Analiza i eksploracja danych biznesowych
|
|
|
- Błażej Kozłowski
- 8 lat temu
- Przeglądów:
Transkrypt
1 Analiza i eksploracja danych biznesowych Business Intelligence systemy wspomagania decyzji Dr inż. Marcin Blachnik

2 Plan zajęć 1. Dane czym są i jak je reprezentować 2. Metody analizy statystycznej (małe przypomnienie) 1. Podstawy statystyki 2. Regresja/korelacja 3. Analiza OLAP 3. Drążenie i eksploracja danych 1. Wstęp (podział zagadnień) 2. Metody grupowania danych 3. Metody klasyfikacji i regresji 4. Metody analizy asocjacyjnej 5. Wyodrębnianie reguł 6. Selekcja cech 7. Wstępne przetwarzanie danych (normalizacja, dyskretyzacja, uzupełnianie wartości brakujących itp)

3 O co chodzi Problem jesteśmy społeczeństwem informacji lecz nie wiedzy!!! Nadmiar informacji prowadzi do chaosu Cel z dużego zbioru danych opisujących zagadnienia biznesowe wydobyć jak najwięcej wiedzy czyli: Drążenie danych (ang. data mining)


4 Drążenie danych czyli czego? Co to są dane i jak je wydobyć? Dane zbiór informacji opisujących obiekty i relacje pomiędzy obiektami Różne sposoby reprezentacji informacji o obiektach i relacjach między nimi: Metoda grafowa Tabela danych metoda graficzna -wykres, rysunek techniczny Koszty 100zł 200zł 132zł Przychody 200zł 450zł 322zl Formuła matematyczna Opis słowny: Jacek ma 182 cm wzrostu, 83kg wagi, jest młodym meżczyzną mieszkającym w Katowicach Wykres

5 Zmienna Cecha atrybut Zaawansowana Analiza Danych Forma tabelaryczna reprezentacji informacji Pogoda Temp. Wilgotnieść Wiatr Grać słoneczna brak nie słoneczna obecny nie pochmurna brak tak deszczowa brak tak deszczowa brak tak deszczowa obecny nie pochmurna obecny tak słoneczna brak nie słoneczna brak tak deszczowa brak tak słoneczna obecny tak pochmurna obecny tak pochmurna brak tak deszczowa obecny nie

6 Typy zmiennych Jakościowe (symboliczne/nominalne) Ilościowe Rzeczywiste Porządkowe Dyskretyzacja Pogoda Temp. Wilgotnieść Wiatr Grać słoneczna ciepło wysoka brak nie słoneczna ciepło wysoka obecny nie pochmurna ciepło wysoka brak tak deszczowa normalnie wysoka brak tak deszczowa zimno normalna brak tak deszczowa zimno normalna obecny nie pochmurna zimno normalna obecny tak słoneczna normalnie wysoka brak nie słoneczna zimno normalna brak tak deszczowa normalnie normalna brak tak słoneczna normalnie normalna obecny tak pochmurna normalnie wysoka obecny tak pochmurna ciepło normalna brak tak deszczowa normalnie wysoka obecny nie Pogoda Temp. Wilgotnieść Wiatr Grać słoneczna brak nie słoneczna obecny nie pochmurna brak tak deszczowa brak tak deszczowa brak tak deszczowa obecny nie pochmurna obecny tak słoneczna brak nie słoneczna brak tak deszczowa brak tak słoneczna obecny tak pochmurna obecny tak pochmurna brak tak deszczowa obecny nie

7 Charakterystyka problemu Uczenie Nadzorowane Uczenie nienadzorowane/analiza koszykowa Pogoda Temp. Wilgotnieść Wiatr Grać słoneczna ciepło wysoka brak nie słoneczna ciepło wysoka obecny nie pochmurna ciepło wysoka brak tak deszczowa normalnie wysoka brak tak deszczowa zimno normalna brak tak deszczowa zimno normalna obecny nie pochmurna zimno normalna obecny tak słoneczna normalnie wysoka brak nie słoneczna zimno normalna brak tak deszczowa normalnie normalna brak tak słoneczna normalnie normalna obecny tak pochmurna normalnie wysoka obecny tak pochmurna ciepło normalna brak tak deszczowa normalnie wysoka obecny nie Pogoda Temp. Wilgotnieść Wiatr Grać słoneczna ciepło wysoka brak nie słoneczna ciepło wysoka obecny nie pochmurna ciepło wysoka brak tak deszczowa normalnie wysoka brak tak deszczowa zimno normalna brak tak deszczowa zimno normalna obecny nie pochmurna zimno normalna obecny tak słoneczna normalnie wysoka brak nie słoneczna zimno normalna brak tak deszczowa normalnie normalna brak tak słoneczna normalnie normalna obecny tak pochmurna normalnie wysoka obecny tak pochmurna ciepło normalna brak tak deszczowa normalnie wysoka obecny nie

8 Podział metod analizy danych Analiza jednowymiarowa Statystyka opisowa Współczynniki statystyczne: średnia, mediana, odchylenie standardowe i wariancja, kwartyle, współczynnik skośności, wsp. asymetrii, kurtoza Wykresy: histogram, wykres pudełkowy (ramka, wąsy) Analiza wielowymiarowa i drążenie danych
")
9 Statystyka opisowa

10 Wybieramy wartość środkową m=0.35 Próba: Zaawansowana Analiza Danych Współczynniki statystyczne Lp Wartość Średnia arytmetyczna (zmienne ilościowe) Gdzie: n liczba prób, x i wartości próby Mediana m (zmienne ilościowe) Wartość środkowa, tzn. taka, że po uporządkowaniu (posortowaniu) wartości powyżej i poniżej niej znajduje się tyle samo prób: Sortujemy dane Lp Wartość

11 Proste współczynniki statystyczne Średnia arytmetyczna CD. Uwaga: jest czuła na wartości odstające (patrz przykład), nie daje się obliczyć dla wartości symbolicznych Można też powiedzieć, że wartość średnia jest to taka wartość dla której μ = argmin x i μ 2 uzyskuje min. Ponadto małe zmiany w danych mogą istotnie wpłynąć na wartość estymowanej średniej Mediana CD. Uwaga: jest nieczuła na wartości odstające Można też powiedzieć, że mediana jest to taka wartość m dla której m = argmin x i m osiąga minimum Statystyka jest odporna małe zmiany w danych nie wpływają na estymowaną wartość, można ją wyznaczyć dla

12 Proste współczynniki statystyczne Dominanta (zmienne jakościowe) Oznacza symbol występujący najczęściej dla danej zmiennej Pogoda słoneczna słoneczna pochmurna deszczowa deszczowa deszczowa pochmurna słoneczna słoneczna deszczowa słoneczna pochmurna Pogoda Częstość słoneczna 5 pochmurna 3 deszczowa D = słoneczna D = 0.9 Dla zmiennej ilościowej (o ciągłym rozkładzie prawdopodobieństwa) dominanta oznacza wartość o największej wartości prawdopodobieństwa
 dominanta oznacza wartość o największej wartości")
13 Proste współczynniki statystyczne Odchylenie standardowe i wariancja Lp Wartość Intuicyjnie odchylenie standardowe informuje o szerokości rozkładu, czyli jak wygląda rozkład punktów wokół średniej. Im większe tym większy rozrzut punktów, im mniejsze tzn. że rozkład jest bardziej skoncentrowany war=2 war=1 war=

14 Proste współczynniki statystyczne Po co podział na odchylenie standardowe i wariancję Odchylenie standardowe wariancja Wariancja lepsza jeśli chcemy porównywać między sobą różne wariancje ponieważ uwypuklone są różnice między wartościami Odchylenie standardowe umożliwia porównywanie i interpretację wartości, gdyż wariancja nie zapewnia zgodności jednostek wariancja => (jednostki) 2 np. dla zmiennej zarobki wariancja ma jednostkę (zł) 2 odchyl std. zł
 2 np.")
15 Proste współczynniki statystyczne Kwartyle i rozstęp ćwiartkowy Kwartyl - parametr opisujący rozkład, przykładem kwartyla jest mediana (kwartyl 1/2), kwartyl (1/4) oznacza, że 25% przypadków w próbie ma mniejszą wartość i 75% przypadków ma wartość większą od niego. kwartyl (3/4) oznacza, że 75% przypadków w próbie ma mniejszą wartość od niego i 25% przypadków ma wartość większą od niego. Rozstęp ćwiartkowy parametr o podobnym znaczeniu jak odchylenie standardowe, obliczany jako IQR = Q(3/4) Q(1/4) Przedział wartości pomiędzy którym znajduje się 50% wartości próby
 Q(1/4) Przedział wartości pomiędzy")
16 Proste współczynniki statystyczne Jak wyznaczyć poszczególne kwartyle: Posortować wartości od najmniejszej do największej Policzyć medianę Q(1/4) Wybrać dolną połówkę i policzyć medianę Q(3/4) Wybrać górną połówkę i policzyć medianę Lp Lp Wartość Wartość Lp Q(1/4) =M( ) = Wartość Lp Q(3/4) =M( ) = Wartość IQR=Q(3/4)-Q(1/4) = =0.15
 =M( ) = 0.275 Wartość 0.2 0.25 0.3 0.35 Lp. 4 5 6 7 Q(3/4) =M( ) = 0.425 Wartość 0.35 0.4 0.")
17 Proste współczynniki statystyczne współczynnik skośności umożliwia określenie asymetrii rozkładu, tzn. chcemy wiedzieć czy rozkład jest w którąś stronę rozciągnięty przyjmuje wartości A= 0 jeśli rozkład jest symetryczny, A<0 jeśli występuje lewostronna asymetria (wydłużone lewe ramię rozkładu) i A>0 jeśli występuje prawostronna asymetria (wydłużone prawe ramię rozkładu) = D = = A D = = M = = A M =
 = 1.2555 D = 0.0371 = 0.6774 A D = 1.7986 0.7 0.6 0.5 0.4 = 1.2555 M = 1.1681 = 0.")
18 Kurtoza miara koncentracji lub spłaszczenia rozkładu, informuje na ile rozkład wartości jest skoncentrowany wokół wartości średniej Typy kurtozy: mezokurtyczne K=0, spłaszczenie rozkładu podobne do spłaszczenia rozkładu normalnego leptokurtyczne K>0, rozkład jest bardziej skoncentrowany niż rozkład normalnym platokurtyczne K<0, rozkład jest bardziej spłaszczony niż rozkład normalny

19 Kurtoza CD Żródło: Jeżeli w przedsiębiorstwie większość osób ma podobne zarobki to K > 0, czyli większość zarabia porównywalnie ze średnią Jeżeli K=0 to oznacza to że w przedsiębiorstwie zarobki mają rozkład normalny Jeżeli K<0 to oznacza to że mamy duży rozrzut zarobków

20 Współczynnik korelacji Bada liniową zależność między zmiennymi Źródło: Pozwala dokonać analizy czy dwie zmienne oddziaływają na siebie : Czy istnieje zależność między sprzedażą a wiekiem klienta. (np. wykorzystując karty lojalnościowe) Czy wielkość udzielanego kredytu zależy od wartości miesięcznych przychodów UWAGA: Założenie że zależność jest liniowa!!!, Gdy zależność jest nieliniowa ale monotoniczna to przechodzimy na rangi np. wsp. korelacji Spearmana
 Czy wielkość udzielanego kredytu zależy od wartości miesięcznych przychodów UWAGA: Założenie")
21 Regresja liniowa Pozwala przewidywać y na podstawie x. Czyli jeśli x i y są skorelowane (patrz korelacja) to na podstawie x możemy przewidywać y y = m i x i + b Problem znaleźć m i oraz b Gdy mamy tylko dwie zmienne x i y to parametry regresji liniowej y = mx + b wyraża się zależnością
22 OLAP OLAP - Online Analytical Processing Najbardziej podstawową metodą analizy danych jest analiza manualna, tzn. taka, w której my sami ręcznie dokonujemy analizy danych np. próbując zweryfikować różne zależności jakie występują pomiędzy różnymi atrybutami tabeli danych.
23 Narzędzie kostka OLAP - wielowymiarowym sześcianem, gdzie każda z krawędzi sześcianu odpowiada pojedynczym zmiennym, a dokładnej reprezentuje zbiór wartości danej zmiennej. >10000 Wartość kredytu 5000 do do do do mies 3 mies 6 mies 12 mies 24 mies 36 mies Zawodowe Średnie Wyższe Wykształcenie kredytobiorcy Okres kredytu
24 Zaawansowana Różne poziomy szczegółowości Analiza Danych 20 >10000 >10000 Wartość kredytu 5000 do do do do mies 3 mies 6 mies 12 mies 24 mies 36 mies Zawodowe Średnie Wyższe Wykształcenie kredytobiorcy Wartość kredytu 5000 do do do do mies 3 mies 6 mies 12 mies 24 mies 36 mies Zawodowe Średnie Wyższe Wykształcenie kredytobiorcy Okres kredytu Okres kredytu Ogółem ilość kredytów udzielanych na okres 12 miesięcy, niezależnie od wartości i wykształcenia Wartość = 436 Całkowita ilość kredytów udzielanych na okres 12 miesięcy, w wysokości 5000 do , niezależnie od wykształcenia Wartość = 137 >10000 >10000 Wartość kredytu 5000 do do do do mies 3 mies 6 mies 12 mies 24 mies 36 mies Zawodowe Średnie Wyższe Wykształcenie kredytobiorcy Wartość kredytu 5000 do do do do mies 3 mies 6 mies 12 mies 24 mies 36 mies Zawodowe Średnie Wyższe Wykształcenie kredytobiorcy Okres kredytu Okres kredytu
25 Kostka OLAP Kostka OLAP pozwala na analizę zależności między atrybutami, na różnym poziomie szczegółowości dzięki agregacji wartości (średnia, suma, mediana, liczba itp) Prosta kostka OLAP => Excel tabela przestawna

26 Prosta kostka OLAP => Excel tabela przestawna Lista atrybutów Etykiety kolumn Etykiety wierszy Widok tabeli przestawnej Atrybuty poddane agregacji
27

28
29 Drążenie danych
30 Drążenie danych lub eksploracja danych Wykorzystanie metod i narzędzi przetwarzania danych do wydobycia wiedzy o przedmiocie badanym: Analiza zmiennych Wizualizacja wielowymiarowych danych Rozwiązywanie problemów klasyfikacyjnych i regresyjnych Techniki analizy asocjacji Grupowanie danych (klasteryzacja/analiza skupień)
31 Logika rozmyta Algorytmy genetyczne Metody statystyczne Sieci neuronowe Wizualizacja Drążenie danych Rachunek prawdopodo bieństwa Rozpoznawa nie wzorców Systemy ekspertowe Uczenie maszynowe
32 Podział metod DM Grupowanie danych (uczenie nienadzorowane) poszukiwanie charakterystycznych skupień w danych Uczenie nadzorowane przewidywanie wartości zmiennych: Problemy klasyfikacyjne gdy zmienna wyjściowa (opisywana) jest zmienną jakościową Problemy regresyjne gdy zmienna wyjściowa (opisywana) jest zmienna ilościową Analiza koszykowa - analiza pod kątem asocjacji (skojarzeń) Selekcja cech Wyodrębnianie reguł Redukcja wymiarowości i wizualizacja
33 Zagadnienia analizy danych: grupowanie danych Alternatywne nazwy: analiza skupień, klasteryzacja, grupowanie danych (tzw. uczenie nienadzorowane) Znaleźć w danych grupy elementów podobnych Problem: Nadmiar danych to chaos więc naszym celem jest znalezienie charakterystycznych wzorców/grup w zgromadzonych danych Dane przed klasteryzacją Po klasteryzacji
34 Narzędzia: Zaawansowana Analiza Danych Grupowanie danych Algorytm kwantyzacji wektorów Kochonena, dendrogramy, algorytm Expectation maximization, dendrogramy Przykład: Określenie grup klientów korzystających z naszych usług, np. w celu określenia grup docelowych procesu reklamowego ( targetowania reklamy ), odgadnięcia oczekiwań poszczególnych grup w celu rozszerzenia oferty
35 Zagadnienia analizy danych: Analiza regresji Tzw. uczenie nadzorowane Wydobycie na podstawie danych informacji o zależności wejście / wyjście, gdzie wyjście jest funkcją ciągłą. Zastosowanie do przewidywanie wartości zmiennych ciągłych na podstawie danych historycznych Uczenie Wykorzystanie Pogoda Temp. Wilgotnieść Wiatr Grać słoneczna brak nie słoneczna obecny nie pochmurna brak tak deszczowa brak tak deszczowa brak tak deszczowa obecny nie pochmurna obecny tak słoneczna brak nie słoneczna brak tak deszczowa brak tak słoneczna obecny tak pochmurna obecny tak pochmurna brak tak deszczowa obecny nie
36 Zagadnienia analizy danych: Analiza regresji Tzw. uczenie nadzorowane Wydobycie na podstawie danych informacji o zależności wejście / wyjście, gdzie wyjście jest funkcją ciągłą. Zastosowanie do przewidywanie wartości zmiennych ciągłych na podstawie danych historycznych Uczenie Wykorzystanie Pogoda Temp. Wilgotnieść Wiatr Grać słoneczna brak nie słoneczna obecny nie pochmurna brak tak deszczowa brak tak deszczowa brak tak deszczowa obecny nie pochmurna obecny tak słoneczna brak nie słoneczna brak tak deszczowa brak tak słoneczna obecny tak pochmurna obecny tak pochmurna brak tak deszczowa obecny nie
37 Zagadnienia analizy danych: problemy klasyfikacyjne Tzw. uczenie nadzorowane Wydobycie na podstawie danych informacji o zależności wejście / wyjście, gdzie wyjście jest zmienną symboliczną. Zastosowanie do przewidywania wartości zmiennych symbolicznych na podstawie danych historycznych Uczenie Wykorzystanie Pogoda Temp. Wilgotnieść Wiatr Grać słoneczna brak nie słoneczna obecny nie pochmurna brak tak deszczowa brak tak deszczowa brak tak deszczowa obecny nie pochmurna obecny tak słoneczna brak nie słoneczna brak tak deszczowa brak tak słoneczna obecny tak pochmurna obecny tak pochmurna brak tak deszczowa obecny nie

38 Zagadnienia analizy danych: problemy klasyfikacyjne Tzw. uczenie nadzorowane Wydobycie na podstawie danych informacji o zależności wejście / wyjście, gdzie wyjście jest zmienną symboliczną. Zastosowanie do przewidywanie wartości zmiennych symbolicznych na podstawie danych historycznych Uczenie Wykorzystanie Pogoda Temp. Wilgotnieść Wiatr Grać słoneczna brak nie słoneczna obecny nie pochmurna brak tak deszczowa brak tak deszczowa brak tak deszczowa obecny nie pochmurna obecny tak słoneczna brak nie słoneczna brak tak deszczowa brak tak słoneczna obecny tak pochmurna obecny tak pochmurna brak tak deszczowa obecny nie
39 Zagadnienia analizy danych: analiza koszykowa Wyznaczenie reguł opisujących asocjacje, czyli charakterystyczne elementy występujące wspólnie co zwykle wrzucamy do koszyka na zakupach: np. kupując chleb zwykle kupujemy masło i mleko
40 Zagadnienia analizy danych: analiza koszykowa Wyznaczenie reguł opisujących asocjacje, czyli charakterystyczne elementy występujące wspólnie co zwykle wrzucamy do koszyka na zakupach: np. kupując chleb zwykle kupujemy masło i mleko
41 Zagadnienia analizy danych: wydobywanie reguł Uczenie nadzorowane Bazuje na reprezentacji wiedzy w postaci prostych i zrozumiałych reguł logicznych Umożliwia rozwiązywanie problemów regresyjnych i klasyfikacyjnych Jeżeli pogoda = słoneczna i wilgotność < 77.5 to grać w golfa = tak W odróżnieniu od innych metod obok wartości predykcji mamy możliwość zrozumienia sposobu podjęcia decyzji Np.. Urządzenie często ulega awarii cel znalezienie powodu jego awarii
42 Zagadnienia analizy danych: selekcja cech Ograniczenie zbioru danych poddanych analizie Wyznaczenie zbioru zmiennych, które są istotne z perspektywy analizowanego (opisu) problemu czyli: wyselekcjonowanie tych parametrów mierzonych danych biznesowych od których istotnie zależy zmienna predykowana Np. Szukamy pracownika do działu sprzedaży i interesują nas, jakie czynniki istotnie wpływają na wielkość sprzedaży
43 Zagadnienia analizy danych: wizualizacja danych Pozwala na podgląd i wyznaczenie obszarów zainteresowań, czasem również wstępne wyznaczenie parametrów metod stosowanych w dalszej analizie danych, czasem wstępny wybór narzędzi analizy danych 1 PCA Przykładowe wykorzystanie wizualizacji do analizy Procesu produkcyjnego
44 Opis narzędzi
45 Co to jest grupowanie Szukanie grup, obszarów stanowiących lokalne gromady punktów
46 Co to jest grupowanie 1 Może tak? Szukanie grup, obszarów stanowiących lokalne gromady punktów
47 Co to jest grupowanie A może tak?
48 Narzędzia i metody grupowania danych: podział Metody bazujące na minimalizacji skalarnego współczynnika jakości Algorytm k-średnich, vq itp.. Metody oparte na teorii grafów, Algorytm hierarchiczny
49 Grupowanie hierarchiczne
50 Grupowanie hierarchiczne 1. Jeżeli liczba obiektów > 1 2. Szuka najbliżej siebie leżących obiektów i łączy je razem w jeden nowy super obiekt 3. Idź do 1
51 Grupowanie hierarchiczne 1. Jeżeli liczba obiektów > 1 2. Szuka najbliżej siebie leżących obiektów i łączy je razem w jeden nowy super obiekt 3. Idź do 1
52 Grupowanie hierarchiczne 1. Jeżeli liczba obiektów > 1 2. Szuka najbliżej siebie leżących obiektów i łączy je razem w jeden nowy super obiekt 3. Idź do 1
53 Grupowanie hierarchiczne 1. Jeżeli liczba obiektów > 1 2. Szuka najbliżej siebie leżących obiektów i łączy je razem w jeden nowy super obiekt 3. Idź do 1
54 Odległości pomiędzy skupiskami Minimum minimalna odległość pomiędzy elementami zbiorów x i x Maksimum - maksymalna odległość pomiędzy elementami zbiorów x i x d min (, ) i min x x' x x' j Norma różnicy wartości średnich d max d m (, ) i j j i max x i x' (, ) m m' i j j x x' x i d x j
55 Metody minimalizacji skalarnego współczynnika jakości
56 Narzędzia i metody grupowania danych: Minimalizacja skalarnego współczynnika jakości Sprowadzenie problemu grupowania do zagadnienia optymalizacji Problem: zdefiniowanie funkcji celu Funkcja celu - funkcja opisująca jakość grupowania Metody MSWJ działają iteracyjnie, tzn powoli od stanu losowego podziału na grupy (chaosu) dokonują reorganizacji w celu wyznaczenia coraz lepszego podziału danych na klastry
57 Oznaczenia K liczba wektorów, obiektów C liczba klasterów na które chcemy dokonać podziału x(k); k=1..k k-aty element z wektora obiektów X i ; i=1..c i-ty element wektora klastrów v i centrum klastra = centrum grupy (grupy wektorów)
58 Algorytm k-średnich Współczynnik jakości uczenia: K C gdzie: J(U) k 1i 1 u ik d ik d x( k) v ik i v i zbiór (wektor) prototypów. 2
59 Przykład
60 Założenia grupowania Zbudować macierz podziału U=[u ik ],dim(u)=c K) Warunki: 1 o każdy element macierzy u ik należy do zbioru u ik {0,1} 2 o w każdej kolumnie suma elementów równa C jest 1 u ik i o suma w wierszach należy K - obrazów C - Klastrów C - k do przedziału K k 1 u ik 0, K
61 Algorytm k-średnich 1. Przyjmujemy macierz podziału U spełniającą trzy przedstawione uprzednio warunki K 2. Wyznacza się położenie prototypów: uikx( k) 3. zwiększa się licznik iteracji z=z+1, 4. szukamy macierzy U tak, by wyznaczyć dla każdego elementu wektora danych x minimalną odległość od wzorców 1 ik 1 i C 1 k K 0 x( k) v pozostaych 5. Sprawdzamy czy spełniony jest warunek u U w 1 i C 6. Jeśli różnica pomiędzy macierzami U w kolejnych iteracjach jest mniejsza od założonego to kończymy proces iteracji, jeśli nie to idź do 2 min j U ( z) ( z 1) j v i x( k) v przypadkach i k 1 K k 1 u ik
62 Narzędzia i metody grupowania danych: Algorytm kwantyzacji wektorów (VQ) 1. Zainicjuj położenie wektorów kodujących 2. Iteracyjnie l-razy 1. Dla każdego wektora treningowego 1. Znajdź najbliższy wektor kodujący (dla danej metryki) 2. Dokonaj aktualizacji położenia (wag) neuronu zgodnie z zależnością (1) 2. Dokonaj aktualizacji wsp. wg. zależności v = v x v i i j i v i x j wektor kodujący podlegający aktualizacji (wektor kodujący leżący najbliżej wektora x j ) Współczynnik uczenia maleje z każdą iteracją programu j-ty wektory uczący
63 Narzędzia i metody grupowania danych: Przykład
64 Metody oraz narzędzia klasyfikacji i regresji
65 Narzędzia klasyfikacji i regresji: problem klasyfikacyjny - separowalność Problem separowalny
66 Narzędzia klasyfikacji i regresji: problem klasyfikacyjny - separowalność 4 Problem nie separowalny
67 Narzędzia klasyfikacji i regresji: problem klasyfikacyjny - separowalność Problem liniowo separowalny
68 Narzędzia klasyfikacji i regresji: Problem liniowo nie separowalny 8 Problem liniowo nie separowalny
69 Narzędzia klasyfikacji i regresji: Jaka hiperpłaszczyzna jest lepsza?
70 Narzędzia klasyfikacji i regresji: Jaka hiperpłaszczyzna jest lepsza?
71 Narzędzia klasyfikacji i regresji: Jaka hiperpłaszczyzna jest lepsza?
72 Narzędzia klasyfikacji i regresji: Klasyfikator Fishera prosta prosta x j
73 Narzędzia klasyfikacji i regresji: Klasyfikator Fishera Duża odległość między średnimi Duża wariancja Mała wariancja Mała odległość między średnimi
74 Narzędzia klasyfikacji i regresji: Klasyfikator Fishera Założenie mamy problem dwuklasowy (klasę 0 i 1) o rozkładzie Gaussa, szukamy optymalnej hierpłaszczyzny separującej. Wyznaczamy średnie dla obydwu klas Wyznaczamy macierze kowariancji danych: C Fisher funkcję kosztu zdefiniował jako stosunek wariancji pomiędzy klasami w stosunku do wariancji wewnątrz klas Gdzie Ostatecznie Gdzie: 2 2 mięięd _ klasowe w y 1 w y 1 w y 1 y 1 w S 2 T T T wewnąewn _ klasowe w Cw w Cw 2w Cw, y 1 y 1 wektor normalny do hiperpłaszczyzny separującej klasy. w C 1 y 1 y y 1 sign wx b 2 b 2 y 1 y 1 w
75 Narzędzia klasyfikacji i regresji: Regresja liniowa Problem: Znaleźć parametry w funkcji liniowej y wx b d i 1 x i w i b y
76 Zapisując: Zaawansowana Analiza Danych Narzędzia klasyfikacji i regresji: Regresja liniowa x1,1 x1,2 x1, n w1 y1 x x x w y Xw y 2,1 2,2 2, n 2 2 xm,1 xm,2 x m, n w n y n Gdzie X jest macierzą reprezentującą cały zbiór uczący o m wektorach, każdy n elementowy Zapisując błąd jako e=xw-y wówczas funkcja kosztu przyjmuje postać: Stąd pochodna: I ostatecznie: J T T x w x y w x y 2 T 1 m i 1 m T 2 w xi yi xi i 1 T w X X X d T X Xw Y J 2
77 Klasyfikacja i regresja Metody nieliniowe
78 Narzędzia klasyfikacji i regresji: algorytm knn Podstawowa zasada: Elementy podobne powinny być rozwiązywane w podobny sposób -> inspiracja kognitywistyczna Problem: co to znaczy podobne i jak zdefiniować podobieństwo? W.Duch Similarity based methods a general framework for classification approximation and association. Control and Cybernetics, 2000 Podobieństwo to różne miary odległości lub ich odwrotności (miary podobieństwa)
79 Narzędzia klasyfikacji i regresji: algorytm 1NN Klasyfikator 1NN (najbliższego sąsiada) Uczenie: Zapamiętaj położenie wszystkich przypadków zbioru treningowego Testowanie/Wykorzystanie klasyfikatora: Dla każdego wektora testowego wyznacz jego odległość do wszystkich wektorów zbioru treningowego. Wybierz spośród wszystkich odległości wektor najbliższy (najbardziej podobny) danego wektora testowego W zależności od problemu: Klasyfikacja -> Przypisz etykietę wektorowi klasyfikowanemu równą etykiecie najbliższego sąsiada. Regresja -> Przypisz wektorowi klasyfikowanemu wartość wyjściową równą wartości wyjściowej najbliższego sąsiada
80 Narzędzia klasyfikacji i regresji: algorytm knn Klasyfikator knn (k najbliższych sąsiadów) Uczenie: Zapamiętaj położenie wszystkich przypadków zbioru treningowego Testowanie/Wykorzystanie klasyfikatora: Wyznacz odległości wektora testowego x do wszystkich przypadków zbioru treningowego. Znajdź k najbliższych sąsiadów W zależności od problemu: Klasyfikacja: przeprowadź głosowanie etykiety wektora testowego pomiędzy k najbliższymi sąsiadami, wybierz klasę najczęściej występującą Regresja: wyznacz średnią arytmetyczną k najbliższych sąsiadów
81 Narzędzia klasyfikacji i regresji: algorytm knn Dokładność klasyfikatora 1NN na zbiorze treningowym zawsze = 100%!!! Gorzej działa w rzeczywistości, choć i tak dobrze W problemach klasyfikacyjnych nigdy nie używaj 2NN, bo w pobliżu granicy decyzji zawsze będzie konflikt podczas głosowania (jeden za, jeden przeciw) knn duży nakład obliczeniowy w przypadku dużych zbiorów treningowych (duża złożoność przy testowaniu)

82 Obszary Voronoi
83 Obszary Voronoi / Przykład 1NN
84 Wada 1NN
85 Narzędzia klasyfikacji i regresji: model liniowy i nieliniowy Co lepsze model liniowy czy nieliniowy? Liniowy nie wszystkie problemy można za jego pomocą rozwiązać Nieliniowy często uczy się za dużo!!!
86 Narzędzia klasyfikacji i regresji: model liniowy i nieliniowy Co lepsze model liniowy czy nieliniowy? Liniowy nie wszystkie problemy można za jego pomocą rozwiązać Nieliniowy często uczy się za dużo!!! 2 y vs. x Linera
87 Narzędzia klasyfikacji i regresji: model liniowy i nieliniowy Co lepsze model liniowy czy nieliniowy? Liniowy nie wszystkie problemy można za jego pomocą rozwiązać Nieliniowy często uczy się za dużo!!! 2 y vs. x Nieliniowa
88 Sieci neuronowe
89 Sieci neuronowe - biologia

90 Sieci neuronowe - biologia
91 Wg. McCullocha i Pittsa: Sieci neuronowe - historia Gdzie: w i i-ta waga x i i-te neuronu (dendryt) z wyjście neuronu (akson) b wolny dendryt do niczego nie podłączony
92 Budowa neuronu neuron nieliniowy typu perceptron Gdzie: w i i-ta waga x i i-te neuronu (dendryt) z wyjście neuronu (akson) b wolny dendryt do niczego nie podłączony f nieliniowa funkcja aktywacji neuronu
93 Budowa neuronu neuron nieliniowy funkcje aktywacji Binarna: unipolarna i bipolarna (Perceptron Rosenblatta) Ciągła: Sigmoidalny również nazywany perceptronem
94 Budowa neuronu neuron nieliniowy funkcje aktywacji - cd Neurony radialne (lokalnym charakter działania) Gaussowski 2 z f( z) exp 2 2 Wielomianowy 2 2 f () z z 2 2 f () z z Hardyego Gdzie f() z z = x - t z np. z xi ti i

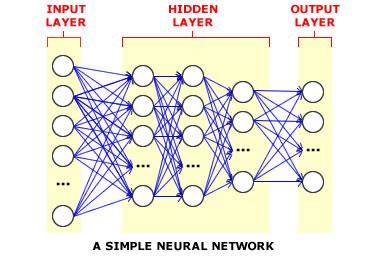
95 Sieci jednokierunkowe
96 Analiza koszykowa
97 Analiza koszykowa i zbiory częste Poszukiwanie zdarzeń często występujących wspólnie stąd analiza koszykowa, czyli jakie produkty zwykle wrzucamy do kszyka razem np. Jak jest chleb to wrzucamy zwykle masło i mleko. Przykład algorytm: Apriori, FP-Growth
98 Analiza koszykowa => Relacja wielu do wielu Zbiór produktów Koszyk (transakcje) W najprostszej wersji relację: koszyk => zbiór produktów można zapisać wykorzystując atrybuty binarne Lista transakcji Asortyment mleko masło chleb bułka parówka musztarda sok Transakcja Transakcja Transakcja Transakcja
99 Algorytm Apriori Najprostszy algorytm do analizy zbiorów częstych bazujący na właściwości Apriori: Zbiór częsty L i zbiór składający się z i- elementów/produktów Właściwość Apriori każdy podzbiór częsty zbioru częstego musi być częsty Operacja łączenia (JOIN) aby znaleźć kandydatów do stworzenia zbioru L k należy przeprowadzić łączenia (JOIN) zbiorów L k-1
100 Pseudo kod: Oznaczenia: Zaawansowana Analiza Danych Algorytm Apriori C k -zbiór kandydujący składający się z k elementów C k zbiór częsty składający się z k-emenetnów Algorytm: L 1 <- generuj wszystkie zbiory jednoelementowe For (k=1; L k!= ; k++) End C k+1 =generuj zbiory kandydujące na podstawie L k Foreach (Transakcja t : Zbiór transakcji) End Zwiększ częstość kandydatom z C k+1 zawartym w transakcji t L k+1 = Z C k+1 wybierz zbiory częstsze niż min_support Return wszystkie zbiory L 1.. L k
101 Warunek Apriori min_support = 2 TID Item 1 ab 2 ad 3 ac 4 acd 5 cd Zaawansowana Analiza Danych Szukamy kombinacji 3 elementowych, więc AB i CD nie możemy połączyć, bo powstanie ABCD Algorytm Apriori Zestaw wygenerowanych zbiorów 3 elementowych L 1 L 2 a b c d ab ac ad bc bd cd abc abd acd 6 bc 7 ac 8 abd 9 ad 10 cd Odpada przez regułę APRIORI. ABC powstało z AB i AC, ale ABC można też stworzyć z BC, a support BC=1 więc ABC nie spełnia warunku APRIORI L 3 acd 1 Odpada przez regułę APRIORI. ABD powstało z AB i AD, ale ABD można też stworzyć z BD, a support BD=1 więc ABD nie spełnia warunku APRIORI
102 Proce działania Zaawansowana Analiza Danych Algorytm FP-Growth Budowa struktury drzewa zwane FP-tree (budowa dwukrotnie przechodząc po zbiorze danych) Wydobycie zbiorów częstych trawersując drzewo Korzyści: Jedynie dwukrotne przejście przez elementy zbioru danych Bez generacji kandydatów Znacznie szybszy niż algorytm Apriori Wady: Rozmiar drzewa Budowa drzewa jest złożona
103 Wczytano transakcje TID=1 Struktura i budowa drzewa FP-tree Wczytano transakcje TID=1i2 Wczytano transakcje TID=1..10 Wczytano transakcje TID=1,2,3 Węzły odpowiadają produktom (items) i posiadają licznik Algorytm jednorazowo czyta jedną transakcję i rzutuje ja na drzewo Dzięki wykorzystaniu sortowania produktów ścieżki mogą się pokrywać Jeśli ścieżki się pokrywają powoduje to inkrementacje ich licznika Drzewo utrzymuje linki między węzłami zabierającymi ten sam produkt (linia kreskowa) Im więcej ścieżek pokrywa się wzajemnie tym większa kompresja drzewa
104 Struktura algorytmu: Przejście nr 1 Zaawansowana Analiza Danych Algorytm FP-Growth Obliczenie częstości każdego z przypadków Odrzucenie przypadków małolicznych Sortowanie przypadków w kolejności malejącej na podstawie ich częstości Przejście nr 2 Wczytanie transakcji i naniesienie ich na drzewo Wydobywanie zbiorów częstych Strategia z dołu do góry zacznij od liści i idź w górę szukając zbiorów częstych, wykorzystaj linki do przechodzenia po sąsiadach z tym samym produktem
105 Narzędzia i metody indukcji reguł
106 Narzędzia i metody indukcji reguł Podział metod indukcji reguł Bezpośrednia indukcja reguł indukcja reguł na podstawie przypadków Indukcja reguł z nauczonych modeli np. sieci neuronowych, modeli statystycznych itp. Transformacja wiedzy zawartej w różnych modelach nie regułowych (w których zgromadzona wiedza dla człowieka nieczytelna)
107 Narzędzia i metody indukcji reguł: algorytm sekwencyjnego pokrywania Najczęściej stosowana strategia metody przeszukiwania połączone z sekwencyjnym pokrywaniem przestrzeni wejściowej. Tworzenie reguł - Od najbardziej ogólnej do najbardziej szczegółowej Gdzie: Najbardziej ogólna reguła - taka która pokrywa maksymalną liczbę przypadków przestrzeni wejściowej X, dla których odpowiedzą systemu jest ta sama wartość Y, oraz jest to reguła o prostszej budowie swojej części warunkowej (mniej warunków) Reguła szczegółowa - pokrywająca małą liczbę wektorów przestrzeni X oraz ma bardziej złożoną część warunkową X Y K L M N A B C D X=(A X=(A lub B lub B) i lub C) Y = i (K lub L) Y=K Y=N
108 Narzędzia i metody indukcji reguł: drzewa decyzji

109 Narzędzia i metody indukcji reguł: drzewa decyzji Korzeń Gałęzie/Krawędzie Węzeł Liście
110 Narzędzia i metody indukcji reguł: drzewa decyzji zapis reguł Forma 1 If (Outlook = rain ) & (windy= False ) then Play = Yes If (Outlook = rain ) & (windy= True ) then Play = No If (Outlook = overcast ) then Play = Yes If (Outlook = sunny ) & (humidity>75) then Play = No If (Outlook = sunny ) & (humidity<=75) then Play = Yes Forma 2 If (Outlook = rain ) then chk_wind = Yes If (Outlook = overcast ) then play = Yes If (Outlook = sunny ) then chk_humidity = Yes If (chk_wind = Yes) & (windy= False ) then Play = Yes If (chk_wind = Yes) & (windy= True ) then Play = No If (chk_humidity = Yes) & (humidity>75) then Play = No If (chk_humidity = Yes) & (humidity<=75) then Play = Yes
111 Narzędzia i metody indukcji reguł: drzewa decyzji
112 Narzędzia i metody indukcji reguł: drzewa decyzji
113 Narzędzia i metody indukcji reguł: drzewa decyzji
114 Narzędzia i metody indukcji reguł: drzewa decyzji
115 Narzędzia i metody indukcji reguł: drzewa decyzji
116 Narzędzia i metody indukcji reguł: drzewa decyzji
117 Narzędzia i metody indukcji reguł: drzewo CART Drzewo binarne Indeks Gini Przycinanie w oparciu o Wsparcie dla danych niekompletnych Wykorzystanie alternatywnych atrybutów w węźle
118 Narzędzia i metody indukcji reguł: drzewo ID3 Indeks zysku informacyjnego Działa jedynie dla atrybutów dyskretnych/symbolicznych Drzewo o zmiennej liczbie potomstwa wychodzącego z jednego węzła Liczba potomków wychodzących z węzła równa jest liczbie wartości unikatowych dla wybranej, najlepszej cechy Problem z liczebnością wartości unikatowych (niestabilność indeksu)
119 Narzędzia i metody indukcji reguł: drzewo C4.5 i C5.0 Rozwinięcie drzewa ID3 Nowe kryterium względny zysk informacyjny Wsparcie dla cech ciągłych Wsparcie dla brakujących wartości (j.w.) Zmodyfikowana metoda oczyszczania C5.0 drzewo komercyjne.
120 Narzędzia i metody indukcji reguł: drzewo SSV Podobne do CART Drzewo binarne Indeks SSV Przycinanie drzewa - test krzyżowy (ang. crosswalidaition)
121 Selekcja cech
122 Narzędzia i metody selekcji cech Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy, które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną informację jak istniejące już cechy Cel wybranie ze zbioru dostępnych cech tych, które nas interesują Interesujące cechy to takie, których kombinacja pozwala na możliwie najlepszą klasyfikację lub regresję!
123 8 7 6 Zaawansowana Analiza Danych Przykład z danymi iris
124 Narzędzia i metody selekcji cech: podział Ze względu na charakter problemu Nadzorowane Nienadzorowame Ze względu na relację z innymi algorytmami nadrzędnymi Filtry Wrappery (opakowane) Frapery kombinacja filtrów i Wrapperów Metody wbudowane
125 Narzędzia i metody selekcji cech: filtry cech Filtry cech to taka grupa metod, która autonomicznie podejmuje decyzję, które z cech będą istotne dla późniejszego procesu uczenia. Decyzja ta podejmowana jest na podstawie niezależnego od klasyfikatora współczynnika takiego jak informacja wzajemna lub dywergencja Kullbacka Leiblera lub inne wskaźniki statystyczne

126 Narzędzia i metody selekcji cech: filtry cech Strategia przeszukiwania Przygotowanie danych i ich preprocessing Filtr Wewnętrzna funkcja oceny Model klasyfikacyjny lub regresyjny
127 Narzędzia i metody selekcji cech: metody opakowane Metody opakowane to grupa metod w której występuje sprzężenie zwrotne pomiędzy elementem decyzyjnym (np.. Siecią neuronową) a algorytmem selekcji cech. Dzięki temu podzbiór cech optymalizowany jest pod kątem konkretnego klasyfikatora
128 Narzędzia i metody selekcji cech: metody opakowane Model klasyfikacyjny lub regresyjny Strategia przeszukiwania Przygotowanie danych i ich preprocesing Metoda opakowana Funkcja oceny Model klasyfikacyjny lub regresyjny
129 Narzędzia i metody selekcji cech: metody filtrów Zalety Uniwersalność uzyskany podzbiór cech jest niezależny od klasyfikatora, dzięki czemu teoretycznie możemy użyć dowolny klasyfikator W problemach medycznych jak analiza DNA zależy nam na znalezieniu genów odpowiedzialnych za pewne cechy, nie chcemy by wynik był zależny od użytej sieci neuronowej Szybkość jesteśmy niezależni od metody klasyfikacyjnej dzięki czemu złożoność obliczeniowa nie wpływa na szybkość i wydajność tego algorytmu Uniwersalność - algorytm tego typu może być wykorzystany do każdego problemu klasyfikacyjnego Wady Konieczność estymacji wielowymiarowych rozkładów prawdopodobieństwa
130 Narzędzia i metody selekcji cech: metody opakowane Zalety Wybrany podzbiór cech jest dostosowany do wymagań lub charakteru algorytmu decyzyjnego (sieci neuronowej itp) Większa dokładność niż metod filtrów Uniwersalność - algorytm tego typu może być wykorzystany do każdego problemu klasyfikacyjnego Wady Często większa złożoność obliczeniowa
131 Narzędzia i metody selekcji cech: kombinacje filtrów i metod opakowanych - Frappery Wykorzystuje się algorytm filtrów do selekcji cech, jednakże parametry filtru dostraja się na podstawie metody opakowującej. Właściwości Szybkość Często większa dokładność niż metod filtrów, lecz mniejsza niż metod opakowanych Uniwersalność - algorytm tego typu może być wykorzystany do każdego problemu klasyfikacyjnego
132 Narzędzia i metody selekcji cech: frappery Strategia przeszukiwania Filtr Model klasyfikacyjny lub regresyjny Wewnętrzna funkcja oceny Przygotowanie danych i ich preprocesing Funkcja oceny Model klasyfikacyjny lub regresyjny
133 Narzędzia i metody selekcji cech: metody wbudowane Metody wbudowane to taka grupa algorytmów, które wykorzystują pewne cechy algorytmów uczenia dokonując automatycznej selekcji cech na etapie uczenia sieci neuronowej lub innego algorytmu decyzyjnego Właściwości Szybkość selekcja cech realizowana jest podczas procesu uczenia, dzięki czemu nie musimy dokonywać żadnych dodatkowych obliczeń Dokładność metody te są zaprojektowane pod kątem konkretnego algorytmu Brak uniwersalności metody te można wykorzystywać jedynie dla danego algorytmu
134 Inne przydatne zagadnienia
135 Narzędzia i metody wstępnego przetwarzania danych Proces przygotowania danych do analizy: Normalizacja / standaryzacja danych Usunięcie wartości brakujących Transformacja pomiędzy różnymi typami cech
136 Narzędzia i metody wstępnego przetwarzania danych: normalizacja / standaryzacja Często analizie poddawane są różne zmienne opisujące różne dane o różnym przedziale wartości np.: Opis zmiennej Wynagrodzenie pracownika Obrót za okres 1 roku Wiek pracownika Przedział zmienności Od 1000 do zł Od do zł Od 20 do 65 lat Uwaga: zmiana wynagrodzenia o 500 zł może stanowić 50% minimalnego wynagrodzenia, podczas gdy zmiana obrotu o 500zł jest zupełnie nie istotna Jak uwzględnić wiek przy budowie modelu?
137 Narzędzia i metody wstępnego przetwarzania danych: normalizacja / standaryzacja Rozwiązanie normalizacja lub standaryzacja danych Opis zmiennej Przedział zmienności Po przeksztalceniu Wynagrodzenie pracownika Od 1000 do zł Od 0 ( ) do 1 (10000) Obrót za okres 1 roku Od do zł Od 0 ( ) do 1 ( ) Wiek pracownika Od 20 do 65 lat Od 0 (20) do 1 (65) Normalizacja: Przekształcenie wszystkich zmiennych tak by ich przedział zmienności był z zakresu od 0 do 1 Wada: bardzo czułe na wartości odstające Zaleta: W normalnej sytuacji zwykle lepiej działa Standaryzacja: Przekształcenie danych tak by ich wartość średnia była równa 0, oraz by odchylenie standardowe było równe 1 Wada: Zwykle nieco gorzej działa niż normalizacja Zaleta: Nie tak bardzo czułe na wartości odstające
138 Narzędzia i metody wstępnego przetwarzania danych: usuwanie wartości brakujących Problem: Często mając dane które chcemy poddać analizie nie dysponujemy pewnymi wartościami poszczególnych zmiennych np. Lp. Wiek Zarobki Obroty Zyski Płeć 1? M K ? ? M
139 Narzędzia i metody wstępnego przetwarzania danych: usuwanie wartości brakujących Rozwiązania: 1. Zastąpienie wartości brakujących średnią, medianą, dominantą etc. 2. Uzupełnienie wartości brakujących poprzez stworzenie pośrednich problemów klasyfikacyjnych (dla zmiennych jakościowych) lub regresyjnych (dla zmiennych ilościowych) 3. Wykorzystanie metod odpornych na wartości brakujące
140 Narzędzia i metody wstępnego przetwarzania danych: transformacje typów zmiennych/cech Niektóre typy metod analizy danych są zależne od typów zmiennych np.. Drzewo decyzji ID3 umożliwia pracę jedynie ze zmiennymi jakościowymi Sieci neuronowe i metody linowe wymagają wejść ciągłych czyli zmiennych ilościowych Rozwiązania: 1. Zastosowanie modeli niezależnych od typów danych 2. Konwersja danych do odpowiedniego typu
141 Narzędzia i metody wstępnego przetwarzania danych: transformacje typów zmiennych/cech Konwersja zmiennych jakościowych na ilościowe: Zamiana wartości symboli na ciągi wartości binarnych. Ciąg binarny składa się z tylu bitów ile występuje symboli w zmiennej jakościowej. Efekt: zwiększenie liczby zmiennych- np. Pogoda (j) słoneczna pochmurna Deszczowa Pogoda (i)
142 Narzędzia i metody wstępnego przetwarzania danych: transformacje typów zmiennych/cech Pogoda Temp. Wilgotność Wiatr Grać słoneczna brak nie słoneczna obecny nie pochmurna brak tak deszczowa brak tak deszczowa brak tak deszczowa obecny nie pochmurna obecny tak słoneczna brak nie słoneczna brak tak deszczowa brak tak słoneczna obecny tak pochmurna obecny tak pochmurna brak tak deszczowa obecny nie Pogoda Temp. Wilgotność Wiatr Grać brak nie obecny nie brak tak brak tak brak tak obecny nie obecny tak brak nie brak tak brak tak obecny tak obecny tak brak tak obecny nie
143 Narzędzia i metody wstępnego przetwarzania danych: transformacje typów zmiennych/cech Konwersja zmiennych ilościowe na jakościowe Wykorzystanie metod dyskretyzacji w celu zamiany wartości ciągłych na skończony zbiór wartości, możliwy do analizy przez algorytmy pracujące na zmiennych jakościowych Dyskretyzacja podział przedziału zmienności zmiennej ilościowej na podobszary np. Przedział zmienności: od 64 do 85 Podział na 3 wartości: 1. od 64 do od 71 do od 78 do 85 Przed dyskretyzacją Temp Po dyskretyzacji Temp
144 Zastosowania narzędzi analizy danych
145 Text Mining Text Mining analiza i rozumienie tekstów Przykłady: Przeszukiwanie baz tekstów (wyszukiwarka) Wyszukiwanie z uzględnieniem błędów - literówek Grupowanie dokumentów automatyczne odnajdywanie grup dokumentów podobnych Automatyczne odnajdywanie kategorii w dużych kolekcjach dokumentów Klasyfikacja dokumentów przydzielanie dokumentów do z góry określonych grup np. odnajdywanie i klasyfikacja spamu, klasyfikacja maili ze względu na treść z przeznaczeniem do odpowiedniego konsultanta
146 Text Mining Problem reprezentacji dokumentów algorytmy wymagają zapisu treści w postaci wektorów. Jeden wektor = jeden dokument (wektory mają stałą długość = stały zestaw atrybutów) Jak zdefiniować reprezentację dokumentu?
147 Typowa reprezentacja Text Mining jedno słowo = jeden atrybut Zbiór atrybutów = zbiór wszystkich słów we wszystkich dokumentach Przykład Dok1: Ala ma kota Dok2: Janek ma psa Dok3: Ala i Janek to para Uwaga: Tekst trzeba podzielić na słowa ten proces to tokenizacja. Zwykle realizowane przez podział dla znaków nie alfanumerycznych Ala ma kota Janek psa i to para Dok Dok Dok
148 Text Mining Inne problemy i wymogi preprocessingu (wstępnego przetwarzania danych) Dok1: Ala ma kota Dok2: Janek ma psa Dok3: Ala i Janek to para Dok4: Kot ali to Burek Problem wielkości liter i końcówek Ala i ali oraz Kot i kota Rozwiązanie: ujednolicenie rozmiaru liter!!! lematyzacja Ala ma kota Janek psa i to para Kot ali Burek Dok Dok Dok Dok
149 Text Mining Lematyzacja redukcja słowa do formy podstawowej czasownik => bezokolicznik, rzeczownik => mianownik liczba pojedyncza Ang. stemming lub redukcja wyrazu do korpusu Język polski => Morfeusz, Dawid Weiss - Stemming engine for Polish, Stempel Język angielski => Snowball, Porter, Lovins, np. usunięcie końcówek ed, usunięcie ing, usunięcie s z końca wyrazów
150 Text Mining Różne formy tworzenia wektorów Postać binarna zapisujemy jedynie 0/1 czy dany wyraz wystąpił czy nie wystąpił w treści dokumentu dobre dla krótkich tekstów, problem przy długich dokumentach Liczba wystąpień słowa w kolumnach zapisujemy liczbę wystąpień danego wyrazu problem jeśli jedne dokumenty są długie a inne krótkie konieczność stosowania odpowiednich miar odległości np. odległość kosinusowa Częstość względna liczba wystąpień unormowana przez liczbę słów w dokumencie TF-IDF miara bazująca na częstości z uwzględnieniem porównania kategorii
151 Text Mining TF-IDF Term Frequency Inverse document frequency. koncepcja miary polegająca na nieliniowym przeskalowaniu częstości poprzez uwzględnienie wag rozróżnialności słów pomiędzy kategoriami Obliczamy częstość występowania wektorów (Term Frequency), Obliczamy odwrotność częstości występowania słów w całej bazie dokumentów z uwzględnieniem kategorii
152 TF-IDF Text Mining gdzie: liczba wystąpień danego termu t i w dokumencie liczba wszystkich termów w dokumencie lub gdzie: - zbiór wszystkich dokumentów - zbiór dokumentów w których wystąpił term t i
153 Text Mining Porównywanie dokumentów zastosowanie odpowiedniej miary odległości przy reprezentacji dokumentów jako wektory. Obliczamy odległości między parą dokumentów i szukamy dwóch najbardziej podobnych Typy miar Odległość Hamminga Odległość Jaccarda Odległość kosinusowa Odległość Euklidesa
154 Text Mining miary odległości między dokumentami Odległość Hamminga do zastosowań dla danych binarnych lub symbolicznych postać binarna reprezentacji dokumentów n x D x, y = i y i 1 x i = y i 0 i=1 W zastosowaniu do analizy podobieństwa dokumentów liczy liczbę zgodnych (niezgodnych) danych suma w ilu przypadkach dany wyraz wystąpił w dokumencie A a nie wystąpił w dokumencie B UWAGA: Uwaga na normalizację długości, wynik zależny od liczby wyrazów w dokumentach!!!
155 Odległość Hamminga przykład Dok1: Ala ma kota Dok2: Janek ma psa Dok3: Pies Janka to Burek Dok4: Kot Ali to Ciapek Reprezentacja po stemmingu ala ma kot janek pies to ciapek burek Dok Dok Dok Dok D(dok1,dok4) = = 3 D(dok2,dok3) = D(dok1,dok2) =
156 Text Mining miary odległości między dokumentami Odległość/podobieństwo Jackarda D x, y = n i=1 n i=1 x i =1 & y i =1 x i =1 y i =1 ala ma kot janek pies to ciapek burek Dok Dok Dok Dok D(dok1,dok4) = = 2 5 D(dok2,dok3) = D(dok1,dok2) =
157 Text Mining miary odległości między dokumentami Odległość kosinusowa do zastosowań jeśli mamy reprezentację dokumentów w postaci liczby występowania słów. Mierzy cos. kąta między wyrazami: Można ją zastąpić miarą euklidesową po uprzedniej normalizacji: Odległość Euclidesa
158 Text Mining miary odległości między dokumentami Odległość Euklidesa Można stosować tylko dla reprezentacji typu: częstość i TF-IDF (wektory muszą być odpowiednio unormowane) Inne opcje: odległość Minkowskiego
159 Jak uwzględniać literówki!!! Nie szukając dokładnego dopasowania słów, a szukając słów najbardziej podobnych Słowa najbardziej podobne szukamy przez miary odległości/podobieństwa między słowami Typy miar odległosci między słowami: Odległość Hamminga Odległość Levensteina
160 Text Mining miary odległości między wyrazami Odległość Hamminga W zastosowaniu do porównywania słów suma w ilu przypadkach litery w słowie A były zgodne z literami w słowie B D x, y = n i=1 x i y i x i = y i 1 0 D( pieczywo, pieczeń ) = Problem jeśli wyrazy o różnej długości konieczna normalizacja długości
161 Odległość Levenstaina Odległość edycyjna podaje ile operacji należy wykonać aby przekształcić jeden napis w drugi Przykład: D(pies ; pies) = 0 D(granat ; granit) = 1 D(orczyk ; oracz) = 3 D(marka ; ariada) = 4
162
163 Odległość Levenstaina Krok 1 Krok 2 Krok 3 Krok 4 Krok 5 Krok 6 Krok 7 Krok 8 Krok 9 Krok 10 Ustalamy długość łańcuchów znaków (dlugoscp długość łańcucha pierwszego, dlugoscd długość łańcucha drugiego), Tworzymy macierz o rozmiarze dlugoscp x dlugoscd Inicjalizujemy pierwszy wiersz wartościami od 0 do dlugoscp Inicjalizujemy pierwszą kolumnę wartościami od 0 do dlugoscd Sprawdzamy każdy znak z łańcucha pierwszego (indeks i od 1 do dlugoscp) Sprawdzamy każdy znak z łańcucha drugiego (indeksy j od 1 do dlugoscd) Jeżeli znak na pozycji i równa się znakowi na pozycji j to koszt jest równy zero Jeżeli znak na pozycji i jest różny od znaku na pozycji j to koszt wynosi 1 Ustawiamy wartość komórki i,j jako minimum: komórka powyżej + 1 komórka z lewej + 1 komórka po skosie (góra, lewo) + koszt Algorytm powtarzamy dla wszystkich znaków, całkowity koszt otrzymamy w komórce o indeksie dlugoscp, dlugoscd
164
165 Problemy: Zaawansowana Analiza Danych Text Mining Wyszukiwanie dokumentów Odnajdywanie w bazie dokumentów tych dokumentów które są najbardziej podobne do wzorcowego (np. zwykła wyszukiwarka lub wyszukiwanie plagiatów) Grupowanie dokumentów Odnalezienie w zbiorze dokumentów, takich dokumentów które pod względem treści są do siebie podobne np. lub Klasyfikacja dokumentów Automatyczna przydzielenie dokumentów do odpowiedniej predefiniowanej grupy Np.: wykrywanie spamu, automatyczne przekierowywanie dokumentów do odpowiedniego działu na podstawie treści
166 Text Mining: Wyszukiwarka 1. Przygotuj zbiór dokumentów do przeszukiwania 2. Zamień dokumenty w bazie (z pkt 1) na zbiór wektorów (to robimy tylko raz) 3. Przygotuj dokument wzorcowy jeśli szukamy plagiatów lub hasło jeśli wyszukiwarka 4. Zamień dokument wzorcowy na wektor 5. Policz odległość między dokumentem wzorcowym a innymi w bazie danych 6. Posortuj odległości od najmniejszej do największej 7. Wyświetl wyniki wyszukiwania

167 Text Mining: Wyszukiwarka Wczytanie bazy dokumentów Przekształcenie dokumentów na wektory Obliczenie odległości między wektorami Dokument wzorcowy / wyszukiwana fraza Zamiana dokumentu wzorcowego na wektor Sortowanie dokumentów wg. odległości UWAGA: ważny jest dobór reprezentacji dokumentów i miary odległości!!!
168 Text Mining: Grupowanie Wczytanie bazy dokumentów Konwersja na reprezentację wektorową (TF IDF) Dokonanie automatycznego grupowania dokumentów w celu identyfikacji zbioru dokumentów podobnych
169 Wynik grupowania UWAGA: Kolory mogą się różnić Kategorie oryginalne UWAGA: Reprezentacja z dużą liczbą cech uwaga na algorytmy grupowania czułe na dużą liczbę cech (EM itp.)

170 Wczytanie poetykietowanych dokumentów (z podziałem na kategorie) Zaawansowana Analiza Danych Text Mining: Klasyfkacja Uczenie klasyfikaotra Przygotowanie klasyfikatora. Robimy raz i zapamiętujemy klasyfikator i statystykę słów Konwersja dokumentów na wektory wyjście word => TF-IDF dla danych testowych Klasyfikacja dokumentów na podstawie wcześniej przygotowanego klasyfikatora Wczytanie dokumentów do klasyfikacji (np. maili) Konwersja dokumentów do postaci wektorów
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Metody selekcji cech
 Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Algorytmy Inteligencji Obliczeniowej. Dr inż. Marcin Blachnik
 Algorytmy Inteligencji Obliczeniowej Dr inż. Marcin Blachnik Plan zajęć 1. Dane czym są i jak je reprezentować 2. Eksploracja danych 1. Podział zagadnień i krótka powtórka z narzędzi 2. Ocena jakości modeli
Algorytmy Inteligencji Obliczeniowej Dr inż. Marcin Blachnik Plan zajęć 1. Dane czym są i jak je reprezentować 2. Eksploracja danych 1. Podział zagadnień i krótka powtórka z narzędzi 2. Ocena jakości modeli
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Sztuczne sieci neuronowe (SNN)
") Sztuczne sieci neuronowe (SNN) Pozyskanie informacji (danych) Wstępne przetwarzanie danych przygotowanie ich do dalszej analizy Selekcja informacji Ostateczny model decyzyjny SSN - podstawy Sieci neuronowe
Sztuczne sieci neuronowe (SNN) Pozyskanie informacji (danych) Wstępne przetwarzanie danych przygotowanie ich do dalszej analizy Selekcja informacji Ostateczny model decyzyjny SSN - podstawy Sieci neuronowe
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Co to są drzewa decyzji
 Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
Drzewa decyzji Co to są drzewa decyzji Drzewa decyzji to skierowane grafy acykliczne Pozwalają na zapis reguł w postaci strukturalnej Przyspieszają działanie systemów regułowych poprzez zawężanie przestrzeni
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY)
") STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
Statystyka. Wykład 4. Magdalena Alama-Bućko. 13 marca Magdalena Alama-Bućko Statystyka 13 marca / 41
 Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
1 n. s x x x x. Podstawowe miary rozproszenia: Wariancja z populacji: Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel:
 Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY)
") STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Dla opisania rozkładu badanej zmiennej, korzystamy z pewnych charakterystyk liczbowych. Dzielimy je na cztery grupy.. Określenie przeciętnej wartości
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Dla opisania rozkładu badanej zmiennej, korzystamy z pewnych charakterystyk liczbowych. Dzielimy je na cztery grupy.. Określenie przeciętnej wartości
1 Podstawy rachunku prawdopodobieństwa
 1 Podstawy rachunku prawdopodobieństwa Dystrybuantą zmiennej losowej X nazywamy prawdopodobieństwo przyjęcia przez zmienną losową X wartości mniejszej od x, tzn. F (x) = P [X < x]. 1. dla zmiennej losowej
1 Podstawy rachunku prawdopodobieństwa Dystrybuantą zmiennej losowej X nazywamy prawdopodobieństwo przyjęcia przez zmienną losową X wartości mniejszej od x, tzn. F (x) = P [X < x]. 1. dla zmiennej losowej
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Inteligentna analiza danych
 Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wykład 5: Statystyki opisowe (część 2)
") Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Pozyskiwanie wiedzy z danych
 Pozyskiwanie wiedzy z danych dr Agnieszka Goroncy Wydział Matematyki i Informatyki UMK PROJEKT WSPÓŁFINANSOWANY ZE ŚRODKÓW UNII EUROPEJSKIEJ W RAMACH EUROPEJSKIEGO FUNDUSZU SPOŁECZNEGO Pozyskiwanie wiedzy
Pozyskiwanie wiedzy z danych dr Agnieszka Goroncy Wydział Matematyki i Informatyki UMK PROJEKT WSPÓŁFINANSOWANY ZE ŚRODKÓW UNII EUROPEJSKIEJ W RAMACH EUROPEJSKIEGO FUNDUSZU SPOŁECZNEGO Pozyskiwanie wiedzy
Metody indukcji reguł
 Metody indukcji reguł Indukcja reguł Grupa metod charakteryzująca się wydobywaniem reguł ostrych na podstawie analizy przypadków. Dane doświadczalne składają się z dwóch części: 1) wejściowych X, gdzie
Metody indukcji reguł Indukcja reguł Grupa metod charakteryzująca się wydobywaniem reguł ostrych na podstawie analizy przypadków. Dane doświadczalne składają się z dwóch części: 1) wejściowych X, gdzie
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Statystyka opisowa PROWADZĄCY: DR LUDMIŁA ZA JĄC -LAMPARSKA
 Statystyka opisowa PRZEDMIOT: PODSTAWY STATYSTYKI PROWADZĄCY: DR LUDMIŁA ZA JĄC -LAMPARSKA Statystyka opisowa = procedury statystyczne stosowane do opisu właściwości próby (rzadziej populacji) Pojęcia:
Statystyka opisowa PRZEDMIOT: PODSTAWY STATYSTYKI PROWADZĄCY: DR LUDMIŁA ZA JĄC -LAMPARSKA Statystyka opisowa = procedury statystyczne stosowane do opisu właściwości próby (rzadziej populacji) Pojęcia:
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Podstawowe pojęcia. Własności próby. Cechy statystyczne dzielimy na
 Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony zbiór jednostek, które
Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony zbiór jednostek, które
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Typy zmiennych. Zmienne i rekordy. Rodzaje zmiennych. Graficzne reprezentacje danych Statystyki opisowe
 Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
TRANSFORMACJE I JAKOŚĆ DANYCH
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Statystyka. Wykład 4. Magdalena Alama-Bućko. 19 marca Magdalena Alama-Bućko Statystyka 19 marca / 33
 Statystyka Wykład 4 Magdalena Alama-Bućko 19 marca 2018 Magdalena Alama-Bućko Statystyka 19 marca 2018 1 / 33 Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności (rozproszenia,
Statystyka Wykład 4 Magdalena Alama-Bućko 19 marca 2018 Magdalena Alama-Bućko Statystyka 19 marca 2018 1 / 33 Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności (rozproszenia,
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne
 WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
Ewelina Dziura Krzysztof Maryański
 Ewelina Dziura Krzysztof Maryański 1. Wstęp - eksploracja danych 2. Proces Eksploracji danych 3. Reguły asocjacyjne budowa, zastosowanie, pozyskiwanie 4. Algorytm Apriori i jego modyfikacje 5. Przykład
Ewelina Dziura Krzysztof Maryański 1. Wstęp - eksploracja danych 2. Proces Eksploracji danych 3. Reguły asocjacyjne budowa, zastosowanie, pozyskiwanie 4. Algorytm Apriori i jego modyfikacje 5. Przykład
Statystyka hydrologiczna i prawdopodobieństwo zjawisk hydrologicznych.
 Statystyka hydrologiczna i prawdopodobieństwo zjawisk hydrologicznych. Statystyka zajmuje się prawidłowościami zaistniałych zdarzeń. Teoria prawdopodobieństwa dotyczy przewidywania, jak często mogą zajść
Statystyka hydrologiczna i prawdopodobieństwo zjawisk hydrologicznych. Statystyka zajmuje się prawidłowościami zaistniałych zdarzeń. Teoria prawdopodobieństwa dotyczy przewidywania, jak często mogą zajść
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)
, które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)") Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
Uczenie sieci radialnych (RBF)
") Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
Inżynieria biomedyczna
 Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
LABORATORIUM 3. Jeśli p α, to hipotezę zerową odrzucamy Jeśli p > α, to nie mamy podstaw do odrzucenia hipotezy zerowej
 LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Próba własności i parametry
 Próba własności i parametry Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony
Próba własności i parametry Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
1. Opis tabelaryczny. 2. Graficzna prezentacja wyników. Do technik statystyki opisowej można zaliczyć:
 Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykład 1. Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy
 Wykład Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy Zbiorowość statystyczna - zbiór elementów lub wyników jakiegoś procesu powiązanych ze sobą logicznie (tzn. posiadających wspólne cechy
Wykład Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy Zbiorowość statystyczna - zbiór elementów lub wyników jakiegoś procesu powiązanych ze sobą logicznie (tzn. posiadających wspólne cechy
PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE
 UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
Zagadnienia optymalizacji i aproksymacji. Sieci neuronowe.
 Zagadnienia optymalizacji i aproksymacji. Sieci neuronowe. zajecia.jakubw.pl/nai Literatura: S. Osowski, Sieci neuronowe w ujęciu algorytmicznym. WNT, Warszawa 997. PODSTAWOWE ZAGADNIENIA TECHNICZNE AI
Zagadnienia optymalizacji i aproksymacji. Sieci neuronowe. zajecia.jakubw.pl/nai Literatura: S. Osowski, Sieci neuronowe w ujęciu algorytmicznym. WNT, Warszawa 997. PODSTAWOWE ZAGADNIENIA TECHNICZNE AI
Analiza składowych głównych
 Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Reguły decyzyjne, algorytm AQ i CN2. Reguły asocjacyjne, algorytm Apriori.
 Analiza danych Reguły decyzyjne, algorytm AQ i CN2. Reguły asocjacyjne, algorytm Apriori. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ REGUŁY DECYZYJNE Metoda reprezentacji wiedzy (modelowania
Analiza danych Reguły decyzyjne, algorytm AQ i CN2. Reguły asocjacyjne, algorytm Apriori. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ REGUŁY DECYZYJNE Metoda reprezentacji wiedzy (modelowania
Statystyka. Wykład 7. Magdalena Alama-Bućko. 16 kwietnia Magdalena Alama-Bućko Statystyka 16 kwietnia / 35
 Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski
 Kamil Krzysztof Derkowski") Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Statystyka. Wykład 5. Magdalena Alama-Bućko. 26 marca Magdalena Alama-Bućko Statystyka 26 marca / 40
 Statystyka Wykład 5 Magdalena Alama-Bućko 26 marca 2018 Magdalena Alama-Bućko Statystyka 26 marca 2018 1 / 40 Uwaga Gdy współczynnik zmienności jest większy niż 70%, czyli V s = s x 100% > 70% (co świadczy
Statystyka Wykład 5 Magdalena Alama-Bućko 26 marca 2018 Magdalena Alama-Bućko Statystyka 26 marca 2018 1 / 40 Uwaga Gdy współczynnik zmienności jest większy niż 70%, czyli V s = s x 100% > 70% (co świadczy
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
MIARY KLASYCZNE Miary opisujące rozkład badanej cechy w zbiorowości, które obliczamy na podstawie wszystkich zaobserwowanych wartości cechy
 MIARY POŁOŻENIA Opisują średni lub typowy poziom wartości cechy. Określają tą wartość cechy, wokół której skupiają się wszystkie pozostałe wartości badanej cechy. Wśród nich można wyróżnić miary tendencji
MIARY POŁOŻENIA Opisują średni lub typowy poziom wartości cechy. Określają tą wartość cechy, wokół której skupiają się wszystkie pozostałe wartości badanej cechy. Wśród nich można wyróżnić miary tendencji
Odkrywanie asocjacji
 Odkrywanie asocjacji Cel odkrywania asocjacji Znalezienie interesujących zależności lub korelacji, tzw. asocjacji Analiza dużych zbiorów danych Wynik procesu: zbiór reguł asocjacyjnych Witold Andrzejewski,
Odkrywanie asocjacji Cel odkrywania asocjacji Znalezienie interesujących zależności lub korelacji, tzw. asocjacji Analiza dużych zbiorów danych Wynik procesu: zbiór reguł asocjacyjnych Witold Andrzejewski,
W1. Wprowadzenie. Statystyka opisowa
 W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
Analiza Statystyczna
 Lekcja 5. Strona 1 z 12 Analiza Statystyczna Do analizy statystycznej wykorzystać można wbudowany w MS Excel pakiet Analysis Toolpak. Jest on instalowany w programie Excel jako pakiet dodatkowy. Oznacza
Lekcja 5. Strona 1 z 12 Analiza Statystyczna Do analizy statystycznej wykorzystać można wbudowany w MS Excel pakiet Analysis Toolpak. Jest on instalowany w programie Excel jako pakiet dodatkowy. Oznacza
Analiza głównych składowych- redukcja wymiaru, wykł. 12
 Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl
 Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Miary położenia wskazują miejsce wartości najlepiej reprezentującej wszystkie wielkości danej zmiennej. Mówią o przeciętnym poziomie analizowanej
 Miary położenia wskazują miejsce wartości najlepiej reprezentującej wszystkie wielkości danej zmiennej. Mówią o przeciętnym poziomie analizowanej cechy. Średnia arytmetyczna suma wartości zmiennej wszystkich
Miary położenia wskazują miejsce wartości najlepiej reprezentującej wszystkie wielkości danej zmiennej. Mówią o przeciętnym poziomie analizowanej cechy. Średnia arytmetyczna suma wartości zmiennej wszystkich
-> Średnia arytmetyczna (5) (4) ->Kwartyl dolny, mediana, kwartyl górny, moda - analogicznie jak
 (4) ->Kwartyl dolny, mediana, kwartyl górny, moda - analogicznie jak") Wzory dla szeregu szczegółowego: Wzory dla szeregu rozdzielczego punktowego: ->Średnia arytmetyczna ważona -> Średnia arytmetyczna (5) ->Średnia harmoniczna (1) ->Średnia harmoniczna (6) (2) ->Średnia
Wzory dla szeregu szczegółowego: Wzory dla szeregu rozdzielczego punktowego: ->Średnia arytmetyczna ważona -> Średnia arytmetyczna (5) ->Średnia harmoniczna (1) ->Średnia harmoniczna (6) (2) ->Średnia
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Klasyfikacja LDA + walidacja
 Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Statystyka opisowa. Robert Pietrzykowski.
 Statystyka opisowa Robert Pietrzykowski email: robert_pietrzykowski@sggw.pl www.ekonometria.info 2 Na dziś Sprawy bieżące Przypominam, że 14.11.2015 pierwszy sprawdzian Konsultacje Sobota 9:00 10:00 pok.
Statystyka opisowa Robert Pietrzykowski email: robert_pietrzykowski@sggw.pl www.ekonometria.info 2 Na dziś Sprawy bieżące Przypominam, że 14.11.2015 pierwszy sprawdzian Konsultacje Sobota 9:00 10:00 pok.
Parametry statystyczne
 I. MIARY POŁOŻENIA charakteryzują średni lub typowy poziom wartości cechy, wokół nich skupiają się wszystkie pozostałe wartości analizowanej cechy. I.1. Średnia arytmetyczna x = x 1 + x + + x n n = 1 n
I. MIARY POŁOŻENIA charakteryzują średni lub typowy poziom wartości cechy, wokół nich skupiają się wszystkie pozostałe wartości analizowanej cechy. I.1. Średnia arytmetyczna x = x 1 + x + + x n n = 1 n
Graficzna prezentacja danych statystycznych
 Szkolenie dla pracowników Urzędu Statystycznego nt. Wybrane metody statystyczne w analizach makroekonomicznych Katowice, 12 i 26 czerwca 2014 r. Dopasowanie narzędzia do typu zmiennej Dobór narzędzia do
Szkolenie dla pracowników Urzędu Statystycznego nt. Wybrane metody statystyczne w analizach makroekonomicznych Katowice, 12 i 26 czerwca 2014 r. Dopasowanie narzędzia do typu zmiennej Dobór narzędzia do
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
SCENARIUSZ LEKCJI. TEMAT LEKCJI: Zastosowanie średnich w statystyce i matematyce. Podstawowe pojęcia statystyczne. Streszczenie.
 SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
Sztuczna inteligencja : Algorytm KNN
 Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Matlab podstawy + testowanie dokładności modeli inteligencji obliczeniowej
 Matlab podstawy + testowanie dokładności modeli inteligencji obliczeniowej Podstawy matlaba cz.ii Funkcje Dotychczas kod zapisany w matlabie stanowił skrypt który pozwalał na określenie kolejności wykonywania
Matlab podstawy + testowanie dokładności modeli inteligencji obliczeniowej Podstawy matlaba cz.ii Funkcje Dotychczas kod zapisany w matlabie stanowił skrypt który pozwalał na określenie kolejności wykonywania
Zastosowania sieci neuronowych
 Zastosowania sieci neuronowych klasyfikacja LABORKA Piotr Ciskowski zadanie 1. klasyfikacja zwierząt sieć jednowarstwowa żródło: Tadeusiewicz. Odkrywanie własności sieci neuronowych, str. 159 Przykład
Zastosowania sieci neuronowych klasyfikacja LABORKA Piotr Ciskowski zadanie 1. klasyfikacja zwierząt sieć jednowarstwowa żródło: Tadeusiewicz. Odkrywanie własności sieci neuronowych, str. 159 Przykład
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Zadania. Przygotowanie zbiorów danych. 1. Sposób 1: 2. Sposób 2:
 Wstęp Jednym z typowych zastosowań metod sztucznej inteligencji i uczenia maszynowego jest przetwarzanie języka naturalnego (ang. Natural Language Processing, NLP), której typowych przykładem jest analiza
Wstęp Jednym z typowych zastosowań metod sztucznej inteligencji i uczenia maszynowego jest przetwarzanie języka naturalnego (ang. Natural Language Processing, NLP), której typowych przykładem jest analiza
Definicje. Algorytm to:
 Algorytmy Definicje Algorytm to: skończony ciąg operacji na obiektach, ze ściśle ustalonym porządkiem wykonania, dający możliwość realizacji zadania określonej klasy pewien ciąg czynności, który prowadzi
Algorytmy Definicje Algorytm to: skończony ciąg operacji na obiektach, ze ściśle ustalonym porządkiem wykonania, dający możliwość realizacji zadania określonej klasy pewien ciąg czynności, który prowadzi
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Prezentacja materiału statystycznego Szeroko rozumiane modelowanie i prognozowanie jest zwykle kluczowym celem analizy danych. Aby zbudować model wyjaśniający relacje pomiędzy różnymi aspektami rozważanego
Prezentacja materiału statystycznego Szeroko rozumiane modelowanie i prognozowanie jest zwykle kluczowym celem analizy danych. Aby zbudować model wyjaśniający relacje pomiędzy różnymi aspektami rozważanego
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą