Analiza regresji część III. Agnieszka Nowak - Brzezińska
|
|
|
- Izabela Tomaszewska
- 6 lat temu
- Przeglądów:
Transkrypt
1 Analiza regresji część III Agnieszka Nowak - Brzezińska
2 Są trzy typy obserwacji, które mogą ale nie muszą wywierać nadmiernego nacisku na wyniki regresji: Obserwacje oddalone (outlier) Obserwacje wysokiej dźwigni (laverage) Obserwacje wpływowe (influential).
3 Identyfikacja obserwacji odstających i obserwacji wpływowych Wykrycie wśród danych obserwacji nietypowych jest niezwykle istotne, gdyż mogą one utrudniać właściwą ich analizę, np. mogą (choć nie muszą) wywierać nadmierny nacisk na wyniki regresji. Szczególnej uwagi wymagają przypadki w których nietypowość danych nie wynika z błędu pomiaru.
4 przykład Nietypową obserwacją może być chociażby zawodnik o wzroście 165 cm w grupie koszykarzy ze średnią wartością wzrostu powyżej 190 cm. Wtedy możemy wyróżnić przynajmniej dwa warte uwagi przypadki: gdy ów niski koszykarz ma wagę zgodną ze średnią wagą całej grupy, lub gdy jego waga jest odpowiednio niższa w stosunku do wyższych kolegów w grupie. Nietypowość pierwszego przypadku będzie polegała na tym, że przy typowej wadze, ów zawodnik ma nietypowy wzrost, i w tym sensie będzie to obserwacja potencjalnie odstająca (być może także wpływowa). Drugi przypadek natomiast będzie dotyczył sytuacji gdy jeden zawodnik w grupie jest po prostu lżejszy i niższy niż reszta grupy - i nie oznacza to, że obserwację należy uznać za odstającą.
5 Należy rozróżnić: (i) nietypową wartość tylko zmiennej objaśnianej y podczas gdy zmienna objaśniająca x ma wartość typową od (ii) nietypowej wartości obu zmiennych: objaśniającej i objaśnianej.
6 Obserwacje odstające W analizie regresji, za odstające (ang. outlier), uznamy obserwacje posiadające nietypowe wartości zmiennej objaśnianej y dla ich wartości zmiennej (bądź zmiennych) objaśniającej x i w konsekwencji dostarczające dużych wartości tzw. rezyduów e. Obserwacja, dla której wartość zmiennej objaśniającej x znacząco odbiega od typowych wartości tej zmiennej jest potencjalną obserwacją wpływową. Dołączenie takich obserwacji do zbioru danych ma w rezultacie duży wpływ na przebieg prostej regresji (zmiany współczynników regresji).
7 Obserwacje odstające Obserwacja odstająca (ang. outlier) jest obserwacją, która nie spełnia równania regresji czyli nie należy do modelu regresji. Obserwacje odstające mogą znacząco wpływać na postać prostej regresji: dla której wartość sumy: ma być możliwie najmniejsza zgodnie z założeniami metody MNK. W przypadku modelu regresji, w którym tylko jedna zmienna objaśniająca określać ma wartość zmiennej objaśnianej, obserwacje odstające można identyfikować sporządzając dla obserwacji wykres rozproszenia. Oko ludzkie zwykle potrafi na nich wykrywać obserwacje nietypowe.
8 Najlepiej jednak (zwłaszcza dla modeli o więcej niż jednej zmiennej objaśniającej) badać tzw. rezydua lub rezydua studentyzowane i wśród nich szukać wartości odstających. Zakładając, że rezyduum e i przyjmuje dla i-tej obserwacji wartość różnicy: między wartością zmiennej objaśnianej a wartością przewidywaną, błąd standardowy (ang. standard error) takiego rezyduum e i jest równy: gdzie S = to przeciętne odchylenie wartości rzeczywistych od wartości przewidywanych zaś h i to wartość wpływu i-tej obserwacji wyrażana jako: Dla małych prób, wartości zmiennej objaśniającej nie są w miarę równomiernie rozłożone i niektóre błędy Se ei mogą znacznie odbiegać od błędu S. Wówczas dobrze jest analizować rezydua przy użyciu tzw. rezyduów studentyzowanych.
9 Wówczas dobrze jest analizować rezydua przy użyciu tzw. rezyduów studentyzowanych r i definiowanych jako: To pozwoli wykrywać obserwacje faktycznie odstające, pomijając te, które przy analizie rezyduów e i sugerowały, że są odstające mimo, że takimi nie były. Dla rezyduów studentyzowanych zakłada się, że przy poziomie ufności równym 0.95 uznaje się je za normalne (zachowujące własność rozkładu normalnego) gdy należą do przedziału [ 2, +2]. Wykres studentyzowanych rezyduów względem ich indeksu identyfikuje duże wartości, które przypuszczalnie odpowiadają obserwacjom odstającym. Metoda ta nie sprawdzi się w sytuacji, gdy mamy w analizowanym zbiorze obserwację wpływową o małej wartości e i. Wówczas bowiem nie określimy jej jako odstającej mimo, że taka w istocie jest.
10 Tutaj z ratunkiem przychodzą tzw. Modyfikowane studentyzowane rezydua d i, badające różnicę między wartością rzeczywistą Y i a wartością przewidywaną dla tej obserwacji, gdy pominiemy ją w analizie. Wartość d i określona jako modyfikowane rezyduum wyznaczana jest następująco: Gdzie to wartość przewidywana zmiennej objaśnianej w modelu regresji dla zbioru wszystkich obserwacji z pominięciem obserwacji i-tej. Studentyzowane modyfikowane rezyduum przyjmuje wartość:
11 Obserwacje wpływowe Obserwacja jest wpływowa (ang. influential), jeśli jej obecność wpływa na prostą regresji, w taki sposób, że zmienia się współczynnik kierunkowy tej prostej. Innymi słowy, usunięcie tej obserwacji ze zbioru danych powoduje dużą zmianę wektora współczynników regresji. Obserwacje odstające mogą, ale nie muszą być obserwacjami wpływowymi.
12 Obserwacje wpływowe Wpływ i-tej obserwacji będziemy określać jako odstępstwo obserwacji x i od. Im większa jest różnica (podnoszona do kwadratu) tym większa wartość wpływu. Dla modelu z jedną zmienną objaśniającą wystarczyłoby w zasadzie sporządzić wykres typu histogram dla tej zmiennej objaśniającej i za jego pomocą wykrywać obserwacje odbiegające od wartości typowej tej zmiennej. Jednak gdy w modelu mamy więcej zmiennych objaśniających, wówczas odbieganie wektora x od wektora średnich gdzie wcale nie oznacza, że któraś ze współrzędnych wektora x będzie odstawać znacznie od odpowiadającej współrzędnej wektora średnich.
13 Z pomocą przychodzi tutaj założenie, że pewna globalna miara odstępstwa obserwacji x i od określona jest przez i-ty diagonalny element macierzy H: hi = hii zwany wpływem obserwacji. Dla modelu o p parametrach (gdzie p to łączna liczba zmiennych objaśniających i objaśnianych) powiemy, że oraz dla każdego To oznacza, że typowa wartość wpływu hi nie powinna przekraczać wartości p/n. Jeśli zaś wartość ta dla analizowanej i-tej obserwacji przekracza wartość 2p/n (a dla małych prób 3p/n) wówczas taką zmienną uznamy za potencjalnie wpływową.
14 Na uwagę zasługuje tu fakt, że dla obserwacji o dużych wartościach wpływu rezydua ei mogą być małe. Dlatego, by upewnić się, że poprawnie zidentyfikowaliśmy obserwacje wpływowe stosując próg 2p/n powinniśmy każdą taką obserwację usunąć ze zbioru i sprawdzić jak bardzo dzięki temu zmienił się wektor spółczynników regresji w stosunku do modelu w którym tę obserwację ujęto w analizie.
15 Równie popularnymi miarami wpływu poszczególnych obserwacji na równanie regresji są:. DFFITS (autorzy: Belsley, Kuh & Welsch, 1980);. Odległość Cooka (autorzy: Cook, 1977);. DFBETAS (autorzy: Belsley, Kuh & Welsch, 1980);
16

17
18
19 Zupełnie innym typem obserwacji, o których raczej nie powiemy, że są odstającymi, są obserwacje dla których wektor zmiennych objaśniających jest znacznie oddalony od typowego wektora wartości objaśniających. Nie zakładamy dla takich obserwacji, że mając nietypowe wartości zmiennych objaśniających nie spełnią równania regresji. Z omawianym zagadnieniem wiąże się jeszcze pojęcie tzw. dźwigni (ang. leverage) obserwacji.
20 Obserwacja cechuje się wysoką dźwignią gdy przy nietypowej wartości zmiennej objaśniającej cechuje się typową wartością zmiennej objaśnianej. Wówczas bowiem rezyduum ei będzie małe a o obserwacji powiemy, że przyciąga linię regresji ˆ Yi blisko Yi. Możemy także powiedzieć, że miarą dźwigni dla i-tej obserwacji jest wartość jej wpływu hi. W regresji prostej mierzy ona odległość danej obserwacji od średniej wartości tej zmiennej. W regresji wielokrotnej zaś mierzy ona po prostu odległość od punktu średnich wartości wszystkich zmiennych objaśniających. Im bardziej różni się wartość zmiennej (bądź zmiennych) objaśniającej dla i-tej obserwacji od wartości średniej, tym większa jest wartość tzw. dźwigni dla tej obserwacji. Zwykle wartości dźwigni mieszczą się w przedziale [0, 1] zatem wartość dźwigni większa od wartości 4/n świadczy o tym, że obserwacja będzie traktowana jako nietypowa (mając tzw. wysoką wartość dźwigni).
21 Masking i Swamping Masking (nazywany maskowaniem odchyleń) zachodzi wówczas, gdy spodziewamy się w zbiorze jednej obserwacji będącej odchyleniem a w rzeczywistości takich odchyleń jest więcej. Wówczas test może nie wykryć odchyleń w ogóle gdyż te - dodatkowe - odchylenia mogą wpływać na wielkości różnych statystyk i w efekcie nie znajdować żadnych odchyleń w danych. Z kolei swamping jest nieuprawnionym dołączaniem obserwacji do zbioru obserwacji wpływowych i/lub odstających.
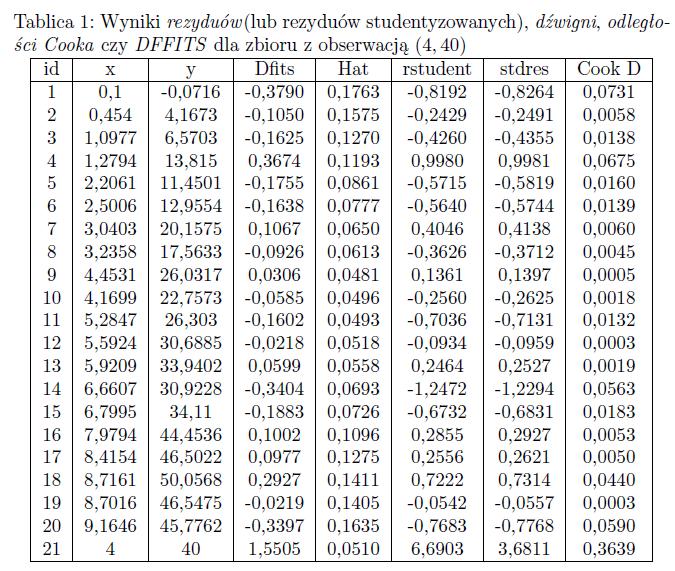
22 Wykrywanie obserwacji odstających, wpływowych i obserwacji wysokiej dźwigni w praktyce Dla przykładowego zbioru danych zawierających 20 obserwacji opisanych dwoma wartościami (po jednej zmiennej objaśniającej x i objaśnianej y) ta część rozdziału będzie przedstawiała krok po kroku procedury wyznaczania obserwacji wpływowych, odstających oraz obserwacji wysokiej dźwigni. Rozważymy trzy przypadki dodając za każdym razem po jednej nietypowej obserwacji do tego zbioru.
23
24

25
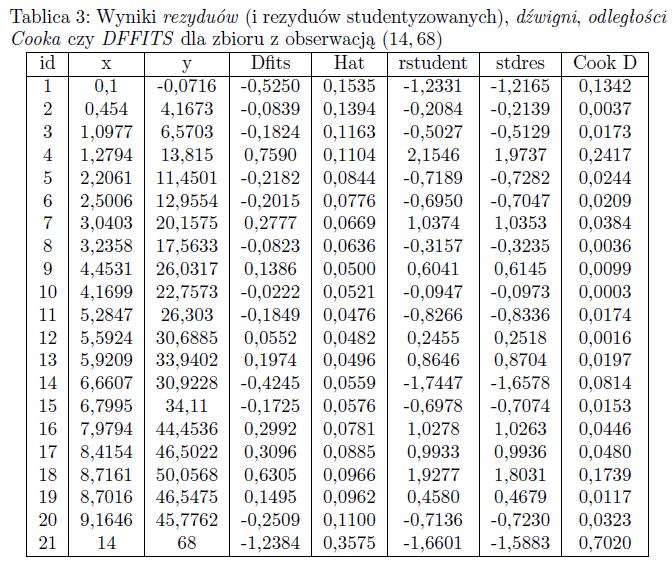
26 Dla tego zbioru rozważymy trzy różne przypadki: dodamy do niego za każdym razem po jednej obserwacji nietypowej: obserwacji odstającej, o niewielkim wpływie na regresję, i nie będącej obserwacją tzw. wysokiej dźwigni (o współrzędnych (4, 40)), obserwacji jednocześnie odstającej, wpływowej i z wysoką dźwignią (o współrzędnych (13, 15)), obserwacji wysokiej dźwigni, nie będącej obserwacją odstającą ani też wpływową (o współrzędnych (14, 68)).
27
28
29 Łatwo zauważyć, że dodanie nowej obserwacji (wyraźnie odstającej, o czym świadczą wartości 4, 40) nie wpłynęło na równanie regresji, zatem możemy wnioskować, że nie jest ona wpływową mimo, że jest odstająca. Dla oryginalnego zbioru danych równanie regresji miało postać: dane$y = dane$x podczas gdy teraz dla zbioru zawierającego obserwację (4, 40) równanie będzie następujące: dane$y = dane$x Dla takiego zbioru postaramy się sprawdzić wartości poszczególnych miar: rezyduów (lub rezyduów studentyzowanych), dźwigni, odległości Cooka czy DFFITS.
30
31 Szukamy obserwacji o dużej wartości rezyduów lub rezyduów studentyzowanych: Tylko nr 21 przekracza próg dopuszczalny równy 2. Obserwacjami wpływowymi są te, których wartość DFFITS przekracza wartość 1 (dla małych prób) bądź wartość odległości Cooka przekracza próg : taką obserwacją jest również tylko obserwacja nr 21 (choć należy zaznaczyć, że wpływ tej obserwacji na zmiany współczynników regresji nie jest znaczący, a i wartość miary DFFITS nieznacznie przekracza wartość progową).
32
33 Będzie to obserwacja wpływowa ale nie będzie obserwacją wysokiej dźwigni
34
35
36 Drugi analizowany przypadek zbioru zawiera obserwację wpływową ale nie odstającą. Do oryginalnego zbioru 20 obserwacji dodajemy obserwację nr 21 o współrzędnych (13, 15).
37
38
39 możemy zauważyć, jak bardzo zmieniły się wszystkie parametry tego modelu. Widać różnice we współczynnikach równania regresji, które teraz wygląda następująco: dane$y = dane$x Różnice widać także dla błędu standardowego rezyduów oraz chociażby wartości współczynnika determinacji R2.
40
41

42
43 Wniosek W tym zbiorze obserwacja nr 21 jest zarówno obserwacją o dużej wartości reszty i reszty studentyzowanej (jest więc obserwacją odstającą), obserwacją wpływową (wartość odległości Cooka jak i miary DFFITS przekraczają dopuszczalny próg) a także obserwacją wysokiej dźwigni.
44 ostatni analizowany przypadek danych nietypowych. Nietypowość jego polega na tym, że nowododana obserwacja nie jest ani odstająca, ani wyraźnie wpływowa, jest zaś obserwacją wysokiej dźwigni. Po dodaniu, do oryginalnego zbioru, obserwacji o współrzędnych (14, 68)
45 Równanie regresji dla tego zbioru jest następujące: dane$ y = dane$x Równanie różni się nieznacznie od równania regresji dla oryginalnego zbioru 20 obserwacji: dane$y = dane$x Zmiany są niewielkie także dla współczynnika determinacji, czy wartości rezyduów. To sugeruje, iż nowo dodana obserwacja nie jest obserwacją wpływową.
46
47
48
49 Ten zbiór jest o tyle interesujący, że obserwacja nr 21 nie jest obserwacją odstającą (umieszczona jest na linii regresji, wartość rezyduum studentyzowanego nie przekracza wartości ±2). Z pewnością obserwacja ta ma wysoką wartość dźwigni. W zbiorze tym zauważamy także inne obserwacje nietypowe. Obserwacje 4, 14, 18 cechują się dużą wartością rezyduów ale nie mają z kolei zbyt dużych wartości odległości Cooka czy miary DFFITS, które świadczyłyby o tym, że są to obserwacje zdecydowanie wpływowe. Owszem, przekraczają one progowe wartości tych miar, jednak odstępstwa nie są znaczące.
50 Obserwacje odstające w R Obserwacja jest odstająca (oddalona) czyli nietypowa gdy ma bardzo dużą bezwzględną wartość standaryzowanej reszty. Wartości resztowe mogą mieć różne wariancje, zatem preferuje się użycie standaryzowanych wartości resztowych w celu identyfikacji punktów oddalonych. Mówimy, że wartości resztowe są standaryzowane, jeśli są podzielone przez ich błąd standardowy, a więc mają wszystkie tę samą skalę.
51 Reszty
52 Wykres reszt Obserwujemy różnice między rzeczywistą wartością y a wartością oszacowaną ŷ.
53 Wykres standaryzowanych reszt
54 Wykres standaryzowanych reszt
55 Normalny wykres kwantylowy
56 W praktyce sporządzając wykres wartości studentyzowanych rezyduów r i względem ich indeksu będziemy potrafili rozpoznawać te duże wartości, które przypuszczalnie będą odstającymi. Podsumowując powiemy, że nowa obserwacja będzie punktem odstającym jeśli będzie się cechować dużą wartością studentyzowanej (standaryzowanej) reszty. W praktyce, obserwacje odstające to takie, których wartość bezwzględnych studentyzowanych reszt przekracza 2.
57 Studentyzowane reszty Studentyzowane reszty różnią się od standaryzowanych reszt tym, że standaryzując i-tą resztę, za ocenę wariancji wybiera się wariancję liczoną na próbie z pominięciem tej obserwacji (tzw. próbie One leave out) r stud i r i 2 ( i) (1 hi ) W środowisku R pomocna będzie funkcja rstudent z pakietu {stats} h i 1 n ( x n i 1 i ( x x) i 2 x) 2
58 reszty Zależności między oryginalnymi y i a ocenami mówią jak bardzo na ocenę y i wpływa wartość y i, a jak pozostałe wartości. Nazywamy je dźwigniami (ang. leverages). Wartości h i opisują wpływ obserwacji y i na Są bardzo użyteczne w diagnostyce modelu. y i h i 1 n ( x n i 1 i ( x x) i 2 x) 2
59 Standaryzowane reszty To reszty dzielone przez ocenę odchylenia standardowego reszt W środowisku R pomocna będzie funkcja rstandard z pakietu {stats} ) (1 2 i i std i h r r n i i i i x x x x n h ) ( ) ( 1
60 Jeśli przez s i,resid oznaczymy błąd standardowy i-tej reszty to Gdzie h i jest dźwignią i-tej obserwacji, a wówczas standardowa wartość resztowa (reszta) jest równa: i resid i h s s 1, resid i i i darized s i s y y reszta, tan, n i i i i x x x x n h ) ( ) ( 1
61 W praktyce oddalone obserwacje to te, których wartość bezwzględnych standaryzowanych reszt przekracza 2. si, resid s 1 hi Np. w naszym zbiorze obserwacje 1 i 4 są oddalone. Ogólnie, jeżeli reszta jest dodatnia, to mówimy że obserwowana wartość y jest większa od przewidywanej dla danej wartości x. Jeżeli reszta jest ujemna, mówimy, że obserwowana wartość y jest mniejsza od przewidywanej dla danej wartości x. reszta i, s tan darized yi s y i, resid i
62 R- wartości oddalone w zbiorze cereals Rozważmy wykres rozrzutu wartości odżywczej względem cukrów. Dwie obserwacje z największymi bezwzględnymi wartościami reszt to All-Bram Extra Fiber i 100% Bran. Zauważmy, że odległość od linii regresji jest większa dla tych dwóch obserwacji niż dla pozostałych rodzajów płatków śniadaniowych, co oznacza największe wartości resztowe.
63
64 Obserwacja wysokiej dźwigni Obserwacja wysokiej dźwigni (high leverage point) to obserwacja, która przyjmuje bardzo duże lub bardzo małe wartości w przestrzeni zmiennych objaśniających. Obserwacja wysokiej dźwigni przyjmuje wartości na skraju zakresu dla zmiennej (zmiennych) x, a wartość zmiennej y nie jest istotna. Więc dźwignia uwzględnia tylko wartości zmiennej x i ignoruje wartości zmiennej y. Pojęcie dźwigni wywodzi się od używanego w fizyce pojęcia dźwigni, za pomocą której można poruszyć Ziemię, gdyby tylko jej ramię było dostatecznie długie. Dźwignię hi dla i-tej obserwacji można obliczyć w następujący sposób: h i 1 n ( x n i 1 i ( x x) i 2 x) 2
65 h i 1 n ( x n i 1 i ( x x) i 2 x) 2 Dla danego zbioru danych wielkości: 1 n oraz ( x x) n i 1 i ( x x) i 2 2 można uważać za stałe. Zatem wartość dźwigni dla i-tej obserwacji zależy jedynie od kwadratu odległości między wartością zmiennej objaśniającej a średnią wartością zmiennych objaśniających. Im bardziej wartość obserwowana różni się od średniej wartości zmiennej x, tym większa jest wartość dźwigni. Kres dolny dla wartości dźwigni to 1/n, a kres górny to 1. Jeżeli wartość dźwigni jest większa od około 2(m+1)/n lub 3(m+1)/n, to uznaje się, że jest ona wysoka (m oznacza tu liczbę zmiennych objaśniających).
66 Obserwacja wpływowa Obserwacja jest wpływowa (ang. influential), jeśli jej obecność wpływa na prostą regresji, w taki sposób, że zmienia się współczynnik kierunkowy tej prostej. Inaczej powiemy, że jeśli obserwacja jest wpływowa to inaczej wygląda prosta regresji w zależności od tego czy ta obserwacja została ujęta w zbiorze, czy też nie (została usunięta). 1 n n ( x x) i 1 i ( x x) Obserwacja jest wpływowa (influential) jeżeli parametry regresji istotnie zmieniają się w zależności od obecności lub nieobecności tej obserwacji w zbiorze danych. i 2 2
67 Identyfikacja obserwacji wpływowych W praktyce, jeśli obserwowana wartość leży w Q1 to mówimy, że ma ona mały wpływ na regresję. Obserwacje leżące między Q1 a Q3 nazywamy wpływowymi. Mówimy także, że czynnik SEe i S 1 1 ( n ( x x) n i 1 i ( x x) i 2 2 we wzorze na SE ei to tzw. wpływ tej obserwacji (czasami nazywany w literaturze ''dźwignią''). Zwykle obserwacje cechujące się wysoką wartością dźwigni będą uznawane za wpływowe. Dodatkowo powiemy, że nawet jeśli obserwacja jest odstająca, ale ma małą wartość wpływu to uznamy, że nie jest ona wpływowa.
68 Wykrywanie odchyleń - metody 1. wysoka dźwignia (Leverages) 2. reszty (Jackknife residuals) 3. odległość Cook a (Cook s distance).
69 Jackknife residuals (Externally studentized residuals): is called a jackknife residual (or R-Student residual). MSE( i) is the residual variance computed with the ith observation deleted. Jackknife residuals have a mean near 0 and a variance that is slightly greater than 1. Jackknife residuals are usually the preferred residual for regression diagnostics.
 x ri:")
70 Odległość Cook a Di: Odległość Cook a do pomiaru obs. wpływowych hi: dźwignia dla mierzenia nietypowości zmiennej (-ych) x ri: Studentyzowane reszty dla pomiaru odchylenia

71
72
73 Odległość Cook a ri = i-ta studentyzowana reszta; Wpływowość jest w relacji z dźwignią i tym, czy obserwacja jest odstająca: Odchylenia o wysokiej dźwigni są wpływowe Odchylenia o niskiej dźwigni są zdecydowanie mniej wpływowe Punkty wysokiej dźwigni które nie są odchyleniami są mniej wpływowe Wysoka wpływowość gdy Di > 1 w środowisku R: cooks.distance(y.lm) Lub plot(y.lm, which=4)
74
75 Metody: Szukając: 1. Odchyleń (na wykresie reszt) szukamy punktów które są wpływowe, czyli takie dla których model regresji nie jest adekwatny 2. Obserwacji wysokiej dźwigni (na wykresie hat diagonal) to punkty potencjalnie wpływowe 3. Obserwacji wpływowych (za pomocą odległości Cook a) szukamy punktów które mogą zaburzać model regresji Pamiętaj, że: 1. Odchylenia nie muszą być wpływowe. 2. Obserwacje wysokiej dźwigni też nie muszą być wpływowe. 3. Obserwacje wpływowe mogą nie być odchyleniami.
76 Odległość Cooka mierzy poziom wpływu obserwacji, uwzględniając zarówno wielkość reszty, jak i wysokość wpływu dla tej obserwacji. Dla i-tej obserwacji odległość Cooka jest obliczana jako: n 2 ( Yj Yj ) 2 Y j Gdzie (i) jest obserwacją przewidywaną dla j-tej obserwacji obliczoną na podstawie danych z usuniętą obserwacją i-tą, zaś będzie wartością przewidywaną dla j-tej obserwacji gdy i-tej obserwacji Y j nie usunięto. Duża wartość D i mówi o dużym wpływie usunięcia i-tej obserwacji, a tym samym obserwację i-tą uznajemy za wpływową. D i j 1 ps 2 ( i) ei ps 2 hi (1 h ) i 2
77 W praktyce obserwacja jest wpływowa jeżeli jej odległość Cooka przekracza wartość 1.
78 Najpierw należy załadować pakiet {car} I następnie wywołać komendę: Wykres obserwacji wpływowych z zaznaczeniem odległości Cooka
, main=\"influence Plot\",sub=\"Rozmiar kółka jest proporcjonalny do odległości")
79 Wykres obserwacji wpływowych z zaznaczeniem odległości Cooka Teraz jeśli chcemy poznać obserwacje wpływowe możemy użyć komendy: > influenceplot(lm(b~a), main="influence Plot",sub="Rozmiar kółka jest proporcjonalny do odległości Cooka)
80
81 Wykres QQ powinien w przybliżeniu pokrywać się z linią prostą Na wykresie Cooka pokazany jest wpływ poszczególnych punktów na regresję wielokrotną interesują nas punkty (a) o wartościach w pobliżu 1, (b) odbiegające znacząco od innych
 której efekty będzie następujący Jak widać, ostatnia kolumna wskazuje na obserwacje wpływowe zaznaczając przy nich symbol *.")
82 Do wykrycia obserwacji wpływowych możemy także użyć funkcji. > influence.measures(model.regresji) której efekty będzie następujący Jak widać, ostatnia kolumna wskazuje na obserwacje wpływowe zaznaczając przy nich symbol *. Z naszych danych wynika, że w zbiorze cereals mamy 2 wpływowe. Są to obserwacje 1 i 4.
83 Wyznaczenie obserwacji odstających w modelu z wieloma zmiennymi objaśniającymi Obserwacje odstające będziemy wykrywać przy użyciu znanego już pakietu car i funkcji outlier.test w ramach tego pakietu. library(car) > outlier.test(model) max rstudent = , degrees of freedom = 73, unadjusted p = , Bonferroni p = Observation: Golden_Crisp Wykryliśmy jedną obserwację odstającą (płatki o nazwie Golden_Crisp).
84 Wyznaczenie obserwacji wpływowych w modelu z wieloma zmiennymi objaśniającymi Wartości wpływowe będziemy wykrywać za pomocą fukcji influence.measures. Wyniki takiej analizy widzimy poniżej. influence.measures(model) Influence measures of lm(formula = rating ~ sugars + fiber, data = dane) : dfb.1_ dfb.sgrs dfb.fibr dffit 100\%_Bran e \%_Natural_Bran e All-Bran e All-Bran_with_Extra_Fiber e Frosted_Flakes e Frosted_Mini-Wheats e Golden_Crisp e Golden_Grahams e Grape_Nuts_Flakes e Grape-Nuts e Shredded_Wheat_'n'Bran e Shredded_Wheat_spoon_size e Wheaties_Honey_Gold e cov.r cook.d hat inf 100\%_Bran e * 100\%_Natural_Bran e All-Bran e * All-Bran_with_Extra_Fiber e *... Frosted_Flakes e Frosted_Mini-Wheats e *... Golden_Crisp e *... Post_Nat._Raisin_Bran e *
85 influence.measures(model) Influence measures of lm(formula = rating ~ sugars + fiber, data = dane) : dfb.1_ dfb.sgrs dfb.fibr dffit 100\%_Bran e \%_Natural_Bran e All-Bran e All-Bran_with_Extra_Fiber e Frosted_Flakes e Frosted_Mini-Wheats e Golden_Crisp e Golden_Grahams e Grape_Nuts_Flakes e Grape-Nuts e Shredded_Wheat_'n'Bran e Shredded_Wheat_spoon_size e Wheaties_Honey_Gold e cov.r cook.d hat inf 100\%_Bran e * 100\%_Natural_Bran e All-Bran e * All-Bran_with_Extra_Fiber e *... Frosted_Flakes e Frosted_Mini-Wheats e *... Golden_Crisp e *... Post_Nat._Raisin_Bran e *
86 Za wpływowe uznamy 6 obserwacji: 100%_Bran All-Bran All-Bran_with_Extra_Fiber Frosted_Mini-Wheats Golden_Crisp (które zresztą uznaliśmy za obserwację odstającą, outlier) oraz Post_Nat._Raisin_Bran.
87 Wyznaczenie obserwacji wpływowych w modelu z wieloma zmiennymi objaśniającymi Wartości wpływowe będziemy wykrywać za pomocą funkcji influence.measures. Wyniki takiej analizy widzimy poniżej. influence.measures(model) Influence measures of lm(formula = rating ~ sugars + fiber, data = dane) : dfb.1_ dfb.sgrs dfb.fibr dffit 100\%_Bran e \%_Natural_Bran e All-Bran e All-Bran_with_Extra_Fiber e Frosted_Flakes e Frosted_Mini-Wheats e Fruit_&_Fibre_Dates,_Walnuts,_and_Oats e Fruitful_Bran e Fruity_Pebbles e Golden_Crisp e Golden_Grahams e Post_Nat._Raisin_Bran e Product_ e Puffed_Rice e Wheaties e Wheaties_Honey_Gold e
88 Wyznaczenie obserwacji wpływowych w modelu z wieloma zmiennymi objaśniającymi cov.r cook.d hat inf 100\%_Bran e * 100\%_Natural_Bran e All-Bran e * All-Bran_with_Extra_Fiber e * Frosted_Mini-Wheats e * Fruit_&_Fibre_Dates,_Walnuts,_and_Oats e Fruitful_Bran e Fruity_Pebbles e Golden_Crisp e * Golden_Grahams e Post_Nat._Raisin_Bran e * Product_ e Puffed_Rice e Wheaties e Wheaties_Honey_Gold e >
89 A więc mamy zapewne 6 obserwacji wpływowych. Są to kolejno płatki: 100%_Bran All-Bran, All-Bran_with_Extra_Fiber Frosted_Mini-Wheats, Golden_Crisp (które zresztą uznaliśmy za obserwację odstającą, outlier) oraz Post_Nat._Raisin_Bran.
90 Wyznaczenie obserwacji odstających w modelu z wieloma zmiennymi objaśniającymi Chcąc przeprowadzić test na obserwacje odstające użyjemy znanego już pakietu car i funkcji outlier.test w ramach tego pakietu. library(car) > outlier.test(model) max rstudent = , degrees of freedom = 73, unadjusted p = , Bonferroni p = Observation: Golden_Crisp Wykryto więc jedną obserwację odstającą (płatki o nazwie Golden_Crisp).
91 obserwacje odstające Wysokiej dźwigni wpływowe definicja Mają dużą bezwzględną wartość standaryzowanej reszty (czyli reszty podzielonej przez błąd standardowy) Przyjmują wartości na skraju zakresu zmiennej (-ych) z a wartość y nie jest istotna. Im bardziej wartość obserwowana różni się od średniej wartości zmiennej x tym większa jest wartość dźwigni. Wpływają na prostą regresji, tak, że zmienia się współczynnik kierunkowy. Jak je wykrywamy? Gdy wartość > 2 Hi 2(m+1)/n Jeśli obserwacja leży między Q1 a Q3, lub jeśli si, resid s 1 hi odległość Cooka przekracza wartość 1
92 Wnioski!!! Punkt oddalony (odstający) może, ale nie musi być wpływowy. Podobnie punkt wysokiej dźwigni, może, ale nie musi być wpływowy. Zwykle wpływowe obserwacje łączą cechy dużej wartości reszty i dużej wartości dźwigni. Istnieje możliwość, że obserwacja nie będzie w pełni rozpoznana jako punkt oddalony ani jako punkt wysokiej dźwigni, ale nadal będzie wpływowa, ponieważ będzie łączyć w sobie obie te cechy.
Analiza regresji. Analiza korelacji.
 Analiza regresji. Analiza korelacji. Levels name mfr type calories protein fat sodium fiber carbo sugars potass vitamins shelf weight cups rating Storage 77 integer 7 integer 2 integer integer integer
Analiza regresji. Analiza korelacji. Levels name mfr type calories protein fat sodium fiber carbo sugars potass vitamins shelf weight cups rating Storage 77 integer 7 integer 2 integer integer integer
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 11-12
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Statystyczne metody analizy danych przy użyciu środowiska R
 Statystyczne metody analizy danych przy użyciu środowiska R Agnieszka Nowak - Brzezińska Instytut Informatyki, Uniwersytet Śląski Wybrane zagadnienia Plan wystąpienia 1. Wprowadzenie. 2. Środowisko R.
Statystyczne metody analizy danych przy użyciu środowiska R Agnieszka Nowak - Brzezińska Instytut Informatyki, Uniwersytet Śląski Wybrane zagadnienia Plan wystąpienia 1. Wprowadzenie. 2. Środowisko R.
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Natalia Nehrebecka Stanisław Cichocki. Wykład 13
 Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Analiza zależności cech ilościowych regresja liniowa (Wykład 13)
") Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
PODSTAWY STATYSTYCZNEJ ANALIZY DANYCH. Wykład 2 Obserwacje nietypowe i wpływowe Regresja nieliniowa
 Wykład 2 Obserwacje nietypowe i wpływowe Regresja nieliniowa Obserwacje nietypowe i wpływowe Obserwacje nietypowe i wpływowe Obserwacje nietypowe w analizie regresji: nietypowe wartości zmiennej Y - prowadzące
Wykład 2 Obserwacje nietypowe i wpływowe Regresja nieliniowa Obserwacje nietypowe i wpływowe Obserwacje nietypowe i wpływowe Obserwacje nietypowe w analizie regresji: nietypowe wartości zmiennej Y - prowadzące
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
WERYFIKACJA MODELI MODELE LINIOWE. Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno
 WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
Stanisław Cichocki. Natalia Nehrebecka. Wykład 9
 Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Analiza regresji - weryfikacja założeń
 Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Agnieszka Nowak Brzezińska Wykład 2 z 5
 Agnieszka Nowak Brzezińska Wykład 2 z 5 metoda typ Zmienna niezależna Regresja liniowa Regresja Wszystkie ilościowe Zakłada liniową zależność, prosta w implementacji Analiza dyskryminacyjna klasyfikacja
Agnieszka Nowak Brzezińska Wykład 2 z 5 metoda typ Zmienna niezależna Regresja liniowa Regresja Wszystkie ilościowe Zakłada liniową zależność, prosta w implementacji Analiza dyskryminacyjna klasyfikacja
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817
 Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Stosowana Analiza Regresji
 prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT. Część I: analiza regresji
 Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
Metody wykrywania odchyleo w danych. Metody wykrywania braków w danych. Korelacja. PED lab 4
 Metody wykrywania odchyleo w danych. Metody wykrywania braków w danych. Korelacja. PED lab 4 Co z danymi oddalonymi? Błędne dane typu dochód z minusem na początku: to błąd we wprowadzaniu danych, czy faktyczny
Metody wykrywania odchyleo w danych. Metody wykrywania braków w danych. Korelacja. PED lab 4 Co z danymi oddalonymi? Błędne dane typu dochód z minusem na początku: to błąd we wprowadzaniu danych, czy faktyczny
Analiza regresji część II. Agnieszka Nowak - Brzezińska
 Analiza regresji część II Agnieszka Nowak - Brzezińska Niebezpieczeństwo ekstrapolacji Analitycy powinni ograniczyć predykcję i estymację, które są wykonywane za pomocą równania regresji dla wartości objaśniającej
Analiza regresji część II Agnieszka Nowak - Brzezińska Niebezpieczeństwo ekstrapolacji Analitycy powinni ograniczyć predykcję i estymację, które są wykonywane za pomocą równania regresji dla wartości objaśniającej
Stanisław Cichocki. Natalia Nehrebecka. Wykład 14
 Stanisław Cichocki Natalia Nehrebecka Wykład 14 1 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne Obserwacje nietypowe i błędne Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2)
Stanisław Cichocki Natalia Nehrebecka Wykład 14 1 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne Obserwacje nietypowe i błędne Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2)
Mikroekonometria 6. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 6 Mikołaj Czajkowski Wiktor Budziński Metody symulacyjne Monte Carlo Metoda Monte-Carlo Wykorzystanie mocy obliczeniowej komputerów, aby poznać charakterystyki zmiennych losowych poprzez
Mikroekonometria 6 Mikołaj Czajkowski Wiktor Budziński Metody symulacyjne Monte Carlo Metoda Monte-Carlo Wykorzystanie mocy obliczeniowej komputerów, aby poznać charakterystyki zmiennych losowych poprzez
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)
, które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)") Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań
 Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań 6.11.1 1 Badanie współzależności atrybutów jakościowych w wielowymiarowych tabelach danych. 1.1 Analiza współzależności
Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań 6.11.1 1 Badanie współzależności atrybutów jakościowych w wielowymiarowych tabelach danych. 1.1 Analiza współzależności
Mikroekonometria 5. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 5 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.medexp3.dta przygotuj model regresji kwantylowej 1. Przygotuj model regresji kwantylowej w którym logarytm wydatków
Mikroekonometria 5 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.medexp3.dta przygotuj model regresji kwantylowej 1. Przygotuj model regresji kwantylowej w którym logarytm wydatków
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej
 Pojęcie losowej próby prostej") 7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
Wykład 5: Statystyki opisowe (część 2)
") Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Regresja liniowa wprowadzenie
 Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
Wykład 9 Wnioskowanie o średnich
 Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.
 znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.") Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Statystyka. Wykład 9. Magdalena Alama-Bućko. 24 kwietnia Magdalena Alama-Bućko Statystyka 24 kwietnia / 34
 Statystyka Wykład 9 Magdalena Alama-Bućko 24 kwietnia 2017 Magdalena Alama-Bućko Statystyka 24 kwietnia 2017 1 / 34 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 9 Magdalena Alama-Bućko 24 kwietnia 2017 Magdalena Alama-Bućko Statystyka 24 kwietnia 2017 1 / 34 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Estymacja parametrów w modelu normalnym
 Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Oszacowanie i rozkład t
 Oszacowanie i rozkład t Marcin Zajenkowski Marcin Zajenkowski () Oszacowanie i rozkład t 1 / 31 Oszacowanie 1 Na podstawie danych z próby szacuje się wiele wartości w populacji, np.: jakie jest poparcie
Oszacowanie i rozkład t Marcin Zajenkowski Marcin Zajenkowski () Oszacowanie i rozkład t 1 / 31 Oszacowanie 1 Na podstawie danych z próby szacuje się wiele wartości w populacji, np.: jakie jest poparcie
Statystyka. Rozkład prawdopodobieństwa Testowanie hipotez. Wykład III ( )
") Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Pochodna i różniczka funkcji oraz jej zastosowanie do obliczania niepewności pomiarowych
 Pochodna i różniczka unkcji oraz jej zastosowanie do obliczania niepewności pomiarowych Krzyszto Rębilas DEFINICJA POCHODNEJ Pochodna unkcji () w punkcie określona jest jako granica: lim 0 Oznaczamy ją
Pochodna i różniczka unkcji oraz jej zastosowanie do obliczania niepewności pomiarowych Krzyszto Rębilas DEFINICJA POCHODNEJ Pochodna unkcji () w punkcie określona jest jako granica: lim 0 Oznaczamy ją
ANALIZA REGRESJI WIELOKROTNEJ. Zastosowanie statystyki w bioinżynierii Ćwiczenia 8
 ANALIZA REGRESJI WIELOKROTNEJ Zastosowanie statystyki w bioinżynierii Ćwiczenia 8 ZADANIE 1A 1. Irysy: Sprawdź zależność długości płatków korony od ich szerokości Utwórz wykres punktowy Wyznacz współczynnik
ANALIZA REGRESJI WIELOKROTNEJ Zastosowanie statystyki w bioinżynierii Ćwiczenia 8 ZADANIE 1A 1. Irysy: Sprawdź zależność długości płatków korony od ich szerokości Utwórz wykres punktowy Wyznacz współczynnik
Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb
 Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Zadania ze statystyki cz. 8 I rok socjologii. Zadanie 1.
 Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Ekonometria ćwiczenia 3. Prowadzący: Sebastian Czarnota
 Ekonometria ćwiczenia 3 Prowadzący: Sebastian Czarnota Strona - niezbędnik http://sebastianczarnota.com/sgh/ Normalność rozkładu składnika losowego Brak normalności rozkładu nie odbija się na jakości otrzymywanych
Ekonometria ćwiczenia 3 Prowadzący: Sebastian Czarnota Strona - niezbędnik http://sebastianczarnota.com/sgh/ Normalność rozkładu składnika losowego Brak normalności rozkładu nie odbija się na jakości otrzymywanych
Regresja liniowa, klasyfikacja metodą k-nn. Agnieszka Nowak Brzezińska
 Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
3. Modele tendencji czasowej w prognozowaniu
 II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
Stanisław Cichocki. Natalia Nehrebecka. Wykład 12
 Stanisław Cichocki Natalia Nehrebecka Wykład 1 1 1. Testy diagnostyczne Testowanie stabilności parametrów modelu: test Chowa. Heteroskedastyczność Konsekwencje Testowanie heteroskedastyczności 1. Testy
Stanisław Cichocki Natalia Nehrebecka Wykład 1 1 1. Testy diagnostyczne Testowanie stabilności parametrów modelu: test Chowa. Heteroskedastyczność Konsekwencje Testowanie heteroskedastyczności 1. Testy
Regresja liniowa w R Piotr J. Sobczyk
 Regresja liniowa w R Piotr J. Sobczyk Uwaga Poniższe notatki mają charakter roboczy. Mogą zawierać błędy. Za przesłanie mi informacji zwrotnej o zauważonych usterkach serdecznie dziękuję. Weźmy dane dotyczące
Regresja liniowa w R Piotr J. Sobczyk Uwaga Poniższe notatki mają charakter roboczy. Mogą zawierać błędy. Za przesłanie mi informacji zwrotnej o zauważonych usterkach serdecznie dziękuję. Weźmy dane dotyczące
Regresja wielokrotna. PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Szkice rozwiązań z R:
 Szkice rozwiązań z R: Zadanie 1. Założono doświadczenie farmakologiczne. Obserwowano przyrost wagi ciała (przyrost [gram]) przy zadanych dawkach trzech preparatów (dawka.a, dawka.b, dawka.c). Obiektami
Szkice rozwiązań z R: Zadanie 1. Założono doświadczenie farmakologiczne. Obserwowano przyrost wagi ciała (przyrost [gram]) przy zadanych dawkach trzech preparatów (dawka.a, dawka.b, dawka.c). Obiektami
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza składowych głównych
 Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
LINIOWOŚĆ METODY OZNACZANIA ZAWARTOŚCI SUBSTANCJI NA PRZYKŁADZIE CHROMATOGRAFU
 LINIOWOŚĆ METODY OZNACZANIA ZAWARTOŚCI SUBSTANCJI NA PRZYKŁADZIE CHROMATOGRAFU Tomasz Demski, StatSoft Polska Sp. z o.o. Wprowadzenie Jednym z elementów walidacji metod pomiarowych jest sprawdzenie liniowości
LINIOWOŚĆ METODY OZNACZANIA ZAWARTOŚCI SUBSTANCJI NA PRZYKŁADZIE CHROMATOGRAFU Tomasz Demski, StatSoft Polska Sp. z o.o. Wprowadzenie Jednym z elementów walidacji metod pomiarowych jest sprawdzenie liniowości
LABORATORIUM 3. Jeśli p α, to hipotezę zerową odrzucamy Jeśli p > α, to nie mamy podstaw do odrzucenia hipotezy zerowej
 LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
Wstęp do teorii niepewności pomiaru. Danuta J. Michczyńska Adam Michczyński
 Wstęp do teorii niepewności pomiaru Danuta J. Michczyńska Adam Michczyński Podstawowe informacje: Strona Politechniki Śląskiej: www.polsl.pl Instytut Fizyki / strona własna Instytutu / Dydaktyka / I Pracownia
Wstęp do teorii niepewności pomiaru Danuta J. Michczyńska Adam Michczyński Podstawowe informacje: Strona Politechniki Śląskiej: www.polsl.pl Instytut Fizyki / strona własna Instytutu / Dydaktyka / I Pracownia
Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI
 Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną
Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną
ANALIZA WYNIKÓW NAUCZANIA W GIMNAZJUM NR 3 Z ZASTOSOWANIEM KALKULATORA EWD 100 ROK 2012
 ANALIZA WYNIKÓW NAUCZANIA W GIMNAZJUM NR 3 Z ZASTOSOWANIEM KALKULATORA EWD 100 ROK 2012 OPRACOWAŁY: ANNA ANWAJLER MARZENA KACZOR DOROTA LIS 1 WSTĘP W analizie wykorzystywany będzie model szacowania EWD.
ANALIZA WYNIKÓW NAUCZANIA W GIMNAZJUM NR 3 Z ZASTOSOWANIEM KALKULATORA EWD 100 ROK 2012 OPRACOWAŁY: ANNA ANWAJLER MARZENA KACZOR DOROTA LIS 1 WSTĘP W analizie wykorzystywany będzie model szacowania EWD.
Stanisław Cichocki. Natalia Nehrebecka. Wykład 13
 Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Testowanie autokorelacji 2. Heteroskedastyczność i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji 3.Problemy z danymi Zmienne pominięte
Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Testowanie autokorelacji 2. Heteroskedastyczność i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji 3.Problemy z danymi Zmienne pominięte
Statystyka w przykładach
 w przykładach Tomasz Mostowski Zajęcia 10.04.2008 Plan Estymatory 1 Estymatory 2 Plan Estymatory 1 Estymatory 2 Własności estymatorów Zazwyczaj w badaniach potrzebujemy oszacować pewne parametry na podstawie
w przykładach Tomasz Mostowski Zajęcia 10.04.2008 Plan Estymatory 1 Estymatory 2 Plan Estymatory 1 Estymatory 2 Własności estymatorów Zazwyczaj w badaniach potrzebujemy oszacować pewne parametry na podstawie
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
1 n. s x x x x. Podstawowe miary rozproszenia: Wariancja z populacji: Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel:
 Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
HISTOGRAM. Dr Adam Michczyński - METODY ANALIZY DANYCH POMIAROWYCH Liczba pomiarów - n. Liczba pomiarów - n k 0.5 N = N =
 HISTOGRAM W pewnych przypadkach interesuje nas nie tylko określenie prawdziwej wartości mierzonej wielkości, ale także zbadanie całego rozkład prawdopodobieństwa wyników pomiarów. W takim przypadku wyniki
HISTOGRAM W pewnych przypadkach interesuje nas nie tylko określenie prawdziwej wartości mierzonej wielkości, ale także zbadanie całego rozkład prawdopodobieństwa wyników pomiarów. W takim przypadku wyniki
K wartość kapitału zaangażowanego w proces produkcji, w tys. jp.
 Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
parametrów strukturalnych modelu = Y zmienna objaśniana, X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających,
 诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
Zadania ze statystyki cz.8. Zadanie 1.
 Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Analizy wariancji ANOVA (analysis of variance)
") ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
Statystyka. Wykład 4. Magdalena Alama-Bućko. 13 marca Magdalena Alama-Bućko Statystyka 13 marca / 41
 Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Wprowadzenie do technik analitycznych Metoda najmniejszych kwadratów
 Wprowadzenie do technik analitycznych Instytut Sterowania i Systemów Informatycznych Uniwersytet Zielonogórski Wykład 2 Korelacja i regresja Przykład: Temperatura latem średnia liczba napojów sprzedawanych
Wprowadzenie do technik analitycznych Instytut Sterowania i Systemów Informatycznych Uniwersytet Zielonogórski Wykład 2 Korelacja i regresja Przykład: Temperatura latem średnia liczba napojów sprzedawanych
Monte Carlo, bootstrap, jacknife
 Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Statystyka w analizie i planowaniu eksperymentu
 23 kwietnia 2014 Korelacja - wspó lczynnik korelacji 1 Gdy badamy różnego rodzaju rodzaju zjawiska (np. przyrodnicze) możemy stwierdzić, że na każde z nich ma wp lyw dzia lanie innych czynników; Korelacja
23 kwietnia 2014 Korelacja - wspó lczynnik korelacji 1 Gdy badamy różnego rodzaju rodzaju zjawiska (np. przyrodnicze) możemy stwierdzić, że na każde z nich ma wp lyw dzia lanie innych czynników; Korelacja
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Wykład Centralne twierdzenie graniczne. Statystyka matematyczna: Estymacja parametrów rozkładu
 Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Estymacja przedziałowa. Przedział ufności
 Estymacja przedziałowa Przedział ufności Estymacja przedziałowa jest to szacowanie wartości danego parametru populacji, ρ za pomocą tak zwanego przedziału ufności. Przedziałem ufności nazywamy taki przedział
Estymacja przedziałowa Przedział ufności Estymacja przedziałowa jest to szacowanie wartości danego parametru populacji, ρ za pomocą tak zwanego przedziału ufności. Przedziałem ufności nazywamy taki przedział
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Typy zmiennych. Zmienne i rekordy. Rodzaje zmiennych. Graficzne reprezentacje danych Statystyki opisowe
 Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Elektroniki
 Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Elektroniki Przetwarzanie Sygnałów Studia Podyplomowe, Automatyka i Robotyka. Wstęp teoretyczny Zmienne losowe Zmienne losowe
Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Elektroniki Przetwarzanie Sygnałów Studia Podyplomowe, Automatyka i Robotyka. Wstęp teoretyczny Zmienne losowe Zmienne losowe
ANALIZA WYNIKÓW NAUCZANIA W GIMNAZJUM NR 3 Z ZASTOSOWANIEM KALKULATORA EWD 100 ROK 2013
 ANALIZA WYNIKÓW NAUCZANIA W GIMNAZJUM NR 3 Z ZASTOSOWANIEM KALKULATORA EWD 100 ROK 2013 OPRACOWAŁY: ANNA ANWAJLER MARZENA KACZOR DOROTA LIS 1 WSTĘP W analizie wykorzystywany będzie model szacowania EWD.
ANALIZA WYNIKÓW NAUCZANIA W GIMNAZJUM NR 3 Z ZASTOSOWANIEM KALKULATORA EWD 100 ROK 2013 OPRACOWAŁY: ANNA ANWAJLER MARZENA KACZOR DOROTA LIS 1 WSTĘP W analizie wykorzystywany będzie model szacowania EWD.
Ekonometria. Modele regresji wielorakiej - dobór zmiennych, szacowanie. Paweł Cibis pawel@cibis.pl. 1 kwietnia 2007
 Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y).
 na zmienną zależną (Y).") Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Lepiej zapobiegać niż leczyć Diagnostyka regresji
 Anceps remedium melius quam nullum Lepiej zapobiegać niż leczyć Diagnostyka regresji Na tych zajęciach nauczymy się identyfikować zagrożenia dla naszej analizy regresji. Jednym elementem jest oczywiście
Anceps remedium melius quam nullum Lepiej zapobiegać niż leczyć Diagnostyka regresji Na tych zajęciach nauczymy się identyfikować zagrożenia dla naszej analizy regresji. Jednym elementem jest oczywiście
Zagadnienia regresji. Cz ± III Regresja wielokrotna Konspekt do zaj : Statystyczne metody analizy danych
 Zagadnienia regresji. Cz ± III Regresja wielokrotna Konspekt do zaj : Statystyczne metody analizy danych 1 Wprowadzenie Agnieszka Nowak-Brzezi«ska 17 listopada 2009 Niech ogólne równanie regresji ma posta
Zagadnienia regresji. Cz ± III Regresja wielokrotna Konspekt do zaj : Statystyczne metody analizy danych 1 Wprowadzenie Agnieszka Nowak-Brzezi«ska 17 listopada 2009 Niech ogólne równanie regresji ma posta
Analizowane modele. Dwa modele: y = X 1 β 1 + u (1) y = X 1 β 1 + X 2 β 2 + ε (2) Będziemy analizować dwie sytuacje:
 y = X 1 β 1 + X 2 β 2 + ε (2) Będziemy analizować dwie sytuacje:") Analizowane modele Dwa modele: y = X 1 β 1 + u (1) Będziemy analizować dwie sytuacje: y = X 1 β 1 + X 2 β 2 + ε (2) zmienne pominięte: estymujemy model (1) a w rzeczywistości β 2 0 zmienne nieistotne:
Analizowane modele Dwa modele: y = X 1 β 1 + u (1) Będziemy analizować dwie sytuacje: y = X 1 β 1 + X 2 β 2 + ε (2) zmienne pominięte: estymujemy model (1) a w rzeczywistości β 2 0 zmienne nieistotne:
ANALIZA REGRESJI SPSS
 NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
istocie dziedzina zajmująca się poszukiwaniem zależności na podstawie prowadzenia doświadczeń jest o wiele starsza: tak na przykład matematycy
 MODEL REGRESJI LINIOWEJ. METODA NAJMNIEJSZYCH KWADRATÓW Analiza regresji zajmuje się badaniem zależności pomiędzy interesującymi nas wielkościami (zmiennymi), mające na celu konstrukcję modelu, który dobrze
MODEL REGRESJI LINIOWEJ. METODA NAJMNIEJSZYCH KWADRATÓW Analiza regresji zajmuje się badaniem zależności pomiędzy interesującymi nas wielkościami (zmiennymi), mające na celu konstrukcję modelu, który dobrze
Następnie przypominamy (dla części studentów wprowadzamy) podstawowe pojęcia opisujące funkcje na poziomie rysunków i objaśnień.
 podstawowe pojęcia opisujące funkcje na poziomie rysunków i objaśnień.") Zadanie Należy zacząć od sprawdzenia, co studenci pamiętają ze szkoły średniej na temat funkcji jednej zmiennej. Na początek można narysować kilka krzywych na tle układu współrzędnych (funkcja gładka,
Zadanie Należy zacząć od sprawdzenia, co studenci pamiętają ze szkoły średniej na temat funkcji jednej zmiennej. Na początek można narysować kilka krzywych na tle układu współrzędnych (funkcja gładka,
JEDNORÓWNANIOWY LINIOWY MODEL EKONOMETRYCZNY
 JEDNORÓWNANIOWY LINIOWY MODEL EKONOMETRYCZNY Będziemy zapisywać wektory w postaci (,, ) albo traktując go jak macierz jednokolumnową (dzięki temu nie będzie kontrowersji przy transponowaniu wektora ) Model
JEDNORÓWNANIOWY LINIOWY MODEL EKONOMETRYCZNY Będziemy zapisywać wektory w postaci (,, ) albo traktując go jak macierz jednokolumnową (dzięki temu nie będzie kontrowersji przy transponowaniu wektora ) Model
W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych:
 W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych: Zmienne losowe skokowe (dyskretne) przyjmujące co najwyżej przeliczalnie wiele wartości Zmienne losowe ciągłe
W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych: Zmienne losowe skokowe (dyskretne) przyjmujące co najwyżej przeliczalnie wiele wartości Zmienne losowe ciągłe
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY)
") STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y. 2. Współczynnik korelacji Pearsona
 KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y 2. Współczynnik korelacji Pearsona 3. Siła i kierunek związku między zmiennymi 4. Korelacja ma sens, tylko wtedy, gdy związek między zmiennymi
KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y 2. Współczynnik korelacji Pearsona 3. Siła i kierunek związku między zmiennymi 4. Korelacja ma sens, tylko wtedy, gdy związek między zmiennymi
Stanisław Cichocki. Natalia Nehrebecka. Wykład 13
 Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Problemy z danymi Obserwacje nietypowe i błędne Współliniowość. Heteroskedastycznośd i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji
Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Problemy z danymi Obserwacje nietypowe i błędne Współliniowość. Heteroskedastycznośd i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji
1. Opis tabelaryczny. 2. Graficzna prezentacja wyników. Do technik statystyki opisowej można zaliczyć:
 Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).