Mikrokontrolery STM32 który do czego?
|
|
|
- Sylwester Nowak
- 6 lat temu
- Przeglądów:
Transkrypt

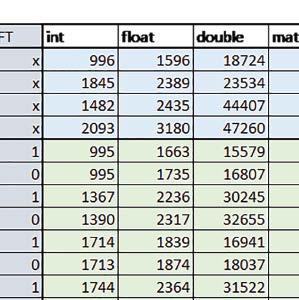
1 Mikrokontrolery STM32 który do czego? Benchmarki porównujące wydajność w różnych aplikacjach Duża liczba dostępnych modeli mikrokontrolerów STM32 oraz wyposażanie ich w różne rdzenie powoduje, że konstruktorzy nie zawsze wiedzą, jaki model wybrać do swojej aplikacji. Postanowiliśmy wykonać serię autorskich testów, których celem było zmierzenie i porównanie wydajności różnych mikrokontrolerów w typowych zastosowaniach, jak również sprawdzenie wpływu różnych ustawień na czas wykonania programu. W artykule przedstawiamy wyniki uzyskane dla STM32 z rdzeniami Cortex-M0, Cortex-M0+, dwóch wersji Cortex-M3, a także Cortex-M4 i Cortex-M7. Jak w każdym teście lub badaniu ogromnie ważną rolę odgrywa używana metoda. Bez jej opisu informacje są niepełne i właściwie bezwartościowe, więc poświęćmy jej kilka słów. Zastosowana metoda Ponieważ zależało nam na podejściu maksymalnie praktycznym, mierzyliśmy czas wykonania zestawu testów reprezentujących typowe operacje wykonywane przez mikrokontrolery. W testach wykorzystano następujące typy mikrokontrolerów: STM32F030R8 (Cortex-M0), STM32L053R8 (Cortex-M0+), STM32F103RB (Cortex-M3), STM32L152RE (Cortex-M3), STM32F446RE (Cortex-M4), STM32F746ZG (Cortex-M7). Kolejne testy obejmowały (na początku podano skrótowe oznaczenia stosowane dalej w tabelach): int proste operacje arytmetyczne i logiczne na liczbach stałopozycyjnych: dodawanie, odejmowanie, mnożenie, dzielenie, modulo, suma logiczna, iloczyn logiczny, różnica symetryczna. float proste operacje na liczbach zmiennopozycyjnych pojedynczej precyzji: dodawanie, odejmowanie, mnożenie, dzielenie, modulo, wartość bezwzględna, pierwiastek kwadratowy, podnoszenie do potęgi. ELEKTRONIKA PRAKTYCZNA 10/













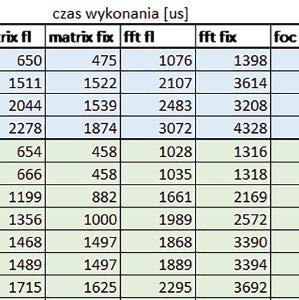
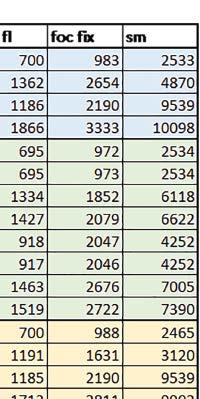
2 double proste operacje na liczbach zmiennopozycyjnych podwójnej precyzji dokładnie takie same operacje jak dla liczb zmiennopozycyjnych pojedynczej precyzji. matrix fl, matrix fix operacje na macierzach liczb odpowiednio zmiennopozycyjnych pojedynczej precyzji i stałopozycyjnych w formacie Q1.31. Wykorzystano funkcje z biblioteki CMSIS: dodawanie, odejmowanie, mnożenie, transpozycja i odwrotność (ostatnie tylko dla liczb zmiennopozycyjnych, ze względu na brak odpowiedniej funkcji operującej na liczbach stałopozycyjnych w bibliotece CMSIS). fft fl, fft fix prosta i odwrotna, szybka transformata Fouriera w wersji operującej na liczbach odpowiednio zmiennopozycyjnych pojedynczej precyzji i stałopozycyjnych w formacie Q1.31. Test został przeprowadzony dla mikrokontrolerów, które miały wystarczająco dużą pamięć, aby można było wgrać program wykorzystujący funkcje z biblioteki CMSIS, tj. STM32L152RE, STM32F446RE, STM32F746ZG. foc fl, foc fix algorytmy wykorzystywane przy Field Oriented Control: PID, transformata Clarka, transformata Parka (prosta i odwrotna). Wykorzystano funkcje z biblioteki CMSIS w wersji operującej na liczbach odpowiednio zmiennopozycyjnych pojedynczej precyzji i stałopozycyjnych w formacie Q1.31. sm skoki i rozejścia warunkowe w Finite State Machine. Jako automat do testów wykorzystany został prosty hex loader. W każdym przypadku częstotliwość taktowania mikrokontrolera została ustawiona na największą możliwą dla danego mikrokontrolera. Sygnał zegarowy mikrokontrolera pochodził z PLL. Tam, gdzie było to możliwe, jako źródło częstotliwości wejściowej PLL wybrano HSE. W przypadku mikrokontrolera STM32F030R8 używana płytka Nucleo była w konfiguracji HSE not used, w związku z czym do taktowania PLL wykorzystano HSI. Do pomiaru czasu wykorzystane zostały sprzętowe timery. Pomiary wykonano z rozdzielczością 1 ms dla mikrokontrolerów: STM32F103RB, STM32F446RE, STM32F746ZG i z rozdzielczością 10 ms dla STM32F030R8, STM32L053R8, STM32L152RE. Wyniki zostały następnie znormalizowane. Żeby nie zakłócać testów przez obsługę przerwań, pomiary polegały na odczytaniu rejestru CNT timera przed i po teście, a następnie wyliczeniu na tej podstawie czasu wykonania testu. Wyniki zostały następnie sprawdzone i ewentualnie skorygowane w przypadku wyników większych niż na podstawie wyników pomiarów przeprowadzonych z 10 razy mniejszą rozdzielczością. Po zakończonych testach wyniki były przesyłane do komputera PC przez UART. Dla wszystkich mikrokontrolerów sprawdzono wpływ następujących opcji: Poziom optymalizacji: o2 vs o3 różnice w otrzymanych wynikach z reguły były niewielkie (w większości przypadków nie przekraczały ±1%), dlatego dalej przedstawiono wyniki dla poziomu optymalizacji o3, a krótkie podsumowanie różnic między o2 i o3 umieszczono przy opisie wyników dla każdego z mikrokontrolerów. Wykorzystanie bądź nie sprzętowej jednostki zmiennopozycyjnej (FPU) tam, gdzie jest ona dostępna (tj. dla ELEKTRONIKA PRAKTYCZNA 10/2016

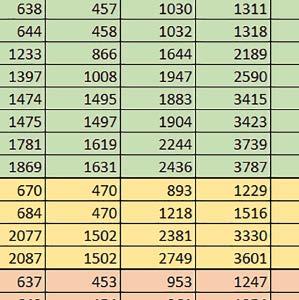
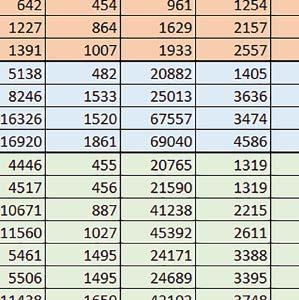
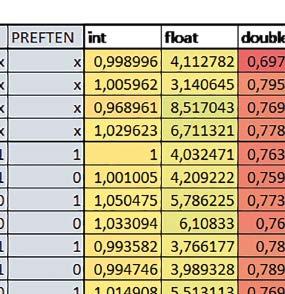
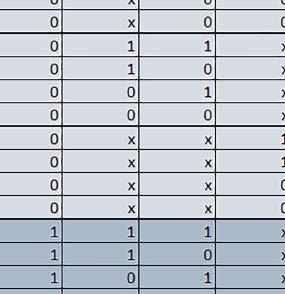
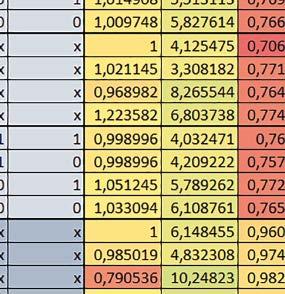
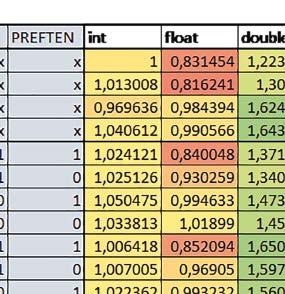
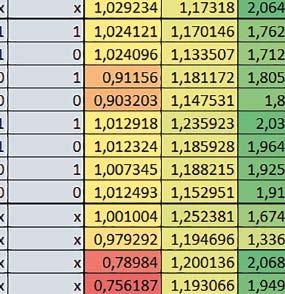
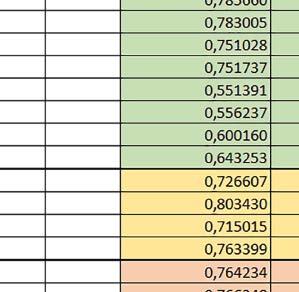
3 Mikrokontrolery STM32 który do czego? STM32F446RE, STM32F746ZG w obu przypadkach jest to jednostka zmiennopozycyjna pojedynczej precyzji). Wykorzystanie biblioteki Microlib zoptymalizowanej na niewielki rozmiar kodu względem biblioteki standardowej. Dla konkretnych mikrokontrolerów sprawdzono wpływ specyficznych opcji mających przyspieszyć wykonanie programów, takich jak: prefetch, buforowanie, kieszenie. Porównano również czas wykonania testów fft i foc w wersji operującej na liczb zmiennopozycyjnych i stałopozycyjnych oraz wyniki testów double i float (te same obliczenia na liczbach podwójnej i pojedynczej precyzji). Wpływ dostępnych opcji na czas wykonywania programu 1. STM32F030R8 (Cortex-M0) W przypadku STM32F030R8 ustawienie bitu PREFTEN w rejestrze FLASH_ACR włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnego słowa po tym, które ostatnio odczytano, jako instrukcję. Wyniki: 1, 2, 3, 4 Wnioski: o2 vs o3 Różnice między poziomem optymalizacji o2 a o3 praktycznie nie występowały (nie przekraczały ±1%). microlib vs std lib Rozmiar kodu wynikowego był o ok. ¼ większy dla biblioteki standardowej. W przypadku automatu i obliczeń na macierzach liczb stałopozycyjnych różnice nie występowały lub były bardzo małe (do ok. 1%). Dla obliczeń zmiennopozycyjnych w przypadku korzystania z Microlib czas wykonania był ok. 1,2 1,7 razy dłuższy. Znaczne różnice wystąpiły w przypadku prostych obliczeń stałopozycyjnych, gdzie czas wykonania wersji wykorzystującej Microlib okazał się ok. 3,5 razy dłuższy. Jeszcze większe w przypadku FOC operującego na liczbach stałopozycyjnych, gdzie użycie Microlib spowodowało ponad 8-krotny wzrost czasu wykonania. PREFTEN Włączenie mechanizmu prefetch spowodowało zmniejszenie czasu wykonania ok. 1,3 1,4 razy. Największy wpływ miało na operacje na macierzach liczb stałopozycyjnych, FOC operujące na liczbach zmiennopozycyjnych, automat oraz, w przypadku korzystania z biblioteki standardowej, na proste operacje stałopozycyjne i FOC operujące na liczbach stałopozycyjnych. double vs float Czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2,5 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3,5 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. floating point vs fixed point Czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 2,5 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 2,5 razy krótszy, jeżeli wykorzystywana była biblioteka Microlib. 2. STM32L053R8 (Cortex-M0+) W przypadku STM32L053R8 ustawienie bitu DISAB_BUF w rejestrze FLASH_ACR wyłącza bufory używane jako kieszenie dla odczytów z NVM (Non-Volatile Memory). Jeśli DISAB_BUF = 0, to ustawienie w rejestrze FLASH_ACR bitu PREFTEN włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnego słowa po tym, które ostatnio odczytano, jako instrukcję, a ustawienie bitu PRE_READ włącza mechanizm pre-read, czyli spekulatywne pobieranie kolejnego słowa danych. Wyniki: 5, 6, 7, 8, 9, - Wnioski: o2 vs o3 Dla automatu czas wykonania w przypadku poziomu optymalizacji o2 był ok. 2 3% krótszy. W pozostałych wypadkach różnice praktycznie nie występowały. microlib vs std lib Rozmiar kodu wynikowego był o ok. 25% większy dla biblioteki standardowej. W przypadku automatu i obliczeń na macierzach liczb stałopozycyjnych różnice nie występowały lub były bardzo małe (do ok. 1%). Dla obliczeń zmiennopozycyjnych w przypadku korzystania z Microlib czas wykonania był ok. 1,2 1,6 razy dłuższy. Znaczne różnice wystąpiły w przypadku prostych obliczeń stałopozycyjnych, gdzie czas wykonania wersji wykorzystującej Microlib okazał się ok. 3 razy dłuższy. Jeszcze większe w przypadku FOC operującego na liczbach stałopozycyjnych, gdzie użycie Microlib spowodowało ok. 8-krotny wzrost czasu wykonania. DISAB_BUF Wyłączenie buforów spowodowało wydłużenie czasu wykonania o maksymalnie kilka procent. Wyłączenie buforów praktycznie nie miało wpływu w przypadku automatu, FOC operującego na liczbach zmiennopozycyjnych i prostych obliczeń stałopozycyjnych, jeżeli wykorzystywana była biblioteka standardowa. Natomiast jeżeli wykorzystywana była biblioteka Microlib, to czas wykonania dla prostych obliczeń stałopozycyjnych był ok. 1,1 razy dłuższy przy wyłączonych buforach. PREFTEN Włączenie mechanizmu prefetch spowodowało zmniejszenie czasu wykonania o ok %. Największy wpływ miało na operacje na macierzach liczb stałopozycyjnych, FOC operujące na liczbach zmiennopozycyjnych oraz, w przypadku korzystania z biblioteki standardowej, na proste operacje stałopozycyjne i FOC operujące na liczbach stałopozycyjnych. PRE_READ Bardzo małe różnice. double vs float Czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2,5 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3,5 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. floating point vs fixed point Czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 2,5 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 2,5 razy krótszy, jeżeli wykorzystywana była biblioteka Microlib. 3. STM32F103RB (Cortex-M3) W przypadku STM32F103RB ustawienie bitu PREFTEN w rejestrze FLASH_ACR włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnego słowa po tym, które ostatnio odczytano jako instrukcję. #, $ Wnioski: o2 vs o3 Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji o2 był do ok. 7% krótszy. W przypadku korzystania z biblioteki standardowej i przy włączonym prefetch dla prostych obliczeń zmiennopozycyjnych ok. 6% krótszy, dla obliczeń na macierzach liczb zmiennopozycyjnych ok. 9% krótszy, natomiast dla FOC operującego na liczbach zmiennopozycyjnych ok. 2% dłuższy. Przy włączonym prefetch dla automatu ok. 2 7% krótszy. W pozostałych przypadkach różnice były niewielkie. microlib vs std lib Rozmiar kodu wynikowego był o ok. 1/6 większy dla biblioteki standardowej. Różnice czasów wykonania w zależności od użycia # $ ELEKTRONIKA PRAKTYCZNA 10/
.")






 i prostych")












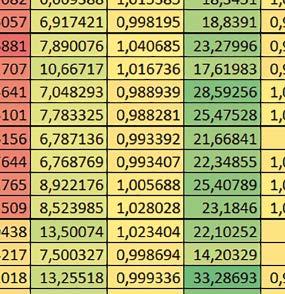
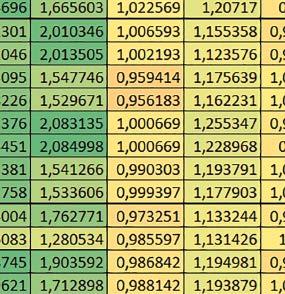
4 biblioteki standardowej lub Microlib były średnio mniejsze niż dla Cortex-M0(+). Różnice były większe przy włączonym prefetch. Dla operacji na liczbach stałopozycyjnych i automatu różnice były niewielkie. W przypadku korzystania z Microlib czas wykonania był ok. 2 razy dłuższy dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji, ok. 1,5 razy dłuższy dla obliczeń na macierzach liczb zmiennopozycyjnych i ok. 1,1 1,2 razy dłuższy dla pozostałych obliczeń zmiennopozycyjnych. PREFTEN Włączenie mechanizmu prefetch spowodowało zmniejszenie czasu wykonania ok. 1,2 1,5 razy. Największe znaczenie miało dla FOC, obliczeń na macierzach (szczególnie zmiennopozycyjnych) i prostych obliczeń na liczbach zmiennopozycyjnych pojedynczej precyzji. Większe różnice występowały, jeżeli wykorzystywana była biblioteka standardowa niż dla Microlib. double vs float Czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2 razy dłuższy, jeżeli wykorzystywana jest biblioteka standardowa i ok. 3,2 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. floating point vs fixed point Czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 6 7 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ponad 8 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. Dla FFT czasy wykonania różniły się odpowiednio ok. 7 8 razy i ok. 10 razy. 4. STM32L152RE (Cortex-M3) W przypadku STM32L152RE ustawienie bitu PREFTEN w rejestrze FLASH_ACR włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnego słowa po tym, które ostatnio odczytano, jako instrukcję. Wyniki: %, ^, &, * Wnioski: o2 vs o3 Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji o2 był do ok. 2 3% krótszy, natomiast w przypadku korzystania z biblioteki standardowej dla prostych obliczeń zmiennopozycyjnych i obliczeń na macierzach liczb zmiennopozycyjnych do ok. 4% dłuższy. W pozostałych przypadkach różnice były niewielkie. micro lib vs std lib Rozmiar kodu wynikowego był o ok. 1/6 większy dla biblioteki standardowej. Różnice czasów wykonania w zależności od użycia % ^ & * ( ) 74 ELEKTRONIKA PRAKTYCZNA 10/2016






 Wnioski: o2 vs o3 W większości wypadków różnice były nieznaczne (poniżej 1%). Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji o2 był do ok.")

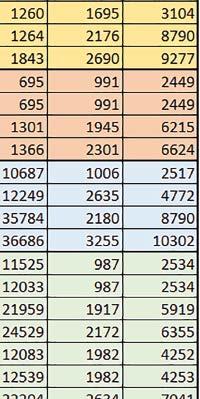
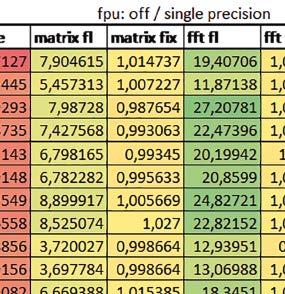
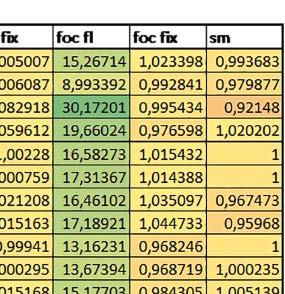
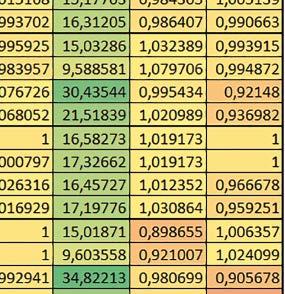
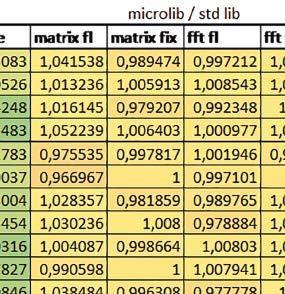
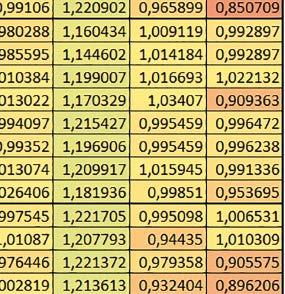
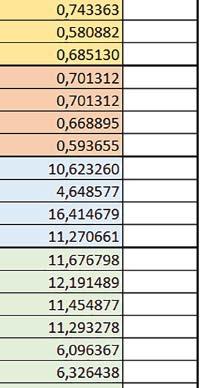
5 Mikrokontrolery STM32 który do czego? biblioteki standardowej lub Microlib były średnio mniejsze niż dla Cortex-M0(+). Dla operacji na liczbach stałopozycyjnych i automatu różnice były bardzo niewielkie. W wypadku korzystania z Microlib czas wykonania był ponad 2 razy dłuższy dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji, ok. 1,7 razy dłuższy dla obliczeń na macierzach liczb zmiennopozycyjnych i ok. 1,3 razy dłuższy dla pozostałych obliczeń zmiennopozycyjnych. PREFTEN Włączenie mechanizmu prefetch spowodowało zmniejszenie czasu wykonania maksymalnie ok. 1,2 razy. Największe znaczenie miało dla obliczeń na liczbach zmiennopozycyjnych pojedynczej i podwójnej precyzji, jeżeli wykorzystywana była biblioteka standardowa. double vs float Czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3,2 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. floating point vs fixed point Czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 6 7 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ponad 8 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. Dla FFT czasy wykonania różniły się odpowiednio ok. 7 8 razy i ok. 10 razy. 5. STM32F446RE (Cortex-M4) W przypadku STM32F446RE ustawienie w rejestrze FLASH_ACR bitu ICEN włącza kieszeń instrukcji o pojemności 64 linii po 128 bitów każda, natomiast ustawienie bitu DCEN włącza kieszeń danych o pojemności 8 linii po 128 bitów każda. Ustawienie PREFTEN w rejestrze FLASH_ACR włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnej 128-bitowej linii zawierającej instrukcje. Wyniki: (, ) Wnioski: o2 vs o3 W większości wypadków różnice były nieznaczne (poniżej 1%). Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji o2 był do ok. 3% krótszy, jeśli włączona była kieszeń instrukcji oraz do ok. 20% krótszy, jeśli kieszeń instrukcji była wyłączona. Dla operacji zmiennopozycyjnych pojedynczej precyzji w przypadku używania biblioteki standardowej przy wyłączonej kieszeni instrukcji i FPU czas wykonania dla poziomu optymalizacji o2 był od kilku do kilkunastu procent krótszy. W przypadku używania FPU, dla FOC operującego na liczbach zmiennopozycyjnych czas wykonania w przypadku poziomu optymalizacji o2 był od kilku do ok. 10% dłuższy. Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji o2 był do ok. 2 3% krótszy, natomiast w przypadku korzystania z biblioteki standardowej dla prostych obliczeń zmiennopozycyjnych i obliczeń na macierzach liczb zmiennopozycyjnych do ok. 4% dłuższy. W pozostałych wypadkach różnice były niewielkie. FPU Wykorzystanie FPU przyspieszyło obliczenia na liczbach zmiennopozycyjnych pojedynczej precyzji ok. 3,5 20 razy dla biblioteki standardowej i ok. 4,5 25 razy dla biblioteki Microlib. Użycie wsparcia sprzętowego dla obliczeń zmiennopozycyjnych było najbardziej korzystne w przypadku FOC i FFT, gdzie przyspieszenie wynosiło razy dla biblioteki standardowej i dla biblioteki Microlib. Trochę mniejsze różnice występowały w przypadku obliczeń na macierzach (6 8 razy dla biblioteki standardowej i dla biblioteki Microlib) i prostych obliczeń (3,5 6 razy dla biblioteki standardowej i 4,5 8 dla biblioteki Microlib). Obliczenia na liczbach zmiennopozycyjnych podwójnej precyzji w przypadku korzystania z FPU wykonywały się o ok. 30% wolniej dla biblioteki standardowej i ok. 4% wolniej dla biblioteki Microlib i włączonej kieszeni instrukcji. Wyniki cd.: q, w, e Wnioski cd.: micro lib vs std lib Rozmiar kodu wynikowego był o ok. 1/6 większy dla biblioteki standardowej. Dla biblioteki Microlib czas wykonania dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji był ok. 1,5 razy dłuższy w przypadku używania FPU, i ok. 2 razy dłuższy, jeśli FPU nie było wykorzystywane. W przypadku niekorzystania z FPU czas wykonania dla biblioteki Microlib był ok. 1,7 razy dłuższy dla obliczeń na macierzach liczb zmiennopozycyjnych i ok. 1,2 1,4 razy dłuższy dla pozostałych obliczeń zmiennopozycyjnych. PREFTEN Jeśli kieszeń instrukcji była włączona, to mechanizm prefetch miał niezbyt duży wpływ na czas wykonania. W większości przypadków wyniki były bardzo podobne. Różnice występowały w kilku przypadkach: przy włączonym prefetch dla obliczeń na macierzach i prostych obliczeń zmiennopozycyjnych podwójnej precyzji czas wykonania był do ok. 1,1 razy krótszy, dla prostych obliczeń q w ELEKTRONIKA PRAKTYCZNA 10/
.")

.")


 Włączenie kieszeni danych największe znaczenie")












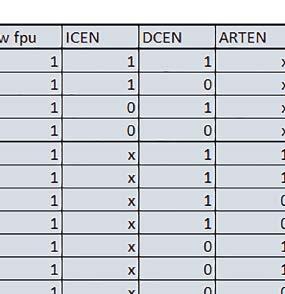
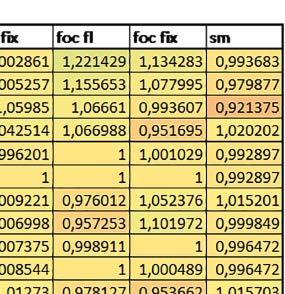
6 zmiennopozycyjnych pojedynczej precyzji do ok. 1,3 razy krótszy (w pojedynczym przypadku 1,5 razy). Jeśli kieszeń instrukcji była wyłączona, prefetch miało znacznie większy wpływ. Włączenie prefetch spowodowało skrócenie czasu wykonania ok. 1,1 1,5 razy (w większości przypadków ponad 1,2 razy). Instruction Cache (ICEN) Włączenie kieszeni instrukcji spowodowało zmniejszenie czasu wykonania ok. 1,1 2 razy. Miało większe znaczenie, jeśli mechanizm prefetch był wyłączony. W wypadku obliczeń zmiennopozycyjnych miało większe znaczenie, jeśli FPU nie było wykorzystywane. Wyniki cd.: r, t Wnioski cd.: Data Cache (DCEN) Włączenie kieszeni danych największe znaczenie miało przy FOC spowodowało skrócenie czasu wykonania ok. 1,2 razy dla wersji stałopozycyjnej i ok. 1,2 1,3 razy dla wersji zmiennopozycyjnej w przypadku nieużywania FPU. Miało niewielkie znaczenie dla pozostałych obliczeń stałopozycyjnych. Włączenie kieszeni danych spowodowało skrócenie o ok. kilka procent czasu wykonania dla automatu, jak również dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji w przypadku używania biblioteki standardowej, prostych obliczeń zmiennopozycyjnych pojedynczej precyzji, jeśli FPU nie było wykorzystywane, oraz dla obliczeń na macierzach liczb zmiennopozycyjnych, jeśli używana była biblioteka standardowa i FPU nie było wykorzystywane. double vs float W wypadku nieużywania FPU czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. W przypadku używania FPU czas wykonania był odpowiednio ok. 10 i ok. 20 razy dłuższy. floating point vs fixed point W wypadku nieużywania FPU, czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. Dla FFT czasy wykonania różniły się odpowiednio ok razy i ok razy. W wypadku używania FPU czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 2 razy krótszy, natomiast FFT ok. 1,4 razy krótszy. 6. STM32F746ZG (Cortex-M7) W przypadku STM32F746ZG możliwe są różne konfiguracje z różnym ulokowaniem kodu i danych w pamięci. Dla różnych konfiguracji różne e r t 76 ELEKTRONIKA PRAKTYCZNA 10/2016
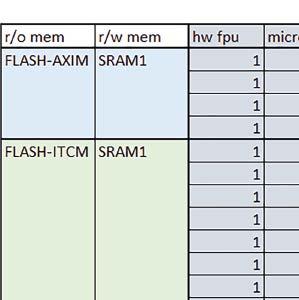
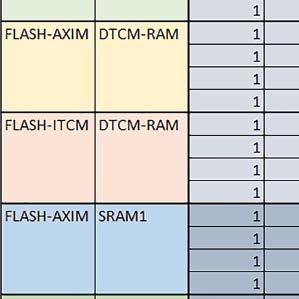
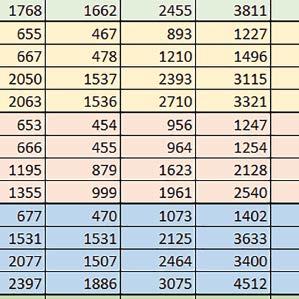
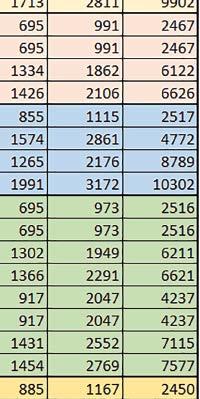

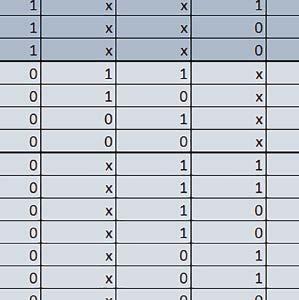
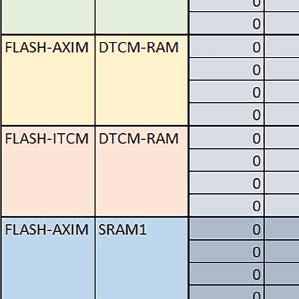

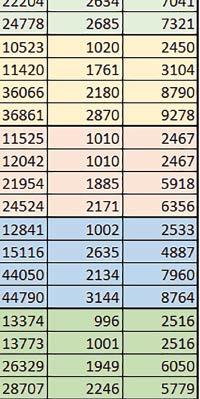
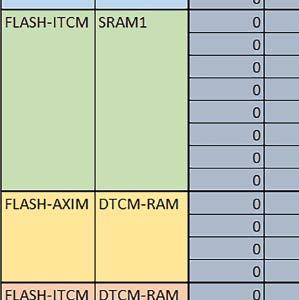
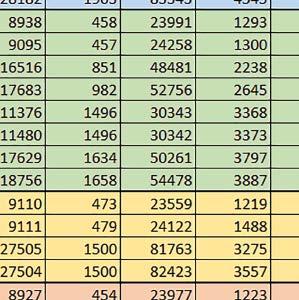
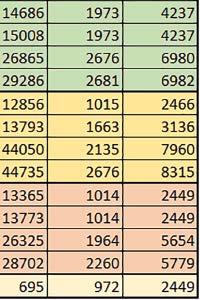
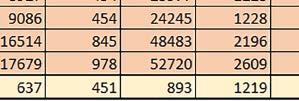
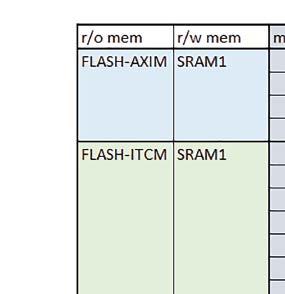
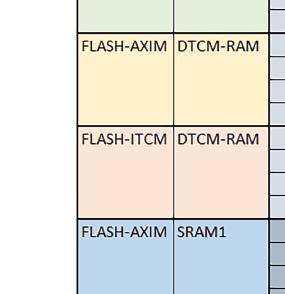
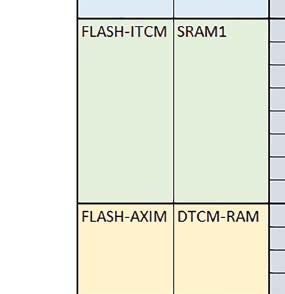
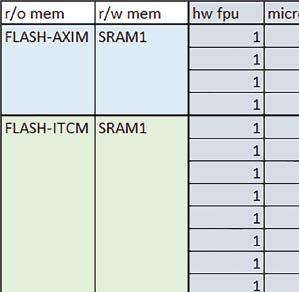
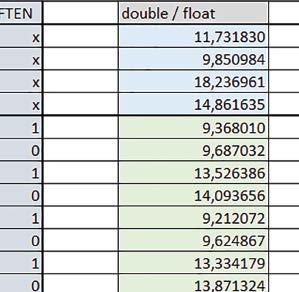
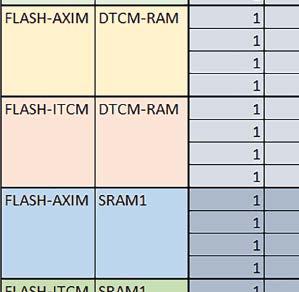
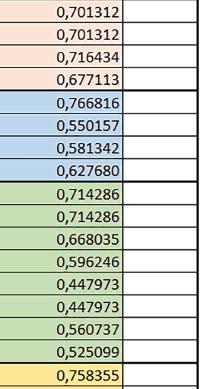
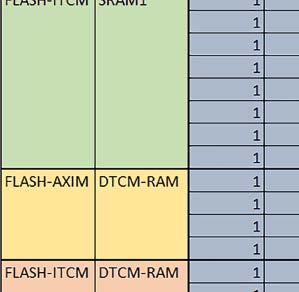
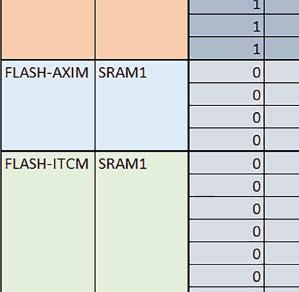
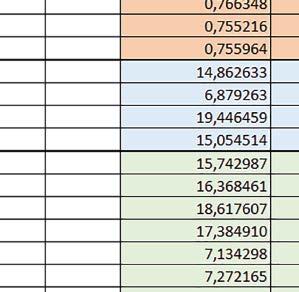
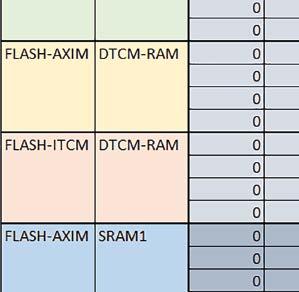
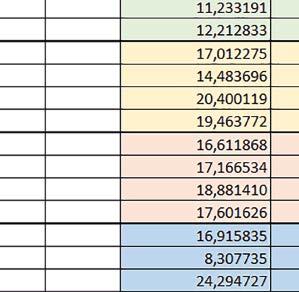
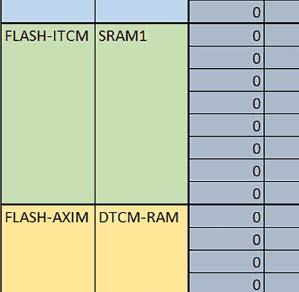
7 Mikrokontrolery STM32 który do czego? są też mechanizmy wspomagające wykonanie programu. W przypadku korzystania z pamięci wewnętrznej mikrokontrolera, kod i stałe (Read Only Memory Area) znajdują się w pamięci Flash, a dostępy do nich mogą następować przez interfejs AHB/AXI (Flash-AXIM) albo przez interfejs ITCM Instruction Tightly-Coupled Memory (Flash-ITCM), natomiast dane (Read/Write Memory Area) mogą być umieszczone w pamięci SRAM, do której dostęp następuje przez interfejs AHB, lub w pamięci DTCM-RAM, do której dostęp następuje przez interfejs DTCM. y ELEKTRONIKA PRAKTYCZNA 10/
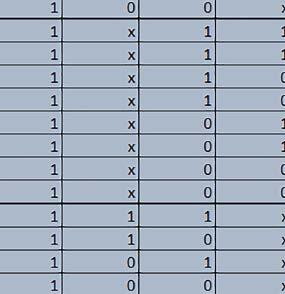
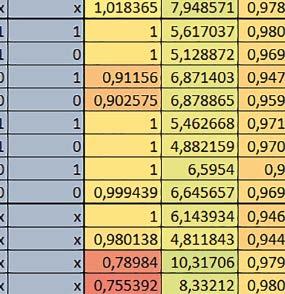
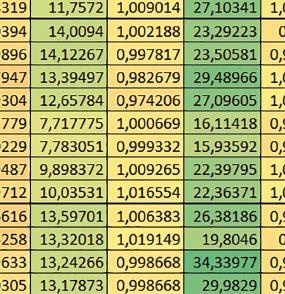
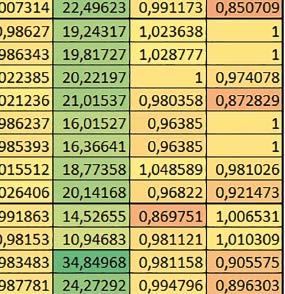
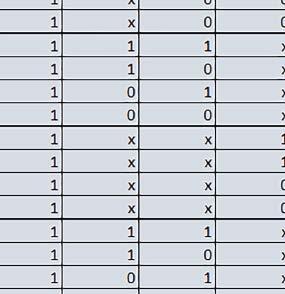

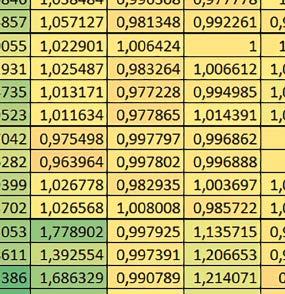
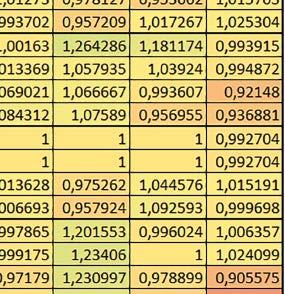
8 u i 78 ELEKTRONIKA PRAKTYCZNA 10/2016
 i SCB_EnableDCache() z biblioteki CMSIS. Każda z kieszeni ma rozmiar 4 KiB.")


.")
 były włączone oraz do ok. 40% krótszy, jeśli nie były włączone.")

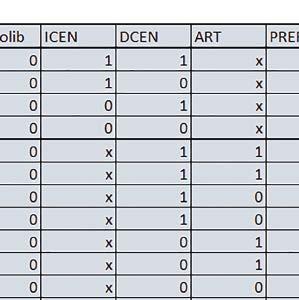
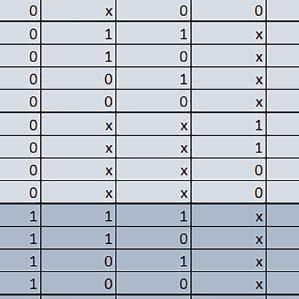
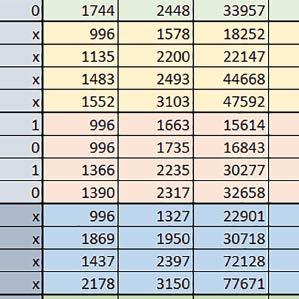
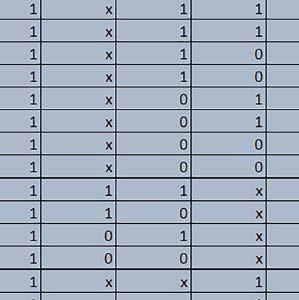
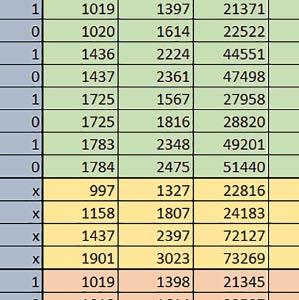
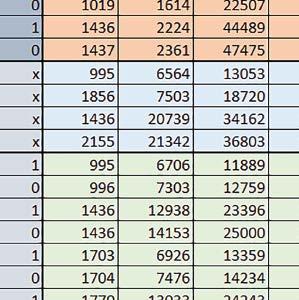
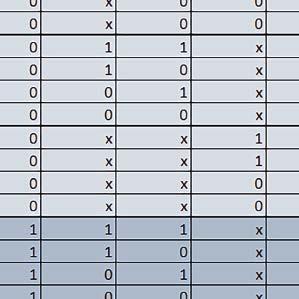
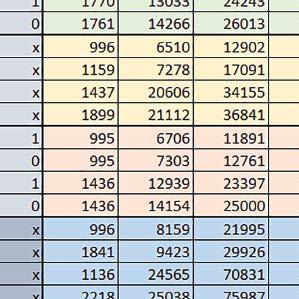
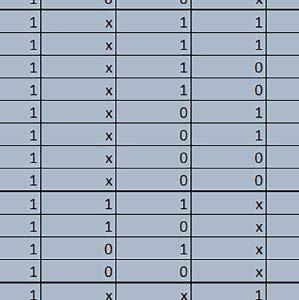
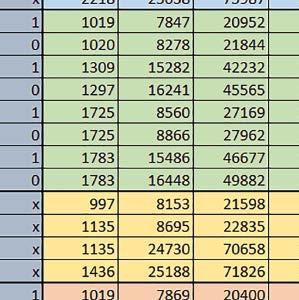
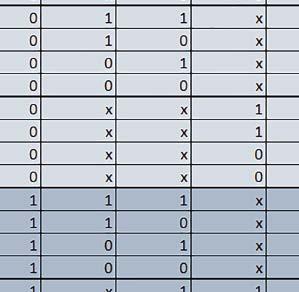
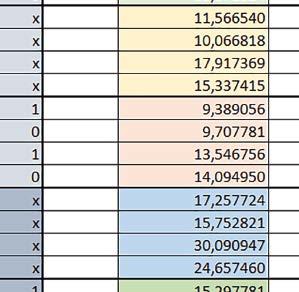
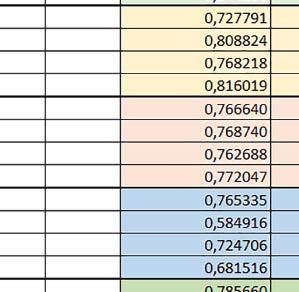
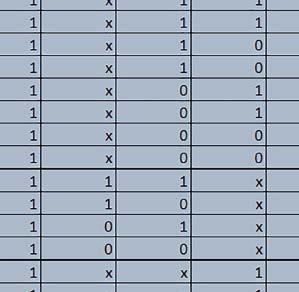
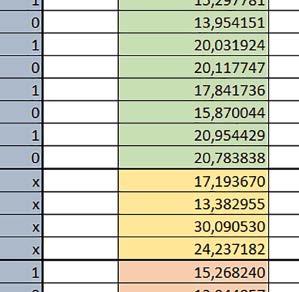
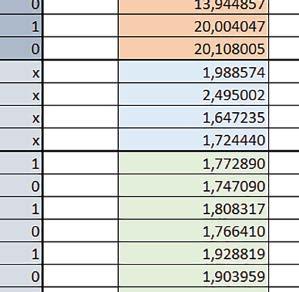
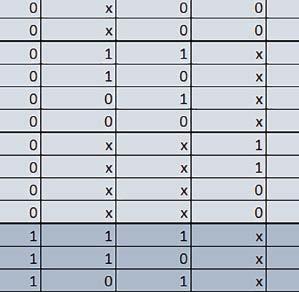
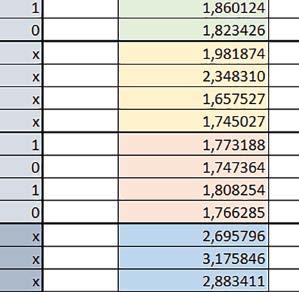
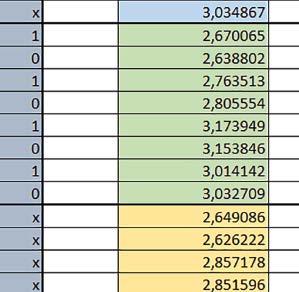
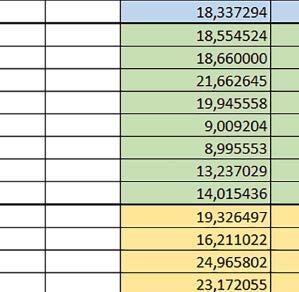
9 Mikrokontrolery STM32 który do czego? Mikrokontroler wyposażony jest w kieszenie instrukcji i danych, które można włączyć korzystając z funkcji SCB_EnableICache() i SCB_EnableDCache() z biblioteki CMSIS. Każda z kieszeni ma rozmiar 4 KiB. Kieszenie mają znaczenie w przypadku, gdy dostępy do pamięci wykonywane są przez interfejs AHB. Mikrokontroler jest również wyposażony w Adaptive Real Time Accelerator (ART). ART dysponuje kieszenią o pojemności 64 linii po 256 bitów każda. Włączenie tej kieszeni następuje przez ustawienie bitu ARTEN w rejestrze FLASH_ACR. ART odpowiada także za mechanizm prefetch. Mechanizm prefetch jest włączany przez ustawienie bitu PREFTEN w rejestrze FLASH_ACR. ART i ART-prefetch mają znaczenie w przypadku, gdy instrukcje są pobierane z Flash przez interfejs ITCM. Przetestowano następujące konfiguracje i wpływ odpowiednich mechanizmów wspomagających: RO-Mem: Flash-AXI, R/W-Mem: SRAM1 kieszeń instrukcji, kieszeń danych, RO-Mem: Flash-ITCM, R/W-Mem: SRAM1 ART i ART-prefetch, kieszeń danych, RO-Mem: Flash-AXI, R/W-Mem: DTCM-RAM kieszeń instrukcji, kieszeń danych (ze względu na możliwy odczyt stałych z pamięci Flash przez interfejs AHB), RO-Mem: Flash-ITCM, R/W-Mem: DTCM-RAM ART i ART-prefetch. Wyniki: y, u, i Wnioski: o2 vs o3 W większości wypadków różnice były nieznaczne (poniżej 2%). Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji o2 był ok. 5 10% krótszy, jeśli odpowiednie mechanizmy wspomagające pobieranie instrukcji (kieszeń instrukcji lub ART i ART-prefetch) były włączone oraz do ok. 40% krótszy, jeśli nie były włączone. Dla FOC operującego na liczbach stałopozycyjnych oraz, jeżeli używane było FPU, dla FOC operującego na liczbach zmiennopozycyjnych czas wykonania w przypadku poziomu optymalizacji o2 był do ok. 15% dłuższy. Jeśli odpowiednie mechanizmy wspomagania pobierania instrukcji nie były włączone, czas wykonania dla automatu był do ok. 15% krótszy przy poziomie optymalizacji o2, jeśli używane było FPU lub biblioteka standardowa oraz do ok. 15% dłuższy, jeśli FPU nie było używane i korzystano z Microlib. FPU Wykorzystanie FPU przyspieszyło obliczenia na liczbach zmiennopozycyjnych pojedynczej precyzji ok. 3,5 30 razy dla biblioteki standardowej i ok razy dla biblioteki Microlib. Użycie wsparcia sprzętowego dla obliczeń zmiennopozycyjnych było najbardziej korzystne w przypadku FOC i FFT, gdzie przyspieszenie wynosiło od ok. 10 do ok. 30 razy. Trochę mniejsze różnice występowały w wypadku obliczeń na macierzach (4 10 razy dla biblioteki standardowej i 7 14 razy dla biblioteki Microlib) i prostych obliczeń (3 8 razy dla biblioteki standardowej i 5 10 razy dla biblioteki Microlib). Obliczenia na liczbach zmiennopozycyjnych podwójnej precyzji w przypadku korzystania z FPU wykonywały się o ok. 30% wolniej dla biblioteki standardowej i ok. 2 5% wolniej dla biblioteki Microlib. micro lib vs std lib Rozmiar kodu wynikowego był o ok. 1/6 większy dla biblioteki standardowej. Dla biblioteki Microlib czas wykonania dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji był ok. 1,2 1,6 razy dłuższy w przypadku używania FPU i ok. 1,3 2 razy dłuższy, jeśli FPU nie było wykorzystywane. W wypadku niekorzystania z FPU czas wykonania dla biblioteki Microlib był ok. 1,5 2 razy dłuższy dla obliczeń na macierzach liczb zmiennopozycyjnych i ok. 1,2 razy dłuższy dla pozostałych obliczeń zmiennopozycyjnych. W wypadku korzystania z FPU czas wykonania dla biblioteki Microlib był do ok. 1,2 razy krótszy dla prostych obliczeń zmiennopozycyjnych pojedynczej precyzji. Dla konfiguracji, gdzie dostęp do kodu następował przez interfejs AXI, czas wykonania dla biblioteki Microlib był do ok. 1,25 razy dłuższy dla FOC. Wyniki cd.: o, p, Q Wnioski cd.: Instruction Cache (IC) Włączenie kieszeni instrukcji spowodowało skrócenie czasu wykonania ok. 1,2 3,8 razy. Największe znaczenie miało w przypadku automatu, operacji na macierzach i na liczbach zmiennopozycyjnych podwójnej precyzji, a w przypadku, gdy FPU nie było wykorzystywane również dla obliczeń na liczbach zmiennopozycyjnych pojedynczej precyzji. Przyspieszenie uzyskane dzięki włączeniu kieszeni instrukcji było większe, jeśli jednocześnie włączona była kieszeń danych. Data Cache (DC) Włączenie kieszeni danych spowodowało skrócenie czasu wykonania maksymalnie ok. 3,3 razy. Włączenie kieszeni danych miało większy wpływ na przyspieszenie wykonania programu, jeśli jednocześnie włączone były odpowiednie mechanizmy wspomagające pobieranie instrukcji (kieszeń instrukcji w przypadku korzystania z interfejsu AHB/AXI, ART w przypadku korzystania z interfejsu ITCM). Włączenie kieszeni danych miało mniejszy wpływ, jeśli dane do odczytu i zapisu znajdowały się w DTCM-RAM, ponieważ wtedy mogło przyspieszyć jedynie odczyt stałych. Włączenie kieszeni danych miało największe znaczenie w przypadku obliczeń na macierzach liczb stałopozycyjnych oraz FFT i FOC operujących na liczbach stałopozycyjnych. Dość istotne było również dla tych samych testów w wersjach operujących na liczbach zmiennopozycyjnych, jeżeli wykorzystywane było FPU. Najmniejsze znaczenie miało dla prostych obliczeń na liczbach zmiennopozycyjnych pojedynczej i podwójnej precyzji oraz dla pozostałych o ELEKTRONIKA PRAKTYCZNA 10/



 Włączenie ART")




 oraz")





 Włączenie mechanizmu")





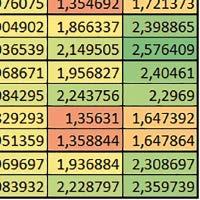
10 obliczeń zmiennopozycyjnych, jeśli FPU nie było używane. Jednak nawet w tym przypadku, jeśli dane do odczytu i zapisu znajdowały się w SRAM1 i używane były odpowiednie mechanizmy wspomagające pobieranie instrukcji, to przyspieszenie wynikające z włączenia kieszeni danych było dość duże. ART Accelarator (ARTEN) Włączenie ART spowodowało skrócenie czasu wykonania maksymalnie ok. 2,6 razy. Włączenie ART miało największe znaczenie w przypadku automatu oraz, jeżeli FPU nie było używane i wykorzystano bibliotekę standardową, w przypadku obliczeń na macierzach liczb zmiennopozycyjnych. Dość duże również dla obliczeń na macierzach w pozostałych konfiguracjach, FOC (szczególnie operującego na liczbach zmiennopozycyjnych) oraz dla prostych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji. Włączenie ART miało większy wpływ na czas wykonania, jeśli mechanizm prefetch nie był włączony. W konfiguracjach, gdzie dane do odczytu i zapisu były umieszczone w SRAM1, przyspieszenie uzyskane dzięki włączeniu ART Accelerator było znacznie mniejsze, jeśli kieszeń danych nie była włączona. Wyniki cd.: W, E, R, T Porównanie konfiguracji Wnioski cd.: ART-prefetch (PREFTEN) Włączenie mechanizmu prefetch spowodowało skrócenie czasu wykonania maksymalnie ok. 1,2 razy. Włączenie mechanizmu prefetch miało większe znaczenie, jeśli ARTEN nie było ustawione. Jeśli ARTEN=1, to włączenie mechanizmu prefetch spowodowało skrócenie czasu wykonania dla prostych obliczeń na liczbach zmiennopozycyjnych pojedynczej i podwójnej precyzji oraz, jeśli FPU nie było używane, także dla pozostałych obliczeń zmiennopozycyjnych. Jeśli ARTEN=0, to istotna poprawa czasu wykonania wystąpiła również w przypadku obliczeń na macierzach liczb stałopozycyjnych oraz FFT i FOC operujących na liczbach stałopozycyjnych. Mechanizmy wspomagające (ogólnie) Różnice czasów wykonania między przypadkiem, gdy mechanizmy wspomagające wykonanie programu są włączone, a przypadkiem, gdy są wyłączone, wyniosły od 1,5 do 7 razy. Jeśli mechanizmy wspomagające wykonanie programu były wyłączone, to czasy wykonania p Q 80 ELEKTRONIKA PRAKTYCZNA 10/2016

















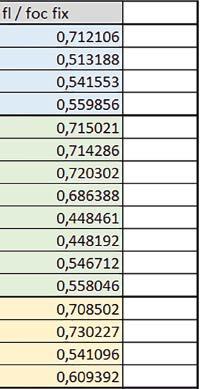
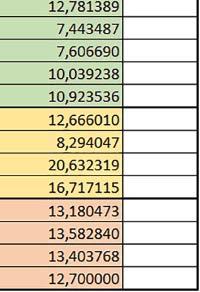
11 Mikrokontrolery STM32 który do czego? W testów były nieraz dość znacząco gorsze niż dla mikrokontrolera STM32F446RE. Porównanie konfiguracji Porównywano wyniki uzyskane, gdy dla danej konfiguracji wszystkie mechanizmy wspomagające były włączone. Read Only Memory Area Różnice czasu wykonania między konfiguracjami różniącymi się interfejsem dostępu do RO-Mem wynosiły maksymalnie 1,2 razy, ale w większości przypadków były małe. Jeżeli wykorzystywany był interfejs ITCM, to dla prostych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji, czasy wykonania były 1,05 1,2 razy krótsze, dla obliczeń na macierzach do ok. 1,5 razy krótsze. W wypadku używania FPU i Microlib, wykorzystanie interfejsu ITCM dało ok. 1,15 razy krótszy czas wykonania dla FOC operującego na liczbach zmiennopozycyjnych i ok. 1,25 razy dla FOC operującego na liczbach stałopozycyjnych. Natomiast jeśli FPU nie było używane, to FOC operujące na liczbach zmiennopozycyjnych wykonywało się 5 10% szybciej w przypadku interfejsu AHB/AXI. Read/Write Memory Area Dla konfiguracji, w których dane do odczytu i zapisu znajdowały się w DTCM-RAM w przypadku FFT operującego na liczbach stałopozycyjnych oraz zmiennopozycyjnych, jeżeli używane było FPU, czasy wykonania były ok. 1,05 1,2 razy krótsze, natomiast w przypadku automatu 1,03 razy krótsze. Dla FOC operującego na liczbach stałopozycyjnych czasy wykonania były o kilka procent krótsze, jeśli dane do odczytu i zapisu znajdowały się w SRAM1. Wyniki cd.: Y Wnioski cd.: double/float W wypadku nieużywania FPU, czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. W wypadku używania FPU, czas wykonania był odpowiednio ok i ok razy dłuższy. floating/fixed point W wypadku nieużywania FPU, czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok razy dłuższy. Dla FFT czasy wykonania różniły się typowo ok razy. W wypadku używania FPU, czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 1,3 razy krótszy, natomiast FFT ok. 1,3 2 razy krótszy. Katarzyna Kosowska E R T ELEKTRONIKA PRAKTYCZNA 10/




12 Y 82 ELEKTRONIKA PRAKTYCZNA 10/2016
Szkolenia specjalistyczne
 Szkolenia specjalistyczne AGENDA Programowanie mikrokontrolerów w języku C na przykładzie STM32F103ZE z rdzeniem Cortex-M3 GRYFTEC Embedded Systems ul. Niedziałkowskiego 24 71-410 Szczecin info@gryftec.com
Szkolenia specjalistyczne AGENDA Programowanie mikrokontrolerów w języku C na przykładzie STM32F103ZE z rdzeniem Cortex-M3 GRYFTEC Embedded Systems ul. Niedziałkowskiego 24 71-410 Szczecin info@gryftec.com
Wykład 6. Mikrokontrolery z rdzeniem ARM
 Wykład 6 Mikrokontrolery z rdzeniem ARM Plan wykładu Cortex-A9 c.d. Mikrokontrolery firmy ST Mikrokontrolery firmy NXP Mikrokontrolery firmy AnalogDevices Mikrokontrolery firmy Freescale Mikrokontrolery
Wykład 6 Mikrokontrolery z rdzeniem ARM Plan wykładu Cortex-A9 c.d. Mikrokontrolery firmy ST Mikrokontrolery firmy NXP Mikrokontrolery firmy AnalogDevices Mikrokontrolery firmy Freescale Mikrokontrolery
STM32Butterfly2. Zestaw uruchomieniowy dla mikrokontrolerów STM32F107
 Zestaw uruchomieniowy dla mikrokontrolerów STM32F107 STM32Butterfly2 Zestaw STM32Butterfly2 jest platformą sprzętową pozwalającą poznać i przetestować możliwości mikrokontrolerów z rodziny STM32 Connectivity
Zestaw uruchomieniowy dla mikrokontrolerów STM32F107 STM32Butterfly2 Zestaw STM32Butterfly2 jest platformą sprzętową pozwalającą poznać i przetestować możliwości mikrokontrolerów z rodziny STM32 Connectivity
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Programowanie mikrokontrolerów 2.0
 4.1 Programowanie mikrokontrolerów 2.0 Taktowanie Marcin Engel Marcin Peczarski Instytut Informatyki Uniwersytetu Warszawskiego 22 listopada 2016 4.2 Drzewo taktowania w STM32F411 Źródło: RM0383 Reference
4.1 Programowanie mikrokontrolerów 2.0 Taktowanie Marcin Engel Marcin Peczarski Instytut Informatyki Uniwersytetu Warszawskiego 22 listopada 2016 4.2 Drzewo taktowania w STM32F411 Źródło: RM0383 Reference
Kod IEEE754. IEEE754 (1985) - norma dotycząca zapisu binarnego liczb zmiennopozycyjnych (pojedynczej precyzji) Liczbę binarną o postaci
 - norma dotycząca zapisu binarnego liczb zmiennopozycyjnych (pojedynczej precyzji) Liczbę binarną o postaci") Kod IEEE754 IEEE Institute of Electrical and Electronics Engineers IEEE754 (1985) - norma dotycząca zapisu binarnego liczb zmiennopozycyjnych (pojedynczej precyzji) Liczbę binarną o postaci (-1) s 1.f
Kod IEEE754 IEEE Institute of Electrical and Electronics Engineers IEEE754 (1985) - norma dotycząca zapisu binarnego liczb zmiennopozycyjnych (pojedynczej precyzji) Liczbę binarną o postaci (-1) s 1.f
Sprawozdanie z projektu MARM. Część druga Specyfikacja końcowa. Prowadzący: dr. Mariusz Suchenek. Autor: Dawid Kołcz. Data: r.
 Sprawozdanie z projektu MARM Część druga Specyfikacja końcowa Prowadzący: dr. Mariusz Suchenek Autor: Dawid Kołcz Data: 01.02.16r. 1. Temat pracy: Układ diagnozujący układ tworzony jako praca magisterska.
Sprawozdanie z projektu MARM Część druga Specyfikacja końcowa Prowadzący: dr. Mariusz Suchenek Autor: Dawid Kołcz Data: 01.02.16r. 1. Temat pracy: Układ diagnozujący układ tworzony jako praca magisterska.
Architektura komputerów. Asembler procesorów rodziny x86
 Architektura komputerów Asembler procesorów rodziny x86 Architektura komputerów Asembler procesorów rodziny x86 Rozkazy mikroprocesora Rozkazy mikroprocesora 8086 można podzielić na siedem funkcjonalnych
Architektura komputerów Asembler procesorów rodziny x86 Architektura komputerów Asembler procesorów rodziny x86 Rozkazy mikroprocesora Rozkazy mikroprocesora 8086 można podzielić na siedem funkcjonalnych
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015
 Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
STM32 Butterfly. Zestaw uruchomieniowy dla mikrokontrolerów STM32F107
 Zestaw uruchomieniowy dla mikrokontrolerów STM32F107 STM32 Butterfly Zestaw STM32 Butterfly jest platformą sprzętową pozwalającą poznać i przetestować możliwości mikrokontrolerów z rodziny STM32 Connectivity
Zestaw uruchomieniowy dla mikrokontrolerów STM32F107 STM32 Butterfly Zestaw STM32 Butterfly jest platformą sprzętową pozwalającą poznać i przetestować możliwości mikrokontrolerów z rodziny STM32 Connectivity
o Instalacja środowiska programistycznego (18) o Blink (18) o Zasilanie (21) o Złącza zasilania (22) o Wejścia analogowe (22) o Złącza cyfrowe (22)
 o Blink (18) o Zasilanie (21) o Złącza zasilania (22) o Wejścia analogowe (22) o Złącza cyfrowe (22)") O autorze (9) Podziękowania (10) Wstęp (11) Pobieranie przykładów (12) Czego będę potrzebował? (12) Korzystanie z tej książki (12) Rozdział 1. Programowanie Arduino (15) Czym jest Arduino (15) Instalacja
O autorze (9) Podziękowania (10) Wstęp (11) Pobieranie przykładów (12) Czego będę potrzebował? (12) Korzystanie z tej książki (12) Rozdział 1. Programowanie Arduino (15) Czym jest Arduino (15) Instalacja
LEKCJA TEMAT: Współczesne procesory.
 LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
Architektura komputerów
 Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
Kurs Zaawansowany S7. Spis treści. Dzień 1
 Spis treści Dzień 1 I Konfiguracja sprzętowa i parametryzacja stacji SIMATIC S7 (wersja 1211) I-3 Dlaczego powinna zostać stworzona konfiguracja sprzętowa? I-4 Zadanie Konfiguracja sprzętowa I-5 Konfiguracja
Spis treści Dzień 1 I Konfiguracja sprzętowa i parametryzacja stacji SIMATIC S7 (wersja 1211) I-3 Dlaczego powinna zostać stworzona konfiguracja sprzętowa? I-4 Zadanie Konfiguracja sprzętowa I-5 Konfiguracja
Wprowadzenie do architektury komputerów systemy liczbowe, operacje arytmetyczne i logiczne
 Wprowadzenie do architektury komputerów systemy liczbowe, operacje arytmetyczne i logiczne 1. Bit Pozycja rejestru lub komórki pamięci służąca do przedstawiania (pamiętania) cyfry w systemie (liczbowym)
Wprowadzenie do architektury komputerów systemy liczbowe, operacje arytmetyczne i logiczne 1. Bit Pozycja rejestru lub komórki pamięci służąca do przedstawiania (pamiętania) cyfry w systemie (liczbowym)
2 Przygotował: mgr inż. Maciej Lasota
 Laboratorium nr 2 1/7 Język C Instrukcja laboratoryjna Temat: Wprowadzenie do języka C 2 Przygotował: mgr inż. Maciej Lasota 1) Wprowadzenie do języka C. Język C jest językiem programowania ogólnego zastosowania
Laboratorium nr 2 1/7 Język C Instrukcja laboratoryjna Temat: Wprowadzenie do języka C 2 Przygotował: mgr inż. Maciej Lasota 1) Wprowadzenie do języka C. Język C jest językiem programowania ogólnego zastosowania
Arduino dla początkujących. Kolejny krok Autor: Simon Monk. Spis treści
 Arduino dla początkujących. Kolejny krok Autor: Simon Monk Spis treści O autorze Podziękowania Wstęp o Pobieranie przykładów o Czego będę potrzebował? o Korzystanie z tej książki Rozdział 1. Programowanie
Arduino dla początkujących. Kolejny krok Autor: Simon Monk Spis treści O autorze Podziękowania Wstęp o Pobieranie przykładów o Czego będę potrzebował? o Korzystanie z tej książki Rozdział 1. Programowanie
dokument DOK 02-05-12 wersja 1.0 www.arskam.com
 ARS3-RA v.1.0 mikro kod sterownika 8 Linii I/O ze zdalną transmisją kanałem radiowym lub poprzez port UART. Kod przeznaczony dla sprzętu opartego o projekt referencyjny DOK 01-05-12. Opis programowania
ARS3-RA v.1.0 mikro kod sterownika 8 Linii I/O ze zdalną transmisją kanałem radiowym lub poprzez port UART. Kod przeznaczony dla sprzętu opartego o projekt referencyjny DOK 01-05-12. Opis programowania
Spis treœci. Co to jest mikrokontroler? Kody i liczby stosowane w systemach komputerowych. Podstawowe elementy logiczne
 Spis treści 5 Spis treœci Co to jest mikrokontroler? Wprowadzenie... 11 Budowa systemu komputerowego... 12 Wejścia systemu komputerowego... 12 Wyjścia systemu komputerowego... 13 Jednostka centralna (CPU)...
Spis treści 5 Spis treœci Co to jest mikrokontroler? Wprowadzenie... 11 Budowa systemu komputerowego... 12 Wejścia systemu komputerowego... 12 Wyjścia systemu komputerowego... 13 Jednostka centralna (CPU)...
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Architektura potokowa RISC
 Architektura potokowa RISC Podział zadania na odrębne części i niezależny sprzęt szeregowe Brak nawrotów" podczas pracy potokowe Przetwarzanie szeregowe i potokowe Podział instrukcji na fazy wykonania
Architektura potokowa RISC Podział zadania na odrębne części i niezależny sprzęt szeregowe Brak nawrotów" podczas pracy potokowe Przetwarzanie szeregowe i potokowe Podział instrukcji na fazy wykonania
Rejestry procesora. Nazwa ilość bitów. AX 16 (accumulator) rejestr akumulatora. BX 16 (base) rejestr bazowy. CX 16 (count) rejestr licznika
 rejestr akumulatora. BX 16 (base) rejestr bazowy. CX 16 (count) rejestr licznika") Rejestry procesora Procesor podczas wykonywania instrukcji posługuje się w dużej części pamięcią RAM. Pobiera z niej kolejne instrukcje do wykonania i dane, jeżeli instrukcja operuje na jakiś zmiennych.
Rejestry procesora Procesor podczas wykonywania instrukcji posługuje się w dużej części pamięcią RAM. Pobiera z niej kolejne instrukcje do wykonania i dane, jeżeli instrukcja operuje na jakiś zmiennych.
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Podstawy Informatyki. Inżynieria Ciepła, I rok. Wykład 5 Liczby w komputerze
 Podstawy Informatyki Inżynieria Ciepła, I rok Wykład 5 Liczby w komputerze Jednostki informacji Bit (ang. bit) (Shannon, 948) Najmniejsza ilość informacji potrzebna do określenia, który z dwóch równie
Podstawy Informatyki Inżynieria Ciepła, I rok Wykład 5 Liczby w komputerze Jednostki informacji Bit (ang. bit) (Shannon, 948) Najmniejsza ilość informacji potrzebna do określenia, który z dwóch równie
Pracownia Komputerowa wykład VI
 Pracownia Komputerowa wykład VI dr Magdalena Posiadała-Zezula http://www.fuw.edu.pl/~mposiada 1 Przypomnienie 125 (10) =? (2) Liczby całkowite : Operacja modulo % reszta z dzielenia: 125%2=62 reszta 1
Pracownia Komputerowa wykład VI dr Magdalena Posiadała-Zezula http://www.fuw.edu.pl/~mposiada 1 Przypomnienie 125 (10) =? (2) Liczby całkowite : Operacja modulo % reszta z dzielenia: 125%2=62 reszta 1
AKADEMIA GÓRNICZO-HUTNICZA im. Stanisława Staszica w Krakowie. Wydział Geologii, Geofizyki i Ochrony Środowiska. Bazy danych 2
 AKADEMIA GÓRNICZO-HUTNICZA im. Stanisława Staszica w Krakowie Wydział Geologii, Geofizyki i Ochrony Środowiska Wydajnośd w bazach danych Grzegorz Surdyka Informatyka Stosowana Kraków, 9 Spis treści. Wstęp...
AKADEMIA GÓRNICZO-HUTNICZA im. Stanisława Staszica w Krakowie Wydział Geologii, Geofizyki i Ochrony Środowiska Wydajnośd w bazach danych Grzegorz Surdyka Informatyka Stosowana Kraków, 9 Spis treści. Wstęp...
Programowanie w C++ Wykład 2. Katarzyna Grzelak. 4 marca K.Grzelak (Wykład 1) Programowanie w C++ 1 / 44
 Programowanie w C++ 1 / 44") Programowanie w C++ Wykład 2 Katarzyna Grzelak 4 marca 2019 K.Grzelak (Wykład 1) Programowanie w C++ 1 / 44 Na poprzednim wykładzie podstawy C++ Każdy program w C++ musi mieć funkcję o nazwie main Wcięcia
Programowanie w C++ Wykład 2 Katarzyna Grzelak 4 marca 2019 K.Grzelak (Wykład 1) Programowanie w C++ 1 / 44 Na poprzednim wykładzie podstawy C++ Każdy program w C++ musi mieć funkcję o nazwie main Wcięcia
LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI. Wprowadzenie do środowiska Matlab
 LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI Wprowadzenie do środowiska Matlab 1. Podstawowe informacje Przedstawione poniżej informacje maja wprowadzić i zapoznać ze środowiskiem
LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI Wprowadzenie do środowiska Matlab 1. Podstawowe informacje Przedstawione poniżej informacje maja wprowadzić i zapoznać ze środowiskiem
Programowanie mikrokontrolerów. 8 listopada 2007
 Programowanie mikrokontrolerów Marcin Engel Marcin Peczarski 8 listopada 2007 Alfanumeryczny wyświetlacz LCD umożliwia wyświetlanie znaków ze zbioru będącego rozszerzeniem ASCII posiada zintegrowany sterownik
Programowanie mikrokontrolerów Marcin Engel Marcin Peczarski 8 listopada 2007 Alfanumeryczny wyświetlacz LCD umożliwia wyświetlanie znaków ze zbioru będącego rozszerzeniem ASCII posiada zintegrowany sterownik
Tab. 1. Zestawienie najważniejszych parametrów wybranych mikrokontrolerów z rodziny LPC2100, które można zastosować w zestawie ZL3ARM.
 ZL3ARM płytka bazowa dla modułu diparm_2106 (ZL4ARM) ZL3ARM Płytka bazowa dla modułu diparm_2106 Płytkę bazową ZL3ARM opracowano z myślą o elektronikach chcących szybko poznać mozliwości mikrokontrolerów
ZL3ARM płytka bazowa dla modułu diparm_2106 (ZL4ARM) ZL3ARM Płytka bazowa dla modułu diparm_2106 Płytkę bazową ZL3ARM opracowano z myślą o elektronikach chcących szybko poznać mozliwości mikrokontrolerów
Przetwornik analogowo-cyfrowy
 Przetwornik analogowo-cyfrowy Przetwornik analogowo-cyfrowy A/C (ang. A/D analog to digital; lub angielski akronim ADC - od słów: Analog to Digital Converter), to układ służący do zamiany sygnału analogowego
Przetwornik analogowo-cyfrowy Przetwornik analogowo-cyfrowy A/C (ang. A/D analog to digital; lub angielski akronim ADC - od słów: Analog to Digital Converter), to układ służący do zamiany sygnału analogowego
ZL2ARM easyarm zestaw uruchomieniowy dla mikrokontrolerów LPC2104/5/6 (rdzeń ARM7TDMI-S)
") ZL2ARM Zestaw uruchomieniowy dla mikrokontrolerów LPC2104/5/6 (rdzeń ARM7TDMI-S) 1 Zestaw ZL2ARM opracowano z myślą o elektronikach chcących szybko zaznajomić się z mikrokontrolerami z rdzeniem ARM7TDMI-S.
ZL2ARM Zestaw uruchomieniowy dla mikrokontrolerów LPC2104/5/6 (rdzeń ARM7TDMI-S) 1 Zestaw ZL2ARM opracowano z myślą o elektronikach chcących szybko zaznajomić się z mikrokontrolerami z rdzeniem ARM7TDMI-S.
Metody optymalizacji soft-procesorów NIOS
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
Instrukcja do ćwiczeń nr 4 typy i rodzaje zmiennych w języku C dla AVR, oraz ich deklarowanie, oraz podstawowe operatory
 Instrukcja do ćwiczeń nr 4 typy i rodzaje zmiennych w języku C dla AVR, oraz ich deklarowanie, oraz podstawowe operatory Poniżej pozwoliłem sobie za cytować za wikipedią definicję zmiennej w informatyce.
Instrukcja do ćwiczeń nr 4 typy i rodzaje zmiennych w języku C dla AVR, oraz ich deklarowanie, oraz podstawowe operatory Poniżej pozwoliłem sobie za cytować za wikipedią definicję zmiennej w informatyce.
ZASOBY ZMIENNYCH W STEROWNIKACH SAIA-BURGESS
 ZASOBY ZMIENNYCH W STEROWNIKACH SAIA-BURGESS Autorzy Wydanie Data : : : Zespół SABUR Sp. z o.o. 3.00 Sierpień 2013 2013 SABUR Sp. z o. o. Wszelkie prawa zastrzeżone Bez pisemnej zgody firmy SABUR Sp. z
ZASOBY ZMIENNYCH W STEROWNIKACH SAIA-BURGESS Autorzy Wydanie Data : : : Zespół SABUR Sp. z o.o. 3.00 Sierpień 2013 2013 SABUR Sp. z o. o. Wszelkie prawa zastrzeżone Bez pisemnej zgody firmy SABUR Sp. z
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Przykładowe pytania DSP 1
 Przykładowe pytania SP Przykładowe pytania Systemy liczbowe. Przedstawić liczby; -, - w kodzie binarnym i hexadecymalnym uzupełnionym do dwóch (liczba 6 bitowa).. odać dwie liczby binarne w kodzie U +..
Przykładowe pytania SP Przykładowe pytania Systemy liczbowe. Przedstawić liczby; -, - w kodzie binarnym i hexadecymalnym uzupełnionym do dwóch (liczba 6 bitowa).. odać dwie liczby binarne w kodzie U +..
Spis treści. Dzień 1. I Rozpoczęcie pracy ze sterownikiem (wersja 1707) II Bloki danych (wersja 1707) ZAAWANSOWANY TIA DLA S7-300/400
 II Bloki danych (wersja 1707) ZAAWANSOWANY TIA DLA S7-300/400") ZAAWANSOWANY TIA DLA S7-300/400 Spis treści Dzień 1 I Rozpoczęcie pracy ze sterownikiem (wersja 1707) I-3 Zadanie Konfiguracja i uruchomienie sterownika I-4 Etapy realizacji układu sterowania I-5 Tworzenie
ZAAWANSOWANY TIA DLA S7-300/400 Spis treści Dzień 1 I Rozpoczęcie pracy ze sterownikiem (wersja 1707) I-3 Zadanie Konfiguracja i uruchomienie sterownika I-4 Etapy realizacji układu sterowania I-5 Tworzenie
Kod produktu: MP01611-ZK
 ZAMEK BEZSTYKOWY RFID ZE ZINTEGROWANĄ ANTENĄ, WYJŚCIE RS232 (TTL) Moduł stanowi gotowy do zastosowania bezstykowy zamek pracujący w technologii RFID dla transponderów UNIQUE 125kHz, zastępujący z powodzeniem
ZAMEK BEZSTYKOWY RFID ZE ZINTEGROWANĄ ANTENĄ, WYJŚCIE RS232 (TTL) Moduł stanowi gotowy do zastosowania bezstykowy zamek pracujący w technologii RFID dla transponderów UNIQUE 125kHz, zastępujący z powodzeniem
1.1. Wymogi bezpieczeństwa Pomoc techniczna TIA Portal V13 instalacja i konfiguracja pakietu...18
 3 Przedmowa...9 Wstęp... 13 1. Pierwsze kroki... 15 1.1. Wymogi bezpieczeństwa...16 1.2. Pomoc techniczna...17 1.3. TIA Portal V13 instalacja i konfiguracja pakietu...18 1.3.1. Opis części składowych środowiska
3 Przedmowa...9 Wstęp... 13 1. Pierwsze kroki... 15 1.1. Wymogi bezpieczeństwa...16 1.2. Pomoc techniczna...17 1.3. TIA Portal V13 instalacja i konfiguracja pakietu...18 1.3.1. Opis części składowych środowiska
Struktura i funkcjonowanie komputera pamięć komputerowa, hierarchia pamięci pamięć podręczna. System operacyjny. Zarządzanie procesami
 Rok akademicki 2015/2016, Wykład nr 6 2/21 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2015/2016
Rok akademicki 2015/2016, Wykład nr 6 2/21 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2015/2016
Literatura. adów w cyfrowych. Projektowanie układ. Technika cyfrowa. Technika cyfrowa. Bramki logiczne i przerzutniki.
 Literatura 1. D. Gajski, Principles of Digital Design, Prentice- Hall, 1997 2. C. Zieliński, Podstawy projektowania układów cyfrowych, PWN, Warszawa 2003 3. G. de Micheli, Synteza i optymalizacja układów
Literatura 1. D. Gajski, Principles of Digital Design, Prentice- Hall, 1997 2. C. Zieliński, Podstawy projektowania układów cyfrowych, PWN, Warszawa 2003 3. G. de Micheli, Synteza i optymalizacja układów
Podstawy Informatyki. Metalurgia, I rok. Wykład 3 Liczby w komputerze
 Podstawy Informatyki Metalurgia, I rok Wykład 3 Liczby w komputerze Jednostki informacji Bit (ang. bit) (Shannon, 1948) Najmniejsza ilość informacji potrzebna do określenia, który z dwóch równie prawdopodobnych
Podstawy Informatyki Metalurgia, I rok Wykład 3 Liczby w komputerze Jednostki informacji Bit (ang. bit) (Shannon, 1948) Najmniejsza ilość informacji potrzebna do określenia, który z dwóch równie prawdopodobnych
Podstawowe operacje arytmetyczne i logiczne dla liczb binarnych
 1 Podstawowe operacje arytmetyczne i logiczne dla liczb binarnych 1. Podstawowe operacje logiczne dla cyfr binarnych Jeśli cyfry 0 i 1 potraktujemy tak, jak wartości logiczne fałsz i prawda, to działanie
1 Podstawowe operacje arytmetyczne i logiczne dla liczb binarnych 1. Podstawowe operacje logiczne dla cyfr binarnych Jeśli cyfry 0 i 1 potraktujemy tak, jak wartości logiczne fałsz i prawda, to działanie
ZL2ARM easyarm zestaw uruchomieniowy dla mikrokontrolerów LPC2104/5/6 (rdzeń ARM7TDMI-S)
") ZL2ARM easyarm zestaw uruchomieniowy dla mikrokontrolerów LPC2104/5/6 (rdzeń ARM7TDMI-S) ZL2ARM Zestaw uruchomieniowy dla mikrokontrolerów LPC2104/5/6 (rdzeń ARM7TDMI-S) 1 Zestaw ZL2ARM opracowano z myślą
ZL2ARM easyarm zestaw uruchomieniowy dla mikrokontrolerów LPC2104/5/6 (rdzeń ARM7TDMI-S) ZL2ARM Zestaw uruchomieniowy dla mikrokontrolerów LPC2104/5/6 (rdzeń ARM7TDMI-S) 1 Zestaw ZL2ARM opracowano z myślą
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Wprowadzenie do metod numerycznych. Krzysztof Patan
 Wprowadzenie do metod numerycznych Krzysztof Patan Metody numeryczne Dział matematyki stosowanej Każde bardziej złożone zadanie wymaga opracowania indywidualnej metody jego rozwiązywania na maszynie cyfrowej
Wprowadzenie do metod numerycznych Krzysztof Patan Metody numeryczne Dział matematyki stosowanej Każde bardziej złożone zadanie wymaga opracowania indywidualnej metody jego rozwiązywania na maszynie cyfrowej
LICZBY ZMIENNOPRZECINKOWE
 LICZBY ZMIENNOPRZECINKOWE Liczby zmiennoprzecinkowe są komputerową reprezentacją liczb rzeczywistych zapisanych w formie wykładniczej (naukowej). Aby uprościć arytmetykę na nich, przyjęto ograniczenia
LICZBY ZMIENNOPRZECINKOWE Liczby zmiennoprzecinkowe są komputerową reprezentacją liczb rzeczywistych zapisanych w formie wykładniczej (naukowej). Aby uprościć arytmetykę na nich, przyjęto ograniczenia
Kurs SIMATIC S7-300/400 i TIA Portal - Zaawansowany. Spis treści. Dzień 1
 Spis treści Dzień 1 I Rozpoczęcie pracy ze sterownikiem (wersja 1503) I-3 Zadanie Konfiguracja i uruchomienie sterownika I-4 Etapy realizacji układu sterowania I-5 Tworzenie nowego projektu I-6 Tworzenie
Spis treści Dzień 1 I Rozpoczęcie pracy ze sterownikiem (wersja 1503) I-3 Zadanie Konfiguracja i uruchomienie sterownika I-4 Etapy realizacji układu sterowania I-5 Tworzenie nowego projektu I-6 Tworzenie
43 Pamięci półprzewodnikowe w technice mikroprocesorowej - rodzaje, charakterystyka, zastosowania
 43 Pamięci półprzewodnikowe w technice mikroprocesorowej - rodzaje, charakterystyka, zastosowania Typy pamięci Ulotność, dynamiczna RAM, statyczna ROM, Miejsce w konstrukcji komputera, pamięć robocza RAM,
43 Pamięci półprzewodnikowe w technice mikroprocesorowej - rodzaje, charakterystyka, zastosowania Typy pamięci Ulotność, dynamiczna RAM, statyczna ROM, Miejsce w konstrukcji komputera, pamięć robocza RAM,
Programowanie w C++ Wykład 2. Katarzyna Grzelak. 5 marca K.Grzelak (Wykład 1) Programowanie w C++ 1 / 41
 Programowanie w C++ 1 / 41") Programowanie w C++ Wykład 2 Katarzyna Grzelak 5 marca 2018 K.Grzelak (Wykład 1) Programowanie w C++ 1 / 41 Reprezentacje liczb w komputerze K.Grzelak (Wykład 1) Programowanie w C++ 2 / 41 Reprezentacje
Programowanie w C++ Wykład 2 Katarzyna Grzelak 5 marca 2018 K.Grzelak (Wykład 1) Programowanie w C++ 1 / 41 Reprezentacje liczb w komputerze K.Grzelak (Wykład 1) Programowanie w C++ 2 / 41 Reprezentacje
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Technologie Informacyjne
 System binarny Szkoła Główna Służby Pożarniczej Zakład Informatyki i Łączności October 7, 26 Pojęcie bitu 2 Systemy liczbowe 3 Potęgi dwójki 4 System szesnastkowy 5 Kodowanie informacji 6 Liczby ujemne
System binarny Szkoła Główna Służby Pożarniczej Zakład Informatyki i Łączności October 7, 26 Pojęcie bitu 2 Systemy liczbowe 3 Potęgi dwójki 4 System szesnastkowy 5 Kodowanie informacji 6 Liczby ujemne
Programowanie mikrokontrolerów 2.0
 Programowanie mikrokontrolerów 2.0 Tryby uśpienia Marcin Engel Marcin Peczarski Instytut Informatyki Uniwersytetu Warszawskiego 19 grudnia 2016 Zarządzanie energią Często musimy zadbać o zminimalizowanie
Programowanie mikrokontrolerów 2.0 Tryby uśpienia Marcin Engel Marcin Peczarski Instytut Informatyki Uniwersytetu Warszawskiego 19 grudnia 2016 Zarządzanie energią Często musimy zadbać o zminimalizowanie
Podstawy programowania sterowników SIMATIC S w języku LAD / Tomasz Gilewski. Legionowo, cop Spis treści
 Podstawy programowania sterowników SIMATIC S7-1200 w języku LAD / Tomasz Gilewski. Legionowo, cop. 2017 Spis treści Przedmowa 9 Wstęp 13 1. Pierwsze kroki 15 1.1. Wymogi bezpieczeństwa 16 1.2. Pomoc techniczna
Podstawy programowania sterowników SIMATIC S7-1200 w języku LAD / Tomasz Gilewski. Legionowo, cop. 2017 Spis treści Przedmowa 9 Wstęp 13 1. Pierwsze kroki 15 1.1. Wymogi bezpieczeństwa 16 1.2. Pomoc techniczna
Wykład 4. Przegląd mikrokontrolerów 16-bit: - PIC24 - dspic - MSP430
 Wykład 4 Przegląd mikrokontrolerów 16-bit: - PIC24 - dspic - MSP430 Mikrokontrolery PIC Mikrokontrolery PIC24 Mikrokontrolery PIC24 Rodzina 16-bitowych kontrolerów RISC Podział na dwie podrodziny: PIC24F
Wykład 4 Przegląd mikrokontrolerów 16-bit: - PIC24 - dspic - MSP430 Mikrokontrolery PIC Mikrokontrolery PIC24 Mikrokontrolery PIC24 Rodzina 16-bitowych kontrolerów RISC Podział na dwie podrodziny: PIC24F
Komputer IBM PC niezależnie od modelu składa się z: Jednostki centralnej czyli właściwego komputera Monitora Klawiatury
 1976 r. Apple PC Personal Computer 1981 r. pierwszy IBM PC Komputer jest wart tyle, ile wart jest człowiek, który go wykorzystuje... Hardware sprzęt Software oprogramowanie Komputer IBM PC niezależnie
1976 r. Apple PC Personal Computer 1981 r. pierwszy IBM PC Komputer jest wart tyle, ile wart jest człowiek, który go wykorzystuje... Hardware sprzęt Software oprogramowanie Komputer IBM PC niezależnie
Architektura komputera. Cezary Bolek. Uniwersytet Łódzki. Wydział Zarządzania. Katedra Informatyki. System komputerowy
 Wstęp do informatyki Architektura komputera Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki System komputerowy systemowa (System Bus) Pamięć operacyjna ROM,
Wstęp do informatyki Architektura komputera Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki System komputerowy systemowa (System Bus) Pamięć operacyjna ROM,
Cyfrowe układy scalone
 Cyfrowe układy scalone Ryszard J. Barczyński, 2012 Politechnika Gdańska, Wydział FTiMS, Katedra Fizyki Ciała Stałego Materiały dydaktyczne do użytku wewnętrznego Publikacja współfinansowana ze środków
Cyfrowe układy scalone Ryszard J. Barczyński, 2012 Politechnika Gdańska, Wydział FTiMS, Katedra Fizyki Ciała Stałego Materiały dydaktyczne do użytku wewnętrznego Publikacja współfinansowana ze środków
Magistrala systemowa (System Bus)
") Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki systemowa (System Bus) Pamięć operacyjna ROM, RAM Jednostka centralna Układy we/wy In/Out Wstęp do Informatyki
Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki systemowa (System Bus) Pamięć operacyjna ROM, RAM Jednostka centralna Układy we/wy In/Out Wstęp do Informatyki
Szkoła programisty PLC : sterowniki przemysłowe / Gilewski Tomasz. Gliwice, cop Spis treści
 Szkoła programisty PLC : sterowniki przemysłowe / Gilewski Tomasz. Gliwice, cop. 2017 Spis treści O autorze 9 Wprowadzenie 11 Rozdział 1. Sterownik przemysłowy 15 Sterownik S7-1200 15 Budowa zewnętrzna
Szkoła programisty PLC : sterowniki przemysłowe / Gilewski Tomasz. Gliwice, cop. 2017 Spis treści O autorze 9 Wprowadzenie 11 Rozdział 1. Sterownik przemysłowy 15 Sterownik S7-1200 15 Budowa zewnętrzna
2. Code Composer Studio v4 zintegrowane środowisko projektowe... 41
 3 Wstęp...11 1. Procesory serii TMS320F2802x/3x/6x Piccolo... 15 1.1. Organizacja układów procesorowych serii F2802x Piccolo...23 1.2. Organizacja układów procesorowych serii F2803x Piccolo...29 1.3. Organizacja
3 Wstęp...11 1. Procesory serii TMS320F2802x/3x/6x Piccolo... 15 1.1. Organizacja układów procesorowych serii F2802x Piccolo...23 1.2. Organizacja układów procesorowych serii F2803x Piccolo...29 1.3. Organizacja
Opracował: Grzegorz Cygan 2012 r. CEZ Stalowa Wola. Pamięci półprzewodnikowe
 Opracował: Grzegorz Cygan 2012 r. CEZ Stalowa Wola Pamięci półprzewodnikowe Pamięć Stosowane układy (urządzenia) DANYCH PROGRAMU OPERACYJNA (program + dane) MASOWA KONFIGURACYJNA RAM ROM (EPROM) (EEPROM)
Opracował: Grzegorz Cygan 2012 r. CEZ Stalowa Wola Pamięci półprzewodnikowe Pamięć Stosowane układy (urządzenia) DANYCH PROGRAMU OPERACYJNA (program + dane) MASOWA KONFIGURACYJNA RAM ROM (EPROM) (EEPROM)
Wykład 2. Przegląd mikrokontrolerów 8-bit: -AVR -PIC
 Wykład 2 Przegląd mikrokontrolerów 8-bit: -AVR -PIC Mikrokontrolery AVR Mikrokontrolery AVR ATTiny Główne cechy Procesory RISC mało instrukcji, duża częstotliwość zegara Procesory 8-bitowe o uproszczonej
Wykład 2 Przegląd mikrokontrolerów 8-bit: -AVR -PIC Mikrokontrolery AVR Mikrokontrolery AVR ATTiny Główne cechy Procesory RISC mało instrukcji, duża częstotliwość zegara Procesory 8-bitowe o uproszczonej
Pracownia Komputerowa wyk ad VI
 Pracownia Komputerowa wyk ad VI dr Magdalena Posiada a-zezula Magdalena.Posiadala@fuw.edu.pl http://www.fuw.edu.pl/~mposiada Magdalena.Posiadala@fuw.edu.pl 1 Przypomnienie 125 (10) =? (2) Liczby ca kowite
Pracownia Komputerowa wyk ad VI dr Magdalena Posiada a-zezula Magdalena.Posiadala@fuw.edu.pl http://www.fuw.edu.pl/~mposiada Magdalena.Posiadala@fuw.edu.pl 1 Przypomnienie 125 (10) =? (2) Liczby ca kowite
Poradnik programowania procesorów AVR na przykładzie ATMEGA8
 Poradnik programowania procesorów AVR na przykładzie ATMEGA8 Wersja 1.0 Tomasz Pachołek 2017-13-03 Opracowanie zawiera opis podstawowych procedur, funkcji, operatorów w języku C dla mikrokontrolerów AVR
Poradnik programowania procesorów AVR na przykładzie ATMEGA8 Wersja 1.0 Tomasz Pachołek 2017-13-03 Opracowanie zawiera opis podstawowych procedur, funkcji, operatorów w języku C dla mikrokontrolerów AVR
Pomoc do programu ISO Manager
 Pomoc do programu ISO Manager Wersja 1.1 1 1. Nawiązanie połączenia detektora ISO-1 z aplikacją ISO Manager Należy pobrać program ISO Manager ze strony producenta www.ratmon.com/pobierz, zainstalować na
Pomoc do programu ISO Manager Wersja 1.1 1 1. Nawiązanie połączenia detektora ISO-1 z aplikacją ISO Manager Należy pobrać program ISO Manager ze strony producenta www.ratmon.com/pobierz, zainstalować na
Zaliczenie Termin zaliczenia: Sala IE 415 Termin poprawkowy: > (informacja na stronie:
 Zaliczenie Termin zaliczenia: 14.06.2007 Sala IE 415 Termin poprawkowy: >18.06.2007 (informacja na stronie: http://neo.dmcs.p.lodz.pl/tm/index.html) 1 Współpraca procesora z urządzeniami peryferyjnymi
Zaliczenie Termin zaliczenia: 14.06.2007 Sala IE 415 Termin poprawkowy: >18.06.2007 (informacja na stronie: http://neo.dmcs.p.lodz.pl/tm/index.html) 1 Współpraca procesora z urządzeniami peryferyjnymi
Zapis liczb binarnych ze znakiem
 Zapis liczb binarnych ze znakiem W tej prezentacji: Zapis Znak-Moduł (ZM) Zapis uzupełnień do 1 (U1) Zapis uzupełnień do 2 (U2) Zapis Znak-Moduł (ZM) Koncepcyjnie zapis znak - moduł (w skrócie ZM - ang.
Zapis liczb binarnych ze znakiem W tej prezentacji: Zapis Znak-Moduł (ZM) Zapis uzupełnień do 1 (U1) Zapis uzupełnień do 2 (U2) Zapis Znak-Moduł (ZM) Koncepcyjnie zapis znak - moduł (w skrócie ZM - ang.
PAMIĘĆ RAM. Rysunek 1. Blokowy schemat pamięci
 PAMIĘĆ RAM Pamięć służy do przechowania bitów. Do pamięci musi istnieć możliwość wpisania i odczytania danych. Bity, które są przechowywane pamięci pogrupowane są na komórki, z których każda przechowuje
PAMIĘĆ RAM Pamięć służy do przechowania bitów. Do pamięci musi istnieć możliwość wpisania i odczytania danych. Bity, które są przechowywane pamięci pogrupowane są na komórki, z których każda przechowuje
ZL10PLD. Moduł dippld z układem XC3S200
 ZL10PLD Moduł dippld z układem XC3S200 Moduły dippld opracowano z myślą o ułatwieniu powszechnego stosowania układów FPGA z rodziny Spartan 3 przez konstruktorów, którzy nie mogą lub nie chcą inwestować
ZL10PLD Moduł dippld z układem XC3S200 Moduły dippld opracowano z myślą o ułatwieniu powszechnego stosowania układów FPGA z rodziny Spartan 3 przez konstruktorów, którzy nie mogą lub nie chcą inwestować
Część 4 życie programu
 1. Struktura programu c++ Ogólna struktura programu w C++ składa się z kilku części: część 1 część 2 część 3 część 4 #include int main(int argc, char *argv[]) /* instrukcje funkcji main */ Część
1. Struktura programu c++ Ogólna struktura programu w C++ składa się z kilku części: część 1 część 2 część 3 część 4 #include int main(int argc, char *argv[]) /* instrukcje funkcji main */ Część
LABORATORIUM PROCESORY SYGNAŁOWE W AUTOMATYCE PRZEMYSŁOWEJ. Zasady arytmetyki stałoprzecinkowej oraz operacji arytmetycznych w formatach Q
 LABORAORIUM PROCESORY SYGAŁOWE W AUOMAYCE PRZEMYSŁOWEJ Zasady arytmetyki stałoprzecinkowej oraz operacji arytmetycznych w formatach Q 1. Zasady arytmetyki stałoprzecinkowej. Kody stałopozycyjne mają ustalone
LABORAORIUM PROCESORY SYGAŁOWE W AUOMAYCE PRZEMYSŁOWEJ Zasady arytmetyki stałoprzecinkowej oraz operacji arytmetycznych w formatach Q 1. Zasady arytmetyki stałoprzecinkowej. Kody stałopozycyjne mają ustalone
Laboratorium Podstaw Pomiarów
 Laboratorium Podstaw Pomiarów Dokumentowanie wyników pomiarów protokół pomiarowy Instrukcja Opracował: dr hab. inż. Grzegorz Pankanin, prof. PW Instytut Systemów Elektronicznych Wydział Elektroniki i Technik
Laboratorium Podstaw Pomiarów Dokumentowanie wyników pomiarów protokół pomiarowy Instrukcja Opracował: dr hab. inż. Grzegorz Pankanin, prof. PW Instytut Systemów Elektronicznych Wydział Elektroniki i Technik
3. Opracować program kodowania/dekodowania pliku tekstowego. Algorytm kodowania:
 Zadania-7 1. Opracować program prowadzący spis pracowników firmy (max.. 50 pracowników). Każdy pracownik opisany jest za pomocą struktury zawierającej nazwisko i pensję. Program realizuje następujące polecenia:
Zadania-7 1. Opracować program prowadzący spis pracowników firmy (max.. 50 pracowników). Każdy pracownik opisany jest za pomocą struktury zawierającej nazwisko i pensję. Program realizuje następujące polecenia:
Modułowy programowalny przekaźnik czasowy firmy Aniro.
 Modułowy programowalny przekaźnik czasowy firmy Aniro. Rynek sterowników programowalnych Sterowniki programowalne PLC od wielu lat są podstawowymi systemami stosowanymi w praktyce przemysłowej i stały
Modułowy programowalny przekaźnik czasowy firmy Aniro. Rynek sterowników programowalnych Sterowniki programowalne PLC od wielu lat są podstawowymi systemami stosowanymi w praktyce przemysłowej i stały
C++ wprowadzanie zmiennych
 C++ wprowadzanie zmiennych Każda zmienna musi być zadeklarowana, należy określić jej nazwę (identyfikator) oraz typ. Opis_typu lista zmiennych Dla każdej zmiennej rezerwowany jest fragment pamięci o określonym
C++ wprowadzanie zmiennych Każda zmienna musi być zadeklarowana, należy określić jej nazwę (identyfikator) oraz typ. Opis_typu lista zmiennych Dla każdej zmiennej rezerwowany jest fragment pamięci o określonym
projekt przetwornika inteligentnego do pomiaru wysokości i prędkości pionowej BSP podczas fazy lądowania;
 PRZYGOTOWAŁ: KIEROWNIK PRACY: MICHAŁ ŁABOWSKI dr inż. ZDZISŁAW ROCHALA projekt przetwornika inteligentnego do pomiaru wysokości i prędkości pionowej BSP podczas fazy lądowania; dokładny pomiar wysokości
PRZYGOTOWAŁ: KIEROWNIK PRACY: MICHAŁ ŁABOWSKI dr inż. ZDZISŁAW ROCHALA projekt przetwornika inteligentnego do pomiaru wysokości i prędkości pionowej BSP podczas fazy lądowania; dokładny pomiar wysokości
W jaki sposób użyć tych n bitów do reprezentacji liczb całkowitych
 Arytmetyka komputerowa Wszelkie liczby zapisuje się przy użyciu bitów czyli cyfr binarnych: 0 i 1 Ile różnych liczb można zapisać używajac n bitów? n liczby n-bitowe ile ich jest? 1 0 1 00 01 10 11 3 000001010011100101110111
Arytmetyka komputerowa Wszelkie liczby zapisuje się przy użyciu bitów czyli cyfr binarnych: 0 i 1 Ile różnych liczb można zapisać używajac n bitów? n liczby n-bitowe ile ich jest? 1 0 1 00 01 10 11 3 000001010011100101110111
Algorytm. a programowanie -
 Algorytm a programowanie - Program komputerowy: Program komputerowy można rozumieć jako: kod źródłowy - program komputerowy zapisany w pewnym języku programowania, zestaw poszczególnych instrukcji, plik
Algorytm a programowanie - Program komputerowy: Program komputerowy można rozumieć jako: kod źródłowy - program komputerowy zapisany w pewnym języku programowania, zestaw poszczególnych instrukcji, plik
1 Podstawy c++ w pigułce.
 1 Podstawy c++ w pigułce. 1.1 Struktura dokumentu. Kod programu c++ jest zwykłym tekstem napisanym w dowolnym edytorze. Plikowi takiemu nadaje się zwykle rozszerzenie.cpp i kompiluje za pomocą kompilatora,
1 Podstawy c++ w pigułce. 1.1 Struktura dokumentu. Kod programu c++ jest zwykłym tekstem napisanym w dowolnym edytorze. Plikowi takiemu nadaje się zwykle rozszerzenie.cpp i kompiluje za pomocą kompilatora,
POLITECHNIKA WARSZAWSKA Wydział Elektryczny Instytut Elektroenergetyki Zakład Elektrowni i Gospodarki Elektroenergetycznej
 POLITECHNIKA WARSZAWSKA Wydział Elektryczny Instytut Elektroenergetyki Zakład Elektrowni i Gospodarki Elektroenergetycznej INSTRUKCJA DO ĆWICZENIA Kalibracja kanału pomiarowego 1. Wstęp W systemach sterowania
POLITECHNIKA WARSZAWSKA Wydział Elektryczny Instytut Elektroenergetyki Zakład Elektrowni i Gospodarki Elektroenergetycznej INSTRUKCJA DO ĆWICZENIA Kalibracja kanału pomiarowego 1. Wstęp W systemach sterowania
Wybrane wyniki w zakresie umiejętności matematycznych
 Wybrane wyniki w zakresie umiejętności matematycznych Struktura badanych umiejętności matematycznych Umiejętności narzędziowe, stosowane w sytuacji typowej stosowane w sytuacji nietypowej Umiejętności
Wybrane wyniki w zakresie umiejętności matematycznych Struktura badanych umiejętności matematycznych Umiejętności narzędziowe, stosowane w sytuacji typowej stosowane w sytuacji nietypowej Umiejętności
Instytut Teleinformatyki
 Instytut Teleinformatyki Wydział Fizyki, Matematyki i Informatyki Politechnika Krakowska Mikrokontrolery i Mikroprocesory DMA (Direct Memory Access) laboratorium: 05 autor: mgr inż. Katarzyna Smelcerz
Instytut Teleinformatyki Wydział Fizyki, Matematyki i Informatyki Politechnika Krakowska Mikrokontrolery i Mikroprocesory DMA (Direct Memory Access) laboratorium: 05 autor: mgr inż. Katarzyna Smelcerz
Logiczny model komputera i działanie procesora. Część 1.
 Logiczny model komputera i działanie procesora. Część 1. Klasyczny komputer o architekturze podanej przez von Neumana składa się z trzech podstawowych bloków: procesora pamięci operacyjnej urządzeń wejścia/wyjścia.
Logiczny model komputera i działanie procesora. Część 1. Klasyczny komputer o architekturze podanej przez von Neumana składa się z trzech podstawowych bloków: procesora pamięci operacyjnej urządzeń wejścia/wyjścia.
Wyświetlacz alfanumeryczny LCD zbudowany na sterowniku HD44780
 Dane techniczne : Wyświetlacz alfanumeryczny LCD zbudowany na sterowniku HD44780 a) wielkość bufora znaków (DD RAM): 80 znaków (80 bajtów) b) możliwość sterowania (czyli podawania kodów znaków) za pomocą
Dane techniczne : Wyświetlacz alfanumeryczny LCD zbudowany na sterowniku HD44780 a) wielkość bufora znaków (DD RAM): 80 znaków (80 bajtów) b) możliwość sterowania (czyli podawania kodów znaków) za pomocą
Cyfrowe układy scalone
 Cyfrowe układy scalone Ryszard J. Barczyński, 2010 2015 Politechnika Gdańska, Wydział FTiMS, Katedra Fizyki Ciała Stałego Materiały dydaktyczne do użytku wewnętrznego Cyfrowe układy scalone Układy cyfrowe
Cyfrowe układy scalone Ryszard J. Barczyński, 2010 2015 Politechnika Gdańska, Wydział FTiMS, Katedra Fizyki Ciała Stałego Materiały dydaktyczne do użytku wewnętrznego Cyfrowe układy scalone Układy cyfrowe
1.2. Architektura rdzenia ARM Cortex-M3...16
 Od Autora... 10 1. Wprowadzenie... 11 1.1. Wstęp...12 1.1.1. Mikrokontrolery rodziny ARM... 14 1.2. Architektura rdzenia ARM Cortex-M3...16 1.2.1. Najważniejsze cechy architektury Cortex-M3... 16 1.2.2.
Od Autora... 10 1. Wprowadzenie... 11 1.1. Wstęp...12 1.1.1. Mikrokontrolery rodziny ARM... 14 1.2. Architektura rdzenia ARM Cortex-M3...16 1.2.1. Najważniejsze cechy architektury Cortex-M3... 16 1.2.2.
Programowanie. programowania. Klasa 3 Lekcja 9 PASCAL & C++
 Programowanie Wstęp p do programowania Klasa 3 Lekcja 9 PASCAL & C++ Język programowania Do przedstawiania algorytmów w postaci programów służą języki programowania. Tylko algorytm zapisany w postaci programu
Programowanie Wstęp p do programowania Klasa 3 Lekcja 9 PASCAL & C++ Język programowania Do przedstawiania algorytmów w postaci programów służą języki programowania. Tylko algorytm zapisany w postaci programu
Układy arytmetyczne. Joanna Ledzińska III rok EiT AGH 2011
 Układy arytmetyczne Joanna Ledzińska III rok EiT AGH 2011 Plan prezentacji Metody zapisu liczb ze znakiem Układy arytmetyczne: Układy dodające Półsumator Pełny sumator Półsubtraktor Pełny subtraktor Układy
Układy arytmetyczne Joanna Ledzińska III rok EiT AGH 2011 Plan prezentacji Metody zapisu liczb ze znakiem Układy arytmetyczne: Układy dodające Półsumator Pełny sumator Półsubtraktor Pełny subtraktor Układy
Przetwarzanie potokowe pipelining
 Przetwarzanie potokowe pipelining (część A) Przypomnienie - implementacja jednocyklowa 4 Add Add PC Address memory ister # isters Address ister # ister # memory Wstęp W implementacjach prezentowanych tydzień
Przetwarzanie potokowe pipelining (część A) Przypomnienie - implementacja jednocyklowa 4 Add Add PC Address memory ister # isters Address ister # ister # memory Wstęp W implementacjach prezentowanych tydzień
PROGRAM TESTOWY LCWIN.EXE OPIS DZIAŁANIA I INSTRUKCJA UŻYTKOWNIKA
 EGMONT INSTRUMENTS PROGRAM TESTOWY LCWIN.EXE OPIS DZIAŁANIA I INSTRUKCJA UŻYTKOWNIKA EGMONT INSTRUMENTS tel. (0-22) 823-30-17, 668-69-75 02-304 Warszawa, Aleje Jerozolimskie 141/90 fax (0-22) 659-26-11
EGMONT INSTRUMENTS PROGRAM TESTOWY LCWIN.EXE OPIS DZIAŁANIA I INSTRUKCJA UŻYTKOWNIKA EGMONT INSTRUMENTS tel. (0-22) 823-30-17, 668-69-75 02-304 Warszawa, Aleje Jerozolimskie 141/90 fax (0-22) 659-26-11
Technologie Informacyjne Wykład 4
 Technologie Informacyjne Wykład 4 Arytmetyka komputerów Wojciech Myszka Jakub Słowiński Katedra Mechaniki i Inżynierii Materiałowej Wydział Mechaniczny Politechnika Wrocławska 30 października 2014 Część
Technologie Informacyjne Wykład 4 Arytmetyka komputerów Wojciech Myszka Jakub Słowiński Katedra Mechaniki i Inżynierii Materiałowej Wydział Mechaniczny Politechnika Wrocławska 30 października 2014 Część
1. Wprowadzenie Programowanie mikrokontrolerów Sprzęt i oprogramowanie... 33
 Spis treści 3 1. Wprowadzenie...11 1.1. Wstęp...12 1.2. Mikrokontrolery rodziny ARM...13 1.3. Architektura rdzenia ARM Cortex-M3...15 1.3.1. Najważniejsze cechy architektury Cortex-M3... 15 1.3.2. Rejestry
Spis treści 3 1. Wprowadzenie...11 1.1. Wstęp...12 1.2. Mikrokontrolery rodziny ARM...13 1.3. Architektura rdzenia ARM Cortex-M3...15 1.3.1. Najważniejsze cechy architektury Cortex-M3... 15 1.3.2. Rejestry
Temat 1: Podstawowe pojęcia: program, kompilacja, kod
 Temat 1: Podstawowe pojęcia: program, kompilacja, kod wynikowy. Przykłady najprostszych programów. Definiowanie zmiennych. Typy proste. Operatory: arytmetyczne, przypisania, inkrementacji, dekrementacji,
Temat 1: Podstawowe pojęcia: program, kompilacja, kod wynikowy. Przykłady najprostszych programów. Definiowanie zmiennych. Typy proste. Operatory: arytmetyczne, przypisania, inkrementacji, dekrementacji,
Podstawy programowania. 1. Operacje arytmetyczne Operacja arytmetyczna jest opisywana za pomocą znaku operacji i jednego lub dwóch wyrażeń.
 Podstawy programowania Programowanie wyrażeń 1. Operacje arytmetyczne Operacja arytmetyczna jest opisywana za pomocą znaku operacji i jednego lub dwóch wyrażeń. W językach programowania są wykorzystywane
Podstawy programowania Programowanie wyrażeń 1. Operacje arytmetyczne Operacja arytmetyczna jest opisywana za pomocą znaku operacji i jednego lub dwóch wyrażeń. W językach programowania są wykorzystywane
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake