Hadoop - wprowadzenie. Łukasz Król
|
|
|
- Kinga Karolina Leszczyńska
- 7 lat temu
- Przeglądów:
Transkrypt


1 Hadoop - wprowadzenie Łukasz Król




2 Hadoop - wprowadzenie obszar działalności: hurtownie danych programowanie ETL Business Intelligence Big Data programowanie obliczeń rozproszonych uczenie maszynowe statystyka narzędzia: SQL Server, Oracle Cloudera (Hadoop) SAS R, Scala, Java Akka Informatica PowerCenter IBM Cognos





3 Hadoop - wprowadzenie
. techniczny cel Hadoop 2.")
4 Hadoop - wprowadzenie Cel: zaawansowana analiza danych od małych do średnich rozmiarów (do kilkuset, praktycznie kilkudziesięciu GB) na jednej maszynie. cel Hadoop 1.0: jakakolwiek analiza danych o rozmiarach rzędu kilkuset TB (problemy skali Google, Facebook). techniczny cel Hadoop 2.0: rodzaj systemu operacyjnego dla klastra kilkunastu do kilkuset tanich maszyn pozwalającego na analizę off-linową (batch) jak i on-linową (datastream processing) różnorodnych danych.


5 Hadoop - mity SQL (przeszłość): NoSQL (przyszłość):
6 Hadoop - mity mit wyjaśnienie Hadoop to narzędzie Zaawansowanej Analizy Danych. Hadoop pozwala na rozproszenie dowolnych obliczeń. Hadoop to najwydajniejsza platforma przetwarzania i analizy danych. Hadoop może w swojej obecnej formie zastąpić klasyczne systemy transakcyjne. Hadoop to jedyna droga do wdrożenia Business Intelligence i Zaawansowanej Analityki w firmie. Hadoop to jednolity produkt łatwy w użyciu i administracji. Dane nieustrukturalizowane (NoSQL) są łatwiejsze w analizie od ustrukturalizowanych (SQL). Hadoop to platforma rozproszonego przetwarzania danych. Hadoop wymusza na programiście stosowanie określonych abstrakcji, często ograniczających ekspresyjność. Hadoop uzyskuje przewagę nad systemami scentralizowanymi dopiero przy naprawdę dużych rozmiarach danych. Hadoop w założeniu nie jest systemem transakcyjnym. Hadoop służy rozwiązaniu problemów rozmiaru danych nie występujących w większości projektów. Hadoop to zbiór różnorodnych systemów o bardzo zróżnicowanych właściwościach. Dane ustrukturalizowane są prostsze w analizie, ale nie każde dane da się ustrukturalizować.
 OLAP Business Intelligence ERP In-Memory CRM EDW Advanced")
 no transaction")
7 Hadoop a Hurtownia Danych Data Integration Data Warehousing ETL (Extract Transform Load) OLAP Business Intelligence ERP In-Memory CRM EDW Advanced Analytics historization simple and single data model aggregation optimized no extensive querrying of production systems (usually) no transaction processing




8 Hadoop a Hurtownia Danych FILE RDBMS APPLIANCE
9 Hadoop a Big Data Big Data Triple V: Volume, Velocity, Variety Danych jest tak dużo, że trzeba je rozproszyć na wiele maszyn. Dane napływają tak szybko, że jedna maszyna nie poradzi sobie z ich przetworzeniem. Dane są tak różnorodne, że nie da się ich przechowywać w schemacie relacyjnym.
10 Źródła Big Data Hadoop a Big Data Social Media Internet of Things Duże zbiory danych biologicznych

11 CZAS OPERACJI Hadoop vs EDW Enterprise Data Warehouse Hadoop ROZMIAR DANYCH
12 Hadoop 1.0 HDFS: Rozproszony system plików. W rzeczywistości zestaw usług w Java (!) korzystających z lokalnych systemów plików węzłów klastra. Domyślny rozmiar bloku to 64MB (!). Zapewnia niezawodność przechowywania przez skopiowanie każdego bloku na domyślnie 3 różne węzły (3 razy więcej danych ). Delikatnie scentralizowany.
13 Hadoop 1.0 MapReduce: Usługa (Java) wykonywania rozproszonych obliczeń. Dane i wyniki pobierane i zapisywane z powrotem do HDFS. Obliczenia definiowane poprzez skompilowanie klasy Java przeciążającej konkretny interfejs i rozesłanie pliku *.jar. Delikatnie scentralizowany.
14 Hadoop 1.0 Pig Latin: Język ułatwiający pisanie procesów przetwarzania danych. Pig Latin jest kompilowany do jarów wykonywalnych przez MapReduce. Wypierany przez Sparka.

15 Hadoop 1.0 Hive: Interfejs SQL do MapReduce. Hive SQL jest kompilowany do jarów wykonywalnych przez MapReduce. W praktyce oferuje funkcjonalność rozproszonej bazy danych bez indeksów, transakcji i zaawansowanego zarządzania uprawnieniami. W nowszych projektach wykorzystywany w oderwaniu od MapReduce (Tez).

16 "podniesienie" środowiska cloudera/cloudera
17 HDFS ćwiczenie (1/3) #uruchomić terminal (np. gnome-terminal) #sprawdzić aktualny folder lokalny pwd #wylistować zawartość lokalnego folderu ls l #przejść do folderu /home/cloudera/lab/00_data cd lab/00_data #wygenerować trochę losowych danych cat /dev/random > garbage.txt
18 HDFS ćwiczenie (2/3) #wyświetlić pomoc hadoop fs hadoop fs help #wylistować zawartość głównego folderu w HDFS hadoop fs ls / #wylistować zawartość folderu /user/cloudera hadoop fs ls /user/cloudera #przekopiować plik garbage.txt na HDFS hadoop fs copyfromlocal garbage.txt /user/cloudera #wylistować zawartość /user/cloudera w trybie human readable hadoop fs ls h /user/cloudera
19 HDFS ćwiczenie (3/3) #obejrzeć zawartość HDFS za pomocą przeglądarkowego interfejsu: #obejrzeć zawartość HDFS za pomocą Hue
20 Hive ćwiczenie (1/2) #uruchomić interpreter Hive SQL hive #sprawdzić istniejące bazy danych show databases; #podłączyć się do lab use lab; #sprawdzić istniejące tabele show tables; #wypisać na ekran zawartość departments select * from departments;
21 Hive ćwiczenie (2/2) #wypisać szczegółowe informacje na temat departments describe formatted departments; #odczytać gdzie w HDFS znajduje się tabela #... #wyjść z interpretera Hive SQL exit; #wypisać zawartość tabeli za pomocą hadoop fs: hadoop fs cat [sciezka z Hive]/part-m #w jaki sposób jest przechowywana fizycznie tabela?

22 Hadoop MapReduce Zadanie policzyć liczbę wystąpień każdego słowa w pliku. A B B B C C C # B B A A A A # B B B C A # B B B A C # # # Model scentralizowany można wykorzystać np. tablicę mieszającą i sekwencyjnie przeskanować plik. Problem dane mogą nie mieścić się na dysku jednej maszyny.
23 Hadoop MapReduce Zadanie policzyć liczbę wystąpień każdego słowa w pliku. A B B B C C C # B B A A A A # B B B C A # B B B A C # # # Model rozproszony można wykonać obliczenia na części danych i scalić wyniki na jednej maszynie. Na której maszynie (ip, hostname, użytkownik, hasło, protokół?!). Programista nie musi znać tych informacji. Ponadto, maszyna wyznaczona do scalania może ulec awarii. Potrzebny jest wyższy poziom abstrakcji przy definiowaniu obliczeń rozproszonych.
24 Hadoop MapReduce 1. Operujemy na parach klucz-wartość (K,V). 2. Operacja Map definiuje przekształcenie (K1,V1) w (K2,V2). 3. Operacja Reduce przekształca 2 pary (K,V) w jedną, dla tych samych wartości klucza. 4. Dodatkowa operacja FlatMap to modyfikacja Map pozwalająca zwracać dla jednego wejściowego (K,V) od 0 do n, wyjściowych (K,V), zamiast dokładnie jednego.
25 Hadoop MapReduce (A B B B C,NULL) (#,NULL) (B B, NULL) (A A, NULL) (#, NULL) (B B B C, NULL) (A #, NULL) (B, NULL) (B B A C, NULL) (# # #, NULL)
26 Hadoop MapReduce (A B B B C,NULL) (#,NULL) (B B, NULL) (A A, NULL) (#, NULL) (B B B C, NULL) (A #, NULL) (B, NULL) (B B A C, NULL) (# # #, NULL) FLAT MAP FLAT MAP (A,1) (B,3) (C,1) (B,2) (A,2) (B,3) (C,1) (A,1) (B,1) (B,2) (A,1) (C,1)
27 Hadoop MapReduce (A B B B C,NULL) (#,NULL) (B B, NULL) (A A, NULL) (#, NULL) (B B B C, NULL) (A #, NULL) (B, NULL) (B B A C, NULL) (# # #, NULL) FLAT MAP FLAT MAP (A,1) (B,3) (C,1) (B,2) (A,2) (B,3) (C,1) (A,1) (B,1) (A,1) (A,2) (A,1) (A,1) (B,2) (A,1) (C,1)
28 Hadoop MapReduce (A B B B C,NULL) (#,NULL) (B B, NULL) (A A, NULL) (#, NULL) (B B B C, NULL) (A #, NULL) (B, NULL) (B B A C, NULL) (# # #, NULL) FLAT MAP FLAT MAP (A,1) (B,3) (C,1) (B,2) (A,2) (B,3) (C,1) (A,1) (B,1) (A,1) (A,2) (A,1) (A,1) (B,3) (B,2) (B,3) (B,1) (B,2) (B,2) (A,1) (C,1)
29 Hadoop MapReduce (A B B B C,NULL) (#,NULL) (B B, NULL) (A A, NULL) (#, NULL) (B B B C, NULL) (A #, NULL) (B, NULL) (B B A C, NULL) (# # #, NULL) FLAT MAP FLAT MAP (A,1) (B,3) (C,1) (B,2) (A,2) (B,3) (C,1) (A,1) (B,1) (B,2) (A,1) (C,1) (A,1) (A,2) (A,1) (A,1) (B,3) (B,2) (B,3) (B,1) (B,2) (C,1) (C,1) (C,1)
30 Hadoop MapReduce (A B B B C,NULL) (#,NULL) (B B, NULL) (A A, NULL) (#, NULL) (B B B C, NULL) (A #, NULL) (B, NULL) (B B A C, NULL) (# # #, NULL) FLAT MAP FLAT MAP (A,1) (B,3) (C,1) (B,2) (A,2) (B,3) (C,1) (A,1) (B,1) (B,2) (A,1) (C,1) (A,1) (A,2) (A,1) (A,1) (B,3) (B,2) (B,3) (B,1) (B,2) (C,1) (C,1) (C,1) REDUCE REDUCE REDUCE (A,5) (B,11) (C,3) MAPPERS REDUCERS
31 MapReduce ćwiczenie Zaproponować sposób na wyliczenie średniej w grupach za pomocą MapReduce. Podpowiedź: Jako wartość można traktować całą strukturę. Można wykonać dwa następujące po sobie mapowania i redukcje. (A,1) (B,2) (A,3) (A,6) (B,7)
32 MapReduce ćwiczenie MAP1: (A,1) (B,2) (A,3) (A,6) (B,7) -> (A,(1,1)) -> (B,(2,1)) -> (A,(3,1)) -> (A,(6,1)) -> (B,(7,1)) REDUCE1: (A,(1,1)) (A,(3,1)) (A,(6,1)) -> (A,(10,3)) (B,(2,1)) (B,(7,1)) -> (B,(9,2)) MAP2: (A,(10,3)) -> (A,(3.33)) (B,(9,2)) -> (B,(4.5)) REDUCE2: (A,3.33) -> (A,3.33) (B,4.5) -> (B,4.5)

33 MapReduce - krytyka Konieczność zapisywania danych do HDFS (dyski) co redukcję. Mało intuicyjny. Niemożliwy do wykorzystania do analizy online. Shuffle phase!
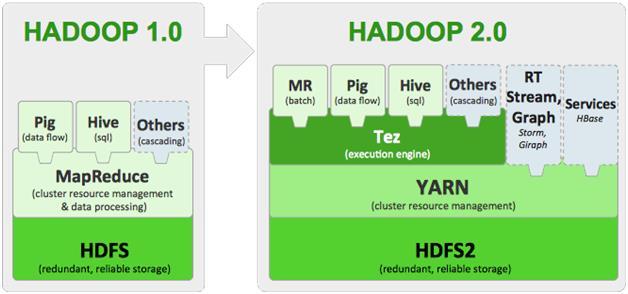
34 Hadoop 2.0
35


36 Dystrybucje Hadoop

37 Hortonworks (nie wspierane w Cloudera)

38 Hortonworks (nie wspierane w Cloudera)

39 Cloudera flagowe projekty
40 Cloudera architektura Service Master Hosts Worker Hosts HDFS Name Node Secondary NameNode Data Node Utility Hosts
41 Cloudera architektura Service Master Hosts Worker Hosts Utility Hosts HDFS YARN NameNode Secondary NameNode ResourceManager JobHistory Server DataNode NodeManager
42 Cloudera architektura Service Master Hosts Worker Hosts Utility Hosts HDFS YARN Hive NameNode Secondary NameNode ResourceManager JobHistory Server Hive Metastore Server HiveServer2 DataNode NodeManager
43 Impala (Dużo) szybsza alternatywa dla Hive. Wykorzystuje HDFS jako system plików. Napisana w C++. Niezależna od MapReduce i od Tez. Zestaw własnych procesów. Open Source, ale stworzona przez Clouderę. Współdzieli metadane z Hive. Poprawnie interpretuje większość Hive SQL. Nie obsługuje transakcji. Stworzona z myślą o obciążeniu agregacyjnym. Wsparcie dla kolumnowych formatów tabel. Szerokie wsparcie dla dostępu z narzędzi Business Intelligence poprzez JDBC i ODBC.
44 Impala - ćwiczenie #uruchomić impala-shell impala-shell #przejść do bazy lab i wylistować tabele use lab; show tables; #wypisać pierwsze 10 wierszy tabeli lab_parquet select * from lab_parquet limit 10 #wypisać 10 najczęściej występujących kombinacji kolumn ref i alt wraz z licznością #? #powtórzyć w Hive #ile warstw MapReduce zostało zaplanowanych przez Hive?
45 Impala - rozwiązanie select ref, alt, count(*) as cnt from lab_parquet group by ref,alt order by cnt desc limit 10;
46 Cloudera architektura Service Master Hosts Worker Hosts Utility Hosts HDFS YARN Hive NameNode Secondary NameNode ResourceManager JobHistory Server Hive Metastore Server HiveServer2 DataNode NodeManager Impala Impala Statestore Impala Deamon Impala Catalog

47 Spark Alternatywa zarówno dla klasycznego MapReduce, jak i dla Tez. Nowa abstrakcja Resilient Distributed Dataset (RDD) Intensywne wykorzystanie pamięci operacyjnej węzłów. Szerszy zbiór operacji niż MapReduce. Nie ma własnych stałych usług zależność od YARN. Umożliwia pisanie zadań w Java, Scala, Python. Koncepcja partycji. Niezawodność poprzez możliwość odtworzenia historii zdefiniowanej operacji. W dużej mierze niezależny od HDFS i YARN.
48 Spark - architektura
49 Spark ćwiczenie 1 #uruchomić spark-shell jako aplikację YARN spark-shell --master yarn #sprawdzić w interfejsie webowym yarn status Sparka: #zamknąć sersję Sparka exit #uruchomić Sparka w trybie lokalnym zajmując 2 rdzenie spark-shell --master local[2] #sprawdzić w interfejsie webowym yarn status Sparka:
50 Spark koncepcja partycji executor 1 executor 2 P1 P2 P3 P4 Niemodyfikowalne. Tworzone na podstawie danych źródłowych lub innych RDD. Leniwe transformacje. Operacje wykonywane na całych partycjach. P5 RDD driver P6
51 Spark tworzenie RDD #tworzenie RDD w locie val localvector = 1 to 2000 val rdd_nums = sc.parallelize(localvector) #tworzenie RDD na podstawie pliku w HDFS val path = "/user/cloudera/flat/products/part-m-00000" val rdd_products = sc.textfile(path) #RDD na podstawie nieistniejącego pliku w HDFS #transformacje sa leniwe, wiec wyrazenie nie bedzie zwalidowane val path = "/path/does/not/exist" val rdd_nonexistent = sc.textfile(path) #sprawdzenie zawartości RDD: rdd_nums.take(3) rdd_products.take(3) rdd_nonexistent.take(3)
52 Spark sterowanie liczbą partycji #tworzenie RDD w locie val localvector = 1 to val rdd_nums = sc.parallelize(localvector) #sprawdzenie liczby partycji rdd_nums.partitions.size #zmiana liczby partycji val rdd_repartitioned = rdd_nums.repartition(8) rdd_nums.partitions.size rdd_repartitioned.partitions.size
53 Spark mapowanie #tworzenie RDD na podstawie pliku w HDFS val path = "/user/cloudera/flat/orders/part-m-00000" val rdd_strings = sc.textfile(path) rdd_strings #map: String -> Array[String] #...
54 Spark mapowanie #String -> Array[String] def stringsplitter1(input: String): Array[String] = { val output = input.split(",") return output } def stringsplitter2(input:string) = input.split(",") val rdd_arrayofstrings = rdd_strings.map(stringsplitter1) val rdd_arrayofstrings = rdd_strings.map(stringsplitter2) val rdd_arrayofstrings = rdd_strings.map(v => v.split(",")) rdd_arrayofstrings.take(3)
55 Spark filtrowanie #String -> Array[String] val rdd_fraud = rdd_arrayofstrings.filter( v => v(3)=="suspected_fraud" ) rdd_fraud.count(rdd_fraud.take(5) )
56 Spark redukcja val path = "/user/cloudera/flat/orders/part-m-00000" val rdd_strings = sc.textfile(path) val rdd_arrayofstrings = sc.map(v => v.split (",")) val rdd_statuses = rdd_arrayofstrings.map( v=> v(3)) val rdd_kv = rdd_statuses.map( v => (v,1) ) val rdd_agg = rdd_kv.reducebykey( (v1,v2) => v1+v2) val localresult = rdd_agg.collect()
57 Spark sortowanie val rdd_aggsorted = rdd_agg.sortby( v => v._2, false //not ascending )
58 Spark zapis do HDFS rdd_fraud. repartition(1). saveastextfile("/user/cloudera/flat/fraud")
59 Spark RDD caching RDD.persist(StorageLevel.MEMORY_ONLY)
60 Spark - RDD join A: RDD[(Int,String)] B: RDD[(Int,String)] C: RDD[(Int,(String,String))] val C = A.join(B)
61 Spark broadcast val filtervalues = Set(1,4,7,9) val bc = sc.broadcast(filtervalues) rdd.filter( v=> bc.value.contains(v._1))


62 Spark Streaming
63 Cloudera architektura Service Master Hosts Worker Hosts Utility Hosts HDFS YARN Hive NameNode Secondary NameNode ResourceManager JobHistory Server Hive Metastore Server HiveServer2 DataNode NodeManager Impala Impala Statestore Impala Deamon Impala Catalog Spark JobHistory Server
64 Cloudera Manager
65 Cloudera architektura Service Master Hosts Worker Hosts Utility Hosts HDFS YARN Hive NameNode Secondary NameNode ResourceManager JobHistory Server Hive Metastore Server HiveServer2 DataNode NodeManager Impala Impala Statestore Impala Deamon Impala Catalog Spark JobHistory Server CM CM Agent CM Agent CM Agent CM Server CM Database
66 Cloudera Navigator
67 Certyfikaty
68 Sqoop Sqoop script Sqoop script RDBMS MR HDFS MR RDBMS
69 Sqoop sqoop import \ --connect jdbc:mysql://localhost:3306/retail_db \ --username root \ --password cloudera \ --table products \ --target-dir /user/cloudera/flat/products \ --delete-target-dir \ -m 1 sqoop import \ --connect jdbc:mysql://localhost:3306/retail_db \ --username root \ --password cloudera \ --table departments \ --hive-import \ --hive-overwrite \ --hive-database lab \ --hive-table departments \ -m 1
70
71 Hadoop a bezpieczeństwo danych Kerberos Szyfrowanie danych w HDFS Szyfrowanie połączeń (TLS/SSL) Włączenie autentykacji w WebHDFS! Zarządzanie uprawnieniami: Sentry lub Ranger
72 Hadoop - przyszłość Enterprise Data Hub Data Lake EDW Symbiosis Data Lake
73 Hadoop - podsumowanie Hadoop służy z założenia rozwiązywaniu problemów analizy danych rzędu od kilku do kilkuset TB. Hadoop otwiera dla firm możliwość analizy danych z zewnątrz : Internet of Things Social Medial Nie brakuje inicjatyw zastępowania klasycznych systemów hurtowni danych przez Hadoopa (koszty licencji rozwiązań komercyjnych). Większość skomplikowanych problemów analizy danych nie wymaga przetwarzania zbiorów większych niż kilkadziesiąt GB, czyli mieszczących się w pamięci operacyjnej jednej maszyny.
74 Pytania
Wprowadzenie do Apache Spark. Jakub Toczek
 Wprowadzenie do Apache Spark Jakub Toczek Epoka informacyjna MapReduce MapReduce Apache Hadoop narodziny w 2006 roku z Apache Nutch open source składa się z systemu plików HDFS i silnika MapReduce napisany
Wprowadzenie do Apache Spark Jakub Toczek Epoka informacyjna MapReduce MapReduce Apache Hadoop narodziny w 2006 roku z Apache Nutch open source składa się z systemu plików HDFS i silnika MapReduce napisany
Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family
 Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów, architektów oraz
Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów, architektów oraz
Hadoop i Spark. Mariusz Rafało
 Hadoop i Spark Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl WPROWADZENIE DO EKOSYSTEMU APACHE HADOOP Czym jest Hadoop Platforma służąca przetwarzaniu rozproszonemu dużych zbiorów danych. Jest
Hadoop i Spark Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl WPROWADZENIE DO EKOSYSTEMU APACHE HADOOP Czym jest Hadoop Platforma służąca przetwarzaniu rozproszonemu dużych zbiorów danych. Jest
Wprowadzenie do Hurtowni Danych
 Wprowadzenie do Hurtowni Danych BIG DATA Definicja Big Data Big Data definiowane jest jako składowanie zbiorów danych o tak dużej złożoności i ilości danych, że jest to niemożliwe przy zastosowaniu podejścia
Wprowadzenie do Hurtowni Danych BIG DATA Definicja Big Data Big Data definiowane jest jako składowanie zbiorów danych o tak dużej złożoności i ilości danych, że jest to niemożliwe przy zastosowaniu podejścia
Organizacyjnie. Prowadzący: dr Mariusz Rafało (hasło: BIG)
") Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Data Camp Architektura Data Lake Repozytorium służące składowaniu i przetwarzaniu danych o
Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Data Camp Architektura Data Lake Repozytorium służące składowaniu i przetwarzaniu danych o
Organizacyjnie. Prowadzący: dr Mariusz Rafało (hasło: BIG)
") Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Automatyzacja Automatyzacja przetwarzania: Apache NiFi Źródło: nifi.apache.org 4 Automatyzacja
Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Automatyzacja Automatyzacja przetwarzania: Apache NiFi Źródło: nifi.apache.org 4 Automatyzacja
SAS Access to Hadoop, SAS Data Loader for Hadoop Integracja środowisk SAS i Hadoop. Piotr Borowik
 SAS Access to Hadoop, SAS Data Loader for Hadoop Integracja środowisk SAS i Hadoop Piotr Borowik Wyzwania związane z Big Data Top Hurdles with Big data Source: Gartner (Sep 2014), Big Data Investment Grows
SAS Access to Hadoop, SAS Data Loader for Hadoop Integracja środowisk SAS i Hadoop Piotr Borowik Wyzwania związane z Big Data Top Hurdles with Big data Source: Gartner (Sep 2014), Big Data Investment Grows
Analityka danych w środowisku Hadoop. Piotr Czarnas, 27 czerwca 2017
 Analityka danych w środowisku Hadoop Piotr Czarnas, 27 czerwca 2017 Hadoop i Business Intelligence - wyzwania 1 Ładowane danych do Hadoop-a jest trudne 2 Niewielu specjalistów dostępnych na rynku Dostęp
Analityka danych w środowisku Hadoop Piotr Czarnas, 27 czerwca 2017 Hadoop i Business Intelligence - wyzwania 1 Ładowane danych do Hadoop-a jest trudne 2 Niewielu specjalistów dostępnych na rynku Dostęp
Hbase, Hive i BigSQL
 Hbase, Hive i BigSQL str. 1 Agenda 1. NOSQL a HBase 2. Architektura HBase 3. Demo HBase 4. Po co Hive? 5. Apache Hive 6. Demo hive 7. BigSQL 1 HBase Jest to rozproszona trwała posortowana wielowymiarowa
Hbase, Hive i BigSQL str. 1 Agenda 1. NOSQL a HBase 2. Architektura HBase 3. Demo HBase 4. Po co Hive? 5. Apache Hive 6. Demo hive 7. BigSQL 1 HBase Jest to rozproszona trwała posortowana wielowymiarowa
Organizacyjnie. Prowadzący: dr Mariusz Rafało (hasło: BIG)
") Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Zaliczenie: Praca na zajęciach Egzamin Projekt/esej zaliczeniowy Plan zajęć # TEMATYKA ZAJĘĆ
Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Zaliczenie: Praca na zajęciach Egzamin Projekt/esej zaliczeniowy Plan zajęć # TEMATYKA ZAJĘĆ
Usługi analityczne budowa kostki analitycznej Część pierwsza.
 Usługi analityczne budowa kostki analitycznej Część pierwsza. Wprowadzenie W wielu dziedzinach działalności człowieka analiza zebranych danych jest jednym z najważniejszych mechanizmów podejmowania decyzji.
Usługi analityczne budowa kostki analitycznej Część pierwsza. Wprowadzenie W wielu dziedzinach działalności człowieka analiza zebranych danych jest jednym z najważniejszych mechanizmów podejmowania decyzji.
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Map-Reduce system Single-node architektura 3 Przykład Googla 4 10 miliardów stron internetowych Średnia
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Map-Reduce system Single-node architektura 3 Przykład Googla 4 10 miliardów stron internetowych Średnia
Organizacyjnie. Prowadzący: dr Mariusz Rafało (hasło: BIG)
") Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) DANE W CZASIE RZECZYWISTYM 3 Tryb analizowania danych 4 Okno analizowania 5 Real-time: Checkpointing
Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) DANE W CZASIE RZECZYWISTYM 3 Tryb analizowania danych 4 Okno analizowania 5 Real-time: Checkpointing
Analityka danych w środowisku Hadoop. Piotr Czarnas, 5 czerwca 2017
 Analityka danych w środowisku Hadoop Piotr Czarnas, 5 czerwca 2017 Pytania stawiane przez biznes 1 Jaka jest aktualnie sytuacja w firmie? 2 Na czym jeszcze możemy zarobić? Które procesy możemy usprawnić?
Analityka danych w środowisku Hadoop Piotr Czarnas, 5 czerwca 2017 Pytania stawiane przez biznes 1 Jaka jest aktualnie sytuacja w firmie? 2 Na czym jeszcze możemy zarobić? Które procesy możemy usprawnić?
Ćwiczenia laboratoryjne nr 11 Bazy danych i SQL.
 Prezentacja Danych i Multimedia II r Socjologia Ćwiczenia laboratoryjne nr 11 Bazy danych i SQL. Celem ćwiczeń jest poznanie zasad tworzenia baz danych i zastosowania komend SQL. Ćwiczenie I. Logowanie
Prezentacja Danych i Multimedia II r Socjologia Ćwiczenia laboratoryjne nr 11 Bazy danych i SQL. Celem ćwiczeń jest poznanie zasad tworzenia baz danych i zastosowania komend SQL. Ćwiczenie I. Logowanie
Iwona Milczarek, Małgorzata Marcinkiewicz, Tomasz Staszewski. Poznań, 30.09.2015
 Iwona Milczarek, Małgorzata Marcinkiewicz, Tomasz Staszewski Poznań, 30.09.2015 Plan Geneza Architektura Cechy Instalacja Standard SQL Transakcje i współbieżność Indeksy Administracja Splice Machince vs.
Iwona Milczarek, Małgorzata Marcinkiewicz, Tomasz Staszewski Poznań, 30.09.2015 Plan Geneza Architektura Cechy Instalacja Standard SQL Transakcje i współbieżność Indeksy Administracja Splice Machince vs.
TECHNOLOGIE BIG DATA A BEZPIECZEŃSTWO INFORMATYCZNE WE KNOW YOU KNOW. silmine.com
 TECHNOLOGIE BIG DATA A BEZPIECZEŃSTWO INFORMATYCZNE WE KNOW YOU KNOW. silmine.com 13 + 13 LAT DOŚWIADCZENIA PONAD 480 ZREALIZOWANYCH PROJEKTÓW PARTNERSTWO Naszą ambicją jest dostarczać klientom szeroki
TECHNOLOGIE BIG DATA A BEZPIECZEŃSTWO INFORMATYCZNE WE KNOW YOU KNOW. silmine.com 13 + 13 LAT DOŚWIADCZENIA PONAD 480 ZREALIZOWANYCH PROJEKTÓW PARTNERSTWO Naszą ambicją jest dostarczać klientom szeroki
Dni: 2. Partner merytoryczny. Opis: Adresaci szkolenia
 Kod szkolenia: Tytuł szkolenia: BIGDATA/STR Strumieniowe przetwarzanie Big Data Dni: 2 Partner merytoryczny Opis: Adresaci szkolenia Szkolenie jest przeznaczone głównie dla programistów i analityków danych,
Kod szkolenia: Tytuł szkolenia: BIGDATA/STR Strumieniowe przetwarzanie Big Data Dni: 2 Partner merytoryczny Opis: Adresaci szkolenia Szkolenie jest przeznaczone głównie dla programistów i analityków danych,
Hadoop : kompletny przewodnik : analiza i przechowywanie danych / Tom White. Gliwice, cop Spis treści
 Hadoop : kompletny przewodnik : analiza i przechowywanie danych / Tom White. Gliwice, cop. 2016 Spis treści Przedmowa 17 Wprowadzenie 19 Kwestie porządkowe 20 Co nowego znajdziesz w wydaniu czwartym? 20
Hadoop : kompletny przewodnik : analiza i przechowywanie danych / Tom White. Gliwice, cop. 2016 Spis treści Przedmowa 17 Wprowadzenie 19 Kwestie porządkowe 20 Co nowego znajdziesz w wydaniu czwartym? 20
Hurtownie danych i business intelligence - wykład II. Zagadnienia do omówienia. Miejsce i rola HD w firmie
 Hurtownie danych i business intelligence - wykład II Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2005-2012 Zagadnienia do omówienia 1. Miejsce i rola w firmie 2. Przegląd architektury
Hurtownie danych i business intelligence - wykład II Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2005-2012 Zagadnienia do omówienia 1. Miejsce i rola w firmie 2. Przegląd architektury
Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family
 Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Partner merytoryczny Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów,
Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Partner merytoryczny Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów,
Rola analityki danych w transformacji cyfrowej firmy
 Rola analityki danych w transformacji cyfrowej firmy Piotr Czarnas Querona CEO Analityka biznesowa (ang. Business Intelligence) Proces przekształcania danych w informacje, a informacji w wiedzę, która
Rola analityki danych w transformacji cyfrowej firmy Piotr Czarnas Querona CEO Analityka biznesowa (ang. Business Intelligence) Proces przekształcania danych w informacje, a informacji w wiedzę, która
Administracja bazami danych
 Administracja bazami danych dr inż. Grzegorz Michalski Na podstawie wykładów dra inż. Juliusza Mikody Klient tekstowy mysql Program mysql jest prostym programem uruchamianym w konsoli shell do obsługi
Administracja bazami danych dr inż. Grzegorz Michalski Na podstawie wykładów dra inż. Juliusza Mikody Klient tekstowy mysql Program mysql jest prostym programem uruchamianym w konsoli shell do obsługi
Big Data & Analytics
 Big Data & Analytics Optymalizacja biznesu Autor: Wiktor Jóźwicki, Scapaflow Senior Consultant Data wydania: 05.02.2014 Wprowadzenie Niniejszy dokument przedstawia zagadnienie Big Data w ujęciu zapotrzebowania
Big Data & Analytics Optymalizacja biznesu Autor: Wiktor Jóźwicki, Scapaflow Senior Consultant Data wydania: 05.02.2014 Wprowadzenie Niniejszy dokument przedstawia zagadnienie Big Data w ujęciu zapotrzebowania
SQL Server 2016 w świecie Big Data
 temat prelekcji.. SQL Server 2016 w świecie Big Data prowadzący Bartłomiej Graczyk Data Platform Solution Architect bartlomiej.graczyk@microsoft.com bartek@graczyk.info.pl Agenda Dane na świecie wczoraj,
temat prelekcji.. SQL Server 2016 w świecie Big Data prowadzący Bartłomiej Graczyk Data Platform Solution Architect bartlomiej.graczyk@microsoft.com bartek@graczyk.info.pl Agenda Dane na świecie wczoraj,
Business Intelligence Beans + Oracle JDeveloper
 Business Intelligence Beans + Oracle JDeveloper 360 Plan rozdziału 361 Wprowadzenie do Java OLAP API Architektura BI Beans Instalacja katalogu BI Beans Tworzenie aplikacji BI Beans Zapisywanie obiektów
Business Intelligence Beans + Oracle JDeveloper 360 Plan rozdziału 361 Wprowadzenie do Java OLAP API Architektura BI Beans Instalacja katalogu BI Beans Tworzenie aplikacji BI Beans Zapisywanie obiektów
Informacje organizacyjne:
 Informacje organizacyjne: 1. Zaliczenie przedmiotu zostanie przeprowadzone w formie testu, z którego będzie można zdobyć maksymalnie 100 punktów. Skala ocen: 00 50 punktów: 2 51 60 punktów: 3 61 70 punktów:
Informacje organizacyjne: 1. Zaliczenie przedmiotu zostanie przeprowadzone w formie testu, z którego będzie można zdobyć maksymalnie 100 punktów. Skala ocen: 00 50 punktów: 2 51 60 punktów: 3 61 70 punktów:
Hurtownie danych i business intelligence - wykład II. Zagadnienia do omówienia. Miejsce i rola HD w firmie
 Hurtownie danych i business intelligence - wykład II Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2005-2008 Zagadnienia do omówienia 1. 2. Przegląd architektury HD 3. Warsztaty
Hurtownie danych i business intelligence - wykład II Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2005-2008 Zagadnienia do omówienia 1. 2. Przegląd architektury HD 3. Warsztaty
Założenia do ćwiczeń: SQL Server UWM Express Edition: 213.184.8.192\SQLEXPRESS. Zapoznaj się ze sposobami użycia narzędzia T SQL z wiersza poleceń.
 Cel: polecenia T-SQL Założenia do ćwiczeń: SQL Server UWM Express Edition: 213.184.8.192\SQLEXPRESS Authentication: SQL Server Authentication Username: student01,, student21 Password: student01,., student21
Cel: polecenia T-SQL Założenia do ćwiczeń: SQL Server UWM Express Edition: 213.184.8.192\SQLEXPRESS Authentication: SQL Server Authentication Username: student01,, student21 Password: student01,., student21
Oracle11g: Wprowadzenie do SQL
 Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
MongoDB. wprowadzenie. dr inż. Paweł Boiński, Politechnika Poznańska
 MongoDB wprowadzenie dr inż. Paweł Boiński, Politechnika Poznańska Plan Historia Podstawowe pojęcia: Dokument Kolekcja Generowanie identyfikatora Model danych Dokumenty zagnieżdżone Dokumenty z referencjami
MongoDB wprowadzenie dr inż. Paweł Boiński, Politechnika Poznańska Plan Historia Podstawowe pojęcia: Dokument Kolekcja Generowanie identyfikatora Model danych Dokumenty zagnieżdżone Dokumenty z referencjami
Architektura rozproszonych magazynów danych
 Big data Big data, large data cloud. Rozwiązania nastawione na zastosowanie w wielkoskalowych serwisach, np. webowych. Stosowane przez Google, Facebook, itd. Architektura rozproszonych magazynów danych
Big data Big data, large data cloud. Rozwiązania nastawione na zastosowanie w wielkoskalowych serwisach, np. webowych. Stosowane przez Google, Facebook, itd. Architektura rozproszonych magazynów danych
PLNOG#10 Hadoop w akcji: analiza logów 1
 PLNOG#10 Hadoop w akcji: analiza logów 1 Hadoop w akcji: analiza logów rkadiusz Osiński arkadiusz.osinski@allegro.pl PLNOG#10 Hadoop w akcji: analiza logów 2 genda 1. Hadoop 2. HDFS 3. YRN 4. Map & Reduce
PLNOG#10 Hadoop w akcji: analiza logów 1 Hadoop w akcji: analiza logów rkadiusz Osiński arkadiusz.osinski@allegro.pl PLNOG#10 Hadoop w akcji: analiza logów 2 genda 1. Hadoop 2. HDFS 3. YRN 4. Map & Reduce
Database Connectivity
 Oprogramowanie Systemów Pomiarowych 15.01.2009 Database Connectivity Dr inŝ. Sebastian Budzan Zakład Pomiarów i Systemów Sterowania Tematyka Podstawy baz danych, Komunikacja, pojęcia: API, ODBC, DSN, Połączenie
Oprogramowanie Systemów Pomiarowych 15.01.2009 Database Connectivity Dr inŝ. Sebastian Budzan Zakład Pomiarów i Systemów Sterowania Tematyka Podstawy baz danych, Komunikacja, pojęcia: API, ODBC, DSN, Połączenie
Informatyka I. Standard JDBC Programowanie aplikacji bazodanowych w języku Java
 Informatyka I Standard JDBC Programowanie aplikacji bazodanowych w języku Java dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2017 Standard JDBC Java DataBase Connectivity uniwersalny
Informatyka I Standard JDBC Programowanie aplikacji bazodanowych w języku Java dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2017 Standard JDBC Java DataBase Connectivity uniwersalny
System Oracle podstawowe czynności administracyjne
 6 System Oracle podstawowe czynności administracyjne Stany bazy danych IDLE nieczynna, pliki zamknięte, procesy tła niedziałaja NOMOUNT stan po odczytaniu pfile-a, zainicjowaniu SGA i uruchomieniu procesów
6 System Oracle podstawowe czynności administracyjne Stany bazy danych IDLE nieczynna, pliki zamknięte, procesy tła niedziałaja NOMOUNT stan po odczytaniu pfile-a, zainicjowaniu SGA i uruchomieniu procesów
Model logiczny SZBD. Model fizyczny. Systemy klientserwer. Systemy rozproszone BD. No SQL
 Podstawy baz danych: Rysunek 1. Tradycyjne systemy danych 1- Obsługa wejścia 2- Przechowywanie danych 3- Funkcje użytkowe 4- Obsługa wyjścia Ewolucja baz danych: Fragment świata rzeczywistego System przetwarzania
Podstawy baz danych: Rysunek 1. Tradycyjne systemy danych 1- Obsługa wejścia 2- Przechowywanie danych 3- Funkcje użytkowe 4- Obsługa wyjścia Ewolucja baz danych: Fragment świata rzeczywistego System przetwarzania
Architecture Best Practices for Big Data Deployments
 GLOBAL SPONSORS Architecture Best Practices for Big Data Deployments Kajetan Mroczek Systems Engineer GLOBAL SPONSORS Rozwój analityki biznesowej EKSPLORACJA DANYCH UCZENIE MASZYNOWE SZTUCZNA INTELIGENCJA
GLOBAL SPONSORS Architecture Best Practices for Big Data Deployments Kajetan Mroczek Systems Engineer GLOBAL SPONSORS Rozwój analityki biznesowej EKSPLORACJA DANYCH UCZENIE MASZYNOWE SZTUCZNA INTELIGENCJA
Migracja Business Intelligence do wersji
 Migracja Business Intelligence do wersji 2016.1 Copyright 2015 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci jest
Migracja Business Intelligence do wersji 2016.1 Copyright 2015 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci jest
Wprowadzenie do technologii Business Intelligence i hurtowni danych
 Wprowadzenie do technologii Business Intelligence i hurtowni danych 1 Plan rozdziału 2 Wprowadzenie do Business Intelligence Hurtownie danych Produkty Oracle dla Business Intelligence Business Intelligence
Wprowadzenie do technologii Business Intelligence i hurtowni danych 1 Plan rozdziału 2 Wprowadzenie do Business Intelligence Hurtownie danych Produkty Oracle dla Business Intelligence Business Intelligence
Wprowadzenie do Hurtowni Danych
 Wprowadzenie do Hurtowni Danych Organizacyjnie Prowadzący: mgr. Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło HD2) Literatura 1. Inmon, W., Linstedt, D. (2014). Data Architecture: A
Wprowadzenie do Hurtowni Danych Organizacyjnie Prowadzący: mgr. Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło HD2) Literatura 1. Inmon, W., Linstedt, D. (2014). Data Architecture: A
Informatyka I. Programowanie aplikacji bazodanowych w języku Java. Standard JDBC.
 Informatyka I Programowanie aplikacji bazodanowych w języku Java. Standard JDBC. dr hab. inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2019 Standard JDBC Java DataBase Connectivity
Informatyka I Programowanie aplikacji bazodanowych w języku Java. Standard JDBC. dr hab. inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2019 Standard JDBC Java DataBase Connectivity
Modelowanie Data Mining na wielką skalę z SAS Factory Miner. Paweł Plewka, SAS
 Modelowanie Data Mining na wielką skalę z SAS Factory Miner Paweł Plewka, SAS Wstęp SAS Factory Miner Nowe narzędzie do data mining - dostępne od połowy 2015 r. Aktualna wersja - 14.1 Interfejs webowy
Modelowanie Data Mining na wielką skalę z SAS Factory Miner Paweł Plewka, SAS Wstęp SAS Factory Miner Nowe narzędzie do data mining - dostępne od połowy 2015 r. Aktualna wersja - 14.1 Interfejs webowy
Instalacja SQL Server Express. Logowanie na stronie Microsoftu
 Instalacja SQL Server Express Logowanie na stronie Microsoftu Wybór wersji do pobrania Pobieranie startuje, przechodzimy do strony z poradami. Wypakowujemy pobrany plik. Otwiera się okno instalacji. Wybieramy
Instalacja SQL Server Express Logowanie na stronie Microsoftu Wybór wersji do pobrania Pobieranie startuje, przechodzimy do strony z poradami. Wypakowujemy pobrany plik. Otwiera się okno instalacji. Wybieramy
Część 1: OLAP. Raport z zajęć laboratoryjnych w ramach przedmiotu Hurtownie i eksploracja danych
 Łukasz Przywarty 171018 Wrocław, 05.12.2012 r. Grupa: CZW/N 10:00-13:00 Raport z zajęć laboratoryjnych w ramach przedmiotu Hurtownie i eksploracja danych Część 1: OLAP Prowadzący: dr inż. Henryk Maciejewski
Łukasz Przywarty 171018 Wrocław, 05.12.2012 r. Grupa: CZW/N 10:00-13:00 Raport z zajęć laboratoryjnych w ramach przedmiotu Hurtownie i eksploracja danych Część 1: OLAP Prowadzący: dr inż. Henryk Maciejewski
DBPLUS Data Replicator Subtitle dla Microsoft SQL Server. dbplus.tech
 DBPLUS Data Replicator Subtitle dla Microsoft SQL Server dbplus.tech Instalacja Program instalacyjny pozwala na zainstalowanie jednego lub obu komponentów: serwera i klienta. Przy zaznaczeniu opcji Serwer
DBPLUS Data Replicator Subtitle dla Microsoft SQL Server dbplus.tech Instalacja Program instalacyjny pozwala na zainstalowanie jednego lub obu komponentów: serwera i klienta. Przy zaznaczeniu opcji Serwer
Przygotowanie bazy do wykonywania kopii bezpieczeństwa
 Przygotowanie bazy do wykonywania kopii bezpieczeństwa Wstęp Wykonywanie kopii bezpieczeństwa i odtwarzanie po awarii jest jednym z kluczowych zadań administratora bazy danych. W momencie wystąpienia awarii
Przygotowanie bazy do wykonywania kopii bezpieczeństwa Wstęp Wykonywanie kopii bezpieczeństwa i odtwarzanie po awarii jest jednym z kluczowych zadań administratora bazy danych. W momencie wystąpienia awarii
Migracja Comarch ERP Altum Business Intelligence do wersji
 Migracja Comarch ERP Altum Business Intelligence do wersji 2016.5 Wersja 2016.5 2 Comarch ERP Altum Wersja 2016.5 Copyright 2016 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości
Migracja Comarch ERP Altum Business Intelligence do wersji 2016.5 Wersja 2016.5 2 Comarch ERP Altum Wersja 2016.5 Copyright 2016 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości
ZALETY NOWSZYCH WERSJI I KIERUNKI ROZWOJU SPDS-A SŁAWOMIR BOKINIEC
 ZALETY NOWSZYCH WERSJI I KIERUNKI ROZWOJU SPDS-A SŁAWOMIR BOKINIEC AGENDA Wybrane zalety wersji 5.1 i wcześniejszych SPDS z SAS Gridem Co kształtuje kierunki rozwoju? Nowsze wersje SPDS z Hadoopem WYBRANE
ZALETY NOWSZYCH WERSJI I KIERUNKI ROZWOJU SPDS-A SŁAWOMIR BOKINIEC AGENDA Wybrane zalety wersji 5.1 i wcześniejszych SPDS z SAS Gridem Co kształtuje kierunki rozwoju? Nowsze wersje SPDS z Hadoopem WYBRANE
dziennik Instrukcja obsługi
 Ham Radio Deluxe dziennik Instrukcja obsługi Wg. Simon Brown, HB9DRV Tłumaczenie SP4JEU grudzień 22, 2008 Zawartość 3 Wprowadzenie 5 Po co... 5 Główne cechy... 5 baza danych 7 ODBC... 7 Który produkt
Ham Radio Deluxe dziennik Instrukcja obsługi Wg. Simon Brown, HB9DRV Tłumaczenie SP4JEU grudzień 22, 2008 Zawartość 3 Wprowadzenie 5 Po co... 5 Główne cechy... 5 baza danych 7 ODBC... 7 Który produkt
Migracja XL Business Intelligence do wersji
 Migracja XL Business Intelligence do wersji 2018.1 Copyright 2017 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci
Migracja XL Business Intelligence do wersji 2018.1 Copyright 2017 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci
Przetwarzanie danych z wykorzystaniem technologii NoSQL na przykładzie serwisu Serp24
 Przetwarzanie danych z wykorzystaniem technologii NoSQL na przykładzie serwisu Serp24 Agenda Serp24 NoSQL Integracja z CMS Drupal Przetwarzanie danych Podsumowanie Serp24 Darmowe narzędzie Ułatwia planowanie
Przetwarzanie danych z wykorzystaniem technologii NoSQL na przykładzie serwisu Serp24 Agenda Serp24 NoSQL Integracja z CMS Drupal Przetwarzanie danych Podsumowanie Serp24 Darmowe narzędzie Ułatwia planowanie
Apache Hadoop framework do pisania aplikacji rozproszonych
 Apache Hadoop framework do pisania aplikacji rozproszonych Piotr Praczyk Wprowadzenie Istnieje wiele rodzajów obliczeń, których wykonywanie na pojedynczej maszynie, nawet najpotężniejszej, jest zbyt czasochłonne.
Apache Hadoop framework do pisania aplikacji rozproszonych Piotr Praczyk Wprowadzenie Istnieje wiele rodzajów obliczeń, których wykonywanie na pojedynczej maszynie, nawet najpotężniejszej, jest zbyt czasochłonne.
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl
 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Plan wykładów Wprowadzenie - integracja
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Plan wykładów Wprowadzenie - integracja
Hurtownie danych - przegląd technologii
 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Plan wykład adów Wprowadzenie - integracja
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Plan wykład adów Wprowadzenie - integracja
Bazy danych i usługi sieciowe
 Bazy danych i usługi sieciowe Wstęp do problematyki baz danych Paweł Daniluk Wydział Fizyki Jesień 2014 P. Daniluk (Wydział Fizyki) BDiUS w. I Jesień 2014 1 / 17 Plan wykładu 1 Bazy danych 1 Motywacja
Bazy danych i usługi sieciowe Wstęp do problematyki baz danych Paweł Daniluk Wydział Fizyki Jesień 2014 P. Daniluk (Wydział Fizyki) BDiUS w. I Jesień 2014 1 / 17 Plan wykładu 1 Bazy danych 1 Motywacja
Wstęp do Business Intelligence
 Wstęp do Business Intelligence Co to jest Buisness Intelligence Business Intelligence (analityka biznesowa) - proces przekształcania danych w informacje, a informacji w wiedzę, która może być wykorzystana
Wstęp do Business Intelligence Co to jest Buisness Intelligence Business Intelligence (analityka biznesowa) - proces przekształcania danych w informacje, a informacji w wiedzę, która może być wykorzystana
Nowe technologie baz danych
 Nowe technologie baz danych Partycjonowanie Partycjonowanie jest fizycznym podziałem danych pomiędzy różne pliki bazy danych Partycjonować można tabele i indeksy bazy danych Użytkownik bazy danych nie
Nowe technologie baz danych Partycjonowanie Partycjonowanie jest fizycznym podziałem danych pomiędzy różne pliki bazy danych Partycjonować można tabele i indeksy bazy danych Użytkownik bazy danych nie
dr inż. Paweł Morawski Informatyczne wsparcie decyzji logistycznych semestr letni 2016/2017
 dr inż. Paweł Morawski Informatyczne wsparcie decyzji logistycznych semestr letni 2016/2017 KONTAKT Z PROWADZĄCYM dr inż. Paweł Morawski e-mail: pmorawski@spoleczna.pl www: http://pmorawski.spoleczna.pl
dr inż. Paweł Morawski Informatyczne wsparcie decyzji logistycznych semestr letni 2016/2017 KONTAKT Z PROWADZĄCYM dr inż. Paweł Morawski e-mail: pmorawski@spoleczna.pl www: http://pmorawski.spoleczna.pl
Szkolenie: Jak mieć więcej czasu na wyciąganie wniosków
 Szkolenie: Jak mieć więcej czasu na wyciąganie wniosków 14 listopada 2018 r 8:45-12:45 Warszawa https://alterdata.evenea.pl "Dzisiaj praca analityka składa się w 15% z analizowania. Cała reszta czynności
Szkolenie: Jak mieć więcej czasu na wyciąganie wniosków 14 listopada 2018 r 8:45-12:45 Warszawa https://alterdata.evenea.pl "Dzisiaj praca analityka składa się w 15% z analizowania. Cała reszta czynności
Bazy Danych i Usługi Sieciowe
 Bazy Danych i Usługi Sieciowe Ćwiczenia I Paweł Daniluk Wydział Fizyki Jesień 2011 P. Daniluk (Wydział Fizyki) BDiUS ćw. I Jesień 2011 1 / 15 Strona wykładu http://bioexploratorium.pl/wiki/ Bazy_Danych_i_Usługi_Sieciowe_-_2011z
Bazy Danych i Usługi Sieciowe Ćwiczenia I Paweł Daniluk Wydział Fizyki Jesień 2011 P. Daniluk (Wydział Fizyki) BDiUS ćw. I Jesień 2011 1 / 15 Strona wykładu http://bioexploratorium.pl/wiki/ Bazy_Danych_i_Usługi_Sieciowe_-_2011z
Migracja XL Business Intelligence do wersji
 Migracja XL Business Intelligence do wersji 2019.0 Copyright 2018 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci
Migracja XL Business Intelligence do wersji 2019.0 Copyright 2018 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci
Firebird Alternatywa dla popularnych darmowych systemów bazodanowych MySQL i Postgres
 Firebird Alternatywa dla popularnych darmowych systemów bazodanowych MySQL i Postgres Artur Kozubski Software Development GigaCon Warszawa 2008 Plan Historia projektu Firebird Architektura serwera Administracja
Firebird Alternatywa dla popularnych darmowych systemów bazodanowych MySQL i Postgres Artur Kozubski Software Development GigaCon Warszawa 2008 Plan Historia projektu Firebird Architektura serwera Administracja
Rozwiązania bazodanowe EnterpriseDB
 Rozwiązania bazodanowe EnterpriseDB Bogumił Stoiński RHC{E,I,X} B2B Sp. z o.o. 519 130 155 bs@bel.pl PostgreSQL Ponad 20 lat na rynku Jedna z najpopularniejszych otwartych relacyjnych baz danych obok MySQL
Rozwiązania bazodanowe EnterpriseDB Bogumił Stoiński RHC{E,I,X} B2B Sp. z o.o. 519 130 155 bs@bel.pl PostgreSQL Ponad 20 lat na rynku Jedna z najpopularniejszych otwartych relacyjnych baz danych obok MySQL
Migracja Business Intelligence do wersji 2013.3
 Migracja Business Intelligence do wersji 2013.3 Copyright 2013 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci jest
Migracja Business Intelligence do wersji 2013.3 Copyright 2013 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci jest
Wybrane działy Informatyki Stosowanej
 Wybrane działy Informatyki Stosowanej Java Enterprise Edition WebServices Serwer aplikacji GlassFish Dr hab. inż. Andrzej Czerepicki a.czerepicki@wt.pw.edu.pl http://www2.wt.pw.edu.pl/~a.czerepicki Aplikacje
Wybrane działy Informatyki Stosowanej Java Enterprise Edition WebServices Serwer aplikacji GlassFish Dr hab. inż. Andrzej Czerepicki a.czerepicki@wt.pw.edu.pl http://www2.wt.pw.edu.pl/~a.czerepicki Aplikacje
HURTOWNIE DANYCH I BUSINESS INTELLIGENCE
 BAZY DANYCH HURTOWNIE DANYCH I BUSINESS INTELLIGENCE Akademia Górniczo-Hutnicza w Krakowie Adrian Horzyk horzyk@agh.edu.pl Google: Horzyk HURTOWNIE DANYCH Hurtownia danych (Data Warehouse) to najczęściej
BAZY DANYCH HURTOWNIE DANYCH I BUSINESS INTELLIGENCE Akademia Górniczo-Hutnicza w Krakowie Adrian Horzyk horzyk@agh.edu.pl Google: Horzyk HURTOWNIE DANYCH Hurtownia danych (Data Warehouse) to najczęściej
Wprowadzenie do Hurtowni Danych. Mariusz Rafało
 Wprowadzenie do Hurtowni Danych Mariusz Rafało mrafalo@sgh.waw.pl WARSTWA PREZENTACJI HURTOWNI DANYCH Wykorzystanie hurtowni danych - aspekty Analityczne zbiory danych (ADS) Zbiór danych tematycznych (Data
Wprowadzenie do Hurtowni Danych Mariusz Rafało mrafalo@sgh.waw.pl WARSTWA PREZENTACJI HURTOWNI DANYCH Wykorzystanie hurtowni danych - aspekty Analityczne zbiory danych (ADS) Zbiór danych tematycznych (Data
XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery
 http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
Informatyka I BAZY DANYCH. dr inż. Andrzej Czerepicki. Politechnika Warszawska Wydział Transportu 2017
 Informatyka I BAZY DANYCH dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2017 Plan wykładu Definicja systemu baz danych Modele danych Relacyjne bazy danych Język SQL Hurtownie danych
Informatyka I BAZY DANYCH dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2017 Plan wykładu Definicja systemu baz danych Modele danych Relacyjne bazy danych Język SQL Hurtownie danych
dr inż. Paweł Morawski Informatyczne wsparcie decyzji logistycznych semestr letni 2018/2019
 dr inż. Paweł Morawski Informatyczne wsparcie decyzji logistycznych semestr letni 2018/2019 KONTAKT Z PROWADZĄCYM dr inż. Paweł Morawski e-mail: pmorawski@spoleczna.pl www: http://pmorawski.spoleczna.pl
dr inż. Paweł Morawski Informatyczne wsparcie decyzji logistycznych semestr letni 2018/2019 KONTAKT Z PROWADZĄCYM dr inż. Paweł Morawski e-mail: pmorawski@spoleczna.pl www: http://pmorawski.spoleczna.pl
Podstawy Pentaho Data Integration
 Podstawy Pentaho Data Integration 1. Instalacja Pentaho Data Integration Program Pentaho Data Integration można pobrać ze strony - http://www.pentaho.com/download, wybierając wersję na prawo czyli data
Podstawy Pentaho Data Integration 1. Instalacja Pentaho Data Integration Program Pentaho Data Integration można pobrać ze strony - http://www.pentaho.com/download, wybierając wersję na prawo czyli data
Zadania do wykonania na laboratorium
 Lab Oracle Katowice 2013v1 Fizyczna i logiczna struktura bazy danych 1 http://platforma.polsl.pl/rau2/mod/folder/view.php?id=9975 RB_lab2_v04st Przykładowe pomocne strony www: Zadania do wykonania na laboratorium
Lab Oracle Katowice 2013v1 Fizyczna i logiczna struktura bazy danych 1 http://platforma.polsl.pl/rau2/mod/folder/view.php?id=9975 RB_lab2_v04st Przykładowe pomocne strony www: Zadania do wykonania na laboratorium
FORMULARZ OFERTY CENOWEJ. Future Processing Sp. z o.o. ul. Bojkowska 37A Gliwice NIP: NIP:
 Załącznik nr 1 do Zapytania ofertowego FORMULARZ OFERTY CENOWEJ Wykonawca: Zamawiający: Future Processing Sp. z o.o. ul. Bojkowska 37A 44-100 Gliwice NIP: NIP: 634-25-32-128 Nawiązując do ogłoszenia o
Załącznik nr 1 do Zapytania ofertowego FORMULARZ OFERTY CENOWEJ Wykonawca: Zamawiający: Future Processing Sp. z o.o. ul. Bojkowska 37A 44-100 Gliwice NIP: NIP: 634-25-32-128 Nawiązując do ogłoszenia o
Z-ID-608b Bazy danych typu Big Data Big Data Databases. Specjalnościowy Obowiązkowy Polski Semestr VI
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angieskim Obowiązuje od roku akademickiego 015/016 Z-ID-608b Bazy danych typu Big Data Big Data Databases A. USYTUOWANIE MODUŁU
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angieskim Obowiązuje od roku akademickiego 015/016 Z-ID-608b Bazy danych typu Big Data Big Data Databases A. USYTUOWANIE MODUŁU
Migracja Business Intelligence do wersji 11.0
 Migracja Business Intelligence do wersji 11.0 Copyright 2012 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci jest
Migracja Business Intelligence do wersji 11.0 Copyright 2012 COMARCH Wszelkie prawa zastrzeżone Nieautoryzowane rozpowszechnianie całości lub fragmentu niniejszej publikacji w jakiejkolwiek postaci jest
Szkolenia SAS Cennik i kalendarz 2017
 Szkolenia SAS Spis treści NARZĘDZIA SAS FOUNDATION 2 ZAAWANSOWANA ANALITYKA 2 PROGNOZOWANIE I EKONOMETRIA 3 ANALIZA TREŚCI 3 OPTYMALIZACJA I SYMULACJA 3 3 ROZWIĄZANIA DLA HADOOP 3 HIGH-PERFORMANCE ANALYTICS
Szkolenia SAS Spis treści NARZĘDZIA SAS FOUNDATION 2 ZAAWANSOWANA ANALITYKA 2 PROGNOZOWANIE I EKONOMETRIA 3 ANALIZA TREŚCI 3 OPTYMALIZACJA I SYMULACJA 3 3 ROZWIĄZANIA DLA HADOOP 3 HIGH-PERFORMANCE ANALYTICS
Bazy danych i usługi sieciowe
 Bazy danych i usługi sieciowe Ćwiczenia I Paweł Daniluk Wydział Fizyki Jesień 2014 P. Daniluk (Wydział Fizyki) BDiUS ćw. I Jesień 2014 1 / 16 Strona wykładu http://bioexploratorium.pl/wiki/ Bazy_danych_i_usługi_sieciowe_-_2014z
Bazy danych i usługi sieciowe Ćwiczenia I Paweł Daniluk Wydział Fizyki Jesień 2014 P. Daniluk (Wydział Fizyki) BDiUS ćw. I Jesień 2014 1 / 16 Strona wykładu http://bioexploratorium.pl/wiki/ Bazy_danych_i_usługi_sieciowe_-_2014z
Hurtownie danych w praktyce
 Hurtownie danych w praktyce Fakty i mity Dr inż. Maciej Kiewra Parę słów o mnie... 8 lat pracy zawodowej z hurtowniami danych Projekty realizowane w kraju i zagranicą Certyfikaty Microsoft z Business Intelligence
Hurtownie danych w praktyce Fakty i mity Dr inż. Maciej Kiewra Parę słów o mnie... 8 lat pracy zawodowej z hurtowniami danych Projekty realizowane w kraju i zagranicą Certyfikaty Microsoft z Business Intelligence
Baza danych in-memory. DB2 BLU od środka 2015-11-10. Artur Wrooski
 TECHNOLOGIE ANALIZY DANYCH I CHMUROWE W ZASTOSOWANIACH BIZNESOWYCH Poznao, 30 września 2015 DB2 BLU od środka Artur Wrooski Baza danych in-memory Baza danych IN-MEMORY system zarządzania bazami danych,
TECHNOLOGIE ANALIZY DANYCH I CHMUROWE W ZASTOSOWANIACH BIZNESOWYCH Poznao, 30 września 2015 DB2 BLU od środka Artur Wrooski Baza danych in-memory Baza danych IN-MEMORY system zarządzania bazami danych,
Problemy techniczne SQL Server
 Problemy techniczne SQL Server Jak utworzyć i odtworzyć kopię zapasową bazy danych za pomocą narzędzi serwera SQL? Tworzenie i odtwarzanie kopii zapasowych baz danych programów Kadry Optivum, Płace Optivum,
Problemy techniczne SQL Server Jak utworzyć i odtworzyć kopię zapasową bazy danych za pomocą narzędzi serwera SQL? Tworzenie i odtwarzanie kopii zapasowych baz danych programów Kadry Optivum, Płace Optivum,
Tematy prac dyplomowych inżynierskich
 inżynierskich Oferujemy możliwość realizowania poniższych tematów w ramach projektu realizowanego ze środków Narodowego Centrum Badań i Rozwoju. Najlepszym umożliwimy realizację pracy dyplomowej w połączeniu
inżynierskich Oferujemy możliwość realizowania poniższych tematów w ramach projektu realizowanego ze środków Narodowego Centrum Badań i Rozwoju. Najlepszym umożliwimy realizację pracy dyplomowej w połączeniu
Problemy techniczne SQL Server
 Problemy techniczne SQL Server Jak utworzyć i odtworzyć kopię zapasową za pomocą narzędzi serwera SQL? Tworzenie i odtwarzanie kopii zapasowych baz danych programów Kadry Optivum, Płace Optivum, MOL Optivum,
Problemy techniczne SQL Server Jak utworzyć i odtworzyć kopię zapasową za pomocą narzędzi serwera SQL? Tworzenie i odtwarzanie kopii zapasowych baz danych programów Kadry Optivum, Płace Optivum, MOL Optivum,
Procesy ETL - wykład V. Struktura. Wprowadzenie. 1. Wprowadzenie. 2. Ekstrakcja 3. Transformacja 4. Ładowanie 5. Studium przypadków.
 Procesy ETL - wykład V Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2012 Struktura 1. Wprowadzenie 2. Ekstrakcja 3. Transformacja 4. Ładowanie 5. Studium przypadków Wprowadzenie
Procesy ETL - wykład V Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2012 Struktura 1. Wprowadzenie 2. Ekstrakcja 3. Transformacja 4. Ładowanie 5. Studium przypadków Wprowadzenie
BACKUP BAZ DANYCH MS SQL
 BACKUP BAZ DANYCH MS SQL SPIS TREŚCI Informacje ogólne... 2 Tworzenie projektu... 2 Krok 1: Informacje Podstawowe... 2 Krok 2: Dane... 3 Krok 3: Planowanie... 4 Krok 4: Zaawansowane... 5 Przywracanie baz
BACKUP BAZ DANYCH MS SQL SPIS TREŚCI Informacje ogólne... 2 Tworzenie projektu... 2 Krok 1: Informacje Podstawowe... 2 Krok 2: Dane... 3 Krok 3: Planowanie... 4 Krok 4: Zaawansowane... 5 Przywracanie baz
Maciej Kiewra mkiewra@qbico.pl. Quality Business Intelligence Consulting http://www.qbico.pl
 Maciej Kiewra mkiewra@qbico.pl Quality Business Intelligence Consulting http://www.qbico.pl Wstęp Integration Services narzędzie do integracji danych Pomyślane do implementacji procesów ETL Extract ekstrakcja
Maciej Kiewra mkiewra@qbico.pl Quality Business Intelligence Consulting http://www.qbico.pl Wstęp Integration Services narzędzie do integracji danych Pomyślane do implementacji procesów ETL Extract ekstrakcja
Wdrożenie modułu płatności eservice. dla systemu oscommerce 2.3.x
 Wdrożenie modułu płatności eservice dla systemu oscommerce 2.3.x - dokumentacja techniczna Wer. 01 Warszawa, styczeń 2014 1 Spis treści: 1 Wstęp... 3 1.1 Przeznaczenie dokumentu... 3 1.2 Przygotowanie
Wdrożenie modułu płatności eservice dla systemu oscommerce 2.3.x - dokumentacja techniczna Wer. 01 Warszawa, styczeń 2014 1 Spis treści: 1 Wstęp... 3 1.1 Przeznaczenie dokumentu... 3 1.2 Przygotowanie
Hurtownie danych - przegląd technologii
 Hurtownie danych - przegląd technologii Problematyka zasilania hurtowni danych - Oracle Data Integrator Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel
Hurtownie danych - przegląd technologii Problematyka zasilania hurtowni danych - Oracle Data Integrator Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel
AUREA BPM Oracle. TECNA Sp. z o.o. Strona 1 z 7
 AUREA BPM Oracle TECNA Sp. z o.o. Strona 1 z 7 ORACLE DATABASE System zarządzania bazą danych firmy Oracle jest jednym z najlepszych i najpopularniejszych rozwiązań tego typu na rynku. Oracle Database
AUREA BPM Oracle TECNA Sp. z o.o. Strona 1 z 7 ORACLE DATABASE System zarządzania bazą danych firmy Oracle jest jednym z najlepszych i najpopularniejszych rozwiązań tego typu na rynku. Oracle Database
Administracja i programowanie pod Microsoft SQL Server 2000
 Administracja i programowanie pod Paweł Rajba pawel@ii.uni.wroc.pl http://www.kursy24.eu/ Zawartość modułu 1 Przegląd zawartości SQL Servera Podstawowe usługi SQL Servera Programy narzędziowe Bazy danych
Administracja i programowanie pod Paweł Rajba pawel@ii.uni.wroc.pl http://www.kursy24.eu/ Zawartość modułu 1 Przegląd zawartości SQL Servera Podstawowe usługi SQL Servera Programy narzędziowe Bazy danych
Tuning SQL Server dla serwerów WWW
 Tuning SQL Server dla serwerów WWW Prowadzący: Cezary Ołtuszyk Zapraszamy do współpracy! Plan szkolenia I. Wprowadzenie do tematu II. Nawiązywanie połączenia z SQL Server III. Parametryzacja i przygotowanie
Tuning SQL Server dla serwerów WWW Prowadzący: Cezary Ołtuszyk Zapraszamy do współpracy! Plan szkolenia I. Wprowadzenie do tematu II. Nawiązywanie połączenia z SQL Server III. Parametryzacja i przygotowanie
ETL darmowe narzędzia
 Piotr Ślatała Tomasz Żurkowski 9 czerwca 2011 Plan prezentacji Plan (Krótkie) przypomnienie problemu Plan prezentacji Plan (Krótkie) przypomnienie problemu Przykładowe scenariusze (przykład biznesowego
Piotr Ślatała Tomasz Żurkowski 9 czerwca 2011 Plan prezentacji Plan (Krótkie) przypomnienie problemu Plan prezentacji Plan (Krótkie) przypomnienie problemu Przykładowe scenariusze (przykład biznesowego
Dostęp do baz danych z serwisu www - PHP. Wydział Fizyki i Informatyki Stosowanej Joanna Paszkowska, 4 rok FK
 Dostęp do baz danych z serwisu www - PHP Wydział Fizyki i Informatyki Stosowanej Joanna Paszkowska, 4 rok FK Bazy Danych I, 8 Grudzień 2009 Plan Trochę teorii Uwagi techniczne Ćwiczenia Pytania Trójwarstwowy
Dostęp do baz danych z serwisu www - PHP Wydział Fizyki i Informatyki Stosowanej Joanna Paszkowska, 4 rok FK Bazy Danych I, 8 Grudzień 2009 Plan Trochę teorii Uwagi techniczne Ćwiczenia Pytania Trójwarstwowy
ZAPOZNANIE SIĘ ZE SPOSOBEM PRZECHOWYWANIA
 LABORATORIUM SYSTEMÓW MOBILNYCH ZAPOZNANIE SIĘ ZE SPOSOBEM PRZECHOWYWANIA DANYCH NA URZĄDZENIACH MOBILNYCH I. Temat ćwiczenia II. Wymagania Podstawowe wiadomości z zakresu obsługi baz danych i języka SQL
LABORATORIUM SYSTEMÓW MOBILNYCH ZAPOZNANIE SIĘ ZE SPOSOBEM PRZECHOWYWANIA DANYCH NA URZĄDZENIACH MOBILNYCH I. Temat ćwiczenia II. Wymagania Podstawowe wiadomości z zakresu obsługi baz danych i języka SQL
Program kadrowo płacowy - wersja wielodostępna z bazą danych Oracle SQL Server 8 lub 9
 Program kadrowo płacowy - wersja wielodostępna z bazą danych Oracle SQL Server 8 lub 9 Uwaga: Masz problem z programem lub instalacją? Nie możesz wykonać wymaganej czynności? Daj nam znać. W celu uzyskania
Program kadrowo płacowy - wersja wielodostępna z bazą danych Oracle SQL Server 8 lub 9 Uwaga: Masz problem z programem lub instalacją? Nie możesz wykonać wymaganej czynności? Daj nam znać. W celu uzyskania
Hurtownie danych. Wstęp. Architektura hurtowni danych. http://zajecia.jakubw.pl/hur CO TO JEST HURTOWNIA DANYCH
 Wstęp. Architektura hurtowni. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/hur CO TO JEST HURTOWNIA DANYCH B. Inmon, 1996: Hurtownia to zbiór zintegrowanych, nieulotnych, ukierunkowanych
Wstęp. Architektura hurtowni. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/hur CO TO JEST HURTOWNIA DANYCH B. Inmon, 1996: Hurtownia to zbiór zintegrowanych, nieulotnych, ukierunkowanych
Laboratorium nr 1. Temat: Wprowadzenie do MySQL-a
 Laboratorium nr 1 Temat: Wprowadzenie do MySQL-a MySQL jest najpopularniejszym darmowym systemem obsługi baz danych rozpowszechnianym na zasadach licencji GPL. Jego nowatorska budowa pozwoliła na stworzenie
Laboratorium nr 1 Temat: Wprowadzenie do MySQL-a MySQL jest najpopularniejszym darmowym systemem obsługi baz danych rozpowszechnianym na zasadach licencji GPL. Jego nowatorska budowa pozwoliła na stworzenie
Serwery LDAP w środowisku produktów w Oracle
 Serwery LDAP w środowisku produktów w Oracle 1 Mariusz Przybyszewski Uwierzytelnianie i autoryzacja Uwierzytelnienie to proces potwierdzania tożsamości, np. przez: Użytkownik/hasło certyfikat SSL inne
Serwery LDAP w środowisku produktów w Oracle 1 Mariusz Przybyszewski Uwierzytelnianie i autoryzacja Uwierzytelnienie to proces potwierdzania tożsamości, np. przez: Użytkownik/hasło certyfikat SSL inne
Wykład I. Wprowadzenie do baz danych
 Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Wdrożenie modułu płatności eservice. dla systemu Magento 1.4 1.9
 Wdrożenie modułu płatności eservice dla systemu Magento 1.4 1.9 - dokumentacja techniczna Wer. 01 Warszawa, styczeń 2014 1 Spis treści: 1 Wstęp... 3 1.1 Przeznaczenie dokumentu... 3 1.2 Przygotowanie do
Wdrożenie modułu płatności eservice dla systemu Magento 1.4 1.9 - dokumentacja techniczna Wer. 01 Warszawa, styczeń 2014 1 Spis treści: 1 Wstęp... 3 1.1 Przeznaczenie dokumentu... 3 1.2 Przygotowanie do