Sprzęt czyli architektury systemów równoległych
|
|
|
- Kacper Czech
- 8 lat temu
- Przeglądów:
Transkrypt
1 Sprzęt czyli architektury systemów równoległych 1
2 Architektura von Neumanna Program i dane w pamięci komputera Pojedynczy procesor: pobiera rozkaz z pamięci rozkodowuje rozkaz i znajduje adresy argumentów pobiera dane z pamięci wykonuje operacje na danych zapisuje wynik w pamięci 2

3 Architektura von Neumanna 3
4 Klasyfikacja Flynna Zwielokrotnienie strumieni przetwarzania rozkazów i danych klasyfikacja Flynna SISD (oryginalna architektura von Neumanna) SIMD jeden strumień rozkazów i wiele strumieni danych MISD wiele strumieni rozkazów i jeden strumień danych nie stosowane w praktyce (nie jest to przetwarzanie potokowe, gdzie różne rozkazy są wykonywane na tym samym egzemplarzu danych, ale w kolejnych chwilach czasu ) MIMD wiele strumieni danych i wiele strumieni rozkazów współczesne systemy komputerowe są złożone, realizują zazwyczaj różne typy przetwarzania, z pojedynczymi elementami odpowiadającymi architekturom SISD, SIMD oraz całością odpowiadającą architekturze MIMD z pamięcią wspólna lub rozproszoną 4
5 Procesory wielordzeniowe Prawo Moore'a wciąż sprawdzające się w praktyce mówi o podwajaniu liczby tranzystorów w pojedynczym układzie scalonym co 18 miesięcy Wykorzystanie tych możliwości do mnożenia etapów przetwarzania potokowego, liczby jednostek funkcjonalnych pracujących nad jednym strumieniem rozkazów i zwiększania częstości taktowania procesorów doprowadziło do kryzysu związanego z wydzielaniem ciepła Rozwiązaniem tego kryzysu jest wykorzystanie prawa Moore'a do umieszczania w jednym układzie wielu rdzeni (czyli praktycznie niewiele okrojonych procesorów) od początków XXI wieku prawo Moore'a może być tłumaczone jako podwajanie liczby rdzeni w pojedynczym układzie 5

6 Wydzielanie ciepła przez procesory 6

7 Kierunki rozwoju procesorów Intel 7
8 Sieci połączeń w systemach równoległych Rodzaje sieci połączeń: podział ze względu na łączone elementy: połączenia procesory pamięć (moduły pamięci) połączenia międzyprocesorowe (międzywęzłowe) podział ze względu na charakterystyki łączenia: sieci statyczne zbiór połączeń dwupunktowych sieci dynamiczne przełączniki o wielu dostępach 8

9 Sieci połączeń Sieci (połączenia) dynamiczne magistrala (bus) krata przełączników (crossbar switch przełącznica krzyżowa) sieć wielostopniowa (multistage network) Sieć wielostopniowa p wejść i p wyjść, stopnie pośrednie (ile?) każdy stopień pośredni złożony z p/2 przełączników 2x2 poszczególne stopnie połączone w sposób realizujący idealne przetasowanie (perfect shuffle) (j=2i lub j=2i+1 p) przy dwójkowym zapisie pozycji wejść i wyjść idealne przetasowanie odpowiada rotacji bitów, przełączniki umożliwiają zmianę wartości ostatniego bitu 9
10 Sieci połączeń Porównanie sieci dynamicznych: wydajność szerokość pasma transferu (przepustowość) możliwość blokowania połączeń koszt liczba przełączników skalowalność zależność wydajności i kosztu od liczby procesorów 10
11 Sieci połączeń Sieci statyczne Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D Kraty z zawinięciem, torusy Drzewa: zwykłe lub tłuste Hiperkostki: 1D, 2D, 3D itd.. Wymiar d, liczba procesorów 2^d Bitowy zapis położenia węzła Najkrótsza droga między 2 procesorami = ilość bitów, którymi różnią się kody położenia procesorów 11

12 Topologia torusa 12

13 Topologie hiperkostki i drzewa 13

14 Sieci połączeń 14
15 15

16 Intel Knights Landing 16
17 Architektura procesora G80 17
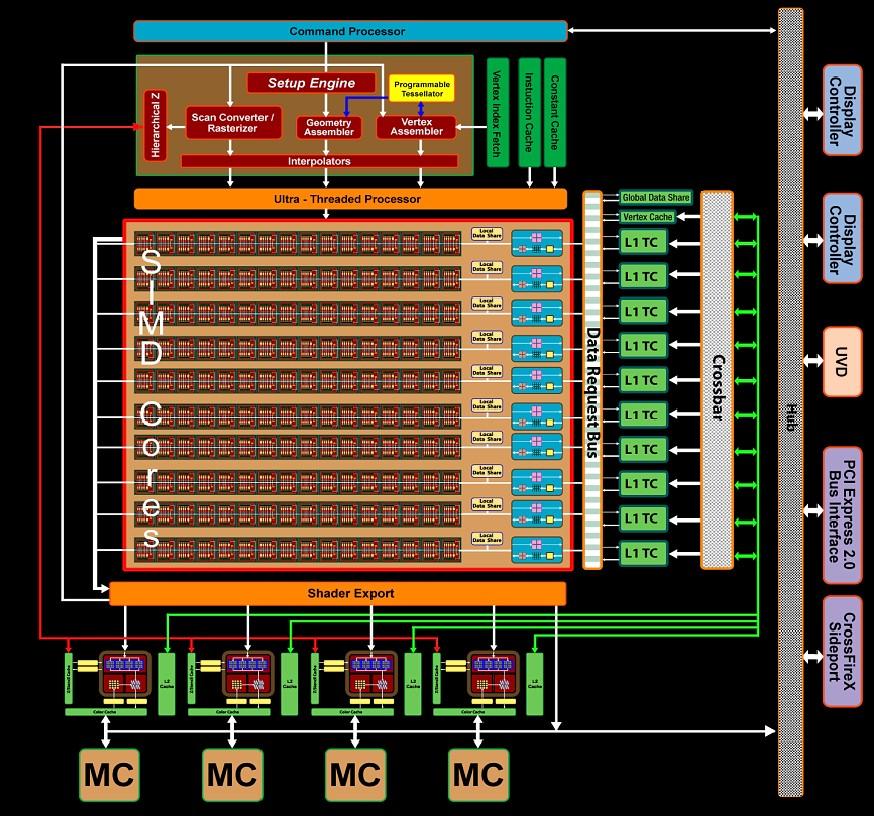
18 ATI FireStream 18
19 19


20 20
21 Alternatywne modele programowania równoległego 21
22 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o dostępie swobodnym (PRAM) wiele procesorów (z własnymi rejestrami), magistrala, wspólna pamięć równoległa realizacja algorytmów poprzez odpowiednie numerowanie procesorów i powiązanie numeracji z realizacją operacji założona automatyczna (sprzętowa) synchronizacja działania procesorów pominięcie zagadnień czasowej złożoności synchronizacji i komunikacji (zapisu i odczytu z i do pamięci) 22
23 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) równoległa maszyna o dostępie swobodnym (PRAM) EREW wyłączny odczyt, wyłączny zapis CREW jednoczesny odczyt, wyłączny zapis ERCW wyłączny odczyt, jednoczesny zapis CRCW jednoczesny odczyt, jednoczesny zapis; strategie: jednolita (common) dopuszcza zapis tylko identycznych danych dowolna (arbitrary) wybiera losowo dane do zapisu priorytetowa (priority) wybiera dane na zasadzie priorytetów 23
24 Algorytmy równoległe dla modelu PRAM Algorytm obliczania elementu maksymalnego tablicy A o rozmiarze n na n2 procesorowej maszynie CRCW PRAM ze strategią jednolitą: element_maks( A, n ): maks{ // uchwyt do tablicy i skrajne indeksy DLA i= 1,...,n { m[i] := PRAWDA } // tablica pomocnicza m DLA i=1,...,n{ // dzięki użyciu n2 procesorów równoległe DLA j=1,...,n{ // wykonanie pętli zajmuje O(1) czasu JEŻELI( A[i] < A[j] ) m[i] := FAŁSZ }} DLA i=1,...,n { JEŻELI( m[i]=prawda ) maks := A[i] } ZWRÓĆ maks } 24
25 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie poprzez przypisanie danych poszczególnym procesorom Wymiana informacji pomiędzy procesorami bez jawnego sterowania przez programistę Implementacja powinna umożliwiać efektywną realizację programów, tak dla systemów z pamięcią wspólną, jak i dla środowisk przesyłania komunikatów bez pamięci wspólnej Realizacja powyższych ambitnych celów jest na tyle trudna, że model nie doczekał się jeszcze rozpowszechnionych implementacji ogólnego przeznaczenia 25
26 High Performance Fortran Specyfikacja nieformalny standard Rozszerzenie Fortranu 95 Realizacja modelu programowania z równoległością danych, głównie dla operacji wektorowych i macierzowych Rozszerzenia w postaci dyrektyw kompilatora uzupełniających standardowe instrukcje Fortranu Z założenia ma udostępniać model programowania prostszy niż przesyłanie komunikatów i równie efektywny 26
27 Fortran 95 Specyfika Fortranu 95 wiąże się z rozbudowanymi operacjami na wektorach i macierzach (tablicach wielowymiarowych): deklaracje dopuszczają macierze wielowymiarowe: REAL, DIMENSION(3,4):: A, B, C zakres poszczególnych indeksów określa kształt macierzy istnieją zdefiniowane operacje dotyczące wektorów i macierzy (iloczyn, suma, itp) oraz pętle operujące na wszystkich lub wybranych elementach wektorów lub macierzy 27
28 Fortran 95 cd. operacje na wektorach i macierzach: dopuszczalne jest odnoszenie się do wybranych fragmentów wektorów i macierzy (każdy fragment ma swój kształt i może być użyty w odpowiednich operacjach), np.: AJ(1:3, 1:3) = OUGH(4, 3:5, 4:8:2) w pętlach wektorowych można stosować maskowanie za pomocą operacji logicznych lub wektorów o wartościach logicznych: WHERE( AJ.NE.0 ) A(1:3) = 1/A(1:3) istnieje wiele wektorowych procedur bibliotecznych, np. SUM, PRODUCT, MINVAL, MAXVAL, itp. 28
29 High Performance Fortran Dyrektywy określające ułożenie procesorów:!hpf$ PROCESSORS, DIMENSION(3,4):: P1!HPF$ PROCESSORS, DIMENSION(2,6):: P2!HPF$ PROCESSORS, DIMENSION(12):: P3!HPF$ PROCESSORS, DIMENSION(2,2,3):: P4 W jednym programie może istnieć wiele zdefiniowanych układów procesorów, wykorzystywanych w różnych miejscach do realizacji różnych operacji 29
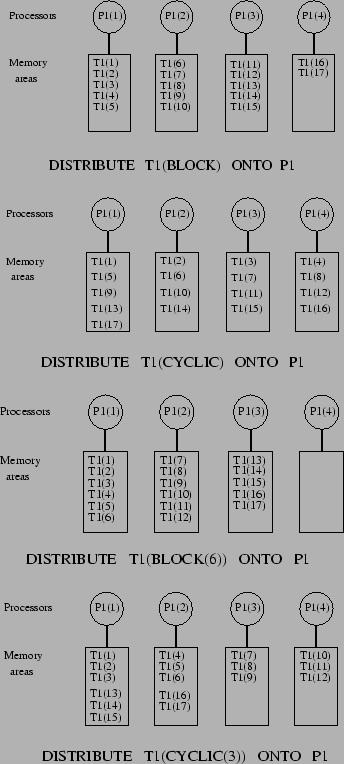
30 High Performance Fortran Przypisanie (dystrybucja) danych odbywa się za pomocą dyrektywy DISTRIBUTE, np.:!hpf$ PROCESSORS, DIMENSION(4):: P REAL, DIMENSION(17):: T1, T2!HPF$ DISTRIBUTE T1(BLOCK) ONTO P!HPF$ DISTRIBUTE T1(CYCLIC) ONTO P!HPF$ DISTRIBUTE T1( CYCLIC(3) ) ONTO P określenie BLOCK (lub BLOCK(n) ) oznacza podział tablicy na bloki przypisywane kolejnym procesorom (n nie może być za małe) określenie CYCLIC (lub CYCLIC(n) ) oznacza przypisywanie kolejnych wyrazów tablicy (kolejnych n-tek wyrazów tablicy) kolejnym procesorom z okresowym zawijaniem 30
31 31
32 High Performance Fortran Dystrybucja tablic wielowymiarowych odbywa się odrębnie dla każdego wymiaru Liczba wymiarów podlegających dystrybucji musi być równa liczbie wymiarów układu procesorów!hpf$ PROCESSORS, DIMENSION(2,2):: P1!HPF$ PROCESSORS, DIMENSION(4):: P2 REAL, DIMENSION(8,8):: T1!HPF$ DISTRIBUTE T1(BLOCK,BLOCK) ONTO P1!HPF$ DISTRIBUTE T1(CYCLIC,CYCLIC) ONTO P1!HPF$ DISTRIBUTE T1(BLOCK,CYCLIC) ONTO P1!HPF$ DISTRIBUTE T1(*,CYCLIC) ONTO P2 32
33 High Performance Fortran Dla uzyskania wysokiej wydajności obliczeń (minimalizacji komunikacji międzyprocesorowej) dystrybucja niektórych tablic jest przeprowadzana zgodnie z dystrybucją innych przez wykorzystanie dyrektywy ALIGN:!HPF$!HPF$!HPF$!HPF$ ALIGN ALIGN ALIGN ALIGN A(:) WITH B(:) C(i,j) WITH D(j,i) C(*,j) WITH A(j) // zwijanie wymiaru B(j) WITH D(j,*) // powielanie wyrazów Wyrównanie może być zdefiniowane dla pustego wzorca (template) zadeklarowanego tak jak rzeczywiste tablice!hpf$ TEMPLATE T(4,5) 33
34 High Performance Fortran Wykonanie równoległe odbywa się poprzez realizację: standardowych operacji wektorowych Fortranu 95 A+B, A*B, A-(B*C) operacje dozwolone dla macierzy zgodnych (conformable) pętli operujących na wszystkich elementach macierzy: FORALL ( i=1..n, j=1..m, A[i,j].NE.0 ) A(i,j) = 1/A(i,j) Równoległość jest uzyskiwana niejawnie programista nie określa, które operacje są wykonywane na konkretnym procesorze 34

35 High Performance Fortran Przykład: dekompozycja LU macierzy A 35
36 Model DSM/PGAS Model programowania z rozproszoną pamięcią wspólną (DSM distributed shared memory) (inna nazwa PGAS, partitioned global adress space, dzielona globalna przestrzeń adresowa) 36


37 SMP, UMA, NUMA, etc. UMA SMP NUMA DSM ccnuma 37
38 Model DSM/PGAS Idee rozwijane od wielu lat w językach takich jak Przystosowane do maszyn NUMA CoArray Fortran Unified Parallel C inne jawna kontrola nad przyporządkowaniem danych do wątków (pojęcie afiniczności) możliwość optymalizacji trudność synchronizacji i utrzymania zgodności przy dostępach do pamięci wspólnej Wzrost zainteresowania w momencie popularyzacji systemów wieloprocesorowych i, w dalszej perspektywie, procesorów wielordzeniowych o architekturze NUMA 38
39 Unified Parallel C UPC (Unified Parallel C) rozszerzenie języka C nowe słowa kluczowe zestaw standardowych procedur bibliotecznych m.in. operacje komunikacji grupowej model programowania DSM/PGAS (distributed shared memory, partitioned global adress space) model programowania SPMD specyfikacja jest modyfikowana ( , , ) szereg implementacji (Cray, HP, UCB, GWU, MTU i inne) środowiska tworzenia kodu debuggery, analizatory, itp. 39
40 Unified Parallel C Sterowanie wykonaniem: THREADS liczba wątków MYTHREAD identyfikator (ranga) wątku klasyczny model (podobnie jak w MPI) polecenie upc_forall (podobnie jak pętla równoległa w OpenMP) określenie liczby wątków w trakcie kompilacji (nowość!) lub w momencie uruchamiania programu bariery (w postaci procedur blokujących i nieblokujących) zamki (podobnie jak mutex y) synchronizacja związana z dostępem do zmiennych wspólnych (konieczność utrzymania zgodności) 40

41 Unified Parallel C Zarządzanie pamięcią (dostęp do zmiennych): zmienne lokalne dostępne wątkowi właścicielowi zmienne globalne dostępne wszystkim, afiniczność 41
42 UPC Słowo kluczowe shared deklaracja umieszczenia zmiennej lub tablicy w pamięci wspólnej afiniczność każdego elementu do pojedynczego wątku 42
43 UPC Rozkład tablic wielowymiarowych oparty jest na standardowym dla C rozłożeniu elementów (wierszami) 43
44 UPC Poza domyślnym rozkładem tablic (po jednym elemencie) można wprowadzić rozkład blokami 44
45 UPC Standardowe procedury języka umożliwiają kopiowanie danych z obszaru wspólnego do obszarów prywatnych wątków Istnieją procedury umożliwiające dynamiczna alokację tablic w obszarze pamięci wspólnej Wskaźniki do zmiennych mogą być: prywatne pokazują na elementy prywatne lub elementy z obszaru wspólnego o powinowactwie z wątkiem posiadającym wskaźnik typu pointer to shared wskazują na elementy w pamięci wspólnej 45

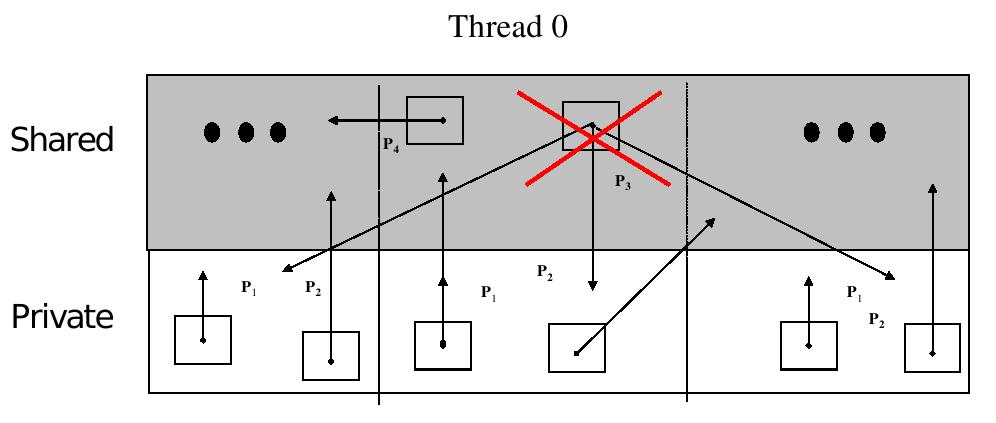
46 UPC 46
47 UPC Równoległa pętla for affinity oznacza powinowactwo dla każdej z iteracji: jeśli jest liczbą związaną z indeksem pętli, iteracja jest przydzielana wątkowi: affinity@threads jeśli odnosi się do egzemplarza danych (ewentualnie także zależnego od indeksu pętli), iteracja jest przydzielana wątkowi posiadającemu powinowactwo do tego egzemplarza 47


48 UPC Dwa przykłady skutkujące tym samym podziałem iteracji pomiędzy wątki: 48
49 UPC Dwa przykłady skutkujące tym samym podziałem iteracji pomiędzy wątki: shared [100/THREADS] int a[100], b[100], c[100]; int i; upc_forall(i=0; i<100; i++; (i*threads)/100 ){ a[i] = b[i] + c[i]; } shared [100/THREADS] int a[100], b[100], c[100]; int i; upc_forall(i=0; i<100; i++; &a[i] ){ a[i] = b[i] + c[i]; } 49
50 UPC Przykład mnożenie macierz wektor w UPC: 50
51 Alternatywne modele programowania OpenHMPP, OpenACC dyrektywy dla programowania heterogenicznego (alternatywa dla OpenCL i CUDA) Chapel, Fortress, Co Array Fortran, X10 alternatywy PGAS dla UPC Ada, C++AMP obiektowe języki i biblioteki równoległe Cilk rozszerzenie wielowątkowe C/C++ Erlang, Concurrent Haskell i inne języki funkcjonalne SALSA język oprogramowania zorientowanego na aktorów Linda model programowania z pamięcią wspólną przestrzenią krotek, tuplespace Sisal model przepływu danych, dataflow (szereg innych języków, środowisk programowania, np. w grafice) i wiele, wiele innych 51
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Alternatywne modele programowania równoległego
 Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Operacje grupowego przesyłania komunikatów
 Operacje grupowego przesyłania komunikatów 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany jest pomiędzy więcej niż dwoma procesami
Operacje grupowego przesyłania komunikatów 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany jest pomiędzy więcej niż dwoma procesami
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Wstęp. Przetwarzanie współbieżne, równoległe i rozproszone
 Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
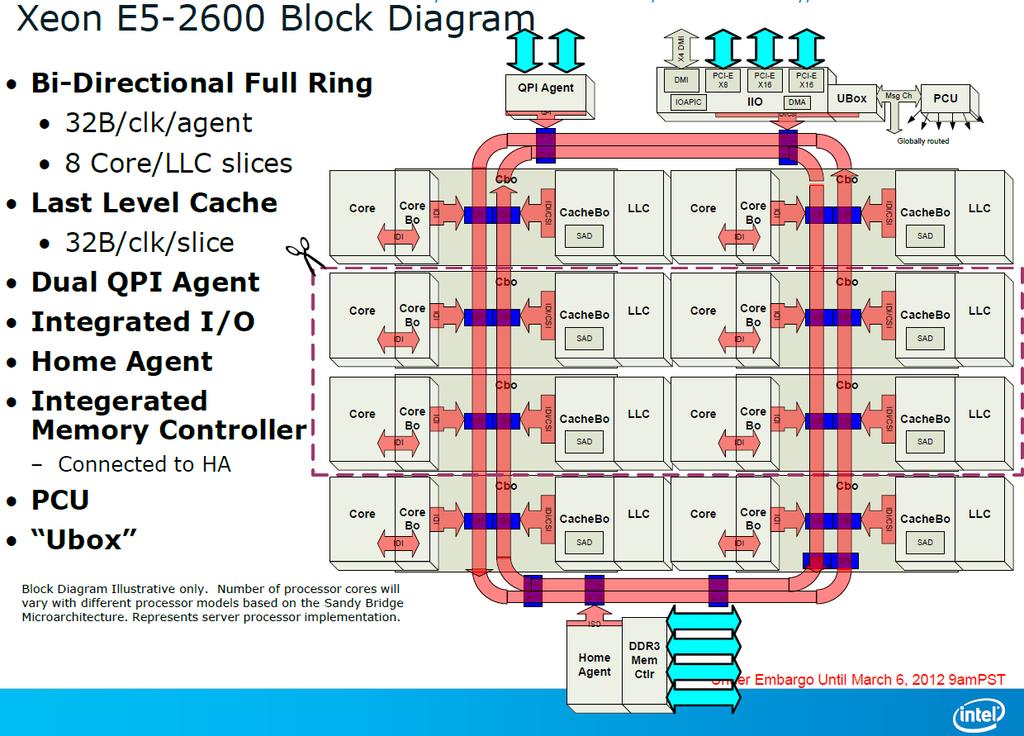
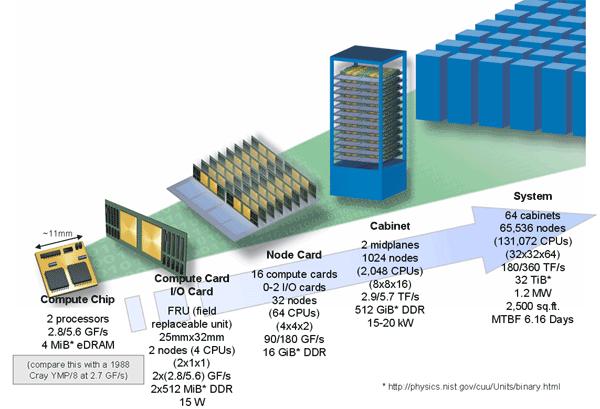
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine
 - Parallel Random Access Machine") 21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
 1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Przetwarzanie równoległesprzęt. Rafał Walkowiak Wybór
 Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
Wydajność komunikacji grupowej w obliczeniach równoległych. Krzysztof Banaś Obliczenia wysokiej wydajności 1
 Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Jak ujarzmić hydrę czyli programowanie równoległe w Javie. dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski
 Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia i ich zastosowań w przemyśle" POKL
 Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
Projektowanie. Projektowanie mikroprocesorów
 WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
Systemy operacyjne. Wprowadzenie. Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak
 Wprowadzenie Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego
Wprowadzenie Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
61 Topologie wirtualne
 61 Topologie wirtualne pozwalają opisać dystrybucję procesów w przestrzeni z uwzględnieniem struktury komunikowania się procesów aplikacji między sobą, umożliwiają łatwą odpowiedź na pytanie: kto jest
61 Topologie wirtualne pozwalają opisać dystrybucję procesów w przestrzeni z uwzględnieniem struktury komunikowania się procesów aplikacji między sobą, umożliwiają łatwą odpowiedź na pytanie: kto jest
Algorytmy Równoległe i Rozproszone Część IV - Model PRAM
 Algorytmy Równoległe i Rozproszone Część IV - Model PRAM Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy Równoległe i Rozproszone Część IV - Model PRAM Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD. Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej
 Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Architektura Komputerów
 1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Obliczenia równoległe
 Instytut Informatyki Politechnika Śląska Obliczenia równoległe Opracował: Zbigniew J. Czech materiały dydaktyczne Gliwice, luty 1 Spis treści 1 Procesy współbieżne Podstawowe modele obliczeń równoległych
Instytut Informatyki Politechnika Śląska Obliczenia równoległe Opracował: Zbigniew J. Czech materiały dydaktyczne Gliwice, luty 1 Spis treści 1 Procesy współbieżne Podstawowe modele obliczeń równoległych
Podstawy programowania w języku C
 Podstawy programowania w języku C WYKŁAD 1 Proces tworzenia i uruchamiania programów Algorytm, program Algorytm przepis postępowania prowadzący do rozwiązania określonego zadania. Program zapis algorytmu
Podstawy programowania w języku C WYKŁAD 1 Proces tworzenia i uruchamiania programów Algorytm, program Algorytm przepis postępowania prowadzący do rozwiązania określonego zadania. Program zapis algorytmu
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Algorytmy numeryczne 1
 Algorytmy numeryczne 1 Wprowadzenie Obliczenie numeryczne są najważniejszym zastosowaniem komputerów równoległych. Przykładem są symulacje zjawisk fizycznych, których przeprowadzenie sprowadza się do rozwiązania
Algorytmy numeryczne 1 Wprowadzenie Obliczenie numeryczne są najważniejszym zastosowaniem komputerów równoległych. Przykładem są symulacje zjawisk fizycznych, których przeprowadzenie sprowadza się do rozwiązania
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Numeryczna algebra liniowa. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak
Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ
 ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A,B,C są tablicami nxn for (int j = 0 ; j
ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A,B,C są tablicami nxn for (int j = 0 ; j
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Programowanie systemów z pamięcią wspólną specyfikacja OpenMP. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie systemów z pamięcią wspólną specyfikacja OpenMP Krzysztof Banaś Obliczenia równoległe 1 OpenMP Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
Programowanie systemów z pamięcią wspólną specyfikacja OpenMP Krzysztof Banaś Obliczenia równoległe 1 OpenMP Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ
 EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A[i][*] lokalność przestrzenna danych rózne A,B,C są
EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A[i][*] lokalność przestrzenna danych rózne A,B,C są
Jeśli chcesz łatwo i szybko opanować podstawy C++, sięgnij po tę książkę.
 Języki C i C++ to bardzo uniwersalne platformy programistyczne o ogromnych możliwościach. Wykorzystywane są do tworzenia systemów operacyjnych i oprogramowania użytkowego. Dzięki niskiemu poziomowi abstrakcji
Języki C i C++ to bardzo uniwersalne platformy programistyczne o ogromnych możliwościach. Wykorzystywane są do tworzenia systemów operacyjnych i oprogramowania użytkowego. Dzięki niskiemu poziomowi abstrakcji
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Operacje grupowego przesyłania komunikatów. Krzysztof Banaś Obliczenia równoległe 1
 Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
Architektura komputerów
 Architektura komputerów Tydzień 5 Jednostka Centralna Zadania realizowane przez procesor Pobieranie rozkazów Interpretowanie rozkazów Pobieranie danych Przetwarzanie danych Zapisanie danych Główne zespoły
Architektura komputerów Tydzień 5 Jednostka Centralna Zadania realizowane przez procesor Pobieranie rozkazów Interpretowanie rozkazów Pobieranie danych Przetwarzanie danych Zapisanie danych Główne zespoły
Przetwarzanie wielowątkowe przetwarzanie współbieżne. Krzysztof Banaś Obliczenia równoległe 1
 Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Podstawy Programowania C++
 Wykład 3 - podstawowe konstrukcje Instytut Automatyki i Robotyki Warszawa, 2014 Wstęp Plan wykładu Struktura programu, instrukcja przypisania, podstawowe typy danych, zapis i odczyt danych, wyrażenia:
Wykład 3 - podstawowe konstrukcje Instytut Automatyki i Robotyki Warszawa, 2014 Wstęp Plan wykładu Struktura programu, instrukcja przypisania, podstawowe typy danych, zapis i odczyt danych, wyrażenia:
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Tablice. Jones Stygar na tropie zmiennych
 Tablice Jones Stygar na tropie zmiennych Czym jest tablica? Obecnie praktycznie wszystkie języki programowania obsługują tablice. W matematyce odpowiednikiem tablicy jednowymiarowej jest ciąg (lub wektor),
Tablice Jones Stygar na tropie zmiennych Czym jest tablica? Obecnie praktycznie wszystkie języki programowania obsługują tablice. W matematyce odpowiednikiem tablicy jednowymiarowej jest ciąg (lub wektor),
Podstawy programowania skrót z wykładów:
 Podstawy programowania skrót z wykładów: // komentarz jednowierszowy. /* */ komentarz wielowierszowy. # include dyrektywa preprocesora, załączająca biblioteki (pliki nagłówkowe). using namespace
Podstawy programowania skrót z wykładów: // komentarz jednowierszowy. /* */ komentarz wielowierszowy. # include dyrektywa preprocesora, załączająca biblioteki (pliki nagłówkowe). using namespace
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Zarządzanie pamięcią operacyjną
 SOE Systemy Operacyjne Wykład 7 Zarządzanie pamięcią operacyjną dr inż. Andrzej Wielgus Instytut Mikroelektroniki i Optoelektroniki WEiTI PW Hierarchia pamięci czas dostępu Rejestry Pamięć podręczna koszt
SOE Systemy Operacyjne Wykład 7 Zarządzanie pamięcią operacyjną dr inż. Andrzej Wielgus Instytut Mikroelektroniki i Optoelektroniki WEiTI PW Hierarchia pamięci czas dostępu Rejestry Pamięć podręczna koszt
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Wydajność programów sekwencyjnych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne.
 Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 MPI dynamiczne zarządzanie procesami MPI 2 umożliwia dynamiczne zarządzanie procesami, choć
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 MPI dynamiczne zarządzanie procesami MPI 2 umożliwia dynamiczne zarządzanie procesami, choć
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Wprowadzenie do architektury komputerów. Taksonomie architektur Podstawowe typy architektur komputerowych
 Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
Sprzęt komputera - zespół układów wykonujących programy wprowadzone do pamięci komputera (ang. hardware) Oprogramowanie komputera - zespół programów
 Oprogramowanie komputera - zespół programów") Sprzęt komputera - zespół układów wykonujących programy wprowadzone do pamięci komputera (ang. hardware) Oprogramowanie komputera - zespół programów przeznaczonych do wykonania w komputerze (ang. software).
Sprzęt komputera - zespół układów wykonujących programy wprowadzone do pamięci komputera (ang. hardware) Oprogramowanie komputera - zespół programów przeznaczonych do wykonania w komputerze (ang. software).
LEKCJA TEMAT: Zasada działania komputera.
 LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
Informatyka I. Typy danych. Operacje arytmetyczne. Konwersje typów. Zmienne. Wczytywanie danych z klawiatury. dr hab. inż. Andrzej Czerepicki
 Informatyka I Typy danych. Operacje arytmetyczne. Konwersje typów. Zmienne. Wczytywanie danych z klawiatury. dr hab. inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2019 1 Plan wykładu
Informatyka I Typy danych. Operacje arytmetyczne. Konwersje typów. Zmienne. Wczytywanie danych z klawiatury. dr hab. inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2019 1 Plan wykładu
LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI. Wprowadzenie do środowiska Matlab
 LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI Wprowadzenie do środowiska Matlab 1. Podstawowe informacje Przedstawione poniżej informacje maja wprowadzić i zapoznać ze środowiskiem
LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI Wprowadzenie do środowiska Matlab 1. Podstawowe informacje Przedstawione poniżej informacje maja wprowadzić i zapoznać ze środowiskiem
Komputery równoległe. Zbigniew Koza. Wrocław, 2012
 Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem