wymienione są poniżej. Złączenie określa sposób dodawania i uaktualniania danych, które istnieją w bazie indeksów. Zapisywanie indeksu, który następnie podlega filtrowaniu przez algorytm wyszukujący. Wielkość indeksu, czyli ilość powierzchni dyskowej do wykorzystania na bazę danych indeksów. 8

12 Szybkość przeglądania indeksu, czyli czas potrzebny na znalezienie szukanego wyrażenia. Przechowywanie indeksu w czasie. Tolerancja na błędy indeksu w obu sensach - semantycznym oraz bazodanowym. W zależności od tego, który czynnik jest ważniejszy w konkretnym przypadku, można indeksować na różnorodne sposoby. Poniżej przedstawione zostaną dwa elementarne sposoby indeksowania, na których będzie opierała się autorska koncepcja. Analizowane przykłady będą opierać się na następujących trzech dokumentach: Dokument 1: Dzisiaj pięknie świeci słońce. Dokument 2: Portfel Zenka świeci pustkami. Dokument 3: Lampa w pokoju pięknie świeci Przykłady sposobów indeksowania Forward indexing Forward indexing w skrócie polega na przypisywaniu do dokumentu listy słów w nim występujących. Dokument 1 Dokument 2 Dokument 3 dzisiaj, pięknie, świeci, słońce portfel, zenka, świeci, pustkami lampa, w, pokoju, pięknie, świeci Składają się na niego więc pary dokument-słowo, gdzie słowo należy do dokumentu. Charakteryzuje on się prostotą oraz szybkością sprawdzania, czy dany wyraz występuje w konkretnym dokumencie. Często spotykana w takiej reprezentacji indeksu jest ilość wystąpień wyrazów. Prosta do wykonania jest transformacja na Inverted indexing, który jest opisany poniżej. Inverted indexing Inverted indexing polega na przypisywaniu do słów listy dokumentów, w których występują. 9

13 pięknie Dokument 1, Dokument 3 świeci Dokument 1, Dokument 2, Dokument 3 lampa Dokument 3 Charakteryzuje on się prostotą oraz szybkością sprawdzania, który dokument posiada dany wyraz. Bardzo często wykorzystywana jest taka forma indeksu w silnikach wyszukiwarek, w których sprawdzamy po prostu czy pewne wyrazy należą do podanych dokumentów, i na tym opieramy nasze wyniki wyszukiwań. Jednocześnie wyszukiwarka może automatycznie sprawdzać inne dokumenty w których występuje dany wyraz. Podobnie jak w Forward Indexing opisanym wcześniej, istnieją pewne rozszerzenia tej metody. Do najczęściej spotykanych należą częstość występowania słowa w dokumencie oraz jego pozycja (zwykle względem otagowania HTML). Oba pozwalają na lepsze sortowanie wyników Własna koncepcja indeksowania Przedstawione przez nas rozwiązanie będzie hybrydą dwóch powyżej opisanych form indeksowania. Dzięki temu podstawowe cechy tych form zostaną zachowane, zwiększy się natomiast funkcjonalność indeksowania. 1. Dla każdego dokumentu tworzona jest lista słów, jak w metodzie forward indexing. 2. Dla każdego słowa z listy znajdowana jest jego podstawowa forma gramatyczna i zwiększana jest o 1 liczba wystąpień danego wyrazu w dokumencie. 3. Dla każdego wyrazu uaktualniana jest lista dokumentów, w których on występuje (inverted indexing), przy uwzględnieniu częstości wystąpienia. 4. Dokonywane jest wyodrębnienie zdań w każdym dokumencie. 5. Do dokumentu przyporządkowuje się kategorię na podstawie częstości występowanych wyrazów. 6. Dla każdego zdania dokonywana jest analiza jego struktury i tworzone są relacje między wyrazami zgodnie z kolejnością występowania wyrazów. Relacje te pozwolą na bardziej trafne wyszukiwanie. W ten sposób otrzymuje się graf nieskierowany, którego wierzchołkami są słowa, a krawędzie określają sąsiedztwo tych słów w dokumencie. 10
. Oba pozwalają na lepsze sortowanie wyników. 2.")
14 Rysunek 2.4: Postać grafowa naszego indeksowania zdania Adam Borowik świeci latarką na czerwone krzesło Formalizacja procesu indeksowania Budowanie indeksu będzie opierać się na trzech następujących funkcjach: δ : D S, gdzie S = {s 1, s 2,..., s n }, s i S, i = 1..n, która zwraca listę słów S ze słownika S występujących w dokumencie d; ϕ : S T, gdzie s i S, s i S i t i T, t i T, T = {t (1), t (2),..., t (T l) }, gdzie T l - liczba termów na liście. Funkcja ta zamienia wyraz ze słownika S, znajdujący się na liście S na term ze zbioru T ; γ : T G, funkcja, która zamienia listę termów na graf. Dla kolejnego termu t (i) T, sprawdza się czy istnieje wierzchołek grafu G o etykiecie t (i). Jeśli nie, jest dodawany do grafu jako v k, tworzona jest pętla (v k, v k, 1) oraz dla m {1, 2,.., 5} szukany jest wierzchołek v p o etykiecie t (i m) i - jeśli taki wierzchołek istnieje - tworzona jest krawędź (v k, v p, 1 ). m Jeśli natomiast istnieje wierzchołek v k o etykiecie t (i), to znajdowana jest krawędź (v k, v k ) i zwiększana jest jej etykieta o 1. Dla każdego m {1, 2,.., 5} jeśli istnieje krawędź między wierzchołkami v k i v p o etykiecie t (i m), to zwiększana jest wartość etykiety krawędzi o 1 ; w m przeciwnym przypadku tworzona jest krawędź (v k, v p, 1 ). Wartości krawędzi wszystkich etykiet grafu G zostają znormalizowane, przy czym m krawędzi o etykiecie z największą wartością zostaje przypisana nowa wartość równa 15, a krawędzi o etykiecie z najmniejszą liczbą zostaje przypisane 1. µ : G K - funkcja przypisująca dokument do danej kategorii. Tworzony jest wektor tymczasowy x o rozmiarze R, gdzie R - ilość kategorii. Dla kazdego v V za pomocą funkcji λ sprawdzane są kategorie, do których może należeć term i dodawana jest wartość etykiety krawędzi (v, v) do pól w wektorze x, oznaczających te właśnie kategorie. 11
 T, sprawdza się czy istnieje wierzchołek grafu G o etykiecie t (i). Jeśli nie, jest dodawany do grafu jako v k, tworzona jest pętla (v k, v k, 1) oraz dla m {1, 2,.")
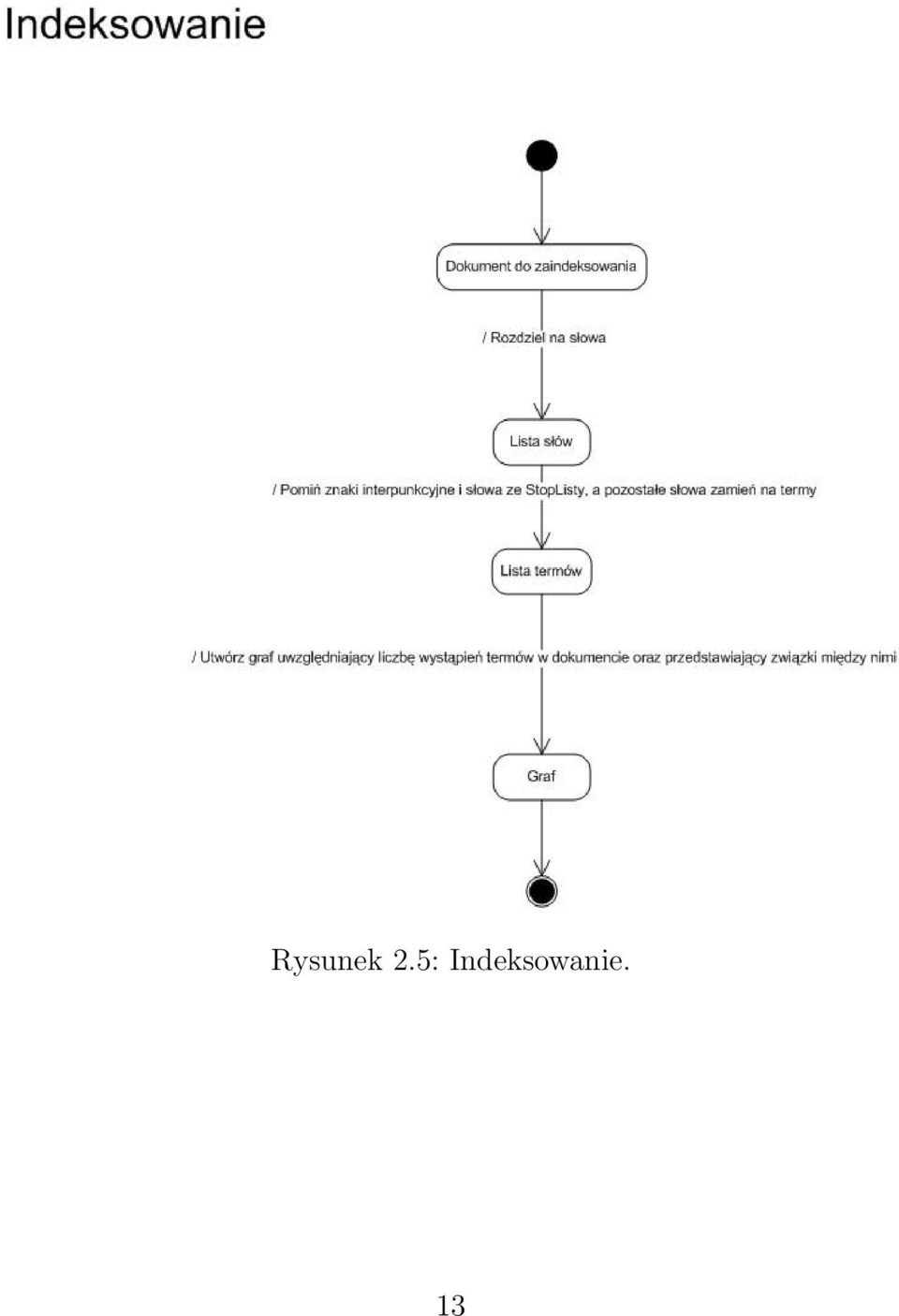
15 Kategoria, która uzyska największą wartość, oznacza kategorię, do której należy graf. Na początku procesu otrzymuje się na wejściu nowy, niezaindeksowany dokument d k D. Za pomocą funkcji δ tworzy się listę słów występujących w dokumencie. Następnie z wykorzystaniem funkcji ϕ dokonuje się przekształcenia każdego słowa z listy na odpowiadający mu term (podstawowa forma gramatyczna). Ponadto w wyniku działania tej funkcji zostają pominięte znaki interpunkcyjne oraz wyrazy z tzw. STOP LISTY. W kolejnym kroku, za pomocą funkcji γ tworzony jest właściwy graf, będący reprezentacją dokumentu, zawierający liczbę wystąpień danych termów w dokumencie, oraz związki między termami z przypisanymi wagami Schemat UML indeksowania Proces indeksowania w formie UML przedstawia rysunek

16 Rysunek 2.5: Indeksowanie. 13
17 2.3 Struktura bazy Dane w bazie systemu będą przechowywane w następujących tabelach: Wyrazy - tabela zawierająca słowa w podstawowej formie gramatycznej. ID-WYR Wyraz 1 słońce 2... Odmiany - pomocnicza tabela wskazująca podstawową formę wyrazu. ID-ODM ID-WYR Wyraz 1 1 słońcem 2 1 słońcu Kategorie - tabela zawierająca kategorie występujące w profilu użytkownika. ID-KAT Kategoria 1 Sport 2... Dokumenty - tabela zawierająca odnośniki URL do dokumentów. ID-DOK URL ID-KAT Historia - tabela informująca o zapytaniach stawianych przez danych użytkowników. ID-HIST ID-UZYT Zapytanie 1 1 Dom 2 1 Czarny pies Ranking - tabela relacyjna z ocenami dokumentów w powiązaniu z poszczególnymi zapytaniami. 14

18 ID-RANK ID-ZAP ID-DOK Ocena

19 Rozdział 3 Mechanizm wyszukiwania 3.1 Meta-język wyszukiwania W wyszukiwarce dostępne będą następujące metody wyszukiwania: słowo - dokumenty, w których występuje słowo, słowo1 słowo2 == (słowo1 słowo2 ) - dokumenty, w których występują oba słowa połączone ze sobą, (słowo1 ) (słowo2 ) - dokumenty, w których występują oba słowa, niekoniecznie połączone ze sobą, (słowo1 ) NOT(słowo2 ) - dokumenty, w których występuje słowo1, ale nie słowo2, (słowo1 ) OR (słowo2 ) - dokumenty, w których występuje słowo1 lub słowo Silnik wyszukiwania Wprowadźmy kolejną funkcję, która przyporządkowuje danemu termowi kategorie, do których może należeć (korzysta przy tym ze słownika WordNet); oznaczmy ją jako λ : T K r, gdzie r - liczba kategorii. Wyszukiwanie: słowo Dane jest zapytanie z ze zbioru Z, gdzie z = s S (jest pojedynczym wyrazem). Z wykorzystaniem funkcji δ, zapytanie sprowadzane jest do termu t. 16
 OR (słowo2 ) - dokumenty, w których występuje słowo1 lub słowo2. 3.")
20 Za pomocą funkcji λ sprawdza się, do jakich kategorii należy term. Jeśli należy do jednej kategorii k, to wyszukiwanie odbywa się wśród dokumentów z tej właśnie kategorii. Jeśli natomiast należy do więcej niż jednej, sprawdzając w profilu użytkownika p listy p k i p l określa się, która z tych kategorii jest najbardziej interesująca dla użytkownika. W zależności od rezultatu szukanie odbywa się we wszystkich kategoriach, do których należy term, bądź w jakiejś ich części. Oznaczmy D D jako podzbiór dokumentów, w których ostatecznie nastąpi wyszukiwanie. Proces wyszukiwania opiera się na grafach g G. Zwracany jest zbiór dokumentów, w których grafach występuje wierzchołek zaetykietowany przez szukany term. Schemat ten w formie UML przedstawia rysunek 3.1. Wyszukiwanie: słowo1 słowo2 == (słowo1 słowo2) Dane jest zapytanie z ze zbioru Z, gdzie z = (s 1 s 2 ) S S. Z wykorzystaniem funkcji δ, zapytanie sprowadzane jest do dwóch termów t 1 i t 2. Za pomocą funkcji λ sprawdza się, do jakich kategorii należą termy. Tworzony jest przekrój wyznaczonych kategorii. Jeśli jest niepusty, to po nim odbywa się wyszukiwanie, a jeśli nie to wyszukuje się po sumie kategorii. Oznaczmy D D jako podzbiór dokumentów, w których ostatecznie nastąpi wyszukiwanie. Proces wyszukiwania opiera się na grafach g G. Zwracany jest zbiór dokumentów, w których grafach występuje krawędź łącząca dwa termy z zapytania. Schemat ten w formie UML przedstawia rysunek 3.2. Wyszukiwanie: słowo1 słowo2 słowo3... słowon Dane jest zapytanie z ze zbioru Z, gdzie z = (s 1 s 2... s n ) S S... S. Z wykorzystaniem funkcji δ, zapytanie sprowadzane jest do dwóch termów t 1, t 2,..., t n. Za pomocą funkcji λ sprawdza się, do jakich kategorii należą termy. Tworzony jest przekrój wyznaczonych kategorii. Jeśli jest niepusty, to po nim odbywa się wyszukiwanie, a jeśli nie to wyszukuje się po sumie kategorii. Oznaczmy D D jako podzbiór dokumentów, w których ostatecznie nastąpi wyszukiwanie. Proces wyszukiwania opiera się na grafach g G. Zwracany jest zbiór dokumentów, w których grafach występuje krawędź pomiędzy dowolnymi termami z zapytania. Schemat ten w formie UML przedstawia rysunek

21 18 Rysunek 3.1: Wyszukiwanie: słowo.
22 19 Rysunek 3.2: Wyszukiwanie: słowo1 słowo2.
23 Rysunek 3.3: Wyszukiwanie: słowo1 słowo2 słowo3... słowon. 20
24 Wyszukiwanie: (słowo1) (słowo2) Dane jest zapytanie z ze zbioru Z, gdzie z = (s 1 s 2 ) S S. Z wykorzystaniem funkcji δ, zapytanie sprowadzane jest do dwóch termów t 1 i t 2. Za pomocą funkcji λ sprawdza się, do jakich kategorii należą termy. Tworzony jest przekrój wyznaczonych kategorii. Jeśli jest niepusty, to po nim odbywa się wyszukiwanie, a jeśli nie to wyszukuje się po sumie kategorii. Oznaczmy D D jako podzbiór dokumentów, w których ostatecznie nastąpi wyszukiwanie. Proces wyszukiwania opiera się na grafach g G. Zwracany jest zbiór dokumentów, w których grafach występują szukane słowa, niezaleznie od tego czy są w związku ze sobą czy też nie. Schemat ten w formie UML przedstawia rysunek 3.4. Wyszukiwanie: (słowo1) OR (słowo2) Dane jest zapytanie z ze zbioru Z, gdzie z = (s 1 s 2 ) S S. Z wykorzystaniem funkcji δ, zapytanie sprowadzane jest do dwóch termów t 1 i t 2. Za pomocą funkcji λ sprawdza się, do jakich kategorii należą termy. Tworzony jest przekrój wyznaczonych kategorii. Jeśli jest niepusty, to po nim odbywa się wyszukiwanie, a jeśli nie to wyszukuje się po sumie kategorii. Oznaczmy D D jako podzbiór dokumentów, w których ostatecznie nastąpi wyszukiwanie. Proces wyszukiwania opiera się na grafach g G. Zwracany jest zbiór dokumentów, w których grafach występuje dowolne ze słów z zapytania. Schemat ten w formie UML przedstawia rysunek 3.5. Wyszukiwanie: (słowo1) NOT(słowo2) Dane jest zapytanie z ze zbioru Z, gdzie z = (s 1 s 2 ) S S. Z wykorzystaniem funkcji δ, zapytanie sprowadzane jest do dwóch termów t 1 i t 2. Za pomocą funkcji λ sprawdza się, do jakich kategorii należą termy. Tworzona jest różnica wyznaczonych kategorii. Jeśli jest niepusta, to po niej odbywa się wyszukiwanie, a jeśli nie to wyszukuje się po kategoriach, do których należy term t 1. Oznaczmy D D jako podzbiór dokumentów, w których ostatecznie nastąpi wyszukiwanie. Proces wyszukiwania opiera się na grafach g G. Zwracany jest zbiór dokumentów, w których grafach występuje pierwszy wyraz, ale nie ma drugiego z podanych. Schemat ten w formie UML przedstawia rysunek
25 Rysunek 3.4: Wyszukiwanie: (słowo1) (słowo2). 22
26 Rysunek 3.5: Wyszukiwanie: (słowo1) OR (słowo2). 23
27 Rysunek 3.6: Wyszukiwanie: (słowo1) NOT (słowo2). 24
28 3.3 Pozycjonowanie Przy wyświetlaniu wyników wyszukiwań będą brane pod uwagę takie parametry jak: znormalizowana wartość wystąpień szukanego termu/związku termów w dokumencie (waga w grafie) - w, ranking publiczny dokumentu (r) Do wyznaczenia pozycji dokumentu w wyświetlonych wynikach, zastosowana będzie odpowiednio zdefiniowana funkcja ψ i (w (1) i, w (2) i,..., w (I) i, r i ), gdzie I - liczba krawędzi w grafie g między krawędziami oznaczającymi różne termy z zapytania. 3.4 Przebieg procesu wyszukiwania W formie UML na rysunku 3.7 można zobaczyć przebieg procesu wyszukiwania oraz indeksowania. 25
29 Rysunek 3.7: Diagram przypadków użycia. 26
30 Rozdział 4 System rekomendacji 4.1 Profil użytkownika Po wyselekcjonowaniu dokumentów spełniających zapytanie użytkownika będą one porządkowane z uwzględnieniem danych zawarte w jego profilu Struktura profilu użytkownika Profil użytkownika zawiera: dane identyfikujące użytkownika (login, hasło, , itp.) zainteresowania, które wybiera z podanej mu listy: biznes dom i rodzina fotografia komputery i internet książki kuchnia kultura, sztuka, film media masowe moda motoryzacja muzyka nauka i technika 27
31 polityka przyroda sport turystyka uroda zdrowie ranking osobisty (lista kategorii z przypisanymi wartościami liczbowymi odzwierciedlającymi zainteresowanie użytkownika daną kategorią). 4.2 Rankingi Użytkownik ma możliwość oceny każdego przeglądanego dokumentu. W ten sposób modyfikowane będą dane zarówno w profilu użytkownika, jak i w rankingu samego dokumentu. Ranking prywatny definiuje, w jakim stopniu użytkownik jest zainteresowany daną tematyką. Początkowo jest to lista kategorii z przypisanymi domyślnymi wartościami 0. Rankingiem dokumentu jest liczba r i, która określa stopień przydatności dokumentu w przypisanej do niego kategorii. Użytkownik, po przeglądnięciu dokumentu może wybrać jedną z poniższych opcji (domyślnie opcja trzecia): dokument jest interesujący - zostaje dopisany punkt do dziedziny, z której pochodzi dokument w p l w profilu użytkownika oraz punkt do rankingu dokumentu; interesująca jest dziedzina, natomiast dokument jest nieprzydatny - zostaje dopisany punkt w p l w profilu użytkownika do dziedziny, z której pochodzi dokument, natomiast w rankingu dokumentu zostaje odjęty punkt; dziedzina nie jest dla mnie interesująca - brak zmian w rankingach. 28
32 4.3 Typy rekomendacji Rekomendacja typu A - nowo zaindeksowane dokumenty Na stronie głównej wyszukiwarki osobno ukazywana jest tabela z pięcioma ostatnio zaindeksowanymi dokumentami d 1, d 2, d 3, d 4, d 5 przypisanymi do kategorii k j, która w profilu użytkownika posiada największą wagę Rekomendacja typu B - na podstawie historii zapytań innych użytkowników System otrzymuje zapytanie z. Znajdowani są użytkownicy, u których w historii zapytań istnieje już zapytanie z. Następnie spośród znalezionych użytkowników, wybierani są ci, którzy mają zainteresowania podobne do zainteresowań aktualnie przeszukującego. Będą to tacy użytkownicy, w których profilach wagi kategorii są najbardziej zbliżone do wag w profilu użytkownika aktualnie wyszukującego dokumenty. W następnym kroku sprawdza się, jakie zapytania występowały w historii wyselekcjonowanych użytkowników zaraz po zapytaniu z. Rekomendowanych jest 5 najczęściej występujących wyników - zapytania: z 1, z 2, z 3, z 4, z Rekomendacja typu C - wykorzystanie synonimów System otrzymuje zapytanie z, które zgodnie z opisanym wcześniej algorytmem (za pomocą funkcji ϕ) zamienia na listę termów: t 1, t 2,..., t n, gdzie n-liczba termów występujących w zapytaniu. Wyszukiwarka sugeruje n wersji zmiany zapytania podmieniając kolejne termy na ich synonimy w ten sposób, że w każdym rekomendowanym zapytaniu podmieniony jest inny term. W tym kroku algorytm opiera się na słowniku WordNet Rekomendacja typu D - na podstawie podobieństwa dokumentów Jak wiadomo, dokumenty przedstawiane są w indeksie w postaci grafów G. Podczas przeglądania dokumentu d i przez użytkownika, proponuje się przeglądnięcie podobnych dokumentów, tj. takich, których grafy są najbardziej zbliżone do grafu odpowiadającego aktualnie przeglądanemu dokumentowi. 29
33 System rekomenduje 5 dokumentów d 1, d 2, d 3, d 4, d 5, których grafy G 1, G 2, G 3, G 4, G 5 są najbliższe G i odpowiadającemu dokumentowi d i. Do zrealizowania tego podejścia należy wprowadzić miarę podobieństwa grafów. Oznaczmy funkcję θ : G G N, która zwraca stopień podobieństwa, zliczając sumę wag krawędzi występujących w obu strukturach. θ(g i, G j ) = (v a,v b,w ab ) G i G j w ab Zatem algorytm rekomendacji typu D, znajdzie 5 grafów o najwyższej wartości funkcji θ w porównaniu z tym, który odpowiada przeglądanemu aktualnie dokumentowi. Dokumenty odpowiadające wyznaczonym grafom, zostaną zarekomendowane użytkownikowi. 4.4 Diagram UML rekomendacji Wszystkie cztery typy rekomendacji w formie UML przedstawia rysunek
34 Rysunek 4.1: Proces rekomendacji typu A, B, C i D. 31
35 Rozdział 5 Wskazówki do implementacji Zaproponowany przez nas system wyszukiwania dokumentów tekstowych można stosunkowo prosto zaimplementować używając w zasadzie dowolnego języka programowania. W tym rozdziale zostaną zaproponowane typy danych, które mogą być użyte do implementacji systemu, wraz z uzasadnieniem. Ogólnie przedstawia się też pseudokod głównych funkcji, które zostały opisane we wcześniejszych rozdziałach. 5.1 Funkcje Główne funkcje które należy zaimplementować są przedstawione poniżej GetWords W formalizacji funkcja opisana jako δ będzie zwracała listę słów, a jej parametrem będzie dokument. Listing 5.1: Funkcja GetWords 1 function GetWords ( string D) 2 new queue l i s t a 3 new int i, j, l a s t s p a c e 4 new string word 5 for i :=0 to length (D) 6 i f D[ i ] == 7 i f i!= l a s t s p a c e+1 8 for j := l a s t s p a c e to i 9 word [ j ] = D[ l a s t s p a c e+j ] 32
36 10 l i s t a. push ( word ) 11 l a s t s p a c e=i 12 else 13 l a s t s p a c e=i 14 return l i s t GetTerms Funkcja opisana w formalizacji jako ϕ zwraca dla każdego słowa znajdującego się na liście wejściowej oznaczenie (term) mu odpowiadające. 1 function Term( string word ) Listing 5.2: Funkcja GetTerms 2 return query ( SELECT ID WYR FROM odmiany WHERE wyraz = +word+ ) 3 4 function GetTerms ( l i s t l i s t a ) 5 new queue l i s t a t 6 new string word 7 repeat 8 l i s t a. pop ( word ) 9 i f Term( word )!= 10 l i s t a t. push (Term( word ) ) 11 until word == 12 return l i s t a t CreateGraph Funkcja γ z formalizacji przekształca listę termów będących na liście dokumentów na reprezentację grafu. Listing 5.3: Funkcja CreateGraph 1 function CreateGraph ( l i s t l i s t a t ) 2 new int i, j, l a s t 5 p l a c e 3 new l i s t l i s t a g 4 new array l a s t 5 [ 5 ] of string, M[ sizeof ( l i s t a t ), sizeof ( l i s t a t ) ] of float 5 new string term 6 repeat // Tworze tymczasowa macierz. 33
Metody indeksowania dokumentów tekstowych
 Metody indeksowania dokumentów tekstowych Paweł Szołtysek 21maja2009 Metody indeksowania dokumentów tekstowych 1/ 19 Metody indeksowania dokumentów tekstowych 2/ 19 Czym jest wyszukiwanie informacji? Wyszukiwanie
Metody indeksowania dokumentów tekstowych Paweł Szołtysek 21maja2009 Metody indeksowania dokumentów tekstowych 1/ 19 Metody indeksowania dokumentów tekstowych 2/ 19 Czym jest wyszukiwanie informacji? Wyszukiwanie
Badania operacyjne: Wykład Zastosowanie kolorowania grafów w planowaniu produkcji typu no-idle
 Badania operacyjne: Wykład Zastosowanie kolorowania grafów w planowaniu produkcji typu no-idle Paweł Szołtysek 12 czerwca 2008 Streszczenie Planowanie produkcji jest jednym z problemów optymalizacji dyskretnej,
Badania operacyjne: Wykład Zastosowanie kolorowania grafów w planowaniu produkcji typu no-idle Paweł Szołtysek 12 czerwca 2008 Streszczenie Planowanie produkcji jest jednym z problemów optymalizacji dyskretnej,
AiSD zadanie trzecie
 AiSD zadanie trzecie Gliwiński Jarosław Marek Kruczyński Konrad Marek Grupa dziekańska I5 5 czerwca 2008 1 Wstęp Celem postawionym przez zadanie trzecie było tzw. sortowanie topologiczne. Jest to typ sortowania
AiSD zadanie trzecie Gliwiński Jarosław Marek Kruczyński Konrad Marek Grupa dziekańska I5 5 czerwca 2008 1 Wstęp Celem postawionym przez zadanie trzecie było tzw. sortowanie topologiczne. Jest to typ sortowania
Algorytmy grafowe. Wykład 1 Podstawy teorii grafów Reprezentacje grafów. Tomasz Tyksiński CDV
 Algorytmy grafowe Wykład 1 Podstawy teorii grafów Reprezentacje grafów Tomasz Tyksiński CDV Rozkład materiału 1. Podstawowe pojęcia teorii grafów, reprezentacje komputerowe grafów 2. Przeszukiwanie grafów
Algorytmy grafowe Wykład 1 Podstawy teorii grafów Reprezentacje grafów Tomasz Tyksiński CDV Rozkład materiału 1. Podstawowe pojęcia teorii grafów, reprezentacje komputerowe grafów 2. Przeszukiwanie grafów
Reprezentacje grafów nieskierowanych Reprezentacje grafów skierowanych. Wykład 2. Reprezentacja komputerowa grafów
 Wykład 2. Reprezentacja komputerowa grafów 1 / 69 Macierz incydencji Niech graf G będzie grafem nieskierowanym bez pętli o n wierzchołkach (x 1, x 2,..., x n) i m krawędziach (e 1, e 2,..., e m). 2 / 69
Wykład 2. Reprezentacja komputerowa grafów 1 / 69 Macierz incydencji Niech graf G będzie grafem nieskierowanym bez pętli o n wierzchołkach (x 1, x 2,..., x n) i m krawędziach (e 1, e 2,..., e m). 2 / 69
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe.
 Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Grafem nazywamy strukturę G = (V, E): V zbiór węzłów lub wierzchołków, Grafy dzielimy na grafy skierowane i nieskierowane:
: V zbiór węzłów lub wierzchołków, Grafy dzielimy na grafy skierowane i nieskierowane:") Wykład 4 grafy Grafem nazywamy strukturę G = (V, E): V zbiór węzłów lub wierzchołków, E zbiór krawędzi, Grafy dzielimy na grafy skierowane i nieskierowane: Formalnie, w grafach skierowanych E jest podzbiorem
Wykład 4 grafy Grafem nazywamy strukturę G = (V, E): V zbiór węzłów lub wierzchołków, E zbiór krawędzi, Grafy dzielimy na grafy skierowane i nieskierowane: Formalnie, w grafach skierowanych E jest podzbiorem
Programowanie obiektowe
 Laboratorium z przedmiotu Programowanie obiektowe - zestaw 02 Cel zajęć. Celem zajęć jest zapoznanie z praktycznymi aspektami projektowania oraz implementacji klas i obiektów z wykorzystaniem dziedziczenia.
Laboratorium z przedmiotu Programowanie obiektowe - zestaw 02 Cel zajęć. Celem zajęć jest zapoznanie z praktycznymi aspektami projektowania oraz implementacji klas i obiektów z wykorzystaniem dziedziczenia.
REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i realizacja serwisu ogłoszeń z inteligentną wyszukiwarką
 REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i realizacja serwisu ogłoszeń z inteligentną wyszukiwarką Autor: Paweł Konieczny Promotor: dr Jadwigi Bakonyi Kategorie: aplikacja www Słowa kluczowe: Serwis
REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i realizacja serwisu ogłoszeń z inteligentną wyszukiwarką Autor: Paweł Konieczny Promotor: dr Jadwigi Bakonyi Kategorie: aplikacja www Słowa kluczowe: Serwis
PageRank i HITS. Mikołajczyk Grzegorz
 PageRank i HITS Mikołajczyk Grzegorz PageRank Metoda nadawania indeksowanym stronom internetowym określonej wartości liczbowej, oznaczającej jej jakość. Algorytm PageRank jest wykorzystywany przez popularną
PageRank i HITS Mikołajczyk Grzegorz PageRank Metoda nadawania indeksowanym stronom internetowym określonej wartości liczbowej, oznaczającej jej jakość. Algorytm PageRank jest wykorzystywany przez popularną
Zasady programowania Dokumentacja
 Marcin Kędzierski gr. 14 Zasady programowania Dokumentacja Wstęp 1) Temat: Przeszukiwanie pliku za pomocą drzewa. 2) Założenia projektu: a) Program ma pobierać dane z pliku wskazanego przez użytkownika
Marcin Kędzierski gr. 14 Zasady programowania Dokumentacja Wstęp 1) Temat: Przeszukiwanie pliku za pomocą drzewa. 2) Założenia projektu: a) Program ma pobierać dane z pliku wskazanego przez użytkownika
Biblioteka Wirtualnej Nauki
 Biblioteka Wirtualnej Nauki BAZA SCOPUS Scopus jest największą na świecie bibliograficzną bazą abstraktów i cytowań recenzowanej literatury naukowej, wyposażoną w narzędzia bibliometryczne do śledzenia,
Biblioteka Wirtualnej Nauki BAZA SCOPUS Scopus jest największą na świecie bibliograficzną bazą abstraktów i cytowań recenzowanej literatury naukowej, wyposażoną w narzędzia bibliometryczne do śledzenia,
Sortowanie topologiczne skierowanych grafów acyklicznych
 Sortowanie topologiczne skierowanych grafów acyklicznych Metody boolowskie w informatyce Robert Sulkowski http://robert.brainusers.net 23 stycznia 2010 1 Definicja 1 (Cykl skierowany). Niech C = (V, A)
Sortowanie topologiczne skierowanych grafów acyklicznych Metody boolowskie w informatyce Robert Sulkowski http://robert.brainusers.net 23 stycznia 2010 1 Definicja 1 (Cykl skierowany). Niech C = (V, A)
Optymalizacja zapytań. Proces przetwarzania i obliczania wyniku zapytania (wyrażenia algebry relacji) w SZBD
 w SZBD") Optymalizacja zapytań Proces przetwarzania i obliczania wyniku zapytania (wyrażenia algebry relacji) w SZBD Elementy optymalizacji Analiza zapytania i przekształcenie go do lepszej postaci. Oszacowanie
Optymalizacja zapytań Proces przetwarzania i obliczania wyniku zapytania (wyrażenia algebry relacji) w SZBD Elementy optymalizacji Analiza zapytania i przekształcenie go do lepszej postaci. Oszacowanie
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych
 Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
Wyszukiwanie informacji w internecie. Nguyen Hung Son
 Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
Programowanie obiektowe
 Laboratorium z przedmiotu - zestaw 02 Cel zajęć. Celem zajęć jest zapoznanie z praktycznymi aspektami projektowania oraz implementacji klas i obiektów z wykorzystaniem dziedziczenia. Wprowadzenie teoretyczne.
Laboratorium z przedmiotu - zestaw 02 Cel zajęć. Celem zajęć jest zapoznanie z praktycznymi aspektami projektowania oraz implementacji klas i obiektów z wykorzystaniem dziedziczenia. Wprowadzenie teoretyczne.
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
a) 7 b) 19 c) 21 d) 34
 7 b) 19 c) 21 d) 34") Zadanie 1. Pytania testowe dotyczące podstawowych własności grafów. Zadanie 2. Przy każdym z zadań może się pojawić polecenie krótkiej charakterystyki algorytmu. Zadanie 3. W zadanym grafie sprawdzenie
Zadanie 1. Pytania testowe dotyczące podstawowych własności grafów. Zadanie 2. Przy każdym z zadań może się pojawić polecenie krótkiej charakterystyki algorytmu. Zadanie 3. W zadanym grafie sprawdzenie
1 Wprowadzenie do algorytmiki
 Teoretyczne podstawy informatyki - ćwiczenia: Prowadzący: dr inż. Dariusz W Brzeziński 1 Wprowadzenie do algorytmiki 1.1 Algorytm 1. Skończony, uporządkowany ciąg precyzyjnie i zrozumiale opisanych czynności
Teoretyczne podstawy informatyki - ćwiczenia: Prowadzący: dr inż. Dariusz W Brzeziński 1 Wprowadzenie do algorytmiki 1.1 Algorytm 1. Skończony, uporządkowany ciąg precyzyjnie i zrozumiale opisanych czynności
Wykład XII. optymalizacja w relacyjnych bazach danych
 Optymalizacja wyznaczenie spośród dopuszczalnych rozwiązań danego problemu, rozwiązania najlepszego ze względu na przyjęte kryterium jakości ( np. koszt, zysk, niezawodność ) optymalizacja w relacyjnych
Optymalizacja wyznaczenie spośród dopuszczalnych rozwiązań danego problemu, rozwiązania najlepszego ze względu na przyjęte kryterium jakości ( np. koszt, zysk, niezawodność ) optymalizacja w relacyjnych
Ogólne wiadomości o grafach
 Ogólne wiadomości o grafach Algorytmy i struktury danych Wykład 5. Rok akademicki: / Pojęcie grafu Graf zbiór wierzchołków połączonych za pomocą krawędzi. Podstawowe rodzaje grafów: grafy nieskierowane,
Ogólne wiadomości o grafach Algorytmy i struktury danych Wykład 5. Rok akademicki: / Pojęcie grafu Graf zbiór wierzchołków połączonych za pomocą krawędzi. Podstawowe rodzaje grafów: grafy nieskierowane,
0 + 0 = 0, = 1, = 1, = 0.
 5 Kody liniowe Jak już wiemy, w celu przesłania zakodowanego tekstu dzielimy go na bloki i do każdego z bloków dodajemy tak zwane bity sprawdzające. Bity te są w ścisłej zależności z bitami informacyjnymi,
5 Kody liniowe Jak już wiemy, w celu przesłania zakodowanego tekstu dzielimy go na bloki i do każdego z bloków dodajemy tak zwane bity sprawdzające. Bity te są w ścisłej zależności z bitami informacyjnymi,
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
Struktury danych i złożoność obliczeniowa Wykład 5. Prof. dr hab. inż. Jan Magott
 Struktury danych i złożoność obliczeniowa Wykład. Prof. dr hab. inż. Jan Magott Algorytmy grafowe: podstawowe pojęcia, reprezentacja grafów, metody przeszukiwania, minimalne drzewa rozpinające, problemy
Struktury danych i złożoność obliczeniowa Wykład. Prof. dr hab. inż. Jan Magott Algorytmy grafowe: podstawowe pojęcia, reprezentacja grafów, metody przeszukiwania, minimalne drzewa rozpinające, problemy
Diagramy związków encji. Laboratorium. Akademia Morska w Gdyni
 Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl
 Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Modelowanie hierarchicznych struktur w relacyjnych bazach danych
 Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Badanie struktury sieci WWW
 Eksploracja zasobów internetowych Wykład 1 Badanie struktury sieci WWW mgr inż. Maciej Kopczyński Białystok 214 Rys historyczny Idea sieci Web stworzona została w 1989 przez Tima BernersaLee z CERN jako
Eksploracja zasobów internetowych Wykład 1 Badanie struktury sieci WWW mgr inż. Maciej Kopczyński Białystok 214 Rys historyczny Idea sieci Web stworzona została w 1989 przez Tima BernersaLee z CERN jako
Maciej Piotr Jankowski
 Reduced Adder Graph Implementacja algorytmu RAG Maciej Piotr Jankowski 2005.12.22 Maciej Piotr Jankowski 1 Plan prezentacji 1. Wstęp 2. Implementacja 3. Usprawnienia optymalizacyjne 3.1. Tablica ekspansji
Reduced Adder Graph Implementacja algorytmu RAG Maciej Piotr Jankowski 2005.12.22 Maciej Piotr Jankowski 1 Plan prezentacji 1. Wstęp 2. Implementacja 3. Usprawnienia optymalizacyjne 3.1. Tablica ekspansji
Załącznik nr 1. Specyfikacja. Do tworzenia Mapy Kompetencji
 Załącznik nr 1 Specyfikacja Do tworzenia Mapy Kompetencji 1. Cel projektu Celem projektu jest utworzenie Mapy kompetencji. Ma ona zawierać informacje o kompetencjach, celach kształcenia, umożliwiać ich
Załącznik nr 1 Specyfikacja Do tworzenia Mapy Kompetencji 1. Cel projektu Celem projektu jest utworzenie Mapy kompetencji. Ma ona zawierać informacje o kompetencjach, celach kształcenia, umożliwiać ich
Algorytmy i złożoności Wykład 5. Haszowanie (hashowanie, mieszanie)
") Algorytmy i złożoności Wykład 5. Haszowanie (hashowanie, mieszanie) Wprowadzenie Haszowanie jest to pewna technika rozwiązywania ogólnego problemu słownika. Przez problem słownika rozumiemy tutaj takie
Algorytmy i złożoności Wykład 5. Haszowanie (hashowanie, mieszanie) Wprowadzenie Haszowanie jest to pewna technika rozwiązywania ogólnego problemu słownika. Przez problem słownika rozumiemy tutaj takie
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Internet, jako ocean informacji. Technologia Informacyjna Lekcja 2
 Internet, jako ocean informacji Technologia Informacyjna Lekcja 2 Internet INTERNET jest rozległą siecią połączeń, między ogromną liczbą mniejszych sieci komputerowych na całym świecie. Jest wszechstronnym
Internet, jako ocean informacji Technologia Informacyjna Lekcja 2 Internet INTERNET jest rozległą siecią połączeń, między ogromną liczbą mniejszych sieci komputerowych na całym świecie. Jest wszechstronnym
Luty 2001 Algorytmy (7) 2000/2001 s-rg@siwy.il.pw.edu.pl
 2000/2001 s-rg@siwy.il.pw.edu.pl") System dziesiętny 7 * 10 4 + 3 * 10 3 + 0 * 10 2 + 5 *10 1 + 1 * 10 0 = 73051 Liczba 10 w tym zapisie nazywa się podstawą systemu liczenia. Jeśli liczba 73051 byłaby zapisana w systemie ósemkowym, co powinniśmy
System dziesiętny 7 * 10 4 + 3 * 10 3 + 0 * 10 2 + 5 *10 1 + 1 * 10 0 = 73051 Liczba 10 w tym zapisie nazywa się podstawą systemu liczenia. Jeśli liczba 73051 byłaby zapisana w systemie ósemkowym, co powinniśmy
Wyszukiwanie boolowskie i strukturalne. Adam Srebniak
 Wyszukiwanie boolowskie i strukturalne Adam Srebniak Wyszukiwanie boolowskie W wyszukiwaniu boolowskim zapytanie traktowane jest jako zdanie logiczne. Zwracane są dokumenty, dla których to zdanie jest
Wyszukiwanie boolowskie i strukturalne Adam Srebniak Wyszukiwanie boolowskie W wyszukiwaniu boolowskim zapytanie traktowane jest jako zdanie logiczne. Zwracane są dokumenty, dla których to zdanie jest
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Matematyka dyskretna. Andrzej Łachwa, UJ, /15
 Matematyka dyskretna Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl 14/15 Grafy podstawowe definicje Graf to para G=(V, E), gdzie V to niepusty i skończony zbiór, którego elementy nazywamy wierzchołkami
Matematyka dyskretna Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl 14/15 Grafy podstawowe definicje Graf to para G=(V, E), gdzie V to niepusty i skończony zbiór, którego elementy nazywamy wierzchołkami
INTERNET - NOWOCZESNY MARKETING
 STRONA INTERNETOWA TO JUŻ ZBYT MAŁO! INTERNET ROZWIJA SIĘ Z KAŻDYM DNIEM MÓWIMY JUŻ O: SEM Search Engine Marketing, czyli wszystko co wiąże się z marketingiem internetowym w wyszukiwarkach. SEM jest słowem
STRONA INTERNETOWA TO JUŻ ZBYT MAŁO! INTERNET ROZWIJA SIĘ Z KAŻDYM DNIEM MÓWIMY JUŻ O: SEM Search Engine Marketing, czyli wszystko co wiąże się z marketingiem internetowym w wyszukiwarkach. SEM jest słowem
Wydział Elektrotechniki, Informatyki i Telekomunikacji. Instytut Informatyki i Elektroniki. Instrukcja do zajęć laboratoryjnych
 Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Matematyka dyskretna. Andrzej Łachwa, UJ, /14
 Matematyka dyskretna Andrzej Łachwa, UJ, 2012 andrzej.lachwa@uj.edu.pl 13/14 Grafy podstawowe definicje Graf to para G=(V, E), gdzie V to niepusty i skończony zbiór, którego elementy nazywamy wierzchołkami
Matematyka dyskretna Andrzej Łachwa, UJ, 2012 andrzej.lachwa@uj.edu.pl 13/14 Grafy podstawowe definicje Graf to para G=(V, E), gdzie V to niepusty i skończony zbiór, którego elementy nazywamy wierzchołkami
Algorytmy sortujące i wyszukujące
 Algorytmy sortujące i wyszukujące Zadaniem algorytmów sortujących jest ułożenie elementów danego zbioru w ściśle określonej kolejności. Najczęściej wykorzystywany jest porządek numeryczny lub leksykograficzny.
Algorytmy sortujące i wyszukujące Zadaniem algorytmów sortujących jest ułożenie elementów danego zbioru w ściśle określonej kolejności. Najczęściej wykorzystywany jest porządek numeryczny lub leksykograficzny.
Zastosowanie CP-grafów do generacji siatek
 Zastosowanie CP-grafów do generacji siatek 1 Cel zajęć Celem zajęć jest praktyczne zaznajomienie się z pojęciem CP-grafu i gramatyk grafowych, przy pomocy których można je tworzyć i nimi manipulować. Jako
Zastosowanie CP-grafów do generacji siatek 1 Cel zajęć Celem zajęć jest praktyczne zaznajomienie się z pojęciem CP-grafu i gramatyk grafowych, przy pomocy których można je tworzyć i nimi manipulować. Jako
Metody Programowania
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Metody Programowania www.pk.edu.pl/~zk/mp_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 8: Wyszukiwanie
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Metody Programowania www.pk.edu.pl/~zk/mp_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 8: Wyszukiwanie
Teoretyczne podstawy informatyki
 Teoretyczne podstawy informatyki Wykład 8b: Algebra relacyjna http://hibiscus.if.uj.edu.pl/~erichter/dydaktyka2009/tpi-2009 Prof. dr hab. Elżbieta Richter-Wąs 1 Algebra relacyjna Algebra relacyjna (ang.
Teoretyczne podstawy informatyki Wykład 8b: Algebra relacyjna http://hibiscus.if.uj.edu.pl/~erichter/dydaktyka2009/tpi-2009 Prof. dr hab. Elżbieta Richter-Wąs 1 Algebra relacyjna Algebra relacyjna (ang.
znalezienia elementu w zbiorze, gdy w nim jest; dołączenia nowego elementu w odpowiednie miejsce, aby zbiór pozostał nadal uporządkowany.
 Przedstawiamy algorytmy porządkowania dowolnej liczby elementów, którymi mogą być liczby, jak również elementy o bardziej złożonej postaci (takie jak słowa i daty). Porządkowanie, nazywane również często
Przedstawiamy algorytmy porządkowania dowolnej liczby elementów, którymi mogą być liczby, jak również elementy o bardziej złożonej postaci (takie jak słowa i daty). Porządkowanie, nazywane również często
Matematyczne Podstawy Informatyki
 Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 2013/2014 Informacje podstawowe 1. Konsultacje: pokój
Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 2013/2014 Informacje podstawowe 1. Konsultacje: pokój
Matematyczne Podstawy Informatyki
 Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 03/0 Przeszukiwanie w głąb i wszerz I Przeszukiwanie metodą
Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 03/0 Przeszukiwanie w głąb i wszerz I Przeszukiwanie metodą
Programowanie dynamiczne
 Programowanie dynamiczne Ciąg Fibonacciego fib(0)=1 fib(1)=1 fib(n)=fib(n-1)+fib(n-2), gdzie n 2 Elementy tego ciągu stanowią liczby naturalne tworzące ciąg o takiej własności, że kolejny wyraz (z wyjątkiem
Programowanie dynamiczne Ciąg Fibonacciego fib(0)=1 fib(1)=1 fib(n)=fib(n-1)+fib(n-2), gdzie n 2 Elementy tego ciągu stanowią liczby naturalne tworzące ciąg o takiej własności, że kolejny wyraz (z wyjątkiem
Algorytmy i złożoności. Wykład 3. Listy jednokierunkowe
 Algorytmy i złożoności Wykład 3. Listy jednokierunkowe Wstęp. Lista jednokierunkowa jest strukturą pozwalającą na pamiętanie danych w postaci uporzadkowanej, a także na bardzo szybkie wstawianie i usuwanie
Algorytmy i złożoności Wykład 3. Listy jednokierunkowe Wstęp. Lista jednokierunkowa jest strukturą pozwalającą na pamiętanie danych w postaci uporzadkowanej, a także na bardzo szybkie wstawianie i usuwanie
Wyszukiwanie plików w systemie Windows
 1 (Pobrane z slow7.pl) Bardzo często pracując na komputerze prędzej czy później łapiemy się na pytaniu - Gdzie jest ten plik? Zapisujemy i pobieramy masę plików i w nawale pracy pewne czynności są wykonywane
1 (Pobrane z slow7.pl) Bardzo często pracując na komputerze prędzej czy później łapiemy się na pytaniu - Gdzie jest ten plik? Zapisujemy i pobieramy masę plików i w nawale pracy pewne czynności są wykonywane
Rozdział 4 KLASY, OBIEKTY, METODY
 Rozdział 4 KLASY, OBIEKTY, METODY Java jest językiem w pełni zorientowanym obiektowo. Wszystkie elementy opisujące dane, za wyjątkiem zmiennych prostych są obiektami. Sam program też jest obiektem pewnej
Rozdział 4 KLASY, OBIEKTY, METODY Java jest językiem w pełni zorientowanym obiektowo. Wszystkie elementy opisujące dane, za wyjątkiem zmiennych prostych są obiektami. Sam program też jest obiektem pewnej
Typy danych, cd. Łańcuchy znaków
 Typy danych, cd. Łańcuchy znaków Typ danych string, jest rozumiany jako łańcuch znaków - liter, cyfr i symboli. Stringi definiuje się w podwójnych lub pojedyńczych cudzysłowach. typ_ kawy = " latte " typ_herbaty
Typy danych, cd. Łańcuchy znaków Typ danych string, jest rozumiany jako łańcuch znaków - liter, cyfr i symboli. Stringi definiuje się w podwójnych lub pojedyńczych cudzysłowach. typ_ kawy = " latte " typ_herbaty
Technologie Internetowe Raport z wykonanego projektu Temat: Internetowy sklep elektroniczny
 Technologie Internetowe Raport z wykonanego projektu Temat: Internetowy sklep elektroniczny AiRIII gr. 2TI sekcja 1 Autorzy: Tomasz Bizon Józef Wawrzyczek 2 1. Wstęp Celem projektu było stworzenie sklepu
Technologie Internetowe Raport z wykonanego projektu Temat: Internetowy sklep elektroniczny AiRIII gr. 2TI sekcja 1 Autorzy: Tomasz Bizon Józef Wawrzyczek 2 1. Wstęp Celem projektu było stworzenie sklepu
Instrukcja obsługi Zaplecza epk w zakresie zarządzania tłumaczeniami opisów procedur, publikacji oraz poradników przedsiębiorcy
 Instrukcja obsługi Zaplecza epk w zakresie zarządzania tłumaczeniami opisów procedur, publikacji oraz poradników przedsiębiorcy Spis treści: 1 WSTĘP... 3 2 DOSTĘP DO SYSTEMU... 3 3 OPIS OGÓLNY SEKCJI TŁUMACZENIA...
Instrukcja obsługi Zaplecza epk w zakresie zarządzania tłumaczeniami opisów procedur, publikacji oraz poradników przedsiębiorcy Spis treści: 1 WSTĘP... 3 2 DOSTĘP DO SYSTEMU... 3 3 OPIS OGÓLNY SEKCJI TŁUMACZENIA...
Bazy danych. Zenon Gniazdowski WWSI, ITE Andrzej Ptasznik WWSI
 Bazy danych Zenon Gniazdowski WWSI, ITE Andrzej Ptasznik WWSI Wszechnica Poranna Trzy tematy: 1. Bazy danych - jak je ugryźć? 2. Język SQL podstawy zapytań. 3. Mechanizmy wewnętrzne baz danych czyli co
Bazy danych Zenon Gniazdowski WWSI, ITE Andrzej Ptasznik WWSI Wszechnica Poranna Trzy tematy: 1. Bazy danych - jak je ugryźć? 2. Język SQL podstawy zapytań. 3. Mechanizmy wewnętrzne baz danych czyli co
ECDL Podstawy programowania Sylabus - wersja 1.0
 ECDL Podstawy programowania Sylabus - wersja 1.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu Podstawy programowania. Sylabus opisuje, poprzez efekty uczenia się, zakres wiedzy
ECDL Podstawy programowania Sylabus - wersja 1.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu Podstawy programowania. Sylabus opisuje, poprzez efekty uczenia się, zakres wiedzy
Graf. Definicja marca / 1
 Graf 25 marca 2018 Graf Definicja 1 Graf ogólny to para G = (V, E), gdzie V jest zbiorem wierzchołków (węzłów, punktów grafu), E jest rodziną krawędzi, które mogą być wielokrotne, dokładniej jednoelementowych
Graf 25 marca 2018 Graf Definicja 1 Graf ogólny to para G = (V, E), gdzie V jest zbiorem wierzchołków (węzłów, punktów grafu), E jest rodziną krawędzi, które mogą być wielokrotne, dokładniej jednoelementowych
Język SQL Złączenia. Laboratorium. Akademia Morska w Gdyni
 Akademia Morska w Gdyni Gdynia 2004 1. Złączenie definicja Złączenie (JOIN) to zbiór rekordów stanowiących wynik zapytania służącego pobraniu danych z połączonych tabel (związki jeden-do-jeden, jeden-do-wiele
Akademia Morska w Gdyni Gdynia 2004 1. Złączenie definicja Złączenie (JOIN) to zbiór rekordów stanowiących wynik zapytania służącego pobraniu danych z połączonych tabel (związki jeden-do-jeden, jeden-do-wiele
2017/2018 WGGiOS AGH. LibreOffice Base
 1. Baza danych LibreOffice Base Jest to zbiór danych zapisanych zgodnie z określonymi regułami. W węższym znaczeniu obejmuje dane cyfrowe gromadzone zgodnie z zasadami przyjętymi dla danego programu komputerowego,
1. Baza danych LibreOffice Base Jest to zbiór danych zapisanych zgodnie z określonymi regułami. W węższym znaczeniu obejmuje dane cyfrowe gromadzone zgodnie z zasadami przyjętymi dla danego programu komputerowego,
Normalizacja baz danych
 Wrocławska Wyższa Szkoła Informatyki Stosowanej Normalizacja baz danych Dr hab. inż. Krzysztof Pieczarka Email: krzysztof.pieczarka@gmail.com Normalizacja relacji ma na celu takie jej przekształcenie,
Wrocławska Wyższa Szkoła Informatyki Stosowanej Normalizacja baz danych Dr hab. inż. Krzysztof Pieczarka Email: krzysztof.pieczarka@gmail.com Normalizacja relacji ma na celu takie jej przekształcenie,
Drzewa rozpinajace, zbiory rozłaczne, czas zamortyzowany
 , 1 2 3, czas zamortyzowany zajęcia 3. Wojciech Śmietanka, Tomasz Kulczyński, Błażej Osiński rozpinajace, 1 2 3 rozpinajace Mamy graf nieskierowany, ważony, wagi większe od 0. Chcemy wybrać taki podzbiór
, 1 2 3, czas zamortyzowany zajęcia 3. Wojciech Śmietanka, Tomasz Kulczyński, Błażej Osiński rozpinajace, 1 2 3 rozpinajace Mamy graf nieskierowany, ważony, wagi większe od 0. Chcemy wybrać taki podzbiór
Kostki OLAP i język MDX
 Kostki OLAP i język MDX 24 kwietnia 2015 r. Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików PDF sformatowanych jak ten. Będą się na nie składały różne rodzaje zadań,
Kostki OLAP i język MDX 24 kwietnia 2015 r. Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików PDF sformatowanych jak ten. Będą się na nie składały różne rodzaje zadań,
Drzewa spinające MST dla grafów ważonych Maksymalne drzewo spinające Drzewo Steinera. Wykład 6. Drzewa cz. II
 Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem
Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem
Języki programowania zasady ich tworzenia
 Strona 1 z 18 Języki programowania zasady ich tworzenia Definicja 5 Językami formalnymi nazywamy każdy system, w którym stosując dobrze określone reguły należące do ustalonego zbioru, możemy uzyskać wszystkie
Strona 1 z 18 Języki programowania zasady ich tworzenia Definicja 5 Językami formalnymi nazywamy każdy system, w którym stosując dobrze określone reguły należące do ustalonego zbioru, możemy uzyskać wszystkie
Według raportu ISO z 1988 roku algorytm JPEG składa się z następujących kroków: 0.5, = V i, j. /Q i, j
 Kompresja transformacyjna. Opis standardu JPEG. Algorytm JPEG powstał w wyniku prac prowadzonych przez grupę ekspertów (ang. Joint Photographic Expert Group). Prace te zakończyły się w 1991 roku, kiedy
Kompresja transformacyjna. Opis standardu JPEG. Algorytm JPEG powstał w wyniku prac prowadzonych przez grupę ekspertów (ang. Joint Photographic Expert Group). Prace te zakończyły się w 1991 roku, kiedy
Temat: Algorytm kompresji plików metodą Huffmana
 Temat: Algorytm kompresji plików metodą Huffmana. Wymagania dotyczące kompresji danych Przez M oznaczmy zbiór wszystkich możliwych symboli występujących w pliku (alfabet pliku). Przykład M = 2, gdy plik
Temat: Algorytm kompresji plików metodą Huffmana. Wymagania dotyczące kompresji danych Przez M oznaczmy zbiór wszystkich możliwych symboli występujących w pliku (alfabet pliku). Przykład M = 2, gdy plik
Programowanie dynamiczne
 Programowanie dynamiczne Patryk Żywica 5 maja 2008 1 Spis treści 1 Problem wydawania reszty 3 1.1 Sformułowanie problemu...................... 3 1.2 Algorytm.............................. 3 1.2.1 Prosty
Programowanie dynamiczne Patryk Żywica 5 maja 2008 1 Spis treści 1 Problem wydawania reszty 3 1.1 Sformułowanie problemu...................... 3 1.2 Algorytm.............................. 3 1.2.1 Prosty
Podstawy programowania 2. Temat: Drzewa binarne. Przygotował: mgr inż. Tomasz Michno
 Instrukcja laboratoryjna 5 Podstawy programowania 2 Temat: Drzewa binarne Przygotował: mgr inż. Tomasz Michno 1 Wstęp teoretyczny Drzewa są jedną z częściej wykorzystywanych struktur danych. Reprezentują
Instrukcja laboratoryjna 5 Podstawy programowania 2 Temat: Drzewa binarne Przygotował: mgr inż. Tomasz Michno 1 Wstęp teoretyczny Drzewa są jedną z częściej wykorzystywanych struktur danych. Reprezentują
Bioinformatyka. Ocena wiarygodności dopasowania sekwencji.
 Bioinformatyka Ocena wiarygodności dopasowania sekwencji www.michalbereta.pl Załóżmy, że mamy dwie sekwencje, które chcemy dopasować i dodatkowo ocenić wiarygodność tego dopasowania. Interesujące nas pytanie
Bioinformatyka Ocena wiarygodności dopasowania sekwencji www.michalbereta.pl Załóżmy, że mamy dwie sekwencje, które chcemy dopasować i dodatkowo ocenić wiarygodność tego dopasowania. Interesujące nas pytanie
Zapisywanie algorytmów w języku programowania
 Temat C5 Zapisywanie algorytmów w języku programowania Cele edukacyjne Zrozumienie, na czym polega programowanie. Poznanie sposobu zapisu algorytmu w postaci programu komputerowego. Zrozumienie, na czym
Temat C5 Zapisywanie algorytmów w języku programowania Cele edukacyjne Zrozumienie, na czym polega programowanie. Poznanie sposobu zapisu algorytmu w postaci programu komputerowego. Zrozumienie, na czym
Podstawowe własności grafów. Wykład 3. Własności grafów
 Wykład 3. Własności grafów 1 / 87 Suma grafów Niech będą dane grafy proste G 1 = (V 1, E 1) oraz G 2 = (V 2, E 2). 2 / 87 Suma grafów Niech będą dane grafy proste G 1 = (V 1, E 1) oraz G 2 = (V 2, E 2).
Wykład 3. Własności grafów 1 / 87 Suma grafów Niech będą dane grafy proste G 1 = (V 1, E 1) oraz G 2 = (V 2, E 2). 2 / 87 Suma grafów Niech będą dane grafy proste G 1 = (V 1, E 1) oraz G 2 = (V 2, E 2).
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
Uwagi dotyczące notacji kodu! Moduły. Struktura modułu. Procedury. Opcje modułu (niektóre)
") Uwagi dotyczące notacji kodu! Wyrazy drukiem prostym -- słowami języka VBA. Wyrazy drukiem pochyłym -- inne fragmenty kodu. Wyrazy w [nawiasach kwadratowych] opcjonalne fragmenty kodu (mogą być, ale nie
Uwagi dotyczące notacji kodu! Wyrazy drukiem prostym -- słowami języka VBA. Wyrazy drukiem pochyłym -- inne fragmenty kodu. Wyrazy w [nawiasach kwadratowych] opcjonalne fragmenty kodu (mogą być, ale nie
Przetwarzanie i analiza danych w języku Python / Marek Gągolewski, Maciej Bartoszuk, Anna Cena. Warszawa, Spis treści
 Przetwarzanie i analiza danych w języku Python / Marek Gągolewski, Maciej Bartoszuk, Anna Cena. Warszawa, 2016 Spis treści Przedmowa XI I Podstawy języka Python 1. Wprowadzenie 3 1.1. Język i środowisko
Przetwarzanie i analiza danych w języku Python / Marek Gągolewski, Maciej Bartoszuk, Anna Cena. Warszawa, 2016 Spis treści Przedmowa XI I Podstawy języka Python 1. Wprowadzenie 3 1.1. Język i środowisko
Programowanie komputerów
 Programowanie komputerów Wykład 1-2. Podstawowe pojęcia Plan wykładu Omówienie programu wykładów, laboratoriów oraz egzaminu Etapy rozwiązywania problemów dr Helena Dudycz Katedra Technologii Informacyjnych
Programowanie komputerów Wykład 1-2. Podstawowe pojęcia Plan wykładu Omówienie programu wykładów, laboratoriów oraz egzaminu Etapy rozwiązywania problemów dr Helena Dudycz Katedra Technologii Informacyjnych
Komputerowe Systemy Przemysłowe: Modelowanie - UML. Arkadiusz Banasik arkadiusz.banasik@polsl.pl
 Komputerowe Systemy Przemysłowe: Modelowanie - UML Arkadiusz Banasik arkadiusz.banasik@polsl.pl Plan prezentacji Wprowadzenie UML Diagram przypadków użycia Diagram klas Podsumowanie Wprowadzenie Języki
Komputerowe Systemy Przemysłowe: Modelowanie - UML Arkadiusz Banasik arkadiusz.banasik@polsl.pl Plan prezentacji Wprowadzenie UML Diagram przypadków użycia Diagram klas Podsumowanie Wprowadzenie Języki
Metody numeryczne Wykład 4
 Metody numeryczne Wykład 4 Dr inż. Michał Łanczont Instytut Elektrotechniki i Elektrotechnologii E419, tel. 4293, m.lanczont@pollub.pl, http://m.lanczont.pollub.pl Zakres wykładu Metody skończone rozwiązywania
Metody numeryczne Wykład 4 Dr inż. Michał Łanczont Instytut Elektrotechniki i Elektrotechnologii E419, tel. 4293, m.lanczont@pollub.pl, http://m.lanczont.pollub.pl Zakres wykładu Metody skończone rozwiązywania
Zaglądamy pod maskę: podstawy działania silnika wyszukiwawczego na przykładzie Lucene
 2..22 Zaglądamy pod maskę: podstawy działania silnika wyszukiwawczego na przykładzie Lucene Dominika Puzio Indeks Podstawy: dokument Dokument: jednostka danych, pojedynczy element na liście wyników wyszukiwania,
2..22 Zaglądamy pod maskę: podstawy działania silnika wyszukiwawczego na przykładzie Lucene Dominika Puzio Indeks Podstawy: dokument Dokument: jednostka danych, pojedynczy element na liście wyników wyszukiwania,
operacje porównania, a jeśli jest to konieczne ze względu na złe uporządkowanie porównywanych liczb zmieniamy ich kolejność, czyli przestawiamy je.
 Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Zawartość. Wstęp. Moduł Rozbiórki. Wstęp Instalacja Konfiguracja Uruchomienie i praca z raportem... 6
 Zawartość Wstęp... 1 Instalacja... 2 Konfiguracja... 2 Uruchomienie i praca z raportem... 6 Wstęp Rozwiązanie przygotowane z myślą o użytkownikach którzy potrzebują narzędzie do podziału, rozkładu, rozbiórki
Zawartość Wstęp... 1 Instalacja... 2 Konfiguracja... 2 Uruchomienie i praca z raportem... 6 Wstęp Rozwiązanie przygotowane z myślą o użytkownikach którzy potrzebują narzędzie do podziału, rozkładu, rozbiórki
1 Automaty niedeterministyczne
 Szymon Toruńczyk 1 Automaty niedeterministyczne Automat niedeterministyczny A jest wyznaczony przez następujące składniki: Alfabet skończony A Zbiór stanów Q Zbiór stanów początkowych Q I Zbiór stanów
Szymon Toruńczyk 1 Automaty niedeterministyczne Automat niedeterministyczny A jest wyznaczony przez następujące składniki: Alfabet skończony A Zbiór stanów Q Zbiór stanów początkowych Q I Zbiór stanów
Podstawy programowania. Wykład 7 Tablice wielowymiarowe, SOA, AOS, itp. Krzysztof Banaś Podstawy programowania 1
 Podstawy programowania. Wykład 7 Tablice wielowymiarowe, SOA, AOS, itp. Krzysztof Banaś Podstawy programowania 1 Tablice wielowymiarowe C umożliwia definiowanie tablic wielowymiarowych najczęściej stosowane
Podstawy programowania. Wykład 7 Tablice wielowymiarowe, SOA, AOS, itp. Krzysztof Banaś Podstawy programowania 1 Tablice wielowymiarowe C umożliwia definiowanie tablic wielowymiarowych najczęściej stosowane
Budowa aplikacji ASP.NET współpracującej z bazą dany do obsługi przesyłania wiadomości
 Budowa aplikacji ASP.NET współpracującej z bazą dany do obsługi przesyłania wiadomości część 2 Zaprojektowaliśmy stronę dodaj_dzial.aspx proszę jednak spróbować dodać nowy dział nie podając jego nazwy
Budowa aplikacji ASP.NET współpracującej z bazą dany do obsługi przesyłania wiadomości część 2 Zaprojektowaliśmy stronę dodaj_dzial.aspx proszę jednak spróbować dodać nowy dział nie podając jego nazwy
5. Praca z klasą. Dodawanie materiałów i plików. Etykieta tematu. Rozdział 5 Praca z klasą
 5. Praca z klasą Jako prowadzący i nauczyciel mamy bardzo duże możliwości, jeżeli chodzi o zamieszczanie i korzystanie z materiałów na platformie e-learningowej. Wykładowca w pierwszej kolejności musi
5. Praca z klasą Jako prowadzący i nauczyciel mamy bardzo duże możliwości, jeżeli chodzi o zamieszczanie i korzystanie z materiałów na platformie e-learningowej. Wykładowca w pierwszej kolejności musi
ANALIZA I INDEKSOWANIE MULTIMEDIÓW (AIM)
") ANALIZA I INDEKSOWANIE MULTIMEDIÓW (AIM) LABORATORIUM 5 - LOKALIZACJA OBIEKTÓW METODĄ HISTOGRAMU KOLORU 1. WYBÓR LOKALIZOWANEGO OBIEKTU Pierwszy etap laboratorium polega na wybraniu lokalizowanego obiektu.
ANALIZA I INDEKSOWANIE MULTIMEDIÓW (AIM) LABORATORIUM 5 - LOKALIZACJA OBIEKTÓW METODĄ HISTOGRAMU KOLORU 1. WYBÓR LOKALIZOWANEGO OBIEKTU Pierwszy etap laboratorium polega na wybraniu lokalizowanego obiektu.
Optimizing Programs with Intended Semantics
 Interaktywna optymalizacja programów 26 kwietnia 2010 Spis treści Spis treści Wstęp Omówienie zaproponowanego algorytmu na przykładzie Wewnętrzna reprezentacja reguł dotyczących optymalizacji Wybrane szczegóły
Interaktywna optymalizacja programów 26 kwietnia 2010 Spis treści Spis treści Wstęp Omówienie zaproponowanego algorytmu na przykładzie Wewnętrzna reprezentacja reguł dotyczących optymalizacji Wybrane szczegóły
Multiwyszukiwarka EBSCO Discovery Service przewodnik
 Multiwyszukiwarka EBSCO Discovery Service to narzędzie zapewniające łatwy i skuteczny dostęp do wszystkich źródeł elektronicznych Biblioteki Uczelnianej (prenumerowanych i Open Access) za pośrednictwem
Multiwyszukiwarka EBSCO Discovery Service to narzędzie zapewniające łatwy i skuteczny dostęp do wszystkich źródeł elektronicznych Biblioteki Uczelnianej (prenumerowanych i Open Access) za pośrednictwem
Jak ustawić cele kampanii?
 Jak ustawić cele kampanii? Czym są cele? Jest to funkcjonalność pozwalająca w łatwy sposób śledzić konwersje wygenerowane na Twojej stronie www poprzez wiadomości email wysłane z systemu GetResponse. Mierzenie
Jak ustawić cele kampanii? Czym są cele? Jest to funkcjonalność pozwalająca w łatwy sposób śledzić konwersje wygenerowane na Twojej stronie www poprzez wiadomości email wysłane z systemu GetResponse. Mierzenie
SQL - Structured Query Language -strukturalny język zapytań SQL SQL SQL SQL
 Wprowadzenie do SQL SQL - Structured Query Language -strukturalny język zapytań Światowy standard przeznaczony do definiowania, operowania i sterowania danymi w relacyjnych bazach danych Powstał w firmie
Wprowadzenie do SQL SQL - Structured Query Language -strukturalny język zapytań Światowy standard przeznaczony do definiowania, operowania i sterowania danymi w relacyjnych bazach danych Powstał w firmie
Wykład 3 Składnia języka C# (cz. 2)
") Wizualne systemy programowania Wykład 3 Składnia języka C# (cz. 2) 1 dr Artur Bartoszewski -Wizualne systemy programowania, sem. III- WYKŁAD Wizualne systemy programowania Metody 2 Metody W C# nie jest
Wizualne systemy programowania Wykład 3 Składnia języka C# (cz. 2) 1 dr Artur Bartoszewski -Wizualne systemy programowania, sem. III- WYKŁAD Wizualne systemy programowania Metody 2 Metody W C# nie jest
Definicje. Algorytm to:
 Algorytmy Definicje Algorytm to: skończony ciąg operacji na obiektach, ze ściśle ustalonym porządkiem wykonania, dający możliwość realizacji zadania określonej klasy pewien ciąg czynności, który prowadzi
Algorytmy Definicje Algorytm to: skończony ciąg operacji na obiektach, ze ściśle ustalonym porządkiem wykonania, dający możliwość realizacji zadania określonej klasy pewien ciąg czynności, który prowadzi
Podstawy Programowania C++
 Wykład 3 - podstawowe konstrukcje Instytut Automatyki i Robotyki Warszawa, 2014 Wstęp Plan wykładu Struktura programu, instrukcja przypisania, podstawowe typy danych, zapis i odczyt danych, wyrażenia:
Wykład 3 - podstawowe konstrukcje Instytut Automatyki i Robotyki Warszawa, 2014 Wstęp Plan wykładu Struktura programu, instrukcja przypisania, podstawowe typy danych, zapis i odczyt danych, wyrażenia:
Pobieranie i przetwarzanie treści stron WWW
 Eksploracja zasobów internetowych Wykład 2 Pobieranie i przetwarzanie treści stron WWW mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Jedną z funkcji silników wyszukiwania danych, a właściwie ich modułów
Eksploracja zasobów internetowych Wykład 2 Pobieranie i przetwarzanie treści stron WWW mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Jedną z funkcji silników wyszukiwania danych, a właściwie ich modułów
Algorytmy i struktury danych. Wykład 4
 Wykład 4 Różne algorytmy - obliczenia 1. Obliczanie wartości wielomianu 2. Szybkie potęgowanie 3. Algorytm Euklidesa, liczby pierwsze, faktoryzacja liczby naturalnej 2017-11-24 Algorytmy i struktury danych
Wykład 4 Różne algorytmy - obliczenia 1. Obliczanie wartości wielomianu 2. Szybkie potęgowanie 3. Algorytm Euklidesa, liczby pierwsze, faktoryzacja liczby naturalnej 2017-11-24 Algorytmy i struktury danych
1 Podstawy c++ w pigułce.
 1 Podstawy c++ w pigułce. 1.1 Struktura dokumentu. Kod programu c++ jest zwykłym tekstem napisanym w dowolnym edytorze. Plikowi takiemu nadaje się zwykle rozszerzenie.cpp i kompiluje za pomocą kompilatora,
1 Podstawy c++ w pigułce. 1.1 Struktura dokumentu. Kod programu c++ jest zwykłym tekstem napisanym w dowolnym edytorze. Plikowi takiemu nadaje się zwykle rozszerzenie.cpp i kompiluje za pomocą kompilatora,
Struktury danych i złożoność obliczeniowa Wykład 7. Prof. dr hab. inż. Jan Magott
 Struktury danych i złożoność obliczeniowa Wykład 7 Prof. dr hab. inż. Jan Magott Problemy NP-zupełne Transformacją wielomianową problemu π 2 do problemu π 1 (π 2 π 1 ) jest funkcja f: D π2 D π1 spełniająca
Struktury danych i złożoność obliczeniowa Wykład 7 Prof. dr hab. inż. Jan Magott Problemy NP-zupełne Transformacją wielomianową problemu π 2 do problemu π 1 (π 2 π 1 ) jest funkcja f: D π2 D π1 spełniająca
Zadanie 1. Suma silni (11 pkt)
") 2 Egzamin maturalny z informatyki Zadanie 1. Suma silni (11 pkt) Pojęcie silni dla liczb naturalnych większych od zera definiuje się następująco: 1 dla n = 1 n! = ( n 1! ) n dla n> 1 Rozpatrzmy funkcję
2 Egzamin maturalny z informatyki Zadanie 1. Suma silni (11 pkt) Pojęcie silni dla liczb naturalnych większych od zera definiuje się następująco: 1 dla n = 1 n! = ( n 1! ) n dla n> 1 Rozpatrzmy funkcję
Skrócona instrukcja obsługi
 Web of Science Skrócona instrukcja obsługi ISI WEB OF KNOWLEDGE SM Można przeszukiwać ponad 9 00 czasopism w ponad językach z różnych dziedzin nauk ścisłych, społecznych i humanistycznych, aby znaleźć
Web of Science Skrócona instrukcja obsługi ISI WEB OF KNOWLEDGE SM Można przeszukiwać ponad 9 00 czasopism w ponad językach z różnych dziedzin nauk ścisłych, społecznych i humanistycznych, aby znaleźć
Oracle11g: Wprowadzenie do SQL
 Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom