IX EKSPLORACJA DANYCH
|
|
|
- Jadwiga Lis
- 9 lat temu
- Przeglądów:
Transkrypt
1 Zastosowanie drzew decyzyjnych do analizy danych Artur Soroczyński Politechnika Warszawska Instytut Technologii Materiałowych

2 Terminologia Datamining Drzewa decyzyjne Plan wykładu Przykład wykorzystania programu MineSet do analizy danych Wnioski

3 Czym jest Eksploracja danych? Definicja1: Nietrywialnie wydobywanie ukrytej, poprzednio nieznanej i potencjalnie użytecznej informacji z danych (W.Frawley, G. Piatetsky-Shapiro, C. Matheus. Knowledge Discovery in Databases: An Overview. AI Magazine, 1992) Definicja2: Nauka zajmująca się wydobywaniem informacji z dużych zbiorów danych lub baz danych (D. Hand, H. Mannila, P. Smyt. Principles of Data Mining. MIT Press, Cambridge, MA, 2001)
 Definicja2: Nauka zajmująca się wydobywaniem informacji z dużych zbiorów danych lub baz")
4 Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać

5 Czym Data mining nie jest Procesem nieodzownie związanym z hurtowniami danych; Typowym narzędziem analitycznym i środkiem do tworzenia sprawozdań; Całkowicie zautomatyzowanym procesem; Łatwym, tanim i szybkim do wdrożenia procesem;

6 Rodzaje problemów i właściwe dla nich metody Data maning Rodzaje problemu Opis zależności Klasyfikacja wzorcowa Metody Statystyczne metody pomiaru zależności Sieci neuronowe typu MLP lub RBF Metody analizy współwystępowania Zbiory przybliżone Funkcje dyskryminacyjne Sieci neuronowe typu MLP Drzewa decyzyjne Systemy regałowe Zbiory przybliżone Metoda k-najbliższych sąsiadów

7 Rodzaje problemów i właściwe dla nich metody Data maning cd. Klasyfikacja bez wzorcowa Metody taksonomiczne Sieci neuronowe samouczące się Metody redukcji wymiaru przestrzeni danych Metody graficzne Algorytmy genetyczne Analiza szeregów czasowych Problemy wyboru Sieci neuronowe typu MLP lub RBF Metoda analizy sygnałów Metody badań sekwencji Algorytmy genetyczne Sieci neuronowe typu Hopfielda Zbiory przybliżone

8 Wybór metody Empiryczna wiedza o danym zjawisku; Wielkość zbiorów danych; Sposób wykorzystania wyników ( funkcjonowanie badanego zjawiska, czarna skrzynka, wykres, reguły decyzyjne) ; Dostępność oprogramowania
 ; Dostępność")
9 Drzewo decyzyjne: jest to system operujący na danych typu nominalnego lub porządkowego. Jest strukturą logiczną (grafem) składającą się z elementów : Korzeń (początek drzewa), z którego wychodzą co najmniej dwie gałęzie do węzłów leżących na niższym poziomie Z każdym węzłem związany jest test sprawdzający wartości atrybutów opisujących przykłady (uczące lub zadane, dla których chcemy znaleźć odpowiedź systemu). Dla każdego z możliwych wyników testu odpowiadająca mu gałąź prowadzi do węzła leżącego na niższym poziomie. Węzły, z których nie wychodzą żadne gałęzie są to liście, którym przypisane są klasy.
. Dla każdego z możliwych wyników testu odpowiadająca mu gałąź prowadzi do węzła leżącego na niższym poziomie.")
10 Drzewo decyzyjne Klasycznym zastosowaniem drzew decyzyjnych jest klasyfikacja Możliwa jest również realizacja zadań typu regresji (aproksymacji funkcji) Uwzględnienie atrybutów o wartościach typu ciągłego wymaga przyjęcia granic przedziałów tych wartości dla testów w węzłach drzewa. Forma uzyskiwanych wyników (zazwyczaj w postaci nierówności) jest inna, niż w przypadku analizy regresji wykonanej innymi metodami, np. statystycznymi.
 jest inna, niż w przypadku analizy regresji")
11 Drzewa decyzyjne-zalety Drzewa decyzyjne to jedna z najczęściej wykorzystywanych technik analizy danych. Mogą być budowane przy wykorzystaniu algorytmicznych technik "dziel i rządź". Metoda ta jest znana ze swej szybkości. Wykorzystują ją niemal wszystkie algorytmy drzew decyzyjnych uczenia. Doskonale bronią się przed szumem w danych. Mogą być wykorzystywane do selekcji i ekstrakcji cech. Modele drzew są względnie łatwe do zrozumienia przez ludzi. Sąłatwe do wizualizacji.

12 Drzewa decyzyjne-problemy Testuje się wartość jednego atrybutu na raz, co powoduje niepotrzebny rozrost drzewa dla danych gdzie poszczególne atrybuty zależą od siebie. Niższe partie drzewa mają b. mało danych, przypadkowe podziały. Nie wszystkie koncepcje dają się dobrze ująć za pomocą DT.

13 Drzewa decyzyjne ze wzmacnianiem (boosted trees) Dla trudnych zadań estymacji i predykcji, przewidywania generowane przez sekwencje prostych drzew są bliższe rzeczywistym wartościom, niż prognozy jednego, złożonego drzewa. Technikę polegającą na stosowaniu sekwencji prostych modeli, przy czym każdy kolejny model przykłada większą "wagę" do tych obserwacji, które zostały błędnie zaklasyfikowane przez poprzednie modele, nazywamy wzmacnianiem (ang. boosting). Drzewa decyzyjne ze wzmacnianiem lepiej modelują zależności złożone (w porównaniu do drzew prostych), ale są trudniejsze w interpretacji oraz wymagają większych nakładów obliczeniowych
.")
14 Ogólne własności 1. Test (węzeł): - podział pojedynczej cechy lub kombinacji - cecha = {wartość} lub cecha > wartość 2. Kryteria rozbudowy: - maksymalizacja ilości informacji (information gain) - maksymalizacja poprawnie przydzielonej liczby obiektów - czystość węzła (purity of node) 3. Przycinanie (pruning): - usuwanie gałęzi które mają zbyt mało przypadków - ocena optymalnej złożoności na zbiorze walidacyjnym - prostsze drzewo jest łatwiejsze w generalizacji 4. Kryterium stopu (między innymi): -osiągnięta zakładana dokładność podziałów -osiągnięta zakładana ilość gałęzi
: - usuwanie gałęzi które mają zbyt mało przypadków - ocena optymalnej złożoności na zbiorze walidacyjnym - prostsze drzewo")
15

16
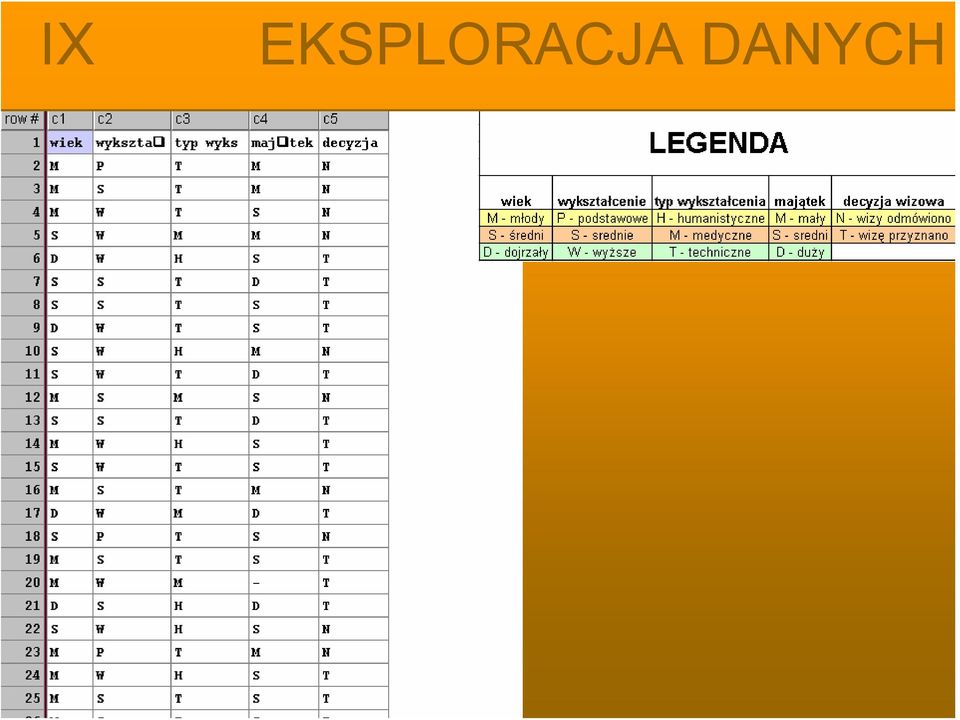
17 Obróbka danych Działania na danych Wizualizacja danych Narzędzia odkrywania wiedzy Zapisywanie danych

18 Wizualizacja danych- scatter

19 W. D. - Splat

20 W. D. - Statistics
21 W. D. Histogram
22 Odkrywanie reguł asocjacji Polega na znajdowaniu związków pomiędzy występowaniem grup atrybutów w bazie danych. Podstawowe do oceny reguły stanowią trzy statystyki (zakładamy, że zależność ma postać A=>B): wsparcie (ang. support), czyli procent klientów, którzy zakupili zarówno produkt A i B, ufność (ang. confidence), tj. prawdopodobieństwo, że klient zakupi produkt B, jeśli wiadomo, że posiada on już produkt A współczynnik podwyższenia (ang. lift), o który wzrasta prawdopodobieństwo zakupu produktu B, jeśli wiadomo, że klient posiada produkt A, w porównaniu do sytuacji, gdy nie wiadomo, czy klient ten produkt posiada. Znajdują one zastosowanie najczęściej do analizy koszyka zakupów, pozwalają podejmować decyzje dotyczące np. promocji obniżek cen, reklam i akcji marketingowych lub rozmieszczenia produktów
23 Odkrywanie reguł asocjacji Statystyczne wskaźniki ważności i siły
24 Odkrywanie reguł asocjacji -wizualizacja
25 Odkrywanie reguł asocjacji - tabela
26 Klastrowanie Polega na znajdowaniu skończonego zbioru kategorii opisujących dane. Kategorie mogą być rozłączne, zupełne, mogą też tworzyć struktury hierarchiczne i nakładające się. Przykładowo, zbiór danych o nieznanych chorobach może zostać w wyniku klastrowania podzielony na szereg grup cechujących się zastosowań klastrowania mogą być: określanie segmentów rynku dla produktu na podstawie informacji o klientach znajdowanie kategorii widmowych spektrum promieniowania nieba
27 Klastrowanie Single k-means podajemy liczbę klastrów na jaki ma być podzielony zbiór danych Iterative k-means podajemy zakres liczby oczekiwanych klastrów
28
29 Klasyfikacja Klasyfikacja polega na znajdowaniu sposobu odwzorowania danych w zbiór predefiniowanych klas. Na podstawie zawartości bazy danych budowany jest model (np. drzewo decyzyjne, reguły logiczne), który służy do klasyfikowania nowych obiektów w bazie danych lub głębszego zrozumienia istniejących klas. Przykładowo, w medycznej bazie danych znalezione mogą być reguły klasyfikujące poszczególne schorzenia, a następnie przy pomocy znalezionych reguł automatycznie może być przeprowadzone diagnozowanie kolejnych pacjentów. Inne przykłady zastosowań klasyfikacji to: rozpoznawanie trendów na rynkach finansowych, automatyczne rozpoznawanie obiektów w dużych bazach danych obrazów, wspomaganie decyzji przyznawania kredytów bankowych.
30 Klasyfikacja
31 Drzewo klasyfikacyjne Drzewo klasyfikacyjne jest drzewem, które posiada dodatkowa interpretacje dla węzłów, gałęzi i liści: węzły odpowiadają testom przeprowadzanym na wartościach atrybutów przykładów, węzeł drzewa, który nie ma żadnych węzłów macierzystych nazywamy korzeniem, gałęzie odpowiadają możliwym wynikom tych testów, liście odpowiadają etykietom klas danego problemu dyskryminacji (w konwencji drzewo klasyfikacyjne ma więcej niż 1 liść), drzewo rośnie od góry do dołu.
32 Drzewo klasyfikacyjne- wizualizacja
33 Przetrenowanie Model H jest zbytnio dopasowany do danych (overfits) gdy: Istnieje model H taki, że: Błąd-treningowy(H) < Błąd-treningowy(H ) Błąd-testowy(H) > Błąd-testowy(H ) Zbyt szczegółowe wnioski przy dla danej populacji przypadków treningowych. Dokładność jako funkcja liczby węzłów drzewa. Wyniki mogą być gorsze niż dla klasyfikatora większościowego!
34 Unikanie przetrenowanie Jak uniknąć przetrenowania i radzić sobie z szumem? 1. Zakończ rozwijanie węzła jeśli jest zbyt mało danych by wiarygodnie dokonać podziału. 2. Zakończ jeśli czystość węzłów (dominacja jednej klasy) jest większa od zadanego progu - forward pruning DT => drzewo prawd. klas. 3. Utwórz drzewo a potem je przytnij (backward pruning) 4. Przycinaj korzystając z wyników dla kroswalidacji lub dla zbioru walidacyjnego. 5. Korzystaj z MDL (Minimum Description Length): Min Rozmiar(Drzewa) + Rozmiar(Drzewa(Błędów)) 6. Oceniaj podziały zaglądając poziom (lub więcej) w głąb.
35 Przycinanie drzew Przycinanie drzew ma na celu rozwiązanie problemu ich nadmiernego dopasowania. Proces ten w uproszczeniu polega na zastąpieniu drzewa wyjściowego jego poddrzewem. Formułując to bardziej obrazowo powiemy, ze ucina się niektóre poddrzewa drzewa wyjściowego, zastępując je liśćmi, którym przypisuje się etykietę klasy najczęściej występującej wśród obserwacji związanych z tym poddrzewem. Drzewo przycięte ma wiec prostsza strukturę, co daje krótszy czas klasyfikacji. Oczywiście dokładność klasyfikacji zbioru uczącego się pogarsza. Przycinanie drzewa odbywa się najczęściej z pomocą zbioru etykietowanych przykładów.
36 Przycinanie drzew
37 Drzewa regresyjne Z regresją mamy do czynienie tam, gdzie chcemy poznać wartość zmiennej ciągłej, na podstawie znajomości wartości jednej lub większej liczby predykcyjnych zmiennych ciągłych oraz, ewentualnie zmiennych kategorialnych. Na przykład, interesuje nas cena domu (ciągła zmienna zależna), przy czym znamy różne ciągłe prefyktory (jak np. powierzchnia mieszkania), jak i predyktory kategorialne (jak np. styl architektoniczny, dzielnica miasta, albo kod pocztowy - zmienna na pozór liczbowa, a jednak, w istocie raczej kategorialna). Używając do predykcji ceny domu prostej regresji wielorakiej lub ogólnego modelu liniowego (GLM), poszukujemy linowego równania, za pomocą którego obliczymy interesującą nas cenę. Jest wiele różnych procedur analitycznych dopasowywania do danych liniowych modeli (GLM, GRM, Regresja), modeli nieliniowych (np. Uogólnione modele liniowe i nieliniowe (GLZ), Uogólnione modele addytywne (GAM), itp.), a także modeli nieliniowych, w pełni określanych przez użytkownika (patrz Estymacja nieliniowa), gdzie wpisać można dowolne równanie zawierające parametry, których wartości znajdzie program.
38 Algorytm umożliwia wybranie atrybutów (kolumn), które najlepiej wyznaczają jeden z atrybutów. Można określić liczbę takich atrybutów oraz takie, o których wiemy, że są istotne i wyszukać następne. Jakość wybranych atrybutów mierzy się współczynnikiem czystości purity. Wybrane kolumny podzielą rekordy na podzbiory. Jeżeli każdy z takich podzbiorów zawiera rekordy przynależne tylko do jednej klasy, to ten podzbiór ma czystość 100. Czystość podzbioru jest 0, jeżeli wszystkie klasy mają równą reprezentację. Wyznaczanie istotności
39 Wyznaczanie istotności (decyzja wizowa) Wpływ zmiennych na decyzję wizową Istotność zmiennej [%] student drzewo wiek wykształcenie typ wykształcenia majątek
40 Operacje na danych
41 Operacje na danych Usuwanie kolumn Dyskretyzacja (Bin columns) - Umożliwia przekształcenie wartości ciągłych w kolumnie lub kolumnach na wartości dyskretne. Użytkownik określa sam wartości graniczne przedziałów lub umożliwia dobór automatyczny Agregacja (Aggregate) - Dodaje rekordy w bazie danych wykonując na ich polach proste operacje jak znalezienie sumy, maksimum, minimum, liczby agregowanych rekordów. Przydatne do usuwania danych nadmiarowych. Filtrowanie (Filter) - Pozwala na usunięcie z danych tych rekordów, które nie spełniają pewnych kryteriów. Kryteriami mogą być wyrażenia wyliczane na podstawie pól rekordu. Np.: usunięcie z bazy rekordów klientów, których wiek jest mniejszy niż 20 lat. Zmiana typu (Change Type) - Umożliwia zmianę nazw kolumn jak i konwersję typów danych. Dodanie kolumny (Add column) - -Podobnie jak filtrowanie umożliwia dodanie kolumny bazującej na wyrażeniu matematycznym z atrybutów pojedynczego rekordu. Zastosowanie modelu (Apply model) - Pozwala na sprawdzenie (zastosowanie) reguł Podział (Sample) - Pozwala wybrać ze zbioru rekordów (danych) przypadkowy podzbiór. Szczególnie przydatne przy dużych zestawach danych lub przy podziale danych na zbiór uczący i zbiór testowy.
42 Wnioski DT: szybkie i proste. Zalety: Zwykle bardzo dobre wyniki w porównaniu z innymi klasyfikatorami. Łatwe w użyciu, prawie nie mają parametrów do ustawiania. Dane nominalne lub numeryczne. Zastosowania: klasyfikacja i regresja. Prawie wszystkie pakiety Data Mining mają drzewa decyzji. Problemy z DT: mało danych, duża liczba ciągłych cech; niższe partie drzewa mają b. mało danych, przypadkowe podziały; nie wszystkie koncepcje dają się dobrze ująć za pomocą DT, np. większość jest za.
43 Wnioski Idee rozwoju Drzewa wieloczynnikowe: skośne granice decyzji; drzewa sieci neuronowych; rekursywny podział za pomocą LDA lub FDA Kryteria podziału: informacja w pobliżu korzenia, dokładność w pobliżu liści. przycinanie na podstawie reguł -działa również przy korzeniu; Komitety drzew: wielokrotne uczenie na randomizowanych danych (boosting) uczenie z różnymi parametrami obcinania Drzewa rozmyte
44 Dziękuję za uwagę!
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
dr inż. Olga Siedlecka-Lamch 14 listopada 2011 roku Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Eksploracja danych
 - Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
- Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
PODSTAWY STATYSTYCZNEGO MODELOWANIA DANYCH. Wykład 6 Drzewa klasyfikacyjne - wprowadzenie. Reguły podziału i reguły przycinania drzew.
 PODSTAWY STATYSTYCZNEGO MODELOWANIA DANYCH Wykład 6 Drzewa klasyfikacyjne - wprowadzenie. Reguły podziału i reguły przycinania drzew. Wprowadzenie Drzewo klasyfikacyjne Wprowadzenie Formalnie : drzewo
PODSTAWY STATYSTYCZNEGO MODELOWANIA DANYCH Wykład 6 Drzewa klasyfikacyjne - wprowadzenie. Reguły podziału i reguły przycinania drzew. Wprowadzenie Drzewo klasyfikacyjne Wprowadzenie Formalnie : drzewo
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Automatyczna predykcja. Materiały/konsultacje. Co to jest uczenie maszynowe? Przykład 6/10/2013. Google Prediction API, maj 2010
 Materiały/konsultacje Automatyczna predykcja http://www.ibp.pwr.wroc.pl/kotulskalab Konsultacje wtorek, piątek 9-11 (uprzedzić) D1-115 malgorzata.kotulska@pwr.wroc.pl Co to jest uczenie maszynowe? Uczenie
Materiały/konsultacje Automatyczna predykcja http://www.ibp.pwr.wroc.pl/kotulskalab Konsultacje wtorek, piątek 9-11 (uprzedzić) D1-115 malgorzata.kotulska@pwr.wroc.pl Co to jest uczenie maszynowe? Uczenie
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Metody selekcji cech
 Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Drzewa decyzyjne i lasy losowe
 Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE
 UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
Data Mining Wykład 4. Plan wykładu
 Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
w analizie wyników badań eksperymentalnych, w problemach modelowania zjawisk fizycznych, w analizie obserwacji statystycznych.
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Proces odkrywania wiedzy z baz danych
 Proces odkrywania wiedzy z baz danych Wydział Informatyki Politechnika Białostocka Marcin Czajkowski email: m.czajkowski@pb.edu.pl Świat pełen danych Świat pełen danych Możliwości analizowania i zrozumienia
Proces odkrywania wiedzy z baz danych Wydział Informatyki Politechnika Białostocka Marcin Czajkowski email: m.czajkowski@pb.edu.pl Świat pełen danych Świat pełen danych Możliwości analizowania i zrozumienia
8. Drzewa decyzyjne, bagging, boosting i lasy losowe
 Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Klasyfikacja. Sformułowanie problemu Metody klasyfikacji Kryteria oceny metod klasyfikacji. Eksploracja danych. Klasyfikacja wykład 1
 Klasyfikacja Sformułowanie problemu Metody klasyfikacji Kryteria oceny metod klasyfikacji Klasyfikacja wykład 1 Niniejszy wykład poświęcimy kolejnej metodzie eksploracji danych klasyfikacji. Na początek
Klasyfikacja Sformułowanie problemu Metody klasyfikacji Kryteria oceny metod klasyfikacji Klasyfikacja wykład 1 Niniejszy wykład poświęcimy kolejnej metodzie eksploracji danych klasyfikacji. Na początek
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
Szkolenie Analiza dyskryminacyjna
 Szkolenie Analiza dyskryminacyjna program i cennik Łukasz Deryło Analizy statystyczne, szkolenia www.statystyka.c0.pl Szkolenie Analiza dyskryminacyjna Co to jest analiza dyskryminacyjna? Inną nazwą analizy
Szkolenie Analiza dyskryminacyjna program i cennik Łukasz Deryło Analizy statystyczne, szkolenia www.statystyka.c0.pl Szkolenie Analiza dyskryminacyjna Co to jest analiza dyskryminacyjna? Inną nazwą analizy
Szczegółowy opis przedmiotu zamówienia
 ZP/ITS/19/2013 SIWZ Załącznik nr 1.1 do Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych dla studentów
ZP/ITS/19/2013 SIWZ Załącznik nr 1.1 do Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych dla studentów
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk
 Wprowadzenie RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk Magdalena Deckert Politechnika Poznańska, Instytut Informatyki Seminarium ISWD, 21.05.2013 M. Deckert Przyrostowy
Wprowadzenie RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk Magdalena Deckert Politechnika Poznańska, Instytut Informatyki Seminarium ISWD, 21.05.2013 M. Deckert Przyrostowy
Automatyczne wyodrębnianie reguł
 Automatyczne wyodrębnianie reguł Jedną z form reprezentacji wiedzy jest jej zapis w postaci zestawu reguł. Ta forma ma szereg korzyści: daje się łatwo interpretować, można zrozumieć sposób działania zbudowanego
Automatyczne wyodrębnianie reguł Jedną z form reprezentacji wiedzy jest jej zapis w postaci zestawu reguł. Ta forma ma szereg korzyści: daje się łatwo interpretować, można zrozumieć sposób działania zbudowanego
Indukowane Reguły Decyzyjne I. Wykład 3
 Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych
 Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Przykład eksploracji danych o naturze statystycznej Próba 1 wartości zmiennej losowej odległość
 Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Optymalizacja systemów
 Optymalizacja systemów Laboratorium - problem detekcji twarzy autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, P. Klukowski Cel zadania Celem zadania jest zapoznanie się z gradientowymi algorytmami optymalizacji
Optymalizacja systemów Laboratorium - problem detekcji twarzy autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, P. Klukowski Cel zadania Celem zadania jest zapoznanie się z gradientowymi algorytmami optymalizacji
WSTĘP I TAKSONOMIA METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING. Adrian Horzyk. Akademia Górniczo-Hutnicza
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
ALGORYTMY SZTUCZNEJ INTELIGENCJI
 ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
Uczenie się maszyn. Dariusz Banasiak. Katedra Informatyki Technicznej Wydział Elektroniki
 Dariusz Banasiak Katedra Informatyki Technicznej Wydział Elektroniki Machine Learning (uczenie maszynowe, uczenie się maszyn, systemy uczące się) interdyscyplinarna nauka, której celem jest stworzenie
Dariusz Banasiak Katedra Informatyki Technicznej Wydział Elektroniki Machine Learning (uczenie maszynowe, uczenie się maszyn, systemy uczące się) interdyscyplinarna nauka, której celem jest stworzenie
Spis treści 377 379 WSTĘP... 9
 Spis treści 377 379 Spis treści WSTĘP... 9 ZADANIE OPTYMALIZACJI... 9 PRZYKŁAD 1... 9 Założenia... 10 Model matematyczny zadania... 10 PRZYKŁAD 2... 10 PRZYKŁAD 3... 11 OPTYMALIZACJA A POLIOPTYMALIZACJA...
Spis treści 377 379 Spis treści WSTĘP... 9 ZADANIE OPTYMALIZACJI... 9 PRZYKŁAD 1... 9 Założenia... 10 Model matematyczny zadania... 10 PRZYKŁAD 2... 10 PRZYKŁAD 3... 11 OPTYMALIZACJA A POLIOPTYMALIZACJA...
data mining machine learning data science
 data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta
 Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Pattern Classification
 Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Drzewa decyzyjne w SAS Enterprise Miner
 Drzewa decyzyjne w SAS Enterprise Miner Aneta Ptak-Chmielewska Instytut Statystyki i Demografii Zakład Analizy Historii Zdarzeń i Analiz Wielopoziomowych www.sgh.waw.pl/zaklady/zahziaw 1 struktura ćwiczeń
Drzewa decyzyjne w SAS Enterprise Miner Aneta Ptak-Chmielewska Instytut Statystyki i Demografii Zakład Analizy Historii Zdarzeń i Analiz Wielopoziomowych www.sgh.waw.pl/zaklady/zahziaw 1 struktura ćwiczeń
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Transformacja wiedzy w budowie i eksploatacji maszyn
 Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Ewelina Dziura Krzysztof Maryański
 Ewelina Dziura Krzysztof Maryański 1. Wstęp - eksploracja danych 2. Proces Eksploracji danych 3. Reguły asocjacyjne budowa, zastosowanie, pozyskiwanie 4. Algorytm Apriori i jego modyfikacje 5. Przykład
Ewelina Dziura Krzysztof Maryański 1. Wstęp - eksploracja danych 2. Proces Eksploracji danych 3. Reguły asocjacyjne budowa, zastosowanie, pozyskiwanie 4. Algorytm Apriori i jego modyfikacje 5. Przykład
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, Spis treści
 Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Testowanie modeli predykcyjnych
 Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
komputery? Andrzej Skowron, Hung Son Nguyen Instytut Matematyki, Wydział MIM, UW
 Czego moga się nauczyć komputery? Andrzej Skowron, Hung Son Nguyen son@mimuw.edu.pl; skowron@mimuw.edu.pl Instytut Matematyki, Wydział MIM, UW colt.tex Czego mogą się nauczyć komputery? Andrzej Skowron,
Czego moga się nauczyć komputery? Andrzej Skowron, Hung Son Nguyen son@mimuw.edu.pl; skowron@mimuw.edu.pl Instytut Matematyki, Wydział MIM, UW colt.tex Czego mogą się nauczyć komputery? Andrzej Skowron,
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
PODSTAWY BAZ DANYCH. 19. Perspektywy baz danych. 2009/2010 Notatki do wykładu "Podstawy baz danych"
 PODSTAWY BAZ DANYCH 19. Perspektywy baz danych 1 Perspektywy baz danych Temporalna baza danych Temporalna baza danych - baza danych posiadająca informację o czasie wprowadzenia lub czasie ważności zawartych
PODSTAWY BAZ DANYCH 19. Perspektywy baz danych 1 Perspektywy baz danych Temporalna baza danych Temporalna baza danych - baza danych posiadająca informację o czasie wprowadzenia lub czasie ważności zawartych
w ekonomii, finansach i towaroznawstwie
 w ekonomii, finansach i towaroznawstwie spotykane określenia: zgłębianie danych, eksploracyjna analiza danych, przekopywanie danych, męczenie danych proces wykrywania zależności w zbiorach danych poprzez
w ekonomii, finansach i towaroznawstwie spotykane określenia: zgłębianie danych, eksploracyjna analiza danych, przekopywanie danych, męczenie danych proces wykrywania zależności w zbiorach danych poprzez
Projekt Sieci neuronowe
 Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
Drzewa Decyzyjne, cz.2
 Drzewa Decyzyjne, cz.2 Inteligentne Systemy Decyzyjne Katedra Systemów Multimedialnych WETI, PG Opracowanie: dr inŝ. Piotr Szczuko Podsumowanie poprzedniego wykładu Cel: przewidywanie wyniku (określania
Drzewa Decyzyjne, cz.2 Inteligentne Systemy Decyzyjne Katedra Systemów Multimedialnych WETI, PG Opracowanie: dr inŝ. Piotr Szczuko Podsumowanie poprzedniego wykładu Cel: przewidywanie wyniku (określania
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Klasyfikacja LDA + walidacja
 Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Stan dotychczasowy. OCENA KLASYFIKACJI w diagnostyce. Metody 6/10/2013. Weryfikacja. Testowanie skuteczności metody uczenia Weryfikacja prosta
 Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne
 WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji
 Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Zastosowania metod odkrywania wiedzy do diagnostyki maszyn i procesów
 Zastosowania metod odkrywania wiedzy do diagnostyki maszyn i procesów Wojciech Moczulski Politechnika Śląska Katedra Podstaw Konstrukcji Maszyn Sztuczna inteligencja w automatyce i robotyce Zielona Góra,
Zastosowania metod odkrywania wiedzy do diagnostyki maszyn i procesów Wojciech Moczulski Politechnika Śląska Katedra Podstaw Konstrukcji Maszyn Sztuczna inteligencja w automatyce i robotyce Zielona Góra,
Zastosowanie metod eksploracji danych (data mining) do sterowania i diagnostyki procesów w przemyśle spożywczym
 do sterowania i diagnostyki procesów w przemyśle spożywczym") POLITECHNIKA WARSZAWSKA Instytut Technik Wytwarzania Zastosowanie metod eksploracji danych (data mining) do sterowania i diagnostyki procesów w przemyśle spożywczym Marcin Perzyk Dlaczego eksploracja danych?
POLITECHNIKA WARSZAWSKA Instytut Technik Wytwarzania Zastosowanie metod eksploracji danych (data mining) do sterowania i diagnostyki procesów w przemyśle spożywczym Marcin Perzyk Dlaczego eksploracja danych?
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Politechnika Warszawska Wydział Elektroniki i Technik Informacyjnych Warszawa, Polska k.mizinski@stud.elka.pw.edu.pl Streszczenie Niniejszy dokument opisuje jedna
Algorytmy klasyfikacji Konrad Miziński Politechnika Warszawska Wydział Elektroniki i Technik Informacyjnych Warszawa, Polska k.mizinski@stud.elka.pw.edu.pl Streszczenie Niniejszy dokument opisuje jedna
Studia podyplomowe w zakresie przetwarzanie, zarządzania i statystycznej analizy danych
 Studia podyplomowe w zakresie przetwarzanie, zarządzania i statystycznej analizy danych PRZEDMIOT (liczba godzin konwersatoriów/ćwiczeń) Statystyka opisowa z elementami analizy regresji (4/19) Wnioskowanie
Studia podyplomowe w zakresie przetwarzanie, zarządzania i statystycznej analizy danych PRZEDMIOT (liczba godzin konwersatoriów/ćwiczeń) Statystyka opisowa z elementami analizy regresji (4/19) Wnioskowanie
SYLABUS. Dotyczy cyklu kształcenia Realizacja w roku akademickim 2016/2017. Wydział Matematyczno - Przyrodniczy
 Załącznik nr 4 do Uchwały Senatu nr 430/01/2015 SYLABUS Dotyczy cyklu kształcenia 2014-2018 Realizacja w roku akademickim 2016/2017 1.1. PODSTAWOWE INFORMACJE O PRZEDMIOCIE/MODULE Nazwa przedmiotu/ modułu
Załącznik nr 4 do Uchwały Senatu nr 430/01/2015 SYLABUS Dotyczy cyklu kształcenia 2014-2018 Realizacja w roku akademickim 2016/2017 1.1. PODSTAWOWE INFORMACJE O PRZEDMIOCIE/MODULE Nazwa przedmiotu/ modułu
Metody Prognozowania
 Wprowadzenie Ewa Bielińska 3 października 2007 Plan 1 Wprowadzenie Czym jest prognozowanie Historia 2 Ciągi czasowe Postępowanie prognostyczne i prognozowanie Predykcja długo- i krótko-terminowa Rodzaje
Wprowadzenie Ewa Bielińska 3 października 2007 Plan 1 Wprowadzenie Czym jest prognozowanie Historia 2 Ciągi czasowe Postępowanie prognostyczne i prognozowanie Predykcja długo- i krótko-terminowa Rodzaje
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 Detekcja twarzy autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się algorytmem gradientu prostego
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 Detekcja twarzy autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się algorytmem gradientu prostego
Hurtownie danych i business intelligence. Plan na dziś : Wprowadzenie do przedmiotu
 i business intelligence Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl Wrocław 2005-2012 Plan na dziś : 1. Wprowadzenie do przedmiotu (co będzie omawiane oraz jak będę weryfikował zdobytą wiedzę
i business intelligence Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl Wrocław 2005-2012 Plan na dziś : 1. Wprowadzenie do przedmiotu (co będzie omawiane oraz jak będę weryfikował zdobytą wiedzę
Algorytmy i bazy danych (wykład obowiązkowy dla wszystkich)
") MATEMATYKA I EKONOMIA PROGRAM STUDIÓW DLA II STOPNIA Data: 2010-11-07 Opracowali: Krzysztof Rykaczewski Paweł Umiński Streszczenie: Poniższe opracowanie przedstawia projekt planu studiów II stopnia na
MATEMATYKA I EKONOMIA PROGRAM STUDIÓW DLA II STOPNIA Data: 2010-11-07 Opracowali: Krzysztof Rykaczewski Paweł Umiński Streszczenie: Poniższe opracowanie przedstawia projekt planu studiów II stopnia na
ID1SII4. Informatyka I stopień (I stopień / II stopień) ogólnoakademicki (ogólno akademicki / praktyczny) stacjonarne (stacjonarne / niestacjonarne)
 ogólnoakademicki (ogólno akademicki / praktyczny) stacjonarne (stacjonarne / niestacjonarne)") Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu ID1SII4 Nazwa modułu Systemy inteligentne 1 Nazwa modułu w języku angielskim Intelligent
Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu ID1SII4 Nazwa modułu Systemy inteligentne 1 Nazwa modułu w języku angielskim Intelligent
Modelowanie glikemii w procesie insulinoterapii
 Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
Drzewa klasyfikacyjne Lasy losowe. Wprowadzenie
 Wprowadzenie Konstrukcja binarnych drzew klasyfikacyjnych polega na sekwencyjnym dzieleniu podzbiorów przestrzeni próby X na dwa rozłączne i dopełniające się podzbiory, rozpoczynając od całego zbioru X.
Wprowadzenie Konstrukcja binarnych drzew klasyfikacyjnych polega na sekwencyjnym dzieleniu podzbiorów przestrzeni próby X na dwa rozłączne i dopełniające się podzbiory, rozpoczynając od całego zbioru X.
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
Wprowadzenie. Metody bayesowskie Drzewa klasyfikacyjne i lasy losowe Sieci neuronowe SVM. Klasyfikacja. Wstęp
 Wstęp Problem uczenia się pod nadzorem, inaczej nazywany uczeniem się z nauczycielem lub uczeniem się na przykładach, sprowadza się do określenia przydziału obiektów opisanych za pomocą wartości wielu
Wstęp Problem uczenia się pod nadzorem, inaczej nazywany uczeniem się z nauczycielem lub uczeniem się na przykładach, sprowadza się do określenia przydziału obiektów opisanych za pomocą wartości wielu
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Metadane. Data Maining. - wykład VII. Paweł Skrobanek, C-3 pok. 323 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2006
 Metadane. Data Maining. - wykład VII Paweł Skrobanek, C-3 pok. 323 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2006 Plan 1. Metadane 2. Jakość danych 3. Eksploracja danych (Data mining) 4. Sprawy róŝne
Metadane. Data Maining. - wykład VII Paweł Skrobanek, C-3 pok. 323 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2006 Plan 1. Metadane 2. Jakość danych 3. Eksploracja danych (Data mining) 4. Sprawy róŝne
Metody klasyfikacji i rozpoznawania wzorców. Najważniejsze rodzaje klasyfikatorów
 Metody klasyfikacji i rozpoznawania wzorców www.michalbereta.pl Najważniejsze rodzaje klasyfikatorów Dla określonego problemu klasyfikacyjnego (tzn. dla danego zestawu danych) należy przetestować jak najwięcej
Metody klasyfikacji i rozpoznawania wzorców www.michalbereta.pl Najważniejsze rodzaje klasyfikatorów Dla określonego problemu klasyfikacyjnego (tzn. dla danego zestawu danych) należy przetestować jak najwięcej
SIEĆ NEURONOWA DO OCENY KOŃCOWEJ PRZEDSIĘWZIĘCIA (PROJEKTU)
") SIEĆ NEURONOWA DO OCENY KOŃCOWEJ PRZEDSIĘWZIĘCIA (PROJEKTU) 1. Opis problemu - ocena końcowa projektu Projekt jako nowe, nietypowe przedsięwzięcie wymaga właściwego zarządzania. Podjęcie się realizacji
SIEĆ NEURONOWA DO OCENY KOŃCOWEJ PRZEDSIĘWZIĘCIA (PROJEKTU) 1. Opis problemu - ocena końcowa projektu Projekt jako nowe, nietypowe przedsięwzięcie wymaga właściwego zarządzania. Podjęcie się realizacji