Analiza regresji część II. Agnieszka Nowak - Brzezińska
|
|
|
- Janusz Nowak
- 8 lat temu
- Przeglądów:
Transkrypt
1 Analiza regresji część II Agnieszka Nowak - Brzezińska

2 Niebezpieczeństwo ekstrapolacji Analitycy powinni ograniczyć predykcję i estymację, które są wykonywane za pomocą równania regresji dla wartości objaśniającej w obrębie przedziału wartości x w zbiorze danych. Np. w zbiorze płatków śniadaniowych najmniejsza zawartość cukru to 0 a największa to 15 więc szacowana wartości odżywcza jest właściwa tylko dla dowolnej wartości z przedziału

3 Ekstrapolacja Ekstrapolacja - szacowanie dla wartości poza przedziałem może być niebezpieczne, ponieważ nie znamy natury relacji pomiędzy x i y poza tym zakresem. Ekstrapolacji należy oczywiście unikać. Załóżmy, że nowe płatki zostały wpuszczone na rynek z bardzo dużą zawartością cukru. Np.. 30 gram. Nasze równanie regresji oszacuje wartość odżywczą płatków na -13.2!

4 rysunek Chcielibyśmy aby nasze punkty układały się tylko jako czarne punkty. Jednak rzeczywiście relacja między x i y składa się zarówno z punktów czarnych (obserwowanych), jak i szarych (nieobserwowanych). Linia regresji oparta jedynie na dostępnych danych jest taka jak na rysunku.
, jak i szarych (nieobserwowanych).")
5 Oszacowanie najmniejszych kwadratów Gdybyśmy mieli inny zbiór płatków to nie możemy zakładać, że zależność pomiędzy wartością odżywczą a zawartością cukrów będzie dokładnie taka sama jak: rating * sugars Nie ponieważ b0 i b1 są statystykami, których wartości zmieniają się w zależności od próby. b0 i b1 są używane do estymacji parametrów populacji, w tym przypadku 0, 1 czyli wyrazu wolnego oraz współczynnika nachylenia prostej regresji. y 0 1

6 Równanie regresji y 0 1 x Reprezentuje prawdziwą liniową zależność między wartością odżywczą płatków a zawartością cukrów dla wszystkich rodzajów płatków śniadaniowych, nie tylko tych z naszej próby 77 typów płatków. Losowy błąd w powyższym równaniu regresji stosuje się w celu uwzględnienia nieoznaczoności w modelu, ponieważ dwa różne rodzaje płatków śniadaniowych mogą mieć tę samą zawartość cukrów ale inną wartość odżywczą.

7 W regresji prostej bada się relację pomiędzy dwiema zmiennymi ilościowymi x i y. Model zależności w prostej regresji dla n elementowej próby jest postaci: Gdzie: i 0 1x i Y i wartość zmiennej y dla obserwacji i-tej X i - wartość zmiennej x dla i-tej obserwacji i zakłócenie losowe o rozkładzie N(0, 2 ) czyli ma rozkład normalny o wariancji 2 1 i n Są niezależne, a więc: cov i j ( i, j ) A 0, 1 są współczynnikami modelu. y 0 i
 czyli ma rozkład normalny o wariancji 2 1 i n Są niezależne, a więc: cov i j ( i, j )")
8 Taki model regresyjny opisuje często spotykaną w praktyce sytuację, gdy obserwowane wartości funkcji nie są dokładne, ponieważ są losowo zakłócane. Znając wartości wektora zmiennych objaśniających oraz losowo zakłócane wartości funkcji d, naszym zadaniem jest odfiltrowanie zakłóceń i podanie dokładnej postaci funkcji. Zmienne objaśniające to zmienne nielosowe, ale to nie ma tu akurat znaczenia.

9 Wyznaczywszy oszacowania parametrów modelu, można obliczyć również wartości reszt, czyli oszacowania dla zakłóceń losowych wyznaczanych jako: i yi 1 xi 0 Metoda najmniejszych kwadratów gwarantuje, że prosta regresji opisana równaniem y 1 x 0 minimalizuje sumę kwadratów reszt dla wszystkich obserwacji.

10 Współczynnik determinacji Pozwala on stwierdzić czy oszacowane równanie regresji jest przydatne do przewidywania czy nie. Nazywa się go często współczynnikiem dopasowania regresji i oznacza jako R 2. Określa on stopień w jakim linia regresji najmniejszych kwadratów wyjaśnia zmienność obserwowanych danych. y Oznacza estymowaną wartość zmiennej objaśnianej y y Oznacza błąd oszacowania lub resztę.

11 Suma kwadratów błędów SSE Całkowita wartość błędu oszacowania gdy użyjemy równania regresji Całkowita suma kwadratów SST 2 SST ( y y) Stanowi miarę całkowitej zmienności wartości y bez odniesienia do zmiennej objaśniającej. Mówi się, że SST jest funkcją wariancji zmiennej y. Regresyjna suma kwadratów SSR 2 SSR ( y y) Stanowi miarę całkowitej poprawy dokładności przewidywań w przypadku stosowania regresji w porównaniu z sytuacją gdy nie uwzględniamy wartości zmiennej objaśniającej SST = SSR + SSE SSE ( y y) 2
 Stanowi miarę całkowitej poprawy dokładności przewidywań w przypadku stosowania")
12 Współczynnik determinacji (ang. coefficient od determination) Mierzy stopień dopasowania regresji jako przybliżenia liniowej zależności pomiędzy zmienną celu a zmienną objaśniającą: 2 r SSR SST Możemy go interpretować jako tę część zmienności zmiennej y, która została wyjaśniona przez regresję, czyli przez liniowy związek pomiędzy zmienną celu a zmienną objaśniającą.

13 Współczynniki regresji Współczynnik determinacji z prostego modelu regresji liniowej dla zestawu danych cereals to 0,

14 Na ile dobra jest regresja? Współczynnik determinacji jest opisową miarą siły liniowego związku między zmiennymi, czyli miarą dopasowania linii regresji do danych współczynnik determinacji ---przyjmuje wartości z przedziału [0,1] i wskazuje jaka część zmienności zmiennej y jest wyjaśniana przez znaleziony model. Na przykład dla R2=0.619 znaleziony model wyjaśnia około 62% zmienności y.

15 Współczynnik determinacji Oczywiście zawsze można znaleźć taką linię regresji metodą najmniejszych kwadratów, która modeluje zależność pomiędzy dwoma dowolnymi ciągłymi zmiennymi. Jednak nie ma gwarancji, że taka regresja będzie przydatna. Zatem powstaje pytanie, w jaki sposób możemy stwierdzić, czy oszacowane równanie regresji jest przydatne do przewidywania. Jedną z miar dopasowania regresji jest współczynnik determinacji R 2. Określa on stopień, w jakim linia regresji najmniejszych kwadratów wyjaśnia zmienność obserwowanych danych. Przypomnijmy, że y oznacza estymowaną wartość zmiennej objaśnianej, a lub resztą. y y jest błędem oszacowania

16 Suma kwadratów błędu oszacowania lub suma kwadratów błędów reprezentuje całkowitą wartość błędu oszacowania w przypadku użycia równania regresji. Jeśli nie znamy wartości zmiennej objaśniającej do oszacowania wartości zmiennej objaśnianej- nasze oszacowania będą oczywiście mało wartościowe. Lepszym oszacowaniem dla y będzie po prostu średnia(y). To zazwyczaj prezentuje pozioma linia na wykresie. Punkty danych jednak koncentrują się bardziej wokół oszacowanej linii regresji a nie wokół tej linii poziomej, co sugeruje, że błędy przewidywania są mniejsze, kiedy uwzględniamy informację o zmiennej x, aniżeli wtedy, gdy tej informacji nie wykorzystujemy. Jeśli liczymy różnice x średnia(x) dla każdego rekordu, a następnie sumę kwadratów tych miar, tak jak przy oszacowanej wartości y ( ), kiedy obliczaliśmy sumę kwadratów błędów otrzymujemy całkowitą y y sumę kwadratów SST (sum of squares total): Stanowi ona miarę całkowitej zmienności wartości samej zmiennej objaśnianej bez odniesienia do zmiennej objaśniającej. Zauważmy, że SST jest funkcją wariancji zmiennej y, gdzie wariancja jest kwadratem odchylenia n 2 standardowego. SST ( y i y) i 1 SST n 2 2 ( yi y) ( n 1) Var ( y) ( n 1) y i 1

17 Współczynnik determinacji r 2 Współczynnik determinacji r 2 : 2 r SSR SST Mierzy stopień dopasowania regresji jako przybliżenia liniowej zależności pomiędzy zmienną celu a zmienną objaśniającą. Jaka jest wartość maksymalna współczynnika determinacji r 2? Jest ona osiągana wtedy, gdy regresja idealnie pasuje do danych, co ma miejsce wtedy gdy każdy z punktów danych leży dokładnie na oszacowanej linii regresji. Wówczas nie ma błędów oszacowania, a więc wartości resztowe (rezydua) wynoszą 0, a więc SSE=0 a wtedy SST = SSR a r 2 =1. Jaka jest wartość minimalna współczynnika determinacji r 2? Jest ona osiągana wtedy, gdy regresja nie wyjaśnia zmienności, wtedy SSR = 0, a więc r 2 =0. Im większa wartość r 2 tym lepsze dopasowanie regresji do zbioru danych.
 wynoszą 0, a więc SSE=0 a wtedy SST = SSR a r 2 =1. Jaka jest wartość minimalna współczynnika determinacji r 2?")
18 Przykład analizy współczynnika R 2 dla wielu zmiennych objaśniających Jak już wspomnieliśmy na początku, często w świecie rzeczywistym mamy do czynienia z zależnościami zmiennej objaśnianej nie od jednej ale raczej od wielu zmiennych objaśniających. Wykonanie tego typu analiz w pakiecie R nie jest rzeczą trudną. Wręcz przeciwnie. Nim przeprowadzimy analizę zależności zmiennej rating od wielu zmiennych objaśniających np. sugars oraz fiber przyjrzyjmy się wykresom rozrzutu dla tych zmiennych osobno. Wykres rozrzutu bowiem doskonale odzwierciedla zależności między pojedynczymi zmiennymi.


19
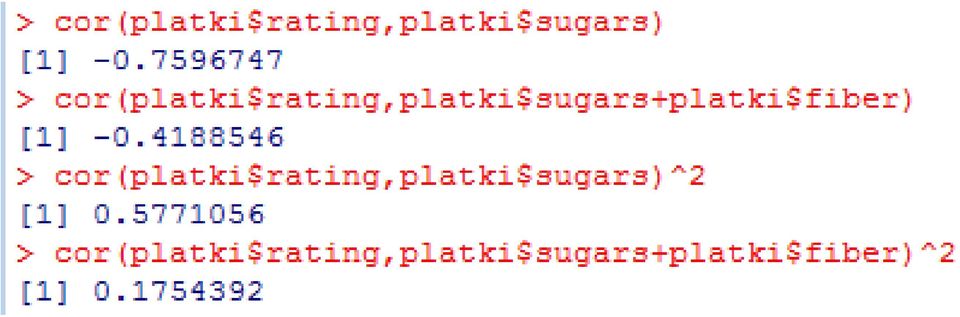
20 Funkcja r.square


21 Funkcja r.square.adjusted
22 Skorygowany R 2 Jest to sposób na wyeliminowanie z modelu zmiennych objaśniających, które nie są przydatne. Dodanie zmiennej do modelu regresji zwiększa wartość współczynnika determinacji, niezależnie od przydatności tej zmiennej. Sposobem jest tu kara miary R 2 dla modeli które uwzględniają nieprzydatne zmienne objaśniające. Taką miarą jest skorygowany współczynnik determinacji ( adjusted R 2 ).
23 Test istotności regresji Ponieważ wartość p jest znacznie mniejsza niż 0,05 odrzucamy hipotezę zerową, że β = 0. Czyli mówimy, że istnieje istotna zależność między zmiennymi w modelu regresji.
24 Sprawdzanie założeń regresji Istnieją dwie podstawowe metody graficzne używane do sprawdzenia założeń regresji: Normalny wykres kwantylowy Wykres standaryzowanych reszt względem wartości przewidywanych
25 Założenia: liniowość, niezależność, normalność i stała wariancja mogą zostać zweryfikowane za pomocą normalnego wykresu kwantylowego i wykresu standaryzowanych reszt względem przewidywanych wartości. Wykres kwantylowy to wykres kwantyli próbkowych rozkładu reszt (rezyduów) względem kwantyli rozkładu normalnego odpowiedniego rzędu. Normalność można ocenić, sprawdzając, czy wykres wykazuje systematyczne odchylenie od linii prostej. Wtedy można wywnioskować, że wykreślone wartości danych (w tym wypadku reszty) nie pochodzą z żadnego szczególnego rozkładu (rozkładu normalnego w tym przykładzie). Nie wykrywamy systematycznych odchyleń od liniowości na wykresie standaryzowanych reszt, a zatem stwierdzamy, że założenie normalności jest nienaruszone.
26 Normalność Normalne mają być rezydua, czyli różnica między modelem a danymi, a nie same dane!!! Jeżeli zmienna była mierzona przyrządem, to jest duża szansa, że ma rozkład normalny Jeżeli wartości zmiennej są średnimi z jakichś liczb, to zmienna jest najprawdopodobniej normalna Jeżeli zmienna oznacza liczbę czegoś na jednostkę (liczbę komórek w objętości) i średnia tej liczby jest 10 lub więcej, to można przyjąć, że zmienna ma rozkład normalny
27 Metoda 1: Normalny wykres kwantylowy Czytanie wykresu Jest wykresem kwantyli próbkowych rozkładu reszt względem kwantyli rozkładu normalnego odpowiedniego rzędu. Używa się go do określenia, czy dany rozkład odbiega od rozkładu normalnego. Na wykresie tym, wartości obserwowane dla badanego rozkładu są porównywane z wartościami dla rozkładu normalnego. Podobnie jak centyl, kwantyl rozkładu jest wartością x p, taką, że p% wartości rozkładu jest mniejsze lub równe x p. Jeżeli rozkład jest normalny to punkty na wykresie powinny tworzyć linię prostą; zaś systematyczne odchylenia od linii prostej wskazują na nieliniowość.
28 Normalny wykres kwantylowy Wykres kwantylowy to wykres kwantyli próbkowych rozkładu reszt (rezyduów) względem kwantyli rozkładu normalnego odpowiedniego rzędu.
29 Dla rozkładu normalnego
30 Dla rozkładu jednostajnego
31 Dla rozkładu Chi2 (prawoskośny)
32 W praktyce Nie możemy liczyć na to że rzeczywiste dane dostarczą nam takich idealnych wykresów kwantylowych. Obecność błędu próbkowania i innych źródeł szumu powoduj zwykle, że wykres będzie miał mniej jednoznaczny kształt.
33
34 Dla zbioru Cereals
35 Metoda 2: Wykres standaryzowanych reszt względem wartości przewidywanych Drugą graficzną metodą używaną do sprawdzenia założeń modelu regresji jest wykres standaryzowanych reszt względem wartości przewidywanych.
36
37 Czytanie wykresu Wykres reszt względem wartości przewidywanych jest sprawdzany ze względu na dostrzegalne wzorce. Jeżeli istnieje oczywista krzywizna na wykresie rozrzutu, to założenie liniowości jest naruszone. Jeżeli pionowy rozrzut punktów na wykresie jest systematycznie niejednakowy, to założenie o stałej wariancji jest naruszone. Gdy nie wykrywamy takich wzorców to stwierdzamy, że założenia liniowości i stałej wariancji są nienaruszone. Założenie niezależności jest sensowne w naszym zbiorze danych ponieważ nie spodziewamy się, że wartość odżywcza jednego rodzaju płatków zależy od wartości innego rodzaju płatków. Dane zależne od czasu mogą być sprawdzone ze względu na niezależność kolejności za pomocą testów przebiegu lub wykresów reszt względem kolejności.
38 Wykres standaryzowanych reszt względem wartości przewidywanych
39
40 Sprawdzamy więc, czy istnieją pewne charakterystyczne układy punktów na wykresach reszt względem wartości przewidywanych. Jeżeli tak, to jedno z założeń zostało naruszone, a jeżeli nie ma takich widocznych wzorców, to założenia pozostają nienaruszone.
41
42 4 wzorce archetypów obserwowane na wykresach reszt względem wartości przewidywanych Wykres A pokazuje poprawny wykres gdzie nie są obserwowane żadne widoczne wzorce i punkty zajmują cały prostokątny obszar od lewej do prawej. Wykres B pokazuje krzywiznę, co świadczy o naruszonym założeniu niezależności. Wykres C pokazuje wzór lejka co świadczy o naruszonym założeniu o stałej wariancji. Wykres D pokazuje wzorzec, który rośnie od lewej strony do prawej, co świadczy o naruszonym założeniu o zerowej średniej.
43 Wykres B Dlaczego mówimy, że założenie niezależności nie jest tu spełnione? Ponieważ zakłada się, że błędy są niezależne, więc reszty (oszacowania błędów) powinny być również niezależne. Jeżeli jednak reszty tworzą zakrzywiony wzorzec, to możemy przypuszczać, że dla danej reszty sąsiadujące z nią reszty (na lewo i na prawo) będą wewnątrz pewnego marginesu błędu. Jeżeli reszty byłyby rzeczywiście niezależne, to taka prognoza nie byłaby możliwa.
44 Dlaczego na wykresie C założenie o stałej wariancji nie jest prawdziwe? Na wykresie A wariancja reszt pokazana jako pionowa odległość, jest niemal stała, niezależnie od wartości x. Z kolei na wykresie C wartości reszt są mniejsze dla mniejszych wartości x i większe dla większych wartości x. Dlatego zmienność nie jest stała co narusza założenie o stałej wariancji.
45 Dlaczego z wykresu D możemy odczytać że zostało naruszone założenie o zerowej średniej? Założenie o zerowej średniej stwierdza, że średnia błędu jest równa zero, niezależnie od wartości x. Jednak na wykresie D dla małych wartości x średnia reszt jest mniejsza od zera, podczas, gdy dla dużych wartości x średnia reszt jest większa od 0. To stanowi naruszenie założenia o zerowej średniej, jak również naruszenie założenie niezależności.
46 Jeżeli wykres kwantylowy nie pokazuje systematycznego odchylenia od linii prostej a wykres reszty względem wartości przewidywanych nie pokazuje widocznych wzorców, to możemy wyciągnąć wniosek, że nie ma graficznych dowodów na naruszenie założeń regresji i możemy kontynuować analizę regresji.
47 Co jednak, gdy te wykresy wskazują na naruszenie założeń regresji? Wtedy możemy zastosować transformację zmiennej celu y, taką jak transformacja logarytmiczna. Transformacja logarytmiczna, ln, czyli logarytm naturalny czyli o podstawie e.
48 Przykład zastosowania transformacji Jak to jest z transformowaniem zmiennych do regresji? Jedni mówią, że można, inni że to manipulowanie danymi? Odpowiedź: można, a nawet czasem TRZEBA
49 Transformacje danych kiedy podejrzewamy, że można log jeżeli stosunek pomiędzy największą a najmniejszą wartością przekracza 10 (i zmienne są skrzywione ) to można, jeżeli przekracza 100, to nawet trzeba

50 Diagnostyka modelu liniowego Aby model można było uznać za dobry, należy wykonać jego diagnostykę. Przykład: Oceny współczynników i statystyki testowe są prawie identyczne
51 wniosek Po dopasowaniu modelu, diagnostyka jest krokiem koniecznym, pozwalającym na ocenę, czy model jest dopasowany poprawnie.
52 Współliniowość Gdy zmienne objaśniające są wysoko skorelowane wyniki analizy regresji mogą być niestabilne. Szacowana wartość zmiennej x i może zmienić wielkość a nawet kierunek zależnie od pozostałych zmiennych objaśniających zawartych w tak testowanym modelu regresji. Taka zależność liniowa między zmiennymi objaśniającymi może zagrażać trafności wyników analizy regresji. Do wskaźników oceniających współliniowość należy, m.in. VIF (Variance Inflation Factor) zwany współczynnikiem podbicia (inflacji) wariancji. VIF pozwala wychwycić wzrost wariancji ze względu na współliniowość cechy. Innymi słowy: wskazuje on o ile wariancje współczynników są zawyżone z powodu zależności liniowych w testowanym modelu. Niektóre pakiety statystyczne pozwalają także alternatywnie mierzyć tzw. współczynnik toleracji (TOL - ang. tolerance), który mierzy się jako: 1/VIF VIF i (1 R 2 1 i ) dla modelu x i = f(x 1,., x i-1, x i+1,, x p ) gdzie zmienna x i będzie wyjaśniana przez wszystkie pozostałe zmienne. Gdy VIF > 10 mówimy, że współliniowość wystąpiła i chcąc się jej pozbyć z modelu, usuwamy te cechy, które są liniową kombinacją innych zmiennych niezależnych.
53 Radą na współliniowość jest według niektórych prac zwiększenie zbioru obserwacji o nowe, tak, by zminimalizować istniejące zależności liniowe pomiędzy zmiennymi objaśniającymi. Oczywiście, zwiększenie liczby obserwacji nie gwarantuje poprawy -stąd takie rozwiązanie na pewno nie należy do najlepszych i jedynych. Lepszym wydaje się komponowanie zmiennych zależnych w nowe zmienne (np. waga i wzrost są skorelowane silnie i zamiast nich stworzenie jednej zmiennej stosunek wzrostu do wagi. Taką nową zmienną nazywa się w literaturze kompozytem. Często - dla dużej liczby zmiennych objaśniających - stosuje sie metodę analizy składowych głównych (ang. principal component analysis) dla redukcji liczby zmiennych do jednego lub kilku kompozytów niezależnych.
54 Przykład modelu ze współliniowością Dla modelu postaci: y i = b 0 + b 1 x 1i + b 2 x 2i + b 3 x 3i + e 1i Gdzie x 3i = 10 * x 1i - 2 * x 2i. Wtedy powiemy, że zmienna x 3 jest kombinacją liniową zmiennych x 1 i x 2. Próba szacowania takiego modelu związana jest ze świadomym popełnianiem błędu, gdyż w modelu tym występuje dokładna współliniowość (jedna ze zmiennych objaśniających jest kombinacją liniową pozostałych).
55 W środowisku R sprawdzanie współliniowości nie jest trudne. Wystarczy skorzystać z funkcji vif której argumentem jest model regresji dla danego zbioru danych. Przykład dotyczący naszego zbioru płatków zbożowych przedstawiamy poniżej: > vif(lm(rating~sugars+fiber, data=dane)) sugars fiber Wartości współczynnika VIF nie są zbyt wysokie toteż uznajemy, że w modelu tym nie występuje zjawisko współliniowości.
56 Współliniowość (ang. multicollinearity) To sytuacja, gdy kilka zmiennych objaśniających jest skorelowanych ze sobą. Prowadzi to bowiem do niestabilności w przestrzeni poszukiwań, a wyniki mogą być niespójne. Aby uniknąć współliniowości, należy zbadać strukturę korelacji między zmiennymi objaśniającymi. Błonnik cukry błonnik Półka 2 Półka potas Dwie zmienne potas i błonnik są silnie skorelowane.
57 Jest też inna metoda Możemy posłużyć się wskaźnikami podbicia wariancji. Co to jest wskaźnik podbicia wariancji? Wartość s bi oznacza zmienność związaną ze współczynnikiem b i dla i-tej zmiennej objaśniającej x i. Wartość s bi możemy wyrazić jako iloczyn standardowego błędu oszacowania s i stałej c i. Stałą c i wyrazimy jako: c i 1 ( n 1) s 2 i 1 Gdzie s i 2 oznacza wariancję próby obserwowanych wartości i-tej zmiennej opisującej x i, A R i 2 oznacza wartość współczynnika regresji wielokrotnej R 2 dla regresji zmiennej x i traktowanej jako zmiennej zależnej względem pozostałych zmiennych objaśniających. R i 2 będzie duże, gdy x i będzie silnie skorelowane z innymi zmiennymi objaśniającymi. 1 R 2 i
58 c i 1 1 ( n 1) s R 2 i 1 2 i Pierwszy czynnik mierzy tylko wewnętrzną zmienność i-tej zmiennej objaśniającej x i, zaś drugi czynnik mierzy korelację między i tą zmienną objaśniającą x i a pozostałymi zmiennymi objaśniającymi. Dlatego drugi czynnik jest nazywany wskaźnikiem podbicia wariancji VIF dla x i : VIF i 1 1 R 2 i
59 W praktyce VIF i 1 1 R 2 i Jeśli zmienna x i jest całkowicie nieskorelowana z pozostalymi zmiennymi objaśniającymi, R i 2 = 0. Wtedy VIF = 1. Czyli minimalna wartość wskaźnika inflacji to 1. W miarę tego jak rośnie stopień korelacji pomiędzy zmienną x i i pozostałymi wartość R 2 i również rośnie. Gdy wartość ta zbliża się do 1, to VIF rośnie do nieskończoności. Zatem nie ma górnej granicy. Praktyczną zasadą dotyczącą interpretacji wartości wskaźnika podbicia wariacji jest oznanie VIF>=5 jako wskazania umiarkowanej współliniowości i VIV >=10 jako wskazania silnej współliniowości. Wskaźnik podbicia wariancji =5 odpowiada wartości R i 2 = Wartość VIF=10 odpowiada R i 2 = 0.9
60 W środowisku R sprawdzanie współliniowości nie jest trudne. Wystarczy skorzystać z funkcji vif której argumentem jest model regresji dla danego zbioru danych. Przykład dotyczący naszego zbioru płatków zbożowych przedstawiamy poniżej: > vif(lm(rating~sugars+fiber, data=dane)) sugars fiber

61
62 Są trzy typy obserwacji, które mogą ale nie muszą wywierać nadmiernego nacisku na wyniki regresji: Obserwacje oddalone Obserwacje wysokiej dźwigni Obserwacje wpływowe.
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y).
 na zmienną zależną (Y).") Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Stosowana Analiza Regresji
 prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
Analiza regresji - weryfikacja założeń
 Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Regresja wielokrotna. PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
WERYFIKACJA MODELI MODELE LINIOWE. Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno
 WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna
 Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817
 Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Współczynnik korelacji. Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ
 Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
Analiza zależności cech ilościowych regresja liniowa (Wykład 13)
") Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
ANALIZA REGRESJI SPSS
 NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
3. Modele tendencji czasowej w prognozowaniu
 II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
Regresja liniowa, klasyfikacja metodą k-nn. Agnieszka Nowak Brzezińska
 Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej
 Pojęcie losowej próby prostej") 7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI
 Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną
Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 11-12
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Statystyka matematyczna dla leśników
 Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Regresja i Korelacja
 Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
parametrów strukturalnych modelu = Y zmienna objaśniana, X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających,
 诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
2. Założenie niezależności zakłóceń modelu - autokorelacja składnika losowego - test Durbina - Watsona
 Sprawdzanie założeń przyjętych o modelu (etap IIIC przyjętego schematu modelowania regresyjnego) 1. Szum 2. Założenie niezależności zakłóceń modelu - autokorelacja składnika losowego - test Durbina - Watsona
Sprawdzanie założeń przyjętych o modelu (etap IIIC przyjętego schematu modelowania regresyjnego) 1. Szum 2. Założenie niezależności zakłóceń modelu - autokorelacja składnika losowego - test Durbina - Watsona
Wstęp do teorii niepewności pomiaru. Danuta J. Michczyńska Adam Michczyński
 Wstęp do teorii niepewności pomiaru Danuta J. Michczyńska Adam Michczyński Podstawowe informacje: Strona Politechniki Śląskiej: www.polsl.pl Instytut Fizyki / strona własna Instytutu / Dydaktyka / I Pracownia
Wstęp do teorii niepewności pomiaru Danuta J. Michczyńska Adam Michczyński Podstawowe informacje: Strona Politechniki Śląskiej: www.polsl.pl Instytut Fizyki / strona własna Instytutu / Dydaktyka / I Pracownia
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Natalia Nehrebecka Stanisław Cichocki. Wykład 13
 Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Zadania ze statystyki, cz.6
 Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 8
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Estymacja parametrów w modelu normalnym
 Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
ANALIZA REGRESJI WIELOKROTNEJ. Zastosowanie statystyki w bioinżynierii Ćwiczenia 8
 ANALIZA REGRESJI WIELOKROTNEJ Zastosowanie statystyki w bioinżynierii Ćwiczenia 8 ZADANIE 1A 1. Irysy: Sprawdź zależność długości płatków korony od ich szerokości Utwórz wykres punktowy Wyznacz współczynnik
ANALIZA REGRESJI WIELOKROTNEJ Zastosowanie statystyki w bioinżynierii Ćwiczenia 8 ZADANIE 1A 1. Irysy: Sprawdź zależność długości płatków korony od ich szerokości Utwórz wykres punktowy Wyznacz współczynnik
Ekonometria ćwiczenia 3. Prowadzący: Sebastian Czarnota
 Ekonometria ćwiczenia 3 Prowadzący: Sebastian Czarnota Strona - niezbędnik http://sebastianczarnota.com/sgh/ Normalność rozkładu składnika losowego Brak normalności rozkładu nie odbija się na jakości otrzymywanych
Ekonometria ćwiczenia 3 Prowadzący: Sebastian Czarnota Strona - niezbędnik http://sebastianczarnota.com/sgh/ Normalność rozkładu składnika losowego Brak normalności rozkładu nie odbija się na jakości otrzymywanych
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Wykład 3 Hipotezy statystyczne
 Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
STATYSTYKA MATEMATYCZNA WYKŁAD 4. WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X.
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Analiza składowych głównych
 Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
LABORATORIUM 3. Jeśli p α, to hipotezę zerową odrzucamy Jeśli p > α, to nie mamy podstaw do odrzucenia hipotezy zerowej
 LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI. Test zgodności i analiza wariancji Analiza wariancji
 WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI Test zgodności i analiza wariancji Analiza wariancji Test zgodności Chi-kwadrat Sprawdza się za jego pomocą ZGODNOŚĆ ROZKŁADU EMPIRYCZNEGO Z PRÓBY Z ROZKŁADEM HIPOTETYCZNYM
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI Test zgodności i analiza wariancji Analiza wariancji Test zgodności Chi-kwadrat Sprawdza się za jego pomocą ZGODNOŚĆ ROZKŁADU EMPIRYCZNEGO Z PRÓBY Z ROZKŁADEM HIPOTETYCZNYM
Zadanie 1. a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1
 Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1") Zadanie 1 a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1 b) W naszym przypadku populacja są inżynierowie w Tajlandii. Czy można jednak przypuszczać, że na zarobki kobiet-inżynierów
Zadanie 1 a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1 b) W naszym przypadku populacja są inżynierowie w Tajlandii. Czy można jednak przypuszczać, że na zarobki kobiet-inżynierów
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
Stanisław Cichocki. Natalia Nehrebecka. Wykład 4
 Stanisław Cichocki Natalia Nehrebecka Wykład 4 1 1. Własności hiperpłaszczyzny regresji 2. Dobroć dopasowania równania regresji. Współczynnik determinacji R 2 Dekompozycja wariancji zmiennej zależnej Współczynnik
Stanisław Cichocki Natalia Nehrebecka Wykład 4 1 1. Własności hiperpłaszczyzny regresji 2. Dobroć dopasowania równania regresji. Współczynnik determinacji R 2 Dekompozycja wariancji zmiennej zależnej Współczynnik
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Analiza głównych składowych- redukcja wymiaru, wykł. 12
 Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
1. Opis tabelaryczny. 2. Graficzna prezentacja wyników. Do technik statystyki opisowej można zaliczyć:
 Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Stanisław Cichocki. Natalia Nehrebecka. Wykład 9
 Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
WSTĘP DO REGRESJI LOGISTYCZNEJ. Dr Wioleta Drobik-Czwarno
 WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
Stanisław Cichocki. Natalia Neherbecka. Zajęcia 13
 Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Błędy przy testowaniu hipotez statystycznych. Decyzja H 0 jest prawdziwa H 0 jest faszywa
 Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
STATYSTYKA MATEMATYCZNA WYKŁAD 4. Testowanie hipotez Estymacja parametrów
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska. Anna Stankiewicz Izabela Słomska
 Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
K wartość kapitału zaangażowanego w proces produkcji, w tys. jp.
 Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych:
 W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych: Zmienne losowe skokowe (dyskretne) przyjmujące co najwyżej przeliczalnie wiele wartości Zmienne losowe ciągłe
W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych: Zmienne losowe skokowe (dyskretne) przyjmujące co najwyżej przeliczalnie wiele wartości Zmienne losowe ciągłe
Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań
 Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań 6.11.1 1 Badanie współzależności atrybutów jakościowych w wielowymiarowych tabelach danych. 1.1 Analiza współzależności
Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań 6.11.1 1 Badanie współzależności atrybutów jakościowych w wielowymiarowych tabelach danych. 1.1 Analiza współzależności
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA
 WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
Teoria błędów. Wszystkie wartości wielkości fizycznych obarczone są pewnym błędem.
 Teoria błędów Wskutek niedoskonałości przyrządów, jak również niedoskonałości organów zmysłów wszystkie pomiary są dokonywane z określonym stopniem dokładności. Nie otrzymujemy prawidłowych wartości mierzonej
Teoria błędów Wskutek niedoskonałości przyrządów, jak również niedoskonałości organów zmysłów wszystkie pomiary są dokonywane z określonym stopniem dokładności. Nie otrzymujemy prawidłowych wartości mierzonej
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
Wykład 4 Związki i zależności
 Wykład 4 Związki i zależności Rozważmy: Dane z dwiema lub więcej zmiennymi Zagadnienia do omówienia: Zmienne objaśniające i zmienne odpowiedzi Wykres punktowy Korelacja Prosta regresji Słownictwo: Zmienna
Wykład 4 Związki i zależności Rozważmy: Dane z dwiema lub więcej zmiennymi Zagadnienia do omówienia: Zmienne objaśniające i zmienne odpowiedzi Wykres punktowy Korelacja Prosta regresji Słownictwo: Zmienna
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja)
") PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
Metody Ilościowe w Socjologii
 Metody Ilościowe w Socjologii wykład 2 i 3 EKONOMETRIA dr inż. Maciej Wolny AGENDA I. Ekonometria podstawowe definicje II. Etapy budowy modelu ekonometrycznego III. Wybrane metody doboru zmiennych do modelu
Metody Ilościowe w Socjologii wykład 2 i 3 EKONOMETRIA dr inż. Maciej Wolny AGENDA I. Ekonometria podstawowe definicje II. Etapy budowy modelu ekonometrycznego III. Wybrane metody doboru zmiennych do modelu
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ
 REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
5. WNIOSKOWANIE PSYCHOMETRYCZNE
 5. WNIOSKOWANIE PSYCHOMETRYCZNE Model klasyczny Gulliksena Wynik otrzymany i prawdziwy Błąd pomiaru Rzetelność pomiaru testem Standardowy błąd pomiaru Błąd estymacji wyniku prawdziwego Teoria Odpowiadania
5. WNIOSKOWANIE PSYCHOMETRYCZNE Model klasyczny Gulliksena Wynik otrzymany i prawdziwy Błąd pomiaru Rzetelność pomiaru testem Standardowy błąd pomiaru Błąd estymacji wyniku prawdziwego Teoria Odpowiadania
Testowanie hipotez statystycznych związanych ą z szacowaniem i oceną ą modelu ekonometrycznego
 Testowanie hipotez statystycznych związanych ą z szacowaniem i oceną ą modelu ekonometrycznego Ze względu na jakość uzyskiwanych ocen parametrów strukturalnych modelu oraz weryfikację modelu, metoda najmniejszych
Testowanie hipotez statystycznych związanych ą z szacowaniem i oceną ą modelu ekonometrycznego Ze względu na jakość uzyskiwanych ocen parametrów strukturalnych modelu oraz weryfikację modelu, metoda najmniejszych
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 8
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 8 Regresja wielokrotna Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X 1, X 2, X 3,...) na zmienną zależną (Y).
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 8 Regresja wielokrotna Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X 1, X 2, X 3,...) na zmienną zależną (Y).
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Testowanie hipotez. Marcin Zajenkowski. Marcin Zajenkowski () Testowanie hipotez 1 / 25
 Testowanie hipotez 1 / 25") Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Rozkłady statystyk z próby
 Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Testy nieparametryczne
 Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Statystyczna analiza danych
 Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych
 Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
ZJAZD 4. gdzie E(x) jest wartością oczekiwaną x
 jest wartością oczekiwaną x") ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych