Odkrywanie wiedzy klasyfikacyjnej z niezrównoważonych danych
|
|
|
- Kinga Janowska
- 7 lat temu
- Przeglądów:
Transkrypt

1 Odkrywanie wiedzy klasyfikacyjnej z niezrównoważonych danych Learning classifiers from imbalanced data Wpływ niezrównoważenia klas na klasyfikator Wykład ZED dla specjal. TPD JERZY STEFANOWSKI Instytut Informatyki Politechnika Poznańska Poznań

2 Uczenie się klasyfikatorów z niezrównoważonych danych Zadajmy pytanie o rozkład przykładów w klasach w zbiorze uczącym Standardowe założenie: Dane są zrównoważone rozkłady liczności przykładów w klasach względnie podobne Przykład: A database of sick and healthy patients contains as many examples of sick patients as it does of healthy ones. Czy takie założenie jest realistyczne?

3 Przykład danych medycznych Chawla et al. SMOTE 2002
4 Niezrównoważenie rozkładu w klasach Dane są niezrównoważone jeśli klasy nie są w przybliżeniu równo liczne Klasa mniejszościowa (minority class) zawiera wyraźnie mniej przykładów niż inne klasy Przykłady z klasy mniejszościowej są często najważniejsze i ich poprawne rozpoznawanie jest głównym celem. Rozpoznawanie rzadkiej, niebezpiecznej choroby CLASS IMBALANCE powoduje trudności w fazie uczenia i obniża zdolność predykcyjną lass imbalance is not the same COST sensitive learning. general cost are unknown!

5 Przykłady niezrównoważonych problemów Niezrównoważenie jest naturalne w : Medical problems rare but dangerous illness. Helicopter Gearbox Fault Monitoring Discrimination between Earthquakes and Nuclear Explosions Document Filtering Direct Marketing Detection of Oil Spills Detection of Fraudulent Telephone Calls Przegląd innych problemów i zastosowań Japkowicz N., Learning from imbalanced data. AAAI Conf., Weiss G.M., Mining with rarity: a unifying framework. ACM Newsletter,2004. Chawla N., Data mining for imbalanced datasets: an overview. In The Data mining and knowledge discovery handbook, Springer He H, Garcia, Mining imbalanced data. IEEE Trans. Data and Knowledge 2009.
6 W czym tkwi trudność? Standardowe algorytmy uczące zakłada się w przybliżeniu zrównoważenie klas Typowe strategie przeszukiwania optymalizują globalne kryteria (błąd, miary entropii, itp.) Przykłady uczące są liczniej reprezentowane przy wyborze hipotez Metody redukcji (pruning) faworyzują przykłady większościowe Strategie klasyfikacyjne ukierunkowane na klasy większościowe
7 Przykład algorytmu indukcji reguł MODLEM [Stefanowski 98] minimalny zbiór reguł. Ocena warunków elementarnych entropia. Niespójne dane pruning reguł albo przybliżenia klas decyzyjnych indukcja pewnych i możliwych reguł. Przetwarzanie atrybutów nominalnych i liczbowych. W połączeniu ze strategiami klasyfikacyjnymi skuteczny klasyfikator Dopasowanie opisu obiektu do części warunkowych. Niejednoznaczności decyzja większościowa obj. a1 a2 a3 a4 D x1 m a C1 if (a1 =m)and (a2 2.6) then (D =C1) {x1,x3,x7} x2 f b C2 if (a2 [1.45, 2.4]) and (a3 2) then (D =C1) x3 m c C1 {x1,x4,x7} x4 f c C1 if (a2 2.4) then (D = C2) {x2,x6} x5 f a C2 if (a1 =f)and (a2 2.15) then (D =C2) {x5,x8} x6 m c C2 x7 m b C1 x8 f a C2
8 Zainteresowanie środowiska ML i DM Początkowo problem znany w zastowaniach Od 10lat wzrost zaintersowania badawczego AAAI 2000 Workshop, org:r. Holte, N. Japkowicz, C. Ling, S. Matwin. ICML 2000 Worshop also on cost sensitive. Dietterich T. et al. ICML 2003 Workshop, org.: N. Chawla, N. Japkowicz, A. Kolcz. ECAI 2004 Workshop, org.: Ferri C., Flach P., Orallo J. Lachice. N. ICMLA 2007 Session on Learning from Imbalanced Data PAKD 2009 Workshop on Imbalanced Data RSCTC 2010 Special Sessions CDMC Special issues: ACM KDDSIGMOD Explorations Newsletter, editors: N. Chawla, N. Japkowicz, A. Kolcz.
9 Miary oceny Jak oceniać klasyfikatory Standardowa trafność bezużyteczna Wyszukiwanie informacji (klasa mniejszościowa 1%) ogólna trafność klasyfikowania 100%, lecz źle rozpoznawana wybrana klasa Miary powinny być z klasą mniejszościową Analiza binarnej macierzy pomyłek confusion matrix Sensitivity i specificity, ROC curve analysis. Actual class Yes No Yes Predicted class TP: True positive FP: False positive No FN: False negative TN: True negative Klasyczne miary: Error Rate: (FP + FN)/N Accuracy Rate: (TP + TN) /N TP Sensitivity = TP + FN TN Specificity = TN + FP
10 Miary oceny wynikające z macierzy pomyłek G-mean F-miara
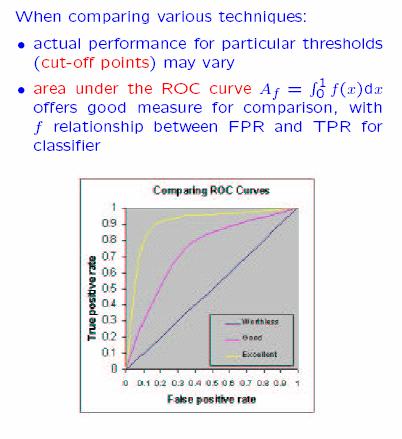
11 Probabilistyczne podstawy ROC
12 Na czym polega trudność? Łatwiejszy problem Trudniejszy Źródła trudności: Zbyt mało przykładów z klasy mniejszościowej, Zaburzenia brzegu klas, Segmentacja klasy Przeglądowe prace: Klasa większ. nakłada się na mniejszościowe Niejednoznaczne przykłady brzegowe Wpływ szumu (noisy examples) Japkowicz N., Learning from imbalanced data. AAAI Conf., Weiss G.M., Mining with rarity: a unifying framework. ACM Newsletter,2004.
13 Czy zawsze niezrównoważenie jest trudnością? Przeanalizuj studia eksperymentalne N.Japkowicz lub przeglądy G.Weiss. Japkowicz The minority class contains small disjuncts sub-clusters of interesting examples surrounded by other examples Niektóre prace eksperymentalne z dysuksją źródeł trudności, e.g: T. Jo, N. Japkowicz. Class imbalances versus small disjuncts. SIGKDD Explorations 6:1 (2004) V. García, R.A. Mollineda, J.S. Sánchez. On the k-nn performance in a challenging scenario of imbalance and overlapping. Pattern Anal Applic (2008) 11: Stefanowski J et al. Learning from imbalanced data in presence of noisy and borderline examples. RSCTC 2010.
14 Eksperymenty p. Japkowicz i współpracowników T. Jo, N. Japkowicz. Class imbalances versus small disjuncts. Przygotowanie sztucznych zbiorów w których zmienia się: Poziom niezrównoważenia (I) Liczność zbioru uczącego (S) Concept complexity (C) dekompozycje klas na podobszary Algorytmy drzewa C4.5, sztuczne sieci neuronowe BP i SWM
15 Rezultaty eksperymentów Obszerne studium z 125 sztucznymi danymi, każdy zróżnicowany poprzez: the concept complexity (C), the size of the training set (S) and the degree of imbalance (I) zmieniane krokowo 1-5. Wybrany wynik dla C4.5 Error rate 60,0 50,0 40,0 30,0 20,0 10,0 0,0 C=1 C=2 C=3 C=4 C=5 S1 I=1 I=2 I=3 I=4 60,0 50,0 40,0 30,0 20,0 10,0 I=5 0,0 C=1 C=2 C=3 C=4 C=5 S5 I=1 I=2 I=3 I=4 I=5 Large Imba Full balan Skuteczność klasyfikacji zależy od: the degree of class imbalance; the complexity of the concept represented by the data; the overall size of the training set;
16 Konkluzje co do wyboru algorytmów Niektóre algorytmy mniej podatne na dane niezrównoważone: Naive Bayes, Support Vector Machines vs. drzewa decyzyjne, reguły decyzyjne, sieci neuronowe, k-nn Error rate C5.0 MLP SVM S = 1; C = 3 Eksperymenty dokładniej opisane przez Japkowicz, Jo I=1 I=2 I=3 I=4 I=5 Large Imbal. Full balance
17 The overall imbalance ratio matches the imbalance ratio corresponding to the overlap region, what could be accepted as a common case. ksperymenty Garcia et al. ze strefami brzegowymi Overlapping Fig. Two different levels of class overlapping: a 0% and b 60% Experiment I: The positive examples are defined on the X-axis in the range [50 100], while those belonging to the majority class are generated in [0 50] for 0% of class overlap, [10 60] for 20%, [20 70] for 40%, [30 80] for 60%, [40 90] for 80%, and [50 100] for 100% of overlap.
18 ksperymenty Garcia et al. ze strefami brzegowymi Niektóre z wyników Skuteczność różnych klasyfikatorów wzrost niejednoznaczność strefy brzegowe silniej obniża AUC niż wzrost niezrównoważenia W dalszych eksperymentach zauważony wpływ lokalnej gęstości przykładów!
19 Dalsze eksperymenty ze sztucznymi danymi J. Stefanowski, 2009 (przy współpracy K.Kałużny) Wpływ różnego typu trudności (kształt pojęc, szum i rzadkie przykłady, nakładające się obszary brzegowe, stopnie niezrównoważenia, dekompozycja klas) na działanie klasyfikatorów C4.5, Ripper i K-NN Dane Kolekcja kilkuset sztucznych zbiorów danych o ściśle kontrolowanej charakterystyce Konkluzje Nieliniowe kształty klas decyzyjnych oraz ich fragmentacja były zdecydowanie poważniejszym problemem niż samo niezrównoważenie klas (rozszerzanie rezultatów znanych z literatury) Najpoważniejszym źródłem trudności była zaburzona granica między klasami oraz obecności szum w klasach decyzyjnych, zwłaszcza w mniejszościowej Klasyfikator J48 1,00 0,90 0,80 0,70 0,60 0,50 0,40 0,30 0,20 0,10 0,00 TP_Rate - klasa mniejszościowa 03subcl3 03subcl4 03subcl5 03subcl6 03subcl3 03subcl4 03subcl5 03subcl6 03subcl3 03subcl4 03subcl5 03subcl Sz
 na efektywność metod wstępnego przetwarzania danych")
20 K. Napierała, J. Stefanowski, Sz. Wilk: Learning from imbalanced data in presence of noisy and borderline examples. RSCTC 2010, LNAI Springer. Problem badawczy Dokładniejsze zbadanie wpływu różnego typu zaburzeń (przypadki brzegowych i zaszumione, dekompozycja klasy mniejszościowej) na efektywność metod wstępnego przetwarzania danych niezrównoważonych Proponowane podejście Eksperymentalne porównanie algorytmów SPIDER, NCR, cluster-oversampling oraz prostego nadlosowywania klasy mniejszościowej Dane Sztuczne zbiory danych o określonej specyfice (niedoskonałości różnego typu) Także niezrównoważone zbiory danych pochodzące z repozytorium UCI Konkluzje Proste nadlosowywanie okazało się najgorszą z rozważanych metod W przypadku małej ilości trudnych przypadków cluter-oversampling okazał się najskuteczniejszy W przypadku silnie zaburzonych danych (np. szum powyżej 30%) lepsze okazały się metody SPIDER oraz częściowo NCR

21 Wybrane sztuczne dane i wyniki Dataset Base Oversampling Filtr Japkowicz NCR SPIDER subclus subclus subclus subclus clover clover clover clover paw paw paw paw Miara oceny: sensitivity Algorytm: C4.5
22 Co z rzeczywistymi danymi? Wizualizacja 2 składowych w metodzie PCA Thyroid Haberman
23 Podstawowe metody Prace przeglądowe Weiss G.M., Mining with rarity: a unifying framework. ACM Newsletter, Chawla N., Data mining for imbalanced datasets: an overview. In The Data mining and knowledge discovery handbook, Springer He H, Garcia, Mining imbalanced data. IEEE Trans. Data and Knowledge Dwa podstawowe kierunki działanie Modyfikacje danych (preprocessing) Modyfikacje algorytmów Najbardziej popularne grupy metod Re-sampling or re-weighting, Zmiany w strategiach uczenia się, użycie nowych miar oceny (np. AUC) Nowe strategie eksploatacji klasyfikatora (classification strategies) Ensemble approaches (najczęściej adaptacyjne klasyfikatory złożone typu boosting) Specjalizowane systemy hybrydowe One-class-learning Transformacje do zadania cost-sensitive learning
24 Modyfikacje algorytmów regułowych Zmiany w fazie poszukiwania reguł albo w strategiach klasyfikacyjnych Schemat tradycyjny: Exploit a greedy search strategy and use criteria that favor the majority class. The majority class rules are more general and cover more examples (strength) than minority class rules. Różne propozycje zmian: Use another inductive bias Modification of CN2 to prevent small disjuncts (Holte et al.) Hybrid approach with different inductive bias between large and small sets of examples (Ting). Use less greedy search for rules Exhaustive depth-bounded search for accurate conjunctions. Brute (Riddle et al..), modification of Apriori like algorithm to handle multiple levels of support (Liu at al.) Specific genetic search more powerful global search (Freitas and Lavington, Weiss et al.)
25 Przykład modyfikacji Nowy Algorytm uczący J.Stefanowski, S.Wilk: KES 2004 Połączenie dwóch zbiorów reguł tzw. satysfakcjonującego (dla klasy mniejszościowej) oraz minimalnego (dla klasy większościowej) Klasa większościowa algorytm LEM2: Przeszukiwanie zachłanne Minimalny zbiór reguł Klasa mniejszościowa algorytm Explore (Stefanowski, Vanderpooten 1994,2001): Wszystkie reguły o wsparciu > minsup Więcej reguł o sumarycznie większym wsparciu Przedstawione podejście nie wymagało strojenia parametrów progi minimalnego wsparcia dla reguł satysfakcjonujących były dobierane automatycznie Alternatywne podejście zmiana strategii klasyfikacyjnej (J.W. Grzymała-Busse et al. 2000) Współczynnik zwiększający siłę reguł mniejszościowych Optymalizacja gain = sensitivity + specificity
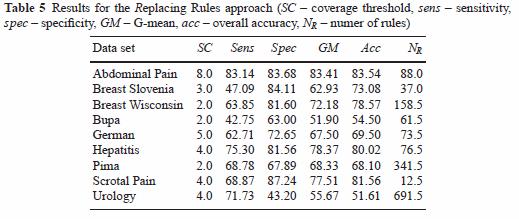
26
27 Niektóre z wyników eksperymentów (sensitivity) Data set Standard classifier Strength multiplier Replace rules Abdominal Bupa Breast German Hepatitis Pima Urology Zdecydowana poprawa miary wrażliwości; także lepsze wartości G- means Więcej J. Stefanowski, Sz. Wilk: Extending rule-based classifiers to improve recognition of imbalanced classes, w Z. Ras (eds) Advanced in Data Managment, Springer 2009
28 Inne podejścia do modyfikacji algorytmów uczących Zmiany w indukcji drzew decyzyjnych Weiss, G.M. Provost, F. (2003) "Learning When Training Data are Costly: The Effect of Class Distribution on Tree Induction" JAIR. Modyfikacje w klasyfikatorach bayesowskich Jason Rennie: Tackling the Poor Assumptions of Naive Bayes Text Classifiers ICML Wykorzystanie cost-learning w algorytmach uczących Domingos 1999; Elkan, 2001; Ting 2002; Zadrozny et al. 2003; Zhou and Liu, 2006 Modyfikacje zadania w SVM K.Morik et al., 1999.; Amari andwu (1999) Wu and Chang (2003), B.Wang, N.Japkowicz: Boosting Support Vector Machines for Imbalanced Data Sets, KAIS, 2009.
29 Metody modyfikujące zbiór uczący Zmiana rozkładu przykładów w klasach przed indukcją klasyfikatora: Proste techniki losowe Over-sampling klasa mniejszościowe Under-sampling - klasa mniejszościowa Specjalizowane nadlosowanie Cluster-oversampling (Japkowicz) Ukierunkowane transformacje Klasa większościowe One-side-sampling (Kubat, Matwin) z Tomek Links Laurikkala s edited nearest neighbor rule Klasa mniejszościowe SMOTE Chawla et al. Borderline SMOTE, Safe Level, Surrounding SMOTE, Podejścia łączone (hybrydowe) SPIDER SMOTE i undersampling Powiązanie z budową klasyfikatorów złożonych
30 esampling modyfikacja zbioru uczącego przed budową asyfikatora esampling pre-processing; celowa zmiana rozkładu rzykładów; balansowanie liczności klas po to aby w kolejnej fazie óc lepiej nauczyć klasyfikator rak teoretycznej gwarancji znalezienia optymalnej postaci ozkładu aczej heurystyka ukierunkowana na to add or remove examples ith the hope of reaching better distribution of the training examples nd thus, realizing the potential ability of classifiers [F.Herrera 2010]. Supervised sample (imbalanced dataset selection (balanced dataset
31 esampling the original data sets ndersampling vs oversampling # examples # examples + under-sampling # examples # examples + # examples over-sampling # examples +

32 Losowe równoważenie klas - dyskusja Random oversampling Kopiowanie przykładów mniejszościowych Czy proporcja 1:1 jest optymalna? Ryzyko przeuczenia Random undersampling: Usuwanie przykładów większośćiowych Utrata informacji

33 luster oversampling specyficzne losowanie dla small isjuncts ekompozycja klas within and between -class imbalance k zidentyfikować small disjuncts rzadkie podobszary w klasach? żyj algorytmu analizy skupień wewnątrz każdej klasy i odpowiednio dlosowuj! Cluster-based resampling identifies rare regions and resamples them individually, so as to avoid the creation of small disjuncts in the learned hypothesis. T. Jo, N. Japkowicz. Class imbalances versus small disjuncts. SIGKDD Explorations 6:1 (2004) 40-49
34 Studium Przypadku - Within-class vs Betweenclass Imbalances: Text Classification Prace Japkowicz i współpracownicy Nickerson A., Milios. E Reuters Dataset Classifying a document according to its topic Positive class is a particular topic Negative class is every other topic
35 II: Within-class vs Between- class Imbalances: Text Classification Method Precision Recall F-Measure Imbalanced Random Oversampling Guided Oversampling I (# Clusters Unknown) Guided OversamplingII (Using Known Clusters)

36 Ukierunkowane modyfikacje danych Focused resampling (Informed approaches): przetwarzaj tylko trudne obszary Czyszczenie borderline, redundant examples: Tomek links i one-side sampling Czyszczenie szumu i borderline: NCR Metoda SPIDER (J.Stefanowski, Sz.Wilk) SMOTE i jej rozszerzenia Czy są to typowe tricki losowania?
37 Powróćmy do charakterystyki przykładów Typy przykładów techniki resampling powinny skupić swoje działanie na niektórych z nich tery typy przykłady z klasy (większościowej) Noise examples Borderline examples Borderline examples are unsafe since a small amount of noise can make them fall on the wrong side of the decision border. Redundant examples Safe examples Modyfikacje undersampling: Znajdź i usuń 2 lub 3 pierwsze typy przykładów
 is the distance between them.")
38 nder-sampling z wykorzystaniem Tomek links Przykład Tomek Links Usuwaj przykłady graniczne i szum z klasy większościowej Tomek link Ei, Ej belong to different classes, d (Ei, Ej) is the distance between them. A (Ei, Ej) pair is called a Tomek link if there is no example El, such that d(ei, El) < d(ei, Ej) or d(ej, El) < d(ei, Ej).
39 nder-sampling z wykorzystaniem zasady CNN NN Condensed Nearest Neighbours specjalizowana odmiana edytowanego K-NN Jedna z najstarszych metod redukcji przykładów (powstało wiele modyfikacji). Idea znaleźć taki podzbiór E zbioru E, który gwarantowałby poprawną klasyfikację wszystkich przykładów ze zbioru E za pomocą algorytmu 1NN. Duda, Hart Usuwanie przykładów granicznych i um Schemat algorytmu: Let E be the original training set Let E contains all positive examples from S and one randomly selected negative example Classify E with the 1-NN rule using the examples in E Move all misclassified example from E to E
40 formed Under-sampling Najbardziej znany OSS One side-sampling Kubat, Matwin 1997 One-sided selection Tomek links + CNN może usuwać zbyt dużo przykładów CNN + Tomek links wprowadził F. Herrera Poszukiwanie Tomek links duże koszty obliczeniowe lepiej wykonuje na zredukowanym zbiorze NCL Nearest Cleaning Rule - Jorma Laurikkala 2001, Inne od OSS, bardziej czyści obszary brzegowe klas niż redukuje przykłady Algorytm: Find three nearest neighbors for each example Ei in the training set If Ei belongs to majority class, & the three nearest neighbors classify it to be minority class, then remove Ei If Ei belongs to minority class, and the three nearest neighbors classify it to be majority class, then remove the three nearest neighbors

41 Nearest Cleaning Rule Przykład ilustracyjny
42 Krytyczna dyskusja podejście hybrydowe NCR and one-side-sampling Zachłannie usuwają (zbyt) wiele przykładów z klasy większościowej Ukierunkowane głównie na poprawie wrażliwości (sensitivity) Mogą prowadzić do zbyt gwałtownego pogorszenia rozpoznawania klas większościowych (specificity, i inne miary) SMOTE Wprowadzają b. wiele przykładów sztucznych z klasy mniejszościowej tworzy odwrotność niezrównoważenia SMOTE ślepo poszukuje kierunku losowania bez obserwacji położenia przykładów większościowych Problematyczne w przypadku dekompozycji klasy większościowej Może prowadzić do dodatkowego wymieszania klas Trudność parametryzacji (k-liczba sąsiadów, r stopień nadlosowania)
43 Selective Preprocesing of Imbalanced Data SPIDER Ukierunkowane na wzrost czułości (ang. sensitivity) dla klasy mniejszościowej przy możliwie jak najmniejszym spadku specyficzności Rozróżnienie rodzaju przykładów: bezpieczne safe (certain lub possible); unsafe (brzegowe, noise, outliers) Metoda hybrydowa ograniczony undersampling i lokalizowany over-sampling Dwie fazy W przypadku klasy większościowej selektywne usunięcie noise certain i części z noise possible Możliwość przetykietowania przykładów noise certain W przypadku klasy mniejszościowej modyfikacje przykładów brzegowych i noise (nadlosowania) weak or strong amplification / SPIDER 1 kopiowanie wybranych przykładów Stopień wzmocnienia zależny od analizy sąsiedztwa (ENN)
44 Selektywny wybór przykładów detale J.Stefanowski, Sz.Wilk, ECML/PKDD 2007 Wykorzystanie modyfikacji zasady k- najbliższych sąsiadów (Wilson s Edited Nearest Neighbor Rule ) Usuń te przykłady, których klasa różni się od trzech najbliższych przykładów. Odległość HDVM z wykorzystaniem miary VDM Cost, Salzberg Dwa etapy selekcji w klasie większościowej: Identyfikacja szumu Lokalizacja przykładów brzegowych.


, spadki specyficzności były mniejsze niż w przypadku algorytmu NCR i losowego")
45 J. Stefanowski, Sz. Wilk: Selective pre-processing of imbalanced data for improving classification performance. DaWaK 2008 Studium eksperymentalne Porównanie z prostym losowym balansowaniem, NCR i podstawową wersją SMOTE Dane Niezrównoważone rzeczywiste zbiory danych pochodzące z repozytorium UCI oraz własnych projektów medycznych Konkluzje SPIDER poprawił wrażliwość klasyfikatorów opartych na drzewach i regułach decyzyjnych (np. lepszy niż SMOTE), spadki specyficzności były mniejsze niż w przypadku algorytmu NCR i losowego balansowania klas SPIDER w znacznie mniejszym stopniu zmodyfikował rozkład przetwarzanych zbiorów danych, niż algorytm SMOTE
46 Miara czułości klasy mniejszościowej Dane Pojed. Klasyfik. Oversampling Undersampling SPIDER breast ca bupa ecoli pima Acl Wisconsin hepatitis Nowe podejście zwiększa znacząco wartość miary Sensitivity
47 SMOTE - Synthetic Minority Oversampling Technique Wprowadzona przez Chawla, Hall, Kegelmeyer 2002 For each minority Sample Find its k-nearest minority neighbours Randomly select j of these neighbours Randomly generate synthetic samples along the lines joining the minority sample and its j selected neighbours (j depends on the amount of oversampling desired) Porównując z simple random oversampling SMOTE rozszerza regiony klasy mniejszościowej starając się robić je mniej specyficzne, paying attention to minority class samples without causing overfitting. SMOTE uznawana za bardzo skuteczną zwłaszcza w połączeniu z odpowiednim undersampling (wyniki Chawla, 2003).
48 Detale generacji sztucznego przykładu w SMOTE Sąsiedzi przykładu p identyfikowani poprzez K-NN z odległością HVDM Ogólny schemat dla atr. liczbowych Take the difference between the feature vector (sample) under consideration and its nearest neighbor. Multiply this difference by a random number between 0 and 1 Add it to the feature vector under consideration. Rozszerzenie dla atrybutów nominalnych wartość najczęściej występująca w zbiorze przykładów składającym się z p oraz jego k najbliższych sąsiadów z tej samej klasy. Consider a sample (6,4) and let (4,3) be its nearest neighbor. (6,4) is the sample for which k-nearest neighbors are bein identified (4,3) is one of its k-nearest neighbors. Let: f1_1 = 6 f2_1 = 4 f2_1 - f1_1 = -2 f1_2 = 4 f2_2 = 3 f2_2 - f1_2 = -1 The new samples will be generated as (f1',f2') = (6,4) + rand(0-1) * (-2,-1) rand(0-1) generates a random number between 0 and 1. * N. Chawla, K. Bowyer, L. Hall, P. Kegelmeyer, SMOTE: Synthetic Minority Over- Sampling Technique, JAIR, vol. 16, , 2002.
49 versampling klasy mniejszościowej w SMOTE MOTE analiza WYŁĄCZNIE klasy mniejszościowej : Przykład kl. mniejszościowej : syntetyczny przykład : Przykład kl. większościowe
50 SMOTE przykład oceny AUC
51 SMOTE zbiorcza ocena K=5 sąsiadów, różny stopień nadlosowania (np. 100% to dwukrotne zwiększenie liczności klasy mniejszościowej)
52 versampling klasy mniejszościowej w SMOTE versampling nie rozważa rozkładów klasy większościowej Pamiętaj, że rozkłady klas mogę się przenikać zwłaszcza w obszarach brzegowych i przy dekompozycji klas (sparse small disjuncts) Co się stanie gdy blisko jest przykład większościowy? : Minority sample : Synthetic sample : Majority sample
53 OTE uwagi krytyczne Overgeneralization SMOTE s procedure is inherently dangerous since it blindly generalizes the minority area without regard to the majority class. This strategy is particularly problematic in the case of highly skewed class distributions since, in such cases, the minority class is very sparse with respect to the majority class, thus resulting in a greater chance of class mixture. Lack of Flexibility The number of synthetic samples generated by SMOTE is fixed in advance, thus not allowing for any flexibility in the re-balancing rate.
54 esampling the original data sets MOTE Shortocomings Overgeneralization!! : Minority sample : Majority sample : Synthetic sample
55 ajnowsze rozszerzenia SMOTE Borderline_SMOTE: H. Han, W.Y. Wang, B.H. Mao. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. International Conference on Intelligent Computing (ICIC'05). Lecture Notes in Computer Science 3644, Springer-Verlag 2005, Hefei (China, 2005) Safe_Level_SMOTE: C. Bunkhumpornpat, K. Sinapiromsaran, C. Lursinsap. Safe-level-SMOTE: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD-09). LNAI 5476, Springer-Verlag 2005, Bangkok (Thailand, 2009) SMOTE_LLE: J. Wang, M. Xu, H. Wang, J. Zhang. Classification of imbalanced data by using the SMOTE algorithm and locally linear embedding. IEEE 8th International Conference on Signal Processing. LN-SMOTE: J. Stefanowski, T.Maciejewski.


56 SMOTE vs. inne rozszerzenia Przykład ilustracyjny
57 ilka uwag podsumowujących metody informed re-sampling Training Set Data Sampling Data Cleaning New Training Set Data Creation Bądź ostrożny, zmieniasz to co masz się nauczyć! Brak jednoznacznych wskazań, które metoda jest najlepsza w danych zastosowaniu Problem możliwego znacznej zmiany rozkładów klasa mniejszościowego może stać się silnie dominująca
58 mmary: Data level vs Algorithm Level. Sun, A. K. C. Wong and M. S. Kamel. Classification f imbalanced data: A review. International Journal of attern Recognition 23:4 (2009)
59 Literatura przeglądowa 1. G. M. Weiss. Mining with Rarity: A Unifying Framework. SIGKDD Explorations, 6(1):7-19, June Chawla N., Data mining for imbalanced datasets: an overview. In The Data mining and knowledge discovery handbook, Springer Garcia V., Sánchez J.S., Mollineda R.A., Alejo R., Sotoca J.M. The class imbalance problem in pattern classification and learning. pp , Visa, S. and Ralescu, A. Issues in mining imbalanced data sets - a review paper. Proceedings of the Midwest Artificial Intelligence and Cognitive Science Conference, Dayton, pp.67-73, Y. Sun, A. K. C. Wong and M. S. Kamel. Classification of imbalanced data: A review. International Journal of Pattern Recognition 23:4 (2009) He, H. and Garcia, E. A. Learning from Imbalanced Data. IEEE Trans. on Knowl. and Data Eng. 21, 9 (Sep. 2009), pp , 2009 IEEE ICDM noted Dealing with Non-static, Unbalanced and Cost-sensitive Data among the 10 Challenging Problems in Data Mining Research
 choć nadal wiele otwartych problemów, Jak wyglądają zastosowania biznesowe? Rzadkie pojęcia słabo reprezentowane (<10%?")
60 Kilka uwag na koniec Odkrywanie wiedzy z danych Potrzeby informacyjne We are drowning in the deluge of data that are being collected world-wide, while starving for knowledge at the same time * Rozwój KDD i pośrednio ML dostarczył wiele metod Badania (tak) choć nadal wiele otwartych problemów, Jak wyglądają zastosowania biznesowe? Rzadkie pojęcia słabo reprezentowane (<10%?) lecz mogą znacząco i negatywnie wpływać na dane zadanie * J. Naisbitt, Megatrends: Ten New Directions Transforming Our Lives.
61 Podsumowanie Niezrównoważony rozkład liczności klas (class imbalance) źródło trudności dla konstrukcji klasyfikatorów Typowe metody uczenia ukierunkowane są na lepsze rozpoznawanie klasy większościowej potrzeba nowych rozwiązań Dyskusja źródeł trudności Nie tylko sama niska liczność klasy mniejszościowej! Rozkład przykładów i jego zaburzenia Rozwiązania: Na poziomie danych (focused re-sampling) Modyfikacje algorytmów Własna metoda selektywnego wyboru przykładów w konstrukcji klasyfikatorów z niezrównoważonych danych Podejście zmiany struktury klasyfikatora regułowego Dalsze kierunki badań: Klasyfikatory złożone (IIvotes) Hybrydyzacja (elementy LN-SMOTE i SPIDER2)
62 Dziękuję za uwagę Pytania lub komentarze? Więcej informacji w moich artykułach! Kontakt: Jerzy.Stefanowski@cs.put.poznan.pl Jerzy.Stefanowski@wsb.poznan.pl
Łączenie indukcji reguł i uczenia z przykładów dla niezrównoważonych klas. Krystyna Napierała Jerzy Stefanowski
 Łączenie indukcji reguł i uczenia z przykładów dla niezrównoważonych klas Krystyna Napierała Jerzy Stefanowski Plan prezentacji Źródła trudności w uczeniu z danych niezrównoważonych (przypomnienie) Indukcja
Łączenie indukcji reguł i uczenia z przykładów dla niezrównoważonych klas Krystyna Napierała Jerzy Stefanowski Plan prezentacji Źródła trudności w uczeniu z danych niezrównoważonych (przypomnienie) Indukcja
Rozszerzenia klasyfikatorów złożonych dla danych niezrównoważonych
 klasyfikatorów złożonych dla danych niezrównoważonych Marcin Szajek Politechnika Poznańska, Instytut Informatyki 23.04.2013 Marcin Szajek Rozsz. klas. złoż. dla danych niezrównoważonych 1 / 30 Plan prezentacji
klasyfikatorów złożonych dla danych niezrównoważonych Marcin Szajek Politechnika Poznańska, Instytut Informatyki 23.04.2013 Marcin Szajek Rozsz. klas. złoż. dla danych niezrównoważonych 1 / 30 Plan prezentacji
Hard-Margin Support Vector Machines
 Hard-Margin Support Vector Machines aaacaxicbzdlssnafiyn9vbjlepk3ay2gicupasvu4iblxuaw2hjmuwn7ddjjmxm1bkcg1/fjqsvt76fo9/gazqfvn8y+pjpozw5vx8zkpvtfxmlhcwl5zxyqrm2vrg5zw3vxmsoezi4ogkr6phieky5crvvjhriqvdom9l2xxftevuwcekj3lktmhghgniauiyutvrwxtvme34a77kbvg73gtygpjsrfati1+xc8c84bvraowbf+uwnipyehcvmkjrdx46vlykhkgykm3ujjdhcyzqkxy0chur6ax5cbg+1m4bbjptjcubuz4kuhvjoql93hkin5hxtav5x6yyqopnsyuneey5ni4keqrxbar5wqaxbik00icyo/iveiyqqvjo1u4fgzj/8f9x67bzmxnurjzmijtlybwfgcdjgfdtajwgcf2dwaj7ac3g1ho1n4814n7wwjgjmf/ys8fenfycuzq==
Hard-Margin Support Vector Machines aaacaxicbzdlssnafiyn9vbjlepk3ay2gicupasvu4iblxuaw2hjmuwn7ddjjmxm1bkcg1/fjqsvt76fo9/gazqfvn8y+pjpozw5vx8zkpvtfxmlhcwl5zxyqrm2vrg5zw3vxmsoezi4ogkr6phieky5crvvjhriqvdom9l2xxftevuwcekj3lktmhghgniauiyutvrwxtvme34a77kbvg73gtygpjsrfati1+xc8c84bvraowbf+uwnipyehcvmkjrdx46vlykhkgykm3ujjdhcyzqkxy0chur6ax5cbg+1m4bbjptjcubuz4kuhvjoql93hkin5hxtav5x6yyqopnsyuneey5ni4keqrxbar5wqaxbik00icyo/iveiyqqvjo1u4fgzj/8f9x67bzmxnurjzmijtlybwfgcdjgfdtajwgcf2dwaj7ac3g1ho1n4814n7wwjgjmf/ys8fenfycuzq==
Odkrywanie wiedzy klasyfikacyjnej inne metody oraz metodyka oceny
 Odkrywanie wiedzy klasyfikacyjnej inne metody oraz metodyka oceny Wykład HiED dla specjal. TWO JERZY STEFANOWSKI Instytut Informatyki Politechnika Poznańska Poznań Poznań, grudzien 2010 Wiedza o klasyfikacji
Odkrywanie wiedzy klasyfikacyjnej inne metody oraz metodyka oceny Wykład HiED dla specjal. TWO JERZY STEFANOWSKI Instytut Informatyki Politechnika Poznańska Poznań Poznań, grudzien 2010 Wiedza o klasyfikacji
Badania w zakresie systemów uczących się w Zakładzie ISWD. Politechnika Poznańska Instytut Informatyki
 Badania w zakresie systemów uczących się w Zakładzie ISWD Politechnika Poznańska Instytut Informatyki Seminarium ML - Poznań, 3 04 2013 Informacje ogólne Politechnika Poznańska Wydział Informatyki, Instytut
Badania w zakresie systemów uczących się w Zakładzie ISWD Politechnika Poznańska Instytut Informatyki Seminarium ML - Poznań, 3 04 2013 Informacje ogólne Politechnika Poznańska Wydział Informatyki, Instytut
Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska
 Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska e-mail: bartosz.krawczyk@pwr.wroc.pl Czym jest klasyfikacja
Metody tworzenia efektywnych komitetów klasyfikatorów jednoklasowych Bartosz Krawczyk Katedra Systemów i Sieci Komputerowych Politechnika Wrocławska e-mail: bartosz.krawczyk@pwr.wroc.pl Czym jest klasyfikacja
Rozpoznawanie twarzy metodą PCA Michał Bereta 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów
 Rozpoznawanie twarzy metodą PCA Michał Bereta www.michalbereta.pl 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów Wiemy, że możemy porównywad klasyfikatory np. za pomocą kroswalidacji.
Rozpoznawanie twarzy metodą PCA Michał Bereta www.michalbereta.pl 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów Wiemy, że możemy porównywad klasyfikatory np. za pomocą kroswalidacji.
9. Praktyczna ocena jakości klasyfikacji
 Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów
 LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
Linear Classification and Logistic Regression. Pascal Fua IC-CVLab
 Linear Classification and Logistic Regression Pascal Fua IC-CVLab 1 aaagcxicbdtdbtmwfafwdgxlhk8orha31ibqycvkdgpshdqxtwotng2pxtvqujmok1qlky5xllzrnobbediegwcap4votk2kqkf+/y/tnphdschtadu/giv3vtea99cfma8fpx7ytlxx7ckns4sylo3doom7jguhj1hxchmy/irhrlgh67lxb5x3blis8jjqynmedqujiu5zsqqagrx+yjcfpcrydusshmzeluzsg7tttiew5khhcuzm5rv0gn1unw6zl3gbzlpr3liwncyr6aaqinx4wnc/rpg6ix5szd86agoftuu0g/krjxdarph62enthdey3zn/+mi5zknou2ap+tclvhob9sxhwvhaqketnde7geqjp21zvjsfrcnkfhtejoz23vq97elxjlpbtmxpl6qxtl1sgfv1ptpy/yq9mgacrzkgje0hjj2rq7vtywnishnnkzsqekucnlblrarlh8x8szxolrrxkb8n6o4kmo/e7siisnozcfvsedlol60a/j8nmul/gby8mmssrfr2it8lkyxr9dirxxngzthtbaejv
Linear Classification and Logistic Regression Pascal Fua IC-CVLab 1 aaagcxicbdtdbtmwfafwdgxlhk8orha31ibqycvkdgpshdqxtwotng2pxtvqujmok1qlky5xllzrnobbediegwcap4votk2kqkf+/y/tnphdschtadu/giv3vtea99cfma8fpx7ytlxx7ckns4sylo3doom7jguhj1hxchmy/irhrlgh67lxb5x3blis8jjqynmedqujiu5zsqqagrx+yjcfpcrydusshmzeluzsg7tttiew5khhcuzm5rv0gn1unw6zl3gbzlpr3liwncyr6aaqinx4wnc/rpg6ix5szd86agoftuu0g/krjxdarph62enthdey3zn/+mi5zknou2ap+tclvhob9sxhwvhaqketnde7geqjp21zvjsfrcnkfhtejoz23vq97elxjlpbtmxpl6qxtl1sgfv1ptpy/yq9mgacrzkgje0hjj2rq7vtywnishnnkzsqekucnlblrarlh8x8szxolrrxkb8n6o4kmo/e7siisnozcfvsedlol60a/j8nmul/gby8mmssrfr2it8lkyxr9dirxxngzthtbaejv
Sztuczna Inteligencja w medycynie projekt (instrukcja) Bożena Kostek
 Bożena Kostek") Sztuczna Inteligencja w medycynie projekt (instrukcja) Bożena Kostek Cel projektu Celem projektu jest przygotowanie systemu wnioskowania, wykorzystującego wybrane algorytmy sztucznej inteligencji; Nabycie
Sztuczna Inteligencja w medycynie projekt (instrukcja) Bożena Kostek Cel projektu Celem projektu jest przygotowanie systemu wnioskowania, wykorzystującego wybrane algorytmy sztucznej inteligencji; Nabycie
Data Mining Wykład 4. Plan wykładu
 Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Machine Learning for Data Science (CS4786) Lecture11. Random Projections & Canonical Correlation Analysis
 Lecture11. Random Projections & Canonical Correlation Analysis") Machine Learning for Data Science (CS4786) Lecture11 5 Random Projections & Canonical Correlation Analysis The Tall, THE FAT AND THE UGLY n X d The Tall, THE FAT AND THE UGLY d X > n X d n = n d d The
Machine Learning for Data Science (CS4786) Lecture11 5 Random Projections & Canonical Correlation Analysis The Tall, THE FAT AND THE UGLY n X d The Tall, THE FAT AND THE UGLY d X > n X d n = n d d The
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów
 Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej. Adam Żychowski
 Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
A Zadanie
 where a, b, and c are binary (boolean) attributes. A Zadanie 1 2 3 4 5 6 7 8 9 10 Punkty a (maks) (2) (2) (2) (2) (4) F(6) (8) T (8) (12) (12) (40) Nazwisko i Imiȩ: c Uwaga: ta część zostanie wypełniona
where a, b, and c are binary (boolean) attributes. A Zadanie 1 2 3 4 5 6 7 8 9 10 Punkty a (maks) (2) (2) (2) (2) (4) F(6) (8) T (8) (12) (12) (40) Nazwisko i Imiȩ: c Uwaga: ta część zostanie wypełniona
Metody oceny wiedzy klasyfikacyjnej odkrytej z danych Jerzy Stefanowski Instytut Informatyki Politechnika Poznańska
 Metody oceny wiedzy klasyfikacyjnej odkrytej z danych Jerzy Stefanowski Instytut Informatyki Politechnika Poznańska Wykład dla spec. Mgr TWO Poznań 2010 dodatek 1 Ocena wiedzy klasyfikacyjnej wykład dla
Metody oceny wiedzy klasyfikacyjnej odkrytej z danych Jerzy Stefanowski Instytut Informatyki Politechnika Poznańska Wykład dla spec. Mgr TWO Poznań 2010 dodatek 1 Ocena wiedzy klasyfikacyjnej wykład dla
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład III 2016/2017
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład III bogumil.konopka@pwr.edu.pl 2016/2017 Wykład III - plan Regresja logistyczna Ocena skuteczności klasyfikacji Macierze pomyłek Krzywe
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład III bogumil.konopka@pwr.edu.pl 2016/2017 Wykład III - plan Regresja logistyczna Ocena skuteczności klasyfikacji Macierze pomyłek Krzywe
Budowa modeli klasyfikacyjnych o skośnych warunkach
 Budowa modeli klasyfikacyjnych o skośnych warunkach Marcin Michalak (Marcin.Michalak@polsl.pl) III spotkanie Polskiej Grupy Badawczej Systemów Uczących Się Wrocław, 17 18.03.2014 Outline 1 Dwa podejścia
Budowa modeli klasyfikacyjnych o skośnych warunkach Marcin Michalak (Marcin.Michalak@polsl.pl) III spotkanie Polskiej Grupy Badawczej Systemów Uczących Się Wrocław, 17 18.03.2014 Outline 1 Dwa podejścia
Michał Kozielski Łukasz Warchał. Instytut Informatyki, Politechnika Śląska
 Michał Kozielski Łukasz Warchał Instytut Informatyki, Politechnika Śląska Algorytm DBSCAN Algorytm OPTICS Analiza gęstego sąsiedztwa w grafie Wstępne eksperymenty Podsumowanie Algorytm DBSCAN Analiza gęstości
Michał Kozielski Łukasz Warchał Instytut Informatyki, Politechnika Śląska Algorytm DBSCAN Algorytm OPTICS Analiza gęstego sąsiedztwa w grafie Wstępne eksperymenty Podsumowanie Algorytm DBSCAN Analiza gęstości
deep learning for NLP (5 lectures)
") TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 6: Finish Transformers; Sequence- to- Sequence Modeling and AJenKon 1 Roadmap intro (1 lecture) deep learning for NLP (5
TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 6: Finish Transformers; Sequence- to- Sequence Modeling and AJenKon 1 Roadmap intro (1 lecture) deep learning for NLP (5
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner
 Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Machine Learning for Data Science (CS4786) Lecture 24. Differential Privacy and Re-useable Holdout
 Lecture 24. Differential Privacy and Re-useable Holdout") Machine Learning for Data Science (CS4786) Lecture 24 Differential Privacy and Re-useable Holdout Defining Privacy Defining Privacy Dataset + Defining Privacy Dataset + Learning Algorithm Distribution
Machine Learning for Data Science (CS4786) Lecture 24 Differential Privacy and Re-useable Holdout Defining Privacy Defining Privacy Dataset + Defining Privacy Dataset + Learning Algorithm Distribution
Wyk lad 8: Leniwe metody klasyfikacji
 Wyk lad 8: Leniwe metody Wydzia l MIM, Uniwersytet Warszawski Outline 1 2 lazy vs. eager learning lazy vs. eager learning Kiedy stosować leniwe techniki? Eager learning: Buduje globalna hipoteze Zaleta:
Wyk lad 8: Leniwe metody Wydzia l MIM, Uniwersytet Warszawski Outline 1 2 lazy vs. eager learning lazy vs. eager learning Kiedy stosować leniwe techniki? Eager learning: Buduje globalna hipoteze Zaleta:
Helena Boguta, klasa 8W, rok szkolny 2018/2019
 Poniższy zbiór zadań został wykonany w ramach projektu Mazowiecki program stypendialny dla uczniów szczególnie uzdolnionych - najlepsza inwestycja w człowieka w roku szkolnym 2018/2019. Składają się na
Poniższy zbiór zadań został wykonany w ramach projektu Mazowiecki program stypendialny dla uczniów szczególnie uzdolnionych - najlepsza inwestycja w człowieka w roku szkolnym 2018/2019. Składają się na
8. Drzewa decyzyjne, bagging, boosting i lasy losowe
 Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Multiklasyfikatory z funkcją kompetencji
 3 stycznia 2011 Problem klasyfikacji Polega na przewidzeniu dyskretnej klasy na podstawie cech obiektu. Obiekt jest reprezentowany przez wektor cech Zbiór etykiet jest skończony x X Ω = {ω 1, ω 2,...,
3 stycznia 2011 Problem klasyfikacji Polega na przewidzeniu dyskretnej klasy na podstawie cech obiektu. Obiekt jest reprezentowany przez wektor cech Zbiór etykiet jest skończony x X Ω = {ω 1, ω 2,...,
TTIC 31210: Advanced Natural Language Processing. Kevin Gimpel Spring Lecture 9: Inference in Structured Prediction
 TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 9: Inference in Structured Prediction 1 intro (1 lecture) Roadmap deep learning for NLP (5 lectures) structured prediction
TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 9: Inference in Structured Prediction 1 intro (1 lecture) Roadmap deep learning for NLP (5 lectures) structured prediction
Tychy, plan miasta: Skala 1: (Polish Edition)
") Tychy, plan miasta: Skala 1:20 000 (Polish Edition) Poland) Przedsiebiorstwo Geodezyjno-Kartograficzne (Katowice Click here if your download doesn"t start automatically Tychy, plan miasta: Skala 1:20 000
Tychy, plan miasta: Skala 1:20 000 (Polish Edition) Poland) Przedsiebiorstwo Geodezyjno-Kartograficzne (Katowice Click here if your download doesn"t start automatically Tychy, plan miasta: Skala 1:20 000
Stan dotychczasowy. OCENA KLASYFIKACJI w diagnostyce. Metody 6/10/2013. Weryfikacja. Testowanie skuteczności metody uczenia Weryfikacja prosta
 Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
Machine Learning for Data Science (CS4786) Lecture 11. Spectral Embedding + Clustering
 Lecture 11. Spectral Embedding + Clustering") Machine Learning for Data Science (CS4786) Lecture 11 Spectral Embedding + Clustering MOTIVATING EXAMPLE What can you say from this network? MOTIVATING EXAMPLE How about now? THOUGHT EXPERIMENT For each
Machine Learning for Data Science (CS4786) Lecture 11 Spectral Embedding + Clustering MOTIVATING EXAMPLE What can you say from this network? MOTIVATING EXAMPLE How about now? THOUGHT EXPERIMENT For each
WYKŁAD 7. Testowanie jakości modeli klasyfikacyjnych metodyka i kryteria
 Wrocław University of Technology WYKŁAD 7 Testowanie jakości modeli klasyfikacyjnych metodyka i kryteria autor: Maciej Zięba Politechnika Wrocławska Testowanie modeli klasyfikacyjnych Dobór odpowiedniego
Wrocław University of Technology WYKŁAD 7 Testowanie jakości modeli klasyfikacyjnych metodyka i kryteria autor: Maciej Zięba Politechnika Wrocławska Testowanie modeli klasyfikacyjnych Dobór odpowiedniego
TTIC 31210: Advanced Natural Language Processing. Kevin Gimpel Spring Lecture 8: Structured PredicCon 2
 TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 8: Structured PredicCon 2 1 Roadmap intro (1 lecture) deep learning for NLP (5 lectures) structured predic+on (4 lectures)
TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 8: Structured PredicCon 2 1 Roadmap intro (1 lecture) deep learning for NLP (5 lectures) structured predic+on (4 lectures)
mgr inż. Magdalena Deckert Poznań, r. Metody przyrostowego uczenia się ze strumieni danych.
 mgr inż. Magdalena Deckert Poznań, 30.11.2010r. Metody przyrostowego uczenia się ze strumieni danych. Plan prezentacji Wstęp Concept drift i typy zmian Algorytmy przyrostowego uczenia się ze strumieni
mgr inż. Magdalena Deckert Poznań, 30.11.2010r. Metody przyrostowego uczenia się ze strumieni danych. Plan prezentacji Wstęp Concept drift i typy zmian Algorytmy przyrostowego uczenia się ze strumieni
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład II 2017/2018
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy
Badania w sieciach złożonych
 Badania w sieciach złożonych Grant WCSS nr 177, sprawozdanie za rok 2012 Kierownik grantu dr. hab. inż. Przemysław Kazienko mgr inż. Radosław Michalski Instytut Informatyki Politechniki Wrocławskiej Obszar
Badania w sieciach złożonych Grant WCSS nr 177, sprawozdanie za rok 2012 Kierownik grantu dr. hab. inż. Przemysław Kazienko mgr inż. Radosław Michalski Instytut Informatyki Politechniki Wrocławskiej Obszar
ZeroR. Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F
 ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 5 T 7 T 5 T 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator ZeroR będzie zawsze odpowiadał T niezależnie
ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 5 T 7 T 5 T 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator ZeroR będzie zawsze odpowiadał T niezależnie
Previously on CSCI 4622
 More Naïve Bayes aaace3icbvfba9rafj7ew423vr998obg2gpzkojyh4rcx3ys4lafzbjmjifdototmhoilml+hf/mn3+kl+jkdwtr64gbj+8yl2/ywklhsfircg/dvnp33s796mhdr4+fdj4+o3fvywvorkuqe5zzh0oanjakhwe1ra5zhaf5xvgvn35f62rlvtcyxpnm50awundy1hzwi46jbmgprbtrrvidrg4jre4g07kak+picee6xfgiwvfaltorirucni64eeigkqhpegbwaxglabftpyq4gjbls/hw2ci7tr2xj5ddfmfzwtazj6ubmyddgchbzpf88dmrktfonct6vazputos5zakunhfweow5ukcn+puq8m1ulm7kq+d154pokysx4zgxw4nwq6dw+rcozwnhbuu9et/tgld5cgslazuci1yh1q2ynca/u9ais0kukspulds3xxegvtyfycu8iwk1598e0z2xx/g6ef94ehbpo0d9ok9yiowsvfskh1ix2zcbpsdvaxgww7wj4zdn+he2hogm8xz9s+e7/4cuf/ata==
More Naïve Bayes aaace3icbvfba9rafj7ew423vr998obg2gpzkojyh4rcx3ys4lafzbjmjifdototmhoilml+hf/mn3+kl+jkdwtr64gbj+8yl2/ywklhsfircg/dvnp33s796mhdr4+fdj4+o3fvywvorkuqe5zzh0oanjakhwe1ra5zhaf5xvgvn35f62rlvtcyxpnm50awundy1hzwi46jbmgprbtrrvidrg4jre4g07kak+picee6xfgiwvfaltorirucni64eeigkqhpegbwaxglabftpyq4gjbls/hw2ci7tr2xj5ddfmfzwtazj6ubmyddgchbzpf88dmrktfonct6vazputos5zakunhfweow5ukcn+puq8m1ulm7kq+d154pokysx4zgxw4nwq6dw+rcozwnhbuu9et/tgld5cgslazuci1yh1q2ynca/u9ais0kukspulds3xxegvtyfycu8iwk1598e0z2xx/g6ef94ehbpo0d9ok9yiowsvfskh1ix2zcbpsdvaxgww7wj4zdn+he2hogm8xz9s+e7/4cuf/ata==
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Analysis of Movie Profitability STAT 469 IN CLASS ANALYSIS #2
 Analysis of Movie Profitability STAT 469 IN CLASS ANALYSIS #2 aaaklnictzzjb9tgfmcnadpg7oy0lxa9edva9kkapdarhyk2k7gourinlwsweyzikuyiigvyleiv/cv767fpf/5crc1xt9va5mx7w3m/ecuqw1kuztpx/rl3/70h73/w4cog9dhhn3z62d6jzy+yzj766txpoir9nzszisjynetqr+rvlfvyoozu5xbybpsxb1wahul8phczdt2v4zgchb7uecwphlyigrgkjcyiflfyci0kxnmr4z6kw0jsokvot8isntpa3gbknlcufiv/h+hh+eur4fomd417rvtfjoit5pfju6yxiab2fmwk0y/feuybobqk+axnke8xzjjhfyd8kkpl9zdoddkazd5j6bzpemjb64smjb6vb4xmehysu08lsrszopxftlzee130jcb0zjxy7r5wa2f1s2off2+dyatrughnrtpkuprlcpu55zlxpss/yqe2eamjkcf0jye8w8yas0paf6t0t2i9stmcua+inbi2rt01tz22tubbqwidypvgz6piynkpobirkxgu54ibzoti4pkw2i5ow9lnuaoabhuxfxqhvnrj6w15tb3furnbm+scyxobjhr5pmj5j/w5ix9wsa2tlwx9alpshlunzjgnrwvqbpwzjl9wes+ptyn+ypy/jgskavtl8j0hz1djdhzwtpjbbvpr1zj7jpg6ve7zxfngj75zee0vmp9qm2uvgu/9zdofq6r+g8l4xctvo+v+xdrfr8oxiwutycu0qgyf8icuyvp/sixfi9zxe11vp6mrjjovpmxm6acrtbia+wjr9bevlgjwlz5xd3rfna9g06qytaoofk8olxbxc7xby2evqjmmk6pjvvzxmpbnct6+036xp5vdbrnbdqph8brlfn/n/khnfumhf6z1v7h/80yieukkd5j0un82t9mynxzmk0s/bzn4tacdziszdhwrl8x5ako8qp1n1zn0k6w2em0km9zj1i4yt1pt3xiprw85jmc2m1ut2geum6y6es2fwx6c+wlrpykblopbuj5nnr2byygfy5opllv4+jmm7s6u+tvhywbnb0kv2lt5th4xipmiij+y1toiyo7bo0d+vzvovjkp6aoejsubhj3qrp3fjd/m23pay8h218ibvx3nicofvd1xi86+kh6nb/b+hgsjp5+qwpurzlir15np66vmdehh6tyazdm1k/5ejtuvurgcqux6yc+qw/sbsaj7lkt4x9qmtp7euk6zbdedyuzu6ptsu2eeu3rxcz06uf6g8wyuveznhkbzynajbb7r7cbmla+jbtrst0ow2v6ntkwv8svnwqnu5pa3oxfeexf93739p93chq/fv+jr8r0d9brhpcxr2w88bvqbr41j6wvrb+u5dzjpvx+veoaxwptzp/8cen+xbg==
Analysis of Movie Profitability STAT 469 IN CLASS ANALYSIS #2 aaaklnictzzjb9tgfmcnadpg7oy0lxa9edva9kkapdarhyk2k7gourinlwsweyzikuyiigvyleiv/cv767fpf/5crc1xt9va5mx7w3m/ecuqw1kuztpx/rl3/70h73/w4cog9dhhn3z62d6jzy+yzj766txpoir9nzszisjynetqr+rvlfvyoozu5xbybpsxb1wahul8phczdt2v4zgchb7uecwphlyigrgkjcyiflfyci0kxnmr4z6kw0jsokvot8isntpa3gbknlcufiv/h+hh+eur4fomd417rvtfjoit5pfju6yxiab2fmwk0y/feuybobqk+axnke8xzjjhfyd8kkpl9zdoddkazd5j6bzpemjb64smjb6vb4xmehysu08lsrszopxftlzee130jcb0zjxy7r5wa2f1s2off2+dyatrughnrtpkuprlcpu55zlxpss/yqe2eamjkcf0jye8w8yas0paf6t0t2i9stmcua+inbi2rt01tz22tubbqwidypvgz6piynkpobirkxgu54ibzoti4pkw2i5ow9lnuaoabhuxfxqhvnrj6w15tb3furnbm+scyxobjhr5pmj5j/w5ix9wsa2tlwx9alpshlunzjgnrwvqbpwzjl9wes+ptyn+ypy/jgskavtl8j0hz1djdhzwtpjbbvpr1zj7jpg6ve7zxfngj75zee0vmp9qm2uvgu/9zdofq6r+g8l4xctvo+v+xdrfr8oxiwutycu0qgyf8icuyvp/sixfi9zxe11vp6mrjjovpmxm6acrtbia+wjr9bevlgjwlz5xd3rfna9g06qytaoofk8olxbxc7xby2evqjmmk6pjvvzxmpbnct6+036xp5vdbrnbdqph8brlfn/n/khnfumhf6z1v7h/80yieukkd5j0un82t9mynxzmk0s/bzn4tacdziszdhwrl8x5ako8qp1n1zn0k6w2em0km9zj1i4yt1pt3xiprw85jmc2m1ut2geum6y6es2fwx6c+wlrpykblopbuj5nnr2byygfy5opllv4+jmm7s6u+tvhywbnb0kv2lt5th4xipmiij+y1toiyo7bo0d+vzvovjkp6aoejsubhj3qrp3fjd/m23pay8h218ibvx3nicofvd1xi86+kh6nb/b+hgsjp5+qwpurzlir15np66vmdehh6tyazdm1k/5ejtuvurgcqux6yc+qw/sbsaj7lkt4x9qmtp7euk6zbdedyuzu6ptsu2eeu3rxcz06uf6g8wyuveznhkbzynajbb7r7cbmla+jbtrst0ow2v6ntkwv8svnwqnu5pa3oxfeexf93739p93chq/fv+jr8r0d9brhpcxr2w88bvqbr41j6wvrb+u5dzjpvx+veoaxwptzp/8cen+xbg==
Algorytmy rozpoznawania obrazów. 11. Analiza skupień. dr inż. Urszula Libal. Politechnika Wrocławska
 Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Kraków, 14 marca 2013 r.
 Scenariusze i trendy rozwojowe wybranych technologii społeczeństwa informacyjnego do roku 2025 Antoni Ligęza Perspektywy rozwoju systemów eksperckich do roku 2025 Kraków, 14 marca 2013 r. Dane informacja
Scenariusze i trendy rozwojowe wybranych technologii społeczeństwa informacyjnego do roku 2025 Antoni Ligęza Perspektywy rozwoju systemów eksperckich do roku 2025 Kraków, 14 marca 2013 r. Dane informacja
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - testy na sztucznych danych
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji - testy na sztucznych danych Mateusz Kobos, 25.11.2009 Seminarium Metody Inteligencji Obliczeniowej 1/25 Spis treści Dolne ograniczenie na wsp.
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - testy na sztucznych danych Mateusz Kobos, 25.11.2009 Seminarium Metody Inteligencji Obliczeniowej 1/25 Spis treści Dolne ograniczenie na wsp.
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Zaawansowana eksploracja danych: Metody oceny wiedzy klasyfikacyjnej odkrytej z danych Jerzy Stefanowski Instytut Informatyki Politechnika Poznańska
 Zaawansowana eksploracja danych: Metody oceny wiedzy klasyfikacyjnej odkrytej z danych Jerzy Stefanowski Instytut Informatyki Politechnika Poznańska Wykład dla spec. Mgr TPD Poznań 2008 popr. 2010 1 Ocena
Zaawansowana eksploracja danych: Metody oceny wiedzy klasyfikacyjnej odkrytej z danych Jerzy Stefanowski Instytut Informatyki Politechnika Poznańska Wykład dla spec. Mgr TPD Poznań 2008 popr. 2010 1 Ocena
ERASMUS + : Trail of extinct and active volcanoes, earthquakes through Europe. SURVEY TO STUDENTS.
 ERASMUS + : Trail of extinct and active volcanoes, earthquakes through Europe. SURVEY TO STUDENTS. Strona 1 1. Please give one answer. I am: Students involved in project 69% 18 Student not involved in
ERASMUS + : Trail of extinct and active volcanoes, earthquakes through Europe. SURVEY TO STUDENTS. Strona 1 1. Please give one answer. I am: Students involved in project 69% 18 Student not involved in
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji
 Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Wybrane zagadnienia uczenia maszynowego. Zastosowania Informatyki w Informatyce W2 Krzysztof Krawiec
 Wybrane zagadnienia uczenia maszynowego Zastosowania Informatyki w Informatyce W2 Krzysztof Krawiec Przygotowane na podstawie T. Mitchell, Machine Learning S.J. Russel, P. Norvig, Artificial Intelligence
Wybrane zagadnienia uczenia maszynowego Zastosowania Informatyki w Informatyce W2 Krzysztof Krawiec Przygotowane na podstawie T. Mitchell, Machine Learning S.J. Russel, P. Norvig, Artificial Intelligence
RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk
 Wprowadzenie RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk Magdalena Deckert Politechnika Poznańska, Instytut Informatyki Seminarium ISWD, 21.05.2013 M. Deckert Przyrostowy
Wprowadzenie RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk Magdalena Deckert Politechnika Poznańska, Instytut Informatyki Seminarium ISWD, 21.05.2013 M. Deckert Przyrostowy
The Overview of Civilian Applications of Airborne SAR Systems
 The Overview of Civilian Applications of Airborne SAR Systems Maciej Smolarczyk, Piotr Samczyński Andrzej Gadoś, Maj Mordzonek Research and Development Department of PIT S.A. PART I WHAT DOES SAR MEAN?
The Overview of Civilian Applications of Airborne SAR Systems Maciej Smolarczyk, Piotr Samczyński Andrzej Gadoś, Maj Mordzonek Research and Development Department of PIT S.A. PART I WHAT DOES SAR MEAN?
Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury. Paweł Kobojek, prof. dr hab. inż. Khalid Saeed
 Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury Paweł Kobojek, prof. dr hab. inż. Khalid Saeed Zakres pracy Przegląd stanu wiedzy w dziedzinie biometrii, ze szczególnym naciskiem
Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury Paweł Kobojek, prof. dr hab. inż. Khalid Saeed Zakres pracy Przegląd stanu wiedzy w dziedzinie biometrii, ze szczególnym naciskiem
Indukowane Reguły Decyzyjne I. Wykład 8
 Indukowane Reguły Decyzyjne I Wykład 8 IRD Wykład 8 Plan Powtórka Krzywa ROC = Receiver Operating Characteristic Wybór modelu Statystyka AUC ROC = pole pod krzywą ROC Wybór punktu odcięcia Reguły decyzyjne
Indukowane Reguły Decyzyjne I Wykład 8 IRD Wykład 8 Plan Powtórka Krzywa ROC = Receiver Operating Characteristic Wybór modelu Statystyka AUC ROC = pole pod krzywą ROC Wybór punktu odcięcia Reguły decyzyjne
Przykład eksploracji danych Case 1.X
 Przykład eksploracji danych Case 1.X JERZY STEFANOWSKI TPD Zaawansowana eksploracja danych edycja 2009/2010 Plan 1. Przykładowe studium przypadki 2. Analiza opisu przypadku 3. Ustalenie celu analizy i
Przykład eksploracji danych Case 1.X JERZY STEFANOWSKI TPD Zaawansowana eksploracja danych edycja 2009/2010 Plan 1. Przykładowe studium przypadki 2. Analiza opisu przypadku 3. Ustalenie celu analizy i
Proposal of thesis topic for mgr in. (MSE) programme in Telecommunications and Computer Science
 programme in Telecommunications and Computer Science") Proposal of thesis topic for mgr in (MSE) programme 1 Topic: Monte Carlo Method used for a prognosis of a selected technological process 2 Supervisor: Dr in Małgorzata Langer 3 Auxiliary supervisor: 4
Proposal of thesis topic for mgr in (MSE) programme 1 Topic: Monte Carlo Method used for a prognosis of a selected technological process 2 Supervisor: Dr in Małgorzata Langer 3 Auxiliary supervisor: 4
Zarządzanie sieciami telekomunikacyjnymi
 SNMP Protocol The Simple Network Management Protocol (SNMP) is an application layer protocol that facilitates the exchange of management information between network devices. It is part of the Transmission
SNMP Protocol The Simple Network Management Protocol (SNMP) is an application layer protocol that facilitates the exchange of management information between network devices. It is part of the Transmission
Few-fermion thermometry
 Few-fermion thermometry Phys. Rev. A 97, 063619 (2018) Tomasz Sowiński Institute of Physics of the Polish Academy of Sciences Co-authors: Marcin Płodzień Rafał Demkowicz-Dobrzański FEW-BODY PROBLEMS FewBody.ifpan.edu.pl
Few-fermion thermometry Phys. Rev. A 97, 063619 (2018) Tomasz Sowiński Institute of Physics of the Polish Academy of Sciences Co-authors: Marcin Płodzień Rafał Demkowicz-Dobrzański FEW-BODY PROBLEMS FewBody.ifpan.edu.pl
Drzewa decyzyjne i lasy losowe
 Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
ZASTOSOWANIE ZBIORÓW PRZYBLIŻONYCH DO ANALIZY SATYSFAKCJI KLIENTA SERWISU POJAZDÓW
 Inżynieria Rolnicza 1(99)/2008 ZASTOSOWANIE ZBIORÓW PRZYBLIŻONYCH DO ANALIZY SATYSFAKCJI KLIENTA SERWISU POJAZDÓW Marek Klimkiewicz, Katarzyna Moczulska Katedra Organizacji i Inżynierii Produkcji, Szkoła
Inżynieria Rolnicza 1(99)/2008 ZASTOSOWANIE ZBIORÓW PRZYBLIŻONYCH DO ANALIZY SATYSFAKCJI KLIENTA SERWISU POJAZDÓW Marek Klimkiewicz, Katarzyna Moczulska Katedra Organizacji i Inżynierii Produkcji, Szkoła
SSW1.1, HFW Fry #20, Zeno #25 Benchmark: Qtr.1. Fry #65, Zeno #67. like
 SSW1.1, HFW Fry #20, Zeno #25 Benchmark: Qtr.1 I SSW1.1, HFW Fry #65, Zeno #67 Benchmark: Qtr.1 like SSW1.2, HFW Fry #47, Zeno #59 Benchmark: Qtr.1 do SSW1.2, HFW Fry #5, Zeno #4 Benchmark: Qtr.1 to SSW1.2,
SSW1.1, HFW Fry #20, Zeno #25 Benchmark: Qtr.1 I SSW1.1, HFW Fry #65, Zeno #67 Benchmark: Qtr.1 like SSW1.2, HFW Fry #47, Zeno #59 Benchmark: Qtr.1 do SSW1.2, HFW Fry #5, Zeno #4 Benchmark: Qtr.1 to SSW1.2,
Weronika Mysliwiec, klasa 8W, rok szkolny 2018/2019
 Poniższy zbiór zadań został wykonany w ramach projektu Mazowiecki program stypendialny dla uczniów szczególnie uzdolnionych - najlepsza inwestycja w człowieka w roku szkolnym 2018/2019. Tresci zadań rozwiązanych
Poniższy zbiór zadań został wykonany w ramach projektu Mazowiecki program stypendialny dla uczniów szczególnie uzdolnionych - najlepsza inwestycja w człowieka w roku szkolnym 2018/2019. Tresci zadań rozwiązanych
tum.de/fall2018/ in2357
 https://piazza.com/ tum.de/fall2018/ in2357 Prof. Daniel Cremers From to Classification Categories of Learning (Rep.) Learning Unsupervised Learning clustering, density estimation Supervised Learning learning
https://piazza.com/ tum.de/fall2018/ in2357 Prof. Daniel Cremers From to Classification Categories of Learning (Rep.) Learning Unsupervised Learning clustering, density estimation Supervised Learning learning
Wojewodztwo Koszalinskie: Obiekty i walory krajoznawcze (Inwentaryzacja krajoznawcza Polski) (Polish Edition)
 (Polish Edition)") Wojewodztwo Koszalinskie: Obiekty i walory krajoznawcze (Inwentaryzacja krajoznawcza Polski) (Polish Edition) Robert Respondowski Click here if your download doesn"t start automatically Wojewodztwo Koszalinskie:
Wojewodztwo Koszalinskie: Obiekty i walory krajoznawcze (Inwentaryzacja krajoznawcza Polski) (Polish Edition) Robert Respondowski Click here if your download doesn"t start automatically Wojewodztwo Koszalinskie:
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU
 WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
Formularz recenzji magazynu. Journal of Corporate Responsibility and Leadership Review Form
 Formularz recenzji magazynu Review Form Identyfikator magazynu/ Journal identification number: Tytuł artykułu/ Paper title: Recenzent/ Reviewer: (imię i nazwisko, stopień naukowy/name and surname, academic
Formularz recenzji magazynu Review Form Identyfikator magazynu/ Journal identification number: Tytuł artykułu/ Paper title: Recenzent/ Reviewer: (imię i nazwisko, stopień naukowy/name and surname, academic
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych Mateusz Kobos, 07.04.2010 Seminarium Metody Inteligencji Obliczeniowej Spis treści Opis algorytmu i zbioru
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych Mateusz Kobos, 07.04.2010 Seminarium Metody Inteligencji Obliczeniowej Spis treści Opis algorytmu i zbioru
MoA-Net: Self-supervised Motion Segmentation. Pia Bideau, Rakesh R Menon, Erik Learned-Miller
 MoA-Net: Self-supervised Motion Segmentation Pia Bideau, Rakesh R Menon, Erik Learned-Miller University of Massachusetts Amherst College of Information and Computer Science Motion Segmentation P Bideau,
MoA-Net: Self-supervised Motion Segmentation Pia Bideau, Rakesh R Menon, Erik Learned-Miller University of Massachusetts Amherst College of Information and Computer Science Motion Segmentation P Bideau,
ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA JEZYKOWA) BY DOUGLAS KENT HALL
 BY DOUGLAS KENT HALL") Read Online and Download Ebook ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA JEZYKOWA) BY DOUGLAS KENT HALL DOWNLOAD EBOOK : ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA Click link bellow and free register
Read Online and Download Ebook ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA JEZYKOWA) BY DOUGLAS KENT HALL DOWNLOAD EBOOK : ARNOLD. EDUKACJA KULTURYSTY (POLSKA WERSJA Click link bellow and free register
Blokowe i przyrostowe klasyfikatory złożone dla strumieni danych ze zmienną definicją klas
 Politechnika Poznańska Wydział Informatyki Streszczenie rozprawy doktorskiej mgr inż. Dariusz Brzeziński Blokowe i przyrostowe klasyfikatory złożone dla strumieni danych ze zmienną definicją klas Promotor:
Politechnika Poznańska Wydział Informatyki Streszczenie rozprawy doktorskiej mgr inż. Dariusz Brzeziński Blokowe i przyrostowe klasyfikatory złożone dla strumieni danych ze zmienną definicją klas Promotor:
SNP SNP Business Partner Data Checker. Prezentacja produktu
 SNP SNP Business Partner Data Checker Prezentacja produktu Istota rozwiązania SNP SNP Business Partner Data Checker Celem produktu SNP SNP Business Partner Data Checker jest umożliwienie sprawdzania nazwy
SNP SNP Business Partner Data Checker Prezentacja produktu Istota rozwiązania SNP SNP Business Partner Data Checker Celem produktu SNP SNP Business Partner Data Checker jest umożliwienie sprawdzania nazwy
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Metodyki projektowania i modelowania systemów Cyganek & Kasperek & Rajda 2013 Katedra Elektroniki AGH
 Kierunek Elektronika i Telekomunikacja, Studia II stopnia Specjalność: Systemy wbudowane Metodyki projektowania i modelowania systemów Cyganek & Kasperek & Rajda 2013 Katedra Elektroniki AGH Zagadnienia
Kierunek Elektronika i Telekomunikacja, Studia II stopnia Specjalność: Systemy wbudowane Metodyki projektowania i modelowania systemów Cyganek & Kasperek & Rajda 2013 Katedra Elektroniki AGH Zagadnienia
STATISTICAL METHODS IN BIOLOGY
 STATISTICAL METHODS IN BIOLOGY 1. Introduction 2. Populations and samples 3. Hypotheses testing and parameter estimation 4. Experimental design for biological data 5. Most widely used statistical tests
STATISTICAL METHODS IN BIOLOGY 1. Introduction 2. Populations and samples 3. Hypotheses testing and parameter estimation 4. Experimental design for biological data 5. Most widely used statistical tests
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Agnostic Learning and VC dimension
 Agnostic Learning and VC dimension Machine Learning Spring 2019 The slides are based on Vivek Srikumar s 1 This Lecture Agnostic Learning What if I cannot guarantee zero training error? Can we still get
Agnostic Learning and VC dimension Machine Learning Spring 2019 The slides are based on Vivek Srikumar s 1 This Lecture Agnostic Learning What if I cannot guarantee zero training error? Can we still get
Domy inaczej pomyślane A different type of housing CEZARY SANKOWSKI
 Domy inaczej pomyślane A different type of housing CEZARY SANKOWSKI O tym, dlaczego warto budować pasywnie, komu budownictwo pasywne się opłaca, a kto się go boi, z architektem, Cezarym Sankowskim, rozmawia
Domy inaczej pomyślane A different type of housing CEZARY SANKOWSKI O tym, dlaczego warto budować pasywnie, komu budownictwo pasywne się opłaca, a kto się go boi, z architektem, Cezarym Sankowskim, rozmawia
INDUKCJA DRZEW DECYZYJNYCH
 INDUKCJA DRZEW DECYZYJNYCH 1. Pojęcia podstawowe. 2. Idea algorytmów TDIT. 3. Kryteria oceny atrybutów entropia. 4. "Klasyczna" postać algorytmu ID3. 5. Przykład ilustracyjny. 6. Transformacja drzewa do
INDUKCJA DRZEW DECYZYJNYCH 1. Pojęcia podstawowe. 2. Idea algorytmów TDIT. 3. Kryteria oceny atrybutów entropia. 4. "Klasyczna" postać algorytmu ID3. 5. Przykład ilustracyjny. 6. Transformacja drzewa do
Wprowadzenie do klasyfikacji
 Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Wojewodztwo Koszalinskie: Obiekty i walory krajoznawcze (Inwentaryzacja krajoznawcza Polski) (Polish Edition)
 (Polish Edition)") Wojewodztwo Koszalinskie: Obiekty i walory krajoznawcze (Inwentaryzacja krajoznawcza Polski) (Polish Edition) Robert Respondowski Click here if your download doesn"t start automatically Wojewodztwo Koszalinskie:
Wojewodztwo Koszalinskie: Obiekty i walory krajoznawcze (Inwentaryzacja krajoznawcza Polski) (Polish Edition) Robert Respondowski Click here if your download doesn"t start automatically Wojewodztwo Koszalinskie:
Algorytmy redukcji danych w uczeniu maszynowym i eksploracji danych. Dr inŝ. Ireneusz Czarnowski Akademia Morska w Gdyni
 Algorytmy redukcji danych w uczeniu maszynowym i eksploracji danych Dr inŝ. Ireneusz Czarnowski Akademia Morska w Gdyni Plan seminarium Wprowadzenie Redukcja danych Zintegrowany model uczenia maszynowego
Algorytmy redukcji danych w uczeniu maszynowym i eksploracji danych Dr inŝ. Ireneusz Czarnowski Akademia Morska w Gdyni Plan seminarium Wprowadzenie Redukcja danych Zintegrowany model uczenia maszynowego
Zakopane, plan miasta: Skala ok. 1: = City map (Polish Edition)
") Zakopane, plan miasta: Skala ok. 1:15 000 = City map (Polish Edition) Click here if your download doesn"t start automatically Zakopane, plan miasta: Skala ok. 1:15 000 = City map (Polish Edition) Zakopane,
Zakopane, plan miasta: Skala ok. 1:15 000 = City map (Polish Edition) Click here if your download doesn"t start automatically Zakopane, plan miasta: Skala ok. 1:15 000 = City map (Polish Edition) Zakopane,
Revenue Maximization. Sept. 25, 2018
 Revenue Maximization Sept. 25, 2018 Goal So Far: Ideal Auctions Dominant-Strategy Incentive Compatible (DSIC) b i = v i is a dominant strategy u i 0 x is welfare-maximizing x and p run in polynomial time
Revenue Maximization Sept. 25, 2018 Goal So Far: Ideal Auctions Dominant-Strategy Incentive Compatible (DSIC) b i = v i is a dominant strategy u i 0 x is welfare-maximizing x and p run in polynomial time
Presented by. Dr. Morten Middelfart, CTO
 Meeting Big Data challenges in Leadership with Human-Computer Synergy. Presented by Dr. Morten Middelfart, CTO Big Data Data that exists in such large amounts or in such unstructured form that it is difficult
Meeting Big Data challenges in Leadership with Human-Computer Synergy. Presented by Dr. Morten Middelfart, CTO Big Data Data that exists in such large amounts or in such unstructured form that it is difficult
Laboratorium 4. Naiwny klasyfikator Bayesa.
 Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Indeksy w bazach danych. Motywacje. Techniki indeksowania w eksploracji danych. Plan prezentacji. Dotychczasowe prace badawcze skupiały się na
 Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Rozmyte drzewa decyzyjne. Łukasz Ryniewicz Metody inteligencji obliczeniowej
 µ(x) x µ(x) µ(x) x x µ(x) µ(x) x x µ(x) x µ(x) x Rozmyte drzewa decyzyjne Łukasz Ryniewicz Metody inteligencji obliczeniowej 21.05.2007 AGENDA 1 Drzewa decyzyjne kontra rozmyte drzewa decyzyjne, problemy
µ(x) x µ(x) µ(x) x x µ(x) µ(x) x x µ(x) x µ(x) x Rozmyte drzewa decyzyjne Łukasz Ryniewicz Metody inteligencji obliczeniowej 21.05.2007 AGENDA 1 Drzewa decyzyjne kontra rozmyte drzewa decyzyjne, problemy
Wprowadzenie do programu RapidMiner, część 5 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 5 Michał Bereta www.michalbereta.pl 1. Przekształcenia atrybutów (ang. attribute reduction / transformation, feature extraction). Zamiast wybierad częśd atrybutów
Wprowadzenie do programu RapidMiner, część 5 Michał Bereta www.michalbereta.pl 1. Przekształcenia atrybutów (ang. attribute reduction / transformation, feature extraction). Zamiast wybierad częśd atrybutów
EXAMPLES OF CABRI GEOMETRE II APPLICATION IN GEOMETRIC SCIENTIFIC RESEARCH
 Anna BŁACH Centre of Geometry and Engineering Graphics Silesian University of Technology in Gliwice EXAMPLES OF CABRI GEOMETRE II APPLICATION IN GEOMETRIC SCIENTIFIC RESEARCH Introduction Computer techniques
Anna BŁACH Centre of Geometry and Engineering Graphics Silesian University of Technology in Gliwice EXAMPLES OF CABRI GEOMETRE II APPLICATION IN GEOMETRIC SCIENTIFIC RESEARCH Introduction Computer techniques
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych
 WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
Adrian Horzyk
 Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Elementy inteligencji obliczeniowej
 Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
Próba formalizacji doboru parametrów generalizacji miejscowości dla opracowań w skalach przeglądowych
 Próba formalizacji doboru parametrów generalizacji miejscowości dla opracowań w skalach przeglądowych Uniwersytet Warszawski Wydział Geografii i Studiów Regionalnych Katedra Kartografii I. Motywacja Infrastruktura
Próba formalizacji doboru parametrów generalizacji miejscowości dla opracowań w skalach przeglądowych Uniwersytet Warszawski Wydział Geografii i Studiów Regionalnych Katedra Kartografii I. Motywacja Infrastruktura
Akademia Morska w Szczecinie. Wydział Mechaniczny
 Akademia Morska w Szczecinie Wydział Mechaniczny ROZPRAWA DOKTORSKA mgr inż. Marcin Kołodziejski Analiza metody obsługiwania zarządzanego niezawodnością pędników azymutalnych platformy pływającej Promotor:
Akademia Morska w Szczecinie Wydział Mechaniczny ROZPRAWA DOKTORSKA mgr inż. Marcin Kołodziejski Analiza metody obsługiwania zarządzanego niezawodnością pędników azymutalnych platformy pływającej Promotor:
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Jakość uczenia i generalizacja
 Jakość uczenia i generalizacja Dokładność uczenia Jest koncepcją miary w jakim stopniu nasza sieć nauczyła się rozwiązywać określone zadanie Dokładność mówi na ile nauczyliśmy się rozwiązywać zadania które
Jakość uczenia i generalizacja Dokładność uczenia Jest koncepcją miary w jakim stopniu nasza sieć nauczyła się rozwiązywać określone zadanie Dokładność mówi na ile nauczyliśmy się rozwiązywać zadania które