Mikroformaty, RDFa, Inicjatywy Open*
|
|
|
- Daria Drozd
- 6 lat temu
- Przeglądów:
Transkrypt
1 Mikroformaty, RDFa, Inicjatywy Open* Mikołaj Morzy Agnieszka Ławrynowicz Instytut Informatyki Poznań, rok akademicki 2013/2014 TSiSS 1
2 Od Sieci Dokumentów do Sieci Danych Sieć dokumentów Hyperlinks Dokumenty Podstawowe elementy: 1. Nazwy (URI) 2. Dokumenty (Zasoby) opisane w HTML, XML, itp. 3. Interakcja poprzez HTTP 4. (Hiper)linki pomiędzy dokumentami lub anchors w dokumentach Wady: Nietypowane linki Wyszukiwarki nie potrafią obsłużyć skomplikowanych zapytań TSiSS 2 2
3 Od Sieci Dokumentów do Sieci Danych Sieć Dokumentów Sieć Danych Typowane Linki Hyperlinks Dokumenty Rzeczy TSiSS 3 3
4 Od Sieci Dokumentów do Sieci Danych Cechy: Linki pomiędzy dowolnymi rzeczami (np. osobami, lokalizacjami, zdarzeniami, budynkami) Sruktura danych na stronach WWW jest jawna Rzeczy opisane na stronach mają nazwę i URI Linki pomiędzy rzeczami są jawne i typowane Sieć danych Rzeczy Typowane linki TSiSS 4 4
5 Wizja Sieci Danych 1/2 Sieć dzisiaj składa się z odizolowanych silosów danych, które są dostępne poprzez wyspecjalizowane wyszukiwarki jedna strona (silos danych) przechowuje filmy, inne recenzje, jeszcze inne informacje o aktorach wiele popularnych rzeczy jest reprezentowanych w wielu różnych zbiorach danych linkowanie identyfikatorów łączy te zbiory danych TSiSS 5 5

6 Wizja Sieci Danych 2/2 Sieć Danych - globalna baza danych składa się z obiektów i ich opisów obiekty są ze sobą powiązane linkami z wysokim stopniem ustrukturalizowania obiektów z jawną semantyką linków i treści zaprojektowana dla ludzi i maszyn TSiSS 6 6

 wiązanie danych (tworzenie linków")

7 Budowa Sieci Danych poprzez publikowanie danych strukturalnych w Sieci wykorzystanie różnych API WWW (2.0) wiązanie danych (tworzenie linków między danymi) osadzanie ustrukturalizowanych danych (mikroformaty, RDFa, GRDDL) TSiSS 7 7
8 Budowa Sieci Danych poprzez publikowanie danych strukturalnych w Sieci wykorzystanie różnych API WWW (2.0) wiązanie danych (tworzenie linków między danymi) osadzanie ustrukturalizowanych danych (mikroformaty, RDFa, GRDDL) TSiSS 8 8
9 Powiązane Dane (ang. Linked Data): definicja The Seman)c Web isn't just about pu5ng data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data. (Tim Berners- Lee) Powiązane Dane wykorzystanie technologii Sieci Semantycznej do publikowania ustrukturalizowanych danych w Sieci i do ustanawiania powiązań między źródłami danych. TSiSS 9 9
10 Powiązane Dane - zasady Używaj URI jako nazwy dla rzeczy. Używaj HTTP URI tak aby ludzie mogli wyszukiwać tych nazw. Kiedy użytkownik wyszukuje URI, dostarcz użytecznej informacji w RDF. Zawrzyj wyrażenia RDF, które są powiązane linkami do innych identyfikatorów URI tak aby mogły one pomóc w wykryciu powiązanych rzeczy. TSiSS 10 10
11 Projekt Linking Open Data (Otwarte Powiązane Dane) Projekt społecznościowy ze wsparciem W3C Cel: Pomoc w utworzeniu Sieci Semantycznej poprzez publikowanie zbiorów danych z wykorzystaniem RDF. Spełnia zasady połączonych danych (Linked Data principles) Główna idea: wziąć istniejące (otwarte) zbiory danych i uczynić je dostępnymi w Sieci w formacie RDF Raz opublikowane w RDF, połączyć je linkami z innymi zbiorami danych Przykładowy link RDF: h]p://dbpedia.org/resource/berlin [Identyfikator Berlina w DBPedia] owl:sameas h]p://sws.geonames.org/ [Identyfikator Berlina w Geonames]. TSiSS 11 11
12 Chmura LOD - Maj 2007 TSiSS 12 12
13 Chmura LOD - Maj 2007 Ogólnie: Chmura Powiązanych Otwartych Danych (Linked Open Data) jest zbiorem powiązanych między sobą zbiorów danych, które zostały opublikowane i powiązane linkami zgodnie z zasadami powiązanych danych. Fakty: Punkty ogniskujące : DBPedia: wersja Wikipiedii w formacie RDF; wiele przychodzących i wychodzących linków Zbiory danych dotyczące muzyki Duże zbiory danych zawierają: FOAF, US Census data Rozmiar w przybliżeniu 1 bilion trójek, 250k linków TSiSS 13 13

14 Chmura LOD - Wrzesień 2008 TSiSS 14 14
15 Chmura LOD - Wrzesień 2008 Fakty: Więcej niż 35 powiązanych zbiorów danych Gracze komercyjni dołączyli do chmury (np. BBC) Firmy zaczęły publikować i przechowywać zbiory danych (OpenLink, Talis, Garlik) Rozmiar w przybliżeniu 2 bilion y trójek, 3 miliony linków TSiSS 15 15

16 Chmura LOD - Marzec 2009 TSiSS 16 16
17 Chmura LOD - Marzec 2009 Fakty: Wielka część z chmury Drug i projektu BIO2RDF Znaczące nowe zbiory danych: Freebase, OpenCalais, ACM/ IEEE Rozmiar > 10 bilionów trójek TSiSS 17 17

18 Chmura LOD - Wrzesień 2011 Liczba zbiorów danych: 295 Liczba trójek:
19 Publikowanie Powiązanych danych w 7 krokach Wybór słowników ważne ponowne wykorzystanie istniejących słowników - interoperacyjność Partycjonowanie grafu RDF do stron danych Przyznanie URI każdej stronie danych Stworzenie wariantów HTML każdej strony danych - do renderowania stron w przeglądarkach Przyznanie URI każdej encji Dodanie metadanych stron i linków np. publisher, license, topics Dodanie semantycznej mapy strony (semanic sitemap) ważna dla pająków w celu znalezienia zbioru danych lub końcowki SPARQL z dostępem do danych TSiSS 19 19
20 Tworzenie powiązań (linków) Popularne predykaty: owl:sameas, foaf:homepage, foaf:topic, foaf:based_near, foaf:maker/foaf:made, foaf:depiction, foaf:page, foaf:primarytopic, rdfs:seealso TSiSS 20 20
21 Przykładowe zbiory danych DBpedia BBC Music Open government (UK), Data.gov (US) Freebase Zbiory danych biologicznych i medycznych TSiSS 21


22 DBpedia Inicjatywa społeczna: Ekstrakcja strukturalnej informacji z Wikipedii Udostępnienie informacji w Sieci na otwartej licencji Powiązanie linkami zbioru danych DBpedii z innymi zbiorami danych w Sieci DBpedia to jeden z najbardziej centralnych hubów w tworzącej się Sieci Danych TSiSS 22
23 Data.gov 1. Zgromadź dane z wielu miejsc, udostępnij je za darmo deweloperom, naukowcom, obywatelom 2. Połącz społeczność w znajdowaniu rozwiązań pozwalających na współpracę poprzez media społecznościowe, wydarzenia, plalormy 3. Dostarcz infrastrukturę w oparciu o standardy i interoperacyjność 4. Zachęć twórców technologii do tworzenia aplikacji, map, wizualizacji danych, które wzmocnią wybory dokonywane przez ludzi 5. Zgromadź więcej danych i połącz więcej ludzi s A Strategy for American Innova2on wrzesień 2009
24 Powiązane Dane Narzędzia i Aplikacje Narzędzia do przenoszenia danych z innych formatów i z funkcjonujących wewnętrznie systemów do Sieci Danych Narzędzia do wykorzystywania Powiązanych Danych: przeszukiwanie, przeglądanie, tworzenie mashups, inne TSiSS 24 24
25 Przenoszenia danych z innych formatów do Sieci Danych Dostarczenie danych przechowywanych w relacyjnych bazach danych do Sieci Danych: Pubby: serwer dostarczający dostępu do składnic trójek w Sieci Triplify: pozwala na specyfikację zapytań SQL i zrenderowanie wyników jako RDF D2RQ, ontop: odwzorowanie relacyjnych baz danych do RDF; dostarczają końcówkę SPARQL z dostępem do danych Virtuoso RDF Views: oferuje deklaratywny język do tworzenia odwzorowań pomiędzy danymi SQL i RDF Ekstrakcja danych z Sieci WWW (np. DBPedia: dane z Wikipedii) Konwersja istniejących danych i ekstrakcja z nich RDF: z JPEG, , BibTex, Java bytecode, Javadoc, Excel TSiSS 25 25
26 Repozytoria trójek RDF OWLIM: natywne, wykorzystuje mechanizm wnioskowania wprzód (forward chaining) i materializację AllegroGraph: natywne Jena TDB: natywne Open Link Virtuoso: hybrydowe, hostuje zbiór Dbpedia, Virtuoso 7 - Virtuoso Column Store BigData: hybrydowe TSiSS 26 26
27 Publikowanie powiązanych - typowe wzorce Źródło:
28 Konsumowanie Powiązanych Danych Przeglądarki Powiązanych Danych: eksplorowanie rzeczy i zbiorów danych i nawigacja pomiędzy nimi Tabulator Browser, Marbles, OpenLink RDF Browser, Zitgist RDF Browser, Disco Hyperdata Browser, Fenfire Mashup y Powiązanych Danych: strony, które łączą ( mieszają ) powiązane dane Revyu.com, DBtune Slashfacet, DBPedia Mobile, Semansc Web Pipes Wyszukiwarki powiązanych danych Falcons, Sindice, MicroSearch, Watson, SWSE, Swoogle TSiSS 28 28
29 Przykładowy Mashup: Revyu.com 1/2 Revyu.com - strona do oceniania wszystkiego. Powiązane Dane wykorzystywane do wzbogacania ocen. Oceny zawierają linki do ocenianej rzeczy i linki seealso do Wikipedii i innych zbiorów danych. TSiSS 29 29

30 Przykładowy Mashup: Revyu.com 2/2 TSiSS 30 30
31 Przykładowa wyszukiwarka: Sindice 1/2 Wyszukiwarka Powiązanych Danych. Pozwala na wyszukiwanie treści Sieci Semantycznej na bazie: - słów kluczowych - URI (identyfikujących obiekty, pojęcia, lub dokumenty). TSiSS 31 31

32 Przykładowa wyszukiwarka: Sindice 2/2 TSiSS 32 32
33 Inne inicjatywy Open* Open Source Open Content Open Science (Open Notebook Science) Open Access Open CourseWare Open Society Foundaions Open Health TSiSS 33





34 Otwarte dane przykład aplikacji Green BuHon 21 million American h can 21 now milionów download amerykańskich th gospodarstw domowych business może energy ściągnąć use dane dot. zużycia energii their local w ich utility domu Następnie wykorzystać aplikacje, które zarządzają Then use ich apps zużyciem to ma energii i zaoszczędzić pieniądze energy use (i być to bardziej save mekologicznym) go green Więcej: Energy.Data.gov More at Energy.Data Źródło: Driving Innovason with Open Data and Interoperability Jeanne Holm Evangelist, Data.gov Listopad 14, 2012

35 Otwarte dane to ekosystem
36 Wspólna wizja 1. Wizja: Co będzie łączyć społeczność, jak współpraca będzie wyglądać w przyszłości? 2. Liderzy: Kto będzie przewodzić społeczności? 3. Uczestnicy: Kto będzie uczestniczyć? 4. Wyniki: Jakie są oczekiwane wyniki, miary ich osiągnięcia? 5. Funckcjonalność: Jakie typy aktywności będą funkjonować (fora, blogi, wiki, rankingi konkursy, aplikacje)? 6. Treść: Jaka treść będzie pokazywana? 7. Interakcyjność: Jak społeczność będzie komunikować się z liderami i z zewnętrznymi osobami, jednostkami?
37 Co to są mikroformaty? - sposób nadania znaczenia elementom HTML i jawnego pokazania struktur danych na stronach HTML - zaprojektowane dla ludzi w pierwszej kolejności, w drugiej dla maszyn - zbiór prostych, otwartych formatów danych, zbudowanych w oparciu o istniejące i szeroko zaadaptowane standardy (np. (X)HTML) - rozwiazują pojedynczy, specyficzny problem (np. reprezentację informacji geograficznej, kalendarzowej) TSiSS 37 37
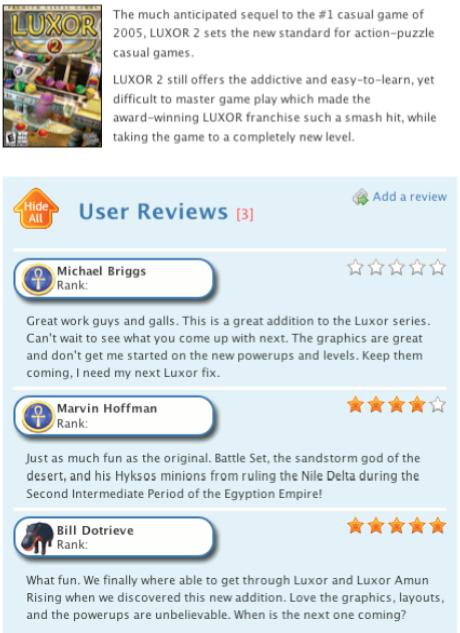
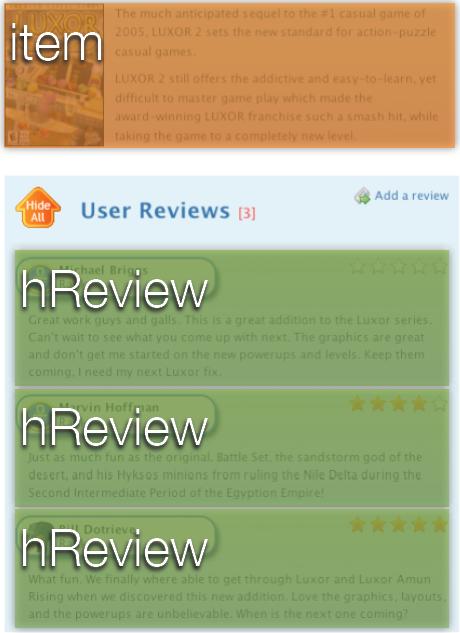
38 Ilustracja microformatów TSiSS 38 38
39 Rodzaje mikroformatów Elementarne mikroformaty (jeden znacznik) Rel-home (strona domowa) <link href=" rel="home" /> Rel-License (licencja) <a href=" rel="license">cc by2.0</a> Inne: rel-tag, rel-encluse, xfn-tags Złożone mikroformaty Często oparte na istniejącym standardzie np. hcard, hcalendar, hevent, hreview TSiSS 39 39
40 Składnia Mikroformaty wykorzystują istniejące atrybuty HTML do osadzenia strukturalnych typów danych w dokumencie HTML i do wskazania obecności metadanych Atrybut rel/rev wykorzystanie w elementarnych mikroformatach. Przykład: <a href= rel= tag >instytut</a> Atrybut class wykorzystanie w złożonych mikroformatach. Przykład: <span class= geo ><span class= latitude >28.42</span><span class= longitude >37.10</span><span> TSiSS 40 40
41 Ekspresywność mikroformatów Mikroformaty rozszerzją siłę wyrażania (ekspresywność) języka HTML Ekspresywność jest ograniczona tym, że mikroformaty są zaprojektowane do wykorzystywania tylko pre- definiowanych słowników. TSiSS 41 41
42 Przykład: złożony mikroformat hcard 1/2 hcard prosty format do reprezentacji danych ludzi, firm, organizacji i miejsc wykorzystujący 1:1 reprezentację własności i wartości standardu vcard (RFC2426) BEGIN: VCARD VERSION: 3 FN: Agnieszka Lawrynowicz ORG: Politechnika Poznanska URL: h]p:// TEL: END: VCARD TSiSS 42 42
43 Przykład: złożony mikroformat hcard 2/2 <div class="vcard > <span class="fn">agnieszka Lawrynowicz</span> <a class="org url href=" Poznanska</a> <a class=" me</a> Phone: <div class="tel"> </div> </div> Example on this slide by Alexander Graf TSiSS 43 43
44 Wady mikroformatów Istnieje jedynie ustalony zbiór mikroformatów Nie ma możliwości łączenia elementów danych Ustalony słownik, nie- rozszerzalny, trudny do dostosowania do konkretnych potrzeb Osobne reguły parsowania potrzebne dla każdego mikroformatu TSiSS 44 44
45 RDFa RDFa = RDF w atrybutach rekomendacja W3C zbiór nowych atrybutów (X)HTML do wyrażenia metadanych wewnątrz (X)HTML format serializacji RDF, gdzie trójki RDF są "osadzone" w (X)HTML niezależne od dziedziny (w przeciwieństwie do dedykowanych dla danej dziedziny mikroformatów) TSiSS 45
46 Składnia: wykorzystanie RDFa w XHTML Odpowienie @src Nowe atrybuty, specyficzne @typeof TSiSS 46 46
47 Opis podstawowych URI, które specyfikuje zasób opisywany określają relację (relację odwrotną) z określają stowarzyszony określa własność dla zawartości ( content ) opcjonalny atrybut, który nadpisuje zawartość elementu, używając atrybutu opcjonalny atrybut, który określa typ danych tekstu do wykorzystania z atrybutem opcjonalny atrybut, który określa typ(y) RDF podmiotu (zasobu opisywanego przez metadane) TSiSS 47
48 Wykorzystanie RDFa w XHTML <html xmlns:foaf="h]p://xmlns.com/foaf/0.1/"> <head> <itle>profil Jana Kochanowskiego</itle> <link rel="foaf:primarytopic foaf:maker" href="#me"/> </head> <body> <div about="#me" typeof="foaf:person"> <span property="foaf:name">jan Kochanowski</span> ma strone domowa <a rel="foaf:homepage" href="h]p://pl.wikipedia.org/wiki/ Jan_Kochanowski">Strona Jana Kochanowskiego</a>. Zna: <a rel="foaf:knows" href="h]p://pl.wikipedia.org/wiki/zygmunt_ii_august#me">zygmunt II August</a>. <span rel="foaf:img"> <img src=h]p://upload.wikimedia.org/wikipedia/commons/4/42/jan_kochanowski.png alt="jan"/> </span> </div> </body> </html> TSiSS 48
49 Ekspresywność RDFa Specyfikacja RDFa definiuje składnię do osadzania RDF w dokumentach w dowolnym języku opartym o język XML. Dlatego RDFa zyskuje swoją ekspresywność z siły wyrażania RDF TSiSS 49 49
50 GRDDL GRDDL ( Gleaning Resource Descripions from Dialects of Languages ) Specyfikacja GRDDL wprowadza znaczniki w oparciu o istniejące standardy deklaracji, że dokument XML zawiera dane kompatybilne z RDF i do łączenia z algorytmami (typowo reprezentowanymi w XSLT) do ekstrakcji tych danych z dokumentu. TSiSS 50 50
 Połaczenie z jednym lub większą liczbą ekstraktorów. (3) Agent GRDDL ekstrahuje RDF z dokumentu.")
51 Transformacje GRDDL Transformacje GRDDL są stosowane w 3 krokach: (1) Deklaracja dokumentu jako źródła. (2) Połaczenie z jednym lub większą liczbą ekstraktorów. (3) Agent GRDDL ekstrahuje RDF z dokumentu. TSiSS 51 51
52 Inicjatywy gigantów h]p://schema.org (współpraca Google, Microso i Yahoo!) schemat znaczników danych strukturalnych wspieranych przez najważniejsze wyszukiwarki internetowe, mikrodane Google knowledge graph hzp:// feature=player_embedded&v=mmql6vgvx- c Facebook Graph API, Open API hzps:// YNvdJk8k
 1964 do dzisiaj format odpowiedź- i- pytanie Przykład: Kategoria: Nauka ogólnie Wskazówka: W")

53 Jeopardy! Jeopardy! to amerykański quiz show (odpowiednik polskiego Va Banque!) 1964 do dzisiaj format odpowiedź- i- pytanie Przykład: Kategoria: Nauka ogólnie Wskazówka: W zderzeniu z elektronami, fosfor wydziela energię elektromagnetyczną w tej formie Odpowiedź: Czym jest światło? dla ludzi, wyzwaniem jest znajomość odpowiedzi dla maszyn, wyzwaniem jest zrozumienie pytania
54 IBM Watson Watson system komputerowy stworzony przez IBM do odpowiadania na pytania zadawane w języku naturalnym Watson wystąpił w Jeopardy! w trzydniowej rozgrywce (2011) h]p://
55 IBM Watson przeciwnikami IBM Watsona byli: Brad Ruzer do tej pory wygrał najwięcej pieniędzy, Ken Jennings był najdłużej niepokonanym mistrzem IBM Watson zajął pierwsze miejsce
56 Problem automatycznego i niezależnego od dziedziny odpowiadania na pytania (QA) Mając dane treściwe pytania w języku naturalnym dot. szerokiej dziedziny wiedzy Dostarcz (w czasie < 3s): precyzyjnych odpowiedzi: określ czego dotyczy pytanie & daj precyzyjną odpowiedź dokładnie wyliczoną pewność odpowiedzi strawne wyjaśnienia co do poprawności odpowiedzi
57 IBM Watson trójząb * Nowy paradygmat oprogramowania coraz więcej zadań obliczeniowych wymaga rozwiązań niedokładnych, które łączą wiele metod w nieprzewidziany sposób Wiedza nie jest celem (o tym za chwilę) Inteligencja maszynowa nie jest inteligencją ludzką Różnica jest najbardziej znaczna w przypadku pomyłek *Wg Chrisa Welty z IBM Research
58 IBM Watson wiedza nie jest celem Klasyczne podejście QA Od zarania SI zakładano, że odpowiadanie na pytania będzie działać na bazie procesu, który całkowicie przekłada język naturalny na jednoznaczną (logiczną) reprezentację; proces wnioskowania będzie działać na tej reprezentacji aby wyprodukować odpowiedzi. JĘZYK NATURALNY WIEDZA pokrycie NLP precyzja akwizycja skala technologie semantyczne
59 IBM Watson wiedza nie jest celem Klasyczne podejście QA Od zarania SI zakładano, że odpowiadanie na pytania będzie działać na bazie procesu, który całkowicie przekłada język naturalny na jednoznaczną (logiczną) reprezentację; proces wnioskowania będzie działać na tej reprezentacji aby wyprodukować odpowiedzi. JĘZYK NATURALNY pokrycie NLP precyzja PORAŻKA! akwizycja WIEDZA skala technologie semantyczne
60 IBM Watson wiedza nie jest celem DeepQA (Watson) generuje i ocenia wiele hipotez wykorzystując kolekcję metod z dziedziny przetwarzania języka naturalnego, uczenia maszynowego, reprezentacji wiedzy i wnioskowania; gromadzą one i ważą dowody pochodzące ze źródeł danych niestrukturalnych i strukturalnych (np. otwartych powiązanych danych) aby ustalić odpowiedź o najwyższej pewności na podstawie odpowiedzi wielu (setek) metod NER JĘZYK NATURALNY parsowanie wyszukiwanie informacji uczenie maszynowe crowd technologie semantyczne ZADANIE
61 IBM Watson jak to działa The science behind an answer h]p://
62 Google: Graf Wiedzy semantyczne wyszukiwanie maj 2012: baza wiedzy wykorzystywana przez Google do rozszerzenia wyników wyszukiwania wiele źródeł wiedzy: CIA World Factbook, Freebase, Wikipedia sieć semantyczna zawiera ponad 570 mln obiektów i ponad 18 mld faktów maj 2013: polska wersja językowa; zadawanie pytań raczej niż wyszukiwanie, informacje i powiązania między nimi raczej niż zestaw linków system poszukujący nie fraz kluczowych, lecz "bytów stojących za wpisanymi w wyszukiwarkę słowami
63 Dwa główne sposoby działania Grafu Wiedzy dopasowywanie odpowiedzi do kontekstu; w przypadku dwuznacznych haseł prezentacja różnych wersji odpowiedzi podsumowania najbardziej istotnych informacji: - biogramy, wyróżnione najważniejsze elementy, powiązania między kluczowymi hasłami, odnośniki do kolejnych informacji

64 Graf Wiedzy: przykład
65 Bibliografia [1] C. Bizer, T. Heath, and T. Berners- lee Linked Data The Story So Far Internasonal Journal on Semansc Web and Informason Systems (IJSWIS) (2009) [2] T. Heath, and C. Bizer (2011) Linked Data: Evolving the Web into a Global Data Space (1st edison). Synthesis Lectures on the Semansc Web: Theory and Technology, 1:1, Morgan & Claypool. [3] RDFa Primer, hzp:// rdfa- primer/ (last accessed on ) 65
66 Wykorzystanie RDFa w XHTML przykład 1/7 Krok 1 tworzenie obiektu osoby - wykorzystany i element słownictwa FOAF (Person) <html xmlns:foaf=" <head> <title>profil Jana Kochanowskiego</title> </head> <body> <div typeof="foaf:person">... </div> </body> </html> TSiSS 66
67 Wykorzystanie RDFa w XHTML przykład 2/7 Krok 2 dodanie informacji personalnej - wykorzystana własność foaf:name, ustawiona za pomocą atrybutu <div typeof="foaf:person"> <span property="foaf:name">jan Kochanowski</span> </div> TSiSS 67
68 Wykorzystanie RDFa w XHTML przykład 3/7 Krok 3 dodanie strony domowej - wykorzystana własność foaf:homepage i atrybut (dodajemy URL) <div typeof="foaf:person"> <span property="foaf:name">jan Kochanowski</span> <a rel="foaf:homepage" href=" Jan_Kochanowski">Strona Jana Kochanowskiego</a> </div> TSiSS 68
69 Wykorzystanie RDFa w XHTML przykład 4/7 Krok 4 dodanie przyjaciół/kolegów - wykorzystana własność foaf:knows i atrybut <div typeof="foaf:person"> <span property="foaf:name">jan Kochanowski</span> <a rel="foaf:homepage" href="h]p://pl.wikipedia.org/wiki/ Jan_Kochanowski">Strona Jana Kochanowskiego</a> <a rel="foaf:knows" href="h]p://pl.wikipedia.org/wiki/ Zygmunt_II_August#me">Zygmunt II August</a> </div> TSiSS 69
70 Wykorzystanie RDFa w XHTML przykład 5/7 Krok 5 dodanie zdjęcia - wykorzystana własność foaf:img <div about="#me" typeof="foaf:person"> <span property="foaf:name">jan Kochanowski</span> <a rel="foaf:homepage" href=" Jan_Kochanowski">Strona Jana Kochanowskiego</a> <a rel="foaf:knows" href=" Zygmunt_II_August#me">Zygmunt II August</a> <span rel="foaf:img"> <img src=" Jan_Kochanowski.png" alt="jan"/> </span> </div> TSiSS 70
71 Wykorzystanie RDFa w XHTML przykład 6/7 Krok 6 ostateczna wersja (łącznie z prezentacją) <html xmlns:foaf="h]p://xmlns.com/foaf/0.1/"> <head> <itle>profil Jana Kochanowskiego</itle> <link rel="foaf:primarytopic foaf:maker" href="#me"/> </head> <body> <div about="#me" typeof="foaf:person"> <span property="foaf:name">jan Kochanowski</span> ma strone domowa <a rel="foaf:homepage" href="h]p://pl.wikipedia.org/wiki/ Jan_Kochanowski">Strona Jana Kochanowskiego</a>. Zna: <a rel="foaf:knows" href="h]p://pl.wikipedia.org/wiki/zygmunt_ii_august#me">zygmunt II August</a>. <span rel="foaf:img"> <img src=h]p://upload.wikimedia.org/wikipedia/commons/4/42/jan_kochanowski.png alt="jan"/> </span> </div> </body> </html> TSiSS 71

72 Wykorzystanie RDFa w XHTML przykład 7/7 Trójki RDF wyrenderowane z dokumentu XHTML np. za pomocą parsera i walidators RDfa Sindice Inspector hzp://inspector.sindice.com/ TSiSS 72
73 Przykładowa przeglądarka: Marbles 1/2 Wskazuje źródło wyświetlanych danych za pomocą kolorowych ikonek Wsparcie dla różnych widoków: Pełen widok: wyświetlone wszystkie dostępne dane. Widok podsumowujący: krótkie tekstowe streszczenie na temat zasobu. Widok zdjęcie : zdjęcie danego zasobu. Pobiera dane z wielu źródeł poprzez (a) wysyłanie równoległych zapytań do wielu wyszukiwarek Powiązanych Danych (b) podążając za linkami owl:sameas i rdfs:seealso. TSiSS 73 73
74 Przykładowa przeglądarka: Marbles 2/2 TSiSS 74 74
Metadane. Agnieszka Ławrynowicz Politechnika Poznańska
 Metadane Agnieszka Ławrynowicz Politechnika Poznańska Metadane Metadane = dane o danych? Dlaczego definicja metadanych ma znaczenie dla rejestru połączeń telefonicznych NSA? Metadane to dane Gdzie przeprowadzić
Metadane Agnieszka Ławrynowicz Politechnika Poznańska Metadane Metadane = dane o danych? Dlaczego definicja metadanych ma znaczenie dla rejestru połączeń telefonicznych NSA? Metadane to dane Gdzie przeprowadzić
rdf:type ex:homepage ex:createdwith http://www.w3c.org /amaya rdf:type ex:htmleditor
 TSiSS, 2010/2011 Ćwiczenie 1. (RDF) Stwórz pliki w formacie RDF i w serializacji XML dla podanych grafów (modelując przestrzeń nazw dla ex jako http://example.org): 1.1 http://www.w3.org/ho me/lassila
TSiSS, 2010/2011 Ćwiczenie 1. (RDF) Stwórz pliki w formacie RDF i w serializacji XML dla podanych grafów (modelując przestrzeń nazw dla ex jako http://example.org): 1.1 http://www.w3.org/ho me/lassila
Bazy wiedzy. Agnieszka Ławrynowicz. Poznań, rok akademicki 2017
 Bazy wiedzy Agnieszka Ławrynowicz Poznań, rok akademicki 2017 Baza wiedzy pragmatyczna definicja Baza wiedzy kolekcja encji, klas i faktów o postaci subject-predicate-object (atrybuty, relacje), istotnych
Bazy wiedzy Agnieszka Ławrynowicz Poznań, rok akademicki 2017 Baza wiedzy pragmatyczna definicja Baza wiedzy kolekcja encji, klas i faktów o postaci subject-predicate-object (atrybuty, relacje), istotnych
Internet Semantyczny. Linked Open Data
 Internet Semantyczny Linked Open Data Dzień dzisiejszy database Internet Dzisiejszy Internet to Internet dokumentów (Web of Dokuments) przeznaczonych dla ludzi. Dzień dzisiejszy Internet (Web) to dokumenty
Internet Semantyczny Linked Open Data Dzień dzisiejszy database Internet Dzisiejszy Internet to Internet dokumentów (Web of Dokuments) przeznaczonych dla ludzi. Dzień dzisiejszy Internet (Web) to dokumenty
Wiedza w grach, gry z celem tworzenia wiedzy
 Wiedza w grach, gry z celem tworzenia wiedzy dr inż. Agnieszka Ławrynowicz Instytut Informatyki Politechniki Poznańskiej ZTG 2013 Kim jestem? Adiunkt w Instytucie Informatyki Politechniki Poznańskiej Zainteresowania:
Wiedza w grach, gry z celem tworzenia wiedzy dr inż. Agnieszka Ławrynowicz Instytut Informatyki Politechniki Poznańskiej ZTG 2013 Kim jestem? Adiunkt w Instytucie Informatyki Politechniki Poznańskiej Zainteresowania:
Semantic Web Internet Semantyczny
 Semantic Web Internet Semantyczny Semantyczny Internet - Wizja (1/2) Pomysłodawca sieci WWW - Tim Berners-Lee, fizyk pracujący w CERN Jego wizja sieci o wiele bardziej ambitna niż istniejąca obecnie (syntaktyczna)
Semantic Web Internet Semantyczny Semantyczny Internet - Wizja (1/2) Pomysłodawca sieci WWW - Tim Berners-Lee, fizyk pracujący w CERN Jego wizja sieci o wiele bardziej ambitna niż istniejąca obecnie (syntaktyczna)
ROLA INTEROPERACYJNOŚCI W BUDOWIE CYFROWYCH USŁUG PUBLICZNYCH ORAZ W UDOSTĘPNIANIU ZASOBÓW OTWARTYCH DANYCH
 ROLA INTEROPERACYJNOŚCI W BUDOWIE CYFROWYCH USŁUG PUBLICZNYCH ORAZ W UDOSTĘPNIANIU ZASOBÓW OTWARTYCH DANYCH Adam Iwaniak Instytut Geodezji i Geoinformatyki, Uniwersytet Przyrodniczy we Wrocławiu Wrocławski
ROLA INTEROPERACYJNOŚCI W BUDOWIE CYFROWYCH USŁUG PUBLICZNYCH ORAZ W UDOSTĘPNIANIU ZASOBÓW OTWARTYCH DANYCH Adam Iwaniak Instytut Geodezji i Geoinformatyki, Uniwersytet Przyrodniczy we Wrocławiu Wrocławski
Linked Open Data z wykorzystaniem wolnego oprogramowania w gospodarce przestrzennej
 Linked Open Data z wykorzystaniem wolnego oprogramowania w gospodarce przestrzennej dr inż. Iwona Kaczmarek Uniwersytet Przyrodniczy we Wrocławiu Otwarte dane rządowe The Memorandum on Transparency and
Linked Open Data z wykorzystaniem wolnego oprogramowania w gospodarce przestrzennej dr inż. Iwona Kaczmarek Uniwersytet Przyrodniczy we Wrocławiu Otwarte dane rządowe The Memorandum on Transparency and
3 grudnia Sieć Semantyczna
 Akademia Górniczo-Hutnicza http://www.agh.edu.pl/ 1/19 3 grudnia 2005 Sieć Semantyczna Michał Budzowski budzow@grad.org 2/19 Plan prezentacji Krótka historia Problemy z WWW Koncepcja Sieci Semantycznej
Akademia Górniczo-Hutnicza http://www.agh.edu.pl/ 1/19 3 grudnia 2005 Sieć Semantyczna Michał Budzowski budzow@grad.org 2/19 Plan prezentacji Krótka historia Problemy z WWW Koncepcja Sieci Semantycznej
Multi-wyszukiwarki. Mediacyjne Systemy Zapytań wprowadzenie. Architektury i technologie integracji danych Systemy Mediacyjne
 Architektury i technologie integracji danych Systemy Mediacyjne Multi-wyszukiwarki Wprowadzenie do Mediacyjnych Systemów Zapytań (MQS) Architektura MQS Cechy funkcjonalne MQS Cechy implementacyjne MQS
Architektury i technologie integracji danych Systemy Mediacyjne Multi-wyszukiwarki Wprowadzenie do Mediacyjnych Systemów Zapytań (MQS) Architektura MQS Cechy funkcjonalne MQS Cechy implementacyjne MQS
Web 3.0 Sieć Pełna Znaczeń (Semantic Web) Perspektywy dla branży motoryzacyjnej i finansowej. Przyjęcie branżowe EurotaxGlass s Polska 10 luty 2012
 Perspektywy dla branży motoryzacyjnej i finansowej. Przyjęcie branżowe EurotaxGlass s Polska 10 luty 2012") Web 3.0 Sieć Pełna Znaczeń (Semantic Web) Perspektywy dla branży motoryzacyjnej i finansowej Przyjęcie branżowe EurotaxGlass s Polska 10 luty 2012 Web 3.0 - prawdziwa rewolucja czy puste hasło? Web 3.0
Web 3.0 Sieć Pełna Znaczeń (Semantic Web) Perspektywy dla branży motoryzacyjnej i finansowej Przyjęcie branżowe EurotaxGlass s Polska 10 luty 2012 Web 3.0 - prawdziwa rewolucja czy puste hasło? Web 3.0
extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl
 extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl Plan wykładu Wprowadzenie: historia rozwoju technik znakowania tekstu Motywacje dla prac nad XML-em Podstawowe koncepcje XML-a XML jako metajęzyk
extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl Plan wykładu Wprowadzenie: historia rozwoju technik znakowania tekstu Motywacje dla prac nad XML-em Podstawowe koncepcje XML-a XML jako metajęzyk
Spis treści Informacje podstawowe Predykaty Przykłady Źródła RDF. Marek Prząda. PWSZ w Tarnowie. Tarnów, 6 lutego 2009
 PWSZ w Tarnowie Tarnów, 6 lutego 2009 1 Interpretacja trójek i SWI-Prolog Składnia 2 3 4 Interpretacja trójek i SWI-Prolog Składnia Opis (ang. Resource Description Framework) jest specyfikacją modelu metadanych,
PWSZ w Tarnowie Tarnów, 6 lutego 2009 1 Interpretacja trójek i SWI-Prolog Składnia 2 3 4 Interpretacja trójek i SWI-Prolog Składnia Opis (ang. Resource Description Framework) jest specyfikacją modelu metadanych,
Rozszerzenie funkcjonalności systemów wiki w oparciu o wtyczki i Prolog
 Knowledge Rozszerzenie funkcjonalności systemów wiki w oparciu o wtyczki i Prolog 9 stycznia 2009 Knowledge 1 Wstęp 2 3 4 5 Knowledge 6 7 Knowledge Duża ilość nieusystematyzowanych informacji... Knowledge
Knowledge Rozszerzenie funkcjonalności systemów wiki w oparciu o wtyczki i Prolog 9 stycznia 2009 Knowledge 1 Wstęp 2 3 4 5 Knowledge 6 7 Knowledge Duża ilość nieusystematyzowanych informacji... Knowledge
Semantyczne Wiki na przykładzie Semantic MediaWiki
 Semantyczne Wiki na przykładzie Semantic MediaWiki Technologie semantyczne i sieci społecznościowe# Agnieszka Ławrynowicz# 16.12.2013# (do przygotowania tych materiałów wykorzystałam częściowo prezentacje
Semantyczne Wiki na przykładzie Semantic MediaWiki Technologie semantyczne i sieci społecznościowe# Agnieszka Ławrynowicz# 16.12.2013# (do przygotowania tych materiałów wykorzystałam częściowo prezentacje
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe.
 Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Semantic Web. dr inż. Aleksander Smywiński-Pohl. Elektroniczne Przetwarzanie Informacji Konsultacje: czw , pokój 3.211
 RDF RDFS i OWL Linked Data Elektroniczne Przetwarzanie Informacji Konsultacje: czw. 14.00-15.30, pokój 3.211 RDF RDFS i OWL Linked Data Plan prezentacji RDF RDFS i OWL Linked Data RDF RDFS i OWL Linked
RDF RDFS i OWL Linked Data Elektroniczne Przetwarzanie Informacji Konsultacje: czw. 14.00-15.30, pokój 3.211 RDF RDFS i OWL Linked Data Plan prezentacji RDF RDFS i OWL Linked Data RDF RDFS i OWL Linked
Semantyczne Wiki! na przykładzie! Semantic MediaWiki!
 Semantyczne Wiki! na przykładzie! Semantic MediaWiki! Agnieszka Ławrynowicz" 7.12.2014" (do przygotowania tych materiałów wykorzystałam częściowo prezentacje z SMWcon Fall 2012-2013 w tym prezentację Introduction
Semantyczne Wiki! na przykładzie! Semantic MediaWiki! Agnieszka Ławrynowicz" 7.12.2014" (do przygotowania tych materiałów wykorzystałam częściowo prezentacje z SMWcon Fall 2012-2013 w tym prezentację Introduction
MODEL SYSTEMU WIELOAGENTOWEGO KORZYSTAJĄCEGO Z DANYCH SIECI SEMANTYCZNEJ W PROJEKCIE OPEN NATURA 2000
 JAKUB BILSKI E-mail: jakub@blsk.pl Katedra Inżynierii Komputerowej, Wydział Elektroniki i Informatyki Politechnika Koszalińska Śniadeckich 2, 75-453 Koszalin MODEL SYSTEMU WIELOAGENTOWEGO KORZYSTAJĄCEGO
JAKUB BILSKI E-mail: jakub@blsk.pl Katedra Inżynierii Komputerowej, Wydział Elektroniki i Informatyki Politechnika Koszalińska Śniadeckich 2, 75-453 Koszalin MODEL SYSTEMU WIELOAGENTOWEGO KORZYSTAJĄCEGO
Instytut Technik Innowacyjnych Semantyczna integracja danych - metody, technologie, przykłady, wyzwania
 Instytut Technik Innowacyjnych Semantyczna integracja danych - metody, technologie, przykłady, wyzwania Michał Socha, Wojciech Górka Integracja danych Prosty export/import Integracja 1:1 łączenie baz danych
Instytut Technik Innowacyjnych Semantyczna integracja danych - metody, technologie, przykłady, wyzwania Michał Socha, Wojciech Górka Integracja danych Prosty export/import Integracja 1:1 łączenie baz danych
Wprowadzenie do technologii semantycznych
 Wprowadzenie do technologii semantycznych Sieć Semantyczna Mikołaj Morzy Agnieszka Ławrynowicz Instytut Informatyki Poznań, rok akademicki 2013/2014 (c) Mikołaj Morzy, Agnieszka Ławrynowicz, Instytut Informatyki
Wprowadzenie do technologii semantycznych Sieć Semantyczna Mikołaj Morzy Agnieszka Ławrynowicz Instytut Informatyki Poznań, rok akademicki 2013/2014 (c) Mikołaj Morzy, Agnieszka Ławrynowicz, Instytut Informatyki
Czy (centralne) katalogi biblioteczne są jeszcze potrzebne? OPAC w infotopii. Dr hab. Marek Nahotko, ISI UJ
 katalogi biblioteczne są jeszcze potrzebne? OPAC w infotopii. Dr hab. Marek Nahotko, ISI UJ") Czy (centralne) katalogi biblioteczne są jeszcze potrzebne? OPAC w infotopii Dr hab. Marek Nahotko, ISI UJ 1 Współpraca bibliotek Cała niezbędna metainformacja funkcjonuje obecnie w formie elektronicznej
Czy (centralne) katalogi biblioteczne są jeszcze potrzebne? OPAC w infotopii Dr hab. Marek Nahotko, ISI UJ 1 Współpraca bibliotek Cała niezbędna metainformacja funkcjonuje obecnie w formie elektronicznej
Tomasz Grześ. Systemy zarządzania treścią
 Tomasz Grześ Systemy zarządzania treścią Co to jest CMS? CMS (ang. Content Management System System Zarządzania Treścią) CMS definicje TREŚĆ Dowolny rodzaj informacji cyfrowej. Może to być np. tekst, obraz,
Tomasz Grześ Systemy zarządzania treścią Co to jest CMS? CMS (ang. Content Management System System Zarządzania Treścią) CMS definicje TREŚĆ Dowolny rodzaj informacji cyfrowej. Może to być np. tekst, obraz,
NOWY PARADYGMAT PUBLIKACJI I WYSZUKIWANIA DANYCH PRZESTRZENNYCH W SIECI WWW
 NOWY PARADYGMAT PUBLIKACJI I WYSZUKIWANIA DANYCH PRZESTRZENNYCH W SIECI WWW dr Adam Iwaniak Filozof GIS XIII Podlaskie Forum GIS, 23-25 czerwca 2016, Supraśl DIGITAL DISRUPTION DIGITAL DISRUPTION Zakłócenia
NOWY PARADYGMAT PUBLIKACJI I WYSZUKIWANIA DANYCH PRZESTRZENNYCH W SIECI WWW dr Adam Iwaniak Filozof GIS XIII Podlaskie Forum GIS, 23-25 czerwca 2016, Supraśl DIGITAL DISRUPTION DIGITAL DISRUPTION Zakłócenia
Technologie cyfrowe. Artur Kalinowski. Zakład Cząstek i Oddziaływań Fundamentalnych Pasteura 5, pokój 4.15 Artur.Kalinowski@fuw.edu.
 Technologie cyfrowe Artur Kalinowski Zakład Cząstek i Oddziaływań Fundamentalnych Pasteura 5, pokój 4.15 Artur.Kalinowski@fuw.edu.pl Semestr letni 2014/2015 Usługi internetowe usługa internetowa (ang.
Technologie cyfrowe Artur Kalinowski Zakład Cząstek i Oddziaływań Fundamentalnych Pasteura 5, pokój 4.15 Artur.Kalinowski@fuw.edu.pl Semestr letni 2014/2015 Usługi internetowe usługa internetowa (ang.
1 XXIII Forum Teleinformatyki, września 2017 r.
 1 XXIII Forum Teleinformatyki, 28-29 września 2017 r. Dostęp do danych planistycznych z wykorzystaniem usług danych przestrzennych województwa mazowieckiego KRZYSZTOF MĄCZEWSKI Geodeta Województwa Dyrektor
1 XXIII Forum Teleinformatyki, 28-29 września 2017 r. Dostęp do danych planistycznych z wykorzystaniem usług danych przestrzennych województwa mazowieckiego KRZYSZTOF MĄCZEWSKI Geodeta Województwa Dyrektor
Opracowywanie map w ArcGIS Online i MS Office. Urszula Kwiecień Esri Polska
 Opracowywanie map w ArcGIS Online i MS Office Urszula Kwiecień Esri Polska Agenda ArcGIS Online - filozofia tworzenia map w chmurze Wizualizacja danych tabelarycznych w MS Excel Opracowanie mapy w MS Excel
Opracowywanie map w ArcGIS Online i MS Office Urszula Kwiecień Esri Polska Agenda ArcGIS Online - filozofia tworzenia map w chmurze Wizualizacja danych tabelarycznych w MS Excel Opracowanie mapy w MS Excel
Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych
 Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych dr inż. Adam Iwaniak Infrastruktura Danych Przestrzennych w Polsce i Europie Seminarium, AR Wrocław
Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych dr inż. Adam Iwaniak Infrastruktura Danych Przestrzennych w Polsce i Europie Seminarium, AR Wrocław
Słowem wstępu. Część rodziny języków XSL. Standard: W3C XSLT razem XPath 1.0 XSLT Trwają prace nad XSLT 3.0
 Słowem wstępu Część rodziny języków XSL Standard: W3C XSLT 1.0-1999 razem XPath 1.0 XSLT 2.0-2007 Trwają prace nad XSLT 3.0 Problem Zakładane przez XML usunięcie danych dotyczących prezentacji pociąga
Słowem wstępu Część rodziny języków XSL Standard: W3C XSLT 1.0-1999 razem XPath 1.0 XSLT 2.0-2007 Trwają prace nad XSLT 3.0 Problem Zakładane przez XML usunięcie danych dotyczących prezentacji pociąga
dlibra 3.0 Marcin Heliński
 dlibra 3.0 Marcin Heliński Plan prezentacji Wstęp Aplikacja Redaktora / Administratora Serwer Aplikacja Czytelnika Aktualizator Udostępnienie API NajwaŜniejsze w nowej wersji Ulepszenie interfejsu uŝytkownika
dlibra 3.0 Marcin Heliński Plan prezentacji Wstęp Aplikacja Redaktora / Administratora Serwer Aplikacja Czytelnika Aktualizator Udostępnienie API NajwaŜniejsze w nowej wersji Ulepszenie interfejsu uŝytkownika
The Binder Consulting
 The Binder Consulting Contents Indywidualne szkolenia specjalistyczne...3 Konsultacje dla tworzenia rozwiazan mobilnych... 3 Dedykowane rozwiazania informatyczne... 3 Konsultacje i wdrożenie mechanizmów
The Binder Consulting Contents Indywidualne szkolenia specjalistyczne...3 Konsultacje dla tworzenia rozwiazan mobilnych... 3 Dedykowane rozwiazania informatyczne... 3 Konsultacje i wdrożenie mechanizmów
Diagramy związków encji. Laboratorium. Akademia Morska w Gdyni
 Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
Wykład I. Wprowadzenie do baz danych
 Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Język RDF. Mikołaj Morzy Agnieszka Ławrynowicz. Instytut Informatyki Poznań, rok akademicki 2013/2014
 Język RDF Mikołaj Morzy Agnieszka Ławrynowicz Instytut Informatyki Poznań, rok akademicki 2013/2014 (c) Mikołaj Morzy, Agnieszka Ławrynowicz, Instytut Informatyki Politechniki Poznańskiej TSiSS 1 Sieci
Język RDF Mikołaj Morzy Agnieszka Ławrynowicz Instytut Informatyki Poznań, rok akademicki 2013/2014 (c) Mikołaj Morzy, Agnieszka Ławrynowicz, Instytut Informatyki Politechniki Poznańskiej TSiSS 1 Sieci
Przetwarzanie języka naturalnego (NLP)
") Przetwarzanie języka naturalnego (NLP) NLP jest dziedziną informatyki łączącą zagadnienia sztucznej inteligencji i lingwistyki zajmującą się automatyzacją analizy, rozumienia, tłumaczenia i generowania
Przetwarzanie języka naturalnego (NLP) NLP jest dziedziną informatyki łączącą zagadnienia sztucznej inteligencji i lingwistyki zajmującą się automatyzacją analizy, rozumienia, tłumaczenia i generowania
serwisy W*S ERDAS APOLLO 2009
 serwisy W*S ERDAS APOLLO 2009 1 OGC (Open Geospatial Consortium, Inc) OGC jest międzynarodowym konsorcjum 382 firm prywatnych, agencji rządowych oraz uniwersytetów, które nawiązały współpracę w celu rozwijania
serwisy W*S ERDAS APOLLO 2009 1 OGC (Open Geospatial Consortium, Inc) OGC jest międzynarodowym konsorcjum 382 firm prywatnych, agencji rządowych oraz uniwersytetów, które nawiązały współpracę w celu rozwijania
Facelets ViewHandler
 JSF i Facelets Wprowadzenie JSP (JavaServer Pages) są natywną i najczęściej używaną technologią do tworzenia warstwy prezentacyjnej dla JSF (JavaServer Faces) Istnieją alternatywne technologie opisu wyglądu
JSF i Facelets Wprowadzenie JSP (JavaServer Pages) są natywną i najczęściej używaną technologią do tworzenia warstwy prezentacyjnej dla JSF (JavaServer Faces) Istnieją alternatywne technologie opisu wyglądu
Wszystko na temat wzoru dokumentu elektronicznego
 Stowarzyszenie PEMI Wszystko na temat wzoru dokumentu elektronicznego Czym jest, kto go tworzy, kto publikuje, kto może z niego skorzystać? Mirosław Januszewski, Tomasz Rakoczy, Andrzej Matejko 2007-07-25
Stowarzyszenie PEMI Wszystko na temat wzoru dokumentu elektronicznego Czym jest, kto go tworzy, kto publikuje, kto może z niego skorzystać? Mirosław Januszewski, Tomasz Rakoczy, Andrzej Matejko 2007-07-25
2 Podstawy tworzenia stron internetowych
 2 Podstawy tworzenia stron internetowych 2.1. HTML5 i struktura dokumentu Podstawą działania wszystkich stron internetowych jest język HTML (Hypertext Markup Language) hipertekstowy język znaczników. Dokument
2 Podstawy tworzenia stron internetowych 2.1. HTML5 i struktura dokumentu Podstawą działania wszystkich stron internetowych jest język HTML (Hypertext Markup Language) hipertekstowy język znaczników. Dokument
INFORMATYKA Pytania ogólne na egzamin dyplomowy
 INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja
INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja
 Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
INNOWACYJNE METODY UDOSTĘPNIANIA PUBLICZNYCH DANYCH PRZESTRZENNYCH
 INNOWACYJNE METODY UDOSTĘPNIANIA PUBLICZNYCH DANYCH PRZESTRZENNYCH Dr inż. Adam Iwaniak Uniwersytet Przyrodniczy we Wrocławiu Wrocławskiego Instytutu Zastosowań Informacji Przestrzennej i Sztucznej Inteligencji
INNOWACYJNE METODY UDOSTĘPNIANIA PUBLICZNYCH DANYCH PRZESTRZENNYCH Dr inż. Adam Iwaniak Uniwersytet Przyrodniczy we Wrocławiu Wrocławskiego Instytutu Zastosowań Informacji Przestrzennej i Sztucznej Inteligencji
Programowanie internetowe
 Programowanie internetowe Wykład 1 HTML mgr inż. Michał Wojtera email: mwojtera@dmcs.pl Plan wykładu Organizacja zajęć Zakres przedmiotu Literatura Zawartość wykładu Wprowadzenie AMP / LAMP Podstawy HTML
Programowanie internetowe Wykład 1 HTML mgr inż. Michał Wojtera email: mwojtera@dmcs.pl Plan wykładu Organizacja zajęć Zakres przedmiotu Literatura Zawartość wykładu Wprowadzenie AMP / LAMP Podstawy HTML
Reporting Services. WinProg 2011/2012. Krzysztof Jeliński Dawid Gawroński 1 / 11
 Reporting Services WinProg 2011/2012 Krzysztof Jeliński Dawid Gawroński 1 / 11 1. SSRS SQL Server Reporting Services SQL Server Reporting Services udostępnia pełen zakres gotowych do użycia narzędzi i
Reporting Services WinProg 2011/2012 Krzysztof Jeliński Dawid Gawroński 1 / 11 1. SSRS SQL Server Reporting Services SQL Server Reporting Services udostępnia pełen zakres gotowych do użycia narzędzi i
Steganografia w HTML. Łukasz Polak
 Steganografia w HTML Łukasz Polak Plan prezentacji Co to jest steganografia? Historia i współczesność Rodzaje steganografii HTML język znaczników Możliwości zastosowania steganografii w HTML Steganografia
Steganografia w HTML Łukasz Polak Plan prezentacji Co to jest steganografia? Historia i współczesność Rodzaje steganografii HTML język znaczników Możliwości zastosowania steganografii w HTML Steganografia
RFP. Wymagania dla projektu. sklepu internetowego B2C dla firmy Oplot
 RFP Wymagania dla projektu sklepu internetowego B2C dla firmy Oplot CEL DOKUMENTU Celem niniejszego dokumentu jest przedstawienie wymagań technicznych i funkcjonalnych wobec realizacji projektu budowy
RFP Wymagania dla projektu sklepu internetowego B2C dla firmy Oplot CEL DOKUMENTU Celem niniejszego dokumentu jest przedstawienie wymagań technicznych i funkcjonalnych wobec realizacji projektu budowy
Model semistrukturalny
 Model semistrukturalny standaryzacja danych z różnych źródeł realizacja złożonej struktury zależności, wielokrotne zagnieżdżania zobrazowane przez grafy skierowane model samoopisujący się wielkości i typy
Model semistrukturalny standaryzacja danych z różnych źródeł realizacja złożonej struktury zależności, wielokrotne zagnieżdżania zobrazowane przez grafy skierowane model samoopisujący się wielkości i typy
ZMIANA PARADYGMATU W WYKORZYSTANIA DANYCH I INFORMACJI PRZESTRZENNYCH W BUDOWIE SPOŁECZEŃSTWA OPARTEGO NA WIEDZY
 ZMIANA PARADYGMATU W WYKORZYSTANIA DANYCH I INFORMACJI PRZESTRZENNYCH W BUDOWIE SPOŁECZEŃSTWA OPARTEGO NA WIEDZY Adam Iwaniak Wrocławski Instytut Zastosowań Informacji Przestrzennej i Sztucznej Inteligencji
ZMIANA PARADYGMATU W WYKORZYSTANIA DANYCH I INFORMACJI PRZESTRZENNYCH W BUDOWIE SPOŁECZEŃSTWA OPARTEGO NA WIEDZY Adam Iwaniak Wrocławski Instytut Zastosowań Informacji Przestrzennej i Sztucznej Inteligencji
Upowszechnianie dorobku naukowego w repozytoriach i bazach danych działania komplementarne czy konkurencyjne?
 Upowszechnianie dorobku naukowego w repozytoriach i bazach danych działania komplementarne czy konkurencyjne? Małgorzata Rychlik Biblioteka Uniwersytecka w Poznaniu Bibliograficzne bazy danych : perspektywy
Upowszechnianie dorobku naukowego w repozytoriach i bazach danych działania komplementarne czy konkurencyjne? Małgorzata Rychlik Biblioteka Uniwersytecka w Poznaniu Bibliograficzne bazy danych : perspektywy
Język zapytań SPARQL. Agnieszka Ławrynowicz. Instytut Informatyki Politechniki Poznańskiej Poznań, 2014
 Język zapytań SPARQL Agnieszka Ławrynowicz Instytut Informatyki Politechniki Poznańskiej Poznań, 2014 Język zapytań SPARQL Stos języków Sieci Semantycznej Turtle Turtle$(Terse$RDF$Triple$Language$):$$
Język zapytań SPARQL Agnieszka Ławrynowicz Instytut Informatyki Politechniki Poznańskiej Poznań, 2014 Język zapytań SPARQL Stos języków Sieci Semantycznej Turtle Turtle$(Terse$RDF$Triple$Language$):$$
Open Acces Otwarty dostęp
 Open Acces Otwarty dostęp Open Acces Otwarty dostęp do treści naukowych zakłada: swobodny dostęp w internecie, każdy użytkownik może je zapisywać na dysku komputera lub innym nośniku danych, kopiować,
Open Acces Otwarty dostęp Open Acces Otwarty dostęp do treści naukowych zakłada: swobodny dostęp w internecie, każdy użytkownik może je zapisywać na dysku komputera lub innym nośniku danych, kopiować,
Tomasz Boiński: 1. Pozycjonowanie stron i zastosowanie mod_rewrite
 Tomasz Boiński: 1 Pozycjonowanie stron i zastosowanie mod_rewrite Pozycjonowanie stron Promocja strony odbywa się poprzez umiejscowienie jej jak najwyżej w wynikach wyszukiwania Wyszukiwarki indeksują
Tomasz Boiński: 1 Pozycjonowanie stron i zastosowanie mod_rewrite Pozycjonowanie stron Promocja strony odbywa się poprzez umiejscowienie jej jak najwyżej w wynikach wyszukiwania Wyszukiwarki indeksują
Oracle11g: Wprowadzenie do SQL
 Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Badanie struktury sieci WWW
 Eksploracja zasobów internetowych Wykład 1 Badanie struktury sieci WWW mgr inż. Maciej Kopczyński Białystok 214 Rys historyczny Idea sieci Web stworzona została w 1989 przez Tima BernersaLee z CERN jako
Eksploracja zasobów internetowych Wykład 1 Badanie struktury sieci WWW mgr inż. Maciej Kopczyński Białystok 214 Rys historyczny Idea sieci Web stworzona została w 1989 przez Tima BernersaLee z CERN jako
2
 1 2 3 4 5 Dużo pisze się i słyszy o projektach wdrożeń systemów zarządzania wiedzą, które nie przyniosły oczekiwanych rezultatów, bo mało kto korzystał z tych systemów. Technologia nie jest bowiem lekarstwem
1 2 3 4 5 Dużo pisze się i słyszy o projektach wdrożeń systemów zarządzania wiedzą, które nie przyniosły oczekiwanych rezultatów, bo mało kto korzystał z tych systemów. Technologia nie jest bowiem lekarstwem
Usługi analityczne budowa kostki analitycznej Część pierwsza.
 Usługi analityczne budowa kostki analitycznej Część pierwsza. Wprowadzenie W wielu dziedzinach działalności człowieka analiza zebranych danych jest jednym z najważniejszych mechanizmów podejmowania decyzji.
Usługi analityczne budowa kostki analitycznej Część pierwsza. Wprowadzenie W wielu dziedzinach działalności człowieka analiza zebranych danych jest jednym z najważniejszych mechanizmów podejmowania decyzji.
Klasyfikacja informacji naukowych w Internecie na przykładzie stron poświęconych kulturze antycznej
 Klasyfikacja informacji naukowych w Internecie na przykładzie stron poświęconych kulturze antycznej Katowice, 15 grudnia 2010 2 Informacja w kontekście projektu i marketingu L. Rosenfeld, P. Morville,
Klasyfikacja informacji naukowych w Internecie na przykładzie stron poświęconych kulturze antycznej Katowice, 15 grudnia 2010 2 Informacja w kontekście projektu i marketingu L. Rosenfeld, P. Morville,
REFERAT O PRACY DYPLOMOWEJ
 REFERAT O PRACY DYPLOMOWEJ Temat pracy: Projekt i implementacja mobilnego systemu wspomagającego organizowanie zespołowej aktywności fizycznej Autor: Krzysztof Salamon W dzisiejszych czasach życie ludzi
REFERAT O PRACY DYPLOMOWEJ Temat pracy: Projekt i implementacja mobilnego systemu wspomagającego organizowanie zespołowej aktywności fizycznej Autor: Krzysztof Salamon W dzisiejszych czasach życie ludzi
E.14.1 Tworzenie stron internetowych / Krzysztof T. Czarkowski, Ilona Nowosad. Warszawa, Spis treści
 E.14.1 Tworzenie stron internetowych / Krzysztof T. Czarkowski, Ilona Nowosad. Warszawa, 2014 Spis treści Przewodnik po podręczniku 8 Wstęp 10 1. Hipertekstowe języki znaczników 1.1. Elementy i znaczniki
E.14.1 Tworzenie stron internetowych / Krzysztof T. Czarkowski, Ilona Nowosad. Warszawa, 2014 Spis treści Przewodnik po podręczniku 8 Wstęp 10 1. Hipertekstowe języki znaczników 1.1. Elementy i znaczniki
1 Wprowadzenie do J2EE
 Wprowadzenie do J2EE 1 Plan prezentacji 2 Wprowadzenie do Java 2 Enterprise Edition Aplikacje J2EE Serwer aplikacji J2EE Główne cele V Szkoły PLOUG - nowe podejścia do konstrukcji aplikacji J2EE Java 2
Wprowadzenie do J2EE 1 Plan prezentacji 2 Wprowadzenie do Java 2 Enterprise Edition Aplikacje J2EE Serwer aplikacji J2EE Główne cele V Szkoły PLOUG - nowe podejścia do konstrukcji aplikacji J2EE Java 2
XHTML - Extensible Hypertext Markup Language, czyli Rozszerzalny Hipertekstowy Język Oznaczania.
 XHTML - Extensible Hypertext Markup Language, czyli Rozszerzalny Hipertekstowy Język Oznaczania. Reformuje on znane zasady języka HTML 4 w taki sposób, aby były zgodne z XML (HTML przetłumaczony na XML).
XHTML - Extensible Hypertext Markup Language, czyli Rozszerzalny Hipertekstowy Język Oznaczania. Reformuje on znane zasady języka HTML 4 w taki sposób, aby były zgodne z XML (HTML przetłumaczony na XML).
Czytelnik w bibliotece cyfrowej
 Czytelnik w bibliotece cyfrowej Adam Dudczak Poznańskie Centrum Superkomputerowo-Sieciowe IV Warsztaty Biblioteki Cyfrowe Poznań, 2007 Do czego służy Aplikacja Czytelnika? Udostępnianie zasobów cyfrowych
Czytelnik w bibliotece cyfrowej Adam Dudczak Poznańskie Centrum Superkomputerowo-Sieciowe IV Warsztaty Biblioteki Cyfrowe Poznań, 2007 Do czego służy Aplikacja Czytelnika? Udostępnianie zasobów cyfrowych
Ontologie, czyli o inteligentnych danych
 1 Ontologie, czyli o inteligentnych danych Bożena Deka Andrzej Tolarczyk PLAN 2 1. Korzenie filozoficzne 2. Ontologia w informatyce Ontologie a bazy danych Sieć Semantyczna Inteligentne dane 3. Zastosowania
1 Ontologie, czyli o inteligentnych danych Bożena Deka Andrzej Tolarczyk PLAN 2 1. Korzenie filozoficzne 2. Ontologia w informatyce Ontologie a bazy danych Sieć Semantyczna Inteligentne dane 3. Zastosowania
REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i realizacja serwisu ogłoszeń z inteligentną wyszukiwarką
 REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i realizacja serwisu ogłoszeń z inteligentną wyszukiwarką Autor: Paweł Konieczny Promotor: dr Jadwigi Bakonyi Kategorie: aplikacja www Słowa kluczowe: Serwis
REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i realizacja serwisu ogłoszeń z inteligentną wyszukiwarką Autor: Paweł Konieczny Promotor: dr Jadwigi Bakonyi Kategorie: aplikacja www Słowa kluczowe: Serwis
Marcin Heliński, Cezary Mazurek, Tomasz Parkoła, Marcin Werla
 Biblioteka cyfrowa jako otwarte, internetowe repozytorium publikacji Marcin Heliński, Cezary Mazurek, Tomasz Parkoła, Marcin Werla Poznańskie Centrum Superkomputerowo-Sieciowe Biblioteka cyfrowa Podstawowe
Biblioteka cyfrowa jako otwarte, internetowe repozytorium publikacji Marcin Heliński, Cezary Mazurek, Tomasz Parkoła, Marcin Werla Poznańskie Centrum Superkomputerowo-Sieciowe Biblioteka cyfrowa Podstawowe
Optymalizacja logo strony. Krok po kroku... Spis treści
 Spis treści Optymalizacja logo strony Krok po kroku... Dlaczego warto optymalizować logo strony? Jak optymalizować logo? - Krok 1 - Umieszczenie kodu logo na stronie. - Krok 2 - Dodawanie atrybutu title
Spis treści Optymalizacja logo strony Krok po kroku... Dlaczego warto optymalizować logo strony? Jak optymalizować logo? - Krok 1 - Umieszczenie kodu logo na stronie. - Krok 2 - Dodawanie atrybutu title
Podstawy (X)HTML i CSS
HTML i CSS") Inżynierskie podejście do budowania stron WWW momat@man.poznan.pl 2005-04-11 1 Hyper Text Markup Language Standardy W3C Przegląd znaczników Przegląd znaczników XHTML 2 Cascading Style Sheets Łączenie z
Inżynierskie podejście do budowania stron WWW momat@man.poznan.pl 2005-04-11 1 Hyper Text Markup Language Standardy W3C Przegląd znaczników Przegląd znaczników XHTML 2 Cascading Style Sheets Łączenie z
XML w bazach danych i bezpieczeństwie
 XML w bazach danych i bezpieczeństwie Patryk Czarnik Instytut Informatyki UW XML i nowoczesne technologie zarzadzania treścia 2007/08 Klasyfikacja wsparcia dla XML-a w bazach danych (Relacyjna) baza danych
XML w bazach danych i bezpieczeństwie Patryk Czarnik Instytut Informatyki UW XML i nowoczesne technologie zarzadzania treścia 2007/08 Klasyfikacja wsparcia dla XML-a w bazach danych (Relacyjna) baza danych
Internet Semantyczny. Idea
 Internet Semantyczny Idea Marcin Skulimowski, Wydział Fizyki i Informatyki Stosowanej, Uniwersytet Łódzki 2012 Internet (dosł. międzysieć; od ang. inter między i ang. net sieć) to sieć komputerowa o światowym
Internet Semantyczny Idea Marcin Skulimowski, Wydział Fizyki i Informatyki Stosowanej, Uniwersytet Łódzki 2012 Internet (dosł. międzysieć; od ang. inter między i ang. net sieć) to sieć komputerowa o światowym
Monitoring procesów z wykorzystaniem systemu ADONIS
 Monitoring procesów z wykorzystaniem systemu ADONIS BOC Information Technologies Consulting Sp. z o.o. e-mail: boc@boc-pl.com Tel.: (+48 22) 628 00 15, 696 69 26 Fax: (+48 22) 621 66 88 BOC Management
Monitoring procesów z wykorzystaniem systemu ADONIS BOC Information Technologies Consulting Sp. z o.o. e-mail: boc@boc-pl.com Tel.: (+48 22) 628 00 15, 696 69 26 Fax: (+48 22) 621 66 88 BOC Management
5-6. Struktura dokumentu html. 2 Określenie charakteru i tematyki strony. Rodzaje witryn. Projekt graficzny witryny. Opracowanie skryptów
 Aplikacje internetowe KL. III Rok szkolny: 013/01 Nr programu: 31[01]/T,SP/MENIS/00.06.1 Okres kształcenia: łącznie ok. 170 godz. lekcyjne Moduł Bok wprowadzający 1. Zapoznanie z programem nauczania i
Aplikacje internetowe KL. III Rok szkolny: 013/01 Nr programu: 31[01]/T,SP/MENIS/00.06.1 Okres kształcenia: łącznie ok. 170 godz. lekcyjne Moduł Bok wprowadzający 1. Zapoznanie z programem nauczania i
Szkolenie autoryzowane. MS Zaawansowany użytkownik programu SharePoint 2016
 Szkolenie autoryzowane MS 55217 Zaawansowany użytkownik programu SharePoint 2016 Strona szkolenia Terminy szkolenia Rejestracja na szkolenie Promocje Opis szkolenia Szkolenie przeznaczone jest dla zaawansowanych
Szkolenie autoryzowane MS 55217 Zaawansowany użytkownik programu SharePoint 2016 Strona szkolenia Terminy szkolenia Rejestracja na szkolenie Promocje Opis szkolenia Szkolenie przeznaczone jest dla zaawansowanych
AUTOMATYKA INFORMATYKA
 AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
#1 Wartościowa treść. #2 Słowa kluczowe. #3 Adresy URL
 #1 Wartościowa treść Treść artykułu powinna być unikatowa (algorytm wyszukiwarki nisko ocenia skopiowaną zawartość, a na strony zawierające powtórzoną treść może zostać nałożony filtr, co skutkuje spadkiem
#1 Wartościowa treść Treść artykułu powinna być unikatowa (algorytm wyszukiwarki nisko ocenia skopiowaną zawartość, a na strony zawierające powtórzoną treść może zostać nałożony filtr, co skutkuje spadkiem
Paweł Rajba pawel@ii.uni.wroc.pl http://www.itcourses.eu/
 Paweł Rajba pawel@ii.uni.wroc.pl http://www.itcourses.eu/ Wprowadzenie WCF Data Services Obsługa żądania OData Podstawy języka OData Narzędzia i biblioteki Gdzie można skorzystać z OData OData w Web API
Paweł Rajba pawel@ii.uni.wroc.pl http://www.itcourses.eu/ Wprowadzenie WCF Data Services Obsługa żądania OData Podstawy języka OData Narzędzia i biblioteki Gdzie można skorzystać z OData OData w Web API
OPIS PRZEDMIOTU ZAMÓWIENIA
 Lubelskie Centrum Transferu Technologii Politechniki Lubelskiej ul. Nadbystrzycka 36, 20-618 Lublin Tel. 81 538 42 70, fax. 81 538 42 67; e-mail: lctt@pollub.pl OPIS PRZEDMIOTU ZAMÓWIENIA Do realizacji
Lubelskie Centrum Transferu Technologii Politechniki Lubelskiej ul. Nadbystrzycka 36, 20-618 Lublin Tel. 81 538 42 70, fax. 81 538 42 67; e-mail: lctt@pollub.pl OPIS PRZEDMIOTU ZAMÓWIENIA Do realizacji
Specyfikacja techniczna dot. mailingów HTML
 Specyfikacja techniczna dot. mailingów HTML Informacje wstępne Wszystkie składniki mailingu (pliki graficzne, teksty, pliki HTML) muszą być przekazane do melog.com dwa dni albo maksymalnie dzień wcześniej
Specyfikacja techniczna dot. mailingów HTML Informacje wstępne Wszystkie składniki mailingu (pliki graficzne, teksty, pliki HTML) muszą być przekazane do melog.com dwa dni albo maksymalnie dzień wcześniej
Przykłady zastosowao rozwiązao typu mapserver w Jednostkach Samorządu Terytorialnego
 Przykłady zastosowao rozwiązao typu mapserver w Jednostkach Samorządu Terytorialnego Plan prezentacji Wprowadzenie Czym jest serwer danych przestrzennych i na czym polega jego działanie? Miejsce serwera
Przykłady zastosowao rozwiązao typu mapserver w Jednostkach Samorządu Terytorialnego Plan prezentacji Wprowadzenie Czym jest serwer danych przestrzennych i na czym polega jego działanie? Miejsce serwera
ActiveXperts SMS Messaging Server
 ActiveXperts SMS Messaging Server ActiveXperts SMS Messaging Server to oprogramowanie typu framework dedykowane wysyłaniu, odbieraniu oraz przetwarzaniu wiadomości SMS i e-mail, a także tworzeniu własnych
ActiveXperts SMS Messaging Server ActiveXperts SMS Messaging Server to oprogramowanie typu framework dedykowane wysyłaniu, odbieraniu oraz przetwarzaniu wiadomości SMS i e-mail, a także tworzeniu własnych
AUDYT DOSTĘPNOŚCI STRONY INTERNETOWEJ
 Poznań, 2012-10-04 AUDYT DOSTĘPNOŚCI STRONY INTERNETOWEJ NAZWA ADRES STRONY ILOŚĆ BŁĘDÓW WCAG 33 ILOŚĆ OSTRZEŻEŃ WCAG 3 TYP DOKUMENTU UŻYTY FORMAT (X)HTML JĘZYK OWANIE STRONY Urząd Marszałkowski Województwa
Poznań, 2012-10-04 AUDYT DOSTĘPNOŚCI STRONY INTERNETOWEJ NAZWA ADRES STRONY ILOŚĆ BŁĘDÓW WCAG 33 ILOŚĆ OSTRZEŻEŃ WCAG 3 TYP DOKUMENTU UŻYTY FORMAT (X)HTML JĘZYK OWANIE STRONY Urząd Marszałkowski Województwa
XML w bazach danych, standardy wiążące dokumenty XML
 XML w bazach danych, standardy wiążące dokumenty XML Patryk Czarnik Instytut Informatyki UW XML i nowoczesne technologie zarządzania treścią 2008/09 Walidacja względem DTD podczas parsowania SAXParserFactory
XML w bazach danych, standardy wiążące dokumenty XML Patryk Czarnik Instytut Informatyki UW XML i nowoczesne technologie zarządzania treścią 2008/09 Walidacja względem DTD podczas parsowania SAXParserFactory
Zakres treści Czas. 2 Określenie charakteru i tematyki strony. Rodzaje witryn. Projekt graficzny witryny. Opracowanie skryptów
 Aplikacje internetowe KL. III Rok szkolny: 011/01 Nr programu: 31[01]/T,SP/MENIS/004.06.14 Okres kształcenia: łącznie ok. 180 godz. lekcyjne Wojciech Borzyszkowski Zenon Kreft Moduł Bok wprowadzający Podstawy
Aplikacje internetowe KL. III Rok szkolny: 011/01 Nr programu: 31[01]/T,SP/MENIS/004.06.14 Okres kształcenia: łącznie ok. 180 godz. lekcyjne Wojciech Borzyszkowski Zenon Kreft Moduł Bok wprowadzający Podstawy
Nazwa biblioteki (w języku oryginalnym) National Library of Scotland Biblioteka Narodowa Szkocji
 National Library of Scotland Biblioteka Narodowa Szkocji") 1 Nazwa biblioteki (w języku oryginalnym) National Library of Scotland Biblioteka Narodowa Szkocji http://www.nls.uk/digitallibrary/index.html 1. Zawartość The National Library of Scotland jest największą
1 Nazwa biblioteki (w języku oryginalnym) National Library of Scotland Biblioteka Narodowa Szkocji http://www.nls.uk/digitallibrary/index.html 1. Zawartość The National Library of Scotland jest największą
Uniwersytet Łódzki Wydział Matematyki i Informatyki, Katedra Analizy Nieliniowej. Wstęp. Programowanie w Javie 2. mgr inż.
 Uniwersytet Łódzki Wydział Matematyki i Informatyki, Katedra Analizy Nieliniowej Wstęp Programowanie w Javie 2 mgr inż. Michał Misiak Agenda Założenia do wykładu Zasady zaliczeń Ramowy program wykładu
Uniwersytet Łódzki Wydział Matematyki i Informatyki, Katedra Analizy Nieliniowej Wstęp Programowanie w Javie 2 mgr inż. Michał Misiak Agenda Założenia do wykładu Zasady zaliczeń Ramowy program wykładu
RDF Schema (schematy RDF)
") RDF Schema (schematy RDF) Schemat RDF nie dostarcza słownictwa dla aplikacji klasy jak np.: Namiot, Książka, lub Osoba; i właściwości, takich jak np.: waga w kg, autor lub jobtitle Schemat RDF zapewnia
RDF Schema (schematy RDF) Schemat RDF nie dostarcza słownictwa dla aplikacji klasy jak np.: Namiot, Książka, lub Osoba; i właściwości, takich jak np.: waga w kg, autor lub jobtitle Schemat RDF zapewnia
Wprowadzenie do multimedialnych baz danych. Opracował: dr inż. Piotr Suchomski
 Wprowadzenie do multimedialnych baz danych Opracował: dr inż. Piotr Suchomski Wprowadzenie bazy danych Multimedialne bazy danych to takie bazy danych, w których danymi mogą być tekst, zdjęcia, grafika,
Wprowadzenie do multimedialnych baz danych Opracował: dr inż. Piotr Suchomski Wprowadzenie bazy danych Multimedialne bazy danych to takie bazy danych, w których danymi mogą być tekst, zdjęcia, grafika,
CMS, CRM, sklepy internetowe, aplikacje Web
 CMS, CRM, sklepy internetowe, aplikacje Web Aplikacje PHP, open source, dodatki Add-ins, templatki, moduły na zamówienie Aplikacje mobilne jquery Mobile + PhoneGap Kilka platform w cenie jednego kodu JavaScript!
CMS, CRM, sklepy internetowe, aplikacje Web Aplikacje PHP, open source, dodatki Add-ins, templatki, moduły na zamówienie Aplikacje mobilne jquery Mobile + PhoneGap Kilka platform w cenie jednego kodu JavaScript!
4. Jak połączyć profil autora w bazie Scopus z identyfikatorem ORCID. 5. Jak połączyć ResearcherID (Web of Science) z identyfikatorem ORCID
 z identyfikatorem ORCID") Identyfikator Plan wystąpienia: 1. Dlaczego ORCID 2. Co to jest ORCID 3. ORCID jak założyć profil 4. Jak połączyć profil autora w bazie Scopus z identyfikatorem ORCID 5. Jak połączyć ResearcherID (Web
Identyfikator Plan wystąpienia: 1. Dlaczego ORCID 2. Co to jest ORCID 3. ORCID jak założyć profil 4. Jak połączyć profil autora w bazie Scopus z identyfikatorem ORCID 5. Jak połączyć ResearcherID (Web
I. KARTA PRZEDMIOTU CEL PRZEDMIOTU
 I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Informatyka
I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Informatyka
STANDARDY SIECI SEMANTYCZNEJ W ZARZĄDZANIU WIEDZĄ ORGANIZACJI
 ZESZYTY NAUKOWE UNIWERSYTETU SZCZECIŃSKIEGO NR 541 STUDIA INFORMATICA NR 23 2009 ILONA PAWEŁOSZEK-KOREK Politechnika Częstochowska STANDARDY SIECI SEMANTYCZNEJ W ZARZĄDZANIU WIEDZĄ ORGANIZACJI Wprowadzenie
ZESZYTY NAUKOWE UNIWERSYTETU SZCZECIŃSKIEGO NR 541 STUDIA INFORMATICA NR 23 2009 ILONA PAWEŁOSZEK-KOREK Politechnika Częstochowska STANDARDY SIECI SEMANTYCZNEJ W ZARZĄDZANIU WIEDZĄ ORGANIZACJI Wprowadzenie
Projekt i implementacja systemu wspomagania planowania w języku Prolog
 Projekt i implementacja systemu wspomagania planowania w języku Prolog Kraków, 29 maja 2007 Plan prezentacji 1 Wstęp Czym jest planowanie? Charakterystyka procesu planowania 2 Przeglad istniejacych rozwiazań
Projekt i implementacja systemu wspomagania planowania w języku Prolog Kraków, 29 maja 2007 Plan prezentacji 1 Wstęp Czym jest planowanie? Charakterystyka procesu planowania 2 Przeglad istniejacych rozwiazań
Kartografia multimedialna krótki opis projektu. Paweł J. Kowalski
 Kartografia multimedialna krótki opis projektu Paweł J. Kowalski Copyright Paweł J. Kowalski 2008 1. Schemat realizacji projektu 2 Celem projektu wykonywanego w ramach ćwiczeń z kartografii multimedialnej
Kartografia multimedialna krótki opis projektu Paweł J. Kowalski Copyright Paweł J. Kowalski 2008 1. Schemat realizacji projektu 2 Celem projektu wykonywanego w ramach ćwiczeń z kartografii multimedialnej
OPEN. Stałe identyfikatory URI tworzenie i zarządzanie. Metadane prezentacji SUPPORT. Moduł szkoleniowy 2.3 DATA
 Metadane prezentacji OPEN DATA SUPPORT Projekt Open Data Support jest finansowany przez Komisję Europejską w ramach umowy SMART 2012/0107 Część 2: Świadczenie usług na rzecz publikacji, udostępniania i
Metadane prezentacji OPEN DATA SUPPORT Projekt Open Data Support jest finansowany przez Komisję Europejską w ramach umowy SMART 2012/0107 Część 2: Świadczenie usług na rzecz publikacji, udostępniania i
Shapefile, GeoPackage czy PostGIS. Marta Woławczyk (QGIS Polska)
") Shapefile, GeoPackage czy PostGIS Marta Woławczyk (QGIS Polska) Shapefile Format plików przechowywujących dane wektorowe (punkty, linie, poligony) opracowany przez firmę ESRI w 1998 roku. Składa się z
Shapefile, GeoPackage czy PostGIS Marta Woławczyk (QGIS Polska) Shapefile Format plików przechowywujących dane wektorowe (punkty, linie, poligony) opracowany przez firmę ESRI w 1998 roku. Składa się z
Spis treści. Dzień 1. I Wprowadzenie (wersja 0906) II Dostęp do danych bieżących specyfikacja OPC Data Access (wersja 0906) Kurs OPC S7
 II Dostęp do danych bieżących specyfikacja OPC Data Access (wersja 0906) Kurs OPC S7") I Wprowadzenie (wersja 0906) Kurs OPC S7 Spis treści Dzień 1 I-3 O czym będziemy mówić? I-4 Typowe sytuacje I-5 Klasyczne podejście do komunikacji z urządzeniami automatyki I-6 Cechy podejścia dedykowanego
I Wprowadzenie (wersja 0906) Kurs OPC S7 Spis treści Dzień 1 I-3 O czym będziemy mówić? I-4 Typowe sytuacje I-5 Klasyczne podejście do komunikacji z urządzeniami automatyki I-6 Cechy podejścia dedykowanego
GML w praktyce geodezyjnej
 GML w praktyce geodezyjnej Adam Iwaniak Kon-Dor s.c. Konferencja GML w praktyce, 12 kwietnia 2013, Warszawa SWING Rok 1995, standard de jure Wymiany danych pomiędzy bazami danych systemów informatycznych
GML w praktyce geodezyjnej Adam Iwaniak Kon-Dor s.c. Konferencja GML w praktyce, 12 kwietnia 2013, Warszawa SWING Rok 1995, standard de jure Wymiany danych pomiędzy bazami danych systemów informatycznych
*Grafomania z. Neo4j. Praktyczne wprowadzenie do grafowej bazy danych.
 *Grafomania z Neo4j Praktyczne wprowadzenie do grafowej bazy danych. Jak zamodelować relacyjną bazę danych reprezentującą następujący fragment rzeczywistości: Serwis WWW opisuje pracowników różnych firm
*Grafomania z Neo4j Praktyczne wprowadzenie do grafowej bazy danych. Jak zamodelować relacyjną bazę danych reprezentującą następujący fragment rzeczywistości: Serwis WWW opisuje pracowników różnych firm
I. KARTA PRZEDMIOTU CEL PRZEDMIOTU
 I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Elektroautomatyka
I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Elektroautomatyka
HTML5 Nowe znaczniki header nav article section aside footer
 Specyfikacja HTML5 wprowadza nowe znaczniki pozwalające w łatwy i intuicyjny sposób budować szkielet strony, który przez zmniejszenie ilości kodu jest czytelniejszy i łatwiejszy w utrzymaniu, pozwala poza
Specyfikacja HTML5 wprowadza nowe znaczniki pozwalające w łatwy i intuicyjny sposób budować szkielet strony, który przez zmniejszenie ilości kodu jest czytelniejszy i łatwiejszy w utrzymaniu, pozwala poza