Bazy wiedzy. Agnieszka Ławrynowicz. Poznań, rok akademicki 2017
|
|
|
- Feliks Brzozowski
- 7 lat temu
- Przeglądów:
Transkrypt
1 Bazy wiedzy Agnieszka Ławrynowicz Poznań, rok akademicki 2017


2 Baza wiedzy pragmatyczna definicja Baza wiedzy kolekcja encji, klas i faktów o postaci subject-predicate-object (atrybuty, relacje), istotnych ogólnie lub w danej dziedzinie, która jest kompleksowa, zorganizowana semantycznie i zdatna do odczytu maszynowego.





3 Grafy wiedzy Facebook En+ty Graph Microso5 Bing Satori

, Fabian Suchanek, Gerhard")
4 Historia baz wiedzy ludzie dla ludzi CyC algorytmy dla maszyn WordNet Wikipedia Na podstawie tutoriala Knowledge Bases in the Age of Big Data Analy+cs (VLDB2014), Fabian Suchanek, Gerhard Weikum
5 Cyc Baza wiedzy zawiera mikro-teorie kolekcje pojęć i faktów dotyczących jakiejś dziedziny zainteresowania. Mikro-teoria musi być wolna od sprzeczności, ale cała baza wiedzy nie musi. Reguły FOL CycL (notacja w Lisp) (#$implies (#$and (#$isa?obj?subset) (#$genls?subset?superset)) (#$isa?obj?superset)) Dostępny wariant OpenCyc
6 WordNet leksykalne kategorie rzeczowników, czasowników, przymiotników, przysłówków słowa z tej samej kategorii, z grubsza synonimy, są pogrupowane w synsety (pojęcia) hierarchie, zdefiniowane by hiperonimy (IS-A) Polska Słowosieć (rozwijana od 2005 roku na Politechnice Wrocławskiej) dog, domestic dog, Canis familiaris => canine, canid => carnivore => placental, placental mammal, eutherian, eutherian mammal => mammal => vertebrate, craniate => chordate => animal, animate being, beast, brute, creature, fauna =>... Źródło: Wikipedia

7 Powiązane Dane (ang. Linked Data): definicja.powiązane Dane wykorzystanie technologii Sieci Semantycznej do publikowania ustrukturalizowanych danych w Sieci i do ustanawiania powiązań między źródłami danych. 7
8 Od Sieci Dokumentów do Sieci Danych Sieć dokumentów Hyperlinks Dokumenty Podstawowe elementy: 1. Nazwy (URI) 2. Dokumenty (Zasoby) opisane w HTML, XML, itp. 3. Interakcja poprzez HTTP 4. (Hiper)linki pomiędzy dokumentami lub anchors w dokumentach Wady: Nietypowane linki Wyszukiwarki nie potrafią obsłużyć skomplikowanych zapytań 8
9 Od Sieci Dokumentów do Sieci Danych Sieć Dokumentów Sieć Danych Typowane Linki Hyperlinks Dokumenty Rzeczy 9
10 Od Sieci Dokumentów do Sieci Danych Cechy: Linki pomiędzy dowolnymi rzeczami (np. osobami, lokalizacjami, zdarzeniami, budynkami) Sruktura danych na stronach WWW jest jawna Rzeczy opisane na stronach mają nazwę i URI Linki pomiędzy rzeczami są jawne i typowane Sieć danych Rzeczy Typowane linki 10
11 Wizja Sieci Danych 1/2 Sieć dzisiaj składa się z odizolowanych silosów danych, które są dostępne poprzez wyspecjalizowane wyszukiwarki jedna strona (silos danych) przechowuje filmy, inne recenzje, jeszcze inne informacje o aktorach wiele popularnych rzeczy jest reprezentowanych w wielu różnych zbiorach danych linkowanie identyfikatorów łączy te zbiory danych 11

12 Wizja Sieci Danych 2/2 Sieć Danych - globalna baza danych składa się z obiektów i ich opisów obiekty są ze sobą powiązane linkami z wysokim stopniem ustrukturalizowania obiektów z jawną semantyką linków i treści zaprojektowana dla ludzi i maszyn 12
13 Powiązane Dane - zasady Używaj URI jako nazwy dla rzeczy. Używaj HTTP URI tak aby ludzie mogli wyszukiwać tych nazw. Kiedy użytkownik wyszukuje URI, dostarcz użytecznej informacji w RDF. Zawrzyj wyrażenia RDF, które są powiązane linkami do innych identyfikatorów URI tak aby mogły one pomóc w wykryciu powiązanych rzeczy. 13
14 Projekt Linking Open Data (Otwarte Powiązane Dane) Projekt społecznościowy ze wsparciem W3C Cel: Pomoc w utworzeniu Sieci Semantycznej poprzez publikowanie zbiorów danych z wykorzystaniem RDF. Spełnia zasady połączonych danych (Linked Data principles) Główna idea: wziąć istniejące (otwarte) zbiory danych i uczynić je dostępnymi w Sieci w formacie RDF Raz opublikowane w RDF, połączyć je linkami z innymi zbiorami danych Przykładowy link RDF: hkp://dbpedia.org/resource/berlin [Identyfikator Berlina w DBPedia] owl:sameas hkp://sws.geonames.org/ [Identyfikator Berlina w Geonames]. 14
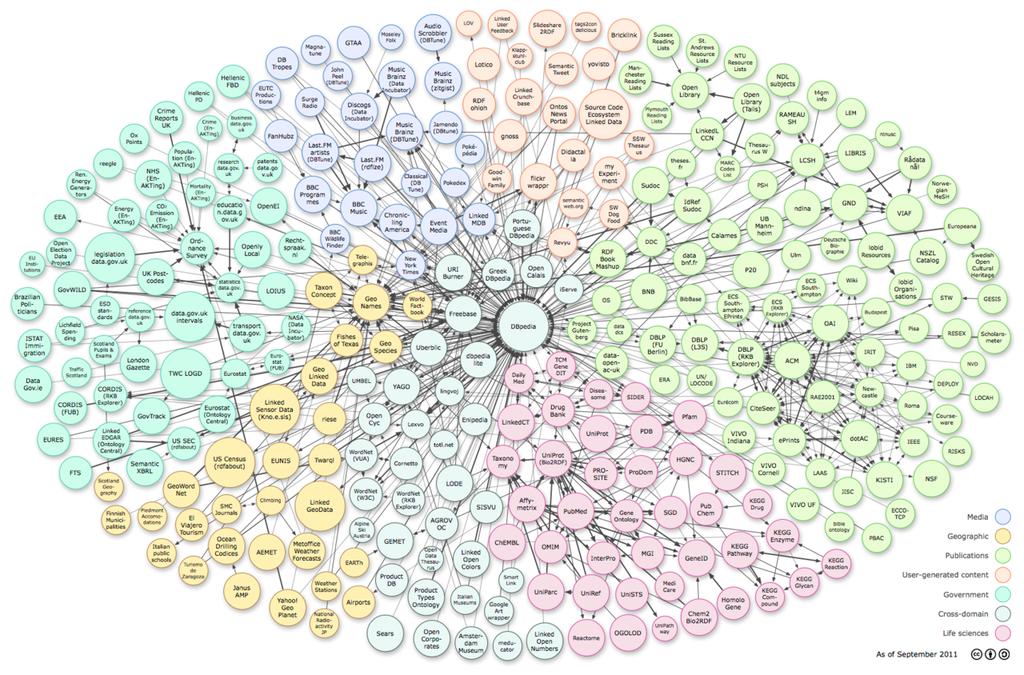
15 Chmura LOD - Maj
16 Chmura LOD - Maj 2007 Ogólnie: Chmura Powiązanych Otwartych Danych (Linked Open Data) jest zbiorem powiązanych między sobą zbiorów danych, które zostały opublikowane i powiązane linkami zgodnie z zasadami powiązanych danych. Fakty: Punkty ogniskujące : DBPedia: wersja Wikipiedii w formacie RDF; wiele przychodzących i wychodzących linków Zbiory danych dotyczące muzyki Duże zbiory danych zawierają: FOAF, US Census data Rozmiar w przybliżeniu 1 bilion trójek, 250k linków 16

17 Chmura LOD - Wrzesień
18 Chmura LOD - Wrzesień 2008 Fakty: Więcej niż 35 powiązanych zbiorów danych Gracze komercyjni dołączyli do chmury (np. BBC) Firmy zaczęły publikować i przechowywać zbiory danych (OpenLink, Talis, Garlik) Rozmiar w przybliżeniu 2 bilion y trójek, 3 miliony linków 18

19 Chmura LOD - Marzec
20 Chmura LOD - Marzec 2009 Fakty: Wielka część z chmury Drug i projektu BIO2RDF Znaczące nowe zbiory danych: Freebase, OpenCalais, ACM/ IEEE Rozmiar > 10 bilionów trójek 20
21 Chmura LOD - Wrzesień 2011 Liczba zbiorów danych: 295 Liczba trójek:

22 Chmura LOD - Sierpień 2014
23 Tworzenie powiązań (linków) Popularne predykaty: owl:sameas, foaf:homepage, foaf:topic, foaf:based_near, foaf:maker/foaf:made, foaf:depiction, foaf:page, foaf:primarytopic, rdfs:seealso 23
24 Przykładowe zbiory danych DBpedia BBC Music Open government (UK), Data.gov (US) Freebase Zbiory danych biologicznych i medycznych


