Rozproszona grafowa baza danych
|
|
|
- Witold Kozłowski
- 8 lat temu
- Przeglądów:
Transkrypt
1 RGBD:RZS -2012/3/15-PC 15 marca 2012 Autor: Patryk Chaber Rozproszona grafowa baza danych Raport ze spotkania (kod ref. RGBD:RZS -2012/3/15-PC ) Opis Raport ze spotkania grupy projektowej 2D. Celem spotkania było podsumowanie dotychczasowych wyników prac oraz dalszych planów

2 RGBD:RZS -2012/3/15-PC 3 Przebieg Spis treści 1 Czas i miejsce 2 2 Cel 2 3 Przebieg Wstęp Przedstawienie dotychczasowych wyników prac Opracowanie przykładowych koncepcji realizacji projektu Wnioski ze spotkania 3 1 Czas i miejsce Spotkanie odbyło się 13. marca 2012 roku w sali laboratoryjnej 518 wydziału Elektroniki i Technik Informacyjnych Politechniki Warszawskiej. Rozpoczęło się ono o godzinie 15:10 i zakończyło o godzinie 16:10. Na spotkanie wszyscy członkowie grupy projektowej przybyli punktualnie. 2 Cel Celem spotkania było dokładne ustalenie tematów, którymi mieli się zajmować poszczególni członkowie grupy projektowej 2D oraz ustalenie ogólnego celu projektu i jego koncepcji, aby łatwiej było skupić się na poszczególnych zadaniach oraz znać kontekst w którym członkowie grupy maja rozpatrywać poszczególne informacje. 3 Przebieg 3.1 Wstęp Członkom grupy projektowej zostało zlecone przeprowadzenie poszukiwań możliwych do analizy aspektów projektu, w zwiazku z czym wiedza na dzień spotkania części członków projektu pokrywała się. Takie podejście było jednak bardzo przydatne ponieważ dzięki temu możliwa była rozmowa i wymiana podstawowych informacji dotyczacych tematu projektu oraz ustalenie przykładowej koncepcji jego powstawania. Poczatkowy przydział tematów wygladał następujaco: Radian Karpuk - Neo4j Paweł Bulwan - języki zapytań Maciej Sikora - grafowe bazy danych Piotr Zakrzewski - REST Dominik Zieliński - rozproszone relacyjne bazy danych Mateusz Cieślak - Neo4j HA (realizacja rozproszenia w pakiecie Neo4j) 2

3 RGBD:RZS -2012/3/15-PC 4 Wnioski ze spotkania Jednocześnie każdy z członków grupy projektowej posiadał podstawowe informacje dotyczace rozproszonych grafowych baz danych. 3.2 Przedstawienie dotychczasowych wyników prac Pierwsza część spotkania została poświęcona na wymianę informacji zdobytych dotychczas przez poszczególnych uczestników projektu. Trwało to około 15 minut, po których cała grupa posiadała w przybliżeniu tę sama wiedzę w zakresie analizowanym przez poszczególne osoby. 3.3 Opracowanie przykładowych koncepcji realizacji projektu Druga częścia było ustalenie przykładowej koncepcji struktury projektu. Celem tego było zorientowanie się na jakie rozwiazanie będziemy się nastawiać - w jaki sposób dokonamy rozproszenia bazy danych. W ramach tej części zostały przedstawione ogólne pomysły rozwiazania tej kwestii, lecz ich dogłębna analiza zostanie przeprowadzona dopiero w ramach drugiego etapu projektu. 4 Wnioski ze spotkania Na koniec w ciagu 5 minut zostały wyciagnięte wnioski dotyczace dotychczasowej pracy - analiza jakich tematów była zbędna, jakie się przydadza, jakie moga być dodatkowo analizowane. W zwiazku z tym zrezygnowaliśmy z opracowywania tematu Neo4j HA, ponieważ uznaliśmy, że tak poważne zagłębianie się w implementację jest pozbawione sensu, zamiast tego postanowiliśmy, że rozejrzymy się w kwestii RMI - mechanizmu JAVA y pozwalajacego na zdalne wywoływanie metod obiektów. Jest to podobne zagadnienie co REST, lecz na chwilę obecna postanowione zostało, że przeanalizujemy obydwa rozwiazania, co pozwoli nam na następnym spotkaniu - po złożeniu końcowych opracowań tematów - na wybranie lepszego mechanizmu lub częściowe wykorzystanie jednego i drugiego rozwia- zania. 3

4 RGBD:RZS -2012/3/24-PC 24 marca 2012 Autor: Patryk Chaber Rozproszona grafowa baza danych Raport ze spotkania (kod ref. RGBD:RZS -2012/3/24-PC ) Opis Raport ze spotkania grupy projektowej 2D. Celem spotkania było podsumowanie dotychczasowych wyników prac oraz omówienie nowych zadań członków grupy projektowej

5 RGBD:RZS -2012/3/24-PC 3 Przebieg Spis treści 1 Czas i miejsce 2 2 Cel 2 3 Przebieg Podsumowanie zdobytej wiedzy oraz jej wykorzystanie w celu zrozumienia problemu Dyskusja dotyczaca ról członków grupy projektowej Podsumowanie rozpoznania tematów Konsultacje z przedmiotu RSO Przydział tematów Wnioski ze spotkania 4 1 Czas i miejsce Spotkanie odbyło się 20. marca 2012 roku w sali laboratoryjnej 518 wydziału Elektroniki i Technik Informacyjnych Politechniki Warszawskiej w godzinach 15:00-16:15. Kontynuowane było ono jednak ciagł a dyskusja na forum grupy, w zwiazku z czym niniejszy raport dotyczy nie tylko samego spotkania, ale także okresu od 20. marca do 23. marca, kiedy to kiedy to podjęte i zaakceptowane przez grupę zostały pewne decyzje. Wszyscy członkowie grupy brali aktywny udział we wszelkich dyskusjach oraz rozmowach. 2 Cel Celem spotkania było oraz omówienie zdobytych, w ramach rozpoznawania tematów, informacji oraz zaplanowanie dalszych działań. Przeprowadzona miała być także dyskusja na temat przyznanych członkom grupy projektowej ról. Ostatnim celem spotkania miało być ustalenie ewentualnych pytań do prowadzacego projekt - wykładowcy dr inż. Tomasza Jordana Kruka - w ramach konsultacji z przedmiotu RSO. 3 Przebieg 3.1 Podsumowanie zdobytej wiedzy oraz jej wykorzystanie w celu zrozumienia problemu Spotkanie rozpoczęło się od dyskusji na temat założeń projektu - jakie sytuacje zaprojektowana przez nas baza danych miałaby przetrzymywać, w jaki sposób mogłoby się to odbywać oraz jakie straty możemy w wypadku takiej awarii ponieść. Rozmowa ta miała na celu skupić rozważania uczestników na konkretnym przykładzie, aby łatwiej było wynaleźć aspekty projektu, o których jeszcze nie było mowy, a w przyszłości moga okazać się kluczowe. Przebieg rozmowy sugerował jednak, że grupa projektowa jest już wystarczajaco dobrze zapoznana z teoria dotyczac a rozproszonych oraz grafowych baz danych, aby płynnie i bez problemów prowadzić na ten temat dyskusje. 2

6 RGBD:RZS -2012/3/24-PC 3 Przebieg 3.2 Dyskusja dotyczaca ról członków grupy projektowej Kolejna częścia było omówienie ról poszczególnych członków grupy projektowej. Propozycje przydziału zadań zostały przedstawione przed spotkaniem za pośrednictwem forum grupy, dzięki czemu ewentualne watpliwości mogły zostać sprawnie przedstawione. Mimo to nie pojawiły się żadne sprzeciwy oraz pytania, w zwiazku z czym nastapiło oficjalne przypisanie ról uczestnikom rozmowy. Wspominane role to: Paweł Bulwan - opieka nad dokumentacja Patryk Chaber - kierownik grupy projektowej Mateusz Cieślak - przygotowanie oraz przeprowadzenie testów projektu Radian Karpuk - prezentacja projektu Maciej Sikora - administracja bazami danych (+ ewentualnymi maszynami wirtualnymi) Piotr Zakrzewski - zarzadzanie repozytorium (SVN) Dominik Zieliński - kontrola jakości kodu Na prośbę kierownika ustalone zostały wymagania dotyczace roli kontrolera jakości kodu, ze względu na brak występowania takiego w znanych nam wcześniej projektach. Z powodu braku watpliwości i sprawnej komunikacji, na ustalenie ról poświęcono około 5 minut. 3.3 Podsumowanie rozpoznania tematów Reszta spotkania poświęcona została na omówienie dotychczasowych wyników pracy, oraz zakończenie i podsumowanie etapu majacego na celu zaznajomienie nas z tematyka poruszana w ramach projektu. Przygotowane zostało tylko jedno pytanie dotyczace projektu - "Jak wielkie straty jesteśmy w stanie ponieść w ramach projektu: awaria węzła może powodować brak dostępu do części systemu, czy ma następować zastapienie nieczynnego serwera jego kopia zapasowa?". Odpowiedź została udzielona jeszcze przed konsultacjami i wynikało z niej, że nie można dopuścić do sytuacji, w której jakakolwiek funkcjonalność systemu jest niedostępna. 3.4 Konsultacje z przedmiotu RSO Mimo braku pytań kierownik został namówiony do pójścia na konsultacje, w celu pozyskania informacji na temat formy oddawania prac, co jednocześnie zaowocowało dodatkowa uwaga na temat sposobu organizacji zasobami ludzkimi przez kierownika. Efektem tego, było przydzielenie kolejnych tematów, członkom zespołu, tym razem traktujacych o konkretnych rozwiazaniach rozproszonych grafowych baz danych. 3.5 Przydział tematów W ciagu kolejnych dni dokonany został przydział tematów poszczególnym osobom: Paweł Bulwan - Flock DB 3

7 RGBD:RZS -2012/3/24-PC 4 Wnioski ze spotkania Patryk Chaber - GraphBase Mateusz Cieślak - HypherGraphDB Radian Karpuk - Neo4J HA Maciej Sikora - OrientDB Piotr Zakrzewski - Infinite Grap Dominik Zieliński - InfoGrid Niestety w zwiazku z brakiem jakiejkolwiek przydatnej dokumentacji oraz brakiem kontaktu z autorami GraphBase, nie powstał dokument opisujacy to rozwiazanie. 4 Wnioski ze spotkania Po przeprowadzeniu rozeznania w tematyce rozproszonych oraz grafowych baz danych, przyszedł czas na analizę dostępnych rozwiazań. Pozwoli to w przyszłości określić dostępne metody rozpraszania grafowych baz danych, dzięki czemu będziemy mogli zrealizować projekt, który nie będzie powtarzał gotowych już rozwiazań. Z drugiej strony można się spodziewać nowych pomysłów na usprawnienie działania grafowych baz danych, inspirowanego istniejacymi rozwiazaniami. Ponieważ do tej pory nie były znane ani potrzebne role poszczególnych członków grupy projektowej, dopiero od rozpoczęcia następnego etapu projektu - odpowiednie osoby będa rozliczane z wypełniania swoich funkcji. 4

8 RGBD:P1EP -2012/3/27-PC 27 marca 2012 Autor: Patryk Chaber Rozproszona grafowa baza danych Podsumowanie pierwszego etapu prac (kod ref. RGBD:P1EP -2012/3/27-PC ) Opis Podsumowanie prac wykonanych od rozpoczęcia projektu do zakończenia pierwszego kamienia milowego. Dokument zawiera załaczniki będace opracowaniami tematów członków zespołu oraz raporty ze spotkań grupy.

9 Spis treści 1. Wstęp Cel projektu Grupa projektowa 2D Analiza dziedziny A. Dokumenty wytworzone w ramach pierwszego etapu

10 1. Wstęp Projekt wykonywany przez grupę projektowa 2D jest to projekt rozproszonej grafowej bazy danych. Temat ten jest rozważany w odniesieniu do popularnej i omawionej w dokumentach RGBD:RT-NEO4J-2012/3/24-RK oraz RGBD:RT-N4JHA-2012/3/25-MC grafowej bazy danych Neo4j Cel projektu Do wykonania w ramach tego projektu sa następujace trzy elementy: analiza dziedziny oraz rozeznanie w tematach zwiazanych z rozproszonymi grafowymi bazami danych zaprojektowanie rozwiazania implementacja rozwiazania oraz przeprowadzenie testów Grupa projektowa 2D Członkami grupy projektowej, o numerze identyfikacyjnym 2D, sa następujace osoby: Paweł Bulwan (opieka nad dokumentacja) Patryk Chaber (kierownik grupy projektowej) Mateusz Cieślak (przygotowanie oraz przeprowadzenie testów projektu) Radian Karpuk (prezentacja projektu) Maciej Sikora (administracja bazami danych oraz ewentualnymi maszynami wirtualnymi) Piotr Zakrzewski (zarzadzanie repozytorium SVN) Dominik Zieliński (kontrola jakości kodu) W nawiasach obok nazwiska danej osoby została zawarta informacja o zakresie odpowiedzialności - roli danego członka grupy. Wynika ona z ustaleń ze spotkania opisanego w dokumencie RGBD:RZS-2012/3/24-PC.

11 2. Analiza dziedziny Ponieważ wszelka analiza podtematów tego projektu została zrealizowana w postaci osobnych dokumentów wykonanych przez poszczególnych członków grupy projektowej, cała treść składajaca się na analizę dziedziny zawiera się w plikach, będacych załaczni- kami do tego dokumentu.

12 A. Dokumenty wytworzone w ramach pierwszego etapu Kolejność załaczonych dokumentów: 1. Rozpoznanie tematu: Rozproszone bazy danych 2. Rozpoznanie tematu: Języki zapytań w grafowych bazach danych 3. Rozpoznanie tematu: Neo4j REST API 4. Rozpoznanie tematu: Grafowe bazy danych - przeglad 5. Rozpoznanie tematu: RMI 6. Rozpoznanie tematu: Neo4j HA 7. Rozpoznanie tematu: Grafowe bazy danych w ujęciu Neo4j 8. Rozpoznanie tematu: InfoGrid 9. Rozpoznanie tematu: HyperGraphDB 10. Rozpoznanie tematu: OrientDB - metody rozpraszania bazy danych 11. Rozpoznanie tematu: FlockDB - przeglad architektury 12. Rozpoznanie tematu: InfiniteGraph The Distributed Graph Database 13. Raport ze spotkania z dnia 15 marca 14. Raport ze spotkania z dnia 23 marca

13 RGBD:RT-RBD -2012/3/18-DZ 18 marca 2012 Autor: Dominik Zieliński Rozproszona grafowa baza danych Rozpoznanie tematu: Rozproszone bazy danych (kod ref. RGBD:RT-RBD -2012/3/18-DZ ) Opis Dokument przybliża technologię rozproszonych bazy danych. Opisane zostaja zalety oraz wady takiego rozwiazania. Przedstawione zostaja mechanizmy replikacji i fragmentacji danych.

14 RGBD:RT-RBD -2012/3/18-DZ 1 Wstęp Spis treści 1 Wstęp Definicja Cechy DDB Zalety DDB Wady DDB Replikacja Typy replikacji Architektury replikacji Master-slave Publikator-Dystrybutor-Subskrybent Fragmentacja Typy fragmentacji Fragmentacja w grafowych bazach danych Wstęp Dokument zawiera opis technologii rozproszonych baz danych. 1.1 Definicja Rozproszona baza danych (distributed database - DDB) nazywa się zorganizowana kolekcję danych cyfrowych umieszczonych fizycznie na wielu węzłach sieci komputerowej traktowana jako logiczna całość. Taka baza danych jest systemem rozproszonym i powinna spełniać postulaty przeźroczystości dla systemów rozproszonych: Przeźroczystość lokacji - Użytkownik nie wie gdzie fizycznie sa przechowywane dane. Przeźroczystość replikacji - Użytkownik nie wie czy i w jaki sposób dane sa powielane. Przeźroczystość fragmentacji - Użytkownik nie wie czy i w jaki sposób dane sa dzielone. 1.2 Cechy DDB Zastosowanie rozproszonej zamiast scentralizowanej bazy danych, pozwala osiagn ać szereg korzyści, jednak wymaga także pewnego nakładu pracy i wzięcia pod uwagę pewnych ograniczeń i niebezpieczeństw wiaż acych się z użyciem tej technologii. Podstawowa zaleta DDB jest zwiększenie niezawodności całego systemu, ponieważ awaria (czasowa lub permanentna) jednego węzła nie powoduje awarii całego systemu. Jednocześnie zastosowanie wielu komputerów zamiast jednego umożliwia zwiększenia objętości przechowywanych danych, przyspieszenie ich przetwarzania oraz w pewnym stopniu zmniejszenie kosztów. Wynika to z tego, że rozproszony system złożony z wielu słabych maszyn może być tańszy i wydajniejszy niż jedna mocna maszyna. W pewnym momencie rozbudowy systemu rozproszenie jest jedynym wyjściem ponieważ nie istnieje pojedynczy 2

15 RGBD:RT-RBD -2012/3/18-DZ 2 Replikacja komputer o dostatecznej wydajności. Ułatwione jest także skalowanie systemu, ponieważ polega na dołaczeniu dodatkowego węzła. Ponadto, poszczególne węzły moga być fizycznie umieszczone w lokalnych biurach organizacji. Lokalna autonomia pozwala na co dzień pracować głównie na danych lokalnych. W przypadku scentralizowanej bazy danych sieć byłaby obciażona zapytaniami ze wszystkich biur lokalnych. Z drugiej strony rozproszona baza danych jest znacznie bardziej złożona niż baza scentralizowana. Wiaże się to z dodatkowymi wydatkami na specjalistyczne oprogramowanie i projekt systemu oraz zwiększonymi kosztami administracji wieloma węzłami sieci. Wymagane sa także mechanizmy zapewniania spójności danych na wszystkich węzłach Zalety DDB Odzwierciedlenie geograficznej struktury organizacji. Równoległe przetwarzanie danych na wielu węzłach. Zwiększenie niezawodności systemu. Zwiększenie maksymalnej wielkości danych. Zwiększenie trwałości danych. Modułowość Wady DDB Potrzeba optymalizacji zapytań. Rozproszone przetwarzanie. Rozproszone zarzadzanie transakcjami. Potrzeba zapewnienia spójności danych. Administracja wieloma węzłami sieci. 2 Replikacja Replikacja jest procesem powielania (kopiowania) informacji i rozprowadzania ich między (częścia lub wszystkimi) węzłami systemu. Pozwala to na zwiększenie niezawodności systemu, czyli zdolności ciagłego, bezawaryjnego działania. Awaria jednego węzła nie uniemożliwia pracy całego systemu, w istocie dla użytkownika powinna być ona niezauważalna. Ponadto, dzięki replikacji możliwa jest poprawa wydajności pracy całego systemu, poprzez możliwość przetwarzania współbieżnego. Przechowywanie wielu kopii danych wiaże się jednak także z potrzeba zapewnienia ich spójności. Oznacza to, że modyfikacja jednej z kopii powinna propagować na wszystkie pozostałe. Wymaganie to może wpływać na wydajność systemu w momencie gdy dane sa częściej modyfikowane niż odczytywane. Wada tego rozwiazania jest także potrzeba zapewniania bezpieczeństwa danych. Każdy z (grupy) węzłów przechowuje całość danych. Oznacza to, że poziom zabezpieczenia całego systemu jest równy poziomowi zabezpieczenia najsłabiej zabezpieczonego węzła. 3

16 RGBD:RT-RBD -2012/3/18-DZ 2 Replikacja Rysunek 1: Schemat replikacji danych. 4

17 RGBD:RT-RBD -2012/3/18-DZ 2 Replikacja 2.1 Typy replikacji Pełna replikacja - każdy z węzłów systemu przechowuje pełna bazę danych. Zapewnia to duża niezawodność systemu (wymagana sprawność tylko jednego węzła), jednak obniża wydajność. Modyfikacja danych na jednym węźle wymusza modyfikację na wszystkich pozostałych. Częściowa replikacja - węzeł przechowuje swoje lokalne dane i dodatkowo część danych z pozostałych węzłów (fragmentacja danych zapasowych węzła). Replikacja master-slaves - transakcje kierowane sa do węzła master, wszelkie zmiany propaguja do podległych mu węzłów typu slave, które przechowuja kopie danych serwera nadrzędnego. W momencie awarii węzła master jego zadanie przejmuje jeden z węzłów slave. Replikacja synchroniczna - aktualizacja danych na wszystkich węzłach następuje w momencie wprowadzania zmian na jednym z nich, w ramach transakcji. Replikacja asynchroniczna - aktualizacja danych na węzłach następuje po zatwierdzeniu transakcji lub w pewnych ustalonych interwałach czasowych. Zastosowanie tego typu replikacji jest możliwe jedynie w systemach gdzie dopuszczalne jest pewne rozspójnienie danych. Replikacja optymistyczna - dopuszczalne czasowe rozspójnienie danych w czasie modyfikacji. Replikacja pesymistyczna - w czasie modyfikacji jednej kopii blokowany jest dostęp do pozostałych. 2.2 Architektury replikacji W architekturach opisujacych proces replikacji nie jest brana pod uwagę możliwa fragmentacja danych, mimo iż replikacja częściowa używa tego mechanizmu Master-slave Węzły sytemu dzielone sa na dwie klasy: master - węzły nadrzędne, do których kierowane sa transakcje. slave - węzły przechowujace kopie zapasowe danych nadrzędnego węzła master. W przypadku bezawaryjnej pracy systemu wszystkie transakcje obsługiwane sa przez węzeł typu master. W razie modyfikacji danych master zleca (synchronicznie lub asynchronicznie) dokonanie zmian na węzłach typu slave. Węzły master moga posiadać wiele węzłów slave, moga je współdzielić lub być węzłami typu slave innych węzłów. W razie awarii węzła master jeden (lub kilka jeżeli dane sa podzielone między węzły) z jego węzłów slave przejmuje jego zadania. Z tego powodu możliwych jest wiele układów tego typu, architektury, przykładowe z nich pokazane sa na rysunku 2. 5

18 RGBD:RT-RBD -2012/3/18-DZ 2 Replikacja 6 Rysunek 2: Przykładowe architektury master-slave

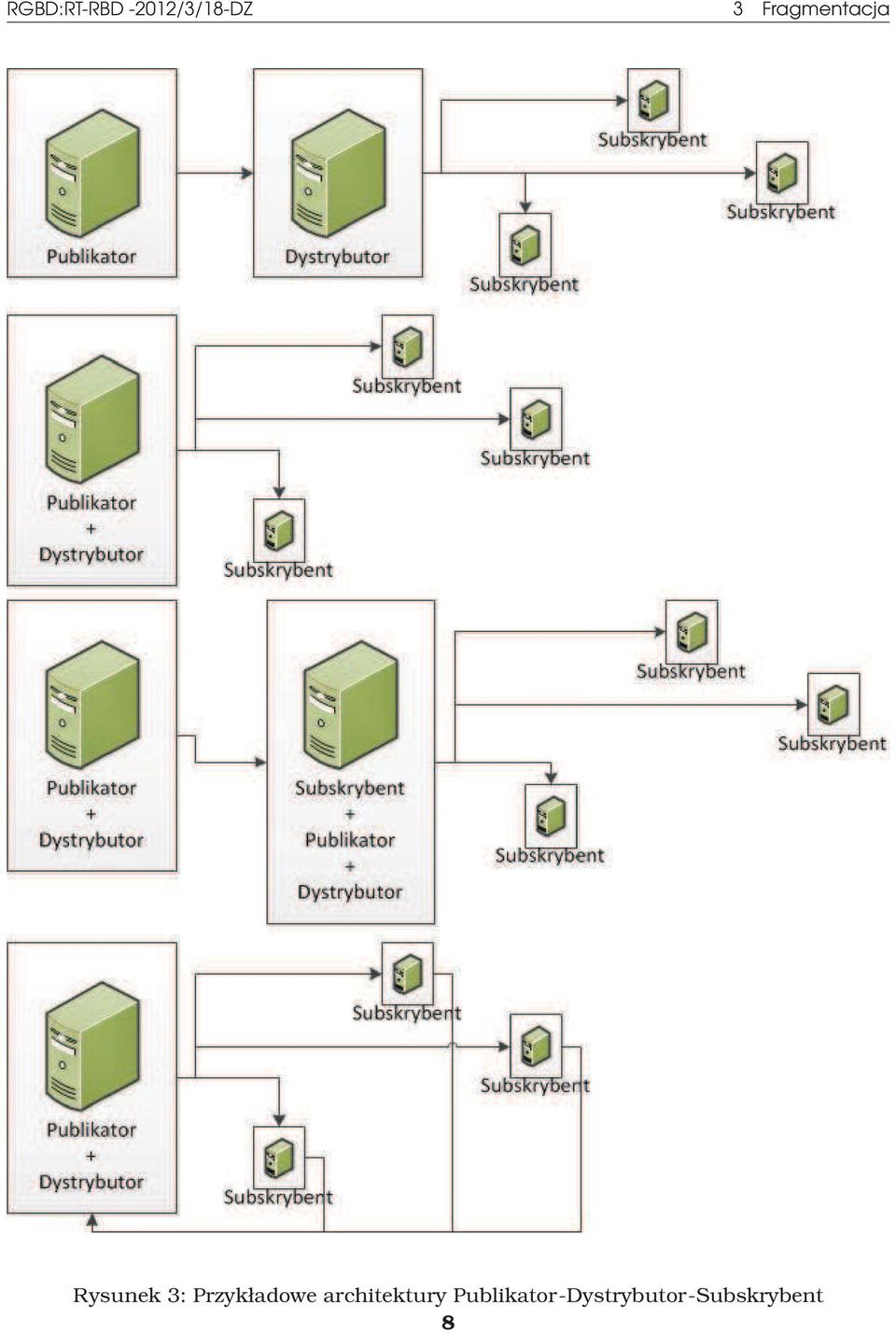
19 RGBD:RT-RBD -2012/3/18-DZ 3 Fragmentacja Publikator-Dystrybutor-Subskrybent Węzły systemu dzielone sa na trzy klasy: Publikator - źródłowy węzeł danych. Subskrybent - węzeł docelowy odbierajacy dane od publikatora. Dystrybutor - węzeł koordynujacy proces replikacji, pośredniczy między publikatorem a subskrybentem. Tego typu architektura używana jest na serwerach MS SQL. W typowym schemacie przepływu danych, dane modyfikowane sa przez węzeł publikacji i przesyłane do węzła dystrybucji, gdzie sa one przetrzymywane do momentu rozesłania ich do węzłów subskrypcyjnych. Subskrybenci pobieraja (lub sa im przesyłane) potrzebne dane od dystrybutora. W takiej architekturze występuja trzy typy replikacji: Migawkowa - wśród subskrybentów rozprowadzany jest obraz (zmaterializowana perspektywa tylko do odczytu) bazy danych z pewnego określonego momentu w czasie. Migawki sa najczęściej rozprowadzane w stałych odstępach czasu,a zmiany następujace między nimi nie sa widocznie dla subskrybentów do czasu opublikowania nowej migawki. Z tego powodu replikacja tego typu jest dobra dla danych nie podlegajacych częstej modyfikacji. Transakcyjna - zapewnia utrzymanie spójności danych publikatorów i subskrybentów. Aktualizacje rozsyłane sa po zatwierdzeniu transakcji. Wymaga stałego poła- czenia publikator-subskrybent i nie pozwala na modyfikację danych przez subskrybenta. Umożliwia zachowania zasad ACID (atomowość, spójność i izolacja transakcji, trwałość danych). Scalajaca - pozwala na modyfikację danych przez subskrybenta. Zmiany sa przetwarzane przez węzeł dystrybucyjny, który na podstawie zdefiniowanych zasad scala dane pochodzace od subskrybenta z danymi publikatora. Podczas modyfikacji nie jest wymagane połaczenie między węzłami systemu. Przykładowe architektury tego typu pokazane sa na rysunku 3. Podobnie jak w przypadku architektury master-slave, w architekturze publikator-dystrybutor-subskrybent możliwe jest wiele układów węzłów systemu, pełniacych różne role. Możliwe jest aby jeden węzeł pełnił wiele wymienionych wyżej funkcji. 3 Fragmentacja Fragmentacja polega na dzieleniu danych i rozprowadzaniu ich między węzłami systemu. Użytkownik łaczy się z jednym węzłem, który w razie potrzeby pobiera potrzebne dane z innych węzłów. Fragmentacja pozwala m.in. na odzwierciedlenie strukturalnego lub geograficznego podziału organizacji. Baza danych sieci sklepów składa się z lokalnych baz poszczególnych salonów sprzedaży. Proces fragmentacji jest częścia procesu replikacji częściowej - zapasowa kopia danych z jednego węzła jest dzielona na fragmenty i umieszczana na innych węzłach. 7

20 RGBD:RT-RBD -2012/3/18-DZ 3 Fragmentacja Rysunek 3: Przykładowe architektury Publikator-Dystrybutor-Subskrybent 8
21 RGBD:RT-RBD -2012/3/18-DZ 3 Fragmentacja Rysunek 4: Schemat fragmentacji danych. 9
22 RGBD:RT-RBD -2012/3/18-DZ 3 Fragmentacja 3.1 Typy fragmentacji Typowo w bazach danych możemy wydzielić zbiory rekordów określonego typu. Baza danych może zawierać tylko jeden taki zbiór (wszystkie rekordy sa tego samego typu) lub wiele zbiorów połaczonych relacjami (jak w relacyjnych bazach danych). Każdy z rekordów posiada pewna liczbę pól. Ich liczba i typy zależa od typu rekordu. Fragmentacja zbioru (pozioma) - dzielone sa zbiory rekordów. Węzły zawieraja pojedyncze rekordy ze zbiorów. Rekordy sa przetrzymywane w całości, czyli tak, że możliwe jest odczytanie rekordu bez dostępu do innych węzłów systemu. Fragmentacja rekordów (pionowa) - dzielone sa rekordy. Węzły zawieraja pojedyncze pola zbioru rekordów. Dane te musza być przetrzymywane w taki sposób, aby możliwe było ich połaczenie i uzyskanie pełnej informacji o rekordzie (typowo klucz rekordu i pole). Nie jest możliwe odczytanie całego rekordu bez dostępu do innych węzłów systemu. Fragmentacja schematu - węzły zawieraja pełne zbiory rekordów. W przypadku gdy baza danych składa się z jednego zbioru rekordów, sprowadza się to do replikacji. 3.2 Fragmentacja w grafowych bazach danych Model grafowej bazy danych jest etykietowanym i skierowanym multigrafem z atrybutami. Składa się z węzłów (odpowiadajacych encjom z relacyjnej bazy danych) i krawędzi, które je łacz a (odpowiadajacych relacjom). Każdy z obiektów tych typów posiada pewne właściwości i atrybuty. Możliwe jest więc zastosowanie kilku rozwiazań w celu uzyskania rozproszonej grafowej bazy danych. Podział bazy - graf bazy danych dzielony jest na podgrafy, które zostaja umieszczone na węzłach systemu. Możliwy jest dostęp do danych zapisanych w lokalnym grafie, bez dostępu do pozostałych węzłów. Podział struktury - węzły i krawędzie grafu sa przechowywane oddzielnie. Podział obiektów - struktura bazy danych przechowywane jest oddzielnie od wartości atrybutów jej węzłów i krawędzi. 10
23 RGBD:RT-RBD -2012/3/18-DZ Literatura Literatura [1] Wikipedia - rozproszona baza danych. Rozproszona_baza_danych. [2] dr inż. Tomasz Traczyk. Bazy danych 2 - wyklad
24 RGBD:RT-JZ -2012/3/19-PB 19 marca 2012 Autor: Paweł Bulwan Rozproszona grafowa baza danych Rozpoznanie tematu: Języki zapytań w grafowych bazach danych (kod ref. RGBD:RT-JZ -2012/3/19-PB ) Opis Dokument przedstawia podstawowe informacje na temat języków zapytań i metod dostępu do danych w grafie dla przykładowego popularnego systemu grafowych baz danych Neo4j.
25 RGBD:RT-JZ -2012/3/19-PB 1 Języki zapytań w Neo4j Spis treści 1 Języki zapytań w Neo4j Przykłady Graf użyty w zapytaniach Przykładowe zapytanie: kogo zna Cypher? Definiowanie wzorców w zapytaniach Pozostałe bloki składni Podsumowanie Języki zapytań w Neo4j W relacyjnych systemach baz danych dominujacym językiem zapytań jest bez watpienia SQL. W zależności od dostawcy systemu zarzadzania baza danych, SQL różni się nieco w składni, czego wymagaja różnice architektur oraz ich specyfika. Oprócz różnych dialektów SQLa istnieja inne języki zapytań do relacyjnych baz danych, ale maja obecnie marginalne znaczenie, często historyczne. O ile język SQL jest de facto standardem dla relacyjnych baz danych, o tyle grafowe bazy danych nie posiadaja w chwili obecnej takiego standardu. Popularna grafowa baza danych Neo4j wspiera obecnie kilka metod dostępu do danych grafu, przy czym poza natywnym interfejsem w Javie dwiema najbardziej rozbudowanymi sa metody wykorzystujace skryptowy język programowania grafów Gremlin oraz, od niedawna, deklaratywny język zapytań Cypher. Gremlin jest projektem open-source, który ma na celu stworzenie uniwersalnego języka programowania grafów. Opracowana składnia pozwala na zwięzłe zapisywanie nawet złożonych zapytań przeszukiwania grafu. Język ten jest kompletny w sensie Turinga. Do niedawna był podstawowym językiem zapytań dla bazy Neo4j. Gremlin nie jest ściśle zwiazany z baza Neo4j, pozwala on na podpięcie do back-enda dowolnej grafowej bazy danych implementujacej model danych Blueprints, np. Tinker- Graph, Neo4j, OrientDB, DEX, InfiniteGraph, Rexster. Gremlin jest językiem skryptowym, co odróżnia go od deklaratywnych języków jak SQL, gdyż wymaga opisania jak wykonać dane zapytanie, a nie tylko co chcemy osiagn ać. Dla przykładu, osoba wykonujaca zapytanie określa czy użyć metody przeszukiwania grafu wgłab czy wszerz i jakiego użyć algorytmu. W chwili obecnej cypher jest często stosowany w przypadku użycia grafowych baz danych jako dość dobrze rozwinięty i udokumentowany. Pozwala też na modyfikację danych bazy (tworzenie węzłów, relacji, właściwości, usuwanie), czego nie obejmuje Cypher. Cypher jest dynamicznie rozwijanym przez Neo4j projektem deklaratywnego języka zapytań grafowych. Projekt jest stosunkowo młody, ale w dokumentacji Neo4j widać duży nacisk na jego rozwój i wykorzystanie jako podstawowego języka zapytań dla tej bazy. Z racji rozwojowego stadium projektu, autorzy nie wykluczaja wprowadzenia w przyszłości zmian (np. rozszerzenia) składni. Raportowane sa też w chwili obecnej różnice efektywności dla niektórych zapytań na korzyść Gremlina (co wymaga pracy nad optymalizatorem zapytań po stronie developerów projektu). Trzeba więc mieć na uwadze, że język ten jest w fazie rozwojowej. Z drugiej strony celem tego rozwoju jest opracowanie możliwie prostej i przejrzystej 2
26 RGBD:RT-JZ -2012/3/19-PB 1 Języki zapytań w Neo4j składni zapytań, łatwej do opanowania także dla poczatkuj acych w tej dziedzinie, podobnie jak to ma miejsce w przypadku SQLa w relacyjnych bazach danych. Ponieważ język jest deklaratywny, budujac zapytanie określany jedynie punkt poczatkowy i parametry oczekiwanego punktu końcowego, natomiast silnik Cyphera sam dobiera odpowiedni algorytm i metodę przeszukiwania grafu. Wydaje się, że z czasem ten język zdobędzie przychylność dużej części użytkowników Neo4j. 1.1 Przykłady Graf użyty w zapytaniach Poniżej przedstawiony jest proces tworzenia przykładowego grafu z konsoli Neo4j: Graf ten posłuży do pokazania kilku zapytań w języku Cypher. Graf stworzony jest z użyciem konsoli Neo4j (łacz acej się z serwerem Neo4j przy pomocy RMI) przy użyciu kilku prostych poleceń - tworzenia węzłów, relacji, nadawania im atrybutów. Przed uruchomieniem konsoli tworzony jest plik konfiguracyjny local.conf wskazujacy jakie właściwości (ang. properties) węzła oraz relacje baza powinna domyślnie indeksować w tym przypadku ustaliłem indeksowanie właściwości name co pozwoli na wykorzystanie jej w zapytaniach Przykładowe zapytanie: kogo zna Cypher? cypher 1.5 start cypher=node:node_auto_index(name= Cypher ) match cypher-[:knows]->someone return someone.name someone.name Agent Smith Zapytanie rozpoczyna deklaracja wersji języka Cypher użytego w zapytaniu, konieczna ze względu na niewielkie ale znaczace różnice w składni powstałe w trakcie jego rozwoju. Słowo kluczowe start określa wzorzec wskazujacy punkty startowe przeszukiwania. W tym wypadku jest to jeden węzeł, na który wskazuje indeks name= Cypher. Sekcja match określa wzorzec przeszukiwania. Wzorzec zapisywany jest w prosty, graficzny sposób, tzn. przy pomocy węzłów i strzałek określajacych krawędzie grafu. Wzorzec ten będa tworzyć podgrafy zawierajace węzeł cypher od którego bezpośrednio biegnie relacja KNOWS do innego węzła, a więc w przypadku badanego grafu węzły 4 i 5. Sekcja return określa które z danych w znalezionym wzorcu należy zwrócić - w tym przypadku wypisane zostały imiona osób które zna Cypher Definiowanie wzorców w zapytaniach W ogólności, najważniejsza i najbardziej rozbudowana sekcja jest sekcja match. Przykładowe wzorce pokazujace w prosty sposób reguły składni znajduja się poniżej: 3
27 RGBD:RT-JZ -2012/3/19-PB 1 Języki zapytań w Neo4j Rysunek 1: Graf użyty w przykładowym zapytaniu 4
28 RGBD:RT-JZ -2012/3/19-PB 1 Języki zapytań w Neo4j MATCH (a)->(b) - wzorzec wskazujace wszystkie pary węzłów połaczone krawędzia skierowana od a do b MATCH p = shortestpath( (a)-[*?]->(x) ) - funkcja znajdujaca najkrótsza ścieżkę między a i x. Liczba węzłów na ścieżce nie jest narzucona (*), ścieżka jest opcjonalna (?), tzn. jeśli nie istnieje zostanie zwrócony null (podobnie jak zachowuje się outer join w SQLu). MATCH (n)-(x) - istnieje relacja między n i x, nie jest brany pod uwagę kierunek ani typ MATCH (n)-[r]->() - pozwala sprawdzić wszystkie relacje (r) wychodzace (co pokazuje kierunek strzałki) z węzła n. MATCH (n)-[r: TYPE WITH SPACE IN IT ]->() - relacje mogę zawierać spacje lub inne znaki spoza zestawu ASCII, można ich użyć pod warunkiem użycia cudzysłowów. MATCH (a)-[:knows]->(b)-[:knows]->(c) - możliwe jest użycie wzorów zawierajacych wiele węzłów i relacji, w tym przypadku trzy. Nie wszystkie wzorce można zapisać w tak prosty liniowy sposób. Wtedy można je oddzielić przecinkami, np: MATCH (a)-[:knows]->(b)-[:knows]->(c), (a)-[:blocks]-(d)-[:knows]-(c) MATCH allshortestpaths( d-[*..15]->e ) - ograniczenie na maksymalna liczbę relacji pomiędzy węzłami D i E, tutaj w połaczeniu z funkcja allshortestpaths. Przedstawiona tutaj składnia powinna wystarczyć do budowania nawet złożonych wzorców przeszukiwań Pozostałe bloki składni Aby ograniczyć zwracane wyniki lub zawęzić zbiór interesujacych nas relacji możemy zastosować klauzulę WHERE podobna do tej spotykanej w SQLu. Możemy też opcjonalnie użyć bloków Aggregation, Order by, Skip oraz Limits. Sa one dobrze opisane w dokumentacji Neo4j Podsumowanie Baza Neo4j nie posiada ujednoliconej metody dostępu do danych, zamiast tego udostępnianych jest wiele różnych interfejsów z których można korzystać zależnie od potrzeby. Tworzenie nowych węzłów może się odbywać na przykład z użyciem API dla Javy, konsoli Neo4j lub języka Gremlin. Do przeszukiwania grafów stworzony został deklaratywny język Cypher, który pozwala na zwięzłe, szybkie i intuicyjne zapisywanie zapytań. Gremlin jako język imperatywny przewyższa go w pewnych sytuacjach możliwościami, tym niemniej w zdecydowanej większości przypadków składnia Cyphera wystarcza aby w pełni opisać cel zapytania. 5
29 RGBD:RT-JZ -2012/3/19-PB Literatura Literatura [1] Cypher Query Language, wykład na Youtube. QveeSaRe6vI. [2] Dokumentacja języka Gremlin. [3] Neo4j Reference, Chapter 15: Cypher Query Language. chunked/stable/reference-documentation.html. 6
30 RGBD:RT-REST -2012/3/20-PZ 20 marca 2012 Autor: Piotr Zakrzewski Rozproszona grafowa baza danych Rozpoznanie tematu: Neo4j REST API (kod ref. RGBD:RT-REST -2012/3/20-PZ ) Opis Dokument zawiera podstawowy opis interfejsu REST API udostepnianego przez oprogramowanie Neo4j.
31 RGBD:RT-REST -2012/3/20-PZ 1 REST - Representational state transfer Spis treści 1 REST - Representational state transfer Resource oriented architecture URI JSON Neo4j REST API Tworzenie węzła (POST) Tworzenie relacji (POST) Usuwanie węzła, relacji (DELETE) Pobieranie relacji (GET) Aktualizowanie/ustawianie właściwości węzła REST - Representational state transfer REST jest wzorcem architektury oprogramowania proponujacym określone praktyki tworzenia aplikacji rozproszonych. Wzorzec ten ten powstał z doświadczeń uzyskanych podczas tworzenia protokołu HTTP. Główne założenia REST: architektura klient - serwer bezstanowość - każde żadanie wysłane do serwera jest traktowane niezależnie, wszystkie informacje o stanie sesji sa trzymane po stronie klienta buforowanie podręczne - przechowywanie w pamięci podręcznej odpowiedzi serwera architektura warstwowa jednolity interfejs - jednolita identyfikacja/adresacja zasobów, manipulacja zasobami przez ich reprezentację, samoopisujace się wiadomości Cele REST: skalowalność interakcji komponentów ogólność interfejsów niezależne wdrażanie komponentów wprowadzanie usług pośredniczacych 1.1 Resource oriented architecture Jest architektura implementujac a założenia REST wykorzystanie URI (uniform resource identifier) - standardu do określania położenia zasobów wykorzystanie znanych metod HTTP do manipulacji zasobami - POST (tworzenie), GET (odczyt), PUT (aktualizacja), DELETE (usuwanie) do wymiany danych wykorzystywany np.: JSON (Neo4j) 2
32 RGBD:RT-REST -2012/3/20-PZ 2 Neo4j REST API 1.2 URI Uniform Resource Identifier jest internetowym standardem służacym do identyfikacji zasobów w sieci. URI jest łańcuchem znaków o określonym formacie określajacym nazwę (URN - Uniform Resource Name) lub adres zasobu (URL - Uniform Resource Locator). Przykładami sa: ftp://ftp.wikipedia.org, mailto:jakas-osoba@wikipedia.org. Ogólniejszy przykład: JSON JavaScript Object Notation to tekstowy format wymiany danych. JSON przechowuje dane jako pary: nazwa - wartość, dzięki czemu jest łatwo interpretowany zarówno przez komputery jak i ludzi. Stanowi alternatywę dla języka XML. 1 { "menu" : { " id " : " f i l e ", " value " : " F i l e ", "popup " : { 5 "menuitem " : [ { " value " : "New", " onclick " : "CreateNewDoc ( ) " }, { " value " : "Open", " onclick " : "OpenDoc ( ) " }, { " value " : " Close ", " onclick " : " CloseDoc ( ) " } ] 10 } } } Wydruk 1: JSON przykład 1 <menu id =" f i l e " value =" F i l e "> <popup> <menuitem value ="New" onclick ="CreateNewDoc ( ) " /> <menuitem value ="Open" onclick ="OpenDoc ( ) " /> 5 <menuitem value =" Close " onclick =" CloseDoc ( ) " /> </popup> </menu> Wydruk 2: powyższy przykład w XML 2 Neo4j REST API REST API jest uniwersalnym interfejsem do grafowej bazy danych Neo4j. Pozwala on na wygodne manipulowanie baza danych. REST API korzysta z protokołu HTTP, języka JSON oraz standardu lokalizacji zasobów URI. Główna zaleta jest możliwość administracji baza przez sieć. 2.1 Tworzenie węzła (POST) W poniższym przykładzie utworzony zostanie węzeł grafu. Do tego celu wykorzystana zostanie funkcja POST oraz obiekt JSON w którym przekazana zostanie dana o węźle. Argumentem funkcji POST jest adres URI katalogu przechowujacego węzły w bazie danych. 3
33 RGBD:RT-REST -2012/3/20-PZ 2 Neo4j REST API Obiekt JSON przesyła wartość oraz etykietę danej. Po utworzeniu węzła w odpowiedzi wyświetlana jest m.in. lokalizacja utworzonego węzła. request: 1 POST http :// localhost :7474/db/data/node Accept : application/json Content Type : application/json { " nazwa\_przedmiotu " : "RSO" } response: 1 201: Created Content Length : 1108 Content Type : application/json Location : http :// localhost :7474/db/data/node/ Tworzenie relacji (POST) W poniższym przykładzie utworzona zostanie relacja pomiędzy dwoma węzłami grafu. Argumentem funkcji POST jest katalog z relacjami węzła od którego relacja wychodzi (w tym przypadku węzeł o identyfikatorze nr 93:.../node/93/relationships). Obiekt JSON przechowuje kolejno: adres URI węzła do którego relacja wchodzi, typ relacji oraz właściwość relacji. W odpowiedzi zwracany jest adres nowo utworzonej relacji oraz obiekt JSON reprezentujacy tę relację. request: 1 POST http :// localhost :7474/db/data/node/93/ relationships Accept : application/json Content Type : application/json 4
34 RGBD:RT-REST -2012/3/20-PZ 2 Neo4j REST API { " to " : " http :// localhost :7474/db/data/node/92", 5 " type " : "LOVES", " data " : { " foo " : " bar " } } response: 1 201: Created Content Type : application/json Location : http :// localhost :7474/db/data/ relationship/30 { 5 " start " : " http :// localhost :7474/db/data/node/93", " data " : { " foo " : " bar " }, " s e l f " : " http :// localhost :7474/db/data/relationship /30", 10 " property " : " http :// localhost :7474/db/data/ relationship/30/properties /{ key } ", " properties " : " http :// localhost :7474/db/data/ relationship/30/properties ", " type " : "LOVES", " extensions " : { }, 15 " end" : " http :// localhost :7474/db/data/node/92" } 2.3 Usuwanie węzła, relacji (DELETE) W celu usunięcia z grafu węzła lub relacji, jako argument funkcji DELETE podajemy adres URI węzła/relacji. Usunięcie węzła: request: 1 DELETE http :// localhost :7474/db/data/node/52 Accept : application/json response: 1 204: No Content Usunięcie relacji: request: 1 DELETE http :// localhost :7474/db/data/ relationship/11 Accept : application/json response: 1 204: No Content 2.4 Pobieranie relacji (GET) Poniższy przykład przedstawia operację zwracania wszystkich relacji wskazanego węzła. Argumentem funkcji GET jest adres katalogu relacji które dotycza określonego węzła. Efektem działania funkcji jest tablica obiektów typu JSON w których zapisane sa informacje o relacjach. 5
35 RGBD:RT-REST -2012/3/20-PZ 2 Neo4j REST API request: 1 GET http :// localhost :7474/db/data/node/137/ relationships/ a l l Accept : application/json response: 1 200: OK Content Type : application/json [ { " start " : " http :// localhost :7474/db/data/node/137", 5 " data " : { }, " s e l f " : " http :// localhost :7474/db/data/relationship /48", " property " : " http :// localhost :7474/db/data/ relationship/48/properties /{ key } ", " properties " : " http :// localhost :7474/db/data/ relationship/48/properties ", 10 " type " : "LIKES", " extensions " : { }, " end" : " http :// localhost :7474/db/data/node/138" }, { 15 " start " : " http :// localhost :7474/db/data/node/139", " data " : { }, " s e l f " : " http :// localhost :7474/db/data/relationship /49", " property " : " http :// localhost :7474/db/data/ relationship/49/properties /{ key } ", 20 " properties " : " http :// localhost :7474/db/data/ relationship/49/properties ", " type " : "LIKES", " extensions " : { }, " end" : " http :// localhost :7474/db/data/node/137" 25 }, { " start " : " http :// localhost :7474/db/data/node/137", " data " : { }, " s e l f " : " http :// localhost :7474/db/data/relationship /50", 30 " property " : " http :// localhost :7474/db/data/ relationship/50/properties /{ key } ", " properties " : " http :// localhost :7474/db/data/ relationship/50/properties ", " type " : "HATES", " extensions " : { }, 6
36 RGBD:RT-REST -2012/3/20-PZ 2 Neo4j REST API 35 " end" : " http :// localhost :7474/db/data/node/140" } ] 2.5 Aktualizowanie/ustawianie właściwości węzła Aby zaktualizować lub ustanowić nowa dana w węźle należy użyć funkcji PUT. request: 1 PUT http :// localhost :7474/db/data/node/9/ properties Accept : application/json Content Type : application/json { 5 " age " : "18" } response: 1 204: No Content 7
37 RGBD:RT-REST -2012/3/20-PZ Literatura Literatura [1] Dokumentacja Neo4j REST API. rest-api.html. 8
38 RGBD:RT-GBD -2012/3/22-MS 22 marca 2012 Autor: Maciej Sikora Rozproszona grafowa baza danych Rozpoznanie tematu: Grafowe bazy danych - przeglad (kod ref. RGBD:RT-GBD -2012/3/22-MS ) Opis Opracowanie przedstawia tematykę grafowych baz danych. Omówiono cechy grafowych baz danych w porównaniu do rozwiazań relacyjnych, poszczególne implementacje baz oraz przykładowe projekty korzystajace z grafowych baz danych.
39 RGBD:RT-GBD -2012/3/22-MS 1 Koncepcja grafowych baz danych Spis treści 1 Koncepcja grafowych baz danych Struktura danych Zalety modelu grafowego Przeglad implementacji grafowych baz danych Neo4j DEX InfoGrid OrientDB HyperGraphDB FlockDB Rzeczywiste zastosowania Twitter FlockDB Smewt (Smart Media Manager) Neo4j Amanzi Wireless Explorer Neo4j Koncepcja grafowych baz danych Grafowe bazy danych reprezentuja dane przy pomocy struktury grafu, wykorzystujac wierzchołki, krawędzie oraz pary klucz-wartość (tzw. własności ang. properties) opisujace je. Wierzchołki maja bezpośrednia informację (w postaci wskaźników krawędzi) o swoich sasiadach. Dlatego przy przechodzeniu przez graf nie sa wymagane żadne lookup y do indeksów, co ma na ogół miejsce w rozwiazaniach relacyjnych. 1.1 Struktura danych Rysunek 1 przedstawia przykład takiego grafu. Wierzchołki reprezentuja encje, np. klienci, produkty, lokale gastronomiczne, pliki i inne obiekty, między którymi moga istnieć pewne relacje. Krawędzie traktuja o relacjach pomiędzy encjami, do tego sa skierowane. Każda krawędź jest konkretnego typu, np. lubi, poleca, jest w zwiazku z, pobrał (plik) itp. Własności opisuja pewne szczegółowe dane dotyczace dotyczace wierzchołków oraz krawędzi. Przykładowo imię = Jan, nazwisko = Kowalski, wiek = 30 dla wierzchołka reprezentujacego osobę oraz od kiedy = , jawność = tajna dla krawędzi reprezentujacej znajomość między ludźmi. 1.2 Zalety modelu grafowego Relacyjne bazy danych, mimo swojej popularności, maja szereg wad [3]: Problemy z wydajności zapytań SQL, które obejmuja wiele tabel (złaczeń). Niska skalowalność, trudności w zmianie struktury bazy po pewnym czasie, trudności w modelowaniu danych hierarchicznych, sieci i innych. Słabe dopasowanie do paradygmatu programowania obiektowego. 2
40 RGBD:RT-GBD -2012/3/22-MS 2 Przeglad implementacji grafowych baz danych Rysunek 1: Fragment grafowej bazy danych źródło: Graph_database Dane półstrukturalne sa często modelowane jako duże tabele z wieloma kolumnami, które sa puste dla większości wierszy, co prowadzi do niskiej wydajności. Odpowiedzia na powyższe problemy sa grafowe bazy danych. Graf jest bardziej intuicyjna struktura danych dla aplikacji zorientowanych obiektowo. Unikamy, słabo wydajnej dla dużych systemów, warstwy ORM 1. Bardzo dobrym przykładem na stosowanie grafowych baz danych sa sieci społecznościowe. Od takiego modelu należy wymagać łatwej skalowalności i dużej elastyczności. Ponadto ważne jest szybkie przeszukiwanie encji pod katem zawartych między nimi relacji. Struktura grafu dobrze spełnia te wymogi w stosunku do modelu relacyjnego. 2 Przeglad implementacji grafowych baz danych 2.1 Neo4j Noe4J to zaawansowana grafowa baza danych. Zapewnia zorientowana obiektowo i elastyczna strukturę danych. Wspiera transakcyjne przetwarzanie i jest projektem open source. Cechy Neo4j: napisana w Java, open source, 1 Object-Relational Mapping, 3
41 RGBD:RT-GBD -2012/3/22-MS 2 Przeglad implementacji grafowych baz danych graf danych typu klucz = wartość, API do Java, Python, Ruby, wbudowana baza danych, wsparcie dla dla ACID 2, używa systemu Apache Lucene 3 do indeksowania i przeszukiwania. Więcej na DEX Skalowalna, napisana w Java i C++ grafowa baza danych. Baza występuję w wersji bezpłatnej dla mniejszych ilości obsługiwanych węzłów oraz w kilku wersjach płatnych, w zależności od ilości obsługiwanych węzłów oraz udostępnianych funkcjonalności. Cechy DEX: napisana w Java, jadro w C++, skierowany, etykietowany multigraf z atrybutami, API do Java, silnik nastawiony na wysoka wydajność, częściowe wsparcie dla ACID (tylko spójność i izolacja). Więcej na InfoGrid InfoGrid łaczy cechy grafowych i relacyjnych baz danych. Aplikacje zbudowane na platformie InfoGrid moga korzystać z różnych silników relacyjnych baz danych lub baz danych nierelacyjnych (tzw. NoSQL) bez zmiany kodu aplikacji. Cechy InfoGrid: napisana w Java, open source, dynamicznie typowany, zorientowany obiektowo graf, API do Java, implementuje wzorzec REST 4. Więcej na 2 atomicity, consistency, isolation, durability; 3 silnik przeszukiwania tekstów, 4 Representational State Transfer 4
42 RGBD:RT-GBD -2012/3/22-MS 2 Przeglad implementacji grafowych baz danych 2.4 OrientDB Jest to grafowe rozwiazanie tzw. dokumentowej bazy danych 5. Łaczy możliwość grafowego przeszukiwania relacji z elastycznościa cechujac a dokumentowe bazy danych. Obsługuje zarówno grafowy język zapytań Gremlin jak również standard SQL, jednak bez możliwości złaczeń (joins). Cechy OrientDB: napisana w Java, open source, API do Java, zgodna z protokołami JSON, REST. Więcej na HyperGraphDB Baza danych zaprojektowana do użycia w projektach wykorzystujacych sztuczna inteligencję oraz sieci semantyczne. Umożliwia przechowywanie danych zarówno w modelu obiektowym, jak i relacyjnym. Bazuje na modelu hipergrafu, gdzie krawędź, tzw. hiperkrawędź, może łaczyć wiele wierzchołków. Cechy HyperGraphDB: napisana w Java, open source nastawiona na wykorzystanie w sztucznej inteligencji oraz w sieciach semantycznych API do Java, struktura hipergrafu. Więcej na FlockDB Jest rozproszona grafowa baza danych przechowujac a listy sasiedztwa. Zapewnia duża szybkość operacji add/update/remove (CRUD 6 ). Wspiera poziome skalowanie wraz z replikacja w celu uzyskania rozproszenia. Cechy FlockDB: napisana w Scala/Java, open source, rozproszona natura, mniej złożona od konkurencyjnych rozwiazań. Więcej na 5 ang. document-oriented database baza danych przechowujaca dane w ustandaryzowanych dokumentach, np. w plikach XML 6 create, update, delete 5
43 RGBD:RT-GBD -2012/3/22-MS 3 Rzeczywiste zastosowania 3 Rzeczywiste zastosowania W tej części opisano duże projekty, w których użyto grafowych baz danych. 3.1 Twitter FlockDB Tweeter jest serwisem społecznościowym, umożliwiajacym wysyłanie i odczytywanie krótkich wiadomości (tweetów). Twitter używa bazy danych FlockDB do przechowywania grafu społeczności (zawierajacego informacje kto śledzi kogo, kto blokuje kogo ) i drugorzędne indeksy (secondary indices). Więcej na Smewt (Smart Media Manager) Neo4j Smewt jest inteligentnym programem zarzadzaj acym zasobami multimedialnymi. Przeszukuje pliki użytkownika, automatycznie rozpoznaje je i zbiera informacje na ich temat z sieci. Przedstawia multimedialna kolekcję nie w postaci listy plików, ale jako semantycznie powiazane informacje. Więcej na Amanzi Wireless Explorer Neo4j Amanzi Wireless Explorer (AWE) jest platforma open source służac a do wizualizacji, zarzadzania danymi, optymalizacji i analizy danych, a także raportowania w dziedzinie wspomagania decyzji inżynierskich. Łaczy koncepcje arkusza kalkulacyjnego, systemu GIS oraz bazy danych. Więcej na 6
44 RGBD:RT-GBD -2012/3/22-MS Literatura Literatura [1] Graph database - wikipedia, the free encyclopedia. wiki/graph_database. [2] The wonderful and emerging world of graph-databases. graph-database.org. [3] Daniel Słotwiński. Grafowe bazy danych - przeglad technologii. http: //ai.ia.agh.edu.pl/wiki/_media/pl:dydaktyka:ztb:2010:projekty:gdb: grafowe_bazy_danych.pdf. 7
45 RGBD:RT-RMI -2012/3/25-MC 25 marca 2012 Autor: Mateusz Cieślak Rozproszona grafowa baza danych Rozpoznanie tematu: RMI (kod ref. RGBD:RT-RMI -2012/3/25-MC ) Opis Dokument opisuje sposób działania i implementację komunikacji RMI.
46 RGBD:RT-RMI -2012/3/25-MC 2 Implementacja Spis treści 1 O RMI 2 2 Implementacja Interfejs Serwer Klient Uruchamianie 6 4 Synchronizacja 7 5 Przekazywanie argumentów 7 1 O RMI RMI (Remote Method Invocation) jest technologia Javy pozwalajac a na zdalne wykonywanie metod, czyli mówiac prościej wykonywać metody obiektu znajdujacego się na innej maszynie wirtualnej Javy niż ta z której wywołujemy metodę. Komunikacja między maszynami wirtualnymi odbywa się protokołem TCP/IP. Działanie opiera się na wysyłaniu żadania wykonania metody przez klienta przez wywołanie jej na odpowiednim interfejsie obiektu. Żadanie przesyłane jest do serwera, na którym jest zarejestrowany w rejestrze RMI obiekt implementujacy interfejs, i wykonywane. Po wykonaniu wyniki (oprócz typów prostych także obiekty - tylko musza być serializowalne) przesyłane sa z powrotem do klienta. Rejestr RMI przechowuje adresy obiektów implementacji interfejsów w postaci nazw serwisów. Serwer oferujacy taki zdalny obiekt musi go najpierw zarejestrować w tym rejestrze. Klient z kolei musi połaczyć się z rejestrem RMI, aby uzyskać tzw. stub, które to stanowi właśnie interfejs zapewniajacy wywołanie zdalne obiektu. Na tym obiekcie stub wykonywane sa metody tak jak na obiekcie implementujacym (obecnym na serwerze) i przy jego pomocy następuje już dalsza komunikacja z serwerem oferujacym obiekt zdalny. Cała komunikacja jest ukryta przed programista, jedynym świadectwem, że istnieje komunikacja przez sieć jest opóźnienie i ewentualny wyjatek w przypadku braku połaczenia. 2 Implementacja Implementacja złożona jest z następujacych punktów: 1. Napisanie interfejsu dziedziczenie po Remote metody rzucaja wyjatek RemoteException 2. Stworzenie implementacji interfejsu i serwera napisanie klasy implementujacej opcjonalnie: implementacja dziedziczy po UnicastRemoteObject 2
47 RGBD:RT-RMI -2012/3/25-MC 2 Implementacja serwer tworzy nowego SecurityManager utworzenie obiektu implementacji zarejestrowanie go w RMI Registry 3. Napisanie klienta utworzenie nowego SecurityManager połaczenie się z RMI Register pobranie stub (interfejsu) obiektu zdalnego Przykładowo zostanie napisany obiekt zdalny wykonujacy podstawowe obliczenia matematyczne. 2.1 Interfejs Na poczatku trzeba stworzyć interfejs obiektu zdalnego. W tym celu interfejs musi dziedziczyć po klasie Remote znajdujacej się w pakiecie java.rmi.*. Należy także zadeklarować, że metody klasy implementujacej interfejs rzucaja wyjatek RemoteException, który jest rzucany automatycznie przez RMI w przypadków np. jakichś problemów z połaczeniem. Przykład: package calc; import java.rmi.remote; import java.rmi.remoteexception; public interface Calculator extends Remote{ public int add(int a, int b) throws RemoteException; public int sub(int a, int b) throws RemoteException; public int mul(int a, int b) throws RemoteException; public int div(int a, int b) throws RemoteException; } 2.2 Serwer Majac napisany interfejs klasy należy przystapić do napisania jego implementacji. Kod: package calc; public class CalculatorImpl implements Calculator{ public CalculatorImpl(){ super(); } 3
48 RGBD:RT-RMI -2012/3/25-MC 2 Implementacja public int add(int a, int b){ System.out.println("Wykonuje dodawanie"); return a+b; } public int sub(int a, int b){ System.out.println("Wykonuje odejmowanie"); return a-b; } public int mul(int a, int b){ System.out.println("Wykonuje mnozenie"); return a*b; } public int div(int a, int b){ System.out.println("Wykonuje dzielenie"); return a/b; } } Majac napisana już klasę implementujac a nasz obiekt zdalny, należy utworzyć klasę serwera, która udostępni ten obiekt na RMI. Aby udostępnić obiekt na RMI należy na poczatku utworzyć nowy obiekt SecurityManager, który będzie się zajmował zezwoleniami dostępu do obiektu zdalnego. Następnie należy utworzyć obiekt implementacji i wyeksportować go, czyli ostatecznie oznaczyć go jako obiekt zdalny. Obiekt eksportuje się za pomoca metody klasy UnicastRemoteObject - exportobject. Kolejnym krokiem jest powiazanie wyeksportowanego obiektu z jakaś nazwa, pod która bedzie identyfikowany w RMI Register (jest to program zajmujacy się komunikacja RMI, ale o tym w dziale uruchamianie). Kod: package calcserver; import java.rmi.remoteexception; import java.rmi.registry.locateregistry; import java.rmi.registry.registry; import java.rmi.server.unicastremoteobject; import calc.*; public class CalculatorServer{ public static void main(string[] args) { if (System.getSecurityManager() == null) { System.setSecurityManager(new SecurityManager()); //tworzymy nowego SecurityManager } try { String name = "Calc"; Calculator calc = new CalculatorImpl(); //Tworzymy obiekt implementacji 4
49 RGBD:RT-RMI -2012/3/25-MC 2 Implementacja Calculator stub = (Calculator) UnicastRemoteObject.exportObject(calc, 0); //zadeklarowanie obiektu zdalnego //Drugi argument specyfikuje port na którym obiekt ma nasłuchiwać żądań //Zero oznacza użycie portu przydzielonego przez RMI albo przez system Registry registry = LocateRegistry.getRegistry(); //pobranie referencji na lokalnie działający rejestr RMI //standardowo na porcie 1099 registry.rebind(name, stub); //powiązanie nazwy z obiektem stub(czyli interfejsu do obiektu zdalnego) //ten obiekt będzie pobrany przez klienta } catch (Exception e) { System.err.println("CalculatorImpl exception:"); e.printstacktrace(); } } } 2.3 Klient Klient, tak samo jak serwer, musi na poczatku utworzyć nowego SecurityManager a. Kolejnym krokiem jest pobranie stub a do naszego obiektu zdalnego - najpierw tworzymy referencję na adres serwera z uruchomionym RMI Registry, a następnie pytamy rejestr o dana usługę poprzez metodę lookup, która w przypadku sukcesu zwróci nam obiekt stub. Kod: package calcclient; import java.rmi.registry.locateregistry; import java.rmi.registry.registry; import calc.calculator; public class Calculate{ public static void main(string args[]){ if (System.getSecurityManager() == null) { System.setSecurityManager(new SecurityManager()); } try { String name = "Calc"; Registry registry = LocateRegistry.getRegistry("nazwa.serwera.rmi.albo.adres.ip.pl"); //pobranie referencji na rejestr RMI pod zadanym adresem i portem 1099 Calculator calc = (Calculator) registry.lookup(name); //paczymy czy w rejestrze jest usługa o zadanej nazwie // jak tak to pobiera stub a, jak nie to rzuca wyjątek 5
50 RGBD:RT-RMI -2012/3/25-MC 3 Uruchamianie System.out.println(calc.add(2,2)); //Obliczenia wykonają się na serwerze(także wypisania wewnątrz metod) //wynik za to zostanie wypisany na kliencie System.out.println(calc.sub(2,2)); System.out.println(calc.mul(2,2)); System.out.println(calc.div(2,2)); } catch (Exception e) { System.err.println("Calculate exception:"); e.printstacktrace(); } } } 3 Uruchamianie Kompilujemy wszystko kompilatorem javac. Odpowiednie pliki klas powinny być przeniesione na odpowiednie maszyny (chyba, że właczane jest wszystko na tym samym komputerze). Pliki interfejsu i implementacji laduj a na kliencie i serwerze. Należy także utworzyć dwa pliki polityk (server.policy i client.policy) dla SecurityManager ów. Przykładowa zawartość dla Windowsa: grant codebase "file:/c:/sciezka/do/plikow/zrodlowych/" { permission java.security.allpermission; }; Przykładowa zawartość dla Linuksa: grant codebase "file:/home/sciezka/do/plikow/zrodlowych/" { permission java.security.allpermission; }; Następnie uruchamiamy rejestr RMI, który to zbiera informacje o udostępnionych obiektach zdalnych. Z niego klient pobiera plik stanowiacy stub/proxy(wzorzec projektowy) do obiektu zdalnego. Start RMI Registry: (Windows) start rmiregistry albo javaw rmiregistry (Linux) rmiregistry Uruchamiamy odpowiednio serwer i klienta: java -cp c:\sciezka\do\zrodel;c:\sciezka\do\plikow_klas -Djava.rmi.server.codebase=file:/c:/sciezka/do/plikow_klas/ -Djava.rmi.server.hostname=nazwa.serwera.rmi.albo.adres.ip.pl -Djava.security.policy=c:/sciezka/do/server.policy calcserver.calculatorserver java -cp c:\sciezka\do\zrodel;c:\sciezka\do\plikow_klas 6
51 RGBD:RT-RMI -2012/3/25-MC 5 Przekazywanie argumentów -Djava.rmi.server.codebase=file:/sciezka/do/plikow_klas -Djava.security.policy=c:/sciezka/do/client.policy calcclient.calculate Po uruchomieniu na serwerze i kliencie powinny zostać wypisane odpowiednie komunikaty i wyniki. 4 Synchronizacja Każde żadanie wywołania metody na serwerze obiektu zdalnego powoduje fork watku wywołujacego metodę. Dlatego jeśli metody obiektu zdalnego operuja na wspólnych zasobach to musza być synchronizowane. Jeśli jest tylko jedna metoda modyfikujaca obiekt to wystarczy oznaczyć ja jako synchronized. W innym przypadku należy też skorzystać z blokowania (i budzenia) watków w postaci wywołań wait i notify w odpowiednich miejscach kodu. 5 Przekazywanie argumentów Argumenty przekazywane do metod do wywołania zdalnego dziela się na dwa typy: lokalne obiekty i referencje do zdalnych obiektów. W przypadku lokalnych obiektów przekazywane sa one przez wartość (czyli sa kopiowane). Obiekty te musza być serializowalne. W pewnych przypadkach przy użyciu RMI, serwer jest w stanie pobrać od klienta odpowiedni plik klasy obiektu przekazywanego (np. chcemy użyć metody obiektu przekazanego,a serwer zna tylko interfejs lub szablon klasy). W przypadku referencji do zdalnych obiektów stosowany jest taki sam mechanizm RMI jak w normalnym użyciu, czyli jeśli serwer użyje metody na przekazanej przez klienta referencji do innego obiektu zdalnego, to ta metoda zostanie wywołana na serwerze na którym znajduje się obiekt do którego należy ta referencja. 7
52 RGBD:RT-RMI -2012/3/25-MC Literatura Literatura [1] Opis i tutorial (deprecated). rmi/rmi.html. [2] Tutorial do RMI. 8
53 RGBD:RT-N4JHA -2012/3/25-MC 25 marca 2012 Autor: Mateusz Cieślak Rozproszona grafowa baza danych Rozpoznanie tematu: Neo4j HA (kod ref. RGBD:RT-N4JHA -2012/3/25-MC ) Opis Krótki opis techniki rozpraszania w bazie danych Neo4j
54 RGBD:RT-N4JHA -2012/3/25-MC 1 O Neo4j HA Spis treści 1 O Neo4j HA Transakcje Reakcja na awarię serwera Zalety i wady O Neo4j HA Jest to metoda rozproszenia dla baz Neo4j. Korzystajac z niej rozpraszane jest obciażenie bazy i zwiększana jest dostępność bazy w przypadku operacji odczytu, a także jej niezawodność. Oparta jest na strukturze master - slave. Master i każdy slave, trzymaja własna kopię całej bazy danych. Ze względu na to można korzystać z bazy przy dużym obciażeniu zapytaniami, gdyż używajacy moga się podłaczyć do któregokolwiek z serwerów. Z tego samego powodu zwiększana jest niezawodność - awaria jednego serwera lub kilku nie powoduje utraty dostępu do bazy danych. 1.1 Transakcje Transakcje (albo inaczej - operacje zapisu do bazy) przeprowadzane na bazie w przypadku połaczenia z serwerem slave powoduja blokadę na tym serwerze i dodatkowo na serwerze master. Następnie baza danych na slave jest synchronizowana (uaktualniana) z baza mastera. Poczatkowo transakcja wykonywana jest na serwerze master, a po zaakceptowaniu jej, dopiero na slave z którego wykonywana jest transakcja. Po tym zdejmowana jest blokada z obydwu serwerów i można na nich wykonywać zapytania. W jednym czasie przynajmniej dwa serwery maja aktualna bazę danych. Reszta serwerów uaktualniana jest asynchronicznie z serwerem master, ale to slave y pytaja (można ustawić interwał co ile maja to robić) o to czy baza się uaktualniła (czyli pull bazy). Master nie stara się sam uaktualniać slave ów (nie pushuje zmian na slave y). 1.2 Reakcja na awarię serwera Awaria serwera slave nie zmienia nic w działaniu bazy danych - dostęp jest zapewniony przez resztę serwerów. Natomiast w przypadku awarii serwera master przeprowadzany jest automatyczny wybór nowego serwera master. Ze względu na wcześniej wspomniany mechanizm transakcji zawsze przynajmniej dwa serwery maja aktualna postać bazy danych, więc jeśli nie ma innych serwerów do wyboru to masterem zostaje serwer na którym ostatnio była wykonywana transakcja. W innym przypadku, czyli kiedy więcej niż dwa serwery miały aktualna postać bazy, to wybierany jest którykolwiek z nich. 1.3 Zalety i wady Zalety: rozprasza ruch w przypadku zapytań do bazy utrata jednego serwera nie powoduje utraty dostępu do bazy 2
55 RGBD:RT-N4JHA -2012/3/25-MC 1 O Neo4j HA Wady: slave y moga mieć nieaktualne dane, jeśli często sa wykonywane transakcje wielkość bazy jest ograniczona sprzętowo, ponieważ musimy zmieścić cała bazę na danej maszynie 3
56 RGBD:RT-N4JHA -2012/3/25-MC Literatura Literatura [1] How Neo4j HA operates. 4
57 RGBD:RT-NEO4J -2012/3/24-RK 24 marca 2012 Autor: Radian Karpuk Rozproszona grafowa baza danych Rozpoznanie tematu: Grafowe bazy danych w ujęciu Neo4j (kod ref. RGBD:RT-NEO4J -2012/3/24-RK ) Opis Dokument zawiera podstawowe informacje dotycz ace reprezentacji grafowych baz danych w architekturze Neo4j. Przedstawia główne cechy i możliwości tej architektury oraz wskazuje na analogie z relacyjnymi bazami danych.
58 RGBD:RT-NEO4J -2012/3/24-RK 1 Wstęp Spis treści 1 Wstęp 2 2 Elementy grafowej bazy danych w Neo4j Węzły Właściwości Krawędzie Indeksy Transakcje w Neo4j 6 1 Wstęp Neo4j jest stworzonym w języku Java systemem zarzadzania grafowymi bazami danych. W przeciwieństwie do relacyjnych baz danych informacje w bazie grafowej przechowywane sa w wierzchołkach i krawędziach grafu, a kolejne informacje odczytuje się poprzez jego przegladanie. Przystępujac do eksploracji grafu, użytkownik może wyspecyfikować sposób jego przegladania: węzeł, od jakiego należy rozpoczać przegladanie grafu metoda przeszukiwania grafu wgłab wszerz warunek stopu (zakończenia przeszukiwania grafu) brak warunku stopu przegladany jest cały graf warunek stopu zdefiniowany przez użytkownika typ krawędzi po których ma się odbywać przegladanie czy należy przechodzić po grafie zgodnie/przeciwnie/dowolnie względem skierowania krawędzi czy wierzchołki (krawędzie) moga być odwiedzane wiele razy Neo4j pozwala na tworzenie baz danych zawierajacych: 2 35 wierzchołków 2 35 krawędzi 2 36 właściwości (wierzchołków lub krawędzi) 2 16 rodzajów krawędzi 2
59 RGBD:RT-NEO4J -2012/3/24-RK 2 Elementy grafowej bazy danych w Neo4j 2 Elementy grafowej bazy danych w Neo4j 2.1 Węzły Węzły obok krawędzi sa głównymi obiektami, w których przechowywane sa informacje grafowej bazy danych. Każdy węzeł zawiera unikalny identyfikator nadawany w momencie tworzenia. Przechowuje on informacje o wchodzacych i wychodzacych z niego krawędziach oraz pętlach, jak również może zawierać praktycznie dowolna ilość właściwości (dokładniej: ograniczona jedynie możliwościami Neo4j odnośnie łacznej ich ilości w bazie). Rysunek 1: Struktura węzła w Neo4j Uwaga 1. Ponieważ Neo4j nadaje każdemu węzłowi unikalny identyfikator, baza nie sprawdza w żaden sposób unikalności dodawanych węzłów (węzły majace identyczne właściwości maja mimo wszystko różne identyfikatory). Z tego powodu, jeśli użytkownik chce wymusić unikalność pewnych węzłów musi przed każda operacja modyfikujac a bazę samodzielnie sprawdzić, czy w bazie taki węzeł już nie istnieje. Uwaga 2. Każdy węzeł posiada dowolna ilość właściwości. Ta dowolność oznacza, że nigdzie w bazie nie ma informacji, jakie właściwości powinny być uwzględnione dla danego węzła, podobnie jak nie ma możliwości określenia typu węzła (sposobem na to może być dodanie właściwości określajacej typ węzła). To od użytkownika zależy jakie doda właściwości i to na nim leży obowiazek pamiętania, jakie właściwości powinien przypisać węzłowi. 3
60 RGBD:RT-NEO4J -2012/3/24-RK 2 Elementy grafowej bazy danych w Neo4j Właściwości Pojedyncza właściwość reprezentowana jest przez parę klucz-wartość. Kluczem jest ciag znaków (String), natomiast wartość może być reprezentowana jako pojedynczy element lub lista jednego z wymienionych poniżej typów: wartość logiczna (boolean) liczba całkowita (byte, short, int, long) liczba zmiennoprzecinkowa (float, double) znak (char) ciag znaków (String) Każda właściwość musi mieć podana wartość. W przypadku, kiedy użytkownik chce określić wartość pusta, należy nie umieszczać w węźle (lub krawędzi) danej właściwości. Jeśli użytkownik chce dodać właściwość o kluczu, który już występuje w danym węźle/krawędzi to nie zostaje ona stworzona, a jedynie nadpisywana jest wartość starej właściwości. Rysunek 2: Budowa pojedynczej właściwości węzła (krawędzi) w Neo4j 2.2 Krawędzie Głównym celem krawędzi jest przedstawienie zależności między węzłami bazy danych. Każda krawędź posiada informację o węźle źródłowym i docelowym (wszystkie krawędzie sa skierowane, jednak to od użytkownika zależy, czy będzie brać pod uwagę orientację krawędzi). Dodatkowo ma wyspecyfikowany typ określajacy rodzaj zależności między węzłami oraz, podobnie jak węzeł, może zawierać dane o właściwościach przedstawianej zależności (patrz punkt 2.1.1). Krawędzie nie sa automatycznie usuwane razem z wierzchołkami do których się odnosza, dlatego też przed usunięciem dowolnego wierzchołka należy zawsze usunać najpierw krawędzie, które do niego wchodza badź wychodza. Jeśli w momencie kończenia transakcji będa istniały w bazie krawędzie, które nie maja wierzchołka poczatkowego lub końcowego, transakcja nie zostanie zatwierdzona. 4
61 RGBD:RT-NEO4J -2012/3/24-RK 2 Elementy grafowej bazy danych w Neo4j Rysunek 3: Budowa pojedynczej krawędzi w Neo4j Uwaga 1. Podobnie jak w przypadku węzłów, można stworzyć wiele identycznych z poziomu użytkownika krawędzi (różniacych się tylko automatycznie nadanym w momencie tworzenia identyfikatorem). Użytkownik w trakcie tworzenia krawędzi identycznej do już istnieja- cej nie otrzyma żadnego ostrzeżenia, a operacja zakończy się sukcesem. Dopiero próba uzyskania dostępu do krawędzi przy użyciu metody getsinglerelationship zwróci wyja- tek w sytuacji, kiedy jest więcej niż 1 krawędź żadanego typu. W tej sytuacji należy użyć metody getrelationships, dzięki której można uzyskać dostęp do iteratora na żadane krawędzie. Uwaga 2. Tak jak zostało wspomniane wcześniej, przed usunięciem wierzchołka, należy usunać wszystkie krawędzie, które do niego wchodza lub wychodza. Jeśli pewna krawędź jest powielona kilka razy, to nie wystarczy usunięcie jednej z nich trzeba usunać każda krawędź. 2.3 Indeksy Indeksy zawieraja odnośniki do elementów bazy danych. Moga one agregować informacje o węzłach albo krawędziach (oddzielne typy indeksów dla węzłów i krawędzi). Każdy indeks ma swoja unikalna nazwę nadawana w trakcie jego tworzenia (nie można stworzyć dwóch indeksów o takich samych nazwach). Jeśli indeks o danej nazwie istnieje, to nie tworzy się nowego indeksu, a jedynie zwracana jest referencja do już istniejacego. Indeks zawiera referencje do przypisanych obiektów (węzłów lub krawędzi), a także parę klucz-wartość, za pomoca której będzie można w przyszłości odszukać dany element w indeksie. Podana w indeksie para klucz-wartość może być dowolna, tzn. nie musi to być jedna z właściwości indeksowanego elementu. Dany obiekt może zostać kilkukrotnie zapisany w indeksie z różnymi parami klucz-wartość. Odszukanie elementu zapisanego w indeksie polega na podaniu pary klucz-wartość żadanego elementu (metoda get). W wyniku takiego działania zwracane sa wszystkie elementy zindeksowane przy użyciu zadanej pary klucz-wartość. Możliwe jest też bardziej elastyczne wyszukiwanie przy użyciu języka zapytań udostępnianego przez Lucene [3] 5
62 RGBD:RT-NEO4J -2012/3/24-RK 3 Transakcje w Neo4j (metoda query). W przypadku indeksów odnoszacych się do krawędzi, przy wyszukiwaniu elementów można także podać żadany węzeł poczatkowy i/lub końcowy. Usunięcie elementów z indeksu wykonywane jest przy użyciu metody remove. W zależności od podanych argumentów usuwane sa: wszystkie wystapienia danego węzła w indeksie (argumentem metody jest referencja do węzła) wszystkie wystapienia danego węzła o zadanym kluczu (należy podać referencję do węzła oraz nazwę klucza) dokładnie 1 wystapienie węzła w indeksie (argumentami sa referencja do węzła, a także klucz i przypisana mu wartość w indeksie) Ponieważ w indeksie może być zapisany wielokrotnie ten sam element (nawet z identycznym kluczem - wystarczy, że jedynie przypisana jest inna wartość do klucza), to Neo4j nie udostępnia możliwości zaktualizowania wartości przypisanej dla danego klucza i elementu. Aby tego dokonać, należy usunać żadany element z indeksu, a następnie dodać go ponownie podajac zaktualizowana wartość. W bazie danych Neo4j rozwijane sa też automatyczne indeksy. Każda baza posiada po jednym indeksie dla węzłów i dla krawędzi. Indeksy sa modyfikowane automatycznie wraz z dodawaniem nowych elementów do bazy, usuwaniem lub ich modyfikacja. Domyślnie automatyczne indeksy sa wyłaczone (w obecnej wersji sa one dopiero w fazie eksperymentalnej). 3 Transakcje w Neo4j Wszystkie operacje modyfikujace dane w Neo4j sa wykonywane w transakcjach. Jak każda szanujaca się baza, Neo4j wspiera model transakcji ACID: Atomicity zapewnienie niepodzielności transakcji Consistency zachowanie spójności danych (po zakończeniu transakcji) Isolation izolacja transakcji działajacych w tym samym czasie Durability trwałość i odporność wyników transakcji. Domyślnym poziomem izolacji jest READ_COMMITED. W czasie odczytu nie nakładane sa żadne blokady, z tego też powodu pomiędzy odczytami dane moga ulec zmianie. Wyższe poziomy izolacji można osiagn ać poprzez ręczne zakładanie blokad na czas transakcji. Blokady sa zdejmowane w momencie zakończenia transakcji. Neo4j posiada mechanizm wykrywania zakleszczeń. W razie wykrycia zakleszczenia, Neo4j wycofuje zmiany wprowadzone do tej pory w transakcji i generuje wyjatek. 6
63 RGBD:RT-NEO4J -2012/3/24-RK Literatura Literatura [1] Dokumentacja API Neo4j w wersji [2] Podręcznik użytkownika Neo4j w wersji [3] Składnia języka zapytań w Apache Lucene. queryparsersyntax.html. 7
64 RGBD:RT-IGRD -2012/3/25-DZ 25 marca 2012 Autor: Dominik Zieliński Rozproszona grafowa baza danych Rozpoznanie tematu: InfoGrid (kod ref. RGBD:RT-IGRD -2012/3/25-DZ ) Opis Dokument przybliża technologię stworzona w ramach projektu InfoGrid. Przedstawione sa cechy tej grafowej bazy danych oraz podstawy jej architektury.
65 RGBD:RT-IGRD -2012/3/25-DZ 2 Architektura Spis treści 1 Wstęp Cechy InfoGrid Architektura Węzły Krawędzie Baza Model Mechanizmy rozproszenia 3 1 Wstęp InfoGrid jest open-source owym projektem systemu rozproszonej grafowej bazy danych stworzonym przez Johannesa Ernsta. Tworzona baza danych na umożliwiać łatwe tworzenie na jej podstawie aplikacji webowych, klientów P2P i aplikacji mobilnych. Moduły systemu, takie jak mechanizmy przechowywania danych, identyfikacji użytkownika i pozyskiwania danych, sa rozwijane w ramach podprojektów w ramach projektu InfoGrid. Dokument ten skupi się na modułach odpowiedzialnych za zarzadzania grafowa baza danych oraz rozproszona grafowa baza danych. 1.1 Cechy InfoGrid InfoGrid jest złożonym systemem rozwijanym od kilku lat. Oparty jest on na wzorcu REST i technologii NoSQL. Poprzez modułowa, oparta o interfejsy strukturę, możliwy jest wybór pomiędzy kilkoma wariantami modułów odpowiedzialnych za mechanizmy wykorzystywane w systemie. W szczególności sposób zachowywania danych po zamknięciu aplikacji nie jest ściśle zdefiniowany, zamiast tego, podczas konfiguracji wybierany jest moduł odpowiedzialny za ta funkcję. Różne moduły umożliwiaja zapisywanie danych w lokalnym systemie plików lub np. eksport do relacyjnej bazy danych. W ramach rozproszonej bazy danych InfoGrid wykorzystuje model zdecentralizowany, w którym poszczególne węzły systemu rozproszonego komunikuja się z soba na równych warunkach przy pomocy autorskiego protokołu XPRISO opartego na technologii P2P. 2 Architektura W tej części dokumentu omówione zostana główne elementy architektury rozproszonej grafowej bazy danych, która powstała w ramach projektu InfoGrid. Grafowa baza danych rozwijana jest w ramach dwóch podprojektów - "Graph Database Projectóraz "Grid Project". Drugi jest rozszerzeniem pierwszego i wprowadza możliwość komunikacji kilku grafowych baz danych. Możliwa jest dzięki temu reprezentacja większej, rozproszonej grafowej bazy danych. W architekturze rozproszonej wprowadzane sa dodatkowe elementy, wspierajace komunikację sieciowa między węzłami systemu. 2
66 RGBD:RT-IGRD -2012/3/25-DZ 3 Mechanizmy rozproszenia Grafowa baza danych składa się z węzłów (ang. nodes), krawędzi (ang. edges) oraz atrybutów (własności) przypisanych do dwóch poprzednich elementów (ang. properties). Elementy te znajduja odwzorowanie w strukturze InfoGrid. 2.1 Węzły Węzeł grafu reprezentowany jest przez MeshObject. Nowostworzony MeshObject posiada jedynie unikalny identyfikator, nadawany automatycznie, podczas tworzenia, przez system InfoGrid. Do węzła moga być dodawane pola atrybutów poprzez namaszczenie (ang. bless) obiektu MeshObject pewnym konceptem opisanym w EntityType. Węzeł otrzymuje wtedy atrybuty przypisane do danego typu. MeshObject może zostać namaszczony wieloma, niekolidujacymi ze soba typami EntityType. Typ (lub typy) węzła wpływaja nie tylko na to jakie atrybuty posiada, ale także na relacje (połaczenia), w które może wejść z innymi węzłami. MeshObject moga być także pozbawiane jednego z typów EntityType poprzez potępienie (ang. unbless). Odpowiednikiem MeshObject w rozproszonej bazie danych jest NetMeshObject. Obiekty tej klasy zapewniaja mechanizmy, dzięki którym dany węzeł grafu może brać udział w komunikacji z innymi węzłami na odległych węzłach rozproszonego systemu. MeshObject moga posiadać termin ważności, po którym sa np. usuwane z bazy. 2.2 Krawędzie Krawędź grafu reprezentowana jest przez Relationship. Łaczy dwa węzły reprezentowane przez MeshObject. Podobnie, jak węzłom, moga im być nadawane i odbierane typy RelationshipType, poprzez namaszczanie i potępianie (ang. bless/unbless). Typ krawędzi definiuje jej atrybuty oraz liczbę MeshObject bioracych w niej udział. Możliwe jest przypisanie kilku MeshObject do pojedynczego Relationship, zarówno po jednej, jak i po drugiej stronie połaczenia. 2.3 Baza W systemie InfoGrid wyróżniono dwa typy bazy danych MeshBase oraz NetMeshBase. Drugi typ umożliwia komunikację z innymi, zdalnymi bazami danych. Obie klasy obiektów posiadaja mechanizmy zarzadzania cyklem życia zawartych w nich obiektów MeshObject i NetMeshObject. 2.4 Model InfoGrid umożliwia tworzenie modelu bazy danych poprzez definiowanie elementów EntityType i RelationshipType opisujacych typy węzłów i krawędzi występujacych w bazie, a także ograniczeń na występowanie pewnych relacji między węzłami. Dzięki dobremu zdefiniowaniu modelu, system sam dba o to, żeby zachowane były pewne zasady dotyczace danych zawartych w bazie. 3 Mechanizmy rozproszenia W systemie InfoGrid wykorzystywane sa mechanizmy replikacji i fragmentacji danych. Każdy z węzłów rozproszonego systemu (serwerów) posiada własna, w pełni dostępna 3
67 RGBD:RT-IGRD -2012/3/25-DZ 3 Mechanizmy rozproszenia bazę danych (typu NetMeshBase). Dane na każdym z nich nie musza być takie same. W istocie, zakłada się, że cały graf rozproszonej bazy danych jest podzielony na podgrafy - każdy składowany na osobnym serwerze. Podgrafy komunikuja się z soba tylko jeżeli zachodzi taka potrzeba, tzn. zaistniała potrzeba modyfikacji lub ściagnięcia zdalnych danych. Komunikacja między poszczególnymi bazami danych przebiega poprzez repliki (reprezentowane przez Replica) konkretnych NetMeshObject). Każdy z węzłów przechowuje swój gra replik (ReplicaGraph. W przypadku wprowadzania modyfikacji w danym węźle, za pomoca grafu replik zmiany propaguja na pozostałe węzły systemu. Jeżeli z danej lokalnej bazy danych wychodzi żadanie dostępu do danych pewnego węzła obecnego na zdalnej bazie danych, a lokalnie nie jest dostępna jego replika, węzeł ten zostanie w całości ściagnięty, a jego graf replik zaktualizowany. 4
68 RGBD:RT-IGRD -2012/3/25-DZ Literatura Literatura [1] Oficjalna strona projektu infogrid. 5
69 RGBD:RT-HGDB -2012/3/25-MC 25 marca 2012 Autor: Mateusz Cieślak Rozproszona grafowa baza danych Rozpoznanie tematu: HyperGraphDB (kod ref. RGBD:RT-HGDB -2012/3/25-MC ) Opis Krótki opis bazy HyperGraphDB
70 RGBD:RT-HGDB -2012/3/25-MC 2 Hipergraf Spis treści 1 Krótko o HyperGraphDB 2 2 Hipergraf 2 3 Warstwy w HyperGraphDB 3 4 Rozproszenie 4 1 Krótko o HyperGraphDB HyperGraphDB jest grafowa baza danych oparta nie na zwykłym grafie, ale na hipergrafie. Baza oparta jest na modelu dwuwarstwowym: warstwie przechowywania i warstwie modelu. Warstwa przechowywania oparta jest na dwóch tablicach klucz-wartość przy użyciu bazy BerkeleyDB. Warstwa modelu przekształca dane z warstwy przechowywania do modelu reprezentujacego hipergraf. Metoda rozproszenia bazy jest pozostawiona dla użytkownika. Udostępniony jest framework komunikacji P2P do tego celu. Baza ta może być albo całkowicie replikowana pomiędzy różnymi serwerami albo podzielona pomiędzy serwery albo można zastosować także kombinację tych dwóch metod. 2 Hipergraf Hipergraf jest uogólnieniem pojęcia grafu. W hipergrafie krawędzie (hiperkrawędzie) moga łaczyć między soba więcej niż dwa wierzchołki. Krawędzie te moga także wskazywać na inne krawędzie. Ideę hipergrafu można sobie łatwiej wyobrazić w przypadku utożsamienia krawędzi ze zbiorem wierzchołków. Rysunek 1: Hipergraf źródło Hipergrafy moga istnieć także w wersji skierowanej, co można skojarzyć jako wielowejściowy i wielowyjściowy graf przepływu. 2
71 RGBD:RT-HGDB -2012/3/25-MC 3 Warstwy w HyperGraphDB Rysunek 2: Skierowany hipergraf W HyperGraphDB wprowadzono pojęcie atomu. Atom może być i wierzchołkiem i krawędzia (i to i to może przechowywać dane). Jedynym rozróżnieniem jest arność atomu, czyli ile dany atom łaczy ze soba innych atomów. W przypadku arności 0 atom jest wierzchołkiem. W przypadku innej arności atom jest krawędzia (ponieważ łaczy ze soba inne atomy). 3 Warstwy w HyperGraphDB Pierwsza warstwa w HGDB nazywana jest warstwa przechowywania (storage layer). Warstwa ta jest stworzona w oparciu o BerkeleyDB i stanowi fizyczne przedstawienie danych (czyli tak jak to wyglada w pliku). Istnieja w niej dwie tablice klucz-wartość: LinkStore: ID -> List<ID> DataStore: ID -> List<byte> Pierwsza tablica reprezentuje połaczenia między atomami, zaś druga wskazuje na wartości konkretnych atomów. Wartości te moga być złożonymi strukturami, więc zapisywane sa po prostu w postaci surowych danych. Warstwa modelu przekształca zapis fizyczny w zapis o danym schemacie (najlepiej odwołać się do [2]): AtomID -> [TypeID, ValueID, TargetID,...,TargetID] TypeID -> AtomID TargetID -> AtomID ValueID -> List<ID> List<byte> W skrócie każda z par klucz-wartość w warstwie przechowywania reprezentuje albo atom albo wartość atomu. Każdy atom posiada typ, wartość i zbiór ID do innych atomów. 3
72 RGBD:RT-HGDB -2012/3/25-MC 4 Rozproszenie 4 Rozproszenie HyperGraphDB nie ma ustalonej metody rozproszenia. Udostępnia tylko framework P2P za pomoca którego projektant bazy ustala metodę rozproszenia. W tym frameworku każdy peer może wyrazić zainteresowanie jakimś atomem będacym na innym peerze. Jeśli wykonywana jest transakcja na danym atomie to peer majacy dany atom informuje wszystkich zainteresowanych atomem o jego zmianie. Każda zmiana jest lokalnie na peerze logowana, przez co ewentualnie zmiany zostana rozpropagowane do innych peerów (w przypadku np. ich nieobecności w czasie wykonania transakcji). Prawdopodobnie (niestety brak jednoznacznej odpowiedzi) kopia atomu którym jest zainteresowany dany peer znajduje się także na nim. Takie zachowanie umożliwia albo pełna replikację - peery sa zainteresowane wszystkimi atomami z danego peer a, więc sa replikowane, albo podział - na każdym peerze jest inny zbiór atomów podczas gdy każdy peer może być zainteresowany atomami posiadanymi przez inne peery. 4
73 RGBD:RT-HGDB -2012/3/25-MC Literatura Literatura [1] HyperGraphDB - Framework P2P. PeerToPeerTutorial&project=hypergraphdb. [2] HyperGraphDB - skrót. [3] HyperGraphDB - Tutorial. FirstSteps&project=hypergraphdb. [4] Wikipedia - Hypergraph. 5
74 RGBD:RT-ODB -2012/3/26-MS 26 marca 2012 Autor: Maciej Sikora Rozproszona grafowa baza danych Rozpoznanie tematu: OrientDB - metody rozpraszania bazy danych (kod ref. RGBD:RT-ODB -2012/3/26-MS ) Opis Niniejsze opracowanie przedstawia techniki jakich użyto w OrientDB do realizacji rozproszonej grafowej bazy danych.
75 RGBD:RT-ODB -2012/3/26-MS 3 Architektura Multi-Master Spis treści 1 Wstęp 2 2 Klasteryzacja 2 3 Architektura Multi-Master 2 1 Wstęp OrientDB może być rozproszona na różne serwery w różny sposób, aby osiagn ać najwyższa wydajność, skalowalność i trwałość. Techniki zastosowane w OrientDB opieraja się na klasteryzacji oraz na replikacji w trybie Multi-Master. W tej architekturze każdy węzeł systemu może czytać/pisać do bazy danych. To się dobrze skaluję, a dodawanie nowych węzłów jest proste. 2 Klasteryzacja Klasteryzacja to tworzenie grup serwerów OrientDB (tzw. klastrów), które dziela ta sama instancję bazy danych w obrębie tej grupy. Klastrów używa się, aby pogrupować dane tego samego typu, przykładowo [4]: Klaster Osoba do zgrupowania wszystkich rekordów typu Osoba. To podobne podejście do relacyjnych baz danych, gdzie każda tabela byłaby klastrem. Klaster Cache do zgrupowania wszystkich rekordów najczęściej odpytywanych. Klaster Dzisiaj do zgrupowania wszystkich rekordów utworzonych dzisiaj. Klaster SamochódMiejski do zgrupowania wszystkich samochodów, tzw. miejskich. 3 Architektura Multi-Master Replikacja Multi-Master pozwala składować dane na grupie komputerów i aktualizować je przez dowolnego z grupy [3]. System jest odpowiedzialny za propagację zmian zrobionych przez każdego członka grupy na resztę grupy i rozwiazywanie konfliktów, które mogły powstać podczas współbieżnych modyfikacji. Taka forma replikacji różni się od replikacji Master-Slave, gdzie pojedynczy węzeł grupy jest wskazany jako Master dla danej porcji (klastra) danych i tylko on może bezpośrednio modyfikować dane. Inne węzły, które chca coś zmienić, musza najpierw skontaktować się z Masterem. OrientDB grupuje dane w klastry, dla których stosuje replikację Multi-Master. W ten sposób realizowana jest rozproszoność. Zalety koncepcji Multi-Master: Jeśli Master ulega awarii, inny węzeł z danego klastra przejmuje jego rolę i może pisać do bazy. Rozproszoność fizyczna węzłów klastra poprawia bezpieczeństwo. 2
76 RGBD:RT-ODB -2012/3/26-MS 3 Architektura Multi-Master Wady: Poprzez mieszana formę replikacji (zarówno synchroniczna jak i asynchroniczna) system taki jest nieściśle spójny i narusza postulaty modelu ACID 1. Coraz większe ryzyko konfliktów wraz ze skalowaniem systemu. 1 atomicity, consistency, isolation, durability 3
77 RGBD:RT-ODB -2012/3/26-MS Literatura Literatura [1] Clustering and high availability. Clustering. [2] Distributed architecture with a multi-master approach. net/lvca/orientdb-distributed-architecture-11. [3] Multi-master replication. replication. [4] Orientdb concepts. 4
78 RGBD:RT-FDB -2012/3/25-PB 25 marca 2012 Autor: Paweł Bulwan Rozproszona grafowa baza danych Rozpoznanie tematu: FlockDB - przeglad architektury (kod ref. RGBD:RT-FDB -2012/3/25-PB ) Opis Dokument przedstawia podstawowe informacje na temat grafowej bazy danych FlockDB, jej architektury oraz sposobów rozproszenia danych w celu zapewnienia jej skalowalności na potrzeby serwisu Twitter.
79 Rysunek 1: Architektura bazy danych Twittera (oparta na FlockDB) 1 FlockDB przeglad architektury 1.1 Wprowadzenie do FlockDB FlockDB jest baza danych zoptymalizowana pod katem szybkiego działania opartego o nia serwisu Twitter. Serwis ten pozwala na śledzenie tweetów czyli postów innych osób, oznaczanie ich jako ulubionych i publikowanie własnych tweetów. Ten model danych można intuicyjnie przedstawić jako graf w którym wierzchołkami sa użytkownicy serwisu i tweety, a krawędziami relacje opublikował, śledzi, dodał do ulubionych. Baza danych FlockDB jest niemal zawsze określana jako grafowa baza danych, choć oparta jest na relacyjnej bazie MySQL, zoptymalizowanej pod katem przechowywania grafów. Nałożone sa jednak na nia ograniczenia pod katem struktury tabel i operacji (dzięki temu baza jest wysoce skalowalna [1]), co też nie pozwala jej klasyfikować jako relacyjnej bazy danych, a raczej zaliczyć do nurtu NoSQL. 1.2 Skalowalność FlockDB FlockDB opiera się na kodzie MySQL, lecz została silnie zoptymalizowana pod katem partycjonowania horyzontalnego, czyli podziału wierszy w tabeli dla celów skalowalności i wydajności, na jednostki, tzw. shardy. Jej interfejsy ograniczone do zapytań odpowiadajacym prostym operacjom na grafie. Dane sa partycjonowane na shardy ze względu na wierzchołki, więc wykonanie operacji dla danego wierzchołka wymaga zwykle zaangażowania tylko niewielkiej części systemu. Krawędzie nieskierowane sa przechowywane w tabelach podwójnie, aby móc wykorzystać indeks do zapytań w obie strony. 2
80 Do rozproszenia bazy używana jest warstwa pośrednia (middleware), w której działa stworzony przez Twittera framework Gizzard (obecnie open-source), rys. [1]. Warto zauważyć że poszczególne shardy sa od siebie niezależne, tzn. nie ma pomiędzy nimi połaczeń. Przyjęto założenie, że operacje zapisu/modyfikacji/usuwania krawędzi sa asynchroniczne, tzn. moga być wykonane fizycznie nawet już po zwróceniu informacji o ich poprawnym wykonaniu do aplikacji [1, 2]. W przypadku niedostępności/awarii sharda obsługujacego dany węzeł warstwa middleware kolejkuje operacje z użyciem systemu zarza- dzania kolejkami Kestrel [2] w oczekiwaniu na dostępność sharda. W ten sposób system zapewnia wysoka dostępność, rezygnujac w przypadku awarii ze spójności danych (do czasu jej naprawienia). FlockDB nie pozwala na szybkie przechodzenie przez graf (ang. graph traversal) podobnie jak inne grafowe bazy danych, umożliwia za to przechowywanie bardzo dużych list sasiedztwa i szybkie wykonywanie prostych zapytań grafowych. Pojedynczy shard zawiera jedynie dwie tabele: z krawędziami i metadanymi, oraz pojedynczy indeks pozwalajacy na szybkie wyszukiwanie potrzebnych danych. 1.3 Podsumowanie Podsumowujac, skalowalność bazy została osiagnięta kosztem radykalnego uproszczenia schematu bazy danych, bardzo prostego interfejsu dostępu do danych, wprowadzeniu asynchronicznych zapisów (co wiaże się z ryzykiem utraty spójności danych na pewien czas i koniecznościa synchronizacji), oraz wprowadzeniu dodatkowej warstwy zarzadzania baza (Gizzard). Zaletami sa uzyskana liniowa skalowalność, możliwość rozproszenia geograficznego i duża odporność na błędy poszczególnych węzłów Zgodnie z informacjami autorów baza zawiera obecnie ponad 13 miliardów krawędzi i poddana jest obciażeniu zapisów/s, odczytów/s [1], mimo to czasy dostępu do danych z punktu widzenia użytkownika sa minimalne. Literatura [1] Introducing FlockDB. introducing-flockdb.html. [2] NoSQL Is For Birds. 3
81 RGBD:RT-IG -2012/3/25-PZ 25 marca 2012 Autor: Piotr Zakrzewski Rozproszona grafowa baza danych Rozpoznanie tematu: InfiniteGraph The Distributed Graph Database (kod ref. RGBD:RT-IG -2012/3/25-PZ ) Opis Dokument zawiera podstawowy opis architektury bazy danych InfiniteGraph.
82 RGBD:RT-IG -2012/3/25-PZ 2 Cechy Spis treści 1 Wstęp 2 2 Cechy 2 3 Architektura 3 1 Wstęp InfiniteGraph jest reklamowana jako sprawdzona, rozproszona, grafowa baza danych. Producent oferuje bazę w wersji komercyjnej jak i darmowej community. Na stronie projektu można znaleźć informację, że baza została wykorzystana przez takie instytucje jak: Boeing, Deloitte, Lockheed Martin, U.S. Air Force, U.S. Army, U.S. Navy czy Amazon. Baza InfiniteGraph dostępna jest na platformy Windows, Linux oraz Mac. 2 Cechy Główna zaleta bazy InfiniteGraph jest możliwość rozpraszania zarówno danych jak i procesów (operacji wykonywanych na bazie). Dzięki temu można zmniejszyć czas i koszt przy jednoczesnym zwiększeniu wydajności. Zaimplementowanym modelem grafu jest etykietowany, skierowany multigraf. Baza wykorzystuje wielowatkowe przetwarzanie. Jadro bazy napisane jest w C++, natomiast reszta w Javie. Obsługuje język zapytań Gremlin. Rysunek 1: Przetwarzanie 1 mld węzłów i krawędzi - źródło: infinitegraph.com/2011/10/25/time-is-money/ 2
83 RGBD:RT-IG -2012/3/25-PZ 3 Architektura Rysunek 2: Przetwarzanie 1 mld węzłów i krawędzi w zależności od zrównoleglenia operacji - źródło: 3 Architektura Baza InfiniteGraph pozwala przechowywać dane lokalnie lub rozproszone w sieci. Rozproszona baza korzysta z plików dziennika zmian. Służa one do przywracania stanu bazy po niespodziewanie przerwanej transakcji. Dane gromadzone sa w niezależnych jednostkach (Storage Unit), co pozwala na zrównoleglanie operacji w bazie danych. Storage Unit stosowane sa zarówno w bazie rozproszonej jak i grafowej bazie na lokalnej maszynie. Do zachowania spójności danych w bazie wykorzystywany jest Lock Server, który znajduje się na jednej z maszyn. Zdaje się, że występuje tu podobne rozwiazanie jak w Neo4j HA tzn. w celu wykonania transakcji baza musi odwołać się do nadrzędnego serwera. AMS (ang. Advanced Multithreaded Server) jest używany przez bazę podczas dostępu do danych zamiast natywnego serwera plików (NFS, MS Windows Network). 3
84 RGBD:RT-IG -2012/3/25-PZ Literatura Rysunek 3: Przetwarzanie 1 mld węzłów i krawędzi w zależności od zrównoleglenia operacji - źródło: Literatura [1] Architektura infinitegraph. php?title=infinitegraph_system_architecture. 4
85 RGBD:RZS -2012/4/12-PC 12 kwietnia 2012 Autor: Patryk Chaber Rozproszona grafowa baza danych Raport ze spotkania (kod ref. RGBD:RZS -2012/4/12-PC ) Opis Raport ze spotkania grupy projektowej 2D. Celem spotkania było wstępne przygotowanie do etapu projektowania rozwiazania oraz ustalenie wymagań funkcjonalnych oraz niefunkcjonalnych projektu.
86 RGBD:RZS -2012/4/12-PC 3 Przebieg Spis treści 1 Czas i miejsce 2 2 Cel 2 3 Przebieg Dyskusja na temat podstawowych wymagań funkcjonalnych realizowanego projektu Analiza poszczególnych wymagań funkcjonalnych Wnioski ze spotkania 4 1 Czas i miejsce Spotkanie odbyło się 12. kwietnia 2012 roku w sali laboratoryjnej 518 wydziału Elektroniki i Technik Informacyjnych Politechniki Warszawskiej w godzinach 14:00-16:15. Jak zawsze wszyscy członkowie grupy projektowej pojawili się punktualnie. 2 Cel Celem spotkania była wstępna dyskusja oraz omówienie podstawowych wymagań funkcjonalnych oraz niefunkcjonalnych realizowanego projektu, dobór architektury sieci, która będa tworzyły serwery rozproszonej bazy danych oraz wielu innych aspektów, co do których decyzje należy podjać jak najwcześniej. 3 Przebieg Wszelkie poniższe informacje dotycza rozwiazania zaproponowanego przez Radiana Karpuka, opisanego w dokumencie zatytułowanym "Implementowane rozwiazanie". 3.1 Dyskusja na temat podstawowych wymagań funkcjonalnych realizowanego projektu Wraz z grupa podjęta została decyzja, że realizowana baza danych powinna spełniać następujace wymagania funkcjonalne: Dodawanie/modyfikacja/usuwanie krawędzi(relacji)/wierzchołków w grafie bazy danych. Tworzenie duplikatów wyżej wymienionych elementów na osobnym serwerze. Synchronizacja fragmentów bazy znajdujacych się na poszczególnych serwerach. Obsługiwanie podłaczaj acych się oraz rozłaczaj acych się serwerów. Interpretowanie oraz zwracanie wyników zapytań napisanych przez użytkownika w języku Gremlin. 2
87 RGBD:RZS -2012/4/12-PC 3 Przebieg Powyższe wymagania sa to właściwie cechy prawie każdej rozproszonej grafowej bazy danych (poza dwoma ostatnimi, mimo, że wiele baz danych udostępnia taka funkcjonalność). Wymienienie jednak tych funkcji projektu pozwoli na łatwiejsza dalsza organizację w trakcie pisania kodu projektu. Użytkownikowi bazy danych nie jest udostępniane tworzenie własnych indeksów. 3.2 Analiza poszczególnych wymagań funkcjonalnych Po ustaleniu tego, co program (zrealizowany w ramach projektu) ma realizować zostały omówione szczegóły dotyczace listy z poprzedniego podrozdziału. W trakcie dyskusji pojawiały się następujace pytania (wraz z ustalonymi na nie odpowiedziami): "W jaki sposób należy przechowywać elementy bazy danych?" - każdy element będzie zapisywany w oddzielnym pliku XML. "Na którym serwerze należy umieścić duplikat utworzonego elementu?" - duplikat jest losowany z "puli" dostępnych serwerów, lecz wprowadzony zostanie także interfejs pozwalajacy na implementację innego rozwiazania (np. łaczenia serwerów w pary i przetrzymywania tych samych fragmentów bazy danych na dwóch serwerach). "W jaki sposób będa przesyłane dane dotyczace utworzenia duplikatu?" - serwer, do którego zostało wysłane żadanie utworzenia elementu będzie tworzył obiekt, i ten gotowy obiekt będzie dopiero przesyłany do serwera przechowujacego duplikat. "Kiedy informacja o utworzeniu elementu jest propagowana na inne serwery?" - dokonywane jest to tuż po utworzeniu węzła na obu serwerach (po skutecznym zakończeniu transakcji). "Jak identyfikować tworzone elementy aby nie wystapił konflikt identyfikatorów w sytuacji gdy na dwóch serwerach dodane zostana elementy o tym samym identyfikatorze?" - wykorzystane zostanie GUID, dzięki czemu identyfikator elementu będzie zależny od serwera na którym zostanie on utworzony (może to spowodować wprowadzenie dwóch elementów o tych samych właściowościach, lecz traktowane będa one z założenia jako różne) "Który serwer jako pierwszy zapisuje dane dodanego elementu: obsługujacy żadanie, czy przechowujacy duplikat?" - z powodu korzystania z mechanizmu RMI wybrana została druga opcja, pozwoli to na uniknięcie sytuacji, w której element powstał na serwerze obsługujacym żadanie, a utworzenie duplikatu nie powiodło się (wtedy utworzony właśnie węzeł musiałby zostać usunięty). "Czy każdy serwer, który dodał element/duplikat wysyła informację o utworzeniu go?" - nie, informację wysyła tylko serwer obsługujacy żadanie, umieszczajac w wiadomości adresy IP obu serwerów posiadajacych kopię utworzonego elementu. "Co się stanie jeśli nie uda się dodać elementu/duplikatu na danym serwerze?" - zostanie zwrócony komunikat o niepowodzeniu lub podjęta będzie próba wysłania żadania dodania elementu/duplikatu do innego serwera. "Które serwery i ile jest blokowanych w sytuacji odczytu, zapisu, modyfikacji?" - w sytuacji odczytu nie potrzebne jest jakiekolwiek blokowanie serwera, w sytuacji 3
88 RGBD:RZS -2012/4/12-PC 4 Wnioski ze spotkania zapisu oraz modyfikacji następuje założenie blokady na odczyt/zapis na serwerze obsługujacym żadanie oraz serwerze przetrzymujacym duplikat elementu, aby nie rozspójnić bazy danych. "W jakiej kolejności blokowane sa serwery w sytuacji zapisu/modyfikacji?" - ponieważ serwery posiadaja identyfikatory numeryczne, pierwszy blokowany jest serwer o niższym numerze identyfikatora, co pozwoli uniknać zakleszczenia. "W przypadku podłaczenia nowego serwera - w jaki sposób otrzyma on informacje o bazie danych?" - dołaczaj ac się do bazy danych serwer "wita się" z pozostałymi, po czym w odpowiedzi otrzymuje on listę identyfikatorów elementów znajdujacych się na danych serwerach. "W przypadku podłaczenia nowego serwera - w jaki sposób otrzyma on nowy identyfikator?" - identyfikatorem serwera jest jego numer IP, który rozsyłany będzie do pozostałych serwerów w ramach przywitania. "Na jakiej podstawie będzie wyciagany wniosek o odłaczeniu serwera?" - pierwsza próba komunikacji zakończona wyjatkiem (wynikajacym z braku połaczenia z danym serwerem) będzie powodowała, że jeśli kolejna próba połaczenia po upływie ustalonego, w pliku konfiguracyjnym, czasu zakończy się niepowodzeniem, to serwer ten zostanie uznany, za odłaczony (np. w wyniku awarii), o czym zostanie poinformowany administrator bazy danych poprzez umieszczenie odpowiedniego komunikatu w dzienniku wydarzeń. "Co dzieje się w sytuacji gdy serwer zostaje odłaczony?" - zadaniem administratora jest potwierdzenie rzeczywistej awarii, po którym wszystkie dane, które były zwiazane z tym serwerem sa duplikowane na pozostałe, czynne serwery, po czym baza danych zachowuje się tak, jakby uszkodzony serwer nigdy nie istniał. "Co się stanie jeśli uszkodzony serwer zechce zajać ponownie swoje miejsce?" - jeśli była to poważna awaria, to przy ponownym jej uruchomieniu serwer (w reakcji na komendę administratora) przywita się z serwerami istniejacymi w sieci i będzie zachowywał się tak, jakby nigdy jeszcze w tej sieci nie istniał. "Co w wypadku chwilowego/długotrwałego odcięcia serwera od sieci?" - od decyzji administratora zależy czy takie zdarzenie będzie traktowane jako poważna awaria (replikacja danych na pozostałe serwery) czy też chwilowa niedostępność (brak reakcji bazy na niedostępność serwera). "Jak będzie wygladała aplikacja kliencka?" - rolę aplikacji klienckiej będzie pełnić konsola języka Gremlin - ograniczy to ilość nauki dla ewentualnych użytkowników z nauki nowej aplikacji, do nauki języka, który może być użyty nie tylko przy korzystaniu z opisywanej bazy danych. 4 Wnioski ze spotkania Nie zostały wciaż podjęte ostateczne decyzje dotyczace wymagań niefunkcjonalnych - ustalone to zostanie na najbliższym spotkaniu. 4
89 RGBD:RZS -2012/4/17-PC 17 kwietnia 2012 Autor: Patryk Chaber Rozproszona grafowa baza danych Raport ze spotkania (kod ref. RGBD:RZS -2012/4/17-PC ) Opis Raport ze spotkania grupy projektowej 2D. Celem spotkania była analiza szczegółów dotyczacych projektu rozwiazania tworzonej rozproszonej grafowej bazy danych.
90 RGBD:RZS -2012/4/17-PC 3 Przebieg Spis treści 1 Czas i miejsce 2 2 Cel 2 3 Przebieg Budowa sieci Indeksy RMI Blokady Podział programu na moduły Wnioski ze spotkania 4 1 Czas i miejsce Spotkanie odbyło się 17. kwietnia 2012 roku w sali laboratoryjnej 518 wydziału Elektroniki i Technik Informacyjnych Politechniki Warszawskiej w godzinach 14:00-16:15. Nieobecny był jedynie Maciej Sikorski (z powodów niezależnych od siebie), reszta członków grupy stawiła się punktualnie. 2 Cel Głównym celem spotkania było ustalenie oraz akceptacja przez wszystkich zaproponowanego diagramu klas dla omawianego projektu. Dokonane zostały także ostateczne ustalenia dotyczace zakresu blokowania elementów oraz sytuacji, w których to blokowanie jest konieczne. Podjęte zostały decyzje w kwestii przechowywania indeksów, realizacji aplikacji klienckiej oraz kilku innych - mniej istotnych. 3 Przebieg Spotkanie przebiegało w postaci ogólnej dyskusji nad planowanym rozwiazaniem, co jakiś czas skupiajacej się na pewnym konkretnym zagadnieniu. Poniżej zostały zamieszczone podjęte decyzje podzielone na kategorie, niekoniecznie odzwierciedlajace ich występowanie w trakcie spotkania. 3.1 Budowa sieci Użytkownik będzie mógł korzystać z rozproszonej bazy danych dzięki użyciu prostej aplikacji klienckiej udostępniajacej interfejs Blueprints. Pozwoli on na podłaczenie do aplikacji konsoli grafowego języka skryptowego Gremlin lub dowolnych aplikacji wykorzystujacych ten standard. Zadaniem klienta jest zapewnienie nieskomplikowanej, przezroczystej dla użytkownia metody dostępu do rozproszonej bazy danych. Ze względu na to, że wszystkie serwery tworzace bazę traktowane będa równorzędnie, konfiguracja klienta może i powinna zawierać kilka adresów IP serwerów bazy. Podczas wykonywania metod udostępnianych przez interfejs klient losowo wybierze aktywny serwer z listy, na którym 2
91 RGBD:RZS -2012/4/17-PC 3 Przebieg wywoła analogiczna metodę z użyciem mechanizmu RMI. Każdy serwer rozproszonej bazy danych powinien w danej chwili wykonać określona metodę z identycznym skutkiem. Wyjatkiem sa sytuacje, w których dopuszczamy tymczasowe, niewielkie niespójności w bazie, np. w momencie dodania nowego węzła, informacja, o którym jeszcze się nie rozpropagowała po całej sieci. 3.2 Indeksy Indeksy na węzły i krawędzie grafu, będace podstawa w naszej koncepcji rozproszenia bazy danych, zostana zaimplementowane w postaci tablicy haszujacej (z użyciem jej standardowej implementacji w języku Java). Kluczem tablicy będzie identyfikator obiektu (typu UUID), natomiast wartościa - obiekt zawierajacy adresy IP obu serwerów, na których znajduje się węzeł. W przypadku, gdy odpytywany serwer sam posiada dane, w indeksie zamiast adresu IP będzie znajdować się lokalizacja pliku z danymi obiektu. 3.3 RMI Wywołanie metod na zdalnym serwerze poprzez RMI wymaga użycia specjalnych obiektów powiazanych z docelowym serwerem. Ponieważ inicjalizacja nowego połaczenia RMI z innym serwerem przy każdym wywołaniu metody jest zbyt czasochłonna i niepraktyczna, inicjalizacja połaczeń będzie odbywać się jednorazowo przy uruchamianiu serwerów. Obiekty RMI dla serwerów przetrzymywane będa w specjalnej tablicy haszujacej, w której kluczem będzie adres IP, a wartościa obiekt RMI. Dane o sieci (listę IP innych serwerów) program będzie otrzymywał po podłaczeniu się do sieci (poprzez podanie adresu IP jednego z działajacych w niej serwerów), jako odpowiedź na przywitanie serwera. 3.4 Blokady Dopuszczalne sa niewielkie, tymczasowe niespójności w danych, takie jak krótkoterminowe różnice w zawartości serwerów w momencie dodawania/usuwania nowego węzła. Pozwoli to na ograniczenie liczby blokad do minimum i pozwoli na większa współbieżność wykonywania zadań. Tym niemniej nieuniknione sa chwilowe blokady podczas operacji modyfikacji węzła/krawędzi oraz usuwania węzła/krawędzi. Maja one miejsce w momencie aktualizacji indeksów w całej bazie (podczas usuwania) oraz podczas modyfikacji danych węzła lub krawędzi (np. dodawania lub usuwania właściwości). Bardzo ważnym ustaleniem jest fakt, że blokowane będa poszczególne elementy, aby modyfikacja jednego z nich nie powodowała zablokowania całej bazy danych znajdujacej się na danym serwerze (co dla serwerów o dużej pojemności byłoby bardzo niewygodne). 3.5 Podział programu na moduły Na spotkaniu omówiony został diagram klas dla projektu. W aplikacji działajacej na każdym serwerze wchodzacym w skład rozproszonej bazy danych można wyróżnić przede wszystkim takie klasy jak: GDBGraph klasa reprezentujaca graf. Implementuje interfejs Graph standardu Blueprints ( oraz metody ściśle zwiazane z rozproszona implementacja grafu, 3
92 RGBD:RZS -2012/4/17-PC 4 Wnioski ze spotkania GDBVertex klasa reprezentujaca wierzchołek, implementuje interfejs Vertex standardu Blueprints GDBEdge klasa reprezentujaca krawędź, implementuje interfejs Edge standardu Blueprints RandomServerManager klasa udostępniajaca metody wyboru serwera backupowego dla danych danego serwera, zgodnie z założona polityka wyboru (np. losowanie z puli serwerów z odkładaniem) ElementsMonitor klasa pomagajaca w synchronizacji dostępu do poszczególnych elementów (zakładania blokad np. na poszczególne wierzchołki lub krawędzie) 4 Wnioski ze spotkania Podsumowaniem spotkania było stworzenie ostatecznego diagramu klas oraz przydzielenie zadań w postaci opisu słownego implementacji metod udostępnianych poprzez interfejs Blueprints. Opisy te sa jednocześnie kolejnymi przypadkami użycia, lecz nie z punktu widzenia samego użytkownika (ponieważ ten może wykonywać zbyt skomplikowane operacje), a z punktu widzenia konsoli korzystajacej z interfejsu Blueprints. Stad opis poszczególnych metod się najlepiej odzwierciedlać dostępne funkcjonalności, jakich oczekuje od nas konsola. Na tej podstawie został wykonany następujacy podział prac: Graph owe funkcjonalności - Paweł Bulwan: FU1: Dodanie elementu (addvertex/addedge) FU2: Usunięcie elementu (removevertex/removeedge) FU3: Pobranie elementu (getvertex/getedge) Funkcjonalności zwiazane z elementem - Maciej Sikora: FU4: Pobierz właściwość elementu (getproperty) FU5: Dodaj/zmodyfikuj właściwość elementu (setproperty) FU6: Usuń właściwość elementu (removeproperty) Funkcjonalności specyficzne dla krawędzi - Mateusz Cieślak: FU7: Pobierz wierzchołek wejściowy/wyjściowy (getinvertex/getoutvertex) FU8: Pobierz nazwę relacji (getlabel) Funkcjonalności specyficzne dla wierzchołka - Dominik Zieliński: FU9: Pobierz krawędzi wchodzace/wychodz ace (getinedges/getoutedges) Funkcjonalności zwiazane z Serwerem - Piotr Zakrzewski: FU10: Przywitanie się przy rozpoczęciu pracy (GraphDataBase - konstruktor) FU11: Obsługa zdarzenia "węzeł nie odpowiada"(przechwycenie wyjatku RemoteException) Niewymieniony wyżej Radian Karpuk ma za zadanie przygotować prezentację na najbliższe oddanie kolejnego podsumowania prac. 4
93 RGBD:RZS -2012/5/23-PC 23 maja 2012 Autor: Patryk Chaber Rozproszona grafowa baza danych Raport ze spotkania (kod ref. RGBD:RZS -2012/5/23-PC ) Opis Raport ze spotkania grupy projektowej 2D. Celem spotkania było wyprodukowanie wykresu Gantta oraz przydział zadań poszczególnym członkom grupy projektowej.
94 RGBD:RZS -2012/5/23-PC 3 Przebieg Spis treści 1 Czas i miejsce 2 2 Cel 2 3 Przebieg Wstęp Przedstawienie wykresu Gantta wyprodukowanego w wyniku spotkania Wnioski ze spotkania 3 1 Czas i miejsce Spotkanie odbyło się 23. maja 2012 roku na czacie portalu społecznościowego FaceBook. Rozpoczęło się ono o godzinie 14:30 i zakończyło o godzinie 15:15. Na spotkanie wszyscy członkowie grupy projektowej przybyli punktualnie. 2 Cel Celem spotkania było ustalenie kolejności oraz zakresu prac. Dodatkowo został wyprodukowany wykres Gantta prezentujacy przebieg etapu implementacyjnego na przestrzeni najbliższych tygodni. 3 Przebieg 3.1 Wstęp Członkom grupy projektowej zostały przydzielone następujace zakresy prac w ramach implementacji: Radian Karpuk - Implementacja mechanizmu synchronizacji na przestrzeni całego projektu Paweł Bulwan - Tworzenie dokumentacji oraz implementacja SerwerManager oraz RandomSerwerManager Maciej Sikora - Dodawanie oraz modyfikacja wierzchołków Piotr Zakrzewski - Mechanizm witania się, usuwania serwera orach replikacji Dominik Zieliński - Kontrola jakości kodu oraz implementacja podstawowych metod elementów grafu Mateusz Cieślak - Przygotowanie testów, realizacja oraz kontrola kodu zwiazanego z mechanizmem RMI 2
95 RGBD:RZS -2012/5/23-PC 4 Wnioski ze spotkania Każdy z członków grupy także został zobowiazany do opracowania części obsługi wyjatków. Dzięki temu ostatnia część etapu będzie mogła przebiec sprawnie, jednocześnie pozwalajac na zapoznanie się każdego członka z całościa kodu. Trzykrotnie w ciagu tego etapu następować będzie kontrola jakości kodu, przeprowadzana przez Dominika. Pozwoli to na utrzymanie kodu spójnego i przejrzystego kodu, który ułatwi późniejsze utrzymanie. Pod koniec zrealizowana zostanie dokumentacja oraz testy do projektu, dzięki czemu oprócz sprawdzenia podstawowej funkcjonalności projektu będzie można przetestować także i bardziej skomplikowne zapytania, które zapewnia konsola Gremlin. Wyniki działania tych zapytań będa główna miara oceny poprawności projektu, ponieważ wykorzystanie interfejsu BluePrints miało służyć właśnie temu, żeby każdy, kto jest zaznajomiony z konsola Gremlin, mógł bez najmniejszego problemu oraz dodatkowego przygotowania być w stanie obsłużyć nasza bazę danych. 3.2 Przedstawienie wykresu Gantta wyprodukowanego w wyniku spotkania Na rysunku 1 przedstawiony jest wykres Gantta, który przedstawia rozłożenie prac na przestrzeni najbliższych tygodni. Każdy zapoznał się z tym wykresem i został on zaakceptowany przez wszystkich członków grupy projektowej. Opóźnienie projektu z powodu przedłużenia zadania znajdujacego się na ścieżce krytycznej spowoduje odjęcie punktów w ostatecznym rozrachunku. Na wykresie zostały uwzględnione przerwy wynikajace z dużej ilości występujacych kolokwiów oraz święta 1. oraz 3. maja. 4 Wnioski ze spotkania Na spotkaniu została ustalona kolejność wykonywanych implementacji oraz innych prac. Wybrany został przydział osób do odpowiednich zakresów funkcjonalności projektu. Dzięki temu implementacja może zostać rozpoczęta natychmiast po zakończeniu obecnego etapu (etapu projektowania). 3

96 RGBD:RZS -2012/5/23-PC 4 Wnioski ze spotkania Rysunek 1: Wykres Gantta. 4
97 RGBD:PS -2012/4/23-PB 23 kwietnia 2012 Autor: Paweł Bulwan Rozproszona grafowa baza danych Projekt Systemu (kod ref. RGBD:PS -2012/4/23-PB ) Opis Projekt systemu uwzględniaj acy szczegółowe ustalenia na temat działania rozproszonej grafowej bazy danych oraz jej implementacji w środowisku Java.
98 RGBD:PS -2012/4/23-PB 2 Architektura i założenia ogólne Spis treści 1 Zawartość dokumentu 2 2 Architektura i założenia ogólne Model grafu Budowa sieci Indeksy RMI Blokady Podział programu na moduły 4 4 Funkcje programu FU1: obsługa zdarzeń addvertex (FU1a) i addedge (FU1b) FU2: obsługa zdarzeń removevertex (FU2a) i removeedge (FU2b) FU3: pobranie elementu wierzchołka lub krawędzi FU4: Pobierz właściwość elementu (getproperty) FU5: Dodaj/zmodyfikuj właściwość elementu (setproperty) FU6: Usuń właściwość elementu (removeproperty) FU7: Pobieranie wierzchołka wejściowego/wyjściowego FU8 Pobierz nazwę relacji FU9 Pobieranie krawędzi węzła FU10: Przywitanie się przy rozpoczęciu pracy (GraphDataBase - konstruktor) FU11: Obsługa zdarzenia węzeł nie odpowiada (przechwycenie wyjatku RemoteException) Środowisko programistyczne i testowe 15 6 Podsumowanie 15 1 Zawartość dokumentu Dokument ten zawiera projekt rozproszonej grafowej bazy danych. Jego celem jest pokazanie w szczegółach interfejsów dostępnych dla użytkownika końcowego bazy, oraz wewnętrznych struktur danych i mechanizmów działania systemu. Przypomniane sa też wszystkie kluczowe ustalenia dotyczace projektu, opisywane do tej pory w raportach ze spotkań. Poniższy tekst powstał w celu skonsolidowania dotychczasowej wiedzy, ma on za zadanie w jasny i przejrzysty sposób dostarczać odpowiedzi i wskazówek w fazie implementacji programu. 2 Architektura i założenia ogólne 2.1 Model grafu Modelem grafu obsługiwanym przez bazę danych jest graf skierowany, w którym zarówno wierzchołki jak i krawędzie posiadaja zestaw właściwości (jako listy par klucz-wartość). 2
99 RGBD:PS -2012/4/23-PB 2 Architektura i założenia ogólne Rysunek 1: Property Graph Model - przykład Każda z krawędzi posiada określony typ. Model taki nazywany jest Property Graph Model, przykładowy graf należacy do tej klasy przedstawia rysunek Budowa sieci Użytkownik końcowy będzie mógł korzystać z rozproszonej bazy danych dzięki użyciu prostej aplikacji klienckiej udostępniajacej interfejs Blueprints. Pozwoli on na podłacze- nie do aplikacji konsoli grafowego języka skryptowego Gremlin lub dowolnych aplikacji wykorzystujacych ten standard. Zadaniem klienta jest zapewnienie nieskomplikowanej, przezroczystej dla użytkownika metody dostępu do rozproszonej bazy danych. Podczas wykonywania metod udostępnianych przez interfejs klient losowo wybierze aktywny serwer z listy, na którym wywoła analogiczna metodę z użyciem mechanizmu RMI. Każdy serwer rozproszonej bazy danych powinien w danej chwili wykonać określona metodę z identycznym skutkiem. Wyjatkiem sa sytuacje, w których dopuszczamy tymczasowe, niewielkie niespójności w bazie. Przykładem może być dodanie nowego węzła, co powoduje różnice w zawartości indeksów do czasu rozpropagowania się informacji w całej sieci. 3
100 RGBD:PS -2012/4/23-PB 3 Podział programu na moduły 2.3 Indeksy Podstawowa struktura pozwalajac a na rozproszenie bazy danych na wiele serwerów sa indeksy. Na każdym serwerze przechowywane będa dwie listy indeksów: na węzły i krawędzie grafu. Zostana zaimplementowane w postaci tablicy haszujacej (z użyciem jej standardowej implementacji w języku Java). Kluczem tablicy będzie identyfikator obiektu (typu UUID), natomiast wartościa - obiekt zawierajacy adresy IP obu serwerów, na których znajduje się węzeł lub krawędź. W przypadku, gdy odpytywany serwer sam posiada dane, w indeksie zamiast adresu IP będzie znajdować się lokalizacja pliku z danymi obiektu. 2.4 RMI Do komunikacji między serwerami użyty zostanie mechanizm RMI, ze względu na jednolite środowisko, w którym pracuja serwery (Java) i prostotę użycia. Wywołanie metod na zdalnym serwerze poprzez RMI wymaga użycia specjalnych obiektów powiazanych z docelowym serwerem. Ponieważ inicjalizacja nowego połaczenia RMI z innym serwerem przy każdym wywołaniu metody jest zbyt czasochłonna i niepraktyczna, inicjalizacja połaczeń będzie odbywać się jednorazowo przy uruchamianiu serwerów. Obiekty RMI dla serwerów przetrzymywane będa w specjalnej tablicy haszujacej, w której kluczem będzie adres IP, a wartościa obiekt RMI. Dane o sieci (listę IP innych serwerów) program będzie otrzymywał po podłaczeniu się do sieci (poprzez podanie adresu IP jednego z działajacych w niej serwerów), jako odpowiedź na przywitanie serwera. 2.5 Blokady Dopuszczalne sa niewielkie, tymczasowe niespójności w danych, takie jak krótkoterminowe różnice w zawartości serwerów w momencie dodawania/usuwania nowego węzła. Pozwoli to na ograniczenie liczby blokad do minimum i pozwoli na większa współbieżność wykonywania zadań. Tym niemniej nieuniknione sa chwilowe blokady podczas operacji modyfikacji węzła/krawędzi oraz usuwania węzła/krawędzi. Maja one miejsce w momencie aktualizacji indeksów w całej bazie (podczas usuwania) oraz podczas modyfikacji danych węzła lub krawędzi (np. dodawania lub usuwania właściwości). Bardzo ważnym ustaleniem jest fakt, że blokowane będa poszczególne elementy, aby modyfikacja jednego z nich nie powodowała zablokowania całej bazy danych znajdujacej się na danym serwerze (co dla serwerów o dużej pojemności byłoby bardzo niewygodne). 3 Podział programu na moduły W tej sekcji przedstawiony zostanie diagram klas projektu. W aplikacji działajacej na każdym serwerze wchodzacym w skład rozproszonej bazy danych można wyróżnić przede wszystkim takie klasy jak: RemoteGraph klasa reprezentujaca graf. Implementuje interfejs Graph standardu Blueprints ( oraz metody ściśle zwiazane z rozproszona implementacja grafu, GDBVertex klasa reprezentujaca wierzchołek, implementuje interfejs Vertex standardu Blueprints 4
101 RGBD:PS -2012/4/23-PB 3 Podział programu na moduły GDBEdge klasa reprezentujaca krawędź, implementuje interfejs Edge standardu Blueprints RandomServerManager klasa udostępniajaca metody wyboru serwera backupowego dla danych danego serwera, zgodnie z założona polityka wyboru (np. losowanie z puli serwerów z odkładaniem) ElementsMonitor klasa pomagajaca w synchronizacji dostępu do poszczególnych elementów (zakładania blokad np. na poszczególne wierzchołki lub krawędzie) Na rysunkach 2 5 przedstawiony jest diagram klas projektu. Rysunek 2 przedstawia zestaw metod w głównym obiekcie reprezentujacym graf. Projektowana klasa GraphDatabase implementuje interfejs RemoteGraph, który dla przejrzystości dziedziczy po interfejsie Graph standardu Blueprints, oraz Remote. Interfejs Graph dostarcza sygnatur metod zgodnych z metodami w aplikacji klienckiej, dzięki czemu przekazywanie wywołań od klienta do jednego z serwerów nie będzie wymagało żadnej konwersji parametrów. Klasa RemoteGraph dziedziczaca po Remote umożliwia zdalny dostęp do metod z użyciem mechanizmu RMI. Zwiazana z tym jest konieczność obsługi wyjatków typu Remote- Exception, ze względu na wielość możliwych scenariuszy awarii sieci. Klasa GraphDatabase zawiera przede wszystkim dwa indeksy zawierajace adresy IP maszyn, w których przechowywane sa dane o wierzchołkach i krawędziach. Przechowywane sa one jako tablica haszujaca, co umożliwia szybkie odnalezienie położenia obiektu gdy znamy jego identyfikator, czyli dla typowego przypadku dostępu do danych. W klasie znajduja się też odniesienia do obiektów ServerManager, lista obiektów ElementsMonitor służaca do realizacji wyłacznego dostępu do plików obiektu w momencie modyfikacji jego właściwości oraz lista adresów serwerów, z którymi program utrzymuje połaczenie. Lista ta jest inicjalizowana przy starcie programu z użyciem danych otrzymanych jako odpowiedź na komunikat przywitania serwera. Rysunek 3 przedstawia klasy opisujace krawędź i wierzchołek należace do grafu. Ze względu na duże podobieństwo tych obiektów w wybranym modelu grafu Property Graph Model, dziedzicza one po wspólnym interfejsie Element (należacym do standardu Blueprints). Zawiera on między innymi metody pozwalajace na dodawanie, modyfikację oraz usuwanie właściwości obiektu. Ponieważ działania te nie różnia się w żaden sposób dla krawędzi oraz wierzchołków, ich implementacje planuje się umieścić w abstrakcyjnej klasie GDBElement, która będzie wspólna dla obiektów obu typów. Klasa GDBVertex opisujaca wierzchołek będzie zawierała zbiory identyfikatorów krawędzi wchodzacych do tego węzła i wychodzacych z niego. Klasa Edge będzie zawierać informację o Id wierzchołków, które łaczy, co pozwoli m.in. na realizację funkcjonalności zwiazanej z usuwaniem krawędzi. ServerManager (rys. 4) udostępnia metody pozwalajace na wybór serwera zapasowego dla danych. Wybór może być losowy, lub zgodny z ustalonym kryterium, np. wybierany będzie serwer, który jest najmniej obciażony. Metoda init() buduję listę serwerów, natomiast GetDestinationServer() szereguje je w kolejności od najbardziej preferowanego do najmniej preferowanego, po czym wybiera pierwszy serwer z listy, który jest w danej chwili dostępny. ElementsMonitor udostęnia monitor, który uniemożliwia równoczesny dostęp do zapisanego na dysku pliku, zawierajacego dane na temat zadanego elementu, gdy zachodzi jego modyfikacja lub usuwanie. Blokada zakładana jest tylko na poszczególne obiekty 5
102 RGBD:PS -2012/4/23-PB 3 Podział programu na moduły Rysunek 2: Klasa opisujaca graf 6

103 RGBD:PS -2012/4/23-PB 3 Podział programu na moduły Rysunek 3: Klasy opisujace obiekty wierzchołków i krawędzi Rysunek 4: Klasa pomocnicza serwera Rysunek 5: Klasa używana do synchronizacji dostępu do plików z danymi obiektów 7
104 RGBD:PS -2012/4/23-PB 4 Funkcje programu (pliki), a nie cała bazę, aby minimalizować opóźnienia wynikajace z oczekiwania na dostęp. 4 Funkcje programu Poniższa sekcja zawiera opis słowny implementacji metod udostępnianych przez interfejs. Jest to uszczegółowiony opis wykonania funkcji zdefiniowanych w standardzie Blueprints, skupiajacy się przede wszystkim na aspekcie rozproszenia bazy danych. Przedstawione zostana następujace funkcjonalności, oznaczone skrótami: FU1: Dodanie elementu (addvertex/addedge) FU2: Usunięcie elementu (removevertex/removeedge) FU3: Pobranie elementu (getvertex/getedge) FU4: Pobierz właściwość elementu (getproperty) FU5: Dodaj/zmodyfikuj właściwość elementu (setproperty) FU6: Usuń właściwość elementu (removeproperty) FU7: Pobierz wierzchołek wejściowy/wyjściowy (getinvertex/getoutvertex) FU8: Pobierz nazwę relacji (getlabel) FU9: Pobierz krawędzi wchodzace/wychodz ace (getinedges/getoutedges) FU10: Przywitanie się przy rozpoczęciu pracy (GraphDataBase - konstruktor) FU11: Obsługa zdarzenia węzeł nie odpowiada (przechwycenie wyjatku Remote- Exception) 4.1 FU1: obsługa zdarzeń addvertex (FU1a) i addedge (FU1b) FU1a: Obsługa metody Vertex addvertex(object Id); Funkcjonalność pozwala utworzyć nowy węzeł w rozproszonej bazie danych. Serwer, na którym wywoływana jest metoda, jest serwerem podstawowym dla dodawanego węzła. W trakcie operacji wybierany jest także serwer dodatkowy, na którym przechowywana będzie kopia węzła. Zadany identyfikator jest obiektem typu UUID (zgodnym z java.util.uuid), lub wartościa typu NULL jeśli identyfikator ma być wygenerowany. 1. Sprawdź czy węzeł o zadanym Id już istnieje w indeksie wierzchołków. Jeśli tak, zakończ cała operację błędem. Jeśli Id nie zostało podane, wygeneruj unikalne UUID. 2. Wybierz serwer zapasowy dla węzła z wykorzystaniem klasy implementujacej interfejs ServerManager. 3. Utwórz pusty obiekt wierzchołka z określonym Id. 4. Wywołaj zdalnie na wybranym serwerze zapasowym metodę dodania wierzchołka. W przypadku błędu zakończ cała operację błędem. 8
105 RGBD:PS -2012/4/23-PB 4 Funkcje programu 5. Zapisz wierzchołek na dysku w postaci pliku XML. 6. Dodaj wierzchołek do indeksu wierzchołków. 7. Zwróć pusty obiekt typu GDBVertex z ustawiona wartościa użytego UUID. FU1b: Obsługa metody Edge addedge(object Id, Vertex outvertex, Vertex invertex, String label); Funkcjonalność pozwala utworzyć nowa krawędź w rozproszonej bazie danych. Serwer, na którym wywoływana jest metoda, jest serwerem podstawowym dla dodawanej krawędzi. W trakcie operacji wybierany jest także serwer dodatkowy, na którym przechowywana będzie jej kopia. Zadany identyfikator jest obiektem typu UUID (zgodnym z java.util.uuid), lub wartościa typu NULL jeśli identyfikator ma być wygenerowany. Obiekt outvertex jest wierzchołkiem poczatkowym dla krawędzi, a invertex końcowym. Wartość label określa etykietę (typ) krawędzi. 1. Sprawdź czy krawędź o zadanym Id już istnieje w indeksie krawędzi. Jeśli tak, zakończ cała operację błędem. Jeśli Id nie zostało podane, wygeneruj unikalne UUID. 2. Sprawdź, czy wierzchołki outvertex i invertex istnieja w indeksie wierzchołków. Jeśli dowolny z nich nie istnieje, zakończ operację błędem. 3. Utwórz pusty obiekt krawędzi o określonym Id. 4. Wybierz serwer zapasowy dla krawędzi z wykorzystaniem klasy implementujacej interfejs ServerManager. 5. Wywołaj zdalnie na wybranym serwerze zapasowym metodę dodania krawędzi. W przypadku błędu zakończ cała operację błędem. 6. Zapisz krawędź na dysku w postaci pliku XML. 7. Dodaj krawędź do indeksu krawędzi. 8. Zwróć pusty obiekt typu GDBEdge z ustawiona wartościa użytego UUID. 4.2 FU2: obsługa zdarzeń removevertex (FU2a) i removeedge (FU2b) FU2a: Obsługa metody void removevertex(vertex vertex); Funkcjonalność pozwala usunać węzeł z rozproszonej bazy danych. Serwer, na którym wywoływana jest metoda jest dowolnym serwerem będacym częścia rozproszonej bazy danych. 1. Sprawdź, czy węzeł o Id zawartym w parametrze istnieje w indeksie wierzchołków. Jeśli nie, zakończ cała operację powodzeniem. 2. Pobierz węzeł przy pomocy funkcji getvertex (FU3). 3. Sprawdź w pobranym węźle, czy jest on zwiazany z jakimikolwiek krawędziami. Jeśli tak, zakończ cała operację błędem. 4. Sprawdź dostępność serwerów zawierajacych wierzchołek. Jeśli dowolny z nich jest niedostępny, zakończ operację błędem. 5. Usuń węzeł z indeksu wierzchołków. 9
106 RGBD:PS -2012/4/23-PB 4 Funkcje programu 6. Poprzez wykonanie zdalnej metody na jednym z dwóch serwerów zawierajacych wierzchołek, wykonaj fizyczne usunięcie plików z danymi wierzchołka. FU2b: Obsługa metody void removeedge(edge edge); Funkcjonalność pozwala usunać krawędź z rozproszonej bazy danych. Serwer, na którym wywoływana jest metoda jest dowolnym serwerem będacym częścia rozproszonej bazy danych. 1. Sprawdź, czy krawędź o Id zawartym w parametrze istnieje w indeksie krawędzi. Jeśli nie, zakończ cała operację powodzeniem. 2. Pobierz krawędź przy pomocy funkcji getedge (FU3). 3. Sprawdź w pobranej krawędzi, jakie węzły łaczy. 4. Sprawdź dostępność serwerów zawierajacych wierzchołek. Jeśli dowolny z nich jest niedostępny, zakończ operację błędem. 5. Usuń krawędź z indeksu krawędzi. 6. Wywołaj na dowolnym z serwerów zawierajacych usuwane przez krawędź węzły metodę usuwajac a krawędź z wewnętrznych indeksów na obu serwerach. 7. Poprzez wykonanie zdalnej metody na jednym z dwóch serwerów zawierajacych krawędź, wykonaj fizyczne usunięcie plików z danymi krawędzi. 4.3 FU3: pobranie elementu wierzchołka lub krawędzi FU3a: Obsługa metody Vertex getvertex(object Id); Funkcjonalność pozwala pobrać obiekt wierzchołka z rozproszonej bazy danych. Metoda może zostać wywołana na dowolnym z serwerów wchodzacych w skład bazy. 1. Sprawdź czy węzeł o zadanym Id istnieje w indeksie wierzchołków. Jeśli nie, zakończ cała operację zwracajac wartość NULL. 2. Spróbuj pobrać wierzchołek z pierwszego z serwerów przy pomocy metody zdalnej. Jeśli operacja się udała, przejdź do punktu Spróbuj pobrać wierzchołek z drugiego z serwerów przy pomocy metody zdalnej. Jeśli operacja się nie udała, zakończ cała operację zwracajac wartość NULL. 4. Zwróć otrzymany obiekt wierzchołka użytkownikowi. FU3a: Obsługa metody Edge getedge(object Id); Funkcjonalność pozwala pobrać obiekt krawędzi z rozproszonej bazy danych. Metoda może zostać wywołana na dowolnym z serwerów wchodzacych w skład bazy Sprawdź czy krawędź o zadanym Id istnieje w indeksie krawędzi. Jeśli nie, zakończ cała operację zwracajac wartość NULL, 2. Spróbuj pobrać krawędź z pierwszego z serwerów przy pomocy metody zdalnej. Jeśli operacja się udała, przejdź do punktu 4, 3. Spróbuj pobrać krawędź z drugiego z serwerów przy pomocy metody zdalnej. Jeśli operacja się nie udała, zakończ cała operację zwracajac wartość NULL, 4. Zwróć otrzymany obiekt krawędzi użytkownikowi. 10
107 RGBD:PS -2012/4/23-PB 4 Funkcje programu 4.4 FU4: Pobierz właściwość elementu (getproperty) Zakładamy, że dany jest obiekt elementu (FU3 zostało wykonane), na którym wykonujemy metodę, podajac jako argument nazwę pożadanej właściwości. 1. Wyszukaj w HashMap ie properties pozycję z zadanym key. Jeśli obiekt nie posiada wpisu z takim key w properties, wynikiem operacji jest NULL, w przeciwnym przypadku wynikiem jest odpowiadajacy value. 2. Zwróć pobrana wartość własności. 4.5 FU5: Dodaj/zmodyfikuj właściwość elementu (setproperty) Przypadek użycia odnosi się zarówno do obiektów krawędzi jak i do obiektów wierzchołków. Ich interfejsy sa w dużej mierze wspólne, ponadto obiekty te dziedzicza po wspólnym, abstrakcyjnym przodku. Zakładamy, że dany jest obiekt elementu (FU3 zostało wykonane), na którym wykonamy metodę. Utworzony został obiekt, który będzie wartościa właściwości. 1. Zablokuj element na obu serwerach, które go przechowuja. 2. Wyszukaj w HashMap ie properties obiekt z danym kluczem. Jeśli nie znaleziono, dodaj nowa pozycję HashMap składajac a się z nowych key, value. W przeciwnym wypadku, zmodyfikuj pozycję HashMap zamieniajac value na nowy. Czynność (dodanie lub modyfikację) powtórz na kopii elementu na drugim serwerze. 3. Odblokuj element na serwerach. 4. Zmodyfikuj odpowiednio zawartość pliku XML na dysku. Czynność powtórz na kopii elementu na drugim serwerze. 4.6 FU6: Usuń właściwość elementu (removeproperty) Zakładamy, że dany jest obiekt elementu (FU3 zostało wykonane), na którym wykonamy metodę, podajac jako argumenty nazwę właściwości. 1. Wyszukaj w HashMap ie properties obiekt z danym kluczem. Jeśli nie znaleziono, przerwij operację zwracajac NULL. W przeciwnym wypadku zachowaj value dla zadanego key oraz Idź do punktu Zablokuj element na obu serwerach, które go przechowuja. 3. Usuń z HashMap y properties pozycję z zadanym key. Czynność powtórz dla kopii elementu na drugim serwerze. 4. Odblokuj element na serwerach. 5. Zmodyfikuj odpowiednio zawartość pliku XML na dysku. Czynność powtórz na kopii elementu na drugim serwerze. 6. Zwróć zachowany value, czyli skasowana wartość. Informacja o wierzchołkach łaczonych przez krawędź jest zapisana jako właściwość w liście właściwości krawędzi. W ten sam sposób przechowywana jest informacja na temat nazwy relacji (typu krawędzi). 11
108 RGBD:PS -2012/4/23-PB 4 Funkcje programu 4.7 FU7: Pobieranie wierzchołka wejściowego/wyjściowego Korzysta z funkcji FU3 i FU4 1. System pobiera Id wierzchołka z hashmapy właściwości, za pomoca FU4, przy użyciu odpowiednio właściwości invertex lub outvertex 2. System pobiera węzeł, o pobranym z krawędzi Id, za pomoca FU3 3. System zwraca żadany wierzchołek Informacja o wierzchołkach łaczonych przez krawędź jest zapisana jako właściwość w liście właściwości krawędzi. W ten sam sposób przechowywana jest informacja na temat nazwy relacji (typu krawędzi). Korzysta z FU4 4.8 FU8 Pobierz nazwę relacji 1. Zwracany jest String z hashmapy skojarzony z właściwościa label za pomoca FU4 GDBVertex zawiera 2 oddzielne kontenery (Vector, ArrayList lub zwykły Array) dla krawędzi - jeden dla krawędzi wchodzacych do tego węzła, drugi dla krawędzi z niego wychodzacych. Każdy kontener zawiera pary postaci Id, label dla przechowywanych krawędzi. Taka postać przechowywanych danych pozwoli na uzyskanie dostępu do odpowiednich krawędzi bez potrzeby pobierania wszystkich krawędzi majacych zwiazek z danym węzłem. Zmniejszy to obciażenie sieci. 4.9 FU9 Pobieranie krawędzi węzła Korzysta z funkcji FU3 (Pobieranie Elementu). Rozszerzana przez funkcje FU9a, FU9b, FU9c. 1. Użytkownik wprowadza Id węzła. 2. System pobiera węzeł o podanym Id przy pomocy funkcji FU3. 3. System tworzy listę Id wybranych krawędzi. 4. Dla każdego Id z listy System pobiera krawędź przy pomocy funkcji FU3 i umieszcza ja na liście zwracanych krawędzi. 5. System zwraca listę zwracanych krawędzi. FU9a: Funkcjonalność pozwala na pobranie krawędzi wchodzacych do węzła. Rozszerza funkcję FU9 w punkcie System dodaje do listy zwracanych Id wszystkie elementy z listy Id krawędzi wchodzacych o zadanej wartości label. 2. System zwraca listę zwracanych Id. FU9b: Funkcjonalność pozwala na pobranie krawędzi wychodzacych z węzła. Rozszerza funkcję FU9 w punkcie 3 12
109 RGBD:PS -2012/4/23-PB 4 Funkcje programu 1. System dodaje do listy zwracanych Id wszystkie elementy z listy Id krawędzi wychodzacych o zadanej wartości label. 2. System zwraca listę zwracanych Id. FU9c Pobieranie wszystkich krawędzi węzła. Rozszerza funkcję FU9 w punkcie 3 1. System dodaje do listy zwracanych Id wszystkie elementy z listy Id krawędzi wychodzacych o zadanej wartości label. 2. System dodaje do listy zwracanych Id wszystkie elementy z listy Id krawędzi wchodzacych o zadanej wartości label. 3. System zwraca listę zwracanych Id FU10: Przywitanie się przy rozpoczęciu pracy (GraphDataBase - konstruktor) Przypadek użycia dzieli się na podprzypadki podzielone ze względu na argument konstruktora (argumentem jest adres serwera znajdujacego się w systemie, który dostarczy listę adresów wszystkich maszyn) oraz istnienie zapisanego na dysku indeksu. Jeśli lista z adresami jest pusta, rozpoczynajacy pracę serwer jest pierwszym w systemie. W przeciwnym przypadku dołacza się do systemu i musi zakomunikować swoja obecność. Jeżeli aplikacja nie stwierdzi obecności zapisanych na dysku indeksów, oznacza to, że pierwszy raz tworzona jest baza na tej maszynie. W przeciwnym przypadku prawdopodobnie baza danych uzyskała sprawność po awarii. FU10a: brak argumentu konstruktora, brak plików z indeksami 1. Start serwera - tworzony jest obiekt GraphDataBase. 2. Brak argumentu konstruktora GraphDataBase. 3. Serwer jest pierwszy w systemie, więc nie musi nikogo informować o swoim istnieniu. 4. Dodanie własnego adresu do listy z adresami. 5. Serwer widzi, że nie ma żadnych węzłów ani krawędzi (lub plików z indeksami) zapisanych na dysku, więc nie wczytuje indeksów. FU10b: brak argumentu konstruktora, istnieja pliki z indeksami 1. Punkty 1-4 jak w FU10a. 2. Serwer stwierdza, że na dysku sa zapisane dane świadczace o tym, że wcześniej na tej maszynie działała baza danych. Prawdopodobnie nastapiło wyłaczenie zasilania. 3. Wczytanie indeksów węzłów oraz krawędzi. Serwer uzyskał sprawność po awarii. FU10c: podany argument konstruktora, brak plików z indeksami 1. Jak w FU10a. 2. Na rzecz adresu serwera z argumentu konstruktora wywoływana jest zdalna metoda, która zwraca listę adresów serwerów znajdujacych się w bazie. 13
110 RGBD:PS -2012/4/23-PB 4 Funkcje programu 3. Wykonywana jest funkcja GraphDataBase.hereIAm(), która poinformuje serwery w systemie o podłaczeniu nowego węzła. Uwaga: funkcja hereiam() będzie działać podobnie do funkcji GraphDataBase.updateIndices(), która rozsyła informację o aktualizacji indeksów do pozostałych serwerów. 4. Na wszystkich maszynach dopisany zostaje adres nowego serwera do listy adresów. Nowy adres jest brany pod uwagę przez obiekt klasy ServerManager. Dodany węzeł również własny adres dopisuje do listy adresów. FU10d: podany argument konstruktora, istnieja pliki z indeksami 1. Punkty 1-4 jak w FU10c. 2. Serwer stwierdza, że na dysku sa zapisane dane świadczace o tym, że wcześniej na tej maszynie działała baza danych. Prawdopodobnie nastapiło wyłaczenie zasilania. 3. Wczytanie indeksów węzłów oraz krawędzi. Serwer uzyskał sprawność po awarii. 4. Uzyskanie aktualnego indeksu - uzupełnienie wczytanego indeksu, zapisanego przed wystapieniem awarii, o informacje, które pojawiły się w systemie podczas nieobecności serwera FU11: Obsługa zdarzenia węzeł nie odpowiada (przechwycenie wyjatku RemoteException) FU11a: 1. Wywołana zostaje metoda na rzecz obiektu zdalnego. Obiekt zdalny nie jest dostępny pod określonym adresem. Zwrócony zostaje wyjatek RemoteException. Startuje procedura wywołania metody zdalnej z serwera zapasowego (FU3). 2. Start timera dla konkretnej maszyny, który będzie zliczał czas od zidentyfikowania niedostępności serwera. 3. Po odliczeniu, określonego w pliku konfiguracyjnym, czasu następuje ponowna próba komunikacji z serwerem. 4. Udało się skomunikować z serwerem. Nie sa podejmowane dalsze działania. FU11b: 1. Punkty 1-3 jak w FU11a 2. Próba komunikacji nie powiodła się. 3. Poinformowanie administratora o awarii jednego z serwerów. Dodanie wpisu o określonej treści do dziennika wydarzeń. 4. Administrator nie potwierdza awarii. System korzysta z kopii zapasowej do czasu kiedy uruchomiony zostanie nie odpowiadajacy serwer. FU11c: 14
111 RGBD:PS -2012/4/23-PB 6 Podsumowanie 1. Punkty 1-5 jak w FU11b 2. Administrator potwierdza awarię nie odpowiadajacego serwera. 3. Wszczynana jest procedura odtworzenia danych znajdujacych się na serwerze, który uległ awarii. Metoda odtwarzania danych, przedstawiona została w koncepcji Radka Karpuka. 4. Aktualizacja indeksów. Dotychczasowe odwołania do nie odpowiadajacego serwera zostaja zastapione adresem nowego serwera. 5. Administrator zobowiazany jest do wyczyszczenia danych na serwerze, który uległ awarii, jeśli będzie on w przyszłości podłaczony do systemu. Jeśli zostanie ponownie podłaczony do systemu, będzie widziany jako czysty serwer. 5 Środowisko programistyczne i testowe Projekt realizowany będzie w środowisku programistycznym Eclipse. Wersja języka Java użyta do budowania aplikacji będzie Java 7. Aplikacja serwerowa powinna być w miarę możliwości niezależna od systemu operacyjnego, jednak docelowe wdrożenie planowane jest w systemie Linux. W zwiazku z tym wszelkie fragmenty kodu zależne od systemu (np. odwoływanie się do ścieżek w systemie plików) powinny brać ten fakt pod uwagę. Aplikacja kliencka powinna być niezależna od systemu operacyjnego. 6 Podsumowanie Powyższy projekt powinien stanowić podstawę dla implementacji rozproszonej grafowej bazy danych. W trakcie prac konieczne może okazać się uzupełnienie klas o brakujace metody lub niewielkie zmiany w działaniu opisanych mechanizmów. Tym niemniej każde odejście od projektu powinno być dobrze uzasadnione i skonsultowane z grupa projektowa, aby nie wpłynęło negatywnie na przebieg prac. 15
112 RGBD:DK-2012/6/13-PB 13 czerwca 2012 Autor: Paweł Bulwan Rozproszona grafowa baza danych Dokumentacja końcowa (kod ref. RGBD:DK-2012/6/13-PB) Opis Dokumentacja końcowa zawierajaca zaktualizowany projekt systemu, szczegółowe ustalenia na temat działania rozproszonej grafowej bazy danych, jej implementacji w środowisku Java oraz testów pozwalajacych ocenić poprawność działania.
113 RGBD:DK-2012/6/13-PB Spis treści Spis treści 1 Zawartość dokumentu 3 2 Architektura i założenia ogólne Model grafu Budowa sieci Indeksy RMI Blokady Podział programu na moduły 5 4 Funkcje programu FU1: obsługa zdarzeń addvertex (FU1a) i addedge (FU1b) FU2: obsługa zdarzeń removevertex (FU2a) i removeedge (FU2b) FU3: pobranie elementu wierzchołka lub krawędzi FU4: Pobierz właściwość elementu (getproperty) FU5: Dodaj/zmodyfikuj właściwość elementu (setproperty) FU6: Usuń właściwość elementu (removeproperty) FU7: Pobieranie wierzchołka wejściowego/wyjściowego FU8 Pobierz nazwę relacji FU9 Pobieranie krawędzi węzła FU10: Przywitanie się przy rozpoczęciu pracy (GraphDataBase - konstruktor) FU11: Obsługa zdarzenia węzeł nie odpowiada (przechwycenie wyjatku RemoteException) Uruchamianie i konfiguracja programu Konfiguracja klienta Konfiguracja aplikacji serwera Fizyczny zapis danych na dysku Testowanie systemu Przykład użycia rozproszonej bazy danych Podsumowanie 21 2
114 RGBD:DK-2012/6/13-PB 2 Architektura i założenia ogólne 1 Zawartość dokumentu Dokument ten zawiera dokumentację końcowa rozproszonej grafowej bazy danych. Jego celem jest pokazanie w szczegółach ostatecznych interfejsów dostępnych dla użytkownika końcowego bazy, oraz wewnętrznych struktur danych i mechanizmów działania systemu. Przypomniane sa też wszystkie kluczowe ustalenia dotyczace projektu. Istotna częścia jest opis procedur testowych bazy, pokazujacych przykładowe zapytania w języku Gremlin obsługiwane przez rozproszona bazę danych. Wymienione sa też elementy standardu Blueprints zgodnie z założeniami projektowymi nie zaimplementowane w systemie (jak np. złożone transakcje). Użytkownik zaznajomiony z dokumentacja końcowa powinien być w stanie skonfigurować samodzielnie środowisko testowe, wywołać dowolne zapytania na rozproszonej bazie danych, a przede wszystkim zrozumieć zasady, zgodnie z którymi akcje wykonywane sa na jednostkach wchodzacych w skład bazy. 2 Architektura i założenia ogólne 2.1 Model grafu Modelem grafu obsługiwanym przez bazę danych jest graf skierowany, w którym zarówno wierzchołki jak i krawędzie posiadaja zestaw właściwości (jako listy par klucz-wartość). Każda z krawędzi posiada określony typ. Model taki nazywany jest Property Graph Model, przykładowy graf należacy do tej klasy przedstawia rysunek Budowa sieci Użytkownik końcowy może korzystać z rozproszonej bazy danych dzięki użyciu prostej aplikacji klienckiej udostępniajacej interfejs Blueprints. Pozwala on na podłaczenie do aplikacji konsoli grafowego języka skryptowego Gremlin lub dowolnych aplikacji wykorzystujacych ten standard. Zadaniem klienta jest zapewnienie nieskomplikowanej, przezroczystej dla użytkownika metody dostępu do rozproszonej bazy danych. Podczas wykonywania metod udostępnianych przez interfejs klient wybiera aktywny serwer z listy, na którym wywoła analogiczna metodę z użyciem mechanizmu RMI. Każdy serwer rozproszonej bazy danych powinien w danej chwili wykonać określona metodę z identycznym skutkiem. Wyjatkiem sa sytuacje, w których dopuszczamy tymczasowe, niewielkie niespójności w bazie. Przykładem może być dodanie nowego węzła, co powoduje różnice w zawartości indeksów do czasu rozpropagowania się informacji w całej sieci. 2.3 Indeksy Podstawowa struktura pozwalajac a na rozproszenie bazy danych na wiele serwerów sa indeksy. Na każdym serwerze przechowywane sa dwie listy indeksów: na węzły i krawędzie grafu. Zostana zaimplementowane w postaci tablicy haszujacej (z użyciem jej standardowej implementacji w języku Java). Kluczem tablicy będzie identyfikator obiektu (typu UUID), natomiast wartościa - obiekt zawierajacy adresy IP obu serwerów, na których znajduje się węzeł lub krawędź. 3
115 RGBD:DK-2012/6/13-PB 2 Architektura i założenia ogólne Rysunek 1: Property Graph Model - przykład 4
116 RGBD:DK-2012/6/13-PB 3 Podział programu na moduły 2.4 RMI Do komunikacji między serwerami użyty został mechanizm RMI, ze względu na jednolite środowisko, w którym pracuja serwery (Java) i prostotę użycia. Wywołanie metod na zdalnym serwerze poprzez RMI wymaga użycia specjalnych obiektów powiazanych z docelowym serwerem. Ponieważ inicjalizacja nowego połaczenia RMI z innym serwerem przy każdym wywołaniu metody jest zbyt czasochłonna i niepraktyczna, inicjalizacja połaczeń będzie odbywać się jednorazowo przy uruchamianiu serwerów oraz w momencie doła- czania kolejnych serwerów do sieci. Obiekty RMI dla serwerów przetrzymywane będa w specjalnej tablicy haszujacej, w której kluczem będzie adres IP, a wartościa obiekt RMI. Dane o sieci (listę IP innych serwerów) program będzie otrzymywał po podłaczeniu się do sieci (poprzez podanie adresu IP jednego z działajacych w niej serwerów), jako odpowiedź na przywitanie serwera. 2.5 Blokady Dopuszczalne sa niewielkie, tymczasowe niespójności w danych, takie jak krótkoterminowe różnice w zawartości serwerów w momencie dodawania/usuwania nowego węzła. Pozwoli to na ograniczenie liczby blokad do minimum i pozwoli na większa współbieżność wykonywania zadań. Tym niemniej nieuniknione sa chwilowe blokady podczas operacji modyfikacji węzła/krawędzi oraz usuwania węzła/krawędzi. Maja one miejsce w momencie aktualizacji indeksów w całej bazie (podczas usuwania) oraz podczas modyfikacji danych węzła lub krawędzi (np. dodawania lub usuwania właściwości). Bardzo ważnym ustaleniem jest fakt, że blokowane będa poszczególne elementy, aby modyfikacja jednego z nich nie powodowała zablokowania całej bazy danych znajdujacej się na danym serwerze (co dla serwerów o dużej pojemności byłoby bardzo niewygodne). 3 Podział programu na moduły W tej sekcji przedstawiony zostanie diagram klas projektu. W aplikacji działajacej na każdym serwerze wchodzacym w skład rozproszonej bazy danych można wyróżnić następujace klasy oraz interfejsy: RemoteGraph interfejs, przez który następuje komunikacja między obiektami serwerów znajdujacych się w sieci, z tego powodu dziedziczy on po interfejsie Remote, a każda metoda tego interfejsu rzuca wyjatek RemoteException. GraphDatabase klasa reprezentujaca graf. Implementuje interfejs Graph standardu Blueprints ( Model) oraz metody ściśle zwiazane z rozproszona implementacja grafu. GDBElement klasa abstrakcyjna, która implementuje metody interfejsu Element standardu Blueprint, jednocześnie implementujac metody wspólne dla klas GDBVertex oraz GDBEdge - takie jak np. pobieranie właściwości z plików XML oraz ich zapisywanie do pliku. GDBVertex klasa reprezentujaca wierzchołek, implementuje interfejs Vertex standardu Blueprint oraz rozszerza klasę GDBElement. 5
117 RGBD:DK-2012/6/13-PB 3 Podział programu na moduły GDBEdge klasa reprezentujaca krawędź, implementuje interfejs Edge standardu Blueprints oraz rozszerza klasę GDBElement. ServerManager - interfejs pozwalajacy na implementację własnej metody wyboru serwera, na którym ma być utworzony i zapisany duplikat, docelowo istnieje pomysł wstrzykiwania klasy implementujacej ten interfejs za pomoca mechanizmu wstrzykiwania zależności. RandomServerManager przykładowa klasa implementujaca interfejs ServerManager, w tym wypadku dobór serwera na duplikat jest dokonywany na podstawie losowania z puli dostępnych serwerów. Na rysunkach 2 4 przedstawiony jest diagram klas projektu. Rysunek 2 przedstawia zestaw metod w głównym obiekcie reprezentujacym graf. Projektowana klasa GraphDatabase implementuje interfejs RemoteGraph, który dla przejrzystości dziedziczy po interfejsie Graph standardu Blueprints, oraz Remote. Interfejs Graph dostarcza sygnatur metod zgodnych z metodami w aplikacji klienckiej, dzięki czemu przekazywanie wywołań od klienta do jednego z serwerów nie będzie wymagało żadnej konwersji parametrów. Klasa RemoteGraph dziedziczaca po Remote umożliwia zdalny dostęp do metod z użyciem mechanizmu RMI. Zwiazana z tym jest konieczność obsługi wyjatków typu Remote- Exception, ze względu na wielość możliwych scenariuszy awarii sieci. Klasa GraphDatabase zawiera przede wszystkim dwa indeksy zawierajace adresy IP maszyn, w których przechowywane sa dane o wierzchołkach i krawędziach. Przechowywane sa one jako tablica haszujaca, co umożliwia szybkie odnalezienie położenia obiektu gdy znamy jego identyfikator, czyli dla typowego przypadku dostępu do danych. W klasie znajduje się też lista adresów serwerów, z którymi program utrzymuje połaczenie. Lista ta jest inicjalizowana przy starcie programu z użyciem danych otrzymanych jako odpowiedź na komunikat przywitania serwera. Rysunek 3 przedstawia klasy opisujace krawędź i wierzchołek należace do grafu. Ze względu na duże podobieństwo tych obiektów w wybranym modelu grafu Property Graph Model, dziedzicza one po wspólnym interfejsie Element (należacym do standardu Blueprints). Zawiera on między innymi metody pozwalajace na dodawanie, modyfikację oraz usuwanie właściwości obiektu. Ponieważ działania te nie różnia się w żaden sposób dla krawędzi oraz wierzchołków, ich implementacje umieszczono w abstrakcyjnej klasie GDBElement, która jest wspólna dla obiektów obu typów. Klasa GDBVertex opisujaca wierzchołek zawiera zbiory identyfikatorów krawędzi wchodzacych do tego węzła i wychodzacych z niego. Klasa Edge zawiera informację o Id wierzchołków, które łaczy, co pozwali m.in. na realizację funkcjonalności zwiazanej z usuwaniem krawędzi. ServerManager (rys. 4) udostępnia metody pozwalajace na wybór serwera zapasowego dla danych. Wybór może być losowy, lub zgodny z ustalonym kryterium, np. wybierany będzie serwer, który jest najmniej obciażony. Metoda init() buduję listę serwerów, natomiast GetDestinationServer() szereguje je w kolejności od najbardziej preferowanego do najmniej preferowanego, po czym wybiera pierwszy serwer z listy, który jest w danej chwili dostępny. 6
118 RGBD:DK-2012/6/13-PB 3 Podział programu na moduły Rysunek 2: Klasa opisujaca graf 7
119 RGBD:DK-2012/6/13-PB 3 Podział programu na moduły Rysunek 3: Klasy opisujace obiekty wierzchołków i krawędzi 8
120 RGBD:DK-2012/6/13-PB 4 Funkcje programu Rysunek 4: Klasa pomocnicza serwera 4 Funkcje programu Poniższa sekcja zawiera opis słowny implementacji metod udostępnianych przez interfejs. Jest to uszczegółowiony opis wykonania funkcji zdefiniowanych w standardzie Blueprints, skupiajacy się przede wszystkim na aspekcie rozproszenia bazy danych. Przedstawione zostana następujace funkcjonalności, oznaczone skrótami: FU1: Dodanie elementu (addvertex/addedge) FU2: Usunięcie elementu (removevertex/removeedge) FU3: Pobranie elementu (getvertex/getedge) FU4: Pobierz właściwość elementu (getproperty) FU5: Dodaj/zmodyfikuj właściwość elementu (setproperty) FU6: Usuń właściwość elementu (removeproperty) FU7: Pobierz wierzchołek wejściowy/wyjściowy (getinvertex/getoutvertex) FU8: Pobierz nazwę relacji (getlabel) FU9: Pobierz krawędzi wchodzace/wychodz ace (getinedges/getoutedges) FU10: Przywitanie się przy rozpoczęciu pracy (GraphDataBase - konstruktor) FU11: Obsługa zdarzenia węzeł nie odpowiada (przechwycenie wyjatku Remote- Exception) 4.1 FU1: obsługa zdarzeń addvertex (FU1a) i addedge (FU1b) FU1a: Obsługa metody Vertex addvertex(object Id); 9
121 RGBD:DK-2012/6/13-PB 4 Funkcje programu Funkcjonalność pozwala utworzyć nowy węzeł w rozproszonej bazie danych. Serwer, na którym wywoływana jest metoda, jest serwerem podstawowym dla dodawanego węzła. W trakcie operacji wybierany jest także serwer dodatkowy, na którym przechowywana będzie kopia węzła. Zadany identyfikator jest obiektem typu UUID (zgodnym z java.util.uuid), lub wartościa typu NULL jeśli identyfikator ma być wygenerowany. 1. Sprawdź czy węzeł o zadanym Id już istnieje w indeksie wierzchołków. Jeśli tak, zakończ cała operację błędem. Jeśli Id nie zostało podane, wygeneruj unikalne UUID. 2. Wybierz serwer zapasowy dla węzła z wykorzystaniem klasy implementujacej interfejs ServerManager. 3. Utwórz pusty obiekt wierzchołka z określonym Id. 4. Wywołaj zdalnie na wybranym serwerze zapasowym metodę dodania wierzchołka. W przypadku błędu zakończ cała operację błędem. 5. Zapisz wierzchołek na dysku w postaci pliku XML. 6. Dodaj wierzchołek do indeksu wierzchołków. 7. Zwróć utworzony obiekt. FU1b: Obsługa metody Edge addedge(object Id, Vertex outvertex, Vertex invertex, String label); Funkcjonalność pozwala utworzyć nowa krawędź w rozproszonej bazie danych. Serwer, na którym wywoływana jest metoda, jest serwerem podstawowym dla dodawanej krawędzi. W trakcie operacji wybierany jest także serwer dodatkowy, na którym przechowywana będzie jej kopia. Zadany identyfikator jest obiektem typu UUID (zgodnym z java.util.uuid), lub wartościa typu NULL jeśli identyfikator ma być wygenerowany. Obiekt outvertex jest wierzchołkiem poczatkowym dla krawędzi, a invertex końcowym. Wartość label określa etykietę (typ) krawędzi. 1. Sprawdź czy krawędź o zadanym Id już istnieje w indeksie krawędzi. Jeśli tak, zakończ cała operację błędem. Jeśli Id nie zostało podane, wygeneruj unikalne UUID. 2. Sprawdź, czy wierzchołki outvertex i invertex istnieja w indeksie wierzchołków. Jeśli dowolny z nich nie istnieje, zakończ operację błędem. 3. Utwórz pusty obiekt krawędzi o określonym Id i określonej etykieccie (Label). 4. Wybierz serwer zapasowy dla krawędzi z wykorzystaniem klasy implementujacej interfejs ServerManager. 5. Wywołaj zdalnie na wybranym serwerze zapasowym metodę dodania krawędzi. W przypadku błędu zakończ cała operację błędem. 6. Zapisz krawędź na dysku w postaci pliku XML. 7. Dodaj krawędź do indeksu krawędzi. 8. Zwróć utworzony obiekt typu GDBEdge z ustawiona wartościa użytego UUID. 10
122 RGBD:DK-2012/6/13-PB 4 Funkcje programu 4.2 FU2: obsługa zdarzeń removevertex (FU2a) i removeedge (FU2b) FU2a: Obsługa metody void removevertex(vertex vertex); Funkcjonalność pozwala usunać węzeł z rozproszonej bazy danych. Serwer, na którym wywoływana jest metoda jest dowolnym serwerem będacym częścia rozproszonej bazy danych. 1. Sprawdź, czy węzeł o Id zawartym w parametrze istnieje w indeksie wierzchołków. Jeśli nie, zakończ cała operację powodzeniem. 2. Pobierz węzeł przy pomocy funkcji getvertex (FU3). 3. Sprawdź w pobranym węźle, czy jest on zwiazany z jakimikolwiek krawędziami. Jeśli tak, zakończ cała operację błędem. 4. Sprawdź dostępność serwerów zawierajacych wierzchołek. Jeśli dowolny z nich jest niedostępny, wywołaj obsługę zdarzenia węzeł nie odpowiada (FU11). 5. Usuń węzeł z indeksu wierzchołków. 6. Poprzez wykonanie zdalnej metody na każdym z dwóch serwerów zawierajacych wierzchołek, wykonaj fizyczne usunięcie plików z danymi wierzchołka. FU2b: Obsługa metody void removeedge(edge edge); Funkcjonalność pozwala usunać krawędź z rozproszonej bazy danych. Serwer, na którym wywoływana jest metoda jest dowolnym serwerem będacym częścia rozproszonej bazy danych. 1. Sprawdź, czy krawędź o Id zawartym w parametrze istnieje w indeksie krawędzi. Jeśli nie, zakończ cała operację powodzeniem. 2. Pobierz krawędź przy pomocy funkcji getedge (FU3). 3. Sprawdź w pobranej krawędzi, jakie węzły łaczy. 4. Sprawdź dostępność serwerów zawierajacych wierzchołek. Jeśli dowolny z nich jest niedostępny, wywołaj obsługę zdarzenia węzeł nie odpowiada (FU11). 5. Usuń krawędź z indeksu krawędzi. 6. Wywołaj na każdym z serwerów zawierajacych usuwane przez krawędź węzły metodę usuwajac a krawędź z wewnętrznych indeksów na obu serwerach. 7. Poprzez wykonanie zdalnej metody na jednym z dwóch serwerów zawierajacych krawędź, wykonaj fizyczne usunięcie plików z danymi krawędzi. 4.3 FU3: pobranie elementu wierzchołka lub krawędzi FU3a: Obsługa metody Vertex getvertex(object Id); Funkcjonalność pozwala pobrać obiekt wierzchołka z rozproszonej bazy danych. Metoda może zostać wywołana na dowolnym z serwerów wchodzacych w skład bazy, a wynik działania tej metody powinien być identyczny z dokładnościa do chwilowej niespójności bazy danych. 1. Sprawdź czy węzeł o zadanym Id istnieje w indeksie wierzchołków. Jeśli nie, zakończ cała operację zwracajac wartość NULL. 11
123 RGBD:DK-2012/6/13-PB 4 Funkcje programu 2. Spróbuj pobrać wierzchołek z pierwszego z serwerów przy pomocy metody zdalnej. Jeśli operacja się udała, przejdź do punktu Spróbuj pobrać wierzchołek z drugiego z serwerów przy pomocy metody zdalnej. Jeśli operacja się nie udała, zakończ cała operację zwracajac wartość NULL. 4. Zwróć otrzymany obiekt wierzchołka użytkownikowi. FU3a: Obsługa metody Edge getedge(object Id); Funkcjonalność pozwala pobrać obiekt krawędzi z rozproszonej bazy danych. Metoda może zostać wywołana na dowolnym z serwerów wchodzacych w skład bazy Sprawdź czy krawędź o zadanym Id istnieje w indeksie krawędzi. Jeśli nie, zakończ cała operację zwracajac wartość NULL, 2. Spróbuj pobrać krawędź z pierwszego z serwerów przy pomocy metody zdalnej. Jeśli operacja się udała, przejdź do punktu 4, 3. Spróbuj pobrać krawędź z drugiego z serwerów przy pomocy metody zdalnej. Jeśli operacja się nie udała, zakończ cała operację zwracajac wartość NULL, 4. Zwróć otrzymany obiekt krawędzi użytkownikowi. 4.4 FU4: Pobierz właściwość elementu (getproperty) Przykładowe wywołanie: obiekt.getproperty(string key, String value) Zakładamy, że dany jest obiekt elementu (FU3 zostało wykonane), na którym wykonujemy metodę, podajac jako argument nazwę pożadanej właściwości. 1. Wyszukaj w HashMap ie properties pozycję z zadanym key. Jeśli obiekt nie posiada wpisu z takim key w properties, wynikiem operacji jest NULL, w przeciwnym przypadku wynikiem jest odpowiadajacy value. 2. Zwróć pobrana wartość własności. 4.5 FU5: Dodaj/zmodyfikuj właściwość elementu (setproperty) Przypadek użycia odnosi się zarówno do obiektów krawędzi jak i do obiektów wierzchołków. Ich interfejsy sa w dużej mierze wspólne, ponadto obiekty te dziedzicza po wspólnym, abstrakcyjnym przodku. Zakładamy, że dany jest obiekt elementu (FU3 zostało wykonane), na którym wykonamy metodę. Utworzony został obiekt, który będzie wartościa właściwości. 1. Zablokuj element na obu serwerach, które go przechowuja. 2. Wyszukaj w HashMap ie properties obiekt z danym kluczem. Jeśli nie znaleziono, dodaj nowa pozycję HashMap składajac a się z nowych key, value. W przeciwnym wypadku, zmodyfikuj pozycję HashMap zamieniajac value na nowy. Czynność (dodanie lub modyfikację) powtórz na kopii elementu na drugim serwerze. 3. Odblokuj element na serwerach. 4. Zmodyfikuj odpowiednio zawartość pliku XML na dysku. Czynność powtórz na kopii elementu na drugim serwerze. 12
124 RGBD:DK-2012/6/13-PB 4 Funkcje programu 4.6 FU6: Usuń właściwość elementu (removeproperty) Zakładamy, że dany jest obiekt elementu (FU3 zostało wykonane), na którym wykonamy metodę, podajac jako argumenty nazwę właściwości. Przykładowe wywołanie: obiekt.removeproperty(string key) 1. Wyszukaj w HashMap ie properties obiekt z danym kluczem. Jeśli nie znaleziono, przerwij operację zwracajac NULL. W przeciwnym wypadku zachowaj value dla zadanego key oraz Idź do punktu Zablokuj element na obu serwerach, które go przechowuja. 3. Usuń z HashMap y properties pozycję z zadanym key. Czynność powtórz dla kopii elementu na drugim serwerze. 4. Odblokuj element na serwerach. 5. Zmodyfikuj odpowiednio zawartość pliku XML na dysku. Czynność powtórz na kopii elementu na drugim serwerze. 6. Zwróć zachowany value, czyli skasowana wartość. 4.7 FU7: Pobieranie wierzchołka wejściowego/wyjściowego Informacja o wierzchołkach łaczonych przez krawędź jest zapisana jako właściwość w liście właściwości krawędzi. W ten sam sposób przechowywana jest informacja na temat nazwy relacji (typu krawędzi). 1. System pobiera Id wierzchołka z hashmapy właściwości, za pomoca FU4, przy użyciu odpowiednio właściwości invertex lub outvertex. 2. System pobiera węzeł, o pobranym z krawędzi Id, za pomoca FU3. 3. System zwraca wierzchołek o podanym Id. 4.8 FU8 Pobierz nazwę relacji Informacja o wierzchołkach łaczonych przez krawędź jest zapisana jako właściwość w liście właściwości krawędzi. W ten sam sposób przechowywana jest informacja na temat nazwy relacji (typu krawędzi). 1. Zwracany jest String z hashmapy skojarzony z właściwościa label za pomoca FU4 4.9 FU9 Pobieranie krawędzi węzła GDBVertex zawiera 2 oddzielne kontenery typu Vector dla krawędzi - jeden dla krawędzi wchodzacych do tego węzła, drugi dla krawędzi z niego wychodzacych. Każdy kontener zawiera pary postaci Id, label dla przechowywanych krawędzi. Taka postać przechowywanych danych pozwoli na uzyskanie dostępu do odpowiednich krawędzi bez potrzeby pobierania wszystkich krawędzi majacych zwiazek z danym węzłem. Zmniejszy to obcia- żenie sieci. 13
125 RGBD:DK-2012/6/13-PB 4 Funkcje programu 1. Użytkownik wprowadza Id węzła. 2. System pobiera węzeł o podanym Id przy pomocy funkcji FU3. 3. System tworzy listę Id wybranych krawędzi. 4. Dla każdego Id z listy System pobiera krawędź przy pomocy funkcji FU3 i umieszcza ja na liście zwracanych krawędzi. 5. System zwraca listę zwracanych krawędzi. FU9a: Funkcjonalność pozwala na pobranie krawędzi wchodzacych do węzła. Rozszerza funkcję FU9 w punkcie System dodaje do listy zwracanych Id wszystkie elementy z listy Id krawędzi wchodzacych o zadanej wartości label. 2. System zwraca listę zwracanych Id. FU9b: Funkcjonalność pozwala na pobranie krawędzi wychodzacych z węzła. Rozszerza funkcję FU9 w punkcie 3 1. System dodaje do listy zwracanych Id wszystkie elementy z listy Id krawędzi wychodzacych o zadanej wartości label. 2. System zwraca listę zwracanych Id. FU9c Pobieranie wszystkich krawędzi węzła. Rozszerza funkcję FU9 w punkcie 3 1. System dodaje do listy zwracanych Id wszystkie elementy z listy Id krawędzi wychodzacych o zadanej wartości label. 2. System dodaje do listy zwracanych Id wszystkie elementy z listy Id krawędzi wchodzacych o zadanej wartości label. 3. System zwraca listę zwracanych Id FU10: Przywitanie się przy rozpoczęciu pracy (GraphDataBase - konstruktor) 1. Parsowany jest plik konfiguracyjny z adresami serwerów wchodzacych w skład bazy 2. Dla każdego serwera: (a) Pobierany jest obiekt zdalny z rejestru RMI. (b) Na obiekcie zdalnym wywoływana jest metoda hereiam(adresip), która informuje serwer o przyłaczeniu nowej maszyny do sieci. 14
126 RGBD:DK-2012/6/13-PB 5 Uruchamianie i konfiguracja programu 4.11 FU11: Obsługa zdarzenia węzeł nie odpowiada (przechwycenie wyjatku RemoteException) FU11a: 1. Wywołana zostaje metoda na rzecz obiektu zdalnego. Obiekt zdalny nie jest dostępny pod określonym adresem. Zwrócony zostaje wyjatek RemoteException. Startuje procedura wywołania metody zdalnej z serwera zapasowego (FU3). FU11b: 1. Punkty 1-3 jak w FU11a 2. Próba komunikacji nie powiodła się. FU11c: 1. Punkty 1-5 jak w FU11b 2. Wszczynana jest procedura odtworzenia danych znajdujacych się na serwerze, który uległ awarii. 3. Aktualizacja indeksów. Dotychczasowe odwołania do nie odpowiadajacego serwera zostaja zastapione adresem nowego serwera. 4. Administrator zobowiazany jest do wyczyszczenia danych na serwerze, który uległ awarii, jeśli będzie on w przyszłości podłaczony do systemu. Jeśli zostanie ponownie podłaczony do systemu, będzie widziany jako czysty serwer. 5 Uruchamianie i konfiguracja programu Projekt realizowany jest wśrodowisku programistycznym Eclipse. Wersja języka Java używana do budowania aplikacji jest Java 7. Zarówno aplikacja kliencka jak i serwerowa tworzone i testowane sa w systemach operacyjnych z rodziny Windows. Uruchomienie aplikacji na systemach UNIXowych wymaga przetestowania wszystkich funkcjonalności programu, w szczególności fragmentów zależnych w dużym stopniu od hostujacego systemu operacyjnego, jak zapis plików, oraz mechanizm RMI. Działanie rozproszonej grafowej bazy danych można zasymulować na pojedynczym komputerze. Mechanizm RMI pozwala na wywoływanie metod na obiektach Javy znajdujacych się w innych maszynach wirtualnych Javy niż kod wywołujacy, w szczególności na innych komputerach połaczonych wspólna siecia. RMI nie nie stwarza jednak przeszkód do wywołania wielu instancji serwera oraz klienta na jednej maszynie, pod warunkiem, że każdy z serwerów nasłuchuje na innym porcie. Dodatkowo, przechwytujac odpowiednie sygnały wysyłane do maszyny Javy, np. podłaczaj ac tzw. shutdown hook obsługujacy zdarzenie po naciśnięciu klawiszy CTRL+C, można w prosty sposób zasymulować planowane odłaczenie węzła, a zamykajac okno konsoli - awarię łaczy prowadzacych do danego węzła. 15
127 RGBD:DK-2012/6/13-PB 5 Uruchamianie i konfiguracja programu 5.1 Konfiguracja klienta Konfiguracja aplikacji klienta znajduje się w pliku config.xml i posiada strukturę analogiczna do pokazanej na listingu 1. <?xml version=" 1.0 "?> <config> <server ip=" " >1078</server> <server ip=" " >1079</server> <server ip=" " >1080</server> <server ip=" " >1081</server> </ config> Wydruk 1: Przykładowa konfiguracja klienta Klient posiada adresy serwerów, z którymi może się łaczyć w celu odczytania lub zapisu informacji. Serwery te z punktu klienta z zasady sa nierozróżnialne, tzn. odczyt z dowolnego serwera z listy pozwala uzyskać tę sama odpowiedź, zapis danych na dowolnym z serwerów jest równoważny wprowadzeniu danych do rozproszonej bazy danych (moga byc one później odczytane po przyłaczeniu do dowolnego innego serwera). Klient kolejno sprawdza dostępność serwerów, dzięki czemu można wyznaczyć preferowany serwer na składowanie danych wprowadzonych poprzez tego klienta (dzięki temu możemy spróbować zapewnić szybki dostęp do lokalnych danych, a w przypadku awarii wolniejszy, ale wciaż ńiezawodny"dostęp do wszystkich danych). Od wyboru tego zależy podstawowe miejsce składowania danych dla klienta, natomiast serwer zapasowy wybierany jest już po stronie bazy danych, na podstawie dowolnych innych reguł (np. najmniej obciażona maszyna). W sytuacji, gdy do bazy przyłaczony zostanie nowy serwer, który nie jest wyszczególniony w konfiguracji klienta, nie może on być serwerem podstawowym dla klienta, tzn. klient nie wiedzac o jego istnieniu nie może się do niego odwoływać bezpośrednio. Ponieważ serwer taki w momencie podłaczenia rejestruje się jednak w rejestrze RMI, jest widoczny dla innych serwerów w bazie i może z powodzeniem być wykorzystywany jako serwer zapasowy. 5.2 Konfiguracja aplikacji serwera Konfiguracja aplikacji klienta znajduje się w pliku config.xml i posiada strukturę analogiczna do pokazanej na listingu 2. <?xml version=" 1.0 "?> <config> <localhost ip=" " >1080</ localhost> <server ip=" " >1079</server> </ config> Wydruk 2: Przykładowa konfiguracja serwera Serwer rejestruje się w rejestrze RMI (dostępnym pod określona w konfiguracji lokalizacja) przy pomocy danych obecnych w konfiguracji: adresu IP oraz liczby identyfikujace instancję serwera w rejestrze RMI. 5.3 Fizyczny zapis danych na dysku Informacje o krawędziach i wierzchołkach sa zapisywane na serwerach w systemie plików, w plikach których nazwa jest unikalny identyfikator obiektu (typ UUID). Przykładowy plik 16
128 RGBD:DK-2012/6/13-PB 6 Testowanie systemu zawierajacy krawędź może mieć strukturę jak na listingu 3. Krawędź ta zawiera informacje o wierzchołkach które łaczy oraz swoim typie, w ogólnym przypadku może też zawierać dowolne inne właściwości (typu string). <?xml version=" 1.0 " encoding="utf 8"?> <GDBEdge id=" 1049fe89 3d35 4c55 b241 d399ac89d671" > <Properties> <Property name=" outvertex " value=" d284f012 c1af 4c86 a3ce 690d " /> <Property name=" label " value=" likes " /> <Property name=" invertex " value=" 26fb37e2 32a bbcd 609febb68557 " /> </ Properties> </GDBEdge> Wydruk 3: Przykładowy plik opisujacy krawędź Przykładowa strukturę pliku dla wierzchołka pokazuje listing 4. Wierzchołek ten nie posiada krawędzi wchodzacych, posiada za to jedna krawędź wychodzac a. Lista właściwości jest pusta. <?xml version=" 1.0 " encoding="utf 8"?> <GDBVertex id=" d284f012 c1af 4c86 a3ce 690d " > <Properties /> <InEdges /> <OutEdges> <Edge id=" 1049fe89 3d35 4c55 b241 d399ac89d671" l a b e l =" l i k e s " /> </OutEdges> </GDBVertex> Wydruk 4: Przykładowy plik opisujacy wierzchołek 6 Testowanie systemu Z punktu widzenia użytkownika najprostszym sposobem komunikacji z rozproszona baza danych jest konsola użytkownika, akceptujaca polecenia języka skryptowego Gremlin. Przykładowy sposób interakcji z konsola jest pokazany na rysunku 5. Możliwe jest również skorzystanie z bazy w wielu popularnych językach programowania ze względu na kompatybliność z interfejsem Blueprints. Możliwe jest korzystanie z większości poleceń języka, którego szerszy opis dostępny jest na stronie Wyjat- kiem sa metody jawnego rozpoczynania i kończenia transakcji, które z założenia zostały pominięte. Projekt zakłada, że transakcja obejmuje jedynie pojedyncze polecenie interfejsu Blueprints, bez możliwości wycofywania zestawu poprzednich zmian. Warto też zwrócić uwage, że dla uproszczenia kodu właściwości wierzchołków i krawędzi nie sa rzutowane na inne typy niż String. Baza przechowuje jedynie pary klucz-wartość, gdzie zarówno klucz i wartość sa traktowane jako stringi (m.in. to zostanie pokazane w poniższym przykładzie). 6.1 Przykład użycia rozproszonej bazy danych Załóżmy chęć stworzenia bazy osób i projektów, pokazanej na rys. 6. Osoby moga należeć do klas programista, projektant i tester. Projekty maja właściwości nazwa, język i data rozpoczęcia. 17
129 RGBD:DK-2012/6/13-PB 6 Testowanie systemu Rysunek 5: Przykład interakcji z baza poprzez konsolę klienta Między osobami moga zachodzić relacje pracował z, między osoba a projektem może zachodzic relacja współtworzył. Relacja pracował z pomiędzy osobami jest dwustronna. Przyjmujac nastepujace wartości własciwości dla obiektów na przedstawionym grafie: 1. 1o imie: Janusz, wiek: 25, stanowisko: programista 2. 2o imie: Stefan, wiek: 32, stanowisko: projektant 3. 3o imie: Janusz, wiek: 32, stanowisko: tester 4. 4o imie: Kleofas, wiek: 22, stanowisko: projektant 5. 5o imie: Michalina, wiek: 23, stanowisko: programista 6. 1p DGDB2D, Java, p SuperProjekt, C++, p Instantkilogram, Java, p PAIN, C#, p Skynet, C++, 1 Możemy zbudować skrypt tworzacy opisana strukturę w rozproszonej bazie danych (listing 5). ClientGDB. getgraphdatabase ( ) gdb. addvertex ( "1o " ) gdb. addvertex ( "2o " ) gdb. addvertex ( "3o " ) gdb. addvertex ( "4o " ) gdb. addvertex ( "5o " ) gdb. addvertex ( "1p" ) 18
 v = gdb. v ( \"1o \" ) v. imie = \"Janusz\" v. wiek = 25 v. stanowisko =\" programista \" v = gdb. v ( \"2o \" ) v. imie = \" Stefan \" v. wiek =32 v. stanowisko = \" projektant \" v = gdb.")
130 RGBD:DK-2012/6/13-PB 6 Testowanie systemu Rysunek 6: Przykład utwodzenia grafu i wykonania zapytań gdb. addvertex ( "2p" ) gdb. addvertex ( "3p" ) gdb. addvertex ( "4p" ) gdb. addvertex ( "5p" ) v = gdb. v ( "1o " ) v. imie = "Janusz" v. wiek = 25 v. stanowisko =" programista " v = gdb. v ( "2o " ) v. imie = " Stefan " v. wiek =32 v. stanowisko = " projektant " v = gdb. v ( "3o " ) v. imie = " Jacek " v. wiek = 32 v. stanowisko = " tester " v = gdb. v ( "4o " ) v. imie = " Krzysztof " v. wiek = 22 v. stanowisko = " projektant " v = gdb. v ( "5o " ) v. imie = "Joanna" v. wiek = 23 v. stanowisko = " programista " v= gdb. v ( "1p" ) v. nazwa = "DGDB2D" v. jezyk = " Java " v. data = 2 v= gdb. v ( "2p" ) v. nazwa = " Matrix " v. jezyk = "C++" v. data = 1 19
*Grafomania z. Neo4j. Praktyczne wprowadzenie do grafowej bazy danych.
 *Grafomania z Neo4j Praktyczne wprowadzenie do grafowej bazy danych. Jak zamodelować relacyjną bazę danych reprezentującą następujący fragment rzeczywistości: Serwis WWW opisuje pracowników różnych firm
*Grafomania z Neo4j Praktyczne wprowadzenie do grafowej bazy danych. Jak zamodelować relacyjną bazę danych reprezentującą następujący fragment rzeczywistości: Serwis WWW opisuje pracowników różnych firm
Programowanie Komponentowe WebAPI
 Programowanie Komponentowe WebAPI dr inż. Ireneusz Szcześniak jesień 2016 roku WebAPI - interfejs webowy WebAPI to interfejs aplikacji (usługi, komponentu, serwisu) dostępnej najczęściej przez Internet,
Programowanie Komponentowe WebAPI dr inż. Ireneusz Szcześniak jesień 2016 roku WebAPI - interfejs webowy WebAPI to interfejs aplikacji (usługi, komponentu, serwisu) dostępnej najczęściej przez Internet,
Podstawowe pojęcia dotyczące relacyjnych baz danych. mgr inż. Krzysztof Szałajko
 Podstawowe pojęcia dotyczące relacyjnych baz danych mgr inż. Krzysztof Szałajko Czym jest baza danych? Co rozumiemy przez dane? Czym jest system zarządzania bazą danych? 2 / 25 Baza danych Baza danych
Podstawowe pojęcia dotyczące relacyjnych baz danych mgr inż. Krzysztof Szałajko Czym jest baza danych? Co rozumiemy przez dane? Czym jest system zarządzania bazą danych? 2 / 25 Baza danych Baza danych
Pojęcie bazy danych. Funkcje i możliwości.
 Pojęcie bazy danych. Funkcje i możliwości. Pojęcie bazy danych Baza danych to: zbiór informacji zapisanych według ściśle określonych reguł, w strukturach odpowiadających założonemu modelowi danych, zbiór
Pojęcie bazy danych. Funkcje i możliwości. Pojęcie bazy danych Baza danych to: zbiór informacji zapisanych według ściśle określonych reguł, w strukturach odpowiadających założonemu modelowi danych, zbiór
Hurtownie danych wykład 5
 Hurtownie danych wykład 5 dr Sebastian Zając SGH Warszawa 7 lutego 2017 1 Współbieżność i integracja Niezgodność impedancji 2 bazy danych Współbieżność i integracja Niezgodność impedancji Bazy relacyjne
Hurtownie danych wykład 5 dr Sebastian Zając SGH Warszawa 7 lutego 2017 1 Współbieżność i integracja Niezgodność impedancji 2 bazy danych Współbieżność i integracja Niezgodność impedancji Bazy relacyjne
AUREA BPM Oracle. TECNA Sp. z o.o. Strona 1 z 7
 AUREA BPM Oracle TECNA Sp. z o.o. Strona 1 z 7 ORACLE DATABASE System zarządzania bazą danych firmy Oracle jest jednym z najlepszych i najpopularniejszych rozwiązań tego typu na rynku. Oracle Database
AUREA BPM Oracle TECNA Sp. z o.o. Strona 1 z 7 ORACLE DATABASE System zarządzania bazą danych firmy Oracle jest jednym z najlepszych i najpopularniejszych rozwiązań tego typu na rynku. Oracle Database
PHP: bazy danych, SQL, AJAX i JSON
 1 PHP: bazy danych, SQL, AJAX i JSON SYSTEMY SIECIOWE Michał Simiński 2 Bazy danych Co to jest MySQL? Jak się połączyć z bazą danych MySQL? Podstawowe operacje na bazie danych Kilka dodatkowych operacji
1 PHP: bazy danych, SQL, AJAX i JSON SYSTEMY SIECIOWE Michał Simiński 2 Bazy danych Co to jest MySQL? Jak się połączyć z bazą danych MySQL? Podstawowe operacje na bazie danych Kilka dodatkowych operacji
Programowanie obiektowe
 Programowanie obiektowe Wykład 13 Marcin Młotkowski 27 maja 2015 Plan wykładu Trwałość obiektów 1 Trwałość obiektów 2 Marcin Młotkowski Programowanie obiektowe 2 / 29 Trwałość (persistence) Definicja Cecha
Programowanie obiektowe Wykład 13 Marcin Młotkowski 27 maja 2015 Plan wykładu Trwałość obiektów 1 Trwałość obiektów 2 Marcin Młotkowski Programowanie obiektowe 2 / 29 Trwałość (persistence) Definicja Cecha
Informacje wstępne Autor Zofia Kruczkiewicz Wzorce oprogramowania 4
 Utrwalanie danych zastosowanie obiektowego modelu danych warstwy biznesowej do generowania schematu relacyjnej bazy danych Informacje wstępne Autor Zofia Kruczkiewicz Wzorce oprogramowania 4 1. Relacyjne
Utrwalanie danych zastosowanie obiektowego modelu danych warstwy biznesowej do generowania schematu relacyjnej bazy danych Informacje wstępne Autor Zofia Kruczkiewicz Wzorce oprogramowania 4 1. Relacyjne
Instalacja SQL Server Express. Logowanie na stronie Microsoftu
 Instalacja SQL Server Express Logowanie na stronie Microsoftu Wybór wersji do pobrania Pobieranie startuje, przechodzimy do strony z poradami. Wypakowujemy pobrany plik. Otwiera się okno instalacji. Wybieramy
Instalacja SQL Server Express Logowanie na stronie Microsoftu Wybór wersji do pobrania Pobieranie startuje, przechodzimy do strony z poradami. Wypakowujemy pobrany plik. Otwiera się okno instalacji. Wybieramy
SZKOLENIE: Administrator baz danych. Cel szkolenia
 SZKOLENIE: Administrator baz danych. Cel szkolenia Kurs Administrator baz danych skierowany jest przede wszystkim do osób zamierzających rozwijać umiejętności w zakresie administrowania bazami danych.
SZKOLENIE: Administrator baz danych. Cel szkolenia Kurs Administrator baz danych skierowany jest przede wszystkim do osób zamierzających rozwijać umiejętności w zakresie administrowania bazami danych.
Krzysztof Kadowski. PL-E3579, PL-EA0312,
 Krzysztof Kadowski PL-E3579, PL-EA0312, kadowski@jkk.edu.pl Bazą danych nazywamy zbiór informacji w postaci tabel oraz narzędzi stosowanych do gromadzenia, przekształcania oraz wyszukiwania danych. Baza
Krzysztof Kadowski PL-E3579, PL-EA0312, kadowski@jkk.edu.pl Bazą danych nazywamy zbiór informacji w postaci tabel oraz narzędzi stosowanych do gromadzenia, przekształcania oraz wyszukiwania danych. Baza
Systemy rozproszone. na użytkownikach systemu rozproszonego wrażenie pojedynczego i zintegrowanego systemu.
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Dokumentacja wstępna TIN. Rozproszone repozytorium oparte o WebDAV
 Piotr Jarosik, Kamil Jaworski, Dominik Olędzki, Anna Stępień Dokumentacja wstępna TIN Rozproszone repozytorium oparte o WebDAV 1. Wstęp Celem projektu jest zaimplementowanie rozproszonego repozytorium
Piotr Jarosik, Kamil Jaworski, Dominik Olędzki, Anna Stępień Dokumentacja wstępna TIN Rozproszone repozytorium oparte o WebDAV 1. Wstęp Celem projektu jest zaimplementowanie rozproszonego repozytorium
WPROWADZENIE DO BAZ DANYCH
 WPROWADZENIE DO BAZ DANYCH Pojęcie danych i baz danych Dane to wszystkie informacje jakie przechowujemy, aby w każdej chwili mieć do nich dostęp. Baza danych (data base) to uporządkowany zbiór danych z
WPROWADZENIE DO BAZ DANYCH Pojęcie danych i baz danych Dane to wszystkie informacje jakie przechowujemy, aby w każdej chwili mieć do nich dostęp. Baza danych (data base) to uporządkowany zbiór danych z
Systemy baz danych w zarządzaniu przedsiębiorstwem. W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi
 Systemy baz danych w zarządzaniu przedsiębiorstwem W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi Proces zarządzania danymi Zarządzanie danymi obejmuje czynności: gromadzenie
Systemy baz danych w zarządzaniu przedsiębiorstwem W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi Proces zarządzania danymi Zarządzanie danymi obejmuje czynności: gromadzenie
Systemy baz danych. mgr inż. Sylwia Glińska
 Systemy baz danych Wykład 1 mgr inż. Sylwia Glińska Baza danych Baza danych to uporządkowany zbiór danych z określonej dziedziny tematycznej, zorganizowany w sposób ułatwiający do nich dostęp. System zarządzania
Systemy baz danych Wykład 1 mgr inż. Sylwia Glińska Baza danych Baza danych to uporządkowany zbiór danych z określonej dziedziny tematycznej, zorganizowany w sposób ułatwiający do nich dostęp. System zarządzania
MongoDB. wprowadzenie. dr inż. Paweł Boiński, Politechnika Poznańska
 MongoDB wprowadzenie dr inż. Paweł Boiński, Politechnika Poznańska Plan Historia Podstawowe pojęcia: Dokument Kolekcja Generowanie identyfikatora Model danych Dokumenty zagnieżdżone Dokumenty z referencjami
MongoDB wprowadzenie dr inż. Paweł Boiński, Politechnika Poznańska Plan Historia Podstawowe pojęcia: Dokument Kolekcja Generowanie identyfikatora Model danych Dokumenty zagnieżdżone Dokumenty z referencjami
Wykład I. Wprowadzenie do baz danych
 Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Specjalizacja magisterska Bazy danych
 Specjalizacja magisterska Bazy danych Strona Katedry http://bd.pjwstk.edu.pl/katedra/ Prezentacja dostępna pod adresem: http://www.bd.pjwstk.edu.pl/bazydanych.pdf Wymagania wstępne Znajomość podstaw języka
Specjalizacja magisterska Bazy danych Strona Katedry http://bd.pjwstk.edu.pl/katedra/ Prezentacja dostępna pod adresem: http://www.bd.pjwstk.edu.pl/bazydanych.pdf Wymagania wstępne Znajomość podstaw języka
Modelowanie hierarchicznych struktur w relacyjnych bazach danych
 Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Baza danych. Baza danych to:
 Baza danych Baza danych to: zbiór danych o określonej strukturze, zapisany na zewnętrznym nośniku (najczęściej dysku twardym komputera), mogący zaspokoić potrzeby wielu użytkowników korzystających z niego
Baza danych Baza danych to: zbiór danych o określonej strukturze, zapisany na zewnętrznym nośniku (najczęściej dysku twardym komputera), mogący zaspokoić potrzeby wielu użytkowników korzystających z niego
Bazy Danych. C. J. Date, Wprowadzenie do systemów baz danych, WNT - W-wa, (seria: Klasyka Informatyki), 2000
, 2000") Bazy Danych LITERATURA C. J. Date, Wprowadzenie do systemów baz danych, WNT - W-wa, (seria: Klasyka Informatyki), 2000 J. D. Ullman, Systemy baz danych, WNT - W-wa, 1998 J. D. Ullman, J. Widom, Podstawowy
Bazy Danych LITERATURA C. J. Date, Wprowadzenie do systemów baz danych, WNT - W-wa, (seria: Klasyka Informatyki), 2000 J. D. Ullman, Systemy baz danych, WNT - W-wa, 1998 J. D. Ullman, J. Widom, Podstawowy
Podyplomowe Studium Informatyki w Bizniesie Wydział Matematyki i Informatyki, Uniwersytet Łódzki specjalność: Tworzenie aplikacji w środowisku Oracle
 Podyplomowe Studium Informatyki w Bizniesie Wydział Matematyki i Informatyki, Uniwersytet Łódzki specjalność: Tworzenie aplikacji w środowisku Oracle EFEKTY KSZTAŁCENIA Wiedza Absolwent tej specjalności
Podyplomowe Studium Informatyki w Bizniesie Wydział Matematyki i Informatyki, Uniwersytet Łódzki specjalność: Tworzenie aplikacji w środowisku Oracle EFEKTY KSZTAŁCENIA Wiedza Absolwent tej specjalności
Bazy danych TERMINOLOGIA
 Bazy danych TERMINOLOGIA Dane Dane są wartościami przechowywanymi w bazie danych. Dane są statyczne w tym sensie, że zachowują swój stan aż do zmodyfikowania ich ręcznie lub przez jakiś automatyczny proces.
Bazy danych TERMINOLOGIA Dane Dane są wartościami przechowywanymi w bazie danych. Dane są statyczne w tym sensie, że zachowują swój stan aż do zmodyfikowania ich ręcznie lub przez jakiś automatyczny proces.
Systemy GIS Systemy baz danych
 Systemy GIS Systemy baz danych Wykład nr 5 System baz danych Skomputeryzowany system przechowywania danych/informacji zorganizowanych w pliki Użytkownik ma do dyspozycji narzędzia do wykonywania różnych
Systemy GIS Systemy baz danych Wykład nr 5 System baz danych Skomputeryzowany system przechowywania danych/informacji zorganizowanych w pliki Użytkownik ma do dyspozycji narzędzia do wykonywania różnych
Przetwarzanie danych z wykorzystaniem technologii NoSQL na przykładzie serwisu Serp24
 Przetwarzanie danych z wykorzystaniem technologii NoSQL na przykładzie serwisu Serp24 Agenda Serp24 NoSQL Integracja z CMS Drupal Przetwarzanie danych Podsumowanie Serp24 Darmowe narzędzie Ułatwia planowanie
Przetwarzanie danych z wykorzystaniem technologii NoSQL na przykładzie serwisu Serp24 Agenda Serp24 NoSQL Integracja z CMS Drupal Przetwarzanie danych Podsumowanie Serp24 Darmowe narzędzie Ułatwia planowanie
INFORMATYKA Pytania ogólne na egzamin dyplomowy
 INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja
INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja
Wybrane działy Informatyki Stosowanej
 Wybrane działy Informatyki Stosowanej Java Enterprise Edition WebServices Serwer aplikacji GlassFish Dr hab. inż. Andrzej Czerepicki a.czerepicki@wt.pw.edu.pl http://www2.wt.pw.edu.pl/~a.czerepicki Aplikacje
Wybrane działy Informatyki Stosowanej Java Enterprise Edition WebServices Serwer aplikacji GlassFish Dr hab. inż. Andrzej Czerepicki a.czerepicki@wt.pw.edu.pl http://www2.wt.pw.edu.pl/~a.czerepicki Aplikacje
Warstwa integracji. wg. D.Alur, J.Crupi, D. Malks, Core J2EE. Wzorce projektowe.
 Warstwa integracji wg. D.Alur, J.Crupi, D. Malks, Core J2EE. Wzorce projektowe. 1. Ukrycie logiki dostępu do danych w osobnej warstwie 2. Oddzielenie mechanizmów trwałości od modelu obiektowego Pięciowarstwowy
Warstwa integracji wg. D.Alur, J.Crupi, D. Malks, Core J2EE. Wzorce projektowe. 1. Ukrycie logiki dostępu do danych w osobnej warstwie 2. Oddzielenie mechanizmów trwałości od modelu obiektowego Pięciowarstwowy
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Bazy danych Database Kierunek: Rodzaj przedmiotu: obieralny Rodzaj zajęć: wykład, laboratorium Matematyka Poziom kwalifikacji: I stopnia Liczba godzin/tydzień: 2W, 2L Semestr: III Liczba
Nazwa przedmiotu: Bazy danych Database Kierunek: Rodzaj przedmiotu: obieralny Rodzaj zajęć: wykład, laboratorium Matematyka Poziom kwalifikacji: I stopnia Liczba godzin/tydzień: 2W, 2L Semestr: III Liczba
Rozproszone bazy danych. Robert A. Kłopotek Wydział Matematyczno-Przyrodniczy. Szkoła Nauk Ścisłych, UKSW
 Rozproszone bazy danych Robert A. Kłopotek r.klopotek@uksw.edu.pl Wydział Matematyczno-Przyrodniczy. Szkoła Nauk Ścisłych, UKSW Scentralizowana baza danych Dane są przechowywane w jednym węźle sieci Można
Rozproszone bazy danych Robert A. Kłopotek r.klopotek@uksw.edu.pl Wydział Matematyczno-Przyrodniczy. Szkoła Nauk Ścisłych, UKSW Scentralizowana baza danych Dane są przechowywane w jednym węźle sieci Można
Problemy niezawodnego przetwarzania w systemach zorientowanych na usługi
 Problemy niezawodnego przetwarzania w systemach zorientowanych na usługi Jerzy Brzeziński, Anna Kobusińska, Dariusz Wawrzyniak Instytut Informatyki Politechnika Poznańska Plan prezentacji 1 Architektura
Problemy niezawodnego przetwarzania w systemach zorientowanych na usługi Jerzy Brzeziński, Anna Kobusińska, Dariusz Wawrzyniak Instytut Informatyki Politechnika Poznańska Plan prezentacji 1 Architektura
Bazy danych 2. Wykład 1
 Bazy danych 2 Wykład 1 Sprawy organizacyjne Materiały i listy zadań zamieszczane będą na stronie www.math.uni.opole.pl/~ajasi E-mail: standardowy ajasi@math.uni.opole.pl Sprawy organizacyjne Program wykładu
Bazy danych 2 Wykład 1 Sprawy organizacyjne Materiały i listy zadań zamieszczane będą na stronie www.math.uni.opole.pl/~ajasi E-mail: standardowy ajasi@math.uni.opole.pl Sprawy organizacyjne Program wykładu
Systemy GIS Tworzenie zapytań w bazach danych
 Systemy GIS Tworzenie zapytań w bazach danych Wykład nr 6 Analizy danych w systemach GIS Jak pytać bazę danych, żeby otrzymać sensowną odpowiedź......czyli podstawy języka SQL INSERT, SELECT, DROP, UPDATE
Systemy GIS Tworzenie zapytań w bazach danych Wykład nr 6 Analizy danych w systemach GIS Jak pytać bazę danych, żeby otrzymać sensowną odpowiedź......czyli podstawy języka SQL INSERT, SELECT, DROP, UPDATE
Diagram wdrożenia. Rys. 5.1 Diagram wdrożenia.
 Diagram wdrożenia Zaprojektowana przez nas aplikacja bazuje na architekturze client-server. W tej architekturze w komunikacji aplikacji klienckiej z bazą danych pośredniczy serwer aplikacji, który udostępnia
Diagram wdrożenia Zaprojektowana przez nas aplikacja bazuje na architekturze client-server. W tej architekturze w komunikacji aplikacji klienckiej z bazą danych pośredniczy serwer aplikacji, który udostępnia
Projektowanie, tworzenie aplikacji mobilnych na platformie Android
 Program szkolenia: Projektowanie, tworzenie aplikacji mobilnych na platformie Android Informacje: Nazwa: Kod: Kategoria: Grupa docelowa: Czas trwania: Forma: Projektowanie, tworzenie aplikacji mobilnych
Program szkolenia: Projektowanie, tworzenie aplikacji mobilnych na platformie Android Informacje: Nazwa: Kod: Kategoria: Grupa docelowa: Czas trwania: Forma: Projektowanie, tworzenie aplikacji mobilnych
PRZESTRZENNE BAZY DANYCH WYKŁAD 2
 PRZESTRZENNE BAZY DANYCH WYKŁAD 2 Baza danych to zbiór plików, które fizycznie przechowują dane oraz system, który nimi zarządza (DBMS, ang. Database Management System). Zadaniem DBMS jest prawidłowe przechowywanie
PRZESTRZENNE BAZY DANYCH WYKŁAD 2 Baza danych to zbiór plików, które fizycznie przechowują dane oraz system, który nimi zarządza (DBMS, ang. Database Management System). Zadaniem DBMS jest prawidłowe przechowywanie
LK1: Wprowadzenie do MS Access Zakładanie bazy danych i tworzenie interfejsu użytkownika
 LK1: Wprowadzenie do MS Access Zakładanie bazy danych i tworzenie interfejsu użytkownika Prowadzący: Dr inż. Jacek Habel Instytut Technologii Maszyn i Automatyzacji Produkcji Zakład Projektowania Procesów
LK1: Wprowadzenie do MS Access Zakładanie bazy danych i tworzenie interfejsu użytkownika Prowadzący: Dr inż. Jacek Habel Instytut Technologii Maszyn i Automatyzacji Produkcji Zakład Projektowania Procesów
LABORATORIUM 8,9: BAZA DANYCH MS-ACCESS
 UNIWERSYTET ZIELONOGÓRSKI INSTYTUT INFORMATYKI I ELEKTROTECHNIKI ZAKŁAD INŻYNIERII KOMPUTEROWEJ Przygotowali: mgr inż. Arkadiusz Bukowiec mgr inż. Remigiusz Wiśniewski LABORATORIUM 8,9: BAZA DANYCH MS-ACCESS
UNIWERSYTET ZIELONOGÓRSKI INSTYTUT INFORMATYKI I ELEKTROTECHNIKI ZAKŁAD INŻYNIERII KOMPUTEROWEJ Przygotowali: mgr inż. Arkadiusz Bukowiec mgr inż. Remigiusz Wiśniewski LABORATORIUM 8,9: BAZA DANYCH MS-ACCESS
Hbase, Hive i BigSQL
 Hbase, Hive i BigSQL str. 1 Agenda 1. NOSQL a HBase 2. Architektura HBase 3. Demo HBase 4. Po co Hive? 5. Apache Hive 6. Demo hive 7. BigSQL 1 HBase Jest to rozproszona trwała posortowana wielowymiarowa
Hbase, Hive i BigSQL str. 1 Agenda 1. NOSQL a HBase 2. Architektura HBase 3. Demo HBase 4. Po co Hive? 5. Apache Hive 6. Demo hive 7. BigSQL 1 HBase Jest to rozproszona trwała posortowana wielowymiarowa
Problemy optymalizacji, rozbudowy i integracji systemu Edu wspomagającego e-nauczanie i e-uczenie się w PJWSTK
 Problemy optymalizacji, rozbudowy i integracji systemu Edu wspomagającego e-nauczanie i e-uczenie się w PJWSTK Paweł Lenkiewicz Polsko Japońska Wyższa Szkoła Technik Komputerowych Plan prezentacji PJWSTK
Problemy optymalizacji, rozbudowy i integracji systemu Edu wspomagającego e-nauczanie i e-uczenie się w PJWSTK Paweł Lenkiewicz Polsko Japońska Wyższa Szkoła Technik Komputerowych Plan prezentacji PJWSTK
Bazy danych Wykład zerowy. P. F. Góra
 Bazy danych Wykład zerowy P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2012 Patron? Św. Izydor z Sewilli (VI wiek), biskup, patron Internetu (sic!), stworzył pierwszy katalog Copyright c 2011-12 P.
Bazy danych Wykład zerowy P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2012 Patron? Św. Izydor z Sewilli (VI wiek), biskup, patron Internetu (sic!), stworzył pierwszy katalog Copyright c 2011-12 P.
Zagadnienia egzaminacyjne INFORMATYKA. Stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
OfficeObjects e-forms
 OfficeObjects e-forms Rodan Development Sp. z o.o. 02-820 Warszawa, ul. Wyczółki 89, tel.: (+48-22) 643 92 08, fax: (+48-22) 643 92 10, http://www.rodan.pl Spis treści Wstęp... 3 Łatwość tworzenia i publikacji
OfficeObjects e-forms Rodan Development Sp. z o.o. 02-820 Warszawa, ul. Wyczółki 89, tel.: (+48-22) 643 92 08, fax: (+48-22) 643 92 10, http://www.rodan.pl Spis treści Wstęp... 3 Łatwość tworzenia i publikacji
XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery
 http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
http://xqtav.sourceforge.net XQTav - reprezentacja diagramów przepływu prac w formacie SCUFL przy pomocy XQuery dr hab. Jerzy Tyszkiewicz dr Andrzej Kierzek mgr Jacek Sroka Grzegorz Kaczor praca mgr pod
Informatyka I. Standard JDBC Programowanie aplikacji bazodanowych w języku Java
 Informatyka I Standard JDBC Programowanie aplikacji bazodanowych w języku Java dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2017 Standard JDBC Java DataBase Connectivity uniwersalny
Informatyka I Standard JDBC Programowanie aplikacji bazodanowych w języku Java dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2017 Standard JDBC Java DataBase Connectivity uniwersalny
Uruchamianie bazy PostgreSQL
 Uruchamianie bazy PostgreSQL PostgreSQL i PostGIS Ten przewodnik może zostać pobrany jako PostgreSQL_pl.odt lub PostgreSQL_pl.pdf Przejrzano 10.09.2016 W tym rozdziale zobaczymy, jak uruchomić PostgreSQL
Uruchamianie bazy PostgreSQL PostgreSQL i PostGIS Ten przewodnik może zostać pobrany jako PostgreSQL_pl.odt lub PostgreSQL_pl.pdf Przejrzano 10.09.2016 W tym rozdziale zobaczymy, jak uruchomić PostgreSQL
Nauczanie na odległość
 P o l i t e c h n i k a W a r s z a w s k a Nauczanie na odległość a standaryzacja materiałów edukacyjnych Krzysztof Kaczmarski Nauczanie na odległość T Nauczanie ustawiczne T Studia przez Internet? T
P o l i t e c h n i k a W a r s z a w s k a Nauczanie na odległość a standaryzacja materiałów edukacyjnych Krzysztof Kaczmarski Nauczanie na odległość T Nauczanie ustawiczne T Studia przez Internet? T
RELACYJNE BAZY DANYCH
 RELACYJNE BAZY DANYCH Aleksander Łuczyk Bielsko-Biała, 15 kwiecień 2015 r. Ludzie używają baz danych każdego dnia. Książka telefoniczna, zbiór wizytówek przypiętych nad biurkiem, encyklopedia czy chociażby
RELACYJNE BAZY DANYCH Aleksander Łuczyk Bielsko-Biała, 15 kwiecień 2015 r. Ludzie używają baz danych każdego dnia. Książka telefoniczna, zbiór wizytówek przypiętych nad biurkiem, encyklopedia czy chociażby
Technologia informacyjna
 Technologia informacyjna Pracownia nr 9 (studia stacjonarne) - 05.12.2008 - Rok akademicki 2008/2009 2/16 Bazy danych - Plan zajęć Podstawowe pojęcia: baza danych, system zarządzania bazą danych tabela,
Technologia informacyjna Pracownia nr 9 (studia stacjonarne) - 05.12.2008 - Rok akademicki 2008/2009 2/16 Bazy danych - Plan zajęć Podstawowe pojęcia: baza danych, system zarządzania bazą danych tabela,
Replikacja bazy danych polega na kopiowaniu i przesyłaniu danych lub obiektów bazodanowych między serwerami oraz na zsynchronizowaniu tych danych w
 J. Karwowska Replikacja bazy danych polega na kopiowaniu i przesyłaniu danych lub obiektów bazodanowych między serwerami oraz na zsynchronizowaniu tych danych w celu utrzymania ich spójności. Dane kopiowane
J. Karwowska Replikacja bazy danych polega na kopiowaniu i przesyłaniu danych lub obiektów bazodanowych między serwerami oraz na zsynchronizowaniu tych danych w celu utrzymania ich spójności. Dane kopiowane
Bazy danych. Plan wykładu. Rozproszona baza danych. Fragmetaryzacja. Cechy bazy rozproszonej. Replikacje (zalety) Wykład 15: Rozproszone bazy danych
 Wykład 15: Rozproszone bazy danych") Plan wykładu Bazy danych Cechy rozproszonej bazy danych Implementacja rozproszonej bazy Wykład 15: Rozproszone bazy danych Małgorzata Krętowska, Agnieszka Oniśko Wydział Informatyki PB Bazy danych (studia
Plan wykładu Bazy danych Cechy rozproszonej bazy danych Implementacja rozproszonej bazy Wykład 15: Rozproszone bazy danych Małgorzata Krętowska, Agnieszka Oniśko Wydział Informatyki PB Bazy danych (studia
WPROWADZENIE DO BAZ DANYCH
 1 Technologie informacyjne WYKŁAD IV WPROWADZENIE DO BAZ DANYCH MAIL: WWW: a.dudek@pwr.edu.pl http://wgrit.ae.jgora.pl/ad Bazy danych 2 Baza danych to zbiór danych o określonej strukturze. zapisany na
1 Technologie informacyjne WYKŁAD IV WPROWADZENIE DO BAZ DANYCH MAIL: WWW: a.dudek@pwr.edu.pl http://wgrit.ae.jgora.pl/ad Bazy danych 2 Baza danych to zbiór danych o określonej strukturze. zapisany na
Replikacje. dr inż. Dziwiński Piotr Katedra Inżynierii Komputerowej. Kontakt:
 dr inż. Dziwiński Piotr Katedra Inżynierii Komputerowej Kontakt: piotr.dziwinski@kik.pcz.pl Replikacje 2 1 Podstawowe pojęcia Strategie replikacji Agenci replikacji Typy replikacji Modele replikacji Narzędzia
dr inż. Dziwiński Piotr Katedra Inżynierii Komputerowej Kontakt: piotr.dziwinski@kik.pcz.pl Replikacje 2 1 Podstawowe pojęcia Strategie replikacji Agenci replikacji Typy replikacji Modele replikacji Narzędzia
Zakres tematyczny dotyczący kursu PHP i MySQL - Podstawy pracy z dynamicznymi stronami internetowymi
 Zakres tematyczny dotyczący kursu PHP i MySQL - Podstawy pracy z dynamicznymi stronami internetowymi 1 Rozdział 1 Wprowadzenie do PHP i MySQL Opis: W tym rozdziale kursanci poznają szczegółową charakterystykę
Zakres tematyczny dotyczący kursu PHP i MySQL - Podstawy pracy z dynamicznymi stronami internetowymi 1 Rozdział 1 Wprowadzenie do PHP i MySQL Opis: W tym rozdziale kursanci poznają szczegółową charakterystykę
Diagramy związków encji. Laboratorium. Akademia Morska w Gdyni
 Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
4 Web Forms i ASP.NET...149 Web Forms...150 Programowanie Web Forms...150 Możliwości Web Forms...151 Przetwarzanie Web Forms...152
 Wstęp...xv 1 Rozpoczynamy...1 Co to jest ASP.NET?...3 W jaki sposób ASP.NET pasuje do.net Framework...4 Co to jest.net Framework?...4 Czym są Active Server Pages (ASP)?...5 Ustawienia dla ASP.NET...7 Systemy
Wstęp...xv 1 Rozpoczynamy...1 Co to jest ASP.NET?...3 W jaki sposób ASP.NET pasuje do.net Framework...4 Co to jest.net Framework?...4 Czym są Active Server Pages (ASP)?...5 Ustawienia dla ASP.NET...7 Systemy
Oracle11g: Wprowadzenie do SQL
 Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Opis Architektury Systemu Galileo
 Opis Architektury Systemu Galileo Sławomir Pawlewicz Alan Pilawa Joanna Sobczyk Marek Sobierajski 5 czerwca 2006 1 Spis treści 1 Wprowadzenie 5 1.1 Cel.......................................... 5 1.2 Zakres........................................
Opis Architektury Systemu Galileo Sławomir Pawlewicz Alan Pilawa Joanna Sobczyk Marek Sobierajski 5 czerwca 2006 1 Spis treści 1 Wprowadzenie 5 1.1 Cel.......................................... 5 1.2 Zakres........................................
Koncepcja wirtualnej pracowni GIS w oparciu o oprogramowanie open source
 Koncepcja wirtualnej pracowni GIS w oparciu o oprogramowanie open source Dr inż. Michał Bednarczyk Uniwersytet Warmińsko-Mazurski w Olsztynie Wydział Geodezji i Gospodarki Przestrzennej Katedra Geodezji
Koncepcja wirtualnej pracowni GIS w oparciu o oprogramowanie open source Dr inż. Michał Bednarczyk Uniwersytet Warmińsko-Mazurski w Olsztynie Wydział Geodezji i Gospodarki Przestrzennej Katedra Geodezji
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
OpenOfficePL. Zestaw szablonów magazynowych. Instrukcja obsługi
 OpenOfficePL Zestaw szablonów magazynowych Instrukcja obsługi Spis treści : 1. Informacje ogólne 2. Instalacja zestawu a) konfiguracja połączenia z bazą danych b) import danych z poprzedniej wersji faktur
OpenOfficePL Zestaw szablonów magazynowych Instrukcja obsługi Spis treści : 1. Informacje ogólne 2. Instalacja zestawu a) konfiguracja połączenia z bazą danych b) import danych z poprzedniej wersji faktur
Część I Tworzenie baz danych SQL Server na potrzeby przechowywania danych
 Spis treści Wprowadzenie... ix Organizacja ksiąŝki... ix Od czego zacząć?... x Konwencje przyjęte w ksiąŝce... x Wymagania systemowe... xi Przykłady kodu... xii Konfiguracja SQL Server 2005 Express Edition...
Spis treści Wprowadzenie... ix Organizacja ksiąŝki... ix Od czego zacząć?... x Konwencje przyjęte w ksiąŝce... x Wymagania systemowe... xi Przykłady kodu... xii Konfiguracja SQL Server 2005 Express Edition...
Cel przedmiotu. Wymagania wstępne w zakresie wiedzy, umiejętności i innych kompetencji 1 Język angielski 2 Inżynieria oprogramowania
 Przedmiot: Bazy danych Rok: III Semestr: V Rodzaj zajęć i liczba godzin: Studia stacjonarne Studia niestacjonarne Wykład 30 21 Ćwiczenia Laboratorium 30 21 Projekt Liczba punktów ECTS: 4 C1 C2 C3 Cel przedmiotu
Przedmiot: Bazy danych Rok: III Semestr: V Rodzaj zajęć i liczba godzin: Studia stacjonarne Studia niestacjonarne Wykład 30 21 Ćwiczenia Laboratorium 30 21 Projekt Liczba punktów ECTS: 4 C1 C2 C3 Cel przedmiotu
PLAN WYNIKOWY PROGRAMOWANIE APLIKACJI INTERNETOWYCH. KL IV TI 6 godziny tygodniowo (6x15 tygodni =90 godzin ),
,") PLAN WYNIKOWY PROGRAMOWANIE APLIKACJI INTERNETOWYCH KL IV TI 6 godziny tygodniowo (6x15 tygodni =90 godzin ), Program 351203 Opracowanie: Grzegorz Majda Tematyka zajęć 2. Przygotowanie środowiska pracy
PLAN WYNIKOWY PROGRAMOWANIE APLIKACJI INTERNETOWYCH KL IV TI 6 godziny tygodniowo (6x15 tygodni =90 godzin ), Program 351203 Opracowanie: Grzegorz Majda Tematyka zajęć 2. Przygotowanie środowiska pracy
Analiza i projektowanie aplikacji Java
 Analiza i projektowanie aplikacji Java Modele analityczne a projektowe Modele analityczne (konceptualne) pokazują dziedzinę problemu. Modele projektowe (fizyczne) pokazują system informatyczny. Utrzymanie
Analiza i projektowanie aplikacji Java Modele analityczne a projektowe Modele analityczne (konceptualne) pokazują dziedzinę problemu. Modele projektowe (fizyczne) pokazują system informatyczny. Utrzymanie
Wykład 2. Relacyjny model danych
 Wykład 2 Relacyjny model danych Wymagania stawiane modelowi danych Unikanie nadmiarowości danych (redundancji) jedna informacja powinna być wpisana do bazy danych tylko jeden raz Problem powtarzających
Wykład 2 Relacyjny model danych Wymagania stawiane modelowi danych Unikanie nadmiarowości danych (redundancji) jedna informacja powinna być wpisana do bazy danych tylko jeden raz Problem powtarzających
Wykład Ćwiczenia Laboratorium Projekt Seminarium
 WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
Monitoring procesów z wykorzystaniem systemu ADONIS
 Monitoring procesów z wykorzystaniem systemu ADONIS BOC Information Technologies Consulting Sp. z o.o. e-mail: boc@boc-pl.com Tel.: (+48 22) 628 00 15, 696 69 26 Fax: (+48 22) 621 66 88 BOC Management
Monitoring procesów z wykorzystaniem systemu ADONIS BOC Information Technologies Consulting Sp. z o.o. e-mail: boc@boc-pl.com Tel.: (+48 22) 628 00 15, 696 69 26 Fax: (+48 22) 621 66 88 BOC Management
Bazy danych - wykład wstępny
 Bazy danych - wykład wstępny Wykład: baza danych, modele, hierarchiczny, sieciowy, relacyjny, obiektowy, schemat logiczny, tabela, kwerenda, SQL, rekord, krotka, pole, atrybut, klucz podstawowy, relacja,
Bazy danych - wykład wstępny Wykład: baza danych, modele, hierarchiczny, sieciowy, relacyjny, obiektowy, schemat logiczny, tabela, kwerenda, SQL, rekord, krotka, pole, atrybut, klucz podstawowy, relacja,
Baza danych to zbiór wzajemnie powiązanych ze sobą i zintegrowanych danych z pewnej dziedziny.
 PI-14 01/12 Baza danych to zbiór wzajemnie powiązanych ze sobą i zintegrowanych danych z pewnej dziedziny.! Likwidacja lub znaczne ograniczenie redundancji (powtarzania się) danych! Integracja danych!
PI-14 01/12 Baza danych to zbiór wzajemnie powiązanych ze sobą i zintegrowanych danych z pewnej dziedziny.! Likwidacja lub znaczne ograniczenie redundancji (powtarzania się) danych! Integracja danych!
Systemy rozproszone System rozproszony
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
współbieżność - zdolność do przetwarzania wielu zadań jednocześnie
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
Temat: Ułatwienia wynikające z zastosowania Frameworku CakePHP podczas budowania stron internetowych
 PAŃSTWOWA WYŻSZA SZKOŁA ZAWODOWA W ELBLĄGU INSTYTUT INFORMATYKI STOSOWANEJ Sprawozdanie z Seminarium Dyplomowego Temat: Ułatwienia wynikające z zastosowania Frameworku CakePHP podczas budowania stron internetowych
PAŃSTWOWA WYŻSZA SZKOŁA ZAWODOWA W ELBLĄGU INSTYTUT INFORMATYKI STOSOWANEJ Sprawozdanie z Seminarium Dyplomowego Temat: Ułatwienia wynikające z zastosowania Frameworku CakePHP podczas budowania stron internetowych
Laboratorium Technologii Informacyjnych. Projektowanie Baz Danych
 Laboratorium Technologii Informacyjnych Projektowanie Baz Danych Komputerowe bazy danych są obecne podstawowym narzędziem służącym przechowywaniu, przetwarzaniu i analizie danych. Gromadzone są dane w
Laboratorium Technologii Informacyjnych Projektowanie Baz Danych Komputerowe bazy danych są obecne podstawowym narzędziem służącym przechowywaniu, przetwarzaniu i analizie danych. Gromadzone są dane w
BAZY DANYCH LABORATORIUM. Studia niestacjonarne I stopnia
 BAZY DANYCH LABORATORIUM Studia niestacjonarne I stopnia Gdańsk, 2011 1. Cel zajęć Celem zajęć laboratoryjnych jest wyrobienie praktycznej umiejętności tworzenia modelu logicznego danych a nastepnie implementacji
BAZY DANYCH LABORATORIUM Studia niestacjonarne I stopnia Gdańsk, 2011 1. Cel zajęć Celem zajęć laboratoryjnych jest wyrobienie praktycznej umiejętności tworzenia modelu logicznego danych a nastepnie implementacji
CZĘŚĆ I. WARSTWA PRZETWARZANIA WSADOWEGO
 Spis treści Przedmowa Podziękowania O książce Rozdział 1. Nowy paradygmat dla Big Data 1.1. Zawartość książki 1.2. Skalowanie tradycyjnej bazy danych 1.2.1. Skalowanie za pomocą kolejki 1.2.2. Skalowanie
Spis treści Przedmowa Podziękowania O książce Rozdział 1. Nowy paradygmat dla Big Data 1.1. Zawartość książki 1.2. Skalowanie tradycyjnej bazy danych 1.2.1. Skalowanie za pomocą kolejki 1.2.2. Skalowanie
Wrocławska Wyższa Szkoła Informatyki Stosowanej. Bazy danych. Dr hab. inż. Krzysztof Pieczarka. Email: krzysztof.pieczarka@gmail.
 Wrocławska Wyższa Szkoła Informatyki Stosowanej Bazy danych Dr hab. inż. Krzysztof Pieczarka Email: krzysztof.pieczarka@gmail.com Literatura: Connoly T., Begg C., Systemy baz danych Praktyczne metody projektowania,
Wrocławska Wyższa Szkoła Informatyki Stosowanej Bazy danych Dr hab. inż. Krzysztof Pieczarka Email: krzysztof.pieczarka@gmail.com Literatura: Connoly T., Begg C., Systemy baz danych Praktyczne metody projektowania,
Zagadnienia egzaminacyjne INFORMATYKA. stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
Definicja bazy danych TECHNOLOGIE BAZ DANYCH. System zarządzania bazą danych (SZBD) Oczekiwania wobec SZBD. Oczekiwania wobec SZBD c.d.
 Oczekiwania wobec SZBD. Oczekiwania wobec SZBD c.d.") TECHNOLOGIE BAZ DANYCH WYKŁAD 1 Wprowadzenie do baz danych. Normalizacja. (Wybrane materiały) Dr inż. E. Busłowska Definicja bazy danych Uporządkowany zbiór informacji, posiadający własną strukturę i wartość.
TECHNOLOGIE BAZ DANYCH WYKŁAD 1 Wprowadzenie do baz danych. Normalizacja. (Wybrane materiały) Dr inż. E. Busłowska Definicja bazy danych Uporządkowany zbiór informacji, posiadający własną strukturę i wartość.
2017/2018 WGGiOS AGH. LibreOffice Base
 1. Baza danych LibreOffice Base Jest to zbiór danych zapisanych zgodnie z określonymi regułami. W węższym znaczeniu obejmuje dane cyfrowe gromadzone zgodnie z zasadami przyjętymi dla danego programu komputerowego,
1. Baza danych LibreOffice Base Jest to zbiór danych zapisanych zgodnie z określonymi regułami. W węższym znaczeniu obejmuje dane cyfrowe gromadzone zgodnie z zasadami przyjętymi dla danego programu komputerowego,
Programowanie obiektowe - 1.
 Programowanie obiektowe - 1 Mariusz.Masewicz@cs.put.poznan.pl Programowanie obiektowe Programowanie obiektowe (ang. object-oriented programming) to metodologia tworzenia programów komputerowych, która
Programowanie obiektowe - 1 Mariusz.Masewicz@cs.put.poznan.pl Programowanie obiektowe Programowanie obiektowe (ang. object-oriented programming) to metodologia tworzenia programów komputerowych, która
Ramowy plan kursu. Lp. Moduły Wyk. Lab. Przekazywane treści
 Ramowy plan kursu Lp. Moduły Wyk. Lab. Przekazywane treści 1 3 4 Technologia MS SQL Server 2008 R2. Podstawy relacyjnego modelu i projektowanie baz. Zaawansowane elementy języka SQL. Programowanie w języku
Ramowy plan kursu Lp. Moduły Wyk. Lab. Przekazywane treści 1 3 4 Technologia MS SQL Server 2008 R2. Podstawy relacyjnego modelu i projektowanie baz. Zaawansowane elementy języka SQL. Programowanie w języku
Sposoby klastrowania aplikacji webowych w oparciu o rozwiązania OpenSource. Piotr Klimek. piko@piko.homelinux.net
 Sposoby klastrowania aplikacji webowych w oparciu o rozwiązania OpenSource Piotr Klimek piko@piko.homelinux.net Agenda Wstęp Po co to wszystko? Warstwa WWW Warstwa SQL Warstwa zasobów dyskowych Podsumowanie
Sposoby klastrowania aplikacji webowych w oparciu o rozwiązania OpenSource Piotr Klimek piko@piko.homelinux.net Agenda Wstęp Po co to wszystko? Warstwa WWW Warstwa SQL Warstwa zasobów dyskowych Podsumowanie
Dokument Detaliczny Projektu Temat: Księgarnia On-line Bukstor
 Koszalin, 15.06.2012 r. Dokument Detaliczny Projektu Temat: Księgarnia On-line Bukstor Zespół projektowy: Daniel Czyczyn-Egird Wojciech Gołuchowski Michał Durkowski Kamil Gawroński Prowadzący: Dr inż.
Koszalin, 15.06.2012 r. Dokument Detaliczny Projektu Temat: Księgarnia On-line Bukstor Zespół projektowy: Daniel Czyczyn-Egird Wojciech Gołuchowski Michał Durkowski Kamil Gawroński Prowadzący: Dr inż.
77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego.
 77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego. Przy modelowaniu bazy danych możemy wyróżnić następujące typy połączeń relacyjnych: jeden do wielu, jeden do jednego, wiele
77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego. Przy modelowaniu bazy danych możemy wyróżnić następujące typy połączeń relacyjnych: jeden do wielu, jeden do jednego, wiele
Podstawowe zagadnienia z zakresu baz danych
 Podstawowe zagadnienia z zakresu baz danych Jednym z najważniejszych współczesnych zastosowań komputerów we wszelkich dziedzinach życia jest gromadzenie, wyszukiwanie i udostępnianie informacji. Specjalizowane
Podstawowe zagadnienia z zakresu baz danych Jednym z najważniejszych współczesnych zastosowań komputerów we wszelkich dziedzinach życia jest gromadzenie, wyszukiwanie i udostępnianie informacji. Specjalizowane
Projektowanie architektury systemu rozproszonego. Jarosław Kuchta Projektowanie Aplikacji Internetowych
 Projektowanie architektury systemu rozproszonego Jarosław Kuchta Zagadnienia Typy architektury systemu Rozproszone przetwarzanie obiektowe Problemy globalizacji Problemy ochrony Projektowanie architektury
Projektowanie architektury systemu rozproszonego Jarosław Kuchta Zagadnienia Typy architektury systemu Rozproszone przetwarzanie obiektowe Problemy globalizacji Problemy ochrony Projektowanie architektury
Referat pracy dyplomowej
 Referat pracy dyplomowej Temat pracy: Wdrożenie intranetowej platformy zapewniającej organizację danych w dużej firmie na bazie oprogramowania Microsoft SharePoint Autor: Bartosz Lipiec Promotor: dr inż.
Referat pracy dyplomowej Temat pracy: Wdrożenie intranetowej platformy zapewniającej organizację danych w dużej firmie na bazie oprogramowania Microsoft SharePoint Autor: Bartosz Lipiec Promotor: dr inż.
REFERAT PRACY DYPLOMOWEJ
 REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i implementacja aplikacji internetowej do wyszukiwania promocji Autor: Sylwester Wiśniewski Promotor: dr Jadwiga Bakonyi Kategorie: aplikacja webowa Słowa
REFERAT PRACY DYPLOMOWEJ Temat pracy: Projekt i implementacja aplikacji internetowej do wyszukiwania promocji Autor: Sylwester Wiśniewski Promotor: dr Jadwiga Bakonyi Kategorie: aplikacja webowa Słowa
Technologia informacyjna
 Technologia informacyjna Bazy danych Dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2016 Plan wykładu Wstęp do baz danych Modele baz danych Relacyjne bazy danych Język SQL Rodzaje
Technologia informacyjna Bazy danych Dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2016 Plan wykładu Wstęp do baz danych Modele baz danych Relacyjne bazy danych Język SQL Rodzaje
ActiveXperts SMS Messaging Server
 ActiveXperts SMS Messaging Server ActiveXperts SMS Messaging Server to oprogramowanie typu framework dedykowane wysyłaniu, odbieraniu oraz przetwarzaniu wiadomości SMS i e-mail, a także tworzeniu własnych
ActiveXperts SMS Messaging Server ActiveXperts SMS Messaging Server to oprogramowanie typu framework dedykowane wysyłaniu, odbieraniu oraz przetwarzaniu wiadomości SMS i e-mail, a także tworzeniu własnych
dlibra 3.0 Marcin Heliński
 dlibra 3.0 Marcin Heliński Plan prezentacji Wstęp Aplikacja Redaktora / Administratora Serwer Aplikacja Czytelnika Aktualizator Udostępnienie API NajwaŜniejsze w nowej wersji Ulepszenie interfejsu uŝytkownika
dlibra 3.0 Marcin Heliński Plan prezentacji Wstęp Aplikacja Redaktora / Administratora Serwer Aplikacja Czytelnika Aktualizator Udostępnienie API NajwaŜniejsze w nowej wersji Ulepszenie interfejsu uŝytkownika
Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych
 Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych dr inż. Adam Iwaniak Infrastruktura Danych Przestrzennych w Polsce i Europie Seminarium, AR Wrocław
Wykorzystanie standardów serii ISO 19100 oraz OGC dla potrzeb budowy infrastruktury danych przestrzennych dr inż. Adam Iwaniak Infrastruktura Danych Przestrzennych w Polsce i Europie Seminarium, AR Wrocław
Zdalne monitorowanie i zarządzanie urządzeniami sieciowymi
 Uniwersytet Mikołaja Kopernika w Toruniu Wydział Matematyki i Informatyki Wydział Fizyki, Astronomii i Infomatyki Stosowanej Piotr Benetkiewicz Nr albumu: 168455 Praca magisterska na kierunku Informatyka
Uniwersytet Mikołaja Kopernika w Toruniu Wydział Matematyki i Informatyki Wydział Fizyki, Astronomii i Infomatyki Stosowanej Piotr Benetkiewicz Nr albumu: 168455 Praca magisterska na kierunku Informatyka
CouchDB. Michał Nowikowski
 CouchDB Michał Nowikowski Agenda Wprowadzenie do CouchDB Mój przypadek Wyniki i wnioski Dokumenty CouchDB Format JSON Pary nazwa wartość Możliwe tablice i struktury Załączniki Brak limitów na liczbę i
CouchDB Michał Nowikowski Agenda Wprowadzenie do CouchDB Mój przypadek Wyniki i wnioski Dokumenty CouchDB Format JSON Pary nazwa wartość Możliwe tablice i struktury Załączniki Brak limitów na liczbę i
Programowanie obiektowe
 Laboratorium z przedmiotu Programowanie obiektowe - zestaw 02 Cel zajęć. Celem zajęć jest zapoznanie z praktycznymi aspektami projektowania oraz implementacji klas i obiektów z wykorzystaniem dziedziczenia.
Laboratorium z przedmiotu Programowanie obiektowe - zestaw 02 Cel zajęć. Celem zajęć jest zapoznanie z praktycznymi aspektami projektowania oraz implementacji klas i obiektów z wykorzystaniem dziedziczenia.
Model logiczny SZBD. Model fizyczny. Systemy klientserwer. Systemy rozproszone BD. No SQL
 Podstawy baz danych: Rysunek 1. Tradycyjne systemy danych 1- Obsługa wejścia 2- Przechowywanie danych 3- Funkcje użytkowe 4- Obsługa wyjścia Ewolucja baz danych: Fragment świata rzeczywistego System przetwarzania
Podstawy baz danych: Rysunek 1. Tradycyjne systemy danych 1- Obsługa wejścia 2- Przechowywanie danych 3- Funkcje użytkowe 4- Obsługa wyjścia Ewolucja baz danych: Fragment świata rzeczywistego System przetwarzania