STATYSTYKA MATEMATYCZNA WISŁA 2013
|
|
|
- Kajetan Turek
- 8 lat temu
- Przeglądów:
Transkrypt
1 XXXIX Konferencja STATYSTYKA MATEMATYCZNA WISŁA 2013 Wisła, 2-6 grudnia 2013 WISŁA 2-6 XII 2013

2 Organizatorzy konferencji Komisja Statystyki Matematycznej Komitetu Matematyki PAN Instytut Matematyki i Informatyki PWr Komitet organizacyjny Małgorzata Bogdan przewodnicząca Alicja Janic Monika Kaczmarz Piotr Sobczyk Krzysztof Szajowski Piotr Szulc Miejsce konferencji Hotel Gawra Wisła-Uzdrowisko ul. Górnośląska Wisła Redakcja Jerzy Baran Piotr Szulc Druk i oprawa Drukarnia Oficyny Wydawniczej PWr 2

3 Część I Program konferencji 3

4 4
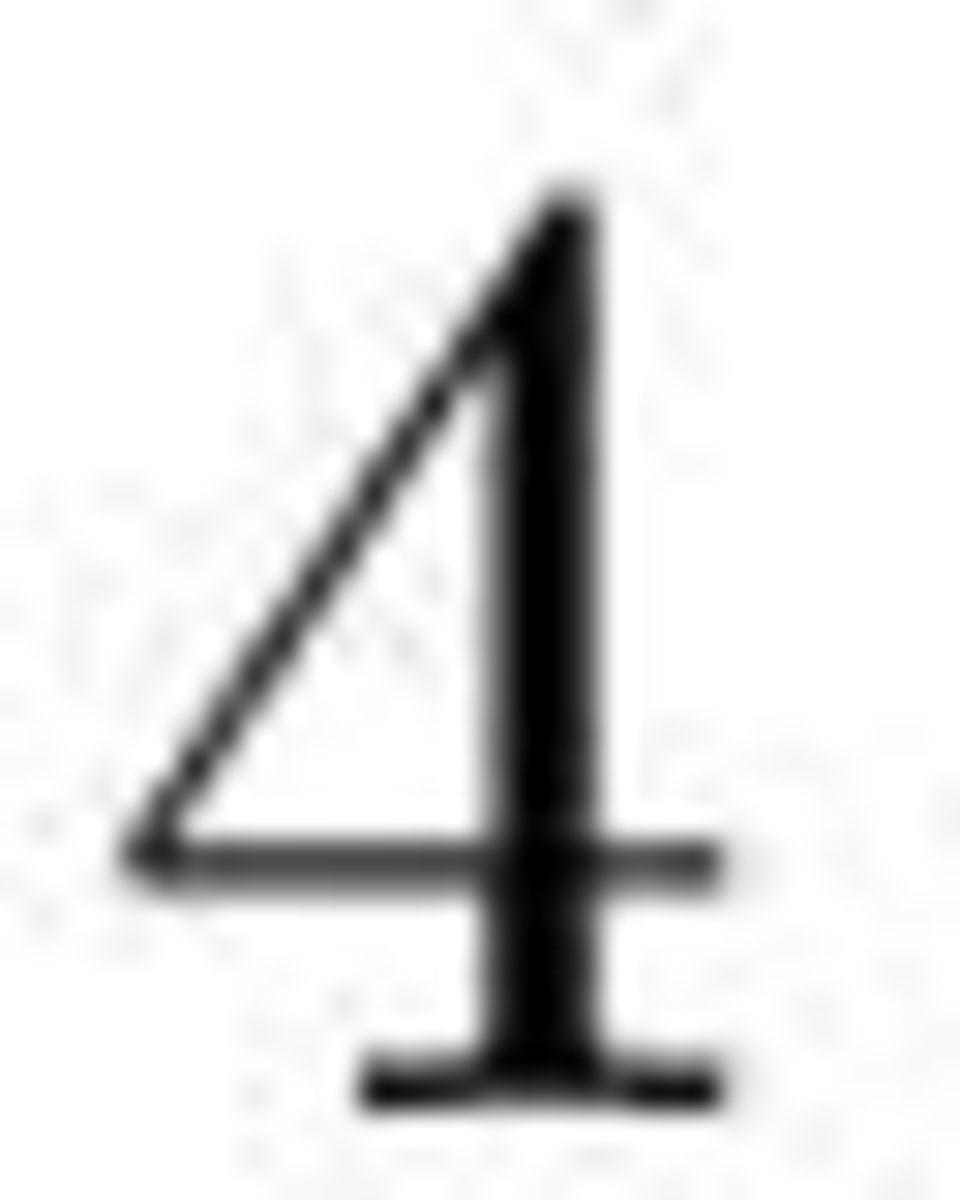
5 Poniedziałek, 2 grudnia :00 Śniadanie 09:00 Otwarcie konferencji 09:15-10:00 Tomasz Burzykowski Wprowadzenie do genetyki i zastosowań statystyki w genetyce 10:00-10:30 Przerwa 10:30-10:50 Stanisław Mejza Profesor Tadeusz Caliński 10:50-11:10 Krystyna Katulska, Łukasz Smaga konkurs D-efektywność chemicznych układów wagowych przy skorelowanych błędach losowych 11:10-11:30 Piotr Szulc konkurs Skąd się biorą gorące miejsca na genomie? 11:30-11:50 Przerwa 11:50-12:10 Aleksandra Maj-Kańska, Piotr Pokarowski, Agnieszka Prochenka konkurs Wybór modelu liniowego poprzez jednoczesne usuwanie zmiennych ciągłych i łączenie poziomów zmiennych czynnikowych 12:10-12:30 Hubert Szymanowski konkurs O normowanym estymatorze Dantziga 12:30-12:50 Pin Pin Oh, Karol Opara konkurs Wklęsłe funkcje straty w kinetycznym modelowaniu reakcji chemicznych 13:00 Obiad 15:00-15:20 Mirosław Krzyśko, Łukasz Waszak konkurs Analiza korelacji kanonicznych dla wielozmiennych danych funkcjonalnych 15:20-15:40 Tomasz Rychlik, Patryk Miziuła konkurs Oszacowania wariancji czasu życia systemów niezawodnościowych z permutowalnymi elementami 15:40-16:00 Piotr Sobczyk konkurs Rozpoznawanie sekwencji kodujących białko w genomach prokariotycznych za pomocą ukrytych łańcuchów Markowa 16:00-16:30 Przerwa 16:30-16:50 Krzysztof Szajowski Wykrywanie losowej liczby rozregulowań z zadaną precyzją 16:50-17:10 Agnieszka Stępień-Baran Estymacja sekwencyjna parametru położenia i potęg parametru skali 17:10-17:30 Anna Czapkiewicz, Paweł Jamer Estymacja parametrów przełącznikowych modeli wielowymiarowych szeregów czasowych 18:00 Kolacja 19:00 Otwarta dyskusja 5

6 Wtorek, 3 grudnia :00 Śniadanie 09:00-09:45 Tomasz Burzykowski Przegląd problemów i metod związanych z analizą danych dotyczących ekspresji genów 09:45-10:30 Przerwa 10:30-10:50 Teresa Ledwina, Grzegorz Wyłupek Wnioskowanie o dodatniej kwadrantowej zależności, I 10:50-11:10 Teresa Ledwina, Grzegorz Wyłupek Wnioskowanie o dodatniej kwadrantowej zależności, II 11:10-11:30 Kamil Dyba Testowanie wielowymiarowej stochastycznej dominacji z wykorzystaniem wielowymiarowych funkcji kwantylowych 11:30-11:50 Przerwa 11:50-12:10 Przemysław Grzegorzewski, Hubert Szymanowski Testy zgodności dla nieprecyzyjnych danych 12:10-12:30 Tadeusz Inglot, Dawid Kujawa Adaptacyjne testy symetrii wokół znanego środka 12:30-12:50 Tadeusz Inglot, Alicja Janic Adaptacyjne testy wynikowe symetrii wokół nieznanego środka 13:00 Obiad 15:00-15:20 Rie Enomoto, Zofia Hanusz, Kazuyuki Koizumi, Takashi Seo Symulacyjne badanie testów wielowymiarowej normalności opartych na skośności i kurtozie 15:20-15:40 Agnieszka Kulawik Odporna estymacja parametrów w wielowymiarowym modelu normalnym wyniki symulacji komputerowych 15:40-16:00 Marta Molińska-Glura, Krzysztof Moliński, Maciej Szydłowski Analiza skupień w detekcji genów warunkujących cechy ilościowe 16:00-16:30 Przerwa 16:30-16:50 Katarzyna Brzozowska-Rup, Antoni Leon Dawidowicz Zastosowanie algorytmu filtru cząsteczkowego do zagadnień ekologii 16:50-17:10 Katarzyna Steliga Zmodyfikowane rozkłady prawdopodobieństwa typu j i ich charakterystyki 17:10-17:30 Wojciech Zieliński Najkrótsze przedziały ufności dla prawdopodobieństwa sukcesu w modelu ujemnym dwumianowym 18:00 Kolacja 6