25 DBpedia Inicjatywa społeczna: Ekstrakcja strukturalnej informacji z Wikipedii Udostępnienie informacji w Sieci na otwartej licencji Powiązanie linkami zbioru danych DBpedii z innymi zbiorami danych w Sieci DBpedia to jeden z najbardziej centralnych hubów w tworzącej się Sieci Danych
26 Data.gov 1. Zgromadź dane z wielu miejsc, udostępnij je za darmo deweloperom, naukowcom, obywatelom 2. Połącz społeczność w znajdowaniu rozwiązań pozwalających na współpracę poprzez media społecznościowe, wydarzenia, plapormy 3. Dostarcz infrastrukturę w oparciu o standardy i interoperacyjność 4. Zachęć twórców technologii do tworzenia aplikacji, map, wizualizacji danych, które wzmocnią wybory dokonywane przez ludzi 5. Zgromadź więcej danych i połącz więcej ludzi s A Strategy for American Innova2on wrzesień 2009
27 Powiązane Dane Narzędzia i Aplikacje Narzędzia do przenoszenia danych z innych formatów i z funkcjonujących wewnętrznie systemów do Sieci Danych Narzędzia do wykorzystywania Powiązanych Danych: przeszukiwanie, przeglądanie, tworzenie mashups, inne 27
28 Przenoszenia danych z innych formatów do Sieci Danych Dostarczenie danych przechowywanych w relacyjnych bazach danych do Sieci Danych: Triplify: pozwala na specyfikację zapytań SQL i zrenderowanie wyników jako RDF D2RQ, ontop: odwzorowanie relacyjnych baz danych do RDF; dostarczają końcówkę SPARQL z dostępem do danych Virtuoso RDF Views: oferuje deklaratywny język do tworzenia odwzorowań pomiędzy danymi SQL i RDF Ekstrakcja danych z Sieci WWW (np. DBPedia: dane z Wikipedii) Konwersja istniejących danych i ekstrakcja z nich RDF: z JPEG, , BibTex, Java bytecode, Javadoc, Excel 28
29 Repozytoria trójek RDF Ontotext GraphDB: natywne, wykorzystuje mechanizm wnioskowania wprzód (forward chaining) i materializację AllegroGraph: natywne Jena TDB: natywne Open Link Virtuoso: hybrydowe, hostuje zbiór DBpedia, Virtuoso 7 - Virtuoso Column Store Blazegraph: natywne 29
30 Publikowanie powiązanych - typowe wzorce Źródło:
31 Konsumowanie Powiązanych Danych Przeglądarki Powiązanych Danych: eksplorowanie rzeczy i zbiorów danych i nawigacja pomiędzy nimi Mashup y Powiązanych Danych: strony, które łączą ( mieszają ) powiązane dane Wyszukiwarki powiązanych danych 31
32 Przykładowy Mashup: Revyu.com 1/2 Revyu.com - strona do oceniania wszystkiego. Powiązane Dane wykorzystywane do wzbogacania ocen. Oceny zawierają linki do ocenianej rzeczy i linki seealso do Wikipedii i innych zbiorów danych. 32

33 Przykładowy Mashup: Revyu.com 2/2 33
34 Inne inicjatywy Open* Open Source Open Content Open Science (Open Notebook Science) Open Access Open CourseWare Open Society Founda+ons Open Health





35 Otwarte dane przykład aplikacji Green Bu-on 21 million American h can 21 now milionów download amerykańskich th gospodarstw domowych business może energy ściągnąć use dane dot. zużycia energii their local w ich utility domu Następnie wykorzystać aplikacje, które zarządzają Then use ich apps zużyciem to ma energii i zaoszczędzić pieniądze energy use (i być to bardziej save mekologicznym) go green Więcej: Energy.Data.gov More at Energy.Data Źródło: Driving Innovavon with Open Data and Interoperability Jeanne Holm Evangelist, Data.gov Listopad 14, 2012

36 Otwarte dane to ekosystem
37 Wspólna wizja 1. Wizja: Co będzie łączyć społeczność, jak współpraca będzie wyglądać w przyszłości? 2. Liderzy: Kto będzie przewodzić społeczności? 3. Uczestnicy: Kto będzie uczestniczyć? 4. Wyniki: Jakie są oczekiwane wyniki, miary ich osiągnięcia? 5. Funckcjonalność: Jakie typy aktywności będą funkcjonować (fora, blogi, wiki, rankingi konkursy, aplikacje)? 6. Treść: Jaka treść będzie pokazywana? 7. Interakcyjność: Jak społeczność będzie komunikować się z liderami i z zewnętrznymi osobami, jednostkami?
38 Google: Graf Wiedzy semantyczne wyszukiwanie maj 2012: baza wiedzy wykorzystywana przez Google do rozszerzenia wyników wyszukiwania wiele źródeł wiedzy: CIA World Factbook, Freebase, Wikipedia sieć semantyczna zawiera ponad 570 mln obiektów i ponad 18 mld faktów maj 2013: polska wersja językowa; zadawanie pytań raczej niż wyszukiwanie, informacje i powiązania między nimi raczej niż zestaw linków system poszukujący nie fraz kluczowych, lecz "bytów stojących za wpisanymi w wyszukiwarkę słowami
39 Dwa główne sposoby działania Grafu Wiedzy dopasowywanie odpowiedzi do kontekstu; w przypadku dwuznacznych haseł prezentacja różnych wersji odpowiedzi podsumowania najbardziej istotnych informacji: - biogramy, wyróżnione najważniejsze elementy, powiązania między kluczowymi hasłami, odnośniki do kolejnych informacji

40 Graf Wiedzy: przykład
![Yago Wordnet + Wikipedia ubclassof tances acy WWW 07] organism person subclassof subclassof American people of Syrian descent type Steve](/docs-images/82/86404126/images/41-0.jpg "Jobs WordNet Wikipedia 33 Na podstawie tutoriala Knowledge Bases in the Age of Big Data Analy+cs (VLDB2014), Fabian Suchanek, Gerhard")
41 Yago Wordnet + Wikipedia ubclassof tances acy WWW 07] organism person subclassof subclassof American people of Syrian descent type Steve Jobs WordNet Wikipedia 33 Na podstawie tutoriala Knowledge Bases in the Age of Big Data Analy+cs (VLDB2014), Fabian Suchanek, Gerhard Weikum
42 Ekstrakcja wiedzy (fakty) dane semi-strukturalne Wikipedia: infoboksy i kategorie tabelki i listy HTML tekst wzorce Hearst płytkie NLP tabele Web
43 Wzorce Hearst Cel: znajdź instancje klas Hearst zdefiniowała leksykalno-syntaktyczne wzorce: X such as Y; X like Y; X and other Y; X including Y; X, especially Y; Znajdywanie takich wzorców w tekście: companies such as Apple Google, Microso} and other companies Internet companies like Amazon and Facebook Wywiedzenie typu (Y,X) type(apple, company), type(google, company),... Na podstawie tutoriala Knowledge Bases in the Age of Big Data Analy+cs (VLDB2014), Fabian Suchanek, Gerhard Weikum


44 język znaczników Ekstrakcja z Infoboksów
45 Ekstrakcja z Infoboksów ekstrakcja za pomocą wyrażeń regularnych Przykład ekstrakcja daty urodzin: \{\{birth date \ (\d+)\ (\d+)\ (\d+)\}\} birth_date = {{birth date }}

46 Tabele Web dostarczają strukturalnej/relacyjnej informacji
47 Pozyskiwanie wiedzy poprzez CrowdSourcing wiedza powszechna (nie-ekspercka) gry z celem pla ormy Amazon Mechanical Turk, CrowdFlower

48 Gry z celem Proces obliczeniowy wykonywany jest poprzez zlecanie niektórych czynności ludziom do wykonania w zabawny, zajmujący sposób GWAP wykorzystuje różnice w umiejętnościach i kosztach pracy ludzi i metod informatycznych w celu osiągnięcia symbiotycznej interakcji człowiek-komputer
49 Gry z celem Luis Von Ahn (2006) Główna motywacja: nie leży w rozwiązaniu instancji problemu obliczeniowego, jest to ludzkie pragnienie zabawy W GWAP ludzie wykonują pożyteczne obliczenia jako efekt uboczny przyjemnej rozrywki Miarą użyteczności GWAP jest kombinacja wygenerowanych wyników i przyjemności rozgrywki
50 Kluczowe elementy GWAP
51 Gry z celem tworzenia treści, wiedzy Adnotacja tekstu/audio/obrazów/video Konstrukcja ontologii Mapowanie ontologii Tworzenie linków między zasobami
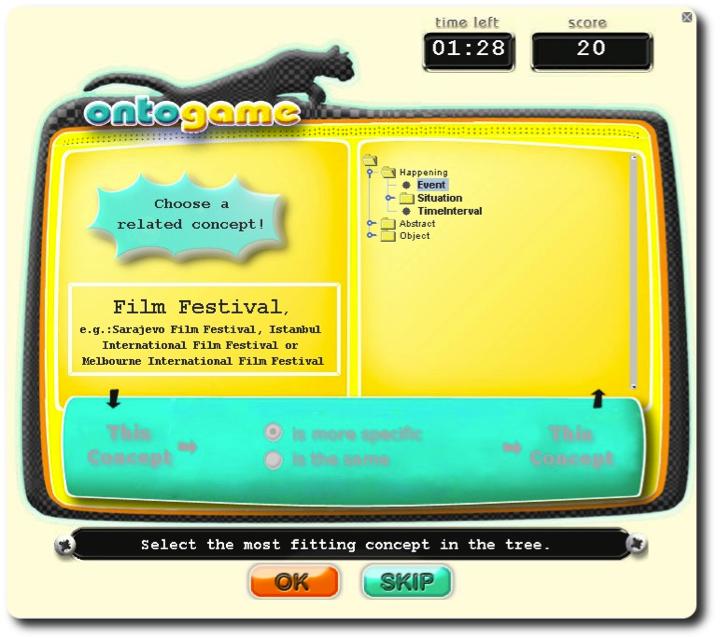
52 Konstrukcja ontologii: OntoPronto (Ontogame) Dwuosobowa gra quizowa Cel: budowa ontologii dziedzinowej będącej rozszerzeniem ontologii Proton Zasady: Gracze czytają streszczenie losowo wybranego artykułu z Wikipedii i odpowiadają na zapytania o relacji tego artykułu w stosunku do ontologii Proton. Dane wyjściowe: Ontologia dziedzinowa ufundowana na ontologii Proton Walidacja: konsensus, większość
")
53 OntoPronto (Ontogame)
54 Mapowanie ontologii: SpotTheLink Dwuosobowa gra quizowa Cel: uzgadnianie ontologii, np. DBpedia i Proton Zasady: Graczom prezentowane jest pojęcie z jednej ontologii. Pierwszy krok: zgadzają się co do odpowiadającego mu pojęcia w drugiej ontologii. Krok drugi: zgadzają się co do relacji wiążącej te dwa pojęcia. Dane wyjściowe: Odwzorowanie (w języku SKOS)pomiędzy pojęciami w ontologiach Walidacja: konsensus, większość
55 SpotTheLink
56 Tworzenie linków między zasobami: VeriLinks Cel: walidacja linków w arbitralnym zbiorze danych Zasady: Zgoda graczy co do poprawności linku jest nagradzana monetami, które są następnie wykorzystywane do zwalczania najeźdźców w grze polegającej na obronie wieży. Dane wyjściowe: zwalidowane linki
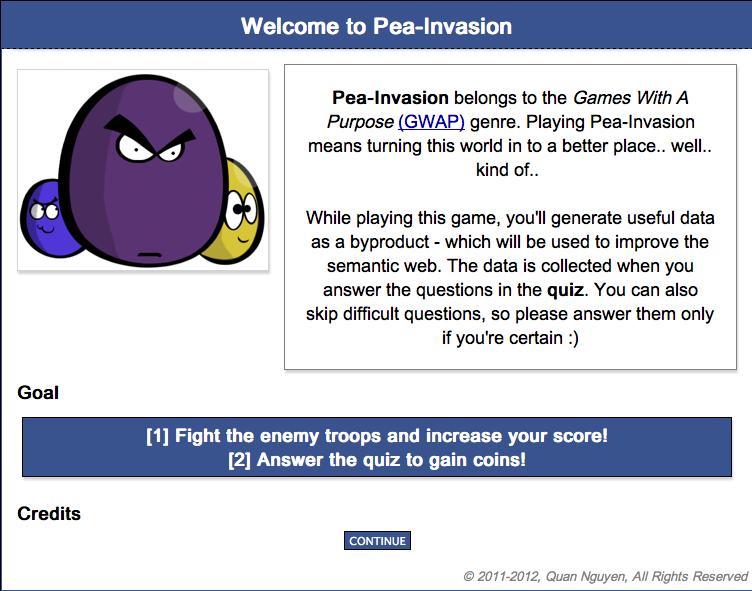
57 VeriLinks

58 CrowdMap Cris+na Sarasua, Elena Simperl, Natalya Fridman Noy: CrowdMap: Crowdsourcing Ontology Alignment with Microtasks. Interna+onal Seman+c Web Conference (1) 2012:
59 Dalsze uwagi Nie każde zadanie da się łatwo przerobić na GWAP (wymóg dekompozycji na mikro-zadania) Tworzenie niektórych ontologii wymaga bardzo specjalistycznej wiedzy To co powstaje w wyniku GWAP jest raczej płytkim modelem GWAP wymaga strategii zapobiegania oszustwom
60 Scenariusze użycia baz wiedzy Semantyczne wyszukiwanie encje a nie słowa Odpowiadanie na pytania np. IBM Waston, nawigatory wiedzy Analityka tekstów, ekstrakcja wiedzy np. teksty medyczne Integracja danych w celu analityki Big Data np. analiza efektów ubocznych kombinacji leków, analiza danych pochodzących z różnych oddziałów międzynarodowych korporacji
61 Bibliografia [1] C. Bizer, T. Heath, and T. Berners-lee Linked Data The Story So Far Internavonal Journal on Semanvc Web and Informavon Systems (IJSWIS) (2009) [2] T. Heath, and C. Bizer (2011) Linked Data: Evolving the Web into a Global Data Space (1st edivon). Synthesis Lectures on the Semanvc Web: Theory and Technology, 1:1, Morgan & Claypool. [3] RDFa Primer, h p:// (last accessed on ) 61
Wiedza w grach, gry z celem tworzenia wiedzy
 Wiedza w grach, gry z celem tworzenia wiedzy dr inż. Agnieszka Ławrynowicz Instytut Informatyki Politechniki Poznańskiej ZTG 2013 Kim jestem? Adiunkt w Instytucie Informatyki Politechniki Poznańskiej Zainteresowania:
Wiedza w grach, gry z celem tworzenia wiedzy dr inż. Agnieszka Ławrynowicz Instytut Informatyki Politechniki Poznańskiej ZTG 2013 Kim jestem? Adiunkt w Instytucie Informatyki Politechniki Poznańskiej Zainteresowania:
Mikroformaty, RDFa, Inicjatywy Open*
 Mikroformaty, RDFa, Inicjatywy Open* Mikołaj Morzy Agnieszka Ławrynowicz Instytut Informatyki Poznań, rok akademicki 2013/2014 TSiSS 1 Od Sieci Dokumentów do Sieci Danych Sieć dokumentów Hyperlinks Dokumenty
Mikroformaty, RDFa, Inicjatywy Open* Mikołaj Morzy Agnieszka Ławrynowicz Instytut Informatyki Poznań, rok akademicki 2013/2014 TSiSS 1 Od Sieci Dokumentów do Sieci Danych Sieć dokumentów Hyperlinks Dokumenty
Internet Semantyczny. Linked Open Data
 Internet Semantyczny Linked Open Data Dzień dzisiejszy database Internet Dzisiejszy Internet to Internet dokumentów (Web of Dokuments) przeznaczonych dla ludzi. Dzień dzisiejszy Internet (Web) to dokumenty
Internet Semantyczny Linked Open Data Dzień dzisiejszy database Internet Dzisiejszy Internet to Internet dokumentów (Web of Dokuments) przeznaczonych dla ludzi. Dzień dzisiejszy Internet (Web) to dokumenty
Semantic Web Internet Semantyczny
 Semantic Web Internet Semantyczny Semantyczny Internet - Wizja (1/2) Pomysłodawca sieci WWW - Tim Berners-Lee, fizyk pracujący w CERN Jego wizja sieci o wiele bardziej ambitna niż istniejąca obecnie (syntaktyczna)
Semantic Web Internet Semantyczny Semantyczny Internet - Wizja (1/2) Pomysłodawca sieci WWW - Tim Berners-Lee, fizyk pracujący w CERN Jego wizja sieci o wiele bardziej ambitna niż istniejąca obecnie (syntaktyczna)
ROLA INTEROPERACYJNOŚCI W BUDOWIE CYFROWYCH USŁUG PUBLICZNYCH ORAZ W UDOSTĘPNIANIU ZASOBÓW OTWARTYCH DANYCH
 ROLA INTEROPERACYJNOŚCI W BUDOWIE CYFROWYCH USŁUG PUBLICZNYCH ORAZ W UDOSTĘPNIANIU ZASOBÓW OTWARTYCH DANYCH Adam Iwaniak Instytut Geodezji i Geoinformatyki, Uniwersytet Przyrodniczy we Wrocławiu Wrocławski
ROLA INTEROPERACYJNOŚCI W BUDOWIE CYFROWYCH USŁUG PUBLICZNYCH ORAZ W UDOSTĘPNIANIU ZASOBÓW OTWARTYCH DANYCH Adam Iwaniak Instytut Geodezji i Geoinformatyki, Uniwersytet Przyrodniczy we Wrocławiu Wrocławski
Zastosowanie Wikipedii w przetwarzaniu języka naturalnego
 Zastosowanie Wikipedii w przetwarzaniu języka naturalnego Plan prezentacji Wikipedia Klasyfikacja Zastosowanie w NLP Plan prezentacji Wikipedia Klasyfikacja Zastosowanie w NLP Rysunek : http://img2.wikia.nocookie.net/
Zastosowanie Wikipedii w przetwarzaniu języka naturalnego Plan prezentacji Wikipedia Klasyfikacja Zastosowanie w NLP Plan prezentacji Wikipedia Klasyfikacja Zastosowanie w NLP Rysunek : http://img2.wikia.nocookie.net/
Linked Open Data z wykorzystaniem wolnego oprogramowania w gospodarce przestrzennej
 Linked Open Data z wykorzystaniem wolnego oprogramowania w gospodarce przestrzennej dr inż. Iwona Kaczmarek Uniwersytet Przyrodniczy we Wrocławiu Otwarte dane rządowe The Memorandum on Transparency and
Linked Open Data z wykorzystaniem wolnego oprogramowania w gospodarce przestrzennej dr inż. Iwona Kaczmarek Uniwersytet Przyrodniczy we Wrocławiu Otwarte dane rządowe The Memorandum on Transparency and
3 grudnia Sieć Semantyczna
 Akademia Górniczo-Hutnicza http://www.agh.edu.pl/ 1/19 3 grudnia 2005 Sieć Semantyczna Michał Budzowski budzow@grad.org 2/19 Plan prezentacji Krótka historia Problemy z WWW Koncepcja Sieci Semantycznej
Akademia Górniczo-Hutnicza http://www.agh.edu.pl/ 1/19 3 grudnia 2005 Sieć Semantyczna Michał Budzowski budzow@grad.org 2/19 Plan prezentacji Krótka historia Problemy z WWW Koncepcja Sieci Semantycznej
Instytut Technik Innowacyjnych Semantyczna integracja danych - metody, technologie, przykłady, wyzwania
 Instytut Technik Innowacyjnych Semantyczna integracja danych - metody, technologie, przykłady, wyzwania Michał Socha, Wojciech Górka Integracja danych Prosty export/import Integracja 1:1 łączenie baz danych
Instytut Technik Innowacyjnych Semantyczna integracja danych - metody, technologie, przykłady, wyzwania Michał Socha, Wojciech Górka Integracja danych Prosty export/import Integracja 1:1 łączenie baz danych
Semantic Web. dr inż. Aleksander Smywiński-Pohl. Elektroniczne Przetwarzanie Informacji Konsultacje: czw , pokój 3.211
 RDF RDFS i OWL Linked Data Elektroniczne Przetwarzanie Informacji Konsultacje: czw. 14.00-15.30, pokój 3.211 RDF RDFS i OWL Linked Data Plan prezentacji RDF RDFS i OWL Linked Data RDF RDFS i OWL Linked
RDF RDFS i OWL Linked Data Elektroniczne Przetwarzanie Informacji Konsultacje: czw. 14.00-15.30, pokój 3.211 RDF RDFS i OWL Linked Data Plan prezentacji RDF RDFS i OWL Linked Data RDF RDFS i OWL Linked
Web 3.0 Sieć Pełna Znaczeń (Semantic Web) Perspektywy dla branży motoryzacyjnej i finansowej. Przyjęcie branżowe EurotaxGlass s Polska 10 luty 2012
 Perspektywy dla branży motoryzacyjnej i finansowej. Przyjęcie branżowe EurotaxGlass s Polska 10 luty 2012") Web 3.0 Sieć Pełna Znaczeń (Semantic Web) Perspektywy dla branży motoryzacyjnej i finansowej Przyjęcie branżowe EurotaxGlass s Polska 10 luty 2012 Web 3.0 - prawdziwa rewolucja czy puste hasło? Web 3.0
Web 3.0 Sieć Pełna Znaczeń (Semantic Web) Perspektywy dla branży motoryzacyjnej i finansowej Przyjęcie branżowe EurotaxGlass s Polska 10 luty 2012 Web 3.0 - prawdziwa rewolucja czy puste hasło? Web 3.0
1 XXIII Forum Teleinformatyki, września 2017 r.
 1 XXIII Forum Teleinformatyki, 28-29 września 2017 r. Dostęp do danych planistycznych z wykorzystaniem usług danych przestrzennych województwa mazowieckiego KRZYSZTOF MĄCZEWSKI Geodeta Województwa Dyrektor
1 XXIII Forum Teleinformatyki, 28-29 września 2017 r. Dostęp do danych planistycznych z wykorzystaniem usług danych przestrzennych województwa mazowieckiego KRZYSZTOF MĄCZEWSKI Geodeta Województwa Dyrektor
Reprezentacja wiedzy wprowadzenie, sieci semantyczne, ramy
 Reprezentacja wiedzy wprowadzenie, sieci semantyczne, ramy Agnieszka Ławrynowicz 17 listopada 2016 Plan wykładu 1 Wprowadzenie: wiedza, reprezentacja, wnioskowanie, bazy wiedzy 2 Systemy oparte o wiedzę
Reprezentacja wiedzy wprowadzenie, sieci semantyczne, ramy Agnieszka Ławrynowicz 17 listopada 2016 Plan wykładu 1 Wprowadzenie: wiedza, reprezentacja, wnioskowanie, bazy wiedzy 2 Systemy oparte o wiedzę
ZMIANA PARADYGMATU W WYKORZYSTANIA DANYCH I INFORMACJI PRZESTRZENNYCH W BUDOWIE SPOŁECZEŃSTWA OPARTEGO NA WIEDZY
 ZMIANA PARADYGMATU W WYKORZYSTANIA DANYCH I INFORMACJI PRZESTRZENNYCH W BUDOWIE SPOŁECZEŃSTWA OPARTEGO NA WIEDZY Adam Iwaniak Wrocławski Instytut Zastosowań Informacji Przestrzennej i Sztucznej Inteligencji
ZMIANA PARADYGMATU W WYKORZYSTANIA DANYCH I INFORMACJI PRZESTRZENNYCH W BUDOWIE SPOŁECZEŃSTWA OPARTEGO NA WIEDZY Adam Iwaniak Wrocławski Instytut Zastosowań Informacji Przestrzennej i Sztucznej Inteligencji
NOWY PARADYGMAT PUBLIKACJI I WYSZUKIWANIA DANYCH PRZESTRZENNYCH W SIECI WWW
 NOWY PARADYGMAT PUBLIKACJI I WYSZUKIWANIA DANYCH PRZESTRZENNYCH W SIECI WWW dr Adam Iwaniak Filozof GIS XIII Podlaskie Forum GIS, 23-25 czerwca 2016, Supraśl DIGITAL DISRUPTION DIGITAL DISRUPTION Zakłócenia
NOWY PARADYGMAT PUBLIKACJI I WYSZUKIWANIA DANYCH PRZESTRZENNYCH W SIECI WWW dr Adam Iwaniak Filozof GIS XIII Podlaskie Forum GIS, 23-25 czerwca 2016, Supraśl DIGITAL DISRUPTION DIGITAL DISRUPTION Zakłócenia
Programowanie i wdrażanie aplikacji sieciowych w języku Python
 Programowanie i wdrażanie aplikacji sieciowych w języku Python Politechnika Lubelska Wydział Elektrotechniki i Informatyki czerwiec 2010 Plan prezentacji 1 O pracy Cel pracy Plan pracy 2 Wykorzystane technologie
Programowanie i wdrażanie aplikacji sieciowych w języku Python Politechnika Lubelska Wydział Elektrotechniki i Informatyki czerwiec 2010 Plan prezentacji 1 O pracy Cel pracy Plan pracy 2 Wykorzystane technologie
Rozszerzenie funkcjonalności systemów wiki w oparciu o wtyczki i Prolog
 Knowledge Rozszerzenie funkcjonalności systemów wiki w oparciu o wtyczki i Prolog 9 stycznia 2009 Knowledge 1 Wstęp 2 3 4 5 Knowledge 6 7 Knowledge Duża ilość nieusystematyzowanych informacji... Knowledge
Knowledge Rozszerzenie funkcjonalności systemów wiki w oparciu o wtyczki i Prolog 9 stycznia 2009 Knowledge 1 Wstęp 2 3 4 5 Knowledge 6 7 Knowledge Duża ilość nieusystematyzowanych informacji... Knowledge
INNOWACYJNE METODY UDOSTĘPNIANIA PUBLICZNYCH DANYCH PRZESTRZENNYCH
 INNOWACYJNE METODY UDOSTĘPNIANIA PUBLICZNYCH DANYCH PRZESTRZENNYCH Dr inż. Adam Iwaniak Uniwersytet Przyrodniczy we Wrocławiu Wrocławskiego Instytutu Zastosowań Informacji Przestrzennej i Sztucznej Inteligencji
INNOWACYJNE METODY UDOSTĘPNIANIA PUBLICZNYCH DANYCH PRZESTRZENNYCH Dr inż. Adam Iwaniak Uniwersytet Przyrodniczy we Wrocławiu Wrocławskiego Instytutu Zastosowań Informacji Przestrzennej i Sztucznej Inteligencji
Czy (centralne) katalogi biblioteczne są jeszcze potrzebne? OPAC w infotopii. Dr hab. Marek Nahotko, ISI UJ
 katalogi biblioteczne są jeszcze potrzebne? OPAC w infotopii. Dr hab. Marek Nahotko, ISI UJ") Czy (centralne) katalogi biblioteczne są jeszcze potrzebne? OPAC w infotopii Dr hab. Marek Nahotko, ISI UJ 1 Współpraca bibliotek Cała niezbędna metainformacja funkcjonuje obecnie w formie elektronicznej
Czy (centralne) katalogi biblioteczne są jeszcze potrzebne? OPAC w infotopii Dr hab. Marek Nahotko, ISI UJ 1 Współpraca bibliotek Cała niezbędna metainformacja funkcjonuje obecnie w formie elektronicznej
extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl
 extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl Plan wykładu Wprowadzenie: historia rozwoju technik znakowania tekstu Motywacje dla prac nad XML-em Podstawowe koncepcje XML-a XML jako metajęzyk
extensible Markup Language, cz. 1 Marcin Gryszkalis, mg@fork.pl Plan wykładu Wprowadzenie: historia rozwoju technik znakowania tekstu Motywacje dla prac nad XML-em Podstawowe koncepcje XML-a XML jako metajęzyk
MODEL SYSTEMU WIELOAGENTOWEGO KORZYSTAJĄCEGO Z DANYCH SIECI SEMANTYCZNEJ W PROJEKCIE OPEN NATURA 2000
 JAKUB BILSKI E-mail: jakub@blsk.pl Katedra Inżynierii Komputerowej, Wydział Elektroniki i Informatyki Politechnika Koszalińska Śniadeckich 2, 75-453 Koszalin MODEL SYSTEMU WIELOAGENTOWEGO KORZYSTAJĄCEGO
JAKUB BILSKI E-mail: jakub@blsk.pl Katedra Inżynierii Komputerowej, Wydział Elektroniki i Informatyki Politechnika Koszalińska Śniadeckich 2, 75-453 Koszalin MODEL SYSTEMU WIELOAGENTOWEGO KORZYSTAJĄCEGO
Reprezentacja wiedzy i wnioskowanie: wprowadzenie, sieci semantyczne, ramy
 Reprezentacja wiedzy i wnioskowanie: wprowadzenie, sieci semantyczne, ramy Agnieszka Ławrynowicz 1 grudnia 2016 Notatki do wykładu z przedmiotu Sztuczna Inteligencja na kierunku Informatyka na Politechnice
Reprezentacja wiedzy i wnioskowanie: wprowadzenie, sieci semantyczne, ramy Agnieszka Ławrynowicz 1 grudnia 2016 Notatki do wykładu z przedmiotu Sztuczna Inteligencja na kierunku Informatyka na Politechnice
 Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
Open Acces Otwarty dostęp
 Open Acces Otwarty dostęp Open Acces Otwarty dostęp do treści naukowych zakłada: swobodny dostęp w internecie, każdy użytkownik może je zapisywać na dysku komputera lub innym nośniku danych, kopiować,
Open Acces Otwarty dostęp Open Acces Otwarty dostęp do treści naukowych zakłada: swobodny dostęp w internecie, każdy użytkownik może je zapisywać na dysku komputera lub innym nośniku danych, kopiować,
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe.
 Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
PageRank i HITS. Mikołajczyk Grzegorz
 PageRank i HITS Mikołajczyk Grzegorz PageRank Metoda nadawania indeksowanym stronom internetowym określonej wartości liczbowej, oznaczającej jej jakość. Algorytm PageRank jest wykorzystywany przez popularną
PageRank i HITS Mikołajczyk Grzegorz PageRank Metoda nadawania indeksowanym stronom internetowym określonej wartości liczbowej, oznaczającej jej jakość. Algorytm PageRank jest wykorzystywany przez popularną
Semantyczny Monitoring Cyberprzestrzeni
 Semantyczny Monitoring Cyberprzestrzeni Partnerzy projektu: Katedra Informatyki Ekonomicznej Uniwersytet Ekonomiczny w Poznaniu Partnerzy projektu: Zarys problemu Źródło internetowe jako zasób użytecznych
Semantyczny Monitoring Cyberprzestrzeni Partnerzy projektu: Katedra Informatyki Ekonomicznej Uniwersytet Ekonomiczny w Poznaniu Partnerzy projektu: Zarys problemu Źródło internetowe jako zasób użytecznych
INFORMATYKA Pytania ogólne na egzamin dyplomowy
 INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja
INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja
Technologie cyfrowe. Artur Kalinowski. Zakład Cząstek i Oddziaływań Fundamentalnych Pasteura 5, pokój 4.15 Artur.Kalinowski@fuw.edu.
 Technologie cyfrowe Artur Kalinowski Zakład Cząstek i Oddziaływań Fundamentalnych Pasteura 5, pokój 4.15 Artur.Kalinowski@fuw.edu.pl Semestr letni 2014/2015 Usługi internetowe usługa internetowa (ang.
Technologie cyfrowe Artur Kalinowski Zakład Cząstek i Oddziaływań Fundamentalnych Pasteura 5, pokój 4.15 Artur.Kalinowski@fuw.edu.pl Semestr letni 2014/2015 Usługi internetowe usługa internetowa (ang.
Ontologie, czyli o inteligentnych danych
 1 Ontologie, czyli o inteligentnych danych Bożena Deka Andrzej Tolarczyk PLAN 2 1. Korzenie filozoficzne 2. Ontologia w informatyce Ontologie a bazy danych Sieć Semantyczna Inteligentne dane 3. Zastosowania
1 Ontologie, czyli o inteligentnych danych Bożena Deka Andrzej Tolarczyk PLAN 2 1. Korzenie filozoficzne 2. Ontologia w informatyce Ontologie a bazy danych Sieć Semantyczna Inteligentne dane 3. Zastosowania
Hurtownie danych wykład 5
 Hurtownie danych wykład 5 dr Sebastian Zając SGH Warszawa 7 lutego 2017 1 Współbieżność i integracja Niezgodność impedancji 2 bazy danych Współbieżność i integracja Niezgodność impedancji Bazy relacyjne
Hurtownie danych wykład 5 dr Sebastian Zając SGH Warszawa 7 lutego 2017 1 Współbieżność i integracja Niezgodność impedancji 2 bazy danych Współbieżność i integracja Niezgodność impedancji Bazy relacyjne
Przetwarzanie języka naturalnego (NLP)
") Przetwarzanie języka naturalnego (NLP) NLP jest dziedziną informatyki łączącą zagadnienia sztucznej inteligencji i lingwistyki zajmującą się automatyzacją analizy, rozumienia, tłumaczenia i generowania
Przetwarzanie języka naturalnego (NLP) NLP jest dziedziną informatyki łączącą zagadnienia sztucznej inteligencji i lingwistyki zajmującą się automatyzacją analizy, rozumienia, tłumaczenia i generowania
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
*Grafomania z. Neo4j. Praktyczne wprowadzenie do grafowej bazy danych.
 *Grafomania z Neo4j Praktyczne wprowadzenie do grafowej bazy danych. Jak zamodelować relacyjną bazę danych reprezentującą następujący fragment rzeczywistości: Serwis WWW opisuje pracowników różnych firm
*Grafomania z Neo4j Praktyczne wprowadzenie do grafowej bazy danych. Jak zamodelować relacyjną bazę danych reprezentującą następujący fragment rzeczywistości: Serwis WWW opisuje pracowników różnych firm
Monitoring procesów z wykorzystaniem systemu ADONIS
 Monitoring procesów z wykorzystaniem systemu ADONIS BOC Information Technologies Consulting Sp. z o.o. e-mail: boc@boc-pl.com Tel.: (+48 22) 628 00 15, 696 69 26 Fax: (+48 22) 621 66 88 BOC Management
Monitoring procesów z wykorzystaniem systemu ADONIS BOC Information Technologies Consulting Sp. z o.o. e-mail: boc@boc-pl.com Tel.: (+48 22) 628 00 15, 696 69 26 Fax: (+48 22) 621 66 88 BOC Management
Tomasz Grześ. Systemy zarządzania treścią
 Tomasz Grześ Systemy zarządzania treścią Co to jest CMS? CMS (ang. Content Management System System Zarządzania Treścią) CMS definicje TREŚĆ Dowolny rodzaj informacji cyfrowej. Może to być np. tekst, obraz,
Tomasz Grześ Systemy zarządzania treścią Co to jest CMS? CMS (ang. Content Management System System Zarządzania Treścią) CMS definicje TREŚĆ Dowolny rodzaj informacji cyfrowej. Może to być np. tekst, obraz,
Semantyczne Wiki na przykładzie Semantic MediaWiki
 Semantyczne Wiki na przykładzie Semantic MediaWiki Technologie semantyczne i sieci społecznościowe# Agnieszka Ławrynowicz# 16.12.2013# (do przygotowania tych materiałów wykorzystałam częściowo prezentacje
Semantyczne Wiki na przykładzie Semantic MediaWiki Technologie semantyczne i sieci społecznościowe# Agnieszka Ławrynowicz# 16.12.2013# (do przygotowania tych materiałów wykorzystałam częściowo prezentacje
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Mechatronika Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych Rodzaj zajęć: wykład, laboratorium BAZY DANYCH I SYSTEMY EKSPERTOWE Database and expert systems Forma
Nazwa przedmiotu: Kierunek: Mechatronika Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych Rodzaj zajęć: wykład, laboratorium BAZY DANYCH I SYSTEMY EKSPERTOWE Database and expert systems Forma
Systemy organizacji wiedzy i ich rola w integracji zasobów europejskich bibliotek cyfrowych
 Systemy organizacji wiedzy i ich rola w integracji zasobów europejskich bibliotek cyfrowych Adam Dudczak Poznańskie Centrum Superkomputerowo-Sieciowe (maneo@man.poznan.pl) I Konferencja Polskie Biblioteki
Systemy organizacji wiedzy i ich rola w integracji zasobów europejskich bibliotek cyfrowych Adam Dudczak Poznańskie Centrum Superkomputerowo-Sieciowe (maneo@man.poznan.pl) I Konferencja Polskie Biblioteki
SEMANTYCZNE ZNACZNIKOWANIE ARTYKUŁÓW WIKIPEDII SYNSETAMI SŁOWNIKA WORDNETA 1
 ZESZYTY NAUKOWE WYDZIAŁU ELEKTRONIKI, TELEKOMUNIKACJI I INFORMATYKI POLITECHNIKI GDAŃSKIEJ Nr 10 Seria:ICT Young 2012 SEMANTYCZNE ZNACZNIKOWANIE ARTYKUŁÓW WIKIPEDII SYNSETAMI SŁOWNIKA WORDNETA 1 Politechnika
ZESZYTY NAUKOWE WYDZIAŁU ELEKTRONIKI, TELEKOMUNIKACJI I INFORMATYKI POLITECHNIKI GDAŃSKIEJ Nr 10 Seria:ICT Young 2012 SEMANTYCZNE ZNACZNIKOWANIE ARTYKUŁÓW WIKIPEDII SYNSETAMI SŁOWNIKA WORDNETA 1 Politechnika
Semantyczne Wiki! na przykładzie! Semantic MediaWiki!
 Semantyczne Wiki! na przykładzie! Semantic MediaWiki! Agnieszka Ławrynowicz" 7.12.2014" (do przygotowania tych materiałów wykorzystałam częściowo prezentacje z SMWcon Fall 2012-2013 w tym prezentację Introduction
Semantyczne Wiki! na przykładzie! Semantic MediaWiki! Agnieszka Ławrynowicz" 7.12.2014" (do przygotowania tych materiałów wykorzystałam częściowo prezentacje z SMWcon Fall 2012-2013 w tym prezentację Introduction
Usługi analityczne budowa kostki analitycznej Część pierwsza.
 Usługi analityczne budowa kostki analitycznej Część pierwsza. Wprowadzenie W wielu dziedzinach działalności człowieka analiza zebranych danych jest jednym z najważniejszych mechanizmów podejmowania decyzji.
Usługi analityczne budowa kostki analitycznej Część pierwsza. Wprowadzenie W wielu dziedzinach działalności człowieka analiza zebranych danych jest jednym z najważniejszych mechanizmów podejmowania decyzji.
Repozytorium Zasobów Wiedzy FTP
 Repozytorium Zasobów Wiedzy FTP Spis treści Wprowadzenie... 1 Architektura Repozytorium Zasobów Wiedzy... 1 Mapy Wiedzy... 4 Wprowadzanie zasobów wiedzy do repozytorium... 7 Prezentacja zasobów wiedzy
Repozytorium Zasobów Wiedzy FTP Spis treści Wprowadzenie... 1 Architektura Repozytorium Zasobów Wiedzy... 1 Mapy Wiedzy... 4 Wprowadzanie zasobów wiedzy do repozytorium... 7 Prezentacja zasobów wiedzy
POZYSKIWANIE, INTEGRACJA I UDOSTĘPNIANIE INFORMACJI PRZESTRZENNEJ W ERZE BIG DATA
 POZYSKIWANIE, INTEGRACJA I UDOSTĘPNIANIE INFORMACJI PRZESTRZENNEJ W ERZE BIG DATA Adam Iwaniak Tomasz Berezowski IGiG UP Wrocław Systemom Informacji Przestrzennej w rolnictwie, Starachowice 25-27 listopada
POZYSKIWANIE, INTEGRACJA I UDOSTĘPNIANIE INFORMACJI PRZESTRZENNEJ W ERZE BIG DATA Adam Iwaniak Tomasz Berezowski IGiG UP Wrocław Systemom Informacji Przestrzennej w rolnictwie, Starachowice 25-27 listopada
AUTOMATYKA INFORMATYKA
 AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
Przetwarzanie danych w chmurze
 Materiały dydaktyczne Katedra Inżynierii Komputerowej Przetwarzanie danych w chmurze Modele przetwarzania w chmurze dr inż. Robert Arsoba Robert.Arsoba@weii.tu.koszalin.pl Koszalin 2017 Wersja 1.0 Modele
Materiały dydaktyczne Katedra Inżynierii Komputerowej Przetwarzanie danych w chmurze Modele przetwarzania w chmurze dr inż. Robert Arsoba Robert.Arsoba@weii.tu.koszalin.pl Koszalin 2017 Wersja 1.0 Modele
Przykłady zastosowao rozwiązao typu mapserver w Jednostkach Samorządu Terytorialnego
 Przykłady zastosowao rozwiązao typu mapserver w Jednostkach Samorządu Terytorialnego Plan prezentacji Wprowadzenie Czym jest serwer danych przestrzennych i na czym polega jego działanie? Miejsce serwera
Przykłady zastosowao rozwiązao typu mapserver w Jednostkach Samorządu Terytorialnego Plan prezentacji Wprowadzenie Czym jest serwer danych przestrzennych i na czym polega jego działanie? Miejsce serwera
Multi-wyszukiwarki. Mediacyjne Systemy Zapytań wprowadzenie. Architektury i technologie integracji danych Systemy Mediacyjne
 Architektury i technologie integracji danych Systemy Mediacyjne Multi-wyszukiwarki Wprowadzenie do Mediacyjnych Systemów Zapytań (MQS) Architektura MQS Cechy funkcjonalne MQS Cechy implementacyjne MQS
Architektury i technologie integracji danych Systemy Mediacyjne Multi-wyszukiwarki Wprowadzenie do Mediacyjnych Systemów Zapytań (MQS) Architektura MQS Cechy funkcjonalne MQS Cechy implementacyjne MQS
CZEGO OCZEKUJĄ OD BIBLIOTEKI
 CZEGO OCZEKUJĄ OD BIBLIOTEKI MŁODZI NAUKOWCY A CZEGO MOGLIBY OCZEKIWAĆ? NA PRZYKŁADZIE BIBLIOTEKI GŁÓWNEJ GUMED Paulina Biczkowska Biblioteka Główna Gdańskiego Uniwersytetu Medycznego BIBLIOTEKA GŁÓWNA
CZEGO OCZEKUJĄ OD BIBLIOTEKI MŁODZI NAUKOWCY A CZEGO MOGLIBY OCZEKIWAĆ? NA PRZYKŁADZIE BIBLIOTEKI GŁÓWNEJ GUMED Paulina Biczkowska Biblioteka Główna Gdańskiego Uniwersytetu Medycznego BIBLIOTEKA GŁÓWNA
Sposoby wyszukiwania multimedialnych zasobów w Internecie
 Sposoby wyszukiwania multimedialnych zasobów w Internecie Lidia Derfert-Wolf Biblioteka Główna Uniwersytetu Technologiczno-Przyrodniczego w Bydgoszczy e-mail: lidka@utp.edu.pl III seminarium z cyklu INFOBROKER:
Sposoby wyszukiwania multimedialnych zasobów w Internecie Lidia Derfert-Wolf Biblioteka Główna Uniwersytetu Technologiczno-Przyrodniczego w Bydgoszczy e-mail: lidka@utp.edu.pl III seminarium z cyklu INFOBROKER:
Specjalizacja magisterska Bazy danych
 Specjalizacja magisterska Bazy danych Strona Katedry http://bd.pjwstk.edu.pl/katedra/ Prezentacja dostępna pod adresem: http://www.bd.pjwstk.edu.pl/bazydanych.pdf Wymagania wstępne Znajomość podstaw języka
Specjalizacja magisterska Bazy danych Strona Katedry http://bd.pjwstk.edu.pl/katedra/ Prezentacja dostępna pod adresem: http://www.bd.pjwstk.edu.pl/bazydanych.pdf Wymagania wstępne Znajomość podstaw języka
Biblioteka Wirtualnej Nauki
 Biblioteka Wirtualnej Nauki BAZA EBSCO EBSCO Publishing oferuje użytkownikom w Polsce dostęp online do pakietu podstawowego baz danych w ramach projektu Electronic Information for Libraries Direct eifl
Biblioteka Wirtualnej Nauki BAZA EBSCO EBSCO Publishing oferuje użytkownikom w Polsce dostęp online do pakietu podstawowego baz danych w ramach projektu Electronic Information for Libraries Direct eifl
Ćwiczenie numer 4 JESS PRZYKŁADOWY SYSTEM EKSPERTOWY.
 Ćwiczenie numer 4 JESS PRZYKŁADOWY SYSTEM EKSPERTOWY. 1. Cel ćwiczenia Celem ćwiczenia jest zapoznanie się z przykładowym systemem ekspertowym napisanym w JESS. Studenci poznają strukturę systemu ekspertowego,
Ćwiczenie numer 4 JESS PRZYKŁADOWY SYSTEM EKSPERTOWY. 1. Cel ćwiczenia Celem ćwiczenia jest zapoznanie się z przykładowym systemem ekspertowym napisanym w JESS. Studenci poznają strukturę systemu ekspertowego,
Klasyfikacja informacji naukowych w Internecie na przykładzie stron poświęconych kulturze antycznej
 Klasyfikacja informacji naukowych w Internecie na przykładzie stron poświęconych kulturze antycznej Katowice, 15 grudnia 2010 2 Informacja w kontekście projektu i marketingu L. Rosenfeld, P. Morville,
Klasyfikacja informacji naukowych w Internecie na przykładzie stron poświęconych kulturze antycznej Katowice, 15 grudnia 2010 2 Informacja w kontekście projektu i marketingu L. Rosenfeld, P. Morville,
The Binder Consulting
 The Binder Consulting Contents Indywidualne szkolenia specjalistyczne...3 Konsultacje dla tworzenia rozwiazan mobilnych... 3 Dedykowane rozwiazania informatyczne... 3 Konsultacje i wdrożenie mechanizmów
The Binder Consulting Contents Indywidualne szkolenia specjalistyczne...3 Konsultacje dla tworzenia rozwiazan mobilnych... 3 Dedykowane rozwiazania informatyczne... 3 Konsultacje i wdrożenie mechanizmów
Informacje wstępne Autor Zofia Kruczkiewicz Wzorce oprogramowania 4
 Utrwalanie danych zastosowanie obiektowego modelu danych warstwy biznesowej do generowania schematu relacyjnej bazy danych Informacje wstępne Autor Zofia Kruczkiewicz Wzorce oprogramowania 4 1. Relacyjne
Utrwalanie danych zastosowanie obiektowego modelu danych warstwy biznesowej do generowania schematu relacyjnej bazy danych Informacje wstępne Autor Zofia Kruczkiewicz Wzorce oprogramowania 4 1. Relacyjne
PODSTAWY BAZ DANYCH. 19. Perspektywy baz danych. 2009/2010 Notatki do wykładu "Podstawy baz danych"
 PODSTAWY BAZ DANYCH 19. Perspektywy baz danych 1 Perspektywy baz danych Temporalna baza danych Temporalna baza danych - baza danych posiadająca informację o czasie wprowadzenia lub czasie ważności zawartych
PODSTAWY BAZ DANYCH 19. Perspektywy baz danych 1 Perspektywy baz danych Temporalna baza danych Temporalna baza danych - baza danych posiadająca informację o czasie wprowadzenia lub czasie ważności zawartych
Strukturalizacja otoczenia agentów: ontologie, CYC, sieci semantyczne
 WYKŁAD 8 Strukturalizacja otoczenia agentów: ontologie, CYC, sieci semantyczne Jan widział X, gdy leciał nad miastem. Jan widział samolot, gdy leciał nad miastem. Jan widział dom, gdy leciał nad miastem.
WYKŁAD 8 Strukturalizacja otoczenia agentów: ontologie, CYC, sieci semantyczne Jan widział X, gdy leciał nad miastem. Jan widział samolot, gdy leciał nad miastem. Jan widział dom, gdy leciał nad miastem.
Rozdział. Sieci semantyczne dotychczasowe doświadczenia i perspektywy rozwoju w ocenie Instytutu EMAG
 Rozdział Sieci semantyczne dotychczasowe doświadczenia i perspektywy rozwoju w ocenie Instytutu EMAG WOJCIECH GÓRKA Instytut Technik Innowacyjnych EMAG wgorka@emag.pl MICHAŁ SOCHA Instytut Technik Innowacyjnych
Rozdział Sieci semantyczne dotychczasowe doświadczenia i perspektywy rozwoju w ocenie Instytutu EMAG WOJCIECH GÓRKA Instytut Technik Innowacyjnych EMAG wgorka@emag.pl MICHAŁ SOCHA Instytut Technik Innowacyjnych
Baza wiedzy instrukcja
 Strona 1 z 12 Baza wiedzy instrukcja 1 Korzystanie z publikacji... 2 1.1 Interaktywny spis treści... 2 1.2 Przeglądanie publikacji... 3 1.3 Przejście do wybranej strony... 3 1.4 Przeglądanie stron za pomocą
Strona 1 z 12 Baza wiedzy instrukcja 1 Korzystanie z publikacji... 2 1.1 Interaktywny spis treści... 2 1.2 Przeglądanie publikacji... 3 1.3 Przejście do wybranej strony... 3 1.4 Przeglądanie stron za pomocą
Open Access w technologii językowej dla języka polskiego
 Open Access w technologii językowej dla języka polskiego Marek Maziarz, Maciej Piasecki Grupa Naukowa Technologii Językowych G4.19 Zakład Sztucznej Inteligencji, Instytut Informatyki, W-8, Politechnika
Open Access w technologii językowej dla języka polskiego Marek Maziarz, Maciej Piasecki Grupa Naukowa Technologii Językowych G4.19 Zakład Sztucznej Inteligencji, Instytut Informatyki, W-8, Politechnika
Nazwa biblioteki (w języku oryginalnym) National Library of Scotland Biblioteka Narodowa Szkocji
 National Library of Scotland Biblioteka Narodowa Szkocji") 1 Nazwa biblioteki (w języku oryginalnym) National Library of Scotland Biblioteka Narodowa Szkocji http://www.nls.uk/digitallibrary/index.html 1. Zawartość The National Library of Scotland jest największą
1 Nazwa biblioteki (w języku oryginalnym) National Library of Scotland Biblioteka Narodowa Szkocji http://www.nls.uk/digitallibrary/index.html 1. Zawartość The National Library of Scotland jest największą
2.3.5. Umiejętności związane z wiedzą 2.4. Podsumowanie analizy literaturowej
 Spis treści 1. Przesłanki dla podjęcia badań 1.1. Wprowadzenie 1.2. Cel badawczy i plan pracy 1.3. Obszar badawczy 1.4. Znaczenie badań dla teorii 1.5. Znaczenie badań dla praktyków 2. Przegląd literatury
Spis treści 1. Przesłanki dla podjęcia badań 1.1. Wprowadzenie 1.2. Cel badawczy i plan pracy 1.3. Obszar badawczy 1.4. Znaczenie badań dla teorii 1.5. Znaczenie badań dla praktyków 2. Przegląd literatury
KARTA PRZEDMIOTU. 1. Informacje ogólne. 2. Ogólna charakterystyka przedmiotu. Metody drążenia danych D1.3
 KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom kształcenia: Profil kształcenia: Forma studiów:
KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom kształcenia: Profil kształcenia: Forma studiów:
KIERUNKI ROZWOJU WORLD WIDE WEB
 KIERUNKI ROZWOJU WORLD WIDE WEB I GEOINFORMATYKI Adam Iwaniak Wrocław 13-14, maja 2010 II Konferencja z cyklu Wolne oprogramowanie w geoinformatyce Celów projektów unijnych Wzrost innowacyjności Wzrost
KIERUNKI ROZWOJU WORLD WIDE WEB I GEOINFORMATYKI Adam Iwaniak Wrocław 13-14, maja 2010 II Konferencja z cyklu Wolne oprogramowanie w geoinformatyce Celów projektów unijnych Wzrost innowacyjności Wzrost
Spis treści Informacje podstawowe Predykaty Przykłady Źródła RDF. Marek Prząda. PWSZ w Tarnowie. Tarnów, 6 lutego 2009
 PWSZ w Tarnowie Tarnów, 6 lutego 2009 1 Interpretacja trójek i SWI-Prolog Składnia 2 3 4 Interpretacja trójek i SWI-Prolog Składnia Opis (ang. Resource Description Framework) jest specyfikacją modelu metadanych,
PWSZ w Tarnowie Tarnów, 6 lutego 2009 1 Interpretacja trójek i SWI-Prolog Składnia 2 3 4 Interpretacja trójek i SWI-Prolog Składnia Opis (ang. Resource Description Framework) jest specyfikacją modelu metadanych,
POZYCJONOWANIE STRONY SKLEPU
 . Wszystko O Pozycjonowaniu I Marketingu. >>>POZYCJONOWANIE STRON LEGNICA POZYCJONOWANIE STRONY SKLEPU >>>WIĘCEJ
. Wszystko O Pozycjonowaniu I Marketingu. >>>POZYCJONOWANIE STRON LEGNICA POZYCJONOWANIE STRONY SKLEPU >>>WIĘCEJ
Szkolenie autoryzowane. MS Zaawansowany użytkownik programu SharePoint 2016
 Szkolenie autoryzowane MS 55217 Zaawansowany użytkownik programu SharePoint 2016 Strona szkolenia Terminy szkolenia Rejestracja na szkolenie Promocje Opis szkolenia Szkolenie przeznaczone jest dla zaawansowanych
Szkolenie autoryzowane MS 55217 Zaawansowany użytkownik programu SharePoint 2016 Strona szkolenia Terminy szkolenia Rejestracja na szkolenie Promocje Opis szkolenia Szkolenie przeznaczone jest dla zaawansowanych
The Office of Scientific and Technical Information (OSTI)
") The Office of Scientific and Technical Information (OSTI) Repozytorium wiedzy z dziedziny nauki i techniki http://www.osti.gov/ 1. Repozytorium wiedzy z dziedziny nauki i techniki (OSTI) jest częścią biura
The Office of Scientific and Technical Information (OSTI) Repozytorium wiedzy z dziedziny nauki i techniki http://www.osti.gov/ 1. Repozytorium wiedzy z dziedziny nauki i techniki (OSTI) jest częścią biura
Ekonomiczny Uniwersytet Dziecięcy. Marketing internetowy
 Ekonomiczny Uniwersytet Dziecięcy Marketing internetowy Dr Leszek Gracz Uniwersytet Szczeciński 25 marca 2015 r. EKONOMICZNY UNIWERSYTET DZIECIĘCY WWW.UNIWERSYTET-DZIECIECY.PL O czym dzisiaj będziemy mówić
Ekonomiczny Uniwersytet Dziecięcy Marketing internetowy Dr Leszek Gracz Uniwersytet Szczeciński 25 marca 2015 r. EKONOMICZNY UNIWERSYTET DZIECIĘCY WWW.UNIWERSYTET-DZIECIECY.PL O czym dzisiaj będziemy mówić
mniej niż minutę Vincit Z Vincit odpowiedź brzmi: Przy dostępie do źródeł danych, ile czasu zajmie Ci stworzenie odpowiedzi na poniższe pytania?
 Przy dostępie do źródeł danych, ile czasu zajmie Ci stworzenie odpowiedzi na poniższe pytania?? Firma Dane kontaktowe oraz logotyp tych klientów, którzy zakupili nasz najdroższy produkt w ostatnim roku.?
Przy dostępie do źródeł danych, ile czasu zajmie Ci stworzenie odpowiedzi na poniższe pytania?? Firma Dane kontaktowe oraz logotyp tych klientów, którzy zakupili nasz najdroższy produkt w ostatnim roku.?
Odkrywanie niewidzialnych zasobów sieci
 Odkrywanie niewidzialnych zasobów sieci Lidia Derfert-Wolf Biblioteka Główna Uniwersytetu Technologiczno-Przyrodniczego w Bydgoszczy II seminarium z cyklu INFOBROKER: Wyszukiwanie i przetwarzanie cyfrowych
Odkrywanie niewidzialnych zasobów sieci Lidia Derfert-Wolf Biblioteka Główna Uniwersytetu Technologiczno-Przyrodniczego w Bydgoszczy II seminarium z cyklu INFOBROKER: Wyszukiwanie i przetwarzanie cyfrowych
Pytania z przedmiotów kierunkowych
 Pytania na egzamin dyplomowy z przedmiotów realizowanych przez pracowników IIwZ studia stacjonarne I stopnia Zarządzanie i Inżynieria Produkcji Pytania z przedmiotów kierunkowych 1. Co to jest algorytm?
Pytania na egzamin dyplomowy z przedmiotów realizowanych przez pracowników IIwZ studia stacjonarne I stopnia Zarządzanie i Inżynieria Produkcji Pytania z przedmiotów kierunkowych 1. Co to jest algorytm?
Forma. Główny cel kursu. Umiejętności nabywane przez studentów. Wymagania wstępne:
 WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
Data Mining Wykład 1. Wprowadzenie do Eksploracji Danych. Prowadzący. Dr inż. Jacek Lewandowski
 Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Internet Semantyczny. Schematy RDF i wnioskowanie
 Internet Semantyczny Schematy RDF i wnioskowanie Ewolucja Internetu Internet dzisiaj Internet Semantyczny Jorge Cardoso, The Syntactic and the Semantic Web, in Semantic Web Services: Theory, Tools, and
Internet Semantyczny Schematy RDF i wnioskowanie Ewolucja Internetu Internet dzisiaj Internet Semantyczny Jorge Cardoso, The Syntactic and the Semantic Web, in Semantic Web Services: Theory, Tools, and
Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych
 Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych dr inż. Adam Iwaniak Infrastruktura Danych Przestrzennych w Polsce i Europie Seminarium, AR Wrocław
Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych dr inż. Adam Iwaniak Infrastruktura Danych Przestrzennych w Polsce i Europie Seminarium, AR Wrocław
I. KARTA PRZEDMIOTU CEL PRZEDMIOTU
 I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Informatyka
I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Informatyka
Bazy danych - wykład wstępny
 Bazy danych - wykład wstępny Wykład: baza danych, modele, hierarchiczny, sieciowy, relacyjny, obiektowy, schemat logiczny, tabela, kwerenda, SQL, rekord, krotka, pole, atrybut, klucz podstawowy, relacja,
Bazy danych - wykład wstępny Wykład: baza danych, modele, hierarchiczny, sieciowy, relacyjny, obiektowy, schemat logiczny, tabela, kwerenda, SQL, rekord, krotka, pole, atrybut, klucz podstawowy, relacja,
REKOMENDACJE DOTYCZĄCE PLATFORMY ZARZADZĄNIA KOMPETENCJAMI
 REKOMENDACJE DOTYCZĄCE PLATFORMY ZARZADZĄNIA KOMPETENCJAMI WYTYCZNE DO MODELU BORYS CZERNIEJEWSKI Rekomendacje dotyczące Platformy Zarządzania Kompetencjami 1. Rekomendacje odnośnie warstwy biznesowej
REKOMENDACJE DOTYCZĄCE PLATFORMY ZARZADZĄNIA KOMPETENCJAMI WYTYCZNE DO MODELU BORYS CZERNIEJEWSKI Rekomendacje dotyczące Platformy Zarządzania Kompetencjami 1. Rekomendacje odnośnie warstwy biznesowej
Model semistrukturalny
 Model semistrukturalny standaryzacja danych z różnych źródeł realizacja złożonej struktury zależności, wielokrotne zagnieżdżania zobrazowane przez grafy skierowane model samoopisujący się wielkości i typy
Model semistrukturalny standaryzacja danych z różnych źródeł realizacja złożonej struktury zależności, wielokrotne zagnieżdżania zobrazowane przez grafy skierowane model samoopisujący się wielkości i typy
Ekonomiczny Uniwersytet Dziecięcy
 Ekonomiczny Uniwersytet Dziecięcy Nowoczesna edukacja Małgorzata Dębowska Miasto Bełchatów 26 maja 2010 r. EKONOMICZNY UNIWERSYTET DZIECIĘCY WWW.UNIWERSYTET-DZIECIECY.PL Dorośli uczący się od dzieci i
Ekonomiczny Uniwersytet Dziecięcy Nowoczesna edukacja Małgorzata Dębowska Miasto Bełchatów 26 maja 2010 r. EKONOMICZNY UNIWERSYTET DZIECIĘCY WWW.UNIWERSYTET-DZIECIECY.PL Dorośli uczący się od dzieci i
Opracowywanie map w ArcGIS Online i MS Office. Urszula Kwiecień Esri Polska
 Opracowywanie map w ArcGIS Online i MS Office Urszula Kwiecień Esri Polska Agenda ArcGIS Online - filozofia tworzenia map w chmurze Wizualizacja danych tabelarycznych w MS Excel Opracowanie mapy w MS Excel
Opracowywanie map w ArcGIS Online i MS Office Urszula Kwiecień Esri Polska Agenda ArcGIS Online - filozofia tworzenia map w chmurze Wizualizacja danych tabelarycznych w MS Excel Opracowanie mapy w MS Excel
Aneta Drabek. Informacja w świecie cyfrowym, Dąbrowa Górnicza, 7-8 marca 2013 r.
 Aneta Drabek Informacja w świecie cyfrowym, Dąbrowa Górnicza, 7-8 marca 2013 r. Pełna nazwa bazy to Arianta Naukowe i Branżowe Polskie Czasopisma Elektroniczne. Adres: www.arianta.pl Arianta rejestruje
Aneta Drabek Informacja w świecie cyfrowym, Dąbrowa Górnicza, 7-8 marca 2013 r. Pełna nazwa bazy to Arianta Naukowe i Branżowe Polskie Czasopisma Elektroniczne. Adres: www.arianta.pl Arianta rejestruje
POZYCJONOWANIE W WYSZUKIWARKACH APTEK INTERNETOWYCH
 ZESZYTY NAUKOWE UNIWERSYTETU SZCZECIŃSKIEGO NR 605 STUDIA INFORMATICA NR 25 2010 PIOTR JÓZWIAK GRZEGORZ SZYMAŃSKI Politechnika Łódzka POZYCJONOWANIE W WYSZUKIWARKACH APTEK INTERNETOWYCH Pozycjonowanie
ZESZYTY NAUKOWE UNIWERSYTETU SZCZECIŃSKIEGO NR 605 STUDIA INFORMATICA NR 25 2010 PIOTR JÓZWIAK GRZEGORZ SZYMAŃSKI Politechnika Łódzka POZYCJONOWANIE W WYSZUKIWARKACH APTEK INTERNETOWYCH Pozycjonowanie
Warsztaty Facebook i media społeczniościowe. Część 1 Anna Miśniakiewicz, Konrad Postawa
 Warsztaty Facebook i media społeczniościowe Część 1 Anna Miśniakiewicz, Konrad Postawa Plan warsztatów 1. Co to są media społecznościowe? 2. Jak wygląda nowoczesna komunikacja - formy, sposoby, treści?
Warsztaty Facebook i media społeczniościowe Część 1 Anna Miśniakiewicz, Konrad Postawa Plan warsztatów 1. Co to są media społecznościowe? 2. Jak wygląda nowoczesna komunikacja - formy, sposoby, treści?
Wstęp do Technologii Semantycznych. Idea, język RDF
 Wstęp do Technologii Semantycznych Idea, język RDF Wielkość Internetu http://www.worldwidewebsize.com/ Wielkość Internetu http://www.worldwidewebsize.com/ Problem Ilość informacji jest tak duża, że realne
Wstęp do Technologii Semantycznych Idea, język RDF Wielkość Internetu http://www.worldwidewebsize.com/ Wielkość Internetu http://www.worldwidewebsize.com/ Problem Ilość informacji jest tak duża, że realne
serwisy W*S ERDAS APOLLO 2009
 serwisy W*S ERDAS APOLLO 2009 1 OGC (Open Geospatial Consortium, Inc) OGC jest międzynarodowym konsorcjum 382 firm prywatnych, agencji rządowych oraz uniwersytetów, które nawiązały współpracę w celu rozwijania
serwisy W*S ERDAS APOLLO 2009 1 OGC (Open Geospatial Consortium, Inc) OGC jest międzynarodowym konsorcjum 382 firm prywatnych, agencji rządowych oraz uniwersytetów, które nawiązały współpracę w celu rozwijania
RDF Schema (schematy RDF)
") RDF Schema (schematy RDF) Schemat RDF nie dostarcza słownictwa dla aplikacji klasy jak np.: Namiot, Książka, lub Osoba; i właściwości, takich jak np.: waga w kg, autor lub jobtitle Schemat RDF zapewnia
RDF Schema (schematy RDF) Schemat RDF nie dostarcza słownictwa dla aplikacji klasy jak np.: Namiot, Książka, lub Osoba; i właściwości, takich jak np.: waga w kg, autor lub jobtitle Schemat RDF zapewnia
Spis treści Technologia informatyczna Strategia zarządzania wiedzą... 48
 Spis treści 1. Przesłanki dla podjęcia badań...11 1.1. Wprowadzenie...11 1.2. Cel badawczy i plan pracy... 12 1.3. Obszar badawczy... 13 1.4. Znaczenie badań dla teorii... 15 1.5. Znaczenie badań dla praktyków...
Spis treści 1. Przesłanki dla podjęcia badań...11 1.1. Wprowadzenie...11 1.2. Cel badawczy i plan pracy... 12 1.3. Obszar badawczy... 13 1.4. Znaczenie badań dla teorii... 15 1.5. Znaczenie badań dla praktyków...
Wprowadzenie do technologii semantycznych
 Wprowadzenie do technologii semantycznych Sieć Semantyczna Mikołaj Morzy Agnieszka Ławrynowicz Instytut Informatyki Poznań, rok akademicki 2013/2014 (c) Mikołaj Morzy, Agnieszka Ławrynowicz, Instytut Informatyki
Wprowadzenie do technologii semantycznych Sieć Semantyczna Mikołaj Morzy Agnieszka Ławrynowicz Instytut Informatyki Poznań, rok akademicki 2013/2014 (c) Mikołaj Morzy, Agnieszka Ławrynowicz, Instytut Informatyki
Szkolenie autoryzowane. MS SharePoint Online Power User. Strona szkolenia Terminy szkolenia Rejestracja na szkolenie Promocje
 Szkolenie autoryzowane MS 55215 SharePoint Online Power User Strona szkolenia Terminy szkolenia Rejestracja na szkolenie Promocje Opis szkolenia Uczestnicy szkolenia zdobędą wiedzę potrzebną w planowaniu,
Szkolenie autoryzowane MS 55215 SharePoint Online Power User Strona szkolenia Terminy szkolenia Rejestracja na szkolenie Promocje Opis szkolenia Uczestnicy szkolenia zdobędą wiedzę potrzebną w planowaniu,
Analiza internetowa czyli Internet jako hurtownia danych
 Analiza internetowa czyli Internet jako hurtownia danych Agenda 1. Hurtownie danych, eksploracja danych i OLAP 3. Internet 5. Analiza Internetowa 7. Google Analytics 9. Podsumowanie Hurtownie danych (definicja)
Analiza internetowa czyli Internet jako hurtownia danych Agenda 1. Hurtownie danych, eksploracja danych i OLAP 3. Internet 5. Analiza Internetowa 7. Google Analytics 9. Podsumowanie Hurtownie danych (definicja)
XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery
 http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
OfficeObjects e-forms
 OfficeObjects e-forms Rodan Development Sp. z o.o. 02-820 Warszawa, ul. Wyczółki 89, tel.: (+48-22) 643 92 08, fax: (+48-22) 643 92 10, http://www.rodan.pl Spis treści Wstęp... 3 Łatwość tworzenia i publikacji
OfficeObjects e-forms Rodan Development Sp. z o.o. 02-820 Warszawa, ul. Wyczółki 89, tel.: (+48-22) 643 92 08, fax: (+48-22) 643 92 10, http://www.rodan.pl Spis treści Wstęp... 3 Łatwość tworzenia i publikacji
Wykład I. Wprowadzenie do baz danych
 Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Deduplikacja danych. Zarządzanie jakością danych podstawowych
 Deduplikacja danych Zarządzanie jakością danych podstawowych normalizacja i standaryzacja adresów standaryzacja i walidacja identyfikatorów podstawowa standaryzacja nazw firm deduplikacja danych Deduplication
Deduplikacja danych Zarządzanie jakością danych podstawowych normalizacja i standaryzacja adresów standaryzacja i walidacja identyfikatorów podstawowa standaryzacja nazw firm deduplikacja danych Deduplication
I. KARTA PRZEDMIOTU CEL PRZEDMIOTU
 I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Elektroautomatyka
I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Elektroautomatyka
Modelowanie i analiza systemów informatycznych
 Modelowanie i analiza systemów informatycznych MBSE/SysML Wykład 11 SYSMOD Wykorzystane materiały Budapest University of Technology and Economics, Department of Measurement and InformaJon Systems: The
Modelowanie i analiza systemów informatycznych MBSE/SysML Wykład 11 SYSMOD Wykorzystane materiały Budapest University of Technology and Economics, Department of Measurement and InformaJon Systems: The