Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
|
|
|
- Katarzyna Zając
- 5 lat temu
- Przeglądów:
Transkrypt
1 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley Designing and Building Parallel Programs; I.Foster, 4. Podstawy programowania współbieżnego, M. Ben-Ari, WNT 5. Programowanie współbieżne i rozproszone, Z.Weiss, T.Gruźlewski, WNT 6. Software Optimization for High-Performance Computing; Wadleigh, Crawford, Prentice Hall /26/2018 Przetwarzanie równoległe - wstęp 1
2 Materiały związane z przedmiotem Użutkownik: student Hasło: /26/2018 Przetwarzanie równoległe - wstęp 2
3 Konsultacje W trakcie zajęć semestru W poniedziałki w godz Zapraszam do konsultacji zagadnień związanych z przedmiotem: projekty, zadania egzaminacyjne, wykładany materiał. 3/26/2018 Przetwarzanie równoległe - wstęp 3
4 Zmiany w stosunku do ubiegłych lat Zaliczenie w formie egzaminu podczas sesji. Forma pytań zaliczeniowych nie zmienia się. Pytania problemowe jako test zrozumienia zagadnień z zakresu przetwarzania równoległego. 3/26/2018 Przetwarzanie równoległe - wstęp 4
5 Przykład 1 zadania egz. Proszę skorzystać z prawa Amdahla. Sp(s;p) jest to przyspieszenie dla obliczeń charakteryzujących się częścią sekwencyjną (niezrównoleglającą się) równą s przeprowadzonych na p procesorach. Analogicznie oznaczona jest efektywność E(s;p). Wiadomo z prawa Amdahla, że przyspieszenie wzrasta z liczbą procesorów. Wiadomo też, że efektywność obliczeń spada wraz z liczbą procesorów. Proszę powiedzieć: Ile i dlaczego będą równe Sp(s;p=nieskończoność), E(s;p=nieskończoność)? Proszę wyjaśnić ile wynosi iloraz E(s=0,2; p=nieskończoność)/ E(s=0,4; p=nieskończoność)? 3/26/2018 Przetwarzanie równoległe - wstęp 5
6 Przykład 2 zadania egz. Za pomocą odpowiedniej funkcji przydzielono 4 wątki na 4 procesory systemu równoległego (z prywatnymi pamięciami podręcznymi o długości linii pp 64 bajty). Obliczenia 4 wątków utworzonych dla kodu podanego poniżej korzystają ze zmiennych współdzielonych typu float (4 bajty). Zmienne i oraz n są przechowywane w rejestrach. 0,5 Z ilu różnych obiektów zmiennych korzystają wątki - proszę wymienić wszystkie? Które obiekty zmiennych są prywatne a które są współdzielone? 1,0 Proszę wyjaśnić - Ile wynosi stosunek trafień do pp dla dostępów (odczyty i zapisy) do zmiennych współdzielonych, a ile do zmiennych prywatnych? int i,n; float a[n],suma; #pragma omp parallel for reduction(suma:+) schedule(static,1) for (i=0; i<n; i++) Suma+=a[i]]; 3/26/2018 Przetwarzanie równoległe - wstęp 6
7 Zakres przedmiotu 1. Motywacje do zagadnień przetwarzania 2. Architektury maszyn 3. Modele przetwarzania 4. Podstawy projektowania algorytmów 5. Ocena efektywności programów 6. Komunikacja w systemach 7. Algorytmy 3/26/2018 Przetwarzanie równoległe - wstęp 7
8 Dlaczego warto studiować przetwarzanie równoległe? Przetwarzanie sekwencyjne jest dziś całkiem szybkie Jednak: Potrzebujemy ciągle rosnącej wydajności Budujemy systemy równoległe np. procesory wielordzeniowe, wieloprocesorowe karty graficzne Potrzebujemy umiejętności tworzenia programów równoległych Równoległość to duże wyzwanie intelektualne dla informatyki modele, języki, algorytmy, sprzęt 3/26/2018 Przetwarzanie równoległe - wstęp 8
9 Zamiana sytuacji w technologii mikroprocesorów Lata mikroprocesory przyspieszały średnio z roku na rok o około 50% (większa efektywność obliczeń) Od 2003: wzrost efektywności około 20% na rok, obserwacja granic wzrostu prędkości wynikających z: właściwości fizycznych materiałów (odprowadzanie energii cieplnej, cieplno - niestabilne systemy, opóźnienia transmisji sygnału), wykorzystania możliwości zrównoleglenia przetwarzania na poziomie pojedynczego procesora (długość słowa, superskalarność) wysokiej złożoności struktury mikroprocesora Dziś równoległość przetwarzania nie tylko w superkomputerach i centrach naukowych. Zamiast projektować i realizować szybsze mikroprocesory umieszcza się wiele procesorów w ramach pojedynczego układu scalonego tzw. rdzenie. 3/26/2018 Przetwarzanie równoległe - wstęp 9
10 Oczekiwania na wzrost efektywności - przykłady Modelowanie klimatu, prognozowanie pogody Nauki biologiczne (badania genomu, struktury białek itp) Badania nad lekarstwami, szczepionkami Poszukiwania nowych źródeł energii Analiza danych w gospodarce 3/26/2018 Przetwarzanie równoległe - wstęp 10
11 Rola programistów co jest problemem? Dodatkowe rdzenie nie powodują wzrostu efektywności obliczeń - jeśli programiści ich nie wykorzystają ( wykorzystywane komputera tylko dla kodu sekwencyjnego). Efektywność przetwarzania programów sekwencyjnych nie wzrasta w systemach wielordzeniowych, wieloprocesorowych. Konieczne rozumienie sposobu działania systemów równoległych, wiedza o programowaniu równoległym i umiejętności przeprowadzenia równoległych obliczeń dla wykorzystania procesorów wielordzeniowych i kart graficznych. 3/26/2018 Przetwarzanie równoległe - wstęp 11
12 Możliwe podejścia w programowaniu dla systemów równolełych Ponowne napisanie programów sekwencyjnych aby stały się Zastosowanie programów zrównoleglających: Ograniczony zakres powodzenia Zrównoleglenie tylko pewnych konstrukcji kodowych np. równoległe wykonanie pętli Trudne zadnie aby było efektywnie (możliwe?) Podejście od nowa - zaprojektowanie algorytmu, tak aby odzwierciedlał równoległość dostępną w problemie i metodzie jego rozwiązania. 3/26/2018 Przetwarzanie równoległe - wstęp 12
13 Dalsze uzasadnienia dla przetwarzania równoległego Skrócenie czasu projektownia i wdrożenia systemów wieloprocesorowych (lub wielordzeniowych) wykorzystanie standardowych interfejsów sprzętowych pozwala na zastosowanie nowych architektur i technologii procesorów, zaawansowane narzędzia projektowe i testujące. Postęp w standaryzacji środowisk przetwarzania równoległego zapewniający dłuższy cykl życia aplikacji równoległych (MPI, Open MP, OpenGL, CUDA) 3/26/2018 Przetwarzanie równoległe - wstęp 13
14 Budowa sprzętu - równoległość wewnętrzna Wzrost złożoności układów scalonych (IC) podwojenie złożoności w ciągu 18 miesięcy (wg Gordona Moora) poprzez nowe technologie wytwarzania IC. Dla wykorzystania możliwego technologicznie wzrostu złożoności IC i jego przekształcenia na wzrost wydajności przetwarzania konieczna praca nad równoległością wewnętrzną procesora (potokowość, superskalarność i aby były możliwe: dynamiczne przetwarzania rozkazów, predykcja rozgałęzień, wstępne pobranie kodu i danych), konieczne zrozumienie równoległości wewnętrznej procesora. 3/26/2018 Przetwarzanie równoległe - wstęp 14
15 Prędkość dostępu do pamięci (ang. memory wall) powiązania z przetwarzaniem równoległym Przyrost prędkości zegarów procesorów przewyższa wzrost prędkości dostępu do jednostki pamięci. Efektem jest konieczność korzystania z szybszych systemów pamięci pamięci podręcznej. Efektywność systemów jest zależna od stopnia obsługi żądań dostępu do pamięci w ramach szybkiej pamięci podręcznej. Zasada lokalności obowiązująca przy projektowaniu algorytmu równoległego prowadzi do kodu efektywnie korzystającego z pamięci podręcznej widoczne tutaj są korzyści z badań nad równoległością dla zapewniania efektywności przetwarzania sekwencyjnego. 3/26/2018 Przetwarzanie równoległe - wstęp 15
16 Lokalność przetwarzania, dostępu do danych W systemach równoległych ogólna przepustowość procesorypamięć jest większa niż w systemach jednoprocesorowych z powodu: większej pamięci podręcznej, równoległego dostępu procesorów do pamięci. Wynik: podział na (równolegle realizowane) podproblemy umożliwia większą lokalność przetwarzania i wyższą efektywność dostępu do pamięci. Dodatkowo wzrost rozmiaru pp (w systemie równoległym) prowadzi do efektywnego przetwarzania (możliwe jest nawet skrócenie czasu przetwarzania w większym stopniu niż wynikający z użytej liczby procesorów). 3/26/2018 Przetwarzanie równoległe - wstęp 16
17 Rozważmy prosty problem Sumowanie elementów tablicy a1 = rdtsc(); for(int i=0;i<max;i++) suma+=table[i]; a2 = rdtsc(); printf("czas obliczeń =%llu us \n", (a2- a1)*3/10000); Czas przetwarzania sekwencyjnego: dla MAX i Intel 2,8 GHz i5 (4 rdzenie) 250 us 3/26/2018 Przetwarzanie równoległe - wstęp 17
18 Zróbmy to równolegle P1 P2 P3 P4 Sumowanie elementów tablicy za pomocą 4 procesów a1 = rdtsc(); #pragma omp parallel #pragma omp for shared(table,suma) for(int i=0;i<max;i++) suma+=table[i]; a2 = rdtsc(); printf("czas obliczeń =%llu us \n", (a2-a1)*3/10000); 3/26/2018 Przetwarzanie równoległe - wstęp 18
19 Równoległe sumowanie elementów Wyniki: wyścig niepoprawne wyścig w dostępie do współdzielonej zmiennej - rezultat nadpisania odczytanych i wykorzystywanych przez inny proces (na tym samych lub innym procesorze) wartości zmiennej suma Rozwiązanie: Synchronizacja dostępu do zmiennej współdzielonej 3/26/2018 Przetwarzanie równoległe - wstęp 19
20 Równoległe sumowanie elementów poprawny program liczy się powoli Rozwiązanie 2: a1 = rdtsc(); #pragma omp parallel #pragma omp for shared(table,suma) for(int i=0;i<max;i++) #pragma omp atomic suma+=table[i]; a2 = rdtsc(); printf("czas obliczeń =%llu us \n", (a2-a1)*3/10000); Wynik poprawny: czas pracy około 2800 us czyli zamiast skrócenia czasu obliczeń - 11 razy dłużej niż sekwencyjnie. Dlaczego? 3/26/2018 Przetwarzanie równoległe - wstęp 20
21 L2 Równoległe sumowanie elementów Memory L2 L3 L2 L2 Koszty: #pragma omp parallel for for(int i=0;i<max;i++) #pragma omp atomic suma+=table[i]; koszt dostępu do pamięci (dyrektywa atomic wprowadza odczyt i zapis wartości zmiennej z/do pamieci przed/po jej wykorzystaniem koszt dostępu do zamka (mutex_lock) dla synchronizacji dostępu do zmiennej na poziomie procesów koszt przepisywania danych pomiędzy poziomami pamięci: procesorem, pamięcią podręczną L1 jednego rdzenia, wspóldzieloną pp L3, L1 innego rdzenia, a nawet do innego procesora (gdy wiele fizycznych procesorów) suma jest: współdzielona modyfikowana ale nie jest lokalna!! nie jest w sposób ciągły dostępna dla wątku w procesorze, na którym wątek 3/26/2018 jest przetwarzany 21 L1 L1 L1 L1 P1 P2 P3 P4 Przepisywanie wartości współdzielonej
22 Równoległe sumowanie elementów Rozwiązanie 3: Większa lokalność przetwarzania prywatna suma #pragma omp parallel { float sumal=0.0; #pragma omp for for(int i=0;i<max;i++) sumal+=table[i]; #pragma omp atomic ;poza pętlą każdy wątek jeden raz } suma+=sumal; Czas przetwarzania na 4 procesorach: 70 us czyli 3,6 x szybciej niż sekwencyjnie. Wnioski: 1. efektywna równoległość = maksymalizacja lokalności dostępów do danych 2. równoległość to często konieczność synchronizacji obliczeń (ale synchronizacji efektywnej rzadko występującej). 3/26/2018 Przetwarzanie równoległe - wstęp 22


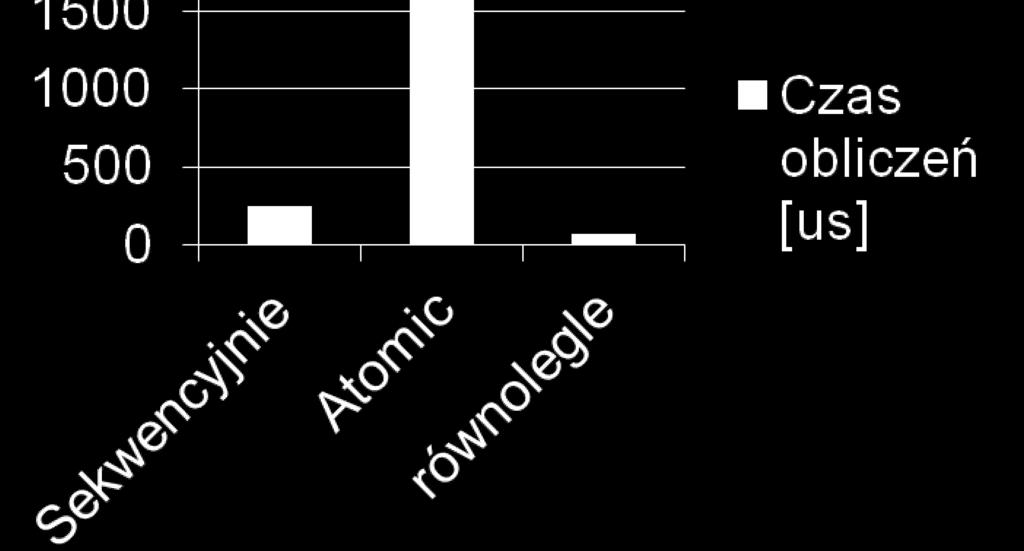
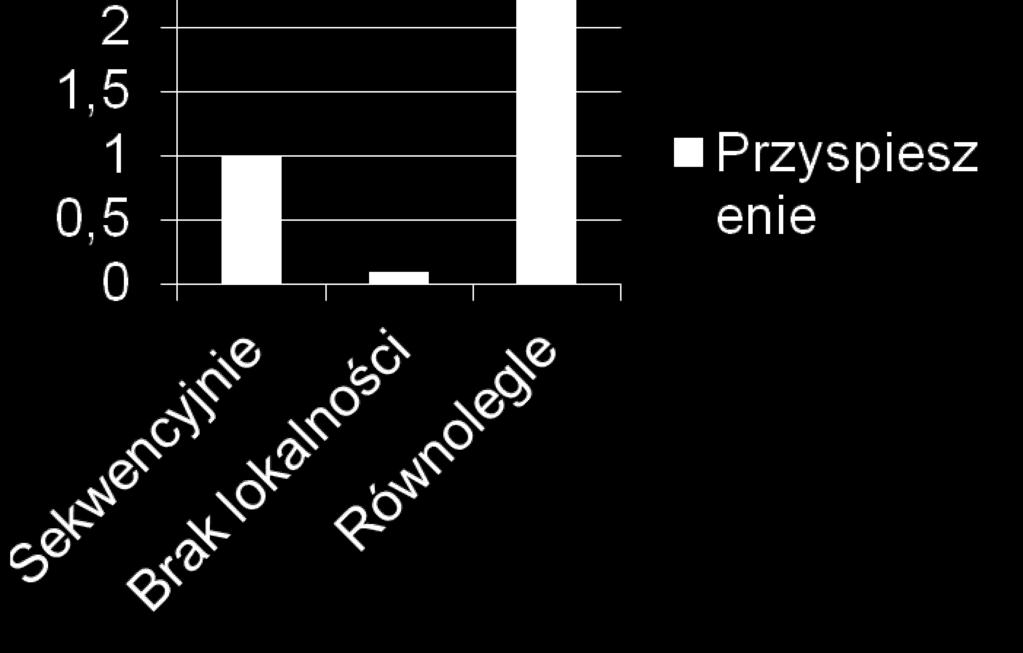
23 Równoległe sumowanie elementów 3/26/2018 Przetwarzanie równoległe - wstęp 23
24 Cele w programowaniu równoległym Skalowalność: kolejne procesory mogą zostać dodane dla szybszego rozwiązania problemu Wydajność: efektywnie wykorzystać dostępne procesory - przyspieszenie Przenośność: oprogramowanie nadające się do przenoszenia między systemami 3/26/2018 Przetwarzanie równoległe - wstęp 24
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Przykładem jest komputer z procesorem 4 rdzeniowym dostępny w laboratorium W skład projektu wchodzi:
 Przetwarzanie równoległe PROJEKT OMP Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego w komputerze równoległym z procesorem wielordzeniowym z pamięcią współdzieloną.
Przetwarzanie równoległe PROJEKT OMP Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego w komputerze równoległym z procesorem wielordzeniowym z pamięcią współdzieloną.
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Poziom kwalifikacji: I stopnia. Liczba godzin/tydzień: 2W E, 2L PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGRAMOWANIE ROZPROSZONE I RÓWNOLEGŁE Distributed and parallel programming Kierunek: Forma studiów: Informatyka Stacjonarne Rodzaj przedmiotu: moduł specjalności obowiązkowy: Sieci komputerowe
Nazwa przedmiotu: PROGRAMOWANIE ROZPROSZONE I RÓWNOLEGŁE Distributed and parallel programming Kierunek: Forma studiów: Informatyka Stacjonarne Rodzaj przedmiotu: moduł specjalności obowiązkowy: Sieci komputerowe
Analiza efektywności przetwarzania współbieżnego
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
Analiza efektywności przetwarzania współbieżnego. Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2017
 Rafał Walkowiak Wersja: wiosna 2017") OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2017 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2017 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak,
 Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2017
 Rafał Walkowiak Wersja: wiosna 2017") OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2017 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2017 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ
 ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A,B,C są tablicami nxn for (int j = 0 ; j
ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A,B,C są tablicami nxn for (int j = 0 ; j
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Informatyka II stopień (I stopień / II stopień) Ogólno akademicki (ogólno akademicki / praktyczny)
 Ogólno akademicki (ogólno akademicki / praktyczny)") Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/2013
Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/2013
Przetwarzanie Rozproszone i Równoległe
 WYDZIAŁ INŻYNIERII ELEKTRYCZNEJ I KOMPUTEROWEJ KATEDRA AUTOMATYKI I TECHNIK INFORMACYJNYCH Przetwarzanie Rozproszone i Równoległe www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński
WYDZIAŁ INŻYNIERII ELEKTRYCZNEJ I KOMPUTEROWEJ KATEDRA AUTOMATYKI I TECHNIK INFORMACYJNYCH Przetwarzanie Rozproszone i Równoległe www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ
 EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A[i][*] lokalność przestrzenna danych rózne A,B,C są
EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A[i][*] lokalność przestrzenna danych rózne A,B,C są
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
SYLABUS DOTYCZY CYKLU KSZTAŁCENIA realizacja w roku akademickim 2016/2017
 Załącznik nr 4 do Uchwały Senatu nr 430/01/2015 SYLABUS DOTYCZY CYKLU KSZTAŁCENIA 2015-2017 realizacja w roku akademickim 2016/2017 1.1. PODSTAWOWE INFORMACJE O PRZEDMIOCIE/MODULE Nazwa przedmiotu/ modułu
Załącznik nr 4 do Uchwały Senatu nr 430/01/2015 SYLABUS DOTYCZY CYKLU KSZTAŁCENIA 2015-2017 realizacja w roku akademickim 2016/2017 1.1. PODSTAWOWE INFORMACJE O PRZEDMIOCIE/MODULE Nazwa przedmiotu/ modułu
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Ograniczenia efektywności systemu pamięci
 Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Projektowanie i użytkowanie systemów operacyjnych Rok akademicki: 2013/2014 Kod: EAR-2-324-n Punkty ECTS: 5 Wydział: Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Kierunek:
Nazwa modułu: Projektowanie i użytkowanie systemów operacyjnych Rok akademicki: 2013/2014 Kod: EAR-2-324-n Punkty ECTS: 5 Wydział: Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Kierunek:
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
KARTA PRZEDMIOTU. Projektowanie systemów czasu rzeczywistego D1_13
 KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom : Profil : Forma studiów: Obszar : Dziedzina:
KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom : Profil : Forma studiów: Obszar : Dziedzina:
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia
 Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia Wydział Matematyki i Informatyki Instytut Informatyki i
Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia Wydział Matematyki i Informatyki Instytut Informatyki i
E-I2S-2001-s1. Informatyka II stopień (I stopień / II stopień) Ogólno akademicki (ogólno akademicki / praktyczny)
 Ogólno akademicki (ogólno akademicki / praktyczny)") Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu E-I2S-2001-s1 Nazwa modułu Programowanie systemów rozproszonych Nazwa modułu w języku angielskim
Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu E-I2S-2001-s1 Nazwa modułu Programowanie systemów rozproszonych Nazwa modułu w języku angielskim
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Ograniczenia efektywności systemu pamięci
 Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP.
 P O L I T E C H N I K A S Z C Z E C I Ń S K A Wydział Informatyki PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP. Autor: Wojciech
P O L I T E C H N I K A S Z C Z E C I Ń S K A Wydział Informatyki PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP. Autor: Wojciech
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Analiza ilościowa w przetwarzaniu równoległym
 Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Modelowanie procesów współbieżnych
 Modelowanie procesów współbieżnych dr inż. Maciej Piotrowicz Katedra Mikroelektroniki i Technik Informatycznych PŁ piotrowi@dmcs.p.lodz.pl http://fiona.dmcs.pl/~piotrowi -> Modelowanie... Literatura M.
Modelowanie procesów współbieżnych dr inż. Maciej Piotrowicz Katedra Mikroelektroniki i Technik Informatycznych PŁ piotrowi@dmcs.p.lodz.pl http://fiona.dmcs.pl/~piotrowi -> Modelowanie... Literatura M.
Wprowadzenie do metodologii modelowania systemów informacyjnych. Strategia (1) Strategia (2) Etapy Ŝycia systemu informacyjnego
 Strategia (2) Etapy Ŝycia systemu informacyjnego") Etapy Ŝycia systemu informacyjnego Wprowadzenie do metodologii modelowania systemów informacyjnych 1. Strategia 2. Analiza 3. Projektowanie 4. Implementowanie, testowanie i dokumentowanie 5. WdroŜenie
Etapy Ŝycia systemu informacyjnego Wprowadzenie do metodologii modelowania systemów informacyjnych 1. Strategia 2. Analiza 3. Projektowanie 4. Implementowanie, testowanie i dokumentowanie 5. WdroŜenie
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami
 Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
HPC na biurku. Wojciech De bski
 na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
Materiały pomocnicze do laboratorium. 1. Miary oceny efektywności 2. Mnożenie macierzy 3. Znajdowanie liczb pierwszych
 Materiały pomocnicze do laboratorium 1. Miary oceny efektywności 2. Mnożenie macierzy 3. Znajdowanie liczb pierwszych 4. Optymalizacja dostępu do pamięci Miary efektywności systemów współbieżnych System
Materiały pomocnicze do laboratorium 1. Miary oceny efektywności 2. Mnożenie macierzy 3. Znajdowanie liczb pierwszych 4. Optymalizacja dostępu do pamięci Miary efektywności systemów współbieżnych System
Jak ujarzmić hydrę czyli programowanie równoległe w Javie. dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski
 Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Wykład Ćwiczenia Laboratorium Projekt Seminarium
 WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
Informatyka I stopień (I stopień / II stopień) Ogólnoakademicki (ogólno akademicki / praktyczny) niestacjonarne (stacjonarne / niestacjonarne)
 Ogólnoakademicki (ogólno akademicki / praktyczny) niestacjonarne (stacjonarne / niestacjonarne)") KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Architektura systemów komputerowych 2 Nazwa modułu w języku angielskim Computer
KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Architektura systemów komputerowych 2 Nazwa modułu w języku angielskim Computer
Uniwersytet w Białymstoku Wydział Ekonomiczno-Informatyczny w Wilnie SYLLABUS na rok akademicki 2010/2011 http://www.wilno.uwb.edu.
 SYLLABUS na rok akademicki 010/011 Tryb studiów Studia stacjonarne Kierunek studiów Informatyka Poziom studiów Pierwszego stopnia Rok studiów/ semestr 1(rok)/1(sem) Specjalność Bez specjalności Kod katedry/zakładu
SYLLABUS na rok akademicki 010/011 Tryb studiów Studia stacjonarne Kierunek studiów Informatyka Poziom studiów Pierwszego stopnia Rok studiów/ semestr 1(rok)/1(sem) Specjalność Bez specjalności Kod katedry/zakładu
Wprowadzenie do programowania współbieżnego
 Wprowadzenie do programowania współbieżnego Marcin Engel Instytut Informatyki Uniwersytet Warszawski Zamiast wstępu... Zamiast wstępu... Możliwość wykonywania wielu akcji jednocześnie może ułatwić tworzenie
Wprowadzenie do programowania współbieżnego Marcin Engel Instytut Informatyki Uniwersytet Warszawski Zamiast wstępu... Zamiast wstępu... Możliwość wykonywania wielu akcji jednocześnie może ułatwić tworzenie
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
KARTA PRZEDMIOTU. Systemy czasu rzeczywistego: D1_9
 KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom : Profil : Forma studiów: Obszar : Dziedzina:
KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom : Profil : Forma studiów: Obszar : Dziedzina:
Dydaktyka Informatyki budowa i zasady działania komputera
 Dydaktyka Informatyki budowa i zasady działania komputera Instytut Matematyki Uniwersytet Gdański System komputerowy System komputerowy układ współdziałania dwóch składowych: szprzętu komputerowego oraz
Dydaktyka Informatyki budowa i zasady działania komputera Instytut Matematyki Uniwersytet Gdański System komputerowy System komputerowy układ współdziałania dwóch składowych: szprzętu komputerowego oraz
NAZWA PRZEDMIOTU/MODUŁU KSZTAŁCENIA:
 NAZWA PRZEDMIOTU/MODUŁU KSZTAŁCENIA: Podstawy programowania Kod przedmiotu: GS_13 Rodzaj przedmiotu: kierunkowy Wydział: Informatyki Kierunek: Grafika Poziom studiów: pierwszego stopnia VI poziom PRK Profil
NAZWA PRZEDMIOTU/MODUŁU KSZTAŁCENIA: Podstawy programowania Kod przedmiotu: GS_13 Rodzaj przedmiotu: kierunkowy Wydział: Informatyki Kierunek: Grafika Poziom studiów: pierwszego stopnia VI poziom PRK Profil
Metody optymalizacji soft-procesorów NIOS
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
4. Procesy pojęcia podstawowe
 4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
4. Procesy pojęcia podstawowe
 4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
SYSTEMY WBUDOWANE CZASU RZECZYWISTEGO. Specjalność magisterska Katedry Systemów Elektroniki Morskiej
 SYSTEMY WBUDOWANE CZASU RZECZYWISTEGO Specjalność magisterska Katedry Systemów Elektroniki Morskiej Co to jest system wbudowany czasu rzeczywistego? Komputer - część większego systemu wykonuje skończoną
SYSTEMY WBUDOWANE CZASU RZECZYWISTEGO Specjalność magisterska Katedry Systemów Elektroniki Morskiej Co to jest system wbudowany czasu rzeczywistego? Komputer - część większego systemu wykonuje skończoną
INŻYNIERIA OPROGRAMOWANIA
 INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
DLA SEKTORA INFORMATYCZNEGO W POLSCE
 DLA SEKTORA INFORMATYCZNEGO W POLSCE SRK IT obejmuje kompetencje najważniejsze i specyficzne dla samego IT są: programowanie i zarządzanie systemami informatycznymi. Z rozwiązań IT korzysta się w każdej
DLA SEKTORA INFORMATYCZNEGO W POLSCE SRK IT obejmuje kompetencje najważniejsze i specyficzne dla samego IT są: programowanie i zarządzanie systemami informatycznymi. Z rozwiązań IT korzysta się w każdej
Programowanie współbieżne Wykład 7. Iwona Kochaoska
 Programowanie współbieżne Wykład 7 Iwona Kochaoska Poprawnośd programów współbieżnych Właściwości związane z poprawnością programu współbieżnego: Właściwośd żywotności - program współbieżny jest żywotny,
Programowanie współbieżne Wykład 7 Iwona Kochaoska Poprawnośd programów współbieżnych Właściwości związane z poprawnością programu współbieżnego: Właściwośd żywotności - program współbieżny jest żywotny,
PROJEKT 3 PROGRAMOWANIE RÓWNOLEGŁE. K. Górzyński (89744), D. Kosiorowski (89762) Informatyka, grupa dziekańska I3
, D. Kosiorowski (89762) Informatyka, grupa dziekańska I3") PROJEKT 3 PROGRAMOWANIE RÓWNOLEGŁE K. Górzyński (89744), D. Kosiorowski (89762) Informatyka, grupa dziekańska I3 17 lutego 2011 Spis treści 1 Opis problemu 2 2 Implementacja problemu 3 2.1 Kod współdzielony........................
PROJEKT 3 PROGRAMOWANIE RÓWNOLEGŁE K. Górzyński (89744), D. Kosiorowski (89762) Informatyka, grupa dziekańska I3 17 lutego 2011 Spis treści 1 Opis problemu 2 2 Implementacja problemu 3 2.1 Kod współdzielony........................
E-ID1G-06-s5. Programowanie współbieżne. Informatyka I stopień (I stopień / II stopień) Ogólno akademicki (ogólno akademicki / praktyczny)
 Ogólno akademicki (ogólno akademicki / praktyczny)") KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu E-ID1G-06-s5 Nazwa modułu Programowanie współbieżne Nazwa modułu w języku angielskim Concurrent
KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu E-ID1G-06-s5 Nazwa modułu Programowanie współbieżne Nazwa modułu w języku angielskim Concurrent
OpenMP środowisko programowania komputerów równoległych ze wspólną pamięcią
 Pro Dialog 15 (2003), 107 121 Wydawnictwo NAKOM Poznań OpenMP środowisko programowania komputerów równoległych ze wspólną pamięcią Monika DEMICHOWICZ, Paweł MAZUR Politechnika Wrocławska, Wydział Informatyki
Pro Dialog 15 (2003), 107 121 Wydawnictwo NAKOM Poznań OpenMP środowisko programowania komputerów równoległych ze wspólną pamięcią Monika DEMICHOWICZ, Paweł MAZUR Politechnika Wrocławska, Wydział Informatyki
Pytania przykładowe (z ubiegłych lat) na zaliczenie przedmiotu Przetwarzanie równoległe Przygotował Rafał Walkowiak Poznań 3.01.
 na zaliczenie przedmiotu Przetwarzanie równoległe Przygotował Rafał Walkowiak Poznań 3.01.") Pytania przykładowe (z ubiegłych lat) na zaliczenie przedmiotu Przetwarzanie równoległe Przygotował Rafał Walkowiak Poznań 3.01.2013 Przetwarzanie w systemach z pamięcią współdzieloną 1. Procesory systemu
Pytania przykładowe (z ubiegłych lat) na zaliczenie przedmiotu Przetwarzanie równoległe Przygotował Rafał Walkowiak Poznań 3.01.2013 Przetwarzanie w systemach z pamięcią współdzieloną 1. Procesory systemu
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Wstęp. Historia i przykłady przetwarzania współbieżnego, równoległego i rozproszonego. Przetwarzanie współbieżne, równoległe i rozproszone
 Wstęp. Historia i przykłady przetwarzania współbieżnego, równoległego i rozproszonego 1 Historia i pojęcia wstępne Przetwarzanie współbieżne realizacja wielu programów (procesów) w taki sposób, że ich
Wstęp. Historia i przykłady przetwarzania współbieżnego, równoległego i rozproszonego 1 Historia i pojęcia wstępne Przetwarzanie współbieżne realizacja wielu programów (procesów) w taki sposób, że ich
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: moduł specjalności obowiązkowy: Inżynieria oprogramowania, Sieci komputerowe Rodzaj zajęć: wykład, laboratorium MODELOWANIE I SYMULACJA Modelling
Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: moduł specjalności obowiązkowy: Inżynieria oprogramowania, Sieci komputerowe Rodzaj zajęć: wykład, laboratorium MODELOWANIE I SYMULACJA Modelling
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
PROCESOR Z ODBLOKOWANYM MNOŻNIKIEM!!! PROCESOR INTEL CORE I7 4790K LGA1150 BOX
 amigopc.pl 883-364-274 SKLEP@AMIGOPC.PL PROCESOR INTEL CORE I7-4790K QUAD CORE, 4.00GHZ, 8MB, LGA1150, 22NM, 84W, VGA, BOX CENA: 1 473,00 PLN CZAS WYSYŁKI: 24H PRODUCENT: INTEL NUMER KATALOGOWY: BX80646I74790K
amigopc.pl 883-364-274 SKLEP@AMIGOPC.PL PROCESOR INTEL CORE I7-4790K QUAD CORE, 4.00GHZ, 8MB, LGA1150, 22NM, 84W, VGA, BOX CENA: 1 473,00 PLN CZAS WYSYŁKI: 24H PRODUCENT: INTEL NUMER KATALOGOWY: BX80646I74790K
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++
 Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona
 Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Zrównoleglenie i przetwarzanie potokowe
 Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Przetwarzanie wielowątkowe przetwarzanie współbieżne. Krzysztof Banaś Obliczenia równoległe 1
 Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Egzamin / zaliczenie na ocenę*
 WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI Zał. nr 4 do ZW33/01 KARTA PRZEDMIOTU Nazwa w języku polskim : INŻYNIERIA OPROGRAMOWANIA Nazwa w języku angielskim: SOFTWARE ENGINEERING Kierunek studiów (jeśli
WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI Zał. nr 4 do ZW33/01 KARTA PRZEDMIOTU Nazwa w języku polskim : INŻYNIERIA OPROGRAMOWANIA Nazwa w języku angielskim: SOFTWARE ENGINEERING Kierunek studiów (jeśli