Bazy danych. Andrzej Łachwa, UJ, /14
|
|
|
- Marta Biernacka
- 7 lat temu
- Przeglądów:
Transkrypt
1 Bazy danych Andrzej Łachwa, UJ, /14
2 Zobacz:
3 Literatura Elmasri R., Navathe S., Wprowadzenie do systemów baz danych. Wyd. Helion, 2005 Garcia-Molina H., Ullman J.D., Widom J., Systemy baz danych. Pełny wykład. WNT, 2006 (seria: Klasyka Informatyki) Celko J., SQL. Zaawansowane techniki programowania. WN PWN 2008 Czapla K. Bazy danych. Podstawy projektowania i języka SQL. Helion 2015 Morzy T., Wykłady z baz danych dla informatyków. oraz inne źródła podawane w trakcie wykładów!
4 Ważne informacje Strona przedmiotu na Efekty kształcenia: K_W03, K_W04, K_U03, K_U04, K_U06, K_U09, K_U11, K_U12, K_U14, K_U15, K_K01, K_K04 Konsultacje: wtorki 12-13, piątki 11-12, pok. C-2.25 Wykłady rozpoczynamy o 10.15! Slajdy z wykładów będą udostępnione na stronie Zakładu PiGK:
5 Zasady zaliczenia modułu Zaliczenie zajęć w laboratorium: obecność na zajęciach, wykonanie projektu, zaliczenie kolokwium z języka SQL. Egzamin pisemny (po uzyskaniu zaliczenia)
6 Baza danych (ang. database) jest zorganizowanym zbiorem danych zapisanych w ściśle określony sposób w strukturach odpowiadających przyjętemu modelowi danych, zbiorem reprezentującym pewien fragment świata rzeczywistego bądź wirtualnego, zwany dalej obszarem analizy (ang. universe of discourse) zbiorem zaprojektowanym, zbudowanym i utrzymywanym dla określonej grupy użytkowników, i dla określonego sposobu korzystania z tych danych.
7 Ochrona prawna bazy danych Zobacz: ustawa o ochronie baz danych prawo autorskie
8 Jednostki danych Dane w bazie relacyjnej składają się z jednostek elementarnych. Są to zwykle liczby, napisy, daty etc. Jednostki te mają stałą strukturę więc dane takie nazywamy strukturalnymi. Jednostki danych, które nie mają stałej struktury lecz zawierają informacje o swojej strukturze, nazywamy semistrukturalnymi. Przykładem takiej jednostki jest dokument XML. Natomiast jednostki, które mogą mieć różną strukturę i nie zawierają informacji o swojej strukturze nazywamy niestrukturalnymi. Przykładem takiej jednostki jest rysunek techniczny.
9 Obecnie coraz częściej korzystamy z takich jednostek danych, jak utwory muzyczne, audycje, audiobooki lub inne twory dźwiękowe, rysunki techniczne, fotografie lub inne obrazy stałe (ang. still picture), dokumenty języka naturalnego, animacje, nagrania wideo, filmy z dźwiękiem i napisami, mapy cyfrowe. Myślimy również o przechowywaniu obiektów, które dopiero w przyszłości będziemy umieli odpowiednio reprezentować (np. znaczenia, zapachy, smaki, odczucia estetyczne, dotykowe, stany psychiczne...). Są to tzw. dane multimedialne.
10 Informacja, to dane do których zostało przypisane znaczenie, to dane zinterpretowane! Informacja ma zawsze charakter subiektywny i jest związana z kontekstem. Różne dane mogą stanowić tę samą informację i na odwrót: te same dane mogą dostarczać różnych informacji. Zob. Z. Jurkiewicz: Semistrukturalne bazy danych wprowadzenie. Wykład dla studentów matematyki. Zob. A. Wieczorkowska: Mutimedia. Wykłady dla studentów informatyki.
11 Rodzaje baz danych Active database Knowledge base Cloud database Operational database Data warehouse Parallel database Distributed database Real-time database Document-oriented database Spatial database Embedded database Temporal database End-user database In-memory database Federated database and Unstructured-data multi-database database Graph database Hypermedia databases Hypertext database i inne!
12 Bazy tradycyjne, obiektowe i multimedialne Struktura tradycyjnej atrybutowej (!) bazy danych reprezentowana jest w jej schemacie, a wszystkie zapytania odwołują się do tej sztywnej struktury. Do tych tradycyjnych baz danych zaliczamy bazy kartotekowe, bazy hierarchiczne i bazy relacyjne. W przypadku baz relacyjnych strukturę tę tworzą: nazwy tabel, nazwy, typy, własności i zakresy wartości atrybutów, związki referencyjne między atrybutami i warunki integralności danych.
13 Obiektowa baza danych to zbiór obiektów, których zachowanie, stan oraz związki są określone zgodnie z obiektowym modelem danych. Obiekt jest więc podstawowym pojęciem służącym do modelowania świata. Jest traktowany jako kontener zawierający pewien zbiór wartości oraz związany z nim zbiór specyficznych operacji do obserwacji i zmiany stanu obiektu. Obiektowe bazy danych przechowują i udostępniają dane w takiej samej postaci w jakiej są przechowywane w programach napisanych w obiektowych językach programowania. Zobacz:
14 Multimedialne bazy danych to systemy, w których informacja przechowywana jest w węzłach różnego rodzaju mediów (np. teksty, dźwięki, filmy, obrazy) połączonych za pomocą tzw. wiązań asocjacyjnych i które oferują użytkownikom możliwości: swobodnej nawigacji od węzła do węzła, udostępniania informacji zawartej w węźle oraz korzystania z urządzeń wyszukiwawczych które przetwarzają dane multimedialne. Multimedialne bazy danych są często obiektowymi bazami danych.
15 Od multimedialnych baz danych odróżnia się bazy danych z multimedialną zawartością, np.: katalogi zdjęć z miniaturami prowadzącymi do obrazów w pełnej rozdzielczości, systemy wideo na żądanie z wyszukiwaniem dotyczącym opisu parametrów filmu (aktor, tytuł, streszczenie ), księgarnie internetowe ze zdjęciami okładek książek, abstraktami, spisami treści i próbkami tekstów, ze zdjęciami okładek płyt, spisami zawartości i próbkami utworów o ile tylko wyszukiwanie zorganizowane jest tradycyjnie, tj. gdy obiektami przeszukiwanymi są opisy zdjęć, filmów, książek czy płyt wpisane w sztywną strukturę (w schemat bazy).
16 Multimedialną zawartość da się upchnąć do popularnych relacyjnych bądź obiektowo-relacyjnych baz danych w postaci obiektów typu BLOB. Wtedy do każdego takiego obiektu dodaje się nagłówek, tj. opis zawartości obiektu binarnego, a wszelkie operacje wyszukiwania mogą uwzględniać wyłącznie zawartość tych nagłówków. Pójdźmy jednak krok dalej: umieśćmy w nagłówku każdego obiektu listę słów charakteryzujących treść obiektu binarnego. Załóżmy, że da się to zrobić w sposób zautomatyzowany przy pomocy pewnej procedury X. W takiej sytuacji da się wyszukiwać obrazy, filmy, nagrania dźwiękowe czy teksty języka naturalnego według zawartych w nich treści, a nie tylko po wartościach atrybutów.
17 Jeżeli teraz usuniemy z nagłówków opisy treści, a procedurę X włączymy do procesu wyszukiwania, to taka baza będzie już bliższa bazie multimedialnej, niż zwykłej bazie relacyjnej z multimedialną zawartością! Jak się okazuje różnica między tymi dwoma rodzajami baz danych jest bardzo subtelna. Zobacz: %20rel...
18 Kilka terminów System z bazą danych (system bazodanowy, ang. DBS) to aplikacja bazodanowa i jej baza danych wykonane przy użyciu technologii informatycznej (sprzęt komputerowy + oprogramowanie + telekomunikacja). System zarządzania bazami danych SZBD (ang. DBMS, Database Management System) to oprogramowanie do tworzenia baz i zarządzania bazami danych. Komponent SZBD przeznaczony do wykonywania operacji CRUD (od ang. create, read, update, delete) na bazie danych nazywamy motorem lub silnikiem bazodanowym (ang. jet, engine).
19 W ramach danego SZBD możemy mieć do wyboru kilka motorów, np. w MySQL mamy motory InnoDB, MyISAM, Memory, Archive, Blackhole i in.). Komponenty tworzące jądro SZBD i świadczące usługi na rzecz innych programów nazywamy serwerem bazodanowym. Przykłady SZBD na licencji GPL: PostgreSQL ( MySQL ( Firebird ( SQLite (
20 Katalog (kartoteka, baza kartotekowa) to spis obiektów jednego typu o ustalonej prostej strukturze, odpowiadający plikowi rekordów w językach programowania. Przykłady kartotek i bazy hierarchicznej
21 Bazy danych Andrzej Łachwa, UJ, /14
22 Języki SQL, SQL 2 (1992), SQL 3 ( ) SQLite MySQL
23 Dane dotyczące czasu Typy danych czasowych pojawiły się w SQL 2. Opis ich jest tak rozbudowany, że nikt go jeszcze nie zaimplementował! Dlaczego jest to tak trudne?
24 1 Rok słoneczny składa się z ok. 365,2422 dni i trwa coraz dłużej. Każdy kalendarz ma całkowitą liczbę dni w roku. Trzeba więc co pewien czas dokonać wyrównania kalendarza z czasem słonecznym.
25 2 Pierwsze ważne wyrównanie kalendarza z czasem słonecznym nastąpiło za Juliusza Cezara (stąd mówimy o kalendarzu juliańskim) w 46 p.n.e. (ten rok miał 445 dni). Wprowadził on lata przestępne co 4 lata (niestety przez pomyłkę kilka pierwszych lat przestępnych przypadało co 3 lata). Pewne są natomiast lata przestępne od 5 roku n.e. i stąd dopiero od tej daty można wyliczać dni tygodnia. Kalendarz juliański spóźniał się o 1 dzień na 128 lat i dlatego zastąpiono go w 1582 kalendarzem gregoriańskim (spóźnienie wynosiło wtedy już około 10 dni, więc w roku 1582 usunięto daty od 5 do 14 października).
26 3 Kalendarz juliański obowiązywał w różnych krajach w różnych okresach, np. w Rosji od 1700 do 1918, w Polsce tylko do 1582, a w Grecji aż do Zmiana kalendarza na gregoriański wprowadzana była w różnych krajach w różnym czasie, np. w Wielkiej Brytanii korektę przeprowadzono dopiero w 1752.
27 4 Przez wiele stuleci dodatkową komplikacją było rozpoczynanie roku w różnym czasie, np. w Wielkiej Brytanii i koloniach początek roku przypadał na 25 marca (październik to zatem miesiąc ósmy, a grudzień dziesiąty: po łacinie octo to osiem, decem dziesięć). WNIOSEK Historyczne daty zwykle nie odpowiadają datom obliczonym dzisiaj według kalendarza gregoriańskiego. Dotyczy to również dni tygodnia i świąt. Niektóre daty w ogóle nie istnieją, podobnie jak nie istnieje 29 lutego 2014.
28 5 FORMATY DAT Dzień 12/16/95 w Bostonie to 16/12/95 w Londynie, w Berlinie i w Sztokholmie. W NATO próbowano stosować liczby rzymskie na oznaczanie miesięcy, więc powyższa data to 16 XII Z kolei w armii amerykańskiej stosowano format YYYY mmm DD, gdzie mmm to pierwsze 3 litery angielskiej nazwy miesiąca, zatem: 1995 JAN 16. Ponadto istnieje wiele standardów przemysłowych. W elektronicznym przetwarzaniu informacji używa się normy ISO 8601.
29 6 CZAS LOKALNY Czas uniwersalny oznacza się jako UTC. Co jakiś czas dodawana jest tzw. sekunda przestępna przez International Earth Rotation Service. Strefy czasowe zmieniały się w niektórych krajach co 15 minut, ale obecnie (od 1998) zmiany dotyczą całych godzin. W USA mamy 4 strefy czasowe oraz tzw. czas prawny.
30 7 CZAS LETNI W USA używa się określenia DST (Daylight Saving Time), w krajach środkowoeuropejskich mamy CET i CEST (Central European Summer Time).
31 8 Istnieje wiele formatów zapisywania czasu. Zwykle w elektronicznym przetwarzaniu informacji stosuje się format zgodny z normą ISO Jednak różni producenci serwerów bazodanowych wprowadzają dodatkowe formaty.
32 Daty i czas wg ISO 8601 YYYY-MM-DD (data kalendarzowa, format rozszerzony) YYYYMMDD (jw, format podstawowy) YYYY-DDD lub YYYYDDD (data porządkowa, DDD to kolejny dzień w roku w formacie 3-cyfrowym) YYYY-Www-D (data tygodniowa, W to symbol stały, ww to numer tygodnia w roku, D to numer dnia tygodnia, np. dziś to 2014W482 (48 tydzień roku, wtorek). hh:mm:ss, hh:mm (czas, format rozszerzony) hhmmss, hhmm i hh (czas, format podstawowy, po liczbie sekund może wystąpić część ułamkowa) 2013:11:19 T 10: :00 (łączny zapis daty i czasu)
33 Uwagi: rok 0001 to 1 rok n.e., a 0000 to 1 rok p.n.e. (1 B.C.) północ w Sylwestra to 24:00 dnia 31 grudnia albo 00:00 dnia 1 stycznia w dacie porządkowej 3 lutego to zawsze 034, ale 31 grudnia to albo 365 albo 366) pierwszy tydzień roku to taki, w którym są co najmniej 4 dni stycznia, więc 30 grudnia 2014 to 2015-W01-2 czas odmierza się zgodnie ze standardem UTC, a nie poprzednio stosowanym GMT, czas lokalny oznacza się przez wskazanie przesunięcia, np. w zimie w Polsce godzina 10:40 to 10:40+01 i jest równa 9:40Z
34 Daty i czas w SQL Standard SQL ma typy danych związane z datą i czasem: DATE, TIME, TIMESTAMP, INTERVAL Interwały typu rok-miesiąc mają domyślną precyzję obejmującą pola YEAR i MONTH. Interwały typu dzień-czas mają precyzję DAY, HOUR, MINUTE i SECOND (z częścią ułamkową). Standard obejmuje też pełny zestaw operatorów dla czasowych typów danych (w różnych produktach pełna składnia i funkcjonalność nie jest implementowana). Koniec czasu to w SQL data
35 Daty i czas w MySQL DATE ma zakres od do oraz (zakres DATETIME kończy się więc na :59:59 ) TIMESTAMP ma zakres jak DATETIME, ale jest zapisywany jako liczba sekund od początku zakresu i nie przyjmuje wartości początku przedziału (wartość 0 jest interpretowana jako :00:00). TIME ma zakres od -838:59:59 do 838:59:59 (w tym zero). YEAR ma zakres od 1901 do 2155 oraz 0000 (ale w formacie 2-cyfrowym od 1970 do 2069, więc 00 to 2000).
36 Przykłady SELECT ADDDATE(' ', INTERVAL 31 DAY); -> ' ' SELECT ADDTIME(' :59: ', '1 1:1: '); -> ' :01: ' SELECT DATE_FORMAT(' :23:00','%W %M %Y'); -> 'Sunday October 2009' SELECT DATE_FORMAT(' ', '%X %V'); -> ' '
37 SELECT NOW(), SLEEP(2), NOW()\G -> :47: :47:36 SELECT SYSDATE(), SLEEP(2), SYSDATE()\G -> :47: :47:46 SELECT WEEKDAY(' :23:00'); -> 6 SELECT MAKETIME(12,15,30); -> '12:15:30'
38 SELECT CURRENT_DATE(), DATEDIFF(CURRENT_DATE(), ) AS "Zyje juz tyle dni!"; CURRENT_DATE() Zyje juz tyle dni! SELECT CONCAT( Dzisiaj mamy,dayofyear(now()), dzien roku,,weekofyear(now()), tydzien roku oraz,dayofweek(now()), dzien tygodnia. ); Dzisiaj mamy 116 dzien roku, 17 tydzien roku oraz 4 dzien tygodnia
39 SELECT CURRENT_TIMESTAMP, DATE_FORMAT(CURRENT_TIMESTAMP, %W :: %M :: %d :: %Y :: %T ) AS "biezaca data i godzina"; CURRENT_TIMESTAMP biezaca data i godzina :57:20 Tuesday :: March :: 28 :: 2006 :: 11:57: Funkcje SUM() i AVG() nie działają na datach i czasie, ale można sobie z tym poradzić, np.: SELECT SEC_TO_TIME(SUM(TIME_TO_SEC(time_col))) FROM...
40 Przykłady w SQLite3 i MySQL
41
42
43
44
45
46
47
48 Wstęp do problematyki danych związanych z czasem: Joe Celko: SQL. Zaawansowane techniki programowania. PWN 2008, rozdział 4 i rozdział 29 Wiele problemów dotyczących czasu dla różnych dialektów języka SQL rozwiązano i opublikowano, m.in. na stronie uniwersytetu
49 Bazy danych Andrzej Łachwa, UJ, /14
50 Specyfikacja wymagań Zanim rozpoczniemy modelowanie, musimy dokładnie określić obszar analizy oraz zrozumieć go! W praktyce analitycy udają się do przedsiębiorstwa czy instytucji, dla której ma być wykonana baza danych, i tam poprzez wywiady, ankiety i obserwacje poznają specyfikę działania pracowników, obieg dokumentów, procedury, czynności, normy etc. Następnie analitycy dokonują uproszczenia: zastępują skomplikowane i szczegółowe okoliczności występujące w świecie rzeczywistym zrozumiałym modelem danych. Modelowaniu danych towarzyszy zawsze modelowanie struktury organizacyjnej i sieci procesów. Baza danych jest bowiem projektowana dla konkretnych użytkowników i dla konkretnego sposobu korzystania z danych.
51 Pomocą w zrozumieniu obszaru analizy i poprawnym zaprojektowaniu bazy jest specyfikacja wymagań. Przyjmuje ona (w naszym podejściu) postać tekstu opisującego dane, ich przetwarzanie i użytkowników. W specyfikacji tej powinny się znaleźć także szacunki dotyczące wielkości bazy, liczby użytkowników, intensywności korzystania z danych, używanego sprzętu i oprogramowania. Specyfikacja wymagań stanowi punkt odniesienia całego projektu. Jest ona ważna także dlatego, że w trakcie wykonywania projektu zmienić może się zarówno obszar analizy, jak i wymagania przyszłych użytkowników.
52 Przykład: MULTIKINO (fragment specyfikacji) W multikinie jest kilka sal. W każdej z nich widownia dzieli się na rzędy i miejsca w rzędzie. Rzędy mogą być różnej długości. Liczba rzędów w różnych salach może być różna. W każdej sali każdego dnia może być kilka seansów. Film może być wyświetlany na wielu seansach w jednej sali, a także w różnych salach równocześnie. Klient może zarezerwować bilety na seans przez Internet. Zarezerwowane bilety wykupuje się w kasie na hasło. Nie zbiera się żadnych informacji o klientach i nie prowadzi się programów lojalnościowych.
53 Dla każdego seansu muszą być ustalone dwie ceny bilet zwykły i ulgowy. Wszystkie bilety na dany seans dla klientów indywidualnych są sprzedawane w tych cenach. Ceny biletów na różne seanse mogą być różne (ustala się je w zależności od dnia tygodnia, godziny seansu, sali, filmu, pogodny, pory roku etc.). Ceny biletów dla grup zorganizowanych są negocjowane. Miejsca są rezerwowane i sprzedawane w tzw. cenie specjalnej. Na dane seans dla różnych grup mogą być ustalone różne ceny specjalne. Projektowana aplikacja ma wspomagać pracę w kasach multikina, pracę menadżera (ustalanie programów, cen biletów, obsługa grup zorganizowanych, analizy ekonomiczne) oraz umożliwiać rezerwacje biletów przez klientów.
54 Diagram związków encji (ang. ERD) Encja to coś: co istnieje niezależnie i jest jednoznacznie identyfikowane, rozpoznawalne, o czym informacje mają być przechowywane w bazie, co występuje (potencjalnie) w wielu egzemplarzach, czemu łatwo nadać nazwę pospolitą (a nie własną)! Typ encji to pojemnik na encje, które są podobne do siebie w tym sensie, że ich charakterystyki (czyli to, co ma być pamiętane w bazie) mają taką samą strukturę. Umawiamy się, że typom encji nadajemy nazwy pospolite w formie liczby pojedynczej.
55 Encją może być: obiekt fizyczny: ten budynek, książka leżąca na półce, samochód w garażu, pracownik, uczeń, klient banku, Twój pies, obraz, który kupujesz w galerii (np. książki w bibliotece to obiekty fizyczne, konkretne przedmioty; każdy opatrzony unikatowym numerem) obiekt abstrakcyjny: książka na witrynie księgarni internetowej, samochód w katalogu, słowo języka polskiego, utwór muzyczny, rachunek bankowy (np. książka w księgarni, to obiekt abstrakcyjny, to tytuł reprezentowany wieloma egzemplarzami stojącymi na półce, a także taki, którego aktualnie brak na półce)
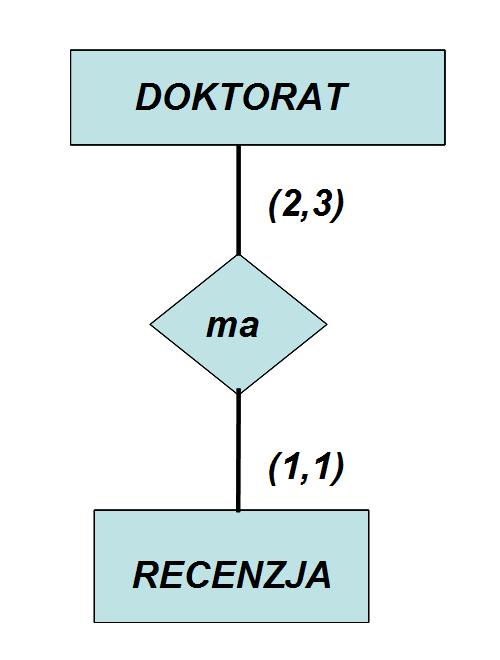
56 zdarzenie: wypadek komunikacyjny, lekcja w szkole, zakup koszyka towarów w sklepie internetowym, przelew bankowy, seans w kinie, wizyta u lekarza pojęcie: kolor, styl w architekturze miejsce: miejsce zamieszkania, miejscowość, obszar geograficzny lub administracyjny kształt proces, czynność...
57 Dla przykładowego obszaru analizy (multikino) możemy zaproponować następujące typy encji: FILM SEANS SALA MIEJSCE REZERWACJA BILET GRUPA Czy na pewno są to typy encji? Czy potrzebne są inne typy encji w tym obszarze?
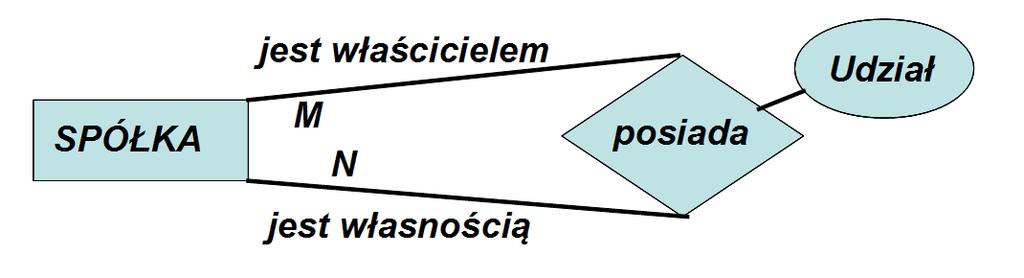
58 Między encjami mogą zachodzić rozmaite związki. Związki te mogą łączyć encje w pary, trójki, czwórki itd. Mówimy wówczas o związkach stopnia 2-go, 3-go czy 4-tego. Związki mogą dotyczyć encji tego samego typu (taki jest np. związek typu PRACOWNIK podlega PRACOWNIK). Związki takie nazywamy unarnymi. Związki mogą dotyczyć encji dwóch różnych typów (np. KLIENT kupuje BILET); nazywamy je binarnymi.
59 Przykładem związku łączącego encje trzech typów jest związek opisujący sytuację, gdy lekarz wypisuje pacjentowi receptę. Możemy to zdarzenie modelować jako związek: wypisuje (LEKARZ, PACJENT, RECEPTA). Jest to związek 3-go stopnia między trzema różnymi typami encji. Z inną sytuacją mamy do czynienia w przypadku związku modelującego sprzedaż nieruchomości: sprzedaje (PODMIOT, PODMIOT, NIERUCHOMOŚĆ). Jest to również związek 3-go stopnia, ale zachodzący między dwoma typami encji. W tym przypadku muszą być nazwane role obu podmiotów wchodzących w ten związek (kto sprzedaje i komu sprzedaje).
60 Związki oznaczamy czasownikami (np. podlega, kupuje, wydaje) lub innymi wyrażeniami predykatywnymi (np. należy do, jest częścią) w taki sposób, by było to jak najbardziej zrozumiałe, intuicyjne i zarazem proste. W omawianym obszarze analizy (multikino) możemy zaproponować m.in. wymienione niżej typy związków: wyświetla (SEANS, FILM) odbywa się (SEANS, SALA) zawiera (SALA, MIEJSCE) łączy (BILET, MIEJSCE, SEANS) dotyczy (REZERWACJA, MIEJSCE) obejmuje (REZERWACJA, SEANS)
61 Krotności związków unarnych i binarnych Związki 2-go stopnia dzielimy na trzy rodzaje oznaczane symbolami 1:1, 1:N (czytaj: jeden do wielu) i N:M (czytaj: wiele do wielu). Przykładem związku 1:1 jest związek między ważnym w danej chwili dowodem rejestracyjnym a pojazdem (jeden pojazd może mieć tylko jeden ważny dowód rejestracyjny i na odwrót: ważny dowód rejestracyjny przypisany jest dokładnie do jednego pojazdu). Związek między dowodem rejestracyjnym a pojazdem jest natomiast związkiem typu N:1, bo dla jednego pojazdu wydaje się kolejno, wiele dowodów rejestracyjnych.
62 Udział encji w związku Udział encji danego typu w związku encji może być udziałem pełnym lub częściowym. Udział pełny oznacza, że każda encja danego typu musi wchodzić w taki związek. Udział częściowy oznacza dowolność: niektóre encje wchodzą w ten związek, inne nie. W omawianym wyżej drugim związku dowodów rejestracyjnych i pojazdów udział encji typu DOWÓD jest pełny, bo każdy dowód jest wydawany dla jakiegoś pojazdu. Udział encji typu POJAZD jest częściowy, bo pojazd, przed pierwszym zarejestrowaniem nie posiada żadnego dowodu rejestracyjnego i dowolnym momencie może być wycofany z ruchu (wyrejestrowany).
63 Warunek strukturalny udziału encji w związku Bardziej ogólną charakterystykę związku encji (od omówionych wyżej określeń liczebności i udziału) dają tzw. warunki strukturalne. Warunek taki ma postać (k,n) i oznacza, że co najmniej k encji i co najwyżej n encji danego typu wchodzi w ten związek. Przykładem warunku strukturalnego jest warunek (2,3) udziału encji typu doktorant w związku z encjami typu recenzent. Oznacza on, że każdy doktorant musi mieć dwie recenzje swojej rozprawy, ale zdarza się, że ma 3 recenzje. Większej liczby recenzji nie dopuszcza się.
64 Atrybuty Wszystkie encje danego typu mają charakterystyki o tej samej strukturze: są to wybrane przez analityka istotne własności encji tego typu, zwane dalej atrybutami, tworzące strukturę drzewa, którego korzeniem jest dana encja. Charakterystykę konkretnej encji tworzy układ wartości atrybutów. Związki encji mogą również posiadać tego rodzaju charakterystyki: układ wartości atrybutów. Atrybuty typów encji i związków encji mogą być atrybutami złożonymi bądź elementarnymi (liście drzewa). Dla każdego atrybutu elementarnego trzeba określić dziedzinę wartości tego atrybutu.
65 Atrybuty mogą być jednowartościowe albo wielowartościowe. Ponadto wyróżnia się atrybuty wyliczeniowe (ich wartości są wyliczane z wartości innych atrybutów). NazwaM NrMieszkania LiczbaMieszkańców NrBudynku Mieszkaniec Kod Miejsce AdresMieszkania Poczta
66 Diagram związków encji jest grafem reprezentującym strukturę danych. Wierzchołki tego grafu reprezentują typy encji, związki i atrybuty, a dla ich odróżniania używa się odpowiednio kształtów prostokąta, rombu i elipsy. Krawędzie jednego typu wiążą prostokąty lub romby z owalami. Krawędzie drugiego typu wiążą prostokąty z rombami. Niektóre z krawędzi drugiego typu mogą być etykietowane.
67

68
69
70 Diagram związków encji (Entity Relationship Diagram) to przyjęty w środowisku projektantów baz danych sposób opisywania świata rzeczywistego, to zbiór koncepcji używanych do opisania struktury danych składających się na projektowaną bazę. Prezentowana notacja elementów diagramu ERD została wprowadzona przez Petera Chena (1976) i jest bardzo popularna. W wielu narzędziach do rysowania diagramów ERD mamy do wyboru także inne notacje (które warto poznać). Na zajęciach będziemy używać edytora yed firmy yworks (

71 SQL 2 (1992), SQL 3 ( )
72 Studium przypadku: komunikacja autobusowa obszar analizy, specyfikacja funkcjonalna i techniczna projekt koncepcyjny (diagram związków encji) projekt logiczny (schemat bazy danych) projekt fizyczny (skrypt definiujący w dialekcie MySQL)
73

74

75
76 SKRYPT DEFINIUJACY BAZĘ (fragment) CREATE TABLE Kurs ( KodKur SMALLINT AUTO_INCREMENT, KodTr VARCHAR(10), Dzien DATE, Godzina TIME, KierID SMALLINT, AutoID SMALLINT, PRIMARY KEY (KodKur) );
77 SKRYPT WYPEŁNIAJĄCY BAZĘ (fragment) INSERT INTO Kurs (KodTr, Dzien, Godzina, KierID, AutoID) VALUES ('KR-WA',DATE_ADD(' ', INTERVAL FLOOR(250*RAND()) DAY), MAKETIME(24*RAND(), 60*RAND(), 00), FLOOR(10*RAND())+1, FLOOR(10*RAND())+1), ('WA-KR',DATE_ADD(' ', INTERVAL FLOOR(250*RAND()) DAY), MAKETIME(24*RAND(), 60*RAND(), 00), FLOOR(10*RAND())+1, FLOOR(10*RAND()) +1),
78 Rozszerzenia ERD (EER) słabe typy encji i związki identyfikujące specjalizacja i podklasy związki isa kategoryzacja
79 Słaby typ encji i związek identyfikujący NrFaktury DataWystawienia DataSprzedaży NrPozycji Opis Jednostka Ilość Cena FAKTURA 1 Wartość jest częścią N POZYCJA
80 Kategoryzacja PRACOWNIK STUDENT U ZAWODNIK PIES ISA Związek ISA LABRADOR
81 ZWIERZĘ Specjalizacja / generalizacja d PIES KOT LIS o d specjalizacja nakładająca specjalizacja rozłączna
82 POZYCJA_FAKTURY 1 1 N WYRÓB jest stanowi M USŁUGA
83 ?

84 Andrzej Łachwa 2009

85 Andrzej Łachwa 2009
86 Bazy danych Andrzej Łachwa, UJ, /14
87 Własności SZBD: możliwość bezpiecznego przechowywania przez długi czas danych mierzonych w tera- i petabajtach, istnienie mechanizmów masowego wprowadzania danych, zapewnienie bezpieczeństwa danych, efektywny dostęp do danych (m. in. możliwość tworzenia zapytań o dane oraz aktualizowania danych za pomocą odpowiedniego języka operacji na danych), sterowanie współbieżnością, trójwarstwowa struktura (jądro, interfejs i narzędzia). możliwość tworzenia nowej bazy danych, tzn. określenia jej schematu i więzów integralności za pomocą jakiegoś języka definiowania danych.
88 Zalety podejścia bazodanowego: niezależność między danymi a programami, ukrywanie szczegółów dotyczących sposobu przechowywania danych w pamięci fizycznej, przechowywanie metadanych, dostarczanie wielu widoków (perspektyw) danych dla różnych grup użytkowników, zapewnienie integralności danych, współdzielenie danych i współbieżne transakcje wielu użytkowników, wysoka niezawodność i bezpieczeństwo...
89 Tabele Codda Teoretyczne podstawy relacyjnych baz danych zostały wprowadzone przez Edwarda Codda w 1970 roku. Zaproponował on przechowywanie danych w tabelach. Tabela jest tutaj czymś podobnym do matematycznej relacji, a zarazem do zwykłej tabeli złożonej z nagłówka, kolumn i wierszy. W nagłówku występuje nazwa tabeli oraz nazwy kolumn. W polach wierszy występują wartości atrybutów. W tabeli Codda nie jest ustalony ani porządek kolumn, ani porządek wierszy! Tabela pusta zawiera tylko nagłówek!
90 Kryteria Codda Informacje są reprezentowane (na poziomie logicznym) w tabelach. Dane są (na poziomie logicznym) dostępne przez podanie nazwy tabeli, wartości klucza głównego i nazwy kolumny. Wartości null są traktowane w jednolity sposób jako brakujące informacje. Nie mogą być traktowane jako puste łańcuchy znaków, puste miejsca, czy zera. Metadane (dane dotyczące bazy danych) są umieszczone w bazie danych dokładnie tak, jak zwykłe dane.
91 Język obsługi danych ma możliwość definiowania danych, perspektyw i więzów integralności, przeprowadzenia autoryzacji, obsługi transakcji i manipulacji danymi. Perspektywy reagują na zmiany swoich tabel bazowych. Odwrotnie, zmiana w perspektywie powoduje automatycznie zmianę w tabeli bazowej. Istnieją pojedyncze operacje pozwalające na wyszukanie, wstawienie, uaktualnienie i usunięcie danych. Operacje użytkownika są logicznie oddzielone od fizycznych danych i metod dostępu do danych. Operacje użytkownika pozwalają na zmianę struktury bazy bez konieczności tworzenia od nowa bazy czy aplikacji ją obsługującej.
92 Więzy integralności są umieszczone i dostępne w metadanych, a nie w programie obsługi bazy danych. Język manipulacji danymi powinien działać bez względu na to, jak i gdzie są rozmieszczone fizyczne dane oraz nie powinien wymagać żadnych zmian, gdy fizyczne dane są centralizowane lub rozpraszane. Operacje na pojedynczych wierszach tabel przeprowadzane w systemie podlegają tym samym zasadom i więzom, co operacje na zbiorach danych.
93 Definicja Relacyjna baza danych jest zbiorem danych tworzących tabele (w sensie Codda) i spełniających określone warunki integralności danych. Tabela Codda reprezentuje relację. Kolumny i wiersze tabel odpowiadają atrybutom i krotkom relacji. Kolumny i wiersze nie są uporządkowane! Nagłówek tabeli odpowiada schematowi relacji.
94 Niech dany będzie zbiór atrybutów {A1, A2, An}, a z każdym atrybutem Ai związana będzie dziedzina Di wartości tego atrybutu. Dowolny podzbiór iloczynu kartezjańskiego D1 x D2 x x Dn nazywamy relacją rozpiętą na schemacie F(A1, A2, An). Schematem relacyjnej bazy danych nazywamy zbiór pustych tabel oraz więzów integralności danych, które można do tych tabel wprowadzić. Tabela wypełniona danymi będzie kojarzona z relacją opartą na danym schemacie.
95 Konwencja 1 Osoba (Pesel*, Nazwisko, DataUr) Pracownik (PeselPracownika, NazwaWydziału) Wydział (Nazwa*, Adres) Symbolem * oznacza się atrybuty tworzące klucz główny tabeli (wartości klucza głównego służą do identyfikowania wierszy tabeli). Strzałki pokazują związek referencyjny między wartościami zwany kluczem obcym.
96 Konwencja 2 OSOBY Pesel* Nazwisko DataUr... PRACOWNICY PeselPracownika NazwaWydziału WYDZIAŁY Nazwa* Adres...
97 Konwencja 3 OSOBY Pesel* Nazwisko DataUr... PRACOWNICY PeselPracownika NazwaWydziału WYDZIAŁY Nazwa* Adres...
98 Więzy WIĘZY DOMENOWE WIĘZY KLUCZY PODSTAWOWYCH WIĘZY INTEGRALNOŚCI REFERENCYJNEJ (WIĘZY KLUCZA OBCEGO) ZALEŻNOŚCI FUNKCYJNE ZALEŻNOŚCI WIELOWARTOŚCIOWE ZALEZNOŚCI ZŁACZENIOWE WARTOŚCI WYMAGANE WIĘZY OGÓLNE

99 Konwencja 4

100 Wybrane rozwiązania

101
102
103

104

105 Dane aktualne czy historyczne?

106
107 Część DDL języka MySQL zob.
108 SQL 2 (1992), SQL 3 ( ) Liczbowe typy danych: INTEGER (INT), SMALLINT, BIGINT, [TINYINT] DECIMAL(p,s), NUMERIC(p,s) FLOAT(p), REAL, DOUBLE PRECISION [BIT, BYTE] W różnych implementacjach różne zakresy. Należy również uważać na zaokrąglanie, obcinanie i konwersje. Cztery operacje arytmetyczne są rozszerzane o różne funkcje matematyczne, np. kwadrat, pierwiastek kwadratowy, modulo, logarytm, funkcje trygonometryczne etc.
109 Przekształcanie liczb na liczebniki Procedura byłaby zbyt skomplikowana. W języku angielskim najlepszym kompromisem między wielkością kodu procedury i wielkością tabeli jest przygotowanie tabeli tłumaczenia liczb mniejszych od 1000 na liczebniki, a potem kolejne obliczanie: liczby mniejszej od tysiąca, liczby tysięcy, milionów, miliardów i na koniec wykonanie konkatenacji odpowiednich liczebników i słów thousand, million, billion (ewentualnie z końcówką s). W języku polskim sprawa znacznie się komplikuje. Prosta procedura dla angielskiego produkowałaby takie niegramatyczne wyrażenia, jak dla przykładu: pięć miliony trzysta dwa tysięcy sto jedenaście
110 Koncepcja elementu danych jako pojedynczej (atomowej) wartości nie zawsze ma sens! Przykład 1: PUNKTY NA PŁASZCZYŹNIE Położenie punktu na płaszczyźnie możemy określić parą liczb w odniesieniu do ustalonego układu współrzędnych. Modelowanie tego w jednej kolumnie (jako wartości atrybutu POŁOŻENIE) byłoby niewygodne. Lepsze jest modelowanie w dwóch kolumnach: ODCIĘTA, RZĘDNA.
111 Przykład 2: PUNKTY NA ZIEMI Położenie punktu na Ziemi można określić przy pomocy współrzędnych geograficznych: wielkości kątowych liczonych względem równika (szerokość geograficzna, ang. Latitude, Lat) i południka zerowego (długość geograficzna, ang. Longitude, Lng). Np. wejście do tego budynku to 50 01' 46.0'' N 19 54' 21.9'' E (format DMS) Lat: Lng: (format WGS84) N: ', E: ' (format GPS) Modelowanie formatu DMS można wykonać w 8 kolumnach, a formatu WGS84 w 2 kolumnach.
112 Przykład procedury Aby obliczyć odległość między dwoma punktami na Ziemi można użyć wzoru ze strony Odleg%C5%82o%C5%9Bci Potrzebne funkcje (pierwiastek, kwadrat, cos) są dostępne w SQL w większości serwerów. Sprawdzić poprawność na GoogleMaps.
113 Przykład 3: ADRESY IP Przechowywanie adresu IP można zrealizować na trzy sposoby: jako łańcuch, jako liczbę całkowitą lub jako cztery oktety. Ten ostatni sposób jest wygodny i czytelny. Przykład 4: WALUTY Waluty można przechowywać z rozbiciem na wartość i kod waluty. Trzeba ustalić liczbę miejsc po przecinku branych pod uwagę w trakcie obliczeń. Przy transakcjach międzynardowych trzeba również uwzględniać tabelę kursów walut i dokonywać przeliczeń. Zob.
114 Przykład 5: PESEL Sprawdzanie poprawności: Procedura, zob.
115
116 Przejście od ERD do schematu relacyjnej bazy danych polega na zastąpieniu wszystkich typów encji i niektórych powiązań między typami encji schematami relacji i łącznikami. DIAGRAM ZWIĄZKÓW ENCJI SCHEMAT RELACYJNEJ BAZY DANYCH
117 1. Atrybuty złożone Kod Lokalizacja Adres Poczta Nip* KLIENT
118 Atrybuty złożone zostały usunięte! Kod Lokalizacja Poczta Nip* KLIENT
119 2. Atrybuty wielowartościowe Kod Lokalizacja Poczta Nip* Telefon KLIENT
120 Atrybuty wielowartościowe zostały usunięte! Kod Lokalizacja Poczta Nip* KLIENT Telefon Nip* Numer* Opis
121 Kółko pojawi się wtedy, gdy wartość pusta atrybutu wielowartościowego była dozwolona! Kod Lokalizacja Poczta Nip* KLIENT Telefon Nip* Numer* Opis
122 3. Zwykłe typy encji Kod Lokalizacja KLIENT Poczta Nip* Klient Nip* Kod Poczta Lokalizacja...
123 Uwaga: wszystkie związki... Kod Lokalizacja Poczta Nip* zamawia KLIENT kupuje
124 ...pozostają na rysunku! Klient Nip* Kod Poczta Lokalizacja... kupuje zamawia
125 4. Słabe typy encji Kod Lokalizacja Poczta Nip* Imię RokUr KLIENT 1 N ma DZIECKO
126 Do klucza częściowego dodajemy klucz zwykłego typu encji. Kod Lokalizacja Poczta KLIENT Nip* Dziecko Nip* Imię* RokUr*
127 5. Związki wyższego stopnia Nazwa* DRUŻYNA Pesel* ZAWODNIK reprezentuje Kod* MECZ
128 Łączymy klucze! Nazwa* DRUŻYNA Pesel* ZAWODNIK Reprezentant Pesel* Kod* Nazwa* Kod* MECZ
129 Nazwa* DRUŻYNA Pesel* ZAWODNIK Reprezentant Pesel* Kod* Nazwa* Kod* MECZ
130 6. Związki typu M:N Nazwa* RokAk* WYKŁAD M N zgłasza Pesel* PROFESOR
131 Nazwa* WYKŁAD RokAk* Pesel* PROFESOR Zgłoszenie Pesel* Nazwa* RokAk*
132 7. Związki typu 1:N Nazwa* Nr* Rok* MATURA LICEUM 1 N wydaje Data
133 Nazwa* Matura LICEUM 1 N Numer* Rok*... wydaje Data
134 Liceum Matura Nazwa*... 1 N Numer* Rok*... wydaje Data
135 Liceum Matura Nazwa*... 1 wydaje N Numer* Rok*... Data
136 Liceum Nazwa*... Matura Numer* Rok*... Data Nazwa
137 8. Związki unarne Kod Poczta Nip* 1 PRACOWNIK kieruje N Pracownik Nip* Kod Poczta... NipKier
138 9. Związki typu 1:1 Id* Data RokProd SAMOCHÓD DOWÓD 1 1 ma Id* Uwaga: dane obrazują dowody rejestracyjne aktualne NrRej
139 Dowód Id* Data ma NrRej Samochód Id* RokProd... a b c trzy możliwości
140 a b c Dowód Id* Data... NrRej IdSam RokProd... a) utrata informacji Samochód Id* RokProd... NrRej IdDow Data... b) puste pola Samochód Id* RokProd... Dowód Id* Data... NrRej IdSam
141 Przykład: komunikacja miejska Kolejność ma N M LINIA N M odjeżdża Nr* Czas Przecznica* Ulica* PRZYSTANEK Orientacja*
142 LINIA Nr* TRASA Ulica Przecznica Orientacja Nr Kolejność ODJAZD Ulica Przecznica Orientacja Nr Czas PRZYSTANEK Ulica* Przecznica* Orientacja*
143 Przykład: zapisy na wykłady Kierunek Nr* Rok STUDENT N Data zapisuje się M Id* PROFESOR N zgłasza M RokSem* Nazwa* WYKŁAD
144 STUDENT Nr* Kierunek Rok ZAPIS Nr Nazwa Data WYKŁAD Nazwa* PROFESOR Id* ZGŁOSZENIE Nazwa Id RokSem Uwaga: wstaw kółka!
145 Przykład: przelewy i zeznania DataOd Nip* Data posiada Typ N N PODATNIK zeznaje Numer* M M US RACHUNEK Nazwa* Data przelewa Kwota
146 PODATNIK NIP* ZEZNANIE NIP Nazwa Typ Data POSIADA NIP Numer OdKiedy PRZELEW NIP Numer Nazwa RACHUNEK Numer* US Nazwa* Uwaga: wstaw kółka!
147 Bazy danych Andrzej Łachwa, UJ, /14
148 Etapy tworzenia bazy danych analiza (zdefiniowanie i poznanie wycinka rzeczywistości, dla którego powstaje baza, wskazanie przyszłych użytkowników i określenie ich wymagań) projektowanie (tworzenie modelu logicznego i więzów integralności danych, transformacja do modelu fizycznego oraz jego normalizacja) implementacja (wybór systemu zarządzania i wykonanie skryptu definiującego znormalizowany model fizyczny) wdrożenie (wypełnienie bazy danymi początkowymi i uruchomienie aplikacji przeznaczonych dla użytkowników)
149 Semantyka schematu relacyjnej bazy danych Schemat bazy danych składa się ze schematów relacji i więzów integralności. Każdy schemat relacji ma atrybuty. Atrybuty posiadają znaczenia związane z rzeczywistością, której strukturę informacji odzwierciedlono w schemacie. Relacją opartą na schemacie nazywamy konkretny zbiór krotek zgodnych ze strukturą i spełniający przyjęte więzy integralności. Każdą relację opartą na schemacie interpretuje się jako zbiór zdań lub faktów opisujących obszar analizy.
150 Jeżeli projekt koncepcyjny zostanie wykonany starannie, a po nim dokona się systematycznego odwzorowania na relacje, większość materiału semantycznego zostanie uwzględniona i projekt wynikowy będzie niemal na pewno zrozumiały. Ogólnie rzecz biorąc, im łatwiej jest objaśnić znaczenie relacji, tym lepszy jest projekt jej schematu. Ramez Elmasri, Shamkant B. Navathe, str. 321
151 Właściwe pogrupowanie atrybutów w schematy relacji ma ogromny wpływ na przestrzeń pamięciową zajmowaną przez bazę. Źle zaprojektowany schemat prowadzi do niepotrzebnego zwiększenia koniecznej do przechowywania danych przestrzeni pamięciowej i powoduje m.in. anomalie wstawiania, anomalie usuwania i anomalie modyfikowania. W razie występowania w schematach anomalii tego rodzaju należy je dokładnie opisać i zapewnić, by procedury aktualizacji danych działały, mimo tych anomalii, poprawnie.
152 Należy unikać sytuacji, kiedy w wielu krotkach występują wartości NULL. Prowadzi to do zwiększenie przestrzeni pamięciowej oraz do trudności interpretacyjnych. Wartości puste mogą występować tylko w sytuacjach wyjątkowych i trzeba zadbać o to, by były zawsze właściwie interpretowane. Oto trzy często stosowane interpretacje wartości pustej: atrybut nie ma zastosowania, wartość atrybutu nie jest znana, wartość jest znana, ale jest nieobecna.
153 Należy unikać schematów, w których występują pasujące do siebie atrybuty (o tych samych nazwach i dziedzinach), które nie tworzą par: klucz główny, klucz obcy. Złączenia naturalne wykonane po takich atrybutach zwykle prowadzą do powstawania tzw. fałszywych krotek, tj. informacji, które nie odpowiadają opisywanej rzeczywistości. Aby atrybuty były właściwie pogrupowane w schematy, schematy te były łatwe do interpretacji w obszarze analizy i nie pojawiały się wymienione wyżej problemy, to oprócz starannie wykonanego i przemyślanego diagramu, oraz poprawnego mapowania na schemat relacyjnej bazy trzeba jeszcze przeprowadzić proces NORMALIZACJI.
154 Mówiąc najbardziej ogólnie proces normalizacji prowadzi do schematu w którym każdy fakt może być zapisany tylko jeden raz! Proces normalizacji korzysta z semantycznych zależności między atrybutami. Najważniejsze są zależności funkcyjne i zależności wielowartościowe. W dużym uproszczeniu zależność funkcyjna oznacza, że jeżeli znamy wartość jednego atrybutu, to możemy określić wartość drugiego. Na przykład, gdy znamy numer części, to możemy określić jej wagę czy kolor. Zależność wielowartościowa oznacza, że jeżeli znamy wartość jednego atrybutu, to możemy określić zbiory wartości innych atrybutów. Na przykład, gdy znamy numer części, to możemy określić numery wszystkich części, z których jest zbudowana.
155 Wybrane elementy MySQL W różnych produktach SQL spotkamy różne rozwiązania szczegółowe i pewne odchylenia od standardu języka. Skrypt języka SQL (zgodny z jakimś standardem) musi być niemal zawsze dopasowany do serwera na którym ma zostać uruchomiony!!! Poniżej wybrałem kilkanaście elementów specyficznych dla serwera MySQL.
156 1. SELECT Name FROM City WHERE Name LIKE 'kr%'; SELECT Name AS Nazwy 6 literowe na literę K FROM City WHERE Name LIKE 'k _'; SELECT Name FROM City WHERE Name LIKE BINARY 'Kr%'; domyślenie wielkość liter nie ma znaczenia (ale można zdefiniować kolumnę wymuszając rozróżnianie wielkości liter, np. Name VARCHAR(20) BINARY
157 2. SELECT 'David_' LIKE 'David\_'; -> 1 SELECT 'David_' LIKE 'David _' ESCAPE ' '; -> 1 SELECT 10 LIKE '1%'; -> 1
158 mysql> SELECT filename, filename LIKE '%\\' FROM t1; filename filename LIKE '%\\' C: 0 C:\ 1 C:\Programs 0 C:\Programs\
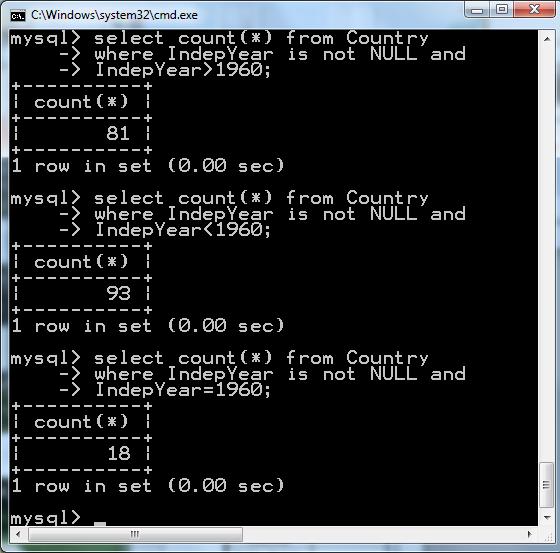
159 3. CREATE TABLE foo (bar VARCHAR(10)); INSERT INTO foo VALUES (NULL), (NULL); SELECT COUNT(*) FROM foo WHERE bar LIKE '%baz%'; > 0 SELECT COUNT(*) FROM foo WHERE bar NOT LIKE '%baz%'; > 0 SELECT COUNT(*) FROM foo WHERE bar NOT LIKE '%baz%' OR bar IS NULL; > 2
160 4. IF(expr1,expr2,expr3) Jeżeli expr1 jest TRUE (expr1 <> 0 oraz expr1 <> NULL) to zwraca expr2; w przeciwnym wypadku zwraca expr3. IF() zwraca wartość liczbową lub łańcuch znaków, zależnie od kontekstu. SELECT IF(1>2,2,3); -> 3 SELECT IF(1<2,'yes','no'); -> 'yes'
161 CASE ma dwie wersje. Pierwsza: CASE WHEN [condition] THEN result [WHEN [condition] THEN result...] [ELSE result] END SELECT CASE WHEN 1>0 THEN 'true' ELSE 'false' END; -> 'true' Druga wersja CASE: CASE value WHEN [compare_value] THEN result [WHEN [compare_value] THEN result...] [ELSE result] END SELECT CASE BINARY 'B' WHEN 'a' THEN 1 WHEN 'b' THEN 2 END; -> NULL
162 5. SELECT count(*) FROM City WHERE Population IS NULL; SELECT IFNULL(101,'yes'); -> 101 SELECT IFNULL(NULL,'yes'); -> 'yes' SELECT Name, IFNULL(Region,'---?---') FROM Country SELECT NULLIF(101,101); -> NULL SELECT NULLIF(101,102); -> 101
163 6. SELECT * FROM City WHERE (Population BETWEEN 1000 AND 2000) AND (Population NOT BETWEEN 1200 AND 1800); SELECT 2 BETWEEN 2 AND '3'; -> 1
164 7. SELECT Name FROM City ORDER BY Name LIMIT 10,5; 8. opuszcza pierwszych 10 wierszy, wyświetla 5 kolejnych i opuszcza wszystkie następne FIND_IN_SET(str,strlist) zwraca wartość od 1 do n, gdy strlist zawiera n elementów. SELECT FIND_IN_SET('b','a,b,c,d'); -> 2
165 9. FORMAT(X,D[,locale]) zwraca X jako łańcuch znaków w formacie '#,###,###.##', zaokrąglonym do D miejsc dziesiętnych. SELECT FORMAT( , 4); -> '12, ' SELECT FORMAT( ,4); -> '12, ' SELECT FORMAT( ,0); -> '12,332' SELECT FORMAT( ,2,'de_DE'); -> '12.332,20'
166 10. SELECT DISTINCT Continent FROM Country; SELECT max(population), min(population), avg(population), sum(population), count(population) FROM Country WHERE Continent LIKE 'Europe' AND Population IS NOT NULL; SELECT Ci.Name, Co.Name FROM City Ci, Country Co WHERE Code=CountryCode; [WHERE Co.Code=Ci.CountryCode]
167 11. CREATE TEMPORARY TABLE Names AS (SELECT Name FROM City UNION SELECT Name FROM Country); Sprawdź: SELECT count(*) FROM City; SELECT count(*) FROM Country; SELECT count(*) FROM Names; i wyjaśnij!
168 12. SELECT O.id "Nr zam.",left(c.name,10) AS "Klient", LEFT(P.name,10) AS "Produkt", O.payment_type AS "Platnosc", DATE_FORMAT(O.date_ordered, %d-%m-%y ) AS "Data", I.price AS "Cena", I.quantity AS "Ilosc" FROM customer C, ord O,item I, product P WHERE C.id=O.customer_id AND O.id=I.ord_id AND P.id =I.product_id AND O.payment_type = CREDIT AND O.date_ordered BETWEEN AND ORDER BY O.id, P.name;
169 SELECT O.id "Nr zam.", LEFT(C.name, 20) "Klient", LEFT(C.city, 20) "Miasto", SUM(I.price * I.quantity) "Suma" FROM customer C, ord O, item I, product P WHERE C.id = O.customer_id AND O.id = I.ord_id AND P.id = I.product_id AND O.payment_type = CREDIT AND O.date_ordered BETWEEN AND GROUP BY O.id, C.name, C.city ORDER BY O.id;
170 13. SELECT first_name, last_name, salary, title FROM emp E1 WHERE E1.salary < (SELECT AVG(salary) FROM emp E2 WHERE E2.title = E1.title) ORDER BY title, salary;
171 14. Funkcje RAND() i RAND(N) zwracają wartość losową z przedziału [0, 1). W drugim przypadku produkuje powtarzalną sekwencję liczb pseudolosowych. mysql> CREATE TABLE t (i INT); mysql> INSERT INTO t VALUES(1),(2),(3);
172 mysql> SELECT i, RAND() FROM t; i RAND() rows in set (0.00 sec) mysql> SELECT i, RAND() FROM t; i RAND() rows in set (0.00 sec)
173 mysql> SELECT i, RAND(3) FROM t; i RAND(3) rows in set (0.00 sec) mysql> SELECT i, RAND(3) FROM t; i RAND(3) rows in set (0.01 sec)
174 mysql> SELECT FLOOR(7+(RAND()*5)); zwraca całkowitą wartość losową z przedziału [7, 12) mysql> SELECT * FROM tbl_name ORDER BY RAND(); zwraca wiersze w kolejności losowej mysql> SELECT * FROM tbl_name ORDER BY RAND()LIMIT 10; zwraca 10 losowo wybranych wierszy
175 15. SELECT SUBSTRING('Quadratically',5); -> 'ratically' SELECT SUBSTRING('foobarbar' FROM 4); -> 'barbar' SELECT SUBSTRING('Quadratically',5,6); -> 'ratica' SELECT SUBSTRING('Sakila', -3); -> 'ila' SELECT SUBSTRING('Sakila', -5, 3); -> 'aki' SELECT SUBSTRING('Sakila' FROM -4 FOR 2); -> 'ki'
176
177 Zależności funkcyjne Wszystkie atrybuty schematu relacyjnej bazy danych nazwiemy, w celu ułatwienia prezentacji pewnych problemów teoretycznych, relacją uniwersalną schematu. R = {A 1, A 2, A n } Zależność funkcyjna to wiązanie integralności między atrybutami: X A, gdzie XTR i AXR, które oznacza, że dla dowolnych krotek t 1 i t 2 należących do relacji r(r): jeżeli t 1 [X]=t 2 [X] to t 1 [A]=t 2 [A].
178 Innymi słowy, wartości atrybutów tworzących zbiór X krotki t relacji r(r) jednoznacznie determinują wartość tej krotki dla atrybutu A. Zależność funkcyjna jest własnością schematu R i ma być spełniona przez wszystkie relacje r(r) rozpięte na tym schemacie. Dla uproszczenia zapisów przyjmujemy, że X Y, gdzie XTR, A i XR, { A 1, A 2, A k } = Y oznacza X A 1, X A 2, X A k.
179 Dla danego schematu relacji o atrybutach tworzących zbiór X, jeżeli Y jest kluczem kandydującym (każda krotka ma inną niepustą wartość na atrybutach Y), to Y Z dla dowolnego podzbioru Z zbioru atrybutów X. Uwaga: przyjmujemy, że klucz kandydujący jest kluczem minimalnym, tzn., że nie można z niego usunąć żadnego atrybutu bez utraty własności identyfikowania krotek.
180 Zależność funkcyjna jest własnością semantyczną(!), a nie własnością formalną. Zależność funkcyjna jest odkrywana przez projektanta. Nie da się jej udowodnić. Można ją tylko uzasadnić właściwościami obszaru analizy. Podobnie jest z innymi więzami integralności. Określenie dziedziny atrybutu, możliwość przyjmowania wartości pustej i jej interpretacja, określenie kluczy kandydujących i wybranie klucza głównego to wszystko decyzje projektanta oparte na jego znajomości obszaru analizy.
181 Projektant określa zależności funkcyjne schematu R, które są semantycznie oczywiste. Niech będzie to zbiór zależności F. Czy dla wszystkich relacji r(r) rozpiętych na tym schemacie mogą istnieć jakieś inne zależności funkcyjne (nie wskazane przez projektanta)? Zwykle tak. Można je wydedukować ze zbioru zależności F i pewnych reguł. Wszystkie zależności zbioru F i wszystkie zależności funkcyjne które można wydedukować ze zbioru F nazywamy domknięciem tego zbioru i oznaczamy F +.
182 Reguły wnioskowania dla zależności funkcyjnych ax X X (zwrotność) X Y ax XZ YZ (powiększanie) X Y, Y Z ax X Z (przechodniość) X YZ ax X Y (dekompozycja) X Y, X Z ax X YZ (sumowanie) X Y, WY Z ax WX Z (pseudoprzechodniość) gdzie napis PQ oznacza dla atrybutów {P, Q} a dla zbiorów atrybutów P U Q, oraz ax jest znakiem inferencji.
183 Pierwsze trzy reguły noszą nazwę aksjomatów Armstronga, albo (lepiej) reguł wnioskowania Armstronga. Mają one tę własność, że można z nich wyprowadzić pozostałe reguły, ale nie można usunąć żadnej z nich, bo stracą tę własność. Domknięcie zbioru zależności F można zatem uzyskać stosując do tych zależności reguły Armstronga. Robi się to zwykle poprzez domknięcie każdego zbioru X (stojącego po lewej stronie zależności funkcyjnej) względem zbioru zależności F. Dwa zbiory zależności funkcyjnych E i F są równoważne wtw gdy E + = F +.
184 Algorytm domknięcia zbioru X wględem F X + := X; repeat oldx + := X + ; for each zależność funkcyjna Y Z w F do if X + VY then X + := X + U Z; until X + = oldx + ; O minimalnych zbiorach zależności funkcyjnych zobacz: [Ramez Elmasri, Shamkant B. Navathe, str. 336]
185 Statystyki w języku SQL W różnych produktach SQL spotkamy rozmaite funkcje wbudowane ułatwiające analizy statystyczne. Jeżeli nie zależy nam na przenośności kodu, to lepiej użyć funkcji wbudowanych.
186 Zacznijmy od najprostszych statystyk (dla bazy World): select c.continent, count(c.continent) as frequency, round(100.0*(count(c.continent))/ (select count(*) from country),2) as percent from country as c group by continent; create temporary table statistics as select c.continent, count(c.continent) frequency, round(100.0*(count(c.continent))/ (select count(*) from country),2) as percent from country as c group by continent order by percent desc;
187
188 select continent,stat.frequency, (select sum(s.frequency) from stats as s where s.frequency>=stat.frequency) as cumulative from stats as stat;
189 select continent, stat.frequency, percent, (select sum(s.percent) from stats as s where s.percent>=stat.percent) as cum_percent from stats as stat;
.")
190 Wartość modalna Wartość modalna to wartość najczęściej pojawiająca się w zbiorze (jeśli są takie dwie wartości, to mówimy że rozkład jest dwumodalny, podobnie trzymodalny etc.). Wykonajmy to zapytanie w kilku krokach:

191

192

193
194
195 Wartość modalna jest słabą statystyką. Na przykład 1. gdy liczymy modalne pobory wśród pracowników, to dokładna wartość tej zmiennej nie jest dobra lepiej dopuścić kilkuprocentowe odchylenie: having count(*)>= all (select count(*)*0.95 from 2. gdy dwie częstości są blisko siebie to dobrym rozwiązaniem jest dopuszczenie odchylenia k wartości

196 Wartość średnia [MySQL 5.6 Reference Manual, p. 1372]
197
198 Mediana Jest to wartość, dla której jest dokładnie tyle samo elementów o wartościach od niej niższych, co elementów o wartościach od niej wyższych. Jeśli taka wartość istnieje w zbiorze danych to nazywamy ją medianą statystyczną, jeżeli nie, to oblicza się medianę finansową. Zbiór danych dzieli się wtedy na dwa równoliczne, tak by elementy pierwszego były mniejsze od elementów drugiego, następnie oblicza się średnią między maksimum pierwszego i minimum drugiego. Inne nazwy: wartość środkowa, wartość przeciętna. Z medianą statystyczną jest problem, gdy wartości środkowych jest kilka (wskazany wyżej podział jest wówczas niemożliwy).
199
200
201
202 Kwartyle Kwartyle dzielą wszystkie obserwacje na cztery równe co do ilości grupy.kwartyl pierwszy (Q1) dzieli obserwacje w stosunku 25% do 75%, co oznacza, że 25% obserwacji jest niższa bądź równa wartości Q1, a 75% obserwacji jest równa bądź większa niż Q1. Kwartyl drugi (Q2), inaczej zwany medianą(!), dzieli obserwacje na dwie części w stosunku 50% do 50%. Kwartyl trzeci (Q3) dzieli obserwacje w stosunku 75% do 25%, co oznacza, że 75% obserwacji jest niższa bądź równa wartości Q3, a 25% obserwacji jest równa bądź większa niż Q3. Odchylenie ćwiartkowe (Q), to połowa różnicy między trzecim a pierwszym kwartylem.
203 Kwantyle Kwantylem rzędu p z przedziału (0,1) jest taka wartość x p zmiennej losowej, że wartości x p są przyjmowane z prawdopodobieństwem co najmniej p, a wartości x p są przyjmowane z prawdopodobieństwem co najmniej 1 p. Kwantyl rzędu ½ to inaczej mediana. Kwantyle rzędu ¼, 2/4, 3/4 to kwartyle Kwantyle rzędu ⅕, ⅖, ⅗, ⅘ to kwintyle. Kwantyle rzędu 1/10, 2/10, to decyle.
204 Przykład
205
206 Pierwsza mediana Date'a
207
208

209
210 a teraz dodam 4 i powinno być
211 skrypt.txt insert into foo(bar) value (4); drop view foo1; drop view foo2; create view foo1 as select bar from foo union all select bar from foo; create view foo2 as select bar from foo1 where (select count(*) from foo)<= (select count(*) from foo1 as f1 where f1.bar>=foo1.bar) and (select count(*) from foo)<= (select count(*) from foo1 as f2 where f2.bar<=foo1.bar); select avg(distinct bar) as median from foo2;
212

213 Pierwsza mediana Celko Liczymy osobno najmniejszą wartość w górnej połowie i największą wartość w dolnej połowie. Operacja grupowania przebiega po wszystkich wierszach tabeli F1 i dlatego należy tabelę FOO uzupełnić o klucz ID:
214
215 Tabela krzyżowa Tworzymy tabelę pomocniczą a następnie połączymy ją z tabelą danych sprzedaży z czterech lat od 2003 do 2006.

216

217

218
219 Ćwiczenie: Wygeneruj wypłaty dla kilku bankomatów dla jednego miesiąca i wykonaj dla takich danych tabelę krzyżową.
220
221 Normalizacja Proces prowadzi do kolejnych, coraz lepszych poziomów normalizacji zwanych postaciami normalnymi: pierwszą, drugą, trzecią, Boyce'a-Codda, czwartą i piątą (1NF, 2NF, 3NF, BCFN, ). Proces normalizacji realizujemy przez dekompozycję schematów relacji. Proces ten musi brać pod uwagę właściwość złączenia bezstratnego i właściwość zachowania zależności. Ta druga może być niekiedy pomijana. Atrybut relacji nazywamy podstawowym (prymarnym), gdy należy do któregokolwiek klucza kandydującego. Gdy nie należy do żadnego klucza, to nazywamy go nieprymarnym.
222 1NF Każdy schemat relacji musi posiadać klucz główny. Dziedzina każdego atrybutu musi zawierać wyłącznie wartości niepodzielne (atomowe), a wartość każdego atrybutu krotki musi być pojedynczą wartością z dziedziny. W takiej sytuacji każdy atrybut jest funkcyjnie zależny od klucza.
223 BŁĄD 1 Macierze lub listy są ukryte w tabeli poprzez spłaszczenie faktycznej struktury. BŁĄD 2 Używanie kilku kolumn, które mają tę samą wartość semantyczną. BŁĄD 3 Lista wartości wpisana do łańcucha znaków.
224 2NF Schemat jest w 1NF i żaden nieprymarny atrybut nie jest częściowo zależny od dowolnego klucza. Mówimy krótko, że w tej postaci nie występują zależności częściowe. Rozkład schematu do 2NF polega na pozbyciu się zależności częściowych.
225 3NF Zależność X A jest nazywana nietrywialną, gdy A nie jest elementem zbioru X. Schemat jest w 2NF i dla każdej nietrywialnej zależności X A albo X jest nadkluczem albo A jest prymarny. Innymi słowy, żaden nieprymarny atrybut nie jest przechodnio zależny od klucza. Musi zależeć od klucza, całego klucza i tylko od klucza! Rozkład schematu do 3NF polega na pozbyciu się zależności przechodnich.
226 BCNF Jest to silniejsza wersja 3NF. Wymaga się, by dla każdej nietrywialnej zależności X A zbiór atrybutów X był nadkluczem. Przeczytaj rozdział 10 [Ramez Elmasri, Shamkant B. Navathe] Zob. wykład o normalizacji na

227
228 Rozkład schematu na podschematy: Praca (NrPracownika, NrProjektu, Data, IleGodzin, Imię, Nazwisko, Termin) KartaPracy (NrPracownika, NrProjektu, Data, IleGodzin) Pracownik (NrPracownika, Imię, Nazwisko) Projekt (NrProjektu, Termin)

229

230
231 Rozkład schematu na podschematy: Uczniowie (NrUcznia, NrKlasy, Wychowawca) Uczniowie (NrUcznia, NrKlasy) Klasy (NrKlasy, Wychowca)

232
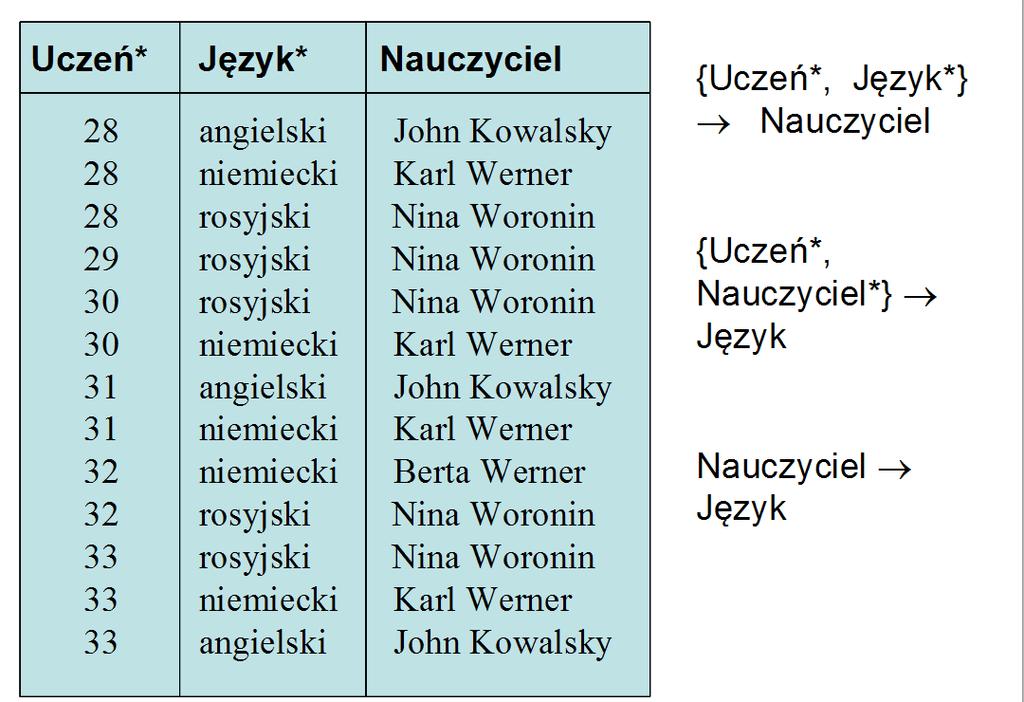
233

234
235
236
237
238
239
240
241 Przykład {UCZEŃ*, JĘZYK*, NAUCZYCIEL} {UCZEŃ, JĘZYK} NAUCZYCIEL NAUCZYCIEL JĘZYK Są możliwe trzy rozkłady: {UCZEŃ*, NAUCZYCIEL*}, {UCZEŃ*, JĘZYK} {JĘZYK, NAUCZYCIEL*}, {JĘZYK*, UCZEŃ*} {NAUCZYCIEL*, JĘZYK}, {NAUCZYCIEL*, UCZEŃ*} Tylko trzeci rozkład, po złączeniu, nie będzie generował fałszywych krotek!
242 Tabele pomocnicze Tabele pomocnicze nie są częścią modelu danych, więc nie powinny pojawiać się na etapie projektowania koncepcyjnego. Wyróżnimy dwa rodzaje takich tabel: tabele słownikowe i tabele funkcyjne. Rozważmy dwa przypadki tabel słownikowych: listę nazw województw oraz listę nazw państw świata. Obie listy powinny być używane zawsze wtedy, gdy użytkownik bazy danych będzie mógł wprowadzać te nazwy jako dane. Wprowadzanie to powinno być zawsze (w tego rodzaju przypadkach) ograniczone do wyboru elementu z listy!... Sprawa nie jest jednak prosta (por. alfabetyczny wykaz krajów ).
243 Tabela funkcyjna jest sposobem zdefiniowania funkcji. Tabela ta jest wykorzystywana do wykonywania zapytań. Często tworzoną tabelą funkcyjną jest kalendarz. Jest tak m. in. dlatego, że daty świąt są bardzo nieregularne (np. wyznaczanie świąt ruchomych, takich jak Wielkanoc czy Ramadan, przy użyciu funkcji byłoby bardzo trudne). Wielkość kalendarza na 20 lat to tylko około 7000 wierszy, czyli bardzo mała tabela. Tabelę taką zapełniamy danymi przygotowanymi w arkuszu kalkulacyjnych bądź pobranymi z Internetu i zabraniamy modyfikacji tych danych użytkownikom bazy (z wyłączeniem administratora danych, bo przecież mogą następować zmiany ustawowe regulujące liczbę i terminy świąt, terminy wakacji szkolnych itp.). Por. kalendarz świąt
244
245 Rozkłady schematów Proces normalizacji polega na rozbijaniu schematów relacji na mniejsze, aż przestanie to być możliwe lub pożądane. Rozkłady powinny pozwalać na złączenie nieaddytywne (odwracalność) oraz w miarę możliwości zachowywać zależności. Rozkład zachowuje zależności jeżeli zbiór zależności w podschematach jest równoważny początkowemu zbiorowi zależności. Rozkład schematu na podschematy nazywamy odwracalnym wtw gdy każda relacja rozpięta na tym schemacie jest złączeniem naturalnym swoich rzutów na podschematy.
246
247
248
249 TABELA POŁĄCZEŃ Rozważmy typowy przykład związku binarnego wiele do wielu oraz odpowiadającego mu schematu złożonego z 3 tabel. M N
250 CREATE TABLE Chłopcy (ImięCh VARCHAR(30) PRIMARY KEY); CREATE TABLE Dziewczyny (ImięD VARCHAR(30) PRIMARY KEY); CREATE TABLE Pary (ImięCh VARCHAR(30), ImięD VARCHAR(30)); Do tabeli Pary możemy wstawić przykładowe wiersze: (Adam, Anna) (Adam, Barbara) (Karol, Barbara) (Adam, Celina) (Adam, Anna) Teraz wprowadzamy więzy integralności. Po pierwsze, nie chcemy dopuszczać wierszy typu (Adam, NULL) czy (NULL, Celina).
251 CREATE TABLE Pary ( ImięCh VARCHAR(30) NOT NULL, ImięD VARCHAR(30) NOT NULL); Po drugie, chcemy aby chłopcy i dziewczyny były wybierane z tabel odpowiadającym typom encji Chłopcy i Dziewczyny. Po trzecie, gdybyśmy chcieli poprawić pisownię imienia w którejś z tabel łączonych, to zmiana ta powinna zostać odzwierciedlona w tabeli połączeń. Po czwarte, gdybyśmy chcieli usunąć z bazy jakąś osobę (encję), to wszystkie pary zawierające imię tej osoby również powinny być usunięte.
252 CREATE TABLE Pary ( ImięCh VARCHAR(30) NOT NULL REFERENCES Chłopcy (ImięCh) ON UPDATE CASCADE ON DELETE CASCADE, ImięD VARCHAR(30) NOT NULL REFERENCES Dziewczyny (ImięD) ON UPDATE CASCADE ON DELETE CASCADE); Po piąte, chcemy zapobiegać powtarzającym się informacjom (w naszym zestawie danych wiersz 1 i wiersz 5).
253 CREATE TABLE Pary ( ImięCh VARCHAR(30) NOT NULL REFERENCES Chłopcy (ImięCh) ON UPDATE CASCADE ON DELETE CASCADE, ImięD VARCHAR(30) NOT NULL REFERENCES Dziewczyny (ImięD) ON UPDATE CASCADE ON DELETE CASCADE, PRIMARY KEY (ImięCh, ImięD)); Po szóste', chcemy by chłopak mógł być w kilku parach, a każda dziewczyna tylko w jednej!
254 CREATE TABLE Pary ( ImięCh VARCHAR(30) NOT NULL REFERENCES Chłopcy (ImięCh) ON UPDATE CASCADE ON DELETE CASCADE, ImięD VARCHAR(30) NOT NULL UNIQUE REFERENCES Dziewczyny (ImięD) ON UPDATE CASCADE ON DELETE CASCADE, PRIMARY KEY (ImięCh, ImięD)); Po szóste'', chcemy by dziewczyna mogła być w kilku parach, a każda chłopak tylko w jednej! I wreszcie po siódme, ograniczmy się do związków monogamicznych.
255 CREATE TABLE Pary ( ImięCh VARCHAR(30) NOT NULL UNIQUE REFERENCES Chłopcy (ImięCh) ON UPDATE CASCADE ON DELETE CASCADE, ImięD VARCHAR(30) NOT NULL UNIQUE REFERENCES Dziewczyny (ImięD) ON UPDATE CASCADE ON DELETE CASCADE, PRIMARY KEY (ImięCh, ImięD)); Mamy tu tzw. klucze zagnieżdżone i klucz nadmiarowy.
256 MODELOWANIE HIERARCHII KLAS W wielu projektach występują klienci-osoby i klienci-firmy. Wygodnie jest modelować tę sytuację jako związek klasy KLIENCI z podklasami OSOBY i FIRMY.
257 CREATE TABLE Klienci ( id CHAR(5) PRIMARY KEY, typ CHAR(1) NOT NULL CHECK(typ IN('O', 'F')), staż TINYINT UNSIGNED NOT NULL DEFAULT 0, obroty DECIMAL(5,2),, UNIQUE (id, typ)); Jakie ograniczenia wprowadzić w podklasach?
258 CREATE TABLE Osoby ( id CHAR(5) PRIMARY KEY, typ CHAR(1) DEFAULT 'O' NOT NULL CHECK (typ='o'), UNIQUE (id, typ) FOREIGN KEY (id, typ) REFERENCES Klienci(id, typ) ON UPDATE CASCADE ON DELETE CASCADE... ); CREATE TABLE Firmy ( id CHAR(5) PRIMARY KEY, typ CHAR(1) DEFAULT 'F' NOT NULL CHECK(typ='F'), UNIQUE (id, typ)...
259 Teraz można to wszystko ukryć w widokach: CREATE VIEW NasiKlienci (Id, Staż, Obroty, ) AS (SELECT Id, Staż, Obroty FROM Klienci); CREATE VIEW OsobyFizyczne (Id, Tytuł, Imię, Nazwisko ) AS (SELECT Id, Tytuł, Imię, Nazwisko FROM Osoby); CREATE VIEW OsobyPrawne (Id, Nazwa, FormaPrawna, ) AS (SELECT Id, Nazwa, FormaPrawna, FROM Firmy);
260 NORMALIZACJA: zależności wielowartościowe Zależność taka powstaje wtedy, gdy encje danego typu posiadają dwa niezależne atrybuty wielowartościowe. Np. student zna kilka języków obcych i kilka języków programowania. W odpowiedniej relacji musi wtedy wystąpić wiele krotek dla każdego studenta i muszą być powtarzane wszystkie wartości jednego atrybutu dla każdej wartości drugiego: Adam Abacki; rosyjski; C++ Adam Abacki; rosyjski; Java Adam Abacki; rosyjski; SQL Adam Abacki; angielski; C++ Adam Abacki; angielski; Java Adam Abacki; angielski; SQL
261 Zależność wielowartościowa pojawia się nie tylko wtedy, gdy w ramach jednego schematu połączymy dwa atrybuty wielowartościowe jednego typu encji, ale także wtedy gdy w jednym schemacie przedstawimy dwa związki jednego typu encji. Np. tabelę przedstawioną wyżej można skojarzyć ze strukturą encji typu STUDENT o dwóch atrybutach wielowartościowych: JĘZYK_NATURALNY, JĘZYK_ PROGRAMOWANIA. Tę samą strukturę informacji można przedstawić jako dwa związki wychodzące z encji typu STUDENT: związek z encjami JĘZYK_NATURALNY i związek z encjami JĘZYK_ PROGRAMOWANIA. Zamiana na schemat uwzględniający oba związki doprowadzi do powstania zależności wielowartościowej.
262 Zauważmy, że prawidłowo wykonane mapowanie dla obu podanych struktur nie doprowadzi do omawianej tabeli z zależnością wielowartościową. W przypadku dwóch związków na diagramie będziemy mieć typy encji STUDENT, JĘZYK_P, JĘZYK_O i dwa związki łączące studenta z językami. Oba związki są typu wiele do wielu i powinny przejść w oddzielne tabele!
263 Definicja Między zbiorami atrybutów X, Y schematu R zachodzi zależność wielowartościowa X Y wtw gdy dla każdej relacji r rozpiętej na R zachodzi: jeżeli w r istnieją krotki t 1 i t 2 takie że t 1 [X]=t 2 [X] to istnieją również krotki krotki t 3 i t 4 takie że t 1 [X]=t 2 [X]=t 3 [X]=t 4 [X] t 1 [Y]=t 3 [Y] oraz t 2 [Y]=t 4 [Y] t 2 [Z]=t 3 [Z] oraz t 1 [Z]=t 4 [Z] gdzie Z=R (XUY).
264 Kiedy w R zachodzi X Y to również zachodzi X Z. Zależność wielowartościową X Y nazywamy trywialną gdy YTX lub R=XUY. Reguły dla zależności wielowartościowych: (1) X Y ax X (R XY) (uzupełnianie) (2) X Y, W V Z ax WX YZ (zwiększanie) (3) X Y, Y Z ax X (Z Y) (przechodniość) gdzie X, Y, Z, W to zbiory atrybutów z R(A 1, A 2, A n ), napis PQ oznacza dla atrybutów {P, Q} a dla zbiorów atrybutów P U Q, oraz ax jest znakiem inferencji.
265 Reguły dla zależności funkcyjnych i wielowartościowych: (4) X Y ax X Y (replikacja) (5) X Y oraz istnieje W taki że WWY=, W Z, YVZ ax X Z (scalanie) Reguły Armstronga, reguły (1)-(3) oraz reguły (4) i (5) stanowią łącznie minimalny i zupełny zbiór reguł wnioskowania dla zależności obu typów (funkcyjnych i wielowartościowych). Używając tych reguł można zbudować domknięcie dowolnego zbioru zależności obu typów.
266 4NF Schemat relacji R ze zbiorem F zależności funkcyjnych i zależności wielowartościowych znajduje się w czwartej postaci normalnej gdy dla każdej nietrywialnej zależności X Y w domknięciu F + zbiór X jest nadkluczem. R(A, B, C, D, E); AB C wtedy na podstawie (1) mamy AB DE (obie zależności są nietrywialne) rozkładamy schemat: R 1 (A, B, C); AB C i R 2 (A, B, D, E); AB DE
267 Zależności złączeniowe i 5NF Może się zdarzyć, że schemat jest już w 4NF oraz istnieje odwracalny rozkład na trzy lub więcej podschematów. Mówimy wtedy o występowaniu zależności złączeniowej. Schemat jest w 5NF jeżeli dla każdej nietrywialnej zależności złączeniowej każdy podschemat wynikający z tej zależności zbudowany jest z atrybutów stanowiących nadklucz klucza schematu.
268 Przykład [Elmasri, Navathe, s.373] Dostawa (Dostawca, Część, Projekt) Nowak, śruba, P1 Nowak, nakrętka, P2 Adamski, śruba, P2 Warecki, nakrętka, P3 Adamski, gwóźdź, P Adamski, śruba, P1 Nowak, śruba, P2 R1 (Dostawca, Część), R2 (Dostawca, Projekt), R3 (Część, Projekt)
269 Postać normalna klucza dziedziny DKNF Jest to ostateczna postać normalna, która uwzględnia wszystkie rodzaje zależności i więzów. Schemat jest w DKNF jeżeli wszystkie więzy i zależności, które powinny być zachowane w każdej relacji rozpiętej na tym schemacie, mogą być wymuszane przez więzy domenowe i więzy kluczy (kluczy głównych i kluczy obcych). Wymuszenie ogólnych więzów integralności (np., że średnia płaca pracownika danej jednostki nie może być mniejsza od połowy płacy kierownika tej jednostki) przez domeny i klucze może być niewykonalne. Zwykle konieczne jest zdefiniowanie odpowiedniej procedury, asercji czy triggera.
270 Przegląd typów danych w MySQL Zob. MySQL 5.6 Reference Manual
271
272 Przechowywanie danych Wykorzystanie systemu plików, dostępu do plików za pośrednictwem systemu operacyjnego i proste rozwiązanie polegające na przechowywaniu każdej tabeli w jednym pliku, informacji o strukturze tabeli w innym pliku, a wyników operacji na tabelach w kolejnym pliku - nie nadaje się do stosowania w bazach danych!
273 Oto kilka powodów: modyfikacja jednego wiersza może spowodować konieczność przesunięcia wszystkich wierszy w pliku, przeszukiwanie może być bardzo kosztowne, bo np. warunek zapytania będzie sprawdzany dla każdego wiersza, działanie takie jak złączenie dwóch tabel będzie realizowane jako utworzenie nowej tabeli zawierającej złączone wiersze, wszystkie dane będą cały czas przechowywane w plikach na urządzeniu pamięci zewnętrznej, użytkownicy nie będą mogli jednocześnie modyfikować tej samej tabeli (tego samego pliku), w wyniku awarii urządzenia można utracić dane bądź wyniki operacji na danych.
274 W rezultacie nawet bardzo proste operacje wymagałyby nieustannego odczytywania i zapisywania zwykle bardzo dużych plików (plików, które nie mieszczą się w pamięci operacyjnej). System zarządzania bazami danych musi wykorzystywać hierarchię pamięci i stosować różne strategie prowadzące do zwiększania wydajności.
275 Przykładem takiej strategii jest szeregowanie żądań dostępu algorytmem windy. Głowice dysku przesuwają się w kierunku od najbardziej wewnętrznego cylindra do najbardziej zewnętrznego i z powrotem. Gdy osiągną cylinder, którego dotyczy żądanie, wykonują żądane zapisy i odczyty, i przesuwają się dalej. Gdy osiągną położenie dla którego nie ma już żądań dla dalszych cylindrów, to zatrzymują się i rozpoczynają ruch w przeciwnym kierunku. Innym przykładem jest wykorzystanie hierarchii pamięci przez wstępne ładowanie bloków. System przewiduje kolejność żądań dostępu do bloków i przesyła bloki do szybszej pamięci, zanim pojawi się żądanie.
276 Najmniejsza, najszybsza i najdroższa jest pamięć podręczna ( cache ) procesora. Pracuje ona z szybkością procesora. Pamięć podręczna poziomu pierwszego (L1-cache) jest zintegrowana w jednym układzie scalonym z mikroprocesorem. Pamięć podręczna poziomu drugiego (L2-cache) stanowi odrębny układ scalony. Kolejno wprowadzono pamięci L3-cache i L4- cache. Pamięci kolejnych poziomów są coraz większe, ale dostęp do danych jest coraz wolniejszy.
277 Dla przykładu, procesor Intel Core i7-5960x ma pamięci: cache L1: 8 x 32kB + 8 x 32 kb cache L2: 8 x 256 kb cache L3: 20 MB i pracuje z szybkością od 3,0 do 3,5 GHz.
278 Większa, wolniejsza ale tańsza jest pamięć operacyjna. Każdej wartości z pamięci podręcznej odpowiada dokładnie jedna wartość w pamięci operacyjnej. Zmiana wartości w pamięci podręcznej często wymaga natychmiastowego skopiowania tej wartości do pamięci operacyjnej; szczególnie w systemach wieloprocesorowych. Obecnie pamięci operacyjne DDR3 DIMM (zwykle 1600 MHz) w komputerach osobistych mają wielkość 8, 16 lub 32 GB, czyli są nawet 1000 razy większe od pamięci cache, ale dostęp do danych jest około 10 razy wolniejszy niż do cache procesora. Podobnie pamięci DDR4 (dwukrotnie większa częstotliwość, rzędu 4000 MHz).
279 Pamięci zewnętrzne w postaci dysków magnetycznych mają pojemność 1 TB lub większą, czyli są około 100 razy większe od pamięci operacyjnych. Czas dostępu (do bloku) jest rzędu >10 ms, podczas gdy dla pamięci cache są to nanosekundy. Dyski SSD mają czas dostępu rzędu >0,1 ms, ale nie oznacza to, że są 100 razy szybsze. Dla przykłady transfery danych zmierzone dla szybkich dysków HDD i SDD wyniosły obecnie odpowiednio 160 MB/s i 400 MB/s. Transfer danych dla SSD jest więc tylko 2,5 raza większy.
280 Pamięci dyskowe zaliczamy do drugorzędnych. Niekiedy wciąż stosowane są jeszcze pamięci trzeciorzędne (pamięci te wymagają znalezienia odpowiedniego nośnika i załadowania go do urządzenia). Pojemności są oczywiście dowolnie duże, ale czas dostępu liczy się tutaj w sekundach, a nawet w minutach.
281 Algorytm wstępnego ładowania bloków przenosi do pamięci operacyjnej całą ścieżkę lub cały cylinder dysku, zanim nastąpi żądanie dostępu do zapisanych tam danych. Podobnie działa wstępne ładowanie danych do pamięci podręcznej. Dane są tam przenoszone, zanim pojawi się żądanie ich odczytu. Przyczytaj: wykład 6 Garcia-Molina, Ullman, Widom...: rozdział 11
282 WSPÓŁBIEŻNOŚĆ Serwer bazodanowy nie może obsługiwać klientów sekwencyjnie: wszyscy musieli by czekać na obsłużenie przez serwer w kolejce. W przypadku większości systemów komunikujących się z bazami danych (np. internetowe programy rezerwacji, systemy bankowe, kasy w supermarketach) wymaga się krótkich czasów odpowiedzi dla setek równolegle pracujących użytkowników. Nie można ich ustawić w kolejkę! Sterowanie współbieżnością to proces zapewniający możliwość przetwarzania opartego na współistnieniu wielu procesów operujących na wspólnych (współdzielonych) danych w SZBD.
283 Transakcją nazywamy grupę instrukcji, które muszą być wykonane, aby odpowiednie zmiany zostały zapisane w bazie. Jeżeli chociaż jedna instrukcja z takiej grupy zakończy się niepowodzeniem, wówczas działanie wszystkich jest odwoływane. BEGIN TRANSACTION rozpoczęcie transakcji COMMIT zakończenie transakcji z zaakceptowaniem wszystkich zmian ROLLBACK zakończenie transakcji z wycofaniem wszystkich zmian ROLLBACK TO SAVEPOINT NazwaPunktuZapisu zakończenie transakcji z wycofaniem wszystkich tych zmian, które nastąpiły od zdefiniowanego (w czasie działania transakcji) punktu zapisu NazwaPunktuZapisu.
284 Transakcja powinna spełniać właściwości określane jako ACID: niepodzielność (Atomicity) spójność (Consistency) izolacja (Isolation) trwałość (Durability) Atomowość to niepodzielność transakcji: albo wszystkie modyfikacje danych zakończą się sukcesem, albo żadna modyfikacja nie nastąpi. Zatem, jeżeli z jakiegoś powodu transakcja nie może być zakończona, to tzw. mechanizm odtwarzania musi zapewnić wycofanie wszystkich zmian wprowadzzonych już przez tę transakcję w bazie danych.
285 Spójność oznacza, że po zakończeniu transakcji baza musi być w stanie spójnym, tj. muszą być zachowane wszystkie więzy integralności, a wewnętrzne struktury bazy (np. indeksy) powinny być doprowadzone do prawidłowego stanu. Własność izolacji mówi, że modyfikacje przeprowadzane przez daną transakcję muszą być odizolowane od innych działających transakcji, nie może kolidować ze współbieżnym wykonywaniem innych transakcji. Trwałość po zakończeniu transakcji jej efekty muszą pozostać w bazie na stałe. Nie mogą zostać utracone w wyniku jakiejkolwiek awarii.

286 PROBLEMY Z TRANSAKCJAMI 1. Problem utraconej modyfikacji (lost update). Modyfikacja wykonana w t 6 przez transakcję A zostaje utracona w momencie t 8.
 przez inną transakcję jeszcze nie zatwierdzoną.")
287 2. Problem czytania brudnopisu (dirty read): Transakcja A odczytuje w czasie t4 wartość zmodyfikowaną wcześniej (w czasie t2) przez inną transakcję jeszcze nie zatwierdzoną. W momencie cofnięcia transakcji B odczyt w czasie t4 staje się fałszywy.

288 3. Problem niespójnej analizy (non-repeatable read): Transakcja A sumuje salda 3 rachunków (r 1, r 2, r 3 ) o wartościach w czasie t1: 200 zł, 300 zł i 4000 zł. Równolegle transakcja B wykonuje przelew 1000 zł z rachunku r 3 na r 1. Gdyby A wykonać ponownie w czasie t10 t12 to wynik byłby inny.
289 4. Wiersze widma (phantom reads): Transakcja A odczytuje rekordy, które spełniają pewne kryterium wyboru. Druga transakcja (B) wstawia nowe rekordy do tej samej tabeli, przy czym niektóre z nich spełniają kryterium sprawdzane przez A. Transakcja B może również modyfikować wiersze w taki sposób, że dodatkowe rekordy zaczną spełniać to kryterium. Mogą zatem pojawić się takie rekordy (fantomy), które spełniają dane kryterium, a które nie zostały odczytane przez A.
290 Lekarstwo na problemy: BLOKADY blokady wyłączne (typu X, blokady do zapisu) blokady wspólne (typu S, blokady do odczytu) 1. Jeśli transakcja założy blokadę X na krotkę p, to próba założenia jakiejkolwiek blokady przez inną transakcję na tej samej krotce zostanie oddalona. 2. Jeśli transakcja A założy blokadę S na krotkę p, to: próba założenia blokady X przez transakcję B na tej samej krotce zostanie oddalona, próba założenia blokady S przez transakcję B na tej samej krotce zostanie zaakceptowana, czyli obie transakcje będą blokować p.
291 Propozycja protokołu dostępu do danych 1. Transakcja, która chce uzyskać dostęp do krotki, musi najpierw uzyskać blokadę S na tej krotce. 2. Transakcja, która chce modyfikować krotkę, musi najpierw uzyskać blokadę X na tej krotce. Jeśli transakcja wcześniej założyła blokadę S, to musi ona zwiększyć poziom blokady z S do X. 3. Jeżeli żądanie blokady od transakcji B zostanie odrzucone ze względu na to, że jest w konflikcie z blokadą założoną wcześniej przez transakcję A, to B przechodzi w stan oczekiwania aż ta blokada zostanie zdjęta (system powinien dbać o to, by transakcja B nie czekała w nieskończoność, tj. by nie nastąpiło zagłodzenie). 4. Blokady S i X są utrzymywane do końca działania transakcji (tj. do polecenia COMMIT lub ROLLBACK).
292 Zakleszczenia Zakleszczenie to sytuacja, w której dwie lub więcej transakcji oczekuje na zwolnienie wzajemnej blokady. Strategie rozwiązywania zakleszczeń: 1. cofnąć losowo wybraną transakcję 2. cofnąć transakcję, które najdłużej trwa 3. cofnąć najkrócej trwającą transakcję
293 Protokół dwufazowego blokowania ( 2 Phase Locking ) 1.Zanim transakcja rozpocznie działanie na pewnym obiekcie w bazie danych, musi założyć na ten obiekt blokadę. 2. Po zwolnieniu blokady transakcja nie może zakładać żadnej nowej blokady na jakimkolwiek obiekcie. Twierdzenie Jeśli wszystkie transakcje spełniają protokół dwufazowego blokowania, to wszystkie przeplatane porządki (współbieżne) są szeregowalne (poprawne).
294 Przeczytaj w podręczniku R.Elmasri, Sh.Navathe: Rozdz. 17. Wprowadzenie do problematyki i teorii przetwarzania transakcji ( ) Rozdz. 18. Techniki sterowania współbieżnego ( )
295 Transakcje i zasady ACID; poziomy izolacji. Transakcją nazywamy grupę instrukcji, które muszą być wykonane, aby odpowiednie zmiany zostały zapisane w bazie. Jeżeli chociaż jedna instrukcja z takiej grupy zakończy się niepowodzeniem, wówczas działanie wszystkich jest odwoływane. Transakcja powinna spełniać właściwości określane jako ACID: niepodzielność (Atomicity) spójność (Consistency) izolacja (Isolation) trwałość (Durability) Z transakcjami związane są blokady dostępu i poziomy izolacji. PYTANIE NA EGZAMIN LICENCJACKI
296 Transakcja może zakładać blokady na elementy danych, zmieniać swoje blokady i zdejmować swoje blokady. Blokada do odczytu (read lock, shared lock) pozwala na współużytkowanie tego elementu danych przez inne transakcje. Blokada pełna (odczytu i zapisu, na wyłączność, read-write lock, exclusive lock) nie pozwala na dostęp do elementu danych innym transakcjom. Transakcja może rozszerzyć blokadę, zawęzić blokadę i znieść blokadę. Transakcja jest zgodna z protokołem blokowania dwufazowego jeżeli występują dwie fazy. W pierwszej transakcja może zakładać i rozszerzać blokady. W drugiej transkacja może zawężać i znosić blokady, ale nie może już ani rozszerzać ani zakładać nowych blokad. Jeżeli każda transakcja w harmonogramie jest zgodna z opisanym protokołem, to harmonogram jest szeregowalny. PYTANIE NA EGZAMIN LICENCJACKI
297 Mechanizm blokad prowadzi do tworzenia kolejek transakcji oczekujących na możliwość założenia blokady, a to może doprowadzić do powstawania zakleszczeń. Musimy więc stosować różne protokoły zapobiegania zakleszczeniom. Poziom izolacji to ustalona przez programistę cecha transakcji. Poziom ten określa się przy użyciu instrukcji ISOLATION LEVEL <X>, gdzie <X> może przyjąć cztery wartości. Serializable to zwykle poziom domyślny. Gwarantuje, że dane odczytywane to dane utworzone wyłącznie przez zatwierdzone transakcje oraz że wartość żadnej danej odczytywanej lub zapisywanej przez daną transakcję nie zostanie zmieniona przez inną transakcję do momentu zakończenia danej transakcji. Innymi sło- PYTANIE NA EGZAMIN LICENCJACKI
298 wy system zarządzania transakcjami nie dopuści do odczytów zmodyfikowanych, odczytów niepowtarzalnych i fantomów. Uwaga: Nie jest to dokładnie to samo co szeregowalność! Repeatable read możliwe wystąpienie fantomów. Read Committed możliwe wystąpienie fantomów i odczytów niepowtarzalnych Read Uncommitted możliwe wszystkie naruszenia. PYTANIE NA EGZAMIN LICENCJACKI
299
300 INDEKSY Indeksy to struktury używane w celu przyspieszenia dostępu do rekordów zapamiętanych w plikach bazy danych. Indeksy działają w oparciu o pola indeksujące, przy czym dla danego pliku można utworzyć różne indeksy (indeksy oparte na różnych polach). Pola indeksujące nazywamy również kluczami indeksowania (nie mylić z kluczem relacji!). Indeks pliku danych to struktura podobna do indeksu książkowego. Ten ostatni to uporządkowana alfabetycznie lista terminów występujących w książce, gdzie przy każdym terminie wypisano adresy stron na których dany termin występuje.
301 Indeksy można podzielić na podstawowe (primary index, indeks główny, założony na atrybucie porządkującym unikatowym), klastrowania (clustering index, na atrybucie porządkującym nieunikatowym) i wtórne (secondary index, indeks drugorzędny, założony na atrybucie nieporządkującym). Inny podział to indeksy gęste (wpis dla każdej wartości klucza indeksowania, tj. dla każdego rekordu pliku danych) i rzadkie (wpisy tylko dla niektórych wartości klucza). Kolejny podział to indeksy jedno poziomowe, dwupoziomowe i wielopoziomowe, a w ramach tych ostatnich B-drzewa w różnych odmianach, m.in. B + -drzewa i B * -drzewa.
302 INDEKS GŁÓWNY Indeks główny jest tworzony dla uporządkowanego pliku rekordów danych na podstawie wartości pola stanowiącego klucz relacji. Taki indeks to uporządkowany plik rekordów. Każdy rekord tego indeksu składa się z dwóch pól stałej wielkości. Pierwsze ma taki typ jak pole klucza uporządkowania w pliku danych, drugie jest wskaźnikiem na blok dyskowy. Wartość pierwszego pola to wartość pola klucza pierwszego rekordu bloku danych wskazywanego przez wskaźnik. Na każdy rekord indeksu głównego przypada jeden blok danych, zatem liczba wpisów w indeksie równa się liczbie bloków danych zajmowanych przez plik indeksowany. Jest to indeks rzadki.
303 Adamski Agatowski Albiński Ariański Adamski Ateński Ateński Aztecki Barański Bielecki Bogdański Bogdański Brunerski Cielecki Czarnecki
304 Policzmy, ile zyskujemy tworząc indeks podstawowy. Jeżeli, dla przykładu, plik uporządkowany ma rekordów po 100 B każdy, a blok na dysku ma 1024 B, to w jednym bloku można zapisać 10 rekordów, a dla całego pliku trzeba bloków. Przeszukiwanie binarne pliku wymaga co najwyżej log = 12 operacji dostępu do bloków. Jeżeli pole klucza uporządkowania ma 9 B, a wskaźnik na blok 6 B, to w jednym bloku zmieści się 68 wpisów indeksu głównego, a na cały indeks potrzeba 45 bloków. Przeszukiwanie binarne indeksu wymaga co najwyżej log 2 45 = 6 dostępów do bloków indeksu plus 1 dostęp do bloku danych, czyli co najwyżej 7 operacji dostępu do bloków.
305 Korzyść: liczba bloków, w których pamiętany jest plik indeksowy jest dużo mniejsza od liczby bloków potrzebnych dla pliku danych, więc wyszukiwania wymaga dostępu do mniejszej liczby bloków Kłopot: wstawienie nowego rekordu do pliku danych wymaga przesunięcia o jedno miejsce wszystkich rekordów o większej wartości pola indeksującego oraz poprawienia pliku indeksującego
306 INDEKS KLASTROWANIA Indeks klastrowania (indeks zgrupowany) tworzymy dla pliku rekordów posortowanych według pola, którego wartości nie są unikatowe. Indeks ten jest także plikiem posortowanym. Każdy wpis indeksu zawiera odrębną wartość pola indeksującego i wskaźnik na pierwszy blok danych, który zawiera rekord o danej wartości pola indeksującego. Uwaga: kilka kolejnych wskaźników indeksu może wskazywać ten sam blok oraz nie wszystkie bloki pliku danych muszą być wskazane w indeksie.
307 INDEKS WTÓRNY Indeks wtórny (drugorzędny) na polu zawierającym wartości powtarzające się budujemy na dwa sposoby. Pierwszy polega na stosowaniu wielu wpisów dla powtarzających się wartości pola. Drugi albo na wpisach o zmiennej długości albo na wpisach ze wskaźnikiem na blok wskaźników. Ma rysunku poniżej mamy jednopoziomowy gęsty indeks drugorzędny z jednym wpisem dla każdej wartości klucza (dla każdego rekordu pliku danych). Wpisy te są uporządkowane, dzięki czemu można będzie na indeksie wykonywać przeszukiwanie binarne. Przy każdej wartości pola indeksującego występuje lista wskaźników do wszystkich bloków dysku zawierających rekordy z daną wartością pola.
308
309
310 INDEKS DWUPOZIOMOWY Indeks dwupoziomowy może być na przykład indeksem indeksu głównego. Poziom pierwszy to indeks główny. Dla niego budujemy nowy indeks główny; znajduje się on na poziomie drugim. Dla omawianego wcześniej pliku uporządkowanego o rekordów po 100 B każdy i blokach 1024 B, cały indeks poziomu drugiego zmieści się w jednym bloku. Dla odszukania rekordu potrzebujemy więc tylko 3 dostępów do bloków. Ponadto indeks najwyższego poziomu trzyma się zwykle w pamięci operacyjnej, więc w omawianym przypadku będą to tylko 2 dostępy do bloków.
311
312 KUBEŁKOWANIE W przypadku indeksu wtórnego (drugorzędnego) z powtarzającymi się wartościami pola indeksującego marnuje się często dużo przestrzeni dyskowej. Rozwiązania z wpisami o zmiennej długości albo z blokami wskaźników też nie są idealne. Zaproponowano więc technikę kubełkowania.
313
314 B-DRZEWA Jest to cała rodzina struktur, które organizują przestrzeń na dysku w zrównoważoną drzewiastą strukturę bloków. Z każdym B-drzewem jest związany parametr p, który wyznacza układ drzewa, a który dobierany jest tak, aby w jednym bloku zmieściło się p-1 par (wartość wyszukiwania, wskaźnik na blok) i p wskaźników drzewa. Dane te tworzą węzeł drzewa, przy czym wartości wyszukiwania są uporządkowane rosnąco. Wskaźnik drzewa kieruje nas do poddrzewa zawierającego wartości wyszukiwania z przedziału ograniczonego dwoma wartościami wyszukiwania sąsiadującymi w węźle z takim wskaźnikiem (a w przypadkach skrajnych jedną wartością).
315
316 W B + -drzewach w węzłach wewnętrznych nie ma wskaźników na bloki danych, są tylko wskaźniki na bloki wierzchołków niższego poziomu drzewa. Wskaźniki na bloki danych występują dopiero w liściach. Ostatni wskaźnik liścia wskazuje na blok następnego liścia z prawej strony. W korzeniu są co najmniej dwa wskaźniki na bloki niższych poziomów. W pozostałych węzłach jest co najmniej połowa liczby możliwych do zapisania tam wskaźników. Przykład: blok ma 4096 B, klucz 4 B, wskaźnik 8 B. W takiej sytuacji szukamy największej wartości p, która spełnia nierówność 4(p- 1)+8p Jest to 341. Zatem wierzchołek wewnętrzny może zawierać co najwyżej 340 kluczy i 341 wskaźników.
317
318 Liść Garcia-Molina, Ullman, Widom, Systemy baz danych, rozdz. 13
319
320 Przykład wstawiania nowej wartości. Do ostatnio omawianego drzewa chcemy wstawić klucz 40. Odnajdujemy liść do którego powinna trafić ta wartość. U nas jest to liść piąty. Nie ma tam miejsca na nową wartość, więc musimy ten liść rozbić na dwa. Do pierwszego z nich idzie wskaźnik od rodzica, ale tam nie ma już miejsca na wskaźnik do drugiego z tych liści. Musimy więc rozbić rodzica na dwa wierzchołki. Por. kolejne rysunki.
321
322
323 Więcej o indeksach i B + -drzewach zobacz: Elmasri: R.14. Struktury indeksowe dla plików Bazy danych wyklad 7 [wazniak.mimuw.edu.pl] Garcia-Molina, Ullman, Widom: Systemy baz danych, R. 13 inne wykłady, np. O indeksach z kluczem złożonym i indeksach ISAM zobacz:
324 B drzewa definicja, algorytm wyszukiwania w B drzewie. PYTANIE NA EGZAMIN LICENCJACKI
325 Zależności funkcyjne, klucze i algorytm obliczania domknięć. W praktyce, w przypadku konkretnej bazy danych, nie jest zwykle możliwe (ani potrzebne), by projektant określił wszystkie zależności funkcyjne na etapie analizy świata danych. Projektant bazy danych określa więc tylko zależności funkcyjne ewidentne z punktu widzenia semantyki modelowanego świata (nazwijmy je pierwotnymi), a następnie oblicza się w sposób zautomatyzowany te zależności, które wynikają z pierwotnych. Wprowadza się dwa pojęcia: pojęcie domknięcia F+ zbioru zależności funkcyjnych F oraz pojęcie domknięcia X+ zbioru atrybutów X względem F. PYTANIE NA EGZAMIN LICENCJACKI
326 Domknięcie F+ to zbiór zależności pierwotnych (tworzących zbiór F) oraz zależności, które można wywnioskować z tamtych. Każda taka nowa zależność musi mieć tę własność, że będzie spełniona dla każdego zbioru danych spełniającego zależności ze zbioru F. Jak zbudować F+? W 1974 W. Armstrong wykazał, że minimalnym zbiorem reguł wnioskowania potrzebnych do zbudowania domknięcia jest zbiór złożony z reguły zwrotności (R1), reguły zwiększania (R2) i reguły przechodniości (R3). W literaturze są one zwane aksjomatami Armstronga. W praktyce używa się również wtórej reguły: reguły dekompozycji (R4). PYTANIE NA EGZAMIN LICENCJACKI
327 Systematyczny sposób budowania domknięcia F+ zbioru zależności funkcyjnych F polega na tym, że dla każdej zależności funkcyjnej X Y tworzy się X X+ gdzie X+ to domknięcie zbioru X względem zbioru zależności F. Wszystkie utworzone w ten sposób zależności X X+ tworzą domknięcie F+. Należy tu pamiętać, że w teorii relacyjnych baz danych litery występujące po prawej i po lewej stronie zależności funkcyjnej mogą oznaczać dowolny atrybut bądź zbiór atrybutów. Pozostaje pytanie, jak utworzyć domknięcie X+ zbioru X względem zbioru F? PYTANIE NA EGZAMIN LICENCJACKI
328 Algorytm obliczania domknięcia X+ := X repeat old X+:= X+ for each zależność funkcyjna Y Z w F do if old X+VY then old X+:= X+UZ; until (X+ = old X+); PYTANIE NA EGZAMIN LICENCJACKI
329 Dwa zbiory zależności funkcyjnych E i F są równoważne jeżeli mają takie same domknięcia: E+=F+. Od projektanta bazy danych wymagamy zatem, by rozpoznał dowolny zbiór pierwotnych zależności funkcyjnych, ale taki, którego domknięcie obejmie wszystkie zależności funkcyjne. Różni projektanci mogą zaproponować różne zbiory zależności pierwotnych, ale muszą być one w powyższym sensie równoważne. Por. R.Elmasri, str PYTANIE NA EGZAMIN LICENCJACKI
330 Normalizacja baz danych; warunek bezstratnego złączenia; pierwsza, druga i trzecia postać normalna, postać normalna Boyce a Codda. Proces normalizacji relacyjnej bazy danych ma na celu usunięcie redundancji i wyeliminowanie anomalii. Polega on na rozkładaniu pojedynczych schematów relacji na mniejsze, które mają odpowiednie właściwości. Rozkłady te muszą gwarantować możliwość nieaadytywnego złączenia i w zasadzie powinny zachowywać zależności. To pierwsze określa się również jako warunek bezstratnego złączenia. PYTANIE NA EGZAMIN LICENCJACKI
331 Warunek bezstratnego złączenia polega na tym, że dla każdej relcji opartej na danym schemacie naturalne złączenie rzutów tej relacji na podschematy jest równe tej relacji (w złączeniu tym nie pojawiają się żadne nowe krotki). Nazwa warunku bierze się stąd, że rozkład niespełniający tego warunku może prowadzić do zmiany zawartości informacyjnej dzielonej w taki sposób relacji, czyli do utraty właściwej informacji. Schemat relacyjnej bazy danych jest w 1NF gdy wszystkie tabele posiadają klucze i wartości w tabelach są atomowe. PYTANIE NA EGZAMIN LICENCJACKI
332 Rozkłady do 2NF i do 3NF gwarantują możliwość nieaadytywnego złączenia jeżeli są wykonywane według określonych zasad związanych z usuwaniem zależności częściowych i zależności tranzytywnych. W szczególności schemat, który jest w 1NF a nie jest w 2NF, zawiera zależności częściowe. Jego prawidłowy rozkład polega na utworzeniu podschematów złożonych z atrybutów występujących w zależnościach częściowych oraz podschematu zawierającego klucz i ewentualnie atrybuty nieuwzględnione w utworzonych już podschematach. PYTANIE NA EGZAMIN LICENCJACKI
333 Schemat, który jest w 2NF ale nie jest w 3NF, zawiera zależności tranzytywne. Jego prawidłowy rozkład polega na utworzeniu dla każdej zależności tranzytywnej X Y Z (nieprymarnych atrybutów Z) podschematu złożonego z atrybutów YZ, a na koniec podschematu złożonego z klucza i atrybutów nieuwzględnionych w utworzonych już podschematach. Taki sposób rozkładu spełnia warunek bezstratnego złączenia, a jednocześnie gwarantuje zachowanie wszystkich zależności funkcyjnych. Rozkłady do wyższych postaci normalnych nie gwarantują zachowania zależności, więc muszą być wykonywane z dużą ostrożnością. PYTANIE NA EGZAMIN LICENCJACKI

334
335 Po wykonaniu modelu danych przechodzimy do budowy modeli procesów. Narzędzia modelowania wzajemnie się uzupełniają, a każde z nich ukazuje wybrany aspekt systemu. Aby analiza była spójna modelowanie danych i modelowanie procesów powinno być wykonywane jednocześnie. W analizie procesów system rozkładamy stopniowo na części w taki sposób, aby każda część dała się opisać na jednej stronie (minispecyfikacje), a także aby każda część była funkcjonalnym elementem całości. Narzędziem modelowania są diagramy przepływu danych (DPD). Diagramy te rysujemy na różnych poziomach w taki sposób, by od spraw ogólnych przechodzić do coraz bardziej szczegółowych. Analizę tę prowadzimy tak głęboko, jak trzeba, by zrozumieć funkcjonowanie systemy rzeczywistego.
336 DPD jest modelem działania systemu rzeczywistego: jest mapą na której widzimy rzeczywiste przepływy danych, rzeczywiste procesy, magazyny danych i terminatory. System może działać, jeżeli każdy proces produkuje poprawne dane wyjściowe na podstawie danych wejściowych, które otrzymuje z przepływów danych bądź pobiera z magazynów danych. Terminatory to obiekty znajdujące się na zewnątrz naszego systemu: firmy, osoby, systemy etc. Terminatory wysyłają dane do systemu i/lub otrzymują dane przetworzone przez system. System przenosi dane (przepływy), przetwarza je (procesy) i przechowuje (magazyny).
337 Diagram kontekstowy to diagram najwyższego poziomu, najbardziej ogólny. Przedstawia on wszystkie procesy realizowane przez analizowany system w postaci jednego głównego procesu. Diagram ten służy do zakreślenia granic naszej analizy i ustalenia właściwego kontekstu analizowanego systemu. Procesy są opisane przy pomocy rozwijających je diagramów niższych poziomów, a procesy najniższego poziomu w minispecyfikacjach. Procesy otrzymują dane z przepływów wchodzących i z magazynów, a produkują dane wyjściowe (przepływy wychodzące do innych procesów, do magazynów i do terminatorów). Procesy nie interesują się źródłami danych ani tym, dokąd wysyłają dane. Procesy pozostają w uśpieniu do czasu otrzymania danych. Wtedy je przetwarzają, wysyłają i wchodzą w stan uśpienia.
338 Przykład diagramu kontekstowego Andrzej Łachwa 2014
339 Przykład DPD pierwszego poziomu Robertson, Robertson Pełna analiza systemowa, WNT 1999, str. 125
340 TEST CRUD C create, R reference, U update, D delete W pierwszym etapie sprawdza się czy każda encja i każdy związek modelu danych mają wszystkie potrzebne procesy CRUD. W etapie drugim, czy każdy atrybut jest tworzony i wykorzystywany, a jeśli potrzeba uaktualniany lub usuwany. Brak jakiegoś procesu CRUD przy encji, związku czy atrybucie oznacza, że pominięto zdarzenia lub że dane są redundantne.
341 Diagramy UML
342 UML (Unified Modeling Language) to Ujednolicony Język Modelowania, język do analizy i modelowania świata obiektów w analizie obiektowej i programowaniu obiektowym. Stosuje się zarówno do opisywania istniejącej rzeczywistości jak i rzeczywistości dopiero projektowanej. Jest używany także do modelowania procesów biznesowych, reprezentowania struktur organizacyjnych, modelowania zagadnień inżynierii systemów i innych. Jest mocno związany z obiektowymi metodami tworzenia oprogramowania. W wersji 2.0 mamy 17 rodzajów diagramów (13 głównych i 4 abstrakcyjne).
343 DIAGRAMY GŁÓWNE diagramy struktury: diagram klas diagram obiektów diagram pakietów diagram struktur połączonych 2 diagramy wdrożeniowe (komponentów i rozlokowania) DIAGRAMY GŁÓWNE diagramy dynamiki: diagram przypadków użycia diagram aktywności diagram maszyny stanowej 4 diagramy interakcji (sekwencji, komunikacji, harmonogramowania i sterowania interakcją)
344 Przykłady diagramów przypadków użycia
345 Przykład diagramu klas
346 Przykład diagramu pakietów
347 Przykład diagramu klas i diagramu obiektów
348 Przykład diagramu sekwencji
349 Przykład diagramu stanów
350 Przykład diagramu aktywności (przepływu)
351 Przykład diagramu wdrożenia
352 Wybrane narzędzia do modelowania UML Borland Together ControlCenter Enterprise Architect IBM Rational Rose Microsoft Visio Sybase PowerDesigner Visual Paradigm for UML StartUML Dia MagicDraw
353
354 Więzy integralności referencyjnej i klucze obce. PYTANIE NA EGZAMIN LICENCJACKI
355 Relacyjny model baz danych. PYTANIE NA EGZAMIN LICENCJACKI
356 Wszystkie wartości danych oparte są na prostych typach danych. Wszystkie dane w bazie relacyjnej przedstawiane są w formie dwuwymiarowych tabel (relacji). Każda tabela zawiera zero lub więcej wierszy (krotek) i jedną lub więcej kolumn (atrybutów). Na każdy wiersz składają się jednakowo ułożone wartości. Po wprowadzeniu danych do bazy, możliwe jest wiązanie danych i wykonywanie stosunkowo złożonych operacji w granicach całej bazy danych. Wszystkie operacje wykonywane są w oparciu o algebrę relacji, bez odwoływania się do położenia wiersza tabeli (wiersze w relacyjnej bazie danych przechowywane są w porządku zupełnie dowolnym nie musi on odzwierciedlać ani kolejności ich wprowadzania, ani kolejności ich przechowywania). Z braku możliwości identyfikacji wiersza przez jego pozycję pojawia się potrzeba obecności jednej lub więcej kolumn o wartościach niepowtarzalnych w granicach całej tabeli, pozwalających odnaleźć konkretny wiersz. Kolumny te określa się jako klucz podstawowy tabeli....
357 Złączenia wewnętrzne i zewnętrzne, algorytmy realizacji złączeń. Zob. Elmasri: R PYTANIE NA EGZAMIN LICENCJACKI
358 HURTOWNIE DANYCH Co trzeci menedżer podejmuje większość decyzji, mając niekompletne informacje, a co drugi nie ma w swojej firmie dostępu do informacji niezbędnych do wykonywania pracy.
359 Baza danych to (1) zorganizowany zbiór danych (2) reprezentujący pewien fragment świata rzeczywistego, (3) zaprojektowany, zbudowany i utrzymywany dla określonej grupy użytkowników, oraz (4) dla określonego sposobu korzystania z tych danych. Z punktu widzenia przedsiębiorstw odróżnia się: bazy operacyjne (bazy transakcyjne, OLTP lub po prostu bazy danych) bazy analityczne (hurtownie danych, bazy OLAP, Data Warehouse, Data Mart, składnice danych).
360 Funkcjonowanie tradycyjnych, czyli operacyjnych baz danych (np. relacyjnych czy obiektowych), opiera się na przetwarzaniu transakcji (OLTP, OnLine Transaction Processing), które obejmują wstawianie, aktualizację i usuwanie danych, oraz na obsłudze zapytań. Zadania OLTP i zapytania służą do obsługi codziennych działań przedsiębiorstwa związanych z dużą liczbą transakcji; dotyczą stosunkowo niewielkich części bazy, zwykle pojedynczych rekordów danych.
361 Hurtownie danych stanowią platformę integrującą: masowe (rzędu TB-ów) dane historyczne i dane zbiorcze pochodzące z różnych źródeł, i sukcesywnie uzupełniane narzędzia do przeprowadzania analiz (także wielowymiarowych) zwane narzędziami bezpośredniego przetwarzania analitycznego (OLAP, OnLine Analytical Processing) narzędzia do eksploracji danych (DM, Data Mining) narzędzia do wspomagania podejmowania decyzji (DSS, Decision Support Systems) narzędzia informowania kierownictwa (EIS, Executive Information Systems)
362 Do typowych funkcji hurtowni należą: analizy przy użyciu narzędzi OLAP (w tym także analizy statystyczne) obsługa zapytań ad hoc (zwykle w SQL) eksploracja danych (metody oparte na statystyce oraz metody sztucznej inteligencji) wspomaganie podejmowania decyzji (narzędzia DSS) informowanie kierownictwa (EIS) narzędzia wizualizacji danych. Funkcje te realizuje zbiór aplikacji nazywany często systemem informacji gospodarczej (Business Intelligence).
363 Studium przypadku Zastosowanie narzędzi BI w szwedzkim mieście Malmo pozwoliło na schwytanie seryjnego mordercy. Zdaniem miejscowej policji wykorzystanie oprogramowania QlikView pozwoliło przeanalizować informacje i raporty z 10 lat. Załadowanie danych i skonfigurowanie interaktywnych raportów zajęło 3 godziny. Ręczne porównanie tych danych przez jednego policjanta zajęłoby 43 lata.

364

365
366 Najważniejszym i najtrudniejszym problemem dotyczącym hurtowni jest eksploracja danych (przekopywanie danych, Data Mining). Są to wszelkiego rodzaju procesy prowadzące do odkrywania ukrytej wiedzy, nieznanych dotąd użytecznych regularności, wzorów zachowań i ich zmian, zależności między zdarzeniami, pojawiania się anomalii etc. W procesach tych wykorzystuje się używane już wcześniej w ekonomii metody statystyczne oraz używane w informatyce metody uczenia się maszyn i inne metody sztucznej inteligencji. Tworzone są również nowe oryginalne metody, specyficzne dla problematyki eksploracji danych.
367 Literatura: D.T. Larose: Odkrywanie wiedzy z danych. Wprowadzenie do eksploracji danych. WN PWN D. Hand i in.: Eksploracja danych. WNT 2005 J. Celko: SQL Zaawansowane techniki programowania. WN PWN 2008 strony producentów oprogramowania:
368 DUMP bazy w MySQL Po uruchomieniu klienta ROOT definiujemy nowego użytkownika, nadajemy mu przywileje i odświeżamy tabelę użytkowników: CREATE USER 'root2'@'localhost' IDENTIFIED BY 'root2'; GRANT ALL PRIVILEGES ON *.* TO 'root2'@'localhost'; FLUSH PRIVILEGES;

369 USE MYSQL; SHOW TABLES; SELECT * FROM USER \G

370

371 F:\my_SQL>mysql\bin\mysqldump new -u root2 -p Enter password: *****
Bazy danych. Andrzej Łachwa, UJ, /14
 Bazy danych Andrzej Łachwa, UJ, 2016 andrzej.lachwa@uj.edu.pl 3/14 Języki SQL, SQL 2 (1992), SQL 3 (1999-2002) https://pl.wikipedia.org/wiki/sql SQLite https://www.sqlite.org/ MySQL https://www.mysql.com/
Bazy danych Andrzej Łachwa, UJ, 2016 andrzej.lachwa@uj.edu.pl 3/14 Języki SQL, SQL 2 (1992), SQL 3 (1999-2002) https://pl.wikipedia.org/wiki/sql SQLite https://www.sqlite.org/ MySQL https://www.mysql.com/
Bazy danych. Andrzej Łachwa, UJ, /14
 Bazy danych Andrzej Łachwa, UJ, 2016 andrzej.lachwa@uj.edu.pl 4/14 Własności SZBD: możliwość bezpiecznego przechowywania przez długi czas danych mierzonych w tera- i petabajtach, istnienie mechanizmów
Bazy danych Andrzej Łachwa, UJ, 2016 andrzej.lachwa@uj.edu.pl 4/14 Własności SZBD: możliwość bezpiecznego przechowywania przez długi czas danych mierzonych w tera- i petabajtach, istnienie mechanizmów
Bazy danych. Andrzej Łachwa, UJ, /14
 Bazy danych Andrzej Łachwa, UJ, 2016 andrzej.lachwa@uj.edu.pl 1/14 Zobacz: http://creativecommons.pl/ Literatura Elmasri R., Navathe S., Wprowadzenie do systemów baz danych. Wyd. Helion, 2005 Garcia-Molina
Bazy danych Andrzej Łachwa, UJ, 2016 andrzej.lachwa@uj.edu.pl 1/14 Zobacz: http://creativecommons.pl/ Literatura Elmasri R., Navathe S., Wprowadzenie do systemów baz danych. Wyd. Helion, 2005 Garcia-Molina
Bazy danych. Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 2/15
 Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 2/15 Specyfikacja wymagań Zanim rozpoczniemy modelowanie, musimy dokładnie określić obszar analizy oraz zrozumieć
Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 2/15 Specyfikacja wymagań Zanim rozpoczniemy modelowanie, musimy dokładnie określić obszar analizy oraz zrozumieć
Bazy danych. Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 1/15
 Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 1/15 Literatura obowiązkowa Elmasri R., Navathe S., Wprowadzenie do systemów baz danych. Wyd. Helion, 2005
Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 1/15 Literatura obowiązkowa Elmasri R., Navathe S., Wprowadzenie do systemów baz danych. Wyd. Helion, 2005
Bazy danych. Andrzej Łachwa, UJ, /14
 Bazy danych Andrzej Łachwa, UJ, 2015 andrzej.lachwa@uj.edu.pl 3/14 Specyfikacja wymagań Zanim rozpoczniemy modelowanie, musimy dokładnie określić obszar analizy oraz zrozumieć go! W praktyce analitycy
Bazy danych Andrzej Łachwa, UJ, 2015 andrzej.lachwa@uj.edu.pl 3/14 Specyfikacja wymagań Zanim rozpoczniemy modelowanie, musimy dokładnie określić obszar analizy oraz zrozumieć go! W praktyce analitycy
Bazy danych. Andrzej Łachwa, UJ, /15
 Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 10/15 Semantyka schematu relacyjnej bazy danych Schemat bazy danych składa się ze schematów relacji i więzów
Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 10/15 Semantyka schematu relacyjnej bazy danych Schemat bazy danych składa się ze schematów relacji i więzów
Bazy danych 7/15. Andrzej Łachwa, UJ,
 Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 7/15 Tabele pomocnicze Tabele pomocnicze nie są częścią modelu danych, więc nie powinny pojawiać się na etapie
Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 7/15 Tabele pomocnicze Tabele pomocnicze nie są częścią modelu danych, więc nie powinny pojawiać się na etapie
030 PROJEKTOWANIE BAZ DANYCH. Prof. dr hab. Marek Wisła
 030 PROJEKTOWANIE BAZ DANYCH Prof. dr hab. Marek Wisła Elementy procesu projektowania bazy danych Badanie zależności funkcyjnych Normalizacja Projektowanie bazy danych Model ER, diagramy ERD Encje, atrybuty,
030 PROJEKTOWANIE BAZ DANYCH Prof. dr hab. Marek Wisła Elementy procesu projektowania bazy danych Badanie zależności funkcyjnych Normalizacja Projektowanie bazy danych Model ER, diagramy ERD Encje, atrybuty,
Bazy danych Wykład zerowy. P. F. Góra
 Bazy danych Wykład zerowy P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2012 Patron? Św. Izydor z Sewilli (VI wiek), biskup, patron Internetu (sic!), stworzył pierwszy katalog Copyright c 2011-12 P.
Bazy danych Wykład zerowy P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2012 Patron? Św. Izydor z Sewilli (VI wiek), biskup, patron Internetu (sic!), stworzył pierwszy katalog Copyright c 2011-12 P.
Diagramy związków encji. Laboratorium. Akademia Morska w Gdyni
 Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
Akademia Morska w Gdyni Gdynia 2004 1. Podstawowe definicje Baza danych to uporządkowany zbiór danych umożliwiający łatwe przeszukiwanie i aktualizację. System zarządzania bazą danych (DBMS) to oprogramowanie
Bazy Danych. C. J. Date, Wprowadzenie do systemów baz danych, WNT - W-wa, (seria: Klasyka Informatyki), 2000
, 2000") Bazy Danych LITERATURA C. J. Date, Wprowadzenie do systemów baz danych, WNT - W-wa, (seria: Klasyka Informatyki), 2000 J. D. Ullman, Systemy baz danych, WNT - W-wa, 1998 J. D. Ullman, J. Widom, Podstawowy
Bazy Danych LITERATURA C. J. Date, Wprowadzenie do systemów baz danych, WNT - W-wa, (seria: Klasyka Informatyki), 2000 J. D. Ullman, Systemy baz danych, WNT - W-wa, 1998 J. D. Ullman, J. Widom, Podstawowy
PRZESTRZENNE BAZY DANYCH WYKŁAD 2
 PRZESTRZENNE BAZY DANYCH WYKŁAD 2 Baza danych to zbiór plików, które fizycznie przechowują dane oraz system, który nimi zarządza (DBMS, ang. Database Management System). Zadaniem DBMS jest prawidłowe przechowywanie
PRZESTRZENNE BAZY DANYCH WYKŁAD 2 Baza danych to zbiór plików, które fizycznie przechowują dane oraz system, który nimi zarządza (DBMS, ang. Database Management System). Zadaniem DBMS jest prawidłowe przechowywanie
Program wykładu. zastosowanie w aplikacjach i PL/SQL;
 Program wykładu 1 Model relacyjny (10 godz.): podstawowe pojęcia, języki zapytań (algebra relacji, relacyjny rachunek krotek, relacyjny rachunek dziedzin), zależności funkcyjne i postaci normalne (BCNF,
Program wykładu 1 Model relacyjny (10 godz.): podstawowe pojęcia, języki zapytań (algebra relacji, relacyjny rachunek krotek, relacyjny rachunek dziedzin), zależności funkcyjne i postaci normalne (BCNF,
Wykład 2. Relacyjny model danych
 Wykład 2 Relacyjny model danych Wymagania stawiane modelowi danych Unikanie nadmiarowości danych (redundancji) jedna informacja powinna być wpisana do bazy danych tylko jeden raz Problem powtarzających
Wykład 2 Relacyjny model danych Wymagania stawiane modelowi danych Unikanie nadmiarowości danych (redundancji) jedna informacja powinna być wpisana do bazy danych tylko jeden raz Problem powtarzających
Bazy danych - wykład wstępny
 Bazy danych - wykład wstępny Wykład: baza danych, modele, hierarchiczny, sieciowy, relacyjny, obiektowy, schemat logiczny, tabela, kwerenda, SQL, rekord, krotka, pole, atrybut, klucz podstawowy, relacja,
Bazy danych - wykład wstępny Wykład: baza danych, modele, hierarchiczny, sieciowy, relacyjny, obiektowy, schemat logiczny, tabela, kwerenda, SQL, rekord, krotka, pole, atrybut, klucz podstawowy, relacja,
Przestrzenne bazy danych Podstawy języka SQL
 Przestrzenne bazy danych Podstawy języka SQL Stanisława Porzycka-Strzelczyk porzycka@agh.edu.pl home.agh.edu.pl/~porzycka Konsultacje: wtorek godzina 16-17, p. 350 A (budynek A0) 1 SQL Język SQL (ang.structured
Przestrzenne bazy danych Podstawy języka SQL Stanisława Porzycka-Strzelczyk porzycka@agh.edu.pl home.agh.edu.pl/~porzycka Konsultacje: wtorek godzina 16-17, p. 350 A (budynek A0) 1 SQL Język SQL (ang.structured
Pawel@Kasprowski.pl Bazy danych. Bazy danych. Podstawy języka SQL. Dr inż. Paweł Kasprowski. pawel@kasprowski.pl
 Bazy danych Podstawy języka SQL Dr inż. Paweł Kasprowski pawel@kasprowski.pl Plan wykładu Relacyjne bazy danych Język SQL Zapytania SQL (polecenie select) Bezpieczeństwo danych Integralność danych Współbieżność
Bazy danych Podstawy języka SQL Dr inż. Paweł Kasprowski pawel@kasprowski.pl Plan wykładu Relacyjne bazy danych Język SQL Zapytania SQL (polecenie select) Bezpieczeństwo danych Integralność danych Współbieżność
Systemy GIS Tworzenie zapytań w bazach danych
 Systemy GIS Tworzenie zapytań w bazach danych Wykład nr 6 Analizy danych w systemach GIS Jak pytać bazę danych, żeby otrzymać sensowną odpowiedź......czyli podstawy języka SQL INSERT, SELECT, DROP, UPDATE
Systemy GIS Tworzenie zapytań w bazach danych Wykład nr 6 Analizy danych w systemach GIS Jak pytać bazę danych, żeby otrzymać sensowną odpowiedź......czyli podstawy języka SQL INSERT, SELECT, DROP, UPDATE
Bazy danych. Plan wykładu. Diagramy ER. Podstawy modeli relacyjnych. Podstawy modeli relacyjnych. Podstawy modeli relacyjnych
 Plan wykładu Bazy danych Wykład 9: Przechodzenie od diagramów E/R do modelu relacyjnego. Definiowanie perspektyw. Diagramy E/R - powtórzenie Relacyjne bazy danych Od diagramów E/R do relacji SQL - perspektywy
Plan wykładu Bazy danych Wykład 9: Przechodzenie od diagramów E/R do modelu relacyjnego. Definiowanie perspektyw. Diagramy E/R - powtórzenie Relacyjne bazy danych Od diagramów E/R do relacji SQL - perspektywy
Model relacyjny. Wykład II
 Model relacyjny został zaproponowany do strukturyzacji danych przez brytyjskiego matematyka Edgarda Franka Codda w 1970 r. Baza danych według definicji Codda to zbiór zmieniających się w czasie relacji
Model relacyjny został zaproponowany do strukturyzacji danych przez brytyjskiego matematyka Edgarda Franka Codda w 1970 r. Baza danych według definicji Codda to zbiór zmieniających się w czasie relacji
Systemy baz danych. mgr inż. Sylwia Glińska
 Systemy baz danych Wykład 1 mgr inż. Sylwia Glińska Baza danych Baza danych to uporządkowany zbiór danych z określonej dziedziny tematycznej, zorganizowany w sposób ułatwiający do nich dostęp. System zarządzania
Systemy baz danych Wykład 1 mgr inż. Sylwia Glińska Baza danych Baza danych to uporządkowany zbiór danych z określonej dziedziny tematycznej, zorganizowany w sposób ułatwiający do nich dostęp. System zarządzania
Bazy danych. Dr inż. Paweł Kasprowski
 Plan wykładu Bazy danych Podstawy relacyjnego modelu danych Dr inż. Paweł Kasprowski pawel@kasprowski.pl Relacyjne bazy danych Język SQL Zapytania SQL (polecenie select) Bezpieczeństwo danych Integralność
Plan wykładu Bazy danych Podstawy relacyjnego modelu danych Dr inż. Paweł Kasprowski pawel@kasprowski.pl Relacyjne bazy danych Język SQL Zapytania SQL (polecenie select) Bezpieczeństwo danych Integralność
Języki programowania wysokiego poziomu. PHP cz.4. Bazy danych
 Języki programowania wysokiego poziomu PHP cz.4. Bazy danych PHP i bazy danych PHP może zostać rozszerzony o mechanizmy dostępu do różnych baz danych: MySQL moduł mysql albo jego nowsza wersja mysqli (moduł
Języki programowania wysokiego poziomu PHP cz.4. Bazy danych PHP i bazy danych PHP może zostać rozszerzony o mechanizmy dostępu do różnych baz danych: MySQL moduł mysql albo jego nowsza wersja mysqli (moduł
Technologie baz danych
 Plan wykładu Technologie baz danych Wykład 2: Relacyjny model danych - zależności funkcyjne. SQL - podstawy Definicja zależności funkcyjnych Reguły dotyczące zależności funkcyjnych Domknięcie zbioru atrybutów
Plan wykładu Technologie baz danych Wykład 2: Relacyjny model danych - zależności funkcyjne. SQL - podstawy Definicja zależności funkcyjnych Reguły dotyczące zależności funkcyjnych Domknięcie zbioru atrybutów
1 Wstęp do modelu relacyjnego
 Plan wykładu Model relacyjny Obiekty relacyjne Integralność danych relacyjnych Algebra relacyjna 1 Wstęp do modelu relacyjnego Od tego się zaczęło... E. F. Codd, A Relational Model of Data for Large Shared
Plan wykładu Model relacyjny Obiekty relacyjne Integralność danych relacyjnych Algebra relacyjna 1 Wstęp do modelu relacyjnego Od tego się zaczęło... E. F. Codd, A Relational Model of Data for Large Shared
2010-10-21 PLAN WYKŁADU BAZY DANYCH MODEL DANYCH. Relacyjny model danych Struktury danych Operacje Integralność danych Algebra relacyjna HISTORIA
 PLAN WYKŁADU Relacyjny model danych Struktury danych Operacje Integralność danych Algebra relacyjna BAZY DANYCH Wykład 2 dr inż. Agnieszka Bołtuć MODEL DANYCH Model danych jest zbiorem ogólnych zasad posługiwania
PLAN WYKŁADU Relacyjny model danych Struktury danych Operacje Integralność danych Algebra relacyjna BAZY DANYCH Wykład 2 dr inż. Agnieszka Bołtuć MODEL DANYCH Model danych jest zbiorem ogólnych zasad posługiwania
Przykładowa baza danych BIBLIOTEKA
 Przykładowa baza danych BIBLIOTEKA 1. Opis problemu W ramach zajęć zostanie przedstawiony przykład prezentujący prosty system biblioteczny. System zawiera informację o czytelnikach oraz książkach dostępnych
Przykładowa baza danych BIBLIOTEKA 1. Opis problemu W ramach zajęć zostanie przedstawiony przykład prezentujący prosty system biblioteczny. System zawiera informację o czytelnikach oraz książkach dostępnych
NARZĘDZIA WIZUALIZACJI
 Kurs interaktywnej komunikacji wizualnej NARZĘDZIA WIZUALIZACJI Andrzej Łachwa andrzej.lachwa@uj.edu.pl 3 4/8 Zobacz film: http://www.ted.com/talks/david_mccandless_the_beauty_of_dat a_visualization.html
Kurs interaktywnej komunikacji wizualnej NARZĘDZIA WIZUALIZACJI Andrzej Łachwa andrzej.lachwa@uj.edu.pl 3 4/8 Zobacz film: http://www.ted.com/talks/david_mccandless_the_beauty_of_dat a_visualization.html
Ref. 7 - Język SQL - polecenia DDL i DML
 Ref. 7 - Język SQL - polecenia DDL i DML Wprowadzenie do języka SQL. Polecenia generujące strukturę bazy danych: CREATE, ALTER i DROP. Polecenia: wprowadzające dane do bazy - INSERT, modyfikujące zawartość
Ref. 7 - Język SQL - polecenia DDL i DML Wprowadzenie do języka SQL. Polecenia generujące strukturę bazy danych: CREATE, ALTER i DROP. Polecenia: wprowadzające dane do bazy - INSERT, modyfikujące zawartość
Wykład I. Wprowadzenie do baz danych
 Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Krzysztof Kadowski. PL-E3579, PL-EA0312,
 Krzysztof Kadowski PL-E3579, PL-EA0312, kadowski@jkk.edu.pl Bazą danych nazywamy zbiór informacji w postaci tabel oraz narzędzi stosowanych do gromadzenia, przekształcania oraz wyszukiwania danych. Baza
Krzysztof Kadowski PL-E3579, PL-EA0312, kadowski@jkk.edu.pl Bazą danych nazywamy zbiór informacji w postaci tabel oraz narzędzi stosowanych do gromadzenia, przekształcania oraz wyszukiwania danych. Baza
Baza danych. Baza danych to:
 Baza danych Baza danych to: zbiór danych o określonej strukturze, zapisany na zewnętrznym nośniku (najczęściej dysku twardym komputera), mogący zaspokoić potrzeby wielu użytkowników korzystających z niego
Baza danych Baza danych to: zbiór danych o określonej strukturze, zapisany na zewnętrznym nośniku (najczęściej dysku twardym komputera), mogący zaspokoić potrzeby wielu użytkowników korzystających z niego
INFORMATYKA GEODEZYJNO- KARTOGRAFICZNA Relacyjny model danych. Relacyjny model danych Struktury danych Operacje Oganiczenia integralnościowe
 Relacyjny model danych Relacyjny model danych Struktury danych Operacje Oganiczenia integralnościowe Charakterystyka baz danych Model danych definiuje struktury danych operacje ograniczenia integralnościowe
Relacyjny model danych Relacyjny model danych Struktury danych Operacje Oganiczenia integralnościowe Charakterystyka baz danych Model danych definiuje struktury danych operacje ograniczenia integralnościowe
Język SQL, zajęcia nr 1
 Język SQL, zajęcia nr 1 SQL - Structured Query Language Strukturalny język zapytań Login: student Hasło: stmeil14 Baza danych: st https://194.29.155.15/phpmyadmin/index.php Andrzej Grzebielec Najpopularniejsze
Język SQL, zajęcia nr 1 SQL - Structured Query Language Strukturalny język zapytań Login: student Hasło: stmeil14 Baza danych: st https://194.29.155.15/phpmyadmin/index.php Andrzej Grzebielec Najpopularniejsze
Podstawowe pojęcia dotyczące relacyjnych baz danych. mgr inż. Krzysztof Szałajko
 Podstawowe pojęcia dotyczące relacyjnych baz danych mgr inż. Krzysztof Szałajko Czym jest baza danych? Co rozumiemy przez dane? Czym jest system zarządzania bazą danych? 2 / 25 Baza danych Baza danych
Podstawowe pojęcia dotyczące relacyjnych baz danych mgr inż. Krzysztof Szałajko Czym jest baza danych? Co rozumiemy przez dane? Czym jest system zarządzania bazą danych? 2 / 25 Baza danych Baza danych
K1A_W11, K1A_W18. Egzamin. wykonanie ćwiczenia lab., sprawdzian po zakończeniu ćwiczeń, egzamin, K1A_W11, K1A_W18 KARTA PRZEDMIOTU
 (pieczęć wydziału) KARTA PRZEDMIOTU 1. Nazwa przedmiotu: BAZY DANYCH 2. Kod przedmiotu: 3. Karta przedmiotu ważna od roku akademickiego: 2014/2015 4. Forma kształcenia: studia pierwszego stopnia 5. Forma
(pieczęć wydziału) KARTA PRZEDMIOTU 1. Nazwa przedmiotu: BAZY DANYCH 2. Kod przedmiotu: 3. Karta przedmiotu ważna od roku akademickiego: 2014/2015 4. Forma kształcenia: studia pierwszego stopnia 5. Forma
Sylabus do programu kształcenia obowiązującego od roku akademickiego 2014/15
 Sylabus do programu kształcenia obowiązującego od roku akademickiego 204/5 Nazwa Bazy danych Nazwa jednostki prowadzącej przedmiot Wydział Matematyczno - Przyrodniczy Kod Studia Kierunek studiów Poziom
Sylabus do programu kształcenia obowiązującego od roku akademickiego 204/5 Nazwa Bazy danych Nazwa jednostki prowadzącej przedmiot Wydział Matematyczno - Przyrodniczy Kod Studia Kierunek studiów Poziom
Zasady transformacji modelu DOZ do projektu tabel bazy danych
 Zasady transformacji modelu DOZ do projektu tabel bazy danych A. Obiekty proste B. Obiekty z podtypami C. Związki rozłączne GHJ 1 A. Projektowanie - obiekty proste TRASA # * numer POZYCJA o planowana godzina
Zasady transformacji modelu DOZ do projektu tabel bazy danych A. Obiekty proste B. Obiekty z podtypami C. Związki rozłączne GHJ 1 A. Projektowanie - obiekty proste TRASA # * numer POZYCJA o planowana godzina
Bazy danych. Plan wykładu. Zależności funkcyjne. Wykład 2: Relacyjny model danych - zależności funkcyjne. Podstawy SQL.
 Plan wykładu Bazy danych Wykład 2: Relacyjny model danych - zależności funkcyjne. Podstawy SQL. Deficja zależności funkcyjnych Klucze relacji Reguły dotyczące zależności funkcyjnych Domknięcie zbioru atrybutów
Plan wykładu Bazy danych Wykład 2: Relacyjny model danych - zależności funkcyjne. Podstawy SQL. Deficja zależności funkcyjnych Klucze relacji Reguły dotyczące zależności funkcyjnych Domknięcie zbioru atrybutów
Przydatne sztuczki - sql. Na przykładzie postgres a.
 Przydatne sztuczki - sql. Na przykładzie postgres a. M. Wiewiórko 05/2014 Plan Uwagi wstępne Przykład Rozwiązanie Tabela testowa Plan prezentacji: Kilka uwag wstępnych. Operacje na typach tekstowych. Korzystanie
Przydatne sztuczki - sql. Na przykładzie postgres a. M. Wiewiórko 05/2014 Plan Uwagi wstępne Przykład Rozwiązanie Tabela testowa Plan prezentacji: Kilka uwag wstępnych. Operacje na typach tekstowych. Korzystanie
Model relacyjny. Wykład II
 Model relacyjny został zaproponowany do strukturyzacji danych przez brytyjskiego matematyka Edgarda Franka Codda w 1970 r. Baza danych według definicji Codda to zbiór zmieniających się w czasie relacji
Model relacyjny został zaproponowany do strukturyzacji danych przez brytyjskiego matematyka Edgarda Franka Codda w 1970 r. Baza danych według definicji Codda to zbiór zmieniających się w czasie relacji
Technologie baz danych
 Technologie baz danych Wykład 4: Diagramy związków encji (ERD). SQL funkcje grupujące. Małgorzata Krętowska Wydział Informatyki Politechnika Białostocka Plan wykładu Diagramy związków encji elementy ERD
Technologie baz danych Wykład 4: Diagramy związków encji (ERD). SQL funkcje grupujące. Małgorzata Krętowska Wydział Informatyki Politechnika Białostocka Plan wykładu Diagramy związków encji elementy ERD
Integralność danych Wersje języka SQL Klauzula SELECT i JOIN
 Integralność danych Wersje języka SQL Klauzula SELECT i JOIN Robert A. Kłopotek r.klopotek@uksw.edu.pl Wydział Matematyczno-Przyrodniczy. Szkoła Nauk Ścisłych, UKSW Integralność danych Aspekty integralności
Integralność danych Wersje języka SQL Klauzula SELECT i JOIN Robert A. Kłopotek r.klopotek@uksw.edu.pl Wydział Matematyczno-Przyrodniczy. Szkoła Nauk Ścisłych, UKSW Integralność danych Aspekty integralności
Uniwersytet Zielonogórski Instytut Sterowania i Systemów Informatycznych Bazy Danych - Projekt. Zasady przygotowania i oceny projektów
 Uniwersytet Zielonogórski Instytut Sterowania i Systemów Informatycznych Bazy Danych - Projekt Zasady przygotowania i oceny projektów 1 Cel projektu Celem niniejszego projektu jest zaprojektowanie i implementacja
Uniwersytet Zielonogórski Instytut Sterowania i Systemów Informatycznych Bazy Danych - Projekt Zasady przygotowania i oceny projektów 1 Cel projektu Celem niniejszego projektu jest zaprojektowanie i implementacja
NARZĘDZIA WIZUALIZACJI
 NARZĘDZIA WIZUALIZACJI Kurs interaktywnej komunikacji wizualnej ANDRZEJ ŁACHWA andrzej.lachwa@uj.edu.pl Kraków, marzec 2014 3 4/8 Zwykłe działanie programu z danymi przechowywanymi w bazie danych polega
NARZĘDZIA WIZUALIZACJI Kurs interaktywnej komunikacji wizualnej ANDRZEJ ŁACHWA andrzej.lachwa@uj.edu.pl Kraków, marzec 2014 3 4/8 Zwykłe działanie programu z danymi przechowywanymi w bazie danych polega
Relacyjny model baz danych, model związków encji, normalizacje
 Relacyjny model baz danych, model związków encji, normalizacje Wyklad 3 mgr inż. Maciej Lasota mgr inż. Karol Wieczorek Politechnika Świętokrzyska Katedra Informatyki Kielce, 2009 Definicje Operacje na
Relacyjny model baz danych, model związków encji, normalizacje Wyklad 3 mgr inż. Maciej Lasota mgr inż. Karol Wieczorek Politechnika Świętokrzyska Katedra Informatyki Kielce, 2009 Definicje Operacje na
PLAN WYKŁADU BAZY DANYCH ZALEŻNOŚCI FUNKCYJNE
 PLAN WYKŁADU Zależności funkcyjne Anomalie danych Normalizacja Postacie normalne Zależności niefunkcyjne Zależności złączenia BAZY DANYCH Wykład 5 dr inż. Agnieszka Bołtuć ZALEŻNOŚCI FUNKCYJNE Niech R
PLAN WYKŁADU Zależności funkcyjne Anomalie danych Normalizacja Postacie normalne Zależności niefunkcyjne Zależności złączenia BAZY DANYCH Wykład 5 dr inż. Agnieszka Bołtuć ZALEŻNOŚCI FUNKCYJNE Niech R
Projektowanie systemów informatycznych. Roman Simiński siminskionline.pl. Modelowanie danych Diagramy ERD
 Projektowanie systemów informatycznych Roman Simiński roman.siminski@us.edu.pl siminskionline.pl Modelowanie danych Diagramy ERD Modelowanie danych dlaczego? Od biznesowego gadania do magazynu na biznesowe
Projektowanie systemów informatycznych Roman Simiński roman.siminski@us.edu.pl siminskionline.pl Modelowanie danych Diagramy ERD Modelowanie danych dlaczego? Od biznesowego gadania do magazynu na biznesowe
Bazy danych. Wykład IV SQL - wprowadzenie. Copyrights by Arkadiusz Rzucidło 1
 Bazy danych Wykład IV SQL - wprowadzenie Copyrights by Arkadiusz Rzucidło 1 Czym jest SQL Język zapytań deklaratywny dostęp do danych Składnia łatwa i naturalna Standardowe narzędzie dostępu do wielu różnych
Bazy danych Wykład IV SQL - wprowadzenie Copyrights by Arkadiusz Rzucidło 1 Czym jest SQL Język zapytań deklaratywny dostęp do danych Składnia łatwa i naturalna Standardowe narzędzie dostępu do wielu różnych
Bazy danych 2. Wykład 1
 Bazy danych 2 Wykład 1 Sprawy organizacyjne Materiały i listy zadań zamieszczane będą na stronie www.math.uni.opole.pl/~ajasi E-mail: standardowy ajasi@math.uni.opole.pl Sprawy organizacyjne Program wykładu
Bazy danych 2 Wykład 1 Sprawy organizacyjne Materiały i listy zadań zamieszczane będą na stronie www.math.uni.opole.pl/~ajasi E-mail: standardowy ajasi@math.uni.opole.pl Sprawy organizacyjne Program wykładu
NARZĘDZIA WIZUALIZACJI
 NARZĘDZIA WIZUALIZACJI Kurs interaktywnej komunikacji wizualnej ANDRZEJ ŁACHWA andrzej.lachwa@uj.edu.pl Kraków, październik 2015 2/4 Zwykłe działanie programu z danymi przechowywanymi w bazie danych polega
NARZĘDZIA WIZUALIZACJI Kurs interaktywnej komunikacji wizualnej ANDRZEJ ŁACHWA andrzej.lachwa@uj.edu.pl Kraków, październik 2015 2/4 Zwykłe działanie programu z danymi przechowywanymi w bazie danych polega
Projektowanie relacyjnych baz danych
 Mam nadzieję, że do tej pory przyzwyczaiłeś się do tabelarycznego układu danych i poznałeś sposoby odczytywania i modyfikowania tak zapisanych danych. W tym odcinku poznasz nieco teorii relacyjnych baz
Mam nadzieję, że do tej pory przyzwyczaiłeś się do tabelarycznego układu danych i poznałeś sposoby odczytywania i modyfikowania tak zapisanych danych. W tym odcinku poznasz nieco teorii relacyjnych baz
Zależności funkcyjne pierwotne i wtórne
 Zależności funkcyjne pierwotne i wtórne W praktyce, w przypadku konkretnej bazy danych, nie jest zwykle możliwe (ani potrzebne), by projektant określił wszystkie zależności funkcyjne na etapie analizy
Zależności funkcyjne pierwotne i wtórne W praktyce, w przypadku konkretnej bazy danych, nie jest zwykle możliwe (ani potrzebne), by projektant określił wszystkie zależności funkcyjne na etapie analizy
Relacyjne bazy danych. Podstawy SQL
 Relacyjne bazy danych Podstawy SQL Język SQL SQL (Structured Query Language) język umożliwiający dostęp i przetwarzanie danych w bazie danych na poziomie obiektów modelu relacyjnego tj. tabel i perspektyw.
Relacyjne bazy danych Podstawy SQL Język SQL SQL (Structured Query Language) język umożliwiający dostęp i przetwarzanie danych w bazie danych na poziomie obiektów modelu relacyjnego tj. tabel i perspektyw.
Funkcje. Rozdział 3a Funkcje wierszowe. Funkcje znakowe (1) Funkcje wierszowe
 Funkcje wierszowe") Funkcje Rozdział 3a Funkcje wierszowe Funkcje wierszowe (funkcje znakowe, funkcje liczbowe, funkcje operujące na datach, funkcje konwersji, funkcje polimorficzne) Przekształcają dane, pobrane przez polecenie
Funkcje Rozdział 3a Funkcje wierszowe Funkcje wierszowe (funkcje znakowe, funkcje liczbowe, funkcje operujące na datach, funkcje konwersji, funkcje polimorficzne) Przekształcają dane, pobrane przez polecenie
Struktura drzewa w MySQL. Michał Tyszczenko
 Struktura drzewa w MySQL Michał Tyszczenko W informatyce drzewa są strukturami danych reprezentującymi drzewa matematyczne. W naturalny sposób reprezentują hierarchię danych toteż głównie do tego celu
Struktura drzewa w MySQL Michał Tyszczenko W informatyce drzewa są strukturami danych reprezentującymi drzewa matematyczne. W naturalny sposób reprezentują hierarchię danych toteż głównie do tego celu
Bazy danych. Andrzej Łachwa, UJ, /15
 Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 6/15 Statystyki w języku SQL W różnych produktach SQL spotkamy rozmaite funkcje wbudowane ułatwiające analizy
Bazy danych Andrzej Łachwa, UJ, 2013 andrzej.lachwa@uj.edu.pl www.uj.edu.pl/web/zpgk/materialy 6/15 Statystyki w języku SQL W różnych produktach SQL spotkamy rozmaite funkcje wbudowane ułatwiające analizy
2017/2018 WGGiOS AGH. LibreOffice Base
 1. Baza danych LibreOffice Base Jest to zbiór danych zapisanych zgodnie z określonymi regułami. W węższym znaczeniu obejmuje dane cyfrowe gromadzone zgodnie z zasadami przyjętymi dla danego programu komputerowego,
1. Baza danych LibreOffice Base Jest to zbiór danych zapisanych zgodnie z określonymi regułami. W węższym znaczeniu obejmuje dane cyfrowe gromadzone zgodnie z zasadami przyjętymi dla danego programu komputerowego,
Bazy danych wykład trzeci. trzeci Modelowanie schematu bazy danych 1 / 40
 Bazy danych wykład trzeci Modelowanie schematu bazy danych Konrad Zdanowski Uniwersytet Kardynała Stefana Wyszyńskiego, Warszawa trzeci Modelowanie schematu bazy danych 1 / 40 Outline 1 Zalezności funkcyjne
Bazy danych wykład trzeci Modelowanie schematu bazy danych Konrad Zdanowski Uniwersytet Kardynała Stefana Wyszyńskiego, Warszawa trzeci Modelowanie schematu bazy danych 1 / 40 Outline 1 Zalezności funkcyjne
LITERATURA. C. J. Date; Wprowadzenie do systemów baz danych WNT Warszawa 2000 ( seria Klasyka Informatyki )
") LITERATURA C. J. Date; Wprowadzenie do systemów baz danych WNT Warszawa 2000 ( seria Klasyka Informatyki ) H. Garcia Molina, Jeffrey D. Ullman, Jennifer Widom; Systemy baz danych. Kompletny podręcznik
LITERATURA C. J. Date; Wprowadzenie do systemów baz danych WNT Warszawa 2000 ( seria Klasyka Informatyki ) H. Garcia Molina, Jeffrey D. Ullman, Jennifer Widom; Systemy baz danych. Kompletny podręcznik
Język SQL. Rozdział 3. Funkcje wierszowe
 Język SQL. Rozdział 3. Funkcje wierszowe Funkcje wierszowe (funkcje znakowe, funkcje liczbowe, funkcje operujące na datach, funkcje konwersji, funkcje polimorficzne). 1 Funkcje Przekształcają dane, pobrane
Język SQL. Rozdział 3. Funkcje wierszowe Funkcje wierszowe (funkcje znakowe, funkcje liczbowe, funkcje operujące na datach, funkcje konwersji, funkcje polimorficzne). 1 Funkcje Przekształcają dane, pobrane
KARTA PRZEDMIOTU 1,5 1,5
 WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI Zał. nr 4 do ZW 33/01 KARTA PRZEDMIOTU Nazwa w języku polskim BAZY DANYCH Nazwa w języku angielskim DATABASE SYSTEMS Kierunek studiów (jeśli dotyczy): INŻYNIERIA
WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI Zał. nr 4 do ZW 33/01 KARTA PRZEDMIOTU Nazwa w języku polskim BAZY DANYCH Nazwa w języku angielskim DATABASE SYSTEMS Kierunek studiów (jeśli dotyczy): INŻYNIERIA
Blaski i cienie wyzwalaczy w relacyjnych bazach danych. Mgr inż. Andrzej Ptasznik
 Blaski i cienie wyzwalaczy w relacyjnych bazach danych. Mgr inż. Andrzej Ptasznik Technologia Przykłady praktycznych zastosowań wyzwalaczy będą omawiane na bazie systemu MS SQL Server 2005 Wprowadzenie
Blaski i cienie wyzwalaczy w relacyjnych bazach danych. Mgr inż. Andrzej Ptasznik Technologia Przykłady praktycznych zastosowań wyzwalaczy będą omawiane na bazie systemu MS SQL Server 2005 Wprowadzenie
Diagramy ERD. Model struktury danych jest najczęściej tworzony z wykorzystaniem diagramów pojęciowych (konceptualnych). Najpopularniejszym
. Najpopularniejszym") Diagramy ERD. Model struktury danych jest najczęściej tworzony z wykorzystaniem diagramów pojęciowych (konceptualnych). Najpopularniejszym konceptualnym modelem danych jest tzw. model związków encji (ERM
Diagramy ERD. Model struktury danych jest najczęściej tworzony z wykorzystaniem diagramów pojęciowych (konceptualnych). Najpopularniejszym konceptualnym modelem danych jest tzw. model związków encji (ERM
I. KARTA PRZEDMIOTU CEL PRZEDMIOTU
 I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: BAZY DANYCH 2. Kod przedmiotu: Bda 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Informatyka Stosowana
I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: BAZY DANYCH 2. Kod przedmiotu: Bda 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Informatyka Stosowana
Bazy danych. Zachodniopomorski Uniwersytet Technologiczny w Szczecinie. Wykład 3: Model związków encji.
 Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Bazy danych Wykład 3: Model związków encji. dr inż. Magdalena Krakowiak makrakowiak@wi.zut.edu.pl Co to jest model związków encji? Model związków
Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Bazy danych Wykład 3: Model związków encji. dr inż. Magdalena Krakowiak makrakowiak@wi.zut.edu.pl Co to jest model związków encji? Model związków
2010-11-22 PLAN WYKŁADU BAZY DANYCH PODSTAWOWE KWESTIE BEZPIECZEŃSTWA OGRANICZENIA DOSTĘPU DO DANYCH
 PLAN WYKŁADU Bezpieczeństwo w języku SQL Użytkownicy Uprawnienia Role BAZY DANYCH Wykład 8 dr inż. Agnieszka Bołtuć OGRANICZENIA DOSTĘPU DO DANYCH Ograniczenie danych z tabeli dla określonego użytkownika
PLAN WYKŁADU Bezpieczeństwo w języku SQL Użytkownicy Uprawnienia Role BAZY DANYCH Wykład 8 dr inż. Agnieszka Bołtuć OGRANICZENIA DOSTĘPU DO DANYCH Ograniczenie danych z tabeli dla określonego użytkownika
Ogólny plan przedmiotu. Strony WWW. Literatura BAZY DANYCH. Materiały do wykładu: http://aragorn.pb.bialystok.pl/~gkret
 Ogólny plan przedmiotu BAZY DANYCH Wykład 1: Wprowadzenie do baz danych Małgorzata Krętowska Politechnika Białostocka Wydział Informatyki Wykład : Wprowadzenie do baz danych Normalizacja Diagramy związków
Ogólny plan przedmiotu BAZY DANYCH Wykład 1: Wprowadzenie do baz danych Małgorzata Krętowska Politechnika Białostocka Wydział Informatyki Wykład : Wprowadzenie do baz danych Normalizacja Diagramy związków
Transformacja modelu ER do modelu relacyjnego
 Transformacja modelu ER do modelu relacyjnego Wykład przygotował: Robert Wrembel BD wykład 4 (1) 1 Plan wykładu Transformacja encji Transformacja związków Transformacja hierarchii encji BD wykład 4 (2)
Transformacja modelu ER do modelu relacyjnego Wykład przygotował: Robert Wrembel BD wykład 4 (1) 1 Plan wykładu Transformacja encji Transformacja związków Transformacja hierarchii encji BD wykład 4 (2)
1 Projektowanie systemu informatycznego
 Plan wykładu Spis treści 1 Projektowanie systemu informatycznego 1 2 Modelowanie pojęciowe 4 2.1 Encja....................................... 5 2.2 Własności.................................... 6 2.3 Związki.....................................
Plan wykładu Spis treści 1 Projektowanie systemu informatycznego 1 2 Modelowanie pojęciowe 4 2.1 Encja....................................... 5 2.2 Własności.................................... 6 2.3 Związki.....................................
Informatyka Ćwiczenie 10. Bazy danych. Strukturę bazy danych można określić w formie jak na rysunku 1. atrybuty
 Informatyka Ćwiczenie 10 Bazy danych Baza danych jest zbiór informacji (zbiór danych). Strukturę bazy danych można określić w formie jak na rysunku 1. Pracownik(ID pracownika, imie, nazwisko, pensja) Klient(ID
Informatyka Ćwiczenie 10 Bazy danych Baza danych jest zbiór informacji (zbiór danych). Strukturę bazy danych można określić w formie jak na rysunku 1. Pracownik(ID pracownika, imie, nazwisko, pensja) Klient(ID
WPROWADZENIE DO BAZ DANYCH
 WPROWADZENIE DO BAZ DANYCH Pojęcie danych i baz danych Dane to wszystkie informacje jakie przechowujemy, aby w każdej chwili mieć do nich dostęp. Baza danych (data base) to uporządkowany zbiór danych z
WPROWADZENIE DO BAZ DANYCH Pojęcie danych i baz danych Dane to wszystkie informacje jakie przechowujemy, aby w każdej chwili mieć do nich dostęp. Baza danych (data base) to uporządkowany zbiór danych z
Bazy danych i usługi sieciowe
 Bazy danych i usługi sieciowe Modelowanie związków encji Paweł Daniluk Wydział Fizyki Jesień 2014 P. Daniluk (Wydział Fizyki) BDiUS w. II Jesień 2014 1 / 28 Modelowanie Modelowanie polega na odwzorowaniu
Bazy danych i usługi sieciowe Modelowanie związków encji Paweł Daniluk Wydział Fizyki Jesień 2014 P. Daniluk (Wydział Fizyki) BDiUS w. II Jesień 2014 1 / 28 Modelowanie Modelowanie polega na odwzorowaniu
Oracle11g: Wprowadzenie do SQL
 Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego.
 77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego. Przy modelowaniu bazy danych możemy wyróżnić następujące typy połączeń relacyjnych: jeden do wielu, jeden do jednego, wiele
77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego. Przy modelowaniu bazy danych możemy wyróżnić następujące typy połączeń relacyjnych: jeden do wielu, jeden do jednego, wiele
PODSTAWY BAZ DANYCH. 5. Modelowanie danych. 2009/ Notatki do wykładu "Podstawy baz danych"
 PODSTAWY BAZ DANYCH 5. Modelowanie danych 1 Etapy tworzenia systemu informatycznego Etapy tworzenia systemu informatycznego - (według CASE*Method) (CASE Computer Aided Systems Engineering ) Analiza wymagań
PODSTAWY BAZ DANYCH 5. Modelowanie danych 1 Etapy tworzenia systemu informatycznego Etapy tworzenia systemu informatycznego - (według CASE*Method) (CASE Computer Aided Systems Engineering ) Analiza wymagań
Modelowanie hierarchicznych struktur w relacyjnych bazach danych
 Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Bazy danych Database Kierunek: Rodzaj przedmiotu: obieralny Rodzaj zajęć: wykład, laboratorium Matematyka Poziom kwalifikacji: I stopnia Liczba godzin/tydzień: 2W, 2L Semestr: III Liczba
Nazwa przedmiotu: Bazy danych Database Kierunek: Rodzaj przedmiotu: obieralny Rodzaj zajęć: wykład, laboratorium Matematyka Poziom kwalifikacji: I stopnia Liczba godzin/tydzień: 2W, 2L Semestr: III Liczba
Projektowanie bazy danych. Jarosław Kuchta Projektowanie Aplikacji Internetowych
 Projektowanie bazy danych Jarosław Kuchta Projektowanie Aplikacji Internetowych Możliwości projektowe Relacyjna baza danych Obiektowa baza danych Relacyjno-obiektowa baza danych Inne rozwiązanie (np. XML)
Projektowanie bazy danych Jarosław Kuchta Projektowanie Aplikacji Internetowych Możliwości projektowe Relacyjna baza danych Obiektowa baza danych Relacyjno-obiektowa baza danych Inne rozwiązanie (np. XML)
Wykład 8. SQL praca z tabelami 5
 Wykład 8 SQL praca z tabelami 5 Podzapytania to mechanizm pozwalający wykorzystywać wyniki jednego zapytania w innym zapytaniu. Nazywane często zapytaniami zagnieżdżonymi. Są stosowane z zapytaniami typu
Wykład 8 SQL praca z tabelami 5 Podzapytania to mechanizm pozwalający wykorzystywać wyniki jednego zapytania w innym zapytaniu. Nazywane często zapytaniami zagnieżdżonymi. Są stosowane z zapytaniami typu
Aplikacje bazodanowe. Laboratorium 1. Dawid Poªap Aplikacje bazodanowe - laboratorium 1 Luty, 22, / 37
 Aplikacje bazodanowe Laboratorium 1 Dawid Poªap Aplikacje bazodanowe - laboratorium 1 Luty, 22, 2017 1 / 37 Plan 1 Informacje wst pne 2 Przygotowanie ±rodowiska do pracy 3 Poj cie bazy danych 4 Relacyjne
Aplikacje bazodanowe Laboratorium 1 Dawid Poªap Aplikacje bazodanowe - laboratorium 1 Luty, 22, 2017 1 / 37 Plan 1 Informacje wst pne 2 Przygotowanie ±rodowiska do pracy 3 Poj cie bazy danych 4 Relacyjne
Wprowadzenie do baz danych
 Wprowadzenie do baz danych Bazy danych stanowią obecnie jedno z ważniejszych zastosowań komputerów. Podstawowe zalety komputerowej bazy to przede wszystkim szybkość przetwarzania danych, ilość dostępnych
Wprowadzenie do baz danych Bazy danych stanowią obecnie jedno z ważniejszych zastosowań komputerów. Podstawowe zalety komputerowej bazy to przede wszystkim szybkość przetwarzania danych, ilość dostępnych
Cel przedmiotu. Wymagania wstępne w zakresie wiedzy, umiejętności i innych kompetencji 1 Język angielski 2 Inżynieria oprogramowania
 Przedmiot: Bazy danych Rok: III Semestr: V Rodzaj zajęć i liczba godzin: Studia stacjonarne Studia niestacjonarne Wykład 30 21 Ćwiczenia Laboratorium 30 21 Projekt Liczba punktów ECTS: 4 C1 C2 C3 Cel przedmiotu
Przedmiot: Bazy danych Rok: III Semestr: V Rodzaj zajęć i liczba godzin: Studia stacjonarne Studia niestacjonarne Wykład 30 21 Ćwiczenia Laboratorium 30 21 Projekt Liczba punktów ECTS: 4 C1 C2 C3 Cel przedmiotu
2 Przygotował: mgr inż. Maciej Lasota
 Laboratorium nr 2 1 Bazy Danych Instrukcja laboratoryjna Temat: Obsługa bazy danych za pomocą phpmyadmin oraz phppgadmin 2 Przygotował: mgr inż. Maciej Lasota 1) Wprowadzenie do phpmyadmin oraz phppgadmin
Laboratorium nr 2 1 Bazy Danych Instrukcja laboratoryjna Temat: Obsługa bazy danych za pomocą phpmyadmin oraz phppgadmin 2 Przygotował: mgr inż. Maciej Lasota 1) Wprowadzenie do phpmyadmin oraz phppgadmin
Normalizacja baz danych
 Wrocławska Wyższa Szkoła Informatyki Stosowanej Normalizacja baz danych Dr hab. inż. Krzysztof Pieczarka Email: krzysztof.pieczarka@gmail.com Normalizacja relacji ma na celu takie jej przekształcenie,
Wrocławska Wyższa Szkoła Informatyki Stosowanej Normalizacja baz danych Dr hab. inż. Krzysztof Pieczarka Email: krzysztof.pieczarka@gmail.com Normalizacja relacji ma na celu takie jej przekształcenie,
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy ogólny Rodzaj zajęć: wykład, laboratorium BAZY DANYCH Databases Forma studiów: Stacjonarne
Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy ogólny Rodzaj zajęć: wykład, laboratorium BAZY DANYCH Databases Forma studiów: Stacjonarne
Bazy danych 6. Klucze obce. P. F. Góra
 Bazy danych 6. Klucze obce P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2018 Dygresja: Metody przechowywania tabel w MySQL Tabele w MySQL moga być przechowywane na kilka sposobów. Sposób ten (żargonowo:
Bazy danych 6. Klucze obce P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2018 Dygresja: Metody przechowywania tabel w MySQL Tabele w MySQL moga być przechowywane na kilka sposobów. Sposób ten (żargonowo:
Dr Michał Tanaś(http://www.amu.edu.pl/~mtanas)
") Dr Michał Tanaś(http://www.amu.edu.pl/~mtanas) Bazy danych podstawowe pojęcia Baza danych jest to zbiór danych zorganizowany zgodnie ze ściśle określonym modelem danych. Model danych to zbiór ścisłych
Dr Michał Tanaś(http://www.amu.edu.pl/~mtanas) Bazy danych podstawowe pojęcia Baza danych jest to zbiór danych zorganizowany zgodnie ze ściśle określonym modelem danych. Model danych to zbiór ścisłych
Przykłady najlepiej wykonywać od razu na bazie i eksperymentować z nimi.
 Marek Robak Wprowadzenie do języka SQL na przykładzie baz SQLite Przykłady najlepiej wykonywać od razu na bazie i eksperymentować z nimi. Tworzenie tabeli Pierwsza tabela W relacyjnych bazach danych jedna
Marek Robak Wprowadzenie do języka SQL na przykładzie baz SQLite Przykłady najlepiej wykonywać od razu na bazie i eksperymentować z nimi. Tworzenie tabeli Pierwsza tabela W relacyjnych bazach danych jedna
Podstawowe pakiety komputerowe wykorzystywane w zarządzaniu przedsiębiorstwem. dr Jakub Boratyński. pok. A38
 Podstawowe pakiety komputerowe wykorzystywane w zarządzaniu przedsiębiorstwem zajęcia 1 dr Jakub Boratyński pok. A38 Program zajęć Bazy danych jako podstawowy element systemów informatycznych wykorzystywanych
Podstawowe pakiety komputerowe wykorzystywane w zarządzaniu przedsiębiorstwem zajęcia 1 dr Jakub Boratyński pok. A38 Program zajęć Bazy danych jako podstawowy element systemów informatycznych wykorzystywanych
FUNKCJE SZBD. ZSE - Systemy baz danych 1
 FUNKCJE SZBD ZSE - Systemy baz danych 1 System zarządzania bazami danych System zarządzania bazami danych (SZBD, ang. DBMS) jest zbiorem narzędzi stanowiących warstwę pośredniczącą pomiędzy bazą danych
FUNKCJE SZBD ZSE - Systemy baz danych 1 System zarządzania bazami danych System zarządzania bazami danych (SZBD, ang. DBMS) jest zbiorem narzędzi stanowiących warstwę pośredniczącą pomiędzy bazą danych
Multimedialne bazy danych. Andrzej Łachwa, WFAiIS UJ 2011
 1 Multimedialne bazy danych Andrzej Łachwa, WFAiIS UJ 2011 1. Hiperteksty Hipertekst jest systemem informacyjnym, w którym informacja jest wyrażona w postaci niezależnych tekstów przechowywanych w węzłach,
1 Multimedialne bazy danych Andrzej Łachwa, WFAiIS UJ 2011 1. Hiperteksty Hipertekst jest systemem informacyjnym, w którym informacja jest wyrażona w postaci niezależnych tekstów przechowywanych w węzłach,
P o d s t a w y j ę z y k a S Q L
 P o d s t a w y j ę z y k a S Q L Adam Cakudis IFP UAM Użytkownicy System informatyczny Aplikacja Aplikacja Aplikacja System bazy danych System zarządzania baz ą danych Schemat Baza danych K o n c e p
P o d s t a w y j ę z y k a S Q L Adam Cakudis IFP UAM Użytkownicy System informatyczny Aplikacja Aplikacja Aplikacja System bazy danych System zarządzania baz ą danych Schemat Baza danych K o n c e p
PLAN WYKŁADU BAZY DANYCH GŁÓWNE ETAPY PROJEKTOWANIA BAZY MODELOWANIE LOGICZNE
 PLAN WYKŁADU Modelowanie logiczne Transformacja ERD w model relacyjny Odwzorowanie encji Odwzorowanie związków Odwzorowanie specjalizacji i generalizacji BAZY DANYCH Wykład 7 dr inż. Agnieszka Bołtuć GŁÓWNE
PLAN WYKŁADU Modelowanie logiczne Transformacja ERD w model relacyjny Odwzorowanie encji Odwzorowanie związków Odwzorowanie specjalizacji i generalizacji BAZY DANYCH Wykład 7 dr inż. Agnieszka Bołtuć GŁÓWNE
Wykład 5. SQL praca z tabelami 2
 Wykład 5 SQL praca z tabelami 2 Wypełnianie tabel danymi Tabele można wypełniać poprzez standardową instrukcję INSERT INTO: INSERT [INTO] nazwa_tabeli [(kolumna1, kolumna2,, kolumnan)] VALUES (wartosc1,
Wykład 5 SQL praca z tabelami 2 Wypełnianie tabel danymi Tabele można wypełniać poprzez standardową instrukcję INSERT INTO: INSERT [INTO] nazwa_tabeli [(kolumna1, kolumna2,, kolumnan)] VALUES (wartosc1,
forma studiów: studia stacjonarne Liczba godzin/tydzień: 1, 0, 2, 0, 0
 Nazwa przedmiotu: Relacyjne Bazy Danych Relational Databases Kierunek: Zarządzanie i Inżynieria Produkcji Kod przedmiotu: ZIP.GD5.03 Rodzaj przedmiotu: Przedmiot Specjalnościowy na kierunku ZIP dla specjalności
Nazwa przedmiotu: Relacyjne Bazy Danych Relational Databases Kierunek: Zarządzanie i Inżynieria Produkcji Kod przedmiotu: ZIP.GD5.03 Rodzaj przedmiotu: Przedmiot Specjalnościowy na kierunku ZIP dla specjalności
Plan wykładu: Relacyjny model danych: opis modelu, podstawowe pojęcia, ograniczenia, więzy.
 Plan wykładu: Relacyjny model danych: opis modelu, podstawowe pojęcia, ograniczenia, więzy. Przejście od modelu związków encji do modelu relacyjnego: odwzorowanie zbiorów encji, odwzorowanie związków encji
Plan wykładu: Relacyjny model danych: opis modelu, podstawowe pojęcia, ograniczenia, więzy. Przejście od modelu związków encji do modelu relacyjnego: odwzorowanie zbiorów encji, odwzorowanie związków encji
Zadanie 1. Suma silni (11 pkt)
") 2 Egzamin maturalny z informatyki Zadanie 1. Suma silni (11 pkt) Pojęcie silni dla liczb naturalnych większych od zera definiuje się następująco: 1 dla n = 1 n! = ( n 1! ) n dla n> 1 Rozpatrzmy funkcję
2 Egzamin maturalny z informatyki Zadanie 1. Suma silni (11 pkt) Pojęcie silni dla liczb naturalnych większych od zera definiuje się następująco: 1 dla n = 1 n! = ( n 1! ) n dla n> 1 Rozpatrzmy funkcję
Relacyjne bazy danych. Podstawy SQL
 Relacyjne bazy danych Podstawy SQL Język SQL SQL (Structured Query Language) język umoŝliwiający dostęp i przetwarzanie danych w bazie danych na poziomie obiektów modelu relacyjnego tj. tabel i perspektyw.
Relacyjne bazy danych Podstawy SQL Język SQL SQL (Structured Query Language) język umoŝliwiający dostęp i przetwarzanie danych w bazie danych na poziomie obiektów modelu relacyjnego tj. tabel i perspektyw.