Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki
|
|
|
- Krzysztof Janiszewski
- 8 lat temu
- Przeglądów:
Transkrypt


1 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl
2 Efektywność OLAP Perspektywy zmaterializowane przepisywanie zapytań wybór zbioru perspektyw anomalie odświeżania Optymalizacja GROUP BY Kompresja Przetwarzanie równoległe Partycjonowanie 2
 sprzedano, sum(sp.")

")
3 Przepisywanie zapytań - przykład (1) create materialized view mv_sprzedaz build immediate refresh force next sysdate + (1/24) ENABLE QUERY REWRITE as select sk.miasto, pr.prod_nazwa, cz.nazwa_miesiaca, sum(sp.l_sztuk) sprzedano, sum(sp.wartosc) wartosc from sprzedaz sp, sklepy sk, produkty pr, czas cz where sp.sklep_id=sk.sklep_id and sp.produkt_id=pr.produkt_id and sp.data=cz.data group by sk.miasto, pr.prod_nazwa, cz.nazwa_miesiaca; select sk.miasto, pr.prod_nazwa, sum(sp.wartosc) wartosc from sprzedaz sp, sklepy sk, produkty pr, czas cz where sp.sklep_id=sk.sklep_id and sp.produkt_id=pr.produkt_id and sp.data=cz.data and sk.miasto='poznań' group by sk.miasto, pr.prod_nazwa, cz.nazwa_miesiaca; Execution Plan SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=37) 1 0 TABLE ACCESS (FULL) OF 'MV_SPRZEDAZ' (Cost=2 Card=1 Bytes=37) 3

4 Przepisywanie zapytań - przykład (2) W celu wyznaczenia wyników zapytania użytkownika, perspektywa zmaterializowana jest łączona z jedną z jej tabel bazowych Perspektywa musi zawierać albo klucz podstawowy tej tabeli bazowej lub ROWID rekordów tabeli bazowej create materialized view mv_sprzedaz1 build immediate refresh complete enable query rewrite as select sk.miasto, pr.produkt_id, cz.nazwa_miesiaca, sum(sp.wartosc) as wartosc from sprzedaz sp, sklepy sk, produkty pr, czas cz where sp.sklep_id=sk.sklep_id and sp.produkt_id=pr.produkt_id and sp.data=cz.data group by sk.miasto, pr.produkt_id, cz.nazwa_miesiaca; 4

5 Przepisywanie zapytań - przykład (3) select sk.miasto, pr.prod_nazwa, sum(sp.wartosc) wartosc from sprzedaz sp, sklepy sk, produkty pr, czas cz where sp.sklep_id=sk.sklep_id and sp.produkt_id=pr.produkt_id and sp.data=cz.data group by sk.miasto, pr.prod_nazwa, cz.nazwa_miesiaca; zależność funkcyjna PRODUKT_ID PROD_NAZWA wyznaczona na podstawie klucza 5
6 Perspektywa zmaterializowana Wybór właściwego zbioru perspektyw zmaterializowanych Kryteria minimalizacja czasu odpowiedzi jak największej liczby zapytań minimalizacja czasu odpowiedzi najbardziej kosztownych zapytań minimalizacja kosztów odświeżania perspektyw minimalizacja wykorzystania przestrzeni dyskowej Problem trudny Wsparcie ze strony oprogramowania systemowego Oracle9i/10g/11g - Summary Advisor/Access Advisor 6
7 Algorytm zachłanny Założenia Cel znany jest szacowany rozmiar danych dla każdego zapytania koszt wykonania zapytania jest reprezentowany rozmiarem odczytanych danych minimalizacja rozmiaru danych odczytywanych przez zapytania przy zadanej liczbie zmaterializowanych perspektyw Harinarayan V., Rajaraman A., Ullman J.: Implementing Data Cubes Efficiently. SIGMOD,
8 D G B E A Przykład działania H 1 10 C F Węzeł zapytanie koszt wykonania zapytania rozmiar odczytanych danych Łuk możliwość wyliczenia zapytania (węzeł docelowy łuku) na podstawie innego zapytania (węzeł początkowy łuku) Przebieg 1 B: 50x5=250 C: 25x5=125 D: 80x2=160 E: 70x3=210 F: 60x2=120 G: 99x1 H: 90x1 8
9 Przykład działania Przebieg 2 G H 1 10 D E F C: 25x2=50 (C i F, H z B) D: 30x2=60 E: 20x3=60 F: (B-F)=70 G: 49 H: 40 (H z B) B C A 100 9
10 Przykład działania Przebieg 3 G H 1 10 D E F C: 25=25 (C, E z B) D: 30x2=60 E: (E-F)=50 G: 49 H: 30 B C A
11 Perspektywa zmaterializowana Konieczność odświeżania automatycznie z zadaną częstotliwością/na żądanie przyrostowo/całkowicie Wykrywanie zmian w źródłach analiza dziennika transakcji (transaction, redo log) wyzwalacze porównanie dwóch stanów źródła własna implementacja dziennika Anomalie odświeżania równoczesna praca transakcji modyfikujących zawartość źródeł danych i procesów odświeżania 11
12 Anomalie odświeżania R1 A B R2 B C 2 4 V=R1 join R2 A B C Wstawienie rekordu [2,4] do R2 źródło informuje HD komunikatem U1=insert(R2, [2,4]) 2. HD konstruuje zapytanie odświeżające Q1=R1 join [2,4] 3. Wstawienie rekordu [4,2] do R1 źródło informuje HD komunikatem U2=insert(R1, [4,2]) 4. HD konstruuje zapytanie odświeżające Q2=[4,2] join R2 5. Źródło wykonuje zapytanie Q1 i przekazuje wynik W1={[1,2,4],[4,2,4]} 6. Źródło wykonuje zapytanie Q2 i przekazuje wynik W2={[4,2,4]} 12
13 Techniki unikania anomalii Kompensacja Zhuge Y., Garcia-Molina H., Hammer J., Widom J.: View Maintenance in Warehousing Environment. SIGMOD, 1995 Zhuge Y., Garcia-Molina H., Wiener J.: The Strobe Algorithms for Multi-Source Warehouse Consistency. PDIS, 1996 Systemowe wersje danych Quass D., Widom J.: On-line Warehouse View Maintenance. SIGMOD, 1997 Teschke M., Ulbrich A.: Concurrent Warehouse Maintenance Without Compromising Session Consistency. DEXA, 1998 Kulkarni S., Mohania M.: Concurrent Maintenance of Views Using Multiple Versions. IDEAS,
14 Kompensacja System przechowuje kolejkę zapytań KZ w trakcie wykonywania tymczasową tabelę WZ z wynikami dotychczas wykonanych zapytań R1 A B 1 2 R2 B C Wstawienie rekordu [2,4] do R2 źródło informuje HD komunikatem U1=insert(R2, [2,4]) 2. HD konstruuje zapytanie odświeżające Q1=R1 join [2,4] 3. Q1 jest wstawiane do KZ, KZ={Q1} 14
15 R1 Kompensacja A B R2 B C Wstawienie rekordu [4,2] do R1 źródło informuje HD komunikatem U2=insert(R1, [4,2]) 4. KZ={Q1}, wynik Q1 obarczony błędem spowodowanym przez U2 do zapytania Q2 należy dołączyć część kompensującą: Q2=[4,2] join R2 - [4,2] join [2,4] 5. Q2 jest wstawiane do KZ, KZ={Q1, Q2} 6. Źródło wykonuje zapytanie Q1 i przekazuje wynik do WZ, WZ={[1,2,4],[4,2,4]}, Q1 jest usuwane z KZ, KZ={Q2} 7. Źródło wykonuje zapytanie Q2: {[4,2,4]}-{[4,2,4]}=Ø i przekazuje wynik do WZ, WZ={[1,2,4],[4,2,4]} + Ø 15
16 Systemowe wersje danych Jedna transakcja odświeżająca HD Wiele transakcji odczytujących dane (transakcje OLAP) Algorytm 2VL (Two Version Locking) w HD mogą istnieć pary wersji bieżąca (dla transakcji OLAP) i przyszła (odświeżana) przeszła (dla transakcji OLAP) i bieżąca (po zakończonym odświeżaniu) każdy rekord został rozszerzony o atrybuty przechowujące drugą wersję danych (horyzontalna redundancja) 16
17 Systemowe wersje danych Redundancja wertykalna kolejne wersje danych przechowywane jako odrębne rekordy rozszerzenie schematu perspektywy zmaterializowanej o atrybuty przechowujące znaczniki czasowe początku i końca ważności rekordu transakcja OLAP czyta tylko te rekordy, których wartość znacznika czasowego początku ważności jest mniejsza niż znacznik czasowy rozpoczęcia transakcji OLAP 17
 --------")

18 Optymalizacja GROUP BY select sklep, produkt, data, sum(kwota_sprz) from sprzedaz group by sklep, produkt, data; SKLEP PRODUKT DATA SUM(KWOTA_SPRZ) Żabka1 łaciate 2% Żabka2 Polityka Żabka1 kajzerka Żabka2 masło ekstra

19 Optymalizacja GROUP BY GROUP BY ROLLUP (sklep, produkt, data) GROUP BY sklep, produkt, data GROUP BY sklep, produkt GROUP BY sklep GROUP BY () SKLEP PRODUKT DATA SUM(KWOTA_SPRZ) Żabka1 kajzerka Żabka1 kajzerka 7.7 Żabka1 łaciate 2% Żabka1 łaciate 2% 3.5 Żabka Żabka2 Polityka Żabka2 Polityka 9 Żabka2 masło ekstra Żabka2 masło ekstra 4.3 Żabka select sklep, produkt, data, sum(kwota_sprz) from sprzedaz group by ROLLUP(sklep, produkt, data); 19
20 Optymalizacja GROUP BY GROUP BY CUBE (sklep, produkt, data) GROUP BY sklep, produkt, data GROUP BY sklep, produkt GROUP BY sklep, data GROUP BY produkt, data GROUP BY sklep GROUP BY produkt GROUP BY data GROUP BY () GROUP BY GROUPING SETS ((sklep, produkt), sklep, ()) GROUP BY sklep, produkt GROUP BY sklep GROUP BY () 20
21 W jaki sposób wyliczać grupowania? total produkt sklep klient data produkt, sklep produkt, klient sklep, klient produkt, data sklep, data klient, data produkt, sklep, klient produkt, sklep, data sklep, klient, data produkt, klient, data produkt, sklep, klient, data 21
22 9 Optymalizacja GROUP BY S P D 13 ( ) SP SD PD Założenia: dla każdego schematu grupowania znana liczba unikalnych wartości koszt wyliczenia na podstawie węzła podrzędnego SPD 30 Cel optymalizacji wyznaczyć wszystkie schematy grupowania w sposób minimalizujący sumę kosztów 22
23 Techniki optymalizacji Najmniejszy węzeł rodzica (smallest parent) obliczenie grupowania wyższego poziomu na podstawie najmniejszego (rozmiarowo) grupowania niższego poziomu Buforowanie wyników w RAM (cache results) wyniki grupowania są wykorzystane do następnego grupowania group by SPD -> group by SP -> group by S Ograniczenie odczytów z dysku (amortize scans) w czasie jednego odczytu z dysku wyliczanych jest wiele schematów grupowania np. jeśli wynik grupowania SPD jest składowany na dysku to wylicza się SP, SD, PD 23
24 Techniki optymalizacji Współdzielenie wyników sortowania (share sorts) jeden schemat sortowania jest wykorzystany do wyliczania wielu schematów grupowania Podział dużej tabeli na części (partycje) zastosowanie haszowania do każdej części scalanie części (możliwe dla funkcji addytywnych) współdzielenie części dla wielu schematów grupowania Agarwal S., Agrawal R., Deshpande M. P., Gupta A., Naughton F. J., Ramakrishnan R., Sarawagi S.: On the Computation of Multidimensional Aggregates. VLDB, 1996 Ross K. A., Srivastava D.: Fast Computation of Sparse Datacubes. VLDB, 1997 Beyer K, Ramakrishnan R.: Bottom-Up Computation of Sparse and Iceberg Cubes. SIGMOD, 1999 Wang W., Feng J., Lu H., Xu Yu J.: Condensed Cube: An Effective Approach to Reducing Data Cube Size. ICDE, 2002 Lakshmanan L., Pei J., Han J.: Quotient cube: How to summarize the semantics of a data cube. VLDB, 2002 Chen Z., Narasayya V.: Efficient Computation of Multiple Group By Queries. SIGMOD, 2005 Morfonios K., Ioannidis Y.: CURE for Cubes: Cubing Using a ROLAP Engine. VLDB,
25 Algorytm PipeSort 9 ( ) S P D SP SD PD 18 Przeszukiwanie grafu Dla każdego poziomu znajdowana jest krawędź o najmniejszym koszcie Wykonywanie grupowania Buforowanie wyników grupowania z poziomu niższego () SPD 30 S SP P SP D SD PD SPD SPD SPD SPD 25
26 Algorytm PipeHash Koncepcja jak PipeSort Założenie: znane jest oszacowanie rozmiaru wierzchołka grafu (wyniku schematu grupowania) Zamiast sortowania wykorzystywane haszowanie 26
27 Algorytm Overlap Koncepcja jak PipeSort Założenie: znane jest oszacowanie rozmiaru wierzchołka grafu (wyniku schematu grupowania) Przeglądanie grafu w szerz na każdym poziomie Wynik grupowania jest dzielony na części Żabka1 łaciate 2% 3.50 Żabka1 kajzerka 7.70 Żabka2 Polityka 9.00 Żabka2 łaciate 2% 3.50 Żabka2 kajzerka 7.70 Żabka2 Polityka 9.00 SP SD SPD 27
28 Algorytmy Memory-Cube i Partitioned-Cube Memory-Cube zakłada, że dane zmieszczą się w RAM i sortowanie będzie możliwe w RAM Partitioned-Cube zakłada, że dane nie zmieszczą się w RAM podział danych na grupy ze względu na atrybuty grupujące, np. sklep, produkt, data dla każdej unikalnej wartości atrybutu wiodącego, np. sklep in {Żabka1, Żabka2,...} w agregacie na poziomie k oblicz agregaty na poziomach k+i za pomocą Memory- Cube 28
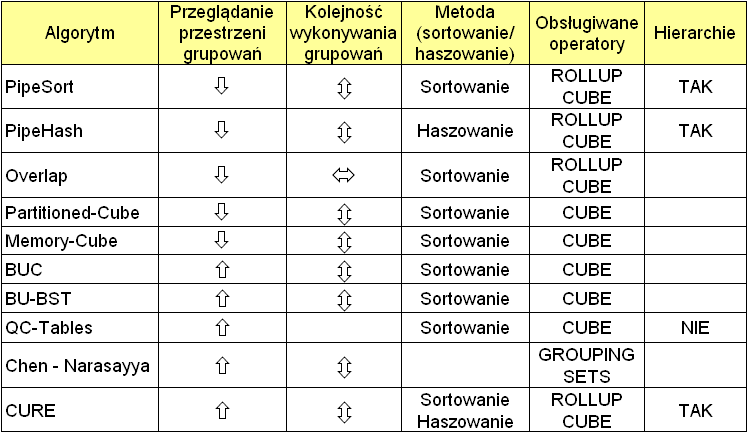
29 Algorytmy optymalizacji 29
30 Kompresja danych Kompresja danych w bloku 30



31 Kompresja słownikowa Słownik kompresji może być przechowywany w dedykowanej tabeli lub w nagłówku bloku danych słownik kompresji 31
32 Kompresja indeksów Nieskompresowane liście B-drzewa K 1 P 1 K 2 P K n-1 P n P next Skompresowane liście B-drzewa K 1 P 1 P K n-1 P n P n+1 P next Kompresja map bitowych w indeksach bitmapowych 32
33 Przetwarzanie równoległe Wykonywanie zapytań SELECT /*+ PARALLEL(sp, 5) */ sklep_id, sum(ilosc) FROM sprzedaz sp GROUP BY sklep_id; Tworzenie kopii tabel create table sklepy_kopia parallel 3 as select * from sklepy; Budowanie indeksów Wczytywanie danych do hurtowni Archiwizowanie danych Odtwarzanie bazy danych po awarii 33

34 Partycjonowanie Podział tabeli/indeksu na mniejsze fragmenty równoległy odczyt partycji równoległe wykonywanie zapytania zrównoważenie obciążenia dysków adresowanie mniejszego zbioru danych (1/n tabeli) 34

35 Standardowa organizacja rekordowa bloki bazy danych Identyfikacja rekordu na podstawie ROWID 35

 w bloku bloki")
36 Organizacja kolumnowa Identyfikacja rekordu na podstawie pozycji (numeru szczeliny) w bloku bloki bazy danych 36




 SADAS")

37 Organizacja kolumnowa (columnoriented) OPROGRAMOWANIE ETL HURTOWNIA DANYCH organizacja kolumnowa Systemy Model projection index Sybase IQ (Sybase, Inc.) SADAS (AdvancedSystems) Vertica i wiele innych syst. komercyjnych i niekomercyjnych 37
38 Optymalizacja (1) run-length encoding 12/02/ /02/ /02/ /02/ /02/ /02/ /03/ /03/ /02/ /03/ delta encoding


39 Optymalizacja (2) discrete domain encoding 39
40 Charakterystyka (1) Efektywne dla operacji projekcji mniej danych jest odczytywanych Efektywne dla GROUP BY Możliwe ułatwienia w implementacji każda kolumna składowana w osobnym pliku zarządzanym przez system operacyjny (np. SADAS) w rozwiązaniu dedykowanym dla HD zasilanie w trybie wsadowym uproszczona organizacja bloku danych nagłówek nagłówek katalog tabel katalog rekordów wolne miejsce dane dane blok tradycyjny blok HD 40




41 Charakterystyka (2) Źródło: prezentacja Sybase system tradycyjny TB dane źródłowe Agregaty 1-2 TB 1TB Sybase IQ TB Indeksy 0.5-3TB Aggregaty: 0-0.1TB Indeksy: TB Tabela: TB Dane źródłowe TB 41
42 Charakterystyka (3) Źródło: prezentacja AdancedSystems Storage Space (Bytes) index Indexes Data Input row-based DBMS SADAS 42
43 Inne techniki optymalizacji - SMA SMA - Small Materialized Aggregates (G. Moerkotte, VLDB 1998) dane na dysku w ramach jednego pliku/przestrzeni tabel są dzielone na obszary (buckets) z każdym obszarem jest związany zbiór SMA wykorzystanie zapytania z zakresem dat SMA obszar1 data min: data max: count: 5 SMA obszar2 data min: data max: count: 5 SMA obszar3 data min: data max: count: 5 43

44 Inne techniki optymalizacji - ZM ZM - Zone Map (Netezza) koncepcja podobna do SMA dla każdej kolumny i każdego segmentu tworzona jest ZM ZM przechowuje wartość MIN i MAX danego atrybutu dla danego segmentu zawartość ZM uaktualniana w czasie wczytywania danych do HD ZM dla dat: wartości MIN i MAX dla różnych ZM nie będą często się nakładały wczytywane dane są skorelowane z czasem, np. sprzedaż 44
45 Inne techniki optymalizacji - ZF ZF - Zone Filter (G. Graefe, DAWAK 2009) koncepcja łączy SMA i ZM dla każdej kolumny i każdego obszaru tworzony jest ZF ZF przechowuje m kolejnych wartości MIN i MAX obsługa wartości NULL, jeśli m=1, to wartością MIN jest NULL nie można wykorzystać do optymalizacji zapytań z zakresem jeśli m=2, to wartości najmniejsze są 2: NULL i konkretna wartość m=3, MIN={4, 7, 12}, zapytanie z warunkiem =, np. a=9 nie wymaga odczytania tego obszaru efektywne jeśli istnieje korelacja pomiędzy wartością atrybutu, a sekwencją wczytywania do HD sprzedaż, notowania giełdowe 45


46 lokalny indeks obszaru filtr na ZF lokalny indeks obszaru Inne techniki optymalizacji - ZF ZF1 data ZF1 otwarcie ZF2 data ZF2 otwarcie Optymalizacja wybór obszarów z wykorzystaniem filtru na ZF wyszukanie rekordów w obszarze z wykorzystaniem lokalnego indeksu 46
Hurtownie danych - przegląd technologii
 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Efektywność OLAP Perspektywy zmaterializowane
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Efektywność OLAP Perspektywy zmaterializowane
Data Warehouse Physical Design: Part III
 Data Warehouse Physical Design: Part III Robert Wrembel Poznan University of Technology Institute of Computing Science Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Lecture outline Group
Data Warehouse Physical Design: Part III Robert Wrembel Poznan University of Technology Institute of Computing Science Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Lecture outline Group
Hurtownie danych - przegląd technologii
 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Efektywność przetwarzania OLAP 1. Indeksowanie
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Efektywność przetwarzania OLAP 1. Indeksowanie
Hurtownie danych - przegląd technologii
 Efektywność przetwarzania OLAP Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel. Indeksowanie
Efektywność przetwarzania OLAP Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel. Indeksowanie
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki
 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Efektywność przetwarzania OLAP 1. Indeksowanie
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Efektywność przetwarzania OLAP 1. Indeksowanie
Optymalizacja poleceń SQL
 Optymalizacja poleceń SQL Przetwarzanie polecenia SQL użytkownik polecenie PARSER słownik REGUŁOWY RBO plan zapytania RODZAJ OPTYMALIZATORA? GENERATOR KROTEK plan wykonania statystyki KOSZTOWY CBO plan
Optymalizacja poleceń SQL Przetwarzanie polecenia SQL użytkownik polecenie PARSER słownik REGUŁOWY RBO plan zapytania RODZAJ OPTYMALIZATORA? GENERATOR KROTEK plan wykonania statystyki KOSZTOWY CBO plan
Systemy OLAP II. Krzysztof Dembczyński. Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska
 Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Technologie Wytwarzania Oprogramowania Semestr letni 2006/07 Plan wykładu Systemy baz
Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Technologie Wytwarzania Oprogramowania Semestr letni 2006/07 Plan wykładu Systemy baz
"Kilka słów" o strojeniu poleceń SQL w kontekście Hurtowni Danych wprowadzenie. Krzysztof Jankiewicz
 "Kilka słów" o strojeniu poleceń SQL w kontekście Hurtowni Danych wprowadzenie Krzysztof Jankiewicz Plan Opis schematu dla "kilku słów" Postać polecenia SQL Sposoby dostępu do tabel Indeksy B*-drzewo Indeksy
"Kilka słów" o strojeniu poleceń SQL w kontekście Hurtowni Danych wprowadzenie Krzysztof Jankiewicz Plan Opis schematu dla "kilku słów" Postać polecenia SQL Sposoby dostępu do tabel Indeksy B*-drzewo Indeksy
Modelowanie wymiarów
 Wymiar Modelowanie wymiarów struktura umożliwiająca grupowanie danych z tabeli faktów implementowana jako obiekt bazy danych DIMENSION wykorzystanie DIMENSION zaawansowane przepisywanie zapytań (ang. query
Wymiar Modelowanie wymiarów struktura umożliwiająca grupowanie danych z tabeli faktów implementowana jako obiekt bazy danych DIMENSION wykorzystanie DIMENSION zaawansowane przepisywanie zapytań (ang. query
Wydajność hurtowni danych opartej o Oracle10g Database
 Wydajność hurtowni danych opartej o Oracle10g Database 123 Plan rozdziału 124 Transformacja gwiaździsta Rozpraszanie przestrzeni tabel Buforowanie tabel Różnicowanie wielkości bloków bazy danych Zarządzanie
Wydajność hurtowni danych opartej o Oracle10g Database 123 Plan rozdziału 124 Transformacja gwiaździsta Rozpraszanie przestrzeni tabel Buforowanie tabel Różnicowanie wielkości bloków bazy danych Zarządzanie
Optymalizacja poleceń SQL Metody dostępu do danych
 Optymalizacja poleceń SQL Metody dostępu do danych 1 Metody dostępu do danych Określają, w jaki sposób dane polecenia SQL są odczytywane z miejsca ich fizycznej lokalizacji. Dostęp do tabeli: pełne przeglądnięcie,
Optymalizacja poleceń SQL Metody dostępu do danych 1 Metody dostępu do danych Określają, w jaki sposób dane polecenia SQL są odczytywane z miejsca ich fizycznej lokalizacji. Dostęp do tabeli: pełne przeglądnięcie,
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl
 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Plan wykładów Wprowadzenie - integracja
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Plan wykładów Wprowadzenie - integracja
Hurtownie danych - przegląd technologii
 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Plan wykład adów Wprowadzenie - integracja
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Plan wykład adów Wprowadzenie - integracja
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki
 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Aktywna hurtownia danych AHD [T. Thalhammer,
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Aktywna hurtownia danych AHD [T. Thalhammer,
Hurtownie danych - przegląd technologii
 Hurtownie danych - przegląd technologii Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Biznesowe słowniki pojęć biznesowych odwzorowania pojęć
Hurtownie danych - przegląd technologii Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Biznesowe słowniki pojęć biznesowych odwzorowania pojęć
OLAP i hurtownie danych c.d.
 OLAP i hurtownie danych c.d. Przypomnienie OLAP -narzędzia analizy danych Hurtownie danych -duże bazy danych zorientowane tematycznie, nieulotne, zmienne w czasie, wspierjące procesy podejmowania decyzji
OLAP i hurtownie danych c.d. Przypomnienie OLAP -narzędzia analizy danych Hurtownie danych -duże bazy danych zorientowane tematycznie, nieulotne, zmienne w czasie, wspierjące procesy podejmowania decyzji
Plan wykładu. Klucz wyszukiwania. Pojęcie indeksu BAZY DANYCH. Pojęcie indeksu - rodzaje indeksów Metody implementacji indeksów.
 Plan wykładu 2 BAZY DANYCH Wykład 4: Indeksy. Pojęcie indeksu - rodzaje indeksów Metody implementacji indeksów struktury statyczne struktury dynamiczne Małgorzata Krętowska Wydział Informatyki PB Pojęcie
Plan wykładu 2 BAZY DANYCH Wykład 4: Indeksy. Pojęcie indeksu - rodzaje indeksów Metody implementacji indeksów struktury statyczne struktury dynamiczne Małgorzata Krętowska Wydział Informatyki PB Pojęcie
Rozszerzenia grupowania
 Rozszerzenia grupowania 226 Plan rozdziału 227 Wprowadzenie ROLLUP CUBE GROUPING SETS GROUPING Rozszerzenia grupowania danych 228 W złożonych magazynach danych oprócz tabel faktów i wymiarów istnieje dodatkowo
Rozszerzenia grupowania 226 Plan rozdziału 227 Wprowadzenie ROLLUP CUBE GROUPING SETS GROUPING Rozszerzenia grupowania danych 228 W złożonych magazynach danych oprócz tabel faktów i wymiarów istnieje dodatkowo
Optymalizacja poleceń SQL Wprowadzenie
 Optymalizacja poleceń SQL Wprowadzenie 1 Fazy przetwarzania polecenia SQL 2 Faza parsingu (1) Krok 1. Test składniowy weryfikacja poprawności składniowej polecenia SQL. Krok 2. Test semantyczny m.in. weryfikacja
Optymalizacja poleceń SQL Wprowadzenie 1 Fazy przetwarzania polecenia SQL 2 Faza parsingu (1) Krok 1. Test składniowy weryfikacja poprawności składniowej polecenia SQL. Krok 2. Test semantyczny m.in. weryfikacja
Oracle10g Database: struktury fizyczne dla hurtowni danych
 Oracle1g Database: struktury fizyczne dla hurtowni danych 86 Plan rozdziału 87 Obiekty DIMENSION Materializowane perspektywy Przepisywanie zapytań Partycjonowanie tabel i indeksów Indeksy bitmapowe Obiekty
Oracle1g Database: struktury fizyczne dla hurtowni danych 86 Plan rozdziału 87 Obiekty DIMENSION Materializowane perspektywy Przepisywanie zapytań Partycjonowanie tabel i indeksów Indeksy bitmapowe Obiekty
Partycjonowanie tabel (1)
") Partycjonowanie tabel (1) Podział tabeli na mniejsze fragmenty operacje dostępu do dysków mogą być wykonywane równolegle; jest równoważone obciążenie dysków; polecenia SQL adresujące różne partycje mogą
Partycjonowanie tabel (1) Podział tabeli na mniejsze fragmenty operacje dostępu do dysków mogą być wykonywane równolegle; jest równoważone obciążenie dysków; polecenia SQL adresujące różne partycje mogą
77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego.
 77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego. Przy modelowaniu bazy danych możemy wyróżnić następujące typy połączeń relacyjnych: jeden do wielu, jeden do jednego, wiele
77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego. Przy modelowaniu bazy danych możemy wyróżnić następujące typy połączeń relacyjnych: jeden do wielu, jeden do jednego, wiele
Perspektywy Stosowanie perspektyw, tworzenie perspektyw prostych i złożonych, perspektywy modyfikowalne i niemodyfikowalne, perspektywy wbudowane.
 Perspektywy Stosowanie perspektyw, tworzenie perspektyw prostych i złożonych, perspektywy modyfikowalne i niemodyfikowalne, perspektywy wbudowane. 1 Perspektywa Perspektywa (ang. view) jest strukturą logiczną
Perspektywy Stosowanie perspektyw, tworzenie perspektyw prostych i złożonych, perspektywy modyfikowalne i niemodyfikowalne, perspektywy wbudowane. 1 Perspektywa Perspektywa (ang. view) jest strukturą logiczną
Fazy przetwarzania polecenia SQL. Faza parsingu (2) Faza parsingu (1) Optymalizacja poleceń SQL Część 1.
 Faza parsingu (1) Optymalizacja poleceń SQL Część 1.") Fazy przetwarzania polecenia SQL Optymalizacja poleceń SQL Część 1. Fazy przetwarzania polecenia SQL, pojęcie i cel optymalizacji, schemat optymalizacji, plan wykonania polecenia SQL, polecenie EXPLAIN
Fazy przetwarzania polecenia SQL Optymalizacja poleceń SQL Część 1. Fazy przetwarzania polecenia SQL, pojęcie i cel optymalizacji, schemat optymalizacji, plan wykonania polecenia SQL, polecenie EXPLAIN
PODSTAWY BAZ DANYCH Wykład 6 4. Metody Implementacji Baz Danych
 PODSTAWY BAZ DANYCH Wykład 6 4. Metody Implementacji Baz Danych 2005/2006 Wykład "Podstawy baz danych" 1 Statyczny model pamiętania bazy danych 1. Dane przechowywane są w pamięci zewnętrznej podzielonej
PODSTAWY BAZ DANYCH Wykład 6 4. Metody Implementacji Baz Danych 2005/2006 Wykład "Podstawy baz danych" 1 Statyczny model pamiętania bazy danych 1. Dane przechowywane są w pamięci zewnętrznej podzielonej
Plan wykładu. Hurtownie danych. Problematyka integracji danych. Cechy systemów informatycznych
 1 Plan wykładu 2 Hurtownie danych Integracja danych za pomocą hurtowni danych Przetwarzanie analityczne OLAP Model wielowymiarowy Implementacje modelu wielowymiarowego ROLAP MOLAP Odświeżanie hurtowni
1 Plan wykładu 2 Hurtownie danych Integracja danych za pomocą hurtowni danych Przetwarzanie analityczne OLAP Model wielowymiarowy Implementacje modelu wielowymiarowego ROLAP MOLAP Odświeżanie hurtowni
Hurtownie danych - przegląd technologii
 Partycjonowanie tabel (1) Hurtownie danych - przegląd technologii Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Podział tabeli na mniejsze fragmenty
Partycjonowanie tabel (1) Hurtownie danych - przegląd technologii Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Podział tabeli na mniejsze fragmenty
Indeksy w hurtowniach danych
 Indeksy w hurtowniach danych Hurtownie danych 2011 Łukasz Idkowiak Tomasz Kamiński Bibliografia Zbyszko Królikowski, Hurtownie danych. Logiczne i fizyczne struktury danych, Wydawnictwo Politechniki Poznańskiej,
Indeksy w hurtowniach danych Hurtownie danych 2011 Łukasz Idkowiak Tomasz Kamiński Bibliografia Zbyszko Królikowski, Hurtownie danych. Logiczne i fizyczne struktury danych, Wydawnictwo Politechniki Poznańskiej,
wykład Organizacja plików Opracował: dr inż. Janusz DUDCZYK
 wykład Organizacja plików Opracował: dr inż. Janusz DUDCZYK 1 2 3 Pamięć zewnętrzna Pamięć zewnętrzna organizacja plikowa. Pamięć operacyjna organizacja blokowa. 4 Bufory bazy danych. STRUKTURA PROSTA
wykład Organizacja plików Opracował: dr inż. Janusz DUDCZYK 1 2 3 Pamięć zewnętrzna Pamięć zewnętrzna organizacja plikowa. Pamięć operacyjna organizacja blokowa. 4 Bufory bazy danych. STRUKTURA PROSTA
Optymalizacja poleceń SQL Indeksy
 Optymalizacja poleceń SQL Indeksy Indeksy Dodatkowe struktury służące przyspieszaniu dostępu do danych. Tworzone dla relacji, są jednak niezależne logicznie i fizycznie od danych relacji. O użyciu indeksu
Optymalizacja poleceń SQL Indeksy Indeksy Dodatkowe struktury służące przyspieszaniu dostępu do danych. Tworzone dla relacji, są jednak niezależne logicznie i fizycznie od danych relacji. O użyciu indeksu
Bazy danych - BD. Indeksy. Wykład przygotował: Robert Wrembel. BD wykład 7 (1)
") Indeksy Wykład przygotował: Robert Wrembel BD wykład 7 (1) 1 Plan wykładu Problematyka indeksowania Podział indeksów i ich charakterystyka indeks podstawowy, zgrupowany, wtórny indeks rzadki, gęsty Indeks
Indeksy Wykład przygotował: Robert Wrembel BD wykład 7 (1) 1 Plan wykładu Problematyka indeksowania Podział indeksów i ich charakterystyka indeks podstawowy, zgrupowany, wtórny indeks rzadki, gęsty Indeks
Hurtownie danych. Przetwarzanie zapytań. http://zajecia.jakubw.pl/hur ZAPYTANIA NA ZAPLECZU
 Hurtownie danych Przetwarzanie zapytań. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/hur ZAPYTANIA NA ZAPLECZU Magazyny danych operacyjnych, źródła Centralna hurtownia danych Hurtownie
Hurtownie danych Przetwarzanie zapytań. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/hur ZAPYTANIA NA ZAPLECZU Magazyny danych operacyjnych, źródła Centralna hurtownia danych Hurtownie
Jakub Pilecki Szymon Wojciechowski
 Indeksy w hurtowniach danych Jakub Pilecki Szymon Wojciechowski Plan prezentacji 1. Czym są indeksy? 2. Cel stosowania indeksó w 3. Co należy indeksować? 4. Rodzaje indeksó w 5. B-drzewa (drzewa zró wnoważone)
Indeksy w hurtowniach danych Jakub Pilecki Szymon Wojciechowski Plan prezentacji 1. Czym są indeksy? 2. Cel stosowania indeksó w 3. Co należy indeksować? 4. Rodzaje indeksó w 5. B-drzewa (drzewa zró wnoważone)
Hurtownie danych. Ładowanie, integracja i aktualizacja danych. http://zajecia.jakubw.pl/hur INTEGRACJA DANYCH ETL
 Hurtownie danych Ładowanie, integracja i aktualizacja danych. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/hur INTEGRACJA DANYCH Źródła danych ETL Centralna hurtownia danych Do hurtowni
Hurtownie danych Ładowanie, integracja i aktualizacja danych. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/hur INTEGRACJA DANYCH Źródła danych ETL Centralna hurtownia danych Do hurtowni
INDEKSY. Biologiczne Aplikacje Baz Danych. dr inż. Anna Leśniewska
 INDEKSY Biologiczne Aplikacje Baz Danych dr inż. Anna Leśniewska alesniewska@cs.put.poznan.pl INDEKSY dodatkowe struktury służące przyspieszaniu dostępu do danych, tworzone dla relacji, są jednak niezależne
INDEKSY Biologiczne Aplikacje Baz Danych dr inż. Anna Leśniewska alesniewska@cs.put.poznan.pl INDEKSY dodatkowe struktury służące przyspieszaniu dostępu do danych, tworzone dla relacji, są jednak niezależne
Systemy OLAP I. Krzysztof Dembczyński. Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska
 Systemy OLAP I Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Technologie Wytwarzania Oprogramowania Semestr zimowy 2008/09 Studia
Systemy OLAP I Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Technologie Wytwarzania Oprogramowania Semestr zimowy 2008/09 Studia
Optymalizacja. Plan wykonania polecenia SQL (1) Plan wykonania polecenia SQL (2) Rozdział 19 Wprowadzenie do optymalizacji poleceń SQL
 Plan wykonania polecenia SQL (2) Rozdział 19 Wprowadzenie do optymalizacji poleceń SQL") Optymalizacja Rozdział 19 Wprowadzenie do optymalizacji poleceń SQL Pojęcie i cel optymalizacji, schemat optymalizacji, plan wykonania polecenia SQL, polecenie EXPLAIN PLAN, dyrektywa AUTOTRACE, wybór
Optymalizacja Rozdział 19 Wprowadzenie do optymalizacji poleceń SQL Pojęcie i cel optymalizacji, schemat optymalizacji, plan wykonania polecenia SQL, polecenie EXPLAIN PLAN, dyrektywa AUTOTRACE, wybór
Rozproszone bazy danych 3
 Rozproszone bazy danych 3 Optymalizacja zapytań rozproszonych Laboratorium przygotował: Robert Wrembel ZSBD laboratorium 3 (1) 1 Plan laboratorium Zapytanie rozproszone i jego plan wykonania Narzędzia
Rozproszone bazy danych 3 Optymalizacja zapytań rozproszonych Laboratorium przygotował: Robert Wrembel ZSBD laboratorium 3 (1) 1 Plan laboratorium Zapytanie rozproszone i jego plan wykonania Narzędzia
Modele danych - wykład V
 Modele danych - wykład V Paweł Skrobanek, C-3 pok. 323 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2006 Zagadnienia 1. Wprowadzenie 2. MOLAP modele danych 3. ROLAP modele danych 4. Podsumowanie 5. Zadanie
Modele danych - wykład V Paweł Skrobanek, C-3 pok. 323 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2006 Zagadnienia 1. Wprowadzenie 2. MOLAP modele danych 3. ROLAP modele danych 4. Podsumowanie 5. Zadanie
Rozproszone bazy danych 1
 Rozproszone bazy danych 1 Replikacja danych Laboratorium przygotował: Robert Wrembel ZSBD laboratorium 1 (1) 1 Plan laboratorium Dostęp do zdalnej bazy danych - łącznik bazy danych Replikowanie danych
Rozproszone bazy danych 1 Replikacja danych Laboratorium przygotował: Robert Wrembel ZSBD laboratorium 1 (1) 1 Plan laboratorium Dostęp do zdalnej bazy danych - łącznik bazy danych Replikowanie danych
Systemy OLAP I. Krzysztof Dembczyński. Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska
 Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Technologie Wytwarzania Oprogramowania Semestr zimowy 2007/08 Studia uzupełniajace magisterskie
Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Technologie Wytwarzania Oprogramowania Semestr zimowy 2007/08 Studia uzupełniajace magisterskie
System Oracle podstawowe czynności administracyjne
 6 System Oracle podstawowe czynności administracyjne Stany bazy danych IDLE nieczynna, pliki zamknięte, procesy tła niedziałaja NOMOUNT stan po odczytaniu pfile-a, zainicjowaniu SGA i uruchomieniu procesów
6 System Oracle podstawowe czynności administracyjne Stany bazy danych IDLE nieczynna, pliki zamknięte, procesy tła niedziałaja NOMOUNT stan po odczytaniu pfile-a, zainicjowaniu SGA i uruchomieniu procesów
UPDATE Studenci SET Rok = Rok + 1 WHERE Rodzaj_studiow =' INŻ_ST'; UPDATE Studenci SET Rok = Rok 1 WHERE Nr_albumu IN ( '111345','100678');
;") polecenie UPDATE służy do aktualizacji zawartości wierszy tabel lub perspektyw składnia: UPDATE { } SET { { = DEFAULT NULL}, {
polecenie UPDATE służy do aktualizacji zawartości wierszy tabel lub perspektyw składnia: UPDATE { } SET { { = DEFAULT NULL}, {
Modele danych - wykład V. Zagadnienia. 1. Wprowadzenie 2. MOLAP modele danych 3. ROLAP modele danych 4. Podsumowanie 5. Zadanie fajne WPROWADZENIE
 Modele danych - wykład V Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2006 Zagadnienia 1. Wprowadzenie 2. MOLAP modele danych 3. modele danych 4. Podsumowanie 5. Zadanie fajne
Modele danych - wykład V Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2006 Zagadnienia 1. Wprowadzenie 2. MOLAP modele danych 3. modele danych 4. Podsumowanie 5. Zadanie fajne
Bazy danych. Plan wykładu. Rozproszona baza danych. Fragmetaryzacja. Cechy bazy rozproszonej. Replikacje (zalety) Wykład 15: Rozproszone bazy danych
 Wykład 15: Rozproszone bazy danych") Plan wykładu Bazy danych Cechy rozproszonej bazy danych Implementacja rozproszonej bazy Wykład 15: Rozproszone bazy danych Małgorzata Krętowska, Agnieszka Oniśko Wydział Informatyki PB Bazy danych (studia
Plan wykładu Bazy danych Cechy rozproszonej bazy danych Implementacja rozproszonej bazy Wykład 15: Rozproszone bazy danych Małgorzata Krętowska, Agnieszka Oniśko Wydział Informatyki PB Bazy danych (studia
BD2 BazyDanych2. dr inż. Tomasz Traczyk 14. Systemy przetwarzania analitycznego
 BD2 BazyDanych2 dr inż. Tomasz Traczyk 14. Systemy przetwarzania analitycznego ³ Copyright c Tomasz Traczyk Instytut Automatyki i Informatyki Stosowanej Politechniki Warszawskiej Materiały dydaktyczne
BD2 BazyDanych2 dr inż. Tomasz Traczyk 14. Systemy przetwarzania analitycznego ³ Copyright c Tomasz Traczyk Instytut Automatyki i Informatyki Stosowanej Politechniki Warszawskiej Materiały dydaktyczne
Technologia HD w IBM DB2
 Technologia HD w IBM DB2 wykład przygotowany na podstawie materiałów w IBM Polska Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel
Technologia HD w IBM DB2 wykład przygotowany na podstawie materiałów w IBM Polska Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel
Przykładowe B+ drzewo
 Przykładowe B+ drzewo 3 8 1 3 7 8 12 Jak obliczyć rząd indeksu p Dane: rozmiar klucza V, rozmiar wskaźnika do bloku P, rozmiar bloku B, liczba rekordów w indeksowanym pliku danych r i liczba bloków pliku
Przykładowe B+ drzewo 3 8 1 3 7 8 12 Jak obliczyć rząd indeksu p Dane: rozmiar klucza V, rozmiar wskaźnika do bloku P, rozmiar bloku B, liczba rekordów w indeksowanym pliku danych r i liczba bloków pliku
Fizyczna organizacja danych w bazie danych
 Fizyczna organizacja danych w bazie danych PJWSTK, SZB, Lech Banachowski Spis treści 1. Model fizyczny bazy danych 2. Zarządzanie miejscem na dysku 3. Zarządzanie buforami (w RAM) 4. Organizacja zapisu
Fizyczna organizacja danych w bazie danych PJWSTK, SZB, Lech Banachowski Spis treści 1. Model fizyczny bazy danych 2. Zarządzanie miejscem na dysku 3. Zarządzanie buforami (w RAM) 4. Organizacja zapisu
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki
 Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Materializowanie wyników zapytania Cel optymalizacja
Hurtownie danych - przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Materializowanie wyników zapytania Cel optymalizacja
Optymalizacja poleceń SQL Statystyki
 Optymalizacja poleceń SQL Statystyki 1 Statystyki (1) Informacje, opisujące dane i struktury obiektów bazy danych. Przechowywane w słowniku danych. Używane przez optymalizator do oszacowania: selektywności
Optymalizacja poleceń SQL Statystyki 1 Statystyki (1) Informacje, opisujące dane i struktury obiektów bazy danych. Przechowywane w słowniku danych. Używane przez optymalizator do oszacowania: selektywności
Materializowanie wyników zapytania
 Materializowanie wyników zapytania Cel optymalizacja zapytań analitycznych Mechanizmy Perspektywy zmaterializowane (materialized views) Przepisywanie zapytań (query rewrite) Oprogramowanie Summary Advisor
Materializowanie wyników zapytania Cel optymalizacja zapytań analitycznych Mechanizmy Perspektywy zmaterializowane (materialized views) Przepisywanie zapytań (query rewrite) Oprogramowanie Summary Advisor
DB2 with BLU acceleration rozwiązanie in-memory szybsze niż pamięć operacyjna&
 DB2 with BLU acceleration rozwiązanie in-memory szybsze niż pamięć operacyjna& Artur Wroński" Priorytety rozwoju technologii Big Data& Analiza większych zbiorów danych, szybciej& Łatwość użycia& Wsparcie
DB2 with BLU acceleration rozwiązanie in-memory szybsze niż pamięć operacyjna& Artur Wroński" Priorytety rozwoju technologii Big Data& Analiza większych zbiorów danych, szybciej& Łatwość użycia& Wsparcie
Statystyki (1) Optymalizacja poleceń SQL Część 2. Statystyki (2) Statystyki (3) Informacje, opisujące dane i struktury obiektów bazy danych.
 Optymalizacja poleceń SQL Część 2. Statystyki (2) Statystyki (3) Informacje, opisujące dane i struktury obiektów bazy danych.") Statystyki (1) Informacje, opisujące dane i struktury obiektów bazy danych. Optymalizacja poleceń SQL Część 2. Statystyki i histogramy, metody dostępu do danych Przechowywane w słowniku danych. Używane
Statystyki (1) Informacje, opisujące dane i struktury obiektów bazy danych. Optymalizacja poleceń SQL Część 2. Statystyki i histogramy, metody dostępu do danych Przechowywane w słowniku danych. Używane
Optymalizacja poleceń SQL
 Optymalizacja poleceń SQL Optymalizacja kosztowa i regułowa, dyrektywa AUTOTRACE w SQL*Plus, statystyki i histogramy, metody dostępu i sortowania, indeksy typu B* drzewo, indeksy bitmapowe i funkcyjne,
Optymalizacja poleceń SQL Optymalizacja kosztowa i regułowa, dyrektywa AUTOTRACE w SQL*Plus, statystyki i histogramy, metody dostępu i sortowania, indeksy typu B* drzewo, indeksy bitmapowe i funkcyjne,
Indeksy w bazach danych. Motywacje. Techniki indeksowania w eksploracji danych. Plan prezentacji. Dotychczasowe prace badawcze skupiały się na
 Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Hurtownie danych 2. Wykład przygotował: Robert Wrembel. Zagadnienia implementacyjne i efektywność przetwarzania OLAP
 Hurtownie danych 2 Zagadnienia implementacyjne i efektywność przetwarzania OLAP Wykład przygotował: Robert Wrembel ZSBD wykład 13 (1) 1 Plan wykładu Odświeżanie hurtowni danych Perspektywy zmaterializowane
Hurtownie danych 2 Zagadnienia implementacyjne i efektywność przetwarzania OLAP Wykład przygotował: Robert Wrembel ZSBD wykład 13 (1) 1 Plan wykładu Odświeżanie hurtowni danych Perspektywy zmaterializowane
Spis tre±ci. Przedmowa... Cz ± I
 Przedmowa.................................................... i Cz ± I 1 Czym s hurtownie danych?............................... 3 1.1 Wst p.................................................. 3 1.2 Denicja
Przedmowa.................................................... i Cz ± I 1 Czym s hurtownie danych?............................... 3 1.1 Wst p.................................................. 3 1.2 Denicja
Język SQL. Rozdział 10. Perspektywy Stosowanie perspektyw, tworzenie perspektyw prostych i złożonych, perspektywy modyfikowalne i niemodyfikowalne.
 Język SQL. Rozdział 10. Perspektywy Stosowanie perspektyw, tworzenie perspektyw prostych i złożonych, perspektywy modyfikowalne i niemodyfikowalne. 1 Perspektywa Perspektywa (ang. view) jest strukturą
Język SQL. Rozdział 10. Perspektywy Stosowanie perspektyw, tworzenie perspektyw prostych i złożonych, perspektywy modyfikowalne i niemodyfikowalne. 1 Perspektywa Perspektywa (ang. view) jest strukturą
Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
 : idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
: idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
Spis treści. Przedmowa
 Spis treści Przedmowa V 1 SQL - podstawowe konstrukcje 1 Streszczenie 1 1.1 Bazy danych 1 1.2 Relacyjny model danych 2 1.3 Historia języka SQL 5 1.4 Definiowanie danych 7 1.5 Wprowadzanie zmian w tabelach
Spis treści Przedmowa V 1 SQL - podstawowe konstrukcje 1 Streszczenie 1 1.1 Bazy danych 1 1.2 Relacyjny model danych 2 1.3 Historia języka SQL 5 1.4 Definiowanie danych 7 1.5 Wprowadzanie zmian w tabelach
ang. file) Pojęcie pliku (ang( Typy plików Atrybuty pliku Fragmentacja wewnętrzna w systemie plików Struktura pliku
 Pojęcie pliku (ang( Typy plików Atrybuty pliku Fragmentacja wewnętrzna w systemie plików Struktura pliku") System plików 1. Pojęcie pliku 2. Typy i struktury plików 3. etody dostępu do plików 4. Katalogi 5. Budowa systemu plików Pojęcie pliku (ang( ang. file)! Plik jest abstrakcyjnym obrazem informacji gromadzonej
System plików 1. Pojęcie pliku 2. Typy i struktury plików 3. etody dostępu do plików 4. Katalogi 5. Budowa systemu plików Pojęcie pliku (ang( ang. file)! Plik jest abstrakcyjnym obrazem informacji gromadzonej
Wykład XII. optymalizacja w relacyjnych bazach danych
 Optymalizacja wyznaczenie spośród dopuszczalnych rozwiązań danego problemu, rozwiązania najlepszego ze względu na przyjęte kryterium jakości ( np. koszt, zysk, niezawodność ) optymalizacja w relacyjnych
Optymalizacja wyznaczenie spośród dopuszczalnych rozwiązań danego problemu, rozwiązania najlepszego ze względu na przyjęte kryterium jakości ( np. koszt, zysk, niezawodność ) optymalizacja w relacyjnych
Informatyka sem. III studia inżynierskie Transport 2018/19 LAB 2. Lab Backup bazy danych. Tworzenie kopii (backup) bazy danych
 bazy danych") Informatyka sem. III studia inżynierskie Transport 2018/19 Lab 2 LAB 2 1. Backup bazy danych Tworzenie kopii (backup) bazy danych Odtwarzanie bazy z kopii (z backup u) 1. Pobieramy skrypt Restore 2. Pobieramy
Informatyka sem. III studia inżynierskie Transport 2018/19 Lab 2 LAB 2 1. Backup bazy danych Tworzenie kopii (backup) bazy danych Odtwarzanie bazy z kopii (z backup u) 1. Pobieramy skrypt Restore 2. Pobieramy
Bazy danych. Andrzej Łachwa, UJ, /15
 Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 15/15 PYTANIA NA EGZAMIN LICENCJACKI 84. B drzewa definicja, algorytm wyszukiwania w B drzewie. Zob. Elmasri:
Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 15/15 PYTANIA NA EGZAMIN LICENCJACKI 84. B drzewa definicja, algorytm wyszukiwania w B drzewie. Zob. Elmasri:
Perspektywy zmaterializowane
 Perspektywy zmaterializowane Robert Wrembel Politechnika Poznaoska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Materializowanie wyników zapytania Cel optymalizacja
Perspektywy zmaterializowane Robert Wrembel Politechnika Poznaoska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Materializowanie wyników zapytania Cel optymalizacja
Tabela wewnętrzna - definicja
 ABAP/4 Tabela wewnętrzna - definicja Temporalna tabela przechowywana w pamięci operacyjnej serwera aplikacji Tworzona, wypełniana i modyfikowana jest przez program podczas jego wykonywania i usuwana, gdy
ABAP/4 Tabela wewnętrzna - definicja Temporalna tabela przechowywana w pamięci operacyjnej serwera aplikacji Tworzona, wypełniana i modyfikowana jest przez program podczas jego wykonywania i usuwana, gdy
Optymalizacja zapytań. Proces przetwarzania i obliczania wyniku zapytania (wyrażenia algebry relacji) w SZBD
 w SZBD") Optymalizacja zapytań Proces przetwarzania i obliczania wyniku zapytania (wyrażenia algebry relacji) w SZBD Elementy optymalizacji Analiza zapytania i przekształcenie go do lepszej postaci. Oszacowanie
Optymalizacja zapytań Proces przetwarzania i obliczania wyniku zapytania (wyrażenia algebry relacji) w SZBD Elementy optymalizacji Analiza zapytania i przekształcenie go do lepszej postaci. Oszacowanie
Rozwiązania wspomagające przetwarzanie wielkich zbiorów danych (VLDB) we współczesnych systemach zarządzania bazami danych
 we współczesnych systemach zarządzania bazami danych") Rozwiązania wspomagające przetwarzanie wielkich zbiorów danych (VLDB) we współczesnych systemach zarządzania bazami danych Tomasz Traczyk ttraczyk@ia.pw.edu.pl Wydział Elektroniki i Technik Informacyjnych
Rozwiązania wspomagające przetwarzanie wielkich zbiorów danych (VLDB) we współczesnych systemach zarządzania bazami danych Tomasz Traczyk ttraczyk@ia.pw.edu.pl Wydział Elektroniki i Technik Informacyjnych
Język SQL. Rozdział 7. Zaawansowane mechanizmy w zapytaniach
 Język SQL. Rozdział 7. Zaawansowane mechanizmy w zapytaniach Ograniczanie rozmiaru zbioru wynikowego, klauzula WITH, zapytania hierarchiczne. 1 Ograniczanie liczności zbioru wynikowego (1) Element standardu
Język SQL. Rozdział 7. Zaawansowane mechanizmy w zapytaniach Ograniczanie rozmiaru zbioru wynikowego, klauzula WITH, zapytania hierarchiczne. 1 Ograniczanie liczności zbioru wynikowego (1) Element standardu
060 SQL FIZYCZNA STRUKTURA BAZY DANYCH. Prof. dr hab. Marek Wisła
 060 SQL FIZYCZNA STRUKTURA BAZY DANYCH Prof. dr hab. Marek Wisła Struktura tabeli Data dane LOB - Large Objects (bitmapy, teksty) Row-Overflow zawiera dane typu varchar, varbinary http://msdn.microsoft.com/en-us/library/ms189051(v=sql.105).aspx
060 SQL FIZYCZNA STRUKTURA BAZY DANYCH Prof. dr hab. Marek Wisła Struktura tabeli Data dane LOB - Large Objects (bitmapy, teksty) Row-Overflow zawiera dane typu varchar, varbinary http://msdn.microsoft.com/en-us/library/ms189051(v=sql.105).aspx
PROJEKT WSPÓŁFINANSOWANY ZE ŚRODKÓW UNII EUROPEJSKIEJ W RAMACH EUROPEJSKIEGO FUNDUSZU SPOŁECZNEGO OPIS PRZEDMIOTU. Rozproszone Systemy Baz Danych
 OPIS PRZEDMIOTU Nazwa przedmiotu Rozproszone Systemy Baz Danych Kod przedmiotu Wydział Instytut/Katedra Kierunek Specjalizacja/specjalność Wydział Matematyki, Fizyki i Techniki Instytut Mechaniki i Informatyki
OPIS PRZEDMIOTU Nazwa przedmiotu Rozproszone Systemy Baz Danych Kod przedmiotu Wydział Instytut/Katedra Kierunek Specjalizacja/specjalność Wydział Matematyki, Fizyki i Techniki Instytut Mechaniki i Informatyki
Wprowadzenie do technologii Business Intelligence i hurtowni danych
 Wprowadzenie do technologii Business Intelligence i hurtowni danych 1 Plan rozdziału 2 Wprowadzenie do Business Intelligence Hurtownie danych Produkty Oracle dla Business Intelligence Business Intelligence
Wprowadzenie do technologii Business Intelligence i hurtowni danych 1 Plan rozdziału 2 Wprowadzenie do Business Intelligence Hurtownie danych Produkty Oracle dla Business Intelligence Business Intelligence
Bazy danych. Plan wykładu. Przetwarzanie zapytań. Etapy przetwarzania zapytania. Translacja zapytań języka SQL do postaci wyrażeń algebry relacji
 Plan wykładu Bazy danych Wykład 12: Optymalizacja zapytań. Język DDL, DML (cd) Etapy przetwarzania zapytania Implementacja wyrażeń algebry relacji Reguły heurystyczne optymalizacji zapytań Kosztowa optymalizacja
Plan wykładu Bazy danych Wykład 12: Optymalizacja zapytań. Język DDL, DML (cd) Etapy przetwarzania zapytania Implementacja wyrażeń algebry relacji Reguły heurystyczne optymalizacji zapytań Kosztowa optymalizacja
sprowadza się od razu kilka stron!
 Bazy danych Strona 1 Struktura fizyczna 29 stycznia 2010 10:29 Model fizyczny bazy danych jest oparty na pojęciu pliku i rekordu. Plikskłada się z rekordów w tym samym formacie. Format rekordujest listą
Bazy danych Strona 1 Struktura fizyczna 29 stycznia 2010 10:29 Model fizyczny bazy danych jest oparty na pojęciu pliku i rekordu. Plikskłada się z rekordów w tym samym formacie. Format rekordujest listą
Systemy GIS Tworzenie zapytań w bazach danych
 Systemy GIS Tworzenie zapytań w bazach danych Wykład nr 6 Analizy danych w systemach GIS Jak pytać bazę danych, żeby otrzymać sensowną odpowiedź......czyli podstawy języka SQL INSERT, SELECT, DROP, UPDATE
Systemy GIS Tworzenie zapytań w bazach danych Wykład nr 6 Analizy danych w systemach GIS Jak pytać bazę danych, żeby otrzymać sensowną odpowiedź......czyli podstawy języka SQL INSERT, SELECT, DROP, UPDATE
Administracja bazy danych Oracle 10g
 Administracja bazy danych Oracle 10g Oracle Database Administration część 5 Zmiana przestrzeni tabel użytkownika Za pomocą SQL*Plus alter user USER_NAME temporary tablespace TEMPOR_NAME; gdzie: USER_NAME
Administracja bazy danych Oracle 10g Oracle Database Administration część 5 Zmiana przestrzeni tabel użytkownika Za pomocą SQL*Plus alter user USER_NAME temporary tablespace TEMPOR_NAME; gdzie: USER_NAME
Oracle11g: Wprowadzenie do SQL
 Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Wprowadzenie do Hurtowni Danych
 Wprowadzenie do Hurtowni Danych Organizacyjnie Prowadzący: mgr. Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło HD2) Literatura 1. Inmon, W., Linstedt, D. (2014). Data Architecture: A
Wprowadzenie do Hurtowni Danych Organizacyjnie Prowadzący: mgr. Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło HD2) Literatura 1. Inmon, W., Linstedt, D. (2014). Data Architecture: A
Hurtownie danych. Hurtownie danych. dr hab. Maciej Zakrzewicz Politechnika Poznańska Instytut Informatyki. Maciej Zakrzewicz (1)
") Hurtownie danych dr hab. Maciej Zakrzewicz Politechnika Poznańska Instytut Informatyki Maciej Zakrzewicz (1) Plan wykładu Wprowadzenie do Business Intelligence (BI) Hurtownia danych Zasilanie hurtowni
Hurtownie danych dr hab. Maciej Zakrzewicz Politechnika Poznańska Instytut Informatyki Maciej Zakrzewicz (1) Plan wykładu Wprowadzenie do Business Intelligence (BI) Hurtownia danych Zasilanie hurtowni
Wstęp do Business Intelligence
 Wstęp do Business Intelligence Co to jest Buisness Intelligence Business Intelligence (analityka biznesowa) - proces przekształcania danych w informacje, a informacji w wiedzę, która może być wykorzystana
Wstęp do Business Intelligence Co to jest Buisness Intelligence Business Intelligence (analityka biznesowa) - proces przekształcania danych w informacje, a informacji w wiedzę, która może być wykorzystana
Indeksy. Rozdział 18. Indeksy. Struktura indeksu. Adres rekordu
 Indeksy Rozdział 8 Indeksy Indeksy B-drzewo i bitmapowe, zwykłe i złoŝone, unikalne i nieunikalne, odwrócone, funkcyjne, skompresowane, bitmapowe połączeniowe. Zarządzanie indeksami. dodatkowe struktury
Indeksy Rozdział 8 Indeksy Indeksy B-drzewo i bitmapowe, zwykłe i złoŝone, unikalne i nieunikalne, odwrócone, funkcyjne, skompresowane, bitmapowe połączeniowe. Zarządzanie indeksami. dodatkowe struktury
STROJENIE BAZ DANYCH: INDEKSY. Cezary Ołtuszyk coltuszyk.wordpress.com
 STROJENIE BAZ DANYCH: INDEKSY Cezary Ołtuszyk coltuszyk.wordpress.com Plan spotkania I. Wprowadzenie do strojenia baz danych II. III. IV. Mierzenie wydajności Jak SQL Server przechowuje i czyta dane? Budowa
STROJENIE BAZ DANYCH: INDEKSY Cezary Ołtuszyk coltuszyk.wordpress.com Plan spotkania I. Wprowadzenie do strojenia baz danych II. III. IV. Mierzenie wydajności Jak SQL Server przechowuje i czyta dane? Budowa
Bazy danych. Plan wykładu. Diagramy ER. Podstawy modeli relacyjnych. Podstawy modeli relacyjnych. Podstawy modeli relacyjnych
 Plan wykładu Bazy danych Wykład 9: Przechodzenie od diagramów E/R do modelu relacyjnego. Definiowanie perspektyw. Diagramy E/R - powtórzenie Relacyjne bazy danych Od diagramów E/R do relacji SQL - perspektywy
Plan wykładu Bazy danych Wykład 9: Przechodzenie od diagramów E/R do modelu relacyjnego. Definiowanie perspektyw. Diagramy E/R - powtórzenie Relacyjne bazy danych Od diagramów E/R do relacji SQL - perspektywy
5. Integracja stron aplikacji, tworzenie zintegrowanych formularzy i raportów
 5. Integracja stron aplikacji, tworzenie zintegrowanych formularzy i raportów 1. W chwili obecnej formularz Edycja prowadzących utworzony w poprzednim zestawie ćwiczeń służy tylko i wyłącznie do edycji
5. Integracja stron aplikacji, tworzenie zintegrowanych formularzy i raportów 1. W chwili obecnej formularz Edycja prowadzących utworzony w poprzednim zestawie ćwiczeń służy tylko i wyłącznie do edycji
Optymalizacja wydajności SZBD
 Optymalizacja wydajności SZBD 1. Optymalizacja wydajności systemu bazodanowego Wydajność SZBD określana jest najczęściej za pomocą następujących parametrów: liczby operacji przeprowadzanych na sekundę,
Optymalizacja wydajności SZBD 1. Optymalizacja wydajności systemu bazodanowego Wydajność SZBD określana jest najczęściej za pomocą następujących parametrów: liczby operacji przeprowadzanych na sekundę,
Informatyka (6) Widoki. Indeksy
 Widoki. Indeksy") Informatyka (6) Widoki. Indeksy dr inż. Katarzyna Palikowska Katedra Transportu Szynowego p. 4 Hydro katpalik@pg.gda.pl katarzyna.palikowska@wilis.pg.gda.pl Decimal(10,2) Szkoła posiada konto. Osoby dokonują
Informatyka (6) Widoki. Indeksy dr inż. Katarzyna Palikowska Katedra Transportu Szynowego p. 4 Hydro katpalik@pg.gda.pl katarzyna.palikowska@wilis.pg.gda.pl Decimal(10,2) Szkoła posiada konto. Osoby dokonują
Cwiczenie 4. Połączenia, struktury dodatkowe
 Cwiczenie 4. Połączenia, struktury dodatkowe Optymalizacja poleceń SQL 1 W niniejszym ćwiczeniu przyjrzymy się, w jaki sposób realizowane są operacje połączeń w poleceniach SQL. Poznamy również dodatkowe
Cwiczenie 4. Połączenia, struktury dodatkowe Optymalizacja poleceń SQL 1 W niniejszym ćwiczeniu przyjrzymy się, w jaki sposób realizowane są operacje połączeń w poleceniach SQL. Poznamy również dodatkowe
Kosztowy optymalizator zapytań
 Kosztowy optymalizator zapytań Marek Wojciechowski, Maciej Zakrzewicz Politechnika Poznańska, Instytut Informatyki marek.wojciechowski@cs.put.poznan.pl maciej.zakrzewicz@cs.put.poznan.pl Streszczenie Praktycznie
Kosztowy optymalizator zapytań Marek Wojciechowski, Maciej Zakrzewicz Politechnika Poznańska, Instytut Informatyki marek.wojciechowski@cs.put.poznan.pl maciej.zakrzewicz@cs.put.poznan.pl Streszczenie Praktycznie
Przykłady najlepiej wykonywać od razu na bazie i eksperymentować z nimi.
 Marek Robak Wprowadzenie do języka SQL na przykładzie baz SQLite Przykłady najlepiej wykonywać od razu na bazie i eksperymentować z nimi. Tworzenie tabeli Pierwsza tabela W relacyjnych bazach danych jedna
Marek Robak Wprowadzenie do języka SQL na przykładzie baz SQLite Przykłady najlepiej wykonywać od razu na bazie i eksperymentować z nimi. Tworzenie tabeli Pierwsza tabela W relacyjnych bazach danych jedna
1.5.3 Do czego słuŝą tymczasowe przestrzenie 1.5.4 Zarządzanie plikami danych
 Załącznik nr 2 do umowy nr 18/DI/PN/2013 Szczegółowy zakres szkoleń dotyczy części nr I zamówienia Lp. Nazwa 1 Administracja bazą danych w wersji 11g prze 6 dni 6 1.1 Struktura danych i typy obiektów 1.2
Załącznik nr 2 do umowy nr 18/DI/PN/2013 Szczegółowy zakres szkoleń dotyczy części nr I zamówienia Lp. Nazwa 1 Administracja bazą danych w wersji 11g prze 6 dni 6 1.1 Struktura danych i typy obiektów 1.2
Cel przedmiotu. Wymagania wstępne w zakresie wiedzy, umiejętności i innych kompetencji 1 Język angielski 2 Inżynieria oprogramowania
 Przedmiot: Bazy danych Rok: III Semestr: V Rodzaj zajęć i liczba godzin: Studia stacjonarne Studia niestacjonarne Wykład 30 21 Ćwiczenia Laboratorium 30 21 Projekt Liczba punktów ECTS: 4 C1 C2 C3 Cel przedmiotu
Przedmiot: Bazy danych Rok: III Semestr: V Rodzaj zajęć i liczba godzin: Studia stacjonarne Studia niestacjonarne Wykład 30 21 Ćwiczenia Laboratorium 30 21 Projekt Liczba punktów ECTS: 4 C1 C2 C3 Cel przedmiotu
Microsoft SQL Server Podstawy T-SQL
 Itzik Ben-Gan Microsoft SQL Server Podstawy T-SQL 2012 przełożył Leszek Biolik APN Promise, Warszawa 2012 Spis treści Przedmowa.... xiii Wprowadzenie... xv Podziękowania... xix 1 Podstawy zapytań i programowania
Itzik Ben-Gan Microsoft SQL Server Podstawy T-SQL 2012 przełożył Leszek Biolik APN Promise, Warszawa 2012 Spis treści Przedmowa.... xiii Wprowadzenie... xv Podziękowania... xix 1 Podstawy zapytań i programowania
Wyzwalacz - procedura wyzwalana, składowana fizycznie w bazie, uruchamiana automatycznie po nastąpieniu określonego w definicji zdarzenia
 Wyzwalacz - procedura wyzwalana, składowana fizycznie w bazie, uruchamiana automatycznie po nastąpieniu określonego w definicji zdarzenia Składowe wyzwalacza ( ECA ): określenie zdarzenia ( Event ) określenie
Wyzwalacz - procedura wyzwalana, składowana fizycznie w bazie, uruchamiana automatycznie po nastąpieniu określonego w definicji zdarzenia Składowe wyzwalacza ( ECA ): określenie zdarzenia ( Event ) określenie
Słowem wstępu. Część rodziny języków XSL. Standard: W3C XSLT razem XPath 1.0 XSLT Trwają prace nad XSLT 3.0
 Słowem wstępu Część rodziny języków XSL Standard: W3C XSLT 1.0-1999 razem XPath 1.0 XSLT 2.0-2007 Trwają prace nad XSLT 3.0 Problem Zakładane przez XML usunięcie danych dotyczących prezentacji pociąga
Słowem wstępu Część rodziny języków XSL Standard: W3C XSLT 1.0-1999 razem XPath 1.0 XSLT 2.0-2007 Trwają prace nad XSLT 3.0 Problem Zakładane przez XML usunięcie danych dotyczących prezentacji pociąga
HURTOWNIE DANYCH Dzięki uprzejmości Dr. Jakuba Wróblewskiego
 HURTOWNIE DANYCH Dzięki uprzejmości Dr. Jakuba Wróblewskiego http://www.jakubw.pl/zajecia/hur/bi.pdf http://www.jakubw.pl/zajecia/hur/dw.pdf http://www.jakubw.pl/zajecia/hur/dm.pdf http://www.jakubw.pl/zajecia/hur/
HURTOWNIE DANYCH Dzięki uprzejmości Dr. Jakuba Wróblewskiego http://www.jakubw.pl/zajecia/hur/bi.pdf http://www.jakubw.pl/zajecia/hur/dw.pdf http://www.jakubw.pl/zajecia/hur/dm.pdf http://www.jakubw.pl/zajecia/hur/
< K (2) = ( Adams, John ), P (2) = adres bloku 2 > < K (1) = ( Aaron, Ed ), P (1) = adres bloku 1 >
 = ( Adams, John ), P (2) = adres bloku 2 > < K (1) = ( Aaron, Ed ), P (1) = adres bloku 1 >") Typy indeksów Indeks jest zakładany na atrybucie relacji atrybucie indeksowym (ang. indexing field). Indeks zawiera wartości atrybutu indeksowego wraz ze wskaźnikami do wszystkich bloków dyskowych zawierających
Typy indeksów Indeks jest zakładany na atrybucie relacji atrybucie indeksowym (ang. indexing field). Indeks zawiera wartości atrybutu indeksowego wraz ze wskaźnikami do wszystkich bloków dyskowych zawierających
Zaawansowane funkcje systemów plików. Ewa Przybyłowicz
 Zaawansowane funkcje systemów plików. Ewa Przybyłowicz Agenda: 1. Idea journalingu. 2. NTFS. 3. ext4. 4. exfat. 5. Porównanie systemów. Idea journalingu. Dziennik systemu plików zapewnia możliwość odzyskiwania
Zaawansowane funkcje systemów plików. Ewa Przybyłowicz Agenda: 1. Idea journalingu. 2. NTFS. 3. ext4. 4. exfat. 5. Porównanie systemów. Idea journalingu. Dziennik systemu plików zapewnia możliwość odzyskiwania
Replikacja danych w bazach danych Oracle9i
 VII Seminarium PLOUG Warszawa Marzec 2003 Replikacja danych w bazach danych Oracle9i Bartosz Bêbel, Robert Wrembel Bartosz.Bebel@cs.put.poznan.pl, Robert.Wrembel@cs.put.poznan.pl Politechnika Poznañska,
VII Seminarium PLOUG Warszawa Marzec 2003 Replikacja danych w bazach danych Oracle9i Bartosz Bêbel, Robert Wrembel Bartosz.Bebel@cs.put.poznan.pl, Robert.Wrembel@cs.put.poznan.pl Politechnika Poznañska,