7 Środa, 4 grudnia :00 Śniadanie 08:45-14:15 Wycieczka 14:30 Obiad 15:30-15:50 Wojciech Rejchel Estymatory regresji rangowej oparte na metodzie LASSO 15:50-16:10 Małgorzata Bogdan SLOPE nowa procedura identyfikacji istotnych zmiennych w modelach liniowych 16:10-16:30 Paweł Teisseyre Wykorzystanie metod losowych podprzestrzeni do predykcji i selekcji zmiennych 16:30-17:00 Przerwa 17:00-17:20 Małgorzata Graczyk O pewnych własnościach układów wagowych 17:20-17:40 Katarzyna Filipiak, Augustyn Markiewicz Optymalne układy doświadczalne w modelach współoddziaływania 17:40-18:00 Katarzyna Ambroży, Iwona Mejza O pewnej metodzie konstrukcji niekompletnych ortogonalnie rozszerzonych układów doświadczalnych typu split-split-plot 18:00 Kolacja 19:00 Posiedzenie Komisji Statystyki Matematycznej Komitetu Matematyki PAN 7

8 Czwartek, 5 grudnia :00 Śniadanie 09:00-09:45 Tomasz Burzykowski Przegląd problemów i metod związanych z analizą danych dotyczących ekspresji białek 09:45-10:30 Przerwa 10:30-10:50 Jan Mielniczuk Wokół twierdzenia Ruuda 10:50-11:10 Zbigniew Szkutnik Minimalizacja ryzyka empirycznego w problemach odwrotnych 11:10-11:30 Mariusz Bieniek Progresywnie modyfikowane statystyki porządkowe 11:30-11:50 Przerwa 11:50-12:10 Andrzej Michalski O testowaniu hipotez liniowych w wielowymiarowych modelach liniowych 12:10-12:30 Mariusz Grządziel Estymacja metodą największej wiarogodności w modelu liniowym z dwoma komponentami wariancyjnymi 12:30-12:50 Czesław Stępniak Porównywanie układów blokowych ze względu na estymację kwadratową 13:00 Obiad 15:00-15:20 Jolanta Grala-Michalak Redukcja wymiarów danych za pomocą transformacji arctg 15:20-15:40 Katarzyna Stąpor Diagonalna analiza dyskryminacyjna 15:40-16:00 Maria Iwińska, Magdalena Szymkowiak Charakteryzacja rozkładów za pomocą wybranych funkcji z teorii niezawodności 16:00-16:30 Przerwa 16:30-16:50 Krzysztof Jasiński Maksymalna wariancja k-tych rekordów 16:50-17:10 Maria Kamińska-Zabierowska Niezmienniczość porządku transformaty GTTT 17:10-17:30 Marcin Makowski, Edward W. Piotrowski Estymacja parametru rozkładu statystycznego metodą maksymalizacji intensywności przetwarzania informacji 18:30 Uroczysta kolacja 8

9 Piątek, 6 grudnia :00 Śniadanie 09:00-09:45 Tomasz Burzykowski Szukanie QTL (quantitative-trait loci) z zastosowaniem technik sekwencjonowania genów nowej generacji 09:45-10:30 Przerwa 10:30-10:50 Iwona Żerda Geometryczna zbieżność algorytmów Gibbsa 10:50-11:10 Anna Szczepańska-Álvarez Wybór punktów czasowych i układu blokowego w modelu krzywych wzrostu 11:10-11:30 Agnieszka Prochenka Modelowanie wieku pacjentów za pomocą częstości metylacji cytozyny w DNA 11:30 Zakończenie konferencji 13:00 Obiad 9

10 10
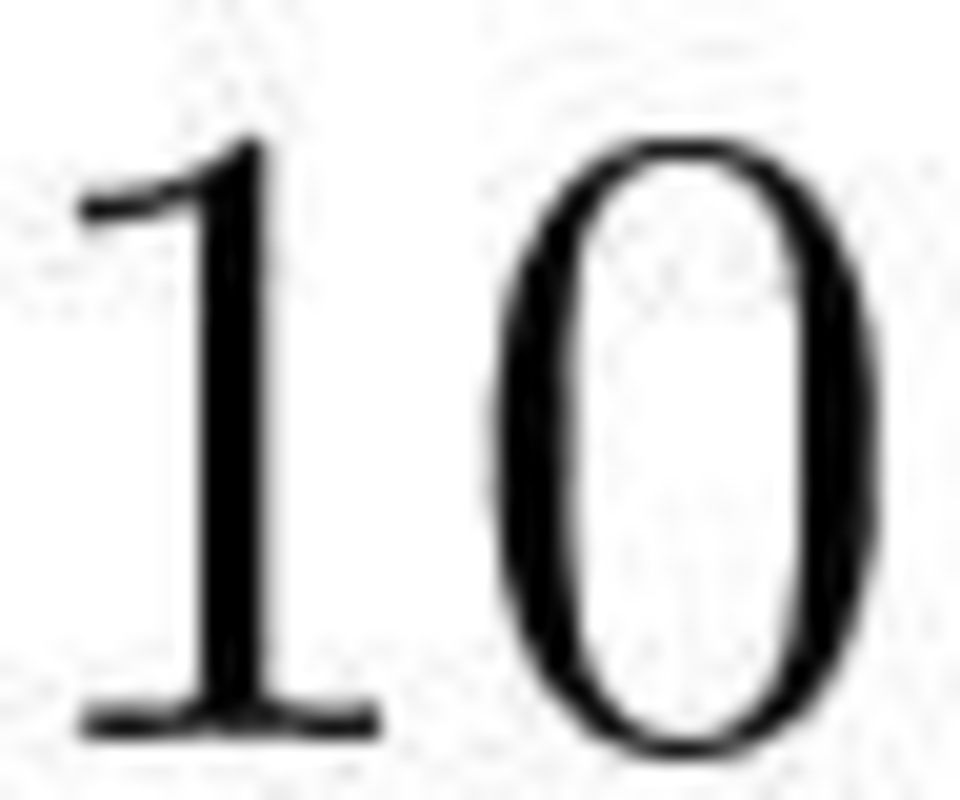
11 Część II Streszczenia 11

12 12

13 O pewnej metodzie konstrukcji niekompletnych ortogonalnie rozszerzonych układów doświadczalnych typu split-split-plot Katarzyna Ambroży, Iwona Mejza Katedra Metod Matematycznych i Statystycznych Uniwersytet Przyrodniczy w Poznaniu W pracy rozważono sytuację, w której układy doświadczalne typu splitsplit-plot są niekompletne ze względu na obiekty czynników występujących na zagnieżdżonych jednostkach I i II rzędu. Dodatkowo założono, że każdy z nich ma obiekt zwany standardem. Trzeci czynnik, którego obiekty są losowo rozmieszczane na jednostkach III rzędu, występuje w podukładzie ortogonalnym. Metodę konstrukcji oparto na iloczynie Kroneckera macierzy. Natomiast jako układy generujące wybrano te same lub różne układy blokowe z klasy ortogonalnie rozszerzonych częściowo zrównoważonych pod względem efektywności układów blokowych z co najwyżej (m+1)-klasami efektywności. Przedstawiono algebraiczne i statystyczne właściwości uzyskanych układów i przykład numeryczny. [1] K. Ambroży, I. Mejza, Doświadczenia trójczynnikowe z krzyżową i zagnieżdżoną strukturą poziomów czynników, Wyd. Polskie Towarzystwo Biometryczne and PRODRUK, Poznań, [2] K. Ambroży, I. Mejza, On the efficiency of some non-orthogonal splitplot split-block designs with control treatments, Journal of Statistical Planning and Inference, Vol. 142, Issue 3, pp , [3] K. Ambroży, I. Mejza, A method of constructing incomplete split-splitplot designs supplemented by whole plot and subplot standards and their analysis, Colloquium Biometricum 43, pp , [4] T. Caliński, S. Kageyama, Block Designs. A Randomization Approach, Volume I. Analysis, Lecture Notes in Statistics 150, Springer-Verlag, New York, [5] A.K. Nigam, P.D. Puri, On partially efficiency balanced designs II, Commun. Statist.-Theor. Meth. 11(24), pp ,

14 Progresywnie modyfikowane statystyki porządkowe Mariusz Bieniek Instytut Matematyki Uniwersytet Marii Curie-Skłodowskiej Lublin W referacie wprowadzony zostanie nowy model uporządkowanych danych statystycznych nazywany progresywnie modyfikowane statystyki porządkowe. Jest to rozszerzenie modelu progresywnie cenzurowanych statystyk porządkowych, w którym z próby usuwa się losowo wybrane elementy po uszkodzeniu jednego z nich. W modelu progresywnie modyfikowanym można w kolejnych krokach usuwać lub dodawać elementy do próby. Model ten służy jako ważny przykład uogólnionych statystyk porządkowych, gdyż podaje ogólną procedurę statystyczną pobierania danych empirycznych, której szczególnymi przypadkami są statystyki porządkowe i wartości rekordowe. 14

15 SLOPE - nowa procedura identyfikacji istotnych zmiennych w modelach liniowych Małgorzata Bogdan Instytut Matematyki i Informatyki Politechniki Wrocławskiej Załóżmy, że dysponujemy obserwacjami z modelu liniowego y = Xβ + z. SLOPE (Sorted L-One Penalized Estimation) proponuje identyfikacjȩ niezerowych elementów wektora β za pomoc a minimalizacji wyrażenia 1 2 y Xb 2 l 2 + λ 1 b (1) + λ 2 b (2) λ p b (p), gdzie λ 1 λ 2... λ p, a b (1) b (2)... b (p) s a statystykami porz adkowymi z wektora wartości bezwglȩdnych estymatorów współczynników regresji. Procedura ta jest podobna do popularnej procedury wielokrotnego testowania Benjaminiego-Hochberga. Zaprezentujemy wyniki teoretyczne gwarantuj ace kontrolȩ Frakcji Fałszywych Odkryć w przypadku gdy macierz eksperymentu jest ortogonalna oraz wyniki symulacyjne ilustruj ace bardzo dobre własności tej metody w innych sytuacjach. Prezentowane wyniki pochodz a z artykułu: M. Bogdan, E. van den Berg, W. Su and E.J. Candès, Statistical Estimation and Testing via the Sorted l1 Norm. 15
, gdzie λ 1 λ 2... λ p, a b (1) b (2)... b (p) s a statystykami porz adkowymi z wektora wartości bezwglȩdnych estymatorów współczynników regresji.")
16 Zastosowanie algorytmu filtru cząsteczkowego do zagadnień ekologii Katarzyna Brzozowska - Rup Katedra Matematyki Politechniki Świętokrzyskiej Antoni Leon Dawidowicz Wydział Matematyki i Informatyki Uniwersytetu Jagiellońskiego Zagadnienia ekologiczne często są opisane za pomocą równań różniczkowych. Wiąże się to z dwoma problemami 1. W odróżnieniu od np. zjawisk fizycznych obserwacja przebiegu zjawiska jest daleko utrudniona. 2. Równania różniczkowe pojawiające się w modelu nie dają się efektywnie analitycznie rozwiązać, a algorytmy numeryczne są obarczone błędem. Proponujemy następującą procedurę. 1. Co ustaloną jednostkę czasu wyznaczamy posiadany opis stanu układu. 2. Stan ten traktujemy jako zmienną obserwowaną. 3. Faktyczne rozwiązanie równania w danej chwili traktujemy, jako zmienną ukrytą. Przykładem może być model drapieżca - ofiara w jego uogólnionej postaci. Wtedy zmienną obserwowaną można szacować w oparciu o dane z Kółek Łowieckich. Do estymacji parametrów strukturalnych modelu proponujemy zastosowanie sekwencyjnej metody Monte Carlo. [1] Katarzyna Brzozowska-Rup, Antoni Leon Dawidowicz, Parameter Estimationfor Nonlinear State-Space Models Using Particle Method Combined with the EM Algorithm, Financial Markets Principles of Modelling Forecasting and Decision-Making, ,

17 [2] A. Jasra, A. Doucet, Sequential Monte Carlo methods for diffusion processes, Proceedings of the Royal Society A 465,pp , 2009 [3] D. Rimmer, A. Doucet, W. J. Fitzgerald, Particle Filters for Stochastic Differential Equations of Nonlinear Diffusions, Technical Report, University of Cambridge, Engineering Dept, 2005 [4] Janusz Uchmański, Klasyczna ekologia matematyczna, PWN Warszawa
![465,pp 3709-3727, 2009 [3] D. Rimmer, A. Doucet, W. J.](/docs-images/42/2663836/images/page_17.jpg "Fitzgerald, Particle Filters for Stochastic Differential Equations of Nonlinear Diffusions,")
18 Estymacja parametrów przełącznikowych modeli wielowymiarowych szeregów czasowych Anna Czapkiewicz, Paweł Jamer AGH w Krakowie, Wydział Zarządzania W zastosowaniach empirycznych często napotykamy rozkłady charakteryzujące się dużą kurtozą i silna asymetrią. Na przykład, do modelowania finansowych szeregów czasowych najczęściej używa się modele GARCH z warunkowym rozkładem skośnym t-studenta. Konsekwencją tego faktu jest trudność konstruowania rozkładów wielowymiarowych, których składowe zachowują swoje własności. W literaturze przedmiotu, do szukania zależności pomiędzy danymi jednowymiarowymi procesami wykorzystuje się funkcje kopuli. W przypadku jednak finansowych wielowymiarowych szeregów czasowych dodatkowym utrudnieniem jest uwzględnienie dynamiki zmian takich procesów. W tym celu konstruuje się tzw. dynamiczne modele Copula-GARCH, w których owa dynamika sterowana jest przez ukryty proces Markowa. Problemem jest estymacja parametrów takiego modelu. Jednym z możliwych podejść jest zastosowanie metody największej wiarogodności z użyciem filtrów Hamiltona. W referacie zostanie przedstawiony sposób estymacji modelu dynamicznego z wykorzysta-niem filtrów Hamiltona. Zostaną rozważone wielowymiarowe kopule Gaussa z k liczbą reżimów procesu Markowa. Zostanie przedstawiony przykład empiryczny estymacji szeregów finansowych dla dwóch i dla trzech reżimów. [1] J. D. Hamilton, Time Series Analysis, Princeton University Press, 1994 [2] O. C. Filho, F.A. Ziegelmann, M.J.Dueker, Modelling dependence dynamics through copulas with regime switching, Insurance Mathematics and Economics,

19 Testowanie wielowymiarowej stochastycznej dominacji z wykorzystaniem wielowymiarowych funkcji kwantylowych Kamil Dyba Instytut Matematyczny Uniwersytetu Wrocławskiego Niech dany będzie rozkład prawdopodobieństwa na R d o dystrybuancie F 0 oraz próba X 1, X 2,..., X n R d z rozkładu o dystrybuancie F. Rozważamy następujący problem testowania: H : x R d F (x) = F 0 (x) vs K : x R d F (x) F 0 (x) F F 0. W przypadku d = 1 znane są liczne rozwiązania powyższego zagadnienia. Jako przykład można tu podać jednostronny test Kołmogorowa-Smirnowa. Jego konstrukcja opiera się na tym, że przy hipotezie H rozkład statystyki sup x R (F n (x) F 0 (x)), gdzie F n oznacza dystrybuantę empiryczną z próby X 1, X 2,..., X n, nie zależy od F (także w granicy przy n ). W przypadku d > 1 powyższa własność nie zachodzi, co zmusza do poszukiwania rozwiązań tego problemu innych niż w przypadku jednowymiarowym. Rozwiązania dyskutowane w literaturze przedmiotu polegają na posługiwaniu się taką samą statystyką testową jak w przypadku d = 1 i wyznaczaniu jej rozkładu przy H w oparciu o metody symulacyjne. W referacie zostanie zaproponowana konstrukcja testu alternatywna w stosunku do metod wykorzystujących symulacje, oparta o wielowymiarowe funkcje kwantylowe w ujęciu Einmahla i Masona. [1] Z. Guo, Stochastic dominance and its applications in portfolio management, 2012 [2] F. Hsieh, B. W. Turnbull, Non- and semi-parametric estimation of the receiver operating characteristic curve, Technical Report 1026, School of Opera- tions Research, Cornell University, 1992 [3] J. H. J. Einmahl, D. M. Mason, Generalized quantile process, Annals of Statistics, 20, pp ,

20 Optymalne układy doświadczalne w modelach współoddziaływania Katarzyna Filipiak, Augustyn Markiewicz Katedra Metod Matematycznych i Statystycznych Uniwersytet Przyrodniczy w Poznaniu W pracy przedstawiono charakterystyki układów optymalnych w modelach współoddziaływania; tzn. w modelach z efektami sąsiedztwa. Wykorzystano je następnie do zbadania optymalności układów zrównoważonych ze względu na wybrany schemat sąsiedztwa, których konstrukcje są przedmiotem licznych badań. 20

21 O pewnych własnościach układów wagowych Małgorzata Graczyk Uniwersytet Przyrodniczy w Poznaniu W pracy przedstawiona zostanie tematyka estymacji nieznanych miar obiektów w modelu sprężynowego układu wagowego przy założeniu, że błędy pomiarów są nieskorelowane i mają różne wariancje. Zostaną przedstawione i porównane warunki konieczne i dostateczne wyznaczające postaci macierzy układów optymalnych względem różnych kryteriów optymalności. Podsumowaniem rozważań jest podanie przykładowych metod konstrukcji macierzy układu optymalnego. [1] M. Graczyk, Regular A-optimal spring balance weighing designs, Revstat 10, pp , 2012 [2] K. Katulska, E. Przybył, On certain D-optimal spring balance weighing designs, Journal of Statistical Theory and Practice 1, pp , 2007 [3] K. Katulska, E. Rychlińska, On regular E-optimality of spring balance weighing design, Colloquium Biometricum 40, pp ,
22 Redukcja wymiarów danych za pomocą transformacji arctg Jolanta Grala-Michalak Wydział Matematyki i Informatyki UAM Instytut Matematyki i Informatyki W pracy opisano przekształcenie, które użyte jako krok wstępny w liniowej analizie dyskryminacji, powoduje albo redukcję wymiaru danych, albo poprawia wynik liniowej dyskryminacji w przypadku danych trudnoseparowalnych. Metoda jest prezentowana na dobrze znanych statystycznych zbiorach danych. [1] K. V. Mardia, P. Jupp, Directional Statistics, 2 ed., Wiley, 2000 [2] J. Grala-Michalak, Dimension reduction via arc tan transformation of data, Comp. Stat. w przygotowaniu 22
23 Estymacja metodą największej wiarogodności w modelu liniowym z dwoma komponentami wariancyjnymi Mariusz Grządziel Katedra Matematyki Uniwersytetu Przyrodniczego we Wrocławiu W normalnych modelach liniowych mieszanych z dwoma komponentami wariancyjnymi funkcja wiarogodności może mieć więcej niż jedno maksimum lokalne, więc zagadnienie wyznaczania wartości estymatorów największej wiarogodności w tych modelach należy do klasy problemów optymalizacji niewypukłej (por. [1] i [2]). W referacie zostanie pokazane, że zagadnienie to można sprowadzić do znajdowania wszystkich miejsc zerowych odpowiednio zdefiniowanego wielomianu. [1] E. Gross, M. Drton, S. Petrović, Maximum likelihood degree of variance components models, Electronic Journal of Statistics 6, s , 2012 [2] S. Welham, R. Thompson, A note on bimodality in the log-likelihood function for penalized spline mixed models, Computational Statistics & Data Analysis 53, s ,
24 Testy zgodności dla nieprecyzyjnych danych Przemysław Grzegorzewski Wydział Matematyki i Nauk Informacyjnych Politechniki Warszawskiej oraz Instytut Badań Systemowych PAN Hubert Szymanowski Interdyscyplinarne Studia Doktoranckie PAN Niech X 1,..., X n oznacza próbkę pochodzącą z nieznanego rozkładu F. Rozważmy problem testowania hipotezy H : F = F 0, gdzie F 0 jest pewną znaną dystrybuantą. Do weryfikacji tak postawionej hipotezy służą liczne testy zgodności, wśród których stosunkowo bogatą podklasę tworzą testy wykorzystujące dystrybuantę empiryczną. Powszechnie stosowane testy zgodności zakładają, że dysponujemy precyzyjnymi pomiarami, tzn. że realizacje próby x 1,..., x n są liczbami rzeczywistymi. Tymczasem w praktyce mamy często do czynienia z danymi nieprecyzyjnymi, których opis i analiza wymagają zastosowania aparatu wykraczającego poza ramy klasycznych metod statystyki. W referacie zostanie przedstawiona konstrukcja testow zgodności bazujących na dystrybuanie empirycznej, pozwalających na weryfikację rozważanej hipotezy dotyczącej postaci rozkładu na podstawie nieprecyzyjnych danych, modelowanych za pomocą zbiorów rozmytych. W szczególności zostaną omówione uogólnienia kilku klasycznych testów zgodności, takich jak test Kolmogorowa, test Craméra-von Misesa oraz test Andersona-Darlinga. [1] P. Filzmoser, R. Viertl, Testing hypotheses with fuzzy data. The fuzzy p-value, Metrika 59, pp , 2004 [2] P. Grzegorzewski, H. Szymanowski, Goodness-of-fit tests for fuzzy data, (zgłoszone do druku) [3] G. Hesamian, S.M. Taheri, Fuzzy empirical distribution function: properties and application, Kybernetika (w druku) 24
25 Symulacyjne badanie testów wielowymiarowej normalności opartych na skośności i kurtozie Zofia Hanusz Katedra Zastosowań Matematyki i Informatyki, Uniwersytet Przyrodniczy w Lublinie Rie Enomoto, Takashi Seo Department of Mathematical Information Science, Tokyo University of Science Kazuyuki Koizumi Department of International College of Arts and Sciences, Yokohama City University W pracy przedstawiono badania symulacyjne nad poziomem istotności i mocą testów do badania wielowymiarowej normalności opartych na skośności i kurtozie z próby. Wykorzystano testy oparte na statystykach Mardii i Srivastavy. Rozważono także test Jarque-Bera bazujący na mieszninie testów opartych na skośności i kurtozie. Rozważane w pracy testy porównano z testem Henze-Zirklera. Badania symulacyne przeprowadzono dla różnych liczebności prób i cech w obserwacjach dla poziomów istotności 0,05; 0,01 oraz 0,1. [1] Z. Hanusz, J. Tarasińska, Z. Osypiuk, On the small sample properties of variants of Mardia s and Srivastava s kurtosis-based tests for multivariate normality, Biometrical Letters 49(2), pp , 2012 [2] K. Koizumi, N.Okamoto, J., T. Seo, On Jarque-Bera tests for assesing multivariate normality, Journal of Statistics: Advances in Theory and Applications 1 (2), pp ,
26 Adaptacyjne testy wynikowe symetrii wokół nieznanego środka Tadeusz Inglot, Alicja Janic Instytut Matematyki i Informatyki Politechniki Wrocławskiej Problem testowania symetrii wokół nieznanego środka jest badany od dawna i uważany w literaturze za trudny. Wiekszość istniejacych testów jest opartych na porównaniu średniej i mediany z próby (np. Cabilio i Massaro, 1996, Zheng i Gastwirth, 2010) lub na pewnych uogólnieniach tej miary asymetrii (Ekström i Jammalamadaka, 2012). A wiec wykrywa tylko pewne typy asymetrii. Zastosowanie teorii testów wynikowych pozwala skonstruować testy o szerokim spektrum czułości na różnego charakteru odstepstwa od symetrii. W referacie przedstawimy konstrukcje statystyki wynikowej i odpowiednich reguł wyboru, dobór estymatorów parametrów zakłócajacych (w tym mediany), wyniki empiryczne, własności asymptotyczne oraz dyskusje zakresu stosowalności testów. 26
27 Adaptacyjne testy symetrii wokół znanego środka Tadeusz Inglot, Dawid Kujawa Instytut Matematyki i Informatyki Politechniki Wrocławskiej W pracy [1] zaproponowano i wszechstronnie przebadano adaptacyjne testy symetrii oparte na układzie wielomianów Legendre a. Cechowały je stabilne, porównywalne z konkurencyjnymi testami moce dla typowych alternatyw oraz znacznie wieksze dla nietypowych alternatyw. Jednak dokładniejsza analiza charakteru asymetrii wielu alternatyw pokazuje, że wielomiany Legendre a nie sa najlepiej dopasowane do mierzenia asymetrii i sugeruje, że wybór odpowiedniego układu ortonormalnego pozwoli otrzymać lepszy test. W referacie zaproponujemy układ ortonormalny funkcji, który realizuje powyższa sugestie. Przypomnimy konstrukcje statystyki wynikowej i reguł wyboru i omówimy własności asymptotyczne nowych testów. Przedstawimy wyniki badań symulacyjnych dla obszernej klasy alternatyw, zawierajacej wszystkie alternatywy rozważane przez innych autorów oraz szereg nowych, reprezentujacych różnorodne rodzaje asymetrii. Potwierdzaja one w pełni oczekiwania. Nowe testy wykazuja duża czułość bez wzgledu na rodzaj asymetrii, przez co można je zaliczyć do najlepszych testów typu omnibus. Przy okazji pokażemy, że test kierunkowy oparty na pierwszej funkcji rozważanego układu jest lepszy od testu Modarresa i Gastwirtha (1998) dla alternatyw o znacznej asymetrii na ogonach. [1] T. Inglot, A. Janic, J. Józefczyk, Data driven tests for univariate symmetry, Probab. Math. Statist. 32, pp ,
28 Charakteryzacje rozkładów za pomocą wybranych funkcji z teorii niezawodności Maria Iwińska, Magdalena Szymkowiak Instytut Matematyki Politechniki Poznańskiej W pracy zostały przedstawione charakteryzacje rozkładów: wykładniczego, Weibulla oraz log-logistycznego. Charakteryzacje przeprowadzono za pomocą wartości oczekiwanych pewnych funkcji z teorii niezawodności. [1] S. Bhattacharjee, A.K. Nanda, S.Kr. Misra, Inequalities involving expectations to characterize distributions, Statistics and Probability Letters 83, pp , 2013 [2] A.K. Nanda, Characterization of distribution through failure rate and mean residual life functions, Statistics and Probability Letters 80, pp ,
29 Maksymalna wariancja k-tych rekordów Krzysztof Jasiński Wydział Matematyki i Informatyki Uniwersytet Mikołaja Kopernika w Toruniu Rozważamy próbę n niezależnych zmiennych losowych o tym samym rozkładzie, o ciągłej dystrybuancie i skończonej wariancji. Klimczak i Rychlik (2004) podali optymalne oszacowania dla wariancji zwykłych i k-tych rekordów w jednostkach wariancji pojedynczej zmiennej losowej. Poszukiwanie ich jest równoznaczne z poszukiwaniem maksimum pewnego wielomianu f(x) na przedziale (0, 1). Nie udowodnili natomiast, że istnieje punkt x 0 = x 0 (k, n) taki, że wielomian rośnie na przedziale (0, x 0 ), a maleje w (x 0, 1). To implikowałoby, że maksimum jest jedno i stanowi rozwiązanie równania f (x) = 0. Przedstawimy rozwiązanie tego problemu dla 1 k max{2, n2 +4n 3n+4 } oraz n 1 stosując własność zmniejszania zmienności (variation diminishing property) funkcji potęgowych na przedziale (0, + ). W tym celu rozszerzymy klasyczną własność zmniejszania zmienności skończonych kombinacji funkcji na przypadek nieskończony. [1] M. Klimczak, T. Rychlik, Maximum variance of kth records, Statist. Probab. Lett. 69, pp , 2004 [2] K. Jasiński, Maximum variance of kth records, submitted,
30 Niezmienniczość porządku transformaty GTTT Maria Kamińska-Zabierowska Instytut Matematyczny Uniwersytetu Wrocławskiego Porządek uogólnionej transformaty TTT (GTTT - generalized total time on test transform) został wprowadzony przez Li i Shakeda, na wzór wcześniej rozważanych porządków, np. zwykłej transformaty TTT, jako punktowe porównanie dwóch transformat. Mówimy, że rozkład F jest mniejszy od rozkładu G w porządku transformaty GTTT indukowanej przez nieujemną funkcję h, jeśli dla wszystkich u (0, 1) zachodzi: F 1 (u) h(f (x))dx o ile obie strony nierówności istnieją. G 1 (u) h(g(x))dx, Przedstawimy operacje, względem których porządek transformaty GTTT jest niezmienniczy, m.in. wyniki wpisujące się w badania Bartoszewicza z Benduch i Skolimowską. [1] J. Bartoszewicz, M. Benduch, Some properties of the generalized TTT transform, J. Statist. Plann. Inference 139, pp , 2009 [2] J. Bartoszewicz, M. Skolimowska, Preservation of stochastic orders under mixtures of exponential distributions, Probab. Engrg. Inform. Sci. 20, pp , 2006 [3] X. Li, M. Shaked, A general family of univariate stochastic orders, J. Statist. Plann. Inference 137, pp , 2007 [4] M. Shaked, J. Shanthikumar, Stochastic orders, Springer, New York, 2007 [5] M. Shaked, M. A. Sordo, A. Suárez-Llorens, A class of location-independent variability orders, with applications, J. Appl. Probab. Volume 47, pp ,
31 D-efektywność chemicznych układów wagowych przy skorelowanych błędach losowych Krystyna Katulska, Łukasz Smaga Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza W pracy rozważany jest problem estymacji nieznanych miar obiektów w chemicznym układzie wagowym w oparciu o kryterium D-optymalności. Przyjęto założenie, że błędy losowe są równo nieujemnie skorelowane i mają takie same wariancje. Udowodnione zostało twierdzenie określające górne ograniczenie wyznacznika macierzy informacji dla chemicznego układu wagowego. Warunki konieczne i dostateczne na to aby to ograniczenie było osiągnięte zostały również wykazane. Zaprezentowano także konstrukcję D-optymalnego układu wagowego, dla którego oszacowanie to jest osiągnięte. Nie dla wszystkich parametrów układu n i p takie układy istnieją. W takich sytuacjach zaproponowane zostały konstrukcje układów wagowych, które jak zostało pokazane charakteryzują się wysoką D-efektywnością. Prezentowane układy zostały porównane (pod względem D-efektywności) z układami uzyskanymi za pomocą znanego w literaturze algorytmu poszukiwania układów D-optymalnych a także wynikami poszukiwania układów D-optymalnych wśród dużej liczby układów generowanych losowo. [1] L. Angelis, E. Bora-Senta, C. Moyssiadis, Optimal exact experimental designs with correlated errors through a simulated annealing algorithm, Computational Statistics & Data Analysis 37, pp , 2001 [2] D.A. Bulutoglu, K.J. Ryan, D-optimal and near D-optimal 2 k fractional factorial designs of resolution V, Journal of Statistical Planning and Inference 139, pp.16-22, 2009 [3] K. Katulska, Ł. Smaga, A note on D-optimal chemical balance weighing designs and their application, Colloquium Biometricum 43, pp.37-45, 2013 [4] J. Masaro, C.S. Wong, D-optimal designs for correlated random vectors, Journal of Statistical Planning and Inference 138, pp , 2008 [5] M.G. Neubauer, R.G. Pace, D-optimal (0, 1)-weighing designs for eight objects, Linear Algebra and its Applications 432, pp ,
32 Analiza korelacji kanonicznych dla wielozmiennych danych funkcjonalnych Mirosław Krzyśko, Łukasz Waszak Wydział Matematyki i Informatyki UAM w Poznaniu W klasycznej analizie korelacji kononicznych obiekty s a charakteryzowane za pomoc a wielu cech obserwowanych w jednym punkcie czasowym. Chcemy wówczas znaleźć zależność pomiȩdzy wektorami Y R p oraz X R q. W ostatnich latach rośnie zainteresowanie danymi reprezentowanymi za pomoc a krzywych, tzw. danymi funkcjonalnymi (Ramsay i Silverman (2005)). W dotychczasowych pracach z tej tematyki obiekty s a charakteryzowane za pomoc a jednej cechy obserwowanej w wielu momentach czasowych, tj. interesuje nas zależność pomiȩdzy procesami losowymi Y (t) L 2 (I 1 ) oraz X(t) L 2 (I 2 ) (Krzyśko i Waszak (2013)). W referacie zostanie zaproponowana konstrukcja zmiennych kanonicznych i korelacji kanonicznych dla wielozmiennych danych funkcjonalnych. Obiekty statystyczne bȩd a charakteryzowane za pomoc a wielu cech obserwowanych w wielu momentach czasowych (dane podwójnie wielowymiarowe). Dokładniej, zaprezentowana zostanie konstrukcja zmiennych kanonicznych i korelacji kanonicznych dla wielowymiarowych procesów stochastycznych Y (t) L 2 (I 1 ) p oraz X(t) L 2 (I 2 ) q oraz pokazany zostanie zwi azek z klasyczn a analiz a kanoniczn a. [1] Krzyśko, M., Waszak, Ł, Canonical correlation analysis for functional data, Biometrical Letters, 2013 [2] Ramsay, J.O., Silverman, B.W., Functional Data Analysis, Springer, Second Edition,
Poniedziałek, 2 grudnia 2013
 Poniedziałek, 2 grudnia 2013 09:00 Otwarcie konferencji 09:15-10:00 Tomasz Burzykowski Wprowadzenie do genetyki i zastosowań statystyki w genetyce 10:00-10:30 Przerwa 10:30-10:50 Stanisław Mejza Profesor
Poniedziałek, 2 grudnia 2013 09:00 Otwarcie konferencji 09:15-10:00 Tomasz Burzykowski Wprowadzenie do genetyki i zastosowań statystyki w genetyce 10:00-10:30 Przerwa 10:30-10:50 Stanisław Mejza Profesor
Program XXXVI Konferencji "Statystyka Matematyczna Wisła 2010"
 Program XXXVI Konferencji "Statystyka Matematyczna Wisła 2010" Poniedziałek 6 grudnia 09:00 Otwarcie konferencji 09:15-10:00 Wojciech Niemiro Algorytmy MCMC i ich zastosowania statystyczne, I 10:00-10:30
Program XXXVI Konferencji "Statystyka Matematyczna Wisła 2010" Poniedziałek 6 grudnia 09:00 Otwarcie konferencji 09:15-10:00 Wojciech Niemiro Algorytmy MCMC i ich zastosowania statystyczne, I 10:00-10:30
Poniedziałek, 4 Grudnia
 Program konferencji Poniedziałek, 4 Grudnia 9:00 9:45 Łukasz Dębowski Praktyczne i teoretyczne problemy statystycznego modelowania języka naturalnego, część I 9:45 10:00 Przerwa 10:00 10:20 Tadeusz Inglot
Program konferencji Poniedziałek, 4 Grudnia 9:00 9:45 Łukasz Dębowski Praktyczne i teoretyczne problemy statystycznego modelowania języka naturalnego, część I 9:45 10:00 Przerwa 10:00 10:20 Tadeusz Inglot
Teoria informacji a statystyka matematyczna, część I Tadeusz Inglot 1
 XXXVIII Konferencja Statystyka Matematyczna Wisła 2012 Program konferencji Poniedziałek, 3 grudnia 9.00-9.15 Otwarcie konferencji 9.15-10.00 Teoria informacji a statystyka matematyczna, część I Tadeusz
XXXVIII Konferencja Statystyka Matematyczna Wisła 2012 Program konferencji Poniedziałek, 3 grudnia 9.00-9.15 Otwarcie konferencji 9.15-10.00 Teoria informacji a statystyka matematyczna, część I Tadeusz
Metody matematyczne w analizie danych eksperymentalnych - sygnały, cz. 2
 Metody matematyczne w analizie danych eksperymentalnych - sygnały, cz. 2 Dr hab. inż. Agnieszka Wyłomańska Faculty of Pure and Applied Mathematics Hugo Steinhaus Center Wrocław University of Science and
Metody matematyczne w analizie danych eksperymentalnych - sygnały, cz. 2 Dr hab. inż. Agnieszka Wyłomańska Faculty of Pure and Applied Mathematics Hugo Steinhaus Center Wrocław University of Science and
Spis treści 3 SPIS TREŚCI
 Spis treści 3 SPIS TREŚCI PRZEDMOWA... 1. WNIOSKOWANIE STATYSTYCZNE JAKO DYSCYPLINA MATEMATYCZNA... Metody statystyczne w analizie i prognozowaniu zjawisk ekonomicznych... Badania statystyczne podstawowe
Spis treści 3 SPIS TREŚCI PRZEDMOWA... 1. WNIOSKOWANIE STATYSTYCZNE JAKO DYSCYPLINA MATEMATYCZNA... Metody statystyczne w analizie i prognozowaniu zjawisk ekonomicznych... Badania statystyczne podstawowe
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Wprowadzenie do teorii ekonometrii. Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe
 Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Jądrowe klasyfikatory liniowe
 Jądrowe klasyfikatory liniowe Waldemar Wołyński Wydział Matematyki i Informatyki UAM Poznań Wisła, 9 grudnia 2009 Waldemar Wołyński () Jądrowe klasyfikatory liniowe Wisła, 9 grudnia 2009 1 / 19 Zagadnienie
Jądrowe klasyfikatory liniowe Waldemar Wołyński Wydział Matematyki i Informatyki UAM Poznań Wisła, 9 grudnia 2009 Waldemar Wołyński () Jądrowe klasyfikatory liniowe Wisła, 9 grudnia 2009 1 / 19 Zagadnienie
WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO
 Zał. nr 4 do ZW WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA STOSOWANA Nazwa w języku angielskim APPLIED STATISTICS Kierunek studiów (jeśli dotyczy): Specjalność
Zał. nr 4 do ZW WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA STOSOWANA Nazwa w języku angielskim APPLIED STATISTICS Kierunek studiów (jeśli dotyczy): Specjalność
Odporność statystyk według Ryszarda Zielińskiego a porządki stochastyczne
 Odporność statystyk według Ryszarda Zielińskiego a porządki stochastyczne Jarosław Bartoszewicz Uniwersytet Wrocławski Zieliński (1977) wprowadził następującą definicję odporności statystycznej. M 0 =
Odporność statystyk według Ryszarda Zielińskiego a porządki stochastyczne Jarosław Bartoszewicz Uniwersytet Wrocławski Zieliński (1977) wprowadził następującą definicję odporności statystycznej. M 0 =
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wykład Centralne twierdzenie graniczne. Statystyka matematyczna: Estymacja parametrów rozkładu
 Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Ekonometryczne modele nieliniowe
 Ekonometryczne modele nieliniowe Wykład 10 Modele przełącznikowe Markowa Literatura P.H.Franses, D. van Dijk (2000) Non-linear time series models in empirical finance, Cambridge University Press. R. Breuning,
Ekonometryczne modele nieliniowe Wykład 10 Modele przełącznikowe Markowa Literatura P.H.Franses, D. van Dijk (2000) Non-linear time series models in empirical finance, Cambridge University Press. R. Breuning,
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Monte Carlo, bootstrap, jacknife
 Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Właściwości testu Jarque-Bera gdy w danych występuje obserwacja nietypowa.
 Właściwości testu Jarque-Bera gdy w danych występuje obserwacja nietypowa. Paweł Strawiński Uniwersytet Warszawski Wydział Nauk Ekonomicznych 16 stycznia 2006 Streszczenie W artykule analizowane są właściwości
Właściwości testu Jarque-Bera gdy w danych występuje obserwacja nietypowa. Paweł Strawiński Uniwersytet Warszawski Wydział Nauk Ekonomicznych 16 stycznia 2006 Streszczenie W artykule analizowane są właściwości
WYMAGANIA WSTĘPNE W ZAKRESIE WIEDZY, UMIEJĘTNOŚCI I INNYCH KOMPETENCJI
 WYDZIAŁ GEOINŻYNIERII, GÓRNICTWA I GEOLOGII KARTA PRZEDMIOTU Nazwa w języku polskim: Statystyka matematyczna Nazwa w języku angielskim: Mathematical Statistics Kierunek studiów (jeśli dotyczy): Górnictwo
WYDZIAŁ GEOINŻYNIERII, GÓRNICTWA I GEOLOGII KARTA PRZEDMIOTU Nazwa w języku polskim: Statystyka matematyczna Nazwa w języku angielskim: Mathematical Statistics Kierunek studiów (jeśli dotyczy): Górnictwo
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Matematyka Stosowana na Politechnice Wrocławskiej. Komitet Matematyki PAN, luty 2017 r.
 Matematyka Stosowana na Politechnice Wrocławskiej Komitet Matematyki PAN, luty 2017 r. Historia kierunku Matematyka Stosowana utworzona w 2012 r. na WPPT (zespół z Centrum im. Hugona Steinhausa) studia
Matematyka Stosowana na Politechnice Wrocławskiej Komitet Matematyki PAN, luty 2017 r. Historia kierunku Matematyka Stosowana utworzona w 2012 r. na WPPT (zespół z Centrum im. Hugona Steinhausa) studia
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/
 Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
UWAGI O TESTACH JARQUE A-BERA
 PRZEGLĄD STATYSTYCZNY R. LVII ZESZYT 4 010 CZESŁAW DOMAŃSKI UWAGI O TESTACH JARQUE A-BERA 1. MIARY SKOŚNOŚCI I KURTOZY W literaturze statystycznej prezentuje się wiele miar skośności i spłaszczenia (kurtozy).
PRZEGLĄD STATYSTYCZNY R. LVII ZESZYT 4 010 CZESŁAW DOMAŃSKI UWAGI O TESTACH JARQUE A-BERA 1. MIARY SKOŚNOŚCI I KURTOZY W literaturze statystycznej prezentuje się wiele miar skośności i spłaszczenia (kurtozy).
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS. wersja 9.2 i 9.3. Szkoła Główna Handlowa w Warszawie
 STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
STATYSTYKA
 Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Modele DSGE. Jerzy Mycielski. Maj Jerzy Mycielski () Modele DSGE Maj / 11
 Modele DSGE Maj / 11") Modele DSGE Jerzy Mycielski Maj 2008 Jerzy Mycielski () Modele DSGE Maj 2008 1 / 11 Modele DSGE DSGE - Dynamiczne, stochastyczne modele równowagi ogólnej (Dynamic Stochastic General Equilibrium Model)
Modele DSGE Jerzy Mycielski Maj 2008 Jerzy Mycielski () Modele DSGE Maj 2008 1 / 11 Modele DSGE DSGE - Dynamiczne, stochastyczne modele równowagi ogólnej (Dynamic Stochastic General Equilibrium Model)
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
Statystyka matematyczna i ekonometria prof. dr hab. inż. Jacek Mercik B4 pok. 55 jacek.mercik@pwr.wroc.pl (tylko z konta studenckiego z serwera PWr) Konsultacje, kontakt itp. Strona WWW Elementy wykładu.
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap
 Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
WYMAGANIA WSTĘPNE W ZAKRESIE WIEDZY, UMIEJĘTNOŚCI I INNYCH KOMPETENCJI
 Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA (EiT stopień) Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność
Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA (EiT stopień) Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów re
 Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
STATYSTYKA MATEMATYCZNA
 Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność (jeśli
Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność (jeśli
166 Wstęp do statystyki matematycznej
 166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Testowanie hipotez. Hipoteza prosta zawiera jeden element, np. H 0 : θ = 2, hipoteza złożona zawiera więcej niż jeden element, np. H 0 : θ > 4.
 Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
5. Analiza dyskryminacyjna: FLD, LDA, QDA
 Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: przedmiot obowiązkowy w ramach treści kierunkowych, moduł kierunkowy ogólny Rodzaj zajęć: wykład, ćwiczenia I KARTA PRZEDMIOTU CEL PRZEDMIOTU
Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: przedmiot obowiązkowy w ramach treści kierunkowych, moduł kierunkowy ogólny Rodzaj zajęć: wykład, ćwiczenia I KARTA PRZEDMIOTU CEL PRZEDMIOTU
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
NOWY PROGRAM STUDIÓW 2016/2017 SYLABUS PRZEDMIOTU AUTORSKIEGO: Wprowadzenie do teorii ekonometrii. Część A
 NOWY PROGRAM STUDIÓW 2016/2017 SYLABUS PRZEDMIOTU AUTORSKIEGO: Autor: 1. Dobromił Serwa 2. Tytuł przedmiotu Sygnatura (będzie nadana, po akceptacji przez Senacką Komisję Programową) Wprowadzenie do teorii
NOWY PROGRAM STUDIÓW 2016/2017 SYLABUS PRZEDMIOTU AUTORSKIEGO: Autor: 1. Dobromił Serwa 2. Tytuł przedmiotu Sygnatura (będzie nadana, po akceptacji przez Senacką Komisję Programową) Wprowadzenie do teorii
Własności estymatorów regresji porządkowej z karą LASSO
 Własności estymatorów regresji porządkowej z karą LASSO Uniwersytet Mikołaja Kopernika w Toruniu Uniwersytet Warszawski Badania sfinansowane ze środków Narodowego Centrum Nauki przyznanych w ramach finansowania
Własności estymatorów regresji porządkowej z karą LASSO Uniwersytet Mikołaja Kopernika w Toruniu Uniwersytet Warszawski Badania sfinansowane ze środków Narodowego Centrum Nauki przyznanych w ramach finansowania
O testach wielowymiarowej normalności opartych na statystyce Shapiro-Wilka
 O testach wielowymiarowej normalności opartych na statystyce Shapiro-Wilka Katedra Zastosowań Matematyki i Informatyki Uniwersytet Przyrodniczy w Lublinie Wisła 2012, 7.12.2012 Plan prezentacji 1 Wprowadzenie
O testach wielowymiarowej normalności opartych na statystyce Shapiro-Wilka Katedra Zastosowań Matematyki i Informatyki Uniwersytet Przyrodniczy w Lublinie Wisła 2012, 7.12.2012 Plan prezentacji 1 Wprowadzenie
Własności estymatora parametru lambda transformacji potęgowej. Janusz Górczyński, Andrzej Zieliński, Wojciech Zieliński
 Własności estymatora parametru lambda transformacji potęgowej Janusz Górczyński, Andrzej Zieliński, Wojciech Zieliński 1. Wstęp Najczęstszym powodem transformowania zmiennej losowej jest jej normalizacja,
Własności estymatora parametru lambda transformacji potęgowej Janusz Górczyński, Andrzej Zieliński, Wojciech Zieliński 1. Wstęp Najczęstszym powodem transformowania zmiennej losowej jest jej normalizacja,
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
PRZYKŁAD ZASTOSOWANIA DOKŁADNEGO NIEPARAMETRYCZNEGO PRZEDZIAŁU UFNOŚCI DLA VaR. Wojciech Zieliński
 PRZYKŁAD ZASTOSOWANIA DOKŁADNEGO NIEPARAMETRYCZNEGO PRZEDZIAŁU UFNOŚCI DLA VaR Wojciech Zieliński Katedra Ekonometrii i Statystyki SGGW Nowoursynowska 159, PL-02-767 Warszawa wojtek.zielinski@statystyka.info
PRZYKŁAD ZASTOSOWANIA DOKŁADNEGO NIEPARAMETRYCZNEGO PRZEDZIAŁU UFNOŚCI DLA VaR Wojciech Zieliński Katedra Ekonometrii i Statystyki SGGW Nowoursynowska 159, PL-02-767 Warszawa wojtek.zielinski@statystyka.info
Własności statystyczne regresji liniowej. Wykład 4
 Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Wykład Ćwiczenia Laboratorium Projekt Seminarium 30
 Zał. nr 4 do ZW WYDZIAŁ CHEMICZNY KARTA PRZEDMIOTU Nazwa w języku polskim Wstęp do statystyki praktycznej Nazwa w języku angielskim Intriduction to the Practice of Statistics Kierunek studiów (jeśli dotyczy):
Zał. nr 4 do ZW WYDZIAŁ CHEMICZNY KARTA PRZEDMIOTU Nazwa w języku polskim Wstęp do statystyki praktycznej Nazwa w języku angielskim Intriduction to the Practice of Statistics Kierunek studiów (jeśli dotyczy):
Przedmowa Wykaz symboli Litery alfabetu greckiego wykorzystywane w podręczniku Symbole wykorzystywane w zagadnieniach teorii
 SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
Porównanie modeli regresji. klasycznymi modelami regresji liniowej i logistycznej
 Porównanie modeli logicznej regresji z klasycznymi modelami regresji liniowej i logistycznej Instytut Matematyczny, Uniwersytet Wrocławski Małgorzata Bogdan Instytut Matematyki i Informatyki, Politechnika
Porównanie modeli logicznej regresji z klasycznymi modelami regresji liniowej i logistycznej Instytut Matematyczny, Uniwersytet Wrocławski Małgorzata Bogdan Instytut Matematyki i Informatyki, Politechnika
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
W2. Zmienne losowe i ich rozkłady. Wnioskowanie statystyczne.
 W2. Zmienne losowe i ich rozkłady. Wnioskowanie statystyczne. dr hab. Jerzy Nakielski Katedra Biofizyki i Morfogenezy Roślin Plan wykładu: 1. Etapy wnioskowania statystycznego 2. Hipotezy statystyczne,
W2. Zmienne losowe i ich rozkłady. Wnioskowanie statystyczne. dr hab. Jerzy Nakielski Katedra Biofizyki i Morfogenezy Roślin Plan wykładu: 1. Etapy wnioskowania statystycznego 2. Hipotezy statystyczne,
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
Importowanie danych do SPSS Eksportowanie rezultatów do formatu MS Word... 22
 Spis treści Przedmowa do wydania pierwszego.... 11 Przedmowa do wydania drugiego.... 15 Wykaz symboli.... 17 Litery alfabetu greckiego wykorzystywane w podręczniku.... 17 Symbole wykorzystywane w zagadnieniach
Spis treści Przedmowa do wydania pierwszego.... 11 Przedmowa do wydania drugiego.... 15 Wykaz symboli.... 17 Litery alfabetu greckiego wykorzystywane w podręczniku.... 17 Symbole wykorzystywane w zagadnieniach
Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice
 Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice Przedmowa do wydania polskiego Przedmowa CZĘŚĆ I. PODSTAWY STATYSTYKI Rozdział 1 Podstawowe pojęcia statystyki
Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice Przedmowa do wydania polskiego Przedmowa CZĘŚĆ I. PODSTAWY STATYSTYKI Rozdział 1 Podstawowe pojęcia statystyki
Ważne rozkłady i twierdzenia c.d.
 Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Metody probabilistyczne
 Metody probabilistyczne 13. Elementy statystki matematycznej I Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 17.01.2019 1 / 30 Zagadnienia statystki Przeprowadzamy
Metody probabilistyczne 13. Elementy statystki matematycznej I Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 17.01.2019 1 / 30 Zagadnienia statystki Przeprowadzamy
Wstęp do Metod Systemowych i Decyzyjnych Opracowanie: Jakub Tomczak
 Wstęp do Metod Systemowych i Decyzyjnych Opracowanie: Jakub Tomczak 1 Wprowadzenie. Zmienne losowe Podczas kursu interesować nas będzie wnioskowanie o rozpatrywanym zjawisku. Poprzez wnioskowanie rozumiemy
Wstęp do Metod Systemowych i Decyzyjnych Opracowanie: Jakub Tomczak 1 Wprowadzenie. Zmienne losowe Podczas kursu interesować nas będzie wnioskowanie o rozpatrywanym zjawisku. Poprzez wnioskowanie rozumiemy
System bonus-malus z mechanizmem korekty składki
 System bonus-malus z mechanizmem korekty składki mgr Kamil Gala Ubezpieczeniowy Fundusz Gwarancyjny dr hab. Wojciech Bijak, prof. SGH Ubezpieczeniowy Fundusz Gwarancyjny, Szkoła Główna Handlowa Zagadnienia
System bonus-malus z mechanizmem korekty składki mgr Kamil Gala Ubezpieczeniowy Fundusz Gwarancyjny dr hab. Wojciech Bijak, prof. SGH Ubezpieczeniowy Fundusz Gwarancyjny, Szkoła Główna Handlowa Zagadnienia
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
Pobieranie prób i rozkład z próby
 Pobieranie prób i rozkład z próby Marcin Zajenkowski Marcin Zajenkowski () Pobieranie prób i rozkład z próby 1 / 15 Populacja i próba Populacja dowolnie określony zespół przedmiotów, obserwacji, osób itp.
Pobieranie prób i rozkład z próby Marcin Zajenkowski Marcin Zajenkowski () Pobieranie prób i rozkład z próby 1 / 15 Populacja i próba Populacja dowolnie określony zespół przedmiotów, obserwacji, osób itp.
Wykład 9 Testy rangowe w problemie dwóch prób
 Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
POISSONOWSKA APROKSYMACJA W SYSTEMACH NIEZAWODNOŚCIOWYCH
 POISSONOWSKA APROKSYMACJA W SYSTEMACH NIEZAWODNOŚCIOWYCH Barbara Popowska bpopowsk@math.put.poznan.pl Politechnika Poznańska http://www.put.poznan.pl/ PROGRAM REFERATU 1. WPROWADZENIE 2. GRAF JAKO MODEL
POISSONOWSKA APROKSYMACJA W SYSTEMACH NIEZAWODNOŚCIOWYCH Barbara Popowska bpopowsk@math.put.poznan.pl Politechnika Poznańska http://www.put.poznan.pl/ PROGRAM REFERATU 1. WPROWADZENIE 2. GRAF JAKO MODEL
Uogolnione modele liniowe
 Uogolnione modele liniowe Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Uogolnione modele liniowe grudzien 2013 1 / 17 (generalized linear model - glm) Zakładamy,
Uogolnione modele liniowe Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Uogolnione modele liniowe grudzien 2013 1 / 17 (generalized linear model - glm) Zakładamy,
Statystyka. Rozkład prawdopodobieństwa Testowanie hipotez. Wykład III ( )
") Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
W4 Eksperyment niezawodnościowy
 W4 Eksperyment niezawodnościowy Henryk Maciejewski Jacek Jarnicki Jarosław Sugier www.zsk.iiar.pwr.edu.pl Badania niezawodnościowe i analiza statystyczna wyników 1. Co to są badania niezawodnościowe i
W4 Eksperyment niezawodnościowy Henryk Maciejewski Jacek Jarnicki Jarosław Sugier www.zsk.iiar.pwr.edu.pl Badania niezawodnościowe i analiza statystyczna wyników 1. Co to są badania niezawodnościowe i
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, Spis treści
 Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
Podstawowe modele probabilistyczne
 Wrocław University of Technology Podstawowe modele probabilistyczne Maciej Zięba maciej.zieba@pwr.edu.pl Rozpoznawanie Obrazów, Lato 2018/2019 Pojęcie prawdopodobieństwa Prawdopodobieństwo reprezentuje
Wrocław University of Technology Podstawowe modele probabilistyczne Maciej Zięba maciej.zieba@pwr.edu.pl Rozpoznawanie Obrazów, Lato 2018/2019 Pojęcie prawdopodobieństwa Prawdopodobieństwo reprezentuje
Natalia Neherbecka. 11 czerwca 2010
 Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
SPIS TEŚCI CZĘŚĆ I RACHUNEK PRAWDOPODOBIEŃSTWA
 SPIS TEŚCI PRZEDMOWA...13 CZĘŚĆ I RACHUNEK PRAWDOPODOBIEŃSTWA 1. ZDARZENIA LOSOWE I PRAWDOPODOBIEŃSTWO...17 1.1. UWAGI WSTĘPNE... 17 1.2. ZDARZENIA LOSOWE... 17 1.3. RELACJE MIĘDZY ZDARZENIAMI... 18 1.4.
SPIS TEŚCI PRZEDMOWA...13 CZĘŚĆ I RACHUNEK PRAWDOPODOBIEŃSTWA 1. ZDARZENIA LOSOWE I PRAWDOPODOBIEŃSTWO...17 1.1. UWAGI WSTĘPNE... 17 1.2. ZDARZENIA LOSOWE... 17 1.3. RELACJE MIĘDZY ZDARZENIAMI... 18 1.4.
UPORZĄDKOWANIE STOCHASTYCZNE ESTYMATORÓW ŚREDNIEGO CZASU ŻYCIA. Piotr Nowak Uniwersytet Wrocławski
 UPORZĄDKOWANIE STOCHASTYCZNE ESTYMATORÓW ŚREDNIEGO CZASU ŻYCIA Piotr Nowak Uniwersytet Wrocławski Wprowadzenie X = (X 1,..., X n ) próba z rozkładu wykładniczego Ex(θ). f (x; θ) = 1 θ e x/θ, x > 0, θ >
UPORZĄDKOWANIE STOCHASTYCZNE ESTYMATORÓW ŚREDNIEGO CZASU ŻYCIA Piotr Nowak Uniwersytet Wrocławski Wprowadzenie X = (X 1,..., X n ) próba z rozkładu wykładniczego Ex(θ). f (x; θ) = 1 θ e x/θ, x > 0, θ >
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej
 Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
OPIS MODUŁ KSZTAŁCENIA (SYLABUS)
") OPIS MODUŁ KSZTAŁCENIA (SYLABUS) I. Informacje ogólne: 1 Nazwa modułu Metody opracowania obserwacji 2 Kod modułu 04-A-MOO-60-1L 3 Rodzaj modułu obowiązkowy 4 Kierunek studiów astronomia 5 Poziom studiów
OPIS MODUŁ KSZTAŁCENIA (SYLABUS) I. Informacje ogólne: 1 Nazwa modułu Metody opracowania obserwacji 2 Kod modułu 04-A-MOO-60-1L 3 Rodzaj modułu obowiązkowy 4 Kierunek studiów astronomia 5 Poziom studiów
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA
 ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności
Estymacja parametrów w modelu normalnym
 Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Spacery losowe generowanie realizacji procesu losowego
 Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Mikroekonometria 5. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 5 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.medexp3.dta przygotuj model regresji kwantylowej 1. Przygotuj model regresji kwantylowej w którym logarytm wydatków
Mikroekonometria 5 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.medexp3.dta przygotuj model regresji kwantylowej 1. Przygotuj model regresji kwantylowej w którym logarytm wydatków
Biostatystyka, # 3 /Weterynaria I/
 Biostatystyka, # 3 /Weterynaria I/ dr n. mat. Zdzisław Otachel Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, p. 221 bud. CIW, e-mail: zdzislaw.otachel@up.lublin.pl
Biostatystyka, # 3 /Weterynaria I/ dr n. mat. Zdzisław Otachel Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, p. 221 bud. CIW, e-mail: zdzislaw.otachel@up.lublin.pl
Regresja wielokrotna. PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
ANALIZA WŁAŚCIWOŚCI FILTRU PARAMETRYCZNEGO I RZĘDU
 POZNAN UNIVE RSITY OF TE CHNOLOGY ACADE MIC JOURNALS No 78 Electrical Engineering 2014 Seweryn MAZURKIEWICZ* Janusz WALCZAK* ANALIZA WŁAŚCIWOŚCI FILTRU PARAMETRYCZNEGO I RZĘDU W artykule rozpatrzono problem
POZNAN UNIVE RSITY OF TE CHNOLOGY ACADE MIC JOURNALS No 78 Electrical Engineering 2014 Seweryn MAZURKIEWICZ* Janusz WALCZAK* ANALIZA WŁAŚCIWOŚCI FILTRU PARAMETRYCZNEGO I RZĘDU W artykule rozpatrzono problem
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Stanisław Cichocki Natalia Nehrebecka. Wykład 7
 Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja) założenie: znany rozkład populacji (wykorzystuje się dystrybuantę)
 założenie: znany rozkład populacji (wykorzystuje się dystrybuantę)") PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład II 2017/2018
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy