Podstawy eksploracji danych wykład I. Agnieszka Nowak - Brzezioska
|
|
|
- Zofia Maciejewska
- 8 lat temu
- Przeglądów:
Transkrypt
1 Podstawy eksploracji danych wykład I Agnieszka Nowak - Brzezioska
2 Plan wykładu Podstawowe pojęcia Możliwości eksploracji danych Metody eksploracji danych Zadania dotąd niezrealizowane w ramach eksploracji danych Przygotowanie danych do analizy I etap ED
3 Definicja nr 1 Eksploracja danych jest procesem odkrywania znaczących nowych powiązań, wzorców i trendów przez przeszukiwanie danych zgromadzonych w skarbnicach, przy wykorzystaniu metod rozpoznawania wzorców, jak również metod statystycznych i matematycznych.
4 Definicja nr 2 Eksploracja danych jest analiza (często ogromnych) zbiorów danych obserwacyjnych w celu znalezienia nieoczekiwanych związków i podsumowania danych w oryginalny sposób tak, aby były zarówno zrozumiałe, jak i przydatne dla ich właściciela przez przeszukiwanie danych zgromadzonych w skarbnicach, przy wykorzystaniu metod rozpoznawania wzorców, jak również metod statystycznych i matematycznych.
5 Definicja nr 3 Eksploracja danych jest między dyscyplinarną dziedziną, łączącą techniki uczenia maszynowego, rozpoznawania wzorców, statystyki, baz danych i wizualizacji w celu uzyskiwania informacji z dużych baz danych.
6 Wszystkie definicje mówią o tym, że celem eksploracji danych jest odkrywanie nowych zależności w zbiorach danych, które nie były wcześniej znane odbiorcy. Wyjątek stanowi tutaj chęd potwierdzenia pewnej określonej hipotezy, czyli potwierdzenia znanej wcześniej zależności w danych. Rezultaty procesu eksploracji są nazywane modelami lub wzorcami. Mogą to byd równania liniowe, reguły, skupienia, grafy, struktury drzewiaste lub wzorce rekurencyjne w szeregach czasowych.

7
8 Schemat ogólny DM 1. Zdefiniowad problem/zadanie i zanalizowad otoczenie. 2. Wybrad zbiór danych do eksploracji i atrybuty. 3. Zdecydowad jak przygotowad dane do przetwarzania. Na przykład: czy wiek reprezentowad jako przedział (np lat), czy jako liczbę (np. 40 lat). 4. Wybrad algorytm (lub ich kombinację) eksploracji i wykonad program realizujący ten algorytm. 5. Zanalizowad wyniki wykonania programu i wybrad te, które uznajemy za rezultat pracy. 6. Przedłożyd wyniki kierownictwu organizacji i zasugerowad sposób ich wykorzystania.
9 Zastosowania KDD znajdują zastosowania przy: eksploracji danych o ruchu internetowym, rozpoznawaniu sygnałów obrazu, mowy, pisma, wspomaganiu diagnostyki medycznej, badaniach genetycznych, analizie operacji bankowych, projektowaniu hurtowni danych, tworzeniu reklam skierowanych (ang. Targeted ads), prognozowaniu sprzedaży (ang. Sales forecast), wdrażaniu strategii Cross-selling'owej, wykrywaniu nadużyd(ang. Fraud detection), ocenie ryzyka kredytowego, segmentacji klientów. Przykładem może byd odkrycie w danych z supermarketu zależności polegającej na tym że klient, który kupuje szampana i kwiaty, kupuje zwykle również czekoladki.
10 Problem eksplozji danych Narzędzia zbierania danych+rozwój systemów bazodanowych gwałtowny wzrost ilości danych zgromadzonych w bazach danych, hurtowniach danych i magazynach danych Np.: N = 10 9 rekordów w danych astronomicznych, d = 10 2 ~ 10 3 atrybutów w systemach diagnozy medycznej
11 Jesteśmy zatopieni w morzu danych, podczas gdy pragniemy wiedzę PROBLEM: jak wydobyd użyteczne informacje/wiedzy z dużego zbioru danych? Rozwiązanie: hurtownia danych + data mining Zbieranie danych (w czasie rzeczywistym) Odkrywanie interesującej wiedzy (reguł, regularności, wzorców, modeli...) z dużych zbiorów danych
12 Ewolucja w bazach danych W latach 60-tych: Kolekcja danych, tworzenie baz danych, IMS oraz sieciowe DBMS W latach 70-tych: Relacyjny model danych, implementacja relacyjnych DBMS W latach 80-tych: RDBMS, zaawansowane modele danych (extendedrelational, OO, deductive,...) oraz aplikacyjnozorientowanedbms Od 90-tych obecnie: Data mining, hurtownia danych, multimedialne bazy danych oraz Web databases
13 10 najważniejszych algorytmów eksploracji danych C4.5, k-means, SVM, Apriori, EM, PageRank, AdaBoost, knn, Naive Bayes, oraz CART. Poznamy je na wykładzie i zajęciach laboratoryjnych PED
14 10 najważniejszych problemów eksploracji danych Oto lista 10 najważniejszych odzwierciedla ważności): problemów eksploracji danych (kolejnośd nie 1. stworzenie Unifikującej Teorii Eksploracji Danych (UTED), 2. opracowanie skalowalnych metod dla problemów opisanych bardzo wieloma wymiarami oraz dla problemów opisanych przez dane strumieniowe, 3. praca nad eksploracją przebiegów czasowych i danych sekwencyjnych, 4. odkrywanie złożonych wzorców w złożonych typach danych, 5. eksploracja struktur sieciowych (zarówno sieci społecznych jak i sieci komputerowych), 6. opracowanie metod rozproszonej eksploracji danych oraz wykorzystanie systemów agentowych do odkrywania wiedzy, 7. eksploracja danych w dziedzinie biologii i ekologii, 8. eksploracja danych opisujących procesy (np. przepływy pracy), 9. bezpieczeostwo, poufnośd i spójnośd danych, 10. praca z danymi, które są niezrównoważone, dynamiczne, podlegające ewolucji.
15 kwartet Anscombe a Francis Anscombe był angielskim statystykiem, który dużą częśd życia spędził na uniwersytetach Yale i Princeton. Anscombe był jednym z pionierów analizy wizualnej i często podkreślał istotnośd wizualizacji zbioru danych poddawanego analizie. Na potrzeby ilustracji stworzył cztery proste zbiory danych, nazwane kwartetem Anscombe a.
16
17 Co jest takiego ciekawego w tych czterech zbiorach? Otóż wszystkie cztery mają dokładnie te same własności statystyczne. Ten przykład dobitnie pokazuje, jak istotne jest zapoznanie się i zaprzyjaźnienie z eksplorowanymi danymi.
18 Data mining I. Zrozumienie dziedziny problemu i celu analizy II. Budowa roboczego zbioru danych III. Przygotowanie i oczyszczenie danych IV. Wybór metody analizy danych V. Eksploracja danych (data mining) VI. Interpretacja znalezionych regularności VII. Wykorzystanie odkrytej wiedzy
19 Każda technika pasuje tylko do pewnych problemów Trudnośd polega na znalezieniu właściwego sformułowania problemu (dobre pytania) Nie ma jeszcze żadnego kryterium, potrzebne jest wyczucie eksperta!!!
20 Techniki eksploracji Eksploracja danych posługuje się różnymi technikami, które budują specyficzne rodzaje wiedzy. W zależności od przeznaczenia odkrywanej wiedzy, może ona odwzorowywad klasyfikacje, regresje, klastrowanie, charakterystyki, dyskryminacje, asocjacje itp.. Poniżej dokonano krótkiej charakterystyki każdej z wymienionych technik eksploracji danych.
21 Klasyfikacja Klasyfikacja polega na znajdowaniu sposobu odwzorowania danych w zbiór predefiniowanych klas. Na podstawie zawartości bazy danych budowany jest model (np. drzewo decyzyjne, reguły logiczne), który służy do klasyfikowania nowych obiektów w bazie danych lub głębszego zrozumienia istniejących klas. Przykładowo, w medycznej bazie danych znalezione mogą byd reguły klasyfikujące poszczególne schorzenia, a następnie przy pomocy znalezionych reguł automatycznie może byd przeprowadzone diagnozowanie kolejnych pacjentów. Inne przykłady zastosowao klasyfikacji to: 1. rozpoznawanie trendów an rynkach finansowych, 2. automatyczne rozpoznawanie obiektów w dużych bazach danych obrazów, 3. wspomaganie decyzji przyznawania kredytów bankowych.
22 Regresja Regresja jest techniką polegającą na znajdowaniu sposobu odwzorowania danych w rzeczywistoliczbowe wartości zmiennych predykcyjnych. Przykłady zastosowao regresji: 1. przewidywanie zawartości biomasy obecnej w ściółce leśnej na podstawie dokonanych zdalnych pomiarów mikrofalowych 2. szacowanie prawdopodobieostwa wyzdrowienia pacjenta na podstawie przeprowadzonych testów diagnostycznych
23 Grupowanie (analiza skupieo) Grupowanie polega na znajdowaniu skooczonego zbioru kategorii opisujących dane. Kategorie mogą byd rozłączne, zupełne, mogą też tworzyd struktury hierarchiczne i nakładające się. Przykładowo, zbiór danych o nieznanych chorobach może zostad w wyniku klastrowania podzielony na szereg grup cechujących sie najsilniejszym podobieostwem symptomów. Innymi przykładami zastosowao klastrowania mogą byd: 1. określanie segmentów rynku dla produktu na podstawie informacji o klientach 2. znajdowanie kategorii widmowych spektrum promieniowania nieba
24 Odkrywanie charakterystyk Odkrywanie charakterystyk polega na znajdowaniu zwięzłych opisów (charakterystyk) podanego zbioru danych. Przykładowo, symptomy określonej choroby mogą byd charakteryzowane przez zbiór reguł charakteryzujących. Inne przykłady odkrywania charakterystyk to: 1. znajdowanie zależności funkcyjnych pomiędzy zmiennymi 2. określanie powszechnych symptomów wskazanej choroby
25 Dyskryminacja Dyskryminacja polega na znajdowaniu cech, które odróżniają wskazaną klasę obiektów (target class) od innych klas (contrasting classes). Przykładowo, zbiór reguł dyskryminujących może opisywad te cechy objawowe, które odróżniają daną chorobę od innych.
26 Odkrywanie asocjacji Odkrywanie asocjacji polega na znajdowaniu związków pomiędzy występowaniem grup elementów w zadanych zbiorach danych. Najpopularniejszym przykładem odkrywania asocjacji jest tzw. analiza koszyka - przetwarzanie baz danych supermarketów i hurtowni w celu znalezienia grup towarów, które są najczęściej kupowane wspólnie. Przykładowo, znalezione asocjacje mogą wskazywad, że kiedy klient kupuje słone paluszki, wtedy kupuje także napoje gazowane.
27 Proces eksploracji danych 1. Data cleaning (to remove noise and inconsistent data) 2. Data integration (where multiple data sources may be combined) 3. Data selection (where data relevant to the analysis task are retrieved fromthe database) 4. Data transformation (where data are transformed or consolidated into forms appropriate for mining by performing summary or aggregation operations, for instance) 5. Data mining (an essential process where intelligent methods are applied in order to extract data patterns) 6. Pattern evaluation (to identify the truly interesting patterns representing knowledge based on some interestingness measures) 7. Knowledge presentation (where visualization and knowledge representation techniques are used to present the mined knowledge to the user)
28 Metody eksploracji Charakterystyka danych (opis) Wzorce, asocjacje, powiązania w danych buys(x; computer ) buys(x; software ) [support = 1%; confidence = 50%] Klasyfikacja i predykcja (drzewa decyzyjne, sieci neuronowe, analiza regresji) Analiza skupieo (grupowanie) Wykrywanie odchyleo
29 Wszystko to są reguły
30 Czy wszystkie wzorce są użyteczne? A data mining system has the potential to generate thousands or even millions of patterns, or rules. only a small fraction of the patterns potentially generated would actually be of interest to any given user. This raises some serious questions for data mining: What makes a pattern interesting? Can a data mining system generate all of the interesting patterns? Can a data mining system generate only interesting patterns?
31 Wzorzec jest interesujący jeśli jest Łatwo zrozumiały dla odbiorcy, Użyteczny i poprawny na nowych danych z zadowalającym stopniem pewności, Niebanalny, Oryginalny (nowy, zaskakujący). Wzorzec jest interesujący jeśli potwierdza (sprawdza) hipotezy stawiane przez użytkownika. Każdy taki wzorzec reprezentuje pewną wiedzę.
32 Przykład reguły asocjacyjnej opis pacjentów chorujących na anginę: pacjenci chorujący na anginę cechują się temperaturą ciała większą niż 37.5 C, bólem gardła, osłabieniem organizmu

33 Przykład reguły asocjacyjnej
34 Ocena stopnia jakości wzorca Istnieje wiele metod. Często stosowanymi są miar z reguł asocjacyjnych: wsparcie i zaufanie. Wsparcie jest stosunkiem ilości wystąpieo przykładów P, które zawierają w całości opisy X oraz Y do ilości wszystkich przykładów P, gdzie P jest dowolnym podzbiorem zawierającym tylko i wyłącznie przykłady Z: Wsparcie(X Y) = PX Y / P Każda reguła może byd więc wspierana, albo naruszana przez przykład. Natomiast zaufanie reguły w zbiorze P definiuje się następująco: Zaufanie(X Y) = PX Y / PX czyli jako stosunek liczby przykładów ze zbioru P, w których opisach występują zarówno opisy X jak i Y do liczby przykładów, w których opisach występują tylko elementy zbioru X, czyli zbioru wartości warunkujących.
35 Przygotowanie danych do analizy I etap eksploracji wiedzy Low-quality data will lead to low-quality mining results. Techniki preprocessingu stosujemy by poprawid jakośd analizowanych danych, by wydobyd z nich potem użyteczną wiedzę. Czyszczenie danych pozwala pozbyd się szumu w danych i poprawid wszelkie nieścisłości w danych. Integracja danych pozwala połączyd dane z wielu źródeł np. hurtowni danych. Transformacja danych (normalizacja) może poprawid dokładnośd i efektywnośd algorytmów eksploracji danych te które stosują miarę odległości w danych. Redukcja danych z kolei pozwala zredukowad rozmiar danych poprzez np. agregację, pewnych cech, eliminację tych nadmiarowych, poprzez grupowanie również. Oczywiście możemy stosowad jednocześnie wszystkie te techniki.
36 Czym mogą byd dane Dokumenty tekstowe Bazy danych ilościowych (numerycznych) i nienumerycznych Obrazy, multimedia Sekwencje DNA Inne.
37 Struktura zbioru danych płed Data_ur Zawód wzrost Id_23 K Informatyk 169 Id_24 M Informatyk 190 Id_25 M Prawnik 173 Id_26 K dziennikarz 167
38 Cechy jakościowe Id_23 Id_24 Id_25 Id_26 płed K M M K Płeć, grupa zawodowa to atrybuty tzw. jakościowe (nominalne) Nie pozwolą nam policzyć wartości średniej, minimalnej, maksymalnej. Nie można więc uporządkować wartości w takim zbiorze.
39 Cechy ilościowe wzrost Id_ Id_ Id_ Id_ Wzrost, waga, dochód, liczba godzin. to atrybuty tzw. ilościowe (numeryczne) Pozwolą nam policzyd wartości średniej, minimalnej, maksymalnej. Można więc uporządkowad takie wartości od najmniejszej do największej. Czy jest jakaś wada?
40 Typy danych W polskiej systematyce podręcznikowej dzielimy typy danych (zmienne) na: ilościowe (mierzalne) - np. wzrost, masa, wiek ciągłe - np. wzrost, masa, wiek (w rozumieniu ilości dni między datą urodzin a datą badania) porządkowe (quasi-ilościowe) - np. klasyfikacja wzrostu: (niski,średni,wysoki) skokowe (dyskretne) - np. ilość posiadanych dzieci, ilość gospodarstw domowych, wiek (w rozumieniu ilości skończonych lat) jakościowe (niemierzalne) - np. kolor oczu, płeć, grupa krwi
41
42 Może więc lepszy taki podział? Cechy statystyczne porządkowe jakościowe ilościowe skokowe ciągłe
43 Cechy jakościowe (niemierzalne) to takie, których nie można jednoznacznie scharakteryzować za pomocą liczb (czyli nie można zmierzyć). Efekt to podział zbioru na podzbiory rozłączne, np. płeć, grupę krwi, kolor włosów, zgon lub przeżycie, stan uodpornienia przeciwko ospie (zaszczepiony lub nie) itp. W przypadku grupy krwi rezultat pomiaru będzie następujący: n1 pacjentów ma grupę krwi A, n2 pacjentów - grupę krwi B, n3 pacjentów - grupę AB i n4 - grupę O. Cechy porządkowe umożliwiają porządkowanie wszystkich elementów zbioru wyników. Cechy takie najlepiej określa się przymiotnikami i ich stopniowaniem, np. dla wzrostu: "niski", "średni" lub "wysoki. Cechy ilościowe (mierzalne) to takie, które dadzą się wyrazić za pomocą jednostek miary w pewnej skali. Cechami mierzalnymi są na przykład: wzrost (w cm), waga (w kg), stężenie hemoglobiny we krwi (w g/dl), wiek (w latach) itp. Cecha ciągła to zmienna, która może przyjmować każdą wartość z określonego skończonego przedziału liczbowego, np. wzrost, masa ciała czy temperatura. Cechy skokowe mogą przyjmować wartości ze zbioru skończonego lub przeliczalnego (zwykle całkowite), na przykład: liczba łóżek w szpitalu, liczba krwinek białych w 1 ml krwi.
44 Cecha objaśniana a objaśniająca? Cecha objaśniana to ta, której wartość próbujemy określić na podstawie wartości cech objaśniających. Cecha objaśniająca to cecha opisująca obserwację w zbiorze. y f (x) Cecha objaśniana Cecha objaśniająca
45 Opis danych Różne statystyczne metody: 1. Opisowe statystyki jak średnia, mediana, minimum, maksimum, moda, odchylenie standardowe, wariancja. 2. Graficzne metody (wykresy): histogram, wykres pudełkowy, wykresy rozrzutu.

46 Statystyka opisowa
47 Co nam daje wartośd średnia? Ile zarabiają dyrektorzy w działach sprzedaży? Średnia zarobków dyrektorów sprzedaży wynosi PLN. Czy dyrektorzy to generalnie bogaci ludzie? Czy można określić ile zarabia konkretny dyrektor? Czy można obliczyć średnią płeć dyrektorów?
48 Co nam daje mediana czy moda? W jakim przedziale mieszczą się zarobki większości dyrektorów? (mediana) Ile zarabia przeciętny dyrektor? (mediana nie BO z bycia w środku nie wynika bycie przeciętnym ), (moda tak, bo przeciętny to najczęściej występujący) Czy prawie wszyscy dyrektorzy to bogaci ludzie? (nie BO nie wiemy NIC o całości badanej grupy) Czy większość dyrektorów to bogaci ludzie? (mediana) Czy zarobki dyrektorów różnią się mocno od siebie? (nie BO nie wiemy NIC o całości badanej grupy) Jakie zarobki są najczęstsze wśród dyrektorów? (nie BO to co jest w środku nie musi być najbardziej popularne), moda tak.
49 Czego nam nie powie moda? W jakim przedziale mieszczą się zarobki większości dyrektorów? Czy większość dyrektorów to bogaci ludzie? (BO najczęstsza wartość wcale nie musi dotyczyć większości) Czy prawie wszyscy dyrektorzy to bogaci ludzie? (BO jeśli nie wiemy nic o większości, to tym bardziej o prawie wszystkich) Czy zarobki dyrektorów różnią się mocno (Od siebie? BO nie wiemy nic o całości grupy)
50 Graficzny opis danych histogramy i wykresy częstości wykresy rozrzutu (scatterplots) wykresy pudełkowe (boxplot)
51
52 histogramy Histogram to jeden z graficznych sposobów przedstawienia rozkładu empirycznego cechy. Składa się z szeregu prostokątów umieszczonych na osi współrzędnych. Na osi X mamy przedziały klasowe wartości cechy np. dla atrybutu płeć: K, M, na osi Y liczebność tych przedziałów. Dla danych jakościowych Porządkują wiedze o danych analizowanych Pokazują odchylenia w danych Pokazują dane dominujące w zbiorze
53 Histogram Najpopularniejsza statystyka graficzna. Przedstawia liczności pacjentów w poszczególnych przedziałach (nazywanych tez kubełkami) danej zmiennej. Domyślnie w funkcji histogram liczba kubełków dobierana jest w zależności od liczby obserwacji jak i ich zmienności. Możemy jednak subiektywnie wybrad interesującą nas liczbę kubełków.

54 Histogram a rodzaj danych Dane jakościowe Dane ilościowe
55 Wykres punktowy (rozrzutu)
56 Dla tych samych danych O tym która linia regresji lepiej odwzrowuje dane decyduje współczynnik determinacji R 2.
57 Wykresy rozrzutu pokazują relację między daną na osi X a daną na osi Y Wykresy rozrzutu też wskazują dobrze odchylenia w danych
58 Typ korelacji Nieliniowa zależnośd danych Scatterplot showing no discernable relationship Korelacja ujemna
59 Wykres pudełkowy Wykres pudełkowy można wyznaczad dla pojedynczej zmiennej, dla kilku zmiennych lub dla pojedynczej zmiennej w rozbiciu na grupy. Wykres przedstawia medianę (środek pudełka), kwartyle (dolna i górna granica pudełka), obserwacje odstające (zaznaczane kropkami) oraz maksimum i minimum po usunięciu obserwacji odstających. Wykres pudełkowy jest bardzo popularną metodą prezentacji zmienności pojedynczej zmiennej.
60
61
62
63 Co można odczytad z wykresów? Boxplot Kwantyl tak nie Mediana tak nie Wartośd min tak tak Wartośd max tak tak Wartośd cechy tak tak Liczebnośd nie tak Częstośd nie tak Wzajemna korelacja zmiennych nie Histogram tak
64 Przed analizą danych obróbka danych Dane są przeważnie: Nieobrobione Niekompletne Zaszumione To sprawia konieczność czyszczenia i przekształcania danych.
65 Np. baza danych zawiera pola przestarzałe lub zbędne, rekordy z brakującymi wartościami, punkty oddalone, dane z niewłaściwym formatem.
66 Czyszczenie danych i ich przekształcanie ma na celu realizację zadania nazywanego często: Minimalizacją GIGO GIGO garbage in garbage out

67 Czyszczenie danych To być może miał być kod lecz niektóre programy jeśli pole jest typem numerycznym to zero na początku nie będzie ujmowane.
68 Maski wprowadzania Maska wprowadzania to zestaw znaków literałowych i znaków masek umożliwiający sterowanie zakresem danych, które można wprowadzać w polu. Maska wprowadzania może na przykład wymagać od użytkowników wprowadzania dat czy numerów telefonów zgodnie z konwencją przyjętą w danym kraju/regionie tak jak w poniższych przykładach: RRRR-MM-DD ( ) - wew.
69 Maski takie ułatwiają zapobieganie wprowadzaniu przez użytkowników nieprawidłowych danych (na przykład wpisaniu numeru telefonu w polu daty). Dodatkowo zapewniają one spójny sposób wprowadzania danych przez użytkowników, co z kolei ułatwia wyszukiwanie danych i obsługę bazy danych.
70 Gdzie stosowad maski: do pola tabeli typu Data/godzina lub formantu pola tekstowego w formularzu powiązanego z polem typu Data/godzina. Masek wprowadzania nie można jednak używać bezkrytycznie. Maski wprowadzania można domyślnie stosować do pól tabeli z typem danych ustawionym na Tekst, Liczba (oprócz identyfikatora replikacji), Waluta i Data/godzina. Maski wprowadzania można także stosować dla formantów formularza, takich jak pola tekstowe, powiązanych z polami tabeli, dla których ustawiono te typy danych. wprowadzania-wartosci-pol-lub-formantow-w-okreslonym-formacie- HA aspx#BM1

71 Co z danymi oddalonymi? Błędne dane typu dochód z minusem na początku: to błąd we wprowadzaniu danych, czy faktyczny ujemny dochód?
72 Odchylenia w danych W bazie danych mogą byd zawarte obiekty, które nie spełniają wymagao ogólnego modelu zachowao. Te obiekty nazywamy odchyleniami. W większości przypadków obiekty takie są odrzucane jako zakłócenia, śmieci lub wyjątki. Niekiedy jednak identyfikacja takich odchyleo może byd bardzo interesująca, na przykład w systemach wykrywania oszustw (fraud detection). Odchylenia mogą byd wykrywane z wykorzystaniem testów statystycznych, w których przyjmowany jest określony rozkład prawdopodobieostwa dla danych. Można też stosowad miary odległości, a obiekty, których odległośd od utworzonych skupieo jest duża traktowane są jako odchylenia
73 Numeryczne metody wykrywania danych oddalonych: 1. Metoda ze średniej i odchylenia standardowego 2. Metoda rozstępu międzykwartylowego
74 Metoda ze średniej i odchylenia standardowego Wyznaczamy przedział tzw. wartości typowych jako: średnia ± k SD gdzie k wynosi 2, 2.5 lub 3 Wartości z poza tego przedziału uznajemy za odstające
75 Rozkład danych metoda Tukeya średnia ± k SD Około 68%, 95%, i 99.7% danych powinno mieścid 1,2, i 3 wielkości różnicy odchylenia standardowego i średniej. Więc obserwacje większe lub mniejsze niż wartośd: śr_x 2 *SD lub śr_x 3 *SD uznajemy za odchylenia. 3.2, 3.4, 3.7, 3.7, 3.8, 3.9, 4, 4, 4.1, 4.2, 4.7, 4.8, 14, 15. śr_x = 5.46, SD=3.86. Dla śr_x 2 *SD: <-2.25, > zaś dla śr_x 3*SD: <-6.11, 17.04>. Wówczas 14 i 15 uznamy za odchylenia dla reguły: śr_x 2 *SD ale nie będą odchyleniami dla reguły: śr_x 3*SD

76 Metoda średniej i odchylenia standardowego Często do wykrywania odchyleń w danych używa się wartości średniej i odchylenia standardowego. Mówi się wówczas, że jeśli jakaś wartość jest większa bądź mniejsza o wartość równą dwukrotnej wartości odchylenia standardowego od wartości średniej to należy ją uznać za odchylenie.
77 Rozstęp międzykwartylowy IQR To bardziej odporna metoda. Kwartyle dzielą zbiór danych na 4 części z których każda zawiera 25 % danych. Rozstęp międzykwartylowy to miara zmienności, która jest dużo bardziej odporna niż odchylenie standardowe IRQ = Q3 Q1
78 Metoda rozstępu międzykwartylowego Metoda boxplotów - Tukey (1977) Dane wejściowe: O1, O3 Dane wyznaczane w algorytmie Tukeya: IQR (interquartile range) = Q3 Q1 <Q1 k* IQR, Q3+ k*iqr> Dane które nie należą do tego przedziału uznajemy za odchylenia. Zauważmy, że wartośd współczynnika k odpowiednio rozszerza albo zawęża ten przedział.
79 Metoda rozstępu międzykwartylowego min max Q 1 1.5*IQR Q 3 1.5* IQR Odchyleniem są obserwacje nie wchodzące do przedziału: min, max IQR Q3 Q1 80
 Jest położona przynajmniej o 1.")
80 Dana jest punktem oddalonym gdy: Jest położona przynajmniej o 1.5 x IQR poniżej Q1 (a więc: Q1-1.5 * IQR ) Jest położona przynajmniej o 1.5 x IQR powyżej Q3 (a więc Q3+1.5 * IQR )
81 Boxploty Zwykły boxplot Boxplot Tukeya
82 Graficzne metody wykrywania wartości oddalonych: Punkty oddalone to skrajne wartości, znajdujące się blisko granic zakresu danych bądź są sprzeczne z ogólnym trendem pozostałych danych. Metody: Histogram lub dwuwymiarowe wykresy rozrzutu, które potrafią wskazać obserwacje oddalone dla więcej niż 1 zmiennej.

83 Histogram lub dwuwymiarowe wykresy rozrzutu pozwalają wykryd odchylenia
84 Inne problemy z danymi? Np. wartość może być prawidłową daną, a może być także błędem w danych. W starszych BD pewne określone wartości oznaczały kod dla niewłaściwie wprowadzonych danych i właśnie wartość może być w tym względzie wartością oznaczającą błąd.

85 Złe dane Np. kolumna wiek czy rok_urodzenia? Czy jest jakas różnica między nimi? Wiek - źle, rok_urodzenia - dobrze
86 Brakujące dane bardzo poważnym problemem przy analizie danych Nie wiadomo jaka jest przyczyna braku danych i jak z tymi brakami w danych postępować. Powody niekompletności danych: atrybuty najbardziej pożądane do analizy mogą być niedostępne dane nie były możliwe do zdobycia w określonym czasie, co spowodowało nie zidentyfikowanie pewnych ważnych zależności czasami winą jest błąd pomiaru dane mogły być zapisane ale potem usunięte o prostu może brakować pewnych wartości dla atrybutów.
87 Metody na brakujące dane: Są 2 możliwości: 1. Pomijanie danych niebezpieczny krok 2. Zastępowanie danych (różne metody): 1. Zastąpienie pewną stałą podaną przez analityka 2. Zastąpienie wartością średnią lub modalną 3. Zastąpienie wartością losową.
88 Ad.1. Zastąpienie pewną stałą podaną przez analityka Braki w danych numerycznych zastępuje się wartością 0 Braki w danych tekstowych zastępuje się wartością missing
89 Ad. 2. Zastąpienie wartością średnią lub modalną Dane numeryczne zastępuje się wartością średnią w zbiorze danych Dane nienumeryczne (tekstowe) zastępuje się wartością modalną a więc wartością najczęściej występującą w zbiorze.
90 w 1 przypadku dane z uwzględnieniem danych brakujących w 2 przypadku dane z uwzględnieniem metod interpolacji w 3 przypadku gdy dane brakujące są ignorowane, a więc nie są brane pod uwagę przy wykreślaniu wykresu.

91 R i Rattle a brakujące dane Przypuśćmy, że mamy do czynienia ze zbiorem danych, w którym brak niektórych informacji. Konkretnie brakuje nam stawki godzinowej w wierszu 2 oraz informacji o czasie pracy w wierszu 11. W Rattle w zakładce Transform możemy użyć jednej z kilku metod radzenia sobie z brakami w danych: Zero/Missing zastępowanie braków w danych wartością 0 Mean zastępowanie braków w danych wartością średnią w danym zbiorze (tutaj można rozważyć także uśrednianie w ramach danej podgrupy!!!) Median zastępowanie braków w danych medianą w danym zbiorze Mode zastępowanie braków w danych modą w danym zbiorze Constant stała wartość, którą będą zastępowane wszelkie braki w danych. Może to być np. wartość 0, "unknown", "N/A" lub -
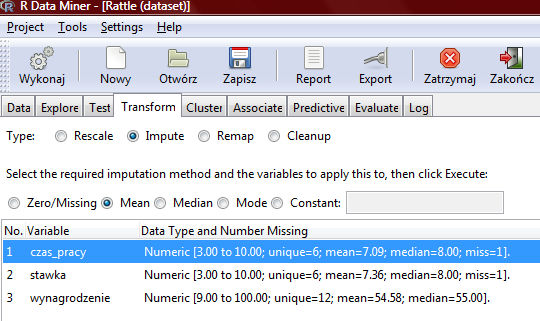
92
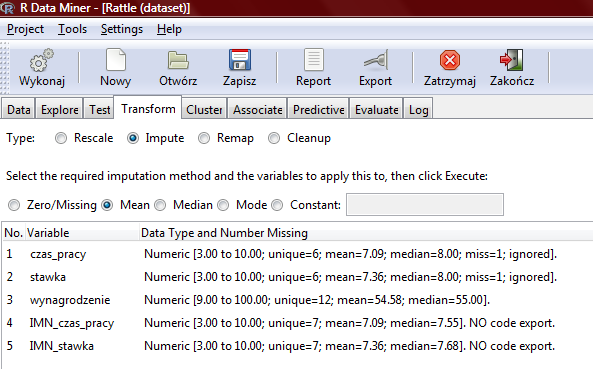
93

94 Efekt: Gdzie widzimy, że zarówno wiersz 2 jak i 11 mają teraz nowe wartości: będące wartościami średnimi w zbiorze.

95 Zero/Missing
96 Efekt:
97 Metoda zastępowania braków w danych w dużej mierze zależy od typu danych. Gdy brakuje danych w kolumnach z danymi numerycznymi często stosuje się uzupełnianie braków w danych wartością średnią czy medianą np. Jednak jeśli brakuje danych w kolumnach z danymi typu nominalnego wówczas powinno się wypełniać braki wartością najczęściej występującą w zbiorze!
98 Zastosowanie metody k-nn do uzupełniania braków w danych Metoda ta polega na tym, by znaleźć K takich przykładów, które są najbardziej podobne do obiektu, dla którego mamy pewne wartości puste. Wówczas brakująca wartość jest wyznaczana jako średnia wartość tej danej (zmiennej, kolumny) wśród tych K wybranych wartości. Wówczas wartość brakująca jest wypełniana jako:, gdzie I Kih jest zbiorem przykładów wziętych pod uwagę jako najbardziej podobne obserwacje, y jh jest wartością brakującą. Wadą tej metody jest fakt, że nie wiadomo jaka wartość liczby K jest najwłaściwsza i dobiera się ją czysto doświadczalnie.
99 Przykład Widzimy, że w komórce K1 brakuje wartości. Excel rozpoznaje komórki z błędnymi wartościami w tym przypadku będzie to zawartość tej komórki równa? i nie wlicza takich wartości przy podstawowych statystykach tupu średnia czy mediana. średnia mediana 4 średnia w grupie
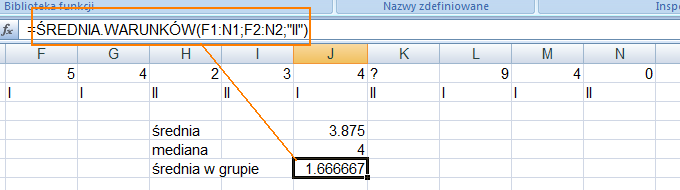
100
101 Przekształcanie danych Dane należy normalizować, by ujednolicić wpływ każdej zmiennej na wyniki. Jest kilka technik normalizacji: 1. Min- Max 2. Standaryzacja Z-score

102 Normalizacja Min-Max

103
104 Normalizacja Min-Max wersja bardziej uniwersalna New_min to nowa wartość minimalna, którą chcemy uzyskać New_max nowa wartość maksymalna. Min to dotychczasowa wartość minimalna Max dotychczasowa wartość maksymalna
105 Min = 50 Max = 130 New_min = 0 New_max = 1
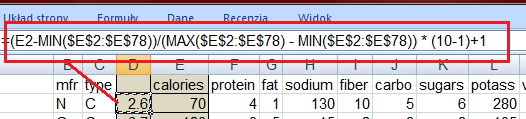
106 1..10
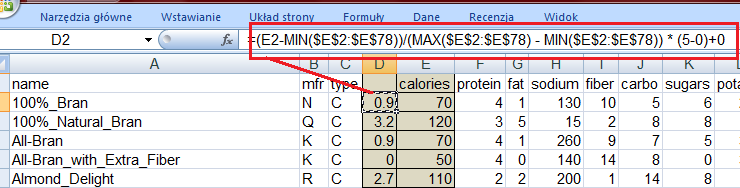
107 0..5
108 Normalizacja Z-score Wartości większe od średniej po standaryzacji będą na pewno dodatnie!
109 Korelacja - definicja Korelacja (współzależność cech) określa wzajemne powiązania pomiędzy wybranymi zmiennymi. Charakteryzując korelację dwóch cech podajemy dwa czynniki: kierunek oraz siłę. Wyrazem liczbowym korelacji jest współczynnik korelacji (r lub R), zawierający się w przedziale [-1; 1].
110 Korelacja Korelacja (współzależnośd cech) określa wzajemne powiązania pomiędzy wybranymi zmiennymi. Charakteryzując korelację dwóch cech podajemy dwa czynniki: kierunek oraz siłę.
111 Współczynnik korelacji Pearsona Współczynnik ten wykorzystywany jest do badania związków prostoliniowych badanych zmiennych, w których zwiększenie wartości jednej z cech powoduje proporcjonalne zmiany średnich wartości drugiej cechy (wzrost lub spadek). Współczynnik ten obliczamy na podstawie wzoru:
112 Korelacja Pearsona Korelacja jest miarą pozwalającą badać stopień zależności między analizowanymi danymi. Jedną z podstawowych miar korelacji jest współczynnik korelacji Pearsona wyrażany wzorem: gdzie xi i yi to poszczególne wartości rzeczywiste zmiennych x i y, x i y określają wartości średnie tych zmiennych zaś sx i sy to odpowiednio odchylenia standardowe tych zmiennych w zbiorze n elementów. Przyjmuje on wartości z przedziału [ 1, 1]. Dodatnia wartość tego współczynnika oznacza, że wzrost wartości jednej zmiennej generalnie pociąga za sobą wzrost wartości drugiej zmiennej (wartość ujemna oznacza odpowiednio spadek wartości dla drugiej zmiennej). Specyficzny przypadek gdy r =0 oznacza brak związku między zmiennymi x i y.

113 Przykład brak korelacji
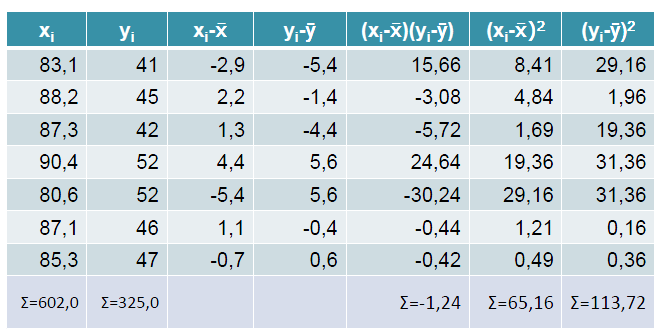
114

115
 oraz badaniom wzroku (xi).")
116 Przykład wysoka korelacja Sportowców poddano badaniom szybkości reakcji na bodziec wzrokowy (yi) oraz badaniom wzroku (xi). Oszacowad współzależnośd obu analizowanych cech
117
118 Występuje bardzo wysoka dodatnia korelacja pomiędzy analizowanymi cechami. Wzrostowi jakości wzroku towarzyszy wzrost szybkości reakcji. r=0,8232 < 0,7;0,9)
119 Współczynnik R Spearmana Współczynnik korelacji rang Spearmana wykorzystywany jest do opisu siły korelacji dwóch cech, w przypadku gdy: cechy mają charakter jakościowy, pozwalający na uporządkowanie ze względu na siłę tej cechy, cechy mają charakter ilościowy, ale ich liczebnośd jest niewielka.
120 Ranga jest to liczba odpowiadająca miejscu w uporządkowaniu każdej z cech. Jeśli w badanej zbiorowości jest więcej jednostek z identycznym natężeniem badanej cechy, to jednostkom tym przypisuje się identyczne rangi, licząc średnią arytmetyczną z rang przynależnych tym samym jednostkom. Współczynnik korelacji rang przyjmuje wartości z przedziału [-1; 1]. Interpretacja jest podobna do współczynnika korelacji liniowej Pearsona. d i 2 - różnica pomiędzy rangami odpowiadających sobie wartości cech x i i y i

121 Na podstawie opinii o zdrowiu 10 pacjentów wydanych przez dwóch lekarzy chcemy ustalid współzależnośd między tymi opiniami, które zostały wyrażone w punktach.

122
123 Korelacja: zalety i wady korelacja dodatnia (wartość współczynnika korelacji od 0 do 1) informuje, że wzrostowi wartości jednej cechy towarzyszy wzrost średnich wartości drugiej cechy, korelacja ujemna (wartość współczynnika korelacji od -1 do 0) -informuje, że wzrostowi wartości jednej cechy towarzyszy spadek średnich wartości drugiej cechy.
124 Wartośd korelacji dodatnie poniżej 0,2 - korelacja słaba (praktycznie brak związku) 0,2 0,4 - korelacja niska (zależność wyraźna) 0,4 0,6 - korelacja umiarkowana 0,4 0,6 - korelacja umiarkowana (zależność istotna) 0,6 0,8 - korelacja wysoka (zależność znaczna) 0,8 0,9 - korelacja bardzo wysoka (zależność bardzo duża) 0,9 1,0 - zależność praktycznie pełna
125 Korelacyjne wykresy rozrzutu
126 Wiadomości testowe? Co to jest korelacja? Jak wykrywad wartości oddalone w zbiorze danych? Jak zastępowad braki w danych? Jak normalizowad dane do jakiegoś przedziału? Czy typ danych ma wpływ na wybór graficznej reprezentacji? W czym może pomóc eksploracja danych?
127 Dziękuję za uwagę!
Metody wykrywania odchyleo w danych. Metody wykrywania braków w danych. Korelacja. PED lab 4
 Metody wykrywania odchyleo w danych. Metody wykrywania braków w danych. Korelacja. PED lab 4 Co z danymi oddalonymi? Błędne dane typu dochód z minusem na początku: to błąd we wprowadzaniu danych, czy faktyczny
Metody wykrywania odchyleo w danych. Metody wykrywania braków w danych. Korelacja. PED lab 4 Co z danymi oddalonymi? Błędne dane typu dochód z minusem na początku: to błąd we wprowadzaniu danych, czy faktyczny
Statystyka BioStatystyka
 Wykłady Statystyka nauka, której przedmiotem zainteresowania są metody pozyskiwania i prezentacji, a przede wszystkim analizy danych opisujących zjawiska, w tym masowe. BioStatystyka nauka, której przedmiotem
Wykłady Statystyka nauka, której przedmiotem zainteresowania są metody pozyskiwania i prezentacji, a przede wszystkim analizy danych opisujących zjawiska, w tym masowe. BioStatystyka nauka, której przedmiotem
Metody wypełniania braków w danych ang. Missing values in data
 Analiza danych wydobywanie wiedzy z danych III Metody wypełniania braków w danych ang. Missing values in data W rzeczywistych zbiorach danych dane są często nieczyste: - niekompletne (brakujące ważne atrybuty,
Analiza danych wydobywanie wiedzy z danych III Metody wypełniania braków w danych ang. Missing values in data W rzeczywistych zbiorach danych dane są często nieczyste: - niekompletne (brakujące ważne atrybuty,
Statystyczne metody analizy danych. Agnieszka Nowak - Brzezińska
 Statystyczne metody analizy danych Agnieszka Nowak - Brzezińska SZEREGI STATYSTYCZNE SZEREGI STATYSTYCZNE odpowiednio usystematyzowany i uporządkowany surowy materiał statystyczny. Szeregi statystyczne
Statystyczne metody analizy danych Agnieszka Nowak - Brzezińska SZEREGI STATYSTYCZNE SZEREGI STATYSTYCZNE odpowiednio usystematyzowany i uporządkowany surowy materiał statystyczny. Szeregi statystyczne
Pojęcie korelacji. Korelacja (współzależność cech) określa wzajemne powiązania pomiędzy wybranymi zmiennymi.
 określa wzajemne powiązania pomiędzy wybranymi zmiennymi.") Pojęcie korelacji Korelacja (współzależność cech) określa wzajemne powiązania pomiędzy wybranymi zmiennymi. Charakteryzując korelację dwóch cech podajemy dwa czynniki: kierunek oraz siłę. Korelacyjne wykresy
Pojęcie korelacji Korelacja (współzależność cech) określa wzajemne powiązania pomiędzy wybranymi zmiennymi. Charakteryzując korelację dwóch cech podajemy dwa czynniki: kierunek oraz siłę. Korelacyjne wykresy
Mail: Pokój 214, II piętro
 Wykład 1 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak jest analizą (często ogromnych) zbiorów danych(...) w celu znalezienia nieoczekiwanych związków i podsumowania
Wykład 1 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak jest analizą (często ogromnych) zbiorów danych(...) w celu znalezienia nieoczekiwanych związków i podsumowania
Laboratorium nr Wyznaczyć podstawowe statystyki (średnia, mediana, IQR, min, max) dla próby:
 dla próby:") Laboratorium nr 1 CZĘŚĆ I : STATYSTYKA OPISOWA : 1. Wyznaczyć podstawowe statystyki (średnia, mediana, IQR, min, max) dla próby: 6,9,1,2,5,2,6,2,1,0,1,4,5,6,3,7,3,2,2,3,8,5,3,4,8,0,8,0,5,1,6,4,8,0,3,2
Laboratorium nr 1 CZĘŚĆ I : STATYSTYKA OPISOWA : 1. Wyznaczyć podstawowe statystyki (średnia, mediana, IQR, min, max) dla próby: 6,9,1,2,5,2,6,2,1,0,1,4,5,6,3,7,3,2,2,3,8,5,3,4,8,0,8,0,5,1,6,4,8,0,3,2
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Wykład 1. Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy
 Wykład Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy Zbiorowość statystyczna - zbiór elementów lub wyników jakiegoś procesu powiązanych ze sobą logicznie (tzn. posiadających wspólne cechy
Wykład Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy Zbiorowość statystyczna - zbiór elementów lub wyników jakiegoś procesu powiązanych ze sobą logicznie (tzn. posiadających wspólne cechy
Analiza współzależności zjawisk. dr Marta Kuc-Czarnecka
 Analiza współzależności zjawisk dr Marta Kuc-Czarnecka Wprowadzenie Prawidłowości statystyczne mają swoje przyczyny, w związku z tym dla poznania całokształtu badanego zjawiska potrzebna jest analiza z
Analiza współzależności zjawisk dr Marta Kuc-Czarnecka Wprowadzenie Prawidłowości statystyczne mają swoje przyczyny, w związku z tym dla poznania całokształtu badanego zjawiska potrzebna jest analiza z
Próba własności i parametry
 Próba własności i parametry Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony
Próba własności i parametry Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony
Typy zmiennych. Zmienne i rekordy. Rodzaje zmiennych. Graficzne reprezentacje danych Statystyki opisowe
 Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
SCENARIUSZ LEKCJI. TEMAT LEKCJI: Zastosowanie średnich w statystyce i matematyce. Podstawowe pojęcia statystyczne. Streszczenie.
 SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Statystyka opisowa. Wykład I. Elementy statystyki opisowej
 Statystyka opisowa. Wykład I. e-mail:e.kozlovski@pollub.pl Spis treści Elementy statystyku opisowej 1 Elementy statystyku opisowej 2 3 Elementy statystyku opisowej Definicja Statystyka jest to nauka o
Statystyka opisowa. Wykład I. e-mail:e.kozlovski@pollub.pl Spis treści Elementy statystyku opisowej 1 Elementy statystyku opisowej 2 3 Elementy statystyku opisowej Definicja Statystyka jest to nauka o
Zajęcia nr VII poznajemy Rattle i pakiet R.
 Okno główne Rattle wygląda następująco: Zajęcia nr VII poznajemy Rattle i pakiet R. Widzimy główne zakładki: Data pozwala odczytad dane z różnych źródeł danych (pliki TXT, CSV) i inne bazy danych. Jak
Okno główne Rattle wygląda następująco: Zajęcia nr VII poznajemy Rattle i pakiet R. Widzimy główne zakładki: Data pozwala odczytad dane z różnych źródeł danych (pliki TXT, CSV) i inne bazy danych. Jak
Statystyka i analiza danych Wstępne opracowanie danych Statystyka opisowa. Dr Anna ADRIAN Paw B5, pok 407 adan@agh.edu.pl
 Statystyka i analiza danych Wstępne opracowanie danych Statystyka opisowa Dr Anna ADRIAN Paw B5, pok 407 adan@agh.edu.pl Wprowadzenie Podstawowe cele analizy zbiorów danych Uogólniony opis poszczególnych
Statystyka i analiza danych Wstępne opracowanie danych Statystyka opisowa Dr Anna ADRIAN Paw B5, pok 407 adan@agh.edu.pl Wprowadzenie Podstawowe cele analizy zbiorów danych Uogólniony opis poszczególnych
Analiza danych i data mining.
 Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych
 Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
Badanie zależności skala nominalna
 Badanie zależności skala nominalna I. Jak kształtuje się zależność miedzy płcią a wykształceniem? II. Jak kształtuje się zależność między płcią a otyłością (opis BMI)? III. Jak kształtuje się zależność
Badanie zależności skala nominalna I. Jak kształtuje się zależność miedzy płcią a wykształceniem? II. Jak kształtuje się zależność między płcią a otyłością (opis BMI)? III. Jak kształtuje się zależność
1 n. s x x x x. Podstawowe miary rozproszenia: Wariancja z populacji: Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel:
 Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Podstawowe pojęcia. Własności próby. Cechy statystyczne dzielimy na
 Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony zbiór jednostek, które
Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony zbiór jednostek, które
Statystyka w pracy badawczej nauczyciela
 Statystyka w pracy badawczej nauczyciela Wykład 1: Terminologia badań statystycznych dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyka (1) Statystyka to nauka zajmująca się zbieraniem, badaniem
Statystyka w pracy badawczej nauczyciela Wykład 1: Terminologia badań statystycznych dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyka (1) Statystyka to nauka zajmująca się zbieraniem, badaniem
Statystyka matematyczna. dr Katarzyna Góral-Radziszewska Katedra Genetyki i Ogólnej Hodowli Zwierząt
 Statystyka matematyczna dr Katarzyna Góral-Radziszewska Katedra Genetyki i Ogólnej Hodowli Zwierząt Zasady zaliczenia przedmiotu: część wykładowa Maksymalna liczba punktów do zdobycia 40. Egzamin będzie
Statystyka matematyczna dr Katarzyna Góral-Radziszewska Katedra Genetyki i Ogólnej Hodowli Zwierząt Zasady zaliczenia przedmiotu: część wykładowa Maksymalna liczba punktów do zdobycia 40. Egzamin będzie
Statystyka i opracowanie danych W5: Wprowadzenie do statystycznej analizy danych. Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl
 Statystyka i opracowanie danych W5: Wprowadzenie do statystycznej analizy danych Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Wprowadzenie Podstawowe cele analizy zbiorów danych Uogólniony opis poszczególnych
Statystyka i opracowanie danych W5: Wprowadzenie do statystycznej analizy danych Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Wprowadzenie Podstawowe cele analizy zbiorów danych Uogólniony opis poszczególnych
W1. Wprowadzenie. Statystyka opisowa
 W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY)
") STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
Eksploracja danych - wykład II
 - wykład 1/29 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Październik 2015 - wykład 2/29 W kontekście odkrywania wiedzy wykład - wykład 3/29 CRISP-DM - standaryzacja
- wykład 1/29 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Październik 2015 - wykład 2/29 W kontekście odkrywania wiedzy wykład - wykład 3/29 CRISP-DM - standaryzacja
Podstawowe pojęcia statystyczne
 Podstawowe pojęcia statystyczne Istnieją trzy rodzaje kłamstwa: przepowiadanie pogody, statystyka i komunikat dyplomatyczny Jean Rigaux Co to jest statystyka? Nauka o metodach ilościowych badania zjawisk
Podstawowe pojęcia statystyczne Istnieją trzy rodzaje kłamstwa: przepowiadanie pogody, statystyka i komunikat dyplomatyczny Jean Rigaux Co to jest statystyka? Nauka o metodach ilościowych badania zjawisk
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
STATYSTYKA IV SEMESTR ALK (PwZ) STATYSTYKA OPISOWA RODZAJE CECH W POPULACJACH I SKALE POMIAROWE
 STATYSTYKA OPISOWA RODZAJE CECH W POPULACJACH I SKALE POMIAROWE") STATYSTYKA IV SEMESTR ALK (PwZ) STATYSTYKA OPISOWA RODZAJE CECH W POPULACJACH I SKALE POMIAROWE CECHY mogą być: jakościowe nieuporządkowane - skala nominalna płeć, rasa, kolor oczu, narodowość, marka samochodu,
STATYSTYKA IV SEMESTR ALK (PwZ) STATYSTYKA OPISOWA RODZAJE CECH W POPULACJACH I SKALE POMIAROWE CECHY mogą być: jakościowe nieuporządkowane - skala nominalna płeć, rasa, kolor oczu, narodowość, marka samochodu,
Statystyka. Wykład 8. Magdalena Alama-Bućko. 23 kwietnia Magdalena Alama-Bućko Statystyka 23 kwietnia / 38
 Statystyka Wykład 8 Magdalena Alama-Bućko 23 kwietnia 2017 Magdalena Alama-Bućko Statystyka 23 kwietnia 2017 1 / 38 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 23 kwietnia 2017 Magdalena Alama-Bućko Statystyka 23 kwietnia 2017 1 / 38 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
4.2. Statystyczne opracowanie zebranego materiału
 4.2. Statystyczne opracowanie zebranego materiału Zebrany i pogrupowany materiał badawczy należy poddać analizie statystycznej w celu dokonania pełnej i szczegółowej charakterystyki interesujących badacza
4.2. Statystyczne opracowanie zebranego materiału Zebrany i pogrupowany materiał badawczy należy poddać analizie statystycznej w celu dokonania pełnej i szczegółowej charakterystyki interesujących badacza
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
STATYSTYKA OPISOWA. Dr Alina Gleska. 12 listopada Instytut Matematyki WE PP
 STATYSTYKA OPISOWA Dr Alina Gleska Instytut Matematyki WE PP 12 listopada 2017 1 Analiza współzależności dwóch cech 2 Jednostka zbiorowości - para (X,Y ). Przy badaniu korelacji nie ma znaczenia, która
STATYSTYKA OPISOWA Dr Alina Gleska Instytut Matematyki WE PP 12 listopada 2017 1 Analiza współzależności dwóch cech 2 Jednostka zbiorowości - para (X,Y ). Przy badaniu korelacji nie ma znaczenia, która
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Graficzna prezentacja danych statystycznych
 Szkolenie dla pracowników Urzędu Statystycznego nt. Wybrane metody statystyczne w analizach makroekonomicznych Katowice, 12 i 26 czerwca 2014 r. Dopasowanie narzędzia do typu zmiennej Dobór narzędzia do
Szkolenie dla pracowników Urzędu Statystycznego nt. Wybrane metody statystyczne w analizach makroekonomicznych Katowice, 12 i 26 czerwca 2014 r. Dopasowanie narzędzia do typu zmiennej Dobór narzędzia do
Wydział Inżynierii Produkcji. I Logistyki. Statystyka opisowa. Wykład 3. Dr inż. Adam Deptuła
 12.03.2017 Wydział Inżynierii Produkcji I Logistyki Statystyka opisowa Wykład 3 Dr inż. Adam Deptuła METODY OPISU DANYCH ILOŚCIOWYCH SKALARNYCH Wykresy: diagramy, histogramy, łamane częstości, wykresy
12.03.2017 Wydział Inżynierii Produkcji I Logistyki Statystyka opisowa Wykład 3 Dr inż. Adam Deptuła METODY OPISU DANYCH ILOŚCIOWYCH SKALARNYCH Wykresy: diagramy, histogramy, łamane częstości, wykresy
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Plan wykładu. Statystyka opisowa. Statystyka matematyczna. Dane statystyczne miary położenia miary rozproszenia miary asymetrii
 Plan wykładu Statystyka opisowa Dane statystyczne miary położenia miary rozproszenia miary asymetrii Statystyka matematyczna Podstawy estymacji Testowanie hipotez statystycznych Żródła Korzystałam z ksiażek:
Plan wykładu Statystyka opisowa Dane statystyczne miary położenia miary rozproszenia miary asymetrii Statystyka matematyczna Podstawy estymacji Testowanie hipotez statystycznych Żródła Korzystałam z ksiażek:
Analiza korespondencji
 Analiza korespondencji Kiedy stosujemy? 2 W wielu badaniach mamy do czynienia ze zmiennymi jakościowymi (nominalne i porządkowe) typu np.: płeć, wykształcenie, status palenia. Punktem wyjścia do analizy
Analiza korespondencji Kiedy stosujemy? 2 W wielu badaniach mamy do czynienia ze zmiennymi jakościowymi (nominalne i porządkowe) typu np.: płeć, wykształcenie, status palenia. Punktem wyjścia do analizy
Eksploracja danych (data mining)
") Eksploracja (data mining) Tadeusz Pankowski www.put.poznan.pl/~pankowsk Czym jest eksploracja? Eksploracja oznacza wydobywanie wiedzy z dużych zbiorów. Eksploracja badanie, przeszukiwanie; np. dziewiczych
Eksploracja (data mining) Tadeusz Pankowski www.put.poznan.pl/~pankowsk Czym jest eksploracja? Eksploracja oznacza wydobywanie wiedzy z dużych zbiorów. Eksploracja badanie, przeszukiwanie; np. dziewiczych
Data Mining Wykład 1. Wprowadzenie do Eksploracji Danych. Prowadzący. Dr inż. Jacek Lewandowski
 Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY)
") STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Dla opisania rozkładu badanej zmiennej, korzystamy z pewnych charakterystyk liczbowych. Dzielimy je na cztery grupy.. Określenie przeciętnej wartości
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Dla opisania rozkładu badanej zmiennej, korzystamy z pewnych charakterystyk liczbowych. Dzielimy je na cztery grupy.. Określenie przeciętnej wartości
Statystyka. Wykład 7. Magdalena Alama-Bućko. 16 kwietnia Magdalena Alama-Bućko Statystyka 16 kwietnia / 35
 Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Parametry statystyczne
 I. MIARY POŁOŻENIA charakteryzują średni lub typowy poziom wartości cechy, wokół nich skupiają się wszystkie pozostałe wartości analizowanej cechy. I.1. Średnia arytmetyczna x = x 1 + x + + x n n = 1 n
I. MIARY POŁOŻENIA charakteryzują średni lub typowy poziom wartości cechy, wokół nich skupiają się wszystkie pozostałe wartości analizowanej cechy. I.1. Średnia arytmetyczna x = x 1 + x + + x n n = 1 n
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
STATYSTYKA OPISOWA Przykłady problemów statystycznych: - badanie opinii publicznej na temat preferencji wyborczych;
 STATYSTYKA OPISOWA Przykłady problemów statystycznych: - badanie opinii publicznej na temat preferencji wyborczych; - badanie skuteczności nowego leku; - badanie stopnia zanieczyszczenia gleb metalami
STATYSTYKA OPISOWA Przykłady problemów statystycznych: - badanie opinii publicznej na temat preferencji wyborczych; - badanie skuteczności nowego leku; - badanie stopnia zanieczyszczenia gleb metalami
Wykład 2. Statystyka opisowa - Miary rozkładu: Miary położenia
 Wykład 2 Statystyka opisowa - Miary rozkładu: Miary położenia Podział miar Miary położenia (measures of location): 1. Miary tendencji centralnej (measures of central tendency, averages): Średnia arytmetyczna
Wykład 2 Statystyka opisowa - Miary rozkładu: Miary położenia Podział miar Miary położenia (measures of location): 1. Miary tendencji centralnej (measures of central tendency, averages): Średnia arytmetyczna
KARTA KURSU. (do zastosowania w roku ak. 2015/16) Kod Punktacja ECTS* 4
 Kod Punktacja ECTS* 4") KARTA KURSU (do zastosowania w roku ak. 2015/16) Nazwa Statystyka 1 Nazwa w j. ang. Statistics 1 Kod Punktacja ECTS* 4 Koordynator Dr hab. Tadeusz Sozański (koordynator, wykłady) Dr Paweł Walawender (ćwiczenia)
KARTA KURSU (do zastosowania w roku ak. 2015/16) Nazwa Statystyka 1 Nazwa w j. ang. Statistics 1 Kod Punktacja ECTS* 4 Koordynator Dr hab. Tadeusz Sozański (koordynator, wykłady) Dr Paweł Walawender (ćwiczenia)
-> Średnia arytmetyczna (5) (4) ->Kwartyl dolny, mediana, kwartyl górny, moda - analogicznie jak
 (4) ->Kwartyl dolny, mediana, kwartyl górny, moda - analogicznie jak") Wzory dla szeregu szczegółowego: Wzory dla szeregu rozdzielczego punktowego: ->Średnia arytmetyczna ważona -> Średnia arytmetyczna (5) ->Średnia harmoniczna (1) ->Średnia harmoniczna (6) (2) ->Średnia
Wzory dla szeregu szczegółowego: Wzory dla szeregu rozdzielczego punktowego: ->Średnia arytmetyczna ważona -> Średnia arytmetyczna (5) ->Średnia harmoniczna (1) ->Średnia harmoniczna (6) (2) ->Średnia
Statystyka opisowa PROWADZĄCY: DR LUDMIŁA ZA JĄC -LAMPARSKA
 Statystyka opisowa PRZEDMIOT: PODSTAWY STATYSTYKI PROWADZĄCY: DR LUDMIŁA ZA JĄC -LAMPARSKA Statystyka opisowa = procedury statystyczne stosowane do opisu właściwości próby (rzadziej populacji) Pojęcia:
Statystyka opisowa PRZEDMIOT: PODSTAWY STATYSTYKI PROWADZĄCY: DR LUDMIŁA ZA JĄC -LAMPARSKA Statystyka opisowa = procedury statystyczne stosowane do opisu właściwości próby (rzadziej populacji) Pojęcia:
1 Podstawy rachunku prawdopodobieństwa
 1 Podstawy rachunku prawdopodobieństwa Dystrybuantą zmiennej losowej X nazywamy prawdopodobieństwo przyjęcia przez zmienną losową X wartości mniejszej od x, tzn. F (x) = P [X < x]. 1. dla zmiennej losowej
1 Podstawy rachunku prawdopodobieństwa Dystrybuantą zmiennej losowej X nazywamy prawdopodobieństwo przyjęcia przez zmienną losową X wartości mniejszej od x, tzn. F (x) = P [X < x]. 1. dla zmiennej losowej
Wykład 5: Statystyki opisowe (część 2)
") Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej
 Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Prezentacja materiału statystycznego Szeroko rozumiane modelowanie i prognozowanie jest zwykle kluczowym celem analizy danych. Aby zbudować model wyjaśniający relacje pomiędzy różnymi aspektami rozważanego
Prezentacja materiału statystycznego Szeroko rozumiane modelowanie i prognozowanie jest zwykle kluczowym celem analizy danych. Aby zbudować model wyjaśniający relacje pomiędzy różnymi aspektami rozważanego
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)
, które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)") Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
INFORMATYKA W SELEKCJI
 INFORMATYKA W SELEKCJI INFORMATYKA W SELEKCJI - zagadnienia 1. Dane w pracy hodowlanej praca z dużym zbiorem danych (Excel) 2. Podstawy pracy z relacyjną bazą danych w programie MS Access 3. Systemy statystyczne
INFORMATYKA W SELEKCJI INFORMATYKA W SELEKCJI - zagadnienia 1. Dane w pracy hodowlanej praca z dużym zbiorem danych (Excel) 2. Podstawy pracy z relacyjną bazą danych w programie MS Access 3. Systemy statystyczne
Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.
 znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.") Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Statystyka. Wykład 4. Magdalena Alama-Bućko. 19 marca Magdalena Alama-Bućko Statystyka 19 marca / 33
 Statystyka Wykład 4 Magdalena Alama-Bućko 19 marca 2018 Magdalena Alama-Bućko Statystyka 19 marca 2018 1 / 33 Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności (rozproszenia,
Statystyka Wykład 4 Magdalena Alama-Bućko 19 marca 2018 Magdalena Alama-Bućko Statystyka 19 marca 2018 1 / 33 Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności (rozproszenia,
W kolejnym kroku należy ustalić liczbę przedziałów k. W tym celu należy wykorzystać jeden ze wzorów:
 Na dzisiejszym wykładzie omówimy najważniejsze charakterystyki liczbowe występujące w statystyce opisowej. Poszczególne wzory będziemy podawać w miarę potrzeby w trzech postaciach: dla szeregu szczegółowego,
Na dzisiejszym wykładzie omówimy najważniejsze charakterystyki liczbowe występujące w statystyce opisowej. Poszczególne wzory będziemy podawać w miarę potrzeby w trzech postaciach: dla szeregu szczegółowego,
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Analiza współzależności zjawisk
 Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Regresja i Korelacja
 Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Statystyka hydrologiczna i prawdopodobieństwo zjawisk hydrologicznych.
 Statystyka hydrologiczna i prawdopodobieństwo zjawisk hydrologicznych. Statystyka zajmuje się prawidłowościami zaistniałych zdarzeń. Teoria prawdopodobieństwa dotyczy przewidywania, jak często mogą zajść
Statystyka hydrologiczna i prawdopodobieństwo zjawisk hydrologicznych. Statystyka zajmuje się prawidłowościami zaistniałych zdarzeń. Teoria prawdopodobieństwa dotyczy przewidywania, jak często mogą zajść
Statystyka. Wykład 7. Magdalena Alama-Bućko. 3 kwietnia Magdalena Alama-Bućko Statystyka 3 kwietnia / 36
 Statystyka Wykład 7 Magdalena Alama-Bućko 3 kwietnia 2017 Magdalena Alama-Bućko Statystyka 3 kwietnia 2017 1 / 36 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 7 Magdalena Alama-Bućko 3 kwietnia 2017 Magdalena Alama-Bućko Statystyka 3 kwietnia 2017 1 / 36 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
TRANSFORMACJE I JAKOŚĆ DANYCH
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Statystyka. Wykład 4. Magdalena Alama-Bućko. 13 marca Magdalena Alama-Bućko Statystyka 13 marca / 41
 Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Statystyka opisowa. Literatura STATYSTYKA OPISOWA. Wprowadzenie. Wprowadzenie. Wprowadzenie. Plan. Tomasz Łukaszewski
 Literatura STATYSTYKA OPISOWA A. Aczel, Statystyka w Zarządzaniu, PWN, 2000 A. Obecny, Statystyka opisowa w Excelu dla szkół. Ćwiczenia praktyczne, Helion, 2002. A. Obecny, Statystyka matematyczna w Excelu
Literatura STATYSTYKA OPISOWA A. Aczel, Statystyka w Zarządzaniu, PWN, 2000 A. Obecny, Statystyka opisowa w Excelu dla szkół. Ćwiczenia praktyczne, Helion, 2002. A. Obecny, Statystyka matematyczna w Excelu
Wykład 3. Metody opisu danych (statystyki opisowe, tabele liczności, wykresy ramkowe i histogramy)
") Wykład 3. Metody opisu danych (statystyki opisowe, tabele liczności, wykresy ramkowe i histogramy) Co na dzisiejszym wykładzie: definicje, sposoby wyznaczania i interpretacja STATYSTYK OPISOWYCH prezentacja
Wykład 3. Metody opisu danych (statystyki opisowe, tabele liczności, wykresy ramkowe i histogramy) Co na dzisiejszym wykładzie: definicje, sposoby wyznaczania i interpretacja STATYSTYK OPISOWYCH prezentacja
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Statystyczne metody analizy danych
 Statystyczne metody analizy danych Statystyka opisowa Wykład I-III Agnieszka Nowak - Brzezińska Definicje Statystyka (ang.statistics) - to nauka zajmująca się zbieraniem, prezentowaniem i analizowaniem
Statystyczne metody analizy danych Statystyka opisowa Wykład I-III Agnieszka Nowak - Brzezińska Definicje Statystyka (ang.statistics) - to nauka zajmująca się zbieraniem, prezentowaniem i analizowaniem
1. Opis tabelaryczny. 2. Graficzna prezentacja wyników. Do technik statystyki opisowej można zaliczyć:
 Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
dr inż. Olga Siedlecka-Lamch 14 listopada 2011 roku Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Eksploracja danych
 - Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
- Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
Wykład ze statystyki. Maciej Wolny
 Wykład ze statystyki Maciej Wolny T1: Zajęcia organizacyjne Agenda 1. Program wykładu 2. Cel zajęć 3. Nabyte umiejętności 4. Literatura 5. Warunki zaliczenia Program wykładu T1: Zajęcia organizacyjne T2:
Wykład ze statystyki Maciej Wolny T1: Zajęcia organizacyjne Agenda 1. Program wykładu 2. Cel zajęć 3. Nabyte umiejętności 4. Literatura 5. Warunki zaliczenia Program wykładu T1: Zajęcia organizacyjne T2:
Analiza Współzależności
 Statystyka Opisowa z Demografią oraz Biostatystyka Analiza Współzależności Aleksander Denisiuk denisjuk@euh-e.edu.pl Elblaska Uczelnia Humanistyczno-Ekonomiczna ul. Lotnicza 2 82-300 Elblag oraz Biostatystyka
Statystyka Opisowa z Demografią oraz Biostatystyka Analiza Współzależności Aleksander Denisiuk denisjuk@euh-e.edu.pl Elblaska Uczelnia Humanistyczno-Ekonomiczna ul. Lotnicza 2 82-300 Elblag oraz Biostatystyka
POJĘCIA WSTĘPNE. STATYSTYKA - nauka traktująca o metodach ilościowych badania prawidłowości zjawisk (procesów) masowych.
 masowych.") [1] POJĘCIA WSTĘPNE STATYSTYKA - nauka traktująca o metodach ilościowych badania prawidłowości zjawisk (procesów) masowych. BADANIE STATYSTYCZNE - ogół prac mających na celu poznanie struktury określonej
[1] POJĘCIA WSTĘPNE STATYSTYKA - nauka traktująca o metodach ilościowych badania prawidłowości zjawisk (procesów) masowych. BADANIE STATYSTYCZNE - ogół prac mających na celu poznanie struktury określonej
Sposoby prezentacji problemów w statystyce
 S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
MIARY KLASYCZNE Miary opisujące rozkład badanej cechy w zbiorowości, które obliczamy na podstawie wszystkich zaobserwowanych wartości cechy
 MIARY POŁOŻENIA Opisują średni lub typowy poziom wartości cechy. Określają tą wartość cechy, wokół której skupiają się wszystkie pozostałe wartości badanej cechy. Wśród nich można wyróżnić miary tendencji
MIARY POŁOŻENIA Opisują średni lub typowy poziom wartości cechy. Określają tą wartość cechy, wokół której skupiają się wszystkie pozostałe wartości badanej cechy. Wśród nich można wyróżnić miary tendencji
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Statystyka. Wykład 2. Magdalena Alama-Bućko. 5 marca Magdalena Alama-Bućko Statystyka 5 marca / 34
 Statystyka Wykład 2 Magdalena Alama-Bućko 5 marca 2018 Magdalena Alama-Bućko Statystyka 5 marca 2018 1 / 34 Banki danych: Bank danych lokalnych : Główny urzad statystyczny: Baza Demografia : https://bdl.stat.gov.pl/
Statystyka Wykład 2 Magdalena Alama-Bućko 5 marca 2018 Magdalena Alama-Bućko Statystyka 5 marca 2018 1 / 34 Banki danych: Bank danych lokalnych : Główny urzad statystyczny: Baza Demografia : https://bdl.stat.gov.pl/
ZJAZD 4. gdzie E(x) jest wartością oczekiwaną x
 jest wartością oczekiwaną x") ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych