UCT. Wybrane modyfikacje i usprawnienia
|
|
|
- Leszek Kwiatkowski
- 7 lat temu
- Przeglądów:
Transkrypt
1 UCT Wybrane modyfikacje i usprawnienia
2 UCT

3 UCT Sposób wybierania kolejnego ruchu podczas symulacji (UCT): Q(s,a) średni dotychczasowy wynik pary stan-ruch N liczba wizyt w danym stanie/wykonań danej akcji akcje nigdy nie wykonane wybierane są w pierwszej kolejności
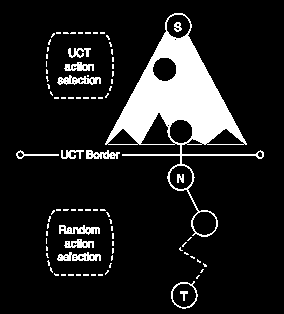
4 UCT c.d.

5 UCT c.d.
6 UCT c.d. Ograniczanie zużycia pamięci: usuwanie danych o węzłach powyżej aktualnego po każdym (realnie) wykonanym ruchu co z pozycjami powtórzonymi w drzewie gry 1. duplikowanie 2. inteligentne wykrywanie, kiedy można je usunąć z pamięci 1. różne sposoby propagowanie wyniku w górę dodawanie tylko jednego nowego węzła per symulacja Modelowanie przeciwnika każdy przeciwnik ma przydzielony swój własny model przeciwnicy podejmują losowe decyzje
7 UCT wnioski Przy modelowaniu wszystkich graczy: asymptotycznie zbieżny do wyników algorytmu minimax czyli: optymalnej gry obu graczy Problemy przy niewielkiej liczbie symulacji: jak częsty to przypadek? bardzo duży wpływ losowości niestacjonarność rezultatów dla pary stan-ruch wynik rozbudowy drzewa UCT w pamięci
8 UCT punkty modyfikacji Sposób rozbudowy drzewa UCT Strategia wyboru ruchów w fazie UCT w szczególności: kolejność ruchów niezbadanych Sposób wyznaczania wartości Q(s,a) w szczególności: sposób propagacji wyników symulacji w górę Strategia wyboru ruchów w fazie Monte-Carlo w szczególności: opcja całkowitego zastąpienia fazy Monte-Carlo innym rozsądnie szybkim podejściem Kryterium ostatecznego wyboru ruchu
9 GO
10 MoGo Strategia wyboru ruchu w fazie MC: ostatni ruch to Atari => wykonaj losowy ruch broniący, jeśli istnieje poszukaj ruchu na 8 pozycjach wokół ostatniego brane pod uwagę ruchy tworzące znany wzorzec 3x3 poszukaj ruchu zamykającego kamienie gdziekolwiek na planszy pierwsza propozycja globalna wykonaj losowy ruch
11 MoGo Modyfikacje funkcji preferencji ruchów
12 MoGo Modyfikacje funkcji preferencji ruchów
13 MoGo Modyfikacje funkcji preferencji ruchów
, które zostały wykonane niżej w drzewie gry ostateczna wartość")
14 MoGo: RAVE RAVE Rapid Action Value Estimate podczas fazy propagacji wyniku dodatkowo wyliczana wynik dla ruchów niewybranych (rodzeństwa wybranego), które zostały wykonane niżej w drzewie gry ostateczna wartość ruchu:
15 MoGo: RLGO MoGo + liniowa funkcja ewaluacyjna cechy: wzorce w Go nauka: TD(0) nauka przez grę z kopią z polityką ε-zachłanną
16 MoGo: RLGO c.d. MoGo + liniowa funkcja ewaluacyjna strategia ε-zachłanna strategia zachłanna z gaussowsko zaszumioną funkcją ewaluacyjną strategia softmax
17 Strategie budowania drzewa UCT All ends 1 nowy węzeł per symulacja Visit count wymóg: co najmniej tyle symulacji ile rodzeństwa Sibling2 j.w., ale z dwukrotnością liczby rodzeństwa
18 Strategie budowania drzewa UCT c.d. Transition probability: warunek visit count lub:

19 Strategie budowania drzewa UCT c.d. Salient winning rate: warunek visit count lub:

20 Strategie budowania drzewa UCT c.d. Visit count estimate: warunek visit count lub: estymacja dla korzenia: oszacowanie liczby symulacji w zadanym czasie

21 General Game Playing
22 General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie gry Turniej w ramach AAAI National Conference corocznie od 2005 roku Przebieg rozgrywki w ramach turnieju: prezentacja zasad i czas na ich analizę (np. 5m) rozgrywka z ograniczeniem czasowym na wykonanie pojedynczego ruchu
23 Model gry Skończona Skończona liczba graczy w tym 1 czyli de facto łamigłówka synchroniczna wszyscy gracze ruszają się równocześnie (ale dopuszczalne ruchy typu noop) skończona liczba legalnych ruchów w każdym ze skończonej liczby stanów zmiany stanu tylko w wyniku ruchów maszyna stanowa

24 Model gry c.d. M. Genesereth, N. Love, and B. Pell. General Game Playing: Overview of the AAAI Competition. AI Magazine, 26(2):62-72, 2005.
25 Game Definition Language (GDL) Opis gry jako maszyny stanowej: zbyt rozwlekły Krótszy sposób opisu: Game Definition Language (GDL) opis gry za pomocą fomuł logicznych język bazujący na zmodyfikowanym Datalogu Datalog to podzbiór Prologa podstawowe relacje: role, true, init, next, legal, does, goal, terminal
, 320-327, Honolulu, Hawaii, 2007.")
26 GDL: Tic-Tac-Toe J. Reisinger, E. Bahceci, I. Karpov, and R. Miikkulainen. Coevolving strategies for general game playing. In Proceedings of the IEEE Symposium on Computational Intelligence and Games (CIG 2007), , Honolulu, Hawaii, IEEE Press.
