Budowa modeli klasyfikacyjnych o skośnych warunkach
|
|
|
- Barbara Kubiak
- 4 lat temu
- Przeglądów:
Transkrypt
1 Budowa modeli klasyfikacyjnych o skośnych warunkach Marcin Michalak (Marcin.Michalak@polsl.pl) III spotkanie Polskiej Grupy Badawczej Systemów Uczących Się Wrocław,
2 Outline 1 Dwa podejścia Ilustracja graficzna 2 Innerozwiązania 3 Naszerozwiązania ORG(ORG 1.0) PCAORG(ORG2.0) PCAORG(ORG2.1) 4
3 Dwa podejścia Dwa podejścia Ilustracja graficzna Podejście jawne drzewa decyzyjne systemy regułowe liniowe SVM Podejście ukryte sztuczne sieci neuronowe nieliniowe SVM GLM
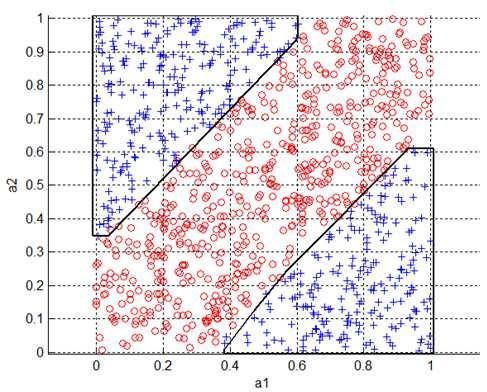
4 Dwa podejścia Ilustracja graficzna Rysunek: Dwuwymiarowy, dwuklasowy zbiór danych


5 Dwa podejścia Ilustracja graficzna Rysunek: Dwuwymiarowy, dwuklasowy zbiór danych.
6 Dwa podejścia Ilustracja graficzna Rysunek: Dwuwymiarowy, dwuklasowy zbiór danych.
7 Dwa podejścia Ilustracja graficzna Rysunek: Dwuwymiarowy, dwuklasowy zbiór danych.


8 Dwa podejścia Ilustracja graficzna Rysunek: Dwuwymiarowy, dwuklasowy zbiór danych.
9 Ekstrapolacja SVM Barakat N., Diederych J. Learning-based Rule-extraction from Support Vector Machines. In 14th International Conference on Computer Theory and Applications ICCTA 2004 Proceedings, Alexandria, Egypt, , 2004 Zbuduj SVM. Wygeneruj nowe przypadki losowo i zaklasyfikuj je zgodnie z SVM. Z gęstszego zbioru wygeneruj reguły decyzyjne.
10 Pokywanie obszaru pod liniowym SVM FungG.,SandilyaS.,RaoR. Rule Extraction from Linear Support Vector Machines. In Proceedings of the 11th ACM SIGKDD international Conference on Knowledge Discovery in Data Mining, 32-40, 2005 Zbuduj liniowy SMV Pokrywaj obszar pod ( nad ) rozłącznymi hiperprostopadłościanami o jednym wierzchołku na OSH

11 Pokywanie obszaru pod liniowym SVM
12 ITER MINERVA Huysmans J., Baesens B., Vanthienen J. ITER: an Algorithm for Predictive Regression Rule Extraction, LNCS 4081: , 2006 Huysmans J., Setiono R., Baesens B., Vanthienen J. Minerva: Sequential Covering for Rule Extraction, IEEE Transactions On Systems, Man, and Cybernetics-Part B: Cybernetics, 38(2): , 2008
13 ITER MINERVA ITER pedagocical regression rule extractor, bazuje na dowolnym regresorze iteracyjnie zwiększa pokrycie hiperprostopadłościanami MINERVA zapobiega pokrywaniu się reguł, ale nadal nie wykrywa skośności

14 ITER MINERVA
15 ITER MINERVA
16 SVMPrototypes NunezH.,AnguloC.,CatalaA. Rule Extraction from Support Vector Machines, proc. of European Symposium on Artificial Networks, , 2002 Zbuduj SVM(znajdź wektory podpierające) Podziel klasy na podklasy(znajdź prototypy podklas) para SV prototyp definiuje regułę(elipsoida albo hiperprostopadłościan)
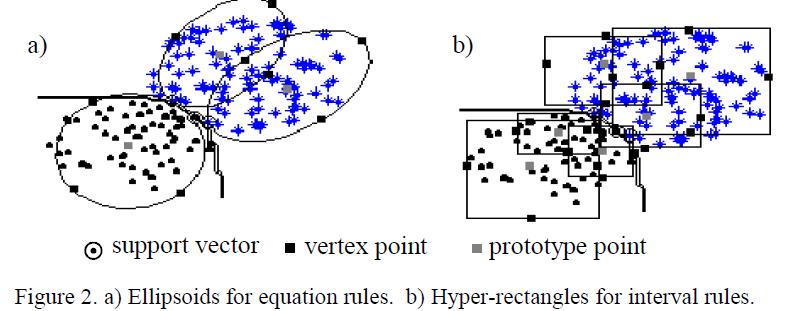
17 SVMPrototype
18 Advanced
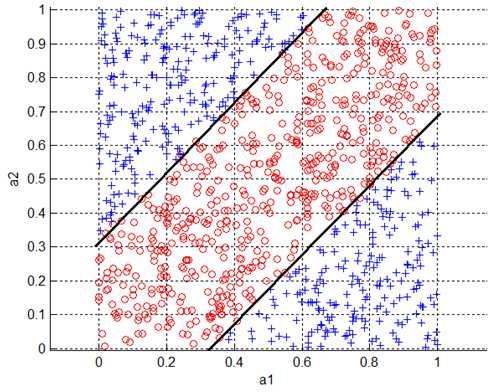
19 Skośne zbiory danych Rysunek: Trzy zbiory skośnych danych: 2d(z lewej); d2d(pośrodku); 3d(z prawej).
20 Oblique Rules Generator Publikacja Michalak M., Sikora M., Ziarnik P.: ORG- Oblique Rules Generator, In: Rutkowski, L., Korytkowski, M., Scherer, R., Tadeusiewicz, R., Zadeh, L.A., Zurada, J.M.(eds.) ICAISC 2012, Part II. LNCS, vol. 7268, pp ,(2012) Główna idea Kolejne skośne warunki(hiperpłaszczyzny) reguły poszukiwane metodą siatkowego przeszukiwania przestrzeni parametrów warunku.
21 Założenia Równanie normalne hiperpłaszczyzny: α 1 x 1 α 2 x 2...α n x n ρ =0 Warunek kosinusów kierunkowych: α 2 1 α α 2 n =1
22 Założenia(c.d.) Ograniczenia wartości kosinusów naturalne; Ograniczenie maksymalnej odległości, przy założeniu, że wszystkie punkty mają dodatnie współrzędne: ( ρ max (θ opt ) = x max cos arctg y ) ( max y max sin arctg y ) max x max x max
23 Algorytm 1: Train All,RCnt 0,Rules 2:while card(rules)<rdo 3: Rule, Train Rule Train 4: while card(rule) < C do 5: bestcond 6: bestcondq 0 7: foreach cell Griddo 8: cond cell 9: condq Q(cond) 10: if condq > bestcondq then 11: bestcondq condq 12: bestcond cond 13: end if 14: end for each 15: Rule temp Rule bestcond 16: if Q(Rule temp)>q(rule) then 17: Rule Rule temp 18: end if 19: Train Rule Train Rule \under(bestcond) 20: if Q(Rule) =1then 21: break 22: end if 23: if card(train Rule ) =0then 24: break 25: end if 26: end while 27: Train Rule Train Rule \covered(rule) 28: Rules Rules Rule 29: end while
24 Podsumowanie Cechy Poszukiwanie skośnych warunków odbywa się metodą siatkową. Budowa reguły odbywa się metodą wspinaczki. Wady Bardzo duża złożoność obliczeniowa. Ocena jakości skośnych warunków jest globalna. Tylko niektore skośne warunki brane są pod uwagę(siatka).
25 PCAORG(ORG2.0) Publikacja Michalak M., Nurzyńska K.: PCA Based Oblique Decision Rules Generating, In: Tomassini, M., Antonioni, A., Daolio, F., Buesser, B. (Eds.): ICANNGA 2013, LNCS, vol. 7824, pp ,(2013) Główna idea opis klasy to opis jej podklas, wyznaczonych metodą grupowania, opis podklasy to hiperprostopadłościan, o krawędziach wyznaczonych przez PCA dla podklasy.
26 Założenia i ich spełnianie Założenia wstępne: Reguły opisują lokalne zależności w danych. Poszukiwanie skośnych warunków odbywa się lokalnie. Mniejsza złożoność obliczeniowa niż ORG 1.0. Spełnienie założeń Ad. 1: Podklasy wygenerowane algorytmem k-means. Ad. 2 i 3: ściany hiperprostopadłościanu są równoległe do kierunków wyznaczonych przez PCA dla podklasy.
27 Pojedyńcza podklasa
28 Nowe kierunki znalezione przez PCA
29 Pary skośnych warunków, równoległe do kierunków z PCA
30 Nowa, wypukła reguła decyzyjna
31 Silne strony Mała liczba reguł przypadająca na każdą klasę. Bardzo wysoka jakość klasyfikacji typowo skośnych zależności. Słabe strony Słabe wyniki dla klas pokrywających się i wklęsłych. Duża liczba parametrów uzyskanych modeli. Brak postprocessingu uzyskanych reguł.
32 Advanced PCA ORG(ORG 2.1) Publikacja(w druku) Michalak M., Nurzyńska K.: Advanced Oblique Rule Generating Based on PCA, ICAISC 2014, LNCS??(2014) Główne idee: przycinanie reguł: eliminacja zbędnych warunków metodą wspinaczki; uogólnianie skośnych warunków: eliminacja zmiennych z warunku, jeśli jej współczynnik jest niski.
33 Przycinanie reguł idea
34 Przycinanie reguł idea
35 Przycinanie reguł idea
36 Przycinanie reguł idea
37 Uogólnianie reguł idea
38 Uogólnianie reguł idea
39 Uogólnianie reguł idea
40 Porównanie wyników dataset accuracy avg(std) ORG ORG2.0 ORG2.1 2d 96.0(1.5) 98.4(1.0) 98.8(0.98) d2d 84.3(3.1) 99.0(1.1) 99.3(0.64) 3d 98.2(1.2) 98.3(1.6) 98.7(1.27) avg. rules total number dataset number of cond. elem. ORG ORG2.0 ORG2.1 ORG ORG2.0 ORG2.1 2d d2d d
41 Porównanie wyników dataset accuracy avg(std) ORG ORG2.0 ORG2.1 iris 94(4.6) 84(8.4) 90.7(7.42) balance 92(2.4) 80(4.2) 76.6(4.7) Ripley 81(8.4) 65(11.6) 74.4(10.76) breast w. 97(1.7) 92(3.0) 89.9(4.86) avg. rules total number dataset number of cond. elem. ORG ORG2.0 ORG2.1 ORG ORG2.0 ORG2.1 iris balance Ripley breastw
42 Porównanie wyników dataset average accuracy(std) PART JRIP ORG2.1 d2d (0.64) 3d (1.27) 2d (0.98) avg. rules total number dataset number of. cond. elem. PART JRIP ORG2.1 PART JRIP ORG2.1 d2d d d
43 Porównanie wyników dataset average accuracy(std) PART JRIP ORG2.1 Ripley (10.76) balance (4.70) breast w (4.86) iris (7.42) vehicle (4.31) avg. rules total number dataset number of. cond. elem. PART JRIP ORG2.1 PART JRIP ORG2.1 Ripley balance breast w iris vehicle
44 Publikacja Sikora M., Gudyś A.: - Convex Hull Based Iterative Algorithm of Rules Aggregation, Fundamenta Informatice 123: , 2013 Główne idee: przycinanie reguł: eliminacja zbędnych warunków metodą wspinaczki; uogólnianie skośnych warunków: eliminacja zmiennych z warunku, jeśli jej współczynnik jest niski. Implementacje w: Matlab Weka

45 - surowe reguły

46 - agregacja
47 - tuning
48 - przycinanie
49 - wyniki

 ul.")
50 strona internetowa: spotkania: czwartki ok 14:00, aula F 2. piętro wydziału Automatyki Elektroniki i Informatyki (Politechnika Śląska) ul. Akademicka 16, Gliwice kontakt: dr inż. Michał Kozielski(Michal.Kozielski@polsl.pl)
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner
 Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
B jest globalnym pokryciem zbioru {d} wtedy i tylko wtedy, gdy {d} zależy od B i nie istnieje B T takie, że {d} zależy od B ;
 Algorytm LEM1 Oznaczenia i definicje: U - uniwersum, tj. zbiór obiektów; A - zbiór atrybutów warunkowych; d - atrybut decyzyjny; IND(B) = {(x, y) U U : a B a(x) = a(y)} - relacja nierozróżnialności, tj.
Algorytm LEM1 Oznaczenia i definicje: U - uniwersum, tj. zbiór obiektów; A - zbiór atrybutów warunkowych; d - atrybut decyzyjny; IND(B) = {(x, y) U U : a B a(x) = a(y)} - relacja nierozróżnialności, tj.
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów
 LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
Michał Kozielski Łukasz Warchał. Instytut Informatyki, Politechnika Śląska
 Michał Kozielski Łukasz Warchał Instytut Informatyki, Politechnika Śląska Algorytm DBSCAN Algorytm OPTICS Analiza gęstego sąsiedztwa w grafie Wstępne eksperymenty Podsumowanie Algorytm DBSCAN Analiza gęstości
Michał Kozielski Łukasz Warchał Instytut Informatyki, Politechnika Śląska Algorytm DBSCAN Algorytm OPTICS Analiza gęstego sąsiedztwa w grafie Wstępne eksperymenty Podsumowanie Algorytm DBSCAN Analiza gęstości
Sztuczna Inteligencja Projekt
 Sztuczna Inteligencja Projekt Temat: Algorytm LEM2 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm LEM 2. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu LEM 2 wygenerować
Sztuczna Inteligencja Projekt Temat: Algorytm LEM2 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm LEM 2. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu LEM 2 wygenerować
Maszyny wektorów podpierajacych w regresji rangowej
 Maszyny wektorów podpierajacych w regresji rangowej Uniwersytet Mikołaja Kopernika Z = (X, Y ), Z = (X, Y ) - niezależne wektory losowe o tym samym rozkładzie X X R d, Y R Z = (X, Y ), Z = (X, Y ) - niezależne
Maszyny wektorów podpierajacych w regresji rangowej Uniwersytet Mikołaja Kopernika Z = (X, Y ), Z = (X, Y ) - niezależne wektory losowe o tym samym rozkładzie X X R d, Y R Z = (X, Y ), Z = (X, Y ) - niezależne
Drzewa decyzyjne i lasy losowe
 Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytm Grovera. Kwantowe przeszukiwanie zbiorów. Robert Nowotniak
 Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Politechnika Łódzka 13 listopada 2007 Plan wystapienia 1 Informatyka Kwantowa podstawy 2 Opis problemu (przeszukiwanie zbioru) 3 Intuicyjna
Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej Politechnika Łódzka 13 listopada 2007 Plan wystapienia 1 Informatyka Kwantowa podstawy 2 Opis problemu (przeszukiwanie zbioru) 3 Intuicyjna
Rozmyte drzewa decyzyjne. Łukasz Ryniewicz Metody inteligencji obliczeniowej
 µ(x) x µ(x) µ(x) x x µ(x) µ(x) x x µ(x) x µ(x) x Rozmyte drzewa decyzyjne Łukasz Ryniewicz Metody inteligencji obliczeniowej 21.05.2007 AGENDA 1 Drzewa decyzyjne kontra rozmyte drzewa decyzyjne, problemy
µ(x) x µ(x) µ(x) x x µ(x) µ(x) x x µ(x) x µ(x) x Rozmyte drzewa decyzyjne Łukasz Ryniewicz Metody inteligencji obliczeniowej 21.05.2007 AGENDA 1 Drzewa decyzyjne kontra rozmyte drzewa decyzyjne, problemy
Optymalizacja reguł decyzyjnych względem pokrycia
 Zakład Systemów Informatycznych Instytut Informatyki, Uniwersytet Śląski Chorzów, 9 grudzień 2014 Wprowadzenie Wprowadzenie problem skalowalności dla optymalizacji reguł decyzjnych na podstawie podejścia
Zakład Systemów Informatycznych Instytut Informatyki, Uniwersytet Śląski Chorzów, 9 grudzień 2014 Wprowadzenie Wprowadzenie problem skalowalności dla optymalizacji reguł decyzjnych na podstawie podejścia
Automatyczne wyodrębnianie reguł
 Automatyczne wyodrębnianie reguł Jedną z form reprezentacji wiedzy jest jej zapis w postaci zestawu reguł. Ta forma ma szereg korzyści: daje się łatwo interpretować, można zrozumieć sposób działania zbudowanego
Automatyczne wyodrębnianie reguł Jedną z form reprezentacji wiedzy jest jej zapis w postaci zestawu reguł. Ta forma ma szereg korzyści: daje się łatwo interpretować, można zrozumieć sposób działania zbudowanego
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Metody Programowania
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Metody Programowania www.pk.edu.pl/~zk/mp_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 8: Wyszukiwanie
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Metody Programowania www.pk.edu.pl/~zk/mp_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 8: Wyszukiwanie
Programowanie liniowe
 Programowanie liniowe Maciej Drwal maciej.drwal@pwr.wroc.pl 1 Problem programowania liniowego min x c T x (1) Ax b, (2) x 0. (3) gdzie A R m n, c R n, b R m. Oznaczmy przez x rozwiązanie optymalne, tzn.
Programowanie liniowe Maciej Drwal maciej.drwal@pwr.wroc.pl 1 Problem programowania liniowego min x c T x (1) Ax b, (2) x 0. (3) gdzie A R m n, c R n, b R m. Oznaczmy przez x rozwiązanie optymalne, tzn.
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
PROGRAMOWANIE DYNAMICZNE W ROZMYTYM OTOCZENIU DO STEROWANIA STATKIEM
 Mostefa Mohamed-Seghir Akademia Morska w Gdyni PROGRAMOWANIE DYNAMICZNE W ROZMYTYM OTOCZENIU DO STEROWANIA STATKIEM W artykule przedstawiono propozycję zastosowania programowania dynamicznego do rozwiązywania
Mostefa Mohamed-Seghir Akademia Morska w Gdyni PROGRAMOWANIE DYNAMICZNE W ROZMYTYM OTOCZENIU DO STEROWANIA STATKIEM W artykule przedstawiono propozycję zastosowania programowania dynamicznego do rozwiązywania
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Adrian Horzyk
 Sztuczne Systemy Skojarzeniowe SSS Asocjacyjne grafowe struktury danych AGDS Associative Graph Data Structure Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki,
Sztuczne Systemy Skojarzeniowe SSS Asocjacyjne grafowe struktury danych AGDS Associative Graph Data Structure Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki,
Metody zbiorów przybliżonych w uczeniu się podobieństwa z wielowymiarowych zbiorów danych
 Metody zbiorów przybliżonych w uczeniu się podobieństwa z wielowymiarowych zbiorów danych WMIM, Uniwersytet Warszawski ul. Banacha 2, 02-097 Warszawa, Polska andrzejanusz@gmail.com 13.06.2013 Dlaczego
Metody zbiorów przybliżonych w uczeniu się podobieństwa z wielowymiarowych zbiorów danych WMIM, Uniwersytet Warszawski ul. Banacha 2, 02-097 Warszawa, Polska andrzejanusz@gmail.com 13.06.2013 Dlaczego
Ćwiczenie 5. Metody eksploracji danych
 Ćwiczenie 5. Metody eksploracji danych Reguły asocjacyjne (association rules) Badaniem atrybutów lub cech, które są powiązane ze sobą, zajmuje się analiza podobieństw (ang. affinity analysis). Metody analizy
Ćwiczenie 5. Metody eksploracji danych Reguły asocjacyjne (association rules) Badaniem atrybutów lub cech, które są powiązane ze sobą, zajmuje się analiza podobieństw (ang. affinity analysis). Metody analizy
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Deep Learning na przykładzie Deep Belief Networks
 Deep Learning na przykładzie Deep Belief Networks Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych PW 20 V 2014 Jan Karwowski (MiNI) Deep Learning
Deep Learning na przykładzie Deep Belief Networks Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych PW 20 V 2014 Jan Karwowski (MiNI) Deep Learning
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Laboratorium 11. Regresja SVM.
 Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej. Adam Żychowski
 Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
Hard-Margin Support Vector Machines
 Hard-Margin Support Vector Machines aaacaxicbzdlssnafiyn9vbjlepk3ay2gicupasvu4iblxuaw2hjmuwn7ddjjmxm1bkcg1/fjqsvt76fo9/gazqfvn8y+pjpozw5vx8zkpvtfxmlhcwl5zxyqrm2vrg5zw3vxmsoezi4ogkr6phieky5crvvjhriqvdom9l2xxftevuwcekj3lktmhghgniauiyutvrwxtvme34a77kbvg73gtygpjsrfati1+xc8c84bvraowbf+uwnipyehcvmkjrdx46vlykhkgykm3ujjdhcyzqkxy0chur6ax5cbg+1m4bbjptjcubuz4kuhvjoql93hkin5hxtav5x6yyqopnsyuneey5ni4keqrxbar5wqaxbik00icyo/iveiyqqvjo1u4fgzj/8f9x67bzmxnurjzmijtlybwfgcdjgfdtajwgcf2dwaj7ac3g1ho1n4814n7wwjgjmf/ys8fenfycuzq==
Hard-Margin Support Vector Machines aaacaxicbzdlssnafiyn9vbjlepk3ay2gicupasvu4iblxuaw2hjmuwn7ddjjmxm1bkcg1/fjqsvt76fo9/gazqfvn8y+pjpozw5vx8zkpvtfxmlhcwl5zxyqrm2vrg5zw3vxmsoezi4ogkr6phieky5crvvjhriqvdom9l2xxftevuwcekj3lktmhghgniauiyutvrwxtvme34a77kbvg73gtygpjsrfati1+xc8c84bvraowbf+uwnipyehcvmkjrdx46vlykhkgykm3ujjdhcyzqkxy0chur6ax5cbg+1m4bbjptjcubuz4kuhvjoql93hkin5hxtav5x6yyqopnsyuneey5ni4keqrxbar5wqaxbik00icyo/iveiyqqvjo1u4fgzj/8f9x67bzmxnurjzmijtlybwfgcdjgfdtajwgcf2dwaj7ac3g1ho1n4814n7wwjgjmf/ys8fenfycuzq==
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
THE PART OF FUZZY SYSTEMS ASSISTING THE DECISION IN DI- AGNOSTICS OF FUEL ENGINE SUBASSEMBLIES DEFECTS
 Journal of KONES Internal Combustion Engines 2005, vol. 12, 3-4 THE PART OF FUZZY SYSTEMS ASSISTING THE DECISION IN DI- AGNOSTICS OF FUEL ENGINE SUBASSEMBLIES DEFECTS Mariusz Topolski Politechnika Wrocławska,
Journal of KONES Internal Combustion Engines 2005, vol. 12, 3-4 THE PART OF FUZZY SYSTEMS ASSISTING THE DECISION IN DI- AGNOSTICS OF FUEL ENGINE SUBASSEMBLIES DEFECTS Mariusz Topolski Politechnika Wrocławska,
Sztuczna Inteligencja Projekt
 Sztuczna Inteligencja Projekt Temat: Algorytm F-LEM1 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm F LEM 1. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu F LEM1
Sztuczna Inteligencja Projekt Temat: Algorytm F-LEM1 Liczba osób realizujących projekt: 2 1. Zaimplementować algorytm F LEM 1. 2. Zaimplementować klasyfikator Classif ier. 3. Za pomocą algorytmu F LEM1
Ontogeniczne sieci neuronowe. O sieciach zmieniających swoją strukturę
 Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Wykorzystanie zbiorów przybliżonych w analizie Kansei
 This paper should be cited as: Ludwiszewski, B., Redlarski, K., & Wachowicz, J. (2010). Wykorzystanie zbiorów przybliżonych w analizie Kansei. Proceedings of the Conference: Interfejs użytkownika - Kansei
This paper should be cited as: Ludwiszewski, B., Redlarski, K., & Wachowicz, J. (2010). Wykorzystanie zbiorów przybliżonych w analizie Kansei. Proceedings of the Conference: Interfejs użytkownika - Kansei
Eksploracja danych. KLASYFIKACJA I REGRESJA cz. 2. Wojciech Waloszek. Teresa Zawadzka.
 Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
UCZENIE MASZYNOWE III - SVM. mgr inż. Adam Kupryjanow
 UCZENIE MASZYNOWE III - SVM mgr inż. Adam Kupryjanow Plan wykładu Wprowadzenie LSVM dane separowalne liniowo SVM dane nieseparowalne liniowo Nieliniowy SVM Kernel trick Przykłady zastosowań Historia 1992
UCZENIE MASZYNOWE III - SVM mgr inż. Adam Kupryjanow Plan wykładu Wprowadzenie LSVM dane separowalne liniowo SVM dane nieseparowalne liniowo Nieliniowy SVM Kernel trick Przykłady zastosowań Historia 1992
Wstęp do przetwarzania języka naturalnego. Wykład 11 Maszyna Wektorów Nośnych
 Wstęp do przetwarzania języka naturalnego Wykład 11 Wojciech Czarnecki 8 stycznia 2014 Section 1 Przypomnienie Wektoryzacja tfidf Przypomnienie document x y z Antony and Cleopatra 5.25 1.21 1.51 Julius
Wstęp do przetwarzania języka naturalnego Wykład 11 Wojciech Czarnecki 8 stycznia 2014 Section 1 Przypomnienie Wektoryzacja tfidf Przypomnienie document x y z Antony and Cleopatra 5.25 1.21 1.51 Julius
Elementy inteligencji obliczeniowej
 Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Sztuczna Inteligencja i Systemy Doradcze
 Sztuczna Inteligencja i Systemy Doradcze Przeszukiwanie przestrzeni stanów algorytmy ślepe Przeszukiwanie przestrzeni stanów algorytmy ślepe 1 Strategie slepe Strategie ślepe korzystają z informacji dostępnej
Sztuczna Inteligencja i Systemy Doradcze Przeszukiwanie przestrzeni stanów algorytmy ślepe Przeszukiwanie przestrzeni stanów algorytmy ślepe 1 Strategie slepe Strategie ślepe korzystają z informacji dostępnej
Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane cd.
 Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane cd. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 2013-11-26 Projekt pn. Wzmocnienie potencjału
Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane cd. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 2013-11-26 Projekt pn. Wzmocnienie potencjału
data mining machine learning data science
 data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
Metody Obliczeniowe w Nauce i Technice
 9 - Rozwiązywanie układów równań nieliniowych Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl Contributors Anna Marciniec
9 - Rozwiązywanie układów równań nieliniowych Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl Contributors Anna Marciniec
RÓWNANIA NIELINIOWE Maciej Patan
 RÓWNANIA NIELINIOWE Maciej Patan Uniwersytet Zielonogórski Przykład 1 Prędkość v spadającego spadochroniarza wyraża się zależnością v = mg ( 1 e c t) m c gdzie g = 9.81 m/s 2. Dla współczynnika oporu c
RÓWNANIA NIELINIOWE Maciej Patan Uniwersytet Zielonogórski Przykład 1 Prędkość v spadającego spadochroniarza wyraża się zależnością v = mg ( 1 e c t) m c gdzie g = 9.81 m/s 2. Dla współczynnika oporu c
1 Wprowadzenie do algorytmiki
 Teoretyczne podstawy informatyki - ćwiczenia: Prowadzący: dr inż. Dariusz W Brzeziński 1 Wprowadzenie do algorytmiki 1.1 Algorytm 1. Skończony, uporządkowany ciąg precyzyjnie i zrozumiale opisanych czynności
Teoretyczne podstawy informatyki - ćwiczenia: Prowadzący: dr inż. Dariusz W Brzeziński 1 Wprowadzenie do algorytmiki 1.1 Algorytm 1. Skończony, uporządkowany ciąg precyzyjnie i zrozumiale opisanych czynności
Metody Numeryczne Optymalizacja. Wojciech Szewczuk
 Metody Numeryczne Optymalizacja Optymalizacja Definicja 1 Przez optymalizację będziemy rozumieć szukanie minimów lub maksimów funkcji. Optymalizacja Definicja 2 Optymalizacja lub programowanie matematyczne
Metody Numeryczne Optymalizacja Optymalizacja Definicja 1 Przez optymalizację będziemy rozumieć szukanie minimów lub maksimów funkcji. Optymalizacja Definicja 2 Optymalizacja lub programowanie matematyczne
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych
 Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
DRZEWA REGRESYJNE I LASY LOSOWE JAKO
 DRZEWA REGRESYJNE I LASY LOSOWE JAKO NARZĘDZIA PREDYKCJI SZEREGÓW CZASOWYCH Z WAHANIAMI SEZONOWYMI Grzegorz Dudek Instytut Informatyki Wydział Elektryczny Politechnika Częstochowska www.gdudek.el.pcz.pl
DRZEWA REGRESYJNE I LASY LOSOWE JAKO NARZĘDZIA PREDYKCJI SZEREGÓW CZASOWYCH Z WAHANIAMI SEZONOWYMI Grzegorz Dudek Instytut Informatyki Wydział Elektryczny Politechnika Częstochowska www.gdudek.el.pcz.pl
Data Mining Wykład 6. Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa.
 Naiwny klasyfikator Bayesa.") GLM (Generalized Linear Models) Data Mining Wykład 6 Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa jest klasyfikatorem statystycznym -
GLM (Generalized Linear Models) Data Mining Wykład 6 Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa jest klasyfikatorem statystycznym -
Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska
 Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska e-mail: bartosz.krawczyk@pwr.wroc.pl Czym jest klasyfikacja
Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska e-mail: bartosz.krawczyk@pwr.wroc.pl Czym jest klasyfikacja
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Uniwersytet Zielonogórski Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Sterowania i Systemów Informatycznych
 Uniwersytet Zielonogórski Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Sterowania i Systemów Informatycznych ELEMENTY SZTUCZNEJ INTELIGENCJI Laboratorium nr 9 PRZESZUKIWANIE GRAFÓW Z
Uniwersytet Zielonogórski Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Sterowania i Systemów Informatycznych ELEMENTY SZTUCZNEJ INTELIGENCJI Laboratorium nr 9 PRZESZUKIWANIE GRAFÓW Z
Metody Sztucznej Inteligencji II
 17 marca 2013 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką, która jest w stanie odbierać i przekazywać sygnały elektryczne. Neuron działanie Jeżeli wartość sygnału
17 marca 2013 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką, która jest w stanie odbierać i przekazywać sygnały elektryczne. Neuron działanie Jeżeli wartość sygnału
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wprowadzenie do klasyfikacji
 Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Grupowanie Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633
 Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Zrównoleglona optymalizacja stochastyczna na dużych zbiorach danych
 Zrównoleglona optymalizacja stochastyczna na dużych zbiorach danych mgr inż. C. Dendek prof. nzw. dr hab. J. Mańdziuk Politechnika Warszawska, Wydział Matematyki i Nauk Informacyjnych Outline 1 Uczenie
Zrównoleglona optymalizacja stochastyczna na dużych zbiorach danych mgr inż. C. Dendek prof. nzw. dr hab. J. Mańdziuk Politechnika Warszawska, Wydział Matematyki i Nauk Informacyjnych Outline 1 Uczenie
zajęcia 1. Bartosz Górski, Tomasz Kulczyński, Błażej Osiński
 zajęcia 1. Bartosz Górski, Tomasz Kulczyński, Błażej Osiński Geometria dla informatyka wyłacznie obliczenia wszystko oparte na liczbach, współrzędnych, miarach programista i/lub użytkownik musi przełożyć
zajęcia 1. Bartosz Górski, Tomasz Kulczyński, Błażej Osiński Geometria dla informatyka wyłacznie obliczenia wszystko oparte na liczbach, współrzędnych, miarach programista i/lub użytkownik musi przełożyć
ID1SII4. Informatyka I stopień (I stopień / II stopień) ogólnoakademicki (ogólno akademicki / praktyczny) stacjonarne (stacjonarne / niestacjonarne)
 ogólnoakademicki (ogólno akademicki / praktyczny) stacjonarne (stacjonarne / niestacjonarne)") Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu ID1SII4 Nazwa modułu Systemy inteligentne 1 Nazwa modułu w języku angielskim Intelligent
Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu ID1SII4 Nazwa modułu Systemy inteligentne 1 Nazwa modułu w języku angielskim Intelligent
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Algorytmy zrandomizowane
 Algorytmy zrandomizowane http://zajecia.jakubw.pl/nai ALGORYTMY ZRANDOMIZOWANE Algorytmy, których działanie uzależnione jest od czynników losowych. Algorytmy typu Monte Carlo: dają (po pewnym czasie) wynik
Algorytmy zrandomizowane http://zajecia.jakubw.pl/nai ALGORYTMY ZRANDOMIZOWANE Algorytmy, których działanie uzależnione jest od czynników losowych. Algorytmy typu Monte Carlo: dają (po pewnym czasie) wynik
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
8. Drzewa decyzyjne, bagging, boosting i lasy losowe
 Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Metody eksploracji danych 2. Metody regresji. Piotr Szwed Katedra Informatyki Stosowanej AGH 2017
 Metody eksploracji danych 2. Metody regresji Piotr Szwed Katedra Informatyki Stosowanej AGH 2017 Zagadnienie regresji Dane: Zbiór uczący: D = {(x i, y i )} i=1,m Obserwacje: (x i, y i ), wektor cech x
Metody eksploracji danych 2. Metody regresji Piotr Szwed Katedra Informatyki Stosowanej AGH 2017 Zagadnienie regresji Dane: Zbiór uczący: D = {(x i, y i )} i=1,m Obserwacje: (x i, y i ), wektor cech x
Algorytm simplex i dualność
 Algorytm simplex i dualność Łukasz Kowalik Instytut Informatyki, Uniwersytet Warszawski April 15, 2016 Łukasz Kowalik (UW) LP April 15, 2016 1 / 35 Przypomnienie 1 Wierzchołkiem wielościanu P nazywamy
Algorytm simplex i dualność Łukasz Kowalik Instytut Informatyki, Uniwersytet Warszawski April 15, 2016 Łukasz Kowalik (UW) LP April 15, 2016 1 / 35 Przypomnienie 1 Wierzchołkiem wielościanu P nazywamy
Arkusz 6. Elementy geometrii analitycznej w przestrzeni
 Arkusz 6. Elementy geometrii analitycznej w przestrzeni Zadanie 6.1. Obliczyć długości podanych wektorów a) a = [, 4, 12] b) b = [, 5, 2 2 ] c) c = [ρ cos φ, ρ sin φ, h], ρ 0, φ, h R c) d = [ρ cos φ cos
Arkusz 6. Elementy geometrii analitycznej w przestrzeni Zadanie 6.1. Obliczyć długości podanych wektorów a) a = [, 4, 12] b) b = [, 5, 2 2 ] c) c = [ρ cos φ, ρ sin φ, h], ρ 0, φ, h R c) d = [ρ cos φ cos
Optymalizacja ciągła
 Optymalizacja ciągła 0. Wprowadzenie Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 28.02.2019 1 / 11 Kontakt wojciech.kotlowski@cs.put.poznan.pl http://www.cs.put.poznan.pl/wkotlowski/mp/
Optymalizacja ciągła 0. Wprowadzenie Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 28.02.2019 1 / 11 Kontakt wojciech.kotlowski@cs.put.poznan.pl http://www.cs.put.poznan.pl/wkotlowski/mp/
A Zadanie
 where a, b, and c are binary (boolean) attributes. A Zadanie 1 2 3 4 5 6 7 8 9 10 Punkty a (maks) (2) (2) (2) (2) (4) F(6) (8) T (8) (12) (12) (40) Nazwisko i Imiȩ: c Uwaga: ta część zostanie wypełniona
where a, b, and c are binary (boolean) attributes. A Zadanie 1 2 3 4 5 6 7 8 9 10 Punkty a (maks) (2) (2) (2) (2) (4) F(6) (8) T (8) (12) (12) (40) Nazwisko i Imiȩ: c Uwaga: ta część zostanie wypełniona
ALGORYTM ZACHŁANNY DLA KONSTRUOWANIA CZĘŚCIOWYCH REGUŁ ASOCJACYJNYCH
 STUDIA INFORMATICA 2010 Volume 31 Number 2A (89) Beata ZIELOSKO Uniwersytet Śląski, Instytut Informatyki ALGORYTM ZACHŁANNY DLA KONSTRUOWANIA CZĘŚCIOWYCH REGUŁ ASOCJACYJNYCH Streszczenie. W artykule przedstawiono
STUDIA INFORMATICA 2010 Volume 31 Number 2A (89) Beata ZIELOSKO Uniwersytet Śląski, Instytut Informatyki ALGORYTM ZACHŁANNY DLA KONSTRUOWANIA CZĘŚCIOWYCH REGUŁ ASOCJACYJNYCH Streszczenie. W artykule przedstawiono
Wykład wprowadzający
 Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Wykład wprowadzający dr inż. Michał Grochowski kiss.pg.mg@gmail.com michal.grochowski@pg.gda.pl
Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Wykład wprowadzający dr inż. Michał Grochowski kiss.pg.mg@gmail.com michal.grochowski@pg.gda.pl
6. Zagadnienie parkowania ciężarówki.
 6. Zagadnienie parkowania ciężarówki. Sterowniki rozmyte Aby móc sterować przebiegiem pewnych procesów lub też pracą urządzeń niezbędne jest stworzenie odpowiedniego modelu, na podstawie którego można
6. Zagadnienie parkowania ciężarówki. Sterowniki rozmyte Aby móc sterować przebiegiem pewnych procesów lub też pracą urządzeń niezbędne jest stworzenie odpowiedniego modelu, na podstawie którego można
Literatura. Sztuczne sieci neuronowe. Przepływ informacji w systemie nerwowym. Budowa i działanie mózgu
 Literatura Wykład : Wprowadzenie do sztucznych sieci neuronowych Małgorzata Krętowska Wydział Informatyki Politechnika Białostocka Tadeusiewicz R: Sieci neuronowe, Akademicka Oficyna Wydawnicza RM, Warszawa
Literatura Wykład : Wprowadzenie do sztucznych sieci neuronowych Małgorzata Krętowska Wydział Informatyki Politechnika Białostocka Tadeusiewicz R: Sieci neuronowe, Akademicka Oficyna Wydawnicza RM, Warszawa
ALGORYTM PROJEKTOWANIA ROZMYTYCH SYSTEMÓW EKSPERCKICH TYPU MAMDANI ZADEH OCENIAJĄCYCH EFEKTYWNOŚĆ WYKONANIA ZADANIA BOJOWEGO
 Szybkobieżne Pojazdy Gąsienicowe (2) Nr 2, 24 Mirosław ADAMSKI Norbert GRZESIK ALGORYTM PROJEKTOWANIA CH SYSTEMÓW EKSPERCKICH TYPU MAMDANI ZADEH OCENIAJĄCYCH EFEKTYWNOŚĆ WYKONANIA ZADANIA BOJOWEGO. WSTĘP
Szybkobieżne Pojazdy Gąsienicowe (2) Nr 2, 24 Mirosław ADAMSKI Norbert GRZESIK ALGORYTM PROJEKTOWANIA CH SYSTEMÓW EKSPERCKICH TYPU MAMDANI ZADEH OCENIAJĄCYCH EFEKTYWNOŚĆ WYKONANIA ZADANIA BOJOWEGO. WSTĘP
Optymalizacja. Wybrane algorytmy
 dr hab. inż. Instytut Informatyki Politechnika Poznańska www.cs.put.poznan.pl/mkomosinski, Andrzej Jaszkiewicz Problem optymalizacji kombinatorycznej Problem optymalizacji kombinatorycznej jest problemem
dr hab. inż. Instytut Informatyki Politechnika Poznańska www.cs.put.poznan.pl/mkomosinski, Andrzej Jaszkiewicz Problem optymalizacji kombinatorycznej Problem optymalizacji kombinatorycznej jest problemem
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
OPTYMALIZACJA CZĘŚCIOWYCH REGUŁ ASOCJACYJNYCH WZGLĘDEM LICZBY POMYŁEK
 STUDIA INFORMATICA 2016 Volume 37 Number 1 (123) Beata ZIELOSKO Uniwersytet Śląski, Instytut Informatyki Marek ROBASZKIEWICZ EL-PLUS Sp. z o.o. OPTYMALIZACJA CZĘŚCIOWYCH REGUŁ ASOCJACYJNYCH WZGLĘDEM LICZBY
STUDIA INFORMATICA 2016 Volume 37 Number 1 (123) Beata ZIELOSKO Uniwersytet Śląski, Instytut Informatyki Marek ROBASZKIEWICZ EL-PLUS Sp. z o.o. OPTYMALIZACJA CZĘŚCIOWYCH REGUŁ ASOCJACYJNYCH WZGLĘDEM LICZBY
Systemy uczące się wykład 1
 Systemy uczące się wykład 1 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 5 X 2018 e-mail: przemyslaw.juszczuk@ue.katowice.pl Konsultacje: na stronie katedry + na stronie domowej
Systemy uczące się wykład 1 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 5 X 2018 e-mail: przemyslaw.juszczuk@ue.katowice.pl Konsultacje: na stronie katedry + na stronie domowej
PROGRAM DO INDUKCJI I OCENY REGUŁ KLASYFIKACYJNYCH, ZINTEGROWANY Z PAKIETEM R
 STUDIA INFORMATICA 2013 Volume 34 Number 2B (112) Wojciech MALARA, Marek SIKORA, Łukasz WRÓBEL Politechnika Śląska, Instytut Informatyki PROGRAM DO INDUKCJI I OCENY REGUŁ KLASYFIKACYJNYCH, ZINTEGROWANY
STUDIA INFORMATICA 2013 Volume 34 Number 2B (112) Wojciech MALARA, Marek SIKORA, Łukasz WRÓBEL Politechnika Śląska, Instytut Informatyki PROGRAM DO INDUKCJI I OCENY REGUŁ KLASYFIKACYJNYCH, ZINTEGROWANY
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Badania w sieciach złożonych
 Badania w sieciach złożonych Grant WCSS nr 177, sprawozdanie za rok 2012 Kierownik grantu dr. hab. inż. Przemysław Kazienko mgr inż. Radosław Michalski Instytut Informatyki Politechniki Wrocławskiej Obszar
Badania w sieciach złożonych Grant WCSS nr 177, sprawozdanie za rok 2012 Kierownik grantu dr. hab. inż. Przemysław Kazienko mgr inż. Radosław Michalski Instytut Informatyki Politechniki Wrocławskiej Obszar
SVM: Maszyny Wektorów Podpieraja cych
 SVM 1 / 24 SVM: Maszyny Wektorów Podpieraja cych Nguyen Hung Son Outline SVM 2 / 24 1 Wprowadzenie 2 Brak liniowej separowalności danych Nieznaczna nieseparowalność Zmiana przetrzeń atrybutów 3 Implementacja
SVM 1 / 24 SVM: Maszyny Wektorów Podpieraja cych Nguyen Hung Son Outline SVM 2 / 24 1 Wprowadzenie 2 Brak liniowej separowalności danych Nieznaczna nieseparowalność Zmiana przetrzeń atrybutów 3 Implementacja
ZeroR. Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F
 ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 5 T 7 T 5 T 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator ZeroR będzie zawsze odpowiadał T niezależnie
ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 5 T 7 T 5 T 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator ZeroR będzie zawsze odpowiadał T niezależnie
Algorytmy i Struktury Danych.
 Algorytmy i Struktury Danych. Metoda Dziel i zwyciężaj. Problem Sortowania, cd. Bożena Woźna-Szcześniak bwozna@gmail.com Jan Długosz University, Poland Wykład 2 Bożena Woźna-Szcześniak (AJD) Algorytmy
Algorytmy i Struktury Danych. Metoda Dziel i zwyciężaj. Problem Sortowania, cd. Bożena Woźna-Szcześniak bwozna@gmail.com Jan Długosz University, Poland Wykład 2 Bożena Woźna-Szcześniak (AJD) Algorytmy
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji
 Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Stosowana Analiza Regresji
 Stosowana Analiza Regresji Wykład VIII 30 Listopada 2011 1 / 18 gdzie: X : n p Q : n n R : n p Zał.: n p. X = QR, - macierz eksperymentu, - ortogonalna, - ma zera poniżej głównej diagonali. [ R1 X = Q
Stosowana Analiza Regresji Wykład VIII 30 Listopada 2011 1 / 18 gdzie: X : n p Q : n n R : n p Zał.: n p. X = QR, - macierz eksperymentu, - ortogonalna, - ma zera poniżej głównej diagonali. [ R1 X = Q
Podstawy robotyki. Wykład II. Robert Muszyński Janusz Jakubiak Instytut Informatyki, Automatyki i Robotyki Politechnika Wrocławska
 Podstawy robotyki Wykład II Ruch ciała sztywnego w przestrzeni euklidesowej Robert Muszyński Janusz Jakubiak Instytut Informatyki, Automatyki i Robotyki Politechnika Wrocławska Preliminaria matematyczne
Podstawy robotyki Wykład II Ruch ciała sztywnego w przestrzeni euklidesowej Robert Muszyński Janusz Jakubiak Instytut Informatyki, Automatyki i Robotyki Politechnika Wrocławska Preliminaria matematyczne
Zastosowanie sztucznej inteligencji w testowaniu oprogramowania
 Zastosowanie sztucznej inteligencji w testowaniu oprogramowania Problem NP Problem NP (niedeterministycznie wielomianowy, ang. nondeterministic polynomial) to problem decyzyjny, dla którego rozwiązanie
Zastosowanie sztucznej inteligencji w testowaniu oprogramowania Problem NP Problem NP (niedeterministycznie wielomianowy, ang. nondeterministic polynomial) to problem decyzyjny, dla którego rozwiązanie
Planowanie drogi robota, algorytm A*
 Planowanie drogi robota, algorytm A* Karol Sydor 13 maja 2008 Założenia Uproszczenie przestrzeni Założenia Problem planowania trasy jest bardzo złożony i trudny. W celu uproszczenia problemu przyjmujemy
Planowanie drogi robota, algorytm A* Karol Sydor 13 maja 2008 Założenia Uproszczenie przestrzeni Założenia Problem planowania trasy jest bardzo złożony i trudny. W celu uproszczenia problemu przyjmujemy
Dariusz Brzeziński. Politechnika Poznańska
 Dariusz Brzeziński Politechnika Poznańska Klasyfikacja strumieni danych Algorytm AUE Adaptacja klasyfikatorów blokowych do przetwarzania przyrostowego Algorytm OAUE Dlasze prace badawcze Blokowa i przyrostowa
Dariusz Brzeziński Politechnika Poznańska Klasyfikacja strumieni danych Algorytm AUE Adaptacja klasyfikatorów blokowych do przetwarzania przyrostowego Algorytm OAUE Dlasze prace badawcze Blokowa i przyrostowa
Podstawy Sztucznej Inteligencji (PSZT)
") Podstawy Sztucznej Inteligencji (PSZT) Paweł Wawrzyński Uczenie maszynowe Sztuczne sieci neuronowe Plan na dziś Uczenie maszynowe Problem aproksymacji funkcji Sieci neuronowe PSZT, zima 2013, wykład 12
Podstawy Sztucznej Inteligencji (PSZT) Paweł Wawrzyński Uczenie maszynowe Sztuczne sieci neuronowe Plan na dziś Uczenie maszynowe Problem aproksymacji funkcji Sieci neuronowe PSZT, zima 2013, wykład 12
Konstrukcja biortogonalnych baz dyskryminacyjnych dla problemu klasyfikacji sygnałów. Wit Jakuczun
 Konstrukcja biortogonalnych baz dyskryminacyjnych dla problemu klasyfikacji sygnałów Politechnika Warszawska Strona 1 Podstawowe definicje Politechnika Warszawska Strona 2 Podstawowe definicje Zbiór treningowy
Konstrukcja biortogonalnych baz dyskryminacyjnych dla problemu klasyfikacji sygnałów Politechnika Warszawska Strona 1 Podstawowe definicje Politechnika Warszawska Strona 2 Podstawowe definicje Zbiór treningowy
Własności estymatorów regresji porządkowej z karą LASSO
 Własności estymatorów regresji porządkowej z karą LASSO Uniwersytet Mikołaja Kopernika w Toruniu Uniwersytet Warszawski Badania sfinansowane ze środków Narodowego Centrum Nauki przyznanych w ramach finansowania
Własności estymatorów regresji porządkowej z karą LASSO Uniwersytet Mikołaja Kopernika w Toruniu Uniwersytet Warszawski Badania sfinansowane ze środków Narodowego Centrum Nauki przyznanych w ramach finansowania
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba Cel zadania Celem zadania jest implementacja klasyfikatorów
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba Cel zadania Celem zadania jest implementacja klasyfikatorów
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU
 WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 17. ALGORYTMY EWOLUCYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska KODOWANIE BINARNE Problem różnych struktur przestrzeni
SZTUCZNA INTELIGENCJA WYKŁAD 17. ALGORYTMY EWOLUCYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska KODOWANIE BINARNE Problem różnych struktur przestrzeni
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium Zadanie nr 3 Osada autor: A Gonczarek Celem poniższego zadania jest zrealizowanie fragmentu komputerowego przeciwnika w grze strategiczno-ekonomicznej
Metody systemowe i decyzyjne w informatyce Laboratorium Zadanie nr 3 Osada autor: A Gonczarek Celem poniższego zadania jest zrealizowanie fragmentu komputerowego przeciwnika w grze strategiczno-ekonomicznej