Ewelina Dziura Krzysztof Maryański
|
|
|
- Sylwester Kruk
- 9 lat temu
- Przeglądów:
Transkrypt
1 Ewelina Dziura Krzysztof Maryański

2 1. Wstęp - eksploracja danych 2. Proces Eksploracji danych 3. Reguły asocjacyjne budowa, zastosowanie, pozyskiwanie 4. Algorytm Apriori i jego modyfikacje 5. Przykład praktycznego zastosowania

3 Eksploracja danych jest analizą (..) zbiorów danych obserwacyjnych, w celu znalezienia nieoczekiwanych związków i podsumowania danych w oryginalny sposób, tak aby były zarówno zrozumiałe, jak i przydatne dla ich właściciela. [4] Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych zbiorach danych [8] Eksploracja danych jest międzydyscyplinarną dziedziną, łączącą techniki uczenia maszynowego, rozpoznawania wzorców, statystyki, baz danych i wizualizacji w celu uzyskiwania informacji z dużych baz danych [2]

4 Eksplorację danych wykorzystuje się wszędzie tam, gdzie zachodzi potrzeba uzyskania użytecznych informacji (na przykład wzorców, trendów) z istniejących dużych zbiorów danych. Głównymi zadaniami do rozwiązania w których stosuje się techniki eksploracji danych są (według [6]): Opis, Szacowanie, Przewidywanie, Klasyfikacja, Grupowanie, Odkrywanie reguł.

5 Wśród metod eksploracji danych wyróżnia się (według [7]): Klasyfikację, Grupowanie, Odkrywanie sekwencji, Odkrywanie charakterystyk, Odkrywanie asocjacji.

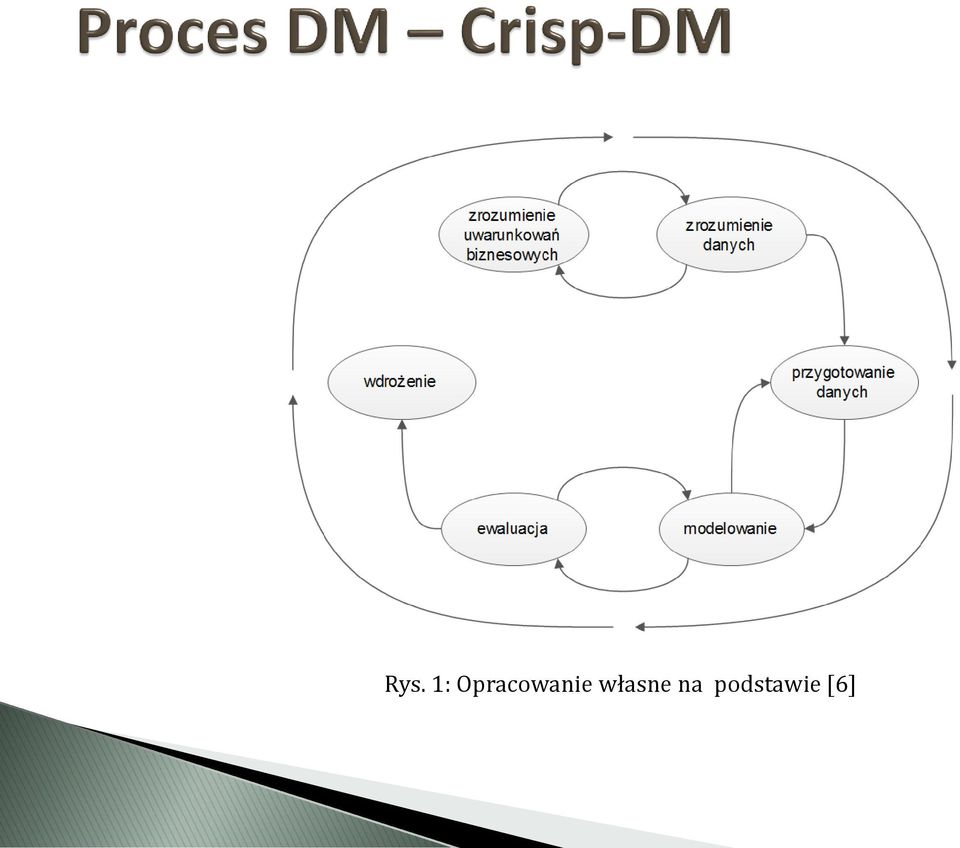
6 Według metodologii Crisp-DM [6] 1. Zrozumienie uwarunkowań biznesowych 2. Zrozumienie danych 3. Przygotowanie danych 4. Modelowanie 5. Ewaluacja 6. Wdrożenie


7 Rys. 1: Opracowanie własne na podstawie [6]
8 Metoda asocjacyjna (odkrywania asocjacji) jest jedną z najpopularniejszych metod eksploracji danych, polegającą na analizowaniu zbioru atrybutów z bazy danych pod kątem występowania w nim powtarzających się zależności. Wynikiem zastosowania tej metody są reguły asocjacyjne i odpowiadające im parametry.

9 Metody eksploracji danych oparte na eksploracji reguł asocjacyjnych znajdują zastosowanie wszędzie tam, gdzie celem jest określenie związków przyczynowo skutkowych pomiędzy zdarzeniami zapisanymi w analizowanej bazie danych. Przykładowe zastosowania odkrywania asocjacji to: Analiza koszyka zakupów, Opracowywanie ofert dla określonych grup klientów, Analiza zachowań użytkowników jakiegoś produktu lub usługi (np. portalu internetowego).

10 Reguły asocjacyjne można podzielić ze względu na (według [7]): Typ przetwarzanych danych, Wymiarowość przetwarzanych danych, Stopień abstrakcji przetwarzanych danych.

11 Podział ze względu na typ przetwarzanych danych: Reguły binarne gdy dane zawarte w regule są zmiennymi binarnymi przyjmującymi tylko wartości prawda albo fałsz, Reguły ilościowe gdy dane zawarte w regule są danymi kategorycznymi (np. rodzaj produktu) lub ciągłymi (np. prędkość).

12 Podział ze względu na wymiarowość przetwarzanych danych: Reguły jednowymiarowe gdy dane zawarte w regule pochodzą z jednej dziedziny wartości, Reguły wielowymiarowe gdy dane zawarte w regule pochodzą z różnych dziedzin wartości.

13 Podział ze względu na stopień abstrakcji przetwarzanych danych: Reguły jednopoziomowe jeżeli dane zawarte w regule mają ten sam poziom abstrakcji, Reguły wielopoziomowe jeżeli dane zawarte w regule mają różne poziomy abstrakcji.

14 Reguły asocjacyjne przedstawiane są w postaci implikacji. Każda reguła składa się z dwóch zbiorów atrybutów: zbioru wartości warunkujących (poprzednika) zbioru wartości warunkowanych (następnika).

15 Reguła ze poprzednikiem X i następnikiem Y jest zapisywana w następujący sposób: X Y Interpretacja : W przypadku wystąpienia wszystkich wartości ze zbioru X często występują również wszystkie wartości ze zbioru Y.

16 Wsparcie (ang. Support) jest parametrem określającym, jaki procent wszystkich reguł asocjacyjnych stanowi dana reguła. Jest to stosunek ilości przypadków w zbiorze danych, które zawierają w całości zbiory X i Y do liczby wszystkich przypadków. s P X Y = P X Y P

17 Pewność (ang. Confidence) jest parametrem określającym, jaki procent reguł asocjacyjnych, które zaczynają się od określonego poprzednika, stanowi dana reguła. Jest to stosunek ilości wystąpień w zbiorze danych przypadków zawierających w całości zbiory X i Y do liczby przypadków, które zawierają jedynie elementy zbioru X. c P X Y = P X Y P X

18 Id Elementy 1 A, B, C 2 A, C, B, D 3 A, C, E 4 B, E, D 5 D, A, C, E Wsparcie dla przykładowej reguły {A, C} D wynosi: S A, C D = 2 5 = 40% Natomiast pewność dla tej reguły wynosi: c A, C D = 2 = 50% 4

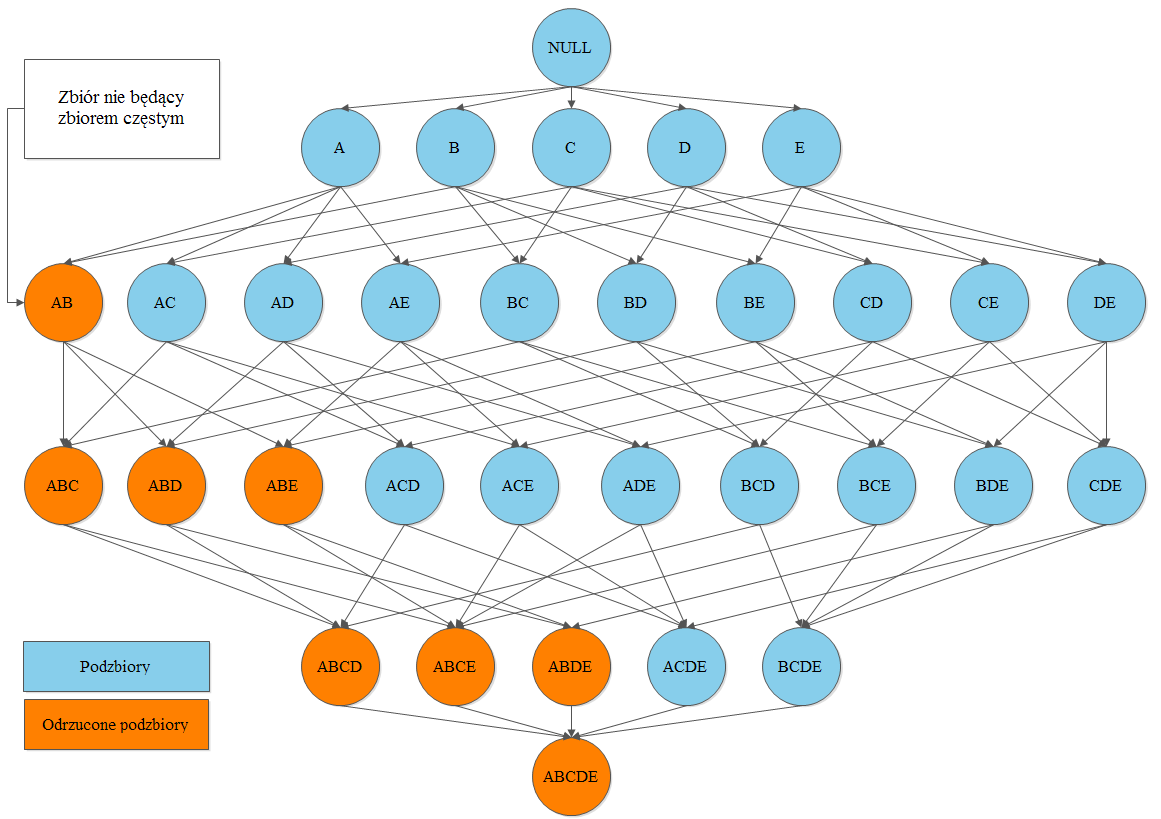
19 W pierwszym etapie znajdowane są wszystkie kombinacje atrybutów mające współczynnik wsparcia większy od minimalnego wsparcia zdefiniowanego wcześniej. Otrzymane kombinacje nazywane są dużymi zbiorami elementów, l-zbiorami albo zbiorami częstymi. Pozostałe kombinacje nie będące l-zbiorami (mające współczynnik wsparcia poniżej minimum) nazywane są małymi zbiorami elementów albo s-zbiorami.
")
20 Drugi etap polega na utworzeniu reguły asocjacyjnej dla każdej pary zbiorów z których jeden jest podzbiorem drugiego. Dla wygenerowanej reguły obliczany są współczynniki pewności oraz wsparcia i jeśli są one wyższe od minimum zdefiniowanego przez użytkownika to reguła jest akceptowana.

21 Po raz pierwszy opisany w 1994 roku w publikacji Fast Algorithms for Mining Association Rules autorstwa R. Agrawala i R. Srikanta. Opiera się na własności funkcji wsparcia (antymonotoniczności) dzięki której wiadomo, że rozszerzenie nieczęstego zbioru o dodatkowe elementy nigdy nie doprowadzi do powstania zbioru częstego.
22 Algorytm Apriori przeszukuje zbiór danych i w każdej kolejnej iteracji generuje rodziny coraz większych zbiorów częstych. 1. W pierwszej iteracji znajdowane są wszystkie jednoelementowe zbiory częste. 2. Zbiór ten jest wykorzystywany do znalezienia dwuelementowych zbiorów kandydujących (procedura AprioriGen). 3. Następnie obliczane jest wsparcie zbiorów kandydujących i po usunięciu tych, których wsparcie jest niższe od zadanego minimum otrzymywane są wszystkie dwuelementowe zbiory częste. Procedura z punktów 2 i 3 jest powtarzana do momentu, kiedy dla kolejnego k nie będzie już żadnego k-elementowego zbioru częstego.
23 Etapy procedury AprioriGen : 1. Łączenie (k-1)-elementowych zbiorów częstych łączony jest z samym sobą poprzez łączenie ze sobą wszystkich par (k-1)- elementowych zbiorów częstych. Para zbiorów częstych jest łączona tylko wtedy, kiedy oba zbiory mają k-2 takich samych elementów na początku. np. zbiory {a,b,c} i {a,b,d} zostaną połączone dając {a,b,c,d} ale {a,b,c} i {a,c,d} już nie.
24 2. Przycinanie Celem operacji przycinania jest wyeliminowanie ze zbioru zbiorów kandydujących tych elementów, które na podstawie wcześniej wspomnianej własności funkcji wsparcia nie mogą być zbiorami częstymi. Usuwane są wszystkie zbiory zawierające (k-1)-elementowe podzbiory niewystępujące w zbiorze (k-1)-elementowych zbiorów częstych.
25 Rys. 2
26 Apriori TiD Apriori Hybrid
27 W stosunku do algorytmu Apriori wprowadzona zostaje dodatkowa struktura (nazywana CountingBase) w której przechowywane są te transakcje z bazy, które popierają co najmniej jeden zbiór kandydujący. Struktura ta jest następnie używana do obliczania wsparcia zbiorów kandydujących. Podstawą działania AprioriTiD jest obserwacja, że transakcja, która nie zawiera żadnego k-zbioru częstego, nie może zawierać żadnego (k+1)-zbioru częstego. Zatem można je wyeliminować z obliczeń w następnych przebiegach algorytmu co powoduje, że Apriori TiD jest szybszy w późniejszych przebiegach niż zwykły Apriori.
28 Algorytm wykorzystujący zalety algorytmów Apriori i Apriori TiD: Algorytm Apriori jest szybszy w początkowych przejściach, Algorytm AprioriTiD jest szybszy w dalszych przejściach. Zasadą działania Apriori Hybrid jest zmiana algorytmu Apriori na AprioriTid w momencie w którym ten drugi zapewnia lepszą wydajność.
29 Dane: Lista klientów firmy wraz z zakupionymi przez nich modułami oprogramowania (zanonimizowane). 134 produkty 396 klientów Narzędzie: Statistica Data Miner 10 Cel: Znalezienie zestawów które są najczęściej kupowane w celu trafniejszego doboru ofert dla poszczególnych klientów.
30 Poprzednik Następnik Wsparcie (%) Zaufanie (%) C ==> B 32, ,5000 B ==> C 32, ,3265 D, C ==> B 23, ,2000 B, C ==> D 23, ,3077 B, D ==> C 23, ,9286 E, C ==> B 21, ,1417 B, C ==> E 21, ,6154 B, E ==> C 21, ,3617 F, C ==> B 21, ,8929 B, C ==> F 21, ,3846 B, F ==> C 21, ,5417 G, C ==> B 19, ,4510 B, C ==> G 19, ,7692 B, G ==> C 19, ,4771 C ==> B, A 32, ,5000 A, C ==> B 32, ,5000 B ==> A, C 32, ,3265 B, C ==> A 32, ,000 B, A ==> C 32, ,3265 D, C ==> B, A 23, ,2000 A, D, C ==> B 23, ,2000
31 Poprzednik Następnik Wsparcie(%) Zaufanie (%) C ==> A 52, ,0000 B ==> A 49, ,0000 D ==> A 46, ,0000 E ==> A 46, ,0000 G ==> A 36, ,0000 D ==> A, E 36, ,2609 E ==> A, D 36, ,2609 E, D ==> A 36, ,0000 A, D ==> E 36, ,2609 A, E ==> D 36, ,2609 D ==> E 36, ,2609 E ==> D 36, ,2609 F ==> A 35, ,0000 C ==> B 32, ,5000 B ==> C 32, ,3265 C ==> B, A 32, ,5000 A, C ==> B 32, ,5000 B ==> A, C 32, ,3265 B, C ==> A 32, ,0000 B, A ==> C 32, ,3265
32 Poprzednik Następnik Wsparcie(%) Zaufanie(%) F ==> A 35, ,0000 H, F ==> A 19, ,0000 G, F ==> A 20, ,0000 H ==> A 22, ,0000 I ==> A 23, ,0000 G ==> A 36, ,0000 L ==> D 22, ,0000 M ==> C 23, ,0000 E, J ==> A, C 19, ,3415 A, E, J ==> C 19, ,3415 E, J ==> C 19, ,3415 D, K ==> A, E 20, ,2381 A, D, K ==> E 20, ,2381 D, K ==> E 20, ,2381 J ==> A, C 23, ,8776 A, J ==> C 23, ,8776 J ==> C 23, ,8776 I ==> B 22, ,6842 I ==> B, A 22, ,6842
33 liczba reguł minsup liczba reguł 100% 0 90% 0 80% 0 70% 0 60% 0 50% 2 40% 8 30% 46 20% % Liczba reguł w zależności od parametru minsup minsup [%] Poziom minconf stały i równy 10%
34 liczba reguł minconf liczba reguł 100% % % % % % % % % % Liczba reguł w zależności od parametru minconf minconf [%] Poziom minsup stały i równy 10%

35 liczba reguł minconf minsup 20% 30% 40% 50% 60% 70% 80% 90% 20% % % % % Liczba reguł w zależności od parametrów minsup i minconf minsup[%] minconf[%]
36 1. Agrawal R., Srikant R., Fast Algorithms for Mining Association Rules, IBM Almaden Research Center, San Jose, California Cabena P., Hadjinian P., Stadler R., Verhees J., Zanasi A., Discovering Data Mining: From Concept to Implementation, Prentice Hall, Upper Saddle River, Cichosz P., Metody odkrywania wiedzy: wykład 11 Odkrywanie reguł asocjacyjnych, 4. Hand D., Mannila H., Smyth P., Eksploracja danych, WNT, Warszawa Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction Springer Larose D.T. Odkrywanie wiedzy z danych. Wprowadzenie do eksploracji danych Wydawnictwo Naukowe PWN, Warszawa Morzy T, Morzy M., Leśniewska A., Kurs eksploracji danych 8. Szymański S., Budziński R., Metody eksploracji reguł asocjacyjnych i ich zastosowanie, w: Acta Universitatis Lodziensis. Folia Oeconomica. - [Z.] 183 (2004)
37
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych. Data Mining Wykład 2
 Data Mining Wykład 2 Odkrywanie asocjacji Plan wykładu Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych Geneza problemu Geneza problemu odkrywania reguł
Data Mining Wykład 2 Odkrywanie asocjacji Plan wykładu Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych Geneza problemu Geneza problemu odkrywania reguł
Metody eksploracji danych. Reguły asocjacyjne
 Metody eksploracji danych Reguły asocjacyjne Analiza podobieństw i koszyka sklepowego Analiza podobieństw jest badaniem atrybutów lub cech, które są powiązane ze sobą. Metody analizy podobieństw, znane
Metody eksploracji danych Reguły asocjacyjne Analiza podobieństw i koszyka sklepowego Analiza podobieństw jest badaniem atrybutów lub cech, które są powiązane ze sobą. Metody analizy podobieństw, znane
Data Mining Wykład 3. Algorytmy odkrywania binarnych reguł asocjacyjnych. Plan wykładu
 Data Mining Wykład 3 Algorytmy odkrywania binarnych reguł asocjacyjnych Plan wykładu Algorytm Apriori Funkcja apriori_gen(ck) Generacja zbiorów kandydujących Generacja reguł Efektywności działania Własności
Data Mining Wykład 3 Algorytmy odkrywania binarnych reguł asocjacyjnych Plan wykładu Algorytm Apriori Funkcja apriori_gen(ck) Generacja zbiorów kandydujących Generacja reguł Efektywności działania Własności
Eksploracja danych - wykład VIII
 I Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 2 grudnia 2016 1/31 1 2 2/31 (ang. affinity analysis) polega na badaniu atrybutów lub cech, które są ze sobą powiązane. Metody
I Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 2 grudnia 2016 1/31 1 2 2/31 (ang. affinity analysis) polega na badaniu atrybutów lub cech, które są ze sobą powiązane. Metody
Odkrywanie asocjacji
 Odkrywanie asocjacji Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Odkrywanie asocjacji wykład 1 Wykład jest poświęcony wprowadzeniu i zaznajomieniu się z problemem odkrywania reguł asocjacyjnych.
Odkrywanie asocjacji Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Odkrywanie asocjacji wykład 1 Wykład jest poświęcony wprowadzeniu i zaznajomieniu się z problemem odkrywania reguł asocjacyjnych.
dr inż. Olga Siedlecka-Lamch 14 listopada 2011 roku Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Eksploracja danych
 - Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
- Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
Systemy Wspomagania Decyzji
 Reguły Asocjacyjne Szkoła Główna Służby Pożarniczej Zakład Informatyki i Łączności March 18, 2014 1 Wprowadzenie 2 Definicja 3 Szukanie reguł asocjacyjnych 4 Przykłady użycia 5 Podsumowanie Problem Lista
Reguły Asocjacyjne Szkoła Główna Służby Pożarniczej Zakład Informatyki i Łączności March 18, 2014 1 Wprowadzenie 2 Definicja 3 Szukanie reguł asocjacyjnych 4 Przykłady użycia 5 Podsumowanie Problem Lista
Odkrywanie asocjacji
 Odkrywanie asocjacji Cel odkrywania asocjacji Znalezienie interesujących zależności lub korelacji, tzw. asocjacji Analiza dużych zbiorów danych Wynik procesu: zbiór reguł asocjacyjnych Witold Andrzejewski,
Odkrywanie asocjacji Cel odkrywania asocjacji Znalezienie interesujących zależności lub korelacji, tzw. asocjacji Analiza dużych zbiorów danych Wynik procesu: zbiór reguł asocjacyjnych Witold Andrzejewski,
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING. EKSPLORACJA DANYCH Ćwiczenia. Adrian Horzyk. Akademia Górniczo-Hutnicza
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING EKSPLORACJA DANYCH Ćwiczenia Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING EKSPLORACJA DANYCH Ćwiczenia Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
Krzysztof Kawa. empolis arvato. e mail: krzysztof.kawa@empolis.com
 XI Konferencja PLOUG Kościelisko Październik 2005 Zastosowanie reguł asocjacyjnych, pakietu Oracle Data Mining for Java do analizy koszyka zakupów w aplikacjach e-commerce. Integracja ze środowiskiem Oracle
XI Konferencja PLOUG Kościelisko Październik 2005 Zastosowanie reguł asocjacyjnych, pakietu Oracle Data Mining for Java do analizy koszyka zakupów w aplikacjach e-commerce. Integracja ze środowiskiem Oracle
Inżynieria biomedyczna
 Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
Analiza i eksploracja danych
 Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Inteligentne Systemy Wspomagania Decyzji Studia magisterskie, semestr I Semestr letni
Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Inteligentne Systemy Wspomagania Decyzji Studia magisterskie, semestr I Semestr letni
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
Algorytmy odkrywania binarnych reguł asocjacyjnych
 Algorytmy odkrywania binarnych reguł asocjacyjnych A-priori FP-Growth Odkrywanie asocjacji wykład 2 Celem naszego wykładu jest zapoznanie się z dwoma podstawowymi algorytmami odkrywania binarnych reguł
Algorytmy odkrywania binarnych reguł asocjacyjnych A-priori FP-Growth Odkrywanie asocjacji wykład 2 Celem naszego wykładu jest zapoznanie się z dwoma podstawowymi algorytmami odkrywania binarnych reguł
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU
 WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych
 Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
A C T A UNIVERSITATIS LODZIENSIS FOLIA OECONOMICA 183,2004. Sebastian Szamański, Ryszard Budziński
 A C T A UNIVERSITATIS LODZIENSIS FOLIA OECONOMICA 183,2004 Sebastian Szamański, Ryszard Budziński METODY EKSPLORACJI REGUŁ ASOCJACYJNYCH I ICH ZASTOSOWANIE Wprowadzenie Ogromny postęp technologiczny ostatnich
A C T A UNIVERSITATIS LODZIENSIS FOLIA OECONOMICA 183,2004 Sebastian Szamański, Ryszard Budziński METODY EKSPLORACJI REGUŁ ASOCJACYJNYCH I ICH ZASTOSOWANIE Wprowadzenie Ogromny postęp technologiczny ostatnich
Ćwiczenie 5. Metody eksploracji danych
 Ćwiczenie 5. Metody eksploracji danych Reguły asocjacyjne (association rules) Badaniem atrybutów lub cech, które są powiązane ze sobą, zajmuje się analiza podobieństw (ang. affinity analysis). Metody analizy
Ćwiczenie 5. Metody eksploracji danych Reguły asocjacyjne (association rules) Badaniem atrybutów lub cech, które są powiązane ze sobą, zajmuje się analiza podobieństw (ang. affinity analysis). Metody analizy
data mining machine learning data science
 data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
1. Odkrywanie asocjacji
 1. 2. Odkrywanie asocjacji...1 Algorytmy...1 1. A priori...1 2. Algorytm FP-Growth...2 3. Wykorzystanie narzędzi Oracle Data Miner i Rapid Miner do odkrywania reguł asocjacyjnych...2 3.1. Odkrywanie reguł
1. 2. Odkrywanie asocjacji...1 Algorytmy...1 1. A priori...1 2. Algorytm FP-Growth...2 3. Wykorzystanie narzędzi Oracle Data Miner i Rapid Miner do odkrywania reguł asocjacyjnych...2 3.1. Odkrywanie reguł
Analiza danych i data mining.
 Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
Wielopoziomowe i wielowymiarowe reguły asocjacyjne
 Wielopoziomowe i wielowymiarowe reguły asocjacyjne Wielopoziomowe reguły asocjacyjne Wielowymiarowe reguły asocjacyjne Asocjacje vs korelacja Odkrywanie asocjacji wykład 3 Kontynuując zagadnienia związane
Wielopoziomowe i wielowymiarowe reguły asocjacyjne Wielopoziomowe reguły asocjacyjne Wielowymiarowe reguły asocjacyjne Asocjacje vs korelacja Odkrywanie asocjacji wykład 3 Kontynuując zagadnienia związane
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Metody eksploracji danych Rok akademicki: 2015/2016 Kod: OWT-1-607-s Punkty ECTS: 4 Wydział: Odlewnictwa Kierunek: Wirtotechnologia Specjalność: - Poziom studiów: Studia I stopnia Forma i
Nazwa modułu: Metody eksploracji danych Rok akademicki: 2015/2016 Kod: OWT-1-607-s Punkty ECTS: 4 Wydział: Odlewnictwa Kierunek: Wirtotechnologia Specjalność: - Poziom studiów: Studia I stopnia Forma i
Analiza asocjacji i reguły asocjacyjne w badaniu wyborów zajęć dydaktycznych dokonywanych przez studentów. Zastosowanie algorytmu Apriori
 Ekonomia nr 34/2013 Analiza asocjacji i reguły asocjacyjne w badaniu wyborów zajęć dydaktycznych dokonywanych przez studentów. Zastosowanie algorytmu Apriori Mirosława Lasek *, Marek Pęczkowski * Streszczenie
Ekonomia nr 34/2013 Analiza asocjacji i reguły asocjacyjne w badaniu wyborów zajęć dydaktycznych dokonywanych przez studentów. Zastosowanie algorytmu Apriori Mirosława Lasek *, Marek Pęczkowski * Streszczenie
Inżynieria Wiedzy i Systemy Ekspertowe. Reguły asocjacyjne
 Inżynieria Wiedzy i Systemy Ekspertowe Reguły asocjacyjne Dr inż. Michał Bereta p. 144 / 10, Instytut Modelowania Komputerowego mbereta@pk.edu.pl beretam@torus.uck.pk.edu.pl www.michalbereta.pl Reguły
Inżynieria Wiedzy i Systemy Ekspertowe Reguły asocjacyjne Dr inż. Michał Bereta p. 144 / 10, Instytut Modelowania Komputerowego mbereta@pk.edu.pl beretam@torus.uck.pk.edu.pl www.michalbereta.pl Reguły
Odkrywanie asocjacji. Cel. Geneza problemu analiza koszyka zakupów
 Odkrywanie asocjacji Cel Celem procesu odkrywania asocjacji jest znalezienie interesujących zależności lub korelacji (nazywanych ogólnie asocjacjami) pomiędzy danymi w dużych zbiorach danych. Wynikiem
Odkrywanie asocjacji Cel Celem procesu odkrywania asocjacji jest znalezienie interesujących zależności lub korelacji (nazywanych ogólnie asocjacjami) pomiędzy danymi w dużych zbiorach danych. Wynikiem
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Odkrywanie reguł asocjacyjnych. Rapid Miner
 Odkrywanie reguł asocjacyjnych Rapid Miner Zbiory częste TS ID_KLIENTA Koszyk 12:57 1123 {mleko, pieluszki, piwo} 13:12 1412 {mleko, piwo, bułki, masło, pieluszki} 13:55 1425 {piwo, wódka, wino, paracetamol}
Odkrywanie reguł asocjacyjnych Rapid Miner Zbiory częste TS ID_KLIENTA Koszyk 12:57 1123 {mleko, pieluszki, piwo} 13:12 1412 {mleko, piwo, bułki, masło, pieluszki} 13:55 1425 {piwo, wódka, wino, paracetamol}
Grzegorz Harańczyk, StatSoft Polska Sp. z o.o.
 CO Z CZYM I PO CZYM, CZYLI ANALIZA ASOCJACJI I SEKWENCJI W PROGRAMIE STATISTICA Grzegorz Harańczyk, StatSoft Polska Sp. z o.o. Jednym z zagadnień analizy danych jest wyszukiwanie w zbiorach danych wzorców,
CO Z CZYM I PO CZYM, CZYLI ANALIZA ASOCJACJI I SEKWENCJI W PROGRAMIE STATISTICA Grzegorz Harańczyk, StatSoft Polska Sp. z o.o. Jednym z zagadnień analizy danych jest wyszukiwanie w zbiorach danych wzorców,
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner. rok akademicki 2014/2015
 Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Analiza asocjacji i sekwencji Analiza asocjacji Analiza asocjacji polega na identyfikacji
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Analiza asocjacji i sekwencji Analiza asocjacji Analiza asocjacji polega na identyfikacji
Reguły asocjacyjne. Żródło: LaroseD.T., Discovering Knowledge in Data. An Introduction to Data Minig, John Wiley& Sons, Hoboken, New Jersey, 2005.
 Reguły asocjacyjne Żródło: LaroseD.T., Discovering Knowledge in Data. An Introduction to Data Minig, John Wiley& Sons, Hoboken, New Jersey, 2005. Stragan warzywny -transakcje zakupów Transakcja Produkty
Reguły asocjacyjne Żródło: LaroseD.T., Discovering Knowledge in Data. An Introduction to Data Minig, John Wiley& Sons, Hoboken, New Jersey, 2005. Stragan warzywny -transakcje zakupów Transakcja Produkty
Sylabus modułu kształcenia na studiach wyższych. Nazwa Wydziału. Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia.
 Załącznik nr 4 do zarządzenia nr 12 Rektora UJ z 15 lutego 2012 r. Sylabus modułu kształcenia na studiach wyższych Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Wydział Matematyki
Załącznik nr 4 do zarządzenia nr 12 Rektora UJ z 15 lutego 2012 r. Sylabus modułu kształcenia na studiach wyższych Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Wydział Matematyki
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów
 LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
Metody Inżynierii Wiedzy
 Metody Inżynierii Wiedzy Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie AGH University of Science and Technology Mateusz Burcon Kraków, czerwiec 2017 Wykorzystane technologie Python 3.4
Metody Inżynierii Wiedzy Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie AGH University of Science and Technology Mateusz Burcon Kraków, czerwiec 2017 Wykorzystane technologie Python 3.4
Analiza i wizualizacja danych Data analysis and visualization
 KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/2013
KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/2013
Hurtownie danych - opis przedmiotu
 Hurtownie danych - opis przedmiotu Informacje ogólne Nazwa przedmiotu Hurtownie danych Kod przedmiotu 11.3-WI-INFD-HD Wydział Kierunek Wydział Informatyki, Elektrotechniki i Automatyki Informatyka / Zintegrowane
Hurtownie danych - opis przedmiotu Informacje ogólne Nazwa przedmiotu Hurtownie danych Kod przedmiotu 11.3-WI-INFD-HD Wydział Kierunek Wydział Informatyki, Elektrotechniki i Automatyki Informatyka / Zintegrowane
Reguły asocjacyjne, wykł. 11
 Reguły asocjacyjne, wykł. 11 Joanna Jędrzejowicz Instytut Informatyki Przykłady reguł Analiza koszyka sklepowego (ang. market basket analysis) - jakie towary kupowane są razem, Jakie towary sprzedają się
Reguły asocjacyjne, wykł. 11 Joanna Jędrzejowicz Instytut Informatyki Przykłady reguł Analiza koszyka sklepowego (ang. market basket analysis) - jakie towary kupowane są razem, Jakie towary sprzedają się
 Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
Statystyka i eksploracja danych
 Wykład I: Formalizm statystyki matematycznej 17 lutego 2014 Forma zaliczenia przedmiotu Forma zaliczenia Literatura Zagadnienia omawiane na wykładach Forma zaliczenia przedmiotu Forma zaliczenia Literatura
Wykład I: Formalizm statystyki matematycznej 17 lutego 2014 Forma zaliczenia przedmiotu Forma zaliczenia Literatura Zagadnienia omawiane na wykładach Forma zaliczenia przedmiotu Forma zaliczenia Literatura
Algorytmy optymalizacji zapytań eksploracyjnych z wykorzystaniem materializowanej perspektywy eksploracyjnej
 Algorytmy optymalizacji zapytań eksploracyjnych z wykorzystaniem materializowanej perspektywy eksploracyjnej Jerzy Brzeziński, Mikołaj Morzy, Tadeusz Morzy, Łukasz Rutkowski RB-006/02 1. Wstęp 1.1. Rozwój
Algorytmy optymalizacji zapytań eksploracyjnych z wykorzystaniem materializowanej perspektywy eksploracyjnej Jerzy Brzeziński, Mikołaj Morzy, Tadeusz Morzy, Łukasz Rutkowski RB-006/02 1. Wstęp 1.1. Rozwój
Odkrywanie wzorców sekwencji
 Odkrywanie wzorców sekwencji Sformułowanie problemu Algorytm GSP Eksploracja wzorców sekwencji wykład 1 Na wykładzie zapoznamy się z problemem odkrywania wzorców sekwencji. Rozpoczniemy od wprowadzenia
Odkrywanie wzorców sekwencji Sformułowanie problemu Algorytm GSP Eksploracja wzorców sekwencji wykład 1 Na wykładzie zapoznamy się z problemem odkrywania wzorców sekwencji. Rozpoczniemy od wprowadzenia
Reguły asocjacyjne w programie RapidMiner Michał Bereta
 Reguły asocjacyjne w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Reguły asocjacyjne mają na celu odkrycie związków współwystępowania pomiędzy atrybutami. Stosuje się je często do danych
Reguły asocjacyjne w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Reguły asocjacyjne mają na celu odkrycie związków współwystępowania pomiędzy atrybutami. Stosuje się je często do danych
Algorytm DIC. Dynamic Itemset Counting. Magdalena Przygórzewska Karolina Stanisławska Aleksander Wieczorek
 Algorytm DIC Dynamic Itemset Counting Magdalena Przygórzewska Karolina Stanisławska Aleksander Wieczorek Spis treści 1 2 3 4 Algorytm DIC jako rozszerzenie apriori DIC Algorytm znajdowania reguł asocjacyjnych
Algorytm DIC Dynamic Itemset Counting Magdalena Przygórzewska Karolina Stanisławska Aleksander Wieczorek Spis treści 1 2 3 4 Algorytm DIC jako rozszerzenie apriori DIC Algorytm znajdowania reguł asocjacyjnych
Rok akademicki: 2017/2018 Kod: JIS AD-s Punkty ECTS: 5. Kierunek: Informatyka Stosowana Specjalność: Modelowanie i analiza danych
 Nazwa modułu: Eksploracja danych Rok akademicki: 2017/2018 Kod: JIS-2-202-AD-s Punkty ECTS: 5 Wydział: Fizyki i Informatyki Stosowanej Kierunek: Informatyka Stosowana Specjalność: Modelowanie i analiza
Nazwa modułu: Eksploracja danych Rok akademicki: 2017/2018 Kod: JIS-2-202-AD-s Punkty ECTS: 5 Wydział: Fizyki i Informatyki Stosowanej Kierunek: Informatyka Stosowana Specjalność: Modelowanie i analiza
Odkrywanie wzorców sekwencji
 Odkrywanie wzorców sekwencji Prefix Span Odkrywanie wzorców sekwencji z ograniczeniami Uogólnione wzorce sekwencji Eksploracja wzorców sekwencji wykład 2 Kontynuujemy nasze rozważania dotyczące odkrywania
Odkrywanie wzorców sekwencji Prefix Span Odkrywanie wzorców sekwencji z ograniczeniami Uogólnione wzorce sekwencji Eksploracja wzorców sekwencji wykład 2 Kontynuujemy nasze rozważania dotyczące odkrywania
Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining
![Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining](/thumbs/26/8053420.jpg "Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining") Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining 0LNRáDM0RU]\ Marek Wojciechowski Instytut Informatyki PP Eksploracja danych 2GNU\ZDQLHZ]RUFyZZGX*\FK
Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining 0LNRáDM0RU]\ Marek Wojciechowski Instytut Informatyki PP Eksploracja danych 2GNU\ZDQLHZ]RUFyZZGX*\FK
Indeksy w bazach danych. Motywacje. Techniki indeksowania w eksploracji danych. Plan prezentacji. Dotychczasowe prace badawcze skupiały się na
 Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
ECDL Podstawy programowania Sylabus - wersja 1.0
 ECDL Podstawy programowania Sylabus - wersja 1.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu Podstawy programowania. Sylabus opisuje, poprzez efekty uczenia się, zakres wiedzy
ECDL Podstawy programowania Sylabus - wersja 1.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu Podstawy programowania. Sylabus opisuje, poprzez efekty uczenia się, zakres wiedzy
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Odkrywanie wiedzy. Marcin Szeląg Zakład ISWD, Instytut Informatyki, Politechnika Poznańska
 Odkrywanie wiedzy Marcin Szeląg Zakład ISWD, Instytut Informatyki, Politechnika Poznańska 7.10.2015 1 Plan prezentacji 1 Informacje organizacyjne 2 Zakres tematyczny przedmiotu 3 Wprowadzenie do Odkrywania
Odkrywanie wiedzy Marcin Szeląg Zakład ISWD, Instytut Informatyki, Politechnika Poznańska 7.10.2015 1 Plan prezentacji 1 Informacje organizacyjne 2 Zakres tematyczny przedmiotu 3 Wprowadzenie do Odkrywania
Odkrywanie reguł asocjacyjnych
 Odkrywanie reguł asocjacyjnych Tomasz Kubik Na podstawie dokumentu: CS583-association-rules.ppt 1 Odkrywanie reguł asocjacyjnych n Autor metody Agrawal et al in 1993. n Analiza asocjacji danych w bazach
Odkrywanie reguł asocjacyjnych Tomasz Kubik Na podstawie dokumentu: CS583-association-rules.ppt 1 Odkrywanie reguł asocjacyjnych n Autor metody Agrawal et al in 1993. n Analiza asocjacji danych w bazach
Plan wykładu. Reguły asocjacyjne. Przykłady asocjacji. Reguły asocjacyjne. Jeli warunki to efekty. warunki efekty
 Plan wykładu Reguły asocjacyjne Marcin S. Szczuka Wykład 6 Terminologia dla reguł asocjacyjnych. Ogólny algorytm znajdowania reguł. Wyszukiwanie czstych zbiorów. Konstruowanie reguł - APRIORI. Reguły asocjacyjne
Plan wykładu Reguły asocjacyjne Marcin S. Szczuka Wykład 6 Terminologia dla reguł asocjacyjnych. Ogólny algorytm znajdowania reguł. Wyszukiwanie czstych zbiorów. Konstruowanie reguł - APRIORI. Reguły asocjacyjne
ANALIZA ZACHOWAŃ UŻYTKOWNIKÓW PORTALU ONET.PL W UJĘCIU REGUŁ ASOCJACYJNYCH
 PAWEŁ WEICHBROTH POLITECHIKA GDAŃSKA, ASYSTET, ZAKŁAD ZARZĄDZAIA TECHOLOGIAMI IFORMATYCZYMI, POLITECHIKA GDAŃSKA 1 STRESZCZEIE Portale internetowe są obecnie powszechnym źródłem informacji, notując bardzo
PAWEŁ WEICHBROTH POLITECHIKA GDAŃSKA, ASYSTET, ZAKŁAD ZARZĄDZAIA TECHOLOGIAMI IFORMATYCZYMI, POLITECHIKA GDAŃSKA 1 STRESZCZEIE Portale internetowe są obecnie powszechnym źródłem informacji, notując bardzo
Michał Kukliński, Małgorzata Śniegocka-Łusiewicz
 A C T A U N I V E R S I T A T I S N I C O L A I C O P E R N I C I EKONOMIA XXXIX NAUKI HUMANISTYCZNO-SPOŁECZNE ZESZYT 389 TORUŃ 2009 Uniwersytet Mikołaja Kopernika w Toruniu Katedra Ekonometrii i Statystyki
A C T A U N I V E R S I T A T I S N I C O L A I C O P E R N I C I EKONOMIA XXXIX NAUKI HUMANISTYCZNO-SPOŁECZNE ZESZYT 389 TORUŃ 2009 Uniwersytet Mikołaja Kopernika w Toruniu Katedra Ekonometrii i Statystyki
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
EKSPLORACJA DANYCH METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING. Adrian Horzyk. Akademia Górniczo-Hutnicza
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING EKSPLORACJA DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING EKSPLORACJA DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
Data Mining Wykład 1. Wprowadzenie do Eksploracji Danych. Prowadzący. Dr inż. Jacek Lewandowski
 Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Eksploracja danych - wykład II
 - wykład 1/29 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Październik 2015 - wykład 2/29 W kontekście odkrywania wiedzy wykład - wykład 3/29 CRISP-DM - standaryzacja
- wykład 1/29 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Październik 2015 - wykład 2/29 W kontekście odkrywania wiedzy wykład - wykład 3/29 CRISP-DM - standaryzacja
Modelowanie wzorców zachowań klientów Delikatesów Alma przy wykorzystaniu reguł asocjacyjnych
 UNIWERSYTET EKONOMICZNY WE WROCŁAWIU WYDZIAŁ ZARZĄDZANIA, INFORMATYKI I FINANSÓW Piotr Skrzypczak Modelowanie wzorców zachowań klientów Delikatesów Alma przy wykorzystaniu reguł asocjacyjnych Praca magisterska
UNIWERSYTET EKONOMICZNY WE WROCŁAWIU WYDZIAŁ ZARZĄDZANIA, INFORMATYKI I FINANSÓW Piotr Skrzypczak Modelowanie wzorców zachowań klientów Delikatesów Alma przy wykorzystaniu reguł asocjacyjnych Praca magisterska
Wyszukiwanie reguł asocjacji i ich zastosowanie w internecie
 Bartosz BACHMAN 1, Paweł Karol FRANKOWSKI 1,2 1 Wydział Elektryczny, 2 Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie E mail: bartosz.bachman@sk.sep.szczecin.pl 1. Wprowadzenie
Bartosz BACHMAN 1, Paweł Karol FRANKOWSKI 1,2 1 Wydział Elektryczny, 2 Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie E mail: bartosz.bachman@sk.sep.szczecin.pl 1. Wprowadzenie
Statystyczna Eksploracja Danych
 Statystyczna Eksploracja Danych Wykład 1 - wprowadzenie, metoda LDA Fishera dr inż. Julian Sienkiewicz 22 lutego 2019 Plan wykładu 1 Sprawy organizacyjne Kontakt i forma zajęć Literatura Zasady zaliczania
Statystyczna Eksploracja Danych Wykład 1 - wprowadzenie, metoda LDA Fishera dr inż. Julian Sienkiewicz 22 lutego 2019 Plan wykładu 1 Sprawy organizacyjne Kontakt i forma zajęć Literatura Zasady zaliczania
mgr inż. Magdalena Deckert Poznań, r. Metody przyrostowego uczenia się ze strumieni danych.
 mgr inż. Magdalena Deckert Poznań, 30.11.2010r. Metody przyrostowego uczenia się ze strumieni danych. Plan prezentacji Wstęp Concept drift i typy zmian Algorytmy przyrostowego uczenia się ze strumieni
mgr inż. Magdalena Deckert Poznań, 30.11.2010r. Metody przyrostowego uczenia się ze strumieni danych. Plan prezentacji Wstęp Concept drift i typy zmian Algorytmy przyrostowego uczenia się ze strumieni
PRZYKŁAD BADANIA WZORCÓW ZACHOWAŃ KLIENTÓW ZA POMOCĄ ANALIZY KOSZYKOWEJ
 PRZYKŁAD BADANIA WZORCÓW ZACHOWAŃ KLIENTÓW ZA POMOCĄ ANALIZY KOSZYKOWEJ Agnieszka Pasztyła, StatSoft Polska Sp. z o.o.; Akademia Ekonomiczna w Krakowie, Katedra Statystyki Cel analizy koszykowej Analiza
PRZYKŁAD BADANIA WZORCÓW ZACHOWAŃ KLIENTÓW ZA POMOCĄ ANALIZY KOSZYKOWEJ Agnieszka Pasztyła, StatSoft Polska Sp. z o.o.; Akademia Ekonomiczna w Krakowie, Katedra Statystyki Cel analizy koszykowej Analiza
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Opisy przedmiotów do wyboru
 Opisy przedmiotów do wyboru moduły specjalistyczne oferowane na stacjonarnych studiach II stopnia (magisterskich) dla 2 roku matematyki semestr letni, rok akademicki 2017/2018 Spis treści 1. Data mining
Opisy przedmiotów do wyboru moduły specjalistyczne oferowane na stacjonarnych studiach II stopnia (magisterskich) dla 2 roku matematyki semestr letni, rok akademicki 2017/2018 Spis treści 1. Data mining
Ćwiczenia z Zaawansowanych Systemów Baz Danych
 Ćwiczenia z Zaawansowanych Systemów Baz Danych Hurtownie danych Zad 1. Projekt schematu hurtowni danych W źródłach danych dostępne są następujące informacje dotyczące operacji bankowych: Klienci banku
Ćwiczenia z Zaawansowanych Systemów Baz Danych Hurtownie danych Zad 1. Projekt schematu hurtowni danych W źródłach danych dostępne są następujące informacje dotyczące operacji bankowych: Klienci banku
KARTA PRZEDMIOTU. 1. Informacje ogólne. 2. Ogólna charakterystyka przedmiotu. Metody drążenia danych D1.3
 KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom kształcenia: Profil kształcenia: Forma studiów:
KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom kształcenia: Profil kształcenia: Forma studiów:
Semestr letni Ekonometria i prognozowanie Nie
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angieskim Obowiązuje od roku akademickiego 2012/2013 Wydobywanie wiedzy z baz danych Knowedge discovery in databases A. USYTUOWANIE
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angieskim Obowiązuje od roku akademickiego 2012/2013 Wydobywanie wiedzy z baz danych Knowedge discovery in databases A. USYTUOWANIE
Laboratorium 3. Odkrywanie reguł asocjacyjnych.
 Laboratorium 3 Odkrywanie reguł asocjacyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Tools SQL Worksheet. W górnym oknie wprowadź i wykonaj
Laboratorium 3 Odkrywanie reguł asocjacyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Tools SQL Worksheet. W górnym oknie wprowadź i wykonaj
Eksploracja danych. KLASYFIKACJA I REGRESJA cz. 2. Wojciech Waloszek. Teresa Zawadzka.
 Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
System monitorowania i sterowania produkcją
 Plan prezentacji System monitorowania i sterowania produkcją Tomasz Żabiński, Tomasz Mączka STAN PRAC 2013 GZPŚ, POIG, 8.2 Harmonogramowanie produkcji Monitorowanie produkcji w toku Sterowanie produkcją
Plan prezentacji System monitorowania i sterowania produkcją Tomasz Żabiński, Tomasz Mączka STAN PRAC 2013 GZPŚ, POIG, 8.2 Harmonogramowanie produkcji Monitorowanie produkcji w toku Sterowanie produkcją
Hurtownie danych. Analiza zachowań użytkownika w Internecie. Ewa Kowalczuk, Piotr Śniegowski. Informatyka Wydział Informatyki Politechnika Poznańska
 Hurtownie danych Analiza zachowań użytkownika w Internecie Ewa Kowalczuk, Piotr Śniegowski Informatyka Wydział Informatyki Politechnika Poznańska 2 czerwca 2011 Wprowadzenie Jak zwiększyć zysk sklepu internetowego?
Hurtownie danych Analiza zachowań użytkownika w Internecie Ewa Kowalczuk, Piotr Śniegowski Informatyka Wydział Informatyki Politechnika Poznańska 2 czerwca 2011 Wprowadzenie Jak zwiększyć zysk sklepu internetowego?
EKSPLORACJA DANYCH METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING. Adrian Horzyk. Akademia Górniczo-Hutnicza
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING EKSPLORACJA DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING EKSPLORACJA DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
Eksploracja danych - wykład IV
 - wykład 1/41 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 27 października 2016 - wykład 2/41 wykład 1 2 3 4 5 - wykład 3/41 CRISP-DM - standaryzacja wykład
- wykład 1/41 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 27 października 2016 - wykład 2/41 wykład 1 2 3 4 5 - wykład 3/41 CRISP-DM - standaryzacja wykład
Transformacja wiedzy w budowie i eksploatacji maszyn
 Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Diagramy związków encji. Laboratorium. Akademia Morska w Gdyni
 Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
SCENARIUSZ LEKCJI. TEMAT LEKCJI: Zastosowanie średnich w statystyce i matematyce. Podstawowe pojęcia statystyczne. Streszczenie.
 SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
Rok akademicki: 2030/2031 Kod: ZZP MK-n Punkty ECTS: 3. Poziom studiów: Studia II stopnia Forma i tryb studiów: Niestacjonarne
 Nazwa modułu: Komputerowe wspomaganie decyzji Rok akademicki: 2030/2031 Kod: ZZP-2-403-MK-n Punkty ECTS: 3 Wydział: Zarządzania Kierunek: Zarządzanie Specjalność: Marketing Poziom studiów: Studia II stopnia
Nazwa modułu: Komputerowe wspomaganie decyzji Rok akademicki: 2030/2031 Kod: ZZP-2-403-MK-n Punkty ECTS: 3 Wydział: Zarządzania Kierunek: Zarządzanie Specjalność: Marketing Poziom studiów: Studia II stopnia
9. Praktyczna ocena jakości klasyfikacji
 Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
HURTOWNIE DANYCH I BUSINESS INTELLIGENCE
 BAZY DANYCH HURTOWNIE DANYCH I BUSINESS INTELLIGENCE Akademia Górniczo-Hutnicza w Krakowie Adrian Horzyk horzyk@agh.edu.pl Google: Horzyk HURTOWNIE DANYCH Hurtownia danych (Data Warehouse) to najczęściej
BAZY DANYCH HURTOWNIE DANYCH I BUSINESS INTELLIGENCE Akademia Górniczo-Hutnicza w Krakowie Adrian Horzyk horzyk@agh.edu.pl Google: Horzyk HURTOWNIE DANYCH Hurtownia danych (Data Warehouse) to najczęściej
Algorytmy i bazy danych (wykład obowiązkowy dla wszystkich)
") MATEMATYKA I EKONOMIA PROGRAM STUDIÓW DLA II STOPNIA Data: 2010-11-07 Opracowali: Krzysztof Rykaczewski Paweł Umiński Streszczenie: Poniższe opracowanie przedstawia projekt planu studiów II stopnia na
MATEMATYKA I EKONOMIA PROGRAM STUDIÓW DLA II STOPNIA Data: 2010-11-07 Opracowali: Krzysztof Rykaczewski Paweł Umiński Streszczenie: Poniższe opracowanie przedstawia projekt planu studiów II stopnia na
SYSTEMY UCZĄCE SIĘ WYKŁAD 1. INFORMACJE WSTĘPNE. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 1. INFORMACJE WSTĘPNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska PLAN WYKŁADU WSTĘP W 1 Uczenie się w ujęciu algorytmicznym. W
SYSTEMY UCZĄCE SIĘ WYKŁAD 1. INFORMACJE WSTĘPNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska PLAN WYKŁADU WSTĘP W 1 Uczenie się w ujęciu algorytmicznym. W
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Eksploracja danych (data mining)
") Eksploracja (data mining) Tadeusz Pankowski www.put.poznan.pl/~pankowsk Czym jest eksploracja? Eksploracja oznacza wydobywanie wiedzy z dużych zbiorów. Eksploracja badanie, przeszukiwanie; np. dziewiczych
Eksploracja (data mining) Tadeusz Pankowski www.put.poznan.pl/~pankowsk Czym jest eksploracja? Eksploracja oznacza wydobywanie wiedzy z dużych zbiorów. Eksploracja badanie, przeszukiwanie; np. dziewiczych
Technologie baz danych
 Plan wykładu Technologie baz danych Wykład 2: Relacyjny model danych - zależności funkcyjne. SQL - podstawy Definicja zależności funkcyjnych Reguły dotyczące zależności funkcyjnych Domknięcie zbioru atrybutów
Plan wykładu Technologie baz danych Wykład 2: Relacyjny model danych - zależności funkcyjne. SQL - podstawy Definicja zależności funkcyjnych Reguły dotyczące zależności funkcyjnych Domknięcie zbioru atrybutów
Z-ID-509a Odkrywanie związków w danych wielowymiarowych. Specjalnościowy Obowiązkowy Polski Semestr V
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angieskim Obowiązuje od roku akademickiego 2015/2016 Z-ID-509a Odkrywanie związków w danych wieowymiarowych Discovering Reationships
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angieskim Obowiązuje od roku akademickiego 2015/2016 Z-ID-509a Odkrywanie związków w danych wieowymiarowych Discovering Reationships
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład I dr inż. 2015/2016
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Odkrywanie wzorców sekwencyjnych z zachowaniem prywatności
 Politechnika Warszawska Wydział Elektroniki i Technik Informacyjnych Instytut Informatyki Rok akademicki 2013/2013 PRACA DYPLOMOWA MAGISTERSKA Andrzej Makarewicz Odkrywanie wzorców sekwencyjnych z zachowaniem
Politechnika Warszawska Wydział Elektroniki i Technik Informacyjnych Instytut Informatyki Rok akademicki 2013/2013 PRACA DYPLOMOWA MAGISTERSKA Andrzej Makarewicz Odkrywanie wzorców sekwencyjnych z zachowaniem
SYLABUS DOTYCZY CYKLU KSZTAŁCENIA REALIZACJA W ROKU AKADEMICKIM 2016/2017
 SYLABUS DOTYCZY CYKLU KSZTAŁCENIA 2014-2018 REALIZACJA W ROKU AKADEMICKIM 2016/2017 1.1. Podstawowe informacje o przedmiocie/module Nazwa przedmiotu/ modułu Metody eksploracji danych Kod przedmiotu/ modułu*
SYLABUS DOTYCZY CYKLU KSZTAŁCENIA 2014-2018 REALIZACJA W ROKU AKADEMICKIM 2016/2017 1.1. Podstawowe informacje o przedmiocie/module Nazwa przedmiotu/ modułu Metody eksploracji danych Kod przedmiotu/ modułu*
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy oólny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK
Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy oólny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1.
 Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Wykład 2. Relacyjny model danych
 Wykład 2 Relacyjny model danych Wymagania stawiane modelowi danych Unikanie nadmiarowości danych (redundancji) jedna informacja powinna być wpisana do bazy danych tylko jeden raz Problem powtarzających
Wykład 2 Relacyjny model danych Wymagania stawiane modelowi danych Unikanie nadmiarowości danych (redundancji) jedna informacja powinna być wpisana do bazy danych tylko jeden raz Problem powtarzających
Eksploracja danych: problemy i rozwiązania
 V Konferencja PLOUG Zakopane Październik 1999 Eksploracja danych: problemy i rozwiązania Tadeusz Morzy morzy@put.poznan.pl Instytut Informatyki Politechnika Poznańska Streszczenie Artykuł zawiera krótką
V Konferencja PLOUG Zakopane Październik 1999 Eksploracja danych: problemy i rozwiązania Tadeusz Morzy morzy@put.poznan.pl Instytut Informatyki Politechnika Poznańska Streszczenie Artykuł zawiera krótką
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 10. WNIOSKOWANIE W LOGICE ROZMYTEJ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WNIOSKOWANIE W LOGICE DWUWARTOŚCIOWEJ W logice
SZTUCZNA INTELIGENCJA WYKŁAD 10. WNIOSKOWANIE W LOGICE ROZMYTEJ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WNIOSKOWANIE W LOGICE DWUWARTOŚCIOWEJ W logice
Opisy przedmiotów do wyboru
 Opisy przedmiotów do wyboru moduły specjalistyczne oferowane na stacjonarnych studiach II stopnia (magisterskich) dla 2 roku matematyki semestr letni, rok akademicki 2017/2018 Spis treści 1. Data mining
Opisy przedmiotów do wyboru moduły specjalistyczne oferowane na stacjonarnych studiach II stopnia (magisterskich) dla 2 roku matematyki semestr letni, rok akademicki 2017/2018 Spis treści 1. Data mining