27 MAST Move-Average Sampling Technique analogiczna do history heuristics dla każdego ruchu (niezależnie od kontekstu wykonania) wyznaczana średnia wyników wszystkich gier, w których został wykonany w fazie MC prawdopodobieństwo wybrania ruchu proporcjonalne do tej średniej (zgodnie z rozkładem Gibbsa) może być zastąpione podejściem ε-zachłannym wg ostatnich testów zwykle skuteczniejszym
28 TO-MAST Tree-Only MAST średnie wyliczane tylko dla ruchów wykonanych w fazie UCT
29 PAST Predicate-Average Sampling Technique wartości wyznaczane dla wszystkich par (predykat, akcja) dla wszystkich predykatów zachodzących w pozycji, w której wykonywana jest akcja prawdopodobieństwo wyboru ruchu proporcjonalne do maksymalnej wartości par dla wszystkich predykatów spełnionych w danym stanie
30 FAST Features-To-Action Sampling Technique funkcja ewaluacyjna w postaci kombinacji liniowej cech generowana za pomocą TD(λ) 2 rodzaje cech (zależnie od gry): liczby kamieni różnych typów położenie kamieni na planszy
31 LGR Last-Good-Reply Policy tylko dla gier 2-osobowych słownik najlepszych odpowiedzi dla sekwencji 1-2 półruchów po wygranej partii wszystkie jej odpowiedzi trafiają do słownika, po przegranej są (o ile istnieją) usuwane
32 NST N-Gram Selection Technique tylko dla gier 2-osobowych średnie wartości wyznaczane nie tylko dla pojedynczych akcji, ale też dla sekwencji 1-3 półruchów (gracza i przeciwnika na przemian) wartość ruchu to średnia z wartości dla wszystkich dostępnych sekwencji sekwencje o długości większej niż 1 brane pod uwagę dopiero po przekroczeniu zadanej liczby (7) symulacji wydaje się najskuteczniejszą techniką

33 Sufficiency Threshold Modyfikacja dla gier deterministycznych z binarnym wynikiem (wygrana/przegrana) potwierdzenie jakiegokolwiek wygrywającego ruchu ważniejsze niż weryfikowanie drobnych różnic między dwoma ruchami
34 Moving Average Return Function częściowe rozwiązanie problemu niestabilności wyników symulacji

35 Early Cutoffs

36 Unexplored Action Urgency
37 Najważniejsza bibliografia Sylvain Gelly and David Silver Combining online and offline knowledge in UCT. In Proceedings of the 24th international conference on Machine learning (ICML '07), Zoubin Ghahramani (Ed.). ACM, New York, NY, USA, Sylvain Gelly, Yizao Wang, Remi Munos, Olivier Teytaud MoGo: Improvements in Monte-Carlo Computer-Go using UCT and sequence-like simulations; Takayuki Yajima, Tsuyoshi Hashimoto, Toshiki Matsui, Junichi Hashimoto, and Kristian Spoerer Node-expansion operators for the UCT algorithm. In Proceedings of the 7th international conference on Computers and games (CG'10), H. Jaap van den Herik, Aske Plaat, and Hiroyuki Iida (Eds.). Springer- Verlag, Berlin, Heidelberg, Stefan F Gudmundsson, Yngvi Björnsson MCTS: Improved Action Selection Techniques for Deterministic Games. In proceeding of: IJCAI'11 Workshop on General Intelligence in Game Playing Agents (GIGA'11) Hilmar Finnsson Generalized Monte-Carlo Tree Search Extensions for General Game Playing. Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, July 22-26, 2012, Toronto, Ontario, Canada. Finnsson, H. & Björnsson, Y. CadiaPlayer: Search-Control Techniques, 2011, KI, Vol. 25(1), pp Finnsson, H. & Björnsson, Y. Simulation Control in General Game Playing Agents, 2009, Proceedings of the IJCAI-09 Workshop on General Game Playing (GIGA'09)
MAGICIAN. czyli General Game Playing w praktyce. General Game Playing
 MAGICIAN czyli General Game Playing w praktyce General Game Playing 1 General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie gry Turniej w ramach AAAI National Conference
MAGICIAN czyli General Game Playing w praktyce General Game Playing 1 General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie gry Turniej w ramach AAAI National Conference
MAGICIAN: GUIDED UCT. Zastosowanie automatycznie generowanej funkcji oceny w GGP
 MAGICIAN: GUIDED UCT Zastosowanie automatycznie generowanej funkcji oceny w GGP GENERAL GAME PLAYING General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie gry Turniej
MAGICIAN: GUIDED UCT Zastosowanie automatycznie generowanej funkcji oceny w GGP GENERAL GAME PLAYING General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie gry Turniej
General Game Playing. Aktualnie stosowane algorytmy i metody konstrukcji agentów
 General Game Playing Aktualnie stosowane algorytmy i metody konstrukcji agentów GENERAL GAME PLAYING General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie gry Turniej
General Game Playing Aktualnie stosowane algorytmy i metody konstrukcji agentów GENERAL GAME PLAYING General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie gry Turniej
MAGICIAN: A GGP Agent. Analiza zależności w opisie reguł gier GGP
 MAGICIAN: A GGP Agent Analiza zależności w opisie reguł gier GGP GENERAL GAME PLAYING General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie gry Turniej w ramach AAAI
MAGICIAN: A GGP Agent Analiza zależności w opisie reguł gier GGP GENERAL GAME PLAYING General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie gry Turniej w ramach AAAI
MAGICIAN: GUIDED UCT. Ekstrakcja uniwersalnej funkcji ewaluacyjnej z rezultatów symulacji UCT
 MAGICIAN: GUIDED UCT Ekstrakcja uniwersalnej funkcji ewaluacyjnej z rezultatów symulacji UCT GENERAL GAME PLAYING General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie
MAGICIAN: GUIDED UCT Ekstrakcja uniwersalnej funkcji ewaluacyjnej z rezultatów symulacji UCT GENERAL GAME PLAYING General Game Playing? Cel: stworzenie systemu umiejącego grać/nauczyć się grać we wszystkie
Jak oceniać, gdy nic nie wiemy?
 Jak oceniać, gdy nic nie wiemy? Jasiek Marcinkowski II UWr 25 października 2012 Jasiek Marcinkowski (II UWr) Jak oceniać, gdy nic nie wiemy? 25 października 2012 1 / 10 Jak się gra w gry, o których dużo
Jak oceniać, gdy nic nie wiemy? Jasiek Marcinkowski II UWr 25 października 2012 Jasiek Marcinkowski (II UWr) Jak oceniać, gdy nic nie wiemy? 25 października 2012 1 / 10 Jak się gra w gry, o których dużo
The game of NoGo. The state-of-art algorithms. Arkadiusz Nowakowski.
 The game of NoGo The state-of-art algorithms Arkadiusz Nowakowski arkadiusz.nowakowski@us.edu.pl Faculty of Computer Science and Materials Science University of Silesia, Poland Sosnowiec 28.11.2016 Plan
The game of NoGo The state-of-art algorithms Arkadiusz Nowakowski arkadiusz.nowakowski@us.edu.pl Faculty of Computer Science and Materials Science University of Silesia, Poland Sosnowiec 28.11.2016 Plan
Porównanie rozwiązań równowagowych Stackelberga w grach z wynikami stosowania algorytmu UCT
 Porównanie rozwiązań równowagowych Stackelberga w grach z wynikami stosowania algorytmu UCT Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych PW
Porównanie rozwiązań równowagowych Stackelberga w grach z wynikami stosowania algorytmu UCT Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych PW
POŁĄCZENIE ALGORYTMÓW SYMULACYJNYCH ORAZ DZIEDZINOWYCH METOD HEURYSTYCZNYCH W ZAGADNIENIACH DYNAMICZNEGO PODEJMOWANIA DECYZJI
 POŁĄCZENIE ALGORYTMÓW SYMULACYJNYCH ORAZ DZIEDZINOWYCH METOD HEURYSTYCZNYCH W ZAGADNIENIACH DYNAMICZNEGO PODEJMOWANIA DECYZJI mgr inż. Karol Walędzik k.waledzik@mini.pw.edu.pl prof. dr hab. inż. Jacek
POŁĄCZENIE ALGORYTMÓW SYMULACYJNYCH ORAZ DZIEDZINOWYCH METOD HEURYSTYCZNYCH W ZAGADNIENIACH DYNAMICZNEGO PODEJMOWANIA DECYZJI mgr inż. Karol Walędzik k.waledzik@mini.pw.edu.pl prof. dr hab. inż. Jacek
Wykład 7 i 8. Przeszukiwanie z adwersarzem. w oparciu o: S. Russel, P. Norvig. Artificial Intelligence. A Modern Approach
 (4g) Wykład 7 i 8 w oparciu o: S. Russel, P. Norvig. Artificial Intelligence. A Modern Approach P. Kobylański Wprowadzenie do Sztucznej Inteligencji 177 / 226 (4g) gry optymalne decyzje w grach algorytm
(4g) Wykład 7 i 8 w oparciu o: S. Russel, P. Norvig. Artificial Intelligence. A Modern Approach P. Kobylański Wprowadzenie do Sztucznej Inteligencji 177 / 226 (4g) gry optymalne decyzje w grach algorytm
Risk-Aware Project Scheduling. SimpleUCT
 Risk-Aware Project Scheduling SimpleUCT DEFINICJA ZAGADNIENIA Resource-Constrained Project Scheduling (RCPS) Risk-Aware Project Scheduling (RAPS) 1 tryb wykonywania działań Czas trwania zadań jako zmienna
Risk-Aware Project Scheduling SimpleUCT DEFINICJA ZAGADNIENIA Resource-Constrained Project Scheduling (RCPS) Risk-Aware Project Scheduling (RAPS) 1 tryb wykonywania działań Czas trwania zadań jako zmienna
Modeling Go Game as a Large Decomposable Decision Process
 Modeling Go Game as a Large Decomposable Decision Process (autoreferat rozprawy doktorskiej) Łukasz Lew 4 października 2011 Od zarania dziejów ludzie marzyli o budowie maszyn, które byłyby godnymi przeciwnikami
Modeling Go Game as a Large Decomposable Decision Process (autoreferat rozprawy doktorskiej) Łukasz Lew 4 października 2011 Od zarania dziejów ludzie marzyli o budowie maszyn, które byłyby godnymi przeciwnikami
Partition Search i gry z niezupełną informacją
 MIMUW 21 stycznia 2010 1 Co to jest gra? Proste algorytmy 2 Pomysł Algorytm Przykład użycia 3 Monte Carlo Inne spojrzenie Definicja Co to jest gra? Proste algorytmy Grą o wartościach w przedziale [0, 1]
MIMUW 21 stycznia 2010 1 Co to jest gra? Proste algorytmy 2 Pomysł Algorytm Przykład użycia 3 Monte Carlo Inne spojrzenie Definicja Co to jest gra? Proste algorytmy Grą o wartościach w przedziale [0, 1]
Analiza stanów gry na potrzeby UCT w DVRP
 Analiza stanów gry na potrzeby UCT w DVRP Seminarium IO na MiNI 04.11.2014 Michał Okulewicz based on the decision DEC-2012/07/B/ST6/01527 Plan prezentacji Definicja problemu DVRP DVRP na potrzeby UCB Analiza
Analiza stanów gry na potrzeby UCT w DVRP Seminarium IO na MiNI 04.11.2014 Michał Okulewicz based on the decision DEC-2012/07/B/ST6/01527 Plan prezentacji Definicja problemu DVRP DVRP na potrzeby UCB Analiza
RISK-AWARE PROJECT SCHEDULING
 RISK-AWARE PROJECT SCHEDULING Z WYKORZYSTANIEM UCT KAROL WALĘDZIK DEFINICJA ZAGADNIENIA RESOURCE-CONSTRAINED PROJECT SCHEDULING (RCPS) Karol Walędzik - RAPS 3 RISK-AWARE PROJECT SCHEDULING (RAPS) 1 tryb
RISK-AWARE PROJECT SCHEDULING Z WYKORZYSTANIEM UCT KAROL WALĘDZIK DEFINICJA ZAGADNIENIA RESOURCE-CONSTRAINED PROJECT SCHEDULING (RCPS) Karol Walędzik - RAPS 3 RISK-AWARE PROJECT SCHEDULING (RAPS) 1 tryb
Algorytm memetyczny w grach wielokryterialnych z odroczoną preferencją celów. Adam Żychowski
 Algorytm memetyczny w grach wielokryterialnych z odroczoną preferencją celów Adam Żychowski Definicja problemu dwóch graczy: P 1 (minimalizator) oraz P 2 (maksymalizator) S 1, S 2 zbiory strategii graczy
Algorytm memetyczny w grach wielokryterialnych z odroczoną preferencją celów Adam Żychowski Definicja problemu dwóch graczy: P 1 (minimalizator) oraz P 2 (maksymalizator) S 1, S 2 zbiory strategii graczy
Zastosowanie metody UCT i drzewa strategii behawioralnej do aproksymacji stanu równowagowego Stackelberga w grach wielokrokowych
 Zastosowanie metody UCT i drzewa strategii behawioralnej do aproksymacji stanu równowagowego Stackelberga w grach wielokrokowych Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział
Zastosowanie metody UCT i drzewa strategii behawioralnej do aproksymacji stanu równowagowego Stackelberga w grach wielokrokowych Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział
Seminarium IO. Zastosowanie algorytmu UCT w Dynamic Vehicle Routing Problem. Michał Okulewicz
 Seminarium IO Zastosowanie algorytmu UCT w Dynamic Vehicle Routing Problem Michał Okulewicz 05.11.2013 Plan prezentacji Przypomnienie Problem DVRP Algorytm UCT Zastosowanie algorytmu UCT/PSO w DVRP Zastosowanie
Seminarium IO Zastosowanie algorytmu UCT w Dynamic Vehicle Routing Problem Michał Okulewicz 05.11.2013 Plan prezentacji Przypomnienie Problem DVRP Algorytm UCT Zastosowanie algorytmu UCT/PSO w DVRP Zastosowanie
Algorytmy dla gier dwuosobowych
 Algorytmy dla gier dwuosobowych Wojciech Dudek Seminarium Nowości Komputerowe 5 czerwca 2008 Plan prezentacji Pojęcia wstępne (gry dwuosobowe, stan gry, drzewo gry) Algorytm MiniMax Funkcje oceniające
Algorytmy dla gier dwuosobowych Wojciech Dudek Seminarium Nowości Komputerowe 5 czerwca 2008 Plan prezentacji Pojęcia wstępne (gry dwuosobowe, stan gry, drzewo gry) Algorytm MiniMax Funkcje oceniające
Tworzenie gier na urządzenia mobilne
 Katedra Inżynierii Wiedzy Teoria podejmowania decyzji w grze Gry w postaci ekstensywnej Inaczej gry w postaci drzewiastej, gry w postaci rozwiniętej; formalny opis wszystkich możliwych przebiegów gry z
Katedra Inżynierii Wiedzy Teoria podejmowania decyzji w grze Gry w postaci ekstensywnej Inaczej gry w postaci drzewiastej, gry w postaci rozwiniętej; formalny opis wszystkich możliwych przebiegów gry z
METODY SZTUCZNEJ INTELIGENCJI 2 Opis projektu
 Kamil Figura Krzysztof Kaliński Bartek Kutera METODY SZTUCZNEJ INTELIGENCJI 2 Opis projektu Porównanie metod uczenia z rodziny TD z algorytmem Layered Learning na przykładzie gry w warcaby i gry w anty-warcaby
Kamil Figura Krzysztof Kaliński Bartek Kutera METODY SZTUCZNEJ INTELIGENCJI 2 Opis projektu Porównanie metod uczenia z rodziny TD z algorytmem Layered Learning na przykładzie gry w warcaby i gry w anty-warcaby
Instytut Badań Systemowych Polskiej Akademii Nauk. Streszczenie rozprawy doktorskiej
 Instytut Badań Systemowych Polskiej Akademii Nauk Streszczenie rozprawy doktorskiej Meta-heurystyczne metody adaptacyjne bazujące na symulacjach w synchronicznych grach wieloosobowych. Mgr inż. Maciej
Instytut Badań Systemowych Polskiej Akademii Nauk Streszczenie rozprawy doktorskiej Meta-heurystyczne metody adaptacyjne bazujące na symulacjach w synchronicznych grach wieloosobowych. Mgr inż. Maciej
Teoria gier. Wykład7,31III2010,str.1. Gry dzielimy
 Wykład7,31III2010,str.1 Gry dzielimy Wykład7,31III2010,str.1 Gry dzielimy ze względu na: liczbę graczy: 1-osobowe, bez przeciwników(np. pasjanse, 15-tka, gra w życie, itp.), Wykład7,31III2010,str.1 Gry
Wykład7,31III2010,str.1 Gry dzielimy Wykład7,31III2010,str.1 Gry dzielimy ze względu na: liczbę graczy: 1-osobowe, bez przeciwników(np. pasjanse, 15-tka, gra w życie, itp.), Wykład7,31III2010,str.1 Gry
Teoria gier. Teoria gier. Odróżniać losowość od wiedzy graczy o stanie!
 Gry dzielimy ze względu na: liczbę graczy: 1-osobowe, bez przeciwników(np. pasjanse, 15-tka, gra w życie, itp.), 2-osobowe(np. szachy, warcaby, go, itp.), wieloosobowe(np. brydż, giełda, itp.); wygraną/przegraną:
Gry dzielimy ze względu na: liczbę graczy: 1-osobowe, bez przeciwników(np. pasjanse, 15-tka, gra w życie, itp.), 2-osobowe(np. szachy, warcaby, go, itp.), wieloosobowe(np. brydż, giełda, itp.); wygraną/przegraną:
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych
 Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
TEORIA GIER DEFINICJA (VON NEUMANN, MORGENSTERN) GRA. jednostek (graczy) znajdujących się w sytuacji konfliktowej (konflikt interesów),w
 GRA. jednostek (graczy) znajdujących się w sytuacji konfliktowej (konflikt interesów),w") TEORIA GIER GRA DEFINICJA (VON NEUMANN, MORGENSTERN) Gra składa się z zestawu reguł określających możliwości wyboru postępowania jednostek (graczy) znajdujących się w sytuacji konfliktowej (konflikt interesów),w
TEORIA GIER GRA DEFINICJA (VON NEUMANN, MORGENSTERN) Gra składa się z zestawu reguł określających możliwości wyboru postępowania jednostek (graczy) znajdujących się w sytuacji konfliktowej (konflikt interesów),w
Metody teorii gier. ALP520 - Wykład z Algorytmów Probabilistycznych p.2
 Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Sztuczna Inteligencja i Systemy Doradcze
 Sztuczna Inteligencja i Systemy Doradcze Przeszukiwanie przestrzeni stanów gry Przeszukiwanie przestrzeni stanów gry 1 Gry a problemy przeszukiwania Nieprzewidywalny przeciwnik rozwiązanie jest strategią
Sztuczna Inteligencja i Systemy Doradcze Przeszukiwanie przestrzeni stanów gry Przeszukiwanie przestrzeni stanów gry 1 Gry a problemy przeszukiwania Nieprzewidywalny przeciwnik rozwiązanie jest strategią
Wyznaczanie strategii w grach
 Wyznaczanie strategii w grach Dariusz Banasiak Katedra Informatyki Technicznej W4/K9 Politechnika Wrocławska Definicja gry Teoria gier i konstruowane na jej podstawie programy stanowią jeden z głównych
Wyznaczanie strategii w grach Dariusz Banasiak Katedra Informatyki Technicznej W4/K9 Politechnika Wrocławska Definicja gry Teoria gier i konstruowane na jej podstawie programy stanowią jeden z głównych
Mixed-UCT: Zastosowanie metod symulacyjnych do poszukiwania równowagi Stackelberga w grach wielokrokowych
 Mixed-UCT: Zastosowanie metod symulacyjnych do poszukiwania równowagi Stackelberga w grach wielokrokowych Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych
Mixed-UCT: Zastosowanie metod symulacyjnych do poszukiwania równowagi Stackelberga w grach wielokrokowych Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych
Uczenie ze wzmocnieniem
 Uczenie ze wzmocnieniem Maria Ganzha Wydział Matematyki i Nauk Informatycznych 2018-2019 O projekcie nr 2 roboty (samochody, odkurzacze, drony,...) gry planszowe, sterowanie (optymalizacja; windy,..) optymalizacja
Uczenie ze wzmocnieniem Maria Ganzha Wydział Matematyki i Nauk Informatycznych 2018-2019 O projekcie nr 2 roboty (samochody, odkurzacze, drony,...) gry planszowe, sterowanie (optymalizacja; windy,..) optymalizacja
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Monte Carlo, bootstrap, jacknife
 Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Wprowadzenie do teorii gier
 Instytut Informatyki Uniwersytetu Śląskiego Wykład 1 1 Klasyfikacja gier 2 Gry macierzowe, macierz wypłat, strategie czyste i mieszane 3 Punkty równowagi w grach o sumie zerowej 4 Gry dwuosobowe oraz n-osobowe
Instytut Informatyki Uniwersytetu Śląskiego Wykład 1 1 Klasyfikacja gier 2 Gry macierzowe, macierz wypłat, strategie czyste i mieszane 3 Punkty równowagi w grach o sumie zerowej 4 Gry dwuosobowe oraz n-osobowe
Algorytmy ewolucyjne (3)
") Algorytmy ewolucyjne (3) http://zajecia.jakubw.pl/nai KODOWANIE PERMUTACJI W pewnych zastosowaniach kodowanie binarne jest mniej naturalne, niż inne sposoby kodowania. Na przykład, w problemie komiwojażera
Algorytmy ewolucyjne (3) http://zajecia.jakubw.pl/nai KODOWANIE PERMUTACJI W pewnych zastosowaniach kodowanie binarne jest mniej naturalne, niż inne sposoby kodowania. Na przykład, w problemie komiwojażera
RISK-AWARE PROJECT SCHEDULING
 RISK-AWARE PROJECT SCHEDULING METODA GRASP KAROL WALĘDZIK DEFINICJA ZAGADNIENIA RESOURCE-CONSTRAINED PROJECT SCHEDULING (RCPS) Karol Walędzik - RAPS 3 RISK-AWARE PROJECT SCHEDULING (RAPS) 1 tryb wykonywania
RISK-AWARE PROJECT SCHEDULING METODA GRASP KAROL WALĘDZIK DEFINICJA ZAGADNIENIA RESOURCE-CONSTRAINED PROJECT SCHEDULING (RCPS) Karol Walędzik - RAPS 3 RISK-AWARE PROJECT SCHEDULING (RAPS) 1 tryb wykonywania
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów
 LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner
 Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej. Adam Żychowski
 Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
Metoda ewolucyjnego doboru współczynników funkcji oceniającej w antywarcabach
 Metoda ewolucyjnego doboru współczynników funkcji oceniającej w antywarcabach Promotor: dr hab. Jacek Mańdziuk Autor: Jarosław Budzianowski Metoda ewolucyjnego doboru współczynników funkcji oceniajacej
Metoda ewolucyjnego doboru współczynników funkcji oceniającej w antywarcabach Promotor: dr hab. Jacek Mańdziuk Autor: Jarosław Budzianowski Metoda ewolucyjnego doboru współczynników funkcji oceniajacej
Dwaj gracze na przemian kładą jednakowe monety na stole tak, aby na siebie nie nachodziły Przegrywa ten, kto nie może dołożyć monety
 Mateusz Lewandowski Krótka filozofia Ciekawość gier Poziomy rozwiązania gier Synchroniczne wykonywanie ruchów w GGP Podejścia do końcówek gier Wykrywanie symetrii Związki z innymi dziedzinami KONSPEKT
Mateusz Lewandowski Krótka filozofia Ciekawość gier Poziomy rozwiązania gier Synchroniczne wykonywanie ruchów w GGP Podejścia do końcówek gier Wykrywanie symetrii Związki z innymi dziedzinami KONSPEKT
Kognitywne podejście do gry w szachy kontynuacja prac
 Kognitywne podejście do gry w szachy kontynuacja prac Stanisław Kaźmierczak Opiekun naukowy: prof. dr hab. Jacek Mańdziuk 2 Agenda Motywacja Kilka badań Faza nauki Wzorce Generowanie ruchów Przykłady Pomysły
Kognitywne podejście do gry w szachy kontynuacja prac Stanisław Kaźmierczak Opiekun naukowy: prof. dr hab. Jacek Mańdziuk 2 Agenda Motywacja Kilka badań Faza nauki Wzorce Generowanie ruchów Przykłady Pomysły
Wykładnicze grafy przypadkowe: teoria i przykłady zastosowań do analizy rzeczywistych sieci złożonych
 Gdańsk, Warsztaty pt. Układy Złożone (8 10 maja 2014) Agata Fronczak Zakład Fizyki Układów Złożonych Wydział Fizyki Politechniki Warszawskiej Wykładnicze grafy przypadkowe: teoria i przykłady zastosowań
Gdańsk, Warsztaty pt. Układy Złożone (8 10 maja 2014) Agata Fronczak Zakład Fizyki Układów Złożonych Wydział Fizyki Politechniki Warszawskiej Wykładnicze grafy przypadkowe: teoria i przykłady zastosowań
Algorytmy heurystyczne w UCB dla DVRP
 Algorytmy heurystyczne w UCB dla DVRP Seminarium IO na MiNI 24.03.2015 Michał Okulewicz based on the decision DEC-2012/07/B/ST6/01527 Plan prezentacji Definicja problemu DVRP UCB na potrzeby DVRP Algorytmy
Algorytmy heurystyczne w UCB dla DVRP Seminarium IO na MiNI 24.03.2015 Michał Okulewicz based on the decision DEC-2012/07/B/ST6/01527 Plan prezentacji Definicja problemu DVRP UCB na potrzeby DVRP Algorytmy
Podejście memetyczne do problemu DCVRP - wstępne wyniki. Adam Żychowski
 Podejście memetyczne do problemu DCVRP - wstępne wyniki Adam Żychowski Na podstawie prac X. S. Chen, L. Feng, Y. S. Ong A Self-Adaptive Memeplexes Robust Search Scheme for solving Stochastic Demands Vehicle
Podejście memetyczne do problemu DCVRP - wstępne wyniki Adam Żychowski Na podstawie prac X. S. Chen, L. Feng, Y. S. Ong A Self-Adaptive Memeplexes Robust Search Scheme for solving Stochastic Demands Vehicle
SPOTKANIE 11: Reinforcement learning
 Wrocław University of Technology SPOTKANIE 11: Reinforcement learning Adam Gonczarek Studenckie Koło Naukowe Estymator adam.gonczarek@pwr.edu.pl 19.01.2016 Uczenie z nadzorem (ang. supervised learning)
Wrocław University of Technology SPOTKANIE 11: Reinforcement learning Adam Gonczarek Studenckie Koło Naukowe Estymator adam.gonczarek@pwr.edu.pl 19.01.2016 Uczenie z nadzorem (ang. supervised learning)
RISK-AWARE PROJECT SCHEDULING
 RISK-AWARE PROJECT SCHEDULING SIMPLEUCT CZ. 2 KAROL WALĘDZIK DEFINICJA ZAGADNIENIA RESOURCE-CONSTRAINED PROJECT SCHEDULING (RCPS) Karol Walędzik - RAPS 3 RISK-AWARE PROJECT SCHEDULING (RAPS) 1 tryb wykonywania
RISK-AWARE PROJECT SCHEDULING SIMPLEUCT CZ. 2 KAROL WALĘDZIK DEFINICJA ZAGADNIENIA RESOURCE-CONSTRAINED PROJECT SCHEDULING (RCPS) Karol Walędzik - RAPS 3 RISK-AWARE PROJECT SCHEDULING (RAPS) 1 tryb wykonywania
1. Symulacje komputerowe Idea symulacji Przykład. 2. Metody próbkowania Jackknife Bootstrap. 3. Łańcuchy Markova. 4. Próbkowanie Gibbsa
 BIOINFORMATYKA 1. Wykład wstępny 2. Bazy danych: projektowanie i struktura 3. Równowaga Hardyego-Weinberga, wsp. rekombinacji 4. Analiza asocjacyjna 5. Analiza asocjacyjna 6. Sekwencjonowanie nowej generacji
BIOINFORMATYKA 1. Wykład wstępny 2. Bazy danych: projektowanie i struktura 3. Równowaga Hardyego-Weinberga, wsp. rekombinacji 4. Analiza asocjacyjna 5. Analiza asocjacyjna 6. Sekwencjonowanie nowej generacji
Algorytmy i struktury danych. Co dziś? Tytułem przypomnienia metoda dziel i zwyciężaj. Wykład VIII Elementarne techniki algorytmiczne
 Algorytmy i struktury danych Wykład VIII Elementarne techniki algorytmiczne Co dziś? Algorytmy zachłanne (greedyalgorithms) 2 Tytułem przypomnienia metoda dziel i zwyciężaj. Problem można podzielić na
Algorytmy i struktury danych Wykład VIII Elementarne techniki algorytmiczne Co dziś? Algorytmy zachłanne (greedyalgorithms) 2 Tytułem przypomnienia metoda dziel i zwyciężaj. Problem można podzielić na
MODELOWANIE RZECZYWISTOŚCI
 MODELOWANIE RZECZYWISTOŚCI Daniel Wójcik Instytut Biologii Doświadczalnej PAN Szkoła Wyższa Psychologii Społecznej d.wojcik@nencki.gov.pl dwojcik@swps.edu.pl tel. 022 5892 424 http://www.neuroinf.pl/members/danek/swps/
MODELOWANIE RZECZYWISTOŚCI Daniel Wójcik Instytut Biologii Doświadczalnej PAN Szkoła Wyższa Psychologii Społecznej d.wojcik@nencki.gov.pl dwojcik@swps.edu.pl tel. 022 5892 424 http://www.neuroinf.pl/members/danek/swps/
Zastosowanie sztucznej inteligencji w testowaniu oprogramowania
 Zastosowanie sztucznej inteligencji w testowaniu oprogramowania Problem NP Problem NP (niedeterministycznie wielomianowy, ang. nondeterministic polynomial) to problem decyzyjny, dla którego rozwiązanie
Zastosowanie sztucznej inteligencji w testowaniu oprogramowania Problem NP Problem NP (niedeterministycznie wielomianowy, ang. nondeterministic polynomial) to problem decyzyjny, dla którego rozwiązanie
DWUKROTNA SYMULACJA MONTE CARLO JAKO METODA ANALIZY RYZYKA NA PRZYKŁADZIE WYCENY OPCJI PRZEŁĄCZANIA FUNKCJI UŻYTKOWEJ NIERUCHOMOŚCI
 DWUKROTNA SYMULACJA MONTE CARLO JAKO METODA ANALIZY RYZYKA NA PRZYKŁADZIE WYCENY OPCJI PRZEŁĄCZANIA FUNKCJI UŻYTKOWEJ NIERUCHOMOŚCI mgr Marcin Pawlak Katedra Inwestycji i Wyceny Przedsiębiorstw Plan wystąpienia
DWUKROTNA SYMULACJA MONTE CARLO JAKO METODA ANALIZY RYZYKA NA PRZYKŁADZIE WYCENY OPCJI PRZEŁĄCZANIA FUNKCJI UŻYTKOWEJ NIERUCHOMOŚCI mgr Marcin Pawlak Katedra Inwestycji i Wyceny Przedsiębiorstw Plan wystąpienia
Uczenie maszynowe end-to-end na przykładzie programu DeepChess. Stanisław Kaźmierczak
 Uczenie maszynowe end-to-end na przykładzie programu DeepChess Stanisław Kaźmierczak 2 Agenda Wprowadzenie Dane treningowe Trening i struktura sieci Redukcja rozmiaru sieci Zmodyfikowane alfa beta Wyniki
Uczenie maszynowe end-to-end na przykładzie programu DeepChess Stanisław Kaźmierczak 2 Agenda Wprowadzenie Dane treningowe Trening i struktura sieci Redukcja rozmiaru sieci Zmodyfikowane alfa beta Wyniki
Uniwersytet Zielonogórski Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Sterowania i Systemów Informatycznych
 Uniwersytet Zielonogórski Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Sterowania i Systemów Informatycznych ELEMENTY SZTUCZNEJ INTELIGENCJI Laboratorium nr 9 PRZESZUKIWANIE GRAFÓW Z
Uniwersytet Zielonogórski Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Sterowania i Systemów Informatycznych ELEMENTY SZTUCZNEJ INTELIGENCJI Laboratorium nr 9 PRZESZUKIWANIE GRAFÓW Z
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
11. Gry Macierzowe - Strategie Czyste i Mieszane
 11. Gry Macierzowe - Strategie Czyste i Mieszane W grze z doskonałą informacją, gracz nie powinien wybrać akcję w sposób losowy (o ile wypłaty z różnych decyzji nie są sobie równe). Z drugiej strony, gdy
11. Gry Macierzowe - Strategie Czyste i Mieszane W grze z doskonałą informacją, gracz nie powinien wybrać akcję w sposób losowy (o ile wypłaty z różnych decyzji nie są sobie równe). Z drugiej strony, gdy
Obliczenia równoległe w General Game Playing
 Obliczenia równoległe w General Game Playing promotor: prof. dr hab. Jacek Mańdziuk 1/66 Plan Krótkie przypomnienie GGP/MiNI-Player Motywacja Pomysł 2012 Pomysł 2013 Porównanie Podsumowanie 2/66 General
Obliczenia równoległe w General Game Playing promotor: prof. dr hab. Jacek Mańdziuk 1/66 Plan Krótkie przypomnienie GGP/MiNI-Player Motywacja Pomysł 2012 Pomysł 2013 Porównanie Podsumowanie 2/66 General
RISK-AWARE PROJECT SCHEDULING
 RISK-AWARE PROJECT SCHEDULING PROUCT - GRASP KAROL WALĘDZIK DEFINICJA ZAGADNIENIA RESOURCE-CONSTRAINED PROJECT SCHEDULING (RCPS) Karol Walędzik - RAPS 3 RISK-AWARE PROJECT SCHEDULING (RAPS) 1 tryb wykonywania
RISK-AWARE PROJECT SCHEDULING PROUCT - GRASP KAROL WALĘDZIK DEFINICJA ZAGADNIENIA RESOURCE-CONSTRAINED PROJECT SCHEDULING (RCPS) Karol Walędzik - RAPS 3 RISK-AWARE PROJECT SCHEDULING (RAPS) 1 tryb wykonywania
AI i ML w grach. Przegląd zagadnień i inspiracje systemów human-like
 Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska AI i ML w grach. Przegląd zagadnień i inspiracje systemów human-like Jacek Mańdziuk PP-RAI 2018, Poznań, 18/10/2018 Gry a poważna nauka
Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska AI i ML w grach. Przegląd zagadnień i inspiracje systemów human-like Jacek Mańdziuk PP-RAI 2018, Poznań, 18/10/2018 Gry a poważna nauka
Stochastyczne dynamiki z opóźnieniami czasowymi w grach ewolucyjnych
 Stochastyczne dynamiki z opóźnieniami czasowymi w grach ewolucyjnych Jacek Miękisz Instytut Matematyki Stosowanej i Mechaniki Uniwersytet Warszawski Warszawa 10 listopada 2016 Proseminarium licencjackie
Stochastyczne dynamiki z opóźnieniami czasowymi w grach ewolucyjnych Jacek Miękisz Instytut Matematyki Stosowanej i Mechaniki Uniwersytet Warszawski Warszawa 10 listopada 2016 Proseminarium licencjackie
Sztuczna Inteligencja i Systemy Doradcze
 Sztuczna Inteligencja i Systemy Doradcze Przeszukiwanie przestrzeni stanów algorytmy ślepe Przeszukiwanie przestrzeni stanów algorytmy ślepe 1 Strategie slepe Strategie ślepe korzystają z informacji dostępnej
Sztuczna Inteligencja i Systemy Doradcze Przeszukiwanie przestrzeni stanów algorytmy ślepe Przeszukiwanie przestrzeni stanów algorytmy ślepe 1 Strategie slepe Strategie ślepe korzystają z informacji dostępnej
Drzewa spinające MST dla grafów ważonych Maksymalne drzewo spinające Drzewo Steinera. Wykład 6. Drzewa cz. II
 Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem
Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem
Uczenie ze wzmocnieniem
 Uczenie ze wzmocnieniem Maria Ganzha Wydział Matematyki i Nauk Informatycznych 2018-2019 Przypomnienia (1) Do tych czas: stan X t u, gdzie u cel aktualizacji: MC : X t G t TD(0) : X y R t+1 + γˆv(x t,
Uczenie ze wzmocnieniem Maria Ganzha Wydział Matematyki i Nauk Informatycznych 2018-2019 Przypomnienia (1) Do tych czas: stan X t u, gdzie u cel aktualizacji: MC : X t G t TD(0) : X y R t+1 + γˆv(x t,
Marcel Stankowski Wrocław, 23 czerwca 2009 INFORMATYKA SYSTEMÓW AUTONOMICZNYCH
 Marcel Stankowski Wrocław, 23 czerwca 2009 INFORMATYKA SYSTEMÓW AUTONOMICZNYCH Przeszukiwanie przestrzeni rozwiązań, szukanie na ślepo, wszerz, w głąb. Spis treści: 1. Wprowadzenie 3. str. 1.1 Krótki Wstęp
Marcel Stankowski Wrocław, 23 czerwca 2009 INFORMATYKA SYSTEMÓW AUTONOMICZNYCH Przeszukiwanie przestrzeni rozwiązań, szukanie na ślepo, wszerz, w głąb. Spis treści: 1. Wprowadzenie 3. str. 1.1 Krótki Wstęp
Outline 1 MCTS. 2 Jednoczesne ruchy. 3 Niepełna informacja. 4 Podsumowanie. Jan Karwowski April 5, / 30
 Outline 1 MCTS 2 Jednoczesne ruchy 3 Niepełna informacja 4 Podsumowanie Jan Karwowski April 5, 2018 1 / 30 Problem drzewo duże. nie mieści się w całości w pamięci stany, akcje wartości w liściach stałe
Outline 1 MCTS 2 Jednoczesne ruchy 3 Niepełna informacja 4 Podsumowanie Jan Karwowski April 5, 2018 1 / 30 Problem drzewo duże. nie mieści się w całości w pamięci stany, akcje wartości w liściach stałe
Podstawy OpenCL część 2
 Podstawy OpenCL część 2 1. Napisz program dokonujący mnożenia dwóch macierzy w wersji sekwencyjnej oraz OpenCL. Porównaj czasy działania obu wersji dla różnych wielkości macierzy, np. 16 16, 128 128, 1024
Podstawy OpenCL część 2 1. Napisz program dokonujący mnożenia dwóch macierzy w wersji sekwencyjnej oraz OpenCL. Porównaj czasy działania obu wersji dla różnych wielkości macierzy, np. 16 16, 128 128, 1024
SID Wykład 4 Gry Wydział Matematyki, Informatyki i Mechaniki UW
 SID Wykład 4 Gry Wydział Matematyki, Informatyki i Mechaniki UW slezak@mimuw.edu.pl Gry a problemy przeszukiwania Nieprzewidywalny przeciwnik rozwiazanie jest strategia specyfikujac a posunięcie dla każdej
SID Wykład 4 Gry Wydział Matematyki, Informatyki i Mechaniki UW slezak@mimuw.edu.pl Gry a problemy przeszukiwania Nieprzewidywalny przeciwnik rozwiazanie jest strategia specyfikujac a posunięcie dla każdej
Adam Meissner. SZTUCZNA INTELIGENCJA Gry dwuosobowe
 Instytut Automatyki i Inżynierii Informatycznej Politechniki Poznańskiej Adam Meissner Adam.Meissner@put.poznan.pl http://www.man.poznan.pl/~ameis SZTUCZNA INTELIGENCJA Gry dwuosobowe Literatura [1] Sterling
Instytut Automatyki i Inżynierii Informatycznej Politechniki Poznańskiej Adam Meissner Adam.Meissner@put.poznan.pl http://www.man.poznan.pl/~ameis SZTUCZNA INTELIGENCJA Gry dwuosobowe Literatura [1] Sterling
Deep Learning na przykładzie Deep Belief Networks
 Deep Learning na przykładzie Deep Belief Networks Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych PW 20 V 2014 Jan Karwowski (MiNI) Deep Learning
Deep Learning na przykładzie Deep Belief Networks Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych PW 20 V 2014 Jan Karwowski (MiNI) Deep Learning
Minimalizacja automatów niedeterministycznych na słowach skończonych i nieskończonych
 Szczepan Hummel Minimalizacja automatów niedeterministycznych na słowach skończonych i nieskończonych 24.11.2005 1. Minimalizacja automatów deterministycznych na słowach skończonych (DFA) [HU] relacja
Szczepan Hummel Minimalizacja automatów niedeterministycznych na słowach skończonych i nieskończonych 24.11.2005 1. Minimalizacja automatów deterministycznych na słowach skończonych (DFA) [HU] relacja
Programowanie Funkcyjne. Prezentacja projektu, 7 stycznia 2008, Juliusz Sompolski
 Programowanie Funkcyjne Prezentacja projektu, 7 stycznia 2008, Juliusz Sompolski Projekt Uniwersalny szablon pozwalający w łatwy sposób podłączać do siebie różne gry (lub ogólniejszą zawartość). Dla gier
Programowanie Funkcyjne Prezentacja projektu, 7 stycznia 2008, Juliusz Sompolski Projekt Uniwersalny szablon pozwalający w łatwy sposób podłączać do siebie różne gry (lub ogólniejszą zawartość). Dla gier
Technologie Informacyjne
 POLITECHNIKA KRAKOWSKA - WIEiK - KATEDRA AUTOMATYKI Technologie Informacyjne www.pk.edu.pl/~zk/ti_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład: Generacja liczb losowych Problem generacji
POLITECHNIKA KRAKOWSKA - WIEiK - KATEDRA AUTOMATYKI Technologie Informacyjne www.pk.edu.pl/~zk/ti_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład: Generacja liczb losowych Problem generacji
Podstawy sztucznej inteligencji
 wykład II Problem solving 03 październik 2012 Jakie problemy możemy rozwiązywać? Cel: Zbudować inteligentnego agenta planującego, rozwiązującego problem. Szachy Kostka rubika Krzyżówka Labirynt Wybór trasy
wykład II Problem solving 03 październik 2012 Jakie problemy możemy rozwiązywać? Cel: Zbudować inteligentnego agenta planującego, rozwiązującego problem. Szachy Kostka rubika Krzyżówka Labirynt Wybór trasy
D. Miszczyńska, M.Miszczyński KBO UŁ 1 GRY KONFLIKTOWE GRY 2-OSOBOWE O SUMIE WYPŁAT ZERO
 D. Miszczyńska, M.Miszczyński KBO UŁ GRY KONFLIKTOWE GRY 2-OSOBOWE O SUMIE WYPŁAT ZERO Gra w sensie niżej przedstawionym to zasady którymi kierują się decydenci. Zakładamy, że rezultatem gry jest wypłata,
D. Miszczyńska, M.Miszczyński KBO UŁ GRY KONFLIKTOWE GRY 2-OSOBOWE O SUMIE WYPŁAT ZERO Gra w sensie niżej przedstawionym to zasady którymi kierują się decydenci. Zakładamy, że rezultatem gry jest wypłata,
Problemy Decyzyjne Markowa
 Problemy Decyzyjne Markowa na podstawie AIMA ch17 i slajdów S. Russel a Wojciech Jaśkowski Instytut Informatyki, Politechnika Poznańska 18 kwietnia 2013 Sekwencyjne problemy decyzyjne Cechy sekwencyjnego
Problemy Decyzyjne Markowa na podstawie AIMA ch17 i slajdów S. Russel a Wojciech Jaśkowski Instytut Informatyki, Politechnika Poznańska 18 kwietnia 2013 Sekwencyjne problemy decyzyjne Cechy sekwencyjnego
10. Wstęp do Teorii Gier
 10. Wstęp do Teorii Gier Definicja Gry Matematycznej Gra matematyczna spełnia następujące warunki: a) Jest co najmniej dwóch racjonalnych graczy. b) Zbiór możliwych dezycji każdego gracza zawiera co najmniej
10. Wstęp do Teorii Gier Definicja Gry Matematycznej Gra matematyczna spełnia następujące warunki: a) Jest co najmniej dwóch racjonalnych graczy. b) Zbiór możliwych dezycji każdego gracza zawiera co najmniej
10. Redukcja wymiaru - metoda PCA
 Algorytmy rozpoznawania obrazów 10. Redukcja wymiaru - metoda PCA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. PCA Analiza składowych głównych: w skrócie nazywana PCA (od ang. Principle Component
Algorytmy rozpoznawania obrazów 10. Redukcja wymiaru - metoda PCA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. PCA Analiza składowych głównych: w skrócie nazywana PCA (od ang. Principle Component
Metody Programowania
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Metody Programowania www.pk.edu.pl/~zk/mp_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 8: Wyszukiwanie
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Metody Programowania www.pk.edu.pl/~zk/mp_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 8: Wyszukiwanie
MODELOWANIE RZECZYWISTOŚCI
 MODELOWANIE RZECZYWISTOŚCI Daniel Wójcik Instytut Biologii Doświadczalnej PAN d.wojcik@nencki.gov.pl tel. 022 5892 424 http://www.neuroinf.pl/members/danek/swps/ Podręcznik Iwo Białynicki-Birula Iwona
MODELOWANIE RZECZYWISTOŚCI Daniel Wójcik Instytut Biologii Doświadczalnej PAN d.wojcik@nencki.gov.pl tel. 022 5892 424 http://www.neuroinf.pl/members/danek/swps/ Podręcznik Iwo Białynicki-Birula Iwona
Gry w postaci normalnej
 Gry w postaci normalnej Rozgrzewka Przykład 1. (Dylemat więźnia) Dwóch przestępców, którzy zorganizowali napad na bank, zostało tymczasowo aresztowanych i czeka ich rozprawa. Jeżeli obaj będa zeznawać
Gry w postaci normalnej Rozgrzewka Przykład 1. (Dylemat więźnia) Dwóch przestępców, którzy zorganizowali napad na bank, zostało tymczasowo aresztowanych i czeka ich rozprawa. Jeżeli obaj będa zeznawać
Sztuczna Inteligencja i Systemy Doradcze
 ztuczna Inteligencja i ystemy Doradcze Przeszukiwanie przestrzeni stanów Przeszukiwanie przestrzeni stanów 1 Postawienie problemu eprezentacja problemu: stany: reprezentują opisy różnych stanów świata
ztuczna Inteligencja i ystemy Doradcze Przeszukiwanie przestrzeni stanów Przeszukiwanie przestrzeni stanów 1 Postawienie problemu eprezentacja problemu: stany: reprezentują opisy różnych stanów świata
Plan. Sztuczne systemy immunologiczne. Podstawowy słownik. Odporność swoista. Architektura systemu naturalnego. Naturalny system immunologiczny
 Sztuczne systemy immunologiczne Plan Naturalny system immunologiczny Systemy oparte na selekcji klonalnej Systemy oparte na modelu sieci idiotypowej 2 Podstawowy słownik Naturalny system immunologiczny
Sztuczne systemy immunologiczne Plan Naturalny system immunologiczny Systemy oparte na selekcji klonalnej Systemy oparte na modelu sieci idiotypowej 2 Podstawowy słownik Naturalny system immunologiczny
Badania w sieciach złożonych
 Badania w sieciach złożonych Grant WCSS nr 177, sprawozdanie za rok 2012 Kierownik grantu dr. hab. inż. Przemysław Kazienko mgr inż. Radosław Michalski Instytut Informatyki Politechniki Wrocławskiej Obszar
Badania w sieciach złożonych Grant WCSS nr 177, sprawozdanie za rok 2012 Kierownik grantu dr. hab. inż. Przemysław Kazienko mgr inż. Radosław Michalski Instytut Informatyki Politechniki Wrocławskiej Obszar
Metody Obliczeniowe w Nauce i Technice
 Metody Obliczeniowe w Nauce i Technice 15. Obliczanie całek metodami Monte Carlo Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl
Metody Obliczeniowe w Nauce i Technice 15. Obliczanie całek metodami Monte Carlo Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl
Algorytmy ewolucyjne NAZEWNICTWO
 Algorytmy ewolucyjne http://zajecia.jakubw.pl/nai NAZEWNICTWO Algorytmy ewolucyjne nazwa ogólna, obejmująca metody szczegółowe, jak np.: algorytmy genetyczne programowanie genetyczne strategie ewolucyjne
Algorytmy ewolucyjne http://zajecia.jakubw.pl/nai NAZEWNICTWO Algorytmy ewolucyjne nazwa ogólna, obejmująca metody szczegółowe, jak np.: algorytmy genetyczne programowanie genetyczne strategie ewolucyjne
Probabilistyka przykłady
 Probabilistyka przykłady Przestrzeń zdarzeń Zapisać przestrzeń zdarzeń dla: 1.liczby wygranych gier w serii liczącej trzy gry 2.liczby wizyt u lekarza w ciągu roku 3.ilości czasu (w minutach) od wezwania
Probabilistyka przykłady Przestrzeń zdarzeń Zapisać przestrzeń zdarzeń dla: 1.liczby wygranych gier w serii liczącej trzy gry 2.liczby wizyt u lekarza w ciągu roku 3.ilości czasu (w minutach) od wezwania
Teoria gier matematyki). optymalności decyzji 2 lub więcej Decyzja wpływa na wynik innych graczy strategiami
. optymalności decyzji 2 lub więcej Decyzja wpływa na wynik innych graczy strategiami") Teoria gier Teoria gier jest częścią teorii decyzji (czyli gałęzią matematyki). Teoria decyzji - decyzje mogą być podejmowane w warunkach niepewności, ale nie zależą od strategicznych działań innych Teoria
Teoria gier Teoria gier jest częścią teorii decyzji (czyli gałęzią matematyki). Teoria decyzji - decyzje mogą być podejmowane w warunkach niepewności, ale nie zależą od strategicznych działań innych Teoria
DIALOG W GRACH POWAŻNYCH
 Studia Ekonomiczne. Zeszyty Naukowe Uniwersytetu Ekonomicznego w Katowicach ISSN 2083-8611 Nr 368 2018 Uniwersytet Ekonomiczny w Katowicach Wydział Informatyki i Komunikacji Katedra Projektowania i Analizy
Studia Ekonomiczne. Zeszyty Naukowe Uniwersytetu Ekonomicznego w Katowicach ISSN 2083-8611 Nr 368 2018 Uniwersytet Ekonomiczny w Katowicach Wydział Informatyki i Komunikacji Katedra Projektowania i Analizy
Algorytmy z powrotami. Algorytm minimax
 Algorytmy z powrotami. Algorytm minimax Algorytmy i struktury danych. Wykład 7. Rok akademicki: 2010/2011 Algorytm z powrotami rozwiązanie problemu budowane jest w kolejnych krokach, po stwierdzeniu (w
Algorytmy z powrotami. Algorytm minimax Algorytmy i struktury danych. Wykład 7. Rok akademicki: 2010/2011 Algorytm z powrotami rozwiązanie problemu budowane jest w kolejnych krokach, po stwierdzeniu (w
GRA Przykład. 1) Zbiór graczy. 2) Zbiór strategii. 3) Wypłaty. n = 2 myśliwych. I= {1,,n} S = {polować na jelenia, gonić zająca} S = {1,,m} 10 utils
 Zbiór graczy. 2) Zbiór strategii. 3) Wypłaty. n = 2 myśliwych. I= {1,,n} S = {polować na jelenia, gonić zająca} S = {1,,m} 10 utils") GRA Przykład 1) Zbiór graczy n = 2 myśliwych I= {1,,n} 2) Zbiór strategii S = {polować na jelenia, gonić zająca} S = {1,,m} 3) Wypłaty jeleń - zając - 10 utils 3 utils U i : S n R i=1,,n J Z J Z J 5 0
GRA Przykład 1) Zbiór graczy n = 2 myśliwych I= {1,,n} 2) Zbiór strategii S = {polować na jelenia, gonić zająca} S = {1,,m} 3) Wypłaty jeleń - zając - 10 utils 3 utils U i : S n R i=1,,n J Z J Z J 5 0
8. Drzewa decyzyjne, bagging, boosting i lasy losowe
 Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Algorytmy rozpoznawania obrazów 8. Drzewa decyzyjne, bagging, boosting i lasy losowe dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Drzewa decyzyjne Drzewa decyzyjne (ang. decision trees), zwane
Uczenie ze wzmocnieniem
 Uczenie ze wzmocnieniem Maria Ganzha Wydział Matematyki i Nauk Informatycznych 2018-2019 Temporal Difference learning Uczenie oparte na różnicach czasowych Problemy predykcyjne (wieloetapowe) droga do
Uczenie ze wzmocnieniem Maria Ganzha Wydział Matematyki i Nauk Informatycznych 2018-2019 Temporal Difference learning Uczenie oparte na różnicach czasowych Problemy predykcyjne (wieloetapowe) droga do
Teoria gier. wstęp. 2011-12-07 Teoria gier Zdzisław Dzedzej 1
 Teoria gier wstęp 2011-12-07 Teoria gier Zdzisław Dzedzej 1 Teoria gier zajmuje się logiczną analizą sytuacji, gdzie występują konflikty interesów, a także istnieje możliwość kooperacji. Zakładamy zwykle,
Teoria gier wstęp 2011-12-07 Teoria gier Zdzisław Dzedzej 1 Teoria gier zajmuje się logiczną analizą sytuacji, gdzie występują konflikty interesów, a także istnieje możliwość kooperacji. Zakładamy zwykle,
ZASADY PROGRAMOWANIA KOMPUTERÓW ZAP zima 2014/2015. Drzewa BST c.d., równoważenie drzew, kopce.
 POLITECHNIKA WARSZAWSKA Instytut Automatyki i Robotyki ZASADY PROGRAMOWANIA KOMPUTERÓW ZAP zima 204/205 Język programowania: Środowisko programistyczne: C/C++ Qt Wykład 2 : Drzewa BST c.d., równoważenie
POLITECHNIKA WARSZAWSKA Instytut Automatyki i Robotyki ZASADY PROGRAMOWANIA KOMPUTERÓW ZAP zima 204/205 Język programowania: Środowisko programistyczne: C/C++ Qt Wykład 2 : Drzewa BST c.d., równoważenie
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Inżynieria biomedyczna
 Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
System prognozowania rynków energii
 System prognozowania rynków energii STERMEDIA Sp. z o. o. Software Development Grupa IT Kontrakt ul. Ostrowskiego13 Wrocław Poland tel.: 0 71 723 43 22 fax: 0 71 733 64 66 http://www.stermedia.eu Piotr
System prognozowania rynków energii STERMEDIA Sp. z o. o. Software Development Grupa IT Kontrakt ul. Ostrowskiego13 Wrocław Poland tel.: 0 71 723 43 22 fax: 0 71 733 64 66 http://www.stermedia.eu Piotr
Security Games: zastosowanie UCT na tle dotychczasowych podejść do problemu
 Security Games: zastosowanie UCT na tle dotychczasowych podejść do problemu Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych PW 14 X 2014 Jan
Security Games: zastosowanie UCT na tle dotychczasowych podejść do problemu Jan Karwowski Zakład Sztucznej Inteligencji i Metod Obliczeniowych Wydział Matematyki i Nauk Informacyjnych PW 14 X 2014 Jan
Planowanie drogi robota, algorytm A*
 Planowanie drogi robota, algorytm A* Karol Sydor 13 maja 2008 Założenia Uproszczenie przestrzeni Założenia Problem planowania trasy jest bardzo złożony i trudny. W celu uproszczenia problemu przyjmujemy
Planowanie drogi robota, algorytm A* Karol Sydor 13 maja 2008 Założenia Uproszczenie przestrzeni Założenia Problem planowania trasy jest bardzo złożony i trudny. W celu uproszczenia problemu przyjmujemy