Analityka wysokiej wydajności. Przegląd możliwości technologii SAS. Adam Bartos
|
|
|
- Gabriela Michalak
- 8 lat temu
- Przeglądów:
Transkrypt

1 Analityka wysokiej wydajności. Przegląd możliwości technologii SAS. Adam Bartos

2 Analityka wysokiej wydajności. Właściwie po co? Big Data 3xV Competing on Analytics
3 Aspekty wysokiej wydajności Wydajność obliczeń Wydajność procesu Act Evaluate Ask Prepare Data Integracja danych Eksploracja analityczna Transformacja danych Modelowanie Skoring Modelowanie masowe Przekazanie na produkcję Zarządzanie modelami Implement Explore Model
4 Uproszczona architektura rozwiązań analitycznych SAS Enterprise Miner Enterprise Guide SAS Factory Miner Workspace Server Serwer SMP Źródła danych Workspace Server Klasyka czyli Single User SMP Silnik analityczny jest uruchamiany niezależnie dla każdego użytkownika na wspólnym serwerze (np. AIX) Algorytm analityczny wykorzystuje wielowątkowość w ramach jednego procesu (thread level) do przetwarzania jednego zbioru danych



5 Uproszczona architektura rozwiązań analitycznych SAS Enterprise Miner Enterprise Guide SAS Factory Miner Workspace Server Serwer SMP Workspace Server Workspace Server Serwer SMP Workspace Server Prawie klasyka czyli Single User + GRID Silnik analityczny jest uruchamiany niezależnie dla każdego użytkownika na jednym z serwerów w GRID Źródła danych Algorytm analityczny wykorzystuje wielowątkowość w ramach jednego procesu do przetwarzania jednego zbioru danych Wiele algorytmów może być równocześnie uruchomionych na kilku maszynach (np. różne metody modelowania w Enterprise Miner)
6 Uproszczona architektura rozwiązań analitycznych SAS Enterprise Miner Enterprise Guide SAS Factory Miner Workspace Server Serwer SMP Workspace Server Węzeł MPP Węzeł MPP Węzeł MPP Węzeł MPP Proces Master Proces Master Klaster MPP Proces Worker Proces Worker Proces Worker Proces Worker Proces Worker Proces Worker Rodzina HPA Single User + MPP Silnik analityczny jest uruchamiany niezależnie dla każdego użytkownika na wspólnym klastrze maszyn Algorytm analityczny wykorzystuje wielowątkowość w ramach wielu procesów (thread & proces level) do przetwarzania jednego zbioru danych Analizowany zbiór danych ładowany do pamięci tymczasowo Źródła danych MPP Data Store
7 Uproszczona architektura rozwiązań analitycznych SAS Visual Analytics Visual Statistics SAS Studio (In-Memory Statistics) Węzeł MPP Węzeł MPP Węzeł MPP Węzeł MPP Server Master Klaster MPP Server Worker Server Worker Server Worker LASR Server: Multi User Server + MPP Wszyscy użytkownicy korzystają ze wspólnego silnika analitycznego na wspólnym klastrze maszyn Algorytm analityczny wykorzystuje wielowątkowość w ramach wielu procesów (thread & proces level) do przetwarzania jednego zbioru danych Współdzielone zbiory danych stale w pamięci Źródła danych MPP Data Store




8 Aplikacje SAS z opcją GRID Prawie klasyka czyli Single User + GRID GRID CONTROL SERVER GRID NODE 1 GRID NODE 2 GRID NODE N Workspace Server Workspace Server 4GL Workspace Server Workspace Server Zarządzanie Obciążeniem Zarządzanie zadaniami, hostami oraz użytkownikami Priorytetyzacja i szeregowanie poprzez zaawansowany mechanizm kolejek Identyfikacja, alokacja i zarządzanie zasobami Wysoka Dostępność Wykrywanie awarii grid i automatyczne przywracanie działania Automatyczny wznawianie zadań z uwzględnieniem wykonanej pracy Wydajność Podział sekwencji zadań na podzadania do wykonania równoległego Podział, dystrybucja i parametryzacja zadań (wybrane zadania ETL, modelowanie)
» Pobierane do pamięci na czas działania procedury, dystrybuowane w całym klastrze» Równoległe ładowanie danych")
9 Procedury zaawansowanej analityki zaimplementowane jako algorytmy przetwarzania równoległego dostępne z poziomu: Kodu SAS 4GL SAS Enterprise Miner/Text Miner (jako węzły w interfejsie użytkownika) SAS Factory Miner Najważniejsze założenia architektoniczne Dane In-Memory (tymczasowo)» Pobierane do pamięci na czas działania procedury, dystrybuowane w całym klastrze» Równoległe ładowanie danych do pamięci» Szybka analiza danych dla algorytmów wieloprzebiegowych» Kopia danych dla każdego wywołania procedury HP* Distributed Computing Model Rodzina Procedur HPA High Performance XXX» Wykorzystanie wielowątkowości (thread) i wielu węzłów (node)» Protokół MPI do komunikacji pomiędzy jednostkami pracy MPP (w tym w środowisku Hadoop) lub SMP (pojedyncza maszyna) CPU RAM CPU



10 FUNKCJONALNOŚĆ SAS HIGH-PERFORMANCE Statistics Data Mining Text Mining Econometrics Optimization Binary target & continuous no. predictions Linear, Non- Complex relationships Tree- and Parsing largescale text collections Extract Probability of events Severity of random Local search optimization Large-scale linear & mixed Linear, & Forest-based entities events integer Mixed Linear modeling Classification Segmentation/ Clustering Variable Auto. stemming & synonym detection problems Selection





11 JAKO TO DZIAŁA? Kontroler SAS Enterprise Miner SAS Text Miner SAS Enterprise Guide (SAS/STAT, SAS/ETS, SAS/OR ) Klaster MPP 11 Copyright 2012, SAS Institute Inc. All rights reserved.

12 Jako to działa? Integracja z SAS Enterprise Miner

13 Lista węzłów SAS Enterprise Miner SAMPLE Append Data Partition File Import Filter Merge Sample Input Data EXPLORE Association Cluster Graph Explore Variable Clustering DMDB MultiPlot Market Basket StatExplore Link Analysis Path Analysis Variable Selection SOM/Kohonen MODIFY Drop Impute Interactive Binning Principal Components Replacement Rules Builder Transform Variables Decision Tree AutoNeural Regression Neural Network Partial Least Squares Dmine Regression DM Neural Ensemble Rule Induction Gradient Boosting LARS MBR Two Stage Model Import MODEL Incremental Response Survival Analysis Credit Scoring* TS Correlation TS Data Prep TS Dimension Reduction TS Decomp. TS Similarity TS Exponential Smoothing HP Explore HP Impute HP HP Variable HP Transform Regression Selection HP Neural HP Forest HP Decision Tree HP Data Partition HP GLM HP SVM HP Cluster HP Principal Components ASSESS Cutoff Decisions Model Comparison Score Segment Profile UTILITY Control Point End Groups Start Groups Open Source Integration Reporter Score Code Export Metadata SAS Code Ext Demo Save Data Register Metadata *Requires Credit Scoring for SAS Enterprise Miner Add-on License.

 5")

14 SAS High-Performance Data Mining Co można uzyskać? DATA EXPLORATION Klasyczny proces Metoda Sieci Neuronowej (1 iteracja) M O D E L D E V E L O P M E N T MODEL DEPLOYMENT Proces z użyciem High- Performance Metoda Sieci Neuronowej (100 iteracji) 5 godzin na policzenie modelu 6 minut na policzenie model Model lift 1.6% Model lift 3.2% Ograniczenie do 1-2 metod Możliwe eksperymenty z wieloma metodami 84 SECONDS
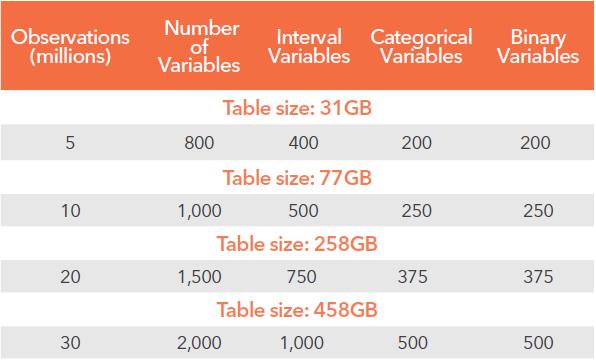
15 High Performance Data Mining na Hadoop Klaster 8 Węzłów, 64-rdzenie, Apache YARN, dane w formacie SASHDAT Data Mining Dane: 2 miliony rekordów 7.6GB 250 przedziałowych zmiennych wejściowych 125 kategoryzujących zmiennych wejściowych 125 binarnych zmiennych wejściowych 1 binarna zmienna objaśniana Obciążenie w tle (ETL w Map Reduce) 1 milion rekordów 3.05GB danych 200 przedziałowych zmiennych wejściowych 100 kategoryzujących zmiennych wejściowych 100 binarny zmiennych wejściowych 1 binarna zmienna objaśniana Węzeł EM SAS High- Performance Data Mining SAS High- Performance Data Mining i zadania w tle Input Data Source Files 00:03:25 00:04:39 HP Explore 00:01:12 00:01:43 HP Partition 00:01:43 00:03:08 HP Impute 00:01:22 00:01:41 HP Variable Selection 00:03:29 00:04:33 HP Transform 00:00:54 00:00:54 HP Regression: Forward 00:02:05 00:02:22 HP Regression: Stepwise 00:02:02 00:02:07 HP Neural 00:02:25 00:02:13 HP Tree 00:02:04 00:02:06 Model Comparison 00:00:02 00:00:02 Total (flow) Run Time 00:20:30 00:24:58 Konfiguracja Systemu: Osiem wirtualnych węzłów w ramach VMWare ESXi vcpu: Intel Xeon CPU E v2, 2.50GHz (8 core na węzeł) Memory: 64GB RAM (na węzeł), razem 512GB Storage: XIV version a with 5TB storage Network: 10GB Ethernet (na każdym węźle)
16 High Performance Data Mining Czy jest sens na PC? Data Mining Dane: 6 miliony rekordów 625 MB Analiza Procedura Czas procedury Czas węzła Regresja logistyczna Drzewo decyzyjne Proc dmreg Proc hplogistic Proc arbor Proc hpsplit 1:16 (cpu 1:16) 0:24 (cpu 1:10) 1:56 (cpu 1:56) 0:41 (cpu 2:23) 2m 31 s 1m 32 s 2m 20 s 1m 09 s Sieć neuronowa Proc neural Proc hpneural 35:37 (cpu 35:27) 2:12 (cpu 4:35) 37 m 4m 7s Konfiguracja Systemu: Pojedynczy PC z Windows 64-bit CPU: 4 Core+Hyper Threading Memory: 64GB RAM
17 SAS High-Performance Data Mining Co jest potrzebne? SAS Software SAS Enterprise Miner (Licencjonowany Odrębnie) SAS/ACCESS Engine Client Environment (SAS 9.4) Windows x64 (64-bit) Linux x64 (64-bit): Novell SuSE; RHEL; OEL IBM AIX (64-bit) HP/UX on Itanium (64-bit) Solaris x64 (64-bit), Solaris on SPARC (64-bit) Server Environment Linux x64 (64-bit): Novell SuSE 11 SP1; RHEL 6.1; OEL 6.1
18 SAS LASR Analytics Server Serwer obliczeniowy in-memory zaprojektowany specjalnie dla potrzeb interaktywnej zaawansowanej analityki i wizualizacji danych Najważniejsze założenia architektoniczne Dane In-Memory» Dane dystrybuowane w całym klastrze - partycjonowanie» Pozwala na szybką analizę danych dla algorytmów wieloprzebiegowe (multipass)» Współdzielony dostęp do danych dla wielu procesów Hybrid Distributed Computing Model» Wykorzystanie wielowątkowości (thread level)» Wykorzystanie wielu węzłów (node level)» Algorytmy równoległe świadome rozłożenia jednostek pracy (maszyna i jej rdzenie) CPU RAM CPU Wbudowane algorytmy zaawansowanej analityki, dziedzictwo 38 lat rozwoju narzędzi SAS. Regresja logistyczna nie zawsze znaczy to samo 2 miliardy kolumn Multi-User = Setki jednoczesnych użytkowników Stateless = nie ma potrzeby wyliczeń a-priori MPP (w tym w środowisku Hadoop) lub SMP (pojedyncza maszyna)

 Data Exploration/ Visualization BOXPLOT CORR CROSSTAB")



19 Data Manipulation SAS Data Step BALANCE COLUMINFO COMPUTE DELETEROWS DISTINCT DROPTABLE FETCH GROUPBY PARTITION PROMOTE PURGETEMPTABLES SET TABLE TRANSFORM UPDATE SAS LASR Analytics Server Funkcje silnika (tzw. Akcje) Data Exploration/ Visualization BOXPLOT CORR CROSSTAB CONTOURPLOT DISTRIBUTIONINFO FREQUENCY HISTOGRAM HYPERGROUP KDE REPLAY SUMMARY Predictive Modeling DECISIONTREE FORECAST LOGISTIC GENMODEL GLM RANDOMWOODS ASSESMENT ARM NEURAL OPTIMIZE Descriptive Modeling CLUSTER SVD Recommender CLUSTER KNN ASSOCIATIONS SVD Text Analytics PARSING SVD Deployment/ Miscellaneous EXTERNAL (C API) FREE SAVE STORE SCORE Data Manipulation Exploration / Visualization Modeling Deployment





20 SAS LASR Analytics Server Jak korzystamy? Visual Analytics Visual Statistics In-Memory Statistics LASR Server Master LASR Server Worker LASR Server Worker LASR Server Worker Klaster MPP
21 In-Memory Statistics (SAS LASR Server) Przykłady wydajności Dane (Modelowanie): rekordów 134 zmienne Łącznie wszystkie zadania 12.56s Skoring: 50 milionów rekordów Regresja liniowa 1.34 s Konfiguracja Systemu: CPU: 4 x 4 rdzenie Zadanie Czas (sec) Akcja PROC IMSTAT Statystyki opisowe dla jednej zmiennej numerycznej (n, min, max, mean, std) 0.03 summary Mediana i decyle dla jednej zmiennej numerycznej 0.11 percentile Rozkład częstości dla jednej zmiennej tekstowej 0.03 frequency Regresja liniowa dla 1 ilościowej zmiennej objaśnianej oraz 20 predyktorów ilościowych wraz z kodem skoringowym 2.43 glm Regresja liniowa dla 1 ilościowej zmiennej objaśnianej oraz 10 predyktorów ilościowych i 10 jakościowych 0.55 glm Regresja logistyczna dla 1 binarnej zmiennej objaśnianej oraz 20 predyktorów ilościowych 1.10 logistic Uogólniony model liniowy dla ilościowej zmiennej objaśnianej, 20 predyktorów ilościowych, rozkład gamma 5.49 genmodel k-means clustering dla 20 aktywnych zmiennych 0.64 cluster k-means clustering dla 100 aktywnych zmiennych 2.18 cluster

22 LASR Server i SAS High-Performance Możliwe architektury w relacji do klastra Hadoop DEDYKOWANY KLASTER DLA LASR/HPA SERVER Węzły LASR/HPA zainstalowane poza węzłami klastra Hadoop Przetwarzanie Hadoop separowane od przetwarzania LASR Asymetryczna architektura ładowania danych, z wykorzystaniem SAS Embedded Process lub tzw. Front Loading Hadoop Hadoop Hadoop Hadoop Hadoop EP EP EP EP EP Network SYMETRYCZNY KLASTER WSPÓŁDZIELONY Węzły LASR/HPA zainstalowane na wszystkich węzłach klastra Hadoop Konfiguracja klastra musi uwzględniać potencjalne konkurowanie o zasoby (np. wykorzystując YARN) Możliwa symetryczna (kolokowana) architektura dla ładowania danych z wykorzystaniem formatu SASHDAT LASR Hadoop LASR LASR LASR Hadoop LASR LASR Hadoop LASR Hadoop LASR ASYMETRYCZNY KLASTER WSPÓŁDZIELONY Węzły LASR/HPA zainstalowane na wybranych węzłach klastra Hadoop Konfiguracja klastra musi uwzględniać potencjalne konkurowanie o zasoby (np. wykorzystując YARN) Asymetryczna architektura ładowania danych, z wykorzystaniem SAS Embedded Process Hadoop EP Hadoop Hadoop LASR Hadoop LASR Hadoop LASR Hadoop EP EP EP EP EP LASR
23 LASR Server i SAS High-Performance Inne wspierane architektury sprzętowe Teradata Teradata 720 appliance połączony do Teradata Database EMC Pivotal Pivotal (Greenplum) Data Compute Appliance połączony do Greenplum Database Oracle Oracle Exalogic/Big Data Appliance/Commodity połączony do Exadata Database (Linux)
24 A co z wydajnością w innych aspektach? Aspekt Wydajność obliczeń Rozwiązania/technologie SAS Integracja Danych SAS Data Loader for Hadoop SAS Data Management Skoring Rodzina SAS Scoring Accelerator SAS Event Stream Processing Wydajność procesu Modelowanie masowe SAS Factory Miner Przekazanie na produkcję SAS Model Manager SAS Decision Manager Zarządzanie modelami SAS Model Manager


25 Agenda Informacje o prezentacjach i prelegentach Możliwość oceny prezentacji

26 Dziękuję za uwagę
27 SAS High-Performance Data Mining 13.2 CORE CAPABILITIES Data summarization High-performance DS2 High-performance data mining database Correlation Sampling Binning Imputation
28 SAS High-Performance Data Mining 13.2 SAS HIGH-PERFORMANCE STATISTICS Logistic regression and model selection Linear regression and model selection Nonlinear regression Partial least squares Quantile regression analysis Generalized linear modeling and model selection Decision trees Finite mixture models Principal components analysis Canonical discriminant analysis
29 SAS High-Performance Data Mining 13.2 SAS HIGH-PERFORMANCE DATA MINING Variable reduction Time series dimensional reduction Neural networks Random forests Random forest scoring Decisions Bayesian network Clustering Support vector machines
30 SAS High- Performance Data Mining 13.2 Champion models are automatically selected using selectable criteria: Kolmogorov-Smirnnov. Lift and cumulative lift. Gain and cumulative gain. Misclassification rate. Percent captured event. Average percent captured event. Average square error.
31 SAS High- Performance Data Mining 13.2 Bayesian Network Model A Bayesian network is a directed acyclic graphical model in which nodes represent random variables and the links between nodes represent conditional dependency of the random variables. Features: structure learning through efficient local learning algorithms efficient variable selection through independence tests automatic selection of the best parameters by using a validation data subset learning of different types of Bayesian network structures handling of both nominal and interval input variables binning of the interval input variables handling of missing values multithreading during the training and scoring phases
32 SAS High- Performance Data Mining 13.2 Splitting criteria: CHAID Chi-square Entropy Fast CHAID Gini Information Gain Ratio F Test Variance Decision Tree Model Subtree methods: Assessment C4.5 Cost-complexity
 dla danego środowiska MPP (skalowalność taka jak środowiska) Wykorzystuje rozproszoną architekturę Hadoop (Map-Reduce) lub mechanizmy platformy MPP")
33 SAS in-database EP udostępnia run-time SAS (tzw. TK) w platformach MPP Wykonuje program EMBEDDED w języku SAS DS2 PROCESS. CO TO JEST? Implementacja specyficzna (zoptymalizowana) dla danego środowiska MPP (skalowalność taka jak środowiska) Wykorzystuje rozproszoną architekturę Hadoop (Map-Reduce) lub mechanizmy platformy MPP (integracja poprzez Table Function UDF) dla optymalizacji i przetwarzania równoległego Jest zarządzany przez mechanizm workload management platformy MPP (np. przez YARN jak każda aplikacja M-R) W środowisku Hadoop wykorzystuje Hive, HCatalog oraz natywny dostęp do HDFS aby zapisywać/odczytywać dane (Avro, ORC, Parquet, RCFile, sequence, binary, delimited, XML) W środowisku MPP RDBMS korzysta z wewnętrznej komunikacji bazy do odczytu/zapisu danych, wykorzystuje mechanizmy optymalizacji platformy (np. Degree of Parelelism w Oracle Exadata) Oprócz Hadoop EP jest dostępny również w środowiskach MPP: IBM DB2 Pivotal Greenplum SAP HANA IBM Netezza Oracle Teradata











34 SCORE Data Manipulation Aggregate Compute Update Append Set Schema DeleteRows DropTables PurgeTempTables Data Exploration Boxplot Corr Crosstab Distinct Fetch Frequency Histogram KDE MDSummary Percentile Summary TopK Capabilities of SAS In-memory Statistics PREPARE DATA ANALYTICAL LIFE CYCLE TEXT Model Evaluation & Deployment DEVELOP MODELS Evaluation, Deployment Assess Misclassification matrix Lift, ROC, Concordance Score Training / Validation EXPLORE DATA Modeling Predictive Modeling Decision Tree Forecast Gen Linear Model Linear Regression Logistic Regression Random Forests Neural Networks Descriptive Modeling Association Path Analysis Clustering (k-means) Clustering (DBSCAN) Utilities Where GroupBy TableInfo, ColumnInfo, ServerInfo Partition, Balance Store, Replay, Free Table, Promote Text Analytics Parsing SVD Topic generation Document projection Recommendation Systems Association Clustering knn SVD Ensemble HDFS I/O Sasiola Sashdat Anyfile Reader



: Teradata, DB2, IBM Netezza, Aster Data, Oracle, SAP HANA,")
35 SAS Scoring Accelerator EMBEDDED PROCESSING (EP) MODEL PUBLISHING METHOD SAS Enterprise Miner Model SAS Scoring Code or Model Package Generated SAS Model Manager or SAS Program Interface Publish SQL query used to run the SAS Program SAS/STAT Model SAS Scoring Code or Itemstore Generated SAS/Access Interface SAS Model Manager Publish DS2 Program Published Registered DS2 Program SAS Embedded Process Registered SAS Formats Database Database Systems Supported (EP Publishing): Teradata, DB2, IBM Netezza, Aster Data, Oracle, SAP HANA, Hadoop & Pivotal (previously Greenplum)



36 SAS Scoring Accelerator WYDAJNOŚĆ
SAS ENTERPRISE MINER JAKO NARZĘDZIE ANALITYKA MARIUSZ DZIECIĄTKO
 SAS MINER JAKO NARZĘDZIE ANALITYKA MARIUSZ DZIECIĄTKO METODYKA SEMMA (SAMPLE, EXPLORE, MODIFY, MODEL, ASSESS) Prognoza Historia MODEL ANALITYCZNY PRZYGOTOWANIE DANYCH Funkcja przypisująca określoną wartość
SAS MINER JAKO NARZĘDZIE ANALITYKA MARIUSZ DZIECIĄTKO METODYKA SEMMA (SAMPLE, EXPLORE, MODIFY, MODEL, ASSESS) Prognoza Historia MODEL ANALITYCZNY PRZYGOTOWANIE DANYCH Funkcja przypisująca określoną wartość
ANALIZA I PRZETWARZANIE DUŻYCH WOLUMENÓW DANYCH NA PLATFORMIE SAS MARIUSZ DZIECIĄTKO
 ANALIZA I PRZETWARZANIE DUŻYCH WOLUMENÓW DANYCH NA PLATFORMIE SAS MARIUSZ DZIECIĄTKO mariusz.dzieciatko@sas.com KTO NAJBARDZIEJ SKORZYSTA Z UŻYCIA HADOOP: ŹRÓDŁO: TDWI Best Practices Report Q2 2015 HADOOP
ANALIZA I PRZETWARZANIE DUŻYCH WOLUMENÓW DANYCH NA PLATFORMIE SAS MARIUSZ DZIECIĄTKO mariusz.dzieciatko@sas.com KTO NAJBARDZIEJ SKORZYSTA Z UŻYCIA HADOOP: ŹRÓDŁO: TDWI Best Practices Report Q2 2015 HADOOP
SAS Access to Hadoop, SAS Data Loader for Hadoop Integracja środowisk SAS i Hadoop. Piotr Borowik
 SAS Access to Hadoop, SAS Data Loader for Hadoop Integracja środowisk SAS i Hadoop Piotr Borowik Wyzwania związane z Big Data Top Hurdles with Big data Source: Gartner (Sep 2014), Big Data Investment Grows
SAS Access to Hadoop, SAS Data Loader for Hadoop Integracja środowisk SAS i Hadoop Piotr Borowik Wyzwania związane z Big Data Top Hurdles with Big data Source: Gartner (Sep 2014), Big Data Investment Grows
BLOK 3 FUNKCJONALNOŚCI OPROGRAMOWANIA DOSTĘPNEGO W RAMACH PIBUK
 BLOK 3 FUNKCJONALNOŚCI OPROGRAMOWANIA DOSTĘPNEGO W RAMACH PIBUK INSTYTUT ŁĄCZNOŚCI, WARSZAWA 2015-11-03 AGENDA BLOK 3 Modelowanie i zarządzanie modelami SAS Enterprise Miner SAS Model Mangager Raportowanie
BLOK 3 FUNKCJONALNOŚCI OPROGRAMOWANIA DOSTĘPNEGO W RAMACH PIBUK INSTYTUT ŁĄCZNOŚCI, WARSZAWA 2015-11-03 AGENDA BLOK 3 Modelowanie i zarządzanie modelami SAS Enterprise Miner SAS Model Mangager Raportowanie
Szkolenia SAS Cennik i kalendarz 2017
 Szkolenia SAS Spis treści NARZĘDZIA SAS FOUNDATION 2 ZAAWANSOWANA ANALITYKA 2 PROGNOZOWANIE I EKONOMETRIA 3 ANALIZA TREŚCI 3 OPTYMALIZACJA I SYMULACJA 3 3 ROZWIĄZANIA DLA HADOOP 3 HIGH-PERFORMANCE ANALYTICS
Szkolenia SAS Spis treści NARZĘDZIA SAS FOUNDATION 2 ZAAWANSOWANA ANALITYKA 2 PROGNOZOWANIE I EKONOMETRIA 3 ANALIZA TREŚCI 3 OPTYMALIZACJA I SYMULACJA 3 3 ROZWIĄZANIA DLA HADOOP 3 HIGH-PERFORMANCE ANALYTICS
Modelowanie Data Mining na wielką skalę z SAS Factory Miner. Paweł Plewka, SAS
 Modelowanie Data Mining na wielką skalę z SAS Factory Miner Paweł Plewka, SAS Wstęp SAS Factory Miner Nowe narzędzie do data mining - dostępne od połowy 2015 r. Aktualna wersja - 14.1 Interfejs webowy
Modelowanie Data Mining na wielką skalę z SAS Factory Miner Paweł Plewka, SAS Wstęp SAS Factory Miner Nowe narzędzie do data mining - dostępne od połowy 2015 r. Aktualna wersja - 14.1 Interfejs webowy
SZKOLENIA SAS. ONKO.SYS Kompleksowa infrastruktura inforamtyczna dla badań nad nowotworami CENTRUM ONKOLOGII INSTYTUT im. Marii Skłodowskiej Curie
 SZKOLENIA SAS ONKO.SYS Kompleksowa infrastruktura inforamtyczna dla badań nad nowotworami CENTRUM ONKOLOGII INSTYTUT im. Marii Skłodowskiej Curie DANIEL KUBIK ŁUKASZ LESZEWSKI ROLE ROLE UŻYTKOWNIKÓW MODUŁU
SZKOLENIA SAS ONKO.SYS Kompleksowa infrastruktura inforamtyczna dla badań nad nowotworami CENTRUM ONKOLOGII INSTYTUT im. Marii Skłodowskiej Curie DANIEL KUBIK ŁUKASZ LESZEWSKI ROLE ROLE UŻYTKOWNIKÓW MODUŁU
Cena netto (PLN) IV kwartał. Cena netto (PLN) Podstawy SAS INTRO 1 1 200 1 260 2 20 4 1 7 2
 IV kwartał. Cena netto (PLN) Podstawy SAS INTRO 1 1 200 1 260 2 20 4 1 7 2") 2015 SAS Education sas.com/poland/training Centrum Szkoleniowe SAS Institute sp. z o.o. ul. Gdańska 27/31, 01-633 Warszawa (22) 560 46 20 cs@spl.sas.com Kalendarz szkoleń Grow With Us Nazwa szkolenia Kod
2015 SAS Education sas.com/poland/training Centrum Szkoleniowe SAS Institute sp. z o.o. ul. Gdańska 27/31, 01-633 Warszawa (22) 560 46 20 cs@spl.sas.com Kalendarz szkoleń Grow With Us Nazwa szkolenia Kod
Część 2: Data Mining
 Łukasz Przywarty 171018 Wrocław, 18.01.2013 r. Grupa: CZW/N 10:00-13:00 Raport z zajęć laboratoryjnych w ramach przedmiotu Hurtownie i eksploracja danych Część 2: Data Mining Prowadzący: dr inż. Henryk
Łukasz Przywarty 171018 Wrocław, 18.01.2013 r. Grupa: CZW/N 10:00-13:00 Raport z zajęć laboratoryjnych w ramach przedmiotu Hurtownie i eksploracja danych Część 2: Data Mining Prowadzący: dr inż. Henryk
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS. wersja 9.2 i 9.3. Szkoła Główna Handlowa w Warszawie
 STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
Zakup oprogramowania SAS
 ZAŁĄCZNIK NR 1 DO SIWZ Specyfikacja oprogramowania w środowiskach (obszarach) użytkowanych przez Zamawiającego i jednostki statystyki publicznej, warunki techniczno-sprzętowe dla tego oprogramowania oraz
ZAŁĄCZNIK NR 1 DO SIWZ Specyfikacja oprogramowania w środowiskach (obszarach) użytkowanych przez Zamawiającego i jednostki statystyki publicznej, warunki techniczno-sprzętowe dla tego oprogramowania oraz
Learn SAS. Training Certification Coaching. Grow With Us. Szkolenia Certyfikaty Mentoring Analiza potrzeb szkoleniowych
 Learn SAS Training Certification Coaching Szkolenia Certyfikaty Mentoring Analiza potrzeb szkoleniowych 2019 Grow With Us Oferta Centrum Szkoleniowego SAS Analiza potrzeb szkoleniowych Gwarancją udanego
Learn SAS Training Certification Coaching Szkolenia Certyfikaty Mentoring Analiza potrzeb szkoleniowych 2019 Grow With Us Oferta Centrum Szkoleniowego SAS Analiza potrzeb szkoleniowych Gwarancją udanego
Specyfikacja dostarczanego oprogramowania.
 ZAŁĄCZNIK NR 6 DO FORMULARZA OFERTY Specyfikacja dostarczanego oprogramowania. 1. Dostawa uzupełniających nieograniczonych czasowo, w wersji SAS 9.4 wraz z dokumentacją oprogramowania, dla wszystkich wymienionych
ZAŁĄCZNIK NR 6 DO FORMULARZA OFERTY Specyfikacja dostarczanego oprogramowania. 1. Dostawa uzupełniających nieograniczonych czasowo, w wersji SAS 9.4 wraz z dokumentacją oprogramowania, dla wszystkich wymienionych
Zarządzanie wieloserwerowym środowiskiem SAS z wykorzystaniem SAS Grid Managera. Katarzyna Wyszomierska
 Zarządzanie wieloserwerowym środowiskiem SAS z wykorzystaniem SAS Grid Managera Katarzyna Wyszomierska Wyzwania administratora Nowe oprogra mowanie Sprzęt Użytkownicy Dane Wyzwania administratora Potrzebne
Zarządzanie wieloserwerowym środowiskiem SAS z wykorzystaniem SAS Grid Managera Katarzyna Wyszomierska Wyzwania administratora Nowe oprogra mowanie Sprzęt Użytkownicy Dane Wyzwania administratora Potrzebne
BigData & Cloud Wprowadzenie
 BigData & Cloud Wprowadzenie Poznań 29-30 wrzesień 2015 IBM Corporation Agenda Dane, dużo danych Przykłady Wyzwania i ogranicznia technologiczne Wbudowana ekspertyza Podsumowanie 2 Dane jako na nowo odkrywany
BigData & Cloud Wprowadzenie Poznań 29-30 wrzesień 2015 IBM Corporation Agenda Dane, dużo danych Przykłady Wyzwania i ogranicznia technologiczne Wbudowana ekspertyza Podsumowanie 2 Dane jako na nowo odkrywany
Zakup oprogramowania SAS CIS-10/2014 ZAŁĄCZNIK NR 1 DO SIWZ. str. 1. Załącznik nr 1 do SIWZ
 ZAŁĄCZNIK NR 1 DO SIWZ Specyfikacja oprogramowania w środowiskach (obszarach) użytkowanych przez Zamawiającego i jednostki statystyki publicznej, warunki techniczno-sprzętowe dla tego oprogramowania oraz
ZAŁĄCZNIK NR 1 DO SIWZ Specyfikacja oprogramowania w środowiskach (obszarach) użytkowanych przez Zamawiającego i jednostki statystyki publicznej, warunki techniczno-sprzętowe dla tego oprogramowania oraz
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner. rok akademicki 2014/2015
 Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Sieci neuronowe Sieci neuronowe w SAS Enterprise Miner Węzeł Neural Network Do
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Sieci neuronowe Sieci neuronowe w SAS Enterprise Miner Węzeł Neural Network Do
Nowe podejście do składowania danych
 Nowe podejście do składowania danych Platforma dla danych transakcyjnych i analitycznych wykorzystująca składowanie kolumnowe w pamięci Hasso Plattner Oddzielne systemy transakcyjne + analityka + akceleracja
Nowe podejście do składowania danych Platforma dla danych transakcyjnych i analitycznych wykorzystująca składowanie kolumnowe w pamięci Hasso Plattner Oddzielne systemy transakcyjne + analityka + akceleracja
Szkolenie: Jak mieć więcej czasu na wyciąganie wniosków
 Szkolenie: Jak mieć więcej czasu na wyciąganie wniosków 14 listopada 2018 r 8:45-12:45 Warszawa https://alterdata.evenea.pl "Dzisiaj praca analityka składa się w 15% z analizowania. Cała reszta czynności
Szkolenie: Jak mieć więcej czasu na wyciąganie wniosków 14 listopada 2018 r 8:45-12:45 Warszawa https://alterdata.evenea.pl "Dzisiaj praca analityka składa się w 15% z analizowania. Cała reszta czynności
Digitize Your Business
 Digitize Your Business Aspekty technologiczne migracji na SAP HANA Prelegenci Błażej Trojan Konsultant technologiczny SAP Basis SI-Consulting Jakub Roguski - Territory Sales Leader Enterprise Systems -
Digitize Your Business Aspekty technologiczne migracji na SAP HANA Prelegenci Błażej Trojan Konsultant technologiczny SAP Basis SI-Consulting Jakub Roguski - Territory Sales Leader Enterprise Systems -
Konsolidacja wysokowydajnych systemów IT. Macierze IBM DS8870 Serwery IBM Power Przykładowe wdrożenia
 Konsolidacja wysokowydajnych systemów IT Macierze IBM DS8870 Serwery IBM Power Przykładowe wdrożenia Mirosław Pura Sławomir Rysak Senior IT Specialist Client Technical Architect Agenda Współczesne wyzwania:
Konsolidacja wysokowydajnych systemów IT Macierze IBM DS8870 Serwery IBM Power Przykładowe wdrożenia Mirosław Pura Sławomir Rysak Senior IT Specialist Client Technical Architect Agenda Współczesne wyzwania:
Informacja na żądanie, czyli rozwiązania sprzętowej akceleracji analityki biznesowej
 Informacja na żądanie, czyli rozwiązania sprzętowej akceleracji analityki biznesowej Tomasz Antonik Systems and Technology Group IBM Lab Services and Training Agenda Trendy w rozwoju systemów analitycznych
Informacja na żądanie, czyli rozwiązania sprzętowej akceleracji analityki biznesowej Tomasz Antonik Systems and Technology Group IBM Lab Services and Training Agenda Trendy w rozwoju systemów analitycznych
Architecture Best Practices for Big Data Deployments
 GLOBAL SPONSORS Architecture Best Practices for Big Data Deployments Kajetan Mroczek Systems Engineer GLOBAL SPONSORS Rozwój analityki biznesowej EKSPLORACJA DANYCH UCZENIE MASZYNOWE SZTUCZNA INTELIGENCJA
GLOBAL SPONSORS Architecture Best Practices for Big Data Deployments Kajetan Mroczek Systems Engineer GLOBAL SPONSORS Rozwój analityki biznesowej EKSPLORACJA DANYCH UCZENIE MASZYNOWE SZTUCZNA INTELIGENCJA
ZALETY NOWSZYCH WERSJI I KIERUNKI ROZWOJU SPDS-A SŁAWOMIR BOKINIEC
 ZALETY NOWSZYCH WERSJI I KIERUNKI ROZWOJU SPDS-A SŁAWOMIR BOKINIEC AGENDA Wybrane zalety wersji 5.1 i wcześniejszych SPDS z SAS Gridem Co kształtuje kierunki rozwoju? Nowsze wersje SPDS z Hadoopem WYBRANE
ZALETY NOWSZYCH WERSJI I KIERUNKI ROZWOJU SPDS-A SŁAWOMIR BOKINIEC AGENDA Wybrane zalety wersji 5.1 i wcześniejszych SPDS z SAS Gridem Co kształtuje kierunki rozwoju? Nowsze wersje SPDS z Hadoopem WYBRANE
Czym jest SAP HANA? Relacyjna baza danych przechowywana i przetwarzana w pamięci RAM. Uniwersalna platforma uruchomieniowa
 Czym jest SAP HANA? Relacyjna baza danych przechowywana i przetwarzana w pamięci RAM Uniwersalna platforma uruchomieniowa 2 SAP HANA Wszystkie aplikacje transakcyjne i analityczne pracują na tym samym
Czym jest SAP HANA? Relacyjna baza danych przechowywana i przetwarzana w pamięci RAM Uniwersalna platforma uruchomieniowa 2 SAP HANA Wszystkie aplikacje transakcyjne i analityczne pracują na tym samym
Organizacyjnie. Prowadzący: dr Mariusz Rafało (hasło: BIG)
") Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Data Camp Architektura Data Lake Repozytorium służące składowaniu i przetwarzaniu danych o
Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Data Camp Architektura Data Lake Repozytorium służące składowaniu i przetwarzaniu danych o
Przegląd dostępnych hypervisorów. Jakub Wojtasz IT Solutions Architect jwojtasz@atom-tech.pl
 Przegląd dostępnych hypervisorów Jakub Wojtasz IT Solutions Architect jwojtasz@atom-tech.pl Agenda Podział hypervisorów Architektura wybranych rozwiązań Najwięksi gracze na rynku Podział hypervisorów Hypervisor
Przegląd dostępnych hypervisorów Jakub Wojtasz IT Solutions Architect jwojtasz@atom-tech.pl Agenda Podział hypervisorów Architektura wybranych rozwiązań Najwięksi gracze na rynku Podział hypervisorów Hypervisor
Wprowadzenie do Hurtowni Danych
 Wprowadzenie do Hurtowni Danych BIG DATA Definicja Big Data Big Data definiowane jest jako składowanie zbiorów danych o tak dużej złożoności i ilości danych, że jest to niemożliwe przy zastosowaniu podejścia
Wprowadzenie do Hurtowni Danych BIG DATA Definicja Big Data Big Data definiowane jest jako składowanie zbiorów danych o tak dużej złożoności i ilości danych, że jest to niemożliwe przy zastosowaniu podejścia
Proces certyfikowania aplikacji na platformie PureSystems. Rafał Klimczak Lab Services Consultant
 Proces certyfikowania aplikacji na platformie PureSystems Rafał Klimczak Lab Services Consultant Produkty Pure Systems w IBM Rodziny produktów IBM: System z Freedom through design Eksperckie systemy zintegrowane:
Proces certyfikowania aplikacji na platformie PureSystems Rafał Klimczak Lab Services Consultant Produkty Pure Systems w IBM Rodziny produktów IBM: System z Freedom through design Eksperckie systemy zintegrowane:
Aktualizacja środowiska JAVA a SAS
 , SAS Institute Polska marzec 2018 Często spotykaną sytuacją są problemy z uruchomieniem aplikacji klienckich oraz serwerów SASowych wynikające z faktu aktualizacji środowiska JAVA zainstalowanego na komputerze.
, SAS Institute Polska marzec 2018 Często spotykaną sytuacją są problemy z uruchomieniem aplikacji klienckich oraz serwerów SASowych wynikające z faktu aktualizacji środowiska JAVA zainstalowanego na komputerze.
Oprogramowanie na miarę z13
 Oprogramowanie na miarę z13 Sebastian Milej, Zespół Oprogramowania Mainframe 11 lutego 2015 IBM z Systems to rozwiązanie kompletne Analytics Clo ud Securit y Mobile Socia l Technologia półprzewodników
Oprogramowanie na miarę z13 Sebastian Milej, Zespół Oprogramowania Mainframe 11 lutego 2015 IBM z Systems to rozwiązanie kompletne Analytics Clo ud Securit y Mobile Socia l Technologia półprzewodników
2011-11-04. Instalacja SQL Server Konfiguracja SQL Server Logowanie - opcje SQL Server Management Studio. Microsoft Access Oracle Sybase DB2 MySQL
 Instalacja, konfiguracja Dr inŝ. Dziwiński Piotr Katedra InŜynierii Komputerowej Kontakt: piotr.dziwinski@kik.pcz.pl 2 Instalacja SQL Server Konfiguracja SQL Server Logowanie - opcje SQL Server Management
Instalacja, konfiguracja Dr inŝ. Dziwiński Piotr Katedra InŜynierii Komputerowej Kontakt: piotr.dziwinski@kik.pcz.pl 2 Instalacja SQL Server Konfiguracja SQL Server Logowanie - opcje SQL Server Management
Monitorowanie VMware Rafał Szypułka Service Management Solution Architect IBM Software Services for Tivoli
 Monitorowanie VMware Rafał Szypułka Service Management Solution Architect IBM Software Services for Tivoli 1 Agenda Monitorowanie środowisk zwirtualizowanych IBM Tivoli Monitoring for Virtual Servers 6.2.3
Monitorowanie VMware Rafał Szypułka Service Management Solution Architect IBM Software Services for Tivoli 1 Agenda Monitorowanie środowisk zwirtualizowanych IBM Tivoli Monitoring for Virtual Servers 6.2.3
Hurtownia danych szansa na nowe życie (starej idei) Jakub Skuratowicz Technical Sales
 Jakub Skuratowicz Technical Sales") Hurtownia danych szansa na nowe życie (starej idei) Jakub Skuratowicz Technical Sales Rys Historyczny Idealna(kiedyś) architektura Data Quality MDM Enterprise Data Warehouse okazał się mitem Ma zawierać
Hurtownia danych szansa na nowe życie (starej idei) Jakub Skuratowicz Technical Sales Rys Historyczny Idealna(kiedyś) architektura Data Quality MDM Enterprise Data Warehouse okazał się mitem Ma zawierać
TTIC 31210: Advanced Natural Language Processing. Kevin Gimpel Spring Lecture 9: Inference in Structured Prediction
 TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 9: Inference in Structured Prediction 1 intro (1 lecture) Roadmap deep learning for NLP (5 lectures) structured prediction
TTIC 31210: Advanced Natural Language Processing Kevin Gimpel Spring 2019 Lecture 9: Inference in Structured Prediction 1 intro (1 lecture) Roadmap deep learning for NLP (5 lectures) structured prediction
Parametry wydajnościowe systemów internetowych. Tomasz Rak, KIA
 Parametry wydajnościowe systemów internetowych Tomasz Rak, KIA 1 Agenda ISIROSO System internetowy (rodzaje badań, konstrukcja) Parametry wydajnościowe Testy środowiska eksperymentalnego Podsumowanie i
Parametry wydajnościowe systemów internetowych Tomasz Rak, KIA 1 Agenda ISIROSO System internetowy (rodzaje badań, konstrukcja) Parametry wydajnościowe Testy środowiska eksperymentalnego Podsumowanie i
PAKIETY STATYSTYCZNE
 . Wykład wstępny PAKIETY STATYSTYCZNE 2. SAS, wprowadzenie - środowisko Windows, Linux 3. SAS, elementy analizy danych edycja danych 4. SAS, elementy analizy danych regresja liniowa, regresja nieliniowa
. Wykład wstępny PAKIETY STATYSTYCZNE 2. SAS, wprowadzenie - środowisko Windows, Linux 3. SAS, elementy analizy danych edycja danych 4. SAS, elementy analizy danych regresja liniowa, regresja nieliniowa
Hadoop i Spark. Mariusz Rafało
 Hadoop i Spark Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl WPROWADZENIE DO EKOSYSTEMU APACHE HADOOP Czym jest Hadoop Platforma służąca przetwarzaniu rozproszonemu dużych zbiorów danych. Jest
Hadoop i Spark Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl WPROWADZENIE DO EKOSYSTEMU APACHE HADOOP Czym jest Hadoop Platforma służąca przetwarzaniu rozproszonemu dużych zbiorów danych. Jest
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS. wersja 9.2 i 9.3. Szkoła Główna Handlowa w Warszawie
 STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
Jak zatrudnić słonie do replikacji baz PostgreSQL
 Jesień Linuksowa 2007, 22 września O projekcie... system replikacji danych dla PostgreSQL rozwijany od 2004 roku Open Source Licencja BSD Jan Wieck@Afilias... i inni aktualna seria 1.2.x
Jesień Linuksowa 2007, 22 września O projekcie... system replikacji danych dla PostgreSQL rozwijany od 2004 roku Open Source Licencja BSD Jan Wieck@Afilias... i inni aktualna seria 1.2.x
BigData. Czy zawsze oznacza BigProblem? Artur Górnik, SAP Polska Piotr Zacharek, HP Polska 14 kwietnia, 2015
 BigData Czy zawsze oznacza BigProblem? Artur Górnik, SAP Polska Piotr Zacharek, HP Polska 14 kwietnia, 2015 Platforma SAP HANA ETL ETL Cache SAP HANA (DRAM) Transact Analyze Accelerate Wybrane aspekty
BigData Czy zawsze oznacza BigProblem? Artur Górnik, SAP Polska Piotr Zacharek, HP Polska 14 kwietnia, 2015 Platforma SAP HANA ETL ETL Cache SAP HANA (DRAM) Transact Analyze Accelerate Wybrane aspekty
Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family
 Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów, architektów oraz
Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów, architektów oraz
Organizacyjnie. Prowadzący: dr Mariusz Rafało (hasło: BIG)
") Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) DANE W CZASIE RZECZYWISTYM 3 Tryb analizowania danych 4 Okno analizowania 5 Real-time: Checkpointing
Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) DANE W CZASIE RZECZYWISTYM 3 Tryb analizowania danych 4 Okno analizowania 5 Real-time: Checkpointing
Jak wiedzieć więcej i szybciej - Analizy in-memory
 Jak wiedzieć więcej i szybciej - Analizy in-memory Michał Grochowski Senior Consultant BI/DWH 1 Copyright 2012, Oracle and/or its affiliates. All rights reserved. 2 Copyright 2012, Oracle and/or its affiliates.
Jak wiedzieć więcej i szybciej - Analizy in-memory Michał Grochowski Senior Consultant BI/DWH 1 Copyright 2012, Oracle and/or its affiliates. All rights reserved. 2 Copyright 2012, Oracle and/or its affiliates.
Linear Classification and Logistic Regression. Pascal Fua IC-CVLab
 Linear Classification and Logistic Regression Pascal Fua IC-CVLab 1 aaagcxicbdtdbtmwfafwdgxlhk8orha31ibqycvkdgpshdqxtwotng2pxtvqujmok1qlky5xllzrnobbediegwcap4votk2kqkf+/y/tnphdschtadu/giv3vtea99cfma8fpx7ytlxx7ckns4sylo3doom7jguhj1hxchmy/irhrlgh67lxb5x3blis8jjqynmedqujiu5zsqqagrx+yjcfpcrydusshmzeluzsg7tttiew5khhcuzm5rv0gn1unw6zl3gbzlpr3liwncyr6aaqinx4wnc/rpg6ix5szd86agoftuu0g/krjxdarph62enthdey3zn/+mi5zknou2ap+tclvhob9sxhwvhaqketnde7geqjp21zvjsfrcnkfhtejoz23vq97elxjlpbtmxpl6qxtl1sgfv1ptpy/yq9mgacrzkgje0hjj2rq7vtywnishnnkzsqekucnlblrarlh8x8szxolrrxkb8n6o4kmo/e7siisnozcfvsedlol60a/j8nmul/gby8mmssrfr2it8lkyxr9dirxxngzthtbaejv
Linear Classification and Logistic Regression Pascal Fua IC-CVLab 1 aaagcxicbdtdbtmwfafwdgxlhk8orha31ibqycvkdgpshdqxtwotng2pxtvqujmok1qlky5xllzrnobbediegwcap4votk2kqkf+/y/tnphdschtadu/giv3vtea99cfma8fpx7ytlxx7ckns4sylo3doom7jguhj1hxchmy/irhrlgh67lxb5x3blis8jjqynmedqujiu5zsqqagrx+yjcfpcrydusshmzeluzsg7tttiew5khhcuzm5rv0gn1unw6zl3gbzlpr3liwncyr6aaqinx4wnc/rpg6ix5szd86agoftuu0g/krjxdarph62enthdey3zn/+mi5zknou2ap+tclvhob9sxhwvhaqketnde7geqjp21zvjsfrcnkfhtejoz23vq97elxjlpbtmxpl6qxtl1sgfv1ptpy/yq9mgacrzkgje0hjj2rq7vtywnishnnkzsqekucnlblrarlh8x8szxolrrxkb8n6o4kmo/e7siisnozcfvsedlol60a/j8nmul/gby8mmssrfr2it8lkyxr9dirxxngzthtbaejv
Nowoczesne narzędzia do ochrony informacji. Paweł Nogowicz
 Nowoczesne narzędzia do ochrony informacji Paweł Nogowicz Agenda Charakterystyka Budowa Funkcjonalność Demo 2 Produkt etrust Network Forensics Kontrola dostępu do zasobów etrust Network Forensics Zarządzanie
Nowoczesne narzędzia do ochrony informacji Paweł Nogowicz Agenda Charakterystyka Budowa Funkcjonalność Demo 2 Produkt etrust Network Forensics Kontrola dostępu do zasobów etrust Network Forensics Zarządzanie
Organizacyjnie. Prowadzący: dr Mariusz Rafało (hasło: BIG)
") Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Automatyzacja Automatyzacja przetwarzania: Apache NiFi Źródło: nifi.apache.org 4 Automatyzacja
Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Automatyzacja Automatyzacja przetwarzania: Apache NiFi Źródło: nifi.apache.org 4 Automatyzacja
Exalogic platforma do aplikacji Oracle i Middleware. Jakub Połeć Business Development Manager CE
 Exalogic platforma do aplikacji Oracle i Middleware Jakub Połeć Business Development Manager CE 2011 Oracle Corporation The following is intended to outline our general product direction. It is intended
Exalogic platforma do aplikacji Oracle i Middleware Jakub Połeć Business Development Manager CE 2011 Oracle Corporation The following is intended to outline our general product direction. It is intended
TECHNOLOGIE BIG DATA A BEZPIECZEŃSTWO INFORMATYCZNE WE KNOW YOU KNOW. silmine.com
 TECHNOLOGIE BIG DATA A BEZPIECZEŃSTWO INFORMATYCZNE WE KNOW YOU KNOW. silmine.com 13 + 13 LAT DOŚWIADCZENIA PONAD 480 ZREALIZOWANYCH PROJEKTÓW PARTNERSTWO Naszą ambicją jest dostarczać klientom szeroki
TECHNOLOGIE BIG DATA A BEZPIECZEŃSTWO INFORMATYCZNE WE KNOW YOU KNOW. silmine.com 13 + 13 LAT DOŚWIADCZENIA PONAD 480 ZREALIZOWANYCH PROJEKTÓW PARTNERSTWO Naszą ambicją jest dostarczać klientom szeroki
Wprowadzenie do sieciowych systemów operacyjnych. Moduł 1
 Wprowadzenie do sieciowych systemów operacyjnych Moduł 1 Sieciowy system operacyjny Sieciowy system operacyjny (ang. Network Operating System) jest to rodzaj systemu operacyjnego pozwalającego na pracę
Wprowadzenie do sieciowych systemów operacyjnych Moduł 1 Sieciowy system operacyjny Sieciowy system operacyjny (ang. Network Operating System) jest to rodzaj systemu operacyjnego pozwalającego na pracę
Hurtownie danych i business intelligence - wykład II. Zagadnienia do omówienia. Miejsce i rola HD w firmie
 Hurtownie danych i business intelligence - wykład II Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2005-2012 Zagadnienia do omówienia 1. Miejsce i rola w firmie 2. Przegląd architektury
Hurtownie danych i business intelligence - wykład II Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2005-2012 Zagadnienia do omówienia 1. Miejsce i rola w firmie 2. Przegląd architektury
IBM PureSystems Czy to naprawdę przełom w branży IT?
 IBM PureSystems Czy to naprawdę przełom w branży IT? Krzysztof Rozanka Pure Systems, Poland & Baltics k.rozanka@pl.ibm.com kom. 693 93 51 42 IBM Polska 2 3 Zintegrowane systemy eksperckie 4 Infrastructure
IBM PureSystems Czy to naprawdę przełom w branży IT? Krzysztof Rozanka Pure Systems, Poland & Baltics k.rozanka@pl.ibm.com kom. 693 93 51 42 IBM Polska 2 3 Zintegrowane systemy eksperckie 4 Infrastructure
Opis przedmiotu zamówienia
 Załącznik nr.1 do SIWZ CIS-15/2015 Opis przedmiotu zamówienia SPIS TREŚCI PRZEDMIOT ZAMÓWIENIA... 2 1. OPIS PRZEDMIOTU ZAMÓWIENIA... 2 1.1. DODATKOWE WYMAGANIA DOT. REALIZACJI PRZEDMIOTU ZAMÓWIENIA...
Załącznik nr.1 do SIWZ CIS-15/2015 Opis przedmiotu zamówienia SPIS TREŚCI PRZEDMIOT ZAMÓWIENIA... 2 1. OPIS PRZEDMIOTU ZAMÓWIENIA... 2 1.1. DODATKOWE WYMAGANIA DOT. REALIZACJI PRZEDMIOTU ZAMÓWIENIA...
Szczypta historii. 2010 Inteligentne rozmieszczanie. Pierwszy magnetyczny dysk twardy. Macierz RAID. Wirtualizacja. danych
 Szczypta historii 1956 Pierwszy magnetyczny dysk twardy IBM 305 RAMAC (Random Access Method of Accounting and Control). 50 dysków o średnicy ok. 60 cm - 5 MB. 1993 Macierz RAID Grupa dysków jest widziana
Szczypta historii 1956 Pierwszy magnetyczny dysk twardy IBM 305 RAMAC (Random Access Method of Accounting and Control). 50 dysków o średnicy ok. 60 cm - 5 MB. 1993 Macierz RAID Grupa dysków jest widziana
PureSystems zautomatyzowane środowisko aplikacyjne. Emilia Smółko Software IT Architect
 PureSystems zautomatyzowane środowisko aplikacyjne. Emilia Smółko Software IT Architect Wbudowana wiedza specjalistyczna Dopasowane do zadania Optymalizacja do aplikacji transakcyjnych Inteligentne Wzorce
PureSystems zautomatyzowane środowisko aplikacyjne. Emilia Smółko Software IT Architect Wbudowana wiedza specjalistyczna Dopasowane do zadania Optymalizacja do aplikacji transakcyjnych Inteligentne Wzorce
Datacenter - Przykład projektu dla pewnego klienta.
 Datacenter - Przykład projektu dla pewnego klienta. Wstęp! Technologie oraz infrastruktury wykorzystywane przez Capgemini. Projekt dla pewnego francuskiego klienta założenia Requests Capgemini datacenters
Datacenter - Przykład projektu dla pewnego klienta. Wstęp! Technologie oraz infrastruktury wykorzystywane przez Capgemini. Projekt dla pewnego francuskiego klienta założenia Requests Capgemini datacenters
Skalowalna Platforma dla eksperymentów dużej skali typu Data Farming z wykorzystaniem środowisk organizacyjnie rozproszonych
 1 Skalowalna Platforma dla eksperymentów dużej skali typu Data Farming z wykorzystaniem środowisk organizacyjnie rozproszonych D. Król, Ł. Dutka, J. Kitowski ACC Cyfronet AGH Plan prezentacji 2 O nas Wprowadzenie
1 Skalowalna Platforma dla eksperymentów dużej skali typu Data Farming z wykorzystaniem środowisk organizacyjnie rozproszonych D. Król, Ł. Dutka, J. Kitowski ACC Cyfronet AGH Plan prezentacji 2 O nas Wprowadzenie
Laboratorium 11. Regresja SVM.
 Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Hard-Margin Support Vector Machines
 Hard-Margin Support Vector Machines aaacaxicbzdlssnafiyn9vbjlepk3ay2gicupasvu4iblxuaw2hjmuwn7ddjjmxm1bkcg1/fjqsvt76fo9/gazqfvn8y+pjpozw5vx8zkpvtfxmlhcwl5zxyqrm2vrg5zw3vxmsoezi4ogkr6phieky5crvvjhriqvdom9l2xxftevuwcekj3lktmhghgniauiyutvrwxtvme34a77kbvg73gtygpjsrfati1+xc8c84bvraowbf+uwnipyehcvmkjrdx46vlykhkgykm3ujjdhcyzqkxy0chur6ax5cbg+1m4bbjptjcubuz4kuhvjoql93hkin5hxtav5x6yyqopnsyuneey5ni4keqrxbar5wqaxbik00icyo/iveiyqqvjo1u4fgzj/8f9x67bzmxnurjzmijtlybwfgcdjgfdtajwgcf2dwaj7ac3g1ho1n4814n7wwjgjmf/ys8fenfycuzq==
Hard-Margin Support Vector Machines aaacaxicbzdlssnafiyn9vbjlepk3ay2gicupasvu4iblxuaw2hjmuwn7ddjjmxm1bkcg1/fjqsvt76fo9/gazqfvn8y+pjpozw5vx8zkpvtfxmlhcwl5zxyqrm2vrg5zw3vxmsoezi4ogkr6phieky5crvvjhriqvdom9l2xxftevuwcekj3lktmhghgniauiyutvrwxtvme34a77kbvg73gtygpjsrfati1+xc8c84bvraowbf+uwnipyehcvmkjrdx46vlykhkgykm3ujjdhcyzqkxy0chur6ax5cbg+1m4bbjptjcubuz4kuhvjoql93hkin5hxtav5x6yyqopnsyuneey5ni4keqrxbar5wqaxbik00icyo/iveiyqqvjo1u4fgzj/8f9x67bzmxnurjzmijtlybwfgcdjgfdtajwgcf2dwaj7ac3g1ho1n4814n7wwjgjmf/ys8fenfycuzq==
tum.de/fall2018/ in2357
 https://piazza.com/ tum.de/fall2018/ in2357 Prof. Daniel Cremers From to Classification Categories of Learning (Rep.) Learning Unsupervised Learning clustering, density estimation Supervised Learning learning
https://piazza.com/ tum.de/fall2018/ in2357 Prof. Daniel Cremers From to Classification Categories of Learning (Rep.) Learning Unsupervised Learning clustering, density estimation Supervised Learning learning
Klaster obliczeniowy
 Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
2014 LENOVO INTERNAL. ALL RIGHTS RESERVED
 2014 LENOVO INTERNAL. ALL RIGHTS RESERVED 3 SUSE OpenStack - Architektura SUSE OpenStack - Funkcje Oprogramowanie Open Source na bazie OpenStack Scentralizowane monitorowanie zasobów Portal samoobsługowy
2014 LENOVO INTERNAL. ALL RIGHTS RESERVED 3 SUSE OpenStack - Architektura SUSE OpenStack - Funkcje Oprogramowanie Open Source na bazie OpenStack Scentralizowane monitorowanie zasobów Portal samoobsługowy
MS Visual Studio 2005 Team Suite - Performance Tool
 MS Visual Studio 2005 Team Suite - Performance Tool przygotował: Krzysztof Jurczuk Politechnika Białostocka Wydział Informatyki Katedra Oprogramowania ul. Wiejska 45A 15-351 Białystok Streszczenie: Dokument
MS Visual Studio 2005 Team Suite - Performance Tool przygotował: Krzysztof Jurczuk Politechnika Białostocka Wydział Informatyki Katedra Oprogramowania ul. Wiejska 45A 15-351 Białystok Streszczenie: Dokument
Hbase, Hive i BigSQL
 Hbase, Hive i BigSQL str. 1 Agenda 1. NOSQL a HBase 2. Architektura HBase 3. Demo HBase 4. Po co Hive? 5. Apache Hive 6. Demo hive 7. BigSQL 1 HBase Jest to rozproszona trwała posortowana wielowymiarowa
Hbase, Hive i BigSQL str. 1 Agenda 1. NOSQL a HBase 2. Architektura HBase 3. Demo HBase 4. Po co Hive? 5. Apache Hive 6. Demo hive 7. BigSQL 1 HBase Jest to rozproszona trwała posortowana wielowymiarowa
BUSINESS INTELLIGENCE
 BUSINESS INTELLIGENCE SAS VISUAL ANALYTICS Copyr i g ht 2012, SAS Ins titut e Inc. All rights res er ve d. Artur Jastrzębski Copyr i g ht 2013, SAS Ins titut e Inc. All rights res er ve d. CO TO JEST BIG
BUSINESS INTELLIGENCE SAS VISUAL ANALYTICS Copyr i g ht 2012, SAS Ins titut e Inc. All rights res er ve d. Artur Jastrzębski Copyr i g ht 2013, SAS Ins titut e Inc. All rights res er ve d. CO TO JEST BIG
SQL Server 2016 w świecie Big Data
 temat prelekcji.. SQL Server 2016 w świecie Big Data prowadzący Bartłomiej Graczyk Data Platform Solution Architect bartlomiej.graczyk@microsoft.com bartek@graczyk.info.pl Agenda Dane na świecie wczoraj,
temat prelekcji.. SQL Server 2016 w świecie Big Data prowadzący Bartłomiej Graczyk Data Platform Solution Architect bartlomiej.graczyk@microsoft.com bartek@graczyk.info.pl Agenda Dane na świecie wczoraj,
Hurtownie Danych i Business Intelligence: przegląd technologii
 Hurtownie Danych i Business Intelligence: przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Tematyka Architektury
Hurtownie Danych i Business Intelligence: przegląd technologii Robert Wrembel Politechnika Poznańska Instytut Informatyki Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Tematyka Architektury
Cyfronet w CTA. Andrzej Oziębło DKDM
 Cyfronet w CTA Andrzej Oziębło DKDM ACK CYFRONET AGH Akademickie Centrum Komputerowe CYFRONET Akademii Górniczo-Hutniczej im. Stanisława Staszica w Krakowie ul. Nawojki 11 30-950 Kraków 61 tel. centrali:
Cyfronet w CTA Andrzej Oziębło DKDM ACK CYFRONET AGH Akademickie Centrum Komputerowe CYFRONET Akademii Górniczo-Hutniczej im. Stanisława Staszica w Krakowie ul. Nawojki 11 30-950 Kraków 61 tel. centrali:
Piotr Zacharek HP Polska
 HP Integrity VSE Rozwój bez ograniczeń HP Restricted Piotr Zacharek HP Polska Technology for better business outcomes 2007 Hewlett-Packard Development Company, L.P. The information contained herein is
HP Integrity VSE Rozwój bez ograniczeń HP Restricted Piotr Zacharek HP Polska Technology for better business outcomes 2007 Hewlett-Packard Development Company, L.P. The information contained herein is
Numer sprawy DP/2310/35/12
 ZAŁĄCZNIK NR 1 I. do formularza Ofertowego Produkt zamawiany Produkt oferowany L.p. Cechy Ilość Nazwa i parametry ilość 1 2 3 4 5 6 7 8 VAT % Cena netto za Wartość brutto 1. 2. STATISTICA Pakiet Zaawansowany
ZAŁĄCZNIK NR 1 I. do formularza Ofertowego Produkt zamawiany Produkt oferowany L.p. Cechy Ilość Nazwa i parametry ilość 1 2 3 4 5 6 7 8 VAT % Cena netto za Wartość brutto 1. 2. STATISTICA Pakiet Zaawansowany
Przykład Rezygnacja z usług operatora
 Przykład Rezygnacja z usług operatora Zbiór CHURN Zbiór zawiera dane o 3333 klientach firmy telefonicznej razem ze wskazaniem, czy zrezygnowali z usług tej firmy Dane pochodzą z UCI Repository of Machine
Przykład Rezygnacja z usług operatora Zbiór CHURN Zbiór zawiera dane o 3333 klientach firmy telefonicznej razem ze wskazaniem, czy zrezygnowali z usług tej firmy Dane pochodzą z UCI Repository of Machine
Wprowadzenie do Apache Spark. Jakub Toczek
 Wprowadzenie do Apache Spark Jakub Toczek Epoka informacyjna MapReduce MapReduce Apache Hadoop narodziny w 2006 roku z Apache Nutch open source składa się z systemu plików HDFS i silnika MapReduce napisany
Wprowadzenie do Apache Spark Jakub Toczek Epoka informacyjna MapReduce MapReduce Apache Hadoop narodziny w 2006 roku z Apache Nutch open source składa się z systemu plików HDFS i silnika MapReduce napisany
Laboratorium Chmur obliczeniowych. Paweł Świątek, Łukasz Falas, Patryk Schauer, Radosław Adamkiewicz
 Laboratorium Chmur obliczeniowych Paweł Świątek, Łukasz Falas, Patryk Schauer, Radosław Adamkiewicz Agenda SANTOS Lab laboratorium badawcze Zagadnienia badawcze Infrastruktura SANTOS Lab Zasoby laboratorium
Laboratorium Chmur obliczeniowych Paweł Świątek, Łukasz Falas, Patryk Schauer, Radosław Adamkiewicz Agenda SANTOS Lab laboratorium badawcze Zagadnienia badawcze Infrastruktura SANTOS Lab Zasoby laboratorium
IBM POWER8 dla SAP HANA
 IBM POWER8 dla SAP HANA SUCCESS STORY Efektywność Innowacyjność Bezpieczeństwo Success Story Pierwsze wdrożenie w Polsce Dzięki współpracy firm itelligence, COMPAREX oraz IBM została zaprojektowana i zrealizowana
IBM POWER8 dla SAP HANA SUCCESS STORY Efektywność Innowacyjność Bezpieczeństwo Success Story Pierwsze wdrożenie w Polsce Dzięki współpracy firm itelligence, COMPAREX oraz IBM została zaprojektowana i zrealizowana
Wirtualizacja infrastruktury według VMware. Michał Małka DNS Polska
 Wirtualizacja infrastruktury według VMware Michał Małka DNS Polska VMware - gama produktów Production Server VirtualCenter ESX Server Test/Development Workstation GSX / VMware Server Enterprise Desktop
Wirtualizacja infrastruktury według VMware Michał Małka DNS Polska VMware - gama produktów Production Server VirtualCenter ESX Server Test/Development Workstation GSX / VMware Server Enterprise Desktop
Tematy projektów Edycja 2019
 Tematy projektów Edycja 2019 Robert Wrembel Poznan University of Technology Institute of Computing Science Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Temat 1 Implementacja modelu predykcji
Tematy projektów Edycja 2019 Robert Wrembel Poznan University of Technology Institute of Computing Science Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Temat 1 Implementacja modelu predykcji
EAL4+ bezpieczeństwo z SUSE Linux Enterprise Server. Dariusz Leonarski Novell Polska dleonarski@novell.pl
 EAL4+ bezpieczeństwo z SUSE Linux Enterprise Server Dariusz Leonarski Novell Polska dleonarski@novell.pl Agenda Common Criteria SLES w zastosowaniach profesjonalnych Bezpieczeństwo w SUSE Novell AppArmor
EAL4+ bezpieczeństwo z SUSE Linux Enterprise Server Dariusz Leonarski Novell Polska dleonarski@novell.pl Agenda Common Criteria SLES w zastosowaniach profesjonalnych Bezpieczeństwo w SUSE Novell AppArmor
Kompleksowe rozwiązania do ochrony danych. Wybrane przykłady wdroŝeń. Tomasz Tubis. Tivoli Summer Academy 2010
 Kompleksowe rozwiązania do ochrony danych. Wybrane przykłady wdroŝeń. Tomasz Tubis Tivoli Summer Academy 2010 Grupa Sygnity Powstała w marcu 2007 roku w wyniku połączenia dwóch giełdowych grup kapitałowych:
Kompleksowe rozwiązania do ochrony danych. Wybrane przykłady wdroŝeń. Tomasz Tubis Tivoli Summer Academy 2010 Grupa Sygnity Powstała w marcu 2007 roku w wyniku połączenia dwóch giełdowych grup kapitałowych:
Dni: 5. Opis: Adresaci szkolenia
 Kod szkolenia: Tytuł szkolenia: HK988S VMware vsphere: Advanced Fast Track Dni: 5 Opis: Adresaci szkolenia Administratorzy systemowi, inżynierowie systemowi, konsultanci i pracownicy help-desku, którzy
Kod szkolenia: Tytuł szkolenia: HK988S VMware vsphere: Advanced Fast Track Dni: 5 Opis: Adresaci szkolenia Administratorzy systemowi, inżynierowie systemowi, konsultanci i pracownicy help-desku, którzy
Baza danych in-memory. DB2 BLU od środka 2015-11-10. Artur Wrooski
 TECHNOLOGIE ANALIZY DANYCH I CHMUROWE W ZASTOSOWANIACH BIZNESOWYCH Poznao, 30 września 2015 DB2 BLU od środka Artur Wrooski Baza danych in-memory Baza danych IN-MEMORY system zarządzania bazami danych,
TECHNOLOGIE ANALIZY DANYCH I CHMUROWE W ZASTOSOWANIACH BIZNESOWYCH Poznao, 30 września 2015 DB2 BLU od środka Artur Wrooski Baza danych in-memory Baza danych IN-MEMORY system zarządzania bazami danych,
Rozwiązania bazodanowe EnterpriseDB
 Rozwiązania bazodanowe EnterpriseDB Bogumił Stoiński RHC{E,I,X} B2B Sp. z o.o. 519 130 155 bs@bel.pl PostgreSQL Ponad 20 lat na rynku Jedna z najpopularniejszych otwartych relacyjnych baz danych obok MySQL
Rozwiązania bazodanowe EnterpriseDB Bogumił Stoiński RHC{E,I,X} B2B Sp. z o.o. 519 130 155 bs@bel.pl PostgreSQL Ponad 20 lat na rynku Jedna z najpopularniejszych otwartych relacyjnych baz danych obok MySQL
Standardowy nowy sait problemy zwiazane z tworzeniem nowego datacenter
 Standardowy nowy sait problemy zwiazane z tworzeniem nowego datacenter O mnie Krzysztof Podobiński Infrastructure/ VMware Consultant ponad10 lat doświadczenia w IT 5 lata w Capgemini Application Support
Standardowy nowy sait problemy zwiazane z tworzeniem nowego datacenter O mnie Krzysztof Podobiński Infrastructure/ VMware Consultant ponad10 lat doświadczenia w IT 5 lata w Capgemini Application Support
Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1
 Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1 Historia i pojęcia wstępne Obliczenia równoległe: dwa lub więcej procesów (wątków) jednocześnie współpracuje (komunikując się wzajemnie)
Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1 Historia i pojęcia wstępne Obliczenia równoległe: dwa lub więcej procesów (wątków) jednocześnie współpracuje (komunikując się wzajemnie)
VMware vsphere 5.5: Install, Configure, Manage
 Kod szkolenia: Tytuł szkolenia: H6D01S VMware vsphere 5.5: Install, Configure, Manage Dni: 5 Opis: Adresaci szkolenia Cel szkolenia Administratorzy systemów Inżynierowie systemowi Operatorzy odpowiedzialni
Kod szkolenia: Tytuł szkolenia: H6D01S VMware vsphere 5.5: Install, Configure, Manage Dni: 5 Opis: Adresaci szkolenia Cel szkolenia Administratorzy systemów Inżynierowie systemowi Operatorzy odpowiedzialni
O mnie
 O mnie Cele sesji Cele sesji Dlaczego? http://www.zdnet.com/article/microsofts-r-strategy/ Źródło: https://azure.microsoft.com/enus/blog/forrester-names-microsoft-azurea-leader-in-big-data-hadoop-cloudsolutions/
O mnie Cele sesji Cele sesji Dlaczego? http://www.zdnet.com/article/microsofts-r-strategy/ Źródło: https://azure.microsoft.com/enus/blog/forrester-names-microsoft-azurea-leader-in-big-data-hadoop-cloudsolutions/
IBM SPSS Modeler 18.0 podręcznik eksploracji w bazie danych IBM
 IBM SPSS Modeler 18.0 podręcznik eksploracji w bazie danych IBM Uwaga Przed skorzystaniem z niniejszych informacji oraz produktu, którego one dotyczą, należy zapoznać się z informacjami zamieszczonymi
IBM SPSS Modeler 18.0 podręcznik eksploracji w bazie danych IBM Uwaga Przed skorzystaniem z niniejszych informacji oraz produktu, którego one dotyczą, należy zapoznać się z informacjami zamieszczonymi
HP Matrix Operating Environment: Infrastructure Administration
 Kod szkolenia: Tytuł szkolenia: HK920S HP Matrix Operating Environment: Infrastructure Administration Dni: 4 Opis: Adresaci szkolenia Doświadczeni administratorzy, którzy zarządzają rozwiązaniami private
Kod szkolenia: Tytuł szkolenia: HK920S HP Matrix Operating Environment: Infrastructure Administration Dni: 4 Opis: Adresaci szkolenia Doświadczeni administratorzy, którzy zarządzają rozwiązaniami private
Wprowadzenie do SAS. Wprowadzenie. Historia SAS. Struktura SAS 8. Interfejs: SAS Explorer. Interfejs. Część I: Łagodny wstęp do SAS Rafał Latkowski
 Wprowadzenie do SAS Część I: Łagodny wstęp do SAS Rafał Latkowski Wprowadzenie 2 Historia SAS Struktura SAS 8 1976 BASE SAS 1980 SAS/GRAPH & SAS/ETS 1985 SAS/IML, BASE SAS for PC Raportowanie i grafika
Wprowadzenie do SAS Część I: Łagodny wstęp do SAS Rafał Latkowski Wprowadzenie 2 Historia SAS Struktura SAS 8 1976 BASE SAS 1980 SAS/GRAPH & SAS/ETS 1985 SAS/IML, BASE SAS for PC Raportowanie i grafika
SAS Lineage. zależności między obiektami w środowisku SAS, perspektywa techniczna i biznesowa
 SAS Lineage zależności między obiektami w środowisku SAS, perspektywa techniczna i biznesowa Agenda Co to jest SAS Lineage Znaczenie w zarządzaniu danymi Produkty i możliwości Baza danych o relacjach Jak
SAS Lineage zależności między obiektami w środowisku SAS, perspektywa techniczna i biznesowa Agenda Co to jest SAS Lineage Znaczenie w zarządzaniu danymi Produkty i możliwości Baza danych o relacjach Jak
Wprowadzenie. Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra.
 N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
NOWY OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA
 NOWY OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA Załącznik nr 4 do SIWZ/ załącznik do umowy Przedmiotem zamówienia jest dostawa 2 serwerów, licencji oprogramowania wirtualizacyjnego wraz z konsolą zarządzającą
NOWY OPIS TECHNICZNY PRZEDMIOTU ZAMÓWIENIA Załącznik nr 4 do SIWZ/ załącznik do umowy Przedmiotem zamówienia jest dostawa 2 serwerów, licencji oprogramowania wirtualizacyjnego wraz z konsolą zarządzającą
Strona główna > Produkty > Systemy regulacji > System regulacji EASYLAB - LABCONTROL > Program konfiguracyjny > Typ EasyConnect.
 Typ EasyConnect FOR THE COMMISSIONING AND DIAGNOSIS OF EASYLAB COMPONENTS, FSE, AND FMS Software for the configuration and diagnosis of controllers Type TCU3, adapter modules TAM, automatic sash device
Typ EasyConnect FOR THE COMMISSIONING AND DIAGNOSIS OF EASYLAB COMPONENTS, FSE, AND FMS Software for the configuration and diagnosis of controllers Type TCU3, adapter modules TAM, automatic sash device
Optymalizacja rozwiązań wirtualizacyjnych
 Optymalizacja rozwiązań wirtualizacyjnych Paweł Lubasiński Romuald Pacek Kwiecień 24, 2013 Eksplozja wirtualizacji 10 nowych VM uruchamianych co minutę To więcej niż rodzi się dzieci w USA. 20 MILLIONÓW
Optymalizacja rozwiązań wirtualizacyjnych Paweł Lubasiński Romuald Pacek Kwiecień 24, 2013 Eksplozja wirtualizacji 10 nowych VM uruchamianych co minutę To więcej niż rodzi się dzieci w USA. 20 MILLIONÓW
Architektura komunikacji
 isqlplus Agenda 1 Rozwój produktu isql*plus ma swoje początki w wersji Oracle 8i, kiedy jest zakończony pierwszy etap prac nad projektem. Interfejs użytkownika jest cienki klient - przeglądarka internetowa,
isqlplus Agenda 1 Rozwój produktu isql*plus ma swoje początki w wersji Oracle 8i, kiedy jest zakończony pierwszy etap prac nad projektem. Interfejs użytkownika jest cienki klient - przeglądarka internetowa,
Hurtownie i eksploracja danych
 Hurtownie i eksploracja danych Laboratorium Część 1: OLAP Cel Poznanie metod budowy środowiska OLAP umożliwiającego wielowymiarową analizę faktów w funkcji wymiarów. Opanowanie umiejętności wykorzystania
Hurtownie i eksploracja danych Laboratorium Część 1: OLAP Cel Poznanie metod budowy środowiska OLAP umożliwiającego wielowymiarową analizę faktów w funkcji wymiarów. Opanowanie umiejętności wykorzystania
Tematy projektów HDiPA 2015
 Tematy projektów HDiPA 2015 Robert Wrembel Poznan University of Technology Institute of Computing Science Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Reguły Projekty zespołowe 2-4 osoby
Tematy projektów HDiPA 2015 Robert Wrembel Poznan University of Technology Institute of Computing Science Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Reguły Projekty zespołowe 2-4 osoby
Nowoczesne bazy danych, czyli przetwarzanie in-memory
 Nowoczesne bazy danych, czyli przetwarzanie in-memory 1. Dlaczego przetwarzanie w pamięci? 2. Komercyjne bazy danych in-memory 3. Zwykła baza danych, a baza w pamięci różnice 4. Wymiarowanie sprzętu 5.
Nowoczesne bazy danych, czyli przetwarzanie in-memory 1. Dlaczego przetwarzanie w pamięci? 2. Komercyjne bazy danych in-memory 3. Zwykła baza danych, a baza w pamięci różnice 4. Wymiarowanie sprzętu 5.
Technologie wirtualizacyjne na platformie Red Hat. Artur Głogowski aglogowski@atom-tech.pl
 Technologie wirtualizacyjne na platformie Red Hat Artur Głogowski aglogowski@atom-tech.pl Atom-tech sp. z o.o. Najbardziej zaawansowany technologicznie Red Hat Advanced Business Partner: Technologie klastrowe
Technologie wirtualizacyjne na platformie Red Hat Artur Głogowski aglogowski@atom-tech.pl Atom-tech sp. z o.o. Najbardziej zaawansowany technologicznie Red Hat Advanced Business Partner: Technologie klastrowe
MATLAB Neural Network Toolbox przegląd
 MATLAB Neural Network Toolbox przegląd WYKŁAD Piotr Ciskowski Neural Network Toolbox: Neural Network Toolbox - zastosowania: przykłady zastosowań sieci neuronowych: The 1988 DARPA Neural Network Study
MATLAB Neural Network Toolbox przegląd WYKŁAD Piotr Ciskowski Neural Network Toolbox: Neural Network Toolbox - zastosowania: przykłady zastosowań sieci neuronowych: The 1988 DARPA Neural Network Study
Inverse problems - Introduction - Probabilistic approach
 Inverse problems - Introduction - Probabilistic approach Wojciech Dȩbski Instytut Geofizyki PAN debski@igf.edu.pl Wydział Fizyki UW, 13.10.2004 Wydział Fizyki UW Warszawa, 13.10.2004 (1) Plan of the talk
Inverse problems - Introduction - Probabilistic approach Wojciech Dȩbski Instytut Geofizyki PAN debski@igf.edu.pl Wydział Fizyki UW, 13.10.2004 Wydział Fizyki UW Warszawa, 13.10.2004 (1) Plan of the talk