Plan wykładów. Co to jest analiza skupień i grupowanie Zastosowania Podział algorytmów Szczegóły:
|
|
|
- Patryk Domagała
- 6 lat temu
- Przeglądów:
Transkrypt

1 Analiza skupień JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan Wersja dla TWO 29 Hurtownie i eksploracja danych Popraw. 2
2 Plan wykładów Co to jest analiza skupień i grupowanie Zastosowania Podział algorytmów Szczegóły: k-means rodzina algorytmów AHC metody hierarchiczne Ocena jakości grupowania Studium przypadku i implementacje w Statistica oraz WEKA. Inne algorytmy dla eksploracji danych o wielkich rozmiarach
3 Acknowledgments: W większości oparty na moich dawnych slajdach i notatkach tradycyjno-papierowych, Slajdy niektóre inspirowane lub pochodzą z J.Han course on data mining G.Piatetsky- Shapiro teaching materials WEKA and Statsoft white papers and documentation
4 Polish aspects in clustering Polish terminology: Cluster Analysis Analiza skupień, Grupowanie. Numerical taxonomy Metody taksonomiczne (ekonomia) Uwaga: znaczenie taksonomii w biologii może mieć inny kontest (podział systematyczny oparty o taksony). Cluster Skupienie, skupisko, grupa/klasa/pojęcie Nigdy nie mów: klaster, klastering, klastrowanie! History:
5 More on Polish History Jan Czekanowski ( ) - wybitny polski antropolog, etnograf, demograf i statystyk, profesor Uniwersytetu Lwowskiego (93 94) oraz Uniwersytetu Poznańskiego (946 96). Nowe odległości i metody przetwarzania macierzy odległości w algorytmach,, tzw. metoda Czekanowskiego. Kontynuacja Jerzy Fierich (9-965) Kraków Hugo Steinhaus, (matematycy Lwów i Wrocław) Wrocławska szkoła taksonomiczna (metoda dendrytowa) Zdzisław Hellwig (Wrocław) wielowymiarowa analizą porównawcza, i inne Współczesnie Sekcja Klasyfikacji i Analizy Danych (SKAD) Polskiego Towarzystwa Statystycznego
6 Referencje do literatury (przykładowe) Koronacki J. Statystyczne systemy uczące się, WNT 25. Pociecha J., Podolec B., Sokołowski A., Zając K. Metody taksonomiczne w badaniach społeczno-ekonomicznych. PWN, Warszawa 988, Stąpor K. Automatyczna klasyfikacja obiektów Akademicka Oficyna Wydawnicza EXIT, Warszawa 25. Hand, Mannila, Smyth, Eksploracja danych, WNT 25. Larose D: Odkrywania wiedzy z danych, PWN 26. Kucharczyk J. Algorytmy analizy skupień w języku ALGOL 6 PWN Warszawa, 982, Materiały szkoleniowe firmy Statsoft.


7 Motywacje do grupowania Astronomia - agregacja podobnych gwiazd, galaktyk, i innych widocznych obiektów,


8 Dawno systemy taksonomiczne w biologii i botanice Carl von Linneus systematic biological taxonomy Karol Linneusz znany jest powszechnie jako ojciec systematyki biologicznej i zasad nazewnictwa organizmów. Jego system klasyfikacji organizmów, przede wszystkim tzw. system płciowy roślin, nie był pierwszą próbą uporządkowania świata ożywionego, był jednak nieporównywalny z niczym, co było wcześniej. Linneusz był niezwykle wnikliwym obserwatorem i rzetelnym, skrupulatnym badaczem, który skodyfikował język opisu, sprecyzował terminy naukowe i stworzył podstawy metodologii badawczej systematyki.
 z punktu widzenia określonego")
9 Grupowanie, analiza skupień Cel: Znajdź grupy naturalnie podobnych do siebie obiektów analiza skupień proces podziału danych na podzbiory zwane klasami (skupieniami) z punktu widzenia określonego kryterium
10 Inne spojrzenie na skupiska Crisp vs. soft clusters
11 Reprezentacja danych problem nienadzorowany Znajdź grupy obiektów podobnych do siebie (wewnątrz skupienia). Obiekty między skupieniami nie podobne do siebie! Clustering is unsupervised Nieznana etykieta przykładu w tabeli danych Sepal length Sepal width Petal length Petal width Type Iris setosa Iris setosa Iris versicolor Iris versicolor Iris virginica Iris virginica
12 Classification vs. Clustering Uczenie z nadzorem vs.bez nadzoru! Classification: Supervised learning: Learns a method for predicting the instance class from pre-labeled (classified) instances Ilustracja obszarów decyzyjnych
13 Wielowymiarowe statystyczne spojrzenie Obiekt opisany za pomocą n zmiennych X, X 2, X n jest punktem x=(x,,x n ) w n-wymiarowej przestrzeni Ω Cel podziału na grupy (S) obiekty podobne (reprezentowane przez punkty znajdujące się blisko siebie w przestrzeni) przydzielone do tej samej grupy, a obiekty niepodobne (reprezentowane przez punkty leżące w dużej odległości w przestrzeni) znajdują się w różnych grupach S i S = ( i j; i, j=,..., p) j U p i = S i = Ω
14 Czym jest skupienie?. Zbiorem najbardziej podobnych obiektów 2. Podzbiór obiektów, dla których odległość jest mniejsza niż ich odległość od obiektów z innych skupień. 3. Podobszar wielowymiarowej przestrzeniu zawierający odpowiednio dużą gęstość obiektów
15 dobre i złe klasyfikacje może istnieć wiele sposobów pogrupowania danych obiektów Problemem nie jest otrzymanie rezultatu prawdziwego lub fałszywego, ale użytecznego lub bezużytecznego (Lance, Williams 77) niektóre kryteria użyteczności tworzonych klasyfikacji:. umożliwiają odkrywanie nowych, nieoczekiwanych pojęć 2. ułatwiają analizę i zrozumienie danych 3. oceniają jakość atrybutów użytych do klasyfikacji 4. powstałe skupienia charakteryzują się dużym podobieństwem wzajemnym obiektów
16 Poszukiwanie zrozumiałych struktur w danych Ma ułatwiać odnalezienie pewnych spójnych podobszarów danych Lecz nadal wiele możliwości
17 Czym jest dobre grupowanie? A good clustering method will produce high quality clusters in which: the intra-class (that is, intra-cluster) similarity is high. the inter-class similarity is low. The quality of a clustering result also depends on both the similarity measure used by the method and its implementation. The quality of a clustering method is also measured by its ability to discover some or all of the hidden patterns. However, objective evaluation is problematic: usually done by human / expert inspection.
18 Różne sposoby reprezentacji skupień (a) a d k g j h e i f c b (b) a d k g j h e i f c b (c) 2 3 (d) a.4..5 b..8. c d...8 e f..4.5 g.7.2. h.5.4. g a c i e d k b j f h
19 Inne cele analizy skupień w KDD Eksploracja danych - etapy Kontrola danych Poszukiwanie obiektów nietypowych (odstających) Wykrycie wewnętrznej struktury obiektów Wykrywanie współzależności między zmiennymi Klasyfikacja Weryfikacja istniejącej typologii Propozycje klasyfikacji obiektów Redukcja danych Agregacja danych Wybór reprezentantów grup
20 Przykłady zastosowań analizy skupień Zastosowania ekonomiczne: Identyfikacja grup klientów bankowych (np. właścicieli kart kredytowych wg. sposobu wykorzystania kart oraz stylu życia, danych osobowych, demograficznych) cele marketingowe. Systemy rekomendacji produktów i usług. Rynek usług ubezpieczeniowych (podobne grupy klientów). Analiza sieci sprzedaży (np. czy punkty sprzedaży podobne pod względem społecznego sąsiedztwa liczby personelu, itp., przynoszą podobne obroty). Poszukiwanie wspólnych rynków dla produktów. Planowanie, np. nieruchomości. Badania naukowe (biologia, medycyna, nauki społeczne). Analiza zachowań użytkowników serwisów WWW. Rozpoznawanie obrazów, dźwięku Wiele innych

21 Specific data mining applications

22 Web Search Result Clustering
23 Problemy do rozstrzygnięcia Jak odwzorować obiekty w przestrzeni? Wybór zmiennych Normalizacja zmiennych Jak mierzyć odległości między obiektami? Jaką metodę grupowania zastosować?
24 Podstawowe struktury danych Data matrix tablica / macierz danych x... x i... x n x f... x if... x nf x p... x ip... x np Dis/similarity matrix d(2,) d(3, ) : d ( n,) d (3,2) : d ( n,2) :......
25 Measuring Dissimilarity or Similarity in Clustering Dissimilarity/Similarity metric: Similarity is expressed in terms of a distance function, which is typically metric: d(i, j) There are also used in quality functions, which estimate the goodness of a cluster. The definitions of distance functions are usually very different for interval-scaled, boolean, categorical, ordinal and ratio variables. Weights should be associated with different variables based on applications and data semantics.
26 Podobieństwo i niepodobieństwo sij - miara podobieństwa (bliskości) dwu obiektów Oi i Oj Miara podobieństwa (ang. similarity) sij powinna mieć poniższe właściwości: i. sij dla wszystkich obiektów Oi i Oj ii. sij = wtedy i tylko wtedy, gdy obiekty Oi i Oj są identyczne iii. sij = sji - symetria W socjologii symetria sij jest często nie zachowana, np. opinie o sobie dwu ekspertów Miara niepodobieństwa (ang. dissimilarity) dij powinna mieć poniższe właściwości: i. dij dla wszystkich obiektów Oi i Oj ii. dij = wtedy i tylko wtedy, gdy obiekty Oi i Oj są identyczne iii. dij = dji - symetria Miarą niepodobieństwa dij może być dowolna funkcja odległości d(x,y), np. odległość euklidesowa.
27 Podstawowe rodzaje zmiennych skale pomiarowe Interval-scaled variables (skale metryczne) Binary variables Nominal, ordinal, and ratio variables Variables of mixed types Remark: variable vs. attribute
28 Distance Measures To discuss whether a set of points is close enough to be considered a cluster, we need a distance measure -D(x, y) The usual axioms for a distance measure D are: D(x, x) = D(x, y) = D(y, x) D(x, y) D(x, z) + D(z, y) the triangle inequality
29 Distance Measures (2) Assume a k-dimensional Euclidean space, the distance between two points, x=[x, x 2,..., x k ] and y=[y, y 2,..., y k ] may be defined using one of the measures: Euclidean distance: ("L 2 norm") k ( x i y i ) i= 2 Manhattan distance: ("L norm") k i= x i y i Max of dimensions: ("L norm") max k i = x i y i
30 Distance Measures (3) Minkowski distance: k ( ( x i y i i= ) q / q ) When there is no Euclidean space in which to place the points, clustering becomes more difficult: Web page accesses, DNA sequences, customer sequences, categorical attributes, documents, etc.

31

32 Charakterystka miar
33 Trudności z różnym zakresem danych liczbowych Normalizacja ma na celu doprowadzenie obiektów lub zmiennych do porównywalnych wielkości. Problem ten dotyczy zmiennych mierzonych w różnych jednostkach (np. sztuki, czas, waluta). Przykład Rozważmy 3 obiekty i dwie zmienne: wiek osoby mierzony w latach i jej dochód mierzony w złotych lub tys. zł. Zmienna -> X Y Y2 Wiek Dochód Dochód Osoba (w latach) (w zł) ( w tys. zł) A , B ,7 C ,

34 Inny przykład wpływ zakresu na analizę skupień Przeskaluje zmienne x podziel przez, y pomnóż przez
35 Standarization / Normalization If the values of attributes are in different units then it is likely that some of them will take vary large values, and hence the "distance" between two cases, on this variable, can be a big number. Other attributes may be small in values, or not vary much between cases, in which case the difference between the two cases will be small. The attributes with high variability / range will dominate the metric. Overcome this by standardization or normalization x x x A i i z = f ( x) = i s B B x i
36 Binary variables A contingency table for binary data Simple matching coefficient (invariant, if the binary variable is symmetric): Jaccard coefficient (noninvariant if the binary variable is asymmetric): d c b a c b j i d = ), ( p d b c a sum d c d c b a b a sum c b a c b j i d = ), ( Object i Object j
37 Nominal, ordinal and ratio variables nominal variables: > 2 states, e.g., red, yellow, blue, green. d ( i, Simple matching: u: # of matches, p: total # of variables. j) = p p u Also, one can use a large number of binary variables. ordinal variables: order is important, e.g., rank. Can be treated like interval-scaled, by replacing x if by their rank r {,..., M } if f and replacing i-th object in the f-th variable by r if z = if M ratio variables: a positive measurement on a nonlinear scale, approximately at exponential scale, such as Bt or One may treat them as continuous ordinal data or perform logarithmic transformation and then treat them as interval-scaled. f Ae Ae Bt
38 Variables of mixed types Data sets may contain all types of attrib./variables: symmetric binary, asymmetric binary, nominal, ordinal, interval and ratio. One may use a weighted formula to combine their effects p ( f ) ( f ) Σ δ d f = ij ij d ( i, j ) = p ( f ) Σ δ f = ij f is binary or nominal: ( f ) d = if x = x or, o.w. ij if jf ( f ) d = ij f is interval-based: use the normalized distance. r f is ordinal or ratio-scaled: compute ranks if and and treat as interval-scaled r z if z if = if M f
39 Podział znanych metod Podziałowo-optymalizacyjne: Znajdź podział na zadaną liczbę skupień wg. zadanego kryterium. Metody hierarchiczne: Zbuduj drzewiastą strukturę skupień. Gęstościowo (Density-based): Poszukuj obszarów o większej gęstości występowania obserwacji Grid-based: wykorzystujące wielowymiarowy podział przestrzeni siatką ograniczeń Model-based: hipoteza co do własności modelu pewnego skupienia i procedura jego estymacji.
40 Jeszcze inny podział Za Jain s tutorial Ponadto: Crisp vs. Fuzzy Inceremental vs. batch
41 Metody hierarchiczne Metody najczęściej stosowane w praktyce. Uzyskana hierarchia (jedne skupienia zawierają się w innych) pozwala na uzyskanie pełnej informacji o strukturze skupień. Ograniczenie tych metod to wymagania pamięci co powoduje, że w przypadku dużych zbiorów danych nie mogą być stosowane. Metody hierarchiczne dzielimy na metody aglomeracyjne i podziałowe. Punktem wyjścia w metodach aglomeracyjnych jest określenie odległości pomiędzy obiektami. metody aglomeracyjne 9 C A S E Label Num I I metody podziałowe
42 Metody hierarchiczne Buduj tree-based hierarchical taxonomy (dendrogram) ze zbioru nieetykietowanych przykładów animal vertebrate invertebrate fish reptile amphib. mammal worm insect crustacean czort tkwi w szczegółach parametryzacji!
43 *Hierarchical clustering Bottom up (aglomerative) Start with single-instance clusters At each step, join the two closest clusters Design decision: distance between clusters e.g. two closest instances in clusters vs. distance between means Top down (divisive approach / deglomerative) Start with one universal cluster Find two clusters Proceed recursively on each subset Can be very fast Both methods produce a dendrogram g a c i e d k b j f h
44 Hierarchiczne metody aglomeracyjne - algorytm. W macierzy odległości znajduje się parę skupień najbliższych sobie. 2. Redukuje się liczbę klas łącząc znalezioną parę 3. Przekształca się macierz odległości metodą wybraną jako kryterium klasyfikacji 4. Powtarza się kroki - 3 dopóki nie powstanie jedna klasa zawierająca wszystkie skupienia.
45 AHC - komentarz Użycie i przekształcanie macierzy odległości. Nie ma predefiniowanej liczby klas k jako parametr wejściowy, ale czy zawsze budujemy pełne drzewo. Parametry: podstawowa odległość i metoda łączenia Step Step Step 2 Step 3 Step 4 a a b b a b c d e c c d e d d e e Step 4 Step 3 Step 2 Step Step agglomerative (AGNES) divisive (DIANA)
46 Przykład ilustracyjny za A.Pankowska
47 Przykład cd
48 AHC wybór metody łączenia. Najbliższego sąsiedztwa (Single linkage, Nearest neighbor) 2. Najdalszego sąsiedztwa (Complete linkage, Furthest neighbor) 3. Mediany (Median clustering) 4. Środka ciężkości (Centroid clustering) 5. Średniej odległości wewnątrz skupień (Average linkage within groups) 6. Średniej odległości między skupieniami (Average linkage between groups) 7. Minimalnej wariancji Warda (Ward s method)
49 Porównanie sposobu wyznaczania odległości między skupieniami w wybranych metodach aglomeracyjnych metoda najbliższego sąsiedztwa metoda najdalszego sąsiedztwa metoda mediany metoda środka ciężkości metoda średniej grupowej metoda Warda
50 Obliczenia odległości między skupieniami Single linkage minimum distance: Complete linkage maximum distance: mean distance: average distance: dmin ( Ci, Cj) = min ' p p dmax ( Ci, Cj) = max ' p p p C, p C d ( C, C ) = m m mean i j i j d ( C C ) = /( nn ) p p ave i, j i j p C, p C i i j p C p C i j ' j ' ' ' m i is the mean for cluster C i n i is the number of points in C i
51 Single Link Agglomerative Clustering Użyj maksymalnego podobieństwa dwóch obiektów: sim( c i, c j ) = max x c, y i c j sim( x, Prowadzi do (long and thin) clusters due to chaining effect (efekt łańcuchowy); prowadzić do formowania grup niejednorodnych (heterogenicznych); Dogodne w specyficznych zastosowaniach Pozwala na wykrycie obserwacji odstających, nie należących do żadnej z grup, i warto przeprowadzić klasyfikację za jej pomocą na samym początku, aby wyeliminować takie obserwacje i przejść bez nich do właściwej części analizy y)
52 Single Link Example
53 Complete Link Agglomerative Clustering Użyj maksymalnej odległości minimalnego podobieństwa sim( c i, c j ) = x c min, y i c j sim( x, y) Ukierunkowana do tight, spherical clusters Metoda zalecana gdy, kiedy obiekty faktycznie formują naturalnie oddzielone "kępki". Metoda ta nie jest odpowiednia, jeśli skupienia są w jakiś sposób wydłużone lub mają naturę "łańcucha".
54 Complete Link Example
55 Single vs. Complete Linkage A.Jain et al.: Data Clustering. A Review. Łańcuch bliskich wysp

56
57 Wrażliwość na wybór metody łączenia Diagram dla 22 przyp. Pojedyncze wiązanie Odległości euklidesowe ACURA AUDI MERCEDES CHRYSLER DODGE VW HONDA PONTIAC SAAB VOLVO NISSAN BMW MITSUB. BUICK OLDS MAZDA TOYOTA CORVETTE FORD PORSCHE ISUZU EAGLE,,5,,5 2, 2,5 3, 3,5 4, 4,5 Odległość wiąz. ACURA OLDS CHRYSLER DODGE VW HONDA PONTIAC NISSAN MITSUB. AUDI MERCEDES BMW SAAB VOLVO BUICK MAZDA TOYOTA FORD CORVETTE PORSCHE EAGLE ISUZU Diagram dla 22 przyp. Metoda Warda Odległości euklidesowe Odległość wiąz.
58 Metoda średnich połączeń [Unweighted pair-group average] W metodzie tej odległość między dwoma skupieniami oblicza się jako średnią odległość między wszystkimi parami obiektów należących do dwóch różnych skupień. Metoda ta jest efektywna, gdy obiekty formują naturalnie oddzielone "kępki", ale zdaje także egzamin w przypadku skupień wydłużonych, mających charakter "łańcucha".
59 Metoda ważonych środków ciężkości (mediany) [Weighted pair-group centroid]. Jest to metoda podobna jak poprzednia, z tym wyjątkiem, że w obliczeniach wprowadza się ważenie, aby uwzględnić różnice między wielkościami skupień (tzn. liczbą zawartych w nich obiektów). Zatem, metoda ta jest lepsza od poprzedniej w sytuacji, gdy istnieją (lub podejrzewamy, że istnieją) znaczne różnice w rozmiarach skupień.
60 Metody łączenia cd. Ward Gdy powiększamy jedno ze skupień Ck, wariancja wewnątrzgrupowa (liczona przez kwadraty odchyleń od średnich w zbiorach Ck) rośnie. Metoda polega na takim powiększaniu zbiorów Ck, która zapewnia najmniejszy przyrost tej wariancji dla danej iteracji. Kryterium grupowania jednostek: minimum zróżnicowania wektorów cech xj tworzących zbiór Ck (k =,..., K) względem wartości średnich w tych zbiorach. Ogólnie, metoda ta jest traktowana jako bardzo efektywna, chociaż zmierza do tworzenia skupień o małej wielkości zrównoważone drzewa
61 Dendrogram: pokazuje proces łączenia Decompose data objects into a several levels of nested partitioning (tree of clusters), called a dendrogram. A clustering of the data objects is obtained by cutting the dendrogram at the desired level, then each connected component forms a cluster.
62 AHC jak odnaleźć liczbę skupień? Figure find a cut point ( kolanko / knee) 5, Wykres odległości wiązania względem etapów wiązania Odległości euklidesowe 4,5 4, 3,5 Odległość wiązan 3, 2,5 2,,5,,5, Wiązania Odległ. Etap
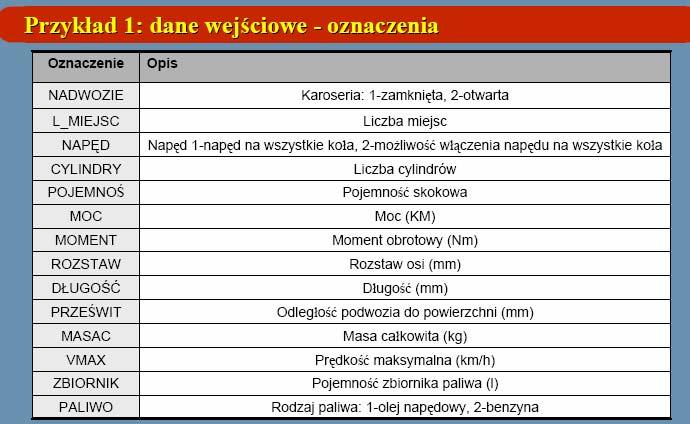
63 Przykład ilustracyjny

64 Dane wejściowe

65 Końcowy dendrogram Wybór skupień?
66 Computational Complexity In the first iteration, all HAC methods need to compute similarity of all pairs of n individual instances which is O(n 2 ). In each of the subsequent n 2 merging iterations, it must compute the distance between the most recently created cluster and all other existing clusters. In order to maintain an overall O(n 2 ) performance, computing similarity to each other cluster must be done in constant time.
67 More on Hierarchical Clustering Methods Major weakness of agglomerative clustering methods: do not scale well: time complexity of at least O(n 2 ), where n is the number of total objects can never undo what was done previously. Integration of hierarchical clustering with distance-based method: BIRCH (996): uses CF-tree and incrementally adjusts the quality of sub-clusters. CURE (998): selects well-scattered points from the cluster and then shrinks them towards the center of the cluster by a specified fraction.
68 Algorytmy podziałowo - optymalizacyjne Zadanie: Podzielenie zbioru obserwacji na K zbiorów elementów (skupień C), które są jak najbardziej jednorodne. Jednorodność funkcja oceny. Intuicja zmienność wewnątrzskupieniowa wc(c) i zmienność międzyskupieniowa bc(c) Możliwe są różne sposoby zdefiniowania np. wybierzmy środki skupień r k (centroidy) Wtedy wc( C) = K k= x C k d( x, r k 2 ) rk = nk x C k x bc( C) = d( r, r j< k K j k 2 )
69 Podstawowe algorytmy podziałowe Metoda K - średnich minimalizacja wc(c) Przeszukiwanie przestrzeni możliwych przypisań bardzo kosztowne (oszacowanie w ks. Koronackiego) Problem optymalizacji kombinatorycznej systematyczne przeszukiwanie metodą iteracyjnego udoskonalania: Rozpocznij od rozwiązania początkowego (losowego). Ponownie przypisz punkty do skupień tak, aby otrzymać największą zmianę w funkcji oceny. Przelicz zaktualizowane środki skupień, Postępuj aż do momentu, w którym nie ma już żadnych zmian w funkcji oceny lub w składzie grup. Zachłanne przeszukiwanie proste i prowadzi do co najmniej lokalnego minimum. Różne modyfikacje, np. rozpoczynania od kilku rozwiązań startowych Złożoność algorytmy K - średnich O(KnI)
70 Partitioning Algorithms: Basic Concept Partitioning method: Construct a partition of a database D of n objects into a set of k clusters Given a k, find a partition of k clusters that optimizes the chosen partitioning criterion. Global optimal: exhaustively enumerate all partitions. Heuristic methods: k-means and k-medoids algorithms. k-means (MacQueen 67): Each cluster is represented by the center of the cluster k-medoids or PAM (Partition around medoids) (Kaufman & Rousseeuw 87): Each cluster is represented by one of the objects in the cluster.
71 Simple Clustering: K-means Basic version works with numeric data only ) Pick a number (K) of cluster centers - centroids (at random) 2) Assign every item to its nearest cluster center (e.g. using Euclidean distance) 3) Move each cluster center to the mean of its assigned items 4) Repeat steps 2,3 until convergence (change in cluster assignments less than a threshold)
72 Illustrating K-Means Example Assign each objects to most similar center reassign Update the cluster means reassign K=2 Arbitrarily choose K object as initial cluster center Update the cluster means
73 K-means example, step Y k Pick 3 initial cluster centers (randomly) k 2 k 3 X
74 K-means example, step 2 Y k Assign each point to the closest cluster center k 2 k 3 X
75 K-means example, step 3 Y k k Move each cluster center to the mean of each cluster k 2 k 2 k 3 k 3 X
76 K-means example, step 4 Reassign points Y closest to a different new cluster center Q: Which points are reassigned? k k 2 k 3 X
77 K-means example, step 4 A: three points with animation Y k 2 k k 3 X
78 K-means example, step 4b re-compute cluster means Y k 2 k k 3 X
79 K-means example, step 5 k Y move cluster centers to cluster means k 2 k 3 X
80 Inny przykład obliczeniowy (k=3 i macierze początk.) Zbiór danych: Początkowy przydział Przeliczenie centroidów Przeliczenie odległości Ponowny przydział do skupień: = = = = = x x x x x = = = = = x x x x x = B() = R() = () B = D()
81 Cdn. Przeliczenie centroidów Ponowny przydział do skupień: Warunek końcowy: B(2) = B() = R() = B(2) },, { x x x G = },, { x x x G = },,, { x x x x G =
82 Metody optymalizacyjno-iteracyjne (k-średnich) Jednocześnie obliczana jest funkcja błędu podziału - ogólna suma kwadratów odległości wewnątrzgrupowych liczonych od środków ciężkości grup: tzn. F = k j= O S i j d ( O, M ) i j 2 gdzie d jest odległością euklidesową. W praktyce proces jest zbieżny po kilku lub kilkunastu iteracjach. Ponieważ w ogólności algorytm nie musi być zbieżny, ustala się maksymalną liczbę iteracji (L).
83 Ustalanie liczby skupień i startowych centroidów Liczbę skupień wybiera się na podstawie przesłanek merytorycznych albo szacuje się je metodami hierarchicznymi. Można dokonać obliczeń dla wszystkich wartości k z ustalonego przedziału: k min k max Możliwe są różne podejścia:. Arbitralny sposób np. przyjmuje się współrzędne pierwszych k obiektów (nie zawierające braków danych) jako zalążki środków ciężkości. 2. Losowy wybór środków ciężkości, przy czym może to być losowy wybór k obiektów ze zbioru danych albo losowy wybór k punktów przestrzeni niekoniecznie pokrywających się z położeniem obiektów. 3. Wykorzystanie algorytmu optymalizującego w pewien sposób położenie początkowych środków ciężkości np. przez uwzględnianie k obiektów leżących daleko względem siebie. 4. Przyjęcie jako początkowych środków ciężkości uzyskanych na podstawie podziału otrzymanego inna metodą, głównie jedną z metod hierarchicznych. k
84 Uwagi nt. podziałowo-optymalizacyjnych Dobór parametru k Kwestia heurystyki wyboru początkowych ziaren Czy jest zawsze zbieżny do optimum globalnego Przykład: initial cluster centers instances Możesz próbować kilka uruchomień z różnymi parametrami
85 K-means krótkie podsumowanie Zalety Proste i łatwe do zrozumienia Reprezentacja skupień jako centroidy Wady Jawne podanie liczby skupień Wszystkie przykłady muszą być przydzielone do skupień Problem z outliers (za duża wrażliwość) Ukierunkowanie na jednorodne sferyczne kształty skupień
86 Time Complexity Assume computing distance between two instances is O(m) where m is the dimensionality of the vectors. Reassigning clusters: O(kn) distance computations, or O(knm). Computing centroids: Each instance vector gets added once to some centroid: O(nm). Assume these two steps are each done once for I iterations: O(Iknm). Linear in all relevant factors, assuming a fixed number of iterations, more efficient than O(n 2 ) HAC.
87 k-means k-medoids The k-means algorithm is sensitive to outliers! Since an object with an extremely large value may substantially distort the distribution of the data. There are other limitations still a need for reducing costs of calculating distances to centroids. K-Medoids: Instead of taking the mean value of the object in a cluster as a reference point, medoids can be used, which is the most centrally located object in a cluster
88 Algorytm K-Medoids i rozszerzenia Znajdź medoidy - obiekty reprezentujące skupienia Wykorzystuje się odległości par obiektów. PAM (Partitioning Around Medoids, 987) Zacznij od początkowego zbioru medoidów i krokowo zamieniaj jeden z obiektów - medoidów przez obiekt, nie będący aktulanie medoidem, jeśli to polepsza całkowitą odległość skupień. PAM efektywny dla małych zbiorów, lecz nieskalowalny dla dużych zbiorów przykładów. CLARA (Kaufmann & Rousseeuw, 99) CLARANS (Ng & Han, 994): Randomized sampling.
89 Ocena jakości skupień Ocena ekspercka Benchmarking on existing labels Comparing clusters with ground-truth categories (partition P) Miary oceny oparte na danych (internal measures) Oparte na odległościach lub Duże podobieństwo obiektów wewnątrz skupienia (Compactness) Same skupienia dość odległe (Isolation)
90 Czy można poszukiwać pojedynczej miary Pewne rady
91 Typowe miary zmienności skupień Intuicja zmienność wewnątrz-skupieniowa wc(c) i zmienność między-skupieniowa bc(c) Można definiować różnymi sposobami Wykorzystaj średni obiekt w skupieniu r k (centroids) Wtedy, np. Zamiast bc odległość od globalnego centrum danych (interclass distance) Preferencja dla zwartych, jednorodnych skupień dość odległych od centrum danych = K Ck k = = j< k K wc( C) d( x, r x bc( C) d( r, r ) id = d( rj, rglob) C j j k ) k r k = n k x Ck x
92 Inne kryteria wewnętrznej jakości skupień Compactness determining the weakest connection within the cluster, i.e., the largest distance between two objects Ri and Rk within the cluster. Isolation determining the strongest connection of a cluster to another cluster, i.e., the smallest distance between a cluster centroid and another cluster centroid. Object positioning the quality of clustering is determined by the extent to which each object Rj has been correctly positioned in given clusters
93
94 Odniesienie do zewnętrznego podziału Różne podejścia Measured by manually labeled data We manually assign tuples into clusters according to their properties (e.g., professors in different research areas) Accuracy of clustering: Percentage of pairs of tuples in the same cluster that share common label This measure favors many small clusters We let each approach generate the same number of clusters
95 Oceny poprzez porównanie do zbioru referencyjnego (ground truth) Przykład tekstowy
96 Ocena grupowania Inna niż w przypadku uczenia nadzorowanego (predykcji wartości) Poprawność grupowania zależna od oceny obserwatora / analityka Różne metody AS są skuteczne przy różnych rodzajach skupień i założeniach, co do danych: Co rozumie się przez skupienie, jaki ma kształt, dobór miary odległości sferyczne vs. inne Dla pewnych metod i zastosowań: Miary zmienności wewnątrz i między skupieniowych Idea zbiorów kategorii odniesienia (np.trec)
97 Trochę praktyki Analiza skupień w Statsoft -Statistica

98 Analiza Skupień Statistica; więcej na Przykład analizy danych o parametrach samochodów



99
100 Dendrogram for Single Linkage ACURA AUDI MERCEDES CHRYSLER DODGE VW HONDA PONTIAC SAAB VOLVO NISSAN BMW MITSUB. BUICK OLDS MAZDA TOYOTA CORVETTE FORD PORSCHE ISUZU EAGLE Diagram dla 22 przyp. Pojedyncze wiązanie Odległości euklidesowe,,5,,5 2, 2,5 3, 3,5 4, 4,5 Odległość wiąz.

101
102 Analysing Agglomeration Steps Figure find a cut point ( kolanko / knee) 5, Wykres odległości wiązania względem etapów wiązania Odległości euklidesowe 4,5 4, 3,5 Odległość wiązan 3, 2,5 2,,5,,5, Wiązania Odległ. Etap


103 Analiza Skupień optymalizacja k-średnich
104 Profile - visulization
105 Inne rozwiązanie Analiza Skupień wweka
106 WEKA Clustering Implemented methods k-means EM Cobweb X-means FarthestFirst Clusters can be visualized and compared to true clusters (if given)
107 Exercise. K-means clustering in WEKA The exercise illustrates the use of the k-means algorithm. The example sample of customers of the bank Bank data (bank-data.cvs -> bank.arff) All preprocessing has been performed on cvs 6 instances described by attributes id,age,sex,region,income,married,children,car,save_act,current_act,mortgage,pep ID2,48,FEMALE,INNER_CITY,7546.,NO,,NO,NO,NO,NO,YES ID22,4,MALE,TOWN,385.,YES,3,YES,NO,YES,YES,NO ID23,5,FEMALE,INNER_CITY,6575.4,YES,,YES,YES,YES,NO,NO ID24,23,FEMALE,TOWN,2375.4,YES,3,NO,NO,YES,NO,NO ID25,57,FEMALE,RURAL,5576.3,YES,,NO,YES,NO,NO,NO... Cluster customers and characterize the resulting customer segments

108 Loading the file and analysing the data
109 Preprocessing for clustering What about non-numerical attributes? Remember about Filters Should we normalize or standarize attributes? How it is handled in WEKA k-means?

110 Choosing Simple k-means Tune proper parameters

111 Clustering results Analyse the result window
112 Characterizing cluster How to describe clusters? What about descriptive statistics for centroids?

113 Understanding the cluster characterization through visualization

114 Finally, cluster assignments
115 Soft Clustering Clustering typically assumes that each instance is given a hard assignment to exactly one cluster. Does not allow uncertainty in class membership or for an instance to belong to more than one cluster. Soft clustering gives probabilities that an instance belongs to each of a set of clusters. Each instance is assigned a probability distribution across a set of discovered categories (probabilities of all categories must sum to ). d e a k g j h i f c b
116 Expectation Maximization (EM Algorithm) Probabilistic method for soft clustering. Direct method that assumes k clusters:{c, c 2, c k } Soft version of k-means. Assumes a probabilistic model of categories that allows computing P(c i E) for each category, c i, for a given example, E. For text, typically assume a naïve-bayes category model. Parameters θ = {P(c i ), P(w j c i ): i {, k}, j {,, V }}
117 Algorytmy analizy skupień dla baz danych o wielkich rozmiarach Scalability Dealing with different types of attributes Discovery of clusters with arbitrary shape Minimal requirements for domain knowledge to determine input parameters Able to deal with noise and outliers Insensitive to order of input records High dimensionality Interpretability and usability.
118 Może pytanie lub komentarze?
Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych
 Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych JERZY STEFANOWSKI Inst. Informatyki PP Wersja dla TPD 2013 Część II Organizacja wykładu Przypomnienie wyboru liczby skupień Studium przypadku
Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych JERZY STEFANOWSKI Inst. Informatyki PP Wersja dla TPD 2013 Część II Organizacja wykładu Przypomnienie wyboru liczby skupień Studium przypadku
Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych. JERZY STEFANOWSKI Inst. Informatyki PP Wersja dla TPD 2009
 Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych JERZY STEFANOWSKI Inst. Informatyki PP Wersja dla TPD 29 Poprawiona 22 Organizacja wykładu Wprowadzenie i możliwe zastosowania Podstawy (odległości,
Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych JERZY STEFANOWSKI Inst. Informatyki PP Wersja dla TPD 29 Poprawiona 22 Organizacja wykładu Wprowadzenie i możliwe zastosowania Podstawy (odległości,
Hard-Margin Support Vector Machines
 Hard-Margin Support Vector Machines aaacaxicbzdlssnafiyn9vbjlepk3ay2gicupasvu4iblxuaw2hjmuwn7ddjjmxm1bkcg1/fjqsvt76fo9/gazqfvn8y+pjpozw5vx8zkpvtfxmlhcwl5zxyqrm2vrg5zw3vxmsoezi4ogkr6phieky5crvvjhriqvdom9l2xxftevuwcekj3lktmhghgniauiyutvrwxtvme34a77kbvg73gtygpjsrfati1+xc8c84bvraowbf+uwnipyehcvmkjrdx46vlykhkgykm3ujjdhcyzqkxy0chur6ax5cbg+1m4bbjptjcubuz4kuhvjoql93hkin5hxtav5x6yyqopnsyuneey5ni4keqrxbar5wqaxbik00icyo/iveiyqqvjo1u4fgzj/8f9x67bzmxnurjzmijtlybwfgcdjgfdtajwgcf2dwaj7ac3g1ho1n4814n7wwjgjmf/ys8fenfycuzq==
Hard-Margin Support Vector Machines aaacaxicbzdlssnafiyn9vbjlepk3ay2gicupasvu4iblxuaw2hjmuwn7ddjjmxm1bkcg1/fjqsvt76fo9/gazqfvn8y+pjpozw5vx8zkpvtfxmlhcwl5zxyqrm2vrg5zw3vxmsoezi4ogkr6phieky5crvvjhriqvdom9l2xxftevuwcekj3lktmhghgniauiyutvrwxtvme34a77kbvg73gtygpjsrfati1+xc8c84bvraowbf+uwnipyehcvmkjrdx46vlykhkgykm3ujjdhcyzqkxy0chur6ax5cbg+1m4bbjptjcubuz4kuhvjoql93hkin5hxtav5x6yyqopnsyuneey5ni4keqrxbar5wqaxbik00icyo/iveiyqqvjo1u4fgzj/8f9x67bzmxnurjzmijtlybwfgcdjgfdtajwgcf2dwaj7ac3g1ho1n4814n7wwjgjmf/ys8fenfycuzq==
CLUSTERING. Metody grupowania danych
 CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
Zagadnienie klasyfikacji (dyskryminacji)
") Zagadnienie klasyfikacji (dyskryminacji) Przykład Bank chce klasyfikować klientów starających się o pożyczkę do jednej z dwóch grup: niskiego ryzyka (spłacających pożyczki terminowo) lub wysokiego ryzyka
Zagadnienie klasyfikacji (dyskryminacji) Przykład Bank chce klasyfikować klientów starających się o pożyczkę do jednej z dwóch grup: niskiego ryzyka (spłacających pożyczki terminowo) lub wysokiego ryzyka
Grupowanie Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633
 Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych
 Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych JERZY STEFANOWSKI Inst. Informatyki PP Wersja dla TPD 29 Email: Jerzy.Stefanowski@cs.put.poznan.pl Organizacja wykładu Wprowadzenie. Możliwe
Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych JERZY STEFANOWSKI Inst. Informatyki PP Wersja dla TPD 29 Email: Jerzy.Stefanowski@cs.put.poznan.pl Organizacja wykładu Wprowadzenie. Możliwe
Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych
 Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych JERZY STEFANOWSKI Inst. Informatyki PP Wersja dla TPD 2009, Aktualizacja 2010 Email: Jerzy.Stefanowski@cs.put.poznan.pl Elementy terminologiczne
Analiza Skupień - Grupowanie Zaawansowana Eksploracja Danych JERZY STEFANOWSKI Inst. Informatyki PP Wersja dla TPD 2009, Aktualizacja 2010 Email: Jerzy.Stefanowski@cs.put.poznan.pl Elementy terminologiczne
Machine Learning for Data Science (CS4786) Lecture11. Random Projections & Canonical Correlation Analysis
 Lecture11. Random Projections & Canonical Correlation Analysis") Machine Learning for Data Science (CS4786) Lecture11 5 Random Projections & Canonical Correlation Analysis The Tall, THE FAT AND THE UGLY n X d The Tall, THE FAT AND THE UGLY d X > n X d n = n d d The
Machine Learning for Data Science (CS4786) Lecture11 5 Random Projections & Canonical Correlation Analysis The Tall, THE FAT AND THE UGLY n X d The Tall, THE FAT AND THE UGLY d X > n X d n = n d d The
TTIC 31210: Advanced Natural Language Processing. Kevin Gimpel Spring Lecture 9: Inference in Structured Prediction
 TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 9: Inference in Structured Prediction 1 intro (1 lecture) Roadmap deep learning for NLP (5 lectures) structured prediction
TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 9: Inference in Structured Prediction 1 intro (1 lecture) Roadmap deep learning for NLP (5 lectures) structured prediction
Linear Classification and Logistic Regression. Pascal Fua IC-CVLab
 Linear Classification and Logistic Regression Pascal Fua IC-CVLab 1 aaagcxicbdtdbtmwfafwdgxlhk8orha31ibqycvkdgpshdqxtwotng2pxtvqujmok1qlky5xllzrnobbediegwcap4votk2kqkf+/y/tnphdschtadu/giv3vtea99cfma8fpx7ytlxx7ckns4sylo3doom7jguhj1hxchmy/irhrlgh67lxb5x3blis8jjqynmedqujiu5zsqqagrx+yjcfpcrydusshmzeluzsg7tttiew5khhcuzm5rv0gn1unw6zl3gbzlpr3liwncyr6aaqinx4wnc/rpg6ix5szd86agoftuu0g/krjxdarph62enthdey3zn/+mi5zknou2ap+tclvhob9sxhwvhaqketnde7geqjp21zvjsfrcnkfhtejoz23vq97elxjlpbtmxpl6qxtl1sgfv1ptpy/yq9mgacrzkgje0hjj2rq7vtywnishnnkzsqekucnlblrarlh8x8szxolrrxkb8n6o4kmo/e7siisnozcfvsedlol60a/j8nmul/gby8mmssrfr2it8lkyxr9dirxxngzthtbaejv
Linear Classification and Logistic Regression Pascal Fua IC-CVLab 1 aaagcxicbdtdbtmwfafwdgxlhk8orha31ibqycvkdgpshdqxtwotng2pxtvqujmok1qlky5xllzrnobbediegwcap4votk2kqkf+/y/tnphdschtadu/giv3vtea99cfma8fpx7ytlxx7ckns4sylo3doom7jguhj1hxchmy/irhrlgh67lxb5x3blis8jjqynmedqujiu5zsqqagrx+yjcfpcrydusshmzeluzsg7tttiew5khhcuzm5rv0gn1unw6zl3gbzlpr3liwncyr6aaqinx4wnc/rpg6ix5szd86agoftuu0g/krjxdarph62enthdey3zn/+mi5zknou2ap+tclvhob9sxhwvhaqketnde7geqjp21zvjsfrcnkfhtejoz23vq97elxjlpbtmxpl6qxtl1sgfv1ptpy/yq9mgacrzkgje0hjj2rq7vtywnishnnkzsqekucnlblrarlh8x8szxolrrxkb8n6o4kmo/e7siisnozcfvsedlol60a/j8nmul/gby8mmssrfr2it8lkyxr9dirxxngzthtbaejv
Algorytmy rozpoznawania obrazów. 11. Analiza skupień. dr inż. Urszula Libal. Politechnika Wrocławska
 Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
Rozpoznawanie twarzy metodą PCA Michał Bereta 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów
 Rozpoznawanie twarzy metodą PCA Michał Bereta www.michalbereta.pl 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów Wiemy, że możemy porównywad klasyfikatory np. za pomocą kroswalidacji.
Rozpoznawanie twarzy metodą PCA Michał Bereta www.michalbereta.pl 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów Wiemy, że możemy porównywad klasyfikatory np. za pomocą kroswalidacji.
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
CLUSTERING II. Efektywne metody grupowania danych
 CLUSTERING II Efektywne metody grupowania danych Plan wykładu Wstęp: Motywacja i zastosowania Metody grupowania danych Algorytmy oparte na podziałach (partitioning algorithms) PAM Ulepszanie: CLARA, CLARANS
CLUSTERING II Efektywne metody grupowania danych Plan wykładu Wstęp: Motywacja i zastosowania Metody grupowania danych Algorytmy oparte na podziałach (partitioning algorithms) PAM Ulepszanie: CLARA, CLARANS
CLUSTERING METODY GRUPOWANIA DANYCH
 CLUSTERING METODY GRUPOWANIA DANYCH Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
CLUSTERING METODY GRUPOWANIA DANYCH Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
Eksploracja danych. Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Metody analizy skupień Wprowadzenie Charakterystyka obiektów Metody grupowania Ocena poprawności grupowania
 Wielowymiarowe metody segmentacji CHAID Metoda Automatycznej Detekcji Interakcji CHAID Cele CHAID Dane CHAID Przebieg analizy CHAID Parametry CHAID Wyniki Metody analizy skupień Wprowadzenie Charakterystyka
Wielowymiarowe metody segmentacji CHAID Metoda Automatycznej Detekcji Interakcji CHAID Cele CHAID Dane CHAID Przebieg analizy CHAID Parametry CHAID Wyniki Metody analizy skupień Wprowadzenie Charakterystyka
Tychy, plan miasta: Skala 1: (Polish Edition)
") Tychy, plan miasta: Skala 1:20 000 (Polish Edition) Poland) Przedsiebiorstwo Geodezyjno-Kartograficzne (Katowice Click here if your download doesn"t start automatically Tychy, plan miasta: Skala 1:20 000
Tychy, plan miasta: Skala 1:20 000 (Polish Edition) Poland) Przedsiebiorstwo Geodezyjno-Kartograficzne (Katowice Click here if your download doesn"t start automatically Tychy, plan miasta: Skala 1:20 000
Machine Learning for Data Science (CS4786) Lecture 11. Spectral Embedding + Clustering
 Lecture 11. Spectral Embedding + Clustering") Machine Learning for Data Science (CS4786) Lecture 11 Spectral Embedding + Clustering MOTIVATING EXAMPLE What can you say from this network? MOTIVATING EXAMPLE How about now? THOUGHT EXPERIMENT For each
Machine Learning for Data Science (CS4786) Lecture 11 Spectral Embedding + Clustering MOTIVATING EXAMPLE What can you say from this network? MOTIVATING EXAMPLE How about now? THOUGHT EXPERIMENT For each
TTIC 31210: Advanced Natural Language Processing. Kevin Gimpel Spring Lecture 8: Structured PredicCon 2
 TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 8: Structured PredicCon 2 1 Roadmap intro (1 lecture) deep learning for NLP (5 lectures) structured predic+on (4 lectures)
TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 8: Structured PredicCon 2 1 Roadmap intro (1 lecture) deep learning for NLP (5 lectures) structured predic+on (4 lectures)
Analiza skupień (Cluster analysis)
") Analiza skupień (Cluster analysis) Analiza skupień jest to podział zbioru obserwacji na podzbiory (tzw. klastry) tak, że obiekty (obserwacje) w tym samym klastrze były podobne (w pewnym sensie). Jest to
Analiza skupień (Cluster analysis) Analiza skupień jest to podział zbioru obserwacji na podzbiory (tzw. klastry) tak, że obiekty (obserwacje) w tym samym klastrze były podobne (w pewnym sensie). Jest to
utrzymania swoich obecnych klientów i dowiedzia la sie, że metody data mining moga
 Imiȩ i nazwisko: Nr indeksu: Egzamin z Wyk ladu Monograficznego p.t. DATA MINING 1. (6 pkt.) Firma X jest dostawca us lug po l aczeń bezprzewodowych (wireless) w USA, która ma 34.6 milionów klientów. Firma
Imiȩ i nazwisko: Nr indeksu: Egzamin z Wyk ladu Monograficznego p.t. DATA MINING 1. (6 pkt.) Firma X jest dostawca us lug po l aczeń bezprzewodowych (wireless) w USA, która ma 34.6 milionów klientów. Firma
tum.de/fall2018/ in2357
 https://piazza.com/ tum.de/fall2018/ in2357 Prof. Daniel Cremers From to Classification Categories of Learning (Rep.) Learning Unsupervised Learning clustering, density estimation Supervised Learning learning
https://piazza.com/ tum.de/fall2018/ in2357 Prof. Daniel Cremers From to Classification Categories of Learning (Rep.) Learning Unsupervised Learning clustering, density estimation Supervised Learning learning
A Zadanie
 where a, b, and c are binary (boolean) attributes. A Zadanie 1 2 3 4 5 6 7 8 9 10 Punkty a (maks) (2) (2) (2) (2) (4) F(6) (8) T (8) (12) (12) (40) Nazwisko i Imiȩ: c Uwaga: ta część zostanie wypełniona
where a, b, and c are binary (boolean) attributes. A Zadanie 1 2 3 4 5 6 7 8 9 10 Punkty a (maks) (2) (2) (2) (2) (4) F(6) (8) T (8) (12) (12) (40) Nazwisko i Imiȩ: c Uwaga: ta część zostanie wypełniona
deep learning for NLP (5 lectures)
") TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 6: Finish Transformers; Sequence- to- Sequence Modeling and AJenKon 1 Roadmap intro (1 lecture) deep learning for NLP (5
TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 6: Finish Transformers; Sequence- to- Sequence Modeling and AJenKon 1 Roadmap intro (1 lecture) deep learning for NLP (5
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
Helena Boguta, klasa 8W, rok szkolny 2018/2019
 Poniższy zbiór zadań został wykonany w ramach projektu Mazowiecki program stypendialny dla uczniów szczególnie uzdolnionych - najlepsza inwestycja w człowieka w roku szkolnym 2018/2019. Składają się na
Poniższy zbiór zadań został wykonany w ramach projektu Mazowiecki program stypendialny dla uczniów szczególnie uzdolnionych - najlepsza inwestycja w człowieka w roku szkolnym 2018/2019. Składają się na
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów
 Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
1. Grupowanie Algorytmy grupowania:
 1. 1.1. 2. 3. 3.1. 3.2. Grupowanie...1 Algorytmy grupowania:...1 Grupowanie metodą k-średnich...3 Grupowanie z wykorzystaniem Oracle Data Miner i Rapid Miner...3 Grupowanie z wykorzystaniem algorytmu K-Means
1. 1.1. 2. 3. 3.1. 3.2. Grupowanie...1 Algorytmy grupowania:...1 Grupowanie metodą k-średnich...3 Grupowanie z wykorzystaniem Oracle Data Miner i Rapid Miner...3 Grupowanie z wykorzystaniem algorytmu K-Means
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Czym jest analiza skupień?
 Statystyczna analiza danych z pakietem SAS Analiza skupień metody hierarchiczne Czym jest analiza skupień? wielowymiarowa technika pozwalająca wykrywać współzależności między obiektami; ściśle związana
Statystyczna analiza danych z pakietem SAS Analiza skupień metody hierarchiczne Czym jest analiza skupień? wielowymiarowa technika pozwalająca wykrywać współzależności między obiektami; ściśle związana
Gradient Coding using the Stochastic Block Model
 Gradient Coding using the Stochastic Block Model Zachary Charles (UW-Madison) Joint work with Dimitris Papailiopoulos (UW-Madison) aaacaxicbvdlssnafj3uv62vqbvbzwarxjsqikaboelgzux7gcaeywtsdp1mwsxeaepd+ctuxcji1r9w5984bbpq1gmxdufcy733bcmjutn2t1fawl5zxsuvvzy2t7z3zn29lkwyguktjywrnqbjwigntuuvi51uebqhjlsdwfxebz8qiwnc79uwjv6mepxgfcoljd88uiox0m1hvlnzwzgowymjn7tjyzertmvpareju5aqkndwzs83thawe64wq1j2httvxo6eopirccxnjekrhqae6wrkuuykl08/gmnjryqwsoqurubu/t2ro1jkyrzozhipvpz3juj/xjdt0ywxu55mina8wxrldkoetukairuekzbubgfb9a0q95fawonqkjoez/7lrdi6trzbcm7pqvwrio4yoarh4aq44bzuwq1ogcba4be8g1fwzjwzl8a78tfrlrnfzd74a+pzb2h+lzm=
Gradient Coding using the Stochastic Block Model Zachary Charles (UW-Madison) Joint work with Dimitris Papailiopoulos (UW-Madison) aaacaxicbvdlssnafj3uv62vqbvbzwarxjsqikaboelgzux7gcaeywtsdp1mwsxeaepd+ctuxcji1r9w5984bbpq1gmxdufcy733bcmjutn2t1fawl5zxsuvvzy2t7z3zn29lkwyguktjywrnqbjwigntuuvi51uebqhjlsdwfxebz8qiwnc79uwjv6mepxgfcoljd88uiox0m1hvlnzwzgowymjn7tjyzertmvpareju5aqkndwzs83thawe64wq1j2httvxo6eopirccxnjekrhqae6wrkuuykl08/gmnjryqwsoqurubu/t2ro1jkyrzozhipvpz3juj/xjdt0ywxu55mina8wxrldkoetukairuekzbubgfb9a0q95fawonqkjoez/7lrdi6trzbcm7pqvwrio4yoarh4aq44bzuwq1ogcba4be8g1fwzjwzl8a78tfrlrnfzd74a+pzb2h+lzm=
Wojewodztwo Koszalinskie: Obiekty i walory krajoznawcze (Inwentaryzacja krajoznawcza Polski) (Polish Edition)
 (Polish Edition)") Wojewodztwo Koszalinskie: Obiekty i walory krajoznawcze (Inwentaryzacja krajoznawcza Polski) (Polish Edition) Robert Respondowski Click here if your download doesn"t start automatically Wojewodztwo Koszalinskie:
Wojewodztwo Koszalinskie: Obiekty i walory krajoznawcze (Inwentaryzacja krajoznawcza Polski) (Polish Edition) Robert Respondowski Click here if your download doesn"t start automatically Wojewodztwo Koszalinskie:
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Zakopane, plan miasta: Skala ok. 1: = City map (Polish Edition)
") Zakopane, plan miasta: Skala ok. 1:15 000 = City map (Polish Edition) Click here if your download doesn"t start automatically Zakopane, plan miasta: Skala ok. 1:15 000 = City map (Polish Edition) Zakopane,
Zakopane, plan miasta: Skala ok. 1:15 000 = City map (Polish Edition) Click here if your download doesn"t start automatically Zakopane, plan miasta: Skala ok. 1:15 000 = City map (Polish Edition) Zakopane,
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
TEORETYCZNE PODSTAWY INFORMATYKI
 1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana II stopień studiów Wykład 13b 2 Eksploracja danych Co rozumiemy pod pojęciem eksploracja danych Algorytmy grupujące (klajstrujące) Graficzna
1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana II stopień studiów Wykład 13b 2 Eksploracja danych Co rozumiemy pod pojęciem eksploracja danych Algorytmy grupujące (klajstrujące) Graficzna
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner. rok akademicki 2014/2015
 Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Sieci Kohonena Sieci Kohonena Sieci Kohonena zostały wprowadzone w 1982 przez fińskiego
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Sieci Kohonena Sieci Kohonena Sieci Kohonena zostały wprowadzone w 1982 przez fińskiego
Revenue Maximization. Sept. 25, 2018
 Revenue Maximization Sept. 25, 2018 Goal So Far: Ideal Auctions Dominant-Strategy Incentive Compatible (DSIC) b i = v i is a dominant strategy u i 0 x is welfare-maximizing x and p run in polynomial time
Revenue Maximization Sept. 25, 2018 Goal So Far: Ideal Auctions Dominant-Strategy Incentive Compatible (DSIC) b i = v i is a dominant strategy u i 0 x is welfare-maximizing x and p run in polynomial time
MS Visual Studio 2005 Team Suite - Performance Tool
 MS Visual Studio 2005 Team Suite - Performance Tool przygotował: Krzysztof Jurczuk Politechnika Białostocka Wydział Informatyki Katedra Oprogramowania ul. Wiejska 45A 15-351 Białystok Streszczenie: Dokument
MS Visual Studio 2005 Team Suite - Performance Tool przygotował: Krzysztof Jurczuk Politechnika Białostocka Wydział Informatyki Katedra Oprogramowania ul. Wiejska 45A 15-351 Białystok Streszczenie: Dokument
Weronika Mysliwiec, klasa 8W, rok szkolny 2018/2019
 Poniższy zbiór zadań został wykonany w ramach projektu Mazowiecki program stypendialny dla uczniów szczególnie uzdolnionych - najlepsza inwestycja w człowieka w roku szkolnym 2018/2019. Tresci zadań rozwiązanych
Poniższy zbiór zadań został wykonany w ramach projektu Mazowiecki program stypendialny dla uczniów szczególnie uzdolnionych - najlepsza inwestycja w człowieka w roku szkolnym 2018/2019. Tresci zadań rozwiązanych
Previously on CSCI 4622
 More Naïve Bayes aaace3icbvfba9rafj7ew423vr998obg2gpzkojyh4rcx3ys4lafzbjmjifdototmhoilml+hf/mn3+kl+jkdwtr64gbj+8yl2/ywklhsfircg/dvnp33s796mhdr4+fdj4+o3fvywvorkuqe5zzh0oanjakhwe1ra5zhaf5xvgvn35f62rlvtcyxpnm50awundy1hzwi46jbmgprbtrrvidrg4jre4g07kak+picee6xfgiwvfaltorirucni64eeigkqhpegbwaxglabftpyq4gjbls/hw2ci7tr2xj5ddfmfzwtazj6ubmyddgchbzpf88dmrktfonct6vazputos5zakunhfweow5ukcn+puq8m1ulm7kq+d154pokysx4zgxw4nwq6dw+rcozwnhbuu9et/tgld5cgslazuci1yh1q2ynca/u9ais0kukspulds3xxegvtyfycu8iwk1598e0z2xx/g6ef94ehbpo0d9ok9yiowsvfskh1ix2zcbpsdvaxgww7wj4zdn+he2hogm8xz9s+e7/4cuf/ata==
More Naïve Bayes aaace3icbvfba9rafj7ew423vr998obg2gpzkojyh4rcx3ys4lafzbjmjifdototmhoilml+hf/mn3+kl+jkdwtr64gbj+8yl2/ywklhsfircg/dvnp33s796mhdr4+fdj4+o3fvywvorkuqe5zzh0oanjakhwe1ra5zhaf5xvgvn35f62rlvtcyxpnm50awundy1hzwi46jbmgprbtrrvidrg4jre4g07kak+picee6xfgiwvfaltorirucni64eeigkqhpegbwaxglabftpyq4gjbls/hw2ci7tr2xj5ddfmfzwtazj6ubmyddgchbzpf88dmrktfonct6vazputos5zakunhfweow5ukcn+puq8m1ulm7kq+d154pokysx4zgxw4nwq6dw+rcozwnhbuu9et/tgld5cgslazuci1yh1q2ynca/u9ais0kukspulds3xxegvtyfycu8iwk1598e0z2xx/g6ef94ehbpo0d9ok9yiowsvfskh1ix2zcbpsdvaxgww7wj4zdn+he2hogm8xz9s+e7/4cuf/ata==
Machine Learning for Data Science (CS4786) Lecture 24. Differential Privacy and Re-useable Holdout
 Lecture 24. Differential Privacy and Re-useable Holdout") Machine Learning for Data Science (CS4786) Lecture 24 Differential Privacy and Re-useable Holdout Defining Privacy Defining Privacy Dataset + Defining Privacy Dataset + Learning Algorithm Distribution
Machine Learning for Data Science (CS4786) Lecture 24 Differential Privacy and Re-useable Holdout Defining Privacy Defining Privacy Dataset + Defining Privacy Dataset + Learning Algorithm Distribution
Few-fermion thermometry
 Few-fermion thermometry Phys. Rev. A 97, 063619 (2018) Tomasz Sowiński Institute of Physics of the Polish Academy of Sciences Co-authors: Marcin Płodzień Rafał Demkowicz-Dobrzański FEW-BODY PROBLEMS FewBody.ifpan.edu.pl
Few-fermion thermometry Phys. Rev. A 97, 063619 (2018) Tomasz Sowiński Institute of Physics of the Polish Academy of Sciences Co-authors: Marcin Płodzień Rafał Demkowicz-Dobrzański FEW-BODY PROBLEMS FewBody.ifpan.edu.pl
Supervised Hierarchical Clustering with Exponential Linkage. Nishant Yadav
 Supervised Hierarchical Clustering with Exponential Linage Nishant Yadav Ari Kobren Nicholas Monath Andrew McCallum At train time, learn A :2 X! Y Supervised Clustering aaab8nicbvdlssnafl2pr1pfvzdugvwvrirdfl147kcfuabymq6aydozslmjvbcp8onc0xc+jxu/bsnbrbaemdgcm69zlntaq36hnftmltfwnzq7xd2dnd2z+ohh61juo1zs2qhnldbgmugqt5chyn9gmxkfgnxbyl/udj6ynv/irpwlyjkspokuojv6/zjgmbkr3cwg1zpx9+zwv4lfbouaa6qx/2homnmjfjbjon5xojbrjryktis08nswidbhrwspjzeyqzspp3dordn1iafsunp190zgymomcwgn84hm2cvf/7xeitf1hgzpmgxxwupcjf5eb3u0ouguuxtyrqzw1wl46jjhrtsxvbgr988ippx9r9yx8ua43boo4ynmapnimpv9cae2hccygoeizxehpqexheny/fampdo7hd5zph3bqvc=
Supervised Hierarchical Clustering with Exponential Linage Nishant Yadav Ari Kobren Nicholas Monath Andrew McCallum At train time, learn A :2 X! Y Supervised Clustering aaab8nicbvdlssnafl2pr1pfvzdugvwvrirdfl147kcfuabymq6aydozslmjvbcp8onc0xc+jxu/bsnbrbaemdgcm69zlntaq36hnftmltfwnzq7xd2dnd2z+ohh61juo1zs2qhnldbgmugqt5chyn9gmxkfgnxbyl/udj6ynv/irpwlyjkspokuojv6/zjgmbkr3cwg1zpx9+zwv4lfbouaa6qx/2homnmjfjbjon5xojbrjryktis08nswidbhrwspjzeyqzspp3dordn1iafsunp190zgymomcwgn84hm2cvf/7xeitf1hgzpmgxxwupcjf5eb3u0ouguuxtyrqzw1wl46jjhrtsxvbgr988ippx9r9yx8ua43boo4ynmapnimpv9cae2hccygoeizxehpqexheny/fampdo7hd5zph3bqvc=
SSW1.1, HFW Fry #20, Zeno #25 Benchmark: Qtr.1. Fry #65, Zeno #67. like
 SSW1.1, HFW Fry #20, Zeno #25 Benchmark: Qtr.1 I SSW1.1, HFW Fry #65, Zeno #67 Benchmark: Qtr.1 like SSW1.2, HFW Fry #47, Zeno #59 Benchmark: Qtr.1 do SSW1.2, HFW Fry #5, Zeno #4 Benchmark: Qtr.1 to SSW1.2,
SSW1.1, HFW Fry #20, Zeno #25 Benchmark: Qtr.1 I SSW1.1, HFW Fry #65, Zeno #67 Benchmark: Qtr.1 like SSW1.2, HFW Fry #47, Zeno #59 Benchmark: Qtr.1 do SSW1.2, HFW Fry #5, Zeno #4 Benchmark: Qtr.1 to SSW1.2,
dr inż. Olga Siedlecka-Lamch 14 listopada 2011 roku Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Eksploracja danych
 - Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
- Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
Grupowanie danych. Wprowadzenie. Przykłady
 Grupowanie danych str. 1 Wprowadzenie Celem procesu grupowania jest podział zbioru obiektów, fizycznych lub abstrakcyjnych, na klasy obiektów o podobnych cechach, nazywane klastrami lub skupieniami Klaster
Grupowanie danych str. 1 Wprowadzenie Celem procesu grupowania jest podział zbioru obiektów, fizycznych lub abstrakcyjnych, na klasy obiektów o podobnych cechach, nazywane klastrami lub skupieniami Klaster
ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA JEZYKOWA) BY DOUGLAS KENT HALL
 BY DOUGLAS KENT HALL") Read Online and Download Ebook ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA JEZYKOWA) BY DOUGLAS KENT HALL DOWNLOAD EBOOK : ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA Click link bellow and free register
Read Online and Download Ebook ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA JEZYKOWA) BY DOUGLAS KENT HALL DOWNLOAD EBOOK : ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA Click link bellow and free register
Proposal of thesis topic for mgr in. (MSE) programme in Telecommunications and Computer Science
 programme in Telecommunications and Computer Science") Proposal of thesis topic for mgr in (MSE) programme 1 Topic: Monte Carlo Method used for a prognosis of a selected technological process 2 Supervisor: Dr in Małgorzata Langer 3 Auxiliary supervisor: 4
Proposal of thesis topic for mgr in (MSE) programme 1 Topic: Monte Carlo Method used for a prognosis of a selected technological process 2 Supervisor: Dr in Małgorzata Langer 3 Auxiliary supervisor: 4
Wprowadzenie do programu RapidMiner, część 5 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 5 Michał Bereta www.michalbereta.pl 1. Przekształcenia atrybutów (ang. attribute reduction / transformation, feature extraction). Zamiast wybierad częśd atrybutów
Wprowadzenie do programu RapidMiner, część 5 Michał Bereta www.michalbereta.pl 1. Przekształcenia atrybutów (ang. attribute reduction / transformation, feature extraction). Zamiast wybierad częśd atrybutów
Fig 5 Spectrograms of the original signal (top) extracted shaft-related GAD components (middle) and
 extracted shaft-related GAD components (middle) and") Fig 4 Measured vibration signal (top). Blue original signal. Red component related to periodic excitation of resonances and noise. Green component related. Rotational speed profile used for experiment
Fig 4 Measured vibration signal (top). Blue original signal. Red component related to periodic excitation of resonances and noise. Green component related. Rotational speed profile used for experiment
Zarządzanie sieciami telekomunikacyjnymi
 SNMP Protocol The Simple Network Management Protocol (SNMP) is an application layer protocol that facilitates the exchange of management information between network devices. It is part of the Transmission
SNMP Protocol The Simple Network Management Protocol (SNMP) is an application layer protocol that facilitates the exchange of management information between network devices. It is part of the Transmission
SubVersion. Piotr Mikulski. SubVersion. P. Mikulski. Co to jest subversion? Zalety SubVersion. Wady SubVersion. Inne różnice SubVersion i CVS
 Piotr Mikulski 2006 Subversion is a free/open-source version control system. That is, Subversion manages files and directories over time. A tree of files is placed into a central repository. The repository
Piotr Mikulski 2006 Subversion is a free/open-source version control system. That is, Subversion manages files and directories over time. A tree of files is placed into a central repository. The repository
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Idea. Algorytm zachłanny Algorytmy hierarchiczne Metoda K-średnich Metoda hierarchiczna, a niehierarchiczna. Analiza skupień
 Idea jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień. Obiekty należące do danego skupienia
Idea jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień. Obiekty należące do danego skupienia
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów re
 Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Przykład Rezygnacja z usług operatora
 Przykład Rezygnacja z usług operatora Zbiór CHURN Zbiór zawiera dane o 3333 klientach firmy telefonicznej razem ze wskazaniem, czy zrezygnowali z usług tej firmy Dane pochodzą z UCI Repository of Machine
Przykład Rezygnacja z usług operatora Zbiór CHURN Zbiór zawiera dane o 3333 klientach firmy telefonicznej razem ze wskazaniem, czy zrezygnowali z usług tej firmy Dane pochodzą z UCI Repository of Machine
Agnostic Learning and VC dimension
 Agnostic Learning and VC dimension Machine Learning Spring 2019 The slides are based on Vivek Srikumar s 1 This Lecture Agnostic Learning What if I cannot guarantee zero training error? Can we still get
Agnostic Learning and VC dimension Machine Learning Spring 2019 The slides are based on Vivek Srikumar s 1 This Lecture Agnostic Learning What if I cannot guarantee zero training error? Can we still get
OSI Network Layer. Network Fundamentals Chapter 5. Version Cisco Systems, Inc. All rights reserved. Cisco Public 1
 OSI Network Layer Network Fundamentals Chapter 5 Version 4.0 1 OSI Network Layer Network Fundamentals Rozdział 5 Version 4.0 2 Objectives Identify the role of the Network Layer, as it describes communication
OSI Network Layer Network Fundamentals Chapter 5 Version 4.0 1 OSI Network Layer Network Fundamentals Rozdział 5 Version 4.0 2 Objectives Identify the role of the Network Layer, as it describes communication
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
POLITECHNIKA ŚLĄSKA INSTYTUT AUTOMATYKI ZAKŁAD SYSTEMÓW POMIAROWYCH
 POLITECHNIKA ŚLĄSKA INSTYTUT AUTOMATYKI ZAKŁAD SYSTEMÓW POMIAROWYCH Gliwice, wrzesień 2005 Pomiar napięcia przemiennego Cel ćwiczenia Celem ćwiczenia jest zbadanie dokładności woltomierza cyfrowego dla
POLITECHNIKA ŚLĄSKA INSTYTUT AUTOMATYKI ZAKŁAD SYSTEMÓW POMIAROWYCH Gliwice, wrzesień 2005 Pomiar napięcia przemiennego Cel ćwiczenia Celem ćwiczenia jest zbadanie dokładności woltomierza cyfrowego dla
4.3 Grupowanie według podobieństwa
 4.3 Grupowanie według podobieństwa Przykłady obiektów to coś więcej niż wektory wartości atrybutów. Reprezentują one poszczególne rasy psów. Ważnym pytaniem, jakie można sobie zadać, jest to jak dobrymi
4.3 Grupowanie według podobieństwa Przykłady obiektów to coś więcej niż wektory wartości atrybutów. Reprezentują one poszczególne rasy psów. Ważnym pytaniem, jakie można sobie zadać, jest to jak dobrymi
Strategic planning. Jolanta Żyśko University of Physical Education in Warsaw
 Strategic planning Jolanta Żyśko University of Physical Education in Warsaw 7S Formula Strategy 5 Ps Strategy as plan Strategy as ploy Strategy as pattern Strategy as position Strategy as perspective Strategy
Strategic planning Jolanta Żyśko University of Physical Education in Warsaw 7S Formula Strategy 5 Ps Strategy as plan Strategy as ploy Strategy as pattern Strategy as position Strategy as perspective Strategy
Poznań, 14 grudnia 2002. Case Study 2 Analiza skupień
 Poznań, 14 grudnia 2002 Case Study 2 Analiza skupień Celem ćwiczenia jest przeprowadzenie procesu grupowania / analizy skupień dla jednego z wybranych zbiorów danych (tj. dostarczonych przez prowadzącego).
Poznań, 14 grudnia 2002 Case Study 2 Analiza skupień Celem ćwiczenia jest przeprowadzenie procesu grupowania / analizy skupień dla jednego z wybranych zbiorów danych (tj. dostarczonych przez prowadzącego).
Data Mining Wykład 4. Plan wykładu
 Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Grupowanie. Iteracyjno-optymalizacyjne metody grupowania Algorytm k-średnich Algorytm k-medoidów. Eksploracja danych. Grupowanie wykład 2
 Grupowanie Iteracyjno-optymalizacyjne metody grupowania Algorytm k-średnich Algorytm k-medoidów Grupowanie wykład 2 Tematem wykładu są iteracyjno-optymalizacyjne algorytmy grupowania. Przedstawimy i omówimy
Grupowanie Iteracyjno-optymalizacyjne metody grupowania Algorytm k-średnich Algorytm k-medoidów Grupowanie wykład 2 Tematem wykładu są iteracyjno-optymalizacyjne algorytmy grupowania. Przedstawimy i omówimy
Estymacja parametrów Wybrane zagadnienia implementacji i wykorzystania
 Estymacja parametrów Wybrane zagadnienia implementacji i wykorzystania Wykład w ramach przedmiotu Komputerowe systemy sterowania i wspomagania decyzji Plan wykładu Potrzeba estymacji parametrów Estymacja
Estymacja parametrów Wybrane zagadnienia implementacji i wykorzystania Wykład w ramach przedmiotu Komputerowe systemy sterowania i wspomagania decyzji Plan wykładu Potrzeba estymacji parametrów Estymacja
Latent Dirichlet Allocation Models and their Evaluation IT for Practice 2016
 Latent Dirichlet Allocation Models and their Evaluation IT for Practice 2016 Paweł Lula Cracow University of Economics, Poland pawel.lula@uek.krakow.pl Latent Dirichlet Allocation (LDA) Documents Latent
Latent Dirichlet Allocation Models and their Evaluation IT for Practice 2016 Paweł Lula Cracow University of Economics, Poland pawel.lula@uek.krakow.pl Latent Dirichlet Allocation (LDA) Documents Latent
Analiza skupień. Idea
 Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Convolution semigroups with linear Jacobi parameters
 Convolution semigroups with linear Jacobi parameters Michael Anshelevich; Wojciech Młotkowski Texas A&M University; University of Wrocław February 14, 2011 Jacobi parameters. µ = measure with finite moments,
Convolution semigroups with linear Jacobi parameters Michael Anshelevich; Wojciech Młotkowski Texas A&M University; University of Wrocław February 14, 2011 Jacobi parameters. µ = measure with finite moments,
Testy jednostkowe - zastosowanie oprogramowania JUNIT 4.0 Zofia Kruczkiewicz
 Testy jednostkowe - zastosowanie oprogramowania JUNIT 4.0 http://www.junit.org/ Zofia Kruczkiewicz 1. Aby utworzyć test dla jednej klasy, należy kliknąć prawym przyciskiem myszy w oknie Projects na wybraną
Testy jednostkowe - zastosowanie oprogramowania JUNIT 4.0 http://www.junit.org/ Zofia Kruczkiewicz 1. Aby utworzyć test dla jednej klasy, należy kliknąć prawym przyciskiem myszy w oknie Projects na wybraną
Knovel Math: Jakość produktu
 Knovel Math: Jakość produktu Knovel jest agregatorem materiałów pełnotekstowych dostępnych w formacie PDF i interaktywnym. Narzędzia interaktywne Knovel nie są stworzone wokół specjalnych algorytmów wymagających
Knovel Math: Jakość produktu Knovel jest agregatorem materiałów pełnotekstowych dostępnych w formacie PDF i interaktywnym. Narzędzia interaktywne Knovel nie są stworzone wokół specjalnych algorytmów wymagających
Katowice, plan miasta: Skala 1: = City map = Stadtplan (Polish Edition)
") Katowice, plan miasta: Skala 1:20 000 = City map = Stadtplan (Polish Edition) Polskie Przedsiebiorstwo Wydawnictw Kartograficznych im. Eugeniusza Romera Click here if your download doesn"t start automatically
Katowice, plan miasta: Skala 1:20 000 = City map = Stadtplan (Polish Edition) Polskie Przedsiebiorstwo Wydawnictw Kartograficznych im. Eugeniusza Romera Click here if your download doesn"t start automatically
Podstawy grupowania danych w programie RapidMiner Michał Bereta
 Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Analysis of Movie Profitability STAT 469 IN CLASS ANALYSIS #2
 Analysis of Movie Profitability STAT 469 IN CLASS ANALYSIS #2 aaaklnictzzjb9tgfmcnadpg7oy0lxa9edva9kkapdarhyk2k7gourinlwsweyzikuyiigvyleiv/cv767fpf/5crc1xt9va5mx7w3m/ecuqw1kuztpx/rl3/70h73/w4cog9dhhn3z62d6jzy+yzj766txpoir9nzszisjynetqr+rvlfvyoozu5xbybpsxb1wahul8phczdt2v4zgchb7uecwphlyigrgkjcyiflfyci0kxnmr4z6kw0jsokvot8isntpa3gbknlcufiv/h+hh+eur4fomd417rvtfjoit5pfju6yxiab2fmwk0y/feuybobqk+axnke8xzjjhfyd8kkpl9zdoddkazd5j6bzpemjb64smjb6vb4xmehysu08lsrszopxftlzee130jcb0zjxy7r5wa2f1s2off2+dyatrughnrtpkuprlcpu55zlxpss/yqe2eamjkcf0jye8w8yas0paf6t0t2i9stmcua+inbi2rt01tz22tubbqwidypvgz6piynkpobirkxgu54ibzoti4pkw2i5ow9lnuaoabhuxfxqhvnrj6w15tb3furnbm+scyxobjhr5pmj5j/w5ix9wsa2tlwx9alpshlunzjgnrwvqbpwzjl9wes+ptyn+ypy/jgskavtl8j0hz1djdhzwtpjbbvpr1zj7jpg6ve7zxfngj75zee0vmp9qm2uvgu/9zdofq6r+g8l4xctvo+v+xdrfr8oxiwutycu0qgyf8icuyvp/sixfi9zxe11vp6mrjjovpmxm6acrtbia+wjr9bevlgjwlz5xd3rfna9g06qytaoofk8olxbxc7xby2evqjmmk6pjvvzxmpbnct6+036xp5vdbrnbdqph8brlfn/n/khnfumhf6z1v7h/80yieukkd5j0un82t9mynxzmk0s/bzn4tacdziszdhwrl8x5ako8qp1n1zn0k6w2em0km9zj1i4yt1pt3xiprw85jmc2m1ut2geum6y6es2fwx6c+wlrpykblopbuj5nnr2byygfy5opllv4+jmm7s6u+tvhywbnb0kv2lt5th4xipmiij+y1toiyo7bo0d+vzvovjkp6aoejsubhj3qrp3fjd/m23pay8h218ibvx3nicofvd1xi86+kh6nb/b+hgsjp5+qwpurzlir15np66vmdehh6tyazdm1k/5ejtuvurgcqux6yc+qw/sbsaj7lkt4x9qmtp7euk6zbdedyuzu6ptsu2eeu3rxcz06uf6g8wyuveznhkbzynajbb7r7cbmla+jbtrst0ow2v6ntkwv8svnwqnu5pa3oxfeexf93739p93chq/fv+jr8r0d9brhpcxr2w88bvqbr41j6wvrb+u5dzjpvx+veoaxwptzp/8cen+xbg==
Analysis of Movie Profitability STAT 469 IN CLASS ANALYSIS #2 aaaklnictzzjb9tgfmcnadpg7oy0lxa9edva9kkapdarhyk2k7gourinlwsweyzikuyiigvyleiv/cv767fpf/5crc1xt9va5mx7w3m/ecuqw1kuztpx/rl3/70h73/w4cog9dhhn3z62d6jzy+yzj766txpoir9nzszisjynetqr+rvlfvyoozu5xbybpsxb1wahul8phczdt2v4zgchb7uecwphlyigrgkjcyiflfyci0kxnmr4z6kw0jsokvot8isntpa3gbknlcufiv/h+hh+eur4fomd417rvtfjoit5pfju6yxiab2fmwk0y/feuybobqk+axnke8xzjjhfyd8kkpl9zdoddkazd5j6bzpemjb64smjb6vb4xmehysu08lsrszopxftlzee130jcb0zjxy7r5wa2f1s2off2+dyatrughnrtpkuprlcpu55zlxpss/yqe2eamjkcf0jye8w8yas0paf6t0t2i9stmcua+inbi2rt01tz22tubbqwidypvgz6piynkpobirkxgu54ibzoti4pkw2i5ow9lnuaoabhuxfxqhvnrj6w15tb3furnbm+scyxobjhr5pmj5j/w5ix9wsa2tlwx9alpshlunzjgnrwvqbpwzjl9wes+ptyn+ypy/jgskavtl8j0hz1djdhzwtpjbbvpr1zj7jpg6ve7zxfngj75zee0vmp9qm2uvgu/9zdofq6r+g8l4xctvo+v+xdrfr8oxiwutycu0qgyf8icuyvp/sixfi9zxe11vp6mrjjovpmxm6acrtbia+wjr9bevlgjwlz5xd3rfna9g06qytaoofk8olxbxc7xby2evqjmmk6pjvvzxmpbnct6+036xp5vdbrnbdqph8brlfn/n/khnfumhf6z1v7h/80yieukkd5j0un82t9mynxzmk0s/bzn4tacdziszdhwrl8x5ako8qp1n1zn0k6w2em0km9zj1i4yt1pt3xiprw85jmc2m1ut2geum6y6es2fwx6c+wlrpykblopbuj5nnr2byygfy5opllv4+jmm7s6u+tvhywbnb0kv2lt5th4xipmiij+y1toiyo7bo0d+vzvovjkp6aoejsubhj3qrp3fjd/m23pay8h218ibvx3nicofvd1xi86+kh6nb/b+hgsjp5+qwpurzlir15np66vmdehh6tyazdm1k/5ejtuvurgcqux6yc+qw/sbsaj7lkt4x9qmtp7euk6zbdedyuzu6ptsu2eeu3rxcz06uf6g8wyuveznhkbzynajbb7r7cbmla+jbtrst0ow2v6ntkwv8svnwqnu5pa3oxfeexf93739p93chq/fv+jr8r0d9brhpcxr2w88bvqbr41j6wvrb+u5dzjpvx+veoaxwptzp/8cen+xbg==
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Algorytm k-średnich. Źródło: LaroseD.T., Okrywanie wiedzy w danych.wprowadzenie do eksploracji danych, PWN, Warszawa 2005.
 Algorytm k-średnich Źródło: LaroseD.T., Okrywanie wiedzy w danych.wprowadzenie do eksploracji danych, PWN, Warszawa 005. Dane a b c d e f g h (,3) (3,3) (4,3) (5,3) (,) (4,) (,) (,) Algorytm k-średnich
Algorytm k-średnich Źródło: LaroseD.T., Okrywanie wiedzy w danych.wprowadzenie do eksploracji danych, PWN, Warszawa 005. Dane a b c d e f g h (,3) (3,3) (4,3) (5,3) (,) (4,) (,) (,) Algorytm k-średnich
TADEUSZ KWATER 1, ROBERT PĘKALA 2, ALEKSANDRA SALAMON 3
 Wydawnictwo UR 2016 ISSN 2080-9069 ISSN 2450-9221 online Edukacja Technika Informatyka nr 4/18/2016 www.eti.rzeszow.pl DOI: 10.15584/eti.2016.4.46 TADEUSZ KWATER 1, ROBERT PĘKALA 2, ALEKSANDRA SALAMON
Wydawnictwo UR 2016 ISSN 2080-9069 ISSN 2450-9221 online Edukacja Technika Informatyka nr 4/18/2016 www.eti.rzeszow.pl DOI: 10.15584/eti.2016.4.46 TADEUSZ KWATER 1, ROBERT PĘKALA 2, ALEKSANDRA SALAMON
Nazwa projektu: Kreatywni i innowacyjni uczniowie konkurencyjni na rynku pracy
 Nazwa projektu: Kreatywni i innowacyjni uczniowie konkurencyjni na rynku pracy DZIAŁANIE 3.2 EDUKACJA OGÓLNA PODDZIAŁANIE 3.2.1 JAKOŚĆ EDUKACJI OGÓLNEJ Projekt współfinansowany przez Unię Europejską w
Nazwa projektu: Kreatywni i innowacyjni uczniowie konkurencyjni na rynku pracy DZIAŁANIE 3.2 EDUKACJA OGÓLNA PODDZIAŁANIE 3.2.1 JAKOŚĆ EDUKACJI OGÓLNEJ Projekt współfinansowany przez Unię Europejską w
Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska
 Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska e-mail: bartosz.krawczyk@pwr.wroc.pl Czym jest klasyfikacja
Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska e-mail: bartosz.krawczyk@pwr.wroc.pl Czym jest klasyfikacja
OpenPoland.net API Documentation
 OpenPoland.net API Documentation Release 1.0 Michał Gryczka July 11, 2014 Contents 1 REST API tokens: 3 1.1 How to get a token............................................ 3 2 REST API : search for assets
OpenPoland.net API Documentation Release 1.0 Michał Gryczka July 11, 2014 Contents 1 REST API tokens: 3 1.1 How to get a token............................................ 3 2 REST API : search for assets
archivist: Managing Data Analysis Results
 archivist: Managing Data Analysis Results https://github.com/pbiecek/archivist Marcin Kosiński 1,2, Przemysław Biecek 2 1 IT Research and Development Grupa Wirtualna Polska 2 Faculty of Mathematics, Informatics
archivist: Managing Data Analysis Results https://github.com/pbiecek/archivist Marcin Kosiński 1,2, Przemysław Biecek 2 1 IT Research and Development Grupa Wirtualna Polska 2 Faculty of Mathematics, Informatics
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Network Services for Spatial Data in European Geo-Portals and their Compliance with ISO and OGC Standards
 INSPIRE Conference 2010 INSPIRE as a Framework for Cooperation Network Services for Spatial Data in European Geo-Portals and their Compliance with ISO and OGC Standards Elżbieta Bielecka Agnieszka Zwirowicz
INSPIRE Conference 2010 INSPIRE as a Framework for Cooperation Network Services for Spatial Data in European Geo-Portals and their Compliance with ISO and OGC Standards Elżbieta Bielecka Agnieszka Zwirowicz
 aforementioned device she also has to estimate the time when the patients need the infusion to be replaced and/or disconnected. Meanwhile, however, she must cope with many other tasks. If the department
aforementioned device she also has to estimate the time when the patients need the infusion to be replaced and/or disconnected. Meanwhile, however, she must cope with many other tasks. If the department
DUAL SIMILARITY OF VOLTAGE TO CURRENT AND CURRENT TO VOLTAGE TRANSFER FUNCTION OF HYBRID ACTIVE TWO- PORTS WITH CONVERSION
 ELEKTRYKA 0 Zeszyt (9) Rok LX Andrzej KUKIEŁKA Politechnika Śląska w Gliwicach DUAL SIMILARITY OF VOLTAGE TO CURRENT AND CURRENT TO VOLTAGE TRANSFER FUNCTION OF HYBRID ACTIVE TWO- PORTS WITH CONVERSION
ELEKTRYKA 0 Zeszyt (9) Rok LX Andrzej KUKIEŁKA Politechnika Śląska w Gliwicach DUAL SIMILARITY OF VOLTAGE TO CURRENT AND CURRENT TO VOLTAGE TRANSFER FUNCTION OF HYBRID ACTIVE TWO- PORTS WITH CONVERSION
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS. wersja 9.2 i 9.3. Szkoła Główna Handlowa w Warszawie
 STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
MaPlan Sp. z O.O. Click here if your download doesn"t start automatically
 Mierzeja Wislana, mapa turystyczna 1:50 000: Mikoszewo, Jantar, Stegna, Sztutowo, Katy Rybackie, Przebrno, Krynica Morska, Piaski, Frombork =... = Carte touristique (Polish Edition) MaPlan Sp. z O.O Click
Mierzeja Wislana, mapa turystyczna 1:50 000: Mikoszewo, Jantar, Stegna, Sztutowo, Katy Rybackie, Przebrno, Krynica Morska, Piaski, Frombork =... = Carte touristique (Polish Edition) MaPlan Sp. z O.O Click
Analiza skupień. Idea
 Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Compatible cameras for NVR-5000 series Main Stream Sub stream Support Firmware ver. 0,2-1Mbit yes yes yes n/d
 NOVUS IP CAMERAS CLASSIC CAMERAS Compatible cameras for NVR-5000 series Main Stream Sub stream Support Firmware ver. Resolution Bitrate FPS GOP Resolution Bitrate FPS GOP Audio Motion detection NVIP 5000
NOVUS IP CAMERAS CLASSIC CAMERAS Compatible cameras for NVR-5000 series Main Stream Sub stream Support Firmware ver. Resolution Bitrate FPS GOP Resolution Bitrate FPS GOP Audio Motion detection NVIP 5000
Traceability. matrix
 Traceability matrix Radek Smilgin W testowaniu od 2002 roku Tester, test manager, konsultant Twórca testerzy.pl i mistrzostw w testowaniu Fan testowania eksploracyjnego i testowania w agile [zdjecie wikipedia:
Traceability matrix Radek Smilgin W testowaniu od 2002 roku Tester, test manager, konsultant Twórca testerzy.pl i mistrzostw w testowaniu Fan testowania eksploracyjnego i testowania w agile [zdjecie wikipedia:
KONSPEKT DO LEKCJI MATEMATYKI W KLASIE 3 POLO/ A LAYER FOR CLASS 3 POLO MATHEMATICS
 KONSPEKT DO LEKCJI MATEMATYKI W KLASIE 3 POLO/ A LAYER FOR CLASS 3 POLO MATHEMATICS Temat: Funkcja logarytmiczna (i wykładnicza)/ Logarithmic (and exponential) function Typ lekcji: Lekcja ćwiczeniowa/training
KONSPEKT DO LEKCJI MATEMATYKI W KLASIE 3 POLO/ A LAYER FOR CLASS 3 POLO MATHEMATICS Temat: Funkcja logarytmiczna (i wykładnicza)/ Logarithmic (and exponential) function Typ lekcji: Lekcja ćwiczeniowa/training
Analiza Sieci Społecznych Pajek
 Analiza Sieci Społecznych Pajek Dominik Batorski Instytut Socjologii UW 25 marca 2005 1 Wprowadzenie Regularności we wzorach relacji często są nazywane strukturą. Analiza sieci społecznych jest zbiorem
Analiza Sieci Społecznych Pajek Dominik Batorski Instytut Socjologii UW 25 marca 2005 1 Wprowadzenie Regularności we wzorach relacji często są nazywane strukturą. Analiza sieci społecznych jest zbiorem
EXAMPLES OF CABRI GEOMETRE II APPLICATION IN GEOMETRIC SCIENTIFIC RESEARCH
 Anna BŁACH Centre of Geometry and Engineering Graphics Silesian University of Technology in Gliwice EXAMPLES OF CABRI GEOMETRE II APPLICATION IN GEOMETRIC SCIENTIFIC RESEARCH Introduction Computer techniques
Anna BŁACH Centre of Geometry and Engineering Graphics Silesian University of Technology in Gliwice EXAMPLES OF CABRI GEOMETRE II APPLICATION IN GEOMETRIC SCIENTIFIC RESEARCH Introduction Computer techniques
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Towards Stability Analysis of Data Transport Mechanisms: a Fluid Model and an Application
 Towards Stability Analysis of Data Transport Mechanisms: a Fluid Model and an Application Gayane Vardoyan *, C. V. Hollot, Don Towsley* * College of Information and Computer Sciences, Department of Electrical
Towards Stability Analysis of Data Transport Mechanisms: a Fluid Model and an Application Gayane Vardoyan *, C. V. Hollot, Don Towsley* * College of Information and Computer Sciences, Department of Electrical