Regionalizacja biomasy ubocznej i odpadowej w Polsce i Europie
|
|
|
- Sławomir Wieczorek
- 6 lat temu
- Przeglądów:
Transkrypt
1 Regionalizacja biomasy ubocznej i odpadowej w Polsce i Europie Przemysław Czaban Warsztaty Ocena potencjału biomasy odpadowej i ubocznej oraz skutki środowiskowe produkcji i wykorzystania biomasy IUNG-PIB, 28 maja 2014
2 Ocena potencjału odpadów z produkcji rolniczej dostępnej dla wytwarzania energii Oryginalne opracowanie zawiera dane dla każdej kategorii odpadu obejmujące obszar UE 27 i Szwajcarię w rozdzielczości NUTS 3 Dane te można przedstawid poglądowo na mapach Jednak jedna mapa może przedstawid tylko jedną kategorię W powyższym przypadku całościowa analiza wymaga pracy z dziesięcioma mapami W celu zredukowania wielowymiarowego zbioru danych do zbioru jednowymiarowego, który dawałby możliwośd łatwiejszej poglądowej oceny danych posłużono się analizą skupieo
3 W ocenie potencjałów biomasy, populację badanych obiektów tworzą europejskie regiony NUTS 3 (1313 regionów) Każdy z nich jest scharakteryzowany zestawem dziesięciu cech wcześniej obliczonym potencjałem dla każdego z dziesięciu rodzajów biomasy odpadowej o 1.1. Nawozy naturalne o 1.2. Słoma o 1.3. Siano o 1.4. Plantacje wieloletnie o 2.0. Biomasa leśna o 3.1. Biomasa miejska o 3.2. Przydrożna o 4.1. Odpady komunalne o 4.2. Odpady przemysłu spożywczego o 4.3. Odpady przemysłu drzewnego W ten sposób pojawia się dziesięciowymiarowa przestrzeo cech mierzalnych W tej przestrzeni można określid odległośd między obiektami, np. za pomocą metryki euklidesowej
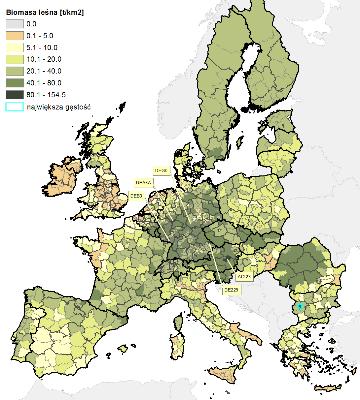
4
5 10 map 10-cio wymiarowa przestrzeo danych Trudna do jednoczesnej analizy
6 Cechy analizy skupieo: Z wyjściowego zbioru danych wydziela jednorodne zbiory danych o podobnej charakterystyce. Jest możliwa do zastosowania bardzo szerokiej klasy danych (przy doborze odpowiedniej metody analizy skupieo). Wystarczy aby dla danych można było określid pewną miarę odległości. Duże trudności w interpretacji (brak jednoznacznej definicji skupienia).
7 Człowiek jest w stanie w doskonały sposób zrobid analizę skupieo za pomocą wykresu rozrzutu i swojego wzroku Ale tylko w dwóch, ewentualnie trzech wymiarach
8 1. Pierwszy krok w przeprowadzonej analizie skupieo: Wybór zmiennych, które mają największy potencjał różnicujący Zastosowano metodę HINoV (Heuristic Identification of Noisy Variables) (Carmone F.J., Kara A., Maxwell S.) opierającą się wyliczeniu odpowiedniego wskaźnika dla założonej liczby skupieo i analizie wykresów osypiska
9
10 Analizy wykresów osypiska wskazują dośd jednoznacznie, że w następnych krokach należy pominąd zmienne 3, 1 i 2 (siano, biomasę uboczną z produkcji zwierzęcej i słomę) Jednakże uznano, iż zmienna 2 (słoma) jest na tyle ważna z punktu widzenia sumarycznego zasobu biomasy w Europie, że usunięcie jej z dalszych obliczeo bardzo zubożyłoby analizę.
11 Wybór metody Pierwsze próby: metody aglomeracyjne brak dobrych efektów (skupienia o bardzo nierównomiernej liczebności i słabo od siebie odseparowane); Następne próby: metoda k-średnich lepsze, obiecujące efekty; Metoda k-średnich wymaga podania z góry liczby skupieo Zastosowano algorytmiczne określenie najlepszej liczby klas poprzez sprawdzenie kilku metod postępowania przy jednoczesnym nadzorze eksperckim, aby finalne skupienia oprócz technicznego uproszczenia zbioru danych dawały interpretowalny obraz w sensie badanego zjawiska
12 Algorytm oparty na indeksie Calioskiego i Harabasza, dany wzorem (Calioski i Harabasz 1974): CH u = tr(b u)/(u 1) tr(w u )/(n u) W powyższym wzorze B u to macierz kowariancji międzyklasowej, zaś W u to macierz kowariancji wewnątrzklasowej, n liczba punktów, zaś u liczba skupieo. Przez tr(a) oznaczono ślad macierzy A. Procedura polega na wyliczeniu indeksu dla wybranego zbioru potencjalnych liczby skupieo i wybraniu takiej liczby skupieo dla której indeks przyjmuje maximum, czyli: u = arg max CH u. u
13 Algorytm oparty na indeksie Huberta i Levina, dany wzorem (Milligan i Cooper 1985): HL u = D u I w D min, I w D max I w D min gdzie D(u) to suma wszystkich odległości międzyklasowych, I w liczba odległości wewnątrzklasowych, D min (u) najmniejsza odległośd wewnątrzklasowa, zaś D max (u) największa odległośd międzyklasowa. W odróżnieniu od punktu 1 należy wybrad u = arg min u HL u.
14 Algorytm oparty na indeksie Krzanowskiego i Lai, dany wzorem (Krzanowski i Lai 1985, Tibshirani i in. 2001): KL u = (u 1) 2/m tr(w u 1 ) u 2 m tr(w u ) (u) 2/m tr(w u ) u+1 2 m tr(w u+1 ), gdzie m to liczba zmiennych. Pozostałe symbole jak wyżej. Podobnie jak w punkcie 1, należy wybrać u = arg max KL u. u
15 Algorytm oparty na indeksie Daviesa i Bouldina dany wzorem (Davies i Bouldin 1979): DB u = 1 u S r = 1 nr p u r=1 max s,r s i P r m j=1 S r +S s d rs,gdzie x ij r z rj q 1 q, zaś m p d rs = z rj z sj, x r ij to j-ta współrzędna i-tego j=1 elemntu klasy r, z rj j-ta współrzędna środka ciężkości r-tej klasy, a P r -zbiór obiektów tejże klasy; q i p to parametry, zazwyczaj przyjmuje się 1 lub 2. W tym punkcie tak jak w przypadku metody Huberta i Levina należy wybrać u = arg min u DB u.
16 Algorytm oparty na indeksie Hartigana dany wzorem (Hartigan 1975): H u = tr(w u) 1 n u 1. tr(w u+1 ) Dla tego algorytmu optymalną liczbą klas jest najmniejsze u, którego H(u) 10. W wyniku przeprowadzonych testów otrzymano wiele zbyt różniących się przesłanek do wyboru liczby klas skupień (tab. 18).
17 Algorytm Liczba klas 1 Algorytm oparty na indeksie Calioskiego i Harabasza Algorytm oparty na indeksie Huberta i Levina 10 3 Algorytm oparty na indeksie Krzanowskiego i Lai Algorytm oparty na indeksie Daviesa i Bouldina 5 5 Algorytm oparty na indeksie Hartigana >=10
18 Rozbieżności w sugerowanej przez algorytmy liczbie skupieo wskazują na, między innymi, dwa fakty: trudności interpretacyjne w analizie skupieo; struktura klasowa w badanym zbiorze danych jest słabo wykształcona Zastosowano matematyczny miernik siły struktury klasowej
19 Miernik siły struktury klasowej, oparty na indeksie Silhouette, dany jest poniższym wzorem: S u = 1 n n i=1 b i a(i) max *a i, b i + gdzie: a i = d ik k *P r \i+, (n r 1) b i = min s r *d i P s +, d i Ps = k P s odpowiednio zbiór obiektów klasy r i s. d ik n s,p r i P s to
20 Liczba skupieo Indeks Silhouette 1 NA 2 0,24 3 0,29 4 0,33 5 0,33 6 0,34 7 0,27 8 0,28 9 0, ,27 indeks Silhouette dla liczby klas równej 6 wynosi 0,34, według autorów metody (Kaufmana i Rousseeuwa) świadczy o słabej, ale występującej strukturze klas
21 Wyniki analizy skupieo przeprowadzonej metodą k-średnich dla liczby skupieo równej 6. Ocena za pomocą dwuwymiarowych wykresów rozrzutu.
22 Analiza danych za pomocą dwuwymiarowych wykresów rozrzutu Przestrzeo danych jest ośmiowymiarowa (z powodu odrzucenia dwóch zmiennych na etapie analizy HINoV) niemożliwa do oceny wzrokowej przez człowieka. Możliwa jest natomiast wzrokowa analiza dwuwymiarowych płaszczyzn, którymi wyjściowa przestrzeo jest przecinana.

23 1.2 Słoma 1.4 Plantacje wieloletnie 2.0 Biomasa leśna 3.1 Biomasa miejska 3.2 Przydrożna 4.1 Odpady komunalne 4.2 Odpady przemysłu spożywczego 4.3 Odpady przemysłu drzewnego Ośmiowymiarowa przestrzeo analizy skupieo zwizualizowana dla wszystkich klas w symetrycznej macierzy

24 1.2 Słoma 1.4 Plantacje wieloletnie 2.0 Biomasa leśna 3.1 Biomasa miejska 3.2 Przydrożna 4.1 Odpady komunalne 4.2 Odpady przemysłu spożywczego 4.3 Odpady przemysłu drzewnego Powiększony obraz przestrzeni analizy skupieo, w których żadna cecha nie odchyla się od średniej o więcej niż 6 odchyleo standardowych.

25 1.2 Słoma 1.4 Plantacje wieloletnie 2.0 Biomasa leśna 3.1 Biomasa miejska 3.2 Przydrożna 4.1 Odpady komunalne 4.2 Odpady przemysłu spożywczego 4.3 Odpady przemysłu drzewnego Losowo wybrana próba 200 NUTS-3

26 Wynikowa mapa analizy skupieo skupienie sadowniczo-spożywcze skupienie leśne skupienie pośrednie skupienie supermiejskie skupienie rolnicze skupienie miejskie
27 Typ biomasy Słoma Uprawy sadownicz e Biomasa leśna Biomasa miejska Biomasa przydrożn a Odpady komunaln e Odpady przem. spoz. Odpady przem. drzew. Zmienna Klasa; b.1.2 b.1.4 b.2.0 b.3.1 b.3.2 b.4.1 b.4.2 b ,1 (-0,3) 35,3 (3,4) 12,5 (-0,6) 0,2 (-0,4) 1,6 (-0,1) 33,2 (-0,2) 38,0 (2,8) 0,4 (-0,8) 2 20,2 (-0,3) 1,0 (-0,2) 47,0 (1,1) 0,3 (-0,3) 1,4 (-0,2) 20,1 (-0,3) 0,5 (-0,2) 2,6 (1,2) 3 32,6 (0,0) 1,9 (-0,1) 14,4 (-0,5) 0,6 (-0,2) 1,2 (-0,2) 42,4 (-0,1) 1,3 (-0,1) 0,7 (-0,6) 4 3,0 (-0,7) 0,0 (-0,3) 5,5 (-1,0) 9,7 (4,3) 14,1 (5,7) 1682,3 (8,7) 0,0 (-0,2) 0,4 (-0,8) 5 154,1 (2,7) 2,4 (-0,1) 14,0 (-0,5) 0,4 (-0,3) 1,1 (-0,3) 24,8 (-0,2) 4,3 (0,1) 0,6 (-0,6) 6 13,8 (-0,5) 0,6 (-0,3) 10,8 (-0,7) 6,1 (2,5) 5,4 (1,7) 329,5 (1,4) 0,5 (-0,2) 0,6 (-0,6)
28 Podejście do regionalizacji nakierowane na określenie preferowanego procesu przetwarzania biomasy W ramach projektu BioBoost została określona preferowana kolejnośd surowców dla poszczególnych typów przetwarzania biomasy: Szybka Piroliza Miskant Odpady przemysłu drzewnego Słoma pszeniczna Piroliza katalityczna Drewno bukowe Miskant Słoma pszeniczna Karbonizacja hydrotermalna Organiczne odpady komunalne Odpady browarnicze Wheat straw
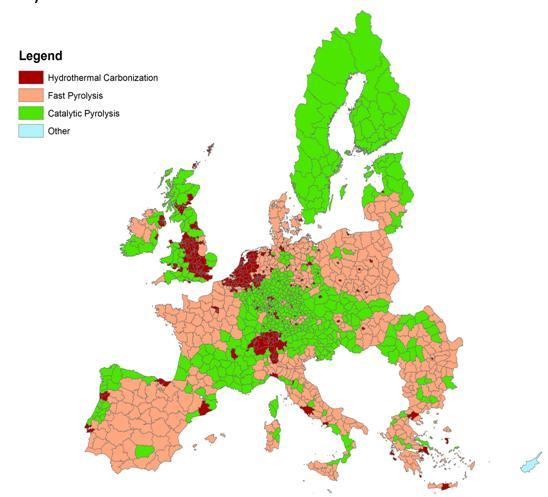
29
30 Dziękuję za uwagę
Magdalena Borzęcka-Walker. Wykorzystanie produktów opartych na biomasie do rozwoju produkcji biopaliw
 Magdalena Borzęcka-Walker Wykorzystanie produktów opartych na biomasie do rozwoju produkcji biopaliw Cele Ocena szybkiej pirolizy (FP), pirolizy katalitycznej (CP) oraz hydrotermalnej karbonizacji (HTC),
Magdalena Borzęcka-Walker Wykorzystanie produktów opartych na biomasie do rozwoju produkcji biopaliw Cele Ocena szybkiej pirolizy (FP), pirolizy katalitycznej (CP) oraz hydrotermalnej karbonizacji (HTC),
OCENA WYBRANYCH PROCEDUR ANALIZY SKUPIEŃ DLA DANYCH PORZĄDKOWYCH. 1. Wstęp
 PRACE NAUKOWE UNIWERSYTETU EKONOMICZNEGO WE WROCŁAWIU Nr 47 009 TAKSONOMIA 16 Klasyfikacja i analiza danych teoria i zastosowania Uniwersytet Ekonomiczny we Wrocławiu OCENA WYBRANYCH PROCEDUR ANALIZY SKUPIEŃ
PRACE NAUKOWE UNIWERSYTETU EKONOMICZNEGO WE WROCŁAWIU Nr 47 009 TAKSONOMIA 16 Klasyfikacja i analiza danych teoria i zastosowania Uniwersytet Ekonomiczny we Wrocławiu OCENA WYBRANYCH PROCEDUR ANALIZY SKUPIEŃ
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Analiza składowych głównych
 Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb
 Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Biomasa uboczna z produkcji rolniczej
 Biomasa uboczna z produkcji rolniczej dr Zuzanna Jarosz Warsztaty Systemy informacji o wpływie zmian klimatu i zasobach biomasy Puławy, 01 grudnia 2015 r. Głównym postulatem Unii Europejskiej, a także
Biomasa uboczna z produkcji rolniczej dr Zuzanna Jarosz Warsztaty Systemy informacji o wpływie zmian klimatu i zasobach biomasy Puławy, 01 grudnia 2015 r. Głównym postulatem Unii Europejskiej, a także
Ocena możliwości rozwoju upraw wieloletnich na cele energetyczne z uwzględnieniem skutków środowiskowych i bezpieczeostwa żywnościowego Antoni Faber
 Ocena możliwości rozwoju upraw wieloletnich na cele energetyczne z uwzględnieniem skutków środowiskowych i bezpieczeostwa żywnościowego Antoni Faber Warsztaty Ocena potencjału biomasy odpadowej i ubocznej
Ocena możliwości rozwoju upraw wieloletnich na cele energetyczne z uwzględnieniem skutków środowiskowych i bezpieczeostwa żywnościowego Antoni Faber Warsztaty Ocena potencjału biomasy odpadowej i ubocznej
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Geoinformacja zasobów biomasy na cele energetyczne
 Geoinformacja zasobów biomasy na cele energetyczne Anna Jędrejek Zakład Biogospodarki i Analiz Systemowych GEOINFORMACJA synonim informacji geograficznej; informacja uzyskiwana poprzez interpretację danych
Geoinformacja zasobów biomasy na cele energetyczne Anna Jędrejek Zakład Biogospodarki i Analiz Systemowych GEOINFORMACJA synonim informacji geograficznej; informacja uzyskiwana poprzez interpretację danych
Zasoby biomasy w Polsce
 Zasoby biomasy w Polsce Ryszard Gajewski Polska Izba Biomasy POWIERZCHNIA UŻYTKÓW ROLNYCH W UE W PRZELICZENIU NA JEDNEGO MIESZKAŃCA Źródło: ecbrec ieo DEFINICJA BIOMASY Biomasa stałe lub ciekłe substancje
Zasoby biomasy w Polsce Ryszard Gajewski Polska Izba Biomasy POWIERZCHNIA UŻYTKÓW ROLNYCH W UE W PRZELICZENIU NA JEDNEGO MIESZKAŃCA Źródło: ecbrec ieo DEFINICJA BIOMASY Biomasa stałe lub ciekłe substancje
POSSIBILITIES OF USING BIOMASS IN POLAND
 POSSIBILITIES OF USING BIOMASS IN POLAND Ryszard Gajewski POLSKA IZBA BIOMASY www.biomasa.org.pl Miskolc, 28 kwietnia 2011 r. Powierzchnia użytków rolnych w UE w przeliczeniu na jednego mieszkańca Źródło:
POSSIBILITIES OF USING BIOMASS IN POLAND Ryszard Gajewski POLSKA IZBA BIOMASY www.biomasa.org.pl Miskolc, 28 kwietnia 2011 r. Powierzchnia użytków rolnych w UE w przeliczeniu na jednego mieszkańca Źródło:
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
MOŻLIWOŚCI POZYSKANIA BIOMASY DRZEWNEJ DO CELÓW ENERGETYCZNYCH W SADOWNICTWIE I LEŚNICTWIE
 MOŻLIWOŚCI POZYSKANIA BIOMASY DRZEWNEJ DO CELÓW ENERGETYCZNYCH W SADOWNICTWIE I LEŚNICTWIE Dr inż. Stanisław Parzych, Dr inż. Agnieszka Mandziuk Wydział Leśny SGGW w Warszawie Mgr inż. Sebastian Dawidowski
MOŻLIWOŚCI POZYSKANIA BIOMASY DRZEWNEJ DO CELÓW ENERGETYCZNYCH W SADOWNICTWIE I LEŚNICTWIE Dr inż. Stanisław Parzych, Dr inż. Agnieszka Mandziuk Wydział Leśny SGGW w Warszawie Mgr inż. Sebastian Dawidowski
Wykorzystanie biomasy na cele energetyczne w UE i Polsce
 Wykorzystanie biomasy na cele energetyczne w UE i Polsce dr Zuzanna Jarosz Biogospodarka w Rolnictwie Puławy, 21-22 czerwca 2016 r. Celem nadrzędnym wprowadzonej w 2012 r. strategii Innowacje w służbie
Wykorzystanie biomasy na cele energetyczne w UE i Polsce dr Zuzanna Jarosz Biogospodarka w Rolnictwie Puławy, 21-22 czerwca 2016 r. Celem nadrzędnym wprowadzonej w 2012 r. strategii Innowacje w służbie
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Idea. Algorytm zachłanny Algorytmy hierarchiczne Metoda K-średnich Metoda hierarchiczna, a niehierarchiczna. Analiza skupień
 Idea jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień. Obiekty należące do danego skupienia
Idea jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień. Obiekty należące do danego skupienia
Ocena potencjału biomasy stałej z rolnictwa
 Ocena potencjału biomasy stałej z rolnictwa dr Zuzanna Jarosz Inżynieria rolnicza w ochronie i kształtowaniu środowiska Lublin, 23-24 września 2015 Głównym postulatem Unii Europejskiej, a także Polski,
Ocena potencjału biomasy stałej z rolnictwa dr Zuzanna Jarosz Inżynieria rolnicza w ochronie i kształtowaniu środowiska Lublin, 23-24 września 2015 Głównym postulatem Unii Europejskiej, a także Polski,
Robert Susmaga. Instytut Informatyki ul. Piotrowo 2 Poznań
 ... Robert Susmaga Instytut Informatyki ul. Piotrowo 2 Poznań kontakt mail owy Robert.Susmaga@CS.PUT.Poznan.PL kontakt osobisty Centrum Wykładowe, blok informatyki, pok. 7 Wyłączenie odpowiedzialności
... Robert Susmaga Instytut Informatyki ul. Piotrowo 2 Poznań kontakt mail owy Robert.Susmaga@CS.PUT.Poznan.PL kontakt osobisty Centrum Wykładowe, blok informatyki, pok. 7 Wyłączenie odpowiedzialności
Regresja i Korelacja
 Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Analiza skupień. Idea
 Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Idea Analiza skupień Analiza skupień jest narzędziem analizy danych służącym do grupowania n obiektów, opisanych za pomocą wektora p-cech, w K niepustych, rozłącznych i możliwie jednorodnych grup skupień.
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
UPRAWY ENERGETYCZNE W CENTRALNEJ I WSCHODNIEJ EUROPIE
 UPRAWY ENERGETYCZNE W CENTRALNEJ I WSCHODNIEJ EUROPIE Bioenergia w krajach Europy Centralnej, uprawy energetyczne. Dr Hanna Bartoszewicz-Burczy, Instytut Energetyki 23 kwietnia 2015 r., SGGW 1. Źródła
UPRAWY ENERGETYCZNE W CENTRALNEJ I WSCHODNIEJ EUROPIE Bioenergia w krajach Europy Centralnej, uprawy energetyczne. Dr Hanna Bartoszewicz-Burczy, Instytut Energetyki 23 kwietnia 2015 r., SGGW 1. Źródła
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Znaczenie biomasy leśnej w realizacji wymogów pakietu energetycznoklimatycznego
 Znaczenie biomasy leśnej w realizacji wymogów pakietu energetycznoklimatycznego w Polsce. Ryszard Gajewski POLSKA IZBA BIOMASY www.biomasa.org.pl Łagów, 5 czerwca 2012 r. Wnioski zużycie energii finalnej
Znaczenie biomasy leśnej w realizacji wymogów pakietu energetycznoklimatycznego w Polsce. Ryszard Gajewski POLSKA IZBA BIOMASY www.biomasa.org.pl Łagów, 5 czerwca 2012 r. Wnioski zużycie energii finalnej
Analiza autokorelacji
 Analiza autokorelacji Oblicza się wartości współczynników korelacji między y t oraz y t-i (dla i=1,2,...,k), czyli współczynniki autokorelacji różnych rzędów. Bada się statystyczną istotność tych współczynników.
Analiza autokorelacji Oblicza się wartości współczynników korelacji między y t oraz y t-i (dla i=1,2,...,k), czyli współczynniki autokorelacji różnych rzędów. Bada się statystyczną istotność tych współczynników.
Skalowanie wielowymiarowe idea
 Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Budowa pionowa drzewostanu w świetle przestrzennego rozkładu punktów lotniczego skanowania laserowego
 Budowa pionowa drzewostanu w świetle przestrzennego rozkładu punktów lotniczego skanowania laserowego Marcin Myszkowski Marek Ksepko Biuro Urządzania Lasu i Geodezji Leśnej Oddział w Białymstoku PLAN PREZENTACJI
Budowa pionowa drzewostanu w świetle przestrzennego rozkładu punktów lotniczego skanowania laserowego Marcin Myszkowski Marek Ksepko Biuro Urządzania Lasu i Geodezji Leśnej Oddział w Białymstoku PLAN PREZENTACJI
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Metody statystyczne wykorzystywane do oceny zróżnicowania kolekcji genowych roślin. Henryk Bujak
 Metody statystyczne wykorzystywane do oceny zróżnicowania kolekcji genowych roślin Henryk Bujak e-mail: h.bujak@ihar.edu.pl Ocena różnorodności fenotypowej Różnorodność fenotypowa kolekcji roślinnych zasobów
Metody statystyczne wykorzystywane do oceny zróżnicowania kolekcji genowych roślin Henryk Bujak e-mail: h.bujak@ihar.edu.pl Ocena różnorodności fenotypowej Różnorodność fenotypowa kolekcji roślinnych zasobów
Biogazownie w energetyce
 Biogazownie w energetyce Temat opracował Damian Kozieł Energetyka spec. EGIR rok 3 Czym jest biogaz? Czym jest biogaz? Biogaz jest to produkt fermentacji metanowej materii organicznej przez bakterie beztlenowe
Biogazownie w energetyce Temat opracował Damian Kozieł Energetyka spec. EGIR rok 3 Czym jest biogaz? Czym jest biogaz? Biogaz jest to produkt fermentacji metanowej materii organicznej przez bakterie beztlenowe
Skrócony opis produktu
 1 Produkt 8: Kalkulator do szacowania ilości biomasy Skrócony opis produktu Kontekst produktu innowacyjnego: Kalkulator do szacowania ilości biomasy to narzędzie służące do szacowania rentowności produkcji
1 Produkt 8: Kalkulator do szacowania ilości biomasy Skrócony opis produktu Kontekst produktu innowacyjnego: Kalkulator do szacowania ilości biomasy to narzędzie służące do szacowania rentowności produkcji
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Wykorzystanie biomasy stałej w Europie
 Wykorzystanie biomasy stałej w Europie Rafał Pudełko POLSKIE Wykorzystanie biomasy stałej w Europie PLAN PREZENTACJI: Aktualne dane statystyczne Pierwsze pomysły dot. energetycznego wykorzystania biomasy
Wykorzystanie biomasy stałej w Europie Rafał Pudełko POLSKIE Wykorzystanie biomasy stałej w Europie PLAN PREZENTACJI: Aktualne dane statystyczne Pierwsze pomysły dot. energetycznego wykorzystania biomasy
Analiza skupień. Waldemar Wołyński, Tomasz Górecki. Wydział Matematyki i Informatyki UAM Poznań. 6 marca 2013
 Analiza skupień Waldemar Wołyński, Tomasz Górecki Wydział Matematyki i Informatyki UAM Poznań 6 marca 2013 W. Wołyński, T. Górecki (UAM) Analiza skupień 6 marca 2013 1 / 46 Idea: Analiza skupień jest narzędziem
Analiza skupień Waldemar Wołyński, Tomasz Górecki Wydział Matematyki i Informatyki UAM Poznań 6 marca 2013 W. Wołyński, T. Górecki (UAM) Analiza skupień 6 marca 2013 1 / 46 Idea: Analiza skupień jest narzędziem
Statystyka. Wykład 9. Magdalena Alama-Bućko. 7 maja Magdalena Alama-Bućko Statystyka 7 maja / 40
 Statystyka Wykład 9 Magdalena Alama-Bućko 7 maja 2018 Magdalena Alama-Bućko Statystyka 7 maja 2018 1 / 40 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia miary
Statystyka Wykład 9 Magdalena Alama-Bućko 7 maja 2018 Magdalena Alama-Bućko Statystyka 7 maja 2018 1 / 40 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia miary
Biogaz i biomasa -energetyczna przyszłość Mazowsza
 Biogaz i biomasa -energetyczna przyszłość Mazowsza Katarzyna Sobótka Specjalista ds. energii odnawialnej Mazowiecka Agencja Energetyczna Sp. z o.o. k.sobotka@mae.mazovia.pl Biomasa Stałe i ciekłe substancje
Biogaz i biomasa -energetyczna przyszłość Mazowsza Katarzyna Sobótka Specjalista ds. energii odnawialnej Mazowiecka Agencja Energetyczna Sp. z o.o. k.sobotka@mae.mazovia.pl Biomasa Stałe i ciekłe substancje
W1. Wprowadzenie. Statystyka opisowa
 W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
Statystyka. Wykład 4. Magdalena Alama-Bućko. 19 marca Magdalena Alama-Bućko Statystyka 19 marca / 33
 Statystyka Wykład 4 Magdalena Alama-Bućko 19 marca 2018 Magdalena Alama-Bućko Statystyka 19 marca 2018 1 / 33 Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności (rozproszenia,
Statystyka Wykład 4 Magdalena Alama-Bućko 19 marca 2018 Magdalena Alama-Bućko Statystyka 19 marca 2018 1 / 33 Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności (rozproszenia,
Analiza współzależności dwóch cech I
 Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
Statystyka opisowa. Wykład I. Elementy statystyki opisowej
 Statystyka opisowa. Wykład I. e-mail:e.kozlovski@pollub.pl Spis treści Elementy statystyku opisowej 1 Elementy statystyku opisowej 2 3 Elementy statystyku opisowej Definicja Statystyka jest to nauka o
Statystyka opisowa. Wykład I. e-mail:e.kozlovski@pollub.pl Spis treści Elementy statystyku opisowej 1 Elementy statystyku opisowej 2 3 Elementy statystyku opisowej Definicja Statystyka jest to nauka o
Kierunek i poziom studiów: Matematyka, studia I stopnia (licencjackie), rok I
, rok I") Uniwersytet Śląski w Katowicach str. 1 Kierunek i poziom studiów: Matematyka, studia I stopnia (licencjackie), rok I Sylabus modułu: Wstęp do algebry liniowej i geometrii analitycznej (03-M01N-12-WALG)
Uniwersytet Śląski w Katowicach str. 1 Kierunek i poziom studiów: Matematyka, studia I stopnia (licencjackie), rok I Sylabus modułu: Wstęp do algebry liniowej i geometrii analitycznej (03-M01N-12-WALG)
Statystyka. Wykład 7. Magdalena Alama-Bućko. 16 kwietnia Magdalena Alama-Bućko Statystyka 16 kwietnia / 35
 Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Wybór optymalnej liczby składowych w analizie czynnikowej Test Równolegości Horn a i test MAP Velicera
 Wybór optymalnej liczby składowych w analizie czynnikowej Test Równolegości Horn a i test MAP Velicera Wielu badaczy podejmuje decyzje o optymalnej liczbie składowych do wyodrębnienia na podstawie arbitralnych
Wybór optymalnej liczby składowych w analizie czynnikowej Test Równolegości Horn a i test MAP Velicera Wielu badaczy podejmuje decyzje o optymalnej liczbie składowych do wyodrębnienia na podstawie arbitralnych
Wykład 1. Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy
 Wykład Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy Zbiorowość statystyczna - zbiór elementów lub wyników jakiegoś procesu powiązanych ze sobą logicznie (tzn. posiadających wspólne cechy
Wykład Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy Zbiorowość statystyczna - zbiór elementów lub wyników jakiegoś procesu powiązanych ze sobą logicznie (tzn. posiadających wspólne cechy
POD- I NADOKREŚLONE UKŁADY ALGEBRAICZNYCH RÓWNAŃ LINIOWYCH
 POD- I NADOKREŚLONE UKŁADY ALGEBRAICZNYCH RÓWNAŃ LINIOWYCH Transport, studia I stopnia rok akademicki 2011/2012 Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko
POD- I NADOKREŚLONE UKŁADY ALGEBRAICZNYCH RÓWNAŃ LINIOWYCH Transport, studia I stopnia rok akademicki 2011/2012 Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej
 Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
METODA SYMPLEKS. Maciej Patan. Instytut Sterowania i Systemów Informatycznych Uniwersytet Zielonogórski
 METODA SYMPLEKS Maciej Patan Uniwersytet Zielonogórski WSTĘP Algorytm Sympleks najpotężniejsza metoda rozwiązywania programów liniowych Metoda generuje ciąg dopuszczalnych rozwiązań x k w taki sposób,
METODA SYMPLEKS Maciej Patan Uniwersytet Zielonogórski WSTĘP Algorytm Sympleks najpotężniejsza metoda rozwiązywania programów liniowych Metoda generuje ciąg dopuszczalnych rozwiązań x k w taki sposób,
KURS FUNKCJE WIELU ZMIENNYCH
 KURS FUNKCJE WIELU ZMIENNYCH Lekcja Ekstrema (lokalne) funkcji wielu zmiennych ZADANIE DOMOWE www.etrapez.pl Strona Częśd : TEST Zaznacz poprawną odpowiedź (tylko jedna jest prawdziwa). Pytanie Wykres
KURS FUNKCJE WIELU ZMIENNYCH Lekcja Ekstrema (lokalne) funkcji wielu zmiennych ZADANIE DOMOWE www.etrapez.pl Strona Częśd : TEST Zaznacz poprawną odpowiedź (tylko jedna jest prawdziwa). Pytanie Wykres
Statystyka. Wykład 4. Magdalena Alama-Bućko. 13 marca Magdalena Alama-Bućko Statystyka 13 marca / 41
 Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Statystyka. Wykład 3. Magdalena Alama-Bućko. 6 marca Magdalena Alama-Bućko Statystyka 6 marca / 28
 Statystyka Wykład 3 Magdalena Alama-Bućko 6 marca 2017 Magdalena Alama-Bućko Statystyka 6 marca 2017 1 / 28 Szeregi rozdzielcze przedziałowe - kwartyle - przypomnienie Po ustaleniu przedziału, w którym
Statystyka Wykład 3 Magdalena Alama-Bućko 6 marca 2017 Magdalena Alama-Bućko Statystyka 6 marca 2017 1 / 28 Szeregi rozdzielcze przedziałowe - kwartyle - przypomnienie Po ustaleniu przedziału, w którym
Pochodne cząstkowe i ich zastosowanie. Ekstrema lokalne funkcji
 Pochodne cząstkowe i ich zastosowanie. Ekstrema lokalne funkcji Adam Kiersztyn Lublin 2014 Adam Kiersztyn () Pochodne cząstkowe i ich zastosowanie. Ekstrema lokalne funkcji maj 2014 1 / 24 Zanim przejdziemy
Pochodne cząstkowe i ich zastosowanie. Ekstrema lokalne funkcji Adam Kiersztyn Lublin 2014 Adam Kiersztyn () Pochodne cząstkowe i ich zastosowanie. Ekstrema lokalne funkcji maj 2014 1 / 24 Zanim przejdziemy
ANALIZA STRUKTURY WIEKOWEJ ORAZ PŁCIOWEJ CZŁONKÓW OFE Z WYKORZYSTANIEM METOD TAKSONOMICZNYCH
 Sugerowany przypis: Chybalski F., Analiza struktury wiekowej oraz płciowej członków OFE z wykorzystaniem metod taksonomicznych [w:] Chybalski F., Staniec I. (red.), 10 lat reformy emerytalnej w Polsce.
Sugerowany przypis: Chybalski F., Analiza struktury wiekowej oraz płciowej członków OFE z wykorzystaniem metod taksonomicznych [w:] Chybalski F., Staniec I. (red.), 10 lat reformy emerytalnej w Polsce.
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Statystyka. Wykład 8. Magdalena Alama-Bućko. 23 kwietnia Magdalena Alama-Bućko Statystyka 23 kwietnia / 38
 Statystyka Wykład 8 Magdalena Alama-Bućko 23 kwietnia 2017 Magdalena Alama-Bućko Statystyka 23 kwietnia 2017 1 / 38 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 23 kwietnia 2017 Magdalena Alama-Bućko Statystyka 23 kwietnia 2017 1 / 38 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Prace nad rozporządzeniem określającym zasady zrównoważonego pozyskania biomasy oraz jej dokumentowania na potrzeby systemu wsparcia
 Prace nad rozporządzeniem określającym zasady zrównoważonego pozyskania biomasy oraz jej dokumentowania na potrzeby systemu wsparcia Jarosław Wiśniewski Zastępca Dyrektora Departamentu Gospodarki Ziemią
Prace nad rozporządzeniem określającym zasady zrównoważonego pozyskania biomasy oraz jej dokumentowania na potrzeby systemu wsparcia Jarosław Wiśniewski Zastępca Dyrektora Departamentu Gospodarki Ziemią
Rozkłady wielu zmiennych
 Rozkłady wielu zmiennych Uogólnienie pojęć na rozkład wielu zmiennych Dystrybuanta, gęstość prawdopodobieństwa, rozkład brzegowy, wartości średnie i odchylenia standardowe, momenty Notacja macierzowa Macierz
Rozkłady wielu zmiennych Uogólnienie pojęć na rozkład wielu zmiennych Dystrybuanta, gęstość prawdopodobieństwa, rozkład brzegowy, wartości średnie i odchylenia standardowe, momenty Notacja macierzowa Macierz
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
POLITECHNIKA OPOLSKA
 POLITECHNIKA OPOLSKA WYDZIAŁ MECHANICZNY Katedra Technologii Maszyn i Automatyzacji Produkcji Laboratorium Podstaw Inżynierii Jakości Ćwiczenie nr 4 Temat: Analiza korelacji i regresji dwóch zmiennych
POLITECHNIKA OPOLSKA WYDZIAŁ MECHANICZNY Katedra Technologii Maszyn i Automatyzacji Produkcji Laboratorium Podstaw Inżynierii Jakości Ćwiczenie nr 4 Temat: Analiza korelacji i regresji dwóch zmiennych
Rozdział 1. Wektory losowe. 1.1 Wektor losowy i jego rozkład
 Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
ODNAWIALNE ŹRÓDŁA ENERGII. Seminarium Biomasa na cele energetyczne założenia i realizacja Warszawa, 3 grudnia 2008 r.
 ODNAWIALNE ŹRÓDŁA ENERGII Seminarium Biomasa na cele energetyczne założenia i realizacja Warszawa, 3 grudnia 2008 r. 1 Odnawialne Źródła Energii w 2006 r. Biomasa stała 91,2 % Energia promieniowania słonecznego
ODNAWIALNE ŹRÓDŁA ENERGII Seminarium Biomasa na cele energetyczne założenia i realizacja Warszawa, 3 grudnia 2008 r. 1 Odnawialne Źródła Energii w 2006 r. Biomasa stała 91,2 % Energia promieniowania słonecznego
Surowce w gospodarce o obiegu zamkniętym Łukasz Sosnowski, Sekretarz Zespołu ds. Gospodarki o Obiegu Zamkniętym
 Surowce w gospodarce o obiegu zamkniętym Łukasz Sosnowski, Sekretarz Zespołu ds. Gospodarki o Obiegu Zamkniętym Surowce dla gospodarki Polski, Kraków 23 maja 2017 r. Nowa wizja europejskiego modelu gospodarczego
Surowce w gospodarce o obiegu zamkniętym Łukasz Sosnowski, Sekretarz Zespołu ds. Gospodarki o Obiegu Zamkniętym Surowce dla gospodarki Polski, Kraków 23 maja 2017 r. Nowa wizja europejskiego modelu gospodarczego
O czym w Sejmie piszczy? Analiza tekstowa przemówień poselskich
 O czym w Sejmie piszczy? Analiza tekstowa przemówień poselskich mgr Aleksander Nosarzewski Szkoła Główna Handlowa w Warszawie pod kierunkiem naukowym dr hab. Bogumiła Kamińskiego, prof. SGH Problem Potrzeba
O czym w Sejmie piszczy? Analiza tekstowa przemówień poselskich mgr Aleksander Nosarzewski Szkoła Główna Handlowa w Warszawie pod kierunkiem naukowym dr hab. Bogumiła Kamińskiego, prof. SGH Problem Potrzeba
Potencjał biomasy nowe kierunki jej wykorzystania
 INSTYTUT GÓRNICTWA ODKRYWKOWEGO Dominika Kufka Potencjał biomasy nowe kierunki jej wykorzystania Transnational Conference 25 th 26 th of November 2014, Wrocław Fostering communities on energy transition,
INSTYTUT GÓRNICTWA ODKRYWKOWEGO Dominika Kufka Potencjał biomasy nowe kierunki jej wykorzystania Transnational Conference 25 th 26 th of November 2014, Wrocław Fostering communities on energy transition,
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Marta Dziechciarz Duda SEGMENTACJA RYNKU DÓBR TRWAŁEGO UŻYTKOWANIA NA PODSTAWIE DANYCH NIEMETRYCZNYCH. 1. Wstęp
 Marta Dziechciarz Duda SEGMENTACJA RYNKU DÓBR TRWAŁEGO UŻYTKOWANIA NA PODSTAWIE DANYCH NIEMETRYCZNYCH 1. Wstęp W statystycznej analizie danych istnieje możliwość stosowania znacznie większej liczby metod,
Marta Dziechciarz Duda SEGMENTACJA RYNKU DÓBR TRWAŁEGO UŻYTKOWANIA NA PODSTAWIE DANYCH NIEMETRYCZNYCH 1. Wstęp W statystycznej analizie danych istnieje możliwość stosowania znacznie większej liczby metod,
Socjo-ekonomiczne aspekty polskich inwestycji biomasowych
 Socjo-ekonomiczne aspekty polskich inwestycji biomasowych Jerzy JANOTA BZOWSKI Bracka 4, 00-502 Warszawa tel.(+4822)6289854, fax. (+4822)6285082 e-mail:jbzowski@ekofundusz.org.pl. www.ekofundusz.org.pl
Socjo-ekonomiczne aspekty polskich inwestycji biomasowych Jerzy JANOTA BZOWSKI Bracka 4, 00-502 Warszawa tel.(+4822)6289854, fax. (+4822)6285082 e-mail:jbzowski@ekofundusz.org.pl. www.ekofundusz.org.pl
Prawdopodobieństwo i statystyka
 Wykład XV: Zagadnienia redukcji wymiaru danych 2 lutego 2015 r. Standaryzacja danych Standaryzacja danych Własności macierzy korelacji Definicja Niech X będzie zmienną losową o skończonym drugim momencie.
Wykład XV: Zagadnienia redukcji wymiaru danych 2 lutego 2015 r. Standaryzacja danych Standaryzacja danych Własności macierzy korelacji Definicja Niech X będzie zmienną losową o skończonym drugim momencie.
Klasyfikacja w oparciu o metrykę budowaną poprzez dystrybuanty empiryczne na przestrzeni wzorców uczących
 Klasyfikacja w oparciu o metrykę budowaną poprzez dystrybuanty empiryczne na przestrzeni wzorców uczących Cezary Dendek Wydział Matematyki i Nauk Informacyjnych PW Plan prezentacji Plan prezentacji Wprowadzenie
Klasyfikacja w oparciu o metrykę budowaną poprzez dystrybuanty empiryczne na przestrzeni wzorców uczących Cezary Dendek Wydział Matematyki i Nauk Informacyjnych PW Plan prezentacji Plan prezentacji Wprowadzenie
Układy równań liniowych
 Układy równań liniowych ozważmy układ n równań liniowych o współczynnikach a ij z n niewiadomymi i : a + a +... + an n d a a an d a + a +... + a n n d a a a n d an + an +... + ann n d n an an a nn n d
Układy równań liniowych ozważmy układ n równań liniowych o współczynnikach a ij z n niewiadomymi i : a + a +... + an n d a a an d a + a +... + a n n d a a a n d an + an +... + ann n d n an an a nn n d
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Zmienne losowe i teoria prawdopodobieństwa 3. Populacje i próby danych 4. Testowanie hipotez i estymacja parametrów 5. Najczęściej wykorzystywane testy statystyczne
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Zmienne losowe i teoria prawdopodobieństwa 3. Populacje i próby danych 4. Testowanie hipotez i estymacja parametrów 5. Najczęściej wykorzystywane testy statystyczne
Statystyka w pracy badawczej nauczyciela
 Statystyka w pracy badawczej nauczyciela Wykład 1: Terminologia badań statystycznych dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyka (1) Statystyka to nauka zajmująca się zbieraniem, badaniem
Statystyka w pracy badawczej nauczyciela Wykład 1: Terminologia badań statystycznych dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyka (1) Statystyka to nauka zajmująca się zbieraniem, badaniem
WYMAGANIA EDUKACYJNE Rok szkolny 2018/2019
 WYMAGANIA EDUKACYJNE Rok szkolny 2018/2019 Przedmiot Klasa Nauczyciele uczący Poziom matematyka 4e Łukasz Jurczak rozszerzony 2. Elementy analizy matematycznej ocena dopuszczająca ocena dostateczna ocena
WYMAGANIA EDUKACYJNE Rok szkolny 2018/2019 Przedmiot Klasa Nauczyciele uczący Poziom matematyka 4e Łukasz Jurczak rozszerzony 2. Elementy analizy matematycznej ocena dopuszczająca ocena dostateczna ocena
Statystyka i eksploracja danych
 Wykład XII: Zagadnienia redukcji wymiaru danych 12 maja 2014 Definicja Niech X będzie zmienną losową o skończonym drugim momencie. Standaryzacją zmiennej X nazywamy zmienną losową Z = X EX Var (X ). Definicja
Wykład XII: Zagadnienia redukcji wymiaru danych 12 maja 2014 Definicja Niech X będzie zmienną losową o skończonym drugim momencie. Standaryzacją zmiennej X nazywamy zmienną losową Z = X EX Var (X ). Definicja
STATYSTYKA MAŁYCH OBSZARÓW I. WPROWADZENIE
 1 STATYSTYKA MAŁYCH OBSZARÓW I. WPROWADZENIE 1.1 Podejścia w statystyce małych obszarów Randomizacyjne Wektor wartości badanej cechy traktowany jest jako nielosowy. Szacowana charakterystyka jest nielosowa
1 STATYSTYKA MAŁYCH OBSZARÓW I. WPROWADZENIE 1.1 Podejścia w statystyce małych obszarów Randomizacyjne Wektor wartości badanej cechy traktowany jest jako nielosowy. Szacowana charakterystyka jest nielosowa
Wykład 10 Skalowanie wielowymiarowe
 Wykład 10 Skalowanie wielowymiarowe Wrocław, 30.05.2018r Skalowanie wielowymiarowe (Multidimensional Scaling (MDS)) Główne cele MDS: przedstawienie struktury badanych obiektów przez określenie treści wymiarów
Wykład 10 Skalowanie wielowymiarowe Wrocław, 30.05.2018r Skalowanie wielowymiarowe (Multidimensional Scaling (MDS)) Główne cele MDS: przedstawienie struktury badanych obiektów przez określenie treści wymiarów
Naszym zadaniem jest rozpatrzenie związków między wierszami macierzy reprezentującej poziomy ekspresji poszczególnych genów.
 ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
Porównanie modeli statystycznych. Monika Wawrzyniak Katarzyna Kociałkowska
 Porównanie modeli statystycznych Monika Wawrzyniak Katarzyna Kociałkowska Jaka jest miara podobieństwa? Aby porównywać rozkłady prawdopodobieństwa dwóch modeli statystycznych możemy użyć: metryki dywergencji
Porównanie modeli statystycznych Monika Wawrzyniak Katarzyna Kociałkowska Jaka jest miara podobieństwa? Aby porównywać rozkłady prawdopodobieństwa dwóch modeli statystycznych możemy użyć: metryki dywergencji
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Sieci Kohonena Grupowanie
 Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Analiza składowych głównych idea
 Analiza składowych głównych idea Analiza składowych głównych jest najczęściej używanym narzędziem eksploracyjnej analizy danych. Na metodę tę można spojrzeć jak na pewną technikę redukcji wymiarowości
Analiza składowych głównych idea Analiza składowych głównych jest najczęściej używanym narzędziem eksploracyjnej analizy danych. Na metodę tę można spojrzeć jak na pewną technikę redukcji wymiarowości
Badanie normalności rozkładu
 Temat: Badanie normalności rozkładu. Wyznaczanie przedziałów ufności. Badanie normalności rozkładu Shapiro-Wilka: jest on najbardziej zalecanym testem normalności rozkładu. Jednak wskazane jest, aby liczebność
Temat: Badanie normalności rozkładu. Wyznaczanie przedziałów ufności. Badanie normalności rozkładu Shapiro-Wilka: jest on najbardziej zalecanym testem normalności rozkładu. Jednak wskazane jest, aby liczebność
Eksploracja danych. Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Statystyka. Wykład 7. Magdalena Alama-Bućko. 3 kwietnia Magdalena Alama-Bućko Statystyka 3 kwietnia / 36
 Statystyka Wykład 7 Magdalena Alama-Bućko 3 kwietnia 2017 Magdalena Alama-Bućko Statystyka 3 kwietnia 2017 1 / 36 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 7 Magdalena Alama-Bućko 3 kwietnia 2017 Magdalena Alama-Bućko Statystyka 3 kwietnia 2017 1 / 36 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Wielowymiarowa analiza regionalnego zróżnicowania rolnictwa w Polsce
 Wielowymiarowa analiza regionalnego zróżnicowania rolnictwa w Polsce Mgr inż. Agata Binderman Dzienne Studia Doktoranckie przy Wydziale Ekonomiczno-Rolniczym Katedra Ekonometrii i Informatyki SGGW Opiekun
Wielowymiarowa analiza regionalnego zróżnicowania rolnictwa w Polsce Mgr inż. Agata Binderman Dzienne Studia Doktoranckie przy Wydziale Ekonomiczno-Rolniczym Katedra Ekonometrii i Informatyki SGGW Opiekun
STATYSTYKA I DOŚWIADCZALNICTWO
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 9 Analiza skupień wielowymiarowa klasyfikacja obiektów Metoda, a właściwie to zbiór metod pozwalających na grupowanie obiektów pod względem wielu cech jednocześnie.
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 9 Analiza skupień wielowymiarowa klasyfikacja obiektów Metoda, a właściwie to zbiór metod pozwalających na grupowanie obiektów pod względem wielu cech jednocześnie.
Instytut Ekonomiki Rolnictwa i Gospodarki Żywnościowej Państwowy Instytut Badawczy
 Instytut Ekonomiki Rolnictwa i Gospodarki Żywnościowej Państwowy Instytut Badawczy Ocena funkcjonowania gospodarstw z dodatnim saldem sekwestracji CO 2 w glebie na tle gospodarstw pozostałych (na przykładzie
Instytut Ekonomiki Rolnictwa i Gospodarki Żywnościowej Państwowy Instytut Badawczy Ocena funkcjonowania gospodarstw z dodatnim saldem sekwestracji CO 2 w glebie na tle gospodarstw pozostałych (na przykładzie
Efektywny rozwój rozproszonej energetyki odnawialnej w połączeniu z konwencjonalną w regionach Biomasa jako podstawowe źródło energii odnawialnej
 Biomasa jako podstawowe źródło energii odnawialnej dr inż. Magdalena Król Spotkanie Regionalne- Warsztaty w projekcie Energyregion, Wrocław 18.02.2013 1-3 Biomasa- źródła i charakterystyka 4 Biomasa jako
Biomasa jako podstawowe źródło energii odnawialnej dr inż. Magdalena Król Spotkanie Regionalne- Warsztaty w projekcie Energyregion, Wrocław 18.02.2013 1-3 Biomasa- źródła i charakterystyka 4 Biomasa jako
Metoda reprezentacyjna
 Metoda reprezentacyjna Stanisław Jaworski Katedra Ekonometrii i Statystyki Zakład Statystyki Populacja, cecha, parametr, próba Metoda reprezentacyjna Przedmiotem rozważań metody reprezentacyjnej są metody
Metoda reprezentacyjna Stanisław Jaworski Katedra Ekonometrii i Statystyki Zakład Statystyki Populacja, cecha, parametr, próba Metoda reprezentacyjna Przedmiotem rozważań metody reprezentacyjnej są metody
ODRZUCANIE WYNIKÓW POJEDYNCZYCH POMIARÓW
 ODRZUCANIE WYNIKÓW OJEDYNCZYCH OMIARÓW W praktyce pomiarowej zdarzają się sytuacje gdy jeden z pomiarów odstaje od pozostałych. Jeżeli wykorzystamy fakt, że wyniki pomiarów są zmienną losową opisywaną
ODRZUCANIE WYNIKÓW OJEDYNCZYCH OMIARÓW W praktyce pomiarowej zdarzają się sytuacje gdy jeden z pomiarów odstaje od pozostałych. Jeżeli wykorzystamy fakt, że wyniki pomiarów są zmienną losową opisywaną
TRANSFORMACJE I JAKOŚĆ DANYCH
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Podstawy grupowania danych w programie RapidMiner Michał Bereta
 Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Definicje PN ISO Definicje PN ISO 3951 interpretacja Zastosowanie normy PN-ISO 3951:1997
 PN-ISO 3951:1997 METODY STATYSTYCZNEJ KONTROI JAKOŚCI WG OCENY ICZBOWEJ ciągła seria partii wyrobów sztukowych dla jednej procedury analizowana jest tylko jedna wartość, która musi być mierzalna w skali
PN-ISO 3951:1997 METODY STATYSTYCZNEJ KONTROI JAKOŚCI WG OCENY ICZBOWEJ ciągła seria partii wyrobów sztukowych dla jednej procedury analizowana jest tylko jedna wartość, która musi być mierzalna w skali
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą