Komputery równoległe. Zbigniew Koza. Wrocław, 2012
|
|
|
- Natalia Żukowska
- 9 lat temu
- Przeglądów:
Transkrypt
1 Komputery równoległe Zbigniew Koza Wrocław, 2012

2 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych

3 Przykład: prognoza pogody Założenia: Siatka obliczeniowa: 700 km x 700 km x 15 km Komórki sześcienne o krawędzi 100 m 6 liczb na komórkę 100 operacji na komórkę na jednostkę czasu Krok symulacji: 2 minuty Prędkość procesora: 4 Gflops Cel symulacji: prognoza 4-dniowa

4 Przykład: prognoza pogody Wynik: Czas obliczeń: 6 dni Zapotrzebowanie na dane: 350 GB W rzeczywistych warunkach potrzebne by było minimum 3,5 TB

5 Przykład: prognoza pogody Jaki komputer zakończy symulacje w pół godziny? 1 Tflops (10 12 operacji na sekundę) Dane nie mogłyby być odległe od procesora dalej niż 0,12 mm W technologii planarnej bajt musiałby być kodowany na obszarze mniejszym od atomu

6 Dlaczego komputery równoległe? 10 lat temu w ciągu 5 lat procesory przyspieszały 10 razy Obecnie wydajność pojedynczego (rdzenia) praktycznie się już nie zmienia; główny postęp spowodowany jest zwiększeniem wielkości i szybkości buforów podręcznych (cache); za to szybko rośnie liczba dostępnych rdzeni The free lunch is over! (Herb Sutter, Dr. Dobb's Journal, 30(3), March 2005)
; za to szybko rośnie liczba dostępnych")
7 The free lunch is over
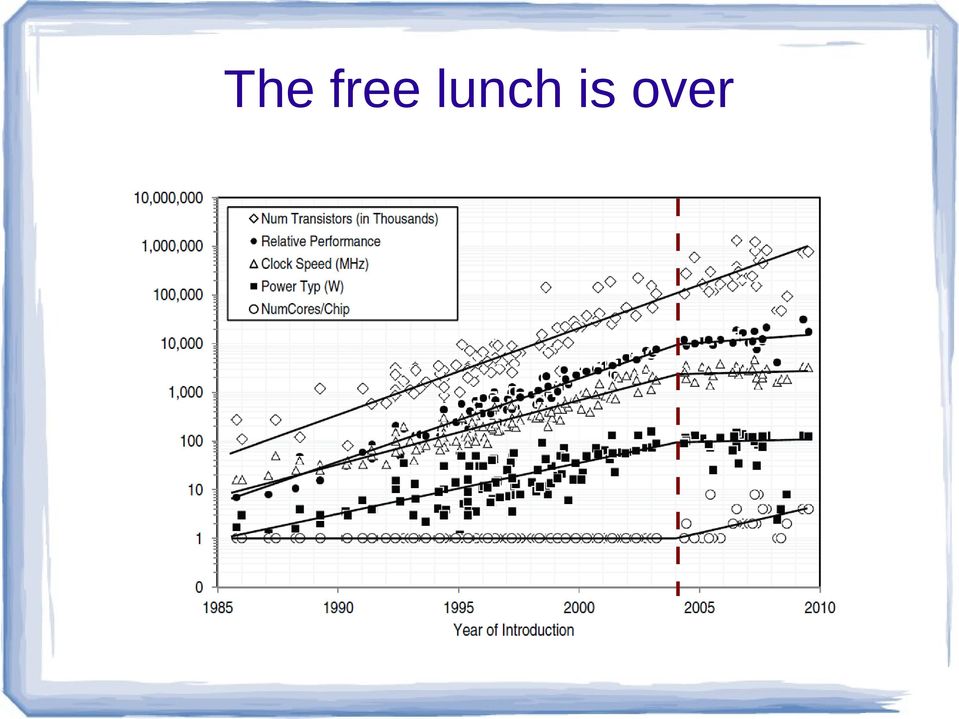
8 Zastosowania Prognoza pogody dla Europy; świata Globalne zmiany klimatyczne Dynamika płynów, zwłaszcza turbulencje Google search Dane astronomiczne CERN Technologie nuklearne (moratorium na wybuchy) Biologia, chemia, fizyka obliczeniowa, nowe materiały Projektowanie układów scalonych Etc.

9 The third pillar of science obserwacja symulacje numeryczne eksperyment teoria

10 Definicje Komputer równoległy Komputer składający się z wielu procesorów Multikomputer SMP (symmetrical multiprocessor) Wiele komputerów połączonych siecią Procesory mają dostęp do wspólnej pamięci

11 Programowanie równoległe Programowanie w języku, który w sposób jawny pozwala wskazać, w jaki sposób różne fragmenty programu mogą się wykonywać jednocześnie na różnych procesorach Nie istnieją metody efektywnego, automatycznego zrównoleglania kodu szeregowego...

12 Obliczenia równoległe Obliczenia wykonywane na komputerach równoległych :-) Obliczenia współbieżne (ang. concurrent) Obliczenia, w których pewne obliczenia zaczynają się, zanim inne się skończą. Mogą być wykonywane na 1 procesorze Obliczenia rozproszone (ang. distributed) Obliczenia w systemach bez globalnej przestrzeni adresowej

13 Obliczenia równoległe Obliczenia wykonywane na komputerach równoległych :-) Obliczenia współbieżne (ang. concurrent) Obliczenia, w których pewne obliczenia zaczynają się, zanim inne się skończą. Mogą być wykonywane na 1 procesorze Obliczenia rozproszone (ang. distributed) Obliczenia w systemach bez globalnej przestrzeni adresowej

14 Historia 1943: ENIAC 350 flops 1976: Cray Mflops 1981: Cosmic Cube 5-10 Mflops, 64 Intel : Beowolf, klastry linuksowe 1 Gflops / 50000$ 1997: ASCI Red 1 Tflops, 9000 x Intel Pentium II 2012: Sequoia 16 Pflops rdzeni 7.8 MW 1.6 PB (peta bajtów) Linux Cel na 2020: 1 Eflops (exaflop/s) / 20 MW

15 Rodzaje równoległości DLP (data level parallelism) równolegość na poziomie danych TLP (task level paralleism, functional parallelism) równoległość na poziomie zadań Pipelining przetwarzanie potokowe ILP (instruction level parallelism) równoległość na poziomie instrukcji (na poziomie procesora)
 równoległość na poziomie instrukcji (na")
16 Ziarnistość Równoległość gruboziarnista (Coarse-grained parallelism) Na poziomie funkcji Równoległość drobnoziarnista (Fine-grained parallelism) Na poziomie pojedynczych instrukcji
 Na poziomie")
17 Paradygmaty programowania równoległego Zrównoleglający kompilator Fortran OpenMP Rozszerzenie istniejącego sekwencyjnego języka programowania MPI, pthreads, CUDA Dodanie warstwy zrównoleglającej zadania szeregowe Stworzenie specjalnego języka programowania równoległego Occam, Fortran 90, C*

18 Paradygmaty programowania równoległego Nie ma jednego paradygmatu Sposób programowania zależy od sprzętu lub innych czynników, np. zgodności z istniejącym oprogramowaniem

19 Bariery Suddenly, even simple tasks, programmed by experienced programmers who were dedicated to the idea of making parallel programming a practical reality, seemd to lead inevitably to upsetting, unpredictable, and totally mystifying bugs

20 Bariery The behavior of even quite short parallel programs can be astonishingly complex. The fact that a program functions correctly once, or even one hundred times, with some particular set of inputs, is no guarantee it will not fail tomorrow with the same inputs

21 Architektury równoległe Komputery połączone w sieci Macierze procesorów Multiprocesory Multikomputery
22 Komputery połączone w sieci Sposób komunikacji: Łącze współdzielone Przełączniki
23 Komputery połączone w sieci Przełączniki (switches): są szybsze gwarantują lepsze skalowanie umożliwiają jednoczesną komunikację między wieloma węzłami lub w obu kierunkach zwykle łączą ze sobą tylko kilka z setek/tysięcy komputerów topologia sieci!
24 Parametry sieci Średnica Szerokość bisekcji Liczba połączeń na węzeł Długość łącza (stała lub nie) Liczba przełączników
25 Główne rodzaje topologii sieci: Siatka 2D Drzewo binarne Hypertree network Sieć typu motyl (butterfly) Sieć typu shufle and exchange

26 Macierze procesorów Do zadań równoległych na poziomie danych Danych musi być dużo Ograniczone pole zastosowań Tylko 1 instrukcja na raz! (drastyczny spadek wydajności w instrukcjach warunkowych)
27 Multiprocesory Są to komputery z wieloma jednostkami centralnymi przyłączonymi do tej samej pamięci, tzw. pamięci współdzielonej (shared memory) Powszechne na rynku (procesory Intel, AMD) UMA = Uniform Memory Acces SMP Symmetric multiprocessor Bufory pamięci podręcznej (cache) <-> pamięć główna Cache coherence problem Synchronizacja procesorów Mutex Bariera
28 Multiprocesory NUMA NUMA Nonuniform Memory Access Multiprocesory typu NUMA dzielą spólną przestrzeń adresową, ale dostęp do różnych jej obszarów może wymagać innego czasu ccnuma Cache Ceherent Nonuniform Memory Access
29 Multikomputery Klastry komputerów połączonych siecią, każdy komputer ma osobną przestrzeń adresową. Symetryczne Asymetryczne
30 Taksonomia Flynna SISD kalkulatory? SIMD np. processor arrays MISD np. W cyfrowej obróbce obrazów MIMD niemal wszystkie współczesne komputery
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Architektura Komputerów
 1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD. Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej
 Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
 1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Klasyfikacja systemów komputerowych. Architektura von Neumanna. dr inż. Jarosław Forenc
 Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne.
 Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine
 - Parallel Random Access Machine") 21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
Składowanie, archiwizacja i obliczenia modelowe dla monitorowania środowiska Morza Bałtyckiego
 Składowanie, archiwizacja i obliczenia modelowe dla monitorowania środowiska Morza Bałtyckiego Rafał Tylman 1, Bogusław Śmiech 1, Marcin Wichorowski 2, Jacek Wyrwiński 2 1 CI TASK Politechnika Gdańska,
Składowanie, archiwizacja i obliczenia modelowe dla monitorowania środowiska Morza Bałtyckiego Rafał Tylman 1, Bogusław Śmiech 1, Marcin Wichorowski 2, Jacek Wyrwiński 2 1 CI TASK Politechnika Gdańska,
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Wstęp. Przetwarzanie współbieżne, równoległe i rozproszone
 Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (28.03.2011) Rok akademicki 2010/2011, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (28.03.2011) Rok akademicki 2010/2011, Wykład
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Wprowadzenie. Klastry komputerowe. Superkomputery. informatyka +
 Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2009/2010 Wykład nr 6 (15.05.2010) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2009/2010 Wykład nr 6 (15.05.2010) dr inż. Jarosław Forenc Rok akademicki
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI
 ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
GRIDY OBLICZENIOWE. Piotr Majkowski
 GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (06.05.2011) Rok akademicki 2010/2011, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (06.05.2011) Rok akademicki 2010/2011, Wykład
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona
 Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Analiza ilościowa w przetwarzaniu równoległym
 Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Klasyfikacja systemów komputerowych. Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż. Jarosław Forenc
 Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011
Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Architektura von Neumanna. Jak zbudowany jest współczesny komputer? Schemat architektury typowego PC-ta. Architektura PC wersja techniczna
 Architektura von Neumanna CPU pamięć wejście wyjście Jak zbudowany jest współczesny komputer? magistrala systemowa CPU jednostka centralna (procesor) pamięć obszar przechowywania programu i danych wejście
Architektura von Neumanna CPU pamięć wejście wyjście Jak zbudowany jest współczesny komputer? magistrala systemowa CPU jednostka centralna (procesor) pamięć obszar przechowywania programu i danych wejście
Systemy operacyjne. Systemy operacyjne. Systemy operacyjne. Zadania systemu operacyjnego. Abstrakcyjne składniki systemu. System komputerowy
 Systemy operacyjne Systemy operacyjne Dr inż. Ignacy Pardyka Literatura Siberschatz A. i inn. Podstawy systemów operacyjnych, WNT, Warszawa Skorupski A. Podstawy budowy i działania komputerów, WKiŁ, Warszawa
Systemy operacyjne Systemy operacyjne Dr inż. Ignacy Pardyka Literatura Siberschatz A. i inn. Podstawy systemów operacyjnych, WNT, Warszawa Skorupski A. Podstawy budowy i działania komputerów, WKiŁ, Warszawa
Obliczenia równoległe. Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl http://aragorn.pb.bialystok.pl/~wkwedlo pokój 205
 Obliczenia równoległe Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl http://aragorn.pb.bialystok.pl/~wkwedlo pokój 205 Plan wykładu (1) Wstęp (2) Programowanie systemów z przesyłaniem
Obliczenia równoległe Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl http://aragorn.pb.bialystok.pl/~wkwedlo pokój 205 Plan wykładu (1) Wstęp (2) Programowanie systemów z przesyłaniem
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
MMX i SSE. Zbigniew Koza. Wydział Fizyki i Astronomii Uniwersytet Wrocławski. Wrocław, 10 marca 2011. Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16
 MMX i SSE 1 / 16") MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1
 Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1 Historia i pojęcia wstępne Obliczenia równoległe: dwa lub więcej procesów (wątków) jednocześnie współpracuje (komunikując się wzajemnie)
Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1 Historia i pojęcia wstępne Obliczenia równoległe: dwa lub więcej procesów (wątków) jednocześnie współpracuje (komunikując się wzajemnie)
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Mikroprocesory rodziny INTEL 80x86
 Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
System mikroprocesorowy i peryferia. Dariusz Chaberski
 System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Architektura Systemów Komputerowych. Architektura potokowa Klasyfikacja architektur równoległych
 Archiekura Sysemów Kompuerowych Archiekura pookowa Klasyfikacja archiekur równoległych 1 Archiekura pookowa Sekwencyjne wykonanie programu w mikroprocesorze o archiekurze von Neumanna Insr.1 Φ1 Insr.1
Archiekura Sysemów Kompuerowych Archiekura pookowa Klasyfikacja archiekur równoległych 1 Archiekura pookowa Sekwencyjne wykonanie programu w mikroprocesorze o archiekurze von Neumanna Insr.1 Φ1 Insr.1
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Systemy rozproszone. Państwowa Wyższa Szkoła Zawodowa w Chełmie. ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej w Lublinie
 Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
Uniwersytet w Białymstoku Wydział Ekonomiczno-Informatyczny w Wilnie SYLLABUS na rok akademicki 2010/2011
 SYLLABUS na rok akademicki 010/011 Tryb studiów Studia stacjonarne Kierunek studiów Informatyka Poziom studiów Pierwszego stopnia Rok studiów/ semestr 1(rok)/1(sem) Specjalność Bez specjalności Kod katedry/zakładu
SYLLABUS na rok akademicki 010/011 Tryb studiów Studia stacjonarne Kierunek studiów Informatyka Poziom studiów Pierwszego stopnia Rok studiów/ semestr 1(rok)/1(sem) Specjalność Bez specjalności Kod katedry/zakładu
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Dostęp do europejskich systemów obliczeniowych Tier-0 w ramach PRACE
 Dostęp do europejskich systemów obliczeniowych Tier-0 w ramach PRACE KONFERENCJA UŻYTKOWNIKÓW KDM 2016 W kierunku obliczeń Exaskalowych Mirosław Kupczyk, PCSS 28.06.2016 Misja PRACE HPC Dla Przemysłu Zagwarantowanie
Dostęp do europejskich systemów obliczeniowych Tier-0 w ramach PRACE KONFERENCJA UŻYTKOWNIKÓW KDM 2016 W kierunku obliczeń Exaskalowych Mirosław Kupczyk, PCSS 28.06.2016 Misja PRACE HPC Dla Przemysłu Zagwarantowanie
Programowanie współbieżne. Iwona Kochańska
 1 Programowanie współbieżne Iwona Kochańska 2 Organizacja przedmiotu Wykład: 1 godzina tygodniowo (piątek, 10:15) 2 kolokwia w trakcie semestru Ocena końcowa: 0.5*(średnia z kolokw.)+0.5*projekt Projekt:
1 Programowanie współbieżne Iwona Kochańska 2 Organizacja przedmiotu Wykład: 1 godzina tygodniowo (piątek, 10:15) 2 kolokwia w trakcie semestru Ocena końcowa: 0.5*(średnia z kolokw.)+0.5*projekt Projekt:
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
Projektowanie. Projektowanie mikroprocesorów
 WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Zasoby i usługi Wrocławskiego Centrum Sieciowo-Superkomputerowego
 Zasoby i usługi Wrocławskiego Centrum Sieciowo-Superkomputerowego Mateusz Tykierko WCSS 20 stycznia 2012 Mateusz Tykierko (WCSS) 20 stycznia 2012 1 / 16 Supernova moc obliczeniowa: 67,54 TFLOPS liczba
Zasoby i usługi Wrocławskiego Centrum Sieciowo-Superkomputerowego Mateusz Tykierko WCSS 20 stycznia 2012 Mateusz Tykierko (WCSS) 20 stycznia 2012 1 / 16 Supernova moc obliczeniowa: 67,54 TFLOPS liczba
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Systemy operacyjne III
 Systemy operacyjne III WYKŁAD 7 Jan Kazimirski 1 Komputery równoległe 2 Wydajność komputerów Rozwój technologii wiąże się z ciągłym wzrostem wydajności komputerów Pierwsze komputery 1-100 operacji/sek.
Systemy operacyjne III WYKŁAD 7 Jan Kazimirski 1 Komputery równoległe 2 Wydajność komputerów Rozwój technologii wiąże się z ciągłym wzrostem wydajności komputerów Pierwsze komputery 1-100 operacji/sek.
Podstawy programowania obliczeń równoległych
 Podstawy programowania obliczeń równoległych Uniwersytet Marii Curie-Skłodowskiej Wydział Matematyki, Fizyki i Informatyki Instytut Informatyki Podstawy programowania obliczeń równoległych Przemysław
Podstawy programowania obliczeń równoległych Uniwersytet Marii Curie-Skłodowskiej Wydział Matematyki, Fizyki i Informatyki Instytut Informatyki Podstawy programowania obliczeń równoległych Przemysław
Architektura komputerów
 Architektura komputerów Tydzień 4 Tryby adresowania i formaty Tryby adresowania Natychmiastowy Bezpośredni Pośredni Rejestrowy Rejestrowy pośredni Z przesunięciem stosowy Argument natychmiastowy Op Rozkaz
Architektura komputerów Tydzień 4 Tryby adresowania i formaty Tryby adresowania Natychmiastowy Bezpośredni Pośredni Rejestrowy Rejestrowy pośredni Z przesunięciem stosowy Argument natychmiastowy Op Rozkaz
SSE (Streaming SIMD Extensions)
") SSE (Streaming SIMD Extensions) Zestaw instrukcji wprowadzony w 1999 roku po raz pierwszy w procesorach Pentium III. SSE daje przede wszystkim możliwość wykonywania działań zmiennoprzecinkowych na 4-elementowych
SSE (Streaming SIMD Extensions) Zestaw instrukcji wprowadzony w 1999 roku po raz pierwszy w procesorach Pentium III. SSE daje przede wszystkim możliwość wykonywania działań zmiennoprzecinkowych na 4-elementowych
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Symulacje kinetyczne Par2cle In Cell w astrofizyce wysokich energii Wykład 7
 Symulacje kinetyczne Par2cle In Cell w astrofizyce wysokich energii Wykład 7 dr Jacek Niemiec Instytut Fizyki Jądrowej PAN, Kraków Jacek.Niemiec@ifj.edu.pl www.oa.uj.edu.pl/j.niemiec/symulacjenumeryczne
Symulacje kinetyczne Par2cle In Cell w astrofizyce wysokich energii Wykład 7 dr Jacek Niemiec Instytut Fizyki Jądrowej PAN, Kraków Jacek.Niemiec@ifj.edu.pl www.oa.uj.edu.pl/j.niemiec/symulacjenumeryczne
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Welcome to the waitless world. Inteligentna infrastruktura systemów Power S812LC i S822LC
 Inteligentna infrastruktura systemów Power S812LC i S822LC Przedstawiamy nową linię serwerów dla Linux Clouds & Clasters IBM Power Systems LC Kluczowa wartość dla klienta Specyfikacje S822LC Technical
Inteligentna infrastruktura systemów Power S812LC i S822LC Przedstawiamy nową linię serwerów dla Linux Clouds & Clasters IBM Power Systems LC Kluczowa wartość dla klienta Specyfikacje S822LC Technical
Wrocławskie Centrum Sieciowo-Superkomputerowe
 Wrocławskie Centrum Sieciowo-Superkomputerowe Mateusz Tykierko WCSS 26 czerwca 2012 Mateusz Tykierko (WCSS) 26 czerwca 2012 1 / 23 Wstęp Wrocławskie Centrum Sieciowo-Superkomputerowe Jednostka działająca
Wrocławskie Centrum Sieciowo-Superkomputerowe Mateusz Tykierko WCSS 26 czerwca 2012 Mateusz Tykierko (WCSS) 26 czerwca 2012 1 / 23 Wstęp Wrocławskie Centrum Sieciowo-Superkomputerowe Jednostka działająca
HPC na biurku. Wojciech De bski
 na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Programowanie Równoległe i Rozproszone
 Programowanie Równoległe i Rozproszone Lucjan Stapp Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska (l.stapp@mini.pw.edu.pl) 1/69 PRiR Wykład 1 Ćwiczenia Zasady zaliczania Aktywność i
Programowanie Równoległe i Rozproszone Lucjan Stapp Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska (l.stapp@mini.pw.edu.pl) 1/69 PRiR Wykład 1 Ćwiczenia Zasady zaliczania Aktywność i
Projektowanie nowoczesnych mieszadeł elektromagnetycznych dla pieców łukowych z wykorzystaniem HPC. Mirosław Kupczyk (PCSS) Poznań
 Poznań") Projektowanie nowoczesnych mieszadeł elektromagnetycznych dla pieców łukowych z wykorzystaniem HPC Mirosław Kupczyk (PCSS) Poznań 13.09.2016 Projektowanie nowoczesnych mieszadeł elektromagnetycznych dla
Projektowanie nowoczesnych mieszadeł elektromagnetycznych dla pieców łukowych z wykorzystaniem HPC Mirosław Kupczyk (PCSS) Poznań 13.09.2016 Projektowanie nowoczesnych mieszadeł elektromagnetycznych dla
ARCHITEKTURA PROCESORA,
 ARCHITEKTURA PROCESORA, poza blokami funkcjonalnymi, to przede wszystkim: a. formaty rozkazów, b. lista rozkazów, c. rejestry dostępne programowo, d. sposoby adresowania pamięci, e. sposoby współpracy
ARCHITEKTURA PROCESORA, poza blokami funkcjonalnymi, to przede wszystkim: a. formaty rozkazów, b. lista rozkazów, c. rejestry dostępne programowo, d. sposoby adresowania pamięci, e. sposoby współpracy
Systemy rozproszone. na użytkownikach systemu rozproszonego wrażenie pojedynczego i zintegrowanego systemu.
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
High Performance Computers in Cyfronet. Andrzej Oziębło Zakopane, marzec 2009
 High Performance Computers in Cyfronet Andrzej Oziębło Zakopane, marzec 2009 Plan Podział komputerów dużej mocy Podstawowe informacje użytkowe Opis poszczególnych komputerów Systemy składowania danych
High Performance Computers in Cyfronet Andrzej Oziębło Zakopane, marzec 2009 Plan Podział komputerów dużej mocy Podstawowe informacje użytkowe Opis poszczególnych komputerów Systemy składowania danych
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM. Juliusz Pukacki,PCSS
 DLA FIRM. Juliusz Pukacki,PCSS") USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
Zarządzanie rozproszoną siatką obliczeniową w równoległych symulacjach adaptacyjną metodą elementów skończonych
 Instytut Podstawowych Problemów Techniki Polska Akademia Nauk Zarządzanie rozproszoną siatką obliczeniową w równoległych symulacjach adaptacyjną metodą elementów skończonych Kazimierz Michalik Promotor:
Instytut Podstawowych Problemów Techniki Polska Akademia Nauk Zarządzanie rozproszoną siatką obliczeniową w równoległych symulacjach adaptacyjną metodą elementów skończonych Kazimierz Michalik Promotor:
dr inż. Konrad Sobolewski Politechnika Warszawska Informatyka 1
 dr inż. Konrad Sobolewski Politechnika Warszawska Informatyka 1 Cel wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działanie systemu operacyjnego
dr inż. Konrad Sobolewski Politechnika Warszawska Informatyka 1 Cel wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działanie systemu operacyjnego
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl