Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
|
|
|
- Laura Włodarczyk
- 9 lat temu
- Przeglądów:
Transkrypt

1 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1

2 2


3 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz! 3

4 Wybór technologii Czy będzie prosty?? 4

5 Wykład - CUDA Typowy kurs oparty na (najlepszych we wszechświecie) materiałach szkoleniowych NVidii 5

6 Wykład - OpenCL Typowy kurs oparty na (najlepszych we wszechświecie) materiałach szkoleniowych NVidii 6
")
7 Lab-y (C/O) Zadanie. 1. Mnożenie dużych macierzy (10 różnych rozmiarów oraz danych wygenerowanych losowo, dostosowanych do ilości pamięci RAM CPU i GPU). Rozliczenie: raport elektroniczny z wykresami i komentarzem! : porównanie szybkości działania GPU (conajmniej 3 różne) vs CPU (taki jaki macie w swoich komputerach) w skali rozmiaru macierzy - wyznaczenie przyrostu szybkości, wyznaczenie udziału czasu komunikacji z pamięcią GPU w czasie obliczeń, sprawdzenie poprawności danych pomiędzy CPU i GPU dla typu float (odchylenie standardowe!!). NA OCENĘ 3! (C+O) Zadanie. 2. Implementacja algorytmu transpozycji macierzy, przynajmniej 3 metodami, optymalizacja kodu CUDA i OpenCL - wyznaczenie przyrostu szybkości: CPU vs CUDA vs OpenCL vs CUDA Optimized NA OCENĘ 4! (C/O) Zadanie 3. Implementacja wybranego przez siebie algorytmu do wykrywania krawędzi - Edge Detection (np. Reverse ED) w wybranym przez siebie statycznym obrazie UltraHD 4K (2160p, YT, np. film Transformers: Age of Extinction) przekonwertowanym do skali szarości, porównanie szybkości CPU vs. GPU, wynik porównania w tabelce na ekranie monitora, prezentacja wykrycia krawędzi na ekranie. NA OCENĘ 5! 7
. NA OCENĘ 3! (C+O) Zadanie. 2.")
8 Rozliczenie przedmiotu Zaliczenie lab-ów: Zadanie 1 na ocenę 3 wraz z wymaganym raportem. Zadanie 2 wraz z porównaniemi na ocenę 4 Zadanie 3 wraz z porównaniem na ocenę 5 ;) Zaliczenie wykładu: Ocena będzie przepisana z lab-ów. Nie przewiduję specjalnego kolokwium. Obecność na lab-ach OBOWIĄZKOWA!. Możliwe dwie nieobecności nieusprawiedliwione. Pozostałe nieobecności wymagają zwolnienia lekarskiego. 8

9 1024 kurczaki czy 2 woły? D.Cray 9

10 Jak uzyskać wydajność? Mamy coraz więcej tranzystorów, co z tego? Jak możemy uzyskać większą wydajność Zwiększamy szybkość procesora MHz -> GHz w ostatnie 30 lat Moc skaluje się z częstotliwością Ilość pamięci musi nadążąć Równoległe wykonanie procedur Współbieżność, wielowątkowość 10

11 Prawo Moor a Przetwarzanie szeregowe osiągnęło już swoje granice Procesory muszą zacząć stawać się szersze a nie szybsze Zadanie: myślenie równoległe! 11

12 Prawo Moor a 12

13 Jak uzyskać wydajność? 13



14 14


15 Myślenie równoległe - Top

16 Pytania? 16

17 Zapraszam za tydzień ;) 17
 17")
18 Architektura GPU vs CPU 18 Źródło: AMD Corp.
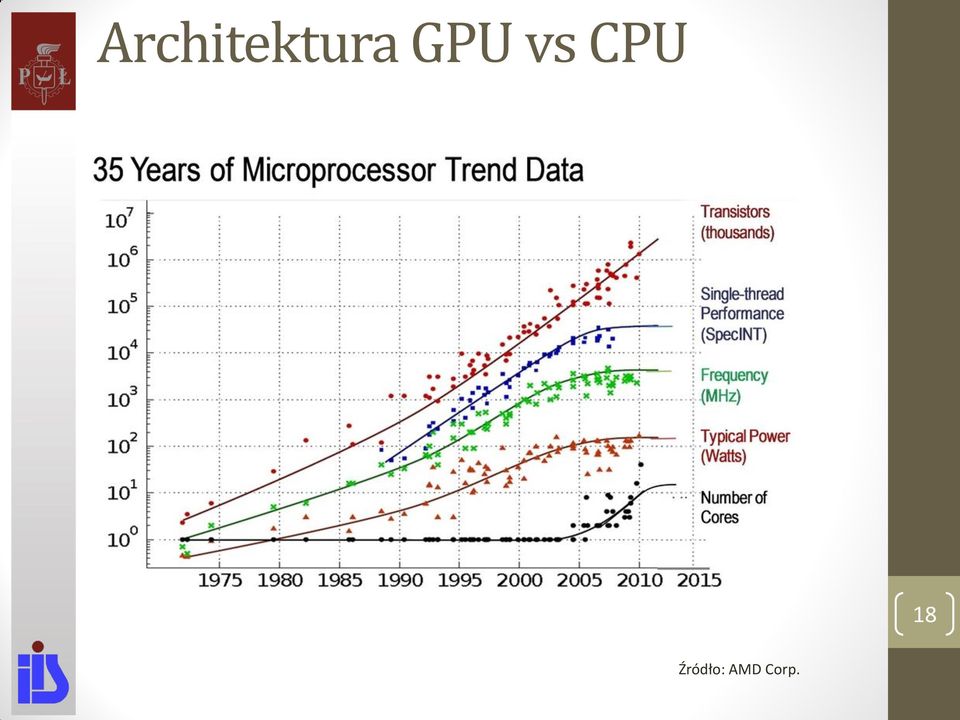

19 Architektura CPU vs GPU GPU poświęca znacznie więcej tranzystorów na proces przetwarzania danych CPU potrafi realizować złożone zadania 19

20 Architektura GPU vs CPU Intel , Intel 10 µm 14 mm² Intel , Intel 1.5 µm 104 mm² Pentium 3,100, Intel 0.8 µm 294 mm² Pentium 4 Willamette 42,000, Intel 180 nm 217 mm² Core 2 Duo Conroe 291,000, Intel 65 nm 143 mm² Core i7 (Quad) 731,000, Intel 45 nm 263 mm² Six-Core Core i7 (Gulftown) 10-Core Xeon Westmere-EX 1,170,000, Intel 32 nm 240 mm² 2,600,000, Intel 32 nm 512 mm² 62-Core Xeon Phi 5,000,000, Intel 22 nm Xbox One Main SoC 5,000,000, Microsoft/AMD 28 nm 363 mm² NV10 17,500, NVIDIA 220 nm 111 mm² NV40 222,000, NVIDIA 130 nm 305 mm² GT200 Tesla 1,400,000,000 [22] 2008 NVIDIA 65 nm 576 mm² Cypress RV870 2,154,000,000 [23] 2009 AMD 40 nm 334 mm² GF100 Fermi 3,200,000,000 [24] Mar 2010 NVIDIA 40 nm 526 mm² GK110 Kepler 7,080,000,000 [27] 2012 NVIDIA 28 nm 561 mm² 20


21 Architektura GPU vs CPU 21 GPU jest specjalnie zaprojektowany do realizacji wysoko-równoległych zadań
22 Architektura GPU vs CPU Rdzenie? 3 miliardy tranzystorów 512 rdzeni CUDA (32 rdzenie w 16 multiprocesorach) 64kB pamięci wbudowanej Wysoka przepustowość wewnętrzna 22 Nvidia GTX 580
23 Architektura GPU vs CPU Pojedynczy rdzeń GPU jest procesorem strumieniowym Rdzenie GPU są grupowane w multiprocesory strumieniowe SM SM jest procesorem typu SIMD (Single Instruction Multiple Data) 23
24 Myślenie równoległe 1024 kurczaki? Są lepsze rozwiązania.. Przemyśl swoje algorytmy tak by były bardziej przyjazne architekturom wysoko-równoległym (masoworównoległym) Masowo-równoległy? Znaczy: Równoległość danych Równoważenie obciążenia Proste obliczenia Szybki dostęp do danych Unikanie konfliktów dostępu do danych Itd., itp 24 Sporo tego, prawda?
25 CUDA & OpenCL CUDA (ang. Compute Unified Device Architecture) OpenCL (ang. Open Computing Language) 25
26 Fakty i mity CUDA i OpenCL są środowiskami programowania kart graficznych, zorienrowanymi na zrównoleglanie obliczeń ogólnego przeznaczenia. CUDA jest własną architekturą programowania procesorów graficznych firmy Nvidia i wspieraną jedynie przez karty tej firmy. Integruje w sobie język programowania oparty na języku C. OpenCL został zaprojektowany początkowo przez firmę Apple, a później przejęty przez The Khronos Group, i uczyniony standardem otwartym. 26
27 Fakty i mity OpenCL jest otwartym standardem działającym na sprzęcie (procesorach graficznych i nie tylko) różnych producentów chyba jedyna obecnie przewaga OpenCL. OpenCL jest w stanie realizować obliecznia na głównym procesorze, w przypadku gdy procesor graficznych nie jest dostępny. Mówi się, że technologia CUDA jest bardziej dojrzała niż OpenCL, jej API jest wyżej poziomowe i bardziej zaawansowane, co oczywiście jest dziś prawdą, ale nie musi być w przyszłości. 27
28 Fakty i mity Zarówno CUDA and OpenCL są wspierane przez niemal wszystkie dostępne na rynku standardy systemów operacyjnych (Windows, Linux, and MacOS). Chodzi po świecie plotka, że wewnętrzne procedury OpenCL są po prostu techniką kopiujwklej przenoszone z technologii CUDA. Lecz CUDA wykonuje je szybcie z racji dostępu do natywnych dla Nvidia procesorów graficznych. OpenCL, jako standard otwarty (jedynie??) wydaje się mieć przed sobą bardziej świetlaną przyszłość. 28
29 Fakty i mity co Pogromcy Mitów na to? 29
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Praca dyplomowa magisterska
 Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Nowinki technologiczne procesorów
 Elbląg 22.04.2010 Nowinki technologiczne procesorów Przygotował: Radosław Kubryń VIII semestr PDBiOU 1 Spis treści 1. Wstęp 2. Intel Hyper-Threading 3. Enhanced Intel Speed Technology 4. Intel HD Graphics
Elbląg 22.04.2010 Nowinki technologiczne procesorów Przygotował: Radosław Kubryń VIII semestr PDBiOU 1 Spis treści 1. Wstęp 2. Intel Hyper-Threading 3. Enhanced Intel Speed Technology 4. Intel HD Graphics
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Nowinki technologiczne procesorów
 Elbląg 22.04.2010 Nowinki technologiczne procesorów Przygotował: Radosław Kubryń VIII semestr PDBiOU 1 Spis treści 1. Wstęp 2. Intel Hyper-Threading 3. Enhanced Intel Speed Technology 4. Intel HD Graphics
Elbląg 22.04.2010 Nowinki technologiczne procesorów Przygotował: Radosław Kubryń VIII semestr PDBiOU 1 Spis treści 1. Wstęp 2. Intel Hyper-Threading 3. Enhanced Intel Speed Technology 4. Intel HD Graphics
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
CUDA część 1. platforma GPGPU w obliczeniach naukowych. Maciej Matyka
 CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo.
 Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Bibliografia: pl.wikipedia.org www.intel.com. Historia i rodzaje procesorów w firmy Intel
 Bibliografia: pl.wikipedia.org www.intel.com Historia i rodzaje procesorów w firmy Intel Specyfikacja Lista mikroprocesorów produkowanych przez firmę Intel 4-bitowe 4004 4040 8-bitowe x86 IA-64 8008 8080
Bibliografia: pl.wikipedia.org www.intel.com Historia i rodzaje procesorów w firmy Intel Specyfikacja Lista mikroprocesorów produkowanych przez firmę Intel 4-bitowe 4004 4040 8-bitowe x86 IA-64 8008 8080
MESco. Testy skalowalności obliczeń mechanicznych w oparciu o licencje HPC oraz kartę GPU nvidia Tesla c2075. Stanisław Wowra
 MESco Testy skalowalności obliczeń mechanicznych w oparciu o licencje HPC oraz kartę GPU nvidia Tesla c2075 Stanisław Wowra swowra@mesco.com.pl Lider w dziedzinie symulacji na rynku od 1994 roku. MESco
MESco Testy skalowalności obliczeń mechanicznych w oparciu o licencje HPC oraz kartę GPU nvidia Tesla c2075 Stanisław Wowra swowra@mesco.com.pl Lider w dziedzinie symulacji na rynku od 1994 roku. MESco
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
Nowinkach technologicznych procesorów
 Elbląg 22.04.2010 Nowinkach technologicznych procesorów Przygotował: Radosław Kubryń VIII semestr PDBiOU 1 Spis treści 1. Wstęp 2. Intel Hyper-Threading 3. Enhanced Intel Speed Technology 4. Intel HD Graphics
Elbląg 22.04.2010 Nowinkach technologicznych procesorów Przygotował: Radosław Kubryń VIII semestr PDBiOU 1 Spis treści 1. Wstęp 2. Intel Hyper-Threading 3. Enhanced Intel Speed Technology 4. Intel HD Graphics
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
SYSTEMY OPERACYJNE WYKŁAD 1 INTEGRACJA ZE SPRZĘTEM
 SYSTEMY OPERACYJNE WYKŁAD 1 INTEGRACJA ZE SPRZĘTEM Marcin Tomana marcin@tomana.net SKRÓT WYKŁADU Zastosowania systemów operacyjnych Architektury sprzętowe i mikroprocesory Integracja systemu operacyjnego
SYSTEMY OPERACYJNE WYKŁAD 1 INTEGRACJA ZE SPRZĘTEM Marcin Tomana marcin@tomana.net SKRÓT WYKŁADU Zastosowania systemów operacyjnych Architektury sprzętowe i mikroprocesory Integracja systemu operacyjnego
Podręcznik użytkownika PCI-x Karta przechwytująca 4xHDMI
 Podręcznik użytkownika PCI-x Karta przechwytująca 4xHDMI Spis treści 1. Specyfikacja... 3 1.1 Cechy:... 3 1.2 Rozdzielczość wideo na wejściu :... 3 1.3 Zawartość opakowania... 3 1.4 Wymagania systemowe...
Podręcznik użytkownika PCI-x Karta przechwytująca 4xHDMI Spis treści 1. Specyfikacja... 3 1.1 Cechy:... 3 1.2 Rozdzielczość wideo na wejściu :... 3 1.3 Zawartość opakowania... 3 1.4 Wymagania systemowe...
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Julia 4D - raytracing
 i przykładowa implementacja w asemblerze Politechnika Śląska Instytut Informatyki 27 sierpnia 2009 A teraz... 1 Fraktale Julia Przykłady Wstęp teoretyczny Rendering za pomocą śledzenia promieni 2 Implementacja
i przykładowa implementacja w asemblerze Politechnika Śląska Instytut Informatyki 27 sierpnia 2009 A teraz... 1 Fraktale Julia Przykłady Wstęp teoretyczny Rendering za pomocą śledzenia promieni 2 Implementacja
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Redukcja czasu wykonania algorytmu Cannego dzięki zastosowaniu połączenia OpenMP z technologią NVIDIA CUDA
 Dariusz Sychel Wydział Informatyki, Zachodniopomorski Uniwersytet Technologiczny w Szczecinie 71-210 Szczecin, Żołnierska 49 Redukcja czasu wykonania algorytmu Cannego dzięki zastosowaniu połączenia OpenMP
Dariusz Sychel Wydział Informatyki, Zachodniopomorski Uniwersytet Technologiczny w Szczecinie 71-210 Szczecin, Żołnierska 49 Redukcja czasu wykonania algorytmu Cannego dzięki zastosowaniu połączenia OpenMP
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Programowanie współbieżne Wprowadzenie do programowania GPU. Rafał Skinderowicz
 Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
MMX i SSE. Zbigniew Koza. Wydział Fizyki i Astronomii Uniwersytet Wrocławski. Wrocław, 10 marca 2011. Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16
 MMX i SSE 1 / 16") MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
Podsystem graficzny. W skład podsystemu graficznego wchodzą: karta graficzna monitor
 Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
Wyniki testów PassMark
 DOA.III.272.1.62.2015 Załącznik nr 1 do SOPZ Wyniki testów PassMark Strona 1 z 41 Spis treści 1. Kategoria Dual CPU (podwójne procesory)... 3 2. Kategoria CPU (pojedyncze procesory)... 7 3. Kategoria VGA
DOA.III.272.1.62.2015 Załącznik nr 1 do SOPZ Wyniki testów PassMark Strona 1 z 41 Spis treści 1. Kategoria Dual CPU (podwójne procesory)... 3 2. Kategoria CPU (pojedyncze procesory)... 7 3. Kategoria VGA
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
XIV International PhD Workshop OWD 2012, October 2012 NOWOCZESNE TECHNIKI WYKONYWANIA ZAAWANSOWANYCH OBLICZEŃ NUMERYCZNYCH
 XIV International PhD Workshop OWD 2012, 20 23 October 2012 NOWOCZESNE TECHNIKI WYKONYWANIA ZAAWANSOWANYCH OBLICZEŃ NUMERYCZNYCH MODERN ADVANCED COMPUTATIONAL METHOD Konrad Andrzej Markowski, Warsaw University
XIV International PhD Workshop OWD 2012, 20 23 October 2012 NOWOCZESNE TECHNIKI WYKONYWANIA ZAAWANSOWANYCH OBLICZEŃ NUMERYCZNYCH MODERN ADVANCED COMPUTATIONAL METHOD Konrad Andrzej Markowski, Warsaw University
Kryptografia na procesorach wielordzeniowych
 Kryptografia na procesorach wielordzeniowych Andrzej Chmielowiec andrzej.chmielowiec@cmmsigma.eu Centrum Modelowania Matematycznego Sigma Kryptografia na procesorach wielordzeniowych p. 1 Plan prezentacji
Kryptografia na procesorach wielordzeniowych Andrzej Chmielowiec andrzej.chmielowiec@cmmsigma.eu Centrum Modelowania Matematycznego Sigma Kryptografia na procesorach wielordzeniowych p. 1 Plan prezentacji
Załącznik nr 6 do SIWZ nr postępowania II.2420.1.2014.005.13.MJ Zaoferowany. sprzęt L P. Parametry techniczne
 L P Załącznik nr 6 do SIWZ nr postępowania II.2420.1.2014.005.13.MJ Zaoferowany Parametry techniczne Ilość sprzęt Gwaran Cena Cena Wartość Wartość (model cja jednostk % jednostkow ogółem ogółem i parametry
L P Załącznik nr 6 do SIWZ nr postępowania II.2420.1.2014.005.13.MJ Zaoferowany Parametry techniczne Ilość sprzęt Gwaran Cena Cena Wartość Wartość (model cja jednostk % jednostkow ogółem ogółem i parametry
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera
 Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Raport Hurtownie Danych
 Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Laptop Kruger&Matz EXPOLRE PRO 1511
 Dane aktualne na dzień: 26-09-2017 10:37 Link do produktu: https://diolut.pl/laptop-krugermatz-expolre-pro-1511-p-20706.html Laptop Kruger&Matz EXPOLRE PRO 1511 Cena brutto Cena netto Stan magazynowy Czas
Dane aktualne na dzień: 26-09-2017 10:37 Link do produktu: https://diolut.pl/laptop-krugermatz-expolre-pro-1511-p-20706.html Laptop Kruger&Matz EXPOLRE PRO 1511 Cena brutto Cena netto Stan magazynowy Czas
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Transformacja Fouriera i biblioteka CUFFT 3.0
 Transformacja Fouriera i biblioteka CUFFT 3.0 Procesory Graficzne w Zastosowaniach Obliczeniowych Karol Opara Warszawa, 14 kwietnia 2010 Transformacja Fouriera Definicje i Intuicje Transformacja z dziedziny
Transformacja Fouriera i biblioteka CUFFT 3.0 Procesory Graficzne w Zastosowaniach Obliczeniowych Karol Opara Warszawa, 14 kwietnia 2010 Transformacja Fouriera Definicje i Intuicje Transformacja z dziedziny
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
SYSTEMY OPERACYJNE I SIECI KOMPUTEROWE
 SYSTEMY OPERACYJNE I SIECI KOMPUTEROWE WINDOWS 1 SO i SK/WIN 007 Tryb rzeczywisty i chroniony procesora 2 SO i SK/WIN Wszystkie 32-bitowe procesory (386 i nowsze) mogą pracować w kilku trybach. Tryby pracy
SYSTEMY OPERACYJNE I SIECI KOMPUTEROWE WINDOWS 1 SO i SK/WIN 007 Tryb rzeczywisty i chroniony procesora 2 SO i SK/WIN Wszystkie 32-bitowe procesory (386 i nowsze) mogą pracować w kilku trybach. Tryby pracy
2 099,00 PLN OPIS PRZEDMIOTU AMIGO CORE I7 8X3,7GHZ 8GB 1TB USB3.0 WIN8.1 883-364-274 SKLEP@AMIGOPC.PL. amigopc.pl CENA: CZAS WYSYŁKI: 24H
 amigopc.pl 883-364-274 SKLEP@AMIGOPC.PL AMIGO CORE I7 8X3,7GHZ 8GB 1TB USB3.0 WIN8.1 CENA: 2 099,00 PLN CZAS WYSYŁKI: 24H PRODUCENT: AMIGOPC NUMER KATALOGOWY: AMIGO XEON 1 RODZAJ PROCESORA: CORE I7 LICZBA
amigopc.pl 883-364-274 SKLEP@AMIGOPC.PL AMIGO CORE I7 8X3,7GHZ 8GB 1TB USB3.0 WIN8.1 CENA: 2 099,00 PLN CZAS WYSYŁKI: 24H PRODUCENT: AMIGOPC NUMER KATALOGOWY: AMIGO XEON 1 RODZAJ PROCESORA: CORE I7 LICZBA
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Welcome to the waitless world. Inteligentna infrastruktura systemów Power S812LC i S822LC
 Inteligentna infrastruktura systemów Power S812LC i S822LC Przedstawiamy nową linię serwerów dla Linux Clouds & Clasters IBM Power Systems LC Kluczowa wartość dla klienta Specyfikacje S822LC Technical
Inteligentna infrastruktura systemów Power S812LC i S822LC Przedstawiamy nową linię serwerów dla Linux Clouds & Clasters IBM Power Systems LC Kluczowa wartość dla klienta Specyfikacje S822LC Technical
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wykład 2. Mikrokontrolery z rdzeniami ARM
 Źródło problemu 2 Wstęp Architektura ARM (Advanced RISC Machine, pierwotnie Acorn RISC Machine) jest 32-bitową architekturą (modelem programowym) procesorów typu RISC. Różne wersje procesorów ARM są szeroko
Źródło problemu 2 Wstęp Architektura ARM (Advanced RISC Machine, pierwotnie Acorn RISC Machine) jest 32-bitową architekturą (modelem programowym) procesorów typu RISC. Różne wersje procesorów ARM są szeroko
I N S T Y T U T I N F O R M A T Y K I S T O S O W A N E J 2016
 I N S T Y T U T I N F O R M A T Y K I S T O S O W A N E J 2016 Programowanie Gier Testowanie i zapewnianie jakości oprogramowania (QA) Grafika i multimedia Inteligentne systemy autonomiczne INŻYNIERIA
I N S T Y T U T I N F O R M A T Y K I S T O S O W A N E J 2016 Programowanie Gier Testowanie i zapewnianie jakości oprogramowania (QA) Grafika i multimedia Inteligentne systemy autonomiczne INŻYNIERIA
INŻYNIERIA OPROGRAMOWANIA
 INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
Programowanie kart graficznych
 Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
MAGISTRALE ZEWNĘTRZNE, gniazda kart rozszerzeń, w istotnym stopniu wpływają na
 , gniazda kart rozszerzeń, w istotnym stopniu wpływają na wydajność systemu komputerowego, m.in. ze względu na fakt, że układy zewnętrzne montowane na tych kartach (zwłaszcza kontrolery dysków twardych,
, gniazda kart rozszerzeń, w istotnym stopniu wpływają na wydajność systemu komputerowego, m.in. ze względu na fakt, że układy zewnętrzne montowane na tych kartach (zwłaszcza kontrolery dysków twardych,
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (28.03.2011) Rok akademicki 2010/2011, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (28.03.2011) Rok akademicki 2010/2011, Wykład
INŻYNIERIA OPROGRAMOWANIA
 INSTYTUT INFORMATYKI STOSOWANEJ 2014 Nowy blok obieralny! Testowanie i zapewnianie jakości oprogramowania INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania
INSTYTUT INFORMATYKI STOSOWANEJ 2014 Nowy blok obieralny! Testowanie i zapewnianie jakości oprogramowania INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania
Artur Janus GNIAZDA PROCESORÓW INTEL
 GNIAZDA PROCESORÓW INTEL Gniazdo mikroprocesora Każdy mikroprocesor musi zostać zamontowany w specjalnie przystosowanym gnieździe umieszczonym na płycie głównej. Do wymiany informacji między pamięcią operacyjną
GNIAZDA PROCESORÓW INTEL Gniazdo mikroprocesora Każdy mikroprocesor musi zostać zamontowany w specjalnie przystosowanym gnieździe umieszczonym na płycie głównej. Do wymiany informacji między pamięcią operacyjną
4 NVIDIA CUDA jako znakomita platforma do zrównoleglenia obliczeń
 Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (06.05.2011) Rok akademicki 2010/2011, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (06.05.2011) Rok akademicki 2010/2011, Wykład
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie aplikacji na iphone. Wstęp do platformy ios. Łukasz Zieliński
 Programowanie aplikacji na iphone. Wstęp do platformy ios. Łukasz Zieliński Plan Prezentacji. Programowanie ios. Jak zacząć? Co warto wiedzieć o programowaniu na platformę ios? Kilka słów na temat Obiective-C.
Programowanie aplikacji na iphone. Wstęp do platformy ios. Łukasz Zieliński Plan Prezentacji. Programowanie ios. Jak zacząć? Co warto wiedzieć o programowaniu na platformę ios? Kilka słów na temat Obiective-C.
XIII International PhD Workshop OWD 2011, October 2011 REALIZACJA OBLICZEŃ W ARCHITEKTURZE MASOWO RÓWNOLEGŁEJ W HETEROGENICZNYCH SYSTEMACH
 XIII International PhD Workshop OWD 2011, 22 25 October 2011 REALIZACJA OBLICZEŃ W ARCHITEKTURZE MASOWO RÓWNOLEGŁEJ W HETEROGENICZNYCH SYSTEMACH CALCULATIONS IN THE MASSIVELY PARALLEL ARCHITECTURE IN HETEROGENEOUS
XIII International PhD Workshop OWD 2011, 22 25 October 2011 REALIZACJA OBLICZEŃ W ARCHITEKTURZE MASOWO RÓWNOLEGŁEJ W HETEROGENICZNYCH SYSTEMACH CALCULATIONS IN THE MASSIVELY PARALLEL ARCHITECTURE IN HETEROGENEOUS
Implementacja sieci neuronowych na karcie graficznej. Waldemar Pawlaszek
 Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Mikroprocesory rodziny INTEL 80x86
 Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP.
 P O L I T E C H N I K A S Z C Z E C I Ń S K A Wydział Informatyki PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP. Autor: Wojciech
P O L I T E C H N I K A S Z C Z E C I Ń S K A Wydział Informatyki PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP. Autor: Wojciech
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
NOWE TRENDY ROZWOJU MIKROPROCESORÓW
 NOWE TRENDY ROZWOJU MIKROPROCESORÓW Marcin LORENC, Krzysztof CEGIELSKI Streszczenie: Celem artykułu jest zaprezentowanie kierunków rozwoju mikrokontrolerów. Przedstawiono krótką historię procesorów, pojęcie
NOWE TRENDY ROZWOJU MIKROPROCESORÓW Marcin LORENC, Krzysztof CEGIELSKI Streszczenie: Celem artykułu jest zaprezentowanie kierunków rozwoju mikrokontrolerów. Przedstawiono krótką historię procesorów, pojęcie
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Zdjęcia i opis stanowisk laboratoryjnych wykorzystywanych w ramach projektu
 Zdjęcia i opis stanowisk laboratoryjnych wykorzystywanych w ramach projektu Koło zainteresowań Teleinformatyk XXI wieku strona 1 Wprowadzenie Podczas zajęć koła zainteresowań Teleinformatyk XXI wieku uczniowie
Zdjęcia i opis stanowisk laboratoryjnych wykorzystywanych w ramach projektu Koło zainteresowań Teleinformatyk XXI wieku strona 1 Wprowadzenie Podczas zajęć koła zainteresowań Teleinformatyk XXI wieku uczniowie
Materiały dodatkowe do podręcznika Urządzenia techniki komputerowej do rozdziału 5. Płyta główna i jej składniki. Test nr 5
 Materiały dodatkowe do podręcznika Urządzenia techniki komputerowej do rozdziału 5. Płyta główna i jej składniki Test nr 5 Test zawiera 63 zadania związane z treścią rozdziału 5. Jest to test zamknięty,
Materiały dodatkowe do podręcznika Urządzenia techniki komputerowej do rozdziału 5. Płyta główna i jej składniki Test nr 5 Test zawiera 63 zadania związane z treścią rozdziału 5. Jest to test zamknięty,
Klasyfikacja systemów komputerowych. Architektura von Neumanna. dr inż. Jarosław Forenc
 Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Mo liwoœæ zastosowania GPU do przetwarzania obrazów dla celów analizy sceny**
 AUTOMATYKA 2011 Tom 15 Zeszyt 3 Magdalena Szymczyk*, Piotr Szymczyk* Mo liwoœæ zastosowania GPU do przetwarzania obrazów dla celów analizy sceny** 1. Wprowadzenie Aplikacje stosowane do przetwarzania obrazu
AUTOMATYKA 2011 Tom 15 Zeszyt 3 Magdalena Szymczyk*, Piotr Szymczyk* Mo liwoœæ zastosowania GPU do przetwarzania obrazów dla celów analizy sceny** 1. Wprowadzenie Aplikacje stosowane do przetwarzania obrazu
Bajt (Byte) - najmniejsza adresowalna jednostka informacji pamięci komputerowej, z bitów. Oznaczana jest literą B.
 - najmniejsza adresowalna jednostka informacji pamięci komputerowej, z bitów. Oznaczana jest literą B.") Jednostki informacji Bajt (Byte) - najmniejsza adresowalna jednostka informacji pamięci komputerowej, składająca się z bitów. Oznaczana jest literą B. 1 kb = 1024 B (kb - kilobajt) 1 MB = 1024 kb (MB -
Jednostki informacji Bajt (Byte) - najmniejsza adresowalna jednostka informacji pamięci komputerowej, składająca się z bitów. Oznaczana jest literą B. 1 kb = 1024 B (kb - kilobajt) 1 MB = 1024 kb (MB -
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++
 Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
Komputer VIPER i x4,2ghz 8GB GTX 1050TI 4GB 1TB USB 3.0
 Dane aktualne na dzień: 11-01-2018 11:01 Link do produktu: http://exite.info/komputer-viper-i7-7700-4x4-2ghz-8gb-gtx-1050ti-4gb-1tb-usb-30-p-10049.html Komputer VIPER i7-7700 4x4,2ghz 8GB GTX 1050TI 4GB
Dane aktualne na dzień: 11-01-2018 11:01 Link do produktu: http://exite.info/komputer-viper-i7-7700-4x4-2ghz-8gb-gtx-1050ti-4gb-1tb-usb-30-p-10049.html Komputer VIPER i7-7700 4x4,2ghz 8GB GTX 1050TI 4GB
Wstęp. Przetwarzanie współbieżne, równoległe i rozproszone
 Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Procesory. Schemat budowy procesora
 Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu